
Skip to content
В этой статье мы рассмотрим разные подходы к одной из самых распространенных и, по моему мнению, важных задач в Excel — как найти в ячейках и в столбцах таблицы повторяющиеся значения.
Работая с большими наборами данных в Excel или объединяя несколько небольших электронных таблиц в более крупные, вы можете столкнуться с большим числом одинаковых строк.
И сегодня я хотел бы поделиться несколькими быстрыми и эффективными методами выявления дубликатов в одном списке. Эти решения работают во всех версиях Excel 2016, Excel 2013, 2010 и ниже. Вот о чём мы поговорим:
- Поиск повторяющихся значений включая первые вхождения
- Поиск дубликатов без первых вхождений
- Определяем дубликаты с учетом регистра
- Как извлечь дубликаты из диапазона ячеек
- Как обнаружить одинаковые строки в таблице данных
- Использование встроенных фильтров Excel
- Применение условного форматирования
- Поиск совпадений при помощи встроенной команды «Найти»
- Определяем дубликаты при помощи сводной таблицы
- Duplicate Remover — быстрый и эффективный способ найти дубликаты
Самой простой в использовании и вместе с тем эффективной в данном случае будет функция СЧЁТЕСЛИ (COUNTIF). С помощью одной только неё можно определить не только неуникальные позиции, но и их первые появления в столбце. Рассмотрим разницу на примерах.
Поиск повторяющихся значений включая первые вхождения.
Предположим, что у вас в колонке А находится набор каких-то показателей, среди которых, вероятно, есть одинаковые. Это могут быть номера заказов, названия товаров, имена клиентов и прочие данные. Если ваша задача — найти их, то следующая формула для вас:
=СЧЁТЕСЛИ(A:A; A2)>1
Где А2 — первая ячейка из области для поиска.
Просто введите это выражение в любую ячейку и протяните вниз вдоль всей колонки, которую нужно проверить на дубликаты.

Как вы могли заметить на скриншоте выше, формула возвращает ИСТИНА, если имеются совпадения. А для встречающихся только 1 раз значений она показывает ЛОЖЬ.
Подсказка! Если вы ищите повторы в определенной области, а не во всей колонке, обозначьте нужный диапазон и “зафиксируйте” его знаками $. Это значительно ускорит вычисления. Например, если вы ищете в A2:A8, используйте
=СЧЕТЕСЛИ($A$2:$A$8, A2)>1
Если вас путает ИСТИНА и ЛОЖЬ в статусной колонке и вы не хотите держать в уме, что из них означает повторяющееся, а что — уникальное, заверните свою СЧЕТЕСЛИ в функцию ЕСЛИ и укажите любое слово, которое должно соответствовать дубликатам и уникальным:
=ЕСЛИ(СЧЁТЕСЛИ($A$2:$A$17; A2)>1;»Дубликат»;»Уникальное»)
Если же вам нужно, чтобы формула указывала только на дубли, замените «Уникальное» на пустоту («»):

=ЕСЛИ(СЧЁТЕСЛИ($A$2:$A$17; A2)>1;»Дубликат»;»»)

В этом случае Эксель отметит только неуникальные записи, оставляя пустую ячейку напротив уникальных.
Поиск неуникальных значений без учета первых вхождений
Вы наверняка обратили внимание, что в примерах выше дубликатами обозначаются абсолютно все найденные совпадения. Но зачастую задача заключается в поиске только повторов, оставляя первые вхождения нетронутыми. То есть, когда что-то встречается в первый раз, оно однозначно еще не может быть дубликатом.
Если вам нужно указать только совпадения, давайте немного изменим:
=ЕСЛИ(СЧЁТЕСЛИ($A$2:$A2; A2)>1;»Дубликат»;»»)
На скриншоте ниже вы видите эту формулу в деле.

Нетрудно заметить, что она не обозначает первое появление слова, а начинает отсчет со второго.
Чувствительный к регистру поиск дубликатов
Хочу обратить ваше внимание на то, что хоть формулы выше и находят 100%-дубликаты, есть один тонкий момент — они не чувствительны к регистру. Быть может, для вас это не принципиально. Но если в ваших данных абв, Абв и АБВ — это три разных параметра – то этот пример для вас.
Как вы могли уже догадаться, выражения, использованные нами ранее, с такой задачей не справятся. Здесь нужно выполнить более тонкий поиск, с чем нам поможет следующая функция массива:
{=ЕСЛИ(СУММ((—СОВПАД($A$2:$A$17;A2)))<=1;»»;»Дубликат»)}
Не забывайте, что формулы массива вводятся комбиинацией Ctrl + Shift + Enter.
Если вернуться к содержанию, то здесь используется функция СОВПАД для сравнения целевой ячейки со всеми остальными ячейками с выбранной области. Результат возвращается в виде ИСТИНА (совпадение) или ЛОЖЬ (не совпадение), которые затем преобразуются в массив из 1 и 0 при помощи оператора (—).
После этого, функция СУММ складывает эти числа. И если полученный результат больше 1, функция ЕСЛИ сообщает о найденном дубликате.
Если вы взглянете на следующий скриншот, вы убедитесь, что поиск действительно учитывает регистр при обнаружении дубликатов:

Смородина и арбуз, которые встречаются дважды, не отмечены в нашем поиске, так как регистр первых букв у них отличается.
Как извлечь дубликаты из диапазона.
Формулы, которые мы описывали выше, позволяют находить дубликаты в определенном столбце. Но часто речь идет о нескольких столбцах, то есть о диапазоне данных.
Рассмотрим это на примере числовой матрицы. К сожалению, с символьными значениями этот метод не работает.

При помощи формулы массива
{=ИНДЕКС(НАИМЕНЬШИЙ(ЕСЛИ(СЧЁТЕСЛИ($A$2:$E$11;$A$2:$E$11)>1;$A$2:$E$11);СТРОКА($1:$100)); НАИМЕНЬШИЙ(ЕСЛИОШИБКА(ЕСЛИ(ПОИСКПОЗ(НАИМЕНЬШИЙ(ЕСЛИ( СЧЁТЕСЛИ($A$2:$E$11;$A$2:$E$11)>1;$A$2:$E$11);СТРОКА($1:$100)); НАИМЕНЬШИЙ(ЕСЛИ(СЧЁТЕСЛИ($A$2:$E$11;$A$2:$E$11)>1;$A$2:$E$11); СТРОКА($1:$100));0)=СТРОКА($1:$100);СТРОКА($1:$100));»»);СТРОКА()-1))}
вы можете получить упорядоченный по возрастанию список дубликатов. Для этого введите это выражение в нужную ячейку и нажмите Ctrl+Alt+Enter.
Затем протащите маркер заполнения вниз на сколько это необходимо.
Чтобы убрать сообщения об ошибке, когда дублирующиеся значения закончатся, можно использовать функцию ЕСЛИОШИБКА:
=ЕСЛИОШИБКА(ИНДЕКС(НАИМЕНЬШИЙ(ЕСЛИ(СЧЁТЕСЛИ($A$2:$E$11;$A$2:$E$11)>1;$A$2:$E$11); СТРОКА($1:$100));НАИМЕНЬШИЙ(ЕСЛИОШИБКА(ЕСЛИ(ПОИСКПОЗ( НАИМЕНЬШИЙ(ЕСЛИ(СЧЁТЕСЛИ($A$2:$E$11;$A$2:$E$11)>1;$A$2:$E$11); СТРОКА($1:$100));НАИМЕНЬШИЙ(ЕСЛИ(СЧЁТЕСЛИ($A$2:$E$11;$A$2:$E$11)>1;$A$2:$E$11); СТРОКА($1:$100));0)=СТРОКА($1:$100);СТРОКА($1:$100));»»);СТРОКА()-1));»»)
Также обратите внимание, что приведенное выше выражение рассчитано на то, что оно будет записано во второй строке. Соответственно выше него будет одна пустая строка.
Поэтому если вам нужно разместить его, к примеру, в ячейке K4, то выражение СТРОКА()-1 в конце замените на СТРОКА()-3.
Обнаружение повторяющихся строк
Мы рассмотрели, как обнаружить одинаковые данные в отдельных ячейках. А если нужно искать дубликаты-строки?
Есть один метод, которым можно воспользоваться, если вам нужно просто выделить одинаковые строки, но не удалять их.
Итак, имеются данные о товарах и заказчиках.
Создадим справа от наших данных формулу, объединяющую содержание всех расположенных слева от нее ячеек.
Предположим, что данные хранятся в столбцах А:C. Запишем в ячейку D2:
=A2&B2&C2
Добавим следующую формулу в ячейку E2. Она отобразит, сколько раз встречается значение, полученное нами в столбце D:
=СЧЁТЕСЛИ(D:D;D2)
Скопируем вниз для всех строк данных.
В столбце E отображается количество появлений этой строки в столбце D. Неповторяющимся строкам будет соответствовать значение 1. Повторам строкам соответствует значение больше 1, указывающее на то, сколько раз такая строка была найдена.
Если вас не интересует определенный столбец, просто не включайте его в выражение, находящееся в D. Например, если вам хочется обнаружить совпадающие строки, не учитывая при этом значение Заказчик, уберите из объединяющей формулы упоминание о ячейке С2.
Обнаруживаем одинаковые ячейки при помощи встроенных фильтров Excel.
Теперь рассмотрим, как можно обойтись без формул при поиске дубликатов в таблице. Быть может, кому-то этот метод покажется более удобным, нежели написание выражений Excel.
Организовав свои данные в виде таблицы, вы можете применять к ним различные фильтры. Фильтр в таблице вы можете установить по одному либо по нескольким столбцам. Давайте рассмотрим на примере.
В первую очередь советую отформатировать наши данные как «умную» таблицу. Напомню: Меню Главная – Форматировать как таблицу.
После этого в строке заголовка появляются значки фильтра. Если нажать один из них, откроется выпадающее меню фильтра, которое содержит всю информацию по данному столбцу. Выберите любой элемент из этого списка, и Excel отобразит данные в соответствии с этим выбором.
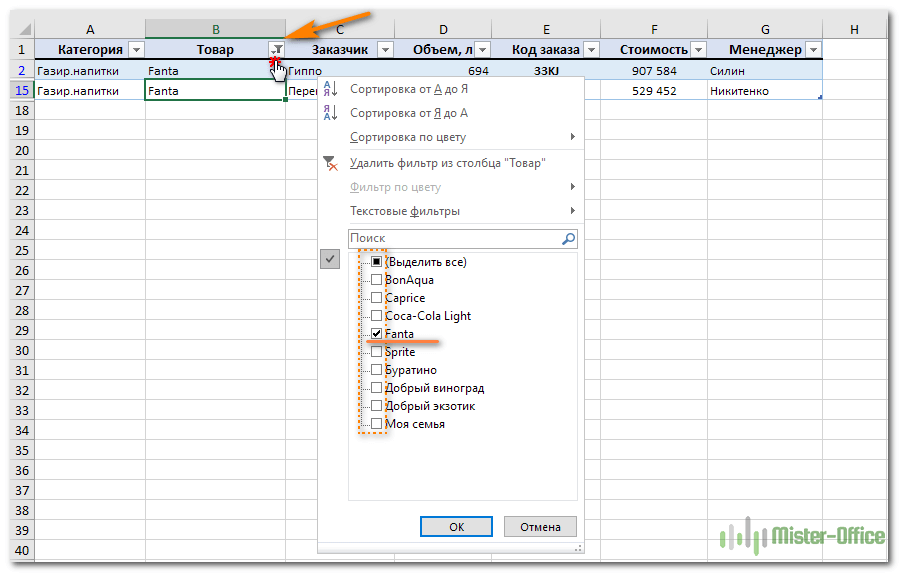
Вы можете убрать галочку с пункта «Выделить все», а затем отметить один или несколько нужных элементов. Excel покажет только те строки, которые содержат выбранные значения. Так можно обнаружить дубликаты, если они есть. И все готово для их быстрого удаления.
Но при этом вы видите дубли только по отфильтрованному. Если данных много, то искать таким способом последовательного перебора будет несколько утомительно. Ведь слишком много раз нужно будет устанавливать и менять фильтр.
Используем условное форматирование.
Выделение цветом по условию – весьма важный инструмент Excel, о котором достаточно подробно мы рассказывали.
Сейчас я покажу, как можно в Экселе найти дубли ячеек, просто их выделив цветом.
Как показано на рисунке ниже, выбираем Правила выделения ячеек – Повторяющиеся. Неуникальные данные будут подсвечены цветом.
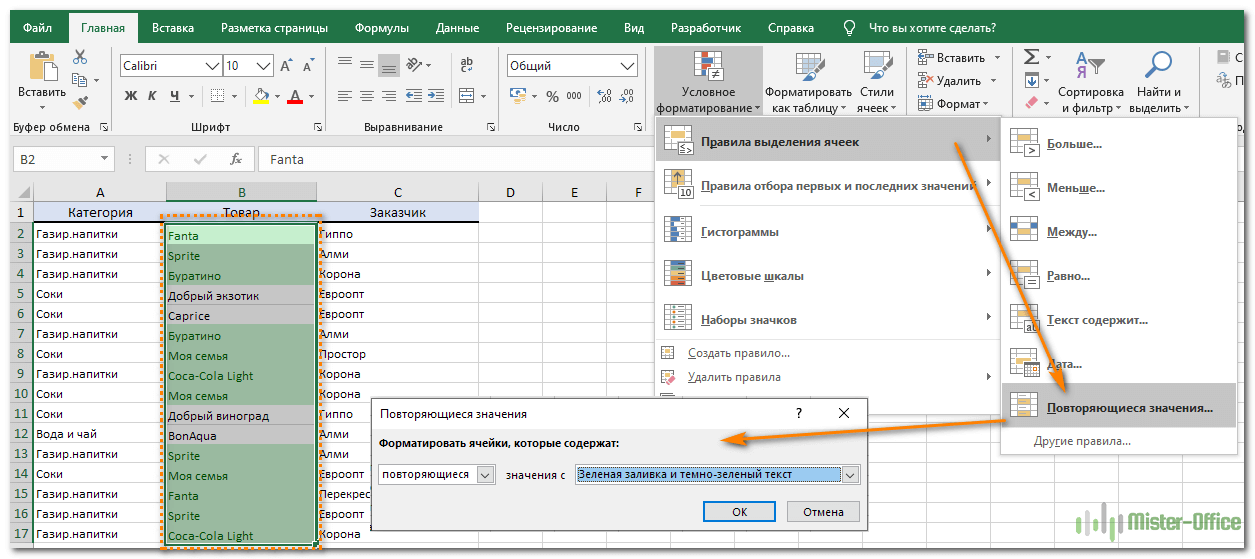
Но здесь мы не можем исключить первые появления – подсвечивается всё.
Но эту проблему можно решить, использовав формулу условного форматирования.
=СЧЁТЕСЛИ($B$2:$B2; B2)>1

Результат работы формулы выденения повторяющихся значений вы видите выше. Они выделены зелёным цветом.
Чтобы освежить память, можете руководствоваться нашим материалом «Как изменить цвет ячейки в зависимости от значения».
Поиск совпадений при помощи команды «Найти».
Еще один простой, но не слишком технологичный способ – использование встроенного поиска.
Зайдите на вкладку Главная и кликните «Найти и выделить». Откроется диалоговое окно, в котором можно ввести что угодно для поиска в таблице. Чтобы избежать опечаток, можете скопировать искомое прямо из списка данных.
Затем нажимаем «Найти все», и видим все найденные дубликаты и места их расположения, как на рисунке чуть ниже.

В случае, когда объём информации очень велик и требуется ускорить работу поиска, предварительно выделите столбец или диапазон, в котором нужно искать, и только после этого начинайте работу. Если этого не сделать, Excel будет искать по всем имеющимся данным, что, конечно, медленнее.
Этот метод еще более трудоемкий, нежели использование фильтра. Поэтому применяют его выборочно, только для отдельных значений.
Как применить сводную таблицу для поиска дубликатов.
Многие считают сводные таблицы слишком сложным инструментом, чтобы постоянно им пользоваться. На самом деле, не все так запутано, как кажется. Для новичков рекомендую к ознакомлению наше руководство по созданию и работе со сводными таблицами.
Для более опытных – сразу переходим к сути вопроса.
Создаем новый макет сводной таблицы. А затем в качестве строк и значений используем одно и то же поле. В нашем случае – «Товар». Поскольку название товара – это текст, то для подсчета таких значений Excel по умолчанию использует функцию СЧЕТ, то есть подсчитывает количество. А нам это и нужно. Если будет больше 1, значит, имеются дубликаты.

Вы наблюдаете на скриншоте выше, что несколько товаров дублируются. И что нам это дает? А далее мы просто можем щелкнуть мышкой на любой из цифр, и на новом листе Excel покажет нам, как получилась эта цифра.
К примеру, откуда взялись 3 дубликата Sprite? Щелкаем на цифре 3, и видим такую картину:

Думаю, этот метод вполне можно использовать. Что приятно – никаких формул не требуется.
Duplicate Remover — быстрый и эффективный способ найти дубликаты в Excel
Теперь, когда вы знаете, как использовать формулы для поиска повторяющихся значений в Excel, позвольте мне продемонстрировать вам еще один быстрый, эффективный и без всяких формул способ: инструмент Duplicate Remover для Excel.
Этот универсальный инструмент может искать повторяющиеся или уникальные значения в одном столбце или же сравнивать два столбца. Он может находить, выбирать и выделять повторяющиеся записи или целые повторяющиеся строки, удалять найденные дубли, копировать или перемещать их на другой лист. Я думаю, что пример практического использования может заменить очень много слов, так что давайте перейдем к нему.
Как найти повторяющиеся строки в Excel за 2 быстрых шага
Сначала посмотрим в работе наиболее простой инструмент — быстрый поиск дубликатов Quick Dedupe. Используем уже знакомую нам таблицу, в которой мы выше искали дубликаты при помощи формул:

Как видите, в таблице несколько столбцов. Чтобы найти повторяющиеся записи в этих трех столбцах, просто выполните следующие действия:
- Выберите любую ячейку в таблице и нажмите кнопку Quick Dedupe на ленте Excel. После установки пакета Ultimate Suite для Excel вы найдете её на вкладке Ablebits Data в группе Dedupe. Это наиболее простой инструмент для поиска дубликатов.
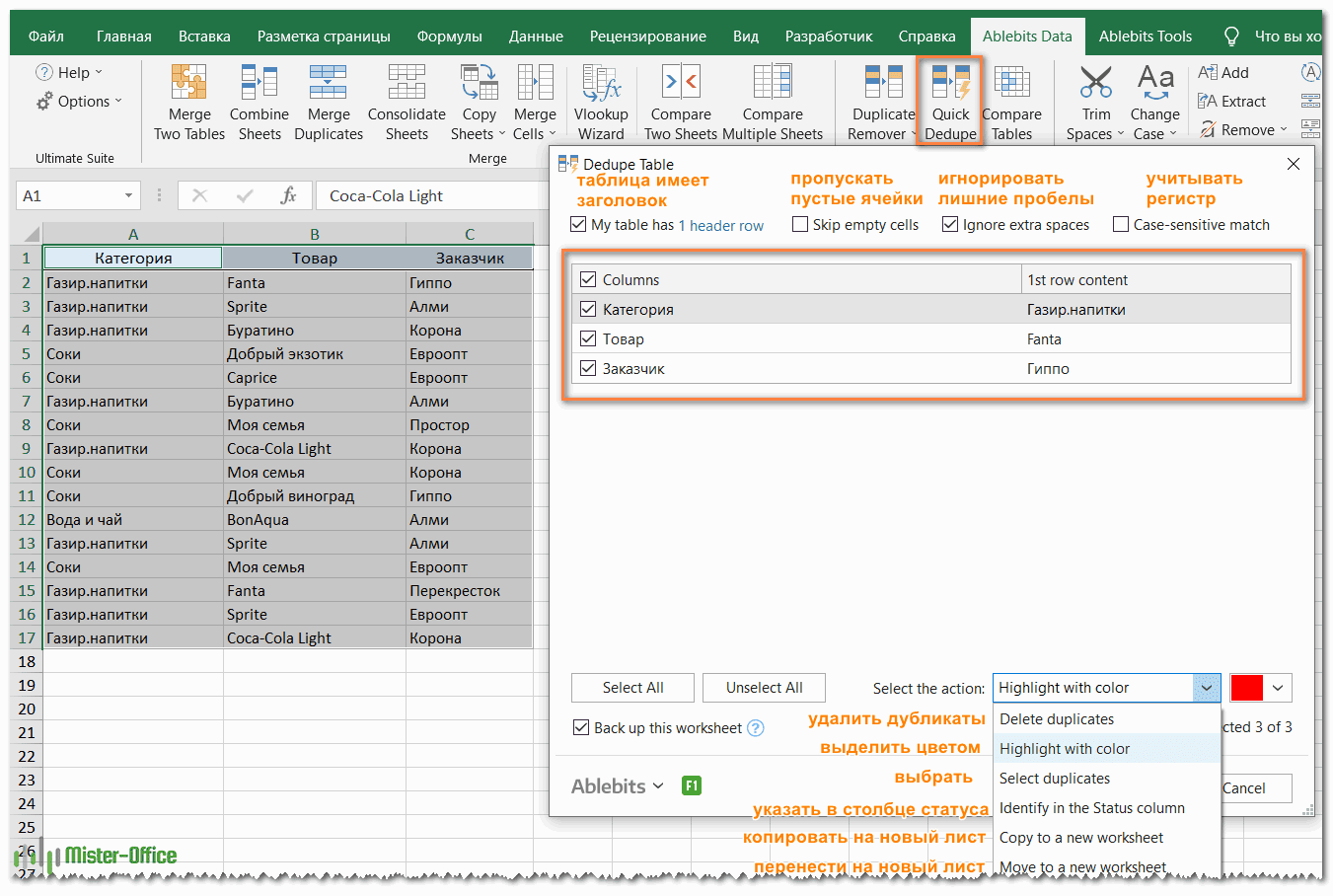
- Интеллектуальная надстройка возьмет всю таблицу и попросит вас указать следующие две вещи:
- Выберите столбцы для проверки дубликатов (в данном примере это все 3 столбца – категория, товар и заказчик).
- Выберите действие, которое нужно выполнить с дубликатами. Поскольку наша цель — выявить повторяющиеся строки, я выбрал «Выделить цветом».
Помимо выделения цветом, вам доступен ряд других опций:
- Удалить дубликаты
- Выбрать дубликаты
- Указать их в столбце статуса
- Копировать дубликаты на новый лист
- Переместить на новый лист
Нажмите кнопку ОК и подождите несколько секунд. Готово! И никаких формул 😊.
Как вы можете видеть на скриншоте ниже, все строки с одинаковыми значениями в первых 3 столбцах были обнаружены (первые вхождения не идентифицируются как дубликаты).

Если вам нужны дополнительные возможности для работы с дубликатами и уникальными значениями, используйте мастер удаления дубликатов Duplicate Remover, который может найти дубликаты с первыми вхождениями или без них, а также уникальные значения. Подробные инструкции приведены ниже.
Мастер удаления дубликатов — больше возможностей для поиска дубликатов в Excel.
В зависимости от данных, с которыми вы работаете, вы можете не захотеть рассматривать первые экземпляры идентичных записей как дубликаты. Одно из возможных решений — использовать разные формулы для каждого сценария, как мы обсуждали в этой статье выше. Если же вы ищете быстрый, точный метод без формул, попробуйте мастер удаления дубликатов — Duplicate Remover. Несмотря на свое название, он не только умеет удалять дубликаты, но и производит с ними другие полезные действия, о чём мы далее поговорим подробнее. Также умеет находить уникальные значения.
- Выберите любую ячейку в таблице и нажмите кнопку Duplicate Remover на вкладке Ablebits Data.
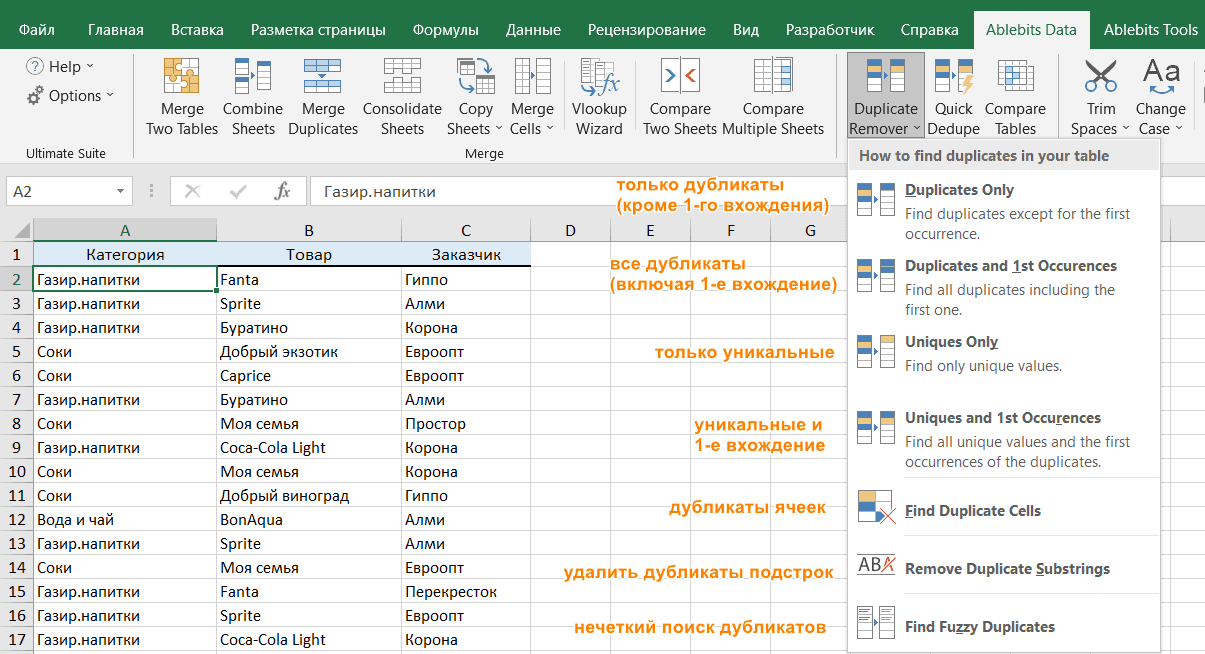
- Вам предложены 4 варианта проверки дубликатов в вашем листе Excel:
- Дубликаты без первых вхождений повторяющихся записей.
- Дубликаты с 1-м вхождением.
- Уникальные записи.
- Уникальные значения и 1-е повторяющиеся вхождения.
В этом примере выберем второй вариант, т.е. Дубликаты + 1-е вхождения:

- Теперь выберите столбцы, в которых вы хотите проверить дубликаты. Как и в предыдущем примере, мы возьмём первые 3 столбца:
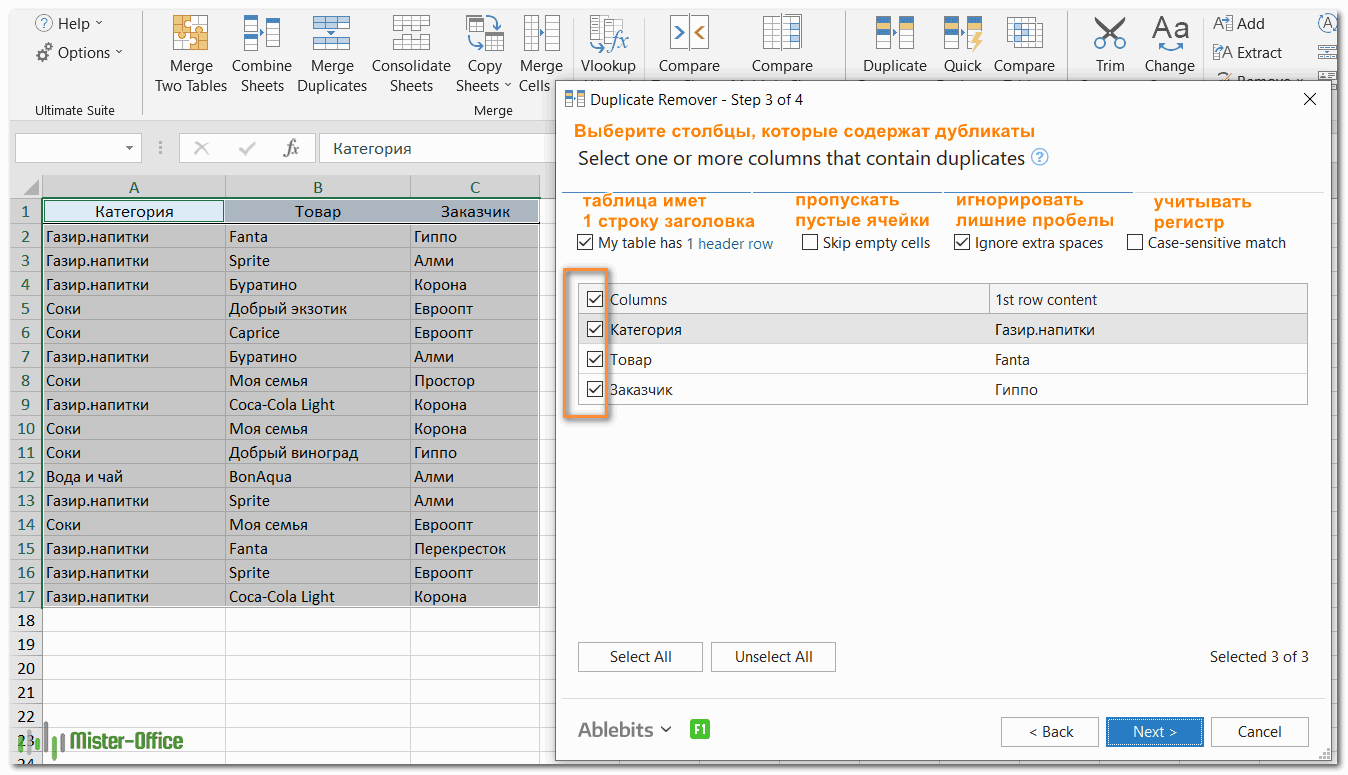
- Наконец, выберите действие, которое вы хотите выполнить с дубликатами. Как и в случае с инструментом быстрого поиска дубликатов, мастер Duplicate Remover может идентифицировать, выбирать, выделять, удалять, копировать или перемещать повторяющиеся данные.

Поскольку цель этого примера – продемонстрировать различные способы определения дубликатов в Excel, давайте отметим параметр «Выделить цветом» (Highlight with color) и нажмите Готово.
Мастеру Duplicate Remover требуется всего лишь несколько секунд, чтобы проверить вашу таблицу и показать результат:

Как видите, результат аналогичен предыдущему. Но здесь мы выделили дубликаты, включая и первое появление повторяющихся записей.
Никаких формул, никакого стресса, никаких ошибок — всегда быстрые и безупречные результаты 
Итак, мы с вам научились различными способами обнаруживать повторяющиеся записи в таблице Excel. В следующих статьях разберем, что мы с этим можем полезного сделать.
Если вы хотите попробовать эти инструменты для поиска дубликатов в таблицах Excel, вы можете загрузить полнофункциональную ознакомительную версию программы. Будем очень признательны за ваши отзывы в комментариях!
Поиск и удаление повторений
Excel для Microsoft 365 Excel 2021 Excel 2019 Excel 2016 Excel 2013 Excel 2010 Excel 2007 Excel Starter 2010 Еще…Меньше
В некоторых случаях повторяющиеся данные могут быть полезны, но иногда они усложняют понимание данных. Используйте условное форматирование для поиска и выделения повторяющихся данных. Это позволит вам просматривать повторения и удалять их по мере необходимости.
-
Выберите ячейки, которые нужно проверить на наличие повторений.
Примечание: В Excel не поддерживается выделение повторяющихся значений в области «Значения» отчета сводной таблицы.
-
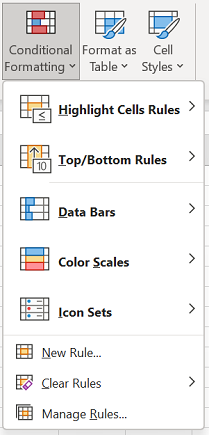
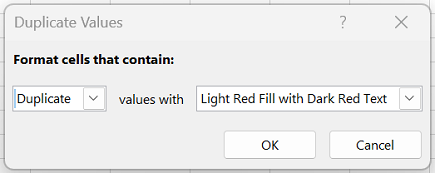
На вкладке Главная выберите Условное форматирование > Правила выделения ячеек > Повторяющиеся значения.

-
В поле рядом с оператором значения с выберите форматирование для применения к повторяющимся значениям и нажмите кнопку ОК.
Удаление повторяющихся значений
При использовании функции Удаление дубликатов повторяющиеся данные удаляются безвозвратно. Чтобы случайно не потерять необходимые сведения, перед удалением повторяющихся данных рекомендуется скопировать исходные данные на другой лист.
-
Выделите диапазон ячеек с повторяющимися значениями, который нужно удалить.
-
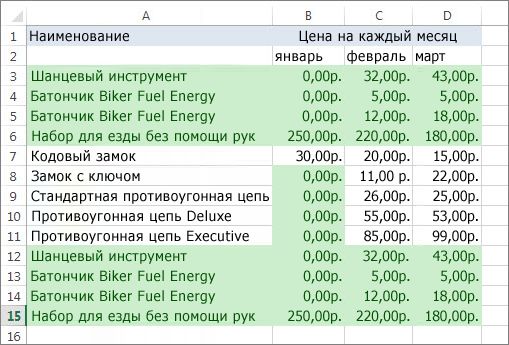
На вкладке Данные нажмите кнопку Удалить дубликаты и в разделе Столбцы установите или снимите флажки, соответствующие столбцам, в которых нужно удалить повторения.
Например, на данном листе в столбце «Январь» содержатся сведения о ценах, которые нужно сохранить.
Поэтому флажок Январь в поле Удаление дубликатов нужно снять.
-
Нажмите кнопку ОК.
Примечание: Количество повторяющихся и уникальных значений, заданных после удаления, может включать пустые ячейки, пробелы и т. д.
Дополнительные сведения

Нужна дополнительная помощь?
Дубликаты внутри ячейки
Про поиск и подсветку дубликатов в разных ячейках и диапазонах я уже не раз писал, но что делать если нужно найти и, возможно, удалить повторяющиеся слова внутри ячейки? Например, мы имеем вот такую таблицу с данными (разделителями могут быть не обязательно пробелы):

Хорошо видно, что некоторые имена в списках внутри ячеек повторяются. Давайте посмотрим, что можно с этим сделать.
Способ 1. Ищем повторения: текст по столбцам и формула массива
Это не самый удобный и быстрый, но зато самый простой вариант решения задачи «на коленке». Выделим исходный список и разобъем его на столбцы по пробелам с помощью команды Данные — Текст по столбцам (Data — Text to columns). В открывшемся окне трёхшагового Мастера выберем формат По разделителю (By delimiter) на первом шаге и поставим флажок Пробел (Space) на втором:

Если в исходных данных могут быть лишние пробелы, то лучше включить и опцию Считать последовательные разделители одним (Treat consecutive delimiters as one) — это избавит нас от лишних столбцов.
На третьем шаге в поле Поместить в зададим пустую ячейку рядом с таблицей, чтобы результаты не затёрли нам исходные данные и нажмём на Готово (Finish):

Наши данные разделятся по ячейкам. Останется подсчитать количество повторов в каждой строке с помощью небольшой, но хитрой формулы массива:

В английской версии это будет =SUMPRODUCT(N(COUNTIF(B2:G2,B2:G2)>1))
Давайте разберём логику её работы на примере первой строки.
- Сначала мы с помощью формулы СЧЁТЕСЛИ(B2:G2;B2:G2) вычисляем по очереди количество вхождений каждого имени в диапазон B2:G2 и получаем на выходе массив {1,2,1,2,1}, т.к. Иван встречается в первой строке 1 раз, Елена — 2 раза, Сергей — 1 и т.д.
- Проверяем с помощью СЧЁТЕСЛИ(B2:G2;B2:G2)>1 какие из полученных чисел больше единицы, т.е. где у нас повторы. На выходе эта формула выдаст нам массив результатов проверки в виде {ЛОЖЬ, ИСТИНА, ЛОЖЬ, ИСТИНА, ЛОЖЬ}.
- Переводим логические значения ЛОЖЬ и ИСТИНА в более удобные для подсчета 0 и 1, соответственно, с помощью функции Ч. На выходе получаем массив {0,1,0,1,0}.
- Суммируем все элементы получившегося массива функцией СУММПРОИЗВ. Можно было бы использовать и обычную функцию СУММ, но тогда пришлось бы жать вместо привычного Enter сочетание клавиш Ctrl+Shift+Enter, чтобы ввести формулу как формулу массива.
По получившемуся столбцу можно легко отфильтровать строки с повторами и работать потом с ними дальше уже вручную.
Минусы такого способа, впрочем, весьма очевидны: при изменении в исходных данных придётся повторять всю процедуру заново, дубликаты не очень заметны и удалять их тоже надо врукопашную. Поэтому идём дальше.
Способ 2. Выделение цветом повторов внутри ячейки макросом
Если дубликаты нужно именно наглядно показать, то удобнее будет использовать для этого специальный макрос. Откроем редактор Visual Basic одноимённой кнопкой на вкладке Разработчик (Developer — Visual Basic) или сочетанием клавиш Alt+F11. Вставим в книгу новый пустой модуль через меню Insert — Module и скопируем туда вот такой код:
Sub Color_Duplicates()
Dim col As New Collection
Dim curpos As Integer, i As Integer
On Error Resume Next
For Each cell In Selection
Set col = Nothing
curpos = 1
'убираем лишние пробелы и разбиваем текст из ячейки по пробелам
arWords = Split(WorksheetFunction.Trim(cell.Value), " ")
For i = LBound(arWords) To UBound(arWords) 'перебираем слова в получившемся массиве
Err.Clear 'сбрасываем ошибки
curpos = InStr(curpos, cell, arWords(i)) 'позиция начала текущего слова
col.Add arWords(i), arWords(i) 'пытаемся добавить текущее слово в коллекцию
If Err.Number <> 0 Then 'если возникает ошибка - значит это повтор, выделяем красным
cell.Characters(Start:=curpos, Length:=Len(arWords(i))).Font.ColorIndex = 3
cell.Characters(Start:=InStr(1, cell, arWords(i)), Length:=Len(arWords(i))).Font.ColorIndex = 3
End If
curpos = curpos + Len(arWords(i)) 'переходим к следующему слову
Next i
Next cell
End Sub
Теперь можно вернуться в главное окно Excel, выделить ячейки с текстом и запустить созданный макрос через кнопку Макросы на вкладке Разработчик (Developer — Macros) или сочетанием клавиш Alt+F8. Этот макрос проходит по всем выделенным ячейкам и помечает повторения красным цветом шрифта прямо внутри ячейки:

Если нужно, чтобы цветом выделялись только клоны, но не первые вхождения (т.е. только вторая и третья, но не первая Алиса, например), то достаточно будет просто убрать из кода строку 20.
Способ 3. Выводим повторы в соседний столбец
Если повторы внутри ячеек нужно не просто подсветить, а явным образом вывести, например, в соседний столбец, то удобнее будет использовать для этого макрофункцию, созданную по образу предыдущего макроса. Добавим в редакторе Visual Basic новый модуль и вставим туда код нашей функции GetDuplicates:
Function GetDuplicates(cell As Range) As String
Dim col As New Collection
Dim i As Integer, sDupes As String
On Error Resume Next
Set col = Nothing
'делим текст в ячейке по пробелам
arWords = Split(WorksheetFunction.Trim(cell.Value), " ")
'проходим в цикле по всем получившимся словам
For i = LBound(arWords) To UBound(arWords)
Err.Clear 'сбрасываем ошибки
col.Add arWords(i), arWords(i) 'пробуем добавить слово в коллекцию
'если ошибки не возникает, то это не повтор - добавляем слово к результату
If Err.Number <> 0 Then sDupes = sDupes & " " & arWords(i)
Next i
GetDuplicates = Trim(sDupes) 'выводим результаты
End Function
Эта функция, как легко догадаться, принимает в качестве единственного аргумента ячейку с текстом и выводит в качестве результата все повторы, которые там найдет:

Способ 4. Удаление повторов внутри ячейки макросом
Если нужно просто удалить дубликаты внутри ячейки, чтобы все оставшиеся там слова не повторялись, то макрос будет похож на предыдущий, но попроще:
Sub Delete_Duplicates()
Dim col As New Collection
Dim i As Integer
On Error Resume Next
For Each cell In Selection
Set col = Nothing
sResult = ""
'делим текст в ячейке по пробелам
arWords = Split(WorksheetFunction.Trim(cell.Value), " ")
'проходим в цикле по всем получившимся словам
For i = LBound(arWords) To UBound(arWords)
Err.Clear 'сбрасываем ошибки
col.Add arWords(i), arWords(i) 'пробуем добавить слово в коллекцию
'если ошибки не возникает, то это не повтор - добавляем слово к результату
If Err.Number = 0 Then sResult = sResult & " " & arWords(i)
Next i
cell.Value = Trim(sResult) 'выводим результаты без повторов
Next cell
End Sub
Способ 5. Удаление повторов внутри ячейки через Power Query
Этот способ использует бесплатную надстройку Excel для обработки данных под названием Power Query. Для Excel 2010-2013 скачать её можно с сайта Microsoft, а в Excel 2016-2019 она уже встроена по умолчанию. Огромным плюсом этого варианта является возможность автоматического обновления — если в будущем исходные данные изменятся, то нам не придется заново проделывать всю обработку (как в Способе 1) или запускать макрос (как в Способе 4) — достаточно будет просто обновить созданный запрос.
Сначала наши данные нужно загрузить в Power Query. Проще всего для этого превратить нашу таблицу в «умную» сочетанием клавиш Ctrl+T или кнопкой Форматировать как таблицу на вкладке Главная (Home — Format as Table), а затем нажать кнопку Из таблицы/диапазона (From table/range) на вкладке Power Query (если у вас Excel 2010-2013) или на вкладке Данные (если у вас Excel 2016 или новее):

Поверх окна Excel откроется окно редактора запросов Power Query с загруженными туда нашими данными:

Дальше делаем следующую цепочку действий:
Удаляем ненужный пока шаг Измененный тип (Changed Type) справа в панели применённых шагов с помощью крестика слева от шага.
Чтобы можно было потом идентифицировать принадлежность каждого имени к исходной строке — добавляем столбец с нумерацией строк на вкладке Добавление столбца — Столбец индекса — От 1 (Add Column — Index Column — From 1):

Выделяем столбец с именами и жмём на вкладке Преобразование — Разделить столбец — По разделителю (Transform — Split Column — By delimiter), а в открывшемся окне выбираем деление по каждому пробелу и — главное — деление на строки, а не на столбцы в расширенных параметрах:

После нажатия на ОК увидим следующее:

Теперь выделяем оба столбца (удерживая клавишу Ctrl или Shift) и удаляем дубликаты через Главная — Удалить строки — Удалить дубликаты (Home — Remove Rows — Remove Duplicates).
Осталось собрать всё обратно в ячейки Для этого выделим столбец Индекс и используем команду Группировать по на вкладке Преобразование (Transform — Group By) со следующими параметрами:

После нажатия на ОК наши имена сгруппируются во вложенные таблицы, имитирующие начальные ячейки — только уже без повторов. Увидеть содержимое свёрнутых таблиц можно, если щёлкнуть мышью в фон ячейки рядом со словом Table (но не в слово Table!):

Осталось вытащить все имена из первой колонки каждой таблицы и склеить их через пробел. Это можно сделать с помощью небольшой формулы на встроенном в Power Query языке М. Выберем на вкладке Добавление столбца команду Настраиваемый столбец (Add Column — Custom Column) и введём в открывшееся окно имя нового столбца и формулу (с соблюдением регистра!):

=Text.Combine([Ячейки][Имена],» «)
Здесь выражение [Ячейки][Имена] извлекает содержимое столбца Имена из каждой таблицы в колонке Ячейки, а функция Text.Combine склеивает затем их все через заданный разделитель (пробел). После нажатия на ОК мы, наконец, увидим желаемое:

Осталось удалить ненужные более столбцы Индекс и Ячейки, щелкнув по их заголовкам правой кнопкой мыши и выбрав команду Удалить столбцы (Remove Columns) и выгрузить результаты на лист через Главная — Закрыть и загрузить — Закрыть и загрузить в (Home — Close & Load — Close & Load to..):

Задача решена! Если в будущем данные в исходной «умной» таблице изменятся или к ней будут дописаны новые строки, то достаточно будет просто обновить запрос, щёлкнув по результирующей зелёной таблице правой кнопкой мыши и выбрав команду Обновить или нажав сочетание клавиш Ctrl+Alt+F5.
Ссылки по теме
- Как найти и вывести отличия в двух списках в Excel
- Как подсветить совпадающие пары дубликатов одинаковым цветом
- Сравнение двух таблиц с помощью ВПР, сводной или Power Query
- Найти и выделить цветом дубликаты в Excel
- Формула проверки наличия дублей в диапазонах
- Внутри диапазона
- !SEMTools, поиск дублей внутри диапазона
- Найти дубли ячеек в столбце, кроме первого
- Найти в столбце дубли ячеек, включая первый
- Найти дубли в столбце без учета лишних пробелов
Найти повторяющиеся значения в столбцах Excel — на поверку не такая уж и простая задача. Есть пара встроенных инструментов, таких как условное форматирование и инструмент удаления дубликатов, но они не всегда подходят для решения реальных задач.
Поиск дублей в Excel может быть очень разным, и, в зависимости от вводных, производиться тоже будет по-разному.
Ключевых моментов несколько:
- Какие конкретно повторяющиеся значения — повторы слов в ячейках, сами повторяющиеся ячейки или повторяющиеся строки?
- Если ячейки, то:
- Какие ячейки мы готовы считать дубликатами — все кроме первой или включая ее?
- Считаем ли дублями строки, отличающиеся только пробелами до/после слов или лишними пробелами между словами?
- Где мы будем искать дубли — в одном столбце, в двух столбцах или в нескольких?
- А может, нам нужно найти неявные дубли?
Сначала рассмотрим простые примеры.
Для выделения дубликатов ячеек подходит инструмент условное форматирование. В процедуре есть ряд готовых правил, в том числе и для повторяющихся значений.
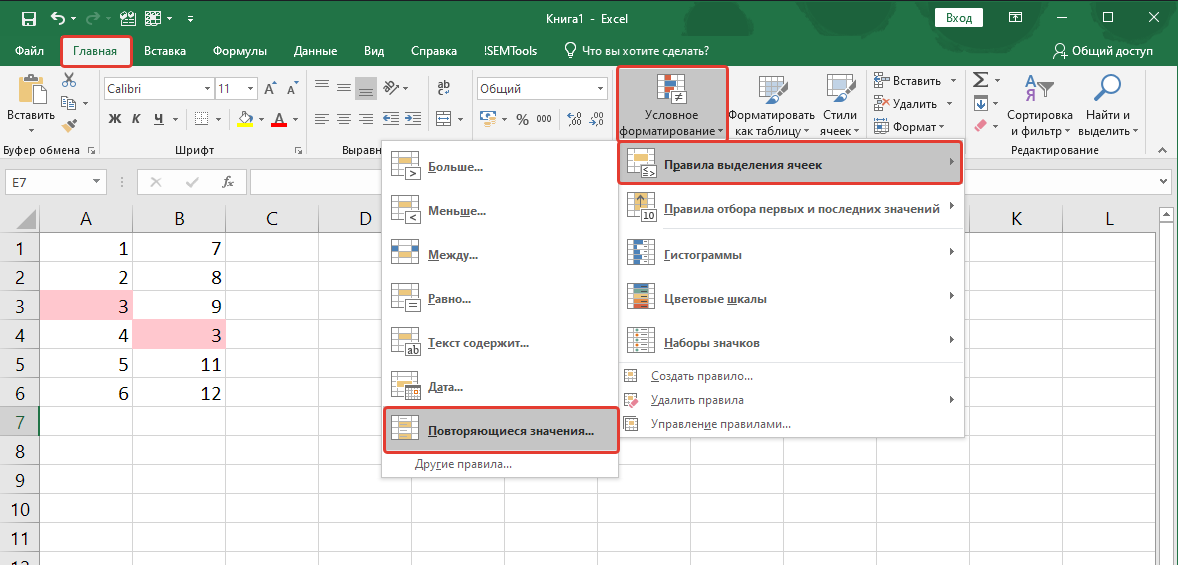
Найти инструмент можно на вкладке программы “Главная”:
Процедура интуитивно понятна:
- Выделяем диапазон, в котором хотим найти дубликаты.
- Вызываем процедуру.
- Выбираем форматирование для отобранных ячеек (есть предустановленные форматы или же можно задать свой вариант).
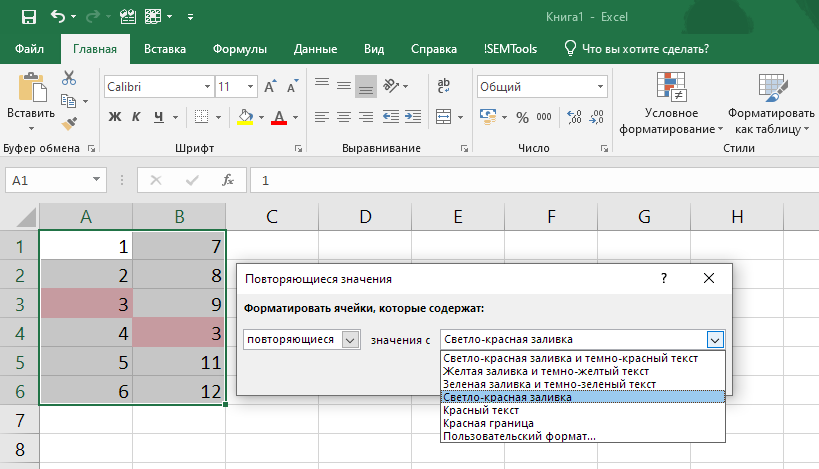
Важно понимать, что процедура находит дубликаты внутри всего диапазона и поэтому может не быть применима для сравнения двух столбцов. Достаточно иметь дубликаты внутри одного столбца — и процедура подсветит их оба, хотя во втором их не будет:
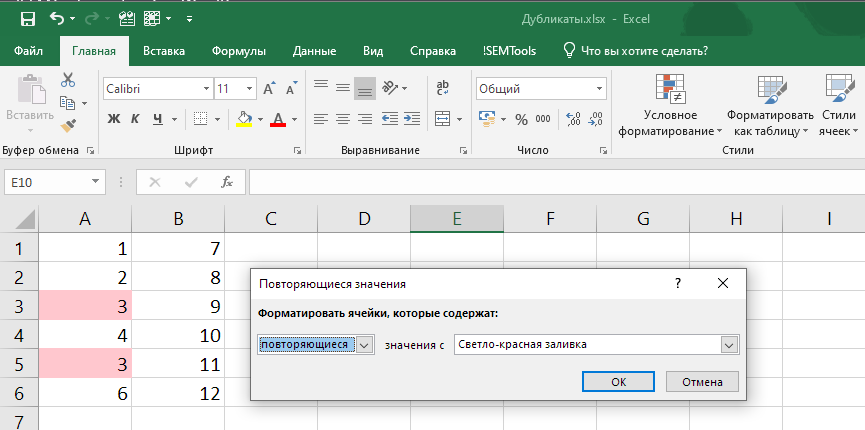
Данное поведение является неочевидным, и об этом факте часто забывают. Если дальше вы планируете удалять повторы, можете потерять оба варианта в одном столбце.
Как избежать подобной ситуации, если хочется найти именно дубли в другом столбце? Простейшее решение: удалить дубли внутри каждого столбца перед применением условного форматирования.
Но есть и другие решения. О них дальше.
Формула проверки наличия дублей в диапазонах
Использование собственной формулы для проверки дубликатов в списке или диапазоне имеет ряд преимуществ, единственная задача — составление такой формулы. Но её я возьму на себя.
Внутри диапазона
Чтобы проверить, есть ли в диапазоне повторяющиеся значения, можно использовать такую формулу массива:
=СУММПРОИЗВ(СЧЁТЕСЛИ(диапазон;тот-же-диапазон)-1)>0
Так выглядит на практике применение формулы:

В чем же преимущество такой формулы, ведь она полностью дублирует опцию условного форматирования, спросите вы.
А дело все в том, что формулу несложно видоизменить и улучшить.
Например, можно улучшить эффективность формулы, добавив в нее функцию СЖПРОБЕЛЫ .Это позволит находить дубликаты, отличающиеся незаметными лишними пробелами:
=СУММПРОИЗВ(--(СЖПРОБЕЛЫ(ячейка)=СЖПРОБЕЛЫ(диапазон)))>1
Эта формула слегка отличается, так как проверяет встречаемость в диапазоне значения одной ячейки.
Если внести ее как правило отбора условного форматирования, она позволит выявлять неявные дубли. Ниже демонстрация того, как работает формула:
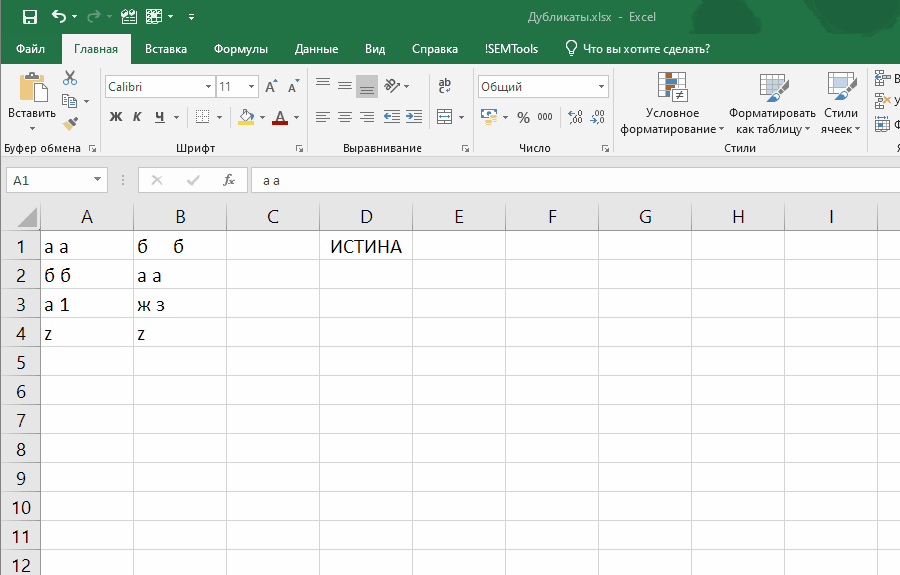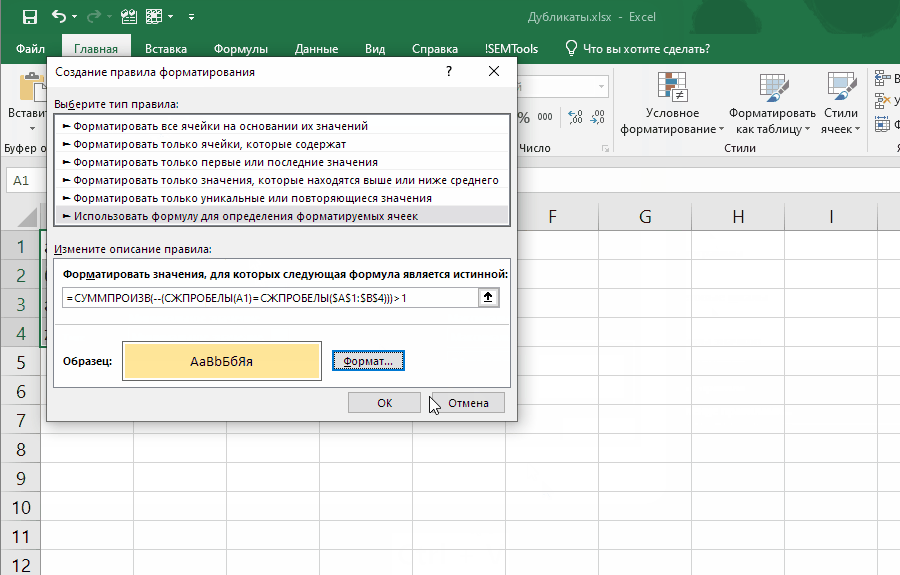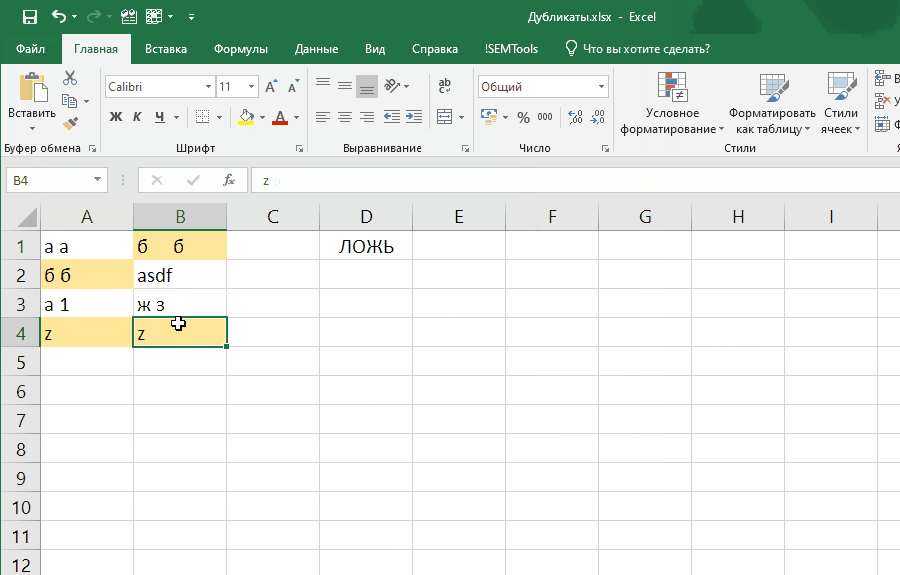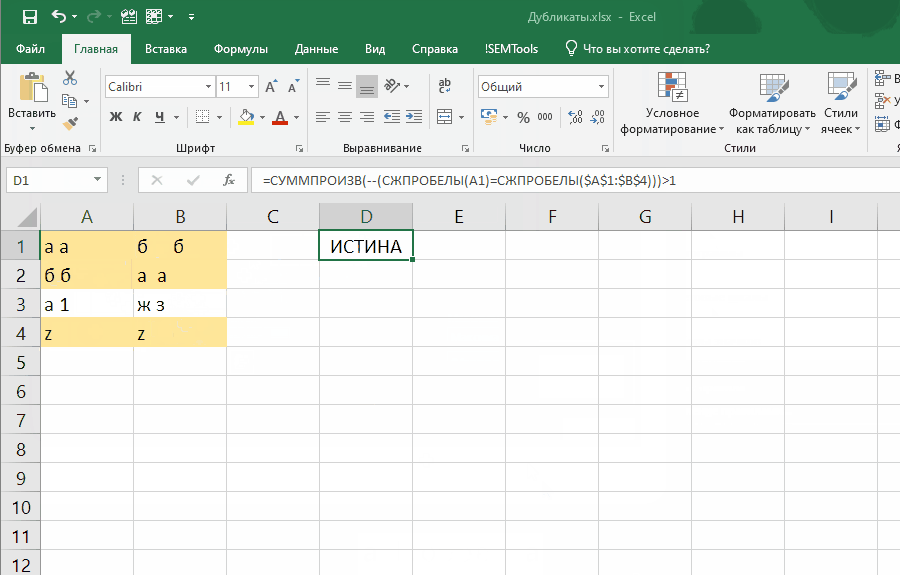
Обратите внимание на один момент в этой демонстрации: диапазон закреплен ($A$1:$B$4), а искомая ячейка (A1) нет. Именно это позволяет условному форматированию находить все дубликаты в диапазоне.
!SEMTools, поиск дублей внутри диапазона
Когда-то я потратил немало времени, пользуясь перечисленными выше методами поиска повторяющихся значений. Все они мне не нравились. Причина была одна: это попросту медленно. Поэтому я решил сделать отдельные процедуры для поиска и удаления дубликатов в Excel в своей надстройке.
Давайте покажу, как они работают.
Найти дубли ячеек в столбце, кроме первого
Процедура позволяет выделить все вторые, третьи и т.д. повторяющиеся значения в столбце.

Найти в столбце дубли ячеек, включая первый
Зачастую нужно найти в столбце все повторяющиеся ячейки, включая первую, для того, чтобы далее отфильтровать их все.

Найти дубли в столбце без учета лишних пробелов
Если мы считаем дубликатами фразы, отличающиеся количеством пробелов между словами или после, наша задача — сначала избавиться от лишних пробелов, и далее произвести тот же поиск дубликатов.
Для первой операции есть отдельный инструмент «Удалить лишние пробелы»:

Найти повторяющиеся значения в Excel и решить сотни других задач поможет надстройка !SEMTools.
Скачайте прямо сейчас и убедитесь сами!
Смотрите также:
- Удалить дубли без смещения строк;
- Удалить неявные дубли;
- Найти повторяющиеся слова в Excel;
- Удалить повторяющиеся слова внутри ячеек.
При совместной работе с таблицами Excel или большом числе записей накапливаются дубли строк. Ста…
При совместной работе с
таблицами Excel или большом числе записей
накапливаются дубли строк. Статья
посвящена тому, как выделить
повторяющиеся значения в Excel,
удалить лишние записи или сгруппировать,
получив максимум информации.

Поиск
одинаковых значений в Excel
Выберем
одну из ячеек в таблице. Рассмотрим, как
в Экселе найти повторяющиеся значения,
равные содержимому ячейки, и выделить
их цветом.
На
рисунке – списки писателей. Алгоритм
действий следующий:
- Выбрать
ячейку I3
с записью «С. А. Есенин». - Поставить
задачу – выделить цветом ячейки с
такими же записями. - Выделить
область поисков. - Нажать
вкладку «Главная». - Далее
группа «Стили». - Затем
«Условное форматирование»; - Нажать
команду «Равно».
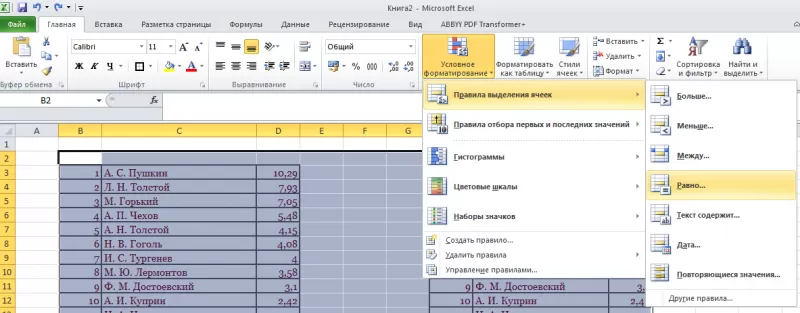
- Появится
диалоговое окно:
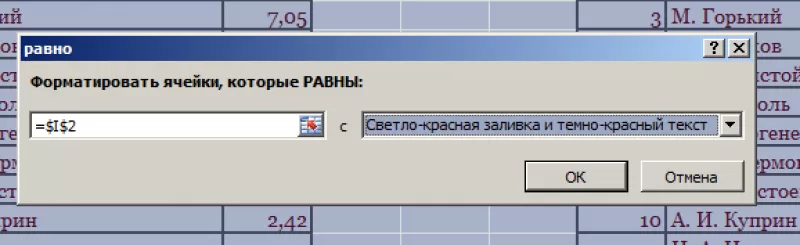
- В
левом поле указать ячейку с I2,
в которой записано «С. А. Есенин». - В
правом поле можно выбрать цвет шрифта. - Нажать
«ОК».
В
таблицах отмечены цветом ячейки, значение
которых равно заданному.
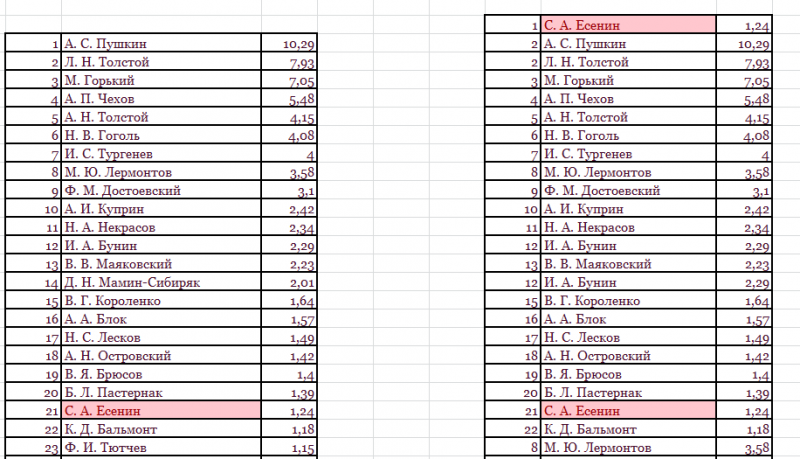
Несложно
понять, как
в Экселе найти одинаковые значения в
столбце.
Просто выделить перед поиском нужную
область – конкретный столбец.
Ищем в таблицах Excel
все повторяющиеся значения
Отметим
все неуникальные записи в выделенной
области. Для этого нужно:
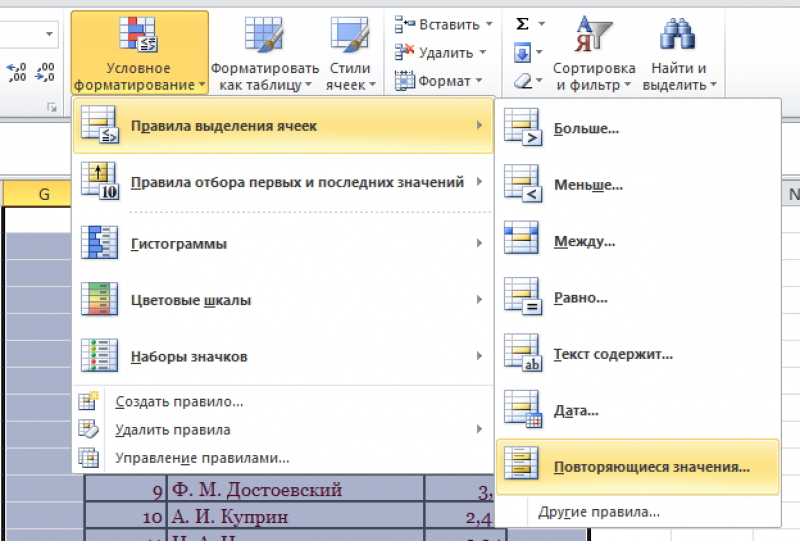
- Зайти
в группу «Стили». - Далее
«Условное форматирование». - Теперь
в выпадающем меню выбрать «Правила
выделения ячеек». - Затем
«Повторяющиеся значения».
- Появится
диалоговое окно:
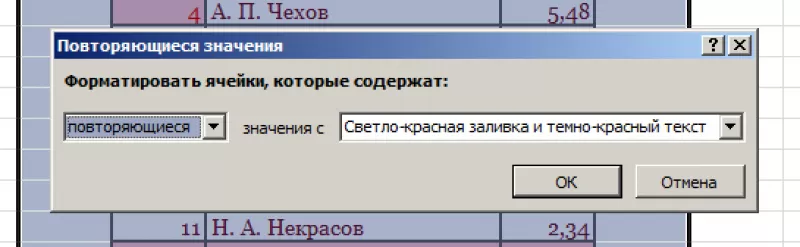
- Нажать
«ОК».
Программа
ищет повторения во всех столбцах.
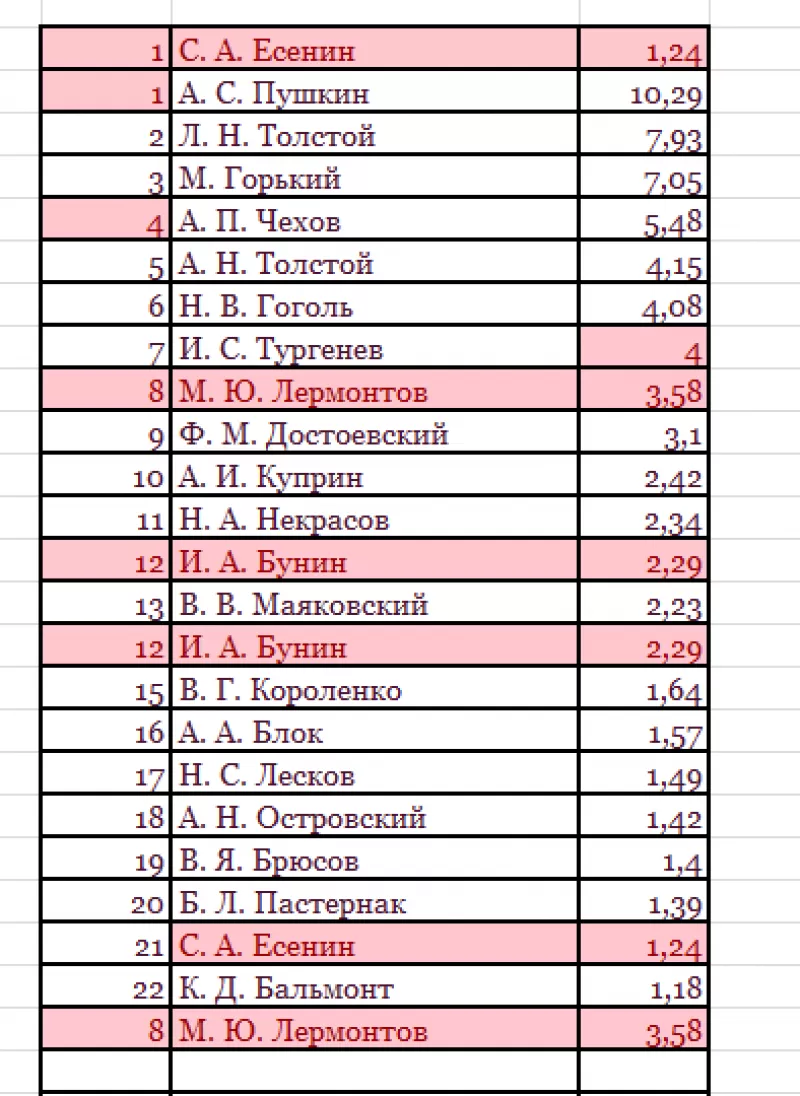
Если
в таблице много неуникальных записей,
то информативность такого поиска
сомнительна.
Удаление одинаковых значений
из таблицы Excel
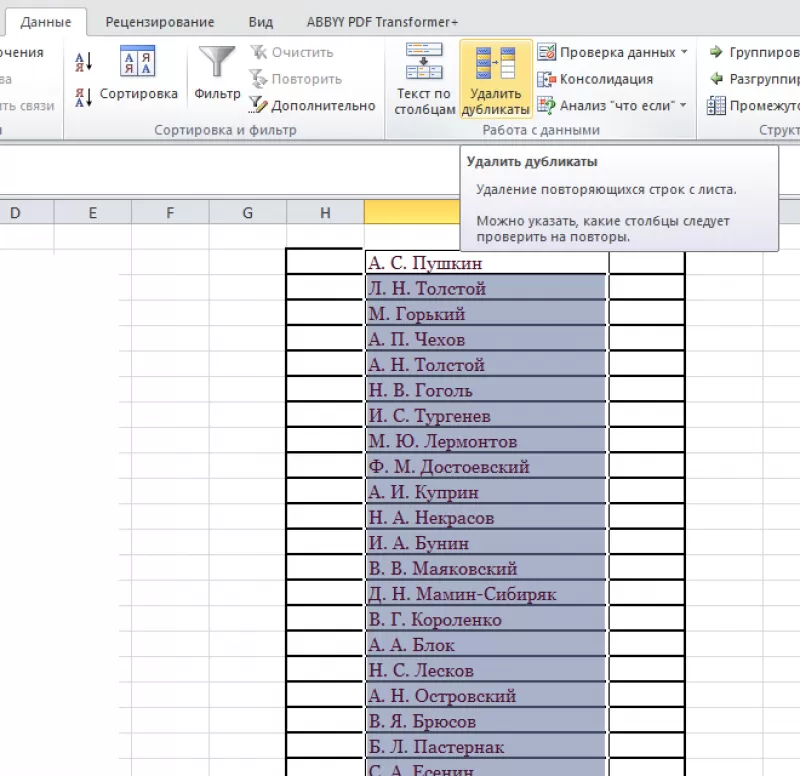
Способ
удаления неуникальных записей:
- Зайти
во вкладку «Данные». - Выделить
столбец, в котором следует искать
дублирующиеся строки. - Опция
«Удалить дубликаты».
В
результате получаем список, в котором
каждое имя фигурирует только один раз.
Список
с уникальными значениями:

Расширенный фильтр: оставляем
только уникальные записи
Расширенный
фильтр – это инструмент для получения
упорядоченного списка с уникальными
записями.
- Выбрать
вкладку «Данные». - Перейти
в раздел «Сортировка и фильтр». - Нажать
команду «Дополнительно»:
- В
появившемся диалоговом окне ставим
флажок «Только уникальные записи». - Нажать
«OK»
– уникальный список готов.
Поиск дублирующихся значений
с помощью сводных таблиц
Составим
список уникальных строк, не теряя данные
из других столбцов и не меняя исходную
таблицу. Для этого используем инструмент
Сводная таблица:
Вкладка
«Вставка».
Пункт
«Сводная таблица».
В
диалоговом окне выбрать размещение
сводной таблицы на новом листе.
В
открывшемся окне отмечаем столбец, в
котором содержатся интересующие нас
значений.
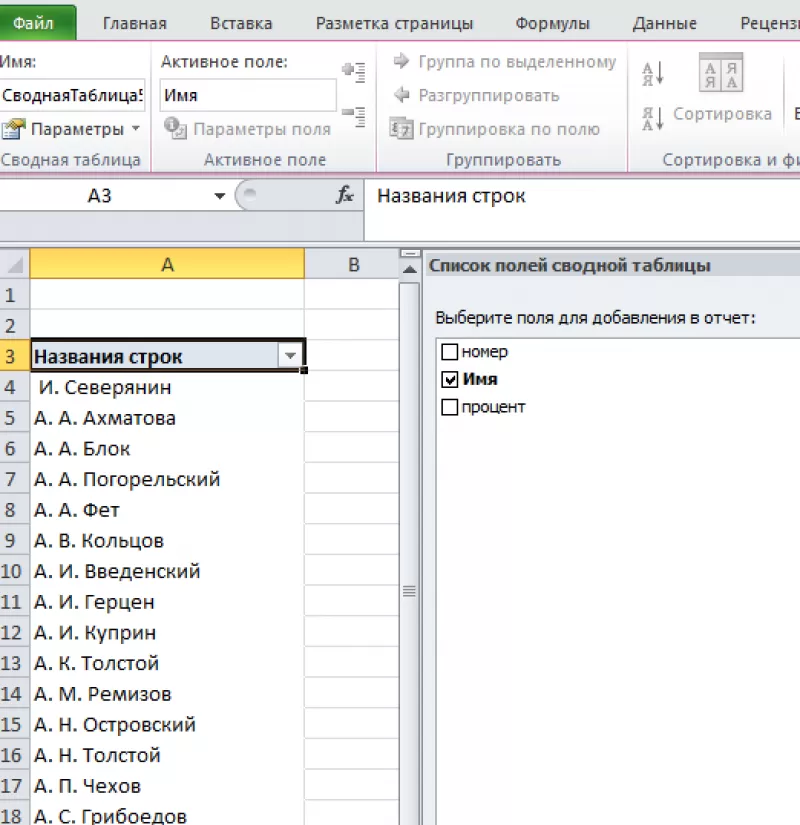
Получаем
упорядоченный список уникальных строк.