
Whether a digital native or immigrant, you probably know the basic functions of Excel inside out. With Excel, it is easy to accomplish simple tasks like sorting, filtering and outlining data and making charts based on them. When the data are highly structured, we can even perform advanced data analysis using pivot and regression models in Excel.
But the problem is, how can we extract scalable data and put them into Excel efficiently? This would be an extremely tedious task if done manually by repetitive typing, searching, copying, and pasting. So, how can we achieve automated data extraction and scraping from websites to Excel?
In this article, you can learn 3 ways to scrape data from websites to Excel to save your time and energy.
Automated Scraping Websites to Excel
If you are looking for a quick tool to scrape data off pages to Excel but don’t know about coding, then you can try Octoparse, an auto-scraping tool, which can scrape website data and export them into Excel worksheets either directly or via API. Download Octoparse to your Windows or Mac device, and get started extracting website data immediately with the easy steps below. Or you can read the step-by-step tutorial of web scraping.
Extract Data from Website to Excel Automatically with Octoparse
- Step 1: Copy and paste the website link to Octoparse product panel, and start auto-detect.
- Step 2: Customize the data field you want to scrape, you can also set the workflow manually.
- Step 3: Run the task after you checked, you can download the data as Excel or other formats after a few minutes.
Video Tutorial: Extract Web Data to Excel Efficiently

Web Scraping Project Customer Service
If time is your most valuable asset and you want to focus on your core businesses, outsourcing such complicated work to a proficient web scraping team that has experience and expertise might be the best option. Data scraping is difficult to scrape data from websites due to the fact that the presence of anti-scraping bots will restrain the practice of web scraping. A proficient web scraping team would help you get data from websites in a proper way and deliver structured data to you in an Excel sheet, or in any format you need.
Here are some customer stories that how Octoparse web scraping service helps businesses of all sizes.
Get Web Data Using Excel Web Queries
Except for transforming data from a web page manually by copying and pasting, Excel Web Queries are used to quickly retrieve data from a standard web page into an Excel worksheet. It can automatically detect tables embedded in the web page’s HTML. Excel Web queries can also be used in situations where a standard ODBC (Open Database Connectivity) connection gets hard to create or maintain. You can directly scrape a table from any website using Excel Web Queries.
Here list the simple steps on how to extract website data with Excel web queries. Or you can check out from this link: http://www.excel-university.com/pull-external-data-into-excel/.
1. Go to Data > Get External Data > From Web.
2. A browser window named “New Web Query” will appear.
3. In the address bar, write the web address.
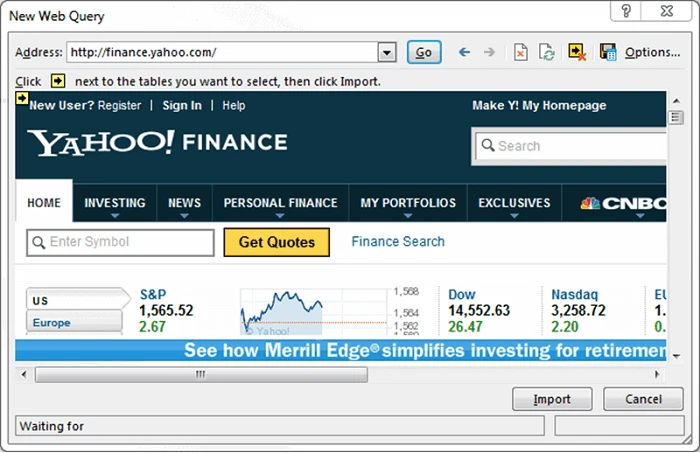
(picture from excel-university.com)
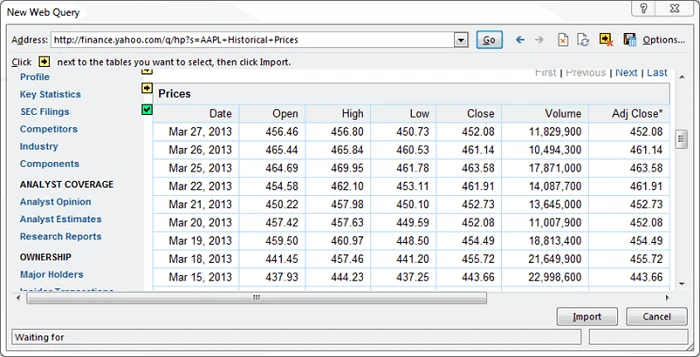
4. The page will load and will show yellow icons against data/tables.
5. Select the appropriate one.
6. Press the Import button.
Now you have the web data scraped into the Excel Worksheet — perfectly arranged in rows and columns as you like.
Scrape Web Data with Excel VBA
Most of us would use formula’s in Excel (e.g. =avg(…), =sum(…), =if(…), etc.) a lot, but are less familiar with the built-in language — Visual Basic for Application a.k.a VBA. It’s commonly known as “Macros” and such Excel files are saved as a **.xlsm. Before using it, you need to first enable the Developer tab in the ribbon (right-click File -> Customize Ribbon -> check Developer tab). Then set up your layout. In this developer interface, you can write VBA code attached to various events. Click HERE (https://msdn.microsoft.com/en-us/library/office/ee814737(v=office.14).aspx) to getting started with VBA in Excel 2010.
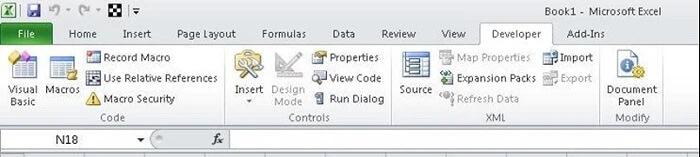
Using Excel VBA is going to be a bit technical — this is not very friendly for non-programmers among us. VBA works by running macros, step-by-step procedures written in Excel Visual Basic. To scrape data from websites to Excel using VBA, we need to build or get some VBA script to send some requests to web pages and get returned data from these web pages. It’s common to use VBA with XML HTTP and regular expressions to parse the web pages. For Windows, you can use VBA with Win HTTP or Internet Explorer to scrape data from websites to Excel.
With some patience and some practice, you would find it worthwhile to learn some Excel VBA code and some HTML knowledge to make your web scraping into Excel much easier and more efficient for automating the repetitive work. There’s a plentiful amount of material and forums for you to learn how to write VBA code.
Top 20 Web Crawling Tools for Extracting Web Data
Top 30 Free Web Scraping Software
10 Simple Excel Functions for Data Analysis
How to Extract Data from PDF to Excel

The data on a website might sometimes be presented in an inconvenient way.
You might want to extract the data on a website as an Excel spreadsheet.
This way, you can actually use the data and realize its full value.
In any case, web scraping tools can be incredibly helpful at helping you turn a website into a simple spreadsheet. In this article, we’ll guide you on how to set up a free web scraper and how to quickly extract the data you need.
ParseHub: A Powerful and Free Web Scraper
To achieve our goal for this project, we will use ParseHub, a free and powerful web scraper that can turn any website into a handy spreadsheet or API for you to use.
Wondering what a web scraper is and how they work? Read our definite guide on web scraping.
For this guide, we will only focus on the spreadsheet side of things.
So, before we get started, make sure to download and install ParseHub for free.
Web Scraping Website Data to Excel Example
For the sake of example, let’s assume we own an imaginary company that sells napkins, paper plates, plastic utensils, straws, and other consumable restaurant items (All our items will be fully recyclable too since our imaginary company is ahead of the competition).
As a result, having an excel spreadsheet with the contact information of every fast food restaurant in town would be incredibly valuable and a great way to build a leads database.
So, we will extract the data from a Yelp search result page into an excel spreadsheet.
Getting Started
- Make sure you’ve downloaded ParseHub and have it up and running on your computer.
- Find the specific webpage(s) you’d like to scrape. In this example, we will use Yelp’s result page for Fast Food restaurants in Toronto.
Create a Project
- In ParseHub, click on “New Project” and enter the URL to scrape.
- Once submitted, the URL will load inside ParseHub and you will be able to start selecting the information you want to extract.
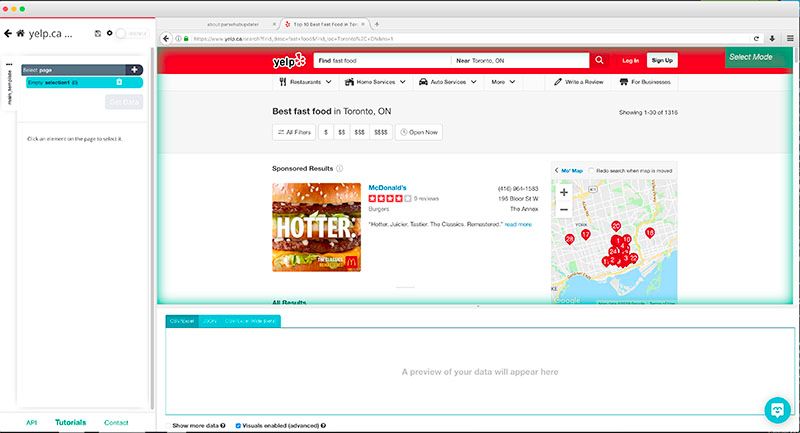
Identify and Select Data to Scrape
- Let’s start by selecting the business name of the first result on the page. Do this by clicking on it. It will then turn green.
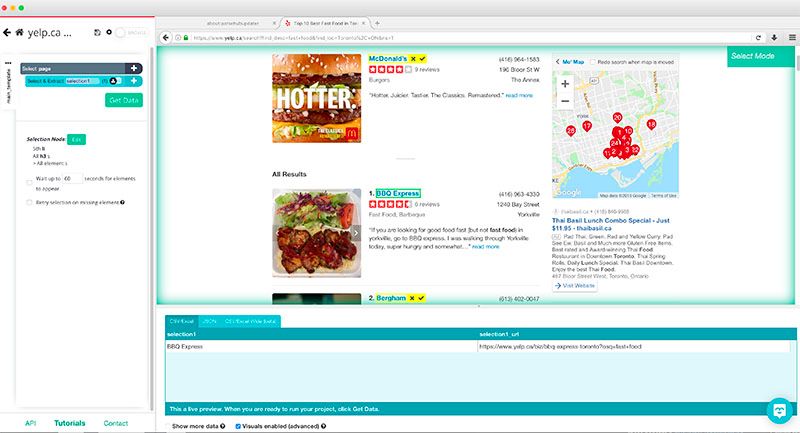
- You will notice that all the business names on the page will turn yellow. Click on the next one to select all of them.
- You will notice that ParseHub is now set to extract the business name for every result on the page plus the URL it is linking to. All business names will now also be green.
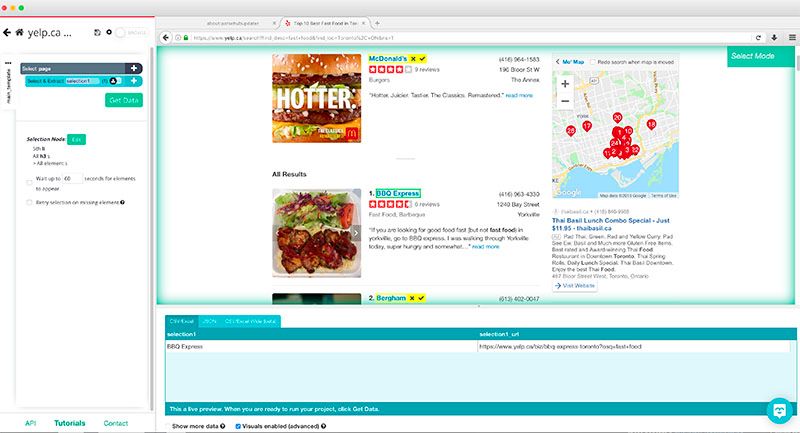
- On the left sidebar, click on the selection you’ve just created and rename it to business
- Then click on the PLUS(+) sign on the selection and choose relative select. This will allow us to extract more data, such as the address and phone number of each business.
- Using Relative Select, click on the first business name and then on the phone number next to it. Rename this Relative Select to phone.
- Using Relative Select again, do the same for the business address. Rename this Relative Select to address. We’ll do the same for the business category.
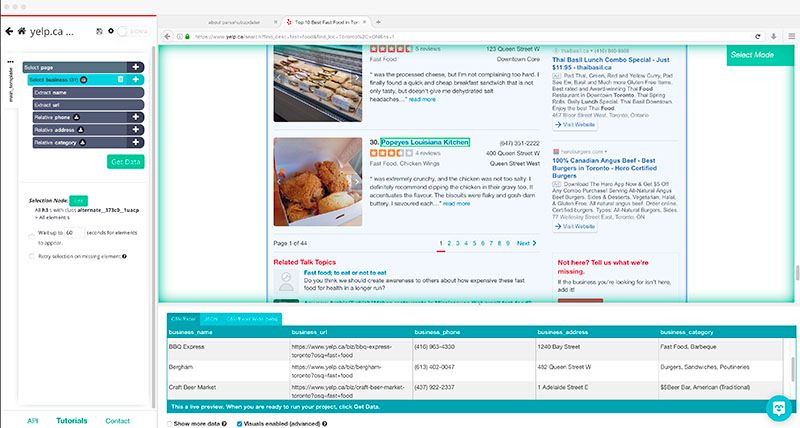
Now, you will notice that this method will only capture the first page of search results. We will now tell ParseHub to scrape the next 5 pages of results.
- Click on the PLUS(+) sign next to the “Select Page” item, choose the Select command and select the “Next” link at the bottom of the page you’d want to scrape.
- Rename this selection to Pagination.
- ParseHub will automatically pull the URL for this link into the spreadsheet. In this case, we will remove these URL’s since we do not need them. Click on the icon next to the selection name and delete the 2 extract commands.
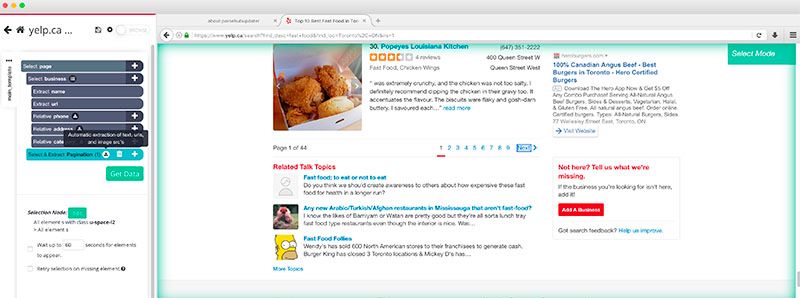
- Now, click on the PLUS(+) sign next to your Pagination selection and use the click command.
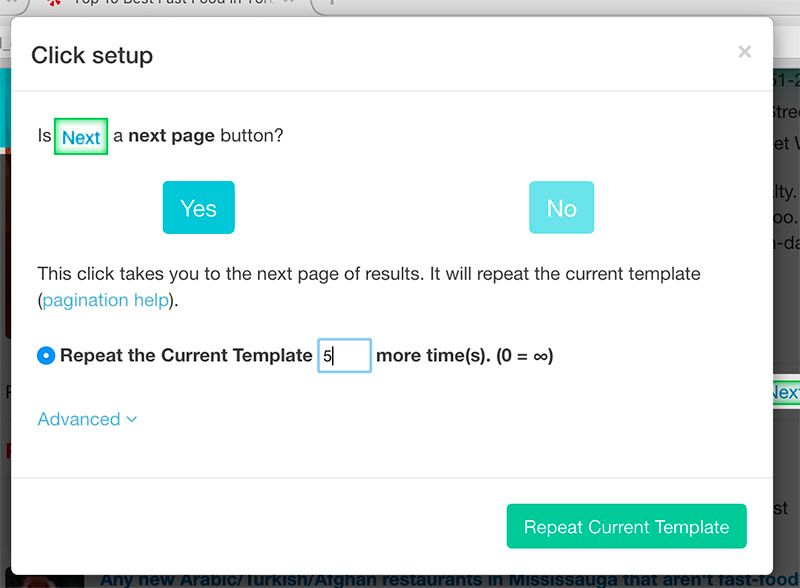
- A window will pop up asking if this is a Next Page link. Click “Yes” and enter the number of times you’d like this cycle to repeat. For this example, we will do it 5 times. Then, click on Repeat Current Template.
Scrape and Export Website Data to Excel
Now that you are all set up, it’s time to actually scrape the data and extract it.
- Click on the green Get Data button on the left sidebar
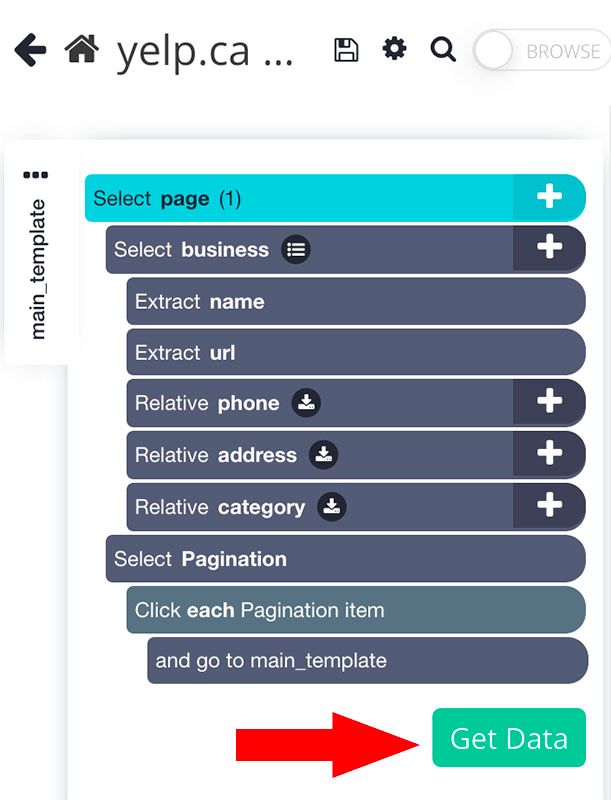
- Here you can either test your scrape run, schedule it for the future or run it right away. In this case, we will run it right away although we recommend to always test your scrapes before running them.
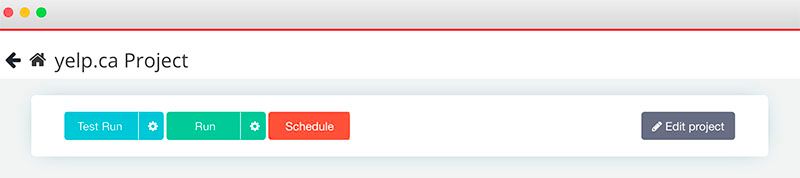
- Now ParseHub is off to scrape all the data you’ve selected. You can either wait on this screen or leave ParseHub, you will be notified once your scrape is complete. In this case, our scrape was completed in under 2 minutes!
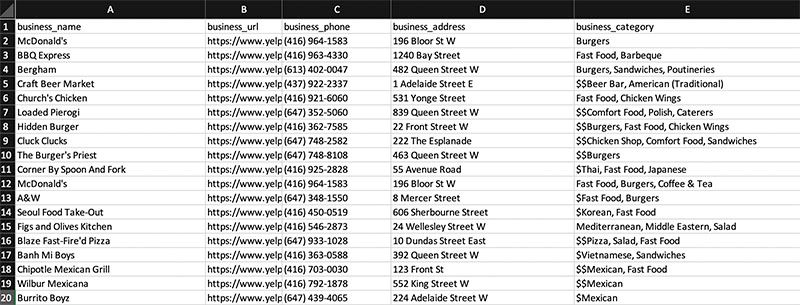
- Once your data is ready to download, click on the CSV/Excel button. Now you can save and rename your file.
Depending on the website you are scraping data from, your CSV file might not display correctly in Excel. In this case, apostrophes were not formatted correctly in our sheet. You can learn more about dealing with pagination here
If you run into these issues, you can quickly solve them by using the import feature on Excel.
Turning a Website data into an Excel Spreadsheet
And that is all that there is to it.
You can now use the power of web scraping to collect info from any website just like we did in this example.
Will you use it to generate more business leads? Or maybe to scrape competitor pricing info? Or maybe you can use it to power up your next Fantasy Football bracket.
If you need to extract a lot of data from a website, consider collecting the data using a package for web scraping with Google Sheets and Excel compatibility.
Table of Contents
-
- 1. Why Use an API to Scrape Data?
- 2. How to Scrape Data into Excel and Google Sheets
- 3. How to Convert Output to Table-Data
Excel and Google Sheets are excellent ways to organize data when you’re extracting many different types from various pages on the website. For instance, if you need to gather the data for more than 300 new products that span more than 20 pages on an eCommerce website, you should scrape data from websites to Excel and Google Sheets to save time and energy.
It’s possible to manually scrape data to Excel and Google Sheets but to boost your business agility, you should use an Application Programming Interface (API) while scraping data. APIs will allow you to engage in automated data scraping from websites into Excel without the need for manual input.
Read on to learn more about how to scrape data from a website into Excel. If you’re already familiar with some of the questions we answer below, feel free to use the Table of Contents to skip to the section(s) you’re most interested in. We’ve provided a step-by-step tutorial showing how you can use an API to pull data from a website into Excel and Google Sheets, using our free Scraping Robot API as an example.
Why Use an API to Scrape Data?

Before we explain how to scrape data from a website into Google Sheets and Excel, let’s discuss how APIs work and why you should use an API to extract data.
APIs are software programs that bridge different web applications or software. Without APIs, these applications and software would not be able to communicate or exchange information or functionalities. In many ways, APIs function like your computer monitor—without your monitor, you wouldn’t be able to see what your computer is doing. Similarly, without an API, many applications—including Excel and Google Sheets—wouldn’t be able to process, store, or manipulate the data you’ve extracted from your website.
In the data scraping world, APIs are used to connect to any database or analytics software. Scraping Robot’s free web scraping API, for instance, can connect to any software and allow you to extract data from any website. APIs can also help you collect data in real-time and move data directly to your software or application without manual input.
Scraping websites without an API is possible, but extremely time-consuming. You would have to download the page yourself and go through all of the HTML elements by hand. Without thorough knowledge and experience of various coding languages and HTML, it’s difficult to scrape websites without an API. As such, you should use an API to pull data from a website into Excel and Google Sheets.

Step 1: Pick and download a web scraping API.
When you are web scraping Google Sheets or Excel data, start by downloading and installing an Excel web scraping API of your choice.
Before you choose your ideal scraper, keep in mind that not every scraper was made equal. To find the best one for you, ask the following questions:
- What functions are a must for you? What do you want to do with the extracted data?
- What is my budget?
- Will I be extracting data from multiple websites at once? If yes, how many sites?
- Not every scraping tool lets you extract data from multiple sites at once. If you’re short on time and need to extract a lot of information from many sites at once, look for a program that allows you to do this.
- Is the scraping tool secure?
- This is an important question to ask if you’re extracting sensitive or confidential data.
For this example, we’ll be using Scraping Robot’s free API. One of the best scraping APIs available, Scraping Robot API is browser-based and doesn’t require you to download or install anything. It allows you to scrape HTML content as well as individual DOM elements on web pages.
Compared to other APIs, this API also lets you extract more information at once. Most web scrapers use an extraction sequence for HTML elements on a page, which means you have to manually pick a category to extract after the first category (typically text) is done. On the other hand, Scraping Robot API automatically gives you every HTML category.
For more information, check out our documentation here.
Step 2: Copy the URL you want to scrape.
Go to the website page you want to scrape and copy the URL.
Step 3: Paste the target site’s URL into your scraper’s bar and click “Run.”
This will start the scraping process. You should receive the final HTML output within a couple of seconds.
Step 4: Download the HTML output.
You should see an option to download the extracted content in your scraper. In Scraping Robot, you’ll see an option to “Download Results” under the black box at the bottom. Once you click on this button, the HTML output will download to your computer.
How to Convert Output to Table-Data

You now have the HTML output, but you need to convert it into a tabular format. Converting the output to table-data will move the extracted information from your web scraper to Excel. Without converting, you will have a hard time gathering and manipulating data, particularly if you want to aggregate the data of many scrapes in one Google Sheet or Excel document.
API response data structure
Before we talk about how to convert the HTML output to table-data let’s take a look at how API responses typically look like. In this example, we’ll be scraping music.apple.com and our goal is to collect a list of track names using XPath.
The API’s JSON response should look like this:
“status”: “SUCCESS”,
“date”: “Tue, 14 Sep 2021 15:21:13 GMT”,
“url”: “https://music.apple.com/us/artist/pearl-jam/467464/see-all?section=top-songs”,
“httpCode”: 200,
“result”: {
“xpathElements”: [
{
“xpath”: “//div[@class=”songs-list-row__song-name”]”,
“textNodes”: [
“Black”,
“Alive”,
“Even Flow”,
“Jeremy”,
“Yellow Ledbetter”,
“Better Man”,
“Last Kiss”,
“Daughter”,
“Better Man”,
“Just Breathe”,
“Just Breathe”,
“Elderly Woman Behind the Counter In a Small Town”,
“Even Flow”,
“Once”,
“Release”,
“Daughter”,
“Sirens”,
“Garden”,
“Elderly Woman Behind the Counter In a Small Town”,
“Jeremy”,
“Why Go”,
“Animal”,
“Yellow Ledbetter”,
“Porch”,
“Oceans”,
“Yellow Ledbetter”,
“Given to Fly”,
“Corduroy”,
“Go”,
“Rearviewmirror”,
“Dissident”,
“Who You Are”,
“Dance Of The Clairvoyants”,
“Last Kiss”,
“Alive (2004 Remix)”,
“Nothingman”,
“Rearviewmirror”,
“Superblood Wolfmoon”,
“State of Love and Trust”,
“World Wide Suicide”,
“Corduroy”,
“Dissident”,
“Deep”,
“Alive (2008 Brendan O’Brien Mix)”,
“Black (2004 Remix)”
],
“htmlElements”: [
“<div tabindex=”-1” role=”checkbox” dir=”auto” aria-checked=”false” class=”songs-list-row__song-name”><!–%+b:32%–>Black<!–%-b:32%–></div>”,
“<div tabindex=”-1” role=”checkbox” dir=”auto” aria-checked=”false” class=”songs-list-row__song-name”><!–%+b:32%–>Alive<!–%-b:32%–></div>”,
“<div tabindex=”-1” role=”checkbox” dir=”auto” aria-checked=”false” class=”songs-list-row__song-name”><!–%+b:32%–>Even Flow<!–%-b:32%–></div>”,
“<div tabindex=”-1” role=”checkbox” dir=”auto” aria-checked=”false” class=”songs-list-row__song-name”><!–%+b:32%–>Jeremy<!–%-b:32%–></div>”,
“<div tabindex=”-1” role=”checkbox” dir=”auto” aria-checked=”false” class=”songs-list-row__song-name”><!–%+b:32%–>Yellow Ledbetter<!–%-b:32%–></div>”,
“<div tabindex=”-1” role=”checkbox” dir=”auto” aria-checked=”false” class=”songs-list-row__song-name”><!–%+b:32%–>Better Man<!–%-b:32%–></div>”,
“<div tabindex=”-1” role=”checkbox” dir=”auto” aria-checked=”false” class=”songs-list-row__song-name”><!–%+b:32%–>Last Kiss<!–%-b:32%–></div>”,
“<div tabindex=”-1” role=”checkbox” dir=”auto” aria-checked=”false” class=”songs-list-row__song-name”><!–%+b:32%–>Daughter<!–%-b:32%–></div>”,
“<div tabindex=”-1” role=”checkbox” dir=”auto” aria-checked=”false” class=”songs-list-row__song-name”><!–%+b:32%–>Better Man<!–%-b:32%–></div>”,
“<div tabindex=”-1” role=”checkbox” dir=”auto” aria-checked=”false” class=”songs-list-row__song-name”><!–%+b:32%–>Just Breathe<!–%-b:32%–></div>”,
“<div tabindex=”-1” role=”checkbox” dir=”auto” aria-checked=”false” class=”songs-list-row__song-name”><!–%+b:32%–>Just Breathe<!–%-b:32%–></div>”,
“<div tabindex=”-1” role=”checkbox” dir=”auto” aria-checked=”false” class=”songs-list-row__song-name”><!–%+b:32%–>Elderly Woman Behind the Counter In a Small Town<!–%-b:32%–></div>”,
“<div tabindex=”-1” role=”checkbox” dir=”auto” aria-checked=”false” class=”songs-list-row__song-name”><!–%+b:32%–>Even Flow<!–%-b:32%–></div>”,
“<div tabindex=”-1” role=”checkbox” dir=”auto” aria-checked=”false” class=”songs-list-row__song-name”><!–%+b:32%–>Once<!–%-b:32%–></div>”,
“<div tabindex=”-1” role=”checkbox” dir=”auto” aria-checked=”false” class=”songs-list-row__song-name”><!–%+b:32%–>Release<!–%-b:32%–></div>”,
“<div tabindex=”-1” role=”checkbox” dir=”auto” aria-checked=”false” class=”songs-list-row__song-name”><!–%+b:32%–>Daughter<!–%-b:32%–></div>”,
“<div tabindex=”-1” role=”checkbox” dir=”auto” aria-checked=”false” class=”songs-list-row__song-name”><!–%+b:32%–>Sirens<!–%-b:32%–></div>”,
“<div tabindex=”-1” role=”checkbox” dir=”auto” aria-checked=”false” class=”songs-list-row__song-name”><!–%+b:32%–>Garden<!–%-b:32%–></div>”,
“<div tabindex=”-1” role=”checkbox” dir=”auto” aria-checked=”false” class=”songs-list-row__song-name”><!–%+b:32%–>Elderly Woman Behind the Counter In a Small Town<!–%-b:32%–></div>”,
“<div tabindex=”-1” role=”checkbox” dir=”auto” aria-checked=”false” class=”songs-list-row__song-name”><!–%+b:32%–>Jeremy<!–%-b:32%–></div>”,
“<div tabindex=”-1” role=”checkbox” dir=”auto” aria-checked=”false” class=”songs-list-row__song-name”><!–%+b:32%–>Why Go<!–%-b:32%–></div>”,
“<div tabindex=”-1” role=”checkbox” dir=”auto” aria-checked=”false” class=”songs-list-row__song-name”><!–%+b:32%–>Animal<!–%-b:32%–></div>”,
“<div tabindex=”-1” role=”checkbox” dir=”auto” aria-checked=”false” class=”songs-list-row__song-name”><!–%+b:32%–>Yellow Ledbetter<!–%-b:32%–></div>”,
“<div tabindex=”-1” role=”checkbox” dir=”auto” aria-checked=”false” class=”songs-list-row__song-name”><!–%+b:32%–>Porch<!–%-b:32%–></div>”,
“<div tabindex=”-1” role=”checkbox” dir=”auto” aria-checked=”false” class=”songs-list-row__song-name”><!–%+b:32%–>Oceans<!–%-b:32%–></div>”,
“<div tabindex=”-1” role=”checkbox” dir=”auto” aria-checked=”false” class=”songs-list-row__song-name”><!–%+b:32%–>Yellow Ledbetter<!–%-b:32%–></div>”,
“<div tabindex=”-1” role=”checkbox” dir=”auto” aria-checked=”false” class=”songs-list-row__song-name”><!–%+b:32%–>Given to Fly<!–%-b:32%–></div>”,
“<div tabindex=”-1” role=”checkbox” dir=”auto” aria-checked=”false” class=”songs-list-row__song-name”><!–%+b:32%–>Corduroy<!–%-b:32%–></div>”,
“<div tabindex=”-1” role=”checkbox” dir=”auto” aria-checked=”false” class=”songs-list-row__song-name”><!–%+b:32%–>Go<!–%-b:32%–></div>”,
“<div tabindex=”-1” role=”checkbox” dir=”auto” aria-checked=”false” class=”songs-list-row__song-name”><!–%+b:32%–>Rearviewmirror<!–%-b:32%–></div>”,
“<div tabindex=”-1” role=”checkbox” dir=”auto” aria-checked=”false” class=”songs-list-row__song-name”><!–%+b:32%–>Dissident<!–%-b:32%–></div>”,
“<div tabindex=”-1” role=”checkbox” dir=”auto” aria-checked=”false” class=”songs-list-row__song-name”><!–%+b:32%–>Who You Are<!–%-b:32%–></div>”,
“<div tabindex=”-1” role=”checkbox” dir=”auto” aria-checked=”false” class=”songs-list-row__song-name”><!–%+b:32%–>Dance Of The Clairvoyants<!–%-b:32%–></div>”,
“<div tabindex=”-1” role=”checkbox” dir=”auto” aria-checked=”false” class=”songs-list-row__song-name”><!–%+b:32%–>Last Kiss<!–%-b:32%–></div>”,
“<div tabindex=”-1” role=”checkbox” dir=”auto” aria-checked=”false” class=”songs-list-row__song-name”><!–%+b:32%–>Alive (2004 Remix)<!–%-b:32%–></div>”,
“<div tabindex=”-1” role=”checkbox” dir=”auto” aria-checked=”false” class=”songs-list-row__song-name”><!–%+b:32%–>Nothingman<!–%-b:32%–></div>”,
“<div tabindex=”-1” role=”checkbox” dir=”auto” aria-checked=”false” class=”songs-list-row__song-name”><!–%+b:32%–>Rearviewmirror<!–%-b:32%–></div>”,
“<div tabindex=”-1” role=”checkbox” dir=”auto” aria-checked=”false” class=”songs-list-row__song-name”><!–%+b:32%–>Superblood Wolfmoon<!–%-b:32%–></div>”,
“<div tabindex=”-1” role=”checkbox” dir=”auto” aria-checked=”false” class=”songs-list-row__song-name”><!–%+b:32%–>State of Love and Trust<!–%-b:32%–></div>”,
“<div tabindex=”-1” role=”checkbox” dir=”auto” aria-checked=”false” class=”songs-list-row__song-name”><!–%+b:32%–>World Wide Suicide<!–%-b:32%–></div>”,
“<div tabindex=”-1” role=”checkbox” dir=”auto” aria-checked=”false” class=”songs-list-row__song-name”><!–%+b:32%–>Corduroy<!–%-b:32%–></div>”,
“<div tabindex=”-1” role=”checkbox” dir=”auto” aria-checked=”false” class=”songs-list-row__song-name”><!–%+b:32%–>Dissident<!–%-b:32%–></div>”,
“<div tabindex=”-1” role=”checkbox” dir=”auto” aria-checked=”false” class=”songs-list-row__song-name”><!–%+b:32%–>Deep<!–%-b:32%–></div>”,
“<div tabindex=”-1” role=”checkbox” dir=”auto” aria-checked=”false” class=”songs-list-row__song-name”><!–%+b:32%–>Alive (2008 Brendan O’Brien Mix)<!–%-b:32%–></div>”,
“<div tabindex=”-1” role=”checkbox” dir=”auto” aria-checked=”false” class=”songs-list-row__song-name”><!–%+b:32%–>Black (2004 Remix)<!–%-b:32%–></div>”
]
}
],
“html”: “<!DOCTYPE html><html prefix=”og: http://ogp.me/ns#” dir=”ltr” lang=”en-US” hydrated=””><head>n <meta charset=”utf-8”><style data-styles=””>apple-podcast-player,apple-tv-plus-player,apple-music-uploaded-content,apple-music-video-player,apple-tv-plus-preview,amp-chrome-player,amp-footer-player,apple-music-card-player,amp-lyrics,amp-episode-list-control,amp-next-episode-control,apple-music-artwork-lockup,apple-music-progress,apple-music-volume,amp-playback-controls-autoplay,apple-music-radio-column-player,amp-ambient-video,amp-background-video,amp-footer-player-metadata,amp-footer-player-progress,amp-launch-button,amp-mediakit-root,amp-playback-controls-pip,amp-text-multiline,amp-transition,state-holder,”></div>n …”
}
Notice that this API response contains the following main fields for the root level:
- date: date of request
- httpCode: the HTTP response code
- status: the status of the task being processed
- url: the page URL
- result: This field has the most useful scraped data, such as nested JSON-objects
The result-field contains three main child fields:
- xPathElements, which contains the data gathered for each provided XPath
- selectorElements, which has the data for each provided CSS selector
- Html, which is the full HTML code of the page
Since our goal is to scrape a list of track names using XPath from music.apple.com, we will be focusing on xPathElements and selectorElements. Each of these elements is associated with a single XPath/selector.
For instance, the segment below is a single XPath/selector:
“xpath”: “//div[@class=”songs-list-row__song-name”]”,
“textNodes”: [
“Black”,
“Alive”,
“Even Flow”,
“Jeremy”,
“Yellow Ledbetter”
],
“htmlElements”: [
“<div tabindex=”-1” role=”checkbox” dir=”auto” aria-checked=”false” class=”songs-list-row__song-name”><!–%+b:32%–>Black<!–%-b:32%–></div>”,
“<div tabindex=”-1” role=”checkbox” dir=”auto” aria-checked=”false” class=”songs-list-row__song-name”><!–%+b:32%–>Alive<!–%-b:32%–></div>”,
“<div tabindex=”-1” role=”checkbox” dir=”auto” aria-checked=”false” class=”songs-list-row__song-name”><!–%+b:32%–>Even Flow<!–%-b:32%–></div>”,
“<div tabindex=”-1” role=”checkbox” dir=”auto” aria-checked=”false” class=”songs-list-row__song-name”><!–%+b:32%–>Jeremy<!–%-b:32%–></div>”,
“<div tabindex=”-1” role=”checkbox” dir=”auto” aria-checked=”false” class=”songs-list-row__song-name”><!–%+b:32%–>Yellow Ledbetter<!–%-b:32%–></div>”
]
}
These segments contain three child fields:
- Xpath, which is a string containing the XPath/selector
- textNodes, which contains the text entries found within all the elements the API has found for this XPath/selector
- htmlElements, which is the HTML code for all of the elements found within this particular XPath/selector
Transforming XPath/Selectors to tabular forms for Excel or Google Sheets
Now, let’s transform this JSON response into a tabular form in Excel or Google Sheets.
For Excel, follow these steps:
- Open a new spreadsheet.
- Click on the Data tab.
- Click “Get Data” on the far right and select “From File.” Then, click the applicable option. For instance, if scraping API’s results are in .JSON format, select “From JSON.”
- Your Excel sheet should now be populated.
- If you have other data associated with other XPath or selectors, add them to the table using the same method.
Follow these steps for Google Sheets:
- Open a new spreadsheet.
- Go to the “File” and select “Import.”
- You will now see a window with four tabs: “My Drive,” “Shared with me,” “Recent,” and “Upload.” Click on “Upload” and pick the file you want to convert into a table. Make sure the checkbox “Convert text to numbers, dates, and formulas” is unselected.
- Pick your import location and separator type and click on the “Import data” button.
If you want to add metadata related to this project to the table, add them to the table. At this point, you’re almost done. All you have to do is add in the table headers so you know what’s what.
Conclusion

Learning how to pull data from a website into Excel or Google Sheets seems difficult, but with powerful scraping APIs like Scraping Robot’s free API, you’ll be able to extract, aggregate, and manipulate data with just a few clicks of your mouse.
Scraping Robot API can be used with any scraping program, but if you’re new to scraping or you want to try out a new scraping tool, consider getting Scraping Robot.
Scraping Robot allows you to scrape websites into JSON—no browser scaling, proxy management, blocks, or captchas required. Our system was built for developers and allows you to use our API to extract and aggregate data within minutes.
We provide the following features and more:
- Automatic metadata parsing
- Javascript rendering
- No proxies required—we will handle this for you
- Stats and usage
- Guaranteed successful results
- Session management (coming soon)
- Webhook callbacks (coming soon)
- POST requests (coming soon)
- Output to Sheets or Zapier (coming soon)
- Screenshots of browser (coming soon)
What’s more, there’s no monthly commitment. You can start with us for free—we offer 5000 free scrapes with all features included. If you need more scrapes, you can then move to the Business and Enterprise tiers, which offer hundreds of thousands of scrapes at extremely affordable prices.
Interested or have questions about Scraping Robot? Contact us today to learn more. Our support team is available 24/7.
The information contained within this article, including information posted by official staff, guest-submitted material, message board postings, or other third-party material is presented solely for the purposes of education and furtherance of the knowledge of the reader. All trademarks used in this publication are hereby acknowledged as the property of their respective owners.
Related Articles
Turning a website into an Excel table can be a chore when done manually. Learn how to automate this extraction in just 3 simple steps.
Attracting over 750 million users worldwide, Microsoft Excel is one of the most popular applications for organizing, formatting, and calculating data. Excel files are a great example of structured data, allowing users to easily manipulate datasets and gain insight into gathered data thanks to tables, graphs, and other visualizations.
Utilizing the unimaginable amount of data available online with the features of Excel would therefore be a powerful combo that could bring your data analysis to a whole new level. In this article, we’ll be looking at ways to extract online data and bring it into Microsoft Excel using web scraping tools that don’t require any programming knowledge.
Can Excel scrape data from a website?
With some time and patience, yes. There are 3 ways you can import online data to Excel without using any additional tools:
- Copy and pasting a website’s content into the application manually
- Using “Web queries”
- Using “Visual Basic for Application” language (VBA)
While using these techniques can be quite straightforward when using online tutorials, they’re either designed to only scrape tables within websites or need some sort of programming knowledge to set up properly.
Web scraping is the process of extracting data from the web automatically. Therefore, using web scraping tools should minimize the effort put into extracting data in bulk, which can be exported in a myriad of machine-readable formats, including Microsoft Excel.
While web scraping tools can be found on portals such as GitHub, intended for developers, platforms like Apify Store try to provide users with a more user-friendly no-code approach to web scraping. Apify does this by offering tools called actors that are designed to scrape specific websites (such as YouTube scraper, Pinterest scraper, and many more) and are easy to set up. You can then choose Excel as the output format, turning the objects on the page into a structured table.
Apify actors make it possible to automate data scraping from any website and you can always download the scraped data in Excel format. Then you just open the Excel file.
📖
actor: a serverless cloud program running on the Apify platform
Is scraping data to Excel legal?
Scraping publicly available data from the web into formats such as Excel is legal. But just like with any other online activity, you still need to comply with certain regulations, especially concerning copyright and personal data. These regulations vary based on where you are in the world, so make sure to do your research before attempting to scrape data that might be intellectual property or private information.
⚖️
Learn more about the legality of web scraping ➜
How to scrape data from a website to Excel
So, let’s get to it! Automated data scraping from websites to Excel with Apify can be broken down into 3 simple steps:
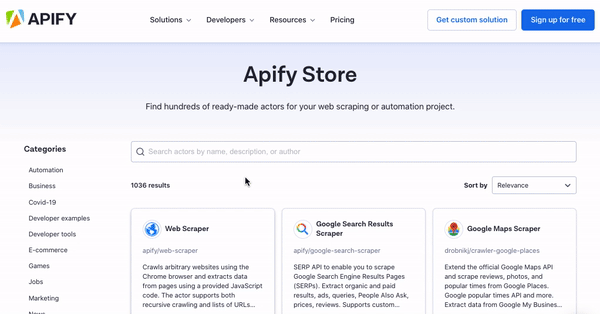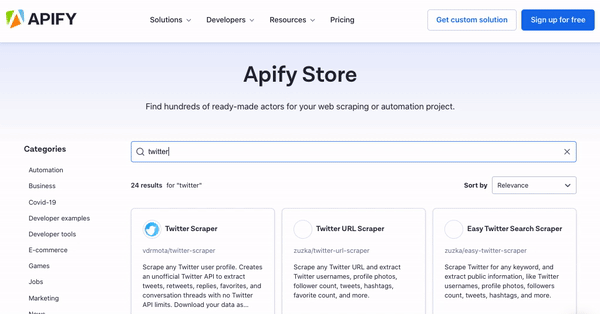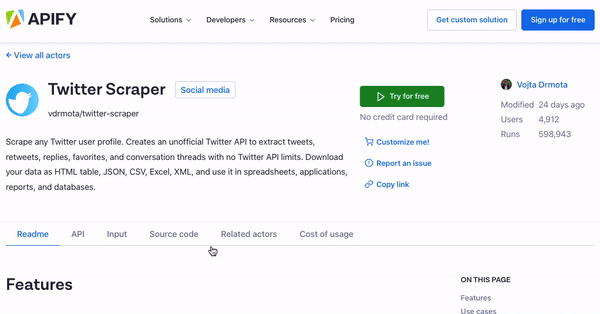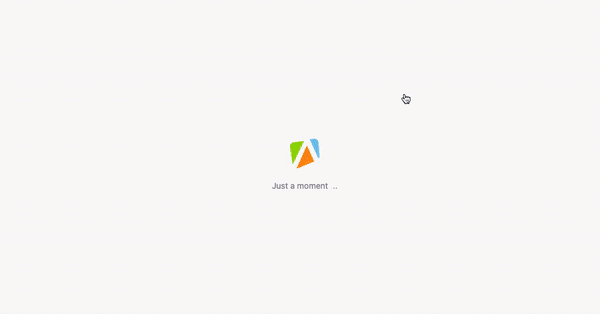
Step 1: Find the right tool in Apify Store
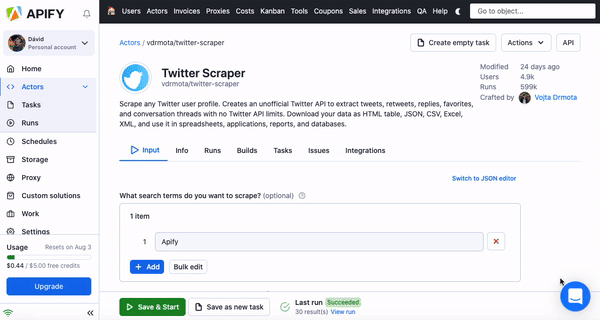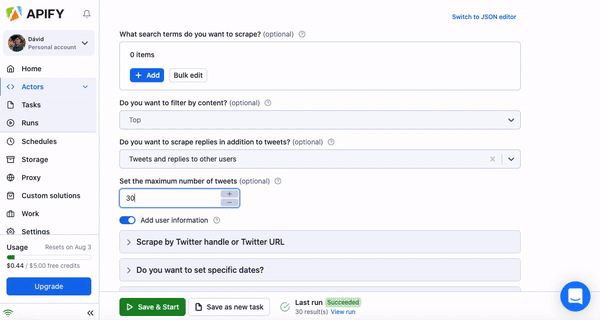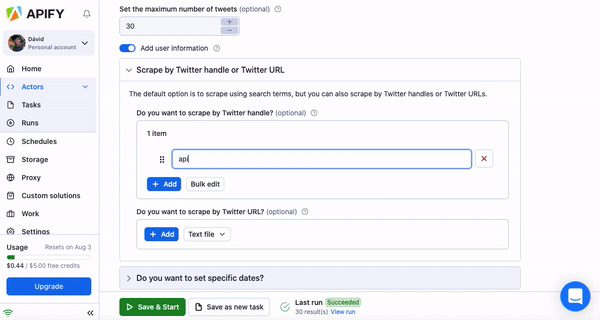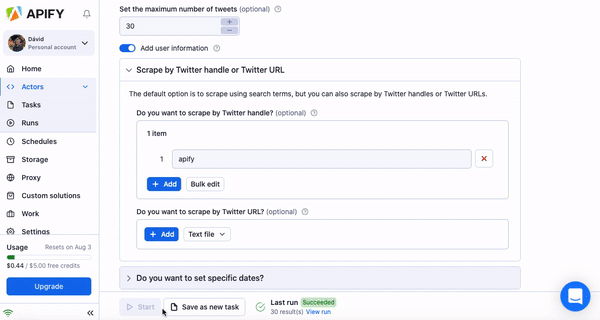
Apify Store works just like any other app store: just search for an actor you’d like to use based on the website you want to scrape. Most scrapers are free, although you may come across some paid ones — no need to worry; even these offer a free trial without the need for a credit card. After you find your scraper, click the Try for free button, after which you’ll be prompted to sign in or make an account if you don’t already have one. Thankfully, you can speed up the process by signing in through your Google or GitHub profile. For this example, we’re going to be using Twitter Scraper.
💡
Didn’t find the right scraper in our Store? Head on over to Apify ideas and submit a suggestion so that Apify’s network of developers know what to work on next ➜
Step 2: Choose the website and data to scrape
Now, fill in the input schema to tell your actor what website you’d like to scrape and what data you want. With Twitter Scraper, we decided to scrape top 30 results from the handle @apify (yup, we’re also on Twitter, so don’t forget to give us a follow). If you’re not sure what the individual inputs mean, hover your mouse over the question mark next to them to get an explanation. The actor readme (you can find this on the actor’s page in Apify Store) can also be of great help if you feel lost when filling out the schema. After you’re done, just hit the Save & Start button and wait for your scrape to finish.
Step 3: Download your results!
After the run is successfully finished, it’s time to get your Excel file. In the output tab, you’ll see two versions of your data — Overview or All fields. After clicking export, you can choose from these two variants. While Overview datasets are simple and neat, if you want to get all of the data from the scraped website, choose All fields.
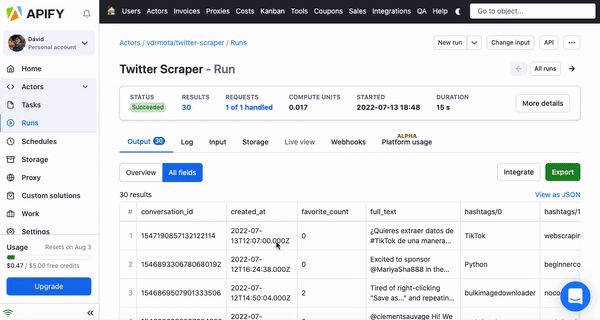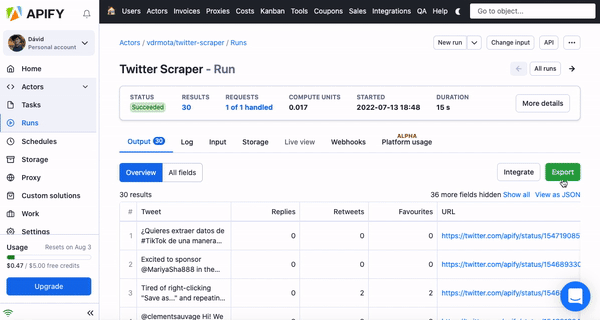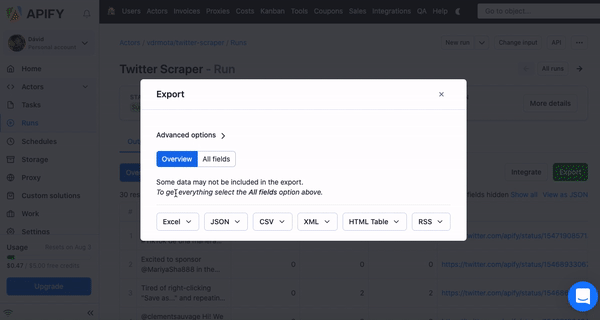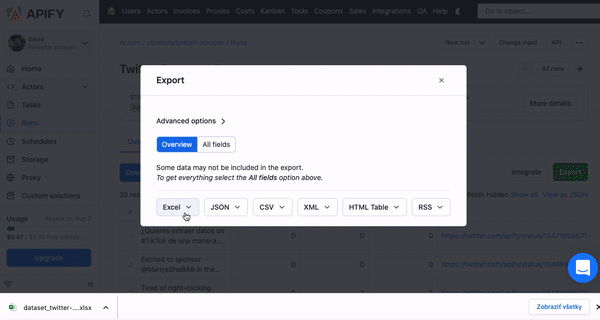
❕
Tip: Not every scraper has the Output / Overview tab. In this case, go to Storage to get the full data in Excel (just like with the Indeed scraper below)
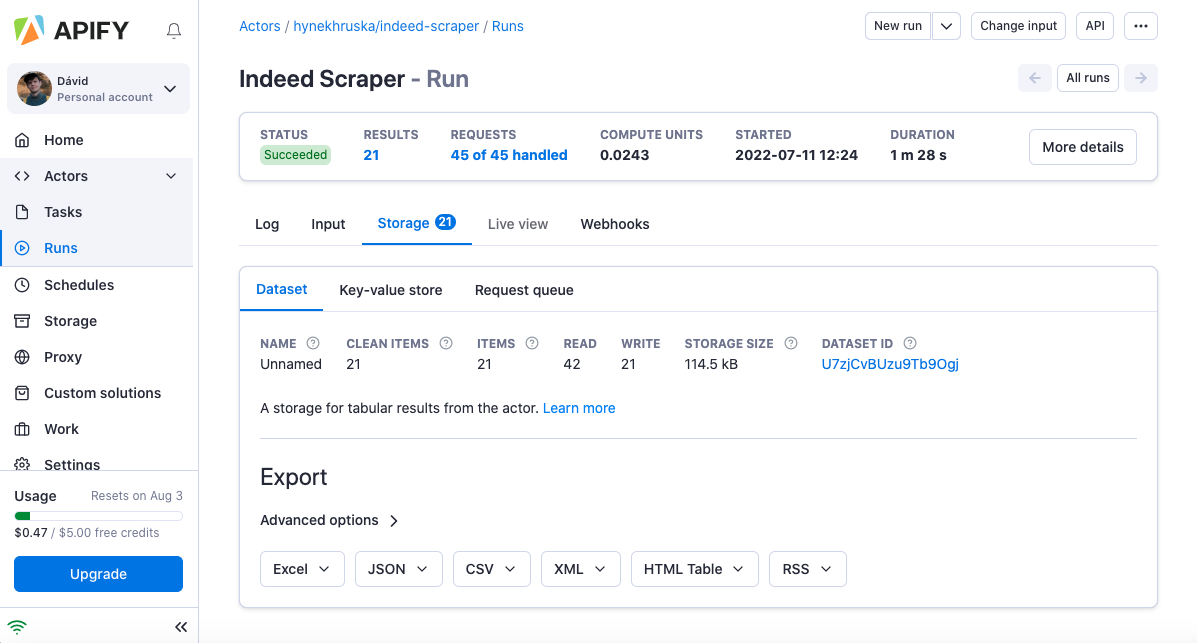
And, don’t forget, you’re not limited to just the Excel format when it comes to exporting data from Apify Console!
Now that you have your data, it’s time to explore the world of web scraping with a bigger pool of actors: Interested in social media? Try our Instagram, TikTok, or Reddit scrapers. If you’d prefer to scrape product listings and their sellers, give the Amazon, eBay, or AliExpress scrapers a go. Looking for new hires? Scrape job listings from Indeed or Glassdoor.
With over a thousand ready-to-use actors in Apify Store, millions of different tables can be exported using our platform. But, naturally, not every website has its own scraping tool (yet 😉). If you’d like to try scraping a page that does not have a dedicated scraper, you can use our most popular actor — Web Scraper. It might be a bit tricky in the beginning, but if you follow our tutorial, you’ll be able to turn any website into an Excel spreadsheet in no time!
Data scraping is a technique used to extract data from sources that are not proposed to be accessed or imported by the user.
Data scraping can be done manually, but it is often done using software that automates the procedure.
Data scraping can be beneficial for extracting data from sources that do not have an API or for extracting data that is not straightforwardly reachable through an API.
Data scraping can also be used to bypass security measures put in place by a website, such as a login page.
In this guide, we’re going to show you how to scrape data from website to excel. There are many ways to do it and analyze the data, but the most common method is to simply use a free web scraper.
A web scraper is a piece of software that simulates a user’s interaction with a website to extract data from the website.
Web scrapers can be written in any programming language, but they are typically written in Python or Ruby.
There is a long debate about whether web scraping is legal or not. In some cases, it may be considered a violation of the terms of service of the website being scraped.
In other cases, it may be considered unauthorized access to the website’s server. It is important to check the terms of service of any website before scraping it.
Some websites explicitly prohibit scraping, while others allow it as long as the scraped data is not used for commercial purposes.
Why Is Data Scraping Done?
Web scraping is a process of extracting data from websites. It can be done manually by copying and pasting data from a website, but this is usually a time-consuming task.
Web scraping tools automate this process and can extract large amounts of data quickly and efficiently.
There are many benefits to web scraping, including the ability to gather large amounts of data that would be difficult or impossible to collect manually.
Web scraping can also be used to keep track of changes on a website over time or to monitor prices on e-commerce platforms.
Additionally, web scraping can be used to generate leads for sales and marketing purposes.
Overall, web scraping is a powerful tool that can be used for a variety of purposes.
When used correctly, it can save a lot of time and effort, and provide valuable data that would otherwise be difficult to obtain.
How to Scrape Data from Website to Excel in 2023
Excel is a powerful tool for web scraping. You can scrape data from website to excel and it will be saved in a format that can be easily analyzed (Excel sheets).
There are a few things to keep in mind when using Excel for web scraping. Firstly, make sure that the website you are scraping allows this kind of activity.
Secondly, be aware of the potential for errors when extracting data from a website.
Excel can be used to extract a variety of information. This includes text, HTML code, images, and more.
To do this, simply open up Excel and navigate to the website that you want to scrape. Then, use the built-in web scraping tools to extract the data that you need.
Excel also aids in data analysis once the data is scraped. It can be used to sort, filter, and analyze data in a variety of ways.
This makes it easy to understand and interpret the data that has been scraped from a website.
After exporting data to Excel it comes in very convenient as you can analyze the data, draw conclusions and take further actions accordingly.
There are three common ways to scrape data from website to Excel for further processing.
1. Create A Custom Web Scraper
When you need data that is not readily available online, web scraping can be an authoritative tool to collect the information you want.
Scraping denotes extracting data from sources that are not proposed to be read or read by humans.
In order to scrape data efficiently, you will need to write a custom web scraper.
A custom web scraper can be written in any programming language, but Python is a widespread choice for this task due to its luxury of use and vigorous libraries.
BeautifulSoup is one such library that can support you to extract data from HTML and XML sources.
Before writing your own web scraper, it is essential to check if the data you need is already available through an API or other means.
If the data is already reachable, web scraping may not be required.
However, if you do need to scrape data from a website, make sure to do so in a way that does not violate the site’s terms of use.
When writing your custom web scraper, there are a few key things to keep in mind:
- The code should be well-written and well-documented
- The scraper should be designed to handle errors gracefully
- The scraper should be able to run on a schedule (if needed)
With these considerations in mind, you can start writing your own custom web scraper.
Custom web scrapers have numerous recompenses over general-purpose web scraping tools.
First, custom web scrapers can be designed specifically for the target website, which means that they are less likely to break when the website’s outline or original code fluctuates.
Second, custom web scrapers can be personalized to extract accurately the data that you need, which makes them more resourceful than general-purpose scrapers.
Finally, custom web scrapers can be unified with other systems more straightforwardly than general-purpose scrapers.
Python code can be used to scrape data into Excel in several ways.
One way is to practice using the BeautifulSoup library, which makes it easy to extract data from HTML documents.
Another way is to use the Selenium library, which can be used to scrape data from web pages that are rendered using JavaScript.
Finally, the Scrapy framework can be used to shape more complex scrapers that can handle things like pagination and form submission.
The commonly used Python code for a custom web scraper is given below.
import requests
from bs4 import BeautifulSoup
class WikipediaScraper:
def __init__(self):
self.url = “https://en.wikipedia.org/wiki/List_of_countries_by_population_(United_Nations)”
def scrape_population_data(self):
page_source = requests.get(self.url).text
soup = BeautifulSoup(page_source, “html.parser”)
tablerows = soup.find(“tbody”).find_all(“tr”)
for row in tablerows:
row_element = row.find_all(“td”)
print(row_element)
country = row_element[0].text
population = row_element[4].text
print([country, population])
c = WikipediaScraper()
c.scrape_population_data()2. Use A Web Scraping Tool For Data Scraping
There are many web scraping tools available that can be used to scrape data from websites.
Some of these tools are free, while others are paid. The tool that you use will depend on your requirements and preferences.
Web scraping tools work by taking advantage of the structure of HTML code to recognize definite pieces of information that you want to extract.
For example, if you want to scrape data about product prices from an online store, the web scraper will look for the HTML tags that specify a price (such as <span> or <p>).
Once the web scraper has found these tags, it will extract the relevant data and save it to your computer in Excel.
The method of web scraping can be automated so that it can be done on a large scale.
For example, a web scraping tool can be programmed to extract data from hundreds or even thousands of websites automatically.
This can be very suitable for gathering large amounts of data for research or other purposes.
Most web scraping tools use the requests library to make HTTP requests. The requests library is a powerful tool that makes it easy to make HTTP requests.
It permits you to make GET, POST, PUT, and DELETE requests.
The requests library also allows you to set headers, cookies, and data. The requests library is a powerful tool that makes it easy to scrape websites.
If you want to scrape data from a website, you can use a library like Python-Requests to make HTTP requests and BeautifulSoup to parse the HTML.
Or you can use a dedicated framework that combines an HTTP client with an HTML parsing library, such as Scrapy.
Choosing The Right Web Scraping Tool For The Job
There are a lot of different web scraping tools out there, and it can be tough to know which one is the right fit for your project. Here are a few things to consider when choosing a web scraping tool:
- What kind of data do you need to scrape?
- How difficult is the website you’re scraping?
- How much experience do you have with web scraping?
If you need to scrape a lot of data from a simple website, then a basic web scraper should suffice.
If you’re scraping a more complex website, or if you need to scrape large amounts of data, then you’ll need a more powerful tool like Bright Data or Apify.
And if you’re new to web scraping, it might be a good idea to start with a tool that is comparatively easy to use like Apify.
Once you’ve considered these aspects, you should have a better idea of which web scraping tool is right for your project. Two of the best web scraping tools are listed and explained below.
A. Bright Data

If you’re looking for a powerful web scraping tool that can help you collect data from any website, then you should check out Bright Data.
With Bright Data, you can easily extract data from even the most complex websites with ease.
Plus, the friendly interface and intuitive design make it extremely easy to use, even for beginners.
👉 Get FREE Account
So if you need a reliable tool for web scraping, be sure to give Bright Data a try.
Bright Data is very easy to integrate with Excel on your computer which helps to scrape data from website to excel which makes it easier to analyze and interpret.
Bright Data, formerly known as “Luminati,” is a proxy provider that has built an infrastructure that has won it the Best Proxy Ecosystem Award.
It is also known for its moral promotion of proxies and its denial to resell proxies.
It also needs a Know Your Customer process that acts as yet another ethical and private feature.
Among all of these, Bright Data also has a diversity of features that differentiate it from other proxy providers.
Features Of Bright Data
Along with being an ethical and customer-friendly web scraping tool, Bright Data also has several other features that make it the number 1 in the market.
Web Blocker
Web Unlocker of Bright Data can handle all your site unblocking requirements and deliver structured, parsed data in any format you want from a single URL.
With its trailblazing technology, you’ll be able to access the information you want swiftly and straightforwardly.
Proxy Manager
Proxy Manager of Bright Data is the most unconventional and resourceful tool that enhances your data collection.
It routes requests with the help of the most cost-competent possibilities, thereby dropping bandwidth usage.
Additionally, Proxy Manager substitutes between proxy networks to guarantee that all your requests are effective.
Database
If you’re looking for a web scraper that can provide you with vast amounts of data, Bright Data is the ideal choice.
With its pre-collected datasets, you can take advantage of over ten million data points to aid you to analyze trends, recognize individuals and social media influencers, and more.
Plus, Bright Data doesn’t bombard you with marketing emails as some other companies do.
It only sends you the important stuff. So why not give Bright Data a try? You won’t be disappointed.
B. Apify

Apify is a web scraping tool that makes it easy to collect data from websites.
It offers a modest interface that permits you to select the data you want to extract and then scrape data from website to excel.
Apify is perfect for collecting data for research, marketing, or any other purpose.
Scraping web data with the help of Apify is simplified. Apify is an excellent tool and it follows the process of using bots and automated tools to crawl websites and extract information.
The data can be downloaded in various formats such as CSV, JSON, XML, Excel, etc., depending on your needs.
By doing this, you can get the information you want without having to go through the hassle of manually gathering it yourself.
Apify is one of the leading data scraper tools available in the market.
The only reason for this popularity is its easy-to-use interface which can be handled even by newbies.
Apify has proven itself worthy of multi-tasking which is mostly needed when you are extracting data from hundreds of sources.
Benefits Of Apify
Apify might be the one tool you need for your every data scraping and sorting task.
Apify comes with a bunch of benefits that make it one of the best data extracting tools worldwide.
An Excellent Way To Scrape Data
Apify is an excellent way to extract data from websites automatically.
It uses APIs to collect data from whole sites, extracting exact info on things like weather forecasts, product prices, and marketing tactics.
Furthermore, Apify crawls your web pages which can assist expand your site’s ranking.
Appropriate For Everyone
Apify is picture-perfect for an extensive range of operators, from programmers and non-coders to enterprises and small businesses.
Whether you’re a student collecting data for a research project, or a startup monitoring your opponent’s site, Apify has the gears you want to prosper.
With its easy-to-use platform and approachable interface, Apify is flawless for anyone looking to get ahead in their field.
Perfect Multi-Tasker
Apify is the perfect solution for anyone requiring to get large amounts of data rapidly and proficiently.
Whether you want to generate a new stock exchange site, build a flight booking app, or analyze a real estate market, Apify can support you get the job done speedily and appropriately.
With Apify, there’s no need to worry about mistakes – just sit back and let the data come rolling in.
Clever Processing
Apify’s API can automatically discover and scrape data from website to excel spreadsheets, making it very appropriate.
It also uses JSON to store data, which is easy to transport between the client and server.
Furthermore, Apify keeps you reorganized about current marketing drifts and delivers feedback on the value of data.
You can use its Search API tool to find good bots on the internet. Apify filters data and generates discrete lists of products for you, making it a very supportive tool.
3. Hire Professional Data Extraction Services
The third way to scrape data from website to excel sheets and any other format to use for your ventures is to hire professional data extractions services.
Data extraction services professionals provide numerous returns for businesses.
They can gather detailed pieces of information from online sources rapidly and resourcefully.
Moreover, data extraction services let businesses subcontract their requirements to specialists who are familiar with the procedure. This can save the company time and money in the long run.
There are many assistants that businesses can gain by working with data extraction services professionals.
By leveraging the power of data extraction, businesses can produce leads, gather related information from rival business web pages, recognize trends from document collections, and expand their analysis of otherwise unstructured information.
These professionals usually make use of data extraction software to help with the extraction method, making it more competent and exact.
Subsequently, businesses that make use of these services can gain a competitive edge in today’s market.
FAQs
Why scrape data from websites?
The biggest reason that we can think of why you might want to scrape data is if you are a brand, and you are trying to glean information online about your competitors so that you can conduct successful market research.
Can I save my data in another format?
We have talked about being able to scrape data from a website and save it into an excel spreadsheet, but the good news is that you can save your data in multiple formats, it all depends on how you would like to look at your data once it has been downloaded.
Final Thoughts
Being able to scrape data from websites and save it to an excel spreadsheet is going to save you a huge amount of time, especially if you are busy with the brand side of things, and you want to be able to see all relevant data laid out in a nicely organized way.
Make the most of the web scraping tools that we’ve talked about above, and good luck conducting market research for the future of your business.