
Поиск и подсчет самых частых значений
Необходимость поиска наибольших и наименьших значений в любом бизнесе очевидна: самые прибыльные товары или ценные клиенты, самые крупные поставки или партии и т.д.
Но наравне с этим, иногда приходится искать в данных не топовые, а самые часто встречающиеся значения, что хоть и звучит похоже, но, по факту, совсем не то же самое. Применительно к магазину, например, это может быть поиск не самых прибыльных, а самых часто покупаемых товаров или самое часто встречающееся количество позиций в заказе, минут в разговоре и т.п.
В такой ситуации задачу придется решать немного по-разному, в зависимости от того, с чем мы имеем дело — с числами или с текстом.
Поиск самых часто встречающихся чисел
Предположим, перед нами стоит задача проанализировать имеющиеся данные по продажам в магазине, с целью определить наиболее часто встречающееся количество купленных товаров. Для определения самого часто встречающегося числа в диапазоне можно использовать функцию МОДА (MODE):

Т.е., согласно нашей статистике, чаще всего покупатели приобретают 3 шт. товара.
Если существует не одно, а сразу несколько значений, встречающихся одинаково максимальное количество раз (несколько мод), то для их выявления можно использовать функцию МОДА.НСК (MODE.MULT). Ее нужно вводить как формулу массива, т.е. выделить сразу несколько пустых ячеек, чтобы хватило на все моды с запасом и ввести в строку формул =МОДА.НСК(B2:B16) и нажать сочетание клавиш Ctrl+Shift+Enter.
На выходе мы получим список всех мод из наших данных:

Т.е., судя по нашим данным, часто берут не только по 3, но и по 16 шт. товаров. Обратите внимание, что в наших данных только две моды (3 и 16), поэтому остальные ячейки, выделенные «про запас», будут с ошибкой #Н/Д.
Частотный анализ по диапазонам функцией ЧАСТОТА
Если же нужно проанализировать не целые, а дробные числа, то правильнее будет оценивать не количество одинаковых значений, а попадание их в заданные диапазоны. Например, нам необходимо понять какой вес чаще всего бывает у покупаемых товаров, чтобы правильно выбрать для магазина тележки и упаковочные пакеты подходящего размера. Другими словами, нам нужно определить сколько чисел попадает в интервал 1..5 кг, сколько в интервал 5..10 кг и т.д.
Для решения подобной задачи можно воспользоваться функцией ЧАСТОТА (FREQUENCY). Для нее нужно заранее подготовить ячейки с интересующими нас интервалами (карманами) и затем выделить пустой диапазон ячеек (G2:G5) по размеру на одну ячейку больший, чем диапазон карманов (F2:F4) и ввести ее как формулу массива, нажав в конце сочетание Ctrl+Shift+Enter:

Частотный анализ сводной таблицей с группировкой
Альтернативный вариант решения задачи: создать сводную таблицу, где поместить вес покупок в область строк, а количество покупателей в область значений, а потом применить группировку — щелкнуть правой кнопкой мыши по значениям весов и выбрать команду Группировать (Group). В появившемся окне можно задать пределы и шаг группировки:

… и после нажатия на кнопку ОК получить таблицу с подсчетом количества попаданий покупателей в каждый диапазон группировки:

Минусы такого способа:
- шаг группировки может быть только постоянным, в отличие от функции ЧАСТОТА, где карманы можно задать абсолютно любые
- сводную таблицу нужно обновлять при изменении исходных данных (щелчком правой кнопки мыши — Обновить), а функция пересчитывается автоматически «на лету»
Поиск самого часто встречающегося текста
Если мы имеем дело не с числами, а с текстом, то подход к решению будет принципиально другой. Предположим, что у нас есть таблица из 100 строк с данными о проданных в магазине товарах, и нам нужно определить, какие товары покупались наиболее часто?
Самым простым и очевидным решением будет добавить рядом столбец с функцией СЧЁТЕСЛИ (COUNTIF), чтобы подсчитать количество вхождений каждого товара в столбце А:

Затем, само-собой, отсортировать получившийся столбец по убыванию и посмотреть на первые строчки.
Или же добавить к исходному списку столбец с единичками и построить по получившейся таблице сводную, подсчитав суммарное количество единичек для каждого товара:

Если исходных данных не очень много и принципиально не хочется пользоваться сводными таблицами, то можно использовать формулу массива:

Давайте разберем ее по кусочкам:
- СЧЁТЕСЛИ(A2:A20;A2:A20) – формула массива, которая ищет по очереди количество вхождений каждого товара в диапазоне A2:A100 и выдаст на выходе массив с количеством повторений, т.е., фактически, заменяет собой дополнительный столбец
- МАКС – находит в массиве вхождений самое большое число, т.е. товар, который покупали чаще всего
- ПОИСКПОЗ – вычисляет порядковый номер строки в таблице, где МАКС нашла самое большое число
- ИНДЕКС – выдает из таблицы содержимое ячейки с номером, который нашла ПОИСКПОЗ
Ссылки по теме
- Подсчет количества уникальных значений в списке
- Извлечение уникальных элементов из списка с повторами
- Группировка в сводных таблицах
Перейти к содержанию
На чтение 2 мин Опубликовано 07.08.2015
Из этого примера вы узнаете, как найти наиболее часто встречающееся слово в Excel.
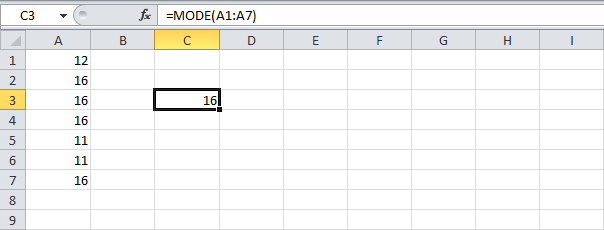
Вы можете использовать функцию MODE (МОДА), чтобы найти наиболее часто встречающееся число. Но эта функция работает только с числами:
=MODE(A1:A7)
=МОДА(A1:A7)
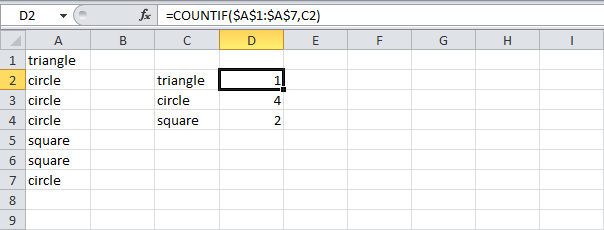
Вы можете использовать функцию COUNTIF (СЧЕТЕСЛИ), чтобы подсчитать количество вхождений каждого слова. Но нам ведь нужна одна единственная формула, которая возвратит наиболее часто встречающееся слово (в нашем примере – это слово «circle»).
=COUNTIF($A$1:$A$7,C2)
=СЧЁТЕСЛИ($A$1:$A$7;C2)
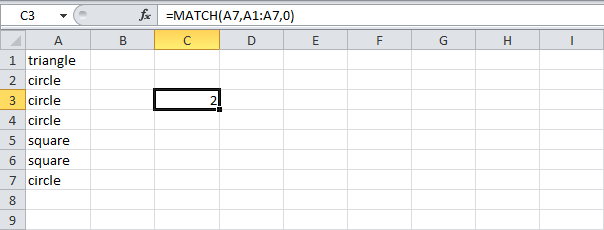
Чтобы найти наиболее часто встречающееся слово, следуйте инструкции ниже:
- Функция MATCH (ПОИСКПОЗ) возвращает позицию значения в заданном диапазоне.
=MATCH(A7,A1:A7,0)
=ПОИСКПОЗ(A7;A1:A7;0)
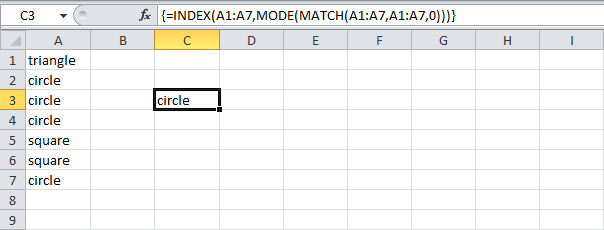
Пояснение: Cлово «circle» (А7) найдено в позиции 2 диапазона A1:A7. Ноль в третьем аргументе позволяет вернуть точное совпадение.
- Чтобы найти положение наиболее часто встречающихся слов, добавим функцию MODE (МОДА) и заменим A7 на A1:A7.
=MODE(MATCH(A1:A7,A1:A7,0))
=МОДА(ПОИСКПОЗ(A1:A7;A1:A7;0)) - Закончим нажатием Ctrl+Shift+Enter.
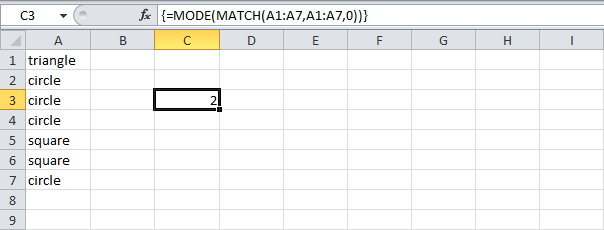
Примечание: Строка формул указывает, что это формула массива, заключая её в фигурные скобки {}. Их не нужно вводить самостоятельно. Они исчезнут, когда вы начнете редактировать формулу.
- Пояснение:
- Диапазон (массив констант), созданный с помощью функции MATCH (ПОИСКПОЗ), хранится в памяти Excel, а не в ячейках листа.
- Массив констант выглядит следующим образом: {1;2;2;2;5;5;2}. Цифры показывают, что слово «triangle» найдено в позиции 1, «circle» в позиции 2, «circle» в позиции 2 и т.д.
- Этот массив констант используется в качестве аргумента для функции MODE (МОДА), давая результат 2 (позиция наиболее часто встречающегося слова).
- Используйте этот результат и функцию INDEX (ИНДЕКС), чтобы вернуть второе слово из диапазона A1:A7, как наиболее часто встречающееся.
=INDEX(A1:A7,MODE(MATCH(A1:A7,A1:A7,0)))
=ИНДЕКС(A1:A7;МОДА(ПОИСКПОЗ(A1:A7;A1:A7;0)))
Оцените качество статьи. Нам важно ваше мнение:
В этой статье рассказывается о том, как найти наиболее часто встречающийся текст на основе определенных критериев из диапазона ячеек в Excel. В то же время я также представлю формулу для извлечения наиболее часто встречающегося текста в столбце.
- Найдите наиболее часто встречающийся текст в столбце с формулой массива
- Найдите наиболее часто встречающийся текст на основе критериев с помощью формул массива
- Найдите наиболее часто встречающийся текст между двумя заданными датами с помощью формулы массива
Найдите наиболее часто встречающийся текст в столбце с формулой массива
Если вы просто хотите найти и извлечь наиболее часто встречающийся текст из списка ячеек, введите следующую формулу:
Синтаксис общей формулы:
=INDEX(range, MODE(MATCH(range, range, 0 )))
- range: is the list of cells that you want to find the most frequent occurring text.
1. Введите или скопируйте эту формулу в пустую ячейку, в которую вы хотите вывести результат:
=INDEX(A2:A15,MODE(MATCH(A2:A15,A2:A15,0)))
- Tips: В этой формуле:
- A2: A15: это список данных, который вы хотите найти, когда текст встречается чаще всего.
2. А затем нажмите Shift + Ctrl + Enter одновременно, и вы получите правильный результат, как показано ниже:

Найдите наиболее часто встречающийся текст на основе критериев с помощью формул массива
Иногда вам может потребоваться найти наиболее часто встречающийся текст в зависимости от определенного условия, например, вы хотите найти наиболее часто встречающееся имя, которым является Project A, как показано ниже:

Синтаксис общей формулы:
=INDEX(range1,MODE(IF(range2=criteria, MATCH(rang1,range1,0))))
- range1: is the range of cells that you want to find the most frequent occurring text.
- range2=criteria: is the range of cells contain the specific criteria that you want to find name based on.
1. Введите или скопируйте приведенную ниже формулу в пустую ячейку:
=INDEX($B$2:$B$15,MODE(IF($A$2:$A$15=D2,MATCH($B$2:$B$15,$B$2:$B$15,0))))
- Tips: В этой формуле:
- B2: B15: это список данных, который вы хотите найти наибольшее количество раз, когда имя встречается.
- A2: A15 = D2: диапазон ячеек, содержащих определенные критерии, по которым вы хотите найти текст.
2. Затем нажмите Shift + Ctrl + Enter одновременно, было извлечено наиболее часто встречающееся имя Project A, см. снимок экрана:

Найдите наиболее часто встречающийся текст между двумя заданными датами с помощью формулы массива
В этом разделе мы поговорим о том, как найти наиболее распространенный текст, который находится между двумя заданными датами. Например, чтобы найти наиболее частое имя на основе дат между 6 и 28, вам может помочь следующая формула массива:
1. Пожалуйста, примените приведенную ниже формулу в пустую ячейку:
=INDEX($B$2:$B$15, MATCH(MODE.SNGL(IF(($A$2:$A$15<=$E$2)*($A$2:$A$15>=$D$2), COUNTIF($B$2:$B$15, «<«&$B$2:$B$15), «»)), COUNTIF($B$2:$B$15, «<«&$B$2:$B$15),0))
- Tips: В этой формуле:
- B2: B15: это список данных, который вы хотите найти наибольшее количество раз, когда имя встречается.
- A2: A15 <= E2: это диапазон дат, меньших или равных определенной дате, по которой вы хотите найти имя.
- A2: A15> = D2: это диапазон дат, который больше или равен определенной дате, по которой вы хотите найти имя.
2. А затем нажмите Shift + Ctrl + Enter вместе, было извлечено наиболее часто встречающееся имя между двумя конкретными датами, см. снимок экрана:

Наиболее часто встречающиеся текстовые статьи:
- Условное форматирование на основе частоты (наиболее распространенное число / текст)
- Например, вы хотите условно отформатировать наиболее часто встречающиеся ячейки в диапазоне, как вы могли бы быстро решить это в Excel? А что если условное форматирование целых строк на основе частот значений в указанном столбце? В этой статье представлены два обходных пути.
- Найдите второе по частоте / частое число или текст в Excel
- Мы можем применить функцию РЕЖИМ, чтобы легко узнать наиболее частое число из диапазона в Excel. Однако как насчет того, чтобы узнать второе по частоте число в столбце? А что, если узнать в столбце второе по распространенности текстовое значение? Здесь мы найдем для вас несколько обходных путей.
- Найдите наиболее частое значение (число или текстовую строку) из списка в Excel
- Предположим, у вас есть список имен, которые содержат несколько дубликатов, и теперь вы хотите извлечь наиболее часто встречающееся значение. Прямой способ — подсчитывать данные по одному из списка, чтобы получить результат, но если в столбце тысячи имен, этот способ будет хлопотным и трудоемким. Следующее руководство познакомит вас с некоторыми приемами, которые помогут быстро и удобно решить эту задачу.
- Сортировка данных по наиболее частому значению в Excel
- Предположим, у вас есть длинный список данных на вашем листе, и теперь вы хотите отсортировать этот список по частоте встречаемости каждого слова. То есть сначала указывается наиболее распространенное значение (например, четыре раза встречается в столбце), а затем следуют слова, которые встречаются три раза, дважды и один раз, как показано на следующих снимках экрана. Как бы вы могли решить эту задачу в Excel?
- Найдите наиболее распространенное текстовое значение в списке в Google Таблицах
- Если у вас есть длинный список ячеек, который содержит несколько повторяющихся значений, теперь вы хотите найти наиболее распространенное текстовое значение, которое появляется в списке данных в таблицах Google. Как можно было решить эту задачу, не проверяя одну за другой?
Лучшие инструменты для работы в офисе
Kutools for Excel Решит большинство ваших проблем и повысит вашу производительность на 80%
- Бар Супер Формулы (легко редактировать несколько строк текста и формул); Макет для чтения (легко читать и редактировать большое количество ячеек); Вставить в отфильтрованный диапазон…
- Объединить ячейки / строки / столбцы и хранение данных; Разделить содержимое ячеек; Объедините повторяющиеся строки и сумму / среднее значение… Предотвращение дублирования ячеек; Сравнить диапазоны…
- Выберите Дубликат или Уникальный Ряды; Выбрать пустые строки (все ячейки пустые); Супер находка и нечеткая находка во многих рабочих тетрадях; Случайный выбор …
- Точная копия Несколько ячеек без изменения ссылки на формулу; Автоматическое создание ссылок на несколько листов; Вставить пули, Флажки и многое другое …
- Избранные и быстро вставляйте формулы, Диапазоны, диаграммы и изображения; Зашифровать ячейки с паролем; Создать список рассылки и отправлять электронные письма …
- Извлечь текст, Добавить текст, Удалить по позиции, Удалить пробел; Создание и печать промежуточных итогов по страницам; Преобразование содержимого ячеек в комментарии…
- Суперфильтр (сохранять и применять схемы фильтров к другим листам); Расширенная сортировка по месяцам / неделям / дням, периодичности и др .; Специальный фильтр жирным, курсивом …
- Комбинируйте книги и рабочие листы; Объединить таблицы на основе ключевых столбцов; Разделить данные на несколько листов; Пакетное преобразование xls, xlsx и PDF…
- Группировка сводной таблицы по номер недели, день недели и другое … Показать разблокированные, заблокированные ячейки разными цветами; Выделите ячейки, у которых есть формула / имя…
")
Вкладка Office — предоставляет интерфейс с вкладками в Office и значительно упрощает вашу работу
- Включение редактирования и чтения с вкладками в Word, Excel, PowerPoint, Издатель, доступ, Visio и проект.
- Открывайте и создавайте несколько документов на новых вкладках одного окна, а не в новых окнах.
- Повышает вашу продуктивность на 50% и сокращает количество щелчков мышью на сотни каждый день!
")
Комментарии (17)
Оценок пока нет. Оцените первым!
Excel для Microsoft 365 Excel для Microsoft 365 для Mac Excel для Интернета Excel 2021 Excel 2021 для Mac Excel 2019 Excel 2019 для Mac Excel 2016 Excel 2016 для Mac Excel 2013 Excel 2010 Excel для Mac 2011 Excel Starter 2010 Еще…Меньше
Возвращает наиболее часто встречающееся или повторяющееся значение в массиве или интервале данных.
Синтаксис
МОДА.ОДН(число1;[число2];…)
Аргументы функции МОДА.ОДН описаны ниже.
-
Число1 Обязательный. Первый аргумент, для которого требуется вычислить моду.
-
Число2… Необязательный. Аргументы 2—254, для которых требуется вычислить моду. Вместо аргументов, разделенных точкой с запятой, можно использовать массив или ссылку на массив.
Замечания
-
Аргументы могут быть либо числами, либо содержащими числа именами, массивами или ссылками.
-
Если аргумент, который является массивом или ссылкой, содержит текст, логические значения или пустые ячейки, эти значения игнорируются; ячейки, содержащие нулевые значения, учитываются.
-
Аргументы, которые являются значениями ошибки или текстами, не преобразуемыми в числа, приводят к возникновению ошибок.
-
Если набор данных не содержит повторяющихся точек данных, функция МОДА.ОДН возвращает значение ошибки #Н/Д.
Примечание: Функция МОДА.ОДН измеряет центральную тенденцию, которая является центром группы чисел в статистическом распределении. Существует три наиболее распространенных способа определения центральной тенденции.
-
Среднее значение — это среднее арифметическое, которое вычисляется путем сложения набора чисел с последующим делением полученной суммы на их количество. Например, средним значением для чисел 2, 3, 3, 5, 7 и 10 будет 5, которое является результатом деления их суммы, равной 30, на их количество, равное 6.
-
Медиана — это число, которое является серединой множества чисел, то есть половина чисел имеют значения большие, чем медиана, а половина чисел имеют значения меньшие, чем медиана. Например, медианой для чисел 2, 3, 3, 5, 7 и 10 будет 4.
-
Мода — это число, наиболее часто встречающееся в данном наборе чисел. Например, модой для чисел 2, 3, 3, 5, 7 и 10 будет 3.
При симметричном распределении множества чисел все три значения центральной тенденции будут совпадать. При смещенном распределении множества чисел значения могут быть разными.
Пример
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
|
Данные |
||
|
5,6 |
||
|
4 |
||
|
4 |
||
|
3 |
||
|
2 |
||
|
4 |
||
|
Формула |
Описание |
Результат |
|
=МОДА.ОДН(A2:A7) |
Мода или наиболее часто встречающееся число |
4 |
Нужна дополнительная помощь?
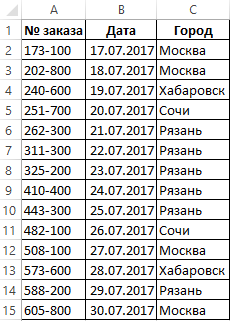
Допустим у нас есть таблица регистра составленных заказов клиентов. Необходимо узнать с какого города поступило наибольшее количество заказов, а с какого – наименьшее. Для решения данной задачи будем использовать формулу с поисковыми и вычислительными функциями.
Поиск наиболее повторяющегося значения в Excel
Чтобы наглядно продемонстрировать работу формулы для примера воспользуемся такой схематической таблицей регистра заказов от клиентов:
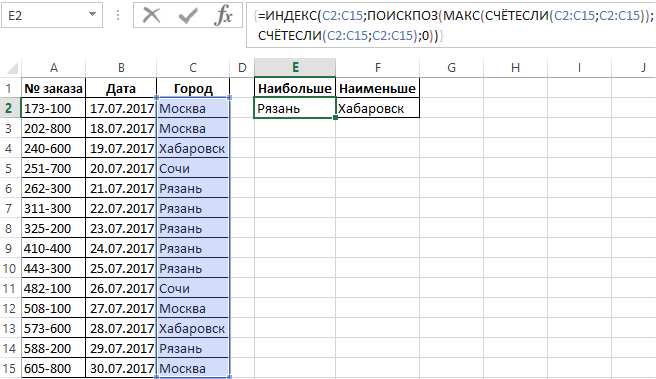
Теперь выполним простой анализ наиболее часто и редко повторяющихся значений таблицы в столбце «Город». Для этого:
- Сначала находим наиболее часто повторяющиеся названия городов. В ячейку E2 введите следующую формулу:
- Обязательно после ввода формулы нажмите комбинацию горячих клавиш CTRL+SHIFT+Enter, так как ее нужно выполнить в массиве.
- Для вычисления наиболее редко повторяющегося названия города вводим весьма похожую формулу:
Результат поиска названий самых популярных и самых редких городов клиентов в регистре заказов, отображен на рисунке:
Если таблица содержит одинаковое количество двух самых часто повторяемых городов или два самых редко повторяющихся города в одном и том же столбце, тогда будет отображаться первый из них.
Принцип действия поиска популярных по повторению значений:
Если посмотреть на синтаксис формул то можно легко заметить, что они отличаются только одним из названием функций: =МАКС() и =МИН(). Все остальные аргументы формулы – идентичны. Функция =СЧЕТЕСЛИ() подсчитывает, сколько раз каждое название города повторяется в диапазоне ячеек C2:C16. Таким образом в памяти создается условный массив значений.
Скачать пример поиска наибольшего и наименьшего повторения значения
Функция МАКС или МИН выбирает из условного массива наибольшее или наименьшее значение. Функция =ПОИСКПОЗ() возвращает номер позиции на которой в столбце C название города соответственного наибольшему или наименьшему количеству повторений. Полученное значение будет передано в качестве аргумента для функции =ИНДЕКС(), которая возвращает конечный результат в ячейку.