
Рассмотрим инструмент Описательная статистика, входящий в надстройку Пакет Анализа. Рассчитаем показатели выборки: среднее, медиана, мода, дисперсия, стандартное отклонение и др.
Задача
описательной статистики
(descriptive statistics) заключается в том, чтобы с использованием математических инструментов свести сотни значений
выборки
к нескольким итоговым показателям, которые дают представление о
выборке
.В качестве таких статистических показателей используются:
среднее
,
медиана
,
мода
,
дисперсия, стандартное отклонение
и др.
Опишем набор числовых данных с помощью определенных показателей. Для чего нужны эти показатели? Эти показатели позволят сделать определенные
статистические выводы о распределении
, из которого была взята
выборка
. Например, если у нас есть
выборка
значений толщины трубы, которая изготавливается на определенном оборудовании, то на основании анализа этой
выборки
мы сможем сделать, с некой определенной вероятностью, заключение о состоянии процесса изготовления.
Содержание статьи:
- Надстройка Пакет анализа;
-
Среднее выборки
;
-
Медиана выборки
;
-
Мода выборки
;
-
Мода и среднее значение
;
-
Дисперсия выборки
;
-
Стандартное отклонение выборки
;
-
Стандартная ошибка
;
-
Ассиметричность
;
-
Эксцесс выборки
;
-
Уровень надежности
.
Надстройка Пакет анализа
Для вычисления статистических показателей одномерных
выборок
, используем
надстройку Пакет анализа
. Затем, все показатели рассчитанные надстройкой, вычислим с помощью встроенных функций MS EXCEL.
СОВЕТ
: Подробнее о других инструментах надстройки
Пакет анализа
и ее подключении – читайте в статье
Надстройка Пакет анализа MS EXCEL
.
Выборку
разместим на
листе
Пример
в файле примера
в диапазоне
А6:А55
(50 значений).
Примечание
: Для удобства написания формул для диапазона
А6:А55
создан
Именованный диапазон
Выборка.
В диалоговом окне
Анализ данных
выберите инструмент
Описательная статистика
.

После нажатия кнопки
ОК
будет выведено другое диалоговое окно,
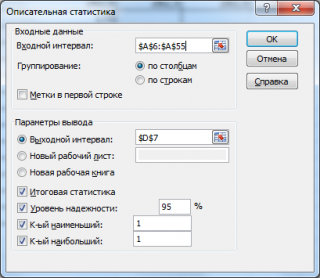
в котором нужно указать:
входной интервал
(Input Range) – это диапазон ячеек, в котором содержится массив данных. Если в указанный диапазон входит текстовый заголовок набора данных, то нужно поставить галочку в поле
Метки в первой строке (
Labels
in
first
row
).
В этом случае заголовок будет выведен в
Выходном интервале.
Пустые ячейки будут проигнорированы, поэтому нулевые значения необходимо обязательно указывать в ячейках, а не оставлять их пустыми;
выходной интервал
(Output Range). Здесь укажите адрес верхней левой ячейки диапазона, в который будут выведены статистические показатели;
Итоговая статистика (
Summary
Statistics
)
. Поставьте галочку напротив этого поля – будут выведены основные показатели выборки:
среднее, медиана, мода, стандартное отклонение
и др.;-
Также можно поставить галочки напротив полей
Уровень надежности (
Confidence
Level
for
Mean
)
,
К-й наименьший
(Kth Largest) и
К-й наибольший
(Kth Smallest).
В результате будут выведены следующие статистические показатели:
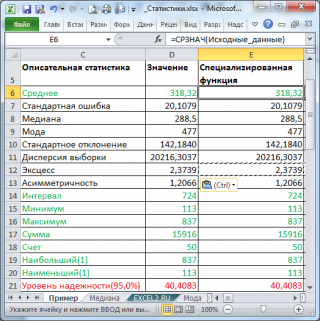
Все показатели выведены в виде значений, а не формул. Если массив данных изменился, то необходимо перезапустить расчет.
Если во
входном интервале
указать ссылку на несколько столбцов данных, то будет рассчитано соответствующее количество наборов показателей. Такой подход позволяет сравнить несколько наборов данных. При сравнении нескольких наборов данных используйте заголовки (включите их во
Входной интервал
и установите галочку в поле
Метки в первой строке
). Если наборы данных разной длины, то это не проблема — пустые ячейки будут проигнорированы.
Зеленым цветом на картинке выше и в
файле примера
выделены показатели, которые не требуют особого пояснения. Для большинства из них имеется специализированная функция:
Интервал
(Range) — разница между максимальным и минимальным значениями;
Минимум
(Minimum) – минимальное значение в диапазоне ячеек, указанном во
Входном интервале
(см.статью про функцию
МИН()
);
Максимум
(Maximum)– максимальное значение (см.статью про функцию
МАКС()
);
Сумма
(Sum) – сумма всех значений (см.статью про функцию
СУММ()
);
Счет
(Count) – количество значений во
Входном интервале
(пустые ячейки игнорируются, см.статью про функцию
СЧЁТ()
);
Наибольший
(Kth Largest) – выводится К-й наибольший. Например, 1-й наибольший – это максимальное значение (см.статью про функцию
НАИБОЛЬШИЙ()
);
Наименьший
(Kth Smallest) – выводится К-й наименьший. Например, 1-й наименьший – это минимальное значение (см.статью про функцию
НАИМЕНЬШИЙ()
).
Ниже даны подробные описания остальных показателей.
Среднее выборки
Среднее
(mean, average) или
выборочное среднее
или
среднее выборки
(sample average) представляет собой
арифметическое среднее
всех значений массива. В MS EXCEL для вычисления среднего выборки используется функция
СРЗНАЧ()
.
Выборочное среднее
является «хорошей» (несмещенной и эффективной) оценкой
математического ожидания
случайной величины (подробнее см. статью
Среднее и Математическое ожидание в MS EXCEL
).
Медиана выборки
Медиана
(Median) – это число, которое является серединой множества чисел (в данном случае выборки): половина чисел множества больше, чем
медиана
, а половина чисел меньше, чем
медиана
. Для определения
медианы
необходимо сначала
отсортировать множество чисел
. Например,
медианой
для чисел 2, 3, 3,
4
, 5, 7, 10 будет 4.
Если множество содержит четное количество чисел, то вычисляется
среднее
для двух чисел, находящихся в середине множества. Например,
медианой
для чисел 2, 3,
3
,
5
, 7, 10 будет 4, т.к. (3+5)/2.
Если имеется длинный хвост распределения, то
Медиана
лучше, чем
среднее значение
, отражает «типичное» или «центральное» значение. Например, рассмотрим несправедливое распределение зарплат в компании, в которой руководство получает существенно больше, чем основная масса сотрудников.
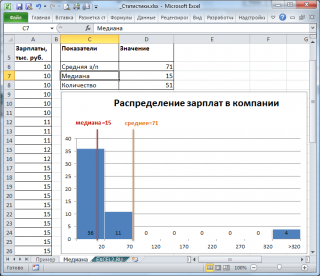
Очевидно, что средняя зарплата (71 тыс. руб.) не отражает тот факт, что 86% сотрудников получает не более 30 тыс. руб. (т.е. 86% сотрудников получает зарплату в более, чем в 2 раза меньше средней!). В то же время медиана (15 тыс. руб.) показывает, что
как минимум
у 50% сотрудников зарплата меньше или равна 15 тыс. руб.
Для определения
медианы
в MS EXCEL существует одноименная функция
МЕДИАНА()
, английский вариант — MEDIAN().
Медиану
также можно вычислить с помощью формул
=КВАРТИЛЬ.ВКЛ(Выборка;2) =ПРОЦЕНТИЛЬ.ВКЛ(Выборка;0,5).
Подробнее о
медиане
см. специальную статью
Медиана в MS EXCEL
.
СОВЕТ
: Подробнее про
квартили
см. статью, про
перцентили (процентили)
см. статью.
Мода выборки
Мода
(Mode) – это наиболее часто встречающееся (повторяющееся) значение в
выборке
. Например, в массиве (1; 1;
2
;
2
;
2
; 3; 4; 5) число 2 встречается чаще всего – 3 раза. Значит, число 2 – это
мода
. Для вычисления
моды
используется функция
МОДА()
, английский вариант MODE().
Примечание
: Если в массиве нет повторяющихся значений, то функция вернет значение ошибки #Н/Д. Это свойство использовано в статье
Есть ли повторы в списке?
Начиная с
MS EXCEL 2010
вместо функции
МОДА()
рекомендуется использовать функцию
МОДА.ОДН()
, которая является ее полным аналогом. Кроме того, в MS EXCEL 2010 появилась новая функция
МОДА.НСК()
, которая возвращает несколько наиболее часто повторяющихся значений (если количество их повторов совпадает). НСК – это сокращение от слова НеСКолько.
Например, в массиве (1; 1;
2
;
2
;
2
; 3;
4
;
4
;
4
; 5) числа 2 и 4 встречаются наиболее часто – по 3 раза. Значит, оба числа являются
модами
. Функции
МОДА.ОДН()
и
МОДА()
вернут значение 2, т.к. 2 встречается первым, среди наиболее повторяющихся значений (см.
файл примера
, лист
Мода
).
Чтобы исправить эту несправедливость и была введена функция
МОДА.НСК()
, которая выводит все
моды
. Для этого ее нужно ввести как
формулу массива
.
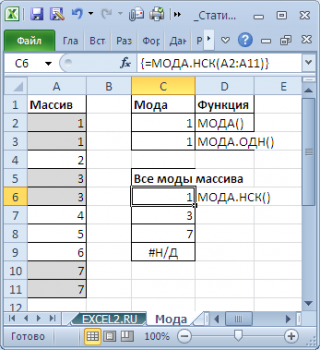
Как видно из картинки выше, функция
МОДА.НСК()
вернула все три
моды
из массива чисел в диапазоне
A2:A11
: 1; 3 и 7. Для этого, выделите диапазон
C6:C9
, в
Строку формул
введите формулу
=МОДА.НСК(A2:A11)
и нажмите
CTRL+SHIFT+ENTER
. Диапазон
C
6:
C
9
охватывает 4 ячейки, т.е. количество выделяемых ячеек должно быть больше или равно количеству
мод
. Если ячеек больше чем м
о
д, то избыточные ячейки будут заполнены значениями ошибки #Н/Д. Если
мода
только одна, то все выделенные ячейки будут заполнены значением этой
моды
.
Теперь вспомним, что мы определили
моду
для выборки, т.е. для конечного множества значений, взятых из
генеральной совокупности
. Для
непрерывных случайных величин
вполне может оказаться, что выборка состоит из массива на подобие этого (0,935; 1,211; 2,430; 3,668; 3,874; …), в котором может не оказаться повторов и функция
МОДА()
вернет ошибку.
Даже в нашем массиве с
модой
, которая была определена с помощью
надстройки Пакет анализа
, творится, что-то не то. Действительно,
модой
нашего массива значений является число 477, т.к. оно встречается 2 раза, остальные значения не повторяются. Но, если мы посмотрим на
гистограмму распределения
, построенную для нашего массива, то увидим, что 477 не принадлежит интервалу наиболее часто встречающихся значений (от 150 до 250).
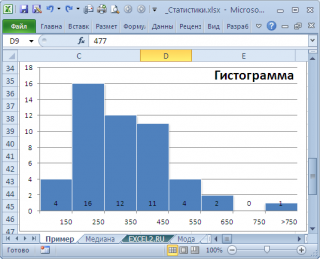
Проблема в том, что мы определили
моду
как наиболее часто встречающееся значение, а не как наиболее вероятное. Поэтому,
моду
в учебниках статистики часто определяют не для выборки (массива), а для функции распределения. Например, для
логнормального распределения
мода
(наиболее вероятное значение непрерывной случайной величины х), вычисляется как
exp
(
m
—
s
2
)
, где m и s параметры этого распределения.
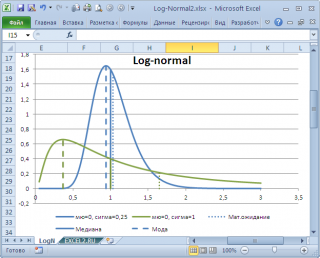
Понятно, что для нашего массива число 477, хотя и является наиболее часто повторяющимся значением, но все же является плохой оценкой для
моды
распределения, из которого взята
выборка
(наиболее вероятного значения или для которого плотность вероятности распределения максимальна).
Для того, чтобы получить оценку
моды
распределения, из
генеральной совокупности
которого взята
выборка
, можно, например, построить
гистограмму
. Оценкой для
моды
может служить интервал наиболее часто встречающихся значений (самого высокого столбца). Как было сказано выше, в нашем случае это интервал от 150 до 250.
Вывод
: Значение
моды
для
выборки
, рассчитанное с помощью функции
МОДА()
, может ввести в заблуждение, особенно для небольших выборок. Эта функция эффективна, когда случайная величина может принимать лишь несколько дискретных значений, а размер
выборки
существенно превышает количество этих значений.
Например, в рассмотренном примере о распределении заработных плат (см. раздел статьи выше, о Медиане),
модой
является число 15 (17 значений из 51, т.е. 33%). В этом случае функция
МОДА()
дает хорошую оценку «наиболее вероятного» значения зарплаты.
Примечание
: Строго говоря, в примере с зарплатой мы имеем дело скорее с
генеральной совокупностью
, чем с
выборкой
. Т.к. других зарплат в компании просто нет.
О вычислении
моды
для распределения
непрерывной случайной величины
читайте статью
Мода в MS EXCEL
.
Мода и среднее значение
Не смотря на то, что
мода
– это наиболее вероятное значение случайной величины (вероятность выбрать это значение из
Генеральной совокупности
максимальна), не следует ожидать, что
среднее значение
обязательно будет близко к
моде
.
Примечание
:
Мода
и
среднее
симметричных распределений совпадает (имеется ввиду симметричность
плотности распределения
).
Представим, что мы бросаем некий «неправильный» кубик, у которого на гранях имеются значения (1; 2; 3; 4; 6; 6), т.е. значения 5 нет, а есть вторая 6.
Модой
является 6, а среднее значение – 3,6666.
Другой пример. Для
Логнормального распределения
LnN(0;1)
мода
равна =EXP(m-s2)= EXP(0-1*1)=0,368, а
среднее значение
1,649.
Дисперсия выборки
Дисперсия выборки
или
выборочная дисперсия (
sample
variance
) характеризует разброс значений в массиве, отклонение от
среднего
.
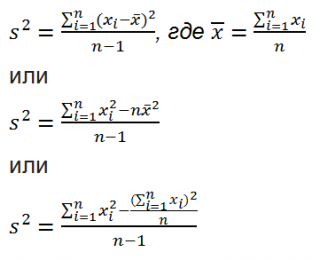
Из формулы №1 видно, что
дисперсия выборки
это сумма квадратов отклонений каждого значения в массиве
от среднего
, деленная на размер выборки минус 1.
В MS EXCEL 2007 и более ранних версиях для вычисления
дисперсии выборки
используется функция
ДИСП()
. С версии MS EXCEL 2010 рекомендуется использовать ее аналог — функцию
ДИСП.В()
.
Дисперсию
можно также вычислить непосредственно по нижеуказанным формулам (см.
файл примера
):
=КВАДРОТКЛ(Выборка)/(СЧЁТ(Выборка)-1) =(СУММКВ(Выборка)-СЧЁТ(Выборка)*СРЗНАЧ(Выборка)^2)/ (СЧЁТ(Выборка)-1)
– обычная формула
=СУММ((Выборка -СРЗНАЧ(Выборка))^2)/ (СЧЁТ(Выборка)-1)
–
формула массива
Дисперсия выборки
равна 0, только в том случае, если все значения равны между собой и, соответственно, равны
среднему значению
.
Чем больше величина
дисперсии
, тем больше разброс значений в массиве относительно
среднего
.
Размерность
дисперсии
соответствует квадрату единицы измерения исходных значений. Например, если значения в выборке представляют собой измерения веса детали (в кг), то размерность
дисперсии
будет кг
2
. Это бывает сложно интерпретировать, поэтому для характеристики разброса значений чаще используют величину равную квадратному корню из
дисперсии – стандартное отклонение
.
Подробнее о
дисперсии
см. статью
Дисперсия и стандартное отклонение в MS EXCEL
.
Стандартное отклонение выборки
Стандартное отклонение выборки
(Standard Deviation), как и
дисперсия
, — это мера того, насколько широко разбросаны значения в выборке
относительно их среднего
.
По определению,
стандартное отклонение
равно квадратному корню из
дисперсии
:
![]()
Стандартное отклонение
не учитывает величину значений в
выборке
, а только степень рассеивания значений вокруг их
среднего
. Чтобы проиллюстрировать это приведем пример.
Вычислим стандартное отклонение для 2-х
выборок
: (1; 5; 9) и (1001; 1005; 1009). В обоих случаях, s=4. Очевидно, что отношение величины стандартного отклонения к значениям массива у
выборок
существенно отличается.
В MS EXCEL 2007 и более ранних версиях для вычисления
Стандартного отклонения выборки
используется функция
СТАНДОТКЛОН()
. С версии MS EXCEL 2010 рекомендуется использовать ее аналог
СТАНДОТКЛОН.В()
.
Стандартное отклонение
можно также вычислить непосредственно по нижеуказанным формулам (см.
файл примера
):
=КОРЕНЬ(КВАДРОТКЛ(Выборка)/(СЧЁТ(Выборка)-1)) =КОРЕНЬ((СУММКВ(Выборка)-СЧЁТ(Выборка)*СРЗНАЧ(Выборка)^2)/(СЧЁТ(Выборка)-1))
Подробнее о
стандартном отклонении
см. статью
Дисперсия и стандартное отклонение в MS EXCEL
.
Стандартная ошибка
В
Пакете анализа
под термином
стандартная ошибка
имеется ввиду
Стандартная ошибка среднего
(Standard Error of the Mean, SEM).
Стандартная ошибка среднего
— это оценка
стандартного отклонения
распределения
выборочного среднего
.
Примечание
: Чтобы разобраться с понятием
Стандартная ошибка среднего
необходимо прочитать о
выборочном распределении
(см. статью
Статистики, их выборочные распределения и точечные оценки параметров распределений в MS EXCEL
) и статью про
Центральную предельную теорему
.
Стандартное отклонение распределения выборочного среднего
вычисляется по формуле σ/√n, где n — объём
выборки, σ — стандартное отклонение исходного
распределения, из которого взята
выборка
. Т.к. обычно
стандартное отклонение
исходного распределения неизвестно, то в расчетах вместо
σ
используют ее оценку
s
—
стандартное отклонение выборки
. А соответствующая величина s/√n имеет специальное название —
Стандартная ошибка среднего.
Именно эта величина вычисляется в
Пакете анализа.
В MS EXCEL
стандартную ошибку среднего
можно также вычислить по формуле
=СТАНДОТКЛОН.В(Выборка)/ КОРЕНЬ(СЧЁТ(Выборка))
Асимметричность
Асимметричность
или
коэффициент асимметрии
(skewness) характеризует степень несимметричности распределения (
плотности распределения
) относительно его
среднего
.
Положительное значение
коэффициента асимметрии
указывает, что размер правого «хвоста» распределения больше, чем левого (относительно среднего). Отрицательная асимметрия, наоборот, указывает на то, что левый хвост распределения больше правого.
Коэффициент асимметрии
идеально симметричного распределения или выборки равно 0.

Примечание
:
Асимметрия выборки
может отличаться расчетного значения асимметрии теоретического распределения. Например,
Нормальное распределение
является симметричным распределением (
плотность его распределения
симметрична относительно
среднего
) и, поэтому имеет асимметрию равную 0. Понятно, что при этом значения в
выборке
из соответствующей
генеральной совокупности
не обязательно должны располагаться совершенно симметрично относительно
среднего
. Поэтому,
асимметрия выборки
, являющейся оценкой
асимметрии распределения
, может отличаться от 0.
Функция
СКОС()
, английский вариант SKEW(), возвращает коэффициент
асимметрии выборки
, являющейся оценкой
асимметрии
соответствующего распределения, и определяется следующим образом:
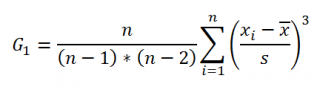
где n – размер
выборки
, s –
стандартное отклонение выборки
.
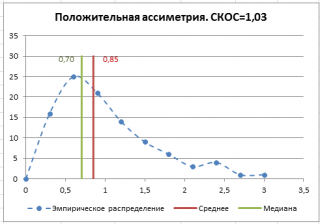
В
файле примера на листе СКОС
приведен расчет коэффициента
асимметрии
на примере случайной выборки из
распределения Вейбулла
, которое имеет значительную положительную
асимметрию
при параметрах распределения W(1,5; 1).
Эксцесс выборки
Эксцесс
показывает относительный вес «хвостов» распределения относительно его центральной части.
Для того чтобы определить, что относится к хвостам распределения, а что к его центральной части, можно использовать границы μ +/-
σ
.
Примечание
: Не смотря на старания профессиональных статистиков, в литературе еще попадается определение
Эксцесса
как меры «остроконечности» (peakedness) или сглаженности распределения. Но, на самом деле, значение
Эксцесса
ничего не говорит о форме пика распределения.
Согласно определения,
Эксцесс
равен четвертому
стандартизированному моменту:
![]()
Для
нормального распределения
четвертый момент равен 3*σ
4
, следовательно,
Эксцесс
равен 3. Многие компьютерные программы используют для расчетов не сам
Эксцесс
, а так называемый Kurtosis excess, который меньше на 3. Т.е. для
нормального распределения
Kurtosis excess равен 0. Необходимо быть внимательным, т.к. часто не очевидно, какая формула лежит в основе расчетов.
Примечание
: Еще большую путаницу вносит перевод этих терминов на русский язык. Термин Kurtosis происходит от греческого слова «изогнутый», «имеющий арку». Так сложилось, что на русский язык оба термина Kurtosis и Kurtosis excess переводятся как
Эксцесс
(от англ. excess — «излишек»). Например, функция MS EXCEL
ЭКСЦЕСС()
на самом деле вычисляет Kurtosis excess.
Функция
ЭКСЦЕСС()
, английский вариант KURT(), вычисляет на основе значений выборки несмещенную оценку
эксцесса распределения
случайной величины и определяется следующим образом:
![]()
Как видно из формулы MS EXCEL использует именно Kurtosis excess, т.е. для выборки из
нормального распределения
формула вернет близкое к 0 значение.
Если задано менее четырех точек данных, то функция
ЭКСЦЕСС()
возвращает значение ошибки #ДЕЛ/0!
Вернемся к
распределениям случайной величины
.
Эксцесс
(Kurtosis excess) для
нормального распределения
всегда равен 0, т.е. не зависит от параметров распределения μ и σ. Для большинства других распределений
Эксцесс
зависит от параметров распределения: см., например,
распределение Вейбулла
или
распределение Пуассона
, для котрого
Эксцесс
= 1/λ.
Уровень надежности
Уровень
надежности
— означает вероятность того, что
доверительный интервал
содержит истинное значение оцениваемого параметра распределения.
Вместо термина
Уровень
надежности
часто используется термин
Уровень доверия
. Про
Уровень надежности
(Confidence Level for Mean) читайте статью
Уровень значимости и уровень надежности в MS EXCEL
.
Задав значение
Уровня
надежности
в окне
надстройки Пакет анализа
, MS EXCEL вычислит половину ширины
доверительного интервала для оценки среднего (дисперсия неизвестна)
.
Тот же результат можно получить по формуле (см.
файл примера
):
=ДОВЕРИТ.СТЬЮДЕНТ(1-0,95;s;n)
s —
стандартное отклонение выборки
, n – объем
выборки
.
Подробнее см. статью про
построение доверительного интервала для оценки среднего (дисперсия неизвестна)
.
Изучаем варианты: анализ «Что-если» в Эксель
Всем доброго дня. У многих моих читателей ежедневная работа связана с поиском ответа на вопрос: «Какой будет ежемесячный доход, если…», «Сколько я переплачу, если…», и много других подобных «если», от которых зависят наши последующие действия. Поиски ответа на такие вопросы принято называть анализом «что если». Способам проведения такого анализа я решил посвятить сегодняшний пост.
К примеру, Вы просчитали депозит, который предлагает банк и хотите понимать, как изменится Ваш доход от депозита при различных параметрах начислений. На рисунке ниже в синей таблице исходные данные, а в желтой – результаты расчетов.

Теперь нам интересно, как будет меняться прибыль при изменении входных параметров. Можно просто изменять их в синей таблице и смотреть результат. Но этот «дедовский» метод не слишком наглядный, да и времени много потребуется. Я предлагаю Вам два более интересных способа провести анализ «Что-Если»:
Используя их, Вы легко сопоставите многие варианты и выберите лучший.
Таблица данных (таблица подстановки)
Можно построить таблицу, которая будет отражать изменение результата расчета в зависимости от входных величин. Она строится благодаря инструменту «Таблица данных» (в версиях Excel до 2010 – «Таблица подстановки»). Такие таблицы можно строить с изменением одного или двух параметров.
Таблица данных с одним параметром
В такой таблице можно изменять одно исходное значение и смотреть, как изменятся результаты. Например, нам нужно узнать, как будет меняться капитал депозита и наша прибыль в зависимости от срока размещения. Делаем заготовку и просчитываем варианты.

- В ячейках F1:H1 запишем заголовки наших выходных формул: «Капитал», «Прибыль», «Прирост». Этот шаг необязательный, но он позволяет лучше понять итоговую таблицу;
- В диапазоне F2:H2 укажем ссылки на ячейки с соответствующими формулами в желтой таблице. Например, в F2 запишем «=В6», т.е. укажем программе откуда брать формулы для этого столбца;
- В ячейках Е3:Е14 запишем различные варианты сроков размещения, для которых будут рассчитаны наши показатели. Я взял периоды от 6 до 72 месяцев;
- Выделяем всю таблицу (Е2:Н14) и выполняем на ленте: Данные – Работа с данными – Анализ «что если» – Таблица данных

- Откроется окно настройки таблицы с двумя полями. Поскольку у нас срок депозита изменяется в строках, то в поле «Подставлять значения по строкам в…» укажем ссылку на поле «Срок размещения» в голубой таблице.
- Нажимаем Ок и видим результат. Можно задать ячейкам соответствующие форматы.

Как видим, если сделать вложение на 6 мес, то заработаем 934 евро, что составит 9% изначального капитала. А если депозит будет размещен на 72 мес, то прибыль составит 19 211 евро (66% вложенной суммы).
Обратите внимание! Инструмент использует формулы массивов, просто выделить ячейку и изменить такую формулу не получится.
Таблица данных с двумя параметрами
Если же нам нужно узнать, как будет изменяться прирост капитала в зависимости от сроков размещения и первого взноса, сделаем другую заготовку, уже с двумя входными параметрами. Для этого делаем новую заготовку:
- В диапазоне Е3:Е14 снова запишем варианты сроков вклада;
- В ячейках F2:O2 – варианты сумм вкладов. Я взял от 1000 до 10000 с шагом в 1000.
- В верхнем левом углу таблицы (ячейка Е2) будет ссылка на ту величину, которую нужно отслеживать, т.е. «Прирост»

- Выделим всю таблицу с шапкой (Е2:О14) и выполним на ленте: Данные – Работа с данными – Анализ «что если» – Таблица данных
- И опять настраиваем таблицу:
- «Подставлять значения по строкам в…» — ссылка на срок размещения в голубой таблице;
- «Подставлять значения по столбцам в…» — ссылка на первый взнос в голубой таблице;
- Нажимаем Ок и получаем результат. В нашем случае применим процентный формат данных, добавим условное форматирование для наглядности.

Применяя такие таблицы, Вы можете визуально оценить преимущества различных комбинаций входных параметров и выбрать оптимальный.
Диспетчер сценариев
Таблицы данных, конечно, хороши. Но у них есть недостатки – можно использовать только один или два входных изменяющихся параметра. Если же нужно моделировать с большим количеством входных переменных, используйте диспетчер сценариев.
Этот инструмент позволяет задать несколько наборов параметров (сценариев) и при необходимости их применять, или же вывести отчет по ним, который будет очень похож на таблицу подстановки.
И так, пусть в нашем примере нужно изменять все три параметра: первый взнос, годовую ставку и длительность размещения депозита. Давайте создадим, например, три сценария и посмотрим, что из этого получится.
- На ленте вызываем команду Данные – Работа с данными – Анализ «что если» — Диспетчер сценариев . Откроется диалоговое окно создания и изменения сценариев.

- Добавим первый сценарий. Нажмем «Добавить»

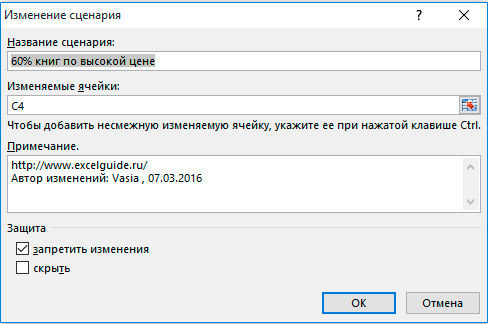
- Заполняем параметры сценария:
- Название сценария – произвольное информативное название для нового набора входных данных;
- Изменяемые ячейки – ссылка на ячейки, которые будут изменяться в этом сценарии;
- Примечание – опишите Ваш сценарий, чтобы в будущем не забыть что он моделирует;
- Защита – установка галок в группе защита позволит применить к сценариям средства защиты Excel;
Вот, что у меня получилось:

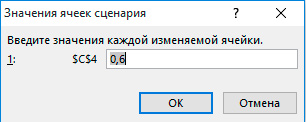
- Жмем Ок и переходим к окну задания указанных параметров. Вот какой набор я внес в первом нашем сценарии:

- Жмем Ок, чтобы сохранить сценарий и закрыть диспетчер. Либо, жмем «Добавить», чтобы создать еще один сценарий.
По приведенной выше схеме я создал 3 сценария с разным набором входных параметров (Первый взнос, годовая ставка, период размещения). Что теперь можно делать?
Давайте снова откроем наш диспетчер, теперь здесь отображены все наши сценарии. Выберем интересный нам сценарий и нажмем кнопку «Вывести». Все исходные данные, записанные в сценарии, будут подставлены в свои ячейки, формулы пересчитаны. Таким образом, мы можем легко переключаться между многими вариантами данных, и смотреть, какие будут результаты. Очень удобный подход для финансового планирования.
Кроме того, можно нажать «Отчет» и выбрать один из двух вариантов построения: структура или сводная таблица.
Выбирайте «Структура», чтобы получить обычный «плоский» отчет, который очень детально покажет Вам зависимость итоговых формул от исходных цифр.
Выберите «Сводная таблица», чтобы использовать для результатов расчета весь инструментарий сводных таблиц.
Для удобства, рекомендую Вам Диспетчер сценариев добавить на панель быстрого доступа.
Вот такие у нас есть возможности моделирования расчетов в Microsoft Excel. Считаю, этого более чем достаточно, чтобы выполнять повседневные, простые и сложные задачи поиска «что если». Ну а в следующей статье мы рассмотрим обратную процедуру – подбор параметров для получения необходимого (известного заранее) результата.
А пока, жду Ваших вопросов и комментариев по этому посту!
Diplom Consult.ru

А нализ «что – если» вExcel
нализ «что – если» вExcel
Анализ «что-если» в Excel
Анализ «что-если» позволяет изменять основные переменные таблицы данных и сразу же видеть результаты этих изменений. Предположим, вы используете анализ, чтобы решить покупать машину или взять ее в прокат. В этом случае можно проверить финансовую модель при различных предположениях о процентных ставках и периодических выплатах и выбрать оптимальное решение.
Таблицы данных
Таблица данных позволяет представить результаты формул в зависимости от значений одной или двух переменных, которые используются в этих формулах. С помощью команды Данные/ Таблица подстановки можно создать два типа таблиц данных: таблицу для одной переменной, которая проверяет воздействие этой переменной на несколько формул, или таблицу для двух переменных, которая проверяет их влияние на одну формулу.
Таблицы данных для одной переменной
Предположим, что вы рассматриваете возможность покупки дома, для чего вам придется взять ссуду под закладную в $200 000 на 30 лет, и вы хотите вычислить месячные выплаты по этой ссуде для нескольких процентных ставок. Эту информацию может предоставить таблица данных для одной переменной.
Ч тобы создать такую таблицу, выполните следующие действия:
тобы создать такую таблицу, выполните следующие действия:
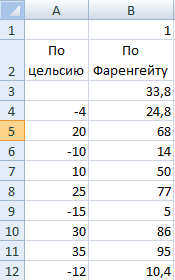
1. На новом рабочем листе введите интересующие вас процентные ставки. Для этого примера введите 6, 6,5, 7, 7,5, 8 и 8,5 процентов в ячейки ВЗ:В8. (Мы называем этот диапазон входным диапазоном, так как он содержит входные значения, которые мы хотим проверить.)
2. Затем введите формулу, которая использует входную переменную. В данном случае введите в ячейку С2 формулу:
где А2/12 — месячная процентная ставка, 360 — срок ссуды в месяцах и 200000 — размер ссуды. Обратите внимание, что эта формула ссылается на ячейку А2, которая в данный момент пустая. (При расчете числовых формул Ms Excel присваивает пустым ячейкам значение 0.) Как вы можете заметить, поскольку А2 пустая, то функция возвращает величину ежемесячных выплат, необходимую для погашения ссуды при нулевой процентной ставке. Ячейка А2 является только меткой, через которую Excel будет подставлять значения из входного диапазона. На самом деле Excel не изменяет хранимое значение в этой ячейке, поэтому такой меткой может быть любая ячейка рабочего листа вне диапазона таблицы данных.
3 . Выделите диапазон таблицы данных — минимальный прямоугольный блок ячеек, включающий в себя формулу и все значения входного диапазона. В данном случае выделите диапазон В2:С8.
. Выделите диапазон таблицы данных — минимальный прямоугольный блок ячеек, включающий в себя формулу и все значения входного диапазона. В данном случае выделите диапазон В2:С8.
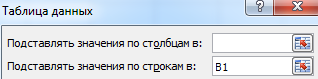
4 . Выполните команду Данные/ Таблица подстановки. В окне диалога Таблица подстановки задайте местонахождение входной ячейки в поле Подставлять значения по строкам в или в поле Подставлять значения по столбцам в. Входная ячейка — это ячейка-метка, на которую ссылается формула таблицы данных, в данном случае, А2. Чтобы таблица данных заполнялась правильно, вы должны ввести ссылку на входную ячейку в нужное поле. Если входные значения расположены в строке, введите ссылку на входную ячейку в поле Подставлять значения по столбцам в. Если значения во входном диапазоне расположены в столбце, используйте поле Подставлять значения по строкам в. В данном примере входные значения расположены в столбце, поэтому введите $А$2 в поле Подставлять значения по строкам в.
. Выполните команду Данные/ Таблица подстановки. В окне диалога Таблица подстановки задайте местонахождение входной ячейки в поле Подставлять значения по строкам в или в поле Подставлять значения по столбцам в. Входная ячейка — это ячейка-метка, на которую ссылается формула таблицы данных, в данном случае, А2. Чтобы таблица данных заполнялась правильно, вы должны ввести ссылку на входную ячейку в нужное поле. Если входные значения расположены в строке, введите ссылку на входную ячейку в поле Подставлять значения по столбцам в. Если значения во входном диапазоне расположены в столбце, используйте поле Подставлять значения по строкам в. В данном примере входные значения расположены в столбце, поэтому введите $А$2 в поле Подставлять значения по строкам в.
5. Нажмите кнопку ОК. Excel выведет значения формулы для каждого входного значения в ячейках диапазона таблицы данных. В нашем примере Excel выведет шесть результатов в диапазоне СЗ:С8. При создании этой таблицы данных Excel ввел формулу массива <=ТАБЛИЦА(;А2)>в каждую ячейку в диапазоне СЗ:С8 (диапазон результатов). В нашей таблице формула ТАБЛИЦА вычисляет значения функции ПЛТ для каждой процентной ставки в столбце В. Например, формула в ячейке С5 вычисляет размер выплаты при ставке, равной 7 процентам.
Функция ТАБЛИЦА, используемая в формуле, имеет следующий синтаксис:
=ТАБЛИЦА(входная ячейка для строки ;входная ячейка для столбца)
Поскольку в нашем примере входные значения расположены в столбце, Excel использует ссылку на входную ячейку для столбца А2 в качестве второго аргумента функции и оставляет первый аргумент пустым (на что указывает точка с запятой).
П осле построения таблицы можно изменить формулу таблицы данных или любые значения во входном диапазоне для создания другого множества результатов. Например, предположим, что для покупки дома вы решили занять только $185 000. Если вы измените формулу в ячейке С2 на =ПЛТ(А2/12;360; 185000) значения в выходном диапазоне изменятся.
осле построения таблицы можно изменить формулу таблицы данных или любые значения во входном диапазоне для создания другого множества результатов. Например, предположим, что для покупки дома вы решили занять только $185 000. Если вы измените формулу в ячейке С2 на =ПЛТ(А2/12;360; 185000) значения в выходном диапазоне изменятся.
Введение в анализ «что если»
С помощью средств анализа «что если» в Excel вы можете экспериментировать с различными наборами значений в одной или нескольких формулах, чтобы изучить все возможные результаты.
Например, можно выполнить анализ «что если» для формирования двух бюджетов с разными предполагаемыми уровнями дохода. Или можно указать нужный результат формулы, а затем определить, какие наборы значений позволят его получить. В Excel предлагается несколько средств для выполнения разных типов анализа.
Обратите внимание на то, что в этой статье приведен только обзор инструментов. Подробные сведения о каждом из них можно найти по ссылкам ниже.
Анализ «что если» — это процесс изменения значений в ячейках, который позволяет увидеть, как эти изменения влияют на результаты формул на листе.
В Excel предлагаются средства анализа «что если» трех типов: сценарии, таблицы данных и подбор параметров. В сценариях и таблицах данных берутся наборы входных значений и определяются возможные результаты. Таблицы данных работают только с одной или двумя переменными, но могут принимать множество различных значений для них. Сценарий может содержать несколько переменных, но допускает не более 32 значений. Подбор параметров отличается от сценариев и таблиц данных: при его использовании берется результат и определяются возможные входные значения для его получения.
Помимо этих трех средств можно установить надстройки для выполнения анализа «что если», например надстройку Поиск решения. Эта надстройка похожа на подбор параметров, но позволяет использовать больше переменных. Вы также можете создавать прогнозы, используя маркер заполнения и различные команды, встроенные в Excel.
Для более сложных моделей можно использовать надстройку Пакет анализа.
Сценарий — это набор значений, которые сохраняются в Excel и могут автоматически подставляться в ячейки на листе. Вы можете создавать и сохранять различные группы значений на листе, а затем переключиться на любой из этих новых сценариев, чтобы просмотреть другие результаты.
Предположим, у вас есть два сценария бюджета: для худшего и лучшего случаев. Вы можете с помощью диспетчера сценариев создать оба сценария на одном листе, а затем переключаться между ними. Для каждого сценария вы указываете изменяемые ячейки и значения, которые нужно использовать. При переключении между сценариями результат в ячейках изменяется, отражая различные значения изменяемых ячеек.
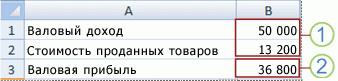
1. Изменяемые ячейки
2. Ячейка результата
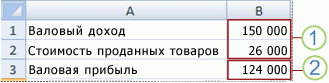
1. Изменяемые ячейки
2. Ячейка результата
Если у нескольких человек есть конкретные данные в отдельных книгах, которые вы хотите использовать в сценариях, вы можете собрать эти книги и объединить их сценарии.
После создания или сбора всех нужных сценариев вы можете создать сводный отчет по сценариям, в который включаются данные из этих сценариев. В отчете по сценариям все данные отображаются в одной таблице на новом листе.
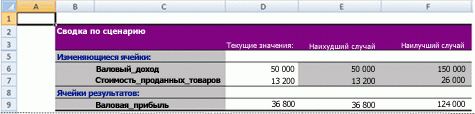
Примечание: В отчетах по сценариям автоматический пересчет не выполняется. Изменения значений в сценарии не будут отражается в уже существующем сводном отчете. Вам потребуется создать новый сводный отчет.
Если вы знаете, какой результат вычисления формулы вам нужен, но не можете определить входные значения, позволяющие его получить, используйте средство подбора параметров. Предположим, что вам нужно занять денег. Вы знаете, сколько вам нужно, на какой срок и сколько вы сможете выплачивать каждый месяц. С помощью средства подбора параметров вы можете определить, какая процентная ставка вам подойдет.

Примечание: Подбор параметров работает только с одним входным значением переменной. Если вы хотите определить несколько входных значений, например сумму ссуды и сумму ежемесячных платежей для займа, следует использовать надстройку «Поиск решения». Дополнительные сведения о надстройке «Поиск решения» можно найти в разделе подготовка прогнозов и расширенных бизнес-моделей, а также переход по ссылкам в разделе » см .
Если у вас есть формула с одной или двумя переменными либо несколько формул, в которых используется одна общая переменная, вы можете просмотреть все результаты в одной таблице данных. С помощью таблиц данных можно легко и быстро проверить несколько возможностей. Поскольку используются всего одна или две переменные, результат можно без труда прочитать или опубликовать в табличной форме. Если для книги включен автоматический пересчет, данные в таблицах данных сразу же пересчитываются, и вы всегда видите свежие данные.
В таблицу данных нельзя помещать больше двух переменных. Для анализа большего количества переменных используйте сценарии. Несмотря на то что переменных не может быть больше двух, можно использовать сколько угодно различных значений переменных. В сценарии можно использовать не более 32 различных значений, зато вы можете создать сколько угодно сценариев.
При подготовке прогнозов вы можете использовать Excel для автоматической генерации будущих значений на базе существующих данных или для автоматического вычисления экстраполированных значений на основе арифметической или геометрической прогрессии.
Вы можете заполнить ряд значений, которые соответствуют простой линейной тенденции или экспоненциального приближения, с помощью маркера заполнения или команды ряд . Для расширения сложных и нелинейных данных можно использовать функции листа или средство регрессионный анализ в надстройке «пакет анализа».
В средстве подбора параметров можно использовать только одну переменную, а с помощью надстройки Поиск решения вы можете создать обратную проекцию для большего количества переменных. Надстройка «Поиск решения» помогает найти оптимальное значение для формулы в одной ячейке листа, которая называется целевой.
Поиск решения работает с группой ячеек, связанных с формулой в целевой ячейке. Поиск решения настраивает значения в заданных изменяемых ячейках, которые называются влияющими ячейками, чтобы получить результат, указанный в формуле целевой ячейки. Вы можете применить ограничения для ограничения значений, которые можно использовать для поиска решения в модели, а ограничения могут ссылаться на другие ячейки, влияющие на формулу целевой ячейки.
Дополнительные сведения
Вы всегда можете задать вопрос специалисту Excel Tech Community, попросить помощи в сообществе Answers community, а также предложить новую функцию или улучшение на веб-сайте Excel User Voice.
Использование анализа «что если» в Excel на примере
Анализ «Что Если» в Excel позволяет попробовать различные значения (сценарии) для формул.
Следующий пример поможет Вам освоить Анализ «что если» быстро и легко.
Предположим, у вас есть книжный магазин и есть 100 книг на продажу. Вы продаете определенный % книг по самой высокой цене в $ 50 и определенный % книг по более низкой цене $ 20.

Если вы продаете 60% книг по самой высокой цене, ячейка D10 вычисляет общую прибыль в размере 60 * $ 50 + 40 * $ 20 = $ 3800.
Скачать рассматриваемый пример Вы можете по этой ссылке: Пример анализа «что если» в Excel.
Создание различных сценариев
Что будет, если Вы продадите 70% книг по высокой цене? А что будет, если Вы продадите 80% книг? Или 90%, или 100%? Каждый другой процент продажи книг — это различный сценарий.
Вы можете использовать «Диспетчер сценариев» для создания этих сценариев.
Примечание: Вы можете просто ввести другой процент в ячейку C4, что бы увидеть результат в ячейке C10. Однако, Анализ «что если» позволит Вам сравнить результаты различных сценариев.
1. На вкладке Данные выберите Анализ «что если» и выберите Диспетчер сценариев из списка.
Откроется диалоговое окно Диспетчер сценариев.

2. Добавьте сценарий, нажав на кнопку Добавить.
3. Введите имя (60% книг по высокой цене), выберите ячейку C4 (% книг, которые продаются по высокой цене) для изменяемой ячейки и нажмите на кнопку OK.
4. Введите соответствующее значение 0,6 и нажмите на кнопку OK еще раз.
5. Далее, добавьте еще 4 других сценария (70%, 80%, 90% и 100% соответсвенно).
И, наконец, ваш Диспетчер сценариев должен соответствовать картинке ниже:
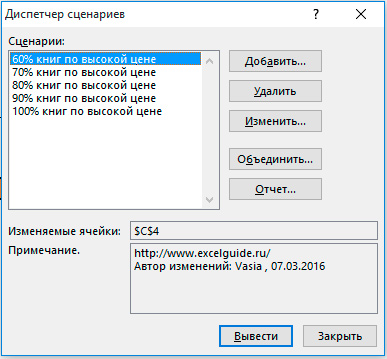
Примечание: чтобы увидеть результат сценария, выберите сценарий и нажмите на кнопку Вывести. Excel изменит значение ячейки C4 в соответствии со сценарием, что бы Вы смогли увидеть результат на листе.
Отчет по сценариям
Для того, чтобы легко сравнить результаты этих сценариев, выполните следующие действия:
1. Кликните по кнопке «Отчет» в Диспетчере сценариев.
2. Далее, выберите ячейку C10 (итого выручка) в качестве ячейки результата и нажмите ОК.


Вывод: Если вы продаете 70% книг по высокой цене, то Вы получите общую выручку в размере $ 4100, если Вы продаете 80% книг по высокой цене, то Вы получаете общую прибыль в размере $ 4400 и т.д. Вот как легко можно использовать Анализ «что если» в Excel.
Подписывайтесь на нас в социальных сетях, оставляйте комментарии к статье. Надеюсь пример использования анализа «что если» в Excel Вам понравился.
Анализ данных в Excel с примерами отчетов скачать
Анализ данных в Excel предполагает сама конструкция табличного процессора. Очень многие средства программы подходят для реализации этой задачи.
Excel позиционирует себя как лучший универсальный программный продукт в мире по обработке аналитической информации. От маленького предприятия до крупных корпораций, руководители тратят значительную часть своего рабочего времени для анализа жизнедеятельности их бизнеса. Рассмотрим основные аналитические инструменты в Excel и примеры применения их в практике.
Инструменты анализа Excel
Одним из самых привлекательных анализов данных является «Что-если». Он находится: «Данные»-«Работа с данными»-«Что-если».
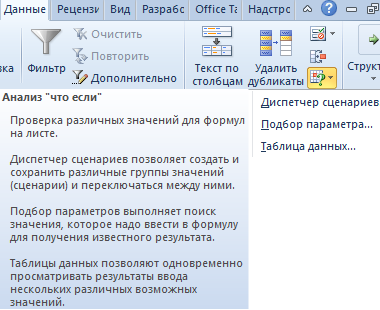
Средства анализа «Что-если»:
- «Подбор параметра». Применяется, когда пользователю известен результат формулы, но неизвестны входные данные для этого результата.
- «Таблица данных». Используется в ситуациях, когда нужно показать в виде таблицы влияние переменных значений на формулы.
- «Диспетчер сценариев». Применяется для формирования, изменения и сохранения разных наборов входных данных и итогов вычислений по группе формул.
- «Поиск решения». Это надстройка программы Excel. Помогает найти наилучшее решение определенной задачи.
Практический пример использования «Что-если» для поиска оптимальных скидок по таблице данных.
Другие инструменты для анализа данных:
Анализировать данные в Excel можно с помощью встроенных функций (математических, финансовых, логических, статистических и т.д.).
Сводные таблицы в анализе данных
Чтобы упростить просмотр, обработку и обобщение данных, в Excel применяются сводные таблицы.
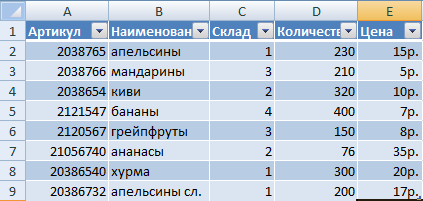
Программа будет воспринимать введенную/вводимую информацию как таблицу, а не простой набор данных, если списки со значениями отформатировать соответствующим образом:
- Перейти на вкладку «Вставка» и щелкнуть по кнопке «Таблица».
- Откроется диалоговое окно «Создание таблицы».

- Указать диапазон данных (если они уже внесены) или предполагаемый диапазон (в какие ячейки будет помещена таблица). Установить флажок напротив «Таблица с заголовками». Нажать Enter.
К указанному диапазону применится заданный по умолчанию стиль форматирования. Станет активным инструмент «Работа с таблицами» (вкладка «Конструктор»).
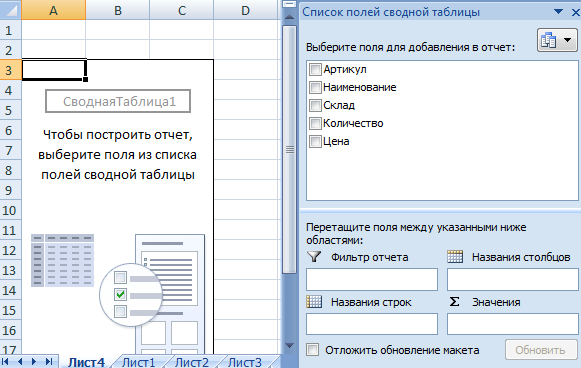
Составить отчет можно с помощью «Сводной таблицы».
- Активизируем любую из ячеек диапазона данных. Щелкаем кнопку «Сводная таблица» («Вставка» — «Таблицы» — «Сводная таблица»).
- В диалоговом окне прописываем диапазон и место, куда поместить сводный отчет (новый лист).
- Открывается «Мастер сводных таблиц». Левая часть листа – изображение отчета, правая часть – инструменты создания сводного отчета.
- Выбираем необходимые поля из списка. Определяемся со значениями для названий строк и столбцов. В левой части листа будет «строиться» отчет.
Создание сводной таблицы – это уже способ анализа данных. Более того, пользователь выбирает нужную ему в конкретный момент информацию для отображения. Он может в дальнейшем применять другие инструменты.
Анализ «Что-если» в Excel: «Таблица данных»
Мощное средство анализа данных. Рассмотрим организацию информации с помощью инструмента «Что-если» — «Таблица данных».
- данные должны находиться в одном столбце или одной строке;
- формула ссылается на одну входную ячейку.
Процедура создания «Таблицы данных»:
- Заносим входные значения в столбец, а формулу – в соседний столбец на одну строку выше.
- Выделяем диапазон значений, включающий столбец с входными данными и формулой. Переходим на вкладку «Данные». Открываем инструмент «Что-если». Щелкаем кнопку «Таблица данных».
- В открывшемся диалоговом окне есть два поля. Так как мы создаем таблицу с одним входом, то вводим адрес только в поле «Подставлять значения по строкам в». Если входные значения располагаются в строках (а не в столбцах), то адрес будем вписывать в поле «Подставлять значения по столбцам в» и нажимаем ОК.
Анализ предприятия в Excel: примеры
Для анализа деятельности предприятия берутся данные из бухгалтерского баланса, отчета о прибылях и убытках. Каждый пользователь создает свою форму, в которой отражаются особенности фирмы, важная для принятия решений информация.
Для примера предлагаем скачать финансовый анализ предприятий в таблицах и графиках составленные профессиональными специалистами в области финансово-экономической аналитике. Здесь используются формы бухгалтерской отчетности, формулы и таблицы для расчета и анализа платежеспособности, финансового состояния, рентабельности, деловой активности и т.д.
With a Data Table in Excel, you can easily vary one or two inputs and perform What-if analysis. A Data Table is a range of cells in which you can change values in some of the cells and come up with different answers to a problem.
There are two types of Data Tables −
- One-variable Data Tables
- Two-variable Data Tables
If you have more than two variables in your analysis problem, you need to use Scenario Manager Tool of Excel. For details, refer to the chapter – What-If Analysis with Scenario Manager in this tutorial.
One-variable Data Tables
A one-variable Data Table can be used if you want to see how different values of one variable in one or more formulas will change the results of those formulas. In other words, with a one-variable Data Table, you can determine how changing one input changes any number of outputs. You will understand this with the help of an example.
Example
There is a loan of 5,000,000 for a tenure of 30 years. You want to know the monthly payments (EMI) for varied interest rates. You also might be interested in knowing the amount of interest and Principal that is paid in the second year.
Analysis with One-variable Data Table
Analysis with one-variable Data Table needs to be done in three steps −
Step 1 − Set the required background.
Step 2 − Create the Data Table.
Step 3 − Perform the Analysis.
Let us understand these steps in detail −
Step 1: Set the required background
-
Assume that the interest rate is 12%.
-
List all the required values.
-
Name the cells containing the values, so that the formulas will have names instead of cell references.
-
Set the calculations for EMI, Cumulative Interest and Cumulative Principal with the Excel functions – PMT, CUMIPMT and CUMPRINC respectively.
Your worksheet should look as follows −
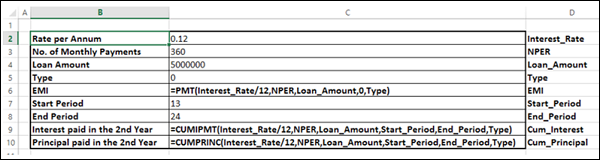
You can see that the cells in column C are named as given in the corresponding cells in column D.
Step 2: Create the Data Table
-
Type the list of values i.e. interest rates that you want to substitute in the input cell down the column E as follows −
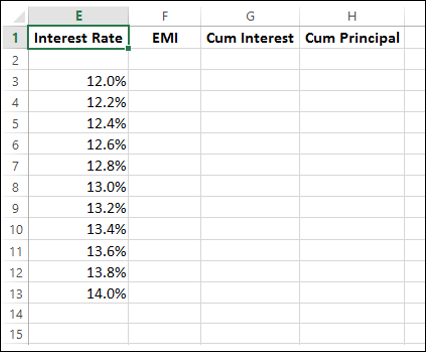
-
Type the first function (PMT) in the cell one row above and one cell to the right of the column of values. Type the other functions (CUMIPMT and CUMPRINC) in the cells to the right of the first function.
Now, the two rows above the Interest Rate values look as follows −
As you observe, there is an empty row above the Interest Rate values. This row is for the formulas that you want to use.

The Data Table looks as given below −
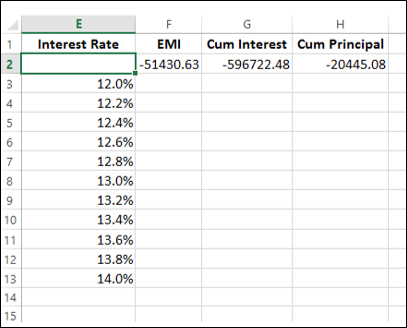
Step 3: Do the analysis with the What-If Analysis Data Table Tool
-
Select the range of cells that contains the formulas and values that you want to substitute, i.e. select the range – E2:H13.
-
Click the DATA tab on the Ribbon.
-
Click What-if Analysis in the Data Tools group.
-
Select Data Table in the dropdown list.
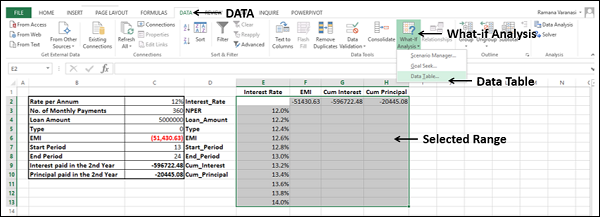
Data Table dialog box appears.
- Click the icon in the Column input cell box.
- Click the cell Interest_Rate, which is C2.
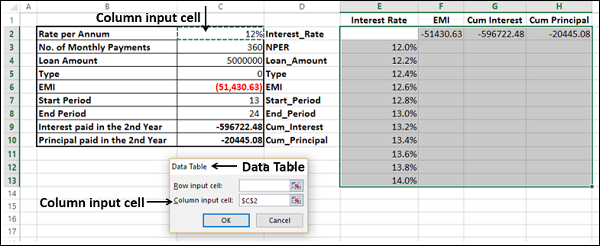
You can see that the Column input cell is taken as $C$2. Click OK.
The Data Table is filled with the calculated results for each of the input values as shown below −
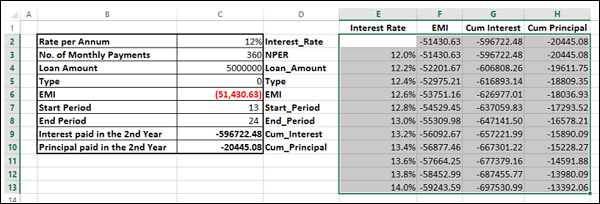
If you can pay an EMI of 54,000, you can observe that the interest rate of 12.6% is suitable for you.
Two-variable Data Tables
A two-variable Data Table can be used if you want to see how different values of two variables in a formula will change the results of that formula. In other words, with a twovariable Data Table, you can determine how changing two inputs changes a single output. You will understand this with the help of an example.
Example
There is a loan of 50,000,000. You want to know how different combinations of interest rates and loan tenures will affect the monthly payment (EMI).
Analysis with Two-variable Data Table
Analysis with two-variable Data Table needs to be done in three steps −
Step 1 − Set the required background.
Step 2 − Create the Data Table.
Step 3 − Perform the Analysis.
Step 1: Set the required background
-
Assume that the interest rate is 12%.
-
List all the required values.
-
Name the cells containing the values, so that the formula will have names instead of cell references.
-
Set the calculation for EMI with the Excel function – PMT.
Your worksheet should look as follows −

You can see that the cells in the column C are named as given in the corresponding cells in the column D.
Step 2: Create the Data Table
-
Type =EMI in cell F2.
-
Type the first list of input values, i.e. interest rates down the column F, starting with the cell below the formula, i.e. F3.
-
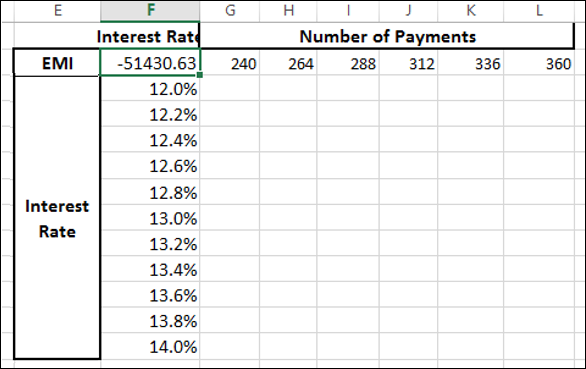
Type the second list of input values, i.e. number of payments across row 2, starting with the cell to the right of the formula, i.e. G2.
The Data Table looks as follows −
Do the analysis with the What-If Analysis Tool Data Table
-
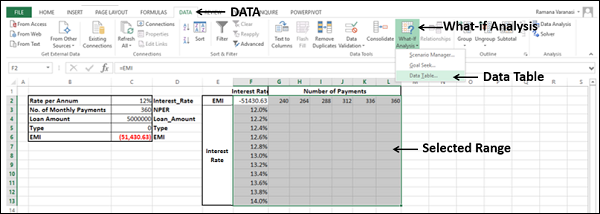
Select the range of cells that contains the formula and the two sets of values that you want to substitute, i.e. select the range – F2:L13.
-
Click the DATA tab on the Ribbon.
-
Click What-if Analysis in the Data Tools group.
-
Select Data Table from the dropdown list.
Data Table dialog box appears.
- Click the icon in the Row input cell box.
- Click the cell NPER, which is C3.
- Again, click the icon in the Row input cell box.
- Next, click the icon in the Column input cell box.
- Click the cell Interest_Rate, which is C2.
- Again, click the icon in the Column input cell box.
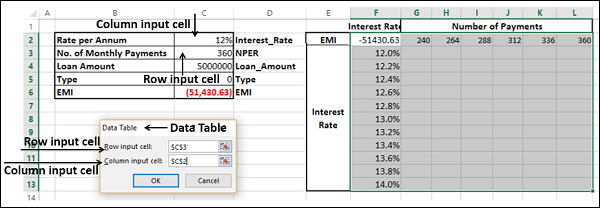
You will see that the Row input cell is taken as $C$3 and the Column input cell is taken as $C$2. Click OK.
The Data Table gets filled with the calculated results for each combination of the two input values −
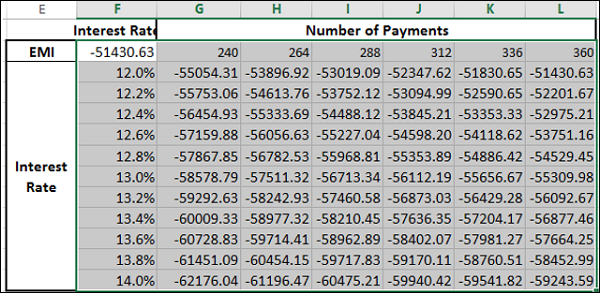
If you can pay an EMI of 54,000, the interest rate of 12.2% and 288 EMIs are suitable for you. This means the tenure of the loan would be 24 years.
Data Table Calculations
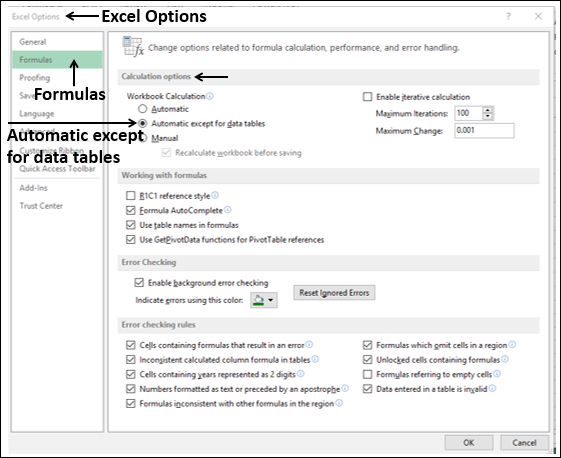
Data Tables are recalculated each time the worksheet containing them is recalculated, even if they have not changed. To speed up the calculations in a worksheet that contains a Data Table, you need to change the calculation options to Automatically Recalculate the worksheet but not the Data Tables, as given in the next section.
Speeding up the Calculations in a Worksheet
You can speed up the calculations in a worksheet containing Data Tables in two ways −
- From Excel Options.
- From the Ribbon.
From Excel Options
- Click the FILE tab on the Ribbon.
- Select Options from the list in the left pane.
Excel Options dialog box appears.
-
From the left pane, select Formulas.
-
Select the option Automatic except for data tables under Workbook Calculation in the Calculation options section. Click OK.
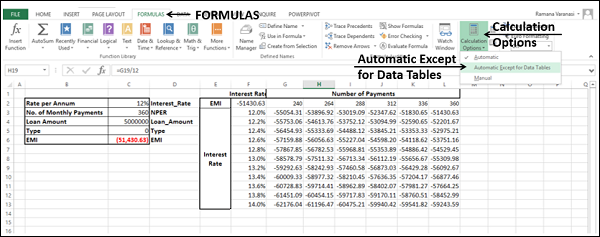
From the Ribbon
-
Click the FORMULAS tab on the Ribbon.
-
Click the Calculation Options in the Calculations group.
-
Select Automatic Except for Data Tables in the dropdown list.
Содержание
- 1 Использование описательной статистики
- 1.1 Подключение «Пакета анализа»
- 1.2 Применение инструмента «Описательная статистика»
- 1.3 Помогла ли вам эта статья?
- 1.4 Статистические процедуры Пакета анализа
- 1.5 Статистические функции библиотеки встроенных функций Excel

Пользователи Эксель знают, что данная программа имеет очень широкий набор статистических функций, по уровню которых она вполне может потягаться со специализированными приложениями. Но кроме того, у Excel имеется инструмент, с помощью которого производится обработка данных по целому ряду основных статистических показателей буквально в один клик.
Этот инструмент называется «Описательная статистика». С его помощью можно в очень короткие сроки, использовав ресурсы программы, обработать массив данных и получить о нем информацию по целому ряду статистических критериев. Давайте взглянем, как работает данный инструмент, и остановимся на некоторых нюансах работы с ним.
Использование описательной статистики
Под описательной статистикой понимают систематизацию эмпирических данных по целому ряду основных статистических критериев. Причем на основе полученного результата из этих итоговых показателей можно сформировать общие выводы об изучаемом массиве данных.
В Экселе существует отдельный инструмент, входящий в «Пакет анализа», с помощью которого можно провести данный вид обработки данных. Он так и называется «Описательная статистика». Среди критериев, которые высчитывает данный инструмент следующие показатели:
- Медиана;
- Мода;
- Дисперсия;
- Среднее;
- Стандартное отклонение;
- Стандартная ошибка;
- Асимметричность и др.
Рассмотрим, как работает данный инструмент на примере Excel 2010, хотя данный алгоритм применим также в Excel 2007 и в более поздних версиях данной программы.
Подключение «Пакета анализа»
Как уже было сказано выше, инструмент «Описательная статистика» входит в более широкий набор функций, который принято называть Пакет анализа. Но дело в том, что по умолчанию данная надстройка в Экселе отключена. Поэтому, если вы до сих пор её не включили, то для использования возможностей описательной статистики, придется это сделать.
- Переходим во вкладку «Файл». Далее производим перемещение в пункт «Параметры».
- В активировавшемся окне параметров перемещаемся в подраздел «Надстройки». В самой нижней части окна находится поле «Управление». Нужно в нем переставить переключатель в позицию «Надстройки Excel», если он находится в другом положении. Вслед за этим жмем на кнопку «Перейти…».
- Запускается окно стандартных надстроек Excel. Около наименования «Пакет анализа» ставим флажок. Затем жмем на кнопку «OK».

После вышеуказанных действий надстройка Пакет анализа будет активирована и станет доступной во вкладке «Данные» Эксель. Теперь мы сможем использовать на практике инструменты описательной статистики.
Применение инструмента «Описательная статистика»
Теперь посмотрим, как инструмент описательная статистика можно применить на практике. Для этих целей используем готовую таблицу.
- Переходим во вкладку «Данные» и выполняем щелчок по кнопке «Анализ данных», которая размещена на ленте в блоке инструментов «Анализ».
- Открывается список инструментов, представленных в Пакете анализа. Ищем наименование «Описательная статистика», выделяем его и щелкаем по кнопке «OK».
- После выполнения данных действий непосредственно запускается окно «Описательная статистика».
В поле «Входной интервал» указываем адрес диапазона, который будет подвергаться обработке этим инструментом. Причем указываем его вместе с шапкой таблицы. Для того, чтобы внести нужные нам координаты, устанавливаем курсор в указанное поле. Затем, зажав левую кнопку мыши, выделяем на листе соответствующую табличную область. Как видим, её координаты тут же отобразятся в поле. Так как мы захватили данные вместе с шапкой, то около параметра «Метки в первой строке» следует установить флажок. Тут же выбираем тип группирования, переставив переключатель в позицию «По столбцам» или «По строкам». В нашем случае подходит вариант «По столбцам», но в других случаях, возможно, придется выставить переключатель иначе.
Выше мы говорили исключительно о входных данных. Теперь переходим к разбору настроек параметров вывода, которые расположены в этом же окне формирования описательной статистики. Прежде всего, нам нужно определиться, куда именно будут выводиться обработанные данные:
- Выходной интервал;
- Новый рабочий лист;
- Новая рабочая книга.
В первом случае нужно указать конкретный диапазон на текущем листе или его верхнюю левую ячейку, куда будет выводиться обработанная информация. Во втором случае следует указать название конкретного листа данной книги, где будет отображаться результат обработки. Если листа с таким наименованием в данный момент нет, то он будет создан автоматически после того, как вы нажмете на кнопку «OK». В третьем случае никаких дополнительных параметров указывать не нужно, так как данные будут выводиться в отдельном файле Excel (книге). Мы выбираем вывод результатов на новом рабочем листе под названием «Итоги».
Далее, если вы хотите чтобы выводилась также итоговая статистика, то нужно установить флажок около соответствующего пункта. Также можно установить уровень надежности, поставив галочку около соответствующего значения. По умолчанию он будет равен 95%, но его можно изменить, внеся другие числа в поле справа.
Кроме этого, можно установить галочки в пунктах «K-ый наименьший» и «K-ый наибольший», установив значения в соответствующих полях. Но в нашем случае этот параметр так же, как и предыдущий, не является обязательным, поэтому флажки мы не ставим.
После того, как все указанные данные внесены, жмем на кнопку «OK».
- После выполнения этих действий таблица с описательной статистикой выводится на отдельном листе, который был нами назван «Итоги». Как видим, данные представлены сумбурно, поэтому их следует отредактировать, расширив соответствующие колонки для более удобного просмотра.
- После того, как данные «причесаны» можно приступать к их непосредственному анализу. Как видим, при помощи инструмента описательной статистики были рассчитаны следующие показатели:
- Асимметричность;
- Интервал;
- Минимум;
- Стандартное отклонение;
- Дисперсия выборки;
- Максимум;
- Сумма;
- Эксцесс;
- Среднее;
- Стандартная ошибка;
- Медиана;
- Мода;
- Счет.

Если какие-то из вышеуказанных данных для конкретного вида анализа не нужны, то их можно удалить, чтобы они не мешали. Далее производится анализ с учетом статистических закономерностей.
Урок: Статистические функции в Excel
Как видим, с помощью инструмента «Описательная статистика» можно сразу получить результат по целому ряду критериев, которые в ином случае рассчитывались с применением отдельно предназначенной для каждого расчета функцией, что заняло бы значительное время у пользователя. А так, все эти расчеты можно получить практически в один клик, использовав соответствующий инструмент — Пакета анализа.
Мы рады, что смогли помочь Вам в решении проблемы.
Задайте свой вопрос в комментариях, подробно расписав суть проблемы. Наши специалисты постараются ответить максимально быстро.
Помогла ли вам эта статья?
Да Нет
Описательная статистика в Эксель. Описательная статистика в MS Excel позволяет представить статистическую информацию как совокупность данных, для характеристики которых могут быть использованы различные показатели.
Использование инструмента «Описательная статистика» рассмотрим на примере MS Excel 2010, а в качестве данных для анализа возьмем статистическую информацию по изменению курса доллара за месяц:

Для начала на вкладке «Данные» в группе «Анализ» выбрать пункт «Анализ данных»:

В открывшемся окне «Анализ данных» выбрать инструмент для анализа «Описательная статистика»:

В новом окне «Описательная статистика»,

следует выбрать исходные данные для анализа:
• Входной интервал – это диапазон ячеек с исходными данными для анализа. В случае, если в исходный диапазон входит текстовый заголовок, тогда следует поставить галочку в поле «Метки в первой строке»
• Выходной интервал – это адрес верхней левой ячейки диапазона, в котором будут представлены результаты статистического анализа.
• Итоговая статистика – позволяет вывести дополнительные расширенные результаты анализа исходных данных.
• Уровень надежности – показывает вероятность того, что исследуемый исходный интервал содержит истинное значение оцениваемого параметра. В математической статистике обычно используют значения: 90%, 95%, 99%. В нашем случае, по умолчанию установлено значение 95%.
• К-ый наименьший – показывает наименьшее значение из исследуемого исходного интервала.
• К-ый наибольший – показывает наибольшее значение из исследуемого исходного интервала.
В результате использования инструмента «Описательная статистика», на основании наших исходных данных, получим:

Таким образом, для проведения сложного статистического или инженерного анализа, чтобы упростить процесс и сэкономить время, следует использовать инструмент «Описательная статистика» MS Exсel.
Основными средствами анализа статистических данных в Excel являются статистические процедуры надстройки Пакет анализа (Analysis ToolРак) и статистические функции библиотеки встроенных функций. Основные сведения обо всех этих средствах имеются в электронной справочной системе Excel.
Однако качество описаний статистических процедур и функций, приведенных в этой системе, заставляет желать лучшего. Некоторые из этих описаний не очень понятны, в них имеются неточности, а подчас и просто ошибки (это относится как к англоязычному оригиналу, так и к русскому переводу). Эти недостатки с завидным постоянством повторяются и во многих пособиях по Excel. Найти необходимые пособия в интернете можно быстро если скачать бесплатно Амиго браузер с усовершенствованным поисковым алгоритмом.
Статистические процедуры Пакета анализа
Наиболее развитыми средствами анализа данных являются статистические процедуры Пакета анализа. Они обладают большими возможностями, чем статистические функции. С их помощью можно решать более сложные задачи обработки статистических данных и выполнять более тонкий анализ этих данных.
В Пакет анализа входят следующие статистические процедуры:
- генерация случайных чисел (Random number generation);
- выборка (Sampling);
- гистограмма (Histogram);
- описательная статистика (Descriptive statistics);
- ранги персентиль (Rank and percentile);
- двухвыборочный z-тест для средних (z-Test: Two Sample for Means);
- двухвыборочный t-тест для средних с одинаковыми дисперсиями (t-Test: Two-Sample Assuming Equal Variances);
- двухвыборочный t-тест для средних с различными дисперсиями (t-Test: Two-Sample Assuming Unequal Variances);
- парный двухвыборочный t-тест для средних (t-Test: Paired Two Sample for Means);
- двухвыборочный F-тест да я дисперсий (F-Test: Two Sample for Variances);
- коварнация (Covariance);
- корреляция (Correlation);
- рецессия (Regression);
- однофакторный дисперсионный анализ (ANOVA: Single Factor);
- двухфакторный дисперсионный анализ без повторений (ANOVA: Two Factor Without Replication);
- двухфакторный дисперсионный анализ с повторениями (ANOVA: Two Factor With Replication);
- скользящее среднее (Moving Average);
- экспоненциальное сглаживание (Exponential Smoothing);
- анализ Фурье (Fourier Analysis).
Для доступа к процедурам Пакета анализа необходимо в меню Сервис (Tools) щелкнуть указателем мыши на строке Анализ данных (Data Analysis). Откроется диалоговое окно с соответствующим названием, в котором перечислены процедуры статистического анализа данных (рис. 1).

Рис.1. Диалоговое окно Анализ данных
Для того чтобы запустить в работу нужную статистическую процедуру, нужно выделить ее указателем мыши и щелкнуть на кнопке ОК. На экране появится диалоговое окно вызванной процедуры. На рис. 2 для примера показано диалоговое окно процедуры Описательная статистика (Descriptive statistics).

Рис.2. Диалоговое окно процедуры Описательная статистика
Диалоговое окно каждой процедуры содержит элементы управления: поля ввода, раскрывающиеся списки, переключатели, флажки и т. п. Эти элементы позволяют задать нужные параметры используемой процедуры. Некоторые элементы управления имеют специфический характер, присущий одной процедуре или небольшой группе процедур. Назначение таких элементов управления будет рассмотрено при описании соответствующих процедур. Другие элементы управления присутствуют в диалоговых окнах почти всех статистических процедур.
К числу общих для большинства процедур элементов управления относятся:
- поле ввода Входной интервал (Input Range). В это поле вводится ссылка на диапазон, содержащий статистические данные, подлежащие обработке. Входной диапазон может быть столбцом пли группой столбцов (строкой или группой строк);
- переключатель Группирование (Grouped By). В том случае, когда входной диапазон представляет собой столбец или группу столбцов, переключатель устанавливается в положение по столбцам (Columns). Если же входной диапазон представляет собой строку или группу строк, то переключатель устанавливается в положение по строкам (Rows). Более точным названием этого переключателя было бы название Расположение;
- флажок Метки (Labels in First Row). Флажок устанавливается в тех случаях, когда первая строка (первый столбец) входного диапазона содержит заголовки. Если такие заголовки отсутствуют, флажок Метки не устанавливают. При этом Excel автоматически создает и выводит на экран стандартные названия для данных выходного диапазона (Столбец1, Столбец2,… или Строка 1. Строка2,…);
- переключатели Выходной интервал/Новый рабочий лист/Новая книга (Output Range/New Worksheet/New Workbook). Эти переключатели определяют место вывода таблицы, содержащей результаты реализации статистической процедуры. В группе может быть выбран только одни переключатель.
При выборе переключателя Выходной интервал таблица результатов решения выводится на тот же рабочий лист, на котором находятся исходные данные. Справа от переключателя открывается поле ввода, в которое надо ввести ссылку на левую верхнюю ячейку таблицы результатов. Если возникает опасность наложения таблицы результатов на уже заполненные ячейки, на экране появляется сообщение о такой опасности. В ответ на это сообщение пользователь должен разрешить удаление старых данных и вывод на их место новых.
В положении Новый рабочий лист открывается новый лист рабочей книги. На этот лист, начиная с ячейки А1, и выводится таблица результатов решения. Справа от переключателя имеется поле ввода, в которое в случае необходимости можно ввести имя нового рабочего листа. При выборе переключателя Новая рабочая книга открывается новая рабочая книга. На первый лист этой новой книги, начиная с ячейки А1, выводится таблица результатов решения.
Следует заметить, что результаты;, получаемые с помощью статистических процедур Пакета анализа, не имеют постоянной связи с исходными данными — в случае изменения исходных данных результаты решения автоматически не изменяются. В том случае, когда необходимо получить результаты, автоматически изменяющиеся вместе с исходными данными, нужно использовать подходящие статистические функции библиотеки встроенных функций.
Эффективным и очень удобным в использовании средством парного регрессионного анализа и анализа временных рядов является процедура Добавить линию тренда (Add Trendline), входящая в комплекс графических средств Excel.
Статистические функции библиотеки встроенных функций Excel
Табличный процессор Excel имеет библиотеку встроенных функции рабочего листа (Worksheet function). Одним из разделов этой библиотеки является раздел Статистические функции. В этот раздел входят 83 функции, предназначенные для решения некоторых наиболее востребованных задач теории вероятностей и математической статистики.
Аргументы статистических функций должны быть числами или ссылками на диапазоны, которые содержат числа Если аргумент, который является массивом или ссылкой, содержит тексты, логические значения или пустые ячейки, то такие значения игнорируются, однако ячейки с нулевыми значениями учитываются.
Когда в качестве какого-либо аргумента встроенной статистической функции введен текст, функция выдает сообщение об ошибке #ЗНАЧ! (#VALUE!). Если в качестве аргумента, который по определению должен быть целым числом, введено число не целое, Excel использует в качестве аргумента целую часть этот числа. Никакие сообщения об этом «несанкционированном округлении» на экран не выводятся.
8 апреля 2022 г.
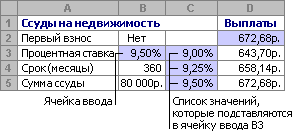
Когда вы вводите данные в Excel, вы можете ограничить входные данные, которые могут вводить пользователи вашего рабочего листа. Например, вы можете захотеть разрешить ввод данных только определенной длины или чисел в пределах предопределенного диапазона. Понимание того, как использовать функцию проверки данных в Excel, поможет вам более эффективно собирать точные данные. В этой статье мы обсудим, как использовать проверку данных в Excel, и объясним, как вы можете применить ее к другим ячейкам.
Проверка данных в Excel — это инструмент, который позволяет вам контролировать, какие входные данные может вводить пользователь. Он позволяет вам определить, какие значения вы хотите ограничить, чтобы вы могли собирать более точные данные в своей книге. Например, проверка данных позволяет:
-
Ограничьте входные данные выбором из раскрывающегося списка, который вы создаете.
-
Запретить время и даты, выходящие за пределы определенного диапазона.
-
Запретить значения, если они слишком длинные или слишком короткие.
-
Разрешить только числовые значения.
-
Разрешить только числа в пределах определенного диапазона.
-
Разрешить только текстовые значения.
-
Найдите неточные записи в проверенных ячейках.
-
Отображение входного сообщения для пользователя Excel.
-
Отображение предупреждающих сообщений при вводе неверных данных.
Как сделать проверку данных в Excel
Вот список шагов по проверке данных:
1. Выберите все ячейки, которые вы хотите проверить
Начните с выбора всех ячеек, которые вы хотите проверить. Если вы хотите проверить все ячейки на листе, вы можете щелкнуть одну ячейку, а затем одновременно нажать клавиши «Ctrl» и «A» на клавиатуре. Если вы хотите проверить только определенный столбец, строку или группу ячеек, щелкните самую верхнюю левую и перетащите курсор по всем соответствующим ячейкам.
2. Откройте всплывающее окно «Проверка данных».
Нажмите на вкладку «Данные», которая находится между вкладками «Формулы» и «Обзор». Найдите группу «Инструменты данных» и нажмите кнопку с надписью «Проверка данных». Кроме того, вы можете открыть всплывающее окно «Проверка данных», нажав клавиши «Alt», «D» и «L» на клавиатуре. Если вы выполняете это сочетание клавиш, убедитесь, что вы нажимаете каждую клавишу одну за другой, а не все одновременно.
3. Установите правило проверки данных
Во всплывающем окне «Проверка данных» перейдите на вкладку «Настройки». Здесь вы можете создать свое правило проверки данных. Одним из наиболее распространенных способов создания правила проверки является ограничение значений, которые может вводить пользователь. Вы можете выбрать, может ли пользователь вводить целые числа, десятичные дроби, даты, время или значения определенной длины. Затем вы можете выбрать желаемую категоризацию, которая может быть «Между», «Не между», «Равно», «Не равно» и другими вариантами. В зависимости от того, какой вариант вы выберете, вы можете ввести минимальные и максимальные значения по мере необходимости.
Вы также можете создать правило проверки данных, используя информацию из другой ячейки. Вместо ввода значений в поля «Минимум» и «Максимум» вы можете ввести имена ячеек. Точно так же вы также можете создать правило проверки данных с помощью формул. Когда вы вводите формулы в поля «Минимум» и «Максимум», убедитесь, что вы вводите формулу точно. Введите знак равенства, чтобы начать формулу, введите имя формулы, добавьте открывающую скобку, введите соответствующие ячейки и закройте формулу закрывающей скобкой.
4. Проверьте свой выбор
После того, как вы введете свой выбор, вы можете просмотреть его. Вы можете установить или снять флажок «Игнорировать пробел». Вы также можете установить флажок внизу, который позволяет применить ваши изменения ко всем другим ячейкам с теми же настройками, если вы хотите это сделать.
5. Создайте входное сообщение
Вы можете найти вкладку «Входящее сообщение» справа от вкладки «Настройки». Если вы нажмете на вкладку «Входящее сообщение», вы можете создать индивидуальное входное сообщение. Это позволяет информировать пользователя Excel о том, какие данные он может вводить. Это может сделать процесс ввода данных более эффективным и предотвратить ошибки пользователя.
После того, как вы откроете вкладку «Входящее сообщение», убедитесь, что вы установили флажок «Показывать входное сообщение, когда выбрана ячейка». Дайте вашему входному сообщению имя, введя его в поле «Заголовок». Чаще всего это имя столбца. Вы также можете ввести инструкции в поле «Ввод сообщения». Этот текст обычно представляет собой короткое предложение, хотя вы можете сделать его более краткой фразой.
6. Добавьте предупреждение об ошибке
Самая правая вкладка во всплывающем окне «Проверка данных» — это вкладка «Предупреждение об ошибке». Вы можете щелкнуть эту вкладку, чтобы создать предупреждение об ошибке, которое отображается всякий раз, когда пользователь вводит неверные данные. Вы можете создать один из трех различных типов предупреждений об ошибках. Первый тип оповещения об ошибке — это оповещение «Стоп», которое Excel выбирает по умолчанию. Это предупреждение является самым строгим, поскольку оно предлагает пользователю попробовать другую запись.
Второй вид предупреждений об ошибках — это предупреждение «Предупреждение». Это предупреждение информирует пользователя о недопустимых данных и сопровождается желтым предупреждающим знаком, но не препятствует его вводу. Третьим типом предупреждений об ошибках является «информационное» предупреждение. Это оповещение просто сообщает пользователю, что он ввел неверные данные, и позволяет ему нажать «ОК», чтобы продолжить работу, или «Отмена», чтобы удалить запись.
7. Нажмите «ОК», чтобы закрыть всплывающее окно «Проверка данных».
После внесения соответствующих изменений на всех трех вкладках можно нажать кнопку «ОК» в правом нижнем углу. Это закроет всплывающее окно «Проверка данных». На этом этапе вы можете начать вводить данные в выбранные вами ячейки.
Как перевести правила проверки данных в другие ячейки
Вы можете добавить свое правило проверки в новые ячейки. Вот список шагов по переносу правил проверки данных в другие ячейки:
-
Щелкните любую ячейку, содержащую ваше правило проверки.
-
Нажмите клавиши «Ctrl» и «C» на клавиатуре, чтобы скопировать эту ячейку.
-
Выделите все ячейки, которые хотите проверить, и используйте клавишу «Ctrl», если хотите выделить несмежные ячейки.
-
Щелкните правой кнопкой мыши свой выбор, выберите «Специальная вставка» и выберите «Проверка».
-
Нажмите «ОК», чтобы добавить правило проверки в новые ячейки.
Примеры проверки данных в Excel
Вот несколько примеров проверки данных в Excel:
Пример 1
Вот пример правила проверки целых чисел:
Владелец цветочного магазина продает различные виды цветов. У каждого цветка есть определенный номер продукта в диапазоне от 2000 до 2500. Владелец отслеживает свой инвентарь в документе Excel.
Они хотят упростить процесс ввода данных и свести к минимуму количество ошибок, поэтому создают правило проверки данных для всех ячеек в столбце А. Правило состоит в том, что ни одна ячейка в столбце А не может содержать число, отличное от 2000 и 2500. Если возникает ошибка, как в ячейке A4, владелец цветочного магазина запрограммировал отображение сообщения об ошибке, в котором говорится: «Пожалуйста, введите четырехзначный номер продукта от 2000 до 2500».
ABC1Номер продукта**Название продукта**Количество22001Тюльпаны1532002Одуванчики154203Орхидеи2552004Нарциссы3062005Калифорнийские маки15
Пример 2
Вот пример правила проверки дат:
Руководитель группы пытается зафиксировать отсутствие сотрудников в первую неделю апреля. Они создают правило проверки, поэтому в столбец А можно вводить только даты между 01.04 и 08.04. После ввода дат в ячейке A3 появляется предупреждение об ошибке, так как там написано «4/22». «4/22» выходит за пределы определенного диапазона, поэтому пользователь может узнать, что он допустил ошибку, и исправить запись так, чтобы она звучала как «4/2».
AB1Дата**Количество отсутствий**24/1534/22244/3154/5064/67### Пример 3
Вот пример правила проверки для списка:
Менеджер пытается выяснить, с какими сотрудниками ему еще нужно встретиться, чтобы обсудить ежегодное повышение зарплаты. Прежде чем открыть группу «Проверка данных», они вводят «Да» и «Нет» в соседние ячейки. В диалоговом окне «Проверка данных» они выбирают параметр «Список» и выбирают ячейки, в которых указано «Да» и «Нет».
Это создает раскрывающееся меню, которое позволяет пользователю подтвердить, встречался ли сотрудник с менеджером или нет. В этом примере ячейка B7 выдает ошибку, поскольку в ней нет значения «Да» или «Нет». Менеджер может использовать эту информацию, чтобы знать, что ему все еще нужно подтвердить статус Патрика Уитакера.
AB1Имя сотрудника**Необходима встреча с менеджером?*2Коллинз, Ирэн, Да3Даллас, ДжонНет4Мерриман, МоллиNo5Пэрриш, НэнсиДа6Ричардсон, МэриНет7Уитакер, Патрикн/aОбратите внимание, что ни одна из компаний, упомянутых в этой статье, не связана с компанией Indeed.*
Содержание
- — Что такое входные данные в Excel?
- — Как создать область ввода в Excel?
- — Что такое ввод и вывод в Excel?
- — Что такое входное сообщение при проверке данных?
- — Что такое ячейка ввода?
- — Как использовать функцию ввода в Excel?
- — Как найти ввод ячеек в Excel?
- — Как вы пишете проверку данных?
- — Как выполняется проверка данных?
Назначение области ввода — облегчить пользователю изменение входных параметров, влияющих на результат модели. … Область ввода модуля состоит только из ссылок на отдельные ячейки, а метка используется для идентификации данных. Во входной области модуля нет вычислений.
Входное сообщение в Excel может использоваться для отображения сообщения, когда ячейка выбрана. Это особенно полезно, если вы хотите показать пользователю некоторые инструкции, когда он / она выбирает ячейку. Примерами могут быть отображение инструкций по заполнению форм или инструкций по вводу данных.
Как создать область ввода в Excel?
Ниже приведены шаги по созданию новой записи с помощью формы ввода данных в Excel:
- Выберите любую ячейку в таблице Excel.
- Щелкните значок формы на панели быстрого доступа.
- Введите данные в поля формы.
- Нажмите клавишу Enter (или нажмите кнопку New), чтобы ввести запись в таблицу и получить пустую форму для следующей записи.
Что такое ввод и вывод в Excel?
В разделе «Ввод» вы должны указать Excel, какую часть данных вы собираетесь использовать для анализа и как они сгруппированы по темам. Другими словами, вы должны указать диапазон ввода данных и столбец или строку в качестве темы. В опции вывода вы должны сообщить Excel, какая статистика вам нужна и где отображать результат.
Что такое входное сообщение при проверке данных?
С помощью параметров, доступных при проверке данных, вы можете отображать сообщения, чтобы давать инструкции людям, использующим вашу электронную таблицу. Есть два типа сообщений проверки данных: Входное сообщение может отображаться, когда ячейка выбрана. Предупреждение об ошибке может отображаться, если в ячейку введены недопустимые данные.
Что такое ячейка ввода?
Любой из пяти типов ячеек может быть установлен в качестве входных ячеек. Только если задано как вход, Пользователь вводит информацию в Режим формы. Идентификатор входной ячейки — это установленный флажок Входная ячейка. Пользователи в режиме формы не имеют доступа к атрибутам ячеек, таким как тип подчеркивания и шрифт.
Как использовать функцию ввода в Excel?
Если вы хотите ввести одно и то же значение в несколько ячеек, вы можете быстро сделать это следующим образом:
- Выделите все ячейки, которые хотите заполнить;
- Введите значение или текст в активную ячейку;
- Нажмите Ctrl + Enter. Т.е. нажмите клавишу Ctrl и, удерживая ее, нажмите Enter (или Return).
Как найти ввод ячеек в Excel?
Используйте стиль Excel для определения ячеек ввода данных
- Щелкните вкладку «Главная» и щелкните раскрывающееся меню «Стили ячеек» в группе «Стили».
- Щелкните Новый стиль ячейки внизу списка. …
- В диалоговом окне «Стиль» введите имя InputCell и нажмите «Формат».
Как вы пишете проверку данных?
Добавить проверку данных в ячейку или диапазон
- Выберите одну или несколько ячеек для проверки.
- На вкладке «Данные» в группе «Работа с данными» щелкните «Проверка данных».
- На вкладке Параметры в поле Разрешить выберите Список.
- В поле Источник введите значения списка, разделенные запятыми. …
- Убедитесь, что установлен флажок в раскрывающемся списке в ячейке.
Как выполняется проверка данных?
Скрипты: обычно выполняется проверка данных использование языка сценариев, такого как Python, для написания сценариев для проверки процесс. Например, вы можете создать XML-файл с именами исходной и целевой баз данных, именами таблиц и столбцами для сравнения. … Например, инструменты проверки данных FME могут проверять и исправлять данные.
Интересные материалы:
Что такое перемычка на жестком диске?
Что такое пример набора данных?
Что такое режим конвекции в духовке?
Что такое сброс настроек браузера?
Что в настройках WhatsApp?
Что вызывает сброс времени и настроек BIOS?
Дешевле ли покупать инструменты в комплекте?
Должен ли быть бетонный столб для почтового ящика?
Должен ли я установить маршрутизатор на https?
Должны быть настройки прокси-сервера включены или выключены?