
This article will demonstrate how to convert a PDF to Word document with a 3rd party free Java API.
Import JAR Dependency (2 Methods)
● Download the Free API (Free Spire.PDF for Java) and unzip it, then add the Spire.Pdf.jar file to your project as dependency.
● Directly add the jar dependency to maven project by adding the following configurations to the pom.xml.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>http://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf.free</artifactId>
<version>3.9.0</version>
</dependency>
</dependencies>
Enter fullscreen mode
Exit fullscreen mode
The original PDF document is shown as below:

Code Snippet
import com.spire.pdf.*;
public class ConvertPDF {
public static void main(String[] args) {
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load the sample PDF file
doc.loadFromFile("C:\Users\Administrator\Desktop\The Scarlet Letter.pdf");
//Save as .doc file
doc.saveToFile("output/ToDoc.doc",FileFormat.DOC);
//Save as. docx file
doc.saveToFile("output/ToDocx.docx",FileFormat.DOCX);
doc.close();
}
}
Enter fullscreen mode
Exit fullscreen mode
The output Word document:

How can I convert a pdf file to word file using Java?
And, is it as easy as it looks like?
![]()
Deduplicator
44.3k7 gold badges65 silver badges115 bronze badges
asked Aug 1, 2013 at 6:05
![]()
7
Try PDFBOX
public class PDFTextReader
{
static String pdftoText(String fileName) {
PDFParser parser;
String parsedText = null;
PDFTextStripper pdfStripper = null;
PDDocument pdDoc = null;
COSDocument cosDoc = null;
File file = new File(fileName);
if (!file.isFile()) {
System.err.println("File " + fileName + " does not exist.");
return null;
}
try {
parser = new PDFParser(new FileInputStream(file));
} catch (IOException e) {
System.err.println("Unable to open PDF Parser. " + e.getMessage());
return null;
}
try {
parser.parse();
cosDoc = parser.getDocument();
pdfStripper = new PDFTextStripper();
pdDoc = new PDDocument(cosDoc);
parsedText = pdfStripper.getText(pdDoc);
} catch (Exception e) {
System.err
.println("An exception occured in parsing the PDF Document."
+ e.getMessage());
} finally {
try {
if (cosDoc != null)
cosDoc.close();
if (pdDoc != null)
pdDoc.close();
} catch (Exception e) {
e.printStackTrace();
}
}
return parsedText;
}
public static void main(String args[]){
try {
String content = pdftoText(PDF_FILE_PATH);
File file = new File("/sample/filename.txt");
// if file doesnt exists, then create it
if (!file.exists()) {
file.createNewFile();
}
FileWriter fw = new FileWriter(file.getAbsoluteFile());
BufferedWriter bw = new BufferedWriter(fw);
bw.write(content);
bw.close();
System.out.println("Done");
} catch (IOException e) {
e.printStackTrace();
}
}
}
answered Aug 1, 2013 at 6:15
![]()
newusernewuser
8,2882 gold badges25 silver badges33 bronze badges
16
I have looked deeply into this matter and I found that for proper results, you need cannot avoid using MS Word. Even funded projects such as LibreOffice struggle with the proper conversion as the Word format is rather complex and changes over the versions. Only MS Word keeps track of this.
For this reason, I implemented documents4j what delegates conversions to MS Word using a Java API. Furthermore, it allows you to move the conversions to a different machine which you can contact using a REST API. You find detailed information on its GitHub page.
answered Aug 27, 2014 at 20:42
![]()
2
Nowadays, it is not difficult to convert PDF documents into Word files using a software. However, if you want to maintain the layout and even the font formatting while converting, it is not something that every software can accomplish. Spire.PDF for Java does it well and offers you the following two modes when converting PDF to Word in Java.
- Convert PDF to Doc/Docx with Fixed Layout
- Convert PDF to Doc/Docx with Flowable Structure
Fixed Layout mode has fast conversion speed and is conducive to maintaining the original appearance of PDF files to the greatest extent. However, the editability of the resulting document will be limited since each line of text in PDF will be presented in a separate frame in the generated Word document.
Flowable Structure is a full recognition mode. The converted content will not be presented in frames, and the structure of the resulting document is flowable. The generated Word document is easy to re-edit but may look different from the original PDF file.
Install Spire.PDF for Java
First, you’re required to add the Spire.Pdf.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project’s pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>9.3.11</version>
</dependency>
</dependencies>
Convert PDF to Doc/Docx with Fixed Layout
The following are the steps to convert PDF to Doc or Docx with fixed layout.
- Create a PdfDocument object.
- Load a PDF file using PdfDocument.loadFromFile() method.
- Convert the PDF document to a Doc or Docx format file using PdfDocument.saveToFile(String fileName, FileFormat fileFormat) method.
- Java
import com.spire.pdf.FileFormat;
import com.spire.pdf.PdfDocument;
public class ConvertPdfToWordWithFixedLayout {
public static void main(String[] args) {
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a sample PDF document
doc.loadFromFile("C:\Users\Administrator\Desktop\sample.pdf");
//Convert PDF to Doc and save it to a specified path
doc.saveToFile("output/ToDoc.doc", FileFormat.DOC);
//Convert PDF to Docx and save it to a specified path
doc.saveToFile("output/ToDocx.docx", FileFormat.DOCX);
doc.close();
}
}
Convert PDF to Doc/Docx with Flowable Structure
The following are the steps to convert PDF to Doc or Docx with flowable structure.
- Create a PdfDocument object.
- Load a PDF file using PdfDocument.loadFromFile() method.
- Set the conversion mode as flow using PdfDocument. getConvertOptions().setConvertToWordUsingFlow() method.
- Convert the PDF document to a Doc or Docx format file using PdfDocument.saveToFile(String fileName, FileFormat fileFormat) method.
- Java
import com.spire.pdf.FileFormat;
import com.spire.pdf.PdfDocument;
public class ConvertPdfToWordWithFlowableStructure {
public static void main(String[] args) {
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a sample PDF document
doc.loadFromFile("C:\Users\Administrator\Desktop\sample.pdf");
//Convert PDF to Word with flowable structure
doc.getConvertOptions().setConvertToWordUsingFlow(true);
//Convert PDF to Doc
doc.saveToFile("output/ToDoc.doc", FileFormat.DOC);
//Convert PDF to Docx
doc.saveToFile("output/ToDocx.docx", FileFormat.DOCX);
doc.close();
}
}
Apply for a Temporary License
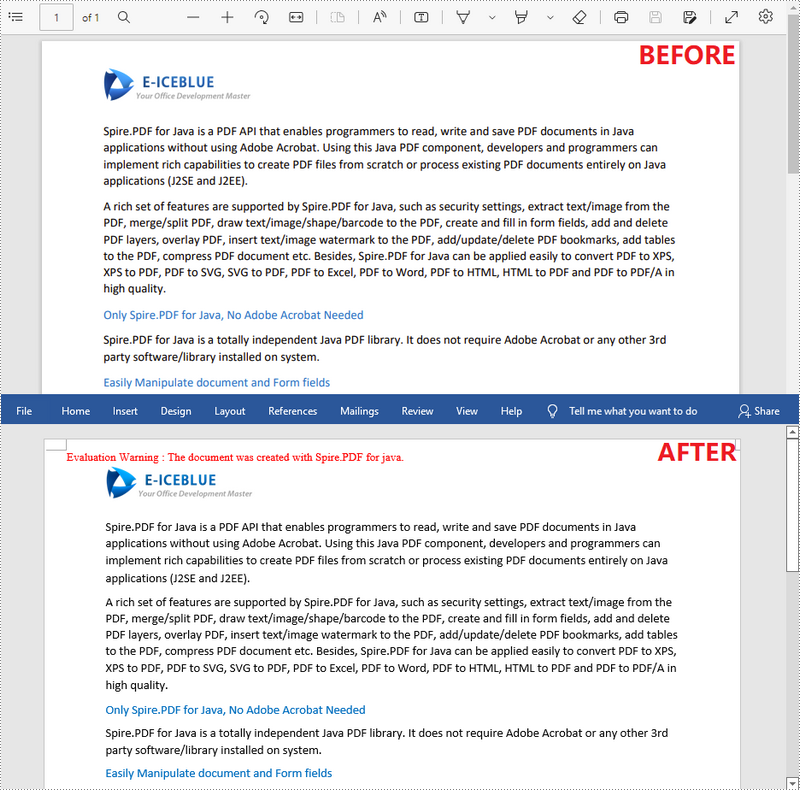
If you’d like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
- Введение
- Ссылки на Maven
- Преобразования из PDF в HTML
- PDF в HTML
- HTML в PDF
- Преобразование PDF в изображение
- PDF в изображение
- Изображение в PDF
- Преобразования PDF в текст
- PDF в текст
- Текст в PDF
- Преобразования PDF в Docx
- Коммерческие библиотеки для преобразования PDF в X
- Заключение
В этой статье мы расскажем о программном преобразовании PDF- файлов в Java. Опишем, как сохранять PDF-файлы в PNG или JPEG, Microsoft Word, экспортировать в HTML. А также как извлекать из них текст, используя библиотеки Java с открытым исходным кодом.
Первая библиотека, которую мы рассмотрим, Pdf2Dom. Начнём с добавления зависимостей Maven в наш проект:
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox-tools</artifactId>
<version>2.0.3</version>
</dependency>
<dependency>
<groupId>net.sf.cssbox</groupId>
<artifactId>pdf2dom</artifactId>
<version>1.6</version>
</dependency>
Мы будем использовать первую зависимость для загрузки выбранного PDF-файла. Вторая зависимость отвечает непосредственно за преобразование. Актуальные версии библиотек доступны по следующим ссылкам: pdfbox-tools и pdf2dom.
Кроме этого мы будем использовать iText для извлечения текста из PDF-файла и POI для создания документа в формате .docx.
Рассмотрим зависимости Maven, которые нужно добавить в проект:
<dependency>
<groupId>com.itextpdf</groupId>
<artifactId>itextpdf</artifactId>
<version>5.5.10</version>
</dependency>
<dependency>
<groupId>com.itextpdf.tool</groupId>
<artifactId>xmlworker</artifactId>
<version>5.5.10</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>3.15</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-scratchpad</artifactId>
<version>3.15</version>
</dependency>
Актуальная версия iText доступна здесь, а Apache POI здесь.
Для работы с файлами HTML используйте Pdf2Dom. Это парсер PDF, преобразующий документы в представление HTML DOM.
Чтобы преобразовать PDF в HTML, применяется библиотека XMLWorker, входящая в состав iText.
Рассмотрим простое преобразование из PDF в HTML:
private void generateHTMLFromPDF(String filename) {
PDDocument pdf = PDDocument.load(new File(filename));
Writer output = new PrintWriter("src/output/pdf.html", "utf-8");
new PDFDomTree().writeText(pdf, output);
output.close();
}
В приведенном выше примере мы загрузили PDF-файл, используя API от PDFBox. После этого мы применили парсер для разбора файла и вывода результата с помощью java.io.Writer.
Обратите внимание, что преобразование PDF в HTML не является на 100% точным. Результат зависят от сложности и структуры конкретного PDF-файла.
Теперь рассмотрим преобразование HTML в PDF:
private static void generatePDFFromHTML(String filename) {
Document document = new Document();
PdfWriter writer = PdfWriter.getInstance(document,
new FileOutputStream("src/output/html.pdf"));
document.open();
XMLWorkerHelper.getInstance().parseXHtml(writer, document,
new FileInputStream(filename));
document.close();
}
При преобразовании HTML в PDF нужно убедиться, что все теги правильно открываются и закрываются. Иначе PDF-документ не будет создан.
Есть много способов преобразовать PDF-файл в изображение. Одно из наиболее популярных решений – библиотека с открытым исходным кодом Apache PDFBox. Для преобразования изображения в PDF-документ мы снова используем iText.
Для конвертации используем зависимость pdfbox-tools, упомянутую в предыдущих разделах. Рассмотрим следующий пример:
private void generateImageFromPDF(String filename, String extension) {
PDDocument document = PDDocument.load(new File(filename));
PDFRenderer pdfRenderer = new PDFRenderer(document);
for (int page = 0; page < document.getNumberOfPages(); ++page) {
BufferedImage bim = pdfRenderer.renderImageWithDPI(
page, 300, ImageType.RGB);
ImageIOUtil.writeImage(
bim, String.format("src/output/pdf-%d.%s", page + 1, extension), 300);
}
document.close();
}
В приведенном примере PDFRenderer применяется, чтобы отрисовать PDF как BufferedImage. При этом каждая страница PDF- файла должна быть отрисована отдельно.
Также мы используем ImageIOUtil из Apache PDFBox Tools для записи изображения в файл с указанным расширением. Поддерживаемые форматы: jpeg, jpg, gif, tiff или png.
Apache PDFBox – это продвинутый инструмент. Он позволяет создавать PDF-файлы с нуля, заполнять формы внутри PDF-файла, подписывать и шифровать его содержимое.
Рассмотрим следующий пример:
private static void generatePDFFromImage(String filename, String extension) {
Document document = new Document();
String input = filename + "." + extension;
String output = "src/output/" + extension + ".pdf";
FileOutputStream fos = new FileOutputStream(output);
PdfWriter writer = PdfWriter.getInstance(document, fos);
writer.open();
document.open();
document.add(Image.getInstance((new URL(input))));
document.close();
writer.close();
}
Расширения выходного файла могут быть следующими: jpeg, jpg, gif, tiff или png.
Чтобы извлечь текст из PDF-файла, нам снова понадобится Apache PDFBox. Для преобразования текста в PDF мы будем использовать iText.
Мы создадим метод generateTxtFromPDF(…) и разделим его код на три функциональных части: загрузка PDF, извлечение текста и создание итогового файла.
Начнём с загрузки PDF:
File f = new File(filename); String parsedText; PDFParser parser = new PDFParser(new RandomAccessFile(f, "r")); parser.parse();
Чтобы прочитать PDF-файл, используем PDFParser с флагом r (read). А также метод parser.parse(), который разберёт файл в поток и создаст из него объект COSDocument.
Часть кода, отвечающая за извлечение текста:
COSDocument cosDoc = parser.getDocument(); PDFTextStripper pdfStripper = new PDFTextStripper(); PDDocument pdDoc = new PDDocument(cosDoc); parsedText = pdfStripper.getText(pdDoc);
Сначала мы сохраняем объект COSDocument в переменную cosDoc. Затем он будет использован для создания PDDocument, который является представлением PDF-документа в памяти. После этого используем PDFTextStripper, чтобы вернуть документ с текстом. В конце вызываем метод close(), чтобы закрыть все использованные потоки.
В последней части метода мы сохраним текст в созданный файл с помощью класса PrintWriter:
PrintWriter pw = new PrintWriter("src/output/pdf.txt");
pw.print(parsedText);
pw.close();
Преобразование текстовых файлов в PDF – операция с подвохом. Чтобы сохранить форматирование исходного файла, необходимо применить дополнительные правила.
В следующем примере мы определяем размер страницы PDF-файла, версию и выходной файл:
Document pdfDoc = new Document(PageSize.A4);
PdfWriter.getInstance(pdfDoc, new FileOutputStream("src/output/txt.pdf"))
.setPdfVersion(PdfWriter.PDF_VERSION_1_7);
pdfDoc.open();
Затем задаем шрифт, а также символ для разделения параграфов:
Font myfont = new Font();
myfont.setStyle(Font.NORMAL);
myfont.setSize(11);
pdfDoc.add(new Paragraph("n"));
После этого добавляем параграфы в созданный PDF-файл:
BufferedReader br = new BufferedReader(new FileReader(filename));
String strLine;
while ((strLine = br.readLine()) != null) {
Paragraph para = new Paragraph(strLine + "n", myfont);
para.setAlignment(Element.ALIGN_JUSTIFIED);
pdfDoc.add(para);
}
pdfDoc.close();
br.close();
Чтобы создать файл Microsoft Word из PDF-файла, понадобятся две библиотеки с открытым исходным кодом: iText – для извлечения текста из PDF- файла, POI – для создания документа в формате .docx.
Рассмотрим код, предназначенный для загрузки PDF-файла:
XWPFDocument doc = new XWPFDocument(); String pdf = filename; PdfReader reader = new PdfReader(pdf); PdfReaderContentParser parser = new PdfReaderContentParser(reader);
После загрузки PDF-файла необходимо прочитать и отрисовать каждую страницу отдельно, а затем записать результат в файл:
for (int i = 1; i <= reader.getNumberOfPages(); i++) {
TextExtractionStrategy strategy =
parser.processContent(i, new SimpleTextExtractionStrategy());
String text = strategy.getResultantText();
XWPFParagraph p = doc.createParagraph();
XWPFRun run = p.createRun();
run.setText(text);
run.addBreak(BreakType.PAGE);
}
FileOutputStream out = new FileOutputStream("src/output/pdf.docx");
doc.write(out);
// Закрыть все открытые файлы
В предыдущих разделах статьи мы рассмотрели библиотеки с открытым исходным кодом. Кроме них существуют и платные решения:
- jPDFImages – позволяет создавать изображения из страниц PDF-документа и экспортировать их в изображения JPEG, TIFF или PNG.
- JPEDAL – мощная библиотека, используемая в SDK для печати, просмотра и преобразования файлов.
- pdfcrowd – библиотека, предназначенная для преобразования из Web/HTML в PDF и из PDF в Web/HTML.
В этой статье мы обсудили пути преобразование PDF-файлов в различные форматы. Полный код примеров, приведенных в данной публикации, доступен на GitHub.
Пожалуйста, опубликуйте ваши комментарии по текущей теме материала. За комментарии, отклики, подписки, лайки, дизлайки низкий вам поклон!