
Содержание
- Способ 1: Использование автоматического инструмента
- Способ 2: Создание формулы разделения текста
- Шаг 1: Разделение первого слова
- Шаг 2: Разделение второго слова
- Шаг 3: Разделение третьего слова
- Вопросы и ответы

Способ 1: Использование автоматического инструмента
В Excel есть автоматический инструмент, предназначенный для разделения текста по столбцам. Он не работает в автоматическом режиме, поэтому все действия придется выполнять вручную, предварительно выбирая диапазон обрабатываемых данных. Однако настройка является максимально простой и быстрой в реализации.
- С зажатой левой кнопкой мыши выделите все ячейки, текст которых хотите разделить на столбцы.
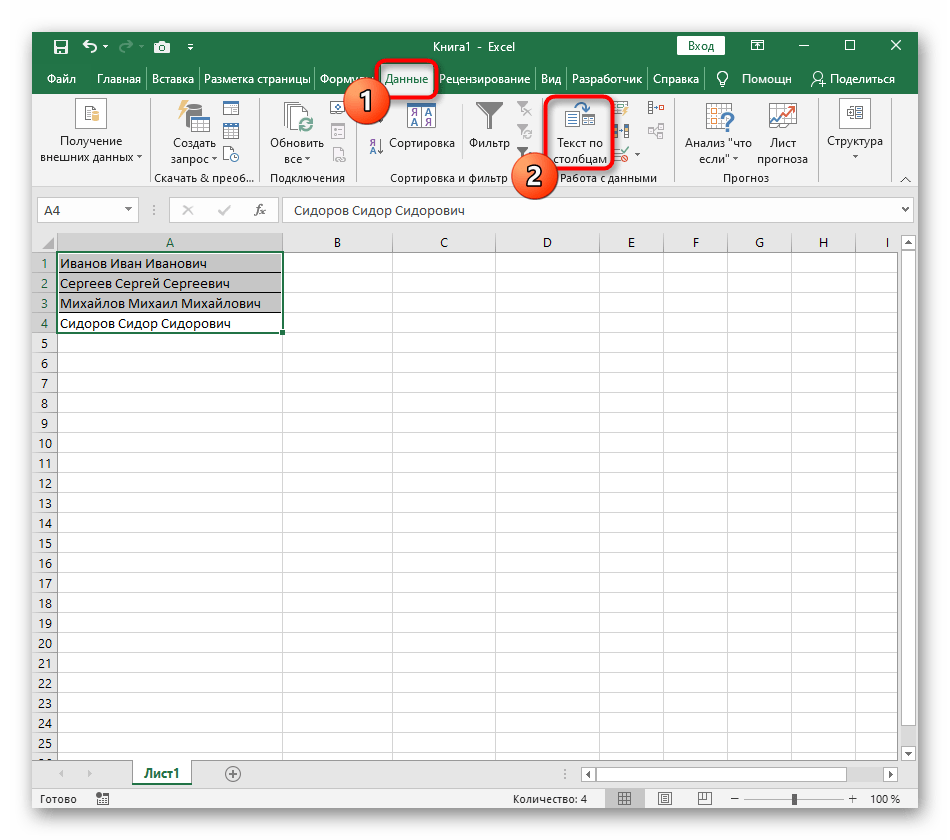
- После этого перейдите на вкладку «Данные» и нажмите кнопку «Текст по столбцам».
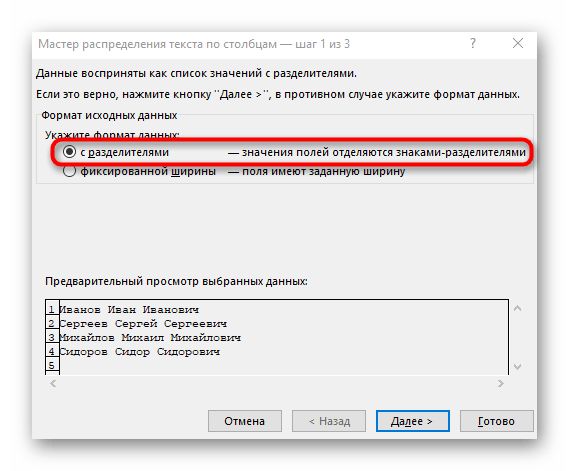
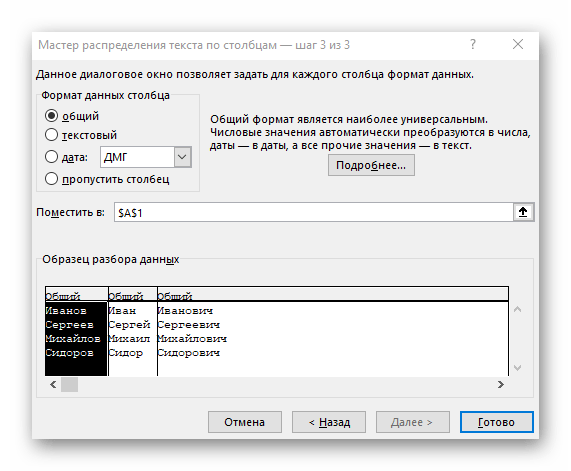
- Появится окно «Мастера разделения текста по столбцам», в котором нужно выбрать формат данных «с разделителями». Разделителем чаще всего выступает пробел, но если это другой знак препинания, понадобится указать его в следующем шаге.
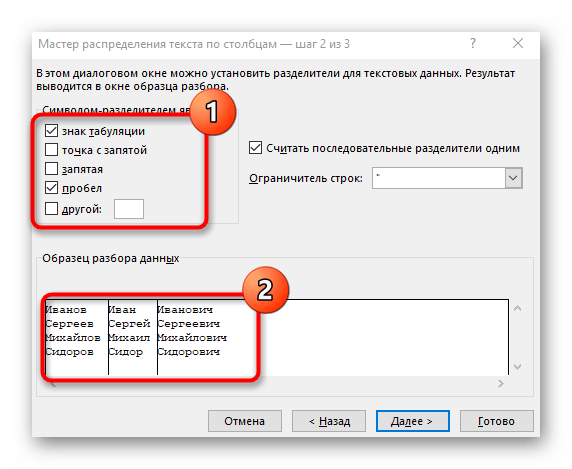
- Отметьте галочкой символ разделения или вручную впишите его, а затем ознакомьтесь с предварительным результатом разделения в окне ниже.
- В завершающем шаге можно указать новый формат столбцов и место, куда их необходимо поместить. Как только настройка будет завершена, нажмите «Готово» для применения всех изменения.
- Вернитесь к таблице и убедитесь в том, что разделение прошло успешно.
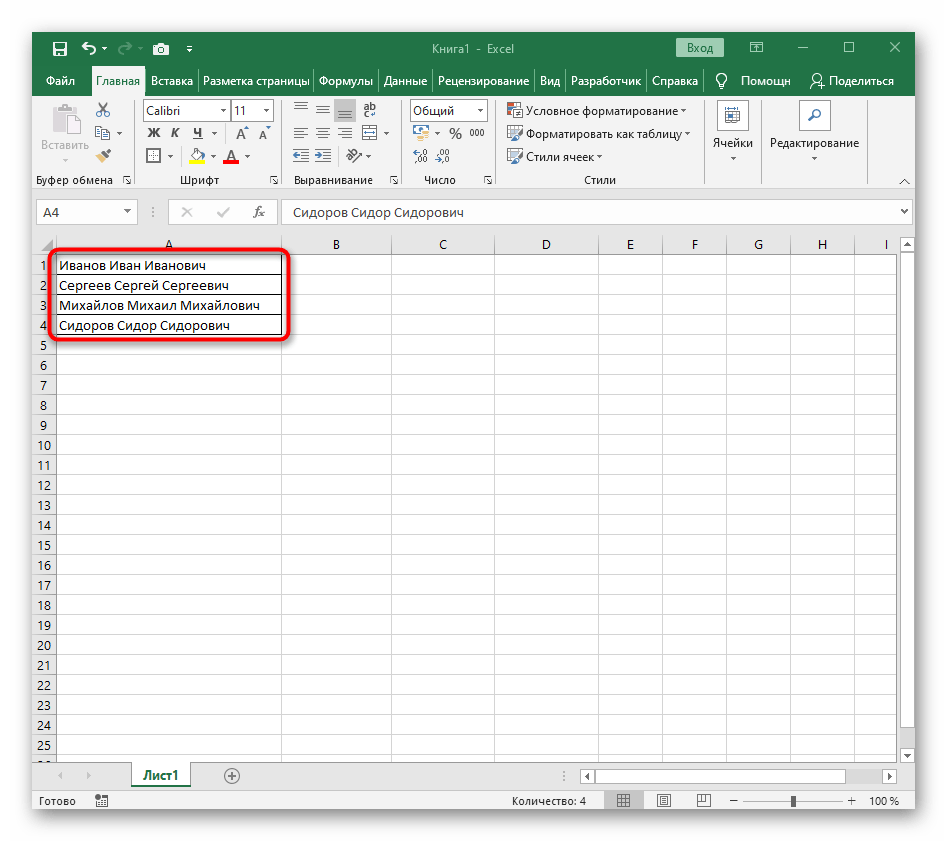
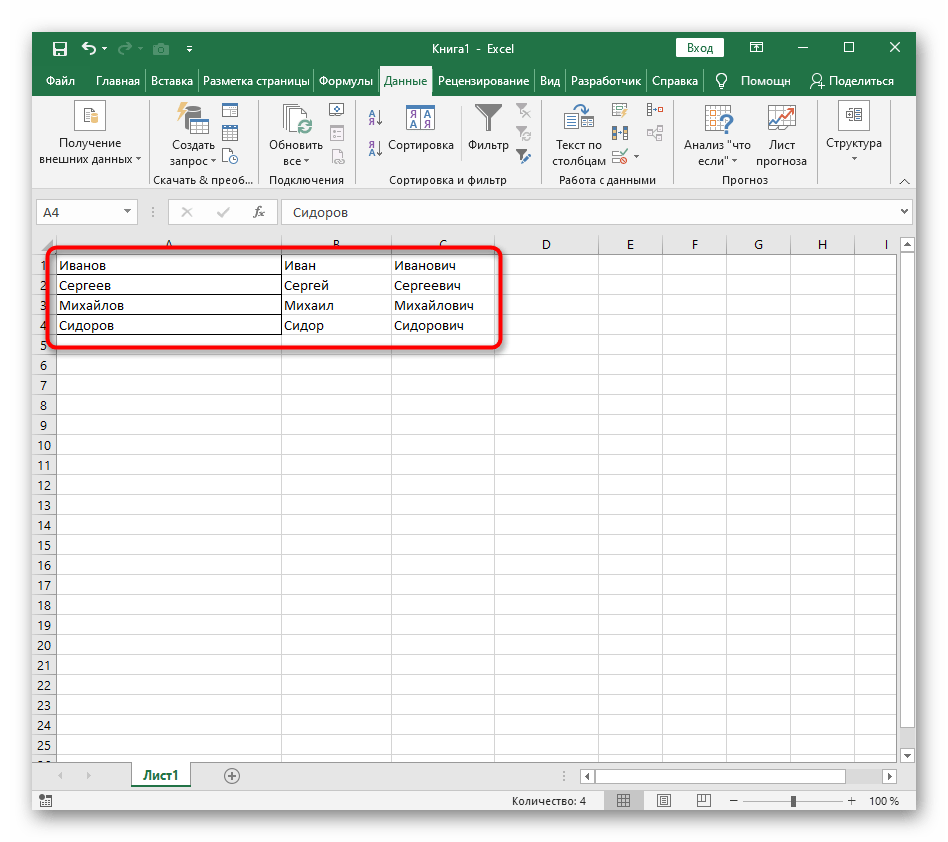
Из этой инструкции можно сделать вывод, что использование такого инструмента оптимально в тех ситуациях, когда разделение необходимо выполнить всего один раз, обозначив для каждого слова новый столбец. Однако если в таблицу постоянно вносятся новые данные, все время разделять их таким образом будет не совсем удобно, поэтому в таких случаях предлагаем ознакомиться со следующим способом.
Способ 2: Создание формулы разделения текста
В Excel можно самостоятельно создать относительно сложную формулу, которая позволит рассчитать позиции слов в ячейке, найти пробелы и разделить каждое на отдельные столбцы. В качестве примера мы возьмем ячейку, состоящую из трех слов, разделенных пробелами. Для каждого из них понадобится своя формула, поэтому разделим способ на три этапа.
Шаг 1: Разделение первого слова
Формула для первого слова самая простая, поскольку придется отталкиваться только от одного пробела для определения правильной позиции. Рассмотрим каждый шаг ее создания, чтобы сформировалась полная картина того, зачем нужны определенные вычисления.
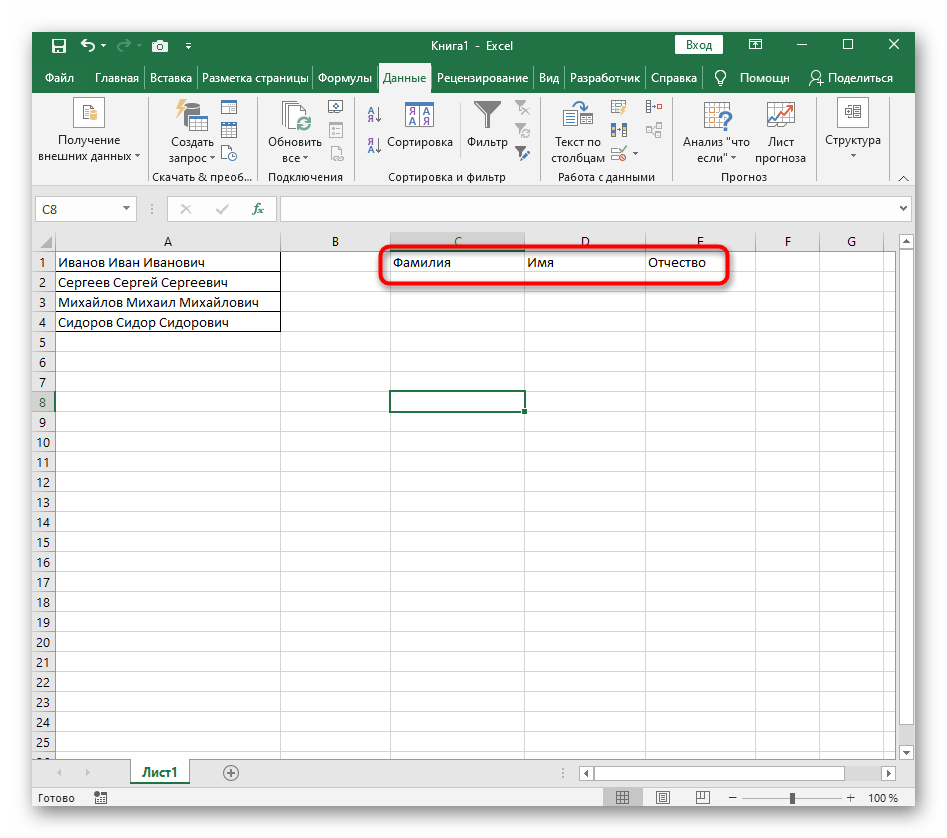
- Для удобства создадим три новые столбца с подписями, куда будем добавлять разделенный текст. Вы можете сделать так же или пропустить этот момент.
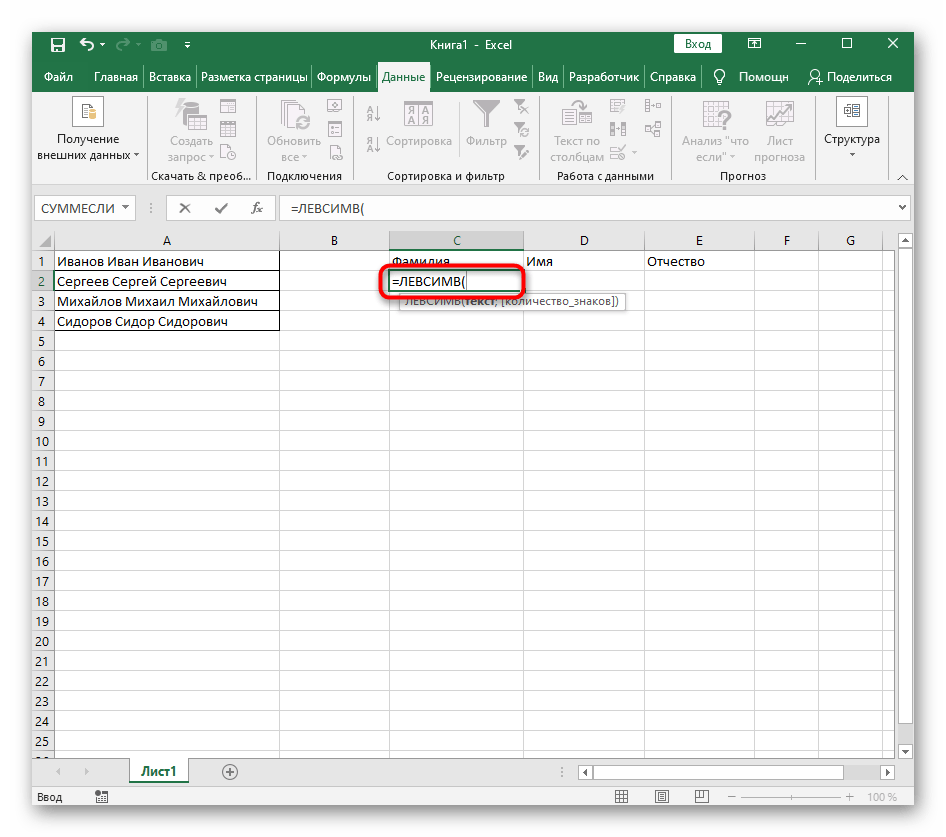
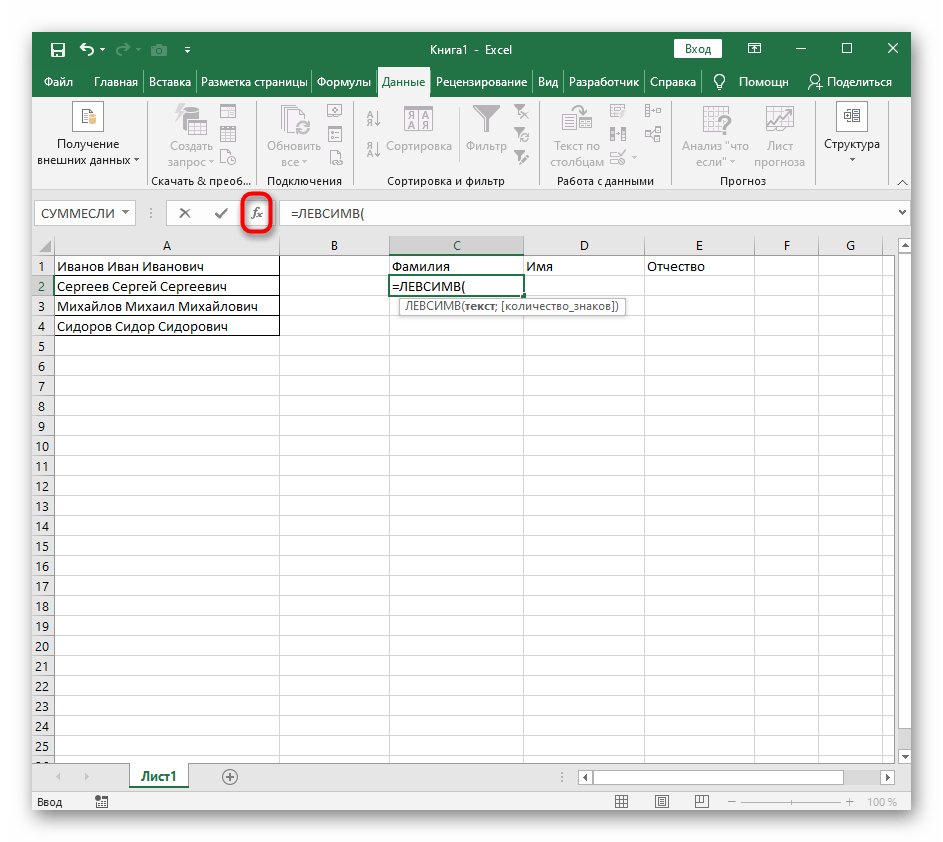
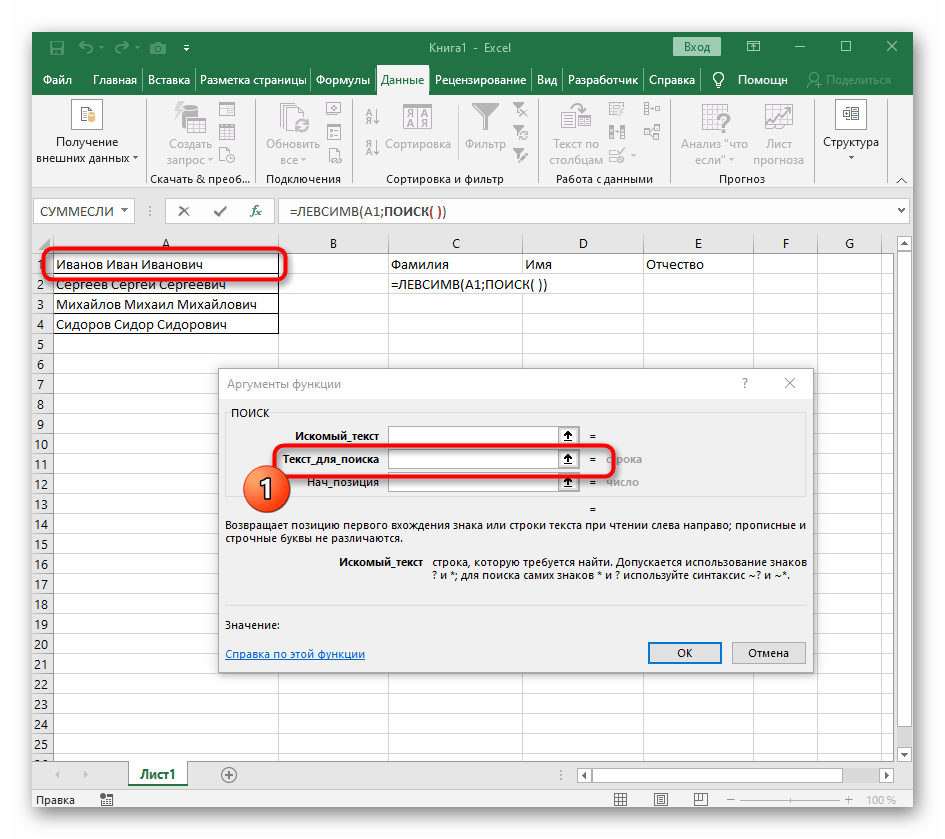
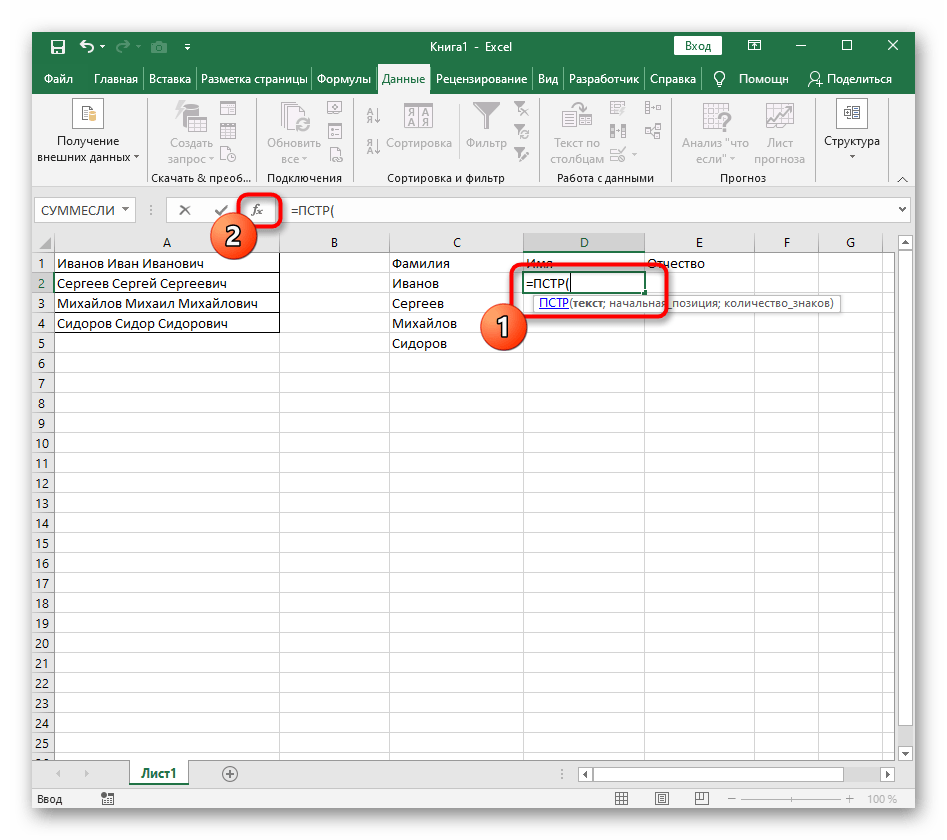
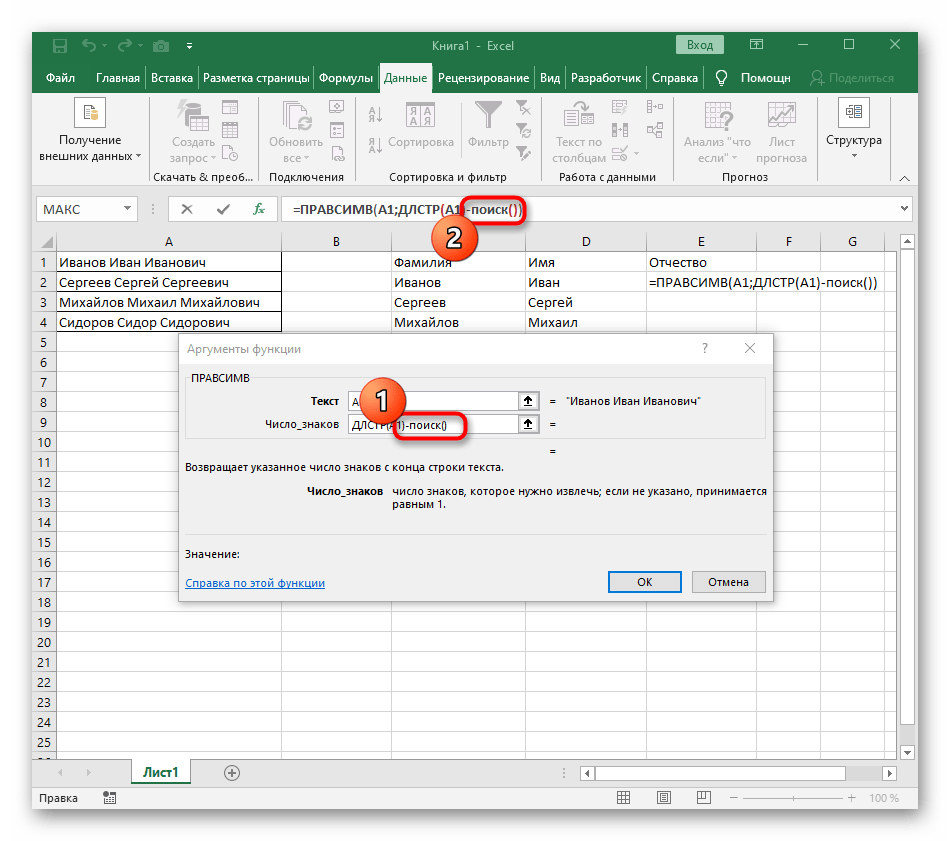
- Выберите ячейку, где хотите расположить первое слово, и запишите формулу
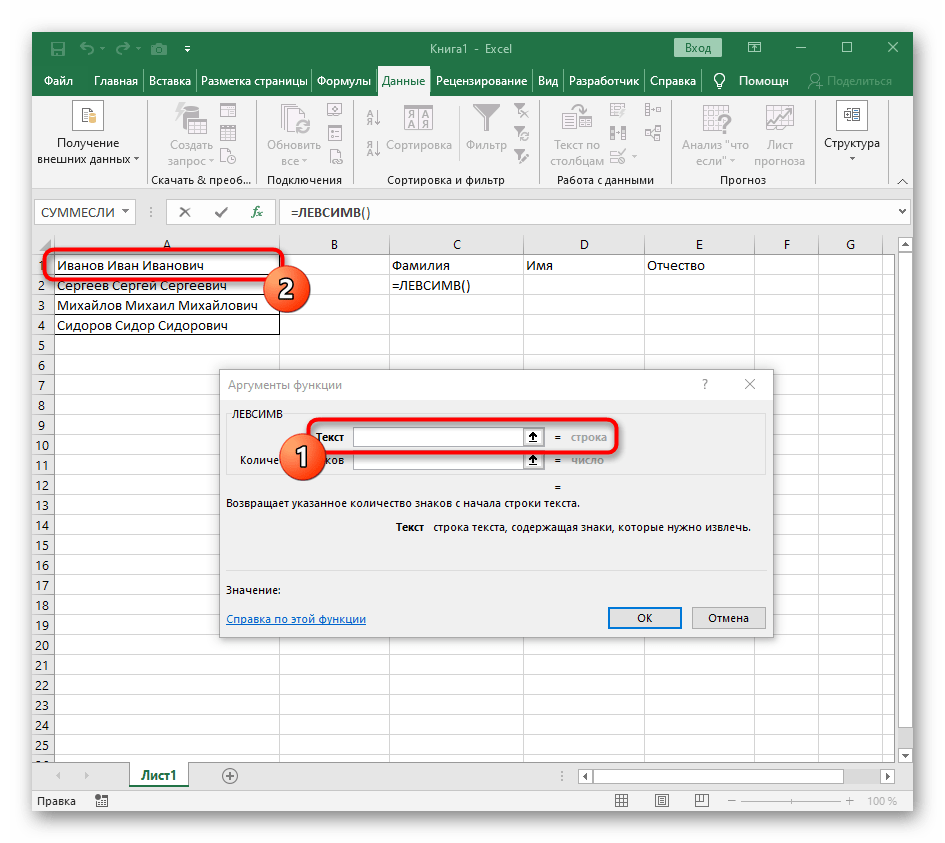
=ЛЕВСИМВ(. - После этого нажмите кнопку «Аргументы функции», перейдя тем самым в графическое окно редактирования формулы.
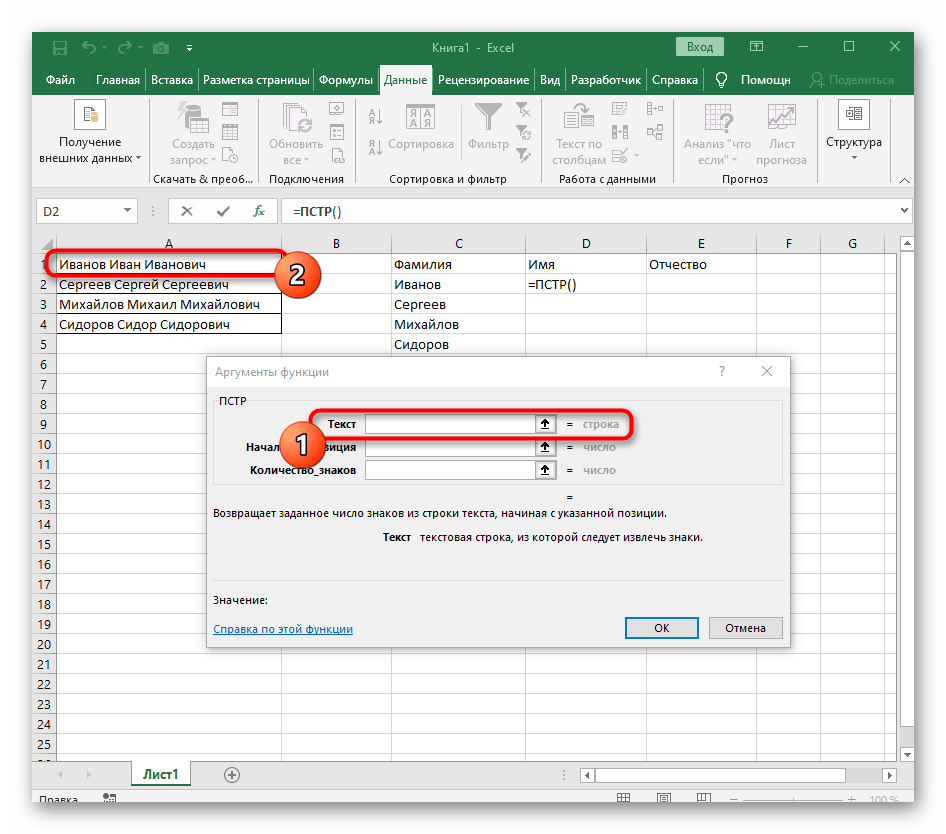
- В качестве текста аргумента указывайте ячейку с надписью, кликнув по ней левой кнопкой мыши на таблице.
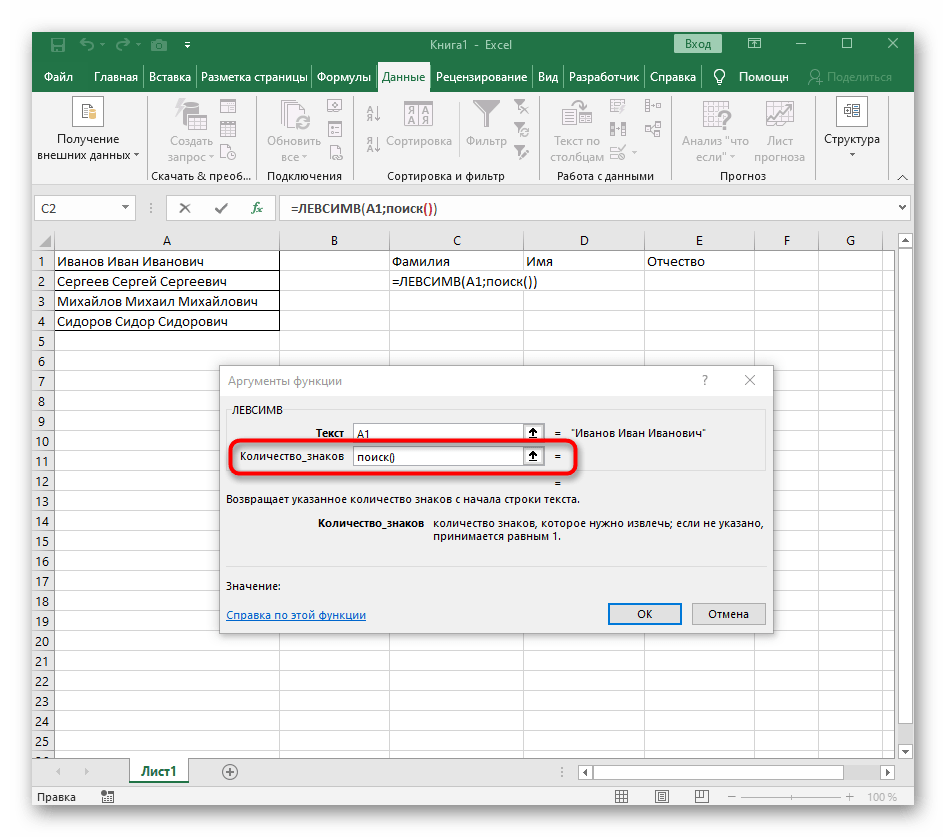
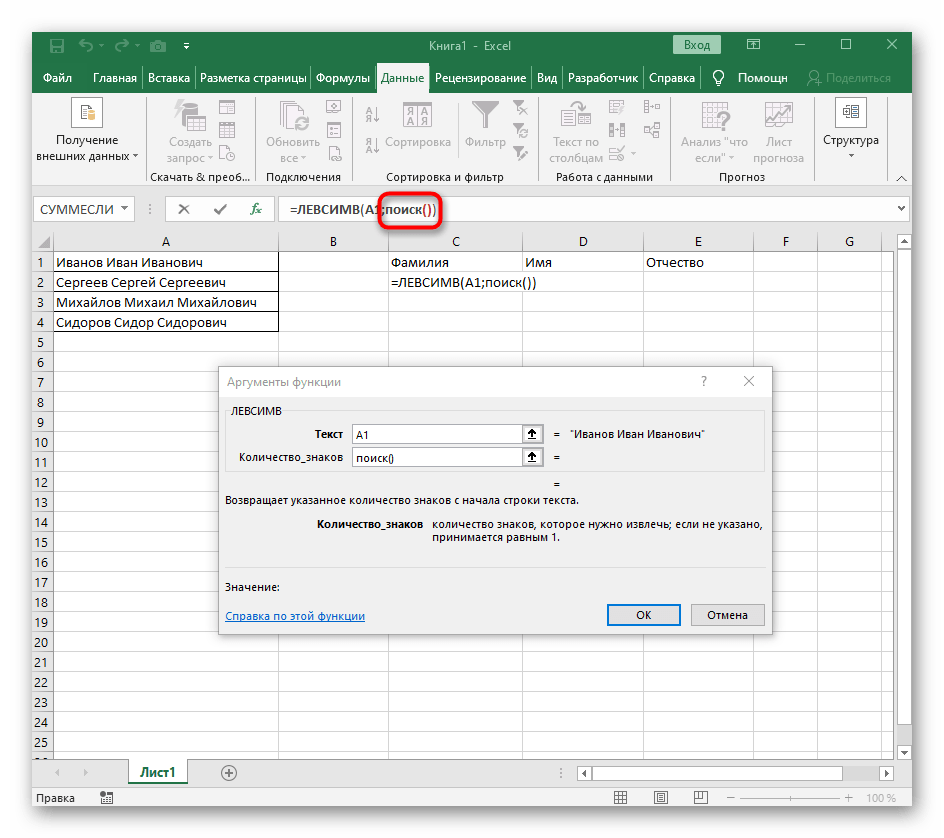
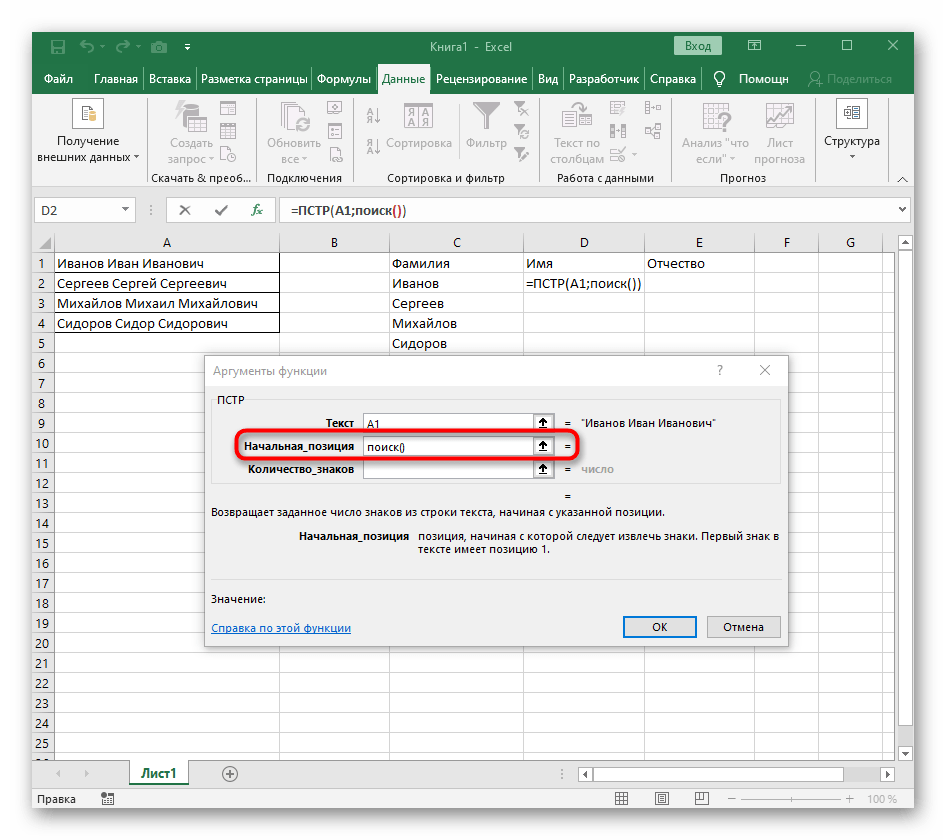
- Количество знаков до пробела или другого разделителя придется посчитать, но вручную мы это делать не будем, а воспользуемся еще одной формулой —
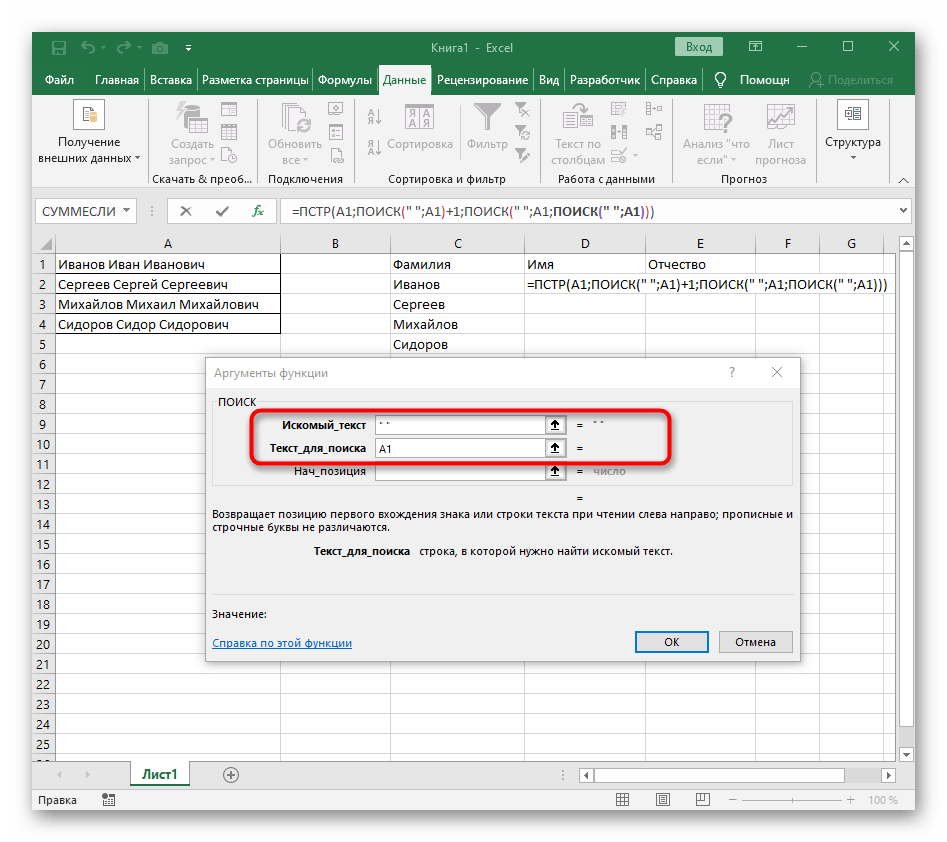
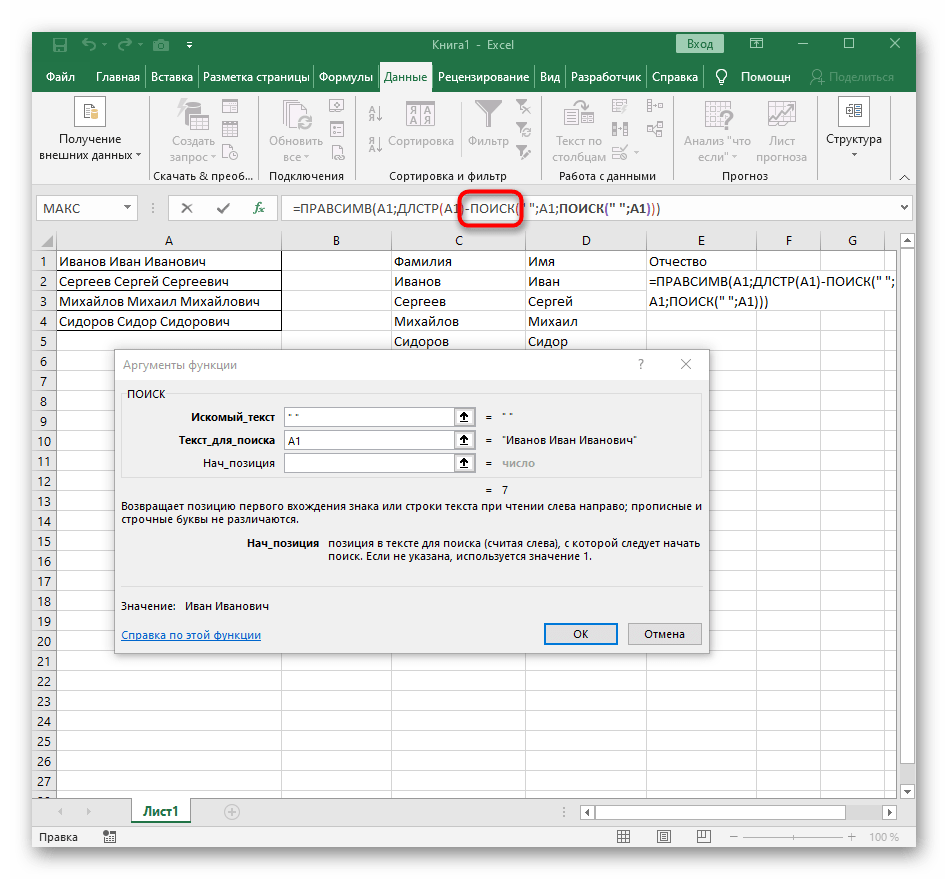
ПОИСК(). - Как только вы запишете ее в таком формате, она отобразится в тексте ячейки сверху и будет выделена жирным. Нажмите по ней для быстрого перехода к аргументам этой функции.
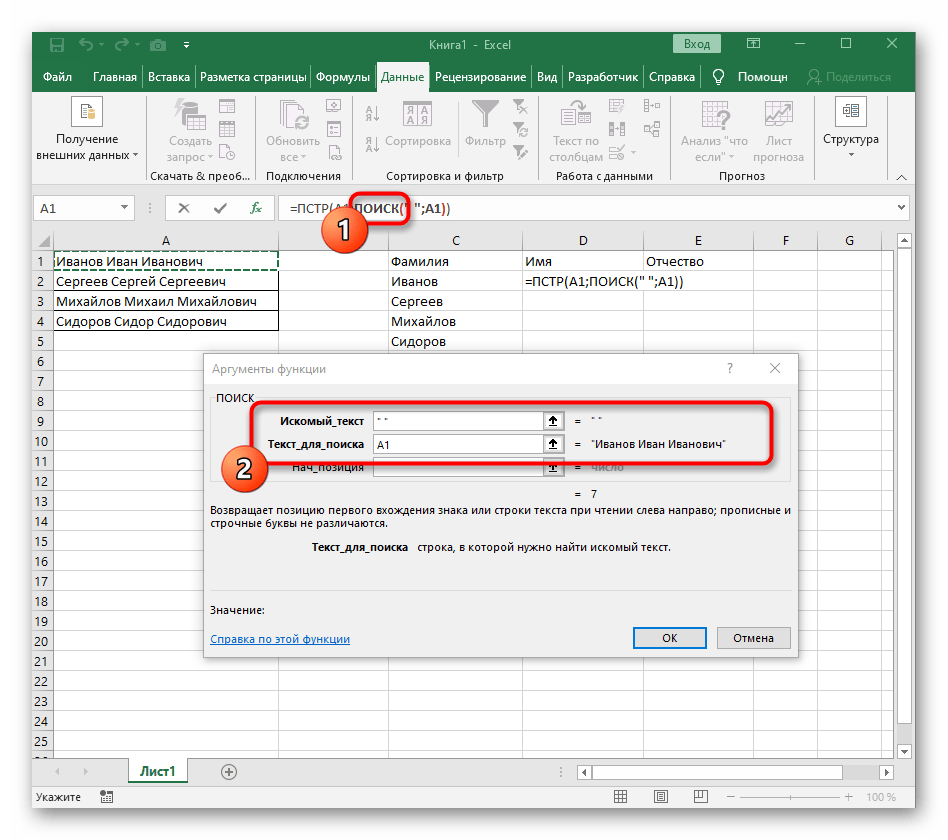
- В поле «Искомый_текст» просто поставьте пробел или используемый разделитель, поскольку он поможет понять, где заканчивается слово. В «Текст_для_поиска» укажите ту же обрабатываемую ячейку.
- Нажмите по первой функции, чтобы вернуться к ней, и добавьте в конце второго аргумента
-1. Это необходимо для того, чтобы формуле «ПОИСК» учитывать не искомый пробел, а символ до него. Как видно на следующем скриншоте, в результате выводится фамилия без каких-либо пробелов, а это значит, что составление формул выполнено правильно. - Закройте редактор функции и убедитесь в том, что слово корректно отображается в новой ячейке.
- Зажмите ячейку в правом нижнем углу и перетащите вниз на необходимое количество рядов, чтобы растянуть ее. Так подставляются значения других выражений, которые необходимо разделить, а выполнение формулы происходит автоматически.

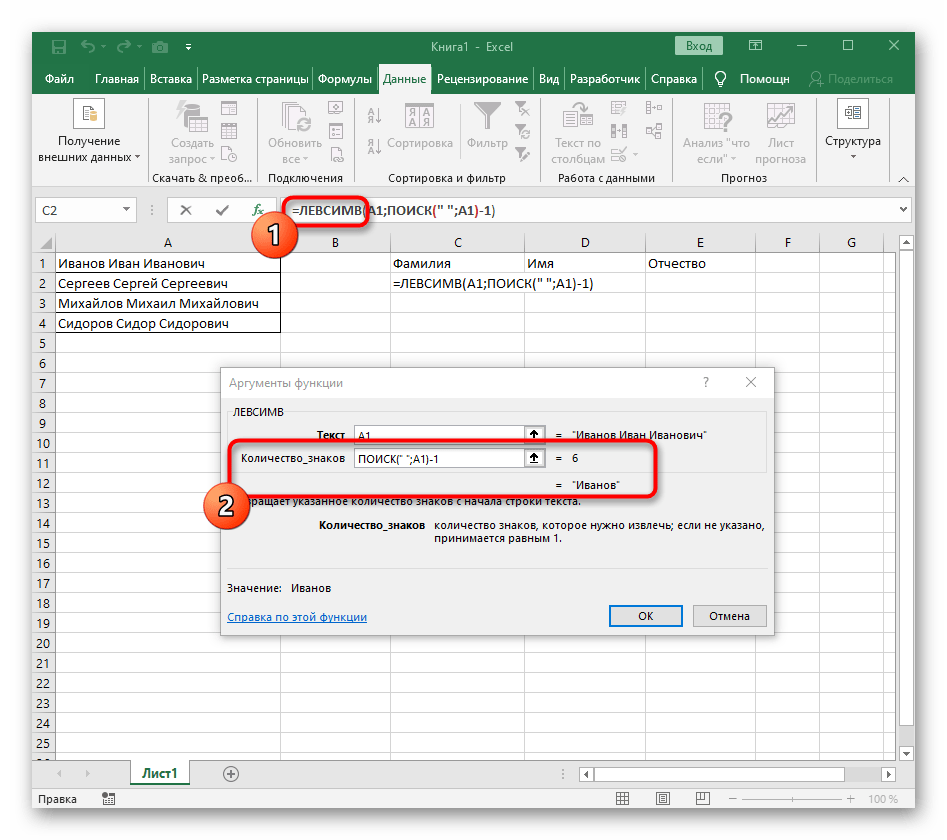
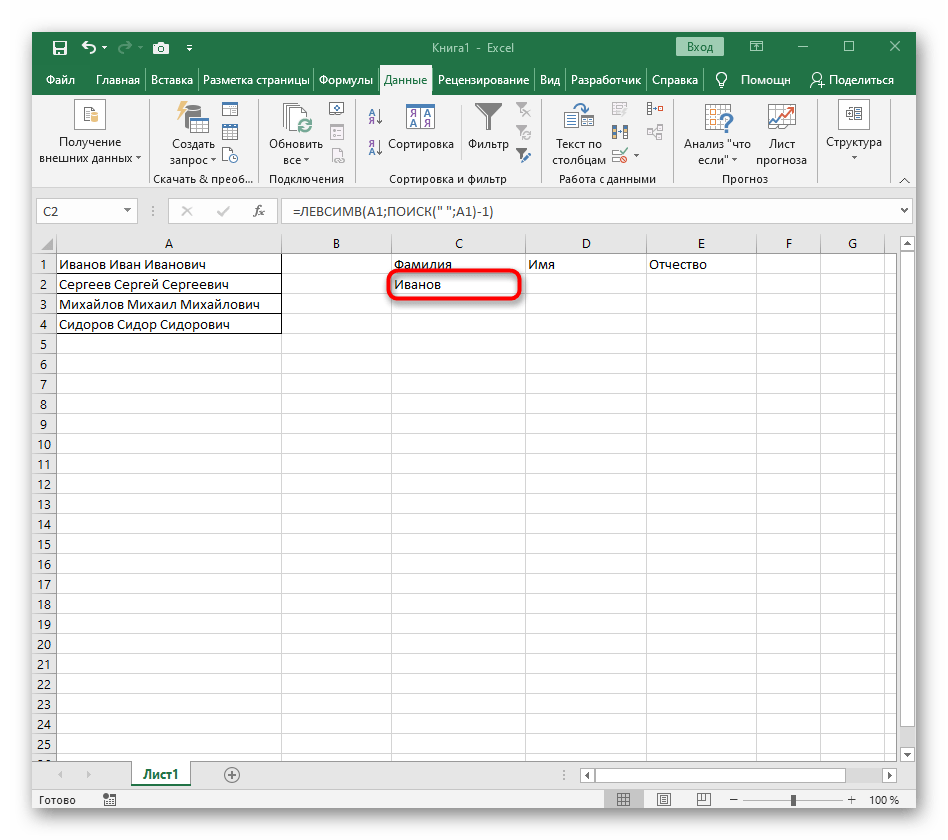
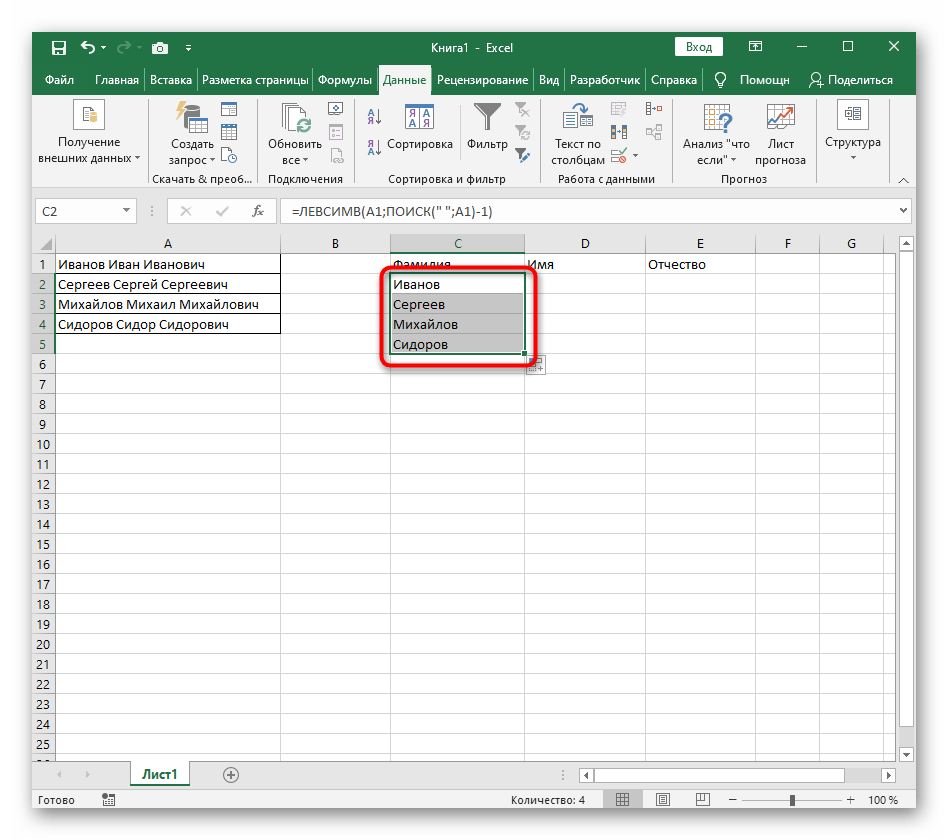
Полностью созданная формула имеет вид =ЛЕВСИМВ(A1;ПОИСК(" ";A1)-1), вы же можете создать ее по приведенной выше инструкции или вставить эту, если условия и разделитель подходят. Не забывайте заменить обрабатываемую ячейку.
Шаг 2: Разделение второго слова
Самое трудное — разделить второе слово, которым в нашем случае является имя. Связано это с тем, что оно с двух сторон окружено пробелами, поэтому придется учитывать их оба, создавая массивную формулу для правильного расчета позиции.
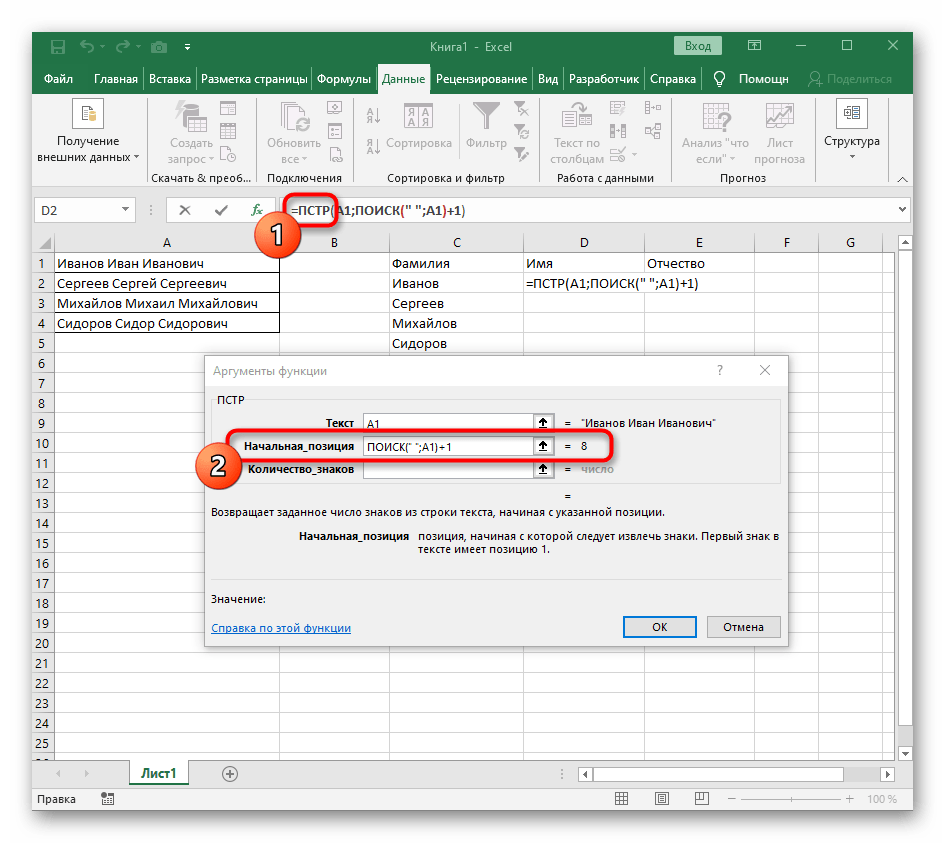
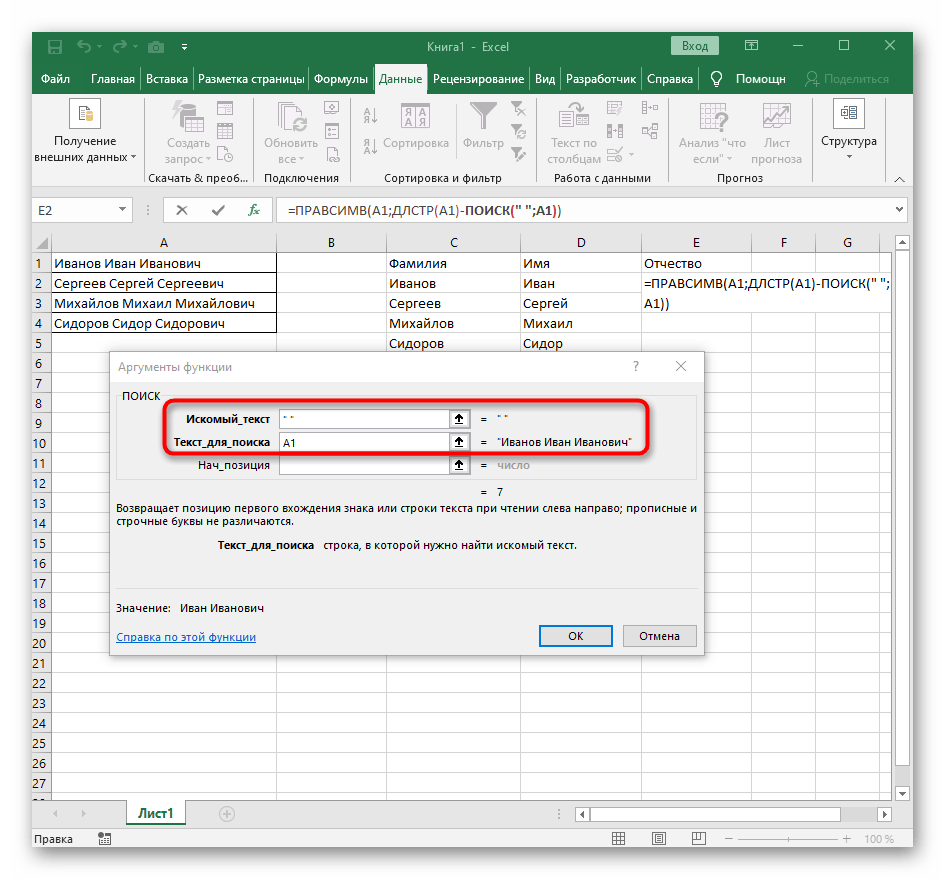
- В этом случае основной формулой станет
=ПСТР(— запишите ее в таком виде, а затем переходите к окну настройки аргументов. - Данная формула будет искать нужную строку в тексте, в качестве которого и выбираем ячейку с надписью для разделения.
- Начальную позицию строки придется определять при помощи уже знакомой вспомогательной формулы
ПОИСК(). - Создав и перейдя к ней, заполните точно так же, как это было показано в предыдущем шаге. В качестве искомого текста используйте разделитель, а ячейку указывайте как текст для поиска.
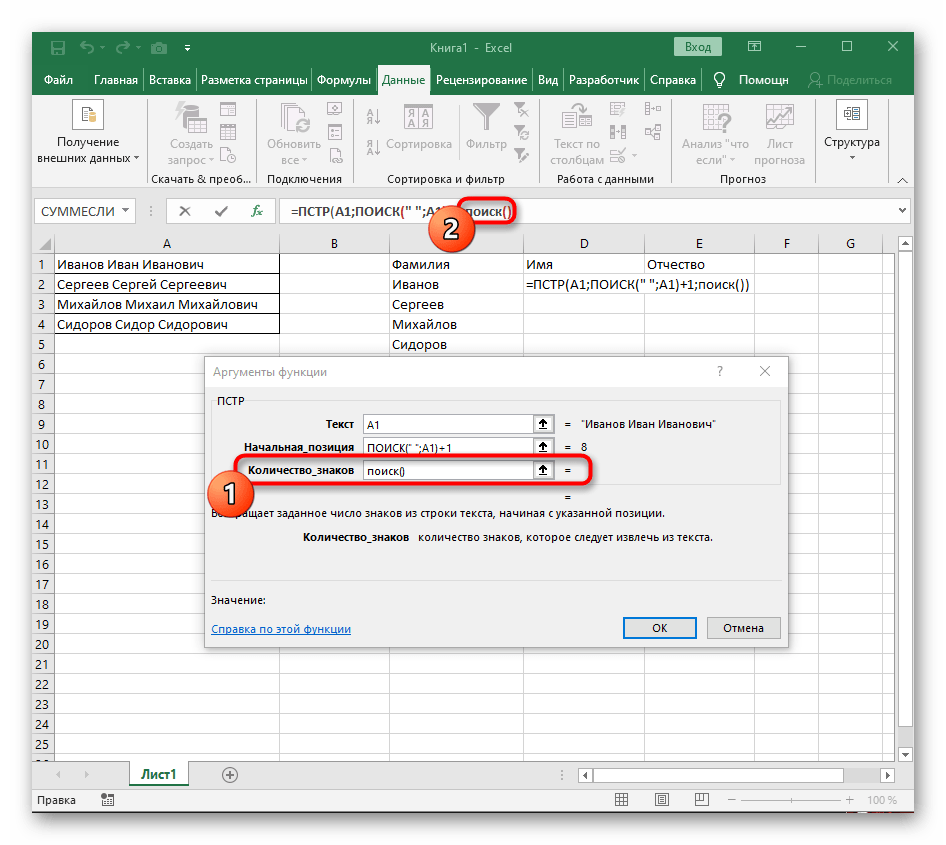
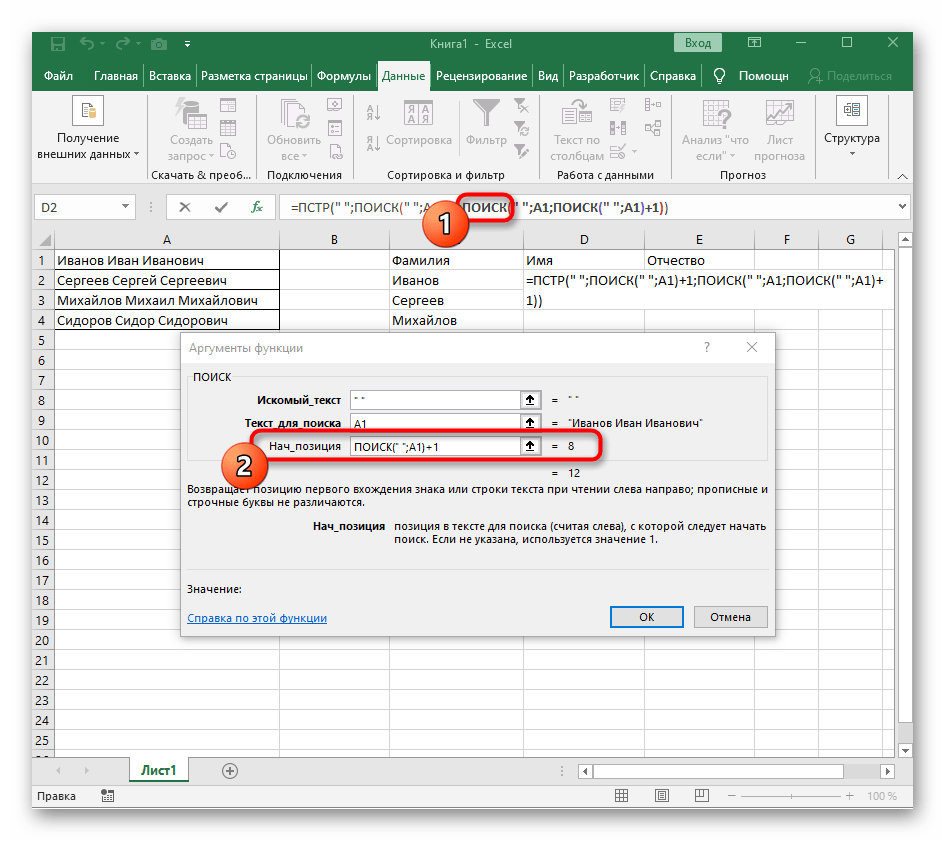
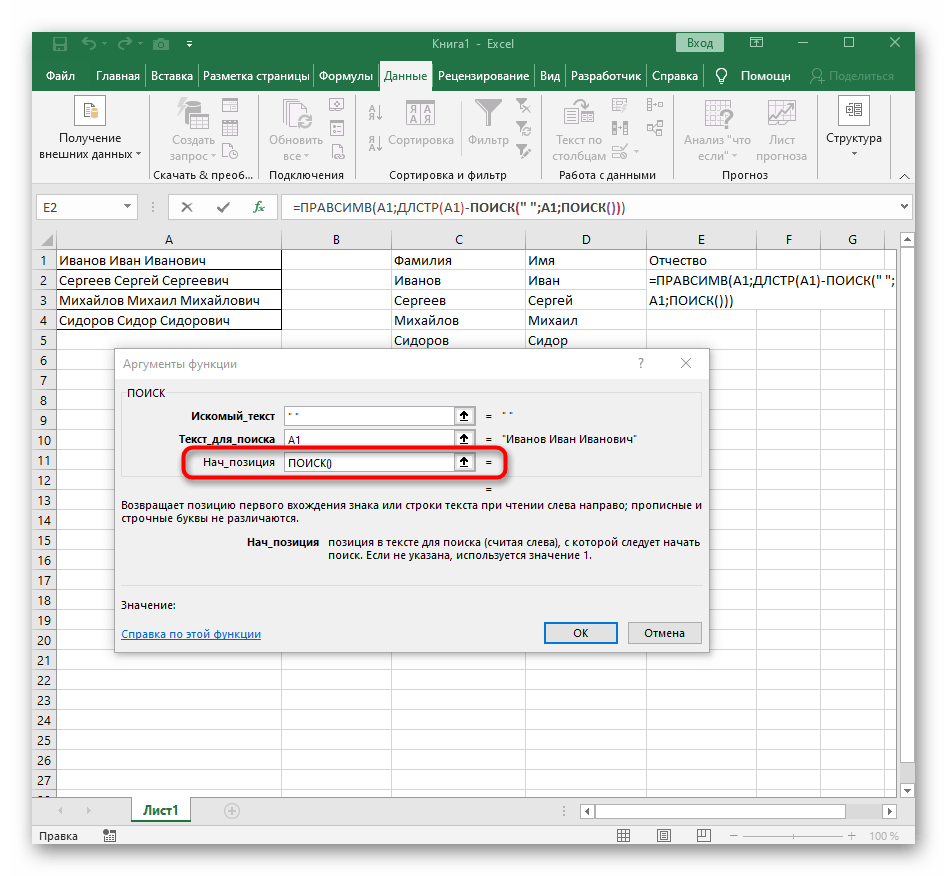
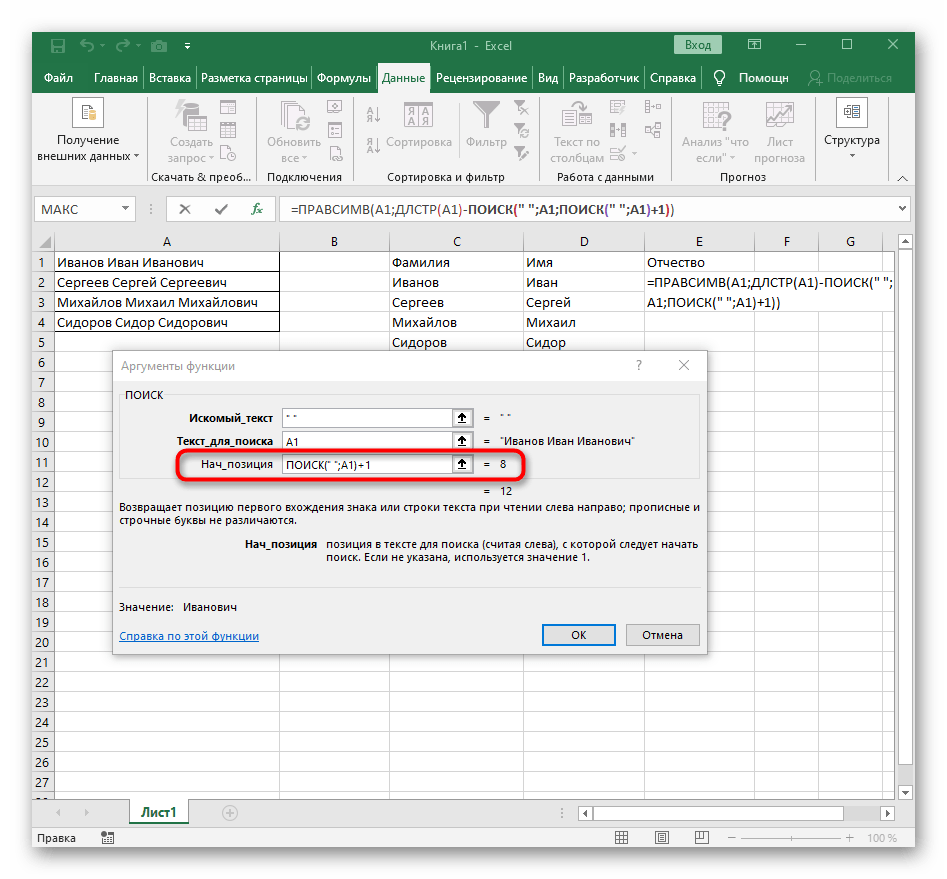
- Вернитесь к предыдущей формуле, где добавьте к функции «ПОИСК»
+1в конце, чтобы начинать счет со следующего символа после найденного пробела. - Сейчас формула уже может начать поиск строки с первого символа имени, но она пока еще не знает, где его закончить, поэтому в поле «Количество_знаков» снова впишите формулу
ПОИСК(). - Перейдите к ее аргументам и заполните их в уже привычном виде.
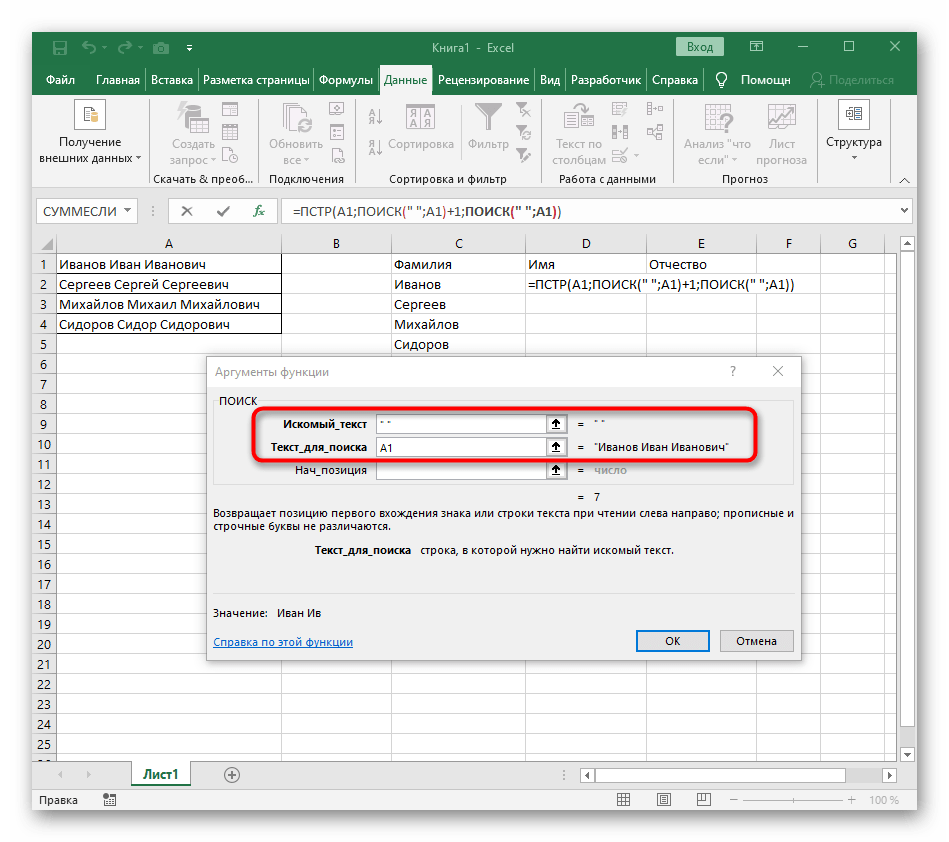
- Ранее мы не рассматривали начальную позицию этой функции, но теперь там нужно вписать тоже
ПОИСК(), поскольку эта формула должна находить не первый пробел, а второй. - Перейдите к созданной функции и заполните ее таким же образом.
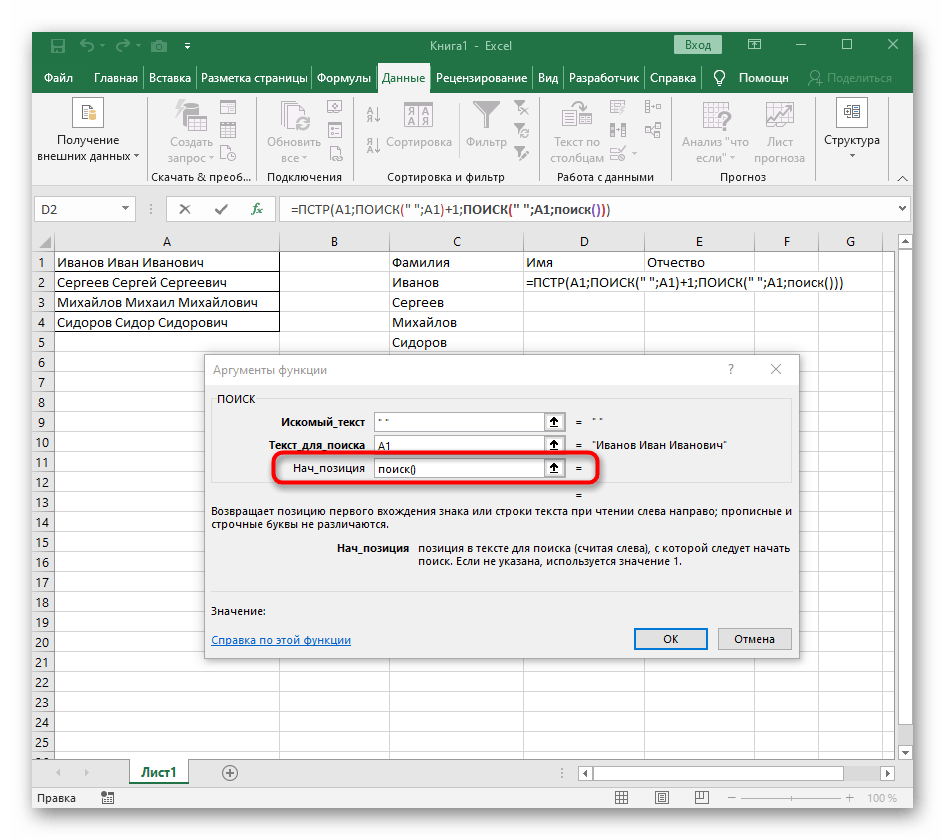
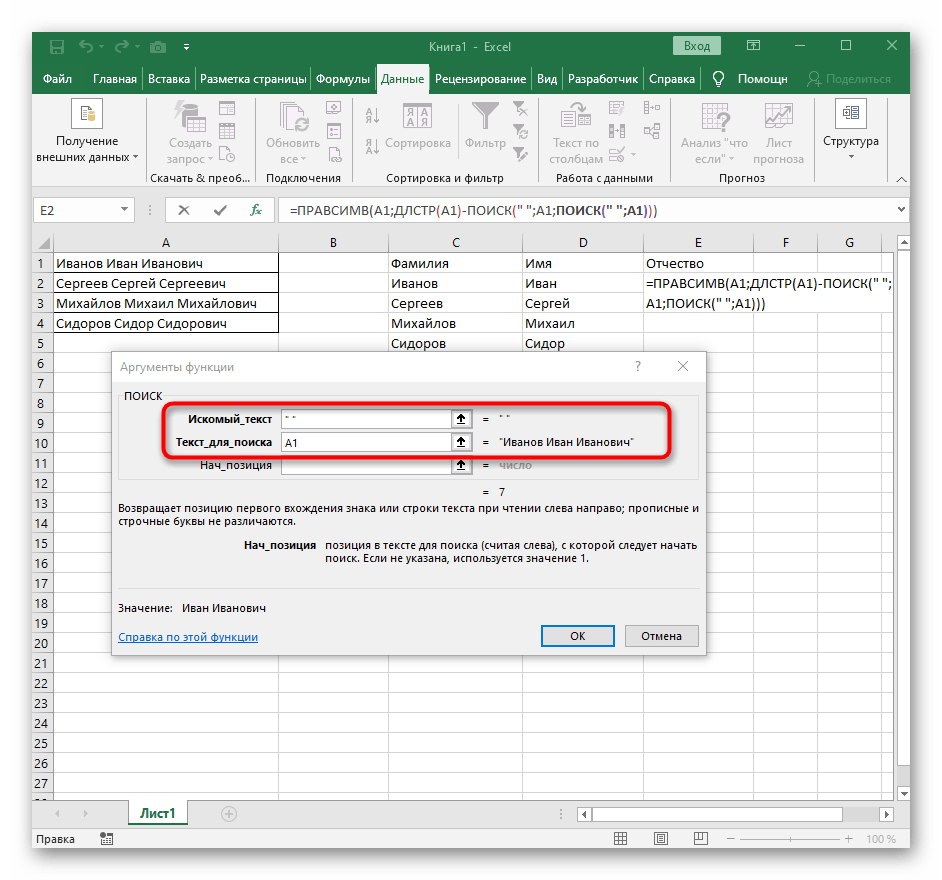
- Возвращайтесь к первому
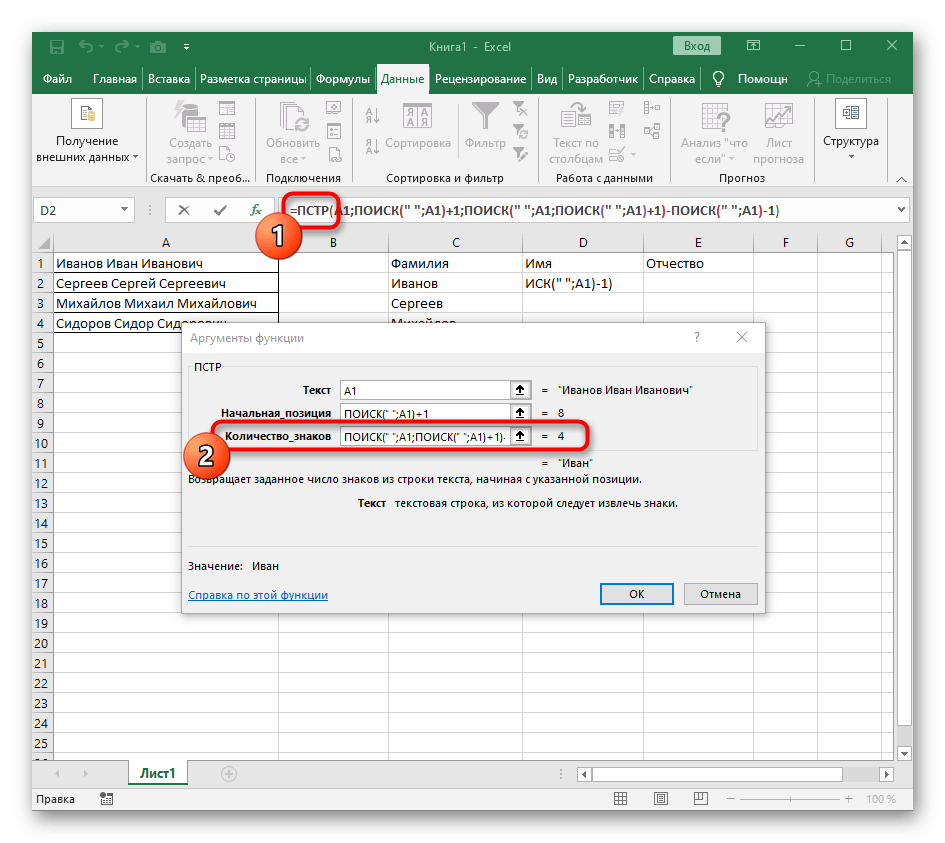
"ПОИСКУ"и допишите в «Нач_позиция»+1в конце, ведь для поиска строки нужен не пробел, а следующий символ. - Кликните по корню
=ПСТРи поставьте курсор в конце строки «Количество_знаков». - Допишите там выражение
-ПОИСК(" ";A1)-1)для завершения расчетов пробелов. - Вернитесь к таблице, растяните формулу и удостоверьтесь в том, что слова отображаются правильно.
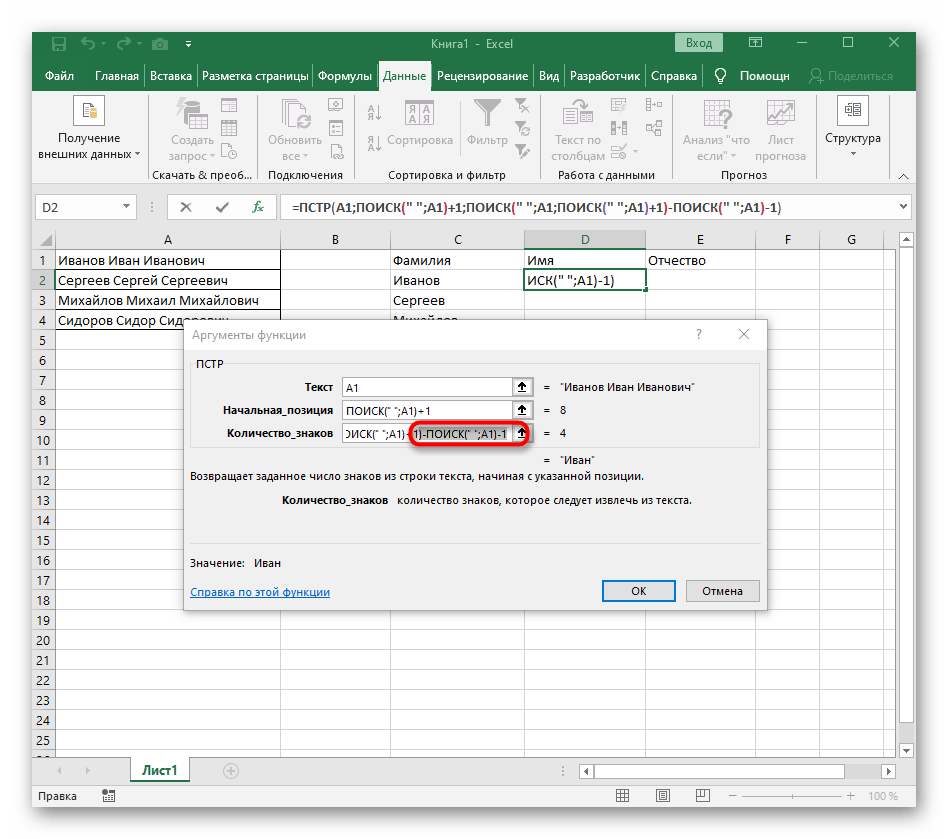
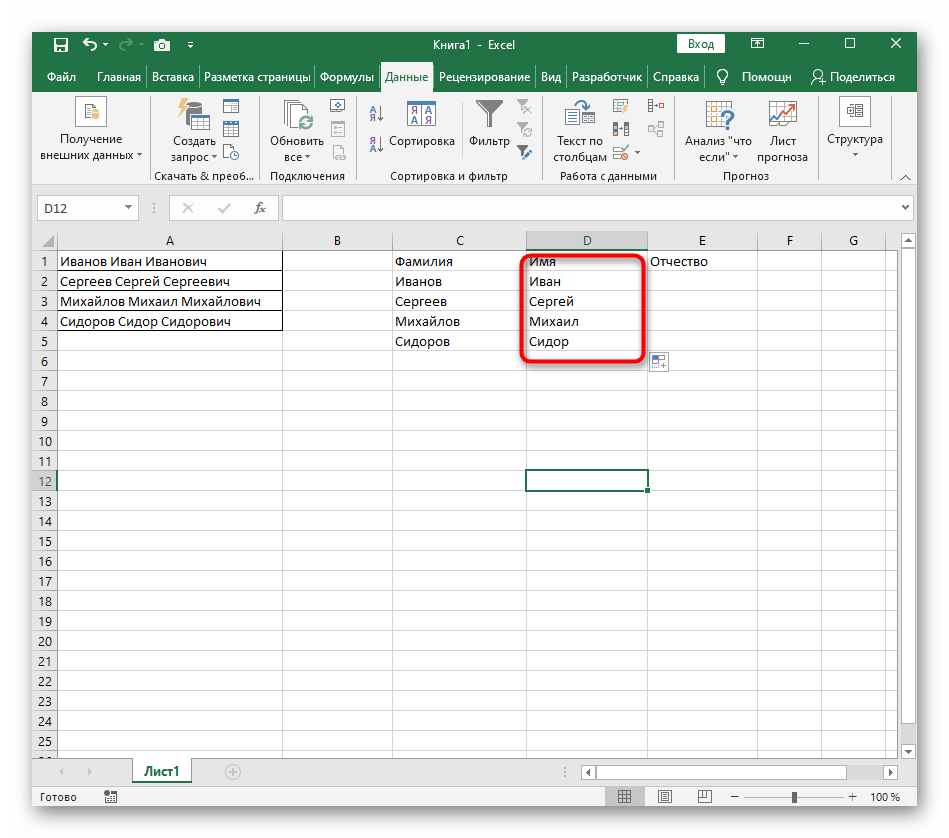
Формула получилась большая, и не все пользователи понимают, как именно она работает. Дело в том, что для поиска строки пришлось использовать сразу несколько функций, определяющих начальные и конечные позиции пробелов, а затем от них отнимался один символ, чтобы в результате эти самые пробелы не отображались. В итоге формула такая: =ПСТР(A1;ПОИСК(" ";A1)+1;ПОИСК(" ";A1;ПОИСК(" ";A1)+1)-ПОИСК(" ";A1)-1). Используйте ее в качестве примера, заменяя номер ячейки с текстом.
Шаг 3: Разделение третьего слова
Последний шаг нашей инструкции подразумевает разделение третьего слова, что выглядит примерно так же, как это происходило с первым, но общая формула немного меняется.
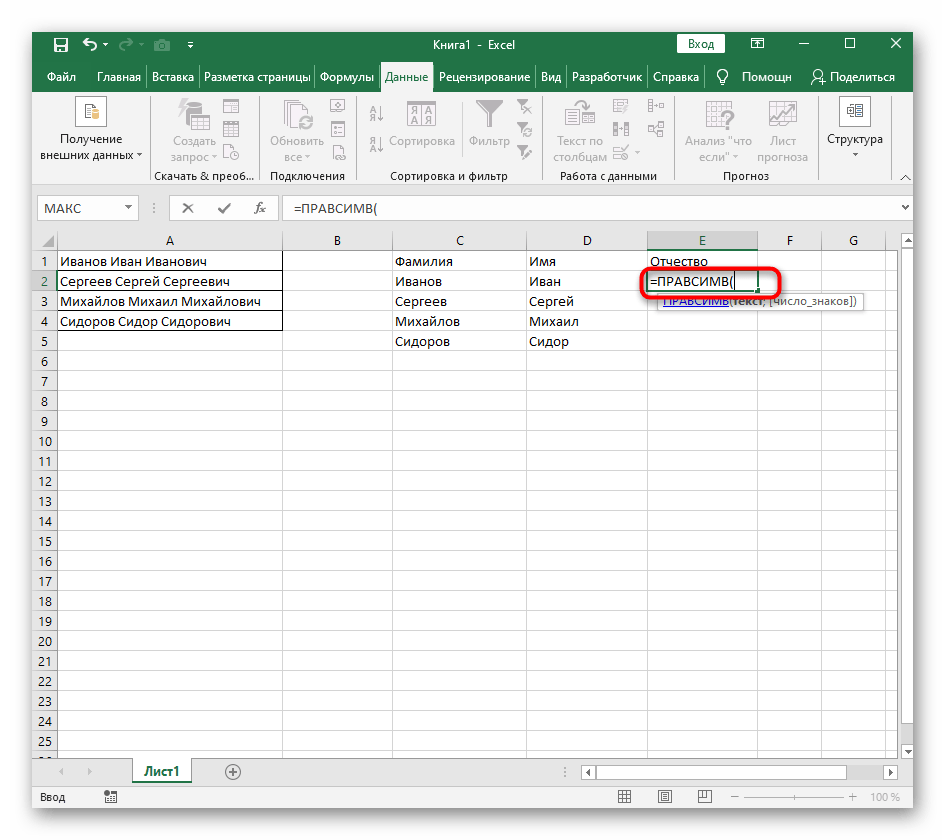
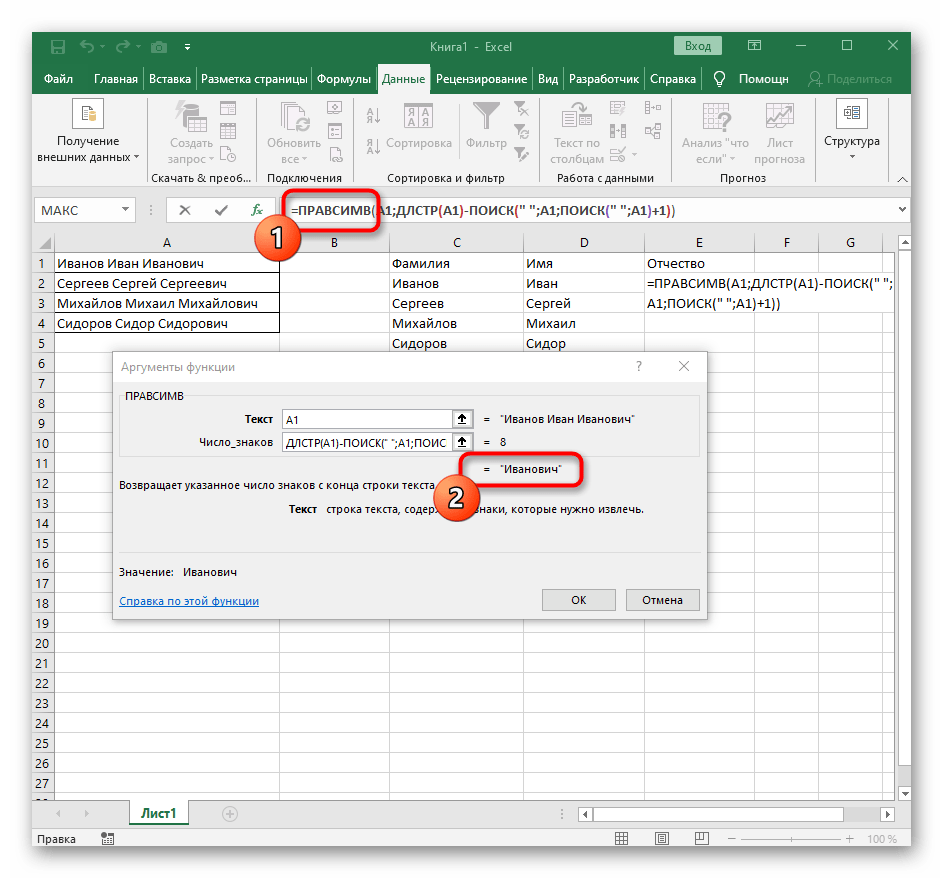
- В пустой ячейке для расположения будущего текста напишите
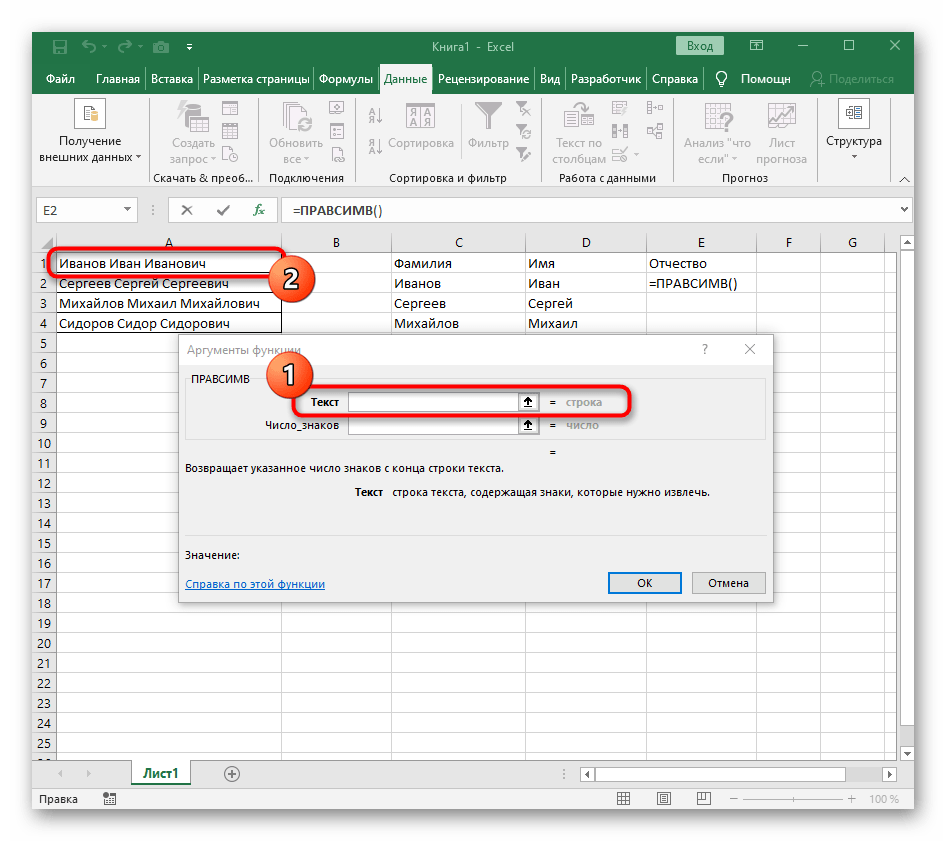
=ПРАВСИМВ(и перейдите к аргументам этой функции. - В качестве текста указывайте ячейку с надписью для разделения.
- В этот раз вспомогательная функция для поиска слова называется
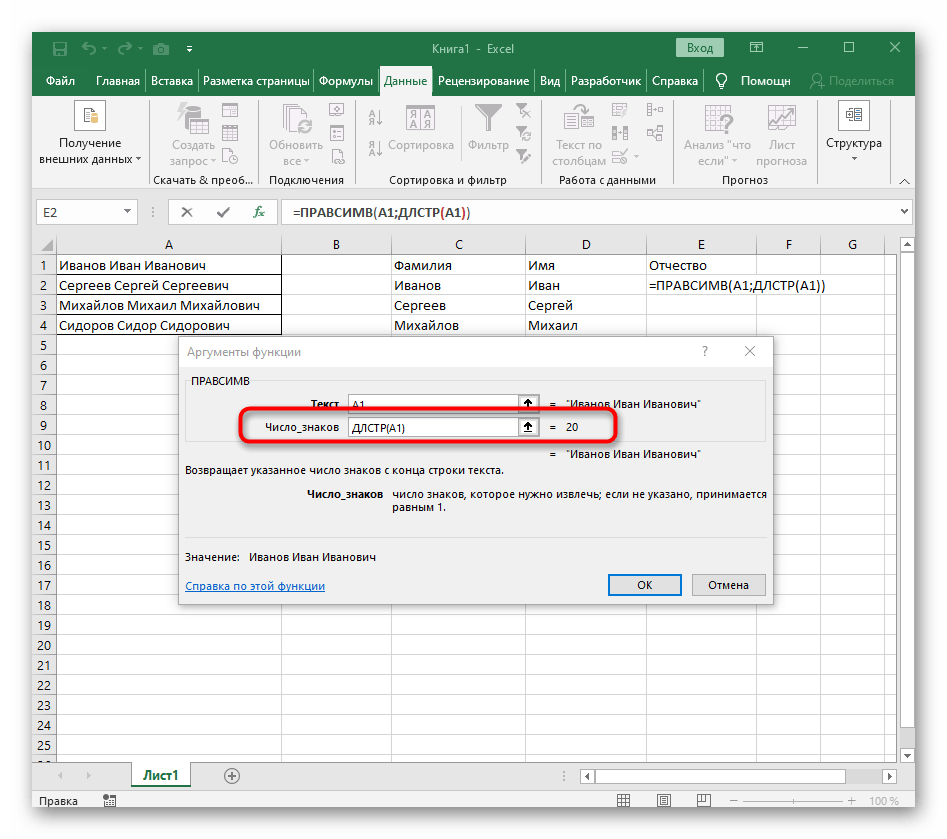
ДЛСТР(A1), где A1 — та же самая ячейка с текстом. Эта функция определяет количество знаков в тексте, а нам останется выделить только подходящие. - Для этого добавьте
-ПОИСК()и перейдите к редактированию этой формулы. - Введите уже привычную структуру для поиска первого разделителя в строке.
- Добавьте для начальной позиции еще один
ПОИСК(). - Ему укажите ту же самую структуру.
- Вернитесь к предыдущей формуле «ПОИСК».
- Прибавьте для его начальной позиции
+1. - Перейдите к корню формулы
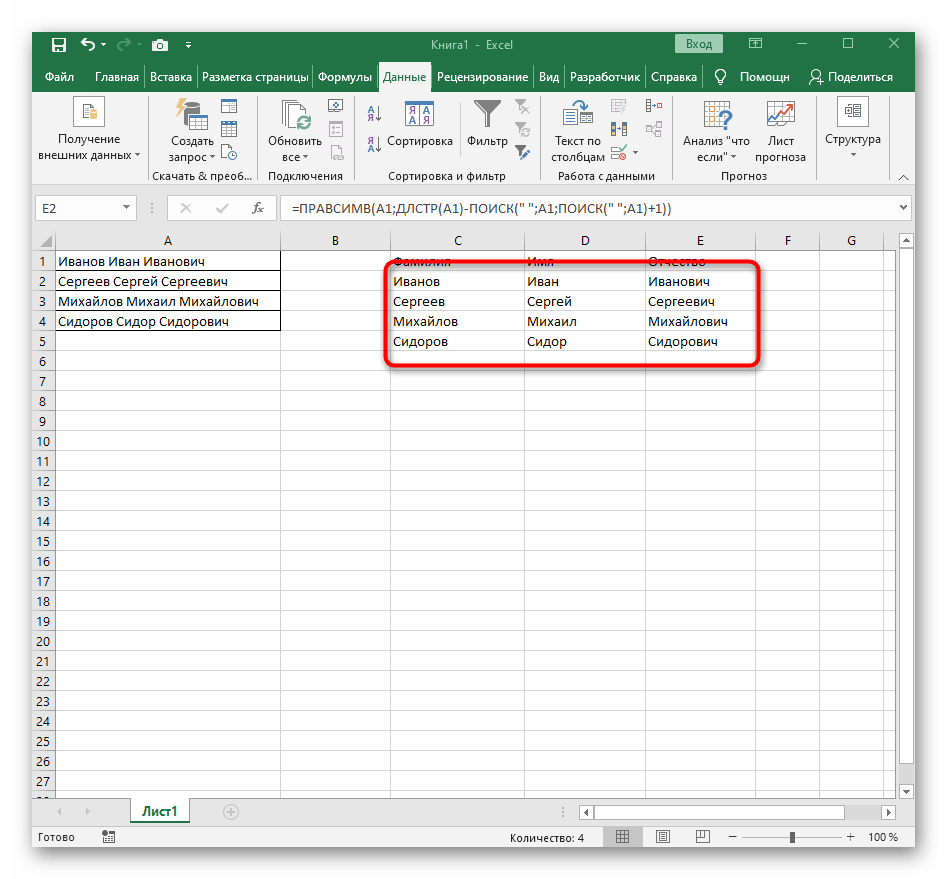
ПРАВСИМВи убедитесь в том, что результат отображается правильно, а уже потом подтверждайте внесение изменений. Полная формула в этом случае выглядит как=ПРАВСИМВ(A1;ДЛСТР(A1)-ПОИСК(" ";A1;ПОИСК(" ";A1)+1)). - В итоге на следующем скриншоте вы видите, что все три слова разделены правильно и находятся в своих столбцах. Для этого пришлось использовать самые разные формулы и вспомогательные функции, но это позволяет динамически расширять таблицу и не беспокоиться о том, что каждый раз придется разделять текст заново. По необходимости просто расширяйте формулу путем ее перемещения вниз, чтобы следующие ячейки затрагивались автоматически.
Еще статьи по данной теме:
Помогла ли Вам статья?
Skip to content
В руководстве объясняется, как разделить ячейки в Excel с помощью формул и стандартных инструментов. Вы узнаете, как разделить текст запятой, пробелом или любым другим разделителем, а также как разбить строки на текст и числа.
Разделение текста из одной ячейки на несколько — это задача, с которой время от времени сталкиваются все пользователи Excel. В одной из наших предыдущих статей мы обсуждали, как разделить ячейки в Excel с помощью функции «Текст по столбцам» и «Мгновенное заполнение». Сегодня мы подробно рассмотрим, как можно разделить текст по ячейкам с помощью формул.
Чтобы разбить текст в Excel, вы обычно используете функции ЛЕВСИМВ (LEFT), ПРАВСИМВ (RIGHT) или ПСТР (MID) в сочетании с НАЙТИ (FIND) или ПОИСК (SEARCH). На первый взгляд, некоторые рассмотренные ниже приёмы могут показаться сложными. Но на самом деле логика довольно проста, и следующие примеры помогут вам разобраться.
Для преобразования текста в ячейках в Excel ключевым моментом является определение положения разделителя в нем. Что может быть таким разделителем? Это запятая, точка с запятой, наклонная черта, двоеточие, тире, восклицательный знак и т.п. И, как мы далее увидим, даже целое слово.
- Как распределить ФИО по столбцам
- Как использовать разделители в тексте
- Разделяем текст по переносам строки
- Как разделить длинный текст на множество столбцов
- Как разбить «текст + число» по разным ячейкам
- Как разбить ячейку вида «число + текст»
- Разделение ячейки по маске (шаблону)
- Использование инструмента Split Text
В зависимости от вашей задачи эту проблему можно решить с помощью функции ПОИСК (без учета регистра букв) или НАЙТИ (с учетом регистра).
Как только вы определите позицию разделителя, используйте функцию ЛЕВСИМВ, ПРАВСИМВ и ПСТР, чтобы извлечь соответствующую часть содержимого.
Для лучшего понимания пошагово рассмотрим несколько примеров.
Делим текст вида ФИО по столбцам.
Если выяснение загадочных поворотов формул Excel — не ваше любимое занятие, вам может понравиться визуальный метод разделения ячеек, который демонстрируется ниже.
В столбце A нашей таблицы записаны Фамилии, имена и отчества сотрудников. Необходимо разделить их на 3 столбца.
Можно сделать это при помощи инструмента «Текст по столбцам». Об этом методе мы достаточно подробно рассказывали, когда рассматривали, как можно разделить ячейку по столбцам.
Кратко напомним:
На ленте «Данные» выбираем «Текст по столбцам» — с разделителями.

Далее в качестве разделителя выбираем пробел.
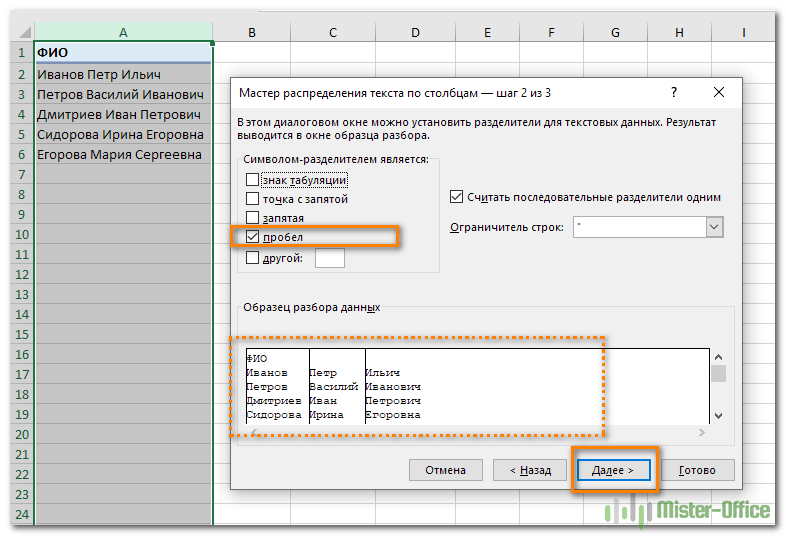
Обращаем внимание на то, как разделены наши данные в окне образца.
В следующем окне определяем формат данных. По умолчанию там будет «Общий». Он нас вполне устраивает, поэтому оставляем как есть. Выбираем левую верхнюю ячейку диапазона, в который будет помещен наш разделенный текст. Если нужно оставить в неприкосновенности исходные данные, лучше выбрать B1, к примеру.
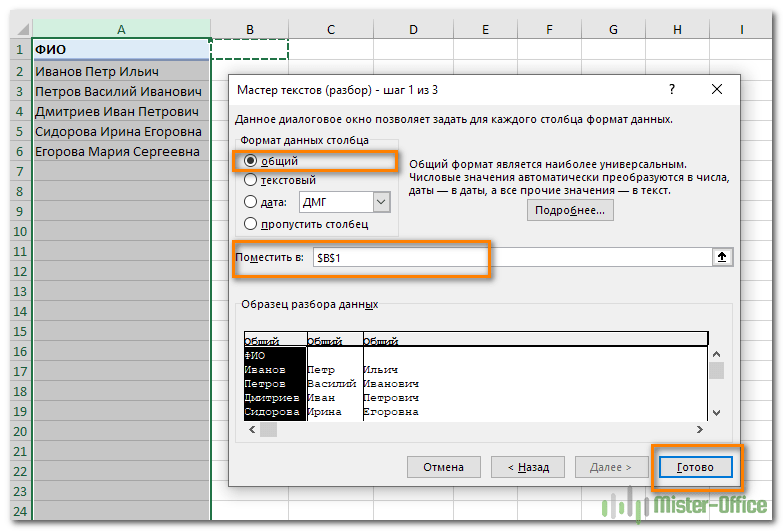
В итоге имеем следующую картину:

При желании можно дать заголовки новым столбцам B,C,D.
А теперь давайте тот же результат получим при помощи формул.
Для многих это удобнее. В том числе и по той причине, что если в таблице появятся новые данные, которые нужно разделить, то нет необходимости повторять всю процедуру с начала, а просто нужно скопировать уже имеющиеся формулы.
Итак, чтобы выделить из нашего ФИО фамилию, будем использовать выражение
=ЛЕВСИМВ(A2; ПОИСК(» «;A2;1)-1)
В качестве разделителя мы используем пробел. Функция ПОИСК указывает нам, в какой позиции находится первый пробел. А затем именно это количество букв (за минусом 1, чтобы не извлекать сам пробел) мы «отрезаем» слева от нашего ФИО при помощи ЛЕВСИМВ.
Далее будет чуть сложнее.
Нужно извлечь второе слово, то есть имя. Чтобы вырезать кусочек из середины, используем функцию ПСТР.
=ПСТР(A2; ПОИСК(» «;A2) + 1; ПОИСК(» «;A2;ПОИСК(» «;A2)+1) — ПОИСК(» «;A2) — 1)
Как вы, наверное, знаете, функция Excel ПСТР имеет следующий синтаксис:
ПСТР (текст; начальная_позиция; количество_знаков)
Текст извлекается из ячейки A2, а два других аргумента вычисляются с использованием 4 различных функций ПОИСК:
- Начальная позиция — это позиция первого пробела плюс 1:
ПОИСК(» «;A2) + 1
- Количество знаков для извлечения: разница между положением 2- го и 1- го пробелов, минус 1:
ПОИСК(» «;A2;ПОИСК(» «;A2)+1) — ПОИСК(» «;A2) – 1
В итоге имя у нас теперь находится в C.
Осталось отчество. Для него используем выражение:
=ПРАВСИМВ(A2;ДЛСТР(A2) — ПОИСК(» «; A2; ПОИСК(» «; A2) + 1))
В этой формуле функция ДЛСТР (LEN) возвращает общую длину строки, из которой вы вычитаете позицию 2- го пробела. Получаем количество символов после 2- го пробела, и функция ПРАВСИМВ их и извлекает.
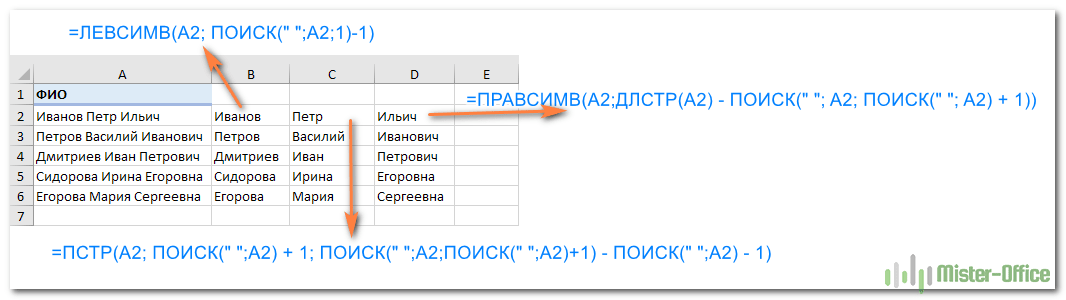
Вот результат нашей работы по разделению фамилии, имени и отчества из одной по отдельным ячейкам.
Распределение текста с разделителями на 3 столбца.
Предположим, у вас есть список одежды вида Наименование-Цвет-Размер, и вы хотите разделить его на 3 отдельных части. Здесь разделитель слов – дефис. С ним и будем работать.
- Чтобы извлечь Наименование товара (все символы до 1-го дефиса), вставьте следующее выражение в B2, а затем скопируйте его вниз по столбцу:
=ЛЕВСИМВ(A2; ПОИСК(«-«;A2;1)-1)
Здесь функция мы сначала определяем позицию первого дефиса («-«) в строке, а ЛЕВСИМВ извлекает все нужные символы начиная с этой позиции. Вы вычитаете 1 из позиции дефиса, потому что вы не хотите извлекать сам дефис.
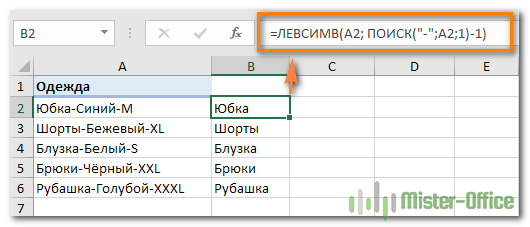
- Чтобы извлечь цвет (это все буквы между 1-м и 2-м дефисами), запишите в C2, а затем скопируйте ниже:
=ПСТР(A2; ПОИСК(«-«;A2) + 1; ПОИСК(«-«;A2;ПОИСК(«-«;A2)+1) — ПОИСК(«-«;A2) — 1)
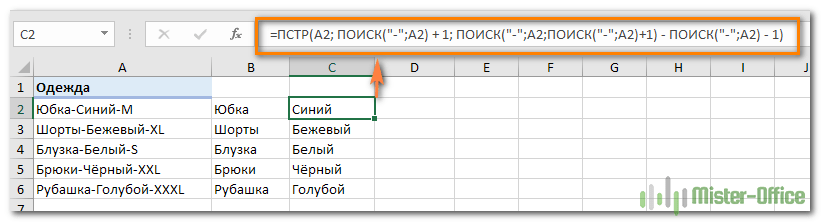
Логику работы ПСТР мы рассмотрели чуть выше.
- Чтобы извлечь размер (все символы после 3-го дефиса), введите следующее выражение в D2:
=ПРАВСИМВ(A2;ДЛСТР(A2) — ПОИСК(«-«; A2; ПОИСК(«-«; A2) + 1))

Аналогичным образом вы можете в Excel разделить содержимое ячейки в разные ячейки любым другим разделителем. Все, что вам нужно сделать, это заменить «-» на требуемый символ, например пробел (« »), косую черту («/»), двоеточие («:»), точку с запятой («;») и т. д.
Примечание. В приведенных выше формулах +1 и -1 соответствуют количеству знаков в разделителе. В нашем примере это дефис (то есть, 1 знак). Если ваш разделитель состоит из двух знаков, например, запятой и пробела, тогда укажите только запятую («,») в ваших выражениях и используйте +2 и -2 вместо +1 и -1.
Как разбить текст по переносам строки.
Чтобы разделить слова в ячейке по переносам строки, используйте подходы, аналогичные тем, которые были продемонстрированы в предыдущем примере. Единственное отличие состоит в том, что вам понадобится функция СИМВОЛ (CHAR) для передачи символа разрыва строки, поскольку вы не можете ввести его непосредственно в формулу с клавиатуры.
Предположим, ячейки, которые вы хотите разделить, выглядят примерно так:

Напомню, что перенести таким вот образом текст внутри ячейки можно при помощи комбинации клавиш ALT + ENTER.
Возьмите инструкции из предыдущего примера и замените дефис («-») на СИМВОЛ(10), где 10 — это код ASCII для перевода строки.
Чтобы извлечь наименование товара:
=ЛЕВСИМВ(A2; ПОИСК(СИМВОЛ(10);A2;1)-1)
Цвет:
=ПСТР(A2; ПОИСК(СИМВОЛ(10);A2) + 1; ПОИСК(СИМВОЛ(10);A2; ПОИСК(СИМВОЛ(10);A2)+1) — ПОИСК(СИМВОЛ(10);A2) — 1)
Размер:
=ПРАВСИМВ(A2;ДЛСТР(A2) — ПОИСК(СИМВОЛ(10); A2; ПОИСК(СИМВОЛ(10); A2) + 1))
Результат вы видите на скриншоте выше.
Таким же образом можно работать и с любым другим символом-разделителем. Достаточно знать его код.
Как распределить текст с разделителями на множество столбцов.
Изучив представленные выше примеры, у многих из вас, думаю, возник вопрос: «А что, если у меня не 3 слова, а больше? Если нужно разбить текст в ячейке на 5 столбцов?»
Если действовать методами, описанными выше, то формулы будут просто мега-сложными. Вероятность ошибки при их использовании очень велика. Поэтому мы применим другой метод.
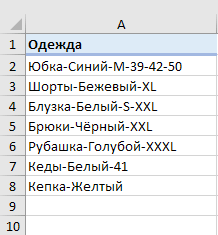
Имеем список наименований одежды с различными признаками, перечисленными через дефис. Как видите, таких признаков у нас может быть от 2 до 6. Делим текст в наших ячейках на 6 столбцов так, чтобы лишние столбцы в отдельных строках просто остались пустыми.
Для первого слова (наименования одежды) используем:
=ЛЕВСИМВ(A2; ПОИСК(«-«;A2;1)-1)
Как видите, это ничем не отличается от того, что мы рассматривали ранее. Ищем позицию первого дефиса и отделяем нужное количество символов.
Для второго столбца и далее понадобится более сложное выражение:
=ЕСЛИОШИБКА(ЛЕВСИМВ(ПОДСТАВИТЬ($A2&»-«; ОБЪЕДИНИТЬ(«-«;ИСТИНА;$B2:B2)&»-«;»»;1); ПОИСК(«-«;ПОДСТАВИТЬ($A2&»-«;ОБЪЕДИНИТЬ(«-«;ИСТИНА;$B2:B2)&»-«;»»;1);1)-1);»»)
Замысел здесь состоит в том, что при помощи функции ПОДСТАВИТЬ мы удаляем из исходного содержимого наименование, которое уже ранее извлекли (то есть, «Юбка»). Вместо него подставляем пустое значение «» и в результате имеем «Синий-M-39-42-50». В нём мы снова ищем позицию первого дефиса, как это делали ранее. И при помощи ЛЕВСИМВ вновь выделяем первое слово (то есть, «Синий»).
А далее можно просто «протянуть» формулу из C2 по строке, то есть скопировать ее в остальные ячейки. В результате в D2 получим
=ЕСЛИОШИБКА(ЛЕВСИМВ(ПОДСТАВИТЬ($A2&»-«; ОБЪЕДИНИТЬ(«-«;ИСТИНА;$B2:C2)&»-«;»»;1); ПОИСК(«-«;ПОДСТАВИТЬ($A2&»-«;ОБЪЕДИНИТЬ(«-«;ИСТИНА;$B2:C2)&»-«;»»;1);1)-1);»»)
Обратите внимание, жирным шрифтом выделены произошедшие при копировании изменения. То есть, теперь из исходного текста мы удаляем все, что было уже ранее найдено и извлечено – содержимое B2 и C2. И вновь в получившейся фразе берём первое слово — до дефиса.
Если же брать больше нечего, то функция ЕСЛИОШИБКА обработает это событие и вставит в виде результата пустое значение «».
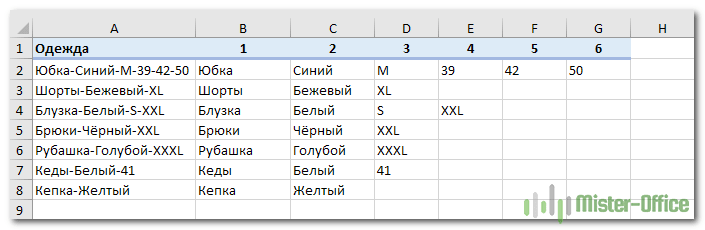
Скопируйте формулы по строкам и столбцам, на сколько это необходимо. Результат вы видите на скриншоте.
Таким способом можно разделить текст в ячейке на сколько угодно столбцов. Главное, чтобы использовались одинаковые разделители.
Как разделить ячейку вида ‘текст + число’.
Начнем с того, что не существует универсального решения, которое работало бы для всех буквенно-цифровых выражений. Выбор зависит от конкретного шаблона, по которому вы хотите разбить ячейку. Ниже вы найдете формулы для двух наиболее распространенных сценариев.
Предположим, у вас есть столбец смешанного содержания, где число всегда следует за текстом. Естественно, такая конструкция рассматривается Excel как символьная. Вы хотите поделить их так, чтобы текст и числа отображались в отдельных ячейках.
Результат может быть достигнут двумя разными способами.
Метод 1. Подсчитайте цифры и извлеките это количество символов
Самый простой способ разбить выражение, в котором число идет после текста:
Чтобы извлечь числа, вы ищите в строке все возможные числа от 0 до 9, получаете общее их количество и отсекаете такое же количество символов от конца строки.
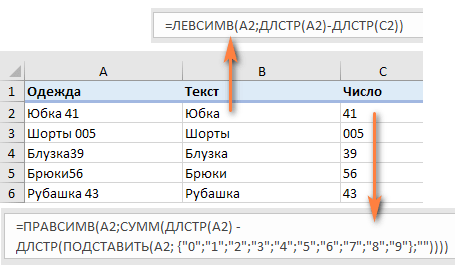
Если мы работаем с ячейкой A2:
=ПРАВСИМВ(A2;СУММ(ДЛСТР(A2) — ДЛСТР(ПОДСТАВИТЬ(A2; {«0″;»1″;»2″;»3″;»4″;»5″;»6″;»7″;»8″;»9″};»»))))
Чтобы извлечь буквы, вы вычисляете, сколько их у нас имеется. Для этого вычитаем количество извлеченных цифр (C2) из общей длины исходной ячейки A2. После этого при помощи ЛЕВСИМВ отрезаем это количество символов от начала ячейки.
=ЛЕВСИМВ(A2;ДЛСТР(A2)-ДЛСТР(C2))
здесь A2 – исходная ячейка, а C2 — извлеченное число, как показано на скриншоте:
Метод 2: узнать позицию 1- й цифры в строке
Альтернативное решение — использовать эту формулу массива для определения позиции первой цифры:
{=МИН(ПОИСК({0;1;2;3;4;5;6;7;8;9};A2&»0123456789″))}
Как видите, мы последовательно ищем каждое число из массива {0,1,2,3,4,5,6,7,8,9}. Чтобы избежать появления ошибки если цифра не найдена, мы после содержимого ячейки A2 добавляем эти 10 цифр. Excel последовательно перебирает все символы в поисках этих десяти цифр. В итоге получаем опять же массив из 10 цифр — номеров позиций, в которых они нашлись. И из них функция МИН выбирает наименьшее число. Это и будет та позиция, с которой начинается группа чисел, которую нужно отделить от основного содержимого.
Также обратите внимание, что это формула массива и ввод её нужно заканчивать не как обычно, а комбинацией клавиш CTRL + SHIFT + ENTER.
Как только позиция первой цифры найдена, вы можете разделить буквы и числа, используя очень простые формулы ЛЕВСИМВ и ПРАВСИМВ.
Чтобы получить текст:
=ЛЕВСИМВ(A2; B2-1)
Чтобы получить числа:
=ПРАВСИМВ(A2; ДЛСТР(A2)-B2+1)
Где A2 — исходная строка, а B2 — позиция первого числа.

Чтобы избавиться от вспомогательного столбца, в котором мы вычисляли позицию первой цифры, вы можете встроить МИН в функции ЛЕВСИМВ и ПРАВСИМВ:
Для вытаскивания текста:
=ЛЕВСИМВ(A2; МИН(ПОИСК({0;1;2;3;4;5;6;7;8;9};A2&»0123456789″))-1)
Для чисел:
=ПРАВСИМВ(A2; ДЛСТР(A2)-МИН(ПОИСК({0;1;2;3;4;5;6;7;8;9};A2&»0123456789″))+1)
Этого же результата можно достичь и чуть иначе.
Сначала мы извлекаем из ячейки числа при помощи вот такого выражения:
=ПРАВСИМВ(A2;СУММ(ДЛСТР(A2) -ДЛСТР(ПОДСТАВИТЬ(A2; {«0″;»1″;»2″;»3″;»4″;»5″;»6″;»7″;»8″;»9″};»»))))
То есть, сравниваем длину нашего текста без чисел с его исходной длиной, и получаем количество цифр, которое нужно взять справа. К примеру, если текст без цифр стал короче на 2 символа, значит справа надо «отрезать» 2 символа, которые и будут нашим искомым числом.
А затем уже берём оставшееся:
=ЛЕВСИМВ(A2;ДЛСТР(A2)-ДЛСТР(C2))

Как видите, результат тот же. Можете воспользоваться любым способом.
Как разделить ячейку вида ‘число + текст’.
Если вы разделяете ячейки, в которых буквы стоят после цифр, вы можете отделять числа по следующей формуле:
=ЛЕВСИМВ(A2;СУММ(ДЛСТР(A2) — ДЛСТР(ПОДСТАВИТЬ(A2; {«0″;»1″;»2″;»3″;»4″;»5″;»6″;»7″;»8″;»9″};»»))))
Она аналогична рассмотренной в предыдущем примере, за исключением того, что вы используете функцию ЛЕВСИМВ вместо ПРАВСИМВ, чтобы получить число теперь уже из левой части выражения.
Теперь, когда у вас есть числа, отделите буквы, вычитая количество цифр из общей длины исходной строки:
=ПРАВСИМВ(A2;ДЛСТР(A2)-ДЛСТР(B2))
Где A2 — исходная строка, а B2 — искомое число, как показано на снимке экрана ниже:

Как разбить текст по ячейкам по маске (шаблону).
Эта опция очень удобна, когда вам нужно разбить список схожих строк на некоторые элементы или подстроки. Сложность состоит в том, что исходный текст должен быть разделен не при каждом появлении определенного разделителя (например, пробела), а только при некоторых определенных вхождениях. Следующий пример упрощает понимание.
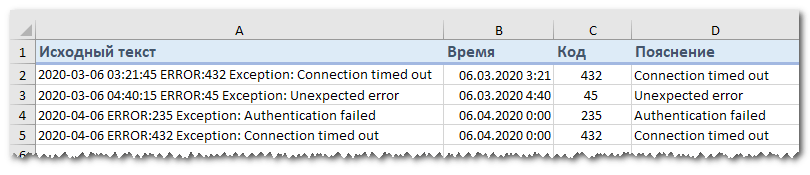
Предположим, у вас есть список строк, извлеченных из некоторого файла журнала:

Вы хотите, чтобы дата и время, если таковые имеются, код ошибки и поясняющие сведения были размещены в 3 отдельных столбцах. Вы не можете использовать пробел в качестве разделителя, потому что между датой и временем также есть пробелы. Также есть пробелы в тексте пояснения, который также должен весь находиться слитно в одном столбце.
Решением является разбиение строки по следующей маске: * ERROR: * Exception: *
Здесь звездочка (*) представляет любое количество символов.
Двоеточия (:) включены в разделители, потому что мы не хотим, чтобы они появлялись в результирующих ячейках.
То есть в данном случае в качестве разделителя по столбцам выступают не отдельные символы, а целые слова.
Итак, в начале ищем позицию первого разделителя.
=ПОИСК(«ERROR:»;A2;1)
Затем аналогичным образом находим позицию, в которой начинается второй разделитель:
=ПОИСК(«Exception:»;A2;1)
Итак, для ячейки A2 шаблон выглядит следующим образом:
С 1 по 20 символ – дата и время. С 21 по 26 символ – разделитель “ERROR:”. Далее – код ошибки. С 31 по 40 символ – второй разделитель “Exception:”. Затем следует описание ошибки.
Таким образом, в первый столбец мы поместим первые 20 знаков:
=—ЛЕВСИМВ(A2;ПОИСК(«ERROR:»;A2;1)-1)
Обратите внимание, что мы взяли на 1 позицию меньше, чем начало первого разделителя. Кроме того, чтобы сразу конвертировать всё это в дату, ставим перед формулой два знака минус. Это автоматически преобразует цифры в число, а дата как раз и хранится в виде числа. Остается только установить нужный формат даты и времени стандартными средствами Excel.
Далее нужно получить код:
=ПСТР(A2;ПОИСК(«ERROR:»;A2;1)+6;ПОИСК(«Exception:»;A2;1)-(ПОИСК(«ERROR:»;A2;1)+6))
Думаю, вы понимаете, что 6 – это количество знаков в нашем слове-разделителе «ERROR:».
Ну и, наконец, выделяем из этой фразы пояснение:
=ПРАВСИМВ(A2;ДЛСТР(A2)-(ПОИСК(«Exception:»;A2;1)+10))
Аналогично добавляем 10 к найденной позиции второго разделителя «Exception:», чтобы выйти на координаты первого символа сразу после разделителя. Ведь функция говорит нам только то, где разделитель начинается, а не заканчивается.
Таким образом, ячейку мы распределили по 3 столбцам, исключив при этом слова-разделители.
Если выяснение загадочных поворотов формул Excel — не ваше любимое занятие, вам может понравиться визуальный метод разделения ячеек в Excel, который демонстрируется в следующей части этого руководства.
Как разделить ячейки в Excel с помощью функции разделения текста Split Text.
Альтернативный способ разбить столбец в Excel — использовать функцию разделения текста, включенную в надстройку Ultimate Suite for Excel. Она предоставляет следующие возможности:
- Разделить ячейку по символу-разделителю.
- Разделить ячейку по нескольким разделителям.
- Разделить ячейку по маске (шаблону).
Чтобы было понятнее, давайте более подробно рассмотрим каждый вариант по очереди.
Разделить ячейку по символу-разделителю.
Выбирайте этот вариант, если хотите разделить содержимое ячейки при каждом появлении определённого символа .
Для этого примера возьмем строки шаблона Товар-Цвет-Размер , который мы использовали в первой части этого руководства. Как вы помните, мы разделили их на 3 разных столбца, используя 3 разные формулы . А вот как добиться того же результата за 2 быстрых шага:
- Предполагая, что у вас установлен Ultimate Suite , выберите ячейки, которые нужно разделить, и щелкните значок «Разделить текст (Split Text)» на вкладке «Ablebits Data».
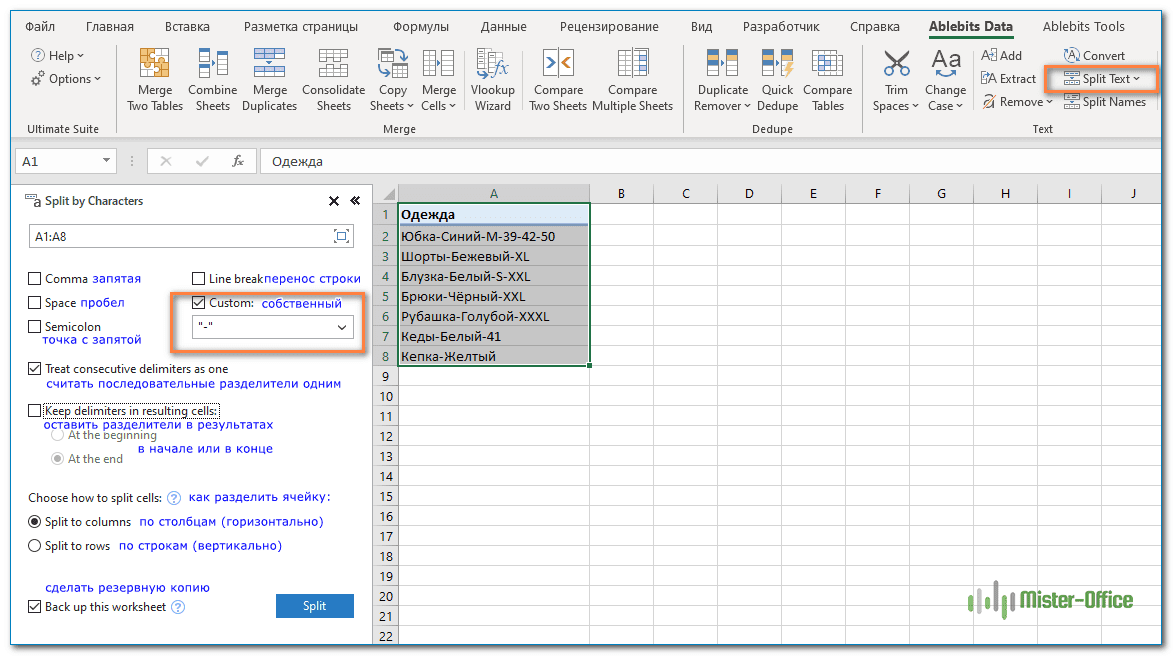
- Панель Разделить текст откроется в правой части окна Excel, и вы выполните следующие действия:
- Разверните группу «Разбить по символам (Split by Characters)» и выберите один из предопределенных разделителей или введите любой другой символ в поле «Пользовательский (Custom)» .
- Выберите, как именно разбивать ячейки: по столбцам или строкам.
- Нажмите кнопку «Разделить (Split)» .
Примечание. Если в ячейке может быть несколько последовательных разделителей (например, более одного символа пробела подряд), установите флажок « Считать последовательные разделители одним».
Готово! Задача, которая требовала 3 формул и 5 различных функций, теперь занимает всего пару секунд и одно нажатие кнопки.

Разделить ячейку по нескольким разделителям.
Этот параметр позволяет разделять текстовые ячейки, используя любую комбинацию символов в качестве разделителя. Технически вы разделяете строку на части, используя одну или несколько разных подстрок в качестве границ.
Например, чтобы разделить предложение на части, используя запятые и союзы, активируйте инструмент «Разбить по строкам (Split by Strings)» и введите разделители, по одному в каждой строке:

В данном случае в качестве разделителей мы используем запятую и союз “или”.
В результате исходная фраза разделяется при появлении любого разделителя:

Примечание. Союзы «или», а также «и» часто могут быть частью слова в вашей исследуемой фразе, так что не забудьте ввести пробел до и после них, чтобы предотвратить разрывы слов на части.
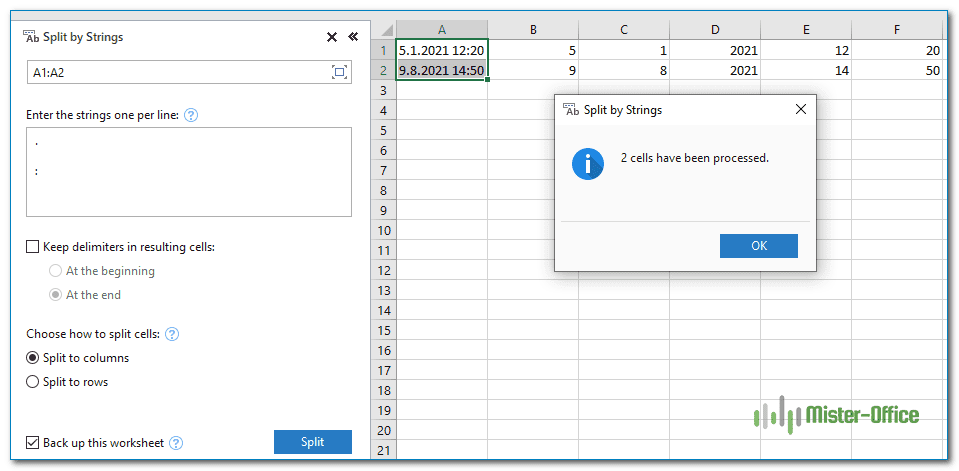
А вот еще один пример. Предположим, вы импортировали столбец дат из внешнего источника, и выглядит он следующим образом:
5.1.2021 12:20
9.8.2021 14:50
Этот формат не является обычным для Excel, и поэтому ни одна из функций даты не распознает здесь какие-либо элементы даты или времени. Чтобы разделить день, месяц, год, часы и минуты на отдельные ячейки, введите следующие символы в поле Spilt by strings:
- Точка (.) Для разделения дня, месяца и года
- Двоеточие (:) для разделения часов и минут
- Пробел для разграничения даты и времени

Нажмите кнопку Split, и вы сразу получите результат:
Разделить ячейки по маске (шаблону).
Эта опция очень удобна, когда вам нужно разбить список однородных строк на некоторые элементы или подстроки.
Сложность заключается в том, что исходный текст не может быть разделен при каждом появлении заданного разделителя, а только при некоторых определенных вхождениях. Следующий пример упростит понимание.
Предположим, у вас есть список строк, извлеченных из некоторого файла журнала. Чуть выше в этой статье мы разбивали этот текст по ячейкам при помощи формул. А сейчас используем специальный инструмент. И вы сами решите, какой из способов удобнее и проще.
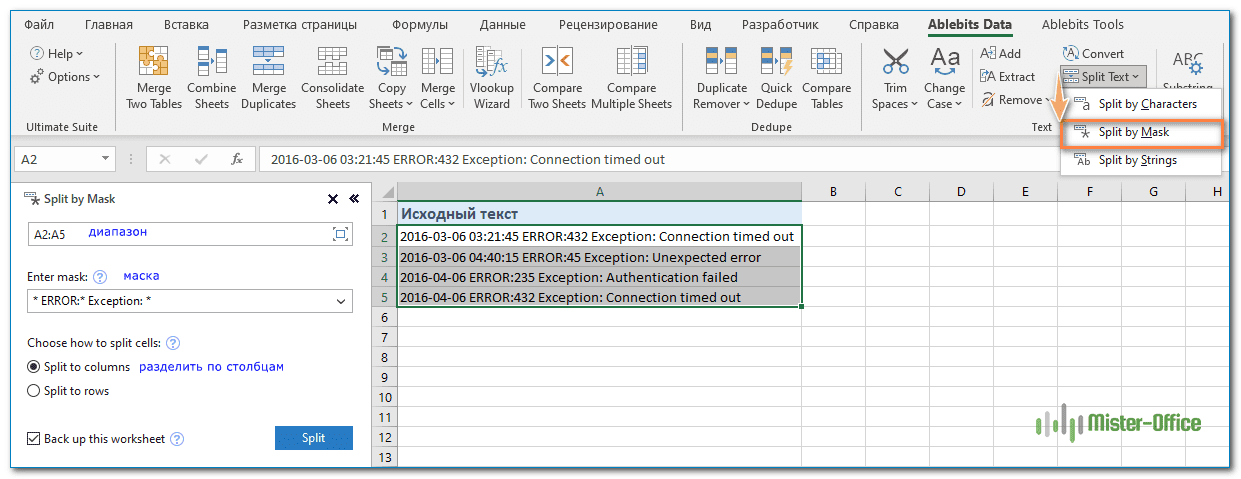
Вы хотите, чтобы дата и время, если таковые имеются, код ошибки и пояснительная информация, были в трех отдельных столбцах. Вы не можете использовать пробел в качестве разделителя, потому что между датой и временем имеются пробелы, которые должны отображаться в одном столбце, и есть пробелы в тексте пояснения, который также должен быть расположен в отдельном столбце.
Решением является разбиение строки по следующей маске:
* ERROR:* Exception: *
Где звездочка (*) представляет любое количество символов.
Двоеточия (:) включены в разделители, потому что мы не хотим, чтобы они появлялись в результирующих ячейках.
А теперь нажмите кнопку «Разбить по маске (Split by Mask)» на панели «Split Text» , введите маску в соответствующее поле и нажмите «Split».
Результат будет примерно таким:

Примечание. При разделении строки по маске учитывается регистр. Поэтому не забудьте ввести символы в шаблоне точно так, как они отображаются в исходных данных.
Большое преимущество этого метода — гибкость. Например, если все исходные строки имеют значения даты и времени, и вы хотите, чтобы они отображались в разных столбцах, используйте эту маску:
* * ERROR:* Exception: *
Проще говоря, маска указывает надстройке разделить исходные строки на 4 части:
- Все символы перед 1-м пробелом в строке (дата)
- Символы между 1-м пробелом и словом ERROR: (время)
- Текст между ERROR: и Exception: (код ошибки)
- Все, что идет после Exception: (текст описания)

Думаю, вы согласитесь, что использование надстройки Split Text гораздо быстрее и проще, нежели использование формул.
Надеюсь, вам понравился этот быстрый и простой способ разделения строк в Excel. Если вам интересно попробовать, ознакомительная версия доступна для загрузки здесь.
Вот как вы можете разделить текст по ячейкам таблицы Excel, используя различные комбинации функций, а также специальные инструменты. Благодарю вас за чтение и надеюсь увидеть вас в нашем блоге на следующей неделе!
Читайте также:
 Поиск ВПР нескольких значений по нескольким условиям — В статье показаны способы поиска (ВПР) нескольких значений в Excel на основе одного или нескольких условий и возврата нескольких результатов в столбце, строке или в отдельной ячейке. При использовании Microsoft…
Поиск ВПР нескольких значений по нескольким условиям — В статье показаны способы поиска (ВПР) нескольких значений в Excel на основе одного или нескольких условий и возврата нескольких результатов в столбце, строке или в отдельной ячейке. При использовании Microsoft…  Формат времени в Excel — Вы узнаете об особенностях формата времени Excel, как записать его в часах, минутах или секундах, как перевести в число или текст, а также о том, как добавить время с помощью…
Формат времени в Excel — Вы узнаете об особенностях формата времени Excel, как записать его в часах, минутах или секундах, как перевести в число или текст, а также о том, как добавить время с помощью…  Как сделать диаграмму Ганта — Думаю, каждый пользователь Excel знает, что такое диаграмма и как ее создать. Однако один вид графиков остается достаточно сложным для многих — это диаграмма Ганта. В этом кратком руководстве я постараюсь показать…
Как сделать диаграмму Ганта — Думаю, каждый пользователь Excel знает, что такое диаграмма и как ее создать. Однако один вид графиков остается достаточно сложным для многих — это диаграмма Ганта. В этом кратком руководстве я постараюсь показать…  Как сделать автозаполнение в Excel — В этой статье рассматривается функция автозаполнения Excel. Вы узнаете, как заполнять ряды чисел, дат и других данных, создавать и использовать настраиваемые списки в Excel. Эта статья также позволяет вам убедиться, что вы…
Как сделать автозаполнение в Excel — В этой статье рассматривается функция автозаполнения Excel. Вы узнаете, как заполнять ряды чисел, дат и других данных, создавать и использовать настраиваемые списки в Excel. Эта статья также позволяет вам убедиться, что вы…  Функция ИНДЕКС в Excel — 6 примеров использования — В этом руководстве вы найдете ряд примеров формул, демонстрирующих наиболее эффективное использование ИНДЕКС в Excel. Из всех функций Excel, возможности которых часто недооцениваются и используются недостаточно, ИНДЕКС определенно занимает место…
Функция ИНДЕКС в Excel — 6 примеров использования — В этом руководстве вы найдете ряд примеров формул, демонстрирующих наиболее эффективное использование ИНДЕКС в Excel. Из всех функций Excel, возможности которых часто недооцениваются и используются недостаточно, ИНДЕКС определенно занимает место…  Быстрое удаление пустых столбцов в Excel — В этом руководстве вы узнаете, как можно легко удалить пустые столбцы в Excel с помощью макроса, формулы и даже простым нажатием кнопки. Как бы банально это ни звучало, удаление пустых…
Быстрое удаление пустых столбцов в Excel — В этом руководстве вы узнаете, как можно легко удалить пустые столбцы в Excel с помощью макроса, формулы и даже простым нажатием кнопки. Как бы банально это ни звучало, удаление пустых…
Раннее мы рассматривали возможность разделить текст по столбцам на примере деления ФИО на составные части. Для этого мы использовали инструмент в Excel «Текст по столбцам».
Несомненно, это очень важный и полезный и инструмент в Excel, который значительно может упростить множество задач. Но у данного способа есть небольшой недостаток. Если вам, например, постоянно присылают данные в определенном виде, а вам постоянно необходимо их делить, то это занимает определенное время, кроме того, если данные вам прислали заново, то вам снова нужно будет проделать все операции.
Содержание
- 1 Пример 1. Делим текст с ФИО по столбцам с помощью формул
- 1.1 Приступаем к делению первой части текста — Фамилии
- 1.2 Приступаем к делению второй части текста — Имя
- 1.3 Приступаем к делению третьей части текста — Отчество
- 2 Пример 2. Как разделить текст по столбцам в Excel с помощью формулы
Пример 1. Делим текст с ФИО по столбцам с помощью формул
Если рассматривать на примере деления ФИО, то разделить текст можно будет с помощью текстовых формул Excel, используя функцию ПСТР и НАЙТИ, которую мы рассматривали в прошлых статьях. В этом случае вам достаточно вставить данные в определенный столбец, а формулы автоматически разделят текст так как вам необходимо. Давайте приступит к рассмотрению данного примера.
У нас есть столбец со списком ФИО, наша задача разместить фамилию, имя отчество по отдельным столбцам.

Попробуем очень подробно описать план действия и разобьем решение задачи на несколько этапов.
Первым делом добавим вспомогательные столбцы, для промежуточных вычислений, чтобы вам было понятнее, а в конце все формулы объединим в одну.
Итак, добавим столбцы позиция 1-го и 2-го пробелам. С помощью функции НАЙТИ, как мы уже рассматривали в предыдущей статье найдем позицию первого пробелам. Для этого в ячейке «H2» пропишем формулу
=НАЙТИ(" ";A2;1)
и протянем вниз. Формулу объяснять не буду — смотрите предыдущую статью

Теперь нам необходимо найти порядковый номер второго пробела. Формула будет такая же, но с небольшим отличием. Если прописать такую же формулу, то функция найдет нам первый пробел, а нам нужен второй пробел. Значит на необходимо поменять третий аргумент в функции НАЙТИ — начальная позиция — то есть позиция с которой функция будет искать искомый текст. Мы видим, что второй пробел находится в любом случае после первого пробела, а позицию первого пробела мы уже нашли, значит прибавив 1 к позиции первого пробелам мы укажем функции НАЙТИ искать пробел начиная с первой буквы после первого пробела. Функция будет выглядеть следующим образом:
=НАЙТИ(" ";A2;H2+1)

Далее протягиваем формулу и получаем позиции 1-го и 2-го пробела.
Приступаем к делению первой части текста — Фамилии
Для этого мы воспользуемся функцией ПСТР, напомню синтаксис данной функции:
=ПСТР(текст; начальная_позиция; число_знаков), где
- текст — это ФИО, в нашем примере это ячейка A2;
- начальная_позиция — в нашем случае это 1, то есть начиная с первой буквы;
- число_знаков — мы видим, что фамилия состоит из всех знаков, начиная с первой буквы и до 1-го пробела. А позиция первого пробела нам уже известна. Это и будет количество знаков минус 1 знак самого пробела.
Формула будет выглядеть следующим образом:
=ПСТР(A2;1;H2-1)

Приступаем к делению второй части текста — Имя
Снова используем функцию =ПСТР(текст; начальная_позиция; число_знаков), где
- текст — это тот же текст ФИО, в нашем примере это ячейка A2;
- начальная_позиция — в нашем случае Имя начинается с первой буква после первого пробела, зная позицию этого пробела получаем H2+1;
- число_знаков — число знаков, то есть количество букв в имени. Мы видим, что имя у нас находится между двумя пробелами, позиции которых мы знаем. Если из позиции второго пробела отнять позицию первого пробела, то мы получим разницу, которая и будет равна количеству символов в имени, то есть I2-H2
Получаем итоговую формулу:
=ПСТР(A2;H2+1;I2-H2)

Приступаем к делению третьей части текста — Отчество
И снова функция =ПСТР(текст; начальная_позиция; число_знаков), где
- текст — это тот же текст ФИО, в нашем примере это ячейка A2;
- начальная_позиция — Отчество у нас находится после 2-го пробелам, значит начальная позиция будет равна позиции второго пробела плюс один знак или I2+1;
- число_знаков — в нашем случае после Отчества никаких знаков нет, поэтому мы просто может взять любое число, главное, чтобы оно было больше возможного количества символов в Отчестве, я взял цифру с большим запасом — 50
Получаем функцию
=ПСТР(A2;I2+1;50)

Далее выделяем все три ячейки и протягиваем формулы вниз и получаем нужный нам результат. На этом можно закончить, а можно промежуточные расчеты позиции пробелов прописать в сами формулы деления текста. Это очень просто сделать. Мы видим, что расчет первого пробела находится в ячейке H2 — НАЙТИ(» «;A2;1), а расчет второго пробела в ячейке I2 — НАЙТИ(» «;A2;H2+1) . Видим, что в формуле ячейки I2 встречается H2 меняем ее на саму формулу и получаем в ячейке I2 вложенную формулу НАЙТИ(» «;A2;НАЙТИ(» «;A2;1)+1)
Смотрим первую формулу выделения Фамилии и смотрим где здесь встречается H2 или I2 и меняем их на формулы в этих ячейках, аналогично с Именем и Фамилией
- Фамилия =ПСТР(A2;1;H2-1) получаем =ПСТР(A2;1;НАЙТИ(» «;A2;1)-1)
- Имя =ПСТР(A2;H2+1;I2—H2) получаем =ПСТР(A2;НАЙТИ(» «;A2;1)+1;
НАЙТИ(» «;A2;НАЙТИ(» «;A2;1)+1)—НАЙТИ(» «;A2;1)) - Отчество =ПСТР(A2;I2+1;50) получаем =ПСТР(A2;НАЙТИ(» «;A2;НАЙТИ(» «;A2;1)+1)+1;50)
Теперь промежуточные вычисления позиции пробелом можно смело удалить. Это один из приемов, когда для простоты сначала ищутся промежуточные данные, а потом функцию вкладывают одну в другую. Согласитесь, если писать такую большую формулу сразу, то легко запутаться и ошибиться.
Надеемся, что данный пример наглядно показал вам, как полезны текстовые функции Excel для работы с текстом и как они позволяют делить текст автоматически с помощью формул однотипные данные. Если вам понравилась статья, то будем благодарны за нажатие на +1 и мне нравится. Подписывайтесь и вступайте в нашу группу вконтакте.
Пример 2. Как разделить текст по столбцам в Excel с помощью формулы
Рассмотрим второй пример, который так же очень часто встречался на практике. Пример похож предыдущий, но данных которые нужно разделить значительно больше. В этом примере я покажу прием, который позволит достаточно быстро решить вопрос и не запутаться.
Допустим у нас есть список чисел, перечисленных через запятую, нам необходимо разбить текст таким образом, чтобы каждое число было в отдельной ячейке (вместо запятых это могут быть любые другие знаки, в том числе и пробелы). То есть нам необходимо разбить текст по словам.

Напомним, что вручную (без формул) это задача очень просто решается с помощью инструмента текст по столбцам, который мы уже рассматривали. В нашем же случае требуется это сделать с помощью формул.
Для начала необходимо найти общий разделить, по которому мы будет разбивать текст. В нашем случае это запятая, но например в первой задаче мы делили ФИО и разделитель был пробел. Наш второй пример более универсальный (более удобный при большом количестве данных), так например мы удобно могли бы делить не только ФИО по отдельным ячейкам, а целое предложение — каждое слово в отдельную ячейку. Собственно такой вопрос поступил в комментариях, поэтому было решено дополнить эту статью.
Для удобства в соседнем столбце укажем этот разделитель, чтобы не прописывать его в формуле а просто ссылаться на ячейку. Это так же позволит нам использовать файл для решения других задач, просто поменяв разделитель в ячейках.

Теперь основная суть приема.
Шаг 1. В вспомогательном столбце находим позицию первого разделителя с помощью функции НАЙТИ. Описывать подробно функцию не буду, так как мы уже рассматривали ее раннее. Пропишем формулу в D1 и протянем ее вниз на все строки
=НАЙТИ(B1;A1;1)
То есть ищем запятую, в тексте, начиная с позиции 1

Шаг 2. Далее в ячейке E1 прописываем формулу для нахождения второго знака (в нашем случае запятой). Формула аналогичная, но с небольшими изменениями.
=НАЙТИ($B1;$A1;D1+1)
Во-первых: закрепим столбец искомого значения и текста, чтобы при протягивании формулы вправо ссылки на ячейки не сдвигалась. Для этого нужно написать доллар перед столбцом B и A — либо вручную, либо выделить A1 и B1, нажать три раза клавишу F4, после этого ссылки станут не относительными, а абсолютными.
Во-вторых: третий аргумент — начало позиции мы рассчитаем как позиция предыдущего разделителя (мы его нашли выше) плюс 1 то есть D1+1 так как мы знаем, что второй разделитель точно находится после первого разделителя и нам его не нужно учитывать.
Пропишем формулу и протянем ее вниз.

Шаг 3. Находимо позиции всех остальных разделителей. Для этого формулу нахождения второго разделителя (шаг 2) протянем вправо на то количество ячеек, сколько всего может быть отдельно разбитых значений с небольшим запасом. Получим все позиции разделителей. Там где ошибка #Знач означает что значения закончились и формула больше не находит разделителей. Получаем следующее

Шаг 4. Отделяем первое число от текст с помощью функции ПСТР.
=ПСТР(A1;1;D1-1)
Начальная позиция у нас 1, количество знаков мы рассчитываем как позиция первого разделителя минус 1: D1-1 протягиваем формулу вниз

Шаг 5. Находимо второе слово так же с помощью функции ПСТР в ячейке P1
=ПСТР($A1;D1+1;E1-D1-1)
Начальная позиция второго числа у нас начинается после первой запятой. Позиция первой запятой у нас есть в ячейке D1, прибавим единицу и получим начальную позицию нашего второго числа.
Количество знаков это есть разница между позицией третьего разделителя и второго и минус один знак, то есть E1-D1-1
Закрепим столбец A исходного текста, чтобы он не сдвигался при протягивании формулы право.
Шаг 6. Протянем формулу полученную на шаге 5 вправо и вниз и получим текст в отдельных ячейках.

Шаг 7. В принципе задача наша уже решена, но для красоты все в той же ячейке P1 пропишем формула отлавливающую ошибку заменяя ее пустым значением. Так же можно сгруппировать и свернуть вспомогательные столбцы, чтобы они не мешали. Получим итоговое решение задачи
=ЕСЛИОШИБКА(ПСТР($A1;D1+1;E1-D1-1);»»)

Примечание. Первую позицию разделителя и первое деление слова мы делали отлично от других и из-за этого могли протянуть формулу только со вторых значений. Во время написания задачи я заметил, что можно было бы упростить задачу. Для этого в столбце С нужно было прописать 0 значения первого разделителя. После этого находим значение первого разделителя
=НАЙТИ($B1;$A1;C1+1)
а первого текста как
=ПСТР($A1;C1+1;D1-C1-1)
После этого можно сразу протягивать формулу на остальные значения. Именно этот вариант оставляю как пример для скачивания. В принципе файлом можно пользоваться как шаблоном. В столбец «A» вставляете данные, в столбце «B» указываете разделитель, протягиваете формулы на нужное количество ячеек и получаете результат.
Внимание! В комментариях заметили, что так как в конце текста у нас нет разделителя, то у нас не считается количество символов от последнего разделителя до конца строки, поэтому последний разделенный текст отсутствует. Чтобы решить вопрос можно либо на первом шаге добавить вспомогательный столбец радом с исходным текстом, где сцепить этот текст с разделителем. Таким образом у нас получится что на конце текста будет разделитель, значит наши формулы посчитают его позицию и все будет работать.
Либо второе решение — это на шаге 3, когда мы составляем формулу вычисления позиций разделителей дополнить ее. Сделать проверку, если ошибка, то указываем заведомо большое число, например 1000.
=ЕСЛИОШИБКА(НАЙТИ($B1;$A1;C1+1);1000)

Таким образом последний текст будет рассчитываться начиная от последней запятой до чуть меньше 1000 знаков, то есть до конца строки, что нам и требуется.
Оба варианта выложу для скачивания.
Скачать пример: Как разделить текст по столбцам с помощью функции_1.xlsx (исправлено: доп поле)
Скачать пример: Как разделить текст по столбцам с помощью функции_2.xlsx (исправлено: заведомо большое число)
Делим слипшийся текст на части
Итак, имеем столбец с данными, которые надо разделить на несколько отдельных столбцов. Самые распространенные жизненные примеры:
- ФИО в одном столбце (а надо — в трех отдельных, чтобы удобнее было сортировать и фильтровать)
- полное описание товара в одном столбце (а надо — отдельный столбец под фирму-изготовителя, отдельный — под модель для построения, например, сводной таблицы)
- весь адрес в одном столбце (а надо — отдельно индекс, отдельно — город, отдельно — улица и дом)
- и т.д.
Поехали..
Способ 1. Текст по столбцам
Выделите ячейки, которые будем делить и выберите в меню Данные — Текст по столбцам (Data — Text to columns). Появится окно Мастера разбора текстов:

На первом шаге Мастера выбираем формат нашего текста. Или это текст, в котором какой-либо символ отделяет друг от друга содержимое наших будущих отдельных столбцов (с разделителями) или в тексте с помощью пробелов имитируются столбцы одинаковой ширины (фиксированная ширина).
На втором шаге Мастера, если мы выбрали формат с разделителями (как в нашем примере) — необходимо указать какой именно символ является разделителем:

Если в тексте есть строки, где зачем-то подряд идут несколько разделителей (несколько пробелов, например), то флажок Считать последовательные разделители одним (Treat consecutive delimiters as one) заставит Excel воспринимать их как один.
Выпадающий список Ограничитель строк (Text Qualifier) нужен, чтобы текст заключенный в кавычки (например, название компании «Иванов, Манн и Фарбер») не делился по запятой
внутри названия.
И, наконец, на третьем шаге для каждого из получившихся столбцов, выделяя их предварительно в окне Мастера, необходимо выбрать формат:
- общий — оставит данные как есть — подходит в большинстве случаев
- дата — необходимо выбирать для столбцов с датами, причем формат даты (день-месяц-год, месяц-день-год и т.д.) уточняется в выпадающем списке
- текстовый — этот формат нужен, по большому счету, не для столбцов с ФИО, названием города или компании, а для столбцов с числовыми данными, которые Excel обязательно должен воспринять как текст. Например, для столбца с номерами банковских счетов клиентов, где в противном случае произойдет округление до 15 знаков, т.к. Excel будет обрабатывать номер счета как число:

Кнопка Подробнее (Advanced) позволяет помочь Excel правильно распознать символы-разделители в тексте, если они отличаются от стандартных, заданных в региональных настройках.
Способ 2. Как выдернуть отдельные слова из текста
Если хочется, чтобы такое деление производилось автоматически без участия пользователя, то придется использовать небольшую функцию на VBA, вставленную в книгу. Для этого открываем редактор Visual Basic:
- в Excel 2003 и старше — меню Сервис — Макрос — Редактор Visual Basic (Tools — Macro — Visual Basic Editor)
- в Excel 2007 и новее — вкладка Разработчик — Редактор Visual Basic (Developer — Visual Basic Editor) или сочетание клавиш Alt+F11
Вставляем новый модуль (меню Insert — Module) и копируем туда текст вот этой пользовательской функции:
Function Substring(Txt, Delimiter, n) As String
Dim x As Variant
x = Split(Txt, Delimiter)
If n > 0 And n - 1 <= UBound(x) Then
Substring = x(n - 1)
Else
Substring = ""
End If
End Function
Теперь можно найти ее в списке функций в категории Определенные пользователем (User Defined) и использовать со следующим синтаксисом:
=SUBSTRING(Txt; Delimeter; n)
где
- Txt — адрес ячейки с текстом, который делим
- Delimeter — символ-разделитель (пробел, запятая и т.д.)
- n — порядковый номер извлекаемого фрагмента
Например:

Способ 3. Разделение слипшегося текста без пробелов
Тяжелый случай, но тоже бывает. Имеем текст совсем без пробелов, слипшийся в одну длинную фразу (например ФИО «ИвановИванИванович»), который надо разделить пробелами на отдельные слова. Здесь может помочь небольшая макрофункция, которая будет автоматически добавлять пробел перед заглавными буквами. Откройте редактор Visual Basic как в предыдущем способе, вставьте туда новый модуль и скопируйте в него код этой функции:
Function CutWords(Txt As Range) As String
Dim Out$
If Len(Txt) = 0 Then Exit Function
Out = Mid(Txt, 1, 1)
For i = 2 To Len(Txt)
If Mid(Txt, i, 1) Like "[a-zа-я]" And Mid(Txt, i + 1, 1) Like "[A-ZА-Я]" Then
Out = Out & Mid(Txt, i, 1) & " "
Else
Out = Out & Mid(Txt, i, 1)
End If
Next i
CutWords = Out
End Function
Теперь можно использовать эту функцию на листе и привести слипшийся текст в нормальный вид:

Ссылки по теме
- Деление текста при помощи готовой функции надстройки PLEX
- Что такое макросы, куда вставлять код макроса, как их использовать
Как разделить текст в ячейке Excel?
 Добрый день уважаемый читатель!
Добрый день уважаемый читатель!
В статье я хочу рассмотреть вопрос о том, как и какими способами, возможно, разделить текст в ячейке, который оказался склеен! Если вы часто работаете с импортированными данными в Excel, то периодически встречаете такие проблемы как выгруженные точки вместо запятых, неправильный формат данных, слепленные слова или значения и многое другое. На этот случай Excel предоставляет несколько возможностей по нормализации данных и у каждого из них есть свои плюсы и минуса.
Разобрать слитый текст на необходимые составляющие возможно произвести с помощью:
Мастер разбора текстов
Рассмотрим самый простой способ разделить текст в ячейке, не по сути, а по исполнению. Для примера, очень наглядно это можно продемонстрировать на ФИО в одной ячейке, которые необходимо разделить на отдельные столбики для удобства сортировки и фильтрации.
Для выполнения задачи вызываем диалоговое окно «Мастер текстов (разбор)» и в 3 шага разделяем текст:
- Для начала нужно выделить данные, которые необходимо разделить, следующим шагом на вкладке «Данные» в разделе «Работа с данными» нажимаете иконку «Текст по столбцам» и в вызванном диалоговом окне мастера указываем формат рабочего текста. Выбираем 2 вида форматов:
- С разделителями – это когда существует текст или символ, который условно будет отделять будущее содержимое отдельных ячеек;
- Фиксированной ширины – это когда при помощи пробелов в тексте имитируется столбики одинаковой ширины.


- Вторым шагом, в нашем примере, указываем символ, выполняющий роль разделителя. В случаях, когда в тексте идут подряд пару разделителей, несколько пробелов, к примеру, то установка флажка для пункта «Считать последовательные разделители одним» укажет для Excel принимать их за один разделитель. Дополнительное условие «Ограничитель строк» поможет указать, что текстовые значения, содержащиеся в кавычках не делить (к примеру, название фирмы «Рудольф, Петер и Саймон»);
- Последним шагом, для уже разделённых столбиков, нужно указать в диалоговом окне мастера, предварительно выделив их, выбрать необходимый формат получаемых данных:

- Общий – не проводит изменения данных, оставляя их в первоначальном виде, будет оптимальным выбором в большинстве случаев;
- Текстовый – данный формат, в основном, необходим для столбиков с числовыми значениями, которые программа в обязательном порядке должна интерпретировать как текст. (К примеру, это числа с разделителем по тысяче или номер пластиковой карточки);
- Дата – этот формат используется для столбиков с датами, кстати, формат самой даты можно выбрать в выпадающем списке.
В случае, когда будете использовать символы, которые не похожи на стандартные, назначенные в региональных настройках, можете использовать кнопку «Подробнее» для правильного их распознавания. 
Рассоединяем текст с помощью формул
Для этого способа нам понадобятся возможности сочетаний функций ПОИСК и ПСТР. При помощи функции ПОИСК мы будем искать все пробелы, которые есть между словами (например, между фамилией, именем и отчеством). Потом функцией ПСТР выделяем необходимое количество символов для дальнейшего разделения.
И если с первыми двумя словами понятно, что и как разделять, то разделителя для последнего слова нет, а это значит что нужно указать в качестве аргумента условно большое количество символов, как аргумент «число_знаков» для функции ПСТР, например, 100, 200 или больше.
А теперь поэтапно рассмотрим формирование формулы для разделения текста в ячейке:
- Во-первых, нам необходимо найти два пробела, которые разделяют наши слова, для поиска первого пробела нужна формула: =ПОИСК(» «;B2;1), а для второго подойдет: =ПОИСК(» «;B2;C2+1);
- Во-вторых, определяем, сколько символов нужно выделить в строке. Поскольку позиции разделителя мы уже определили, то символов для разделения у нас будет на один меньше. Значит, будем использовать функцию ПСТР для изъятия слов, с ячейки используя как аргумент «количество_знаков» результат работы предыдущей формулы. Для определения первого слова (Фамилии) нужна формула: =ПСТР(B2;1;ПОИСК(» «;B2;1)), для определения второго значения (Имя): =ПСТР(B2;ПОИСК(» «;B2;1)+1;ПОИСК(» «;B2;ПОИСК(» «;B2;1)+1) -ПОИСК(» «;B2;1)), а теперь определим последнее значение (Отчество): =ПСТР(B2;ПОИСК(» «;B2;ПОИСК(» «;B2;1)+1)+1;100).
 В результате мы разделили ФИО на три слова, что позволит с ними эффективно работать.
В результате мы разделили ФИО на три слова, что позволит с ними эффективно работать.
Если же значение в ячейке будете делить на две части, то ищете только один пробел (или иной разделитель), а вот чтобы разделить более 4 слов, в формулу добавьте поиск необходимых разделителей.
Выдергиваем слова с помощью макросов VBA
Рассмотрим два способа разделить текст в ячейке:
- Выдергиваем отдельные слова по разделителю;
- Делим текст без пробелов.
Способ №1.
Поскольку вас интересует автоматическое деление текста, значит надо написать хорошую функцию на VBA и внедрить ее в рабочую книгу. Для начала переходим на вкладку «Разработчик» и выбираем «Visual Basic» или вызываем эту возможность с помощью горячего сочетания клавиш Alt+F11. (детальнее в статье «Как создать макрос в Excel»).
Создаем новый модуль в меню «Insert» наживаем пункт «Module» и переносим в него нижеприведенный код:
Как разделить текст в MS Excel
Многие знают, что для того, чтобы объединить текст в двух ячейках достаточно воспользоваться функцией СЦЕПИТЬ (CONCATENATE), однако, как быть, если необходимо не объединить, а наоборот разделить текст в ячейке? Если количество символов, которое необходимо отделить известно (не важно справа или слева), тогда можно воспользоваться функциями ЛЕВСИМВ (LEFT) или ПРАВСИМВ (RIGHT), в зависимости с какой стороны необходимо выделить определенное количество символов.
Однако, как быть, если необходимо разделить ячейку в которой заведомо не известно количество символов, которые нужно отделить, а известно лишь сколько частей необходимо получить в результате операции. Самым простым примером такой ситуации может быть необходимость выделить из ячейки в которой занесено ФИО человека, отдельно фамилию, имя и отчество. Фамилии у всех разные, поэтому заранее узнать количество символов, которые необходимо отделить, не получится.
На Ваше обозрение представим два способа разделения текста. Один очень быстрый — для тех кому надо просто разделить текст заменив имеющийся, а второй с использованием формул.
Первый способ — супер быстрый.
На самом деле в MS Excel существует встроенная возможность быстрого разделения текста в ячейке, если там присутствует или присутствуют разделитель/разделители (например, простой пробел или запятая). Причем таких разделителей может быть несколько, т.е. текст будет разделятся если в строке присутствует или пробел, или точка с запятой или запятая и т.д.
Для этого необходимо выделить ячейки с текстом, который необходимо разделить и воспользоваться командой «Текст по столбцам».

В англоязычной версии MS Excel данная команда звучит как «Text to Columns» вкладки «DATA».

После несложных подсказок мастера (на самом деле, в нашем примере после выбора разделителя — пробела можно смело жать «Готово»)

А вот и, собственно, результат.

Второй способ — с использованием формул.
В такой ситуации понадобится сочетание функций: ПОИСК (SEARCH) и ПСТР (MID). Для начала, с помощью первой находим пробел между словами (между фамилией и именем и именем и отчеством), а потом подключаем вторую для того, чтобы выделить необходимое количество символов. Грубо говоря, первой функцией определяем количество символов, а второй — уже разделяем.
Кроме того, поскольку разделительного знака в конце строки нет, то количество символов в последнем слове (нашем случае — отчестве) вычислить не удастся, но это не проблема, достаточно указать заведомо большее количество символов в качестве аргумента «число знаков» функции ПСТР, например, 100.
Рассмотрим вышесказанное на примере. Сначала, для лучшего понимания, разнесем формулы и, таким образом, разделим весь процесс на два этапа.


Для того, чтобы определить количество символов, которые необходимо выделить в строке, необходимо определить позиции разделителей (в нашем случае пробела) их будет на один меньше нежели слов в ячейке.
Поскольку информация о количестве необходимых символах получена, следующим этапом будет использование функции ПСТР (MID).


Здесь, в качестве аргументов, используются промежуточные значения, полученные с помощью функции ПОИСК. Для последней колонки количество символов неизвестно, поэтому было взято заведомо бОльшее количество символов (в нашем случае 100).
Теперь попробуем соединить промежуточные расчеты в одну формулу.


Если текст в ячейке необходимо разделить лишь на две части, то необходимо произвести поиск лишь одного пробела (либо другого разделителя, который находится между словами), а для разделения на 4 и больше частей формулу придется усложнить поиском 3го, 4го и т.д. разделителей.
Делим слипшийся текст на части
Итак, имеем столбец с данными, которые надо разделить на несколько отдельных столбцов. Самые распространенные жизненные примеры:
- ФИО в одном столбце (а надо — в трех отдельных, чтобы удобнее было сортировать и фильтровать)
- полное описание товара в одном столбце (а надо — отдельный столбец под фирму-изготовителя, отдельный — под модель для построения, например, сводной таблицы)
- весь адрес в одном столбце (а надо — отдельно индекс, отдельно — город, отдельно — улица и дом)
- и т.д.
Способ 1. Текст по столбцам
Выделите ячейки, которые будем делить и выберите в меню Данные — Текст по столбцам (Data — Text to columns) . Появится окно Мастера разбора текстов:
На первом шаге Мастера выбираем формат нашего текста. Или это текст, в котором какой-либо символ отделяет друг от друга содержимое наших будущих отдельных столбцов (с разделителями) или в тексте с помощью пробелов имитируются столбцы одинаковой ширины (фиксированная ширина).
На втором шаге Мастера, если мы выбрали формат с разделителями (как в нашем примере) — необходимо указать какой именно символ является разделителем:
Если в тексте есть строки, где зачем-то подряд идут несколько разделителей (несколько пробелов, например), то флажок Считать последовательные разделители одним (Treat consecutive delimiters as one) заставит Excel воспринимать их как один.
Выпадающий список Ограничитель строк (Text Qualifier) нужен, чтобы текст заключенный в кавычки (например, название компании «Иванов, Манн и Фарбер») не делился по запятой
внутри названия.
И, наконец, на третьем шаге для каждого из получившихся столбцов, выделяя их предварительно в окне Мастера, необходимо выбрать формат:
- общий — оставит данные как есть — подходит в большинстве случаев
- дата — необходимо выбирать для столбцов с датами, причем формат даты (день-месяц-год, месяц-день-год и т.д.) уточняется в выпадающем списке
- текстовый — этот формат нужен, по большому счету, не для столбцов с ФИО, названием города или компании, а для столбцов с числовыми данными, которые Excel обязательно должен воспринять как текст. Например, для столбца с номерами банковских счетов клиентов, где в противном случае произойдет округление до 15 знаков, т.к. Excel будет обрабатывать номер счета как число:
Кнопка Подробнее (Advanced) позволяет помочь Excel правильно распознать символы-разделители в тексте, если они отличаются от стандартных, заданных в региональных настройках.
Способ 2. Как выдернуть отдельные слова из текста
Если хочется, чтобы такое деление производилось автоматически без участия пользователя, то придется использовать небольшую функцию на VBA, вставленную в книгу. Для этого открываем редактор Visual Basic:
- в Excel 2003 и старше — меню Сервис — Макрос — Редактор Visual Basic(Tools — Macro — Visual Basic Editor)
- в Excel 2007 и новее — вкладка Разработчик — Редактор Visual Basic (Developer — Visual Basic Editor) или сочетание клавиш Alt+F11
Вставляем новый модуль (меню Insert — Module) и копируем туда текст вот этой пользовательской функции:
Теперь можно найти ее в списке функций в категории Определенные пользователем (User Defined) и использовать со следующим синтаксисом:
=SUBSTRING(Txt; Delimeter; n)
- Txt — адрес ячейки с текстом, который делим
- Delimeter — символ-разделитель (пробел, запятая и т.д.)
- n — порядковый номер извлекаемого фрагмента
Способ 3. Разделение слипшегося текста без пробелов
Тяжелый случай, но тоже бывает. Имеем текст совсем без пробелов, слипшийся в одну длинную фразу (например ФИО «ИвановИванИванович»), который надо разделить пробелами на отдельные слова. Здесь может помочь небольшая макрофункция, которая будет автоматически добавлять пробел перед заглавными буквами. Откройте редактор Visual Basic как в предыдущем способе, вставьте туда новый модуль и скопируйте в него код этой функции:
Теперь можно использовать эту функцию на листе и привести слипшийся текст в нормальный вид:
Как разделить текст по ячейкам формула в Excel
Часто приходится оптимизировать структуру данных после импорта в Excel. Некоторые разные значения попадают в одну и туже ячейку образуя целую строку как одно значение. Возникает вопрос: как разбить строку на ячейки в Excel. Программа располагает разными поисковыми функциями: одни ищут по ячейках другие ищут по содержимому ячеек. Ведь выполнять поиск по текстовой строке, которая содержится в ячейке ¬– это также распространенная потребность пользователей Excel. Их мы и будем использовать для разделения строк.
Как разделить текст на две ячейки Excel
Допустим на лист Excel были импортированные данные из другой программы. Из-за несовместимости структуры данных при импорте некоторые значение из разных категорий были внесены в одну ячейку. Необходимо из этой ячейки отделить целые числовые значения. Пример таких неправильно импортированных данных отображен ниже на рисунке:

Сначала определим закономерность, по которой можно определить, что данные из разных категорий, несмотря на то, что они находятся в одной и той же строке. В нашем случае нас интересуют только числа, которые находятся вне квадратных скобок. Каким способом можно быстро выбрать из строк целые числа и поместить их в отдельные ячейки? Эффективным решением является гибкая формула основана на текстовых функциях.
В ячейку B3 введите следующую формулу:
Теперь скопируйте эту формулу вдоль целого столбца:
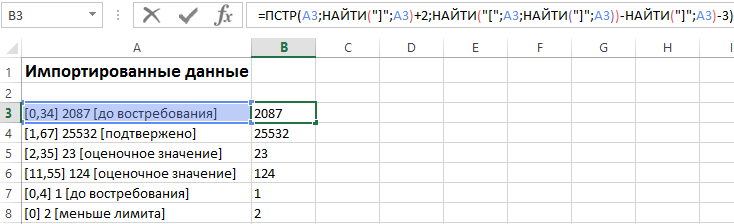
Выборка чисел из строк в отдельные ячейки.
Описание формулы для разделения текста по ячейкам:
Функция ПСТР возвращает текстовое значение содержащие определенное количество символов в строке. Аргументы функции:
- Первый аргумент – это ссылка на ячейку с исходным текстом.
- Второй аргумент – это позиция первого символа, с которого должна начинаться разделенная строка.
- Последний аргумент – это количество символов, которое должна содержать разделенная строка.
С первым аргументом ПСТР все понятно – это ссылка на ячейку A3. Второй аргумент мы вычисляем с помощью функции НАЙТИ(«]»;A3)+2. Она возвращает очередной номер символа первой закрывающейся квадратной скобки в строке. И к этому номеру мы добавляем еще число 2, так как нам нужен номер символа после пробела за квадратной скобкой. В последнем аргументе функция вычисляет какое количество символов будет содержать разделенная строка после разделения, учитывая положение квадратной скобки.
Обратите внимание! Что в нашем примере все исходные и разделенные строки имеют разную длину и разное количество символов. Именно поэтому мы называли такую формулу – гибкой, в начале статьи. Она подходит для любых условий при решении подобного рода задач. Гибкость придает ей сложная комбинация из функций НАЙТИ. Пользователю формулы достаточно определить закономерность и указать их в параметрах функций: будут это квадратные скобки либо другие разделительные знаки. Например, это могут быть пробелы если нужно разделить строку на слова и т.п.
В данном примере функция НАЙТИ во втором аргументе определяет положение относительно первой закрывающейся скобки. А в третьем аргументе эта же функция вычисляет положение нужного нам текста в строке относительно второй открывающийся квадратной скобки. Вычисление в третьем аргументе более сложное и оно подразумевает вычитание одной большей длинны текста от меньшей. А чтобы учитывать еще 2 пробела следует вычитать число 3. В результате чего получаем правильное количество символов в разделенной строке. С помощью такой гибкой формулы можно делать выборку разной длинны разделенного текста из разных длинны исходных строк.
Как разделить текст в Excel по столбцам?
Часто мы сталкиваемся с проблемой, когда у нас есть данные только в одном столбце, при этом было бы гораздо удобнее расцепить текст на несколько столбцов.
Например, разделить столбец с полными именами (Фамилия Имя Отчество) на отдельные столбцы с именами (Фамилия, Имя, Отчество).
Давайте разберемся как разбить текст в ячейке по столбцам на конкретном примере.
Предположим у нас имеется таблица с ФИО сотрудников компании:
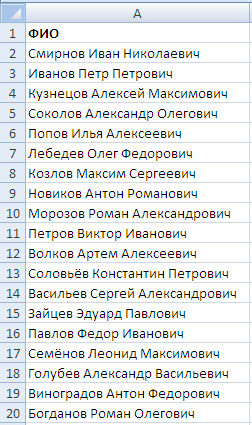
Исходные данные для разделения
Для того, чтобы разделить текст в Excel по столбцам идем на панель вкладок и выбираем Данные -> Работа с данными -> Текст по столбцам:
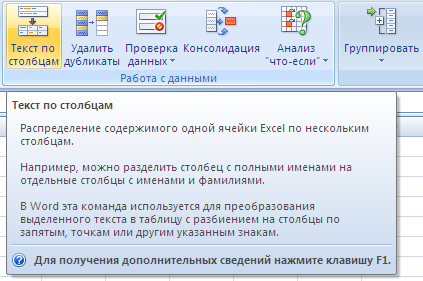
Указание формата данных
На первом шаге выбираем формат данных:

Шаг 1. Указание формата данных
На выбор есть 2 варианта формата данных:
- С разделителями — разделение происходит по знаку-разделителю (пробел, запятая, точка и т.д.);
- Фиксированная ширина — разделение происходит по фиксированной ширине столбца.
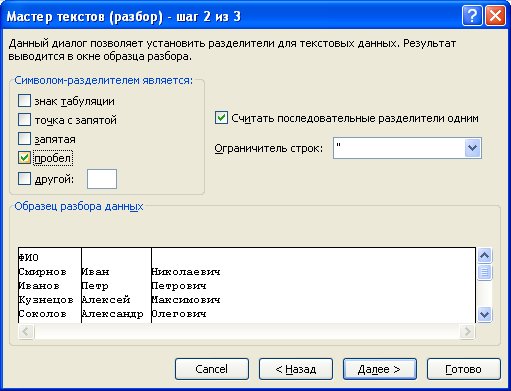
Выбор разделителя для данных
В случае выбора формата с разделителями, как в нашем примере, на втором шаге выбираем какой конкретно знак-разделитель мы будем использовать:
Шаг 2. Выбор разделителя для данных
Можно выбрать как из стандартных знаков (знак табуляции, точка с запятой, запятая, пробел), так и из любых других (например, точка, символы $, @ и т.п.).
Флажок Считать последовательные разделители одним необходим если в исходных данных разделитель может быть продублирован (например, двойной пробел и т.д.).
Параметр Ограничитель строк позволяет не разделять по столбцам текст заключенный в кавычки.
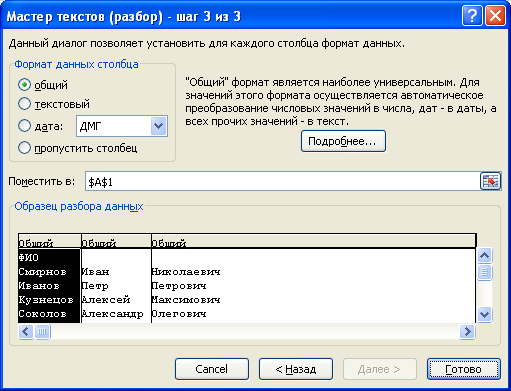
Выбор формата данных для каждого столбца
На третьем шаге выбираем формат данных для каждого нового сформированного столбца:
Шаг 3. Выбор формата данных для каждого столбца

В EXCEL есть очень удобная функция для «вытаскивания» из текста или слова определенного заданного нами количества символов.
Зачастую такие задачи возникают при обработке кодов, артикулов, номеров телефонов и т.д.
В нашем примере мы «вытащим» левую трехзначную часть кода и правую часть, имеющую различную разрядность без использования ПРАВСИМВ и ЛЕВСИМВ и их сочетаний с другими вспомогательными функциями.
Для этого:
- В ячейке напротив кода введем =ПСТР( и нажмем fx.
- В аргументах функции укажем ячейку с исходным текстом , первоначальным кодом.
- Зададим Начальную позицию (номер символа, с которого начнет вытаскивать текст функция).
- Количество знаков – то самое к-во, которое должно быть «вытащено» из текста или строки. Пробел и символы – также являются знаками.

Для работы с правой частью кода , нам необходимо сдвинуть Начальную позицию за трехзначный код с разделителем.
Для этого:
- Выполняем те же самые операции, что и ранее, но в Начальной позиции указываем «5» , т.е. это номер символа после кода и разделителя.


Необходимо обратить внимание , что такое разделение возможно только при унифицированной системе ведения кодов.
Если вдруг первая часть окажется двухзначной или четырёхзначной, то единообразия не получится.
Если материал Вам понравился или даже пригодился, Вы можете поблагодарить автора, переведя определенную сумму по кнопке ниже:
(для перевода по карте нажмите на VISA и далее «перевести»)
Как извлечь слова из строки таблицы Excel
Чтобы извлечь первое слово из строки, формула должна найти позицию первого символа пробела, а затем использовать эту информацию в качестве аргумента для функции ЛЕВСИМВ. Следующая формула делает это: =ЛЕВСИМВ(A1;НАЙТИ(» «;A1)-1) .
Эта формула возвращает весь текст до первого пробела в ячейке A1. Однако у нее есть небольшой недостаток: она возвращает ошибку, если текст в ячейке А1 не содержит пробелов, потому что состоит из одного слова. Несколько более сложная формула решает проблему с помощью новой функции ЕСЛИОШИБКА, отображая все содержимое ячейки, если произошла ошибка:
=ЕСЛИОШИБКА(ЛЕВСИМВ(A1;НАЙТИ(» «;A1)-1);A1) .
Если вам нужно, чтобы формула была совместима с более ранними версиями Excel, вы не можете использовать ЕСЛИОШИБКА. В таком случае придется обойтись функцией ЕСЛИ и функцией ЕОШ для проверки на ошибку:
=ЕСЛИ(ЕОШ(НАЙТИ(» «;A1));A1;ЛЕВСИМВ(A1;НАЙТИ(» «;A1)-1))
Извлечение последнего слова строки
Извлечение последнего слова строки — более сложная задача, поскольку функция НАЙТИ работает только слева направо. Таким образом, проблема состоит в поиске последнего символа пробела. Следующая формула, однако, решает эту проблему. Она возвращает последнее слово строки (весь текст, следующий за последним символом пробела):
=ПРАВСИМВ(A1;ДЛСТР(A1)-НАЙТИ(«*»;ПОДСТАВИТЬ(A1;» «;»*»;ДЛСТР(A1)-ДЛСТР(ПОДСТАВИТЬ(A1;»»;»»)))))
Но у этой формулы есть такой же недостаток, как и у первой формулы из предыдущего раздела: она вернет ошибку, если строка не содержит по крайней мере один пробел. Решение заключается в использовании функции ЕСЛИОШИБКА и возврате всего содержимого ячейки А1, если возникает ошибка:
=ЕСЛИОШИБКА(ПРАВСИМВ(A1;ДЛСТР(A1)-НАЙТИ(«*»;ПОДСТАВИТЬ(A1;» «;»*»;ДЛСТР(A1)-ДЛСТР(ПОДСТАВИТЬ(A1;» «;»»)))));A1)
Следующая формула совместима со всеми версиями Excel:
=ЕСЛИ(ЕОШ(НАЙТИ(» «;A1));A1;ПРАВСИМВ(A1;ДЛСТР(A1)-НАЙТИ(«*»;ПОДСТАВИТЬ(A1;»»;»*»;ДЛСТР(A1)-ДЛСТР(ПОДСТАВИТЬ(A1;» «;»»))))))
Извлечение всего, кроме первого слова строки
Следующая формула возвращает содержимое ячейки А1, за исключением первого слова:
=ПРАВСИМВ(A1;ДЛСТР(A1)-НАЙТИ(» «:A1;1)) .
Если ячейка А1 содержит текст 2008 Operating Budget, то формула вернет Operating Budget.
Формула возвращает ошибку, если ячейка содержит только одно слово. Следующая версия формулы использует функцию ЕСЛИОШИБКА, чтобы можно было избежать ошибки; формула возвращает пустую строку, если ячейка не содержит более одного слова:
=ЕСЛИОШИБКА(ПРАВСИМВ(A1;ДЛСТР(A1)-НАЙТИ(» «;A1;1));»»)
А эта версия совместима со всеми версиями Excel:
=ЕСЛИ(ЕОШ(НАЙТИ(» «;A1));»»;ПРАВСИМВ(A1;ДЛСТР(A1)-НАЙТИ(» «;A1;1)))
Как в Эксель (Excel) вытащить часть текста из ячейки в другую ячейку?
Например, в ячейке написана категория товара и информация о товаре.
Как выташить в отдельную ячейку только название категории («Перчатки хозяйственные», «Молоток слесарный» и т.п.)?

Очевидно, что вытащить часть текста в другую ячейку можно с помощью специальных функций для работы со строками.
В Excel их довольно много, и в первую очередь можно выделить такие функции, как:
ЛЕВСИМВ и ПРАВСИМВ — излекают определённое число символов слева и справа соответственно.
ДЛСТР — длина строки.
НАЙТИ — возвращает позицию, с которой подстрока или символ входит в строку.
ПОДСТРОКА — извлекает подстроку из текста, которая отделена определённым символом-разделителе<wbr />м.
ПСТР — извлекает указанное число знаков из строки (начиная с указанной позиции).
КОНЕЦСТРОКИ и НАЧАЛОСТРОКИ — возвращает строку после / до указанной подстроки.
Но здесь всё зависит от того, как именно эти данные расположены в исходной строке — одно дело в самом конце / начале, а другое — в середине.
В любом случае нужно постараться найти какой-то признак — слово или символ, до или после которого в ячейке находятся нужные данные, после чего использовать его в качестве аргумента в функциях, про которые я написал выше.
Пример 1
Исходные данные такие:

Предположим, нужно извлечь в отдельную ячейку цену товара (3500 рублей, 4200 рублей).
Можно увидеть, что в этих ячейках цене предшествует текст «размеры, » — то есть можно воспользоваться функцией КОНЕЦСТРОКИ и вытащить всё, что находится после этого текста.
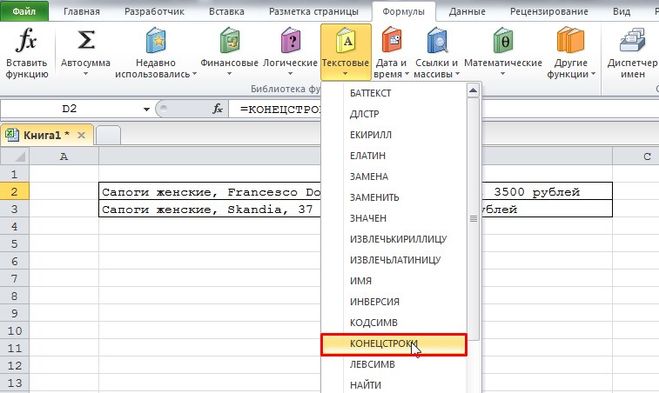
Итак, ставим курсор в ячейку, куда нужно извлечь цену, и на вкладке «Формулы» выбираем «Текстовые» -> «КОНЕЦСТРОКИ».
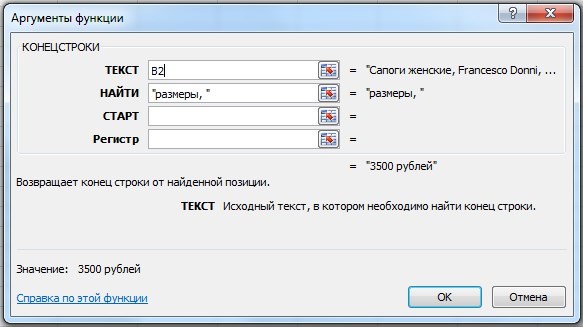
Указываем аргументы функции (обязательные):
ТЕКСТ — указываем ячейку, из которой нужно извлечь подстроку (B2 или B3).
НАЙТИ — указываем подстроку, после которой должно начаться извлечение текста («размеры, «).
Нажимаем на кнопку «OK» и получаем то, что было нужно:

Формула получилась такая:
А если требуется, чтобы было только число (без рублей), то можно, например, использовать функцию НАЧАЛОСТРОКИ.
В этом случае в качестве 1 аргумента (исходной строки) вводим формулу, созданную выше, а в качестве 2 аргумента — » «.

Пример 2
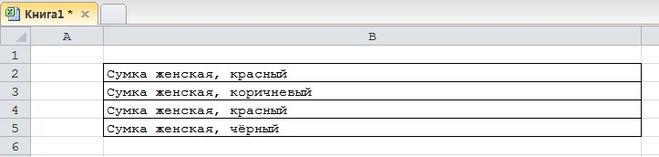
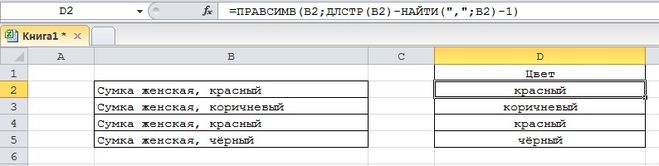
Нужно извлечь в отдельную ячейку название цвета (красный, коричневый и т.п.).
Здесь всё проще, так как название цвета находится в самом конце строки — и можно, например, использовать функцию ПРАВСИМВ.
У этой функции 2 аргумента:
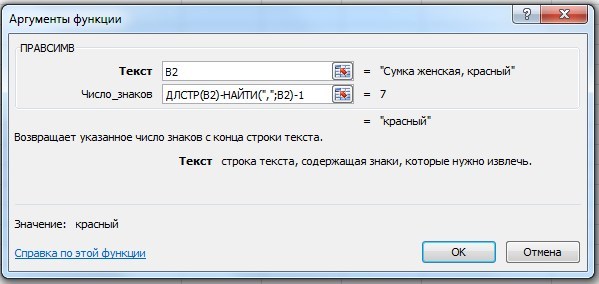
Текст — указываем ячейку, из которой нужно извлечь подстроку.
Число_знаков — это разность между длиной исходной строки (функция ДЛСТР) и позицией запятой в этой строке (функция НАЙТИ), также дополнительно нужно отнять единицу, так как после запятой стоит пробел.
Формула и результат:
Но мне всё же больше нравится вариант с упомянутой выше функцией КОНЕЦСТРОКИ.
![]()
Она менее громоздкая и не содержит вложенных функций.
Эксель многие любят за то, что можно быстро обрабатывать и менять таблицы, так как надо.
Вот и в этом случаи, для того, чтобы вытащить из ячейки текст, нужно в пустой рядом столбик ввести формулу. Но тут не так всё просто. В зависимости от того, с какой стороны нужен текст, вводим формулу Левсимв и Правсимв. Одна из этих функций выведет нужный текст справа, другая слева. При этом формула будет выглядеть примерно так:=ЛЕВСИМВ(В1;10). В данном случаи 10 число символов. Но если число символов не одинаковое, то метод не совсем подойдёт.
Тогда можно будет попробовать функцию текстовые, конец строки. Если перед нужной вам фразой стоит одно и тоже слово в каждой строке. Появится окошко, и в строке найти добавить это слова. Нужный текст после этого слова переместится.
Открывайте ячейку из которой надо вытащить часть текста, клацаете по тексту что бы курсор в тексте начал моргать, выделяете эту часть текста которую хотите утащить в другое место, щелкаете по выделенке ПКМ (правой кнопкой мышки) выбираете «копировать»
Переходите в окно куда нужно вставить, щелкаете в нем ЛКМ (левой кнопкой мышки) что бы активировать работу ввода данных в этой ячейки, следом щелкаете ПКМ, выбираете «вставить» и все.
Если в таблице одна или 2 строки, тогда можно воспользоваться функцией нажатия клавиш Ctrl+C скопировать и Ctrl+V вставить, а если в таблице нужно поменять цену для большого количества параметров, переходите в шапку инструментов, и действуйте по алгоритму, который находится под кнопой формулы — текстовые и в выпадающем меню находите среди абракадабры из сокращений «конецстроки»
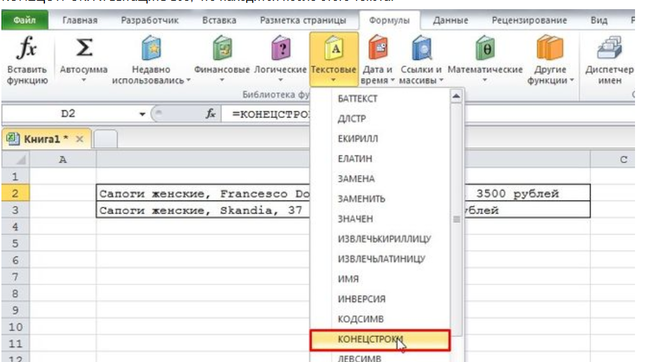
далее следуя указаниям меняете в открытых окнах параметры. Подставляете какие заданы, а машина сама все посчитает. За это эксель и любят бухгалтеры, по мне так самая кривая программа после ворда. имхо для бв.
Что касается абракадабры в выпадающем меню, на это есть подсказки, например
ЛЕВСИМВ — левые символы
ПРАВСИМВ — правые символы
ДЛСТР — длина строки
НАЙТИ — возвращает позицию, с которой подстрока или символ входит в строку.
КОНЕЦСТРОКИ возврат строки до конца
НАЧАЛОСТРОКИ — возврат строки в начало
Если у Вас данные (которые нужно обработать, все эти «молотки» и «перчатки») всегда отделены от остальной части текста запятой и первая ячейка с данными это B2, то формула такая
напишите ее в любую свободную ячейку (например правее) в той же строке, а потом растяните вниз и все ваши тысячи строк будут обработаны.
Как вариант можно использовать следующий способ:
Сначала выделяем столбец, который хотим разделить, затем на вкладке данные выбираем «Текст по столбцам», в появившемся окне изменяем тип разделителя (там есть варианты — табуляция, точка, запятая. ), а затем заканчиваем действие.
В итоге ваш исходный текст будет разбит на отдельные столбцы с нужным содержанием.
Довольно сложный вопрос, но в Ексель можно сделать и такое, в этом редакторе есть подобные функции работы со строками.
Эти функции мы ищем в верхнем меню во вкладке «Формулы» — «Текстовые»:

Желательно, чтобы записи в ячейках были бы хоть как-то структурированы, например, если в ячейках сначала записано наименование товара, потом через запятую, в конце записи, цена товара, с такими ячейками будет работать несложно. Поработаем вот с этими ячейками, попробуем цену товара перенести в отдельные ячейки:

Текст у нас написан для этого отлично, цена товара стоит в конце строки, после слова «размеры» и запятой, поэтому мы воспользуемся функцией КОНЕЦСТРОКИ из вкладки «Текстовые» (см. выше). Открывается вот такое окошечко, в поле ТЕКСТ указываем столбец, в котором находятся наши ячейки, в поле НАЙТИ — слова, после которых текст надо переносить в отдельную ячейку.
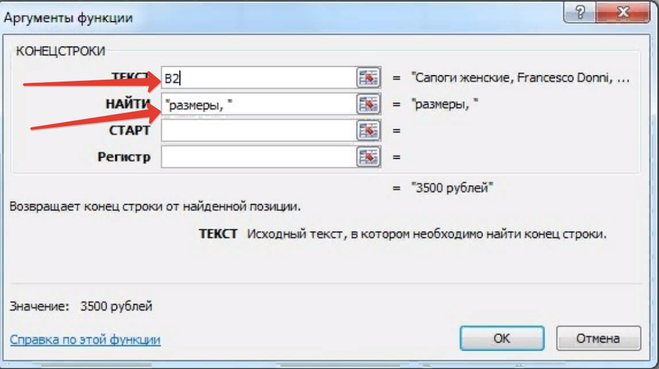
Нажимаем ОК, получаем то, что хотели:

Теперь можно, используя тот же алгоритм, поработать с новыми ячейками с помощью функции НАЧАЛОСТРОКИ и получить число без рублей:

Работа в Excel очень упрощает рабочую деятельность, ведь стоит правильно все оформить и программа за тебя все посчитает. Но надо уметь работать с программой, чтобы итог был верным.
Иногда необходимо часть текста перетащить в другую ячейку. Если это одна-две строки, можно и скопировать, но когда строк много, такой способ совсем не годится.
К примеру, имея такую большую таблицу, следует подготовить отчет по отдельным филиалам.
Нам помогут функций ЛЕВСИМВ и ПРАВСИМВ, которые помогут, если нужные символы находятся в самом начале или в самом конце текста.

А вот если нужный текст находится в середине, то такая функция не подойдет. Но в этом случае стоит воспользоваться ПСТР.

Для того, чтобы скопировать из ячейки Excel часть текста, нужно в выбранной ячейке дважды кликнуть мышкой, так чтобы курсор стал как в Word. Затем выделить нужную часть текста, скопировать и вставить комбинацией клавиш Ctrl+C, Ctrl+V или через контекстное меню правой клавишей мышки.
Единого алгоритма для вытаскивания части текста нет. Есть понимание процесса, как это сделать.
Можно это сделать с помощью символов. Для извлечения определенного количества символов справа и слева — ПРАВСИМВ ЛЕВСИМВ, для возвращения позиции, с которой подстрока или символ входит в строку — НАЙТИ, длина строки — ДЛСТР, возвращение строки — КОНЕЦСТРОКИ и НАЧАЛОСТРОКИ.
Из символов составляется формулировка того, что требуется, вставляется в свободную строку и растягивается на все нужные строки. Все части ячейки будут обработаны.
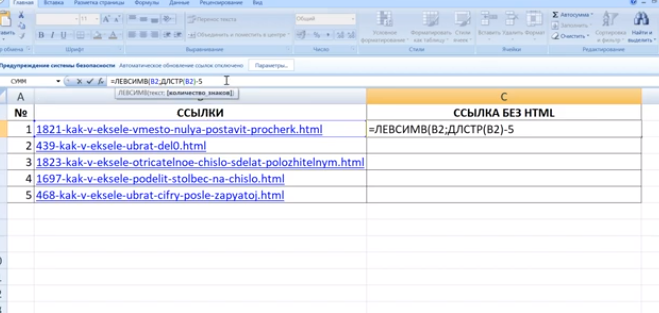
Чтобы выбрать подстроку из текстовой строчки требуется знать разделитель и номер вхождения подстроки.
Считаем что строчка записана в ячейке A3, а номер вхождения подстроки записан в ячейке H1 и в качестве разделителя используется символ «,»
тогда получим формулы граничных символов искомой подстроки
=НАЙТИ( СИМВОЛ(3) ; ПОДСТАВИТЬ( «,»&A3&»,» ; «,» ; СИМВОЛ(3) ; H1))+1
=НАЙТИ( СИМВОЛ(3) ; ПОДСТАВИТЬ( «,»&A3&»,» ; «,» ; СИМВОЛ(3) ; H1+1))-1
формула для подстроки с номером вхождения в ячейке H1 (исходная строка в A3 и разделитель «,»):
=ПСТР( «,»&A3&»,»; НАЙТИ( СИМВОЛ(3); ПОДСТАВИТЬ(«,»&A3&»,<wbr />»; «,»; СИМВОЛ(3); H1))+1; НАЙТИ( СИМВОЛ(3); ПОДСТАВИТЬ(«,»&A3&»,<wbr />»; «,»; СИМВОЛ(3);H1+1)) — НАЙТИ( СИМВОЛ(3); ПОДСТАВИТЬ(«,»&A3&»,<wbr />»; «,»; СИМВОЛ(3); H1))-1)
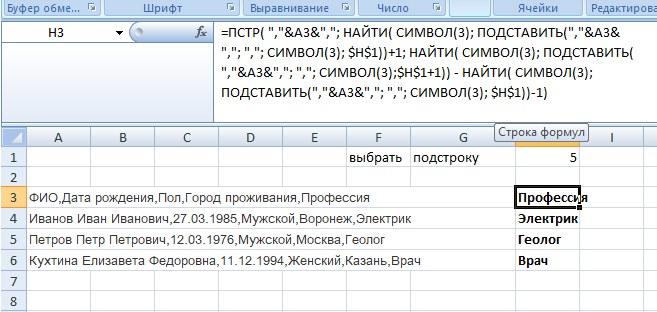
для разделителя «;» формула имеет вид:
=ПСТР( «;»&A3&»;»; НАЙТИ( СИМВОЛ(3); ПОДСТАВИТЬ(«;»&A3&»;<wbr />»; «;»; СИМВОЛ(3); H1))+1; НАЙТИ( СИМВОЛ(3); ПОДСТАВИТЬ(«;»&A3&»;<wbr />»; «;»; СИМВОЛ(3);H1+1)) — НАЙТИ( СИМВОЛ(3); ПОДСТАВИТЬ(«;»&A3&»;<wbr />»; «;»; СИМВОЛ(3); H1))-1)
Можно воспользоваться разными способами. Например, если в нужных ячейках только числа, то можно воспользоваться функцией счет. Чтобы ее вызвать щелкаем вверху fx — при этом появляется диалоговое окно мастера функций. Далее в разделе статистические и ищем нужную функцию. Не забыть выделить нужный диапазон. Она выдает нам количество ячеек в диапазоне с числами.
Если в ячейках и числа и текст и нам нужно определить их количество, то воспользуемся функцией счетз — именно эта функции, которая находится в разделе статистические позволяет считать количество непустых ячеек. Эта функция более универсвльна.
Работая в Excel часто приходится округлять числа. И это в электронных таблицах от Microsoft делается очень просто.
Самым простым способом является нажатие на всплывающем меню (можно вызвать правой кнопкой мыши) соответствующего значка разрядности. Их два. Первый уменьшает разрядность, а второй увеличивает. Вы можете выбрать такую разрядность, которая вам необходима тем самым округлить до нужного числа простым нажатием на кнопку.
Второй способ — это обратиться к верхней панели «Число», где также стоят эти два значка округления чисел. Выделите нужный массив чисел в таблице Excel и нажмите на панели соответствующий значок округления столько раз, сколько требуется для округления до требуемой точности (до десятых, сотых, тысячных).
Третий способ — самый верный, поскольку он работает даже в старых версиях Excel. Чтобы округлить число вам нужно выделить массив чисел, нажать правой кнопкой мыши, выбрать в панели «Формат ячеек», далее «Числовой» формат и в этом же окне справа выбрать нужное «Число десятичных знаков». По умолчанию стоит значение, равное 2 (округление до сотых).
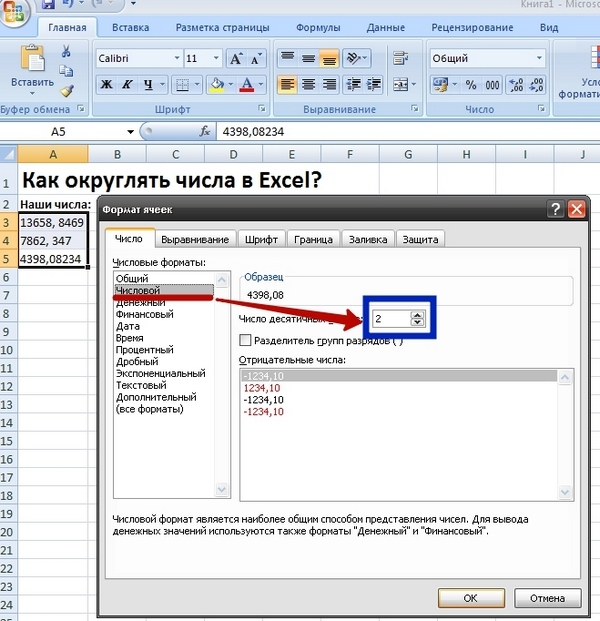
Как видите ничего сложного здесь нет. Однако, есть и другой, более сложный четвертый способ округления чисел в электронных таблицах Excel, который требует использования стандартных функций Excel. Одна из них (наиболее простая и стандартная в использовании) называется ОКРУГЛ.
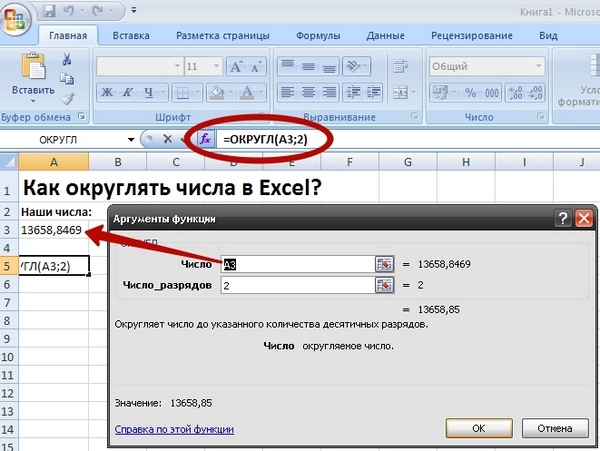
Данная функция Excel округляет выбранное число до нужной разрядности. Для того, чтобы перейти в окно функций, нужно нажать на значок f(x) в верхней панели на строке функций. В появившемся окне следует набрать в поиске функцию ОКРУГЛ. После этого нужно выставить параметры функции округления числа. Их два: число для округления и число разрядов. Число, которое требуется округлить можно напечатать в виде числа, а можно просто выбрать ячейку, в которой она уже есть в Excel. В нашем примере число стоит в ячейке A3. Однако это может быть не просто одна ячейка, а сразу массив чисел в нескольких ячейках (его нужно выделить).
Это все способы округления чисел в Excel. Вы можете выбрать самый удобный для вас.
Содержание
- Microsoft Excel
- Как извлечь слова из строки таблицы Excel
- Извлечение первого слова из строки
- Извлечение последнего слова строки
- Извлечение всего, кроме первого слова строки
- ПРАВСИМВ, ПРАВБ (функции ПРАВСИМВ, ПРАВБ)
- Описание
- Синтаксис
- Пример
- Последнее слово
- Способ 1. Формулы
- Способ 2. Макрофункция
- Способ 3. Power Query
- Удалить последнее слово в ячейках Excel / удалить последние N слов
- Удалить последнее слово из ячейки: формула
- Удаление с помощью регулярного выражения
- Удалить последнее слово/N последних слов во всем столбце
- Заключение
Microsoft Excel
трюки • приёмы • решения
Как извлечь слова из строки таблицы Excel
Формулы в этой статье полезны для извлечения слов из текста, содержащегося в ячейке. Например, вы можете создать формулу для извлечения первого слова в предложении.
Извлечение первого слова из строки
Если вам нужно, чтобы формула была совместима с более ранними версиями Excel, вы не можете использовать ЕСЛИОШИБКА. В таком случае придется обойтись функцией ЕСЛИ и функцией ЕОШ для проверки на ошибку:
=ЕСЛИ(ЕОШ(НАЙТИ(» «;A1));A1;ЛЕВСИМВ(A1;НАЙТИ(» «;A1)-1))
Извлечение последнего слова строки
Извлечение последнего слова строки — более сложная задача, поскольку функция НАЙТИ работает только слева направо. Таким образом, проблема состоит в поиске последнего символа пробела. Следующая формула, однако, решает эту проблему. Она возвращает последнее слово строки (весь текст, следующий за последним символом пробела):
=ПРАВСИМВ(A1;ДЛСТР(A1)-НАЙТИ(«*»;ПОДСТАВИТЬ(A1;» «;»*»;ДЛСТР(A1)-ДЛСТР(ПОДСТАВИТЬ(A1;»»;»»)))))
Но у этой формулы есть такой же недостаток, как и у первой формулы из предыдущего раздела: она вернет ошибку, если строка не содержит по крайней мере один пробел. Решение заключается в использовании функции ЕСЛИОШИБКА и возврате всего содержимого ячейки А1, если возникает ошибка:
=ЕСЛИОШИБКА(ПРАВСИМВ(A1;ДЛСТР(A1)-НАЙТИ(«*»;ПОДСТАВИТЬ(A1;» «;»*»;ДЛСТР(A1)-ДЛСТР(ПОДСТАВИТЬ(A1;» «;»»)))));A1)
Следующая формула совместима со всеми версиями Excel:
=ЕСЛИ(ЕОШ(НАЙТИ(» «;A1));A1;ПРАВСИМВ(A1;ДЛСТР(A1)-НАЙТИ(«*»;ПОДСТАВИТЬ(A1;»»;»*»;ДЛСТР(A1)-ДЛСТР(ПОДСТАВИТЬ(A1;» «;»»))))))
Извлечение всего, кроме первого слова строки
Формула возвращает ошибку, если ячейка содержит только одно слово. Следующая версия формулы использует функцию ЕСЛИОШИБКА, чтобы можно было избежать ошибки; формула возвращает пустую строку, если ячейка не содержит более одного слова:
=ЕСЛИОШИБКА(ПРАВСИМВ(A1;ДЛСТР(A1)-НАЙТИ(» «;A1;1));»»)
А эта версия совместима со всеми версиями Excel:
=ЕСЛИ(ЕОШ(НАЙТИ(» «;A1));»»;ПРАВСИМВ(A1;ДЛСТР(A1)-НАЙТИ(» «;A1;1)))
Источник
ПРАВСИМВ, ПРАВБ (функции ПРАВСИМВ, ПРАВБ)
В этой статье описаны синтаксис формулы и использование функций ПРАВСИМВ и ПРАВБ в Microsoft Excel.
Описание
Функция ПРАВСИМВ возвращает последний символ или несколько последних символов текстовой строки на основе заданного числа символов.
Функция ПРАВБ возвращает последний символ или несколько последних символов текстовой строки на основе заданного числа байтов.
Эти функции могут быть доступны не на всех языках.
Функция ПРАВСИМВ предназначена для языков с однобайтовой кодировкой, а ПРАВБ — для языков с двухбайтовой кодировкой. Язык по умолчанию, заданный на компьютере, влияет на возвращаемое значение следующим образом.
Функция ПРАВСИМВ всегда считает каждый символ (одно- или двухбайтовый) за один вне зависимости от языка по умолчанию.
Функция ПРАВБ считает каждый двухбайтовый символ за два, если включена поддержка ввода на языке с двухбайтовой кодировкой, а затем этот язык назначен языком по умолчанию. В противном случае функция ПРАВБ считает каждый символ за один.
К языкам, поддерживающим БДЦС, относятся японский, китайский (упрощенное письмо), китайский (традиционное письмо) и корейский.
Синтаксис
Аргументы функций ПРАВСИМВ и ПРАВБ описаны ниже.
Текст Обязательный. Текстовая строка, содержащая символы, которые требуется извлечь.
Число_знаков Необязательный. Количество символов, извлекаемых функцией ПРАВСИМВ.
Значение «число_знаков» должно быть больше нуля или равно ему.
Если значение «число_знаков» превышает длину текста, функция ПРАВСИМВ возвращает весь текст.
Если значение «число_знаков» опущено, оно считается равным 1.
Число_байтов Необязательный. Количество символов, извлекаемых функцией ПРАВБ.
Num_bytes должен быть больше нуля или равен нулю.
Если num_bytes больше, чем длина текста, то right возвращает весь текст.
Если num_bytes опущен, предполагается, что это 1.
Пример
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
Источник
Последнее слово
Простая, на первый взгляд, задача с не очевидным решением: извлечь из строки текста последнее слово. Ну или, в общем случае, последний фрагмент, отделенный заданным символом-разделителем (пробелом, запятой и т.д.) Другими словами, необходимо реализовать реверсивный поиск (от конца к началу) в строке заданного символа и извлечь потом все символы справа от него.
Давайте рассмотрим традиционно несколько способов решения на выбор: формулами, макросами и через Power Query.
Способ 1. Формулы

Теперь отрежем от конца получившегося текста 20 символов с помощью функции ПРАВСИМВ (RIGHT) :
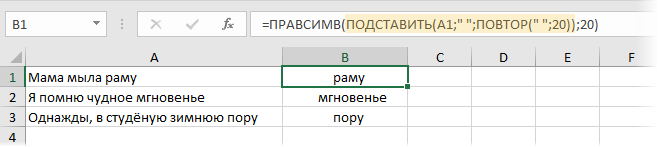
Уже теплее, да? Осталось убрать лишние пробелы с помощью функции СЖПРОБЕЛЫ (TRIM) и задача будет решена:

В английской версии наша формула будет выглядеть, соответственно:
=TRIM(RIGHT(SUBSTITUTE(A1;» «;REPT(» «;20));20))
И если исходный текст нужно разделить не по пробелу, а по другому символу-разделителю (например, по запятой), то нашу формулу надо будет чуть-чуть подправить:

Способ 2. Макрофункция
Теперь можно сохранить книгу (в формате с поддержкой макросов!) и воспользоваться созданной функцией в следующем синтаксисе:
=LastWord(txt ; delim ; n)
При любых изменениях в исходном тексте в будущем наша макрофункция будет «на лету» пересчитываться, как и любая стандартная функция листа Excel.
Способ 3. Power Query
Наша задача по отделению последнего слова или фрагмента через заданный разделитель с помощью Power Query решается очень легко.
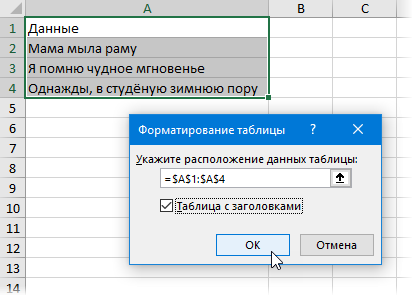
Затем загрузим созданную «умную таблицу» в Power Query с помощью команды Из таблицы / диапазона (From table/range) на вкладке Данные (если у вас Excel 2016) или на вкладке Power Query (если у вас Excel 2010-2013):
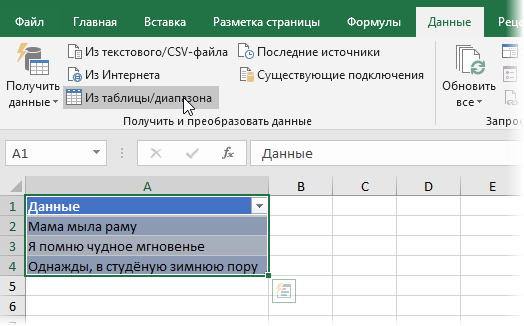
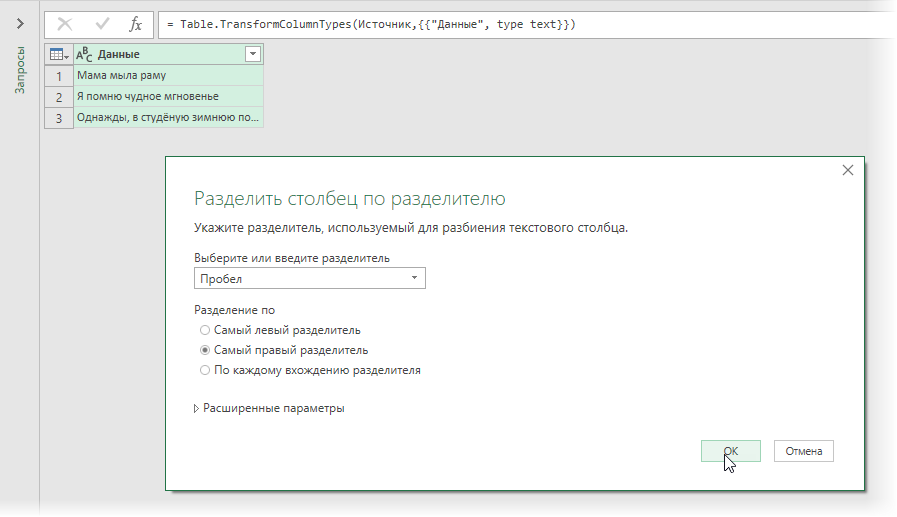
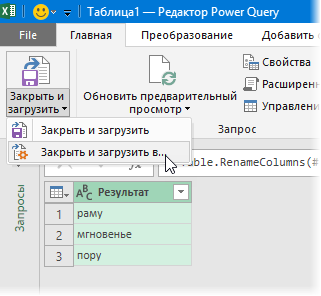
И в итоге получаем:
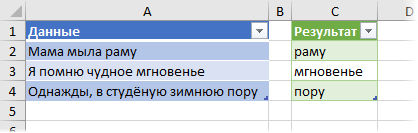
Если в будущем исходный список изменится, то достаточно будет правой кнопкой мыши или сочетанием клавиш Ctrl + Alt + F5 обновить наш запрос.
Источник
Удалить последнее слово в ячейках Excel / удалить последние N слов
Иногда при работе с Excel возникает необходимость удалить последнее слово или несколько слов в конце фраз в ячейках.
Для решения задачи можно объединить несколько функций программы, чтобы осуществить поиск справа налево в ячейке, но есть помимо обычных формул и другие способы. Расскажу обо всем по порядку.
Удалить последнее слово из ячейки: формула
В отличие от процедуры удаления первого слова из ячейки, где формула довольно простая в силу того, что функция ПОИСК ищет слева направо, формула для удаления последнего слова существенно сложнее.
К сожалению, эквивалента ПОИСК, которая искала бы символ в строке не слева направо, а наоборот, справа, нет. Ниже пошаговое описание формулы, которая позволит, тем не менее, сочетанием функций найти его. После этого удалить последнее слово будет уже несложно.
Формула получается заменой A1 на полное выражение без знака равенства во втором шаге.
=ДЛСТР(ПОДСТАВИТЬ(A1;» «;»»))
Если вы точно уверены, можно использовать конкретный символ, например, «».
Можно повысить уверенность с помощью функции ЮНИСИМВ — она позволяет вставлять на лист какие угодно символы из UNICODE-таблицы.
Например, =ЮНИСИМВ(23456)
Возвращает: 宠
Полагаю, это китайский или японский.
У функции ПОДСТАВИТЬ есть необязательный четвертый аргумент, обозначающий позицию символа, который нужно заменить. На втором шаге мы его не использовали, чтобы он удалил все пробелы. На этом шаге вставляем в него формулу из четвертого шага.
Третьим аргументом будет формула из пятого шага.
=ПОДСТАВИТЬ(A1;» «;ЮНИСИМВ(23456);ДЛСТР(A1)-ДЛСТР(ПОДСТАВИТЬ(A1;» «;»»)))
На этот раз функция ПОИСК замечательно справится. Поскольку символ в строке гарантированно в единственном экземпляре, его можно искать и слева направо.
=ПОИСК(ЮНИСИМВ(23456);A1;ПОДСТАВИТЬ(A1;» «;ЮНИСИМВ(23456);ДЛСТР(A1)-ДЛСТР(ПОДСТАВИТЬ(A1;» «;»»))))
=ПОИСК(ЮНИСИМВ(23456);A1;ПОДСТАВИТЬ(A1;» «;ЮНИСИМВ(23456);ДЛСТР(A1)-ДЛСТР(ПОДСТАВИТЬ(A1;» «;»»))))-1
=ЛЕВСИМВ(A1;ПОИСК(ЮНИСИМВ(23456);A1;ПОДСТАВИТЬ(A1;» «;ЮНИСИМВ(23456);ДЛСТР(A1)-ДЛСТР(ПОДСТАВИТЬ(A1;» «;»»))))-1)
Чтобы обезопасить себя от ситуаций, когда в ячейке одно слово и чтобы формула в таких случаях его удаляла, а не возвращала ошибку.
=ЛЕВСИМВ(» «&A1;ПОИСК(ЮНИСИМВ(23456);ПОДСТАВИТЬ(» «&A1;» «;ЮНИСИМВ(23456);ДЛСТР(» «&A1)-ДЛСТР(ПОДСТАВИТЬ(» «&A1;» «;»»))))-1)
Предыдущий шаг добавит обезопасит от ошибок, но добавит лишний пробел слева. Функция удалит его и любые другие лишние пробелы между слов или в конце строки.
Итак, формула удаления последнего слова из ячейки:
Удаление с помощью регулярного выражения
Регулярные выражения в Excel наделяют специалиста, знакомого с их синтаксисом, практически неограниченными возможностями по поиску, извлечению, замене и удалению текстовых данных без использования монструозных мегаформул, описанных выше.
Функциями листа можно пользоваться абсолютно бесплатно, а подробно об этом синтаксисе можно почитать в моей статье:
Удалить последнее слово/N последних слов во всем столбце

Удаляем последние 2 слова в конце всех ячеек:
 Удаление последних двух слов в ячейках столбца в 2 клика
Удаление последних двух слов в ячейках столбца в 2 клика
Аналогично решается задача для нескольких — можно использовать пункт «Последние N», чтобы указать количество удаляемых слов, считая справа:
 Удаляем последние 4 слова в ячейках столбца, вводя необходимое количество слов самостоятельно
Удаляем последние 4 слова в ячейках столбца, вводя необходимое количество слов самостоятельно
Заключение
Источник
- Первое слово ячейки Excel с большой буквы
- Вывести первое слово в отдельную ячейку — формула
- Оставить только первое слово в ячейке
- Взять первые 2/3/N слов ячейки
- Процедуры !SEMTools для извлечения первых N слов
Первое слово (до пробела) в Excel-ячейке часто приковывает внимание тех, кто работает с текстовыми данными. Его часто нужно выделить как отдельную единицу, с которой уже определенным образом оперировать — сделать его с заглавной буквы, выделить в отдельную ячейку, оставить только его в исходной ячейке и т.д.
Помимо первого слова ячейки, бывает также важно взять первое слово после него, и так далее.
Часто после извлечения требуется удалить первые слова из ячеек, но это уже кардинально другое действие, смотрите соответствующую статью.
Сделать первое слово ячейки с большой буквы не очень сложно, если перед ним нет никаких других символов. Но если там кавычки, скобки, тире или еще какая-то пунктуация, решение может быть существенно более сложным, чем просто взять первый символ ячейки и сделать его заглавным.
Поэтому я рассмотрел эту задачу в отдельной статье “Как сделать первую букву ячейки заглавной“.
Вывести первое слово в отдельную ячейку — формула
Если под первым словом понимаются символы строки до первого пробела, то функция довольно проста:
=ЛЕВСИМВ(A1;ПОИСК(" ";A1&" ")-1)
Здесь A1 – ячейка с искомым словом.
Обратили внимание на дополнительный пробел, добавляемый к значению исходной ячейки через амперсанд (&)? Он используется для ситуаций, когда первое слово в ячейке является единственным, или слов в ячейке нет совсем. Если не добавлять этот пробел, функция в таких случаях вернет ошибку.

А ошибки нам тут ни к чему, поэтому рекомендуется использовать формулу выше. Удобство формул в том, что, если их протянуть на весь второй столбец, при изменении данных в первом столбце первые слова будут автоматически вставляться в соседние ячейки.
Оставить только первое слово в ячейке
Простейший вариант сделать подобное в Excel – штатной процедурой “Найти и заменить“. Можно вызвать процедуру горячим сочетанием клавиш Ctrl + H, в первом окошке ввести пробел со звёздочкой (см. подстановочные символы в Excel), а второе оставить пустым как есть.

Есть и вариант с использованием !SEMTools, процедура находится в подразделе ИЗВЛЕЧЬ – Извлечь Слова – по порядку:

Взять первые 2/3/N слов ячейки
Чем больше число слов, которые вы хотите извлечь из ячейки, тем сложнее это будет сделать. В Google Spreadsheets есть замечательная функция SPLIT, с её помощью можно разбить ячейку на отдельные слова и брать каждое из них по его индексу, что делает инструмент идеальным для такой задачи. Но в Excel, к сожалению, подобной функции нет.
Однако, есть альтернативы. Например, чтобы взять первые два слова, один из вариантов формулы будет выглядеть так:
=ЛЕВСИМВ(A1;ПОИСК(ЮНИСИМВ(23456);ПОДСТАВИТЬ(A1&" ";" ";ЮНИСИМВ(23456);2))-1)
Формула использует особенные свойства функций ПОДСТАВИТЬ и ЮНИСИМВ:
- функция ПОДСТАВИТЬ позволяет заменить N-ую подстроку в ячейке на заданное значение
- а ЮНИСИМВ позволяет задать это значение настолько уникальным, насколько возможно, чтобы быть уверенным, что оно будет единственным в ячейке
Далее функция ПОИСК находит позицию этого символа, чтобы функция ЛЕВСИМВ взяла все что до него (из позиции вычитается единица).
Неплохая надёжная формула со своими преимуществами и недостатками.
Преимущество в том, что легко поддаётся модификации под задачу с извлечением 3,4 и далее слов, просто нужно заменить в формуле аргумент функции подставить, который 2, на соответствующее число.
Недостаток – ЮНИСИМВ работает только в Excel 2013 и старше. Вот аналог для более ранних версий, использующий функцию СИМВОЛ:
=ЛЕВСИМВ(A1;ПОИСК(СИМВОЛ(9);ПОДСТАВИТЬ(A1&" ";" ";СИМВОЛ(9);2))-1)
Функция добавляет в строку символ табуляции, также с высокой вероятностью изначально в ней отсутствующий.
Процедуры !SEMTools для извлечения первых N слов
Знание функций и формул Excel очень помогает в работе, для энтузиастов у меня есть целый Справочник функций Excel. Однако тратить время на составление сложных конструкций может быть накладно, равно как и хранить где-то на диске огромный файл с примерами их использования.
Тем, кто ценит время, будут полезны процедуры моей надстройки, среди которых и такая, которая позволяет взять первые N слов во всех выделенных ячейках. И либо вставить в соседний столбец, либо оставить в изначальных ячейках. За режим вывода отвечает маленький флажок в надстройке:

Хотите так же быстро извлекать слова по их позиции в Excel?
!SEMTools поможет с этой и решит многие другие задачи за пару кликов!
Формулы в этой статье полезны для извлечения слов из текста, содержащегося в ячейке. Например, вы можете создать формулу для извлечения первого слова в предложении.
Извлечение первого слова из строки
Чтобы извлечь первое слово из строки, формула должна найти позицию первого символа пробела, а затем использовать эту информацию в качестве аргумента для функции ЛЕВСИМВ. Следующая формула делает это: =ЛЕВСИМВ(A1;НАЙТИ(" ";A1)-1).
Эта формула возвращает весь текст до первого пробела в ячейке A1. Однако у нее есть небольшой недостаток: она возвращает ошибку, если текст в ячейке А1 не содержит пробелов, потому что состоит из одного слова. Несколько более сложная формула решает проблему с помощью новой функции ЕСЛИОШИБКА, отображая все содержимое ячейки, если произошла ошибка:
=ЕСЛИОШИБКА(ЛЕВСИМВ(A1;НАЙТИ(" ";A1)-1);A1).
Если вам нужно, чтобы формула была совместима с более ранними версиями Excel, вы не можете использовать ЕСЛИОШИБКА. В таком случае придется обойтись функцией ЕСЛИ и функцией ЕОШ для проверки на ошибку:
=ЕСЛИ(ЕОШ(НАЙТИ(" ";A1));A1;ЛЕВСИМВ(A1;НАЙТИ(" ";A1)-1))
Извлечение последнего слова строки
Извлечение последнего слова строки — более сложная задача, поскольку функция НАЙТИ работает только слева направо. Таким образом, проблема состоит в поиске последнего символа пробела. Следующая формула, однако, решает эту проблему. Она возвращает последнее слово строки (весь текст, следующий за последним символом пробела):
=ПРАВСИМВ(A1;ДЛСТР(A1)-НАЙТИ("*";ПОДСТАВИТЬ(A1;" ";"*";ДЛСТР(A1)-ДЛСТР(ПОДСТАВИТЬ(A1;"";"")))))
Но у этой формулы есть такой же недостаток, как и у первой формулы из предыдущего раздела: она вернет ошибку, если строка не содержит по крайней мере один пробел. Решение заключается в использовании функции ЕСЛИОШИБКА и возврате всего содержимого ячейки А1, если возникает ошибка:
=ЕСЛИОШИБКА(ПРАВСИМВ(A1;ДЛСТР(A1)-НАЙТИ("*";ПОДСТАВИТЬ(A1;" ";"*";ДЛСТР(A1)-ДЛСТР(ПОДСТАВИТЬ(A1;" ";"")))));A1)
Следующая формула совместима со всеми версиями Excel:
=ЕСЛИ(ЕОШ(НАЙТИ(" ";A1));A1;ПРАВСИМВ(A1;ДЛСТР(A1)-НАЙТИ("*";ПОДСТАВИТЬ(A1;"";"*";ДЛСТР(A1)-ДЛСТР(ПОДСТАВИТЬ(A1;" ";""))))))
Извлечение всего, кроме первого слова строки
Следующая формула возвращает содержимое ячейки А1, за исключением первого слова:
=ПРАВСИМВ(A1;ДЛСТР(A1)-НАЙТИ(" ":A1;1)).
Если ячейка А1 содержит текст 2008 Operating Budget, то формула вернет Operating Budget.
Формула возвращает ошибку, если ячейка содержит только одно слово. Следующая версия формулы использует функцию ЕСЛИОШИБКА, чтобы можно было избежать ошибки; формула возвращает пустую строку, если ячейка не содержит более одного слова:
=ЕСЛИОШИБКА(ПРАВСИМВ(A1;ДЛСТР(A1)-НАЙТИ(" ";A1;1));"")
А эта версия совместима со всеми версиями Excel:
=ЕСЛИ(ЕОШ(НАЙТИ(" ";A1));"";ПРАВСИМВ(A1;ДЛСТР(A1)-НАЙТИ(" ";A1;1)))
Когда вы работаете с данными в своей книге Microsoft Excel, это не всегда просто цифры. Может быть, ваша таблица содержит имена клиентов, клиентов, сотрудников или контактов. И в зависимости от того, откуда берутся ваши данные, вам, возможно, придется манипулировать ими, чтобы удовлетворить ваши потребности в списке рассылки или базе данных.
Если вам нужно разделить имя и фамилию в Excel, у вас есть несколько гибких опций. Это включает в себя не только имя и фамилию, но и отчество, префиксы и суффиксы. Вот полезное руководство, которое показывает, как разделить имена в Excel.

Мнение эксперта
Витальева Анжела, консультант по работе с офисными программами
Со всеми вопросами обращайтесь ко мне!
Задать вопрос эксперту
Если вы хотите разбить ячейку в Excel на несколько, другими словами, также означает разделение объединенной ячейки на отдельные ячейки. Если же вам нужны дополнительные объяснения, обращайтесь ко мне!
На рис. 2 имеются тексты «Введите A:», «Введите B:», «Итог A / B =». Эти тексты введены вручную в соответствующие ячейки A2, A3 иA4. Ячейки B2, B3, B4 дополнительно обведены в рамочку (для наглядности).

Excel вставка с разделителем — Все о Windows 10
- Выберите столбец или ячейки, содержащие имена, которые вы хотите разделить. Столбец или ячейки будут выделены.
- Нажмите на Данные вкладка и выберите Текст в столбцы в твоей ленте.
- Во всплывающем окне выберите разграниченный для типа файла, который лучше всего описывает ваши данные.
- Нажмите следующий,
- Под Разделители, снимите флажок табуляция и проверить Космос,
- Нажмите следующий,
- Под Формат данных столбца, выбирать Текст, Если вам нужно выбрать другой Место назначения для ваших результатов, введите его в это поле.
- Нажмите Конец,
Теперь откройте новую электронную таблицу и нажмите Файл> Импорт… Выберите файл CSV и используйте мастер импорта, чтобы разбить данные на два столбца (вы будете использовать те же шаги, что и в мастере «Текст в столбцы»). Выбрав «Пробел» в разделе «Разделители», вы скажете Microsoft Excel разделить данные, где бы они ни находились, чтобы изолировать цифры и текст.
Извлечение чисел или текста из ячеек смешанного формата
ЛЕВО ПРАВО ПОИСК
Основная функция, которую мы будем здесь использовать, это LEFT, которая возвращает самые левые символы из ячейки. Как вы можете видеть в нашем наборе данных выше, у нас есть ячейки с одно-, двух- и трехсимвольными числами, поэтому нам нужно будет вернуть самый левый один, два или три символа из ячеек. Сочетая ВЛЕВО с функцией ПОИСК
Это вернет все слева от пространства. Использование ручки заполнения
чтобы применить формулу к остальным ячейкам, вот что мы получаем (вы можете увидеть формулу в панели функций в верхней части изображения):
Как видите, теперь у нас есть все изолированные числа, поэтому ими можно манипулировать. Хотите также выделить текст? Мы можем использовать функцию RIGHT таким же образом:
Это возвращает x символов справа от ячейки, где x — общая длина ячейки минус количество символов слева от пробела.
Теперь текстом можно манипулировать. Хотите объединить их снова? Просто используйте функцию CONCATENATE со всеми ячейками в качестве входных данных:
Очевидно, что этот метод работает лучше всего, если у вас есть только цифры и единицы, и ничего больше. Если у вас есть другие форматы ячеек, вам, возможно, придется проявить творческий подход к формулам, чтобы все работало правильно. Если у вас есть гигантский набор данных, это будет стоить времени, которое понадобится для выяснения формулы!
Текст в столбцы
Функция «Текст в столбцы» полезна для столбцов, содержащих только цифры, но она также может упростить жизнь, если у вас есть ячейки смешанного формата. Выберите столбец, с которым хотите работать, и нажмите Данные> Текст в столбцы. Затем вы можете использовать мастер, чтобы выбрать разделитель (пробел, как правило, лучший) и разделить столбец так, как вы хотите.
Если у вас есть только одно- и двузначные числа, опция «Фиксированная ширина» также может быть полезна, поскольку она будет разделять только первые два или три символа ячейки (вы можете создать несколько разбиений, если хотите, но я сохраню полное объяснение разбиения по фиксированной ширине для другой статьи).
Если ваш набор данных содержит много столбцов, и вы не хотите использовать текст в столбцах для каждого из них, вы можете легко получить тот же эффект, используя быстрый экспорт и импорт. Сначала экспортируйте вашу электронную таблицу в виде файла значений, разделенных запятыми (CSV). Нажмите Файл> Сохранить как… и сохраните ваш файл в формате CSV.
Теперь откройте новую электронную таблицу и нажмите Файл> Импорт… Выберите файл CSV и используйте мастер импорта, чтобы разбить данные на два столбца (вы будете использовать те же шаги, что и в мастере «Текст в столбцы»). Выбрав «Пробел» в разделе «Разделители», вы скажете Microsoft Excel разделить данные, где бы они ни находились, чтобы изолировать цифры и текст.
Когда закончите, нажмите «Готово», и вы получите новую электронную таблицу, в которой столбцы разделены на две части. Конечно, если у вас в ячейке более одного пробела, вы получите более двух столбцов, как вы можете видеть здесь:
К сожалению, нет хорошего решения для этого с использованием этого метода; вам просто нужно соединить ячейки вместе.
Мнение эксперта
Витальева Анжела, консультант по работе с офисными программами
Со всеми вопросами обращайтесь ко мне!
Задать вопрос эксперту
Теперь у нашего будущего пользователя пока еще не написанной нами программы кода появилась возможность ввести значения A и B в соответствующие ячейки. Если же вам нужны дополнительные объяснения, обращайтесь ко мне!
Что может ввести пользователь неправильно? Он может вместо чисел ввести в ячейки B2 и B3 не числовые значения. Проверить, что ввел пользователь, можно с помощью экселевской функции ТИП. Эта функция выдает значение 1, если в проверяемой ячейке записано число. Но если в проверяемую ячейку вводится не число, то функция даст другой результат, например, 2, 4, 16, 32 и тому подобное.
Найти и заменить в Excel.
Иногда случаются варианты, когда при выгрузке данных с других источников, можно получить большой текст из склеенных воедино слов (например, ОрловСтепанФедорович), такой текст нужно обязательно разделить пробелами на составляющие его части.
Поиск и замена данных
Еще удобнее применить сочетание горячих клавиш найти и заменить в Excel – Ctrl+H.
Диалоговое окно увеличится на одно поле, в котором указываются новые символы, которые будут вставлены вместо найденных.

По аналогии с простым поиском, менять можно и формат.

Кнопка Заменить все позволяет одним махом заменить одни символы на другие. После замены Excel показывается информационное окно с количеством произведенных замен. Кнопка Заменить позволяет производить замену по одной ячейке после каждого нажатия. Если найти и заменить в Excel не работает, попробуйте изменить параметры поиска.


Теперь вы знаете, как в эксель сделать поиск по столбцу, строке, любому диапазону, листу или даже книге.
Текст в столбцы
На любом описанным выше этапе можно нажать кнопку «Готово» для предоставления возможности приложению Excel самостоятельно завершить разделение текста в ячейках столбца. Но если Вы хотите контролировать весь процесс, то продолжайте нажимать «Далее».
Мнение эксперта
Витальева Анжела, консультант по работе с офисными программами
Со всеми вопросами обращайтесь ко мне!
Задать вопрос эксперту
Дополнительное условие Ограничитель строк поможет указать, что текстовые значения, содержащиеся в кавычках не делить к примеру, название фирмы Рудольф, Петер и Саймон ;. Если же вам нужны дополнительные объяснения, обращайтесь ко мне!
Основная функция, которую мы будем здесь использовать, это LEFT, которая возвращает самые левые символы из ячейки. Как вы можете видеть в нашем наборе данных выше, у нас есть ячейки с одно-, двух- и трехсимвольными числами, поэтому нам нужно будет вернуть самый левый один, два или три символа из ячеек. Сочетая ВЛЕВО с функцией ПОИСК
Имена с префиксом, удалить префикс
Поскольку вас интересует автоматическое деление текста, значит надо написать хорошую функцию на VBA и внедрить ее в рабочую книгу. Для начала переходим на вкладку «Разработчик» и выбираем «Visual Basic» или вызываем эту возможность с помощью горячего сочетания клавиш Alt+F11. (детальнее в статье «Как создать макрос в Excel»).