
TL;DR Generate Word/PDF documents from SQL Server,
Oracle, and MySQL
using SQL queries.
In every organization, database plays an important role in holding the
entire organization’s data across functions/departments. Organizations
create a variety of documents from this data including sales proposals,
invoices, contracts, compliance documents, and NDAs, etc.
Some industries such as legal, mortgage, and real estate are inherently
document-intensive and documents play a central role in their day-to-day
transactions. The document-generation requirements tend to vary a lot from
on-demand creation of a single document to bulk generation of thousands of documents in one go.
The generated documents are shared with internal and external
stakeholders including customers, vendors, and partners. It could be a simple mail or part of a
complex business process that involves e-sign, approvals, etc.
In essence, database to PDF and Word document generation and their distribution
is an essential job in every organization.
Challenges in Document generation from Database
In traditional databases, data inside the database is stored in tables and
they have a logical connection among them. Hence, Database solutions don’t
have document design capabilities. NoSQL/document databases store data in
JSON or a JSON-like documents and not great for document generation either.
If you are a master of SQL commands, you have a lot of choices including
off-the-shelf PL/SQL packages. But for a non-technical user/business user,
the options are limited. The first option is to knock on the IT department door
for help. However, business documents undergo frequent changes, and getting
IT bandwidth every time for document generation is difficult.
Hence, you find business users tend to look for a solution that allows them
to
-
Create/modify templates easily conforming to the organization’s brand and
design guidelines. - Generate documents with a click of a button.
Let’s look at the tools for addressing these requirements.
Common Tools for Database PDF
The most common solutions being used are not built for database documents generation
and hence offer only a little automation.
Reporting/BI tools:
Tools such as Tableau, Jasper,
Crystal reports generate reports but they lack in document design. These
are best suited for creating interactive reports. Though they make the
document generation easy, business users still need to depend on IT help
for template creation and template changes.
Publishing tools:
Data merge and Mail merge functionality offered by publishing tools such as
Indesign, Microsoft Word is good only for basic document merge. For
example, if you are looking to create a nice report with bullets,
conclusions, other written text, and pre-formatted numbers then a
publishing tool is not the right choice. Moreover, these tools have several
limitations including the inability to suppress blank rows, date &
number formatting errors, etc.
EDocGen for Database to Word and PDF Generation
The system addresses the creation of documents from the databases in a very
elegant fashion. Business users can create/edit templates in their favorite
editors. With a DIY interface, it can populate database data into templates
to generate documents. Users can use existing documents as templates for
document generation. Thus as in previous approaches, they don’t have to go through the
pain of template creation from
scratch or employing developers for template creation.
EDocGen offers the dynamic population of text, tables, hyperlinks, content blocks, and images.
The system also supports the BLOB population into the template. Thus the
extremely flexible to cater to different kinds of business documents including contracts, invoices, etc.
As it
is a cloud application, it enhances collaboration, intelligence, and
mobility of your team to work from anywhere on any device.
Let’s see how it creates documents from different databases.
- As a first step, select the database from which you want to generate documents.
- Enter the connection
details. You can connect to on-premise as well as cloud databases to the system. - Enter the query to extract data from the database.
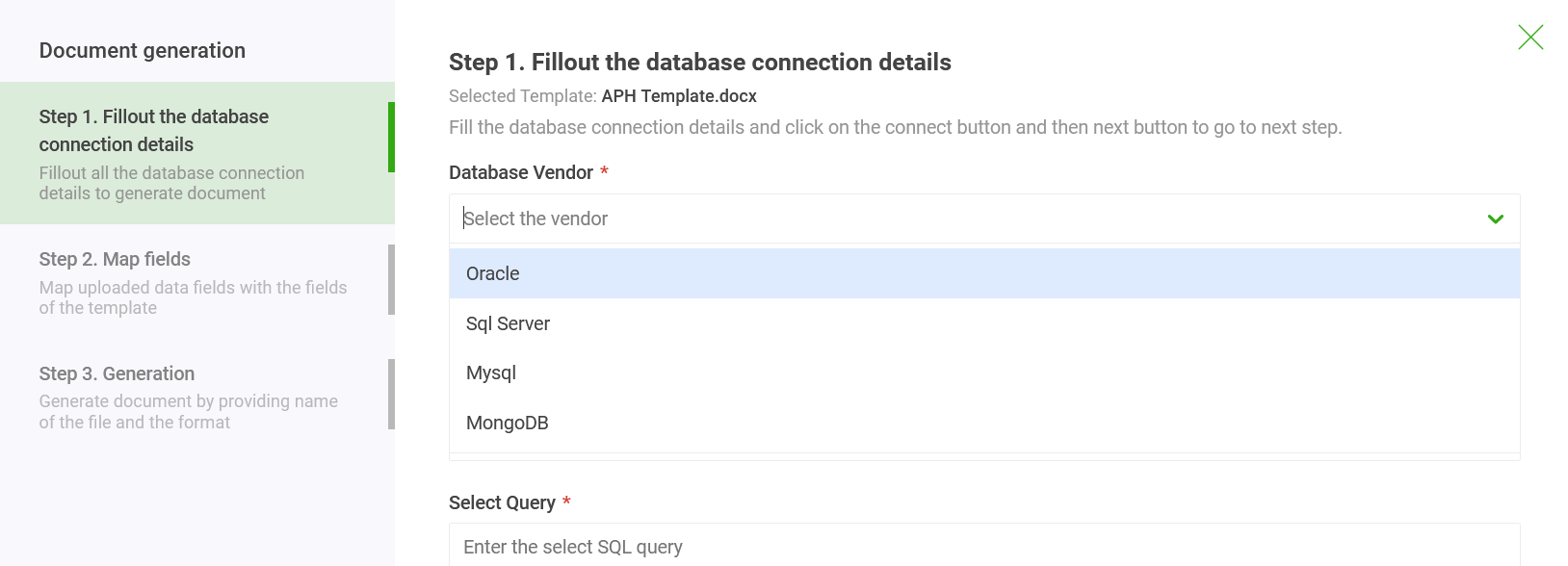
If you cannot enter connection details, alternatively you can extract database data in XML/JSON/Excel
formats and use this data for document automation.
SQL Server: Using FOR XML and FOR JSON, retrieve SQL Server data in XML /JSON format
with a simple SELECT query
and populate results into templates for document generation. Refer to SQL to PDF, SQL to Word for details
on how to go about creating PDF and Word documents from SQL Server.
You can also use API integration for on-demand document generation from SQL Server.
SELECT Title,
FirstName,
MiddleName,
LastName,
Suffix
FROM Person.Person
FOR XML AUTO
GO
MySQL: MySQL allows you to retrieve SQL data into a local CSV file through a simple SELECT query.
Populate that into the template for Database documents generation.
You can also export query data into JSON file as well as shown below using
‘JSON_OBJECT’ function.
SELECT CONCAT('[',GROUP_CONCAT(JSON_OBJECT('ID', department_id, 'name', department_name)),']')
FROM departments
Refer to JSON to Word for details about JSON population into Word template.
Oracle: Using XMLElement and XMLForest, you can export XML data from Oracle
database. Use EDocGen to populate XML data into your template to generate
multiple documents.
Refer to Oracle to PDF, Oracle to Word for details
on how to go about creating PDF and Word documents from the Oracle database.
Document Databases: Document databases such as MongoDB store
data as documents. Thus querying MongoDB data is not straightforward.
You can retrieve the data using db.collection.find() method. Let’s say you have a «students» collection.
Enter «db.students.find()» in the select query input area to retrieve all records of students.
Online Databases: Databases such as Knack, Caspio, etc. offer Zapier
integration. Again here as well integrate with EDocGen to generate
documents. For example, you can set-up a trigger for every new record entry
into the database. This trigger fires and creates a document every time a
record gets added to the database. Even the delivery of documents to
recipients via email can be automated.
In the next step of document generation, map the dynamic fields to query columns. If the names match,
the system auto-maps the fields. Thus you avoid
costly data transformations. Changing of table structure would never affect the document generation.
You can
generate thousands of documents in seconds.
In summary, EDocGen document generation software is the perfect solution
for the database to PDF file and Word document creation. You can use both Word and
PDF templates for database documents creation.
Even more solutions / points to consider
In addition to the suggestions offered by fellow members of the community, I would like to also give you some further points for consideration, which are a number of important learning points that I have picked up over the years while working on similar projects that may have had very similar pitfalls or complexities to battle against!
Your initial database that features barcodes and contains all of the databases and spreadsheets, could be described as a Repository of information assets, described briefly using systematic metadata which would be a detailed list of the indices that follow prescribed systematic procedures using look-up files to complete a 13 digit unique number which would be translated by a computer using a barcode.
Information assets would include all sorts of electronic files, e.g. it could be a list of three live databases, or a log of quarter 3 project working documents, perhaps even individually labelled project files and all other electronic instances of data sets that should all be tagged and registered as information assets.
Every single entry should be systematically registered using the appopriate reference lists to describe the details of owner, purpose, type, system, risk, planned disposal data and other similar datasets that would be related or associated.
Updates or revised data sets would continue to be developed and coded identically with all other sets of the same source, however version control procedures would be followed to maintain accurate logs as described in the document storage policy and procedures manual.
A new information asset or registration of data set could be registered once it has been created or obtained, by identifying a barcode to describe the content/owner/subject/details of the dataset as the 13 digit code would be broken down to show how every code represents a set of referenced lists of variables that would be described as the metadata fields within the overall data.
A library of various national releases of datasets are referenced as collections of data or statutory collections with hyperlinks to the actual source. It is standard practice not to recreate copies of the same data unless edited, which should then be appropriately labelled to reflect new version that describes any related documents or reports that were produced based on edited datasets.
The languages used to maintain directories, indices, version controls and catalogues of many different datasets or electronic reports would resemble the architecture of the Intranet which uses HTML and CSS with additional features using javascript and php to provide dynamic web pages that would all be managed by a systems administrator, however the engine would be a complex network of various Microsoft SQL server, MySQL and VisualBasic based software applications being connected in ways that ensure full connectivity between systems should there be a significant loss of power, with added support of suppliers who may have control over certain functions of deployed systems. This is typical of a large organisation operating across many different platforms with multiple software suites not designed to be connected in any way that modern technology provides simple codes to achieve even across different environments.
I have also developed a completely different index of electronic files based on the XML schema to process large data files and register specific metadata entries on a central repository. However, every database was then restructured to follow the XML schema that then allowed every entry to be used as the underlying raw data that would be securely hosted on an intranet that would be easily retrieved by MySQL stored procedures and functions based on triggers that ran scripts based on various different sets of rules.
I’ve seen some brand new programs that are based on versions of php that were introduced for very specialised projects, including all of the types of projects you’ve mentioned, so without taking up any more of your time, let me leave you with a link to a website that probably gives you a whole suite of codes and functions that may deliver what you no longer need to create from scratch, with the added supporting documentation that is easy to understand yet very detailed indeed.
DOCTRINE (php) and Yama Schema
Perhaps, you would be interested to know about the Doctrine/Yama solution that is designed to handle complexity with simple classes, trees, labels and functions to make it fairly simple to see sensible models be easily built without much of the hard work you might need to put in to setting up and securing other systems.
- Doctrine ORM: Introduction to Models
- Doctrine ORM: YAML Schema Files
Have you ever wondered about
storing documents into your Oracle database and just didn’t know where to
start? Here is a quick introduction to the basics you need to know.
Manipulating
Oracle Files with UTL_FILE showed you how to read the alert log
and do some manipulation on the file while it was external to the database. You
should review this article as it contains some background information you will
need to know, along with some explanation of some of the procedures in this
code that I will not go into here. The next logical extension to the last
article is the manipulation of external files, such as documents, and the
storage in the database. This article will take you through a brief overview of
the datatypes and procedures in order to store word documents within the
database.
The Datatypes
When talking about manipulating documents within a database,
there are only a few choices for a datatype that can handle a large document.
These large objects (LOBs) can use any one of the four datatypes depending on
the characteristics of the object you are storing. These large objects can be
in the form of text, graphics, video or audio.
| Datatype | Description |
|
BLOB |
Used to store unstructured binary data up to 4G. This |
|
CLOB/NCLOB |
Used to store up to 4G of character data. This datatype |
|
BFILE |
Used to point at large objects that are external to the |
Benefits of LOBs
It use to be that the largest object you could store in the
database was of the datatype LONG. Oracle has for the last few releases kept
telling us to convert our LONG datatypes to a LOB datatype (maybe they will
too). The reason for converting our LONGs to LOBs can be seen in this short
list of benefits.
- LOB
columns can reach the size of 4G. - You
can store LOB data internally within a table or externally. - You
can perform random access to the LOB data. - It
is easier to do transformations on LOB columns. - You
can replicate the tables that contain LOB columns.
Create a Table to Store the Document
In order to store the documents into the database you must
obviously first create an object to store the information. Following is the DDL
to create the table MY_DOCS. You will notice that there is a holder for the
bfile location and a column (DOC_BLOB) to hold the document.
CREATE TABLE my_docs
(doc_id NUMBER,
bfile_loc BFILE,
doc_title VARCHAR2(255),
doc_blob BLOB DEFAULT EMPTY_BLOB() );
The Load Procedure
The load procedure takes as arguments the document name and
an id number for the document. The procedure will then prime a row for update
based on the document id, BFILE location and document name (which becomes the
document title). The procedure will then open internal and external BLOBs and
load the internal from the external. At this point, the document has been
loaded into the database table.
| Code | Meaning |
bfile_loc := BFILENAME('DOC_DIR', in_doc);
|
In order to load the document, you must first point to the |
INSERT INTO my_docs (doc_id, bfile_loc, doc_title) VALUES (1, bfile_loc, in_doc); |
This statement is to prime the row into which the external |
SELECT doc_blob INTO temp_blob FROM my_docs WHERE doc_id = in_id FOR UPDATE; |
Associate the temporary blob object to the table blob |
DBMS_LOB.OPEN(bfile_loc, DBMS_LOB.LOB_READONLY); |
Open the external blob object for reading. |
|
DBMS_LOB.OPEN(temp_blob, DBMS_LOB.LOB_READWRITE); |
Open the temporary blob object for reading and writing. |
DBMS_LOB.LOADFROMFILE (temp_blob, bfile_loc, Bytes_to_load); |
Copy the entire external blob object (BFILE) into the |
The Search Procedure
The search procedure takes as arguments a document id and a
search string. The search procedure takes as arguments a document id and a search string. The procedure then converts the search string into raw format and places it into the variable named PATTERN. Once the variable PATTERN is populated, it is used for searching the loaded temporary BLOB DOC_BLOB to see if the particular pattern exists.
Pattern := utl_raw.cast_to_raw(in_search); |
Take the input search characters and convert them to raw |
SELECT doc_blob INTO lob_doc FROM my_docs WHERE doc_id = in_id; |
Put the document into a temporary BLOB for manipulation. |
DBMS_LOB.OPEN (lob_doc, DBMS_LOB.LOB_READONLY); |
Open the temporary BLOB for reading. |
Position := DBMS_LOB.INSTR (lob_doc, Pattern, Offset, Occurrence); |
Search the temporary BLOB for the supplied search string. |
How to Use the code.
The procedures that I have given you are very simplistic in
nature and are intended to be part of a larger application for managing
external documents within a database. They are intended to setup a directory
where your documents live, load the documents into a database, and then search
for string patterns in the document id provided. I personally can see you taking
out the reliance of supplying a document id and allowing the search to span
multiple documents within your library. Below I have given a brief description
on how to use the code as is but feel free to modify and integrate into your
own set of procedures.
How to Use
- log into your database of choice as the SYS user
- compile the package
SQL> @mydocs.sql
- set serveroutput on
SQL> set serveroutput on
- initial setup of directory object where your documents
live
SQL> exec mydocs.doc_dir_setup
- Check to make sure you can read one of your documents on
disk.
SQL> exec mydocs.list(Your Document Here.doc');
- Load your document into the database
SQL> exec mydocs.load(Your Document Here.doc', 1);
- Search your documents for a string pattern
SQL> exec mydocs.search(Search Pattern', 1);
The Code
CREATE OR REPLACE PACKAGE
mydocs
AS
PROCEDURE doc_dir_setup;
PROCEDURE list (in_doc IN VARCHAR2);
PROCEDURE load (in_doc IN VARCHAR2,
in_id IN NUMBER);
PROCEDURE search (in_search IN VARCHAR2,
in_id IN NUMBER);
END mydocs;
/
CREATE OR REPLACE PACKAGE BODY
mydocs
AS
vexists BOOLEAN;
vfile_length NUMBER;
vblocksize NUMBER;PROCEDURE doc_dir_setup IS
BEGIN
EXECUTE IMMEDIATE
‘CREATE DIRECTORY DOC_DIR AS’||
”'”E:jkoopmannpublishdatabasejournalOracle””’;
END doc_dir_setup;PROCEDURE list (in_doc IN VARCHAR2) IS
BEGIN
UTL_FILE.FGETATTR(‘DOC_DIR’,
in_doc,
vexists,
vfile_length,
vblocksize);
IF vexists THEN
dbms_output.put_line(in_doc||’ ‘||vfile_length);
END IF;
END list;PROCEDURE load (in_doc IN VARCHAR2,
in_id IN NUMBER) IS
temp_blob BLOB := empty_blob();
bfile_loc BFILE;
Bytes_to_load INTEGER := 4294967295;
BEGIN
bfile_loc := BFILENAME(‘DOC_DIR’, in_doc);
INSERT INTO my_docs (doc_id, bfile_loc, doc_title)
VALUES (in_id, bfile_loc, in_doc);
SELECT doc_blob INTO temp_blob
FROM my_docs WHERE doc_id = in_id
FOR UPDATE;
DBMS_LOB.OPEN(bfile_loc, DBMS_LOB.LOB_READONLY);
DBMS_LOB.OPEN(temp_blob, DBMS_LOB.LOB_READWRITE);
DBMS_LOB.LOADFROMFILE(temp_blob, bfile_loc, Bytes_to_load);
DBMS_LOB.CLOSE(temp_blob);
DBMS_LOB.CLOSE(bfile_loc);
COMMIT;
END load;PROCEDURE search (in_search VARCHAR2,
in_id NUMBER) IS
lob_doc BLOB;
Pattern VARCHAR2(30);
Position INTEGER := 0;
Offset INTEGER := 1;
Occurrence INTEGER := 1;
BEGIN
Pattern := utl_raw.cast_to_raw(in_search);
SELECT doc_blob INTO lob_doc
FROM my_docs WHERE doc_id = in_id;
DBMS_LOB.OPEN (lob_doc, DBMS_LOB.LOB_READONLY);
Position := DBMS_LOB.INSTR(lob_doc, Pattern, Offset, Occurrence);
IF Position = 0 THEN
DBMS_OUTPUT.PUT_LINE(‘Pattern not found’);
ELSE
DBMS_OUTPUT.PUT_LINE(‘The pattern occurs at ‘|| position);
END IF;
DBMS_LOB.CLOSE (lob_doc);
END search;BEGIN
DBMS_OUTPUT.ENABLE(1000000);
END mydocs;
/
»
See All Articles by Columnist James Koopmann

James Koopmann
James Koopmann has fourteen years of database design, development and performance tuning experience. In addition, he has extensive database administration experience in Oracle and other relational databases in production environments, specializing in performance tuning of database engines and SQL based applications.
Koopmann is an accomplished author with several technical papers in various Oracle related publications such as Oracle Magazine, Oracle Professional and SQL>UPDATE_RMOUG. He is a featured author and database expert for DatabaseJournal, a member of the editorial review committee for Select Journal (The Magazine for the International Oracle Users Group), an Oracle Certified Professional DBA and noted speaker at local Oracle User Groups around the country.

Creating a Database for Multiple Word Documents
Locked
by
lo0oly
·
about 7 years, 11 months ago
What is the best method to create a database of hyperlinked Word Documents? I have multiple Microsoft Word docs, and I am trying to create a database for them. So, I would be able to look at the Table of Contents and click on a specific content and be taken there. Also, some of the Word Docs reference other word documents in the same database, so I would like to be able to click on the reference mention and be taken to the other document.
Use case : To store MicroSoft Word documents(each doc < 16 MB) and have full text content search on all the documents( 2 to 3 TB).
Although Sharepoint & Alfresco fit the bill I felt either of them would be an overkill for our use case so want to explore NOSQL DB space for the same. I heard NOSQL databases are not great for managing files, but being a novice I was not sure. Please suggest.
![]()
asked Sep 7, 2015 at 4:25
![]()
I would also go with the statement that you have heard. You may get confused by the term «document-oriented database». This category of NoSQL databases (MongoDB and CouchDB belong to it) are mostly storing their data in JSON or a JSON-like documents. They work best for this kind of data, but if you need to you could use alternate storage specifications for other data formats/use cases (for MongoDB this could be GridFS).
Nevertheless, I would recommend to stay with SharePoint. It was built for such use cases and if you use the managed meta-data and search features SharePoint works better than MongoDB or CouchDB in that kind of use case (and you don’t have to built an application for accessing your data).
answered Sep 7, 2015 at 13:59
![]()
Horizon_NetHorizon_Net
5,9494 gold badges31 silver badges34 bronze badges
1
You might take a look at SenseNet (Disclosure: my company is a SenseNet solution partner.) SenseNet advertises itself as an open source «SharePoint Alternative», and leverages the best of both NoSQL and Relational databases by giving you a flexible schema system but stored in SQL Server.
It handles native MS Office documents easily, scales well, and is very performant. It uses the Apache Lucene for indexing, so if you upload a Word document, it’s instantly indexed and searchable with Google-like commands. The learning curve is steep, but as with any sophisticated framework such as Sharepoint or Alfresco, you will have to evaluate the learning cost versus the benefits.
answered Dec 25, 2015 at 1:07
![]()
Thane PlummerThane Plummer
7,2433 gold badges25 silver badges29 bronze badges