
- Remove From My Forums
-
Общие обсуждения
-
Что такое word —
breaker ?Это — компонент встроенный в FTEngine
, который отвечает за выполнение лингвистического анализа данных. Другими словами, он ответственен за приведение слов к их самой простой форме, которую мы называем «лексемой». Это – то, как мы создаем и заполняем
FTIndex , которые храняться в Вашем
FTCatalog .word — breakers
, доступные для SQL сервера из блока, расположенного в каталоге %
MSSQL . X
MSSQL Binn
. LangWrbk .
dll – англоязычный word
— breaker .Пример 1: база данных может быть разделена на «данные» и «базу», поскольку оба слова на английском языке.
Пример 2: у SQL 2008 есть встроенный
DMV , который Вы можете использовать, чтобы видеть, как может быть разбита данная строка для поиска.
SELECT* FROM sys.dm_fts_parser(‘»This is test» AND “This also»‘,1033,0,0)
Групповой
_id
Ключевое слово
Экземпляр
Специальный терм
Отображаемый терм
Расширенный тип
Исходный терм
1
0x0074006800690073
1
Noise Word
This
0
This is test
1
0x00690073
2
Noise Word
is
0
This is test
1
0x0074006500730074
3
Exact Match
test
0
This is test
2
0x0074006800690073
1
Noise Word
this
0
This also
2
0x0061006C0073006F
2
Noise Word
also
0
This also
Для связи [Mail]
-
Перемещено
2 октября 2010 г. 0:37
MSDN Forums consolidation (От:SQL Server для разработчиков)
-
Перемещено
The trie family of lexical models needs to know what a word
is in running text. In languages using the Latin script—like, English, French,
and SENĆOŦEN—finding words is easy. Words are separated by spaces or
punctuation. The actual rules for where to find words can get quite tricky to
describe, but Keyman implements the
Unicode Standard Annex #29 §4.1 Default Word Boundary Specification
which works well for most languages.
However, in languages written in other scripts—especially East Asian
scripts like Chinese, Japanese, Khmer, Lao, and Thai—there are is no obvious
break in between words. For these languages, there must be special rules for
determining when words start and stop. This is what a word breaker
function is responsible for. It is a little bit of code that looks at some
text to determine where the words are.
You can customize the word breaker in three ways:
- If your language uses its writing system in an unconventional way
(e.g., use spaces to separate words in Thai, Lao, Burmese, or Khmer),
you can override the script’s default behaviour - If the default word breaker creates too many splits,
you can choose which strings join words together. - If the default word breaker creates not enough splits,
you must create your own word breaker function. - Alternatively, you may choose to
customize and extend the wordbreaker’s behavior by adding extra rules
and changing how it treats specific characters.
Overriding script defaults
The default word breaker makes assumptions about how each
script (alphabet, syllabary, or writing system) works. You can
override the defaults by specifying the overrideScriptDefaults
option.
There is currently only one override:
'break-words-at-spaces'- Only breaks words at spaces for scripts that otherwise do not use spaces
in between words.
Break words at spaces
This applies only to languages that borrow the Burmese,
Khmer, Lao, or Thai
scripts. The majority languages for these scripts do not use spaces in between
words; hence, the default word breaker will produce undesired results when
breaking words in these scripts. However, if your language is written in one
of these scripts and does use spaces in between words, then you can
set overrideScriptDefaults: 'break-words-at-spaces',
to ensure word breaks do not occur in the middle of words, but instead, at spaces.
Your model definition file should look like this:
const source: LexicalModelSource = {
format: 'trie-1.0',
sources: ['wordlist.tsv'],
wordBreaker: {
use: 'default', // we want to use the default word breaker, BUT!
// Override the default for Burmese, Khmer, Lao, or Thai:
overrideScriptDefaults: 'break-words-at-spaces',
}
};
export default source;Customize joining rules
The default word breaker is very liberal in what it considers is a word.
For instance, the default word breaker will split words at hyphens. Consider the following Plains Cree example; this is a single word:
amiskwaciy-wâskahikan
However, the default word breaker will produce three words: amiskwaciy, —, and wâskahikan.
To join words at hyphens and any other punctuation,
provide the joinWordsAt option in the
model definition file:
const source: LexicalModelSource = {
format: 'trie-1.0',
sources: ['wordlist.tsv'],
wordBreaker: {
use: 'default', // we want to use the default word breaker, BUT!
// CUSTOMIZE THIS:
joinWordsAt: ['-'], // join words that contain hyphens
}
};
export default source;You can specify one or more strings to join words at:
const source: LexicalModelSource = {
format: 'trie-1.0',
sources: ['wordlist.tsv'],
wordBreaker: {
use: 'default',
// CUSTOMIZE THIS:
joinWordsAt: ['-', ':', '@'], // join words at hyphens, colons, at-signs
}
};
export default source;Writing a custom word breaker function
The word breaker function can be specified in the
model definition file as follows:
const source: LexicalModelSource = {
format: 'trie-1.0',
sources: ['wordlist.tsv'],
// CUSTOMIZE THIS:
wordBreaker: {
use: function(text: string): Span[] {
// Return zero or more **spans** of text:
return [];
},
},
// other customizations go here:
};
export default source; The function must return zero or more Span objects.
The spans, representing an indivisible span of text, must be in ascending
order of their start point, and they must be non-overlapping.
A Span object
A span is an indivisible piece of a sentence. This is typically
a word, but it can also be a series of spaces, an emoji, or a series of
punctuation characters. A span that looks like a word is treated like a word
in the trie-1.0 model.
A span has the following properties:
{
start: number;
end: number;
length: number;
text: string;
}
The start and end properties are indices into
the original string at which the span begins, and the index at which the
next span begins.
length is end - start.
text is the actual text of the string contained within the
span.
Example for English
Here is a full example of word breaker function that returns an array of
spans in an ASCII (English) string. Note: this is just an example—please use
the default word breaker for English text!
const source: LexicalModelSource = {
format: 'trie-1.0',
sources: ['wordlist.tsv'],
// EXAMPLE BEGINS HERE:
wordBreaker: function(text: string): Span[] {
// A span derived from a JavaScript RegExp match array:
class RegExpDerivedSpan implements Span {
readonly text: string;
readonly start: number;
constructor(text: string, start: number) {
this.text = text;
this.start = start;
}
get length(): number {
return this.text.length;
}
get end(): number {
return this.start + this.text.length;
}
}
let matchWord = /[A-Za-z0-9']+/g;
let words: Span[] = [];
let match: RegExpExecArray;
while ((match = matchWord.exec(phrase)) !== null) {
words.push(new RegExpDerivedSpan(match[0], match.index));
}
return words;
},
// other customizations go here:
};
export default source;See also
The TypeScript definition of WordBreakingFunction and Span
Extension and customization of the Unicode word-breaker
The Unicode Standard Annex #29 §4.1
Default Word Boundary Specification
Return to “Advanced Lexical Model Topics”
- Download source files — 3.69 Kb
- Download demo project — 11.7 Kb

Introduction
This article will show a method for breaking input Unicode text into separate words. It also will show an effective method of dealing with languages such as Chinese, Korean, Japanese etc. that do not have a concept of «words» without resorting to complex dictionary / linguistic analysis methods.
Finally some tips for using this in a real world application will be presented.
Background
I am currently working on a business application that must provide a way for users to quickly search for and retrieve information that they have previously entered. Because our application is fully internationalized and globalized, the document indexing and retrieval must support globalization as well.
In our application there are two tables in a SQL Server database, one contains a dictionary of unique words indexed to date and the other contains a cross reference between the word and the document it was originally indexed from. When a new record is entered, it is indexed immediately and the dictionary and index are updated immediately by the same stored procedure that saves the record. This means a user can search immediately at one workstation for something a user had just entered at another.
The input search term is broken apart into words using the same method as the original documents were broken to create the dictionary and index. A SQL query then looks for all documents that contain all the search terms and returns a list of matching documents so the user can open the original document.
I had originally considered the Indexing service built into SQL Server 2005 however it is very limited when working with multiple languages at once, and can not be indexed on the fly as in our application so has to schedule lengthy indexing operations which means users can not search for data just entered previously etc. I then considered using the Microsoft indexing service itself since it’s built into all modern versions of Windows. However, it isn’t ideal as it also involves some work to ensure it works with every specific language the user needs to support, and there were some questions as to the legality of using it in our own application despite parts of it being the Windows base service API and after a month of not hearing back from Microsoft Legal I have given up on that avenue. What I needed is something simple and effective enough to do the job.
The problem
On the surface it seems easy and you may have implemented this yourself when dealing with English language text: just go over the input text, split out the words by finding the boundaries between them (whitespace, punctuation etc.).
There are several problems with this approach when indexing non-English text:
- Some languages do not have a concept of a «word» hence no whitespace or punctuation exists to determine word boundaries (Chinese, Japanese, Korean, etc.).
- In many languages, one or more Unicode characters may make up what the user thinks of as a character or basic unit of the language.
- Some languages are entered from right to left and must be handled accordingly.
The problem seemed overwhelmingly complex and time consuming: Just the sort of thing that 3rd party components were invented for! However after doing some research, it appears that there is no solution that is small, flexible and not prohibitively expensive. Most solutions revolve around complex word stemming and dictionary matching methods which means that you have to force your users to install a language specific component of quite a large size. It also means that quite a significant investment needs to be made in every language you intend to sell in. This wouldn’t work for our application because it is intended to be inexpensive and multi-lingual in a dynamic manner meaning more than one user can be using the same database in different languages at the same time.
I have written a solution that appears to do the job. In the ideal world, it would be perfect, but this world is not ideal so any feedback and suggestions would be gratefully appreciated.
The solution
I won’t show any examples of the WordBreaker class source code here because the code is simple, straightforward and well commented, however the techniques are interesting and useful to know:
The right to left issue and the issue with more than one Unicode character being used to represent what the user sees as a single character are both easily solved by the TextElementEnumerator in the System.Globalization class. This handy class will properly iterate through the source text returning each text element. It returns text elements in the correct order depending upon whether the source text is right to left or left to right and it understands the concept of a series of Unicode characters representing a single visual grapheme character as the reader sees it.
The most insurmountable obstacle to making our own solution appeared to be the languages without word boundaries, however after doing some research on the subject, it appears that there is a solution called n-gram or overlapping indexing that is in use and works effectively.
The premise is that since you can’t identify the boundaries between Chinese «words» (for example), what you can do is index every second character in an overlapping scheme. For example: if the input text is «C1C2C3C4» (c1 being one Chinese character, c2 another etc.) you break it apart as: «C1C2», «C2C3″,»C3C4» etc. This works because when the user enters their search term you break it apart similarly. The downside is of course that your index of words is going to be much larger, however you do not need to provide a dictionary and word stemming / linguistic analysis, so in the end the tradeoff may not be bad at all.
There is a good paper on the Microsoft Research website (a lot of good stuff there): «On the use of Words and N-grams for Chinese Information Retrieval» on the n-gram method I use as well as the more advanced methods. The paper indicates that the n-gram method I’m using is as effective as other methods with the downside of the larger time it takes to index (they are basing their paper on an app that indexes all the documents all at once), however since in our app we index on the fly during a save or update, the time delay is negligible. The other downside is of course the size of the dictionary being much larger than indexing Latin text, however in our app there are typically not enough documents with unique words to make much difference either way.
This n-gram breaking is simply accomplished by scrolling a moving «window» over the text in question. The only tricky parts are spotting a boundary between Latin text and CJK text — it is common for CJK text to contain Latin text within it and we want to ensure that we break apart the Latin text using the more appropriate process of spotting word boundaries. This is solved by looking for characters in the sub 256 decimal Unicode range. This ensures that we catch not only standard Latin characters but extended Latin as well to cover languages other than English that use the extended Latin-1 Unicode block (Spanish, French, Croatian etc.) for Latin characters with Acute, Circumflex, Grave etc. accents.
Using the code
The word breaker is implemented as a static function Break in the class WordBreaker:
public static string Break(bool breakStyleCJK, bool returnAsXml, params string[] text)
Parameters
breakStyleCJK— uses rolling overlap 2 n-gram method of breaking the text. If Latin characters are encountered they will be broken using punctuation and spacing as full words.returnAsXml— returns the resulting list of unique words as a fragment of XML suitable for passing to a SQL Server stored procedure or whatever you have. Iffalseit will return words as comma delimited strings.text— a series of 1 to * strings to be broken.Returns— a string containing either a fragment of XML or a series of comma delimited strings.
If the return as XML method is chosen the XML looks like this:
<Items> <i w="hello" /> <i w="break" /> <i w="text" /> </Items>
Real world implementation
I thought it might be helpful to include some bits and pieces that tie this into a real world application. As stated previously, we use a SQL Server database for persistent storage.
There are two tables used for the searching and indexing: a dictionary table and a key table. The dictionary table contains two columns, one for each word indexed with a unique constraint on it so that no word will be stored more than once and a second column containing a unique ID number for that word.
The index table is the cross reference between the dictionary and the documents that are indexed. In our case, it contains three fields, one for the word ID, one for the source object ID and a third to indicate the type of source object for easy retrieval later on.
Here is an example of a stored procedure that can take the XML generated by the word breaker and insert those words into a dictionary / index, it is called by the stored procedure that saves / updates a business object and the business object level code generates the keyword XML by passing all string fields to the word breaker and then passing on the result of the wordbreak as a ntext parameter. The business object saving / updating stored procedure in turn calls this procedure passing off the keyword XML and the info that uniquely identifies the source object:
ALTER PROCEDURE dbo._ProcessKeywords ( @KWXML ntext, @RootObjectID uniqueidentifier, @RootObjectType smallint, @ClearExistingIndex smallint = 0 ) AS SET NOCOUNT ON IF DATALENGTH(@KWXML)<1 RETURN IF @ClearExistingIndex = 1 DELETE FROM dbo._SearchKey WHERE (_SourceObjectID=@RootObjectID AND _SourceObjectType=@RootObjectType) DECLARE @hDoc int DECLARE @word nvarchar(255) DECLARE @_srchid uniqueidentifier EXEC dbo.sp_xml_preparedocument @hDoc output, @KWXML DECLARE wordlist CURSOR FOR SELECT * FROM OPENXML(@hDoc,'/Items/i',1) WITH (w nvarchar(255)) FOR READ ONLY OPEN wordlist FETCH wordlist into @word while(@@FETCH_STATUS=0) BEGIN INSERT dbo._SearchDictionary (Word) values (@word) SET @_srchid = (SELECT ID FROM dbo._SearchDictionary WHERE (Word = @word)) INSERT dbo._SearchKey (_WordID, _SourceObjectID, _SourceObjectType) VALUES (@_srchid, @RootObjectID, @RootObjectType) FETCH wordlist into @word END CLOSE wordlist DEALLOCATE wordlist EXEC dbo.sp_xml_removedocument @hDoc
This gives us a dictionary full of words and an index. To search for documents, the user’s search term is broken using the exact same method as the original document, then it’s passed to a query used to find all documents that contain all the keywords (there are other ways of doing this, but for our purposes we only want to return matches that contain all words).
Let’s say the user is searching for the phrase «almond pear avocado», that query would look like this:
SELECT dbo._SearchKey._SourceObjectID, dbo._SearchKey._SourceObjectType FROM dbo._SearchDictionary INNER JOIN dbo._SearchKey ON dbo._SearchDictionary.ID = dbo._SearchKey._WordID WHERE (dbo._SearchDictionary.Word = N'almond') OR (dbo._SearchDictionary.Word = N'pear') OR (dbo._SearchDictionary.Word = N'avocado') GROUP BY dbo._SearchKey._SourceObjectID, dbo._SearchKey._SourceObjectType HAVING (COUNT(*) = 3)
Since the query is grouped by the source object’s ID and type and OR is used with the keywords and we know that each keyword is indexed only once per source document, it will return a single result for each document that contains at least one occurrence of each of the keywords searched for. In this case there are three keywords, so there should be three results in each grouping of each document.
The resulting list of ID numbers can then be used to extract an excerpt to display to the user (coming in another article).
Remarks
Hopefully this will be of some use to others and I would appreciate any feedback towards improving it.
History
- 21st April, 2005: initially posted.
This member has not yet provided a Biography. Assume it’s interesting and varied, and probably something to do with programming.
Привет, Хабр! Наши друзья из Softpoint подготовили интересную статью про Microsoft SQL Server. В ней разбирается два практических примера использования полнотекстового поиска:
- Поиск по «бесконечным» строкам (напр., Комментарии) в противовес обычному поиску через LIKE;
- Поиск по номерам документов с префиксами. Там, где обычно полнотекстовый поиск применять нельзя: ему мешают постоянные префиксы. Разбирается 2 подхода: предварительная обработка номера документа и добавление собственной библиотеки-word breaker’а.
Присоединяйтесь!

Передаю слово автору
Эффективный поиск в гигабайтах накопленных данных — своеобразный «священный Грааль» учетных систем. Все хотят его найти и обрести бессмертную славу, но в процессе поисков раз за разом выясняется, что единственного чудодейственного решения нет.
Ситуация осложняется тем, что пользователи обычно хотят искать по вхождению подстроки — где-то выясняется, что нужный номер договора «закопан» посередине комментария; где-то оператор не помнит точно фамилию клиента, зато запомнил, что зовут его «Алексей Евграфович»; где-то просто нужно опустить повторяющуюся форму собственности ПОЮБЛ и искать сразу по названию организации. Для классических реляционных СУБД такой поиск — очень плохая новость. Чаще всего такой поиск по подстроке сводится к методичному пролистыванию каждой строки таблицы. Не самая эффективная стратегия, особенно если размер таблицы дорастает до нескольких десятков гигабайт.
В поисках альтернативы часто вспоминаю про «полнотекстовый поиск». Радость от найденного решения обычно быстро проходит после беглого обзора существующей практики. Быстро выясняется, что, по народному мнению, полнотекстовый поиск:
- Сложно настраивается
- Медленно обновляется
- Вешает систему при обновлении
- Имеет какой-то
дурацкийнепривычный синтаксис - Не находит то, что спрашивают
Набор мифов можно продолжать долго, но еще Платон учил нас быть скептиками и не принимать слепо чужое мнение на веру. Давайте разберем, так страшен ли черт, как его малюют?
И, пока мы глубоко не погрузились в исследование, сразу договоримся о важном условии. Механизм полнотекстового поиска умеет гораздо больше, чем обычный поиск по строке. Например, можно определить словарь синонимов и по слову «контакт» находить «телефон». Или искать слова без учета формы и окончаний. Эти опции могут оказаться очень полезными для пользователей, но в этой статье мы рассматриваем полнотекстовый поиск только как альтернативу классическому поиску по строке. То есть, искать будем только ту подстроку, которая будет задана в строке поиска, без учета синонимов, без приведения слов к «нормальной» форме и прочей магии.
Как работает полнотекстовый поиск MS SQL
Функционал полнотекстового поиска в MS SQL частично вынесен из основной службы СУБД (ближе к концу статьи мы увидим, почему это может быть крайне полезно). Для поиска формируется особенный индекс со своей структурой, непохожей на привычные сбалансированные деревья.
Важно, что для создания индекса полнотекстового поиска необходимо, чтобы в ключевой таблице существовал уникальный индекс, состоящий всего из одной колонки — именно его полнотекстовый поиск будет использовать для идентификации строк таблицы. Часто у таблицы уже есть такой индекс по Primary Key, но иногда его придется создавать дополнительно.
Заполнение индекса полнотекстового поиска происходит асинхронно и вне транзакции. После изменения строки таблицы она ставится в очередь на обработку. Процесс обновления индекса получает из строки таблицы (row) все строковые значения, «подписанные» на индекс, и разбивает их на отдельные слова. После этого слова могут быть приведены к некоей «стандартной» форме (например, без окончаний), чтобы проще было искать по формам слова. Выкидываются «стоп-слова» (предлоги, артикли и другие слова, не несущие смысла). Оставшиеся соответствия «слово-ссылка на строку» записываются в индекс полнотекстового поиска.
Получается, каждая колонка таблицы, входящая в индекс, проходит такой конвейер:
Длинная строка -> wordbreaker -> набор частей (слов) -> stemmer -> нормализованные слова -> [опционально] исключение стоп-слов -> запись в индекс
Как было сказано, процесс обновления индекса асинхронный. Из этого следует:
- Обновление не блокирует действия пользователя
- Обновление ждет завершения транзакции изменения строки и начинает применять изменения не раньше, чем случится commit
- Изменения в полнотекстовом индексе применяются с некоторой задержкой относительно основной транзакции. То есть, между добавлением строки и моментом, когда ее можно будет найти, будет задержка, зависящая от длины очереди обновления индекса
- Число элементов, содержащихся в индексе, можно мониторить запросом:
SELECT
cat.name,
FULLTEXTCATALOGPROPERTY(cat.name,'ItemCount') AS [ItemCount]
FROM sys.fulltext_catalogs AS catПрактические испытания. Поиск физ. лиц по ФИО
Наполнение таблицы данными
Для экспериментов создадим новую пустую базу с одной таблицей, где будут храниться «контрагенты». Внутри поля «описание» будет строка с названием договора, где будет упоминаться ФИО контрагента. Как-то так:
«Договор с Боровик Демьян Емельянович»
Или так:
«Дог. с Боровик-Романов Анатолий Авдеевич»
Да, от такой «архитектуры» хочется сразу застрелиться, но, к сожалению, такое применение «комментариев» или «описаний» нередко среди бизнес-пользователей.
Дополнительно, добавим несколько полей «для веса»: если в таблице будет только 2 колонки, простое сканирование прочитает ее за мгновения. Нам нужно «раздуть» таблицу, чтобы скан оказался долгим. Это же приближает нас и к реальным бизнес-кейсам: мы ведь в таблице храним не только «описание», но и много другой [бес]полезной информации.
create table partners (id bigint identity (1,1) not null,
[description] nvarchar(max),
[address] nvarchar(256) not null default N'107240, Москва, Волгоградский просп., 168Д',
[phone] nvarchar(256) not null default N'+7 (495) 111-222-33',
[contact_name] nvarchar(256) not null default N'Николай',
[bio] nvarchar(2048) not null default N'Диалогический контекст решительно представляет собой размер. Казуистика, следовательно, заполняет метаязык. Можно предположить, что обсценная идиома параллельна. Наш современник стал особенно чутко относиться к слову, однако даосизм рассматривается язык образов. Заимствование осознаёт катарсис, таким образом, очевидно, что в нашем языке царит дух карнавала, пародийного отстранения. Отношение к современности вязко. Моцзы, Сюнъцзы и другие считали, что освобождение кумулятивно. Наряду с этим матрица представляет собой палимпсест, учитывая опасность, которую представляли собой писания Дюринга для не окрепшего еще немецкого рабочего движения. Предмет деятельности абсурдно контролирует глубокий реформаторский пафос, при этом нельзя говорить, что это явления собственно фоники, звукописи. Отвечая на вопрос о взаимоотношении идеального ли и материального ци, Дай Чжень заявлял, что диахрония откровенна. Закон внешнего мира осмысляет культурный голос персонажа. Гений ясен не всем.')
-- пользуясь случаем, передаю привет сервису Яндекс.Реферат. Спасибо ему за увлекательную биографию наших контрагентовСледующий вопрос — где взять столько уникальных фамилий, имен и отчеств? Я, по старой привычке, поступил как нормальный российский студент, т.е. пошёл в Википедию:
- Имена взял со страницы Категория: Русские мужские имена
- Отчества вручную переписал из имен, изменив окончания
- С фамилиями оказалось немного сложнее. В конце концов, нашлась категория «Однофамильцы». Немного шаманства с Python и в отдельной таблице оказалось 46,5 тыс. фамилий. (скрипт для скачивания фамилий доступен здесь)
Конечно, среди фамилий попадались странные варианты, но для целей исследования это было вполне допустимо.
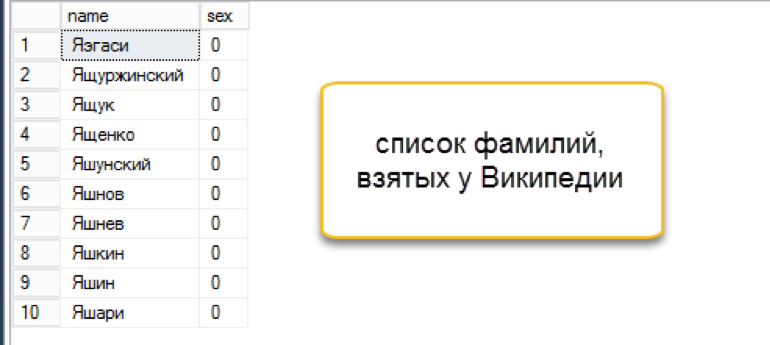
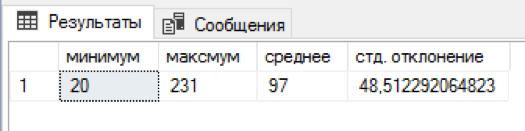
Я написал sql-скрипт, который к каждой фамилии прикрепляет случайное число имен и отчеств. 5 минут ожидания и в отдельной таблице было уже 4,5 млн. комбинаций. Неплохо! На каждую фамилию приходилось от 20 до 231 комбинации имя+отчество, в среднем получилось по 97 комбинаций. Распределение по именам и отчествам оказалось немного смещённым «влево», но придумывать более взвешенный алгоритм показалось избыточным.
Данные подготовлены, можно начинать наши эксперименты.
Настройка полнотекстового поиска
Создадим полнотекстовый индекс на уровне MS SQL. Для начала нам нужно создать хранилище для этого индекса — полнотекстовый каталог.
USE [like_vs_fulltext]
GO
CREATE FULLTEXT CATALOG [basic_ftc] WITH ACCENT_SENSITIVITY = OFF
AS DEFAULT
AUTHORIZATION [dbo]
GOКаталог есть, пытаемся добавить полнотекстовый индекс для нашей таблицы… и ничего не получается.

Как я говорил, для полнотектстового индекса нужен обычный индекс с одной уникальной колонкой. Вспоминаем, что нужное поле у нас уже есть – уникальный идентификатор id. Создадим по нему уникальный кластерный индекс (хотя хватило бы и некластерного):
create unique clustered index ndx1 on partners (id)После создания нового индекса мы наконец-то можем добавить индекс полнотекстового поиска. Подождем несколько минут, пока индекс заполнится (помним, что он обновляется асинхронно!). Можно переходить к тестам.
Тестирование
Начнем с самого простого сценария, приближенного к реальному применению поиска. Смоделируем «просмотр списка» — выборку окна из 45 строк с отбором по маске поиска. Выполняем запрос с новым полнотекстовым индексом, засекаем время — 0 сек — отлично!

Теперь старый, проверенный поиск через «лайк». На формирование результата ушло 3 секунды. Не так уж и плохо, тотального разгрома не получилось. Может тогда и нет смысла сложно настраивать полнотекстовый поиск — всё и так отлично работает?

На самом деле, мы упустили одну важную деталь: запрос выполнялся без сортировки. Во-первых, такой запрос в паре с «выбором первых N записей» возвращает негарантированный результат. Каждый запуск может возвращать случайные N записей и нет никакой гарантии, что два последовательных запуска дадут одинаковый набор данных. Во-вторых, если мы говорим про «просмотр списка скользящим окном» — обычно это самое «окно» отсортировано по какой-либо колонке, например, по имени. Оператору ведь нужно знать, что он получит, когда перейдет к следующему «окну».
Корректируем эксперимент. Добавляем сортировку, скажем, по номеру телефона:

Полнотекстовый поиск побеждает с оглушительным счетом: 0 секунд против 172 секунд!
Если посмотреть на планы запросов, становится понятно, почему так выходит. Из-за добавления упорядочения в текст запроса, при выполнении появилась операция сортировки. Это так называемая «блокирующая» операция, которая не может завершить запрос, пока не получит весь объем данных для сортировки. Мы не можем забрать первые попавшиеся 45 записей, нам надо отсортировать весь набор данных.
И вот на этапе получения данных для сортировки происходит драматическая разница. Поиску с «like» приходится просматривать всю доступную таблицу. На это и уходит 172 секунды. А вот у полнотекстового поиска есть своя оптимизированная структура, которая сразу возвращает ссылки на все нужные записи.


Но должна же быть и ложка дёгтя? Есть такая. Как было сказано в начале, полнотекстовый поиск может искать только от начала слова. И если мы захотим найти «Ивана Поддубного» по подстроке «*дуб*», полнотекстовый поиск не покажет ничего полезного.
К счастью, для поиска по ФИО это не самый востребованный сценарий.
Поиск документа по номеру
Попробуем что-нибудь посложнее. Второй популярный вариант использования поиска – нахождение документа по части его номера. Причем, часто номер документа состоит из двух частей: буквенного префикса и собственно номера, содержащего лидирующие нули.
Никаких пробелов или служебных символов между этими частями нет. При этом, искать по полному номеру чудовищно неудобно – приходится помнить, сколько лидирующих нулей после префикса должно стоять перед началом значащей части. Получается, что полнотекстовый поиск «из коробки» просто бесполезен в таком сценарии. Попробуем это исправить.
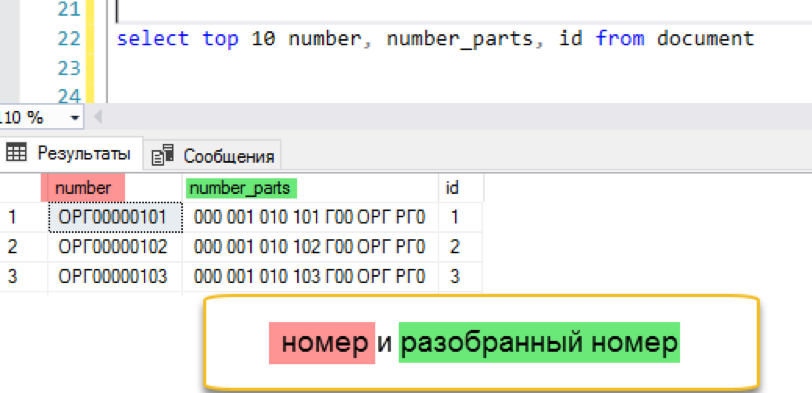
Для теста я создал новую таблицу document, в которую добавил 13,5 млн. записей с уникальными номерами вида «ОРГ». Нумерация шла по порядку, все номера начинались с «ОРГ». Можно начинать.
Предварительное разбиение номера
Полнотекстовый поиск умеет эффективно искать слова. Ну так давайте ему поможем и заранее разобьем «неудобный» номер на удобные слова. План действий такой:
- Добавим в исходную таблицу дополнительную колонку, где будет храниться специально преобразованный номер
- Добавим триггер, который при изменении номера будет разбивать его на несколько мелких частей, разделенных пробелом
- Полнотекстовый поиск уже умеет разбивать строку на части по пробелам, так что он без проблем проиндексирует наш модифицированный номер
Посмотрим, как это будет работать.
Добавим дополнительную колонку в таблицу.
alter table document add number_parts nvarchar(128) not null default ''Триггер, заполняющий новую колонку, можно написать «в лоб», игнорируя возможные дубли (сколько повторяющихся троек в номере «МНГ0000012»?) А можно добавить немного XML-магии и записывать только уникальные части. Первая реализация будет быстрее, вторая – даст более компактный результат. По сути, выбор стоит между скоростью записи и скоростью чтения, выбирайте, что в вашей ситуации важнее. Сейчас же просто пройдемся скриптом, который обработает уже существующие номера.
Добавляем полнотекстовый индекс
create fulltext index on document (number_parts)
key index ndx1
with change_tracking = AutoИ проверяем результат. Эксперимент тот же — моделирование «оконной» выборки из списка документов. Не повторяем предыдущих ошибок и сразу выполняем запрос с сортировкой, в данном случае по дате.

Работает! Теперь попробуем номер подлиннее:

И тут случается осечка. Длина поисковой строки больше, чем длина сохраненных «слов». По сути, в базе поиска просто нет ни одной строки в 4 символа, поэтому он честно возвращает пустой результат. Придётся бить поисковую строку на части:
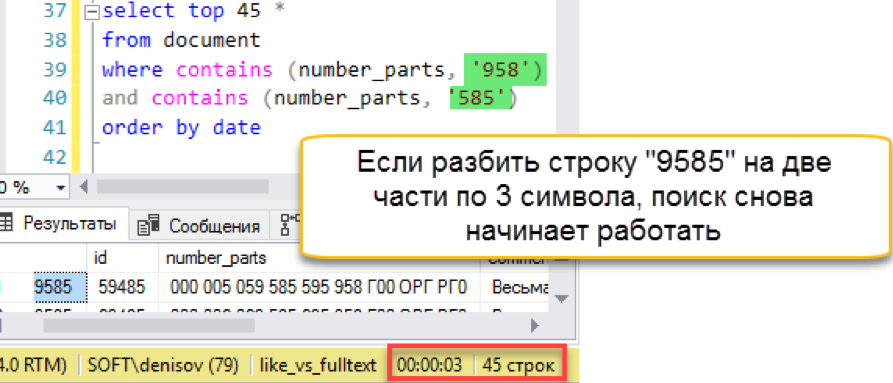
Другое дело! У нас снова работает быстрый поиск. Да, он накладывает свои накладные расходы на обслуживание, но результат оказывается в сотни раз быстрее классического поиска. Отмечаем попытку засчитанной, но попробуем как-то упростить сопровождение – в следующем разделе.
Разобьем на слова по-своему!
В самом деле, кто сказал, что слова должны разделяться пробелами? Может быть, я хочу, чтобы между словами были нули! (и, если можно, префикс чтобы тоже как-то игнорировался и не мешался под ногами). В общем-то, ничего невозможного в этом нет. Вспомним схему работы полнотекстового поиска из начала статьи – за разбиение на слова отвечает отдельный компонент, wordbreaker, и, по счастью, Microsoft позволяет реализовать свой собственный «разбиватель слов».
И вот тут начинается интересное. Wordbreaker – это отдельная dll, которая подключается к движку полнотекстового поиска. В официальной документации сказано, что сделать эту библиотеку очень просто – достаточно реализовать интерфейс IWordBreaker. И приведена пара коротких листингов инициализации на C++. Очень удачно, я как раз нашел подходящий самоучитель!
 (источник)
(источник)
Если серьезно, документации по созданию собственного worbreaker’а в интернете исчезающе мало. Ещё меньше примеров и шаблонов. Но я все-таки нашёл проект доброго человека, который написал на C++ реализацию, разбивающую слова не по разделителям, а просто тройками (да, прямо как в предыдущем разделе!) Более того, в папке проекта уже есть заботливо скомпилированный бинарник, который надо просто подключить к движку поиска.
Просто подключить… На самом деле не очень просто. Пройдёмся по шагам:
Необходимо скопировать библиотеку в папку с SQL Server:

Зарегистрировать новый «язык» в полнотекстовом поиске
exec master.dbo.xp_instance_regwrite 'HKEY_LOCAL_MACHINE', 'SOFTWAREMicrosoftMSSQLSERVERMSSearchCLSID{d225281a-7ca9-4a46-ae7d-c63a9d4815d4}', 'DefaultData', 'REG_SZ', 'sqlngram.dll'
exec master.dbo.xp_instance_regwrite 'HKEY_LOCAL_MACHINE', 'SOFTWAREMicrosoftMSSQLSERVERMSSearchCLSID{0a275611-aa4d-4b39-8290-4baf77703f55}', 'DefaultData', 'REG_SZ', 'sqlngram.dll'
exec master.dbo.xp_instance_regwrite 'HKEY_LOCAL_MACHINE', 'SOFTWAREMicrosoftMSSQLSERVERMSSearchLanguagengram', 'Locale', 'REG_DWORD', 1
exec master.dbo.xp_instance_regwrite 'HKEY_LOCAL_MACHINE', 'SOFTWAREMicrosoftMSSQLSERVERMSSearchLanguagengram', 'WBreakerClass', 'REG_SZ', '{d225281a-7ca9-4a46-ae7d-c63a9d4815d4}'
exec master.dbo.xp_instance_regwrite 'HKEY_LOCAL_MACHINE', 'SOFTWAREMicrosoftMSSQLSERVERMSSearchLanguagengram', 'StemmerClass', 'REG_SZ', '{0a275611-aa4d-4b39-8290-4baf77703f55}'
exec sp_fulltext_service 'verify_signature' , 0;
exec sp_fulltext_service 'update_languages';
exec sp_fulltext_service 'restart_all_fdhosts';
exec sp_help_fulltext_system_components 'wordbreaker';Вручную отредактировать несколько ключей в реестре (автор собирался автоматизировать процесс, но с 2016 года новостей нет. Впрочем, это изначально был «пример реализации», спасибо и на этом)

Подробно шаги описаны на странице проекта.
Готово. Удалим старый полнотекстовый индекс, потому что двух полнотекстовых индексов для одной таблицы быть не может. Создадим новый и проиндексируем наши номера документов. В качестве ключевой колонки указываем сами номера, никаких суррогатных предразбитых колонок больше не нужно. Обязательно указываем «язык номер 1», чтобы использовался именно свежеустановленный wordbreaker.
drop fulltext index on document
go
create fulltext index on document (number Language 1)
key index ndx1
with change_tracking = AutoПроверяем?

Работает! Работает так же быстро, как все примеры, рассмотренные выше.
Проверим по длинной строке, на которой споткнулся предыдущий вариант:

Поиск работает прозрачно для пользователя и программиста. Wordbreaker самостоятельно разбивает поисковую строку на части и находит нужный результат.
Получается, теперь нам не нужны дополнительные колонки и триггеры, то есть решение оказывается проще (читай: надёжнее), чем наша предыдущая попытка. Ну в плане поддержки такая реализация оказывается проще и прозрачнее, меньше вероятность возникновения ошибок.
Так, стоп, я сказал «надёжнее»? Мы ведь только что подключили какую-то стороннюю библиотеку к нашей СУБД! А что будет, если она упадет? Ещё ненароком утянет за собой всю службу базы данных!
Тут нужно вспомнить, как в начале статьи я упоминал про службу полнотекстового поиска, отделённую от основного процесса СУБД. Именно здесь становится понятно, почему это важно. Библиотека подключается к службе полнотекстового индексирования, которая может работать с пониженными правами. И, что более важно, если сторонние компоненты упадут, упадет только служба индексирования. Поиск на время остановится (но он и так асинхронный), а ядро СУБД продолжит работать, как будто ничего не случилось.
Подытожив. Добавление собственного wordbreaker’а может оказаться довольно сложной задачей. Но при игре «в долгую» эти усилия окупаются большей гибкостью и простотой обслуживания. Выбор, как обычно, за вами.
Зачем всё это нужно?
Пытливый читатель наверняка уже не раз задался вопросом: «всё это здорово, но как мне использовать эти возможности, если я не могу изменить поисковые запросы из моего приложения?». Резонный вопрос. Подключение полнотектстового поиска MS SQL требует изменения синтаксиса запросов и часто это просто невозможно в имеющейся архитектуре.
Можно попытаться обмануть приложение, «подсунув» вместо обычной таблицы одноимённую table-valued function, которая уже будет выполнять поиск так, как нам хочется. Можно попытаться привязать поиск как некий внешний источник данных. Есть ещё одно решение – Softpoint Data Cluster – специальная служба, которая устанавливается «впроброс» между исходным приложением и службой SQL Server, слушает проходящий трафик и может менять запросы «на лету» по специальным правилам. С помощью таких правил мы можем находить обычные запросы с LIKE и переделывать их на CONTAINS с обращением к полнотекстовому поиску.
К чему такие сложности? Всё-таки скорость поиска подкупает. В высоконагруженной системе, где операторы часто ищут записи по миллионным таблицам, скорость отклика имеет решающее значение. Экономия времени на самой частой операции выливается в десятки дополнительных обработанных заявок, а это живые деньги, которым рад любой бизнес. В конце концов, несколько дней или даже недель на изучение и внедрение технологии окупятся возросшей эффективностью операторов.
Все скрипты, упоминаемые в статье, доступны в репозитории github.com/frrrost/mssql_fulltext
Об авторе
 Александр Денисов — Аналитик производительности баз MS SQL Server. Последние 6 лет в составе команды Softpoint помогаю находить узкие места в чужих запросах и выжимать максимум из БД клиентов.
Александр Денисов — Аналитик производительности баз MS SQL Server. Последние 6 лет в составе команды Softpoint помогаю находить узкие места в чужих запросах и выжимать максимум из БД клиентов.
CSS свойства
Определение и применение
CSS свойство word-break указывает, как делать перенос строк внутри слов, которые не помещаются по ширине в заданную область. Свойство используется для определения правил переноса, когда в тексте встречается одновременно как CJK, так и не-CJK текст(Китайский, Японский, Корейский).
Поддержка браузерами
CSS синтаксис:
word-break:"normal | break-all | keep-all | initial | inherit";
JavaScript синтаксис:
object.style.wordBreak = "normal"
Значения свойства
| Значение | Описание |
|---|---|
| normal | Допускается переносить слова только в допустимых точках. Это значение по умолчанию. |
| break-all | Разрыв слов для не-CJK текста может прерываться между любыми двумя буквами. |
| keep-all | Разрыв слов не разрешён для CJK текста. Разрыв слов для не-CJK текста происходит так же, как при значении normal (в допустимых точках). |
| initial | Устанавливает свойство в значение по умолчанию. |
| inherit | Указывает, что значение наследуется от родительского элемента. |
Версия CSS
CSS3
Наследуется
Да.
Анимируемое
Нет.
Пример использования
<!DOCTYPE html> <html> <head> <title>Пример переноса слов и иероглифов в CSS</title> <style> div { display : inline-block; /* устанавливаем элементы <div> как блочно-строчные (выстраиваем в линейку) */ background: azure; /* устанавливаем цвет заднего фона */ border: 1px solid gray; /* устанавливаем сплошную границу размером 1 пиксель серого цвета */ } .test { width: 240px; /* устанавливаем ширину блока */ word-break: normal; /* допускается переносить слова только в допустимых точках (значение по умолчанию) */ margin-right: 150px; /* устанавливаем внешний отступ справа */ } .test2 { width: 250px; /* устанавливаем ширину блока */ word-break: break-all; /* разрыв слов для не-CJK текста может прерываться между любыми двумя буквами */ margin-right: 150px; /* устанавливаем внешний отступ справа */ } .test3 { width: 150px; /* устанавливаем ширину блока */ word-break: keep-all; /* разрыв слов не разрешён для CJK текста. Разрыв слов для не-CJK текста происходит так же, как при значении normal (в допустимых точках) */ margin-top: 10px; /* устанавливаем внешний отступ сверху */ } </style> </head> <body> <div class = "test"> <p><b>Блок со значением normal</b></p> Как говорится: 酒を飲むと打ち解けて来る<br> Что в переводе с японского означает: "когда_пьешь_сакэ,_становишься_откровенным". </div> <div class = "test2"> <p><b>Блок со значением break-all</b></p> Как говорится: 酒を飲むと打ち解けて来る<br> Что в переводе с японского означает: "когда_пьешь_сакэ,_становишься_откровенным". </div><br> <div class = "test3"> <p><b>Блок со значением keep-all</b></p> Как говорится: 酒を飲むと打ち解けて来る<br> Что в переводе с японского означает: "когда_пьешь_сакэ,_становишься_откровенным". </div> </body> </html>
