
Derivational
analysis – word-formation analysis.The
basic elementary units of the derivative structure of words are:
derivational
bases, derivational affixes and derivational patterns.
1.Derivational
base –
is a part of word to which a rule of word-formation is applied.
Structurally
derivational bases fall into three classes:
1)
bases that coincide with morphological stems of different degrees of
complexity, e.g. dutiful,
dutifully;
day-dream,
to day-dream, daydreamer.
Derivationally
the stems may be:
-
simple,
which consist of only one, semantically non motivated constituent
(pocket,
motion, retain, horrible).
b)
derived
stems are semantically and structurally motivated, and are the
results of the application of word-formation rules (girl
– girlish, to weekend)
c)
compound
stems are always binary and semantically motivated (match-box,
letter-writer)
2)
bases that coincide with word-forms; e.g. paper-bound,
unsmiling,
This
class of bases is confined to verbal word-forms
— the
present and the past participles.
3)
bases that coincide with word-grоups
of different degrees of stability, e ,g. second-rateness,
This
class is made of word-groups. Bases of this kind are most active with
derivational affixes in the class of adjectives and nouns, e.g.
blue-eyed,
2.Derivational
affixes.
Derivational
affixes are ICs of numerous derivatives in all parts of speech.
Derivational affixes possess two basic functions:
1)
that of stem-building and 2) that of word-building. In most cases
derivational affixes perform both functions simultaneously.
3.Derivational
patterns: A
derivational pattern is a regular meaningful arrangement, a structure
that imposes rigid rules on the order and the nature of the
derivational bases and affixes that may be brought together.
There
are two types of DPs — structural that specify base classes and
individual affixes, and structural-semantic that specify semantic
peculiarities of bases and the individual meaning of the affix. DPs
of different levels of generalisation signal: 1) the class of source
unit that motivates the derivative and the direction of motivation
between different classes of words; 2) the part of speech of the
derivative; 3) the lexical sets and semantic features of derivatives.
12. Affixation in English
Affixation
– is the formation of new words by adding derivative affixes to
derivational bases.
Classification
of affixes: 1. According to the number of words they create, all
affixes may be classified into productive (un-, re-, -er) and
non-productive (….,
— hood); 2. From the point of view of their current participation in
word-formation process, the derivational affixes are divided into
active and non-active, or dead affixes (for- in forgive, forbid,
forget); 3. From the point of view of their origin: native (-dom,
-hood, over-) and borrowed (-able, -ist); 4. Synchronically all the
affixes are divided into verbal, adj., adv., (womanly – quickly)
Affixation
is subdivided into suffixation
and prefixation.
Prefixation
is the formation of words with the help of prefixes.
Prefixes
may be classified on different principles. Diachronically distinction
is made between prefixes of native and foreign origin.1
Synchronically prefixes may be classified:
-
according
to the class of words they preferably form. The majority of prefixes
tend to function either in nominal parts of speech
or
in verbs -
as
to the type of lexical-grammatical character of the base they are
added to. -
semantically
prefixes fall into mono- and polysemantic. -
as
to the generic denotational meaning: negative (un-, non-, in-,
dis-); reversative (un-, de-, dis-); perjorative (mis-, mal-,
pseudo-); prefixes of time and order (fore-, pre-, post-, ex-);
prefix of repetition (re-); locative prefixes (super-, sub-, inter-,
trans-). -
neutral
stylistic reference (un-, out-, re-, under-) and those possessing
quite a definite stylistic value, they have literary-bookish
character (pseudo-, super-, ultra-). -
prefixes
may be also classified as to the degree of productivity into
highly-productive, productive and non-productive.
Suffixation
– is the formation of words with the help of suffixes. There are
indentified from 60 to 130 suffixes. There
are different classifications of suffixes:
-
The
first principle of classification that, one might say, suggests
itself is the part of speech formed:
Noun-suffixes
(-er, -dom, -ness, -ation)
Adjective-suffixes
(-able, -less, -ful, -ic, -ous)
Verb-suffixes
(-en, -fy, -ise)
Adverb-suffixes
(-ly, -ward)
2) Suffixes
may also be classified into various groups according to the
lexico-grammatical character of the base the affix is usually added
to:
a)
deverbal suffixes (those added to the verbal base), e.g. -er,
-ing, -ment, -able, etc.
(speaker,
reading);
-
denominal
suffixes (those added to the noun base), e.g. -less,
-ish, -ful, -ist, -some, etc.
(handless,
childish); -
de-adjectival
suffixes (those affixed to the adjective base), e.g. -en,
-ly, -ish, -ness, etc.
(blacken,
slowly).
3)
A
classification of suffixes may also be based on the criterion of
sense expressed by a set of suffixes:
a)
the agent of an action, e.g. -er,
-ant (baker, dancer);
-
appurtenance,
e.g. -an,
-ian, —ese,
etc. (Russian,
Chinese, Japanese, etc.); -
collectivity,
e.g. -age,
-dom, -ery (-ry), etc.
(freightage,
officialdom); -
diminutiveness,
e.g. -ie, -let, -ling, etc. (birdie,
girlie, cloudlet).
4)
From the angle of stylistic reference:
a)
those
characterised by neutral stylistic reference such as -able,
-er,
-ing, etc.;
-
those
having a certain stylistic value such as -oid,
-i/form, -aceous, -tron, etc.
5)
Suffixes
are also classified as to the degree of their productivity.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #

1
Seminar 3
When studying word-structure there are two levels of approach: the level of the morphemic analysis and
the derivational or word-formation analysis. For the purposes of this seminar, we will focus on the
derivational analysis. However, in what follows you are given some information on the morphemic
analysis as well.
Morphemic analysis
Morpheme = the smallest meaningful unit in a language that cannot be further divided
= the basic unit of the morphemic level
= not independent and are found in speech only as integral parts of the word
Types of morphemes:
a) root-morpheme = the lexical nucleus of the word; it has a very general and abstract lexical meaning
common to a set of semantically related words constituting one word-cluster (e.g. (to) teach, teacher,
teaching)
— do not possess the part-of-speech meaning which is not found in roots
— roots are what remains of a word after all affixes have been removed and their
fundamental characteristic is that they are not further divisible into other constituent parts that should
have meaning
affixational morpheme = include inflectional affixes or inflections and derivational affixes
— Inflections carry only grammatical meaning and are thus relevant only for the
formation of word-forms
— Derivational affixes are relevant for building various types of words (this is the
concern of Lexicology)
o Lexically always dependent on the root which they modify
o Most of them have the part-of-speech meaning which makes them
structurally the important part of the word as they condition the lexico-
grammatical class the word belongs to (classified into affixes building
different parts of speech: nouns, verbs, adjectives or adverbs)
e.g. helpless, handy, blackness, Londoner
the root-morphemes help-, hand-, black-, London- are
understood as the lexical centres of the words; and –less, -y, -ness, —er are felt as morphemes dependent
on these roots.
b) free morphemes coincide with word-forms of independently functioning words
can be found only among roots the morpheme boy— in the word boy is a free
morpheme; in the word undesirable there is only one free morpheme desire—; pen-holder has two free
morphemes pen- and hold-; fancy-dress—maker has three free morphemes.
10.1. The morphological structure of English words.
10.2. Definition of word-formation. Synchronic and diachronic approaches to word formation.
10.3. Main units of word-formation. Derivational analysis.
10.4. Ways of word-formation.
10.5. Functional approach to word-formation.
10.6. The communicative aspect of word-formation.
10.1. Structurally, words are divisible into smaller units which are called morphemes. Morphemes are the smallest indivisible two-facet (significant) units. A morpheme exists only as a constituent part of the word.
One morpheme may have different phonemic shapes, i.e. it is represented by allomorphs (its variants),
e.g. in please, pleasure, pleasant [pli: z], [ple3-], [plez-] are allomorphs of one morpheme.
Semantically, all morphemes are classified into roots and affixes. The root is the lexical centre of the word, its basic part; it has an individual lexical meaning,
e.g. in help, helper, helpful, helpless, helping, unhelpful — help- is the root.
Affixes are used to build stems; they are classified into prefixes and suffixes; there are also infixes. A prefix precedes the root, a suffix follows it; an infix is inserted in the body of the word,
e.g. prefixes: re -think, mis -take, dis -cover, over -eat, ex -wife;
suffixes: danger- ous, familiar- ize, kind- ness, swea- ty etc.
Structurally, morphemes fall into: free morphemes, bound morphemes, semi-bound (semi-free) morphemes.
A free morpheme is one that coincides with a stem or a word-form. A great many root-morphemes are free,
e.g. in friendship the root -friend — is free as it coincides with a word-form of the noun friend.
A bound morpheme occurs only as a part of a word. All affixes are bound morphemes because they always make part of a word,
e.g. in friendship the suffix -ship is a bound morpheme.
Some root morphemes are also bound as they always occur in combination with other roots and/or affixes,
e.g. in conceive, receive, perceive — ceive — is a bound root.
To this group belong so-called combining forms, root morphemes of Greek and Latin origin,
e.g. tele -, mega, — logy, micro -, — phone: telephone, microphone, telegraph, etc.
Semi-bound morphemes are those that can function both as a free root morpheme and as an affix (sometimes with a change of sound form and/or meaning),
e.g. proof, a. » giving or having protection against smth harmful or unwanted» (a free root morpheme): proof against weather;
-proof (in adjectives) » treated or made so as not to be harmed by or so as to give protection against» (a semi-bound morpheme): bulletproof, ovenproof, dustproof, etc.
Morphemic analysis aims at determining the morphemic (morphological) structure of a word, i.e. the aim is to split the word into morphemes and state their number, types and the pattern of arrangement. The basic unit of morphemic analysis is the morpheme.
In segmenting words into morphemes, we use the method of Immediate and Unltimate Constituents. At each stage of the analysis, a word is broken down into two meaningful parts (ICs, i.e. Immediate Constituents). At the next stage, each IC is broken down into two smaller meaningful elements. The analysis is completed when we get indivisible constituents, i.e. Ultimate Constituents, or morphs, which represent morphemes in concrete words,
e.g. 
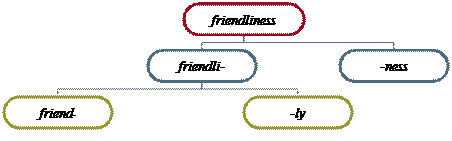
Friend-, -ly, -ness are indivisible into smaller meaningful units, so they are Ultimate Constituents (morphs) and the word friendliness consists of 3 morphemes: friend-+-li+-ness.
There are two structural types of words at the morphemic level of analysis: monomorphic (non-segmentable, indivisible) and polymorphic words (segmentable, divisible). The former consist only of a root morpheme, e.g. cat, give, soon, blue, oh, three. The latter consist of two or more morphemes, e.g. disagreeableness is a polymorphic word which consists of four morphemes, one root and three affixes: dis- + -agree- + -able + -ness. The morphemic structure is Pr + R + Sf1 + Sf2.
10.2. Word-Formation (W-F) is building words from available linguistic material after certain structural and semantic patterns. It is also a branch of lexicology that studies the process of building words as well as the derivative structure of words, the patterns on which they are built and derivational relations between words.
Synchronically, linguists study the system of W-F at a given time; diachronically, they are concerned with the history of W-F, and the history of building concrete words. The results of the synchronic and the diachronic analysis may not always coincide,
e.g. historically, to beg was derived from beggar, but synchronically the noun beggar is considered derived from the verb after the pattern v + -er/-ar → N, as the noun is structurally and semantically more complex. Cf. also: peddle- ← -pedlar/peddler, lie ← liar.
10.3. The aim of derivational analysis is to determine the derivational structure of a word, i.e. to state the derivational pattern after which it is built and the derivational base (the source of derivation).
Traditionally, the basic units of derivational analysis are: the derived word (the derivative), the derivational base, the derivational pattern, the derivational affix.
The derivational base is the source of a derived word, i.e. a stem, a word-form, a word-group (sometimes even a sentence) which motivates the derivative semantically and on which the latter is based structurally,
e.g. in dutifully the base is dutiful-, which is a stem;
in unsmiling it is the word-form smiling (participle I);
in blue-eyed it is the word-group blue eye.
In affixation, derivational affixes are added to derivational bases to build new words, i.e. derivatives. They repattern the bases, changing them structurally and semantically. They also mark derivational relations between words,
e.g. in encouragement en- and -ment are derivational affixes: a prefix and a suffix; they are used to build the word encouragement: (en- + courage) + -ment.
They also mark the derivational relations between courage and encourage, encourage and encouragement.
A derivational pattern is a scheme (a formula) describing the structure of derived words already existing in the language and after which new words may be built,
e.g. the pattern of friendliness is a+ -ness- → N, i.e. an adjective stem + the noun-forming suffix -ness.
Derivationally, all words fall into two classes: simple (non-derived) words and derivatives. Simple words are those that are non-motivated semantically and independent of other linguistic units structurally, e.g. boy, run, quiet, receive, etc. Derived words are motivated structurally and semantically by other linguistic units, e.g. to spam, spamming, spammer, anti-spamming are motivated by spam.
Each derived word is characterized by a certain derivational structure. In traditional linguistics, the derivational structure is viewed as a binary entity, reflecting the relationship between derivational bases and derivatives and consisting of a stem and a derivational affix,
e.g. the structure of nationalization is nationaliz- + -ation
(described by the formula, or pattern v + -ation → N).
But there is a different point of view. In modern W-F, the derivational structure of a word is defined as a finite set of derivational steps necessary to produce (build) the derived word,
e.g. [(nation + -al) + — ize ] + -ation.
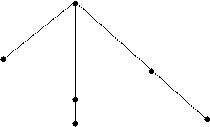
To describe derivational structures and derivational relations, it is convenient to use the relator language and a system of oriented graphs. In this language, a word is generated by joining relators to the amorphous root O. Thus, R1O describes the structure of a simple verb (cut, permiate); R2O shows the structure of a simple noun (friend, nation); R3O is a simple adjective (small, gregarious) and R4O is a simple adverb (then, late).
e.g. The derivational structure of nationalization is described by the R-formula R2R1R3R2O; the R-formula of unemployment is R2R2R1O (employ → employment → unemployment).
In oriented graphs, a branch slanting left and down » /» correspond to R1; a vertical branch » I» corresponds to R2; a branch slanting right and down » » to R3, and a horizontal right branch to R4.
 Thus we can show the derivational structure of unemployment like this:
Thus we can show the derivational structure of unemployment like this:
and dutifulness like this:
Words whose derivational structures can be described by one R-formula are called monostructural, e.g. dutifulness, encouragement; words whose derivational structures can be described by two (or more) R-formulas are polystructural,
e.g. disagreement R2R2R1O / R2R1R1O
(agree → disagree → disagreement R2R1R1O or
agree → agreement → disagreement R2R2R1O)
There are complex units of word-formation. They are derivational clusters and derivational sets.
A derivational cluster is a group of words that have the same root and are derivationally related. The structure of a cluster can be shown with the help of a graph,
 e.g. READ
e.g. READ
reread read
misreadreaderreadable
reading
readership ∙ unreadable
A derivational set is a group of words that are built after the same derivational pattern,
e.g. n + -ish → A: mulish, dollish, apish, bookish, wolfish, etc,
Table TWO TYPES OF STRUCTURAL ANALYSIS
| MORPHEMIC ANALYSIS | DERIVATIONAL ANALYSIS | |
| AIM | to find out the morphemic structure (composition) | to determine the derivational structure |
| BASIC UNITS | morphemes (roots and affixes) | derived word, derivational pattern, derivational base, derivational step, derivational means (e.g. affix) |
| RESULTS: CLASSES OF WORDS | monomorphic (non-segmentable) and polymorphic (segmentable) words | simple and derived words |
| EXAMPLES | 1. cut, v. and cut, n. are monomorphic (root) words | 1. cut, v. is a simple word (R1O); cut, n. is derived from it (R2R1O) |
| 2. encouragement, unemployment consist of three morphemes and have the same morphemic composition: Pr + R + Sf | 2. encouragement and unemployment have different derivational structures: v + -ment → N (R2R1R2O) and un- + n → N (R2R2R1O) |
10.4. Traditionally, the following ways of W-F are distinguished:
affixation, compounding, conversion, shortening, blending, back-formation. Sound interchange, sound imitation, distinctive stress, lexicalization, coinage certainly do not belong to word-formation as no derivational patterns are used.
Affixation is formation of words by adding derivational affixes to derivational bases. Affixation is devided into prefixation and suffixation,
e.g. the following prefixes and suffixes are used to build words with negative or opposite meanings: un-, non-, a-, contra-, counter-, de-, dis-, in-, mis-, -less, e.g. non-toxic.
Compounding is building words by combining two (or more) derivational bases (stems or word-forms),
e.g. big -ticket (= expensive), fifty-fifty, laid-back, statesman.
Among compounds, we distinguish derivational compounds, formed by adding a derivational affix (usu. a suffix) to a word group,
e.g. heart-shaped (= shaped like a heart), stone-cutter (= one who cuts stone).
Conversion consists in making a word from some existing word by transferring it into another part of speech. The new word acquires a new paradigm; the sound form and the morphimic composition remain unchanged. The most productive conversion patterns are n → V (i.e. formation of verbs from noun-stems), v → N (formation of nouns from verb stems), a → V (formation of verbs from adjective stems),
e.g. a drink, a do, a go, a swim: Have another try.
to face, to nose, to paper, to mother, to ape;
to cool, to pale, to rough, to black, to yellow, etc.
Nouns and verbs can be converted from other parts of speech, too, for example, adverbs: to down, to out, to up; ifs and buts.
Shortening consists in substituting a part for a whole. Shortening may result in building new lexical items (i.e. lexical shortenings) and so-called graphic abbreviations, which are not words but signs representing words in written speech; in reading, they are substituted by the words they stand for,
e.g. Dr = doctor, St = street, saint, Oct = 0ctober, etc.
Lexical shortenings are produced in two ways:
(1) clipping, i.e. a new word is made from a syllable (or two syllables) of the original word,
e.g. back-clippings: pro ← professional, chimp ← chimpanzee,
fore-clippings: copter ← helicopter, gator ← alligator,
fore-and-aft clippings: duct ← deduction, tec ← detective,
(2) abbreviation, i.e. a new word is made from the initial letters of the original word or word-group. Abbreviations are devided into letter-based initialisms (FBI ← the Federal Bureau of Investigation) and acronyms pronounced as root words (AIDS, NATO).
Blending is building new words, called blends, fusions, telescopic words, or portmanteau words, by merging (usu.irregular) fragments of two existing words,
e.g. biopic ← biography + picture, alcoholiday ← alcohol + holiday.
Back-formation is derivation of new words by subtracting a real or supposed affix (usu. a suffix) from existing words (on analogy with existing derivational pairs),
e.g. to enthuse ← enthusiasm, to intuit ← intuition.
Sound interchange and distinctive stress are not ways of word-formation. They are ways of distinguishing words or word forms,
e.g. food -feed, speech — speak, life — live;
‘ insult, n. — in ‘ sult, v., ‘ perfect, a. — per ‘ fect, v.
Sound interchange may be combined with affixation and/or the shift of stress,
e.g. strong — strength, wide — width.
10.5. Productivity and activity of derivational ways and means.
Productivity and activity in W-F are close but not identical. By productivity of derivational ways/types/patterns/means we mean ability to derive new words,
e.g. The suffix -er/ the pattern v + -er → N is highly productive.
By activity we mean the number of words derived with the help of a certain derivational means or after a derivational pattern,
e.g. — er is found in hundreds of words so it is active.
Sometimes productivity and activity go together, but they may not always do.
| DERIVATIONAL MEANS | EXAMPLE | PRODUCTIVITY | ACTIVITY |
| -ly | nicely | + | + |
| -ous | dangerous | _ | + |
| -th | breadth | _ | _ |
In modern English, the most productive way of W-P is affixation (suffixation more so than prefixation), then comes compounding, shortening takes third place, with conversion coming fourth.
Productivity may change historically. Some derivational means / patterns may be non-productive for centuries or decades, then become productive, then decline again,
e.g. In the late 19th c. US -ine was a popular feminine suffix on the analogy of heroine, forming such words as actorine, doctorine, speakerine. It is not productive or active now.
|
Функция спроса населения на данный товар Функция спроса населения на данный товар: Qd=7-Р. Функция предложения: Qs= -5+2Р,где… |
Аальтернативная стоимость. Кривая производственных возможностей В экономике Буридании есть 100 ед. труда с производительностью 4 м ткани или 2 кг мяса… |
Вычисление основной дактилоскопической формулы Вычислением основной дактоформулы обычно занимается следователь. Для этого все десять пальцев разбиваются на пять пар… |
Расчетные и графические задания Равновесный объем — это объем, определяемый равенством спроса и предложения… |




WORD STRUCTURE IN MODERN ENGLISH
I. The morphological structure of a word. Morphemes. Types of morphemes. Allomorphs.
II. Structural types of words.
III. Principles of morphemic analysis.
IV. Derivational level of analysis. Stems. Types of stems. Derivational types of words.
I. The morphological structure of a word. Morphemes. Types of Morphemes. Allomorphs.
There are two levels of approach to the study of word- structure: the level of morphemic analysis and the level of derivational or word-formation analysis.
Word is the principal and basic unit of the language system, the largest on the morphologic and the smallest on the syntactic plane of linguistic analysis.
It has been universally acknowledged that a great many words have a composite nature and are made up of morphemes, the basic units on the morphemic level, which are defined as the smallest indivisible two-facet language units.
The term morpheme is derived from Greek morphe “form ”+ -eme. The Greek suffix –eme has been adopted by linguistic to denote the smallest unit or the minimum distinctive feature.
The morpheme is the smallest meaningful unit of form. A form in these cases a recurring discrete unit of speech. Morphemes occur in speech only as constituent parts of words, not independently, although a word may consist of single morpheme. Even a cursory examination of the morphemic structure of English words reveals that they are composed of morphemes of different types: root-morphemes and affixational morphemes. Words that consist of a root and an affix are called derived words or derivatives and are produced by the process of word building known as affixation (or derivation).
The root-morpheme is the lexical nucleus of the word; it has a very general and abstract lexical meaning common to a set of semantically related words constituting one word-cluster, e.g. (to) teach, teacher, teaching. Besides the lexical meaning root-morphemes possess all other types of meaning proper to morphemes except the part-of-speech meaning which is not found in roots.
Affixational morphemes include inflectional affixes or inflections and derivational affixes. Inflections carry only grammatical meaning and are thus relevant only for the formation of word-forms. Derivational affixes are relevant for building various types of words. They are lexically always dependent on the root which they modify. They possess the same types of meaning as found in roots, but unlike root-morphemes most of them have the part-of-speech meaning which makes them structurally the important part of the word as they condition the lexico-grammatical class the word belongs to. Due to this component of their meaning the derivational affixes are classified into affixes building different parts of speech: nouns, verbs, adjectives or adverbs.
Roots and derivational affixes are generally easily distinguished and the difference between them is clearly felt as, e.g., in the words helpless, handy, blackness, Londoner, refill, etc.: the root-morphemes help-, hand-, black-, London-, fill-, are understood as the lexical centers of the words, and –less, -y, -ness, -er, re- are felt as morphemes dependent on these roots.
Distinction is also made of free and bound morphemes.
Free morphemes coincide with word-forms of independently functioning words. It is obvious that free morphemes can be found only among roots, so the morpheme boy- in the word boy is a free morpheme; in the word undesirable there is only one free morpheme desire-; the word pen-holder has two free morphemes pen- and hold-. It follows that bound morphemes are those that do not coincide with separate word- forms, consequently all derivational morphemes, such as –ness, -able, -er are bound. Root-morphemes may be both free and bound. The morphemes theor- in the words theory, theoretical, or horr- in the words horror, horrible, horrify; Angl- in Anglo-Saxon; Afr- in Afro-Asian are all bound roots as there are no identical word-forms.
It should also be noted that morphemes may have different phonemic shapes. In the word-cluster please , pleasing , pleasure , pleasant the phonemic shapes of the word stand in complementary distribution or in alternation with each other. All the representations of the given morpheme, that manifest alternation are called allomorphs/or morphemic variants/ of that morpheme.
The combining form allo- from Greek allos “other” is used in linguistic terminology to denote elements of a group whose members together consistute a structural unit of the language (allophones, allomorphs). Thus, for example, -ion/ -tion/ -sion/ -ation are the positional variants of the same suffix, they do not differ in meaning or function but show a slight difference in sound form depending on the final phoneme of the preceding stem. They are considered as variants of one and the same morpheme and called its allomorphs.
Allomorph is defined as a positional variant of a morpheme occurring in a specific environment and so characterized by complementary description.
Complementary distribution is said to take place, when two linguistic variants cannot appear in the same environment.
Different morphemes are characterized by contrastive distribution, i.e. if they occur in the same environment they signal different meanings. The suffixes –able and –ed, for instance, are different morphemes, not allomorphs, because adjectives in –able mean “ capable of beings”.
Allomorphs will also occur among prefixes. Their form then depends on the initials of the stem with which they will assimilate.
Two or more sound forms of a stem existing under conditions of complementary distribution may also be regarded as allomorphs, as, for instance, in long a: length n.
II. Structural types of words.
The morphological analysis of word- structure on the morphemic level aims at splitting the word into its constituent morphemes – the basic units at this level of analysis – and at determining their number and types. The four types (root words, derived words, compound, shortenings) represent the main structural types of Modern English words, and conversion, derivation and composition the most productive ways of word building.
According to the number of morphemes words can be classified into monomorphic and polymorphic. Monomorphic or root-words consist of only one root-morpheme, e.g. small, dog, make, give, etc. All polymorphic word fall into two subgroups: derived words and compound words – according to the number of root-morphemes they have. Derived words are composed of one root-morpheme and one or more derivational morphemes, e.g. acceptable, outdo, disagreeable, etc. Compound words are those which contain at least two root-morphemes, the number of derivational morphemes being insignificant. There can be both root- and derivational morphemes in compounds as in pen-holder, light-mindedness, or only root-morphemes as in lamp-shade, eye-ball, etc.
These structural types are not of equal importance. The clue to the correct understanding of their comparative value lies in a careful consideration of: 1)the importance of each type in the existing wordstock, and 2) their frequency value in actual speech. Frequency is by far the most important factor. According to the available word counts made in different parts of speech, we find that derived words numerically constitute the largest class of words in the existing wordstock; derived nouns comprise approximately 67% of the total number, adjectives about 86%, whereas compound nouns make about 15% and adjectives about 4%. Root words come to 18% in nouns, i.e. a trifle more than the number of compound words; adjectives root words come to approximately 12%.
But we cannot fail to perceive that root-words occupy a predominant place. In English, according to the recent frequency counts, about 60% of the total number of nouns and 62% of the total number of adjectives in current use are root-words. Of the total number of adjectives and nouns, derived words comprise about 38% and 37% respectively while compound words comprise an insignificant 2% in nouns and 0.2% in adjectives. Thus it is the root-words that constitute the foundation and the backbone of the vocabulary and that are of paramount importance in speech. It should also be mentioned that root words are characterized by a high degree of collocability and a complex variety of meanings in contrast with words of other structural types whose semantic structures are much poorer. Root- words also serve as parent forms for all types of derived and compound words.
III. Principles of morphemic analysis.
In most cases the morphemic structure of words is transparent enough and individual morphemes clearly stand out within the word. The segmentation of words is generally carried out according to the method of Immediate and Ultimate Constituents. This method is based on the binary principle, i.e. each stage of the procedure involves two components the word immediately breaks into. At each stage these two components are referred to as the Immediate Constituents. Each Immediate Constituent at the next stage of analysis is in turn broken into smaller meaningful elements. The analysis is completed when we arrive at constituents incapable of further division, i.e. morphemes. These are referred to Ultimate Constituents.
A synchronic morphological analysis is most effectively accomplished by the procedure known as the analysis into Immediate Constituents. ICs are the two meaningful parts forming a large linguistic unity.
The method is based on the fact that a word characterized by morphological divisibility is involved in certain structural correlations. To sum up: as we break the word we obtain at any level only ICs one of which is the stem of the given word. All the time the analysis is based on the patterns characteristic of the English vocabulary. As a pattern showing the interdependence of all the constituents segregated at various stages, we obtain the following formula:
un+ { [ ( gent- + -le ) + -man ] + -ly}
Breaking a word into its Immediate Constituents we observe in each cut the structural order of the constituents.
A diagram presenting the four cuts described looks as follows:
1. un- / gentlemanly
2. un- / gentleman / — ly
3. un- / gentle / — man / — ly
4. un- / gentl / — e / — man / — ly
A similar analysis on the word-formation level showing not only the morphemic constituents of the word but also the structural pattern on which it is built.
The analysis of word-structure at the morphemic level must proceed to the stage of Ultimate Constituents. For example, the noun friendliness is first segmented into the ICs: [frendlı-] recurring in the adjectives friendly-looking and friendly and [-nıs] found in a countless number of nouns, such as unhappiness, blackness, sameness, etc. the IC [-nıs] is at the same time an UC of the word, as it cannot be broken into any smaller elements possessing both sound-form and meaning. Any further division of –ness would give individual speech-sounds which denote nothing by themselves. The IC [frendlı-] is next broken into the ICs [-lı] and [frend-] which are both UCs of the word.
Morphemic analysis under the method of Ultimate Constituents may be carried out on the basis of two principles: the so-called root-principle and affix principle.
According to the affix principle the splitting of the word into its constituent morphemes is based on the identification of the affix within a set of words, e.g. the identification of the suffix –er leads to the segmentation of words singer, teacher, swimmer into the derivational morpheme – er and the roots teach- , sing-, drive-.
According to the root-principle, the segmentation of the word is based on the identification of the root-morpheme in a word-cluster, for example the identification of the root-morpheme agree- in the words agreeable, agreement, disagree.
As a rule, the application of these principles is sufficient for the morphemic segmentation of words.
However, the morphemic structure of words in a number of cases defies such analysis, as it is not always so transparent and simple as in the cases mentioned above. Sometimes not only the segmentation of words into morphemes, but the recognition of certain sound-clusters as morphemes become doubtful which naturally affects the classification of words. In words like retain, detain, contain or receive, deceive, conceive, perceive the sound-clusters [rı-], [dı-] seem to be singled quite easily, on the other hand, they undoubtedly have nothing in common with the phonetically identical prefixes re-, de- as found in words re-write, re-organize, de-organize, de-code. Moreover, neither the sound-cluster [rı-] or [dı-], nor the [-teın] or [-sı:v] possess any lexical or functional meaning of their own. Yet, these sound-clusters are felt as having a certain meaning because [rı-] distinguishes retain from detain and [-teın] distinguishes retain from receive.
It follows that all these sound-clusters have a differential and a certain distributional meaning as their order arrangement point to the affixal status of re-, de-, con-, per- and makes one understand —tain and –ceive as roots. The differential and distributional meanings seem to give sufficient ground to recognize these sound-clusters as morphemes, but as they lack lexical meaning of their own, they are set apart from all other types of morphemes and are known in linguistic literature as pseudo- morphemes. Pseudo- morphemes of the same kind are also encountered in words like rusty-fusty.
IV. Derivational level of analysis. Stems. Types of Stems. Derivational types of word.
The morphemic analysis of words only defines the constituent morphemes, determining their types and their meaning but does not reveal the hierarchy of the morphemes comprising the word. Words are no mere sum totals of morpheme, the latter reveal a definite, sometimes very complex interrelation. Morphemes are arranged according to certain rules, the arrangement differing in various types of words and particular groups within the same types. The pattern of morpheme arrangement underlies the classification of words into different types and enables one to understand how new words appear in the language. These relations within the word and the interrelations between different types and classes of words are known as derivative or word- formation relations.
The analysis of derivative relations aims at establishing a correlation between different types and the structural patterns words are built on. The basic unit at the derivational level is the stem.
The stem is defined as that part of the word which remains unchanged throughout its paradigm, thus the stem which appears in the paradigm (to) ask ( ), asks, asked, asking is ask-; thestem of the word singer ( ), singer’s, singers, singers’ is singer-. It is the stem of the word that takes the inflections which shape the word grammatically as one or another part of speech.
The structure of stems should be described in terms of IC’s analysis, which at this level aims at establishing the patterns of typical derivative relations within the stem and the derivative correlation between stems of different types.
There are three types of stems: simple, derived and compound.
Simple stems are semantically non-motivated and do not constitute a pattern on analogy with which new stems may be modeled. Simple stems are generally monomorphic and phonetically identical with the root morpheme. The derivational structure of stems does not always coincide with the result of morphemic analysis. Comparison proves that not all morphemes relevant at the morphemic level are relevant at the derivational level of analysis. It follows that bound morphemes and all types of pseudo- morphemes are irrelevant to the derivational structure of stems as they do not meet requirements of double opposition and derivative interrelations. So the stem of such words as retain, receive, horrible, pocket, motion, etc. should be regarded as simple, non- motivated stems.
Derived stems are built on stems of various structures though which they are motivated, i.e. derived stems are understood on the basis of the derivative relations between their IC’s and the correlated stems. The derived stems are mostly polymorphic in which case the segmentation results only in one IC that is itself a stem, the other IC being necessarily a derivational affix.
Derived stems are not necessarily polymorphic.
Compound stems are made up of two IC’s, both of which are themselves stems, for example match-box, driving-suit, pen-holder, etc. It is built by joining of two stems, one of which is simple, the other derived.
In more complex cases the result of the analysis at the two levels sometimes seems even to contracted one another.
The derivational types of words are classified according to the structure of their stems into simple, derived and compound words.
Derived words are those composed of one root- morpheme and one or more derivational morpheme.
Compound words contain at least two root- morphemes, the number of derivational morphemes being insignificant.
Derivational compound is a word formed by a simultaneous process of composition and derivational.
Compound words proper are formed by joining together stems of word already available in the language.
Теги:
Word structure in modern english
Реферат
Английский
Просмотров: 27496
Найти в Wikkipedia статьи с фразой: Word structure in modern english