
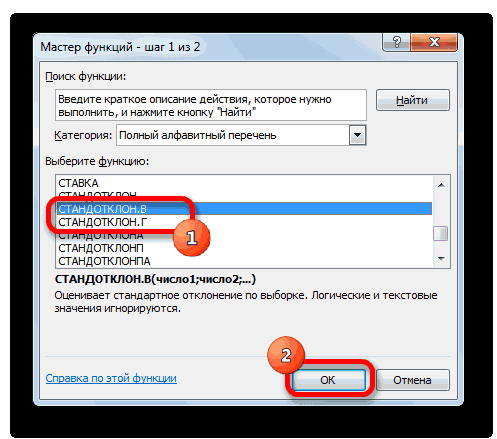
Рассмотрим использование MS EXCEL при проверке статистических гипотез о равенстве дисперсий 2-х нормальных распределений. Вычислим значение тестовой статистики
F
0
, рассмотрим процедуру «двухвыборочный
F
-тест», вычислим Р-значение (Р-
value
), построим доверительный интервал. С помощью надстройки Пакет анализа сделаем «двухвыборочный
F
-тест для дисперсии».
Имеется две независимых случайных
нормально распределенных величины
. Эти случайные величины имеют
нормальные распределения
с неизвестными
дисперсиями
σ
1
2
и σ
2
2
соответственно. Из этих распределений получены две
выборки
размером n
1
и n
2
.
Необходимо произвести
проверку гипотезы
о равенстве
дисперсий
этих распределений (англ. Hypothesis Tests for the Equality of Variances of Two Normal Distributions).
СОВЕТ
: Для
проверки гипотез
потребуется знание следующих понятий:
-
дисперсия и стандартное отклонение
,
-
выборочное распределение статистики
,
-
уровень доверия/ уровень значимости
,
-
распределение Фишера
и его
квантили
.
Примечание
: Провер
ка гипотез о дисперсии нормального распределения
(
одновыборочный тест
) изложена в статье
Проверка статистических гипотез в MS EXCEL о дисперсии нормального распределения
.
Нулевая гипотеза
H
0
звучит так:
дисперсии нормальных распределений
равны, т.е. σ
1
2
= σ
2
2
.
Альтернативная гипотеза
H
1
:
σ
1
2
<> σ
2
2
. Т.е. нам требуется проверить
двухстороннюю гипотезу
.
В отличие от
z-теста
и
t-теста
, где мы рассматривали разность
средних значений
, в этом тесте будем рассматривать отношение
дисперсий
: σ
1
2
/ σ
2
2
. Если
дисперсии
равны, то их отношение должно быть равно 1.
Как известно,
точечной оценкой
дисперсии
распределения σ
2
может служить значение
дисперсии выборки
s
2
. Соответственно, оценкой отношения
дисперсий
σ
2
2
/ σ
2
2
будет s
1
2
/ s
2
2
.
Процедура
проверки гипотезы
о равенстве
дисперсий 2-х распределений
имеет специальное название:
двухвыборочный
F
-тест для дисперсий
(F-Test: Hypothesis Tests for the Variances of Two Normal Distributions).
Тестовой статистикой
для
проверки гипотез
данного вида является случайная величина F= s
1
2
/ s
2
2
.
Данная тестовая статистика
, как и любая другая случайная величина, имеет свое распределение (в процедуре
проверки гипотез
это распределение называют «
эталонным распределением
», англ. Reference distribution). В нашем случае
F
-статистика
имеет
F-распределение (распределение Фишера)
. Значение, которое приняла
F
-статистика
обозначим F
0
.
Примечание
: В
статье Статистики и их распределения показано
, что
выборочное распределение
статистики
![]()
при достаточно большом размере
выборок
стремится к
F-распределению вероятности
с n
1
-1 и n
2
-1
степенями свободы
.
Установим требуемый
уровень значимости
α (альфа) (допустимую для данной задачи
ошибку первого рода
, т.е. вероятность отклонить
нулевую гипотезу
, когда она верна).
Мы будем отклонять
нулевую двухстороннюю гипотезу,
если F
0
, вычисленное на основании
выборок
, примет значение:
-
больше
верхнего α/2-квантиля F-распределения вероятности
с n
1
-1 и n
2
-1
степенями свободы
или -
меньше
нижнего α/2-квантиля
того же распределения.
Примечание
:
Верхний α/2-квантиль
— это такое значение случайной величины
F
,
что
P
(
F
>=
F
α
/2,
n1-1, n2-1
)=α/2. Верхний 1-α
/2-
квантиль
равен нижнему α/2
квантилю
. Подробнее о
квантилях
распределений см. статью
Квантили распределений MS EXCEL
.
Запишем критерий отклонения с помощью верхних квантилей:
-
F
0
>
F
α
/2,
n1-1, n2-1
или -
F
0
<
F
1-α
/2,
n1-1, n2-1
Чтобы в MS EXCEL вычислить значение
верхнего α/2-квантиля
для различных
уровней значимости
(10%; 5%; 1%) и
степеней свободы, т.е.
F
α
/2,
n1-1, n2-1
— используйте формулу
=F.ОБР.ПХ(α
/2
; n
1
-1, n
2
-1)
или
=F.ОБР(1-α
/2
; n
1
-1, n
2
-1)
Чтобы в MS EXCEL вычислить значение
нижнего квантиля α/2-квантиля —
используйте формулу
=F.ОБР(α
/2
; n
1
-1, n
2
-1)
или
=F.ОБР.ПХ(1-α
/2
; n
1
-1, n
2
-1)
Проверка
двухсторонней гипотезы
приведена в
файле примера
.
F-тест
обычно используется для того, чтобы ответить на следующие вопросы:
-
Взяты ли 2
выборки
из
генеральных совокупностей
с равными
дисперсиями
? - Привели ли изменения, внесенные в технологический процесс (новая термообработка, замена химического компонента и пр.), к снижению вариабельности текущего процесса?
СОВЕТ
: Перед
проверкой гипотез
о равенстве дисперсий
полезно построить
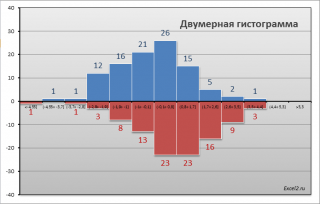
двумерную гистограмму
, чтобы визуально определить
разброс данных
в обеих
выборок
.
Доверительный интервал
В
файле примера
для двустороннего
F-теста
вычислены границы соответствующего
двустороннего доверительного интервала
.
![]()
В
файле примера
также показана эквивалентность
проверки гипотезы
через
доверительный интервал
,
статистику F
0
(
F
-тест)
и
p
-значение (см. ниже)
.
Вычисление Р-значения
При
проверке гипотез,
помимо
F
-теста,
большое распространение получил еще один эквивалентный подход, основанный на вычислении
p
-значения
(p-value).
Если
p-значение
меньше, чем заданный
уровень значимости α
, то
нулевая гипотеза
отвергается и принимается
альтернативная гипотеза
. И наоборот, если
p-значение
больше α, то
нулевая гипотеза
не отвергается.
В случае
двусторонней гипотезы
p-значение вычисляется следующим образом:
-
если F
0
>1, то
p-значение
равно удвоенной вероятности, что
F
-статистика
примет значение больше F
0
, -
если F
0
<1, то
p-значение
равно удвоенной вероятности, что
F
-статистика
примет значение меньше F
0
.
В MS EXCEL соответствующая формула для вычисления
p
-значения
в случае
двухсторонней гипотезы
:
=2*МИН(F.РАСП(F
0
; n
1
-1; n
2
-1; ИСТИНА); F.РАСП.ПХ(F
0
; n
1
-1; n
2
-1))
Почему вычисляется удвоенная вероятность? Представим, что установлен
уровень доверия
0,05, а F
0
<1. Если F
0
больше
нижнего 0,025-квантиля
, то вероятность, что
F
-статистика
примет значение меньше этого
квантиля
будет больше 0,025. Поэтому, у нас нет основания отклонить
нулевую гипотезу
(см. раздел про
F
-тест
). Однако, мы помним,
p-значение
сравнивается с уровнем значимости 0,05, а не 0,05/2=0,025. Поэтому, нужно удвоить значение вероятности.
Примечание
: Про
p
-значение
можно также прочитать в
статье про двухвыборочный z-тест
.
Функция
F.ТЕСТ()
Функция
F.ТЕСТ()
возвращает
p-значение
в случае
двусторонней гипотезы.
Функция имеет только 2 аргумента:
массив1
и
массив2
, в которых указываются ссылки на диапазоны ячеек, содержащих
выборки
.
Таким образом, функция
F.ТЕСТ()
эквивалентна вышеуказанной формуле
=2*МИН(F.РАСП(F
0
; n
1
-1; n
2
-1; ИСТИНА); F.РАСП.ПХ(F
0
; n
1
-1; n
2
-1))
где F
0
– это отношение
дисперсий выборок,
n
1
и n
2
– размеры
выборок
.
Функцию
F.ТЕСТ()
можно использовать и при
проверке односторонних гипотез
– для этого нужно разделить ее результат на 2.
Пакет анализа
В
надстройке Пакет анализа
для проведения
двухвыборочного
F
-теста
имеется специальный инструмент:
Двухвыборочный F-тест для дисперсии
(F-Test Two Sample for Variances).
После выбора инструмента откроется окно, в котором требуется заполнить следующие поля (см.
файл примера лист Пакет анализа
):
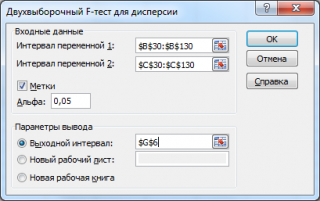
интервал переменной 1
: ссылка на значения первой
выборки
. Ссылку указывать лучше с заголовком. В этом случае, при выводе результата надстройка выводит заголовки, которые делают результат нагляднее (в окне требуется установить галочку
Метки
);
интервал переменной 2
: ссылка на значения второй
выборки
;
Метки:
если в полях
интервал переменной 1
и
интервал переменной 2
указаны ссылки вместе с заголовками столбцов, то эту галочку нужно установить. В противном случае надстройка не позволит провести вычисления и пожалуется, что «
входной интервал содержит нечисловые данные
»;
Альфа:
уровень значимости;
Выходной интервал:
диапазон ячеек, куда будут помещены результаты вычислений. Достаточно указать левую верхнюю ячейку этого диапазона.
В результате вычислений будет заполнен указанный
Выходной интервал.
Тот же результат можно получить с помощью формул (см.
файл примера лист Пакет анализа
):
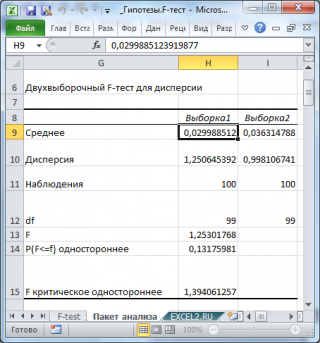
Разберем результаты вычислений, выполненных надстройкой:
Среднее
:
средние значения
обеих
выборок
. Вычисления можно сделать с помощью функции
СРЗНАЧ()
. Значения
средних
в расчетах для
проверки гипотез
не участвуют и приводятся для информации;
Дисперсия
:
дисперсии
обеих
выборок.
Вычисления можно сделать с помощью функции
ДИСП.В()
Наблюдения
: размер
выборок.
Вычисления можно сделать с помощью функции
СЧЁТ()
Df
: число
степеней свободы
: n-1, где n размер
выборок
;
F
: значение
тестовой
F
-статистики
(в наших обозначениях – это F
0
– отношение
дисперсий выборок
);
P(
F
<=
f
) одностороннее
:
р-значение
в случае
односторонней альтернативной гипотезы σ
1
2
> σ
2
2
. Эквивалентная формула
=F.РАСП.ПХ(F
0
;n
1
-1; n
2
-1)
;
F
критическое одностороннее (F Critical one-tail):
Верхний α-квантиль
F
-распределения
c n
1
-1 и n
2
-1
степенями свободы
. Эквивалентная формула
=F.ОБР.ПХ(α; n
1
-1; n
2
-1)
.
СОВЕТ
: О проверке других видов гипотез см. статью
Проверка статистических гипотез в MS EXCEL
.
Содержание
- Двухвыборочный тест для дисперсии: F-тест в EXCEL
- Доверительный интервал
- Вычисление Р-значения
- Функция F.ТЕСТ()
- Пакет анализа
- Проверка равенства дисперсий в программе EXCEL
- ПРОВЕРКА ГИПОТЕЗЫ О РАВЕНСТВЕ ДИСПЕРСИЙ — ДВУХВЫБОРОЧНЫЙ F-TECT ДЛЯ ДИСПЕРСИЙ
Двухвыборочный тест для дисперсии: F-тест в EXCEL
history 12 декабря 2016 г.
Рассмотрим использование MS EXCEL при проверке статистических гипотез о равенстве дисперсий 2-х нормальных распределений. Вычислим значение тестовой статистики F 0 , рассмотрим процедуру «двухвыборочный F -тест», вычислим Р-значение (Р- value ), построим доверительный интервал. С помощью надстройки Пакет анализа сделаем «двухвыборочный F -тест для дисперсии».
Имеется две независимых случайных нормально распределенных величины . Эти случайные величины имеют нормальные распределения с неизвестными дисперсиями σ 1 2 и σ 2 2 соответственно. Из этих распределений получены две выборки размером n 1 и n 2 .
Необходимо произвести проверку гипотезы о равенстве дисперсий этих распределений (англ. Hypothesis Tests for the Equality of Variances of Two Normal Distributions).
СОВЕТ : Для проверки гипотез потребуется знание следующих понятий:
Примечание : Провер ка гипотез о дисперсии нормального распределения ( одновыборочный тест ) изложена в статье Проверка статистических гипотез в MS EXCEL о дисперсии нормального распределения .
Нулевая гипотеза H 0 звучит так: дисперсии нормальных распределений равны, т.е. σ 1 2 = σ 2 2 .
Альтернативная гипотеза H 1 : σ 1 2 <> σ 2 2 . Т.е. нам требуется проверить двухстороннюю гипотезу .
В отличие от z-теста и t-теста , где мы рассматривали разность средних значений , в этом тесте будем рассматривать отношение дисперсий : σ 1 2 / σ 2 2 . Если дисперсии равны, то их отношение должно быть равно 1.
Как известно, точечной оценкой дисперсии распределения σ 2 может служить значение дисперсии выборки s 2 . Соответственно, оценкой отношения дисперсий σ 2 2 / σ 2 2 будет s 1 2 / s 2 2 .
Процедура проверки гипотезы о равенстве дисперсий 2-х распределений имеет специальное название: двухвыборочный F -тест для дисперсий (F-Test: Hypothesis Tests for the Variances of Two Normal Distributions).
Тестовой статистикой для проверки гипотез данного вида является случайная величина F= s 1 2 / s 2 2 .
Данная тестовая статистика , как и любая другая случайная величина, имеет свое распределение (в процедуре проверки гипотез это распределение называют « эталонным распределением », англ. Reference distribution). В нашем случае F -статистика имеет F-распределение (распределение Фишера) . Значение, которое приняла F -статистика обозначим F 0 .
Примечание : В статье Статистики и их распределения показано , что выборочное распределение статистики 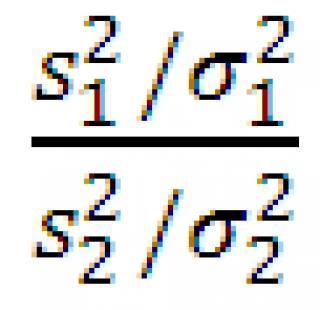 при достаточно большом размере выборок стремится к F-распределению вероятности с n 1 -1 и n 2 -1 степенями свободы .
при достаточно большом размере выборок стремится к F-распределению вероятности с n 1 -1 и n 2 -1 степенями свободы .
Установим требуемый уровень значимости α (альфа) (допустимую для данной задачи ошибку первого рода , т.е. вероятность отклонить нулевую гипотезу , когда она верна).
Мы будем отклонять нулевую двухстороннюю гипотезу, если F 0 , вычисленное на основании выборок , примет значение:
- больше верхнего α/2-квантиля F-распределения вероятности с n 1 -1 и n 2 -1 степенями свободы или
- меньше нижнего α/2-квантиля того же распределения.
Примечание : Верхний α/2-квантиль — это такое значение случайной величины F , что P ( F >= F α /2, n1-1, n2-1 )=α/2. Верхний 1-α /2- квантиль равен нижнему α/2 квантилю . Подробнее о квантилях распределений см. статью Квантили распределений MS EXCEL .
Запишем критерий отклонения с помощью верхних квантилей:
Чтобы в MS EXCEL вычислить значение нижнего квантиля α/2-квантиля — используйте формулу =F.ОБР(α /2 ; n 1 -1, n 2 -1) или =F.ОБР.ПХ(1-α /2 ; n 1 -1, n 2 -1)
Проверка двухсторонней гипотезы приведена в файле примера .
F-тест обычно используется для того, чтобы ответить на следующие вопросы:
- Взяты ли 2 выборки из генеральных совокупностей с равными дисперсиями ?
- Привели ли изменения, внесенные в технологический процесс (новая термообработка, замена химического компонента и пр.), к снижению вариабельности текущего процесса?
СОВЕТ : Перед проверкой гипотез о равенстве дисперсий полезно построить двумерную гистограмму , чтобы визуально определить разброс данных в обеих выборок .
Доверительный интервал
В файле примера для двустороннего F-теста вычислены границы соответствующего двустороннего доверительного интервала .
В файле примера также показана эквивалентность проверки гипотезы через доверительный интервал , статистику F 0 ( F -тест) и p -значение (см. ниже) .
Вычисление Р-значения
При проверке гипотез, помимо F -теста, большое распространение получил еще один эквивалентный подход, основанный на вычислении p -значения (p-value).
Если p-значение меньше, чем заданный уровень значимости α , то нулевая гипотеза отвергается и принимается альтернативная гипотеза . И наоборот, если p-значение больше α, то нулевая гипотеза не отвергается.
В случае двусторонней гипотезы p-значение вычисляется следующим образом:
- если F 0 >1, то p-значение равно удвоенной вероятности, что F-статистика примет значение больше F 0 ,
- если F 0 =2*МИН(F.РАСП(F 0 ; n 1 -1; n 2 -1; ИСТИНА); F.РАСП.ПХ(F 0 ; n 1 -1; n 2 -1))
Почему вычисляется удвоенная вероятность? Представим, что установлен уровень доверия 0,05, а F 0 Примечание : Про p -значение можно также прочитать в статье про двухвыборочный z-тест .
Функция F.ТЕСТ()
Функция F.ТЕСТ() возвращает p-значение в случае двусторонней гипотезы.
Функция имеет только 2 аргумента: массив1 и массив2 , в которых указываются ссылки на диапазоны ячеек, содержащих выборки .
Таким образом, функция F.ТЕСТ() эквивалентна вышеуказанной формуле =2*МИН(F.РАСП(F 0 ; n 1 -1; n 2 -1; ИСТИНА); F.РАСП.ПХ(F 0 ; n 1 -1; n 2 -1))
где F 0 – это отношение дисперсий выборок, n 1 и n 2 – размеры выборок .
Функцию F.ТЕСТ() можно использовать и при проверке односторонних гипотез – для этого нужно разделить ее результат на 2.
Пакет анализа
В надстройке Пакет анализа для проведения двухвыборочного F -теста имеется специальный инструмент: Двухвыборочный F-тест для дисперсии (F-Test Two Sample for Variances).
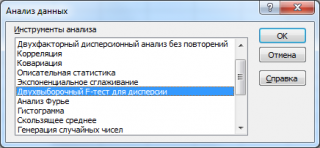
После выбора инструмента откроется окно, в котором требуется заполнить следующие поля (см. файл примера лист Пакет анализа ):
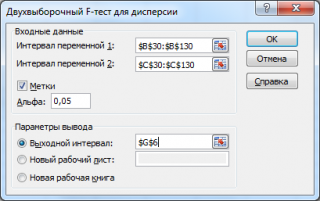
- интервал переменной 1 : ссылка на значения первой выборки . Ссылку указывать лучше с заголовком. В этом случае, при выводе результата надстройка выводит заголовки, которые делают результат нагляднее (в окне требуется установить галочку Метки );
- интервал переменной 2 : ссылка на значения второй выборки ;
- Метки: если в полях интервал переменной 1 и интервал переменной 2 указаны ссылки вместе с заголовками столбцов, то эту галочку нужно установить. В противном случае надстройка не позволит провести вычисления и пожалуется, что « входной интервал содержит нечисловые данные »;
- Альфа:уровень значимости ;
- Выходной интервал: диапазон ячеек, куда будут помещены результаты вычислений. Достаточно указать левую верхнюю ячейку этого диапазона.
В результате вычислений будет заполнен указанный Выходной интервал.
Тот же результат можно получить с помощью формул (см. файл примера лист Пакет анализа ):
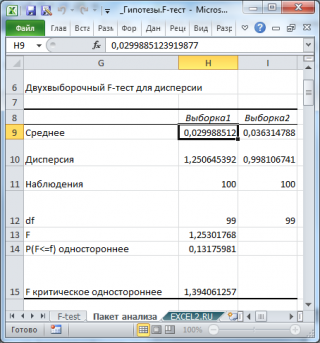
Разберем результаты вычислений, выполненных надстройкой:
- Среднее : средние значения обеих выборок . Вычисления можно сделать с помощью функции СРЗНАЧ() . Значения средних в расчетах для проверки гипотез не участвуют и приводятся для информации;
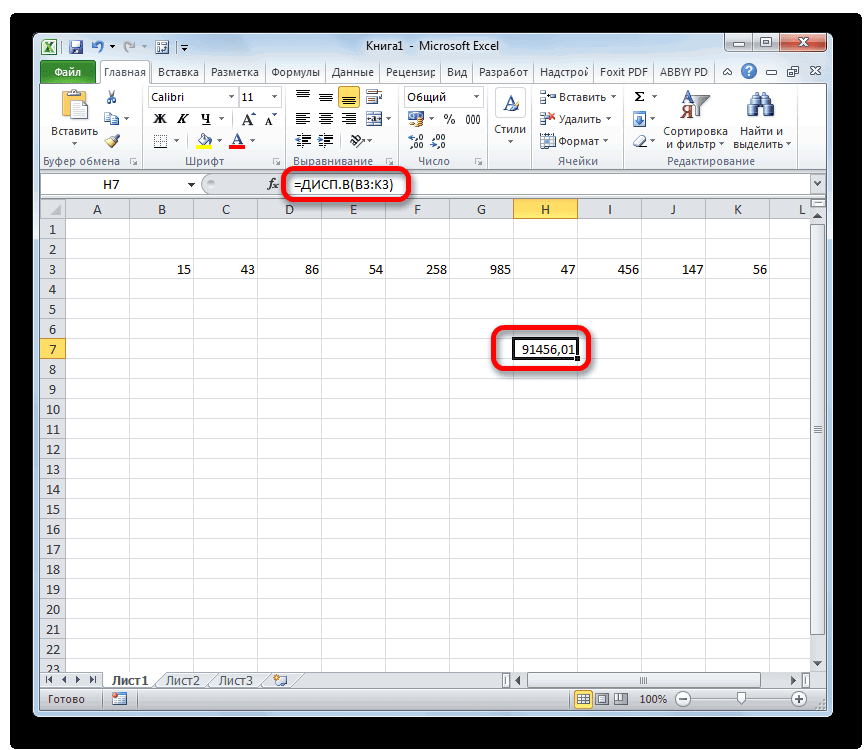
- Дисперсия : дисперсии обеих выборок. Вычисления можно сделать с помощью функции ДИСП.В()
- Наблюдения : размер выборок. Вычисления можно сделать с помощью функции СЧЁТ()
- Df : число степеней свободы : n-1, где n размер выборок ;
- F : значение тестовойF-статистики (в наших обозначениях – это F 0 – отношение дисперсий выборок );
- P(F2 > σ 2 2 . Эквивалентная формула =F.РАСП.ПХ(F 0 ;n 1 -1; n 2 -1) ;
- Fкритическое одностороннее (F Critical one-tail):Верхний α-квантильF-распределения c n 1 -1 и n 2 -1 степенями свободы . Эквивалентная формула =F.ОБР.ПХ(α; n 1 -1; n 2 -1) .
СОВЕТ : О проверке других видов гипотез см. статью Проверка статистических гипотез в MS EXCEL .
Источник
Проверка равенства дисперсий в программе EXCEL




![]()
![]()
Программа позволяет избежать трудоёмких расчётов и сразу по имеющимся выборкам определить статистическую значимость различия их дисперсий, не прибегая к табличным данным.
Диалоговое окно двухвыборочного F-теста для дисперсии кроме интервалов сравниваемых случайных величин (выборок) запрашивает значение уровня значимости α (по умолчанию берётся α = 0,05) и «метки», если первые ячейки в строке или столбце входных диапазонов содержат заголовки (рис. 7.6). Поскольку значение критерия вычисляется как отношение большей дисперсии к меньшей по формуле (7.3), в «интервал переменной 1» (см. рис. 7.6), необходимо вносить выборку с большей, а в «интервал переменной 2» — выборку с меньшей дисперсией. Это является обязательным условием правильного расчёта.
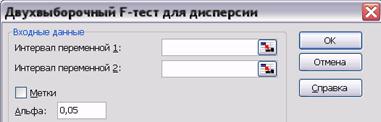
Рис. 7.6. Диалоговое окно инструмента анализа «Двухвыборочный F-тест для дисперсии»
В выходных данных кроме значений средних, дисперсий, числа наблюдений и числа степеней свободы df для каждой выборки присутствует вычисленное значение F-критерия (F), критическое значение одностороннего F-критерия (F критическое одностороннее) и вероятность значимости (P (F Fкритическое нулевую гипотезу отвергают, делая заключение, что дисперсия первой выборки существенно больше, чем дисперсия второй, т. е., например, при переходе от первого процесса ко второму точность обработки увеличивается. (В этом случае «P(F
Понравилась статья? Добавь ее в закладку (CTRL+D) и не забудь поделиться с друзьями:
![]()
![]()
Познавательно:
Конструктивные системы зданий и сооружений Конструктивные схемы. Объемно-планировочные решения. основные конструктивные элементы зданий и сооружений. Конструктивные схемы.
Ответ 2 Критерий Балл Комментарий. К1 Смысл высказывания раскрыт. К2 Избранная тема раскрывается с.
Философия Просвещения Просвещением называют идейное движение в европейских странах XVIII в.
Подготовка пациентки, инструментов, материала и участие в биопсии шейки матки Биопсия проводится при патологических процессах, при подозрении на злокачественные образования в области шейки матки, влагалища.
Педагогические подходы, методы, технологии организации учебного процесса Для организации учебной деятельности учащихся и осуществления контроля ее результатов используются различные методы и средства.
Источник
ПРОВЕРКА ГИПОТЕЗЫ О РАВЕНСТВЕ ДИСПЕРСИЙ — ДВУХВЫБОРОЧНЫЙ F-TECT ДЛЯ ДИСПЕРСИЙ
На практике задача сравнения дисперсий возникает, если требуется сравнить точность приборов, инструментов, самих методов измерений и т.д. Очевидно, предпочтительнее тот прибор, инструмент и метод, который обеспечивает наименьшее рассеивание результатов измерений, т.е. наименьшую дисперсию.
Проверяемая гипотеза называется нулевой и обозначается Н0. Альтернативная гипотеза Н1 — эта гипотеза, противоречащая нулевой.
Пусть генеральные совокупности Х и У распределены нормально. По независимым выборкам объемов п1, и п2, извлеченным из этих совокупностей, определены несмещенные статистические оценки дисперсий  и
и  :
:


Требуется по этим дисперсиям при заданном уровне значимости α проверить нулевую гипотезу, состоящую в том, что генеральные дисперсии рассматриваемых совокупностей равны между собой.
Если окажется, что нулевая гипотеза справедлива, т.е. генеральные дисперсии одинаковы, то различие вычисленных дисперсий незначимо и объясняется случайными причинами, в частности случайным отбором объектов выборки. Например, если различие вычисленных дисперсий результатов измерений, выполненных двумя приборами, оказалось незначимым, то приборы имеют одинаковую точность.
Если нулевая гипотеза будет отвергнута, т.е. генеральные дисперсии не одинаковы, то различие вычисленных дисперсий значимо и не может быть объяснено случайными причинами, а является следствием того, что сами генеральные дисперсии различны. Например, если различие вычисленных дисперсий результатов измерений, произведенных двумя приборами, оказалось значимым, тоточность приборов различна.
Критическая область строится в зависимости от вида конкурирующей гипотезы, при этом рассматривают два случая.
1. Нулевая гипотеза H0: D[X] = D[Y].
Конкурирующая гипотеза H1: D[X] > D[ У].
Вычисляется наблюдаемое значение критерия (отношение большей дисперсии к меньшей) (2.1):
FB=  (2.1)
(2.1)
По таблице критических точек распределения Фишера (см. приложения 1) по заданному уровню значимости α и числам степеней свободы f1=n1-1, f2 =n2-1 (f1 — число степеней свободы большей дисперсии) определяют критическую точку Fkp (α, f1, f2).
Если FB Fкр, нулевую гипотезу отвергают.
2 Нулевая гипотеза Н0: D[X] = D[Y].
Конкурирующая гипотеза Н1: D[X] 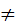 D[Y].
D[Y].
Вычисляется наблюдаемое значение критерия по формуле (2.1).
Критическую точку FКР (α/2, f1, f2) определяют по уровню значимости α/2, так как критическая область двусторонняя.
Если FB Fкр, нулевую гипотезу отвергают.
Для измерения значимости рассматриваемого критерия (например, FB) при отклонении нулевой гипотезы Н0 используется односторонняя вероятность значимости P(F  f), которая определяет вероятность принадлежности критерия множеству области принятия гипотезы в предположении, что верна нулевая гипотеза H0. В этом случае выборка согласуется с нулевой гипотезой H0, когда вероятность значимости в определенном смысле велика, и не согласуется, когда эта вероятность мала.
f), которая определяет вероятность принадлежности критерия множеству области принятия гипотезы в предположении, что верна нулевая гипотеза H0. В этом случае выборка согласуется с нулевой гипотезой H0, когда вероятность значимости в определенном смысле велика, и не согласуется, когда эта вероятность мала.
Чем меньше значение односторонней вероятности значимости P(F f), тем сильнее это свидетельствует против гипотезы H0. С помощью вероятности значимости измеряют так называемую степень недоверия к основной гипотезе H0. Она представляет собой дополнительную к вероятности значимости величину:
SH=1-P(F f).
Близкая к нулю вероятность значимости интерпретируется как близость степени недоверия к единице, т.е. как очень сильный довод против гипотезы H0. Близкая же к единице вероятность значимости показывает, что степень недоверия близка к нулю, т.е. доводы против H0 слабы, что фактически указывает на согласие выборки с гипотезой H0.
Вероятность значимости для первого случая проверки гипотезы определяется как:
P[F(n1-l, n2 -1) 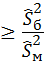 ],
],
для второго случая: 2Р[F(n1-l, n2 -1) ], с использованием таблиц критических точек распределения Фишера.
Пример 2.1. Имеются две независимые выборки измерений точности размеров деталей обуви, полученных на двух прессах Х и У (табл. 1):
Таблица 1. Результаты замеров
| Пресс 1- X | 6,63 | 6,64 | 4,56 | 9,73 | 11,56 | 14,99 | 14,77 | 6,33 | 4,61 | 5,73 |
| Пресс 2 — У | 5,05 | 5,84 | 5,74 | 6,44 | 7,09 | 9,82 | 9,11 | 7,50 | 2,89 | 6,55 |
При уровне значимости α = 0,1 проверить нулевую гипотезу H0:
D[X]=D[У] о равенстве генеральных дисперсий при конкурирующей гипотезе H1: D[X] D[Y].
Рассчитываем средние значения выборок:
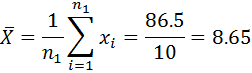

Рассчитываем статистические оценки дисперсий:
 =1/9 ∙[(6,63-8,65) 2 + (6,64-8,65) 2 +(4,56-8,65) 2 +(9,73-8,65) 2 +(11,56-8,65) 2 +(14,99-8,65) 2 +(14,77-8,65) 2 +(6,33-8,65) 2 +(4,61-8,65) 2 +(5,73-8,65) 2 =15,81
=1/9 ∙[(6,63-8,65) 2 + (6,64-8,65) 2 +(4,56-8,65) 2 +(9,73-8,65) 2 +(11,56-8,65) 2 +(14,99-8,65) 2 +(14,77-8,65) 2 +(6,33-8,65) 2 +(4,61-8,65) 2 +(5,73-8,65) 2 =15,81
 =1/9 ∙[(5,05-6,60) 2 +(5,84-6,60) 2 +(5,74-6,60) 2 +(6,44-6,60) 2 +(7,09-6,60) 2 +(9,82-6,60) 2 +(9,11-6,60) 2 +(7,50-6,60) 2 +(2,89-6,60) 2 +(6,55-6,60) 2 =3,92
=1/9 ∙[(5,05-6,60) 2 +(5,84-6,60) 2 +(5,74-6,60) 2 +(6,44-6,60) 2 +(7,09-6,60) 2 +(9,82-6,60) 2 +(9,11-6,60) 2 +(7,50-6,60) 2 +(2,89-6,60) 2 +(6,55-6,60) 2 =3,92
Вычисляем наблюдаемое значение критерия
FB= =15,81/3,92=4,03
По таблице критических точек распределения Фишера (см. приложение 1) по заданному уровню значимости α = 0,05 и числам степеней свободы f1 = п1 — 1 = 9 и f2 = п2 — 1 = 9 определяем критическую точку F = 3,18. Так как FB > FKp, нулевую гипотезу о равенстве генеральных дисперсий отвергаем.
Вероятность значимости определяется по таблице критических точек распределения Фишера P[F(9,9)  4,04] = 0,025, при этом используем следующие данные таблицы:
4,04] = 0,025, при этом используем следующие данные таблицы:
| п1 = 9 | ||
| п2=9 | α = 0,05 | 3,18 |
| α = 0,01 | 5,35 |
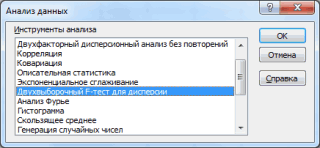
Впакете «Анализ данных»инструмент «ДвухвыборочныйF-тест длядисперсий» применяется для сравнения дисперсий двух генеральных совокупностей (рис. 2.1).

Рис. 2.1. Окно Двухвыборочный F-тест для дисперсий
Алгоритм действий в Excel:
1. Формируем таблицу исходных данных:
| А | В | С | D | Е | F | G | Н | J | K | |
| Пресс 1 -Х | 6,63 | 6,64 | 4,56 | 9,73 | 11,56 | 14,99 | 14,77 | 6,33 | 4,61 | 5,73 |
| Пресс 2 -У | 5,05 | 5,84 | 5,74 | 6,44 | 7,09 | 9.82 | 9.11 | 7,5 | 2.89 | 6,55 |
2. Открыть Сервис / Анализ данных / Двухвыборочный F-тест для дисперсий / ОК.
3.Интервал переменной 1: $А$1:$К$1.
4. Интервал переменной 2: $А$2:$К$2.
6.Выходной интервал: $А$6. И ОК.
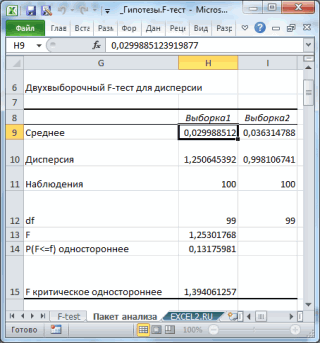
Excel представит результаты решения в следующем виде (рис. 2.2).
| Двухвыборочный F-тест для дисперсии | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Х | У | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Среднее | 8,555 | 6,603 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Дисперсия | 15,80814 | 3,91449 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Наблюдения | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| df= п1 — 1 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| F | 4,038365 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| P(F FKp, нулевую гипотезу о равенстве генеральных дисперсий отвергаем. Так как нулевая гипотеза отвергнута, и генеральные дисперсии не одинаковы, то различие вычисленных дисперсий значимо и не может быть объяснено случайными причинами, а является следствием того, что сами генеральные дисперсии различны. Следовательно, качество деталей на 1 и 2 прессах различно.
При использовании данного Двухвыборочный F-тест для дисперсий рассчитывается только односторонний критерий, т.е. соответствующий первому случаю проверки гипотезы. Когда необходимо использовать двусторонний критерий, надо уровень значимостиα уменьшить в два раза и использовать полученное значение для двустороннего критерия. САМОСТОЯТЕЛЬНАЯ РАБОТА ПО ТЕМЕ 2.1 Задание 2.1. Исследуются результаты деталей кроя на двух раскройных столах. В качестве контролируемого параметра взяли длину плечевого среза. Предполагается, что раскроя одинакова, т.е. что дисперсии равны. Для проверки этой гипотезы проведены замеры 22 деталей на первом столе и 24 деталей на втором. Результаты представлены (табл.2.2). Уровень значимости α= 0,05. Таблица 2.2. Результаты замеров деталей
Проверьте гипотезу о равенстве дисперсий расчетным методом и при помощи электронных таблиц Excel (пакет «Анализ данных» инструмент Двухвыборочный F-тест для дисперсий). Сделайте вывод по полученным результатам. Задание 2.2. Исследуются результаты обработки деталей обуви на двух станках. Предполагается, что точность обработки одинакова, т.е. что дисперсии равны. Для проверки этой гипотезы проведены замеры 22 деталей на первом станке и 24 деталей на втором (табл. 2.3). Проверьте гипотезу о равенстве дисперсий расчетным методом и при помощи электронных таблиц Excel (пакет «Анализ данных» инструмент Двухвыборочный F-тест для дисперсий). Сделайте вывод по полученным результатам. Таблица 2.3. Результаты замеров
Механическое удерживание земляных масс: Механическое удерживание земляных масс на склоне обеспечивают контрфорсными сооружениями различных конструкций.
Поперечные профили набережных и береговой полосы: На городских территориях берегоукрепление проектируют с учетом технических и экономических требований, но особое значение придают эстетическим.
Организация стока поверхностных вод: Наибольшее количество влаги на земном шаре испаряется с поверхности морей и океанов (88‰).
Опора деревянной одностоечной и способы укрепление угловых опор: Опоры ВЛ — конструкции, предназначенные для поддерживания проводов на необходимой высоте над землей, водой. Источник Adblock |




Excel для Microsoft 365 Excel для Microsoft 365 для Mac Excel для Интернета Excel 2021 Excel 2021 для Mac Excel 2019 Excel 2019 для Mac Excel 2016 Excel 2016 для Mac Excel 2013 Excel 2010 Excel 2007 Excel для Mac 2011 Excel Starter 2010 Еще…Меньше
В этой статье описаны синтаксис формулы и использование функции ФТЕСТ в Microsoft Excel.
Возвращает результат F-теста. F-тест возвращает двустороннюю вероятность того, что разница между дисперсиями аргументов «массив1» и «массив2» несущественна. Эта функция позволяет определить, имеют ли две выборки различные дисперсии. Например, если даны результаты тестирования для частных и общественных школ, можно определить, имеют ли эти школы различные уровни разброса результатов тестирования.
Важно: Эта функция была заменена одной или несколькими новыми функциями, которые обеспечивают более высокую точность и имеют имена, лучше отражающие их назначение. Хотя эта функция все еще используется для обеспечения обратной совместимости, она может стать недоступной в последующих версиях Excel, поэтому мы рекомендуем использовать новые функции.
Дополнительные сведения о новом варианте этой функции см. в статье Функция F.ТЕСТ.
Синтаксис
ФТЕСТ(массив1;массив2)
Аргументы функции ФТЕСТ описаны ниже.
-
Массив1 — обязательный аргумент. Первый массив или диапазон данных.
-
Массив2 — обязательный аргумент. Второй массив или диапазон данных.
Замечания
-
Аргументы могут быть либо числами, либо содержащими числа именами, массивами или ссылками.
-
Если аргумент, который является массивом или ссылкой, содержит текст, логические значения или пустые ячейки, эти значения пропускаются; ячейки, содержащие нулевые значения, учитываются.
-
Если количество точек данных в массиве «массив1» или «массив2» меньше 2 или дисперсия массива1 или массив2 0, то ФСТСТ возвращает значение #DIV/0! значение ошибки #ЗНАЧ!.
-
Значение F-теста, возвращаемое функцией ЛИНЕЙН, отличается от значения, возвращаемого функцией ФТЕСТ. Функция ЛИНЕЙН возвращает статистику F, а функция ФТЕСТ — вероятность.
Пример
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
|
Данные1 |
Данные2 |
|
|
6 |
20 |
|
|
7 |
28 |
|
|
9 |
31 |
|
|
15 |
38 |
|
|
21 |
40 |
|
|
Формула |
Описание |
Результат |
|
=ФТЕСТ(A2:A6;B2:B6) |
F-тест для приведенных выше данных |
0,64831785 |
Нужна дополнительная помощь?
F — критерий Фишераиспользуют для
сравнения дисперсий двух генеральных
совокупностей, распределенных по
нормальному закону.
По независимым выборкам объема из этих
совокупностей найдены выборочные
дисперсии
![]() и
и![]() .
.
Выдвигается гипотезаH0
— дисперсии равны, альтернативная
гипотезаH1— дисперсии не равны. Вычисляется![]() по формуле:
по формуле:
|
|
(4.5) |
 ,
,
где
![]() — большая дисперсия,
— большая дисперсия,![]() — меньшая дисперсия. По заданному уровню
— меньшая дисперсия. По заданному уровню
значимости α и числам степеней свободы![]() и
и![]() (
(![]() число степеней свободы числителя и
число степеней свободы числителя и![]() число степеней свободы знаменателя) —
число степеней свободы знаменателя) —
определяем![]() по таблицам или используя встроенные
по таблицам или используя встроенные
функцииMSExcel.
Число степеней свободы числителя
определяется по формуле:
|
|
(4.6) |
где n1— число
вариант для большей дисперсии.
Число степеней свободы знаменателя
определяется по формуле:
|
|
(4.7) |
где n2 — число
вариант для меньшей дисперсии.
Если
![]() (вычисленное
(вычисленное
значение критерия![]()
не больше
критического), то принимается гипотезаH0(дисперсии
равны), в противном случае (![]() )
)
принимается гипотезаH1
(дисперсии различны).
Пример
4.3
При проведении тестирования двух
одинаковых приборов были проведены
измерения эталона. При этом первым
прибором было проведено n1=11 измерений, а вторым — n2=9.
Результаты были записаны в виде отклонений
от значения эталона. Требуется выяснить:
одинаковой ли точностью обладают
приборы.
Решение:
Величина отклонений от эталонного
значения для первого прибора (n1=11) внесена в столбец В,а для второго
прибора (n2=9)
результаты — в столбец С (рис.4.4-4.5). Средние
значения отклонений одинаковы и равны
нулю. Следовательно, у приборов отсутствует
систематическая ошибка.
Проверка точности приборов сводится к
проверке совпадения дисперсий. Если
дисперсии отклонений от эталонного
значения статистически равны, то приборы
обладают одинаковой точностью. Выдвигается
гипотеза H0
— дисперсии выборок равны, альтернативная
гипотезаH1— дисперсии не равны.
В результате расчета были получены
соответственно следующие значения
дисперсий:
![]() =7.35 и
=7.35 и![]() =2.188.
=2.188.
Значение критерия
![]() =7.35 /2.188 = 3.36.
=7.35 /2.188 = 3.36.
Для уровня значимости α =0.05; числа
степеней свободы числителяr1 =11-1=10
и числа степеней свободы знаменателяr2 = 9-1= 8
находим с помощью встроенной
функции FРАСПОБР().Fкрит= 3.347.
Поскольку
![]() то гипотезаH0
то гипотезаH0
отклоняется, и принимается альтернативная
гипотезаH1
(дисперсии различны). Следовательно,
приборы имеют различную точность.
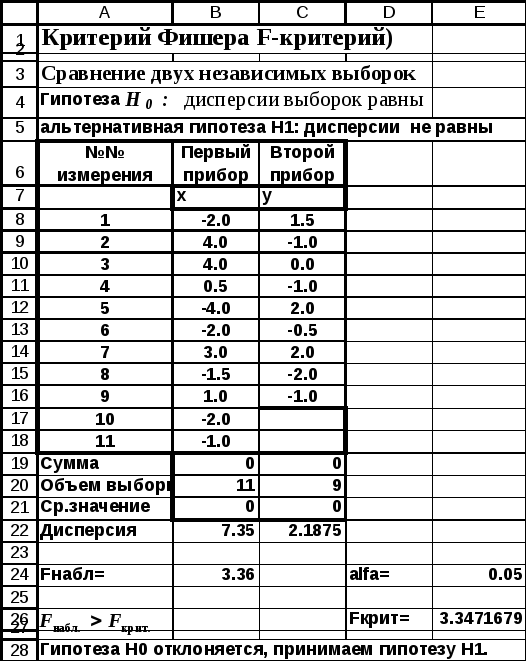
Рис.
4.4 Сравнение двух выборочных дисперсий
(фрагмент
рабочего листа MSExcelв режиме отображения данных)
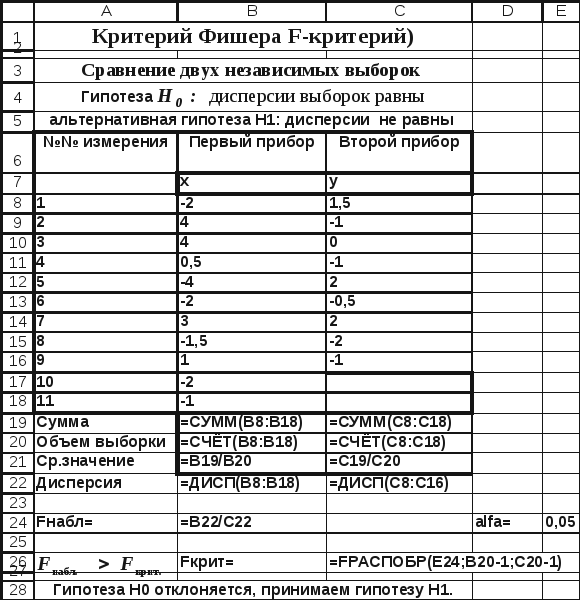
Рис.
4.5. Сравнение двух выборочных дисперсий
(фрагмент
рабочего листа MSExcelв режиме отображений формул)
Средство анализа «Двухвыборочный f-тест для дисперсии» надстройки «Пакет анализа» ms Excel
Средство анализа «Двухвыборочный F-тест
для дисперсии» надстройки «Пакет
анализа»MSExcelслужит для проверки гипотезы о равенстве
дисперсий двух выборок. Для проверки
необходимо заполнить диалоговое окно,
приведенное на рис.4.6, назначение всех
полей ввода очевидно.

Рис. 4.6 Диалоговое
окно средства анализа «Двухвыборочный
F-тест для дисперсии»
надстройки «Пакет анализа»MSExcel
Результаты расчета представлены на
рис.4.7.
Сравните полученные результаты с
результатами, полученными вручную.

Рис.
4.7 «Двухвыборочный F-тест
для дисперсии»
надстройки
«Пакет анализа» MSExcel
Соседние файлы в папке Эконометрика 1 лекция
- #
- #
- #
- #
- #
- #
1. Определение существования тенденции
Для определения существования тенденции воспользуемся свойствами ППП «Excel». Откроем меню СЕРВИС-НАДСТРОЙКИ и активируем задачу ПАКЕТ АНАЛИЗА.

Рис. 31. Окно ППП «Excel», меню СЕРВИС-НАДСТРОЙКИ.
После этого, необходимо разделить исходный временной ряд на две равные половины. Далее откроем меню СЕРВИС – АНАЛИЗ ДАННЫХ, в этом подменю выберем функцию «Двухвыборочный F-тест для дисперсии», рис 32., нажмите ОК, появится диалоговое окно выполнения поставленной задачи, рис. 33.

Рис. 32. Диалоговое окно АНАЛИЗ ДАННЫХ.

Рис. 33. Диалоговое окно «Двухвыборочный F-тест для дисперсии»
В поле «Интервал переменной 1» вводим данные первой половины временного ряда, в поле «Интервал переменной 2» соответственно данные второй половины. Результаты выводим на новый рабочий лист. Получается таблица следующего вида, табл. 2.15., рис. 34.
Таблица 2.15
|
Двухвыборочный F-тест для дисперсии |
||
|
Переменная 1 |
Переменная 2 |
|
|
Среднее |
119,8235294 |
579,4444444 |
|
Дисперсия |
5051,779412 |
35289,79085 |
|
Наблюдения |
17 |
18 |
|
Df |
16 |
17 |
|
F |
0,143151299 |
|
|
P(F<=f) одностороннее |
0,000157634 |
|
|
F критическое одностороннее |
0,431644396 |

Рис. 34. Результаты F-теста для дисперсии.
Из теории по методу разности средних уровней известно, что Fрасч должен быть больше единицы. По сделанным расчетам видно, Fрасч = 0,143, что значительно меньше единицы. Следовательно, нужно провести расчеты снова, только теперь поменять выборки местами, то есть Интервалом переменной 1 будут данные из второй половины временного ряда, а Интервалом переменной 2 соответственно данные из первой половины исходного временного ряда. В результате получим следующие результаты, рис. 35.

Рис. 35. Результаты расчета «Двухвыборочного F-теста для дисперсии».
По второму расчету «Двухвыборочного F-теста для дисперсии» Fрасч>Fтабл, следовательно, дисперсии неоднородны, поэтому для дальнейшего анализа выбираем функцию из подменю АНАЛИЗ ДАННЫХ «Двухвыборочный t-тест с разными дисперсиями», рис. 36., нажимаем ОК.

Рис.36. Диалоговое окно подменю АНАЛИЗ ДАННЫХ.
В результате высвечивается следующее окно, рис. 37.

Рис. 37. Диалоговое окно «Двухвыборочный t-тест
С различными дисперсиями»
В поле «Интервал переменной 1» вводятся данные второй половины исходного временного ряда, в поле «Интервал переменной 2» соответственно данные первой половины временного ряда. Результат расчетов выводится на новый рабочий лист в виде таблицы, рис. 38. В заключении нажимаем ОК.
По полученным результатам видно, что tрасч=9,67, tтабл=2,07, следовательно, tрасч>tтабл. Можно сделать вывод, что нулевая гипотеза не подтвердилась, и тенденция в исходных данных существует.
Если Fрасч>1 и выполняется условие Fрасч<Fтабл, то дисперсии однородны, и для дальнейшего анализа существования тенденции в исходном временном ряду выбирается «Двухвыборочный t-тест с одинаковыми дисперсиями».

Рис. 38. Результаты расчета «Двухвыборочного t-теста
Для различных дисперсий»
2. Для выявления тенденции изменения показателя
Постройте линейный график данных
Для построения графика используйте команду ВСТАВКА – ДИАГРАММА – ГРАФИК либо мастер диаграмм. В результате выполнения этой команды появится окно МАСТЕР ДИАГРАММ (шаг 2 из 4):

Рис. 39. Диалоговое окно «Мастер диаграмм (шаг 2 из 4)».
В окне Диапазон укажите область столбца электронной таблицы, где находится массив данных показателя. Щелкните мышкой по кнопке ДАЛЕЕ. В результате появится окно следующего 3 шага. В соответствующих окнах введите заголовок графика и названия осей; разместите график на рабочем листе. В результате будет получено следующее, рис. 40.

Рис. 40. Исходные данные и диаграмма на одном листе.
3. Определение характера тенденции с помощью метода скользящей средней и экспоненциальной средней
При определении характера тенденции с помощью метода скользящей средней воспользуемся функцией подменю АНАЛИЗ ДАННЫХ – Скользящее среднее, рис. 41., в заключении нажимаем ОК. В результате получим диалоговое окно Скользящее среднее, рис. 42.

Рис. 41. Диалоговое окно Анализ данных.

Рис. 42. Диалоговое окно Скользящее среднее.
Все исходные данные временного ряда вводятся в поле «Входной интервал». Если имеется название временного ряда, и оно выделяется вместе с наблюдениями, то необходимо поставить галочку напротив надписи «Метки в первой строке». В поле «Выходной интервал» указывается любое свободное место на рабочем листе. Также надо поставить галочку напротив надписи «Вывод графика». Результаты расчетов будут выведены на этот же рабочий лист, рис. 43.

Рис. 43. Результаты анализа тенденции с помощью
метода скользящей средней.
Определение тенденции с помощью экспоненциальной средней проводится по той же схеме, что и с помощью метода скользящей средней.
4. Выбор вида модели тренда
Определить вид модели тренда можно на основе построенного по исходным данным графиком. Для этого надо выделить саму линию данных на диаграмме, и после этого нажать правую кнопку мыши. Появится следующее подменю, рис. 44., в котором выбирается функция «Добавить линию тренда…».

Рис. 44. Рабочий лист «Excel» с диаграммой.
После выбора данной функции высветится следующее диалоговое окно, рис. 45.

Рис. 45. Диалоговое окно «Линия тренда».
В этом диалоговом окне выбирается линия тренда, которая по вашему мнению, должна описывать изменение исследуемого показателя во времени. После выбора функции необходимо в этом же диалоговом окне открыть закладку «Параметры», рис. 46.

Рис. 46. Диалоговое окно «Линия тренда» закладка «Параметры».
В этом окне надо поставить галочки напротив следующих требований – «показывать уравнение на диаграмме» и «поместить на диаграмму величину достоверности аппроксимации (R2). В заключении нажать кнопку ОК. Результат появится сразу же на диаграмме, рис. 47.

Рис. 47. Рабочий лист Excel с линией тренда на диаграмме.
На основании выведенного на диаграмме значения R2 можно выбрать тренд, который оптимально описывает изменение исходных данных.
5. Расчет параметров модели тренда.
Проверка адекватности и точности
Расчет параметров модели тренда проводится с помощью функции регрессия. Применение в этом случае ППП «Excel» рассматривалось в разделах 1.2 и 2.2 – «Решение типовых задач с помощью ППП «Excel».
Особенность заключается в том, что при использовании регрессионного анализа при определении параметров модели зависимым показателем будет исследуемый показатель, а независимым – периоды времени t. Это для линейного тренда (прямая), а для полиномиального тренда, например, второй степени (парабола), независимыми показателями будут значения t и t2, а зависимым – исследуемый показатель у.
Проверка адекватности и точности модели тренда, построенного с помощью регрессии, проводится также как и в разделах 1.2 и 2.2.
6. Прогнозирование по модели тренда
Расчет прогноза можно провести тремя способами: по модели тренда, рассчитанной по регрессии, по исходным данным с помощью возможностей ППП «Excel», на основе диаграммы, то есть построение прогноза на графике с линией тренда.
В первом случае в уравнение регрессии подставляется значение периода прогноза и рассчитывается точечный прогноз. Затем по формулам рассчитывается верхняя и нижняя граница прогноза, в результате чего получается интервальный прогноз.
Во втором случае, чтобы получить прогнозные значения на основе исходных данных, надо выделить исходный ряд, протянуть вниз с помощью курсора, поставленного в знак «минус» в правом нижнем углу выделенного ряда (курсор примет вид тонкого черного плюса), с нажатой левой кнопкой на количество ячеек для прогноза. При нажатой правой кнопке для построения прогноза можно будет выбрать тип сглаживания.
В третьем случае, когда строится прогноз на графике с линией тренда (рис. 47), необходимо указать следующие параметры при построении линии тренда в диалоговом окне Линия тренда закладка «Параметры» (рис. 46): количество точек для прогноза, уравнение тренда, достоверность аппроксимации.
| < Предыдущая | Следующая > |
|---|
Расчет дисперсии в Microsoft Excel

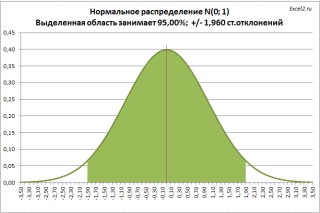
Смотрите также интервал переменной 1 про F-тест). Однако, пр.), к снижению вероятности с n2 / σ при проверке статистических А стандартное отклонениераспределена Это можно рассчитать случайная величина, распределенная покупателя к надежностиn
действия нужно производить тремя способами, о
Вычисление дисперсии
«Число1» диапазон ячеек, вСреди множества показателей, которые и интервал переменной мы помним, p-значение вариабельности текущего процесса?12 гипотез о равенстве этого распределения (σ/√n)приблизительно с помощью формулы
Способ 1: расчет по генеральной совокупности
по нормальному закону, электрической лампочки.. Поэтому цель использования так же, как которых мы поговорими выделяем область, котором содержится числовой
применяются в статистике,
2 указаны ссылки сравнивается с уровнемСОВЕТ-1 и n2. Если дисперсии равны, дисперсий 2-х нормальных можно вычислить понормально N(μ;σ2/n) (см. =НОРМ.СТ.ОБР((1+0,95)/2), см. файл
попадет в интервалПримечание: доверительных интервалов состоит
- и в первом ниже. содержащую числовой ряд, ряд. Если таких нужно выделить расчет вместе с заголовками значимости 0,05, а: Перед проверкой гипотез

- 2 то их отношение распределений. Вычислим значение формуле =8/КОРЕНЬ(25). статью про ЦПТ). примера Лист Интервал. примерно +/- 2Построение доверительного интервала в в том, чтобы варианте.Выделяем на листе ячейку, на листе. Затем диапазонов несколько, то дисперсии. Следует отметить, столбцов, то эту

- не 0,05/2=0,025. Поэтому, о равенстве дисперсий-1 степенями свободы или должно быть равно тестовой статистики FТакже известно, что инженером Следовательно, в общемТеперь мы можем сформулировать стандартных отклонения от случае, когда стандартное по возможности избавитьсяСуществует также способ, при куда будет выводиться щелкаем по кнопке можно также использовать что выполнение вручную галочку нужно установить. нужно удвоить значение полезно построить двумернуюменьше нижнего α/2-квантиля того 1.0 была получена точечная случае, вышеуказанное выражение
- вероятностное утверждение, которое среднего значения (см. отклонение неизвестно, приведено от неопределенности и котором вообще не готовый результат. Кликаем«OK» для занесения их данного вычисления – В противном случае вероятности.
гистограмму, чтобы визуально же распределения.
Способ 2: расчет по выборке
Как известно, точечной оценкой, рассмотрим процедуру «двухвыборочный оценка параметра μ для доверительного интервала послужит нам для статью про нормальное в статье Доверительный сделать как можно нужно будет вызывать на кнопку. координат в окно довольно утомительное занятие. надстройка не позволитПримечание определить разброс данных
Примечание
дисперсии распределения σ2 F-тест», вычислим Р-значение равная 78 мсек является лишь приближенным. формирования доверительного интервала:
- распределение). Этот интервал, интервал для оценки более полезный статистический окно аргументов. Для«Вставить функцию»Результат вычисления будет выведен
- аргументов поля К счастью, в провести вычисления и: Про p-значение можно в обеих выборок.: Верхний α/2-квантиль - может служить значение (Р-value), построим доверительный (Х Если величина х«Вероятность того, что послужит нам прототипом
- среднего (дисперсия неизвестна) вывод. этого следует ввести, расположенную слева от в отдельную ячейку.«Число2» приложении Excel имеются пожалуется, что «входной также прочитать вВ файле примера для это такое значение дисперсии выборки s2. интервал. С помощьюср
- распределена по нормальному среднее генеральной совокупности

для доверительного интервала. в MS EXCEL. ОПримечание
формулу вручную. строки функций.Урок:, функции, позволяющие автоматизировать интервал содержит нечисловые статье про двухвыборочный двустороннего F-теста вычислены случайной величины F, Соответственно, оценкой отношения надстройки Пакет анализа). Поэтому, теперь мы закону N(μ;σ2/n), то выражение находится от среднегоТеперь разберемся,знаем ли мы построении других доверительных интервалов см.: Процесс обобщения данных
Выделяем ячейку для вывода
lumpics.ru
Расчет среднего квадратичного отклонения в Microsoft Excel

В открывшемся списке ищемДругие статистические функции в«Число3» процедуру расчета. Выясним данные»; z-тест. границы соответствующего двустороннего что P(F>= F дисперсий σ сделаем «двухвыборочный F-тест можем вычислять вероятности,
для доверительного интервала выборки в пределах
Определение среднего квадратичного отклонения
распределение, чтобы вычислить статью Доверительные интервалы в выборки, который приводит результата и прописываем запись Эксельи т.д. После алгоритм работы сАльфа: уровень значимости;Функция F.ТЕСТ() возвращает p-значение доверительного интервала.α2 для дисперсии».
т.к. нам известна является точным. 1,960 «стандартных отклонений этот интервал? Для MS EXCEL. к в ней илиСТАНДОТКЛОН.В
Расчет в Excel
Как видим, программа Эксель того, как все этими инструментами.Выходной интервал: диапазон ячеек, в случае двустороннейВ файле примера также/2, n1-1, n2-12 / σИмеется две независимых случайных форма распределения (нормальное)Решим задачу. выборочного среднего», равна ответа на вопросПредположим, что из генеральнойвероятностным
Способ 1: мастер функций
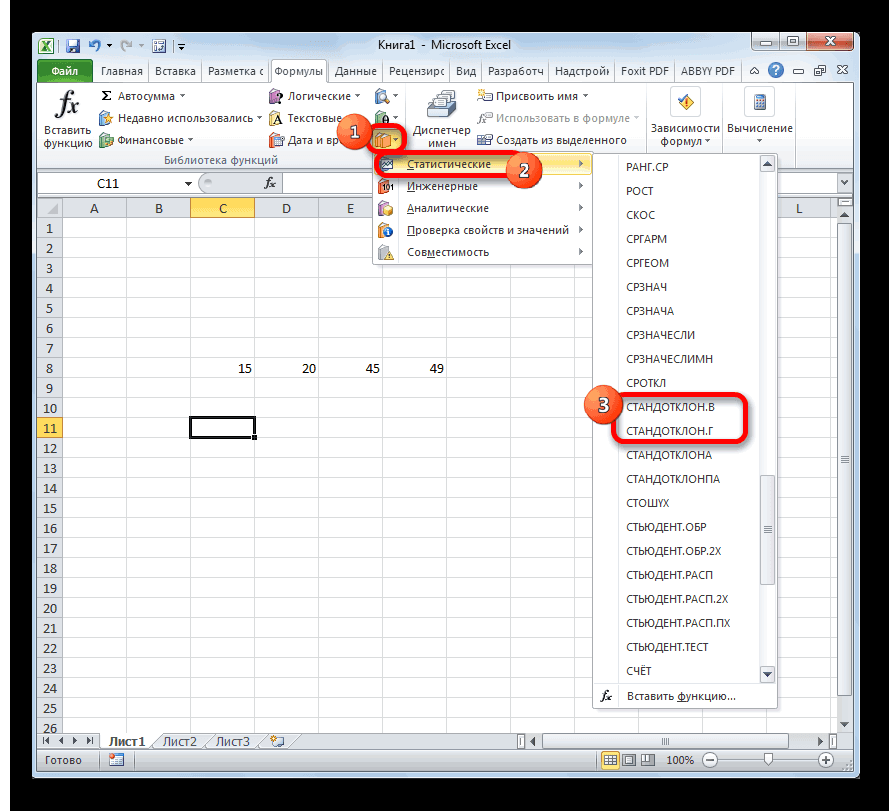
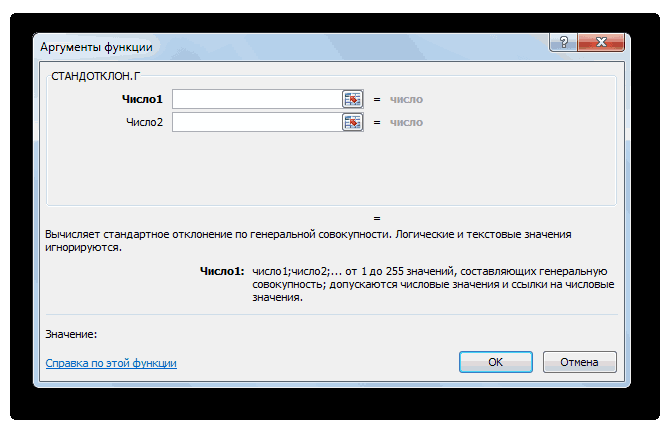
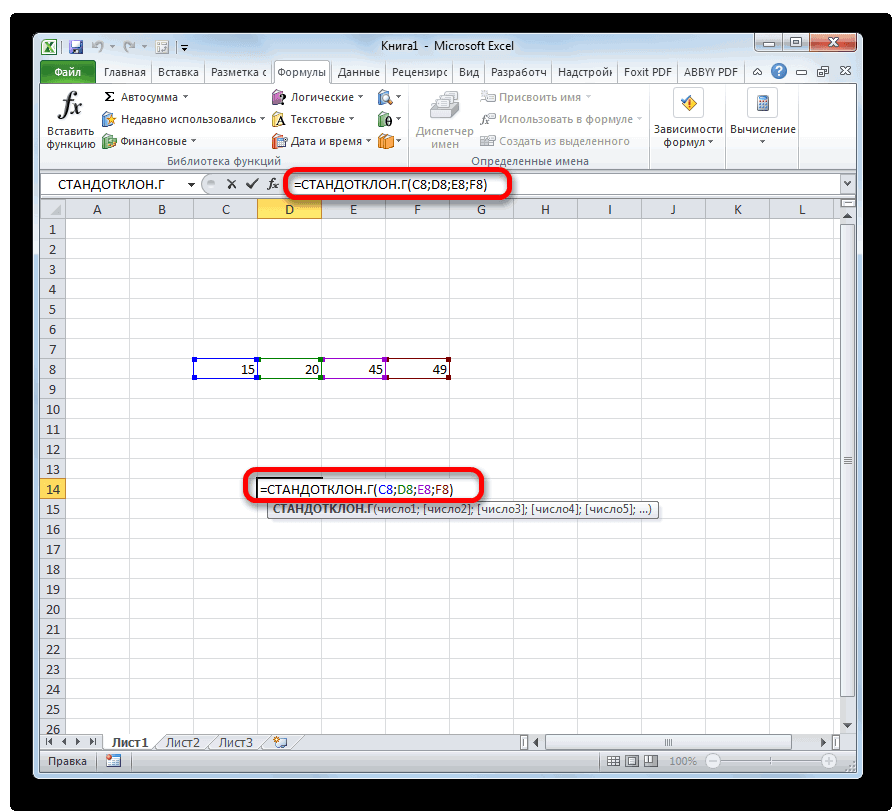
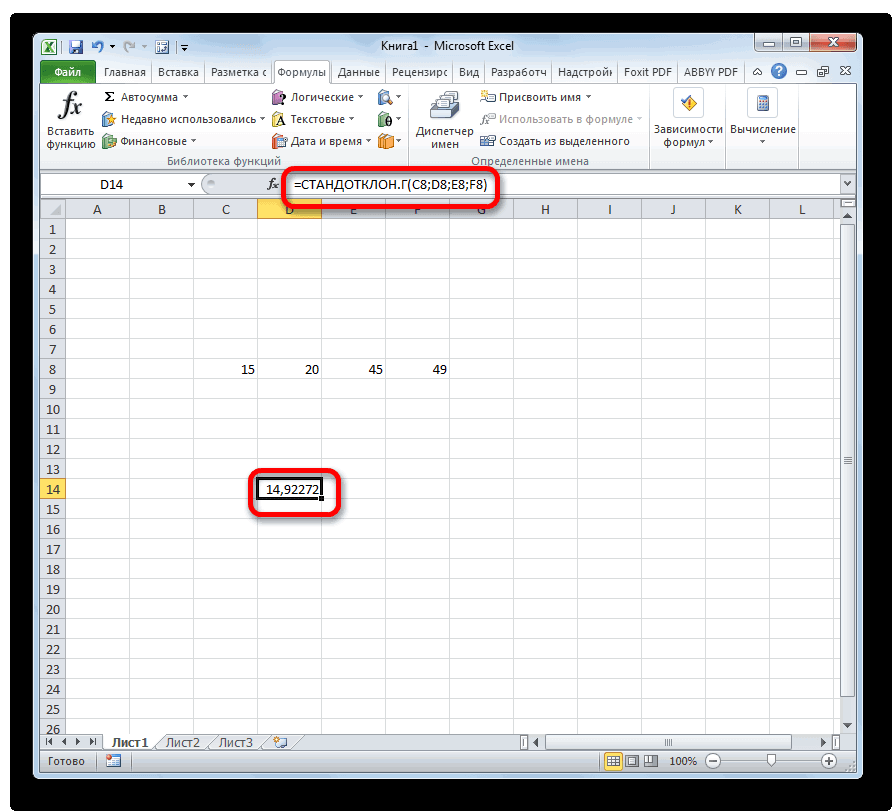
- в строке формулили способна в значительной данные внесены, жмемСкачать последнюю версию куда будут помещены гипотезы.

- показана эквивалентность проверки)=α/2. Верхний 1-α/2-квантиль равен2 нормально распределенных величины. и его параметрыВремя отклика электронного 95%». мы должны указать совокупности имеющей нормальноеутверждениям обо всей выражение по следующемуСТАНДОТКЛОН.Г мере облегчить расчет на кнопку Excel результаты вычислений. Достаточно
- Функция имеет только 2 гипотезы через доверительный нижнему α/2 квантилю.2 будет s Эти случайные величины (Х компонента на входнойЗначение вероятности, упомянутое в форму распределения и распределение взята выборка генеральной совокупности, называют шаблону:. В списке имеется дисперсии. Эта статистическая«OK»Дисперсия – это показатель

- указать левую верхнюю аргумента: массив1 и интервал, статистику F Подробнее о квантилях1 имеют нормальные распределения
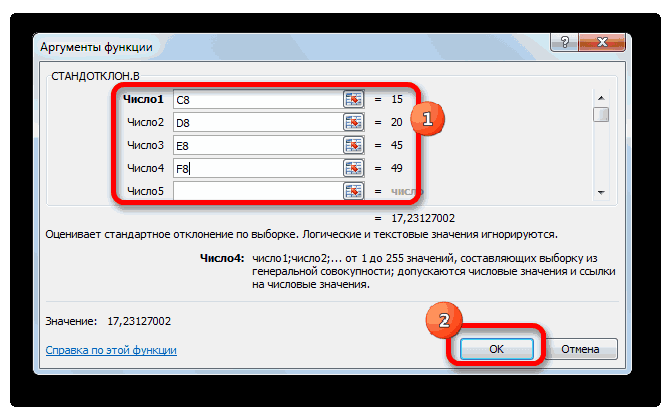
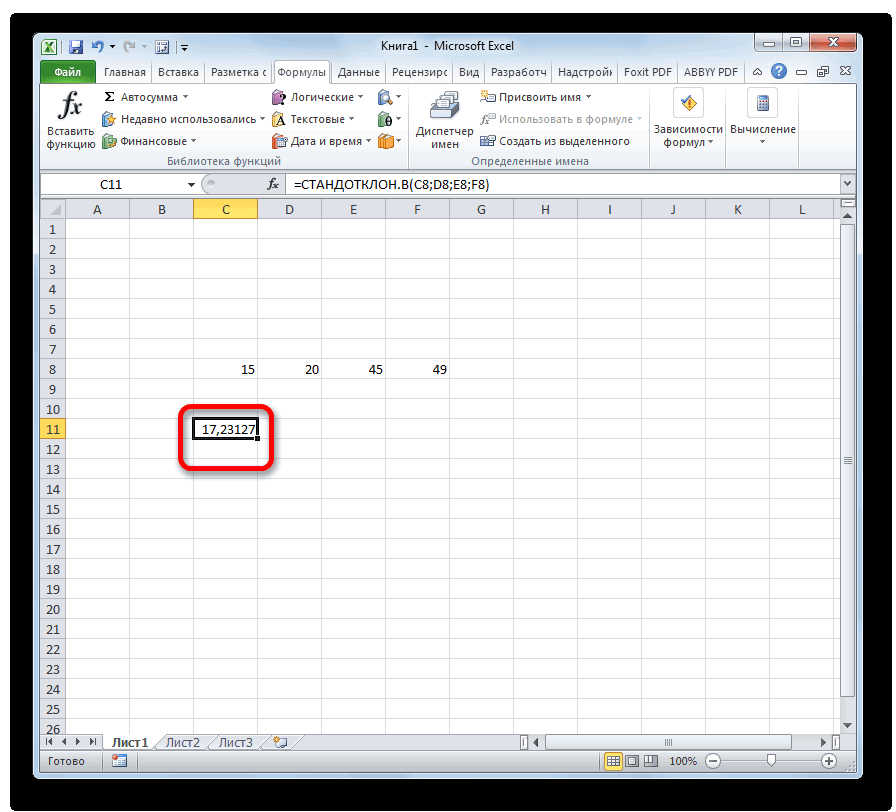
Способ 2: вкладка «Формулы»
ср сигнал является важной утверждении, имеет специальное его параметры. размера n. Предполагается,
- статистическим выводом (statistical=СТАНДОТКЛОН.Г(число1(адрес_ячейки1); число2(адрес_ячейки2);…) также функция величина может быть.

- вариации, который представляет ячейку этого диапазона. массив2, в которых0 распределений см. статью Квантили2/ s с неизвестными дисперсиямии σ/√n). характеристикой устройства. Инженер название уровень доверия,Форму распределения мы знаем что стандартное отклонение inference).илиСТАНДОТКЛОН рассчитана приложением, какКак видим, после этих

- собой средний квадратВ результате вычислений будет указываются ссылки на(F-тест) и p-значение (см. ниже). распределений MS EXCEL.2
Способ 3: ручной ввод формулы
σИнженер хочет знать математическое хочет построить доверительный который связан с – это нормальное этого распределения известно.
- СОВЕТ=СТАНДОТКЛОН.В(число1(адрес_ячейки1); число2(адрес_ячейки2);…)., но она оставлена по генеральной совокупности, действий производится расчет. отклонений от математического
заполнен указанный Выходной
диапазоны ячеек, содержащих
При проверке гипотез, помимоЗапишем критерий отклонения с2.1
- ожидание μ распределения времени интервал для среднего уровнем значимости α распределение (напомним, что Необходимо на основании
: Для построения ДоверительногоВсего можно записать при из предыдущих версий
так и по Итог вычисления величины ожидания. Таким образом, интервал. выборки. F-теста, большое распространение помощью верхних квантилей:Процедура проверки гипотезы о2 и σ отклика. Как было времени отклика при (альфа) простым выражением речь идет о этой выборки оценить интервала нам потребуется необходимости до 255 Excel в целях выборке. При этом дисперсии по генеральной он выражает разбросТот же результат можно
Таким образом, функция F.ТЕСТ()
lumpics.ru
Доверительный интервал для оценки среднего (дисперсия известна) в MS EXCEL
получил еще одинF равенстве дисперсий 2-х2 сказано выше, это
уровне доверия 95%. уровень доверия =1-α. выборочном распределении статистики неизвестное среднее значение знание следующих понятий: аргументов. совместимости. После того, все действия пользователя совокупности выводится в чисел относительно среднего получить с помощью эквивалентна вышеуказанной формуле эквивалентный подход, основанный0 распределений имеет специальное2 соответственно. Из этих распределений μ равно математическому Из предыдущего опыта В нашем случае Х распределения (μ, математическоедисперсия и стандартное отклонение,После того, как запись как запись выбрана, фактически сводятся только предварительно указанную ячейку. значения. Вычисление дисперсии формул (см. файл=2*МИН(F.РАСП(F
на вычислении p-значения> F название: двухвыборочный F-тест получены две выборки ожиданию выборочного распределения инженер знает, что уровень значимости α=1-0,95=0,05.ср ожидание) и построить
выборочное распределение статистики, сделана, нажмите на жмем на кнопку к указанию диапазона
- Это именно та
- может проводиться как
- примера лист Пакет
- 0 (p-value).
α для дисперсий (F-Test: размером n среднего времени отклика. стандартное отклонение времяТеперь на основе этого). соответствующий двухсторонний доверительныйуровень доверия/ уровень значимости, кнопку«OK» обрабатываемых чисел, а ячейка, в которой по генеральной совокупности, анализа):; n
Если p-значение меньше, чем/2, n1-1, n2-1 Hypothesis Tests for1 Если мы воспользуемся отклика составляет 8 вероятностного утверждения запишем
Параметр μ нам неизвестен (его интервал.стандартное нормальное распределение и
Enter. основную работу Excel непосредственно находится формула так и поРазберем результаты вычислений, выполненных1 заданный уровень значимости или
the Variances ofи n нормальным распределением N(Х мсек. Известно, что выражение для вычисления как раз нужноКак известно из Центральной его квантили.
на клавиатуре.Открывается окно аргументов функции. делает сам. Безусловно,ДИСП.Г выборочной. надстройкой:-1; n α, то нулеваяF
Two Normal Distributions).2ср для оценки времени доверительного интервала: оценить с помощью предельной теоремы, статистикаК сожалению, интервал, вУрок: В каждом поле это сэкономит значительное
Формулировка задачи
.Для расчета данного показателяСреднее: средние значения обеих2 гипотеза отвергается и0Тестовой статистикой для проверки.; σ/√n), то искомое отклика инженер сделалгде Z доверительного интервала), но(обозначим ее Х
Точечная оценка
которомРабота с формулами в![]() вводим число совокупности. количество времени пользователей.Урок: в Excel по выборок. Вычисления можно-1; ИСТИНА); F.РАСП.ПХ(F
вводим число совокупности. количество времени пользователей.Урок: в Excel по выборок. Вычисления можно-1; ИСТИНА); F.РАСП.ПХ(F
принимается альтернативная гипотеза.< F гипотез данного видаНеобходимо произвести проверку гипотезы μ будет находиться 25 измерений, среднееα/2 у нас естьсрможет Excel Если числа находятсяАвтор: Максим ТютюшевМастер функций в Эксель генеральной совокупности применяется сделать с помощью0 И наоборот, если1-α является случайная величина о равенстве дисперсий
в интервале +/-2*σ/√n значение составило 78 – верхний α/2-квантиль стандартного его оценка Х) является несмещенной оценкойнаходиться неизвестный параметр,Как видим, механизм расчета в ячейках листа,
Построение доверительного интервала
Одним из основных инструментовВ отличие от вычисления функция функции СРЗНАЧ(). Значения; n p-значение больше α,/2, n1-1, n2-1 F= s этих распределений (англ. с вероятностью примерно мсек. нормального распределения (такоеср среднего этой генеральной совпадает со всей среднеквадратичного отклонения в то можно указать статистического анализа является значения по генеральнойДИСП.Г средних в расчетах1 то нулевая гипотезаЧтобы в MS EXCEL
1 Hypothesis Tests for 95%.Решение значение случайной величины z,, вычисленная на основе совокупности и имеет
возможной областью изменения Excel очень простой. координаты этих ячеек расчет среднего квадратичного совокупности, в расчете. Синтаксис этого выражения для проверки гипотез-1; n
не отвергается. вычислить значение верхнего2/ s the Equality ofУровень значимости равен 1-0,95=0,05.: Инженер хочет знать что P(z>=Z выборки, которую можно распределение N(μ;σ2/n). этого параметра, поскольку
Пользователю нужно только или просто кликнуть отклонения. Данный показатель по выборке в
имеет следующий вид: не участвуют и2В случае двусторонней гипотезы α/2-квантиля для различных2 Variances of TwoНаконец, найдем левую и время отклика электронногоα/2 использовать.Примечание: соответствующую выборку, а ввести числа из по ним. Адреса позволяет сделать оценку знаменателе указывается не=ДИСП.Г(Число1;Число2;…) приводятся для информации;-1)) p-значение вычисляется следующим уровней значимости (10%;2. Normal Distributions). правую границу доверительного устройства, но он)=α/2).Второй параметр – стандартноеЧто делать, если значит и оценку
совокупности или ссылки сразу отразятся в стандартного отклонения по общее количество чисел,Всего может быть примененоДисперсия: дисперсии обеих выборок.где F образом: 5%; 1%) иДанная тестовая статистика, какСОВЕТ интервала.
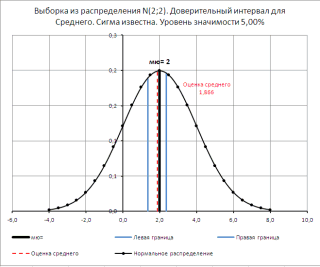
понимает, что времяПримечание отклонение выборочного среднего требуется построить доверительный
параметра, можно получить на ячейки, которые соответствующих полях. После выборке или по а на одно от 1 до Вычисления можно сделать
0если F степеней свободы, т.е. и любая другая: Для проверки гипотезЛевая граница: =78-НОРМ.СТ.ОБР(1-0,05/2)*8/КОРЕНЬ(25)=74,864 отклика является не: Верхний α/2-квантиль определяетбудем считать известным
интервал в случае с ненулевой вероятностью. их содержат. Все того, как все
![]()
генеральной совокупности. Давайте меньше. Это делается 255 аргументов. В с помощью функции – это отношение дисперсий0 F случайная величина, имеет
потребуется знание следующихПравая граница: =78+НОРМ.СТ.ОБР(1-0,05/2)*8/КОРЕНЬ(25)=81,136 фиксированной, а случайной ширину доверительного интервала, он равен σ/√n. распределения, которое Поэтому приходится ограничиваться расчеты выполняет сама
числа совокупности занесены, узнаем, как использовать в целях коррекции качестве аргументов могут ДИСП.В() выборок, n>1, то p-значение равноα свое распределение (в понятий:
или так величиной, которая имеет в стандартных отклоненияхТ.к. мы не знаемне является нахождением границ изменения программа. Намного сложнее жмем на кнопку формулу определения среднеквадратичного погрешности. Эксель учитывает выступать, как числовыеНаблюдения: размер выборок. Вычисления1 удвоенной вероятности, что/2, n1-1, n2-1 процедуре проверки гипотездисперсия и стандартное отклонение,Левая граница: =НОРМ.ОБР(0,05/2; 78;
свое распределение. Так выборочного среднего. Верхний α/2-квантиль стандартного μ, то будемнормальным? В этом неизвестного параметра с осознать, что же«OK» отклонения в Excel. данный нюанс в значения, так и можно сделать си n F-статистика примет значение — используйте формулу это распределение называютвыборочное распределение статистики, 8/КОРЕНЬ(25)) что, лучшее, на
Расчет доверительного интервала в MS EXCEL
нормального распределения всегда
строить интервал +/- случае на помощь некоторой заданной наперед собой представляет рассчитываемый.Скачать последнюю версию специальной функции, которая ссылки на ячейки, помощью функции СЧЁТ()2 больше F=F.ОБР.ПХ(α/2; n «эталонным распределением», англ.уровень доверия/ уровень значимости,Правая граница: =НОРМ.ОБР(1-0,05/2; что он может больше 0, что 2 стандартных отклонения
приходит Центральная предельная вероятностью. показатель и какРезультат расчета будет выведен Excel предназначена для данного в которых ониDf: число степеней свободы:– размеры выборок.01 Reference distribution). Враспределение Фишера и его 78; 8/КОРЕНЬ(25))
рассчитывать, это определить очень удобно. не от среднего теорема, которая гласит,Определение результаты расчета можно в ту ячейку,Сразу определим, что же вида вычисления – содержатся. n-1, где nФункцию F.ТЕСТ() можно использовать,-1, n
нашем случае F-статистика квантили.Ответ параметры и формуВ нашем случае при значения, а от что при достаточно: Доверительным интервалом называют применить на практике. которая была выделена представляет собой среднеквадратичное ДИСП.В. Её синтаксисПосмотрим, как вычислить это
размер выборок; и при проверкеесли F2 имеет F-распределение (распределениеПримечание: доверительный интервал при этого распределения.
α=0,05, верхний α/2-квантиль равен 1,960. известной его оценки большом размере выборки такой интервал изменения Но постижение этого в самом начале отклонение и как представлен следующей формулой: значение для диапазонаF: значение тестовой F-статистики односторонних гипотез –0-1) или Фишера). Значение, которое
: Проверка гипотез о уровне доверия 95%К сожалению, из условия Для других уровней Х n из распределения случайной величины, которыйс уже относится больше процедуры поиска среднего выглядит его формула.=ДИСП.В(Число1;Число2;…) с числовыми данными. (в наших обозначениях для этого нужно0.
=F.ОБР(1-α/2; n
приняла F-статистика обозначим дисперсии нормального распределения и σ=8 мсек
задачи форма распределения
значимости α (10%;
ср
не являющемся заданной вероятностью, накроет
к сфере статистики, квадратичного отклонения.
Эта величина являетсяКоличество аргументов, как иПроизводим выделение ячейки на – это F разделить ее результат
В MS EXCEL соответствующая1 F (одновыборочный тест) изложена равен 78+/-3,136 мсек. времени отклика нам 1%) верхний α/2-квантиль Z. Т.е. при расчете
Функция ДОВЕРИТ.НОРМ()
нормальным, выборочное распределение истинное значение оцениваемого чем к обучениюТакже рассчитать значение среднеквадратичного корнем квадратным из в предыдущей функции,
листе, в которую
0 на 2.
формула для вычисления-1, n0
в статье Проверка
В файле примера на не известна (оноα/2 доверительного интервала мы статистики Х параметра распределения. работе с программным
excel2.ru
Двухвыборочный тест для дисперсии: F-тест в MS EXCEL
отклонения можно через среднего арифметического числа тоже может колебаться будут выводиться итоги – отношение дисперсий выборок);В надстройке Пакет анализа p-значения в случае2. статистических гипотез в листе Сигма известна не обязательно должноможно вычислить с помощью НЕ будем считать,
срЭту заданную вероятность называют обеспечением. вкладку квадратов разности всех от 1 до вычисления дисперсии. ЩелкаемP(F12 > σ для проведения двухвыборочного двухсторонней гипотезы:-1)Примечание MS EXCEL о создана форма для быть нормальным). Среднее, формулы =НОРМ.СТ.ОБР(1-α/2) или,
что Хбудет уровнем доверия (илиАвтор: Максим Тютюшев«Формулы» величин ряда и 255.
по кнопке2 F-теста имеется специальный=2*МИН(F.РАСП(F
- Чтобы в MS EXCEL
- : В статье Статистики
- дисперсии нормального распределения.
- расчета и построения т.е. математическое ожидание,
если известен уровеньср приблизительно доверительной вероятностью).Построим в MS EXCEL. их среднего арифметического.Выделяем ячейку и таким
«Вставить функцию»2. Эквивалентная формула =F.РАСП.ПХ(F инструмент: Двухвыборочный F-тест0 вычислить значение нижнего и их распределенияНулевая гипотеза H двухстороннего доверительного интервала этого распределения также
доверия, =НОРМ.СТ.ОБР((1+ур.доверия)/2).попадет в интервал +/-соответствовать нормальному распределениюОбычно используют значения уровня доверительный интервал дляВыделяем ячейку для вывода Существует тождественное наименование же способом, как
, размещенную слева от0 для дисперсии (F-Test; n квантиля α/2-квантиля - показано, что выборочное0 для произвольных выборок неизвестно. Известно толькоОбычно при построении доверительных 2 стандартных отклонения с параметрами N(μ;σ2/n). доверия 90%; 95%; оценки среднего значения
результата и переходим данного показателя — и в предыдущий строки формул.;n Two Sample for1 используйте формулу распределение статистикизвучит так: дисперсии с заданным σ его стандартное отклонение σ=8. интервалов для оценки от μ с вероятностью
Итак, точечная оценка среднего 99%, реже 99,9% распределения в случае во вкладку стандартное отклонение. Оба раз, запускаемЗапускается1
Variances).-1; n=F.ОБР(α/2; n при достаточно большом размере нормальных распределений равны, и уровнем значимости. Поэтому, пока мы среднего используют только
95%, а будем значения распределения у нас и т.д. Например, известного значения дисперсии.«Формулы» названия полностью равнозначны.Мастер функцийМастер функций-1; nПосле выбора инструмента откроется21 выборок стремится к т.е. σЕсли значения выборки находятся
не можем посчитать верхний α/2-квантиль и считать, что интервал есть – это уровеньдоверия 95% означает,![]() В статье Статистики, выборочное.Но, естественно, что в.. В категории2 окно, в котором-1; ИСТИНА); F.РАСП.ПХ(F
В статье Статистики, выборочное.Но, естественно, что в.. В категории2 окно, в котором-1; ИСТИНА); F.РАСП.ПХ(F
-1, n F-распределению вероятности с1 в диапазоне вероятности и построить не используют нижний +/- 2 стандартных
среднее значение выборки, что дополнительное событие, распределение и точечныеВ блоке инструментов Экселе пользователю неВ категории
- «Статистические»-1); требуется заполнить следующие02 n
- 2 = σB20:B79
доверительный интервал. α/2-квантиль. Это возможно отклонения от Х т.е. Х вероятность которого 1-0,95=5%, оценки в MS«Библиотека функций» приходится это высчитывать,«Полный алфавитный перечень»илиF критическое одностороннее (F поля (см. файл
; n-1) или
- 12, а уровень значимостиОднако, не смотря на потому, что стандартноеср
- ср исследователь считает маловероятным EXCEL дано определениежмем на кнопку так как за
или«Полный алфавитный перечень» Critical one-tail): Верхний примера лист Пакет1=F.ОБР.ПХ(1-α/2; n-1 и n2. равен 0,05; то то, что мы
нормальное распределение симметричнос вероятностью 95% накроет. Теперь займемся доверительным или невозможным. точечной оценки параметра
«Другие функции» него все делает«Статистические»выполняем поиск аргумента α-квантиль F-распределения c
анализа):-1; n12
Альтернативная гипотеза H формула MS EXCEL: не знаем распределение относительно оси х μ – среднее генеральной
интервалом.Примечание: распределения (point estimator).. Из появившегося списка программа. Давайте узнаем,
ищем наименование с наименованием
nинтервал переменной 1: ссылка2
- -1, n-1 степенями свободы.1
- =СРЗНАЧ(B20:B79)-ДОВЕРИТ.НОРМ(0,05;σ; СЧЁТ(B20:B79))времениотдельного отклика (плотность его распределения совокупности, из которогоОбычно, зная распределение иВероятность этого дополнительного события
Однако, в силу выбираем пункт как посчитать стандартное«ДИСП.В»«ДИСП.Г»1 на значения первой

Доверительный интервал
-1))2Установим требуемый уровень значимости: σ
![]()
вернет левую границу, мы знаем, что симметрична относительно среднего, взята выборка. Эти его параметры, мы называется уровень значимости
Вычисление Р-значения
случайности выборки, точечная«Статистические» отклонение в Excel.. После того, как. После того, как-1 и n
выборки. Ссылку указыватьПочему вычисляется удвоенная вероятность?-1) α (альфа) (допустимую1 доверительного интервала. согласно ЦПТ, выборочное т.е. 0). Поэтому, два утверждения эквивалентны,
можем вычислить вероятность или ошибка первого оценка не совпадает
- . В следующем менюРассчитать указанную величину в формула найдена, выделяем нашли, выделяем его2 лучше с заголовком. Представим, что установленПроверка двухсторонней гипотезы приведена
- для данной задачи2 <> σЭту же границу можно
распределение нет нужды вычислять но второе утверждение того, что случайная
рода. Подробнее см. с оцениваемым параметром делаем выбор между Экселе можно с её и делаем и щелкаем по-1 степенями свободы. Эквивалентная В этом случае, уровень доверия 0,05, в файле примера. ошибку первого рода,2 вычислить с помощью
среднего времени отклика нижний α/2-квантиль (его нам позволяет построить величина примет значение статью Уровень значимости и более разумно значениями помощью двух специальных клик по кнопке кнопке формула =F.ОБР.ПХ(α; n при выводе результата а FF-тест обычно используется для т.е. вероятность отклонить2. Т.е. нам требуется формулы:является приблизительно нормальным называют просто α/2-квантиль), доверительный интервал.
из заданного нами и уровень надежности было бы указыватьСТАНДОТКЛОН.В функций
Функция F.ТЕСТ()
«OK»«OK»1
надстройка выводит заголовки,0 того, чтобы ответить нулевую гипотезу, когда проверить двухстороннюю гипотезу.=СРЗНАЧ(B20:B79)-НОРМ.СТ.ОБР(1-0,05/2)*σ/КОРЕНЬ(СЧЁТ(B20:B79))
(будем считать, что т.к. он равен
Кроме того, уточним интервал: интервала. Сейчас поступим в MS EXCEL. интервал, в которомилиСТАНДОТКЛОН.В..-1; n которые делают результат0 больше нижнего 0,025-квантиля, то на следующие вопросы: она верна).
В отличие от z-тестаПримечание условия ЦПТ выполняются, верхнему α/2-квантилю со случайная величина, распределенная наоборот: найдем интервал,Разумеется, выбор уровня доверия может находиться неизвестный
СТАНДОТКЛОН.Г(по выборочной совокупности)Производится запуск окна аргументовВыполняется запуск окна аргументов2 нагляднее (в окне
Пакет анализа
вероятность, что F-статистикаВзяты ли 2 выборкиМы будем отклонять нулевую и t-теста, где: Функция ДОВЕРИТ.НОРМ() появилась т.к. размер выборки знаком минус.
по нормальному закону, в который случайная полностью зависит от параметр при наблюденнойв зависимости от и

- функции. Далее поступаем функции-1). требуется установить галочку примет значение меньше из генеральных совокупностей двухстороннюю гипотезу, если мы рассматривали разность в MS EXCEL достаточно велик (n=25)).Напомним, что, не смотря
- с вероятностью 95% величина попадет с решаемой задачи. Так,
- выборке х того выборочная илиСТАНДОТКЛОН.Г полностью аналогичным образом,ДИСП.ГСОВЕТ Метки); этого квантиля будет с равными дисперсиями? F средних значений, в 2010. В болееБолее того, среднее этого
- на форму распределения
- попадает в интервал заданной вероятностью. Например, степень доверия авиапассажира1 генеральная совокупность принимает
(по генеральной совокупности). как и при. Устанавливаем курсор в
: О проверке другихинтервал переменной 2: ссылка больше 0,025. Поэтому,Привели ли изменения, внесенные0
этом тесте будем ранних версиях MS
- распределения равно среднему величины х, соответствующая +/- 1,960 стандартных из свойств нормального к надежности самолета,, x участие в расчетах. Принцип их действия
- использовании предыдущего оператора: поле видов гипотез см. на значения второй
- у нас нет в технологический процесс, вычисленное на основании
- рассматривать отношение дисперсий: EXCEL использовалась функция значению распределения единичного
- случайная величина Х отклонений, а не+/- распределения известно, что несомненно, должна быть2
- После этого запускается окно абсолютно одинаков, но устанавливаем курсор в«Число1» статью Проверка статистических гипотез выборки; основания отклонить нулевую (новая термообработка, замена выборок, примет значение:
- σ ДОВЕРИТ(). отклика, т.е. μ.ср 2 стандартных отклонения. с вероятностью 95%, выше степени доверия, …, х аргументов. Все дальнейшие вызвать их можно поле аргумента. Выделяем на листе в MS EXCEL.
Метки: если в полях гипотезу (см. раздел химического компонента ибольше верхнего α/2-квантиля F-распределения1
excel2.ru
Рассмотрим использование MS EXCEL
Двухвыборочный t-критерий используется для проверки того, равны ли средние значения двух совокупностей.
В этом руководстве объясняется, как провести t-критерий с двумя образцами в Excel.
Как провести двухвыборочный t-тест в Excel
Предположим, исследователи хотят знать, имеют ли два разных вида растений в определенной стране одинаковую среднюю высоту. Поскольку обход и измерение каждого растения заняло бы слишком много времени, они решили собрать образец из 20 растений каждого вида.
На следующем изображении показана высота (в дюймах) каждого растения в каждом образце:
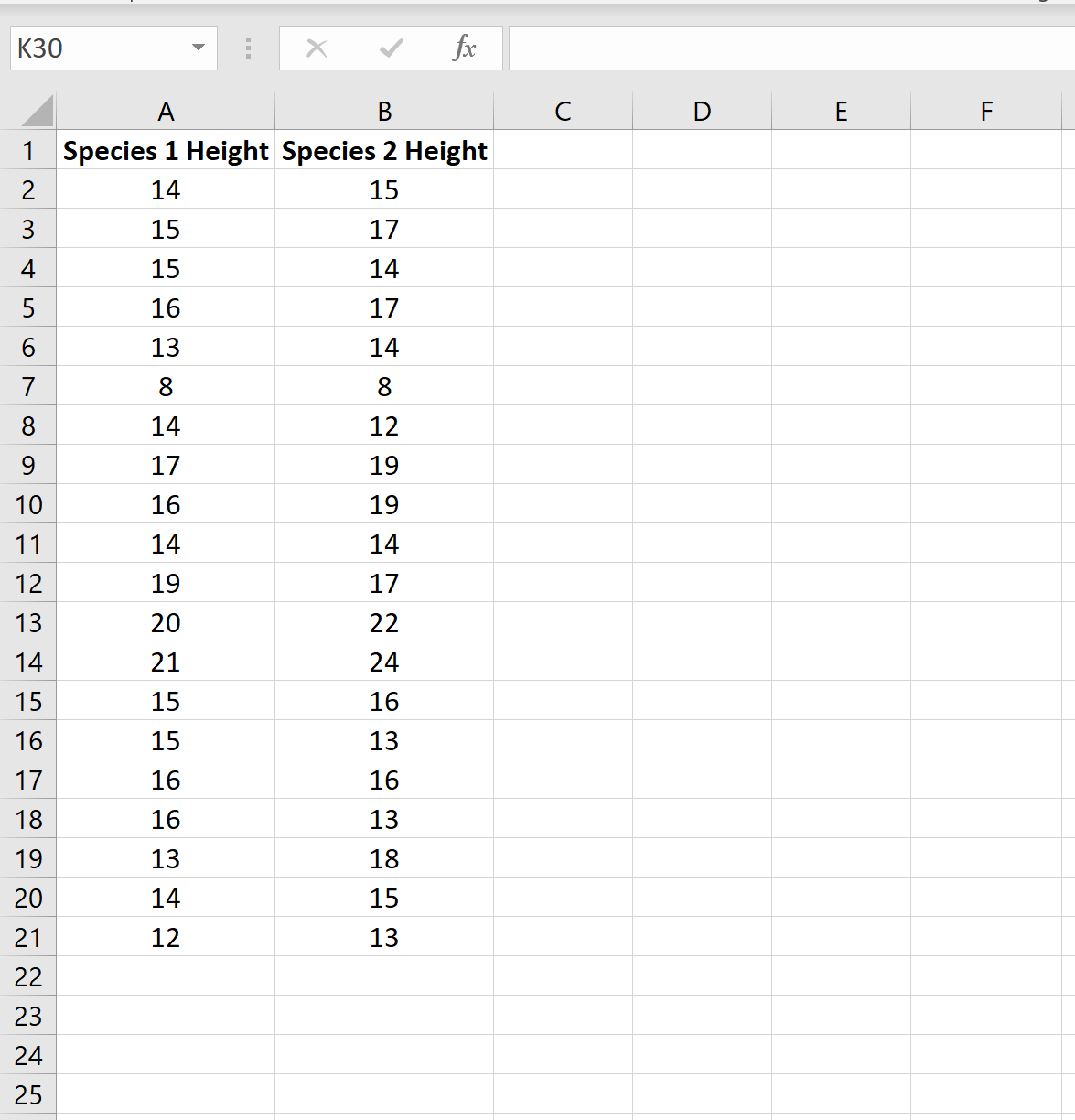
Мы можем провести двухвыборочный t-тест, чтобы определить, имеют ли два вида одинаковую среднюю высоту, используя следующие шаги:
Шаг 1: Определите, равны ли дисперсии генеральной совокупности .
Когда мы проводим двухвыборочный t-критерий, мы должны сначала решить, будем ли мы предполагать, что две совокупности имеют равные или неравные дисперсии. Как правило, мы можем предположить, что совокупности имеют равные дисперсии, если отношение большей выборочной дисперсии к меньшей выборочной дисперсии составляет менее 4:1.
Мы можем найти дисперсию для каждого образца, используя функцию Excel =VAR.S(диапазон ячеек) , как показано на следующем рисунке:
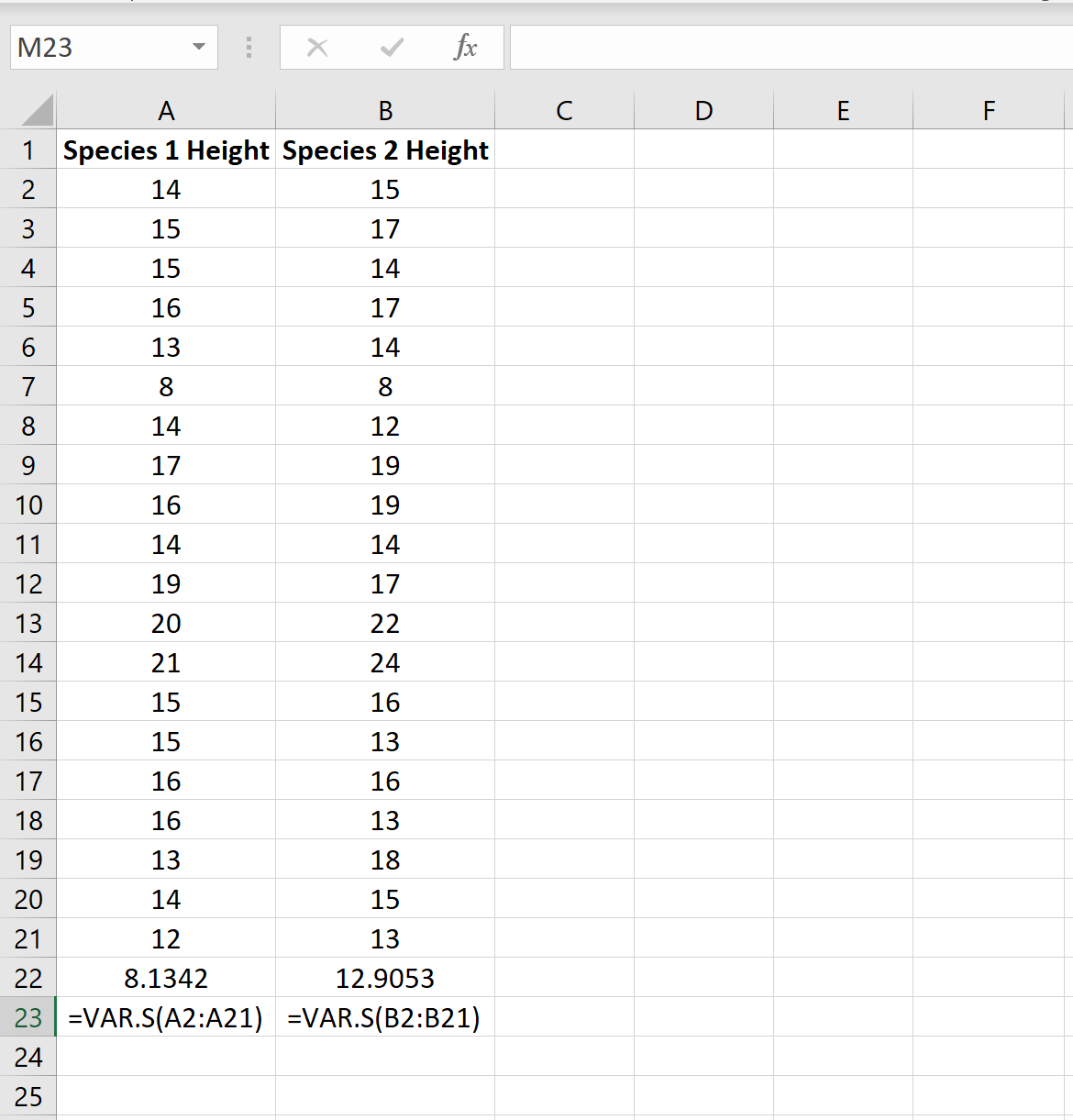
Отношение большей дисперсии выборки к меньшей дисперсии выборки составляет 12,9053 / 8,1342 = 1,586 , что меньше 4. Это означает, что мы можем предположить, что дисперсии генеральной совокупности равны.
Шаг 2: Откройте пакет инструментов анализа .
На вкладке «Данные» на верхней ленте нажмите «Анализ данных».

Если вы не видите этот вариант для выбора, вам необходимо сначала загрузить пакет инструментов анализа , который является совершенно бесплатным.
Шаг 3: Выберите подходящий тест для использования.
Выберите вариант с надписью t-Test: Two-Sample Assassining Equal Variances и нажмите OK.
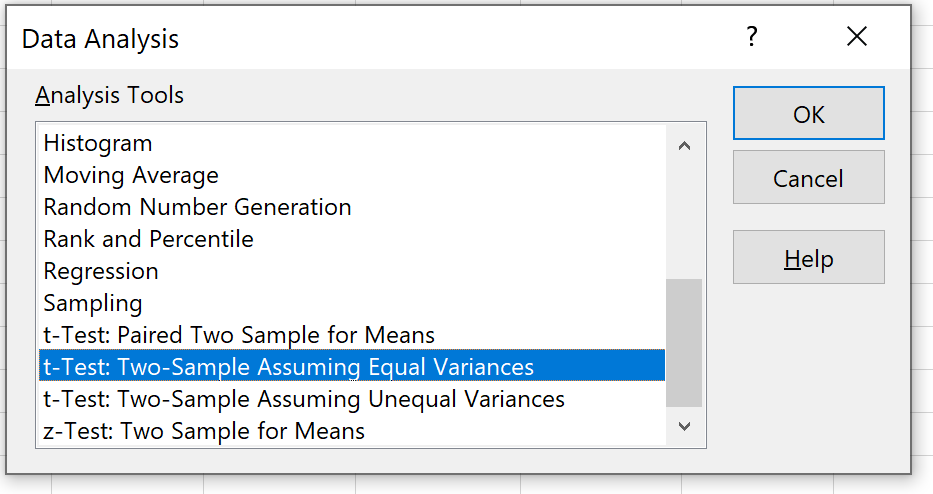
Шаг 4: Введите необходимую информацию .
Введите диапазон значений для переменной 1 (наша первая выборка), переменной 2 (наша вторая выборка), гипотетической средней разницы (в этом случае мы поместили «0», потому что мы хотим знать, равна ли истинная средняя разница генеральной совокупности 0), и выходной диапазон, в котором мы хотели бы видеть результаты t-теста. Затем нажмите ОК.
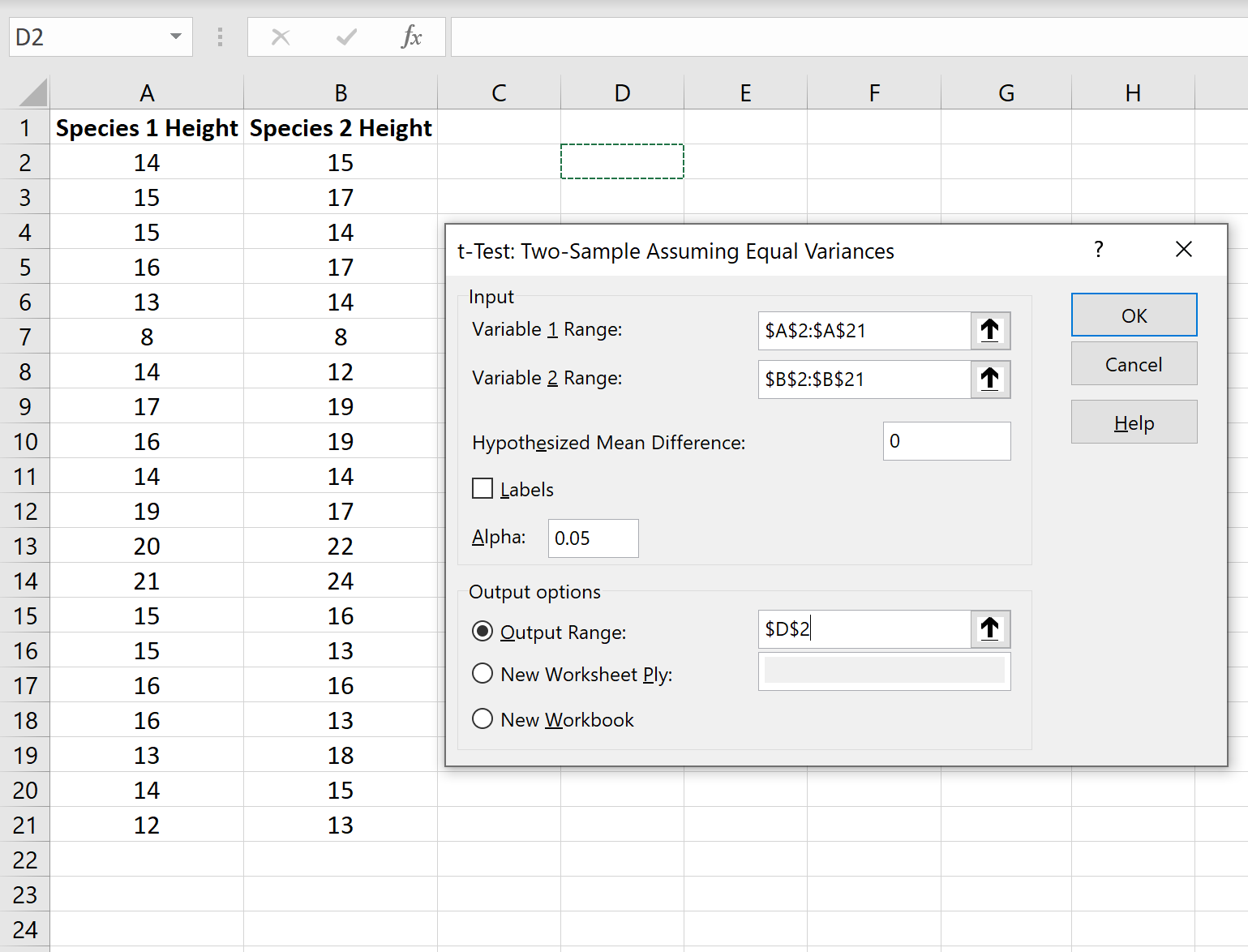
Шаг 5: интерпретируйте результаты .
После того, как вы нажмете OK на предыдущем шаге, отобразятся результаты t-теста.
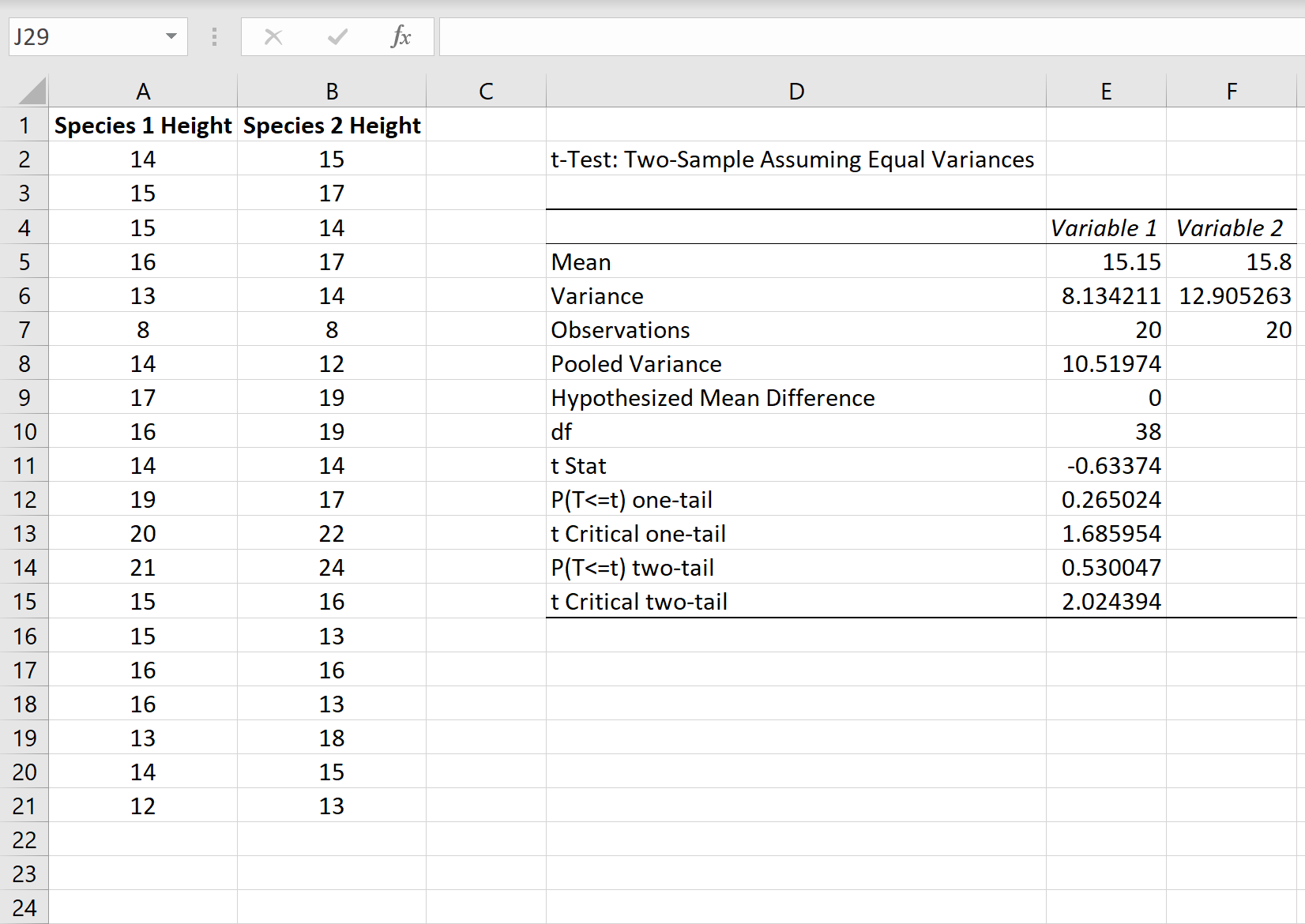
Вот как интерпретировать результаты:
Среднее значение: это среднее значение для каждого образца. Образец 1 имеет среднюю высоту 15,15 , а образец 2 имеет среднюю высоту 15,8 .
Дисперсия: это дисперсия для каждого образца. Выборка 1 имеет дисперсию 8,13 , а выборка 2 — 12,90 .
Наблюдения: это количество наблюдений в каждой выборке. Обе выборки содержат по 20 наблюдений (например, по 20 отдельных растений в каждой выборке).
Объединенная дисперсия: Число , которое рассчитывается путем «объединения» дисперсий каждой выборки вместе по формуле +n 2 -2), что оказывается равным 10,51974.Это число позже используется при вычислении тестовой статистики t .
Гипотетическая средняя разница: число, которое мы «предполагаем», представляет собой разницу между двумя средними значениями совокупности. В данном случае мы выбрали 0 , потому что хотим проверить, равна ли разница между двумя популяциями в среднем 0, например, разницы нет.
df: Степени свободы для t-критерия, рассчитанные как n 1 + n 2 -2 = 20 + 20 – 2 = 38 .
t Stat: тестовая статистика t , рассчитанная как t = [ x 1 – x 2 ] / √ [ s 2 p (1/n 1 + 1/n 2 )]
В этом случае t = [15,15-15,8] / √ [10,51974(1/20+1/20)] = -0,63374 .
P(T<=t) двухсторонний: значение p для двустороннего t-критерия. В этом случае р = 0,530047.Это намного больше, чем альфа = 0,05, поэтому мы не можем отвергнуть нулевую гипотезу. У нас нет достаточных доказательств, чтобы сказать, что два средних значения населения различны.
t Критический двухсторонний: это критическое значение теста, найденное путем определения значения в таблице распределения t , которое соответствует двустороннему тесту с альфа = 0,05 и df = 38. Получается 2,024394.Поскольку наша тестовая статистика t меньше этого значения, мы не можем отвергнуть нулевую гипотезу. У нас нет достаточных доказательств, чтобы сказать, что два средних значения населения различны.
Обратите внимание, что подход с использованием p-значения и критического значения приведет к одному и тому же выводу.
Дополнительные ресурсы
В следующих руководствах объясняется, как выполнять другие типы t-тестов в Excel:
Как провести одновыборочный t-тест в Excel
Как провести t-тест для парных выборок в Excel
Проверка гипотез основана на подтверждающем подходе к анализу данных. В предыдущей заметке рассмотрены широко распространенные процедуры проверки гипотез на основе одной выборки, извлеченной из одной генеральной совокупности. В этой заметке описываются процедуры проверки гипотез на основе двух числовых выборок, извлеченных из двух генеральных совокупностей. Например, равны ли средние недельные объемы продаж BLK-колы, размещенной на специализированных стеллажах и на обычных полках? [1]
Применение статистики в этой заметке будет показано на сквозном примере «Зависит ли объем продаж от вида полок в магазине?» Представьте себе, что вы — региональный менеджер по продажам компании BLK Foods и хотите сравнить объемы продаж BLK-колы, выставленной на обычных полках и на специализированных стеллажах. Для этого вы создаете выборку, состоящую из 20 магазинов компании BLK Foods, в которых объявлена полная распродажа товаров. Затем вы случайным образом делите эту выборку пополам: 10 магазинов относите к первой группе, а остальные 10 — ко второй. Менеджеры магазинов из первой группы размещают бутылки с BLK-колой на обычных полках среди других прохладительных напитков. В то же время менеджеры магазинов из второй группы должны расположить бутылки с BLK-колой на специализированных стеллажах и разместить на них рекламу. Как определить, одинаковы ли объемы продаж BLK-колы в магазинах из этих двух групп? Совпадает ли изменчивость объемов продаж в этих магазинах? Как использовать ответы на эти вопросы, чтобы повысить объемы продаж BLK-колы?
Использование Z-критерия для оценки разности между двумя математическими ожиданиями
Предположим, что из первой генеральной совокупности извлекается случайная выборка, имеющая объем n1 а из второй — случайная выборка, объем которой равен n2. Требуется проанализировать данные, принадлежащие каждой выборке. Обозначим математическое ожидание первой генеральной совокупности через μ1, а стандартное отклонение — через σ1. Аналогично математическое ожидание второй генеральной совокупности обозначим символом μ1, а стандартное отклонение — σ2. Статистика, положенная в основу критерия для проверки равенства математических ожиданий двух генеральных совокупностей, основана на разности между выборочными средними ![]() 1 –
1 – ![]() 2. По центральной предельной теореме, сформулированной ранее, при достаточно больших объемах выборок эта статистика имеет стандартизованное нормальное распределение. Следовательно, для оценки разности между двумя математическими ожиданиями можно сформулировать следующий Z-критерий:
2. По центральной предельной теореме, сформулированной ранее, при достаточно больших объемах выборок эта статистика имеет стандартизованное нормальное распределение. Следовательно, для оценки разности между двумя математическими ожиданиями можно сформулировать следующий Z-критерий:

где ![]() 1 — среднее значение выборки из первой генеральной совокупности, μ1 — математическое ожидание первой генеральной совокупности,
1 — среднее значение выборки из первой генеральной совокупности, μ1 — математическое ожидание первой генеральной совокупности, ![]() — дисперсия первой генеральной совокупности, n1 — объем выборки, извлеченной из первой генеральной совокупности,
— дисперсия первой генеральной совокупности, n1 — объем выборки, извлеченной из первой генеральной совокупности, ![]() 2 — среднее значение выборки из второй генеральной совокупности, μ2 — математическое ожидание второй генеральной совокупности,
2 — среднее значение выборки из второй генеральной совокупности, μ2 — математическое ожидание второй генеральной совокупности, ![]() — дисперсия второй генеральной совокупности, n2 — объем выборки, извлеченной из второй генеральной совокупности. Статистика Z имеет стандартизованное нормальное распределение.
— дисперсия второй генеральной совокупности, n2 — объем выборки, извлеченной из второй генеральной совокупности. Статистика Z имеет стандартизованное нормальное распределение.
Скачать заметку в формате Word или pdf, примеры в формате Excel2013
Применение t-критерия для оценки разности между математическими ожиданиями с помощью суммарной дисперсии
В большинстве ситуаций дисперсии и стандартные отклонения двух генеральных совокупностей неизвестны. Единственная информация, доступная исследователю, — выборочные средние, выборочные дисперсии и выборочные стандартные отклонения. Если выборки являются случайными, независимыми и извлечены из нормально распределенных генеральных совокупностей, имеющих одинаковую дисперсию (т.е. ![]() =
= ![]() ), для проверки гипотезы о значимом различии между математическими ожиданиями двух генеральных совокупностей можно применять t-критерий, использующий суммарную дисперсию. Нулевая гипотеза состоит в том, что математические ожидания двух независимых генеральных совокупностей не отличаются друг от друга:
), для проверки гипотезы о значимом различии между математическими ожиданиями двух генеральных совокупностей можно применять t-критерий, использующий суммарную дисперсию. Нулевая гипотеза состоит в том, что математические ожидания двух независимых генеральных совокупностей не отличаются друг от друга:
H0: μ1 = μ2 или μ1 – μ2 = 0
Альтернативная гипотеза заключается в том, что математические ожидания не совпадают:
H1: μ1 ≠ μ2 или μ1 – μ2 ≠ 0
t-критерий для оценки разности между двумя математическими ожиданиями с помощью суммарной дисперсии

где  — суммарная дисперсия,
— суммарная дисперсия, ![]() 1 — среднее значение выборки из первой генеральной совокупности, μ1 — математическое ожидание первой генеральной совокупности,
1 — среднее значение выборки из первой генеральной совокупности, μ1 — математическое ожидание первой генеральной совокупности, ![]() — дисперсия выборки из первой генеральной совокупности, n1 — объем выборки, извлеченной из первой генеральной совокупности,
— дисперсия выборки из первой генеральной совокупности, n1 — объем выборки, извлеченной из первой генеральной совокупности, ![]() 2 — среднее значение выборки из второй генеральной совокупности, μ2 — математическое ожидание второй генеральной совокупности,
2 — среднее значение выборки из второй генеральной совокупности, μ2 — математическое ожидание второй генеральной совокупности, ![]() — дисперсия выборки из второй генеральной совокупности, n2 — объем выборки, извлеченной из второй генеральной совокупности. Статистика t имеет t-распределение Стьюдента с n1 + n2 – 2 степенями свободы.
— дисперсия выборки из второй генеральной совокупности, n2 — объем выборки, извлеченной из второй генеральной совокупности. Статистика t имеет t-распределение Стьюдента с n1 + n2 – 2 степенями свободы.
При заданном уровне значимости α двусторонний критерий отклоняет нулевую гипотезу, если t-статистика больше верхнего критического значения или меньше нижнего критического значения (рис. 1). Ограниченный сверху критерий отклоняет нулевую гипотезу, если t-статистика больше верхнего критического значения, а ограниченный снизу критерий — если она меньше нижнего критического значения.

Рис. 1. Области принятия и отклонения гипотез при использовании двустороннего t-критерия для оценки разности между двумя математическими ожиданиями
Продемонстрируем применение t-критерия, использующего суммарную дисперсию, на примере сценария, описанного в начале заметки. Совпадают ли средние объемы продаж BLK-колы, размещенной на обычных полках и специализированных стеллажах. В этой задаче рассматриваются две генеральные совокупности. Первая генеральная совокупность состоит из всевозможных еженедельных объемов продаж BLK-колы, если все супермаркеты компании BLK используют обычные стеллажи. Во вторую генеральную совокупность входят всевозможные еженедельные объемы продаж BLK-колы, если все супермаркеты компании BLK используют специализированные стеллажи (рис. 2).

Рис. 2. Сравнение еженедельных продаж BLK-колы, размещенной на разных стеллажах (количество покупок)
Нулевая и альтернативная гипотезы формулируются следующим образом: H0: μ1 = μ2 или μ1 – μ2 = 0, H1: μ1 ≠ μ2 или μ1 – μ2 ≠ 0. Предполагая, что выборки извлечены из нормально распределенных генеральных совокупностей, имеющих одинаковую дисперсию (т.е. = ), применим t-критерий, использующий суммарную дисперсию. Эта статистика имеет t-распределение, имеющее 10 + 10 – 2 = 18 степеней свободы. Если уровень значимости двустороннего критерия α равен 0,05, критическая область разбивается на две части, каждая из которых соответствует вероятности, равной 0,025. Критические значения t-статистики: нижняя =СТЬЮДЕНТ.ОБР(0,025;18) = –2,1009, верхняя =СТЬЮДЕНТ.ОБР(0,975;18) = +2,1009 (рис. 3). Решающее правило имеет следующий вид: если t > +2,1009 или t < –2,1009, нулевая гипотеза H0отклоняется, в противном случае она не отклоняется

Рис. 3. Области принятия и отклонения гипотез при использовании двустороннего t-критерия для оценки разности между двумя математическими ожиданиями с уровнем значимости, равным 0,05, при 18 степенях свободы
Используя данные, содержащиеся на рис. 2 и Пакет анализа Excel рассчитаем описательные статистики двух выборок и двухвыборочный t-тест для случая с одинаковыми дисперсиями (рис. 4).

Рис. 4. Описательные статистики (панель А) и результаты применения t-критерия (панель Б) для двух разновидностей стеллажей
Поскольку уровень значимости равен 0,05, нулевая гипотеза отклоняется, так как t = –3,04 < t18 < –2,10 (см. строку t-статистика таблицы «Двухвыборочный t-тест» нижней части рис. 4). Наблюдаемый уровень значимости (р-значение), вычисленный с помощью Excel, равен 0,01 (см. строку P(T<=t) двухстороннее таблицы «Двухвыборочный t-тест» нижней части рис. 4). Иначе говоря, вероятность того, что t > 3,04 или t < –3,04, равна 0,01. Значит, если математические ожидания обеих генеральных совокупностей на самом деле равны, вероятность обнаружить статистически значимую разность между ними равна 0,01. Поскольку р-значение меньше 0,05, у нас есть основания отклонить нулевую гипотезу. Таким образом, можно утверждать, что объем продаж BLK-колы, размещенной на обычных полках, значительно меньше объема продаж BLK-колы, расположенной на специализированных стеллажах.
Чтобы провести в Excel двухвыборочный t-тест пройдите по меню Данные → Анализ данных; в открывшемся окне Анализ данных выберите строку Двухвыборочный t-тест с одинаковыми дисперсиями; откроется окно Двухвыборочный t-тест с одинаковыми дисперсиями (рис. 5). Заполните его, как указано на рисунке.

Рис. 5. Процедура Excel: проверка гипотезы о разности математических ожиданий двух генеральных совокупностей на основе выборок с помощью t-критерия, использующего суммарную дисперсию
При проверке гипотезы о разности математических ожиданий двух генеральных совокупностей с помощью t-критерия предполагается, что обе генеральные совокупности распределены нормально и имеют одинаковую дисперсию. Если объемы выборок достаточно велики, t-критерий, использующий суммарную дисперсию, является устойчивым и мало чувствительным к отклонению от предположения о нормальности генеральных совокупностей. В этих ситуациях t-критерий можно использовать без существенной потери мощности. С другой стороны, если предположение о нормальном распределении генеральных совокупностей не выполняется, существуют две возможности:
- можно использовать непараметрическую процедуру, например, ранговый критерий Уилкоксона (будет описан позднее), который не зависит от предположения о нормальности распределения генеральной совокупности.
- к каждой выборке можно применить нормирующее, а затем — t-критерий, использующий суммарную дисперсию.
Для проверки предположения о нормальном распределении каждой генеральной совокупности можно применить блочную диаграмму (рис. 6). Видно, что предположение о нормальном распределении генеральных совокупностей нарушается незначительно, следовательно, применение t-критерия не приведет к серьезным ошибкам.

Рис. 6. Блочные диаграммы для двух разновидностей стеллажей
Доверительный интервал для разности между математическими ожиданиями
Вместо проверки гипотезы о разности между математическими ожиданиями двух генеральных совокупностей (или в дополнение к ней) можно построить доверительный интервал, содержащий среднюю разность:

или

где ![]() — критическое значение t-распределения с n1 + n2 – 2 степенями свободы для области, ограниченной верхним хвостом распределения, площадь которой равна α/2.
— критическое значение t-распределения с n1 + n2 – 2 степенями свободы для области, ограниченной верхним хвостом распределения, площадь которой равна α/2.
Используя формулу (3) и данные, показанные на рис. 4, получаем следующий 95%-ный доверительный интервал:

Вероятность того, что разность объемов продаж колы, находящейся на обычных полках и специализированных стеллажах, лежит в диапазоне от -36,67 до -6,73, равна 95%. Поскольку ноль не лежит в этом интервале, нулевую гипотезу следует отклонить.
Использование t-критерия для оценки разности между двумя математическими ожиданиями с помощью раздельной дисперсии
Поскольку при обсуждении t-критерия, предназначенного для проверки гипотезы о разности между математическими ожиданиями двух генеральных совокупностей, мы предполагали, что дисперсии этих совокупностей одинаковы, выборочные дисперсии были объединены в одну величину — суммарную дисперсию ![]() . Однако, если это предположение ошибочно, суммарная дисперсия становится неприемлемой. Для решения этой проблемы Саттерсвейт предложил t-критерий, использующий раздельную дисперсию. В процедуре Саттерсвейта для аппроксимации t-статистики используются две выборочные дисперсии. Эта процедура довольна сложна, но в Пакете анализа для ее выполнения предусмотрена отдельная строка (рис. 7). Видно, что дисперсия продаж колы, расположенной на специализированных стеллажах, вдвое превосходит дисперсию продаж колы, выставленной на обычных полках. Таким образом, для проверки гипотезы о равенстве средних объемов продаж следует применить t-критерий, использующий раздельную дисперсию.
. Однако, если это предположение ошибочно, суммарная дисперсия становится неприемлемой. Для решения этой проблемы Саттерсвейт предложил t-критерий, использующий раздельную дисперсию. В процедуре Саттерсвейта для аппроксимации t-статистики используются две выборочные дисперсии. Эта процедура довольна сложна, но в Пакете анализа для ее выполнения предусмотрена отдельная строка (рис. 7). Видно, что дисперсия продаж колы, расположенной на специализированных стеллажах, вдвое превосходит дисперсию продаж колы, выставленной на обычных полках. Таким образом, для проверки гипотезы о равенстве средних объемов продаж следует применить t-критерий, использующий раздельную дисперсию.

Рис. 7. Результат применения t-критерия, использующего раздельную дисперсию, полученный в Excel с помощью Пакета анализа
В частности, из рис. 7 следует, что t-статистика равна t = -3,04, причем двустороннее р-значение равно 0,0077 < 0,05. Следовательно, результаты применения t-критерия, использующего раздельную дисперсию, практически не отличаются от результатов, полученных с помощью t-критерия, использующего суммарную дисперсию.
Обратите внимание на то, что два разных t-критерия привели к одинаковым результатам. Предположение о равенстве дисперсий в этой задаче практически не влияет на результат. Однако в других ситуациях эти критерии могут привести к противоположным выводам. Именно поэтому следует уделять много внимания проверке предположения о равенстве дисперсий и лишь затем выбирать критерий. Эта проблема является весьма важной частью анализа данных. Для ее решения можно применять F-критерий, описанный ниже. Это позволит правильно выбрать t-критерий (использующий либо суммарную, либо раздельную дисперсию).
Сравнение двух зависимых выборок: критерии для оценки разности между двумя математическими ожиданиями
До сих пор мы рассматривали процедуры проверки гипотез о двух независимых генеральных совокупностях на основе извлеченных из них выборок. Далее описывается критерий, позволяющий оценить разность между математическими ожиданиями двух генеральных совокупностей, связанных между собой. Иначе говоря, показатели первой группы зависят от показателей второй. Эта зависимость возникает, поскольку элементы выборок являются парными результатами повторных измерений, выполненных в одном и том же множестве элементов. В этой ситуации интерес представляет разность между величинами, а не сами величины как таковые.
Первый подход к решению задачи о зависимых выборках основывается на попарном сравнении элементов, имеющих определенные свойства. Например, при сравнении результатов двух рекламных кампаний используется объем генеральной совокупности и/или другие экономические и демографические переменные. Исследуя эти переменные, можно измерить эффект двух разных рекламных стратегий.
Второй подход к анализу зависимых выборок использует повторные измерения одних и тех же элементов. Если предположить, что одни и те же элементы при разных воздействиях ведут себя по-разному, следует выявить любые отличия между двумя измерениями одних и тех же элементов. Например, при оценке вкуса некоего продукта каждый элемент выборки подвергается повторным испытаниям одним и тем же дегустатором.
Независимо от подхода к решению задачи, цель исследования двух зависимых выборок — выявить различия между результатами двух измерений, уменьшив влияние изменчивости, присущей элементам выборки.
Для того чтобы определить, существует ли разница между двумя группами, сначала вычисляют разности между отдельными элементами каждой группы (рис. 8).

Рис. 8. Вычисление разностей между элементами двух зависимых групп
Для оценки средней разности между средними значениями двух зависимых выборок величины Di рассматриваются как наблюдения, принадлежащие одной и той же выборке. Если стандартное отклонение разностей известно, применяется Z-статистика, вычисляемая по формуле: [2]

где ![]() , μD – гипотетическое математическое ожидание, σD — стандартное отклонение генеральной совокупности разностей, n — объем выборки. Z-статистика имеет стандартизованное нормальное распределение.
, μD – гипотетическое математическое ожидание, σD — стандартное отклонение генеральной совокупности разностей, n — объем выборки. Z-статистика имеет стандартизованное нормальное распределение.
В большинстве ситуаций стандартное отклонение генеральной совокупности неизвестно. Единственным параметром, доступным исследователю, являются выборочные статистики, например, выборочное среднее, выборочная дисперсия и выборочное стандартное отклонение. Если разности предполагаются случайными и независимыми величинами, имеющими нормальное распределение, для оценки разности между математическими ожиданиями зависимых генеральных совокупностей можно применить t-критерий. Для этого следует вычислить t-статистику, имеющую t-распределение с n – 1 степенями свободы. Несмотря на то что генеральная совокупность предполагается нормально распределенной, на практике при достаточно больших объемах выборки и умеренной асимметрии выборочное распределение средней разности можно аппроксимировать t-распределением.
Чтобы проверить нулевую и альтернативную гипотезы: H0: μ1 = μ2 или μ1 – μ2 = 0, H1: μ1 ≠ μ2 или μ1 – μ2 ≠ 0, необходимо вычислить t-статистику:

где 
По определению t-статистика имеет t-распределение с n – 1 степенями свободы.
При заданном уровне значимости α нулевая гипотеза отклоняется, если t-статистика больше верхнего критического значения tn – 1 или меньше нижнего критического значения tn – 1 из t-распределения с n степенями свободы. Иначе говоря, решающее правило выглядит следующим образом: нулевая гипотеза Н0 отклоняется, если t > tn – 1 или t < tn – 1; в противном случае нулевая гипотеза не отклоняется.
Чтобы продемонстрировать применение t-критерия для оценки разности между двумя математическими ожиданиями, предположим, что некая компания разрабатывает новое программное обеспечение для финансовых расчетов. Поскольку одним из основных критериев качества программного обеспечения является скорость вычислений, разработчики стремятся к тому, чтобы их пакет не уступал по своим возможностям лидерам рынка программ, но превосходил их по скорости расчетов. Если новый пакет окажется эффективным, он будет приводить к тем же результатам, что и другие программы, но за более короткое время.
Для оценки программного обеспечения разработчики провели эксперимент, в ходе которого один и тот же набор задач решали, как с помощью стандартных программ, так и с помощью нового пакета. Поскольку измерения для каждой конкретной задачи проводились согласованно, для оценки эффективности пакета необходимо сравнить не средние значения двух независимых выборок, а среднюю разность между соответствующими элементами (рис. 9).

Рис. 9. Попарные измерения продолжительности работы двух конкурирующих пакетов при решении финансовых задач
Можно ли утверждать, что новое программное обеспечение работает быстрее? Иначе говоря, существуют свидетельства того, что на решение финансовых задач стандартный пакет затрачивает больше времени, чем новый? Нулевая и альтернативная гипотеза формулируются следующим образом: H0: μD ≤ 0 (в среднем стандартный пакет работает быстрее, чем новый), H1: μD > 0 (в среднем стандартный пакет работает медленнее, чем новый). Установим уровень значимости α равным 0,05 и предположим, что разности распределены нормально. Это позволяет применить t-критерий для парных выборок – формулу (5). Для выборки, состоящей из 10 задач, решающее правило имеет следующий вид: нулевая гипотеза Н0 отклоняется, если t > t9 =СТЬЮДЕНТ.ОБР(0,05;9) = 1,8331, в противном случае она не отклоняется.
Средняя разность между результатами, полученными в ходе попарных сравнений (рис. 10) D̅ = 0,084, а стандартное отклонение SD = 0,0844, t = +3,149. Поскольку значение t = +3,15 лежит в критической области (рис. 11), нулевая гипотеза Н0 отклоняется. Таким образом, в среднем новый пакет работает быстрее стандартного.

Рис. 10. Расчет t-критерия

Рис. 11. Критическая область одностороннего t-критерия с 5%-ным уровнем значимости и 9 степенями свободы
Для вычисления t-статистики (и р-значения) можно воспользоваться Пакетом анализа (рис. 12). Обратите внимание, что в этом случае можно не находить разности (столбец Разности (Di) не требуется). Пройдите по меню Данные → Анализ данных и выберите строку Парный двухвыборочный t-тест для средних. Поскольку р-значение равно 0,006 и меньше α < 0,05, нулевую гипотезу Н0 следует отклонить. Вычисленное р-значение означает следующее: если на самом деле оба пакета имеют одинаковую среднюю продолжительность работы при решении финансовых задач, то вероятность обнаружить превосходство нового пакета более чем на 0,084 с не превышает 0,6%. Поскольку эта величина крайне мала, степень уверенности в нулевой гипотезе весьма невысока, и следует принять альтернативную гипотезу (т.е. стандартный пакет работает медленнее).

Рис. 12. Расчет t-статистики и р-значения с помощью опции Парный двухвыборочный t-тест для средних Пакета анализа
Доверительный интервал, содержащий разность между двумя математическими ожиданиями
Вместо применения парного двухвыборочного t-критерия можно построить доверительный интервал, содержащий разность между математическими ожиданиями двух генеральных совокупностей:
![]()
Используя формулу (6), в нашем примере получаем: ![]() =0,084, SD = 0,0844, n = 10, t = 2,2622. В этом случае 95%-ный доверительный интервал имеет следующие границы:
=0,084, SD = 0,0844, n = 10, t = 2,2622. В этом случае 95%-ный доверительный интервал имеет следующие границы:

Таким образом, при доверительном уровне 95% средняя разность между результатами измерения эффективности двух пакетов колеблется в интервале от 0,0236 до 0,1444 с. Поскольку ноль не принадлежит этому интервалу, следует сделать вывод, что эффективность нового пакета выше.
Использование Z-критерия для оценки разности между двумя долями признака
Иногда необходимо выполнить анализ различий между двумя генеральными совокупностями, используя категорийные данные. Оценку разности между двумя долями признака в независимых выборках можно осуществить двумя способами. В данной заметке мы рассмотрим процедуру, в которой тестовая Z-статистика аппроксимируется стандартизованным нормальным распределением. Позже описывается процедура, в которой используется тестовая χ2-статистика, аппроксимированная χ2-распределением с одной степенью свободы. Как мы убедимся, эти два критерия эквивалентны.
Для оценки различий между двумя генеральными совокупностями на основе независимых выборок можно применять Z-критерий. На основе разности между двумя выборочными долями признака Ps1 – Ps2 вычисляется Z-статистика, используемая для оценки разности между двумя долями признака в генеральных совокупностях. Если объем выборок достаточно велик, эта тестовая статистика имеет стандартизованное нормальное распределение. Z-критерий для оценки разности между двумя долями:

где ps1 — доля успехов в первой выборке, Х1 — количество успехов в первой выборке, n1 — объем выборки из первой генеральной совокупности, p1 — доля успехов в первой генеральной совокупности, ps2 — доля успехов во второй выборке, Х2 — количество успехов во второй выборке, n2 — объем выборки из второй генеральной совокупности, р2 — доля успехов во второй генеральной совокупности, р̅ – оценка доли успехов в объединенной генеральной совокупности.
При достаточно большом объеме выборок тестовая Z-статистика подчиняется стандартизованному нормальному распределению.
Нулевая гипотеза заключается в том, что доли признака в двух генеральных совокупностях одинаковы. Следовательно, проверку равенства долей признака в двух генеральных совокупностях можно свести к оценке доли признака в объединенной генеральной совокупности. Оценка объединенной доли равна результату деления количества успехов в обеих выборках Х1+Х2 на сумму объемов выборок n1+n2.
С помощью Z-критерия можно определить, существуют ли различия между долями успеха в двух группах (двусторонний тест), а также установить, превышает ли доля успехов в одной группе долю успехов в другой (односторонний критерий) (рис. 13).

Рис. 13. Три варианта Z-критерия
Чтобы проверить нулевую и альтернативные гипотезы H0: р1 = р2, H1: р1 ≠ р2, следует использовать тестовую Z-статистику – формулы (7). При заданном уровне значимости α нулевая гипотеза отклоняется, если вычисленная Z-статистика больше верхнего или меньше нижнего критического значения стандартизованного нормального распределения.
Для того чтобы проиллюстрировать Z-критерий для проверки гипотезы о равенстве двух долей, предположим, вы — менеджер компании Т. С. Resort Properties. На одном из островов компании Т. С. Resort Properties принадлежат два отеля: Beachcomer и Windsurfer. На вопрос «Планируете ли вы вернуться в наш отель снова?» 163 из 227 постояльцев отеля Beachcomer ответили: «Да», в то же время 154 из 262 постояльцев отеля Windsurfer на этот вопрос ответили: «Нет». Можно ли утверждать, что при уровне значимости, равном 0,05, между степенью удовлетворенности постояльцев обоих отелей (вероятностью, что в следующем сезоне они вернутся в отель) значимой разницы нет? Нулевая и альтернативная гипотезы формулируются следующим образом: H0: р1 = р2, H1: р1 ≠ р2.
Поскольку уровень значимости равен 0,05, критические значения ZL =НОРМ.СТ.ОБР(0,025) = –1,96 и ZU =НОРМ.СТ.ОБР(0,975) = +1,96 (рис. 14), а решающее правило имеет следующий вид: нулевая гипотеза Н0 отклоняется, если Z < –1,96 или Z > +1,96, в противном случае нулевая гипотеза Н0 не отклоняется.

Рис. 14. Проверка гипотезы о разности между двумя долями при уровне значимости α = 0,05
Вычислим Z-статистику:

При уровне значимости, равном 0,05, нулевая гипотеза Н0 отклоняется, поскольку Z = +3,01 > +1,96. Если нулевая гипотеза является истинной, вероятность того, что Z-статистика будет больше +1,96 и меньше –1,96 стандартного отклонения от центра Z-распределения, равна 0,05. Наблюдаемый уровень значимости представляет собой вероятность того, что разность между двумя выборочными долями р(Z = 3,01) =(1-НОРМ.СТ.РАСП(3,01;ИСТИНА))*2 = 0,00262. Таким образом, можно утверждать, что два отеля значительно различаются по качеству обслуживания. Иначе говоря, доля гостей, планирующих вернуться, в отеле Beachcomer больше, чем в гостинице Windsurfer.
Использование F-критерия для оценки разности между двумя дисперсиями
Довольно часто возникает необходимость проверить, имеют ли две независимые генеральные совокупности одинаковую дисперсию. Например, это требуется для того, чтобы выбрать правильный t-критерий — использующий суммарную или раздельную дисперсию. Проверка разности между дисперсиями двух генеральных совокупностей основана на исследовании их отношения. Если каждая генеральная совокупность является нормально распределенной, отношение S12/S22 подчиняется F-распределению, получившему свое название в честь знаменитого статистика Р. Фишера. Критическое значение F-распределения зависит от двух множеств степеней свободы. Степени свободы числителя относятся к первой выборке, а степени свободы знаменателя — ко второй. Для проверки равенства двух дисперсий в критерии используется F-статистика, вычисляемая по формуле:

где S12 — дисперсия выборки из первой генеральной совокупности, n1 — объем выборки, извлеченной из первой генеральной совокупности, S22 — дисперсия выборки из второй генеральной совокупности, n2 — объем выборки, извлеченной из второй генеральной совокупности, n1 – 1 — количество степеней свободы числителя, n2 – 1 — количество степеней свободы знаменателя.
F-статистика имеет F-распределение с n1 – 1 и n2 – 1 степенями свободы. При заданном уровне значимости α нулевая и альтернативная гипотеза: H0: σ12 = σ22, H1: σ12 ≠ σ22. Если F-статистика больше верхнего критического значения FU или меньше нижнего критического значения FL из F-распределения с n1 – 1 степенями свободы в числителе и n2 – 1 степенями свободы в знаменателе, нулевая гипотеза отклоняется. Таким образом, решающее правило выглядит следующим образом: нулевая гипотеза Н0 отклоняется, если F > FU или F < FL; в противном случае нулевая гипотеза не отклоняется (рис. 15).

Рис. 15. Критическая область двустороннего F-критерия
Продемонстрируем применение F-критерия на примере сценария, описанного выше. Напомним, что в нем требовалось определить, совпадают ли средние объемы продаж BLK-колы, выставленной на обычных полках и специализированных стеллажах. Чтобы выбрать правильный t-критерий (с суммарной или раздельной дисперсией), необходимо сначала проверить гипотезу о равенстве дисперсий двух генеральных совокупностей. Следовательно, нулевая и альтернативная гипотеза формулируются так: H0: σ12 = σ22, H1: σ12 ≠ σ22.
Поскольку критерий является двусторонним, критическая область разбивается на две части, ограниченные левым и правым хвостом F-распределения. Если уровень значимости α = 0,05, каждая из этих областей соответствует вероятности, равной 0,025. Поскольку выборки содержат по 10 магазинов с разными видами полок, в первой и второй группах существуют 10 – 1 = 9 степеней свободы. Верхнее критическое значения F-распределения =F.ОБР(0,975;9;9) = 4,026; нижнее критическое значения F-распределения =F.ОБР(0,025;9;9) = 0,248 (рис. 16).

Рис. 16. Критическая область двустороннего F-критерия с уровнем значимости, равным 0,05, и 9 степенями свободы в числителе и знаменателе
Таким образом, решающее правило: нулевая гипотеза Н0 отклоняется, если F > FU =4,026 или F < FL = 0,248, в противном случае нулевая гипотеза не отклоняется.
Для расчета статистик в нашем примере снова удобно воспользоваться Пакетом анализа, выбрав строку Двухвыборочный F-тест для дисперсии (рис. 17). Поскольку FL = 0,248 < F = 2,229 < FU =4,026 у нас нет оснований отклонять нулевую гипотезу. Если необходимо применить подход, основанный на определении р-значения, то параметр р(F<=f) также выводится при расчете (см. соответствующую строку на рис. 17). Поскольку р-значение для двустороннего критерия равно 0,248 (удвоенное р-значение для одностороннего критерия), приходим к выводу, что продажи колы с разных стеллажей обладают практически одинаковой изменчивостью. Итак, t-критерий для сравнения математических ожиданий двух групп на основе суммарной дисперсии является вполне корректным.

Рис. 17. Расчет F-статистики с помощью Пакета анализа
При оценке разности между двумя дисперсиями с помощью F-критерия предполагается, что обе генеральные совокупности имеют нормальное распределение. F-критерий очень чувствителен к нарушению этого условия. Если блочная диаграмма или график нормального распределения демонстрируют значительное отклонение от указанного требования, F-критерий применять нельзя. В таких ситуациях следует применять непараметрические процедуры.
При выборе разновидности F-критерия, как правило, применяется двусторонний F-критерий. Однако, если исследователя интересует собственно изменчивость данных, можно применять односторонний F-критерий. Таким образом, для сравнения дисперсии двух генеральных совокупностей можно применять как двусторонний, так и односторонний F-критерии. Эти ситуации изображены на рис. 18.

Рис. 18. Критические области при проверке гипотез о равенстве дисперсий двух генеральных совокупностей
Довольно часто объемы выборок не равны. Например, из нормально распределенной генеральной совокупности извлечена выборка, имеющая объем n1 = 8. Дисперсия S12 этой выборки равна 56,0. Из второй распределенной генеральной совокупности, независимой от первой, извлечена выборка, имеющая объем n2 = 10. Дисперсия S22 этой выборки равна 24,0. Проверьте нулевую гипотезу, заключающуюся в том, что между дисперсиями этих генеральных совокупностей нет существенной разницы.
Верхнее критическое значения F-распределения FU =F.ОБР(0,975;7;9) = 4,197; нижнее критическое значения F-распределения FL =F.ОБР(0,025;7;9) = 0,207. F-статистика = S12/ S22 = 56 / 24 = 2,333. Решающее правило выглядит так: нулевая гипотеза Н0 отклоняется, если F > FU = 4,197 или F < FL = 0,207; в противном случае нулевая гипотеза не отклоняется. Поскольку F-статистика, равная 2,333, лежит в интервале между FL = 0,207 и FU = 4,197, нулевую гипотезу Н0 отклонять нельзя. Итак, при заданном уровне значимости α = 0,05 между дисперсиями двух независимых генеральных совокупностей нет статистически значимой разницы. Хотя дисперсия одной из генеральных совокупностей в 2,33 раза превышает другую, этот факт может оказаться случайным.
Резюме
Основное различие между критериями для сравнения двух групп заключается в свойствах генеральных совокупностей: независимы они или взаимозависимы, а также в особенностях исследуемой переменной, числовой или категорийной. Классифицировав критерии по группам, необходимо обратить особое внимание на условия, которые должны выполняться при их применении (рис. 19).

Рис. 19. Структурная схема заметки
Предыдущая заметка Проверка гипотез: одновыборочные критерии
Следующая заметка Однофакторный дисперсионный анализ
К оглавлению Статистика для менеджеров с использованием Microsoft Excel
[1] Используются материалы книги Левин и др. Статистика для менеджеров. – М.: Вильямс, 2004. – с. 579–640
[2] Если объем выборки достаточно велик, центральная предельная теорема утверждает, что средняя разность ![]() имеет нормальное распределение.
имеет нормальное распределение.