
Поиск и подсчет самых частых значений
Необходимость поиска наибольших и наименьших значений в любом бизнесе очевидна: самые прибыльные товары или ценные клиенты, самые крупные поставки или партии и т.д.
Но наравне с этим, иногда приходится искать в данных не топовые, а самые часто встречающиеся значения, что хоть и звучит похоже, но, по факту, совсем не то же самое. Применительно к магазину, например, это может быть поиск не самых прибыльных, а самых часто покупаемых товаров или самое часто встречающееся количество позиций в заказе, минут в разговоре и т.п.
В такой ситуации задачу придется решать немного по-разному, в зависимости от того, с чем мы имеем дело — с числами или с текстом.
Поиск самых часто встречающихся чисел
Предположим, перед нами стоит задача проанализировать имеющиеся данные по продажам в магазине, с целью определить наиболее часто встречающееся количество купленных товаров. Для определения самого часто встречающегося числа в диапазоне можно использовать функцию МОДА (MODE):

Т.е., согласно нашей статистике, чаще всего покупатели приобретают 3 шт. товара.
Если существует не одно, а сразу несколько значений, встречающихся одинаково максимальное количество раз (несколько мод), то для их выявления можно использовать функцию МОДА.НСК (MODE.MULT). Ее нужно вводить как формулу массива, т.е. выделить сразу несколько пустых ячеек, чтобы хватило на все моды с запасом и ввести в строку формул =МОДА.НСК(B2:B16) и нажать сочетание клавиш Ctrl+Shift+Enter.
На выходе мы получим список всех мод из наших данных:

Т.е., судя по нашим данным, часто берут не только по 3, но и по 16 шт. товаров. Обратите внимание, что в наших данных только две моды (3 и 16), поэтому остальные ячейки, выделенные «про запас», будут с ошибкой #Н/Д.
Частотный анализ по диапазонам функцией ЧАСТОТА
Если же нужно проанализировать не целые, а дробные числа, то правильнее будет оценивать не количество одинаковых значений, а попадание их в заданные диапазоны. Например, нам необходимо понять какой вес чаще всего бывает у покупаемых товаров, чтобы правильно выбрать для магазина тележки и упаковочные пакеты подходящего размера. Другими словами, нам нужно определить сколько чисел попадает в интервал 1..5 кг, сколько в интервал 5..10 кг и т.д.
Для решения подобной задачи можно воспользоваться функцией ЧАСТОТА (FREQUENCY). Для нее нужно заранее подготовить ячейки с интересующими нас интервалами (карманами) и затем выделить пустой диапазон ячеек (G2:G5) по размеру на одну ячейку больший, чем диапазон карманов (F2:F4) и ввести ее как формулу массива, нажав в конце сочетание Ctrl+Shift+Enter:

Частотный анализ сводной таблицей с группировкой
Альтернативный вариант решения задачи: создать сводную таблицу, где поместить вес покупок в область строк, а количество покупателей в область значений, а потом применить группировку — щелкнуть правой кнопкой мыши по значениям весов и выбрать команду Группировать (Group). В появившемся окне можно задать пределы и шаг группировки:

… и после нажатия на кнопку ОК получить таблицу с подсчетом количества попаданий покупателей в каждый диапазон группировки:

Минусы такого способа:
- шаг группировки может быть только постоянным, в отличие от функции ЧАСТОТА, где карманы можно задать абсолютно любые
- сводную таблицу нужно обновлять при изменении исходных данных (щелчком правой кнопки мыши — Обновить), а функция пересчитывается автоматически «на лету»
Поиск самого часто встречающегося текста
Если мы имеем дело не с числами, а с текстом, то подход к решению будет принципиально другой. Предположим, что у нас есть таблица из 100 строк с данными о проданных в магазине товарах, и нам нужно определить, какие товары покупались наиболее часто?
Самым простым и очевидным решением будет добавить рядом столбец с функцией СЧЁТЕСЛИ (COUNTIF), чтобы подсчитать количество вхождений каждого товара в столбце А:

Затем, само-собой, отсортировать получившийся столбец по убыванию и посмотреть на первые строчки.
Или же добавить к исходному списку столбец с единичками и построить по получившейся таблице сводную, подсчитав суммарное количество единичек для каждого товара:

Если исходных данных не очень много и принципиально не хочется пользоваться сводными таблицами, то можно использовать формулу массива:

Давайте разберем ее по кусочкам:
- СЧЁТЕСЛИ(A2:A20;A2:A20) – формула массива, которая ищет по очереди количество вхождений каждого товара в диапазоне A2:A100 и выдаст на выходе массив с количеством повторений, т.е., фактически, заменяет собой дополнительный столбец
- МАКС – находит в массиве вхождений самое большое число, т.е. товар, который покупали чаще всего
- ПОИСКПОЗ – вычисляет порядковый номер строки в таблице, где МАКС нашла самое большое число
- ИНДЕКС – выдает из таблицы содержимое ячейки с номером, который нашла ПОИСКПОЗ
Ссылки по теме
- Подсчет количества уникальных значений в списке
- Извлечение уникальных элементов из списка с повторами
- Группировка в сводных таблицах
Содержание
- Поиск и подсчет самых частых значений
- Поиск самых часто встречающихся чисел
- Частотный анализ по диапазонам функцией ЧАСТОТА
- Частотный анализ сводной таблицей с группировкой
- Поиск самого часто встречающегося текста
- Наиболее часто встречающееся слово в Excel
- 1. ВПР
- 2. ГПР
- 3. ЕСЛИ
- 4. ЕСЛИОШИБКА
- 5. СУММЕСЛИМН
- 6. СЧЁТЕСЛИМН
- 7. СЖПРОБЕЛЫ
- 8. ЛЕВСИМВ и ПРАВСИМВ
- 9. СЦЕПИТЬ
- 10.ЗНАЧЕН
Поиск и подсчет самых частых значений
Необходимость поиска наибольших и наименьших значений в любом бизнесе очевидна: самые прибыльные товары или ценные клиенты, самые крупные поставки или партии и т.д.
Но наравне с этим, иногда приходится искать в данных не топовые, а самые часто встречающиеся значения, что хоть и звучит похоже, но, по факту, совсем не то же самое. Применительно к магазину, например, это может быть поиск не самых прибыльных, а самых часто покупаемых товаров или самое часто встречающееся количество позиций в заказе, минут в разговоре и т.п.
В такой ситуации задачу придется решать немного по-разному, в зависимости от того, с чем мы имеем дело — с числами или с текстом.
Поиск самых часто встречающихся чисел
Предположим, перед нами стоит задача проанализировать имеющиеся данные по продажам в магазине, с целью определить наиболее часто встречающееся количество купленных товаров. Для определения самого часто встречающегося числа в диапазоне можно использовать функцию МОДА (MODE) :
Т.е., согласно нашей статистике, чаще всего покупатели приобретают 3 шт. товара.
Если существует не одно, а сразу несколько значений, встречающихся одинаково максимальное количество раз (несколько мод), то для их выявления можно использовать функцию МОДА.НСК (MODE.MULT) . Ее нужно вводить как формулу массива, т.е. выделить сразу несколько пустых ячеек, чтобы хватило на все моды с запасом и ввести в строку формул =МОДА.НСК(B2:B16) и нажать сочетание клавиш Ctrl+Shift+Enter.
На выходе мы получим список всех мод из наших данных:
Т.е., судя по нашим данным, часто берут не только по 3, но и по 16 шт. товаров. Обратите внимание, что в наших данных только две моды (3 и 16), поэтому остальные ячейки, выделенные «про запас», будут с ошибкой #Н/Д.
Частотный анализ по диапазонам функцией ЧАСТОТА
Если же нужно проанализировать не целые, а дробные числа, то правильнее будет оценивать не количество одинаковых значений, а попадание их в заданные диапазоны. Например, нам необходимо понять какой вес чаще всего бывает у покупаемых товаров, чтобы правильно выбрать для магазина тележки и упаковочные пакеты подходящего размера. Другими словами, нам нужно определить сколько чисел попадает в интервал 1..5 кг, сколько в интервал 5..10 кг и т.д.
Для решения подобной задачи можно воспользоваться функцией ЧАСТОТА (FREQUENCY) . Для нее нужно заранее подготовить ячейки с интересующими нас интервалами (карманами) и затем выделить пустой диапазон ячеек (G2:G5) по размеру на одну ячейку больший, чем диапазон карманов (F2:F4) и ввести ее как формулу массива, нажав в конце сочетание Ctrl+Shift+Enter:
Частотный анализ сводной таблицей с группировкой
Альтернативный вариант решения задачи: создать сводную таблицу, где поместить вес покупок в область строк, а количество покупателей в область значений, а потом применить группировку — щелкнуть правой кнопкой мыши по значениям весов и выбрать команду Группировать (Group) . В появившемся окне можно задать пределы и шаг группировки:
. и после нажатия на кнопку ОК получить таблицу с подсчетом количества попаданий покупателей в каждый диапазон группировки:
Минусы такого способа:
- шаг группировки может быть только постоянным, в отличие от функции ЧАСТОТА, где карманы можно задать абсолютно любые
- сводную таблицу нужно обновлять при изменении исходных данных (щелчком правой кнопки мыши — Обновить), а функция пересчитывается автоматически «на лету»
Поиск самого часто встречающегося текста
Если мы имеем дело не с числами, а с текстом, то подход к решению будет принципиально другой. Предположим, что у нас есть таблица из 100 строк с данными о проданных в магазине товарах, и нам нужно определить, какие товары покупались наиболее часто?
Самым простым и очевидным решением будет добавить рядом столбец с функцией СЧЁТЕСЛИ (COUNTIF) , чтобы подсчитать количество вхождений каждого товара в столбце А:
Затем, само-собой, отсортировать получившийся столбец по убыванию и посмотреть на первые строчки.
Или же добавить к исходному списку столбец с единичками и построить по получившейся таблице сводную, подсчитав суммарное количество единичек для каждого товара:
Если исходных данных не очень много и принципиально не хочется пользоваться сводными таблицами, то можно использовать формулу массива:
Давайте разберем ее по кусочкам:
- СЧЁТЕСЛИ(A2:A20;A2:A20) – формула массива, которая ищет по очереди количество вхождений каждого товара в диапазоне A2:A100 и выдаст на выходе массив с количеством повторений, т.е., фактически, заменяет собой дополнительный столбец
- МАКС – находит в массиве вхождений самое большое число, т.е. товар, который покупали чаще всего
- ПОИСКПОЗ – вычисляет порядковый номер строки в таблице, где МАКС нашла самое большое число
- ИНДЕКС – выдает из таблицы содержимое ячейки с номером, который нашла ПОИСКПОЗ
Источник
Наиболее часто встречающееся слово в Excel
Из этого примера вы узнаете, как найти наиболее часто встречающееся слово в Excel.
Вы можете использовать функцию MODE (МОДА), чтобы найти наиболее часто встречающееся число. Но эта функция работает только с числами:
Вы можете использовать функцию COUNTIF (СЧЕТЕСЛИ), чтобы подсчитать количество вхождений каждого слова. Но нам ведь нужна одна единственная формула, которая возвратит наиболее часто встречающееся слово (в нашем примере – это слово «circle»).
Чтобы найти наиболее часто встречающееся слово, следуйте инструкции ниже:
- Функция MATCH (ПОИСКПОЗ) возвращает позицию значения в заданном диапазоне.
Пояснение: Cлово «circle» (А7) найдено в позиции 2 диапазона A1:A7. Ноль в третьем аргументе позволяет вернуть точное совпадение.
Чтобы найти положение наиболее часто встречающихся слов, добавим функцию MODE (МОДА) и заменим A7 на A1:A7.
Закончим нажатием Ctrl+Shift+Enter.
Примечание: Строка формул указывает, что это формула массива, заключая её в фигурные скобки <>. Их не нужно вводить самостоятельно. Они исчезнут, когда вы начнете редактировать формулу.
- Пояснение:
- Диапазон (массив констант), созданный с помощью функции MATCH (ПОИСКПОЗ), хранится в памяти Excel, а не в ячейках листа.
- Массив констант выглядит следующим образом: <1;2;2;2;5;5;2>. Цифры показывают, что слово «triangle» найдено в позиции 1, «circle» в позиции 2, «circle» в позиции 2 и т.д.
- Этот массив констант используется в качестве аргумента для функции MODE (МОДА), давая результат 2 (позиция наиболее часто встречающегося слова).
- Используйте этот результат и функцию INDEX (ИНДЕКС), чтобы вернуть второе слово из диапазона A1:A7, как наиболее часто встречающееся.
Источник
Excel содержит огромное количество самых разнообразных функций, однако не все они нужны при анализе данных. В этой статье вы узнаете о 10 наиболее популярных функций, которые будут нужны при работе с информацией. Эти функции позволяют выполнить большинство задач, которые появляются при анализе данных.
1. ВПР
Эта функция является одной из самых популярных и часто используемых в Excel. Если вам необходимо найти данные в одном столбце в таблице и получить значение из другого столбца таблицы, то эта функция вам поможет. Ее синтаксис:
ВПР (искомое значение; таблица; номер столбца; интервальный просмотр)
— Искомое значение — это то значение, которое мы будем искать в таблице с данными
— Таблица — диапазон данных, в первом столбце которого мы будем искать искомое значение
— Номер столбца — этот параметр обозначает, на какое количество столбцов надо сдвинуться вправо в таблице для получения результата
— Интервальный просмотр — Может принимать параметр 0 или ЛОЖЬ, что обозначает что совпадение между искомым значением и значением в первом столбце таблицы должен быть точным; либо 1 или ИСТИНА, соответственно совпадение должно быть неточным. Настоятельно рекомендую использовать только параметр ЛОЖЬ, иначе можно получать непредсказуемые результаты.
Если хотите изучить более подробно, как работает функция ВПР, прочитайте нашу статью «Функция ВПР в Excel».
2. ГПР
Функция ГПР выполняет туже задачу, что и ВПР, только она просматривает первую строку в поиске искомого значения и для получения результата сдвигается на указанное количество строк вниз.
ГПР(искомое значение;таблица;номер строки;интервальный просмотр)
В примере выше мы ищем выручку за сентябрь в помесячном отчете по выручке. В формуле ГПР(A5;B1:M2;2;0) первый параметр (А5) — ссылка на месяц, по которому мы хотим получить выручку; второй параметр (B1:M2) — ссылка на таблицу, где в первой строке указаны месяцы, среди которых нам нужно найти выбранный; третий параметр «2» — из какой строки ниже мы будем получать данные; четвертый параметр «0» — ищем точное совпадение.
Если вы хотите более подробно изучить, как пользоваться функцией ГПР — прочитайте статью на нашем сайте «Функция ГПР в Excel».
3. ЕСЛИ
Функция ЕСЛИ является очень популярной в Excel. Она позволяет автоматически выполнять какое-либо действие, в зависимости от поставленного условия.
ЕСЛИ(логическое выражение; значение если истина; значение если ложь)
— Логическое выражение — выражение, которое по итогу своего вычисления должно вырнуться значение ИСТИНА или ЛОЖЬ.
— Значение, если истина — устанавливаем указанное значение, если логическое выражение вернуло ИСТИНА
— Значение, если ложь — устанавливает указанное значение, если логическое выражение вернуло ЛОЖЬ.
В примере выше мы хотим определить, получили ли мы за месяц выручку больше 500 рублей или нет. В формуле ЕСЛИ(B2>500;»Да»;»Нет») первый параметр (B2>500) проверяет, выручка за месяц больше 500 рублей или нет; второй параметр («Да») — функция вернет Да, если выручка больше 500 рублей и соответственно Нет (третий параметр), если выручка меньше.
Обратите внимание, что значения при истине или лжи могут быть не только текстовые, числовые, но также и функции(в том числе и ЕСЛИ), что позволяет реализовать достаточно сложные логические конструкции.
4. ЕСЛИОШИБКА
При работе с формулами в Excel, можно время от времени сталкиваться с различными ошибками. Так в примере ниже функция ВПР вернула ошибку #Н/Д из-за того, что в базе данных по ФИО нет искомой нами фамилии (более подробно об ошибке #Н/Д вы можете прочитать в этой статье: «Как исправить ошибку #Н/Д в Excel»)
Для обработки таких ситуаций отлично подойдет функция ЕСЛИОШИБКА. Ее синтаксис следующий:
ЕСЛИОШИБКА(значение; значение если ошибка)
— Значение, результат которого проверяется на ошибку.
— Значение, если ошибка — В случае, если в результате работы функции получаем ошибку, то выводится не ошибка, а данное значение.
В случае с нашим примером выше, мы можем предположить, что фамилия может быть некорректной, соответственно ЕСЛИОШИБКА вернет нам предупреждение, что бы мы проверили написание фамилии.
В примере выше, мы проверяем результат работы функции ВПР(E2;A1:C6;2;0) и в случае, если вернется ошибка, то выдаем сообщение «Проверьте фамилию!».
5. СУММЕСЛИМН
Функция СУММЕСЛИМН позволяет суммировать значения по определенным условиям. Условий может быть несколько. В Excel также есть функция СУММЕСЛИ, которая позволяет суммировать по одному критерию. Призываю вас использовать более универсальную формулу.
СУММЕСЛИМН(Диапазон суммирования; Диапазон условия 1; Условие 1;. )
— Диапазон суммирования — область листа Эксель, из которой мы суммируем данные
— Диапазон условия 1 — Диапазон ячеек, которые мы проверяем на соответствие условию
— Условие 1 — Условие, которое проверяется на соответствие в Диапазоне 1.
Обратите внимание, что диапазонов условий и соответственно условий может быть столько, сколько вам нужно.
Для примера выше мы хотим получит выручку, которую принес нам Петров в городе Москва. Формула имеет вид СУММЕСЛИМН(C2:C13;A2:A13;E2;B2:B13;F2), где C2:C13 — диапазон со значениями выручки, которые необходимо просуммировать; А2:А13 — диапазон с фамилиями, которые мы будем проверять; Е2 — ссылка на конкретную фамилию; B2:B13 — ссылка на диапазон с городами; F2 — ссылка на конкретный город.
Более подробно о функциях СУММЕСЛИМН и СУММЕСЛИ рассказано в статье «СУММЕСЛИ и СУММЕСЛИМН в Excel».
6. СЧЁТЕСЛИМН
СЧЁТЕСЛИМН очень похожа на функцию СУММЕСЛИМН, только в отличии от нее, она не суммируется значения, а только считает количество ячеек, которые соответствуют определенным условиям. Как и в случае с СУММЕСЛИМН, у СЧЁТЕСЛИМН есть упрощенная форма СЧЁТЕСЛИ, который считает количество ячеек только по одному критерию, но лучше используйте более общий вариант.
СЧЁТЕСЛИМН(диапазон условия 1; условие 1;. )
— Диапазон условия 1 — Диапазон ячеек, которые проверяются на соответствие определенному условию.
— Условие 1 — Условие, которое определяет какие ячейки надо учитывать при подсчете.
Обратите внимания, что диапазонов условий и соответственно условий может быть несколько.
В примере выше, мы считаем сколько в таблице ячеек, в которых фамилия — Петров, а город — Москва. В формуле СЧЁТЕСЛИМН(A2:A13;E2;B2:B13;F2) диапазон A2:A13 — диапазон фамилий, которые мы проверяем, Е2 — та фамилия, которую мы ищем в диапазоне; B2:B13 — диапазон городов и соответственно F2 — город, который мы учитываем при подсчете ячеек. Получившееся число 3 — это количество строк в таблице, где фамилия равна Иванов, а город равен Москва.
7. СЖПРОБЕЛЫ
При работе с данными в Excel, мы можем получать их из разных источников, что может привести к тому, что получаемые значения имеют «мусорную» информацию, очень часто это лишние пробелы, которые надо удалить. Можно удалять вручную, но это долго и муторно. На выручку нам приходит функция СЖПРОБЕЛЫ, которая удаляет лишние пробелы, в случае если их больше одного подряд. Синтаксис у функции очень простой:
— Текст — тот текст, из которого надо убрать лишние пробелы.
Как видно из примера выше, функция успешно удалила лишние пробелы из исходной строки.
8. ЛЕВСИМВ и ПРАВСИМВ
Функции ЛЕВСИМВ и ПРАВСИМВ возвращают определенное количество знаков с начала (ЛЕВСИМВ) либо с конца (ПРАВСИМВ) строки. Эти функции нужны для получения части строки. Синтаксис у функций однотипный:
ЛЕВСИМВ(текст; количество знаков)
ПРАВСИМВ(текст; количество знаков)
— Текст — то строковое выражение, из которого мы хотим получить часть.
— Количество знаков — число символов, которое мы хотим получить.
9. СЦЕПИТЬ
Функция СПЕПИТЬ позволяет объединить значения из нескольких ячеек. Синтаксис у функции достаточно простой:
— Текст 1 — Текст, который надо соединить в одну строку
— Текст 2 — Текст, который надо соединить в одну строку
Обратите внимание, что вы можете объединить до 255 текстовых значений.
10.ЗНАЧЕН
Часто данные, которые мы получаем из внешних источников, имеют текстовый формат и мы не можем производить с ними математических действий (складывать, вычитать и т.п.). Нам требуется сначала преобразовать текст в число, для этого используйте функцию ЗНАЧЕН. Синтаксис у функции следующий:
— Текст — число, представленное в текстовом формате
Как видно в примере выше, у нас есть число 12522, которое представлено в виде текста, при помощи функции ЗНАЧЕН мы преобразовали его в число 12 522, с которым в дальнейшем можем работать, как с любыми другими числами.
Спасибо, что дочитали статью. Я постарался выбрать 10 наиболее полезных функций в Excel, которые нужны при анализе данных. Жду ваши комментарии.
Источник
Анализ N-грамм в Excel
Для поисковой рекламы и SEO анализ n-грамм — один из самых эффективных методов. Однако долгое время n-gram анализ оставался в силу сложности реализации алгоритма доступен только крупным агентствам с программистами в штате, или продвинутым специалистам со знанием программирования.
Чтобы популяризовать подход и сделать его доступным всем, у кого есть Windows и Excel, инструменты для анализа n-грамм были реализованы в !SEMTools для Excel. Ниже перечислены различные подходы анализа со схематичными примерами.
Во всех кейсах создается отдельный лист с результатами подсчета, исходные данные никак не изменяются.
Простой анализ n-gram (анализ встречаемости)
Данный подход самый простой — берется N-грамма и для нее анализируется ее встречаемость в тексте.
Анализ частотности слов, или как посчитать в тексте уникальные слова и вывести списком с их встречаемостью
Как посчитать, сколько раз встречается слово в Excel-таблице? Если мы ищем лишь одно слово, может помочь формула СЧЁТЕСЛИ. Формула ниже посчитает количество строк, в которых встречается последовательность символов «слова» вне зависимости от их регистра.
Символ звездочки определяет, что перед и после указанной последовательности символов могут быть любые другие или их отсутствие. В связи с этим могут быть учтены строки со словами «словарь», «словарный» и т.д. Чтобы найти слова по точному совпадению, нужно добавить символ пробела в начало и конец всех ячеек столбца, и воспользоваться подсчетом с учетом пробелов:
Но и это решение не убережет нас от ситуаций, когда слово повторяется в строке 2 и более раз, если мы хотим посчитать все повторения. Т.к. формула считает именно строки.
Поэтому был реализован макрос в !SEMTools, с легкостью выполняющий эту задачу.
Выделяем текст, выбираем слова, готово. Текст может быть как 5 строк, так и миллион строк — процедура займет секунды. Главное, чтобы уникальных слов в тексте было не больше 1048575 — иначе их не получится вывести на лист. Но такая ситуация — редкость.
Можно обратить внимание, что разные словоформы рассматриваются как отдельные слова, поэтому, если нужно проанализировать встречаемость без учета словоформ, текст нужно предварительно лемматизировать. Тогда вы составите не просто частотный словарь слов, а частотный словарь лемм.
Анализ встречаемости биграмм (2-gram)
Аналогично предыдущему, но берутся биграммы — последовательности из двух слов. Как посчитать в данном случае триграммы и т.д., кажется, уже понятно.
Анализ n-gram с частотностью
Когда текст состоит из фраз, и для каждой фразы известна определенная метрика (в поисковой рекламе это частотность), чтобы более достоверно измерить вес каждой словоформы или леммы, требуется производить анализ уже с учетом этой метрики.
В !SEMTools это вшито по умолчанию — просто нужно выделить два столбца вместе со столбцом используемой метрики. Аналогично можно составлять частотность биграмм, триграмм и т.д.
N-gram анализ по нескольким метрикам
Ранжируем отдельные слова по метрикам эффективности.
Такая аналитика может дать много полезных инсайтов. Выявить высококонверсионные связки слов для последующего интенсивного биддинга на них, например. Или, наоборот, выявления низкоконверсионных связок для исключения их из рекламы, в то время как слова, из которых они составлены, в среднем по больнице не выделялись низкой конверсией.
Измеряем расчетные метрики эффективности словосочетаний по набору абсолютных метрик и их значений
Заключение
Примеры, приведенные выше, позволяют производить анализ не только поисковых запросов или ключевых слов, но и любого текста, который будет дан на вход, вне зависимости от его длины. Нужно только удалить лишние пробелы, перевести весь текст в нижний регистр и можно производить анализ.
Если у вас остались вопросы — подписывайтесь на канал автора и задавайте вопросы в чате: https://t.me/semtoolschat
Часто сталкиваетесь с этой или похожими задачами при работе в Excel?
Скачивайте !SEMTools и начинайте экономить рабочее время, выделяя его для более важных задач!

Мнение эксперта
Знайка, самый умный эксперт в Цветочном городе
Если у вас есть вопросы, задавайте их мне!
Задать вопрос эксперту
Нажимаем клавишу Далее, в Мастере диаграмм указываем название диаграммы Полигон частот , удаляем легенду, редактируем шкалу и характеристики диаграммы для наибольшей наглядности. Если же вы хотите что-то уточнить, я с радостью помогу!
Функция СРЗНАЧ (или AVERAGE) вычисляет выборочное (или генеральное) среднее, то есть среднее арифметическое значение признака выборочной (или генеральной) совокупности. Аргументом функции СРЗНАЧ является набор чисел, как правило, задаваемый в виде интервала ячеек, например, =СРЗНАЧ (А3:А201).

Как найти размах в excel
- Найдите панель функций с обозначением «Fx». Она над основной рабочей областью таблицы.
- Поставьте курсор в любую ячейку.
- Введите в поле «Fx» аргумент. Он начинается со знака равенства. Потом идёт формула и адрес диапазона/клетки.
- Должно получиться что-то вроде «=МАКС(B8:B11)» (максимальное), «=МИН(F7:V11)» (минимальное), «=СРЗНАЧ(D14:W15)» (среднее).
- Кликните на «галочку» рядом с полем функций. Или просто нажмите Enter. В выделенной ячейке появится нужное значение.
- Формулу можно скопировать непосредственно в саму клетку. Эффект будет тот же.
Сутью этой формулы является функция НАИМЕНЬШИЙ, которая просто возвращает n-е наименьшее значение в списке значений, которое соответствует номеру строки. Номера строк были «отфильтрованы» функцией ЕСЛИ, которая применяет логику для совпадения.
Мнение эксперта
Знайка, самый умный эксперт в Цветочном городе
Если у вас есть вопросы, задавайте их мне!
Задать вопрос эксперту
Если вы хотите получить информацию из таблицы на основе частичного совпадения, вы можете сделать это с помощью ВПР в режиме точного соответствия, и групповые символы. Если же вы хотите что-то уточнить, я с радостью помогу!
Excel поддерживает символы подстановки «*» и «?». Тем не менее, если вы используете специальные символы с номером, вы будете преобразовывать числовое значение в текстовое значение. Другими словами, «*» & 99 & «*» = «* 99 *» (текстовая строка).
Функция СЧЁТЕСЛИ и подсчет количества значения ячейки в Excel
- Совершенствование умений и навыков нахождения статистических характеристик случайной величины, работа с расчетами в Excel;
- применение информационно коммутативных технологий для анализа данных; работа с различными информационными носителями.
- Сегодня на уроке мы научимся рассчитывать статистические характеристики для больших по объему выборок, используя возможности современных компьютерных технологий.
- Для начала вспомним:
В некоторых случаях перед нами может стоять задача – посчитать в массиве данных только пустые ячейки. Тогда крайне полезной окажется функция СЧИТАТЬПУСТОТЫ, которая проигнорирует все ячейки, за исключением пустых.
| Уровень безработицы | ||
| Исходные данные | ||
| I | BEL(%) | ZVET(%) |
| 3,2 | 6,9 | |
| 3,1 | 6,7 | |
| 3,2 | 6,5 | |
| 3,3 | 7,1 | |
| 3,3 | 6,8 | |
| 3,2 | 6,4 | |
| 3,2 | 6,6 | |
| 3,1 | 7,3 | |
| 3,0 | 6,5 | |
| 3,0 | 6,5 | |
| 3,0 | 6,0 | |
| 2,9 | 5,7 | |
| 3,1 | 6,0 | |
| 3,1 | 6,9 | |
| 3,1 | 6,5 | |
| 3,0 | 7,0 | |
| 3,2 | 6,4 |
Мнение эксперта
Знайка, самый умный эксперт в Цветочном городе
Если у вас есть вопросы, задавайте их мне!
Задать вопрос эксперту
Чтобы проверить ячейку для одной из нескольких вещей, и вернуть последнее совпадение, найденное в списке, вы можете использовать формулу, основанную на ПРОСМОТР и ПОИСК функций. Если же вы хотите что-то уточнить, я с радостью помогу!
Только что мы научились считать простейшим способом. Конечно, таким образом можно вычислить и более сложные вещи. Главное, не забывать ставить скобки, где нужно. Например: =((375*230)+(1263-455))/(120*33)
Получить первое, последнее или определенное значение читать подробную статью
В этой формуле, значение представляет собой именованный диапазон, который относится к Н2, а также данные , представляет собой именованный диапазон , который относится к B3: E102. Без названных диапазонов, формула может быть записана следующим образом:
Перейти к содержанию
На чтение 2 мин Опубликовано 07.08.2015
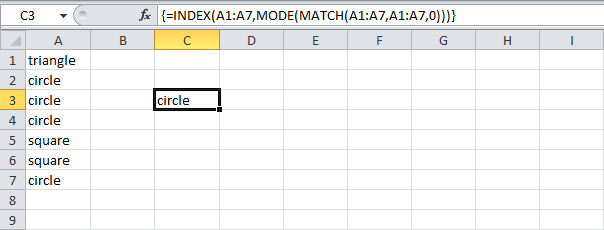
Из этого примера вы узнаете, как найти наиболее часто встречающееся слово в Excel.
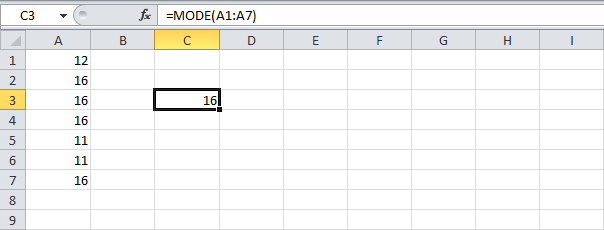
Вы можете использовать функцию MODE (МОДА), чтобы найти наиболее часто встречающееся число. Но эта функция работает только с числами:
=MODE(A1:A7)
=МОДА(A1:A7)
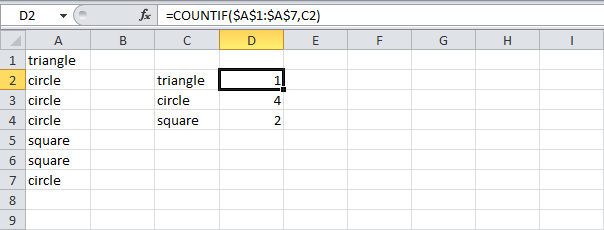
Вы можете использовать функцию COUNTIF (СЧЕТЕСЛИ), чтобы подсчитать количество вхождений каждого слова. Но нам ведь нужна одна единственная формула, которая возвратит наиболее часто встречающееся слово (в нашем примере – это слово «circle»).
=COUNTIF($A$1:$A$7,C2)
=СЧЁТЕСЛИ($A$1:$A$7;C2)
Чтобы найти наиболее часто встречающееся слово, следуйте инструкции ниже:
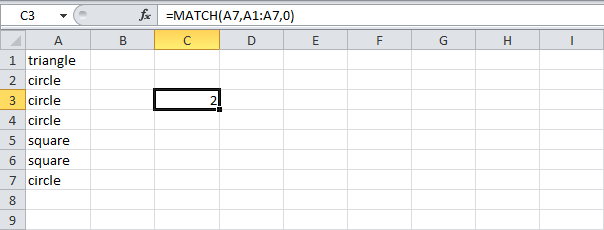
- Функция MATCH (ПОИСКПОЗ) возвращает позицию значения в заданном диапазоне.
=MATCH(A7,A1:A7,0)
=ПОИСКПОЗ(A7;A1:A7;0)
Пояснение: Cлово «circle» (А7) найдено в позиции 2 диапазона A1:A7. Ноль в третьем аргументе позволяет вернуть точное совпадение.
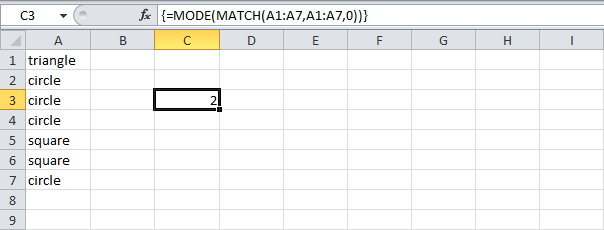
- Чтобы найти положение наиболее часто встречающихся слов, добавим функцию MODE (МОДА) и заменим A7 на A1:A7.
=MODE(MATCH(A1:A7,A1:A7,0))
=МОДА(ПОИСКПОЗ(A1:A7;A1:A7;0)) - Закончим нажатием Ctrl+Shift+Enter.
Примечание: Строка формул указывает, что это формула массива, заключая её в фигурные скобки {}. Их не нужно вводить самостоятельно. Они исчезнут, когда вы начнете редактировать формулу.
- Пояснение:
- Диапазон (массив констант), созданный с помощью функции MATCH (ПОИСКПОЗ), хранится в памяти Excel, а не в ячейках листа.
- Массив констант выглядит следующим образом: {1;2;2;2;5;5;2}. Цифры показывают, что слово «triangle» найдено в позиции 1, «circle» в позиции 2, «circle» в позиции 2 и т.д.
- Этот массив констант используется в качестве аргумента для функции MODE (МОДА), давая результат 2 (позиция наиболее часто встречающегося слова).
- Используйте этот результат и функцию INDEX (ИНДЕКС), чтобы вернуть второе слово из диапазона A1:A7, как наиболее часто встречающееся.
=INDEX(A1:A7,MODE(MATCH(A1:A7,A1:A7,0)))
=ИНДЕКС(A1:A7;МОДА(ПОИСКПОЗ(A1:A7;A1:A7;0)))
Оцените качество статьи. Нам важно ваше мнение:
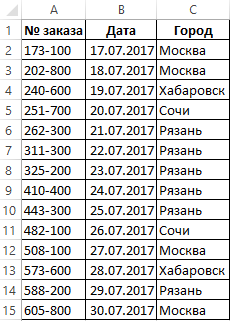
Допустим у нас есть таблица регистра составленных заказов клиентов. Необходимо узнать с какого города поступило наибольшее количество заказов, а с какого – наименьшее. Для решения данной задачи будем использовать формулу с поисковыми и вычислительными функциями.
Поиск наиболее повторяющегося значения в Excel
Чтобы наглядно продемонстрировать работу формулы для примера воспользуемся такой схематической таблицей регистра заказов от клиентов:
Теперь выполним простой анализ наиболее часто и редко повторяющихся значений таблицы в столбце «Город». Для этого:
- Сначала находим наиболее часто повторяющиеся названия городов. В ячейку E2 введите следующую формулу:
- Обязательно после ввода формулы нажмите комбинацию горячих клавиш CTRL+SHIFT+Enter, так как ее нужно выполнить в массиве.
- Для вычисления наиболее редко повторяющегося названия города вводим весьма похожую формулу:
Результат поиска названий самых популярных и самых редких городов клиентов в регистре заказов, отображен на рисунке:
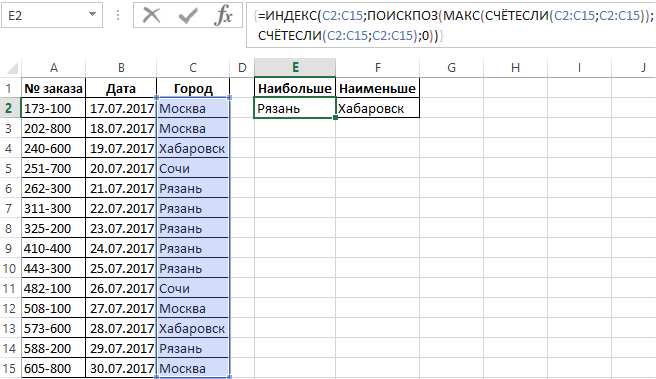
Если таблица содержит одинаковое количество двух самых часто повторяемых городов или два самых редко повторяющихся города в одном и том же столбце, тогда будет отображаться первый из них.
Принцип действия поиска популярных по повторению значений:
Если посмотреть на синтаксис формул то можно легко заметить, что они отличаются только одним из названием функций: =МАКС() и =МИН(). Все остальные аргументы формулы – идентичны. Функция =СЧЕТЕСЛИ() подсчитывает, сколько раз каждое название города повторяется в диапазоне ячеек C2:C16. Таким образом в памяти создается условный массив значений.
Скачать пример поиска наибольшего и наименьшего повторения значения
Функция МАКС или МИН выбирает из условного массива наибольшее или наименьшее значение. Функция =ПОИСКПОЗ() возвращает номер позиции на которой в столбце C название города соответственного наибольшему или наименьшему количеству повторений. Полученное значение будет передано в качестве аргумента для функции =ИНДЕКС(), которая возвращает конечный результат в ячейку.
На чтение 6 мин. Просмотров 88 Опубликовано 20.05.2021
Предположим, у вас есть список имен, которые содержат несколько дубликатов, и теперь вы хотите извлечь значение, которое появляется наиболее часто. Прямой способ – подсчитывать данные по одному из списка, чтобы получить результат, но если в столбце тысячи имен, этот способ будет хлопотным и трудоемким. В следующем руководстве представлены некоторые приемы для быстрого и удобного решения этой задачи.
- Найдите наиболее распространенное значение (число или текстовую строку) из списка с помощью Формула массива
- Найдите наиболее распространенное значение (число или текстовую строку) из списка с кодом VBA
- Быстро находите максимальное значение запятой (число или текстовую строку) из списка/столбца с помощью нескольких щелчков мыши
Вкладка Office Включает редактирование и просмотр с вкладками в Office и делает вашу работу намного проще …
Подробнее … Скачать бесплатно …
Kutools for Excel решает большинство ваших проблем и увеличивает вашу производительность на 80%
- Повторно использовать что угодно: добавляйте наиболее часто используемые или сложные формулы, диаграммы и все остальное в избранное и быстро используйте их в будущем.
- Более 20 текстовых функций: Извлечение числа из текстовой строки; Извлечь или удалить часть текстов; Преобразование чисел и валют в английские слова.
- Инструменты слияния: несколько книг и листов в одну; Объединить несколько ячеек/строк/столбцов без потери данных; Объедините повторяющиеся строки и суммируйте.
- Инструменты разделения: разделение данных на несколько листов в зависимости от значения; Из одной книги в несколько файлов Excel, PDF или CSV; Один столбец в несколько столбцов.
- Вставить пропуск скрытых/отфильтрованных строк; Подсчет и сумма по цвету фона; Массовая отправка персонализированных писем нескольким получателям.
- Суперфильтр: создавайте расширенные схемы фильтров и применяйте их к любым листам; Сортировать по неделе, дню, частоте и т. Д. Фильтр жирным шрифтом, формулами, комментарием …
- Более 300 мощных функций; Работает с Office 2007-2019 и 365; Поддерживает все языки; Простое развертывание на вашем предприятии или в организации.
Подробнее … Бесплатная загрузка …
->
Содержание
- Найти наиболее распространенное значение (число или текстовую строку) из списка с помощью формулы массива
- Удобная сортировка по частоте появления в Excel
- Найдите наиболее распространенное значение (число или текстовая строка) из списка с кодом VBA
- Быстро найти максимальное значение запятой (число или текстовая строка ) из списка/столбца несколькими щелчками мыши
-
Kutools for Excel включает более 300 удобных инструментов для Excel, которые можно бесплатно попробовать без ограничений в течение 30 дней. Загрузить и бесплатную пробную версию!
Статьи по теме:
Найдите наименьший общий знаменатель или наибольший общий знаменатель в Excel
Все мы, возможно, помним, что нас просили вычислить наименьший общий знаменатель или наибольший общий знаменатель некоторых чисел, когда мы учимся. Но если их десять и более и какие-то большие числа, эта работа будет сложной. К счастью, в Excel есть несколько функций для получения наименьшего общего знаменателя или наибольшего общего делителя чисел. Пожалуйста, прочтите эту статью для подробностей.Как найти общие значения в 3 столбцах Excel?
В общем случае вам может потребоваться найти и выбрать одинаковые значения между двумя столбцами в Excel, но пытались ли вы когда-нибудь найти общие значения среди трех столбцов, что означает, что значения существуют в 3 столбцах одновременно, как показано на следующем снимке экрана. В этой статье я расскажу о некоторых методах выполнения этой задачи в Excel..Как найти наиболее распространенное число или текст в список в Excel?
Если у вас есть список чисел, включая несколько дубликатов, и вы хотите найти число, которое чаще всего встречается в этом списке, кроме подсчета их по одному, я могу представить несколько уловок, чтобы быстро найти наиболее часто встречающийся номер списка в Excel. - Статьи по теме:
Найти наиболее распространенное значение (число или текстовую строку) из списка с помощью формулы массива
Обычно мы можем применить функцию MODE ( = MODE (A1: A16) ) к найти наиболее распространенный номер из диапазона. Но эта функция РЕЖИМ не работает с текстовыми строками. Чтобы извлечь наиболее часто встречающееся значение, можно применить следующую формулу массива. Пожалуйста, сделайте следующее:
В пустой ячейке, помимо данных, введите формулу ниже и одновременно нажмите клавиши Shift + Ctrl + Enter .
= ИНДЕКС ($ A $ 1: $ A $ 16, РЕЖИМ (ПОИСКПОЗ ($ A $ 1: $ A $ 16, $ A $ 1: $ A $ 16,0)))

Примечания :
1. A1:A16 – это диапазон данных, для которого вы хотите получить наиболее частое значение. Вы можете изменить его по своему усмотрению.
2. Эта формула массива не может работать, если в списке есть пустые ячейки.
 |
Формула слишком сложна для запоминания? Сохраните формулу как запись Auto Text для повторного использования одним щелчком мыши в будущем! Подробнее… Бесплатная пробная версия |
Удобная сортировка по частоте появления в Excel
Kutools for Excel’s Advanced Sort Утилита поддерживает быструю сортировку данных по длине текста, фамилии, абсолютному значению, частоте и т. д. в Excel. 30-дневная бесплатная пробная версия полнофункциональной версии!

Kutools for Excel – включает более 300 удобных инструментов для Excel. Полнофункциональная бесплатная 30-дневная пробная версия, кредитная карта не требуется! Получить сейчас
Найдите наиболее распространенное значение (число или текстовая строка) из списка с кодом VBA
с помощью следующего VBA кода, вы можете не только найти наиболее часто встречающееся значение, но и подсчитать, сколько раз встречается наиболее часто встречающееся слово.
1 . Удерживая нажатыми клавиши ALT + F11 , откроется окно Microsoft Visual Basic для приложений .
2 . Нажмите Insert > Module и вставьте следующий код в окно модуля .
Код VBA: найдите наиболее распространенное значение из списка
3 . Затем нажмите клавишу F5 , чтобы запустить этот код, и появится всплывающее окно с напоминанием о выборе диапазона, который вы хотите использовать. См. Снимок экрана:

4 . Затем нажмите OK , появится окно с подсказкой, в котором отображается следующая информация:

Быстро найти максимальное значение запятой (число или текстовая строка ) из списка/столбца несколькими щелчками мыши
Если у вас установлен Kutools for Excel, вы можете легко применить его Найти формула для наиболее частого значения запятой , чтобы быстро получить наиболее частое значение из списка или столбца в Excel.
Kutools for Excel – включает более 300 удобных инструментов для Excel.. Полнофункциональная бесплатная 30-дневная пробная версия, кредитная карта не требуется! Бесплатная пробная версия!
Kutools for Excel – объединяет более 300 дополнительных функций и инструментов для Microsoft Excel
Перейти к загрузке
Бесплатная пробная версия 60 днейПокупка
PayPal/MyCommerce
->
1 . Выберите пустую ячейку, в которую вы поместите найденное значение, и нажмите Kutools > Помощник по формулам > Помощник по формулам .
2. В диалоговом окне Помощник по формулам выберите Поиск из раскрывающегося списка Тип формулы , щелкните, чтобы выбрать Найти наиболее общее значение в поле списка Выберите формулу , укажите список/столбец в поле Range и нажмите ОК . См. Снимок экрана:

И тогда вы увидите, что наиболее распространенное/частое значение имеет найден и помещен в выбранную ячейку. См. Снимок экрана:

Kutools for Excel – Включает более 300 удобных инструментов для Excel. Полнофункциональная бесплатная 30-дневная пробная версия, кредитная карта не требуется! Получить сейчас
Kutools for Excel включает более 300 удобных инструментов для Excel, которые можно бесплатно попробовать без ограничений в течение 30 дней. Загрузить и бесплатную пробную версию !
Kutools for Excel включает более 300 удобных инструментов для Excel, которые можно бесплатно попробовать без ограничений в течение 30 дней. Загрузить и бесплатную пробную версию !
Статьи по теме:
Найдите наименьший общий знаменатель или наибольший общий знаменатель в Excel
Все мы, возможно, помним, что нас просили вычислить наименьший общий знаменатель или наибольший общий знаменатель некоторых чисел, когда мы учимся. Но если их десять и более и какие-то большие числа, эта работа будет сложной. К счастью, в Excel есть несколько функций для получения наименьшего общего знаменателя или наибольшего общего делителя чисел. Пожалуйста, прочтите эту статью для подробностей.
Как найти общие значения в 3 столбцах Excel?
В общем случае вам может потребоваться найти и выбрать одинаковые значения между двумя столбцами в Excel, но пытались ли вы когда-нибудь найти общие значения среди трех столбцов, что означает, что значения существуют в 3 столбцах одновременно, как показано на следующем снимке экрана. В этой статье я расскажу о некоторых методах выполнения этой задачи в Excel..
Как найти наиболее распространенное число или текст в список в Excel?
Если у вас есть список чисел, включая несколько дубликатов, и вы хотите найти число, которое чаще всего встречается в этом списке, кроме подсчета их по одному, я могу представить несколько уловок, чтобы быстро найти наиболее часто встречающийся номер списка в Excel.
|
Топ наиболее часто повторяющихся значений |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |



17 авг. 2022 г.
читать 2 мин
В следующем пошаговом примере показано, как отфильтровать первые 10 значений в сводной таблице Excel.
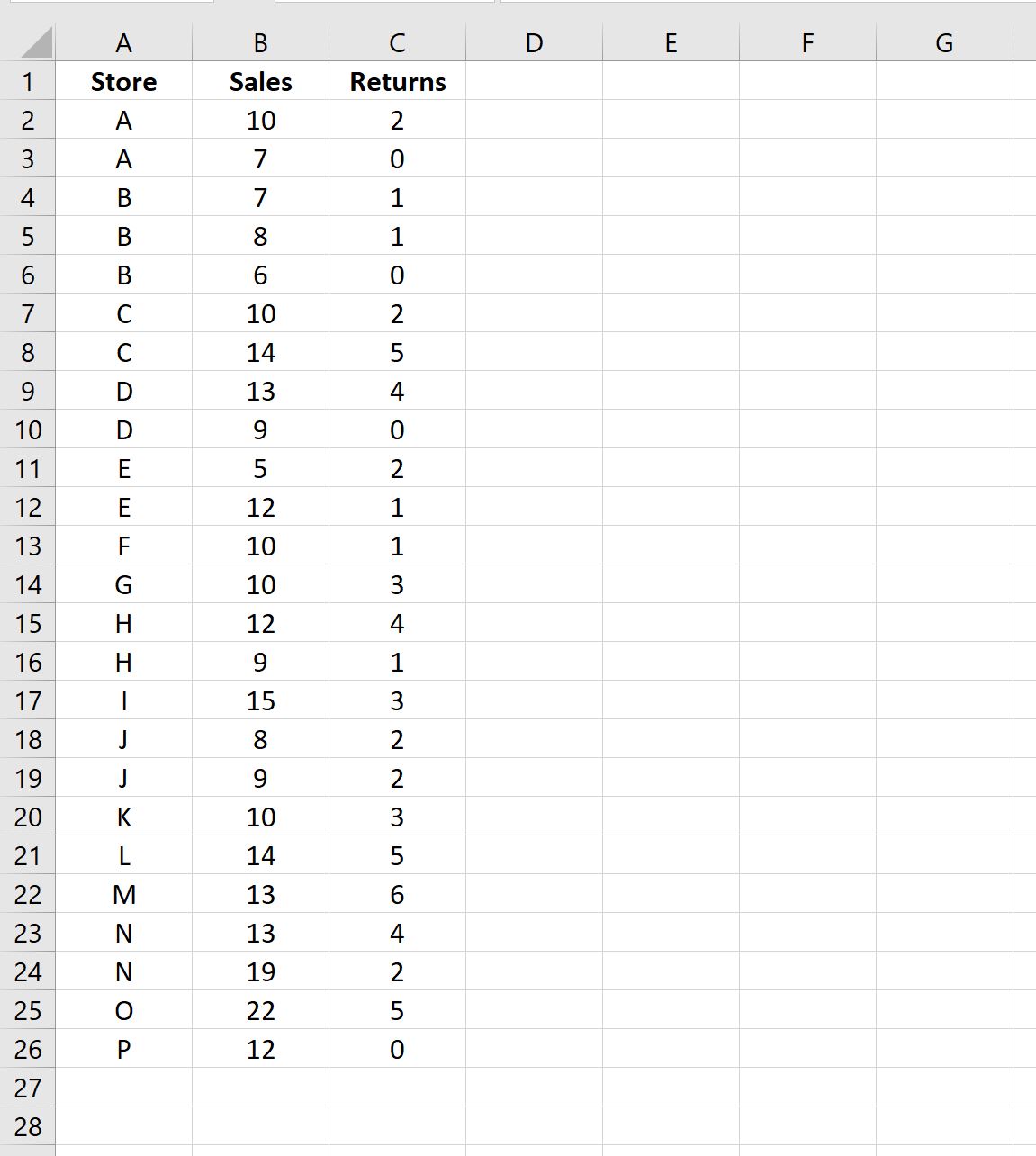
Шаг 1: введите данные
Во-первых, давайте введем следующие данные о продажах для 15 разных магазинов:
Шаг 2: Создайте сводную таблицу
Чтобы создать сводную таблицу, щелкните вкладку « Вставка » на верхней ленте, а затем щелкните значок «Сводная таблица»:
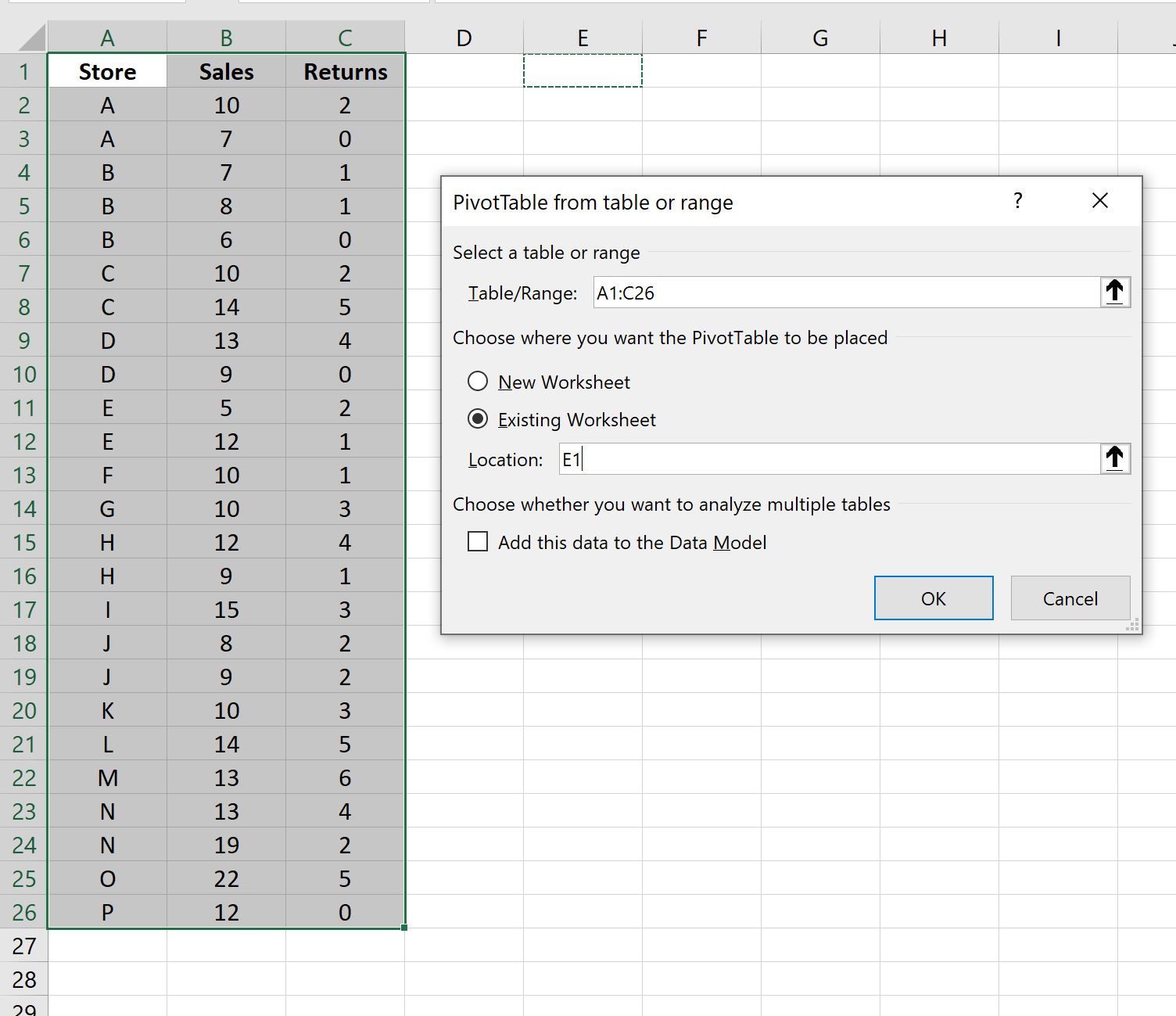
В появившемся новом окне выберите A1: C26 в качестве диапазона и поместите сводную таблицу в ячейку E1 существующего рабочего листа:
После того, как вы нажмете OK , в правой части экрана появится новая панель полей сводной таблицы .
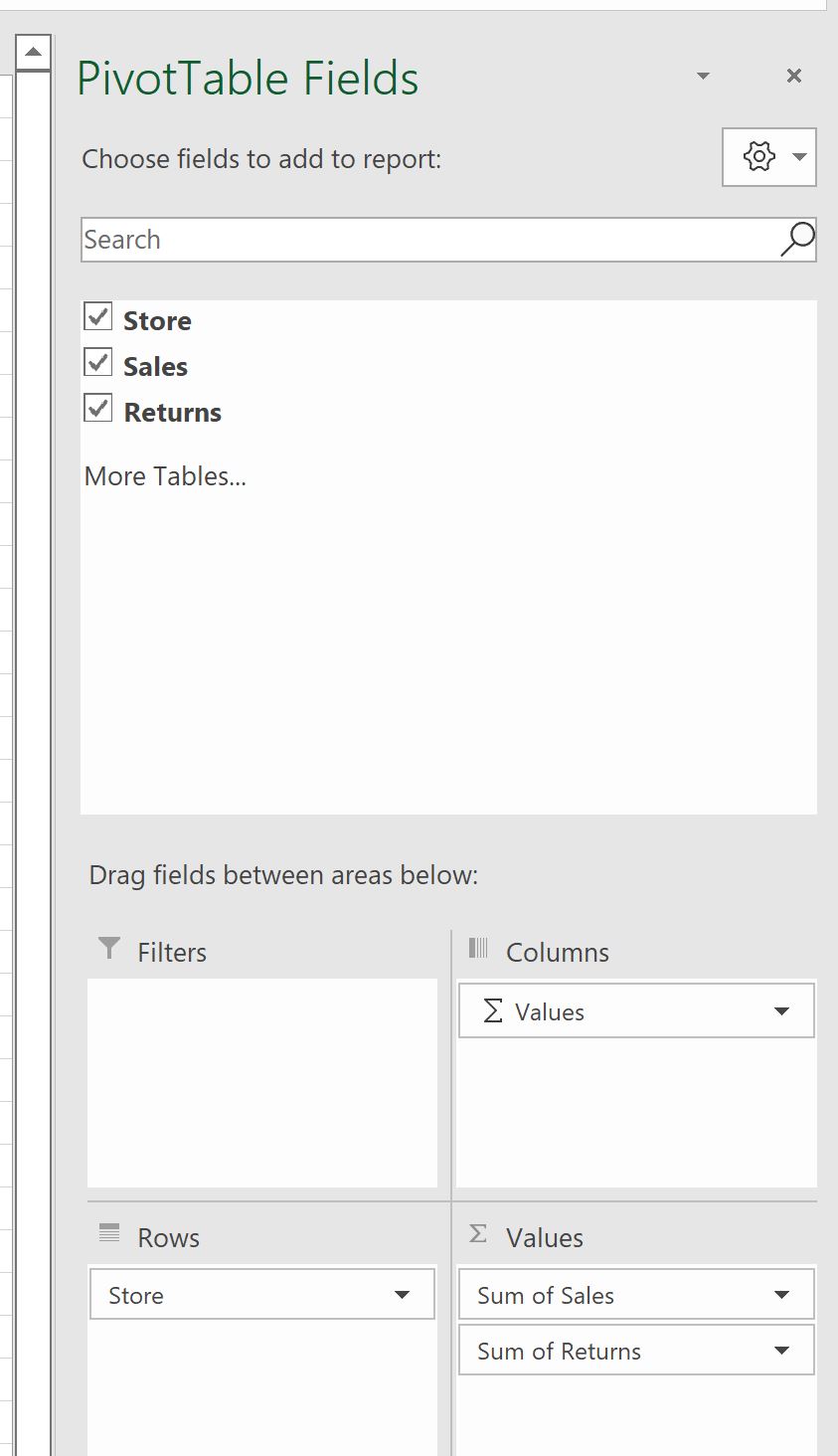
Перетащите поле « Магазин » в поле « Строки », затем перетащите поля « Продажи » и « Возвраты» в поле « Значения »:
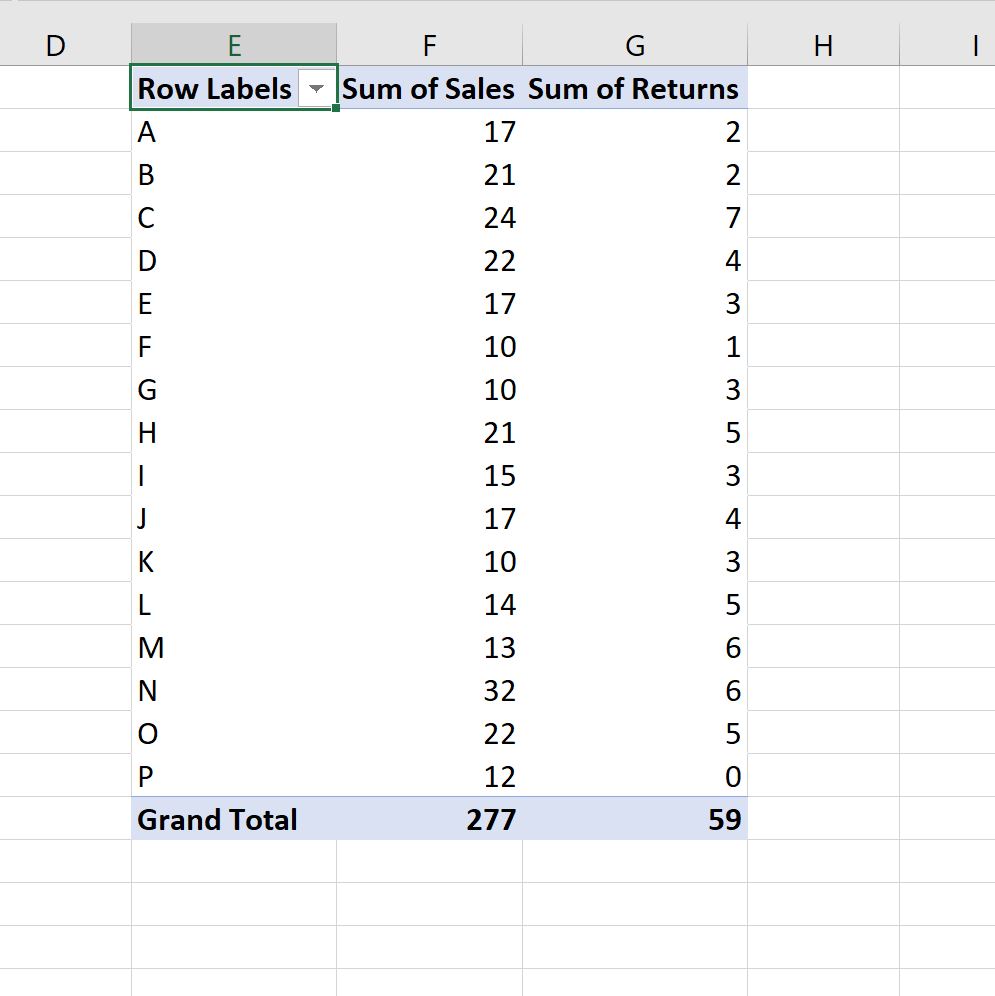
Сводная таблица будет автоматически заполнена следующими значениями:
Шаг 3: Отфильтруйте 10 лучших значений в сводной таблице
Чтобы отобразить только 10 магазинов с самыми высокими значениями в столбце « Сумма продаж », щелкните правой кнопкой мыши имя любого магазина.
В появившемся раскрывающемся меню нажмите « Фильтр » , затем нажмите « 10 лучших »:
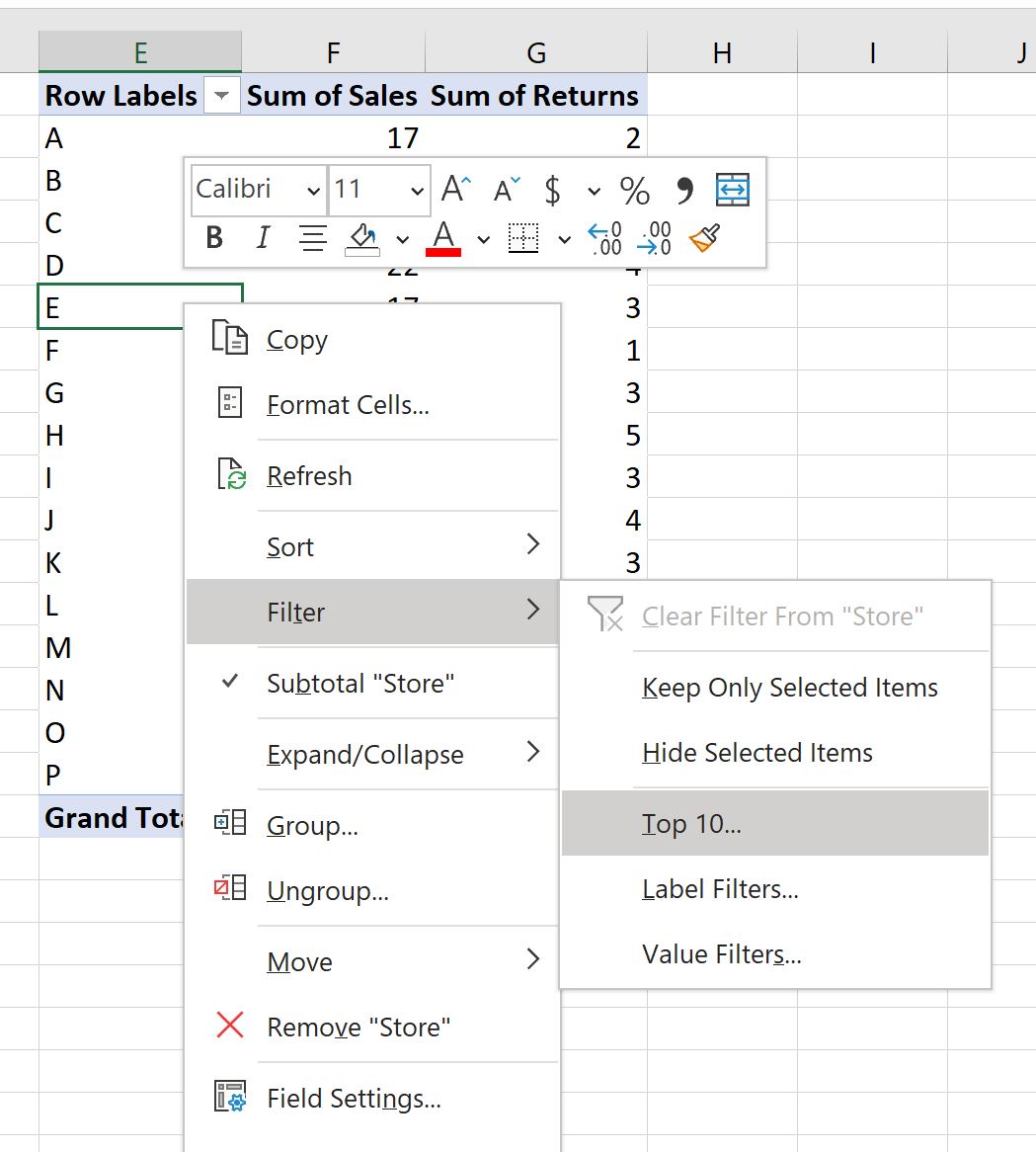
В появившемся новом окне выберите «10 лучших товаров по сумме продаж », затем нажмите « ОК »:
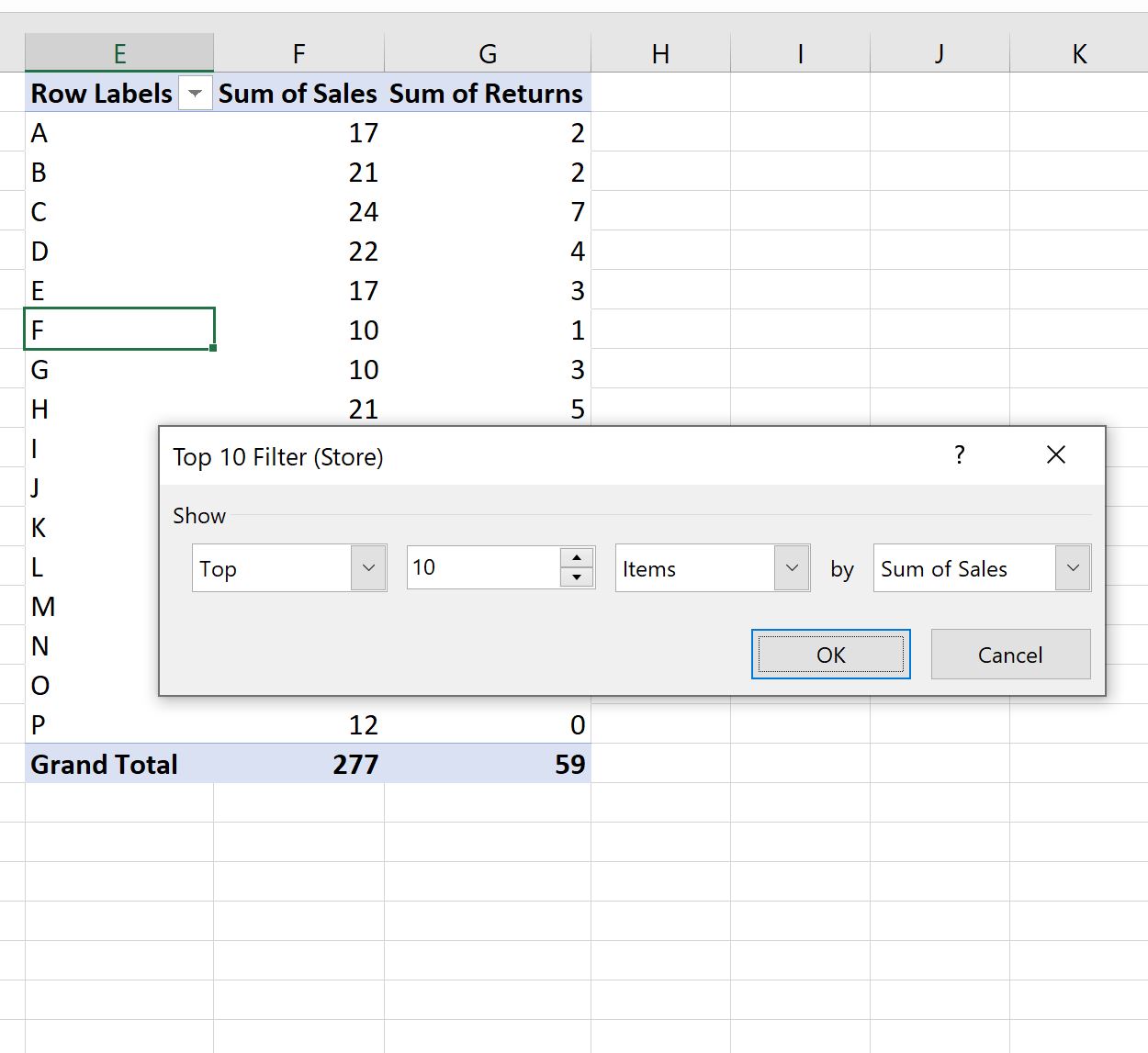
Сводная таблица будет автоматически отфильтрована, чтобы отображались только 10 магазинов с 10 лучшими значениями столбца « Сумма продаж »:
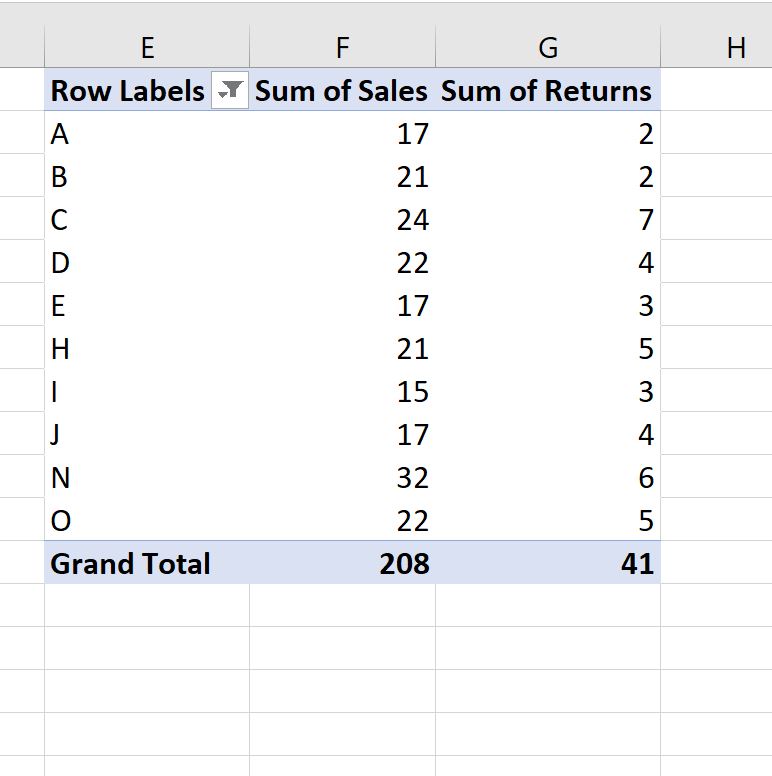
Примечание.Вы можете использовать число, отличное от 10, чтобы отфильтровать другое количество верхних значений.
Шаг 4. Отсортируйте первые 10 значений в сводной таблице (необязательно)
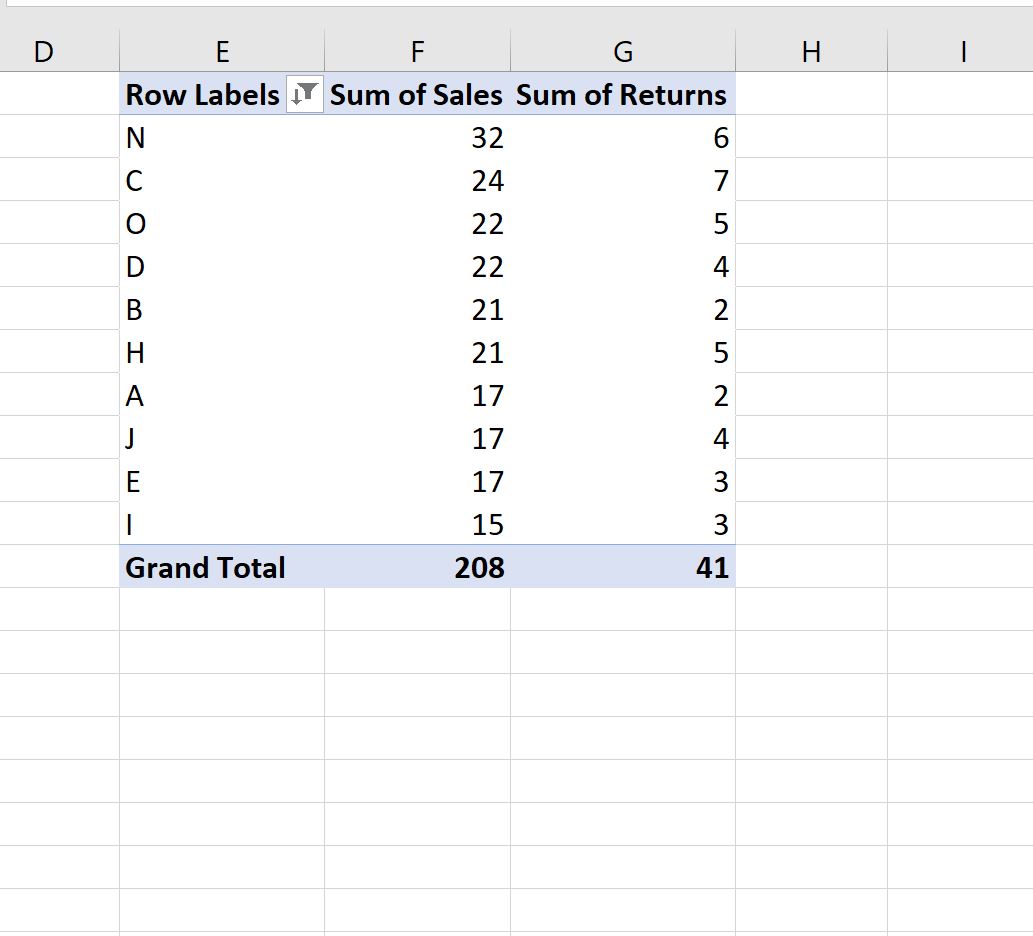
Обратите внимание, что параметр фильтра отображает 10 магазинов с самыми высокими значениями продаж, но не отображает их автоматически в отсортированном порядке.
Чтобы отсортировать магазины по значениям продаж, щелкните правой кнопкой мыши любое значение в столбце « Сумма продаж », затем нажмите « Сортировать », затем нажмите « Сортировать от наибольшего к наименьшему» :
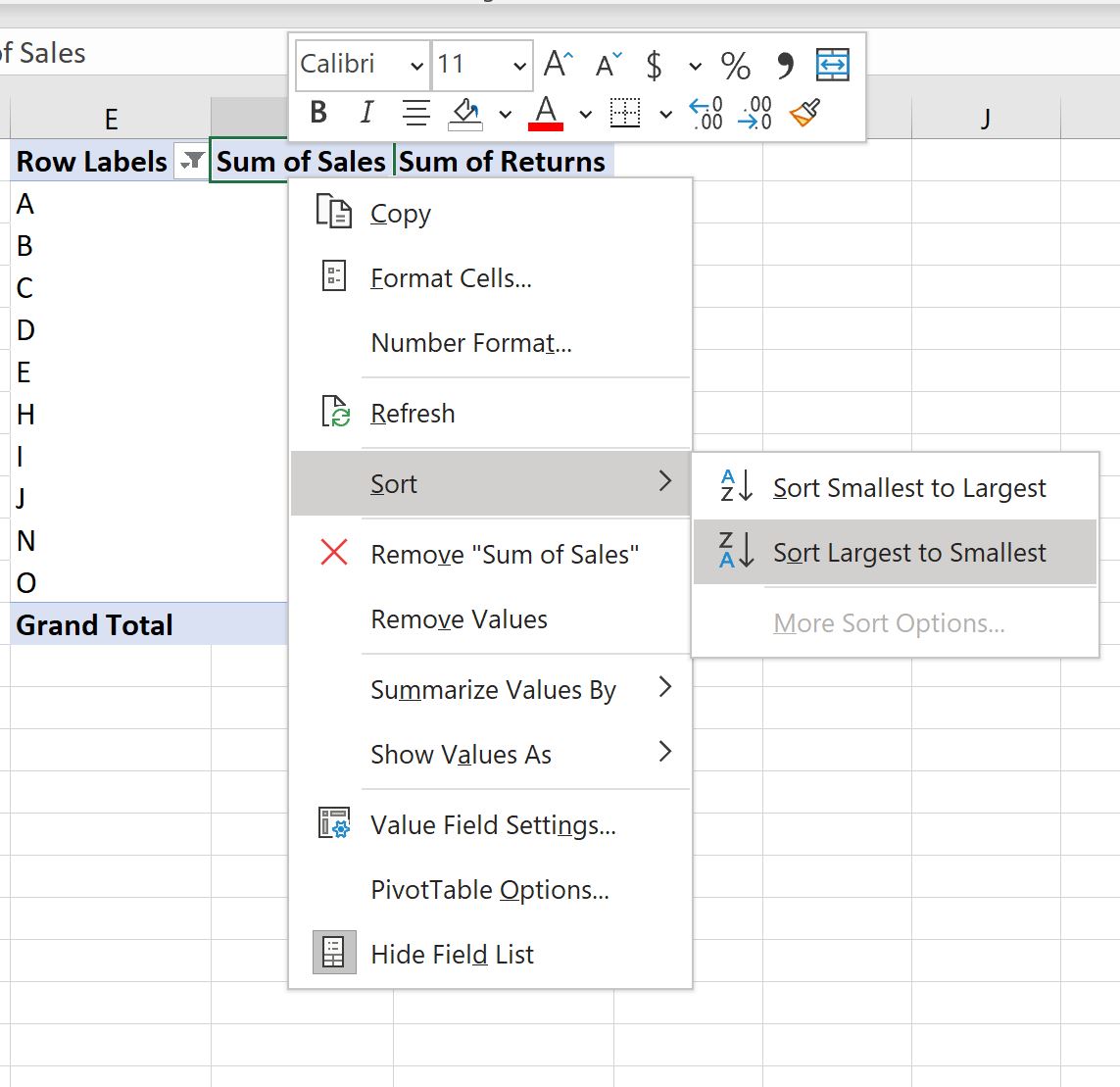
Магазины в сводной таблице будут автоматически отсортированы от самого большого к самому маленькому в зависимости от продаж:
Дополнительные ресурсы
В следующих руководствах объясняется, как выполнять другие распространенные задачи в Excel:
Как отсортировать сводную таблицу по общей сумме в Excel
Как сгруппировать значения в сводной таблице по диапазону в Excel
Как сгруппировать по месяцам и годам в сводной таблице в Excel