
#Руководства
- 5 авг 2022
-

0
Как из сотен строк отобразить только необходимые? Как отфильтровать таблицу сразу по нескольким условиям и столбцам? Разбираемся на примерах.
Иллюстрация: Meery Mary для Skillbox Media

Рассказывает просто о сложных вещах из мира бизнеса и управления. До редактуры — пять лет в банке и три — в оценке имущества. Разбирается в Excel, финансах и корпоративной жизни.
Фильтры в Excel — инструмент, с помощью которого из большого объёма информации выбирают и показывают только нужную в данный момент. После фильтрации в таблице отображаются данные, которые соответствуют условиям пользователя. Данные, которые им не соответствуют, скрыты.
В статье разберёмся:
- как установить фильтр по одному критерию;
- как установить несколько фильтров одновременно и отфильтровать таблицу по заданному условию;
- для чего нужен расширенный фильтр и как им пользоваться;
- как очистить фильтры.
Фильтрация данных хорошо знакома пользователям интернет-магазинов. В них не обязательно листать весь ассортимент, чтобы найти нужный товар. Можно заполнить критерии фильтра, и платформа скроет неподходящие позиции.
Фильтры в Excel работают по тому же принципу. Пользователь выбирает параметры данных, которые ему нужно отобразить, — и Excel убирает из таблицы всё лишнее.
Разберёмся, как это сделать.
Для примера воспользуемся отчётностью небольшого автосалона. В таблице собрана информация о продажах: характеристики авто, цены, даты продажи и ответственные менеджеры.
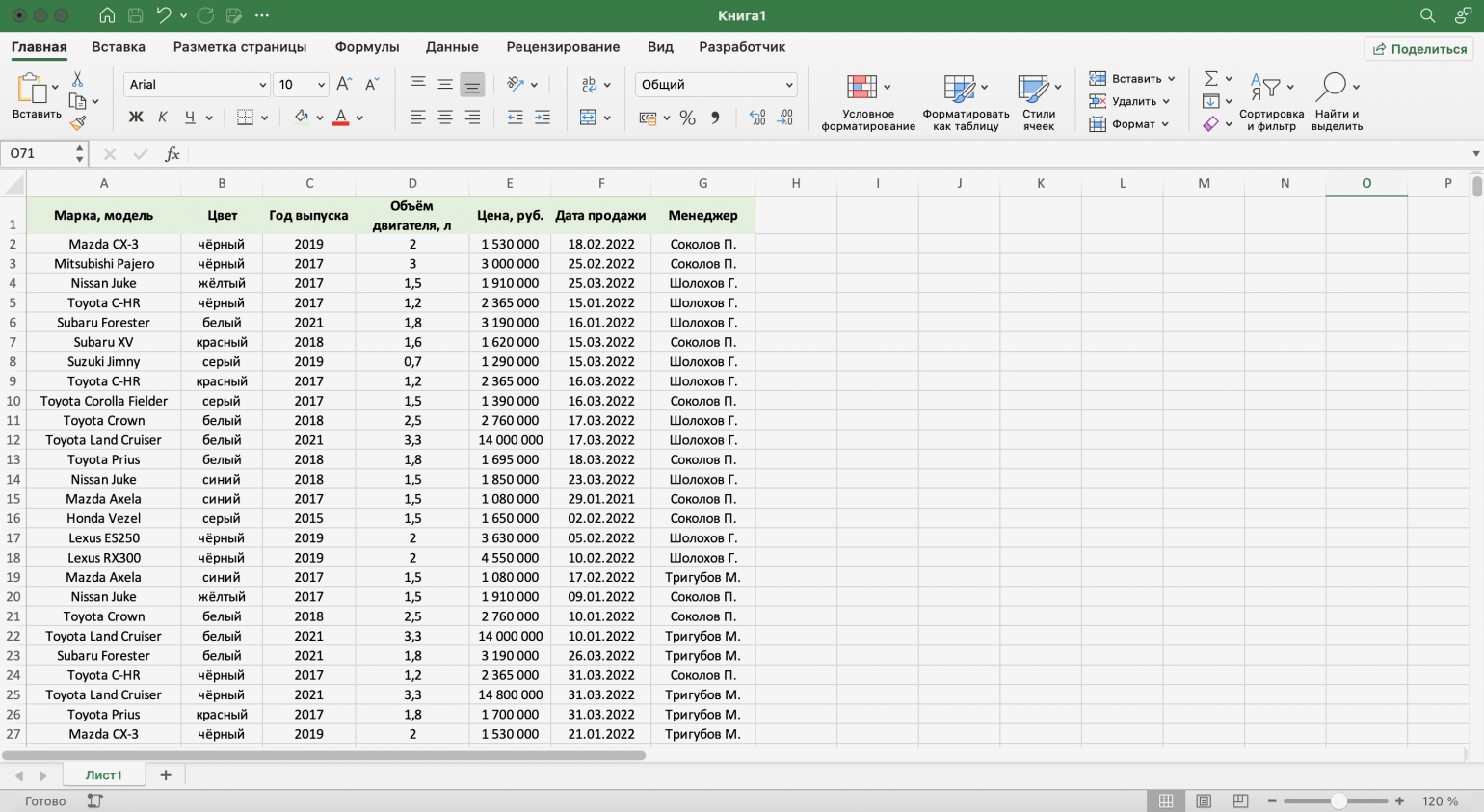
Скриншот: Excel / Skillbox Media
Допустим, нужно показать продажи только одного менеджера — Соколова П. Воспользуемся фильтрацией.
Шаг 1. Выделяем ячейку внутри таблицы — не обязательно ячейку столбца «Менеджер», любую.
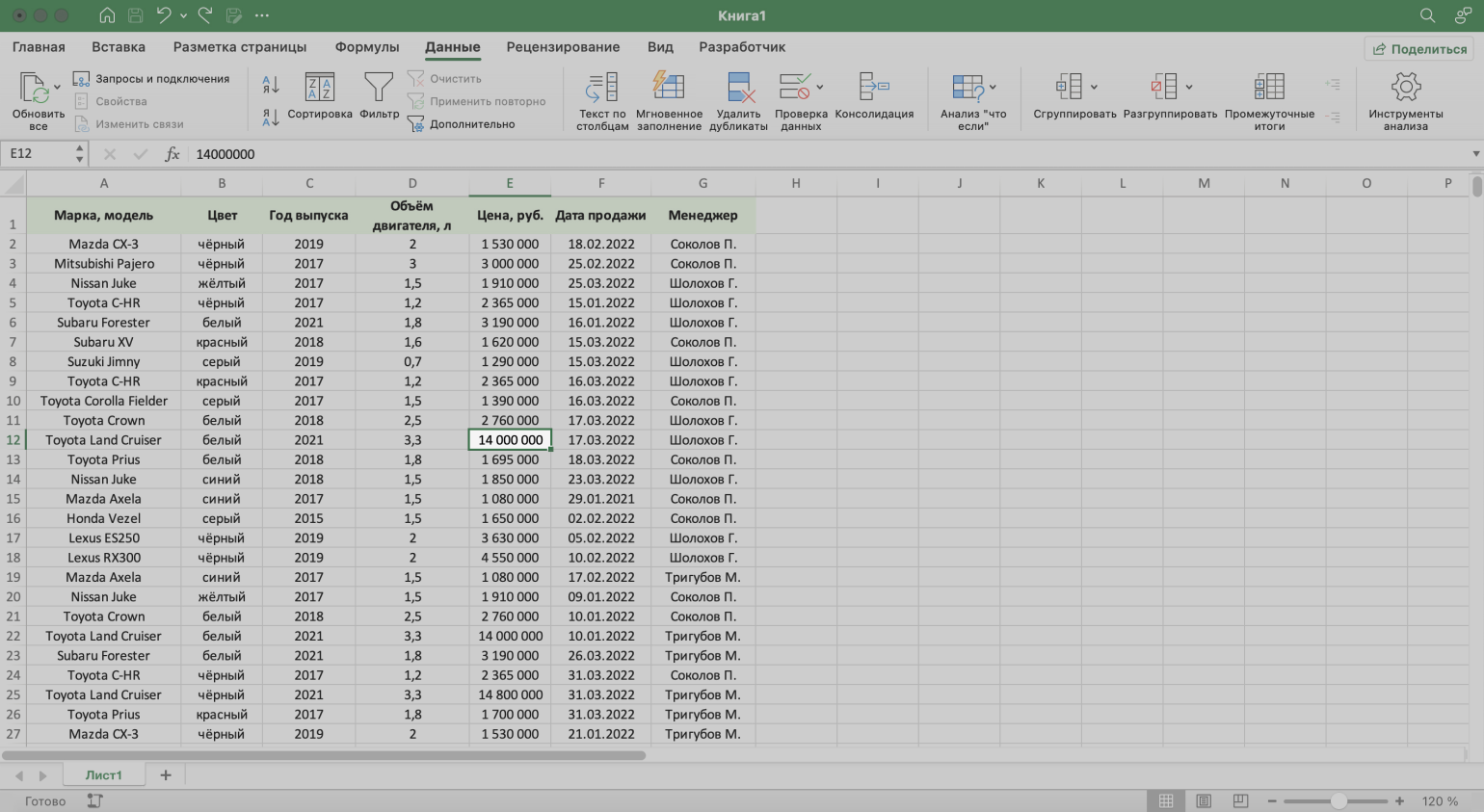
Скриншот: Excel / Skillbox Media
Шаг 2. На вкладке «Главная» нажимаем кнопку «Сортировка и фильтр».
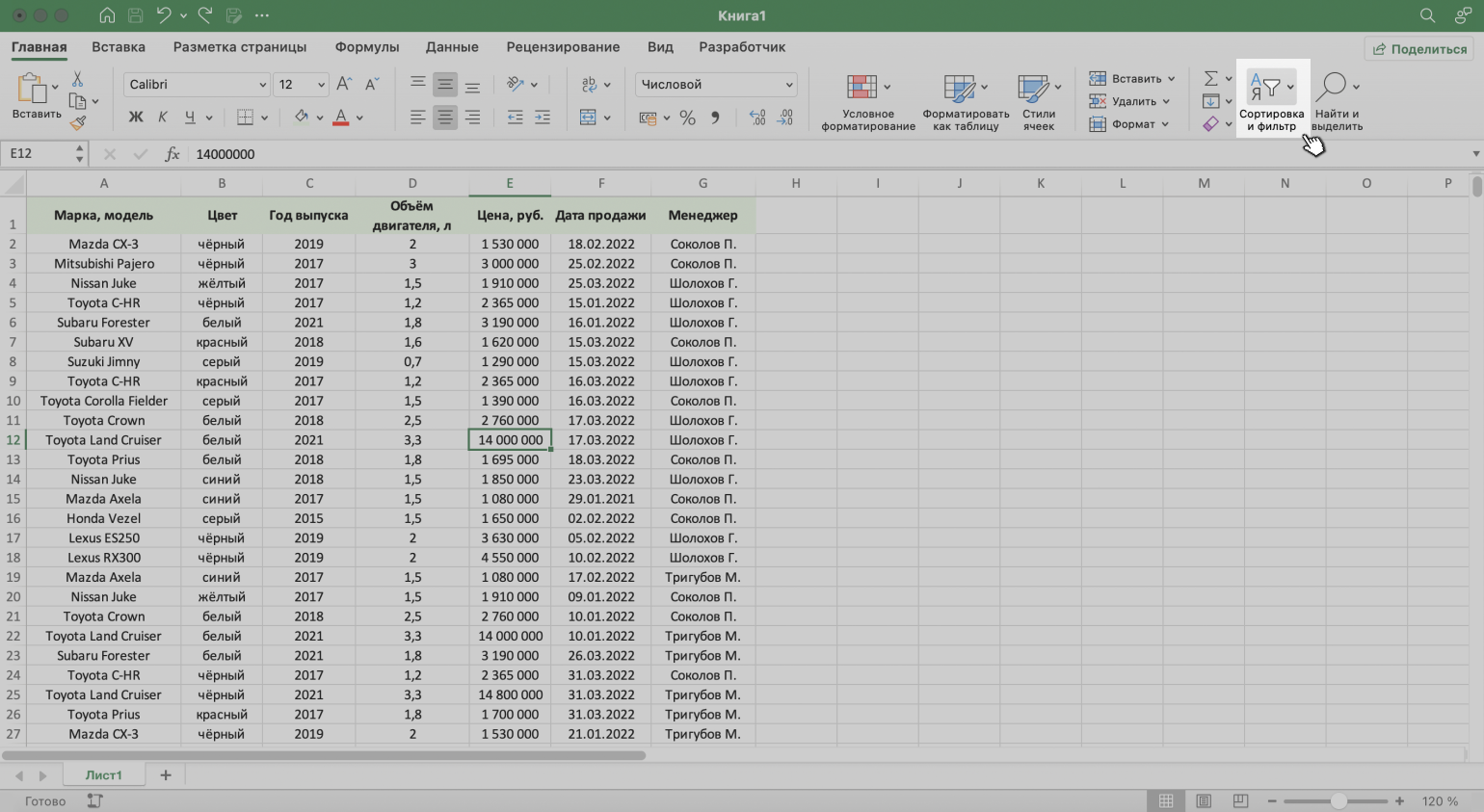
Скриншот: Excel / Skillbox Media
Шаг 3. В появившемся меню выбираем пункт «Фильтр».
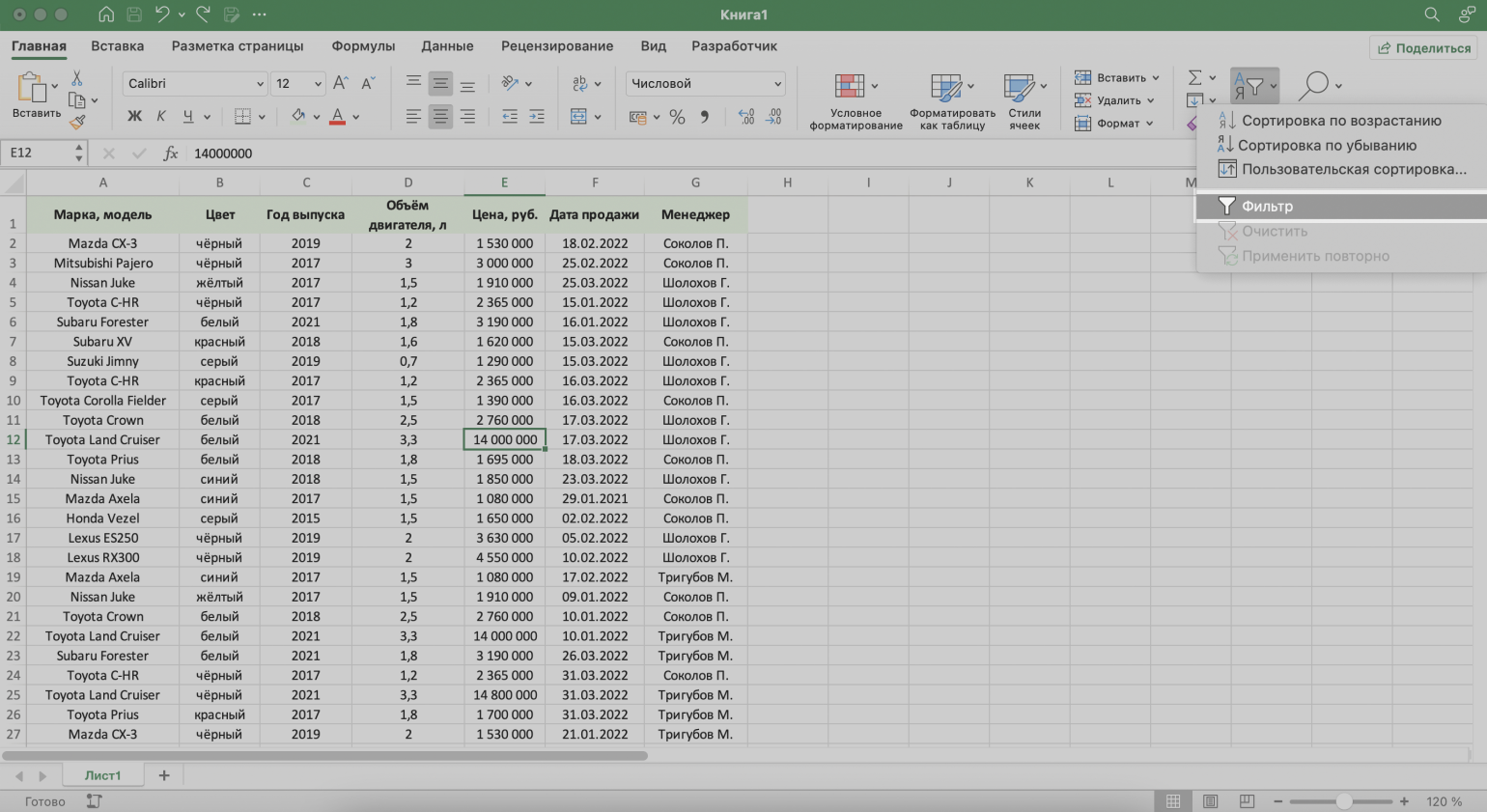
Скриншот: Excel / Skillbox Media
То же самое можно сделать через кнопку «Фильтр» на вкладке «Данные».
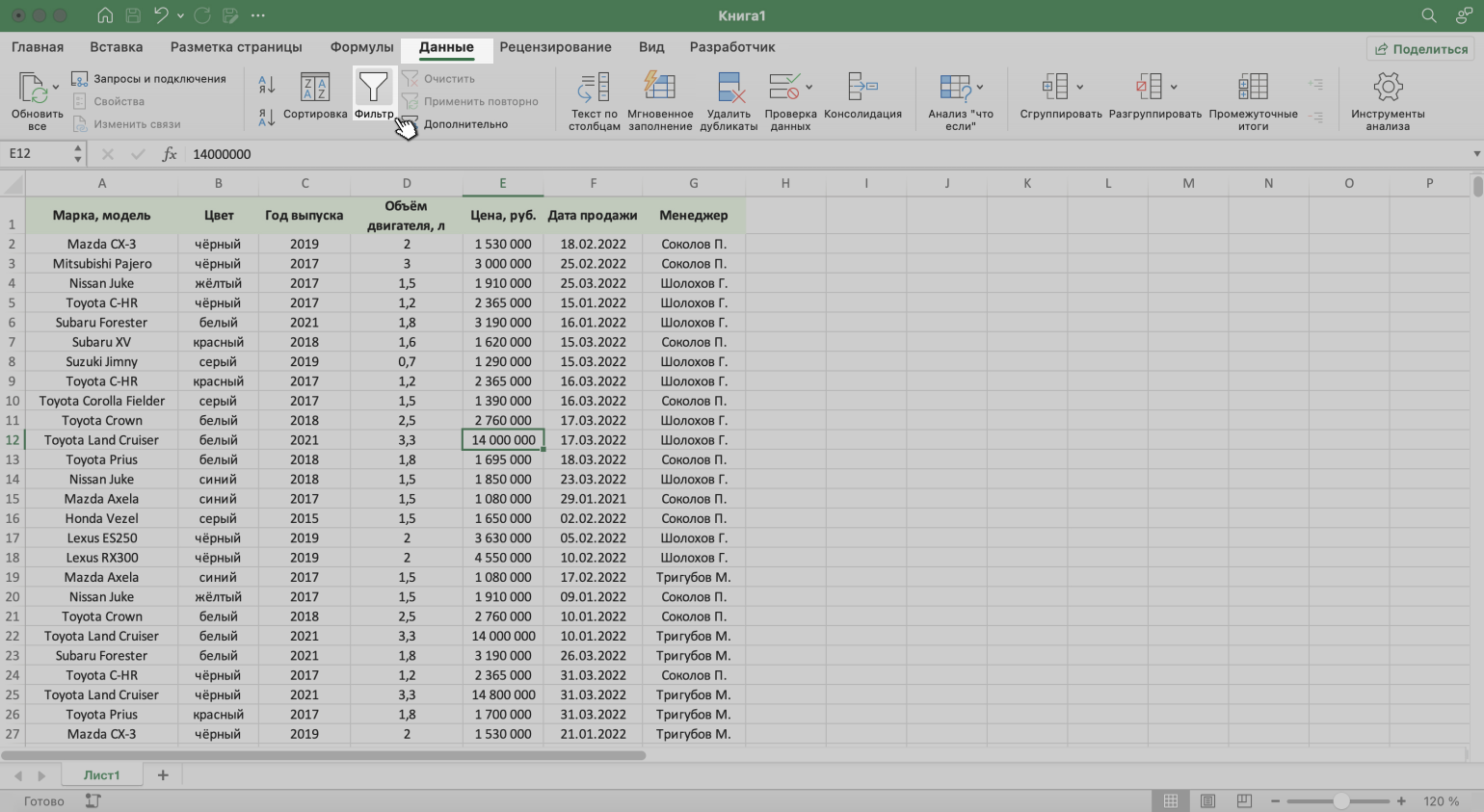
Скриншот: Excel / Skillbox Media
Шаг 4. В каждой ячейке шапки таблицы появились кнопки со стрелками — нажимаем на кнопку столбца, который нужно отфильтровать. В нашем случае это столбец «Менеджер».
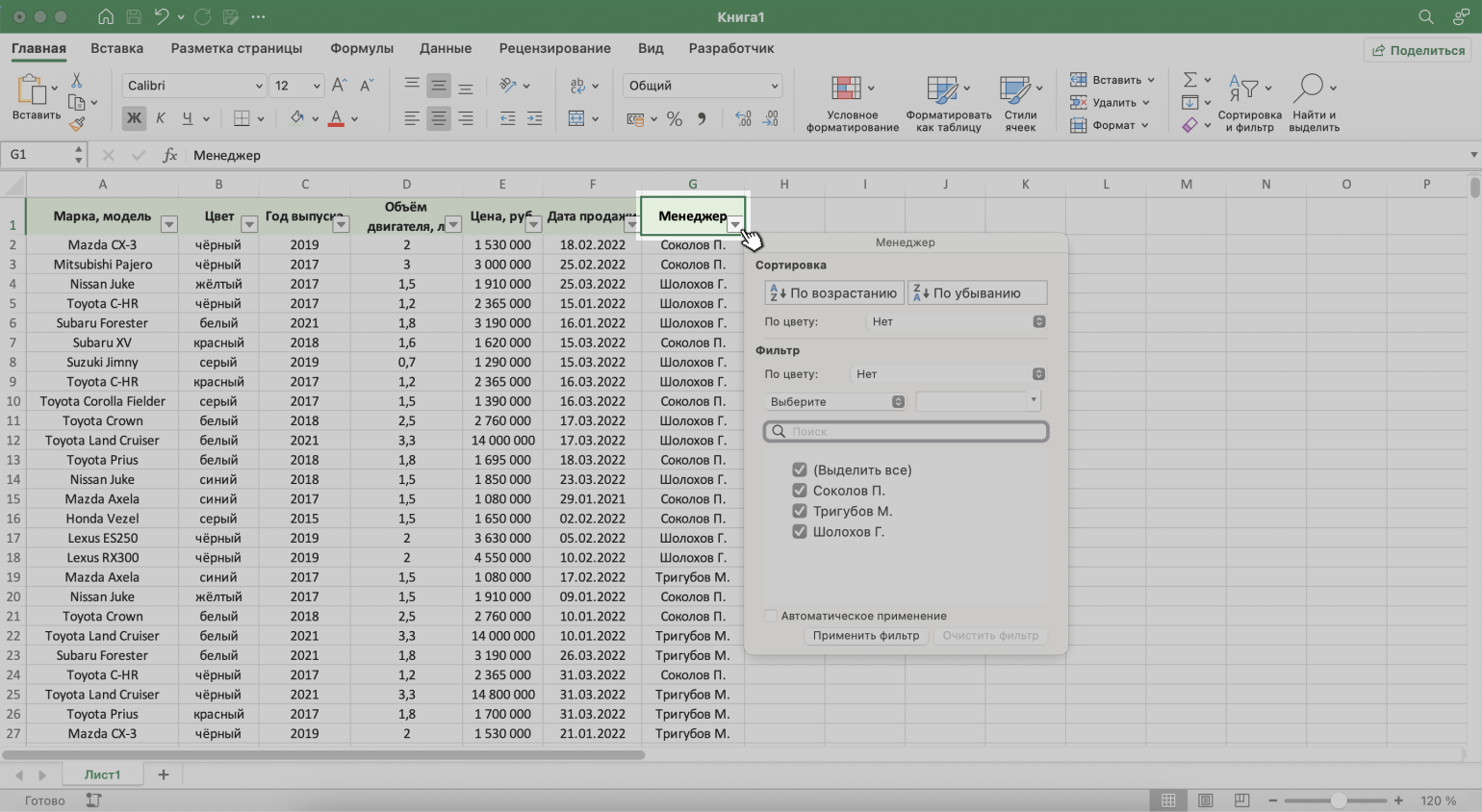
Скриншот: Excel / Skillbox Media
Шаг 5. В появившемся меню флажком выбираем данные, которые нужно оставить в таблице, — в нашем случае данные менеджера Соколова П., — и нажимаем кнопку «Применить фильтр».
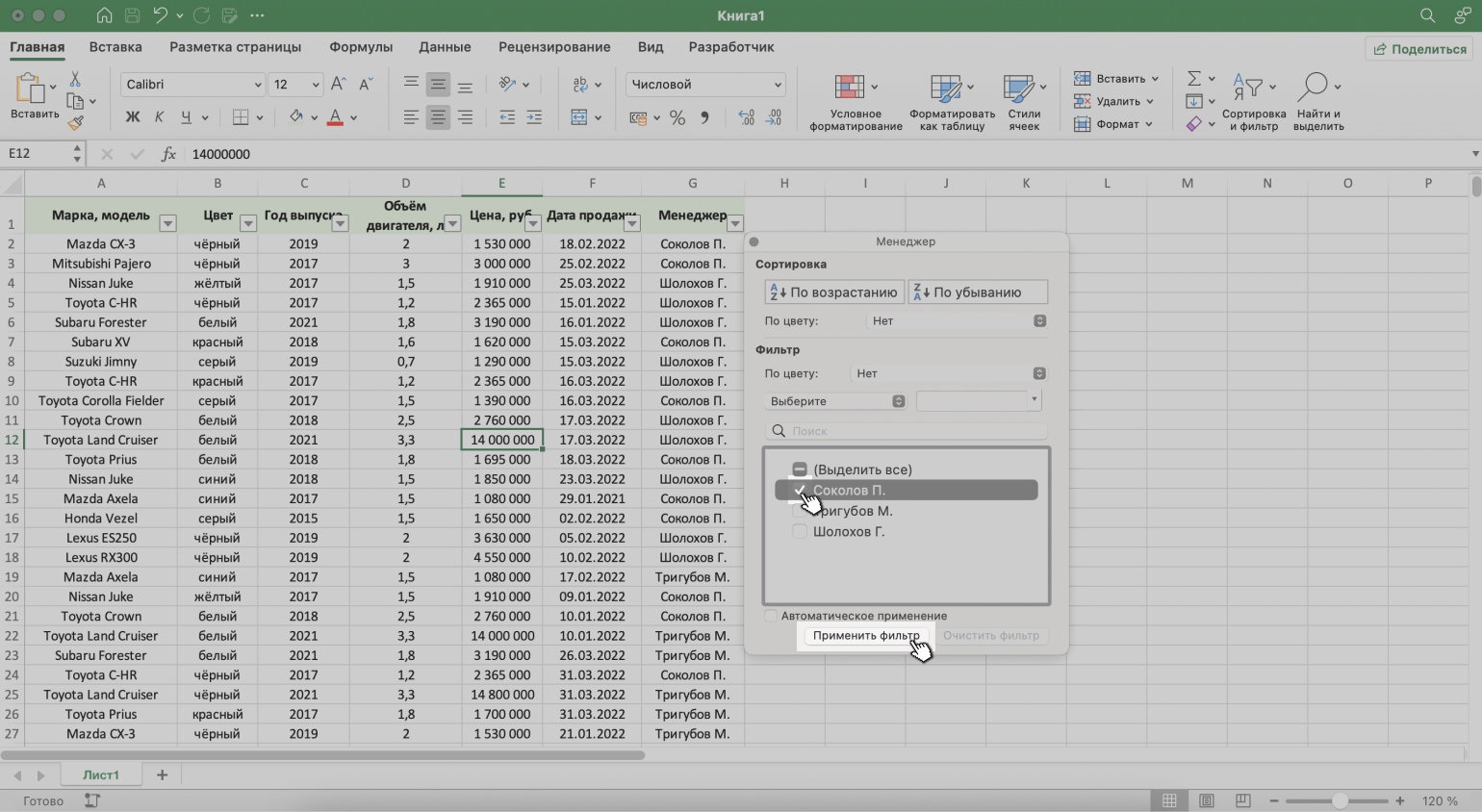
Скриншот: Excel / Skillbox Media
Готово — таблица показывает данные о продажах только одного менеджера. На кнопке со стрелкой появился дополнительный значок. Он означает, что в этом столбце настроена фильтрация.
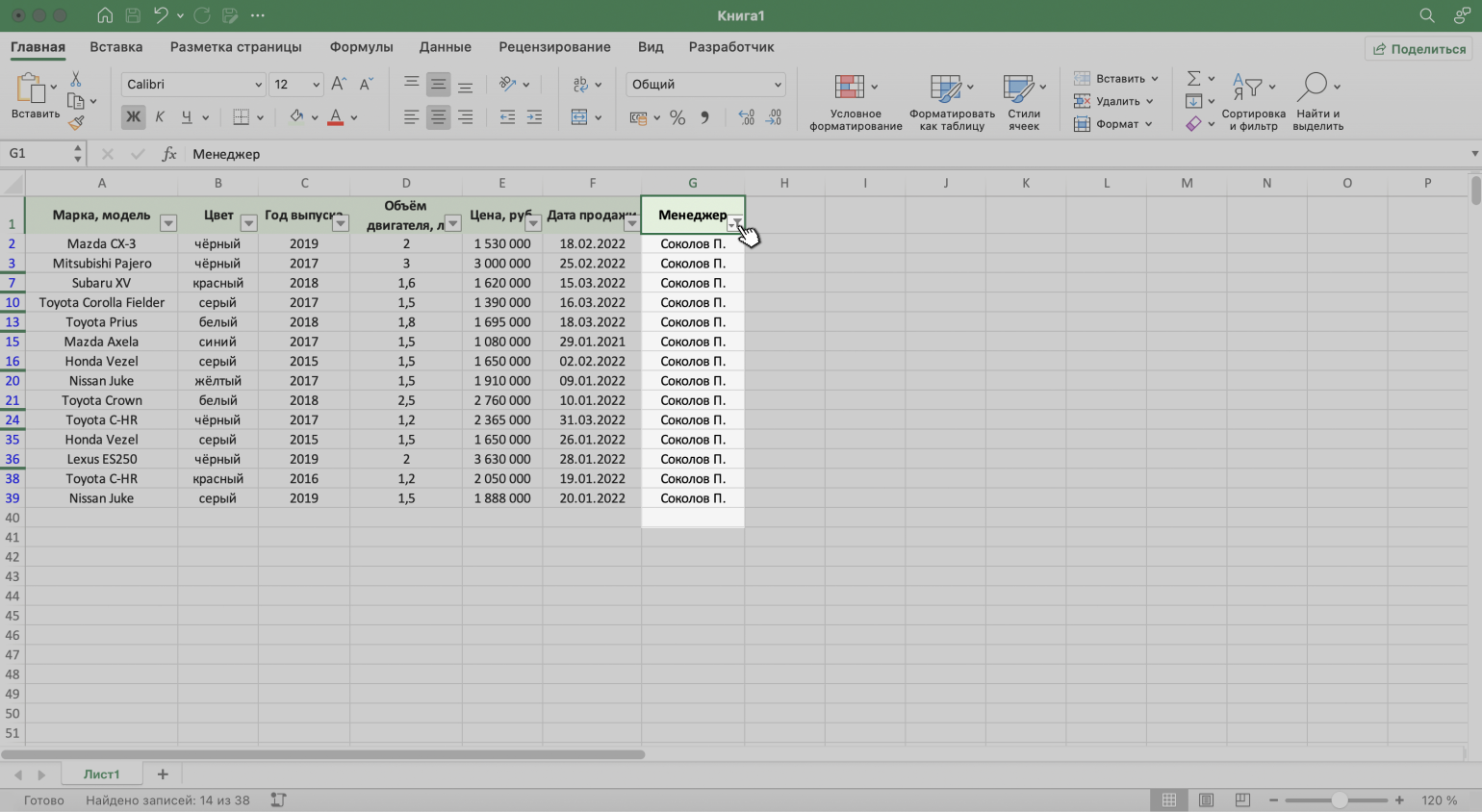
Скриншот: Excel / Skillbox Media
Чтобы ещё уменьшить количество отображаемых в таблице данных, можно применять несколько фильтров одновременно. При этом как фильтр можно задавать не только точное значение ячеек, но и условие, которому отфильтрованные ячейки должны соответствовать.
Разберём на примере.
Выше мы уже отфильтровали таблицу по одному параметру — оставили в ней продажи только менеджера Соколова П. Добавим второй параметр — среди продаж Соколова П. покажем автомобили дороже 1,5 млн рублей.
Шаг 1. Открываем меню фильтра для столбца «Цена, руб.» и нажимаем на параметр «Выберите».
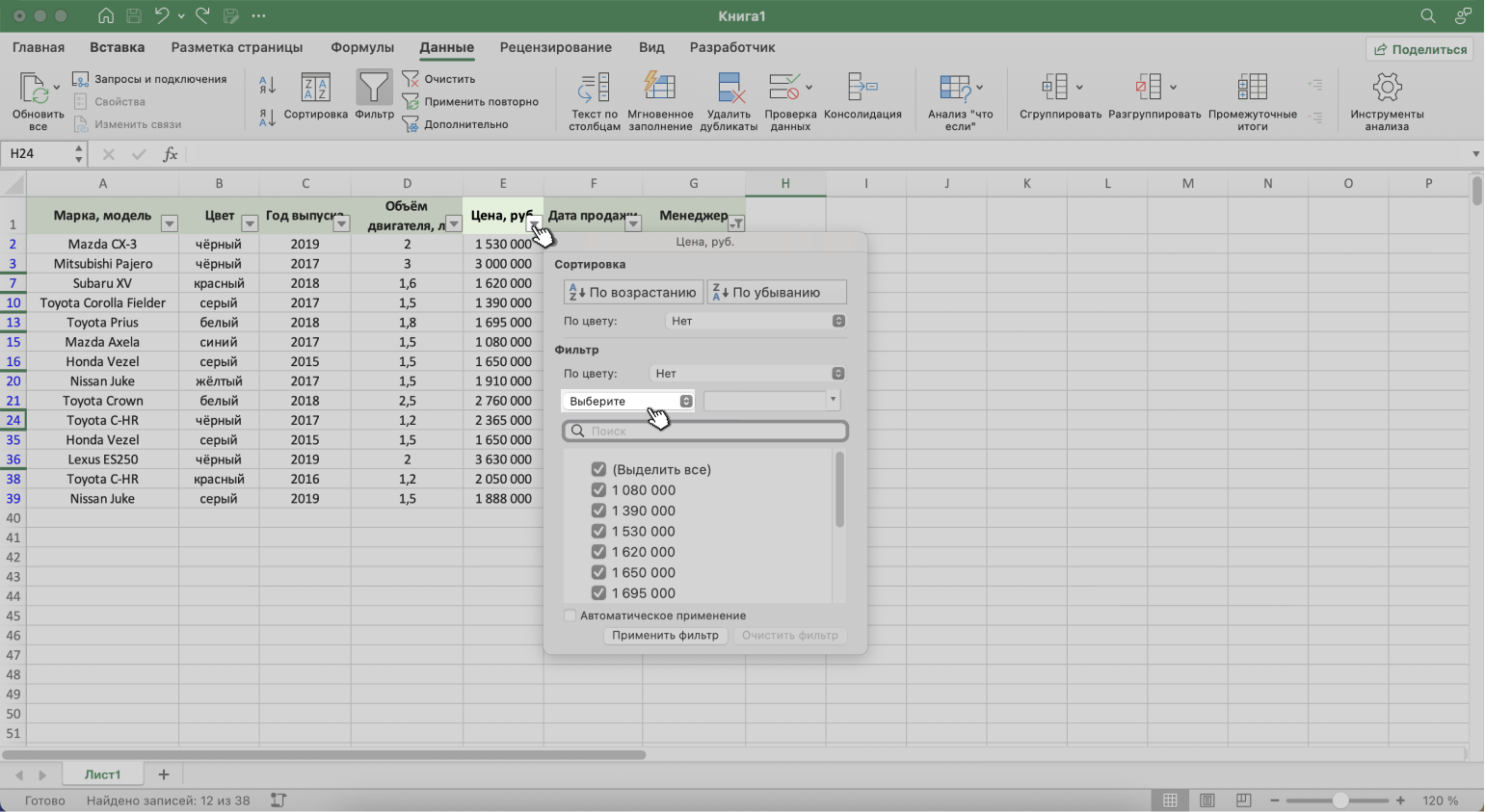
Скриншот: Excel / Skillbox Media
Шаг 2. Выбираем критерий, которому должны соответствовать отфильтрованные ячейки.
В нашем случае нужно показать автомобили дороже 1,5 млн рублей — выбираем критерий «Больше».
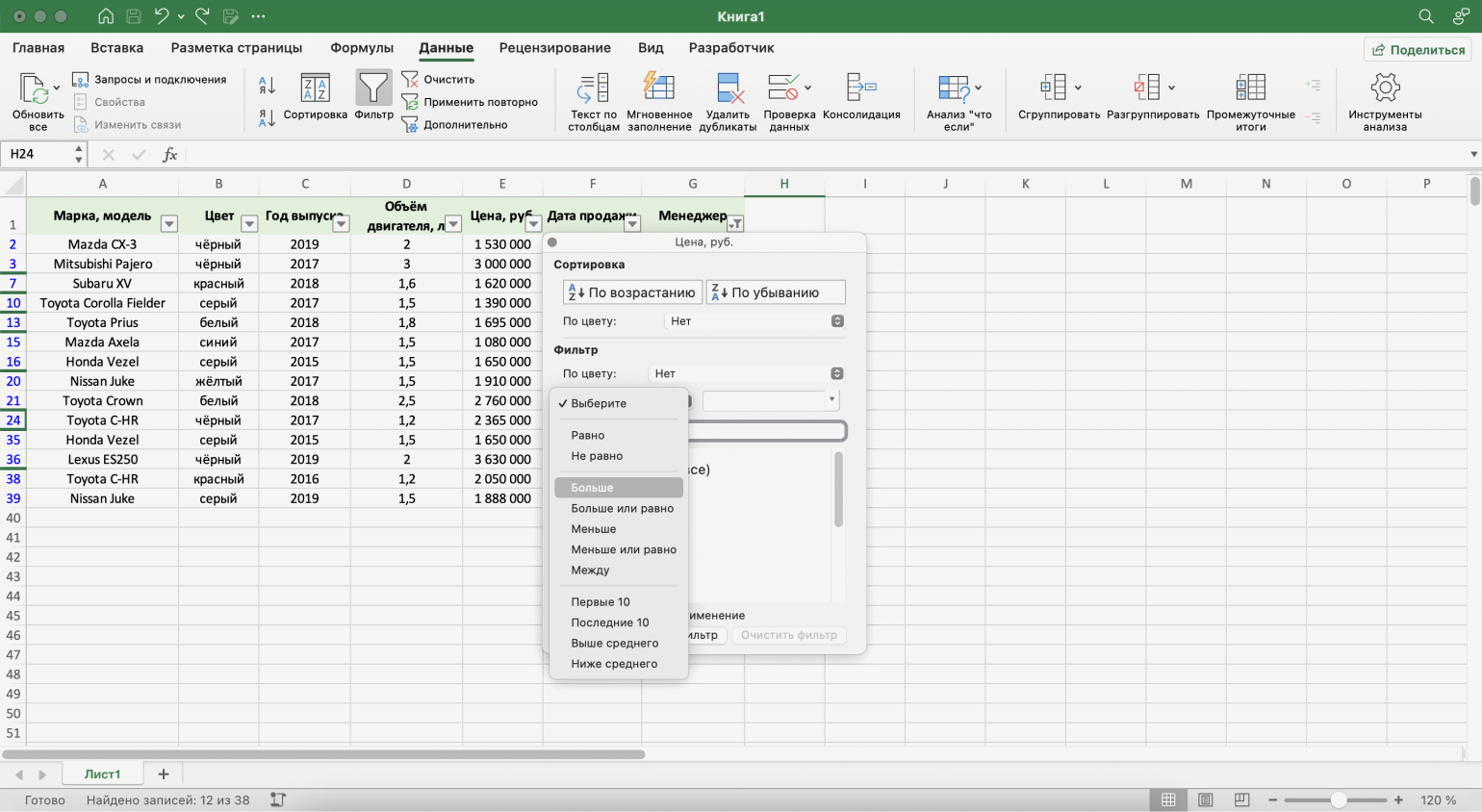
Скриншот: Excel / Skillbox Media
Шаг 3. Дополняем условие фильтрации — в нашем случае «Больше 1500000» — и нажимаем «Применить фильтр».
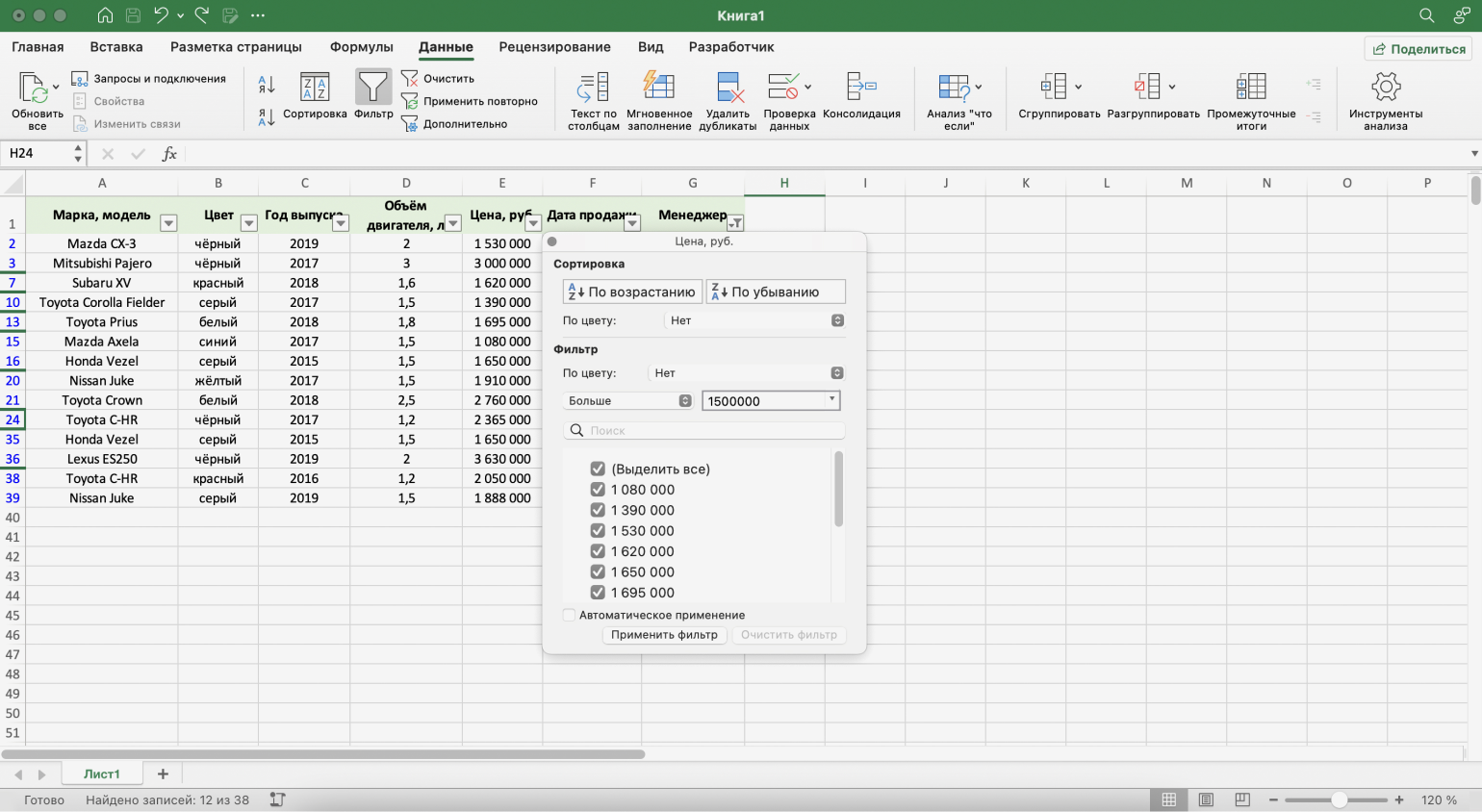
Скриншот: Excel / Skillbox Media
Готово — фильтрация сработала по двум параметрам. Теперь таблица показывает только те проданные менеджером авто, цена которых была выше 1,5 млн рублей.
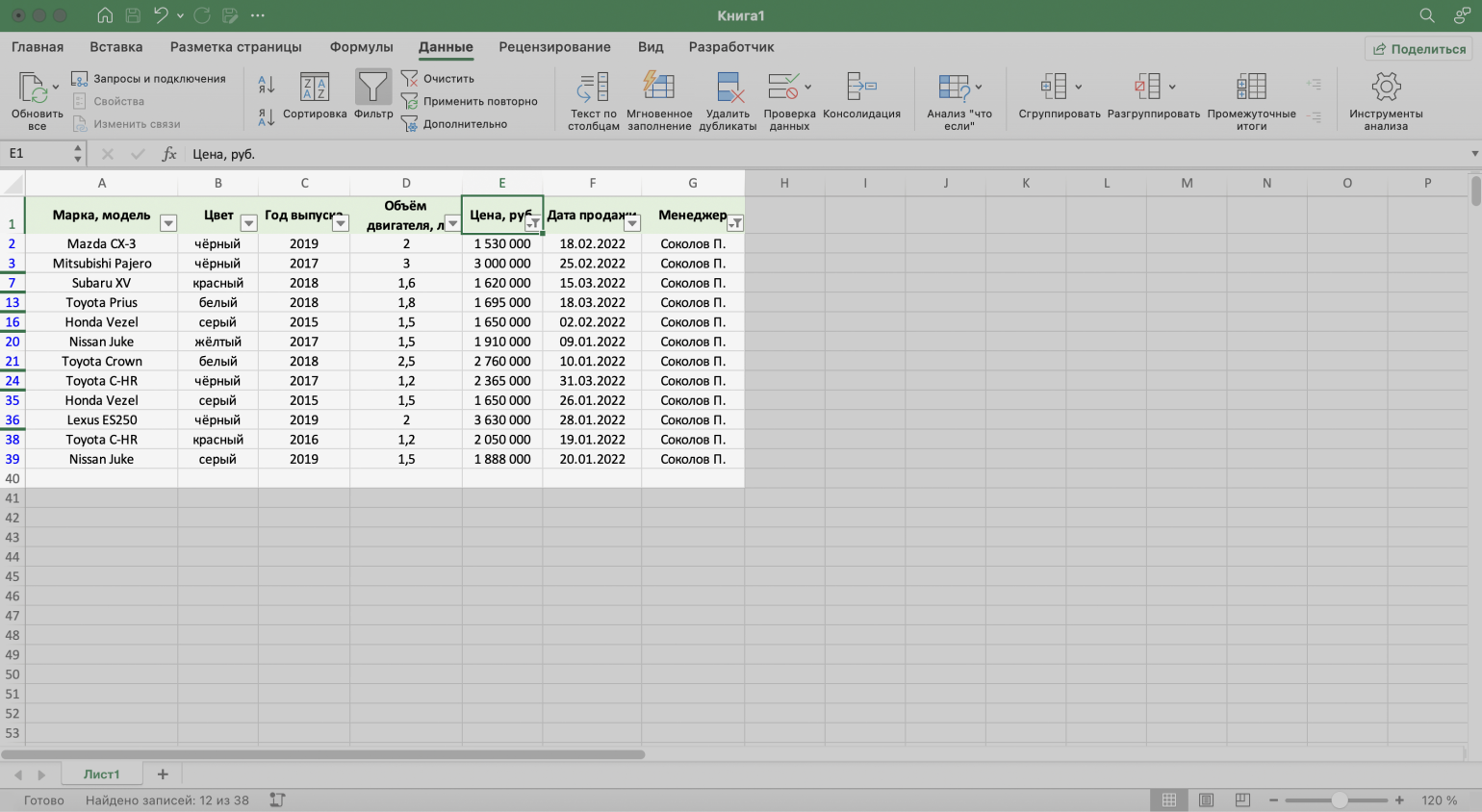
Скриншот: Excel / Skillbox Media
Расширенный фильтр позволяет фильтровать таблицу по сложным критериям сразу в нескольких столбцах.
Это можно сделать способом, который мы описали выше: поочерёдно установить несколько стандартных фильтров или фильтров с условиями пользователя. Но в случае с объёмными таблицами этот способ может быть неудобным и трудозатратным. Для экономии времени применяют расширенный фильтр.
Принцип работы расширенного фильтра следующий:
- Копируют шапку исходной таблицы и создают отдельную таблицу для условий фильтрации.
- Вводят условия.
- Запускают фильтрацию.
Разберём на примере. Отфильтруем отчётность автосалона по трём критериям:
- менеджер — Шолохов Г.;
- год выпуска автомобиля — 2019-й или раньше;
- цена — до 2 млн рублей.
Шаг 1. Создаём таблицу для условий фильтрации — для этого копируем шапку исходной таблицы и вставляем её выше.
Важное условие — между таблицей с условиями и исходной таблицей обязательно должна быть пустая строка.
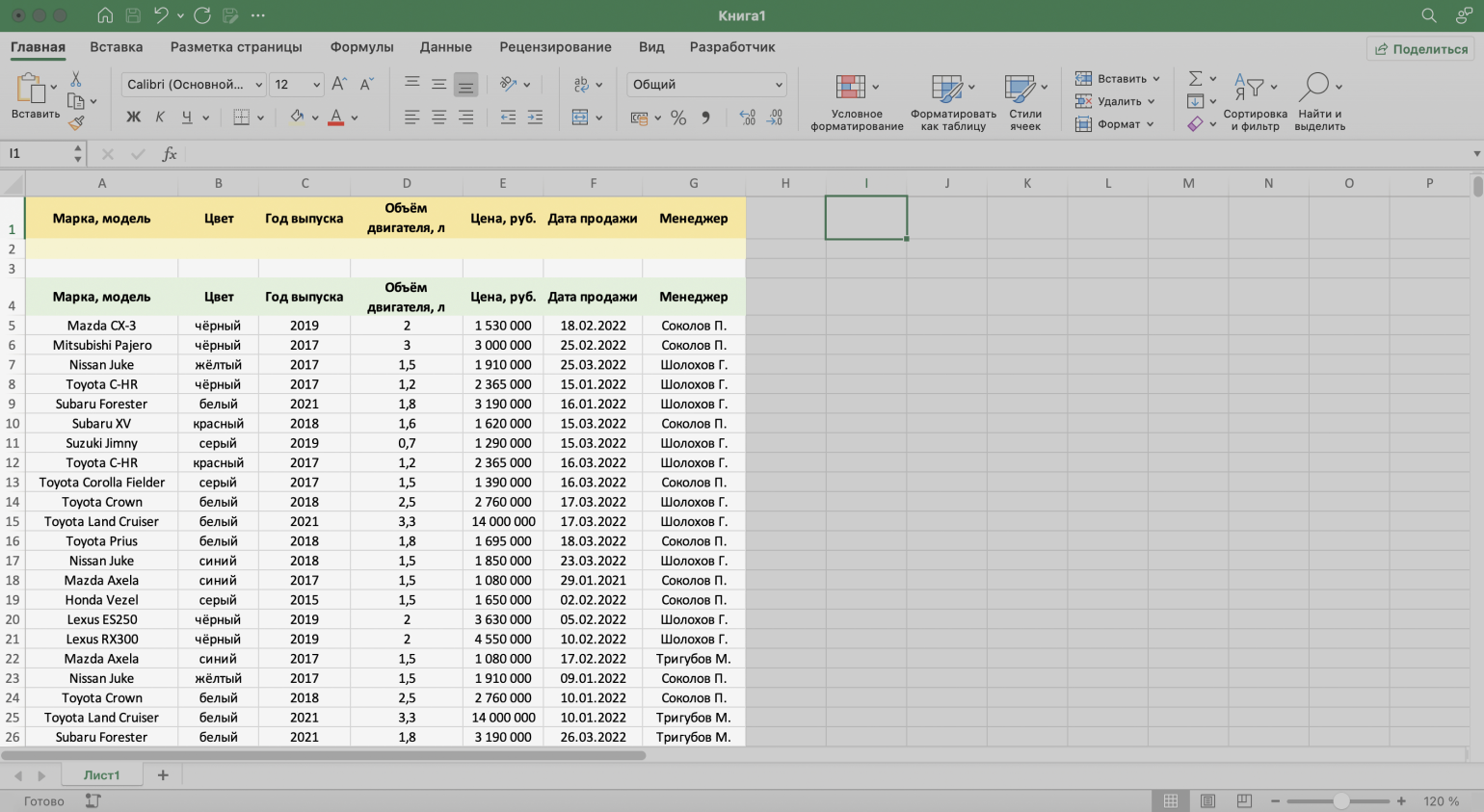
Скриншот: Excel / Skillbox Media
Шаг 2. В созданной таблице вводим критерии фильтрации:
- «Год выпуска» → <=2019.
- «Цена, руб.» → <2000000.
- «Менеджер» → Шолохов Г.
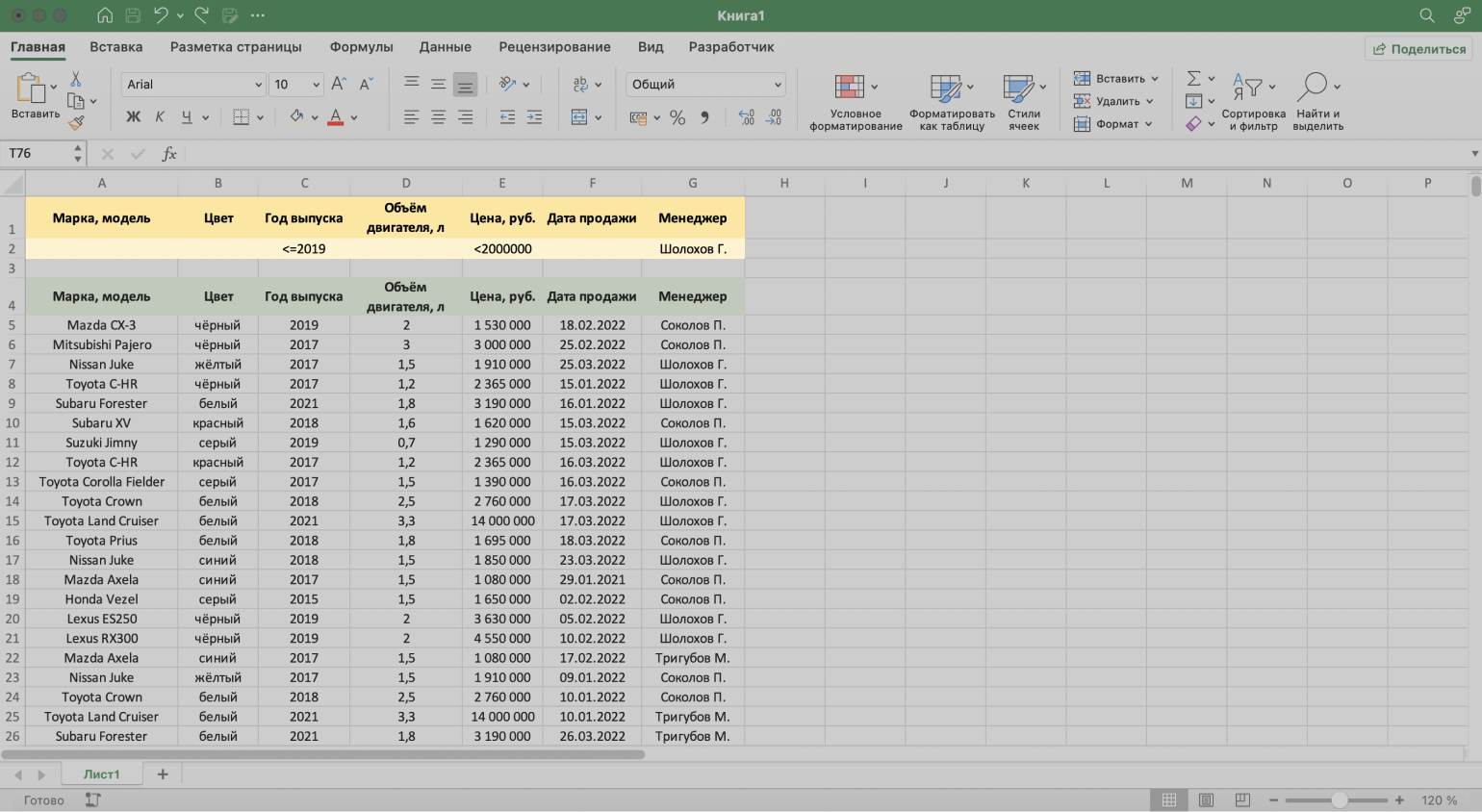
Скриншот: Excel / Skillbox Media
Шаг 3. Выделяем любую ячейку исходной таблицы и на вкладке «Данные» нажимаем кнопку «Дополнительно».
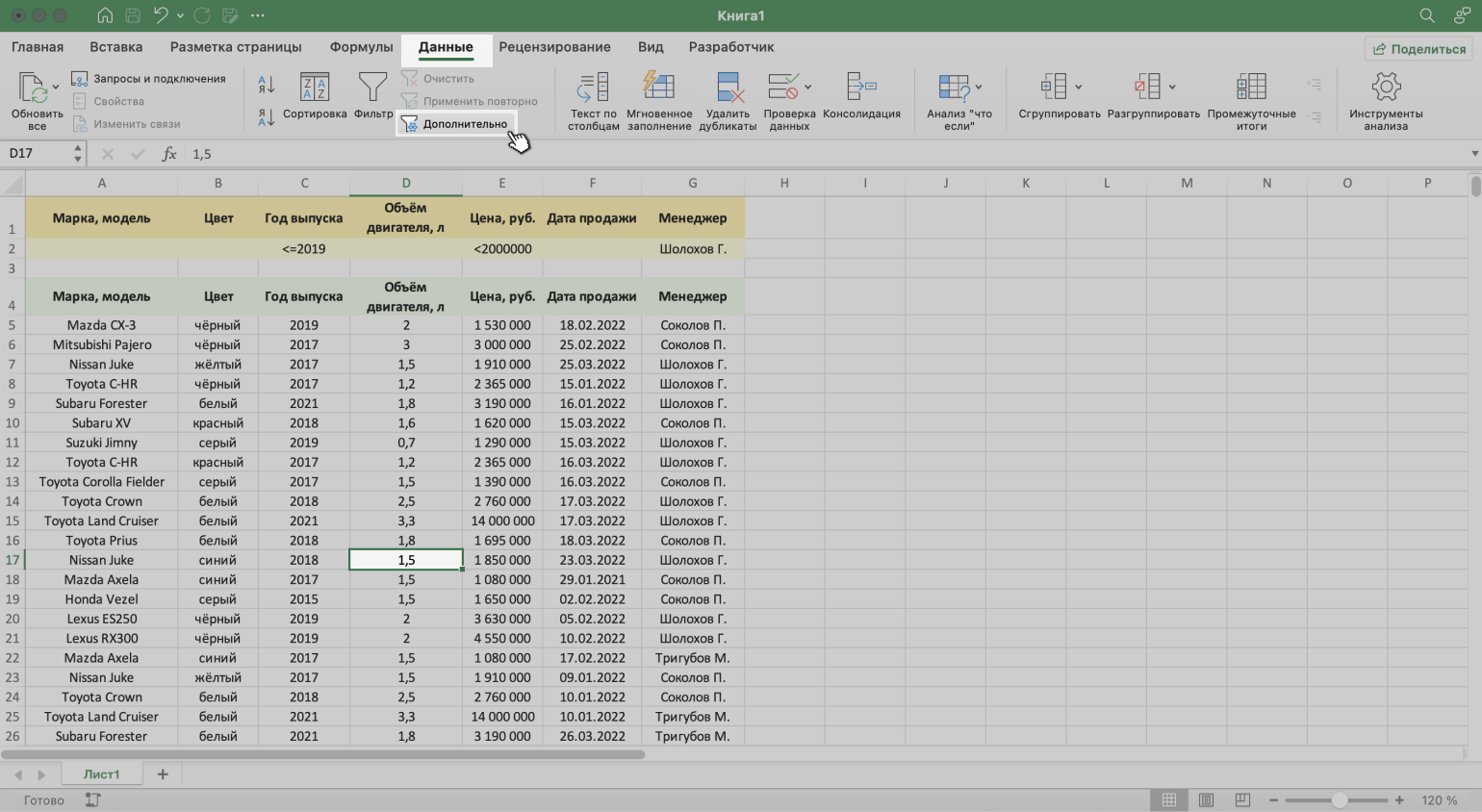
Скриншот: Excel / Skillbox Media
Шаг 4. В появившемся окне заполняем параметры расширенного фильтра:
- Выбираем, где отобразятся результаты фильтрации: в исходной таблице или в другом месте. В нашем случае выберем первый вариант — «Фильтровать список на месте».
- Диапазон списка — диапазон таблицы, для которой нужно применить фильтр. Он заполнен автоматически, для этого мы выделяли ячейку исходной таблицы перед тем, как вызвать меню.
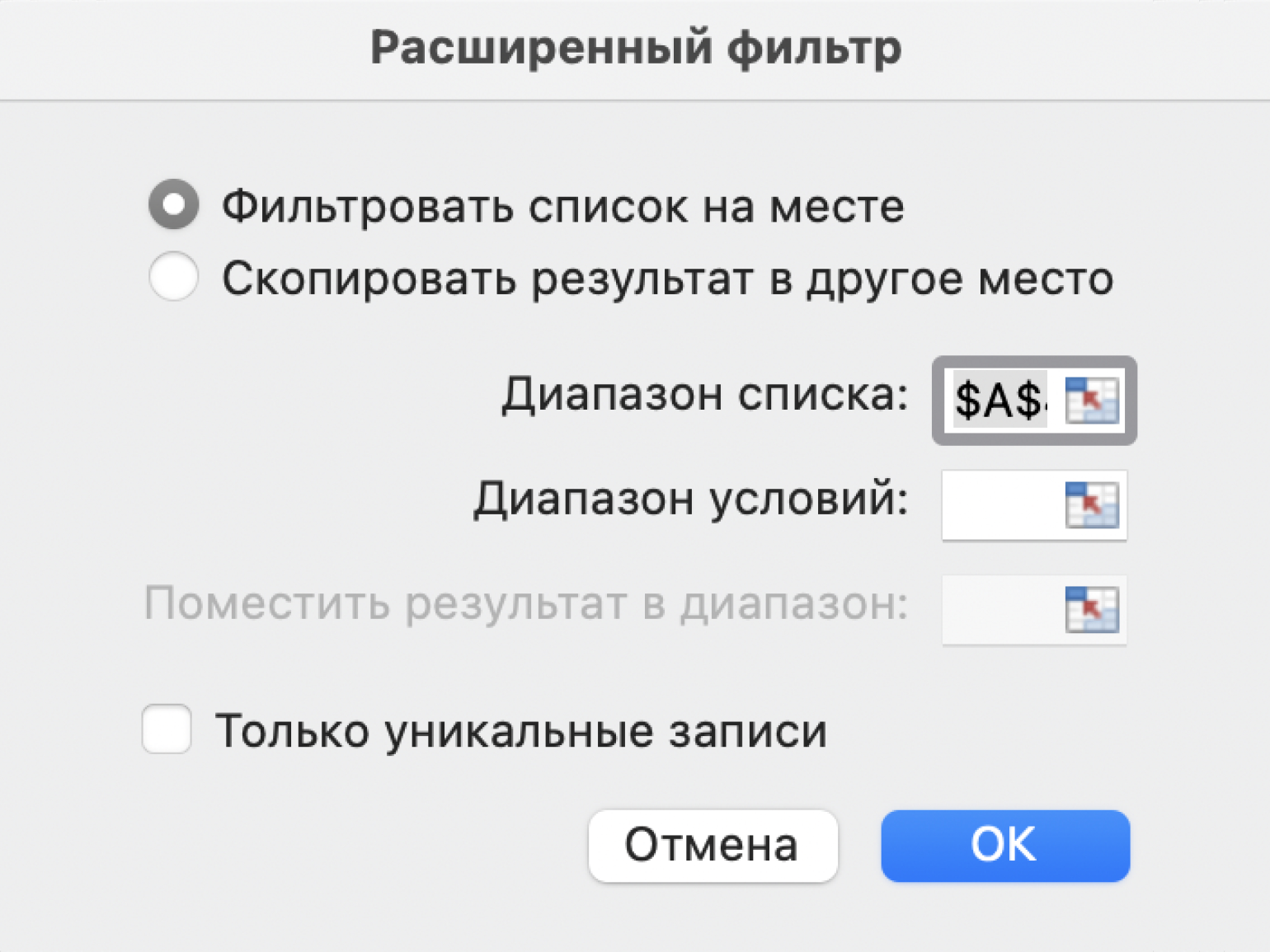
Скриншот: Excel / Skillbox Media
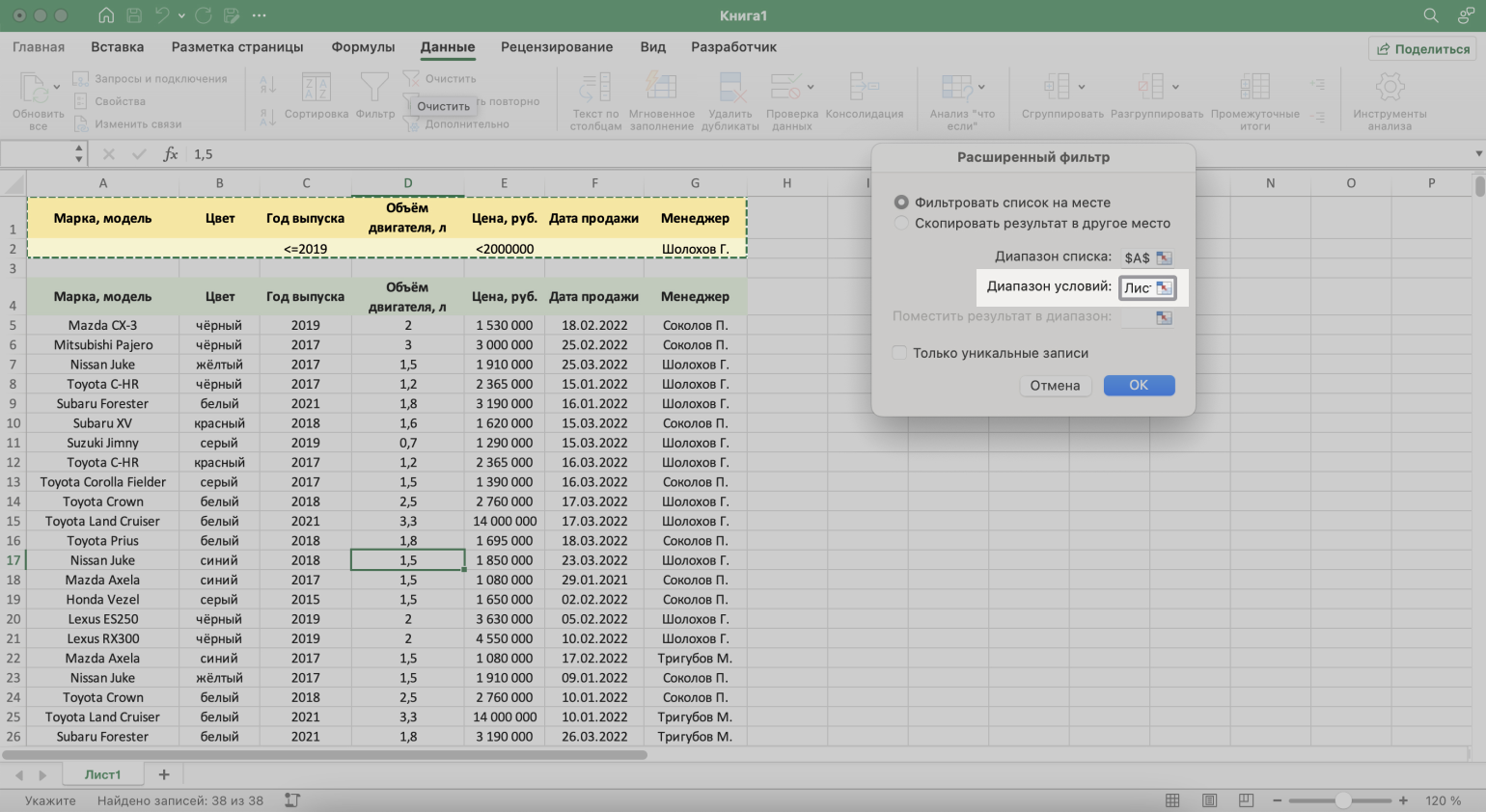
- Диапазон условий — диапазон таблицы с условиями фильтрации. Ставим курсор в пустое окно параметра и выделяем диапазон: шапку таблицы и строку с критериями. Данные диапазона автоматически появляются в окне параметров расширенного фильтра.
Скриншот: Excel / Skillbox Media
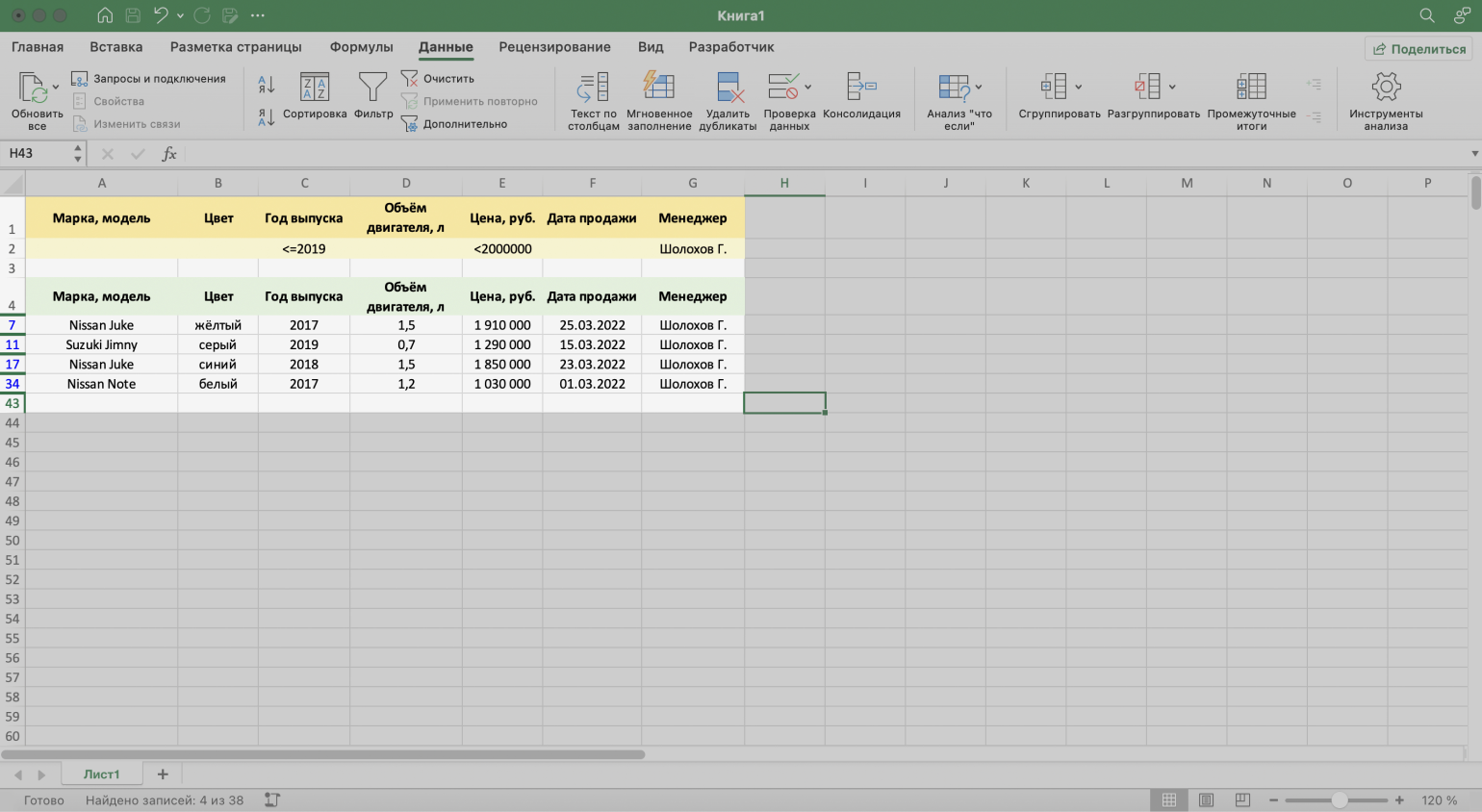
Шаг 5. Нажимаем «ОК» в меню расширенного фильтра.
Готово — исходная таблица отфильтрована по трём заданным параметрам.
Скриншот: Excel / Skillbox Media
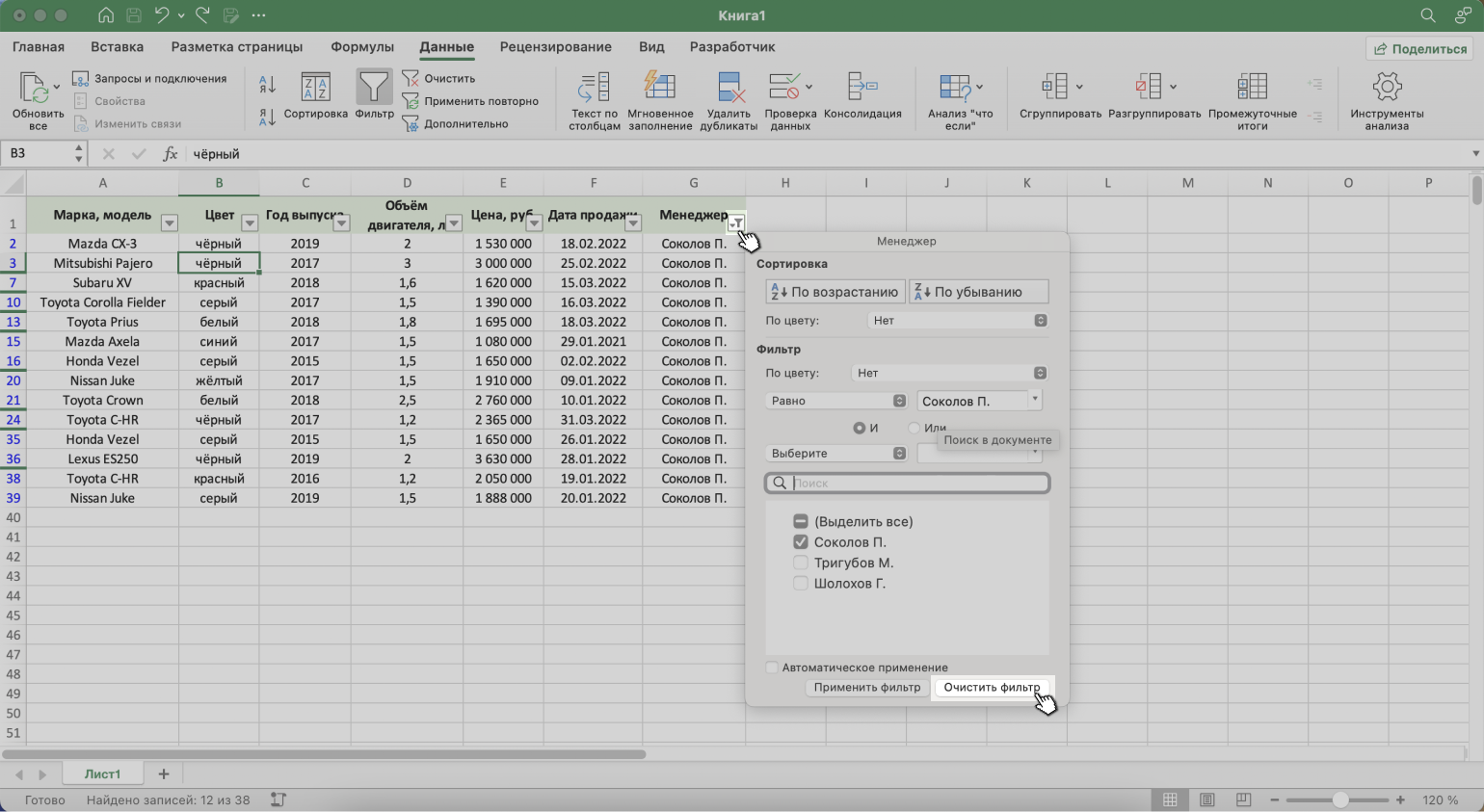
Отменить фильтрацию можно тремя способами:
1. Вызвать меню отфильтрованного столбца и нажать на кнопку «Очистить фильтр».
Скриншот: Excel / Skillbox Media
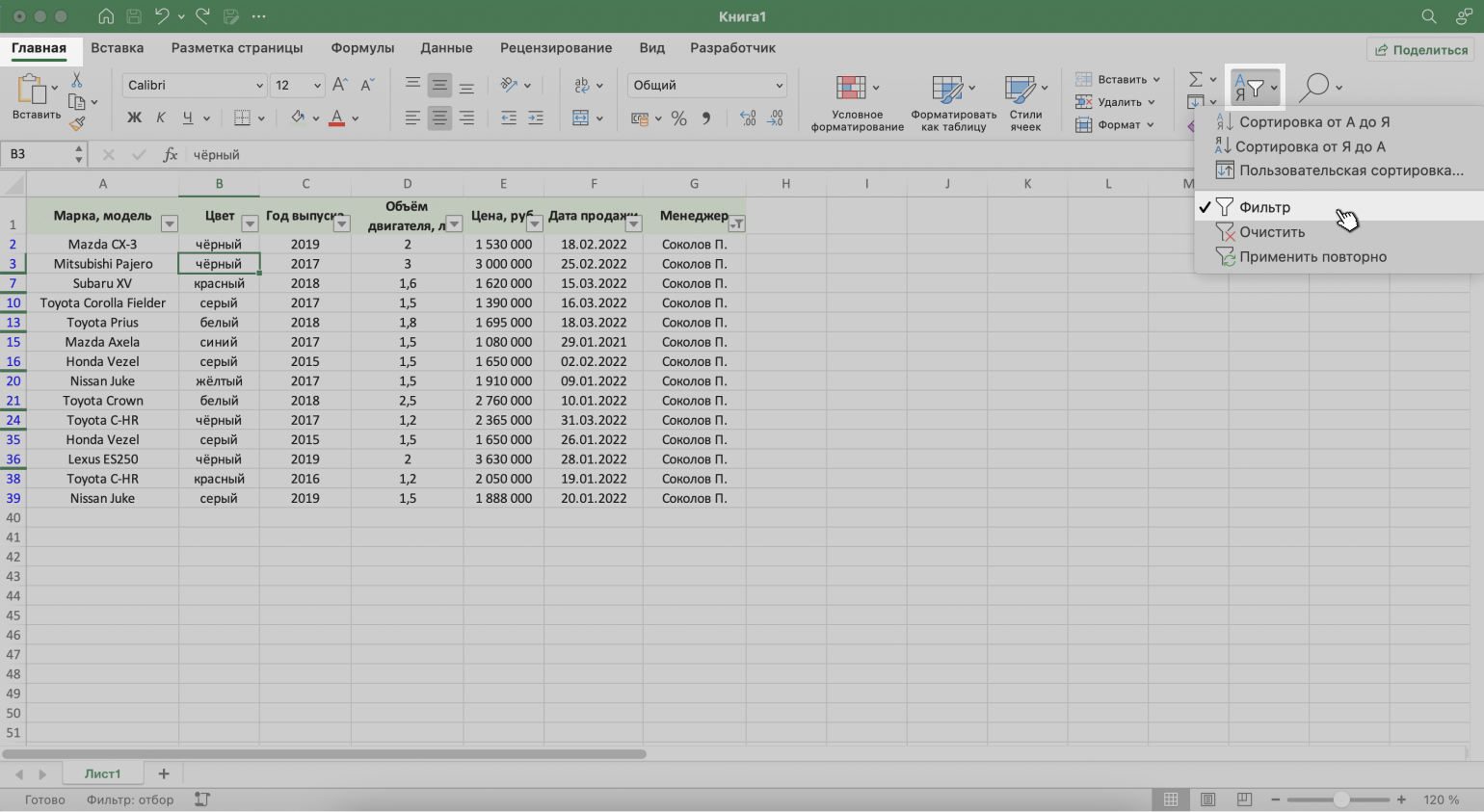
2. Нажать на кнопку «Сортировка и фильтр» на вкладке «Главная». Затем — либо снять галочку напротив пункта «Фильтр», либо нажать «Очистить фильтр».
Скриншот: Excel / Skillbox Media
3. Нажать на кнопку «Очистить» на вкладке «Данные».
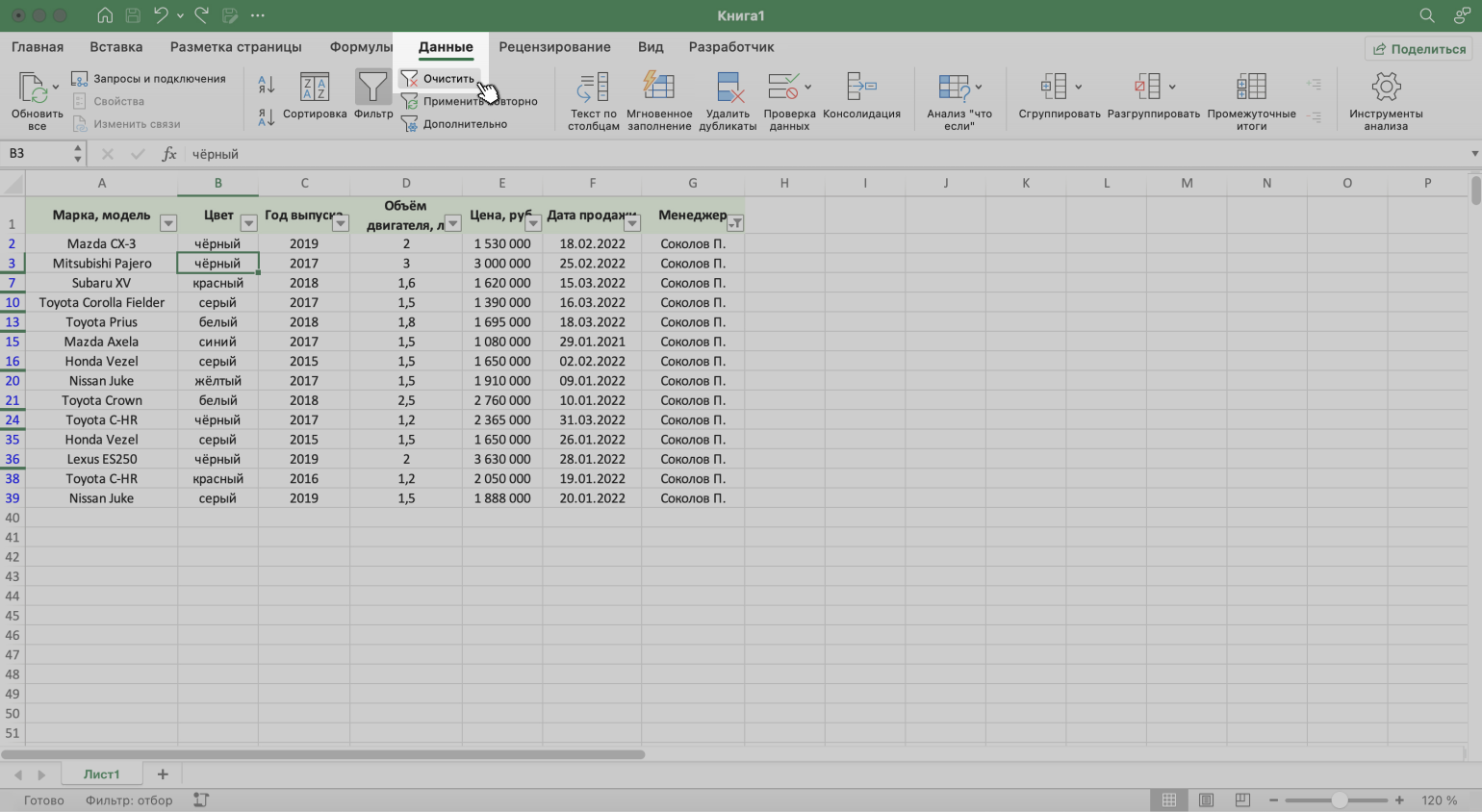
Скриншот: Excel / Skillbox Media
Научитесь: Excel + Google Таблицы с нуля до PRO
Узнать больше
Самый быстрый ВПР
Если в ваших таблицах всего лишь несколько десятков строк, то, скорее всего, эта статья не будет для вас актуальной. На таких небольших объемах данных любой способ будет работать достаточно шустро, чтобы вы этого не замечали. Если же число строк в ваших списках измеряется тысячами, да и самих таблиц не одна-две, то время мучительного ожидания на пересчете формул в Excel может доходить до нескольких минут.
В этом случае, правильный выбор функции, применяемой для связывания таблиц, играет решающую роль — разница в производительности между ними, как мы увидим далее, может составлять более 20 раз!
Когда я писал свою первую книжку пять лет назад, то уже делал сравнительный скоростной тест различных способов поиска и подстановки данных функциями ВПР, ИНДЕКС+ПОИСКПОЗ, СУММЕСЛИ и др. С тех пор сменилось три версии Office, появились надстройки Power Query и Power Pivot, кардинально изменившие весь процесс работы с данными. А в прошлом году ещё и обновился вычислительный движок Excel, получив поддержку динамических массивов и новые функции ПРОСМОТРХ, ФИЛЬТР и т.п.
Так что пришла пора снова взяться за секундомер и выяснить — кто же самый быстрый. Ну и, заодно, проверить — какие способы поиска и подстановки данных в Excel вы знаете 🙂
Подопытный кролик
Тест будем проводить на следующем примере:
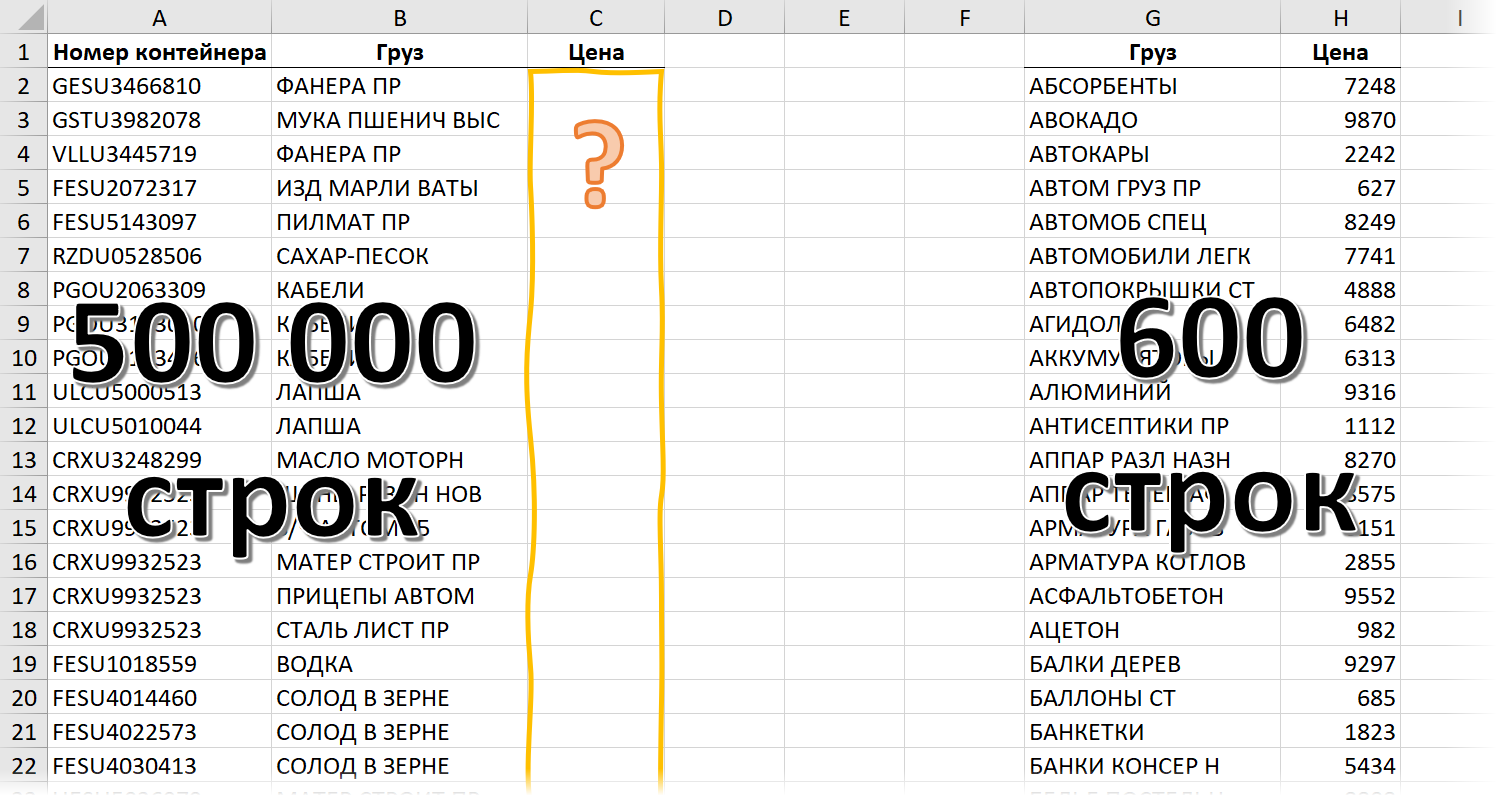
Это книга Excel с одним листом, где расположены две таблицы: отгрузки (500 000 строк) и прайс-лист (600 строк). Наша задача — подставить цены из прайс-листа в таблицу отгрузок. Для каждого способа будем вводить формулу в ячейку С2 и копировать вниз на весь столбец, замеряя время, которое потребуется Excel, чтобы просчитать весь столбец из полумиллиона ячеек. Полученные значения, безусловно, зависят от множества факторов (поколение процессора, объем оперативной памяти, текущая загрузка системы, версия Office и т.д.), но нам важны не конкретные цифры, а, скорее, их сравнение друг с другом. Важно понимать прожорливость каждого способа и их ограничения.
Способ 1. ВПР
Сначала — классика 🙂 Легендарная функция вертикального просмотра — ВПР (VLOOKUP) , которая приходит в голову первой в подобных ситуациях:
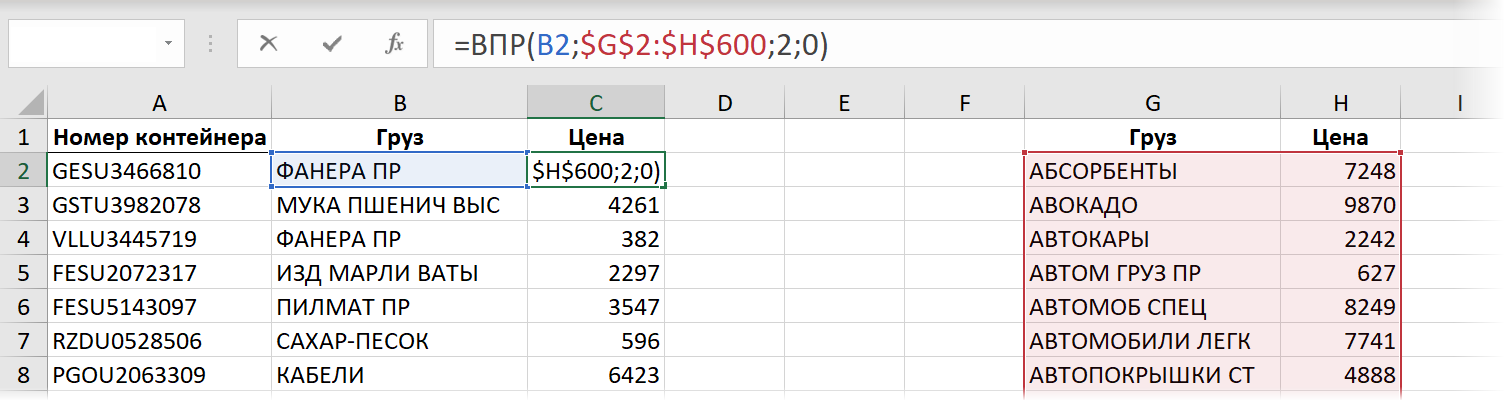
- B2 — искомое значение, т.е. название товара, который мы хотим найти в прайс-листе
- $G$2:$H$600 — закреплённая знаками доллара (чтобы не сползала при копировании формулы вниз) абсолютная ссылка на прайс
- 2 — номер столбца в прайс-листе, откуда мы хотим взять цену
- 0 или ЛОЖЬ — переключение в режим поиска точного соответствия, когда любое некорректное название товара (например, ФОНЕРА) в столбце B в таблице отгрузок приведёт к появлению ошибки #Н/Д как результата работы функции.
Время вычисления = 4,3 сек.
Способ 2. ВПР с выделением столбцов целиком
Многие пользователи, применяя ВПР, во втором аргументе этой функции, где нужно задать поисковую таблицу (прайс), выделяют не ограниченный диапазон ( $G$2:$H$600 ), а сразу столбцы G:H целиком. Это проще, быстрее, позволяет не думать про F4 и то, что завтра прайс-лист может быть на несколько строк больше. Формула в этом случае выглядит тоже компактнее:
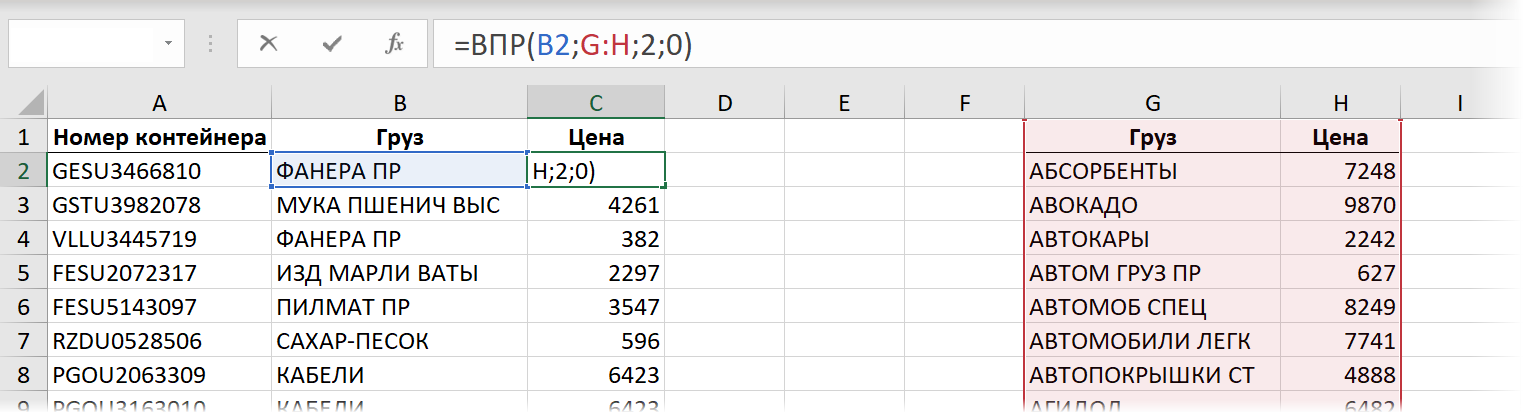
В старых версиях Excel такое выделение не сильно влияло на скорость вычислений, но сейчас (неожиданно для меня, признаюсь) результат получился в разы хуже предыдущего.
Время вычисления = 14,5 сек.
Способ 3. ИНДЕКС и ПОИСКПОЗ
Следующей после ВПР ступенью эволюции для многих пользователей Microsoft Excel обычно является переход на использование связки функций ИНДЕКС (INDEX) и ПОИСКПОЗ (MATCH) . Выглядит эта формула так:
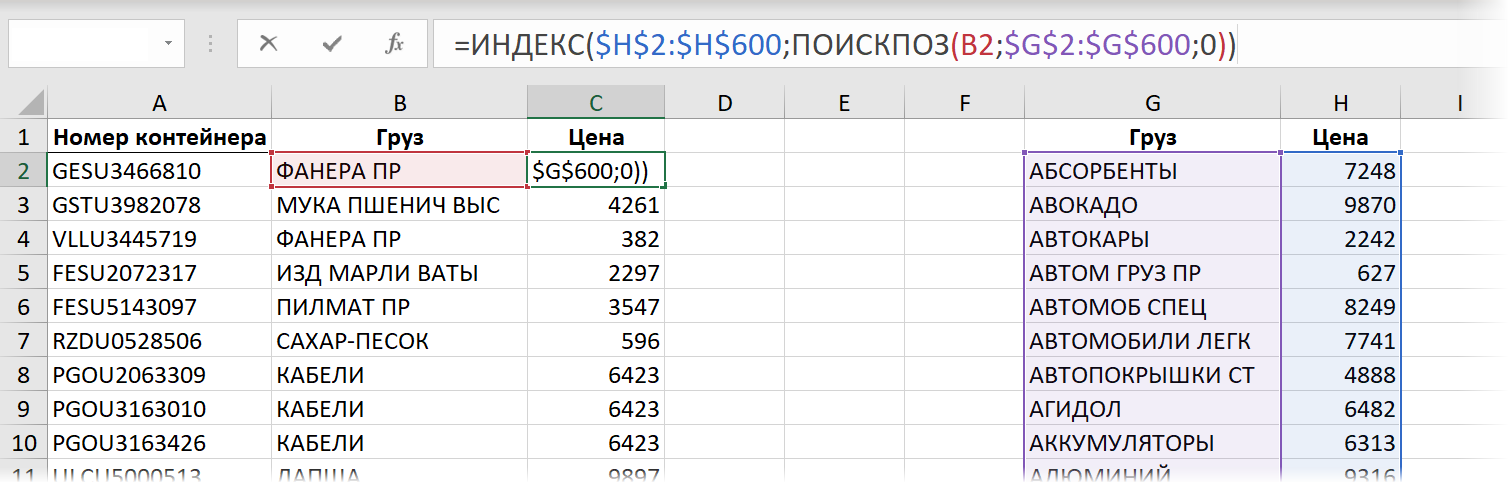
Функция ИНДЕКС извлекает из заданного в первом аргументе диапазона (столбца $H$2:$H$600 с ценами в прайс-листе) содержимое ячейки с заданным номером. А номер этот, в свою очередь, определяется функцией ПОИСКПОЗ, у которой три аргумента:
- Что нужно найти — название товара из B2
- Где мы это ищем — столбец с названиями товаров в прайсе ( $G$2:$G$600 )
- Режим поиска: 0 — точный, 1 или -1 — приблизительный с округлением в меньшую или большую сторону, соответственно.
Формула выходит чуть сложнее, но, при этом имеет несколько ощутимых преимуществ перед классической ВПР, а именно:
- Не нужно отсчитывать номер столбца (как в третьем аргументе ВПР).
- Можно извлекать данные, которые находятся левее столбца, где просходит поиск.
По скорости, однако же, этот способ проигрывает ВПР почти в два раза:
Время вычисления = 7,8 сек.
Если же, вдобавок, полениться и выделять не ограниченные диапазоны, а столбцы целиком:
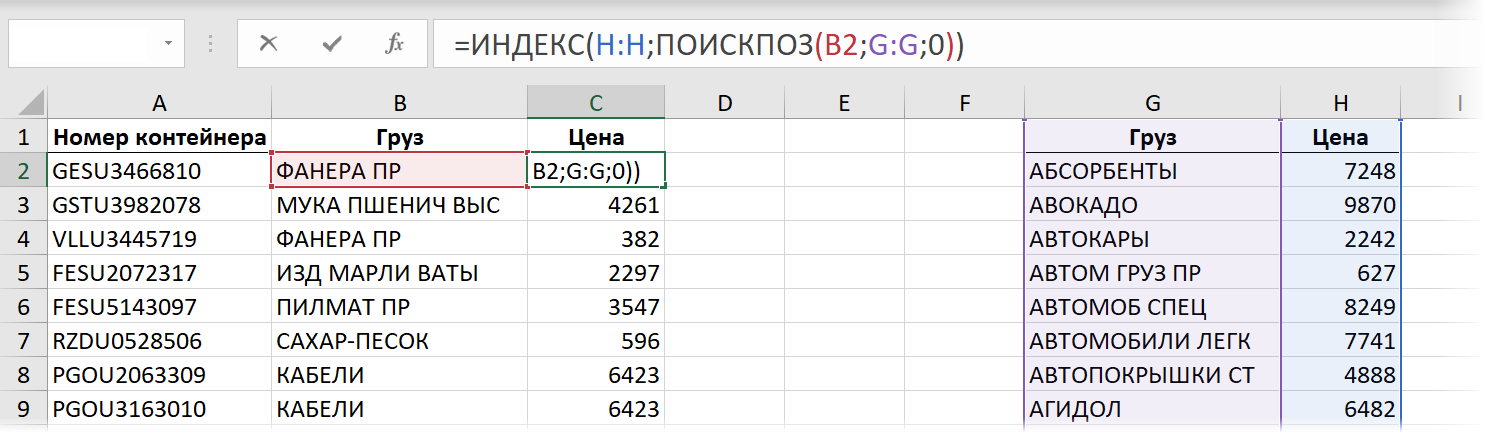
. то результат получается совсем печальный:
Время вычисления = 28,5 сек.
28 секунд, Карл! В 6 раз медленнее ВПР!
Способ 4. СУММЕСЛИ
Если нужно найти не текстовые, а именно числовые данные (как в нашем случае — цену), то вместо ВПР вполне можно использовать функцию СУММЕСЛИ (SUMIF) . Изначально она задумывалась как инструмент для выборочного суммирования данных по условию (найди и сложи мне все продажи кабелей, например), но можно заставить её искать нужный нам товар и в прайс-листе. Если грузы в нём не повторяются, то суммировать будет не с чем и эта функция просто выведет искомое значение:
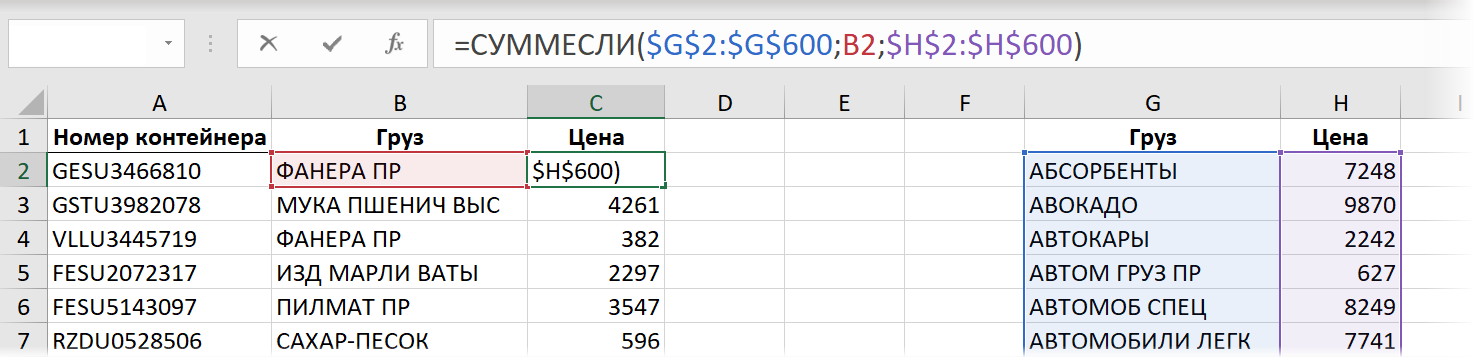
- Первый аргумент СУММЕСЛИ — это диапазон проверяемых ячеек, т.е. названия товаров в прайсе ( $G$2:$G$600 ).
- Второй аргумент ( B2 ) — что мы ищем.
- Третий аргумент — диапазон ячеек с ценами $H$2:$H$600 , числа из которых мы хотим просуммировать, если в соседних ячейках проверяемого диапазона есть искомое значение.
Очевидным минусом такого подхода является то, что он работает только с числами. Также этот способ не удобен, если прайс-лист находится в отдельном файле — придется всё время держать его открытым, т.к. функция СУММЕСЛИ не умеет брать данные из закрытых книг, в отличие от ВПР, для которой это не проблема.
В плюсы же можно записать удобство при поиске сразу по нескольким столбцам — для этого идеально подходит более продвинутая версия этой функции — СУММЕСЛИМН (SUMIFS) . Скорость вычислений же, при этом, весьма посредственная:
Время вычисления = 12,8 сек.
При выделении столбцов целиком, т.е. использовании формулы вида =СУММЕСЛИ( G:G ; B2 ; H:H ) всё ещё хуже:
Время вычисления = 41,7 сек.
Это самый плохой результат в нашем тесте.
Способ 5. СУММПРОИЗВ
Этот подход сейчас встречается не часто, но всё ещё достаточно регулярно. Обычно так любят извращаться пользователи старой школы, ещё хорошо помнящие те времена, когда в Excel было всего 255 столбцов и 56 цветов 🙂
Суть этого метода заключается в использовании функции СУММПРОИЗВ (SUMPRODUCT) , изначально предназначенной для поэлементного перемножения нескольких диапазонов с последующим суммированием полученных произведений. В нашем случае, вместо одного из массивов будет выступать условие, а вторым будут цены:
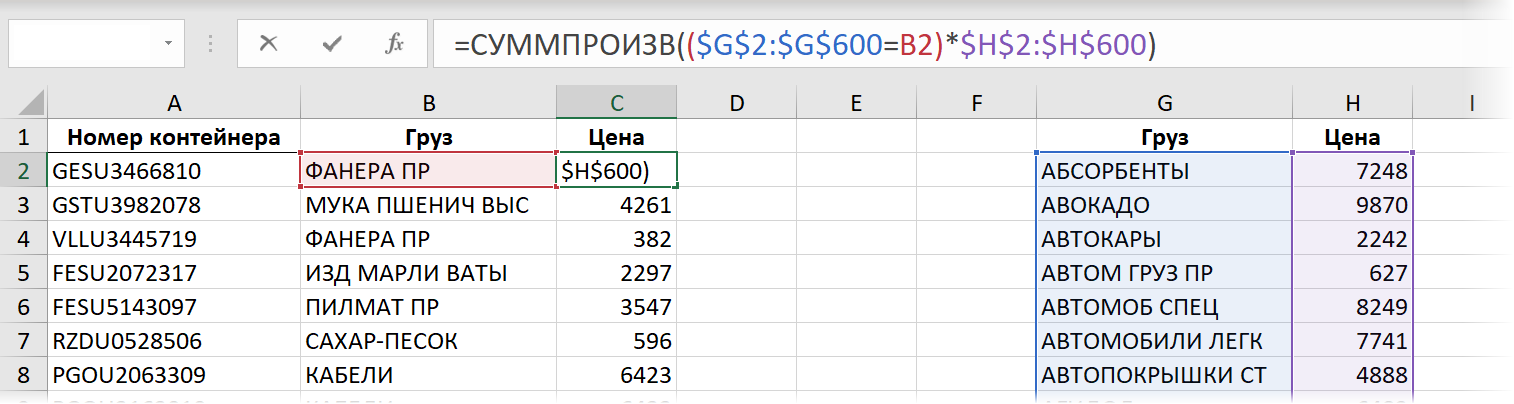
Выражение ($G$2:$G$600=B2) , по сути, проверяет каждое название груза в прайс-листе на предмет соответствия искомому значению (ФАНЕРА ПР). Результатом каждого сравнения будет логическое значение ИСТИНА (TRUE ) или ЛОЖЬ (FALSE) , что в Excel интерпретируется как 1 и 0, соответственно. Последующее умножение этих нулей и единиц на цены оставит в живых цену только того товара, который нам, в данном случае, и нужен.
Эта формула является, по сути, формулой массива, но не требует нажатия обычного для них сочетания клавиш Ctrl + Shift + Enter , т.к. функция СУММПРОИЗВ поддерживает массивы уже сама по себе. Возможно, по этой же причине (формулы массива всегда медленнее, чем обычные) такой скорость пересчёта такой формулы — не очень:
Время вычисления = 11,8 сек.
- Совместимость с любыми, самыми древними версиями Excel.
- Возможность задавать сложные условия (и несколько)
- Способность этой формулы работать с данными из закрытых файлов, если добавить перед ней двойное бинарное отрицание (два подряд знака «минус»). СУММЕСЛИМН таким похвастаться не может.
Способ 6. ПРОСМОТР
Ещё один относительно экзотический способ поиска и подстановки данных, наравне с ВПР — это использование функции ПРОСМОТР (LOOKUP) . Только не перепутайте её с новой, буквально, на днях появившейся функцией ПРОСМОТРХ (XLOOKUP) — про неё мы поговорим дальше особо. Функция ПРОСМОТР существовала в Excel начиная с самых ранних версий и тоже вполне может решить нашу задачу:
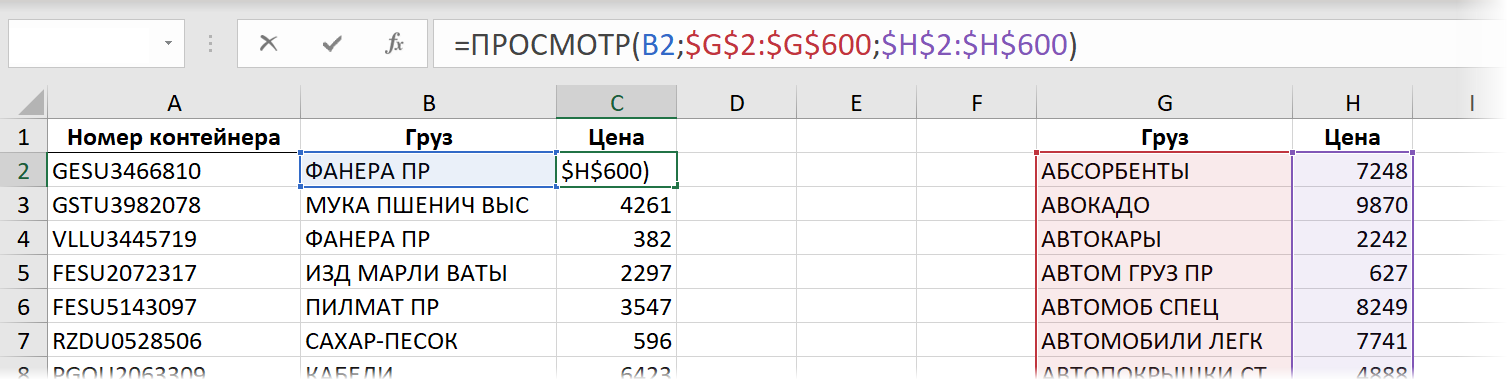
- B2 — название груза, которое мы ищем
- $G$2:$G$600 — одномерный диапазон-вектор (столбец или строка), где мы ищем совпадение
- $H$2:$H$600 — такого же размера диапазон, откуда нужно вернуть найденный результат (цену)
На первый взгляд всё выглядит очень удобно и логично, но всю картину портят два неочевидных момента:
- Эта функция требует обязательной сортировки прайс-листа по возрастанию (алфавиту) и без этого не работает.
- Если в таблице отгрузок искомое значение будет написано с опечаткой (например, АГ Е ДОЛ вместо АГИДОЛ), то функция ПРОСМОТР выдаст не ошибку #Н/Д, а цену для ближайшего предыдущего товара:
При работе с неидеальными данными в реальном мире это гарантированно создаст проблемы, как вы понимаете.
Скорость же вычислений у функции ПРОСМОТР (LOOKUP) весьма приличная:
Время вычисления = 7,6 сек.
Способ 7. Новая функция ПРОСМОТРХ
Эта функция пришла с одним из недавних обновлений пока только пользователям Office 365 и пока отсутствует во всех остальных версиях (Excel 2010, 2013, 2016, 2019). По сравнению с классической ВПР у этой функции есть масса преимуществ (упрощенный синтаксис, возможность искать не только сверху-вниз, возможность сразу задать значение вместо #Н/Д и т.д.) Формула для решения нашей задачи будет выглядеть в этом случае так:
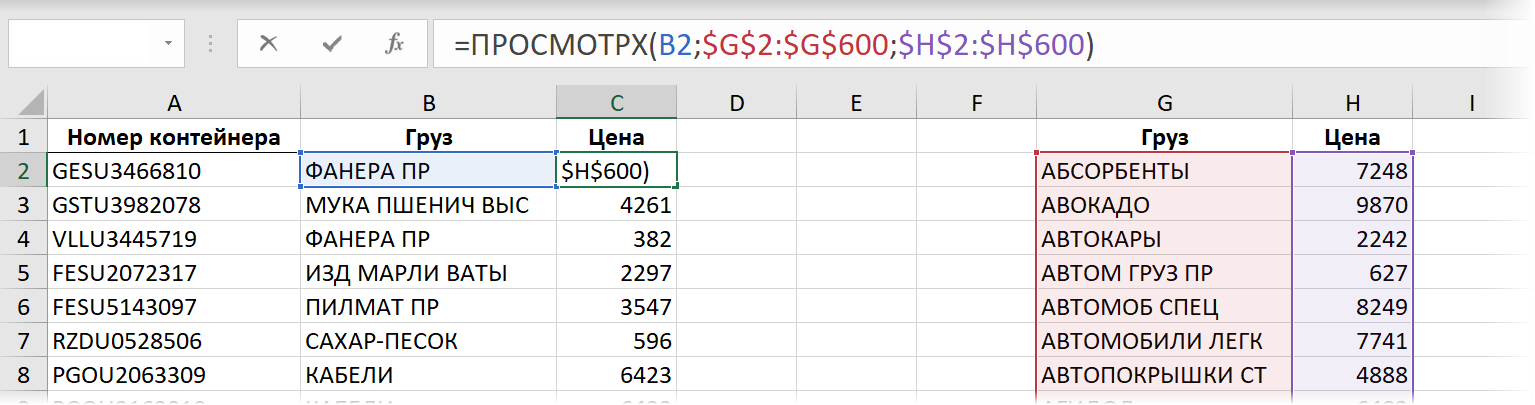
Если не брать в расчёт необязательные 4,5,6 аргументы, то синтаксис этой функции полностью совпадает с её предшественником — функцией ПРОСМОТР (LOOKUP) . Скорость вычислений при тестировании на наши 500000 строк тоже оказалась аналогичной:
Время вычисления = 7,6 сек.
Почти в два раза медленнее, чем у ВПР, вместо которой Microsoft предлагает теперь использовать ПРОСМОТРХ. Жаль.
И, опять же, если полениться и выделить диапазоны в прайс-листе целыми столбцами:
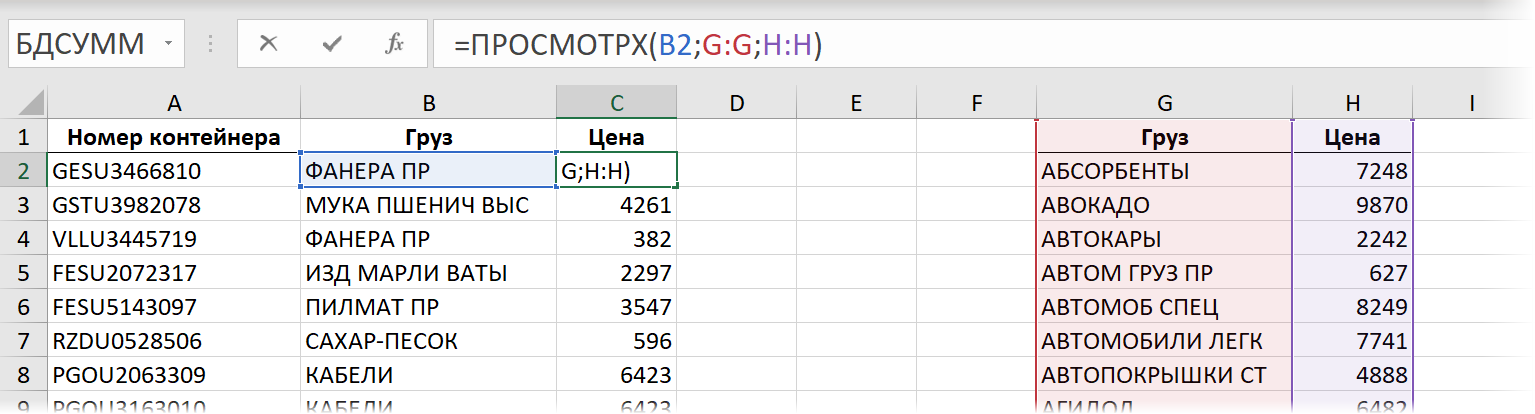
. то скорость падает до совершенно неприличных уже значений:
Время вычисления = 28,3 сек.
А если на динамических массивах?
Прошлогоднее (осень 2019) обновление вычислительного движка Microsoft Excel добавило ему поддержку динамических массивов (Dynamic Arrays), о которых я уже писал. Это принципиально новый подход к работе с данными, который можно использовать почти с любыми классическими функциями Excel. На примере ВПР это будет выглядеть так:
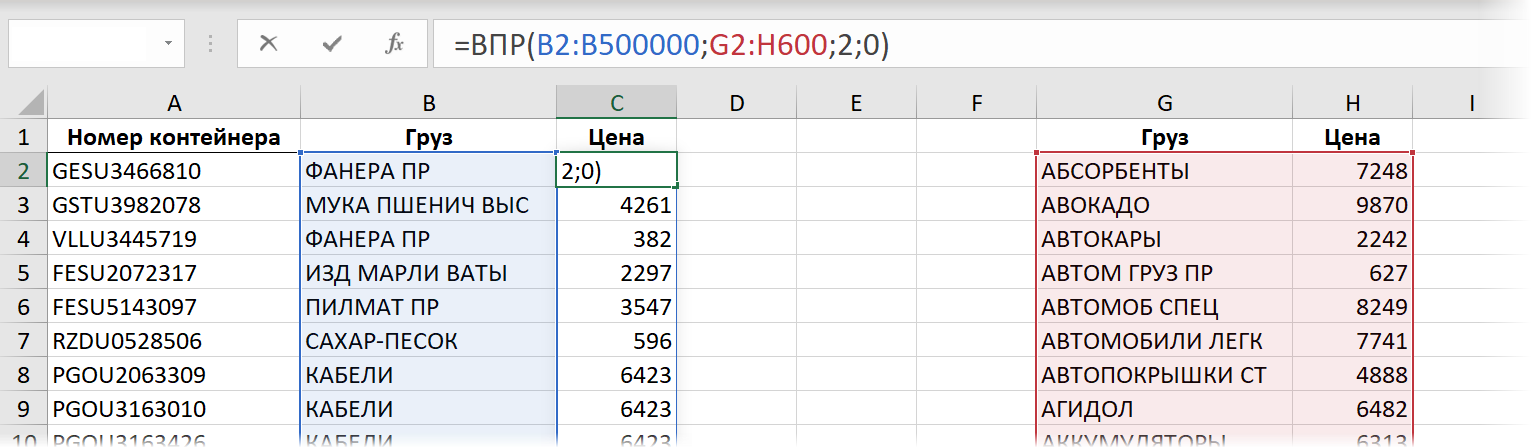
Разница с классическим вариантом в том, что первым аргументом ВПР здесь выступает не одно искомое значение (а формулу потом нужно копировать вниз на остальные строки), а сразу весь массив из полумиллиона грузов B2:B500000, цены для которых мы хотим найти. Формула при этом сама распространяется вниз, занимая требуемое количество ячеек.
Скорость пересчета в таком варианте меня, откровенно говоря, ошеломила — пауза между нажатием на Enter после ввода формулы и получением результатов почти отсутствовала.
Время вычисления = 1 сек.
Что интересно, и новая ПРОСМОТРХ, и старая ПРОСМОТР, и связка ИНДЕКС+ПОИСКПОЗ в таком режиме тоже были очень быстрыми — время вычислений не больше 1 секунды! Фантастика.
А вот олдскульные подходы на основе СУММПРОИЗВ и СУММЕСЛИ(МН) с динамическими массивами работать отказались 🙁
Что с умными таблицами?
Обрадовавшись фантастическим результатам, полученным на динамических массивах, я решил вдогон попробовать протестировать разницу в скорости при работе с обычными и «умными» таблицами. Я имею ввиду те самые «красивые таблицы», в которые вы можете преобразовать ваш диапазон с помощью команды Форматировать как таблицу на вкладке Главная (Home — Format as Table) или с помощью сочетания клавиш Ctrl + T .
Если предварительно превратить наши отгрузки и прайс в «умные» (по умолчанию они получат имена Таблица1 и Таблица2, соответственно), то формула с той же ВПР будет выглядеть как:
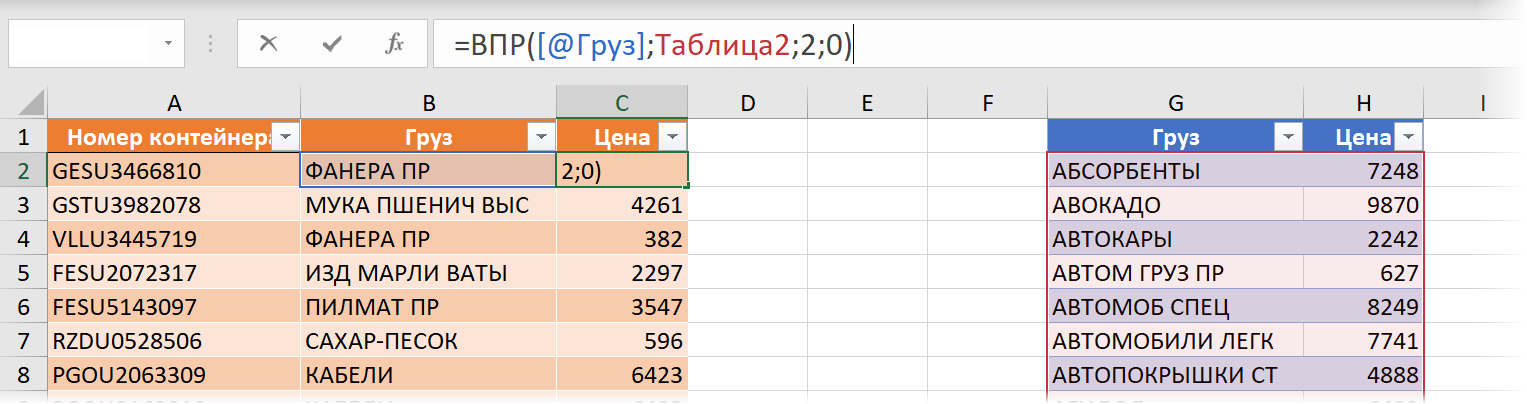
- [@Груз] — ссылка на ячейку B2, означающая, в данном случае, что нужно взять значение из той же строки из столбца Груз текущей умной таблицы.
- Таблица2 — ссылка на прайс-лист
Жирным плюсом такого подхода будет возможность легко добавлять данные в наши таблицы в будущем. При дописывании новых строк в отгрузки или к прайс-листу, наши «умные» таблицы будут растягиваться автоматически.
Скорость же, как выяснилось, тоже вырастает очень значительно и примерно равна скорости работы на динамических массивах:
Время вычисления = 1 сек.
У меня есть подозрение, что дело тут не в самих «умных» таблицах, а всё в том же обновлении вычислительного движка, т.к. на старых версиях Excel такого прироста в скорости на умных таблицах я не помню.
Бонус. Запрос Power Query
Замерять, так замерять! Давайте, для полноты картины, сравним наши перечисленные способы еще и с запросом Power Query, который тоже может решить нашу задачу. Кто-то скажет, что некорректно сравнивать пересчёт формул с механизмом обновления запроса, но мне, откровенно говоря, просто самому было интересно — кто быстрее?
- Превращаем обе наши таблицы в «умные» с помощью команды Форматировать как таблицу на вкладке Главная (Home — Format as Table) или с помощью сочетания клавиш Ctrl + T .
- По очереди загружаем таблицы в Power Query с помощью команды Данные — Из таблицы / диапазона (Data — From Table/Range) .
- После загрузки в Power Query возвращаемся обратно в Excel, оставляя загруженные данные как подключение. Для этого в окне Power Query выбираем Главная — Закрыть и загрузить — Закрыть и загрузить в. — Только создать подключение (Home — Close&Load — Close&Load to. — Only create connection) .
- После того, как обе исходные таблицы будут загружены как подключения, создадим ещё один, третий запрос, который будет объединять их между собой, подставляя цены из прайса в отгрузки. Для этого на вкладке Данные выберем Получить данные / Создать запрос — Объединить запросы — Объединить (Get Data / New Query — Merge queries — Merge) :
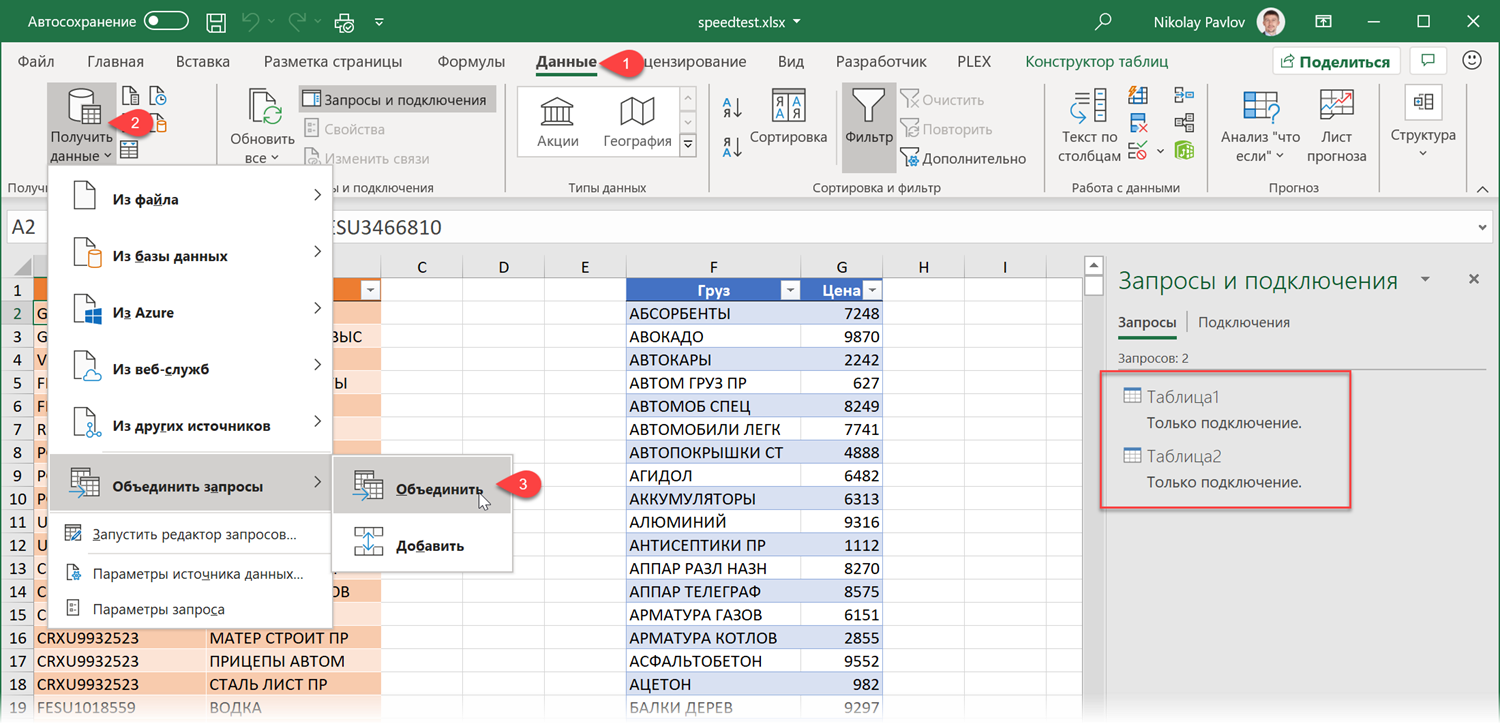
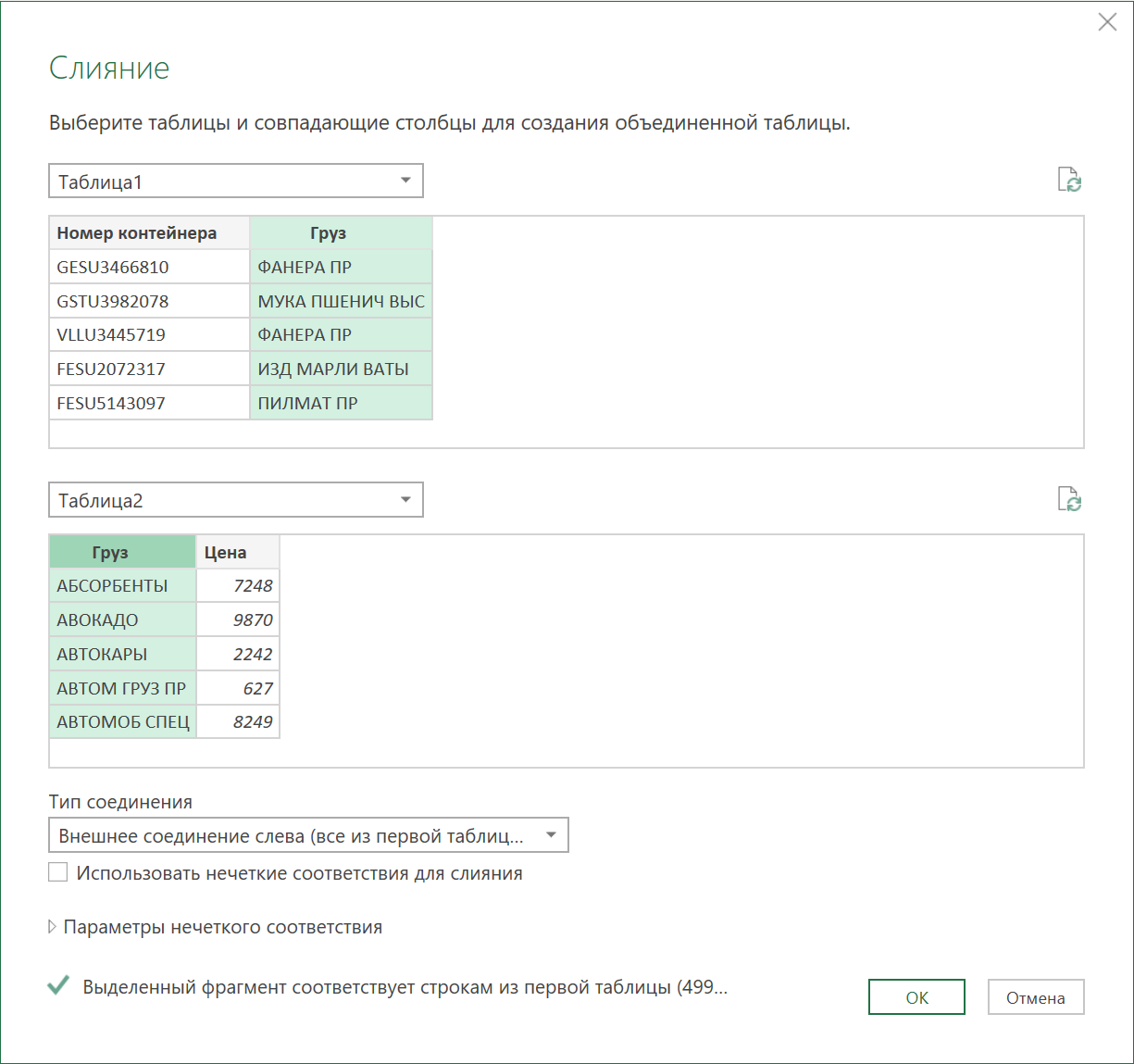
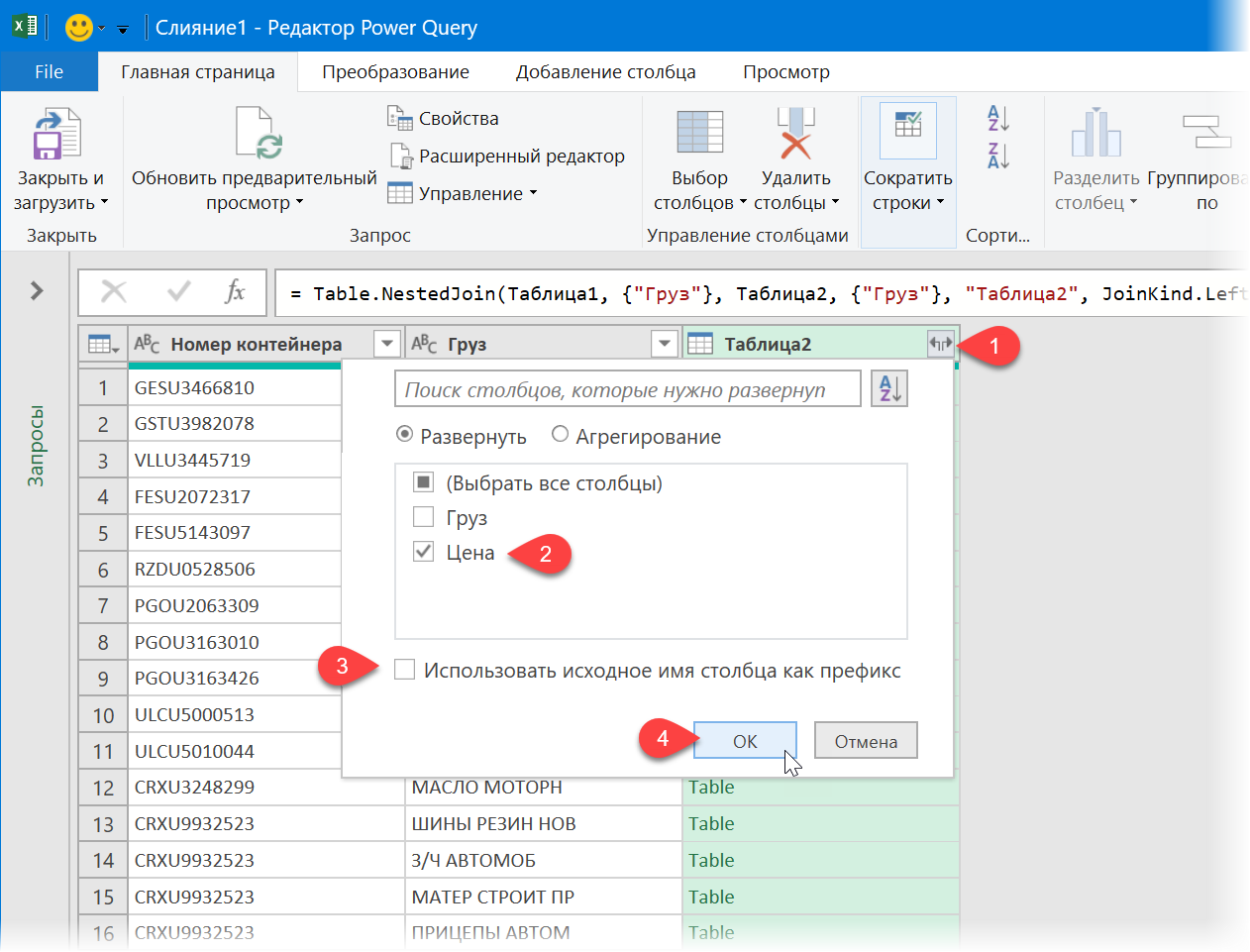
В отличие от формул, запросы Power Query не обновляются автоматически «на лету», а требуют щелчка правой кнопкой мыши по таблице (или запросу в правой панели) и выбору команды Обновить (Refresh) . Также можно воспользоваться командой Обновить все (Refresh All) на вкладке Данные (Data) .
Время обновления = 8,2 сек.
Итоговая таблица и выводы
Если вы честно дочитали до этого места, то какие-то выводы, наверное, уже сделали самостоятельно. Если же пропустили все детали и сразу перешли к итогам, то вот вам общая результирующая таблица по скорости всех методов:
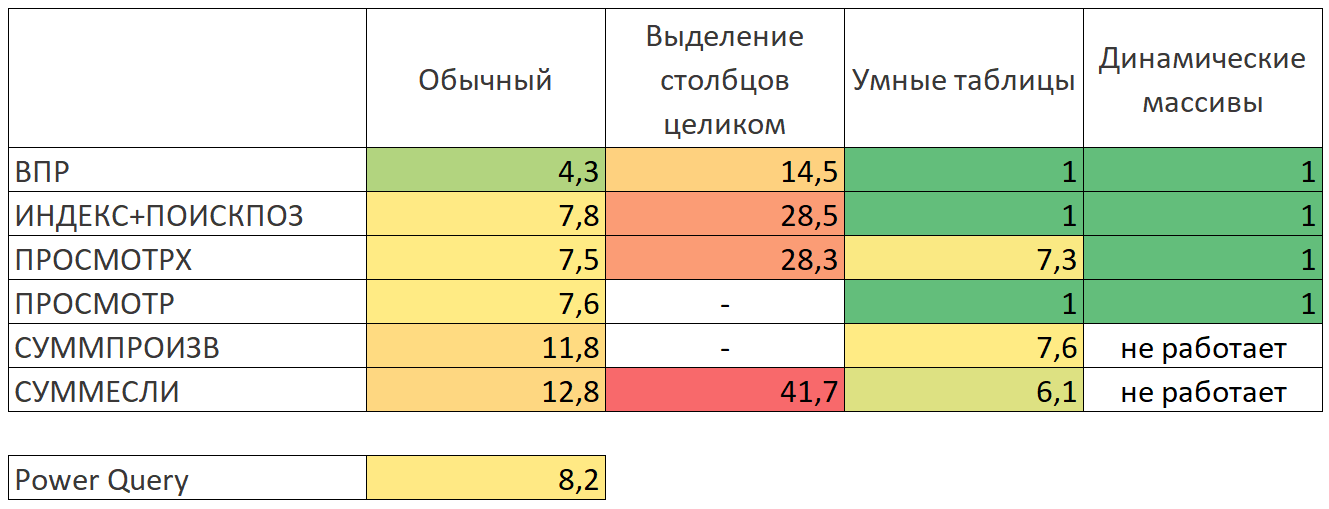
Само-собой, у каждого из нас свои предпочтения, задачи и тараканы, но для себя я сформулировал выводы после этого тестирования так:
ВПР с несколькими условиями: 5 примеров.
Очень часто наши требования к поиску данных не ограничиваются одним условием. К примеру, нам нужна выручка по магазину за определенный месяц, количество конкретного товара, проданного определенному покупателю и т.д. Обычными средствами функции ВПР эту задачу решить сложно и даже не всегда возможно. Ведь там предусмотрено использование только одного критерия поиска.
Мы предложим вам несколько вариантов решения проблемы поиска по нескольким условиям.
ВПР по нескольким условиям с использованием дополнительного столбца.
Задачу, рассмотренную в предыдущем примере, можно решить и другим способом – без использования формулы массива. Ведь работа с массивами многим представляется сложной и недоступной для понимания. Дополнительный столбец для поиска по нескольким условиям будет в определенном отношении более простым вариантом.
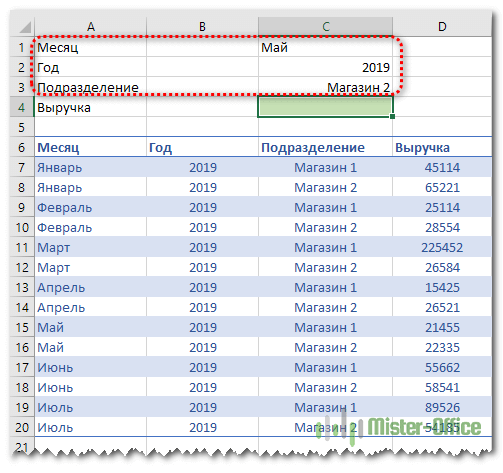
Итак, необходимо выбрать значение выручки за определенный месяц, год и по нужному магазину. В итоге имеем 3 условия отбора.
Сразу по трем столбцам функция ВПР искать не может. Поэтому нам нужно объединить их в один. И, поскольку поиск производится всегда в крайнем левом (первом) столбце, то нужно добавить его в нашу таблицу тоже слева.
Вставляем перед таблицей с данными дополнительный столбец A. Затем при помощи оператора & объединяем в нем содержимое B,C и D. Записываем в А7
и копируем в находящиеся ниже ячейки.
Формула поиска в D4 будет выглядеть:
В диапазон поиска включаем и наш дополнительный столбец. Критерий поиска – также объединение 3 значений. И извлекаем результат из 5 колонки.
Все работает, однако вид несколько портит дополнительный столбец. В крайнем случае, его можно скрыть, используя контекстное меню по нажатию правой кнопки мыши.

Вид станет приятнее, а на результаты это никак не повлияет.
ВПР по двум условиям при помощи формулы массива.
У нас есть таблица, в которой записана выручка по каждому магазину за день. Мы хотим быстро найти сумму продаж по конкретному магазину за определенный день.
Для этого в верхней части нашего листа запишем критерии поиска: дата и магазин. В ячейке B3 будем выводить сумму выручки.
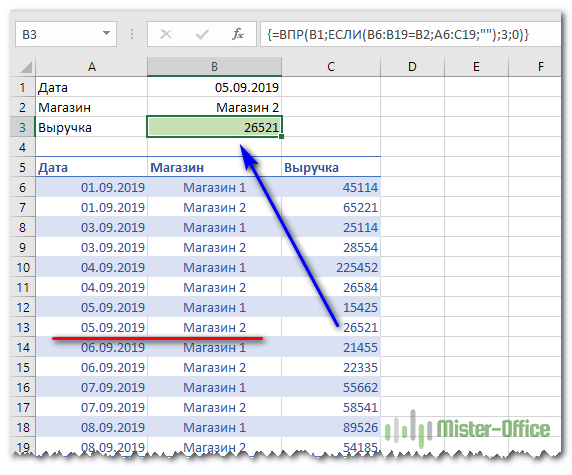
Формула в B3 выглядит следующим образом:
Обратите внимание на фигурные скобки, которые означают, что это формула массива. То есть наша функция ВПР работает не с отдельными значениями, а разу с массивами данных.
Разберем процесс подробно.
Мы ищем дату, записанную в ячейке B1. Но вот только разыскивать мы ее будем не в нашем исходном диапазоне данных, а в немного видоизмененном. Для этого используем условие
То есть, в том случае, если наименование магазина совпадает с критерием в ячейке B2, мы оставляем исходные значения из нашего диапазона. А если нет – заменяем их на пробелы. И так по каждой строке.
В результате получим вот такой виртуальный массив данных на основе нашей исходной таблицы:

Как видите, строки, в которых ранее был «Магазин 1», заменены на пустые. И теперь искать нужную дату мы будем только среди информации по «Магазин 2». И извлекать значения выручки из третьей колонки.
С такой работой функция ВПР вполне справится.
Такой ход стал возможен путем применения формулы массива. Поэтому обратите особое внимание: круглые скобки в формуле писать руками не нужно! В ячейке B3 вы записываете формулу
И затем нажимаете комбинацию клавиш CTRL+Shift+Enter. При этом Excel поймет, что вы хотите ввести формулу массива и сам подставит скобки.
Таким образом, функция ВПР поиск по двум столбцам производит в 2 этапа: сначала мы очищаем диапазон данных от строк, не соответствующих одному из условий, при помощи функции ЕСЛИ и формулы массива. А затем уже в этой откорректированной информации производим обычный поиск по одному только второму критерию при помощи ВПР.
Чтобы упростить работу в будущем и застраховать себя от возможных ошибок при добавлении новой информации о продажах, мы рекомендуем использовать «умную» таблицу. Она автоматически подстроит свой размер с учетом добавленных строк, и никакие ссылки в формулах не нужно будет менять.

Вот как это будет выглядеть.
ВПР по нескольким критериям с применением массивов — способ 2.
Выше мы уже рассматривали, как при помощи формулы массива можно организовать поиск ВПР с несколькими условиями. Предлагаем еще один способ.
Условия возьмем те же, что и в предыдущем примере.
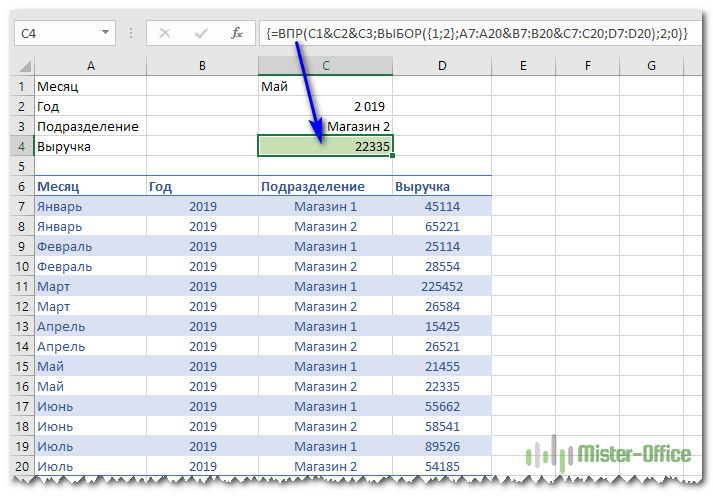
Формулу в С4 введем такую:
Естественно, не забываем нажать CTRL+Shift+Enter.
Теперь давайте пошагово разберем, как это работает.
Наше задача здесь – также создать дополнительный столбец для работы функции ВПР. Только теперь мы создаем его не на листе рабочей книги Excel, а виртуально.
Как и в предыдущем примере, мы ищем текст из объединенных в одно целое условий поиска.
Далее определяем данные, среди которых будем искать.
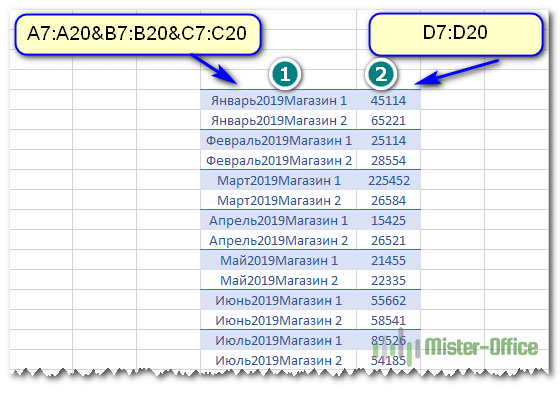
Конструкция вида A7:A20&B7:B20&C7:C20;D7:D20 создает 2 элемента. Первый – это объединение колонок A, B и C из исходных данных. Если помните, то же самое мы делали в нашем дополнительном столбце. Второй D7:D20 – это значения, одно из которых нужно в итоге выбрать.
Функция ВЫБОР позволяет из этих элементов создать массив. как раз и означает, что нужно взять сначала первый элемент, затем второй, и объединить их в виртуальную таблицу – массив.
В первой колонке этой виртуальной таблицы мы будем искать, а из второй – извлекать результат.
Таким образом, для работы функции ВПР с несколькими условиями мы вновь используем дополнительный столбец. Только создаем его не реально, а виртуально.
Двойной ВПР при помощи ИНДЕКС + ПОИСКПОЗ
Далее речь у нас пойдет уже не о функции ВПР, но задачу мы будем решать ту же самую. В качестве критерия поиска нам опять нужно использовать несколько условий.

Формула в С4 теперь выглядит так:
И не забываем при вводе нажать CTRL+Shift+Enter! Это формула массива.
Теперь давайте разбираться, как это работает.
Функция ИНДЕКС в нашем случае позволяет извлечь элемент из списка по его порядковому номеру. Список – это диапазон D7:D20, где записаны суммы выручки. А вот порядковый номер, который нужно извлечь, мы определяем при помощи ПОИСКПОЗ.
Синтаксис здесь следующий:
ПОИСКПОЗ(что_ищем; где_ищем; тип_поиска)
Тип поиска ставим 0, то есть точное совпадение. В нашем случае мы будем искать 1. Далее мы определим массив, в котором будем работать.
Выражение (A7:A20=C1)*(B7:B20=C2)*(C7:C20=C3) позволит создать виртуальную таблицу примерно такого вида:

Как видите, первоначально мы последовательно сравниваем каждое значение с нашим критерием отбора. В столбце А у нас записаны месяцы – сравниваем их с месяцем-критерием из ячейки C1. В случае совпадения получаем ИСТИНА, иначе – ЛОЖЬ. Аналогично последовательно проверяем год и название магазина. А затем просто перемножаем значения. Поскольку логические переменные для Excel – это либо 0, либо 1, то произведение их может быть равно 1 только в том случае, если мы имеем по каждой колонке ИСТИНА (то есть,1). Во всех остальных случаях получаем 0.
Убеждаемся, что цифра 1 встречается только единожды.
При помощи ПОИСКПОЗ определяем, на какой позиции она находится. На какой позиции находится 1, на той же позиции находится в массиве и искомая сумма выручки. В нашем случае это 10-я.
Далее при помощи ИНДЕКС извлекаем 10-ю по счету выручку.

Таким образом мы выбрали значение по нескольким условиям без использования функции ВПР.
Достойная замена – функция СУММПРОИЗВ.
У нас есть данные о продажах нескольких менеджеров в различных регионах. Нужно сделать выборку по дате, менеджеру и региону.
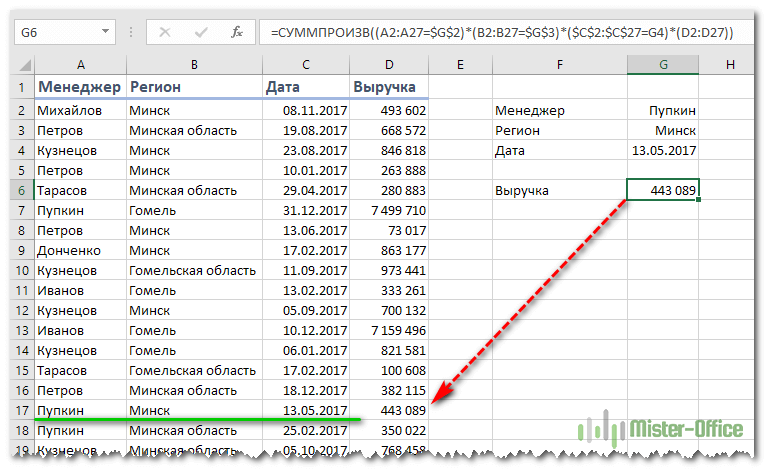
Работает как формула массива, хотя по факту таковой не является. В этом заключается замечательное свойство функции СУММПРОИЗВ, о которой мы еще много будем говорить в других статьях.
Последовательно по каждой строке диапазона от 2-й до 27-й она проверяет совпадение каждого соответствующего значения с критерием поиска. Эти результаты перемножаются между собой и в итоге еще умножаются на сумму выручки. Если среди трех условий будет хотя бы одно несовпадение, то итогом будет 0. В случае совпадения сумма выручки трижды умножится на 1.
Затем все эти 27 произведений складываются, и результатом будет выручка нужного менеджера в каком-то регионе за определенную дату.
В качестве бонуса можно продолжить этот пример и рассчитать общую сумму продаж менеджера в определенном регионе.

Для этого из формулы просто уберем сравнение по дате.
Кстати, возможен и другой вариант расчета с этой же функцией:
Итак, мы рассмотрели примеры использования функции ВПР с двумя и с несколькими условиями. А также обнаружили, что этой ценной функции есть замечательная альтернатива.
Примеры использования функции ВПР:
 Как объединить две или несколько таблиц в Excel — В этом руководстве вы найдете некоторые приемы объединения таблиц Excel путем сопоставления данных в одном или нескольких столбцах. Как часто при анализе в Excel вся необходимая информация собирается на одном…
Как объединить две или несколько таблиц в Excel — В этом руководстве вы найдете некоторые приемы объединения таблиц Excel путем сопоставления данных в одном или нескольких столбцах. Как часто при анализе в Excel вся необходимая информация собирается на одном…

2 способа извлечь данные из разных таблиц при помощи ВПР. — Задача: Данные, которые нужно найти и извлечь при помощи функции ВПР, находятся в нескольких таблицах. Эти таблицы имеют одинаковую структуру (то есть, одни и те же столбцы, расположенные в одном…
/> Вычисление номера столбца для извлечения данных в ВПР — Задача: Наиболее простым способом научиться указывать тот столбец, из которого функция ВПР будет извлекать данные. При этом мы не будем изменять саму формулу, поскольку это может привести в случайным ошибкам.… 4 способа, как сделать левый ВПР в Excel. — Функция ВПР – одна из самых популярных, когда нужно найти и извлечь из таблицы какие-либо данные. Но при этом она имеет один существенный недостаток. Поиск она производит в крайнем левом…
4 способа, как сделать левый ВПР в Excel. — Функция ВПР – одна из самых популярных, когда нужно найти и извлечь из таблицы какие-либо данные. Но при этом она имеет один существенный недостаток. Поиск она производит в крайнем левом… Формула ВПР в Excel для сравнения двух таблиц — 4 способа — Сравнение таблиц – это задача, которую в Excel приходится довольно часто решать. Например, у нас есть старый прайс-лист и его новая версия. Нужно просмотреть, цены на какие товары изменились и…
Формула ВПР в Excel для сравнения двух таблиц — 4 способа — Сравнение таблиц – это задача, которую в Excel приходится довольно часто решать. Например, у нас есть старый прайс-лист и его новая версия. Нужно просмотреть, цены на какие товары изменились и…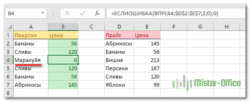 Почему не работает ВПР в Excel? — Функция ВПР – это очень мощный инструмент поиска. Но если он по каким-то причинам завершился неудачно, то вы получите сообщение об ошибке #Н/Д (#N/A в английском варианте). Давайте постараемся вместе…
Почему не работает ВПР в Excel? — Функция ВПР – это очень мощный инструмент поиска. Но если он по каким-то причинам завершился неудачно, то вы получите сообщение об ошибке #Н/Д (#N/A в английском варианте). Давайте постараемся вместе… Функция ВПР в Excel: пошаговая инструкция с 5 примерами — ВПР — это функция Excel для поиска и извлечения данных из определенного столбца в таблице. Она поддерживает приблизительное и точное сопоставление, а также подстановочные знаки (* и ?). Значения поиска…
Функция ВПР в Excel: пошаговая инструкция с 5 примерами — ВПР — это функция Excel для поиска и извлечения данных из определенного столбца в таблице. Она поддерживает приблизительное и точное сопоставление, а также подстановочные знаки (* и ?). Значения поиска… Формула ВПР в Excel — 22 факта, которые нужно знать. — В процессе работы в Excel часто возникает задача извлечения нужных данных из рабочих таблиц. Для этой цели в Excel предусмотрена формула ВПР (VLOOKUP в английском варианте). И хотя ВПР относительно…
Формула ВПР в Excel — 22 факта, которые нужно знать. — В процессе работы в Excel часто возникает задача извлечения нужных данных из рабочих таблиц. Для этой цели в Excel предусмотрена формула ВПР (VLOOKUP в английском варианте). И хотя ВПР относительно…
Суть запроса на выборку – выбрать из исходной таблицы строки, удовлетворяющие определенным критериям (подобно применению стандартного Фильтра ). Произведем отбор значений из исходной таблицы с помощью формул массива . В отличие от применения Фильтра ( CTRL+SHIFT+L или Данные/ Сортировка и фильтр/ Фильтр ) отобранные строки будут помещены в отдельную таблицу.
В этой статье рассмотрим наиболее часто встречающиеся запросы, например: отбор строк таблицы, у которых значение из числового столбца попадает в заданный диапазон (интервал); отбор строк, у которых дата принаждежит определенному периоду; задачи с 2-мя текстовыми критериями и другие. Начнем с простых запросов.
1. Один числовой критерий (Выбрать те Товары, у которых цена выше минимальной)
Пусть имеется Исходная таблица с перечнем Товаров и Ценами (см. файл примера, лист Один критерий — число ).
Необходимо отобразить в отдельной таблице только те записи (строки) из Исходной таблицы, у которых цена выше 25.
Решить эту и последующие задачи можно легко с помощью стандартного фильтра . Для этого выделите заголовки Исходной таблицы и нажмите CTRL+SHIFT+L . Через выпадающий список у заголовка Цены выберите Числовые фильтры. , затем задайте необходимые условия фильтрации и нажмите ОК.
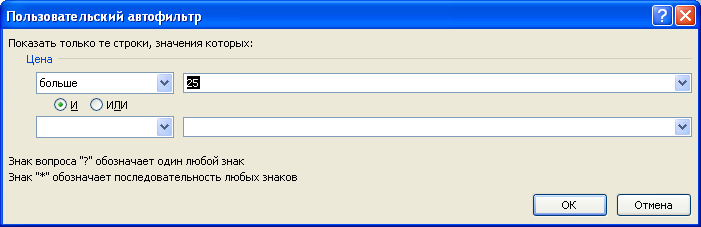
Будут отображены записи удовлетворяющие условиям отбора.
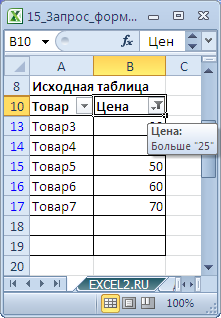
Другим подходом является использование формул массива . В отличие от фильтра отобранные строки будут помещены в отдельную таблицу — своеобразный Отчет , который, например, можно отформатировать в стиль отличный от Исходной таблицы или производить другие ее модификации.
Критерий (минимальную цену) разместим в ячейке Е6 , таблицу для отфильтрованных данных — в диапазоне D10:E19 .
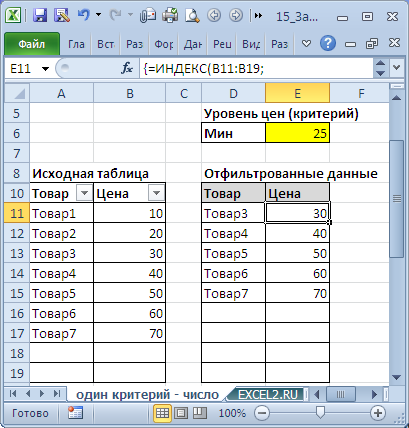
Теперь выделим диапазон D11:D19 (столбец Товар) и в Строке формул введем формулу массива :
Вместо ENTER нажмите сочетание клавиш CTRL+SHIFT+ENTER .
Те же манипуляции произведем с диапазоном E11:E19 куда и введем аналогичную формулу массива :
В результате получим новую таблицу, которая будет содержать только товары, у которых цены попадают в интервал, указанный в ячейках Е5 и Е6 .
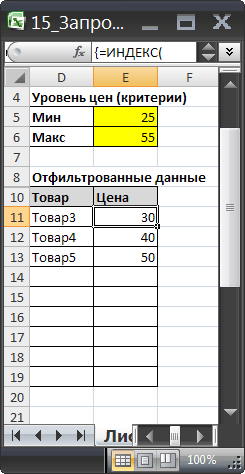
Чтобы показать динамизм полученного Отчета (Запроса на выборку) введем в Е6 значение 65. В новую таблицу будет добавлена еще одна запись из Исходной таблицы, удовлетворяющая новому критерию.
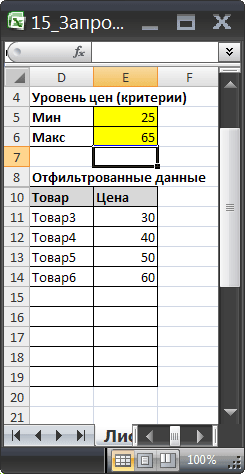
Если в Исходную таблицу добавить новый товар с Ценой в диапазоне от 25 до 65, то в новую таблицу будет добавлена новая запись.
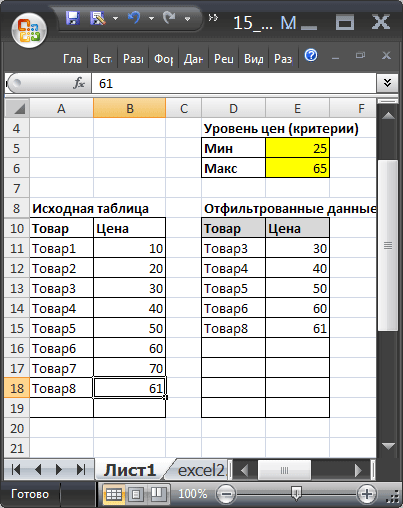
В файле примера также содержатся формулы массива с обработкой ошибок, когда в столбце Цена содержится значение ошибки, например #ДЕЛ/0! (см. лист Обработка ошибок ).
Следующие задачи решаются аналогичным образом, поэтому не будем их рассматривать так детально.
3. Один критерий Дата (Выбрать те Товары, у которых Дата поставки совпадает заданной)
Пусть имеется Исходная таблица с перечнем Товаров и Датами поставки (см. файл примера, лист Один критерий — Дата ).
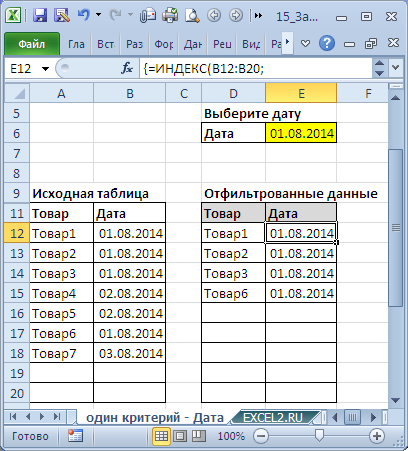
Для отбора строк используются формулы массива, аналогичные Задаче1 (вместо критерия =$B$12:$B$20)*(СТРОКА($B$12:$B$20)-СТРОКА($B$11));$J$12-СТРОКА(A12)+СТРОКА($B$11)+1))
Примечание : После ввода формулы вместо клавиши ENTER (ВВОД) нужно нажать сочетание клавиш CTRL+SHIFT+ENTER. Это сочетание клавиш используется для ввода формул массива.
Скопируйте формулу массива вниз на нужное количество ячеек. Формула вернет только те значения Товаров, которые были поставлены в диапазоне указанных дат. В остальных ячейках будут содержаться ошибки #ЧИСЛО! Ошибки в файле примера (Лист 4.Диапазон Дат) скрыты с помощью Условного форматирования .
Аналогичную формулу нужно ввести и для дат в столбец E.
В ячейке J12 вычислено количество строк исходной таблицы, удовлетворяющих критериям:
Решение2 : Для отбора строк можно использовать формулы массива, аналогичные Задаче2 (т.е. формулы массива, возвращающие несколько значений ):
Для ввода первой формулы выделите диапазон ячеек G12:G20 . После ввода формулы вместо клавиши ENTER (ВВОД) нужно нажать сочетание клавиш CTRL+SHIFT+ENTER.
Решение3 : Если столбец Дат СОРТИРОВАН, то можно не использовать формулы массива.
Сначала необходимо вычислить первую и последнюю позиции строк, которые удовлетворяют критериям. Затем вывести строки с помощью функции СМЕЩ() .
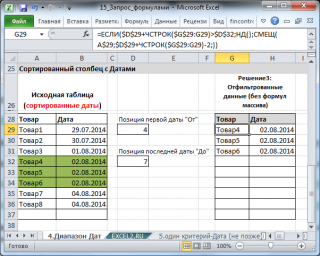
Этот пример еще раз наглядно демонстрирует насколько предварительная сортировка данных облегчает написание формул.
5. Один критерий Дата (Выбрать те Товары, у которых Дата поставки не раньше/ не позже заданной)
Пусть имеется Исходная таблица с перечнем Товаров и Датами поставки (см. файл примера, лист Один критерий — Дата (не позже) ).
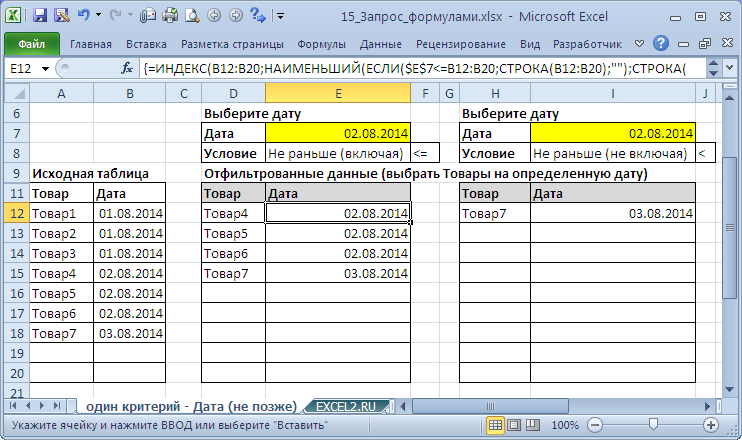
Для отбора строк, дата которых не раньше (включая саму дату), используется формула массива:
= ИНДЕКС(A12:A20;НАИМЕНЬШИЙ(ЕСЛИ($E$7 C15;И($B$7>=B15;$B$7 =$B$13:$B$21)*($B$13:$B$21>0);СТРОКА($B$13:$B$21);»»);СТРОКА($B$13:$B$21)-СТРОКА($B$12)) -СТРОКА($B$12))
Условие $E$7=$A$13:$A$21 гарантирует, что будут отобраны товары только определенного типа. Условие $E$8>=$B$13:$B$21 гарантирует, что будут отобраны даты не позже заданной (включая). Условие $B$13:$B$21>0 необходимо, если в диапазоне дат имеются пустые ячейки. Знак * (умножение) используется для задания Условия И (все 3 критерия должны выполняться для строки одновременно).
Примечание . Случай, когда список несортирован, рассмотрен в статье Поиск ДАТЫ (ЧИСЛА) ближайшей к заданной, с условием в MS EXCEL. Несортированный список .
7. Один Текстовый критерий (Выбрать Товары определенного вида)
Пусть имеется Исходная таблица с перечнем Товаров и Ценами (см. файл примера, лист Один критерий — Текст ).
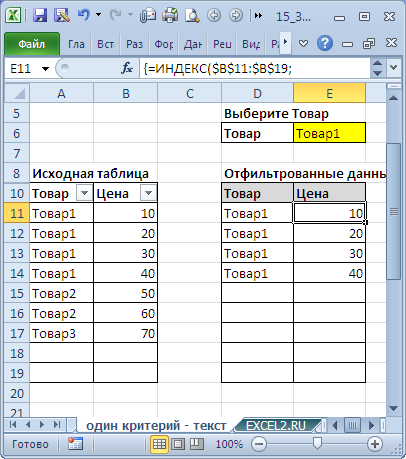
Задача решается аналогично Задачам 1 и 3. Более подробное решение см. в статье Поиск ТЕКСТовых значений в MS EXCEL с выводом их в отдельный список. Часть1. Обычный поиск .
8. Два Текстовых критерия (Выбрать Товары определенного вида, поставленные в заданный месяц)
Пусть имеется Исходная таблица с перечнем Товаров и Ценами (см. файл примера, лист 2 критерия — текст (И) ).
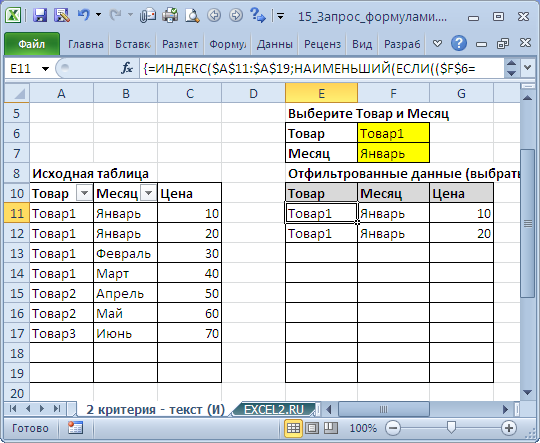
Для отбора строк используется формула массива:
Выражение ($F$6=$A$11:$A$19)*($F$7=$B$11:$B$19) задает оба условия (Товар и Месяц).
Выражение СТРОКА(ДВССЫЛ(«A1:A»&ЧСТРОК($A$11:$A$19))) формирует массив последовательных чисел , т.е. номера строк в таблице.
9. Два Текстовых критерия (Выбрать Товары определенных видов)
Пусть имеется Исходная таблица с перечнем Товаров и Ценами (см. файл примера, лист 2 критерия — текст (ИЛИ) ).
В отличие от Задачи 7 отберем строки с товарами 2-х видов ( Условие ИЛИ ).
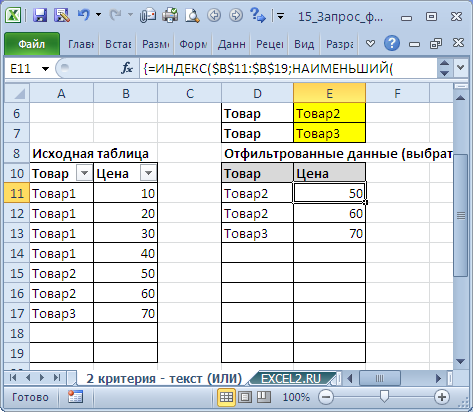
Для отбора строк используется формула массива:
= ИНДЕКС(A$11:A$19; НАИБОЛЬШИЙ((($E$6=$A$11:$A$19)+($E$7=$A$11:$A$19))*(СТРОКА($A$11:$A$19)-СТРОКА($A$10)); СЧЁТЕСЛИ($A$11:$A$19;$E$6)+СЧЁТЕСЛИ($A$11:$A$19;$E$7)-ЧСТРОК($A$11:A11)+1))
Условие ($E$6=$A$11:$A$19)+($E$7=$A$11:$A$19) гарантирует, что будут отобраны товары только заданных видов из желтых ячеек (Товар2 и Товар3). Знак + (сложение) используется для задания Условие ИЛИ (должен быть выполнен хотя бы 1 критерий).
Вышеуказанное выражение вернет массив . Умножив его на выражение СТРОКА($A$11:$A$19)-СТРОКА($A$10) , т.е. на массив последовательных чисел , получим массив позиций (номеров строк таблицы), удовлетворяющих критериям. В нашем случае это будет массив .
С помощью функции НАИБОЛЬШИЙ() выведем 3 значения из позиции 5 (строка 15 листа), 6 (16) и 7 (17), т.е. значения Товар2, Товар2 и Товар3. Для этого используем выражение СЧЁТЕСЛИ($A$11:$A$19;$E$6)+СЧЁТЕСЛИ($A$11:$A$19;$E$7)-ЧСТРОК($A$11:A11)+1 , которое последовательно (начиная со строки 11) будет возвращать числа 3; 2; 1; 0; -1; -2; . Формула НАИБОЛЬШИЙ(. ;3) вернет число 5, НАИБОЛЬШИЙ(. ;2) вернет число 6, НАИБОЛЬШИЙ(. ;1) вернет число 7, а НАИБОЛЬШИЙ(. ;0) и далее вернет ошибку, которую мы скроем условным форматированием .
И наконец, с помощью функции ИНДЕКС() последовательно выведем наши значения из соответствующих позиций: = ИНДЕКС(A$11:A$19;5) вернет Товар2, = ИНДЕКС(A$11:A$19;6) вернет Товар2, = ИНДЕКС(A$11:A$19;7) вернет Товар3.
10. Отбор значений с учетом повторов
В разделе Отбор на основании повторяемости собраны статьи о запросах с группировкой данных. Из повторяющихся данных сначала отбираются уникальные значения, а соответствующие им значения в других столбцах — группируются (складываются, усредняются и пр.).
Наиболее популярные статьи из этого раздела:
В качестве примера приведем решения следующей задачи: Выбрать Товары, цена которых лежит в определенном диапазоне и повторяется заданное количество раз или более.
В качестве исходной возьмем таблицу партий товаров.
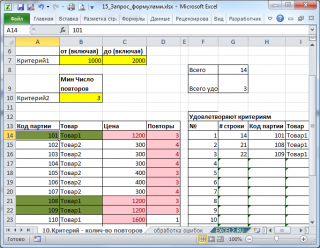
Предположим, что нас интересует сколько и каких партий товаров поставлялось по цене от 1000р. до 2000р. (критерий 1). Причем, партий с одинаковой ценой должно быть минимум 3 (критерий 2).
Решением является формула массива:
Эта формула возвращает номера строк, которые удовлетворяют обоим критериям.
Формула =СУММПРОИЗВ(($C$14:$C$27>=$B$7)*($C$14:$C$27 =$B$10)) подсчитывает количество строк, которые удовлетворяют критериям.
В файле примера на листе «10.Критерий — колич-во повторов» настроено Условное форматирование , которое позволяет визуально определить строки удовлетворяющие критериям, а также скрыть ячейки, в которых формула массива возвращает ошибку #ЧИСЛО!
11. Используем значение критерия (Любой) или (Все)
В фильтре Сводных таблиц MS EXCEL используется значение (Все), чтобы вывести все значения столбца. Другими словами, в выпадающем списке значений критерия содержится особое значение, которое отменяет сам критерий (см. статью Отчеты в MS EXCEL , Отчет №3).
В файле примера на листе «11. Критерий Любой или (Все)» реализован данный вариант критерия.
Формула в этом случае должна содержать функцию ЕСЛИ() . Если выбрано значение (Все), то используется формула для вывода значений без учета данного критерия. Если выбрано любое другое значение, то критерий работает обычным образом.
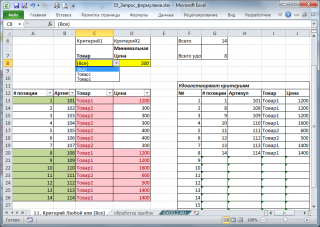
Остальная часть формулы аналогична рассмотренным выше.
12. Актуальная цена
Пусть для товара ежедневно заполняется таблица цен (цена может меняться, но не каждый день). Нужно найти актуальнуй цену, т.е. цену на последнюю дату. Если товар всего один, то можно отсортировать по дате и в последней строке будет нужная актуальная цена. Если товаров много, то нужно сначала выбрать Автофильтром нужный товар, затем опять отсортировать по цене.
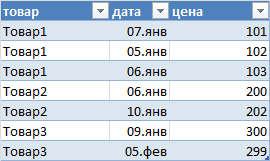
Чтобы иметь перечень товаров с актуальными ценами придется использовать формулы:
2) определяем последнюю (максимальную) дату для каждого товара с помощью формулы массива =МАКС((Таблица1[товар]=E8)*Таблица1[дата])
3) наконец, выводим актуальную цену =СУММЕСЛИМН(Таблица1[цена];Таблица1[товар];E8;Таблица1[дата];F8)
Для товара не должно быть повторов дат, иначе цены будут суммироваться (если повторяется последняя дата).
Одновременная фильтрация нескольких сводных таблиц
При создании сложных отчетов и, особенно, дашбордов в Microsoft Excel, весьма часто возникает необходимость одновременной фильтрации сразу нескольких сводных таблиц. Давайте разберёмся, как такое можно можно реализовать.
Способ 1. Общий срез для фильтрации сводных на одном источнике данных
Если сводные построены по одной исходной таблице данных, то проще всего использовать для их одновременной фильтрации срез — графический кнопочный фильтр, подключенный сразу ко всем сводным таблицам.
Чтобы его добавить, выделите любую ячейку в одной из сводных и на вкладке Анализ выберите команду Вставить срез (Analyze — Insert slicer). В открывшемся окошке пометьте галочками те столбцы, по которым вы хотите фильтровать данные и нажмите ОК:

Созданный срез будет, по умолчанию, фильтровать только ту сводную, для которой он был создан. Однако, воспользовавшись кнопкой Подключения к отчетам (Report connections) на вкладке Срез (Slicer) мы можем легко добавить к списку фильтруемых таблиц другие сводные:

Способ 2. Общий срез для фильтрации сводных на разных источниках
Если ваши сводные были построены не по одной, а по разным исходным таблицам данных, то приведённый выше способ не сработает, т.к. в окне Подключения к отчётам отображаются только те сводные, которые были построены по одному источнику.
Однако, можно легко обойти это ограничение, если использовать Модель Данных (мы подробно разбирали её в этой статье). Если загрузить наши таблицы в Модель и связать их там, то фильтрация станет распространяться на обе таблицы одновременно.
Допустим, что в качестве исходных данных у нас есть две таблицы по продажам и транспортным расходам:

Предположим, что перед нами стоит задача по каждой из них построить свою сводную и фильтровать их затем одновременно по городам общим срезом.
Делаем следующее:
1. Превращаем наши исходные таблицы в динамические «умные» с помощью сочетания клавиш Ctrl+T или команды Главная — Форматировать как таблицу (Home — Format as Table) и даём им имена таблПродажи и таблТранспорт на вкладке Конструктор (Design).
2. Загружаем по очереди обе таблицы в Модель с помощью кнопки Добавить в модель данных (Add to Data Model) на вкладке Power Pivot.
Напрямую связать эти таблицы в Модели не получится, т.к. пока Power Pivot поддерживает только тип связей «один-ко-многим», т.е. требует, чтобы в одной из таблиц не было дубликатов в столбце, по которому мы связываем. У нас же в обеих таблицах в поле Город присутствуют повторения. Так что потребуется создать ещё одну промежуточную таблицу-справочник со списком уникальных названий городов из обеих таблиц. Проще всего это сделать с помощью функционала надстройки Power Query, которая встроена в Excel начиная с 2016 версии (а для Excel 2010-2013 бесплатно скачивается с сайта Microsoft).
3. Выделив любую ячейку внутри «умной» таблицы, загружаем их по очереди в Power Query кнопкой Из таблицы / диапазона на вкладке Данные (Data — From table/range) и затем в окне Power Query выбираем на Главной команды Закрыть и загрузить — Закрыть и загрузить в (Home — Close&Load — Close&Load to…) и вариант импорта Только создать подключение (Only create connection):

4. Соединяем обе таблицы в одну командой Данные — Объединить запросы — Добавить (Data — Combine queries — Append). Совпадающие по названиям в шапке колонки встанут друг под друга (как столбец Город), а не совпадающие будут разнесены в разные столбцы (но для нас это не важно).
5. Удаляем все столбцы, кроме колонки Город, щёлкнув по её заголовку правой кнопкой мыши и выбрав команду Удалить другие столбцы (Remove other columns) и затем удаляем все дубликаты названий городов, щёлкнув ещё раз правой кнопкой мыши по заголовку столбца и выбрав команду Удалить дубликаты (Remove duplicates):

6. Созданный список-справочник выгружаем в Модель Данных через Главная — Закрыть и загрузить — Закрыть и загрузить в (Home — Close&Load — Close&Load to…) и выбираем вариант Только создать подключение (Only create connection) и — самое главное! — включаем флажок Добавить эти данные в модель данных (Add this data to Data Model):

7. Теперь можем, вернувшись в окно Power Pivot (вкладка Power Pivot — кнопка Управление), переключиться в Представление диаграммы (Diagram view) и связать наши таблицы продаж и траспортных расходов через созданный промежуточный справочник по городам (перетаскиванием полей между таблицами):

8. Теперь можно создать все требуемые сводные таблицы по созданной модели с помощью кнопки Сводная таблица (Pivot Table) на Главной (Home) вкладке в окне Power Pivot и, выделив любую ячейку в любой сводной, на вкладке Анализ добавить срез кнопкой Вставить срез (Analyze — Insert Slicer) и выбрать для среза в списке поле Город в добавленном справочнике:

Теперь, нажав на знакомую кнопку Подключения к отчетам на вкладке Срез (Slicer — Report connections) мы увидим все наши сводные, т.к. построены они теперь по связанным исходным таблицам. Останется включить недостающие флажки и нажать на ОК — и наш срез начнёт фильтровать все выбранные сводные таблицы одновременно.
Ссылки по теме
- Преимущества сводной по Модели Данных
- План-факт анализ в сводной таблице с Power Pivot и Power Query
- Независимая группировка сводных таблиц
Содержание
- Создание связанных таблиц
- Способ 1: прямое связывание таблиц формулой
- Способ 2: использование связки операторов ИНДЕКС — ПОИСКПОЗ
- Способ 3: выполнение математических операций со связанными данными
- Способ 4: специальная вставка
- Способ 5: связь между таблицами в нескольких книгах
- Разрыв связи между таблицами
- Способ 1: разрыв связи между книгами
- Способ 2: вставка значений
- Вопросы и ответы

При выполнении определенных задач в Excel иногда приходится иметь дело с несколькими таблицами, которые к тому же связаны между собой. То есть, данные из одной таблицы подтягиваются в другие и при их изменении пересчитываются значения во всех связанных табличных диапазонах.
Связанные таблицы очень удобно использовать для обработки большого объема информации. Располагать всю информацию в одной таблице, к тому же, если она не однородная, не очень удобно. С подобными объектами трудно работать и производить по ним поиск. Указанную проблему как раз призваны устранить связанные таблицы, информация между которыми распределена, но в то же время является взаимосвязанной. Связанные табличные диапазоны могут находиться не только в пределах одного листа или одной книги, но и располагаться в отдельных книгах (файлах). Последние два варианта на практике используют чаще всего, так как целью указанной технологии является как раз уйти от скопления данных, а нагромождение их на одной странице принципиально проблему не решает. Давайте узнаем, как создавать и как работать с таким видом управления данными.
Создание связанных таблиц
Прежде всего, давайте остановимся на вопросе, какими способами существует возможность создать связь между различными табличными диапазонами.
Способ 1: прямое связывание таблиц формулой
Самый простой способ связывания данных – это использование формул, в которых имеются ссылки на другие табличные диапазоны. Он называется прямым связыванием. Этот способ интуитивно понятен, так как при нем связывание выполняется практически точно так же, как создание ссылок на данные в одном табличном массиве.
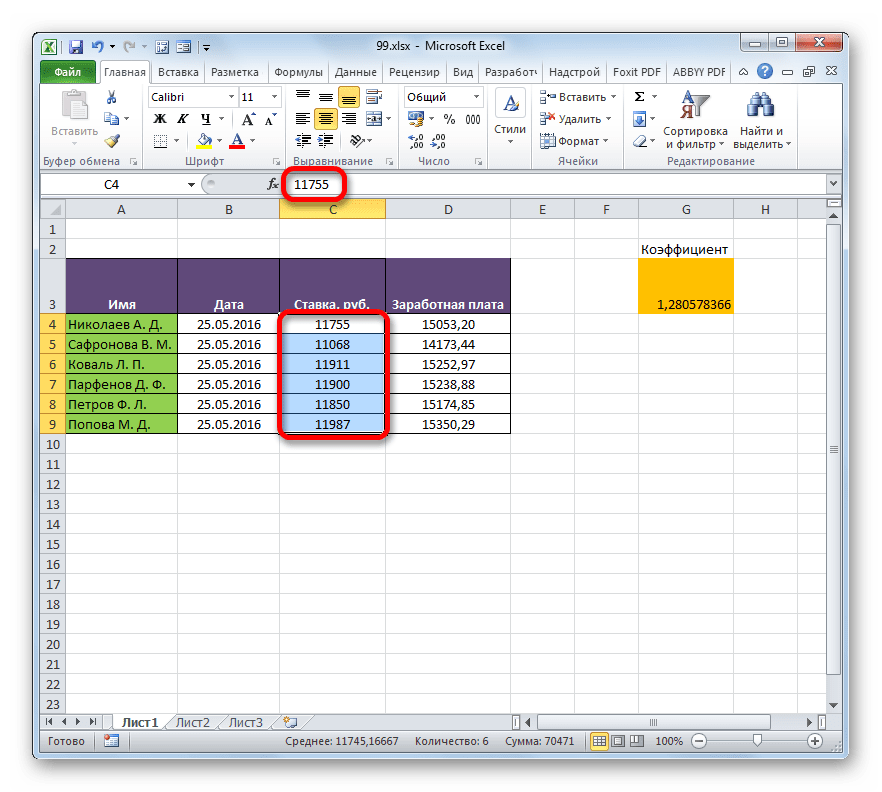
Посмотрим, как на примере можно образовать связь путем прямого связывания. Имеем две таблицы на двух листах. На одной таблице производится расчет заработной платы с помощью формулы путем умножения ставки работников на единый для всех коэффициент.
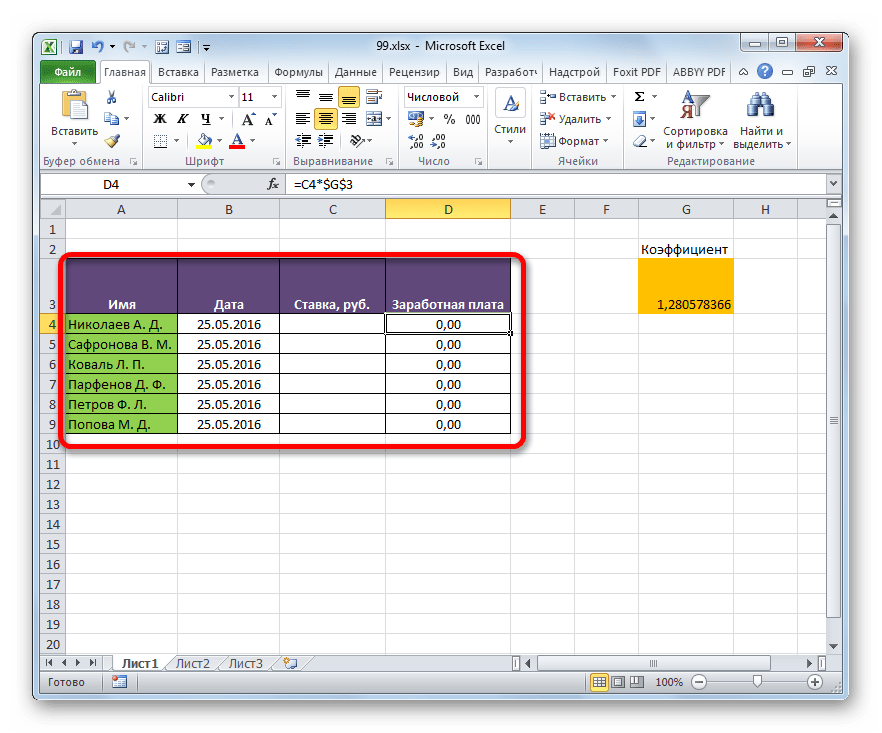
На втором листе расположен табличный диапазон, в котором находится перечень сотрудников с их окладами. Список сотрудников в обоих случаях представлен в одном порядке.
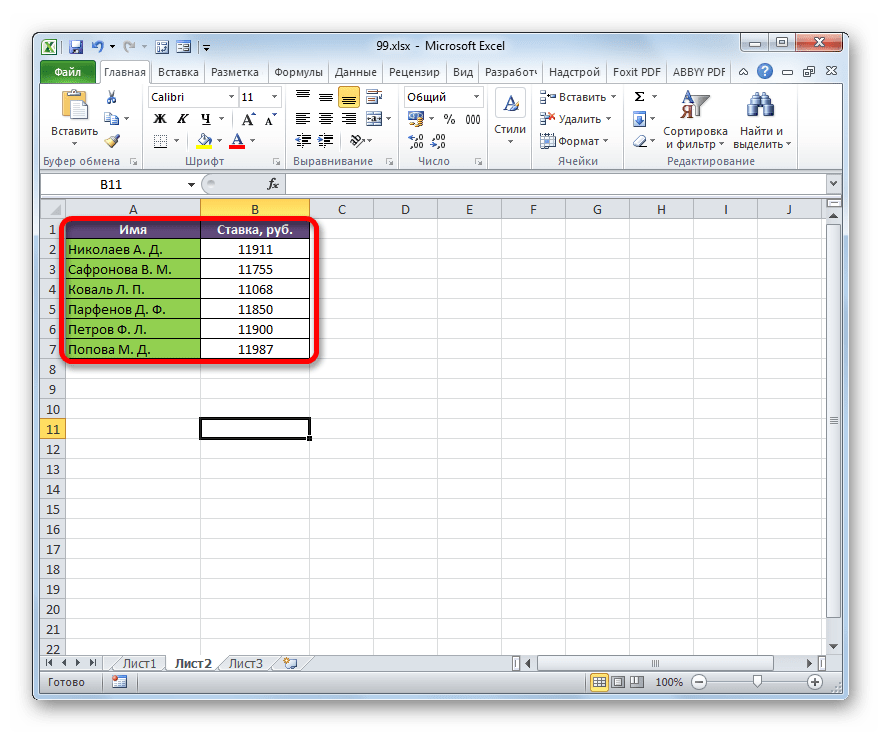
Нужно сделать так, чтобы данные о ставках из второго листа подтягивались в соответствующие ячейки первого.
- На первом листе выделяем первую ячейку столбца «Ставка». Ставим в ней знак «=». Далее кликаем по ярлычку «Лист 2», который размещается в левой части интерфейса Excel над строкой состояния.
- Происходит перемещения во вторую область документа. Щелкаем по первой ячейке в столбце «Ставка». Затем кликаем по кнопке Enter на клавиатуре, чтобы произвести ввод данных в ячейку, в которой ранее установили знак «равно».
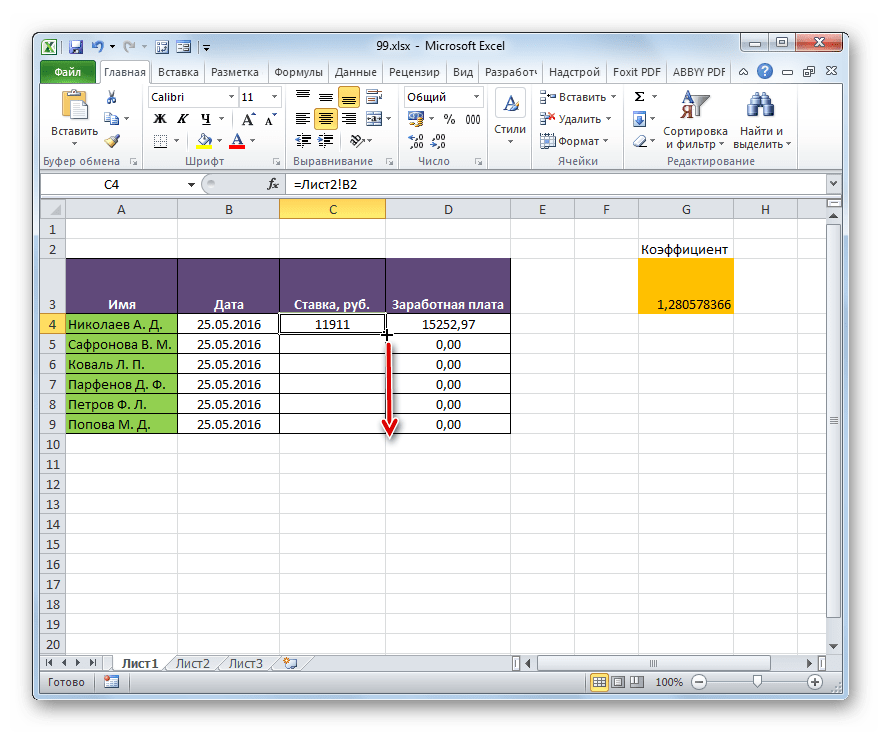
- Затем происходит автоматический переход на первый лист. Как видим, в соответствующую ячейку подтягивается величина ставки первого сотрудника из второй таблицы. Установив курсор на ячейку, содержащую ставку, видим, что для вывода данных на экран применяется обычная формула. Но перед координатами ячейки, откуда выводятся данные, стоит выражение «Лист2!», которое указывает наименование области документа, где они расположены. Общая формула в нашем случае выглядит так:
=Лист2!B2 - Теперь нужно перенести данные о ставках всех остальных работников предприятия. Конечно, это можно сделать тем же путем, которым мы выполнили поставленную задачу для первого работника, но учитывая, что оба списка сотрудников расположены в одинаковом порядке, задачу можно существенно упростить и ускорить её решение. Это можно сделать, просто скопировав формулу на диапазон ниже. Благодаря тому, что ссылки в Excel по умолчанию являются относительными, при их копировании происходит сдвиг значений, что нам и нужно. Саму процедуру копирования можно произвести с помощью маркера заполнения.
Итак, ставим курсор в нижнюю правую область элемента с формулой. После этого курсор должен преобразоваться в маркер заполнения в виде черного крестика. Выполняем зажим левой кнопки мыши и тянем курсор до самого низа столбца.
- Все данные из аналогичного столбца на Листе 2 были подтянуты в таблицу на Листе 1. При изменении данных на Листе 2 они автоматически будут изменяться и на первом.





Способ 2: использование связки операторов ИНДЕКС — ПОИСКПОЗ
Но что делать, если перечень сотрудников в табличных массивах расположен не в одинаковом порядке? В этом случае, как говорилось ранее, одним из вариантов является установка связи между каждой из тех ячеек, которые следует связать, вручную. Но это подойдет разве что для небольших таблиц. Для массивных диапазонов подобный вариант в лучшем случае отнимет очень много времени на реализацию, а в худшем – на практике вообще будет неосуществим. Но решить данную проблему можно при помощи связки операторов ИНДЕКС – ПОИСКПОЗ. Посмотрим, как это можно осуществить, связав данные в табличных диапазонах, о которых шел разговор в предыдущем способе.
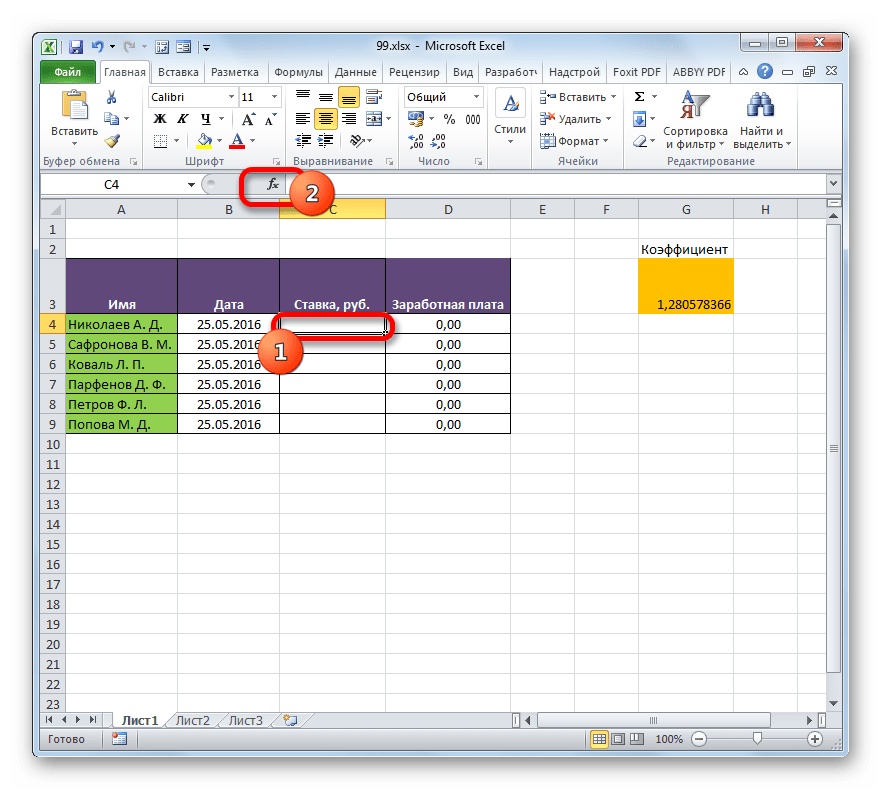
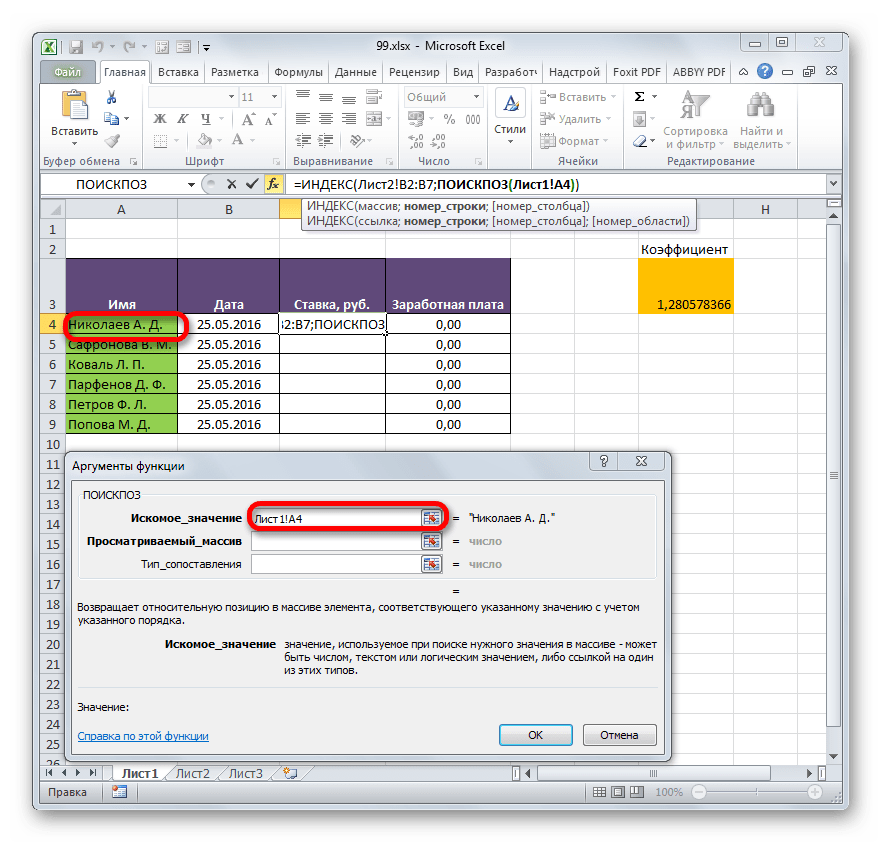
- Выделяем первый элемент столбца «Ставка». Переходим в Мастер функций, кликнув по пиктограмме «Вставить функцию».
- В Мастере функций в группе «Ссылки и массивы» находим и выделяем наименование «ИНДЕКС».
- Данный оператор имеет две формы: форму для работы с массивами и ссылочную. В нашем случае требуется первый вариант, поэтому в следующем окошке выбора формы, которое откроется, выбираем именно его и жмем на кнопку «OK».
- Выполнен запуск окошка аргументов оператора ИНДЕКС. Задача указанной функции — вывод значения, находящегося в выбранном диапазоне в строке с указанным номером. Общая формула оператора ИНДЕКС такова:
=ИНДЕКС(массив;номер_строки;[номер_столбца])«Массив» — аргумент, содержащий адрес диапазона, из которого мы будем извлекать информацию по номеру указанной строки.
«Номер строки» — аргумент, являющийся номером этой самой строчки. При этом важно знать, что номер строки следует указывать не относительно всего документа, а только относительно выделенного массива.
«Номер столбца» — аргумент, носящий необязательный характер. Для решения конкретно нашей задачи мы его использовать не будем, а поэтому описывать его суть отдельно не нужно.
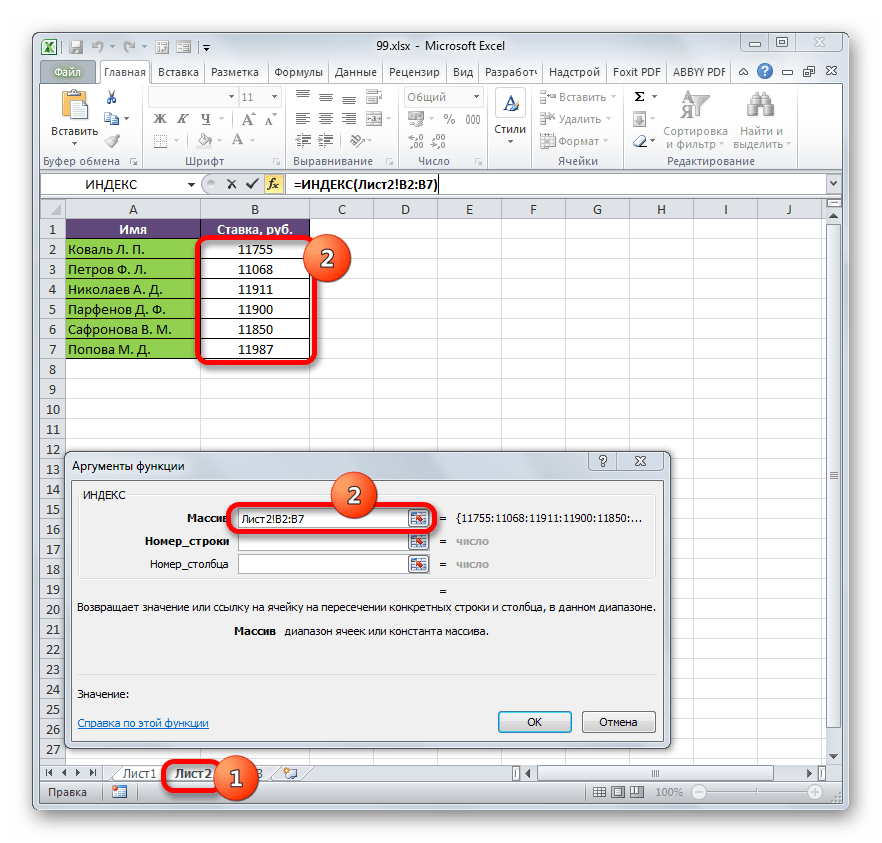
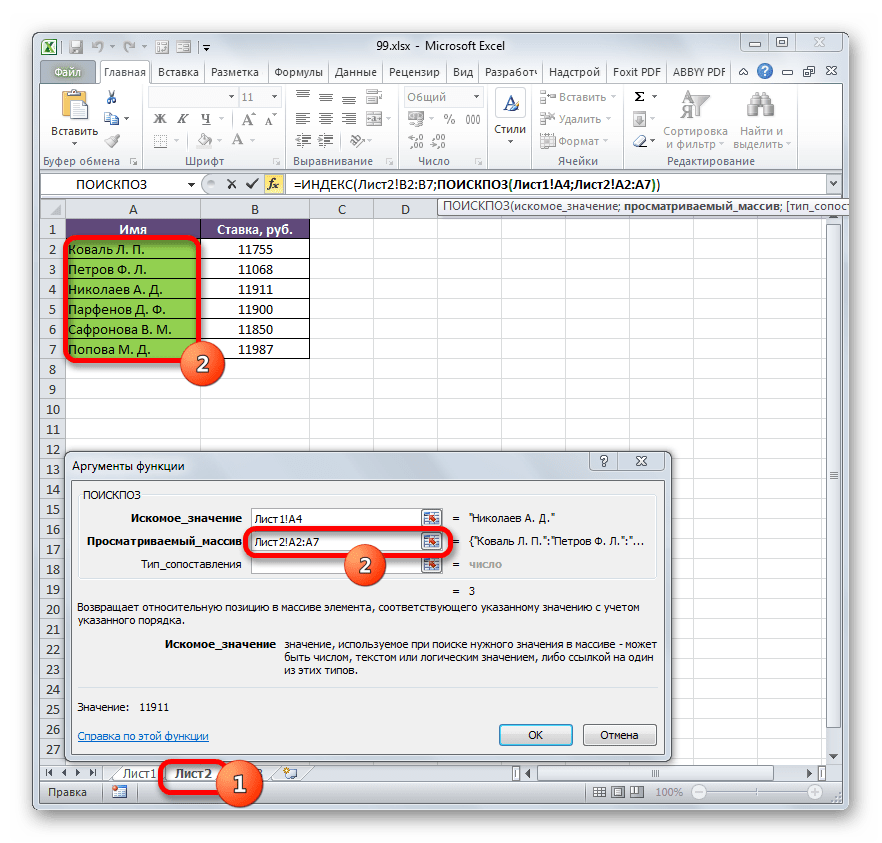
Ставим курсор в поле «Массив». После этого переходим на Лист 2 и, зажав левую кнопку мыши, выделяем все содержимое столбца «Ставка».
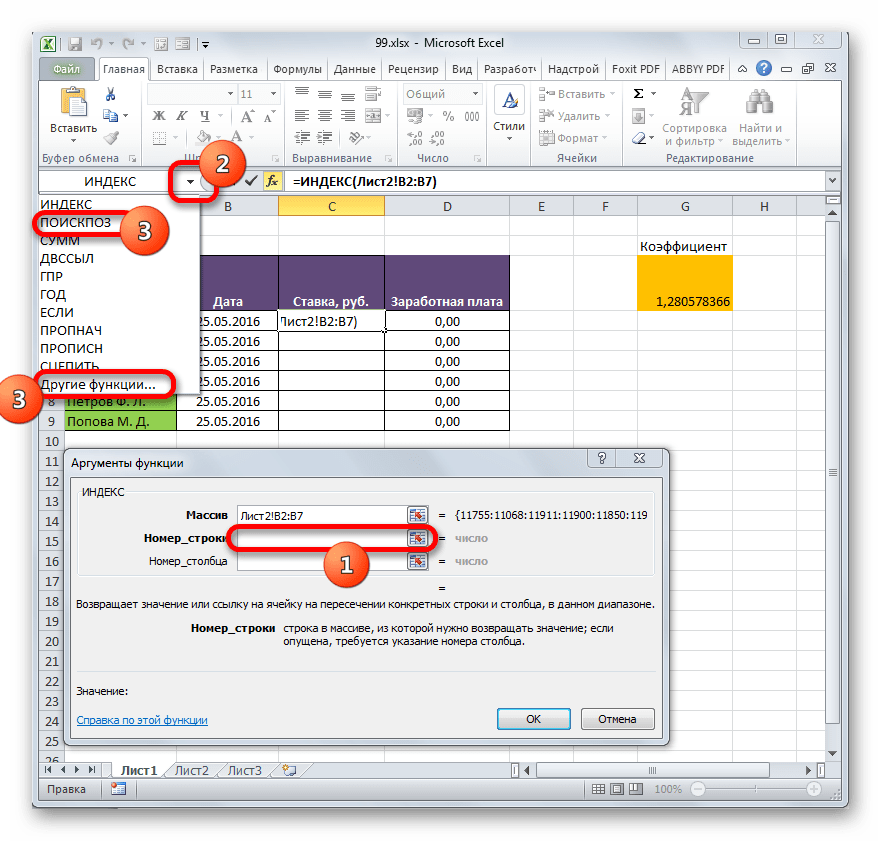
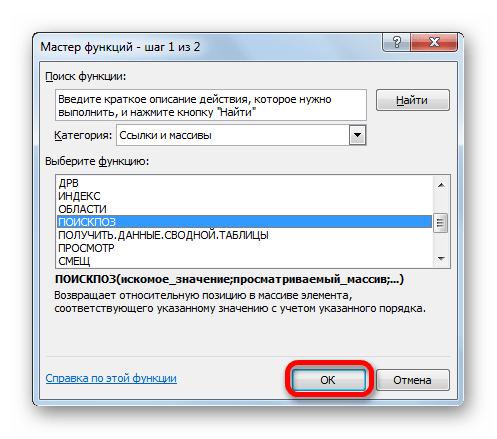
- После того, как координаты отобразились в окошке оператора, ставим курсор в поле «Номер строки». Данный аргумент мы будем выводить с помощью оператора ПОИСКПОЗ. Поэтому кликаем по треугольнику, который расположен слева от строки функций. Открывается перечень недавно использованных операторов. Если вы среди них найдете наименование «ПОИСКПОЗ», то можете кликать по нему. В обратном случае кликайте по самому последнему пункту перечня – «Другие функции…».
- Запускается стандартное окно Мастера функций. Переходим в нем в ту же самую группу «Ссылки и массивы». На этот раз в перечне выбираем пункт «ПОИСКПОЗ». Выполняем щелчок по кнопке «OK».
- Производится активация окошка аргументов оператора ПОИСКПОЗ. Указанная функция предназначена для того, чтобы выводить номер значения в определенном массиве по его наименованию. Именно благодаря данной возможности мы вычислим номер строки определенного значения для функции ИНДЕКС. Синтаксис ПОИСКПОЗ представлен так:
=ПОИСКПОЗ(искомое_значение;просматриваемый_массив;[тип_сопоставления])«Искомое значение» — аргумент, содержащий наименование или адрес ячейки стороннего диапазона, в которой оно находится. Именно позицию данного наименования в целевом диапазоне и следует вычислить. В нашем случае в роли первого аргумента будут выступать ссылки на ячейки на Листе 1, в которых расположены имена сотрудников.
«Просматриваемый массив» — аргумент, представляющий собой ссылку на массив, в котором выполняется поиск указанного значения для определения его позиции. У нас эту роль будет исполнять адрес столбца «Имя» на Листе 2.
«Тип сопоставления» — аргумент, являющийся необязательным, но, в отличие от предыдущего оператора, этот необязательный аргумент нам будет нужен. Он указывает на то, как будет сопоставлять оператор искомое значение с массивом. Этот аргумент может иметь одно из трех значений: -1; 0; 1. Для неупорядоченных массивов следует выбрать вариант «0». Именно данный вариант подойдет для нашего случая.
Итак, приступим к заполнению полей окна аргументов. Ставим курсор в поле «Искомое значение», кликаем по первой ячейке столбца «Имя» на Листе 1.
- После того, как координаты отобразились, устанавливаем курсор в поле «Просматриваемый массив» и переходим по ярлыку «Лист 2», который размещен внизу окна Excel над строкой состояния. Зажимаем левую кнопку мыши и выделяем курсором все ячейки столбца «Имя».
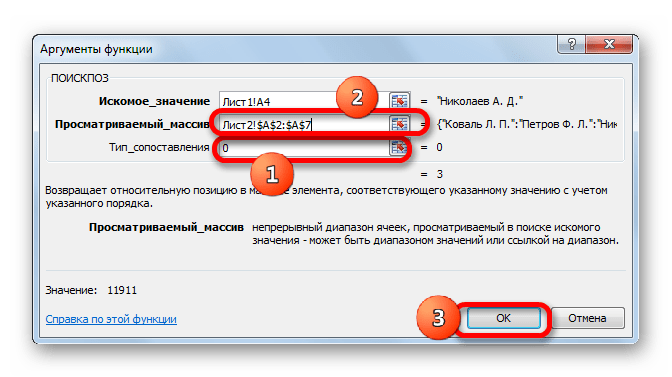
- После того, как их координаты отобразились в поле «Просматриваемый массив», переходим к полю «Тип сопоставления» и с клавиатуры устанавливаем там число «0». После этого опять возвращаемся к полю «Просматриваемый массив». Дело в том, что мы будем выполнять копирование формулы, как мы это делали в предыдущем способе. Будет происходить смещение адресов, но вот координаты просматриваемого массива нам нужно закрепить. Он не должен смещаться. Выделяем координаты курсором и жмем на функциональную клавишу F4. Как видим, перед координатами появился знак доллара, что означает то, что ссылка из относительной превратилась в абсолютную. Затем жмем на кнопку «OK».
- Результат выведен на экран в первую ячейку столбца «Ставка». Но перед тем, как производить копирование, нам нужно закрепить ещё одну область, а именно первый аргумент функции ИНДЕКС. Для этого выделяем элемент колонки, который содержит формулу, и перемещаемся в строку формул. Выделяем первый аргумент оператора ИНДЕКС (B2:B7) и щелкаем по кнопке F4. Как видим, знак доллара появился около выбранных координат. Щелкаем по клавише Enter. В целом формула приняла следующий вид:
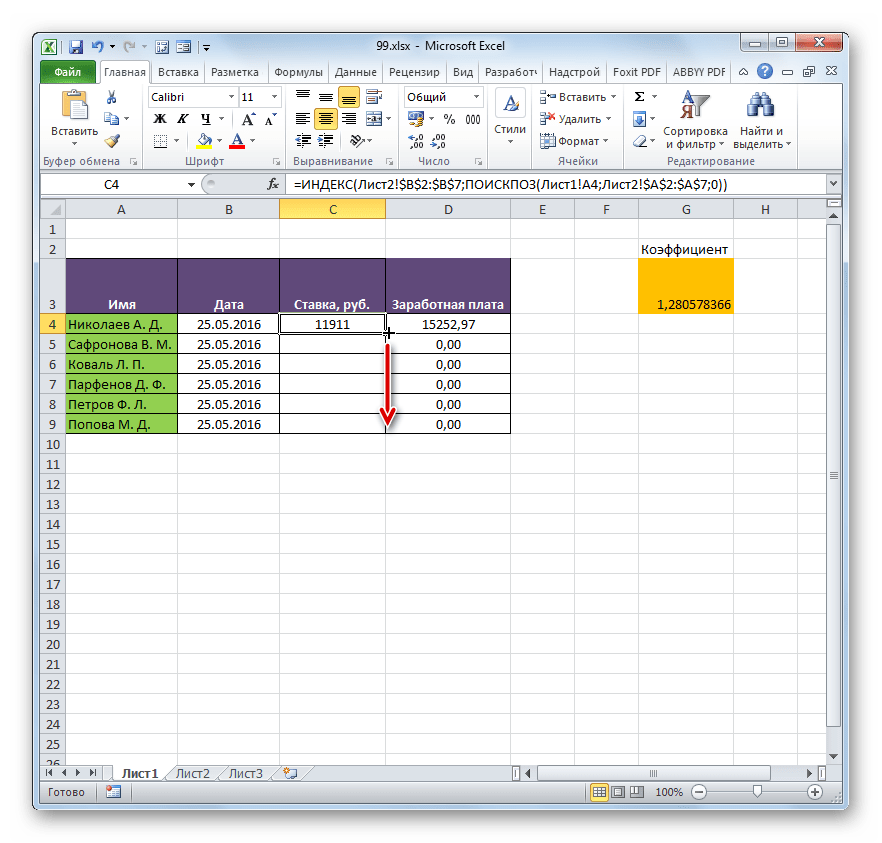
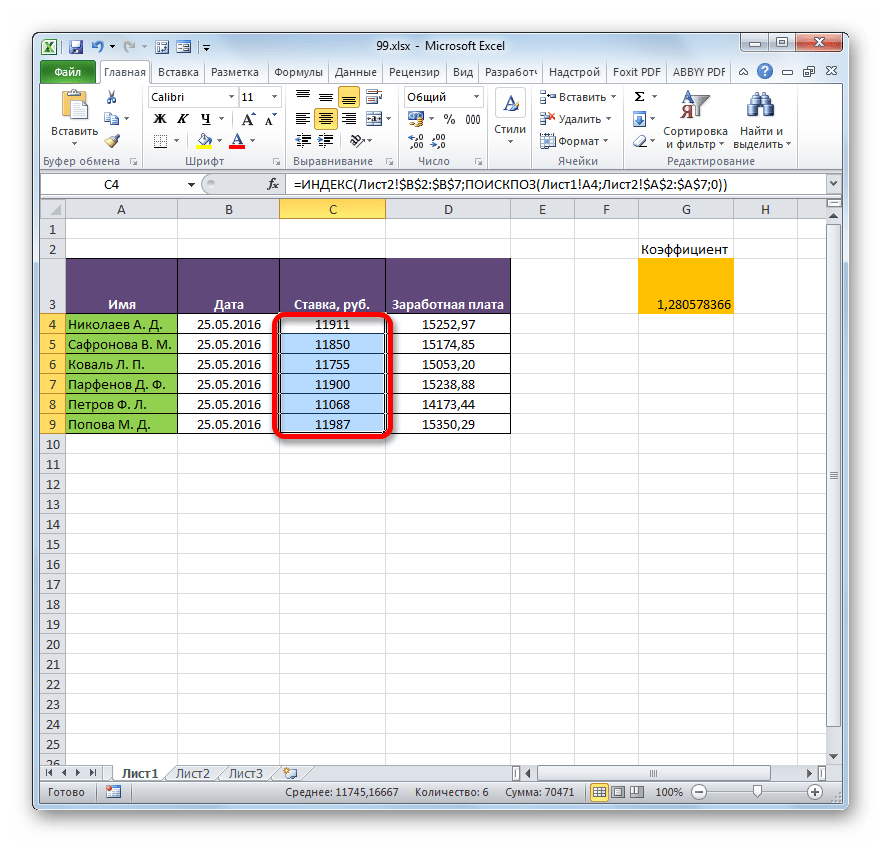
=ИНДЕКС(Лист2!$B$2:$B$7;ПОИСКПОЗ(Лист1!A4;Лист2!$A$2:$A$7;0)) - Теперь можно произвести копирование с помощью маркера заполнения. Вызываем его тем же способом, о котором мы говорили ранее, и протягиваем до конца табличного диапазона.
- Как видим, несмотря на то, что порядок строк у двух связанных таблиц не совпадает, тем не менее, все значения подтягиваются соответственно фамилиям работников. Этого удалось достичь благодаря применению сочетания операторов ИНДЕКС—ПОИСКПОЗ.



Читайте также:
Функция ИНДЕКС в Экселе
Функция ПОИСКПОЗ в Экселе
Способ 3: выполнение математических операций со связанными данными
Прямое связывание данных хорошо ещё тем, что позволяет не только выводить в одну из таблиц значения, которые отображаются в других табличных диапазонах, но и производить с ними различные математические операции (сложение, деление, вычитание, умножение и т.д.).
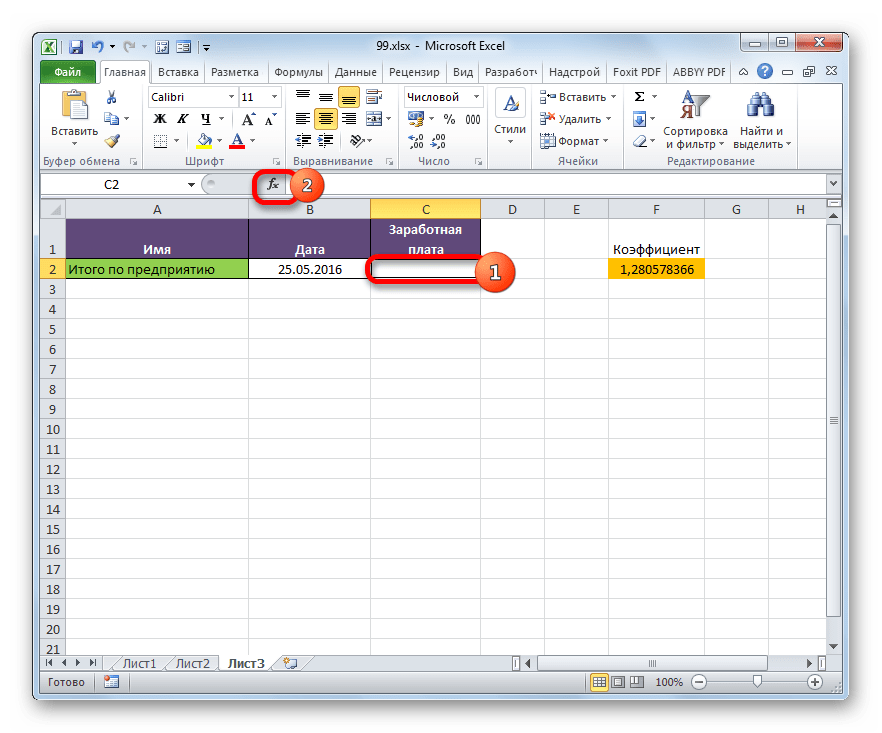
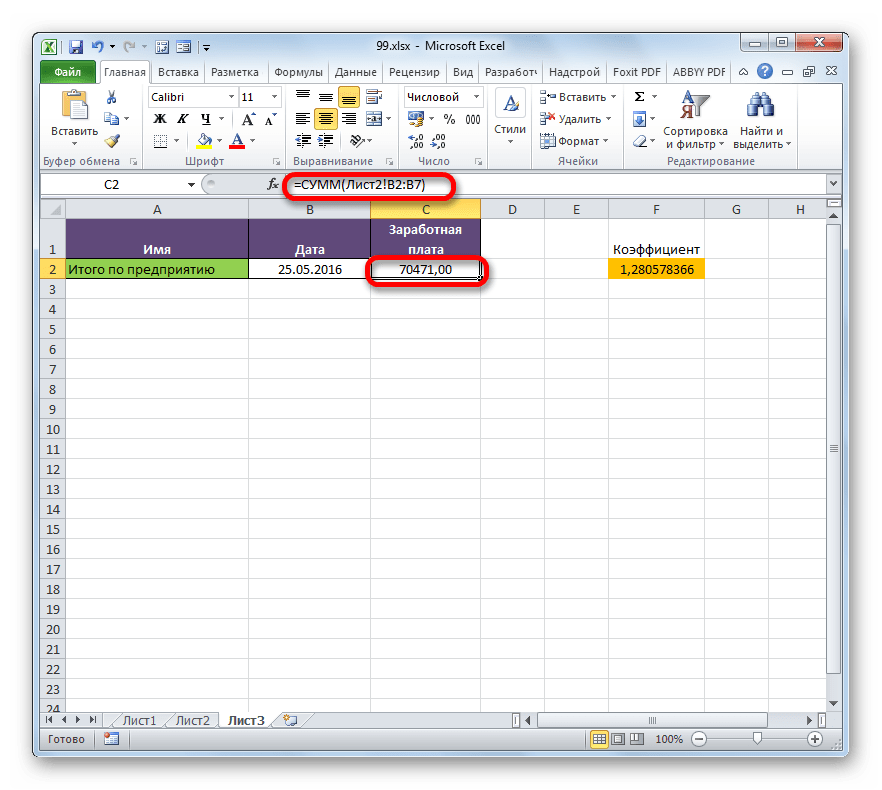
Посмотрим, как это осуществляется на практике. Сделаем так, что на Листе 3 будут выводиться общие данные заработной платы по предприятию без разбивки по сотрудникам. Для этого ставки сотрудников будут подтягиваться из Листа 2, суммироваться (при помощи функции СУММ) и умножаться на коэффициент с помощью формулы.
- Выделяем ячейку, где будет выводиться итог расчета заработной платы на Листе 3. Производим клик по кнопке «Вставить функцию».
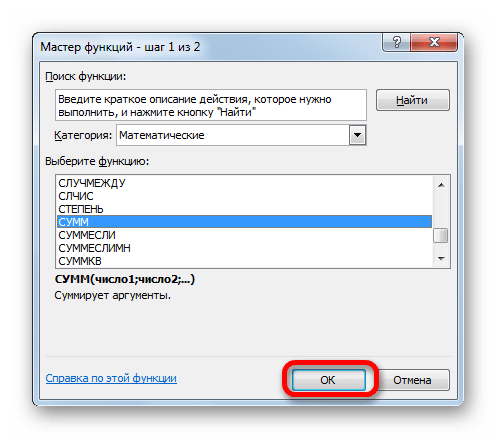
- Следует запуск окна Мастера функций. Переходим в группу «Математические» и выбираем там наименование «СУММ». Далее жмем по кнопке «OK».
- Производится перемещение в окно аргументов функции СУММ, которая предназначена для расчета суммы выбранных чисел. Она имеет нижеуказанный синтаксис:
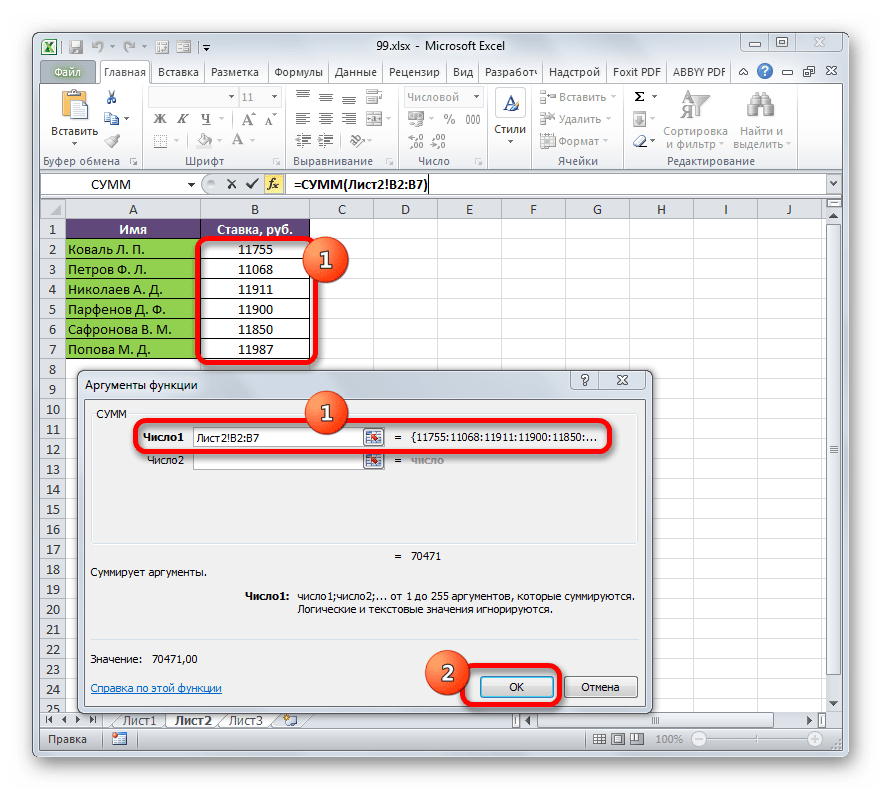
=СУММ(число1;число2;…)Поля в окне соответствуют аргументам указанной функции. Хотя их число может достигать 255 штук, но для нашей цели достаточно будет всего одного. Ставим курсор в поле «Число1». Кликаем по ярлыку «Лист 2» над строкой состояния.
- После того, как мы переместились в нужный раздел книги, выделяем столбец, который следует просуммировать. Делаем это курсором, зажав левую кнопку мыши. Как видим, координаты выделенной области тут же отображаются в поле окна аргументов. Затем щелкаем по кнопке «OK».
- После этого мы автоматически перемещаемся на Лист 1. Как видим, общая сумма размера ставок работников уже отображается в соответствующем элементе.
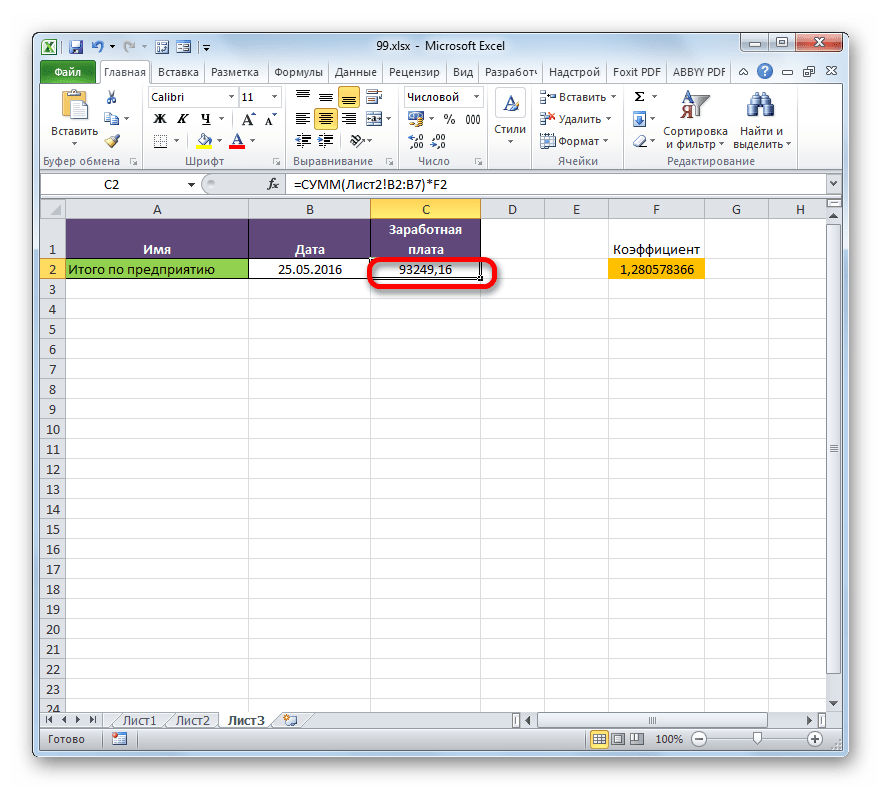
- Но это ещё не все. Как мы помним, зарплата вычисляется путем умножения величины ставки на коэффициент. Поэтому снова выделяем ячейку, в которой находится суммированная величина. После этого переходим к строке формул. Дописываем к имеющейся в ней формуле знак умножения (*), а затем щелкаем по элементу, в котором располагается показатель коэффициента. Для выполнения вычисления щелкаем по клавише Enter на клавиатуре. Как видим, программа рассчитала общую заработную плату по предприятию.
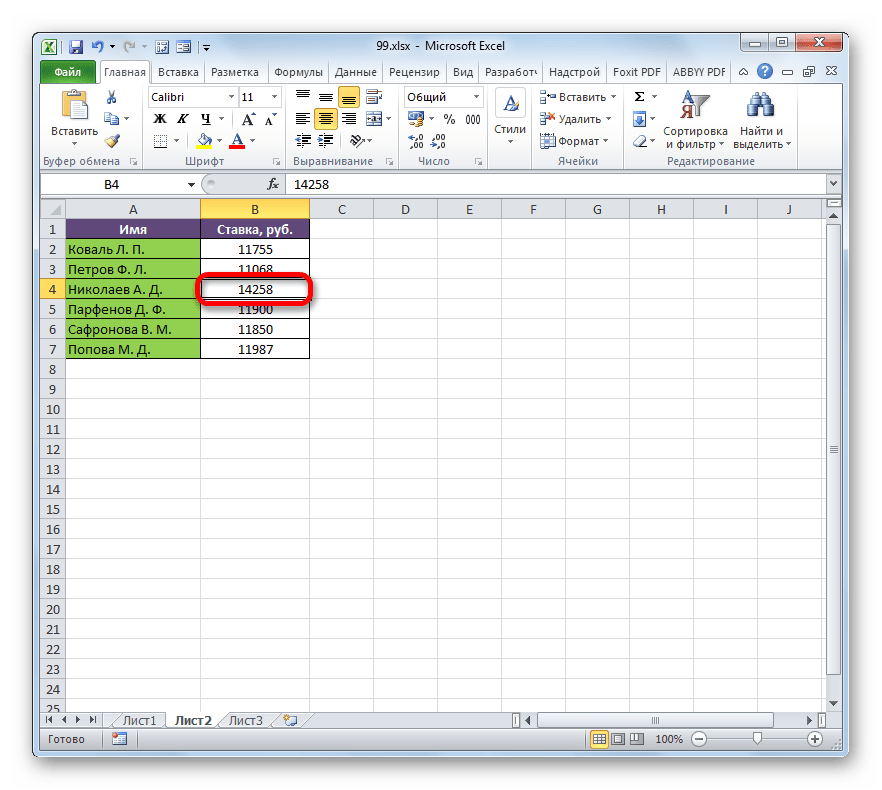
- Возвращаемся на Лист 2 и изменяем размер ставки любого работника.
- После этого опять перемещаемся на страницу с общей суммой. Как видим, из-за изменений в связанной таблице результат общей заработной платы был автоматически пересчитан.


Способ 4: специальная вставка
Связать табличные массивы в Excel можно также при помощи специальной вставки.
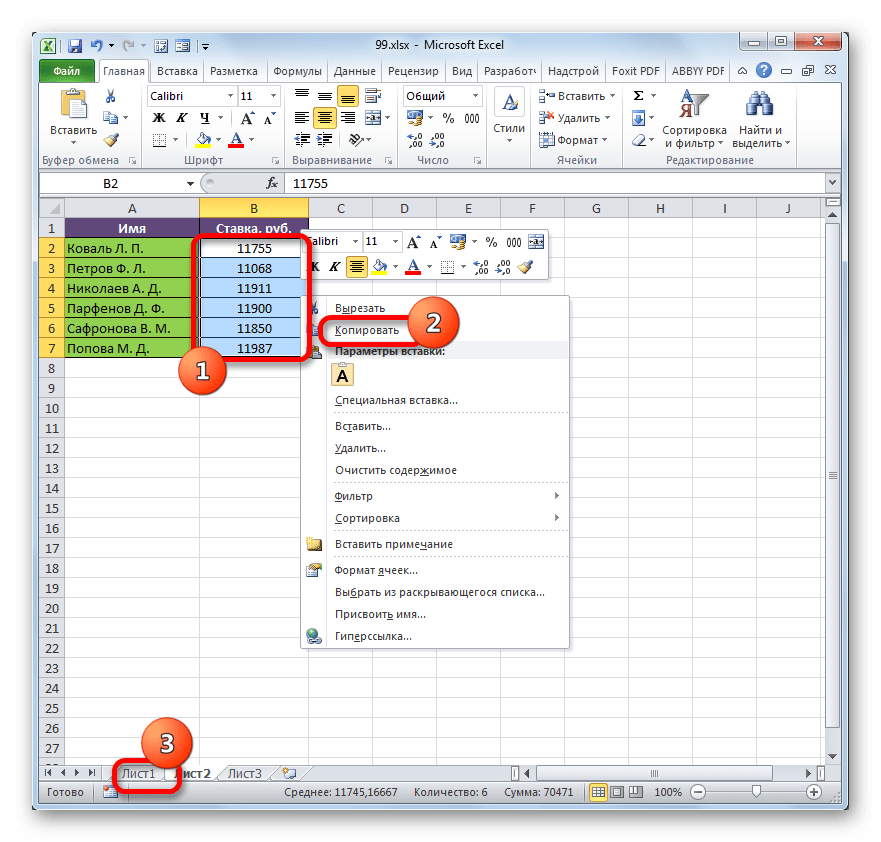
- Выделяем значения, которые нужно будет «затянуть» в другую таблицу. В нашем случае это диапазон столбца «Ставка» на Листе 2. Кликаем по выделенному фрагменту правой кнопкой мыши. В открывшемся списке выбираем пункт «Копировать». Альтернативной комбинацией является сочетание клавиш Ctrl+C. После этого перемещаемся на Лист 1.
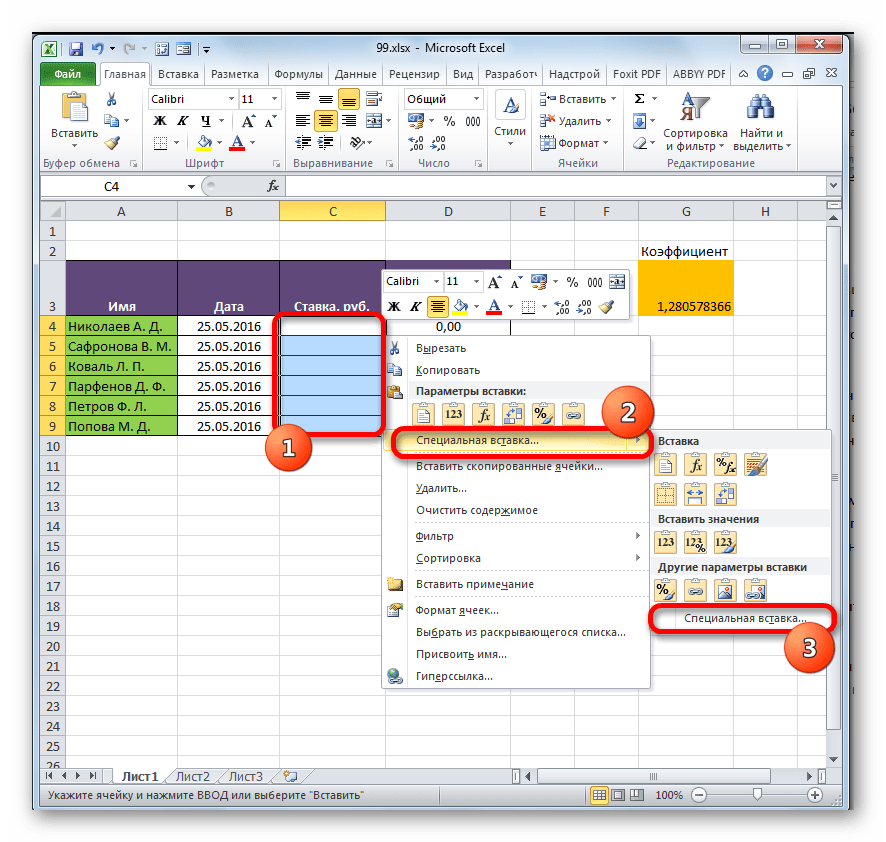
- Переместившись в нужную нам область книги, выделяем ячейки, в которые нужно будет подтягивать значения. В нашем случае это столбец «Ставка». Щелкаем по выделенному фрагменту правой кнопкой мыши. В контекстном меню в блоке инструментов «Параметры вставки» щелкаем по пиктограмме «Вставить связь».

Существует также альтернативный вариант. Он, кстати, является единственным для более старых версий Excel. В контекстном меню наводим курсор на пункт «Специальная вставка». В открывшемся дополнительном меню выбираем позицию с одноименным названием.
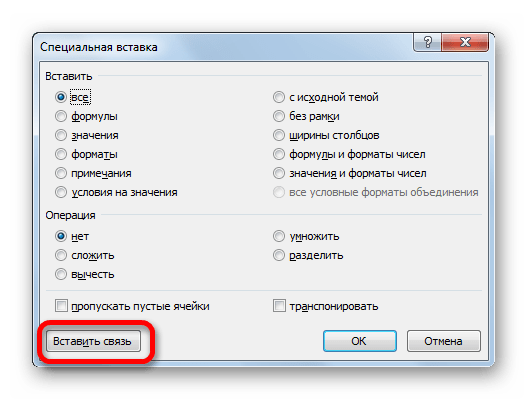
- После этого открывается окно специальной вставки. Жмем на кнопку «Вставить связь» в нижнем левом углу ячейки.
- Какой бы вариант вы не выбрали, значения из одного табличного массива будут вставлены в другой. При изменении данных в исходнике они также автоматически будут изменяться и во вставленном диапазоне.


Урок: Специальная вставка в Экселе
Способ 5: связь между таблицами в нескольких книгах
Кроме того, можно организовать связь между табличными областями в разных книгах. При этом используется инструмент специальной вставки. Действия будут абсолютно аналогичными тем, которые мы рассматривали в предыдущем способе, за исключением того, что производить навигацию во время внесений формул придется не между областями одной книги, а между файлами. Естественно, что все связанные книги при этом должны быть открыты.
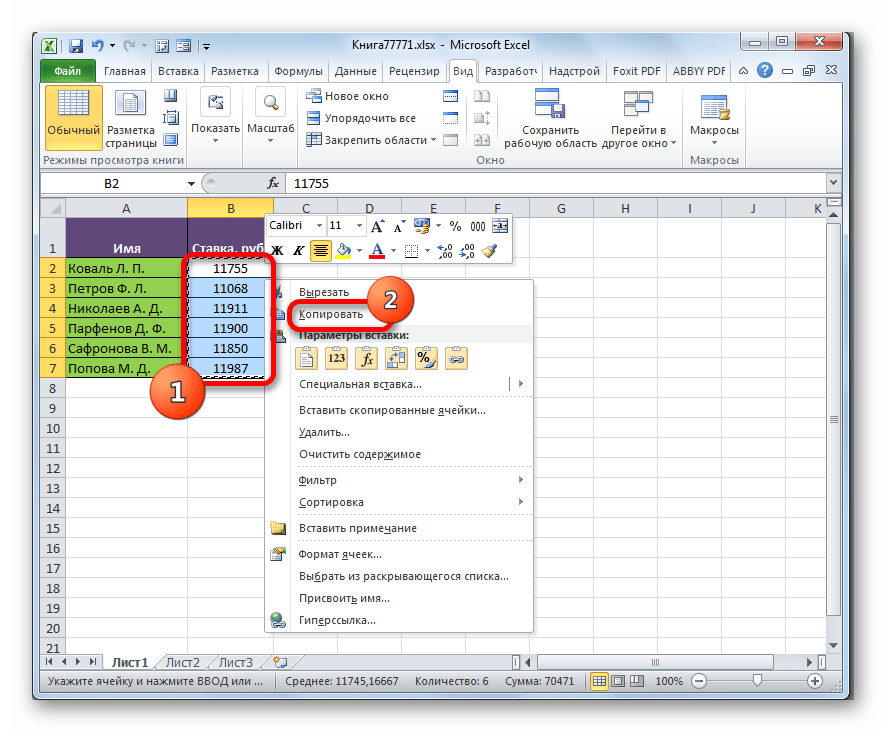
- Выделяем диапазон данных, который нужно перенести в другую книгу. Щелкаем по нему правой кнопкой мыши и выбираем в открывшемся меню позицию «Копировать».
- Затем перемещаемся к той книге, в которую эти данные нужно будет вставить. Выделяем нужный диапазон. Кликаем правой кнопкой мыши. В контекстном меню в группе «Параметры вставки» выбираем пункт «Вставить связь».
- После этого значения будут вставлены. При изменении данных в исходной книге табличный массив из рабочей книги будет их подтягивать автоматически. Причем совсем не обязательно, чтобы для этого были открыты обе книги. Достаточно открыть одну только рабочую книгу, и она автоматически подтянет данные из закрытого связанного документа, если в нем ранее были проведены изменения.

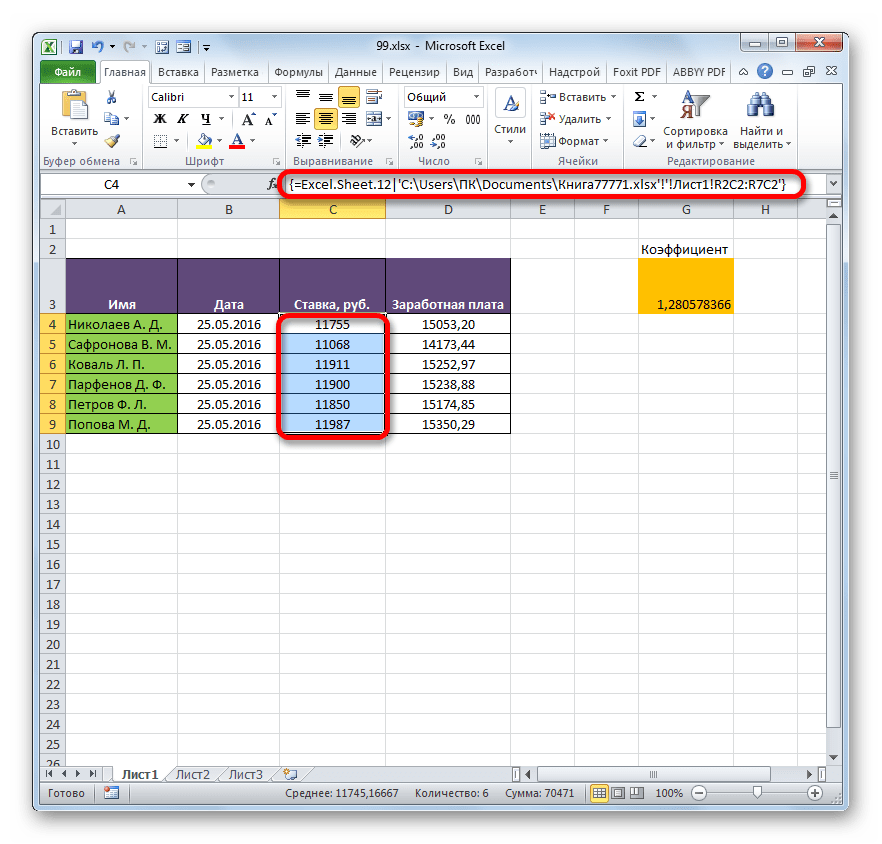
Но нужно отметить, что в этом случае вставка будет произведена в виде неизменяемого массива. При попытке изменить любую ячейку со вставленными данными будет всплывать сообщение, информирующее о невозможности сделать это.

Изменения в таком массиве, связанном с другой книгой, можно произвести только разорвав связь.
Разрыв связи между таблицами
Иногда требуется разорвать связь между табличными диапазонами. Причиной этого может быть, как вышеописанный случай, когда требуется изменить массив, вставленный из другой книги, так и просто нежелание пользователя, чтобы данные в одной таблице автоматически обновлялись из другой.
Способ 1: разрыв связи между книгами
Разорвать связь между книгами во всех ячейках можно, выполнив фактически одну операцию. При этом данные в ячейках останутся, но они уже будут представлять собой статические не обновляемые значения, которые никак не зависят от других документов.
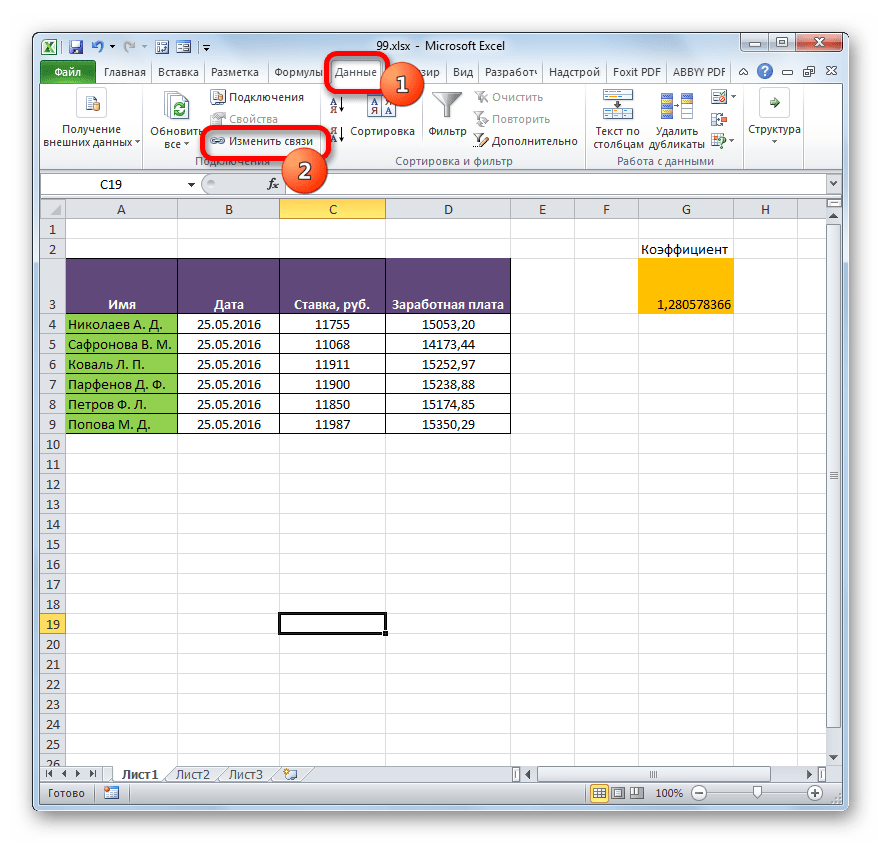
- В книге, в которой подтягиваются значения из других файлов, переходим во вкладку «Данные». Щелкаем по значку «Изменить связи», который расположен на ленте в блоке инструментов «Подключения». Нужно отметить, что если текущая книга не содержит связей с другими файлами, то эта кнопка является неактивной.
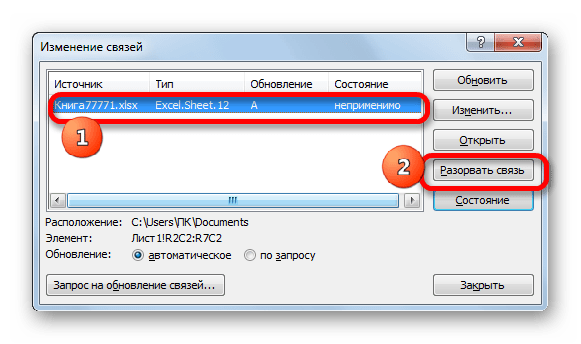
- Запускается окно изменения связей. Выбираем из списка связанных книг (если их несколько) тот файл, с которым хотим разорвать связь. Щелкаем по кнопке «Разорвать связь».
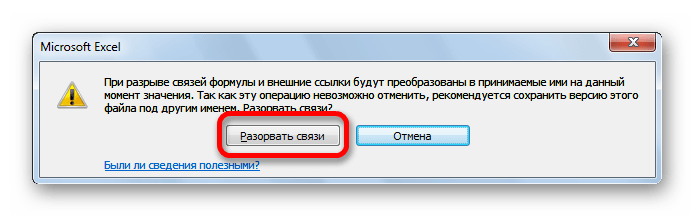
- Открывается информационное окошко, в котором находится предупреждение о последствиях дальнейших действий. Если вы уверены в том, что собираетесь делать, то жмите на кнопку «Разорвать связи».
- После этого все ссылки на указанный файл в текущем документе будут заменены на статические значения.

Способ 2: вставка значений
Но вышеперечисленный способ подходит только в том случае, если нужно полностью разорвать все связи между двумя книгами. Что же делать, если требуется разъединить связанные таблицы, находящиеся в пределах одного файла? Сделать это можно, скопировав данные, а затем вставив на то же место, как значения. Кстати, этим же способом можно проводить разрыв связи между отдельными диапазонами данных различных книг без разрыва общей связи между файлами. Посмотрим, как этот метод работает на практике.
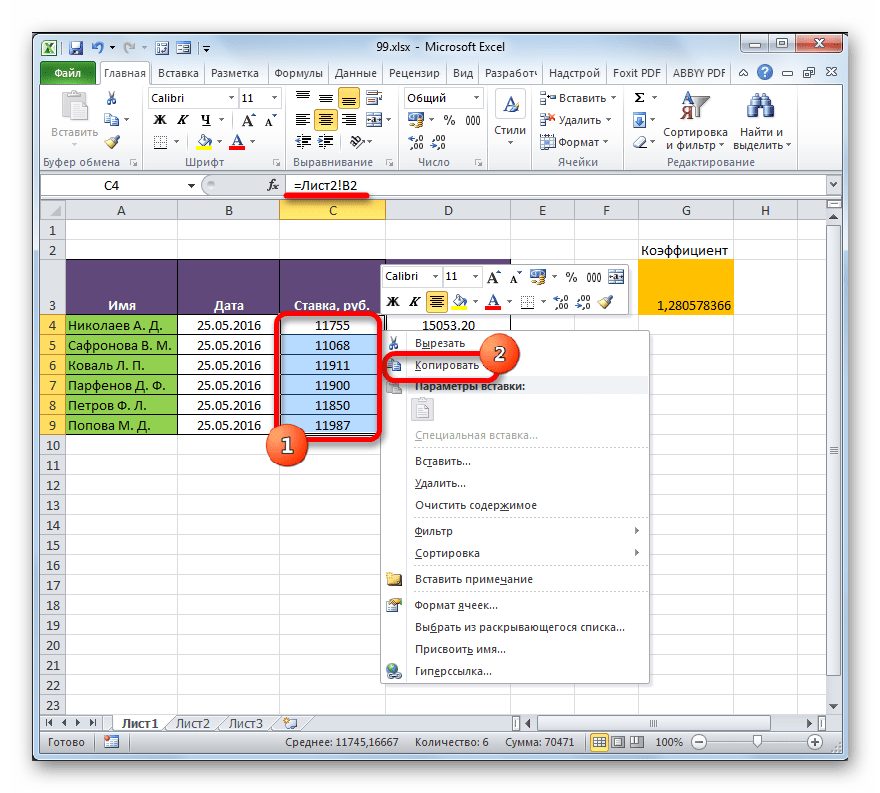
- Выделяем диапазон, в котором желаем удалить связь с другой таблицей. Щелкаем по нему правой кнопкой мыши. В раскрывшемся меню выбираем пункт «Копировать». Вместо указанных действий можно набрать альтернативную комбинацию горячих клавиш Ctrl+C.
- Далее, не снимая выделения с того же фрагмента, опять кликаем по нему правой кнопкой мыши. На этот раз в списке действий щелкаем по иконке «Значения», которая размещена в группе инструментов «Параметры вставки».
- После этого все ссылки в выделенном диапазоне будут заменены на статические значения.

Как видим, в Excel имеются способы и инструменты, чтобы связать несколько таблиц между собой. При этом, табличные данные могут находиться на других листах и даже в разных книгах. При необходимости эту связь можно легко разорвать.
MulTEx »
28 Июль 2017 9821 просмотров
Переместить фильтр
Данная функция является частью надстройки MulTEx
Вызов команды:
MulTEx -группа Ячейки/Диапазоны —Диапазоны —Переместить фильтр
Команда копирует фильтр из одной таблицы и переносит его на любую другую таблицу, сохраняя все условия фильтрации. Для чего это может быть нужно? Предположим, имеется таблица:

В ней отфильтрованы данные по трем столбцам: Контрагент, Отсрочка платежа дни, Штрафы за просрочку оплаты. При этом из более чем 80-ти контрагентов отобрано фильтром только 25 необходимых, для отсрочки платежа установлено условие не показывать строки с просрочкой 25 дней и менее, а для штрафов — не показывать строки с суммами меньше или равные 1000р.
Ситуация1: точно такие же условия надо применить к такой же таблице, но за другие периоды. Вручную придется в другой таблице заново выбирать всех контрагентов и проставлять условия на другие столбцы.
Ситуация2: в таблицу необходимо добавить еще один столбец — Условия предоставления кредитного лимита. И поверх прежних условий фильтрации применить фильтр еще и по новому столбцу. Вручную придется сначала полностью убрать фильтр с листа, добавить столбец, установить фильтр заново и прописать все условия. Никак по-другому не получится(если только речь не об умной таблице — Вставка -Таблица).
С помощью команды Переместить фильтр обе ситуации становятся решаемыми очень просто. Все, что необходимо — выделить диапазон с нужным фильтром, перейти на вкладку MulTEx -группа Ячейки/Диапазоны —Диапазоны —Переместить фильтр:

Копировать условия фильтра из диапазона: указывается одна ячейка или диапазон ячеек в листе, условия фильтра из которого необходимо скопировать. Даже если таблица выделена не полностью, указана всего одна ячейка или ячейка выходит за границы таблицы — область работы фильтра будет определена автоматически.
И распространить эти условия на диапазон: указывается диапазон ячеек вместе с заголовком, к которому необходимо применить скопированные условия фильтрации.
Если столбцов в новом диапазоне меньше, чем в скопированном фильтре — то в новую таблицу будут перенесены условия первых n столбцов скопированного фильтра, где n — количество столбцов в новой таблице. Если столбцов больше — фильтр будет установлен на все указанные столбцы.
Если условия скопированного фильтра необходимо распространить на умную таблицу(Вставка(Insert) —Таблица(Table)), то в поле И распространить эти условия на диапазон допускается указать одну любую ячейку внутри этой таблицы. Границы такой таблицы будут определены автоматически.
Расскажи друзьям, если статья оказалась полезной:
![]() Видеоинструкции по использованию надстройки MulTEx
Видеоинструкции по использованию надстройки MulTEx