
Что приходит Вам в голову при упоминании «Data Mining»? Наверняка высокая, почти космическая, сложность алгоритмов, непонятные манипуляции с огромными массивами данных, нереальные объемы программного кода с применением множества разнообразных framework-ов с пугающими названиями – одним словом что-то недоступное обыкновенному человеку. Но все ли задачи представляют из себя нечто подобное? Попробуем разобраться на примере простой задачи классификации и простого метода k-ближайших соседей(kNN), применяемого для ее решения.
Есть таблица со значениями 2-ух параметров, по которым некоторые объекты разделяется на типы: «хорошо», «плохо», «средне». Есть объект, у которого известно значение параметров (5.2;3.1), но не известно какого он типа.
Для понимания создадим на том же листе в excel точечную диаграмму, в качестве значений по оси X зададим данные из второго столбца, а качестве оси Y – из первого.
Для того, чтобы лучше видеть наши значения можно ограничить значения по осям и добавить подписи. Должно получиться примерно так:
Добавим и наш объект, тип которого нужно определить. Основная идея метода, который мы хотим применить, состоит в расчете расстояний между нашим объектом и объектами, тип которых уже определен.
Для того, чтобы вычислить это расстояние, воспользуемся формулой для расчета расстояния в многомерном пространстве (Евклидово расстояние):
В excel это будет выглядеть так:
«Протянем» формулу на все строки, где есть значения параметров. В соседнем столбце слева можно ранжировать значение каждого расстояния среди остальных значений расстояний с помощью функции «=РАНГ(), а в правый просто копируем значение типа. Должно получиться так:
Теперь для того, чтобы определить тип нашего объекта достаточно выбрать k-первых значений из получившегося массива (по возрастанию). В качестве числа k возьмем максимальное целое число, которое меньше корня квадратного из числа заданных значений. Для нас это будет число 3.
Можно заметить, что наибольшее количество (в данном случае все) k-ближайших соседей относятся к «плохо». Следовательно, наш объект тоже относится к «плохо».
Для того, чтобы сделать «куличик» в песочнице, не следует подгонять экскаватор. Есть ситуации, например, когда вы строите дом, где без спецтехники не обойтись. Но в случае с куличиком результат будет похож на ковш и весьма вероятно накроет собой всю песочницу.
Иными словами, некоторые задачи Data mining не требуют ни «космической сложности алгоритмов», ни глубоких познаний в высшей математике, не предполагают также использования «разнообразных framework-ов с пугающими названиями» и доступны любому, кто умеет пользоваться важнейшим из инструментов «уверенного пользователя ПК» — excel.
Introduction
In the lesson 18, we learned how to install the plugin to administer and query Data Mining Models using Excel. We also learned how to create a Cluster Model using Excel. In this new lesson we will learn how to clean the information, how to explore information, how to get a sample of data, how to classify the data using decision trees and finally how to query the model.
Requirements
Here are the assumptions for this article.
- We are using SQL Server 2014 for this lesson, but SQL Server 2005/2008/2012 can be also be used. We are assuming that you already have the Data Mining Project used in the Data Mining Part 13. If you do not, you can install it or use any other Data Mining Project already installed.
- We are using Microsoft Office 2013, but earlier versions can also be used.
- The Data Mining plugin for Excel 2007 and SQL Server 2008 can be downloaded here.
- We are using the Data Mining plugin for Excel 2010, 2013 and SQL 2012 and 2014, which can be downloaded here.
- There is also an Excel File with sample data very useful to learn data mining with Excel. You can download the file here.
Explore Data
Explore Data let you create nice charts using the information. Follow these steps to create a chart.
1. In Excel, click on the Data Mining Menu Option and then press the Explore Data Icon.
2. The Explore Data Wizard will be displayed. Press the next Button.
3. If you did not select the data, select the data to be explored. In this sample, we selected the occupation column to be explored. Press Next.
4. As you can see, a bar char is displayed showing the occupation and the number of customers per occupation.
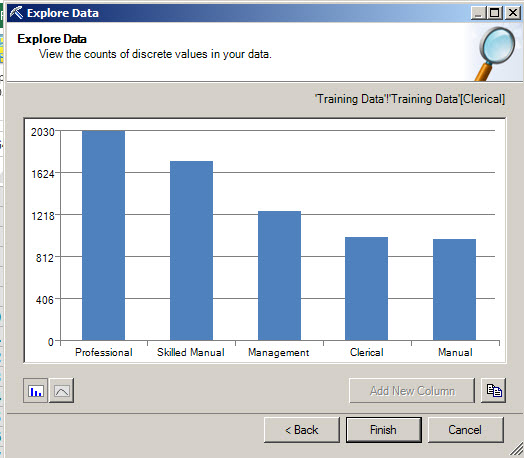
The Explore Data option can create nice charts that allow you to visualize the information.
Outliers
The Outliers button provides a good way to clean the information. Sometimes we have some typos, or some customers who do not help to the model.
1. The next task is to clean the data. First, we will work with the Outliers option. For this sample, we will select the Yearly Income column.
2. Select the Clean Data icon and then Outliers
3. The Wizard will be displayed. Press next.
4. You can select the data to be used in this option, or if you did this before in step 5, the data will be already selected. Press next.
5. You will have a graph of the salaries and the number of customers per salary. With the sliders you can remove some data to clean it.
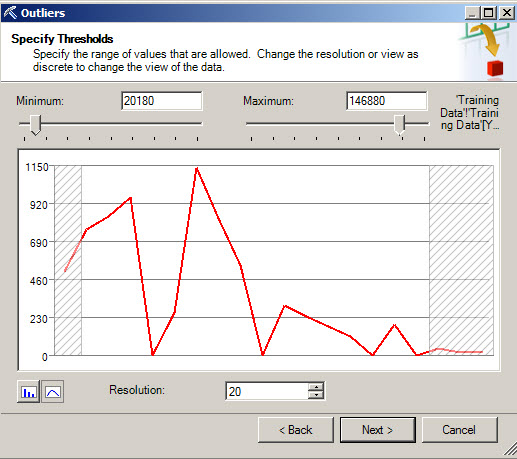
This is very useful when you have garbage in your information. For example, imagine that you have Bill Gates in your database as a customer.

Do you believe that it is a great idea or it will help to your Mining Model to have a billionaire in your list? It is recommended to ensure your data is clean and without unusual values. The same could be true if you have customers without a job. There are useless for our model.

6. Once you have selected the area to remove or change, you can change values to the specified limits, change values to mean, change value to null or delete the rows containing outliers. You can press next after selecting an option.
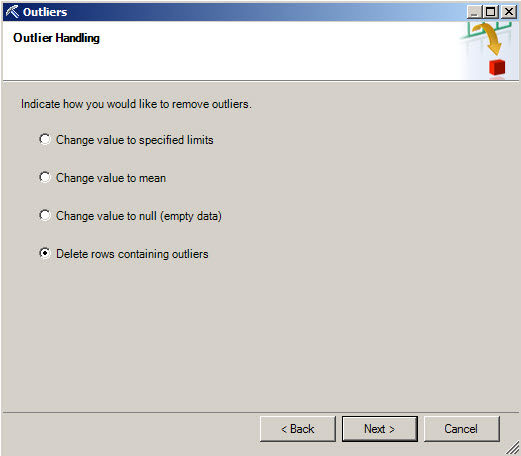
7. You can copy the data modified in a new worksheet or change the data in place. Press Next after selecting an option.
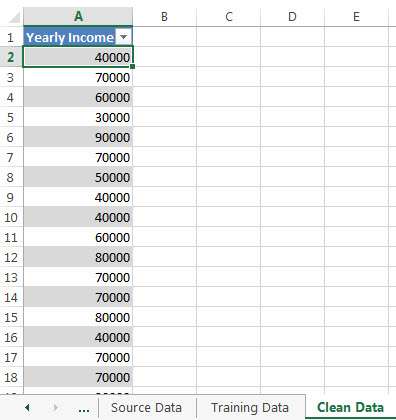
8. Now, the outliers have been removed and a new sheet with the data modified is created.
Re-label
1. The next exercise is to re-label the information. Select the Occupation column.
2. To re-label the information, go to Clean Data and select the Re-label option.
3. In the new Wizard, press next.
4. If not selected, select the range of data and press next.
5. The re-label process can be used to change the information into different languages or to create a more descriptive description.
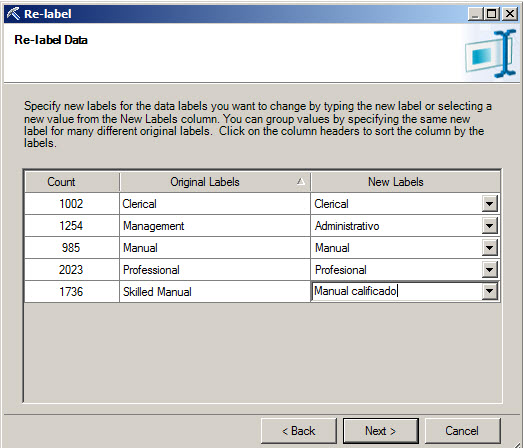
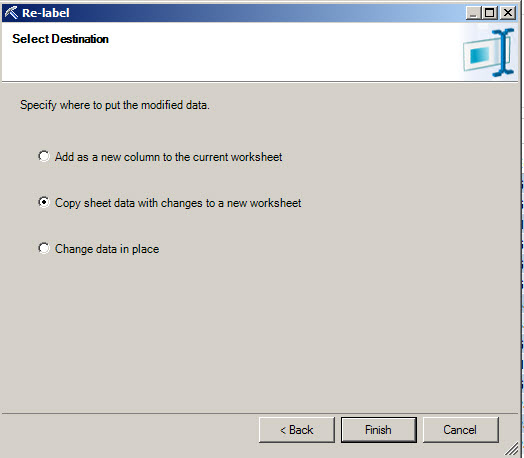
6. You can add the information the worksheet, change the data in place or copy in a new worksheet.
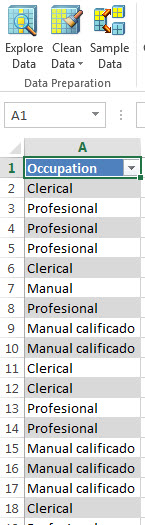
7. If everything is OK, you will have all the information in the worksheet.
Sample Data
You can get a sample of data with this option. I think this option is pretty cool and useful.
1. Click the sample data icon.
2. A new wizard will be displayed. Press next.
3. Select the range of data if not selected before.

4. You can select a random sampling and press next.
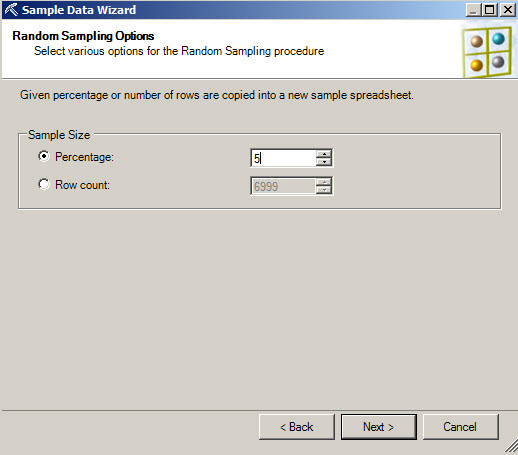
5. You can select the percentage of the sample. You can also select a specific Row count.
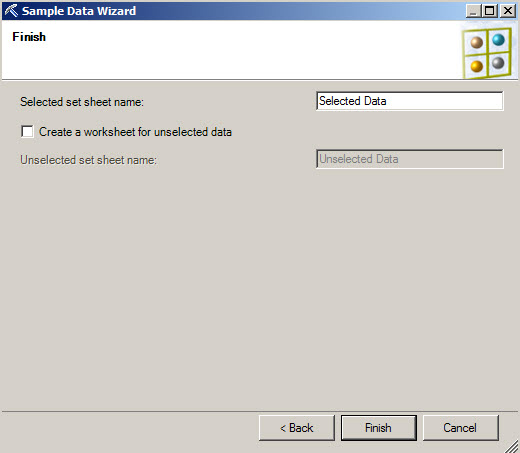
6. You can have a worksheet with the selected data and a worksheet of unselected data.
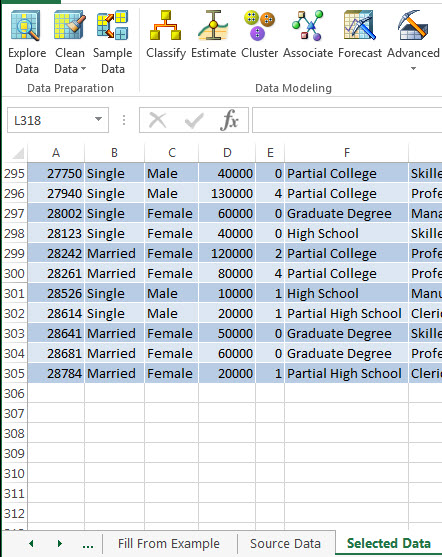
7. In this picture, you will be able to see the sample of data.
 Classify with decision trees
Classify with decision trees
Classify
The classify option lets you create a decision tree algorithm with the current information. If you are not familiar with decision trees, please read the lesson 2 of this series.
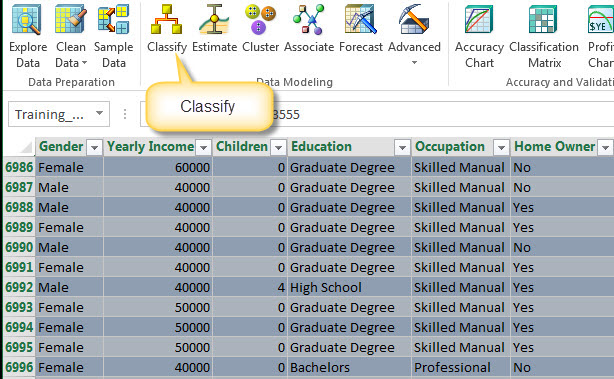
1. To start this, select your data to analyze and press the Classify option.
2. The Classify Wizard will be displayed. Press next.
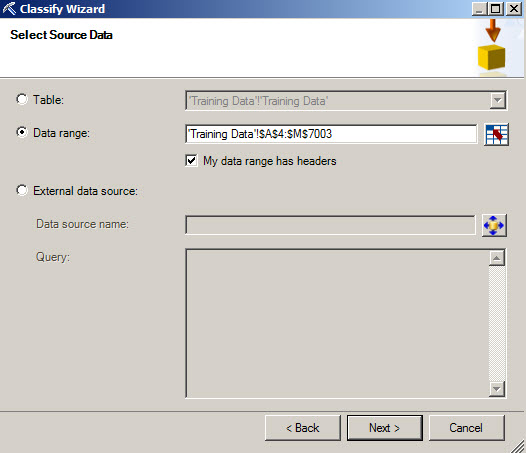
3. If not selected before, select the range of cells.
4. Select the column to analyze. Please select the bike buyer option. Also, select the columns used as input. You also have a Parameters option. Press it.
5. If you are not familiar with the Decision Trees parameters, please refer to this link. Do not change anything in this Window I just wanted to present it to you. Press OK and in the input window press next.
6. The data used requires data to train the model and the rest to test the accuracy of the model. Leave the default values and press next.
7. Finally, you can write the name of the structure, the model, the description and the options to Browse and Drillthrow. Once selected this options, press finish.
8. If everything is OK, you will have the decision trees windows with all the options of the decision tree
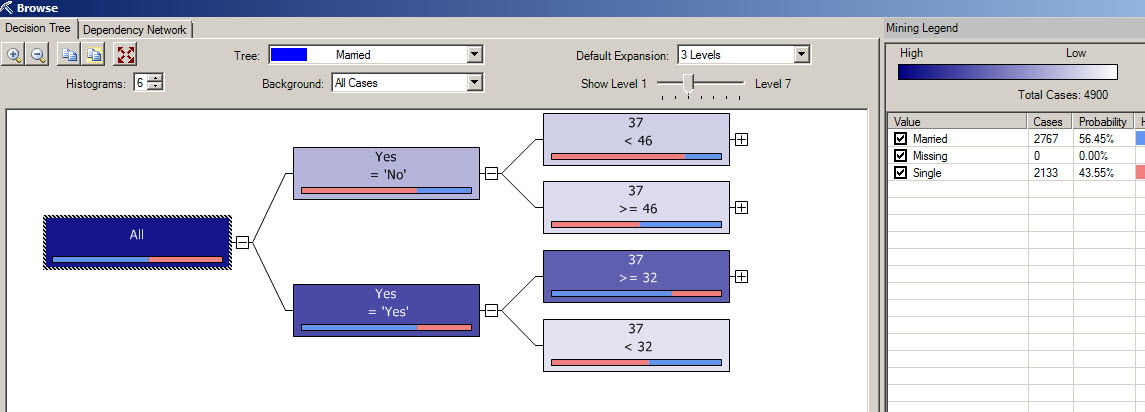
How to create Data Mining queries in Excel
There is an option to create your DMX queries visually or manually. If you need to create queries, this section is for you. You do not need to know DMX for this section, but if you need more advanced options, I recommend you to learn it. For more information about DMX, read the lesson 12.
1. In order to create queries select the Data Mining menu and press the Query icon.
2. In the Data Mining Query Wizard, press next.
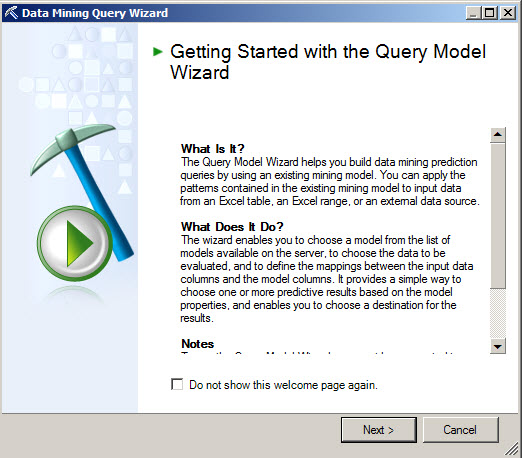
3. Select a Model that in this case would be decision tree model created before.
4. If not selected, select the range of data and press next.
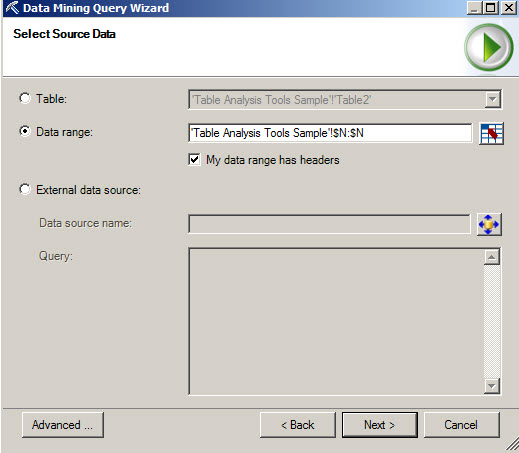
5. If the relationship was not established, create a relationship between the Mining Model and the Table Column. This option will create a relationship between the columns of the Mining Model and the Excel file.
6. In the Choose Output, select the Add Output button.
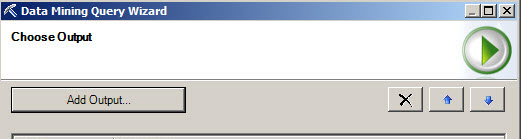
7. Select the Purchased Bike option and select Predict Probability and press OK.
8. You can see the MDX query created with the Advanced button, press it to check.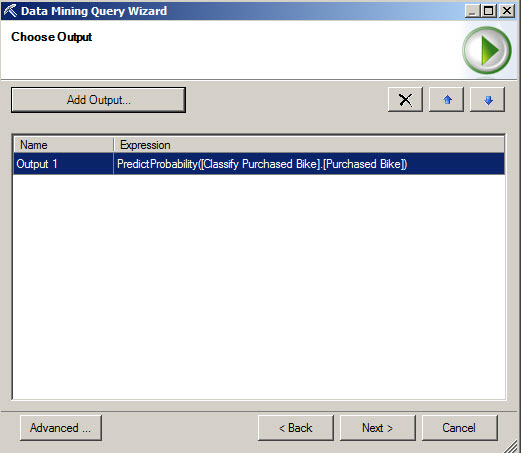
9. You can watch the DMX query here and edit the query. Press OK and in the Choose Output Window, press next.
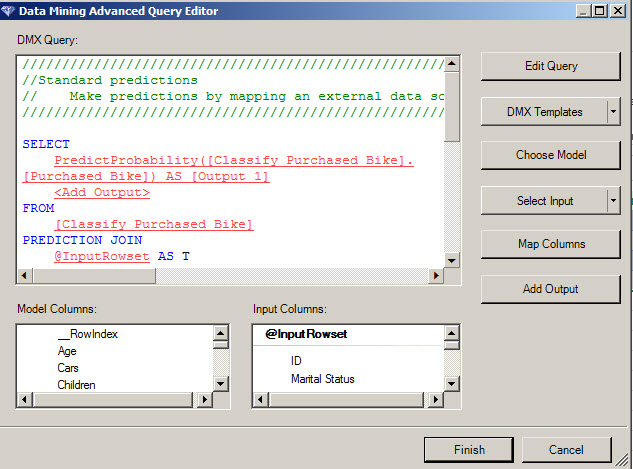
10. You can append the Data, create a new worksheet with the new information or add to an existing worksheet.
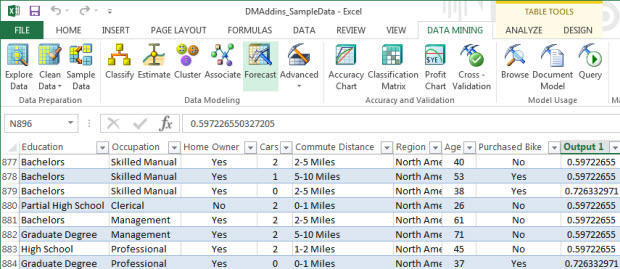
11. As you can see, a new column was created with the probability of the customers to buy a bike.
Conclusion
As you can see, there are nice tools to explore the information, clean the information and by the other hand we show how to create the Decision Trees and how to query the models with Microsoft Excel.
The Excel for Data Mining Add-ins is a straightforward tool that anyone can learn easily.
References
http://msdn.microsoft.com/en-us/library/dn282385.aspx
Содержание
- Data Mining Part 19: Excel and Data Mining, Samples, Queries
- Introduction
- Requirements
- Explore Data
- Outliers
- Re-label
- Sample Data
- Classify
- How to create Data Mining queries in Excel
- Conclusion
- Как решать задачи Data Mining с помощью Excel?
Data Mining Part 19: Excel and Data Mining, Samples, Queries
Introduction
In the lesson 18, we learned how to install the plugin to administer and query Data Mining Models using Excel. We also learned how to create a Cluster Model using Excel. In this new lesson we will learn how to clean the information, how to explore information, how to get a sample of data, how to classify the data using decision trees and finally how to query the model.
Requirements
Here are the assumptions for this article.
- We are using SQL Server 2014 for this lesson, but SQL Server 2005/2008/2012 can be also be used. We are assuming that you already have the Data Mining Project used in the Data Mining Part 13. If you do not, you can install it or use any other Data Mining Project already installed.
- We are using Microsoft Office 2013, but earlier versions can also be used.
- The Data Mining plugin for Excel 2007 and SQL Server 2008 can be downloaded here.
- We are using the Data Mining plugin for Excel 2010, 2013 and SQL 2012 and 2014, which can be downloaded here.
- There is also an Excel File with sample data very useful to learn data mining with Excel. You can download the file here.
Explore Data
Explore Data let you create nice charts using the information. Follow these steps to create a chart.
1. In Excel, click on the Data Mining Menu Option and then press the Explore Data Icon.
2. The Explore Data Wizard will be displayed. Press the next Button.
3. If you did not select the data, select the data to be explored. In this sample, we selected the occupation column to be explored. Press Next.
4. As you can see, a bar char is displayed showing the occupation and the number of customers per occupation.
The Explore Data option can create nice charts that allow you to visualize the information.
Outliers
The Outliers button provides a good way to clean the information. Sometimes we have some typos, or some customers who do not help to the model.
1. The next task is to clean the data. First, we will work with the Outliers option. For this sample, we will select the Yearly Income column.
2. Select the Clean Data icon and then Outliers
3. The Wizard will be displayed. Press next.
4. You can select the data to be used in this option, or if you did this before in step 5, the data will be already selected. Press next.
5. You will have a graph of the salaries and the number of customers per salary. With the sliders you can remove some data to clean it.
This is very useful when you have garbage in your information. For example, imagine that you have Bill Gates in your database as a customer.
Do you believe that it is a great idea or it will help to your Mining Model to have a billionaire in your list? It is recommended to ensure your data is clean and without unusual values. The same could be true if you have customers without a job. There are useless for our model.
6. Once you have selected the area to remove or change, you can change values to the specified limits, change values to mean, change value to null or delete the rows containing outliers. You can press next after selecting an option.
7. You can copy the data modified in a new worksheet or change the data in place. Press Next after selecting an option.
8. Now, the outliers have been removed and a new sheet with the data modified is created.
Re-label
1. The next exercise is to re-label the information. Select the Occupation column.
2. To re-label the information, go to Clean Data and select the Re-label option.
3. In the new Wizard, press next.
4. If not selected, select the range of data and press next.
5. The re-label process can be used to change the information into different languages or to create a more descriptive description.
6. You can add the information the worksheet, change the data in place or copy in a new worksheet.
7. If everything is OK, you will have all the information in the worksheet.
Sample Data
You can get a sample of data with this option. I think this option is pretty cool and useful.
1. Click the sample data icon.
2. A new wizard will be displayed. Press next.
3. Select the range of data if not selected before.
4. You can select a random sampling and press next.
5. You can select the percentage of the sample. You can also select a specific Row count.
6. You can have a worksheet with the selected data and a worksheet of unselected data.
7. In this picture, you will be able to see the sample of data.
Classify with decision trees
Classify
The classify option lets you create a decision tree algorithm with the current information. If you are not familiar with decision trees, please read the lesson 2 of this series.
1. To start this, select your data to analyze and press the Classify option.
2. The Classify Wizard will be displayed. Press next.
3. If not selected before, select the range of cells.
4. Select the column to analyze. Please select the bike buyer option. Also, select the columns used as input. You also have a Parameters option. Press it.
5. If you are not familiar with the Decision Trees parameters, please refer to this link. Do not change anything in this Window I just wanted to present it to you. Press OK and in the input window press next.
6. The data used requires data to train the model and the rest to test the accuracy of the model. Leave the default values and press next.
7. Finally, you can write the name of the structure, the model, the description and the options to Browse and Drillthrow. Once selected this options, press finish.
8. If everything is OK, you will have the decision trees windows with all the options of the decision tree
How to create Data Mining queries in Excel
There is an option to create your DMX queries visually or manually. If you need to create queries, this section is for you. You do not need to know DMX for this section, but if you need more advanced options, I recommend you to learn it. For more information about DMX, read the lesson 12 .
1. In order to create queries select the Data Mining menu and press the Query icon.
2. In the Data Mining Query Wizard, press next.
3. Select a Model that in this case would be decision tree model created before.
4. If not selected, select the range of data and press next.
5. If the relationship was not established, create a relationship between the Mining Model and the Table Column. This option will create a relationship between the columns of the Mining Model and the Excel file.
6. In the Choose Output, select the Add Output button.
7. Select the Purchased Bike option and select Predict Probability and press OK.
8. You can see the MDX query created with the Advanced button, press it to check.
9. You can watch the DMX query here and edit the query. Press OK and in the Choose Output Window, press next.
10. You can append the Data, create a new worksheet with the new information or add to an existing worksheet.
11. As you can see, a new column was created with the probability of the customers to buy a bike.
Conclusion
As you can see, there are nice tools to explore the information, clean the information and by the other hand we show how to create the Decision Trees and how to query the models with Microsoft Excel.
The Excel for Data Mining Add-ins is a straightforward tool that anyone can learn easily.
Источник
Как решать задачи Data Mining с помощью Excel?
Что приходит Вам в голову при упоминании «Data Mining»? Наверняка высокая, почти космическая, сложность алгоритмов, непонятные манипуляции с огромными массивами данных, нереальные объемы программного кода с применением множества разнообразных framework-ов с пугающими названиями – одним словом что-то недоступное обыкновенному человеку. Но все ли задачи представляют из себя нечто подобное? Попробуем разобраться на примере простой задачи классификации и простого метода k-ближайших соседей(kNN), применяемого для ее решения.
Есть таблица со значениями 2-ух параметров, по которым некоторые объекты разделяется на типы: «хорошо», «плохо», «средне». Есть объект, у которого известно значение параметров (5.2;3.1), но не известно какого он типа.
Для понимания создадим на том же листе в excel точечную диаграмму, в качестве значений по оси X зададим данные из второго столбца, а качестве оси Y – из первого.
Для того, чтобы лучше видеть наши значения можно ограничить значения по осям и добавить подписи. Должно получиться примерно так:
Добавим и наш объект, тип которого нужно определить. Основная идея метода, который мы хотим применить, состоит в расчете расстояний между нашим объектом и объектами, тип которых уже определен.
Для того, чтобы вычислить это расстояние, воспользуемся формулой для расчета расстояния в многомерном пространстве (Евклидово расстояние):
В excel это будет выглядеть так:
«Протянем» формулу на все строки, где есть значения параметров. В соседнем столбце слева можно ранжировать значение каждого расстояния среди остальных значений расстояний с помощью функции «=РАНГ(), а в правый просто копируем значение типа. Должно получиться так:
Теперь для того, чтобы определить тип нашего объекта достаточно выбрать k-первых значений из получившегося массива (по возрастанию). В качестве числа k возьмем максимальное целое число, которое меньше корня квадратного из числа заданных значений. Для нас это будет число 3.
Можно заметить, что наибольшее количество (в данном случае все) k-ближайших соседей относятся к «плохо». Следовательно, наш объект тоже относится к «плохо».
Для того, чтобы сделать «куличик» в песочнице, не следует подгонять экскаватор. Есть ситуации, например, когда вы строите дом, где без спецтехники не обойтись. Но в случае с куличиком результат будет похож на ковш и весьма вероятно накроет собой всю песочницу.
Иными словами, некоторые задачи Data mining не требуют ни «космической сложности алгоритмов», ни глубоких познаний в высшей математике, не предполагают также использования «разнообразных framework-ов с пугающими названиями» и доступны любому, кто умеет пользоваться важнейшим из инструментов «уверенного пользователя ПК» — excel.
Источник
Время на прочтение
10 мин
Количество просмотров 10K
Считается, что Data Mining — это магическое снадобье из SQL, Python, Power BI и других волшебных компонент. Мало кто знает, что при правильном подходе с Data Mining может совладать офисный планктон с помощью одного лишь Excel.
Если вы абсолютно далеки от Data Mining, но хотите причаститься его таинств, это руководство в картинках по шагам сделано для вас. Особенно полезно тем, кто никогда бы даже не подумал сделать подобное самостоятельно.
Если вы владеете специальными инструментами для работы с данными, то будет интересно узнать ваше мнение о решениях без «рокет сайнс» (как о явлении в целом, так и о данном кейсе).

В качестве практического вопроса будем рассматривать визуализацию данных из объявлений на популярных сайтах продажи квартир. Визуальный анализ — основа основ Data Mining, а при отсутствии специальных знаний — и вовсе единственный способ для понимания смысла, содержащегося в большом количестве данных. Это настолько фундаментальный навык, что ему посвящена целая народная мудрость:
Лучше один раз увидеть, чем сто раз услышать*
*Это все, что нужно знать о достоинствах визуального анализа.
Термины
Тепловая карта (heat map) – обозначение какого-либо показателя цветом:
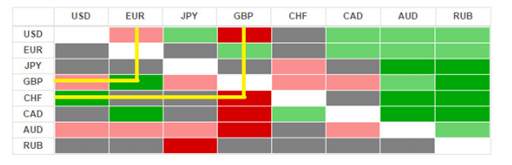
Как правило, более высокие значения обозначаются красными оттенками, более низкие – синими. Обычная цветовая шкала выглядит так:
![]()
Географическая тепловая карта – обозначение показателя цветом на географической карте. Более высокие значения температуры показаны более красными оттенками в привязке к географическим точкам:
Географическая тепловая карта цен – обозначение цветом цен в разных географических местах.
В нашем случае это будут цены на квартиры.
Данные
Цены на квартиры будем брать с общеизвестных досок объявлений А и Ц. Для сбора объявлений без программирования нужно воспользоваться готовым парсером. В данном случае выберем наиболее доступный по причине его бесплатности и наиболее удобный из-за простоты установки в три клика в Excel.
Парсеру надо дать понять какие объявления нужно скачивать. Для этого используется ссылка на доску объявлений.
Для подготовки ссылки для скачивания объявлений с доски объявления А открываем браузер, в браузере открываем сайт доски объявлений, выбираем регион (для примера → Брянск) и раздел → квартиры. В адресном поле браузера получаем ссылку: https://www.avito.ru/bryanskaya_oblast/kvartiry. В последней части ссылки видим раздел → kvartiry, перед ней расположен регион → bryanskaya_oblast. Вместо Брянска можно указать свой регион, а вместо раздела квартир можно указать дома-дачи-коттеджи или земельные-участки. Также можно использовать фильтры (например новостройки или вторичка, количество комнат) и они отобразятся в составе ссылки. Скажем спасибо доске объявлений А за такой понятный порядок формирования ссылок.
Для подготовки ссылки с доски объявлений Ц придется сделать дополнительный шаг: после выбора региона, раздела, фильтров и нажатия кнопки «Найти» нужная ссылка еще не будет готова. Для завершения подготовки ссылки нужно перейти на вторую страницу списка объявлений. После этого ссылка в адресной строке браузера примет вид https:// cian.ru/cat.php?deal_type=sale&engine_version=2&offer_type=flat&p=2®ion=4562&room1=1&room2=1. Раздел квартир здесь будет в offer_type=flat, а регион – в region=4562. Скажем «фу» доске объявлений Ц за не самый удобный порядок формирования ссылок.
Готовые ссылки как есть копируем из адресной строки браузера (нажатием кнопок Ctrl+A и Ctrl+C) и вставляем в парсере нажатием кнопки Добавить ссылку. Для обеих ссылок можно указать один и тот же новый файл Excel, в который будут сохраняться объявления.
Чтобы код для парсинга доски объявлений А загрузился в Excel → в настройках парсера (расположены в Excel на вкладке Надстройки) ставим галочку у парсера доски объявлений А и выключаем галочки у сохранения фотографий из объявлений, у сохранения копии объявлений, у открывания номера телефона и у других ненужных опций. То же самое повторяем с настройками парсера доски объявлений Ц.
Теперь ссылки полностью готовы для загрузки объявлений. Нажимаем в меню парсера кнопку Старт и ждем около 20 секунд до загрузки первого объявления. Да, процесс совсем не быстрый и займет время. Можно уменьшить интервал запросов в настройках парсера до 10 или 5 секунд и иногда это даже прокатывает. Но обычно доски объявлений очень не любят ботов и сразу закрывают доступ к данным (бан). Конечно, эти ограничения можно обойти и загружать данные в 100 раз быстрее, но это дороже.
Загружаемые объявления выглядят примерно так:

Таких строк может быть несколько тысяч. В нашем примере это около 5000 объявлений для Брянской области в октябре 2021.
Из множества данных нам понадобятся только широта, долгота, цена, общая площадь и офер:
|
Широта |
Долгота |
Цена |
Общая |
Офер |
|
53,2656 |
34,35292 |
5030000 |
64,2 |
Продам |
|
53,20856 |
34,46647 |
2443000 |
51 |
Продам |
|
53,26398 |
34,33171 |
10000 |
40 |
Сдам |
|
53,54983 |
33,76486 |
750000 |
35 |
Продам |
|
… |
Это сырые данные, которые требуют подготовки.
Подготовка
Отделим аренду от продажи. Для этого добавим фильтр по полю «офер» и выделим только предложения продажи. Можно и наоборот – оставить только предложения аренды и работать дальше с ними.

Выделим отфильтрованные данные, Ctrl+G → только видимые:

Копируем их Ctrl+C и вставим на новый лист Ctrl+V:
|
Широта |
Долгота |
Цена |
Общая |
|
53,2656 |
34,35292 |
5030000 |
64,2 |
|
53,20856 |
34,46647 |
2443000 |
51 |
|
53,54983 |
33,76486 |
750000 |
35 |
|
53,31711 |
34,30244 |
1450000 |
62 |
|
53,26612 |
34,33491 |
2950000 |
36 |
|
… |
Если показывать цены на многокомнатные квартиры одним цветом и цены однушек другим цветом, в результате получим карту размещения жилья по числу комнат. Для анализа цен этот показатель слишком сырой. Вместо него используем среднюю цену за квадратный метр.
При делении цены квартиры на общую площадь получим цену одного квадратного метра. Этот показатель лучше отражает ценность жилья с учетом всех ценообразующих факторов: расположения, состояния, отделки и окружения. Поэтому добавим колонку с ценой одного квадратного метра и уберем колонки с ценой и общей площадью:
|
Широта |
Долгота |
За 1 кв.м. |
|
53,2656 |
34,35292 |
78348,91 |
|
53,20856 |
34,46647 |
47901,96 |
|
53,54983 |
33,76486 |
21428,57 |
|
53,31711 |
34,30244 |
23387,1 |
|
53,26612 |
34,33491 |
81944,44 |
|
… |
Теперь проведем стандартные процедуры проверки заведомо ошибочных данных.
У нас есть две группы данных: географическое положение и цена. Для проверки обеих групп используем визуальный контроль.
Поместим имеющиеся географические точки на обычную диаграмму Excel:

Посмотрим координаты крайних точек Брянской области. Широта должна быть от 51,5039 до 54,021, долгота от 31,1432 до 35,1917. Некоторые наши точки выходят за эти пределы. Опустим здесь рассмотрение причин появления испорченных данных и возможных путей их восстановления, т.к. это не относится прямо к цели визуализации данных и противоречит принятому ограничению квалификации пользователя. По этой же причине используем грубый, но простой способ избавления от испорченных данных.
Заменим нулями строки, где долгота и широта выходят за границы региона → с помощью простой формулы:

Затем добавим фильтр и уберем отображение строк с нолями:

Выделим все строки отфильтрованных колонок данных, затем Сtrl+G → только видимые:

Копируем их Ctrl+C и вставим в новое место (рядом) Ctrl+V.
Очищенные таким образом долготы и широты точек отправляем на новую диаграмму Excel и видим результат очистки:

Теперь также с помощью визуального анализа очистим данные о ценах.
Для этого построим гистограмму, чтобы посмотреть сколько каких значений цены в нашей выборке.
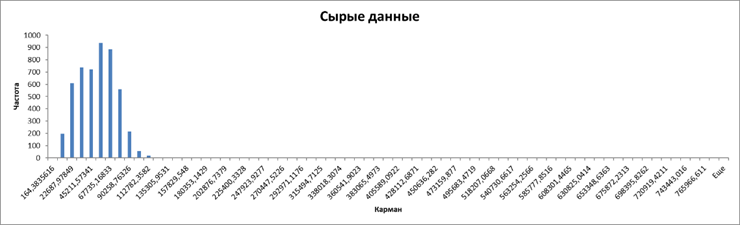
Город рос в естественных условиях (построен не одномоментно по единому плану), имеет развитое сельское хозяйство и небольшие промышленные предприятия (не лакшери центр). Теория говорит, что при таких обстоятельствах цены на финансовые активы (жилье – один из базовых финансовых активов) должны быть распределены логнормально.
Присутствие на гистограмме длиннющего тощего хвоста и асимметрия основной части распределения являются характерными признаками логнормального распределения. То есть в данном случае практика соответствует теории.
Практический смысл этой гистограммы: если данные из правой части отметить на карте одним цветом, из средней — вторым и из левой — третьим, то вся карта будет залита одним цветом. Потому что в средней и в правой частях точек почти нет. Аналитического смысла у такой карты не будет.
Чтобы избавиться от упомянутого эффекта нужно отбросить хвост распределения, а заодно и данные из первого левого кармана. В результате получим такую гистограмму:

Теперь количество данных в разных частях более-менее сопоставимо. Количество карманов здесь посчитано Excel автоматически и оно явно избыточно для того, чтобы каждый уровень цены обозначать своим цветом. Поэтому в дальнейшем перестроим гистограмму по количеству карманов в соответствии с количеством цветов, которые будут использованы на карте. В нашем случае будем использовать 7 цветов.
Перед разбивкой данных по карманам рассмотрим еще одно обстоятельство, которое стоит учесть на этапе подготовки данных. Дело в том, что точки на карте могут располагаться слишком тесно. Например, здесь шесть объявлений расположены в одном доме и перекрывают друг друга даже на самом крупном масштабе:
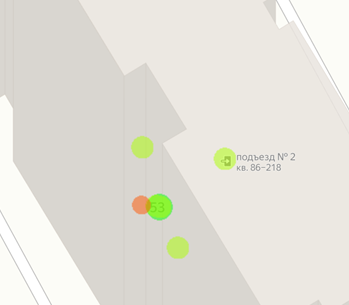
На более мелких масштабах эти метки полностью сольются и станут неразличимы.
Чтобы избавиться от излишней в данном случае детализации данных проведем их усреднение. Для усреднения данных воспользуемся следующим приемом.
Обычная точность указания координат использует 6 знаков после запятой. Например, широта 52,549374 и долгота 31,897056. Четвертый знак после запятой соответствует масштабу придомовой территории. В нашем примере в диапазон долготы от 31,8965 до 31,8974 попадают все объявления, относящиеся к одному строению. Используем это обстоятельство для группировки данных в процессе усреднения.
Добавляем к имеющимся данным столбцы с округленными до 3 знака широтой и долготой. Еще одним столбцом добавляем символьную сумму этих двух последних столбцов:

Что в результате дает:

После чего сортируем все столбцы по колонке с текстом и применяем Промежуточный итог:

В результате данные разбиваются на группы близколежащих точек, для которых вычисляются средние цены и координаты:

Для замены групп на точки со средними значениями → сворачиваем все группы, выделяем колонки координат и цены:

Затем выделяем только видимые ячейки Ctrl+G → только видимые, копируем Ctrl+C:

После чего вставляем скопированное на новый лист. Теперь на каждом здании будет не больше одной точки с данными, которая соответствует среднему значению всех относящихся к зданию объявлений:

С помощью такого приема можно провести усреднение цен на уровне группы зданий или по кварталу.
После такого прореживания осталось меньше половины точек. Благодаря этому карта цен будет значительно меньше перегружена данными в самых насыщенных местах.
Получившийся набор данных предстоит разложить по карманам в зависимости от величины цены. Для 7 цветов = 7 карманов гистограмма выглядит так:

Данные из первого левого столбца гистограммы будут синего цвета, из последнего правого — красными, а из расположенных между ними — оттенками зеленого:

Цвет получается смешиванием красного (R), зеленого (G) и синего (B). Интенсивность каждого цвета находится в диапазоне от 0 до 255. Смешивание для получения показанных цветов приведено в следующей таблице.
|
Цвет |
R |
G |
B |
Код |
|
Синий |
0 |
171 |
255 |
0,171,255 |
|
0 |
171 |
171 |
0,171,171 |
|
|
0 |
255 |
171 |
0,255,171 |
|
|
Зеленый |
0 |
255 |
0 |
0,255,0 |
|
171 |
255 |
0 |
171,255,0 |
|
|
255 |
85 |
0 |
255,85,0 |
|
|
Красный |
255 |
42 |
0 |
255,42,0 |
Обозначения из столбца Код будут использованы для окрашивания данных на карте.
Полученный результат можно считать подготовленными данными для отображения их на карте.
Обработка
Имеющиеся цены разделим на 7 равных интервалов. (В этой области знаний интервалы синонимы диапазонов, и еще их называют карманами.)
Для определения ширины интервала разницу максимальной и минимальной цен нужно разделить на количество карманов. В нашем случае данные такие:
|
Минимум |
4000 |
|
Максимум |
109253,1 |
|
Кол-во карманов |
7 |
|
Ширина кармана |
15036 |
И карманы:
|
1 |
3999 |
— |
19035 |
|
2 |
19035 |
— |
34071 |
|
3 |
34071 |
— |
49107 |
|
4 |
49107 |
— |
64144 |
|
5 |
64144 |
— |
79180 |
|
6 |
79180 |
— |
94216 |
|
7 |
94216 |
— |
109253 |
Для получения данных первого кармана нужно скопировать данные широты и долготы для цен от 3999 до 19035 и вставить в новое место. Цены копировать не нужно, они использовались только для разбивки данных по карманам и больше не пригодятся. Аналогично для второго кармана копируем широты и долготы для цен от 19035 до 34071 и вставляем их рядом с данными из первого кармана. Повторив семь раз получим в результате:

В каждом кармане две колонки: левая — широта и правая — долгота. Количество строк в каждом кармане разное, как было показано на последней гистограмме.
Теперь данные полностью готовы для их помещения на карту.
Карта
Для построения карты нужно сделать три шага:
Добавить шаблон карты → Заполнить шаблон данными → Показать результат
Шаблон карты добавляется кнопкой Добавить в меню парсера. Если в меню парсера нет кнопок для работы с картой, то в настройках парсера нужно включить опцию Excel → График на карте.

В первой строке шаблона указаны значения по умолчанию, которые можно изменять. В левой таблице вставляются подготовленные данные о ценах. Правая таблица служит для вывода на карте подписей к конкретным точкам.
Для вставки в шаблон данных о ценах из первого кармана нужно в ячейку A3 вставить ссылку на диапазон данных о широте и долготе, которые указаны в двух колонках первого кармана, вот эти:

Для примера это диапазон Q4:R582 на листе По карманам в файле Брянск 10(октябрь)-21.xlsx.
Вставить ссылку на этот диапазон можно с помощью функции Ссылка(диапазон).
В ячейке А3 шаблона пишем название функции:
")
В качестве единственного аргумента функции Ссылка указываем диапазон Q4:R582 на листе По карманам:

В результате получаем:

Точки данных первого кармана ранее условились обозначать синим цветом с кодом 0,171,255. Для примера формулы ниже: таблица с кодами цветов находится на листе Палитра. Код синего цвета находится в ячейке Е3:
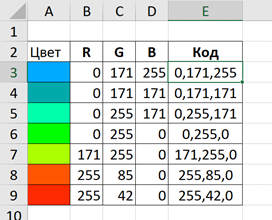
Для вставки ссылки на ячейку в Excel не требуется использовать специальную функцию, поэтому в ячейке шаблона В3 вставляем ссылку на ячейку кода синего цвета обычным способом:

В результате:

Размер точек определяется из субъективных соображений. Для примера примем размер 10:

На этом шаблон карты полностью готов для отображения данных из первого кармана.
Посмотрим что получилось. Для этого нажимаем кнопку Отобразить в меню парсера, после чего открывается новое окно:

Метки на карте отсутствуют из-за масштаба. Зумим колесом мышки и получаем:

Закрываем окно с картой, добавляем данные из второго кармана:

Данные из второго кармана отображаются поверх данных первого кармана:

После добавления всех оставшихся карманов:

На карте:
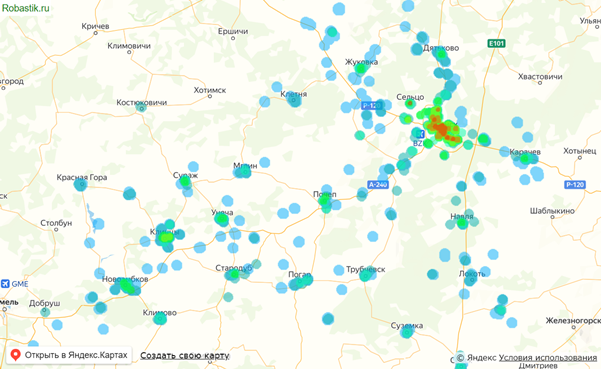
Это и есть визуализация цен на географической карте, сделанная в Excel без программирования. Ее можно зумить и двигать как обычную карту в браузере. Для копирования карты в буфер в парсере есть специальная кнопка Копировать.
В завершение отметим на карте какое-нибудь место, например Аграрный университет. Координаты широты и долготы БГАУ возьмем по указанной ссылке и вставим в ячейки J3 и К3. Ссылку на ячейки с координатами вставим в ячейку шаблона Н3:

Увидим БГАУ на карте и оценим его влияние на цену недвижимости:

Файл Excel с примером можно скачать здесь.
Posted by
on
Tuesday, April 2nd, 2013
What is data mining? Do you have to be a mathematical genius to find patterns in hidden data? Most software programs for data mining cost thousands of dollars, but there is one program sitting on your desktop that makes a perfect data mining tool for beginners: Excel.

Image source: Willscullypower.wordpress.com
You’ve probably heard the term “data mining” bandied about, but figured it was something you can’t do for your business because the software is too expensive and you need to hire an expert to analyze all that raw data.
Data mining is mainly used in research, marketing, communication, financial and retail sectors.
Data mining, or knowledge discovery is a valuable tool for finding patterns or correlations in fields of relational data resources. It is true that in many instances, data mining isn’t something for the average person to take on. It requires a familiarity and comfortable approach to dealing with numbers and statistics. If you have that kind of analytic mind, you understand Excel and aren’t intimidated by software programs, give it a try.
Microsoft and other sites have free online tutorials to help you learn predictive analytics.
It may seem daunting, but you can learn data mining with Excel for your small business. There are experts in the field who use extremely expensive software and complex algorithms involving vast amounts of data, but your small business doesn’t require that kind of analysis and you don’t have that volume of data.
Because it would take more than this post to explain data mining in detail, we are just going to let you know about resources for your small business, so that you can perform predictive analytics and determine where your business is going.
With Excel, you can use data mining to predict your profitability with regard to customer engagement. You do this by using your customer order history and other historical data to predict future patterns in sales.

Image source: Transformsolution.com
Data mining helps you use that information in many effective ways and helps you to reduce costs and increase revenue, especially in a retail environment. By asking these types of questions and using the appropriate data, you will be able to come up with the answers:
- Who is my target customer? You need to know who is buying your product or service and tailor your marketing and sales to that demographic.
- What products are the most popular?
- What trends have been the most successful for my business?
- Should I expand my business to a new location and what is the ideal location for my business?
- How can I identify new sales prospects for my business?

Image source: Sqlservercentral.com
By using a data mining add-in to Excel, provided by Microsoft, you can start planning for future growth. Add to that, a PDF to Excel converter to help you collect all of that data from the various sources and convert the information to a spreadsheet, and you are ready to go.
There is no harm in stretching your skills and learning something new that can be a benefit to your business. Part of the problem with many new ventures is that they can’t see where they should be taking their business. No one can predict the future, however, by using innovative and cost effective software you can gain a considerable deal of perspective and find the direction you need to grow.