
Поиск последнего вхождения (инвертированный ВПР)
Все классические функции поиска и подстановки типа ВПР (VLOOKUP), ГПР (HLOOKUP), ПОИСКПОЗ (MATCH) и им подобные имеют одну важную особенность — они ищут от начала к концу, т.е. слева-направо или сверху-вниз по исходным данным. Как только находится первое подходящее совпадение — поиск останавливается и найденным оказывается только первое вхождение нужного нам элемента.
Что же делать, если нам требуется найти не первое, а последнее вхождение? Например, последнюю сделку по клиенту, последний платёж, самую свежую заявку и т.д.?
Способ 1. Поиск последней строки формулой массива
Если в исходной таблице нет столбца с датой или порядковым номером строки (заказа, платежа…), то наша задача сводится, по сути, к поиску последней строки, удовлетворяющей заданному условию. Реализовать подобное можно вот такой формулой массива:

Здесь:
- Функция ЕСЛИ (IF) проверяет по очереди все ячейки в столбце Клиент и выводит номер строки, если в ней лежит нужное нам имя. Номер строки на листе нам даёт функция СТРОКА (ROW), но поскольку нам нужен номер строки в таблице, то дополнительно приходится вычитать 1, т.к. у нас в таблице есть шапка.
- Затем функция МАКС (MAX) выбирает из сформированного набора номеров строк максимальное значение, т.е. номер самой последней строки клиента.
- Функция ИНДЕКС (INDEX) выдаёт содержимое ячейки с найденным последним номером из любого другого требуемого столбца таблицы (Код заказа).
Всё это нужно вводить как формулу массива, т.е.:
- В Office 365 с последними установленными обновлениями и поддержкой динамических массивов — можно просто жать Enter.
- Во всех остальных версиях после ввода формулы придется нажимать сочетание клавиш Ctrl+Shift+Enter, что автоматически добавит к ней фигурные скобки в строке формул.
Способ 2. Обратный поиск новой функцией ПРОСМОТРХ
Я уже писал большую статью с видео про новую функцию ПРОСМОТРХ (XLOOKUP), которая появилась в последних версиях Office на замену старушке ВПР (VLOOKUP). При помощи ПРОСМОТРХ наша задача решается совершенно элементарно, т.к. для этой функции (в отличие от ВПР) можно явно задавать направление поиска: сверху-вниз или снизу-вверх — за это отвечает её последний аргумент (-1):

Способ 3. Поиск строки с последней датой
Если в исходных данных у нас есть столбец с порядковым номером или датой, играющей аналогичную роль, то задача видоизменяется — нам требуется найти уже не последнюю (самую нижнюю) строку с совпадением, а строку с самой поздней (максимальной) датой.
Как это сделать с помощью классических функций я уже подробно разбирал, а теперь давайте попробуем использовать мощь новых функций динамических массивов. Исходную таблицу для пущей красоты и удобства тоже заранее преобразуем в «умную» с помощью сочетания клавиш Ctrl+T или команды Главная — Форматировать как таблицу (Home — Format as Table).
С их помощью этой «убойной парочки» наша задача решается весьма изящно:

Здесь:
- Сначала функция ФИЛЬТР (FILTER) отбирает только те строки из нашей таблицы, где в столбце Клиент — нужное нам имя.
- Потом функция СОРТ (SORT) сортирует отобранные строки по убыванию даты, чтобы самая последняя сделка оказалась сверху.
- Функция ИНДЕКС (INDEX) извлекает первую строку, т.е. выдает нужную нам последнюю сделку.
- И, наконец, внешняя функция ФИЛЬТР убирает из результатов лишние 1-й и 3-й столбцы (Код заказа и Клиент) и оставляет только дату и сумму. Для этого используется массив констант {0;1;0;1}, определяющий какие именно столбцы мы хотим (1) или не хотим (0) выводить.
Способ 4. Поиск последнего совпадения в Power Query
Ну, и для полноты картины, давайте рассмотрим вариант решения нашей задачи обратного поиска с помощью надстройки Power Query. С её помощью всё решается очень быстро и красиво.
1. Преобразуем нашу исходную таблицу в «умную» с помощью сочетания клавиш Ctrl+T или команды Главная — Форматировать как таблицу (Home — Format as Table).
2. Загружаем её в Power Query кнопкой Из таблицы/диапазона на вкладке Данные (Data — From Table/Range).
3. Сортируем (через выпадающий список фильтра в шапке) нашу таблицу по убыванию даты, чтобы самые последние сделки оказались сверху.
4. На вкладке Преобразование выбираем команду Группировать по (Transform — Group By) и задаем группировку по клиентам, а в качестве агрегирующей функции выбираем вариант Все строки (All rows). Назвать новый столбец можно как угодно — например Подробности.

После группировки получим список уникальных имен наших клиентов и в столбце Подробности — таблицы со всеми сделками каждого из них, где первой строкой будет идти самая последняя сделка, которая нам и нужна:

5. Добавляем новый вычисляемый столбец кнопкой Настраиваемый столбец на вкладке Добавить столбец (Add column — Add custom column) и вводим следующую формулу:

Здесь Подробности — это столбец, откуда мы берем таблицы по клиентам, а {0} — это номер строки, которую мы хотим извлечь (нумерация строк в Power Query начинается с нуля). Получаем столбец с записями (Record), где каждая запись — первая строка из каждой таблицы:

Осталось развернуть содержимое всех записей кнопкой с двойными стрелками в шапке столбца Последняя сделка, выбрав нужные столбцы:

… и удалить потом ненужный более столбец Подробности щёлкнув по его заголовку правой кнопкой мыши — Удалить столбцы (Remove columns).
После выгрузки результатов на лист через Главная — Закрыть и загрузить — Закрыть и загрузить в (Home — Close & Load — Close & Load to…) получим вот такую симпатичную таблицу со списком последних сделок, как и хотели:

При изменении исходных данных результаты нужно не забыть обновить, щёлкнув по ним правой кнопкой мыши — команда Обновить (Refresh) или сочетанием клавиш Ctrl+Alt+F5.
Ссылки по теме
- Функция ПРОСМОТРХ — наследник ВПР
- Как использовать новые функции динамических массивов СОРТ, ФИЛЬТР и УНИК
- Поиск последней непустой ячейки в строке или столбце функцией ПРОСМОТР
- Обычная составная формула
- Формулы массива для поиска символа с конца строки
- С помощью МАКС
- С помощью ПОИСКПОЗ

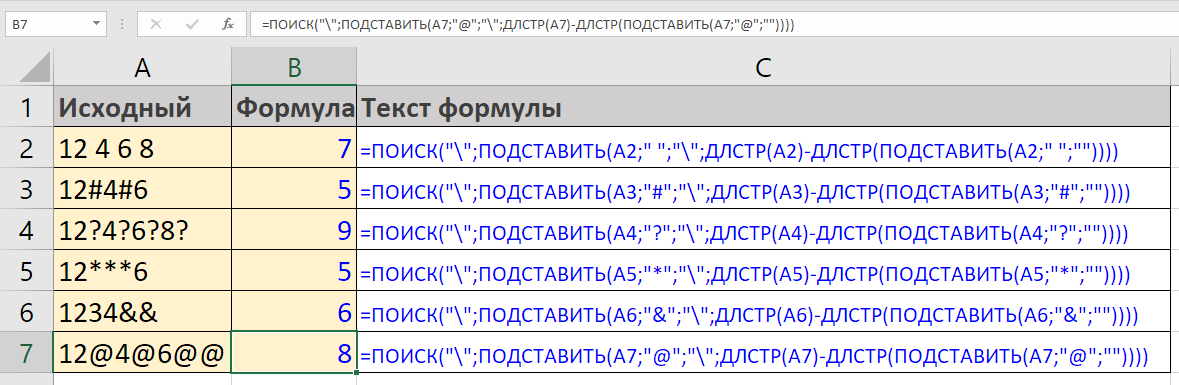
Поиск позиции последнего вхождения значения внутри ячейки Excel – довольно сложная задача.
Тем не менее, иногда ее необходимо решить, например, чтобы удалить или заменить это вхождение.
Так а в чем же проблема?
Все дело в том, что функции поиска позиции ПОИСК и НАЙТИ ищут только с начала ячейки, и у них нет параметра переключения на поиск с конца.
Процедура Найти и Заменить также не подойдет. Она ищет не с конца строки, а просто находит (и заменяет) все вхождения.
Ниже я покажу пару способов, как осуществить поиск с конца строки.
Обычная составная формула
Формула, похожая на ту, что ниже, рассматривается подробно в статье о том, как удалить последнее слово в ячейке Excel. Поиск пробела с конца строки как раз является необходимым в этом случае.
Формула ниже ищет пробел с конца ячейки A1:
=ПОИСК(ЮНИСИМВ(23456);ПОДСТАВИТЬ(A1;" ";ЮНИСИМВ(23456);ДЛСТР(A1)-ДЛСТР(ПОДСТАВИТЬ(A1;" ";""))))
Как она работает:
- Фрагмент, обозначенный красным цветом, вычисляет количество пробелов в ячейке. Подробнее можно почитать в описании функции ПОДСТАВИТЬ.
- Это количество является аргументом еще одной подстановки, где заменяется лишь последний пробел (выделено жирным)
- Вместо пробела в его последнюю позицию вставляется достаточно редкий символ. В данном случае это иероглиф, который создается функцией СИМВОЛ. Но можно и прописать символ вручную. В формуле ниже это обратная косая черта:
=ПОИСК("";ПОДСТАВИТЬ(A1;" ";"";ДЛСТР(A1)-ДЛСТР(ПОДСТАВИТЬ(A1;" ";""))))
- Функция ПОИСК находит позицию этого символа. Поскольку он встречается в строке всего один раз и стоит на месте последнего пробела, это и позволяет нам сказать, что поиск произведен справа налево.
Если вам необходимо найти с конца строки какой-то другой символ или текстовый фрагмент, замените пробелы в этой формуле на него.
Формулы массива для поиска символа с конца строки
Поиск слева направо с помощью функции ПОДСТАВИТЬ, описанный выше, имеет пару недостатков.
Первый – регистрозависимость этой функции, но это легко учесть, обернув нужные фрагменты функциями изменения регистра.
А второй уже серьезнее – формула не очень универсальна, т.к. использует замену на символ, который может оказаться в строке, и тогда она выдаст неверное значение.
От обоих проблем избавят формулы массива. Они обе создают массивы значений, внутри которых функция выбирает последнее.
С помощью МАКС
Формула ниже находит позицию символа “а” в любом регистре.
={МАКС((ПСТР(A1;СТРОКА(ДВССЫЛ("1:"&ДЛСТР(A1)));1)="а")*СТРОКА(ДВССЫЛ("1:"&ДЛСТР(A1))))}
ВАЖНО: Это формула массива! Она вводится без фигурных скобок. Но не клавишей Enter а сочетанием: Ctrl+Shift+Enter После этого фигурные скобки появятся сами. Если ввести формулу обычным способом, она не сработает.

Механика ее работы пошагово:
- Функция ДЛСТР измеряет длину ячейки в символах
- ДВССЫЛ создает из текстового представления длины ссылку на диапазон строк с 1 по строку, равную этой длине
- Функция СТРОКА возвращает массив чисел, соответствующих этим длинам, соответственно, {1;2;3;…”длина строки”}
- Функция ПСТР, обрабатывая этот массив, возвращает для каждого числа символ, стоящий на этой позиции в строке
- Текстовое сравнение с символом “а” возвращает булевый массив (значения ИСТИНА или ЛОЖЬ)
- Этот массив умножается на повторно созданный массив чисел (пункты 1:3). ЛОЖЬ эквивалентна нулю, а ИСТИНА – единице, поэтому для всех символов, не равных “а”, в результирующем числовом массиве будут нули, а для равных – их позиции
- Функция МАКС возвращает наибольшее число в этом массиве.
С помощью ПОИСКПОЗ
Чуть более хитрая механика делает формулу короче, вместе с тем существенно быстрее, а задействует функцию ПОИСКПОЗ:
{=ПОИСКПОЗ(2;1/(ПСТР(A1;СТРОКА(ДВССЫЛ("1:"&ДЛСТР(A1)));1)="а");1)}
ВАЖНО: Это формула массива! Она вводится без фигурных скобок. Но не клавишей Enter а сочетанием: Ctrl+Shift+Enter После этого фигурные скобки появятся сами. Если ввести формулу обычным способом, она не сработает.

Здесь алгоритм такой:
- Как и в предыдущем варианте, с помощью тех же функций ДЛСТР, СТРОКА, ДВССЫЛ, ПСТР и текстового сравнения создается булевый массив;
- Но на этом этапе единица делится на него. ЛОЖЬ эквивалентна нулю и выдается ошибка деления на ноль. ИСТИНА возвращает единицу.
- Функция ПОИСКПОЗ с последним параметром “1” при поиске 2 (на месте 2 может быть любое число больше 1) возвращает позицию последнего наибольшего числа, меньшее, чем 2. Т.е. последней единицы, которой и соответствует последний найденный в строке символ.
Смотрите также по теме:
Формулы массива в Excel
Удалить последнее слово в ячейке
Найти и заменить первую букву в ячейке на заглавную
Предыдущая статья о формулах массива:
Учимся формулам массива 3/4:
Извлечь текст до первой цифры в ячейке
Часто сталкиваетесь с этой или похожими задачами при работе в Excel?
Сотни инструментов надстройки для Excel !SEMTools помогут вам упростить их решение и сэкономят ваше время!
Содержание
- Получение последней позиции символа с помощью формулы Excel
- Получение последней позиции символа с помощью пользовательской функции (VBA)
В этом руководстве вы узнаете, как найти позицию последнего вхождения символа в строке в Excel.
Несколько дней назад коллега столкнулся с этой проблемой.
У него был список URL-адресов, как показано ниже, и ему нужно было извлечь все символы после последней косой черты («/»).
Так, например, с https://example.com/archive/Январь ему пришлось извлечь «январь».

Это было бы очень просто, если бы в URL-адресах была только одна косая черта.
У него был огромный список из тысяч URL-адресов разной длины и с различным количеством косых черт.
В таких случаях хитрость заключается в том, чтобы найти позицию последнего появления косой черты в URL-адресе.
В этом уроке я покажу вам два способа сделать это:
- Использование формулы Excel
- Использование пользовательской функции (созданной через VBA)
Когда у вас есть позиция последнего вхождения, вы можете просто извлечь что-нибудь справа от него, используя функцию ВПРАВО.
Вот формула, которая находит последнюю позицию косой черты и извлекает весь текст справа от нее.
= ПРАВО (A2; LEN (A2) -НАЙТИ ("@", ПОДСТАВИТЬ (A2, "/", "@", LEN (A2) -LEN (ПОДСТАВИТЬ (A2, "/", ""))), 1 ))

Как работает эта формула?
Давайте разберем формулу и объясним, как работает каждая ее часть.
- ЗАМЕНА (A2; ”/”,“”) — Эта часть формулы заменяет косую черту пустой строкой. Так, например, если вы хотите найти вхождение любой строки, кроме косой черты, используйте ее здесь.
- LEN (A2) -LEN (ЗАМЕНА (A2; ”/”,“”)) — Эта часть сообщит вам, сколько косых черт в строке. Он просто вычитает длину строки без косой черты из длины строки с косой чертой.
- ПОДСТАВИТЬ (A2, ”/”, ”@”, LEN (A2) -LEN (ПОДСТАВИТЬ (A2, ”/”, ””))) — Эта часть формулы заменит последнюю косую черту на @. Идея состоит в том, чтобы сделать этого персонажа уникальным. Вы можете использовать любой персонаж, какой захотите. Просто убедитесь, что он уникален и его еще нет в строке.
- НАЙТИ («@», ПОДСТАВИТЬ (A2, «/», «@», LEN (A2) -LEN (ПОДСТАВИТЬ (A2, «/», »»))), 1) — Эта часть формулы даст вам позицию последней косой черты.
- LEN (A2) -FIND («@», ПОДСТАВИТЬ (A2, «/», «@», LEN (A2) -LEN (ПОДСТАВИТЬ (A2, «/», »»))), 1) — Эта часть формулы сообщает нам, сколько символов стоит после последней косой черты.
- = ПРАВО (A2; LEN (A2) -НАЙТИ («@», ПОДСТАВИТЬ (A2, «/», «@», LEN (A2) -LEN (ПОДСТАВИТЬ (A2, «/», »»))), 1 )) — Теперь это просто даст нам строку после последней косой черты.
Получение последней позиции символа с помощью пользовательской функции (VBA)
Вышеупомянутая формула прекрасна и работает как шарм, но она немного сложна.
Если вам удобно использовать VBA, вы можете использовать настраиваемую функцию (также называемую функцией, определяемой пользователем), созданную с помощью VBA. Это может упростить формулу и сэкономить время, если вам придется делать это часто.
Давайте воспользуемся тем же набором данных URL-адресов (как показано ниже):

Для этого случая я создал функцию с именем LastPosition, которая находит последнюю позицию указанного символа (в данном случае это косая черта).
Вот формула, которая сделает это:
= ПРАВО (A2; LEN (A2) -LastPosition (A2; "/") + 1)

Вы можете видеть, что это намного проще, чем тот, который мы использовали выше.
Вот как это работает:
- LastPosition — наша настраиваемая функция — возвращает позицию косой черты. Эта функция принимает два аргумента — ссылку на ячейку с URL-адресом и символ, позицию которого нам нужно найти.
- Затем функция ВПРАВО дает нам все символы после косой черты.
Вот код VBA, создавший эту функцию:
Функция LastPosition (rCell As Range, rChar As String) 'Эта функция выдает последнюю позицию указанного символа' Этот код был разработан Sumit Bansal (https://trumpexcel.com) Dim rLen As Integer rLen = Len (rCell) For i = rLen To 1 Step -1 If Mid (rCell, i - 1, 1) = rChar Then LastPosition = i Exit Function End If Next i End Function
Чтобы эта функция работала, вам нужно поместить ее в редактор VB. После этого вы можете использовать эту функцию, как любую другую обычную функцию Excel.
Вот шаги, чтобы скопировать и вставить этот код в серверную часть VB:
Вот шаги, чтобы поместить этот код в редактор VB:
- Перейдите на вкладку Разработчик.

- Выберите вариант Visual Basic. Это откроет редактор VB в бэкэнде.
- На панели Project Explorer в редакторе VB щелкните правой кнопкой мыши любой объект книги, в которую вы хотите вставить код. Если вы не видите Project Explorer, перейдите на вкладку View и нажмите Project Explorer.
- Перейдите во вкладку «Вставить» и нажмите «Модуль». Это вставит объект модуля для вашей книги.
- Скопируйте и вставьте код в окно модуля.




Теперь формула будет доступна на всех листах книги.
Обратите внимание, что вам необходимо сохранить книгу в формате .XLSM, поскольку в ней есть макрос. Кроме того, если вы хотите, чтобы эта формула была доступна во всех используемых вами книгах, вы можете сохранить ее в личной книге макросов или создать на ее основе надстройку.
Вам также могут понравиться следующие руководства по Excel:
- Как узнать количество слов в Excel.
- Как использовать ВПР с несколькими критериями.
- Найдите последнее вхождение подстановочного значения в списке в Excel.
- Извлечь подстроку в Excel.
Вы поможете развитию сайта, поделившись страницей с друзьями
I’m a little late to the party, but maybe this could help. The link in the question had a similar formula, but mine uses the IF() statement to get rid of errors.
If you’re not afraid of Ctrl+Shift+Enter, you can do pretty well with an array formula.
String (in cell A1):
«one.two.three.four»
Formula:
{=MAX(IF(MID(A1,ROW($1:$99),1)=".",ROW($1:$99)))} use Ctrl+Shift+Enter
Result: 14
First,
ROW($1:$99)
returns an array of integers from 1 to 99: {1,2,3,4,...,98,99}.
Next,
MID(A1,ROW($1:$99),1)
returns an array of 1-length strings found in the target string, then returns blank strings after the length of the target string is reached: {"o","n","e",".",..."u","r","","",""...}
Next,
IF(MID(I16,ROW($1:$99),1)=".",ROW($1:$99))
compares each item in the array to the string «.» and returns either the index of the character in the string or FALSE: {FALSE,FALSE,FALSE,4,FALSE,FALSE,FALSE,8,FALSE,FALSE,FALSE,FALSE,FALSE,14,FALSE,FALSE.....}
Last,
=MAX(IF(MID(I16,ROW($1:$99),1)=".",ROW($1:$99)))
returns the maximum value of the array: 14
Advantages of this formula is that it is short, relatively easy to understand, and doesn’t require any unique characters.
Disadvantages are the required use of Ctrl+Shift+Enter and the limitation on string length. This can be worked around with a variation shown below, but that variation uses the OFFSET() function which is a volatile (read: slow) function.
Not sure what the speed of this formula is vs. others.
Variations:
=MAX((MID(A1,ROW(OFFSET($A$1,,,LEN(A1))),1)=".")*ROW(OFFSET($A$1,,,LEN(A1)))) works the same way, but you don't have to worry about the length of the string
=SMALL(IF(MID(A1,ROW($1:$99),1)=".",ROW($1:$99)),2) determines the 2nd occurrence of the match
=LARGE(IF(MID(A1,ROW($1:$99),1)=".",ROW($1:$99)),2) determines the 2nd-to-last occurrence of the match
=MAX(IF(MID(I16,ROW($1:$99),2)=".t",ROW($1:$99))) matches a 2-character string **Make sure you change the last argument of the MID() function to the number of characters in the string you wish to match!
На чтение 7 мин. Просмотров 29.7k.
Содержание
- Получить первое не пустое значение в списке
- Получить первое текстовое значение в списке
- Получить первое текстовое значение с ГПР
- Получить позицию последнего совпадения
- Получить последнее совпадение содержимого ячейки
- Получить n-е совпадение
- Получить n-ое совпадение с ИНДЕКС/ПОИСКПОЗ
- Получить n-ое совпадение с ВПР
- Если ячейка содержит одну из многих вещей
- Поиск первой ошибки
- Поиск следующего наибольшего значения
- Несколько совпадений в списке, разделенных запятой
- Частичное совпадение чисел с шаблоном
- Частичное совпадение с ВПР
- Положение первого частичного совпадения
Получить первое не пустое значение в списке
{ = ИНДЕКС( диапазон ; ПОИСКПОЗ( ЛОЖЬ; ЕПУСТО ( диапазон ); 0 )) }

Если вам нужно получить первое не пустое значение (текст или число) в диапазоне в одной колонке вы можете использовать формулу массива на основе функций ИНДЕКС, ПОИСКПОЗ и ЕПУСТО.
В данном примере мы используем эту формулу:
{ = ИНДЕКС( B3: B11; ПОИСКПОЗ( ЛОЖЬ; ЕПУСТО ( B3: B11 ); 0 )) }
Таким образом, суть проблемы заключается в следующем: мы хотим получить первую не пустую ячейку, но для этого нет конкретной формулы в Excel. Мы могли бы использовать ВПР с шаблоном *, но это будет работать только для текста, а не для чисел.
Таким образом, нам нужно строить функциональные возможности для нужных нам формул. Способ сделать это состоит в использовании функции массива, которая «тестирует» ячейки и возвращает массив истина/ложь значения, которые мы можем сопрягать с ПОИСКПОЗ.
Работая изнутри, ЕПУСТО оценивает ячейки в диапазоне В3: В11 и возвращает результат и массив, который выглядит следующим образом:
{ИСТИНА; ЛОЖЬ; ИСТИНА; ЛОЖЬ; ЛОЖЬ; ИСТИНА; ИСТИНА; ИСТИНА; ИСТИНА}
Каждая ЛОЖЬ представляет собой ячейку в диапазоне, который не является пустой.
Далее, ПОИСКПОЗ ищет ЛОЖЬ внутри массива и возвращает позицию первого наденного совпадения, в этом случае 2. На данный момент, формула в примере теперь выглядит следующим образом:
{ = ИНДЕКС( B3: B11; 2; 0 )) }
И, наконец, функция ИНДЕКС выводит значение в положении 2 в массиве, в этом случае число 10.
Получить первое текстовое значение в списке
= ВПР ( «*»; диапазон; 1; ЛОЖЬ)
Если вам нужно получить первое текстовое значение в списке (диапазон один столбец), вы можете использовать функцию ВПР, чтобы установить точное соответствие, с шаблонным символом для поиска.

В данном примере формула в D7 является:
= ВПР ( «*» ; B5: B11 ; 1 ; ЛОЖЬ)
Групповой символ звездочка (*) соответствует любому текстовому значению.
Получить первое текстовое значение с ГПР
= ГПР ( «*»; диапазон; 1; ЛОЖЬ)

Для поиска и получения первого текстового значения во всем диапазоне столбцов, вы можете использовать функцию ГПР с групповым символом. В примере формула в F5 является:
= ГПР ( «*»; С5: Е5; 1; 0 )
Значение поиска является «*», групповым символом, который соответствует одному или более текстовому значению.
Получить позицию последнего совпадения
{ = МАКС( ЕСЛИ ( Величины = знач ; СТРОКА(величина) — СТРОКА(ИНДЕКС( Величины; 1 ; 1 )) + 1 )) }
Для того, чтобы получить позицию последнего совпадения (т.е. последнего вхождения) от значения поиска, вы можете использовать формулу, основанную на ЕСЛИ, СТРОКА, ИНДЕКС, ПОИСКПОЗ и MAКС функций.

В примере формула в G6:
=МАКС(ЕСЛИ(B4:B11=G5;СТРОКА(B4:B11)-СТРОКА(ИНДЕКС(B4:B11;1;1))+1))
Суть этой формулы состоит в том, что мы строим список номеров строк для данного диапазона, соответствующие по значению, а затем используем функцию MAКС, чтобы получить наибольшее количество строк, что соответствует последнему значению соответствия.
Получить последнее совпадение содержимого ячейки
= ПРОСМОТР( 2 ; 1 / ПОИСК ( вещи ; А1 ); вещи )
Чтобы проверить ячейку для одной из нескольких вещей, и вернуть последнее совпадение, найденное в списке, вы можете использовать формулу, основанную на ПРОСМОТР и ПОИСК функций. В случае нескольких найденных совпадений, формула вернет последнее совпадение из списка «вещей».

В примере формула в С5:
=ПРОСМОТР(2;1/ПОИСК($E$4:$E$7;B4);$E$4:$E$7)
Получить n-е совпадение
= НАИМЕНЬШИЙ( ЕСЛИ( логический тест; СТРОКА( список ) — МИН( СТРОКА( список )) + 1 ); n )
Для того, чтобы получить позицию n-го совпадения (например, второе значение соответствия заданному, третье значение соответствия и т.д.), вы можете использовать формулу, основанную на функции НАИМЕНЬШИЙ.
= НАИМЕНЬШИЙ( ЕСЛИ( список = E5 ; СТРОКА( список ) — МИН( СТРОКА( список )) + 1 ); F5 )
Эта формула возвращает позицию второго появления «красных» в списке.
Сутью этой формулы является функция НАИМЕНЬШИЙ, которая просто возвращает n-е наименьшее значение в списке значений, которое соответствует номеру строки. Номера строк были «отфильтрованы» функцией ЕСЛИ, которая применяет логику для совпадения.
Получить n-ое совпадение с ИНДЕКС/ПОИСКПОЗ
{ = ИНДЕКС( массив; НАИМЕНЬШИЙ( ЕСЛИ( величины = знач ; СТРОКА ( величины ) — СТРОКА ( ИНДЕКС( величины; 1 ; 1 )) + 1 ); n-й )) }

Чтобы получить n-ое совпадение, используя ИНДЕКС и ПОИСКПОЗ, вы можете использовать формулу массива с функциями ЕСЛИ и НАИМЕНЬШИЙ, чтобы выяснить номер строки совпадения.
Получить n-ое совпадение с ВПР
= ВПР( id_формулы; стол; 4; 0 )
Чтобы получить n-ое совпадение с ВПР, вам необходимо добавить вспомогательный столбец в таблицу , которая строит уникальный идентификатор , который включает счетчик.

Эта формула зависит от вспомогательного столбца, который добавляется в качестве первого столбца таблицы исходных данных. Вспомогательный столбец содержит формулу, которая строит уникальное значение взгляда вверх от существующего идентификатора и счетчика. Счетчик подсчитывает сколько раз уникальный идентификатор появился в таблице данных.
В примере, формула ячейки J6 вспомогательного столбца выглядит следующим образом:
=ВПР(J3&»-«&I6;B4:G11;4;0)
Если ячейка содержит одну из многих вещей
{ = ИНДЕКС( результаты ;ПОИСКПОЗ( ИСТИНА ; ЕЧИСЛО( ПОИСК( вещи ; A1 )); 0 )) }
Чтобы проверить ячейку для одной из нескольких вещей, и вернуть пользовательский результат для первого найденного совпадения, вы можете использовать формулу ИНДЕКС/ПОИСКПОЗ, основанную на функции поиска.
{ = ИНДЕКС( результаты ; ПОИСКПОЗ( ИСТИНА ; ЕЧИСЛО( ПОИСК ( вещи ; B5 )); 0 )) }
Эта формула использует два названных диапазона: E5: E8 называется «вещи» и F5: F8 называется «Результаты». Убедитесь, что вы используете диапазоны имен с одинаковыми именами (на основе ваших данных). Если вы не хотите использовать именованные диапазоны, используйте абсолютные ссылки вместо этого.
Поиск первой ошибки
{ = ПОИСКПОЗ( ИСТИНА ; ЕОШИБКА(диап ); 0 ) }
Если вам нужно найти первую ошибку в диапазоне ячеек, вы можете использовать формулу массива, основанную на ПОИСКПОЗ и ЕОШИБКА функциях.

В приведенном примере формула:
{ = ПОИСКПОЗ( ИСТИНА ; ЕОШИБКА( B4: B11 ); 0 ) }
Работая изнутри, функция ЕОШИБКА возвращает значение ИСТИНА, если значение является признанной ошибкой, и ЛОЖЬ, если нет.
Когда дается диапазон ячеек (массив ячеек) функция ЕОШИБКА будет возвращать массив истина/ложь значений. В примере, это результирующий массив выглядит следующим образом:
{ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ИСТИНА; ЛОЖЬ; ЛОЖЬ}
Обратите внимание, что 6-е значение (что соответствует 6-й ячейке в диапазоне) истинно, так как ячейка В9 содержит #Н/A.
Поиск следующего наибольшего значения
=ИНДЕКС ( данные; ПОИСКПОЗ( поиск ; значения ) + 1 )

Для того, чтобы найти «следующее наибольшее» значение в справочной таблице, можно использовать формулу, основанную на ИНДЕКС и ПОИСКПОЗ. В примере формула в F6 является:
=ИНДЕКС(C5:C9;ПОИСКПОЗ(F4;B5:B9)+1)
Несколько совпадений в списке, разделенных запятой
{ = ОБЪЕДИНИТЬ ( «;» ; ИСТИНА ; ЕСЛИ( диапазон1 = E5 ; диапазон2 ; «» )) }
Для поиска и извлечения нескольких совпадений, разделенных запятыми (в одной ячейке), вы можете использовать функцию ЕСЛИ с функцией ОБЪЕДИНИТЬ.
{ = ОБЪЕДИНИТЬ( «;» ; ИСТИНА ; ЕСЛИ( группа = E5 ; имя ; «» )) }
Эта формула использует «имя» — именованный диапазон (B5: B11) и «группа» — (C5: C11).
Частичное совпадение чисел с шаблоном
{ = ПОИСКПОЗ( «*» & номер & «*» ; ТЕКСТ( диапазон ; «0» ); 0 ) }
Для того, чтобы выполнить частичное совпадение (подстроки) против чисел, вы можете использовать формулу массива, основанную на ПОИСКПОЗ и ТЕКСТ.

Excel поддерживает символы подстановки «*» и «?». Тем не менее, если вы используете специальные символы с номером, вы будете преобразовывать числовое значение в текстовое значение. Другими словами, «*» & 99 & «*» = «* 99 *» (текстовая строка).
Если попытаться найти текстовое значение в диапазоне чисел, совпадение завершится неудачно.
Решение
Одно из решений заключается в преобразовании чисел в диапазоне поиска для текстовых значений, а затем сделать нормальный поиск с ПОИСКПОЗ, ВПР и т.д.
Другой вариант
Другой способ, чтобы преобразовать числа в текст, чтобы сцепить пустую строку. Эта формула работает так же, как выше формуле:
= ПОИСКПОЗ ( «*» & Е5 & «*» ; В5: В10 & «» ; 0 )
Частичное совпадение с ВПР
Если вы хотите получить информацию из таблицы на основе частичного совпадения, вы можете сделать это с помощью ВПР в режиме точного соответствия, и групповые символы.

В примере формула ВПР выглядит следующим образом:
=ВПР($H$2&»*»;$B$3:$E$12;2;0)
В этой формуле, значение представляет собой именованный диапазон, который относится к Н2, а также данные , представляет собой именованный диапазон , который относится к B3: E102. Без названных диапазонов, формула может быть записана следующим образом:
Положение первого частичного совпадения
= ПОИСКПОЗ ( «* текст *» ; диапазон; 0 )
Для того, чтобы получить позицию первого частичного совпадения (то есть ячейку, которая содержит текст, который вы ищете), вы можете использовать функцию ПОИСКПОЗ со специальными символами.

В примере формула в Е7:
=ПОИСКПОЗ(«*»&E6&»*»;B5:B10;0)
Функция ПОИСКПОЗ возвращает позицию или «индекс» в первом совпадении на основании значения поиска в диапазоне.
ПОИСКПОЗ поддерживает подстановочное согласование со звездочкой «*» (один или несколько символов) или знаком вопроса «?» (один символ), но только тогда, когда третий аргумент, тип_сопоставления, установлен в ЛОЖЬ или ноль.