
уважаемые посетители блога, если Вам понравилась, то, пожалуйста, помогите автору с лечением. Подробности тут.
Сегодня, в последний рабочий день недели, практически весь день провозился над передачей данных из Delphi в Word. Так как подозрение есть, что работа продолжится то решил кое-какие моменты по работе с Microsoft Word в Delphi запечатлеть и у себя в блоге. Написать такую мини-шпаргалку (тем более, что по Excel уже кое что есть).
Для начала, немного общих моментов по работе с MS Office в Delphi. И первое, что мы сделаем — это создадим объект Word.Application. Создается этот объект абсолютно также, как и объект Excel.Application:
uses ComObj; var Word: variant; [...] procedure CreateWord(const Visible: boolean); begin Word:=CreateOleObject('Word.Application'); Word.Visible:=Visible; end;
Всё достаточно просто. Далее мы можем работать с объектом следующим образом:
- Создавать документ Word с нуля
- Открыть уже существующий документ и изменить в нем текст для получения необходимой формы документа.
Рассмотрим оба варианта, т.к. оба они имеют как свои плюсы, так и недостатки.
Чтобы создать новый документ необходимо выполнить метод Add у коллекции Documents, т.е.:
[...] Word.Documents.Add [...]
и после этой операции уже начинать работать с документам обращаясь к нему по индексу или имени в коллекции. Также, можно создать новый документ по шаблону (*.dot). Для этого необходимо выполнить тот же метод Add, но с одним входным параметром — путем к файлу-шаблону:
[...] Word.Documents.Add(TamplatePath:string); [...]
Чтобы получить список всех открытых в данный момент документов Word можно воспользоваться следующим листингом:
[...] var List: TStringList; i: integer; begin List:=TStringList.Create; for i:=1 to Word.Documents.Count do List.Add(Word.Documents.Item(i).Name); end; [...]
Обратите внимание, что нумерация начинается с 1, а не с нуля. Чтобы активировать любой документ из коллекции для работы, необходимо выполнить метод Activate:
Word.Documents.Item(index).Activate
где index — номер документа в коллекции.
Теперь можно приступать к записи и чтению документа. Для работы с текстов в документе Word, как и в Excel для работы с ячейками таблицы, определен объект Range. Именно методы этого объекта и дают нам возможность работы с текстом. Для начала рассмотрим работу двух основных методов: InsertBefore и InsertAfter.
Как следует из название — первый метод вставляет текст в начало содержимого Range, а второй — в конец. При этом сам объект Range может содержать как весть документ (Document) так и какую-либо его часть. Например, в следующем листинге я вставлю строку в начало документа и затем методом InsertAfter буду добавлять несколько строк текста в конец документа:
[...] Word.ActiveDocument.Range.InsertBefore('Hello World'); Word.ActiveDocument.Range.InsertAfter('текст после Hello World'); Word.ActiveDocument.Range.InsertAfter('окончание строки в документа'); [...]
При выполнении этих трех операции Range содержал весь документ.
Если работать со всем документом неудобно, а необходимо, например выделить фрагмент с 50 по 100 символ и работать с ним, то можно воспользоваться функцией Range, которая вернет нам необходимый объект Range:
var MyRange: variant; begin MyRange:=WordActiveDocument.Range(50,100); MyRange.InsertBefore('Привет');//всё, что было после 50-го символа сдвинулось вправо end;
Это что касается записи текста. Решение обратной задачи — чтения текста из документа ещё проще. Достаточно воспользоваться свойством Text у объекта Range:
[...] ShowMessage(Word.ActiveDocument.Range.Text) //весь текст в документе [...]
Также для чтения документа можно воспользоваться коллекцией документа Words (слова). За слово принимается непрерывный набор символов — цифр и букв, который оканчивается пробелом.
Перечисляются слова документа точно также как и при работе с коллекцией документов, т.е. первое слово имеет индекс 1 последнее — Word.Count.
[...] ShowMessage(Word.ActiveDocument.Words.Item(Word.ActiveDocument.Words.Count).Text) [...]
В данном случае я вывел на экран последнее слово в документе.
Очевидно, что приведенный выше способ работы с документам хорош в случае, когда требуется создать относительно простой документ Word и не требуется лишний раз рассчитывать фрагменты текста, правильно вставлять таблицы и т.д. Если же необходимо работать с документами, которые имеют сложное содержание, например текст в перемежку с рисунками, таблицами, а сам текст выводится различными шрифтами, то, на мой взгляд наиболее удобно использовать второй способ работы с Word в Delphi — просто заменить текст в уже заранее заготовленном документа.
2. Работа с документами Word в Delphi. Открытие готового документа и замена текста.
Чтобы открыть заранее заготовленный документ Word в Delphi достаточно воспользоваться методом Open у коллекции Documents, например так:
var FilePath: string; [...] Word.Documents.Open(FilePath) [...]
Метод Open можно вызывать с несколькими аргументами:
- FileName: string — путь и имя файла;
- ConfirmConversions: boolean — False — не открывать диалоговое окно «Преобразование файла» при открытии файла, формат которого не соответствует формату Word (doc или docx)
- ReadOnly:boolean — True — открыть документ в режиме «Только для чтения»
- AddToRecentFiles: boolean — True, чтобы добавить документ в список недавно открытых документов.
- PasswordDocument: string — пароль для открытия документа
- PasswordTemplate: string — пароль для открытия шаблона
- Revert : boolean — True, чтобы вернуться к сохраненному документу, если этот документ открывается повторно.
- WritePasswordDocument: string — пароль для сохранения измененного документа в файле
- WritePasswordTemplate:string — пароль для сохранения изменений в шаблоне
- Format:integer — формат открываемого документа.
Обязательным параметром метода Open является только FileName, остальные — могут отсутствовать. Если же Вам необходимо воспользоваться несколькими параметрами, то их необходимо явно указывать при вызове метода, например:
[...] Word.Documents.Open(FileName:=FilePath, ReadOnly:=true) [...]
В этом случае документ открывается в режиме «Только для чтения». При таком способе вызова (с явным указанием аргументов) положение аргументов может быть произвольным.
Что касается последнего аргумента — Format, то он может принимать целочисленные значения (применительно к версиям Microsoft Word 2007 и выше) от 0 до 13. При этом, для того, чтобы открыть «родные» вордовские документы (doc) достаточно использовать значения 0 или 6.
Теперь, когда документ открыт его необходимо преобразовать. Обычно я делаю следующим образом: в тех местах документа, в которые необходимо вставить текст я расставляю либо закладки, либо простые строки текста, например, обрамленные символом $ или #. И затем просто выполняю поиск и замену подстрок следующим образом:
function FindAndReplace(const FindText,ReplaceText:string):boolean; const wdReplaceAll = 2; begin Word.Selection.Find.MatchSoundsLike := False; Word.Selection.Find.MatchAllWordForms := False; Word.Selection.Find.MatchWholeWord := False; Word.Selection.Find.Format := False; Word.Selection.Find.Forward := True; Word.Selection.Find.ClearFormatting; Word.Selection.Find.Text:=FindText; Word.Selection.Find.Replacement.Text:=ReplaceText; FindAndReplace:=Word.Selection.Find.Execute(Replace:=wdReplaceAll); end;
Приведенная выше функция позволяет провести поиск и замену текстового фрагмента во всём документе. Для того, чтобы ограничить возможности пользователя при работе с шаблоном документа я обычно ставлю на необработанный файл пароль, а после обработки — пароль снимаю и сохраняю документ с другим названием в необходимую директорию.
Вот, наверное, самые-самые простые методы работы с Word в Delphi. Кстати, пишу пост и, думаю, что у кого-то из читателей может возникнуть вопрос: причём тут Delphi в Internet и Word в Delphi?  Честно говоря, приведенный выше фрагменты кода можно использовать для нужд в Internet с натяжкой, например, при автосоставлении небольших отчётов по чему-либо. А вообще, в недалеком будущем, есть в планах поразбираться с Тезаурусом Word и попробовать составить небольшой синонимайзер для собственных нужд — он-то и пригодится нам в Internet
Честно говоря, приведенный выше фрагменты кода можно использовать для нужд в Internet с натяжкой, например, при автосоставлении небольших отчётов по чему-либо. А вообще, в недалеком будущем, есть в планах поразбираться с Тезаурусом Word и попробовать составить небольшой синонимайзер для собственных нужд — он-то и пригодится нам в Internet
3.1
8
голоса
Рейтинг статьи
уважаемые посетители блога, если Вам понравилась, то, пожалуйста, помогите автору с лечением. Подробности тут.
|
|
|
|




Пожалуйста, выделяйте текст программы тегом [сode=pas] … [/сode]. Для этого используйте кнопку [code=pas] в форме ответа или комбобокс, если нужно вставить код на языке, отличном от Дельфи/Паскаля.
Соблюдайте общие правила форума
Следующие вопросы задаются очень часто, подробно разобраны в FAQ и, поэтому, будут безжалостно удаляться:
1. Преобразовать переменную типа String в тип PChar (PAnsiChar)
2. Как «свернуть» программу в трей.
3. Как «скрыться» от Ctrl + Alt + Del (заблокировать их и т.п.)
4. Как запустить программу/файл? (и дождаться ее завершения)
5. Как перехватить API-функции, поставить hook? (перехват сообщений от мыши, клавиатуры — внедрение в удаленное адресное прстранство)
… (продолжение следует) …
Внимание:
Попытки открытия обсуждений реализации вредоносного ПО, включая различные интерпретации спам-ботов, наказывается предупреждением на 30 дней.
Повторная попытка — 60 дней. Последующие попытки — бан.
Мат в разделе — бан на три месяца…
Полезные ссылки:  MSDN Library
MSDN Library  FAQ раздела
FAQ раздела  Поиск по разделу
Поиск по разделу  Как правильно задавать вопросы
Как правильно задавать вопросы
Выразить свое отношение к модераторам раздела можно здесь: ![]() Rouse_,
Rouse_, ![]() Krid
Krid

Delphi и Word
, Не могу выделить текст
- Подписаться на тему
- Сообщить другу
- Скачать/распечатать тему
|
|
|
|
Народ!!! |
|
Modest Wizard |
|
|
Var Word:Variant; begin Word:=CreateOleObject(‘Word.Application’); Word.Documents.Open(‘c:myfile.doc’,emptyparam,emptyparam,emptyparam,emptyparam,emptyparam,emptyparam,emptyparam,emptyparam,emptyparam,1251); Word.Selection.WholeStory; Word.Visible:=true; end; |


Rouse_ |
|
|
Moderator
Рейтинг (т): 320 |
unit Unit1; interface uses Windows, Messages, SysUtils, Variants, Classes, Graphics, Controls, Forms, Dialogs, ComObj, StdCtrls; type TForm1 = class(TForm) Button1: TButton; procedure Button1Click(Sender: TObject); procedure FormDestroy(Sender: TObject); private { Private declarations } public { Public declarations } end; var Form1: TForm1; W: Variant; implementation {$R *.dfm} procedure TForm1.Button1Click(Sender: TObject); begin W := CreateOleObject(‘Word.Application’); W.Documents.Open(FileName := ‘c:tmp.doc’, ReadOnly:=False); W.Visible := True; W.ActiveDocument.Range(Start := 10, End := 40).Select; end; procedure TForm1.FormDestroy(Sender: TObject); begin W.Quit(SaveChanges:=True); end; end. |


|
Kryak |
|
|
Посибки |

|
Shaden |
|
|
Junior
Рейтинг (т): 0 |
Извините, а как скопировать, допустим, с третьей по шестую строку текста, содержащего 10 строк и вставить скопированный текст после десятой строки? Сообщение отредактировано: Shaden — 14.09.05, 03:45 |


Krid |
|
|
Moderator
Рейтинг (т): 237 |
Цитата Shaden @ 14.09.05, 03:44 Извините, а как скопировать, допустим, с третьей по шестую строку текста, содержащего 10 строк и вставить скопированный текст после десятой строки?
const wdGoToLine=3; wdGoToAbsolute=1; wdLine = 5; wdExtend=1; wdGoToLast=-1; var W,Sel: Variant; procedure TForm1.Button1Click(Sender: TObject); begin W := CreateOleObject(‘Word.Application’); W.Documents.Open(FileName := ‘c:tmp.doc’, ReadOnly:=False); W.Visible := True; Sel:=W.Selection; Sel.GoTo(What:=wdGoToLine, Which:=wdGoToAbsolute, Count:=3); Sel.MoveDown(Unit:=wdLine, Count:=3, Extend:=wdExtend); Sel.Copy; Sel.GoTo(What:=wdGoToLine, Which:=wdGoToLast); Sel.EndKey( Unit:=wdLine); Sel.TypeParagraph; Sel.Paste; Sel:=Unassigned; end; |

|
yurant |
|
|
Junior
Рейтинг (т): 0 |
А можно ли выделить весь текст БЕЗ открытия |
|
vet |
|
|
Full Member
Рейтинг (т): 16 |
Открывать-то придется, но если его не делать видимым, то никто ничего и не узнает
var Word: variant; begin Word := CreateOleObject(‘Word.Application’); Word.Documents.Open(‘C:666.doc’); Word.Selection.WholeStory; Word.Selection.Copy; Memo.PasteFromClipboard; Word.Quit; Word := Unassigned; end; Вообще-то узнает, так как будет задержка на открытие документа |
|
dron-s |
|
|
yurant
var word:variant; begin Word := CreateOleObject(‘Word.Application’); Word.Documents.Open(‘C:333.doc’); RichEdit1.Text := word.ActiveDocument.Range.Text; word.Quit; это без буфера обмена… |
|
valyan |
|
|
Full Member
Рейтинг (т): нет |
Здравствуйте. Вопрос таков — в документе порядка 100 страниц, на каждой странице есть информация о человеке, эта информация — переменная величина (для каждого человека), так вот как выделить эти строки (информацию о человеке) |

|
VahaC |
|
|
Имхо лучше всего делать вот так: Берем весь текст из ворда и пихаем его к примеру в RichEdit Цитата dron-s @ 30.11.05, 05:10 yurant
var word:variant; begin Word := CreateOleObject(‘Word.Application’); Word.Documents.Open(‘C:333.doc’); RichEdit1.Text := word.ActiveDocument.Range.Text; word.Quit; а потом парсим текст в этом RichEdit`е с помощью Pos, PosEx и иже с ними Сообщения были разделены в тему «Вставка текста в середину страницы. Word» |
|
evg_reg35 |
|
|
Добрый вечер. Подскажите пожалуйста. Для удобства решил написать программу, но не получается. |
0 пользователей читают эту тему (0 гостей и 0 скрытых пользователей)
0 пользователей:
- Предыдущая тема
- Delphi: Система, Windows API
- Следующая тема
![]()
![]()
[ Script execution time: 0,0361 ] [ 16 queries used ] [ Generated: 13.04.23, 22:37 GMT ]

Здравствуйте, нужна помощь в решении следующей задачи:
Нужно скопировать достаточно большой фрагмент текста из вордовского документа А вордовский документ Б, не потеряв форматирования. В копируемых фрагментах текста присутствуют списки, но нет таблиц.
Должны быть определены хотябы места вставки(т.е. копирование всего документа А в определенное место в документе Б), в идеале конечно хотелось бы определить и места копирования. К примеру:
Найти и копировать из документа А ВСЕ что заключено между тегами [Copy][/Copy] в документ Б в место заключенное между тегами [Paste][/Paste] с заменой тэгов вставки.
Но в реализации я вас не ограничиваю если есть другие варианты с удовольсвием приму и их.
Помогите пожалуйста, заранее спасибо
Добавлено через 11 часов 21 минуту
ап, —…—
Добавлено через 4 минуты
Вот почва для размышлений: код копирует весь документ 1 в определенное место в документе 2, но единственная проблема в том что он полностью заменяет весь текст в документе 2 на весь текст из документа 1.
А нужно чтобы одно ключевое слово из документа 2 заменилось на весь текст документа 1…
Надеюсь вы меня поняли
| Pascal | ||
|
Предположим, у нас уже
открыт файл. Вопросы открытия и сохранения документов уже были в других статьях,
так что подробно на этом останавливаться не будем. Просто по ходу дела будет
приведено то, чего раньше не встречалось — выход из документа без сохрания
изменений. Как-то забыл, извините:)
Текст
Сначала о самом простом
— добавлении в документ Word нужной строки текста. Поместим на форму компоненты
WordDocument, WordApplicationи WordParagraphFormat с
палитры Servers. Нас интересуют в первую очередь свойство Range
компонента WordDocument и свойство Selection компонента
WordApplication. Классики утверждают, что они являются ссылкой на объекты
Range и Selection. Range представляет из себя, проще говоря,
кусок текста, это может быть как весь текст документа, так и любая его часть.
Его пределы задаются двумя (или меньше) параметрами типа OleVariant.
Например:
var range1, range2, range3, a, b : OleVariant; ... range1:=WordDocument1.Range; a:=5; b:=15; range2:=WordDocument1.Range(a,b); range3:=WordDocument1.Range(a);
Первый наш объект включает в себя весь текст документа, у второго мы ограничили
пределы 5-м и 15-м символами, третий представляет из себя весь последующий текст
документа, начиная с 5-го символа. Объект имеет несколько полезных методов,
например, с его помощью можем добавить текст в документ:
range2.InsertAfter('MS Word');
Это
мы вставили текст после выделенного Range. Точно также можем вставить
текст и перед ним, для этого служит метод InsertBefore(). Текст,
заключенный в объекте Range, можем получить так:
WordDocument1.Range(a,b).Text; Кроме
того, с помощью Range можем изменить шрифт в пределах объекта. Пример:
a:=5; b:=15; WordDocument1.Range(a,b).Font.Bold:=1; WordDocument1.Range(a,b).Font.Size:=14; WordDocument1.Range(a,b).Font.Color:=clRed;
Если
хотим отменить выделение жирным шрифтом, присваиваем 0. Аналогично можно сделать
шрифт курсивом, подчеркнутым — наберите WordDocument1.Range.Font., и
среда сама подскажет, какие могут быть варианты. Методы Select, Cut, Copy и
Paste работают как в обычном тексте. С помощью Paste можем на место выбранного
Range вставить не только строки, но и рисунок, находящийся в буфере
обмена.
WordDocument1.Range(a,b).Select; WordDocument1.Range(a,b).Cut; WordDocument1.Range(a,b).Copy; WordDocument1.Range(a,b).Paste;
С
помощью Range можем найти в документе нужную строку. Пусть в тексте содержится
слово «picture». Например, нам на его место надо будет вставить рисунок.
var a, b, vstart, vend: OleVariant; j, ilengy: Integer; ... ilengy:=Length(WordDocument1.Range.Text); for j:=0 to ilengy-8 do begin a:=j; b:=j+7; if WordDocument1.Range(a,b).Text='picture' then begin vstart:=j; vend:=j+7; end; end; WordDocument1.Range(vstart,vend).Select;
Такая
процедура находит и выделяет нужный кусок текста.Теперь про Selection, представляющий из себя выделенный фрагмент
документа. Если выделения нет, это текущая позиция курсора в документе. С его
помощью можем вставить что-либо на место выделенного фрагмента, сделать
выравнивание, изменить шрифт. Он также имеет методы InsertAfter() и
InsertBefore():
WordApplication1.Selection.InsertAfter("text1");
WordApplication1.Selection.InsertBefore("text2");
Форматирование выделенного текста происходит аналогично Range, например:
WordApplication1.Selection.Font.Bold:=1; WordApplication1.Selection.Font.Size:=16; WordApplication1.Selection.Font.Color:=clGreen;
Для
выравнивания проще воспользоваться компонентом WordParagraphFormat.
Сначала только нужно «подключить» его к выделенному фрагменту текста:
WordParagraphFormat1.ConnectTo(WordApplication1.Selection.ParagraphFormat); WordParagraphFormat1.Alignment:=wdAlignParagraphCenter;
Значения его свойства Alignment может принимать значения
wdAlignParagraphCenter, wdAlignParagraphLeft, wdAlignParagraphRight, смысл
которых очевиден. Имеются и методы Cut, Copy и Paste, которые в пояснениях вряд
ли нуждаются:
WordApplication1.Selection.Cut; WordApplication1.Selection.Copy; WordApplication1.Selection.Paste;
Убираем выделение с помощью метода Collapse.
При этом необходимо указать, в какую сторону сместится курсор, будет ли он до
ранее выделенного фрагмента или после:
var vcol: OleVariant; ... vcol:=wdCollapseStart; WordApplication1.Selection.Collapse(vcol);
При
этом выделение пропадет, а курсор займет позицию перед фрагментом текста. Если
присвоить переменной значение wdCollapseEnd, то курсор переместится назад. Можно
просто поставить в скобках «пустышку»:
WordApplication1.Selection.Collapse(EmptyParam);
Тогда
свертывание выделения производится по умолчанию, к началу выделенного текста.
РисункиЛогично было бы предположить, что рисунки документа будут представлять из себя
коллекцию, аналогичную таблицам, и мы, обратившись к конкретной картинке, сможем
менять ее свойства — обтекание, размер и т.д. Однако ничего подобного в WordDocument не обнаруживается. Потому возможности управления встраиваемыми в
документ изображениями сильно ограничены. Простейший метод вставить в документ рисунок — по упомянутым причинам он же и
единственный — скопировать его в Word из буфера обмена. Предположим, рисунок у
нас находится в компоненте DBImage. Сначала нужно загнать его в буфер обмена:
Clipboard.Assign(DBImage1.Picture);
Теперь для его вставки следует воспользоваться методом Paste объектов Range или
Selection: WordApplication1.Selection.Paste или WordDocument1.Range(a,b).Paste.
Оставить для рисунка достаточное количество пустых строк и попасть в нужное
место — это уже наша забота. Если он попадет посреди текста, вид будет довольно
противный — при такой вставке обтекание текстом рисунка происходит как-то
странно. Можно приготовить для отчета шаблон, где заменяем рисунком какое-либо
ключевое слово. О том, как найти в документе нужный текст, см. выше.
А
теперь о несколько ином способе вставки рисунка, который устраняет проблемы с
обтеканием и дает нам возможность перемещать его по документу, масштабировать и
задавать отступы между рисунком и текстом. Способ, собственно, тот же — копируем
из буфера обмена, но не прямо в документ, а в «рамку» — текстовую вставку. В ней
может находиться не только текст, но и картинка, чем и воспользуемся.
«Рамки» образуют коллекцию Frames, нумеруются целым индексом, пробегающим
значения от 1 до WordDocument1.Frames.Count. Добавим в документ рамку,
изменим ее размер и вставим рисунок:
Clipboard.Assign(DBImage1.Picture); vstart:=1; vend:=2; WordDocument1.Frames.Add(WordDocument1.Range(vstart,vend)); i:=1; WordDocument1.Frames.Item(i).Height:=DBImage1.Height; WordDocument1.Frames.Item(i).Width:=DBImage1.Width; WordDocument1.Frames.Item(i).Select; WordApplication1.Selection.Paste;
Здесь
для простоты предполагается, что размер DBImage равен размеру самой
картинки, а также что до этого рамок у нас в документе не было. Обратить
внимание следует на несколько моментов. Размер рамки надо задавать до того, как
копировать в нее рисунок. Иначе она будет иметь размер по умолчанию, под который
замасштабируется и наша картинка. При попытке изменить размер рамки задним
числом размер картинки уже не изменится. Кроме того, параметр Range при
добавлении рамки часто никакой роли не играет. Рамка изначально все равно
появится в левом верхнем углу документа, а указанный кусок текста при этом не
пострадает. Но это только в том случае, если он не выделен. Если в документе
есть выделение, рамка появится вместо выделенного фрагмента. Таким образом можем
ее вставить в нужное место взамен какого-то ключевого слова.
При желании можем ее подвигать в документе и «вручную». Для этого служат
свойства горизонтального и вертикального позиционирования, которые задают ее
отступ от левого верхнего «угла» документа:
i:=1; WordDocument1.Frames.Item(i).VerticalPosition:=30; WordDocument1.Frames.Item(i).HorizontalPosition:=50; Отступ между краями рамки и текстом задается следующим образом: WordDocument1.Frames.Item(i).HorizontalDistanceFromText:=10; WordDocument1.Frames.Item(i).VerticalDistanceFromText:=10;
А
теперь о масштабировании. Для этого достаточно длину и ширину рамки умножить на
одно и то же число. Например:
WordDocument1.Frames.Item(i).Height:=DBImage1.Height*1.5; WordDocument1.Frames.Item(i).Width:=DBImage1.Width*1.5;
При
этом наша картинка в полтора раза пропорционально растянется. Точно также можно
и уменьшить, но делить, как и множить, следует на одно число. Растягивать длину
и ширину по-разному у меня лично не получалось. Задавать размер опять-таки надо
еще до вставки рисунка. Ну и, наконец, удаление рамки:
WordDocument1.Frames.Item(i).Delete;
Списки Списки в документе образуют коллекцию Lists, к отдельному списку
обращаемся WordDocument1.Lists.Item(i), где i целое число от 1 до
WordDocument1.Lists.Count … на этом все. Нет методов, позволяющих не то
что создать новый список, а даже добавить пункт к уже существующему. Ничего
страшного, настоящие герои всегда идут в обход:)) Сейчас мы все же проделаем и
то, и другое. Все что нам понадобится — свойство Range отдельного списка, то
есть его текст без разделения на пункты, а также возможность его выделить:
WordDocument1.Lists.Item(i).Range.Select;
Для
этого в любом случае потребуется заготовка. Неважно, вставлена она в общий
шаблонный документ или хранится в отдельном файле. Заготовку делаем так:
выбираем в меню Формат/Список, и сохраняем, если это отдельный шаблон списка. У
нас появляется пустой список без текста с одним маркером. Далее вспоминаем, как
мы делали списки вручную — писали текст, нажимали «Enter», появлялся новый
элемент списка. Теперь то же самое, только программно. Предположим, у нас уже
открыт документ с заготовкой, и мы хотим внести в список пункты «Item 1» и «Item
2»:
var i: Integer;
vcol: OleVariant;
...
i:=1;
vcol:=wdCollapseEnd;
WordDocument1.Lists.Item(i).Range.Select;
WordApplication1.Selection.Collapse(vcol);
WordApplication1.Selection.InsertAfter('Item 1');
WordDocument1.Lists.Item(i).Range.Select;
WordApplication1.Selection.Collapse(vcol);
WordApplication1.Selection.InsertAfter(#13);
WordDocument1.Lists.Item(i).Range.Select;
WordApplication1.Selection.Collapse(vcol);
WordApplication1.Selection.InsertAfter('Item 2');
WordDocument1.Lists.Items(i).Range.Select;
WordApplication1.Selection.Copy;
То
есть мы вставляем в документ текст первого пункта списка, он попадает на свое
место. Потом посылаем в Word символ перехода строки, он честно переходит и тем
самым сам создает нам второй пункт списка, куда и вставляем нужную строку. Ну и
так далее, нужное количество раз. Последние две строки нужны, если список
заготовлен в отдельном файле — после их выполнения список оказывается в буфере
обмена. Здесь выгода в том, что можем иметь заготовки списков разных стилей и по
ходу дела выбирать, какой список создать. Затем открываем документ, где должен
быть список, выделяем с помощью Range нужный кусок, копируем из буфера обмена
через WordDocument1.Range(a,b).Paste. Чтобы не испортить файл с заготовкой,
можем сразу после открытия пересохранить его под другим именем, а можем просто
выйти из него без сохранения изменений
var vsave: OleVariant; ... vsave:=wdDoNotSaveChanges; WordDocument1.Close(vsave);
Константа сохранения изменений может принимать значения
|
Символьное обозначение |
|
|
wdSaveChanges |
$FFFFFFFF |
|
wdDoNotSaveChanges |
$00000000 |
|
wdPromptToSaveChanges |
$FFFFFFFE |
Первое значение
сохраняет изменения, второе дает возможность выйти без сохранения изменений.
Последняя константа вызывает при выходе стандартный диалог сохранения изменений.
Можем сделать и несколько по-другому. Хотя мы не можем создать новый элемент
списка, но текст в уже существующем изменить можно:
var i,j: Integer; ... i:=1; j:=1; WordDocument1.Lists.Item(i).ListParagraphs.Item(j).Range.Text:='Item 1';
Так что можно с помощью переходов строки создать нужное количество элементов, а затем их заполнить:
WordDocument1.Lists.Item(i).Range.Select; WordApplication1.Selection.Collapse(vcol); WordApplication1.Selection.InsertAfter(#13); j:=1; WordDocument1.Lists.Item(i).ListParagraphs.Item(j).Range.Text:='Item 1'; j:=2; WordDocument1.Lists.Item(i).ListParagraphs.Item(j).Range.Text:='Item 2';
Это
было в предположении, что у нас один элемент списка в заготовке уже есть. Ну
вот, в общем-то, и все про текст, списки и картинкиСтатистика документовВ
данном небольшом материале рассматривается вопрос подсчета статистики файлов
*.doc и *.rtf. Такой вопрос у меня возник, когда пришлось сделать небольшую базу
данных по учету документов, куда надо было заносить и статистику документа —
число знаков, слов и т.п. Открывать каждый раз Word, считать статистику и
забивать ее в форму ввода было лень, так что пришла в голову мысль это дело
автоматизировать. Информации по данному вопросу найти так и не удалось, так что
основным источником знаний служили заголовочный файл Word2000.pas и
справка по Visual Basic for Applications. Ну и, конечно, множество разных
экспериментов. Сразу
оговорюсь, что я не профессиональный программист, так что в тонкости интерфейсов
вникать не будем — сам в них не особо разбираюсь. Потому, не мудрствуя лукаво,
просто поместим на форме компоненты WordApplication и WordDocument
с палитры Servers. Для работы используются свойства и методы этих
компонентов. Встроенная статистика Word подсчитывает статистику обычного текста, обычных и
концевых сносок. Для подсчета статистики используется метод компонента
WordDocument ComputeStatistic(). Он имеет один параметр, характеризующий,
что именно считать, представляющий из себя шестнадцатеричную константу.
Константы описаны в заголовочном файле Word2000.pas, он лежит обычно в
/Delphi/Ocx/Servers.
|
Шестнадцатеричная |
Символьное обозначение |
Смысл |
|
$00000000 |
wdStatisticWords |
Количество слов |
|
$00000001 |
wdStatisticLines |
Количество строк |
|
$00000002 |
wdStatisticPages |
Количество страниц |
|
$00000003 |
wdStatisticCharacters |
Знаки без пробелов |
|
$00000004 |
wdStatisticParagraphs |
Количество разделов |
|
$00000005 |
wdStatisticCharactersWithSpaces |
Знаки с пробелами |
Это было основное, что
надо знать. Ну а теперь по порядку. Поместив на форму упомянутые компоненты, видим, что свойств и методов у них
совсем мало. В первую очередь следует определиться с методом ConnectKind
компонента WordApplication. Оно может принимать различные значения, но мы
оставим присваемое по умолчанию значение ckRunningOrNew. Это означает, что
соединение происходит с уже работающим сервером, при его отсутствии запускается
новый. Как правило, это вполне устраивает. Первым делом откроем документ. Предварительно надо объявить переменную FileName,
она будет типа OleVariant, которой присвоим строку с именем файла.
WordApplication1.Connect; WordApplication1.Documents.Open(FileName, EmptyParam,EmptyParam,EmptyParam, EmptyParam,EmptyParam,EmptyParam, EmptyParam,EmptyParam,EmptyParam, EmptyParam,EmptyParam); WordDocument1.ConnectTo(WordApplication1.ActiveDocument);
Обратите внимание на количество параметров-«пустышек».
Их число больше того, которое обычно
приводится в книжках. Ну, в моих, во всяком случае. Объясняется это тем, что
«книжные» функции предназначены для MS Word 97, а такая запись для работы с Word
2000 и Word XP.
«Plain Text»Объявив нужное количество переменных типа LongInt (в очень большом файле или при
суммировании по нескольким документам в принципе может оказаться больше знаков,
чем пределы обычного целого типа), можем уже и приступать к подсчету. Например,
посчитаем число слов, знаков с пробелами и без пробелов обычного текста, а также
количество страниц в документе. Результаты сохраним соответственно в «длинных»
переменных
WCount:=WordDocument1.ComputeStatistics($00000000); CCount:=WordDocument1.ComputeStatistics($00000003); SCount:=WordDocument1.ComputeStatistics($00000005); PCount:=WordDocument1.ComputeStatistics($00000002);
Открыв нужный документ в Word’е и вызвав диалог подсчета статистики, нетрудно
увидеть, что значения переменных равны параметрам вордовской статистики со
сброшенным флажком «Учитывать все сноски».
СноскиСноски в документах могут быть обычные и концевые. То есть если первые
располагаются внизу данной страницы, то концевые — строго в конце документа.
Кроме того, они могут отличаться и нумерацией — автоматической или заданной
пользователем. Начнем с обычных сносок как с самого простого. В терминологии
объектной модели Word — Footnotes. Сначала надо вычислить количество самих
сносок:
ifcount:=WordDocument1.DefaultInterface.Footnotes.Count;
Подсчет статистики текста в сноске производится так:
FWCount:=WordDocument1.DefaultInterface.Footnotes.Item(ifoot).Range.ComputeStatistics($00000000);
Здесь
ifoot — целое число, «нумерующее» сноску. Для того, чтобы учесть сами номера
сносок, сделаем так:
FWCount:=FWCount+WordDocument1.DefaultInterface.Footnotes.Item(ifoot).Reference.ComputeStatistics($00000000);
Это
мы посчитали для примера количество слов в сноске с номером ifoot и ее метке —
при пользовательской нумерации в качестве «номера» может быть целое предложение.
Далее начинаем перебирать их одну за другой. При этом следует учесть, что кроме
статистики сносок необходимо получить и статистику их «номеров». То есть:
for ifoot:=1 to ifcount do begin FWCount:=FWCount+WordDocument1.DefaultInterface.Footnotes.Item(ifoot).Range.ComputeStatistics($00000000); FCCount:=FCCount+WordDocument1.DefaultInterface.Footnotes.Item(ifoot).Range.ComputeStatistics($00000003); FSCount:=FSCount+WordDocument1.DefaultInterface.Footnotes.Item(ifoot).Range.ComputeStatistics($00000005); FCCount:=FCCount+WordDocument1.DefaultInterface.Footnotes.Item(ifoot).Reference.ComputeStatistics($00000003); FSCount:=FSCount+WordDocument1.DefaultInterface.Footnotes.Item(ifoot).Reference.ComputeStatistics($00000005)+1; if WordDocument1.DefaultInterface.Footnotes.Item(ifoot).Reference.Text<>IntToStr(ifoot) then begin FWCount:=FWCount+ WordDocument1.DefaultInterface.Footnotes.Item(ifoot).Reference.ComputeStatistics($00000000); end; end;
Прибавление единицы появляется оттого, что сумма статистики сносок и номеров не
совпадает с тем, что выдает встроенная статистика Word. Между номером сноски и
текстом сноски Word ставит пробел, который почему-то не учитывается. Условный
оператор определяет, как пронумерована данная сноска — по умолчанию или нет. В
последнем случае следует проверить количество слов в обозначении сноски. Такая
схема дает результат, совпадающий со показаниями встроенной статистики. Кроме
того, цикл у нас идет от 1 — так начинается нумерация сносок в MS Word, да и
практически всех остальных объектов тоже.Теперь перейдем к концевым сноскам. Теоретически все то же самое, только вместо
слова «Footnotes» пишем «Endnotes». И тут наталкиваемся на сюрприз — почему-то
оно считает неточно. Я в данном случае поступил так: сохраняю документ под
другим именем, переконвертирую концевые сноски в обычные и далее все, как
сказано выше. Сохранение документа:
WordDocument1.SaveAs(FileName, FileFormat),
где в скобках стоят два параметра типа OleVariant — имя файла и шестнадцатеричная
константа, задающая формат файла. Некоторые константы:
|
|
|
|
| $00000000 |
wdFormatDocument |
Документ Word |
|
$00000004 |
wdFormatDOSText |
Простой текст |
|
$00000006 |
wdFormatRTF |
Файл RTF |
Полный список констант
формата можно найти все в том же файле Word2000.pas. И еще один интересный
момент — если просто поставить в скобки обе константы, работать не будет.
Следует предварительно объявить две переменных, присвоить им соответствующие
значения и только потом сохранять. Ну, а
теперь, собственно, можем вернуться к сноскам. Конвертирование концевых сносок в
обычные происходит так:
WordDocument1.DefaultInterface.Endnotes.Convert;
Теперь мы имеем документ, в котором содержатся только обычные сноски. С ними
никаких проблем не возникает, пример, как с ними работать, см. выше. Если
интересует статистика отдельно разных типов сносок, считаем предварительно
статистику обычных сносок, сохраняем ее в «буферных» переменных и считаем еще
раз после конвертирования. Разница даст статистику концевых сносок по
отдельности. Сложив статистику сносок и простого текста, получаем статистику
документа с учетом сносок так, как ее дает сам Word.
Дополнительно…Тут
по традиции несколько покритикуем Microsoft. Как оказалось, Word показывает не
все, что содержится в документе. Не принимаются в расчет колонтитулы. А ведь в
них может содержаться изрядный кусок текста, особенно в справках, бланках и т.п.
Оказывается, Word их на самом деле считает, но нам не показывает. Вот и
посмотрим, как же его можно заставить это сделать. Колонтитулы в документе тесно связаны с несколько загадочной штукой под
названием «разделы» — Sections. Каждый раздел может иметь верхние и нижние
колонтитулы. Потому первым делом определяем количество абзацев.
isectct:=WordDocument1.DefaultInterface.Sections.Count;
Здесь
у нас целые переменные isectct, icofct, icohct обозначают
соответственно количество разделов как таковых, количество нижних и верхних
колонтитулов данного раздела. Переменная isec служит «номером» раздела,
переменные icof, icoh «нумеруют» соответственно нижние и верхние
колонтитулы в пределах данного раздела. Количество колонтитулов в разделе
определяем так:
icofct:=WordDocument1.DefaultInterface.Sections.Item(isec).Footers.Count; icohct:=WordDocument1.DefaultInterface.Sections.Item(isec).Headers.Count;
Теперь уже можем «достать» текст из колонтитула:
CBWCount:= WordDocument1.DefaultInterface.Sections.Item(isec).Footers.Item(icof).Range.ComputeStatistics($00000000);
В
данном случае мы для примера посчитали число слов, содержащихся в нижнем
колонтитуле под номером icof, принадлежащем разделу под номером isec.
Теперь можем написать «двойной» цикл для подсчета статистики верхних и нижних
колонтитулов.
Работа со строками и символами
Обработка текста — одна из часто встречающихся задач программирования. Если требуется обработать какие-либо текстовые данные, то без знаний того материала, что будет изложен ниже, просто не обойтись. Особенно, если данные сформированы не лично вами, а какой-либо сторонней программой или другим человеком.
Символы
Символ — это одна единица текста. Это буква, цифра, какой-либо знак. Кодовая таблица символов состоит из 256 позиций, т.е. каждый символ имеет свой уникальный код от 0 до 255. Символ с некоторым кодом N записывают так: #N. Прямо так символы и указываются в коде программы. Так как код символа представляет собой число не более 255, то очевидно, что в памяти символ занимает 1 байт. Как известно, менее байта размерности нет. Точнее, она есть — это бит, но работать с битами в программе мы не можем: байт — минимальная единица. Просмотреть таблицу символов и их коды можно с помощью стандартной утилиты «Таблица символов», входящей в Windows (ярлык расположен в меню Пуск — Программы — Стандартные — Служебные). Но совсем скоро мы и сами напишем нечто подобное.
Строки
Строка, она же текст — это набор символов, любая их последовательность. Соответственно, один символ — это тоже строка, тоже текст. Текстовая строка имеет определённую длину. Длина строки — это количество символов, которые она содержит. Если один символ занимает 1 байт, то строка из N символов занимает соответственно N байт.
Есть и другие кодовые таблицы, в которых 1 символ представлен не одним байтом, а двумя. Это Юникод (Unicode). В таблице Юникода есть символы всех языков мира. К сожалению, работа с Юникодом довольно затруднена и его поддержка пока что носит лишь локальный характер. Delphi не предоставляет возможностей для работы с Юникодом. Программная часть есть, но вот визуальные элементы — формы, кнопки и т.д. не умеют отображать текст в формате Юникода. Будем надеяться, в ближайшем будущем такая поддержка появится. 2 байта также называют словом (word). Отсюда и название соответствующего числового типа данных — Word (число, занимающее в памяти 2 байта, значения от 0 до 65535). Количество «ячеек» в таблице Юникода составляет 65536 и этого вполне достаточно для хранения всех языков мира. Если вы решили, что «1 байт — 256 значений, значит 2 байта — 2*256 = 512 значений», советую вспомнить двоичную систему и принцип хранения данных в компьютере.
Типы данных
Перейдём непосредственно к программированию. Для работы с символами и строками существуют соответствующие типы данных:
· Char — один символ (т.е. 1 байт);
· String — строка символов, текст (N байт).
Официально строки вмещают лишь 255 символов, однако в Delphi в строку можно записать гораздо больше. Для хранения больших текстов и текстов со специальными символами существуют специальные типы данных AnsiString и WideString (последний, кстати, двухбайтовый, т.е. для Юникода).
Для задания текстовых значений в Pascal используются одинарные кавычки (не двойные!). Т.е. когда вы хотите присвоить строковой переменной какое-либо значение, следует сделать это так:
s:=’text’;
Символы указываются аналогично, только в кавычках присутствует один-единственный символ.
Если вы хотите жёстко ограничить длину текста, хранимого в строковой переменной, можно сделать это следующим образом:
В скобках указывается максимальная длина строки.
Операции со строками
Основной операцией со строками является сложение. Подобно числам, строки можно складывать. И если в числах стулья с апельсинами складывать нельзя, то в строках — можно. Сложение строк — это просто их объединение. Пример:
var s: string;
...
s:='123'+'456';
//s = "123456"
Поскольку каждая строка — это последовательность символов, каждый символ имеет свой порядковый номер. В Pascal нумерация символов в строках начинается с 1. Т.е. в строке «ABC» символ «A» — первый, «B» — второй и т.д.
Порядковый номер символа в строке придуман не случайно, ведь именно по этим номерам, индексам, осуществляются действия над строками. Получить любой символ из строки можно указанием его номера в квадратных скобках рядом с именем переменной. Например:
var s: string; c: char;
...
s:='Hello!';
c:=s[2];
//c = "e"
Чуть позже, когда мы будем изучать массивы, станет понятно, что строка — это массив символов. Отсюда следует и форма обращения к отдельным символам.
Обработка строк
Перейдём к функциям и процедурам обработки строк.
Длину строки можно узнать с помощью функции Length(). Функция принимает единственный параметр — строку, а возвращает её длину. Пример:
var Str: String; L: Integer;
{ ... }
Str:='Hello!';
L:=Length(Str);
//L = 6
Нахождение подстроки в строке
Неотъемлемой задачей является нахождение подстроки в строке. Т.е. задача формулируется так: есть строка S1. Определить, начиная с какой позиции в неё входит строка S2. Без выполнения этой операции ни одну обработку представить невозможно.
Итак, для такого нахождения существует функция Pos(). Функция принимает два параметра: первый — подстроку, которую нужно найти, второй — строку, в которой нужно выполнить поиск. Поиск осуществляется с учётом регистра символов. Если функция нашла вхождение подстроки в строку, возвращается номер позиции её первого вхождения. Если вхождение не найдено, функция даёт результат 0. Пример:
var Str1, Str2: String; P: Integer;
{ ... }
Str1:='Hi! How do you do?';
Str2:='do';
P:=Pos(Str2, Str1);
//P = 9
Удаление части строки
Удалить часть строки можно процедурой Delete(). Следует обратить внимание, что это именно процедура, а не функция — она производит действия непосредственно над той переменной, которая ей передана. Итак, первый параметр — переменная строкового типа, из которой удаляется фрагмент (именно переменная! конкретное значение не задаётся, т.к. процедура не возвращает результат), второй параметр — номер символа, начиная с которого нужно удалить фрагмент, третий параметр — количество символов для удаления. Пример:
var Str1: String;
{ ... }
Str1:='Hello, world!';
Delete(Str1, 6, 7);
// Str1 = "Hello!"
Следует отметить, что если длина удаляемого фрагмента окажется больше количества символов в строке, начиная с указанной позиции (т.е. «вылезем за край»), функция нормально отработает. Поэтому, если нужно удалить фрагмент из строки с какого-то символа до конца, не нужно вычислять количество этих символов. Лучшим способом будет задать длину самой этой строки.
Вот пример. Допустим, требуется найти в строке первую букву «a» и удалить следующую за ней часть строки. Сделаем следующим образом: позицию буквы в строке найдём функцией Pos(), а фрагмент удалим функцией Delete().
var Str: String;
{ ... }
Str:='This is a test.';
Delete(Str,Pos('a',Str),Length(Str));
Попробуем подставить значения и посмотреть, что передаётся функции Delete. Первая буква «a» в строке стоит на позиции 9. Длина всей строки — 15 символов. Значит вызов функции происходит такой: Delete(Str,9,15). Видно, что от буквы «a» до конца строки всего 7 символов… Но функция сделает своё дело, не смотря на эту разницу. Результатом, конечно, будет строка «This is «. Данный пример одновременно показал и комбинирование нескольких функций.
Копирование (извлечение) части строки
Ещё одной важной задачей является копирование части строки. Например, извлечение из текста отдельных слов. Выделить фрагмент строки можно удалением лишних частей, но этот способ неудобен. Функция Copy() позволяет скопировать из строки указанную часть. Функция принимает 3 параметра: текст (строку), откуда копировать, номер символа, начиная с которого скопировать и количество символов для копирования. Результатом работы функции и будет фрагмент строки.
Пример: пусть требуется выделить из предложения первое слово (слова разделены пробелом). На форме разместим Edit1 (TEdit), в который будет введено предложение. Операцию будет выполнять по нажатию на кнопку. Имеем:
procedure TForm1.Button1Click(Sender: TObject);
var s,word: string;
begin
s:=Edit1.Text;
word:=Copy(s,1,Pos(' ',s)-1);
ShowMessage('Первое слово: '+word);
end;
В данном случае из строки копируется фрагмент от начала до первого пробела. Число символов берётся на единицу меньше, т.к. в противном случае пробел также будет скопирован.
Вставка подстроки в строку
Если требуется в имеющуюся строку вставить другую строку, можно использовать процедуру Insert(). Первый параметр — строка для вставки, второй — переменная, содержащая строку, куда нужно вставить, третий — позиция (номер символа), начиная с которого будет вставлена строка. Пример:
procedure TForm2.Button1Click(Sender: TObject);
var S: String;
begin
S:='1234567890';
Insert('000',S,3);
ShowMessage(S)
end;
В данном случае результатом будет строка «1200034567890».
Пример «посерьёзнее»
Примеры, приведённые выше, лишь демонстрируют принцип работы со строками с помощью функций Length(), Pos(), Delete() и Copy(). Теперь решим задачу посложнее, которая потребует комбинированного применения этих функций.
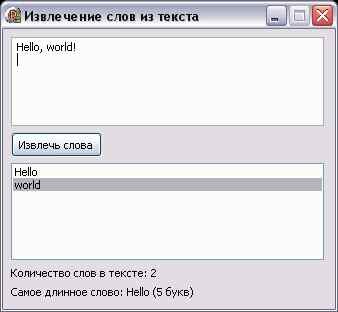
Задача: текст, введённый в поле Memo, разбить на слова и вывести их в ListBox по одному на строке. Слова отделяются друг от друга пробелами, точками, запятыми, восклицательными и вопросительными знаками. Помимо этого вывести общее количество слов в тексте и самое длинное из этих слов.
Вот уж да… Задача вовсе не простая. Во-первых, вы сразу должны догадаться, что нужно использовать циклы. Без них никак, ведь мы не знаем, какой текст будет передан программе для обработки. Во-вторых, слова отделяются разными символами — это создаёт дополнительные трудности. Что ж, пойдём по порядку.
Интерфейс: Memo1 (TMemo), Button1 (TButton), ListBox1 (TListBox), Label1, Label2 (TLabel).
Сначала перенесём введённый текст в переменную. Для того, чтобы разом взять весь текст из Memo, обратимся к свойству Lines.Text:
procedure TForm1.Button1Click(Sender: TObject);
var Text: string;
begin
Text:=Memo1.Lines.Text;
end;
Теперь перейдём к обработке. Первое, что нужно сделать — разобраться с символами-разделителями. Дело в том, что такие символы могут запросто идти подряд, ведь после запятых, точек и других знаков ставится пробел. Обойти эту трудность можно таким простым способом: все разделяющие символы заменим на какой-то один, например на запятую. Для этого пройдём все символы и сделаем необходимые замены. Чтобы определить, является ли символ разделителем, запишем все разделители в отдельную строковую переменную (константу), а затем будем искать в этой строке каждый символ функцией Pos(). Все эти замены будут производиться в переменной, чтобы оригинальный текст в Memo (т.е. на экране) не был затронут. Тем не менее, для проверки промежуточных результатов работы имеет смысл выводить обработанный текст куда-либо. Например, в другое поле Memo. Чтобы пройти все символы, воспользуемся циклом FOR, где переменная пройдёт порядковые номера всех символов, т.е. от 1 до длины строки текста:
procedure TForm1.Button1Click(Sender: TObject);
const DelSym = ' .,!?';
var Text: string; i: integer;
begin
Text:=Memo1.Lines.Text;
for i := 1 to Length(Text) do
if Pos(Text[i],DelSym) > 0 then
Text[i]:=',';
Memo2.Text:=Text;
end;
Теперь нужно устранить помехи. Во-первых, первый символ не должен быть разделителем, т.е. если первый символ — запятая, его нужно удалить. Далее, если подряд идут несколько запятых, их нужно заменить на одну. И наконец, чтобы корректно обработать весь текст, последним символом должна быть запятая.
if Text[1] = ',' then
Delete(Text,1,1);
while Pos(',,',Text) > 0 do
Delete(Text,Pos(',,',Text),1);
if Text[Length(Text)] <> ',' then
Text:=Text+',';
Здесь замена произведена следующим образом: организован цикл, в котором одна из запятых удаляется, но происходит это до тех пор, пока в тексте есть две идущие подряд запятые.
Ну вот, теперь в тексте не осталось ничего лишнего — только слова, разделённые запятыми. Сначала добьёмся того, чтобы программа извлекла из текста первое слово. Для этого найдём первую запятую, скопируем слово от начала текста до этой запятой, после чего удалим это слово из текста вместе с запятой. Удаление делается для того, чтобы далее можно было, проделав ту же самую операцию, вырезать следующее слово.
var Word: string;
{...}
Word:=Copy(Text,1,Pos(',',Text)-1);
Delete(Text,1,Length(Word)+1);
Теперь в переменной Word у нас слово из текста, а в переменной Text вся остальная часть текста. Вырезанное слово теперь добавляем в ListBox, вызывая ListBox.Items.Add(строка_для_добавления).
Теперь нам нужно организовать такой цикл, который позволил бы вырезать из текста все слова, а не только первое. В данном случае подойдёт скорее REPEAT, чем WHILE. В качестве условия следует указать Length(Text) = 0, т.е. завершить цикл тогда, когда текст станет пустым, т.е. когда мы вырежем из него все слова.
repeat
Word:=Copy(Text,1,Pos(',',Text)-1);
Delete(Text,1,Length(Word)+1);
ListBox1.Items.Add(Word);
until Length(Text) = 0;
Итак, на данный момент имеем:
procedure TForm1.Button1Click(Sender: TObject);
const DelSym = ' .,!?';
var Text,Word: string; i: integer;
begin
Text:=Memo1.Lines.Text;
for i := 1 to Length(Text) do
if Pos(Text[i],DelSym) > 0 then
Text[i]:=',';
if Text[1] = ',' then
Delete(Text,1,1);
while Pos(',,',Text) > 0 do
Delete(Text,Pos(',,',Text),1);
repeat
Word:=Copy(Text,1,Pos(',',Text)-1);
Delete(Text,1,Length(Word)+1);
ListBox1.Items.Add(Word);
until Length(Text) = 0;
end;
Если вы сейчас запустите программу, то увидите, что всё отлично работает. За исключением одного момента — в ListBox в конце появились какие-то пустые строки… Возникает вопрос: откуда же они взялись? Об этом вы узнаете в следующем разделе урока, а пока давайте реализуем требуемое до конца.
Количество слов в тексте определить очень просто — не нужно заново ничего писать. Т.к. слова у нас занесены в ListBox, достаточно просто узнать, сколько там строк — ListBox.Items.Count.
Label1.Caption:='Количество слов в тексте: '+IntToStr(ListBox1.Items.Count);
Теперь нужно найти самое длинное из всех слов. Алгоритм нахождения максимального числа таков: принимаем в качестве максимального первое из чисел. Затем проверяем все остальные числа таким образом: если число больше того, которое сейчас записано как максимальное, делаем максимальным это число. В нашем случае нужно искать максимальную длину слова. Для этого можно добавить код в цикл вырезания слов из текста или произвести поиск после добавления всех слов в ListBox. Сделаем вторым способом: организуем цикл по строкам ListBox. Следует отметить, что строки нумеруются с нуля, а не с единицы! В отдельной переменной будем хранить самое длинное слово. Казалось бы, нужно ведь ещё хранить максимальную длину слова, чтобы было с чем сравнивать… Но не нужно заводить для этого отдельную переменную, ведь мы всегда можем узнать длину слова функцией Length(). Итак, предположим, что первое слово самое длинное…
var LongestWord: string;
{...}
LongestWord:=ListBox1.Items[0];
for i := 1 to ListBox1.Items.Count-1 do
if Length(ListBox1.Items[i]) > Length(LongestWord) then
LongestWord:=ListBox1.Items[i];
Label2.Caption:='Самое длинное слово: '+LongestWord+' ('+IntToStr(Length(LongestWord))+' букв)';
Почему цикл до ListBox.Items.Count-1, а не просто до Count, разберитесь самостоятельно
Вот теперь всё готово!
procedure TForm1.Button1Click(Sender: TObject);
const DelSym = ' .,!?';
var Text,Word,LongestWord: string; i: integer;
begin
Text:=Memo1.Lines.Text;
for i := 1 to Length(Text) do
if Pos(Text[i],DelSym) > 0 then
Text[i]:=',';
if Text[1] = ',' then
Delete(Text,1,1);
while Pos(',,',Text) > 0 do
Delete(Text,Pos(',,',Text),1);
Text:=AnsiReplaceText(Text,Chr(13),'');
Text:=AnsiReplaceText(Text,Chr(10),'');
repeat
Word:=Copy(Text,1,Pos(',',Text)-1);
Delete(Text,1,Length(Word)+1);
ListBox1.Items.Add(Word);
until Length(Text) = 0;
Label1.Caption:='Количество слов в тексте: '+IntToStr(ListBox1.Items.Count);
LongestWord:=ListBox1.Items[0];
for i := 1 to ListBox1.Items.Count-1 do
if Length(ListBox1.Items[i]) > Length(LongestWord) then
LongestWord:=ListBox1.Items[i];
Label2.Caption:='Самое длинное слово: '+LongestWord+' ('+IntToStr(Length(LongestWord))+' букв)';
end;
Работа с символами
Собственно, работа с символами сводится к использованию двух основных функций — Ord() и Chr(). С ними мы уже встречались. Функция Ord() возвращает код указанного символа, а функция Chr() — наоборот, возвращает символ с указанным кодом.
Помните «Таблицу символов»? Давайте сделаем её сами!
Вывод осуществим в TStringGrid. Этот компонент представляет собой таблицу, где в каждой ячейке записано текстовое значение. Компонент расположен на вкладке Additional (по умолчанию следует прямо за Standard). Перво-наперво настроим нашу табличку. Нам нужны всего две колонки: в одной будем отображать код символа, а в другой — сам символ. Количество колонок задаётся в свойстве с логичным названием ColCount. Устанавливаем его равным 2. По умолчанию у StringGrid задан один фиксированный столбец и одна фиксированная строка (они отображаются серым цветом). Столбец нам не нужен, а вот строка очень кстати, поэтому ставим FixedCols = 0, а FixedRows оставляем = 1.
Заполнение осуществим прямо при запуске программы, т.е. не будем ставить никаких кнопок. Итак, создаём обработчик события OnCreate() формы.
Количество символов в кодовой таблице 256, плюс заголовок — итого 257. Зададим число строк программно (хотя можно задать и в Инспекторе Объекта):
procedure TForm1.FormCreate(Sender: TObject);
begin
StringGrid1.RowCount:=257;
end;
Вывод делается крайне просто — с помощью цикла. Просто проходим числа от 0 до 255 и выводим соответствующий символ. Также выводим надписи в заголовок. Доступ к ячейкам StringGrid осуществляется с помощью свойства Cells: Cells[номер_столбца,номер_строки]. В квадратных скобках указываются номера столбца и строки (начинаются с нуля). Значения текстовые.
procedure TForm1.FormCreate(Sender: TObject);
var
i: Integer;
begin
StringGrid1.RowCount:=257;
StringGrid1.Cells[0,0]:='Код';
StringGrid1.Cells[1,0]:='Символ';
for i := 0 to 255 do
begin
StringGrid1.Cells[0,i+1]:=IntToStr(i);
StringGrid1.Cells[1,i+1]:=Chr(i);
end;
end;
Запускаем, смотрим.
Специальные символы
Если вы внимательно посмотрите на нашу таблицу, то увидите, что многие символы отображаются в виде квадратиков. Нет, это не значки. Так отображаются символы, не имеющие визуального отображения. Т.е. символ, например, с кодом 13 существует, но он невидим. Эти символы используются в дополнительных целях. К примеру, символ #0 (т.е. символ с кодом 0) часто применяется для указания отсутствия символа. Существуют также строки, называемые null-terminated — это строки, заканчивающиеся символом #0. Такие строки используются в языке Си.
По кодам можно опознавать нажатия клавиш. К примеру, клавиша Enter имеет код 13, Escape — 27, пробел — 32, Tab — 9 и т.д.
Давайте добавим в нашу программу возможность узнать код любой клавиши. Для этого обработаем событие формы OnKeyPress(). Чтобы этот механизм работал, необходимо установить у формы KeyPreview = True.
procedure TForm1.FormKeyPress(Sender: TObject; var Key: Char);
begin
ShowMessage('Код нажатой клавиши: '+IntToStr(Ord(Key)));
end;
Здесь мы выводим окошко с текстом. У события есть переменная Key, в которой хранится символ, соответствующий нажатой клавише. С помощью функции Ord() узнаём код этого символа, а затем функцией IntToStr() преобразуем это число в строку.
Пример «посерьёзнее» — продолжение
Вернёмся к нашему примеру. Пришло время выяснить, откуда в ListBox берутся пустые строки. Дело в том, что они не совсем пустые. Да, визуально они пусты, но на самом деле в каждой из них по 2 специальных символа. Это символы с кодами 13 и 10 (т.е. строка #13#10). В Windows такая последовательность этих двух не визуальных символов означает конец текущей строки и начало новой строки. Т.е. в любом файле и вообще где угодно переносы строк — это два символа. А весь текст, соответственно, остаётся непрерывной последовательностью символов. Эти символы можно (и даже нужно) использовать в случаях, когда требуется вставить перенос строки.
Доведём нашу программу по поиску слов до логического конца. Итак, чтобы избавиться от пустых строк, нам нужно удалить из текста символы #13 и #10. Сделать это можно с помощью цикла, по аналогии с тем, как мы делали замену двух запятых на одну:
while Pos(Chr(13),Text) > 0 do
Delete(Text,Pos(Chr(13),Text),1);
while Pos(Chr(10),Text) > 0 do
Delete(Text,Pos(Chr(10),Text),1);
Ну вот — теперь программа полностью работоспособна!
Дополнительные функции для работы со строками — модуль StrUtils
Дополнительный модуль StrUtils.pas содержит дополнительные функции для работы со строками. Среди этих функций множество полезных. Вот краткое описание часто используемых функций:
PosEx(подстрока, строка, отступ) — функция, аналогичная функции Pos(), но выполняющая поиск с указанной позиции (т.е. с отступом от начала строки). К примеру, если вы хотите найти в строке второй пробел, а не первый, без этой функции вам не обойтись. Чтобы сделать поиск второго пробела вручную, нужно предварительно вырезать часть из исходной строки.
AnsiReplaceStr, AnsiReplaceText (строка, текст_1, текст_2) — функции выполняют замену в строке строка строки текст_1 на текст_2. Функции отличаются только тем, что первая ведёт замену с учётом регистра символов, а вторая — без него.
В нашей программе можно использовать эти функции для вырезания из строки символов #13 и #10 — для этого в качестве текста для замены следует указать пустую строку. Вот решение в одну строку кода:
Text:=AnsiReplaceText(AnsiReplaceText(Text,Chr(13),''),Chr(10),'');
DupeString(строка, число_повторений) — формирует строку, состоящую из строки строка путём повторения её заданное количество раз.
ReverseString(строка) — инвертирует строку («123» -> «321»).
Также следует упомянуть у функциях преобразования регистра.
UpperCase(строка) — преобразует строку в верхний регистр; LowerCase(строка) — преобразует строку в нижний регистр.
Для преобразования отдельных символов следует использовать эти же функции.
Подробную информацию о каждой функции можно получить, введя её название в любом месте редактора кода, установив курсор на это название (или выделив его) и нажав F1.
Скриншоты программ, описанных в статье
|
Программа извлечения слов из текста |
Таблица символов |

Заключение
Длинный получился урок. Итак, сегодня мы познакомились со строками и символами и научились с ними работать. Изученные приёмы используются практически повсеместно. Не бойтесь экспериментировать — самостоятельно повышайте свой уровень навыков программирования!