
Уважаемые коллеги, мы рады предложить вам, разрабатываемый нами учебный курс по программированию ПЛК фирмы Beckhoff с применением среды автоматизации TwinCAT. Курс предназначен исключительно для самостоятельного изучения в ознакомительных целях. Перед любым применением изложенного материала в коммерческих целях просим связаться с нами. Текст из предложенных вам статей скопированный и размещенный в других источниках, должен содержать ссылку на наш сайт heaviside.ru. Вы можете связаться с нами по любым вопросам, в том числе создания для вас систем мониторинга и АСУ ТП.
Типы данных в языках стандарта МЭК 61131-3
Уважаемые коллеги, в этой статье мы будем рассматривать важнейшую для написания программ тему — типы данных. Чтобы читатели понимали, в чем отличие одних типов данных от других и зачем они вообще нужны, мы подробно разберем, каким образом данные представлены в процессоре. В следующем занятии будет большая практическая работа, выполняя которую, можно будет потренироваться объявлять переменные и на практике познакомится с особенностями выполнения математических операций с различными типами данных.
Простые типы данных
В прошлой статье мы научились записывать цифры в двоичной системе счисления. Именно такую систему счисления используют все компьютеры, микропроцессоры и прочая вычислительная техника. Теперь мы будем изучать типы данных.
Любая переменная, которую вы используете в своем коде, будь то показания датчиков, состояние выхода или выхода, состояние катушки или просто любая промежуточная величина, при выполнении программы будет хранится в оперативной памяти. Чтобы под каждую используемую переменную на этапе компиляции проекта была выделена оперативная память, мы объявляем переменные при написании программы. Компиляция, это перевод исходного кода, написанного программистом, в команды на языке ассемблера понятные процессору. Причем в зависимости от вида применяемого процессора один и тот же исходный код может транслироваться в разные ассемблерные команды (вспомним что ПЛК Beckhoff, как и персональные компьютеры работают на процессорах семейства x86).
Как помните, из статьи Знакомство с языком LD, при объявлении переменной необходимо указать, к какому типу данных будет принадлежать переменная. Как вы уже можете понять, число B016 будет занимать гораздо меньший объем памяти чем число 4 C4E5 01E7 7A9016. Также одни и те же операции с разными типами данных будут транслироваться в разные ассемблерные команды. В TwinCAT используются следующие типы данных:
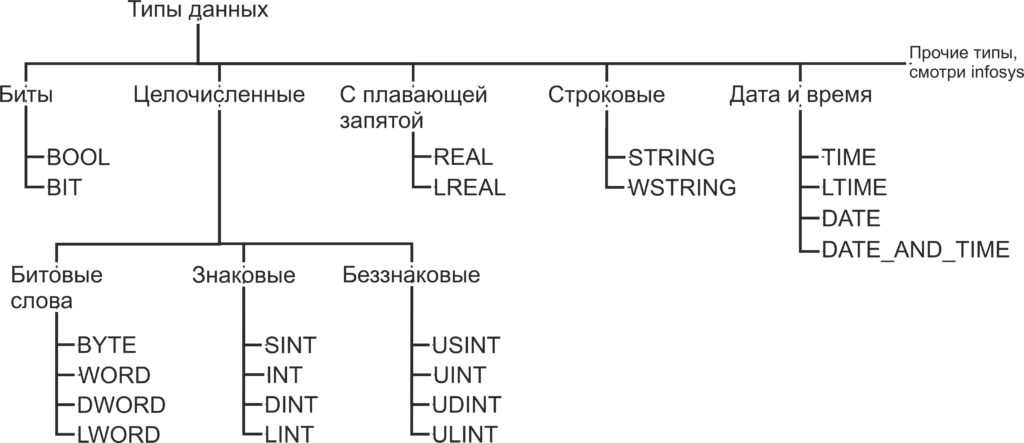
Биты
BOOL — это простейший тип данных, как уже было сказано, этот тип данных может принимать только два значения 0 и 1. Так же в TwinCAT, как и в большинстве языков программирования, эти значения, наравне с 0 и 1, обозначаются как TRUE и FALSE и несут в себе количество информации, соответствующее одному биту. Минимальным объемом данных, который читается из памяти за один раз, является байт, то есть восемь бит. Поэтому, для оптимизации скорости доступа к данным, переменная типа BOOL занимает восемь бит памяти. Для хранения самой переменной используется нулевой бит, а биты с первого по седьмой заполнены нулями. Впрочем, на практике о таком нюансе приходится вспоминать достаточно редко.
BIT — то же самое, что и BOOL, но в памяти занимает 1 бит. Как можно догадаться, операции с этим типом данных медленнее чем с типом BOOL, но он занимает меньше места в памяти. Тип данных BIT отсутствует в стандарте МЭК 61131-3 и поддерживается исключительно в TwinCAT, поэтому стоит отдавать предпочтение типу BOOL, когда у вас нет явных поводов использовать тип BIT.
Целочисленные типы данных
BYTE — тип данных, по размеру соответствующий одному байту. Хоть с типом BYTE можно производить математические операции, но в первую очередь он предназначен для хранения набора из 8 бит. Иногда в таком виде удобнее, чем побитно, передавать данные по цифровым интерфейсам, работать с входами выходами и так далее. С такими вопросами мы будем знакомится далее по мере изучения курса. В переменную типа BYTE можно записать числа из диапазона 0..255 (0..28-1).
WORD — то же самое, что и BYTE, но размером 16 бит. В переменную типа WORD можно записать числа из диапазона 0..65 535 (0..216-1). Тип данных WORD переводится с английского как «слово». Давным-давно термином машинное слово называли группу бит, обрабатываемых вычислительной машиной за один раз. Была уместна фраза «Программа состоит из машинных слов.». Со временем этим термином перестали пользоваться в прямом его значении, и сейчас под термином «машинное слово» обычно подразумевается группа из 16 бит.
DWORD — то же самое, что и BYTE, но размером 32 бит. В переменную типа DWORD можно записать числа из диапазона 0..4 294 967 295 (0..232-1). DWORD — это сокращение от double word, что переводится как двойное слово. Довольно часто буква «D» перед каким-либо типом данных значит, что этот тип данных в два раза длиннее, чем исходный.
LWORD — то же самое, что и BYTE, но размером 64 ;бит. В переменную типа LWORD можно записать числа из диапазона 0..18 446 744 073 709 551 615 (0..264-1). LWORD — это сокращение от long word, что переводится как длинное слово. Приставка «L» перед типом данных, как правило, означает что такой тип имеет длину 64 бита.
SINT — знаковый тип данных, длинной 8 бит. В переменную типа SINT можно записать числа из диапазона -128..127 (-27..27-1). В отличии от всех предыдущих типов данных этот тип данных предназначен для хранения именно чисел, а не набора бит. Слово знаковый в описании типа означает, что такой тип данных может хранить как положительные, так и отрицательные значения. Для хранения знака числа предназначен старший, в данном случае седьмой, разряд числа. Если старший разряд имеет значение 0, то число интерпретируется как положительное, если 1, то число интерпретируется как отрицательное. Приставка «S» означает short, что переводится с английского как короткий. Как вы догадались, SINT короткий вариант типа INT.
USINT — беззнаковый тип данных, длинной 8 бит. В переменную типа USINT можно записать числа из диапазона 0..255 (0..28-1). Приставка «U» означает unsigned, переводится как беззнаковый.
Остальные целочисленные типы аналогичны уже описанным и отличаются только размером. Сведем все целочисленные типы в таблицу.
| Тип данных | Нижний предел | Верхний предел | Занимаемая память |
| BYTE | 0 | 255 | 8 бит |
| WORD | 0 | 65 535 | 16 бит |
| DWORD | 0 | 4 294 967 295 | 32 бит |
| LWORD | 0 | 264-1 | 64 бит |
| SINT | -128 | 127 | 8 бит |
| USINT | 0 | 255 | 8 бит |
| INT | -32 768 | 32 767 | 16 бит |
| UINT | 0 | 65 535 | 16 бит |
| DINT | -2 147 483 648 | 2 147 483 647 | 32 бит |
| UDINT | 0 | 4 294 967 295 | 32 бит |
| LINT | -263 | -263-1 | 64 бит |
| ULINT | 0 | -264-1 | 64 бит |
Выше мы рассматривали целочисленные типы данных, то есть такие типы данных, в которых отсутствует запятая. При совершении математических операций с целочисленными типами данных есть некоторые особенности:
- Округление при делении: округление всегда выполняется вниз. То есть дробная часть просто отбрасывается. Если делимое меньше делителя, то частное всегда будет равно нулю, например, 10/11 = 0.
- Переполнение: если к целочисленной переменной, например, SINT, имеющей значение 255, прибавить 1, переменная переполнится и примет значение 0. Если прибавить 2, переменная примет значение 1 и так далее. При операции 0 — 1 результатом будет 255. Это свойство очень схоже с устройством стрелочных часов. Если сейчас 2 часа, то 5 часов назад было 9 часов. Только шкала часов имеет пределы не 1..12, а 0..255. Иногда такое свойство может использоваться при написании программ, но как правило не стоит допускать переполнения переменных.
Подробно такие нюансы разбираются в пособиях по дискретной математике. Мы на них пока что останавливаться не будем, но о приведенных двух особенностях не стоит забывать при написании программ.
Можно встретить упоминания о данных с фиксированной запятой, это такие данные, в которых количество знаков после запятой строго фиксировано. В TwinCAT типы данных с фиксированной запятой отсутствуют в чистом виде. TwinCAT поддерживает типы данных с плавающей запятой, то есть количество знаков до и после запятой может быть любым в пределах поддерживаемого диапазона.
Типы данных с плавающей запятой
REAL — тип данных с плавающей запятой длинной 32 бита. В переменную типа REAL можно записать числа из диапазона -3.402 82*1038..3.402 82*1038.
LREAL — тип данных с плавающей запятой длинной 64 бита. В переменную типа LREAL можно записать числа из диапазона -1.797 693 134 862 315 8*10308..1.797 693 134 862 315 8*10308.
При присваивании значения типам REAL и LREAL присваиваемое значение должно содержать целую часть, разделительную точку и дробную часть, например, 7.4 или 560.0.
Так же при записи значения типа REAL и LREAL использовать экспоненциальную (научную) форму. Примером экспоненциальной формы записи будет Me+P, в этом примере
- M называется мантиссой.
- e называется экспонентой (от англ. «exponent»), означающая «·10^» («…умножить на десять в степени…»),
- P называется порядком.
Примерами такой формы записи будет:
- 1.64e+3 расшифровывается как 1.64e+3 = 1.64*103 = 1640.
- 9.764e+5 расшифровывается как 9.764e+5 = 9.764*105 = 976400.
- 0.3694e+2 расшифровывается как 0.3694e+2 = 0.3694*102 = 36.94.
Еще один способ записи присваиваемого значения переменной типа REAL и LREAL, это добавить к числу префикс REAL#, например, REAL#7.4 или REAL#560. В таком случае можно не указывать дробную часть.
Старший, 31-й бит переменной типа REAL представляет собой знак. Следующие восемь бит, с 30-го по 23-й отведены под экспоненту. Оставшиеся 23 бита, с 22-го по 0-й используются для записи мантиссы.
В переменной типа LREAL старший, 63-й бит также используется для записи знака. В следующие 11 бит, с 62 по 52-й, записана экспонента. Оставшиеся 52 бита, с 51-го по 0-й, используются для записи мантиссы.
При записи числа с большим количеством значащих цифр в переменные типа REAL и LREAL производится округление. Необходимо не забывать об этом в расчетах, к которым предъявляются строгие требования по точности. Еще одна особенность, вытекающая из прошлой, если вы хотите сравнить два числа типа REAL или LREAL, прямое сравнение мало применимо, так как если в результате округления числа отличаются хоть на малую долю результат сравнения будет FALSE. Чтобы выполнить сравнение более корректно, можно вычесть одно число из другого, а потом оценить больше или меньше модуль получившегося результата вычитания, чем наибольшая допустимая разность. Поведение системы при переполнении переменных с плавающей запятой не определенно стандартом МЭК 61131-3, допускать его не стоит.
Строковые типы данных
STRING — тип данных для хранения символов. Каждый символ в переменной типа STRING хранится в 1 байте, в кодировке Windows-1252, это значит, что переменные такого типа поддерживают только латинские символы. При объявлении переменной количество символов в переменной указывается в круглых или квадратных скобках. Если размер не указан, при объявлении по умолчанию он равен 80 символам. Для данных типа STRING количество содержащихся в переменной символов не ограниченно, но функции для обработки строк могут принять до 255 символов.
Объем памяти, необходимый для переменной STRING, всегда составляет 1 байт на символ +1 дополнительный байт, например, переменная объявленная как «STRING [80]» будет занимать 81 байт. Для присвоения константного значения переменной типа STRING присваемый текст необходимо заключить в одинарные кавычки.
Пример объявления строки на 35 символов:
sVar : STRING(35) := 'This is a String'; (*Пример объявления переменной типа STRING*)
WSTRING — этот тип данных схож с типом STRING, но использует по 2 байта на символ и кодировку Unicode. Это значит что переменные типа WSTRING поддерживают символы кириллицы. Для присвоения константного значения переменной типа WSTRING присваемый текст необходимо заключить в двойные кавычки.
Пример объявления переменной типа WSTRING:
wsVar : WSTRING := "This is a WString"; (*Пример объявления переменной типа WSTRING*)Если значение, присваиваемое переменной STRING или WSTRING, содержит знак доллара ($), следующие два символа интерпретируются как шестнадцатеричный код в соответствии с кодировкой Windows-1252. Код также соответствует кодировке ASCII.
| Код со знаком доллара | Его значение в переменной |
| $<восьмибитное число> | Восьмибитное число интерпретируется как символ в кодировке ISO / IEC 8859-1 |
| ‘$41’ | A |
| ‘$9A’ | © |
| ‘$40’ | @ |
| ‘$0D’, ‘$R’, ‘$r’ | Разрыв строки |
| ‘$0A’, ‘$L’, ‘$l’, ‘$N’, ‘$n’ | Новая строка |
| ‘$P’, ‘$p’ | Конец страницы |
| ‘$T’, ‘$t’ | Табуляция |
| ‘$$’ | Знак доллара |
| ‘$’ ‘ | Одиночная кавычка |
Такое разнообразие кодировок связанно с тем, что у всех из них первые 128 символов соответствуют кодовой таблице ASCII, но в статье для каждого случая кодировка указывалась так же, как она указана в infosys.
Пример:
VAR CONSTANT
sConstA : STRING :='Hello world';
sConstB : STRING :='Hello world $21'; (*Пример объявления переменной типа STRING с спец символом*)
END_VAR
Типы данных времени
TIME — тип данных, предназначенный для хранения временных промежутков. Размер типа данных 32 бита. Этот тип данных интерпретируется в TwinCAT, как переменная типа DWORD, содержащая время в миллисекундах. Нижний допустимый предел 0 (0 мс), верхний предел 4 294 967 295 (49 дней, 17 часов, 2 минуты, 47 секунд, 295 миллисекунд). Для записи значений в переменные типа TIME используется префикс T# и суффиксы d: дни, h: часы, m: минуты, s: секунды, ms: миллисекунды, которые должны располагаться в порядке убывания.
Примеры корректного присваивания значения переменной типа TIME:
TIME1 : TIME := T#14ms;
TIME1 : TIME := T#100s12ms; // Допускается переполнение в старшем отрезке времени.
TIME1 : TIME := t#12h34m15s;Примеры некорректного присваивания значения переменной типа TIME, при компиляции будет выдана ошибка:
TIME1 : TIME := t#5m68s; // Переполнение не в старшем отрезке времени недопустимо
TIME1 : TIME := 15ms; // Пропущен префикс T#
TIME1 : TIME := t#4ms13d; // Не соблюден порядок записи временных отрезокLTIME — тип данных аналогичен TIME, но его размер составляет 64 бита, а временные отрезки хранятся в наносекундах. Нижний допустимый предел 0, верхний предел 213 503 дней, 23 часов, 34 минуты, 33 секунд, 709 миллисекунд, 551 микросекунд и 615 наносекунд. Для записи значений в переменные типа LTIME используется префикс LTIME#. Помимо суффиксов, используемых для записи типа TIME для LTIME, используются µs: микросекунды и ns: наносекунды.
Пример:
LTIME1 : LTIME := LTIME#1000d15h23m12s34ms2us44ns; (*Пример объявления переменной типа LTIME*)TIME_OF_DAY (TOD) — тип данных для записи времени суток. Имеет размер 32 бита. Нижнее допустимое значение 0, верхнее допустимое значение 23 часа, 59 минут, 59 секунд, 999 миллисекунд. Для записи значений в переменные типа TOD используется префикс TIME_OF_DAY# или TOD#, значение записывается в виде <часы : минуты : секунды> . В остальном этот тип данных аналогичен типу TIME.
Пример:
TIME_OF_DAY#15:36:30.123
tod#00:00:00Date — тип данных для записи даты. Имеет размер 32 бита. Нижнее допустимое значение 0 (01.01.1970), верхнее допустимое значение 4 294 967 295 (7 февраля 2106), да, здесь присутствует возможный компьютерный апокалипсис, но учитывая запас по верхнему пределу, эта проблема не слишком актуальна. Для записи значений в переменные типа TOD используется префикс DATE# или D#, значение записывается в виде <год — месяц — дата>. В остальном этот тип данных аналогичен типу TIME.
DATE#1996-05-06
d#1972-03-29DATE_AND_TIME (DT) — тип данных для записи даты и времени. Имеет размер 32 бита. Нижнее допустимое значение 0 (01.01.1970), верхнее допустимое значение 4 294 967 295 (7 февраля 2106, 6:28:15). Для записи значений в переменные типа DT используется префикс DATE_AND_TIME # или DT#, значение записывается в виде <год — месяц — дата — час : минута : секунда>. В остальном этот тип данных аналогичен типу TIME.
DATE_AND_TIME#1996-05-06-15:36:30
dt#1972-03-29-00:00:00На этом раз мы заканчиваем рассмотрение типов данных. Сейчас мы разобрали не все типы данных, остальные можно найти в infosys по пути TwinCAT 3 → TE1000 XAE → PLC → Reference Programming → Data types.
Следующая статья будет целиком состоять из практической работы, мы напишем калькулятор на языке LD.
Целые числа
Данные каким-либо образом необходимо представлять в памяти компьютера. Существует множество различных типов данных, простых и довольно сложных, имеющих большое число компонентов и свойств. Однако, для компьютера необходимо использовать некий унифицированный способ представления данных, некоторые элементарные составляющие, с помощью которых можно представить данные абсолютно любых типов. Этими составляющими являются числа, а вернее, цифры, из которых они состоят. С помощью цифр можно закодировать практически любую дискретную информацию. Поэтому такая информация часто называется цифровой (в отличие от аналоговой, непрерывной).
Первым делом необходимо выбрать систему счисления, наиболее подходящую для применения в конкретных устройствах. Для электронных устройств самой простой реализацией является двоичная система: есть ток — нет тока, или малый уровень тока — большой уровень тока. Хотя наиболее эффективной являлась бы троичная система. Наверное, выбор двоичной системы связан еще и с использование перфокарт, в которых она проявляется в виде наличия или отсутствия отверстия. Отсюда в качестве цифр для представления информации используются 0 и 1.
Таким образом данные в компьютере представляются в виде потока нулей и единиц. Один разряд этого потока называется битом. Однако в таком виде неудобно оперировать с данными вручную. Стандартом стало разделение всего потока на равные последовательные группы из 8 битов — байты или октеты. Далее несколько байтов могут составлять слово. Здесь следует разделять машинное слово и слово как тип данных. В первом случае его разрядность обычно равна разрядности процессора, т.к. машинное слово является наиболее эффективным элементом для его работы. В случае, когда слово трактуется как тип данных (word), его разрядность всегда равна 16 битам (два последовательных байта). Также как типы данных существую двойные слова (double word, dword, 32 бита), четверные слова (quad word, qword, 64 бита) и т.п.
Теперь мы вплотную подошли к представлению целых чисел в памяти. Т.к. у нас есть байты и различные слова, то можно создать целочисленные типы данных, которые будут соответствовать этим элементарным элементам: byte (8 бит), word (16 бит), dword (32 бита), qword (64 бита) и т.д. При этом любое число этих типов имеет обычное двоичное представление, дополненное нулями до соответствующей размерности. Можно заметить, что число меньшей размерности можно легко представить в виде числа большей размерности, дополнив его нулями, однако в обратном случае это не верно. Поэтому для представления числа большей размерности необходимо использовать несколько чисел меньшей размерности. Например:
- qword (64 бита) можно представить в виде 2 dword (32 бита) или 4 word (16 бит) или 8 byte (8 бит);
- dword (32 бита) можно представить в виде 2 word (16 бит) или 4 byte (8 бит);
- word (16 бит) можно представить в виде 2 byte (8 бит);
Если A — число, B1..Bk — части числа, N — разрядность числа, M — разрядность части, N = k*M, то:
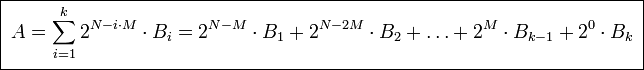
Например:
- A = F1E2D3C4B5A69788 (qword)
- A = 232 * F1E2D3C4 (dword) + 20 * B5A69788 (dword)
- A = 248 * F1E2 (word) + 232 * D3C4 (word) + 216 * B5A6 (word) + 20 * 9788 (word)
- A = 256 * F1 (byte) + 248 * E2 (byte) + … + 28 * 97 (byte) + 20 * 88 (byte)
Существуют понятия младшая часть (low) и старшая часть (hi) числа. Старшая часть входит в число с коэффициентом 2N-M, а младшая с коэффициентом 20. Например:
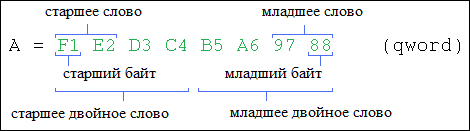
Байты числа можно хранить в памяти в различном порядке. В настоящее время используются два способа расположения: в прямом порядке байт и в обратном порядке байт. В первом случае старший байт записывается в начале, затем последовательно записываются остальные байты, вплоть до младшего. Такой способ используется в процессорах Motorola и SPARC. Во втором случае, наоборот, сначала записывает младший байт, а затем последовательно остальные байты, вплоть до старшего. Такой способ используется в процессорах архитектуры x86 и x64. Далее приведен пример:

Используя подобные целочисленные типы можно представить большое количество неотрицательных чисел: от 0 до 2N-1, где N — разрядность типа. Однако, целочисленный тип подразумевает представление также и отрицательных чисел. Можно ввести отдельные типы для отрицательных чисел от -2N до -1, но тогда такие типы потеряют универсальность хранить и неотрицательные, и отрицательные числа. Поэтому для определения знака числа можно выделить один бит из двоичного представления. По соглашению, это старший бит. Остальная часть числа называется мантиссой.
Если старший бит равен нулю, то мантисса есть обычное представление числа от 0 до 2N-1-1. Если же старший бит равен 1, то число является отрицательным и мантисса представляет собой так называемый дополнительный код числа. Поясним на примере:
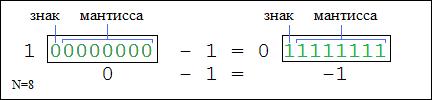
Как видно из рисунка, дополнительный код равен разнице между числом 2N-1 и модулем исходного отрицательного числа (127 (1111111) = 128 (10000000) — |-1| (0000001)). Из этого вытекает, что сумма основного и дополнительного кода одного и того же числа равна 2N-1.
Из вышеописанного получается, что можно использовать только целочисленные типы со знаком для описания чисел. Однако существует множество сущностей, которые не требуют отрицательных значений, а значит, место под знак можно включить в представление неотрицательного числа, удвоив количество различных неотрицательных значений. Как результат, в современных компьютерах используются как типы со знаком или знаковые типы, так и типы без знака или беззнаковые типы.
В итоге можно составить таблицу наиболее используемых целочисленных типов данных:
| Общее название | Название в Pascal | Название в C++ | Описание | Диапазон значений |
| unsigned byte | byte | unsigned char | беззнаковый 8 бит | 0..255 |
| signed byte | shortint | char | знаковый 8 бит | -128..127 |
| unsigned word | word | unsigned short | беззнаковый 16 бит | 0..65535 |
| signed word | smallint | short | знаковый 16 бит | -32768..32767 |
| unsigned double word | cardinal | unsigned int | беззнаковый 32 бита | 0..232-1 |
| signed double word | integer | int | знаковый 32 бита | -231..231-1 |
| unsigned quad word | uint64 | unsigned long long unsigned __int64_t (VC++) |
беззнаковый 64 бита | 0..264-1 |
| signed quad word | int64 | long long __int64_t (VC++) |
знаковый 64 бита | -263..263-1 |
Home * Programming * Data * Double Word
According to Intel’s definition of a x86 16-bit Word, a Double Word refers a 32-bit entity, while IBM 360 and successors with 32-bit words have double words with 64-bit.
Contents
- 1 Integer and long
- 2 Ranges
- 3 Alignment
- 4 Endianness
- 4.1 Litte-endian Layout
- 4.2 Big-endian Layout
- 5 See also
- 6 External Links
Integer and long
Even in x86-64, double words are still considered as default word size. x86 and and x86-64 C-Compiler use double words as signed and unsigned integers, Java integers as well. Microsoft 64 bit compiler long is a 32-bit Double word as well, while with 64-bit GCC uses 64-bit Quad Words as longs.
typedef unsigned int DWORD;
Ranges
| language | type | min | max |
|---|---|---|---|
| C, C++ | unsigned int | 0 | 4,294,967,295 |
| hexadecimal | 0x00000000 | 0xFFFFFFFF | |
| C, C++, Java |
int | -2,147,483,648 | 2,147,483,647 |
| hexadecimal | 0x80000000 | 0x7FFFFFFF |
Alignment
Double Words stored in memory should be stored at byte addresses divisible by four. Otherwise at runtime it will cause a miss-alignment exception on some processors, or a huge penalty on others.
Endianness
Main article: Endianness.
Litte-endian Layout
The little-endian memory layout, as typical for Intel x86 cpus.
For instance the double word integer 16909060 or 0x01020304:
| Address | Byte | Significance |
|---|---|---|
| 0x0000 | 0x04 | LS Byte |
| 0x0001 | 0x03 | |
| 0x0002 | 0x02 | |
| 0x0003 | 0x01 | MS Byte |
Big-endian Layout
The big-endian memory layout, as typical for Motorola cpus.
For instance the double word integer 16909060 or 0x01020304:
| Address | Byte | Significance |
|---|---|---|
| 0x0000 | 0x01 | MS Byte |
| 0x0001 | 0x02 | |
| 0x0002 | 0x03 | |
| 0x0003 | 0x04 | LS Byte |
See also
- Piece-Sets
- Byte
- Word
- Quad Word
External Links
- Dword, Qword, and Oword from Wikipedia
- Byte from Wikipedia
- Endianness from Wikipedia
- Understanding Big and Little Endian Byte Order
- DAV’s Endian FAQ — ON HOLY WARS AND A PLEA FOR PEACE by Danny Cohen
Up one Level
Double-words are 32-bit (four byte)
unsigned
integers with a
range of 0 to 4,294,967,295 ( 0 to 2^32-1). The type-specifier
character for a Double-word is: ???.
Double-word variables are identified by
following the variable name with three question marks (i.e., var???),
or by using the DEFDWD
statement as described in the previous discussion of Integers. You
can also declare Double word variables using the DWORD keyword with the
DIM statement. For example:
DIM I AS DWORD
As for Word values and
Integers, Double-word values have a larger positive range than a Long-integer,
and still require only four bytes. Double-word values are useful
for indicating absolute memory addresses, such as may be used to store
pointer values.
A PowerBASIC Double-word is equivalent to a UINT32 in C/C++.
In 32-bit C/C++ code, a UINT is also equivalent to a PowerBASIC
Double-word variable. Note that 16-bit C/C++ code uses UINT
to describe a 16-bit Word variable.
A C++ unsigned int and a Delphi longword are equivalent
to a PowerBASIC Double-word.
See Also
Array Data
Types
Bit Data Types
Constants
and Literals
Floating Point Data Types
GUID Data Types
Integer Data Types
Object Data
Types
Pointer Data Types
String Data Types
User
Defined Types
Unions
Variant
Data Types
One of the first things that is going to strike many first-time programmers of the Win32 API is that there are tons and tons of old data types to deal with. Sometimes, just keeping all the correct data types in order can be more difficult than writing a nice program. This page will talk a little bit about some of the data types that a programmer will come in contact with.
Hungarian Notation[edit | edit source]
First, let’s make a quick note about the naming convention used for some data types, and some variables. The Win32 API uses the so-called «Hungarian Notation» for naming variables. Hungarian Notation requires that a variable be prefixed with an abbreviation of its data type, so that when you are reading the code, you know exactly what type of variable it is. The reason this practice is done in the Win32 API is because there are many different data types, making it difficult to keep them all straight. Also, there are a number of different data types that are essentially defined the same way, and therefore some compilers will not pick up on errors when they are used incorrectly. As we discuss each data type, we will also note the common prefixes for that data type.
Putting the letter «P» in front of a data type, or «p» in front of a variable usually indicates that the variable is a pointer. The letters «LP» or the prefix «lp» stands for «Long Pointer», which is exactly the same as a regular pointer on 32 bit machines. LP data objects are simply legacy objects that were carried over from Windows 3.1 or earlier, when pointers and long pointers needed to be differentiated. On modern 32-bit systems, these prefixes can be used interchangeably.
LPVOID[edit | edit source]
LPVOID data types are defined as being a «pointer to a void object». This may seem strange to some people, but the ANSI-C standard allows for generic pointers to be defined as «void*» types. This means that LPVOID pointers can be used to point to any type of object, without creating a compiler error. However, the burden is on the programmer to keep track of what type of object is being pointed to.
Also, some Win32 API functions may have arguments labeled as «LPVOID lpReserved». These reserved data members should never be used in your program, because they either depend on functionality that hasn’t yet been implemented by Microsoft, or else they are only used in certain applications. If you see a function with an «LPVOID lpReserved» argument, you must always pass a NULL value for that parameter — some functions will fail if you do not do so.
LPVOID objects frequently do not have prefixes, although it is relatively common to prefix an LPVOID variable with the letter «p», as it is a pointer.
DWORD, WORD, BYTE[edit | edit source]
These data types are defined to be a specific length, regardless of the target platform. There is a certain amount of additional complexity in the header files to achieve this, but the result is code that is very well standardized, and very portable to different hardware platforms and different compilers.
DWORDs (Double WORDs), the most commonly occurring of these data types, are defined always to be unsigned 32-bit quantities. On any machine, be it 16, 32, or 64 bits, a DWORD is always 32 bits long. Because of this strict definition, DWORDS are very common and popular on 32-bit machines, but are less common on 16-bit and 64-bit machines.
WORDs (Single WORDs) are defined strictly as unsigned 16-bit values, regardless of what machine you are programming on. BYTEs are defined strictly as being unsigned 8-bit values. QWORDs (Quad WORDs), although rare, are defined as being unsigned 64-bit quantities. Putting a «P» in front of any of these identifiers indicates that the variable is a pointer. putting two «P»s in front indicates it’s a pointer to a pointer. These variables may be unprefixed, or they may use any of the prefixes common with DWORDs. Because of the differences in compilers, the definition of these data types may be different, but typically these definitions are used:
#include <stdint.h>
typedef uint8_t BYTE; typedef uint16_t WORD; typedef uint32_t DWORD; typedef uint64_t QWORD;
Notice that these definitions are not the same in all compilers. It is a known issue that the GNU GCC compiler uses the long and short specifiers differently from the Microsoft C Compiler. For this reason, the windows header files typically will use conditional declarations for these data types, depending on the compiler being used. In this way, code can be more portable.
As usual, we can define pointers to these types as:
#include <stdint.h>
typedef uint8_t * PBYTE; typedef uint16_t * PWORD; typedef uint32_t * PDWORD; typedef uint64_t * PQWORD;
typedef uint8_t ** PPBYTE; typedef uint16_t ** PPWORD; typedef uint32_t ** PPDWORD; typedef uint64_t ** PPQWORD;
DWORD variables are typically prefixed with «dw». Likewise, we have the following prefixes:
| Data Type | Prefix |
|---|---|
| BYTE | «b» |
| WORD | «w» |
| DWORD | «dw» |
| QWORD | «qw» |
LONG, INT, SHORT, CHAR[edit | edit source]
These types are not defined to a specific length. It is left to the host machine to determine exactly how many bits each of these types has.
- Types
typedef long LONG; typedef unsigned long ULONG; typedef int INT; typedef unsigned int UINT; typedef short SHORT; typedef unsigned short USHORT; typedef char CHAR; typedef unsigned char UCHAR;
- LONG notation
- LONG variables are typically prefixed with an «l» (lower-case L).
- UINT notation
- UINT variables are typically prefixed with an «i» or a «ui» to indicate that it is an integer, and that it is unsigned.
- CHAR, UCHAR notation
- These variables are usually prefixed with a «c» or a «uc» respectively.
If the size of the variable doesn’t matter, you can use some of these integer types. However, if you want to exactly specify the size of a variable, so that it has a certain number of bits, use the BYTE, WORD, DWORD, or QWORD identifiers, because their lengths are platform-independent and never change.
STR, LPSTR[edit | edit source]
STR data types are string data types, with storage already allocated. This data type is less common than the LPSTR. STR data types are used when the string is supposed to be treated as an immediate array, and not as a simple character pointer. The variable name prefix for a STR data type is «sz» because it’s a zero-terminated string (ends with a null character).
Most programmers will not define a variable as a STR, opting instead to define it as a character array, because defining it as an array allows the size of the array to be set explicitly. Also, creating a large string on the stack can cause greatly undesirable stack-overflow problems.
LPSTR stands for «Long Pointer to a STR», and is essentially defined as such:
#define STR * LPSTR;
LPSTR can be used exactly like other string objects, except that LPSTR is explicitly defined as being ASCII, not unicode, and this definition will hold on all platforms. LPSTR variables will usually be prefixed with the letters «lpsz» to denote a «Long Pointer to a String that is Zero-terminated». The «sz» part of the prefix is important, because some strings in the Windows world (especially when talking about the DDK) are not zero-terminated. LPSTR data types, and variables prefixed with the «lpsz» prefix can all be used seamlessly with the standard library <string.h> functions.
TCHAR[edit | edit source]
TCHAR data types, as will be explained in the section on Unicode, are generic character data types. TCHAR can hold either standard 1-byte ASCII characters, or wide 2-byte Unicode characters. Because this data type is defined by a macro and is not set in stone, only character data should be used with this type. TCHAR is defined in a manner similar to the following (although it may be different for different compilers):
#ifdef UNICODE #define TCHAR WORD #else #define TCHAR BYTE #endif
TSTR, LPTSTR[edit | edit source]
Strings of TCHARs are typically referred to as TSTR data types. More commonly, they are defined as LPTSTR types as such:
#define TCHAR * LPTSTR
These strings can be either UNICODE or ASCII, depending on the status of the UNICODE macro. LPTSTR data types are long pointers to generic strings, and may contain either ASCII strings or Unicode strings, depending on the environment being used. LPTSTR data types are also prefixed with the letters «lpsz».
HANDLE[edit | edit source]
HANDLE data types are some of the most important data objects in Win32 programming, and also some of the hardest for new programmers to understand. Inside the kernel, Windows maintains a table of all the different objects that the kernel is responsible for. Windows, buttons, icons, mouse pointers, menus, and so on, all get an entry in the table, and each entry is assigned a unique address known as a HANDLE. If you want to pick a particular entry out of that table, you need to give Windows the HANDLE value, and Windows will return the corresponding table entry.
HANDLEs are defined as void pointers (void*). They are used as unique identifiers to each Windows object in our program such as a button, a window an icon, etc. Specifically their definition follows:
typedef PVOID HANDLE;
and
typedef void *PVOID;
In other words HANDLE = void*.
HANDLEs are generally prefixed with an «h». Handles are unsigned integers that Windows uses internally to keep track of objects in memory. Windows moves objects like memory blocks in memory to make room, if the object is moved in memory, the handles table is updated.
Below are a few special handles that are worth discussing:
HWND[edit | edit source]
HWND data types are «Handles to a Window», and are used to keep track of the various objects that appear on the screen. To communicate with a particular window, you need to have a copy of the window’s handle. HWND variables are usually prefixed with the letters «hwnd», just so the programmer knows they are important.
Canonically, main windows are defined as:
HWND hwnd;
Child windows are defined as:
HWND hwndChild1, hwndChild2...
and Dialog Box handles are defined as:
HWND hDlg;
Although you are free to name these variables whatever you want in your own program, readability and compatibility suffer when an idiosyncratic naming scheme is chosen — or worse, no scheme at all.
HINSTANCE[edit | edit source]
HINSTANCE variables are handles to a program instance. Each program gets a single instance variable, and this is important so that the kernel can communicate with the program. If you want to create a new window, for instance, you need to pass your program’s HINSTANCE variable to the kernel, so that the kernel knows what program instance the new window belongs to. If you want to communicate with another program, it is frequently very useful to have a copy of that program’s instance handle. HINSTANCE variables are usually prefixed with an «h», and furthermore, since there is frequently only one HINSTANCE variable in a program, it is canonical to declare that variable as such:
HINSTANCE hInstance;
It is usually a benefit to make this HINSTANCE variable a global value, so that all your functions can access it when needed.
[edit | edit source]
If your program has a drop-down menu available (as most visual Windows programs do), that menu will have an HMENU handle associated with it. To display the menu, or to alter its contents, you need to have access to this HMENU handle. HMENU handles are frequently prefixed with simply an «h».
WPARAM, LPARAM[edit | edit source]
In the earlier days of Microsoft Windows, parameters were passed to a window in one of two formats: WORD-length (16-bit) parameters, and LONG-length (32-bit) parameters. These parameter types were defined as being WPARAM (16-bit) and LPARAM (32-bit). However, in modern 32-bit systems, WPARAM and LPARAM are both 32 bits long. The names however have not changed, for legacy reasons.
WPARAM and LPARAM variables are generic function parameters, and are frequently type-cast to other data types including pointers and DWORDs.
Next Chapter[edit | edit source]
- Unicode

In the C programming language, data types constitute the semantics and characteristics of storage of data elements. They are expressed in the language syntax in form of declarations for memory locations or variables. Data types also determine the types of operations or methods of processing of data elements.
The C language provides basic arithmetic types, such as integer and real number types, and syntax to build array and compound types. Headers for the C standard library, to be used via include directives, contain definitions of support types, that have additional properties, such as providing storage with an exact size, independent of the language implementation on specific hardware platforms.[1][2]
Basic types[edit]
Main types[edit]
The C language provides the four basic arithmetic type specifiers char, int, float and double, and the modifiers signed, unsigned, short, and long. The following table lists the permissible combinations in specifying a large set of storage size-specific declarations.
| Type | Explanation | Minimum size (bits) | Format specifier | Range | Suffix for decimal constants |
|---|---|---|---|---|---|
char |
Smallest addressable unit of the machine that can contain basic character set. It is an integer type. Actual type can be either signed or unsigned. It contains CHAR_BIT bits.[3] | 8 | %c |
CHAR_MIN / CHAR_MAX |
n/a |
signed char |
Of the same size as char, but guaranteed to be signed. Capable of containing at least the [−127, +127] range.[3][a] | 8 | %c (or %hhi for numerical output) |
SCHAR_MIN / SCHAR_MAX[5] |
n/a |
unsigned char |
Of the same size as char, but guaranteed to be unsigned. Contains at least the [0, 255] range.[6] | 8 | %c (or %hhu for numerical output) |
0 / UCHAR_MAX |
n/a |
shortshort intsigned shortsigned short int |
Short signed integer type. Capable of containing at least the [−32,767, +32,767] range.[3][a] | 16 | %hi or %hd |
SHRT_MIN / SHRT_MAX |
n/a |
unsigned shortunsigned short int |
Short unsigned integer type. Contains at least the [0, 65,535] range.[3] | 16 | %hu |
0 / USHRT_MAX |
n/a |
intsignedsigned int |
Basic signed integer type. Capable of containing at least the [−32,767, +32,767] range.[3][a] | 16 | %i or %d |
INT_MIN / INT_MAX |
none[7] |
unsignedunsigned int |
Basic unsigned integer type. Contains at least the [0, 65,535] range.[3] | 16 | %u |
0 / UINT_MAX |
u or U[7]
|
longlong intsigned longsigned long int |
Long signed integer type. Capable of containing at least the [−2,147,483,647, +2,147,483,647] range.[3][a] | 32 | %li or %ld |
LONG_MIN / LONG_MAX |
l or L[7]
|
unsigned longunsigned long int |
Long unsigned integer type. Capable of containing at least the [0, 4,294,967,295] range.[3] | 32 | %lu |
0 / ULONG_MAX |
both u or U and l or L[7]
|
long longlong long intsigned long longsigned long long int |
Long long signed integer type. Capable of containing at least the [−9,223,372,036,854,775,807, +9,223,372,036,854,775,807] range.[3][a] Specified since the C99 version of the standard. | 64 | %lli or %lld |
LLONG_MIN / LLONG_MAX |
ll or LL[7]
|
unsigned long longunsigned long long int |
Long long unsigned integer type. Contains at least the [0, 18,446,744,073,709,551,615] range.[3] Specified since the C99 version of the standard. | 64 | %llu |
0 / ULLONG_MAX |
both u or U and ll or LL[7]
|
float |
Real floating-point type, usually referred to as a single-precision floating-point type. Actual properties unspecified (except minimum limits); however, on most systems, this is the IEEE 754 single-precision binary floating-point format (32 bits). This format is required by the optional Annex F «IEC 60559 floating-point arithmetic». | Converting from text:[b]
|
f or F
|
||
double |
Real floating-point type, usually referred to as a double-precision floating-point type. Actual properties unspecified (except minimum limits); however, on most systems, this is the IEEE 754 double-precision binary floating-point format (64 bits). This format is required by the optional Annex F «IEC 60559 floating-point arithmetic». |
|
|||
long double |
Real floating-point type, usually mapped to an extended precision floating-point number format. Actual properties unspecified. It can be either x86 extended-precision floating-point format (80 bits, but typically 96 bits or 128 bits in memory with padding bytes), the non-IEEE «double-double» (128 bits), IEEE 754 quadruple-precision floating-point format (128 bits), or the same as double. See the article on long double for details. | %Lf %LF%Lg %LG%Le %LE%La %LA[c] |
l or L
|
- ^ a b c d e The minimal ranges −(2n−1−1) to 2n−1−1 (e.g. [−127,127]) come from the various integer representations allowed by the standard (ones’ complement, sign-magnitude, two’s complement).[4] However, most platforms use two’s complement, implying a range of the form −2m−1 to 2m−1−1 with m ≥ n for these implementations, e.g. [−128,127] (
SCHAR_MIN= −128 andSCHAR_MAX= 127) for an 8-bit signed char. - ^ These format strings also exist for formatting to text, but operate on a double.
- ^ a b Uppercase differs from lowercase in the output. Uppercase specifiers produce values in the uppercase, and lowercase in lower (%A, %E, %F, %G produce such values as INF, NAN and E (exponent) in uppercase)
The actual size of the integer types varies by implementation. The standard requires only size relations between the data types and minimum sizes for each data type:
The relation requirements are that the long long is not smaller than long, which is not smaller than int, which is not smaller than short. As char‘s size is always the minimum supported data type, no other data types (except bit-fields) can be smaller.
The minimum size for char is 8 bits, the minimum size for short and int is 16 bits, for long it is 32 bits and long long must contain at least 64 bits.
The type int should be the integer type that the target processor is most efficiently working with. This allows great flexibility: for example, all types can be 64-bit. However, several different integer width schemes (data models) are popular. Because the data model defines how different programs communicate, a uniform data model is used within a given operating system application interface.[8]
In practice, char is usually 8 bits in size and short is usually 16 bits in size (as are their unsigned counterparts). This holds true for platforms as diverse as 1990s SunOS 4 Unix, Microsoft MS-DOS, modern Linux, and Microchip MCC18 for embedded 8-bit PIC microcontrollers. POSIX requires char to be exactly 8 bits in size.[9][10]
Various rules in the C standard make unsigned char the basic type used for arrays suitable to store arbitrary non-bit-field objects: its lack of padding bits and trap representations, the definition of object representation,[6] and the possibility of aliasing.[11]
The actual size and behavior of floating-point types also vary by implementation. The only requirement is that long double is not smaller than double, which is not smaller than float. Usually, the 32-bit and 64-bit IEEE 754 binary floating-point formats are used for float and double respectively.
The C99 standard includes new real floating-point types float_t and double_t, defined in <math.h>. They correspond to the types used for the intermediate results of floating-point expressions when FLT_EVAL_METHOD is 0, 1, or 2. These types may be wider than long double.
C99 also added complex types: float _Complex, double _Complex, long double _Complex.
Boolean type[edit]
C99 added a boolean (true/false) type _Bool. Additionally, the <stdbool.h> header defines bool as a convenient alias for this type, and also provides macros for true and false. _Bool functions similarly to a normal integer type, with one exception: any assignments to a _Bool that are not 0 (false) are stored as 1 (true). This behavior exists to avoid integer overflows in implicit narrowing conversions. For example, in the following code:
unsigned char b = 256; if (b) { /* do something */ }
Variable b evaluates to false if unsigned char has a size of 8 bits. This is because the value 256 does not fit in the data type, which results in the lower 8 bits of it being used, resulting in a zero value. However, changing the type causes the previous code to behave normally:
_Bool b = 256; if (b) { /* do something */ }
The type _Bool also ensures true values always compare equal to each other:
_Bool a = 1, b = 2; if (a == b) { /* this code will run */ }
Size and pointer difference types[edit]
The C language specification includes the typedefs size_t and ptrdiff_t to represent memory-related quantities. Their size is defined according to the target processor’s arithmetic capabilities, not the memory capabilities, such as available address space. Both of these types are defined in the <stddef.h> header (cstddef in C++).
size_t is an unsigned integer type used to represent the size of any object (including arrays) in the particular implementation. The operator sizeof yields a value of the type size_t. The maximum size of size_t is provided via SIZE_MAX, a macro constant which is defined in the <stdint.h> header (cstdint header in C++). size_t is guaranteed to be at least 16 bits wide. Additionally, POSIX includes ssize_t, which is a signed integer type of the same width as size_t.
ptrdiff_t is a signed integer type used to represent the difference between pointers. It is guaranteed to be valid only against pointers of the same type; subtraction of pointers consisting of different types is implementation-defined.
Interface to the properties of the basic types[edit]
Information about the actual properties, such as size, of the basic arithmetic types, is provided via macro constants in two headers: <limits.h> header (climits header in C++) defines macros for integer types and <float.h> header (cfloat header in C++) defines macros for floating-point types. The actual values depend on the implementation.
Properties of integer types[edit]
CHAR_BIT– size of the char type in bits (at least 8 bits)SCHAR_MIN,SHRT_MIN,INT_MIN,LONG_MIN,LLONG_MIN(C99) – minimum possible value of signed integer types: signed char, signed short, signed int, signed long, signed long longSCHAR_MAX,SHRT_MAX,INT_MAX,LONG_MAX,LLONG_MAX(C99) – maximum possible value of signed integer types: signed char, signed short, signed int, signed long, signed long longUCHAR_MAX,USHRT_MAX,UINT_MAX,ULONG_MAX,ULLONG_MAX(C99) – maximum possible value of unsigned integer types: unsigned char, unsigned short, unsigned int, unsigned long, unsigned long longCHAR_MIN– minimum possible value of charCHAR_MAX– maximum possible value of charMB_LEN_MAX– maximum number of bytes in a multibyte character
Properties of floating-point types[edit]
FLT_MIN,DBL_MIN,LDBL_MIN– minimum normalized positive value of float, double, long double respectivelyFLT_TRUE_MIN,DBL_TRUE_MIN,LDBL_TRUE_MIN(C11) – minimum positive value of float, double, long double respectivelyFLT_MAX,DBL_MAX,LDBL_MAX– maximum finite value of float, double, long double, respectivelyFLT_ROUNDS– rounding mode for floating-point operationsFLT_EVAL_METHOD(C99) – evaluation method of expressions involving different floating-point typesFLT_RADIX– radix of the exponent in the floating-point typesFLT_DIG,DBL_DIG,LDBL_DIG– number of decimal digits that can be represented without losing precision by float, double, long double, respectivelyFLT_EPSILON,DBL_EPSILON,LDBL_EPSILON– difference between 1.0 and the next representable value of float, double, long double, respectivelyFLT_MANT_DIG,DBL_MANT_DIG,LDBL_MANT_DIG– number ofFLT_RADIX-base digits in the floating-point significand for types float, double, long double, respectivelyFLT_MIN_EXP,DBL_MIN_EXP,LDBL_MIN_EXP– minimum negative integer such thatFLT_RADIXraised to a power one less than that number is a normalized float, double, long double, respectivelyFLT_MIN_10_EXP,DBL_MIN_10_EXP,LDBL_MIN_10_EXP– minimum negative integer such that 10 raised to that power is a normalized float, double, long double, respectivelyFLT_MAX_EXP,DBL_MAX_EXP,LDBL_MAX_EXP– maximum positive integer such thatFLT_RADIXraised to a power one less than that number is a normalized float, double, long double, respectivelyFLT_MAX_10_EXP,DBL_MAX_10_EXP,LDBL_MAX_10_EXP– maximum positive integer such that 10 raised to that power is a normalized float, double, long double, respectivelyDECIMAL_DIG(C99) – minimum number of decimal digits such that any number of the widest supported floating-point type can be represented in decimal with a precision ofDECIMAL_DIGdigits and read back in the original floating-point type without changing its value.DECIMAL_DIGis at least 10.
Fixed-width integer types[edit]
The C99 standard includes definitions of several new integer types to enhance the portability of programs.[2] The already available basic integer types were deemed insufficient, because their actual sizes are implementation defined and may vary across different systems. The new types are especially useful in embedded environments where hardware usually supports only several types and that support varies between different environments. All new types are defined in <inttypes.h> header (cinttypes header in C++) and also are available at <stdint.h> header (cstdint header in C++). The types can be grouped into the following categories:
- Exact-width integer types that are guaranteed to have the same number n of bits across all implementations. Included only if it is available in the implementation.
- Least-width integer types that are guaranteed to be the smallest type available in the implementation, that has at least specified number n of bits. Guaranteed to be specified for at least N=8,16,32,64.
- Fastest integer types that are guaranteed to be the fastest integer type available in the implementation, that has at least specified number n of bits. Guaranteed to be specified for at least N=8,16,32,64.
- Pointer integer types that are guaranteed to be able to hold a pointer. Included only if it is available in the implementation.
- Maximum-width integer types that are guaranteed to be the largest integer type in the implementation.
The following table summarizes the types and the interface to acquire the implementation details (n refers to the number of bits):
| Type category | Signed types | Unsigned types | ||||
|---|---|---|---|---|---|---|
| Type | Minimum value | Maximum value | Type | Minimum value | Maximum value | |
| Exact width | intn_t |
INTn_MIN |
INTn_MAX
|
uintn_t |
0 | UINTn_MAX
|
| Least width | int_leastn_t |
INT_LEASTn_MIN |
INT_LEASTn_MAX
|
uint_leastn_t |
0 | UINT_LEASTn_MAX
|
| Fastest | int_fastn_t |
INT_FASTn_MIN |
INT_FASTn_MAX
|
uint_fastn_t |
0 | UINT_FASTn_MAX
|
| Pointer | intptr_t |
INTPTR_MIN |
INTPTR_MAX
|
uintptr_t |
0 | UINTPTR_MAX
|
| Maximum width | intmax_t |
INTMAX_MIN |
INTMAX_MAX
|
uintmax_t |
0 | UINTMAX_MAX
|
Printf and scanf format specifiers[edit]
The <inttypes.h> header (cinttypes in C++) provides features that enhance the functionality of the types defined in the <stdint.h> header. It defines macros for printf format string and scanf format string specifiers corresponding to the types defined in <stdint.h> and several functions for working with the intmax_t and uintmax_t types. This header was added in C99.
- Printf format string
The macros are in the format PRI{fmt}{type}. Here {fmt} defines the output formatting and is one of d (decimal), x (hexadecimal), o (octal), u (unsigned) and i (integer). {type} defines the type of the argument and is one of n, FASTn, LEASTn, PTR, MAX, where n corresponds to the number of bits in the argument.
- Scanf format string
The macros are in the format SCN{fmt}{type}. Here {fmt} defines the output formatting and is one of d (decimal), x (hexadecimal), o (octal), u (unsigned) and i (integer). {type} defines the type of the argument and is one of n, FASTn, LEASTn, PTR, MAX, where n corresponds to the number of bits in the argument.
- Functions
|
This section needs expansion. You can help by adding to it. (October 2011) |
Additional floating-point types[edit]
Similarly to the fixed-width integer types, ISO/IEC TS 18661 specifies floating-point types for IEEE 754 interchange and extended formats in binary and decimal:
_FloatNfor binary interchange formats;_DecimalNfor decimal interchange formats;_FloatNxfor binary extended formats;_DecimalNxfor decimal extended formats.
Structures[edit]
Structures aggregate the storage of multiple data items, of potentially differing data types, into one memory block referenced by a single variable. The following example declares the data type struct birthday which contains the name and birthday of a person. The structure definition is followed by a declaration of the variable John that allocates the needed storage.
struct birthday { char name[20]; int day; int month; int year; }; struct birthday John;
The memory layout of a structure is a language implementation issue for each platform, with a few restrictions. The memory address of the first member must be the same as the address of structure itself. Structures may be initialized or assigned to using compound literals. A function may directly return a structure, although this is often not efficient at run-time. Since C99, a structure may also end with a flexible array member.
A structure containing a pointer to a structure of its own type is commonly used to build linked data structures:
struct node { int val; struct node *next; };
Arrays[edit]
For every type T, except void and function types, there exist the types «array of N elements of type T«. An array is a collection of values, all of the same type, stored contiguously in memory. An array of size N is indexed by integers from 0 up to and including N−1. Here is a brief example:
int cat[10]; // array of 10 elements, each of type int
Arrays can be initialized with a compound initializer, but not assigned. Arrays are passed to functions by passing a pointer to the first element. Multidimensional arrays are defined as «array of array …», and all except the outermost dimension must have compile-time constant size:
int a[10][8]; // array of 10 elements, each of type 'array of 8 int elements'
Pointers[edit]
Every data type T has a corresponding type pointer to T. A pointer is a data type that contains the address of a storage location of a variable of a particular type. They are declared with the asterisk (*) type declarator following the basic storage type and preceding the variable name. Whitespace before or after the asterisk is optional.
char *square; long *circle; int *oval;
Pointers may also be declared for pointer data types, thus creating multiple indirect pointers, such as char ** and int ***, including pointers to array types. The latter are less common than an array of pointers, and their syntax may be confusing:
char *pc[10]; // array of 10 elements of 'pointer to char' char (*pa)[10]; // pointer to a 10-element array of char
The element pc requires ten blocks of memory of the size of pointer to char (usually 40 or 80 bytes on common platforms), but element pa is only one pointer (size 4 or 8 bytes), and the data it refers to is an array of ten bytes (sizeof *pa == 10).
Unions[edit]
A union type is a special construct that permits access to the same memory block by using a choice of differing type descriptions. For example, a union of data types may be declared to permit reading the same data either as an integer, a float, or any other user declared type:
union { int i; float f; struct { unsigned int u; double d; } s; } u;
The total size of u is the size of u.s – which happens to be the sum of the sizes of u.s.u and u.s.d – since s is larger than both i and f. When assigning something to u.i, some parts of u.f may be preserved if u.i is smaller than u.f.
Reading from a union member is not the same as casting since the value of the member is not converted, but merely read.
Function pointers[edit]
Function pointers allow referencing functions with a particular signature. For example, to store the address of the standard function abs in the variable my_int_f:
int (*my_int_f)(int) = &abs; // the & operator can be omitted, but makes clear that the "address of" abs is used here
Function pointers are invoked by name just like normal function calls. Function pointers are separate from pointers and void pointers.
Type qualifiers[edit]
The aforementioned types can be characterized further by type qualifiers, yielding a qualified type. As of 2014 and C11, there are four type qualifiers in standard C: const (C89), volatile (C89), restrict (C99) and _Atomic (C11) – the latter has a private name to avoid clashing with user names,[12] but the more ordinary name atomic can be used if the <stdatomic.h> header is included. Of these, const is by far the best-known and most used, appearing in the standard library and encountered in any significant use of the C language, which must satisfy const-correctness. The other qualifiers are used for low-level programming, and while widely used there, are rarely used by typical programmers.[citation needed]
See also[edit]
- C syntax
- Uninitialized variable
- Integer (computer science)
References[edit]
- ^ Barr, Michael (2 December 2007). «Portable Fixed-Width Integers in C». Retrieved 18 January 2016.
- ^ a b ISO/IEC 9899:1999 specification, TC3 (PDF). p. 255, § 7.18 Integer types <stdint.h>.
- ^ a b c d e f g h i j ISO/IEC 9899:1999 specification, TC3 (PDF). p. 22, § 5.2.4.2.1 Sizes of integer types <limits.h>.
- ^ Rationale for International Standard—Programming Languages—C Revision 5.10 (PDF). p. 25, § 5.2.4.2.1 Sizes of integer types <limits.h>.
- ^ «C and C++ Integer Limits».
- ^ a b ISO/IEC 9899:1999 specification, TC3 (PDF). p. 37, § 6.2.6.1 Representations of types – General.
- ^ a b c d e f ISO/IEC 9899:1999 specification, TC3 (PDF). p. 56, § 6.4.4.1 Integer constants.
- ^ «64-Bit Programming Models: Why LP64?». The Open Group. Retrieved 9 November 2011.
- ^ «Width of Type (The GNU C Library)». www.gnu.org. Retrieved 30 July 2022.
- ^ «<limits.h>». pubs.opengroup.org. Retrieved 30 July 2022.
- ^ ISO/IEC 9899:1999 specification, TC3 (PDF). p. 67, § 6.5 Expressions.
- ^ C11:The New C Standard, Thomas Plum
from Wikipedia, the free encyclopedia
This article is not adequately provided with supporting documents (for example individual proofs ). Information without sufficient evidence could be removed soon. Please help Wikipedia by researching the information and including good evidence.
A data word or just a word is a certain amount of data that a computer can process in one step in the arithmetic-logic unit of the processor . If a maximum amount of data is meant, its size is called word width, processing width or bus width.
In programming languages, however , the data word is a platform-independent data unit or the designation for a data type and generally corresponds to 16 bits or 32 bits (see examples ).
Twice a word — in context — is a double word (English double word , short DWord ) or long word referred. For four times a word there is in English also have the designation quadruple word , short Quad Word or QWord . The data unit with half the word width is correspondingly referred to as a half word .
Smallest addressable unit
Depending on the system, the word length can differ considerably, with the variants in computers produced so far, starting from 4 bits, almost always following a power of two , i.e. a respective doubling of the word length. (Exceptions to this were, for example, the mainframe computers TR 4 and TR 440 from the 1960s / 1970s with 50 and 52-bit wide words.)
In addition to the largest possible number that can be processed in one computing step, the word length primarily determines the size of the maximum directly addressable memory . Therefore, a tendency towards longer word lengths can be seen:
- The first main processors only had 4-bit data words ( nibbles ). With 4 bits you can map 16 states, this is sufficient for the representation of the ten digits 0 to 9. Many digital clocks and simple pocket calculators still have 4-bit CPUs today .
- In the 1970s, the 8-bit CPUs established themselves and dominated the market for home users until around 1990 . With 8 bits it was now possible to store 256 different characters in one data word. The computers now used alphanumeric inputs and outputs, which were much more legible and opened up new possibilities. The resulting 8-bit character sets , e.g. B. EBCDIC or the various 8-bit extensions to the 7-bit ASCII — Codes have been preserved in part to the 32-bit era, and simple text files are still often in an 8-bit format.
- Since then, the word length is within the x86 — processor family has repeatedly doubled:
- With its first models, this had a 16-bit architecture ,
- which was soon followed by the 32-bit architecture of numerous PC processors, e. B. in the Pentium , Athlon , G4 and Core Duo processors.
- Currently (as of 2019) the 64-bit architecture is common, e.g. B. the Athlon-64 -, G5 -, newer Pentium-4 -, Core-2-Duo -, the Intel-Core-i-series as well as various server processors (e.g. Itanium , UltraSparc , Power4 , Opteron , newer Xeon ).
Different meanings
In programming languages for x86 systems, the size of a word has not grown , partly out of habit, but mainly in order to maintain compatibility with previous processors, but is now colloquially used to denote a bit sequence of 16 bits, i.e. the status of the 8086 processor.
For later x86 processors the designations Doppelwort / DWORD (English double word , also long word / Long ) and QWORD (English quad word ) were introduced. When changing from 32-bit architectures and operating systems to 64-bit , the meaning of long has been separated:
- In the Windows world , the width of such a long word remained 32 bits
- in the Linux world it was expanded to 64 bit.
In other computer architectures (e.g. PowerPC , Sparc ) a word often means a bit sequence of 32 bits (the original word length of these architectures), which is why the designation half-word is used there for sequences of 16 bits.
Examples
Processors of the IA-32 -80×86- architecture
| Data width | Data type | Processor register |
|---|---|---|
| 4 bits = ½ byte | Nibble | no registers of their own |
| 8 bits = 1 byte | byte | z. B. the registers AL and AH |
| 16 bits = 2 bytes | Word | z. B. the register AX |
| 32 bits = 4 bytes | Double word | z. B. the register EAX |
| 64 bits = 8 bytes | Quadruple Word | z. B. the register MM0 |
| 128 bits = 16 bytes | Double Quadruple Word | z. B. the register XMM0 |
The term Word (or word) is also used in the Windows API for a 16-bit number.
PLC
When programming programmable logic controllers (PLC), the IEC 61131-3 standard defines the word sizes as follows:
| Data width | Bit data types | Integer data types | Range of values | |
|---|---|---|---|---|
| unsigned | signed | |||
| 8 bits = 1 byte | BYTE (byte) | (U) SINT (short integer) | 0..255 | −128..127 |
| 16 bits = 2 bytes | WORD (word) | (U) INT (integer) | 0..65 535 | −32 768..32 767 |
| 32 bits = 4 bytes | DWORD (double word) | (U) DINT (Double Integer) | 0..2 32 -1 | -2 31 ..2 31 -1 |
| 64 bits = 8 bytes | LWORD (long word) | (U) LINT (Long Integer) | 0..2 64 -1 | -2 63 ..2 63 -1 |
If the letter U is placed in front of an integer data type (e.g. U DINT), this means “unsigned” (unsigned), without U the integer values are signed .
Individual evidence
- ↑ http://www.wissen.de/lexikon/ververarbeitungbreite
- ↑ QuinnRadich: Windows Data Types (BaseTsd.h) — Win32 apps. Retrieved January 15, 2020 (American English).
- ↑ May, Cathy .: The PowerPC architecture: a specification for a new family of RISC processors . 2nd Edition. Morgan Kaufman Publishers, San Francisco 1994, ISBN 1-55860-316-6 .
- ↑ Agner Fog: Calling conventions for different C ++ compilers and operating systems: Chapter 3, Data Representation (PDF; 416 kB) February 16, 2010. Accessed August 30, 2010.
- ↑ Christof Lange: API programming for beginners . 1999. Retrieved December 19, 2010.