
Many times it is required to count the occurrence of each word in a text file. To achieve so, we make use of a dictionary object that stores the word as the key and its count as the corresponding value. We iterate through each word in the file and add it to the dictionary with a count of 1. If the word is already present in the dictionary we increment its count by 1.
File sample.txt
First, we create a text file in which we want to count the words in Python. Let this file be sample.txt with the following contents
Mango banana apple pear Banana grapes strawberry Apple pear mango banana Kiwi apple mango strawberry
Example 1: Count occurrences of each word in a given text file
Here, we use a Python loop to read each line, and from that line, we are converting each line to lower for the unique count and then split each word to count its number.
Python3
text = open("sample.txt", "r")
d = dict()
for line in text:
line = line.strip()
line = line.lower()
words = line.split(" ")
for word in words:
if word in d:
d[word] = d[word] + 1
else:
d[word] = 1
for key in list(d.keys()):
print(key, ":", d[key])
Output:
mango : 3 banana : 3 apple : 3 pear : 2 grapes : 1 strawberry : 2 kiwi : 1
Example 2: Count occurrences of specific words in a given text file
In this example, we will count the number of “apples” present in the text file.
Python3
word = "apple"
count = 0
with open("temp.txt", 'r') as f:
for line in f:
words = line.split()
for i in words:
if(i==word):
count=count+1
print("Occurrences of the word", word, ":", count)
Output:
Occurrences of the word apple: 2
Example 3: Count total occurrences of words in a given text file
In this example, we will count the total number of words present in a text file.
Python3
count = 0
f = open("sample.txt", "r")
for line in f:
word = line.split(" ")
count += len(word)
print("Total Number of Words: " + str(count))
f.close()
Output:
Total Number of Words: 15
Consider the files with punctuation
Sample.txt:
Mango! banana apple pear. Banana, grapes strawberry. Apple- pear mango banana. Kiwi "apple" mango strawberry.
Code:
Python3
import string
text = open("sample.txt", "r")
d = dict()
for line in text:
line = line.strip()
line = line.lower()
line = line.translate(line.maketrans("", "", string.punctuation))
words = line.split(" ")
for word in words:
if word in d:
d[word] = d[word] + 1
else:
d[word] = 1
for key in list(d.keys()):
print(key, " ", d[key])
Output:
mango : 3 banana : 3 apple : 3 pear : 2 grapes : 1 strawberry : 2 kiwi : 1
I’m trying to find the number of occurrences of a word in a string.
word = "dog"
str1 = "the dogs barked"
I used the following to count the occurrences:
count = str1.count(word)
The issue is I want an exact match. So the count for this sentence would be 0.
Is that possible?
asked Jun 24, 2013 at 6:07
![]()
lost9123193lost9123193
10.2k26 gold badges66 silver badges111 bronze badges
If you’re going for efficiency:
import re
count = sum(1 for _ in re.finditer(r'b%sb' % re.escape(word), input_string))
This doesn’t need to create any intermediate lists (unlike split()) and thus will work efficiently for large input_string values.
It also has the benefit of working correctly with punctuation — it will properly return 1 as the count for the phrase "Mike saw a dog." (whereas an argumentless split() would not). It uses the b regex flag, which matches on word boundaries (transitions between w a.k.a [a-zA-Z0-9_] and anything else).
If you need to worry about languages beyond the ASCII character set, you may need to adjust the regex to properly match non-word characters in those languages, but for many applications this would be an overcomplication, and in many other cases setting the unicode and/or locale flags for the regex would suffice.
answered Jun 24, 2013 at 6:09
![]()
5
You can use str.split() to convert the sentence to a list of words:
a = 'the dogs barked'.split()
This will create the list:
['the', 'dogs', 'barked']
You can then count the number of exact occurrences using list.count():
a.count('dog') # 0
a.count('dogs') # 1
If it needs to work with punctuation, you can use regular expressions. For example:
import re
a = re.split(r'W', 'the dogs barked.')
a.count('dogs') # 1
answered Jun 24, 2013 at 6:10
![]()
grcgrc
22.7k4 gold badges41 silver badges63 bronze badges
5
Use a list comprehension:
>>> word = "dog"
>>> str1 = "the dogs barked"
>>> sum(i == word for word in str1.split())
0
>>> word = 'dog'
>>> str1 = 'the dog barked'
>>> sum(i == word for word in str1.split())
1
split() returns a list of all the words in a sentence. Then we use a list comprehension to count how many times the word appears in a sentence.
answered Jun 24, 2013 at 6:09
![]()
TerryATerryA
58.4k11 gold badges118 silver badges141 bronze badges
14
import re
word = "dog"
str = "the dogs barked"
print len(re.findall(word, str))
answered Jun 24, 2013 at 9:58
![]()
AaronAaron
411 bronze badge
1
You need to split the sentence into words. For you example you can do that with just
words = str1.split()
But for real word usage you need something more advanced that also handles punctuation. For most western languages you can get away with replacing all punctuation with spaces before doing str1.split().
This will work for English as well in simple cases, but note that «I’m» will be split into two words: «I» and «m», and it should in fact be split into «I» and «am». But this may be overkill for this application.
For other cases such as Asian language, or actual real world usage of English, you might want to use a library that does the word splitting for you.
Then you have a list of words, and you can do
count = words.count(word)
answered Jun 24, 2013 at 6:12
![]()
Lennart RegebroLennart Regebro
165k41 gold badges222 silver badges251 bronze badges
2
#counting the number of words in the text
def count_word(text,word):
"""
Function that takes the text and split it into word
and counts the number of occurence of that word
input: text and word
output: number of times the word appears
"""
answer = text.split(" ")
count = 0
for occurence in answer:
if word == occurence:
count = count + 1
return count
sentence = "To be a programmer you need to have a sharp thinking brain"
word_count = "a"
print(sentence.split(" "))
print(count_word(sentence,word_count))
#output
>>> %Run test.py
['To', 'be', 'a', 'programmer', 'you', 'need', 'to', 'have', 'a', 'sharp', 'thinking', 'brain']
2
>>>
Create the function that takes two inputs which are sentence of text and word.
Split the text of a sentence into the segment of words in a list,
Then check whether the word to be counted exist in the segmented words and count the occurrence as a return of the function.
answered Aug 2, 2018 at 10:37
![]()
If you don’t need RegularExpression then you can do this neat trick.
word = " is " #Add space at trailing and leading sides.
input_string = "This is some random text and this is str which is mutable"
print("Word count : ",input_string.count(word))
Output -- Word count : 3
answered May 18, 2019 at 19:21
![]()
Haseeb MirHaseeb Mir
9081 gold badge13 silver badges22 bronze badges
Below is a simple example where we can replace the desired word with the new word and also for desired number of occurrences:
import string
def censor(text, word):<br>
newString = text.replace(word,"+" * len(word),text.count(word))
print newString
print censor("hey hey hey","hey")
output will be : +++ +++ +++
The first Parameter in function is search_string.
Second one is new_string which is going to replace your search_string.
Third and last is number of occurrences .
![]()
Kara
6,08516 gold badges51 silver badges57 bronze badges
answered Aug 5, 2015 at 6:34
![]()
1
Let us consider the example s = "suvotisuvojitsuvo".
If you want to count no of distinct count «suvo» and «suvojit» then you use the count() method… count distinct i.e) you don’t count the suvojit to suvo.. only count the lonely «suvo».
suvocount = s.count("suvo") // #output: 3
suvojitcount = s.count("suvojit") //# output : 1
Then find the lonely suvo count you have to negate from the suvojit count.
lonelysuvo = suvocount - suvojicount //# output: 3-1 -> 2
![]()
Neil
14k3 gold badges30 silver badges50 bronze badges
answered Mar 29, 2017 at 1:10
![]()
This would be my solution with help of the comments:
word = str(input("type the french word chiens in english:"))
str1 = "dogs"
times = int(str1.count(word))
if times >= 1:
print ("dogs is correct")
else:
print ("your wrong")
answered Jul 15, 2017 at 19:51
![]()
rogerroger
231 silver badge5 bronze badges
If you want to find the exact number of occurrence of the specific word in the sting and you don’t want to use any count function, then you can use the following method.
text = input("Please enter the statement you want to check: ")
word = input("Please enter the word you want to check in the statement: ")
# n is the starting point to find the word, and it's 0 cause you want to start from the very beginning of the string.
n = 0
# position_word is the starting Index of the word in the string
position_word = 0
num_occurrence = 0
if word.upper() in text.upper():
while position_word != -1:
position_word = text.upper().find(word.upper(), n, len(text))
# increasing the value of the stating point for search to find the next word
n = (position_word + 1)
# statement.find("word", start, end) returns -1 if the word is not present in the given statement.
if position_word != -1:
num_occurrence += 1
print (f"{word.title()} is present {num_occurrence} times in the provided statement.")
else:
print (f"{word.title()} is not present in the provided statement.")
answered Nov 27, 2019 at 8:07
![]()
wgetDJwgetDJ
1,1991 gold badge8 silver badges11 bronze badges
This is simple python program using split function
str = 'apple mango apple orange orange apple guava orange'
print("n My string ==> "+ str +"n")
str = str.split()
str2=[]
for i in str:
if i not in str2:
str2.append(i)
print( i,str.count(i))
answered Sep 10, 2020 at 10:34
![]()
RutujaRutuja
2212 silver badges3 bronze badges
I have just started out to learn coding in general and I do not know any libraries as such.
s = "the dogs barked"
value = 0
x = 0
y=3
for alphabet in s:
if (s[x:y]) == "dog":
value = value+1
x+=1
y+=1
print ("number of dog in the sentence is : ", value)
![]()
Dharman♦
29.9k22 gold badges82 silver badges132 bronze badges
answered Jun 24, 2021 at 16:51
![]()
Another way to do this is by tokenizing string (breaking into words)
Use Counter from collection module of Python Standard Library
from collections import Counter
str1 = "the dogs barked"
stringTokenDict = { key : value for key, value in Counter(str1.split()).items() }
print(stringTokenDict['dogs'])
#This dictionary contains all words & their respective count
answered Dec 5, 2021 at 8:07
![]()
Tarun KumarTarun Kumar
6611 gold badge7 silver badges16 bronze badges
Introduction
Counting the word frequency in a list element in Python is a relatively common task — especially when creating distribution data for histograms.
Say we have a list ['b', 'b', 'a'] — we have two occurrences of «b» and one of «a». This guide will show you three different ways to count the number of word occurrences in a Python list:
- Using Pandas and NumPy
- Using the
count()Function - Using the Collection Module’s
Counter - Using a Loop and a Counter Variable
In practice, you’ll use Pandas/Numpy, the count() function or a Counter as they’re pretty convenient to use.
Using Pandas and NumPy
The shortest and easiest way to get value counts in an easily-manipulable format (DataFrame) is via NumPy and Pandas. We can wrap the list into a NumPy array, and then call the value_counts() method of the pd instance (which is also available for all DataFrame instances):
import numpy as np
import pandas as pd
words = ['hello', 'goodbye', 'howdy', 'hello', 'hello', 'hi', 'bye']
pd.value_counts(np.array(words))
This results in a DataFrame that contains:
hello 3
goodbye 1
bye 1
howdy 1
hi 1
dtype: int64
You can access its values field to get the counts themselves, or index to get the words themselves:
df = pd.value_counts(np.array(words))
print('Index:', df.index)
print('Values:', df.values)
This results in:
Index: Index(['hello', 'goodbye', 'bye', 'howdy', 'hi'], dtype='object')
Values: [3 1 1 1 1]
Using the count() Function
The «standard» way (no external libraries) to get the count of word occurrences in a list is by using the list object’s count() function.
The count() method is a built-in function that takes an element as its only argument and returns the number of times that element appears in the list.
The complexity of the
count()function is O(n), wherenis the number of factors present in the list.
The code below uses count() to get the number of occurrences for a word in a list:
words = ['hello', 'goodbye', 'howdy', 'hello', 'hello', 'hi', 'bye']
print(f'"hello" appears {words.count("hello")} time(s)')
print(f'"howdy" appears {words.count("howdy")} time(s)')
This should give us the same output as before using loops:
"hello" appears 3 time(s)
"howdy" appears 1 time(s)
The count() method offers us an easy way to get the number of word occurrences in a list for each individual word.
Using the Collection Module’s Counter
The Counter class instance can be used to, well, count instances of other objects. By passing a list into its constructor, we instantiate a Counter which returns a dictionary of all the elements and their occurrences in a list.
From there, to get a single word’s occurrence you can just use the word as a key for the dictionary:
from collections import Counter
words = ['hello', 'goodbye', 'howdy', 'hello', 'hello', 'hi', 'bye']
word_counts = Counter(words)
print(f'"hello" appears {word_counts["hello"]} time(s)')
print(f'"howdy" appears {word_counts["howdy"]} time(s)')
This results in:
"hello" appears 3 time(s)
"howdy" appears 1 time(s)
Using a Loop and a Counter Variable
Ultimately, a brute force approach that loops through every word in the list, incrementing a counter by one when the word is found, and returning the total word count will work!
Check out our hands-on, practical guide to learning Git, with best-practices, industry-accepted standards, and included cheat sheet. Stop Googling Git commands and actually learn it!
Of course, this method gets more inefficient as the list size grows, it’s just conceptually easy to understand and implement.
The code below uses this approach in the count_occurrence() method:
def count_occurrence(words, word_to_count):
count = 0
for word in words:
if word == word_to_count:
# update counter variable
count = count + 1
return count
words = ['hello', 'goodbye', 'howdy', 'hello', 'hello', 'hi', 'bye']
print(f'"hello" appears {count_occurrence(words, "hello")} time(s)')
print(f'"howdy" appears {count_occurrence(words, "howdy")} time(s)')
If you run this code you should see this output:
"hello" appears 3 time(s)
"howdy" appears 1 time(s)
Nice and easy!
Most Efficient Solution?
Naturally — you’ll be searching for the most efficient solution if you’re dealing with a large corpora of words. Let’s benchmark all of these to see how they perform.
The task can be broken down into finding occurrences for all words or a single word, and we’ll be doing benchmarks for both, starting with all words:
import numpy as np
import pandas as pd
import collections
def pdNumpy(words):
def _pdNumpy():
return pd.value_counts(np.array(words))
return _pdNumpy
def countFunction(words):
def _countFunction():
counts = []
for word in words:
counts.append(words.count(word))
return counts
return _countFunction
def counterObject(words):
def _counterObject():
return collections.Counter(words)
return _counterObject
import timeit
words = ['hello', 'goodbye', 'howdy', 'hello', 'hello', 'hi', 'bye']
print("Time to execute:n")
print("Pandas/Numpy: %ss" % timeit.Timer(pdNumpy(words)).timeit(1000))
print("count(): %ss" % timeit.Timer(countFunction(words)).timeit(1000))
print("Counter: %ss" % timeit.Timer(counterObject(words)).timeit(1000))
Which results in:
Time to execute:
Pandas/Numpy: 0.33886080000047514s
count(): 0.0009540999999444466s
Counter: 0.0019409999995332328s
The count() method is extremely fast compared to the other variants, however, it doesn’t give us the labels associated with the counts like the other two do.
If you need the labels — the Counter outperforms the inefficient process of wrapping the list in a NumPy array and then counting.
On the other hand, you can make use of DataFrame’s methods for sorting or other manipulation that you can’t do otherwise. Counter has some unique methods as well.
Ultimately, you can use the Counter to create a dictionary and turn the dictionary into a DataFrame as as well, to leverage the speed of Counter and the versatility of DataFrames:
df = pd.DataFrame.from_dict([Counter(words)]).T
If you don’t need the labels — count() is the way to go.
Alternatively, if you’re looking for a single word:
import numpy as np
import pandas as pd
import collections
def countFunction(words, word_to_search):
def _countFunction():
return words.count(word_to_search)
return _countFunction
def counterObject(words, word_to_search):
def _counterObject():
return collections.Counter(words)[word_to_search]
return _counterObject
def bruteForce(words, word_to_search):
def _bruteForce():
counts = []
count = 0
for word in words:
if word == word_to_search:
# update counter variable
count = count + 1
counts.append(count)
return counts
return _bruteForce
import timeit
words = ['hello', 'goodbye', 'howdy', 'hello', 'hello', 'hi', 'bye']
print("Time to execute:n")
print("count(): %ss" % timeit.Timer(countFunction(words, 'hello')).timeit(1000))
print("Counter: %ss" % timeit.Timer(counterObject(words, 'hello')).timeit(1000))
print("Brute Force: %ss" % timeit.Timer(bruteForce(words, 'hello')).timeit(1000))
Which results in:
Time to execute:
count(): 0.0001573999998072395s
Counter: 0.0019498999999996158s
Brute Force: 0.0005682000000888365s
The brute force search and count() methods outperform the Counter, mainly because the Counter inherently counts all words instead of one.
Conclusion
In this guide, we explored finding the occurrence of the word in a Python list, assessing the efficiency of each solution and weighing when each is more suitable.
In this tutorial, you’ll learn how to use Python to count the number of words and word frequencies in both a string and a text file. Being able to count words and word frequencies is a useful skill. For example, knowing how to do this can be important in text classification machine learning algorithms.
By the end of this tutorial, you’ll have learned:
- How to count the number of words in a string
- How to count the number of words in a text file
- How to calculate word frequencies using Python
Reading a Text File in Python
The processes to count words and calculate word frequencies shown below are the same for whether you’re considering a string or an entire text file. Because of this, this section will briefly describe how to read a text file in Python.
If you want a more in-depth guide on how to read a text file in Python, check out this tutorial here. Here is a quick piece of code that you can use to load the contents of a text file into a Python string:
# Reading a Text File in Python
file_path = '/Users/datagy/Desktop/sample_text.txt'
with open(file_path) as file:
text = file.read()I encourage you to check out the tutorial to learn why and how this approach works. However, if you’re in a hurry, just know that the process opens the file, reads its contents, and then closes the file again.
Count Number of Words In Python Using split()
One of the simplest ways to count the number of words in a Python string is by using the split() function. The split function looks like this:
# Understanding the split() function
str.split(
sep=None # The delimiter to split on
maxsplit=-1 # The number of times to split
)By default, Python will consider runs of consecutive whitespace to be a single separator. This means that if our string had multiple spaces, they’d only be considered a single delimiter. Let’s see what this method returns:
# Splitting a string with .split()
text = 'Welcome to datagy! Here you will learn Python and data science.'
print(text.split())
# Returns: ['Welcome', 'to', 'datagy!', 'Here', 'you', 'will', 'learn', 'Python', 'and', 'data', 'science.']We can see that the method now returns a list of items. Because we can use the len() function to count the number of items in a list, we’re able to generate a word count. Let’s see what this looks like:
# Counting words with .split()
text = 'Welcome to datagy! Here you will learn Python and data science.'
print(len(text.split()))
# Returns: 11Count Number of Words In Python Using Regex
Another simple way to count the number of words in a Python string is to use the regular expressions library, re. The library comes with a function, findall(), which lets you search for different patterns of strings.
Because we can use regular expression to search for patterns, we must first define our pattern. In this case, we want patterns of alphanumeric characters that are separated by whitespace.
For this, we can use the pattern w+, where w represents any alphanumeric character and the + denotes one or more occurrences. Once the pattern encounters whitespace, such as a space, it will stop the pattern there.
Let’s see how we can use this method to generate a word count using the regular expressions library, re:
# Counting words with regular expressions
import re
text = 'Welcome to datagy! Here you will learn Python and data science.'
print(len(re.findall(r'w+', text)))
# Returns: 11Calculating Word Frequencies in Python
In order to calculate word frequencies, we can use either the defaultdict class or the Counter class. Word frequencies represent how often a given word appears in a piece of text.
Using defaultdict To Calculate Word Frequencies in Python
Let’s see how we can use defaultdict to calculate word frequencies in Python. The defaultdict extend on the regular Python dictionary by providing helpful functions to initialize missing keys.
Because of this, we can loop over a piece of text and count the occurrences of each word. Let’s see how we can use it to create word frequencies for a given string:
# Creating word frequencies with defaultdict
from collections import defaultdict
import re
text = 'welcome to datagy! datagy will teach data. data is fun. data data data!'
counts = defaultdict(int)
for word in re.findall('w+', text):
counts[word] += 1
print(counts)
# Returns:
# defaultdict(<class 'int'>, {'welcome': 1, 'to': 1, 'datagy': 2, 'will': 1, 'teach': 1, 'data': 5, 'is': 1, 'fun': 1})Let’s break down what we did here:
- We imported both the
defaultdictfunction and therelibrary - We loaded some text and instantiated a defaultdict using the
intfactory function - We then looped over each word in the word list and added one for each time it occurred
Using Counter to Create Word Frequencies in Python
Another way to do this is to use the Counter class. The benefit of this approach is that we can even easily identify the most frequent word. Let’s see how we can use this approach:
# Creating word frequencies with Counter
from collections import Counter
import re
text = 'welcome to datagy! datagy will teach data. data is fun. data data data!'
counts = Counter(re.findall('w+', text))
print(counts)
# Returns:
# Counter({'data': 5, 'datagy': 2, 'welcome': 1, 'to': 1, 'will': 1, 'teach': 1, 'is': 1, 'fun': 1})Let’s break down what we did here:
- We imported our required libraries and classes
- We passed the resulting list from the
findall()function into theCounterclass - We printed the result of this class
One of the perks of this is that we can easily find the most common word by using the .most_common() function. The function returns a sorted list of tuples, ordering the items from most common to least common. Because of this, we can simply access the 0th index to find the most common word:
# Finding the Most Common Word
from collections import Counter
import re
text = 'welcome to datagy! datagy will teach data. data is fun. data data data!'
counts = Counter(re.findall('w+', text))
print(counts.most_common()[0])
# Returns:
# ('data', 5)Conclusion
In this tutorial, you learned how to generate word counts and word frequencies using Python. You learned a number of different ways to count words including using the .split() method and the re library. Then, you learned different ways to generate word frequencies using defaultdict and Counter. Using the Counter method, you were able to find the most frequent word in a string.
Additional Resources
To learn more about related topics, check out the tutorials below:
- Python
str.split()– Official Documentation - Python Defaultdict: Overview and Examples
- Python: Count Number of Occurrences in List (6 Ways)
- Python: Count Number of Occurrences in a String (4 Ways!)
Last update on August 19 2022 21:50:47 (UTC/GMT +8 hours)
Python String: Exercise-12 with Solution
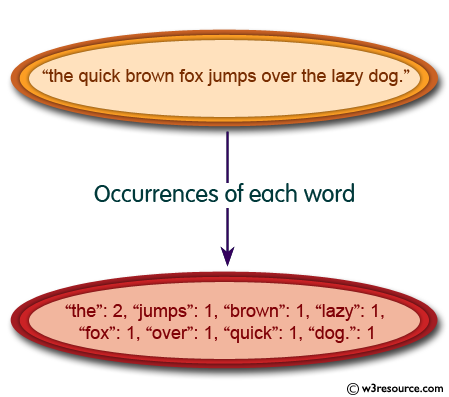
Write a Python program to count the occurrences of each word in a given sentence.
Sample Solution:-
Python Code:
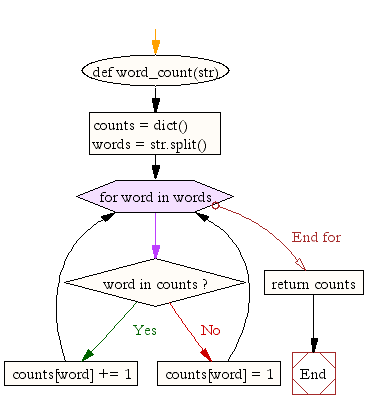
def word_count(str):
counts = dict()
words = str.split()
for word in words:
if word in counts:
counts[word] += 1
else:
counts[word] = 1
return counts
print( word_count('the quick brown fox jumps over the lazy dog.'))
Sample Output:
{'the': 2, 'jumps': 1, 'brown': 1, 'lazy': 1, 'fox': 1, 'over': 1, 'quick': 1, 'dog.': 1}
Flowchart:
Visualize Python code execution:
The following tool visualize what the computer is doing step-by-step as it executes the said program:
Python Code Editor:
Have another way to solve this solution? Contribute your code (and comments) through Disqus.
Previous: Write a Python program to remove the characters which have odd index values of a given string.
Next: Write a Python script that takes input from the user and displays that input back in upper and lower cases.
What is the difficulty level of this exercise?
Test your Programming skills with w3resource’s quiz.
Python: Tips of the Day
Converts a string to kebab case:
Example:
from re import sub
def tips_kebab(s):
return sub(
r"(s|_|-)+","-",
sub(
r"[A-Z]{2,}(?=[A-Z][a-z]+[0-9]*|b)|[A-Z]?[a-z]+[0-9]*|[A-Z]|[0-9]+",
lambda mo: mo.group(0).lower(), s))
print(tips_kebab('sentenceCase'))
print(tips_kebab('Python Tutorial'))
print(tips_kebab('the-quick_brown Fox jumps_over-the-lazy Dog'))
print(tips_kebab('hello-world'))
Output:
sentencecase python-tutorial the-quick-brown-fox-jumps-over-the-lazy-dog hello-world
- Weekly Trends
- Java Basic Programming Exercises
- SQL Subqueries
- Adventureworks Database Exercises
- C# Sharp Basic Exercises
- SQL COUNT() with distinct
- JavaScript String Exercises
- JavaScript HTML Form Validation
- Java Collection Exercises
- SQL COUNT() function
- SQL Inner Join
- JavaScript functions Exercises
- Python Tutorial
- Python Array Exercises
- SQL Cross Join
- C# Sharp Array Exercises