
Содержание
- ПОИСК, ПОИСКБ (функции ПОИСК, ПОИСКБ)
- Описание
- Синтаксис
- Замечание
- Примеры
- Сравнение текста с шаблоном в Excel
- Описание функции
- Пример 1
- Пример 2
- Пример 3
- Пример 4
- Пример 5
- Пример 6
- Пример 7
- Excel поиск по шаблону
- Что возвращает функция
- Синтаксис
- Аргументы функции
- Дополнительная информация
- Примеры использования функции ПОИСК в Excel
- Пример 1. Ищем слово внутри текстовой строки (с начала)
- Пример 2. Ищем слово внутри текстовой строки (с указанием стартовой позиции поиска)
- Пример 3. Поиск слова при наличии нескольких совпадений в тексте
- Пример 4. Используем подстановочные знаки при работе функции ПОИСК в Excel
- Примеры использования функции ПОИСК в Excel
- Пример использования функции ПОИСК и ПСТР
- Пример формулы ПОИСК и ЗАМЕНИТЬ
- Чем отличается функция ПОИСК от функции НАЙТИ в Excel?
- Описание
- Синтаксис
- Замечание
- Примеры
ПОИСК, ПОИСКБ (функции ПОИСК, ПОИСКБ)
В этой статье описаны синтаксис формулы и использование функций ПОИСК и ПОИСКБ в Microsoft Excel.
Описание
Функции ПОИСК И ПОИСКБ находят одну текстовую строку в другой и возвращают начальную позицию первой текстовой строки (считая от первого символа второй текстовой строки). Например, чтобы найти позицию буквы «n» в слове «printer», можно использовать следующую функцию:
Эта функция возвращает 4, так как «н» является четвертым символом в слове «принтер».
Можно также находить слова в других словах. Например, функция
возвращает 5, так как слово «base» начинается с пятого символа слова «database». Можно использовать функции ПОИСК и ПОИСКБ для определения положения символа или текстовой строки в другой текстовой строке, а затем вернуть текст с помощью функций ПСТР и ПСТРБ или заменить его с помощью функций ЗАМЕНИТЬ и ЗАМЕНИТЬБ. Эти функции показаны в примере 1 данной статьи.
Эти функции могут быть доступны не на всех языках.
Функция ПОИСКБ отсчитывает по два байта на каждый символ, только если языком по умолчанию является язык с поддержкой БДЦС. В противном случае функция ПОИСКБ работает так же, как функция ПОИСК, и отсчитывает по одному байту на каждый символ.
К языкам, поддерживающим БДЦС, относятся японский, китайский (упрощенное письмо), китайский (традиционное письмо) и корейский.
Синтаксис
Аргументы функций ПОИСК и ПОИСКБ описаны ниже.
Искомый_текст Обязательный. Текст, который требуется найти.
Просматриваемый_текст Обязательный. Текст, в котором нужно найти значение аргумента искомый_текст.
Начальная_позиция Необязательный. Номер знака в аргументе просматриваемый_текст, с которого следует начать поиск.
Замечание
Функции ПОИСК и ПОИСКБ не учитывают регистр. Если требуется учитывать регистр, используйте функции НАЙТИ и НАЙТИБ.
В аргументе искомый_текст можно использовать подстановочные знаки: вопросительный знак ( ?) и звездочку ( *). Вопросительный знак соответствует любому знаку, звездочка — любой последовательности знаков. Если требуется найти вопросительный знак или звездочку, введите перед ним тильду (
Если значение find_text не найдено, #VALUE! возвращается значение ошибки.
Если аргумент начальная_позиция опущен, то он полагается равным 1.
Если start_num больше нуля или больше, чем длина аргумента within_text, #VALUE! возвращается значение ошибки.
Аргумент начальная_позиция можно использовать, чтобы пропустить определенное количество знаков. Допустим, что функцию ПОИСК нужно использовать для работы с текстовой строкой «МДС0093.МужскаяОдежда». Чтобы найти первое вхождение «М» в описательной части текстовой строки, задайте для аргумента начальная_позиция значение 8, чтобы поиск не выполнялся в той части текста, которая является серийным номером (в данном случае — «МДС0093»). Функция ПОИСК начинает поиск с восьмого символа, находит знак, указанный в аргументе искомый_текст, в следующей позиции, и возвращает число 9. Функция ПОИСК всегда возвращает номер знака, считая от начала просматриваемого текста, включая символы, которые пропускаются, если значение аргумента начальная_позиция больше 1.
Примеры
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
Источник
Сравнение текста с шаблоном в Excel
Описание функции
Функция =ТЕКСТКАК(ТЕКСТ, ШАБЛОН) имеет два обязательных аргумента:
- ТЕКСТ — строка в которой необходимо произвести сравнение по заданному шаблону.
- ШАБЛОН, задающий сравнение текста. В шаблоне можно применять специальные обозначения:
- ? — Любой отдельный знак.
- * — Ноль или больше знаков.
- # — Любая отдельная цифра.
- [ ] — Любой отдельный знак из скобок.
- [! ] — Любой отдельный знак отсутствующий в скобках
Теперь к практике. Далее привожу множество примеров использования данной функции.
Пример 1
Как найти фамилии, заканчивающиеся на букву «а»?
Решением является формула =ТЕКСТКАК(ТЕКСТ;»*а»), где символ * указывает на неограниченное количество букв и символов перед последней буквой а.

Пример 2
Как привести телефонный справочник в порядок.
Используем формулу =ТЕКСТКАК(ТЕКСТ;»+# ### ###-##-##»), где знак # обозначает, что на этом месте может быть расположена любая цифра.

Пример 3
Найти слова которые содержат сочетание «сто» в любой части слова

Пример 4
Найти слова которые содержат сочетание «раст» или «рост» в любой части слова

Пример 5
Найти слова которые содержат любое сочетание кроме «раст»

Пример 6
Найти текст, который начинается с цифры

Пример 7
Проверка правильности введенного email. Сразу оговорюсь, проверка email в данном случае не полноценная, написана для в качестве примера, объясняющего принцип работы.
Источник
Excel поиск по шаблону
Функция ПОИСК (SEARCH) в Excel используется для определения расположения текста внутри какого-либо текста и указания его точной позиции.
Что возвращает функция
Функция возвращает числовое значение, обозначающее стартовую позицию искомого текста внутри другого текста. Позиция обозначает порядковый номер символа, с которого начинается искомый текст.
Синтаксис
=SEARCH(find_text, within_text, [start_num]) – английская версия
=ПОИСК(искомый_текст;просматриваемый_текст;[начальная_позиция]) – русская версия
Аргументы функции
- find_text (искомый_текст) – текст или текстовая строка которую вы хотите найти;
- within_text (просматриваемый_текст) – текст, внутри которого вы осуществляете поиск;
- [start_num] ([начальная_позиция]) – числовое значение, обозначающее позицию, с которой вы хотите начать поиск. Если не указать этот аргумент, то функци начнет поиск с начала текста.
Дополнительная информация
- Если стартовая позиция поиска не указана, то поиск текста осуществляется сначала текста;
- Функция не чувствительна к регистру. Если вам нужна чувствительность к регистру, то используйте функцию НАЙТИ;
- Функция может обрабатывать подстановочные знаки. В Excel существует три подстановочных знака – ?, *,
- знак “?” – сопоставляет любой одиночный символ;
- знак “*” – сопоставляет любые дополнительные символы;
- знак “
” – используется, если нужно найти сам вопросительный знак или звездочку.
Функция возвращает ошибку, в случае если искомый текст не найден.
Примеры использования функции ПОИСК в Excel
Пример 1. Ищем слово внутри текстовой строки (с начала)

На примере выше видно, что когда мы ищем слово “доброе” в тексте “Доброе утро”, функция возвращает значение “1”, что соответствует позиции слова “доброе” в тексте “Доброе утро”.
Так как функция не чувствительна к регистру, нет разницы каким образом мы указываем искомое слово “доброе”, будь то “ДОБРОЕ”, “Доброе”, “дОброе” и.т.д. функция вернет одно и то же значение.
Если вам необходимо осуществить поиск чувствительный к регистру – используйте функцию НАЙТИ в Excel.
Пример 2. Ищем слово внутри текстовой строки (с указанием стартовой позиции поиска)

Третий аргумент функции указывает на порядковый номер позиции внутри текста, с которой будет осуществлен поиск. На примере выше, функция возвращает значение “1” при поиске слова “доброе” в тексте “Доброе утро”, начиная свой поиск с первой позиции.
Вместе с тем, если мы указываем функции, что поиск следует начинать со второго символа текста “Доброе утро”, то есть функция в этом случае видит текст как “оброе утро” и ищет слово “доброе”, то результатом будет ошибка.
Если вы не указываете в качестве аргумента стартовую позицию для поиска, функция автоматически начнет поиск с начала текста.
Пример 3. Поиск слова при наличии нескольких совпадений в тексте

Функция начинает искать текст со стартовой позиции которую мы можем указать в качестве аргумента, или она начнет поиск с начала текста автоматически. На примере выше, мы ищем слово “доброе ” в тексте “Доброе доброе утро” со стартовой позицией для поиска “1”. В этом случае функция возвращает “1”, так как первое найденное слово “Доброе” начинается с первого символа текста.
Если мы укажем функции начало поиска, например, со второго символа, то результатом вычисления функции будет “8”.
Пример 4. Используем подстановочные знаки при работе функции ПОИСК в Excel

При поиске функция учитывает подстановочные знаки. На примере выше мы ищем текст “c*l”. Наличие подстановочного знака “*” в данном запросе обозначает что мы ищем любо слово, которое начинается с буквы “c” и заканчивается буквой “l”, а что между этими двумя буквами не важно. Как результат, функция возвращает значение “3”, так как в слове “Excel”, расположенном в ячейке А2 буква “c” находится на третьей позиции.
В приложении Excel предусмотрено большое разнообразие инструментов для обработки текстовых и числовых данных. Одним из наиболее востребованных является функция ПОИСК. Она позволяет определять в строке, ячейке с текстовой информацией позицию искомой буквенной или числовой комбинации и записывать ее с помощью чисел.
Примеры использования функции ПОИСК в Excel
Для нахождения позиции текстовой строки в другой аналогичной применяют ПОИСК и ПОИСКБ. Расчет ведется с первого символа анализируемой ячейки. Так, если задать функцию ПОИСК “л” для слова «апельсин» мы получим значение 4, так как именно такой по счету выступает заданная буква в текстовом выражении.
Функция ПОИСК работает не только для поиска позиции отдельных букв в тексте, но и для целой комбинации. Например, задав данную команду для слов «book», «notebook», мы получим значение 5, так как именно с этого по счету символа начинается искомое слово «book».
Используют функцию ПОИСК наряду с такими, как:
- НАЙТИ (осуществляет поиск с учетом регистра);
- ПСТР (возвращает текст);
- ЗАМЕНИТЬ (заменяет символы).
Важно помнить, что рассматриваемая команда ПОИСК не учитывает регистра. Если мы с помощью нее станем искать положение буквы «а» в слове «Александр», в ячейке появится выражение 1, так как это первый символ в анализируемой информации. При задании команды НАЙТИ «а» в том же отрезке текста, мы получим значение 6, так как именно 6 позицию занимает строчная «а» в слове «Александр».
Кроме того, функция ПОИСК работает не для всех языков. От команды ПОИСКБ она отличается тем, что на каждый символ отсчитывает по 1 байту, в то время как ПОИСКБ — по два.
Чтобы воспользоваться функцией, необходимо ввести следующую формулу:
В этой формуле задаваемые значения определяются следующим образом.
- Искомый текст. Это числовая и буквенная комбинация, позицию которой требуется найти.
- Анализируемый текст. Это тот фрагмент текстовой информации, из которого требуется вычленить искомую букву или сочетание и вернуть позицию.
- Начальная позиция. Данный фрагмент необязателен для ввода. Но, если вы желаете найти, к примеру, букву «а» в строке со значением «А015487.Мужская одежда», то необходимо указать в конце формулы 8, чтобы анализ этого фрагмента проводился с восьмой позиции, то есть после артикула. Если этот аргумент не указан, то он по умолчанию считается равным 1. При указании начальной позиции положение искомого фрагмента все равно будет считаться с первого символа, даже если начальные 8 были пропущены в анализе. То есть в рассматриваемом примере букве «а» в строке «А015487.Мужская одежда» будет присвоено значение 14.
При работе с аргументом «искомый_текст» можно использовать следующие подстановочные знаки.
- Вопросительный знак (?). Он будет соответствовать любому знаку.
- Звездочка (*). Этот символ будет соответствовать любой комбинации знаков.
Если же требуется найти подобные символы в строке, то в аргументе «искомый_текст» перед ними нужно поставить тильду (
Если искомый текст не был найден приложением или начальная позиция установлена меньше 0, больше общего количества присутствующих символов, в ячейке отобразиться ошибка #ЗНАЧ.
Если «искомый_текст» не найден, возвращается значение ошибки #ЗНАЧ.
Пример использования функции ПОИСК и ПСТР
Пример 1. Есть набор текстовой информации с контактными данными клиентов и их именами. Информация записана в разных форматах. Необходимо найти, с какого символа начинается номер телефона.
Введем исходные данные в таблицу:

В ячейке, которая будет учитывать данные клиентов без телефона, введем следующую формулу:
Нажмем Enter для отображения искомой информации:

Далее мы можем использовать любые другие функции для отображения представленной информации в удобном формате:

На рисунке видно, как с помощью формулы из двух функций ПСТР и ПОИСК мы вырезаем фрагмент текста из строк разной длины. Притом разделяем текстовый фрагмент в нужном месте так, чтобы отделить ее от номера телефона.
Пример формулы ПОИСК и ЗАМЕНИТЬ
Пример 2. Есть таблица с текстовой информацией, в которой слово «маржа» нужно заменить на «объем».
Откроем книгу Excel с обрабатываемыми данными. Пропишем формулу для поиска нужного слова «маржа»:

Теперь дополним формулу функцией ЗАМЕНИТЬ:

Чем отличается функция ПОИСК от функции НАЙТИ в Excel?
Функция ПОИСК очень схожа с функцией НАЙТИ по принципу действия. Более того у них фактически одинаковые аргументы. Только лишь названия аргументов отличаются, а по сути и типам значений – одинаковые:
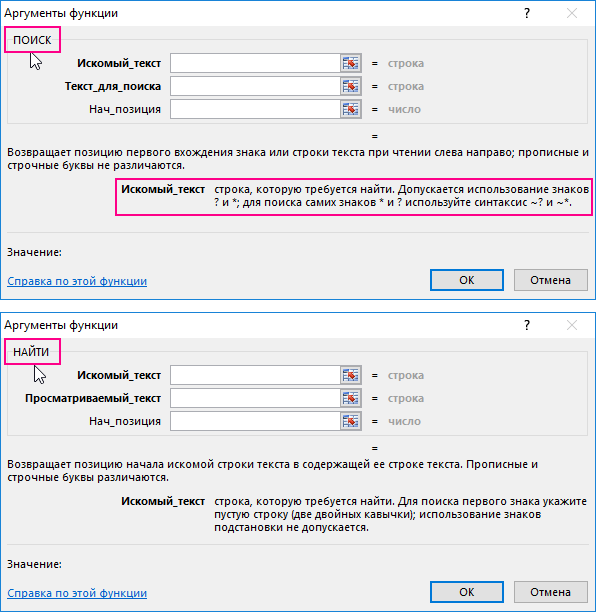
Но опытный пользователь Excel знает, что отличие у этих двух функций очень существенные.
Отличие №1. Чувствительность к верхнему и нижнему регистру (большие и маленькие буквы). Функция НАЙТИ чувствительна к регистру символов. Например, есть список номенклатурных единиц с артикулом. Необходимо найти позицию маленькой буквы «о».
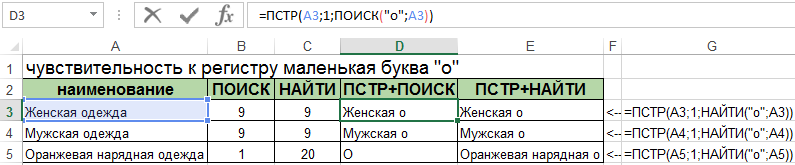
Теперь смотрите как ведут себя по-разному эти две функции при поиске большой буквы «О» в критериях поиска:
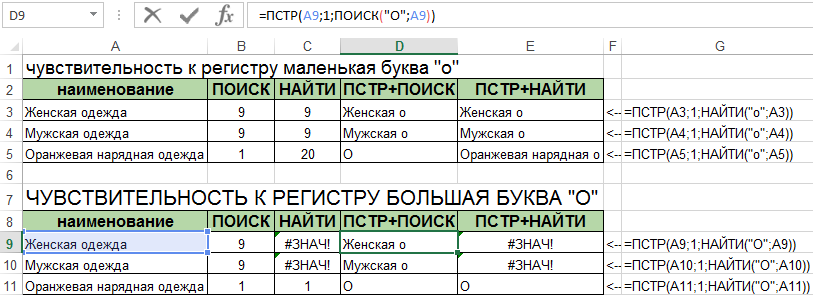
Отличие №2. В первом аргументе «Искомый_текст» для функции ПОИСК мы можем использовать символы подстановки для указания не точного, а приблизительного значения, которое должно содержаться в исходной текстовой строке. Вторая функция НАЙТИ не умеет использовать в работе символы подстановки масок текста: «*»; «?»; «
Для примера попробуем в этих же исходных строках столбца «наименования» найти приблизительный текст. Для этого укажем следующий вид критерия поиска используя символы подстановки: «н*ая».
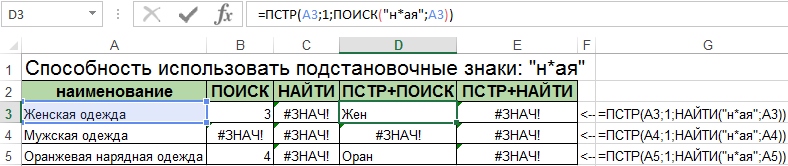
Как видим во втором отличии функция НАЙТИ совершенно не умеет работать и распознавать спецсимволы для подстановки текста в критериях поиска при неточном совпадении в исходной строке.
Примечание: Мы стараемся как можно оперативнее обеспечивать вас актуальными справочными материалами на вашем языке. Эта страница переведена автоматически, поэтому ее текст может содержать неточности и грамматические ошибки. Для нас важно, чтобы эта статья была вам полезна. Просим вас уделить пару секунд и сообщить, помогла ли она вам, с помощью кнопок внизу страницы. Для удобства также приводим ссылку на оригинал (на английском языке).
В этой статье описаны синтаксис формулы и использование функций ПОИСК и ПОИСКБ в Microsoft Excel.
Описание
Функции ПОИСК И ПОИСКБ находят одну текстовую строку в другой и возвращают начальную позицию первой текстовой строки (считая от первого символа второй текстовой строки). Например, чтобы найти позицию буквы «n» в слове «printer», можно использовать следующую функцию:
Эта функция возвращает 4, так как «н» является четвертым символом в слове «принтер».
Можно также находить слова в других словах. Например, функция
возвращает 5, так как слово «base» начинается с пятого символа слова «database». Можно использовать функции ПОИСК и ПОИСКБ для определения положения символа или текстовой строки в другой текстовой строке, а затем вернуть текст с помощью функций ПСТР и ПСТРБ или заменить его с помощью функций ЗАМЕНИТЬ и ЗАМЕНИТЬБ. Эти функции показаны в примере 1 данной статьи.
Эти функции могут быть доступны не на всех языках.
Функция ПОИСКБ отсчитывает по два байта на каждый символ, только если языком по умолчанию является язык с поддержкой БДЦС. В противном случае функция ПОИСКБ работает так же, как функция ПОИСК, и отсчитывает по одному байту на каждый символ.
К языкам, поддерживающим БДЦС, относятся японский, китайский (упрощенное письмо), китайский (традиционное письмо) и корейский.
Синтаксис
Аргументы функций ПОИСК и ПОИСКБ описаны ниже.
Искомый_текст Обязательный. Текст, который требуется найти.
Просматриваемый_текст Обязательный. Текст, в котором нужно найти значение аргумента искомый_текст.
Начальная_позиция Необязательный. Номер знака в аргументе просматриваемый_текст, с которого следует начать поиск.
Замечание
Функции ПОИСК и ПОИСКБ не учитывают регистр. Если требуется учитывать регистр, используйте функции НАЙТИ и НАЙТИБ.
В аргументе искомый_текст можно использовать подстановочные знаки: вопросительный знак ( ?) и звездочку ( *). Вопросительный знак соответствует любому знаку, звездочка — любой последовательности знаков. Если требуется найти вопросительный знак или звездочку, введите перед ним тильду (
Если значение аргумента искомый_текст не найдено, #VALUE! возвращено значение ошибки.
Если аргумент начальная_позиция опущен, то он полагается равным 1.
Если Нач_позиция не больше 0 или больше, чем длина аргумента просматриваемый_текст , #VALUE! возвращено значение ошибки.
Аргумент начальная_позиция можно использовать, чтобы пропустить определенное количество знаков. Допустим, что функцию ПОИСК нужно использовать для работы с текстовой строкой «МДС0093.МужскаяОдежда». Чтобы найти первое вхождение «М» в описательной части текстовой строки, задайте для аргумента начальная_позиция значение 8, чтобы поиск не выполнялся в той части текста, которая является серийным номером (в данном случае — «МДС0093»). Функция ПОИСК начинает поиск с восьмого символа, находит знак, указанный в аргументе искомый_текст, в следующей позиции, и возвращает число 9. Функция ПОИСК всегда возвращает номер знака, считая от начала просматриваемого текста, включая символы, которые пропускаются, если значение аргумента начальная_позиция больше 1.
Примеры
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
Источник
 Одной из самых трудоемких и неприятных задач при работе с текстом в Excel является парсинг — разбор буквенно-цифровой «каши» на составляющие и извлечение из нее нужных нам фрагментов. Например:
Одной из самых трудоемких и неприятных задач при работе с текстом в Excel является парсинг — разбор буквенно-цифровой «каши» на составляющие и извлечение из нее нужных нам фрагментов. Например:
- извлечение почтового индекса из адреса (хорошо, если индекс всегда в начале, а если нет?)
- нахождение номера и даты счета из описания платежа в банковской выписке
- извлечение ИНН из разношерстных описаний компаний в списке контрагентов
- поиск номера автомобиля или артикула товара в описании и т.д.
Обычно во подобных случаях, после получасового муторного ковыряния в тексте вручную, в голову начинают приходить мысли как-то автоматизировать этот процесс (особенно если данных много). Решений тут несколько и с разной степенью сложности-эффективности:
- Использовать встроенные текстовые функции Excel для поиска-нарезки-склейки текста: ЛЕВСИМВ (LEFT), ПРАВСИМВ (RIGHT), ПСТР (MID), СЦЕПИТЬ (CONCATENATE) и ее аналоги, ОБЪЕДИНИТЬ (JOINTEXT), СОВПАД (EXACT) и т.д. Этот способ хорош, если в тексте есть четкая логика (например, индекс всегда в начале адреса). В противном случае формулы существенно усложняются и, порой, дело доходит даже до формул массива, что сильно тормозит на больших таблицах.
- Использование оператора проверки текстового подобия Like из Visual Basic, обернутого в пользовательскую макро-функцию. Это позволяет реализовать более гибкий поиск с использованием символов подстановки (*,#,? и т.д.) К сожалению, этот инструмент не умеет извлекать нужную подстроку из текста — только проверять, содержится ли она в нем.
Кроме вышеперечисленного, есть еще один подход, очень известный в узких кругах профессиональных программистов, веб-разработчиков и прочих технарей — это регулярные выражения (Regular Expressions = RegExp = «регэкспы» = «регулярки»). Упрощенно говоря, RegExp — это язык, где с помощью специальных символов и правил производится поиск нужных подстрок в тексте, их извлечение или замена на другой текст. Регулярные выражения — это очень мощный и красивый инструмент, на порядок превосходящий по возможностям все остальные способы работы с текстом. Многие языки программирования (C#, PHP, Perl, JavaScript…) и текстовые редакторы (Word, Notepad++…) поддерживают регулярные выражения.
Microsoft Excel, к сожалению, не имеет поддержки RegExp по-умолчанию «из коробки», но это легко исправить с помощью VBA. Откройте редактор Visual Basic с вкладки Разработчик (Developer) или сочетанием клавиш Alt+F11. Затем вставьте новый модуль через меню Insert — Module и скопируйте туда текст вот такой макрофункции:
Public Function RegExpExtract(Text As String, Pattern As String, Optional Item As Integer = 1) As String
On Error GoTo ErrHandl
Set regex = CreateObject("VBScript.RegExp")
regex.Pattern = Pattern
regex.Global = True
If regex.Test(Text) Then
Set matches = regex.Execute(Text)
RegExpExtract = matches.Item(Item - 1)
Exit Function
End If
ErrHandl:
RegExpExtract = CVErr(xlErrValue)
End Function
Теперь можно закрыть редактор Visual Basic и, вернувшись в Excel, опробовать нашу новую функцию. Синтаксис у нее следующий:
=RegExpExtract( Txt ; Pattern ; Item )
где
- Txt — ячейка с текстом, который мы проверяем и из которого хотим извлечь нужную нам подстроку
- Pattern — маска (шаблон) для поиска подстроки
- Item — порядковый номер подстроки, которую надо извлечь, если их несколько (если не указан, то выводится первое вхождение)
Самое интересное тут, конечно, это Pattern — строка-шаблон из спецсимволов «на языке» RegExp, которая и задает, что именно и где мы хотим найти. Вот самые основные из них — для начала:
| Паттерн | Описание |
| . | Самое простое — это точка. Она обозначает любой символ в шаблоне на указанной позиции. |
| s | Любой символ, выглядящий как пробел (пробел, табуляция или перенос строки). |
| S | Анти-вариант предыдущего шаблона, т.е. любой НЕпробельный символ. |
| d | Любая цифра |
| D | Анти-вариант предыдущего, т.е. любая НЕ цифра |
| w | Любой символ латиницы (A-Z), цифра или знак подчеркивания |
| W | Анти-вариант предыдущего, т.е. не латиница, не цифра и не подчеркивание. |
| [символы] |
В квадратных скобках можно указать один или несколько символов, разрешенных на указанной позиции в тексте. Например ст[уо]л будет соответствовать любому из слов: стол или стул. Также можно не перечислять символы, а задать их диапазоном через дефис, т.е. вместо [ABDCDEF] написать [A-F]. или вместо [4567] ввести [4-7]. Например, для обозначения всех символов кириллицы можно использовать шаблон [а-яА-ЯёЁ]. |
| [^символы] | Если после открывающей квадратной скобки добавить символ «крышки» ^, то набор приобретет обратный смысл — на указанной позиции в тексте будут разрешены все символы, кроме перечисленных. Так, шаблон [^ЖМ]уть найдет Путь или Суть или Забудь, но не Жуть или Муть, например. |
| | | Логический оператор ИЛИ (OR) для проверки по любому из указанных критериев. Например (счет|счёт|invoice) будет искать в тексте любое из указанных слов. Обычно набор вариантов заключается в скобки. |
| ^ | Начало строки |
| $ | Конец строки |
| b | Край слова |
Если мы ищем определенное количество символов, например, шестизначный почтовый индекс или все трехбуквенные коды товаров, то на помощь нам приходят квантификаторы или кванторы — специальные выражения, задающие количество искомых знаков. Квантификаторы применяются к тому символу, что стоит перед ним:
| Квантор | Описание |
| ? | Ноль или одно вхождение. Например .? будет означать один любой символ или его отсутствие. |
| + | Одно или более вхождений. Например d+ означает любое количество цифр (т.е. любое число от 0 до бесконечности). |
| * | Ноль или более вхождений, т.е. любое количество. Так s* означает любое количество пробелов или их отсутствие. |
|
{число} или {число1,число2} |
Если нужно задать строго определенное количество вхождений, то оно задается в фигурных скобках. Например d{6} означает строго шесть цифр, а шаблон s{2,5} — от двух до пяти пробелов |
Теперь давайте перейдем к самому интересному — разбору применения созданной функции и того, что узнали о паттернах на практических примерах из жизни.
Извлекаем числа из текста
Для начала разберем простой случай — нужно извлечь из буквенно-цифровой каши первое число, например мощность источников бесперебойного питания из прайс-листа:

Логика работы регулярного выражения тут простая: d — означает любую цифру, а квантор + говорит о том, что их количество должно быть одна или больше. Двойной минус перед функцией нужен, чтобы «на лету» преобразовать извлеченные символы в полноценное число из числа-как-текст.
Почтовый индекс
На первый взгляд, тут все просто — ищем ровно шесть цифр подряд. Используем спецсимвол d для цифры и квантор {6} для количества знаков:

Однако, возможна ситуация, когда левее индекса в строке стоит еще один большой набор цифр подряд (номер телефона, ИНН, банковский счет и т.д.) Тогда наша регулярка выдернет из нее первых 6 цифр, т.е. сработает некорректно:

Чтобы этого не происходило, необходимо добавить в наше регулярное выражение по краям модификатор b означающий конец слова. Это даст понять Excel, что нужный нам фрагмент (индекс) должен быть отдельным словом, а не частью другого фрагмента (номера телефона):

Телефон
Проблема с нахождением телефонного номера среди текста состоит в том, что существует очень много вариантов записи номеров — с дефисами и без, через пробелы, с кодом региона в скобках или без и т.д. Поэтому, на мой взгляд, проще сначала вычистить из исходного текста все эти символы с помощью нескольких вложенных друг в друга функций ПОДСТАВИТЬ (SUBSTITUTE), чтобы он склеился в единое целое, а потом уже примитивной регуляркой d{11} вытаскивать 11 цифр подряд:

ИНН
Тут чуть сложнее, т.к. ИНН (в России) бывает 10-значный (у юрлиц) или 12-значный (у физлиц). Если не придираться особо, то вполне можно удовлетвориться регуляркой d{10,12}, но она, строго говоря, будет вытаскивать все числа от 10 до 12 знаков, т.е. и ошибочно введенные 11-значные. Правильнее будет использовать два шаблона, связанных логическим ИЛИ оператором | (вертикальная черта):

Обратите внимание, что в запросе мы сначала ищем 12-разрядные, и только потом 10-разрядные числа. Если же записать нашу регулярку наоборот, то она будет вытаскивать для всех, даже длинных 12-разрядных ИНН, только первые 10 символов. То есть после срабатывания первого условия дальнейшая проверка уже не производится:

Это принципиальное отличие оператора | от стандартной экселевской логической функции ИЛИ (OR), где от перестановки аргументов результат не меняется.
Артикулы товаров
Во многих компаниях товарам и услугам присваиваются уникальные идентификаторы — артикулы, SAP-коды, SKU и т.д. Если в их обозначениях есть логика, то их можно легко вытаскивать из любого текста с помощью регулярных выражений. Например, если мы знаем, что наши артикулы всегда состоят из трех заглавных английских букв, дефиса и последующего трехразрядного числа, то:

Логика работы шаблона тут проста. [A-Z] — означает любые заглавные буквы латиницы. Следующий за ним квантор {3} говорит о том, что нам важно, чтобы таких букв было именно три. После дефиса мы ждем три цифровых разряда, поэтому добавляем на конце d{3}
Денежные суммы
Похожим на предыдущий пункт образом, можно вытаскивать и цены (стоимости, НДС…) из описания товаров. Если денежные суммы, например, указываются через дефис, то:
 из текста")
Паттерн d с квантором + ищет любое число до дефиса, а d{2} будет искать копейки (два разряда) после.
Если нужно вытащить не цены, а НДС, то можно воспользоваться третьим необязательным аргументом нашей функции RegExpExtract, задающим порядковый номер извлекаемого элемента. И, само-собой, можно заменить функцией ПОДСТАВИТЬ (SUBSTITUTE) в результатах дефис на стандартный десятичный разделитель и добавить двойной минус в начале, чтобы Excel интерпретировал найденный НДС как нормальное число:

Автомобильные номера
Если не брать спецтранспорт, прицепы и прочие мотоциклы, то стандартный российский автомобильный номер разбирается по принципу «буква — три цифры — две буквы — код региона». Причем код региона может быть 2- или 3-значным, а в качестве букв применяются только те, что похожи внешне на латиницу. Таким образом, для извлечения номеров из текста нам поможет следующая регулярка:

Время
Для извлечения времени в формате ЧЧ:ММ подойдет такое регулярное выражение:

После двоеточия фрагмент [0-5]d, как легко сообразить, задает любое число в интервале 00-59. Перед двоеточием в скобках работают два шаблона, разделенных логическим ИЛИ (вертикальной чертой):
- [0-1]d — любое число в интервале 00-19
- 2[0-3] — любое число в интервале 20-23
К полученному результату можно применить дополнительно еще и стандартную Excel’евскую функцию ВРЕМЯ (TIME), чтобы преобразовать его в понятный программе и пригодный для дальнейших расчетов формат времени.
Проверка пароля
Предположим, что нам надо проверить список придуманных пользователями паролей на корректность. По нашим правилам, в паролях могут быть только английские буквы (строчные или прописные) и цифры. Пробелы, подчеркивания и другие знаки препинания не допускаются.
Проверку можно организовать с помощью вот такой несложной регулярки:

По сути, таким шаблоном мы требуем, чтобы между началом (^) и концом ($) в нашем тексте находились только символы из заданного в квадратных скобках набора. Если нужно проверить еще и длину пароля (например, не меньше 6 символов), то квантор + можно заменить на интервал «шесть и более» в виде {6,}:

Город из адреса
Допустим, нам нужно вытащить город из строки адреса. Поможет регулярка, извлекающая текст от «г.» до следующей запятой:

Давайте разберем этот шаблон поподробнее.
Если вы прочитали текст выше, то уже поняли, что некоторые символы в регулярных выражениях (точки, звездочки, знаки доллара и т.д.) несут особый смысл. Если же нужно искать сами эти символы, то перед ними ставится обратная косая черта (иногда это называют экранированием). Поэтому при поиске фрагмента «г.» мы должны написать в регулярке г. если ищем плюсик, то + и т.д.
Следующих два символа в нашем шаблоне — точка и звездочка-квантор — обозначают любое количество любых символов, т.е. любое название города.
На конце шаблона стоит запятая, т.к. мы ищем текст от «г.» до запятой. Но ведь в тексте может быть несколько запятых, правда? Не только после города, но и после улицы, дома и т.д. На какой из них будет останавливаться наш запрос? Вот за это отвечает вопросительный знак. Без него наша регулярка вытаскивала бы максимально длинную строку из всех возможных:

В терминах регулярных выражений, такой шаблон является «жадным». Чтобы исправить ситуацию и нужен вопросительный знак — он делает квантор, после которого стоит, «скупым» — и наш запрос берет текст только до первой встречной запятой после «г.»:

Имя файла из полного пути
Еще одна весьма распространенная ситуация — вытащить имя файла из полного пути. Тут поможет простая регулярка вида:

Тут фишка в том, что поиск, по сути, происходит в обратном направлении — от конца к началу, т.к. в конце нашего шаблона стоит $, и мы ищем все, что перед ним до первого справа обратного слэша. Бэкслэш заэкранирован, как и точка в предыдущем примере.
P.S.
«Под занавес» хочу уточнить, что все вышеописанное — это малая часть из всех возможностей, которые предоставляют регулярные выражения. Спецсимволов и правил их использования очень много и на эту тему написаны целые книги (рекомендую для начала хотя бы эту). В некотором смысле, написание регулярных выражений — это почти искусство. Почти всегда придуманную регулярку можно улучшить или дополнить, сделав ее более изящной или способным работать с более широким диапазоном вариантов входных данных.
Для анализа и разбора чужих регулярок или отладки своих собственных есть несколько удобных онлайн-сервисов: RegEx101, RegExr и др.
К сожалению, не все возможности классических регулярных выражений поддерживаются в VBA (например, обратный поиск или POSIX-классы) и умеют работать с кириллицей, но и того, что есть, думаю, хватит на первое время, чтобы вас порадовать.
Если же вы не новичок в теме, и вам есть чем поделиться — оставляйте полезные при работе в Excel регулярки в комментариях ниже. Один ум хорошо, а два сапога — пара!
Ссылки по теме
- Замена и зачистка текста функцией ПОДСТАВИТЬ (SUBSTITUTE)
- Поиск и подсветка символов латиницы в русском тексте
- Поиск ближайшего похожего текста (Иванов = Ивонов = Иваноф и т.д.)
Зачастую, при работе с данными в Excel приходится выборочно удалять или скрывать часть информации, чаще всего это строки либо столбцы, содержащие, либо не содержащие определенные слова, буквы, цифры, символы, либо их сочетания. Помогают в этом такие стандартные средства Excel, как поиск, фильтр и расширенный фильтр. Если этих инструментов для решения задачи недостаточно – на помощь приходит VBA.
Простейшим способом поиска заданного слова, буквы, цифры, символа либо сочетания из них является стандартный поиск. Все параметры для поиска вводятся в диалоговом окне «Найти и заменить», которое можно вызвать из главного меню, либо при помощи сочетания горячих клавиш «Ctrl+f» (где f-первая буква английского слова find – найти). Кроме обычного поиска можно выполнять также поиск с заменой.
Использование фильтров для поиска заданного слова, буквы, цифры или символа в Excel
Для выбора строк, содержащих определенную пользователем информацию можно использовать фильтрацию. В Excel 2007 и выше, например, кроме обычного текстового фильтра, предусмотрен фильтр по цвету заливки ячеек и по цвету шрифта. Текстовый фильтр позволяет использовать такие условия как «равно…», «не равно…», «начинается с…», «заканчивается на…», «содержит…», «не содержит…». После того как все необходимые строки отфильтрованы, можно производить с ними любые действия, в том числе и удаление строк.
Как программно найти и удалить определенные строки в Excel, используя VBA-оператор Like?
По разным причинам стандартные средства Excel не всегда подходят для решения тех или иных задач. Ниже приведен программный код макроса, позволяющего находить в ячейках используемого диапазона определенный шаблоном текст и удалять всю строку активного рабочего листа, содержащую ячейку с заданным текстом. Искомый текст присваивается переменной «Shablon» при помощи специальных символов совпадения с образцом.
Sub Udalenie_Strok_Po_Shablonu()
Dim r As Long, FirstRow As Long, LastRow As Long
Dim Region As Range, iRow As Range, Cell As Range
Dim Shablon As String
Shablon = "здесь вводится искомый текст"
Set Region = ActiveSheet.UsedRange
FirstRow = Region.Row
LastRow = Region.Row - 1 + Region.Rows.Count
For r = LastRow To FirstRow Step -1
Set iRow = Region.Rows(r - FirstRow + 1)
For Each Cell In iRow.Cells
If Cell Like Shablon Then
Rows(r).Delete
End If
Next Cell
Next r
End Sub
Для того, чтобы перенести этот программный код на свой компьютер, наведите курсор мыши на поле с программным кодом, нажмите на одну из двух кнопкок ![]() в правом верхнем углу этого поля, скопируйте программный код и вставьте его в модуль проекта на своем компьютере (подробнее о том, как сохранить программный код макроса).
в правом верхнем углу этого поля, скопируйте программный код и вставьте его в модуль проекта на своем компьютере (подробнее о том, как сохранить программный код макроса).
В этом макросе для поиска необходимых фраз используется нечеткий поиск и VBA-оператор сравнения Like, позволяющий сравнивать строки с образцом. При сравнении строк этот оператор различает буквы верхнего и нижнего регистра и результат сравнения зависит от инструкции Option Compare.
Для решения подобных задач могут использоваться также VBA-функции Instr и Find.
Аналогичные действия выполняет надстройка для Excel, использование которой позволяет вводить искомый текст без специальных символов в диалоговом окне и задавать различные области поиска.

 надстройка для выборочного удаления ячеек, строк и столбцов по условию
надстройка для выборочного удаления ячеек, строк и столбцов по условию
Другие материалы по теме:
Функция ПОИСК (SEARCH) в Excel используется для определения расположения текста внутри какого-либо текста и указания его точной позиции.
Что возвращает функция
Функция возвращает числовое значение, обозначающее стартовую позицию искомого текста внутри другого текста. Позиция обозначает порядковый номер символа, с которого начинается искомый текст.
Синтаксис
=SEARCH(find_text, within_text, [start_num]) – английская версия
=ПОИСК(искомый_текст;просматриваемый_текст;[начальная_позиция]) – русская версия
Аргументы функции
- find_text (искомый_текст) – текст или текстовая строка которую вы хотите найти;
- within_text (просматриваемый_текст) – текст, внутри которого вы осуществляете поиск;
- [start_num] ([начальная_позиция]) – числовое значение, обозначающее позицию, с которой вы хотите начать поиск. Если не указать этот аргумент, то функци начнет поиск с начала текста.
Дополнительная информация
- Если стартовая позиция поиска не указана, то поиск текста осуществляется сначала текста;
- Функция не чувствительна к регистру. Если вам нужна чувствительность к регистру, то используйте функцию НАЙТИ;
- Функция может обрабатывать подстановочные знаки. В Excel существует три подстановочных знака – ?, *,
.
- знак “?” – сопоставляет любой одиночный символ;
- знак “*” – сопоставляет любые дополнительные символы;
- знак “
” – используется, если нужно найти сам вопросительный знак или звездочку.
Пример 1. Ищем слово внутри текстовой строки (с начала)
На примере выше видно, что когда мы ищем слово “доброе” в тексте “Доброе утро”, функция возвращает значение “1”, что соответствует позиции слова “доброе” в тексте “Доброе утро”.
Так как функция не чувствительна к регистру, нет разницы каким образом мы указываем искомое слово “доброе”, будь то “ДОБРОЕ”, “Доброе”, “дОброе” и.т.д. функция вернет одно и то же значение.
Если вам необходимо осуществить поиск чувствительный к регистру – используйте функцию НАЙТИ в Excel.
Пример 2. Ищем слово внутри текстовой строки (с указанием стартовой позиции поиска)
Третий аргумент функции указывает на порядковый номер позиции внутри текста, с которой будет осуществлен поиск. На примере выше, функция возвращает значение “1” при поиске слова “доброе” в тексте “Доброе утро”, начиная свой поиск с первой позиции.
Вместе с тем, если мы указываем функции, что поиск следует начинать со второго символа текста “Доброе утро”, то есть функция в этом случае видит текст как “оброе утро” и ищет слово “доброе”, то результатом будет ошибка.
Если вы не указываете в качестве аргумента стартовую позицию для поиска, функция автоматически начнет поиск с начала текста.
Пример 3. Поиск слова при наличии нескольких совпадений в тексте
Функция начинает искать текст со стартовой позиции которую мы можем указать в качестве аргумента, или она начнет поиск с начала текста автоматически. На примере выше, мы ищем слово “доброе ” в тексте “Доброе доброе утро” со стартовой позицией для поиска “1”. В этом случае функция возвращает “1”, так как первое найденное слово “Доброе” начинается с первого символа текста.
Если мы укажем функции начало поиска, например, со второго символа, то результатом вычисления функции будет “8”.
Пример 4. Используем подстановочные знаки при работе функции ПОИСК в Excel
При поиске функция учитывает подстановочные знаки. На примере выше мы ищем текст “c*l”. Наличие подстановочного знака “*” в данном запросе обозначает что мы ищем любо слово, которое начинается с буквы “c” и заканчивается буквой “l”, а что между этими двумя буквами не важно. Как результат, функция возвращает значение “3”, так как в слове “Excel”, расположенном в ячейке А2 буква “c” находится на третьей позиции.
В приложении Excel предусмотрено большое разнообразие инструментов для обработки текстовых и числовых данных. Одним из наиболее востребованных является функция ПОИСК. Она позволяет определять в строке, ячейке с текстовой информацией позицию искомой буквенной или числовой комбинации и записывать ее с помощью чисел.
Примеры использования функции ПОИСК в Excel
Для нахождения позиции текстовой строки в другой аналогичной применяют ПОИСК и ПОИСКБ. Расчет ведется с первого символа анализируемой ячейки. Так, если задать функцию ПОИСК “л” для слова «апельсин» мы получим значение 4, так как именно такой по счету выступает заданная буква в текстовом выражении.
Функция ПОИСК работает не только для поиска позиции отдельных букв в тексте, но и для целой комбинации. Например, задав данную команду для слов «book», «notebook», мы получим значение 5, так как именно с этого по счету символа начинается искомое слово «book».
Используют функцию ПОИСК наряду с такими, как:
- НАЙТИ (осуществляет поиск с учетом регистра);
- ПСТР (возвращает текст);
- ЗАМЕНИТЬ (заменяет символы).
Важно помнить, что рассматриваемая команда ПОИСК не учитывает регистра. Если мы с помощью нее станем искать положение буквы «а» в слове «Александр», в ячейке появится выражение 1, так как это первый символ в анализируемой информации. При задании команды НАЙТИ «а» в том же отрезке текста, мы получим значение 6, так как именно 6 позицию занимает строчная «а» в слове «Александр».
Кроме того, функция ПОИСК работает не для всех языков. От команды ПОИСКБ она отличается тем, что на каждый символ отсчитывает по 1 байту, в то время как ПОИСКБ — по два.
Чтобы воспользоваться функцией, необходимо ввести следующую формулу:
В этой формуле задаваемые значения определяются следующим образом.
- Искомый текст. Это числовая и буквенная комбинация, позицию которой требуется найти.
- Анализируемый текст. Это тот фрагмент текстовой информации, из которого требуется вычленить искомую букву или сочетание и вернуть позицию.
- Начальная позиция. Данный фрагмент необязателен для ввода. Но, если вы желаете найти, к примеру, букву «а» в строке со значением «А015487.Мужская одежда», то необходимо указать в конце формулы 8, чтобы анализ этого фрагмента проводился с восьмой позиции, то есть после артикула. Если этот аргумент не указан, то он по умолчанию считается равным 1. При указании начальной позиции положение искомого фрагмента все равно будет считаться с первого символа, даже если начальные 8 были пропущены в анализе. То есть в рассматриваемом примере букве «а» в строке «А015487.Мужская одежда» будет присвоено значение 14.
При работе с аргументом «искомый_текст» можно использовать следующие подстановочные знаки.
- Вопросительный знак (?). Он будет соответствовать любому знаку.
- Звездочка (*). Этот символ будет соответствовать любой комбинации знаков.
Если же требуется найти подобные символы в строке, то в аргументе «искомый_текст» перед ними нужно поставить тильду (
Если искомый текст не был найден приложением или начальная позиция установлена меньше 0, больше общего количества присутствующих символов, в ячейке отобразиться ошибка #ЗНАЧ.
Если «искомый_текст» не найден, возвращается значение ошибки #ЗНАЧ.
Пример использования функции ПОИСК и ПСТР
Пример 1. Есть набор текстовой информации с контактными данными клиентов и их именами. Информация записана в разных форматах. Необходимо найти, с какого символа начинается номер телефона.
Введем исходные данные в таблицу:
В ячейке, которая будет учитывать данные клиентов без телефона, введем следующую формулу:
Нажмем Enter для отображения искомой информации:
Далее мы можем использовать любые другие функции для отображения представленной информации в удобном формате:
На рисунке видно, как с помощью формулы из двух функций ПСТР и ПОИСК мы вырезаем фрагмент текста из строк разной длины. Притом разделяем текстовый фрагмент в нужном месте так, чтобы отделить ее от номера телефона.
Пример формулы ПОИСК и ЗАМЕНИТЬ
Пример 2. Есть таблица с текстовой информацией, в которой слово «маржа» нужно заменить на «объем».
Откроем книгу Excel с обрабатываемыми данными. Пропишем формулу для поиска нужного слова «маржа»:
Теперь дополним формулу функцией ЗАМЕНИТЬ:
Чем отличается функция ПОИСК от функции НАЙТИ в Excel?
Функция ПОИСК очень схожа с функцией НАЙТИ по принципу действия. Более того у них фактически одинаковые аргументы. Только лишь названия аргументов отличаются, а по сути и типам значений – одинаковые:
Но опытный пользователь Excel знает, что отличие у этих двух функций очень существенные.
Отличие №1. Чувствительность к верхнему и нижнему регистру (большие и маленькие буквы). Функция НАЙТИ чувствительна к регистру символов. Например, есть список номенклатурных единиц с артикулом. Необходимо найти позицию маленькой буквы «о».
Теперь смотрите как ведут себя по-разному эти две функции при поиске большой буквы «О» в критериях поиска:
Отличие №2. В первом аргументе «Искомый_текст» для функции ПОИСК мы можем использовать символы подстановки для указания не точного, а приблизительного значения, которое должно содержаться в исходной текстовой строке. Вторая функция НАЙТИ не умеет использовать в работе символы подстановки масок текста: «*»; «?»; «
Для примера попробуем в этих же исходных строках столбца «наименования» найти приблизительный текст. Для этого укажем следующий вид критерия поиска используя символы подстановки: «н*ая».
Как видим во втором отличии функция НАЙТИ совершенно не умеет работать и распознавать спецсимволы для подстановки текста в критериях поиска при неточном совпадении в исходной строке.
Примечание: Мы стараемся как можно оперативнее обеспечивать вас актуальными справочными материалами на вашем языке. Эта страница переведена автоматически, поэтому ее текст может содержать неточности и грамматические ошибки. Для нас важно, чтобы эта статья была вам полезна. Просим вас уделить пару секунд и сообщить, помогла ли она вам, с помощью кнопок внизу страницы. Для удобства также приводим ссылку на оригинал (на английском языке).
В этой статье описаны синтаксис формулы и использование функций ПОИСК и ПОИСКБ в Microsoft Excel.
Описание
Функции ПОИСК И ПОИСКБ находят одну текстовую строку в другой и возвращают начальную позицию первой текстовой строки (считая от первого символа второй текстовой строки). Например, чтобы найти позицию буквы «n» в слове «printer», можно использовать следующую функцию:
Эта функция возвращает 4, так как «н» является четвертым символом в слове «принтер».
Можно также находить слова в других словах. Например, функция
возвращает 5, так как слово «base» начинается с пятого символа слова «database». Можно использовать функции ПОИСК и ПОИСКБ для определения положения символа или текстовой строки в другой текстовой строке, а затем вернуть текст с помощью функций ПСТР и ПСТРБ или заменить его с помощью функций ЗАМЕНИТЬ и ЗАМЕНИТЬБ. Эти функции показаны в примере 1 данной статьи.
Эти функции могут быть доступны не на всех языках.
Функция ПОИСКБ отсчитывает по два байта на каждый символ, только если языком по умолчанию является язык с поддержкой БДЦС. В противном случае функция ПОИСКБ работает так же, как функция ПОИСК, и отсчитывает по одному байту на каждый символ.
К языкам, поддерживающим БДЦС, относятся японский, китайский (упрощенное письмо), китайский (традиционное письмо) и корейский.
Синтаксис
Аргументы функций ПОИСК и ПОИСКБ описаны ниже.
Искомый_текст Обязательный. Текст, который требуется найти.
Просматриваемый_текст Обязательный. Текст, в котором нужно найти значение аргумента искомый_текст.
Начальная_позиция Необязательный. Номер знака в аргументе просматриваемый_текст, с которого следует начать поиск.
Замечание
Функции ПОИСК и ПОИСКБ не учитывают регистр. Если требуется учитывать регистр, используйте функции НАЙТИ и НАЙТИБ.
В аргументе искомый_текст можно использовать подстановочные знаки: вопросительный знак ( ?) и звездочку ( *). Вопросительный знак соответствует любому знаку, звездочка — любой последовательности знаков. Если требуется найти вопросительный знак или звездочку, введите перед ним тильду (
Если значение аргумента искомый_текст не найдено, #VALUE! возвращено значение ошибки.
Если аргумент начальная_позиция опущен, то он полагается равным 1.
Если Нач_позиция не больше 0 или больше, чем длина аргумента просматриваемый_текст , #VALUE! возвращено значение ошибки.
Аргумент начальная_позиция можно использовать, чтобы пропустить определенное количество знаков. Допустим, что функцию ПОИСК нужно использовать для работы с текстовой строкой «МДС0093.МужскаяОдежда». Чтобы найти первое вхождение «М» в описательной части текстовой строки, задайте для аргумента начальная_позиция значение 8, чтобы поиск не выполнялся в той части текста, которая является серийным номером (в данном случае — «МДС0093»). Функция ПОИСК начинает поиск с восьмого символа, находит знак, указанный в аргументе искомый_текст, в следующей позиции, и возвращает число 9. Функция ПОИСК всегда возвращает номер знака, считая от начала просматриваемого текста, включая символы, которые пропускаются, если значение аргумента начальная_позиция больше 1.
Примеры
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
Wildcard is a term for a special kind of a character that can represent one or more «unknown» characters, and Excel has a wildcard character support. You can use wildcards for filtering, searching, or inside the formulas. In this guide, we’re going to show you how to use Excel Wildcard characters for setting up formula criteria.
Download Workbook
Excel wildcard characters
Excel supports 3 kinds of wildcard characters:
| Asterisk (*) | Any value of zero or more |
| Question mark (?) | Any single character |
| Tilde (~) |
Escape for an actual question mark, asterisk, or tilde character.
|
You can use these characters to generate a text pattern for strings that are to be matched. Please note that wildcard characters only work with texts, and do not work with numbers.
Let’s look at some examples:
| Pattern | Meaning | Sample |
| ? | Any one character | «A», «a», «1», «-«, etc. |
| ?? | Any two characters | «A1», «9a», «9.», etc. |
| * | Any characters | «excel», «supp0rtz», «wi!d cards», etc. |
| A* | Starts with «A» | «A», «Anchor», «A string», etc. |
| ?* | At least one character | «Z», «1», «Z1», etc. |
| (???) ???-???? | 10 characters with parenthesis and a hyphen | «(123) 456-7890», «(A10) XYZ-8866», etc. |
| *lec* | Contains «lec» | «electric», dialectic», «lecture», etc. |
| *~? | Ends with a question mark (?) | «O Brother, Where Art Thou?», » Dude, Where’s My Car?», etc. |
Formulas that support using wildcard criteria
All …IFS and …IF Functions
All statistical functions in Excel that end with either «IFS» or «IF» support wildcards.
- SUMIFS
- SUMIF
- COUNTIFS
- COUNTIF
- AVERAGEIFS
- AVERAGEIF
- MAXIFS
- MINIFS
Using wildcard criteria can increase the versatility of these functions. Use strings with wildcards in criteria arguments. The following examples show the difference between using and not using wildcards.

The upper set of formulas are using the «*FIRE*» string which represents any text that contains «FIRE». Thus, the formulas calculates 3 rows of data: «FIRE», «FIRE» and «FIRE, FLYING».
On the other hand, the formulas work on only two of examples without any wildcards: «FIRE» and «FIRE».
VLOOKUP and HLOOKUP
Both VLOOKUP and HLOOKUP functions support wildcard characters. Although both functions have an approximate match mode, using them in this mode may not return the correct result every time. Wildcards gives you more precision on your search. Use a string with a wildcard for lookup value argument to search.
The following screenshot shows an example for each formula. VLOOKUP function searches the «C*n» value, and matches with «Charmeleon». On the other side, HLOOKUP function searches a two-character string that matches «HP».

MATCH
MATCH function is another lookup function that support wildcard characters. Aside from returning a value on a different column, MATCH function returns the position of the found value. Once again, use wildcard characters in the lookup value argument.

SEARCH
You can use the SEARCH function with wildcards to find a string pattern in another string. In our example, we searched for a pattern like «a?to*e» to locate a string starts with «a», followed by any single character, which is followed by «to», and any number of characters until an «e» character is found.
