
Начать стоит от печки, то есть с постановки задачи. Откуда берется сама задача word embedding?
Лирическое отступление: К сожалению, русскоязычное сообщество еще не выработало единого термина для этого понятия, поэтому мы будем использовать англоязычный.
Сам по себе embedding — это сопоставление произвольной сущности (например, узла в графе или кусочка картинки) некоторому вектору.
Сегодня мы говорим про слова и стоит обсудить, как делать такое сопоставление вектора слову.
Вернемся к предмету: вот у нас есть слова и есть компьютер, который должен с этими словами как-то работать. Вопрос — как компьютер будет работать со словами? Ведь компьютер не умеет читать, и вообще устроен сильно иначе, чем человек. Самая первая идея, приходящая в голову — просто закодировать слова цифрами по порядку следования в словаре. Идея очень продуктивна в своей простоте — натуральный ряд бесконечен и можно перенумеровать все слова, не опасаясь проблем. (На секунду забудем про ограничения типов, тем более, в 64-битное слово можно запихнуть числа от 0 до 2^64 — 1, что существенно больше количества всех слов всех известных языков.)
Но у этой идеи есть и существенный недостаток: слова в словаре следуют в алфавитном порядке, и при добавлении слова нужно перенумеровывать заново большую часть слов. Но даже это не является настолько важным, а важно то, буквенное написание слова никак не связано с его смыслом (эту гипотезу еще в конце XIX века высказал известный лингвист Фердинанд де Соссюр). В самом деле слова “петух”, “курица” и “цыпленок” имеют очень мало общего между собой и стоят в словаре далеко друг от друга, хотя очевидно обозначают самца, самку и детеныша одного вида птицы. То есть мы можем выделить два вида близости слов: лексический и семантический. Как мы видим на примере с курицей, эти близости не обязательно совпадают. Можно для наглядности привести обратный пример лексически близких, но семантически далеких слов — «зола» и «золото». (Если вы никогда не задумывались, то имя Золушка происходит именно от первого.)
Чтобы получить возможность представить семантическую близость, было предложено использовать embedding, то есть сопоставить слову некий вектор, отображающий его значение в “пространстве смыслов”.
Какой самый простой способ получить вектор из слова? Кажется, что естественно будет взять вектор длины нашего словаря и поставить только одну единицу в позиции, соответствующей номеру слова в словаре. Этот подход называется one-hot encoding (OHE). OHE все еще не обладает свойствами семантической близости:

Значит нам нужно найти другой способ преобразования слов в вектора, но OHE нам еще пригодится.
Отойдем немного назад — значение одного слова нам может быть и не так важно, т.к. речь (и устная, и письменная) состоит из наборов слов, которые мы называем текстами. Так что если мы захотим как-то представить тексты, то мы возьмем OHE-вектор каждого слова в тексте и сложим вместе. Т.е. на выходе получим просто подсчет количества различных слов в тексте в одном векторе. Такой подход называется “мешок слов” (bag of words, BoW), потому что мы теряем всю информацию о взаимном расположении слов внутри текста.
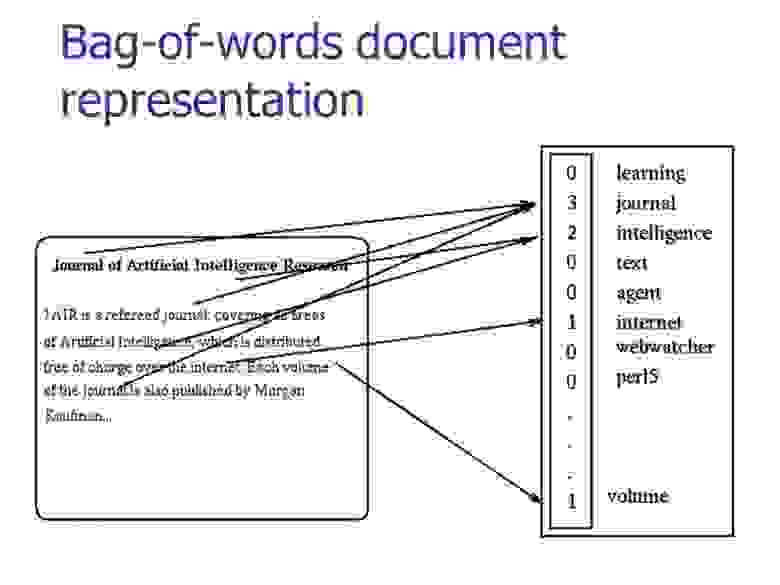
Но несмотря на потерю этой информации так тексты уже можно сравнивать. Например, с помощью косинусной меры.
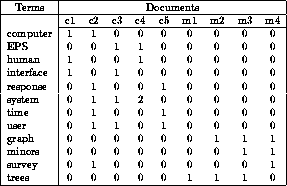
Мы можем пойти дальше и представить наш корпус (набор текстов) в виде матрицы “слово-документ” (term-document). Стоит отметить, что в области информационного поиска (information retrieval) эта матрица носит название «обратного индекса» (inverted index), в том смысле, что обычный/прямой индекс выглядит как «документ-слово» и очень неудобен для быстрого поиска. Но это опять же выходит за рамки нашей статьи.
Эта матрица приводит нас к тематическим моделям, где матрицу “слово-документ” пытаются представить в виде произведения двух матриц “слово-тема” и “тема-документ”. В самом простом случае мы возьмем матрицу и с помощью SVD-разложения получим представление слов через темы и документов через темы:

Здесь  — слова,
— слова,  — документы. Но это уже будет предметом другой статьи, а сейчас мы вернемся к нашей главной теме — векторному представлению слов.
— документы. Но это уже будет предметом другой статьи, а сейчас мы вернемся к нашей главной теме — векторному представлению слов.
Пусть у нас есть такой корпус:
s = ['Mars has an athmosphere', "Saturn 's moon Titan has its own athmosphere",
'Mars has two moons', 'Saturn has many moons', 'Io has cryo-vulcanoes']С помощью SVD-преобразования, выделим только первые две компоненты, и нарисуем:
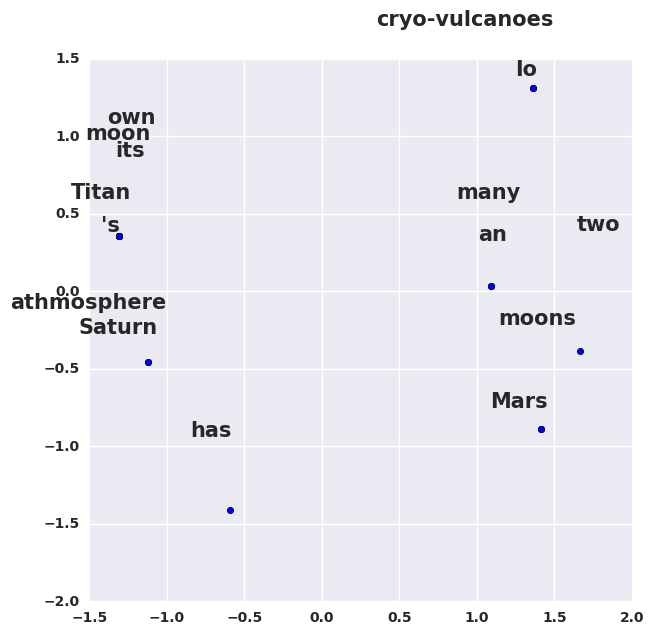
Что интересного на этой картинке? То, что Титан и Ио — далеко друг от друга, хотя они оба являются спутниками Сатурна, но в нашем корпусе про это ничего нет. Слова «атмосфера» и «Сатурн» очень близко друг другу, хотя не являются синонимами. В то же время «два» и «много» стоят рядом, что логично. Но общий смысл этого примера в том, что результаты, которые вы получите очень сильно зависят от корпуса, с которым вы работаете. Весь код для получения картинки выше можно посмотреть здесь.
Логика повествования выводит на следующую модификацию матрицы term-document — формулу TF-IDF. Эта аббревиатура означает «term frequency — inverse document frequency».

Давайте попробуем разобраться, что это такое. Итак, TF — это частота слова  в тексте
в тексте  , здесь нет ничего сложного. А вот IDF — существенно более интересная вещь: это логарифм обратной частоты распространенности слова в корпусе
, здесь нет ничего сложного. А вот IDF — существенно более интересная вещь: это логарифм обратной частоты распространенности слова в корпусе  . Распространенностью называется отношение числа текстов, в которых встретилось искомое слово, к общему числу текстов в корпусе. С помощью TF-IDF тексты также можно сравнивать, и делать это можно с меньшей опаской, чем при использовании обычных частот.
. Распространенностью называется отношение числа текстов, в которых встретилось искомое слово, к общему числу текстов в корпусе. С помощью TF-IDF тексты также можно сравнивать, и делать это можно с меньшей опаской, чем при использовании обычных частот.
Новая эпоха
Описанные выше подходы были (и остаются) хороши для времен (или областей), где количество текстов мало и словарь ограничен, хотя, как мы видели, там тоже есть свои сложности. Но с приходом в нашу жизнь интернета все стало одновременно и сложнее и проще: в доступе появилось великое множество текстов, и эти тексты с изменяющимся и расширяющимся словарем. С этим надо было что-то делать, а ранее известные модели не могли справиться с таким объемом текстов. Количество слов в английском языке очень грубо составляет миллион — матрица совместных встречаемостей только пар слов будет 10^6 x 10^6. Такая матрица даже сейчас не очень лезет в память компьютеров, а, скажем, 10 лет назад про такое можно было не мечтать. Конечно, были придуманы множество способов, упрощающих или распараллеливающих обработку таких матриц, но все это были паллиативные методы.
И тогда, как это часто бывает, был предложен выход по принципу “тот, кто нам мешает, тот нам поможет!” А именно, в 2013 году тогда мало кому известный чешский аспирант Томаш Миколов предложил свой подход к word embedding, который он назвал word2vec. Его подход основан на другой важной гипотезе, которую в науке принято называть гипотезой локальности — “слова, которые встречаются в одинаковых окружениях, имеют близкие значения”. Близость в данном случае понимается очень широко, как то, что рядом могут стоять только сочетающиеся слова. Например, для нас привычно словосочетание «заводной будильник». А сказать “заводной апельсин” мы не можем* — эти слова не сочетаются.
Основываясь на этой гипотезе Томаш Миколов предложил новый подход, который не страдал от больших объемов информации, а наоборот выигрывал [1].

Модель, предложенная Миколовым очень проста (и потому так хороша) — мы будем предсказывать вероятность слова по его окружению (контексту). То есть мы будем учить такие вектора слов, чтобы вероятность, присваиваемая моделью слову была близка к вероятности встретить это слово в этом окружении в реальном тексте.

Здесь  — вектор целевого слова,
— вектор целевого слова,  — это некоторый вектор контекста, вычисленный (например, путем усреднения) из векторов окружающих нужное слово других слов. А
— это некоторый вектор контекста, вычисленный (например, путем усреднения) из векторов окружающих нужное слово других слов. А  — это функция, которая двум векторам сопоставляет одно число. Например, это может быть упоминавшееся выше косинусное расстояние.
— это функция, которая двум векторам сопоставляет одно число. Например, это может быть упоминавшееся выше косинусное расстояние.
Приведенная формула называется softmax, то есть “мягкий максимум”, мягкий — в смысле дифференцируемый. Это нужно для того, чтобы наша модель могла обучиться с помощью backpropagation, то есть процесса обратного распространения ошибки.
Процесс тренировки устроен следующим образом: мы берем последовательно (2k+1) слов, слово в центре является тем словом, которое должно быть предсказано. А окружающие слова являются контекстом длины по k с каждой стороны. Каждому слову в нашей модели сопоставлен уникальный вектор, который мы меняем в процессе обучения нашей модели.
В целом, этот подход называется CBOW — continuous bag of words, continuous потому, что мы скармливаем нашей модели последовательно наборы слов из текста, a BoW потому что порядок слов в контексте не важен.
Также Миколовым сразу был предложен другой подход — прямо противоположный CBOW, который он назвал skip-gram, то есть “словосочетание с пропуском”. Мы пытаемся из данного нам слова угадать его контекст (точнее вектор контекста). В остальном модель не претерпевает изменений.
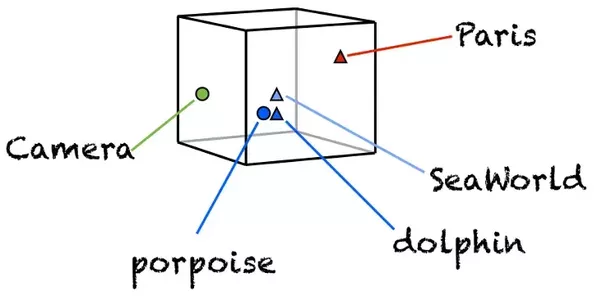
Что стоит отметить: хотя в модель не заложено явно никакой семантики, а только статистические свойства корпусов текстов, оказывается, что натренированная модель word2vec может улавливать некоторые семантические свойства слов. Классический пример из работы автора:
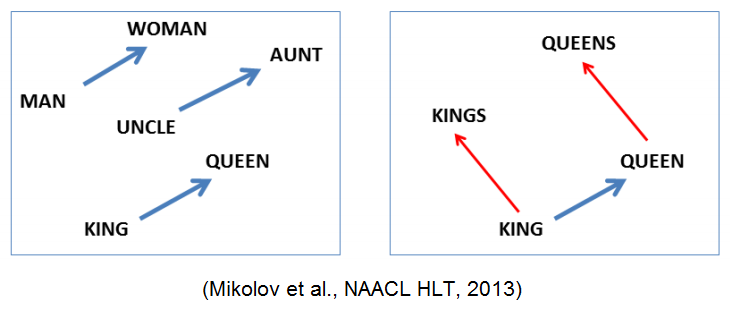
Слово «мужчина» относится к слову «женщина» так же, как слово «дядя» к слову «тётя», что для нас совершенно естественно и понятно, но в других моделям добиться такого же соотношения векторов можно только с помощью специальных ухищрений. Здесь же — это происходит естественно из самого корпуса текстов. Кстати, помимо семантических связей, улавливаются и синтаксические, справа показано соотношение единственного и множественного числа.
Более сложные вещи
На самом деле, за прошедшее время были предложены улучшения ставшей уже также классической модели Word2Vec. Два самых распространенных будут описаны ниже. Но этот раздел может быть пропущен без ущерба для понимания статьи в целом, если покажется слишком сложным.
Negative Sampling
В стандартной модели CBoW, рассмотренной выше, мы предсказываем вероятности слов и оптимизируем их. Функцией для оптимизации (минимизации в нашем случае) служит дивергенция Кульбака-Лейблера:

Здесь  — распределение вероятностей слов, которое мы берем из корпуса,
— распределение вероятностей слов, которое мы берем из корпуса,  — распределение, которое порождает наша модель. Дивергенция — это буквально «расхождение», насколько одно распределение не похоже на другое. Т.к. наши распределения на словах, т.е. являются дискретными, мы можем заменить в этой формуле интеграл на сумму:
— распределение, которое порождает наша модель. Дивергенция — это буквально «расхождение», насколько одно распределение не похоже на другое. Т.к. наши распределения на словах, т.е. являются дискретными, мы можем заменить в этой формуле интеграл на сумму:

Оказалось так, что оптимизировать эту формулу достаточно сложно. Прежде всего из-за того, что рассчитывается с помощью softmax по всему словарю. (Как мы помним, в английском сейчас порядка миллиона слов.) Здесь стоит отметить, что многие слова вместе не встречаются, как мы уже отмечали выше, поэтому большая часть вычислений в softmax является избыточной. Был предложен элегантный обходной путь, который получил название Negative Sampling. Суть этого подхода заключается в том, что мы максимизируем вероятность встречи для нужного слова в типичном контексте (том, который часто встречается в нашем корпусе) и одновременно минимизируем вероятность встречи в нетипичном контексте (том, который редко или вообще не встречается). Формулой мысль выше записывается так:

Здесь  — точно такой же, что и в оригинальной формуле, а вот остальное несколько отличается. Прежде всего стоит обратить внимание на то, что формуле теперь состоит из двух частей: позитивной () и негативной (
— точно такой же, что и в оригинальной формуле, а вот остальное несколько отличается. Прежде всего стоит обратить внимание на то, что формуле теперь состоит из двух частей: позитивной () и негативной ( ). Позитивная часть отвечает за типичные контексты, и
). Позитивная часть отвечает за типичные контексты, и  здесь — это распределение совместной встречаемости слова и остальных слов корпуса. Негативная часть — это, пожалуй, самое интересное — это набор слов, которые с нашим целевым словом встречаются редко. Этот набор порождается из распределения
здесь — это распределение совместной встречаемости слова и остальных слов корпуса. Негативная часть — это, пожалуй, самое интересное — это набор слов, которые с нашим целевым словом встречаются редко. Этот набор порождается из распределения  , которое на практике берется как равномерное по всем словам словаря корпуса. Было показано, что такая функция приводит при своей оптимизации к результату, аналогичному стандартному softmax [2].
, которое на практике берется как равномерное по всем словам словаря корпуса. Было показано, что такая функция приводит при своей оптимизации к результату, аналогичному стандартному softmax [2].
Hierarchical SoftMax
Также люди зашли и с другой стороны — можно не менять исходную формулу, а попробовать посчитать сам softmax более эффективно. Например, используя бинарное дерево [3]. По всем словам в словаре строится дерево Хаффмана. В полученном дереве  слов располагаются на листьях дерева.
слов располагаются на листьях дерева.
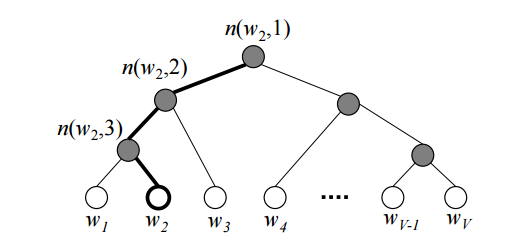
На рисунке изображен пример такого бинарного дерева. Жирным выделен путь от корня до слова  . Длину пути обозначим
. Длину пути обозначим  , а
, а  -ую вершину на пути к слову обозначим через
-ую вершину на пути к слову обозначим через  . Можно доказать, что внутренних вершин (не листьев)
. Можно доказать, что внутренних вершин (не листьев)  .
.
С помощью иерархического softmax вектора  предсказывается для
предсказывается для  внутренних вершин. А вероятность того, что слово будет выходным словом (в зависимости от того, что мы предсказываем: слово из контекста или заданное слово по контексту) вычисляется по формуле:
внутренних вершин. А вероятность того, что слово будет выходным словом (в зависимости от того, что мы предсказываем: слово из контекста или заданное слово по контексту) вычисляется по формуле:
![$p(w=w_o)=prodlimits_{j=1}^{L(w)-1}sigma([n(w,j+1)=lch(n(w,j))] v_{n(w,j)}^T u)$](https://habrastorage.org/getpro/habr/formulas/018/e83/e8f/018e83e8fb17212f7b2c6a6be6d09635.svg)
где  — функция softmax;
— функция softmax; ![$[true]=1,[false]=-1$](https://habrastorage.org/getpro/habr/formulas/870/680/f3e/870680f3ef96594c5444eaeca1440677.svg) ;
;  — левый сын вершины
— левый сын вершины  ;
;  , если используется метод skip-gram,
, если используется метод skip-gram,  , то есть, усредненный вектор контекста, если используется CBOW.
, то есть, усредненный вектор контекста, если используется CBOW.
Формулу можно интуитивно понять, представив, что на каждом шаге мы можем пойти налево или направо с вероятностями:


Затем на каждом шаге вероятности перемножаются ( шагов) и получается искомая формула.
шагов) и получается искомая формула.
При использовании простого softmax для подсчета вероятности слова, приходилось вычислять нормирующую сумму по всем словам из словаря, требовалось  операций. Теперь же вероятность слова можно вычислить при помощи последовательных вычислений, которые требуют
операций. Теперь же вероятность слова можно вычислить при помощи последовательных вычислений, которые требуют  .
.
Другие модели
Помимо word2vec были, само собой, предложены и другие модели word embedding. Стоит отметить модель, предложенную лабораторией компьютерной лингвистики Стенфордского университета, под названием Global Vectors (GloVe), сочетающую в себе черты SVD разложения и word2vec [4].
Также надо упомянуть о том, что т.к. изначально все описанные модели были предложены для английского языка, то там не так остро стоит проблема словоизменения, характерная для синтетических языков (это — лингвистический термин), вроде русского. Везде выше по тексту неявно предполагалось, что мы либо считаем разные формы одного слова разными словами — и тогда надеяться, что нашего корпуса будет достаточно модели, чтобы выучить их синтаксическую близость, либо используем механизмы стеммирования или лемматизации. Стеммирование — это обрезание окончания слова, оставление только основы (например, “красного яблока” превратится в “красн яблок”). А лемматизация — замена слова его начальной формой (например, “мы бежим” превратится в “я бежать”). Но мы можем и не терять эту информацию, а использовать ее — закодировав OHE в новый вектор, и сконкатинировать его с вектором для основы или леммы.
Еще стоит сказать, что то, с чем мы начинали — буквенное представление слова — тоже не кануло в Лету: предложены модели по использованию буквенного представления слова для word embedding [5].
Практическое применение
Мы поговорили о теории, пришло время посмотреть, к чему все вышеописанное применимо на практике. Ведь любая самая красивая теория без практического применения — не более чем игра ума. Рассмотрим применение Word2Vec в двух задачах:
1) Задача классификации, необходимо по последовательности посещенных сайтов определять пользователя;
2) Задача регрессии, необходимо по тексту статьи определить ее рейтинг на Хабрахабре.
Классификация
# загрузим библиотеки и установим опции
from __future__ import division, print_function
# отключим всякие предупреждения Anaconda
import warnings
warnings.filterwarnings('ignore')
#%matplotlib inline
import numpy as np
import pandas as pd
from sklearn.metrics import roc_auc_scoreCкачать данные для первой задачи можно со страницы соревнования «Catch Me If You Can»
# загрузим обучающую и тестовую выборки
train_df = pd.read_csv('data/train_sessions.csv')#,index_col='session_id')
test_df = pd.read_csv('data/test_sessions.csv')#, index_col='session_id')
# приведем колонки time1, ..., time10 к временному формату
times = ['time%s' % i for i in range(1, 11)]
train_df[times] = train_df[times].apply(pd.to_datetime)
test_df[times] = test_df[times].apply(pd.to_datetime)
# отсортируем данные по времени
train_df = train_df.sort_values(by='time1')
# посмотрим на заголовок обучающей выборки
train_df.head()
sites = ['site%s' % i for i in range(1, 11)]
#заменим nan на 0
train_df[sites] = train_df[sites].fillna(0).astype('int').astype('str')
test_df[sites] = test_df[sites].fillna(0).astype('int').astype('str')
#создадим тексты необходимые для обучения word2vec
train_df['list'] = train_df['site1']
test_df['list'] = test_df['site1']
for s in sites[1:]:
train_df['list'] = train_df['list']+","+train_df[s]
test_df['list'] = test_df['list']+","+test_df[s]
train_df['list_w'] = train_df['list'].apply(lambda x: x.split(','))
test_df['list_w'] = test_df['list'].apply(lambda x: x.split(','))#В нашем случае предложение это набор сайтов, которые посещал пользователь
#нам необязательно переводить цифры в названия сайтов, т.к. алгоритм будем выявлять взаимосвязь их друг с другом.
train_df['list_w'][10]['229', '1500', '33', '1500', '391', '35', '29', '2276', '40305', '23']# подключим word2vec
from gensim.models import word2vec#объединим обучающую и тестовую выборки и обучим нашу модель на всех данных
#с размером окна в 6=3*2 (длина предложения 10 слов) и итоговыми векторами размерности 300, параметр workers отвечает за количество ядер
test_df['target'] = -1
data = pd.concat([train_df,test_df], axis=0)
model = word2vec.Word2Vec(data['list_w'], size=300, window=3, workers=4)
#создадим словарь со словами и соответсвующими им векторами
w2v = dict(zip(model.wv.index2word, model.wv.syn0))Т.к. сейчас мы каждому слову сопоставили вектор, то нужно решить, что сопоставить целому предложению из слов.
Один из возможных вариантов это просто усреднить все слова в предложении и получить некоторый смысл всего предложения (если слова нет в тексте, то берем нулевой вектор).
class mean_vectorizer(object):
def __init__(self, word2vec):
self.word2vec = word2vec
self.dim = len(next(iter(w2v.values())))
def fit(self, X):
return self
def transform(self, X):
return np.array([
np.mean([self.word2vec[w] for w in words if w in self.word2vec]
or [np.zeros(self.dim)], axis=0)
for words in X
])data_mean=mean_vectorizer(w2v).fit(train_df['list_w']).transform(train_df['list_w'])
data_mean.shape(253561, 300)Т.к. мы получили distributed representation, то никакое число по отдельности ничего не значит, а значит лучше всего покажут себя линейные алгоритмы. Попробуем нейронные сети, LogisticRegression и проверим нелинейный метод XGBoost.
# Воспользуемся валидацией
def split(train,y,ratio):
idx = round(train.shape[0] * ratio)
return train[:idx, :], train[idx:, :], y[:idx], y[idx:]
y = train_df['target']
Xtr, Xval, ytr, yval = split(data_mean, y,0.8)
Xtr.shape,Xval.shape,ytr.mean(),yval.mean()((202849, 300), (50712, 300), 0.009726446765820882, 0.006389020350212968)# подключим библиотеки keras
from keras.models import Sequential, Model
from keras.layers import Dense, Dropout, Activation, Input
from keras.preprocessing.text import Tokenizer
from keras import regularizers# опишем нейронную сеть
model = Sequential()
model.add(Dense(128, input_dim=(Xtr.shape[1])))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation('sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['binary_accuracy'])history = model.fit(Xtr, ytr,
batch_size=128,
epochs=10,
validation_data=(Xval, yval),
class_weight='auto',
verbose=0)classes = model.predict(Xval, batch_size=128)
roc_auc_score(yval, classes)0.91892341356995644Получили неплохой результат. Значит Word2Vec смог выявить зависимости между сессиями.
Посмотрим, что произойдет с алгоритмом XGBoost.
import xgboost as xgbdtr = xgb.DMatrix(Xtr, label= ytr,missing = np.nan)
dval = xgb.DMatrix(Xval, label= yval,missing = np.nan)
watchlist = [(dtr, 'train'), (dval, 'eval')]
history = dict()params = {
'max_depth': 26,
'eta': 0.025,
'nthread': 4,
'gamma' : 1,
'alpha' : 1,
'subsample': 0.85,
'eval_metric': ['auc'],
'objective': 'binary:logistic',
'colsample_bytree': 0.9,
'min_child_weight': 100,
'scale_pos_weight':(1)/y.mean(),
'seed':7
}model_new = xgb.train(params, dtr, num_boost_round=200, evals=watchlist, evals_result=history, verbose_eval=20)Обучение
[0] train-auc:0.954886 eval-auc:0.85383
[20] train-auc:0.989848 eval-auc:0.910808
[40] train-auc:0.992086 eval-auc:0.916371
[60] train-auc:0.993658 eval-auc:0.917753
[80] train-auc:0.994874 eval-auc:0.918254
[100] train-auc:0.995743 eval-auc:0.917947
[120] train-auc:0.996396 eval-auc:0.917735
[140] train-auc:0.996964 eval-auc:0.918503
[160] train-auc:0.997368 eval-auc:0.919341
[180] train-auc:0.997682 eval-auc:0.920183Видим, что алгоритм сильно подстраивается под обучающую выборку, поэтому возможно наше предположение о необходимости использовать линейные алгоритмы подтверждено.
Посмотрим, что покажет обычный LogisticRegression.
from sklearn.linear_model import LogisticRegression
def get_auc_lr_valid(X, y, C=1, seed=7, ratio = 0.8):
# разделим выборку на обучающую и валидационную
idx = round(X.shape[0] * ratio)
# обучение классификатора
lr = LogisticRegression(C=C, random_state=seed, n_jobs=-1).fit(X[:idx], y[:idx])
# прогноз для валидационной выборки
y_pred = lr.predict_proba(X[idx:, :])[:, 1]
# считаем качество
score = roc_auc_score(y[idx:], y_pred)
return scoreget_auc_lr_valid(data_mean, y, C=1, seed=7, ratio = 0.8)0.90037148150108237Попробуем улучшить результаты.
Теперь вместо обычного среднего, чтобы учесть частоту с которой слово встречается в тексте, возьмем взвешенное среднее. В качестве весов возьмем IDF. Учёт IDF уменьшает вес широко употребительных слов и увеличивает вес более редких слов, которые могут достаточно точно указать на то, к какому классу относится текст. В нашем случае, кому принадлежит последовательность посещенных сайтов.
#пропишем класс выполняющий tfidf преобразование.
from sklearn.feature_extraction.text import TfidfVectorizer
from collections import defaultdict
class tfidf_vectorizer(object):
def __init__(self, word2vec):
self.word2vec = word2vec
self.word2weight = None
self.dim = len(next(iter(w2v.values())))
def fit(self, X):
tfidf = TfidfVectorizer(analyzer=lambda x: x)
tfidf.fit(X)
max_idf = max(tfidf.idf_)
self.word2weight = defaultdict(
lambda: max_idf,
[(w, tfidf.idf_[i]) for w, i in tfidf.vocabulary_.items()])
return self
def transform(self, X):
return np.array([
np.mean([self.word2vec[w] * self.word2weight[w]
for w in words if w in self.word2vec] or
[np.zeros(self.dim)], axis=0)
for words in X
])data_mean = tfidf_vectorizer(w2v).fit(train_df['list_w']).transform(train_df['list_w'])Проверим изменилось ли качество LogisticRegression.
get_auc_lr_valid(data_mean, y, C=1, seed=7, ratio = 0.8)0.90738924587178804видим прирост на 0.07, значит скорее всего взвешенное среднее помогает лучше отобразить смысл всего предложения через word2vec.
Предсказание популярности
Попробуем Word2Vec уже в текстовой задаче — предсказании популярности статьи на Хабрхабре.
Испробуем силы алгоритма непосредственно на текстовых данных статей Хабра. Мы преобразовали данные в csv таблицы. Скачать их вы можете здесь: train, test.
Xtrain = pd.read_csv('data/train_content.csv')
Xtest = pd.read_csv('data/test_content.csv')
print(Xtrain.shape,Xtest.shape)
Xtrain.head()
Пример текста
‘Доброго хабрадня!
rn
rnПерейду сразу к сути. С недавнего времени на меня возложилась задача развития контекстной сети текстовых объявлений. Задача возможно кому-то покажется простой, но есть несколько нюансов. Страна маленькая, 90% интернет-пользователей сконцентрировано в одном городе. С одной стороны легко охватить, с другой стороны некуда развиваться.
rn
rnТак как развитие интернет-проектов у нас слабое, и недоверие клиентов к местным проектам преобладает, то привлечь рекламодателей тяжело. Но самое страшное это привлечь площадки, которые знают и Бегун и AdSense, но абсолютно не знают нас. В целом проблема такая: площадки не регистрируются, потому что нет рекламодателей с деньгами, а рекламодатели не дают объявления, потому что список площадок слаб.
rn
rnКак выходят из такого положения Хабраспециалисты?’
Будем обучать модель на всем содержании статьи. Для этого совершим некоторые преобразования над текстом.
Напишем функцию, которая будет преобразовывать тестовую статью в лист из слов необходимый для обучения Word2Vec.
Функция получает строку, в которой содержится весь текстовый документ.
1) Сначала функция будет удалять все символы кроме букв верхнего и нижнего регистра;
2) Затем преобразовывает слова к нижнему регистру;
3) После чего удаляет стоп слова из текста, т.к. они не несут никакой информации о содержании;
4) Лемматизация, процесс приведения словоформы к лемме — её нормальной (словарной) форме.
Функция возвращает лист из слов.
# подключим необходимые библиотеки
from sklearn.metrics import mean_squared_error
import re
from nltk.corpus import stopwords
import pymorphy2
morph = pymorphy2.MorphAnalyzer()
stops = set(stopwords.words("english")) | set(stopwords.words("russian"))
def review_to_wordlist(review):
#1)
review_text = re.sub("[^а-яА-Яa-zA-Z]"," ", review)
#2)
words = review_text.lower().split()
#3)
words = [w for w in words if not w in stops]
#4)
words = [morph.parse(w)[0].normal_form for w in words ]
return(words)
Лемматизация занимает много времени, поэтому ее можно убрать в целях более быстрых подсчетов.
# Преобразуем время
Xtrain['date'] = Xtrain['date'].apply(pd.to_datetime)
Xtrain['year'] = Xtrain['date'].apply(lambda x: x.year)
Xtrain['month'] = Xtrain['date'].apply(lambda x: x.month)Будем обучаться на 2015 году, а валидироваться по первым 4 месяцам 2016, т.к. в нашей тестовой выборке представлены данные за первые 4 месяца 2017 года. Более правдивую валидацию можно сделать, идя по годам, увеличивая нашу обучающую выборку и смотря качество на первых четырех месяцах следующего года
Xtr = Xtrain[Xtrain['year']==2015]
Xval = Xtrain[(Xtrain['year']==2016)& (Xtrain['month']<=4)]
ytr = Xtr['favs_lognorm']
yval = Xval['favs_lognorm']
Xtr.shape,Xval.shape,ytr.mean(),yval.mean()((23425, 15), (7556, 15), 3.4046228249071526, 3.304679829935242)data = pd.concat([Xtr,Xval],axis = 0,ignore_index = True)#у нас есть nan, поэтому преобразуем их к строке
data['content_clear'] = data['content'].apply(str)%%time
data['content_clear'] = data['content_clear'].apply(review_to_wordlist)model = word2vec.Word2Vec(data['content_clear'], size=300, window=10, workers=4)
w2v = dict(zip(model.wv.index2word, model.wv.syn0))Посмотрим чему выучилась модель:
model.wv.most_similar(positive=['open', 'data','science','best'])Результат
[(‘massive’, 0.6958945393562317),
(‘mining’, 0.6796239018440247),
(‘scientist’, 0.6742461919784546),
(‘visualization’, 0.6403135061264038),
(‘centers’, 0.6386666297912598),
(‘big’, 0.6237790584564209),
(‘engineering’, 0.6209672689437866),
(‘structures’, 0.609510600566864),
(‘knowledge’, 0.6094595193862915),
(‘scientists’, 0.6050446629524231)]
Модель обучилась достаточно неплохо, посмотрим на результаты алгоритмов:
data_mean = mean_vectorizer(w2v).fit(data['content_clear']).transform(data['content_clear'])
data_mean.shapedef split(train,y,ratio):
idx = ratio
return train[:idx, :], train[idx:, :], y[:idx], y[idx:]
y = data['favs_lognorm']
Xtr, Xval, ytr, yval = split(data_mean, y,23425)
Xtr.shape,Xval.shape,ytr.mean(),yval.mean()((23425, 300), (7556, 300), 3.4046228249071526, 3.304679829935242)from sklearn.linear_model import Ridge
from sklearn.metrics import mean_squared_error
model = Ridge(alpha = 1,random_state=7)
model.fit(Xtr, ytr)
train_preds = model.predict(Xtr)
valid_preds = model.predict(Xval)
ymed = np.ones(len(valid_preds))*ytr.median()
print('Ошибка на трейне',mean_squared_error(ytr, train_preds))
print('Ошибка на валидации',mean_squared_error(yval, valid_preds))
print('Ошибка на валидации предсказываем медиану',mean_squared_error(yval, ymed))Ошибка на трейне 0.734248488422
Ошибка на валидации 0.665592676973
Ошибка на валидации предсказываем медиану 1.44601638512data_mean_tfidf = tfidf_vectorizer(w2v).fit(data['content_clear']).transform(data['content_clear'])y = data['favs_lognorm']
Xtr, Xval, ytr, yval = split(data_mean_tfidf, y,23425)
Xtr.shape,Xval.shape,ytr.mean(),yval.mean()((23425, 300), (7556, 300), 3.4046228249071526, 3.304679829935242)model = Ridge(alpha = 1,random_state=7)
model.fit(Xtr, ytr)
train_preds = model.predict(Xtr)
valid_preds = model.predict(Xval)
ymed = np.ones(len(valid_preds))*ytr.median()
print('Ошибка на трейне',mean_squared_error(ytr, train_preds))
print('Ошибка на валидации',mean_squared_error(yval, valid_preds))
print('Ошибка на валидации предсказываем медиану',mean_squared_error(yval, ymed))Ошибка на трейне 0.743623730976
Ошибка на валидации 0.675584372744
Ошибка на валидации предсказываем медиану 1.44601638512Попробуем нейронные сети.
# подключим библиотеки keras
from keras.models import Sequential, Model
from keras.layers import Dense, Dropout, Activation, Input
from keras.preprocessing.text import Tokenizer
from keras import regularizers
from keras.wrappers.scikit_learn import KerasRegressor# Опишем нашу сеть.
def baseline_model():
model = Sequential()
model.add(Dense(128, input_dim=Xtr.shape[1], kernel_initializer='normal', activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1, kernel_initializer='normal'))
model.compile(loss='mean_squared_error', optimizer='adam')
return model
estimator = KerasRegressor(build_fn=baseline_model,epochs=20, nb_epoch=20, batch_size=64,validation_data=(Xval, yval), verbose=2)estimator.fit(Xtr, ytr)Обучение
Train on 23425 samples, validate on 7556 samples
Epoch 1/20
1s — loss: 1.7292 — val_loss: 0.7336
Epoch 2/20
0s — loss: 1.2382 — val_loss: 0.6738
Epoch 3/20
0s — loss: 1.1379 — val_loss: 0.6916
Epoch 4/20
0s — loss: 1.0785 — val_loss: 0.6963
Epoch 5/20
0s — loss: 1.0362 — val_loss: 0.6256
Epoch 6/20
0s — loss: 0.9858 — val_loss: 0.6393
Epoch 7/20
0s — loss: 0.9508 — val_loss: 0.6424
Epoch 8/20
0s — loss: 0.9066 — val_loss: 0.6231
Epoch 9/20
0s — loss: 0.8819 — val_loss: 0.6207
Epoch 10/20
0s — loss: 0.8634 — val_loss: 0.5993
Epoch 11/20
1s — loss: 0.8401 — val_loss: 0.6093
Epoch 12/20
1s — loss: 0.8152 — val_loss: 0.6006
Epoch 13/20
0s — loss: 0.8005 — val_loss: 0.5931
Epoch 14/20
0s — loss: 0.7736 — val_loss: 0.6245
Epoch 15/20
0s — loss: 0.7599 — val_loss: 0.5978
Epoch 16/20
1s — loss: 0.7407 — val_loss: 0.6593
Epoch 17/20
1s — loss: 0.7339 — val_loss: 0.5906
Epoch 18/20
1s — loss: 0.7256 — val_loss: 0.5878
Epoch 19/20
1s — loss: 0.7117 — val_loss: 0.6123
Epoch 20/20
0s — loss: 0.7069 — val_loss: 0.5948
Получили более хороший результат по сравнению с гребневой регрессией.
Заключение
Word2Vec показал свою пользу на практических задачах анализа текстов, все-таки не зря на текущий момент на практике используется в основном именно он и — гораздо менее популярный — GloVe. Тем не менее, может быть в вашей конкретной задаче, вам пригодятся подходы, которым для эффективной работы не требуются такие объемы данных, как для word2vec.
Код ноутбуков с примерами можно взять здесь. Код практического применения — вот тут.
Пост написан совместно с demonzheg.
Литература
- Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient estimation
of word representations in vector space. CoRR, abs/1301.3781, - Tomas Mikolov, Ilya Sutskever, Kai Chen, Gregory S. Corrado, and Jeffrey Dean. Distributed representations of words and phrases and their compositionality. In Advances in Neural Information Processing Systems 26: 27th Annual Conference on Neural Information Processing Systems 2013. Proceedings of a meeting held December 5-8, 2013, Lake Tahoe, Nevada, United States, pages 3111–3119, 2013.
- Morin, F., & Bengio, Y. Hierarchical Probabilistic Neural Network Language Model. Aistats, 5, 2005.
- Jeffrey Pennington, Richard Socher, and Christopher D. Manning. GloVe: Global Vectors for Word Representation. 2014.
- Piotr Bojanowski, Edouard Grave, Armand Joulin, and Tomas Mikolov. Enriching word vectors
with subword information. arXiv preprint arXiv:1607.04606, 2016.
* Да, это специальная пасхалка для любителей творчества Энтони Бёрджеса.
Как привычные слова изменяют цифровой мир вокруг нас, рассказывает доктор технических наук Владимир Крылов, консультант Artezio.
Современные системы распознавания речи и текста открывают для людей новые возможности, значительно упрощая общение человека и машины. Мы можем отдавать голосовые команды автопилоту, спросить в чате у бота, какая завтра будет погода или получить рекомендации, как улучшить текст для книги. Все это стало возможным благодаря уникальным разработкам ученых и привычным словам, которые искусственный интеллект научился понимать с помощью эмбеддингов.
.jpg")
Термин «эмбеддинг» (от англ. embedding – вложение) — стал часто встречаться в описаниях систем искусственного интеллекта только в последние несколько лет, а впервые появился в работах специалистов по обработке текстов на естественных языках. Естественный язык – это привычный способ общения людей. Например, язык машин – это двоичный код, в который компилируются все другие языки программирования. Однако в нашем случае речь идет именно об обработке естественного языка человека.
Технологии искусственного интеллекта включают в себя обработку текста на естественных языках, сокращённо NLP, то есть Natural Language Processing (не путайте с нейролингвистическим программированием!). Эмбеддинг в NLP означает процесс или, чаще, результат процесса преобразования языковой сущности – слова, предложения, параграфа или целого текста в набор чисел – числовой вектор
В русскоязычной литературе эмбеддингами обычно называют именно такие числовые векторы, которые получены из слов или других языковых сущностей. Напомню, что числовым вектором размерности k называют список из k чисел, в котором порядок чисел строго определен. Например, трехмерным вектором можно считать (2.3, 1.0, 7.35), а (1, 0, 0, 2, 0.1, 0, 0, 7.9) – восьмимерным числовым вектором.
В самой примитивной форме эмбеддинги слов получают простой нумерацией слов в некотором достаточно обширном словаре и установкой значения единицы в длинном векторе размерности, равной числу слов в словаре. Например, возьмем Толковый словарь Ушакова и пронумеруем все слова с первого до последнего. Так слово «абака» преобразуется в число 5, «абажур» — в 7 и так далее. Всего слов в словаре 85 289 слов. Эмбеддинг слова «абака» будет иметь 85288 нулей на всех позициях, кроме пятой, где будет стоять 1, а слово «абажур» — соответственно будет иметь нули на всех 85288 позициях кроме седьмой, где будет единица. Этот метод построения эмбеддингов называют унитарным кодированием, а в современной англоязычной литературе – one-hot encoding.
Любому предложению на русском языке можно попытаться поставить в соответствие последовательность – более правильно с математической точки сказать — кортеж таких 85289-мерных векторов. И тогда действия над словами могут быть преобразованы в действия над этими числовыми векторами, что собственно и свойственно компьютеру. Однако все не так просто. Первая проблема применения таких эмбеддингов, с которой вы столкнетесь, это отсутствие в выбранном словаре слова, для которого ищется эмбеддинг.
Посмотрите в упомянутый Толковый словарь Ушакова – вы не найдете там такого популярного слова как «компьютер». Существенно снизить вероятность такой проблемы можно не используя специальный словарь, а нумеруя слова в произвольном обширном наборе текстов, например, в Википедии, Большой российской энциклопедии. Для этих целей сегодня создаются специальные наборы, называемые корпусами текстов.
Ну, а какие действия над числовыми эквивалентами слов мы хотели бы совершать и зачем? Наверное, для того, чтобы компьютер мог сам без вмешательства человека предпринять какие-то действия в зависимости от содержания имеющегося у него текста. Самый простой пример – это распространённые сегодня мобильные ассистенты – Google Assistant или Siri. Они работают как с голосовыми командами и запросами, так и с текстовыми. В зависимости от содержания запроса ассистент выполняет определённые действия: формирует сводку погоды, запускает программы или производит математическое действие. Однако, использование представительных корпусов (корпус текстов — подобранная и обработанная по определённым правилам совокупность текстов, используемых в качестве базы для исследования языка) само по себе не помогает извлечь какую-либо пользу из превращения конкретного текста в кортеж чисел. Ведь любой текст на естественном языке представляет собой не только набор слов, но и несет некоторую семантику, смысл.
Задача научить компьютерную систему как-либо понимать смысл текста, извлекать из него семантическую информацию, используя примитивный эмбеддинг, является неразрешимой. Иными словами, системе нужна дополнительная информация, не только простые значения. Поэтому следующий шаг в обработке текстов был сделан путем учёта того факта, насколько часто каждое слово языка (термин) встречается в корпусе и насколько важно его появление в конкретном тексте. Так возник частотный эмбеддинг, в котором каждому слову в позицию, соответствующую его номеру, ставится в соответствие число — частота слова, а точнее, скорректированное значение частоты. Если для первого понятия все очевидно: для каждого слова в тексте рассчитывается число его вхождений и делится на общее число слов, то второй термин посложнее. Я говорю про обратную частоту документа, а если точнее, то об инверсии частоты, с которой некоторое слово встречается в документах коллекции.
Благодаря данному показателю можно снизить весомость наиболее широко используемых слов (предлогов, союзов, общих терминов и понятий). Для каждого термина в рамках определённого корпуса текстов предусматривается лишь одно единственное значение частоты слова. Показатель обратной частоты будет выше, если определённое слово с большой частотой используется в конкретном тексте, но редко — в других документах. Используя эмбеддинги в виде таких векторов, удалось впервые осуществить автоматический семантический анализ текстов, определяя имеющиеся в корпусе текстов темы и классифицировать тексты по основным темам.
Существует несколько успешно применяемых алгоритмов такого анализа: латентный семантический анализ, латентное размещение Дирихле и тематические модели Biterm для коротких текстов. Использование таких моделей, например, позволило сортировать гигантские потоки электронных писем по тематике и направлять их согласно предписанным правилам. На этом этапе внутри NLP начал формироваться мощный поток технологий, которые получили общую формулировку, как «понимание естественного языка».
В революционной работе
Томаша Миколова, исследователя Google, и его коллег в 2013 году было предложено использовать гипотезу локальности: «слова, которые встречаются в одинаковых окружениях, имеют близкие значения». Близость в данном случае – это стоящие рядом сочетающиеся слова. Например, для нас привычно словосочетание «заводной будильник». А сказать “заводной океан” мы не можем — эти слова не сочетаются. Для получения таких свойств нужно строить эмбеддинги слов в высокоразмерном (но не зависящем от числа слов) векторном пространстве. Чтобы каждому слову теперь соответствовал набор из двух-пяти сотен чисел, и эти наборы удовлетворяли свойствам математического векторного пространства.
То есть, чтобы их можно было складывать, умножать на скаляры, находить между ними расстояния и при этом каждое такое действие с числовыми векторами имело смысл как некоторое действие над словами. Все публикации и лекции об эмбеддингах сегодня сопровождает известная картинка, поясняющая сказанное.

Мы видим, что семантическое отношение «МУЖЧИНА-ЖЕНЩИНА» для эмбеддингов этих слов сводится к наличию некоторого вектора разности между ними, который удивительно сохраняется и для эквивалентного семантического отношения ДЯДЯ ~ ТЕТЯ, КОРОЛЬ ~ КОРОЛЕВА. Это позволяет записать простое математическое соотношение: ЖЕНЩИНА-МУЖЧИНА=КОРОЛЕВА-КОРОЛЬ. Сделаем простое преобразование этой формулы: ЖЕНЩИНА-КОРОЛЕВА=МУЖЧИНА-КОРОЛЬ. И правда, это выглядит справедливым: женщина без звания королевы – то же самое, что мужчина без звания короля. А вот вторая картинка поясняет, что эмбеддинги сохраняют и отношение «один» ~ «много». Миколов назвал метод получения таких эмбеддингов «word2vec».
Он основан на использовании вероятностной оценки совместного употребления групп слов и самообучаемой на корпусах текстов нейронной сети. Идея оказалась плодотворной, и уже вскоре мы были свидетелями построения ещё более изощрённых моделей для получения эмбеддингов как отдельных слов, так и предложений, и целых документов. Это модель GloVe, разработанная в Стэнфорде, fastText, doc2vec – модель, отображающая в числовой вектор целый документ. В последние годы эмбеддинги получают с помощью весьма сложных моделей глубокого обучения для сохранения в свойствах векторов всё более тонких отношений естественного языка. Получаемые результаты настолько впечатляют, что эксперты отметили появление таких моделей как новую эру эмбеддинга.
Понимая всю сложность моделей такого уровня, не могу не удержаться от попытки рассказать, как же все-таки получаются эмбеддинги в самой хайповой сегодня модели BERT, разработанной Google AI Language в 2018 году.
В основе лежит нейроархитектура, называемая Transformer. Каждое слово кодируется уникальным ключом, и последовательность слов подается на так называемую рекуррентную нейронную сеть для предсказания некоторого числового многомерного вектора – эмбеддинга.
BERT может предсказывать не только слова, но и целые предложения. В процессе обучения BERT модель получает пары предложений в качестве входных данных и учится предсказывать, является ли второе предложение в паре последующим предложением в исходном документе. Во время обучения 50% входных данных представляют собой пару, в которой второе предложение является последующим предложением в оригинальном документе, в то время как в остальных 50% входных данных в качестве второго предложения выбирается случайное предложение из корпуса. Предполагается, что случайное предложение будет отсоединено от первого предложения.
BERT можно использовать для самых разных языковых задач, например, модифицируя нейронную сеть.
Результаты применения эмбеддингов BERT впечатляют. Кроме уже привычных оценок тональности текста — позитивных и негативных высказываний, компьютер стал определять наличие сарказма в тексте высказывания, обнаруживать ложь и страх. Это, кстати, уже используется электронными ассистентами. Определение эмоций человека позволяет добиться лучшей коммуникации с машиной. Да и сам человек начинает относиться к программе с большим доверием, в какой-то степени, как к человеку. Вот какие глубокие особенности человеческой психологии удается превратить в алгебраические соотношения эмбеддингов.
Эмбеддинги открыли возможность одновременного оперирования на разных естественных языках. Ведь если построить пространство эмбеддингов предложений и слов на английском и русском языке, то одинаковым семантическим понятиям должны соответствовать одни и те же эмбеддинги. Такое совмещение должно осуществляться в процессе обучения нейропереводчика. Тогда перевод нового текста с английского будет сводиться к его эмбеддингу и декодированию в словах русского языка, на который нужно осуществить перевод. Известны поисковые машины, которые принимают запрос на одном языке и отыскивают информацию на любом языке, используя обратный индекс на основе эмбеддингов.
Перед искусственным интеллектом (ИИ) открыта масса задач не только понимать особенности высказанного человеком и выбирать заранее декларированные возможные решения на их основе, но и строить сами решения. Достижение таких целей в системах искусственного интеллекта осуществляется использованием архитектур с многими нейронными сетями, генетических алгоритмов, деревьев выбора и других. Все они как правило работают эффективно, если данные для них представлены в виде числовых векторов. Это означает, что все данные для искусственного интеллекта следует представлять эмбеддингами.
В последнее время появилось несколько работ, посвященных эмбеддингам сущностей, отличных от лингвистических. Хотя здесь можно и сомневаться, нужно ли интеллекту искусственному, да и естественному, знать какие-то сущности, кроме выраженных средствами языка, естественного или искусственного, но воспринимаемого человеком. В конечном итоге и отношения между сущностями описываются средствами языка, а значит могут рассматриваться равноправно наряду с отношениями слов, предложений и текстов. Все это говорит о том, что путь эмбеддинга для любых сущностей, с которыми должен оперировать ИИ, является перспективным и корректным.

Обратимся к примерам. Например, социальная платформа Pinterest создала и использует 128-мерные эмбеддинги как для сущностей называемых Pin – страницы или изображения из Интернет и сущностей Pinner — пользователей.
В нашей лаборатории ведутся исследования в области использования эмбеддингов для представления правового пространства – статей уголовного кодекса, гражданского кодекса, трудового кодекса, судебных решений совместно с представлением нарративов (повествовательных текстов), описывающих некоторые факты. Уже сегодня нам удалось построить весьма качественный ИИ, который может заменить аппарат суда для квалификации материалов дела на этапе подготовки проекта судебного решения: какие нормативные акты нарушаются в описании фактов, представленных нарративом.
Сегодня всё больше и больше людей занимаются разработкой эмбеддингов. В принципе, уже можно говорить о том, что достаточно универсальный подход может базироваться на идее, что ИИ должен «мыслить» словами, в языковой форме. Другая идея опирается на предположение, что состояния мира могут преобразовываться в эмбеддинги, минуя словесное описание, например изображения или аудиозаписи можно сразу преобразовывать в многомерные вектора.
Если обучать модель для такого эмбеддинга совместно с текстами, то ИИ сможет оперировать как с однородными данными и с картинками, и со словами, и со звуками. Совсем недавно в своей лекции в Беркли Дэн Гиллик из Google предложил строить ИИ для поиска информации размещая все различные объекты / сущности в одном и том же векторном пространстве, независимо от того, составлены они из текста, изображений, видео или аудио.
ИИ на таком принципе сможет отвечать на вопросы, заданные на различных языках, иллюстрациями и звукозаписями, письменно и устно. Какой размерности потребуются эмбеддинги для таких универсальных описаний и достаточно ли структуры и мощности многомерного векторного пространства для сохранения всей необходимой сложности и разнообразия мира, в котором должен работать искусственный интеллект — вопрос текущих и будущих исследований.
Автор: доктор технических наук Владимир Крылов, консультант Artezio
Фото: sitebuilderreport.com, Shatterstock (предоставлено Artezio)
From Wikipedia, the free encyclopedia
In natural language processing (NLP), a word embedding is a representation of a word. The embedding is used in text analysis. Typically, the representation is a real-valued vector that encodes the meaning of the word in such a way that words that are closer in the vector space are expected to be similar in meaning.[1] Word embeddings can be obtained using language modeling and feature learning techniques, where words or phrases from the vocabulary are mapped to vectors of real numbers.
Methods to generate this mapping include neural networks,[2] dimensionality reduction on the word co-occurrence matrix,[3][4][5] probabilistic models,[6] explainable knowledge base method,[7] and explicit representation in terms of the context in which words appear.[8]
Word and phrase embeddings, when used as the underlying input representation, have been shown to boost the performance in NLP tasks such as syntactic parsing[9] and sentiment analysis.[10]
Development and history of the approach[edit]
In Distributional semantics, a quantitative methodological approach to understanding meaning in observed language, word embeddings or semantic vector space models have been used as a knowledge representation for some time.[11] Such models aim to quantify and categorize semantic similarities between linguistic items based on their distributional properties in large samples of language data. The underlying idea that «a word is characterized by the company it keeps» was proposed in a 1957 article by John Rupert Firth,[12] but also has roots in the contemporaneous work on search systems[13] and in cognitive psychology.[14]
The notion of a semantic space with lexical items (words or multi-word terms) represented as vectors or embeddings is based on the computational challenges of capturing distributional characteristics and using them for practical application to measure similarity between words, phrases, or entire documents. The first generation of semantic space models is the vector space model for information retrieval.[15][16][17] Such vector space models for words and their distributional data implemented in their simplest form results in a very sparse vector space of high dimensionality (cf. Curse of dimensionality). Reducing the number of dimensions using linear algebraic methods such as singular value decomposition then led to the introduction of latent semantic analysis in the late 1980s and the Random indexing approach for collecting word cooccurrence contexts.[18][19][20][21] In 2000 Bengio et al. provided in a series of papers the «Neural probabilistic language models» to reduce the high dimensionality of words representations in contexts by «learning a distributed representation for words».[22][23]
A study published in NeurIPS (NIPS) 2002 introduced the use of both word and document embeddings applying the method of kernel CCA to bilingual (and multi-lingual) corpora, also providing an early example of self-supervised learning of word embeddings [24]
Word embeddings come in two different styles, one in which words are expressed as vectors of co-occurring words, and another in which words are expressed as vectors of linguistic contexts in which the words occur; these different styles are studied in (Lavelli et al., 2004).[25] Roweis and Saul published in Science how to use «locally linear embedding» (LLE) to discover representations of high dimensional data structures.[26] Most new word embedding techniques after about 2005 rely on a neural network architecture instead of more probabilistic and algebraic models, since some foundational work by Yoshua Bengio and colleagues.[27][28]
The approach has been adopted by many research groups after advances around year 2010 had been made on theoretical work on the quality of vectors and the training speed of the model and hardware advances allowed for a broader parameter space to be explored profitably. In 2013, a team at Google led by Tomas Mikolov created word2vec, a word embedding toolkit that can train vector space models faster than the previous approaches. The word2vec approach has been widely used in experimentation and was instrumental in raising interest for word embeddings as a technology, moving the research strand out of specialised research into broader experimentation and eventually paving the way for practical application.[29]
Polysemy and homonymy[edit]
Historically, one of the main limitations of static word embeddings or word vector space models is that words with multiple meanings are conflated into a single representation (a single vector in the semantic space). In other words, polysemy and homonymy are not handled properly. For example, in the sentence «The club I tried yesterday was great!», it is not clear if the term club is related to the word sense of a club sandwich, baseball club, clubhouse, golf club, or any other sense that club might have. The necessity to accommodate multiple meanings per word in different vectors (multi-sense embeddings) is the motivation for several contributions in NLP to split single-sense embeddings into multi-sense ones.[30][31]
Most approaches that produce multi-sense embeddings can be divided into two main categories for their word sense representation, i.e., unsupervised and knowledge-based.[32] Based on word2vec skip-gram, Multi-Sense Skip-Gram (MSSG)[33] performs word-sense discrimination and embedding simultaneously, improving its training time, while assuming a specific number of senses for each word. In the Non-Parametric Multi-Sense Skip-Gram (NP-MSSG) this number can vary depending on each word. Combining the prior knowledge of lexical databases (e.g., WordNet, ConceptNet, BabelNet), word embeddings and word sense disambiguation, Most Suitable Sense Annotation (MSSA)[34] labels word-senses through an unsupervised and knowledge-based approach, considering a word’s context in a pre-defined sliding window. Once the words are disambiguated, they can be used in a standard word embeddings technique, so multi-sense embeddings are produced. MSSA architecture allows the disambiguation and annotation process to be performed recurrently in a self-improving manner.[35]
The use of multi-sense embeddings is known to improve performance in several NLP tasks, such as part-of-speech tagging, semantic relation identification, semantic relatedness, named entity recognition and sentiment analysis.[36][37]
As of the late 2010s, contextually-meaningful embeddings such as ELMo and BERT have been developed.[38] Unlike static word embeddings, these embeddings are at the token-level, in that each occurrence of a word has its own embedding. These embeddings better reflect the multi-sense nature of words, because occurrences of a word in similar contexts are situated in similar regions of BERT’s embedding space.[39][40]
For biological sequences: BioVectors[edit]
Word embeddings for n-grams in biological sequences (e.g. DNA, RNA, and Proteins) for bioinformatics applications have been proposed by Asgari and Mofrad.[41] Named bio-vectors (BioVec) to refer to biological sequences in general with protein-vectors (ProtVec) for proteins (amino-acid sequences) and gene-vectors (GeneVec) for gene sequences, this representation can be widely used in applications of deep learning in proteomics and genomics. The results presented by Asgari and Mofrad[41] suggest that BioVectors can characterize biological sequences in terms of biochemical and biophysical interpretations of the underlying patterns.
Game design[edit]
Word embeddings with applications in game design have been proposed by Rabii and Cook[42] as a way to discover emergent gameplay using logs of gameplay data. The process requires to transcribe actions happening during the game within a formal language and then use the resulting text to create word embeddings. The results presented by Rabii and Cook[42] suggest that the resulting vectors can capture expert knowledge about games like chess, that are not explicitly stated in the game’s rules.
Sentence embeddings[edit]
The idea has been extended to embeddings of entire sentences or even documents, e.g. in the form of the thought vectors concept. In 2015, some researchers suggested «skip-thought vectors» as a means to improve the quality of machine translation.[43] A more recent and popular approach for representing sentences is Sentence-BERT, or SentenceTransformers, which modifies pre-trained BERT with the use of siamese and triplet network structures.[44]
Software[edit]
Software for training and using word embeddings includes Tomas Mikolov’s Word2vec, Stanford University’s GloVe,[45] GN-GloVe,[46] Flair embeddings,[36] AllenNLP’s ELMo,[47] BERT,[48] fastText, Gensim,[49] Indra,[50] and Deeplearning4j. Principal Component Analysis (PCA) and T-Distributed Stochastic Neighbour Embedding (t-SNE) are both used to reduce the dimensionality of word vector spaces and visualize word embeddings and clusters.[51]
Examples of application[edit]
For instance, the fastText is also used to calculate word embeddings for text corpora in Sketch Engine that are available online.[52]
Ethical Implications[edit]
Word embeddings may contain the biases and stereotypes contained in the trained dataset, as Bolukbasi et al. points out in the 2016 paper “Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings” that a publicly available (and popular) word2vec embedding trained on Google News texts (a commonly used data corpus), which consists of text written by professional journalists, still shows disproportionate word associations reflecting gender and racial biases when extracting word analogies (Bolukbasi et al. 2016). For example, one of the analogies generated using the aforementioned word embedding is “man is to computer programmer as woman is to homemaker”.[53]
The applications of these trained word embeddings without careful oversight likely perpetuates existing bias in society, which is introduced through unaltered training data. Furthermore, word embeddings can even amplify these biases (Zhao et al. 2017).[54] Given word embeddings popular usage in NLP applications such as search ranking, CV parsing and recommendation systems, the biases that exist in pre-trained word embeddings may have further reaching impact than we realize.
See also[edit]
- Brown clustering
- Distributional–relational database
References[edit]
- ^ Jurafsky, Daniel; H. James, Martin (2000). Speech and language processing : an introduction to natural language processing, computational linguistics, and speech recognition. Upper Saddle River, N.J.: Prentice Hall. ISBN 978-0-13-095069-7.
- ^ Mikolov, Tomas; Sutskever, Ilya; Chen, Kai; Corrado, Greg; Dean, Jeffrey (2013). «Distributed Representations of Words and Phrases and their Compositionality». arXiv:1310.4546 [cs.CL].
- ^ Lebret, Rémi; Collobert, Ronan (2013). «Word Emdeddings through Hellinger PCA». Conference of the European Chapter of the Association for Computational Linguistics (EACL). Vol. 2014. arXiv:1312.5542.
- ^ Levy, Omer; Goldberg, Yoav (2014). Neural Word Embedding as Implicit Matrix Factorization (PDF). NIPS.
- ^ Li, Yitan; Xu, Linli (2015). Word Embedding Revisited: A New Representation Learning and Explicit Matrix Factorization Perspective (PDF). Int’l J. Conf. on Artificial Intelligence (IJCAI).
- ^ Globerson, Amir (2007). «Euclidean Embedding of Co-occurrence Data» (PDF). Journal of Machine Learning Research.
- ^ Qureshi, M. Atif; Greene, Derek (2018-06-04). «EVE: explainable vector based embedding technique using Wikipedia». Journal of Intelligent Information Systems. 53: 137–165. arXiv:1702.06891. doi:10.1007/s10844-018-0511-x. ISSN 0925-9902. S2CID 10656055.
- ^ Levy, Omer; Goldberg, Yoav (2014). Linguistic Regularities in Sparse and Explicit Word Representations (PDF). CoNLL. pp. 171–180.
- ^ Socher, Richard; Bauer, John; Manning, Christopher; Ng, Andrew (2013). Parsing with compositional vector grammars (PDF). Proc. ACL Conf.
- ^ Socher, Richard; Perelygin, Alex; Wu, Jean; Chuang, Jason; Manning, Chris; Ng, Andrew; Potts, Chris (2013). Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank (PDF). EMNLP.
- ^ Sahlgren, Magnus. «A brief history of word embeddings».
- ^ Firth, J.R. (1957). «A synopsis of linguistic theory 1930–1955». Studies in Linguistic Analysis: 1–32. Reprinted in F.R. Palmer, ed. (1968). Selected Papers of J.R. Firth 1952–1959. London: Longman.
- ^ }Luhn, H.P. (1953). «A New Method of Recording and Searching Information». American Documentation. 4: 14–16. doi:10.1002/asi.5090040104.
- ^ Osgood, C.E.; Suci, G.J.; Tannenbaum, P.H. (1957). The Measurement of Meaning. University of Illinois Press.
- ^ Salton, Gerard (1962). «Some experiments in the generation of word and document associations». Proceeding AFIPS ’62 (Fall) Proceedings of the December 4–6, 1962, Fall Joint Computer Conference. AFIPS ’62 (Fall): 234–250. doi:10.1145/1461518.1461544. ISBN 9781450378796. S2CID 9937095.
- ^ Salton, Gerard; Wong, A; Yang, C S (1975). «A Vector Space Model for Automatic Indexing». Communications of the Association for Computing Machinery (CACM). 18 (11): 613–620. doi:10.1145/361219.361220. hdl:1813/6057. S2CID 6473756.
- ^ Dubin, David (2004). «The most influential paper Gerard Salton never wrote». Retrieved 18 October 2020.
- ^ Kanerva, Pentti, Kristoferson, Jan and Holst, Anders (2000): Random Indexing of Text Samples for Latent Semantic Analysis, Proceedings of the 22nd Annual Conference of the Cognitive Science Society, p. 1036. Mahwah, New Jersey: Erlbaum, 2000.
- ^ Karlgren, Jussi; Sahlgren, Magnus (2001). Uesaka, Yoshinori; Kanerva, Pentti; Asoh, Hideki (eds.). «From words to understanding». Foundations of Real-World Intelligence. CSLI Publications: 294–308.
- ^ Sahlgren, Magnus (2005) An Introduction to Random Indexing, Proceedings of the Methods and Applications of Semantic Indexing Workshop at the 7th International Conference on Terminology and Knowledge Engineering, TKE 2005, August 16, Copenhagen, Denmark
- ^ Sahlgren, Magnus, Holst, Anders and Pentti Kanerva (2008) Permutations as a Means to Encode Order in Word Space, In Proceedings of the 30th Annual Conference of the Cognitive Science Society: 1300–1305.
- ^ Bengio, Yoshua; Ducharme, Réjean; Vincent, Pascal; Jauvin, Christian (2003). «A Neural Probabilistic Language Model» (PDF). Journal of Machine Learning Research. 3: 1137–1155.
- ^ Bengio, Yoshua; Schwenk, Holger; Senécal, Jean-Sébastien; Morin, Fréderic; Gauvain, Jean-Luc (2006). A Neural Probabilistic Language Model. Studies in Fuzziness and Soft Computing. Vol. 194. pp. 137–186. doi:10.1007/3-540-33486-6_6. ISBN 978-3-540-30609-2.
- ^ Vinkourov, Alexei; Cristianini, Nello; Shawe-Taylor, John (2002). Inferring a semantic representation of text via cross-language correlation analysis (PDF). Advances in Neural Information Processing Systems. Vol. 15.
- ^ Lavelli, Alberto; Sebastiani, Fabrizio; Zanoli, Roberto (2004). Distributional term representations: an experimental comparison. 13th ACM International Conference on Information and Knowledge Management. pp. 615–624. doi:10.1145/1031171.1031284.
- ^ Roweis, Sam T.; Saul, Lawrence K. (2000). «Nonlinear Dimensionality Reduction by Locally Linear Embedding». Science. 290 (5500): 2323–6. Bibcode:2000Sci…290.2323R. CiteSeerX 10.1.1.111.3313. doi:10.1126/science.290.5500.2323. PMID 11125150. S2CID 5987139.
- ^ Morin, Fredric; Bengio, Yoshua (2005). «Hierarchical probabilistic neural network language model» (PDF). In Cowell, Robert G.; Ghahramani, Zoubin (eds.). Proceedings of the Tenth International Workshop on Artificial Intelligence and Statistics. Proceedings of Machine Learning Research. Vol. R5. pp. 246–252.
- ^ Mnih, Andriy; Hinton, Geoffrey (2009). «A Scalable Hierarchical Distributed Language Model». Advances in Neural Information Processing Systems. Curran Associates, Inc. 21 (NIPS 2008): 1081–1088.
- ^ «word2vec». Google Code Archive. Retrieved 23 July 2021.
- ^ Reisinger, Joseph; Mooney, Raymond J. (2010). Multi-Prototype Vector-Space Models of Word Meaning. Vol. Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics. Los Angeles, California: Association for Computational Linguistics. pp. 109–117. ISBN 978-1-932432-65-7. Retrieved October 25, 2019.
- ^ Huang, Eric. (2012). Improving word representations via global context and multiple word prototypes. OCLC 857900050.
- ^ Camacho-Collados, Jose; Pilehvar, Mohammad Taher (2018). «From Word to Sense Embeddings: A Survey on Vector Representations of Meaning». arXiv:1805.04032 [cs.CL].
- ^ Neelakantan, Arvind; Shankar, Jeevan; Passos, Alexandre; McCallum, Andrew (2014). «Efficient Non-parametric Estimation of Multiple Embeddings per Word in Vector Space». Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). Stroudsburg, PA, USA: Association for Computational Linguistics: 1059–1069. arXiv:1504.06654. doi:10.3115/v1/d14-1113. S2CID 15251438.
- ^ Ruas, Terry; Grosky, William; Aizawa, Akiko (2019-12-01). «Multi-sense embeddings through a word sense disambiguation process». Expert Systems with Applications. 136: 288–303. arXiv:2101.08700. doi:10.1016/j.eswa.2019.06.026. hdl:2027.42/145475. ISSN 0957-4174. S2CID 52225306.
- ^ Agre, Gennady; Petrov, Daniel; Keskinova, Simona (2019-03-01). «Word Sense Disambiguation Studio: A Flexible System for WSD Feature Extraction». Information. 10 (3): 97. doi:10.3390/info10030097. ISSN 2078-2489.
- ^ a b Akbik, Alan; Blythe, Duncan; Vollgraf, Roland (2018). «Contextual String Embeddings for Sequence Labeling». Proceedings of the 27th International Conference on Computational Linguistics. Santa Fe, New Mexico, USA: Association for Computational Linguistics: 1638–1649.
- ^ Li, Jiwei; Jurafsky, Dan (2015). «Do Multi-Sense Embeddings Improve Natural Language Understanding?». Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA, USA: Association for Computational Linguistics: 1722–1732. arXiv:1506.01070. doi:10.18653/v1/d15-1200. S2CID 6222768.
- ^ Devlin, Jacob; Chang, Ming-Wei; Lee, Kenton; Toutanova, Kristina (June 2019). «BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding». Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Association for Computational Linguistics: 4171–4186. doi:10.18653/v1/N19-1423. S2CID 52967399.
- ^ Lucy, Li, and David Bamman. «Characterizing English variation across social media communities with BERT.» Transactions of the Association for Computational Linguistics 9 (2021): 538-556.
- ^ Reif, Emily, Ann Yuan, Martin Wattenberg, Fernanda B. Viegas, Andy Coenen, Adam Pearce, and Been Kim. «Visualizing and measuring the geometry of BERT.» Advances in Neural Information Processing Systems 32 (2019).
- ^ a b Asgari, Ehsaneddin; Mofrad, Mohammad R.K. (2015). «Continuous Distributed Representation of Biological Sequences for Deep Proteomics and Genomics». PLOS ONE. 10 (11): e0141287. arXiv:1503.05140. Bibcode:2015PLoSO..1041287A. doi:10.1371/journal.pone.0141287. PMC 4640716. PMID 26555596.
- ^ a b Rabii, Younès; Cook, Michael (2021-10-04). «Revealing Game Dynamics via Word Embeddings of Gameplay Data». Proceedings of the AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment. 17 (1): 187–194. doi:10.1609/aiide.v17i1.18907. ISSN 2334-0924. S2CID 248175634.
- ^ Kiros, Ryan; Zhu, Yukun; Salakhutdinov, Ruslan; Zemel, Richard S.; Torralba, Antonio; Urtasun, Raquel; Fidler, Sanja (2015). «skip-thought vectors». arXiv:1506.06726 [cs.CL].
- ^ Reimers, Nils, and Iryna Gurevych. «Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks.» In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 3982-3992. 2019.
- ^ «GloVe».
- ^ Zhao, Jieyu; et al. (2018) (2018). «Learning Gender-Neutral Word Embeddings». arXiv:1809.01496 [cs.CL].
- ^ «Elmo».
- ^ Pires, Telmo; Schlinger, Eva; Garrette, Dan (2019-06-04). «How multilingual is Multilingual BERT?». arXiv:1906.01502 [cs.CL].
- ^ «Gensim».
- ^ «Indra». GitHub. 2018-10-25.
- ^ Ghassemi, Mohammad; Mark, Roger; Nemati, Shamim (2015). «A Visualization of Evolving Clinical Sentiment Using Vector Representations of Clinical Notes» (PDF). Computing in Cardiology. 2015: 629–632. doi:10.1109/CIC.2015.7410989. ISBN 978-1-5090-0685-4. PMC 5070922. PMID 27774487.
- ^ «Embedding Viewer». Embedding Viewer. Lexical Computing. Retrieved 7 Feb 2018.
- ^ Bolukbasi, Tolga; Chang, Kai-Wei; Zou, James; Saligrama, Venkatesh; Kalai, Adam (2016-07-21). «Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings». arXiv:1607.06520 [cs.CL].
- ^ Petreski, Davor; Hashim, Ibrahim C. (2022-05-26). «Word embeddings are biased. But whose bias are they reflecting?». AI & Society. doi:10.1007/s00146-022-01443-w. ISSN 1435-5655. S2CID 249112516.
Векторное представление слов (англ. word embedding) — общее название для различных подходов к моделированию языка и обучению представлений в обработке естественного языка, направленных на сопоставление словам из некоторого словаря векторов небольшой размерности.
Содержание
- 1 One-hot encoding
- 2 word2vec
- 3 fastText
- 4 Примеры кода с использованием библиотеки Gensim
- 4.1 Загрузка предобученной модели русского корпуса
- 4.2 Обучение модели word2vec и fastText на текстовом корпусе
- 5 ELMO
- 6 BERT
- 7 См. также
- 8 Источники информации
One-hot encoding
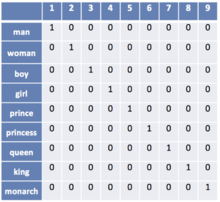
Рисунок 1. Пример one-hot encoding для словаря из 9 слов. Источник
Пусть число различных слов равно . Сопоставим слову с номером вектор длины , в котором -тая координата равна единице, а все остальные — нулям (рис. 1). Недостатком one-hot encoding является то, что по векторным представлениям нельзя судить о схожести смысла слов. Также вектора имеют очень большой размер, из-за чего их неэффективно хранить в памяти.
word2vec
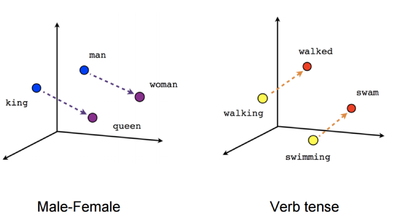
Рисунок 2. Полученные векторы-слова отражают различные грамматические и семантические концепции.
word2vec — способ построения сжатого пространства векторов слов, использующий нейронные сети. Принимает на вход большой текстовый корпус и сопоставляет каждому слову вектор. Сначала он создает словарь, а затем вычисляет векторное представление слов. Векторное представление основывается на контекстной близости: слова, встречающиеся в тексте рядом с одинаковыми словами (а следовательно, имеющие схожий смысл) (рис. 2), в векторном представлении имеют высокое косинусное сходство (англ. cosine similarity):
В word2vec существуют две основных модели обучения: Skip-gram (рис. 3) и CBOW (англ. Continuous Bag of Words) (рис. 4). В модели Skip-gram по слову предсказываются слова из его контекста, а в модели CBOW по контексту подбирается наиболее вероятное слово. На выходном слое используется функция или его вариация, чтобы получить на выходе распределение вероятности каждого слова. В обеих моделях входные и выходные слова подаются в one-hot encoding, благодаря чему при умножении на матрицу , соединяющую входной и скрытый слои, происходит выбор одной строки . Размерность является гиперпараметром алгоритма, а обученная матрица — выходом, так как ее строки содержат векторные представления слов.
Для ускорения обучения моделей Skip-gram и CBOW используются модификации , такие как иерархический и negative sampling, позволяющие вычислять распределение вероятностей быстрее, чем за линейное время от размера словаря.
fastText
Недостатком word2vec является то, что с его помощью не могут быть представлены слова, не встречающиеся в обучающей выборке. fastText решает эту проблему с помощью -грамм символов. Например, -граммами для слова яблоко являются ябл, бло, лок, око. Модель fastText строит векторные представления -грамм, а векторным представлением слова является сумма векторных представлений всех его -грамм. Части слов с большой вероятностью встречаются и в других словах, что позволяет выдавать векторные представления и для редких слов.
Примеры кода с использованием библиотеки Gensim
Загрузка предобученной модели русского корпуса
import gensim import gensim.downloader as download_api russian_model = download_api.load('word2vec-ruscorpora-300')
# Выведем первые 10 слов корпуса.
# В модели "word2vec-ruscorpora-300" после слова указывается часть речи: NOUN (существительное), ADJ (прилагательное) и так далее.
# Но существуют также предоубученные модели без разделения слов по частям речи, смотри репозиторий list(russian_model.vocab.keys())[:10] # ['весь_DET', 'человек_NOUN', 'мочь_VERB', 'год_NOUN', 'сказать_VERB', 'время_NOUN', 'говорить_VERB', 'становиться_VERB', 'знать_VERB', 'самый_DET']
# Поиск наиболее близких по смыслу слов. russian_model.most_similar('кошка_NOUN') # [('кот_NOUN', 0.7570087909698486), ('котенок_NOUN', 0.7261239290237427), ('собака_NOUN', 0.6963180303573608), # ('мяукать_VERB', 0.6411399841308594), ('крыса_NOUN', 0.6355636119842529), ('собачка_NOUN', 0.6092042922973633), # ('щенок_NOUN', 0.6028496026992798), ('мышь_NOUN', 0.5975362062454224), ('пес_NOUN', 0.5956044793128967), # ('кошечка_NOUN', 0.5920293927192688)]
# Вычисление сходства слов russian_model.similarity('мужчина_NOUN', 'женщина_NOUN') # 0.85228276
# Поиск лишнего слова russian_model.doesnt_match('завтрак_NOUN хлопья_NOUN обед_NOUN ужин_NOUN'.split()) # хлопья_NOUN
# Аналогия: Женщина + (Король - Мужчина) = Королева russian_model.most_similar(positive=['король_NOUN','женщина_NOUN'], negative=['мужчина_NOUN'], topn=1) # [('королева_NOUN', 0.7313904762268066)]
# Аналогия: Франция = Париж + (Германия - Берлин) russian_model.most_similar(positive=['париж_NOUN','германия_NOUN'], negative=['берлин_NOUN'], topn=1) # [('франция_NOUN', 0.8673800230026245)]
Обучение модели word2vec и fastText на текстовом корпусе
from gensim.models.word2vec import Word2Vec from gensim.models.fasttext import FastText import gensim.downloader as download_api
# Скачаем небольшой текстовый корпус (32 Мб) и откроем его как итерируемый набор предложений: iterable(list(string)) # В этом текстовом корпусе часть речи для слов не указывается corpus = download_api.load('text8')
# Обучим модели word2vec и fastText word2vec_model = Word2Vec(corpus, size=100, workers=4) fastText_model = FastText(corpus, size=100, workers=4)
word2vec_model.most_similar('car')[:3] # [('driver', 0.8033335208892822), ('motorcycle', 0.7368553876876831), ('cars', 0.7001584768295288)]
fastText_model.most_similar('car')[:3] # [('lcar', 0.8733218908309937), ('boxcar', 0.8559106588363647), ('ccar', 0.8268736004829407)]
ELMO
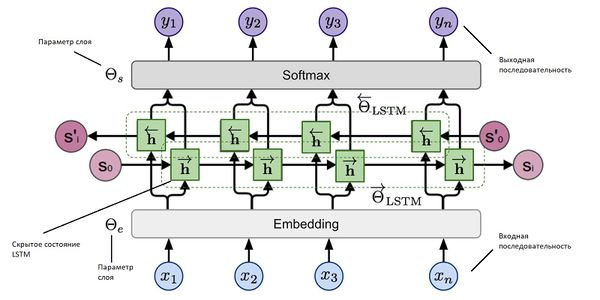
ELMO — это многослойная двунаправленная рекуррентная нейронная сеть c LSTM (рис. 5).
При использовании word2vec или fastText не учитывается семантическая неоднозначность слов.
Так, word2vec назначает слову один вектор независимо от контекста.
ELMO решает эту проблему. В основе стоит идея использовать скрытые состояния языковой модели многослойной LSTM.
Было замечено, что нижние слои сети отвечают за синтаксис и грамматику, а верхние — за смысл слов.
Пусть даны токены , на которые поделено предложение. Будем считать логарифм правдоподобия метки слова в обоих направлениях, учитывая контекст слева и контекст справа, то есть на основании данных от начала строки до текущего символа и данных от текущего символа и до конца строки.
Таким образом, модель предсказывает вероятность следующего токена с учетом истории.
Пусть есть слоев сети. Входные и выходные данные будем представлять в виде векторов, кодируя слова. Тогда каждый результирующий вектор будем считать на основании множества:
.
Здесь — входящий токен, а и — скрытые слои в одном и в другом направлении.
Тогда результат работы ELMO будет представлять из себя выражение:
.
Обучаемый общий масштабирующий коэффициент регулирует то, как могут отличаться друг от друга по норме векторные представления слов.
Коэффициенты — это обучаемые параметры, нормализованные функцией .
Модель применяют дообучая ее: изначально берут предобученную ELMO, а затем корректируют и под конкретную задачу. Тогда вектор, который подается в используемую модель для обучения, будет представлять собой взвешенную сумму значений этого векторах на всех скрытых слоях ELMO.
На данный момент предобученную модель ELMO можно загрузить и использовать в языке программирования Python.
BERT
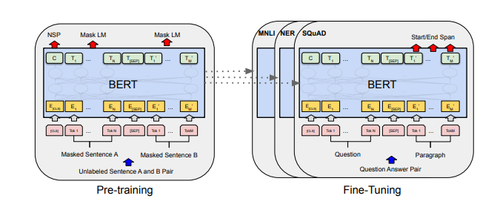
BERT — это многослойный двунаправленный кодировщик Transformer. В данной архитектуре (рис. 6) используется двунаправленное самовнимание (англ. self-attention).
Модель используется в совокупности с некоторым классификатором, на вход которого подается результат работы BERT — векторное представление входных данных.
В основе обучения модели лежат две идеи.
Первая заключается в том, чтобы заменить слов масками и обучить сеть предсказывать эти слова.
Второй трюк состоит в том, чтобы дополнительно научить BERT определять, может ли одно предложение идти после другого.
Точно так же, как и в обычном трансформере, BERT принимает на вход последовательность слов, которая затем продвигается вверх по стеку энкодеров.
Каждый слой энкодера применяет самовнимание и передает результаты в сеть прямого распространения, после чего направляет его следующему энкодеру.
Для каждой позиции на выход подается вектор размерностью ( в базовой модели).
Этот вектор может быть использован как входной вектор для классификатора.
Bert поддерживается в качестве модели в языке Python, которую можно загрузить.
См. также
- Обработка естественного языка
Источники информации
- Word embedding — статья о векторных представлениях в английской Википедии
- (YouTube) Обработка естественного языка — лекция на русском Даниила Полыковского в курсе Техносферы
- (YouTube) Word Vector Representations: word2vec — лекция на английском в Стэнфордском Университете
- word2vec article — оригинальная статья по word2vec от Томаса Миколова
- word2vec code — исходный код word2vec на Google Code
- Gensim tutorial on word2vec — небольшое руководство по работе с word2vec в библиотеке Gensim
- Gensim documentation on fastText — документация по fastText в библиотеке Gensim
- Gensim Datasets — репозиторий предобученных моделей для библиотеки Gensim
- fastText — NLP библиотека от Facebook
- fastText article — оригинальная статья по fastText от Piotr Bojanowski
- RusVectōrēs — онлайн сервис для работы с семантическими отношениями русского языка
- Cornell univerity arxiv — оригинальная статья про Bert
- Cornell univerity arxiv — оригинальная статья с описанием ELMO
Что такое вложение слов для текста?
Перевод
Ссылка на автора
Вложения слов — это тип представления слов, который позволяет словам с одинаковым значением иметь одинаковое представление.
Они представляют собой распределенное представление текста, которое, возможно, является одним из ключевых достижений для впечатляющей эффективности методов глубокого обучения в решении проблем обработки естественного языка.
В этом посте вы познакомитесь с подходом встраивания слов для представления текстовых данных.
Прочитав этот пост, вы узнаете:
- Что такое подход встраивания слов для представления текста и чем он отличается от других методов извлечения признаков.
- Что есть 3 основных алгоритма для изучения встраивания слова из текстовых данных.
- Что вы можете либо обучить новому встраиванию, либо использовать предварительно обученное встраивание в своей задаче обработки естественного языка.
Давайте начнем.

обзор
Этот пост разделен на 3 части; они есть:
- Что такое вложение слов?
- Алгоритмы встраивания слов
- Использование вложения Word
Что такое вложение слов?
Вложение слова — это заученное представление для текста, где слова, имеющие одинаковое значение, имеют похожее представление.
Именно такой подход к представлению слов и документов можно считать одним из ключевых достижений глубокого изучения сложных проблем обработки естественного языка.
Одним из преимуществ использования плотных и низкоразмерных векторов является вычислительный: большинство наборов инструментов нейронной сети не очень хорошо работают с очень многомерными разреженными векторами. … Основным преимуществом плотных представлений является способность к обобщению: если мы считаем, что некоторые функции могут предоставлять аналогичные ключи, то стоит предоставить представление, способное уловить эти сходства.
— страница 92, Методы нейронной сети в обработке естественного языка, 2017
Вложения слов на самом деле представляют собой класс методов, в которых отдельные слова представлены в виде вещественных векторов в предопределенном векторном пространстве. Каждое слово сопоставляется с одним вектором, и значения вектора изучаются способом, который напоминает нейронную сеть, и, следовательно, техника часто сводится в область глубокого обучения.
Ключом к подходу является идея использования плотного распределенного представления для каждого слова.
Каждое слово представлено действительным вектором, часто десятками или сотнями измерений. Это противопоставлено тысячам или миллионам измерений, необходимых для разреженных представлений слов, таких как однократное кодирование.
ассоциировать с каждым словом в словаре вектор признаков распределенного слова… Вектор признаков представляет различные аспекты слова: каждое слово связано с точкой в векторном пространстве. Количество функций … намного меньше, чем размер словарного запаса
— Нейро-вероятностная языковая модель, 2003.
Распределенное представление изучается на основе использования слов. Это позволяет словам, которые используются подобным образом, приводить к тому, что они имеют сходные представления, естественно отражая их значение. Это может быть противопоставлено четкому, но хрупкому представлению в модели мешка слов, где, если не указано иное, разные слова имеют разные представления, независимо от того, как они используются.
За этим подходом лежит более глубокая лингвистическая теория, а именно:гипотеза распределения”Zellig Harris, который можно обобщить так: слова, имеющие одинаковый контекст, будут иметь сходные значения. Более подробно см. Статью Харриса 1956 года « Распределительная структура «.
Это понятие, позволяющее использовать слово для определения его значения, может быть обобщено часто повторяемым замечанием Джона Фёрта:
Вы узнаете слово от компании, которую оно хранит!
— Страница 11, « Краткий обзор лингвистической теории 1930-1955 гг. «В исследованиях по лингвистическому анализу 1930-1955, 1962.
Алгоритмы встраивания слов
Методы встраивания слов изучают реальное векторное представление для предопределенного словаря фиксированного размера из совокупности текста.
Процесс обучения либо связан с моделью нейронной сети для выполнения какой-либо задачи, такой как классификация документов, либо является процессом без надзора, использующим статистику документов.
В этом разделе рассматриваются три метода, которые можно использовать для изучения встраивания слов из текстовых данных.
1. Встраивание слоя
Слой внедрения, из-за отсутствия лучшего имени, — это вложение слова, которое изучается совместно с моделью нейронной сети для конкретной задачи обработки естественного языка, такой как моделирование языка или классификация документов.
Требуется, чтобы текст документа был очищен и подготовлен таким образом, чтобы каждое слово кодировалось в горячем виде. Размер векторного пространства указывается как часть модели, например, 50, 100 или 300 измерений. Векторы инициализируются небольшими случайными числами. Слой встраивания используется на внешнем интерфейсе нейронной сети и устанавливается под наблюдением с использованием алгоритма обратного распространения
… Когда вход в нейронную сеть содержит символьные категориальные признаки (например, признаки, которые принимают один из k различных символов, таких как слова из закрытого словаря), обычно ассоциируется каждое возможное значение свойства (то есть каждое слово в словаре) с d-мерным вектором для некоторого d. Эти векторы затем считаются параметрами модели и обучаются совместно с другими параметрами.
— Страница 49, Методы нейронной сети в обработке естественного языка, 2017
Закодированные одним словом слова отображаются на векторы слов. Если используется многослойная модель Perceptron, то векторы слов объединяются перед подачей в качестве входных данных в модель. Если используется рекуррентная нейронная сеть, то каждое слово может быть взято как один вход в последовательности.
Этот подход к изучению уровня внедрения требует большого количества обучающих данных и может быть медленным, но он изучит встраивание как для конкретных текстовых данных, так и для задачи НЛП.
2. Word2Vec
Word2Vec — это статистический метод для эффективного обучения встраиванию отдельных слов из текстового корпуса.
Он был разработан Томасом Миколовым и соавт. в Google в 2013 году в ответ на повышение эффективности обучения встраиванию на основе нейронных сетей, которое с тех пор стало стандартом де-факто для разработки предварительно обученного встраивания слов.
Кроме того, работа включала анализ изученных векторов и исследование векторной математики на представлениях слов. Например, что вычитаяЧеловек-Несс» от «корольИ добавив «женщины-Несс«Приводит к слову«Королева«Захватив аналогию»король королеве как мужчина женщине«.
Мы находим, что эти представления удивительно хороши для захвата синтаксических и семантических закономерностей в языке, и что каждое отношение характеризуется зависимым от отношения векторным смещением. Это позволяет ориентироваться на вектор, основываясь на смещениях между словами. Например, отношения между мужчиной и женщиной выучиваются автоматически, и с помощью индуцированных представлений вектора «король — мужчина + женщина» получается вектор, очень близкий к «королеве».
— Лингвистические закономерности в представлении слов в непрерывном пространстве, 2013.
Были введены две разные модели обучения, которые можно использовать как часть подхода word2vec для изучения встраивания слова; они есть:
- Непрерывный Bag-of-Words или модель CBOW.
- Непрерывная модель скип-грамма.
Модель CBOW изучает вложение, предсказывая текущее слово на основе его контекста. Непрерывная модель скип-граммы учится, предсказывая окружающие слова по текущему слову.
Непрерывная модель скип-граммы учится, предсказывая окружающие слова по текущему слову.

Обе модели ориентированы на изучение слов с учетом их локального контекста использования, где контекст определяется окном соседних слов. Это окно является настраиваемым параметром модели.
Размер скользящего окна сильно влияет на результирующее векторное сходство. Большие окна имеют тенденцию создавать больше актуальных сходств […], в то время как меньшие окна имеют тенденцию создавать больше функциональных и синтаксических сходств.
— страница 128, Методы нейронной сети в обработке естественного языка, 2017
Основное преимущество этого подхода заключается в том, что высококачественные вложения слов могут быть эффективно изучены (малое пространство и временная сложность), что позволяет изучать более крупные вложения (большее количество измерений) из гораздо больших массивов текста (миллиарды слов).
3. Перчатка
Алгоритм глобальных векторов для представления слов, или GloVe, является расширением метода word2vec для эффективного изучения векторов слов, разработанного Pennington, et al. в Стэнфорде.
Классические представления моделей в векторном пространстве слов были разработаны с использованием методов матричной факторизации, таких как латентный семантический анализ (LSA), которые хорошо справляются с использованием глобальной текстовой статистики, но не так хороши, как изученные методы, такие как word2vec, для захвата значения и демонстрации его в задачах. как вычисление аналогий (например, пример короля и королевы выше).
GloVe — это подход, объединяющий глобальную статистику методов матричной факторизации, таких как LSA, с локальным контекстным обучением в word2vec.
Вместо того, чтобы использовать окно для определения локального контекста, GloVe создает явный словосочетание контекста или матрицы совпадений слов, используя статистику по всему текстовому корпусу. В результате получается модель обучения, которая может привести к улучшению вложения слов.
GloVe — это новая глобальная лог-билинейная регрессионная модель для неконтролируемого обучения представлений слов, которая превосходит другие модели по аналогии слов, сходству слов и задачам распознавания именованных сущностей.
— GloVe: глобальные векторы для представления слов 2014
Использование вложения Word
У вас есть несколько вариантов, когда приходит время использовать вложения слов в вашем проекте обработки естественного языка.
В этом разделе описываются эти варианты.
1 Изучите вложение
Вы можете выбрать вложение слова для вашей проблемы.
Это потребует большого количества текстовых данных, чтобы обеспечить изучение полезных вложений, таких как миллионы или миллиарды слов.
При обучении встраиванию слов у вас есть два основных варианта:
- Учись автономногде модель обучается изучению встраивания, которое сохраняется и используется как часть другой модели для вашей задачи позже. Это хороший подход, если вы хотите использовать одно и то же вложение в нескольких моделях.
- Учимся вместегде встраивание изучается как часть большой модели конкретной задачи. Это хороший подход, если вы собираетесь использовать вложение только для одной задачи.
2. Повторное использование вложения
Исследователи часто предоставляют предварительно подготовленные вложения слов бесплатно, часто по разрешающей лицензии, чтобы вы могли использовать их в своих собственных академических или коммерческих проектах.
Например, вложения слов word2vec и GloVe доступны для бесплатной загрузки.
Они могут быть использованы в вашем проекте вместо обучения ваших собственных встраиваний с нуля.
У вас есть два основных варианта использования предварительно обученных вложений:
- статическийгде вложение сохраняется статичным и используется как компонент вашей модели. Это подходящий подход, если вложение хорошо подходит для вашей задачи и дает хорошие результаты.
- обновленныйгде предварительно обученное вложение используется для заполнения модели, но вложение обновляется совместно во время обучения модели. Это может быть хорошим вариантом, если вы хотите получить максимальную отдачу от модели и встраивать в свою задачу.
Какой вариант вы должны использовать?
Изучите различные варианты и, если возможно, проверьте, какие из них дают наилучшие результаты по вашей проблеме.
Возможно, начните с быстрых методов, таких как использование предварительно обученного встраивания, и используйте новое вложение только в том случае, если это приведет к повышению производительности вашей проблемы.
Дальнейшее чтение
Этот раздел предоставляет больше ресурсов по этой теме, если вы хотите углубиться.
статьи
- Встраивание слов в Википедии
- Word2vec в Википедии
- GloVe в Википедии
- Обзор вложений в слова и их связи с семантическими моделями распределения, 2016
- Deep Learning, NLP и представительства 2014
документы
- Распределительная структура 1956 г.
- Нейро-вероятностная языковая модель, 2003.
- Единая архитектура для обработки естественного языка: глубокие нейронные сети с многозадачным обучением, 2008.
- Модели языка непрерывного пространства, 2007.
- Эффективная оценка словесных представлений в векторном пространстве, 2013
- Распределенные представления слов и фраз и их композиционность, 2013.
- GloVe: глобальные векторы для представления слов 2014
проектов
- word2vec в Google Code
- GloVe: глобальные векторы для представления слов
книги
- Методы нейронной сети в обработке естественного языка, 2017
Резюме
В этом посте вы обнаружили, что Word Embeddings является методом представления текста в приложениях глубокого обучения.
В частности, вы узнали:
- Что такое подход встраивания слов для представления текста и чем он отличается от других методов извлечения признаков.
- Что есть 3 основных алгоритма для изучения встраивания слова из текстовых данных.
- Таким образом, вы можете либо обучить новому встраиванию, либо использовать предварительно обученное встраивание в своей задаче обработки естественного языка.
У вас есть вопросы?
Задайте свои вопросы в комментариях ниже, и я сделаю все возможное, чтобы ответить.