
ПОИСК, ПОИСКБ (функции ПОИСК, ПОИСКБ)
Excel для Microsoft 365 Excel для Microsoft 365 для Mac Excel для Интернета Excel 2019 Excel 2019 для Mac Excel 2016 Excel 2016 для Mac Excel 2013 Excel 2010 Excel 2007 Excel для Mac 2011 Excel Starter 2010 Еще…Меньше
В этой статье описаны синтаксис формулы и использование функций ПОИСК и ПОИСКБ в Microsoft Excel.
Описание
Функции ПОИСК И ПОИСКБ находят одну текстовую строку в другой и возвращают начальную позицию первой текстовой строки (считая от первого символа второй текстовой строки). Например, чтобы найти позицию буквы «n» в слове «printer», можно использовать следующую функцию:
=ПОИСК(«н»;»принтер»)
Эта функция возвращает 4, так как «н» является четвертым символом в слове «принтер».
Можно также находить слова в других словах. Например, функция
=ПОИСК(«base»;»database»)
возвращает 5, так как слово «base» начинается с пятого символа слова «database». Можно использовать функции ПОИСК и ПОИСКБ для определения положения символа или текстовой строки в другой текстовой строке, а затем вернуть текст с помощью функций ПСТР и ПСТРБ или заменить его с помощью функций ЗАМЕНИТЬ и ЗАМЕНИТЬБ. Эти функции показаны в примере 1 данной статьи.
Важно:
-
Эти функции могут быть доступны не на всех языках.
-
Функция ПОИСКБ отсчитывает по два байта на каждый символ, только если языком по умолчанию является язык с поддержкой БДЦС. В противном случае функция ПОИСКБ работает так же, как функция ПОИСК, и отсчитывает по одному байту на каждый символ.
К языкам, поддерживающим БДЦС, относятся японский, китайский (упрощенное письмо), китайский (традиционное письмо) и корейский.
Синтаксис
ПОИСК(искомый_текст;просматриваемый_текст;[начальная_позиция])
ПОИСКБ(искомый_текст;просматриваемый_текст;[начальная_позиция])
Аргументы функций ПОИСК и ПОИСКБ описаны ниже.
-
Искомый_текст Обязательный. Текст, который требуется найти.
-
Просматриваемый_текст Обязательный. Текст, в котором нужно найти значение аргумента искомый_текст.
-
Начальная_позиция Необязательный. Номер знака в аргументе просматриваемый_текст, с которого следует начать поиск.
Замечание
-
Функции ПОИСК и ПОИСКБ не учитывают регистр. Если требуется учитывать регистр, используйте функции НАЙТИ и НАЙТИБ.
-
В аргументе искомый_текст можно использовать подстановочные знаки: вопросительный знак (?) и звездочку (*). Вопросительный знак соответствует любому знаку, звездочка — любой последовательности знаков. Если требуется найти вопросительный знак или звездочку, введите перед ним тильду (~).
-
Если значение find_text не найдено, #VALUE! возвращается значение ошибки.
-
Если аргумент начальная_позиция опущен, то он полагается равным 1.
-
Если start_num больше нуля или больше, чем длина аргумента within_text, #VALUE! возвращается значение ошибки.
-
Аргумент начальная_позиция можно использовать, чтобы пропустить определенное количество знаков. Допустим, что функцию ПОИСК нужно использовать для работы с текстовой строкой «МДС0093.МужскаяОдежда». Чтобы найти первое вхождение «М» в описательной части текстовой строки, задайте для аргумента начальная_позиция значение 8, чтобы поиск не выполнялся в той части текста, которая является серийным номером (в данном случае — «МДС0093»). Функция ПОИСК начинает поиск с восьмого символа, находит знак, указанный в аргументе искомый_текст, в следующей позиции, и возвращает число 9. Функция ПОИСК всегда возвращает номер знака, считая от начала просматриваемого текста, включая символы, которые пропускаются, если значение аргумента начальная_позиция больше 1.
Примеры
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
|
Данные |
||
|
Выписки |
||
|
Доход: маржа |
||
|
маржа |
||
|
Здесь «босс». |
||
|
Формула |
Описание |
Результат |
|
=ПОИСК(«и»;A2;6) |
Позиция первого знака «и» в строке ячейки A2, начиная с шестого знака. |
7 |
|
=ПОИСК(A4;A3) |
Начальная позиция строки «маржа» (искомая строка в ячейке A4) в строке «Доход: маржа» (ячейка, в которой выполняется поиск — A3). |
8 |
|
=ЗАМЕНИТЬ(A3;ПОИСК(A4;A3);6;»объем») |
Заменяет слово «маржа» словом «объем», определяя позицию слова «маржа» в ячейке A3 и заменяя этот знак и последующие пять знаков текстовой строкой «объем.» |
Доход: объем |
|
=ПСТР(A3;ПОИСК(» «;A3)+1,4) |
Возвращает первые четыре знака, которые следуют за первым пробелом в строке «Доход: маржа» (ячейка A3). |
марж |
|
=ПОИСК(«»»»;A5) |
Позиция первой двойной кавычки («) в ячейке A5. |
5 |
|
=ПСТР(A5;ПОИСК(«»»»;A5)+1;ПОИСК(«»»»;A5;ПОИСК(«»»»;A5)+1)-ПОИСК(«»»»;A5)-1) |
Возвращает из ячейки A5 только текст, заключенный в двойные кавычки. |
босс |
Нужна дополнительная помощь?
Функция
ПОИСК(
)
, английский вариант SEARCH(),
находит первое вхождение одной текстовой строки в другой строке и возвращает начальную позицию найденной строки.
Синтаксис функции
ПОИСК
(
искомый_текст
;
просматриваемая_строка
;[нач_позиция])
Искомый_текст
— текст, который требуется найти.
Просматриваемая_строка
— текст, в которой ищется
Искомый_текст
.
Нач_позиция
— позиция знака в просматриваемой_строке, с которой должен начинаться поиск. Если аргумент
нач_позиция
опущен, то предполагается значение 1.
В аргументе
искомый_текст
можно использовать
подстановочные знаки
— вопросительный знак (?) и звездочку (*). Вопросительный знак соответствует любому знаку; звездочка — любой последовательности знаков. Если нужно найти в тексте вопросительный знак или звездочку, следует поставить перед ними тильду (~).
Если искомый_текст не найден, возвращается значение ошибки #ЗНАЧ!
Функция
ПОИСК()
не учитывает РЕгиСТР букв. Для поиска с учетом регистра следует воспользоваться функцией
НАЙТИ()
.
Примеры
Формула
=ПОИСК(«к»;»Первый канал»)
вернет 8, т.к. буква
к
находится на 8-й позиции слева.
Пусть в ячейке
А2
введена строка
Первый канал — лучший
. Формула
=ПОИСК(СИМВОЛ(32);A2)
вернет 7, т.к. символ пробела (код 32) находится на 7-й позиции.
Формула
=ПОИСК(«#???#»;»Артикул #123# ID»)
будет искать в строке »
Артикул #123# ID
» последовательность из 5 символов, которая начинается и заканчивается на знак #.
Чтобы найти позицию второго вхождения буквы «а» в строке «мама мыла раму» используйте формулу
=ПОИСК(«а»;»мама мыла раму»;ПОИСК(«а»;»мама мыла раму»)+1).
Чтобы определить есть ли третье вхождение буквы «м» в строке «мама мыла раму» используйте формулу
=ЕСЛИ(ДЛСТР(ПОДСТАВИТЬ(«мама мыла раму»;»м»;»»;3))=ДЛСТР(«мама мыла раму»);»Нет третьего вхождения м»;»Есть третье вхождение м»)
Формула
=ПОИСК(«клад?»;»докладная»)
вернет 3, т.е. в слове «докладная» содержится слово из 5 букв, первые 4 из которых
клад
(начиная с третьей буквы слова
докладная
).
Функция
НАЙТИ()
vs
ПОИСК()
Функция
НАЙТИ()
учитывает РЕгиСТР букв и не допускает использование подстановочных знаков. Для поиска без учета регистра, а также для поиска с использованием
подстановочных знаков
пользуйтесь функцией
ПОИСК()
.
Связь с функциями
ЛЕВСИМВ()
,
ПРАВСИМВ()
и
ПСТР()
Функция
ПОИСК()
может быть использована совместно с функциями
ЛЕВСИМВ()
,
ПРАВСИМВ()
и
ПСТР()
.
Например, в ячейке
А2
содержится фамилия и имя «Иванов Иван», то формула
=ЛЕВСИМВ(A2;ПОИСК(СИМВОЛ(32);A2)-1)
извлечет фамилию, а
=ПРАВСИМВ(A2;ДЛСТР(A2)-ПОИСК(СИМВОЛ(32);A2))
— имя. Если между именем и фамилией содержится более одного пробела, то для работоспособности вышеупомянутых формул используйте функцию
СЖПРОБЕЛЫ()
.
Содержание
- НАЙТИ, НАЙТИБ (функции НАЙТИ, НАЙТИБ)
- Описание
- Синтаксис
- Замечания
- Примеры
- Функция ПОИСК() в EXCEL
- Синтаксис функции
- Примеры
- Функция НАЙТИ() vs ПОИСК()
- Связь с функциями ЛЕВСИМВ() , ПРАВСИМВ() и ПСТР()
- Поиск данных в таблице или диапазоне ячеек с помощью встроенных функций Excel
- Описание
- Создание образца листа
- Определения терминов
- Функции
- LOOKUP ()
- INDEX () и MATCH ()
- СМЕЩ () и MATCH ()
- Поиск значений в списке данных
- Что необходимо сделать
- Точное совпадение значений по вертикали в списке
- Примеры ВРОТ
- Примеры индексов и совпадений
- Подыыывка значений по вертикали в списке с помощью приблизительного совпадения
- Подстановка значений по вертикали в списке неизвестного размера с использованием точного совпадения
- Точное совпадение значений по горизонтали в списке
- Подыыывка значений по горизонтали в списке с использованием приблизительного совпадения
- Создание формулы подступа с помощью мастера подметок (толькоExcel 2007 )
НАЙТИ, НАЙТИБ (функции НАЙТИ, НАЙТИБ)
В этой статье описаны синтаксис формулы и использование функций НАЙТИ и НАЙТИБ в Microsoft Excel.
Описание
Функции НАЙТИ и НАЙТИБ находят вхождение одной текстовой строки в другую и возвращают начальную позицию искомой строки относительно первого знака второй строки.
Эти функции могут быть доступны не на всех языках.
Функция НАЙТИ предназначена для языков с однобайтовой кодировкой, а функция НАЙТИБ — для языков с двухбайтовой кодировкой. Заданный на компьютере язык по умолчанию влияет на возвращаемое значение указанным ниже образом.
Функция НАЙТИ при подсчете всегда рассматривает каждый знак, как однобайтовый, так и двухбайтовый, как один знак, независимо от выбранного по умолчанию языка.
Функция НАЙТИБ при подсчете рассматривает каждый двухбайтовый знак как два знака, если включена поддержка языка с БДЦС и такой язык установлен по умолчанию. В противном случае функция НАЙТИБ рассматривает каждый знак как один знак.
К языкам, поддерживающим БДЦС, относятся японский, китайский (упрощенное письмо), китайский (традиционное письмо) и корейский.
Синтаксис
Аргументы функций НАЙТИ и НАЙТИБ описаны ниже.
Искомый_текст — обязательный аргумент. Текст, который необходимо найти.
Просматриваемый_текст — обязательный аргумент. Текст, в котором нужно найти искомый текст.
Начальная_позиция — необязательный аргумент. Знак, с которого нужно начать поиск. Первый знак в тексте «просматриваемый_текст» имеет номер 1. Если номер опущен, он полагается равным 1.
Замечания
Функции НАЙТИ и НАЙТИБ работают с учетом регистра и не позволяют использовать подстановочные знаки. Если необходимо выполнить поиск без учета регистра или использовать подстановочные знаки, воспользуйтесь функцией ПОИСК или ПОИСКБ.
Если в качестве аргумента «искомый_текст» задана пустая строка («»), функция НАЙТИ выводит значение, равное первому знаку в строке поиска (знак с номером, соответствующим аргументу «нач_позиция» или 1).
Искомый_текст не может содержать подстановочные знаки.
Если find_text не отображаются в within_text, find и FINDB возвращают #VALUE! значение ошибки #ЗНАЧ!.
Если start_num не больше нуля, то найти и найтиБ возвращает значение #VALUE! значение ошибки #ЗНАЧ!.
Если start_num больше, чем длина within_text, то поиск и НАЙТИБ возвращают #VALUE! значение ошибки #ЗНАЧ!.
Аргумент «нач_позиция» можно использовать, чтобы пропустить нужное количество знаков. Предположим, например, что для поиска строки «МДС0093.МесячныеПродажи» используется функция НАЙТИ. Чтобы найти номер первого вхождения «М» в описательную часть текстовой строки, задайте значение аргумента «нач_позиция» равным 8, чтобы поиск в той части текста, которая является серийным номером, не производился. Функция НАЙТИ начинает со знака 8, находит искомый_текст в следующем знаке и возвращает число 9. Функция НАЙТИ всегда возвращает номер знака, считая от левого края текста «просматриваемый_текст», а не от значения аргумента «нач_позиция».
Примеры
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
Источник
Функция ПОИСК() в EXCEL
history 12 апреля 2013 г.
Синтаксис функции
ПОИСК ( искомый_текст ; просматриваемая_строка ;[нач_позиция])
Искомый_текст — текст, который требуется найти.
Просматриваемая_строка — текст, в которой ищется Искомый_текст .
Нач_позиция — позиция знака в просматриваемой_строке, с которой должен начинаться поиск. Если аргумент нач_позиция опущен, то предполагается значение 1.
В аргументе искомый_текст можно использовать подстановочные знаки — вопросительный знак (?) и звездочку (*). Вопросительный знак соответствует любому знаку; звездочка — любой последовательности знаков. Если нужно найти в тексте вопросительный знак или звездочку, следует поставить перед ними тильду (
Если искомый_текст не найден, возвращается значение ошибки #ЗНАЧ!
Функция ПОИСК() не учитывает РЕгиСТР букв. Для поиска с учетом регистра следует воспользоваться функцией НАЙТИ() .
Примеры
Формула =ПОИСК(«к»;»Первый канал») вернет 8, т.к. буква к находится на 8-й позиции слева.
Пусть в ячейке А2 введена строка Первый канал — лучший . Формула =ПОИСК(СИМВОЛ(32);A2) вернет 7, т.к. символ пробела (код 32) находится на 7-й позиции.
Формула =ПОИСК(«#. #»;»Артикул #123# ID») будет искать в строке » Артикул #123# ID » последовательность из 5 символов, которая начинается и заканчивается на знак #.
Чтобы найти позицию второго вхождения буквы «а» в строке «мама мыла раму» используйте формулу =ПОИСК(«а»;»мама мыла раму»;ПОИСК(«а»;»мама мыла раму»)+1). Чтобы определить есть ли третье вхождение буквы «м» в строке «мама мыла раму» используйте формулу =ЕСЛИ(ДЛСТР(ПОДСТАВИТЬ(«мама мыла раму»;»м»;»»;3))=ДЛСТР(«мама мыла раму»);»Нет третьего вхождения м»;»Есть третье вхождение м»)
Формула =ПОИСК(«клад?»;»докладная») вернет 3, т.е. в слове «докладная» содержится слово из 5 букв, первые 4 из которых клад (начиная с третьей буквы слова докладная ).
Функция НАЙТИ() vs ПОИСК()
Функция НАЙТИ() учитывает РЕгиСТР букв и не допускает использование подстановочных знаков. Для поиска без учета регистра, а также для поиска с использованием подстановочных знаков пользуйтесь функцией ПОИСК() .
Связь с функциями ЛЕВСИМВ() , ПРАВСИМВ() и ПСТР()
Функция ПОИСК() может быть использована совместно с функциями ЛЕВСИМВ() , ПРАВСИМВ() и ПСТР() .
Например, в ячейке А2 содержится фамилия и имя «Иванов Иван», то формула =ЛЕВСИМВ(A2;ПОИСК(СИМВОЛ(32);A2)-1) извлечет фамилию, а =ПРАВСИМВ(A2;ДЛСТР(A2)-ПОИСК(СИМВОЛ(32);A2)) — имя. Если между именем и фамилией содержится более одного пробела, то для работоспособности вышеупомянутых формул используйте функцию СЖПРОБЕЛЫ() .
Источник
Поиск данных в таблице или диапазоне ячеек с помощью встроенных функций Excel
Примечание: Мы стараемся как можно оперативнее обеспечивать вас актуальными справочными материалами на вашем языке. Эта страница переведена автоматически, поэтому ее текст может содержать неточности и грамматические ошибки. Для нас важно, чтобы эта статья была вам полезна. Просим вас уделить пару секунд и сообщить, помогла ли она вам, с помощью кнопок внизу страницы. Для удобства также приводим ссылку на оригинал (на английском языке).
Описание
В этой статье приведены пошаговые инструкции по поиску данных в таблице (или диапазоне ячеек) с помощью различных встроенных функций Microsoft Excel. Для получения одного и того же результата можно использовать разные формулы.
Создание образца листа
В этой статье используется образец листа для иллюстрации встроенных функций Excel. Рассматривайте пример ссылки на имя из столбца A и возвращает возраст этого человека из столбца C. Чтобы создать этот лист, введите указанные ниже данные в пустой лист Excel.
Введите значение, которое вы хотите найти, в ячейку E2. Вы можете ввести формулу в любую пустую ячейку на том же листе.
Определения терминов
В этой статье для описания встроенных функций Excel используются указанные ниже условия.
Вся таблица подстановки
Значение, которое будет найдено в первом столбце аргумента «инфо_таблица».
Просматриваемый_массив
-или-
Лукуп_вектор
Диапазон ячеек, которые содержат возможные значения подстановки.
Номер столбца в аргументе инфо_таблица, для которого должно быть возвращено совпадающее значение.
3 (третий столбец в инфо_таблица)
Ресулт_аррай
-или-
Ресулт_вектор
Диапазон, содержащий только одну строку или один столбец. Он должен быть такого же размера, что и просматриваемый_массив или Лукуп_вектор.
Логическое значение (истина или ложь). Если указано значение истина или опущено, возвращается приближенное соответствие. Если задано значение FALSE, оно будет искать точное совпадение.
Это ссылка, на основе которой вы хотите основать смещение. Топ_целл должен ссылаться на ячейку или диапазон смежных ячеек. В противном случае функция СМЕЩ возвращает #VALUE! значение ошибки #ИМЯ?.
Число столбцов, находящегося слева или справа от которых должна указываться верхняя левая ячейка результата. Например, значение «5» в качестве аргумента Оффсет_кол указывает на то, что верхняя левая ячейка ссылки состоит из пяти столбцов справа от ссылки. Оффсет_кол может быть положительным (то есть справа от начальной ссылки) или отрицательным (то есть слева от начальной ссылки).
Функции
LOOKUP ()
Функция Просмотр находит значение в одной строке или столбце и сопоставляет его со значением в той же позицией в другой строке или столбце.
Ниже приведен пример синтаксиса формулы подСТАНОВКи.
= Просмотр (искомое_значение; Лукуп_вектор; Ресулт_вектор)
Следующая формула находит возраст Марии на листе «образец».
= ПРОСМОТР (E2; A2: A5; C2: C5)
Формула использует значение «Мария» в ячейке E2 и находит слово «Мария» в векторе подстановки (столбец A). Формула затем соответствует значению в той же строке в векторе результатов (столбец C). Так как «Мария» находится в строке 4, функция Просмотр возвращает значение из строки 4 в столбце C (22).
Примечание. Для функции Просмотр необходимо, чтобы таблица была отсортирована.
Чтобы получить дополнительные сведения о функции Просмотр , щелкните следующий номер статьи базы знаний Майкрософт:
Функция ВПР или вертикальный просмотр используется, если данные указаны в столбцах. Эта функция выполняет поиск значения в левом столбце и сопоставляет его с данными в указанном столбце в той же строке. Функцию ВПР можно использовать для поиска данных в отсортированных или несортированных таблицах. В следующем примере используется таблица с несортированными данными.
Ниже приведен пример синтаксиса формулы ВПР :
= ВПР (искомое_значение; инфо_таблица; номер_столбца; интервальный_просмотр)
Следующая формула находит возраст Марии на листе «образец».
= ВПР (E2; A2: C5; 3; ЛОЖЬ)
Формула использует значение «Мария» в ячейке E2 и находит слово «Мария» в левом столбце (столбец A). Формула затем совпадет со значением в той же строке в Колумн_индекс. В этом примере используется «3» в качестве Колумн_индекс (столбец C). Так как «Мария» находится в строке 4, функция ВПР возвращает значение из строки 4 В столбце C (22).
Чтобы получить дополнительные сведения о функции ВПР , щелкните следующий номер статьи базы знаний Майкрософт:
INDEX () и MATCH ()
Вы можете использовать функции индекс и ПОИСКПОЗ вместе, чтобы получить те же результаты, что и при использовании поиска или функции ВПР.
Ниже приведен пример синтаксиса, объединяющего индекс и Match для получения одинаковых результатов поиска и ВПР в предыдущих примерах:
= Индекс (инфо_таблица; MATCH (искомое_значение; просматриваемый_массив; 0); номер_столбца)
Следующая формула находит возраст Марии на листе «образец».
= ИНДЕКС (A2: C5; MATCH (E2; A2: A5; 0); 3)
Формула использует значение «Мария» в ячейке E2 и находит слово «Мария» в столбце A. Затем он будет соответствовать значению в той же строке в столбце C. Так как «Мария» находится в строке 4, формула возвращает значение из строки 4 в столбце C (22).
Обратите внимание Если ни одна из ячеек в аргументе «число» не соответствует искомому значению («Мария»), эта формула будет возвращать #N/А.
Чтобы получить дополнительные сведения о функции индекс , щелкните следующий номер статьи базы знаний Майкрософт:
СМЕЩ () и MATCH ()
Функции СМЕЩ и ПОИСКПОЗ можно использовать вместе, чтобы получить те же результаты, что и функции в предыдущем примере.
Ниже приведен пример синтаксиса, объединяющего смещение и сопоставление для достижения того же результата, что и функция Просмотр и ВПР.
= СМЕЩЕНИЕ (топ_целл, MATCH (искомое_значение; просматриваемый_массив; 0); Оффсет_кол)
Эта формула находит возраст Марии на листе «образец».
= СМЕЩЕНИЕ (A1; MATCH (E2; A2: A5; 0); 2)
Формула использует значение «Мария» в ячейке E2 и находит слово «Мария» в столбце A. Формула затем соответствует значению в той же строке, но двум столбцам справа (столбец C). Так как «Мария» находится в столбце A, формула возвращает значение в строке 4 в столбце C (22).
Чтобы получить дополнительные сведения о функции СМЕЩ , щелкните следующий номер статьи базы знаний Майкрософт:
Источник
Поиск значений в списке данных
Предположим, что вы хотите найти расширение телефона сотрудника, используя его номер эмблемы или правильную ставку комиссионных за объем продаж. Вы можете искать данные для быстрого и эффективного поиска определенных данных в списке, а также для автоматической проверки правильности данных. После поиска данных можно выполнить вычисления или отобразить результаты с возвращаемой величиной. Существует несколько способов поиска значений в списке данных и отображения результатов.
Что необходимо сделать
Точное совпадение значений по вертикали в списке
Для этого можно использовать функцию ВLOOKUP или сочетание функций ИНДЕКС и НАЙТИПОЗ.
Примеры ВРОТ

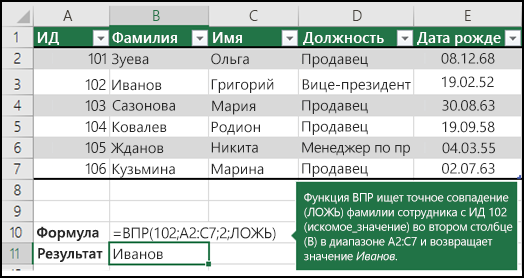
Дополнительные сведения см. в этой информации.
Примеры индексов и совпадений
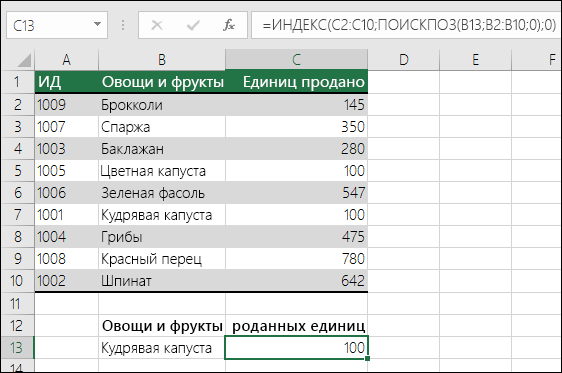
=ИНДЕКС(нужно вернуть значение из C2:C10, которое будет соответствовать ПОИСКПОЗ(первое значение «Капуста» в массиве B2:B10))
Формула ищет в C2:C10 первое значение, соответствующее значению «Ольга» (в B7), и возвращает значение в C7 (100),которое является первым значением, которое соответствует значению «Ольга».
Подыыывка значений по вертикали в списке с помощью приблизительного совпадения
Для этого используйте функцию ВЛВП.
Важно: Убедитесь, что значения в первой строке отсортировали в порядке возрастания.
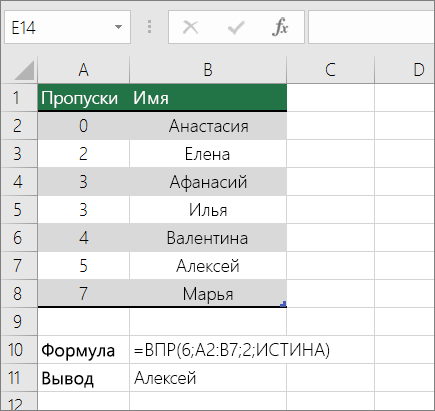
В примере выше ВРОТ ищет имя учащегося, у которого 6 просмотров в диапазоне A2:B7. В таблице нет записи для 6 просмотров, поэтому ВРОТ ищет следующее самое высокое совпадение меньше 6 и находит значение 5, связанное с именем Виктор,и таким образом возвращает Его.
Дополнительные сведения см. в этой информации.
Подстановка значений по вертикали в списке неизвестного размера с использованием точного совпадения
Для этого используйте функции СМЕЩЕНИЕ и НАЙТИВМЕСЯК.
Примечание: Используйте этот подход, если данные в диапазоне внешних данных обновляются каждый день. Вы знаете, что цена находится в столбце B, но вы не знаете, сколько строк данных возвращает сервер, а первый столбец не отсортировали по алфавиту.
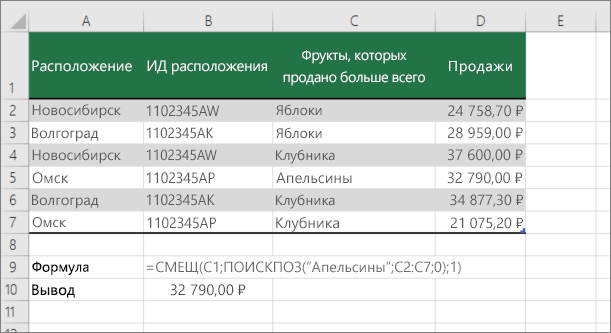
C1 — это левые верхние ячейки диапазона (также называемые начальной).
MATCH(«Оранжевая»;C2:C7;0) ищет «Оранжевые» в диапазоне C2:C7. В диапазон не следует включать запускаемую ячейку.
1 — количество столбцов справа от начальной ячейки, из которых должно быть возвращено значение. В нашем примере возвращается значение из столбца D, Sales.
Точное совпадение значений по горизонтали в списке
Для этого используйте функцию ГГПУ. См. пример ниже.
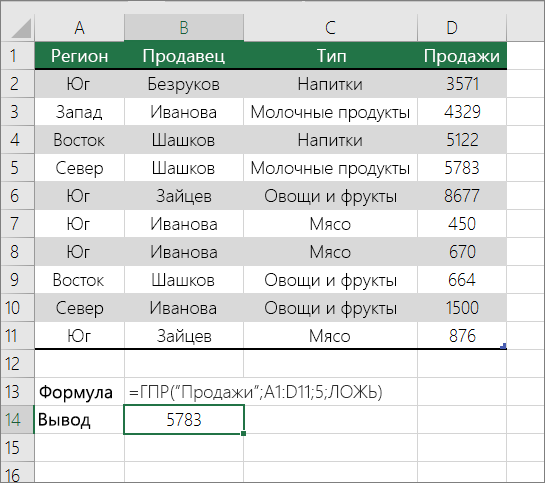
Г ПРОСМОТР ищет столбец «Продажи» и возвращает значение из строки 5 в указанном диапазоне.
Дополнительные сведения см. в сведениях о функции Г ПРОСМОТР.
Подыыывка значений по горизонтали в списке с использованием приблизительного совпадения
Для этого используйте функцию ГГПУ.
Важно: Убедитесь, что значения в первой строке отсортировали в порядке возрастания.
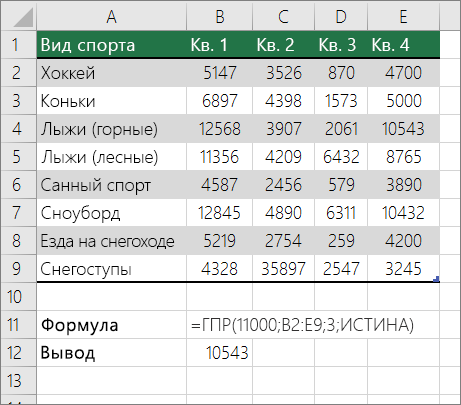
В примере выше ГЛЕБ ищет значение 11000 в строке 3 указанного диапазона. Она не находит 11000, поэтому ищет следующее наибольшее значение меньше 1100 и возвращает значение 10543.
Дополнительные сведения см. в сведениях о функции Г ПРОСМОТР.
Создание формулы подступа с помощью мастера подметок (толькоExcel 2007 )
Примечание: В Excel 2010 больше не будет надстройки #x0. Эта функция была заменена мастером функций и доступными функциями подменю и справки (справка).
В Excel 2007 создается формула подытов на основе данных на основе данных на основе строк и столбцов. Если вы знаете значение в одном столбце и наоборот, мастер под поисков помогает находить другие значения в строке. В формулах, которые он создает, используются индекс и MATCH.
Щелкните ячейку в диапазоне.
На вкладке Формулы в группе Решения нажмите кнопку Под поиск.
Если команда Подытов недоступна, вам необходимо загрузить мастер под надстройка подытогов.
Загрузка надстройки «Мастер подстройок»
Нажмите кнопку Microsoft Office  , выберите Параметры Excel и щелкните категорию Надстройки.
, выберите Параметры Excel и щелкните категорию Надстройки.
В поле Управление выберите элемент Надстройки Excel и нажмите кнопку Перейти.
В диалоговом окне Доступные надстройки щелкните рядом с полем Мастер подстрок инажмите кнопку ОК.
Источник
Ссылка на это место страницы:
#title
- Получить первое не пустое значение в списке
- Получить первое текстовое значение в списке
- Получить первое текстовое значение с ГПР
- Получить позицию последнего совпадения
- Получить последнее совпадение содержимого ячейки
- Получить n-е совпадение
- Получить n-ое совпадение с ИНДЕКС/ПОИСКПОЗ
- Получить n-ое совпадение с ВПР
- Если ячейка содержит одну из многих вещей
- Поиск первой ошибки
- Поиск следующего наибольшего значения
- Несколько совпадений в списке, разделенных запятой
- Частичное совпадение чисел с шаблоном
- Частичное совпадение с ВПР
- Положение первого частичного совпадения
- Скачать файл
Ссылка на это место страницы:
#punk01
{ = ИНДЕКС( диапазон ; ПОИСКПОЗ( ЛОЖЬ; ЕПУСТО ( диапазон ); 0 )) }
{ = INDEX( диапазон ; MATCH( FALSE; ISBLANK ( диапазон ); 0 )) }

Если вам нужно получить первое не пустое значение (текст или число) в диапазоне в одной колонке вы можете использовать формулу массива на основе функций ИНДЕКС, ПОИСКПОЗ и ЕПУСТО.
В данном примере мы используем эту формулу:
{ = ИНДЕКС( B3: B11; ПОИСКПОЗ( ЛОЖЬ; ЕПУСТО ( B3: B11 ); 0 )) }
{ = INDEX( B3:B11; MATCH( FALSE; ISBLANK ( B3:B11 ); 0 )) }
Таким образом, суть проблемы заключается в следующем: мы хотим получить первую не пустую ячейку, но для этого нет конкретной формулы в Excel. Мы могли бы использовать ВПР с шаблоном *, но это будет работать только для текста, а не для чисел.
Таким образом, нам нужно строить функциональные возможности для нужных нам формул. Способ сделать это состоит в использовании функции массива, которая «тестирует» ячейки и возвращает массив истина/ложь значения, которые мы можем сопрягать с ПОИСКПОЗ.
Работая изнутри, ЕПУСТО оценивает ячейки в диапазоне В3: В11 и возвращает результат и массив, который выглядит следующим образом:
{ИСТИНА; ЛОЖЬ; ИСТИНА; ЛОЖЬ; ЛОЖЬ; ИСТИНА; ИСТИНА; ИСТИНА; ИСТИНА}
Каждая ЛОЖЬ представляет собой ячейку в диапазоне, который не является пустой.
Далее, ПОИСКПОЗ ищет ЛОЖЬ внутри массива и возвращает позицию первого наденного совпадения, в этом случае 2. На данный момент, формула в примере теперь выглядит следующим образом:
{ = ИНДЕКС( B3: B11; 2; 0 )) }
{ = INDEX( B3:B11; 2; 0 )) }
И, наконец, функция ИНДЕКС выводит значение в положении 2 в массиве, в этом случае число 10.
Ссылка на это место страницы:
#punk02
= ВПР ( «*»; диапазон; 1; ЛОЖЬ)
= VLOOKUP ( «*»; диапазон; 1; FALSE)
Если вам нужно получить первое текстовое значение в списке (диапазон один столбец), вы можете использовать функцию ВПР, чтобы установить точное соответствие, с шаблонным символом для поиска.

В данном примере формула в D7 является:
= ВПР ( «*» ; B5: B11 ; 1 ; ЛОЖЬ)
= VLOOKUP ( «*» ; B5:B11 ; 1 ; FALSE)
Групповой символ звездочка (*) соответствует любому текстовому значению.
Ссылка на это место страницы:
#punk03
= ГПР ( «*»; диапазон; 1; ЛОЖЬ)
= HLOOKUP ( «*»; диапазон; 1; FALSE)

Для поиска и получения первого текстового значения во всем диапазоне столбцов, вы можете использовать функцию ГПР с групповым символом. В примере формула в F5 является:
= ГПР ( «*»; диапазон; 1; ЛОЖЬ)
= HLOOKUP ( «*»; диапазон; 1; FALSE)
Значение поиска является «*», групповым символом, который соответствует одному или более текстовому значению.
Ссылка на это место страницы:
#punk04
= ГПР ( «*»; диапазон; 1; ЛОЖЬ)
= HLOOKUP ( «*»; диапазон; 1; FALSE)
Для того, чтобы получить позицию последнего совпадения (т.е. последнего вхождения) от значения поиска, вы можете использовать формулу, основанную на ЕСЛИ, СТРОКА, ИНДЕКС, ПОИСКПОЗ и MAКС функций.

=МАКС(ЕСЛИ(B4:B11=G5;СТРОКА(B4:B11)-СТРОКА(ИНДЕКС(B4:B11;1;1))+1))
=MAX(IF(B4:B11=G5;ROW(B4:B11)-ROW(INDEX(B4:B11;1;1))+1))
Суть этой формулы состоит в том, что мы строим список номеров строк для данного диапазона, соответствующие по значению, а затем используем функцию MAКС, чтобы получить наибольшее количество строк, что соответствует последнему значению соответствия.
Ссылка на это место страницы:
#punk05
=МАКС(ЕСЛИ(B4:B11=G5;СТРОКА(B4:B11)-СТРОКА(ИНДЕКС(B4:B11;1;1))+1))
=MAX(IF(B4:B11=G5;ROW(B4:B11)-ROW(INDEX(B4:B11;1;1))+1))
Чтобы проверить ячейку для одной из нескольких вещей, и вернуть последнее совпадение, найденное в списке, вы можете использовать формулу, основанную на ПРОСМОТР и ПОИСК функций. В случае нескольких найденных совпадений, формула вернет последнее совпадение из списка «вещей».

=ПРОСМОТР(2;1/ПОИСК($E$4:$E$7;B4);$E$4:$E$7)
=LOOKUP(2;1/SEARCH($E$4:$E$7;B4);$E$4:$E$7)
Ссылка на это место страницы:
#punk06
= НАИМЕНЬШИЙ( ЕСЛИ( логический тест; СТРОКА( список ) — МИН( СТРОКА( список )) + 1 ); n )
= SMALL( IF( логический тест; СТРОКА( список ) — MIN( ROW( список )) + 1 ); n )
Для того, чтобы получить позицию n-го совпадения (например, второе значение соответствия заданному, третье значение соответствия и т.д.), вы можете использовать формулу, основанную на функции НАИМЕНЬШИЙ.
= НАИМЕНЬШИЙ( ЕСЛИ( список = E5 ; СТРОКА( список ) — МИН( СТРОКА( список )) + 1 ); F5 )
= SMALL( IF( список = E5 ; ROW( список ) — MIN( ROW( список )) + 1 ); F5 )
Эта формула возвращает позицию второго появления «красных» в списке.
Сутью этой формулы является функция НАИМЕНЬШИЙ, которая просто возвращает n-е наименьшее значение в списке значений, которое соответствует номеру строки. Номера строк были «отфильтрованы» функцией ЕСЛИ, которая применяет логику для совпадения.
Ссылка на это место страницы:
#punk07
{ = ИНДЕКС( массив; НАИМЕНЬШИЙ( ЕСЛИ( величины = знач ; СТРОКА ( величины ) — СТРОКА ( ИНДЕКС( величины; 1 ; 1 )) + 1 ); n-й )) }
{ = INDEX( массив; SMALL( IF( величины = знач ; ROW ( величины ) — ROW ( INDEX( величины; 1 ; 1 )) + 1 ); n-й )) }

Эта формула возвращает позицию второго появления «красных» в списке.
Сутью этой формулы является функция НАИМЕНЬШИЙ, которая просто возвращает n-е наименьшее значение в списке значений, которое соответствует номеру строки. Номера строк были «отфильтрованы» функцией ЕСЛИ, которая применяет логику для совпадения.
Ссылка на это место страницы:
#punk08
= ВПР( id_формулы; стол; 4; 0 )
= VLOOKUP( id_формулы; стол; 4; 0 )
Чтобы получить n-ое совпадение с ВПР, вам необходимо добавить вспомогательный столбец в таблицу , которая строит уникальный идентификатор , который включает счетчик.

Эта формула зависит от вспомогательного столбца, который добавляется в качестве первого столбца таблицы исходных данных.
Вспомогательный столбец содержит формулу, которая строит уникальное значение взгляда вверх от существующего идентификатора и счетчика. Счетчик подсчитывает сколько раз уникальный идентификатор появился в таблице данных.
В примере, формула ячейки J6 вспомогательного столбца выглядит следующим образом:
=ВПР(J3&»-«&I6;B4:G11;4;0)
=VLOOKUP(J3&»-«&I6;B4:G11;4;0)
Ссылка на это место страницы:
#punk09
{ = ИНДЕКС( результаты ;ПОИСКПОЗ( ИСТИНА ; ЕЧИСЛО( ПОИСК( вещи ; A1 )); 0 )) }
{ = INDEX( результаты ;MATCH( TRUE ; ISNUMBER( SEARCH( вещи ; A1 )); 0 )) }
Чтобы проверить ячейку для одной из нескольких вещей, и вернуть пользовательский результат для первого найденного совпадения, вы можете использовать формулу ИНДЕКС/ПОИСКПОЗ, основанную на функции поиска.
{ = ИНДЕКС( результаты ; ПОИСКПОЗ( ИСТИНА ; ЕЧИСЛО( ПОИСК ( вещи ; B5 )); 0 )) }
= INDEX( результаты ; MATCH( TRUE ; ISNUMBER( SEARCH ( вещи ; B5 )); 0 ))
Эта формула использует два названных диапазона: E5: E8 называется «вещи» и F5: F8 называется «Результаты». Убедитесь, что вы используете диапазоны имен с одинаковыми именами (на основе ваших данных). Если вы не хотите использовать именованные диапазоны, используйте абсолютные ссылки вместо этого.
Ссылка на это место страницы:
#punk10
{ = ПОИСКПОЗ( ИСТИНА ; ЕОШИБКА(диап ); 0 ) }
{ = MATCH( TRUE ; ISERROR(диап ); 0 ) }
Если вам нужно найти первую ошибку в диапазоне ячеек, вы можете использовать формулу массива, основанную на ПОИСКПОЗ и ЕОШИБКА функциях.

В приведенном примере формула:
{ = ПОИСКПОЗ( ИСТИНА ; ЕОШИБКА( B4: B11 ); 0 ) }
{ = MATCH( TRUE ; ISERROR( B4:B11 ); 0 ) }
Работая изнутри, функция ЕОШИБКА возвращает значение ИСТИНА, если значение является признанной ошибкой, и ЛОЖЬ, если нет.
Когда дается диапазон ячеек (массив ячеек) функция ЕОШИБКА будет возвращать массив истина/ложь значений. В примере, это результирующий массив выглядит следующим образом:
{ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ИСТИНА; ЛОЖЬ; ЛОЖЬ}
Обратите внимание, что 6-е значение (что соответствует 6-й ячейке в диапазоне) истинно, так как ячейка В9 содержит #Н/A.
Ссылка на это место страницы:
#punk11
=ИНДЕКС ( данные; ПОИСКПОЗ( поиск ; значения ) + 1 )
=INDEX ( данные; MATCH( поиск ; значения ) + 1 )

Для того, чтобы найти «следующее наибольшее» значение в справочной таблице, можно использовать формулу, основанную на ИНДЕКС и ПОИСКПОЗ. В примере формула в F6 является:
=ИНДЕКС ( данные; ПОИСКПОЗ( поиск ; значения ) + 1 )
=INDEX ( данные; MATCH( поиск ; значения ) + 1 )
Ссылка на это место страницы:
#punk12
{ = ОБЪЕДИНИТЬ ( «;» ; ИСТИНА ; ЕСЛИ( диапазон1 = E5 ; диапазон2 ; «» )) }
{ = ОБЪЕДИНИТЬ ( «;» ; TRUE ; IF( диапазон1 = E5 ; диапазон2 ; «» )) }
Для поиска и извлечения нескольких совпадений, разделенных запятыми (в одной ячейке), вы можете использовать функцию ЕСЛИ с функцией ОБЪЕДИНИТЬ.
{ = ОБЪЕДИНИТЬ( «;» ; ИСТИНА ; ЕСЛИ( группа = E5 ; имя ; «» )) }
Эта формула использует «имя» — именованный диапазон (B5: B11) и «группа» — (C5: C11).
Ссылка на это место страницы:
#punk13
{ = ПОИСКПОЗ( «*» & номер & «*» ; ТЕКСТ( диапазон ; «0» ); 0 ) }
{ = MATCH( «*» & номер & «*» ; TEXT( диапазон ; «0» ); 0 ) }
Для того, чтобы выполнить частичное совпадение (подстроки) против чисел, вы можете использовать формулу массива, основанную на ПОИСКПОЗ и ТЕКСТ.

Excel поддерживает символы подстановки «*» и «?». Тем не менее, если вы используете специальные символы с номером, вы будете преобразовывать числовое значение в текстовое значение. Другими словами, «*» & 99 & «*» = «* 99 *» (текстовая строка).
Если попытаться найти текстовое значение в диапазоне чисел, совпадение завершится неудачно.
Одно из решений заключается в преобразовании чисел в диапазоне поиска для текстовых значений, а затем сделать нормальный поиск с ПОИСКПОЗ, ВПР и т.д.
Другой способ, чтобы преобразовать числа в текст, чтобы сцепить пустую строку. Эта формула работает так же, как выше формуле:
= ПОИСКПОЗ ( «*» & Е5 & «*» ; В5: В10 & «» ; 0 )
= MATCH ( «*» & Е5 & «*» ; В5: В10 & «» ; 0 )
Ссылка на это место страницы:
#punk14
Если вы хотите получить информацию из таблицы на основе частичного совпадения, вы можете сделать это с помощью ВПР в режиме точного соответствия, и групповые символы.

В примере формула ВПР выглядит следующим образом:
=ВПР($H$2&»*»;$B$3:$E$12;2;0)
=VLOOKUP($H$2&»*»;$B$3:$E$12;2;0)
В этой формуле, значение представляет собой именованный диапазон, который относится к Н2, а также данные , представляет собой именованный диапазон , который относится к B3: E102. Без названных диапазонов, формула может быть записана следующим образом:
Ссылка на это место страницы:
#punk15
= ПОИСКПОЗ ( «* текст *» ; диапазон; 0 )
= MATCH ( «* текст *» ; диапазон; 0 )
Для того, чтобы получить позицию первого частичного совпадения (то есть ячейку, которая содержит текст, который вы ищете), вы можете использовать функцию ПОИСКПОЗ со специальными символами.

=ПОИСКПОЗ(«*»&E6&»*»;B5:B10;0)
=MATCH(«*»&E6&»*»;B5:B10;0)
Функция ПОИСКПОЗ возвращает позицию или «индекс» в первом совпадении на основании значения поиска в диапазоне.
ПОИСКПОЗ поддерживает подстановочное согласование со звездочкой «*» (один или несколько символов) или знаком вопроса «?» (один символ), но только тогда, когда третий аргумент, тип_сопоставления, установлен в ЛОЖЬ или ноль.
Ссылка на это место страницы:
#punk16
Файлы статей доступны только зарегистрированным пользователям.
1. Введите свою почту
2. Нажмите Зарегистрироваться
3. Обновите страницу
Вместо этого блока появится ссылка для скачивания материалов.

Привет! Меня зовут Дмитрий. С 2014 года Microsoft Cretified Trainer. Вместе с командой управляем этим сайтом. Наша цель — помочь вам эффективнее работать в Excel.
Изучайте наши статьи с примерами формул, сводных таблиц, условного форматирования, диаграмм и макросов. Записывайтесь на наши курсы или заказывайте обучение в корпоративном формате.

Подписывайтесь на нас в соц.сетях:
На чтение 7 мин. Просмотров 29.7k.
Содержание
- Получить первое не пустое значение в списке
- Получить первое текстовое значение в списке
- Получить первое текстовое значение с ГПР
- Получить позицию последнего совпадения
- Получить последнее совпадение содержимого ячейки
- Получить n-е совпадение
- Получить n-ое совпадение с ИНДЕКС/ПОИСКПОЗ
- Получить n-ое совпадение с ВПР
- Если ячейка содержит одну из многих вещей
- Поиск первой ошибки
- Поиск следующего наибольшего значения
- Несколько совпадений в списке, разделенных запятой
- Частичное совпадение чисел с шаблоном
- Частичное совпадение с ВПР
- Положение первого частичного совпадения
Получить первое не пустое значение в списке
{ = ИНДЕКС( диапазон ; ПОИСКПОЗ( ЛОЖЬ; ЕПУСТО ( диапазон ); 0 )) }

Если вам нужно получить первое не пустое значение (текст или число) в диапазоне в одной колонке вы можете использовать формулу массива на основе функций ИНДЕКС, ПОИСКПОЗ и ЕПУСТО.
В данном примере мы используем эту формулу:
{ = ИНДЕКС( B3: B11; ПОИСКПОЗ( ЛОЖЬ; ЕПУСТО ( B3: B11 ); 0 )) }
Таким образом, суть проблемы заключается в следующем: мы хотим получить первую не пустую ячейку, но для этого нет конкретной формулы в Excel. Мы могли бы использовать ВПР с шаблоном *, но это будет работать только для текста, а не для чисел.
Таким образом, нам нужно строить функциональные возможности для нужных нам формул. Способ сделать это состоит в использовании функции массива, которая «тестирует» ячейки и возвращает массив истина/ложь значения, которые мы можем сопрягать с ПОИСКПОЗ.
Работая изнутри, ЕПУСТО оценивает ячейки в диапазоне В3: В11 и возвращает результат и массив, который выглядит следующим образом:
{ИСТИНА; ЛОЖЬ; ИСТИНА; ЛОЖЬ; ЛОЖЬ; ИСТИНА; ИСТИНА; ИСТИНА; ИСТИНА}
Каждая ЛОЖЬ представляет собой ячейку в диапазоне, который не является пустой.
Далее, ПОИСКПОЗ ищет ЛОЖЬ внутри массива и возвращает позицию первого наденного совпадения, в этом случае 2. На данный момент, формула в примере теперь выглядит следующим образом:
{ = ИНДЕКС( B3: B11; 2; 0 )) }
И, наконец, функция ИНДЕКС выводит значение в положении 2 в массиве, в этом случае число 10.
Получить первое текстовое значение в списке
= ВПР ( «*»; диапазон; 1; ЛОЖЬ)
Если вам нужно получить первое текстовое значение в списке (диапазон один столбец), вы можете использовать функцию ВПР, чтобы установить точное соответствие, с шаблонным символом для поиска.

В данном примере формула в D7 является:
= ВПР ( «*» ; B5: B11 ; 1 ; ЛОЖЬ)
Групповой символ звездочка (*) соответствует любому текстовому значению.
Получить первое текстовое значение с ГПР
= ГПР ( «*»; диапазон; 1; ЛОЖЬ)

Для поиска и получения первого текстового значения во всем диапазоне столбцов, вы можете использовать функцию ГПР с групповым символом. В примере формула в F5 является:
= ГПР ( «*»; С5: Е5; 1; 0 )
Значение поиска является «*», групповым символом, который соответствует одному или более текстовому значению.
Получить позицию последнего совпадения
{ = МАКС( ЕСЛИ ( Величины = знач ; СТРОКА(величина) — СТРОКА(ИНДЕКС( Величины; 1 ; 1 )) + 1 )) }
Для того, чтобы получить позицию последнего совпадения (т.е. последнего вхождения) от значения поиска, вы можете использовать формулу, основанную на ЕСЛИ, СТРОКА, ИНДЕКС, ПОИСКПОЗ и MAКС функций.

В примере формула в G6:
=МАКС(ЕСЛИ(B4:B11=G5;СТРОКА(B4:B11)-СТРОКА(ИНДЕКС(B4:B11;1;1))+1))
Суть этой формулы состоит в том, что мы строим список номеров строк для данного диапазона, соответствующие по значению, а затем используем функцию MAКС, чтобы получить наибольшее количество строк, что соответствует последнему значению соответствия.
Получить последнее совпадение содержимого ячейки
= ПРОСМОТР( 2 ; 1 / ПОИСК ( вещи ; А1 ); вещи )
Чтобы проверить ячейку для одной из нескольких вещей, и вернуть последнее совпадение, найденное в списке, вы можете использовать формулу, основанную на ПРОСМОТР и ПОИСК функций. В случае нескольких найденных совпадений, формула вернет последнее совпадение из списка «вещей».

В примере формула в С5:
=ПРОСМОТР(2;1/ПОИСК($E$4:$E$7;B4);$E$4:$E$7)
Получить n-е совпадение
= НАИМЕНЬШИЙ( ЕСЛИ( логический тест; СТРОКА( список ) — МИН( СТРОКА( список )) + 1 ); n )
Для того, чтобы получить позицию n-го совпадения (например, второе значение соответствия заданному, третье значение соответствия и т.д.), вы можете использовать формулу, основанную на функции НАИМЕНЬШИЙ.
= НАИМЕНЬШИЙ( ЕСЛИ( список = E5 ; СТРОКА( список ) — МИН( СТРОКА( список )) + 1 ); F5 )
Эта формула возвращает позицию второго появления «красных» в списке.
Сутью этой формулы является функция НАИМЕНЬШИЙ, которая просто возвращает n-е наименьшее значение в списке значений, которое соответствует номеру строки. Номера строк были «отфильтрованы» функцией ЕСЛИ, которая применяет логику для совпадения.
Получить n-ое совпадение с ИНДЕКС/ПОИСКПОЗ
{ = ИНДЕКС( массив; НАИМЕНЬШИЙ( ЕСЛИ( величины = знач ; СТРОКА ( величины ) — СТРОКА ( ИНДЕКС( величины; 1 ; 1 )) + 1 ); n-й )) }

Чтобы получить n-ое совпадение, используя ИНДЕКС и ПОИСКПОЗ, вы можете использовать формулу массива с функциями ЕСЛИ и НАИМЕНЬШИЙ, чтобы выяснить номер строки совпадения.
Получить n-ое совпадение с ВПР
= ВПР( id_формулы; стол; 4; 0 )
Чтобы получить n-ое совпадение с ВПР, вам необходимо добавить вспомогательный столбец в таблицу , которая строит уникальный идентификатор , который включает счетчик.

Эта формула зависит от вспомогательного столбца, который добавляется в качестве первого столбца таблицы исходных данных. Вспомогательный столбец содержит формулу, которая строит уникальное значение взгляда вверх от существующего идентификатора и счетчика. Счетчик подсчитывает сколько раз уникальный идентификатор появился в таблице данных.
В примере, формула ячейки J6 вспомогательного столбца выглядит следующим образом:
=ВПР(J3&»-«&I6;B4:G11;4;0)
Если ячейка содержит одну из многих вещей
{ = ИНДЕКС( результаты ;ПОИСКПОЗ( ИСТИНА ; ЕЧИСЛО( ПОИСК( вещи ; A1 )); 0 )) }
Чтобы проверить ячейку для одной из нескольких вещей, и вернуть пользовательский результат для первого найденного совпадения, вы можете использовать формулу ИНДЕКС/ПОИСКПОЗ, основанную на функции поиска.
{ = ИНДЕКС( результаты ; ПОИСКПОЗ( ИСТИНА ; ЕЧИСЛО( ПОИСК ( вещи ; B5 )); 0 )) }
Эта формула использует два названных диапазона: E5: E8 называется «вещи» и F5: F8 называется «Результаты». Убедитесь, что вы используете диапазоны имен с одинаковыми именами (на основе ваших данных). Если вы не хотите использовать именованные диапазоны, используйте абсолютные ссылки вместо этого.
Поиск первой ошибки
{ = ПОИСКПОЗ( ИСТИНА ; ЕОШИБКА(диап ); 0 ) }
Если вам нужно найти первую ошибку в диапазоне ячеек, вы можете использовать формулу массива, основанную на ПОИСКПОЗ и ЕОШИБКА функциях.

В приведенном примере формула:
{ = ПОИСКПОЗ( ИСТИНА ; ЕОШИБКА( B4: B11 ); 0 ) }
Работая изнутри, функция ЕОШИБКА возвращает значение ИСТИНА, если значение является признанной ошибкой, и ЛОЖЬ, если нет.
Когда дается диапазон ячеек (массив ячеек) функция ЕОШИБКА будет возвращать массив истина/ложь значений. В примере, это результирующий массив выглядит следующим образом:
{ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ИСТИНА; ЛОЖЬ; ЛОЖЬ}
Обратите внимание, что 6-е значение (что соответствует 6-й ячейке в диапазоне) истинно, так как ячейка В9 содержит #Н/A.
Поиск следующего наибольшего значения
=ИНДЕКС ( данные; ПОИСКПОЗ( поиск ; значения ) + 1 )

Для того, чтобы найти «следующее наибольшее» значение в справочной таблице, можно использовать формулу, основанную на ИНДЕКС и ПОИСКПОЗ. В примере формула в F6 является:
=ИНДЕКС(C5:C9;ПОИСКПОЗ(F4;B5:B9)+1)
Несколько совпадений в списке, разделенных запятой
{ = ОБЪЕДИНИТЬ ( «;» ; ИСТИНА ; ЕСЛИ( диапазон1 = E5 ; диапазон2 ; «» )) }
Для поиска и извлечения нескольких совпадений, разделенных запятыми (в одной ячейке), вы можете использовать функцию ЕСЛИ с функцией ОБЪЕДИНИТЬ.
{ = ОБЪЕДИНИТЬ( «;» ; ИСТИНА ; ЕСЛИ( группа = E5 ; имя ; «» )) }
Эта формула использует «имя» — именованный диапазон (B5: B11) и «группа» — (C5: C11).
Частичное совпадение чисел с шаблоном
{ = ПОИСКПОЗ( «*» & номер & «*» ; ТЕКСТ( диапазон ; «0» ); 0 ) }
Для того, чтобы выполнить частичное совпадение (подстроки) против чисел, вы можете использовать формулу массива, основанную на ПОИСКПОЗ и ТЕКСТ.

Excel поддерживает символы подстановки «*» и «?». Тем не менее, если вы используете специальные символы с номером, вы будете преобразовывать числовое значение в текстовое значение. Другими словами, «*» & 99 & «*» = «* 99 *» (текстовая строка).
Если попытаться найти текстовое значение в диапазоне чисел, совпадение завершится неудачно.
Решение
Одно из решений заключается в преобразовании чисел в диапазоне поиска для текстовых значений, а затем сделать нормальный поиск с ПОИСКПОЗ, ВПР и т.д.
Другой вариант
Другой способ, чтобы преобразовать числа в текст, чтобы сцепить пустую строку. Эта формула работает так же, как выше формуле:
= ПОИСКПОЗ ( «*» & Е5 & «*» ; В5: В10 & «» ; 0 )
Частичное совпадение с ВПР
Если вы хотите получить информацию из таблицы на основе частичного совпадения, вы можете сделать это с помощью ВПР в режиме точного соответствия, и групповые символы.

В примере формула ВПР выглядит следующим образом:
=ВПР($H$2&»*»;$B$3:$E$12;2;0)
В этой формуле, значение представляет собой именованный диапазон, который относится к Н2, а также данные , представляет собой именованный диапазон , который относится к B3: E102. Без названных диапазонов, формула может быть записана следующим образом:
Положение первого частичного совпадения
= ПОИСКПОЗ ( «* текст *» ; диапазон; 0 )
Для того, чтобы получить позицию первого частичного совпадения (то есть ячейку, которая содержит текст, который вы ищете), вы можете использовать функцию ПОИСКПОЗ со специальными символами.

В примере формула в Е7:
=ПОИСКПОЗ(«*»&E6&»*»;B5:B10;0)
Функция ПОИСКПОЗ возвращает позицию или «индекс» в первом совпадении на основании значения поиска в диапазоне.
ПОИСКПОЗ поддерживает подстановочное согласование со звездочкой «*» (один или несколько символов) или знаком вопроса «?» (один символ), но только тогда, когда третий аргумент, тип_сопоставления, установлен в ЛОЖЬ или ноль.