
I’m trying to print out a dataframe from pandas into Excel. Here I am using to_excel() functions. However, I found that the 1st column in Excel is the «index»,
0 6/6/2021 0:00 8/6/2021 0:00
1 4/10/2024 0:00 6/10/2024 0:00
2 4/14/2024 0:00 6/14/2024 0:00
Is there any ways to get rid of the first column?
![]()
smci
31.9k19 gold badges113 silver badges146 bronze badges
asked Feb 28, 2014 at 7:52
![]()
0
Example: index = False
import pandas as pd
writer = pd.ExcelWriter("dataframe.xlsx", engine='xlsxwriter')
dataframe.to_excel(writer,sheet_name = dataframe, index=False)
writer.save()
answered Nov 23, 2018 at 14:33
![]()
0
I did that and got the error message:
TypeError: ‘DataFrame’ objects are mutable, thus they cannot be hashed.
The code is as follows where ‘test’ is a dataframe with no column names
test = pd.DataFrame(biglist)
writer = pd.ExcelWriter("test.xlsx", engine='xlsxwriter')
test.to_excel(writer,sheet_name=test, index=False)
writer.save()
answered May 20, 2022 at 15:49
![]()
3
You can use the following syntax to export a pandas DataFrame to an Excel file and not include the index column:
df.to_excel('my_data.xlsx', index=False)
The argument index=False tells pandas not to include the index column when exporting the DataFrame to an Excel file.
The following example shows how to use this syntax in practice.
Suppose we have the following pandas DataFrame that contains information about various basketball players:
import pandas as pd #create DataFrame df = pd.DataFrame({'team': ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H'], 'points': [18, 22, 19, 14, 14, 11, 20, 28], 'assists': [5, 7, 7, 9, 12, 9, 9, 4], 'rebounds': [11, 8, 10, 6, 6, 5, 9, 12]}) #view DataFrame print(df) team points assists rebounds 0 A 18 5 11 1 B 22 7 8 2 C 19 7 10 3 D 14 9 6 4 E 14 12 6 5 F 11 9 5 6 G 20 9 9 7 H 28 4 12
If we use the to_excel() function to export the DataFrame to an Excel file, pandas will include the index column by default:
#export DataFrame to Excel file
df.to_excel('basketball_data.xlsx')
Here is what the Excel file looks like:

Notice that the index column is included in the Excel file by default.
To export the DataFrame to an Excel file without the index column, we must specify index=False:
#export DataFrame to Excel file without index column
df.to_excel('basketball_data.xlsx', index=False)
Here is what the Excel file looks like:

Notice that the index column is no longer included in the Excel file.
Note: You can find the complete documentation for the pandas to_excel() function here.
Additional Resources
The following tutorials explain how to perform other common tasks in pandas:
How to Skip Specific Columns when Importing Excel File in Pandas
How to Combine Multiple Excel Sheets in Pandas
How to Write Pandas DataFrames to Multiple Excel Sheets
17 авг. 2022 г.
читать 2 мин
Часто вас может заинтересовать экспорт фрейма данных pandas в Excel. К счастью, это легко сделать с помощью функции pandas to_excel() .
Чтобы использовать эту функцию, вам нужно сначала установить openpyxl , чтобы вы могли записывать файлы в Excel:
pip install openpyxl
В этом руководстве будет объяснено несколько примеров использования этой функции со следующим фреймом данных:
import pandas as pd
#create DataFrame
df = pd.DataFrame({'points': [25, 12, 15, 14, 19],
'assists': [5, 7, 7, 9, 12],
'rebounds': [11, 8, 10, 6, 6]})
#view DataFrame
df
points assists rebounds
0 25 5 11
1 12 7 8
2 15 7 10
3 14 9 6
4 19 12 6
Пример 1: базовый экспорт
В следующем коде показано, как экспортировать DataFrame по определенному пути к файлу и сохранить его как mydata.xlsx :
df.to_excel (r'C:UsersZachDesktopmydata.xlsx')
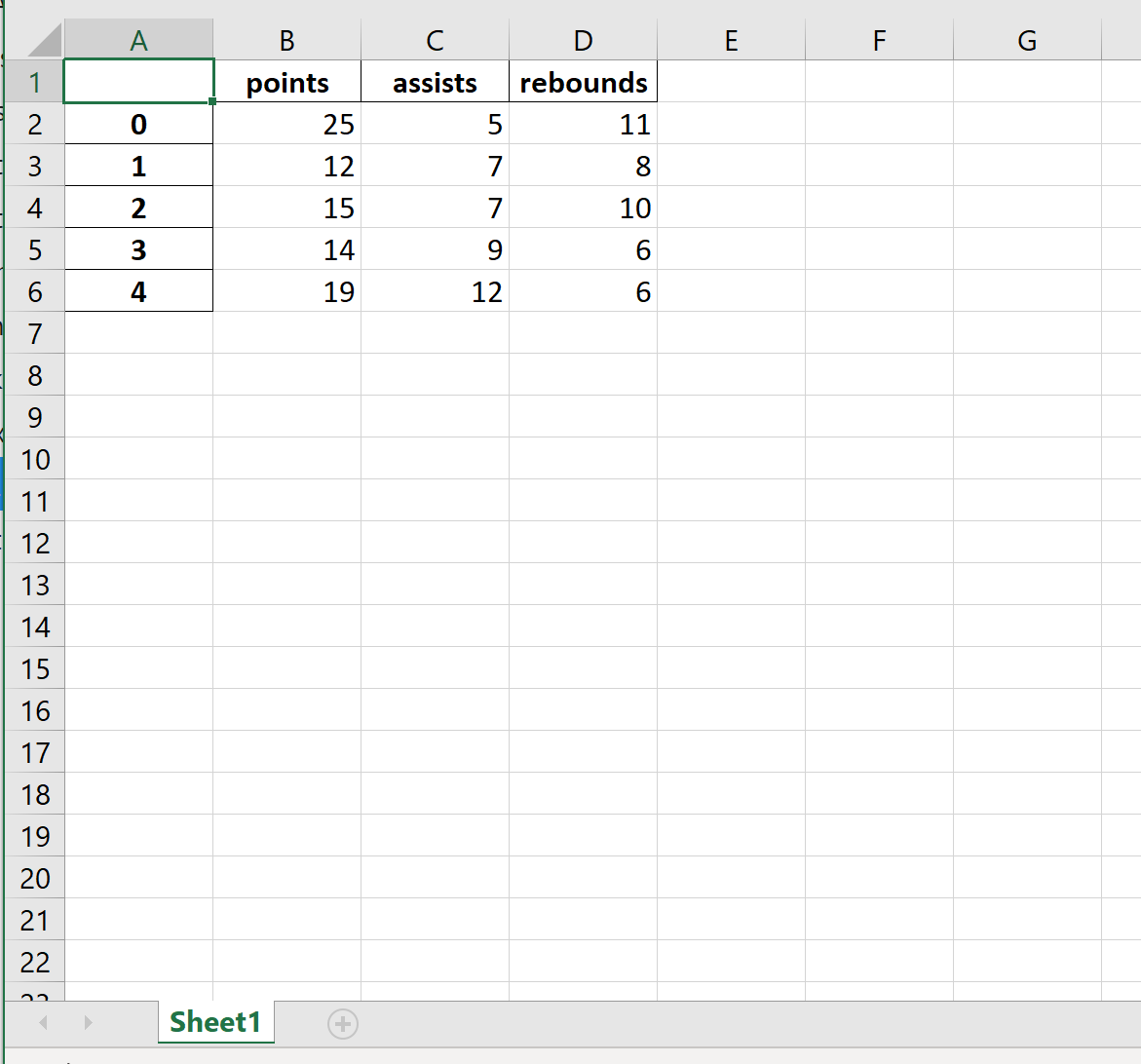
Вот как выглядит фактический файл Excel:
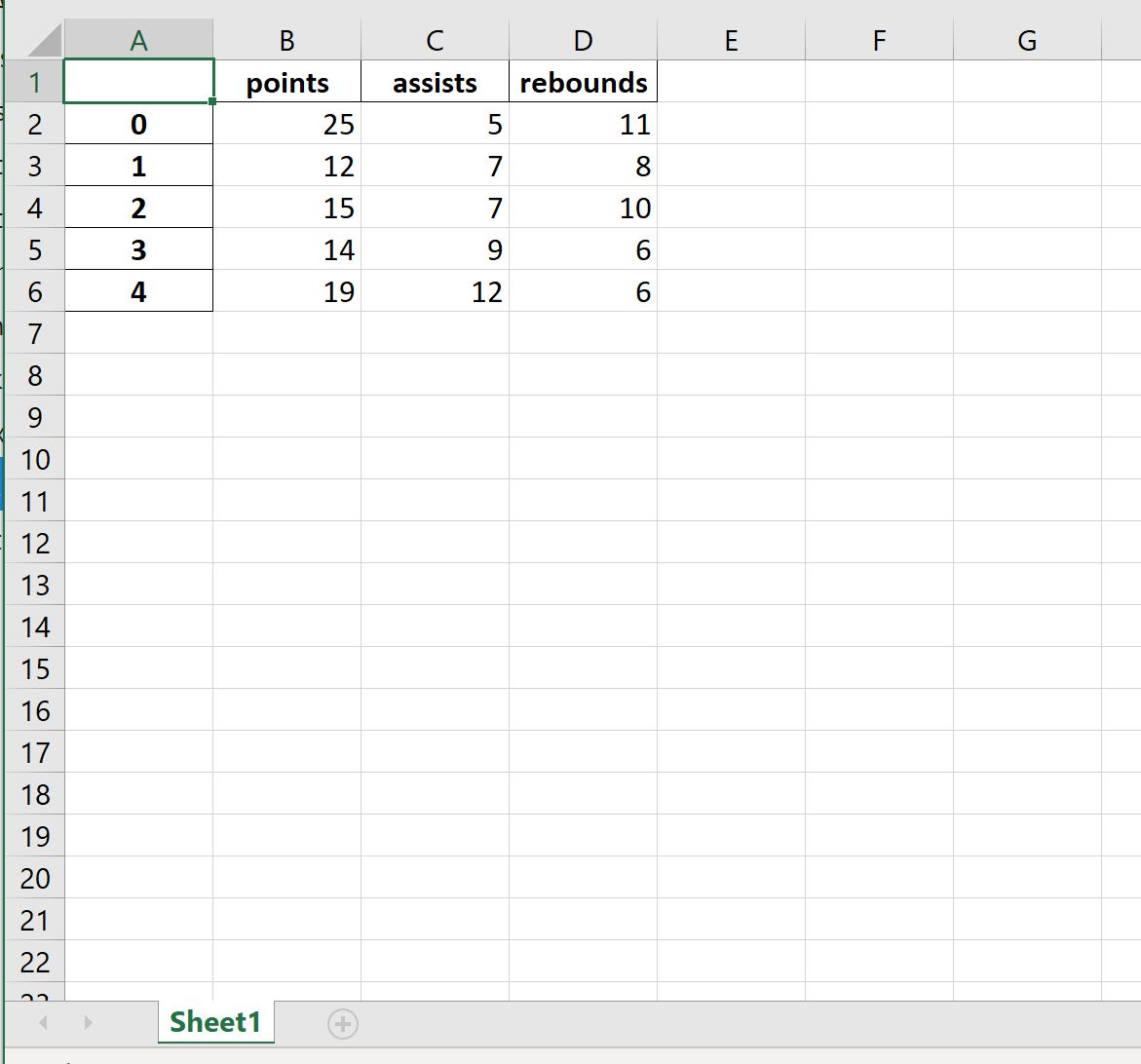
Пример 2: Экспорт без индекса
В следующем коде показано, как экспортировать DataFrame в определенный путь к файлу и удалить столбец индекса:
df.to_excel (r'C:UsersZachDesktopmydata.xlsx', index= False )
Вот как выглядит фактический файл Excel:
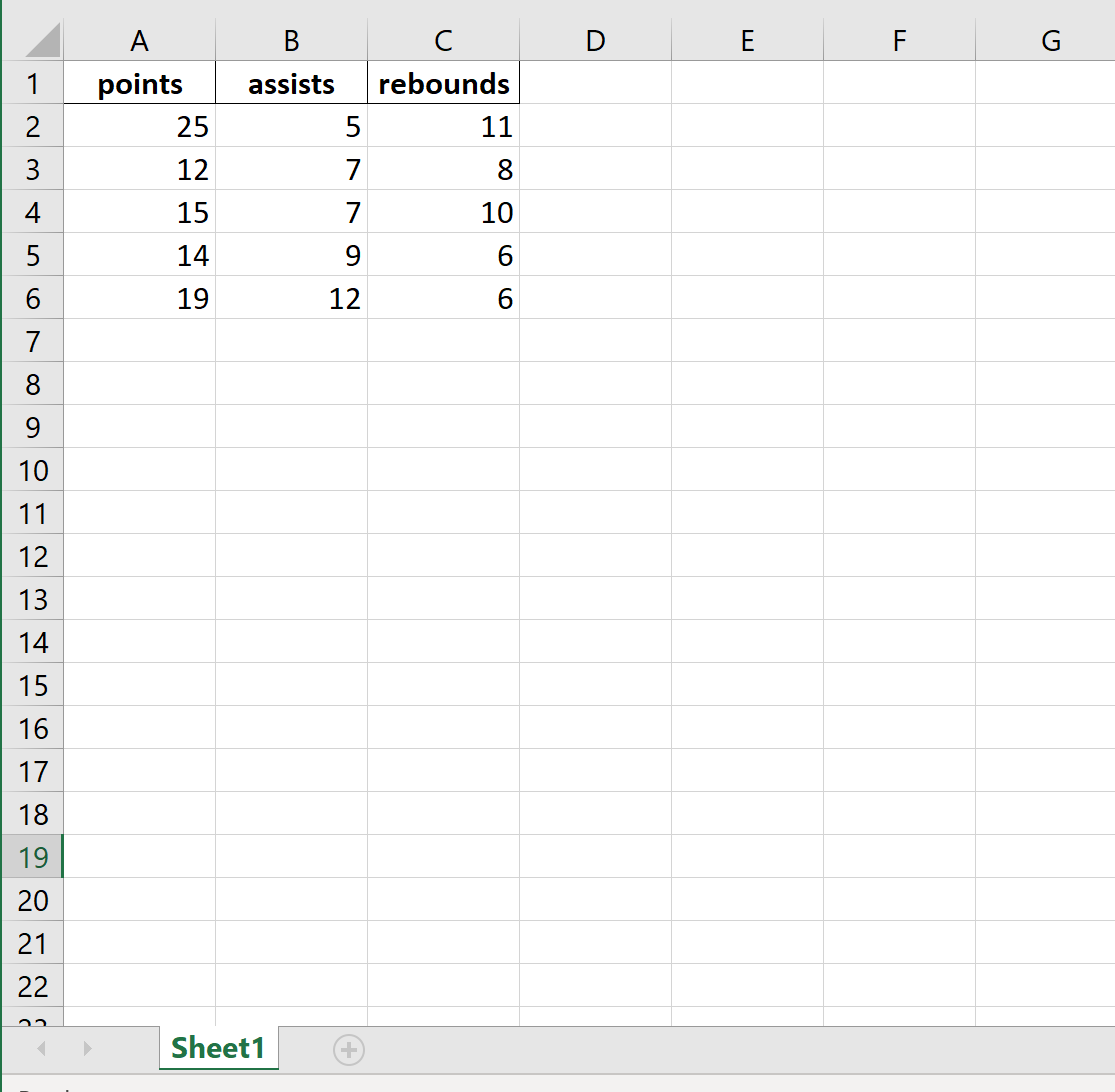
Пример 3: Экспорт без индекса и заголовка
В следующем коде показано, как экспортировать DataFrame в определенный путь к файлу и удалить столбец индекса и строку заголовка:
df.to_excel (r'C:UsersZachDesktopmydata.xlsx', index= False, header= False )
Вот как выглядит фактический файл Excel:
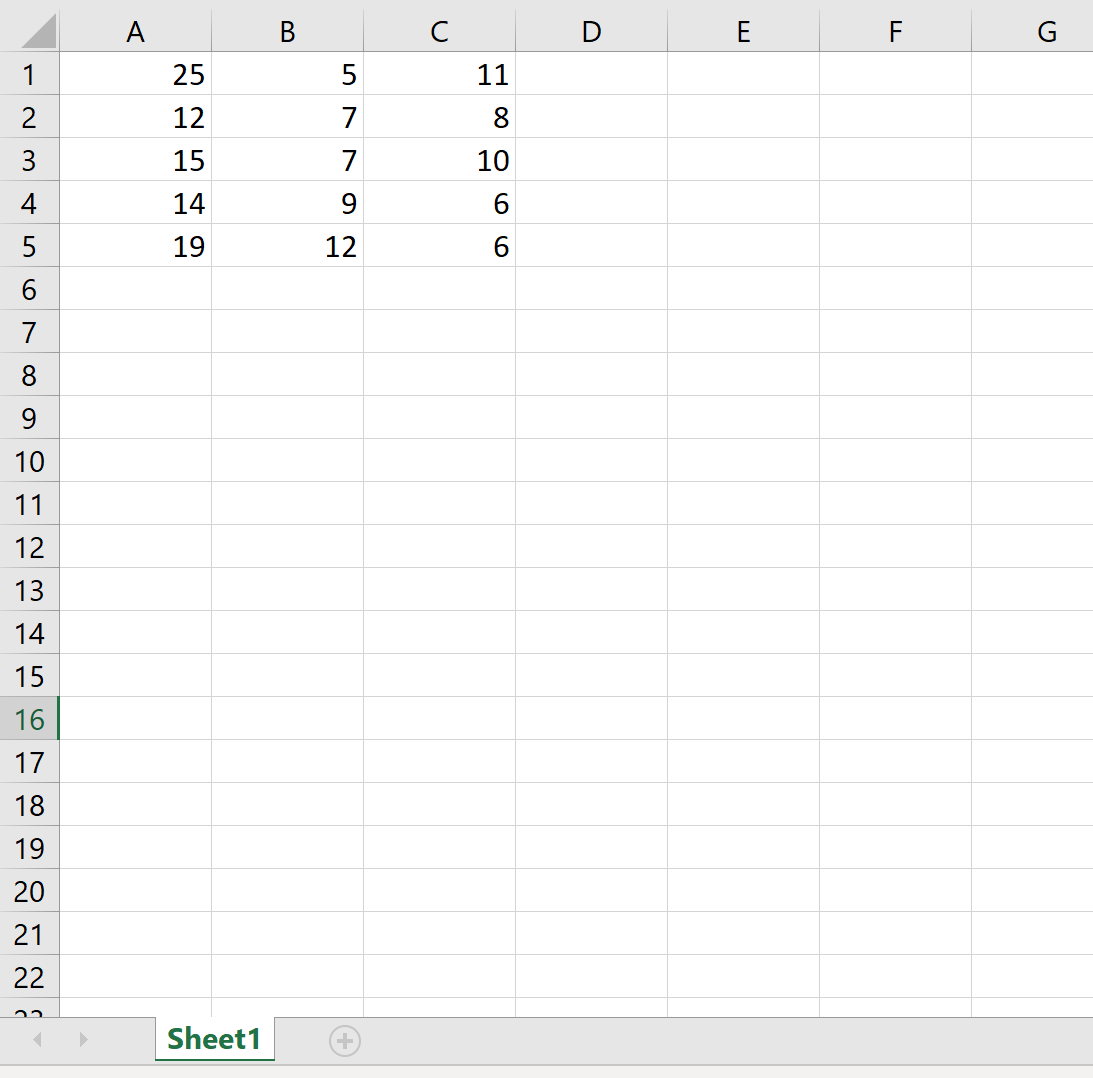
Пример 4: Экспорт и имя листа
В следующем коде показано, как экспортировать DataFrame в определенный путь к файлу и назвать рабочий лист Excel:
df.to_excel (r'C:UsersZachDesktopmydata.xlsx', sheet_name='this_data')
Вот как выглядит фактический файл Excel:
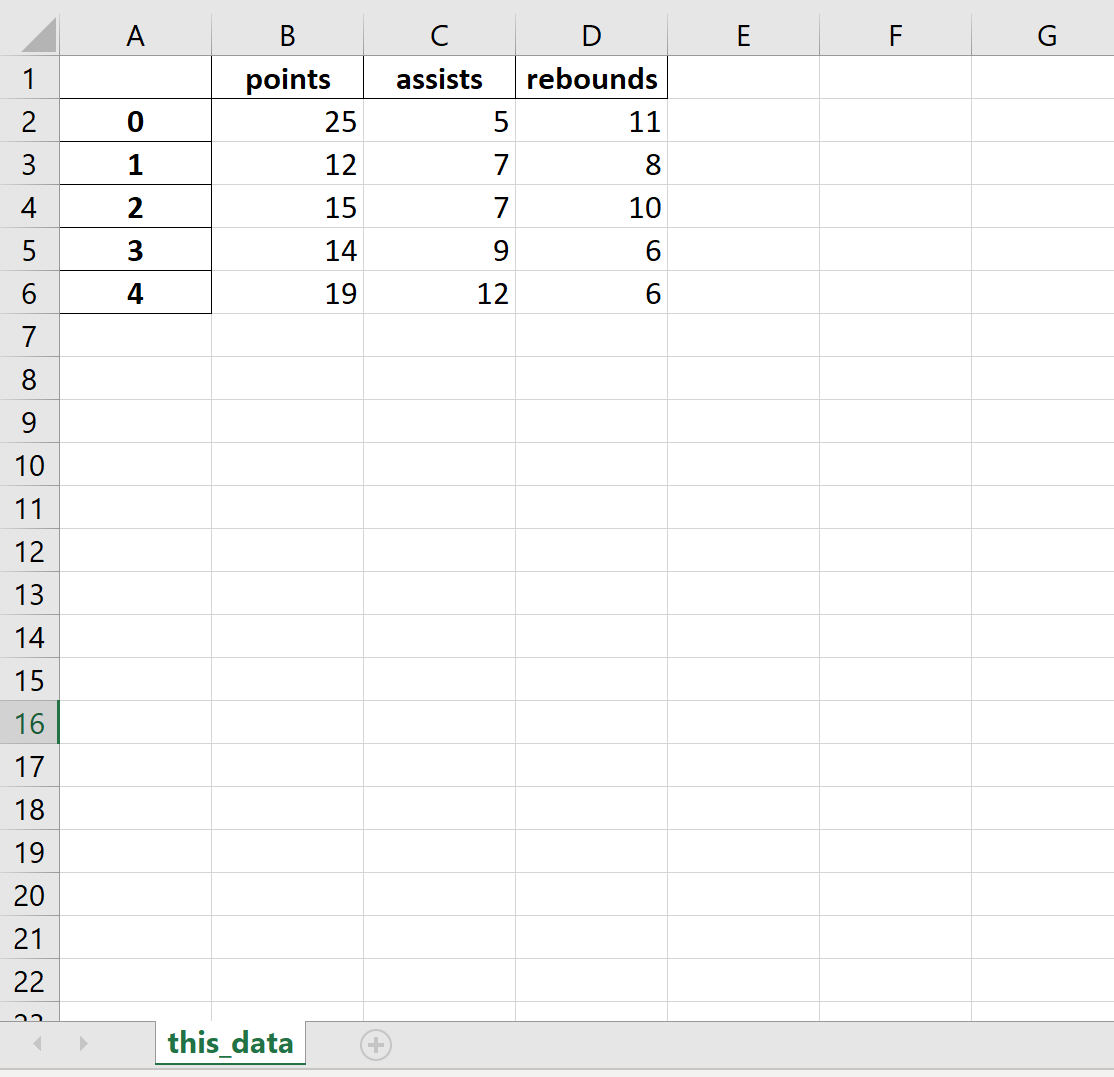
Полную документацию по функции to_excel() можно найти здесь .
You are here: Home / Pandas 101 / How To Save Pandas Dataframe as Excel File?
In this post, we will see examples of saving a Pandas dataframe as Excel file. Pandas has to_excel() function to write a dataframe into Excel file.
Let us load Pandas.
# load pandas import pandas as pd
We will create two lists and us these to create a dataframe as before.
education = ["Bachelor's", "Less than Bachelor's","Master's","PhD","Professional"] salary = [110000,105000,126000,144200,96000]
We can create a Pandas dataframe using the two lists to make a dictionary with DataFrame() function. Our toy dataframe contains two columns.
# Create dataframe in one step
df = pd.DataFrame({"Education":education,
"Salary":salary})
df
Education Salary
0 Bachelor's 110000
1 Less than Bachelor's 105000
2 Master's 126000
3 PhD 144200
4 Professional 95967
Now we have the dataframe ready and we can use Pandas’ to_excel() function to write the dataframe to excel file. In the example, below we specify the Excel file name as argument to to_excel() function.
# wrkite dataframe to excel file
df.to_excel("education_salary.xls")
Pandas to_excel() function has number of useful arguments to customize the excel file. For example, we can save the dataframe as excel file without index using “index=False” as additional argument.
# wrkite dataframe to excel file with no index
df.to_excel("education_salary.xls", index=False)
One of the common uses in excel file is naming the excel sheet. We can name the sheet using “sheet_name” argument as shown below.
# write dataframe to excel file with sheet name
df.to_excel("education_salary.xls",
index=False,
sheet_name="data")
This post is part of the series on Byte Size Pandas: Pandas 101, a tutorial covering tips and tricks on using Pandas for data munging and analysis.
Содержание
- pandas.DataFrame.to_excel#
- pandas.DataFrame.to_excel#
- Как экспортировать фрейм данных Pandas в Excel
- Пример 1: базовый экспорт
- Пример 2: Экспорт без индекса
- Пример 3: Экспорт без индекса и заголовка
- Пример 4: Экспорт и имя листа
- Write Excel with Python Pandas
- installxlwt, openpyxl
- Write Excel
- Write DataFrame to Excel file
- Write multiple DataFrames to Excel files
- Append to an existing Excel file
- Pandas – Save DataFrame to an Excel file
- The to_excel() function
- Examples
- 1. Save dataframe to an excel file with default parameters
- 2. Save dataframe to an excel file with custom sheet name
- 3. Save to multiple sheets in the same workbook
pandas.DataFrame.to_excel#
Write object to an Excel sheet.
To write a single object to an Excel .xlsx file it is only necessary to specify a target file name. To write to multiple sheets it is necessary to create an ExcelWriter object with a target file name, and specify a sheet in the file to write to.
Multiple sheets may be written to by specifying unique sheet_name . With all data written to the file it is necessary to save the changes. Note that creating an ExcelWriter object with a file name that already exists will result in the contents of the existing file being erased.
Parameters excel_writer path-like, file-like, or ExcelWriter object
File path or existing ExcelWriter.
sheet_name str, default вЂSheet1’
Name of sheet which will contain DataFrame.
na_rep str, default вЂвЂ™
Missing data representation.
float_format str, optional
Format string for floating point numbers. For example float_format=»%.2f» will format 0.1234 to 0.12.
columns sequence or list of str, optional
Columns to write.
header bool or list of str, default True
Write out the column names. If a list of string is given it is assumed to be aliases for the column names.
index bool, default True
Write row names (index).
index_label str or sequence, optional
Column label for index column(s) if desired. If not specified, and header and index are True, then the index names are used. A sequence should be given if the DataFrame uses MultiIndex.
startrow int, default 0
Upper left cell row to dump data frame.
startcol int, default 0
Upper left cell column to dump data frame.
engine str, optional
Write engine to use, вЂopenpyxl’ or вЂxlsxwriter’. You can also set this via the options io.excel.xlsx.writer , io.excel.xls.writer , and io.excel.xlsm.writer .
Deprecated since version 1.2.0: As the xlwt package is no longer maintained, the xlwt engine will be removed in a future version of pandas.
Write MultiIndex and Hierarchical Rows as merged cells.
encoding str, optional
Encoding of the resulting excel file. Only necessary for xlwt, other writers support unicode natively.
Deprecated since version 1.5.0: This keyword was not used.
Representation for infinity (there is no native representation for infinity in Excel).
verbose bool, default True
Display more information in the error logs.
Deprecated since version 1.5.0: This keyword was not used.
Specifies the one-based bottommost row and rightmost column that is to be frozen.
storage_options dict, optional
Extra options that make sense for a particular storage connection, e.g. host, port, username, password, etc. For HTTP(S) URLs the key-value pairs are forwarded to urllib.request.Request as header options. For other URLs (e.g. starting with “s3://”, and “gcs://”) the key-value pairs are forwarded to fsspec.open . Please see fsspec and urllib for more details, and for more examples on storage options refer here.
New in version 1.2.0.
Write DataFrame to a comma-separated values (csv) file.
Class for writing DataFrame objects into excel sheets.
Read an Excel file into a pandas DataFrame.
Read a comma-separated values (csv) file into DataFrame.
Add styles to Excel sheet.
For compatibility with to_csv() , to_excel serializes lists and dicts to strings before writing.
Once a workbook has been saved it is not possible to write further data without rewriting the whole workbook.
Create, write to and save a workbook:
To specify the sheet name:
If you wish to write to more than one sheet in the workbook, it is necessary to specify an ExcelWriter object:
ExcelWriter can also be used to append to an existing Excel file:
To set the library that is used to write the Excel file, you can pass the engine keyword (the default engine is automatically chosen depending on the file extension):
Источник
pandas.DataFrame.to_excel#
Write object to an Excel sheet.
To write a single object to an Excel .xlsx file it is only necessary to specify a target file name. To write to multiple sheets it is necessary to create an ExcelWriter object with a target file name, and specify a sheet in the file to write to.
Multiple sheets may be written to by specifying unique sheet_name . With all data written to the file it is necessary to save the changes. Note that creating an ExcelWriter object with a file name that already exists will result in the contents of the existing file being erased.
Parameters excel_writer path-like, file-like, or ExcelWriter object
File path or existing ExcelWriter.
sheet_name str, default вЂSheet1’
Name of sheet which will contain DataFrame.
na_rep str, default вЂвЂ™
Missing data representation.
float_format str, optional
Format string for floating point numbers. For example float_format=»%.2f» will format 0.1234 to 0.12.
columns sequence or list of str, optional
Columns to write.
header bool or list of str, default True
Write out the column names. If a list of string is given it is assumed to be aliases for the column names.
index bool, default True
Write row names (index).
index_label str or sequence, optional
Column label for index column(s) if desired. If not specified, and header and index are True, then the index names are used. A sequence should be given if the DataFrame uses MultiIndex.
startrow int, default 0
Upper left cell row to dump data frame.
startcol int, default 0
Upper left cell column to dump data frame.
engine str, optional
Write engine to use, вЂopenpyxl’ or вЂxlsxwriter’. You can also set this via the options io.excel.xlsx.writer or io.excel.xlsm.writer .
merge_cells bool, default True
Write MultiIndex and Hierarchical Rows as merged cells.
inf_rep str, default вЂinf’
Representation for infinity (there is no native representation for infinity in Excel).
freeze_panes tuple of int (length 2), optional
Specifies the one-based bottommost row and rightmost column that is to be frozen.
storage_options dict, optional
Extra options that make sense for a particular storage connection, e.g. host, port, username, password, etc. For HTTP(S) URLs the key-value pairs are forwarded to urllib.request.Request as header options. For other URLs (e.g. starting with “s3://”, and “gcs://”) the key-value pairs are forwarded to fsspec.open . Please see fsspec and urllib for more details, and for more examples on storage options refer here.
New in version 1.2.0.
Write DataFrame to a comma-separated values (csv) file.
Class for writing DataFrame objects into excel sheets.
Read an Excel file into a pandas DataFrame.
Read a comma-separated values (csv) file into DataFrame.
Add styles to Excel sheet.
For compatibility with to_csv() , to_excel serializes lists and dicts to strings before writing.
Once a workbook has been saved it is not possible to write further data without rewriting the whole workbook.
Create, write to and save a workbook:
To specify the sheet name:
If you wish to write to more than one sheet in the workbook, it is necessary to specify an ExcelWriter object:
ExcelWriter can also be used to append to an existing Excel file:
To set the library that is used to write the Excel file, you can pass the engine keyword (the default engine is automatically chosen depending on the file extension):
Источник
Как экспортировать фрейм данных Pandas в Excel
Часто вас может заинтересовать экспорт фрейма данных pandas в Excel. К счастью, это легко сделать с помощью функции pandas to_excel() .
Чтобы использовать эту функцию, вам нужно сначала установить openpyxl , чтобы вы могли записывать файлы в Excel:
В этом руководстве будет объяснено несколько примеров использования этой функции со следующим фреймом данных:
Пример 1: базовый экспорт
В следующем коде показано, как экспортировать DataFrame по определенному пути к файлу и сохранить его как mydata.xlsx :
Вот как выглядит фактический файл Excel:
Пример 2: Экспорт без индекса
В следующем коде показано, как экспортировать DataFrame в определенный путь к файлу и удалить столбец индекса:
Вот как выглядит фактический файл Excel:
Пример 3: Экспорт без индекса и заголовка
В следующем коде показано, как экспортировать DataFrame в определенный путь к файлу и удалить столбец индекса и строку заголовка:
Вот как выглядит фактический файл Excel:
Пример 4: Экспорт и имя листа
В следующем коде показано, как экспортировать DataFrame в определенный путь к файлу и назвать рабочий лист Excel:
Вот как выглядит фактический файл Excel:
Полную документацию по функции to_excel() можно найти здесь .
Источник
Write Excel with Python Pandas
Write Excel with Python Pandas. You can write any data (lists, strings, numbers etc) to Excel, by first converting it into a Pandas DataFrame and then writing the DataFrame to Excel.
To export a Pandas DataFrame as an Excel file (extension: .xlsx, .xls), use the to_excel() method.
installxlwt, openpyxl
to_excel() uses a library called xlwt and openpyxl internally.
- xlwt is used to write .xls files (formats up to Excel2003)
- openpyxl is used to write .xlsx (Excel2007 or later formats).
Both can be installed with pip. (pip3 depending on the environment)
Write Excel
Write DataFrame to Excel file
Importing openpyxl is required if you want to append it to an existing Excel file described at the end.
A dataframe is defined below:
You can specify a path as the first argument of the to_excel() method .
Note: that the data in the original file is deleted when overwriting.
The argument new_sheet_name is the name of the sheet. If omitted, it will be named Sheet1 .
If you do not need to write index (row name), columns (column name), the argument index, columns is False.
Write multiple DataFrames to Excel files
The ExcelWriter object allows you to use multiple pandas. DataFrame objects can be exported to separate sheets.
As an example, pandas. Prepare another DataFrame object.
Then use the ExcelWriter() function like this:
You don’t need to call writer.save(), writer.close() within the blocks.
Append to an existing Excel file
You can append a DataFrame to an existing Excel file. The code below opens an existing file, then adds two sheets with the data of the dataframes.
Note: Because it is processed using openpyxl, only .xlsx files are included.
Источник
Pandas – Save DataFrame to an Excel file
Excel files can be a great way of saving your tabular data particularly when you want to display it (and even perform some formatting to it) in a nice GUI like Microsoft Excel. In this tutorial, we’ll look at how to save a pandas dataframe to an excel .xlsx file.
Note: The terms “excel file” and “excel workbook” are used interchangeably in this tutorial.
The to_excel() function
The pandas DataFrame to_excel() function is used to save a pandas dataframe to an excel file. It’s like the to_csv() function but instead of a CSV, it writes the dataframe to a .xlsx file. The following is its syntax:
Here, df is a pandas dataframe and is written to the excel file file_name.xlsx present at the location path . By default, the dataframe is written to Sheet1 but you can also give custom sheet names. You can also write to multiple sheets in the same excel workbook as well (See the examples below).
Note that once the excel workbook is saved, you cannot write further data without rewriting the whole workbook.
Examples
First, we’ll create a sample dataframe that we’ll be using throughout this tutorial.

Now, let’s look at examples of some of the different use-cases where the to_excel() function might be useful.
1. Save dataframe to an excel file with default parameters
If you just pass the file name to the to_excel() function and use the default values for all the other parameters, the resulting Excel file gets saved in your current working directory with the given file name. Here’s a snapshot of the file when opened in Excel.

You can see that by default, the dataframe is saved to the sheet Sheet1 . Also, note that the index of the dataframe is saved as a separate column. Pass index=False if you don’t want the index as a separate column in the excel file.
Here’s how the saved excel file looks now.

2. Save dataframe to an excel file with custom sheet name
You can specify the name of the worksheet using the sheet_name parameter.

You can see in the above snapshot that the resulting excel file has stocks as its sheet name.
3. Save to multiple sheets in the same workbook
You can also save dataframes to multiple worksheets within the same workbook using the to_excel() function. For this, you need to specify an ExcelWriter object which is a pandas object used to write to excel files. See the example below:
Here’s how the saved excel file looks.

In the above example, an ExcelWriter object is used to write the dataframes df and df2 to the worksheets stocks1 and stocks2 respectively.
Note that creating an ExcelWriter object with a file name that already exists will result in the contents of the existing file being erased.
For more on the pandas dataframe to_excel() function, refer to its official documentation.
You might also be interested in –
With this, we come to the end of this tutorial. The code examples and results presented in this tutorial have been implemented in a Jupyter Notebook with a python (version 3.8.3) kernel having pandas version 1.0.5
Subscribe to our newsletter for more informative guides and tutorials.
We do not spam and you can opt out any time.
Источник