
I. Read the word combinations and translate them into Russian
to
transport people and cargo, orbital velocity, Earth’s surface, liquid
hydrogen, liquid oxygen, to exhaust the propellants, for reuse, a
winged orbiter, cargo bay, to put into service, cosmic objects,
entire system, to jettison the boosters, a replacement orbiter, for
assembly, astronaut crew, to release the tank, to disintegrate on
reentering the atmosphere.
II. Make up the word combinations
|
1. winged 2. orbital 3. reusable 4.unpowered 5. weightless 6. solid 7. pressurized 8. orbiting 9. booster 10. |
a)
b)
c) d) tank
e)
f)
g)
h)
i)
j) |
III. Fill in the missing words (jettisoned, liftoff, thrust, unpowered, an external tank, returned)
1. At …
the entire system weighs 2 million kilograms.
2. The U.S.
space shuttle consists of three major components: a winged orbiter, …
and a pair of strap-on booster rockets.
3. During
launch the boosters and the orbiter’s main engines produce about
31,000 kilonewtons of … .
4. After liftoff the boosters
are … and are … to Earth by parachute for reuse.
5. The orbiter makes an …
descent and landing similar to a glider.
IV. Find synonyms in the list of words
major, to meet, cargo, to
transport, load, main, to rendezvous, launch, team, to lift off,
entire, to reach, to fly off, crew, whole, liftoff, to attain, to
ferry.
V. Find antonyms in the list of words
partially,
expendable, to jettison, to increase, completely, vertically, to
return, internal, to lift off, reusable, to land, horizontally,
external, to keep, to leave, to reduce.
VI. Agree or disagree with the following statements
1.
Space shuttle is not designed to
transport people and cargo to and from orbiting spacecraft.
2. At liftoff the entire
system weighs 2 million kilograms.
3. After
the boosters are jettisoned about two minutes after liftoff, they
don’t return to Earth.
4. Space shuttle combines the
features of an expendable rocket launcher and a glider.
5. Since the invention of
space shuttle the high cost of spaceflight was reduced.
VII. Match the questions with the answers
|
1. When |
а) |
|
2. Who |
b) |
|
3. When |
c) |
|
4. What |
d) |
|
5. What |
e) |
VIII. Answer the questions
1. What is
a space shuttle?
2. What does it consist of?
3. What happens during the
liftoff?
4. Can you describe the
process of flight?
5. What is
space shuttle used for?
6. Which
purpose was shuttle designed for?
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
© 2023 Prezi Inc.
Terms & Privacy Policy
Content Filtering
Pete F. Nicoletti, in Computer and Information Security Handbook (Third Edition), 2013
Bayesian Filters
Particular word combinations and phrases have certain probabilities of occurring together on websites. For instance, the word “breast” can have a number of contexts depending on other words around it. The first could be cooking, as in Chicken Breast, second could be health as in Breast Cancer Awareness, and finally it could be porn. Bayesian analysis, as it is used in website content categorization, looks for patterns such as the words breast, cooking, baking, seasoning, degrees, and recipe. In this example the website would be classified as food related. While Bayesian analysis works well for this purpose, there is a drawback that it needs to be trained to recognize these patterns. To train the filter, the user or external “grader” must manually indicate whether a new website is a porn site, cooking site, or health care–related site. Eventually, the filter will learn enough from the training process to make decisions on its own and can continue to learn new word patterns without too much human tuning. Typically, most fee-based subscription services, such as the ones we will explore later in this chapter, have gone through the process of training their filters, so you would not have to.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780128038437000879
Content Filtering
Pete Nicoletti CISSP, CISA, CCSK, in Computer and Information Security Handbook (Second Edition), 2013
Bayesian Filters
Particular word combinations and phrases have certain probabilities of occurring together on Web sites. For instance, the word “breast” can have a number of contexts depending on other words around it. The first could be cooking, as in Chicken Breast, second could be health as in Breast Cancer Awareness, and finally it could be porn. Bayesian Analysis, as it is used in web site content categorization, looks for patterns such as the words: breast, cooking, baking, seasoning, degrees, recipe. In this example the website would be classified as food related. While Bayesian analysis works well for this purpose there is a drawback which is it needs to be trained to recognize these patterns. To train the filter, the user or external “grader” must manually indicate whether a new web site is a porn site, cooking site or healthcare related site. Eventually, the filter will learn enough from the training process to make decisions on it’s own and can continue to learn new word patterns without too much human tuning. Typically most fee based subscription services, such as the ones we will explore later in this chapter, have gone through the process of training their filters, so you won’t have to.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780123943972000933
Emerging Business Intelligence Trends
David Loshin, in Business Intelligence (Second Edition), 2013
Entity Recognition and Entity Extraction
A consequence of the growing flood of unstructured artifacts is the challenge in isolating key terms in text (such as people, places, and things) and establishing linkages and relationships among those concepts. “Real-time” entity identity recognition has traditionally been a batch process, but time-critical operations relating to online comments, customer service, call center operations, or more sensitive activities involving security, bank secrecy act/anti–money laundering, or other “persons of interest” applications become significantly more effective when individual identities can be recognized in real time.
Entity recognition in text is a specific pattern analysis task of scanning word sequences and isolating phrases and word combinations that represent recognized named entities (either parties, named locations, items, etc.). While this may sound simplistic, the challenge goes beyond scanning text strings and looking for name patterns in sequential text. The complexity increases in relation to the desire to isolate entity relationships embedded (and sometimes implicit) within the text.
This builds on natural language processing concepts coupled with semantics and taxonomies to expose explicit relationships (such as an individual’s affinity for a particular charity), causal relationships (such as correlation of product issues within geographical regions), or multiple references to the same entity (such as the introduction of pronouns like “He” or “It” that refer to named entities with proper nouns such as “George Washington”). It also requires matching string patterns to items within organized hierarchies (such as recognizing that “electric drill” is a concept contained within a set of items referred to as “power tools”).
In fact, entity recognition and extraction is not limited to text; there are entity recognition algorithms that can be applied to visual media (such as streaming video or images) and to audio as well. Real-time identity recognition enables rapid linkage between individuals and their related attributes, characteristics, profiles, and transaction histories, and can be used in real-time embedded predictive models to enhance operational decision-making.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B978012385889400020X
Keeping up to date and being competent
Julia Gross, in Building Your Library Career with Web 2.0, 2012
Describing (tagging) bookmarks
The key to unlocking the potential of social bookmarking is to effectively describe your bookmarked links at the point when you save them on Delicious or Diigo. You do this by tagging each bookmark. When you save a bookmark to Delicious or Diigo the system offers you the option to tag (assign keywords) and add some personal notes and a description of each link. Tags are similar to keywords and they provide the metadata that is crucial for later retrieval.
Note that tags should be entered as one word without any commas. Multi-word phrases must be linked together to form one word. So, for example, the two words ‘career development’ would become the tag: ‘career_development’ or ‘careerdevelopment’ or other one-word combinations.
It does not matter how you combine multiple terms, but do not leave them as separate words, or the system will make separate tags out of them. There is no limit to the number of tags you can add for each bookmark, so use the tagging function liberally. The true librarian in you will relish the describing and organising aspect of social bookmarking. Be quite thorough at this stage – a disorganised social book-marking account will only confuse you when you go back in later. The time spent tagging bookmarks at the outset will save you time later. What tag should you use? You may have your own schema that you use for other Web 2.0 sites. Try to be systematic here so you do not have to do a clean-up later. However, on both Delicious and Diigo you can go back and edit your saved bookmarks and add new tags and descriptions later if you wish. This method of making up your own tags is known as a folksonomy and is not meant to be perfect. Folksonomies are systems ‘of classification derived from the practice and method of collaboratively creating and managing tags to annotate and categorize content’ (Wikipedia, folksonomy definition). Once you have a number of tagged bookmarks in your social bookmarking account, start to organise them into groups or lists.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9781843346517500108
Online Community Empowerment, Emotional Connection, and Armed Love in the Black Lives Matter Movement
Joshua Schuschke, Brendesha M. Tynes, in Emotions, Technology, and Social Media, 2016
Community Building Online and Offline
Returning to one of our initial research questions: does the movement’s online community foster offline community building and emotional bonding? We found that even beyond the shared experiences of participants, many feel a familial bond to victims of police violence, offering humanizing tweets and building avenues for connections beyond their online spaces. Movement participants in online discussions are also working to build a more inclusive community, particularly as it pertains to Black LGBTQ members. When looking at the “#BlackLivesMatter Community” (Fig. 2.5) themes, words stemming from “build” were frequently mentioned. In looking at the content of most tweets using this word combination, users tend to call for community uplift and solidarity.

Fig. 2.5. BLM community.
A close relationship between “SayHerName,” “#StopTransMurders,” and “#BlackTransLivesMatter” is an important finding, which shows the movement’s attempt to be more inclusive and provide community for the Black Trans community to get recognition in this movement as their victimization had previously been ignored (Crenshaw et al., 2015). The hashtag “#SayHerName” (Fig. 2.6) was created to raise awareness about police violence against Black women when movement leaders began to realize the male-centered narrative evolving on the national scene. Raising awareness about Black women’s disproportionate victimization at the hands of the state has since been focal point of movement discourse, along with raising awareness of women’s contributions to pushing the movement forward. Therefore, it was not surprising to see words like “forget” and “justice” as frequently associated words with the hashtag.

Fig. 2.6. SayHerName (SHN).
When combining results from all the search inquiries (Fig. 2.7), we found that a number of the hashtags and words associated with the #SayHerName campaign were among the most frequently mentioned content. Hashtags such as #BlackTransLivesMatter and #StopTransMurders were among the most frequently associated words in this analysis, despite their relatively low appearance in the #BlackLivesMatter search. This is potential evidence that the movement has reflexive capabilities (Tynes, Schuschke, & Noble, 2016) to correct itself in offline environments, following the critiques of those pointing out its hetero-patriarchal bias (Garza, 2014). With heavy influence from the #SayHerName hashtag in our aggregate results, we see the intersectional nature and awareness-raising power of the movement as a whole for not just the movement but also for the Black community as a whole.

Fig. 2.7. All searches.
Our findings initially suggest that while both the #BlackLivesMatter and #SayHerName hashtags are popular and influential, they have markedly different purposes. While #SayHerName provided us less qualitative data relating directly to self-love and emotional connection, it provided some insight into community awareness and helped shift the conversation from a male-centered narrative to a more inclusive discussion around police brutality.
Beyond community expansion, intrinsic communal bonds build emotional connections among movement participants that are often represented as familial. In association with the word, “brother” (Fig. 2.8) are the words “rest” and “peace” in reference to “rest in peace” as a condolence to Black male victims of police brutality. This highlights the emotional connection that many feel to the victims, as they feel that they have lost a loved one or a “brother.”

Fig. 2.8. BLM brother.
Continuing with the familial connections, the word “sister” (Fig. 2.9) was also closely connected to “brother” indicating that fictive kin or symbolic kinship may have been forged by members of the community. “Love” (discussed later) was another frequently connected word, which would become a common finding in our frequency analysis of familial and community terms.

Fig. 2.9. BLM sister, SHN brother, SHN community, SHN sister.
With the “#SayHerName Family” (Fig. 2.10) search phrase, we see more association with the word “love.” In this particular case, most were discussing the passing of a loved one. However, a coinciding word that also showed the communal nature of Twitter was the frequent use of the word “help” and the retweeting of tweet asking for help on behalf of a family unable to pay for funeral costs of their loved one. This kind of connection between the family and the larger community in general is continued with “#SayHerName Sister” where words such as “mother,” “daughter,” and “friend” are frequently used to describe victims as a way to humanize them and build emotional bonds with the community at large. “#BlackLivesMatter Sisters” featured word associations frequently mentioned in the #SayHerName search, which raises awareness of cis and transgendered women who are victims of police brutality, along with the reciprocal frequent mention of “brothers.” Perfectly encapsulating this notion is the tweet from @ValerieCarey: She was a mother. She was a daughter. She was a sister. She was a friend. #SayHerName #MiriamCarey.

Fig. 2.10. SHN family.
Moving from the shared experience to the community and family element of BlackLivesMatter discussions on Twitter, we see that not only do participants have a shared cultural experience, but in fact this experience creates community that has intrinsic bonds among members. As highlighted in this section on community building, “love” becomes an emergent theme, indicating the emotional aspect of this movement. Returning to the concept of armed love, we begin to see how emotional needs are met and are advocated through the Black Lives Matter movement.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780128018576000026
Language Acquisition
B.J. MacWhinney, in International Encyclopedia of the Social & Behavioral Sciences, 2001
5 Word Combinations
Throughout the second year, the child struggles with perfecting the sounds and meanings of the first words. For several months, children produces isolated single words. However, eventually they need to go beyond this one-word level. They need to associate predicates such as want, more, or go with arguments such as cookie or Mommy. The association of predicates to arguments is the first step in syntactic development. As in the other areas of language development, these first steps are taken in a very gradual fashion. Before producing a smooth combination of two words such as ‘my horsie’, children will often string together a series of single-word utterances that appear to be searching out some syntactic form. For example, a child might say ‘my, that, that, horsie’ with pauses between each word. Later, the pauses will be gone and the child will say ‘that horsie, my horsie.’ This tentative combination of words involves groping on both intonational and semantic levels. On the one hand, children must figure out how to join words together smoothly in production. On the other hand, they also must figure out which words can meaningfully be combined with which others.
As was the case in the learning of single words, this learning is guided by earlier developments in comprehension. We have to assess children’s early syntactic comprehension by controlled experiments in the laboratory. Here, again, researchers have used the preferential looking paradigm (Golinkoff et al. 1999). To the right of the child, there is a TV monitor with a movie of Big Bird tickling Cookie Monster. To the child’s left, there is a TV monitor with a movie of Cookie Monster tickling Big Bird. The experimenter produces the sentence ‘Big Bird is tickling Cookie Monster.’ If children look at the matching TV monitor, they are reinforced and a correct look is scored. Using this technique, researchers have found that 17-month-olds already have a good idea about the correct word order for English sentences. This is about 5–6 months before they begin to use word order systematically in production.
The grammar of the first word combinations is extremely basic. The child learns that each predicate should appear in a constant position vis-à-vis the arguments it requires. For example, in English, the word more appears before the noun it modifies and the verb run appears after the subject with which it combines. Slot-filler relations can control this basic type of grammatical combination. Each predicate specifies a slot for the argument. For example, more has a slot for a following noun. When a noun, such as milk, is selected to appear with more, that noun becomes a filler for the slot opened up by the word more. The result is the combination ‘more milk.’ Later, the child can treat this whole unit as an argument to the verb want and the result is ‘want more milk.’ Finally, the child can express the second argument of the verb want and the result is ‘I want more milk.’ Thus, bit by bit, children build up longer sentences and a more complex grammar. This level of simple combinatorial grammar is based on individual words as the controlling structures. This type of word-based learning is present even in adults. In languages with strong morphological marking systems, word-based patterns specify the attachment of affixes, rather than just the linear position of words. In fact, most languages of the world make far more use of morphological marking than does English (Slobin 1985). In this regard, English is a rather exotic language.
5.1 Missing Glue
The child’s first sentences are almost all incomplete and ungrammatical. Instead of saying, ‘This is Mommy’s chair’, the child produces only ‘Mommy chair’ with the possessive suffix, the demonstrative, and the copula verb all deleted. Just as the first words are full of phonological deletions and simplifications, the first sentences include only the most important words, without any of the glue. In some cases, children simply have not yet learned the missing words and devices. In other cases, they may know the ‘glue words’ but find it difficult to coordinate the production of so many words in the correct order.
These early omissions provide evidence for two major processes in language development. First, children try to make sure that the most important and substantive parts of the communication are not omitted. Unfortunately, children make this evaluation from their own, egocentric perspective. In an utterance like ‘Mommy chair’ it is not clear whether the child means ‘This is Mommy’s chair’ or ‘Mommy is sitting in the chair’, although the choice between these interpretations may be clear in context (Bloom 1973). The second factor that shapes early omissions is phrasal frequency. Children tend to preserve frequent word combinations, such as ‘like it’ or ‘want some.’ These combinations are often treated as units, producing errors such as ‘I like it the ball’ or ‘I want some a banana.’
5.2 Productivity
Productivity can be demonstrated in the laboratory by teaching children names for new objects. For example, we can show a child a picture of a funny-looking creature and call it a wug. As we noted before, the positioning of the word wug after the article a induces the child to treat the word as a common noun. Children can then move from this fact to infer that the noun wug can pluralize as wugs, even if they have never heard the word wugs (MacWhinney 1978).
Three-year-olds also demonstrate some limited productive use of syntactic patterns for new verbs. However, children tend to be conservative and unsure about how to use verbs productively until about age five years. From the child’s perspective, these laboratory experiments with strange new toys and new words tend to encourage a conservative approach. As they get older and braver, children start to show productive use of constructions such as the double object, the passive, or the causative (Brooks et al. 1999). For example, an experimenter can introduce a new verb like griff in the frame ‘Tim griffed the ball to Frank’ and the five-year-old will productively generalize to ‘Tim griffed Frank the ball.’
The control of productivity is based on two complementary sets of cues: semantics and co-occurrence. When children hear a wug, they correctly infer that wug is a count noun. In fact, because they also see a picture of a cute little animal, they infer that wug is a common, count, name for an animate creature. These semantic features allow them to generalize their knowledge by producing the form wugs. However, we could also view this extension as based on co-occurrence learning. The child learns that words that take the indefinite article also form plurals. On the other hand, words that take the quantifier some do not form plurals. In this way, the child can use both semantic and co-occurrence information to build up knowledge about the parts of speech. This knowledge can then be fed into existing syntactic generalizations to produce new combinations and new forms of newly learned words. The bulk of grammatical acquisition relies on this process.
5.3 The Logical Problem of Language Acquisition
The problem with productivity is that it produces overgeneralization. For example, an English-speaking child will soon learn to form the past tense of a new verb by adding one of the variant forms of —ed. This knowledge helps the child produce forms such as jumped or wanted. Unfortunately, it may also lead the child to produce an error such as goed. When this occurs, we can say that the child has formulated an overly general grammar. One way of convincing the child to reject the overly general grammar in which goed occurs is to provide the child with negative feedback. This requires the parent to tell the child, ‘No, you can’t say goed.’ The problem here is that children seem to ignore parental feedback regarding the form of language. If the child calls a hamburger a hot dog, the parent can say, ‘No, it is a hamburger.’ The child will accept this type of semantic correction. But children are notoriously resistant to being corrected for formal grammatical features.
The fact that children tend to ignore formal correction has important consequences for language acquisition theory. In the 1960s, work in formal analysis convinced some linguists that the task of learning the grammar of a language was impossible unless negative feedback was provided. Since negative feedback appeared to be unavailable or unused, this meant that language could not be learned without some additional innate constraints. This argument has led to many hundreds of research articles exploring the ways in which children’s learning places constraints on the form of grammar. Referring back to Plato’s Republic and the Allegory of the Cave, Chomsky and others have characterized the task of language learning as a logical problem.
In fact, children have more resources available to them than Chomsky seems to suggest. Using these resources, the child can recover from overgeneralization without negative feedback. In the case of goed, everyone agrees that recovery is easy. All the child has to do is to realize that there is only one way of producing the past tense of go and that is went. In other words, the irregular form went comes to block production of the overregularized form goed. Here, recovery from overgeneralization is based on the competition between the regular pattern and the irregular form.
Consider another example. Suppose that a child decides that the verb recommend patterns like the verb give. After all, both verbs involve a beneficiary and an object being transferred. However, only give allows a double object construction, as in ‘John gave the library the book.’ Most people find ‘John recommended the library the book’ ungrammatical. One solution to this error is to avoid making it in the first place. However, a more general solution is to record the strength of the competing syntactic patterns. The correct way of saying ‘John recommended the library the book’ is to say ‘John recommended the book to the library.’ This correct formulation should be strengthened whenever it is heard. As the strength of the frame for the verb recommend grows in comparison to the ungrammatical frame, the use of the competing frame is blocked. This solution assumes that the child realizes that the two frames are in competition. It may be that reaching this realization requires some attention to syntactic form. However, this solution does not require children to pay attention to corrective feedback. Instead, they only need to attend to correct sentences and to make sure that they understand that these are competing ways of saying roughly the same thing.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B0080430767015709
Visual Pattern Mining
In Learning-Based Local Visual Representation and Indexing, 2015
5.2 Discriminative 3D Pattern Mining
In this section, the proposed CBoP descriptor generation is presented. Our 3D pattern mining and CBoP descriptor construction are deployed based on the bag-of-words image representation. Suppose we have M target of interest (ToI) in total, each of which could be an object instance, a scene, a landmark, or a product. For each ToI, we also have a set of reference images captured from different viewpoints. For the sake of generality, we assume these reference images do not have tags to identify the viewing angles, e.g., inter- and intracamera parameters.2 For each ToI, we first introduce a 3D sphere coding scheme to build the initial pattern candidate collection, following by a novel gravity distance-based pattern mining algorithm in Section 5.2.1. Finally, patterns from individual ToIs are pooled together to extract the CBoP histogram as detailed in Section 5.2.2.
5.2.1 The Proposed Mining Scheme
3D sphere coding. Formally speaking, for each reference image Ii(i ∈ [1,nt]) of the tth ToI (t ∈ [1,M]), suppose there are J local descriptors L(i) = [L1(i),…,LJ(i)] extracted from Ii, which is quantized into an m-dimensional bag-of-words histogram V(i) = [V1(i),…,Vm(i)]. We denote the spatial positions of L(i) as S(i) = [S1(i),…,SJ(i)], where each Sj(i) (j ∈ [1,J]) is the 2D or 3D spatial position of the jth local descriptor. For each Sj(i), we scan its spatial k-nearest neighborhood to identify all concurrent words
(5.1)Tj(i)=Lj′(i)|Lj′(i)∈L(i),Sj′(i)∈kNNSj(i)
where Tj(i) (if any) is called an “transaction” built for Sj(i) in Ii. We denote all transactions in Ii with order K as:
(5.2)Tk(i)=Tj(i)j∈[1,J]
All k-order transactions found for images [I1,…,Int] in the tth ToI is defined as Tk(ToIt) = {Tk(1),…,Tk(nt)}. The goal of pattern mining is to mine nt patterns from Tk(ToIt)k=1K, i.e., Pt=P1,…,Pnt form each tth ToI and ensemble them together as Ptt=1M.3
While the traditional pattern candidates are built based on the coding the 2D concurrences of visual words within individual reference images, we propose to search the k-nearest neighbors in the 3D point cloud of each tth ToI. Such a point cloud is constructed by structure-from-motion over the reference images with bundle adjustment [121]. Figure 5.3 shows several 3D sphere coding examples in the 3D point clouds of representative landmarks as detailed in Section 5.4.

Figure 5.3. Visualized examples about the point clouds for visual pattern candidate construction. Exemplar landmark locations are within Peking University.
Distance-based pattern mining. Previous works in visual pattern mining mainly resort to Transaction-based Colocation pattern Mining (TCM). For instance, works in [69–71] built transaction features by coding the k-nearest words in 2D.4 A transaction in TCM can be defined by coding the 2D spatial layouts of neighborhood words. Then frequent itemset mining algorithms like a Priori [122] are deployed to discover meaningful word combinations as patterns, which typically check the pattern candidates from orders 1 to K.
TCM can be formulated as follows: Let {V1,V2,…,Vm} be the set of all potential items, each of which corresponds to a visual word in our case. Let D = {T1,T2,…,Tn} be all possible transactions extracted as above, each is a possible combination of several items within V after spatial coding. Here for simplification, we use i ∈ [1,n] to denote all transactions discovered with orders 1 to K and in ToIs 1 to M. Let A be an “itemset” for the a given transaction T, we define the support of an itemset as
(5.3)support(A)={T∈D|A⊆T}|D|,
If and only if support(A) ≥ s, the itemset A is defined as a frequent itemset of D, where s is the threshold to restrict the minimal support rate. Note that any two Ti and Tj are induplicated.
We then define the confidence of each frequent itemset as:
(5.4)condifence(A→B)=support(A∪B)support(A)=T∈D|(A∪B)⊆T{T∈DA⊆T}|,
where A and B are two itemsets. The confidence in Equation (5.4) is defined as the maximal likelihood that B is correct in the case that A is also correct. Confidence-based restriction is to guarantee that the found patterns can discover the minimal item subsets, which are most helpful in representing the visual features at order k ∈ [2,K].
To give a minimal association hyperplane to bound A, an Association Hyperedge of each A is defined as:
(5.5)AH(A)=1Nconfidence(A−{Vi})→Vi.
Finally, by checking all possible itemset combinations in D from order 2 to K, the itemsets with support() ≥ s and AH ≥ γ are defined as frequent patterns.
One crucial issue lies in TCM would generate repeated patterns in texture regions containing dense words. To address this issue, distance-based Colocation pattern mining (DCM) is proposed with two new measures named participation ratio (pr) and participation index (pi).
First, a R-reachable measure is introduced as the basis of both pi and pr: Two words Vi and Vj are R-reachable when
(5.6)dis(Vi,Vj)<dthres,
where dis() is the distance metric such as Euclidean and dthres is the distance threshold. Subsequently, for a given word Vi, we define its partition rate pr(V,Vi) as the percentage of subset V −{Vi} that are R-reachable:
(5.7)pr(V,Vi)=πinstance(V)instance(Vi),
where π is the relational projection operation with deduplication. The participation index pi is defined as:
(5.8)pi(V,Vi)=mini=1m{pr(V,Vi)},
where pi describes the frequency of subset V − Vi in the neighborhood. Note that only item subsets with pi larger than a give threshold is defined as patterns in DCM.
Gravity distance R-reachable: In many cases, the Euclidean distance cannot discriminatively describe the colocation visual patterns, which is due to it ignores the word discriminability and scale in building items. Intuitively, words from the same scale tend to share more commonsense in building items, and more discriminative words also produce more meaningful items. We then proposed a novel gravity distance R-reachable (GD R-reachable) to incorporate both cues. Two words Vi and Vj are GD R-reachable once Ri,j < Crirj in the traditional DCM model, where ri and rj are the local feature scales of Vi and Vj, respectively, C is the fixed parameter, and Ri,j = dis(Vi,Vj) is the Euclidean distance of two words.
For interpretation, we can image that every word has a certain “gravity” to the other words, which is proportional to the square of its local feature scale. If this gravity is larger than a minimal threshold Fmin, we denote these two words as GD R-reachable:
(5.9)Fi,j=επ(ri)2π(rj)2(Ri,j)2,εis a constantFi,j>Fmin→επ(ri)2π(rj)2(Ri,j)2>Fmin→Ri,j<Crirj.
Similar to DCM, the input of the gravity distance-based mining is all instances of visual words. Each instance contains the following attributes: original local features, visual word ID, location, and scale of this local feature (word instance). To unify the description, we embed the word ID of each feature with its corresponding location into the mining. Then, we run the similar procedure as in DCM to mine colocation patterns. Algorithm 5.1 outlines the workflow of our gravity distance-based visual pattern mining. Figure 5.4 shows some case studies of the mined patterns between the gravity-based pattern mining and the Euclidean distance-based pattern mining.

Figure 5.4. Case study of the mined patterns between the gravity-based pattern mining and the Euclidean distance-based pattern mining.
Algorithm 5.1
Gravity distance based visual pattern mining

5.2.2 Sparse Pattern Coding
Sparse coding formulation. Given the mined pattern collection P, not all patterns are equivalently important and discriminative in terms of feature representation. Indeed, there are typically redundancy and noise in this initial pattern mining results. However, how to come up with a compact yet discriminative pattern-level features are left unexploited in the literature. In this section, we formulate the pattern-level representation as a sparse pattern coding problem, aiming to maximally reconstruct the original bag-of-words histogram using a minimal number of patterns.
Formally speaking, let P = {P1,…,PL} be the mined patterns with maximal order K. In online coding, given the bag-of-words histogram V(q) = [V1(q),…,Vm(q)] extracted from image Iq, we aim to encode V(q) by using a compact yet discriminative subset of patterns, say P(q)⊂P. We formulate this target as seeking an optimal tradeoff between the maximal reconstruction capability and the minimal coding length:
(5.10)argminw∑i=1N||V(i)−wTP(i)||2+α||w||1,
where P is the patterns mined previously, from which a minimal set is selected to lossy reconstruct each bag-of-words histogram V(i) as close as possible. w serves as a weighted linear combination of all nonzero patterns in P, which pools patterns to encode each V(i) as:
(5.11)fP(i)=w1P1+w2P2+,⋯,wmPm,
where [w1,,wm] is the weighted vector learned to reconstruct V(i) in Equation (5.10). Each wj is assigned either 0 or 1, performing a binary pattern selection.
Learning with respect to Equations (5.10) and (5.13) are achieved by spare coding over the pattern pool P. While guaranteeing the real sparsity through L0 is intractable, we approximate a sparse solution for the coefficients w using L1 penalty, which results in a Lasso-based effective solution [124].
Finally, we denote the selected pattern subset as Qselected, which contains nselected patterns as [Q1,…,Qnselected]. nselected is typically very small, say 100. Therefore, each reference or query image is represented as an nselected-bin pattern histogram.
Supervised coding. Once the supervised labels {Li}i=1N (e.g., category label or prediction from a compensative source) for reference image {Ii}i=1N are also available, we can further incorporate Li to refine the coding of Equation (5.10) as:
(5.12)argminw∑i=1N||V(i)−(wTu)TP(i)||2+α||w||1,
where we integrate the supervised label {Li}i=1N into the coding function of P for I(i) as:
(5.13)(wTu)TP(i)=w1u1P1+w2u2P2+,⋯,wmumPm.
[u1,…,um] adds the prior distribution of patterns to bias the selection of [w1,…,wm], where uj is the discriminability of the jth pattern based on its information gain to Li:
(5.14)uj=H(Li)−H(Li|Pj)
Here, H(Li) is the prior of label Li given Ii, H(Li|Pj) is the conditional entropy of label Li given Pj, which is obtained by averaging the intraclass observation of Pj divided by the interclass distribution of Pj:
(5.15)H(Li|Pj)=p(Pj|Lj)∑lp(Pj|Ll).
In this sense, the definition of supervised label Li is quite flexible, e.g., category labels or positive/negative tags, which also allows the case of missing labels.
In terms of compact visual descriptor, CBoP preserves the higher order statistics comparing to the transitional nonzero coding scheme [112] as well as the state-of-the-art boosting-based codeword selection scheme [120]. Different from all previous unsupervised descriptor learning schemes [69–72, 112], CBoP further provides a supervised coding alternative as an optional choice, which yet differs from the work in [120] that demands online side information from the query.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780128024096000054
Language Development, Neural Basis of
H.M. Feldman, in International Encyclopedia of the Social & Behavioral Sciences, 2001
4 Evidence from ERP and fMRI
Using ERP techniques on normal children learning language, a picture emerges that initial development of language requires a wide and bilateral neural network and that progressive neural specialization and lateralization occurs in association with language experience rather than strictly with age. Specific ERP components in toddlers 13 to 20 months of age demonstrate differences between words that the child understands and words that are incomprehensible. Word comprehension shows both age and experience components. At 13 months of age, the comprehension effects can be found over both the right and left hemisphere and over anterior and posterior regions. By 20 months of age, the effects are detectable only over the posterior left hemisphere. However, younger toddlers who are more advanced in language development show this laterality effect at a younger age than do less advanced children (Mills et al. 1997).
Data from children with early focal brain injury corroborate the view of initial bilateral involvement in language development. Children with focal injury to either hemisphere experience developmental delays in prelinguistic skills, including the onset of babbling and communicative gestures (Marchman et al. 1991) and in the onset of vocabulary development and use of word combinations in parent–child conversations (Feldman et al. 1992, Thal et al. 1991). Once the children with focal injury begin to acquire functional vocabulary and syntactic skills, their rate of developmental progress as measured by vocabulary use and mean length of utterance is comparable to each other and to children developing typically (Feldman et al. 1992). By age 4, children with focal LH damage can even master the complex morphosyntactic structures of a language like Hebrew (Levy et al. 1994). However, at school age, children with damage to either the LH or RH show delays compared with children developing typically in the creation of narrative discourse (Reilly et al. 1998). These findings are suggestive that both hemispheres participate in advanced language skills such as narrative discourse in school aged children.
Research also indicates that individual differences in developmental rate relate to the location of injury. Children ages 10 to 17 months of age with RH damage have been shown to have greater initial delays in word comprehension and production than do children with LH damage. However, at the point of word and syntax development children with LH temporal lobe injury demonstrate slower development than do those with damage to other areas of the RH or LH (Thal et al. 1991). These data are compatible with a view of increasing specialization during language development. However, it is important to note that individual differences also relate to other variables besides the size and site of the lesion, such as the presence of seizures and the use of anticonvulsant medications (Dall’Oglio et al. 1994).
Studies using fMRI in children developing typically demonstrate that predominant LH activation during language tasks is present by about age 7 to 9 years, and as with adults, bilateral activation occurs under some circumstances. The activation of neural networks on fMRI was studied during sentence processing in adults, normal school aged children and also children with perinatal focal brain injury (Booth et al. 1999, 2000). In a relatively natural linguistic task, children listened to sentences and then responded true or false to a statement about each sentence. Adults and children show lower accuracy levels to difficult object-relative sentences, such as ‘The pig that the dog jumped ate the trash in the street,’ intermediate accuracy to moderate subject-relative sentences, such as ‘The principal that tripped the janitor used the phone to call home,’ and highest accuracy levels to relatively easy conjoined-verb-phrase sentences, such as ‘The cat chased the rabbit and enjoyed the hunt in the yard.’ However, children are less accurate than are adults. Children, as well as adults, are more accurate when true–false statements test for the subject of the first verb, for example, ‘The dog jumped the pig,’ than for the subject of the second verb, for example, ‘The principal used the phone.’
In adults, the fMRI showed that the sentence comprehension task produced more activation in the LH than in the RH. The greatest activation was found in the superior temporal, middle temporal, and inferior frontal areas, the traditional language areas but also in prefrontal areas, the brain region associated with working memory. Healthy children activated similar neurocognitive networks as did the adults with LH predominance. However, the distribution of activity across these networks was related to response accuracy, strategy use, and task difficulty. Greater activation was associated with higher response accuracy and with consistent use of a comprehension strategy, whether correct or incorrect. Improved performance was also associated with more activation in the anterior middle temporal area suggesting that this area was important in the syntactic processing demanded by the task. Activation of occipital regions was greater in children who were less accurate in the task. These findings suggest that some children may have been using a different and immature strategy in complex sentence processing, possibly trying to visualize the sentence as an aid to comprehension. In both normal adults and children, the number of areas activated correlated with the difficulty of the sentences. The RH was recruited for difficult sentences (Booth et al. 2000).
Children with LH damage showed patterns of activation consistent with organization of cognitive processing into homologous areas of the contralateral hemisphere. The size of their lesion was associated with the degree of their cognitive deficit. These results confirmed earlier findings of RH language in many individuals with left hemisphere damage undergoing a carotid amytal infusion (Rasmussen and Milner 1977).
Studies of children with LH damage indicate that though the RH can participate in language processing, the LH has a more central role in language tasks at school age. Dennis and co-workers found that despite comparable intelligence, children with LH hemidecortication were inferior to children with RH hemidecortication on the ease and speed of syntactic discrimination, interpretation of passive negative sentences, and repetition of syntactically complex sentences (Dennis and Kohn 1975, Dennis and Whitaker 1976, Dennis 1987). Aram and co-workers similarly found expressive and receptive syntactic difficulties in children with LH focal damage from embolic events (Aram et al. 1986, Aram and Ekelman 1987). However, it is important to note that children with LH damage acquired in early infancy or childhood have only subtle deficits, and are not frankly aphasic as are adults with comparable lesions.
It is difficult to assess if syntax is particularly vulnerable in children with these lesions acquired later in life. An alternative hypothesis is that subjects with LH damage had greatest difficulty with the most developmentally advanced items on the assessment (Bishop 1983). Children with LH injuries and LH perinatal damage also show difficulty in tests of comprehension of difficult verbal material, formulating sentences, and lexical retrieval (MacWhinney et al. 2000).
To determine the specificity of underlying information-processing deficits after early injury, MacWhinney et al. (2000) used on-line reaction time methodology. School-aged children underwent visual and auditory tasks of signal detection, recognition, and choice as well as rapid naming to visual and auditory stimuli. The results showed that children with LH, RH, and with mixed lesions generally were as accurate as age-matched controls but consistently had slower reaction times. The reaction times of normal learners lawfully decreased as the children went from 5 to 10 years of age. Similarly, in the subjects with early lesions, the reaction times became shorter as the children got older and the slopes suggested that by adulthood the reaction times might converge. The two tasks that best distinguished children with LH injuries from children with other lesions were verbally repeating numbers presented in the auditory mode and naming numbers presented in the visual mode, though there was considerable overlap across groups. Interestingly, both these tasks required phonological access and verbal output.
Taken together, these findings on school-aged children suggest that despite adequate functional communication skills, children with LH injuries may have more difficulty than do children with other lesions performing precise, constrained, high-level language tasks, particularly in tasks that require speed. The areas of greatest difficulty seem to be developmentally challenging syntactic skills, comprehension of difficult oral directions, and formulating sentences with a constrained vocabulary. Phonological access, as evidenced in naming and repeating verbal items, also differentiates subjects with damage to the LH from other children without injuries.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B008043076703610X
Patient Safety
Harvey J Murff, … David W Bates, in Journal of Biomedical Informatics, 2003
Using an electronic medical record, Honigman et al. [53] developed a tool that searched a patient’s administrative data, medication history, and clinical narrative from the visit note to identify adverse drug events. The tool initially parsed the visit note into words and word combinations. These terms were then filtered through a medical dictionary database and joined into master concepts, which could be indicative of an adverse drug event. Drugs and drug classes were then linked to the reported adverse drug events. For example, if the term diarrhea was mentioned within the clinical narrative, this term was joined to the adverse drug event concept of “diarrhea” and linked to any medication the patient might be taking that could cause diarrhea, such as omeprazole. In a study comparing multiple detection methods (ICD-9-CM screening, allergy screening, event monitor, and text searching) the overall positive predictive value of this process was low (7.2%, 95% CI 6.8–7.5), but this methodology was estimated to have detected 91% of all adverse drug events recorded in the chart [53].
Read full article
URL:
https://www.sciencedirect.com/science/article/pii/S1532046403000686
Machine Learning, Deep Learning and Statistical Analysis for forecasting building energy consumption — A systematic review
Mohamad Khalil, … Sara Walker, in Engineering Applications of Artificial Intelligence, 2022
1.2 Research methodology
The research methodology was composed of different steps in order to systematically identify research publications that are relevant to the area of this study (Okoli and Schabram, 2010). Scopus database was used to perform a keyword-based search to select publications that related to the subject of this review. It is noteworthy that, the search terms have been chosen to represent the field that involve interdisciplinary research around Artificial Intelligence (AI) and forecasting building energy consumption. Furthermore, for the relevancy of the latest research activities, the date of publications was selected from 2015 onwards. The key words combinations can be seen in the formula below.
[ ALL (“Machine Learning” OR “Deep Learning” OR “Reinforcement Learning”) AND (“Buildings Energy” OR “Forecasting Buildings Energy Consumption”) ].
A total number of (4907) research publications were retrieved after the search, then they evaluated by the following selection criteria: (I) all the publications were screened by the title of the papers; (II) the abstract of the papers. However, it was found that not all of them were relevant to subject of this review and only (505) papers were classified as candidate papers. Then (III) the whole text of the candidate studies was screened according to two eligibility criteria for selecting the final papers for inclusion in this review: (A) the forecasting application of the studies focusing on buildings energy (including whole building load, Heating-Ventilation-Air-Conditioning, Heat Pumps, lighting and other loads); and (2) the approaches that were used to forecast end use energy are ML/DL/SA. Finally, 60 papers are included in this review to be analysed and reviewed from multiple perspectives.
Read full article
URL:
https://www.sciencedirect.com/science/article/pii/S0952197622003372
Main Body
3. Word Recognition Skills: One of Two Essential Components of Reading Comprehension
Maria S. Murray
Abstract
After acknowledging the contributions of recent scientific discoveries in reading that have led to new understandings of reading processes and reading instruction, this chapter focuses on word recognition, one of the two essential components in the Simple View of Reading. The next chapter focuses on the other essential component, language comprehension. The Simple View of Reading is a model, or a representation, of how skillful reading comprehension develops. Although the Report of the National Reading Panel (NRP; National Institute of Child Health and Human Development [NICHD], 2000) concluded that the best reading instruction incorporates explicit instruction in five areas (phonemic awareness, phonics, fluency, vocabulary, and comprehension), its purpose was to review hundreds of research studies to let instructors know the most effective evidence-based methods for teaching each. These five areas are featured in the Simple View of Reading in such a way that we can see how the subskills ultimately contribute to two essential components for skillful reading comprehension. Children require many skills and elements to gain word recognition (e.g., phoneme awareness, phonics), and many skills and elements to gain language comprehension (e.g., vocabulary). Ultimately, the ability to read words (word recognition) and understand those words (language comprehension) lead to skillful reading comprehension. Both this chapter and the next chapter present the skills, elements, and components of reading using the framework of the Simple View of Reading, and in this particular chapter, the focus is on elements that contribute to automatic word recognition. An explanation of each element’s importance is provided, along with recommendations of research-based instructional activities for each.
Learning Objectives
After reading this chapter, readers will be able to
- identify the underlying elements of word recognition;
- identify research-based instructional activities to teach phonological awareness, decoding, and sight recognition of irregular sight words;
- discuss how the underlying elements of word recognition lead to successful reading comprehension.
Introduction
Throughout history, many seemingly logical beliefs have been debunked through research and science. Alchemists once believed lead could be turned into gold. Physicians once assumed the flushed red skin that occurred during a fever was due to an abundance of blood, and so the “cure” was to remove the excess using leeches (Worsley, 2011). People believed that the earth was flat, that the sun orbited the earth, and until the discovery of microorganisms such as bacteria and viruses, they believed that epidemics and plagues were caused by bad air (Byrne, 2012). One by one, these misconceptions were dispelled as a result of scientific discovery. The same can be said for misconceptions in education, particularly in how children learn to read and how they should be taught to read.1
In just the last few decades there has been a massive shift in what is known about the processes of learning to read. Hundreds of scientific studies have provided us with valuable knowledge regarding what occurs in our brains as we read. For example, we now know there are specific areas in the brain that process the sounds in our spoken words, dispelling prior beliefs that reading is a visual activity requiring memorization (Rayner, Foorman, Perfetti, Pesetsky, & Seidenberg, 2001). Also, we now know how the reading processes of students who learn to read with ease differ from those who find learning to read difficult. For example, we have learned that irregular eye movements do not cause reading difficulty. Many clever experiments (see Rayner et al., 2001) have shown that skilled readers’ eye movements during reading are smoother than struggling readers’ because they are able to read with such ease that they do not have to continually stop to figure out letters and words. Perhaps most valuable to future teachers is the fact that a multitude of studies have converged, showing us which instruction is most effective in helping people learn to read. For instance, we now know that phonics instruction that is systematic (i.e., phonics elements are taught in an organized sequence that progresses from the simplest patterns to those that are more complex) and explicit (i.e., the teacher explicitly points out what is being taught as opposed to allowing students to figure it out on their own) is most effective for teaching students to read words (NRP, 2000).
As you will learn, word recognition, or the ability to read words accurately and automatically, is a complex, multifaceted process that teachers must understand in order to provide effective instruction. Fortunately, we now know a great deal about how to teach word recognition due to important discoveries from current research. In this chapter, you will learn what research has shown to be the necessary elements for teaching the underlying skills and elements that lead to accurate and automatic word recognition, which is one of the two essential components that leads to skillful reading comprehension. In this textbook, reading comprehension is defined as “the process of simultaneously extracting and constructing meaning through interaction and involvement with written language” (Snow, 2002, p. xiii), as well as the “capacities, abilities, knowledge, and experiences” one brings to the reading situation (p. 11).
Learning to Read Words Is a Complex Process
It used to be a widely held belief by prominent literacy theorists, such as Goodman (1967), that learning to read, like learning to talk, is a natural process. It was thought that since children learn language and how to speak just by virtue of being spoken to, reading to and with children should naturally lead to learning to read, or recognize, words. Now we know it is not natural, even though it seems that some children “pick up reading” like a bird learns to fly. The human brain is wired from birth for speech, but this is not the case for reading the printed word. This is because what we read—our alphabetic script—is an invention, only available to humankind for the last 3,800 years (Dehaene, 2009). As a result, our brains have had to accommodate a new pathway to translate the squiggles that are our letters into the sounds of our spoken words that they symbolize. This seemingly simple task is, in actuality, a complex feat.
The alphabet is an amazing invention that allows us to represent both old and new words and ideas with just a few symbols. Despite its efficiency and simplicity, the alphabet is actually the root cause of reading difficulties for many people. The letters that make up our alphabet represent phonemes—individual speech sounds—or according to Dehaene, “atoms” of spoken words (as opposed to other scripts like Chinese whereby the characters represent larger units of speech such as syllables or whole words). Individual speech sounds in spoken words (phonemes) are difficult to notice for approximately 25% to 40% of children (Adams, Foorman, Lundberg, & Beeler, 1998). In fact, for some children, the ability to notice, or become aware of the individual sounds in spoken words (phoneme awareness) proves to be one of the most difficult academic tasks they will ever encounter. If we were to ask, “How many sounds do you hear when I say ‘gum’?” some children may answer that they hear only one, because when we say the word “gum,” the sounds of /g/ /u/ and /m/ are seamless. (Note the / / marks denote the sound made by a letter.) This means that the sounds are coarticulated; they overlap and melt into each other, forming an enveloped, single unit—the spoken word “gum.” There are no crisp boundaries between the sounds when we say the word “gum.” The /g/ sound folds into the /u/ sound, which then folds into the /m/ sound, with no breaks in between.
So why the difficulty and where does much of it begin? Our speech consists of whole words, but we write those words by breaking them down into their phonemes and representing each phoneme with letters. To read and write using our alphabetic script, children must first be able to notice and disconnect each of the sounds in spoken words. They must blend the individual sounds together to make a whole word (read). And they must segment the individual sounds to represent each with alphabetic letters (spell and write). This is the first stumbling block for so many in their literacy journeys—a difficulty in phoneme awareness simply because their brains happen to be wired in such a way as to make the sounds hard to notice. Research, through the use of brain imaging and various clever experiments, has shown how the brain must “teach itself” to accommodate this alphabet by creating a pathway between multiple areas (Dehaene, 2009).
Instruction incorporating phoneme awareness is likely to facilitate successful reading (Adams et al., 1998; Snow, Burns, & Griffin, 1998), and it is for this reason that it is a focus in early school experiences. For some children, phoneme awareness, along with exposure to additional fundamentals, such as how to hold a book, the concept of a word or sentence, or knowledge of the alphabet, may be learned before formal schooling begins. In addition to having such print experiences, oral experiences such as being talked to and read to within a literacy rich environment help to set the stage for reading. Children lacking these literacy experiences prior to starting school must rely heavily on their teachers to provide them.
The Simple View of Reading and the Strands of Early Literacy Development
Teachers of reading share the goal of helping students develop skillful reading comprehension. As mentioned previously, the Simple View of Reading (Gough & Tunmer, 1986) is a research-supported representation of how reading comprehension develops. It characterizes skillful reading comprehension as a combination of two separate but equally important components—word recognition skills and language comprehension ability. In other words, to unlock comprehension of text, two keys are required—being able to read the words on the page and understanding what the words and language mean within the texts children are reading (Davis, 2006). If a student cannot recognize words on the page accurately and automatically, fluency will be affected, and in turn, reading comprehension will suffer. Likewise, if a student has poor understanding of the meaning of the words, reading comprehension will suffer. Students who have success with reading comprehension are those who are skilled in both word recognition and language comprehension.
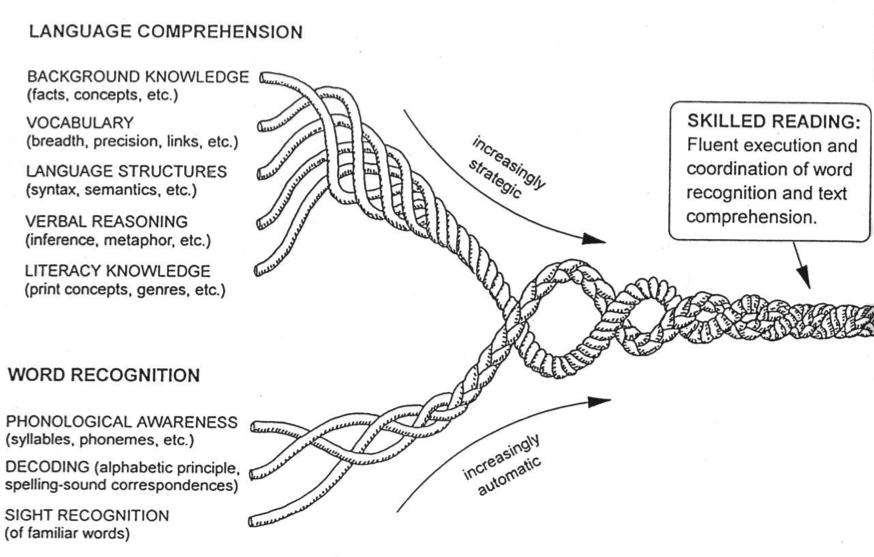
These two essential components of the Simple View of Reading are represented by an illustration by Scarborough (2002). In her illustration, seen in Figure 1, twisting ropes represent the underlying skills and elements that come together to form two necessary braids that represent the two essential components of reading comprehension. Although the model itself is called “simple” because it points out that reading comprehension is comprised of reading words and understanding the language of the words, in truth the two components are quite complex. Examination of Scarborough’s rope model reveals how multifaceted each is. For either of the two essential components to develop successfully, students need to be taught the elements necessary for automatic word recognition (i.e., phonological awareness, decoding, sight recognition of frequent/familiar words), and strategic language comprehension (i.e., background knowledge, vocabulary, verbal reasoning, literacy knowledge). The sections below will describe the importance of the three elements that lead to accurate word recognition and provide evidence-based instructional methods for each element. Chapter 4 in this textbook will cover the elements leading to strategic language comprehension.
Word Recognition
Word recognition is the act of seeing a word and recognizing its pronunciation immediately and without any conscious effort. If reading words requires conscious, effortful decoding, little attention is left for comprehension of a text to occur. Since reading comprehension is the ultimate goal in teaching children to read, a critical early objective is to ensure that they are able to read words with instant, automatic recognition (Garnett, 2011). What does automatic word recognition look like? Consider your own reading as an example. Assuming you are a skilled reader, it is likely that as you are looking at the words on this page, you cannot avoid reading them. It is impossible to suppress reading the words that you look at on a page. Because you have learned to instantly recognize so many words to the point of automaticity, a mere glance with no conscious effort is all it takes for word recognition to take place. Despite this word recognition that results from a mere glance at print, it is critical to understand that you have not simply recognized what the words look like as wholes, or familiar shapes. Even though we read so many words automatically and instantaneously, our brains still process every letter in the words subconsciously. This is evident when we spot misspellings. For example, when quickly glancing at the words in the familiar sentences, “Jack be nimble, Jack be quick. Jack jamped over the canbleslick,” you likely spotted a problem with a few of the individual letters. Yes, you instantly recognized the words, yet at the same time you noticed the individual letters within the words that are not correct.
To teach students word recognition so that they can achieve this automaticity, students require instruction in: phonological awareness, decoding, and sight recognition of high frequency words (e.g., “said,” “put”). Each of these elements is defined and their importance is described below, along with effective methods of instruction for each.
Phonological Awareness
One of the critical requirements for decoding, and ultimately word recognition, is phonological awareness (Snow et al., 1998). Phonological awareness is a broad term encompassing an awareness of various-sized units of sounds in spoken words such as rhymes (whole words), syllables (large parts of words), and phonemes (individual sounds). Hearing “cat” and “mat,” and being aware that they rhyme, is a form of phonological awareness, and rhyming is usually the easiest and earliest form that children acquire. Likewise, being able to break the spoken word “teacher” into two syllables is a form of phonological awareness that is more sophisticated. Phoneme awareness, as mentioned previously, is an awareness of the smallest individual units of sound in a spoken word—its phonemes; phoneme awareness is the most advanced level of phonological awareness. Upon hearing the word “sleigh,” children will be aware that there are three separate speech sounds—/s/ /l/ /ā/—despite the fact that they may have no idea what the word looks like in its printed form and despite the fact that they would likely have difficulty reading it.
Because the terms sound similar, phonological awareness is often confused with phoneme awareness. Teachers should know the difference because awareness of larger units of sound—such as rhymes and syllables—develops before awareness of individual phonemes, and instructional activities meant to develop one awareness may not be suitable for another. Teachers should also understand and remember that neither phonological awareness nor its most advanced form—phoneme awareness—has anything whatsoever to do with print or letters. The activities that are used to teach them are entirely auditory. To help remember this, simply picture that they can be performed by students if their eyes are closed. Adults can teach phonological awareness activities to a child in a car seat during a drive. The child can be told, “Say ‘cowboy.’ Now say ‘cowboy’ without saying ‘cow.’” Adults can teach phoneme awareness activities as well by asking, “What sound do you hear at the beginning of ‘sssun,’ ‘sssail,’ and ‘ssssoup’?” or, “In the word ‘snack,’ how many sounds do you hear?” or by saying, “Tell me the sounds you hear in ‘lap.’” Notice that the words would not be printed anywhere; only spoken words are required. Engaging in these game-like tasks with spoken words helps children develop the awareness of phonemes, which, along with additional instruction, will facilitate future word recognition.
Why phonological awareness is important
An abundance of research emerged in the 1970s documenting the importance of phoneme awareness (the most sophisticated form of phonological awareness) for learning to read and write (International Reading Association, 1998). Failing to develop this awareness of the sounds in spoken words leads to difficulties learning the relationship between speech and print that is necessary for learning to read (Snow et al., 1998). This difficulty can sometimes be linked to specific underlying causes, such as a lack of instructional experiences to help children develop phoneme awareness, or neurobiological differences that make developing an awareness of phonemes more difficult for some children (Rayner et al., 2001). Phoneme awareness facilitates the essential connection that is “reading”: the sequences of individual sounds in spoken words match up to sequences of printed letters on a page. To illustrate the connection between phoneme awareness and reading, picture the steps that children must perform as they are beginning to read and spell words. First, they must accurately sound out the letters, one at a time, holding them in memory, and then blend them together correctly to form a word. Conversely, when beginning to spell words, they must segment a spoken word (even if it is not audible they are still “hearing the word” in their minds) into its phonemes and then represent each phoneme with its corresponding letter(s). Therefore, both reading and spelling are dependent on the ability to segment and blend phonemes, as well as match the sounds to letters, and as stated previously, some students have great difficulty developing these skills. The good news is that these important skills can be effectively taught, which leads to a discussion about the most effective ways to teach phonological (and phoneme) awareness.
Phonological awareness instruction
The National Reading Panel (NRP, 2000) report synthesized 52 experimental studies that featured instructional activities involving both phonological awareness (e.g., categorizing words similar in either initial sound or rhyme) and phoneme awareness (e.g., segmenting or blending phonemes). In this section, both will be discussed.


A scientifically based study by Bradley and Bryant (1983) featured an activity that teaches phonological awareness and remains popular today. The activity is sorting or categorizing pictures by either rhyme or initial sound (Bradley & Bryant, 1983). As shown in Figure 2, sets of cards are shown to children that feature pictures of words that rhyme or have the same initial sound. Typically one picture does not match the others in the group, and the students must decide which the “odd” one is. For instance, pictures of a fan, can, man, and pig are identified to be sure the students know what they are. The teacher slowly pronounces each word to make sure the students clearly hear the sounds and has them point to the word that does not rhyme (match the others). This is often referred to as an “oddity task,” and it can also be done with pictures featuring the same initial sound as in key, clock, cat, and scissors (see Blachman, Ball, Black, & Tangel, 2000 for reproducible examples).
Evidence-based activities to promote phoneme awareness typically have students segment spoken words into phonemes or have them blend phonemes together to create words. In fact, the NRP (2000) identified segmenting and blending activities as the most effective when teaching phoneme awareness. This makes sense, considering that segmenting and blending are the very acts performed when spelling (segmenting a word into its individual sounds) and reading (blending letter sounds together to create a word). The NRP noted that if segmenting and blending activities eventually incorporate the use of letters, thereby allowing students to make the connection between sounds in spoken words and their corresponding letters, there is even greater benefit to reading and spelling. Making connections between sounds and their corresponding letters is the beginning of phonics instruction, which will be described in more detail below.
An activity that incorporates both segmenting and blending was first developed by a Russian psychologist named Elkonin (1963), and thus, it is often referred to as “Elkonin Boxes.” Children are shown a picture representing a three- or four-phoneme picture (such as “fan” or “lamp”) and told to move a chip for each phoneme into a series of boxes below the picture. For example, if the word is “fan,” they would say /fffff/ while moving a chip into the first box, then say /aaaaa/ while moving a chip into the second box, and so on. Both Elkonin boxes (see Figure 3) and a similar activity called “Say It and Move It” are used in the published phonological awareness training manual, Road to the Code by Blachman et al. (2000). In each activity children must listen to a word and move a corresponding chip to indicate the segmented sounds they hear, and they must also blend the sounds together to say the entire word.
Decoding
Another critical component for word recognition is the ability to decode words. When teaching children to accurately decode words, they must understand the alphabetic principle and know letter-sound correspondences. When students make the connection that letters signify the sounds that we say, they are said to understand the purpose of the alphabetic code, or the “alphabetic principle.” Letter-sound correspondences are known when students can provide the correct sound for letters and letter combinations. Students can then be taught to decode, which means to blend the letter sounds together to read words. Decoding is a deliberate act in which readers must “consciously and deliberately apply their knowledge of the mapping system to produce a plausible pronunciation of a word they do not instantly recognize” (Beck & Juel, 1995, p. 9). Once a word is accurately decoded a few times, it is likely to become recognized without conscious deliberation, leading to efficient word recognition.
The instructional practices teachers use to teach students how letters (e.g., i, r, x) and letter clusters (e.g., sh, oa, igh) correspond to the sounds of speech in English is called phonics (not to be confused with phoneme awareness). For example, a teacher may provide a phonics lesson on how “p” and “h” combine to make /f/ in “phone,” and “graph.” After all, the alphabet is a code that symbolizes speech sounds, and once students are taught which sound(s) each of the symbols (letters) represents, they can successfully decode written words, or “crack the code.”
Why decoding is important
Similar to phonological awareness, neither understanding the alphabetic principle nor knowledge of letter-sound correspondences come naturally. Some children are able to gain insights about the connections between speech and print on their own just from exposure and rich literacy experiences, while many others require instruction. Such instruction results in dramatic improvement in word recognition (Boyer & Ehri, 2011). Students who understand the alphabetic principle and have been taught letter-sound correspondences, through the use of phonological awareness and letter-sound instruction, are well-prepared to begin decoding simple words such as “cat” and “big” accurately and independently. These students will have high initial accuracy in decoding, which in itself is important since it increases the likelihood that children will willingly engage in reading, and as a result, word recognition will progress. Also, providing students effective instruction in letter-sound correspondences and how to use those correspondences to decode is important because the resulting benefits to word recognition lead to benefits in reading comprehension (Brady, 2011).
Decoding instruction
Teaching children letter-sound correspondences and how to decode may seem remarkably simple and straightforward. Yet teaching them well enough and early enough so that children can begin to read and comprehend books independently is influenced by the kind of instruction that is provided. There are many programs and methods available for teaching students to decode, but extensive evidence exists that instruction that is both systematic and explicit is more effective than instruction that is not (Brady, 2011; NRP, 2000).
As mentioned previously, systematic instruction features a logical sequence of letters and letter combinations beginning with those that are the most common and useful, and ending with those that are less so. For example, knowing the letter “s” is more useful in reading and spelling than knowing “j” because it appears in more words. Explicit instruction is direct; the teacher is straightforward in pointing out the connections between letters and sounds and how to use them to decode words and does not leave it to the students to figure out the connections on their own from texts. The notable findings of the NRP (2000) regarding systematic and explicit phonics instruction include that its influence on reading is most substantial when it is introduced in kindergarten and first grade, it is effective in both preventing and remediating reading difficulties, it is effective in improving both the ability to decode words as well as reading comprehension in younger children, and it is helpful to children from all socioeconomic levels. It is worth noting here that effective phonics instruction in the early grades is important so that difficulties with decoding do not persist for students in later grades. When this happens, it is often noticeable when students in middle school or high school struggle to decode unfamiliar, multisyllabic words.
When providing instruction in letter-sound correspondences, we should avoid presenting them in alphabetical order. Instead, it is more effective to begin with high utility letters such as “a, m, t, i, s, d, r, f, o, g, l” so that students can begin to decode dozens of words featuring these common letters (e.g., mat, fit, rag, lot). Another reason to avoid teaching letter-sound correspondences in alphabetical order is to prevent letter-sound confusion. Letter confusion occurs in similarly shaped letters (e.g., b/d, p/q, g/p) because in day-to-day life, changing the direction or orientation of an object such as a purse or a vacuum does not change its identity—it remains a purse or a vacuum. Some children do not understand that for certain letters, their position in space can change their identity. It may take a while for children to understand that changing the direction of letter b will make it into letter d, and that these symbols are not only called different things but also have different sounds. Until students gain experience with print—both reading and writing—confusions are typical and are not due to “seeing letters backward.” Nor are confusions a “sign” of dyslexia, which is a type of reading problem that causes difficulty with reading and spelling words (International Dyslexia Association, 2015). Students with dyslexia may reverse letters more often when they read or spell because they have fewer experiences with print—not because they see letters backward. To reduce the likelihood of confusion, teach the /d/ sound for “d” to the point that the students know it consistently, before introducing letter “b.”
To introduce the alphabetic principle, the Elkonin Boxes or “Say It and Move It” activities described above can be adapted to include letters on some of the chips. For example, the letter “n” can be printed on a chip and when students are directed to segment the words “nut,” “man,” or “snap,” they can move the “n” chip to represent which sound (e.g., the first, second, or last) is /n/. As letter-sound correspondences are taught, children should begin to decode by blending them together to form real words (Blachman & Tangel, 2008).
For many students, blending letter sounds together is difficult. Some may experience letter-by-letter distortion when sounding out words one letter at a time. For example, they may read “mat” as muh-a-tuh, adding the “uh” sound to the end of consonant sounds. To prevent this, letter sounds should be taught in such a way to make sure the student does not add the “uh” sound (e.g., “m” should be learned as /mmmm/ not /muh/, “r” should be learned as /rrrr/ not /ruh/). To teach students how to blend letter sounds together to read words, it is helpful to model (see Blachman & Murray, 2012). Begin with two letter words such as “at.” Write the two letters of the word separated by a long line: a_______t. Point to the “a” and demonstrate stretching out the short /a/ sound—/aaaa/ as you move your finger to the “t” to smoothly connect the /a/ to the /t/. Repeat this a few times, decreasing the length of the line/time between the two sounds until you pronounce it together: /at/. Gradually move on to three letter words such as “sad” by teaching how to blend the initial consonant with the vowel sound (/sa/) then adding the final consonant. It is helpful at first to use continuous sounds in the initial position (e.g., /s/, /m/, /l/) because they can be stretched and held longer than a “stop consonant” (e.g., /b/, /t/, /g/).
An excellent activity featured in many scientifically-based research studies that teaches students to decode a word thoroughly and accurately by paying attention to all of the sounds in words rather than guessing based on the initial sounds is word building using a pocket chart with letter cards (see examples in Blachman & Tangel). Have students begin by building a word such as “pan” using letter cards p, a, and n. (These can be made using index cards cut into four 3″ x 1.25″ sections. It is helpful to draw attention to the vowels by making them red as they are often difficult to remember and easily confused). Next, have them change just one sound in “pan” to make a new word: “pat.” The sequence of words may continue with just one letter changing at a time: pan—pat—rat—sat—sit—sip—tip—tap—rap. The student will begin to understand that they must listen carefully to which sound has changed (which helps their phoneme awareness) and that all sounds in a word are important. As new phonics elements are taught, the letter sequences change accordingly. For example, a sequence featuring consonant blends and silent-e may look like this: slim—slime—slide—glide—glade—blade—blame—shame—sham. Many decoding programs that feature strategies based on scientifically-based research include word building and provide samples ranging from easy, beginning sequences to those that are more advanced (Beck & Beck, 2013; Blachman & Tangel, 2008).
A final important point to mention with regard to decoding is that teachers must consider what makes words (or texts) decodable in order to allow for adequate practice of new decoding skills. When letters in a word conform to common letter-sound correspondences, the word is decodable because it can be sounded out, as opposed to words containing “rule breaker” letters and sounds that are in words like “colonel” and “of.” The letter-sound correspondences and phonics elements that have been learned must be considered. For example, even though the letters in the word “shake” conform to common pronunciations, if a student has not yet learned the sound that “sh” makes, or the phonics rule for a long vowel when there is a silent “e,” this particular word is not decodable for that child. Teachers should refrain from giving children texts featuring “ship” or “shut” to practice decoding skills until they have been taught the sound of /sh/. Children who have only been taught the sounds of /s/ and /h/ may decode “shut” /s/ /h/ /u/ /t/, which would not lead to high initial accuracy and may lead to confusion.
Sight Word Recognition
The third critical component for successful word recognition is sight word recognition. A small percentage of words cannot be identified by deliberately sounding them out, yet they appear frequently in print. They are “exceptions” because some of their letters do not follow common letter-sound correspondences. Examples of such words are “once,” “put,” and “does.” (Notice that in the word “put,” however, that only the vowel makes an exception sound, unlike the sound it would make in similar words such as “gut,” “rut,” or “but.”) As a result of the irregularities, exception words must be memorized; sounding them out will not work.
Since these exception words must often be memorized as a visual unit (i.e., by sight), they are frequently called “sight words,” and this leads to confusion among teachers. This is because words that occur frequently in print, even those that are decodable (e.g., “in,” “will,” and “can”), are also often called “sight words.” Of course it is important for these decodable, highly frequent words to be learned early (preferably by attending to their sounds rather than just by memorization), right along with the others that are not decodable because they appear so frequently in the texts that will be read. For the purposes of this chapter, sight words are familiar, high frequency words that must be memorized because they have irregular spellings and cannot be perfectly decoded.
Why sight word recognition is important
One third of beginning readers’ texts are mostly comprised of familiar, high frequency words such as “the” and “of,” and almost half of the words in print are comprised of the 100 most common words (Fry, Kress, & Fountoukidis, 2000). It is no wonder that these words need to be learned to the point of automaticity so that smooth, fluent word recognition and reading can take place.
Interestingly, skilled readers who decode well tend to become skilled sight word “recognizers,” meaning that they learn irregular sight words more readily than those who decode with difficulty (Gough & Walsh, 1991). This reason is because as they begin learning to read, they are taught to be aware of phonemes, they learn letter-sound correspondences, and they put it all together to begin decoding while practicing reading books. While reading a lot of books, they are repeatedly exposed to irregularly spelled, highly frequent sight words, and as a result of this repetition, they learn sight words to automaticity. Therefore, irregularly spelled sight words can be learned from wide, independent reading of books. However, children who struggle learning to decode do not spend a lot of time practicing reading books, and therefore, do not encounter irregularly spelled sight words as often. These students will need more deliberate instruction and additional practice opportunities.
Sight word recognition instruction
Teachers should notice that the majority of letters in many irregularly spelled words do in fact follow regular sound-symbol pronunciations (e.g., in the word “from” only the “o” is irregular), and as a result attending to the letters and sounds can often lead to correct pronunciation. That is why it is still helpful to teach students to notice all letters in words to anchor them in memory, rather than to encourage “guess reading” or “looking at the first letter,” which are both highly unreliable strategies as anyone who has worked with young readers will attest. Interestingly, Tunmer and Chapman (2002) discovered that beginning readers who read unknown words by “sounding them out” outperformed children who employed strategies such as guessing, looking at the pictures, rereading the sentence on measures of word reading and reading comprehension, at the end of their first year in school and at the middle of their third year in school.
Other than developing sight word recognition from wide, independent reading of books or from exposure on classroom word walls, instruction in learning sight words is similar to instruction used to learn letter-sound correspondences. Sources of irregularly spelled sight words can vary. For instance, they can be preselected from the text that will be used for that day’s reading instruction. Lists of irregularly spelled sight words can be found in reading programs or on the Internet (search for Fry lists or Dolch lists). When using such lists, determine which words are irregularly spelled because they will also feature highly frequent words that can be decoded, such as “up,” and “got.” These do not necessarily need deliberate instructional time because the students will be able to read them using their knowledge of letters and sounds.
Regardless of the source, sight words can be practiced using flash cards or word lists, making sure to review those that have been previously taught to solidify deep learning. Gradual introduction of new words into the card piles or lists should include introduction such as pointing out features that may help learning and memorization (e.g., “where” and “there” both have a tall letter “h” which can be thought of as an arrow or road sign pointing to where or there). Sets of words that share patterns can be taught together (e.g., “would,” “could,” and “should”). Games such as Go Fish, Bingo, or Concentration featuring cards with these words can build repetition and exposure, and using peer-based learning, students can do speed drills with one another and record scores.
Any activity requiring the students to spell the words aloud is also helpful. I invented an activity that I call “Can You Match It?” in which peers work together to practice a handful of sight words. An envelope or flap is taped across the top of a small dry erase board. One student chooses a card, tells the partner what the word is, and then places the card inside the envelope or flap so that it is not visible. The student with the dry erase board writes the word on the section of board that is not covered by the envelope, then opens the envelope to see if their spelling matches the word on the card. The ultimate goal in all of these activities is to provide a lot of repetition and practice so that highly frequent, irregularly spelled sight words become words students can recognize with just a glance.
Word Recognition Summary
As seen in the above section, in order for students to achieve automatic and effortless word recognition, three important underlying elements—phonological awareness, letter-sound correspondences for decoding, and sight recognition of irregularly spelled familiar words—must be taught to the point that they too are automatic. Word recognition, the act of seeing a word and recognizing its pronunciation without conscious effort, is one of the two critical components in the Simple View of Reading that must be achieved to enable successful reading comprehension. The other component is language comprehension, which will be discussed in Chapter 4. Both interact to form the skilled process that is reading comprehension. Because they are so crucial to reading, reading comprehension is likened to a two-lock box, with both “key” components needed to open it (Davis, 2006).
The two essential components in the Simple View of Reading, automatic word recognition and strategic language comprehension, contribute to the ultimate goal of teaching reading: skilled reading comprehension. According to Garnett (2011), fluent execution of the underlying elements as discussed in this chapter involves “teaching…accompanied by supported and properly framed interactive practice” (p. 311). When word recognition becomes effortless and automatic, conscious effort is no longer needed to read the words, and instead it can be devoted to comprehension of the text. Accuracy and effortlessness, or fluency, in reading words serves to clear the way for successful reading comprehension.
It is easy to see how success in the three elements that lead to automatic word recognition are prerequisite to reading comprehension. Learning to decode and to automatically read irregularly spelled sight words can prevent the development of reading problems. Students who are successful in developing effortless word recognition have an easier time reading, and this serves as a motivator to young readers, who then proceed to read a lot. Students who struggle with word recognition find reading laborious, and this serves as a barrier to young readers, who then may be offered fewer opportunities to read connected text or avoid reading as much as possible because it is difficult. Stanovich (1986) calls this disparity the “Matthew Effects” of reading, where the rich get richer—good readers read more and become even better readers and poor readers lose out. Stanovich (1986) also points out an astonishing quote from Nagy and Anderson (1984, p. 328): “the least motivated children in the middle grades might read 100,000 words a year while the average children at this level might read 1,000,000. The figure for the voracious middle grade reader might be 10,000,000 or even as high as 50,000,000.” Imagine the differences in word and world knowledge that result from reading 100,000 words a year versus millions! As teachers, it is worthwhile to keep these numbers in mind to remind us of the importance of employing evidence-based instructional practices to ensure that all students learn phoneme awareness, decoding, and sight word recognition—the elements necessary for learning how to succeed in word recognition.
Summary
In order for students to comprehend text while reading, it is vital that they be able to read the words on the page. Teachers who are aware of the importance of the essential, fundamental elements which lead to successful word recognition—phonological awareness, decoding, and sight recognition of irregular words—are apt to make sure to teach their students each of these so that their word reading becomes automatic, accurate, and effortless. Today’s teachers are fortunate to have available to them a well-established bank of research and instructional activities that they can access in order to facilitate word recognition in their classrooms.
The Simple View of Reading’s two essential components, automatic word recognition and strategic language comprehension, combine to allow for skilled reading comprehension. Students who can both recognize the words on the page and understand the language of the words and sentences are much more likely to enjoy the resulting advantage of comprehending the meaning of the texts that they read.
Questions and Activities
- List the two main components of the simple view of reading, and explain their importance in developing reading comprehension.
- Explain the underlying elements of word recognition. How does each contribute to successful reading comprehension?
- Discuss instructional activities that are helpful for teaching phonological awareness, decoding, and sight recognition of irregularly spelled, highly frequent words.
- View the following video showing a student named Nathan who has difficulty with word recognition: https://www.youtube.com/watch?v=lpx7yoBUnKk (Rsogren, 2008). Which of the underlying elements of word recognition (e.g., phonological awareness, letter-sound correspondences, decoding) do you believe may be at the root of this student’s difficulties? How might you develop a new instructional plan to address these difficulties?
References
Adams, M. J., Foorman, B. R., Lundberg, I., & Beeler, T. (1998). The elusive phoneme: Why phonemic awareness is so important and how to help children develop it. American Educator, 22, 18-29. Retrieved from http://literacyconnects.org/img/2013/03/the-elusive-phoneme.pdf
Beck, I. L., & Beck, M. E. (2013). Making sense of phonics: The hows and whys (2nd ed.). New York, NY: Guilford Press.
Beck, I. L., & Juel, C. (1995). The role of decoding in learning to read. American Educator, 19, 8-25. Retrieved from http://www.scholastic.com/Dodea/Module_2/resources/dodea_m2_pa_roledecod.pdf
Blachman, B. A., Ball, E. W., Black, R., & Tangel, D. M. (2000). Road to the code: A phonological awareness program for young children. Baltimore, MD: Paul H. Brookes Publishing Co.
Blachman, B. A., & Murray, M. S. (2012). Teaching tutorial: Decoding instruction. Charlottesville, VA: Division for Learning Disabilities. Retrieved from http://teachingld.org/tutorials
Blachman, B. A., & Tangel, D. M. (2008). Road to reading: A program for preventing and remediating reading difficulties. Baltimore: Brookes Publishing.
Boyer, N., & Ehri, L. (2011). Contribution of phonemic segmentation instruction with letters and articulation pictures to word reading and spelling in beginners. Scientific Studies of Reading, 15, 440-470. doi:10.1080/10888438.2010.520778
Bradley, L., & Bryant, P. E. (1983). Categorizing sounds and learning to read: A causal connection. Nature, 303, 419-421. doi:10.1038/301419a0
Brady, S. (2011). Efficacy of phonics teaching for reading outcomes: Indicators from post-NRP research. In S. A. Brady, D. Braze, & C. A. Fowler (Eds.), Explaining individual differences in reading: Theory and evidence (pp. 69–96). New York, NY: Psychology Press.
Byrne, J. P. (2012). Encyclopedia of the Black Death. Santa Barbara, CA: ABC-CLIO.
Davis, M. (2006). Reading instruction: The two keys. Charlottesville, VA: Core Knowledge Foundation.
Dehaene, S. (2009). Reading in the brain. New York, NY: Penguin Books.
Elkonin, D. B. (1963). The psychology of mastering the elements of reading. In B. Simon & J. Simon (Eds.), Educational psychology in the U.S.S.R. (pp. 165-179). London, England: Routledge & Kegan Paul.
Fry, E., Kress, J., & Fountoukidis, D. (2000). The reading teacher’s book of lists (4th ed.). Paramus, NJ: Prentice-Hall.
Garnett, K. (2011). Fluency in learning to read: Conceptions, misconceptions, learning disabilities, and instructional moves. In J. R. Birsh (Ed.), Multisensory teaching of basic language skills (p. 293-320). Baltimore, MD: Brookes Publishing.
Goodman, K. (1967). Reading: A psycholinguistic guessing game. Journal of the Reading Specialist, 6, 126-135. doi:10.1080/19388076709556976
Gough, P. B., & Tunmer, W. E. (1986). Decoding, reading, and reading disability. Remedial and Special Education, 7, 6-10. doi:10.1177/074193258600700104
Gough, P. B., & Walsh, M. (1991). Chinese, Phoenicians, and the orthographic cipher of English. In S. Brady & D. Shankweiler (Eds.), Phonological processes in literacy (pp. 199-209). Hillsdale, NJ: Erlbaum.
International Dyslexia Association. (2015). Definition of dyslexia. Retrieved from http://eida.org/definition-of-dyslexia/
International Reading Association. (1998). Phonemic awareness and the teaching of reading: A position statement from the board of directors of the International Reading Association. Retrieved from http://www.reading.org/Libraries/position-statements-and-resolutions/ps1025_phonemic.pdf
Nagy, W., & Anderson, R. C. (1984). How many words are there in printed school English? Reading Research Quarterly, 19, 304-330. doi:10.2307/747823
National Institute of Child Health and Human Development. (2000). Report of the National Reading Panel: Teaching children to read: An evidence-based assessment of the scientific research literature on reading and its implications for reading instruction: Reports of the subgroups. (NIH Publication No. 00-4754). Washington, DC: U.S. Government Printing Office. Retrieved from http://www.nichd.nih.gov/publications/pubs/nrp/documents/report.pdf
Rayner, K., Foorman, B. R., Perfetti, C. A., Pesetsky, D., & Seidenberg, M. S. (2001). How psychological science informs the teaching of reading. Psychological Science in the Public Interest, 2, 31-74.
Scarborough, H. S. (2002). Connecting early language and literacy to later reading (dis)abilities: Evidence, theory, and practice. In S. B. Neuman & D. K. Dickinson (Eds.), Handbook of early literacy research (pp. 97-110). New York, NY: Guilford Press.
Snow, C. E. (Chair). (2002). Reading for understanding: Toward an R & D program in reading comprehension. Santa Monica, CA: Rand. Retrieved from http://www.prgs.edu/content/dam/rand/pubs/monograph_reports/2005/MR1465.pdf
Snow, C. E., Burns, M. S., & Griffin, P. (Eds.). (1998). Preventing reading difficulties in young children. Washington, DC: National Academy Press.
Rsogren, N. (2008, June 13). Misunderstood minds chapter 2 [Video file]. Available from https://www.youtube.com/watch?v=lpx7yoBUnKk
Stanovich, K. E. (1986). Matthew effects in reading: Some consequences of individual differences in the acquisition of literacy. Reading Research Quarterly, 21, 360–407. doi:10.1598/RRQ.21.4.1
Tunmer, W. E., & Chapman, J. W. (2002). The relation of beginning readers’ reported word identification strategies to reading achievement, reading-related skills, and academic self-perceptions. Reading and Writing: An Interdisciplinary Journal, 15, 341-358. doi:10.1023/A:1015219229515
Worsley, L. (2011). If walls could talk: An intimate history of the home. New York, NY: Bloomsbury.
Endnotes
1: For detailed information on scientifically-based research in education, see Chapter 2 by Munger in this volume. Return
Wordsmyth’s Word Combinations, technically known as “collocations,” provide what is almost like a thesaurus in another dimension. You will find them in most entries in the Advanced Dictionary. Instead of listing synonyms, that is, words you might use instead of the word you are using, Word Combinations provide words to use with the word you are using. In other words, they help you start building a bigger chunk of a sentence.
Compare the thesaurus’s “similar words” for the verb “laugh”:
cackle, chortle, chuckle, giggle, guffaw, howl, snicker, snigger, tee-hee, titter…
…with the Word Combination adverbs for the verb “laugh”:
The similar words allow you to choose from among words for more specific kinds of laugh: from a quiet titter to a hearty guffaw. The Word Combinations allow you to choose from among adverbs that writers frequently use to modify the verb “laugh.” “Ashley laughed uneasily at the cruel joke,” you might write. Or, “Ashley laughed good-naturedly when her error was pointed out.” (Ashley’s a likable person, evidently.)
Word Combinations are the most frequent companions of the headword in published writing and broadcast speech. Thus, they represent the many ways in which the headword-concept is typically talked about and the words typically used to talk about them.
In the entries, word combinations are organized by part of speech combination. Take, for example, the word “election.” The word combinations for the noun “election” fall into four kinds:
adjective + (n.) election
verb + (n.) election
(n.) election + verb
noun + (n.) election
These formulas show you the kind of word (part of speech) and the position (before or after “election”) in which it appears in the corpus of texts. Notice that “election” has some verbs that appear before it and some that appear after it. Here are the full word combinations entries, with some comments in red:
adjective + (n.)election coming, competitive, congressional, contested, democratic, direct, disputed, fair, federal, forthcoming, fraudulent, free, general, gubernatorial, judicial, legislative, local, mayoral, mid-term, multi-party, multiracial, municipal, nationwide, nonpartisan, off-year, parliamentary, periodic, presidential, primary, provincial, scheduled, statewide, transitional, upcoming
verb + (n.)election boycott, cancel, certify, contest, delay, disrupt, influence, hold, monitor, oversee, overturn, postpone, precede, rig, schedule, steal, supervise (These verbs that frequently have the word “election” as their object will give you a glimpse at all the things we can do to an election. )
(n.)election + verb loom, near
(Which of these two verbs would you choose to talk about a coming election? It really depends how you feel about it.)
noun + (n.)election ballot, boycott, candidate, eve, fall, financing, landslide, legitimacy, midterm, month, outcome, poll, primary, recall, registration, round, run-up, runoff, turnout, vote, voting
If you have read through these words, you may have noticed that some make sense when placed immediately before or after the headword “election”: “a fair election,” “postponed the election,” and “a fall [i.e., autumn] election.” True, you have to insert an article, “the” between “postpone” and “election,” but generally these are recognizable phrases that make sense.
Others, especially in the noun+noun category, don’t seem like a chunk of a sentence: “legitimacy election” and “voting election,” for example. Often a preposition will need to be inserted between the words: “the legitimacy of the election,” “voting in this election” are some possible ways the word combinations will work in these cases.
If you don’t know how to fit the two words together, a Google search on the two words will often return a number of similar examples of how they do.
You can try this little exercise to get a feel for how to fill out a word combination:
Complete these common noun + noun word combinations with the correct prepositions and articles.
1. the eve ____ ____ election
2. the outcome ____ ____ election
3. the turnout ____ ____ election
Word Combinations is a subscription feature, but you can try it by signing up for a 15-day free Trial Subscription, no strings attached. (There is a Trial Subscription button on most pages of the Wordsmyth website.) We also include Word Combinations with many Academic Vocabulary of the Day posts.
Read more about collocations here.