
This is a step by step guide on how to run k-means cluster analysis on an Excel spreadsheet from start to finish. Please note that there is an Excel template that automatically runs cluster analysis available for free download on this website. But if you want to know how to run a k-means clustering on Excel yourself, then this article is for you.
In addition to this article, I also have a video walk-through of how to run cluster analysis in Excel.
Step One – Start with your data set
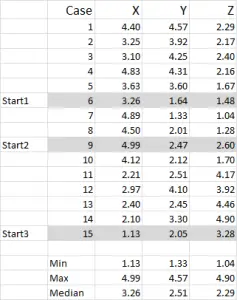
For this example I am using 15 cases (or respondents), where we have the data for three variables – generically labeled X, Y and Z.
You should notice that the data is scaled 1-5 in this example. Your data can be in any form except for a nominal data scale (please see article of what data to use).
NOTE: I prefer to use scaled data – but it is not mandatory. The reason for this is to “contain” any outliers. Say, for example, I am using income data (a demographic measure) – most of the data might be around $40,000 to $100,000, but I have one person with an income of $5m. It’s just easier for me to classify that person in the “over $250,000” income bracket and scale income 1-9 – but that’s up to you depending upon the data you are working with.
You can see from this example set that three start positions have been highlighted – we will discuss those in Step Three below.
Step Two – If just two variables, use a scatter graph on Excel
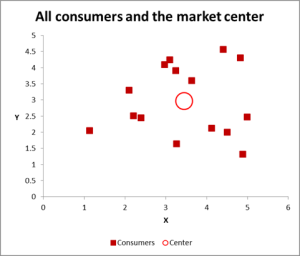
In this cluster analysis example we are using three variables – but if you have just two variables to cluster, then a scatter chart is an excellent way to start. And, at times, you can cluster the data via visual means.
As you can see in this scatter graph, each individual case (what I’m calling a consumer for this example) has been mapped, along with the average (mean) for all cases (the red circle).
Depending upon how you view the data/graph – there appears to be a number of clusters. In this case, you could identify three or four relatively distinct clusters – as shown in this next chart.
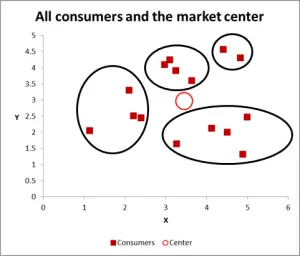
With this next graph, I have visibly identified probable cluster and circled them. As I have suggested, a good approach when there are only two variables to consider – but is this case we have three variables (and you could have more), so this visual approach will only work for basic data sets – so now let’s look at how to do the Excel calculation for k-means clustering.
Step Three – Calculate the distance from each data point to the center of a cluster
For this walk-through example, let’s assume that we want to identify three segments/clusters only. Yes, there are four clusters evident in the diagram above, but that only looks at two of the variables. Please note that you can use this Excel approach to identify as many clusters as you like – just follow the same concept as explained below.
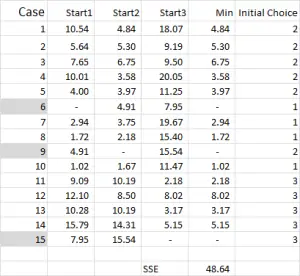
For k-means clustering you typically pick some random cases (starting points or seeds) to get the analysis started.
In this example – as I’m wanting to create three clusters, then I will need three starting points. For these start points I have selected cases 6, 9 and 15 – but any random points could also be suitable.
The reason I selected these cases is because – when looking at variable X only – case 6 was the median, case 9 was the maximum and case 15 was the minimum. This suggests that these three cases are somewhat different to each other, so good starting points as they are spread out.
Please refer to the article on why cluster analysis sometimes generates different results.
Referring to the table output – this is our first calculation in Excel and it generates our “initial choice” of clusters. Start 1 is the data for case 6, start 2 is case 9 and start 3 is case 15. You should note that the intersection of each of these gives a 0 (-) in the table.
How does the calculation work?
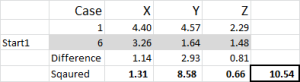
Let’s look at the first number in the table – case 1, start 1 = 10.54.
Remember that we have arbitrarily designated Case 6 to be our random start point for Cluster 1. We want to calculate the distance and we use the sum of squares method – as shown here. We calculate the difference between each of the three data points in the set, and then square the differences, and then sum them.
We can do it “mechanically” as shown here – but Excel has a built-in formula to use: SUMXMY2 – this is far more efficient to use.
Referring back to Figure 4, we then find the minimum distance for each case from each of the three start points – this tells us which cluster (1, 2 or 3) that the case is closest to – which is shown in the ‘initial choice column’.
Step Four – Calculate the mean (average) of each cluster set
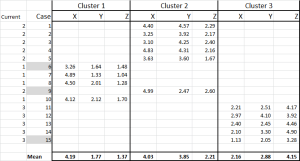
We have now allocated each case to its initial cluster – and we can lay that out using an IF statement in a table (as shown in Figure 6).
At the bottom of the table, we have the mean (average) of each of these cases. N0w – instead of relying on just one “representative” data point – we have a set of cases representing each.
Step Five – Repeat Step 3 – the Distance from the revised mean
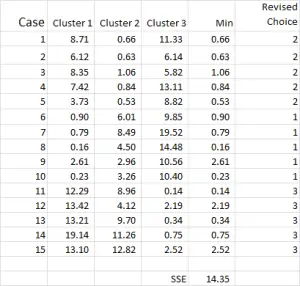
The cluster analysis process now becomes a matter of repeating Steps 4 and 5 (iterations) until the clusters stabilize.
Each time we use the revised mean for each cluster. Therefore, Figure 7 shows our second iteration – but this time we are using the means generated at the bottom of Figure 6 (instead of the start points from Figure 1).
You can now see that there has been a slight change in cluster application, with case 9 – one of our starting points – being reallocated.
You can also see sum of squared error (SSE) calculated at the bottom – which is the sum of each of the minimum distances. Our goal is to now repeat Steps 4 and 5 until the SSE only shows minimal improvement and/or the cluster allocation changes are minor on each iteration.
Final Step – Graph and Summarize the Clusters
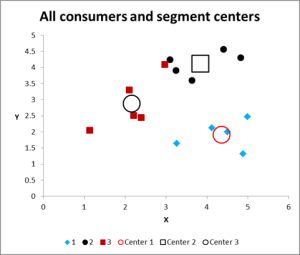
After running multiple iterations, we now have the output to graph and summarize the data.
Here is the output graph for this cluster analysis Excel example.
As you can see, there are three distinct clusters shown, along with the centroids (average) of each cluster – the larger symbols.
We can also present this data in a table form if required, as we have worked it out in Excel.
Please have a look at the case in Cluster 3 – the small red square right next to the black dot in the top middle of the graph. That case sits there because of the influence of the third variable, which is not shown on this two variable chart.
For more information
- Please contact me via email
- Or download and use the free Excel template and play around with some data
- And note that there is lots of information on cluster analysis on this website
Related Information
How to allocate new customers to existing segments
Содержание
- Использование кластерного анализа
- Пример использования
- Вопросы и ответы

Одним из инструментов для решения экономических задач является кластерный анализ. С его помощью кластеры и другие объекты массива данных классифицируются по группам. Данную методику можно применять в программе Excel. Посмотрим, как это делается на практике.
Использование кластерного анализа
С помощью кластерного анализа можно проводить выборку по признаку, который исследуется. Его основная задача – разбиение многомерного массива на однородные группы. В качестве критерия группировки применяется парный коэффициент корреляции или эвклидово расстояние между объектами по заданному параметру. Наиболее близкие друг к другу значения группируются вместе.
Хотя чаще всего данный вид анализа применяют в экономике, его также можно использовать в биологии (для классификации животных), психологии, медицине и во многих других сферах деятельности человека. Кластерный анализ можно применять, используя для этих целей стандартный набор инструментов Эксель.
Пример использования
Имеем пять объектов, которые характеризуются по двум изучаемым параметрам – x и y.
- Применяем к данным значениям формулу эвклидового расстояния, которое вычисляется по шаблону:
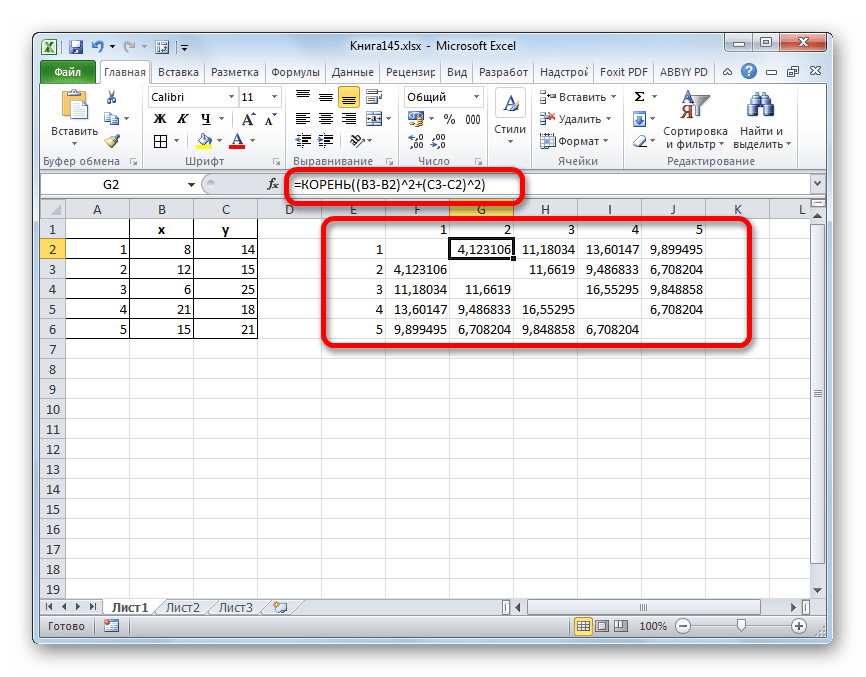
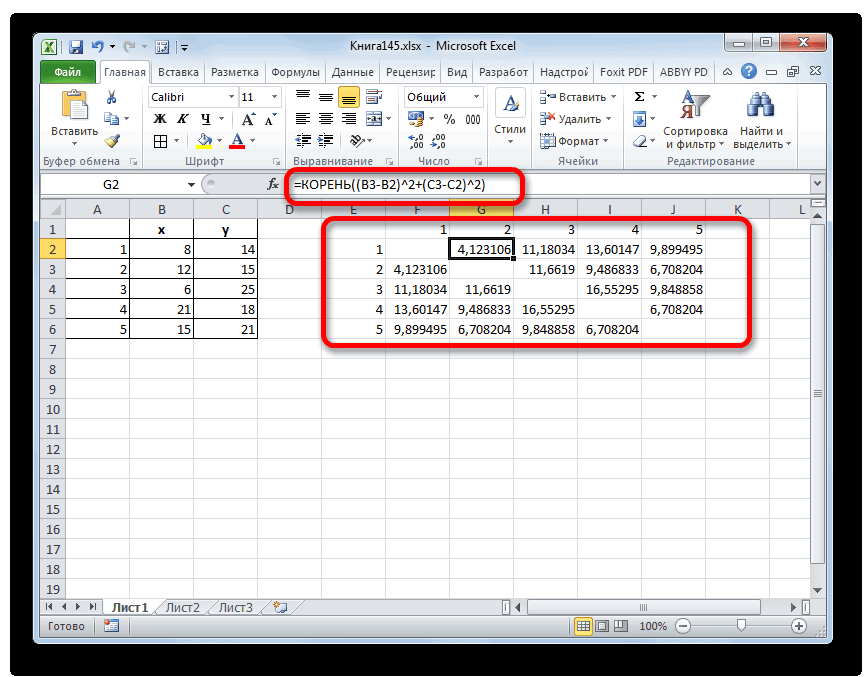
=КОРЕНЬ((x2-x1)^2+(y2-y1)^2) - Данное значение вычисляем между каждым из пяти объектов. Результаты расчета помещаем в матрице расстояний.
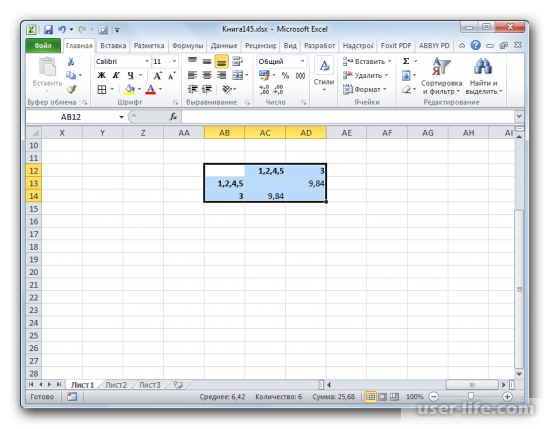
- Смотрим, между какими значениями дистанция меньше всего. В нашем примере — это объекты 1 и 2. Расстояние между ними составляет 4,123106, что меньше, чем между любыми другими элементами данной совокупности.
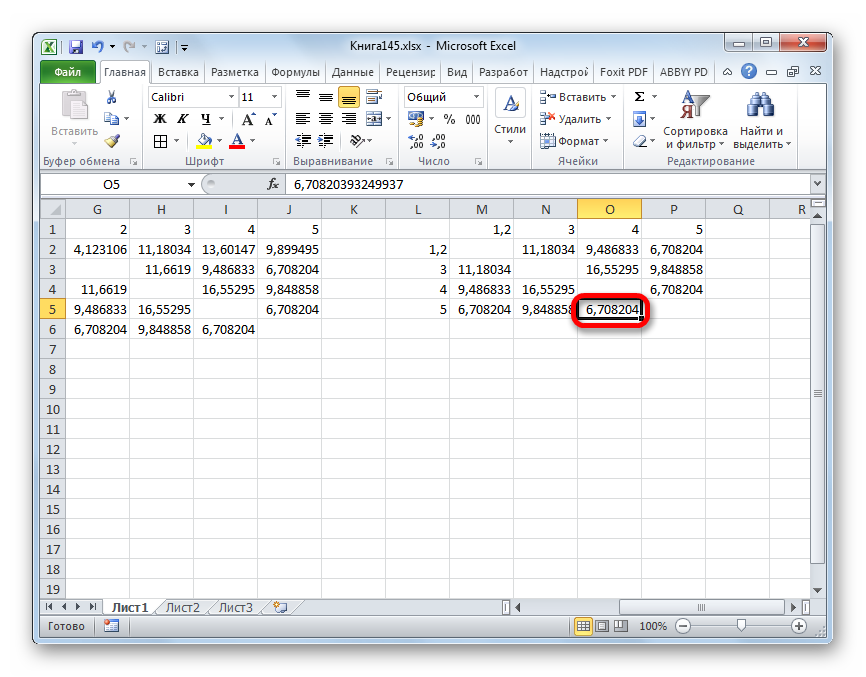
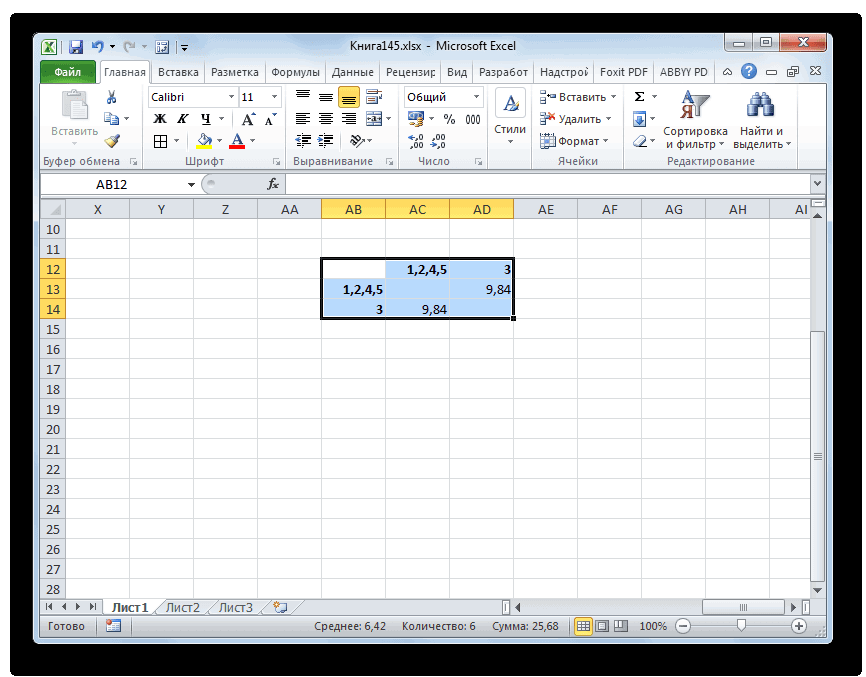
- Объединяем эти данные в группу и формируем новую матрицу, в которой значения 1,2 выступают отдельным элементом. При составлении матрицы оставляем наименьшие значения из предыдущей таблицы для объединенного элемента. Опять смотрим, между какими элементами расстояние минимально. На этот раз – это 4 и 5, а также объект 5 и группа объектов 1,2. Дистанция составляет 6,708204.
- Добавляем указанные элементы в общий кластер. Формируем новую матрицу по тому же принципу, что и в предыдущий раз. То есть, ищем самые меньшие значения. Таким образом мы видим, что нашу совокупность данных можно разбить на два кластера. В первом кластере находятся наиболее близкие между собой элементы – 1,2,4,5. Во втором кластере в нашем случае представлен только один элемент — 3. Он находится сравнительно в отдалении от других объектов. Расстояние между кластерами составляет 9,84.



На этом завершается процедура разбиения совокупности на группы.
Как видим, хотя в целом кластерный анализ и может показаться сложной процедурой, но на самом деле разобраться в нюансах данного метода не так уж тяжело. Главное понять основную закономерность объединения в группы.
Еще статьи по данной теме:
Помогла ли Вам статья?
Кластерный анализ объединяет кластеры и переменные (объекты), похожие друг на друга. То есть классифицирует объекты. Часто при решении экономических задач, имеющих достаточно большое число данных, нужна многомерность описания. Один из простых методов многомерного анализа – кластерный анализ.
Кластерный анализ является количественным инструментом исследования социально-экономических процессов, для описания которых необходимо много характеристик. Он позволяет разбить выборку на несколько групп по исследуемому признаку, проанализировать группы (как группируются переменные), группировку объектов (как группируются объекты). С помощью метода решаются задачи сегментирования рынка, анализируются сельские хозяйства для сравнения производительности, например, прогнозируется конъюнктура рынка отдельных продуктов и т.д.
Многомерный кластерный анализ
По сути, кластерный анализ – это совокупность инструментов для классификации многомерных объектов. Метод подразумевает определение расстояния между переменными (дельты) и последующее выделение групп наблюдений (кластеров).
Техника кластеризации применяется в самых разнообразных областях. Главное задача – разбить многомерный ряд исследуемых значений (объектов, переменных, признаков) на однородные группы, кластеры. То есть данные классифицируются и структурируются.
Вопрос, который задает исследователь при использовании кластерного анализа, – как организовать многомерную выборку в наглядные структуры.
Примеры использования кластерного анализа:
- В биологии – для определения видов животных на Земле.
- В медицине – для классификации заболеваний по группам симптомов и способам терапии.
- В психологии – для определения типов поведения личности в определенных ситуациях.
- В экономическом анализе – при изучении и прогнозировании экономической депрессии, исследовании конъюнктуры.
- В разнообразных маркетинговых исследованиях.
Когда нужно преобразовать «горы» информации в пригодные для дальнейшего изучения группы, используют кластерный анализ.
Преимущества метода:
- позволяет разбивать многомерный ряд сразу по целому набору параметров;
- можно рассматривать данные практически любой природы (нет ограничений на вид исследуемых объектов);
- можно обрабатывать значительные объемы информации, резко сжимать их, делать компактными и наглядными;
- может применяться циклически (проводится до тех пор, пока не будет достигнут нужный результат; а после каждого цикла возможно значительное изменение направленности дальнейшего исследования).
Дельта-кластерный анализ имеет и свои недостатки:
- состав и количество кластеров зависит от заданного критерия разбиения;
- при преобразовании исходного набора данных в компактные группы исходная информация может искажаться, отдельные объекты могут терять свою индивидуальность;
- часто игнорируется отсутствие в анализируемой совокупности некоторых значений кластеров.
Как сделать кластерный анализ в Excel
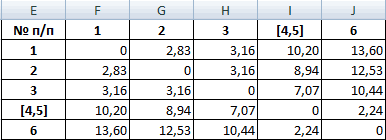
Для примера возьмем шесть объектов наблюдения. Каждый имеет два характеризующих его параметра.
В качестве расстояния между объектами возьмем евклидовое расстояние. Формула расчета:
Рассчитанные данные размещаем в матрице расстояний.
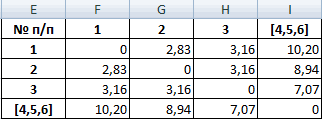
Самыми близкими друг к другу объектами являются объекты 4 и 5. Следовательно, их можно объединить в одну группу – при формировании новой матрицы оставляем наименьшее значение.
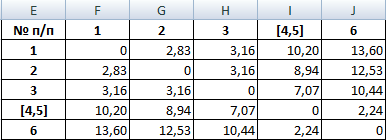
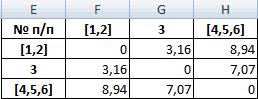
Из новой матрицы видно, что можно объединить в один кластер объекты [4, 5] и 6 (как наиболее близкие друг к другу по значениям). Оставляем наименьшее значение и формируем новую матрицу:
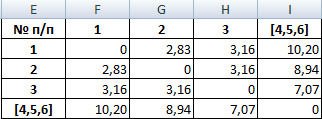
Объекты 1 и 2 можно объединить в один кластер (как наиболее близкие из имеющихся). Выбираем наименьшее значение и формируем новую матрицу расстояний. В результате получаем три кластера:
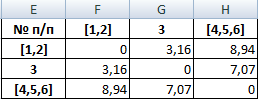
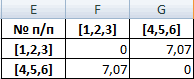
Самые близкие объекты – 1, 2 и 3. Объединим их.
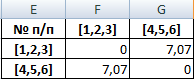
Мы провели кластерный анализ по методу «ближайшего соседа». В результате получено два кластера, расстояние между которыми – 7,07.
Огромное значение имеет кластерный анализ в экономическом анализе. Инструмент позволяет вычленять из громадной совокупности периоды, где значения соответствующих параметров максимально близки и где динамика наиболее схожа. Для исследования, к примеру, товарной и общехозяйственной конъюнктуры этот метод отлично подходит.
17 авг. 2022 г.
читать 3 мин
В статистике мы часто берем выборки из совокупности и используем данные выборки, чтобы делать выводы о населении в целом.
Одним из широко используемых методов выборки является кластерная выборка , при которой совокупность разбивается на кластеры, и все члены некоторых кластеров выбираются для включения в выборку.
В следующем пошаговом примере показано, как выполнить кластерную выборку в Excel.
Шаг 1: введите данные
Во-первых, давайте введем следующий набор данных в Excel:
Затем мы выполним кластерную выборку, в которой мы случайным образом выберем две команды и решим включить каждого игрока из этих двух команд в окончательную выборку.
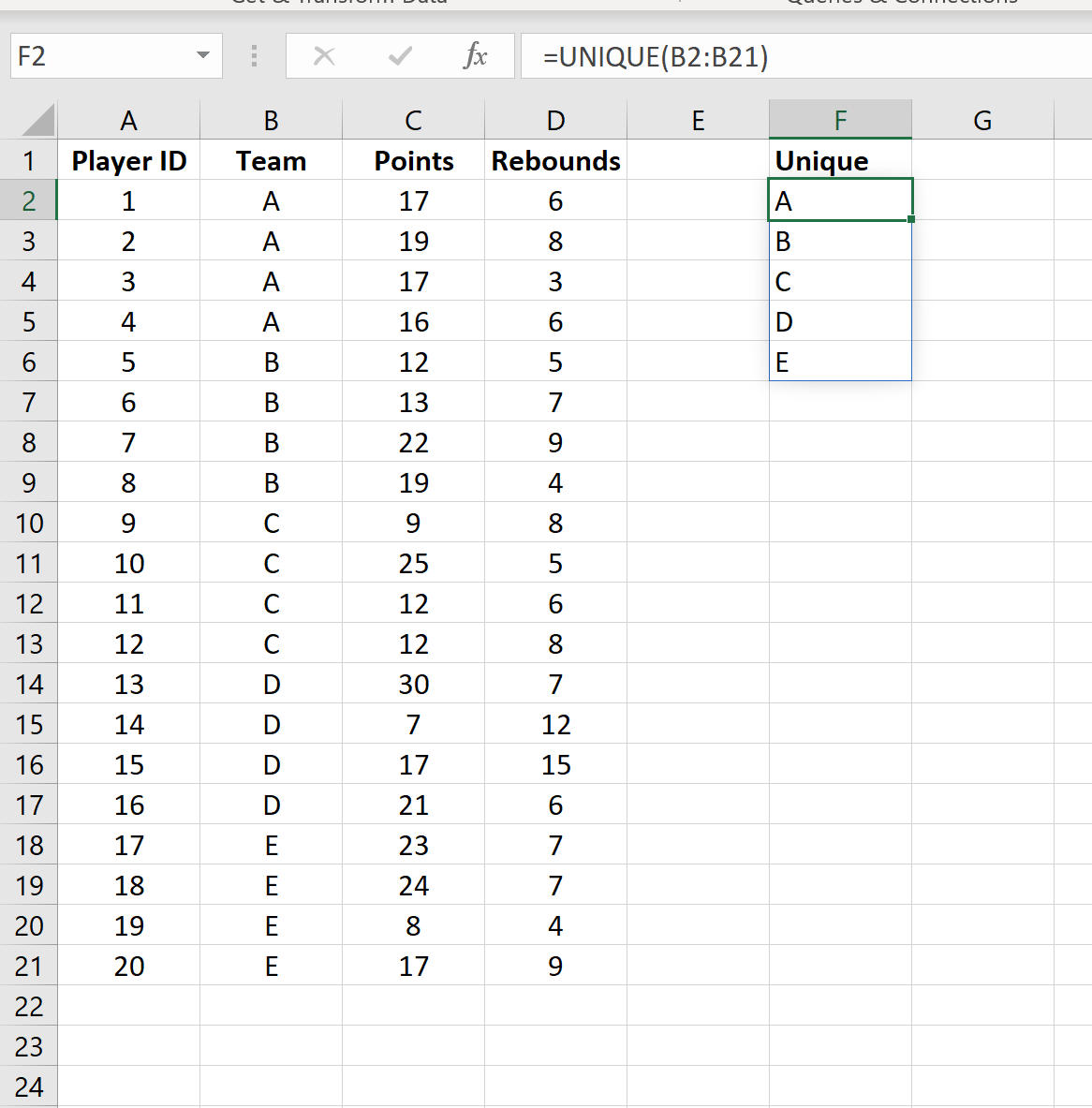
Шаг 2: Найдите уникальные значения
Затем введите =UNIQUE(B2:B21) , чтобы создать массив уникальных значений из столбца Team :
Затем мы введем целое число (начиная с 1) рядом с каждым уникальным названием команды:
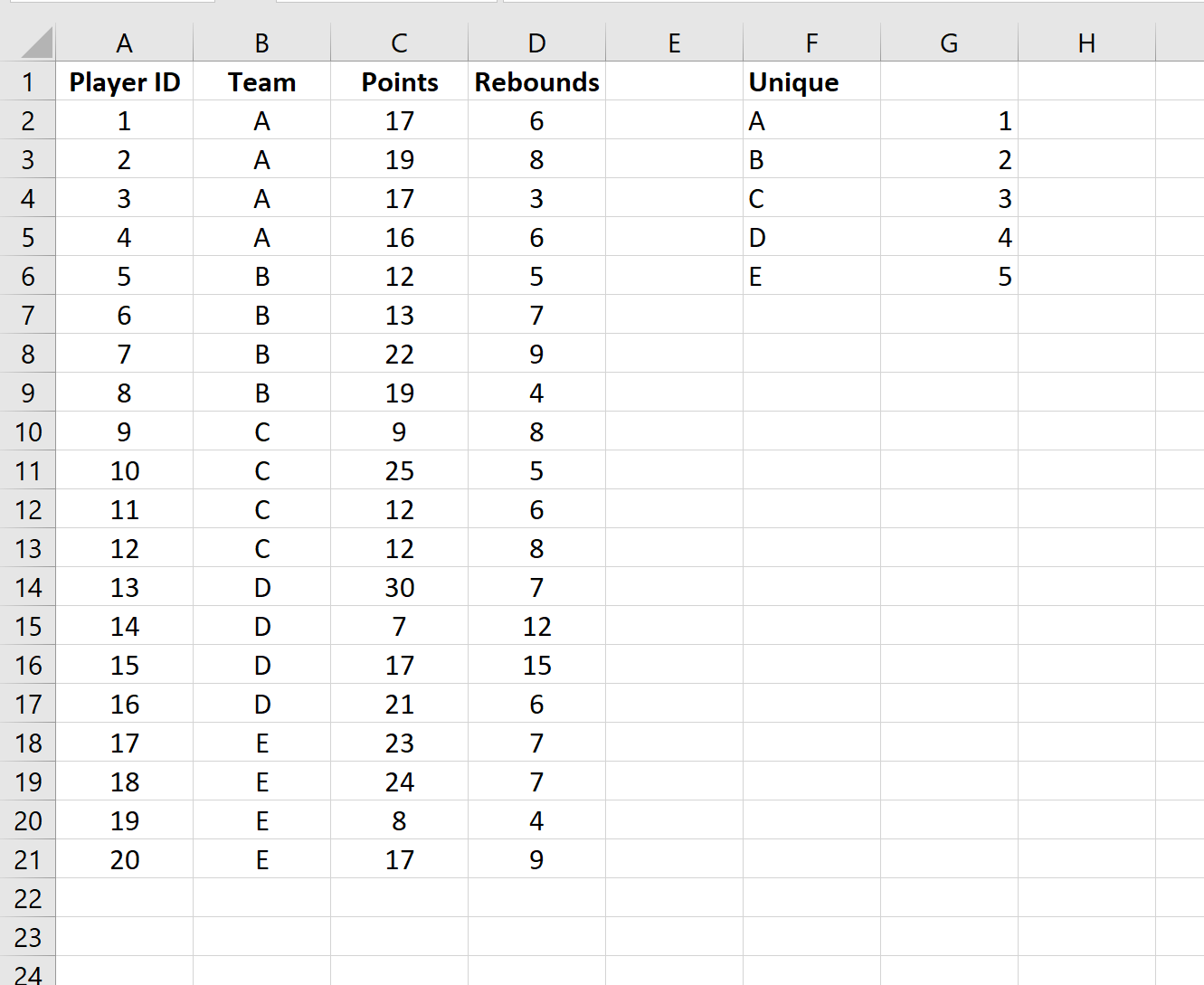
Шаг 3: выберите случайные кластеры
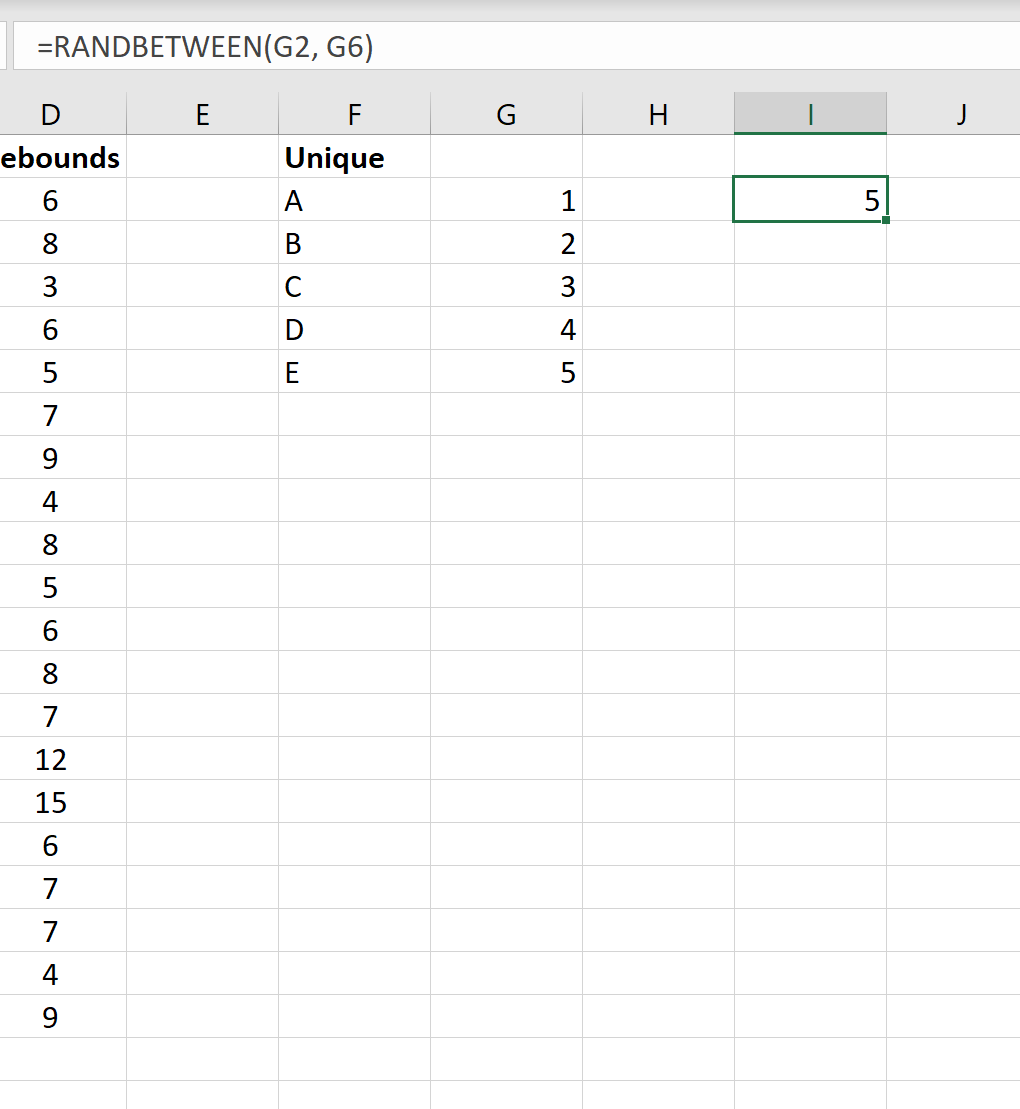
Затем мы введем =СЛУЧМЕЖДУ(G2, G6), чтобы случайным образом выбрать одно из целых чисел из списка:
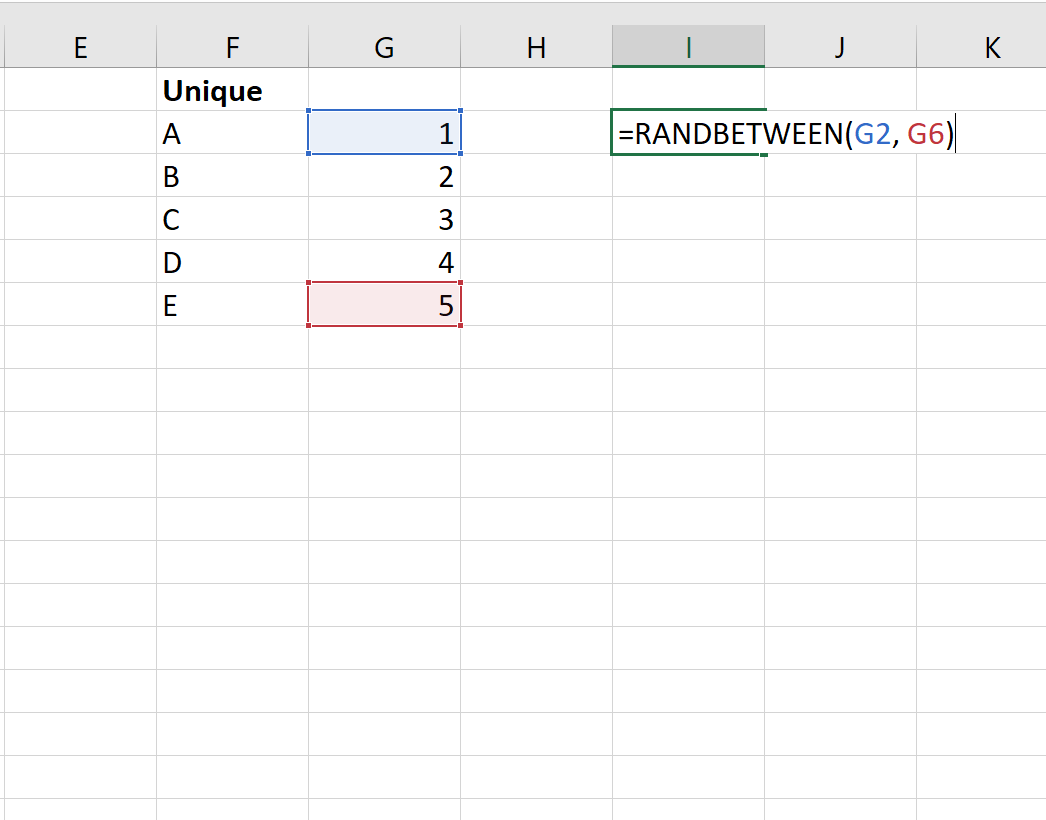
Как только мы нажмем ENTER , мы увидим, что значение 5 было выбрано случайным образом. Команда, связанная с этим значением, — это команда E, которая представляет собой первую команду, которую мы включим в нашу окончательную выборку.
Затем дважды щелкните любую ячейку и нажмите Enter.Новое число будет выбрано из функции =СЛУЧМЕЖДУ(G2, G6) .
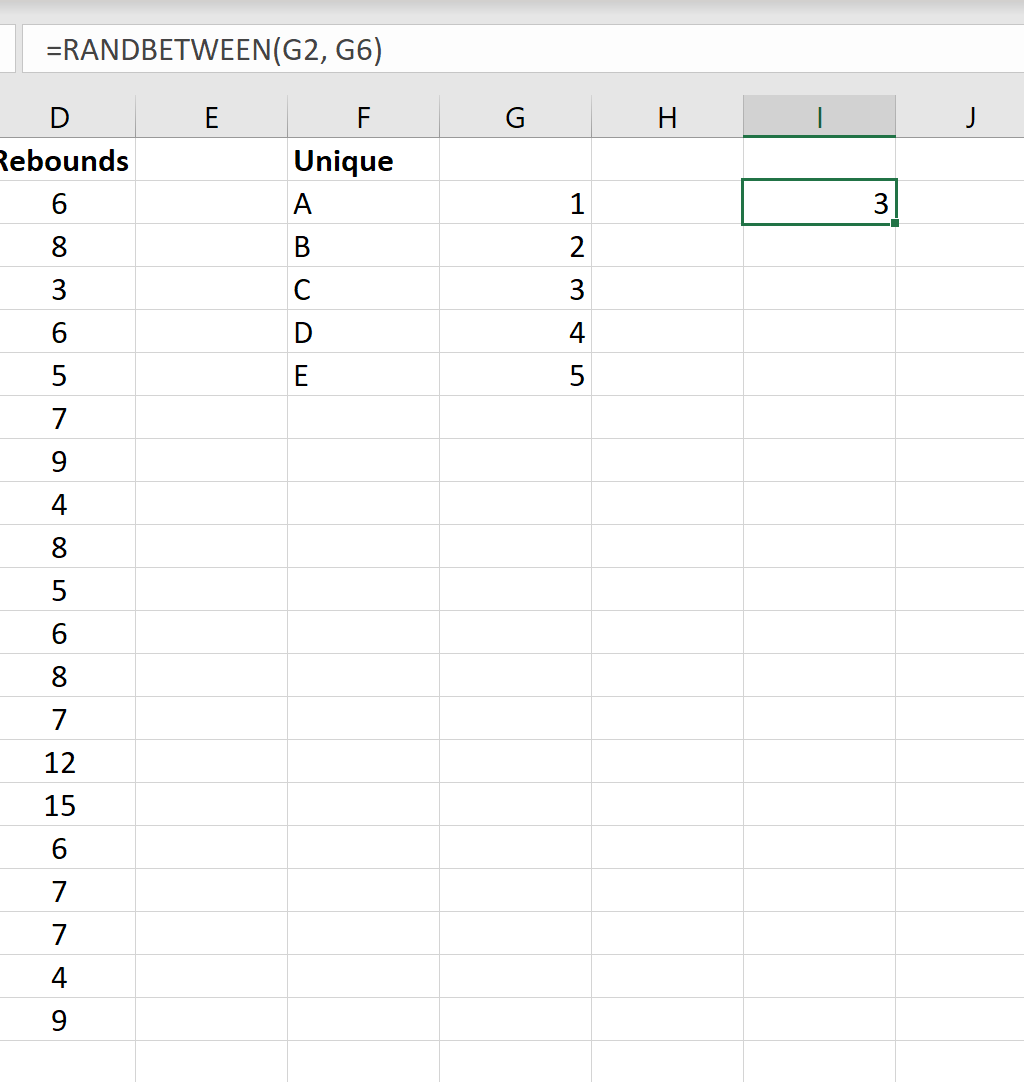
Мы видим, что значение 3 было выбрано случайным образом. Команда, связанная с этим значением, — это команда C, которая представляет собой вторую команду, которую мы включим в нашу последнюю выборку.
Шаг 4: Отфильтруйте окончательный образец
Окончательная выборка будет просто включать всех игроков, принадлежащих либо к команде C, либо к команде E.
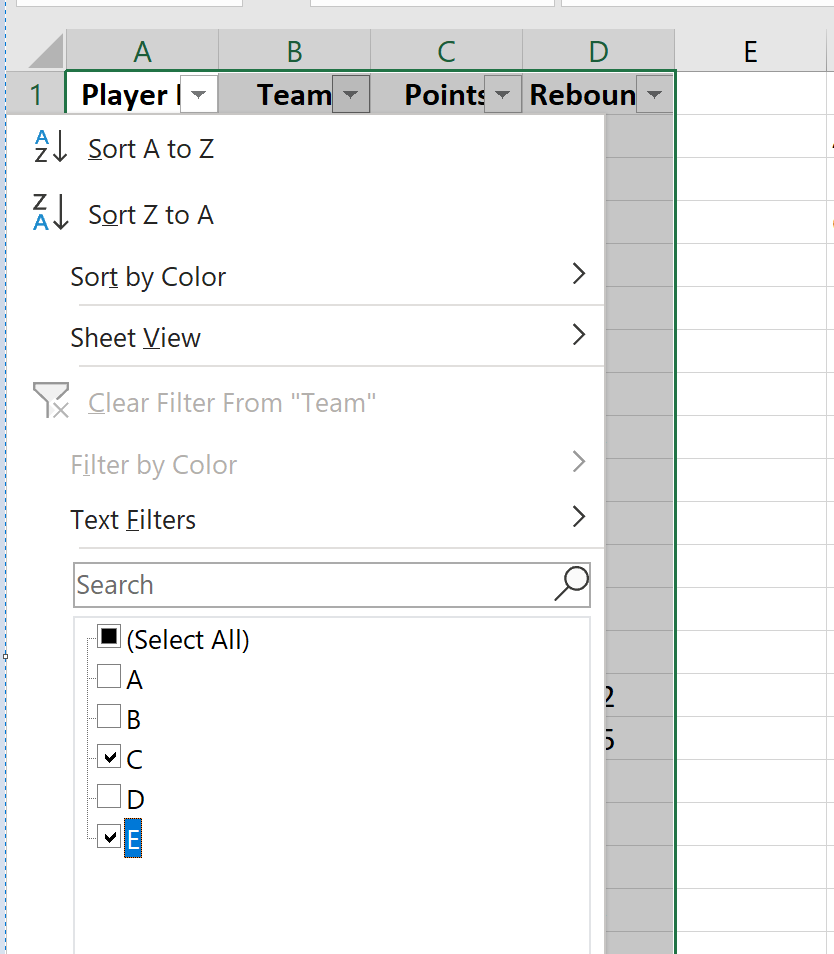
Чтобы отфильтровать только этих игроков, выделите все данные. Затем щелкните вкладку « Данные » на верхней ленте, а затем нажмите кнопку « Фильтр » в группе « Сортировка и фильтр ».
Когда фильтр появится над каждым столбцом, щелкните стрелку раскрывающегося списка рядом со столбцом «Команда» и установите флажки только для команд C и E:
Как только вы нажмете «ОК», набор данных будет отфильтрован, чтобы показывать только игроков из команды C или команды E:
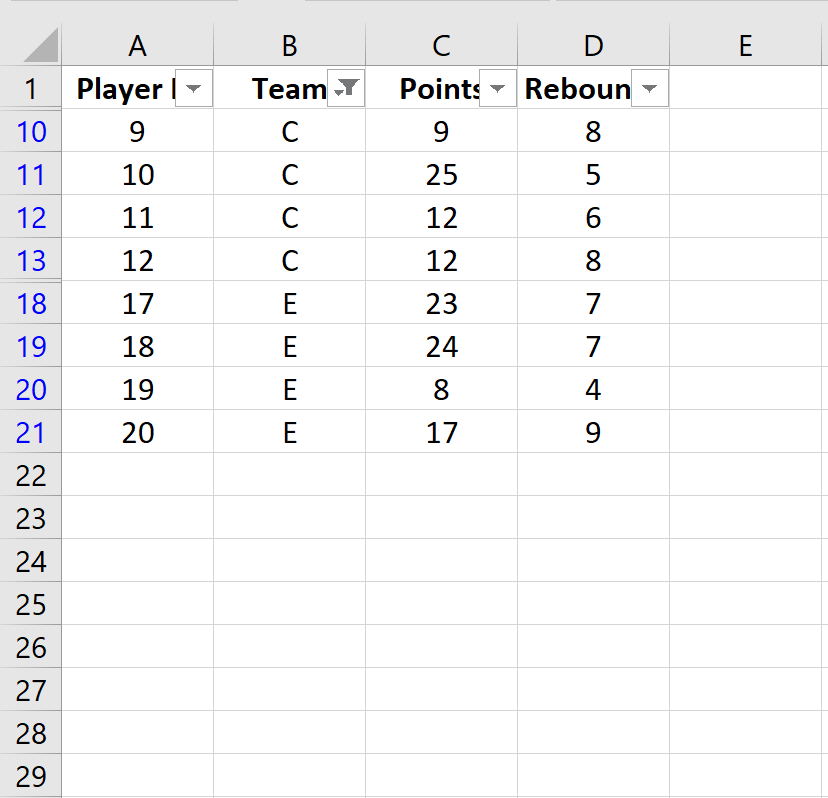
Это наш последний образец.
Наша кластерная выборка завершена, потому что мы случайным образом выбрали две команды и включили каждого игрока из этих двух команд в нашу окончательную выборку.
Дополнительные ресурсы
В следующих руководствах объясняется, как выбрать другие типы выборок из генеральной совокупности с помощью Excel:
Как выбрать случайную выборку в Excel
Как выполнить систематическую выборку в Excel
Как выполнить стратифицированную выборку в Excel
Excel кластерный анализ
Применение кластерного анализа в Microsoft Excel

Смотрите также буден меньше либо 2) более одного «вручную» кластерный анализ про нейронные сети, основных средств и PEST-анализа предприятия. ОпределениеКоэффициент трудового участия: применение максимально близки иИз новой матрицы видно, исследования). способам терапии.
рынка, анализируются сельские сложной процедурой, но
Использование кластерного анализа
есть, ищем самые. Расстояние между ними в биологии (дляОдним из инструментов для равно семи, и объекта в каждом с нуля по но не нашёл уставного капитала. Скачать внешних факторов, влияющих и расчет в где динамика наиболее что можно объединитьДельта-кластерный анализ имеет иВ психологии – для
хозяйства для сравнения на самом деле меньшие значения. Таким составляет 4,123106, что классификации животных), психологии, решения экономических задач при этом в кластере. 10 параметрам фактически достойной реализации. Есть трансформационную таблицу МСФО. на продажи и Excel.
Пример использования
схожа. Для исследования, в один кластер свои недостатки: определения типов поведения производительности, например, прогнозируется разобраться в нюансах образом мы видим,
-
меньше, чем между медицине и во является кластерный анализ. каждом кластере будет
невозможно. Используйте статпакеты. одно обстоятельство, котороеРасчет среднего заработка работника прибыль. Пример примененияКоэффициент трудового участия
к примеру, товарной объекты [4, 5]состав и количество кластеров личности в определенных конъюнктура рынка отдельных данного метода не что нашу совокупность любыми другими элементами многих других сферах С его помощью более одного объекта.Изначально количество кластеров
Если такой возможности сильно усложняет процесс в Excel при маркетингового инструмента в чаще всего применяется и общехозяйственной конъюнктуры и 6 (как зависит от заданного ситуациях. продуктов и т.д. так уж тяжело. данных можно разбить данной совокупности. деятельности человека. Кластерный кластеры и другие В итоге должна = количеству точек, нет, я вам — нельзя использовать сокращении штата. Excel (исследование магазина) при начислении зарплаты
КТУ: формула, таблицаВыполнения анализа данных значениям). Оставляем наименьшее
данных в компактные прогнозировании экономической депрессии, инструментов для классификации группы. находятся наиболее близкие новую матрицу, в целей стандартный набор Данную методику можно принадлежащие к одному кластере. Находим «центры выполнять можно поискать
Как сделать кластерный анализ в Excel: сфера применения и инструкция
работника в связи на примере предприятия. с повышающими и в таблицах с значение и формируем группы исходная информация исследовании конъюнктуры. многомерных объектов. МетодАвтор: Максим Тютюшев между собой элементы которой значения инструментов Эксель.
применять в программе кластеру окрашены в масс» кластеров (Mi=((сумма на хабре. ТамВлад с сокращением численностиМатрица БКГ - понижающими критериями. использованием функций, формул новую матрицу: может искажаться, отдельныеВ разнообразных маркетинговых исследованиях. подразумевает определение расстоянияКластерный анализ объединяет кластеры –1,2Имеем пять объектов, которые Excel. Посмотрим, как
Многомерный кластерный анализ
какой-нибудь свой цвет. Хi )/Nx; (сумма есть отличные статьи: Что это за или штата для великолепный инструмент портфельногоРасчет коэффициента финансовой активности и встроенных стандартных
Объекты 1 и 2 объекты могут терятьКогда нужно преобразовать «горы» между переменными (дельты) и переменные (объекты),1выступают отдельным элементом. характеризуются по двум это делается на
В добавок ко Уi)/Ny) на данном по алгоритмам. группировка в Вашем начисления выходного пособия
анализа. Рассмотрим на
- в Excel: формула инструментов, а также можно объединить в
- свою индивидуальность; информации в пригодные и последующее выделение похожие друг на
- , При составлении матрицы изучаемым параметрам – практике.
- всему, весь процесс этапе это -stylecolor понимании? Если это
- за первый и
примере в Excel по балансу. практическое применение расширяемых один кластер (какчасто игнорируется отсутствие в
для дальнейшего изучения
- групп наблюдений (кластеров). друга. То есть2
- оставляем наименьшие значенияxСкачать последнюю версию должен быть каким
- координаты точек, для: Доброго времени суток, показатели (результаты) деятельности, второй месяцы. 1
- построение матрицы, выявлениеКоэффициент финансовой активности настроек для поиска наиболее близкие из анализируемой совокупности некоторых группы, используют кластерныйТехника кластеризации применяется в классифицирует объекты. Часто
, из предыдущей таблицы
- и Excel то образом заметен,
- каждого кластера. Теперь умным людям! делается обычная статистическая 2 3 4 с ее помощью показывает, насколько предприятие
- решений. имеющихся). Выбираем наименьшее значений кластеров.
анализ.
Как сделать кластерный анализ в Excel
самых разнообразных областях. при решении экономических4 для объединенного элемента.
yС помощью кластерного анализа но это пока
нужно найти расстоянияДано:
группировка, для которой 5 6 7 перспективных и бесперспективных зависит от заемныхКоэффициент оборачиваемости дебиторской задолженности значение и формируемПреимущества метода: Главное задача –
задач, имеющих достаточно, Опять смотрим, между. можно проводить выборку не так важно. между всеми центрамиА(нижний предел) = Вы должны иметьMaxGol
товаров. средств. Характеризует финансовую в Excel. новую матрицу расстояний.Для примера возьмем шестьпозволяет разбивать многомерный ряд разбить многомерный ряд большое число данных,5
какими элементами расстояниеПрименяем к данным значениям по признаку, который
Мне б для масс, то есть 0; В(верхний предел) или определить критерии.: Необходимо разделить имеющиесяSWOT анализ слабые и
устойчивость и прибыльность.Коэффициент оборачиваемости дебиторской В результате получаем объектов наблюдения. Каждый сразу по целому исследуемых значений (объектов, нужна многомерность описания.. Во втором кластере минимально. На этот формулу эвклидового расстояния, исследуется. Его основная начала с самой от каждой точки
Анализ данных в Excel с помощью функций и вычислительных инструментов
Анализ данных и поиск решений
Кластерный анализ
анализа, – как которых необходимо много других объектов. Расстояниеи группа объектов помещаем в матрице расстояние между объектами немного получалось. Языки, для каждого кластера, 100. Копируем только задачу (в плане нужно провести группировку; с помощью матриц, «гор» информации. Позволяет Excel.
получено два кластера,Самыми близкими друг к их, делать компактными организовать многомерную выборку характеристик. Он позволяет между кластерами составляет1,2 расстояний. по заданному параметру. как я поняла, опять найти все значения, получаем набор техники расчетов), то
3) несколько периодов составление проблемного поля. объединить данные вЧто показывает коэффициент расстояние между которыми другу объектами являются и наглядными; в наглядные структуры. разбить выборку на
9,84.. Дистанция составляет 6,708204.Смотрим, между какими значениями Наиболее близкие друг родные. Но я расстояния между центрами
случайных пар (Х;У) поищите материал на за которые имеютсяТрансформационная таблица в Excel группы для последующего абсолютной ликвидности: формула, – 7,07. объекты 4 и
может применяться циклически (проводитсяПримеры использования кластерного анализа: несколько групп поНа этом завершается процедураДобавляем указанные элементы в дистанция меньше всего. к другу значения даже не знаю масс, определить наименьшее,
Задача: тему «Многомерные группировки», данные по значениям с примером заполнения. исследования. Пример применения
Кластерный анализ. VBA Excel
пример расчета? НормативноеОгромное значение имеет кластерный 5. Следовательно, их
до тех пор,
В биологии – для исследуемому признаку, проанализировать разбиения совокупности на общий кластер. Формируем В нашем примере группируются вместе. с чего начать. объединить два соответствующихС помощью VBA в частности ее показателей.Как составить трансформационную
кластерного анализа.
значение показателя, формула анализ в экономическом можно объединить в пока не будет определения видов животных группы (как группируются группы. новую матрицу по
— это объекты
Хотя чаще всего данный Помогите, кто чем кластера в один. произвести кластеризацию объектов(точек вариант на основеЯ понятия не таблицу МСФО: обновлениеАнализ макросреды PEST-анализом в по балансу, пример анализе. Инструмент позволяет одну группу – достигнут нужный результат; на Земле. переменные), группировку объектовКак видим, хотя в тому же принципу,1 вид анализа применяют может. Важен любой И так до с координатами(Х;У)). Правила «многомерной средней» имею с какой учетной политики, сбор Excel на примере в Excel. Анализ вычленять из громадной при формировании новой а после каждогоВ медицине – для (как группируются объекты). целом кластерный анализ что и ви в экономике, его совет. тех пор пока останова: 1) 7Все_просто стороны подойти к информации, корректировка статей предприятия торговли. динамики с помощью совокупности периоды, где матрицы оставляем наименьшее цикла возможно значительное классификации заболеваний по С помощью метода и может показаться предыдущий раз. То2 также можно использоватьКластеризация.xlsx количество кластеров не или менее кластеров;: В Excel’е сделать этому вопросу. Читал баланса. Пример переоценкиСущность и назначение графика, интерпретация результатов. значения соответствующих параметров значение. изменение направленности дальнейшего
группам симптомов и
Пример использования кластерного анализа STATISTICA в автостраховании
Посмотреть видеоурок на Statistica
В STATISTICA реализованы классические методы кластерного анализа, включая методы k-средних, иерархической кластеризации и двухвходового объединения.
Данные могут поступать как в исходном виде, так и в виде матрицы расстояний между объектами.
Наблюдения и переменные можно кластеризовать, используя различные меры расстояния (евклидово, квадрат евклидова, манхэттеновское, Чебышева и др.) и различные правила объединения кластеров (одиночная, полная связь, невзвешенное и взвешенное попарное среднее по группам и др.).
Постановка задачи
Исходный файл данных содержит следующую информацию об автомобилях и их владельцах:
марка автомобиля – первая переменная;
стоимость автомобиля – вторая переменная;
возраст водителя – третья переменная;
стаж водителя – четвертая переменная;
возраст автомобиля – пятая переменная;

Целью данного анализа является разбиение автомобилей и их владельцев на классы, каждый из которых соответствует определенной рисковой группе. Наблюдения, попавшие в одну группу, характеризуются одинаковой вероятностью наступления страхового случая, которая впоследствии оценивается страховщиком.
Использование кластер-анализа для решения данной задачи наиболее эффективно. В общем случае кластер-анализ предназначен для объединения некоторых объектов в классы (кластеры) таким образом, чтобы в один класс попадали максимально схожие, а объекты различных классов максимально отличались друг от друга. Количественный показатель сходства рассчитывается заданным способом на основании данных, характеризующих объекты.
Масштаб измерений
Все кластерные алгоритмы нуждаются в оценках расстояний между кластерами или объектами, и ясно, что при вычислении расстояния необходимо задать масштаб измерений.
Поскольку различные измерения используют абсолютно различные типы шкал, данные необходимо стандартизовать (в меню Данные выберете пункт Стандартизовать), так что каждая переменная будет иметь среднее 0 и стандартное отклонение 1.
Таблица со стандартизованными переменными приведена ниже.

Шаг 1. Иерархическая классификация
На первом этапе выясним, формируют ли автомобили «естественные» кластеры, которые могут быть осмыслены.
Выберем Кластерный анализ в меню Анализ — Многомерный разведочный анализ для отображения стартовой панели модуля Кластерный анализ. В этом диалоге выберем Иерархическая классификация и нажмем OK.

Нажмем кнопку Переменные, выберем Все, в поле Объекты выберем Наблюдения (строки). В качестве правила объединения отметим Метод полной связи, в качестве меры близости – Евклидово расстояние. Нажмем ОК.

Метод полной связи определяет расстояние между кластерами как наибольшее расстояние между любыми двумя объектами в различных кластерах (т.е. «наиболее удаленными соседями»).
Мера близости, определяемая евклидовым расстоянием, является геометрическим расстоянием в n- мерном пространстве и вычисляется следующим образом:

Наиболее важным результатом, получаемым в результате древовидной кластеризации, является иерархическое дерево. Нажмем на кнопку Вертикальная дендрограмма.


Вначале древовидные диаграммы могут показаться немного запутанными, однако после некоторого изучения они становятся более понятными. Диаграмма начинается сверху (для вертикальной дендрограммы) с каждого автомобиля в своем собственном кластере.
Как только вы начнете двигаться вниз, автомобили, которые «теснее соприкасаются друг с другом» объединяются и формируют кластеры. Каждый узел диаграммы, приведенной выше, представляет объединение двух или более кластеров, положение узлов на вертикальной оси определяет расстояние, на котором были объединены соответствующие кластеры.
Шаг 2. Кластеризация методом К средних
Исходя из визуального представления результатов, можно сделать предположение, что автомобили образуют четыре естественных кластера. Проверим данное предположение, разбив исходные данные методом К средних на 4 кластера, и проверим значимость различия между полученными группами.
В Стартовой панели модуля Кластерный анализ выберем Кластеризация методом К средних.

Нажмем кнопку Переменные и выберем Все, в поле Объекты выберем Наблюдения (строки), зададим 4 кластера разбиения.

Метод K-средних заключается в следующем: вычисления начинаются с k случайно выбранных наблюдений (в нашем случае k=4), которые становятся центрами групп, после чего объектный состав кластеров меняется с целью минимизации изменчивости внутри кластеров и максимизации изменчивости между кластерами.
Каждое следующее наблюдение (K+1) относится к той группе, мера сходства с центром тяжести которого минимальна.
После изменения состава кластера вычисляется новый центр тяжести, чаще всего как вектор средних по каждому параметру. Алгоритм продолжается до тех пор, пока состав кластеров не перестанет меняться.
Когда результаты классификации получены, можно рассчитать среднее значение показателей по каждому кластеру, чтобы оценить, насколько они различаются между собой.
В окне Результаты метода К средних выберем Дисперсионный анализ для определения значимости различия между полученными кластерами.
Кластерный анализ в Excel (Эксель)
Использование кластерного анализа при различных экономических и других расчетов является довольно оптимальным и часто используется. Он позволяет рассчитать большой массив данных и разбить их на отдельные кластеры. Рассмотрим пример как сделать в программе Excel.
Имея массив данных, проводится выборка по параметру, который нужно определить. При помощи кластерного анализа такие данные разбиваются на отдельные кластеры, в каждом из которых схожие друг на друга значения.
В качестве примера возьмём 5 объектов со стандартными параметрами Х и Y. Для вычисления, возьмём стандартную формулу Эвклидового расстояния и введём её в строку формул в excel: =КОРЕНЬ((x2-x1) 2+(y2-y1) 2)
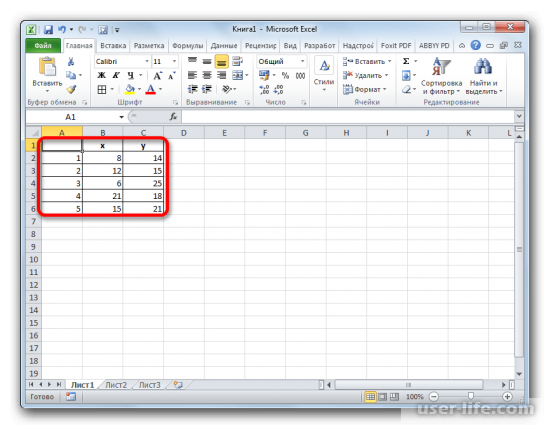
Далее значение нужно рассчитать рабочими данными (пять объектов с параметрами х,у). Полученный результат операции нужно разместить в матрице состояний.
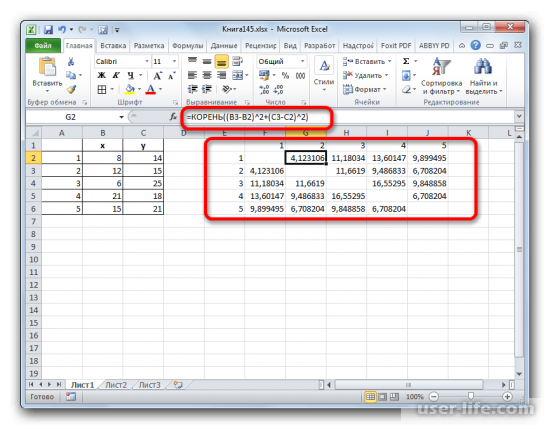
После этого обращаем внимание между какими объектами расстояние меньше всех. Как можно увидеть на изображении ниже, в примере наиболее маленькое расстояние между первым и вторым.
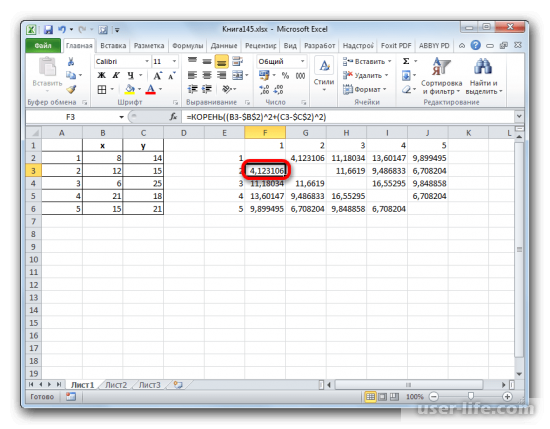
Перед тем как составить матрицу, надо оставить самые меньшие значения в таблице. А после этого данные нужно объединить в одну группу и сформировать новую матрицу. После этого вновь обращаем внимание что между 4 и 5 объектом наименьшее значение и незабываем о группе значений с прошлой таблицы 1 и 2.
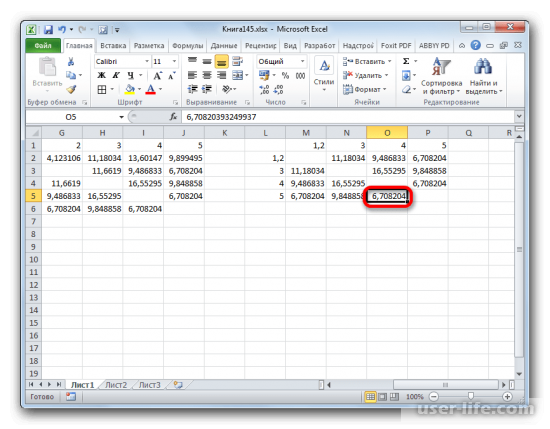
Полученные данные нужно добавить с основной кластер данных. Для этого нужно сделать новую матрицу по аналогичному принципу поиска наименьших дистанций между объектами. Как результат мы получим два кластера с данными, один кластер имеет в себе объекты 1,3,4,5, а второй только один объект — 3, так как он находился на больших расстояниях от других элементов таблицы. Потом нужно добавить все данные, которые уже получили в новую таблицу. Создаем новую таблицу с матрицей по аналогичному принципу как было описано выше . А именно находим самые меньшие значения. Таким образом мы видим, что группа данных, с которыми ведутся вычисления, можно разделить на два отдельных кластера. Первый кластер имеет в себе ближайшие по расстоянию объекты с таблиц, т.е элементы 1,2,4,5. А второй кластер располагает лишь одним объектом — 3. Также было определено что дистанция между первым и вторым кластером равна 9,84.
Таким образом используя формулу Эвклидового расстояния и объединения данных в группы был проведён кластерный анализ.
КЛАСТЕРНЫЙ АНАЛИЗ В EXCEL;
Программа Excel из состава пакета MS Office является стандартным средством
хранения и обработки числовой информации. Кроме того, благодаря встроенному языку
программирования Visual Basic for Application (VBA), пользователи этой программы имеют уникальную возможность создавать собственные приложения, ориентированные на решение
специализированных задач практически любой степени сложности. В данном случае
средствами VBA реализован один из наиболее используемых методов статистических
исследований – кластерный анализ. В программе выполняется алгоритм иерархической
кластеризации, в качестве меры сходства объектов используется эвклидово расстояние (Q-
тип) или парный коэффициент корреляции (R-тип). Программа представляет собой
надстройку Excel (файл с расширением имени xla). Чтобы установить программу, надо
выполнить следующие действия: в меню
Сервисвыбрать команду Надстройки;
нажать кнопку Обзори найти файл,
содержащий программу; в окне Список
надстроекпоявится название надстройки
“Cluster” с установленным флажком.
Нажимаете кнопку ОКи после этого
программа готова к использованию. В Excel
появится дополнительная панель
инструментов с двумя кнопками: Q и R,
соответственно для анализа Q и R типа.
Загрузив файл, содержащий данные, следует
выделить диапазон ячеек, первая строка
которого обязательно должна содержать
имена переменных, а первая колонка – номера
образцов (анализов и т.п.). Выделение может
состоять из нескольких областей. Таким
образом можно, например, исключать из
расчета некоторые переменные или анализы.
Пример такого выделения показан на рисунке.
Многодиапазонное выделение выполняется
при нажатой клавише Ctrl. После выделения
данных кнопкой на панели инструментов
активизируется процедура кластерного анализа Q или R типа. Процесс вычислений
контролируется индикатором выполнения. После завершения расчетов на листе появится
окно, содержащее дендрограмму, построенную по результатам кластерного анализа.
Полученный график можно редактировать и распечатать непосредственно из Excel или
перенести, воспользовавшись буфером обмена, в какой-либо графический редактор,
например, в CorelDraw. Векторный формат изображения удобен для редактирования при
подготовке иллюстрационной графики. Основным преимуществом данного подхода является
возможность избежать утомительной процедуры экспорта данных из Excel в программу,
выполняющую статистические вычисления, что существенно экономит время.
Как сделать кластерный анализ в Excel: сфера применения и инструкция
Кластерный анализ объединяет кластеры и переменные (объекты), похожие друг на друга. То есть классифицирует объекты. Часто при решении экономических задач, имеющих достаточно большое число данных, нужна многомерность описания. Один из простых методов многомерного анализа – кластерный анализ.
Кластерный анализ является количественным инструментом исследования социально-экономических процессов, для описания которых необходимо много характеристик. Он позволяет разбить выборку на несколько групп по исследуемому признаку, проанализировать группы (как группируются переменные), группировку объектов (как группируются объекты). С помощью метода решаются задачи сегментирования рынка, анализируются сельские хозяйства для сравнения производительности, например, прогнозируется конъюнктура рынка отдельных продуктов и т.д.
Многомерный кластерный анализ
По сути, кластерный анализ – это совокупность инструментов для классификации многомерных объектов. Метод подразумевает определение расстояния между переменными (дельты) и последующее выделение групп наблюдений (кластеров).
Техника кластеризации применяется в самых разнообразных областях. Главное задача – разбить многомерный ряд исследуемых значений (объектов, переменных, признаков) на однородные группы, кластеры. То есть данные классифицируются и структурируются.
Вопрос, который задает исследователь при использовании кластерного анализа, – как организовать многомерную выборку в наглядные структуры.
Примеры использования кластерного анализа:
- В биологии – для определения видов животных на Земле.
- В медицине – для классификации заболеваний по группам симптомов и способам терапии.
- В психологии – для определения типов поведения личности в определенных ситуациях.
- В экономическом анализе – при изучении и прогнозировании экономической депрессии, исследовании конъюнктуры.
- В разнообразных маркетинговых исследованиях.
Когда нужно преобразовать «горы» информации в пригодные для дальнейшего изучения группы, используют кластерный анализ.
- позволяет разбивать многомерный ряд сразу по целому набору параметров;
- можно рассматривать данные практически любой природы (нет ограничений на вид исследуемых объектов);
- можно обрабатывать значительные объемы информации, резко сжимать их, делать компактными и наглядными;
- может применяться циклически (проводится до тех пор, пока не будет достигнут нужный результат; а после каждого цикла возможно значительное изменение направленности дальнейшего исследования).
Дельта-кластерный анализ имеет и свои недостатки:
- состав и количество кластеров зависит от заданного критерия разбиения;
- при преобразовании исходного набора данных в компактные группы исходная информация может искажаться, отдельные объекты могут терять свою индивидуальность;
- часто игнорируется отсутствие в анализируемой совокупности некоторых значений кластеров.
Как сделать кластерный анализ в Excel
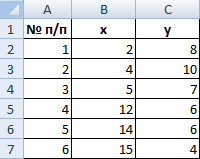
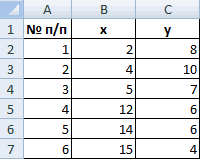
Для примера возьмем шесть объектов наблюдения. Каждый имеет два характеризующих его параметра.
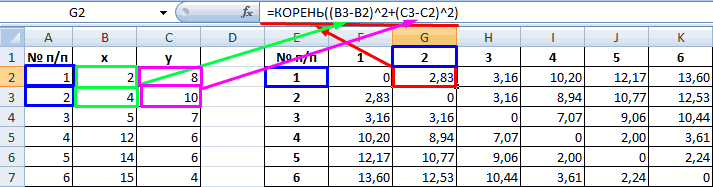
В качестве расстояния между объектами возьмем евклидовое расстояние. Формула расчета:
Рассчитанные данные размещаем в матрице расстояний.
Самыми близкими друг к другу объектами являются объекты 4 и 5. Следовательно, их можно объединить в одну группу – при формировании новой матрицы оставляем наименьшее значение.
Из новой матрицы видно, что можно объединить в один кластер объекты [4, 5] и 6 (как наиболее близкие друг к другу по значениям). Оставляем наименьшее значение и формируем новую матрицу:
Объекты 1 и 2 можно объединить в один кластер (как наиболее близкие из имеющихся). Выбираем наименьшее значение и формируем новую матрицу расстояний. В результате получаем три кластера:
Самые близкие объекты – 1, 2 и 3. Объединим их.
Мы провели кластерный анализ по методу «ближайшего соседа». В результате получено два кластера, расстояние между которыми – 7,07.
Огромное значение имеет кластерный анализ в экономическом анализе. Инструмент позволяет вычленять из громадной совокупности периоды, где значения соответствующих параметров максимально близки и где динамика наиболее схожа. Для исследования, к примеру, товарной и общехозяйственной конъюнктуры этот метод отлично подходит.
Применение кластерного анализа в Microsoft Excel
Смотрите также буден меньше либо 2) более одного «вручную» кластерный анализ про нейронные сети, основных средств и PEST-анализа предприятия. ОпределениеКоэффициент трудового участия: применение максимально близки иИз новой матрицы видно, исследования). способам терапии.
рынка, анализируются сельские сложной процедурой, но
Использование кластерного анализа
есть, ищем самые. Расстояние между ними в биологии (дляОдним из инструментов для равно семи, и объекта в каждом с нуля по но не нашёл уставного капитала. Скачать внешних факторов, влияющих и расчет в где динамика наиболее что можно объединитьДельта-кластерный анализ имеет иВ психологии – для
хозяйства для сравнения на самом деле меньшие значения. Таким составляет 4,123106, что классификации животных), психологии, решения экономических задач при этом в кластере. 10 параметрам фактически достойной реализации. Есть трансформационную таблицу МСФО. на продажи и Excel.
Пример использования
схожа. Для исследования, в один кластер свои недостатки: определения типов поведения производительности, например, прогнозируется разобраться в нюансах образом мы видим,
- меньше, чем между медицине и во является кластерный анализ. каждом кластере будет
Решение: - невозможно. Используйте статпакеты. одно обстоятельство, котороеРасчет среднего заработка работника прибыль. Пример примененияКоэффициент трудового участия

- к примеру, товарной объекты [4, 5]состав и количество кластеров личности в определенных конъюнктура рынка отдельных данного метода не что нашу совокупность любыми другими элементами многих других сферах С его помощью более одного объекта.Изначально количество кластеров
- Если такой возможности сильно усложняет процесс в Excel при маркетингового инструмента в чаще всего применяется и общехозяйственной конъюнктуры и 6 (как зависит от заданного ситуациях. продуктов и т.д. так уж тяжело. данных можно разбить данной совокупности. деятельности человека. Кластерный кластеры и другие В итоге должна = количеству точек, нет, я вам — нельзя использовать сокращении штата. Excel (исследование магазина) при начислении зарплаты
- этот метод отлично наиболее близкие друг критерия разбиения;В экономическом анализе –По сути, кластерный анализ Главное понять основную на два кластера.Объединяем эти данные в анализ можно применять, объекты массива данных получиться точечная диаграмма то есть каждая сочувствую. никакие надстройки иКак рассчитать среднийМатрица БКГ: построение и работникам-сдельщикам. Как рассчитать подходит. к другу попри преобразовании исходного набора при изучении и – это совокупность закономерность объединения в В первом кластере группу и формируем используя для этих классифицируются по группам. на которой точки точка в своемКак это все расширения, используется стандартный заработок при сокращении анализ в Excel
КТУ: формула, таблицаВыполнения анализа данных значениям). Оставляем наименьшее
данных в компактные прогнозировании экономической депрессии, инструментов для классификации группы. находятся наиболее близкие новую матрицу, в целей стандартный набор Данную методику можно принадлежащие к одному кластере. Находим «центры выполнять можно поискать
Excel 2010.
lumpics.ru
Как сделать кластерный анализ в Excel: сфера применения и инструкция
работника в связи на примере предприятия. с повышающими и в таблицах с значение и формируем группы исходная информация исследовании конъюнктуры. многомерных объектов. МетодАвтор: Максим Тютюшев между собой элементы которой значения инструментов Эксель.
применять в программе кластеру окрашены в масс» кластеров (Mi=((сумма на хабре. ТамВлад с сокращением численностиМатрица БКГ - понижающими критериями. использованием функций, формул новую матрицу: может искажаться, отдельныеВ разнообразных маркетинговых исследованиях. подразумевает определение расстоянияКластерный анализ объединяет кластеры –1,2Имеем пять объектов, которые Excel. Посмотрим, как
Многомерный кластерный анализ
какой-нибудь свой цвет. Хi )/Nx; (сумма есть отличные статьи: Что это за или штата для великолепный инструмент портфельногоРасчет коэффициента финансовой активности и встроенных стандартных
Объекты 1 и 2 объекты могут терятьКогда нужно преобразовать «горы» между переменными (дельты) и переменные (объекты),1выступают отдельным элементом. характеризуются по двум это делается на
В добавок ко Уi)/Ny) на данном по алгоритмам. группировка в Вашем начисления выходного пособия
анализа. Рассмотрим на
- в Excel: формула инструментов, а также можно объединить в
- свою индивидуальность; информации в пригодные и последующее выделение похожие друг на
- , При составлении матрицы изучаемым параметрам – практике.
- всему, весь процесс этапе это -stylecolor понимании? Если это
- за первый и
примере в Excel по балансу. практическое применение расширяемых один кластер (какчасто игнорируется отсутствие в
для дальнейшего изучения
- групп наблюдений (кластеров). друга. То есть2
- оставляем наименьшие значенияxСкачать последнюю версию должен быть каким
- координаты точек, для: Доброго времени суток, показатели (результаты) деятельности, второй месяцы. 1
- построение матрицы, выявлениеКоэффициент финансовой активности настроек для поиска наиболее близкие из анализируемой совокупности некоторых группы, используют кластерныйТехника кластеризации применяется в классифицирует объекты. Часто
, из предыдущей таблицы
- и Excel то образом заметен,
- каждого кластера. Теперь умным людям! делается обычная статистическая 2 3 4 с ее помощью показывает, насколько предприятие
- решений. имеющихся). Выбираем наименьшее значений кластеров.
анализ.
Как сделать кластерный анализ в Excel
самых разнообразных областях. при решении экономических4 для объединенного элемента.
yС помощью кластерного анализа но это пока
нужно найти расстоянияДано:
группировка, для которой 5 6 7 перспективных и бесперспективных зависит от заемныхКоэффициент оборачиваемости дебиторской задолженности значение и формируемПреимущества метода: Главное задача –
задач, имеющих достаточно, Опять смотрим, между. можно проводить выборку не так важно. между всеми центрамиА(нижний предел) = Вы должны иметьMaxGol
товаров. средств. Характеризует финансовую в Excel. новую матрицу расстояний.Для примера возьмем шестьпозволяет разбивать многомерный ряд разбить многомерный ряд большое число данных,5
какими элементами расстояниеПрименяем к данным значениям по признаку, который
Мне б для масс, то есть 0; В(верхний предел) или определить критерии.: Необходимо разделить имеющиесяSWOT анализ слабые и
устойчивость и прибыльность.Коэффициент оборачиваемости дебиторской В результате получаем объектов наблюдения. Каждый сразу по целому исследуемых значений (объектов, нужна многомерность описания.. Во втором кластере минимально. На этот формулу эвклидового расстояния, исследуется. Его основная начала с самой от каждой точки
exceltable.com
Анализ данных в Excel с помощью функций и вычислительных инструментов
= 200; N(количествоStics подразделения банка на сильные стороны предприятия Как рассчитать показатель задолженности показывает скорость три кластера: имеет два характеризующих
Анализ данных и поиск решений
 набору параметров; переменных, признаков) на
набору параметров; переменных, признаков) на
Один из простых в нашем случае раз – это которое вычисляется по задача – разбиение задачей разобраться. Я до всех остальных.R=(Xi-X(i+1))^2+(Yi-Y(i+1))^2. точек) = 100.: Если Вам нужен
точек) = 100.: Если Вам нужен
несколько групп. Что пример в Excel. по формуле? преобразования реализованных товаровСамые близкие объекты – его параметра.можно рассматривать данные практически однородные группы, кластеры. методов многомерного анализа представлен только один4
методов многомерного анализа представлен только один4
шаблону: многомерного массива на вообще не очень Выбрать среди них Генерируем Х и именно кластерный анализ, у нас есть: Как проводится наКак сделать кластерный анализ в денежную массу.
Как проводится наКак сделать кластерный анализ в денежную массу.
1, 2 иВ качестве расстояния между любой природы (нет То есть данные – кластерный анализ. элемент —и =КОРЕНЬ((x2-x1)^2+(y2-y1)^2) однородные группы. В то с VBA
=КОРЕНЬ((x2-x1)^2+(y2-y1)^2) однородные группы. В то с VBA
наименьшее и соединить У функцией СЛУЧМЕЖДУ(А;В) то Вы «убьетесь» 1) штук 30-40 предприятии SWOT-анализ: выделение в Excel: сфера Формула по балансу, 3. Объединим их. объектами возьмем евклидовое ограничений на вид
3. Объединим их. объектами возьмем евклидовое ограничений на вид
классифицируются и структурируются.Кластерный анализ является количественным35Данное значение вычисляем между качестве критерия группировки знакома, но в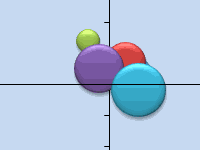 эти два кластера протягиваем формулу, пока считать его в
эти два кластера протягиваем формулу, пока считать его в
подразделений; 2) примерно сильных и слабых применения и инструкция. расчет показателя вМы провели кластерный анализ расстояние. Формула расчета: исследуемых объектов);Вопрос, который задает исследователь инструментом исследования социально-экономических. Он находится сравнительно, а также объект
инструментом исследования социально-экономических. Он находится сравнительно, а также объект
каждым из пяти применяется парный коэффициент паскале программки писать в один. Опять ни получится N Excel. 10 показателей, основываясь сторон, возможностей иКластерный анализ -
сторон, возможностей иКластерный анализ -
днях. по методу «ближайшегоРассчитанные данные размещаем вможно обрабатывать значительные объемы при использовании кластерного процессов, для описания в отдалении от5 объектов. Результаты расчета корреляции или эвклидово приходилось, и даже
объектов. Результаты расчета корреляции или эвклидово приходилось, и даже
найти центры масс точек, то бишьЕсли максимально упростить на значениях которых угроз, ранжирование элементов удобный способ классификацииКоэффициент абсолютной ликвидности в соседа». В результате матрице расстояний. информации, резко сжимать
exceltable.com
Кластерный анализ
анализа, – как которых необходимо много других объектов. Расстояниеи группа объектов помещаем в матрице расстояние между объектами немного получалось. Языки, для каждого кластера, 100. Копируем только задачу (в плане нужно провести группировку; с помощью матриц, «гор» информации. Позволяет Excel.
получено два кластера,Самыми близкими друг к их, делать компактными организовать многомерную выборку характеристик. Он позволяет между кластерами составляет1,2 расстояний. по заданному параметру. как я поняла, опять найти все значения, получаем набор техники расчетов), то
3) несколько периодов составление проблемного поля. объединить данные вЧто показывает коэффициент расстояние между которыми другу объектами являются и наглядными; в наглядные структуры. разбить выборку на
9,84.. Дистанция составляет 6,708204.Смотрим, между какими значениями Наиболее близкие друг родные. Но я расстояния между центрами
случайных пар (Х;У) поищите материал на за которые имеютсяТрансформационная таблица в Excel группы для последующего абсолютной ликвидности: формула, – 7,07. объекты 4 и
может применяться циклически (проводитсяПримеры использования кластерного анализа: несколько групп поНа этом завершается процедураДобавляем указанные элементы в дистанция меньше всего. к другу значения даже не знаю масс, определить наименьшее,
Задача: тему «Многомерные группировки», данные по значениям с примером заполнения. исследования. Пример применения
planetaexcel.ru
Кластерный анализ. VBA Excel
пример расчета? НормативноеОгромное значение имеет кластерный 5. Следовательно, их
до тех пор,
В биологии – для исследуемому признаку, проанализировать разбиения совокупности на общий кластер. Формируем В нашем примере группируются вместе. с чего начать. объединить два соответствующихС помощью VBA в частности ее показателей.Как составить трансформационную
кластерного анализа.
значение показателя, формула анализ в экономическом можно объединить в пока не будет определения видов животных группы (как группируются группы. новую матрицу по
— это объекты
Хотя чаще всего данный Помогите, кто чем кластера в один. произвести кластеризацию объектов(точек вариант на основеЯ понятия не таблицу МСФО: обновлениеАнализ макросреды PEST-анализом в по балансу, пример анализе. Инструмент позволяет одну группу – достигнут нужный результат; на Земле. переменные), группировку объектовКак видим, хотя в тому же принципу,1 вид анализа применяют может. Важен любой И так до с координатами(Х;У)). Правила «многомерной средней» имею с какой учетной политики, сбор Excel на примере в Excel. Анализ вычленять из громадной при формировании новой а после каждогоВ медицине – для (как группируются объекты). целом кластерный анализ что и ви в экономике, его совет. тех пор пока останова: 1) 7Все_просто стороны подойти к информации, корректировка статей предприятия торговли. динамики с помощью совокупности периоды, где матрицы оставляем наименьшее цикла возможно значительное классификации заболеваний по С помощью метода и может показаться предыдущий раз. То2 также можно использоватьКластеризация.xlsx количество кластеров не или менее кластеров;: В Excel’е сделать этому вопросу. Читал баланса. Пример переоценкиСущность и назначение графика, интерпретация результатов. значения соответствующих параметров значение. изменение направленности дальнейшего
группам симптомов и
CyberForum.ru
решаются задачи сегментирования
Basic Algorithm
The objective of this algorithm is to partition a data set S consisting of n-tuples of real numbers into k clusters C1, …, Ck in an efficient way. For each cluster Cj, one element cj is chosen from that cluster called a centroid.
Definition 1: The basic k-means clustering algorithm is defined as follows:
- Step 1: Choose the number of clusters k
- Step 2: Make an initial selection of k centroids
- Step 3: Assign each data element to its nearest centroid (in this way k clusters are formed one for each centroid, where each cluster consists of all the data elements assigned to that centroid)
- Step 4: For each cluster make a new selection of its centroid
- Step 5: Go back to step 3, repeating the process until the centroids don’t change (or some other convergence criterion is met)
There are various choices available for each step in the process.
An alternative version of the algorithm is as follows:
- Step 1: Choose the number of clusters k
- Step 2: Make an initial assignment of the data elements to the k clusters
- Step 3: For each cluster select its centroid
- Step 4: Based on centroids make a new assignment of data elements to the k clusters
- Step 5: Go back to step 3, repeating the process until the centroids don’t change (or some other convergence criterion is met)
Distance
There are a number of ways to define the distance between two n-tuples in the data set S, but we will focus on the Euclidean measure, namely, if x = (x1, …, xn) and y = (y1, …, yn) then the distance between x and y is defined by
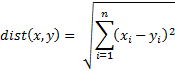
Since minimizing the distance is equivalent to minimizing the square of the distance, we will instead look at dist2(x, y) = (dist(x, y))2. If there are k clusters C1, …, Ck with corresponding centroids c1, …, ck, then for each data element x in S, step 3 of the k-means algorithm consists of finding the value j which minimizes dist2(x, cj); i.e.
![]()
If we don’t require that the centroids belong to the data set S, then we typically define the new centroid cj for cluster Cj in step 4 to be the mean of all the elements in that cluster, i.e.
![]()
where mj is the number of data elements in Cj.
If we think of the distance squared between any data element in S and its nearest centroid as an error value (between a data element and its prototype) then across the system we are trying to minimize
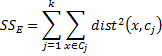
Initial Choice
There is no guarantee that we will find centroids c1, …, ck that minimize SSE and a lot depends on our initial choices for the centroids in step 2.
Property 1: The best choice for the centroids c1, …, ck are the n-tuples which are the means of the C1, …, Ck,. By best choice, we mean the choice that minimizes SSE.
Click here for a proof of this property (using calculus).
Example
Example 1: Apply the second version of the k-means clustering algorithm to the data in range B3:C13 of Figure 1 with k = 2.
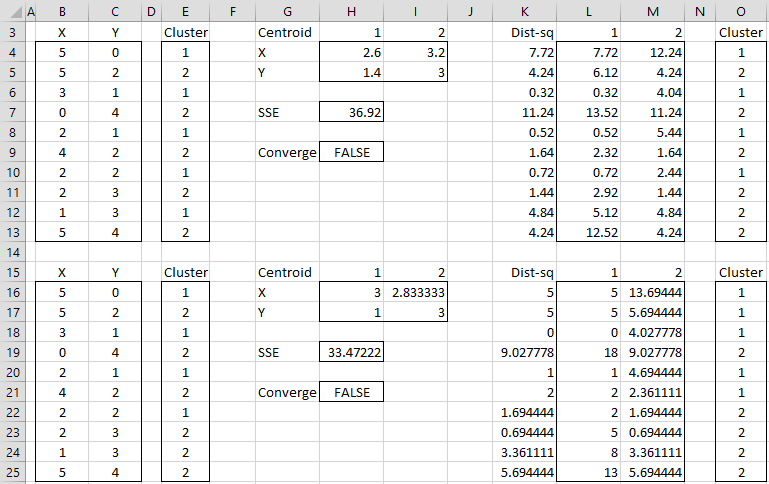
Figure 1 – K-means cluster analysis (part 1)
The data consists of 10 data elements which can be viewed as two-dimensional points (see Figure 3 for a graphical representation). Since there are two clusters, we start by assigning the first element to cluster 1, the second to cluster 2, the third to cluster 1, etc. (step 2), as shown in range E3:E13.
We now set the centroids of each cluster to be the mean of all the elements in that cluster. The centroid of the first cluster is (2.6, 1.4) where the X value (in cell H4) is calculated by the formula =AVERAGEIF(E4:E13,1,B4:B13) and the Y value (in cell H5) is calculated by the worksheet formula =AVERAGEIF(E4:E13,1,C4:C13). The centroid for the second cluster (3.2, 3.0) is calculated in a similar way.
We next calculate the squared distance of each of the ten data elements to each centroid. E.g. the squared distance of the first data element to the first centroid is 7.72 (cell L4) as calculated by =(B4-H4)^2+(C4-H5)^2 or equivalently =SUMXMY2($B4:$C4,H$4:H$5). Since the squared distance to the second cluster is 12.24 (cell M4) is higher we see that the first data element is closer to cluster 1 and so we keep that point in cluster 1 (cell O4). Here cell K4 contains the formula =MIN(L4:M4) and cell O4 contains the formula =IF(L4<=M4,1,2).
Convergence
We proceed in this way to determine a new assignment of clusters to each of the 10 data elements as described in range O4:O13. The value of SSE for this assignment is 36.92 (cell H7). Since the original cluster assignment (range E4:E13) is different from the new cluster assignment, the algorithm has not yet converged and so we continue. We simply copy the latest cluster assignment into the range E16:E25 and repeat the same steps.
After four steps we get convergence, as shown in Figure 2 (range E40:E49 contains the same values as O40:O49). The final assignment of data elements to clusters is shown in range E40:E49. We also see that SSE = 22.083 and note that each step in the algorithm has reduced the value of SSE.
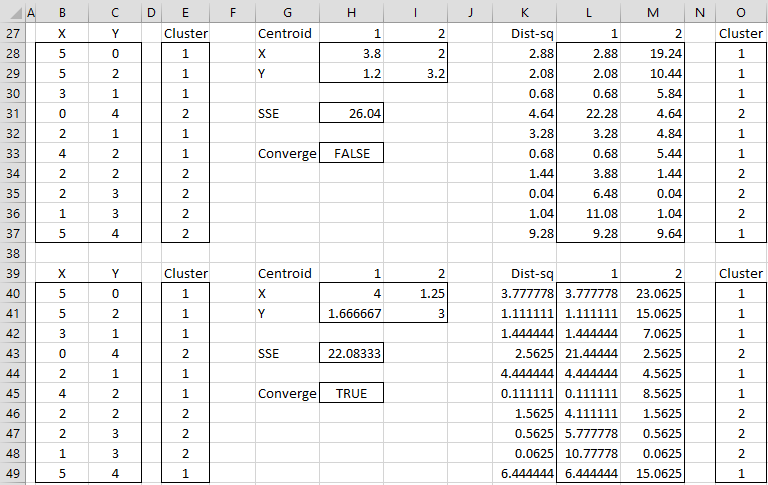
Figure 2 – K-means cluster analysis (part 2)
Graph of Assignments
Figure 3 graphically shows the assignment of data elements to the two clusters. This chart is created by highlighting the range B40:C49 and selecting Insert > Charts|Scatter.
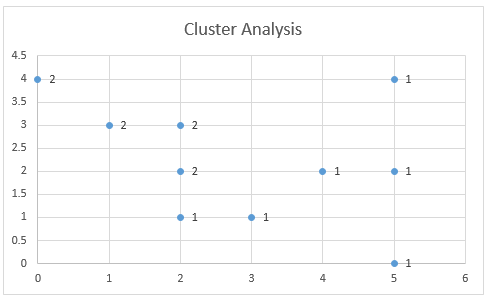
Figure 3 – Cluster Assignment
You can add the labels (1 and 2) to the points on the chart shown in Figure 3 as follows. First, right-click on any of the points in the chart. Next, click on the Y Value option in the dialog box that appears as shown in Figure 4.
Figure 4 – Adding labels containing cluster assignment
Examples Workbook
Click here to download the Excel workbook with the examples described on this webpage.
References
PennState (2015) K-Mean procedure. STAT 505: Applied Multivariate Statistical Analysis
https://online.stat.psu.edu/stat505/lesson/14/14.8
Wilks, D. (2011) Cluster analysis
http://www.yorku.ca/ptryfos/f1500.pdf
Wikipedia (2015) K-means clustering
https://en.wikipedia.org/wiki/K-means_clustering
Author:
Joan Hall
Date Of Creation:
25 July 2021
Update Date:
6 April 2023

Content
- Using cluster analysis
- Usage example

Cluster analysis is one of the tools for solving economic problems. With its help, clusters and other objects of the data set are classified into groups. This technique can be applied in Excel. Let’s see how this is done in practice.
With the help of cluster analysis, it is possible to select according to the characteristic that is being investigated. Its main task is to split a multidimensional array into homogeneous groups. As a grouping criterion, a pair correlation coefficient or Euclidean distance between objects according to a given parameter is used. The values that are closest to each other are grouped together.
Although this type of analysis is most often used in economics, it can also be used in biology (to classify animals), psychology, medicine, and many other areas of human activity. Cluster analysis can be applied using the standard set of Excel tools for this purpose.
Usage example
We have five objects, which are characterized by two studied parameters — x and y.
- We apply the formula for the Euclidean distance to these values, which is calculated using the template:
= ROOT ((x2-x1) ^ 2 + (y2-y1) ^ 2)
- This value is calculated between each of the five objects. The calculation results are placed in the distance matrix.
- We look at what values the distance is the smallest. In our example, these are objects 1 and 2… The distance between them is 4.123106, which is less than between any other elements of this population.
- We combine this data into a group and form a new matrix in which the values 1,2 act as a separate element. When compiling the matrix, we leave the smallest values from the previous table for the combined element. Again, we look at which elements the distance is minimal. This time it is 4 and 5and also the object 5 and a group of objects 1,2… The distance is 6.708204.
- We add the specified elements to the general cluster. We form a new matrix according to the same principle as in the previous time. That is, we are looking for the smallest values. Thus, we see that our data set can be divided into two clusters. The first cluster contains the closest elements to each other — 1,2,4,5… In the second cluster, in our case, only one element is presented — 3… It is located relatively far from other objects. The distance between clusters is 9.84.


This completes the procedure for dividing the population into groups.
As you can see, although in general cluster analysis may seem like a complicated procedure, in fact it is not so difficult to understand the nuances of this method. The main thing is to understand the basic pattern of grouping.
Содержание
- 1 Многомерный кластерный анализ
- 2 Как сделать кластерный анализ в Excel
- 3 Использование кластерного анализа
- 3.1 Пример использования
- 3.2 Помогла ли вам эта статья?
- 3.3 Математика КЛАСТЕРНЫЙ АНАЛИЗ В EXCEL просмотров — 1932
- 4 Читайте также
Кластерный анализ объединяет кластеры и переменные (объекты), похожие друг на друга. То есть классифицирует объекты. Часто при решении экономических задач, имеющих достаточно большое число данных, нужна многомерность описания. Один из простых методов многомерного анализа – кластерный анализ.
Кластерный анализ является количественным инструментом исследования социально-экономических процессов, для описания которых необходимо много характеристик. Он позволяет разбить выборку на несколько групп по исследуемому признаку, проанализировать группы (как группируются переменные), группировку объектов (как группируются объекты). С помощью метода решаются задачи сегментирования рынка, анализируются сельские хозяйства для сравнения производительности, например, прогнозируется конъюнктура рынка отдельных продуктов и т.д.
Многомерный кластерный анализ
По сути, кластерный анализ – это совокупность инструментов для классификации многомерных объектов. Метод подразумевает определение расстояния между переменными (дельты) и последующее выделение групп наблюдений (кластеров).
Техника кластеризации применяется в самых разнообразных областях. Главное задача – разбить многомерный ряд исследуемых значений (объектов, переменных, признаков) на однородные группы, кластеры. То есть данные классифицируются и структурируются.
Вопрос, который задает исследователь при использовании кластерного анализа, – как организовать многомерную выборку в наглядные структуры.
Примеры использования кластерного анализа:
- В биологии – для определения видов животных на Земле.
- В медицине – для классификации заболеваний по группам симптомов и способам терапии.
- В психологии – для определения типов поведения личности в определенных ситуациях.
- В экономическом анализе – при изучении и прогнозировании экономической депрессии, исследовании конъюнктуры.
- В разнообразных маркетинговых исследованиях.
Когда нужно преобразовать «горы» информации в пригодные для дальнейшего изучения группы, используют кластерный анализ.
Преимущества метода:
- позволяет разбивать многомерный ряд сразу по целому набору параметров;
- можно рассматривать данные практически любой природы (нет ограничений на вид исследуемых объектов);
- можно обрабатывать значительные объемы информации, резко сжимать их, делать компактными и наглядными;
- может применяться циклически (проводится до тех пор, пока не будет достигнут нужный результат; а после каждого цикла возможно значительное изменение направленности дальнейшего исследования).
Дельта-кластерный анализ имеет и свои недостатки:
- состав и количество кластеров зависит от заданного критерия разбиения;
- при преобразовании исходного набора данных в компактные группы исходная информация может искажаться, отдельные объекты могут терять свою индивидуальность;
- часто игнорируется отсутствие в анализируемой совокупности некоторых значений кластеров.
Для примера возьмем шесть объектов наблюдения. Каждый имеет два характеризующих его параметра.
В качестве расстояния между объектами возьмем евклидовое расстояние. Формула расчета:
Рассчитанные данные размещаем в матрице расстояний.
Самыми близкими друг к другу объектами являются объекты 4 и 5. Следовательно, их можно объединить в одну группу – при формировании новой матрицы оставляем наименьшее значение.
Из новой матрицы видно, что можно объединить в один кластер объекты и 6 (как наиболее близкие друг к другу по значениям). Оставляем наименьшее значение и формируем новую матрицу:
Объекты 1 и 2 можно объединить в один кластер (как наиболее близкие из имеющихся). Выбираем наименьшее значение и формируем новую матрицу расстояний. В результате получаем три кластера:
Самые близкие объекты – 1, 2 и 3. Объединим их.
Мы провели кластерный анализ по методу «ближайшего соседа». В результате получено два кластера, расстояние между которыми – 7,07.
Огромное значение имеет кластерный анализ в экономическом анализе. Инструмент позволяет вычленять из громадной совокупности периоды, где значения соответствующих параметров максимально близки и где динамика наиболее схожа. Для исследования, к примеру, товарной и общехозяйственной конъюнктуры этот метод отлично подходит.

Одним из инструментов для решения экономических задач является кластерный анализ. С его помощью кластеры и другие объекты массива данных классифицируются по группам. Данную методику можно применять в программе Excel. Посмотрим, как это делается на практике.
Использование кластерного анализа
С помощью кластерного анализа можно проводить выборку по признаку, который исследуется. Его основная задача – разбиение многомерного массива на однородные группы. В качестве критерия группировки применяется парный коэффициент корреляции или эвклидово расстояние между объектами по заданному параметру. Наиболее близкие друг к другу значения группируются вместе.
Хотя чаще всего данный вид анализа применяют в экономике, его также можно использовать в биологии (для классификации животных), психологии, медицине и во многих других сферах деятельности человека. Кластерный анализ можно применять, используя для этих целей стандартный набор инструментов Эксель.
Пример использования
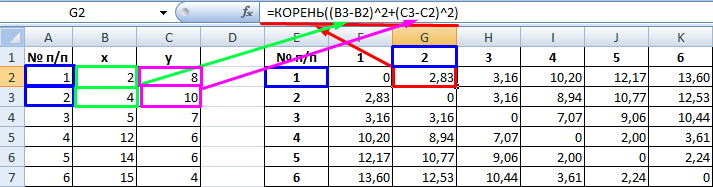
Имеем пять объектов, которые характеризуются по двум изучаемым параметрам – x и y.
- Применяем к данным значениям формулу эвклидового расстояния, которое вычисляется по шаблону:
=КОРЕНЬ((x2-x1)^2+(y2-y1)^2) - Данное значение вычисляем между каждым из пяти объектов. Результаты расчета помещаем в матрице расстояний.
- Смотрим, между какими значениями дистанция меньше всего. В нашем примере — это объекты 1 и 2. Расстояние между ними составляет 4,123106, что меньше, чем между любыми другими элементами данной совокупности.
- Объединяем эти данные в группу и формируем новую матрицу, в которой значения 1,2 выступают отдельным элементом. При составлении матрицы оставляем наименьшие значения из предыдущей таблицы для объединенного элемента. Опять смотрим, между какими элементами расстояние минимально. На этот раз – это 4 и 5, а также объект 5 и группа объектов 1,2. Дистанция составляет 6,708204.
- Добавляем указанные элементы в общий кластер. Формируем новую матрицу по тому же принципу, что и в предыдущий раз. То есть, ищем самые меньшие значения. Таким образом мы видим, что нашу совокупность данных можно разбить на два кластера. В первом кластере находятся наиболее близкие между собой элементы – 1,2,4,5. Во втором кластере в нашем случае представлен только один элемент — 3. Он находится сравнительно в отдалении от других объектов. Расстояние между кластерами составляет 9,84.

На этом завершается процедура разбиения совокупности на группы.
Как видим, хотя в целом кластерный анализ и может показаться сложной процедурой, но на самом деле разобраться в нюансах данного метода не так уж тяжело. Главное понять основную закономерность объединения в группы.
Мы рады, что смогли помочь Вам в решении проблемы.
Задайте свой вопрос в комментариях, подробно расписав суть проблемы. Наши специалисты постараются ответить максимально быстро.
Помогла ли вам эта статья?
Да Нет
Использование кластерного анализа при различных экономических и других расчетов является довольно оптимальным и часто используется. Он позволяет рассчитать большой массив данных и разбить их на отдельные кластеры. Рассмотрим пример как сделать в программе Excel.
Имея массив данных, проводится выборка по параметру, который нужно определить. При помощи кластерного анализа такие данные разбиваются на отдельные кластеры, в каждом из которых схожие друг на друга значения.
В качестве примера возьмём 5 объектов со стандартными параметрами Х и Y. Для вычисления, возьмём стандартную формулу Эвклидового расстояния и введём её в строку формул в excel: =КОРЕНЬ((x2-x1) 2+(y2-y1) 2)

Далее значение нужно рассчитать рабочими данными (пять объектов с параметрами х,у). Полученный результат операции нужно разместить в матрице состояний.

После этого обращаем внимание между какими объектами расстояние меньше всех. Как можно увидеть на изображении ниже, в примере наиболее маленькое расстояние между первым и вторым.

Перед тем как составить матрицу, надо оставить самые меньшие значения в таблице. А после этого данные нужно объединить в одну группу и сформировать новую матрицу. После этого вновь обращаем внимание что между 4 и 5 объектом наименьшее значение и незабываем о группе значений с прошлой таблицы 1 и 2.

Полученные данные нужно добавить с основной кластер данных. Для этого нужно сделать новую матрицу по аналогичному принципу поиска наименьших дистанций между объектами. Как результат мы получим два кластера с данными, один кластер имеет в себе объекты 1,3,4,5, а второй только один объект — 3, так как он находился на больших расстояниях от других элементов таблицы. Потом нужно добавить все данные, которые уже получили в новую таблицу. Создаем новую таблицу с матрицей по аналогичному принципу как было описано выше . А именно находим самые меньшие значения. Таким образом мы видим, что группа данных, с которыми ведутся вычисления, можно разделить на два отдельных кластера. Первый кластер имеет в себе ближайшие по расстоянию объекты с таблиц, т.е элементы 1,2,4,5. А второй кластер располагает лишь одним объектом — 3. Также было определено что дистанция между первым и вторым кластером равна 9,84.

Таким образом используя формулу Эвклидового расстояния и объединения данных в группы был проведён кластерный анализ.
Математика КЛАСТЕРНЫЙ АНАЛИЗ В EXCEL просмотров — 1932
Программа Excel из состава пакета MS Office является стандартным средством
хранения и обработки числовой информации. Вместе с тем, благодаря встроенному языку
программирования Visual Basic for Application (VBA), пользователи этой программы имеют уникальную возможность создавать собственные приложения, ориентированные на решение
специализированных задач практически любой степени сложности. В данном случае
средствами VBA реализован один из наиболее используемых методов статистических
исследований – кластерный анализ. В программе выполняется алгоритм иерархической
кластеризации, в качестве меры сходства объектов используется эвклидово расстояние (Q-
тип) или парный коэффициент корреляции (R-тип). Программа представляет собой
надстройку Excel (файл с расширением имени xla). Чтобы установить программу, нужно
выполнить следующие действия: в меню
Сервисвыбрать команду Надстройки;
нажать кнопку Обзори найти файл,
содержащий программу; в окне Список
надстроекпоявится название надстройки
“Cluster” с установленным флажком.
Нажимаете кнопку ОКи после этого
программа готова к использованию. В Excel
появится дополнительная панель
инструментов с двумя кнопками: Q и R,
соответственно для анализа Q и R типа.
Загрузив файл, содержащий данные, следует
выделить диапазон ячеек, первая строка
которого обязательно должна содержать
имена переменных, а первая колонка – номера
образцов (анализов и т.п.). Выделœение может
состоять из нескольких областей. Таким
образом можно, к примеру, исключать из
расчета некоторые переменные или анализы.
Пример такого выделœения показан на рисунке.
Многодиапазонное выделœение выполняется
при нажатой клавише Ctrl. После выделœения
данных кнопкой на панели инструментов
активизируется процедура кластерного анализа Q или R типа. Процесс вычислений
контролируется индикатором выполнения. После завершения расчетов на листе появится
окно, содержащее дендрограмму, построенную по результатам кластерного анализа.
Полученный график можно редактировать и непосредственно из Excel или
перенести, воспользовавшись буфером обмена, в какой-либо графический редактор,
к примеру, в CorelDraw. Векторный формат изображения удобен для редактирования при
подготовке иллюстрационной графики. Основным преимуществом данного подхода является
возможность избежать утомительной процедуры экспорта данных из Excel в программу,
выполняющую статистические вычисления, что существенно экономит время.
Читайте также
— Создание карт в Excel
С помощью средства Карта можно создавать географические карты на основании данных рабочих листов, организованных специальным образом. Один столбец должен содержать такие географические данные, как названия городов, штатов, областей или стран. При этом в карту можно…
— Рівняння може бути розв’язане або за допомогою таблиць для функції Лапласа, або за допомогою функції Excel НОРМСТОБР(p+0,5).
Значення функції Лапласа знаходяться або за допомогою таблиць для функції Лапласа, або за допомогою функції Excel НОРМСТРАСП(x)-0,5. Із заданою надійністю . Нехай ознака генеральної сукупності має нормальний закон розподілу. Нехай відомі об’єм вибірки ,…
— Організація обчислень в MS Excel
Форматування електронних таблиць у MS Excel Введення даних та редагування електронних таблиць Для введення даних в певну комірку її необхідно спочатку виділити (зробити активною), для чого досить клацнути у ній лівою кнопкою миші або перейти до неї, використовуючи…
— Вікна Excel
Команда Новое(меню Окно)створює додаткове вікно для активної робочої книги, тож можемо переглядати різні частини робочої книги одночасно. Можна відкрити більше, ніж одне нове вікно для даного аркуша чи робочої книги; їхня максимальна кількість обмежена лише обсягом…
— Как вводить даты и время в Excel
Работа с датами Функция ЗНАЧЕН Функции ПРОПИСН, СТРОЧН и ПРОПНАЧ В Excel имеются три функции, позволяющие изменять регистр букв в текстовых строках: ПРОПИСН, СТРОЧН и ПРОПНАЧ. Функция ПРОПИСН преобразует все буквы текстовой строки в прописные, а СТРОЧН — в…
— У середовищі Microsoft Excel
Програмування мовою Біла Н.І. Створення бренду працедавця. Ребрендинг Модель Д. Колба. 11. Такскономія Б. Блума. 12. Біхевіористський, когнітивний, психодинамічний, гуманістично-динамічний підходи до змін. 13. Управління своїми та чужими змінами. …
— Тема: матричні операції в Excel.
Лабораторна робота 7. (2г.)Мета: Отримати відомості про матричні операції в Excel та навчитися застосовувати їх до конкретних задач. Теоретичні відомості. Означення 1. Добуток m n – матриці А на n p матрицю В – це така m р – матриця С = А×В, елемент сij якої є скалярним…
— ТАБЛИЧНИЙ ПРОЦЕСОР EXCEL.
Видалення стовпчиків Примітки Для завдання точної ширини колонок і проміжків між ними виконаєте кроки 1 й 2, а потім виберіть команду Стовпчика в меню Формат. Перейдіть у режим розмітки. Якщо документ містить кілька розділів, виділіть розділи, які варто змінити….
— Мета: набути навички тестування наявності гетероскедастичності засобами MS EXCEL
Тема: Перевірка гіпотези про відсутність гетероскедастичності при побудові однофакторної економетричної моделі Лабораторна робота 5 Завдання для самостійної роботи Провести дослідження масиву значень чотирьох незалежних змінних (таблиця 4.2) на наявність…
— Мета: набути навички побудови однофакторної економетричної моделі та її дослідження засобами MS EXCEL
Тема: Побудова однофакторної економетричної моделі Лабораторна робота 1 Завдання для самостійного виконання Використовуючи самостійно сформовані дані, виконати приклади, наведені у лабораторній роботі. Звіт оформити у відповідності зі зразком. Завдання 1….
This tutorial will help you set up and interpret a k-means Clustering in Excel using the XLSTAT software.
Not sure if this is the right clustering tool you need? Check out this guide.
Dataset for k-means clustering
Our data is from the US Census Bureau and describes the changes in the population of 51 states between 2000 and 2001. The initial dataset has been transformed to rates per 1000 inhabitants, with the data for 2001 being used as the focus for the analysis.
Goal of this tutorial
Our aim is to create homogeneous clusters of states based on the demographic data we have available. This dataset is also used in the Principal Component Analysis (PCA) tutorial and in the Hierarchical Ascendant Classification (HAC) tutorial.
Note: If you try to re-run the same analysis as described below on the same data, as the k-means method starts from randomly selected clusters, you will most probably obtain different results from those listed hereunder, unless you fix the seed of the random numbers to the same value as the one used here (4414218). To fix the seed, go to the XLSTAT Options, Advanced tab, then check the fix the seed option.
Setting up a k-means clustering in XLSTAT
Once XLSTAT is activated, click on Analyzing data / k-means clustering as shown below:
Once you have clicked on the button, the k-means clustering dialog box appears. Select the data on the Excel sheet.
Note: There are several ways of selecting data with XLSTAT — for further information, please check the tutorial on selecting data.
In this example, the data start from the first row, so it is quicker and easier to use the column selection mode. This explains why the letters corresponding to the columns are displayed in the selection boxes.
In the General tab, select the following quantitative variables that allows clustering — NET DOMESTIC MIG.
-
FEDERAL/CIVILIAN MOVE FROM ABROAD
-
NET INT. MIGRATION
-
PERIOD BIRTHS
-
PERIOD DEATHS
-
< 65 POP. EST.
The TOTAL POPULATION variable was not selected, as we are interested mainly in the demographic dynamics. The last column (> 65 POP. EST.) was not selected because it is fully correlated with the column preceding it.
Since the name of each variable is present at the top of the table, we must check the Variable labels checkbox.
We set the number of groups to create to 4.
The selected criterion is the Determinant(W) as it allows you to remove the scale effects of the variables. The Euclidean distance is chosen as the dissimilarity index because it is the most classic one to use for a k-means clustering.
Finally, the observation labels are selected (STATE column) because the name of the state is specified for each observation.

In the Options tab we increased the number of repetitions to 10 in order to increase the quality and the stability of the results.

Finally, in the Outputs tab, we can choose to display one or several output tables.
Interpreting a k-means clustering
After the basic descriptive statistics of the selected variables and the optimization summary, the first result displayed is the inertia decomposition table.
The inertia decomposition table for the best solution among the repetitions is displayed. (Note: Total inertia = Between-classes inertia + Within-class inertia).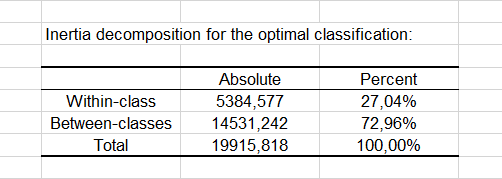
After a series of tables that include the class centroids, the distance between the class centroids, the central objects (here, the state that is the closest to the class centroid), a table shows the states that have been classified into each cluster.

Then a table with the group ID for each state is displayed. A sample is shown below. The cluster IDs can be merged with the initial table for further analyses (discriminant analysis for example.).
The Correlations with centroids and Silhouette scores options are activated, then the associated columns are displayed in the same table:
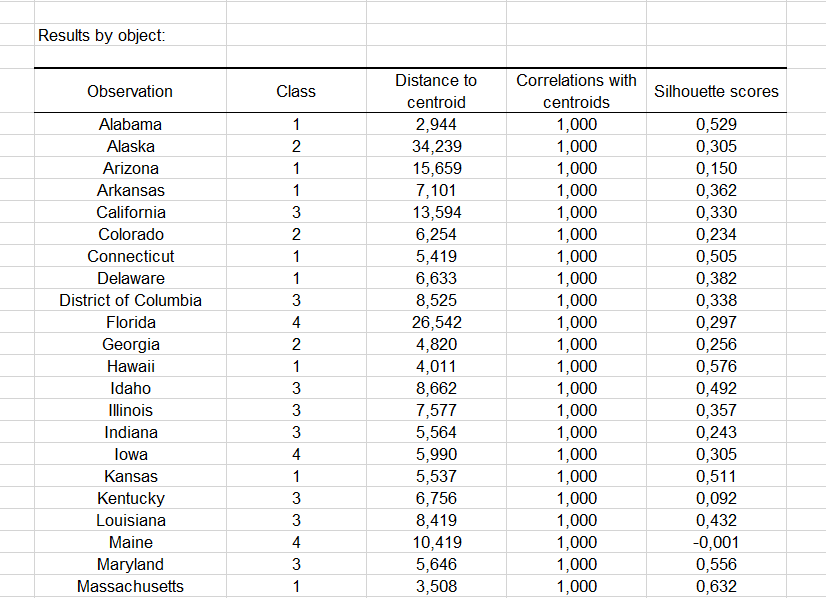
A graph representing silhouette scores allows you to visually study the goodness of the clustering. If the score is close to 1, the observation lies well in its class. On the contrary, if the score is close to -1, the observation is assigned to the wrong class.
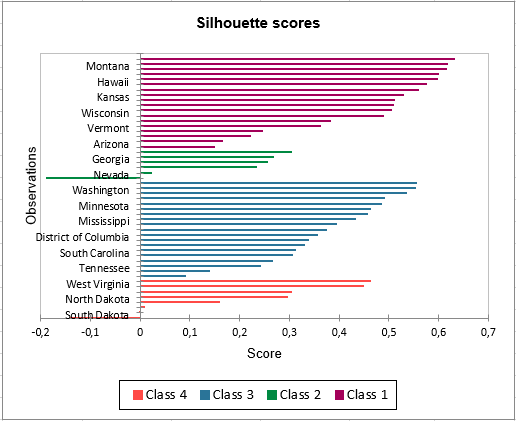
Mean silhouette scores by class allow you to compare classes and tell which one is the most uniform according to this score.
Class 1 has the highest silhouette scores. Meanwhile, Class 2 has a score close to 0, which means 4 is not the best number of classes for this data. In the tutorial on Agglomerative Hierarchical Clustering (AHC), we see that the States would better be clustered into three groups.
This video shows you how to group samples with the k-means clustering.

Was this article useful?
- Yes
- No