

The results of a search for the term «lunar eclipse» in a web-based image search engine
A search engine is a software system designed to carry out web searches. They search the World Wide Web in a systematic way for particular information specified in a textual web search query. The search results are generally presented in a line of results, often referred to as search engine results pages (SERPs). When a user enters a query into a search engine, the engine scans its index of web pages to find those that are relevant to the user’s query. The results are then ranked by relevancy and displayed to the user. The information may be a mix of links to web pages, images, videos, infographics, articles, research papers, and other types of files. Some search engines also mine data available in databases or open directories. Unlike web directories and social bookmarking sites, which are maintained by human editors, search engines also maintain real-time information by running an algorithm on a web crawler. Any internet-based content that cannot be indexed and searched by a web search engine falls under the category of deep web.
History[edit]
| Year | Engine | Current status |
|---|---|---|
| 1993 | W3Catalog | Inactive |
| ALIWEB | Inactive | |
| JumpStation | Inactive | |
| WWW Worm | Inactive | |
| 1994 | WebCrawler | Active |
| Go.com | Inactive, redirects to Disney | |
| Lycos | Active | |
| Infoseek | Inactive, redirects to Disney | |
| 1995 | Yahoo! Search | Active, initially a search function for Yahoo! Directory |
| Daum | Active | |
| Search.ch | Active | |
| Magellan | Inactive | |
| Excite | Active | |
| MetaCrawler | Active | |
| AltaVista | Inactive, acquired by Yahoo! in 2003, since 2013 redirects to Yahoo! | |
| 1996 | RankDex | Inactive, incorporated into Baidu in 2000 |
| Dogpile | Active | |
| HotBot | Inactive (used Inktomi search technology) | |
| Ask Jeeves | Active (rebranded ask.com) | |
| 1997 | AOL NetFind | Active (rebranded AOL Search since 1999) |
| Northern Light | Inactive | |
| Yandex | Active | |
| 1998 | Active | |
| Ixquick | Active as Startpage.com | |
| MSN Search | Active as Bing | |
| empas | Inactive (merged with NATE) | |
| 1999 | AlltheWeb | Inactive (URL redirected to Yahoo!) |
| GenieKnows | Inactive, rebranded Yellowee (was redirecting to justlocalbusiness.com) | |
| Naver | Active | |
| Teoma | Inactive (redirect to Ask.com) | |
| 2000 | Baidu | Active |
| Exalead | Inactive | |
| Gigablast | Active | |
| 2001 | Kartoo | Inactive |
| 2003 | Info.com | Active |
| 2004 | A9.com | Inactive |
| Clusty | Inactive (redirect to DuckDuckGo) | |
| Mojeek | Active | |
| Sogou | Active | |
| 2005 | SearchMe | Inactive |
| KidzSearch | Active, Google Search | |
| 2006 | Soso | Inactive, merged with Sogou |
| Quaero | Inactive | |
| Search.com | Active | |
| ChaCha | Inactive | |
| Ask.com | Active | |
| Live Search | Active as Bing, rebranded MSN Search | |
| 2007 | wikiseek | Inactive |
| Sproose | Inactive | |
| Wikia Search | Inactive | |
| Blackle.com | Active, Google Search | |
| 2008 | Powerset | Inactive (redirects to Bing) |
| Picollator | Inactive | |
| Viewzi | Inactive | |
| Boogami | Inactive | |
| LeapFish | Inactive | |
| Forestle | Inactive (redirects to Ecosia) | |
| DuckDuckGo | Active | |
| 2009 | Bing | Active, rebranded Live Search |
| Yebol | Inactive | |
| Scout (Goby) | Active | |
| NATE | Active | |
| Ecosia | Active | |
| Startpage.com | Active, sister engine of Ixquick | |
| 2010 | Blekko | Inactive, sold to IBM |
| Cuil | Inactive | |
| Yandex (English) | Active | |
| Parsijoo | Active | |
| 2011 | YaCy | Active, P2P |
| 2012 | Volunia | Inactive |
| 2013 | Qwant | Active |
| 2014 | Egerin | Active, Kurdish / Sorani |
| Swisscows | Active | |
| Searx | Active | |
| 2015 | Yooz | Inactive |
| Cliqz | Inactive | |
| 2016 | Kiddle | Active, Google Search |
| 2020 | Petal | Active |
| 2021 | Brave Search | Active |
Pre-1990s[edit]
A system for locating published information intended to overcome the ever increasing difficulty of locating information in ever-growing centralized indices of scientific work was described in 1945 by Vannevar Bush, who wrote an article in The Atlantic Monthly titled «As We May Think»[1] in which he envisioned libraries of research with connected annotations not unlike modern hyperlinks.[2] Link analysis would eventually become a crucial component of search engines through algorithms such as Hyper Search and PageRank.[3][4]
1990s: Birth of search engines[edit]
The first internet search engines predate the debut of the Web in December 1990: WHOIS user search dates back to 1982,[5] and the Knowbot Information Service multi-network user search was first implemented in 1989.[6] The first well documented search engine that searched content files, namely FTP files, was Archie, which debuted on 10 September 1990.[7]
Prior to September 1993, the World Wide Web was entirely indexed by hand. There was a list of webservers edited by Tim Berners-Lee and hosted on the CERN webserver. One snapshot of the list in 1992 remains,[8] but as more and more web servers went online the central list could no longer keep up. On the NCSA site, new servers were announced under the title «What’s New!».[9]
The first tool used for searching content (as opposed to users) on the Internet was Archie.[10] The name stands for «archive» without the «v».[11] It was created by Alan Emtage,[11][12][13][14] computer science student at McGill University in Montreal, Quebec, Canada. The program downloaded the directory listings of all the files located on public anonymous FTP (File Transfer Protocol) sites, creating a searchable database of file names; however, Archie Search Engine did not index the contents of these sites since the amount of data was so limited it could be readily searched manually.
The rise of Gopher (created in 1991 by Mark McCahill at the University of Minnesota) led to two new search programs, Veronica and Jughead. Like Archie, they searched the file names and titles stored in Gopher index systems. Veronica (Very Easy Rodent-Oriented Net-wide Index to Computerized Archives) provided a keyword search of most Gopher menu titles in the entire Gopher listings. Jughead (Jonzy’s Universal Gopher Hierarchy Excavation And Display) was a tool for obtaining menu information from specific Gopher servers. While the name of the search engine «Archie Search Engine» was not a reference to the Archie comic book series, «Veronica» and «Jughead» are characters in the series, thus referencing their predecessor.
In the summer of 1993, no search engine existed for the web, though numerous specialized catalogues were maintained by hand. Oscar Nierstrasz at the University of Geneva wrote a series of Perl scripts that periodically mirrored these pages and rewrote them into a standard format. This formed the basis for W3Catalog, the web’s first primitive search engine, released on September 2, 1993.[15]
In June 1993, Matthew Gray, then at MIT, produced what was probably the first web robot, the Perl-based World Wide Web Wanderer, and used it to generate an index called «Wandex». The purpose of the Wanderer was to measure the size of the World Wide Web, which it did until late 1995. The web’s second search engine Aliweb appeared in November 1993. Aliweb did not use a web robot, but instead depended on being notified by website administrators of the existence at each site of an index file in a particular format.
JumpStation (created in December 1993[16] by Jonathon Fletcher) used a web robot to find web pages and to build its index, and used a web form as the interface to its query program. It was thus the first WWW resource-discovery tool to combine the three essential features of a web search engine (crawling, indexing, and searching) as described below. Because of the limited resources available on the platform it ran on, its indexing and hence searching were limited to the titles and headings found in the web pages the crawler encountered.
One of the first «all text» crawler-based search engines was WebCrawler, which came out in 1994. Unlike its predecessors, it allowed users to search for any word in any webpage, which has become the standard for all major search engines since. It was also the search engine that was widely known by the public. Also in 1994, Lycos (which started at Carnegie Mellon University) was launched and became a major commercial endeavor.
The first popular search engine on the Web was Yahoo! Search.[17] The first product from Yahoo!, founded by Jerry Yang and David Filo in January 1994, was a Web directory called Yahoo! Directory. In 1995, a search function was added, allowing users to search Yahoo! Directory.[18][19] It became one of the most popular ways for people to find web pages of interest, but its search function operated on its web directory, rather than its full-text copies of web pages.
Soon after, a number of search engines appeared and vied for popularity. These included Magellan, Excite, Infoseek, Inktomi, Northern Light, and AltaVista. Information seekers could also browse the directory instead of doing a keyword-based search.
In 1996, Robin Li developed the RankDex site-scoring algorithm for search engines results page ranking[20][21][22] and received a US patent for the technology.[23] It was the first search engine that used hyperlinks to measure the quality of websites it was indexing,[24] predating the very similar algorithm patent filed by Google two years later in 1998.[25] Larry Page referenced Li’s work in some of his U.S. patents for PageRank.[26] Li later used his Rankdex technology for the Baidu search engine, which was founded by him in China and launched in 2000.
In 1996, Netscape was looking to give a single search engine an exclusive deal as the featured search engine on Netscape’s web browser. There was so much interest that instead Netscape struck deals with five of the major search engines: for $5 million a year, each search engine would be in rotation on the Netscape search engine page. The five engines were Yahoo!, Magellan, Lycos, Infoseek, and Excite.[27][28]
Google adopted the idea of selling search terms in 1998, from a small search engine company named goto.com. This move had a significant effect on the search engine business, which went from struggling to one of the most profitable businesses in the Internet.[29]
Search engines were also known as some of the brightest stars in the Internet investing frenzy that occurred in the late 1990s.[30] Several companies entered the market spectacularly, receiving record gains during their initial public offerings. Some have taken down their public search engine, and are marketing enterprise-only editions, such as Northern Light. Many search engine companies were caught up in the dot-com bubble, a speculation-driven market boom that peaked in March 2000.
2000s–present: Post dot-com bubble[edit]
Around 2000, Google’s search engine rose to prominence.[31] The company achieved better results for many searches with an algorithm called PageRank, as was explained in the paper Anatomy of a Search Engine written by Sergey Brin and Larry Page, the later founders of Google.[4] This iterative algorithm ranks web pages based on the number and PageRank of other web sites and pages that link there, on the premise that good or desirable pages are linked to more than others. Larry Page’s patent for PageRank cites Robin Li’s earlier RankDex patent as an influence.[26][22] Google also maintained a minimalist interface to its search engine. In contrast, many of its competitors embedded a search engine in a web portal. In fact, the Google search engine became so popular that spoof engines emerged such as Mystery Seeker.
By 2000, Yahoo! was providing search services based on Inktomi’s search engine. Yahoo! acquired Inktomi in 2002, and Overture (which owned AlltheWeb and AltaVista) in 2003. Yahoo! switched to Google’s search engine until 2004, when it launched its own search engine based on the combined technologies of its acquisitions.
Microsoft first launched MSN Search in the fall of 1998 using search results from Inktomi. In early 1999 the site began to display listings from Looksmart, blended with results from Inktomi. For a short time in 1999, MSN Search used results from AltaVista instead. In 2004, Microsoft began a transition to its own search technology, powered by its own web crawler (called msnbot).
Microsoft’s rebranded search engine, Bing, was launched on June 1, 2009. On July 29, 2009, Yahoo! and Microsoft finalized a deal in which Yahoo! Search would be powered by Microsoft Bing technology.
As of 2019, active search engine crawlers include those of Google, Petal, Sogou, Baidu, Bing, Gigablast, Mojeek, DuckDuckGo and Yandex.
Approach[edit]
A search engine maintains the following processes in near real time:
- Web crawling
- Indexing
- Searching[32]
Web search engines get their information by web crawling from site to site. The «spider» checks for the standard filename robots.txt, addressed to it. The robots.txt file contains directives for search spiders, telling it which pages to crawl and which pages not to crawl. After checking for robots.txt and either finding it or not, the spider sends certain information back to be indexed depending on many factors, such as the titles, page content, JavaScript, Cascading Style Sheets (CSS), headings, or its metadata in HTML meta tags. After a certain number of pages crawled, amount of data indexed, or time spent on the website, the spider stops crawling and moves on. «[N]o web crawler may actually crawl the entire reachable web. Due to infinite websites, spider traps, spam, and other exigencies of the real web, crawlers instead apply a crawl policy to determine when the crawling of a site should be deemed sufficient. Some websites are crawled exhaustively, while others are crawled only partially».[33]
Indexing means associating words and other definable tokens found on web pages to their domain names and HTML-based fields. The associations are made in a public database, made available for web search queries. A query from a user can be a single word, multiple words or a sentence. The index helps find information relating to the query as quickly as possible.[32] Some of the techniques for indexing, and caching are trade secrets, whereas web crawling is a straightforward process of visiting all sites on a systematic basis.
Between visits by the spider, the cached version of the page (some or all the content needed to render it) stored in the search engine working memory is quickly sent to an inquirer. If a visit is overdue, the search engine can just act as a web proxy instead. In this case, the page may differ from the search terms indexed.[32] The cached page holds the appearance of the version whose words were previously indexed, so a cached version of a page can be useful to the website when the actual page has been lost, but this problem is also considered a mild form of linkrot.

High-level architecture of a standard Web crawler
Typically when a user enters a query into a search engine it is a few keywords.[34] The index already has the names of the sites containing the keywords, and these are instantly obtained from the index. The real processing load is in generating the web pages that are the search results list: Every page in the entire list must be weighted according to information in the indexes.[32] Then the top search result item requires the lookup, reconstruction, and markup of the snippets showing the context of the keywords matched. These are only part of the processing each search results web page requires, and further pages (next to the top) require more of this post-processing.
Beyond simple keyword lookups, search engines offer their own GUI- or command-driven operators and search parameters to refine the search results. These provide the necessary controls for the user engaged in the feedback loop users create by filtering and weighting while refining the search results, given the initial pages of the first search results.
For example, from 2007 the Google.com search engine has allowed one to filter by date by clicking «Show search tools» in the leftmost column of the initial search results page, and then selecting the desired date range.[35] It’s also possible to weight by date because each page has a modification time. Most search engines support the use of the boolean operators AND, OR and NOT to help end users refine the search query. Boolean operators are for literal searches that allow the user to refine and extend the terms of the search. The engine looks for the words or phrases exactly as entered. Some search engines provide an advanced feature called proximity search, which allows users to define the distance between keywords.[32] There is also concept-based searching where the research involves using statistical analysis on pages containing the words or phrases you search for.
The usefulness of a search engine depends on the relevance of the result set it gives back. While there may be millions of web pages that include a particular word or phrase, some pages may be more relevant, popular, or authoritative than others. Most search engines employ methods to rank the results to provide the «best» results first. How a search engine decides which pages are the best matches, and what order the results should be shown in, varies widely from one engine to another.[32] The methods also change over time as Internet usage changes and new techniques evolve. There are two main types of search engine that have evolved: one is a system of predefined and hierarchically ordered keywords that humans have programmed extensively. The other is a system that generates an «inverted index» by analyzing texts it locates. This first form relies much more heavily on the computer itself to do the bulk of the work.
Most Web search engines are commercial ventures supported by advertising revenue and thus some of them allow advertisers to have their listings ranked higher in search results for a fee. Search engines that do not accept money for their search results make money by running search related ads alongside the regular search engine results. The search engines make money every time someone clicks on one of these ads.[36]
Local search[edit]
Local search is the process that optimizes the efforts of local businesses. They focus on change to make sure all searches are consistent. It’s important because many people determine where they plan to go and what to buy based on their searches.[37]
[edit]
As of January 2022, Google is by far the world’s most used search engine, with a market share of 92.01%, and the world’s other most used search engines were Bing, Yahoo!, Baidu, Yandex, and DuckDuckGo.[38]
Russia and East Asia[edit]
In Russia, Yandex has a market share of 62.6%, compared to Google’s 28.3%.[39] In China, Baidu is the most popular search engine.[40] South Korea’s homegrown search portal, Naver, is used for 62.8% of online searches in the country.[41] Yahoo! Japan and Yahoo! Taiwan are the most popular avenues for Internet searches in Japan and Taiwan, respectively.[42] China is one of few countries where Google is not in the top three web search engines for market share. Google was previously a top search engine in China, but withdrew after a disagreement with the government over censorship, and a cyberattack. But Bing is in top three web search engine with a market share of 14.5%[43]
Europe[edit]
Most countries’ markets in the European Union are dominated by Google, except for the Czech Republic, where Seznam is a strong competitor.[44]
The search engine Qwant is based in Paris, France, where it attracts most of its 50 million monthly registered users from.
Search engine bias[edit]
Although search engines are programmed to rank websites based on some combination of their popularity and relevancy, empirical studies indicate various political, economic, and social biases in the information they provide[45][46] and the underlying assumptions about the technology.[47] These biases can be a direct result of economic and commercial processes (e.g., companies that advertise with a search engine can become also more popular in its organic search results), and political processes (e.g., the removal of search results to comply with local laws).[48] For example, Google will not surface certain neo-Nazi websites in France and Germany, where Holocaust denial is illegal.
Biases can also be a result of social processes, as search engine algorithms are frequently designed to exclude non-normative viewpoints in favor of more «popular» results.[49] Indexing algorithms of major search engines skew towards coverage of U.S.-based sites, rather than websites from non-U.S. countries.[46]
Google Bombing is one example of an attempt to manipulate search results for political, social or commercial reasons.
Several scholars have studied the cultural changes triggered by search engines,[50] and the representation of certain controversial topics in their results, such as terrorism in Ireland,[51] climate change denial,[52] and conspiracy theories.[53]
Customized results and filter bubbles[edit]
There has been concern raised that search engines such as Google and Bing provide customized results based on the user’s activity history, leading to what has been termed echo chambers or filter bubbles by Eli Pariser in 2011.[54] The argument is that search engines and social media platforms use algorithms to selectively guess what information a user would like to see, based on information about the user (such as location, past click behaviour and search history). As a result, websites tend to show only information that agrees with the user’s past viewpoint. According to Eli Pariser users get less exposure to conflicting viewpoints and are isolated intellectually in their own informational bubble. Since this problem has been identified, competing search engines have emerged that seek to avoid this problem by not tracking or «bubbling» users, such as DuckDuckGo. However many scholars have questioned Pariser’s view, finding that there is little evidence for the filter bubble.[55][56][57] On the contrary, a number of studies trying to verify the existence of filter bubbles have found only minor levels of personalisation in search,[57] that most people encounter a range of views when browsing online, and that Google news tends to promote mainstream established news outlets.[58][56]
Religious search engines[edit]
The global growth of the Internet and electronic media in the Arab and Muslim World during the last decade has encouraged Islamic adherents in the Middle East and Asian sub-continent, to attempt their own search engines, their own filtered search portals that would enable users to perform safe searches. More than usual safe search filters, these Islamic web portals categorizing websites into being either «halal» or «haram», based on interpretation of the «Law of Islam». ImHalal came online in September 2011. Halalgoogling came online in July 2013. These use haram filters on the collections from Google and Bing (and others).[59]
While lack of investment and slow pace in technologies in the Muslim World has hindered progress and thwarted success of an Islamic search engine, targeting as the main consumers Islamic adherents, projects like Muxlim, a Muslim lifestyle site, did receive millions of dollars from investors like Rite Internet Ventures, and it also faltered. Other religion-oriented search engines are Jewogle, the Jewish version of Google,[60] and SeekFind.org, which is Christian. SeekFind filters sites that attack or degrade their faith.[61]
Search engine submission[edit]
Web search engine submission is a process in which a webmaster submits a website directly to a search engine. While search engine submission is sometimes presented as a way to promote a website, it generally is not necessary because the major search engines use web crawlers that will eventually find most web sites on the Internet without assistance. They can either submit one web page at a time, or they can submit the entire site using a sitemap, but it is normally only necessary to submit the home page of a web site as search engines are able to crawl a well designed website. There are two remaining reasons to submit a web site or web page to a search engine: to add an entirely new web site without waiting for a search engine to discover it, and to have a web site’s record updated after a substantial redesign.
Some search engine submission software not only submits websites to multiple search engines, but also adds links to websites from their own pages. This could appear helpful in increasing a website’s ranking, because external links are one of the most important factors determining a website’s ranking. However, John Mueller of Google has stated that this «can lead to a tremendous number of unnatural links for your site» with a negative impact on site ranking.[62]
[edit]
In comparison to search engines, a social bookmarking system has several advantages over traditional automated resource location and classification software, such as search engine spiders. All tag-based classification of Internet resources (such as web sites) is done by human beings, who understand the content of the resource, as opposed to software, which algorithmically attempts to determine the meaning and quality of a resource. Also, people can find and bookmark web pages that have not yet been noticed or indexed by web spiders.[63] Additionally, a social bookmarking system can rank a resource based on how many times it has been bookmarked by users, which may be a more useful metric for end-users than systems that rank resources based on the number of external links pointing to it. However, both types of ranking are vulnerable to fraud, (see Gaming the system), and both need technical countermeasures to try to deal with this.
Technology[edit]
Archie[edit]
The first web search engines was Archie, created in 1990[64] by Alan Emtage, a student at McGill University in Montreal. The author originally wanted to call the program «archives,» but had to shorten it to comply with the Unix world standard of assigning programs and files short, cryptic names such as grep, cat, troff, sed, awk, perl, and so on.
The primary method of storing and retrieving files was via the File Transfer Protocol (FTP). This was (and still is) a system that specified a common way for computers to exchange files over the Internet. It works like this: Some administrator decides that he wants to make files available from his computer. He sets up a program on his computer, called an FTP server. When someone on the Internet wants to retrieve a file from this computer, he or she connects to it via another program called an FTP client. Any FTP client program can connect with any FTP server program as long as the client and server programs both fully follow the specifications set forth in the FTP protocol.
Initially, anyone who wanted to share a file had to set up an FTP server in order to make the file available to others. Later, «anonymous» FTP sites became repositories for files, allowing all users to post and retrieve them.
Even with archive sites, many important files were still scattered on small FTP servers. Unfortunately, these files could be located only by the Internet equivalent of word of mouth: Somebody would post an e-mail to a message list or a discussion forum announcing the availability of a file.
Archie changed all that. It combined a script-based data gatherer, which fetched site listings of anonymous FTP files, with a regular expression matcher for retrieving file names matching a user query. (4) In other words, Archie’s gatherer scoured FTP sites across the Internet and indexed all of the files it found. Its regular expression matcher provided users with access to its database.[65]
Veronica[edit]
In 1993, the University of Nevada System Computing Services group developed Veronica.[64] It was created as a type of searching device similar to Archie but for Gopher files. Another Gopher search service, called Jughead, appeared a little later, probably for the sole purpose of rounding out the comic-strip triumvirate. Jughead is an acronym for Jonzy’s Universal Gopher Hierarchy Excavation and Display, although, like Veronica, it is probably safe to assume that the creator backed into the acronym. Jughead’s functionality was pretty much identical to Veronica’s, although it appears to be a little rougher around the edges.[65]
The Lone Wanderer[edit]
The World Wide Web Wanderer, developed by Matthew Gray in 1993[66] was the first robot on the Web and was designed to track the Web’s growth. Initially, the Wanderer counted only Web servers, but shortly after its introduction, it started to capture URLs as it went along. The database of captured URLs became the Wandex, the first web database.
Matthew Gray’s Wanderer created quite a controversy at the time, partially because early versions of the software ran rampant through the Net and caused a noticeable netwide performance degradation. This degradation occurred because the Wanderer would access the same page hundreds of time a day. The Wanderer soon amended its ways, but the controversy over whether robots were good or bad for the Internet remained.
In response to the Wanderer, Martijn Koster created Archie-Like Indexing of the Web, or ALIWEB, in October 1993. As the name implies, ALIWEB was the HTTP equivalent of Archie, and because of this, it is still unique in many ways.
ALIWEB does not have a web-searching robot. Instead, webmasters of participating sites post their own index information for each page they want listed. The advantage to this method is that users get to describe their own site, and a robot does not run about eating up Net bandwidth. Unfortunately, the disadvantages of ALIWEB are more of a problem today. The primary disadvantage is that a special indexing file must be submitted. Most users do not understand how to create such a file, and therefore they do not submit their pages. This leads to a relatively small database, which meant that users are less likely to search ALIWEB than one of the large bot-based sites. This Catch-22 has been somewhat offset by incorporating other databases into the ALIWEB search, but it still does not have the mass appeal of search engines such as Yahoo! or Lycos.[65]
Excite[edit]
Excite, initially called Architext, was started by six Stanford undergraduates in February 1993. Their idea was to use statistical analysis of word relationships in order to provide more efficient searches through the large amount of information on the Internet.
Their project was fully funded by mid-1993. Once funding was secured. they released a version of their search software for webmasters to use on their own web sites. At the time, the software was called Architext, but it now goes by the name of Excite for Web Servers.[65]
Excite was the first serious commercial search engine which launched in 1995.[67] It was developed in Stanford and was purchased for $6.5 billion by @Home. In 2001 Excite and @Home went bankrupt and InfoSpace bought Excite for $10 million.
Some of the first analysis of web searching was conducted on search logs from Excite[68][69]
Yahoo![edit]
In April 1994, two Stanford University Ph.D. candidates, David Filo and Jerry Yang, created some pages that became rather popular. They called the collection of pages Yahoo! Their official explanation for the name choice was that they considered themselves to be a pair of yahoos.
As the number of links grew and their pages began to receive thousands of hits a day, the team created ways to better organize the data. In order to aid in data retrieval, Yahoo! (www.yahoo.com) became a searchable directory. The search feature was a simple database search engine. Because Yahoo! entries were entered and categorized manually, Yahoo! was not really classified as a search engine. Instead, it was generally considered to be a searchable directory. Yahoo! has since automated some aspects of the gathering and classification process, blurring the distinction between engine and directory.
The Wanderer captured only URLs, which made it difficult to find things that were not explicitly described by their URL. Because URLs are rather cryptic to begin with, this did not help the average user. Searching Yahoo! or the Galaxy was much more effective because they contained additional descriptive information about the indexed sites.
Lycos[edit]
At Carnegie Mellon University during July 1994, Michael Mauldin, on leave from CMU,developed the Lycos search engine.
Types of web search engines[edit]
Search engines on the web are sites enriched with facility to search the content stored on other sites. There is difference in the way various search engines work, but they all perform three basic tasks.[70]
- Finding and selecting full or partial content based on the keywords provided.
- Maintaining index of the content and referencing to the location they find
- Allowing users to look for words or combinations of words found in that index.
The process begins when a user enters a query statement into the system through the interface provided.
| Type | Example | Description |
|---|---|---|
| Conventional | librarycatalog | Search by keyword, title, author, etc. |
| Text-based | Google, Bing, Yahoo! | Search by keywords. Limited search using queries in natural language. |
| Voice-based | Google, Bing, Yahoo! | Search by keywords. Limited search using queries in natural language. |
| Multimedia search | QBIC, WebSeek, SaFe | Search by visual appearance (shapes, colors,..) |
| Q/A | Stack Exchange, NSIR | Search in (restricted) natural language |
| Clustering Systems | Vivisimo, Clusty | |
| Research Systems | Lemur, Nutch |
There are basically three types of search engines: Those that are powered by robots (called crawlers; ants or spiders) and those that are powered by human submissions; and those that are a hybrid of the two.
Crawler-based search engines are those that use automated software agents (called crawlers) that visit a Web site, read the information on the actual site, read the site’s meta tags and also follow the links that the site connects to performing indexing on all linked Web sites as well. The crawler returns all that information back to a central depository, where the data is indexed. The crawler will periodically return to the sites to check for any information that has changed. The frequency with which this happens is determined by the administrators of the search engine.
Human-powered search engines rely on humans to submit information that is subsequently indexed and catalogued. Only information that is submitted is put into the index.
In both cases, when you query a search engine to locate information, you’re actually searching through the index that the search engine has created —you are not actually searching the Web. These indices are giant databases of information that is collected and stored and subsequently searched. This explains why sometimes a search on a commercial search engine, such as Yahoo! or Google, will return results that are, in fact, dead links. Since the search results are based on the index, if the index has not been updated since a Web page became invalid the search engine treats the page as still an active link even though it no longer is. It will remain that way until the index is updated.
So why will the same search on different search engines produce different results? Part of the answer to that question is because not all indices are going to be exactly the same. It depends on what the spiders find or what the humans submitted. But more important, not every search engine uses the same algorithm to search through the indices. The algorithm is what the search engines use to determine the relevance of the information in the index to what the user is searching for.
One of the elements that a search engine algorithm scans for is the frequency and location of keywords on a Web page. Those with higher frequency are typically considered more relevant. But search engine technology is becoming sophisticated in its attempt to discourage what is known as keyword stuffing, or spamdexing.
Another common element that algorithms analyze is the way that pages link to other pages in the Web. By analyzing how pages link to each other, an engine can both determine what a page is about (if the keywords of the linked pages are similar to the keywords on the original page) and whether that page is considered «important» and deserving of a boost in ranking. Just as the technology is becoming increasingly sophisticated to ignore keyword stuffing, it is also becoming more savvy to Web masters who build artificial links into their sites in order to build an artificial ranking.
Modern web search engines are highly intricate software systems that employ technology that has evolved over the years. There are a number of sub-categories of search engine software that are separately applicable to specific ‘browsing’ needs. These include web search engines (e.g. Google), database or structured data search engines (e.g. Dieselpoint), and mixed search engines or enterprise search. The more prevalent search engines, such as Google and Yahoo!, utilize hundreds of thousands computers to process trillions of web pages in order to return fairly well-aimed results. Due to this high volume of queries and text processing, the software is required to run in a highly dispersed environment with a high degree of superfluity.
Another category of search engines is scientific search engines. These are search engines which search scientific literature. Best known example is GoogleScholar. Researchers are working on improve search engine technology by making the engines understand the content element of the articles, such as extracting theoretical constructs or key research findings.[71]
See also[edit]
- Comparison of web search engines
- Filter bubble
- Google effect
- Information retrieval
- Use of web search engines in libraries
- List of search engines
- Question answering
- Search engine manipulation effect
- Search engine privacy
- Semantic Web
- Spell checker
- Web development tools
- Web query
- Wikipedia:Search engine test, for a tutorial on using search engines for researching Wikipedia articles
References[edit]
- ^ «Search Engine History.com». www.searchenginehistory.com. Retrieved 2020-07-02.
- ^ «Penn State WebAccess Secure Login». webaccess.psu.edu. Retrieved 2020-07-02.
- ^ Marchiori, Massimo (1997). «The Quest for Correct Information on the Web: Hyper Search Engines». Proceedings of the Sixth International World Wide Web Conference (WWW6). Retrieved 2021-01-10.
- ^ a b Brin, Sergey; Page, Larry (1998). «The Anatomy of a Large-Scale Hypertextual Web Search Engine» (PDF). Proceedings of the Seventh International World Wide Web Conference (WWW7). Retrieved 2021-01-10.
- ^ Harrenstien, K.; White, V. (1982). «RFC 812 — NICNAME/WHOIS». ietf.org. doi:10.17487/RFC0812.
- ^ «Knowbot programming: System support for mobile agents». cnri.reston.va.us.
- ^ Deutsch, Peter (September 11, 1990). «[next] An Internet archive server server (was about Lisp)». groups.google.com. Retrieved 2017-12-29.
- ^ «World-Wide Web Servers». W3.org. Retrieved 2012-05-14.
- ^ «What’s New! February 1994». Home.mcom.com. Retrieved 2012-05-14.
- ^ «Internet History — Search Engines» (from Search Engine Watch), Universiteit Leiden, Netherlands, September 2001, web: LeidenU-Archie Archived 2009-04-13 at the Wayback Machine.
- ^ a b pcmag. «Archie». pcmag.com. Retrieved 2020-09-20.
- ^ Alexandra Samuel (21 February 2017). «Meet Alan Emtage, the Black Technologist Who Invented ARCHIE, the First Internet Search Engine». ITHAKA. Retrieved 2020-09-20.
- ^ loop news barbados. «Alan Emtage- a Barbadian you should know». loopnewsbarbados.com. Retrieved 2020-09-21.
- ^ Dino Grandoni, Alan Emtage (April 2013). «Alan Emtage: The Man Who Invented The World’s First Search Engine (But Didn’t Patent It)». huffingtonpost.co.uk. Retrieved 2020-09-21.
- ^ Oscar Nierstrasz (2 September 1993). «Searchable Catalog of WWW Resources (experimental)».
- ^ «Archive of NCSA what’s new in December 1993 page». 2001-06-20. Archived from the original on 2001-06-20. Retrieved 2012-05-14.
- ^ «What is first mover?». SearchCIO. TechTarget. September 2005. Retrieved 5 September 2019.
- ^ Oppitz, Marcus; Tomsu, Peter (2017). Inventing the Cloud Century: How Cloudiness Keeps Changing Our Life, Economy and Technology. Springer. p. 238. ISBN 9783319611617.
- ^ «Yahoo! Search». Yahoo!. 28 November 1996. Archived from the original on 28 November 1996. Retrieved 5 September 2019.
- ^ Greenberg, Andy, «The Man Who’s Beating Google», Forbes magazine, October 5, 2009
- ^ Yanhong Li, «Toward a Qualitative Search Engine,» IEEE Internet Computing, vol. 2, no. 4, pp. 24–29, July/Aug. 1998, doi:10.1109/4236.707687
- ^ a b «About: RankDex», rankdex.com
- ^ USPTO, «Hypertext Document Retrieval System and Method», US Patent number: 5920859, Inventor: Yanhong Li, Filing date: Feb 5, 1997, Issue date: Jul 6, 1999
- ^ «Baidu Vs Google: The Twins Of Search Compared». FourWeekMBA. 18 September 2018. Retrieved 16 June 2019.
- ^ Altucher, James (March 18, 2011). «10 Unusual Things About Google». Forbes. Retrieved 16 June 2019.
- ^ a b «Method for node ranking in a linked database». Google Patents. Archived from the original on 15 October 2015. Retrieved 19 October 2015.
- ^ «Yahoo! And Netscape Ink International Distribution Deal» (PDF). Archived from the original (PDF) on 2013-11-16. Retrieved 2009-08-12.
- ^ «Browser Deals Push Netscape Stock Up 7.8%». Los Angeles Times. 1 April 1996.
- ^ Pursel, Bart. Search Engines. Penn State Pressbooks. Retrieved February 20, 2018.
- ^ Gandal, Neil (2001). «The dynamics of competition in the internet search engine market». International Journal of Industrial Organization. 19 (7): 1103–1117. doi:10.1016/S0167-7187(01)00065-0.
- ^ «Our History in depth». W3.org. Retrieved 2012-10-31.
- ^ a b c d e f Jawadekar, Waman S (2011), «8. Knowledge Management: Tools and Technology», Knowledge Management: Text & Cases, New Delhi: Tata McGraw-Hill Education Private Ltd, p. 278, ISBN 978-0-07-07-0086-4, retrieved November 23, 2012
- ^ Dasgupta, Anirban; Ghosh, Arpita; Kumar, Ravi; Olston, Christopher; Pandey, Sandeep; and Tomkins, Andrew. The Discoverability of the Web. http://www.arpitaghosh.com/papers/discoverability.pdf
- ^ Jansen, B. J., Spink, A., and Saracevic, T. 2000. Real life, real users, and real needs: A study and analysis of user queries on the web. Information Processing & Management. 36(2), 207–227.
- ^ Chitu, Alex (August 30, 2007). «Easy Way to Find Recent Web Pages». Google Operating System. Retrieved 22 February 2015.
- ^ «how search engine works?». GFO = 26 June 2018.
- ^ «What Is Local SEO & Why Local Search Is Important». Search Engine Journal. Retrieved 2020-04-26.
- ^ «Search Engine Market Share Worldwide». StatCounter GlobalStats. Retrieved March 1, 2022.
- ^ «Live Internet — Site Statistics». Live Internet. Retrieved 2014-06-04.
- ^ Arthur, Charles (2014-06-03). «The Chinese technology companies poised to dominate the world». The Guardian. Retrieved 2014-06-04.
- ^ «How Naver Hurts Companies’ Productivity». The Wall Street Journal. 2014-05-21. Retrieved 2014-06-04.
- ^ «Age of Internet Empires». Oxford Internet Institute. Retrieved 15 August 2019.
- ^ Waddell, Kaveh (2016-01-19). «Why Google Quit China—and Why It’s Heading Back». The Atlantic. Retrieved 2020-04-26.
- ^ Seznam Takes on Google in the Czech Republic. Doz.
- ^ Segev, El (2010). Google and the Digital Divide: The Biases of Online Knowledge, Oxford: Chandos Publishing.
- ^ a b Vaughan, Liwen; Mike Thelwall (2004). «Search engine coverage bias: evidence and possible causes». Information Processing & Management. 40 (4): 693–707. CiteSeerX 10.1.1.65.5130. doi:10.1016/S0306-4573(03)00063-3. S2CID 18977861.
- ^ Jansen, B. J. and Rieh, S. (2010) The Seventeen Theoretical Constructs of Information Searching and Information Retrieval. Journal of the American Society for Information Sciences and Technology. 61(8), 1517–1534.
- ^ Berkman Center for Internet & Society (2002), «Replacement of Google with Alternative Search Systems in China: Documentation and Screen Shots», Harvard Law School.
- ^ Introna, Lucas; Helen Nissenbaum (2000). «Shaping the Web: Why the Politics of Search Engines Matters». The Information Society. 16 (3): 169–185. CiteSeerX 10.1.1.24.8051. doi:10.1080/01972240050133634. S2CID 2111039.
- ^ Hillis, Ken; Petit, Michael; Jarrett, Kylie (2012-10-12). Google and the Culture of Search. Routledge. ISBN 9781136933066.
- ^ Reilly, P. (2008-01-01). Spink, Prof Dr Amanda; Zimmer, Michael (eds.). ‘Googling’ Terrorists: Are Northern Irish Terrorists Visible on Internet Search Engines?. Information Science and Knowledge Management. Vol. 14. Springer Berlin Heidelberg. pp. 151–175. Bibcode:2008wsis.book..151R. doi:10.1007/978-3-540-75829-7_10. ISBN 978-3-540-75828-0. S2CID 84831583.
- ^ Hiroko Tabuchi, «How Climate Change Deniers Rise to the Top in Google Searches», The New York Times, Dec. 29, 2017. Retrieved November 14, 2018.
- ^ Ballatore, A (2015). «Google chemtrails: A methodology to analyze topic representation in search engines». First Monday. 20 (7). doi:10.5210/fm.v20i7.5597.
- ^ Pariser, Eli (2011). The filter bubble : what the Internet is hiding from you. New York: Penguin Press. ISBN 978-1-59420-300-8. OCLC 682892628.
- ^ O’Hara, K. (2014-07-01). «In Worship of an Echo». IEEE Internet Computing. 18 (4): 79–83. doi:10.1109/MIC.2014.71. ISSN 1089-7801. S2CID 37860225.
- ^ a b Bruns, Axel (2019-11-29). «Filter bubble». Internet Policy Review. 8 (4). doi:10.14763/2019.4.1426. ISSN 2197-6775. S2CID 211483210.
- ^ a b Haim, Mario; Graefe, Andreas; Brosius, Hans-Bernd (2018). «Burst of the Filter Bubble?». Digital Journalism. 6 (3): 330–343. doi:10.1080/21670811.2017.1338145. ISSN 2167-0811. S2CID 168906316.
- ^ Nechushtai, Efrat; Lewis, Seth C. (2019). «What kind of news gatekeepers do we want machines to be? Filter bubbles, fragmentation, and the normative dimensions of algorithmic recommendations». Computers in Human Behavior. 90: 298–307. doi:10.1016/j.chb.2018.07.043. S2CID 53774351.
- ^ «New Islam-approved search engine for Muslims». News.msn.com. Archived from the original on 2013-07-12. Retrieved 2013-07-11.
- ^ «Jewogle — FAQ».
- ^ «Halalgoogling: Muslims Get Their Own «sin free» Google; Should Christians Have Christian Google? — Christian Blog». Christian Blog. 2013-07-25.
- ^ Schwartz, Barry (2012-10-29). «Google: Search Engine Submission Services Can Be Harmful». Search Engine Roundtable. Retrieved 2016-04-04.
- ^ Heymann, Paul; Koutrika, Georgia; Garcia-Molina, Hector (February 12, 2008). «Can Social Bookmarking Improve Web Search?». First ACM International Conference on Web Search and Data Mining. Retrieved 2008-03-12.
- ^ a b Priti Srinivas Sajja; Rajendra Akerkar (2012). Intelligent technologies for web applications. Boca Raton: CRC Press. p. 87. ISBN 978-1-4398-7162-1. Retrieved 3 June 2014.
- ^ a b c d «A History of Search Engines». Wiley. Retrieved 1 June 2014.
- ^ Priti Srinivas Sajja; Rajendra Akerkar (2012). Intelligent technologies for web applications. Boca Raton: CRC Press. p. 86. ISBN 978-1-4398-7162-1. Retrieved 3 June 2014.
- ^ «The Major Search Engines». 21 January 2014. Retrieved 1 June 2014.
- ^ Jansen, B. J., Spink, A., Bateman, J., and Saracevic, T. 1998. Real life information retrieval: A study of user queries on the web. SIGIR Forum, 32(1), 5 -17.
- ^ Jansen, B. J., Spink, A., and Saracevic, T. 2000. Real life, real users, and real needs: A study and analysis of user queries on the web. Information Processing & Management. 36(2), 207–227.
- ^ Priti Srinivas Sajja; Rajendra Akerkar (2012). Intelligent technologies for web applications. Boca Raton: CRC Press. p. 85. ISBN 978-1-4398-7162-1. Retrieved 3 June 2014.
- ^ Li, Jingjing; Larsen, Kai; Abbasi, Ahmed (2020-12-01). «TheoryOn: A Design Framework and System for Unlocking Behavioral Knowledge Through Ontology Learning». MIS Quarterly. 44 (4): 1733–1772. doi:10.25300/MISQ/2020/15323. S2CID 219401379.
Further reading[edit]
- Steve Lawrence; C. Lee Giles (1999). «Accessibility of information on the web». Nature. 400 (6740): 107–9. Bibcode:1999Natur.400..107L. doi:10.1038/21987. PMID 10428673. S2CID 4347646.
- Bing Liu (2007), Web Data Mining: Exploring Hyperlinks, Contents and Usage Data. Springer,ISBN 3-540-37881-2
- Bar-Ilan, J. (2004). The use of Web search engines in information science research. ARIST, 38, 231–288.
- Levene, Mark (2005). An Introduction to Search Engines and Web Navigation. Pearson.
- Hock, Randolph (2007). The Extreme Searcher’s Handbook.ISBN 978-0-910965-76-7
- Javed Mostafa (February 2005). «Seeking Better Web Searches». Scientific American. 292 (2): 66–73. Bibcode:2005SciAm.292b..66M. doi:10.1038/scientificamerican0205-66.
- Ross, Nancy; Wolfram, Dietmar (2000). «End user searching on the Internet: An analysis of term pair topics submitted to the Excite search engine». Journal of the American Society for Information Science. 51 (10): 949–958. doi:10.1002/1097-4571(2000)51:10<949::AID-ASI70>3.0.CO;2-5.
- Xie, M.; et al. (1998). «Quality dimensions of Internet search engines». Journal of Information Science. 24 (5): 365–372. doi:10.1177/016555159802400509. S2CID 34686531.
- Information Retrieval: Implementing and Evaluating Search Engines. MIT Press. 2010.
External links[edit]
- Search Engines at Curlie
: computer software used to search data (such as text or a database) for specified information
also
: a site on the World Wide Web that uses such software to locate key words in other sites

Example Sentences
Recent Examples on the Web
Microsoft’s Bing search engine now uses ChatGPT. Lee, a computer scientist who runs Microsoft research around the world, is particularly interested in the medical and scientific potential of ChatGPT.
— Karen Weintraub, USA TODAY, 1 Apr. 2023
Karen Weintraub, USA TODAY, 1 Apr. 2023
Enlarge Microsoft Microsoft has spent a lot of time and energy over the last few months adding generative AI features to all its products, particularly its long-standing, long-struggling Bing search engine.
—Andrew Cunningham, Ars Technica, 31 Mar. 2023
The news is the culmination of a years-long effort by Microsoft to reinvent its search engine, which has long played second fiddle to Google before getting a boost from OpenAI’s GPT-4.
—Julia Malleck, Quartz, 30 Mar. 2023
In 2010, Google Inc. stopped censoring the internet for China by shifting its search engine off the mainland to Hong Kong.
—Chicago Tribune, 22 Mar. 2023
Google is opening public access to the conversational computer program Bard, its answer to the viral chatbot ChatGPT, while stopping short of integrating the new tool into its flagship search engine.
—Miles Kruppa, WSJ, 21 Mar. 2023
The technology already drives the chatbot available to a limited number of people using Microsoft’s Bing search engine.
—Cade Metz, New York Times, 14 Mar. 2023
Microsoft’s Bing search engine has passed the 100 million daily active users milestone just weeks after the software maker launched its AI-powered Bing Chat feature.
—Tom Warren, The Verge, 9 Mar. 2023
On Twitter, Musk has been calling out the flaws of ChatGPT, which is being integrated into Microsoft’s Bing search engine to enhance the experience.
—PCMAG, 17 Feb. 2023
See More
These examples are programmatically compiled from various online sources to illustrate current usage of the word ‘search engine.’ Any opinions expressed in the examples do not represent those of Merriam-Webster or its editors. Send us feedback about these examples.
Word History
First Known Use
1984, in the meaning defined above
Time Traveler
The first known use of search engine was
in 1984
Dictionary Entries Near search engine
Cite this Entry
“Search engine.” Merriam-Webster.com Dictionary, Merriam-Webster, https://www.merriam-webster.com/dictionary/search%20engine. Accessed 13 Apr. 2023.
Share
More from Merriam-Webster on search engine
Last Updated:
8 Apr 2023
— Updated example sentences
Subscribe to America’s largest dictionary and get thousands more definitions and advanced search—ad free!
Merriam-Webster unabridged
Meaning Search engine
What does Search engine mean? Here you find 105 meanings of the word Search engine. You can also add a definition of Search engine yourself
1 |
0 A very large searchable database of links to different websites, created by robots which trawl the internet looking for information.
|


2 |
0 Search engineGoogle, Bing, Yahoo, etc., are examples of Search Engines which locate, list and rank (according to various crietria and unknown algorithms) relevant websites and website content on the [..]
|
3 |
0 Search engineA search engine is a set of computer programs that finds web pages. There are general search engines that search large portions of the Web and specialized content search engines that target selected a [..]
|
4 |
0 Search engineA website that allows users to search the Web for specific information by entering keywords. Can include paid or organic listings of websites and sometimes specific images, products, videos, music, pl [..]
|
5 |
0 Search engineSoftware that makes it possible to look for and retrieve material on the Internet, particularly the Web. Some popular search engines are Alta Vista, Google, HotBot, Yahoo!, Web Crawler, and Lycos.
|
6 |
0 Search engineA program that indexes documents, then attempts to match documents relevant to the users search requests. Search engine can refer to the program on an individual site, or those on broad Internet sites such as Google, Yahoo! and MSN.
|
7 |
0 Search engineA tool that searches documents by keyword and returns a list of possible matches; most often used in reference to programs such as Google that are used by your web browser to search the Internet for a [..]
|
8 |
0 Search engineA large, searchable index of Web pages that is automatically updated by spiders or Web crawlers and housed on a central server connected to the Internet. Examples include Yahoo and AltaVista.
|
9 |
0 Search enginea program that indexes documents, then attempts to match documents relevant to the users search requests.
|
10 |
0 Search enginecomputer program that searches documents on the World Wide Web based on a keyword or set of keywords, and presents the results in a list.
|
11 |
0 Search engineA search engine is a website through which users can search internet content. To do this, users enter the desired search term into the search field. The search engine then looks through its index for [..]
|
12 |
0 Search engineA database system for searching the information available on the Web.
|
13 |
0 Search engineCopyright by Matisse «Search Engine» Enzer —>A (usually web-based) system for searching the information available on the Web. Some search engines work by automatically searching the cont [..]
|
14 |
0 Search engineA program that searches information on the World Wide Web by looking for specific keywords and returns a list of information found on that topic. Google (www.google.com) is an example of a search engine.
|
15 |
0 Search engineAny service generally designed to allow
|
16 |
0 Search engineA utility that will search the Internet, an Intranet, a site, or a database for terms that you select. Search engines on the web consist of four elements: a program that roams the area to be searched, [..]
|
17 |
0 Search enginea tool that allows a person to enter a word or phrase and then lists web pages or items in a database that contain that phrase. The success of such a search depends on a variety of factors including: [..]
|
18 |
0 Search engineAn Internet service that helps users to locate specific websites. Entering a word, phrase or topic into the search box will garner a host of related options. Experimenting with diffe [..]
|
19 |
0 Search engineA specialized program that facilitates information retrieval from large segments of the Internet. Note 1: Search engines attempt to help a user locate desired information or resources by seeking matches to user-specified key words. The usual method for finding and isolating this information is to compile and maintain an index of Web resources that [..]
|
20 |
0 Search engineGoogle, Excite, Lycos, AltaVista, Infoseek, and Yahoo are all search engines. They index millions of sites on the Web, so that Web surfers like you and me can easily find Web sites with the informatio [..]
|
21 |
0 Search engineA WWW site that serves as an index to other sites on the Web.
|
22 |
0 Search engineHuge databases in which information from Internet documents are stored for the purpose of searching. (Unit 7> Tips for Using the Internet)
|
23 |
0 Search engineWebGuest Dictionary Web site that allows users to search for keywords on Web pages . Every search engine has its own strategy for collecting data, so it’s no wonder that one particular search produces different results on different search engines.
|
24 |
0 Search engineThis term refers to a program that helps users find information in text-oriented databases.
|
25 |
0 Search engineA programme that collects, stores, arranges and normally ranks the various resources available on the internet. It is most commonly on a website and used to find other websites – much like the yellow pages is used in the brick and mortar world.
|
26 |
0 Search engineA program which indexes and retrieves web sites based on keywords input by a user. Using Search Engines is a convenient way to look for web sites relating to a topic of interest. Some use an index bui [..]
|
27 |
0 Search engineA search engine is a software system that collects information from the World Wide Web and presents it to users who are looking for specific information. A search engine conducts the following process [..]
|
28 |
0 Search engineA search engine enables a computer user to search information on the Internet. It is a type of software that creates indexes of databases or Internet sites based on the titles of files, keywords, or the full text of files. The most popular search engines are Google.com.au, Yahoo.com.au and Bing.com.au.
|
29 |
0 Search engineSearch engines are programs that search documents for specified keywords and returns a list of the documents where the keywords were found. A search engine is really a general class of programs, howe [..]
|
30 |
0 Search engineOriginally, a hardware device designed to search a text-based database for specific character strings (queries) typed as input by the user. More recently, computer software designed to help the user l [..]
|
31 |
0 Search engineInvestigación con Computadora en el Internet
|
32 |
0 Search engineSearch engines are tools that allow web users to search for content on a particular web site or on the internet as a whole. Popular search engines include Google, Microsoft Bing, and AOL Search.
|
33 |
0 Search engineis comprised of three parts: (1) a spider that goes to every page or representative pages on every Web site that wants to be searchable and reads it, using hypertext links on each page to discover and [..]
|
34 |
0 Search enginean automatized way to index and find documents on the internet. Search engines will «crawl,» or explore, the internet and index every file they find. Examples of search engines are www.altav [..]
|
35 |
0 Search engineA search facility provided at a number of sites on the World Wide Web. Search engines enable the user to search the whole of the Web for key words and phrases and to locate related websites. This is a [..]
|
36 |
0 Search engineThe vehicle that provides results for items of interest to Internet surfers. For example Google, Yahoo, and Bing are the biggest search engines.
|
37 |
0 Search engineThe basis of all SEO, a search engine is the tool used to look for information online.
|
38 |
0 Search engineA site that allows you to quickly locate relevant pages across the Web
|
39 |
0 Search engineProgram that searches its indices or databases in response to a user’s query, retrieving lists of documents containing specific keywords. Google, Yahoo!, Bing and Ask.com are some of the top search engines which use software algorithms to create indexes of information. This is different from directories, which are compiled by human editors.
|
40 |
0 Search enginea database of WWW pages.
|
41 |
0 Search engineA web based database used to find websites. Work on the basis of a websites relevance to a search phrase.
|
42 |
0 Search engineA web search engine examines websites on the internet in order to provide a catalog of information contained on those websites. Although there are many search engines, Google is arguably the most succ [..]
|
43 |
0 Search engineSites that aid users in finding Web pages relating to chosen topics. For example: Google, Yahoo, and Infoseek. These sites contain programs that allow users to search through at least one database that searches for words throughout the internet. Web directories are those that actually index the Web (usually only a portion), and those such as [..]
|
44 |
0 Search enginea program that searches for Web documents with keyword (s) you specify. Yahoo and Google are just two examples of search engines that have been created to meet the demand for quickly finding information.
|
45 |
0 Search enginespecialized software, such as AltaVista and Yahoo, that lets WWW browser users search for information on the Web by using keywords, phrases, and boolean logic. Different search engines have different [..]
|
46 |
0 Search engineA site that supports general searches of the Internet. Search word(s) are typed in and the search engine site returns results with the “most significant” at the top. The methods for ranking sites are not disclosed in detail, however, content relevance and inbound link strength are generally thought to play major roles. The traffic that goes to [..]
|
47 |
0 Search engineYou use a search engine to search for information on the World Wide Web. Each search engine works differently; many send ‘spiders’ that ‘crawl’ pages following the links (usually the main page [..]
|
48 |
0 Search engineA tool or device used to find relevant information. Search engines consist of a spider, index, relevancy algorithms and search results.
|
49 |
0 Search engineA server or a collection of servers dedicated to indexing internet web pages, storing the results and returning lists of pages which match particular queries. The indexes are normally generated using [..]
|
50 |
0 Search engineA tool for searching information on the Internet by topic. Popular search engines include Yahoo!, Hotbot, InfoSeek, and Alta Vista. season:
|
51 |
0 Search engineA web-based computer program, called a spider, crawler, or robot, that performs keyword searches for information on the Internet, and creates an automated search index. This is a database that indexes some or all of the words appearing on web pages, except for common words such as «a,» «and,» «in,» «to,» &quo [..]
|
52 |
0 Search engineA search engine is a type of software tool that creates indexes of Internet sites based on the titles of files, keywords, or the full text of files. The search engine has an interface that allows you [..]
|
53 |
0 Search enginea program used by an Internet browser to look for specific words and sort them for information.
|
54 |
0 Search engineA collection of programs that gather information from the Web (see also spider), index it, and put it in a database so it can be searched. The search engine takes the keywords or phrases you enter, se [..]
|
55 |
0 Search engineA Web search engine is a search engine designed to search for information on the World Wide Web. Information may consist of web pages, images and other types of files.
|
56 |
0 Search engineA search engine is a tool that allows you to find information on the Internet. Typically, you would type in some keywords and click a search button to look for information. Google, Yahoo, and Dogpile [..]
|
57 |
0 Search engineA computer program that searches for specific words and returns a list of documents in which the search term was found.
|
58 |
0 Search engineSoftware system designed to search for information on the internet (or World Wide Web).
|
59 |
0 Search engineComputer program capable of seeking information on the World Wide Web (or indeed any large data base) based upon search criteria specified by a user. See also: World Wide Web.
|
60 |
0 Search engineA publicly accessible site where people can browse information on any topic or question they like gathered by the Search Engine provider who uses special ‘bots’ to roam the Internet collecting the [..]
|
61 |
0 Search engineA Search Engine is a system for searching the information available on the Web. Search engines on the web consist of four elements: a program that roams the area to be searched, collecting data record [..]
|
62 |
0 Search engineA software program that allows one to perform searches on the Internet based on terms and phrases.
|
63 |
0 Search engineA system dedicated to the search and retrieval of information for the purpose of cataloging the results. Usually based on an index of several HTML documents, so you can easily locate the document(s) y [..]
|
64 |
0 Search engineWhen it comes to searching the Web, there are plenty of online services to choose from — HotBot, Excite, Infoseek, Yahoo, and AltaVista, to name a few. Each offers its own pros and cons, and each requ [..]
|
65 |
0 Search engineA Search Engine is a website which allows you to search the internet for other sites which cover a topic or query which you specify.
|
66 |
0 Search engineA program that searches indexes of addresses using keywords. The depth of the search is up to you and/or the extent of its index.
|
67 |
0 Search engineA website that allows a person to find web pages and other content on the World Wide Web by matching them with key words or phrases, and sometimes other specialized criteria.
|
68 |
0 Search engineAn internet website that offers people the ability to search for things, usually websites.
|
69 |
0 Search engineA (usually web based) system for searching for information on the web. Some search engines work by automatically searching the contents of other systems and creating a database of the results. other s [..]
|
70 |
0 Search engineA program that indexes documents, then attempts to match documents relevant to a user’s search requests (Source)
|
71 |
0 Search engineA tool on the web that you can use to track down specific information and web pages (i.e. Yahoo!, Lycos, etc.)
|
72 |
0 Search engineA search engine is a website used for finding information on the internet. Examples include Google and Bing.
|
73 |
0 Search engineSearch engines are specialized Web sites that constantly collect and index or categorize information about other Web sites so you can find information of interest to you. Yahoo, Alta Vista, and Excite are prominent Internet search engines.
|
74 |
0 Search engineAn online service which searches the internet far and wide for the keywords you specify to find the information you are looking for. All search engine return results and you can organize these by date [..]
|
75 |
0 Search engineAn Internet service that stores a vast number of Web pages and allows for fast searching among them. Also, a piece of software that implements a Web site’s search functionality.
|
76 |
0 Search engineIs a searchable database or index, containing thousands or millions of Web sites, pages or documents. It allows the user to search by entering keyword(s) or phrases, then executes the search in its [..]
|
77 |
0 Search engineAnother name for a Web index. It uses special software programs (called robots, spiders or crawlers) to find Web pages and "index" or list all words within each one. You may then search for words and find Web pages or documents that contain them.
|
78 |
0 Search engineThis term refers to a program that helps users find information in text-oriented databases.
|
79 |
0 Search engineA tool to help people locate information available on the World Wide Web
|
80 |
0 Search engineThere are millions and millions of pages on the World Wide Web, and millions more in newsgroups and lists. A search engine is software that goes out into the Internet and hunts down the information on [..]
|
81 |
0 Search engineIf you don’t know what a search engine is you have no business being on the web. Please turn your computer off and apply for a job at McDonald’s.
|
82 |
0 Search engineA program or web site that enables users to search for keywords on web pages throughout the World Wide Web. For example, Alta Vista is a popular search engine located at http://www.altavista.digital.com
|
83 |
0 Search engineA site that finds other sites or files based on keywords. Google is a search engine where Yahoo is a directory.
|
84 |
0 Search engineA web search engine is designed to search for information on the World Wide Web. The search results are generally presented in a line of results often referred to as search engine results pages (SERP& [..]
|
85 |
0 Search engineA utility capable of returning references to relevant information resources in response to a query.
|
86 |
0 Search engineAn online service which can trawl through the contents of the Web (Websites, newsgroups, email addresses) looking for specific phrases or words. The engine asks you for keywords and then provides a list of web sites that contain your chosen words. Clicking on the listed web sites will take you to the relevant web page.
|
87 |
0 Search engineA search engine is a computer system designed to help find information over a computer network such as the World Wide Web, inside a corporate or proprietary network or a personal computer. The search [..]
|
88 |
0 Search engineA program on the Internet that allows users to search for files and information.
|
89 |
0 Search engineA search engine is a program that uses a specific algorithm to identify the most relevant results to a user based on a string of keywords called a «query». Search Engine [..]
|
90 |
0 Search engineA search engine is a tool that enables you to search for specific information from a database or network. Google and Yahoo! are online search engines.
|
91 |
0 Search engineGoogle, Excite, Lycos, AltaVista, Infoseek, Bing and Yahoo are all search engines. They index millions of sites on the Web, so that Web surfers like you and me can easily find Web sites with the information we want. By creating indexes, or large databases of Web sites (based on titles, keywords, and the text in the pages), search engines can loca [..]
|
92 |
0 Search engineSoftware used to locate data or information stored in machine-readable form locally or at a distance such as an Internet site.
|
93 |
0 Search engineA software system that searches for information on the World Wide Web.
|
94 |
0 Search engineis a software system that is designed to search for information on the World Wide Web.
|
95 |
0 Search engineA search engine is a program that searches documents (i.e. web pages, which are HTML documents) for specified keywords and returns the list of documents. A search engine has two parts, a spider and an [..]
|
96 |
0 Search engineSearch engine is a service that allows Internet users to search for content via the World Wide Web (WWW). A user enters keywords or key phrases into a search engine and receives a list of Web content [..]
|
97 |
0 Search engineA program used to find information on the world wide web using specific keywords. Some search engines include Google, Yahoo , AltaVista, and Lycos.
|
98 |
0 Search engineA search aid that indexes Web pages and checks them for sites that match a researcher’s request.
|
99 |
0 Search engineThis is a tool used to search through websites and webpages. Popular search engines include Google, Yahoo and Bing.
|
100 |
0 Search engineA remotely accessible program that lets you do keyword searches for information on the Internet. The search engine is a server program and should not be confused with the browser or other programs that run on your desktop PC. There are a number of search utilities for the WWW (Yahoo, Lycos, etc.). The other Internet services typically have one sear [..]
|
101 |
0 Search engineis designed to search for information on the world wide web (www). Search results are usually presented as a list of results and are commonly called hits. The information may consist of web pages, ima [..]
|
102 |
0 Search engineA searchable database of pages on the Web. Different from an Index (like Yahoo) in that pages are not reviewed by a human editor before inclusion
|
103 |
0 Search engineA Web site that helps you find other Web sites on the Internet.
|
104 |
0 Search engineA program that lets you do keyword searches for information on the Web or within a website.
|
105 |
0 Search engine(computing) an application that searches for, and retrieves, data based on some criteria, especially one that searches the Internet for documents containing specified words colloquial
|
Dictionary.university is a dictionary written by people like you and me.
Please help and add a word. All sort of words are welcome!
Add meaning
search engine
n.
1. A software program that searches a database and gathers and reports information that contains or is related to specified terms.
2. A website whose primary function is providing a search engine for gathering and reporting information available on the internet or a portion of the internet.
American Heritage® Dictionary of the English Language, Fifth Edition. Copyright © 2016 by Houghton Mifflin Harcourt Publishing Company. Published by Houghton Mifflin Harcourt Publishing Company. All rights reserved.
search engine
n
(Computer Science) computing a service provided on the internet enabling users to search for items of interest
Collins English Dictionary – Complete and Unabridged, 12th Edition 2014 © HarperCollins Publishers 1991, 1994, 1998, 2000, 2003, 2006, 2007, 2009, 2011, 2014
search′ en`gine
n.
a computer program that searches documents, esp. on the World Wide Web, for a specified word or phrase and provides a list of documents in which this word or phrase is found.
[1990–95]
Random House Kernerman Webster’s College Dictionary, © 2010 K Dictionaries Ltd. Copyright 2005, 1997, 1991 by Random House, Inc. All rights reserved.
search engine
A device used to find material on the World Wide Web by looking for combinations of words.
Dictionary of Unfamiliar Words by Diagram Group Copyright © 2008 by Diagram Visual Information Limited
What is a search engine?
A search engine is a coordinated set of programs that searches for and identifies items in a database that match specified criteria. Search engines are used to access information on the World Wide Web.
How do search engines work?
Google is the most commonly used internet search engine. Google search takes place in the following three stages:
- Crawling. Crawlers discover what pages exist on the web. A search engine constantly looks for new and updated pages to add to its list of known pages. This is referred to as URL discovery. Once a page is discovered, the crawler examines its content. The search engine uses an algorithm to choose which pages to crawl and how often.
- Indexing. After a page is crawled, the textual content is processed, analyzed and tagged with attributes and metadata that help the search engine understand what the content is about. This also enables the search engine to weed out duplicate pages and collect signals about the content, such as the country or region the page is local to and the usability of the page.
- Searching and ranking. When a user enters a query, the search engine searches the index for matching pages and returns the results that appear the most relevant on the search engine results page (SERP). The engine ranks content on a number of factors, such as the authoritativeness of a page, back links to the page and keywords a page contains.
Specialized content search engines are more selective about the parts of the web they crawl and index. For example, Creative Commons Search is a search engine for content shared explicitly for reuse under Creative Commons license. This search engine only looks for that specific type of content.
Country-specific search engines may prioritize websites presented in the native language of the country over English websites. Individual websites, such as large corporate sites, may use a search engine to index and retrieve only content from that company’s site. Some of the major search engine companies license or sell their search engines for use on individual sites.

How search engines rank results
Not every search engine ranks content the same way, but some have similar ranking algorithms. Google search and other search engines like it rank relevant results based on the following criteria:
- Query meaning. The search engine looks at user queries to establish searcher intent, which is the specific type of information the user is looking for. Search engines use language models to do this. Language models are algorithms that read user input, understand what it means and determine the type of information that a user is looking for.
- Relevance. Keywords from search queries are matched to keywords in content. Keywords that appear in several places in the content signify more relevance than others.
- Quality. Search engines look for indicators of expertise, authority and trustworthiness in the content. If other prominent websites link to the content, it is considered more trustworthy.
- Usability. Search engines evaluate the accessibility and general user experience of content and reward content with better page experience. One example of page usability is mobile-friendliness, which is a measure of how easy a webpage is to use on a mobile device.
- User data. A user’s past search history, search settings and location data are a few of the data types search engines use to determine the content rankings they choose.
Search engines might use other website performance metrics, such as bounce rate and time spent on page, to determine where websites rank on a results page. Search engines might return different results for the same term searched as text-based content versus an image or video search.
Content creators use search engine optimization (SEO) to take advantage of the above processes. Optimizing the content on a page for search engines increases its visibility to searchers and its ranking on the SERP. For example, a content creator could insert keywords relevant to a given search query to improve results for that query. If the content creator wants people searching for dogs to land on their page, they might add the keywords bone, leash and hound. They might also include links to pages that Google deems authoritative.
What is the goal of search engines?
The primary goal of a search engine is to help people search for and find information. Search engines are designed to provide people with the right information based on a set of criteria, such as quality and relevance.
Webpage and website providers use search engines to make money and to collect data, such as clickstream data, about searchers. These are secondary goals that require users to trust that the content they are getting on a SERP is enough to engage with it. Users must see the information they’re getting is the right information.
User trust can be earned in different ways, including the following:
- Organic results. Unpaid organic results are seen as more trustworthy than paid, ad-based results.
- Authority. Google seeks to establish a webpage’s authority to identify it as the source of true information.
- Privacy. DuckDuckGo is a search engine that uses privacy protection to establish trust. It protects user privacy and avoids skewed search results that can come from using personal information to target users or place them in limited search categories, known as filter bubbles.
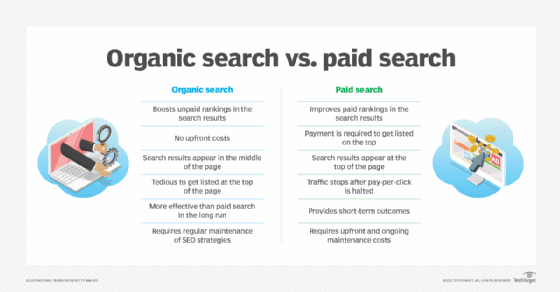
How do search engines make money?
Search engines make money in several ways, including the following:
- Pay-per-click ads. Advertisers or third-party advertising networks place ads on SERPs and on the content itself. The more views or clicks a search-related keyword gets, the more advertisers pay to have their advertisements associated with it.
- User data. Search engines also make money from the user data that they collect. Examples include search history and location data. This data is used to create a digital profile for a given searcher, which search engine providers can use to serve targeted ads to that user.
- Contextual ads. Search engines also capitalize on serving up contextual ads that are directly related to the user’s current search. If a search engine includes a shopping feature on the platform, it might display contextual ads for products related to the user’s search in the sidebar of a website where advertisements are displayed. For example, if the online store sells books, an ad may appear in the corner of the page for reading glasses.
- Donations. Some search engines are designed help nonprofits solicit donations.
- Affiliate links. Some engines include affiliate links, where the search engine has a partnership in which the partner pays the search engine when a user clicks the partner’s link.
How do search engines personalize results?
Search engines personalize results based on digital searcher profiles created from user data. User data is collected from the application or device a user accesses the search engine with. User data collected includes the following:
- search history
- search date and time
- location information
- audio data
- user ID
- device identification
- IP address
- device diagnostic data
- contact lists
- purchase history
Cookies are used to track browsing history and other data. They are small text files sent from the websites a user visits to their web browser. Search engines use cookies to track user preferences and personalize results and ads. They are able to remember settings, such as passwords, language preferences, content filters, how many results per page and session information.
Using private browsing settings or incognito browsing protects users from tracking but only at the device level. Search history and other information accumulated during search is not saved and is deleted after the search session. However, internet service providers, employers and the domain owners of the websites visited are able to track digital information left behind during a search.
Popular search engines
Google is the most popular search engine, capturing over 92% of the search engine market share worldwide, according to web traffic analysis service StatCounter. Yahoo and Microsoft Bing come in second and third with nearly 4% and just over 1% of the market, respectively.
DuckDuckGo has gained some popularity because of its focus on protecting users’ private search data. Some users may prefer to use Bing or Yahoo for their other integrated offerings.
Other popular search engines in the world are the following:
- Baidu
- BoardReader
- Brave Search
- Creative Commons Search
- Ecosia
- Ekoru
- Gibiru
- Gigablast
- GiveWater
- Haystak
- Mojeek
- MetaGer
- Naver
- OneSearch
- Onion Search
- Recon
- Search Encrypt
- SearX
- Sentient Hyper-Optimized Data Access Network (Shodan)
- Startpage
- Swisscows
- Qwant
- Wiki.com
- Wolfram Alpha
- Yandex
Some of these engines, such as Ecosia and Startpage, use their own crawlers but rely on larger, more mainstream search engines, like Google and Bing, for indexing. Others, such as Mojeek, use their own crawlers and maintain their own index.
Alternative search engines, like HaystakOnion Search and Recon, let users browse the dark web using the Tor browser, which encrypts user traffic for added privacy and security. The dark web is a hidden part of the internet not accessible by traditional browsers.
Other search engines focus on specific information types. For instance, Wolfram Alpha is an internet search engine for science and math topics. Shodan is a search tool for internet-connected devices.
Browsers generally have a default search engine. For example, Google Chrome and Safari for iOS use Google.
The future of search engines
Search engines and the companies that develop them are likely to use new technologies to improve the accuracy, relevance and quality of the answers search engines provide. They’ll also use advanced technologies, such as artificial intelligence, to improve user experience in the future. For example, a user might someday be able to upload a picture of a computer to Google, ask «Is this a good computer for gaming?» and get a thoughtful, nuanced answer.
Google is likely to continue to retain the majority of the search market. Given that, SEO companies can expect Google to keep updating its core search engine algorithm periodically. Google does this to keep those companies from optimizing content for a specific algorithm.
However, more niche engines might emerge in the future to provide the specificity and privacy that many users perceive Google lacks. Users may gravitate to search tools that provide enhanced privacy or better quality by only indexing a portion of the internet.
Some experts also believe that search engine use is declining because more information seeking will happen on other applications and social media sites, such as Facebook, TikTok and LinkedIn, in the future.
Although Google keeps its algorithm a secret, content creators can have some control over content performance. Learn ways to improve your search engine ranking.
This was last updated in November 2022
Continue Reading About search engine
- Search beyond search engines
- Top SEO marketing challenges
- Tips for creating a content marketing SEO strategy
- How can analytics improve content management?
- How a content tagging taxonomy improves enterprise search
What Does Search Engine Mean?
A search engine is a service that allows Internet users to search for content via the World Wide Web (WWW). A user enters keywords or key phrases into a search engine and receives a list of Web content results in the form of websites, images, videos or other online data that semantically match with the search query.
The list of content returned via a search engine to a user is known as a search engine results page (SERP).
Techopedia Explains Search Engine
A search engine performs a number of steps to do its job. First a spider/web crawler trawls the web for content that is added to the search engine’s index. These small bots can scan all sections and subpages of a website, including content such as video and images.
Hyperlinks are parsed to find internal pages or new sources to crawl when they point to external websites. To help bots do their crawling work in a more efficient way, larger websites usually submit a special XML sitemap to the search engine that acts as a roadmap of the site itself.
Once all data has been fetched by the bots, the crawler adds it to a massive online library of all discovered URLs. This constant and recursive process is known as indexing, and is necessary for a website to be displayed in the SERP. Then, when a user queries a search engine, relevant results are returned based on the search engine’s algorithm.
The higher a website is ranked in the SERP, the more relevant it should be to the searcher’s query. Since most users only browse the top results, it is particularly important for a website to rank high enough for certain queries to ensure its success in terms of traffic.
A whole science developed in the last few decades to make sure that a website, or at least some of its pages, “scale” the ranking to reach the first positions. This discipline is known as Search Engine Optimization (SEO).
Early search engines results were based largely on page content, but as websites learned to game the system through advanced SEO practices, algorithms have become much more complex and search results returned can be based on literally hundreds of variables.
Each search engine now uses its proprietary algorithm that weighs many complex factors such as relevancy, accessibility, usability, page speed, content quality, and user intent in order to sort the pages in a certain order.
Those employed as SEOs often expend huge energy trying to unravel the algorithm as the companies are not transparent with how they run, due to the proprietary nature of their business and their desire to prevent manipulation of search engine results.
There used to be a number of search engines with significant market share. As of 2020, Google controls the vast majority of the western market; Microsoft Bing has a small presence in second place. While Yahoo generates many queries, their back-end search technology is outsourced to Microsoft.
In other regions of the world, other search engines hold the majority of the market. In China, for example, the most widely used search engine is Baidu, which was originally launched in 2000, while in Russia more than 50% of users use Yandex.
[Master Computers – From beginner to expert in one week with this quick start course from Udemy]
Each day we are searching for tons of information on the Internet. Sometimes the results are not what we are looking for and sometimes just the opposite. But how does the Internet know what we want? The answer is Search Engine.
You must have words like Google, Bing, Yahoo, etc. All these are search engines that curate top results for the queries that we enter. Let us dive deeper to understand what is a search engine?
Search Engine Definition
A search engine is a software that is accessed on the internet to assist a user to search its query on the world wide web. The search engine is helpful as it carries out a systematic search on the web and displays the results that best match the user’s query.
The results are usually retrieved in the form of a list often referred to as SERPs or Search Engine Result Pages. These results or information may be links to web pages, or a mix of images and videos, research papers, newspaper articles, etc.
There are various search engines available, google being the most popular of all. All these search engines are capable of searching so quickly due to the web crawler. Let us learn about what a search engine is in detail.
How does a Search Engine work?
With thousands of informative web pages available on the internet, how does a search engine displays the relevant ones? How does it list these pages on our screen? What are the criteria? let us look at how to do search engines work.
The search engine follows three steps to execute the query of the user-
- Crawling
- Indexing
- Ranking
The search engine follows these steps to provide relevant results to the user.
Crawling
Discovering new web pages on the internet starts with crawling. All search engines use these bots called web crawlers or spider bots that follow links to the new webpages present in the known ones.
They get the information by crawling from site to site. Once the information is collected it is indexed. While indexing is going on the spider keeps going with discovering new pages. Once a certain amount of time is spent or base on the amount of data collected, the spider stops crawling.
Indexing
Once the data is crawled it is sent for indexing-saving data on the database of the search engine called the index.
It is the job of the index to find information related to the query as soon as possible. This process can be performed quickly by adopting any of these steps-
- Stripping out the stop words.
- Listing links to other pages.
- Listing information about images or embedded media on the page.
Any website has to be indexed to get listed on search results. Sometimes when a query is entered, the index results are obtained quickly because it has already stored a few website links containing the keywords.
Ranking
The last step is to rank the results on the SERP. The search engines have their criteria based on which the search results are listed. These signals or criteria are hidden from the public. It is the work of the ranking to determine the order of the web links on the results page.
One of the most common doubt is- do all search engines give the same results? And the answer is, not necessarily. Each search engine has its algorithm, based on which it performs the search on the web.
These searches are also based on the factors like your location, what was the preference of other users for the same keyword, what have been your past searches, etc. Therefore, all the search engines tend to give different search results.
What are the top 5 Search Engines?
Google is of course the leader of search engines with more than 90% of the market share. So much so that, it has become synonymous with searching on the internet.

Let us look at some of the other most popular search engines apart from Google.
1. Bing (renamed as Microsoft Bing in October 2020)
This one is almost as popular as the google search. Bing is the default search engine of the windows PC. One might find various similarities between google and bing with result features like – images, videos, places, maps, and news.
Though Microsoft might have attempted to make it as successful as Google it still holds only 2-3 percent of the total search engine market share.

2. Yahoo
Yahoo used to be one of the most popular sites to visit at one time. It is exclusively provided by Bing. It is also a default for Firefox users in the United States.

3. Baidu
This one is a popular engine in China. Though not very popular, its shares are increasing worldwide, according to Alexa. It is available all around the world but only in Chinese.

4. Yandex
Yandex.ru is a popular search engine in countries like Russia, Ukraine, Turkey, etc. Its name is derived from Yet Another Indexer. It has less than 1 percent market share of the overall search engine.

5. DuckDuckGo
This not-so-popular search engine has about 0.45 percent of the market share. Its competitors are also small search engines like Bing and Yahoo. Unlike most search engines it does not have a search index of its own, instead uses a variety of sources.
In other words, it does not have data of its own and depends on other sites like yahoo, Bing, etc. But what makes it unique from the lot is that it’s much cleaner and is not full of trash ads.

Conclusion
There is no such as the best search engine. Though, Google’s algorithm might be superior to the others it does not mean it will always curate the best results. Various upcoming search engines are fighting their way into the most popular search engine category. Try all these search engines yourself and decide which one gives the perfect solutions to your queries.

Kuldeep is the founder and lead author of ArtOfTesting. He is skilled in test automation, performance testing, big data, and CI-CD. He brings his decade of experience to his current role where he is dedicated to educating the QA professionals. You can connect with him on LinkedIn.
Educalingo cookies are used to personalize ads and get web traffic statistics. We also share information about the use of the site with our social media, advertising and analytics partners.
Download the app
educalingo


The Web provides a very easy way to immediately grasp what’s going on. It really offers the transparency, so you can see, especially with the search engine, how people are using Twitter at one glance. The phone doesn’t allow for that.
Jack Dorsey
![]()
![]()
![]()
PRONUNCIATION OF SEARCH ENGINE
![]()
![]()
![]()
![]()
GRAMMATICAL CATEGORY OF SEARCH ENGINE
Search engine is a noun.
A noun is a type of word the meaning of which determines reality. Nouns provide the names for all things: people, objects, sensations, feelings, etc.
WHAT DOES SEARCH ENGINE MEAN IN ENGLISH?
Web search engine
A web search engine is a software system that is designed to search for information on the World Wide Web. The search results are generally presented in a line of results often referred to as search engine results pages. The information may be a mix of web pages, images, and other types of files. Some search engines also mine data available in databases or open directories. Unlike web directories, which are maintained only by human editors, search engines also maintain real-time information by running an algorithm on a web crawler.
Definition of search engine in the English dictionary
The definition of search engine in the dictionary is a service provided on the internet enabling users to search for items of interest.
Synonyms and antonyms of search engine in the English dictionary of synonyms
Translation of «search engine» into 25 languages

TRANSLATION OF SEARCH ENGINE
Find out the translation of search engine to 25 languages with our English multilingual translator.
The translations of search engine from English to other languages presented in this section have been obtained through automatic statistical translation; where the essential translation unit is the word «search engine» in English.
Translator English — Chinese
搜索引擎
1,325 millions of speakers
Translator English — Spanish
motor de búsqueda
570 millions of speakers
Translator English — Hindi
खोज इंजन
380 millions of speakers
Translator English — Arabic
مُحَرِّكُ البَحْث
280 millions of speakers
Translator English — Russian
поисковая система
278 millions of speakers
Translator English — Portuguese
mecanismo de pesquisa
270 millions of speakers
Translator English — Bengali
খোঁজ যন্ত্র
260 millions of speakers
Translator English — French
moteur de recherche
220 millions of speakers
Translator English — Malay
enjin carian
190 millions of speakers
Translator English — German
Suchmaschine
180 millions of speakers
Translator English — Japanese
検索エンジン
130 millions of speakers
Translator English — Korean
검색 엔진
85 millions of speakers
Translator English — Javanese
Search engine
85 millions of speakers
Translator English — Vietnamese
công cụ tìm kiếm
80 millions of speakers
Translator English — Tamil
தேடல் இயந்திரம்
75 millions of speakers
Translator English — Marathi
शोध इंजिन
75 millions of speakers
Translator English — Turkish
arama motoru
70 millions of speakers
Translator English — Italian
motore di ricerca
65 millions of speakers
Translator English — Polish
wyszukiwarka
50 millions of speakers
Translator English — Ukrainian
система пошуку
40 millions of speakers
Translator English — Romanian
motor de căutare
30 millions of speakers
Translator English — Greek
μηχανή αναζήτησης
15 millions of speakers
Translator English — Afrikaans
soektog
14 millions of speakers
Translator English — Swedish
sökmotor
10 millions of speakers
Translator English — Norwegian
søkemotor
5 millions of speakers
Trends of use of search engine
TENDENCIES OF USE OF THE TERM «SEARCH ENGINE»
The term «search engine» is very widely used and occupies the 4.243 position in our list of most widely used terms in the English dictionary.

FREQUENCY
Very widely used
The map shown above gives the frequency of use of the term «search engine» in the different countries.
Principal search tendencies and common uses of search engine
List of principal searches undertaken by users to access our English online dictionary and most widely used expressions with the word «search engine».
FREQUENCY OF USE OF THE TERM «SEARCH ENGINE» OVER TIME
The graph expresses the annual evolution of the frequency of use of the word «search engine» during the past 500 years. Its implementation is based on analysing how often the term «search engine» appears in digitalised printed sources in English between the year 1500 and the present day.
Examples of use in the English literature, quotes and news about search engine
10 QUOTES WITH «SEARCH ENGINE»
Famous quotes and sentences with the word search engine.
Some say Google is God. Others say Google is Satan. But if they think Google is too powerful, remember that with search engines unlike other companies, all it takes is a single click to go to another search engine.
The kind of environment that we developed Google in, the reason that we were able to develop a search engine, is the web was so open. Once you get too many rules, that will stifle innovation.
Google actually relies on our users to help with our marketing. We have a very high percentage of our users who often tell others about our search engine.
I’d rather have a search engine or a compiler on a deserted island than a game.
The Web provides a very easy way to immediately grasp what’s going on. It really offers the transparency, so you can see, especially with the search engine, how people are using Twitter at one glance. The phone doesn’t allow for that.
Why can’t Google, which likes to see itself as a ‘Don’t Be Evil’ benevolent force in society, just write us a big check for using our stories, so we can keep checks and balances alive and continue to provide the search engine with our stories?
I had just turned 28 and sold my first book, a travel guide for vegetarians, but I’d tell people about the day job that I didn’t care about instead — I placed banner advertisements on the web for a search engine company.
In the early days, I really felt the pain of not being able to find information easily. I guess that helped me to develop an urge to write things like a search engine.
Search engine marketing and search engine optimization are critically important to online businesses. You can spend every penny you have on a website, but it will all be for nothing if nobody knows your site is there.
Good website practice and optimizing for conversion usually makes for good search engine optimization. These work together to ensure you drive quality traffic and can persuade that traffic to help you meet your business goals.
10 ENGLISH BOOKS RELATING TO «SEARCH ENGINE»
Discover the use of search engine in the following bibliographical selection. Books relating to search engine and brief extracts from same to provide context of its use in English literature.
1
Search Engines: Information Retrieval in Practice
This is the eBook of the printed book and may not include any media, website access codes, or print supplements that may come packaged with the bound book.
Bruce Croft, Donald Metzler, Trevor Strohman, 2011
2
Search Engine Optimization (SEO) Secrets
This unique book taps the relatively unknown market of advanced SEO knowledge, and reveals secrets used by only the best SEO consultants.
Danny Dover, Erik Dafforn, 2011
3
Global Search Engine Marketing: Fine-Tuning Your …
Global Search Engine Marketing Use search to reach all your best customers—worldwide!Don’t settle for U.S.-only, English-only search marketing: master global search marketing, and reach «all» your most profitable customers and prospects— …
Anne F. Kennedy, Kristjan Mar Hauksson, 2012
4
Search Engine Marketing, Inc.: Driving Search Traffic to …
In this book, two world-class experts present today’s best practices, step-by-step techniques, and hard-won tips for using search engine marketing to achieve your sales and marketing goals, whatever they are.
Mike Moran, Bill Hunt, 2008
5
Search Engine Visibility
Aimed at developers, designers, programmers, and online marketers, explains how to build user-friendly and effective Web sites that attract traffic from search engines.
6
The Truth About Search Engine Optimization
In this book, leading search optimization expert Rebecca Lieb brings together more than 50 absolutely crucial facts and insights decision-makers must know to drive more web traffic through better search engine placement.
7
Search Engine Optimization
SEO—short for Search Engine Optimization—is the art, craft, and science of driving web traffic to web sites.
8
Search Engine Advertising: Buying Your Way to the Top to …
Key features in this book include learning how to: • Buy top positions on the major search engines profitably • Transform poor ad copy into ads that deliver results • Increase visitor-to-buyer conversions • Begin paid search …
Kevin Lee, Catherine Seda, 2009
Helps programmers optimize websites for search engine visibility, using proven guidelines and techniques for planning and executing a comprehensive strategy, and explores the theory behind search engine optimization and how search engines …
10
Pay-Per-Click Search Engine Marketing: An Hour a Day
Successful pay-per-click campaigns are a key component of online marketing This guide breaks the project down into manageable tasks, valuable for the small-business owner as well as for marketing officers and consultants Explains core PPC …
David Szetela, Joseph Kerschbaum, 2010
10 NEWS ITEMS WHICH INCLUDE THE TERM «SEARCH ENGINE»
Find out what the national and international press are talking about and how the term search engine is used in the context of the following news items.
Google Is Hiring An SEO Manager To Improve Its Rankings In Google
The job listing is for a “Program Manager, Search Engine Optimization. … develop the web code to ensure quality, content and readability by search engines. «Search Engine Land, Jul 15»
Google: Lower CPCs Are Because Of YouTube, Not Mobile Search
Pichette blamed YouTube rather than mobile paid search for the lower CPCs. … Be a part of the world’s largest search marketing conference, Search Engine … «Search Engine Land, Apr 15»
Mobilegeddon Checklist: How To Prepare For This Week’s Google …
The Google Mobile Friendly Update launches tomorrow, a day that many including ourselves here at Search Engine Land are calling “Mobilegeddon.” We first … «Search Engine Land, Apr 15»
Problems & Solutions: Analyzing The EU’s Antitrust Charges Against …
Search engines operated this way before Google existed (yes, there was a time like this). Even as Microsoft, which is a major backer of the EU action, does this … «Search Engine Land, Apr 15»
Oh No They Didn’t: European Parliament Calls For Break Up Of …
But Google certainly won’t be giving thanks for the European Parliament’s vote in favor of a resolution to “unbundle” Google’s search engine from the rest of its … «Search Engine Land, Nov 14»
Europeans Have Authority To Seek Google Break Up Though …
The recommendation is likely to be to separate Google’s search engine from the rest of the business. Needless to say, if this were to come to pass it would be … «Search Engine Land, Nov 14»
The EU’s Right To Be Forgotten Is A Mess & How Google’s Making It …
So — according to what Google has confirmed for Search Engine Land — if an “Emily White” objected to a story showing for her name, and Google granted a … «Search Engine Land, Jul 14»
Your Privacy Is Now At Risk From Search Engines — Even If The …
Last week the European Union’s Court of Justice ordered Google to grant people the right to be forgotten, giving people the ability to have themselves removed … «Forbes, Jun 14»
The Myths & Realities Of How Of The EU’s New “Right To Be …
It’s not clear whether the search engines would be required to remove the listing for searches for someone’s name plus other words, such as “Did Jamie Doe go … «Search Engine Land, May 14»
The “Right To Be Forgotten” – EU Court Gives People Ability To …
It applies to search engines even where the underlying site or data source (a newspaper site in this case) is not required to remove the content and continues to … «Search Engine Land, May 14»
REFERENCE
« EDUCALINGO. Search engine [online]. Available <https://educalingo.com/en/dic-en/search-engine>. Apr 2023 ».
Download the educalingo app
Discover all that is hidden in the words on ![]()
- Search Engine
-
Поиско́вая систе́ма — веб-сайт, предоставляющий возможность поиска информации в Интернете. Большинство поисковых систем ищут информацию на сайтах Всемирной паутины, но существуют также системы, способные искать файлы на ftp-серверах, товары в интернет-магазинах, а также информацию в .
Как правило, основной частью поисковой системы является поиско́вая маши́на (поиско́вый движо́к) — комплекс программ, обеспечивающий функциональность поисковой системы. Основными критериями качества работы поисковой машины являются релевантность(степень соответствия запроса и найденного, то есть уместность результата), полнота базы, учёт морфологии языка. Индексация информации осуществляется специальными поисковыми роботами. В последнее время появился новый тип поисковых движков, основанных на технологии
Улучшение поиска — это одна из приоритетных задач сегодняшнего Интернета (см. про основные проблемы в работе поисковых систем в Глубокая паутина).
По данным компании Net Applications[1] в декабре 2007 года рыночная доля распределялась:
- Yahoo — 12,46 %
- Microsoft Live Search — 2,57 %
- Ask — 1,38 %
- Excite — 0,07 %
- All the Web — 0,02 %
По данным аналитической компании comScore все поисковые сайты в декабре 2007 года обработали 66 млрд 221 млн поисковых запросов.[2][3] Яндекс попал в статистику и находится на 9-ом месте.
Содержание
- 1 История
- 2 Популярные поисковые системы
- 3 Примечания
- 4 См. также
- 5 Ссылки
- 6 Литература
История
Хронология Год Система Событие 1993 Aliweb Запуск 1993 JumpStation Запуск 1994 WebCrawler Запуск 1994 AltaVista Запуск 1995 Excite Запуск 1995 Open Text Запуск 1995 Magellan Запуск 1995 SAPO Запуск 1996 Inktomi Основана 1996 HotBot Основана 1996 Ask Jeeves Основана 1996 Aport Запуск 1997 Northern Light Запуск 1997 Яндекс Запуск 1998 Mail.ru Запуск 1999 Teoma Основана 2000 Окончательный запуск 2004 MSN Search Запуск (бета) 2005 бета) 2006 Ask.com Запуск 2006 Live Search Запуск 2006 Gogo.ru Запуск (бета) Одним из первых инструментов поиска в интернете (до WWW) был Archie.
Первой поисковой системой для Всемирной паутины был «Wandex», уже не существующий индекс, который создавал «World Wide Web Wanderer» — бот, разработанный Мэтью Грэем (англ. Matthew Gray) из Массачусетского технологического института в 1993. Также в 1993 году появилась поисковая система «Aliweb», работающая до сих пор. Первой полнотекстовой (т. н. «crawler-based», то есть индексирующей ресурсы при помощи робота) поисковой системой стала «WebCrawler», запущенная в 1994. В отличие от своих предшественников, она позволяла пользователям искать по любым ключевым словам на любой веб-странице — с тех пор это стало стандартом во всех основных поисковых системах. Кроме того, это был первый поисковик, о котором было известно в широких кругах. В 1994 был запущен «
Вскоре появилось множество других конкурирующих поисковых машин, таких как «Excite», «Infoseek», «Inktomi», «Northern Light» и «интернет-каталогами, такими, как «Yahoo!». Позже каталоги соединились или добавили к себе поисковые машины, чтобы увеличить функциональность. В 1996 году русскоязычным пользователям интернета стало доступно морфологическое расширение к поисковой машине Altavista и оригинальные российские поисковые машины Aport. 23 сентября 1997 была открыта поисковая машина Яндекс.
В последнее время завоёвывает всё большую популярность практика применения методов кластерного анализа и метапоиска. Из международных машин такого плана наибольшую известность получила «Clusty» компании Vivísimo. В 2005 году на российских просторах при поддержке МГУ запущен поисковик кластеризацию. В 2006 году открылась российская метамашина [4] с визуальной кластеризацией.
Помимо поисковых машин для Всемирной паутины, существовали и поисковики для других протоколов, такие как Archie для поиска по анонимным Gopher.
Популярные поисковые системы
- Всеязычные:
- [5])
- Yahoo! (0,4 % Рунета) и принадлежащие этой компании поисковые машины:
- Inktomi
- MSN (0,2 % Рунета) (принадлежит компании Англоязычные и международные:
- AskJeeves (механизм Teoma)
- Русскоязычные — большинство «русскоязычных» поисковых систем индексируют и ищут тексты на многих языках — украинском, белорусском, английском и др. Отличаются же они от «всеязычных» систем, индексирующих все документы подряд, тем, что в основном индексируют ресурсы, расположенные в доменных зонах, где доминирует русский язык или другими способами ограничивают своих роботов русскоязычными сайтами.
- Яндекс (44,4 % Рунета)
- Gogo.ru (0,3 % Рунета)
- Aport (0,2 % Рунета)
Примечания
- ↑ http://marketshare.hitslink.com/report.aspx?qprid=4&qptimeframe=M&qpsp=107&qpdt=1&qpct=3&qpf=1
- ↑ http://www.comscore.com/press/release.asp?press=2018
- ↑ http://habrahabr.ru/blog/yandex/34614.html
- ↑ 12.06.2006: Nigma.ru тестирует AJAX-интерфейс для поиска
- ↑ данные об охвате русскоязычных поисковых запросов указаны согласно статистике LiveInternet
См. также
- Список поисковых машин
- Информационный поиск
- Поисковая оптимизация
- Статистика запросов
- Глубокая паутина
- Поисковый спам
- Каталог ресурсов в Интернете
- DataparkSearch
- Wikia Search
- Списки библиотек и поисковые системы
-
Ссылки
- Захаров Н. В. Информационно-поисковые системы в филологических науках
- История поисковых систем
- UFOSETI — поиск НЛО и пришельцев в интернете
- Портал поисковых технологий «Search Tools» (англ.)
Литература
- Ашманов Игорь Станиславович, Иванов Андрей Александрович Продвижение сайта в поисковых системах. — М.: «Вильямс», 2007. — С. 304. — ISBN 978-5-8459-1155-1
- Колисниченко Денис Николаевич Поисковые системы и продвижение сайтов в Интернете. — М.: «Диалектика», 2007. — С. 272. — ISBN 978-5-8459-1269-5
Wikimedia Foundation.
2010.
Полезное
Смотреть что такое «Search Engine» в других словарях:
-
search engine — ˈsearch ˌengine noun [countable] COMPUTING a computer program that searches the Internet or a computer network for information, especially by looking for documents that contain particular words: • Around 2001, the Google search engine rose to… … Financial and business terms
-
search engine — n. A software application that allows users to search for the appearance of particular words or images on websites. The Essential Law Dictionary. Sphinx Publishing, An imprint of Sourcebooks, Inc. Amy Hackney Blackwell. 2008. search engine … Law dictionary
-
Search Engine — Search En|gine [ sə:tʃ endʒin] die; , s […inz] <aus gleichbed. engl. search engine, zu engine »Maschine«> Suchmaschine [im Internet] … Das große Fremdwörterbuch
-
search engine — search engines N COUNT A search engine is a computer program that searches for documents containing a particular word or words on the Internet … English dictionary
-
Search Engine — Search Engine, Suchmaschine … Universal-Lexikon
-
search engine — search .engine n a computer program that helps you find information on the Internet … Dictionary of contemporary English
-
search engine — search ,engine noun count * a computer program used for searching for information on the Internet … Usage of the words and phrases in modern English
-
search engine — ► NOUN Computing ▪ a program for the retrieval of data, files, or documents from a database or network, especially the Internet … English terms dictionary
-
search engine — n. software designed to examine documents, websites, etc. in order to locate items on a specified topic or having a given property … English World dictionary
-
search engine — a computer program that searches documents, esp. on the World Wide Web, for a specified word or phrase and provides a list of documents in which this word or phrase is found. [1990 95] * * * Tool for finding information, especially on the… … Universalium
-
search engine — A special Web site that lets you perform keyword searches to locate Web pages; see Appendix A for a list of popular search engines. To use a search engine, you enter one or more keywords or, in some cases, a more complex search string such… … Dictionary of networking
- Top Definitions
- Quiz
- Related Content
- Examples
- British
- Cultural
This shows grade level based on the word’s complexity.
[ surch-en-juhn ]
/ ˈsɜrtʃ ˌɛn dʒən /
This shows grade level based on the word’s complexity.
noun Digital Technology.
a computer program that searches documents, especially on the World Wide Web, for a specified word or words and provides a list of documents in which they are found.
QUIZ
CAN YOU ANSWER THESE COMMON GRAMMAR DEBATES?
There are grammar debates that never die; and the ones highlighted in the questions in this quiz are sure to rile everyone up once again. Do you know how to answer the questions that cause some of the greatest grammar debates?
Which sentence is correct?
Also called re·triev·al en·gine [ri-tree-vuhl en-juhn] /rɪˈtri vəl ˌɛn dʒən/ .
Origin of search engine
First recorded in 1990–95
Words nearby search engine
sear, sea ranger, sea raven, search, search dog, search engine, search engine optimization, searching, searchless, searchlight, search me
Dictionary.com Unabridged
Based on the Random House Unabridged Dictionary, © Random House, Inc. 2023
Words related to search engine
How to use search engine in a sentence
-
Google’s John Mueller posted 12 tips and more on how to optimize your images for search engines.
-
So while you may have assiduously compiled a list of the most relevant keywords, it’s unlikely that they’ll dominate search engines within a few months.
-
If you take the time and put a little extra effort into properly optimizing your site’s images for both users and search engines every time you add an image to your website, you can give your pages a little extra edge in the search engines.
-
An external link is a source of free traffic for your website and is a crucial element of Google’s search engine algorithm.
-
This needs to change, and in order for that to happen, we need to stop thinking of Google as a search engine.
-
They not only disrupted service in China, they apparently crashed the search engine worldwide.
-
But what started out as a search engine has evolved into a search-and-destroy machine.
-
Revenge, it seems, is a dish best served through search engine optimization.
-
We make things easier for the people as well as the search engine.
-
I doubt the company wants to risk millions of people taking their search engine relationship elsewhere.
-
He did not need an Intel inside computer or search engine to find what he wanted.
British Dictionary definitions for search engine
noun
computing a service provided on the internet enabling users to search for items of interest
Collins English Dictionary — Complete & Unabridged 2012 Digital Edition
© William Collins Sons & Co. Ltd. 1979, 1986 © HarperCollins
Publishers 1998, 2000, 2003, 2005, 2006, 2007, 2009, 2012
Cultural definitions for search engine
Web sites or software that search the Internet for documents that contain a key word, phrase, or subject that is specified by the user to the search engine. Each engine has its own method of searching for information.
The New Dictionary of Cultural Literacy, Third Edition
Copyright © 2005 by Houghton Mifflin Harcourt Publishing Company. Published by Houghton Mifflin Harcourt Publishing Company. All rights reserved.