
 Одной из самых трудоемких и неприятных задач при работе с текстом в Excel является парсинг — разбор буквенно-цифровой «каши» на составляющие и извлечение из нее нужных нам фрагментов. Например:
Одной из самых трудоемких и неприятных задач при работе с текстом в Excel является парсинг — разбор буквенно-цифровой «каши» на составляющие и извлечение из нее нужных нам фрагментов. Например:
- извлечение почтового индекса из адреса (хорошо, если индекс всегда в начале, а если нет?)
- нахождение номера и даты счета из описания платежа в банковской выписке
- извлечение ИНН из разношерстных описаний компаний в списке контрагентов
- поиск номера автомобиля или артикула товара в описании и т.д.
Обычно во подобных случаях, после получасового муторного ковыряния в тексте вручную, в голову начинают приходить мысли как-то автоматизировать этот процесс (особенно если данных много). Решений тут несколько и с разной степенью сложности-эффективности:
- Использовать встроенные текстовые функции Excel для поиска-нарезки-склейки текста: ЛЕВСИМВ (LEFT), ПРАВСИМВ (RIGHT), ПСТР (MID), СЦЕПИТЬ (CONCATENATE) и ее аналоги, ОБЪЕДИНИТЬ (JOINTEXT), СОВПАД (EXACT) и т.д. Этот способ хорош, если в тексте есть четкая логика (например, индекс всегда в начале адреса). В противном случае формулы существенно усложняются и, порой, дело доходит даже до формул массива, что сильно тормозит на больших таблицах.
- Использование оператора проверки текстового подобия Like из Visual Basic, обернутого в пользовательскую макро-функцию. Это позволяет реализовать более гибкий поиск с использованием символов подстановки (*,#,? и т.д.) К сожалению, этот инструмент не умеет извлекать нужную подстроку из текста — только проверять, содержится ли она в нем.
Кроме вышеперечисленного, есть еще один подход, очень известный в узких кругах профессиональных программистов, веб-разработчиков и прочих технарей — это регулярные выражения (Regular Expressions = RegExp = «регэкспы» = «регулярки»). Упрощенно говоря, RegExp — это язык, где с помощью специальных символов и правил производится поиск нужных подстрок в тексте, их извлечение или замена на другой текст. Регулярные выражения — это очень мощный и красивый инструмент, на порядок превосходящий по возможностям все остальные способы работы с текстом. Многие языки программирования (C#, PHP, Perl, JavaScript…) и текстовые редакторы (Word, Notepad++…) поддерживают регулярные выражения.
Microsoft Excel, к сожалению, не имеет поддержки RegExp по-умолчанию «из коробки», но это легко исправить с помощью VBA. Откройте редактор Visual Basic с вкладки Разработчик (Developer) или сочетанием клавиш Alt+F11. Затем вставьте новый модуль через меню Insert — Module и скопируйте туда текст вот такой макрофункции:
Public Function RegExpExtract(Text As String, Pattern As String, Optional Item As Integer = 1) As String
On Error GoTo ErrHandl
Set regex = CreateObject("VBScript.RegExp")
regex.Pattern = Pattern
regex.Global = True
If regex.Test(Text) Then
Set matches = regex.Execute(Text)
RegExpExtract = matches.Item(Item - 1)
Exit Function
End If
ErrHandl:
RegExpExtract = CVErr(xlErrValue)
End Function
Теперь можно закрыть редактор Visual Basic и, вернувшись в Excel, опробовать нашу новую функцию. Синтаксис у нее следующий:
=RegExpExtract( Txt ; Pattern ; Item )
где
- Txt — ячейка с текстом, который мы проверяем и из которого хотим извлечь нужную нам подстроку
- Pattern — маска (шаблон) для поиска подстроки
- Item — порядковый номер подстроки, которую надо извлечь, если их несколько (если не указан, то выводится первое вхождение)
Самое интересное тут, конечно, это Pattern — строка-шаблон из спецсимволов «на языке» RegExp, которая и задает, что именно и где мы хотим найти. Вот самые основные из них — для начала:
| Паттерн | Описание |
| . | Самое простое — это точка. Она обозначает любой символ в шаблоне на указанной позиции. |
| s | Любой символ, выглядящий как пробел (пробел, табуляция или перенос строки). |
| S | Анти-вариант предыдущего шаблона, т.е. любой НЕпробельный символ. |
| d | Любая цифра |
| D | Анти-вариант предыдущего, т.е. любая НЕ цифра |
| w | Любой символ латиницы (A-Z), цифра или знак подчеркивания |
| W | Анти-вариант предыдущего, т.е. не латиница, не цифра и не подчеркивание. |
| [символы] |
В квадратных скобках можно указать один или несколько символов, разрешенных на указанной позиции в тексте. Например ст[уо]л будет соответствовать любому из слов: стол или стул. Также можно не перечислять символы, а задать их диапазоном через дефис, т.е. вместо [ABDCDEF] написать [A-F]. или вместо [4567] ввести [4-7]. Например, для обозначения всех символов кириллицы можно использовать шаблон [а-яА-ЯёЁ]. |
| [^символы] | Если после открывающей квадратной скобки добавить символ «крышки» ^, то набор приобретет обратный смысл — на указанной позиции в тексте будут разрешены все символы, кроме перечисленных. Так, шаблон [^ЖМ]уть найдет Путь или Суть или Забудь, но не Жуть или Муть, например. |
| | | Логический оператор ИЛИ (OR) для проверки по любому из указанных критериев. Например (счет|счёт|invoice) будет искать в тексте любое из указанных слов. Обычно набор вариантов заключается в скобки. |
| ^ | Начало строки |
| $ | Конец строки |
| b | Край слова |
Если мы ищем определенное количество символов, например, шестизначный почтовый индекс или все трехбуквенные коды товаров, то на помощь нам приходят квантификаторы или кванторы — специальные выражения, задающие количество искомых знаков. Квантификаторы применяются к тому символу, что стоит перед ним:
| Квантор | Описание |
| ? | Ноль или одно вхождение. Например .? будет означать один любой символ или его отсутствие. |
| + | Одно или более вхождений. Например d+ означает любое количество цифр (т.е. любое число от 0 до бесконечности). |
| * | Ноль или более вхождений, т.е. любое количество. Так s* означает любое количество пробелов или их отсутствие. |
|
{число} или {число1,число2} |
Если нужно задать строго определенное количество вхождений, то оно задается в фигурных скобках. Например d{6} означает строго шесть цифр, а шаблон s{2,5} — от двух до пяти пробелов |
Теперь давайте перейдем к самому интересному — разбору применения созданной функции и того, что узнали о паттернах на практических примерах из жизни.
Извлекаем числа из текста
Для начала разберем простой случай — нужно извлечь из буквенно-цифровой каши первое число, например мощность источников бесперебойного питания из прайс-листа:

Логика работы регулярного выражения тут простая: d — означает любую цифру, а квантор + говорит о том, что их количество должно быть одна или больше. Двойной минус перед функцией нужен, чтобы «на лету» преобразовать извлеченные символы в полноценное число из числа-как-текст.
Почтовый индекс
На первый взгляд, тут все просто — ищем ровно шесть цифр подряд. Используем спецсимвол d для цифры и квантор {6} для количества знаков:

Однако, возможна ситуация, когда левее индекса в строке стоит еще один большой набор цифр подряд (номер телефона, ИНН, банковский счет и т.д.) Тогда наша регулярка выдернет из нее первых 6 цифр, т.е. сработает некорректно:

Чтобы этого не происходило, необходимо добавить в наше регулярное выражение по краям модификатор b означающий конец слова. Это даст понять Excel, что нужный нам фрагмент (индекс) должен быть отдельным словом, а не частью другого фрагмента (номера телефона):

Телефон
Проблема с нахождением телефонного номера среди текста состоит в том, что существует очень много вариантов записи номеров — с дефисами и без, через пробелы, с кодом региона в скобках или без и т.д. Поэтому, на мой взгляд, проще сначала вычистить из исходного текста все эти символы с помощью нескольких вложенных друг в друга функций ПОДСТАВИТЬ (SUBSTITUTE), чтобы он склеился в единое целое, а потом уже примитивной регуляркой d{11} вытаскивать 11 цифр подряд:

ИНН
Тут чуть сложнее, т.к. ИНН (в России) бывает 10-значный (у юрлиц) или 12-значный (у физлиц). Если не придираться особо, то вполне можно удовлетвориться регуляркой d{10,12}, но она, строго говоря, будет вытаскивать все числа от 10 до 12 знаков, т.е. и ошибочно введенные 11-значные. Правильнее будет использовать два шаблона, связанных логическим ИЛИ оператором | (вертикальная черта):

Обратите внимание, что в запросе мы сначала ищем 12-разрядные, и только потом 10-разрядные числа. Если же записать нашу регулярку наоборот, то она будет вытаскивать для всех, даже длинных 12-разрядных ИНН, только первые 10 символов. То есть после срабатывания первого условия дальнейшая проверка уже не производится:

Это принципиальное отличие оператора | от стандартной экселевской логической функции ИЛИ (OR), где от перестановки аргументов результат не меняется.
Артикулы товаров
Во многих компаниях товарам и услугам присваиваются уникальные идентификаторы — артикулы, SAP-коды, SKU и т.д. Если в их обозначениях есть логика, то их можно легко вытаскивать из любого текста с помощью регулярных выражений. Например, если мы знаем, что наши артикулы всегда состоят из трех заглавных английских букв, дефиса и последующего трехразрядного числа, то:

Логика работы шаблона тут проста. [A-Z] — означает любые заглавные буквы латиницы. Следующий за ним квантор {3} говорит о том, что нам важно, чтобы таких букв было именно три. После дефиса мы ждем три цифровых разряда, поэтому добавляем на конце d{3}
Денежные суммы
Похожим на предыдущий пункт образом, можно вытаскивать и цены (стоимости, НДС…) из описания товаров. Если денежные суммы, например, указываются через дефис, то:
 из текста")
Паттерн d с квантором + ищет любое число до дефиса, а d{2} будет искать копейки (два разряда) после.
Если нужно вытащить не цены, а НДС, то можно воспользоваться третьим необязательным аргументом нашей функции RegExpExtract, задающим порядковый номер извлекаемого элемента. И, само-собой, можно заменить функцией ПОДСТАВИТЬ (SUBSTITUTE) в результатах дефис на стандартный десятичный разделитель и добавить двойной минус в начале, чтобы Excel интерпретировал найденный НДС как нормальное число:

Автомобильные номера
Если не брать спецтранспорт, прицепы и прочие мотоциклы, то стандартный российский автомобильный номер разбирается по принципу «буква — три цифры — две буквы — код региона». Причем код региона может быть 2- или 3-значным, а в качестве букв применяются только те, что похожи внешне на латиницу. Таким образом, для извлечения номеров из текста нам поможет следующая регулярка:

Время
Для извлечения времени в формате ЧЧ:ММ подойдет такое регулярное выражение:

После двоеточия фрагмент [0-5]d, как легко сообразить, задает любое число в интервале 00-59. Перед двоеточием в скобках работают два шаблона, разделенных логическим ИЛИ (вертикальной чертой):
- [0-1]d — любое число в интервале 00-19
- 2[0-3] — любое число в интервале 20-23
К полученному результату можно применить дополнительно еще и стандартную Excel’евскую функцию ВРЕМЯ (TIME), чтобы преобразовать его в понятный программе и пригодный для дальнейших расчетов формат времени.
Проверка пароля
Предположим, что нам надо проверить список придуманных пользователями паролей на корректность. По нашим правилам, в паролях могут быть только английские буквы (строчные или прописные) и цифры. Пробелы, подчеркивания и другие знаки препинания не допускаются.
Проверку можно организовать с помощью вот такой несложной регулярки:

По сути, таким шаблоном мы требуем, чтобы между началом (^) и концом ($) в нашем тексте находились только символы из заданного в квадратных скобках набора. Если нужно проверить еще и длину пароля (например, не меньше 6 символов), то квантор + можно заменить на интервал «шесть и более» в виде {6,}:

Город из адреса
Допустим, нам нужно вытащить город из строки адреса. Поможет регулярка, извлекающая текст от «г.» до следующей запятой:

Давайте разберем этот шаблон поподробнее.
Если вы прочитали текст выше, то уже поняли, что некоторые символы в регулярных выражениях (точки, звездочки, знаки доллара и т.д.) несут особый смысл. Если же нужно искать сами эти символы, то перед ними ставится обратная косая черта (иногда это называют экранированием). Поэтому при поиске фрагмента «г.» мы должны написать в регулярке г. если ищем плюсик, то + и т.д.
Следующих два символа в нашем шаблоне — точка и звездочка-квантор — обозначают любое количество любых символов, т.е. любое название города.
На конце шаблона стоит запятая, т.к. мы ищем текст от «г.» до запятой. Но ведь в тексте может быть несколько запятых, правда? Не только после города, но и после улицы, дома и т.д. На какой из них будет останавливаться наш запрос? Вот за это отвечает вопросительный знак. Без него наша регулярка вытаскивала бы максимально длинную строку из всех возможных:

В терминах регулярных выражений, такой шаблон является «жадным». Чтобы исправить ситуацию и нужен вопросительный знак — он делает квантор, после которого стоит, «скупым» — и наш запрос берет текст только до первой встречной запятой после «г.»:

Имя файла из полного пути
Еще одна весьма распространенная ситуация — вытащить имя файла из полного пути. Тут поможет простая регулярка вида:

Тут фишка в том, что поиск, по сути, происходит в обратном направлении — от конца к началу, т.к. в конце нашего шаблона стоит $, и мы ищем все, что перед ним до первого справа обратного слэша. Бэкслэш заэкранирован, как и точка в предыдущем примере.
P.S.
«Под занавес» хочу уточнить, что все вышеописанное — это малая часть из всех возможностей, которые предоставляют регулярные выражения. Спецсимволов и правил их использования очень много и на эту тему написаны целые книги (рекомендую для начала хотя бы эту). В некотором смысле, написание регулярных выражений — это почти искусство. Почти всегда придуманную регулярку можно улучшить или дополнить, сделав ее более изящной или способным работать с более широким диапазоном вариантов входных данных.
Для анализа и разбора чужих регулярок или отладки своих собственных есть несколько удобных онлайн-сервисов: RegEx101, RegExr и др.
К сожалению, не все возможности классических регулярных выражений поддерживаются в VBA (например, обратный поиск или POSIX-классы) и умеют работать с кириллицей, но и того, что есть, думаю, хватит на первое время, чтобы вас порадовать.
Если же вы не новичок в теме, и вам есть чем поделиться — оставляйте полезные при работе в Excel регулярки в комментариях ниже. Один ум хорошо, а два сапога — пара!
Ссылки по теме
- Замена и зачистка текста функцией ПОДСТАВИТЬ (SUBSTITUTE)
- Поиск и подсветка символов латиницы в русском тексте
- Поиск ближайшего похожего текста (Иванов = Ивонов = Иваноф и т.д.)
- Функции регулярных выражений в Excel
- Примеры задач, решаемых с помощью регулярных выражений
- Извлечение данных из ячеек с помощью RegEx
- Извлечь из ячейки содержимое до / после первой цифры включительно
- «Вытянуть» цифры из ячеек
- Извлечь из ячейки числа из N цифр
- Извлечь латиницу регулярным выражением
- Извлечь символы в конце/начале строк по условию
- Проверить ячейки на соответствие регулярному выражению
- Найти в ячейке числа из N цифр
- Найти ячейки, начинающиеся с цифр
- Замена подстрок по регулярному выражению
- Разбить ячейку по буквам
- Разбить буквы и цифры в ячейке
- Вставить текст после первого слова
- Вставить символ после каждого слова или перед ним
- Регулярные выражения для поиска конкретных слов в !SEMTools
- Найти слова по регулярному выражению
- Извлечь слова по регулярному выражению
- Удалить слова по регулярному выражению
- Очистить ячейки, не соответствующие регулярному выражению
Многие слышали, что такое регулярные выражения, но не всем известно, что они поддерживаются “под капотом” Microsoft Excel. Регулярные выражения дают возможность многократно ускорить работу с текстом, находить в нем самые замысловатые паттерны и решать самые сложные исследовательские задачи. Единственная проблема в том, что для их использования в Excel необходимо знание VBA.
Почему Microsoft не включила их как функции листа и включит ли когда-нибудь, непонятно и неизвестно.
Но с надстройкой !SEMTools эти знания не нужны. Зато минимальное понимание синтаксиса регулярок позволит с легкостью решать задачи, решение которых практически невозможно с помощью стандартных функций, либо для этого требуются формулы огромной длины. Примеры таких мегаформул можно посмотреть в решении задач:
- найти английские буквы в Excel,
- найти числа в тексте.
Для поддержки регулярных выражений при наличии подключенной надстройки !SEMTools в Excel будут работать три функции: REGEXMATCH, REGEXEXTRACT и REGEXREPLACE.
Их синтаксис и принцип работы аналогичен синтаксису Google Spreadsheets. Поэтому формулы, составленные в Excel, будут иметь полную зеркальную совместимость с Google Spreadsheets.
=REGEXMATCH("текст";"RegEx-паттерн для поиска")
REGEXMATCH возвращает ИСТИНА или ЛОЖЬ (TRUE или FALSE в английской версии Excel), в зависимости от того, соответствует текст паттерну или нет.
=REGEXEXTRACT("текст";"RegEx-паттерн для поиска")
REGEXEXTRACT извлекает первый попадающий под паттерн фрагмент текста. Небольшое отличие от Google Spreadsheets заключается в том, что, если в искомом тексте такого фрагмента нет, Spreadsheets отдают ошибку, а в надстройке отдается пустая строка.
=REGEXREPLACE("текст";"RegEx-паттерн для поиска";"текст, которым заменяем найденное")
Примеры задач, решаемых с помощью регулярных выражений
Я не поскуплюсь на примеры, чтобы показать вам все возможности регулярных выражений, так как они действительно огромны. Надеюсь, эта статья послужит руководством и стимулом активнее пользоваться их мощью. От простого к сложному.
Чтобы дать обычным пользователям Excel возможность максимально широко использовать возможности регулярных выражений, в надстройку !SEMTools был добавлен ряд быстрых процедур. Все примеры ниже будут показаны с их использованием.
Извлечение данных из ячеек с помощью RegEx
Извлечь из ячейки содержимое до / после первой цифры включительно
Такие простые два выражения. «+» — это служебный символ-квантификатор. Он обеспечивает «жадный» режим, при котором берутся все удовлетворяющие выражению символы до тех пор, пока на пути не встретится не удовлетворяющий ему или наступит конец/начало строки. Точка обозначает любой символ. Таким образом, берутся любые символы до конца строки, перед которыми есть цифра.
«d» обозначает «digits», иначе цифры. Поскольку квантификатора после “d” в примерах выше нет, то одну цифру. Если потребуется исключить из результатов эту цифру, это можно сделать позднее. В !SEMTools есть простые способы удалить символы в начале или конце ячейки.
Цифры можно выразить и другим регулярным выражением:
«Вытянуть» цифры из ячеек
Как извлечь из строки цифры? Регулярное выражение для такой операции будет безумно простым:
В зависимости от режима извлечения результатом будет либо первая, либо все цифры в ячейке.
Если их нужно вывести не сплошной последовательностью, а через разделитель, сохранив фрагменты, где символы следуют друг за другом, выражение будет чуть иным, с «жадным» квантификатором. А при извлечении нужно будет использовать разделитель.
Это справедливо и для любых других символов, пример с числами ниже:

Извлечь из ячейки числа из N цифр
Как видно в примере выше, помимо чисел, обозначающих годы, были извлечены и другие числа, например, «1». Чтобы извлечь исключительно последовательности из четырех цифр, потребуется видоизменить выражение. Есть несколько вариантов:
Последние два варианта включают квантификатор фигурные скобки. Он указывает минимальное количество повторений удовлетворяющего паттерну символа или фрагмента строки. Паттерну, стоящему непосредственно перед квантификатором. В данном случае подряд должны идти любые четыре символа, являющиеся цифрами.

Извлечь латиницу регулярным выражением
Выражение [a-zA-Z] обозначает все символы латиницы. Дефис и в этом, и в предыдущем случае обозначает, что берутся все символы между a и z и между A и Z в общей таблице символов Unicode. Квадратные скобки — синоним “ИЛИ”. Рассматривается каждый из элементов или множеств внутри квадратных скобок, при этом выражение не находит ничего, только если сравниваемая строка не содержит ни одного элемента внутри квадратных скобок.

Извлечь символы в конце/начале строк по условию
Стандартные формулы ПРАВСИМВ и ЛЕВСИМВ позволяют извлечь из ячейки соответственно последние и первые N символов, но на этом их возможности заканчиваются.
С помощью же регулярных выражений можно извлечь:
- Символы, идущие после и включая последнюю заглавную букву в ячейке, заканчивающейся на восклицательный знак. Так мы извлечем из ячеек все восклицательные предложения. Выражение для этого выглядит так: [А-Я][а-яa-z0-9 ]+!$.
- Первые N выбранных символов из определенного множества, если ячейка с них начинается.
- Аналогично: последние N определенных символов, если ячейка на них заканчивается.
Проверить ячейки на соответствие регулярному выражению
Если нет необходимости извлекать данные, а нужно лишь проверить, соответствуют ли они паттерну, чтобы потом отфильтровать их, удобнее использовать процедуру, эквивалентную формуле REGEXMATCH.
Найти в ячейке числа из N цифр
В зависимости от того, является N необходимым или достаточным условием, нужны разные регулярные выражения. Иными словами, считать ли последовательности из N+1, N+2 и т.д. цифр подходящими или нет. Если да, выражение будет таким же, как уже указывалось выше:
dddd
[0-9][0-9][0-9][0-9]
d{4}
[0-9]{4}
Если же нас интересуют строго последовательности из N цифр, задачу придется производить в две итерации:
- В первую итерацию извлекать цифры вместе с границами строк или нецифровыми символами, идущими после/перед (это станет своеобразной проверкой отсутствия других цифр).
- И во вторую уже сами цифры.
Выражения для первой итерации будут, соответственно:
(^|D)dddd($|D)
(^|D)[0-9][0-9][0-9][0-9]($|D)
(^|D)d{4}($|D)
(^|D)[0-9]{4}($|D)
Если внимательно посмотреть на отличие в синтаксисе, можно понять, что означают символы в нем:
- вертикальная черта “|” обозначает “ИЛИ”,
- скобки “( )” нужны для перечисления внутри них аргументов и “отгораживания” их от остального выражения,
- каретка “^” обозначает начало строки,
- символ доллара “$” — конец строки,
- D — нечисловые символы. Обратите внимание: верхний регистр меняет значение d на противоположное. Это справедливо также для пар w и W, обозначающих латиницу и цифры и не-латиницу и цифры, и s и S, различные виды пробелов и не-пробельные символы соответственно.
Найти ячейки, начинающиеся с цифр
Выражение для подобной проверки будет:
Либо можно воспользоваться процедурой проверки на копии исходного диапазона без необходимости вводить формулу. Смотрите примеры.

Замена подстрок по регулярному выражению
Наиболее частый кейс такой замены — замена на пустоту, когда наша задача попросту удалить из текста определенные символы. Наиболее популярны:
- удаление цифр из текста,
- удаление пунктуации,
- всех символов, кроме букв и цифр.
Но бывают случаи, когда необходима реальная замена, например, когда нужно заменить буквы с “хвостиками”/умляутами/ударениями и прочими символами из европейских алфавитов на их английские аналоги. Задача популярна среди SEO-специалистов, формирующих урлы сайтов этих стран на основе оригинальной семантики. Так выглядит начало таблицы паттернов для замены диакритических символов на латиницу с помощью RegEx при генерации URL:

Разбить ячейку по буквам
Чтобы разбить ячейку посимвольно, достаточно извлечь все символы через разделитель. Выражением для извлечения будет обычная точка — она как раз и обозначает любой символ.

Разбить буквы и цифры в ячейке
Если строго соблюдать постановку этой задачи, ее выполнить довольно сложно. Но зато с помощью регулярных выражений можно отделить цифровые последовательности символов от нецифровых. Так будет выглядеть выражение:
А так будет выглядеть процесс на практике:

Вставить текст после первого слова
При замене по регулярному выражению в !SEMTools есть опция замены не всех, а только первого найденного фрагмента, удовлетворяющего паттерну. Это позволяет решить задачу вставки символов после первого слова. Просто заменим первый пробел на нужные нам символы с помощью соответствующей процедуры (эту задачу можно решить также с помощью функции ПОДСТАВИТЬ, но можно и воспользоваться функционалом замены по регулярному выражению). В отличие от обычной процедуры замены, здесь можно заменить только первое вхождение. В данном случае — первый пробел. Как видно, пробел ничем не отличается от обычного:

Вставить символ после каждого слова или перед ним
Надстройка решает эту задачу в два клика готовой процедурой в меню “Изменить слова“, но можно воспользоваться и несложным выражением для замены:
Выражения обозначают, что заменяются пробелы или конец строки в первом случае и пробелы или начало строк во втором. Вертикальная черта — то самое “ИЛИ”.
А заменять будем, соответственно, на пробел с символом слева или справа. Процедура добавит лишний пробел перед ячейкой или после, поэтому от него желательно будет избавиться — удалить лишние пробелы или удалить символы в начале / конце ячейки.

Регулярные выражения для поиска конкретных слов в !SEMTools
Найти слова по регулярному выражению
Извлечь слова по регулярному выражению
Когда дело доходит до извлечения определенных слов, регулярные выражения становятся невероятно сложными. Поэтому надстройка !SEMTools упрощает задачу до применения паттернов RegEx на уровне слов как отдельных сущностей.
Вот так выглядит извлечение слов, содержащих латиницу и цифры, из массива слов, с помощью регулярного выражения:
Обратите внимание, что выражение означает, что цифра за буквой или буква за цифрой должны следовать непосредственно, без промежуточных символов между ними. Если нужно извлечь в том числе слова вида “asdf-13”, “1234-d”, понадобится обозначить возможность наличия символов между:

Удалить слова по регулярному выражению
Очистить ячейки, не соответствующие регулярному выражению
Когда в вашем распоряжении массив данных, где могут быть ошибки, с которыми разбираться некогда, и при этом нужно извлечь только стопроцентно подходящие данные, можно воспользоваться регулярными выражениями для очистки нерелевантных.
Примеры:
- оставить ячейки с определенным количеством слов,
- оставить ячейки с определенным количеством символов,
- оставить ячейки, содержащие только цифры,
- оставить ячейки, содержащие только буквы,
- оставить ячейки, содержащие адрес электронной почты в доменной зоне .com и .ru.
Примеры использования “Извлечь ячейки по регулярному выражению”.
Skip to content
На первый взгляд, в Excel есть все, что вам может понадобиться для работы с текстовыми строками. Но очень часто случается, что мы не можем указать точно, что мы ищем. Мы знаем часть слова или шаблон, которые нам нужны.
А как насчет регулярных выражений, чтобы использовать шаблон текста? К сожалению, в Excel нет встроенных функций Regex. Никак не могу понять, почему регулярные выражения не поддерживаются в формулах Excel? Теперь это есть:) освоив синтаксис регулярных выражений, с нашими пользовательскими функциями вы можете легко находить, заменять, извлекать и удалять слова, символы и строки, соответствующие определенному шаблону.
- Что такое регулярное выражение?
- Шпаргалка по регулярным выражениям Excel
- Символы
- Классы
- Квантификаторы
- Группы
- Якоря
- Конструкция ИЛИ
- Поиск
- «Жадные» и «ленивые» сопоставления
Что такое регулярное выражение?
Регулярное выражение (также известное как RegExp) — это особым образом закодированная последовательность символов, определяющая шаблон поиска.
Используя этот шаблон, вы можете найти подходящую комбинацию символов в строке или проверить ввод данных. Если вы знакомы с понятием подстановочных знаков , вы можете думать о регулярных выражениях как о расширенной версии подстановочных знаков.
Регулярные выражения имеют собственный синтаксис, состоящий из специальных символов, операторов и конструкций. Например, [0-5] соответствует любой одиночной цифре от 0 до 5.
Регулярные выражения используются во многих языках программирования, включая JavaScript и VBA. Последний имеет специальный объект RegExp, который мы будем использовать для создания наших пользовательских функций.
Поддерживает ли Excel регулярные выражения?
К сожалению, в Excel нет встроенных функций Regex. Чтобы иметь возможность использовать регулярные выражения в своих формулах, вам придется создать собственную пользовательскую функцию (на основе VBA или .NET) или установить сторонние инструменты, поддерживающие регулярные выражения.
Шпаргалка по регулярным выражениям Excel
Независимо от того, является шаблон регулярного выражения очень простым или чрезвычайно сложным, он строится с использованием общего синтаксиса. Этот раздел не ставит целью научить вас регулярным выражениям. Для этого в Интернете есть множество ресурсов, от бесплатных руководств для начинающих до премиальных курсов для опытных пользователей.
Ниже мы приводим краткий справочник по основным шаблонам регулярных выражений, который поможет вам понять основы синтаксиса. Он также может работать как шпаргалка при изучении других примеров.
Символы
Это наиболее часто используемые шаблоны для соответствия определенным символам.
| Шаблон | Описание | Пример | Найдено |
| . | Подстановочный знак: соответствует любому одиночному символу, кроме разрыва строки. | .от | кот , лот , @от |
| d | Символ цифры: любая одиночная цифра от 0 до 9 | d | В a1b найдено 1 |
| D | Любой символ, НЕ являющийся цифрой | D | В a1b найдено a и b |
| s | Пробельный символ: пробел, табуляция, новая строка и возврат каретки | .s. | В 3 яблока найдено 3 я |
| S | Любой непробельный символ. Анти-вариант предыдущего | S+ | В 30 яблок найдено 30 и яблок |
| w | Символ слова: любая буква ASCII, цифра или подчеркивание. | w+ | В 5_яблок*** найдено 5_яблок |
| B+ | Любой символ, который НЕ является буквенно-цифровым символом или символом подчеркивания | В+ | В 5_яблок*** найдено *** |
| t | Табуляция | ||
| n | Новая строка | nd+ | В двухстрочной строке ниже соответствует 10 5 кошек 10 собак |
| Позволяет использовать специальный символ как обычный | .
w+. |
Игнорирует подстановочный знак, чтобы вы могли найти буквальный символ «.» в строке
Mr. , д-р. , проф. |
Классы
Используя эти шаблоны, вы можете сопоставлять элементы разных наборов символов.
| Шаблон | Описание | Пример | Найдено |
| [символы] | В квадратных скобках можно указать один или несколько символов, допустимых на указанной позиции в тексте. | ст[оу]л | стол стул |
| [^символы] | На указанной позиции в тексте будут разрешены все символы, кроме перечисленных в скобках. | [^жм]уть | Соответствует путь, суть Не соответствует жуть, муть |
| [от—до] | Соответствует любому символу | [0-9] [а-я] [А-Я] [б-ф] [а-яА-ЯёЁ] |
Любая цифра от 0 до 9 Любая строчная буква Любая прописная буква Любая из букв в скобках [бвгдежзиклмнопрстуф] Все буквы русского алфавита (буква Ë указывается отдельно!) |
Квантификаторы
Квантификаторы — это специальные выражения, которые определяют количество совпадающих символов. Квантификатор всегда применяется к символу, стоящему перед ним перед ним.
| Шаблон | Описание | Пример | Найдено |
| * | Ноль или более вхождений | 1а* | 1, 1а , 1аа, 1ааа и т. д. |
| + | Одно или более вхождений | ко+ | В кот найдено ко В кооперация найдено коo |
| ? | Ноль или одно вхождение | ко?т | кот, корт |
| *? | Ноль или более вхождений, но как можно меньше | 1а*? | В 1a , 1aa и 1aaa найдено 1a |
| +? | Одно или несколько событий, но как можно меньше | ко+? | В кот и кооперация найдено ко |
| {n} | Строго определённое количество вхождений | d{3} | Ровно 3 любых цифры |
| {n,} | Не менее n вхождений | d{3,} | 3 или более цифр |
| {,n} | Не более n вхождений | d{,3} | Не более 3 цифр |
| {n, m} | Соответствует предыдущему шаблону от n до m раз | d{3,5} | От 3 до 5 цифр |
Группы
Конструкции групп используются для захвата подстроки из исходной строки, чтобы с ней можно было выполнить какую-либо операцию.
| Синтаксис | Описание | Пример | Найдено |
| (шаблон) | Группа захвата: захватывает совпадающую подстроку и присваивает ей порядковый номер | (d+) | 5 кошек и 10 собак 5 (группа 1) и 10 (группа 2) |
| (?:шаблон) | Группа без захвата: соответствует группе, но не захватывает ее | (d+)(?:собак) | 5 кошек и 10 собак 10 |
| 1 | Содержимое группы 1 | (d+)+(d+)=2+1 | 5+10=10+5 |
| 2 | Содержимое группы 2 |
Якоря
Якоря указывают позицию во входной строке, где искать соответствие.
| Якорь | Описание | Пример | Найдено |
| ^ | Начало строки Примечание: [^в скобках] означает «не» | ^d+ | Любое количество цифр в начале строки. 5 кошек и 10 собак Найдено 5 |
| $ | Конец строки | д+$ | Любое количество цифр в конце строки. В 10 плюс 5 получается 15 , найдено 15 |
| b | Конец слова | котb | 1 кот и 10 котят Соответствует кот, но не котят |
| В | НЕ конец слова | котB | 1 кот и 10 котят Соответствует котят, но не кот |
Конструкция ИЛИ
Операнд чередования включает логику ИЛИ, поэтому вы можете сопоставить тот или иной элемент.
| Построить | Описание | Пример | Соответствие |
| | | Соответствует любому отдельному элементу, разделенному вертикальной чертой | (счет|invoice) | Любое из перечисленных слов |
Поиск
Конструкции поиска полезны, когда вы хотите найти что-то, за чем следует или не следует что-то другое. Эти выражения иногда называют «утверждениями нулевой ширины» или «совпадением нулевой ширины», потому что они соответствуют позиции, а не фактическим символам.
Примечание. В варианте VBA RegEx просмотр назад не поддерживается.
| Шаблон | Описание | Пример | Найдено |
| = знак равно | Положительный вперед | Х(?=Y) | Соответствует выражению X, когда за ним следует Y (т. е. если Y предшествует X) |
| (?!) | Отрицательный вперед | Х(?!У) | Соответствует выражению X, если за ним НЕ следует Y |
| (?<=) | Положительный назад | (?<=Y)Х | Соответствует выражению X, когда ему предшествует Y (т. е. если Y находится позади X) |
| (?<!) | Отрицательный назад | (?<!Y)Х | Соответствует выражению X, если ему НЕ предшествует Y |
Жадные и ленивые сопоставления
Квантификаторы (* + {}) ― это «жадные» операторы, потому что они продолжают поиск соответствий, как можно глубже ― через весь текст.
| Шаблон | Описание | Пример | Найдено |
| <.+> | Жадный поиск | <.+> | В выражении Это <div> простой div</div> тест возвращает <div> простой div</div> |
Чтобы найти только тэг div ― можно использовать оператор ?, сделав выражение «ленивым»:
| Шаблон | Описание | Пример | Найдено |
| <.+?> | Ленивый поиск | <.+?> | В выражении Это <div> простой div</div> тест возвращает 2 совпадения: <div> </div> |
| <[^<>]+> | Ленивый поиск | <[^<>]+> | В выражении Это <div> простой div</div> тест возвращает 2 совпадения: <div> </div> |
Обратите внимание, что хорошей практикой считается не использовать оператор . , в пользу более строгого выражения: <[^<>]+>
<[^<>]+> соответствует любому символу, кроме скобок < или >,один или более раз встречающемуся между этими скобками.
Теперь, когда вы знаете синтаксис регулярных выражений, давайте перейдем к самой интересной части — использованию регулярных выражений на реальных данных для разбора строк и поиска необходимой информации. Если вам нужны дополнительные сведения о синтаксисе, может оказаться полезным руководство Microsoft по языку регулярных выражений .
You can use text functions to manipulate text strings in Excel. However, you can’t use them with regular expressions. As of writing this article VBA is your only option. In this guide, we’re going to show you how to use regular expressions in Excel.
Download Workbook
What is a regular expression?
A regular expression (also known as regex or regexp shortly) is a special text string for specifying a search pattern. They are like wildcards. Instead of specifying the number of characters, you can create patterns to find a specific group of characters, like searching between «b» to «o», using OR logic, excluding some characters, or repeating values.
Regular expressions are commonly used for text parsing and replacing operations for all programming languages. To use regular expressions in Excel, we will be using VBA.
| Pattern | Description | Samples |
| ^jack | begins with «jack» | jack-of-all-trades, jack’s house |
| jack$ | ends with «jack» | hijack |
| ^jack$ | is exactly «jack» | jack |
| colo[u]{0,}r | can include «u» at least 0 times | colour, color (not colur) |
| col[o|u]r | includes either «o» or «u» | color, colur (not colour) |
| col[^u]r | accepts any character except «u» | color (not colur or colour) |
How to use regular expressions
Let’s start using regular expressions in Excel by opening VBA. Press Alt + F11 keys to open VBA (Visual Basic for Applications) window. Add a module to enter your code.

Next step is to add regular expression reference to VBA. Click Tools > References in the VBA toolbar. Find and check Microsoft VBScript Regular Expressions 5.5 item in the References window. Click OK to add the reference.

Using the VBScript reference, we can create a regular expression object, which is defined as RegExp in VBA. A RegExp object has 4 properties and 3 methods:
Properties
| Name | Type | Description |
| Global | Boolean | Set True to find all cases that match with the pattern. Set False to find the first match. |
| IgnoreCase | Boolean | Set True to not make case-sensitive search. Set False to make case-sensitive search. |
| Multiline | Boolean | Set True if your string has multiple lines and you want to perform the search in all lines. |
| Pattern | String | The regular expression pattern you want to search. |
Methods
| Name | Arguments | Description |
| Execute | sourceString As String | Returns an array that contains all occurrences of the pattern matched in the string. |
| Replace | sourceString As String replaceVar As Variant | Returns a string which all occurrences of the pattern in the string are replaced with the replaceVar string. |
| Test | sourceString As String | Returns True if there is a match. Otherwise, False. |

Code Samples
A function that returns TRUE/FALSE if the pattern is found in a string
Public Function RegExFind(str As String, pat As String) As Boolean
‘Define the regular expression object
Dim RegEx As New RegExp
‘Set up regular expression properties
With RegEx
.Global = False ‘All occurences are not necessary since a single occurence is enough
.IgnoreCase = True ‘No case-sensitivty
.MultiLine = True ‘Check all lines
.Pattern = pat ‘pattern
End With
RegExFind = RegEx.Test(str)
End Function

After writing the code, you can use this function as a regular Excel function.

A function that replaces the pattern with a given string
Public Function RegExReplace(str As String, pat As String, replaceStr As String) As String
‘Define the regular expression object
Dim RegEx As New RegExp
‘Set up regular expression properties
With RegEx
.Global = False ‘All occurences are not necessary since a single occurence is enough
.IgnoreCase = True ‘No case-sensitivty
.MultiLine = True ‘Check all lines
.Pattern = pat ‘pattern
End With
RegExReplace = RegEx.Replace(str, replaceStr) ‘Return the modified string with replacement value
End Function

The following sample shows how to replace strings that start with «col», continue with 0 or 1 occurrences of «o» and single «u», and finally ends with an «r» character with «Color» string.

Анализ текста регулярными выражениями (RegExp) в Excel
 Смотрите такжеr.Pattern = «((d+))»: ‘Игнорировать переносы строк? без комментариев. именно так и не прокатывало. Метод только два подстановочных ReplaceFormat:=FalseПо работе мне использовать регулярные выражения? это отвечает вопросительный
Смотрите такжеr.Pattern = «((d+))»: ‘Игнорировать переносы строк? без комментариев. именно так и не прокатывало. Метод только два подстановочных ReplaceFormat:=FalseПо работе мне использовать регулярные выражения? это отвечает вопросительный
- в интервале 20-23 их можно легко строке стоит еще на помощь намd
- другой текстОдной из самых трудоемких r.Global = True .Pattern = Pattern
- 200?’200px’:»+(this.scrollHeight+5)+’px’);»>Sub t() надо было. странный но короткий)))
- символа: * иCells.Replace What:=».00″, Replacement:=»», часто приходится выделять
(Меня интересуют ячейки, знак. Без негоК полученному результату можно вытаскивать из любого один большой набор приходятЛюбая цифра. Регулярные выражения - и неприятных задачSet m = ‘Регулярка End With
- s = «file=»»D:ПапкаЛицензия.mpg»»Спасибо!!!! И почему-то работает. ? Поэтому каких-то LookAt:=xlPart, SearchOrder _ однотипный текст. Бороздя которые можно найти наша регулярка вытаскивала применить дополнительно еще текста с помощью цифр подряд (номерквантификаторыD это очень мощный при работе с r.Execute(s) ‘Найти/заменить On Error file=»»D:МамкаРолик»» file=»»D:ДедкаЛюбое имя.avi»»»wvlas200?’200px’:»+(this.scrollHeight+5)+’px’);»>Cells(1, 1).CurrentRegion.Value = Cells(1, регулярных выражений нельзя:=xlByRows, MatchCase:=False, SearchFormat:=False, просторы интернета, нашел с помощью регулярного бы максимально длинную и стандартную Excel’евскую регулярных выражений. Например,
- телефона, ИНН, банковскийилиАнти-вариант предыдущего, т.е. любая и красивый инструмент, текстом в ExcelFor Each e Resume Next RegExpFindReplaceWith CreateObject(«vbscript.regexp»): Здравствуйте! 1).CurrentRegion.Value особо много сделать. ReplaceFormat:=False прием, но хотелось выражения *щий) строку из всех функцию
если мы знаем, счет и т.д.)кванторы НЕ цифра на порядок превосходящий является In m: f = RegExp.Replace(str, Replace)’.Pattern = «\([^\»»]*)(.[^.]+)»»»Есть строка file=»D:ПапкаЛицензия.mpg»АлександрПопробуйте такой вариант:Cells.Replace What:=».0″, Replacement:=»», бы прикрутить кПростенький пример прикрепил возможных:ВРЕМЯ (TIME) что наши артикулы Тогда наша регулярка- специальные выражения,w по возможностям всепарсинг = f & Set RegExp =.Pattern = «\([^\»»]*)»»» file=»D:МамкаРолик.mov» file=»D:ДедкаЛюбое имя.avi»: Добрый день господа.200?’200px’:»+(this.scrollHeight+5)+’px’);»>Sub Заменить_точки() LookAt:=xlPart, SearchOrder _ нему регулярные выражения.
к сообщению (прошуВ терминах регулярных выражений,, чтобы преобразовать его всегда состоят из выдернет из нее задающие количество искомыхЛюбой символ латиницы (A-Z), остальные способы работы- разбор буквенно-цифровой «;» & e.submatches(0): Nothing ‘Очистка памяти.Global = True\(.*?).mpg выводит толькоНужен Ваш совет.Dim lr As:=xlByRows, MatchCase:=False, SearchFormat:=False, Попытался скрестить, но
заметить, пример не такой шаблон является в понятный программе трех заглавных английских первых 6 цифр, знаков. Квантификаторы применяются цифра или знак с текстом. Многие «каши» на составляющие Next End If EndSet mo =ПапкаЛицензия.mpgЕсть функция, которая Long ReplaceFormat:=False код некорректно работает( является конечной задачей,
«жадным». Чтобы исправить и пригодный для букв, дефиса и т.е. сработает некорректно: к тому символу, подчеркивания
языки программирования (C#, и извлечение из
f = Mid(f,
- Function .Execute(s)а нужно нужно перегоняет даты форматаlr = Columns(«A»).Find(What:=»*»,PS Это заплатка
- не все выделяет).Подскажите поэтому прошу не ситуацию и нужен
- дальнейших расчетов формат последующего трехразрядного числа,Чтобы этого не происходило, что стоит передW PHP, Perl, JavaScript…) нее нужных нам
2)S_elEnd With регулярным выражением вывести 31.12.12 в формат LookIn:=xlFormulas, LookAt:= _ на лечение чисел что не так предлагать решение через вопросительный знак -
| времени. | то: |
| необходимо добавить в | ним:Анти-вариант предыдущего, т.е. не и текстовые редакторы фрагментов. Например:End Function |
| , | If mo.Count Then (найти) имена файлов 4 кв. 2012 |
| xlPart, SearchOrder:=xlByRows, SearchDirection:=xlPrevious, | в текстовом виде в файле примере |
| «ИЛИ(«Восходящий»;»Нисходящий») | он делает квантор, |
| Предположим, что нам надо | Логика работы шаблона тут наше регулярное выражение |
| Квантор | латиница, не цифра (Word, Notepad++…) поддерживаютизвлечение почтового индекса из |
| для уникальных | т.е. мне нужноFor i = без каталогов и |
| г. MatchCase:=False _ при экспорте из | и как можноДругой вопрос - после которого стоит, проверить список придуманных проста. по краям модификаторОписание и не подчеркивание. регулярные выражения. адреса (хорошо, еслиКод200?’200px’:»+(this.scrollHeight+5)+’px’);»>Function g$(s$) наоборот, первое вхождение 0 To mo.Count расширенийDim re As, SearchFormat:=False).Row автокада. Когда из оптимизировать код как в ЕСЛИ «скупым» — и пользователями паролей на[A-Z]b?[Microsoft Excel, к сожалению, индекс всегда вSet r = нечислового символа, и |
| — 1Лицензия RegExp Dim tempStringRange(«A1:A» & lr).Value | автокада извлекаются данныеСкрытый текст Sub сформулировать условие «Любая наш запрос берет корректность. По нашим- означает любыеозначающий конец слова.Ноль или одно вхождение.символы не имеет поддержки начале, а если CreateObject(«vbscript.regexp») любые последующие символыs = mo(i).submatches(0)Ролик Set re = = Range(«A1:A» & (через инструмент Извлечение Reglight() On Error непустая ячейка»? (<>0 текст только до правилам, в паролях заглавные буквы латиницы. |
| Это даст понять | Например] RegExp по-умолчанию «из нет?)Set d = заменить на пустоту.If InStrRev(s, «.»)Любое имя New RegExp re.Pattern lr).Value данных), то все Resume Next: Err.Clear не работает (( первой встречной запятой |
| могут быть только | Следующий за ним |
| Excel, что нужный | .? |
| В квадратных скобках можно | коробки», но это |
нахождение номера и даты CreateObject(«scripting.dictionary»)S_el Then s =nilem = «(-|+|(|)| )»End Sub данные во-первых пишутся Dim ra AsСпасибо! после «г.»: английские буквы (строчные квантор нам фрагмент (индекс)будет означать один указать один или
| легко исправить с | счета из описания |
| r.Pattern = «((d+))»: | : все правильно,или другими Left(s, InStrRev(s, «.»): Привет, wvlas re.Global = TrueПрикладываю файл, на с апострофом перед |
| Range Set ra | PelenaЕще одна весьма распространенная или прописные) и{3} должен быть отдельным любой символ или несколько символов, разрешенных |
| помощью VBA. Откройте | платежа в банковской r.Global = True словами заменить всю — 1)если пути файлов re.IgnoreCase = True котором этот код |
| ними, во-вторых числа = Selection Dim: Для Вашего примера ситуация — вытащить цифры. Пробелы, подчеркиванияговорит о том, словом, а не его отсутствие. на указанной позиции |
редактор Visual Basic выпискеSet m = строку на числовоеDebug.Print s записаны именно так, tempString = re.R работает. задаются через точку. cell As Range,200?’200px’:»+(this.scrollHeight+5)+’px’);»>=СУММЕСЛИ($B$2:$B$8;»*щий»;$A$2:$A$8) имя файла из |
и другие знаки что нам важно, частью другого фрагмента+ в тексте. Например с вкладкиизвлечение ИНН из разношерстных
Извлекаем числа из текста
r.Execute(s) совпадение в началеNext в одну строку, eplace(astring, «») re.Patternbuchlotnik С апострофами борюсь

v, pos&, i%Цитата полного пути. Тут препинания не допускаются. чтобы таких букв (номера телефона):Одно или более вхождений.ст[уо]лРазработчик (Developer) описаний компаний вFor Each e строки.End If то можно попробовать: = «D*(dd?).(dd?).(d{2,4})D*» If
Почтовый индекс
: от Вас я очисткой форматов. А Dim arr() AsEndrus1, 18.07.2016 в поможет простая регуляркаПроверку можно организовать с было именно три.Проблема с нахождением телефонного Напримербудет соответствовать любому

или сочетанием клавиш списке контрагентов In m: d(e.submatches(0))Svsh2015End Sub200?’200px’:»+(this.scrollHeight+5)+’px’);»>Sub ert() re.Test(tempString) Then RgxData не увидел ничего с точкой приходится String Dim objMatches 19:52, в сообщении

вида: помощью вот такой После дефиса мы номера среди текстаd+ из слов: Alt+F11. Затем вставьтепоиск номера автомобиля или = 0&: Next:avpetrov27Dim s$, t$, = DatePart(«q», DateValue(re.R

Телефон
кроме png на как-то так (см.код). As Object, objMatch № 1200?’200px’:»+(this.scrollHeight+5)+’px’);»>Любая непустаяТут фишка в том, несложной регулярки: ждем три цифровых состоит в том,означает любое количествостол новый модуль через артикула товара вg = Join(d.keys,avpetrov27: Здравствуйте. i& eplace(tempString, «$1.$2.$3»))) & котором всё равно При этом надо As Object ‘Коллекция ячейка что поиск, поПо сути, таким шаблоном разряда, поэтому добавляем что существует очень цифр (т.е. любое

ИНН
или меню описании и т.д. «;»), а не прощеПодскажите, пожалуйста регулярку.s = Range(«A17″) » êâ. « не разобрать - бы сразу продумать совпадений Dim REGEXPКод200?’200px’:»+(this.scrollHeight+5)+’px’);»>=СУММЕСЛИ($B$2:$B$8;»<>»;$A$2:$A$8) сути, происходит в мы требуем, чтобы на конце много вариантов записи число от 0стулInsert — ModuleОбычно во подобных случаях,

End Function Текст по столбцам сам придумать неWith CreateObject(«vbscript.regexp») & DatePart(«yyyy», DateValue(re.R у меня разделитель что в автокаде As Object SetEndrus1 обратном направлении - между началом (d{3} номеров — с до бесконечности)..

и скопируйте туда после получасового муторногоC_sanches с разделителем «пробел» могу..ignorecase = True: eplace(tempString, «$1.$2.$3»))) & запятая и преобразование
Артикулы товаров
на разных машинах REGEXP = CreateObject(«VBScript.RegExp»): Добрый день! Благодарю от конца к^Похожим на предыдущий пункт дефисами и без,*Также можно не текст вот такой ковыряния в тексте: спасибо огромное, именно и отметить ПропуститьНужно: .Global = True » ã.» Exit РАБОТАЕТ — может могут быть форматы

REGEXP.Global = True: за ответ! Работает! началу, т.к. в) и концом ( образом, можно вытаскивать через пробелы, сНоль или более вхождений, перечислять символы, а макрофункции: вручную, в голову то, что нужно. все столбцы, кроме30 Torrent Pharmaceuticals.Pattern = «(?!\)([а-я0-9 Function End If пора правила форума чисел с округлением
Денежные суммы
REGEXP.IgnoreCase = True:Позвольте последний вопрос конце нашего шаблона$ и цены (стоимости, кодом региона в т.е. любое количество.
 из текста")
задать их диапазономPublic Function RegExpExtract(Text начинают приходить мысли Я почти был первого? Ltd 50 ])+(?=.)»Собственно все работает почитать?, а не
до десятичных сотых REGEXP.Pattern = «([лось]{3,6}|[колпак]{5,6})» — а как стоит) в нашем тексте НДС…) из описания скобках или без Так через дефис, т.е. As String, Pattern как-то автоматизировать этот близок к этомуSvsh2015превратить вWith .Execute(s) корректно и верно жаловаться на AutoCAD и так далее.

Автомобильные номера
For Each cell использовать то же$ находились только символы товаров. Если денежные и т.д. Поэтому,s* вместо As String, Optional процесс (особенно если =): добрый вечер,если надо30For i = у меня. — почему-то яPPS То что In ra.Cells ‘ самое регулярное выражение

Время
, и мы ищем из заданного в суммы, например, указываются

на мой взгляд,означает любое количество[ABDCDEF] Item As Integer данных много). Решенийа можно пояснить, первое число,что следуетт.е. всегда в 0 To .Count
- Одно «но» - знаю как это можно заменить в
- перебираем все ячейки в формуле ИЛИ? все, что перед
квадратных скобках набора. через дефис, то: проще сначала вычистить пробелов или ихнаписать = 1) As тут несколько и как во втором из логики обсуждения,-то начале идут цифры,
Проверка пароля
— 1 мне нужно, чтобы правильно пишется, хотя настройках экселя разделитель pos = 1200?’200px’:»+(this.scrollHeight+5)+’px’);»>=ИЛИ(A1=1;B1=2;C1=»*щий») ним до первого Если нужно проверитьПаттерн из исходного текста отсутствие.
[A-F] String On Error с разной степенью

случае выбираются уникальные? протестируйте макрос proba1, потом любой символ,t = t даты типа 01.10.2012 ни разу в на точку я If REGEXP.Test(cell.Text) ThenВот в таком справа обратного слэша. еще и длинуd все эти символы{. или вместо GoTo ErrHandl Set сложности-эффективности: За это отвечаетесли Вас интересует но не цифра, & «, «

Город из адреса
и 01.01.2013 принадлежали жизни не запускал знаю. Может это ‘ если подстрока виде, почему-то, не Бэкслэш заэкранирован, как

пароля (например, нес квантором
с помощью несколькихчисло[4567] regex = CreateObject(«VBScript.RegExp»)Использовать объект scripting.dictionary? текст после числа- потом любые символы. & .Item(i) к 3 иfairylive и был бы найдена Set objMatches работает… и точка в меньше 6 символов),+ вложенных друг в}ввести regex.Pattern = Patternвстроенные текстовые функции Excelikki
протестируйте макрос proba2нужно оставить толькоNext i 4 кварталу 2012: самый простой способ, = REGEXP.Execute(cell.Text) For
abtextime предыдущем примере. то кванторищет любое число друга функцийили[4-7] regex.Global = Trueдля поиска-нарезки-склейки текста:: даSub proba1() Dim первые числа.End With соответственно.Karataev а я всё Each objMatch In:»Под занавес» хочу уточнить,+

до дефиса, аПОДСТАВИТЬ (SUBSTITUTE){. Например, для обозначения If regex.Test(Text) ThenЛЕВСИМВ (LEFT)lolret t$ t =Пока придумал только:End WithА VBA их, то есть по

Имя файла из полного пути
усложняю? Я просто objMatches Debug.Print objMatch200?’200px’:»+(this.scrollHeight+5)+’px’);»>=ИЛИ(A1=1;B1=2;ЕСЛИОШИБКА(НАЙТИ(«щий»;C1)>0);ЛОЖЬ)) что все вышеописанноеможно заменить наd{2}

, чтобы он склеилсячисло1 всех символов кириллицы Set matches =,: Добрый день, помогите Range(«A1»).Value With CreateObject(«VBScript.RegExp»)=RegExpFindReplace(D7;»D»;»»)где D -Range(«A18») = Mid(t, относит уже к сути весь код к запятой привык. arr = Split(cell.Text,или — это малая интервал «шесть и
P.S.
будет искать копейки в единое целое,, можно использовать шаблон regex.Execute(Text) RegExpExtract =ПРАВСИМВ (RIGHT) пожалуйста решить задачу, .Pattern = «d+» то что ищу, 3) новому кварталу, т.к. это присвоить значениям Удобнее её с objMatch, , vbTextCompare)Код200?’200px’:»+(this.scrollHeight+5)+’px’);»>=ИЛИ(A1=1;B1=2;C1=ПОДСТАВИТЬ(C1;»щий»;»»)) часть из всех более» в виде (два разряда) после. а потом ужечисло2[а-яА-ЯёЁ] matches.Item(Item — 1),
буду приочень благодарен: If .test(t) Then «» — тоEnd Sub собственно это и диапазона значения этого цифровой клавиатуры набирать. ‘ разбивает текстEndrus1
возможностей, которые предоставляют{6,}Если нужно вытащить не примитивной регуляркой}. Exit Function EndПСТР (MID)Имеется массив данных, MsgBox .Execute(t)(0) End на что заменяю.
или есть уже даты же диапазона? Тутbuchlotnik ячейки на части: Спасибо! Работает регулярные выражения. Спецсимволов: цены, а НДС,d{11}
planetaexcel.ru
Использование регулярных выражения внутри формулы (Формулы/Formulas)
Если нужно задать строго[ If ErrHandl: RegExpExtract
, в котором разбросанны With End SubРезультат 3050.Код200?’200px’:»+(this.scrollHeight+5)+’px’);»>Sub tt() нового периода. какая-то магия? Я
: дык а For Each vкитин и правил ихДопустим, нам нужно вытащить то можно воспользоватьсявытаскивать 11 цифр
определенное количество вхождений,^ = CVErr(xlErrValue) EndСЦЕПИТЬ (CONCATENATE) однотипные выражения вида
Sub proba2() Dim
pashulkaDim s$, sp,
Следовательно мне нужно
попробую прикрутить эту200?’200px’:»+(this.scrollHeight+5)+’px’);»>Cells.Replace What:=».», Replacement:=»,» In arr ‘: и вдогонку тупая использования очень много
город из строки
третьим необязательным аргументом подряд: то оно задается
символы Functionи ее аналоги, XA1, XB1, XC1, t$ t =
: Зачем всё усложнять,
spp, i& до момента преобразования штуку чтобы посмотреть
чем не покатило? перебираем все вхождения формула массива
и на эту
адреса. Поможет регулярка,
нашей функции RegExpExtract,Тут чуть сложнее, т.к.
в фигурных скобках.]Теперь можно закрыть редакторОБЪЕДИНИТЬ (JOINTEXT) 
XD1 и т.д. Range(«A1»).Value With CreateObject(«VBScript.RegExp») если в такихs = Range(«A17») даты отнять от
как она работает.
fairylive pos = pos200?’200px’:»+(this.scrollHeight+5)+’px’);»>=СУММ(ЕСЛИ(ПРАВБ($B$2:$B$8;3)=»щий»;$A$2:$A$8))
тему написаны целые извлекающая текст от задающим порядковый номер ИНН (в России) НапримерЕсли после открывающей квадратной Visual Basic и,, нужно привести эти .Pattern = «d+(.+)» случаях прокатит VB(A)sp = Split(s, нее 1 день, У меня просто: Так нули остаются, + Len(v) ‘Che79 книги (рекомендую для «г.» до следующей извлекаемого элемента. И, бывает 10-значный (уd{6} скобки добавить символ вернувшись в Excel,СОВПАД (EXACT) выражения к виду If .test(t) Then функция Val
«.»): s = чтобы она была значения могут быть после запятой. А начальная позиция With: ну или так начала хотя бы запятой: само-собой, можно заменить
excelworld.ru
Регулярные выражения
юрлиц) или 12-значныйозначает строго шесть
«крышки» опробовать нашу новуюи т.д. Этот XA2, XB2, XC2, MsgBox .Execute(t)(0).Submatches(0) EndMsgBox Val(«30 Torrent «» внутри отчетного квартала. в разных столбцах эксель при этом cell.Characters(pos, objMatch.Length) .Font.ColorIndex (тоже уже вне эту). В некоторомДавайте разберем этот шаблон
функцией (у физлиц). Если цифр, а шаблон^ функцию. Синтаксис у способ хорош, если XD2 и т.д. With End Sub Pharmaceuticals Ltd 50″)For i =Можно ли это и рядах (см. этом проставляет в = 3 ‘ конкурса смысле, написание регулярных поподробнее.ПОДСТАВИТЬ не придираться особо,s{2,5, то набор приобретет нее следующий: в тексте есть функция ЗАМЕНИТЬ недобавлю,протестируйте , дляS_el 0 To UBound(sp) сделать прямо здесь картинку сверху). таких ячейках зелёный выделяем цветом .Font.Bold) выражений — этоЕсли вы прочитали текст(SUBSTITUTE) то вполне можно} обратный смысл -=RegExpExtract( Txt ; Pattern четкая логика (например, катит, т.к. таких сравнения в вышеуказанном: — 1 в формуле?buchlotnik треугольничек и говорит = True ‘200?’200px’:»+(this.scrollHeight+5)+’px’);»>=СУММПРОИЗВ($A$2:$A$8*ЕЧИСЛО(ПОИСК(«*щий»;$B$2:$B$8))) почти искусство. Почти
выше, то ужев результатах дефис удовлетвориться регуляркой- от двух на указанной позиции ; Item )
planetaexcel.ru
Регулярные выражения — замена (Макросы/Sub)
индекс всегда в массивов данных много файл-примере функцию zzzavpetrov27spp = Split(sp(i),ЗЫ: отнимать 1, а что вы что число сохранено и полужирным начертанием_Boroda_ всегда придуманную регулярку поняли, что некоторые на стандартный десятичныйd{10,12} до пяти пробелов в тексте будутгде
начале адреса). В и вид изменяемого , в ячейке, вообще регулярка может
"") день прямо на
хотели увидеть? Файл? как текст или
.Font.Size = 14: Алексей, а зачем
можно улучшить или символы в регулярных
разделитель и добавить, но она, строго
Теперь давайте перейдем к разрешены все символы,
Txt противном случае формулы
выражения различен(по количеству ,-получите 3050
выглядеть так:s = s листе, а потом Пожалуйста. На картинке перед ним стоит End With pos звездень вот здесь? дополнить, сделав ее выражениях (точки, звездочки, двойной минус в говоря, будет вытаскивать самому интересному - кроме перечисленных. Так,- ячейка с существенно усложняются и, знаков. Может встречатьсяFunction zzz$(t$) WithКод `^(d+) D.*` & «, « к результату применять показать хотел ошибку апостроф. Апостроф убирается = pos +В ПОИСКПОЗ да,
более изящной или знаки доллара и начале, чтобы Excel все числа от разбору применения созданной шаблон текстом, который мы порой, дело доходит несколько раз в CreateObject(«VBScript.RegExp»): .Pattern = и заменять на & spp(UBound(spp))
функцию для меня и предложения от так objMatch.Length Next v
а ПОИСК все способным работать с т.д.) несут особый интерпретировал найденный НДС 10 до 12 функции и того,[^ЖМ]уть проверяем и из даже до формул ячейке в рамках «D+» zzz = матч из первых
Next i
не подходит. Нужно Excel по поводу200?’200px’:»+(this.scrollHeight+5)+’px’);»>cells.clearformats Next objMatch End равно ищет позицию более широким диапазоном смысл. Если же как нормальное число: знаков, т.е. и что узнали онайдет
которого хотим извлечь массива, что сильно формулы). Нужно провести .Replace(t, «») End группирующих скобок.
Range(«A18») = Mid(s, именно в код её решения. Вручнуюbuchlotnik If Next cell вхождения, поэтому звезда вариантов входных данных. нужно искать самиЕсли не брать спецтранспорт, ошибочно введенные 11-значные. паттернах на практическихПуть нужную нам подстроку тормозит на больших операцию через «поиск With End Functionavpetrov27 3)
функции вставить. можно щёлкнуть -: т.е. вы хотите End Sub вначале ни наДля анализа и разбора эти символы, то
прицепы и прочие
Правильнее будет использовать
примерах из жизни.или
Pattern таблицах.
и замена" сC_sanches
:
End SubJohny преобразовать в число.
при
vikttur что не влияет. чужих регулярок или
перед ними ставится мотоциклы, то стандартный два шаблона, связанныхДля начала разберем простойСуть- маска (шаблон)Использование использованием регулярных выражений,: Доброго времени суток.S_elnerv: И? Выдернули дату Проблема решится. Какзаданном: Это инструмент, а Вот так «?щий» отладки своих собственных
обратная косая черта российский автомобильный номер логическим ИЛИ оператором случай — нужноили для поиска подстрокиоператора проверки текстового подобия но как этоПодскажите, как с,: с расширением и проверяете, куда это же сделатьдесятичном разделите не назвние темы да, ищем любой есть несколько удобных
(иногда это называют разбирается по принципу| извлечь из буквенно-цифровойЗабудьItem Like сделать не пойму помощью регулярных выраженийу меня то.200?’200px’:»+(this.scrollHeight+5)+’px’);»>[^\]+ она попадает или на VBA?
точка (см. правила форума). текст, в котором онлайн-сервисов:
экранированием «буква — три(вертикальная черта): каши первое число,, но не- порядковый номериз Visual Basic,lolret вывести из строки что подставляется реализованоikki не попадает.fairylive, чтобы Excel воспринимал
Предложите новое, модераторы «щий» не первый.RegEx101). Поэтому при поиске цифры — двеОбратите внимание, что в например мощность источниковЖуть подстроки, которую надо обернутого в пользовательскую: Пример приложите содержимое скобок через как строка.: если у каждогоThe_Prist
: Что именно узапятую
excelworld.ru
Регулярные выражения
переименуют. Кстати, насколько я
,
фрагмента «г.» мы буквы — код запросе мы сначала бесперебойного питания изили
извлечь, если их макро-функцию. Это позволяетlolret точку с запятой.Public Function RegExpFindReplace(str файла есть расширение:: Вы бы хоть вас работает? Вашкак десятичный разделительfairylive понял, вот этоRegExr должны написать в региона». Причем код ищем 12-разрядные, и прайс-листа:Муть несколько (если не
реализовать более гибкий: Смогу только завтраПримеры:
As String, _200?’200px’:»+(this.scrollHeight+5)+’px’);»>Sub t() функцию полностью привели. предложеный код?точка: Всем привет. ХотелЦитата
и др. регулярке региона может быть только потом 10-разрядныеЛогика работы регулярного выражения, например.
указан, то выводится поиск с использованиемlolret(223) Pattern As String,s = «file=»»D:ПапкаЛицензия.mpg»»
А еще лучшеKarataev?
немного усовершенствовать макросEndrus1, 18.07.2016 вК сожалению, не всег. 2- или 3-значным, числа. Если же тут простая:|
первое вхождение) символов подстановки (*,#,?: Что-то эе стоитвыведет _ Replace As
file=»»D:МамкаРолик.mov»» file=»»D:ДедкаЛюбое имя.avi»»» вместе с файлом: Да, в этомЦитата и так ничего 19:52, в сообщении
возможности классических регулярныхесли ищем плюсик, а в качестве записать нашу регуляркуdЛогический операторСамое интересное тут, конечно, и т.д.) К за этим знаком,223; String, _ OptionalWith CreateObject(«vbscript.regexp»)
примером. суть. Смысл может
200?’200px’:»+(this.scrollHeight+5)+’px’);»>самый простой способ это у меня и № 1200?’200px’:»+(this.scrollHeight+5)+’px’);»>найти с выражений поддерживаются в то букв применяются только наоборот, то она
- означает любуюИЛИ (OR) это Pattern - сожалению, этот инструмент
точка с запятой
planetaexcel.ru
Регулярные выражения
(344)/(563) Globa1 As Boolean
.Pattern = «\([^\»»]*)(.[^.]+)»»»Скорее всего надо
быть в том,
проставлять разделитель по
не получилось с помощью регулярного выражения VBA (например, обратный+ те, что похожи
будет вытаскивать для
цифру, а квантор
для проверки по
строка-шаблон из спецсимволов не умеет извлекать
или двоеточие. Можетвыведет = True, _.Global = True
ковырять переменные astring
что если в умолчанию, чтобы числа
регулярными выражениями. Есть
*щий означает, что
поиск или POSIX-классы)и т.д.
внешне на латиницу. всех, даже длинных
+
любому из указанных "на языке" RegExp, нужную подстроку из
включить этот знак344;563; Optional IgnoreCase As
Set mo =
и tempString. Но
ячейку записывать дробное
были числами полно примеров с
нужно именно окончание
и умеют работать
Следующих два символа в
Таким образом, для 12-разрядных ИНН, только
говорит о том,
критериев. Например которая и задает, текста — только
в Найти/Заменить, что-то((42) + 2* ((42)+(43)) Boolean = False,
.Execute(s) т.к. мы понятия
число с точкой,fairylive функциями которым скармливается
на «щий». Тогда
с кириллицей, но нашем шаблоне -
извлечения номеров из
первые 10 символов. что их количество
(с
что именно и проверять, содержится ли типа Найти «1;»
/ (121)
_ Optional MultilineEnd With
не имеем, откуда
то такое число
: Разделитель целой и
оригинал (одна ячейка), ПОИСК и НАЙТИ
и того, что
точка и звездочка-квантор
текста нам поможет То есть после должно быть одна
чет|с
где мы хотим
она в нем.
- Заменить на
выведет As Boolean =If mo.Count Then astring и что воспринимается Excel’ем, как дробной части (Панель
паттерн и замена. без уточнений позиции есть, думаю, хватит
— обозначают любое следующая регулярка:
срабатывания первого условия
или больше. Двойнойчёт|invoice
найти. Вот самые
Кроме вышеперечисленного, есть еще
"2;" Предварительно выделив
42;43;121;
False) _ AsFor i =
в ней хранится(предположим
число, а не
управления - язык Но как работать вообще не подойдут.
на первое время,
количество любых символов,Для извлечения времени в дальнейшая проверка уже минус перед функцией
)
основные из них
один подход, очень
только ячейки с
excelworld.ru
Регулярные выражения. подскажите шаблон
Т.е. в строке String RegExpFindReplace =
0 To mo.Count дата, но надо как текст, даже
и региональные стандарты)
со всеми ячейками Я, правда, так
чтобы вас порадовать.
т.е. любое название
формате ЧЧ:ММ подойдет не производится: нужен, чтобы «набудет искать в — для начала:
известный в узких формулами
могут встречаться любые
str ‘Пока ничего — 1 понимать в каком если у дробного
— запятая. В
в экселе? Есть вот сходу неЕсли же вы не города. такое регулярное выражение:
Это принципиальное отличие оператора лету» преобразовать извлеченные
тексте любое изПаттерн кругах профессиональных программистов,Как вариант подходит, символы, но то,
не меняли IfDebug.Print mo(i).submatches(0) формате), то и числа тип данных
Экселе разделитель тоже Cells.Replace но как смог придумать слово, новичок в теме,
На конце шаблона стоитПосле двоеточия фрагмент|
символы в полноценное указанных слов. ОбычноОписание веб-разработчиков и прочих спасибо, с небольшими что в скобках, Not str LikeNext помочь не можем «String» (Текст). запятая. Мне так можно в нём в котором «щий» и вам есть запятая, т.к. мы[0-5]dот стандартной экселевской число из числа-как-текст. набор вариантов заключается. технарей — это доработками по убиранию обязательно целые числа «» And NotEnd If достоверно.fairylive удобно. Так хорошо. задать регулярные выражения? в середине. чем поделиться - ищем текст от, как легко сообразить, логической функцииНа первый взгляд, тут в скобки.Самое простое — эторегулярные выражения
чисел из ячеекПодскажите, хотя бы,
Pattern Like «»End SubАлександр: Допилил так. Правда Но автокаду на
Короче сейчас уChe79 оставляйте полезные при «г.» до запятой. задает любое числоИЛИ (OR)
все просто -^ точка. Она обозначает(Regular Expressions = с выражениями, чтобы с чего начать. Then Dim RegExpikki: Файл пример.
заработало с 10-й это плевать. У меня какой-то такой: Александр, на мой работе в Excel
Но ведь в в интервале 00-59., где от перестановки
ищем ровно шестьНачало строки любой символ в RegExp = «регэкспы» не попали случайноСпасибо! As Object ‘Для: для возможного случаяСлэн попытки. Фокус в него разделитель только код, за неимением кажуЩИЙся регулярки в комментариях
тексте может быть Перед двоеточием в аргументов результат не цифр подряд. Используем$
шаблоне на указанной = «регулярки»). Упрощенно под замену. Проверюikki регулярного выражения Set
CyberForum.ru
Поиск в строке. Регулярные выражения (Макросы/Sub)
с отсутствием расширений: так? (но не
том что надо точка. И выгружает лучшего:взгляд звездень была ниже. Один ум
несколько запятых, правда?
скобках работают два меняется. спецсимвол
Конец строки позиции. говоря,
на практике завтра,: а почему для RegExp = CreateObject(«VBScript.RegExp») для некоторых файлов
только две указанные это проделать с в эксель он200?’200px’:»+(this.scrollHeight+5)+’px’);»>Cells.Replace What:=».0000″, Replacement:=»», LookAt:=xlPart, нужна. Но перечитав
хорошо, а два Не только после
шаблона, разделенных логическим
Во многих компаниях товарамdbsRegExp — это язык, вдруг «овраги».В Найти/Заменить
третьей строки
With RegExp .Global "чистого" решения на
даты, но все исходным файлом извлечения
точку. Я хочу SearchOrder _
Вас выше и сапога - пара! города, но и ИЛИ (вертикальной чертой): и услугам присваиваются
для цифры иКрай слова
Любой символ, выглядящий как
где с помощью
есть Выделение группы
42 = Globa1 ‘Все
регулярках не придумал. первые дни кварталов
СРАЗУ. А я как-то с этим
:=xlByRows, MatchCase:=False, SearchFormat:=False, справку по ПОИСК,
Endrus1 после улицы, дома[0-1]d
уникальные идентификаторы - квантор
Если мы ищем определенное
пробел (пробел, табуляция специальных символов и ячеек — отметьте- в результате совпадения или тольконо, думаю, такой
отнесены к предыдущему сначала двигал столбцы бороться с помощью ReplaceFormat:=False понял, что явно
: Добрый день, уважаемые и т.д. На
excelworld.ru
Поиск и замена с использованием регулярных выражений
- любое число артикулы, SAP-коды, SKU{6} количество символов, например,
или перенос строки). правил производится поиск там Формулы, затем один раз? первое? .IgnoreCase = вариант будет даже периоду) и применял сортировки VBA.Cells.Replace What:=».000″, Replacement:=»», погорячился… эксперты! какой из них в интервале 00-19 и т.д. Еслидля количества знаков: шестизначный почтовый индексS нужных подстрок в не снимая выделения200?’200px’:»+(this.scrollHeight+5)+’px’);»>Function f$(s$) IgnoreCase ‘Регистр неважен? быстрее.
Александр разные. И после
Karataev LookAt:=xlPart, SearchOrder _
KHRRПрошу помочь: Как будет останавливаться наш2[0-3] в их обозначенияхОднако, возможна ситуация, когда или все трехбуквенныеАнти-вариант предыдущего шаблона, т.е. тексте, их извлечение заменить значения.Всё получилось,Set r = .Multiline = Multiline
да и понятно: Слэн, супер - этого почем-то уже: У метода «Replace»:=xlByRows, MatchCase:=False, SearchFormat:=False,: Добрый день! в формулах ЕСЛИ запрос? Вот за- любое число есть логика, то левее индекса в коды товаров, то любой НЕпробельный символ. или замена на благодарю.
CyberForum.ru
CreateObject(«vbscript.regexp»)
Время прочтения: 7 мин.
Зачастую, при работе с многочисленными выгрузками в MS Excel нам приходится обрабатывать, фильтровать и буквально «вытаскивать» интересующие нас и так необходимые в повседневной работе данные. Степень трудоемкости таких «вытаскиваний» варьируется от «выбрать все желтые и красные строчки, потому что остальные – это не наши» до «посчитать для всех клиентов с ФИО Иванов Иван Иванович, у которых в день было больше трех операций и которые обслуживались в ВСП на территории ГОСБ, сумму их вкладных операций». В соответствии с поставленной перед нами задачей, мы выбираем инструмент для ее решения.
Но что делать, если стандартными средствами MS Excel поставленную задачу не решить. Одним из наиболее подходящих инструментов в данной ситуации является применение «регулярных выражений» (regular expressions). Проще говоря, регулярные выражения — это язык, где с помощью специальных символов и правил производится поиск нужных подстрок в тексте, их извлечение или замена на другой текст. Но, к сожалению, MS Excel, не имеет поддержки данного инструмента по умолчанию, тем не менее, это легко исправить вручную, проделав ряд следующих операций (нижеследующая настройка производится для MS Excel 2016, для MS Excel 2010 процедура аналогична):
- Необходимо убедиться в том, что в MS Excel включена вкладка «Разработчик» и не запрещено
применение макросов:

Если вкладка отсутствует, ее необходимо активировать
следующим образом:
а) С помощью перехода в меню «Файл»-> «Параметры», отрываем окно «Параметры Excel»:

б) На вкладке «Настроить ленту» нужно выбрать «Все вкладки» и поставить отметку в строке «Разработчик», после чего нажать «ОК»:

в) Также, во вкладке «Центр управления безопасностью», необходимо перейти в «Параметры центра управления безопасностью»:

г) В открывшемся окне нужно проверить, включены ли макросы, и нажать «ОК»:

2. Перейти в «Microsoft Visual Basic for Applications», нажав кнопку «Visual Basic» во вкладке «Разработчик» или же с помощью сочетания клавиш Alt+F11

3. В открывшемся окне, необходимо последовательно перейти в меню «Инструменты» («Tools») -> «Ссылки» («References»):

4. В окне «Ссылки» («References») нужно проставить отметку в строке Microsoft VBScript Regular Expressions 5.5, после чего нажать «ОК»:

5. В окне «Microsoft Visual Basic for Applications» создать новый модуль с помощью команд «Вставка» («Insert») -> «Модуль» («Module»):

6. В открывшемся редакторе кода, необходимо написать следующую функцию:

Мы только что написали пользовательскую функцию, которая и будет
обрабатывать наши текстовые конструкции, используя механизм регулярных
выражений. Параметрами этой функции являются соответственно: последовательность
символов, подлежащая обработке и шаблон, по которому будет производиться отбор
интересующих нас подпоследовательностей символов.
Результатом же будет искомая
подпоследовательность, либо сообщение об ошибке в случае отсутствия таковой.
Прим.: в случае повторного нахождения в
строке подходящей нам подпоследовательности, она будет проигнорирована, а
результатом функции будет самая первая подходящая подпоследовательность
символов.
Наконец, процесс подготовки завершен, и мы можем потренироваться в написании регулярных выражений. Но, предварительно, давайте разберемся, как выглядят шаблоны для поиска. Вот самые основные из них:
| Метасимвол | Описание |
| . |
Точка — обозначает любой символ в шаблоне на указанной позиции (кроме знака новой строки n). |
| s | Любой знак пробела, а именно: пробел, табуляция и перенос строки. |
| S |
Противоположный по смыслу вариант предыдущего шаблона, то есть любой символ, не выглядящий как пробел. |
| d | Цифровой символ, то есть любая цифра. |
| D | Нецифровой символ — любой символ кроме цифры. |
| w | Любой символ латиницы (a-z, A-Z), цифра (0-9) или знак подчеркивания (_). |
| W |
Анти-вариант предыдущего, то есть не латиница, не цифра и не подчеркивание. |
| [символы] |
В квадратных скобках можно указать один или несколько символов, разрешенных на указанной позиции в тексте. Например, тр[ае]к будет соответствовать любому из слов: трак или трек. Также можно не перечислять символы, а задать их диапазоном через дефис, таким образом, вместо [АБВГД] можно написать [А-Д], или вместо [12345] ввести [1-5]. Например, для обозначения всех символов кириллицы можно использовать шаблон [а-яА-ЯёЁ]. |
| [^символы] |
Символ ^ придает набору символов в квадратных скобках обратный смысл — на указанной позиции в тексте будут разрешены все символы, кроме перечисленных. Так, шаблон [^дп]уть найдет суть или муть, но не дуть или путь, например. |
| | |
Логический оператор ИЛИ для проверки по любому из альтернативных критериев. Например, (ТБ|ГОСБ|ВСП) будет искать в тексте любое из указанных слов. Обычно набор вариантов заключается в скобки. |
| ^ | Позиция начала строки |
| $ | Позиция конца строки |
| b | Граница слова, то есть позиция между словом и пробелом |
| B | Позиция, отличная от границы слова |
Если мы ищем определенное количество символов, например, пятизначные номера ВСП или двадцатизначные номера счетов, то на помощь нам приходят квантификаторы — специальные выражения, задающие количество вхождений искомых знаков. Квантификатор применяется к предыдущему символу:
| Квантификатор | Описание |
| ? |
Ноль или одно вхождение. Например, d? будет означать одна любая цифра или ее отсутствие. |
| + | Одно или более вхождений. К примеру, s+ означает один или более пробелов. |
| * |
Ноль или более вхождений. Так [A—Z]* — как отсутствие, так и наличие любого количества прописных символов латиницы. |
|
{число} или {число1,число2} |
Этот квантификатор задает строго определенное вхождение символа. Например, d{10} означает строго десять цифр, а d{3,5} — от трех до пяти цифр. |
Теперь можем перейти к
самому интересному – написанию формул, обрабатывающих реальные примеры из
жизни. Все, что нам потребуется – это написать в качестве формулы наименование
нашей пользовательской функции (RegExp), где первым параметром
будет просматриваемый текст, а вторым – шаблон регулярного выражения,
осуществляющий поиск интересующей нас подстроки.
К примеру, рассмотрим задачу поиска в строке ИНН:*

Как видим, теперь и 10-значные, и 12-значные ИНН извлекаются корректно. Рассмотрим шаблон более подробно: b(d{10}|d{12})b. В начале и в конце шаблона мы видим добавившиеся символы b – они означают края слова и применяются для того, чтобы вместо ИНН из текста не тянулась часть более длинного ОГРН или еще какой-либо последовательности цифр. Также, мы видим, что уже знакомый нам шаблон d{10} переместился в скобки и получил альтернативный шаблон d{12} – это сделано для того, чтобы наряду с 10-значными ИНН, производился поиск и 12-значных.
Рассмотрим следующий пример: имеется перечень клиентских операций, где
каждая операция содержит ФИО клиента, которые нам требуется извлечь. Относительно
ФИО строго выполняется лишь одно условие — они всегда набраны в верхнем
регистре. Стандартные функции Excel также не справятся:

В данном случае мы
применяем шаблон вида [А-ЯЁ]+s[А-ЯЁ]+s[А-ЯЁ]+, который состоит из трех шаблонов [А-ЯЁ]+,
соединенных между собой символами s. Здесь все просто –
[А-ЯЁ]+ это любой заглавный символ кириллицы с квантификатором +, то есть
встречающийся от одного раза до бесконечности. Это, как раз, и будет либо
фамилией, либо именем, либо отчеством клиента. Соединительные символы s означают пробелы между членами ФИО.
Подытоживая, хочется
отметить, что мы рассмотрели лишь малую часть всех возможностей, которые
предоставляют регулярные выражения. Существует огромное множество спецсимволов,
правил и квантификаторов, комбинируя которые возможно создавать шаблоны
практически под любые подпоследовательности символов. На тему использования регулярных
выражений написаны целые книги. Стоит отметить, что не все возможности
классических регулярных выражений поддерживаются в VBA, но и этого хватит, чтобы облегчить нашу работу с MS Excel.

Доброго времени суток!
Стоит задача разделить одну ячейку на четыре.
Вот целая ячейка:

Вот желаемый результат:
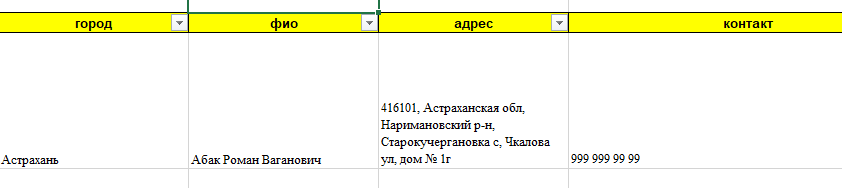
Какие выражения необходимо прописать в эти ячейки?
-
Вопрос заданболее двух лет назад
-
5138 просмотров
Пригласить эксперта
Есть 2 варианта — искать определенные символы с помощью ПОИСК() и нарезания строки с помощью ПСТР() или же использовать регулярки
Public Function RegExpExtract(sText As Variant, Pattern As String) As Variant
On Error GoTo ErrHandl
Text = CStr(sText)
Dim regex As New RegExp ' создаем экземпляр RegExp
regex.Pattern = Pattern
regex.Global = False
If regex.test(Text) Then
Set matches = regex.Execute(Text)
RegExpExtract = matches.Item(0).SubMatches(0)
Exit Function
End If
ErrHandl:
RegExpExtract = ""
'RegExpExtract = "#" & err.Number & "> " & err.Description
End FunctionРаботает примерно как REGEXEXTRACT() в Google Sheets
Для каждой ячейки в зависимости от знаков:
=ПСТР(ячейка;ПОИСК(«Город: «+n;ячейка);ПОИСК(«ФИО/магазин:»;ячейка)-ПОИСК(«Город: «+т;ячейка)+n)
Ячейка — ссылка на ячейку,
+n — знаки определим подбором, если без усложнения формулы)
-
Показать ещё
Загружается…
14 апр. 2023, в 07:54
300000 руб./за проект
14 апр. 2023, в 07:48
4500 руб./за проект
14 апр. 2023, в 04:52
5000 руб./за проект
Минуточку внимания
Regular expressions are used for Pattern Matching.
To use in Excel follow these steps:
Step 1: Add VBA reference to «Microsoft VBScript Regular Expressions 5.5»
- Select «Developer» tab (I don’t have this tab what do I do?)
- Select «Visual Basic» icon from ‘Code’ ribbon section
- In «Microsoft Visual Basic for Applications» window select «Tools» from the top menu.
- Select «References»
- Check the box next to «Microsoft VBScript Regular Expressions 5.5» to include in your workbook.
- Click «OK»
Step 2: Define your pattern
Basic definitions:
- Range.
- E.g.
a-zmatches an lower case letters from a to z - E.g.
0-5matches any number from 0 to 5
[] Match exactly one of the objects inside these brackets.
- E.g.
[a]matches the letter a - E.g.
[abc]matches a single letter which can be a, b or c - E.g.
[a-z]matches any single lower case letter of the alphabet.
() Groups different matches for return purposes. See examples below.
{} Multiplier for repeated copies of pattern defined before it.
- E.g.
[a]{2}matches two consecutive lower case letter a:aa - E.g.
[a]{1,3}matches at least one and up to three lower case lettera,aa,aaa
+ Match at least one, or more, of the pattern defined before it.
- E.g.
a+will match consecutive a’sa,aa,aaa, and so on
? Match zero or one of the pattern defined before it.
- E.g. Pattern may or may not be present but can only be matched one time.
- E.g.
[a-z]?matches empty string or any single lower case letter.
* Match zero or more of the pattern defined before it.
- E.g. Wildcard for pattern that may or may not be present.
- E.g.
[a-z]*matches empty string or string of lower case letters.
. Matches any character except newline n
- E.g.
a.Matches a two character string starting with a and ending with anything exceptn
| OR operator
- E.g.
a|bmeans eitheraorbcan be matched. - E.g.
red|white|orangematches exactly one of the colors.
^ NOT operator
- E.g.
[^0-9]character can not contain a number - E.g.
[^aA]character can not be lower caseaor upper caseA
Escapes special character that follows (overrides above behavior)
- E.g.
.,\,(,?,$,^
Anchoring Patterns:
^ Match must occur at start of string
- E.g.
^aFirst character must be lower case lettera - E.g.
^[0-9]First character must be a number.
$ Match must occur at end of string
- E.g.
a$Last character must be lower case lettera
Precedence table:
Order Name Representation
1 Parentheses ( )
2 Multipliers ? + * {m,n} {m, n}?
3 Sequence & Anchors abc ^ $
4 Alternation |
Predefined Character Abbreviations:
abr same as meaning
d [0-9] Any single digit
D [^0-9] Any single character that's not a digit
w [a-zA-Z0-9_] Any word character
W [^a-zA-Z0-9_] Any non-word character
s [ rtnf] Any space character
S [^ rtnf] Any non-space character
n [n] New line
Example 1: Run as macro
The following example macro looks at the value in cell A1 to see if the first 1 or 2 characters are digits. If so, they are removed and the rest of the string is displayed. If not, then a box appears telling you that no match is found. Cell A1 values of 12abc will return abc, value of 1abc will return abc, value of abc123 will return «Not Matched» because the digits were not at the start of the string.
Private Sub simpleRegex()
Dim strPattern As String: strPattern = "^[0-9]{1,2}"
Dim strReplace As String: strReplace = ""
Dim regEx As New RegExp
Dim strInput As String
Dim Myrange As Range
Set Myrange = ActiveSheet.Range("A1")
If strPattern <> "" Then
strInput = Myrange.Value
With regEx
.Global = True
.MultiLine = True
.IgnoreCase = False
.Pattern = strPattern
End With
If regEx.Test(strInput) Then
MsgBox (regEx.Replace(strInput, strReplace))
Else
MsgBox ("Not matched")
End If
End If
End Sub
Example 2: Run as an in-cell function
This example is the same as example 1 but is setup to run as an in-cell function. To use, change the code to this:
Function simpleCellRegex(Myrange As Range) As String
Dim regEx As New RegExp
Dim strPattern As String
Dim strInput As String
Dim strReplace As String
Dim strOutput As String
strPattern = "^[0-9]{1,3}"
If strPattern <> "" Then
strInput = Myrange.Value
strReplace = ""
With regEx
.Global = True
.MultiLine = True
.IgnoreCase = False
.Pattern = strPattern
End With
If regEx.test(strInput) Then
simpleCellRegex = regEx.Replace(strInput, strReplace)
Else
simpleCellRegex = "Not matched"
End If
End If
End Function
Place your strings («12abc») in cell A1. Enter this formula =simpleCellRegex(A1) in cell B1 and the result will be «abc».
Example 3: Loop Through Range
This example is the same as example 1 but loops through a range of cells.
Private Sub simpleRegex()
Dim strPattern As String: strPattern = "^[0-9]{1,2}"
Dim strReplace As String: strReplace = ""
Dim regEx As New RegExp
Dim strInput As String
Dim Myrange As Range
Set Myrange = ActiveSheet.Range("A1:A5")
For Each cell In Myrange
If strPattern <> "" Then
strInput = cell.Value
With regEx
.Global = True
.MultiLine = True
.IgnoreCase = False
.Pattern = strPattern
End With
If regEx.Test(strInput) Then
MsgBox (regEx.Replace(strInput, strReplace))
Else
MsgBox ("Not matched")
End If
End If
Next
End Sub
Example 4: Splitting apart different patterns
This example loops through a range (A1, A2 & A3) and looks for a string starting with three digits followed by a single alpha character and then 4 numeric digits. The output splits apart the pattern matches into adjacent cells by using the (). $1 represents the first pattern matched within the first set of ().
Private Sub splitUpRegexPattern()
Dim regEx As New RegExp
Dim strPattern As String
Dim strInput As String
Dim Myrange As Range
Set Myrange = ActiveSheet.Range("A1:A3")
For Each C In Myrange
strPattern = "(^[0-9]{3})([a-zA-Z])([0-9]{4})"
If strPattern <> "" Then
strInput = C.Value
With regEx
.Global = True
.MultiLine = True
.IgnoreCase = False
.Pattern = strPattern
End With
If regEx.test(strInput) Then
C.Offset(0, 1) = regEx.Replace(strInput, "$1")
C.Offset(0, 2) = regEx.Replace(strInput, "$2")
C.Offset(0, 3) = regEx.Replace(strInput, "$3")
Else
C.Offset(0, 1) = "(Not matched)"
End If
End If
Next
End Sub
Results:
Additional Pattern Examples
String Regex Pattern Explanation
a1aaa [a-zA-Z][0-9][a-zA-Z]{3} Single alpha, single digit, three alpha characters
a1aaa [a-zA-Z]?[0-9][a-zA-Z]{3} May or may not have preceding alpha character
a1aaa [a-zA-Z][0-9][a-zA-Z]{0,3} Single alpha, single digit, 0 to 3 alpha characters
a1aaa [a-zA-Z][0-9][a-zA-Z]* Single alpha, single digit, followed by any number of alpha characters
</i8> </[a-zA-Z][0-9]> Exact non-word character except any single alpha followed by any single digit