

- Различия между SPSS и EXCEL
Различия между SPSS и EXCEL
SPSS называется Статистическим пакетом для социальных наук. SPSS является основным участником рынка с точки зрения инструментов статистической упаковки, которые можно эффективно использовать в качестве производной для манипулирования данными и их хранения. Он в основном используется для пакетной обработки с точки зрения интерактивных пакетов и неинтерактивных пакетов.
Это был продукт, инкубированный SPSS Inc., затем он был приобретен IBM в 2009 году, и он переходит под зонтик и был переименован в IBM SPSS Statistics в версии 2015 года. В настоящее время он имеет стабильную сборку V-2015.
SPSS поставляется с версией с открытым исходным кодом под названием PSPP. Он справедливо обслуживает процесс статистики и разработки методов манипулирования данными с очень немногими исключениями, которые используются для профессионального манипулирования большими порциями данных. У него очень хороший атрибут с версией с открытым исходным кодом, срок действия которого не истечет в будущем, вы можете продолжать использовать то же самое время, которое хотите использовать.
SPSS предоставляет графику, которая имеет больше аналитических функций. После того как вы создали стандартную графику в SPSS, вы можете выделить данные или диапазоны и т. Д. SPSS также позволяет выводить графику в виде файлов HTML5 / .mht. Это делает их доступными через веб-браузер.
Excel позволяет пользователю хранить информацию в табличном формате и взаимодействовать со своими данными бесконечным количеством способов. Наиболее распространенной является сортировка и фильтрация данных, а также использование формул и сводных таблиц для манипулирования данными для создания новых идей.
Excel также позволяет использовать несколько методов импорта и экспорта данных, что позволяет интегрировать их в рабочие процессы. У этого также есть своя собственная способность программирования автоматизировать шаги или создать Ваши собственные пользовательские функции, известные как VBA.
Excel — это инструмент, используемый для ввода данных и создания записей, который может использоваться в дальнейшем для дальнейшего использования и манипулирования в соответствии с требованиями пользователя, и, будь то манипулирование или управление данными, он является очень жизнеспособным инструментом. Он также предоставляет гибкость в использовании внешней базы данных для анализа, составления отчетов и т. Д., Что позволяет сэкономить много времени. Excel с последними версиями имеет высокие графические инструменты и методы визуализации.
Сравнение лицом к лицу между SPSS и EXCEL
Ниже приведены 8 лучших отличий SPSS от EXCEL 
Ключевые различия между SPSS и EXCEL
Ниже приведены списки точек, описывающих ключевые различия между SPSS и EXCEL.
1. SPSS — это инструмент, используемый для вычислений, которые состоят из различных предметов, таких как хранилища данных и форматы данных. В то время как Excel также включает в себя математические понятия, такие как статистика, алгебра, исчисление, расширенная статистика и т. Д.,
2.SPSS дает нам знания о том, как процесс встроен в пакеты и работает, а также об управлении памятью в областях программирования. Excel дает нам представление о том, как данные могут быть использованы для изучения того, как данные будут храниться, обрабатываться и обрабатываться, чтобы уменьшить избыточность и сделать ее значимой для дальнейшего использования.
3.SPSS дает нам подробное представление об использовании вычислительных хранилищ и эффективности системы памяти. Excel показывает, как извлечь информацию и знания из данных в различных форматах.
4. Подразделы SPSS включают вычисления, вероятностные теории, рассуждения, дискретные структуры и базу данных. Excel включает в себя гораздо более сложные и простые математические операции и аналитику.
5.SPSS — это основной инструмент для обработки и статистического анализа, а Excel — стандартное приложение для обработки данных.
6.SPSS полностью об эффективном использовании методов манипулирования данными для получения хороших результатов, а Excel — о безопасной обработке и хранении данных.
7.SPSS — это полностью пакетная обработка со статистикой, в то время как Excel — это метод вычисления и формирования данных.
8.SPSS развивается с использованием передовых концепций, а IBM предлагает более эффективные и передовые алгоритмы. Excel растет день ото дня, что усложняет его обработку и эффективное обслуживание, но все еще требует гораздо больших улучшений.
9. SPSS имеет дело со статистическими алгоритмами, уделяющими больше внимания манипулированию данными. Excel представляет собой сочетание математики и хранения данных в нескольких форматах.
SPSS против EXCEL Сравнительная таблица
Ниже приведена таблица сравнения между SPSS и EXCEL.
| ОСНОВА ДЛЯ
СРАВНЕНИЕ |
SPSS | EXCEL |
| Определение | Статистический пакет для социальных наук, инструмент, разработанный для статистического анализа данных. | Продукт Microsoft, используемый для ввода данных и манипулирования данными для хранения некоторой информации. |
| использование | Статистические расчеты и манипулирование данными в соответствии с рекомендациями IBM. | Управление и хранение данных с помощью сформулированных операций, определенных Microsoft. |
| Преимущества | Скорость и производительность | Сокращение избыточности данных |
| Использование в реальном времени | Использование современных и сверхбыстрых устройств, таких как суперкомпьютеры | Обслуживание и обработка больших объемов данных клиентов |
| Академики | Существует со многих лет под зонтиком SPSS теперь под IBM | Существует и развивается с развитием отрасли науки и техники |
| Промышленность | Data Scientist / Analyst — профессия, которой можно стать после обучения в этой области. | Data Scientist / Analyst — профессия, которой можно стать после обучения в этой области. |
| Приложения | Относится ко всем техническим отраслям и крупным компаниям | Относится к компаниям, где необходимо управлять крупными конфиденциальными данными |
| поле | Охватывает всю технологическую область, которая является надмножеством Data Science | Подмножество компьютерных наук, где изучение данных осуществляется с использованием различных методов и технологий. |
Вывод — SPSS против EXCEL
Наконец, заключаем, что есть огромная разница между SPSS и Excel. Excel — это программное обеспечение для работы с электронными таблицами, SPSS — это программное обеспечение для статистического анализа.
В Excel вы можете выполнить некоторый статистический анализ, но SPSS более мощный. SPSS имеет встроенные инструменты манипулирования данными, такие как перекодирование, преобразование переменных, и в Excel у вас много работы, если вы хотите выполнить эту работу.
SPSS позволяет выполнять сложную аналитику, такую как факторный анализ, логистическая регрессия, кластерный анализ и т. Д. И т. Д.
В SPSS каждый столбец является одной переменной, Excel не обрабатывает столбцы и строки таким образом (при обработке тома и строк SPSS больше похож на Access, чем на Excel).
Excel не дает вам бумажный след, где вы можете легко воспроизвести точные шаги, которые вы сделали. Это также становится громоздким для использования, когда число переменных и наблюдений начинает становиться действительно большим.
Но и SPSS, и EXCEL служат вам в своих областях исключительно хорошо. Итак, и SPSS, и EXCEL являются королями своей территории.
Рекомендуемая статья
Это было руководство по различиям между SPSS и EXCEL, здесь мы обсудили их значение, сравнение между собой, ключевые различия и выводы. Вы также можете посмотреть следующие статьи, чтобы узнать больше —
- Узнайте 10 лучших отличий между HTML5 и Flash
- Контролируемое обучение против глубокого обучения — лучшее 5 полезных сравнений
- Java против Python — Лучшие 9 важных сравнений, которые вы должны изучить
- Hadoop vs Cassandra — узнай 17 удивительных отличий
- Прогнозирующая аналитика против описательной аналитики — какая из них лучше
Содержание
- IBM SPSS Advantage for Microsoft Excel
- Specialized tools extending the capabilities of Excel to manage and analyze business datasets
- Getting started
- Conduct RFM analysis
- Easily identify groups
- Find unusual data
- Prepare and transform data
- Save Excel tables to native IBM SPSS Statistics data files
- Importing Data into SPSS from Excel
- Preparing Excel
- Importing Data from Excel into SPSS
- Read Excel File Dialog Box
- Check Your Data Within SPSS
- Variable View
- EZSPSS on YouTube
- Используем Excel для написания синтаксиса SPSS
IBM SPSS Advantage for Microsoft Excel
Specialized tools extending the capabilities of Excel to manage and analyze business datasets
- Overview
- Features and Benefits
- System Requirements
IBM® SPSS® Advantage™ for Microsoft® Excel® gives you selected IBM SPSS Statistics functionality seamlessly integrated with this highly popular spreadsheet program.
While Excel is a very useful business tool, it has limitations – and now that it can handle large datasets, you also need help to manage this data. IBM SPSS Advantage for Microsoft Excel gives you advanced tools to more efficiently and effectively manage and analyze business datasets.
IBM SPSS Advantage for Microsoft Excel puts the right tools at your fingertips, enabling you to:
- Conduct RFM analysis
- Easily identify groups
- Find unusual data
- Prepare and transform data
- Save Excel tables to native IBM SPSS data files
For decades, analysts have relied on IBM SPSS Statistics to help them guide decision-making through data analysis. IBM SPSS Advantage for Excel 2007 provides selected IBM SPSS Statistics techniques, plus the ability to access, manage and analyze enormous amounts of data.
This means you can discover information in your data even if you don’t have a detailed knowledge of statistics. IBM SPSS Advantage for Microsoft Excel includes 10 procedures specifically chosen to enable business users to use advanced data preparation and analysis tools within Excel. In particular, it features procedures for conducting recency, frequency and monetary value (RFM) analysis. Wizards guide you through the steps to help you manage and explore data, find value in your large datasets and perform analysis.
Getting started
IBM SPSS Advantage for Microsoft Excel seamlessly integrates into the Excel interface. Just click on “IBM SPSS Advantage” from the Excel menu, and select a procedure from the ribbon to get started. Each IBM SPSS Statistics function is operated through a wizard or tabbed dialog, making it easy for you to get results. You don’t need the scripting or programming skills often required to utilize complex statistical products.
Conduct RFM analysis
Recency, frequency and monetary value (RFM) analysis is a technique often used in direct marketing for identifying your most profitable customers. Experience has shown that recency (the most recent time you had an interaction with a customer), frequency (the number of interactions you have you have had with a customer), and monetary value (the amount of money you have received from the customer) are the best predictors of a propensity to buy from you in the future.
With IBM SPSS Advantage for Microsoft Excel, you can very easily conduct RFM analysis to identify these customers. Wizards help you create RFM scores for customer or transaction data by stepping you through RFM analysis. IBM SPSS Advantage for Excel 2007 also produces charts for diagnostic tests, which help you understand the distribution of your data. Once you have results, you’ll be ready to market to existing customers who are most likely to respond to a new offer.
Easily identify groups
IBM SPSS Advantage for Microsoft Excel enables you to create highly visual classification trees that help you identify market segments. For example, use classification trees to identify the characteristics of customers likely to buy certain product types. Because you display results visually, you can more clearly spot relationships in your data. This advanced, yet easy-to-use classification tree analysis enables you to explore results and find specific subgroups and relationships in your data that you might not uncover by using the statistics in Excel.
Find unusual data
Now that Excel datasets can be much larger than before, it’s no longer possible to “eyeball” your data to make sure nothing is amiss. Additionally, more data means a higher risk of bad data.
A specific procedure in IBM SPSS Advantage for Microsoft Excel enables you to catch problem data so that you can remove or correct them prior to analysis.
Use this procedure to detect invalid values caused by data entry errors and to detect truly unusual cases that are unsuitable for analysis. IBM SPSS Advantage for Microsoft Excel will highlight the cell of data and provide a brief explanation as to why it found it anomalous.
Prepare and transform data
IBM SPSS Advantage for Microsoft Excel provides you with procedures that enable you to prepare and transform data. Use these procedures to re-organize data and put them in a format to aid analysis. Additionally, you gain more options to explore data, which makes it easier to find value in larger datasets.
- Join tables – With IBM SPSS Advantage for Microsoft Excel, you can merge two Excel tables based on criteria that match rows in one table with rows in the other table.
- Restructure data – You can restructure tables to combine information from multiple rows. For example, use this procedure to restructure transactional data. You can create a single row for each customer, with each transaction recorded in a separate column – giving you a new way to look at the data.
- Aggregate rows – Combine groups of rows in a selected table into single rows to easily create a new, aggregated table containing summary data for each group. For example, if you have a table that records each purchase made by a customer on a separate row and identifies each customer by a unique ID value, you can group the records by ID value. IBM SPSS Advantage for Microsoft Excel enables you to create an aggregated table with one row for each customer, using selected summary values for other columns from the original table.
- Group data into ranges – Sometimes you want to “bin” data so that you can look at its ranges. For example, you might want to group ages by ranges (less than 20, 20-29, 30-39, 40-49, and so forth) to examine the buying habits of different age groups. The bin values procedure in IBM SPSS Advantage for Microsoft Excel provides you with an easy-to-use interface to establish data ranges.
IBM SPSS Advantage for Microsoft Excel presents you with automatically set cutpoints that you can customize to best fit the distribution of your data. When you save binned values, IBM SPSS Advantage for Microsoft Excel creates a new column containing data grouped into ranges. You can also create a new column containing text values that describes each range, as well as a column containing the sequential integer values assigned to each range category in ascending order. - Optimize bins for models – With IBM SPSS Advantage for Microsoft Excel, you can transform scale-type data by distributing the values into bins. You can then use the binned data instead of original data values for further analysis. For example, you might want to optimize data into bins to safeguard the privacy of data sources. Instead of reporting the actual values, you can use the binned numbers. Additionally, some analysis is more efficient when working with a reduced number of variables. Optimized binning creates groups for the column of choice (such as ages) in relation to another variable.
Save Excel tables to native IBM SPSS Statistics data files
For additional data management and analysis capabilities, you may want to consider updating to the full version of IBM SPSS Statistics. Whether you choose to do this in the near or long-term future, you will be able to use your Excel tables in IBM SPSS Statistics. IBM SPSS Advantage for Microsoft Excel enables you to save Excel tables in IBM SPSS Statistics-formatted data files.
Источник
Importing Data into SPSS from Excel
This tutorial explains how to import data from Excel into the SPSS statistics package.
Preparing Excel
Open the Excel spreadsheet from which you wish to import data.
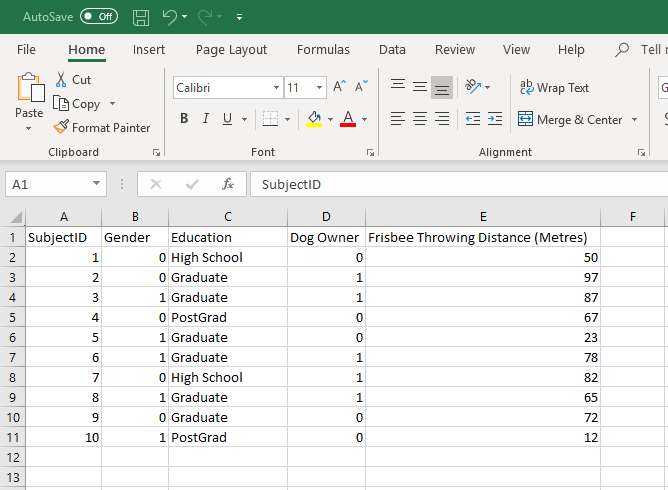
You can see in our example that we have 5 columns of data.
Before you begin the process of importing your data into SPSS, you need to ensure that your variable names are in the first row of the worksheet, and that there is no gap between the first and second rows. Our worksheet satisfies both these requirements.
It’s also wise to clean up your data. For example, if you had coded one of the Frisbee Throwing Distance items as “50m” rather than just “50”, this would be a good time to make a correction.
Once you have got your worksheet straight, you can open up SPSS.
Importing Data from Excel into SPSS
There are a number of different ways to import data into SPSS. We’re going to use a method that allows backward compatibility with older versions of SPSS.
To start, click File -> Open -> Data (as below).
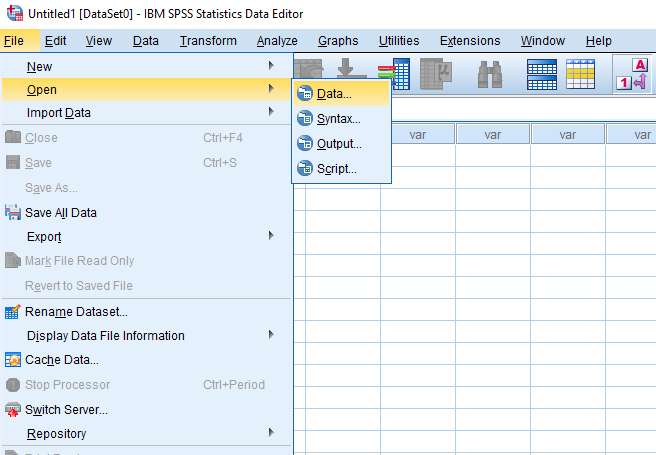
Once you click Data, the Open Data box will appear.
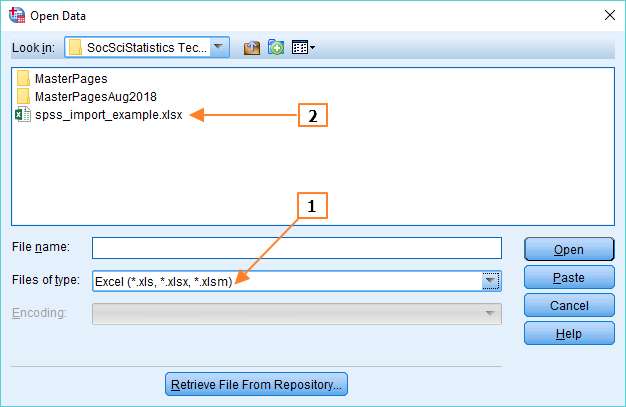
In the Files of type box, you need to select Excel (see 1 above, though obviously things will look slightly different if you’re using a Mac). Then navigate to the folder that contains your Excel file, and you’ll see your Excel file pop up (see 2 above). Open the file, and you’ll get the Read Excel File dialog box.
Read Excel File Dialog Box
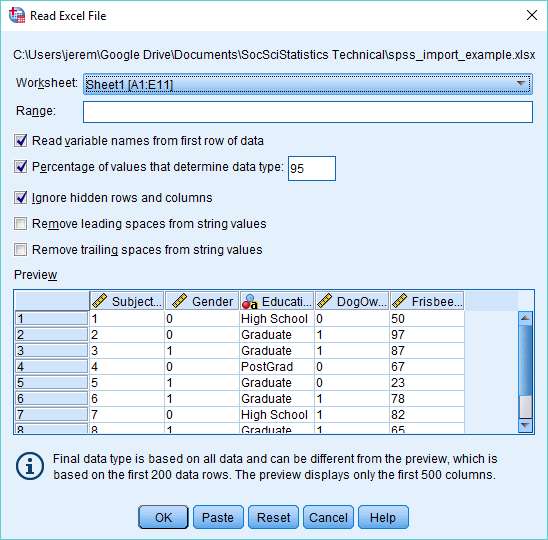
This dialog box offers a number of options. Mainly these are self-explanatory, but it is probably worth explaining the “Percentage of values that determine data type” option. This is how the latest version of SPSS assigns a data type to your variables. The percentage is the proportion of values in a particular column that must match a specific data type for SPSS to assign that data type to a variable. In our example, a variable will be assigned to a particular data type if 95% of values match that type (for example, if 95% of values are numeric in form). The value can be any number above 50. If SPSS is unable to determine a data type on this basis it will assign the variable to a string type.
Once you’ve selected the options you require, and checked your data looks okay in the preview window, press OK to begin the import.
Check Your Data Within SPSS
SPSS will import your data into a new Data View with variable names at the top.
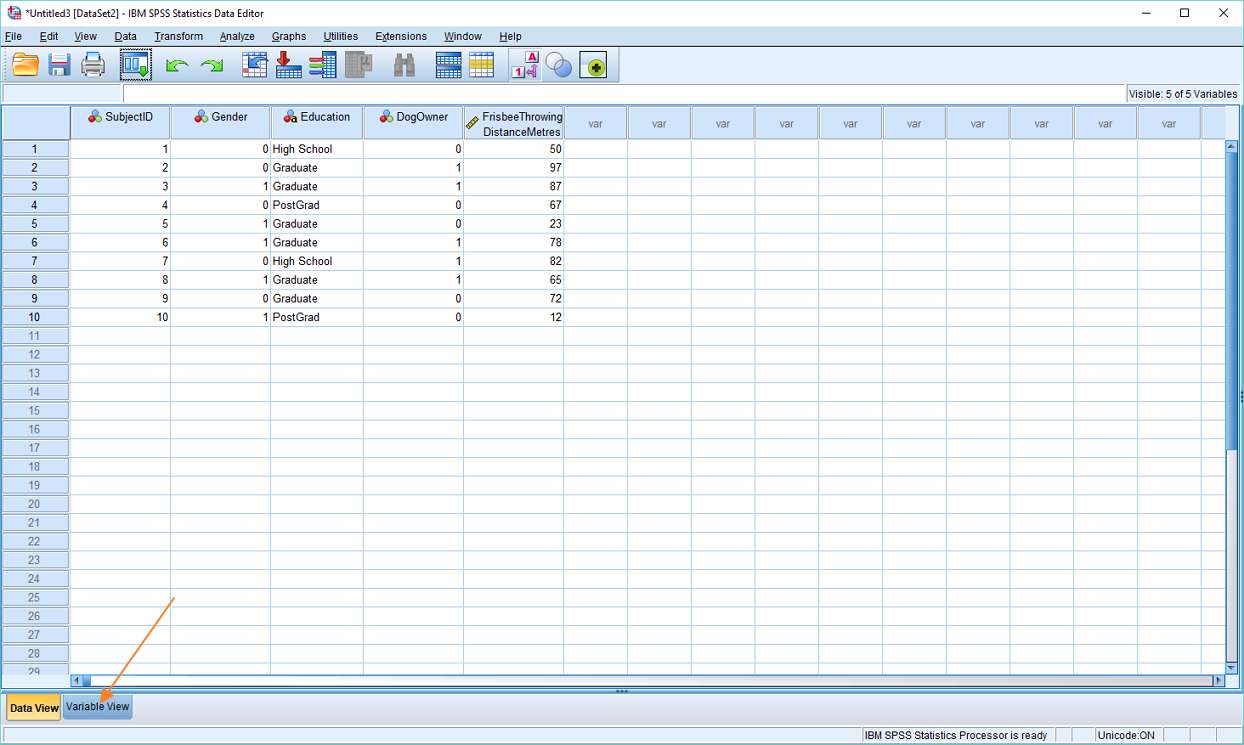
Obviously, the first thing to do here is to check that the data has come across successfully. If everything looks okay, the next stage is to check whether the various data parameters have been set correctly. Is numerical data correctly set as numerical, for example?
To check this, click on the Variable View tab (see red arrow, above). This will bring up the variable view within SPSS.
Variable View
As you can see from the image below, SPSS did a good job with our sample data, correctly identifying SubjectID, Gender, DogOwner and FrisbeeThrowing as data type numeric, and Education as data type string.
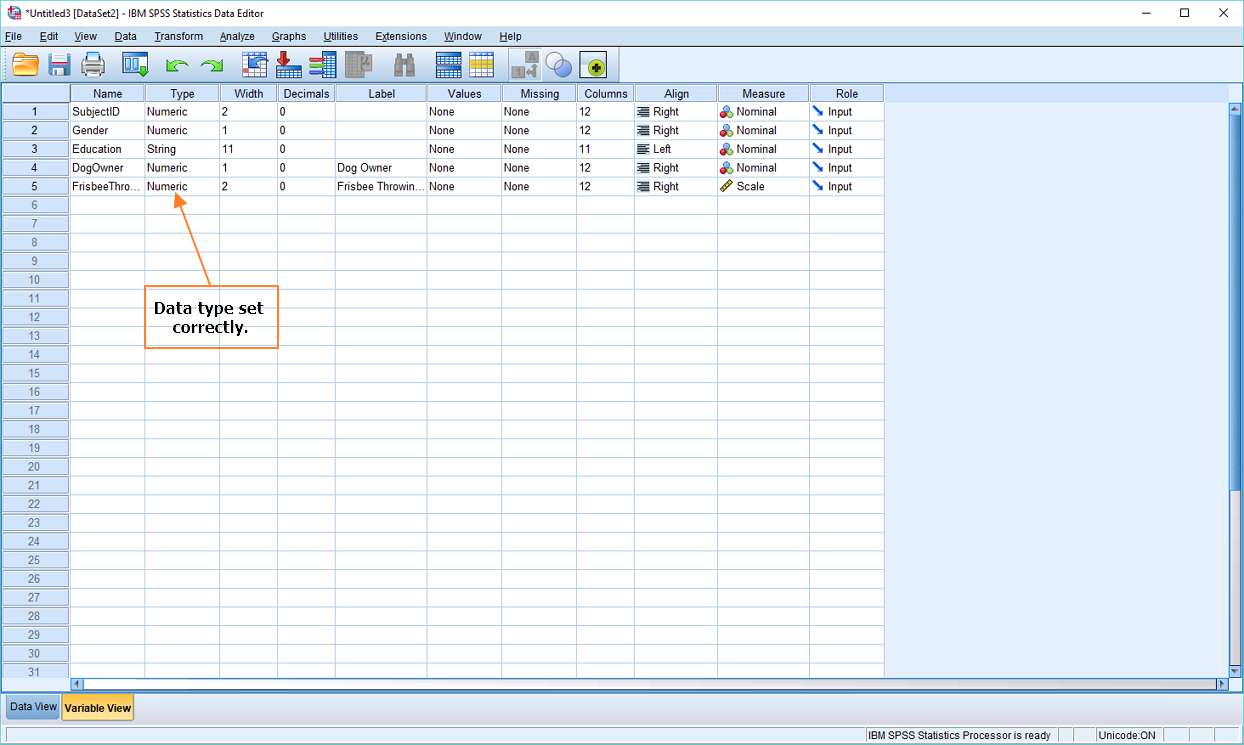
It also got level of measurement correct (see the Measure column), identifying SubjectID, Gender, Education and DogOwner as nominal data, and FrisbeeThrowing as scale (that is, as interval/ratio data).
That’s pretty much it for this tutorial. You should now have a good idea of how to import data from Excel into the SPSS statistics package.
EZSPSS on YouTube
We have a video tutorial that covers this same material in slightly more detail. Check it out!
Источник
Используем Excel для написания синтаксиса SPSS
IBM SPSS Statistics и Microsoft Excel – инструменты, отлично дополняющие друг друга. Мы используем файлы Excel для импорта и экспорта данных из/в SPSS, экспорта и правки результатов. В этой публикации мы рассмотрим небольшой «трюк» в Excel, который существенно ускоряет разработку кода (синтаксиса) SPSS.
Случается, что под рукой имеются структурированные метаданные (описания, метки, правила категоризации переменных), которые вы хотели бы переложить в командный синтаксис SPSS. Вот несколько примеров таких ситуаций:
- Есть список имен и список меток переменных. Вы хотели бы создать синтаксис, который назначает метки для соответствующих переменных ( VARIABLE LABELS );
- Есть списки старых и новых имен переменных, и вам необходимо создать синтаксис, который бы переименовал переменные в соответствии с этими правилами;
- Есть перечень значений некоторой категориальной переменной и перечень меток этих значений. Необходимо назначить метки значений (с помощью команды VALUE LABELS );
- Есть набор границ (диапазонов) значения числовой переменной и соответствующие им значения и метки для создаваемой категориальной переменной. Необходимо разработать синтаксис, создающий категориальную переменную на основе заданных диапазонов, и описывающий ее.
В ситуации, когда указанные списки достаточно длинные, простое их копирование в редактор синтаксиса с последующим ручным «превращением» этих заготовок в валидный синтаксис, может быть утомительным.
К счастью, функции работы со строками Excel помогут автоматизировать разработку синтаксиса, так, что ничего вручную писать не потребуется. В следующем примере мы увидим, как с помощью одной лишь функции =СЦЕПИТЬ() , или, в английском интерфейсе Excel, =CONCATENATE() , мы сможем быстро назначить метки огромному списку (сотен или тысяч) значений. Для наполнения примера мы возьмем синтаксис назначения меток округов США к кодам FIPS (см. оригинал http://spsstools.net/en/syntax/syntax-index/standard-data-files/create-labels-with-common-names-for-us-county-fips-codes/). Как мы могли бы получить этот синтаксис, если бы коды округов и метки (названия) округов изначально имелись бы в Excel-файле, таком как приведенный ниже?
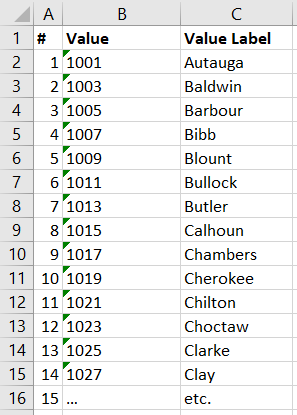
Рисунок 1. Исходные метаданные (метки значений) на листе Excel
Предположим, в SPSS коды округов находятся в строковой переменной county (строковой, так как нам необходимо сохранить ведущие нули). В SPSS синтаксис назначения меток должен выглядеть примерно так:
Мы очень быстро можем создать «костяк» данного синтаксиса, введя в новый столбец Excel следующую формулу:
В англоязычном интерфейсе Excel функция будет называться иначе:
Суть этой формулы – в создании нового строкового значения по следующим правилам:
- Значение начинается с 4-х пробелов (вообще говоря, они не обязательны и используются здесь лишь для визуальной отбивки синтаксиса).
- Затем вставляется одинарная кавычка. И пробелы, и одинарная кавычка помещается между двойными кавычками, так как для Excel это – текстовое значение.
- Затем вставляется значение кода округа из ячейки B2 .
- Вставляется закрывающая кавычка для текстового значения кода, затем пробел, и снова открывающая кавычка.
- Вставляется метка значения из ячейки C2 .
- Наконец, вставляем еще одну одинарную кавычку – описание метки закончено.
Соединяемые фрагменты строки перечисляются, по правилам Excel, точкой с запятой.
После того, как мы ввели эту формулу в ячейку D2 , в ней отобразится результирующая строка:
Осталось «протянуть» данную формулу вниз до конца списка. И это делается очень быстро, независимо от количества округов и их названий. Excel автоматически изменит ссылки в копируемой формуле. В итоге лист будет выглядеть примерно так:
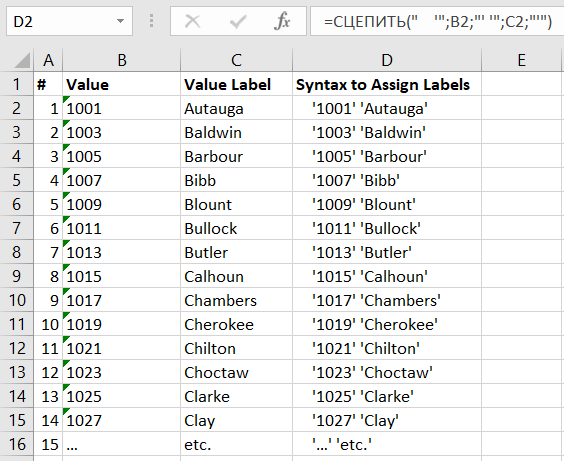
Рисунок 2. Определения меток значений, оформленные по правилам синтаксиса SPSS с помощью функции СЦЕПИТЬ в Excel
Теперь скопируем все строки из вновь созданного столбца D , начиная со второй строки, и вставим их в Редактор синтаксиса SPSS.
Вставленные строки являются частью спецификации команды VALUE LABELS . Нам остается поместить перед ними начало этой команды: VALUE LABELS county .
Проследите, чтобы между добавленной строкой и строками, вставленными из Excel, не было точки или пустой строки.
Теперь после всех меток значений поместим точку ( . ) . Это будет означать окончание команды VALUE LABELS . Так должен выглядеть финальный результат в Редакторе синтаксиса:
Теперь команда готова к запуску. Запустите команду и проверьте, что SPSS заполнил метки значений для переменной county . Это можно сделать в представлении Вид Переменные (Variable View) Редактора данных SPSS:
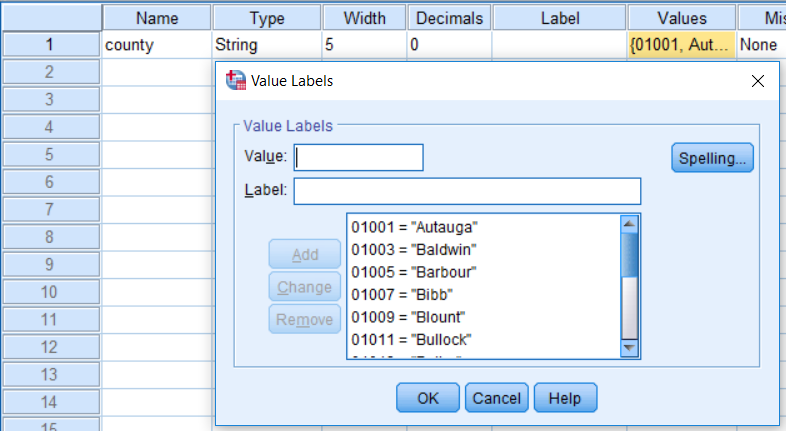
Рисунок 3. Заданные метки значений в Редакторе данных SPSS
Вот и все. Вкратце повторим основные действия:
- Мы начали работу с открытия файла с метаданными в Excel. Эти метаданные должны быть определённым образом структурированы.
- Мы разобрали ситуацию и продемонстрировали необходимые шаги для создания на основе метаданных из Excel валидного синтаксиса SPSS. Мы ограничились в примере лишь функцией =СЦЕПИТЬ() , но вам, возможно, придут в голову кейсы, в которых может оказаться полезным применить и другие функции Excel.
- Действия включали 3 основных шага: 1 – ввести формулу, которая формирует строку синтаксиса на основе фрагментов метаданных из разных столбцов, 2 – протянуть эту формулу, чтобы формула автоматически создала значения для остальных строк в файле, 3 – выделить и вставить результирующие строки в Редактор синтаксиса SPSS и, при необходимости, завершить спецификацию синтаксиса вводом начальных или завершающих элементов команды.
«Бонусом» такого подхода к разработке синтаксиса на основе Excel является удобный «интерфейс» для последующего добавления/правки спецификаций синтаксиса. Изменение имени переменной, значения или его метки в исходном столбце приведет к автоматическому обновлению результата функции конкатенации. Таким образом, после внесения изменений в Excel, у вас будут под рукой готовые обновленные фрагменты синтаксиса, которые останется вставить в Редактор синтаксиса SPSS. —
Подумайте, как бы вы могли автоматизировать свою работу с помощью этого нехитрого приёма!
Источник
Случается, что под рукой имеются структурированные метаданные (описания, метки, правила категоризации переменных), которые вы хотели бы переложить в командный синтаксис SPSS. Вот несколько примеров таких ситуаций:
- Есть список имен и список меток переменных. Вы хотели бы создать синтаксис, который назначает метки для соответствующих переменных (
VARIABLE LABELS); - Есть списки старых и новых имен переменных, и вам необходимо создать синтаксис, который бы переименовал переменные в соответствии с этими правилами;
- Есть перечень значений некоторой категориальной переменной и перечень меток этих значений. Необходимо назначить метки значений (с помощью команды
VALUE LABELS); - Есть набор границ (диапазонов) значения числовой переменной и соответствующие им значения и метки для создаваемой категориальной переменной. Необходимо разработать синтаксис, создающий категориальную переменную на основе заданных диапазонов, и описывающий ее.
В ситуации, когда указанные списки достаточно длинные, простое их копирование в редактор синтаксиса с последующим ручным «превращением» этих заготовок в валидный синтаксис, может быть утомительным.
К счастью, функции работы со строками Excel помогут автоматизировать разработку синтаксиса, так, что ничего вручную писать не потребуется. В следующем примере мы увидим, как с помощью одной лишь функции =СЦЕПИТЬ(), или, в английском интерфейсе Excel, =CONCATENATE(), мы сможем быстро назначить метки огромному списку (сотен или тысяч) значений. Для наполнения примера мы возьмем синтаксис назначения меток округов США к кодам FIPS (см. оригинал http://spsstools.net/en/syntax/syntax-index/standard-data-files/create-labels-with-common-names-for-us-county-fips-codes/). Как мы могли бы получить этот синтаксис, если бы коды округов и метки (названия) округов изначально имелись бы в Excel-файле, таком как приведенный ниже?
Рисунок 1. Исходные метаданные (метки значений) на листе Excel
Предположим, в SPSS коды округов находятся в строковой переменной county (строковой, так как нам необходимо сохранить ведущие нули). В SPSS синтаксис назначения меток должен выглядеть примерно так:
VALUE LABELS county '01001' 'Autauga' '01003' 'Baldwin' ‘last code’ ‘last label’.
Мы очень быстро можем создать «костяк» данного синтаксиса, введя в новый столбец Excel следующую формулу:
=СЦЕПИТЬ(" '";B2;"' '";C2;"'")
В англоязычном интерфейсе Excel функция будет называться иначе:
=CONCATENATE(" '";B2;"' '";C2;"'")
Суть этой формулы – в создании нового строкового значения по следующим правилам:
- Значение начинается с 4-х пробелов (вообще говоря, они не обязательны и используются здесь лишь для визуальной отбивки синтаксиса).
- Затем вставляется одинарная кавычка. И пробелы, и одинарная кавычка помещается между двойными кавычками, так как для Excel это – текстовое значение.
- Затем вставляется значение кода округа из ячейки
B2. - Вставляется закрывающая кавычка для текстового значения кода, затем пробел, и снова открывающая кавычка.
- Вставляется метка значения из ячейки
C2. - Наконец, вставляем еще одну одинарную кавычку – описание метки закончено.
Соединяемые фрагменты строки перечисляются, по правилам Excel, точкой с запятой.
После того, как мы ввели эту формулу в ячейку D2, в ней отобразится результирующая строка:
Осталось «протянуть» данную формулу вниз до конца списка. И это делается очень быстро, независимо от количества округов и их названий. Excel автоматически изменит ссылки в копируемой формуле. В итоге лист будет выглядеть примерно так:
Рисунок 2. Определения меток значений, оформленные по правилам синтаксиса SPSS с помощью функции СЦЕПИТЬ в Excel
Теперь скопируем все строки из вновь созданного столбца D, начиная со второй строки, и вставим их в Редактор синтаксиса SPSS.
Вставленные строки являются частью спецификации команды VALUE LABELS. Нам остается поместить перед ними начало этой команды: VALUE LABELS county.
Проследите, чтобы между добавленной строкой и строками, вставленными из Excel, не было точки или пустой строки.
Теперь после всех меток значений поместим точку (.) . Это будет означать окончание команды VALUE LABELS. Так должен выглядеть финальный результат в Редакторе синтаксиса:
VALUE LABELS county '01001' 'Autauga' '01003' 'Baldwin' '01005' 'Barbour' '01007' 'Bibb' '01009' 'Blount' '01011' 'Bullock' '01013' 'Butler' '01015' 'Calhoun' '01017' 'Chambers' '01019' 'Cherokee' '01021' 'Chilton' '01023' 'Choctaw' '01025' 'Clarke' '01027' 'Clay'.
Теперь команда готова к запуску. Запустите команду и проверьте, что SPSS заполнил метки значений для переменной county. Это можно сделать в представлении Вид Переменные (Variable View) Редактора данных SPSS:
Рисунок 3. Заданные метки значений в Редакторе данных SPSS
Вот и все. Вкратце повторим основные действия:
- Мы начали работу с открытия файла с метаданными в Excel. Эти метаданные должны быть определённым образом структурированы.
- Мы разобрали ситуацию и продемонстрировали необходимые шаги для создания на основе метаданных из Excel валидного синтаксиса SPSS. Мы ограничились в примере лишь функцией
=СЦЕПИТЬ(), но вам, возможно, придут в голову кейсы, в которых может оказаться полезным применить и другие функции Excel. - Действия включали 3 основных шага: 1 – ввести формулу, которая формирует строку синтаксиса на основе фрагментов метаданных из разных столбцов, 2 – протянуть эту формулу, чтобы формула автоматически создала значения для остальных строк в файле, 3 – выделить и вставить результирующие строки в Редактор синтаксиса SPSS и, при необходимости, завершить спецификацию синтаксиса вводом начальных или завершающих элементов команды.
«Бонусом» такого подхода к разработке синтаксиса на основе Excel является удобный «интерфейс» для последующего добавления/правки спецификаций синтаксиса. Изменение имени переменной, значения или его метки в исходном столбце приведет к автоматическому обновлению результата функции конкатенации. Таким образом, после внесения изменений в Excel, у вас будут под рукой готовые обновленные фрагменты синтаксиса, которые останется вставить в Редактор синтаксиса SPSS. —
Подумайте, как бы вы могли автоматизировать свою работу с помощью этого нехитрого приёма!
Related pages
- UsingExcelToWriteSPSSSyntax_v1.xlsx – original metadata and the concatenated data according to SPSS syntax writing rules
- UsingExcelToWriteSPSSSyntax.sps – syntax with sample data to describe, and syntax to assign value labels, pasted from Excel
This tutorial explains how to import data from Excel into the SPSS statistics package.
Preparing Excel
Open the Excel spreadsheet from which you wish to import data.
You can see in our example that we have 5 columns of data.
Before you begin the process of importing your data into SPSS, you need to ensure that your variable names are in the first row of the worksheet, and that there is no gap between the first and second rows. Our worksheet satisfies both these requirements.
It’s also wise to clean up your data. For example, if you had coded one of the Frisbee Throwing Distance items as “50m” rather than just “50”, this would be a good time to make a correction.
Once you have got your worksheet straight, you can open up SPSS.
There are a number of different ways to import data into SPSS. We’re going to use a method that allows backward compatibility with older versions of SPSS.
To start, click File -> Open -> Data (as below).
Once you click Data, the Open Data box will appear.
In the Files of type box, you need to select Excel (see 1 above, though obviously things will look slightly different if you’re using a Mac). Then navigate to the folder that contains your Excel file, and you’ll see your Excel file pop up (see 2 above). Open the file, and you’ll get the Read Excel File dialog box.
Read Excel File Dialog Box
This dialog box offers a number of options. Mainly these are self-explanatory, but it is probably worth explaining the “Percentage of values that determine data type” option. This is how the latest version of SPSS assigns a data type to your variables. The percentage is the proportion of values in a particular column that must match a specific data type for SPSS to assign that data type to a variable. In our example, a variable will be assigned to a particular data type if 95% of values match that type (for example, if 95% of values are numeric in form). The value can be any number above 50. If SPSS is unable to determine a data type on this basis it will assign the variable to a string type.
Once you’ve selected the options you require, and checked your data looks okay in the preview window, press OK to begin the import.
Check Your Data Within SPSS
SPSS will import your data into a new Data View with variable names at the top.
Obviously, the first thing to do here is to check that the data has come across successfully. If everything looks okay, the next stage is to check whether the various data parameters have been set correctly. Is numerical data correctly set as numerical, for example?
To check this, click on the Variable View tab (see red arrow, above). This will bring up the variable view within SPSS.
Variable View
As you can see from the image below, SPSS did a good job with our sample data, correctly identifying SubjectID, Gender, DogOwner and FrisbeeThrowing as data type numeric, and Education as data type string.
It also got level of measurement correct (see the Measure column), identifying SubjectID, Gender, Education and DogOwner as nominal data, and FrisbeeThrowing as scale (that is, as interval/ratio data).
***************
That’s pretty much it for this tutorial. You should now have a good idea of how to import data from Excel into the SPSS statistics package.
***************
EZSPSS on YouTube
We have a video tutorial that covers this same material in slightly more detail. Check it out!
Основным инструментом анализа и визуализации статистических данных для меня всегда был Excel. Я работаю с ним ежедневно. По нему написал больше всего заметок и прочитал наибольшее число книг. Пожалуй, лучшее сочетание статистики и Excel я нашел в книге Левин. Статистика для менеджеров с использованием Microsoft Excel. Вторым инструментом, к которому я только прикоснулся, был R (см., например, Алексей Шипунов. Наглядная статистика. Используем R!). А недавно прочитал любопытную книгу Нил Дж. Салкинд. Статистика для тех, кто (думает, что) ненавидит статистику. В ней автор все примеры иллюстрирует в программе SPSS. Так что я решил попробовать и этот продукт.
На сайте IBM доступна пробная версия, которая будет работать на вашем ПК 14 дней. Регистрируетесь и скачиваете программу SPSS Statistics. При регистрации запомните пароль. Он вам пригодится для входа в программу. После запуска появляется приветственное окно:
Рис. 1. Приветственное окно SPSS; чтобы увеличить изображение кликните на нем правой кнопкой мыши и выберите Открыть картинку в новой вкладке
Скачать заметку в формате Word или pdf, примеры в формате SPSS
Если вы не хотите видеть этот экран каждый раз при запуске SPSS, то в левом нижнем углу окна кликните Не показывать это диалоговое окно в будущем.
Кликните Закрыть в правом нижнем углу экрана. Появится окно Редактор данных. По виду и функционалу Редактор похож на электронную таблицу, как лист Excel.
Рис. 2. Редактор данных
Хотя этого и не видно, когда SPSS открывается в первый раз, но есть еще одно открытое (хотя и неактивное) окно. Это Окно вывода (Viewer). Оно показывает создаваемые вами статистические результаты и графики. Набор данных создается при помощи Редактора данных, а после анализа или построения графиков вы изучаете результаты анализа в Окне вывода.
Рис. 3. Окно вывода
Панель инструментов и строка состояния
Если вы хотите узнать, что делает иконка на панели инструментов, просто наведите на нее указатель мыши. Некоторые кнопки на панели инструментов затенены. Это означает, что они не активны.

Рис. 4. Панель инструментов
В нижней части окна расположена Строка состояния. Она показывает, какие действия выполняет SPSS. Например, сообщение «Процессор IBM SPSS Statistics готов» говорит о том, что SPSS готова к вашим указаниям или вводу данных.

Рис. 5. Строка состояния
Использование справки
Справка настолько подробна, что может указать вам путь, даже если вы новичок в работе с программой. Меню Справка содержит 10 разделов.
Рис. 6. Меню справки
Нажмите Темы, и перейдете в браузер на страницу центра знаний IBM на русском языке. Здесь представлена собственно справка, а также Учебное пособие, Разбор конкретных случаев, Инструктор по статистике, Разделы для подключаемых модулей Python и R.
Открытие файла
Вы можете импортировать данные из Excel, или ввести значения в таблицу, после чего сохранить в новом файле SPSS, или открыть готовый файл. В этой заметке мы используем файл Sample Data Set.sav. Пройдите по меню Файл –> Открыть –> Данные. Выберите файл. Данные загрузятся в окно редактора:
Рис. 7. Данные загружены из файла в окно редактора
Таблица и диаграмма
Допустим, мы хотим посчитать, сколько мужчин и женщин находится в нашей выборке, и вывести результат в виде столбчатой диаграммы. В окне Редактора данных пройдите по меню Анализ –> Описательные статистики –> Частоты. В открывшемся окне Частоты, выберите Gender, нажмите кнопку для переноса переменной в правое окно (или дважды кликните на Gender). Нажмите копку Диаграммы. Выберите Столбчатые. Нажмите Продолжить. Нажмите Ok.
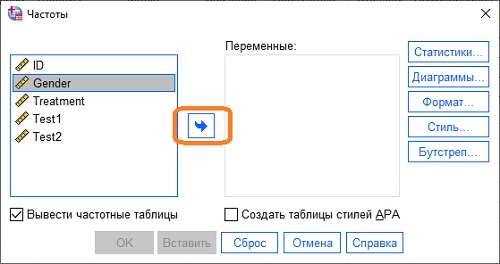
Рис. 8. Выбор переменной для анализа частоты
В окне вывода появится таблица и диаграмма:
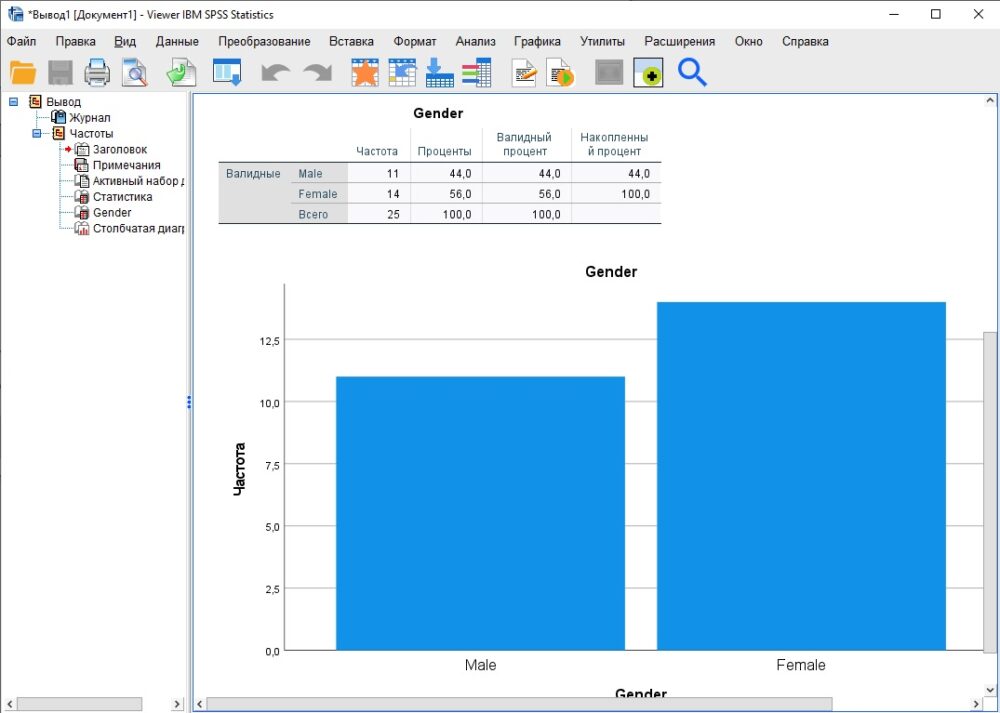
Рис. 9. Таблица и диаграмма в окне вывода
Оценка t-критерия
Давайте проверим, отличаются ли средние значения результатов Test 1 у мужчин и женщин. Этот анализ основан на t-критерии для независимых выборок. В редакторе данных пройдите по меню Анализ –> Сравнение средних –> Т-критерий для независимых выборок. В открывшемся окне переместите переменную Test1 в область Проверяемые параметры, а переменную Gender – в область Группировать по:
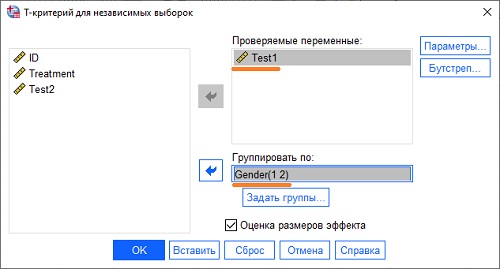
Рис. 10. Настройка расчета t-критерия для независимых выборок
Нажмите Ok. Программа сформирует таблицы проверки по t-критерию, и покажет их в окне вывода:
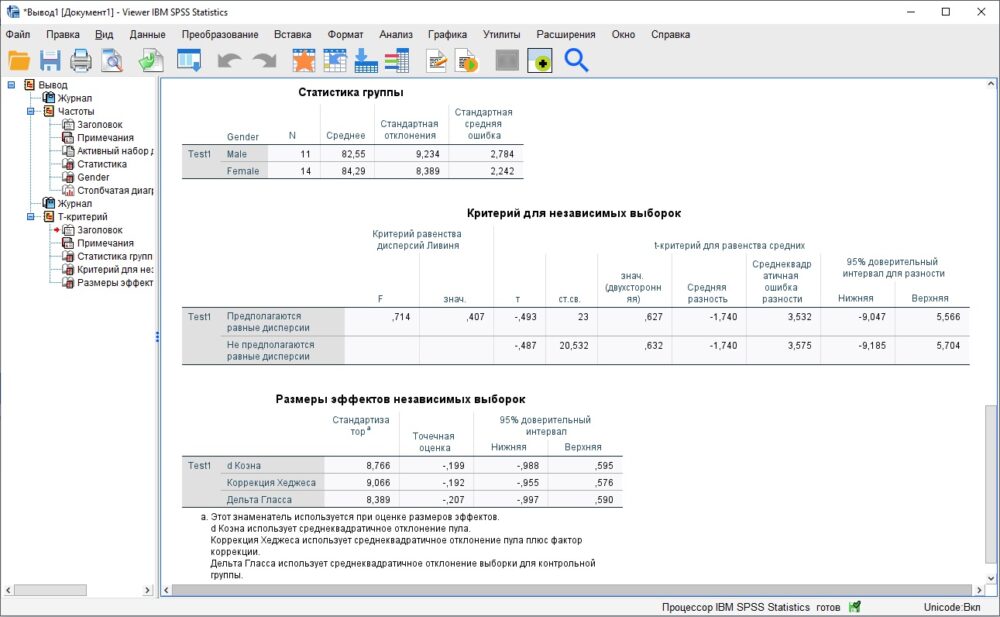
Рис. 11. Результаты проверки t-критерия для независимых выборок
T-тест показал, что различие между мужчинами и женщинами при прохождении Test1 незначимо.
Создание и редактирование файла данных
Давайте создадим набор данных, который только что загрузили из файла Sample Data Set.sav. Сначала определим переменные, а затем введем данные. В окне Редактора данных пройдите по меню Файл –> Создать –> Данные. Откроется новое окно Редактора данных. Обратите внимание, что окно открылось на вкладке Переменные (SPSS подсказывает, что сначала надо заняться ими).
Если вы поместите курсор в первую ячейку в колонке Имя, введёте любое имя и нажмёте Enter, SPSS для всех характеристик переменной автоматически проставит значения по умолчанию (см. строку 1 на рис. ниже).
Рис. 12. Параметры по умолчанию
Подробнее о параметрах переменной:
- Имя переменной должно начинаться с буквы, иметь длину не более 64 символов, не содержать пробелы, подробнее см. здесь;
- Тип:
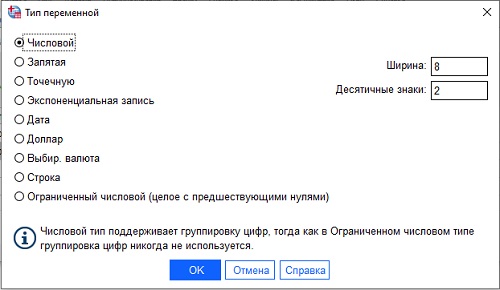
Рис. 13. Типы переменных
- Ширина задает количество символов в столбце, содержащем данную переменную;
- Десятичные определяет количество десятичных знаков;
- Метка задает метку переменной длиной до 256 символов;
- Значения устанавливает соответствие числовых значений и категорий; например, 1 для мужчин и 2 для женщин;
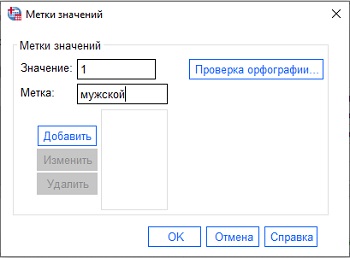
Рис. 14. Введение значений для категорийных переменных
Категорийные переменные в SPSS можно вводить в виде текстовых строк, например, Male и Female, а можно назначить им значения. Когда дело дойдет до анализа, окажется, что очень трудно работать с нечисловыми записями. Но при визуальном просмотре файла, наоборот, имена (метки) нагляднее. Окно Метки значений позволяет вводить в SPSS числа, а выводить на экран метки: и волки сыты, и овцы целы. Чтобы это работало, находясь в Редакторе данных на закладке Данные, перейдите в меню Вид, и поставьте галочку напротив Метки значений.
- Пропущенные – указывает, как обращаться с пропущенными значениями;
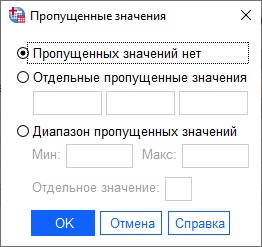
Рис. 15. Управление пропущенными значениями
- Ширина столбца определяет количество символов, выделенное для переменной в окне представления данных;
- Выравнивание – определяет, как будут выровнены данные в ячейке (влево, вправо, по центру);
- Мера – определяет шкалу измерения, которая лучше всего описывает переменную (номинальная, порядковая или интервальная);
- Роль – определяет роль, которую играет переменная в анализе (входная, целевая и т.д.).
Определите следующие переменные:
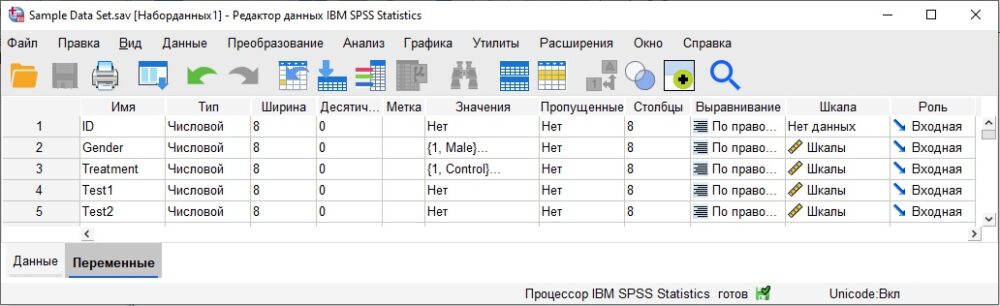
Рис. 16. Пять переменных в окне Редактора данных на закладке Переменные
Теперь вы можете переключиться на вкладку Данные и просто ввести все данные, которые представлены на рис. 7.
Печать из SPSS
Чтобы распечатать весь файл данных или его часть:
- убедитесь, что файл, который вы хотите напечатать, находится в активном окне;
- кликните Файл –> Печать;
- откроется диалоговое окно печати (рис. 17);
- выберите, что вы хотите распечатать: файл целиком или выделенный фрагмент (если предварительно фрагмент не был выбран, эта опция неактивна); нажмите Ok.
Рис. 17. Диалоговое окно печати
Вместо выбора принтера можно задать создание файл *.pdf.
Создание диаграммы в SPSS
Воспользуемся данными из файла Sample Data Set.sav. Откройте файл, на вкладке Данные, кликните меню Графика. Выберите одну из опций: Мастер диаграмм, Панель выбора диаграмм, Устаревшие диалоговые окна. Последняя опция позволяет выбрать один из стандартных типов диаграмм. Первые две опции проведут вас по пути создания диаграммы, наиболее подходящей к выбранным данным.
Рис. 18. Типы диаграмм
Выберите Столбцы, откроется диалоговое окно, предлагающее несколько вариантов оформления:

Рис. 19. Виды столбчатой диаграммы
Выберите Простая и Итоги по группам наблюдений. Нажмите Задать. Откроется окно Простые столбцы. Задайте, что будет анализировать диаграмма:
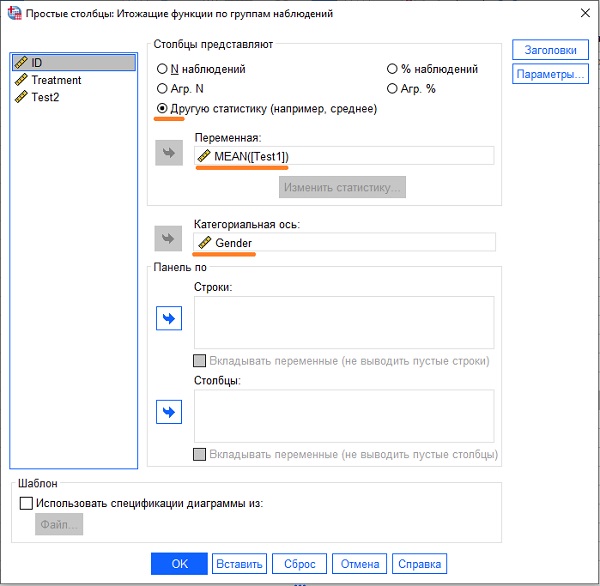
Рис. 20. Параметры аналитики диаграммы
Нажмите Ok. В окне вывода появится диаграмма: среднее значение Test1 раздельно по полу:
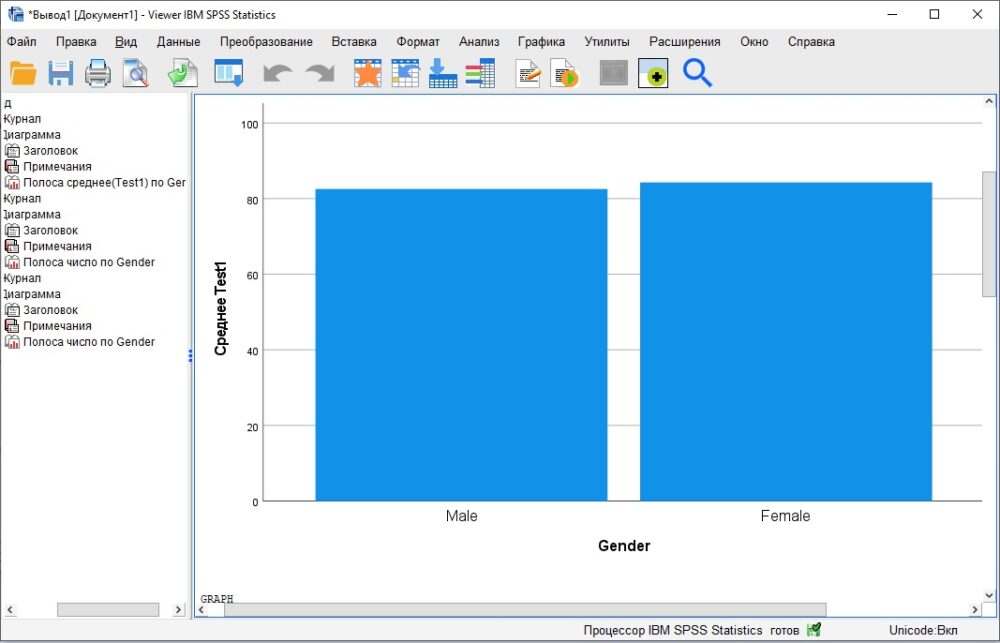
Рис. 21. Средние результаты Теста 1
Сохранение диаграммы
Диаграмма является частью окна вывода. В этом окне сохраняется любой выполняемый вами анализ. Диаграмма не является самостоятельной сущностью, и ее нельзя сохранить в качестве таковой. Для того чтобы сохранить диаграмму, вам нужно сохранить содержимое всего окна вывода. Для этого:
- кликните Файл –> Сохранить;
- задайте имя для окна вывода и папку;
- нажмите Ok; вывод сохранится в файле с расширением *.spo.
Редактирование диаграммы
Для изменения диаграммы используйте Редактор диаграмм. Чтобы вызвать его дважды кликните на диаграмме в окне вывода.
Чтобы добавить заголовок кликните на соответствующей иконке на панели инструментов Редактора диаграмм:
Рис. 22. Кнопка Редактор диаграмм
На диаграмме появится область для ввода заголовка и окно Свойства, где можно выбрать шрифты, границы и заливку. Для добавления подзаголовка (или даже нескольких) кликните на иконке Вставить заголовок повторно.
Для изменения любого элемента дважды щелкните на нем. Можно отдельно щелкнуть на названии оси, подписях и самой оси. В первых двух случаях можно будет отредактировать шрифты и стили оформления, а в последнем – масштаб.
Чтобы выйти из Редактора диаграмм просто кликните на крестике окна или пройдите Файл –> Закрыть.
Описание данных
Частоты и сопряженные таблицы. Частоты подсчитывают количество случаев возникновения определенного значения. Сопряженные таблицы позволяют подсчитать количество случаев возникновения определенного значения с разбивкой по одной или более категориям, например, по полу и возрасту. Для вычисления частот перейдите в окно Редактора данных, кликните Анализ –> Описательные статистики –> Частоты. Откроется диалоговое окно Частоты (см. выше рис. 8). Дважды щелкните мышью по переменным, для которых вы хотите посчитать частоты. В нашем случае это Test 1 и Test 2:
Рис. 23. Диалоговое окно Частоты
Щелкните по кнопке Статистики. Откроется диалоговое окно Частоты: статистики. В разделе Разброс отметьте Стандартное отклонение. В разделе Положение центра распределения отметьте Среднее:
Рис. 24. Диалоговое окно Частоты: Статистики
Нажмите Продолжить, а затем Ok.
В окне вывода появится три таблицы: обобщенная, и подробная для каждой переменной – Test 1 и Test 2:
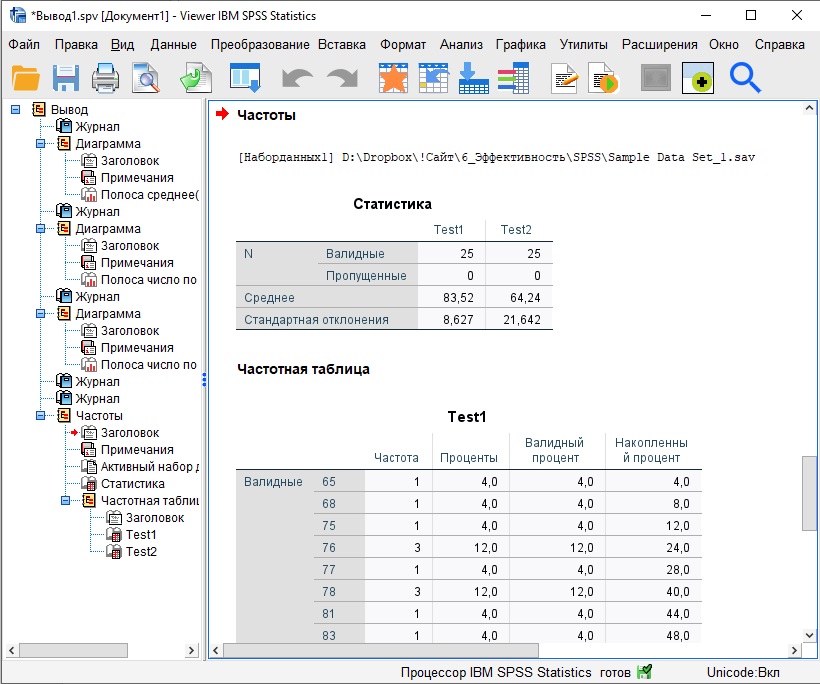
Рис. 25. Обобщенная статистика частот и фрагмент подробной таблицы частот Test 1
Выход из SPSS
Кликните Файл –> Выход. SPSS позаботится о том, чтобы сохранить все не сохраненные ранее или отредактированные окна, а затем закроется.
Только что вы кратко познакомились с SPSS. Однако эти навыки ничего не значат, если вы не понимаете смысла того, что делаете. Так что не восхищайтесь своими или чужими навыками пользования такими программами, как SPSS. Восхищайтесь, когда люди могут рассказать, что означает тот или иной вывод и какой ответ он дает на поставленный вопрос. И особенно восхищайтесь, если вы сами можете это сделать!