
Содержание
MS Excel
27 сентября, 2017
Евгений Довженко о том, как можно эффективно работать даже с огромными массивами данных.

Любой сотрудник компании, работающий в отделе продаж, финансов, маркетинга, логистики, сталкивается с необходимостью работать с данными, анализировать их.

Excel — незаменимый помощник для достижения этих целей. Мы импортируем информацию, «подтягиваем» ее, систематизируем. На ее основе строим диаграммы, сводные таблицы, планируем, прогнозируем.
Однако в Excel до недавнего времени было 2 важных ограничения:

Мы не могли разместить на рабочем листе Excel более миллиона строк (а наши данные о продажах за 2 года занимают, например, 10 млн строк).

Мы знали, как создать и настроить интерактивные и обновляемые отчеты, но это отнимало много времени.
Единственный инструмент в Excel — сводные таблицы — позволял быстро обрабатывать наши данные.
С другой стороны, есть категория пользователей, которые работают со сложными BI-системами. Это системы бизнес-аналитики (business intelligence), которые дают возможность быстро визуализировать, «крутить» данные и извлекать из них ценную информацию (data mining). Однако внедрение и поддержка таких систем требует значительного участия IT-специалистов и больших финансовых вложений.
До Excel 2010 было четкое разделение на анализ малого и большого объема данных: Excel с одной стороны и сложные BI-системы — с другой.
Начиная с версии 2010, в Excel добавили инструменты, в названиях которых присутствует слово power: Power Query, Power Pivot и Power View. Они позволили сгладить грань между пользователями Excel и комплексных BI-систем.
Power Query
Чтобы работать с данными, к ним нужно подключиться, отобрать, преобразовать или, другими словами, привести их к нужному виду.
Для этого и необходим Power Query. До версии Excel 2013 включительно этот инструмент был в виде надстройки, которую можно было установить бесплатно с сайта Microsoft.
В версии 2016 это уже встроенный в программу инструментарий, находящийся на вкладке «Данные» (Data) в разделе «Скачать и преобразовать» (Get and Transform).
Перечень источников информации, к которым можно подключаться — огромный: от баз данных (их в последней версии 10) до Facebook и Google таблиц (рис. 1).
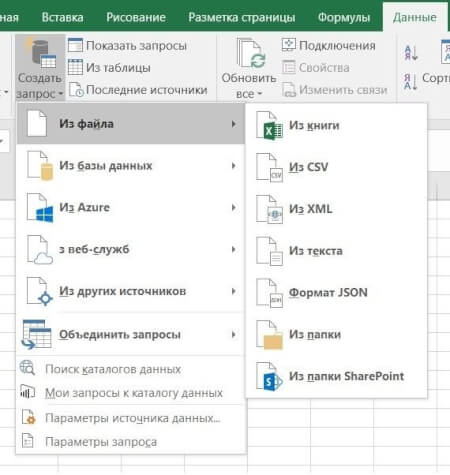
Рис 1. Выбор источника данных в Power Query
Вот некоторые возможности Power Query по подготовке и преобразованию данных:

отбор строк и столбцов, создание пользовательских (вычисляемых) столбцов

преобразование данных с помощью числовых, текстовых функций, функций даты и времени

транспонирование таблицы, разворачивание по столбцам (Pivot) и наоборот — сворачивание данных, организованных по столбцам, в построчный вид (Unpivot)

объединение нескольких таблиц: как вниз — одну под другую, так и связывание по общей колонке (единому ключу)
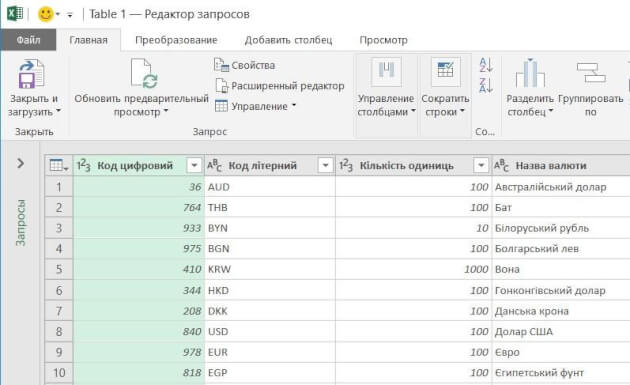
Рис 2. Окно редактора Power Query
Ну и конечно, после выгрузки подготовленных данных в Excel они будут автоматически обновляться, если в источнике данных появятся новые строки.
Пример
Компания в своей аналитике использует текущие курсы трех валют, которые ежедневно обновляются на сайте Национального банка.
Таблица на сайте непригодна для прямого использования (рисунок 2-1):

все валюты не нужны

в колонке «Курс» в качестве разделителя целой и дробной частей используется точка (в наших региональных настройках — запятая)

в колонке «Курс» отображается показатель за разное количество единиц валюты: за 100, за 1000 и т. д. (указано в отдельной колонке «Количество единиц»)
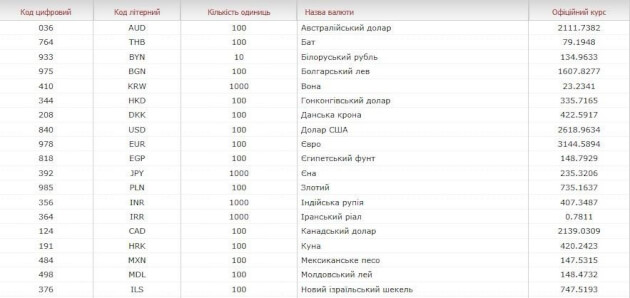
Рис. 2-1. Так выглядит таблица с курсами валют на сайте Нацбанка.
С помощью Power Query мы подключаемся к таблице текущих курсов валют на сайте НБУ и в этом редакторе готовим запрос на извлечение данных:

В колонке «Курс» меняем точку на запятую (инструмент «Замена значений»).

Создаем вычисляемый столбец, в котором курсы валют в колонке «Курс» делятся на количество единиц валюты из колонки «Количество единиц».

Удаляем лишние столбцы и оставляем только строки валют, с которыми работаем.

Выгружаем полученную таблицу на рабочий лист Excel.
Результат показан на рисунке 2-2.
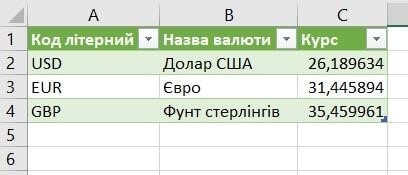
Рис. 2-2. Так выглядит результирующая таблица в нашем Excel файле.
Курсы валют на сайте Нацбанка меняются каждый день. Но при обновлении данных в документе Excel наш, один раз подготовленный, запрос пройдет через все шаги, и результирующая таблица всегда будет в нужном виде, но уже с актуальными курсами.
Power Pivot
У вас данные находятся в разрозненных источниках? Некоторые таблицы содержат больше 1 млн строк? Вам нужно все это объединить в одну модель данных и анализировать с помощью, например, сводной таблицы Excel? Здесь понадобится Power Pivot — надстройка Excel, которая по умолчанию включена в версии Pro Plus и выше (начиная с версии 2010).
В Power Pivot вы можете добавлять данные из разных источников, связывать таблицы между собой (рисунок 3). Таблицы при этом не обязательно должны находиться на рабочих листах Excel. Вместо этого они по-прежнему будут храниться в файле Excel, но просматривать их можно в окне Power Pivot (рис. 4). Поэтому нет ограничения на количество строк — в вашем файле Excel могут находиться таблицы и в сотни миллионов строк.
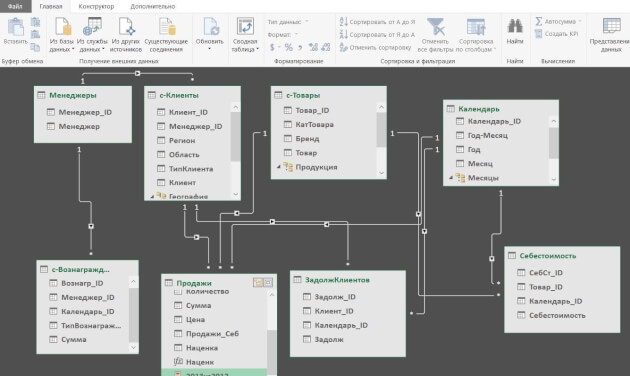
Рис. 3. Окно Power Pivot в представлении диаграммы
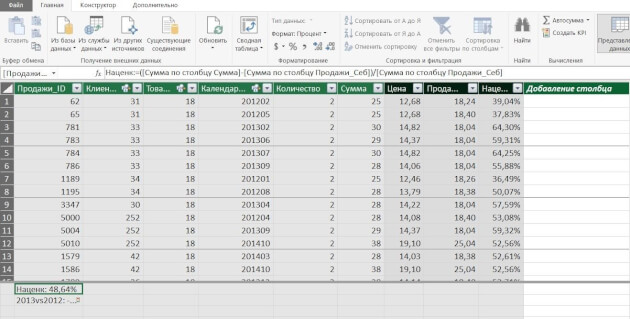
Рис. 4. Окно Power Pivot в представлении данных
Вот некоторые возможности Power Pivot, помимо описанных выше:

добавлять вычисляемые столбцы и поля (меры), в том числе основанные на расчетах из нескольких таблиц

создавать и мониторить в сводной таблице ключевые показатели эффективности (KPI)

создавать иерархические структуры (например, по географическому признаку — регион, область, город, район)
И обрабатывать все это с помощью сводной таблицы Excel, построенной на модели данных.
Пример. У предприятия в базе данных (или отдельных файлах Excel) в 5 таблицах хранится информация о продажах, клиентах, товаре и его классификации, менеджерах по продажам и закупочных ценах продукции. Необходимо провести анализ по объемам продаж и маржинальности по менеджерам.
С помощью Power Pivot:
добавляем все 5 таблиц в модель данных

связываем таблицы по общим ключам (столбцам)

в таблице «Продажи» создаем вычисляемый столбец «Продажи в закупочных ценах», умножив количество штук из таблицы «Продажи» на закупочную цену из таблицы «Цена закупки»

создаем вычисляемое поле (меру) «Маржа»

с помощью инструмента «Ключевые показатели эффективности» устанавливаем цель по маржинальности и настраиваем визуализацию — как выполнение цели будет визуализироваться в сводной таблице
Теперь можно «крутить» эти данные в сводной таблице или в отчете Power View (следующий инструмент) и анализировать маржинальность по товарам, менеджерам, регионам, клиентам.
Power View
Иногда сводная таблица — не лучший вариант визуализации данных. В таком случае можно создавать отчеты Power View. Как и Power Pivot, Power View — это надстройка Excel, которая по умолчанию включена в версии Pro Plus и выше (начиная с версии 2010).
В отличие от сводной таблицы, в отчет Power View можно добавлять диаграммы и другие визуальные объекты. Здесь нет такого количества настроек, как в диаграммах Excel. Но в том то и сила инструмента — мы не тратим время на настройку, а быстро создаем отчет, визуализирующий данные в определенном разрезе.
Вот некоторые возможности Power View:

— быстро добавлять в отчет таблицы, диаграммы (без необходимости настройки)

организовывать срезы и фильтры

уходить на разные уровни детализации данных

добавлять карты и располагать на них данные

создавать анимированные диаграммы
Пример отчета Power View — на рисунке 5.
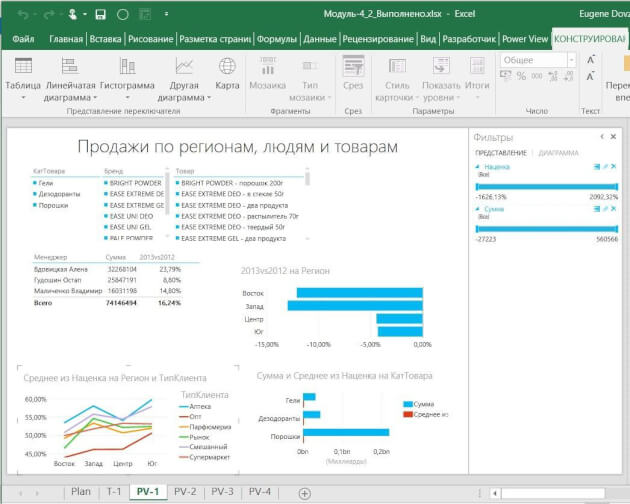
Рис. 5. Пример отчета Power View
Даже самые внушительные массивы данных можно систематизировать и визуализировать — главное не ограничиваться поверхностными возможностями Excel, а брать из его функций все возможное.


Хотите получать дайджест статей?
Одно письмо с лучшими материалами за неделю. Подписывайтесь, чтобы ничего не упустить.
Спасибо за подписку!
Курс по теме:
«Advanced Excel»
Программы
Ведет
Никита
Свидло
![]()
16 мая
13 июня


На сайте с 05.01.2020
Offline
240
Дык. Задачи определяют. Где СУБД, где Python, а какой шарлатан и BI какому радый.

На сайте с 15.12.2019
Offline
51
Виктор Петров #:
Дык. Задачи определяют. Где СУБД, где Python, а какой шарлатан и BI какому радый.
Я в этом деле мало что понимаю)))
Цель: запихнуть 6 миллионов строк в эксель, обычный файловый, не облачная версия. (ну если это возможно)

На сайте с 08.12.2010
Offline
170
NikSolovov #:
запихнуть 6 миллионов строк в эксель
Как обрабатывать потом? У вас не просто домашний комп, а сервер должен быть, чтобы потом в excel переваривать такое количество строк.
А уж про выполнение на нем функций сортировок или еще каких-то действий — вообще под вопросом.
Проще, как выше написали, работать с такими объемами в БД и дополнительным ПО, если потребуется, на мой взгляд excel для таких объемов малопригоден.
D
На сайте с 06.01.2022
Offline
9
Powerquery
На сайте с 15.12.2019
Offline
51
Алеандр #:
Как обрабатывать потом? У вас не просто домашний комп, а сервер должен быть, чтобы потом в excel переваривать такое количество строк.
А уж про выполнение на нем функций сортировок или еще каких-то действий — вообще под вопросом.
Проще, как выше написали, работать с такими объемами в БД и дополнительным ПО, если потребуется, на мой взгляд excel для таких объемов малопригоден.
У меня комп хороший ryzen 5900 проц оперативки 64. База в миллион летает вроде.
Цель простая: есть 2 столбика на 6 миллионов строк.
Через фильтр вбиваю запрос и получаю все данные по этому запросу.
Сейчас приходится открывать за раз 6 Эксель файлов и делать 6 раз одно и тоже действие.
А хочется все объеденить и за раз вытаскивать данные.
AD
На сайте с 05.05.2007
Offline
230
В Notepad 10+ мильонов строк добавлял, но нужен мощный аппарат.
W1
На сайте с 22.01.2021
Offline
197
Делайте нормальную базу данных и работайте с ней. Excel предназначен для других целей.

На сайте с 13.06.2020
Offline
72
NikSolovov :
Всем привет я так понял в Excel есть ограничения (не могу добавить в 1 файл больше 1 миллиона строк (ну там миллион с копейками получается).
Сейчас разбил на 6 файлов по 1 миллиону, но это жутко неудобно.
Есть какие-то решения или альтернативы? Спасибо.
Попробуйте OpenOffice он полегче MS Excel и сохраняйте файл в формате CSV. Должно получиться с очень большой вероятностью.
P.S. CSV это по сути текстовый файл без лишнего мусора и OpenOffice его кушает на раз два. А работать можно со всеми удобствами таблиц Excel.

На сайте с 18.11.2010
Offline
617
А если так? На php?
Создание и продвижение сайтов — https://alaev.net , аудиты сайтов, контекстная реклама

На сайте с 25.11.2006
Offline
1686
Моя старая инструкция: https://searchengines.guru/ru/forum/877149/page66#comment_15209991
Возможно вам поможет.

Существует ограничение в 1 048 576 строк, которое можно просматривать / просматривать в Excel 2007/2010.
В этом случае файл содержит 1,2 миллиона строк и, таким образом, хотя строки существуют в файле, их нельзя просмотреть / открыть в Excel.
Лицо, предоставляющее данные, предлагает не использовать Excel для открытия файлов.
Один из возможных подходов к просмотру необработанных данных — при условии, что это «распакованный файл.xslx»1) — использовать Блокнот для открытия файла (если Блокнот не работает, запись может). Вот несколько подходов сделать это:
- Щелкните правой кнопкой мыши по файлу и перейдите к «Открыть с помощью -> Выбрать программу по умолчанию..», затем выберите «Блокнот» (обязательно снимите флажок «Всегда использовать..»);
- Переименуйте расширение файла в «.txt», чтобы оно было связано с обычным редактором (возможно, «Блокнотом») по умолчанию;
- Запустите Блокнот, а затем «Открыть» указанный файл.
Если данные были предоставлены в CSV, все строки не могли быть просмотрены в Excel (например, после импорта) из-за указанного ограничения. Если этот файл является «распакованным.xsls», тогда данные уже являются обычным текстом, и файл с расширением.xsls (vs .txt) в значительной степени не имеет значения — расширение существует для ассоциации программы / файла.
Другой вариант — посмотреть, может ли другая программа для работы с электронными таблицами (например, Open Office Calc, Kingsoft Office Suite) отображать такое количество строк. YMMV.
1 Не все файлы «.xslx» одинаковы, и Excel довольно снисходительно относится к формату данных, содержащемуся в файлах с таким расширением, которые можно открыть. В этом случае другой человек кажется уверенным, что разумно рассматривать этот файл как необработанный текст — даже если работа с данными, вероятно, будет громоздкой.
It is known that Excel sheets can display a maximum of 1 million rows. Is there any row limit for csv data, i.e. does Excel allow more than 1 million rows in csv format?
One more question: About this 1 million limitation; Can Excel hold more than 1 million data rows, even though it only displays a maximum of 1 million data rows?
![]()
Andreass
3,1781 gold badge21 silver badges25 bronze badges
asked May 20, 2014 at 11:01
![]()
user1254579user1254579
3,87120 gold badges64 silver badges103 bronze badges
CSV files have no limit of rows you can add to them. Excel won’t hold more that the 1 million lines of data if you import a CSV file having more lines.
Excel will actually ask you whether you want to proceed when importing more than 1 million data rows. It suggests to import the remaining data by using the text import wizard again — you will need to set the appropriate line offset.
answered May 20, 2014 at 11:43
![]()
0
In my memory, excel (versions >= 2007) limits the power 2 of 20: 1.048.576 lines.
Csv is over to this boundary, like ordinary text file. So you will be care of the transfer between two formats.
![]()
Dherik
17.2k11 gold badges118 silver badges161 bronze badges
answered Jun 17, 2015 at 6:43
![]()
staticorstaticor
6109 silver badges18 bronze badges
Using the Excel Text import wizard to import it if it is a text file, like a CSV file, is another option and can be done based on which row number to which row numbers you specify. See: This link
![]()
Hasan Fathi
5,4604 gold badges42 silver badges56 bronze badges
answered Oct 18, 2017 at 11:54
![]()
ChrisChris
311 bronze badge
Как часто вы сталкиваетесь с необходимостью выгрузить в MS Excel более миллиона строк? Все фильтры на выгрузку уже были наложены ранее, но, увы, она до сих пор «не проходит по габаритам». Перед нами встает дилемма – делить, или … воспользоваться готовыми решениями для python, не изучая python!
Речь сегодня пойдет о трех библиотеках, которые позволяют писать код и при этом не писать его, а также оперировать внушительными объемами данных с минимальными знаниями английского языка или синтаксиса пресловутых «панд» (здесь и далее «панды»: pandas – open-source библиотека для python для работы с табличными данными – прим. автора). Для примера будем использовать объявления о продаже автомобилей Toyota с известного сайта.
Первая библиотека, с которой хотелось бы Вас познакомить – Bamboolib. Не секрет, что панды питаются бамбуком, и, как за всякое пропитание, за него нужно платить. Да, у Bamboolib есть платная версия, в которой реализована поддержка Apache Spark, а также есть возможность использовать свои внутренние библиотеки и нет ограничения по плагинам, в остальном же достаточно бесплатной версии.
Устанавливаем:
pip install — upgrade bamboolib — userИмпортируем:
import bamboolib as bamРаботаем:
bamПосле этого появляется графический интерфейс и возможность открыть .csv файл…

… и работать с ним через GUI, как с обычным Excel. Считанная таблица:

Обратите внимание:
- таблица имеет категориальные признаки оснащения автомобиля – «допы» вынесены в колонки, из-за чего фрейм «раздут» до 193 (!) столбцов. В обычном случае таблица не поместилась бы в стандартный вывод тетради и нам бы пришлось использовать параметр display.max_columns, чтобы посмотреть на все поля, но здесь полоса прокрутки уже есть.
- Названия столбцов содержат префикс, на скриншоте видны «o» и «I» — так нам сообщают, что типы данных в столбцах это object и int соответственно. Долгота, широта, расход топлива и объем топливного бака «f» – float. Объем бака при этом не имеет отличных от 0 значений после точки и его можно конвертировать в int просто кликнув по столбцу, выбрав из выпадающего списка целочисленный тип и нажав Execute.

Большая зеленая кнопка «Explore DataFrame» позволит нам увидеть как типы данных всех остальных столбцов, так и количество пропусков и уникальных значений, а в соседних вкладках обнаруживаются тепловая карта и матрица корреляций.

Если необходимо детально познакомиться со статистиками содержимого в столбце Seller_type, проваливаемся в него одним кликом и видим распределение, а в соседних вкладках взаимозависимости.

Слева от большой зеленой кнопки «Explore DataFrame» есть функция построения графиков. Я захотел узнать объявлений о продаже каких моделей больше всего:

Визуализация с помощью plotly и ее контекстное меню справа в углу графика позволяют работать с графиком.
Разумеется, помимо EDA и визуализации в библиотеке есть и методы для работы с датафреймом. Если Вы знакомы с «пандами», то вас встретит привычный набор методов и функций, если же нет – достаточно будет начальных знаний английского языка – все доступные операции перечислены в выпадающем списке:

Удаление, переименование, сортировка, etc. При этом интерфейс фильтрации напоминает тот самый сайт-источник. Например, мы хотим просмотреть все объявления о продаже 5-дверных полноприводных Toyota в Самаре? Пожалуйста. Отсортировать по цене? Ничего проще 🙂 Удалить столбцы? Сию минуту 🙂

Также бывает полезна группировка, это делается достаточно просто, а в дополнение мы получаем код, который библиотека написала за нас (включая импорт «панд») – его можно сохранить и использовать в том числе и без установленной bamboolib!
import pandas as pd
df = pd.read_csv(r'C:UsersolegsDesktopvato_ru.csv', sep=',', decimal='.')
df = df.loc[(df['city_name'].isin(['Самара'])) & (df['body_type'].isin(['ALLROAD_5_DOORS']))]
df = df.sort_values(by=['price'], ascending=[True])
df = df.drop(columns=['latitude', 'longitude'])
dfКак видим, «из коробки» нам предоставляется необходимый базовый набор операций с данными, включая такие вещи, как статистики и графики.
Аналогичным образом работает и библиотека Mito. Устанавливаем:
python -m pip install mitoinstaller
python -m mitoinstaller installИмпортируем:
import mitosheetРаботаем:
mitosheet.sheet()Как и у Bamboolib, у Mito есть корпоративная версия, PRO с дополнительным функционалом и бесплатная Open Source. Будем использовать последнюю, в которой помимо инструментов для исследования и трансформирования данных заявлена даже поддержка пользователей (ее не было в бесплатной версии Bamboolib).
После открытия GUI сразу же бросается в глаза различие в интерфейсе – команды выведены в «шапку», а также присутствует pivot table – сводные таблицы – и команды Undo и Redo (откатить/вернуть действие) и даже STEP HISTORY, которых не было в предыдущей библиотеке. Возможности группировки нет.

Наш датафрейм:

Полосы прокрутки на месте, в отличие от размерности. Изменить тип данных столбца (наименования которых здесь, кстати, отличаются) так же интуитивно просто – повторим те же манипуляции с фильтрацией, удалением колонок и т.д. и сравним код:
# Imported vato_ru.csv
import pandas as pd
vato_ru = pd.read_csv(r'C:UsersolegsDesktopvato_ru.csv')
# Changed trunk_volume to dtype int
vato_ru['trunk_volume'] = vato_ru['trunk_volume'].fillna(0).astype('int')
# Filtered city_name
vato_ru = vato_ru[vato_ru['city_name'] == 'Самара']
# Sorted price in ascending order
vato_ru = vato_ru.sort_values(by='price', ascending=True, na_position='first')
# Filtered body_type
vato_ru = vato_ru[vato_ru['body_type'] == 'ALLROAD_5_DOORS']
# Deleted columns latitude
vato_ru.drop(['latitude'], axis=1, inplace=True)
# Deleted columns longitude
vato_ru.drop(['longitude'], axis=1, inplace=True) С каждой манипуляцией фрейм так же перезаписывался (кроме удаления столбцов, но использован параметр inplace = True), а в случае необходимости отката нас спасает STEP HISTORY. Также среди незначительных отличий использование точного соответствия вместо .isin() при фильтрации (выпадающего списка, как в bamboolib, здесь нет) и ряд других, вдобавок каждое действие закомментировано.
Статистика менее подробная, но must have атрибуты присутствуют:

Корреляция/ковариация отсутствует. Функционал блока визуализации (также на plotly) достаточный.

К плюсам можно также отнести то, что можно подгрузить несколько датафреймов, и они будут отображаться вкладками, как листы Excel.
Третья библиотека, которая предоставляет возможность интерактивного взаимодействия с данными на языке Python без знания языка Python — D-Tale. Она бесплатная.
Устанавливаем:
pip install dtaleИмпортируем:
import dtale
import pandas as pdРаботаем:
df = pd.read_csv(‘data.csv’)
d = dtale.show(df)
d.open_browser()Да, нам действительно пришлось самим импортировать «панд», считать файл и даже вызвать пару функций из dtale, что, по сравнению с функционалом предыдущих библиотек, может показаться непростительно трудозатратным, но:

…фрейм сразу открывается в отдельном окне! Также сразу видим его размерность слева сверху и полосы прокрутки, но ни одной кнопки или тулбара. Все спрятано на кнопке в левом верхнем углу, при нажатии на которую открывается богатое меню функций – тепловая карта, корреляции, анализ пропусков, подсвечивание выбросов, графики, можно даже поставить темную тему. Сравните, как выглядят статистики (меню Describe) по столбцу «Тип продавца»:

Соседняя вкладка с распределением значений:

Функционал действительно впечатляет, из ранее упомянутых функций присутствуют не только pivot table и group by, но и transpose и resample:

Множество поддерживаемых функций влечет за собой очевидное неудобство – для простейшей конвертации типа данных столбца необходимо сначала ее найти:

…а для фильтрации знать немного синтаксиса:

Я не буду подробно демонстрировать работу всех имеющихся функций, но проведу «традиционную» манипуляцию с датафреймом и выгружу получившийся код для сравнения:
df.loc[:, 'trunk_volume'] = pd.Series(s.astype('int'), name='trunk_volume', index=df['trunk_volume'].index)
df = df[[c for c in df.columns if c not in ['latitude']]]
df = df[[c for c in df.columns if c not in ['longitude']]]
df = df.query("""(city_name == 'Самара') and (body_type == 'ALLROAD_5_DOORS')""")
df = df.sort_values(['price'], ascending=[True])Обратите внимание, что удаление столбцов происходит с использованием спискового включения, конвертация через Series, а для фильтрации используется функция .query(), что разительно отличает такой подход от ранее увиденных.
Как итог, с уверенностью можно утверждать, что на поле пользовательских интерфейсов для взаимодействия с данными есть инструменты, не требующие изучения языка программирования, но предоставляющие базовый, а иногда даже и расширенный арсенал для работы с таблицами. И арсенал этот достаточно велик для того, чтобы каждый нашел для себя библиотеку по потребностям – с user-friendly интерфейсом или упором на функциональность.
https://t.me/english_forprogrammers
источник
Просмотры: 599