
Functions help find top or bottom N values in excel very easily. The functions used to find Nth largest and Nth smallest number are = LARGE(array, k) and = SMALL(array, k) respectively.
Cell Reference
Before understanding the LARGE and SMALL functions. We first need to have a fine knowledge of cell references. Cell reference is of two types:
- Relative Reference
Relative reference is the reference that changes with cells.
- If we try dragging the same formula down across a column then numbers will increase.
- If we try dragging the same formula side across a row, then alphabets will increase.
Here is an example for better understanding: Consider a data set of Students with their Physics and Math marks. Calculate the total marks.
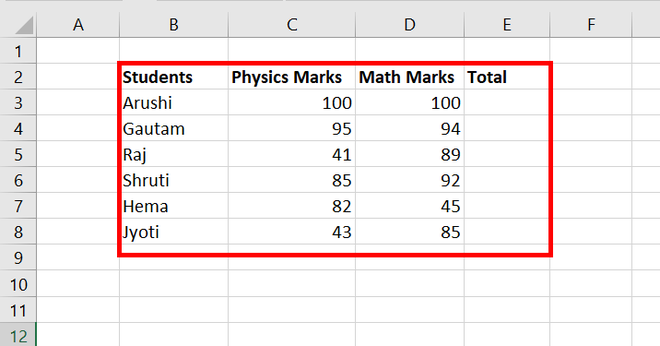
Steps for finding total
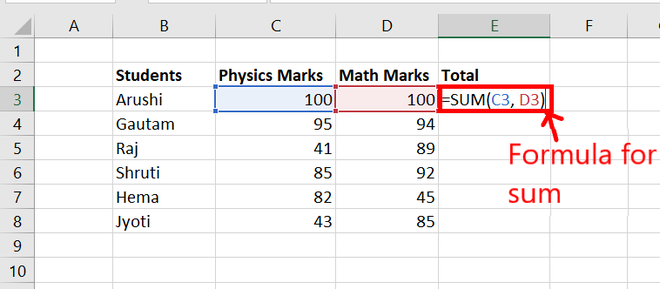
Step 1: Write a formula for sum i.e. = SUM(value1, value2) and press Enter.
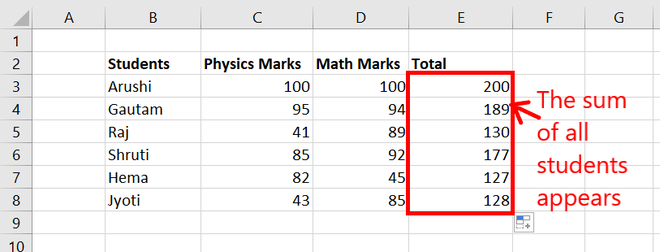
Step 2: Try dragging the same formula downward and hence we get the sum of all students.
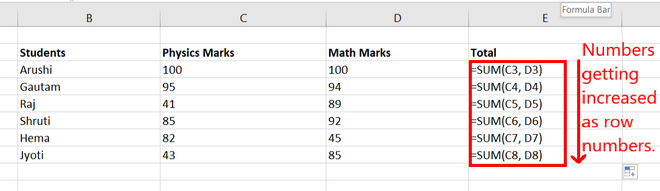
Step 3: Go to Formula Tab and click on Show Formulas. Now, all the formulas of the given worksheet will appear.
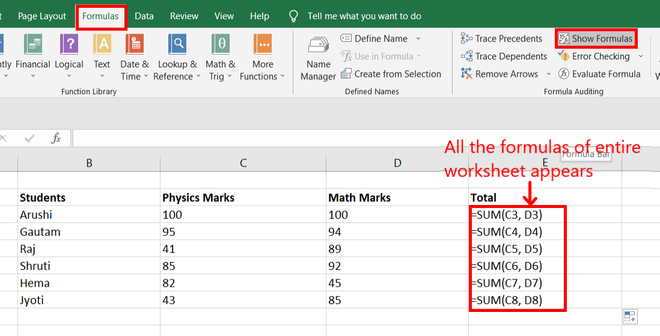
Step 4: We find in range E3:E9 that the values inside the functions are increasing as we go downward in a row. For Example: in cell E3, the formula is =SUM(C3, D3) and in cell E4, the formula is =SUM(C4, D4).
- Absolute Reference
The absolute reference remains static even if the rows or columns are changing. There can be two ways to make a selected cell with absolute reference:
- Use $ symbol: Write $ after each and every character of the selected cells.
- Use F4: Press Fn + F4 on your keyboard to make absolute reference to a selected cell.
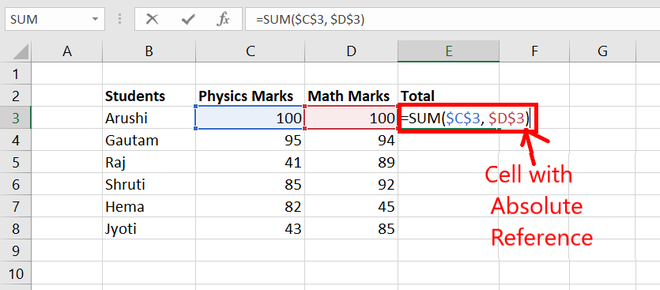
Consider the same data set as above. Try using the same formula for total but with absolute reference.
Steps of finding total with absolute reference
Step 1: Considering the same data set and write the function with absolute reference.
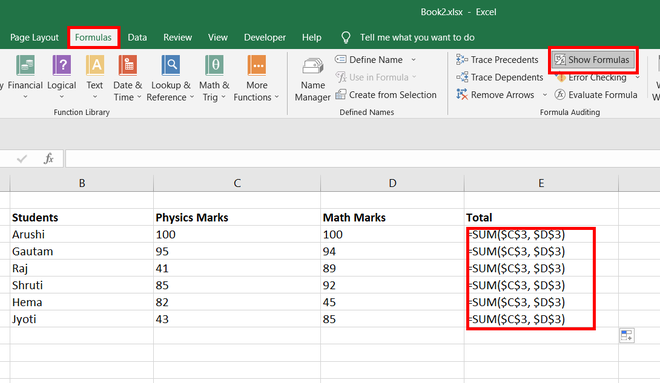
Step 2: Now, go to Formulas Tab and click on Show Formulas. All formulas of the given worksheet appear.
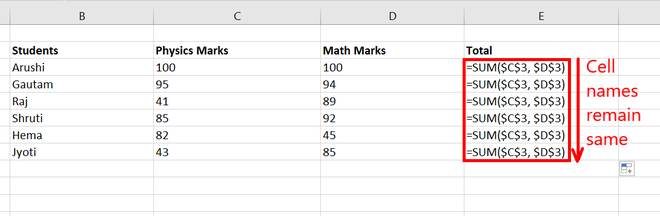
Step 3: We observe that while going downward in a row the selected cells remain the same.
Top N values
Given a data set of Students and their Marks. Try finding the highest 3 marks scored by students.
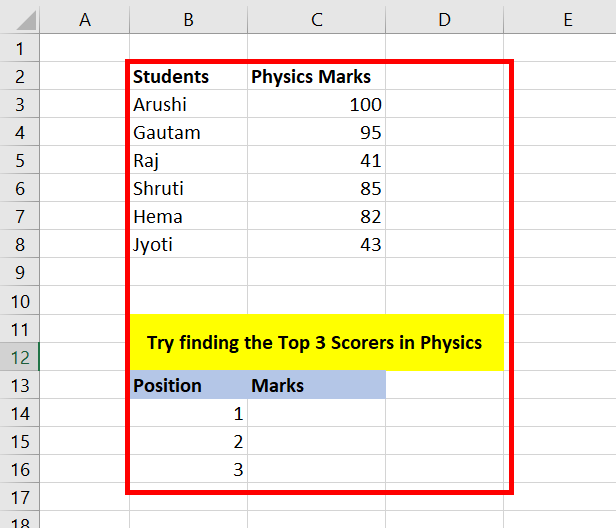
Steps for top N values
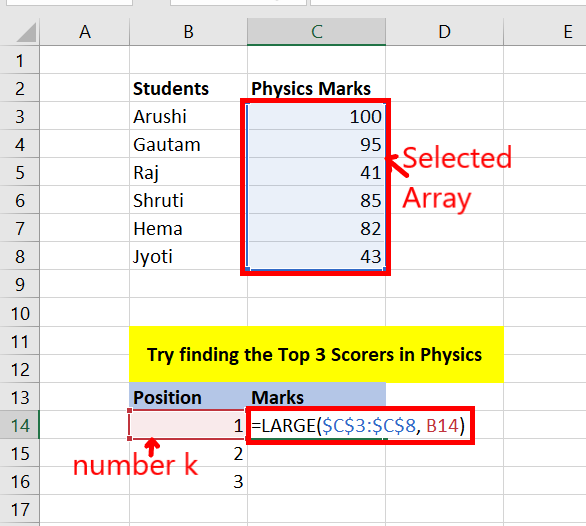
Step 1: Use = LARGE(Array, k) function to have kth largest number in an array. Press Enter.
- Array: It is the first argument of the LARGE function. We need to provide an absolute reference for this array.
- k: It is the second argument of the LARGE function. It specifies which largest number you want. We will provide a relative reference to this number.
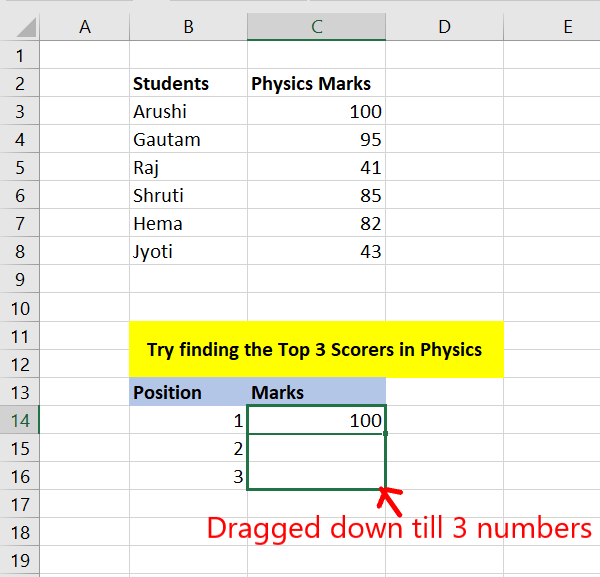
Step 2: You will get the kth largest number from the array. Now, drag down till the N numbers you want. For example: drag down to 3 cells for the given data set.
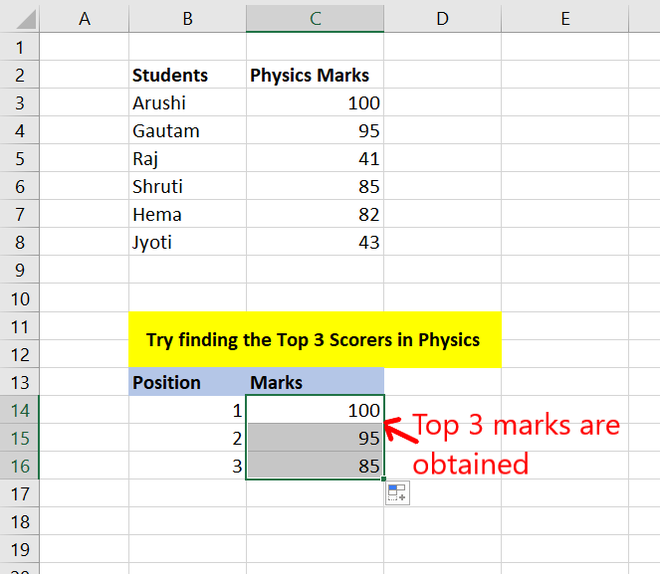
Step 3: You have obtained the highest 3 marks scored by students.
Bottom N values
Consider the same data set of Students and their Marks. Try finding the lowest 3 marks obtained by students.
Steps for bottom N values
Step 1: Use = SMALL(Array, k) function to have kth smallest number in an array. For example, if the value of k is 1, then the function will return the smallest number in the array. If the value of k is 2, then the function will return the second smallest number in the array. Press Enter.
- Array: It is the first argument of the SMALL function. We need to provide an absolute reference for this array.
- k: It is the second argument of the SMALL function. It specifies which smallest number you want. We will provide a relative reference to this number.
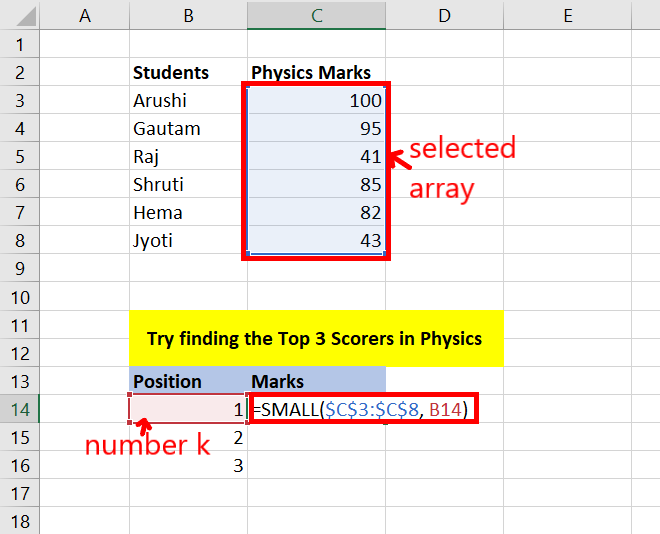
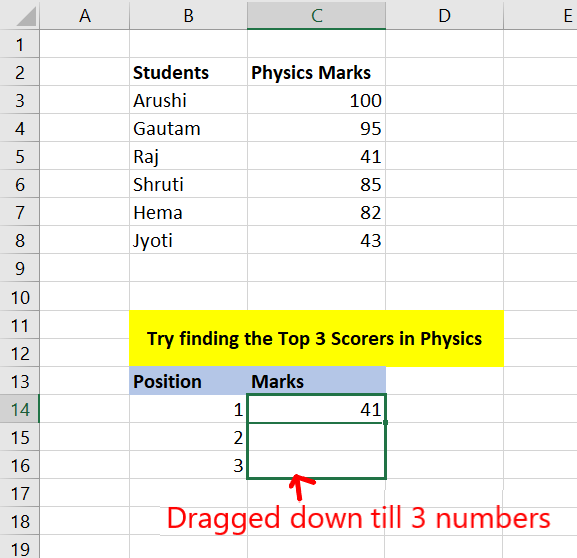
Step 2: You will get the kth smallest number from that array. Now, drag down till the N numbers you want. For example: drag down to 3 cells for the given data set.
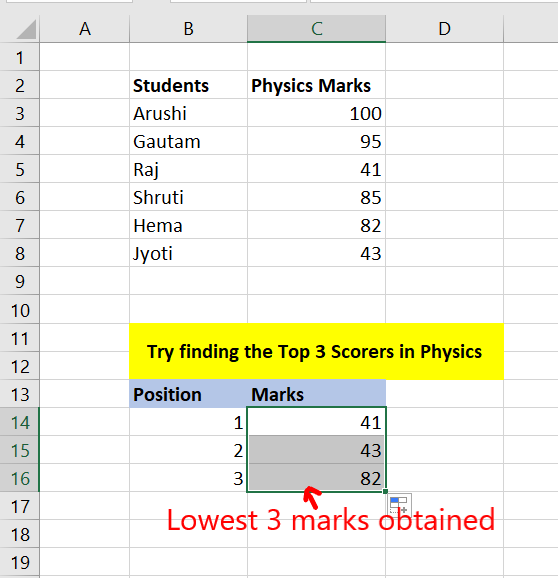
Step 3: You have obtained the lowest 3 marks scored by students.
Поиск последней непустой ячейки в строке или столбце функцией ПРОСМОТР
На практике часто возникает необходимость быстро найти значение последней (крайней) непустой ячейки в строке или столбце таблицы. Предположим, для примера, что у нас есть вот такая таблица с данными продаж по нескольким филиалам:

Задача: найти значение продаж в последнем месяце по каждому филиалу, т.е. для Москвы это будет 78, для Питера — 41 и т.д.
Если бы в нашей таблице не было пустых ячеек, то путь к решению был бы очевиден — можно было бы посчитать количество заполненных ячеек в каждой строке и брать потом ячейку с этим номером. Но филиалы работают неравномерно: Москва простаивала в марте и августе, филиал в Тюмени открылся только с апреля и т.д., поэтому такой способ не подойдет.
Универсальным решением будет использование функции ПРОСМОТР (LOOKUP):

У этой функции хитрая логика:
- Она по очереди (слева-направо) перебирает непустые ячейки в диапазоне (B2:M2) и сравнивает каждую из них с искомым значением (9999999).
- Если значение очередной проверяемой ячейки совпало с искомым, то функция останавливает просмотр и выводит содержимое ячейки.
- Если точного совпадения нет и очередное значение меньше искомого, то функция переходит к следующей ячейке в строке.
Легко сообразить, что если в качестве искомого значения задать достаточно большое число, то функция пройдет по всей строке и, в итоге, выдаст содержимое последней проверенной ячейки. Для компактности, можно указать искомое число в экспоненциальном формате, например 1E+11 (1*1011 или сто миллиардов).
Если в таблице не числа, а текст, то идея остается той же, но «очень большое число» нужно заменить на «очень большой текст»:

Применительно к тексту, понятие «большой» означает код символа. В любом шрифте символы идут в следующем порядке возрастания кодов:
- латиница прописные (A-Z)
- латиница строчные (a-z)
- кириллица прописные (А-Я)
- кириллица строчные (а-я)
Поэтому строчная «я» оказывается буквой с наибольшим кодом и слово из нескольких подряд «яяяяя» будет, условно, «очень большим словом» — заведомо «большим», чем любое текстовое значение из нашей таблицы.
Вот так. Не совсем очевидное, но красивое и компактное решение. Для поиска последней непустой ячейки в столбцах работает тоже «на ура».
Ссылки по теме
- Поиск и подстановка по нескольким условиям (ВПР по 2 и более критериям)
- Поиск ближайшего похожего текста (max совпадений символов)
- Двумерный поиск в таблице (ВПР 2D)
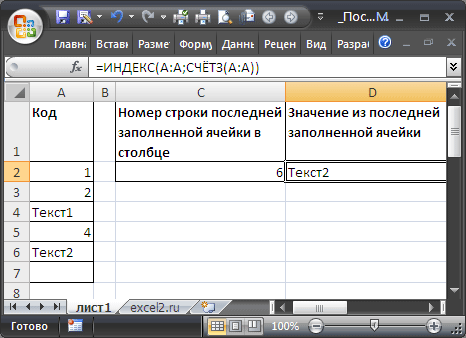
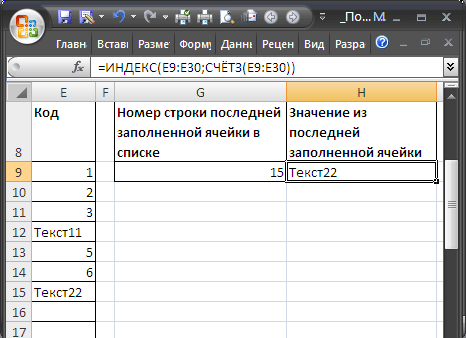
Найдем номер строки последней заполненной ячейки в столбце и списке. По номеру строки найдем и само значение.
Рассмотрим диапазон значений, в который регулярно заносятся новые данные.
Диапазон без пропусков и начиная с первой строки
В случае, если в столбце значения вводятся, начиная с первой строки и без пропусков, то определить номер строки последней заполненной ячейки можно формулой:
=СЧЁТЗ(A:A))
Формула работает для числовых и текстовых диапазонов (см.
Файл примера
)
Значение из последней заполненной ячейки в столбце выведем с помощью функции
ИНДЕКС()
:
=ИНДЕКС(A:A;СЧЁТЗ(A:A))
Ссылки на целые столбцы и строки достаточно ресурсоемки и могут замедлить пересчет листа. Если есть уверенность, что при вводе значений пользователь не выйдет за границы определенного диапазона, то лучше указать ссылку на диапазон, а не на столбец. В этом случае формула будет выглядеть так:
=ИНДЕКС(A1:A20;СЧЁТЗ(A1:A20))
Диапазон без пропусков в любом месте листа
Если список, в который вводятся значения расположен в диапазоне
E8:E30
(т.е. не начинается с первой строки), то формулу для определения номера строки последней заполненной ячейки можно записать следующим образом:
=СЧЁТЗ(E9:E30)+СТРОКА(E8)
Формула
СТРОКА(E8)
возвращает номер строки заголовка списка. Значение из последней заполненной ячейки списка выведем с помощью функции
ИНДЕКС()
:
=ИНДЕКС(E9:E30;СЧЁТЗ(E9:E30))
Диапазон с пропусками (числа)
В случае
наличия пропусков
(пустых строк) в столбце, функция
СЧЕТЗ()
будет возвращать неправильный (уменьшенный) номер строки: оно и понятно, ведь эта функция подсчитывает только значения и не учитывает
пустые
ячейки.
Если диапазон заполняется
числовыми
значениями, то для определения номера строки последней заполненной ячейки можно использовать формулу
=ПОИСКПОЗ(1E+306;A:A;1)
. Пустые ячейки и текстовые значения игнорируются.
Так как в качестве просматриваемого массива указан целый столбец (
A:A
), то функция
ПОИСКПОЗ()
вернет номер последней заполненной строки. Функция
ПОИСКПОЗ()
(с третьим параметром =1) находит позицию наибольшего значения, которое меньше или равно значению первого аргумента (1E+306). Правда, для этого требуется, чтобы массив был
отсортирован
по возрастанию. Если он не отсортирован, то эта функция возвращает позицию последней заполненной строки столбца, т.е. то, что нам нужно.
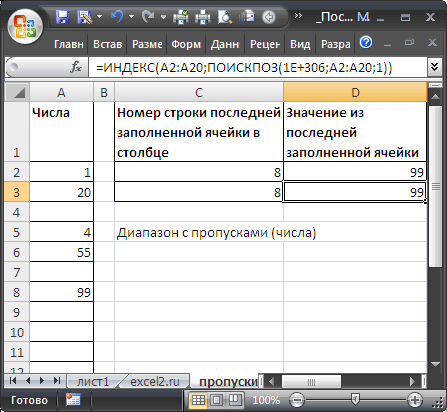
Чтобы вернуть значение в последней заполненной ячейке списка, расположенного в диапазоне
A2:A20
, можно использовать формулу:
=ИНДЕКС(A2:A20;ПОИСКПОЗ(1E+306;A2:A20;1))
Диапазон с пропусками (текст)
В случае необходимости определения номера строки последнего
текстового
значения (также при наличии пропусков), формулу нужно переделать:
=ПОИСКПОЗ(«*»;$A:$A;-1)
Пустые ячейки, числа и текстовое значение
Пустой текст
(«») игнорируются.
Диапазон с пропусками (текст и числа)
Если столбец содержит и
текстовые и числовые значения
, то для определения номера строки последней заполненной ячейки можно предложить универсальное решение:
=МАКС(ЕСЛИОШИБКА(ПОИСКПОЗ(«*»;$A:$A;-1);0); ЕСЛИОШИБКА(ПОИСКПОЗ(1E+306;$A:$A;1);0))
Функция
ЕСЛИОШИБКА()
нужна для подавления ошибки возникающей, если столбец
A
содержит только текстовые или только числовые значения.
Другим универсальным решением является
формула массива
:
=МАКС(СТРОКА(A1:A20)*(A1:A20<>»»))
Или
=МАКС(СТРОКА(A1:A20)*НЕ(ЕПУСТО(A1:A20)))
После ввода
формулы массива
нужно нажать
CTRL + SHIFT + ENTER
. Предполагается, что значения вводятся в диапазон
A1:A20
. Лучше задать фиксированный диапазон для поиска, т.к. использование в
формулах массива
ссылок на целые строки или столбцы является достаточно ресурсоемкой задачей.
Значение из последней заполненной ячейки, в этом случае, выведем с помощью функции
ДВССЫЛ()
:
=ДВССЫЛ(«A»&МАКС(СТРОКА(A1:A20)*(A1:A20<>»»)))
Или
=ДВССЫЛ(«A»&МАКС(СТРОКА(A1:A20)*НЕ(ЕПУСТО(A1:A20))))
Как обычно, после ввода
формулы массива
нужно нажать
CTRL + SHIFT + ENTER
вместо
ENTER
.
СОВЕТ:
Как видно, наличие пропусков в диапазоне существенно усложняет подсчет. Поэтому имеет смысл при заполнении и проектировании таблиц придерживаться правил приведенных в статье
Советы по построению таблиц
.
Функция ПОИСК осуществляет поиск текста, символа, цифры в указанной области. Она похожа на функцию НАЙТИ, которая так же ищет значение в указанной области, но у них есть отличия, которые мы разберем на примерах.
Как работает функция ПОИСК в Excel
Синтаксис данной функции выглядит следующим образом:

У нас есть слово «Excel». В этом примере нужно найти положение буквы «Х» в слове. Функция возвратит значение 2, поскольку буква находится по счету на втором месте в искомых данных:
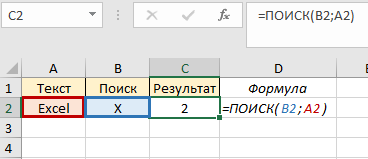
Несмотря на то, что искомая буква «Х» находится в верхнем регистре, функция нашла ее аналог в нижнем регистре и выдала результат. В этом и есть отличие с функцией НАЙТИ – она обращает внимание на соответствие регистров.
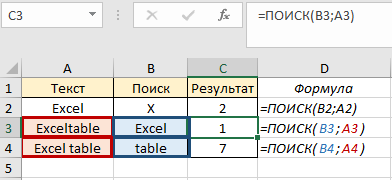
Также мы можем искать часть слова или слово в искомой области, например найти слово «Excel» в «Exceltable» и «table» во фразе «Excel table». В первом случае в результате мы получим 1, потому что слово «Excel» начинается с первого символа. Во втором случае у нас будет результат 7, потому что «table» начинается с седьмого символа:
Аргумент начальная_позиция используем, когда нужно отсчитать положение символа, начиная с которого возвратится искомое значение. Например, нужно отследить с какой позиции начинается буквенное значение кода. Если не указать номер позиции, у нас возвратится число «2», поскольку буква «о» в ячейке А8 находится второй по порядку:
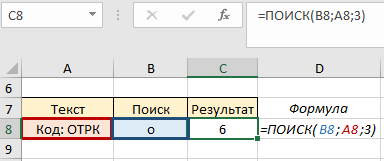
Благодаря этой функции можно возвращать части фраз, которые требует условие, а не только порядочное положение символа. Для этого функцию ПОИСК нужно комбинировать с другими функциями. Однако, такие комбинации функции могут быть довольно объёмными и существуют функции, более подходящие для выполнения таких задач.
Функция ПОИСКа значения в столбце Excel
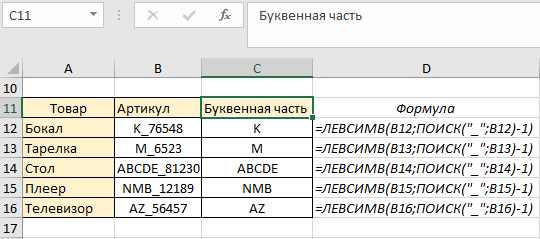
В данном примере будет использоваться формула комбинации функции ПОИСК с функциями: ЛЕВСИМВ, ПРАВСИМВ, ДЛСТР. Рассмотрим поэтапно пример, где мы сможем извлекать части фраз с текста, из которого получим искомое значение. У нас есть товар и артикул товара. Наше задание – возвратить только буквенную часть названия артикула. Для этого в ячейке C12 начинаем писать формулу. Для получения результата нам нужна функция ЛЕВСИМВ.
- Первый аргумент — текст, в котором происходит поиск (ячейка B12).
- Второй аргумент — нужна длина искомого слова. В первом артикуле она равна 3, а в последующих меняется, поэтому используем формулу ПОИСК(«_»;B12).
Формула с аргументами («_»;B12) указала, что будут возвращаться те символы, которые расположены перед символом нижнего подчеркивания. Проверим наш результат:
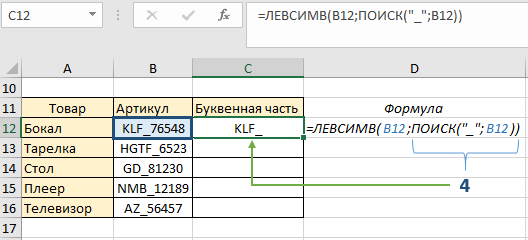
Функция ПОИСК возвратила число 4 (порядочное положение знака нижнего подчеркивания), и в качестве второго аргумента функции ЛЕВСИМВ указала какие символы будут находиться в ячейке С12. Пока что это не совсем то, что необходимо получить – знак «_» в идеале должен отсутствовать. Для этого немного подкорректируем формулу: перед вторым аргументом (формулой ПОИСК) отнимаем единицу, этим мы указали что вывод символов будет без знака нижнего подчеркивания (4-1):
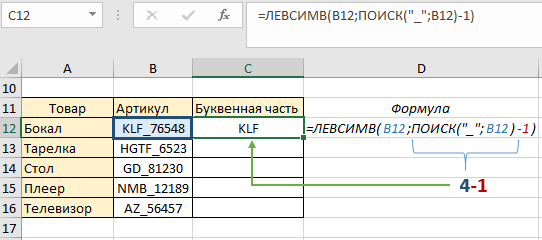
Поскольку формула у нас динамическая, копируем ее до конца столбца и наблюдаем результат нашей работы – по каждому артикулу мы получили буквенное значение независимо от количества букв:
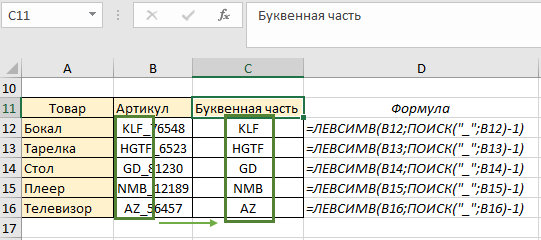
Если вдруг вам понадобится в этой же таблице изменить артикул – функция среагирует на изменения корректно и автоматически возвратит текстовое значение заменённого артикула. Например для товара «Бокал» будет буквенная часть «К», для «Тарелки» — «М», для «Стола» — ADCDE:
Теперь рассмотрим пример, где будем извлекать символы не ПЕРЕД нижним подчеркиванием, а ПОСЛЕ. В этом нам поможет функция ДЛСТР. Она помогает узнать длину текстовой строки. В ячейке С20 пишем формулу:
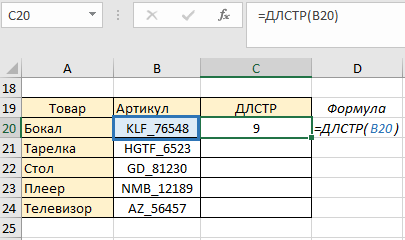
В результате она возвратила нам длину артикула товара «Бокал». Скопируем формулу до конца столбца и в следующем этапе в ячейке Е20 напишем формулу ПОИСК. Нижнее подчеркивание – это искомое значение (аргумент 1), возвращаемое значение – позиция порядковый номер положения нижнего подчеркивания. Копируем до конца столбца:
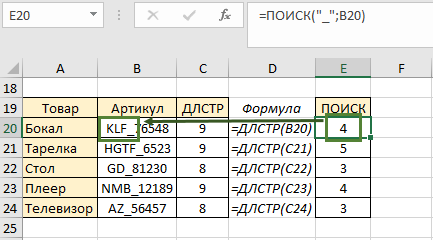
Затем нам нужен столбец, где мы от длины строки отнимаем позицию нижнего подчеркивания (9 — 4) и копируем формулу до конца столбца. То есть этот столбец содержит длину числового значения артикула (значения ПОСЛЕ нижнего подчеркивания):
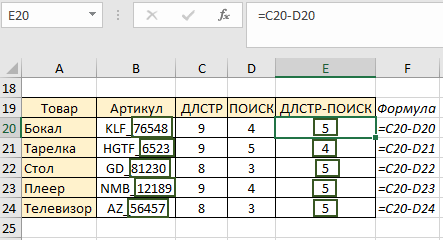
Теперь в ячейке F20 пишем функцию ПРАВСИМВ, которая возвратит нам текст, часть фразы, которую мы запрашимаем. Первый аргумент функции – это ячейка, которую проверяет формула, а второй – длина возвращаемого значения:
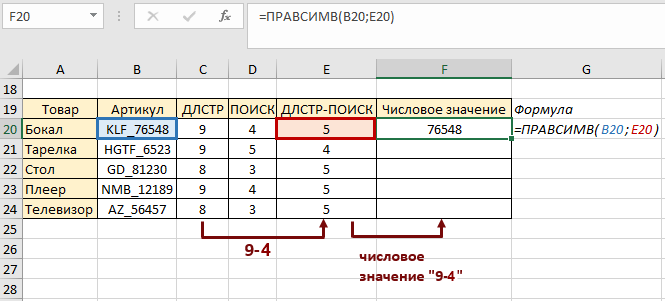
Функция возвратила нам числовое значение артикула товара. Копируем до конца столбца и получаем результат по каждому товару:
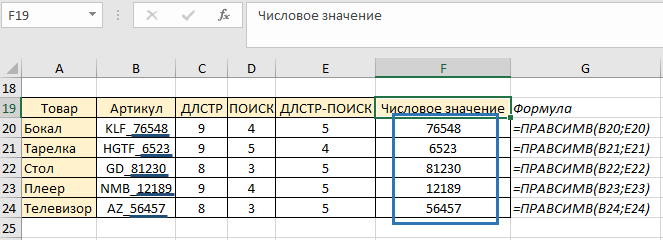
Данный пример был рассмотрен поэтапно для более понятного алгоритма выполнения задачи, однако можно числовое значение получить одним шагом:
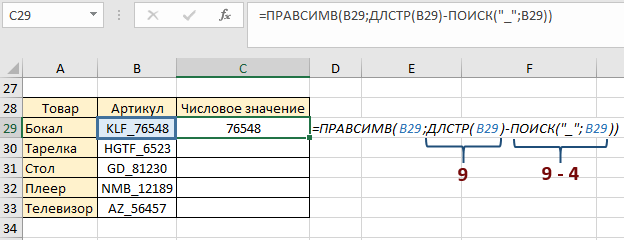
В этом примере мы сделали то же самое, что и ранее, только все операции сделали в одной формуле: нашли длину текста, отняли длину текста после знака «_» и возвратили эту длину функцией ПРАВСИМВ.
Как использовать функцию ПОИСК с функцией ЕСЛИ
Рассмотрим пример, где будем проверять частичное совпадение текста в проверяемом тексте. У нас есть несколько адресов и нам нужно знать локальные они или нет:
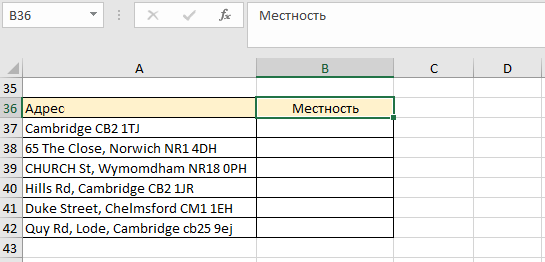
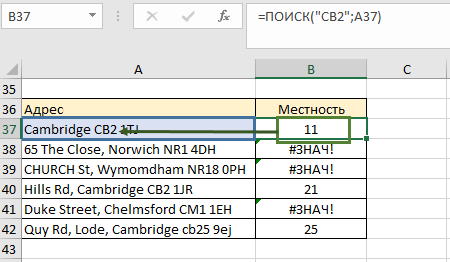
Если почтовый индекс начинается с СВ2, тогда это локальный адрес. Мы не можем использовать функцию ЕСЛИ в её обычном выражении, потому что в ячейках много другого текста. Нам нужно знать содержит ли ячейка часть «СВ2». Чтобы лучше понимать логику построения функции, будем делать это от простого к более сложному выражению:
- Строим функцию ПОИСК: 1-й аргумент – «СВ2», 2-й аргумент – ячейка А37, копируем до конца столбца. Так мы указали что и где будем искать. Там, где нет текста СВ2, возвратилась ошибка. Но сейчас у нас есть только номер позиции текста СВ2. А функция ЕСЛИ будет искать идентичное совпадение. То есть она будет искать число 11 в тексте ячейки А37, которого у нас, конечно, не будет нигде.
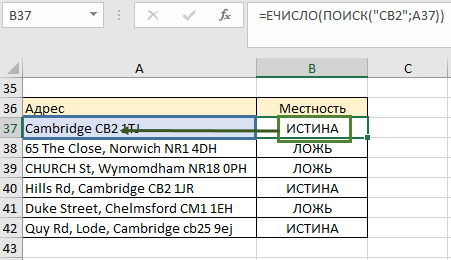
- Формулу функции ПОИСК вкладываем в функцию ЕЧИСЛО (имеет только 1 аргумент), которая будет указателем в дальнейшем для ЕСЛИ, что результатом функции ПОИСК является число (как сейчас, у нас 11):
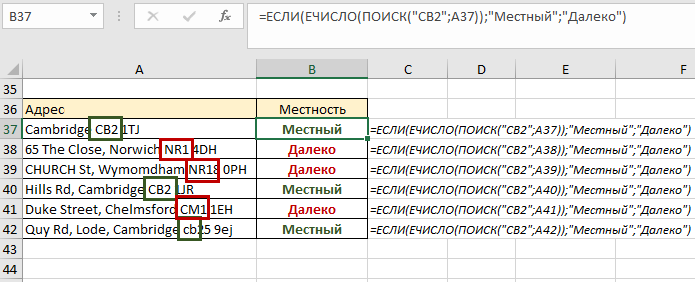
- Полученную формулу вкладываем в ЕСЛИ, указывая, что для значения ИСТИНА у нас будет слово «Местный», а для значения ЛОЖЬ – «Далеко». Копируем до конца столбца:
 Скачать примеры формул с функцией ПОИСК в Excel
Скачать примеры формул с функцией ПОИСК в Excel
Теперь у нас есть информация об адресах в зависимости от их почтового индекса. Вполне логичное предположение, что можно также было использовать НАЙТИ, но поскольку НАЙТИ учитывает регистр, полезнее и надежнее будет работа с ПОИСКом.
|
Вывести число из самой нижней строки с опре-нного столбца |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |




