
Класс Counter в Python является частью модуля Collections. Counter является подклассом Dictionary и используется для отслеживания элементов и их количества.
Counter – это неупорядоченная коллекция, в которой элементы хранятся, как ключи Dict, а их количество – как значение dict.
Количество элементов счетчика может быть положительным, нулевым или отрицательным целым числом. Однако нет никаких ограничений на его ключи и значения. Хотя значения предназначены быть числами, мы можем хранить и другие объекты.
Содержание
- Создание объекта
- Методы
- Получение количества элементов
- Установка количества элементов
- Удаление элемента из счетчика
- elements()
- most_common(n)
- subtract() и update()
- Арифметические операции
- Разные операции
Создание объекта
Мы можем создать пустой счетчик или начать с некоторых начальных значений.
from collections import Counter
# empty Counter
counter = Counter()
print(counter) # Counter()
# Counter with initial values
counter = Counter(['a', 'a', 'b'])
print(counter) # Counter({'a': 2, 'b': 1})
counter = Counter(a=2, b=3, c=1)
print(counter) # Counter({'b': 3, 'a': 2, 'c': 1})
Мы также можем использовать любой Iterable в качестве аргумента для создания объекта Counter. Таким образом, строковый литерал и список также могут использоваться для создания объекта Counter.
# Iterable as argument for Counter
counter = Counter('abc')
print(counter) # Counter({'a': 1, 'b': 1, 'c': 1})
# List as argument to Counter
words_list = ['Cat', 'Dog', 'Horse', 'Dog']
counter = Counter(words_list)
print(counter) # Counter({'Dog': 2, 'Cat': 1, 'Horse': 1})
# Dictionary as argument to Counter
word_count_dict = {'Dog': 2, 'Cat': 1, 'Horse': 1}
counter = Counter(word_count_dict)
print(counter) # Counter({'Dog': 2, 'Cat': 1, 'Horse': 1})
Как я упоминал выше, мы также можем использовать нечисловые данные для значений счетчика, но это нарушит назначение класса Counter.
# Counter works with non-numbers too
special_counter = Counter(name='Pankaj', age=20)
print(special_counter) # Counter({'name': 'Pankaj', 'age': 20})
Методы
Давайте рассмотрим методы класса Counter и некоторые другие операции, которые мы можем с ним выполнять.
Получение количества элементов
# getting count
counter = Counter({'Dog': 2, 'Cat': 1, 'Horse': 1})
countDog = counter['Dog']
print(countDog) # 2
Если мы попытаемся получить количество несуществующего ключа, он вернет 0 и не выбросит KeyError.
# getting count for non existing key, don't cause KeyError print(counter['Unicorn']) # 0
Установка количества элементов
Мы также можем установить количество существующих элементов в счетчике. Если элемент не существует, он добавляется в счетчик.
counter = Counter({'Dog': 2, 'Cat': 1, 'Horse': 1})
# setting count
counter['Horse'] = 0
print(counter) # Counter({'Dog': 2, 'Cat': 1, 'Horse': 0})
# setting count for non-existing key, adds to Counter
counter['Unicorn'] = 1
print(counter) # Counter({'Dog': 2, 'Cat': 1, 'Unicorn': 1, 'Horse': 0})
Удаление элемента из счетчика
Мы можем использовать del для удаления элемента из объекта счетчика.
# Delete element from Counter
del counter['Unicorn']
print(counter) # Counter({'Dog': 2, 'Cat': 1, 'Horse': 0})
elements()
Этот метод в Python возвращает список элементов счетчика. Возвращаются только элементы с положительным счетом.
counter = Counter({'Dog': 2, 'Cat': -1, 'Horse': 0})
# elements()
elements = counter.elements() # doesn't return elements with count 0 or less
for value in elements:
print(value)
Приведенный выше код напечатает «Собака» два раза, потому что его счетчик равен 2. Другие элементы будут проигнорированы, потому что у них нет положительного счета. Counter – это неупорядоченная коллекция, поэтому элементы возвращаются в произвольном порядке.
most_common(n)
Этот метод возвращает самые распространенные элементы из счетчика. Если мы не предоставляем значение «n», то отсортированный словарь возвращается из наиболее и наименее распространенных элементов.
Мы можем использовать нарезку, чтобы получить наименее распространенные элементы в этом отсортированном словаре.
counter = Counter({'Dog': 2, 'Cat': -1, 'Horse': 0})
# most_common()
most_common_element = counter.most_common(1)
print(most_common_element) # [('Dog', 2)]
least_common_element = counter.most_common()[:-2:-1]
print(least_common_element) # [('Cat', -1)]
subtract() и update()
Метод subtract() используется для вычитания количества элементов из другого счетчика. update() используется для добавления счетчиков из другого счетчика.
counter = Counter('ababab')
print(counter) # Counter({'a': 3, 'b': 3})
c = Counter('abc')
print(c) # Counter({'a': 1, 'b': 1, 'c': 1})
# subtract
counter.subtract(c)
print(counter) # Counter({'a': 2, 'b': 2, 'c': -1})
# update
counter.update(c)
print(counter) # Counter({'a': 3, 'b': 3, 'c': 0})
Арифметические операции
Мы также можем выполнять некоторые арифметические операции со счетчиками, как и числа. Однако с помощью этих операций возвращаются только элементы с положительным счетчиком.
# arithmetic operations
c1 = Counter(a=2, b=0, c=-1)
c2 = Counter(a=1, b=-1, c=2)
c = c1 + c2 # return items having +ve count only
print(c) # Counter({'a': 3, 'c': 1})
c = c1 - c2 # keeps only +ve count elements
print(c) # Counter({'a': 1, 'b': 1})
c = c1 c2 # intersection min(c1[x], c2[x])
print(c) # Counter({'a': 1})
c = c1 | c2 # union max(c1[x], c2[x])
print(c) # Counter({'a': 2, 'c': 2})
Разные операции
Давайте посмотрим на некоторые фрагменты кода для различных операций, которые мы можем выполнять с объектами Counter.
counter = Counter({'a': 3, 'b': 3, 'c': 0})
# miscellaneous examples
print(sum(counter.values())) # 6
print(list(counter)) # ['a', 'b', 'c']
print(set(counter)) # {'a', 'b', 'c'}
print(dict(counter)) # {'a': 3, 'b': 3, 'c': 0}
print(counter.items()) # dict_items([('a', 3), ('b', 3), ('c', 0)])
# remove 0 or negative count elements
counter = Counter(a=2, b=3, c=-1, d=0)
counter = +counter
print(counter) # Counter({'b': 3, 'a': 2})
# clear all elements
counter.clear()
print(counter) # Counter()
View the word count and other information in your document. Learn how to insert and update the word count in to the body of your document.
Show the word count
-
To see the number of words in your document, look at the status bar at the lower left bottom of the Word window.

Find word count statistics
Click on the word count in the status bar to see the number of characters, lines, and paragraphs in your document.
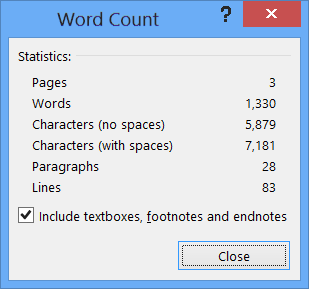
Insert the word count in your document
-
Click in your document where you want the word count to appear.
-
Click Insert > Quick Parts > Field.
-
In the Field nameslist, click NumWords, and then click OK.
-
To update the word count, right-click the number, and then choose Update Field.
Want more?
Show word count
I am working on a Word document for a school assignment, and I don’t need to write more than 1,000 words.
Luckily, Word 2013 provides a few handy word counting features that will help me keep below my word limit.
As I work on my document, I can keep an eye on my word count on the status bar, down in the lower left corner of the Word window.
If you don’t see the word count in your document, right-click anywhere on the status bar to bring up this menu, and then click Word Count.
As I type, or remove text in my document, the Word Count updates automatically.
And if I click the Word Count in the status bar, a box appears giving me even more detail, including the number of characters and the number of lines that my document contains.
I don’t want to include my document’s footnotes in my total word count, so I’ll uncheck this box.
This section of my document can’t be more than a third of the total document length. To check the length, I select the paragraphs in this section, and the status bar shows the number of words in my selected text.
It looks like I have 205 words in my selected text, out of a total of 968 words, so I am still below my target.
I want to insert the word count in my document, so my teacher can see it when I hand-in my paper.
I click in my document where I want the word count to appear.
In the ribbon, on the INSERT tab, I click Quick Parts, and then click Field.
I select NumWords in the list of Field names, and then click OK.
If I make changes to the document, the word count won’t update automatically. To update it, I’ll right-click the Word Count, and choose Update Field.
To make sure that the latest word count appears when I print my document, I click FILE and then Options.
In the left panel, I click Display, and then under Printing options, I select Update fields before printing.
For more information about word counts, see the course summary.
Задача состояла в том, чтобы написать функцию с именем count_letter, которая берет список слов и определенную букву и возвращает количество слов, в которых эта буква встречается хотя бы один раз. И мы должны использовать цикл for. Итак, я составил список некоторых языков программирования и букву «а» и попытался применить все, что мы узнали до сих пор, а также несколько руководств в Интернете, чтобы понять, как перевести человеческую логику в строки кода, но, очевидно, я что-то упускаю, потому что это не так. не работает  Вот как мой код выглядит на данный момент:
Вот как мой код выглядит на данный момент:
mylist = ['fortran', 'basic', 'java', 'python', 'c++']
letter = 'a'
a_list = []
def count_letter(mylist):
count = 0
for i in range(len(mylist)):
if letter in i:
count += 1
a_list.append(i)
return a_list
print(len(a_list))
Результат — нет результата. Компилятор онлайн-python возвращает ответ ** Процесс завершен — код возврата: 0 ** Мой вопрос: что я мог пропустить или неправильно расположить, что цикл не работает. Я хочу понять это для себя. В учебниках я нашел одну конструкцию, которая возвращает правильный ответ (и выглядит очень элегантно и компактно), но у нее нет никакой функции, поэтому это не совсем то, что нам нужно было написать:
mylist = ['fortran', 'basic', 'java', 'python', 'c++']
letter = 'a'
res = len ([ele for ele in mylist if letter in ele])
print ('Amount of words containing a: ' +str(res))
Здесь ответ системы: 3 , как и ожидалось.
Скажите, пожалуйста, что я должен проверить в коде № 1.
4 ответа
Несколько ошибок, которые я нашел в вашем коде:
-
Когда вы выполняете for i in range(len(mylist)), вы фактически перебираете числа 1,2,… вместо элементов mylist. Таким образом, вы должны использовать «for i in mylist» для перебора элементов массива mylist.
-
Когда вы возвращаетесь из функции, код после возврата не выполняется. Поэтому вы должны сначала напечатать его, а затем вернуться из функции.
-
Не забудьте вызвать функцию. В противном случае функция не будет выполнена.
-
Нет необходимости использовать переменную count, так как вы можете получить доступ к длине, используя метод len.
mylist = ['fortran', 'basic', 'java', 'python', 'c++']
letter = 'a'
a_list = []
def count_letter(mylist):
for i in mylist:
if letter in i:
a_list.append(i)
print(len(a_list))
return a_list
print(count_letter(mylist))
Всего наилучшего в вашем путешествии!
1
Muhammed Jaseem
8 Май 2021 в 23:39
Лично я нахожу исходный код Python более легким для чтения, когда он разделен на четыре пробела. Итак, вот ваша функция снова с более широким отступом:
def count_letter(mylist):
count = 0
for i in range(len(mylist)):
if letter in i:
count += 1
a_list.append(i)
return a_list
print(len(a_list))
for i in range(...) будет перебирать набор целых чисел. Таким образом, i будет принимать новое целочисленное значение для каждой итерации цикла. Сначала i будет 0, затем 1 на следующей итерации и так далее.
Затем вы спрашиваете if letter in i:. Это никогда не может быть правдой. letter — это строка, а i — целое число. Строка никогда не может быть «внутри» целого числа, поэтому этот оператор if никогда не будет выполняться. Скорее, вы хотите проверить, находится ли letter в текущем слове (i-е слово в списке). Оператор if должен читать:
if letter in mylist[i]:
...
Где mylist[i] — текущее слово.
Затем вы увеличиваете count и добавляете i к a_list. Вероятно, вы хотели добавить mylist[i] к a_list, но я не понимаю, зачем вам вообще нужно a_list. Вам просто нужно count, так как это отслеживает, сколько слов вы встретили до сих пор, для которых условие истинно. count также является переменной, которую вы должны вернуть в конце, так как это цель функции: вернуть количество слов (а не самих слов), которые содержат определенную букву.
Кроме того, отступ последнего оператора print делает его частью тела функции. Однако это после return, что означает, что у него никогда не будет возможности напечатать. Когда вы используете return внутри функции, она завершает функцию, и поток выполнения возвращается к тому месту, из которого функция была первоначально вызвана.
Последнее изменение, которое необходимо применить, заключается в том, что ваша функция должна принимать букву для поиска в качестве параметра. Сейчас ваша функция принимает только один параметр — список слов, по которым нужно искать.
Вот изменения, которые я бы применил к вашему коду:
def count_letter(words, letter): # I find 'words' is a better name than 'mylist'.
count = 0
for i in range(len(words)):
current_word = words[i]
if letter in current_word:
count += 1
return count
Вот как вы можете использовать эту функцию:
words = ["hello", "world", "apple", "sauce"]
letter = "e"
count = count_letter(words, letter)
print("The letter '{}' appeared in {} words.".format(letter, count))
Выход:
The letter 'e' appeared in 3 words.
1
Paul M.
8 Май 2021 в 23:49
Я думаю, что «принимает» означает, что функция должна быть определена с двумя параметрами: words_list и letter:
def count_letter(words_list, letter):
Алгоритм на естественном языке может быть таким: дайте мне сумму слов, где буква присутствует для каждого слова в списке слов.
В Python это может быть выражено как:
def count_letter(words_list, letter):
return sum(letter in word for word in words_list)
Некоторое объяснение: letter in word возвращает логическое значение (True или False), а в Python логические значения являются подклассом целого числа (True равно 1, а False равно 0). Если буква есть в слове, результат будет 1, а если нет, то 0. Подведение итогов дает количество слов, в которых присутствует буква.
1
Aivar Paalberg
8 Май 2021 в 23:53
Я прочитал все ваши ответы, некоторые важные моменты я записал, сегодня снова сидел со своим кодом, и после еще нескольких попыток он сработал… Итак, окончательный вариант выглядит так:
words = ['fortran', 'basic', 'java', 'python', 'c++']
letter = "a"
def count_letter(words, letter):
count = 0
for word in words:
if letter in word:
count += 1
return count
print(count_letter((words),letter))
Ответ системы: 3
Что для меня пока не очевидно: правильные отступы (они тоже были частью проблемы), и дополнительная пара скобок вокруг words в строке print. Но это приходит с обучением.
Спасибо еще раз!
In this Python tutorial, we will learn about Python Count Words in File. Here we assume the file as a simple Text file (.txt). Also, we will cover these topics.
- Python Count Words in File
- Python Count Specific Words in File
- Python Count Words in Multiple Files
- Python Count Unique Words Files
- Python Count Words in Excel File
- Python Count Unique Words in Text File
- Python Program to Count Number of Words in File
- Python Count Word Frequency in a File
- Python Word Count CSV File
In this section, we will learn about python count words in file. In other words, we will learn to count the total number of words from a text file using Python.
- The entire process is divided into three simple steps:
- open a text file in read only mode
- read the information of file
- split the sentences into words and find the len.
- Using
file = open('file.txt', 'r')we can open the file in a read-only mode and store this information in a file variable. read_data = file.read()this statement is used to read the entire data in one go and store it in a variable named read_data.- It’s time to split the sentences into words and that can be done using
per_word = read_data.split()here split() method is used to split each sentence in read_data and all this information is stored in a variable named per_word. - final step is to print the length of per_word variable. Please note that lenght is counting total words in the file. Here is the statement to print a message with total count of words
print('Total Words: ', len(per_word)).
Source Code:
Here is the source code to implement the Python Count Words in a File.
file = open('file.txt', 'r')
read_data = file.read()
per_word = read_data.split()
print('Total Words:', len(per_word))Output:
Here is the output of counting words in a file using Python. In this output, the text file we have used has 221 words.

Read: Python Counter
Python Count Specific Words in File
In this section, we will learn about Python Count Specific Words in File. The user will provide any word and our program will display the total occurrence of that word.
- Occurrence of specific word can be counted in 5 simple steps:
- Ask for user input
- Open the file in read only mode
- Read the data of the file
- convert the data in lower case and count the occurrence of specific word
- Print the count
seach_word_count = input('Enter the word')in this code, user input is collected and stored in a variable. Whatever word user will iput here that word will be searched in a file.file = open('file.txt', 'r')in this code file.txt is a file that is opened in a read only mode and the result is stored in a ‘file’ variable.- Once we have opened a file, next step is to read the data in it so using the code
read_data = file.read()we have read the entire data and stored the information in a variable named ‘read_data’. - word_count = read_data.lower().count(search_word_count) In this code, we have converted the data to lower case and using count method we have searched for the word that user has provided. The entire result is stored in a variable named ‘word_count’.
- Last step in the process is to print the message with count. We have used formatted string to make our message descriptive. Here is the code for that.
print(f"The word '{search_word_count}' appeard {word_count} times.")
Source Code
Here is the complete source code to perform python count specific words in a file.
# asking for user input
search_word_count = input('Enter the word: ')
# opening text file in read only mode
file = open("file.txt", "r")
# reading data of the file
read_data = file.read()
# converting data in lower case and the counting the occurrence
word_count = read_data.lower().count(search_word_count)
# printing word and it's count
print(f"The word '{search_word_count}' appeared {word_count} times.")
Output:
Here is the output of Python Count Specific Word in a File. In this output, we searched for the word ‘the’ in a text file. The result showed that ‘the’ has appeared 4 times in a text file.

Read: Python get all files in directory
Python Count Words in Multiple Files
In this section, we will learn about Python Count Words in Multiple Files. We have three text files that we are going to use and we will count words from all of these files.
- Counting words from multiple files can be done in five easy steps:
- import glob module in Python
- create an empty list to store text files and a counter with 0 as default value.
- start a loop, recognize the text file using glob and add it to emty list we created in previous step.
- start another loop on that empty list, total number of files will decide the number of times loop will run. Each time loop runs a file is opened, read, splitted in words and then length of total words in added to words variable.
- In the end print the word variable with descriptive message.
- glob is used to return all file with a specific extension. Since we need all the files with .txt extension so we have used glob here.
text_file=[]this empty list will store all the files with .txt extension.word=0this will keep a track of all the words in multiple files.
for file in glob.glob("*.txt"):
txt_files.append(file)- In this code, we have started a loop and glob is used to scan all the files with .txt extension.
- each file is added to an empty list. So everytime loop runs a filename from the current folder having txt extension is added to an empty list.
for f in txt_files:
file = open(f, "r")
read_data = file.read()
per_word = read_data.split()
words += len(per_word)- In this code we have started a loop on the empty list because not that empty list has all the text files in it.
- Each time loop runs a file is opened, read, all the sentences are splitted in words and total count of words are added to a variable.
- In this way lets say file one has 20 words and file two has 30 then the words variable will show 50 (20+30) words in the end of the loop.
print('Total Words:',words)total words are printed with descriptive message.
Source Code:
Here is the source code to implement Python Count Words in Multiple Files.
import glob
# empty list and variable
txt_files = []
words = 0
# loop to add text files to a list
for file in glob.glob("*.txt"):
txt_files.append(file)
# loop to read, split and count word of each file
for f in txt_files:
file = open(f, "r")
read_data = file.read()
per_word = read_data.split()
words += len(per_word)
# print total words in multiple files
print('Total Words:',words)Output:
Here is the output of the above source code to implement Python Count Words in Multiple Files.

Read: Python dictionary of lists
Python Count Unique Words in a File
In this section, we will learn about Python Count Unique Words in a File. The python program will check the occurrences of each word in a text file and then it will count only unique words in a file.
- Using Python we can count unique words from a file in six simple steps:
- create a counter and assign default value as zero
- open a file in read only mode.
- read the data of file
- split the data in words and store it in a set
- start a for loop and keep on incrementing the counter with each word.
- Ultimately, print the counter
count = 0is the counter with default value set to zero. This counter will increment later.file = open("names.txt", "r")in this code we are opening a text file in a read-only mode and information is stored in a file variable.read_data = file.read()in this code, we are reading the data stored in a file.words = set(read_data.split())In this code, we have split the data and also we have removed the duplicate values. Set always keep only unique data.- we have started a for loop on total words and each time the loop runs it adds one to the counter. So if there are 35 unique words then loop will run 35 times and counter will have 35.
- In the end, count is printed as an output.
Source Code:
Here is the source code for implementing Python Count Unique Words in a File.
count = 0
file = open("names.txt", "r")
read_data = file.read()
words = set(read_data.split())
for word in words:
count += 1
print('Total Unique Words:', count)Output:
Here is the output of a program to count unique words in a file using Python. In this output, we have read a file and it has 85 unique words in it.

Read: Python Dictionary to CSV
Python Count Words in Excel File
In this section, we will learn about Python Count Words in Excel File.
- The best way to count words in excel files using python is by using Pandas module in python.
- you need to install pandas on your device
# anaconda
conda install pandas
# pip
pip install pandas- Using
df.count()method in pandas we can count the total number of words in a file with columns. - Using
df.count().sum()we can get the final value of total words in a file. - Here is the implementation on Jupyter Notebook.
Read: Pandas in Python
Python Count Unique Words in Text File
n this section, we will learn about Python Count Unique Words in a File. The python program will check the occurrences of each word in a text file and then it will count only unique words in a file.
- Using Python we can count unique words from a file in six simple steps:
- create a counter and assign default value as zero
- open a file in read only mode.
- read the data of file
- split the data in words and store it in a set
- start a for loop and keep on incrementing the counter with each word.
- Ultimately, print the counter
count = 0is the counter with default value set to zero. This counter will increment later.file = open("names.txt", "r")in this code we are opening a text file in a read-only mode and information is stored in a file variable.read_data = file.read()in this code, we are reading the data stored in a file.words = set(read_data.split())In this code, we have split the data and also we have removed the duplicate values. Set always keep only unique data.- we have started a for loop on total words and each time the loop runs it adds one to the counter. So if there are 35 unique words then loop will run 35 times and counter will have 35.
- In the end, count is printed as an output with the descriptive message.
Source Code:
Here is the source code to implement Python Count Unique Words in Text File.
count = 0
file = open("names.txt", "r")
read_data = file.read()
words = set(read_data.split())
for word in words:
count += 1
print('Total Unique Words:', count)Output:
Here is the output of a program to count unique words in a file using Python. In this output, we have read a file and it has 85 unique words in it.
Read: Python Pandas CSV
Python Program to Count Number of Words in File
In this section, we will learn about python count words in files. In other words, we will learn to count the total number of words from a text file using Python.
- The entire process is divided into three simple steps:
- open a text file in read only mode
- read the information of file
- split the sentences into words and find the len.
- Using
file = open('file.txt', 'r')we can open the file in a read-only mode and store this information in a file variable. read_data = file.read()this statement is used to read the entire data in one go and store it in a variable named read_data.- It’s time to split the sentences into words and that can be done using
per_word = read_data.split()here split() method is used to split each sentence in read_data and all this information is stored in a variable named per_word. - final step is to print the length of per_word variable. Please note that lenght is counting total words in the file. Here is the statement to print a message with total count of words
print('Total Words: ', len(per_word)).
Source Code:
Here is the source code to implement the Python Count Words in a File.
file = open("file.txt", "r")
read_data = file.read()
per_word = read_data.split()
print('Total Words:', len(per_word))Output:
Here is the output of counting words in a file using Python. In this output, the text file we have used has 221 words.
Read: Python built-in functions
Python Count Word Frequency in a File
In this section, we will learn about Python Count Word Frequency in a File. In other words, we will count the number of times a word appeared in the file.
- Frequency of each word can be counted in 3 simple steps in Python.
- Import counter from collections module in python.
- create a function that accepts filename, inside the function open the file, read the data and split sentences to words. and keep all of these inside the counter method.
- call the function and print it with descriptive message.
- In this we have imported Counter from collections. Counter holds the data in key-vaue format. Dictionary format would be best to display name and their occurrences.
- in the function count_word(), we have opened the textfile and then returned each word with their total occurrences
- In the end we have called the function and print it with descriptive message.
Source Code:
Here is the source code to implement Python Count Word Frequency in a File.
from collections import Counter
def count_word(file_name):
with open(file_name) as f:
return Counter(f.read().split())
print("Frequency :",count_word("names.txt"))
Output:
In this output, each word is displayed with their total occurrences in Python.

Read: Get current directory Python
Python Word Count CSV File
In this section, we will learn about Python Word Count in CSV files.
- The best way to count words in excel files using python is by using Pandas module in python.
- you need to install pandas on your device.
# anaconda
conda install pandas
# pip
pip install pandasdf.count()method in pandas we can count the total number of words in a file with columns.- Using
df.count().sum()we can get the final value of total words in a file. - Here is the implementation on Jupyter Notebook.
You may also like to read the following articles.
- Create an empty array in Python
- Python find index of element in list
- Python Array with Examples
- Hash table in python
- If not condition in python
- Python create empty set
- Python find number in String
In this tutorial, we have learned about Python Count Words in File. Also, we have covered these topics.
- Python Count Words in File
- Python Count Specific Words in File
- Python Count Words in Multiple Files
- Python Count Unique Words Files
- Python Count Words in Excel File
- Python Count Unique Words in Text File
- Python Program to Count Number of Words in File
- Python Count Word Frequency in a File
- Python Word Count CSV File

Python is one of the most popular languages in the United States of America. I have been working with Python for a long time and I have expertise in working with various libraries on Tkinter, Pandas, NumPy, Turtle, Django, Matplotlib, Tensorflow, Scipy, Scikit-Learn, etc… I have experience in working with various clients in countries like United States, Canada, United Kingdom, Australia, New Zealand, etc. Check out my profile.
In this tutorial, you’ll learn how to use Python to count the number of words and word frequencies in both a string and a text file. Being able to count words and word frequencies is a useful skill. For example, knowing how to do this can be important in text classification machine learning algorithms.
By the end of this tutorial, you’ll have learned:
- How to count the number of words in a string
- How to count the number of words in a text file
- How to calculate word frequencies using Python
Reading a Text File in Python
The processes to count words and calculate word frequencies shown below are the same for whether you’re considering a string or an entire text file. Because of this, this section will briefly describe how to read a text file in Python.
If you want a more in-depth guide on how to read a text file in Python, check out this tutorial here. Here is a quick piece of code that you can use to load the contents of a text file into a Python string:
# Reading a Text File in Python
file_path = '/Users/datagy/Desktop/sample_text.txt'
with open(file_path) as file:
text = file.read()I encourage you to check out the tutorial to learn why and how this approach works. However, if you’re in a hurry, just know that the process opens the file, reads its contents, and then closes the file again.
Count Number of Words In Python Using split()
One of the simplest ways to count the number of words in a Python string is by using the split() function. The split function looks like this:
# Understanding the split() function
str.split(
sep=None # The delimiter to split on
maxsplit=-1 # The number of times to split
)By default, Python will consider runs of consecutive whitespace to be a single separator. This means that if our string had multiple spaces, they’d only be considered a single delimiter. Let’s see what this method returns:
# Splitting a string with .split()
text = 'Welcome to datagy! Here you will learn Python and data science.'
print(text.split())
# Returns: ['Welcome', 'to', 'datagy!', 'Here', 'you', 'will', 'learn', 'Python', 'and', 'data', 'science.']We can see that the method now returns a list of items. Because we can use the len() function to count the number of items in a list, we’re able to generate a word count. Let’s see what this looks like:
# Counting words with .split()
text = 'Welcome to datagy! Here you will learn Python and data science.'
print(len(text.split()))
# Returns: 11Count Number of Words In Python Using Regex
Another simple way to count the number of words in a Python string is to use the regular expressions library, re. The library comes with a function, findall(), which lets you search for different patterns of strings.
Because we can use regular expression to search for patterns, we must first define our pattern. In this case, we want patterns of alphanumeric characters that are separated by whitespace.
For this, we can use the pattern w+, where w represents any alphanumeric character and the + denotes one or more occurrences. Once the pattern encounters whitespace, such as a space, it will stop the pattern there.
Let’s see how we can use this method to generate a word count using the regular expressions library, re:
# Counting words with regular expressions
import re
text = 'Welcome to datagy! Here you will learn Python and data science.'
print(len(re.findall(r'w+', text)))
# Returns: 11Calculating Word Frequencies in Python
In order to calculate word frequencies, we can use either the defaultdict class or the Counter class. Word frequencies represent how often a given word appears in a piece of text.
Using defaultdict To Calculate Word Frequencies in Python
Let’s see how we can use defaultdict to calculate word frequencies in Python. The defaultdict extend on the regular Python dictionary by providing helpful functions to initialize missing keys.
Because of this, we can loop over a piece of text and count the occurrences of each word. Let’s see how we can use it to create word frequencies for a given string:
# Creating word frequencies with defaultdict
from collections import defaultdict
import re
text = 'welcome to datagy! datagy will teach data. data is fun. data data data!'
counts = defaultdict(int)
for word in re.findall('w+', text):
counts[word] += 1
print(counts)
# Returns:
# defaultdict(<class 'int'>, {'welcome': 1, 'to': 1, 'datagy': 2, 'will': 1, 'teach': 1, 'data': 5, 'is': 1, 'fun': 1})Let’s break down what we did here:
- We imported both the
defaultdictfunction and therelibrary - We loaded some text and instantiated a defaultdict using the
intfactory function - We then looped over each word in the word list and added one for each time it occurred
Using Counter to Create Word Frequencies in Python
Another way to do this is to use the Counter class. The benefit of this approach is that we can even easily identify the most frequent word. Let’s see how we can use this approach:
# Creating word frequencies with Counter
from collections import Counter
import re
text = 'welcome to datagy! datagy will teach data. data is fun. data data data!'
counts = Counter(re.findall('w+', text))
print(counts)
# Returns:
# Counter({'data': 5, 'datagy': 2, 'welcome': 1, 'to': 1, 'will': 1, 'teach': 1, 'is': 1, 'fun': 1})Let’s break down what we did here:
- We imported our required libraries and classes
- We passed the resulting list from the
findall()function into theCounterclass - We printed the result of this class
One of the perks of this is that we can easily find the most common word by using the .most_common() function. The function returns a sorted list of tuples, ordering the items from most common to least common. Because of this, we can simply access the 0th index to find the most common word:
# Finding the Most Common Word
from collections import Counter
import re
text = 'welcome to datagy! datagy will teach data. data is fun. data data data!'
counts = Counter(re.findall('w+', text))
print(counts.most_common()[0])
# Returns:
# ('data', 5)Conclusion
In this tutorial, you learned how to generate word counts and word frequencies using Python. You learned a number of different ways to count words including using the .split() method and the re library. Then, you learned different ways to generate word frequencies using defaultdict and Counter. Using the Counter method, you were able to find the most frequent word in a string.
Additional Resources
To learn more about related topics, check out the tutorials below:
- Python
str.split()– Official Documentation - Python Defaultdict: Overview and Examples
- Python: Count Number of Occurrences in List (6 Ways)
- Python: Count Number of Occurrences in a String (4 Ways!)