
 Одной из самых трудоемких и неприятных задач при работе с текстом в Excel является парсинг — разбор буквенно-цифровой «каши» на составляющие и извлечение из нее нужных нам фрагментов. Например:
Одной из самых трудоемких и неприятных задач при работе с текстом в Excel является парсинг — разбор буквенно-цифровой «каши» на составляющие и извлечение из нее нужных нам фрагментов. Например:
- извлечение почтового индекса из адреса (хорошо, если индекс всегда в начале, а если нет?)
- нахождение номера и даты счета из описания платежа в банковской выписке
- извлечение ИНН из разношерстных описаний компаний в списке контрагентов
- поиск номера автомобиля или артикула товара в описании и т.д.
Обычно во подобных случаях, после получасового муторного ковыряния в тексте вручную, в голову начинают приходить мысли как-то автоматизировать этот процесс (особенно если данных много). Решений тут несколько и с разной степенью сложности-эффективности:
- Использовать встроенные текстовые функции Excel для поиска-нарезки-склейки текста: ЛЕВСИМВ (LEFT), ПРАВСИМВ (RIGHT), ПСТР (MID), СЦЕПИТЬ (CONCATENATE) и ее аналоги, ОБЪЕДИНИТЬ (JOINTEXT), СОВПАД (EXACT) и т.д. Этот способ хорош, если в тексте есть четкая логика (например, индекс всегда в начале адреса). В противном случае формулы существенно усложняются и, порой, дело доходит даже до формул массива, что сильно тормозит на больших таблицах.
- Использование оператора проверки текстового подобия Like из Visual Basic, обернутого в пользовательскую макро-функцию. Это позволяет реализовать более гибкий поиск с использованием символов подстановки (*,#,? и т.д.) К сожалению, этот инструмент не умеет извлекать нужную подстроку из текста — только проверять, содержится ли она в нем.
Кроме вышеперечисленного, есть еще один подход, очень известный в узких кругах профессиональных программистов, веб-разработчиков и прочих технарей — это регулярные выражения (Regular Expressions = RegExp = «регэкспы» = «регулярки»). Упрощенно говоря, RegExp — это язык, где с помощью специальных символов и правил производится поиск нужных подстрок в тексте, их извлечение или замена на другой текст. Регулярные выражения — это очень мощный и красивый инструмент, на порядок превосходящий по возможностям все остальные способы работы с текстом. Многие языки программирования (C#, PHP, Perl, JavaScript…) и текстовые редакторы (Word, Notepad++…) поддерживают регулярные выражения.
Microsoft Excel, к сожалению, не имеет поддержки RegExp по-умолчанию «из коробки», но это легко исправить с помощью VBA. Откройте редактор Visual Basic с вкладки Разработчик (Developer) или сочетанием клавиш Alt+F11. Затем вставьте новый модуль через меню Insert — Module и скопируйте туда текст вот такой макрофункции:
Public Function RegExpExtract(Text As String, Pattern As String, Optional Item As Integer = 1) As String
On Error GoTo ErrHandl
Set regex = CreateObject("VBScript.RegExp")
regex.Pattern = Pattern
regex.Global = True
If regex.Test(Text) Then
Set matches = regex.Execute(Text)
RegExpExtract = matches.Item(Item - 1)
Exit Function
End If
ErrHandl:
RegExpExtract = CVErr(xlErrValue)
End Function
Теперь можно закрыть редактор Visual Basic и, вернувшись в Excel, опробовать нашу новую функцию. Синтаксис у нее следующий:
=RegExpExtract( Txt ; Pattern ; Item )
где
- Txt — ячейка с текстом, который мы проверяем и из которого хотим извлечь нужную нам подстроку
- Pattern — маска (шаблон) для поиска подстроки
- Item — порядковый номер подстроки, которую надо извлечь, если их несколько (если не указан, то выводится первое вхождение)
Самое интересное тут, конечно, это Pattern — строка-шаблон из спецсимволов «на языке» RegExp, которая и задает, что именно и где мы хотим найти. Вот самые основные из них — для начала:
| Паттерн | Описание |
| . | Самое простое — это точка. Она обозначает любой символ в шаблоне на указанной позиции. |
| s | Любой символ, выглядящий как пробел (пробел, табуляция или перенос строки). |
| S | Анти-вариант предыдущего шаблона, т.е. любой НЕпробельный символ. |
| d | Любая цифра |
| D | Анти-вариант предыдущего, т.е. любая НЕ цифра |
| w | Любой символ латиницы (A-Z), цифра или знак подчеркивания |
| W | Анти-вариант предыдущего, т.е. не латиница, не цифра и не подчеркивание. |
| [символы] |
В квадратных скобках можно указать один или несколько символов, разрешенных на указанной позиции в тексте. Например ст[уо]л будет соответствовать любому из слов: стол или стул. Также можно не перечислять символы, а задать их диапазоном через дефис, т.е. вместо [ABDCDEF] написать [A-F]. или вместо [4567] ввести [4-7]. Например, для обозначения всех символов кириллицы можно использовать шаблон [а-яА-ЯёЁ]. |
| [^символы] | Если после открывающей квадратной скобки добавить символ «крышки» ^, то набор приобретет обратный смысл — на указанной позиции в тексте будут разрешены все символы, кроме перечисленных. Так, шаблон [^ЖМ]уть найдет Путь или Суть или Забудь, но не Жуть или Муть, например. |
| | | Логический оператор ИЛИ (OR) для проверки по любому из указанных критериев. Например (счет|счёт|invoice) будет искать в тексте любое из указанных слов. Обычно набор вариантов заключается в скобки. |
| ^ | Начало строки |
| $ | Конец строки |
| b | Край слова |
Если мы ищем определенное количество символов, например, шестизначный почтовый индекс или все трехбуквенные коды товаров, то на помощь нам приходят квантификаторы или кванторы — специальные выражения, задающие количество искомых знаков. Квантификаторы применяются к тому символу, что стоит перед ним:
| Квантор | Описание |
| ? | Ноль или одно вхождение. Например .? будет означать один любой символ или его отсутствие. |
| + | Одно или более вхождений. Например d+ означает любое количество цифр (т.е. любое число от 0 до бесконечности). |
| * | Ноль или более вхождений, т.е. любое количество. Так s* означает любое количество пробелов или их отсутствие. |
|
{число} или {число1,число2} |
Если нужно задать строго определенное количество вхождений, то оно задается в фигурных скобках. Например d{6} означает строго шесть цифр, а шаблон s{2,5} — от двух до пяти пробелов |
Теперь давайте перейдем к самому интересному — разбору применения созданной функции и того, что узнали о паттернах на практических примерах из жизни.
Извлекаем числа из текста
Для начала разберем простой случай — нужно извлечь из буквенно-цифровой каши первое число, например мощность источников бесперебойного питания из прайс-листа:

Логика работы регулярного выражения тут простая: d — означает любую цифру, а квантор + говорит о том, что их количество должно быть одна или больше. Двойной минус перед функцией нужен, чтобы «на лету» преобразовать извлеченные символы в полноценное число из числа-как-текст.
Почтовый индекс
На первый взгляд, тут все просто — ищем ровно шесть цифр подряд. Используем спецсимвол d для цифры и квантор {6} для количества знаков:

Однако, возможна ситуация, когда левее индекса в строке стоит еще один большой набор цифр подряд (номер телефона, ИНН, банковский счет и т.д.) Тогда наша регулярка выдернет из нее первых 6 цифр, т.е. сработает некорректно:

Чтобы этого не происходило, необходимо добавить в наше регулярное выражение по краям модификатор b означающий конец слова. Это даст понять Excel, что нужный нам фрагмент (индекс) должен быть отдельным словом, а не частью другого фрагмента (номера телефона):

Телефон
Проблема с нахождением телефонного номера среди текста состоит в том, что существует очень много вариантов записи номеров — с дефисами и без, через пробелы, с кодом региона в скобках или без и т.д. Поэтому, на мой взгляд, проще сначала вычистить из исходного текста все эти символы с помощью нескольких вложенных друг в друга функций ПОДСТАВИТЬ (SUBSTITUTE), чтобы он склеился в единое целое, а потом уже примитивной регуляркой d{11} вытаскивать 11 цифр подряд:

ИНН
Тут чуть сложнее, т.к. ИНН (в России) бывает 10-значный (у юрлиц) или 12-значный (у физлиц). Если не придираться особо, то вполне можно удовлетвориться регуляркой d{10,12}, но она, строго говоря, будет вытаскивать все числа от 10 до 12 знаков, т.е. и ошибочно введенные 11-значные. Правильнее будет использовать два шаблона, связанных логическим ИЛИ оператором | (вертикальная черта):

Обратите внимание, что в запросе мы сначала ищем 12-разрядные, и только потом 10-разрядные числа. Если же записать нашу регулярку наоборот, то она будет вытаскивать для всех, даже длинных 12-разрядных ИНН, только первые 10 символов. То есть после срабатывания первого условия дальнейшая проверка уже не производится:

Это принципиальное отличие оператора | от стандартной экселевской логической функции ИЛИ (OR), где от перестановки аргументов результат не меняется.
Артикулы товаров
Во многих компаниях товарам и услугам присваиваются уникальные идентификаторы — артикулы, SAP-коды, SKU и т.д. Если в их обозначениях есть логика, то их можно легко вытаскивать из любого текста с помощью регулярных выражений. Например, если мы знаем, что наши артикулы всегда состоят из трех заглавных английских букв, дефиса и последующего трехразрядного числа, то:

Логика работы шаблона тут проста. [A-Z] — означает любые заглавные буквы латиницы. Следующий за ним квантор {3} говорит о том, что нам важно, чтобы таких букв было именно три. После дефиса мы ждем три цифровых разряда, поэтому добавляем на конце d{3}
Денежные суммы
Похожим на предыдущий пункт образом, можно вытаскивать и цены (стоимости, НДС…) из описания товаров. Если денежные суммы, например, указываются через дефис, то:
 из текста")
Паттерн d с квантором + ищет любое число до дефиса, а d{2} будет искать копейки (два разряда) после.
Если нужно вытащить не цены, а НДС, то можно воспользоваться третьим необязательным аргументом нашей функции RegExpExtract, задающим порядковый номер извлекаемого элемента. И, само-собой, можно заменить функцией ПОДСТАВИТЬ (SUBSTITUTE) в результатах дефис на стандартный десятичный разделитель и добавить двойной минус в начале, чтобы Excel интерпретировал найденный НДС как нормальное число:

Автомобильные номера
Если не брать спецтранспорт, прицепы и прочие мотоциклы, то стандартный российский автомобильный номер разбирается по принципу «буква — три цифры — две буквы — код региона». Причем код региона может быть 2- или 3-значным, а в качестве букв применяются только те, что похожи внешне на латиницу. Таким образом, для извлечения номеров из текста нам поможет следующая регулярка:

Время
Для извлечения времени в формате ЧЧ:ММ подойдет такое регулярное выражение:

После двоеточия фрагмент [0-5]d, как легко сообразить, задает любое число в интервале 00-59. Перед двоеточием в скобках работают два шаблона, разделенных логическим ИЛИ (вертикальной чертой):
- [0-1]d — любое число в интервале 00-19
- 2[0-3] — любое число в интервале 20-23
К полученному результату можно применить дополнительно еще и стандартную Excel’евскую функцию ВРЕМЯ (TIME), чтобы преобразовать его в понятный программе и пригодный для дальнейших расчетов формат времени.
Проверка пароля
Предположим, что нам надо проверить список придуманных пользователями паролей на корректность. По нашим правилам, в паролях могут быть только английские буквы (строчные или прописные) и цифры. Пробелы, подчеркивания и другие знаки препинания не допускаются.
Проверку можно организовать с помощью вот такой несложной регулярки:

По сути, таким шаблоном мы требуем, чтобы между началом (^) и концом ($) в нашем тексте находились только символы из заданного в квадратных скобках набора. Если нужно проверить еще и длину пароля (например, не меньше 6 символов), то квантор + можно заменить на интервал «шесть и более» в виде {6,}:

Город из адреса
Допустим, нам нужно вытащить город из строки адреса. Поможет регулярка, извлекающая текст от «г.» до следующей запятой:

Давайте разберем этот шаблон поподробнее.
Если вы прочитали текст выше, то уже поняли, что некоторые символы в регулярных выражениях (точки, звездочки, знаки доллара и т.д.) несут особый смысл. Если же нужно искать сами эти символы, то перед ними ставится обратная косая черта (иногда это называют экранированием). Поэтому при поиске фрагмента «г.» мы должны написать в регулярке г. если ищем плюсик, то + и т.д.
Следующих два символа в нашем шаблоне — точка и звездочка-квантор — обозначают любое количество любых символов, т.е. любое название города.
На конце шаблона стоит запятая, т.к. мы ищем текст от «г.» до запятой. Но ведь в тексте может быть несколько запятых, правда? Не только после города, но и после улицы, дома и т.д. На какой из них будет останавливаться наш запрос? Вот за это отвечает вопросительный знак. Без него наша регулярка вытаскивала бы максимально длинную строку из всех возможных:

В терминах регулярных выражений, такой шаблон является «жадным». Чтобы исправить ситуацию и нужен вопросительный знак — он делает квантор, после которого стоит, «скупым» — и наш запрос берет текст только до первой встречной запятой после «г.»:

Имя файла из полного пути
Еще одна весьма распространенная ситуация — вытащить имя файла из полного пути. Тут поможет простая регулярка вида:

Тут фишка в том, что поиск, по сути, происходит в обратном направлении — от конца к началу, т.к. в конце нашего шаблона стоит $, и мы ищем все, что перед ним до первого справа обратного слэша. Бэкслэш заэкранирован, как и точка в предыдущем примере.
P.S.
«Под занавес» хочу уточнить, что все вышеописанное — это малая часть из всех возможностей, которые предоставляют регулярные выражения. Спецсимволов и правил их использования очень много и на эту тему написаны целые книги (рекомендую для начала хотя бы эту). В некотором смысле, написание регулярных выражений — это почти искусство. Почти всегда придуманную регулярку можно улучшить или дополнить, сделав ее более изящной или способным работать с более широким диапазоном вариантов входных данных.
Для анализа и разбора чужих регулярок или отладки своих собственных есть несколько удобных онлайн-сервисов: RegEx101, RegExr и др.
К сожалению, не все возможности классических регулярных выражений поддерживаются в VBA (например, обратный поиск или POSIX-классы) и умеют работать с кириллицей, но и того, что есть, думаю, хватит на первое время, чтобы вас порадовать.
Если же вы не новичок в теме, и вам есть чем поделиться — оставляйте полезные при работе в Excel регулярки в комментариях ниже. Один ум хорошо, а два сапога — пара!
Ссылки по теме
- Замена и зачистка текста функцией ПОДСТАВИТЬ (SUBSTITUTE)
- Поиск и подсветка символов латиницы в русском тексте
- Поиск ближайшего похожего текста (Иванов = Ивонов = Иваноф и т.д.)
You can use text functions to manipulate text strings in Excel. However, you can’t use them with regular expressions. As of writing this article VBA is your only option. In this guide, we’re going to show you how to use regular expressions in Excel.
Download Workbook
What is a regular expression?
A regular expression (also known as regex or regexp shortly) is a special text string for specifying a search pattern. They are like wildcards. Instead of specifying the number of characters, you can create patterns to find a specific group of characters, like searching between «b» to «o», using OR logic, excluding some characters, or repeating values.
Regular expressions are commonly used for text parsing and replacing operations for all programming languages. To use regular expressions in Excel, we will be using VBA.
| Pattern | Description | Samples |
| ^jack | begins with «jack» | jack-of-all-trades, jack’s house |
| jack$ | ends with «jack» | hijack |
| ^jack$ | is exactly «jack» | jack |
| colo[u]{0,}r | can include «u» at least 0 times | colour, color (not colur) |
| col[o|u]r | includes either «o» or «u» | color, colur (not colour) |
| col[^u]r | accepts any character except «u» | color (not colur or colour) |
How to use regular expressions
Let’s start using regular expressions in Excel by opening VBA. Press Alt + F11 keys to open VBA (Visual Basic for Applications) window. Add a module to enter your code.

Next step is to add regular expression reference to VBA. Click Tools > References in the VBA toolbar. Find and check Microsoft VBScript Regular Expressions 5.5 item in the References window. Click OK to add the reference.

Using the VBScript reference, we can create a regular expression object, which is defined as RegExp in VBA. A RegExp object has 4 properties and 3 methods:
Properties
| Name | Type | Description |
| Global | Boolean | Set True to find all cases that match with the pattern. Set False to find the first match. |
| IgnoreCase | Boolean | Set True to not make case-sensitive search. Set False to make case-sensitive search. |
| Multiline | Boolean | Set True if your string has multiple lines and you want to perform the search in all lines. |
| Pattern | String | The regular expression pattern you want to search. |
Methods
| Name | Arguments | Description |
| Execute | sourceString As String | Returns an array that contains all occurrences of the pattern matched in the string. |
| Replace | sourceString As String replaceVar As Variant | Returns a string which all occurrences of the pattern in the string are replaced with the replaceVar string. |
| Test | sourceString As String | Returns True if there is a match. Otherwise, False. |

Code Samples
A function that returns TRUE/FALSE if the pattern is found in a string
Public Function RegExFind(str As String, pat As String) As Boolean
‘Define the regular expression object
Dim RegEx As New RegExp
‘Set up regular expression properties
With RegEx
.Global = False ‘All occurences are not necessary since a single occurence is enough
.IgnoreCase = True ‘No case-sensitivty
.MultiLine = True ‘Check all lines
.Pattern = pat ‘pattern
End With
RegExFind = RegEx.Test(str)
End Function

After writing the code, you can use this function as a regular Excel function.

A function that replaces the pattern with a given string
Public Function RegExReplace(str As String, pat As String, replaceStr As String) As String
‘Define the regular expression object
Dim RegEx As New RegExp
‘Set up regular expression properties
With RegEx
.Global = False ‘All occurences are not necessary since a single occurence is enough
.IgnoreCase = True ‘No case-sensitivty
.MultiLine = True ‘Check all lines
.Pattern = pat ‘pattern
End With
RegExReplace = RegEx.Replace(str, replaceStr) ‘Return the modified string with replacement value
End Function

The following sample shows how to replace strings that start with «col», continue with 0 or 1 occurrences of «o» and single «u», and finally ends with an «r» character with «Color» string.

Skip to content
На первый взгляд, в Excel есть все, что вам может понадобиться для работы с текстовыми строками. Но очень часто случается, что мы не можем указать точно, что мы ищем. Мы знаем часть слова или шаблон, которые нам нужны.
А как насчет регулярных выражений, чтобы использовать шаблон текста? К сожалению, в Excel нет встроенных функций Regex. Никак не могу понять, почему регулярные выражения не поддерживаются в формулах Excel? Теперь это есть:) освоив синтаксис регулярных выражений, с нашими пользовательскими функциями вы можете легко находить, заменять, извлекать и удалять слова, символы и строки, соответствующие определенному шаблону.
- Что такое регулярное выражение?
- Шпаргалка по регулярным выражениям Excel
- Символы
- Классы
- Квантификаторы
- Группы
- Якоря
- Конструкция ИЛИ
- Поиск
- «Жадные» и «ленивые» сопоставления
Что такое регулярное выражение?
Регулярное выражение (также известное как RegExp) — это особым образом закодированная последовательность символов, определяющая шаблон поиска.
Используя этот шаблон, вы можете найти подходящую комбинацию символов в строке или проверить ввод данных. Если вы знакомы с понятием подстановочных знаков , вы можете думать о регулярных выражениях как о расширенной версии подстановочных знаков.
Регулярные выражения имеют собственный синтаксис, состоящий из специальных символов, операторов и конструкций. Например, [0-5] соответствует любой одиночной цифре от 0 до 5.
Регулярные выражения используются во многих языках программирования, включая JavaScript и VBA. Последний имеет специальный объект RegExp, который мы будем использовать для создания наших пользовательских функций.
Поддерживает ли Excel регулярные выражения?
К сожалению, в Excel нет встроенных функций Regex. Чтобы иметь возможность использовать регулярные выражения в своих формулах, вам придется создать собственную пользовательскую функцию (на основе VBA или .NET) или установить сторонние инструменты, поддерживающие регулярные выражения.
Шпаргалка по регулярным выражениям Excel
Независимо от того, является шаблон регулярного выражения очень простым или чрезвычайно сложным, он строится с использованием общего синтаксиса. Этот раздел не ставит целью научить вас регулярным выражениям. Для этого в Интернете есть множество ресурсов, от бесплатных руководств для начинающих до премиальных курсов для опытных пользователей.
Ниже мы приводим краткий справочник по основным шаблонам регулярных выражений, который поможет вам понять основы синтаксиса. Он также может работать как шпаргалка при изучении других примеров.
Символы
Это наиболее часто используемые шаблоны для соответствия определенным символам.
| Шаблон | Описание | Пример | Найдено |
| . | Подстановочный знак: соответствует любому одиночному символу, кроме разрыва строки. | .от | кот , лот , @от |
| d | Символ цифры: любая одиночная цифра от 0 до 9 | d | В a1b найдено 1 |
| D | Любой символ, НЕ являющийся цифрой | D | В a1b найдено a и b |
| s | Пробельный символ: пробел, табуляция, новая строка и возврат каретки | .s. | В 3 яблока найдено 3 я |
| S | Любой непробельный символ. Анти-вариант предыдущего | S+ | В 30 яблок найдено 30 и яблок |
| w | Символ слова: любая буква ASCII, цифра или подчеркивание. | w+ | В 5_яблок*** найдено 5_яблок |
| B+ | Любой символ, который НЕ является буквенно-цифровым символом или символом подчеркивания | В+ | В 5_яблок*** найдено *** |
| t | Табуляция | ||
| n | Новая строка | nd+ | В двухстрочной строке ниже соответствует 10 5 кошек 10 собак |
| Позволяет использовать специальный символ как обычный | .
w+. |
Игнорирует подстановочный знак, чтобы вы могли найти буквальный символ «.» в строке
Mr. , д-р. , проф. |
Классы
Используя эти шаблоны, вы можете сопоставлять элементы разных наборов символов.
| Шаблон | Описание | Пример | Найдено |
| [символы] | В квадратных скобках можно указать один или несколько символов, допустимых на указанной позиции в тексте. | ст[оу]л | стол стул |
| [^символы] | На указанной позиции в тексте будут разрешены все символы, кроме перечисленных в скобках. | [^жм]уть | Соответствует путь, суть Не соответствует жуть, муть |
| [от—до] | Соответствует любому символу | [0-9] [а-я] [А-Я] [б-ф] [а-яА-ЯёЁ] |
Любая цифра от 0 до 9 Любая строчная буква Любая прописная буква Любая из букв в скобках [бвгдежзиклмнопрстуф] Все буквы русского алфавита (буква Ë указывается отдельно!) |
Квантификаторы
Квантификаторы — это специальные выражения, которые определяют количество совпадающих символов. Квантификатор всегда применяется к символу, стоящему перед ним перед ним.
| Шаблон | Описание | Пример | Найдено |
| * | Ноль или более вхождений | 1а* | 1, 1а , 1аа, 1ааа и т. д. |
| + | Одно или более вхождений | ко+ | В кот найдено ко В кооперация найдено коo |
| ? | Ноль или одно вхождение | ко?т | кот, корт |
| *? | Ноль или более вхождений, но как можно меньше | 1а*? | В 1a , 1aa и 1aaa найдено 1a |
| +? | Одно или несколько событий, но как можно меньше | ко+? | В кот и кооперация найдено ко |
| {n} | Строго определённое количество вхождений | d{3} | Ровно 3 любых цифры |
| {n,} | Не менее n вхождений | d{3,} | 3 или более цифр |
| {,n} | Не более n вхождений | d{,3} | Не более 3 цифр |
| {n, m} | Соответствует предыдущему шаблону от n до m раз | d{3,5} | От 3 до 5 цифр |
Группы
Конструкции групп используются для захвата подстроки из исходной строки, чтобы с ней можно было выполнить какую-либо операцию.
| Синтаксис | Описание | Пример | Найдено |
| (шаблон) | Группа захвата: захватывает совпадающую подстроку и присваивает ей порядковый номер | (d+) | 5 кошек и 10 собак 5 (группа 1) и 10 (группа 2) |
| (?:шаблон) | Группа без захвата: соответствует группе, но не захватывает ее | (d+)(?:собак) | 5 кошек и 10 собак 10 |
| 1 | Содержимое группы 1 | (d+)+(d+)=2+1 | 5+10=10+5 |
| 2 | Содержимое группы 2 |
Якоря
Якоря указывают позицию во входной строке, где искать соответствие.
| Якорь | Описание | Пример | Найдено |
| ^ | Начало строки Примечание: [^в скобках] означает «не» | ^d+ | Любое количество цифр в начале строки. 5 кошек и 10 собак Найдено 5 |
| $ | Конец строки | д+$ | Любое количество цифр в конце строки. В 10 плюс 5 получается 15 , найдено 15 |
| b | Конец слова | котb | 1 кот и 10 котят Соответствует кот, но не котят |
| В | НЕ конец слова | котB | 1 кот и 10 котят Соответствует котят, но не кот |
Конструкция ИЛИ
Операнд чередования включает логику ИЛИ, поэтому вы можете сопоставить тот или иной элемент.
| Построить | Описание | Пример | Соответствие |
| | | Соответствует любому отдельному элементу, разделенному вертикальной чертой | (счет|invoice) | Любое из перечисленных слов |
Поиск
Конструкции поиска полезны, когда вы хотите найти что-то, за чем следует или не следует что-то другое. Эти выражения иногда называют «утверждениями нулевой ширины» или «совпадением нулевой ширины», потому что они соответствуют позиции, а не фактическим символам.
Примечание. В варианте VBA RegEx просмотр назад не поддерживается.
| Шаблон | Описание | Пример | Найдено |
| = знак равно | Положительный вперед | Х(?=Y) | Соответствует выражению X, когда за ним следует Y (т. е. если Y предшествует X) |
| (?!) | Отрицательный вперед | Х(?!У) | Соответствует выражению X, если за ним НЕ следует Y |
| (?<=) | Положительный назад | (?<=Y)Х | Соответствует выражению X, когда ему предшествует Y (т. е. если Y находится позади X) |
| (?<!) | Отрицательный назад | (?<!Y)Х | Соответствует выражению X, если ему НЕ предшествует Y |
Жадные и ленивые сопоставления
Квантификаторы (* + {}) ― это «жадные» операторы, потому что они продолжают поиск соответствий, как можно глубже ― через весь текст.
| Шаблон | Описание | Пример | Найдено |
| <.+> | Жадный поиск | <.+> | В выражении Это <div> простой div</div> тест возвращает <div> простой div</div> |
Чтобы найти только тэг div ― можно использовать оператор ?, сделав выражение «ленивым»:
| Шаблон | Описание | Пример | Найдено |
| <.+?> | Ленивый поиск | <.+?> | В выражении Это <div> простой div</div> тест возвращает 2 совпадения: <div> </div> |
| <[^<>]+> | Ленивый поиск | <[^<>]+> | В выражении Это <div> простой div</div> тест возвращает 2 совпадения: <div> </div> |
Обратите внимание, что хорошей практикой считается не использовать оператор . , в пользу более строгого выражения: <[^<>]+>
<[^<>]+> соответствует любому символу, кроме скобок < или >,один или более раз встречающемуся между этими скобками.
Теперь, когда вы знаете синтаксис регулярных выражений, давайте перейдем к самой интересной части — использованию регулярных выражений на реальных данных для разбора строк и поиска необходимой информации. Если вам нужны дополнительные сведения о синтаксисе, может оказаться полезным руководство Microsoft по языку регулярных выражений .
- Функции регулярных выражений в Excel
- Примеры задач, решаемых с помощью регулярных выражений
- Извлечение данных из ячеек с помощью RegEx
- Извлечь из ячейки содержимое до / после первой цифры включительно
- «Вытянуть» цифры из ячеек
- Извлечь из ячейки числа из N цифр
- Извлечь латиницу регулярным выражением
- Извлечь символы в конце/начале строк по условию
- Проверить ячейки на соответствие регулярному выражению
- Найти в ячейке числа из N цифр
- Найти ячейки, начинающиеся с цифр
- Замена подстрок по регулярному выражению
- Разбить ячейку по буквам
- Разбить буквы и цифры в ячейке
- Вставить текст после первого слова
- Вставить символ после каждого слова или перед ним
- Регулярные выражения для поиска конкретных слов в !SEMTools
- Найти слова по регулярному выражению
- Извлечь слова по регулярному выражению
- Удалить слова по регулярному выражению
- Очистить ячейки, не соответствующие регулярному выражению
Многие слышали, что такое регулярные выражения, но не всем известно, что они поддерживаются “под капотом” Microsoft Excel. Регулярные выражения дают возможность многократно ускорить работу с текстом, находить в нем самые замысловатые паттерны и решать самые сложные исследовательские задачи. Единственная проблема в том, что для их использования в Excel необходимо знание VBA.
Почему Microsoft не включила их как функции листа и включит ли когда-нибудь, непонятно и неизвестно.
Но с надстройкой !SEMTools эти знания не нужны. Зато минимальное понимание синтаксиса регулярок позволит с легкостью решать задачи, решение которых практически невозможно с помощью стандартных функций, либо для этого требуются формулы огромной длины. Примеры таких мегаформул можно посмотреть в решении задач:
- найти английские буквы в Excel,
- найти числа в тексте.
Для поддержки регулярных выражений при наличии подключенной надстройки !SEMTools в Excel будут работать три функции: REGEXMATCH, REGEXEXTRACT и REGEXREPLACE.
Их синтаксис и принцип работы аналогичен синтаксису Google Spreadsheets. Поэтому формулы, составленные в Excel, будут иметь полную зеркальную совместимость с Google Spreadsheets.
=REGEXMATCH("текст";"RegEx-паттерн для поиска")
REGEXMATCH возвращает ИСТИНА или ЛОЖЬ (TRUE или FALSE в английской версии Excel), в зависимости от того, соответствует текст паттерну или нет.
=REGEXEXTRACT("текст";"RegEx-паттерн для поиска")
REGEXEXTRACT извлекает первый попадающий под паттерн фрагмент текста. Небольшое отличие от Google Spreadsheets заключается в том, что, если в искомом тексте такого фрагмента нет, Spreadsheets отдают ошибку, а в надстройке отдается пустая строка.
=REGEXREPLACE("текст";"RegEx-паттерн для поиска";"текст, которым заменяем найденное")
Примеры задач, решаемых с помощью регулярных выражений
Я не поскуплюсь на примеры, чтобы показать вам все возможности регулярных выражений, так как они действительно огромны. Надеюсь, эта статья послужит руководством и стимулом активнее пользоваться их мощью. От простого к сложному.
Чтобы дать обычным пользователям Excel возможность максимально широко использовать возможности регулярных выражений, в надстройку !SEMTools был добавлен ряд быстрых процедур. Все примеры ниже будут показаны с их использованием.
Извлечение данных из ячеек с помощью RegEx
Извлечь из ячейки содержимое до / после первой цифры включительно
Такие простые два выражения. «+» — это служебный символ-квантификатор. Он обеспечивает «жадный» режим, при котором берутся все удовлетворяющие выражению символы до тех пор, пока на пути не встретится не удовлетворяющий ему или наступит конец/начало строки. Точка обозначает любой символ. Таким образом, берутся любые символы до конца строки, перед которыми есть цифра.
«d» обозначает «digits», иначе цифры. Поскольку квантификатора после “d” в примерах выше нет, то одну цифру. Если потребуется исключить из результатов эту цифру, это можно сделать позднее. В !SEMTools есть простые способы удалить символы в начале или конце ячейки.
Цифры можно выразить и другим регулярным выражением:
«Вытянуть» цифры из ячеек
Как извлечь из строки цифры? Регулярное выражение для такой операции будет безумно простым:
В зависимости от режима извлечения результатом будет либо первая, либо все цифры в ячейке.
Если их нужно вывести не сплошной последовательностью, а через разделитель, сохранив фрагменты, где символы следуют друг за другом, выражение будет чуть иным, с «жадным» квантификатором. А при извлечении нужно будет использовать разделитель.
Это справедливо и для любых других символов, пример с числами ниже:

Извлечь из ячейки числа из N цифр
Как видно в примере выше, помимо чисел, обозначающих годы, были извлечены и другие числа, например, «1». Чтобы извлечь исключительно последовательности из четырех цифр, потребуется видоизменить выражение. Есть несколько вариантов:
Последние два варианта включают квантификатор фигурные скобки. Он указывает минимальное количество повторений удовлетворяющего паттерну символа или фрагмента строки. Паттерну, стоящему непосредственно перед квантификатором. В данном случае подряд должны идти любые четыре символа, являющиеся цифрами.

Извлечь латиницу регулярным выражением
Выражение [a-zA-Z] обозначает все символы латиницы. Дефис и в этом, и в предыдущем случае обозначает, что берутся все символы между a и z и между A и Z в общей таблице символов Unicode. Квадратные скобки — синоним “ИЛИ”. Рассматривается каждый из элементов или множеств внутри квадратных скобок, при этом выражение не находит ничего, только если сравниваемая строка не содержит ни одного элемента внутри квадратных скобок.

Извлечь символы в конце/начале строк по условию
Стандартные формулы ПРАВСИМВ и ЛЕВСИМВ позволяют извлечь из ячейки соответственно последние и первые N символов, но на этом их возможности заканчиваются.
С помощью же регулярных выражений можно извлечь:
- Символы, идущие после и включая последнюю заглавную букву в ячейке, заканчивающейся на восклицательный знак. Так мы извлечем из ячеек все восклицательные предложения. Выражение для этого выглядит так: [А-Я][а-яa-z0-9 ]+!$.
- Первые N выбранных символов из определенного множества, если ячейка с них начинается.
- Аналогично: последние N определенных символов, если ячейка на них заканчивается.
Проверить ячейки на соответствие регулярному выражению
Если нет необходимости извлекать данные, а нужно лишь проверить, соответствуют ли они паттерну, чтобы потом отфильтровать их, удобнее использовать процедуру, эквивалентную формуле REGEXMATCH.
Найти в ячейке числа из N цифр
В зависимости от того, является N необходимым или достаточным условием, нужны разные регулярные выражения. Иными словами, считать ли последовательности из N+1, N+2 и т.д. цифр подходящими или нет. Если да, выражение будет таким же, как уже указывалось выше:
dddd
[0-9][0-9][0-9][0-9]
d{4}
[0-9]{4}
Если же нас интересуют строго последовательности из N цифр, задачу придется производить в две итерации:
- В первую итерацию извлекать цифры вместе с границами строк или нецифровыми символами, идущими после/перед (это станет своеобразной проверкой отсутствия других цифр).
- И во вторую уже сами цифры.
Выражения для первой итерации будут, соответственно:
(^|D)dddd($|D)
(^|D)[0-9][0-9][0-9][0-9]($|D)
(^|D)d{4}($|D)
(^|D)[0-9]{4}($|D)
Если внимательно посмотреть на отличие в синтаксисе, можно понять, что означают символы в нем:
- вертикальная черта “|” обозначает “ИЛИ”,
- скобки “( )” нужны для перечисления внутри них аргументов и “отгораживания” их от остального выражения,
- каретка “^” обозначает начало строки,
- символ доллара “$” — конец строки,
- D — нечисловые символы. Обратите внимание: верхний регистр меняет значение d на противоположное. Это справедливо также для пар w и W, обозначающих латиницу и цифры и не-латиницу и цифры, и s и S, различные виды пробелов и не-пробельные символы соответственно.
Найти ячейки, начинающиеся с цифр
Выражение для подобной проверки будет:
Либо можно воспользоваться процедурой проверки на копии исходного диапазона без необходимости вводить формулу. Смотрите примеры.

Замена подстрок по регулярному выражению
Наиболее частый кейс такой замены — замена на пустоту, когда наша задача попросту удалить из текста определенные символы. Наиболее популярны:
- удаление цифр из текста,
- удаление пунктуации,
- всех символов, кроме букв и цифр.
Но бывают случаи, когда необходима реальная замена, например, когда нужно заменить буквы с “хвостиками”/умляутами/ударениями и прочими символами из европейских алфавитов на их английские аналоги. Задача популярна среди SEO-специалистов, формирующих урлы сайтов этих стран на основе оригинальной семантики. Так выглядит начало таблицы паттернов для замены диакритических символов на латиницу с помощью RegEx при генерации URL:

Разбить ячейку по буквам
Чтобы разбить ячейку посимвольно, достаточно извлечь все символы через разделитель. Выражением для извлечения будет обычная точка — она как раз и обозначает любой символ.

Разбить буквы и цифры в ячейке
Если строго соблюдать постановку этой задачи, ее выполнить довольно сложно. Но зато с помощью регулярных выражений можно отделить цифровые последовательности символов от нецифровых. Так будет выглядеть выражение:
А так будет выглядеть процесс на практике:

Вставить текст после первого слова
При замене по регулярному выражению в !SEMTools есть опция замены не всех, а только первого найденного фрагмента, удовлетворяющего паттерну. Это позволяет решить задачу вставки символов после первого слова. Просто заменим первый пробел на нужные нам символы с помощью соответствующей процедуры (эту задачу можно решить также с помощью функции ПОДСТАВИТЬ, но можно и воспользоваться функционалом замены по регулярному выражению). В отличие от обычной процедуры замены, здесь можно заменить только первое вхождение. В данном случае — первый пробел. Как видно, пробел ничем не отличается от обычного:

Вставить символ после каждого слова или перед ним
Надстройка решает эту задачу в два клика готовой процедурой в меню “Изменить слова“, но можно воспользоваться и несложным выражением для замены:
Выражения обозначают, что заменяются пробелы или конец строки в первом случае и пробелы или начало строк во втором. Вертикальная черта — то самое “ИЛИ”.
А заменять будем, соответственно, на пробел с символом слева или справа. Процедура добавит лишний пробел перед ячейкой или после, поэтому от него желательно будет избавиться — удалить лишние пробелы или удалить символы в начале / конце ячейки.

Регулярные выражения для поиска конкретных слов в !SEMTools
Найти слова по регулярному выражению
Извлечь слова по регулярному выражению
Когда дело доходит до извлечения определенных слов, регулярные выражения становятся невероятно сложными. Поэтому надстройка !SEMTools упрощает задачу до применения паттернов RegEx на уровне слов как отдельных сущностей.
Вот так выглядит извлечение слов, содержащих латиницу и цифры, из массива слов, с помощью регулярного выражения:
Обратите внимание, что выражение означает, что цифра за буквой или буква за цифрой должны следовать непосредственно, без промежуточных символов между ними. Если нужно извлечь в том числе слова вида “asdf-13”, “1234-d”, понадобится обозначить возможность наличия символов между:

Удалить слова по регулярному выражению
Очистить ячейки, не соответствующие регулярному выражению
Когда в вашем распоряжении массив данных, где могут быть ошибки, с которыми разбираться некогда, и при этом нужно извлечь только стопроцентно подходящие данные, можно воспользоваться регулярными выражениями для очистки нерелевантных.
Примеры:
- оставить ячейки с определенным количеством слов,
- оставить ячейки с определенным количеством символов,
- оставить ячейки, содержащие только цифры,
- оставить ячейки, содержащие только буквы,
- оставить ячейки, содержащие адрес электронной почты в доменной зоне .com и .ru.
Примеры использования “Извлечь ячейки по регулярному выражению”.
Регулярные выражения в VBA Excel. Объекты RegExp, Match, Matches Collection и их свойства. Символы и метасимволы. Создание объекта RegExp с ранней, поздней привязкой и его методы.
Регулярные выражения (по Википедии) – это формальный язык поиска и осуществления манипуляций с подстроками в тексте. Они используются для обработки текстов с помощью шаблонов, состоящих из символов и метасимволов, и представлены объектом RegExp.
В VBA Excel для работы с регулярными выражениями используется библиотека «Microsoft VBScript Regular Expression».
Создание объекта RegExp
Ранняя привязка
Обычно рекомендуется использовать объекты с ранней привязкой, так как у них выше быстродействие, а также при написании и редактировании кода доступны подсказки в виде листа свойств-методов, появляющегося автоматически или вызываемого, при необходимости, сочетанием клавиш Ctrl+Пробел.
Раннее связывание заключается в присвоении нового экземпляра объекта RegExp переменной, уже объявленной, как переменная определенного типа (в нашем случае, как RegExp).
Для осуществления ранней привязки необходимо подключить к проекту VBA ссылку на библиотеку «Microsoft VBScript Regular Expression», для чего в редакторе VBA выбираем Tools — References…

В открывшемся окне «References» находим строку «Microsoft VBScript Regular Expression 5.5» (если у вас ее нет, то строку «Microsoft VBScript Regular Expression 1.0»), отмечаем ее галочкой и нажимаем «ОК».

Готово — ссылка добавлена.
Создание объекта RegExp с ранней привязкой:
|
‘Вариант 1 Dim myRegExp As RegExp Set myRegExp = New RegExp ‘————————- ‘Вариант 2 Dim myRegExp As New RegExp |
Поздняя привязка
Позднее связывание заключается в присвоении нового экземпляра объекта RegExp переменной, объявленной как Object, с помощью функции CreateObject.
Создание объекта RegExp с поздней привязкой:
|
Dim myRegExp As Object Set myRegExp = CreateObject(«VBScript.RegExp») |
Свойства и методы объекта RegExp
Свойства объекта RegExp
| Свойство | Описание | Значение по умолчанию |
|---|---|---|
| Global | Определяет продолжительность поиска: False — до первого совпадения True — по всему тексту |
False |
| IgnoreCase | Определяет чувствительность к регистру символов: False — учитывать регистр True — не учитывать регистр |
False |
| Multiline | Определяет структуру объекта: False — однострочный True — многострочный |
False |
| Pattern | Строка, используемая как шаблон | Пустая строка |
Свойства объекта RegExp доступны для чтения и записи.
Методы объекта RegExp
| Метод | Синтаксис | Описание |
|---|---|---|
| Execute | Execute(myStr) myStr — строка для поиска |
Возвращает коллекцию найденных по шаблону подстрок в виде агрегатного объекта |
| Replace | Replace(myStr,myRep) myStr — строка для поиска myRep — строка для замены |
Возвращает строку, в которой найденные по шаблону вхождения в исходной строке заменены на указанную подстроку. |
| Test | Test(myText) myText — строка для проверки |
Возвращает булево значение как результат проверки соответствия строки шаблону |
Свойства объектов Match и Matches Collection
Метод Execute объекта RegExp возвращает агрегатный объект Matches Collection, который содержит коллекцию объектов Match, представляющих все совпадения, найденные механизмом регулярных выражений, в том порядке, в котором они присутствуют в исходной строке. Если совпадений нет, метод возвращает объект Matches Collection без членов.
Свойства объекта Matches Collection
| Свойство | Описание |
|---|---|
| Count | Количество объектов Match, содержащихся в объекте Matches Collection |
| Item | Индекс члена коллекции от нуля до значения свойства Count минус 1 |
Свойства объекта Matches Collection доступны только для чтения.
Свойства объекта Match
| Свойство | Описание |
|---|---|
| FirstIndex | Позиция в исходной строке, где произошло совпадение, причем первая позиция в строке равна нулю |
| Length | Длина совпавшей подстроки |
| Value | Найденная подстрока (является свойством по умолчанию) |
Свойства объекта Match доступны только для чтения.
Символы и метасимволы
Все знаки, используемые для составления шаблонов, обычно делят на символы и метасимволы. Символы — это знаки, которые в шаблонах обозначают сами себя, а метасимволы (спецсимволы) — знаки, имеющие другое значение. Метасимволы могут использоваться как отдельно, так и в сочетании с другими символами и спецсимволами.
Таблица основных метасимволов и их сочетаний с другими символами
| Метасимвол (сочетание символов) |
Значение |
|---|---|
| После этого знака метасимвол обозначает сам себя, а некоторые символы приобретают другое значение | |
| ^ | Начало строки |
| $ | Конец строки |
| ? | Ни одного или один любой символ |
| * | Ни одного или несколько любых символов |
| + | Один или несколько любых символов |
| . | Любой символ, кроме знака «новая строка» |
| — | Определяет интервал символов |
| | | Знак «или» |
| {n} | Точное количество символов, стоящих перед {n} |
| {n,m} | Количество от n до m символов, стоящих перед {n,m} |
| [abc] | Любой из указанных символов |
| [^abc] | Любой из неуказанных символов |
| [a-z] | Любой символ из диапазона |
| [^a-z] | Любой символ, не входящий в диапазон |
| b | Конец слова |
| B | Не конец слова |
| d | Цифра |
| D | Не цифра |
| w | Любая буква, цифра или знак подчеркивания |
| W | Не буква, не цифра и не знак подчеркивания |
| s | Пробел |
| S | Не пробел |
В таблицу не включены редко используемые сочетания, ознакомиться с которыми можно в справочной системе разработчика. А примеры использования метасимволов в шаблонах очень хорошо представлены на этом ресурсе в разделе 4. Метасимволы.
Пример использования RegExp
Пример использования регулярных выражений в VBA Excel для извлечения email-адресов из текстового файла.
Для извлечения текстовой информации из файла в переменную используется функция GetText, которую вы можете скопировать из статьи Парсинг сайтов, html-страниц и файлов.
В файл «Новый документ.txt» вставлен произвольный текст с четырьмя примерами email-адресов, которые необходимо извлечь.
Код VBA Excel для извлечения email-адресов из текстового файла с помощью регулярных выражений:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
Sub Primer() Dim htmlText As String, myRegExp As Object, myObj As Object, myStr1 As Object, myStr2 As String ‘Присваиваем переменной htmlText текстовую информацию из файла «Новый документ.txt» htmlText = GetText(«C:UsersEvgeniyDownloadsНовый документ.txt») ‘Присваиваем переменной myRegExp ссылку на новый экземпляр RegExp Set myRegExp = CreateObject(«VBScript.RegExp») With myRegExp ‘Задаем поиск по всему тексту .Global = True ‘Задаем шаблон поиска .Pattern = «([w.-]+)@([w.-]+).([A-Za-z]{2,6})» ‘Присваиваем переменной myObj коллекцию найденных по шаблону email-адресов Set myObj = .Execute(htmlText) End With For Each myStr1 In myObj ‘Извлекаем email-адреса из коллекции myObj по очереди в объектную переменную myStr1 ‘и записываем их построчно в текстовую переменную myStr2 myStr2 = myStr2 & myStr1 & vbNewLine Next ‘Смотрим, что получилось MsgBox myStr2 End Sub |
У меня результат работы кода выглядел так:

Регулярные выражения VBA
Заметка написана Андреем Макаренко
Регулярные выражения (regular expressions) — очень мощный механизм для обработки строк. С его помощью можно найти нужные части текста, проверить, удовлетворяет ли строка определённой маске, заменить найденный текст. Такие выражения вcтроены во многие языки программирования, такие, как Perl, Php, JavaScript, и, конечно VBA.
Рассмотрим, как это работает на примере обработки счетов на доставку товаров. Исходные данные содержатся в отчете Excel в форме полного адреса (рис. 1). Наша задача — из строки вида «677000, Россия, Саха /Якутия/ Респ., г. Якутск, ул. Ойунского» выделить название города.

Рис. 1. Исходные данные
Скачать заметку в формате Word или pdf, примеры в архиве (политика провайдера не позволяет напрямую загружать на сайт файлы Excel, содержащие макросы)
Для использования регулярных выражений, необходимо подключить библиотеку MS Windows Script. Для подключения, запускаем VBA (меню Разработчик –> Visual Basic). В открывшемся окне VBA проходим по меню Tools –> References и в окне References — VBAProject ставим флажок в строке Microsoft VBScript Regular Expressions 5.5 (рис. 2).
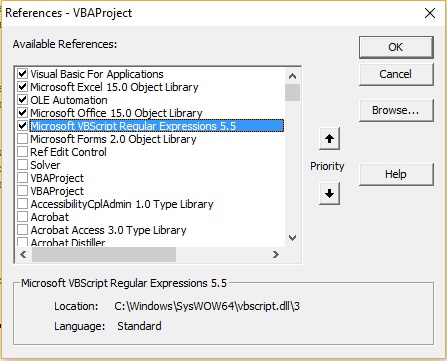
Рис. 2. Подключение библиотеки MS Windows Script для работы с регулярными выражениями
Теперь в Visual Basic добавился объект RegExp, который содержит в себе всё, что нужно для работы с регулярными выражениями. Код, выполняющий поставленную задачу, выглядит так:
Sub RegExp()
Dim myRegExp As New RegExp ‘ создаем экземпляр RegExp
Dim aMatch As Match ‘ один из совпавших образцов
Dim colMatches As MatchCollection ‘ коллекция этих образцов
Dim strTest As String ‘ тестируемая строка
‘ устанавливаем свойства объекта RegExp
myRegExp.Global = False ‘ если Global = True, то поиск ведётся во всей строке, _
если False, то только до первого совпадения
myRegExp.IgnoreCase = True ‘ игнорировать регистр символов при поиске
myRegExp.Pattern = » , (г|c|п). .*?, » ‘ шаблон для поиска
strTest = Sheets( » Накладные » ).Range( » E2 » ).Text ‘ присваиваем переменной текст из текущей ячейки
Set colMatches = myRegExp.Execute(strTest) ‘ получаем коллекцию совпадений с образцом
‘ перебираем коллекцию и просматриваем результаты
For Each aMatch In colMatches ‘ проходим по всей коллекции
a = aMatch.FirstIndex ‘ порядковый номер первого символа найденного образца
b = aMatch.Length ‘ кол-во символов в найденном образце
c = aMatch.Value ‘ полный образец
Next aMatch
c = Mid(c, 6, Len(c) — 6)
MsgBox a & » | » & b & » | » & c ‘ смотрим, что получилось
‘ производим замену найденного выражения
d = myRegExp.Replace(strTest, » (здесь раньше был город) » )
MsgBox d ‘ смотрим, что получилось
End Sub
В примере мы рассмотрели работу с одной ячейки. Для обработки массива данных, нужно организовать цикл, двигаясь по строчкам, например, до строчки с пустым значением.
Отдельного рассмотрения заслуживает синтаксис создания шаблона для поиска. Возможности его поистине неисчерпаемы. Несколько лет назад я работал в издательстве телегида. Еженедельно требовалось в ограниченные сроки подготовить тексты телепрограмм для публикации. В приведении их к единому стандарту были заняты три редактора и два верстальщика в течение нескольких часов. Программная обработка с использованием регулярных выражений занимала несколько минут после чего один корректор и один верстальщик «подчищали» результат в течение получаса. Реальная проблема, с которой мне пришлось столкнуться, это потеря предсказуемости результата при построении слишком сложных конструкций. Поэтому рекомендую вместо одной сложной использовать несколько последовательных трансформаций.
Описание синтаксиса для создания шаблона можно найти в Интернете (см., например, msdn). Здесь я дам лишь краткое представление о возможностях (рис. 3) и прокомментирую шаблон, использованный в примере.

Рис. 3. Специальные символы
Разберем использованный нами в примере шаблон:
Сам шаблон берется в кавычки. Начинается шаблон с запятой и пробела, далее следует конструкция (г|c|п), которая позволят выбрать один из трех вариантов обозначения населенного пункта: г – город, с – село, п – поселок.
. — это просто точка. Обратная косая поставлена для того, чтобы отличить ее от спецсимвола
пробел — это и есть пробел
. — точка — любой символ
* — множитель, берет ни одного или множество символов, стоящих слева от него (а это точка – то есть, любой символ) между пробелом и запятой
? — ограничивает поиск первой встреченной запятой. Если его не использовать, то выражение вернет значение » , г. Якутск, ул. Ойунского, » . Т.е., до последней запятой в тексте.
Итак, шаблон позволяет найти текст, который начинается с запятой, пробела, буквы («г», «с» или «п») с точкой и пробела, а заканчивается первой встреченной после этого запятой. В нашем случае шаблон извлекает следующий текст:
Далее оператор c = Mid(c, 6, Len(c) — 6) оставляет от него лишь
Регулярные выражения в Excel
Регулярные выражение (Regular Expressions, RegExp) – это мощный инструмент для обработки текстовых данных, позволяющий осуществлять поиск и выполнять манипуляции с подстроками в тексте. По сути, регулярное выражение является шаблоном текста, состоящим из обычных и специальных символов. Excel не позволяет использовать всю мощь регулярных выражений на пользовательском уровне, но язык VBA, на котором создаются макросы в Excel, предоставляет такую возможность. Данный вебинар посвящен тому, как при помощи элементов языка VBA (оператора VBA Like и объекта RegExp) освоить процесс создания регулярных выражений в «Экселе».
Занятие проведёт замечательный преподаватель-практик с многосторонним опытом работы Ожиганов Сергей Иванович. Сертифицированный тренер Microsoft, обладатель статуса MCTS (Managing Projects With Microsoft Project 2013) и ряда других престижных сертификацией корпорации «Майкрософт». Виртуозно владея «Экселем», он решает реальные практические задачи, связанные со сложным анализом данных и оптимизацией работы. Участвует в разработке программного обеспечения, ежедневно оказывает услуги консалтинга по продуктам «Майрософт» и отлично понимает, какие вопросы могут возникнуть у слушателей. Сергей Иванович прекрасно умеет объяснять материал с позиции практика, не оставляя ни одной сложной темы без конкретных примеров. Среди его выпускников – специалисты крупнейших российских и международных компаний, включая ООО «МЕТРО Кэш энд Керри», ОАО «Вымпелком», ООО «Газпром-Медиа» и др.
Ближайшие группы Сортировать:
Заказ добавлен в Корзину.
Для завершения оформления, пожалуйста, перейдите в Корзину!
Анализ текста регулярными выражениями (RegExp) в Excel
Одной из самых трудоемких и неприятных задач при работе с текстом в Excel является парсинг — разбор буквенно-цифровой «каши» на составляющие и извлечение из нее нужных нам фрагментов. Например:
- извлечение почтового индекса из адреса (хорошо, если индекс всегда в начале, а если нет?)
- нахождение номера и даты счета из описания платежа в банковской выписке
- извлечение ИНН из разношерстных описаний компаний в списке контрагентов
- поиск номера автомобиля или артикула товара в описании и т.д.
Обычно во подобных случаях, после получасового муторного ковыряния в тексте вручную, в голову начинают приходить мысли как-то автоматизировать этот процесс (особенно если данных много). Решений тут несколько и с разной степенью сложности-эффективности:
- Использовать встроенные текстовые функции Excel для поиска-нарезки-склейки текста: ЛЕВСИМВ (LEFT) , ПРАВСИМВ (RIGHT) , ПСТР (MID) , СЦЕПИТЬ(CONCATENATE)и ее аналоги , ОБЪЕДИНИТЬ (JOINTEXT) , СОВПАД(EXACT) и т.д. Этот способ хорош, если в тексте есть четкая логика (например, индекс всегда в начале адреса). В противном случае формулы существенно усложняются и, порой, дело доходит даже до формул массива, что сильно тормозит на больших таблицах.
- Использование оператора проверки текстового подобия Like из Visual Basic, обернутого в пользовательскую макро-функцию. Это позволяет реализовать более гибкий поиск с использованием символов подстановки (*,#,? и т.д.) К сожалению, этот инструмент не умеет извлекать нужную подстроку из текста — только проверять, содержится ли она в нем.
Кроме вышеперечисленного, есть еще один подход, очень известный в узких кругах профессиональных программистов, веб-разработчиков и прочих технарей — это регулярные выражения (Regular Expressions = RegExp = «регэкспы» = «регулярки»). Упрощенно говоря, RegExp — это язык, где с помощью специальных символов и правил производится поиск нужных подстрок в тексте, их извлечение или замена на другой текст. Регулярные выражения — это очень мощный и красивый инструмент, на порядок превосходящий по возможностям все остальные способы работы с текстом. Многие языки программирования (C#, PHP, Perl, JavaScript. ) и текстовые редакторы (Word, Notepad++. ) поддерживают регулярные выражения.
Microsoft Excel, к сожалению, не имеет поддержки RegExp по-умолчанию «из коробки», но это легко исправить с помощью VBA. Откройте редактор Visual Basic с вкладки Разработчик (Developer) или сочетанием клавиш Alt + F11 . Затем вставьте новый модуль через меню Insert — Module и скопируйте туда текст вот такой макрофункции:
Теперь можно закрыть редактор Visual Basic и, вернувшись в Excel, опробовать нашу новую функцию. Синтаксис у нее следующий:
=RegExpExtract( Txt ; Pattern ; Item )
- Txt — ячейка с текстом, который мы проверяем и из которого хотим извлечь нужную нам подстроку
- Pattern — маска (шаблон) для поиска подстроки
- Item — порядковый номер подстроки, которую надо извлечь, если их несколько (если не указан, то выводится первое вхождение)
Самое интересное тут, конечно, это Pattern — строка-шаблон из спецсимволов «на языке» RegExp, которая и задает, что именно и где мы хотим найти. Вот самые основные из них — для начала:
VBA Excel. Регулярные выражения (объекты, свойства, методы)
Регулярные выражения в VBA Excel. Объекты RegExp, Match, Matches Collection и их свойства. Символы и метасимволы. Создание объекта RegExp с ранней, поздней привязкой и его методы.
Регулярные выражения (по Википедии — формальный язык поиска и осуществления манипуляций с подстроками в тексте), необходимы для обработки текстов с помощью шаблонов, состоящих из символов и метасимволов, и представлены объектом RegExp.
В VBA Excel для работы с регулярными выражениями используется библиотека «Microsoft VBScript Regular Expression».
Создание объекта RegExp
Ранняя привязка
Обычно рекомендуется использовать объекты с ранней привязкой, так как у них выше быстродействие, а также при написании и редактировании кода доступны подсказки в виде листа свойств-методов, появляющегося автоматически или вызываемого, при необходимости, сочетанием клавиш Ctrl+Пробел.
Раннее связывание заключается в присвоении нового экземпляра объекта RegExp переменной, уже объявленной, как переменная определенного типа (в нашем случае, как RegExp).
Для осуществления ранней привязки необходимо подключить к проекту VBA ссылку на библиотеку «Microsoft VBScript Regular Expression», для чего в редакторе VBA выбираем Tools — References.
В открывшемся окне «References» находим строку «Microsoft VBScript Regular Expression 5.5» (если у вас ее нет, то строку «Microsoft VBScript Regular Expression 1.0»), отмечаем ее галочкой и нажимаем «ОК».
Готово — ссылка добавлена.
Создание объекта RegExp с ранней привязкой:
Поздняя привязка
Позднее связывание заключается в присвоении нового экземпляра объекта RegExp переменной, объявленной как Object, с помощью функции CreateObject.
Создание объекта RegExp с поздней привязкой:
Open Notes
Обо всём, что мне интересно
Использование регулярных выражений в VBA для извлечения текста из сообщений Outlook
Есть несколько способов поиска определённого текста в теле письма с помощью VBA. Можно воспользоваться функциями InStr, Len, Left или Right, чтобы найти и извлечь текст, а можно воспользоваться регулярными выражениями. Именно о применении регулярных выражений в коде VBA пойдёт речь в данной статье.
Например, требуется извлечь код отслеживания посылки UPS, отправленной с Amazon.com. Такой код имеет формат как на скриншете ниже:
![]()
Нужно находить в тексте слова «Carrier Tracking ID», затем, возможно, пробел и двоеточие.
.Pattern = «(Carrier Tracking IDs*[:]+s*(w*)s*)»
Такое выражение извлечёт из текста из примера цифро-буквенный код 1Z2V37F8YW51233715.
Используйте s* для определения неизвестного количества пробелов (пробелы, символы табуляции, перевода строки и т.д.)
Используйте d* для определения только цифр
Используйте w* для определения цифро-буквенных символов, как используются в кодах отслеживания посылок UPS.
Чтобы использовать этот образец кода откройте редактор VBA с помощью комбинации Alt+F11. Правой кнопкой мыши нажмите на Проекте и выберите Insert > Module. Скопируйте и вставьте код макроса в модуль. Для работы макроса нужно задействовать библиотеку Microsoft VBScript Regular Expressions 5.5 в меню Tools -> References… VBA-редактора:

Если включена библиотека VBScript Expressions 1, то отключите её сняв соответствующую галочку. Невозможно одновременно использовать v1 и v5.5.
Sub GetValueUsingRegEx() ‘ Подключите библиотеку VB Script ‘ Microsoft VBScript Regular Expressions 5.5 Dim olMail As Outlook.MailItem Dim Reg1 As RegExp Dim M1 As MatchCollection Dim M As Match Set olMail = Application.ActiveExplorer().Selection(1) ‘ Debug.Print olMail.Body Set Reg1 = New RegExp ‘ s* = скрытые пробелы ‘ d* = цифры ‘ w* = цифро-буквенные выражения With Reg1 .Pattern = «Carrier Tracking IDs*[:]+s*(w*)s*» .Global = True End With If Reg1.test(olMail.Body) Then Set M1 = Reg1.Execute(olMail.Body) For Each M In M1 ‘ M.SubMatches(1) is the (w*) in the pattern ‘ use M.SubMatches(2) for the second one if you have two (w*) Debug.Print M.SubMatches(1) Next End If End Sub
Если будем искать только двоеточие .Pattern =»([:]+s*(w*)s*)» , тогда код вернёт только первое слово после двоеточия из каждой строки:
UPS
May
Standard
1Z2V37F8YW51233715
Diane
Это потому, что (w*) указывает, что нужно получить следующую после двоеточия цифро-буквенную строку, не всю строку, и не включать пробелы.
Получение двух и более значений из сообщения
Если вам требуется использовать два или несколько шаблонов, то можно повторить часть c With Reg1 до End If, для каждого из шаблонов или воспользоваться оператором Case.
Код ниже осуществляет поиск по трём шаблонам, создает строку и добавляет ее в поле темы сообщения. Каждый Case представляет свой шаблон. В этом примере отыскивается только первое вхождение каждого шаблона. .Global = False указывает, что нужно остановиться, когда находится первое совпадение.
Данные, которые мы ищем имеют следующий формат:
Order ID : VBNSA-123456
Order Date: 09 AUG 2013
Total $54.65
/n в конце шаблона соответствует концу строки, а strSubject = Replace(strSubject, Chr(13), «») удаляет любые переносы строки.
Sub GetValueUsingRegEx() Dim olMail As Outlook.MailItem Dim Reg1 As RegExp Dim M1 As MatchCollection Dim M As Match Dim strSubject As String Dim testSubject As String Set olMail = Application.ActiveExplorer().Selection(1) Set Reg1 = New RegExp For i = 1 To 3 With Reg1 Select Case i Case 1 .Pattern = «(Order IDs[:]([w-s]*)s*)n» .Global = False Case 2 .Pattern = «(Date[:]([w-s]*)s*)n» .Global = False Case 3 .Pattern = «(([d]*.[d]*))s*n» .Global = False End Select End With If Reg1.test(olMail.Body) Then Set M1 = Reg1.Execute(olMail.Body) For Each M In M1 Debug.Print M.SubMatches(1) strSubject = M.SubMatches(1) strSubject = Replace(strSubject, Chr(13), «») testSubject = testSubject & «; » & Trim(strSubject) Debug.Print i & testSubject Next End If Next i Debug.Print olMail.Subject & testSubject olMail.Subject = olMail.Subject & testSubject olMail.Save Set Reg1 = Nothing End Sub
Использование функции RegEx
Эта функция позволяет использовать регулярное выражение в более чем одном макросе.
Если вам нужно использовать более чем один шаблон с функцией, задайте для шаблон в макросе regPattern = «([0-9]<4>)» и используйте это в функции: regEx.Pattern = regPattern . Не забудьте добавить Dim regPattern As String в верхней части модуля.
Function ExtractText(Str As String) ‘ As String Dim regEx As New RegExp Dim NumMatches As MatchCollection Dim M As Match ‘этот шаблон ищет 4 подряд идущие цифры в теме письма regEx.Pattern = «([0-9]<4>)» ‘ используейте это, если нужно задвать разные шаблоны ‘ regEx.Pattern = regPattern Set NumMatches = regEx.Execute(Str) If NumMatches.Count = 0 Then ExtractText = «» Else Set M = NumMatches(0) ExtractText = M.SubMatches(0) End If code = ExtractText End Function
Этот макрос показывает, как использовать функцию Regex. Если в теме письма есть соответствующая шаблону комбинация (в пример функции, 4-х значное число), то будет создан ответ. Если нет, то появляется окно с сообщением. Чтобы использовать функцию с разными макросами, раскомментируйте строки, содержащие regPattern.
Когда я работал в издательстве, то очень активно пользовался обработкой текста с помощью шаблонов. Тогда я использовал программу PageMaker (ныне InDesign) и язык скриптов. Позже я перенес этот опыт на обработку текста в Word и Excel, но использовал в макросах возможности, предоставляемые самими программами. Несколько лет назад я открыл для себя язык регулярных выражений. Прочитал книгу Бена Форта Регулярные выражения за 10 минут. К сожалению, доступ к регулярным выражениям открывался только через код VBA или специальные программы, что затрудняло понимание прочитанного и дальнейшее практическое использование регэкспов.
И вот совсем недавно я наткнулся на заметку Николая Павлова, в которой предлагается пользовательская функция RegExpExtract, переносящая всю работу с регулярными выражениями на листы Excel. В заметке также есть ссылка на два ресурса для проверки регулярных выражений в режиме онлайн: https://regex101.com/, https://regexr.com/. Рекомендую! Ваши шаблоны будут разобраны на элементы и показана их работа.
Поняв, как упростить работу с регулярными выражениями в Excel, я решил сделать второй подход к теме. Для чего взял фундаментальный труд Джеффри Фридла и изложил его фрагменты на примерах в Excel.
Джеффри Фридл. Регулярные выражения, 3-е издание. – СПб.: Символ-Плюс, 2008. – 608 с.

Скачать заметку в формате Word или pdf, примеры в формате zip-архива (внутри файл Excel с поддержкой макросов)
Купить цифровую книгу в ЛитРес
Для начала настроим функцию RegExpExtract
Посмотрите, есть ли на вашей ленте Excel вкладка Разработчик. Если нет, пройдите по меню Файл –> Параметры. Перейдите на вкладку Настроить ленту.
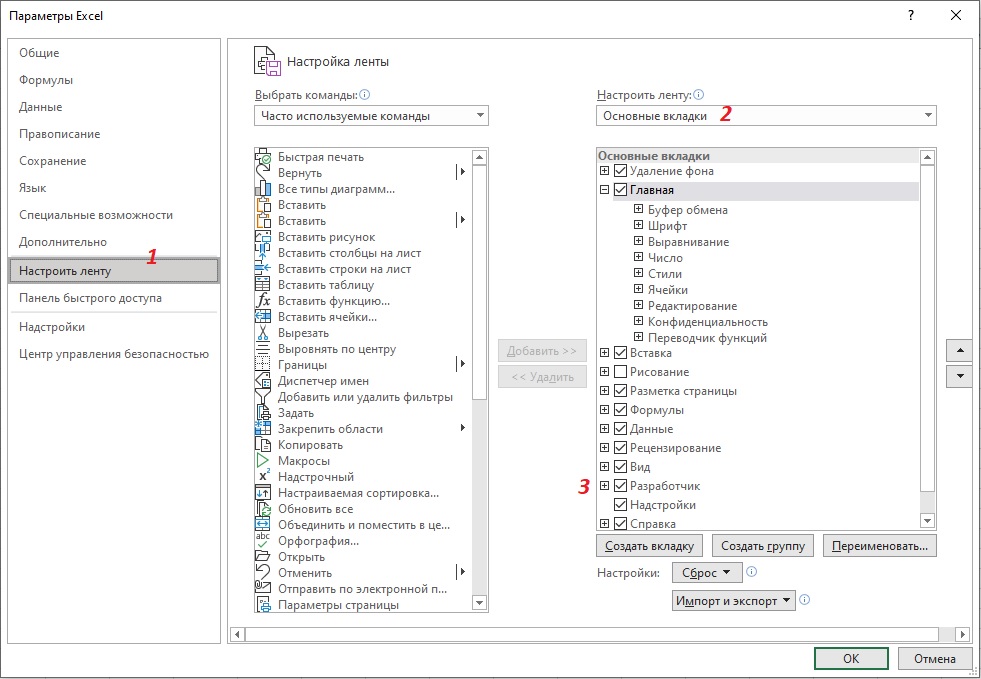
Рис. 1. Добавление вкладки Разработчик на ленту Excel; чтобы увеличить изображение кликните на нем правой кнопкой мыши и выберите Открыть картинку в новой вкладке
В окне Настройка ленты в области Основные вкладки установите флажок Разработчик. Нажмите Ok. В окне Excel перейдите на вкладку Разработчик. Кликните на кнопку Visual Basic. В окне редактора VBA кликните на строку VBAProject [название вашего файла]. Вставьте новый модуль, пройдя по меню Insert –> Module (рис. 2). Скопируйте код во вновь созданный модуль (я дополнил функцию Николая Павлова еще одним параметром – учетом регистра):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
Public Function RegExpExtract( _ Text As String, _ Pattern As String, _ Optional Item As Integer = 1, _ Optional IgnoreCase As Boolean = 0 _ ) As String On Error GoTo ErrHandl Set regex = CreateObject(«VBScript.RegExp») regex.Pattern = Pattern regex.Global = True regex.IgnoreCase = IgnoreCase If regex.Test(Text) Then Set matches = regex.Execute(Text) RegExpExtract = matches.Item(Item — 1) Exit Function End If ErrHandl: RegExpExtract = CVErr(xlErrValue) End Function |
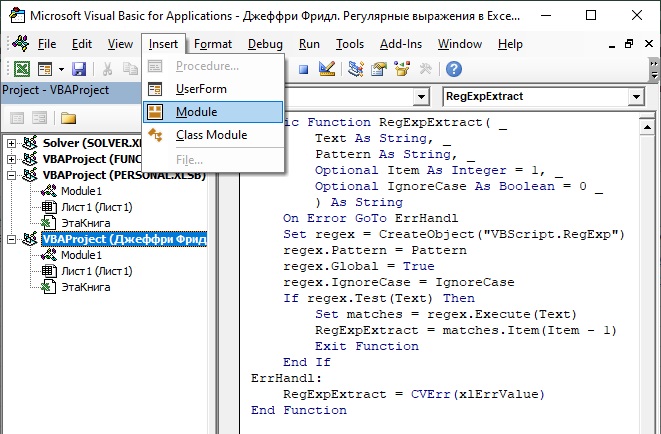
Рис. 2. Код функции RegExpExtract
Поскольку вы поместили код в модуль, относящийся к конкретной книге Excel, он не будет работать в иной книге. Сохраните файл Excel в формате с поддержкой макросов *.xslm. Функция RegExpExtract имеет четыре параметра:
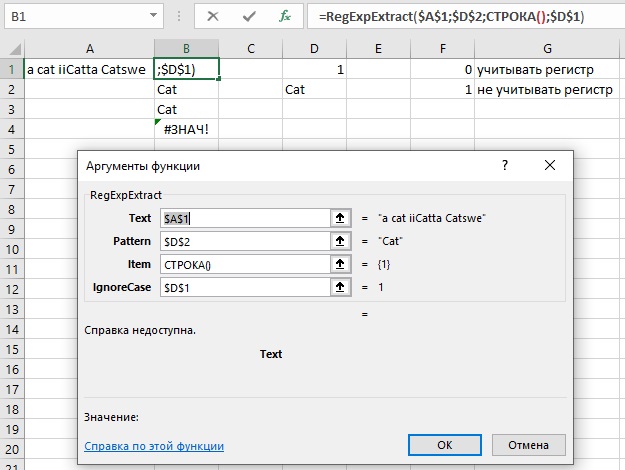
Рис. 3. Синтаксис функции RegExpExtract
Следует заметить, что регулярные выражения в VBA могут инициироваться двумя способами: ранним и поздним связыванием. Выше в коде функции RegExpExtract продемонстрировано позднее связывание. Оно заключается в присвоении нового экземпляра объекта RegExp переменной, объявленной с помощью функции CreateObject:
|
Set regex = CreateObject(«VBScript.RegExp») |
Открывая файл на другом ПК, где библиотека VBScript явным образом не инициирована, пользовательская функция RegExpExtract всё равно будет работать.
Однако чаще рекомендуется использовать объекты с ранней привязкой, так как у них выше быстродействие, а также при написании и редактировании кода доступны подсказки свойств и методов. Для осуществления ранней привязки необходимо подключить к проекту VBA ссылку на новую библиотеку. В редакторе VBA пройдите по меню Tools –> References, и в окне References — VBAProject поставьте флажок в строке Microsoft VBScript Regular Expressions 5.5.
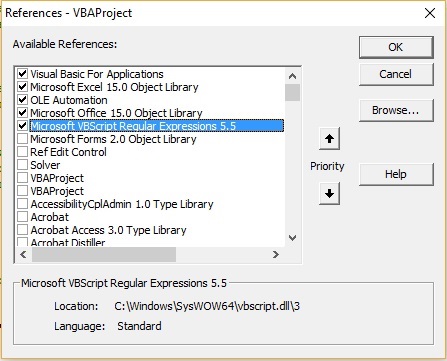
Рис. 3а. Раннее связывание через подключение библиотеки регулярных выражений
После этого объект RegExp может быть создан, например, так:
|
Dim myRegExp As RegExp Set myRegExp = New RegExp |
Далее в этой заметке будет использоваться только код с поздней привязкой.
Глава 1. Знакомство с регулярными выражениями
Регулярные выражения – это шаблоны и язык их обработки. Регулярные выражения способны вставлять, удалять, выделять и выполнять самые невероятные операции с текстовыми данными любого вида.
Регулярное выражение состоит из двух типов символов. Специальные символы (вроде * в файловых шаблонах) называются метасимволами. Все остальные символы, т.е. обычный текст, называются литералами.
Простейшими метасимволами являются ^ (крышка, циркумфлекс) и $ (доллар), представляющие соответственно начало и конец проверяемой строки. Для выражения ^cat совпадение происходит лишь в том случае, если символы cat находятся в начале строки.
Символьные классы
Допустим, необходимо найти строку grey, которая также может быть записана в виде gray. При помощи конструкции […], называемой символьным классом, можно перечислить символы, которые могут находиться в данной позиции текста. Таким образом, выражение gr[ea]y означает: «Найти символ g, за которым следует r, за которым следует e или a, и все это завершается символом y».
В контексте символьного класса метасимвол — (дефис) обозначает интервал символов. Классы [0-9] и [a-z] обычно используются соответственно для поиска цифр и символов нижнего регистра. Символьный класс может содержать несколько интервалов, поэтому класс [0123456789abcdefABCDEF] записывается в виде [0-9a-fA-F] при этом порядок перечисления роли не играет. Такое выражение пригодится при обработке шестнадцатеричных чисел. Интервалы также можно объединять с литералами: выражение [0-9A-Z_!.?] совпадает с цифрой, символом верхнего регистра, символом подчеркивания, восклицательным знаком, точкой или вопросительным знаком.
Обратите внимание: дефис выполняет функции метасимвола только внутри символьного класса – в остальных случаях он совпадает с обычным дефисом. Более того, даже в символьных классах дефис не всегда интерпретируется как метасимвол. Если дефис является первым символом, указанным в классе, он заведомо не может определять интервал и поэтому интерпретируется как литерал. Аналогично, вопросительный знак и точка считаются метасимволами в контексте обычных регулярных выражений, но не в контексте класса.
Если вместо […] используется запись [^…], класс совпадает с любыми символами, не входящими в приведенный список. Символ ^ является метасимволом символьного класса лишь в том случае, если следует сразу же после открывающей скобки (в противном случае он интерпретируется как обычный символ).
Один произвольный символ
Метасимвол . (точка) представляет собой сокращенную форму записи для символьного класса, совпадающего с любым символом. Он применяется в тех случаях, когда в некоторых позициях регулярного выражения могут находиться произвольные символы. Допустим, надо найти дату, которая может быть записана в формате 19/03/76, 19-03-76 или даже 19.03.76. Конечно, можно сконструировать регулярное выражение, в котором между числами указываются все допустимые символы-разделители, например 19[-./]03[-./]76. Однако возможен и другой вариант – просто ввести выражение 19.03.76.
В приведенном примере имеется ряд неочевидных аспектов. В выражении 19[-./]03[-./]76 точки не являются метасимволами, поскольку они находятся внутри символьного класса. Дефисы в данном случае тоже интерпретируются как литералы, поскольку они следуют сразу же после [ и [^ Если бы дефисы не стояли на первых местах (например, [.-/]), они интерпретировались бы как интервальные метасимволы, что в данном случае привело бы к ошибке. В выражении 19.03.76 точки являются метасимволами, совпадающими с любым символом.
Очень удобный метасимвол | означает «или». Он позволяет объединить несколько регулярных выражений в одно, совпадающее с любым из выражений-компонентов. Подвыражения, объединенные этим способом, называются альтернативами.
Вернемся к примеру gr[ea]y. Выражение также можно записать в виде grey|gray и даже gr(a|e)y. Круглые скобки отделяют конструкцию выбора от остального выражения (и тоже являются метасимволами). Конструкция вида gr[a|e]y не подойдет – в символьном классе символ | является обычным символом.
Конструкция выбора действует только внутри круглых скобок. Будьте внимательны и не путайте конструкцию выбора с символьными классами. Символьный класс представляет один символ целевого текста. В конструкциях выбора каждая альтернатива может являться полноценным регулярным выражением, совпадающим с произвольным количеством символов. Символьные классы обладают собственным мини-языком (и, в частности, собственными представлениями о метасимволах), тогда как конструкция выбора является частью «основного» языка регулярных выражений.
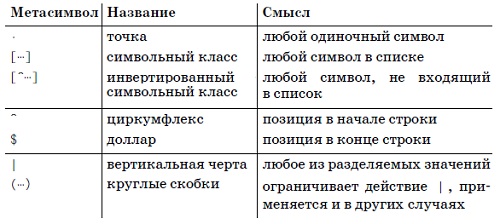
Рис. 4. Сводка метасимволов
Необязательные элементы
Рассмотрим пример поиска слова color или colour. Поскольку эти два слова отличаются только символом u, для их поиска можно использовать выражение colou?r. Метасимвол ? (знак вопроса) означает, что предшествующий ему символ является необязательным.
Рассмотрим поиск даты 4 июля (July), где название месяца July может быть записано как July или Jul, а число может быть записано как fourth, 4th или просто 4. Мы могли бы использовать выражение (July|Jul)•(fourth|4th|4). Здесь символ • используется для обозначения пробела в тексте книги; в коде используется обычный пробел.
Часть (July|Jul) можно сократить до July? Ликвидация метасимвола | позволяет убрать круглые скобки, ставшие ненужными. Наличие круглых скобок не повлияет на конечный результат, однако выражение July? без скобок воспринимается проще. Выражение 4th|4 можно сократить до 4(th)? Знак ? может присоединяться и к выражениям в круглых скобках. Подвыражение внутри скобок может быть сколь угодно сложным, но «снаружи» оно воспринимается как единое целое.
После упрощений наше выражение принимает вид July?•(fourth|4(th)?)
Квантификаторы повторения
Метасимвол + обозначает один или несколько экземпляров непосредственно предшествующего элемента, a * – любое количество экземпляров элемента (в том числе и нулевое). Иначе говоря, * означает «найти столько экземпляров, сколько это возможно, но при необходимости обойтись и без них». Конструкция + имеет похожий смысл (она также пытается найти как можно большее число экземпляров указанного элемента), но при отсутствии хотя бы одного экземпляра сопоставление завершается неудачей. Три метасимвола, которые могут совпадать с переменным количеством экземпляров элемента, ?, + и *, называются квантификаторами, поскольку они определяют количество элементов, на которые воздействуют.
Совпадение для конструкций * и ?, существует всегда. Вопрос лишь в том, какой текст будет (и будет ли вообще) содержаться в совпадении. Конструкция + требует наличия хотя бы одного экземпляра искомого текста. Например, выражение •? допускает не более одного необязательного пробела, тогда как •* – произвольное число необязательных пробелов.
Например, шаблон <H[1-6]> позволяет искать заголовков HTML; <Н1>, <Н2>, <Н3> и т.д. Однако в спецификации HTML говорится, что непосредственно перед закрывающей угловой скобкой допускаются пробелы – например, <H3•> или <H4•••>. Вставляя •* в ту позицию регулярного выражения, где могут находиться (а могут и отсутствовать) пробелы, мы получаем <H[1-6]•*>. Выражение по-прежнему совпадает с <H1>, поскольку наличие пробелов необязательно, но при этом также подходит и для других вариантов.
Попробуем организовать поиск тегов HTML вида <HК•SIZE=14>, этот тег означает, что на экране рисуется горизонтальная линия толщиной 14 пикселов. Перед закрывающей угловой скобкой могут стоять необязательные пробелы. Кроме того, пробелы могут находиться и по обе стороны знака =. Наконец, минимум один пробел должен разделять HR и SIZE, хотя их может быть и больше. В последнем случае мы воспользуемся •+. Плюс разрешает дополнительные пробелы, но требует обязательного присутствия хотя бы одного пробела. В итоге мы приходим к выражению <HR•+SIZE•*=•*14•*>.
Если вместо поиска тегов с одной конкретной толщиной линии (14) мы хотим найти все варианты, заменим 14 на любое число цифр. Цифра определяется выражением [0-9], а чтобы отыскать «одну или несколько цифр» достаточно добавить символ +. Символьный класс является отдельным элементом, поэтому применение к нему метасимволов + или ? не требует круглых скобок. В итоге получаем <HR•+SIZE•*=•*[0-9]+•*>
К счастью VBA может игнорировать регистр символов, поэтому нам не пришлось использовать [Hh][Rr] и т.д.
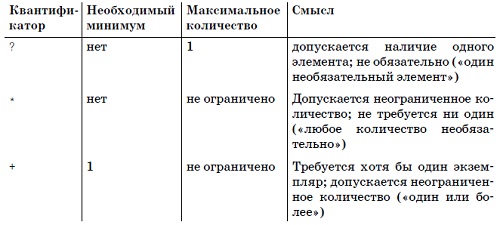
Рис. 5. Сводка квантификаторов
В VBA также поддерживается метапоследовательность для явного определения минимального и максимального количества совпадений: {min, max}. Эта конструкция называется интервальным квантификатором. Например, выражение [a-zA-Z]{1,5} может использоваться для поиска обозначений биржевых котировок – от одной до пяти букв. В следующем примере шаблон в Е2 позволяет найти три разных вхождения последовательностей букв t, а шаблон в Е8 – только два.
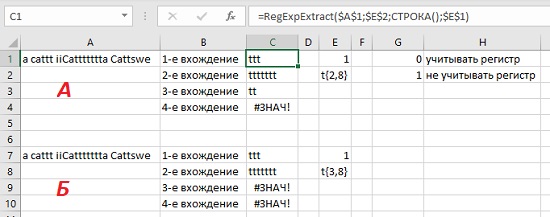
Рис. 6. Работа интервального квантификатора: а) t{2,8}, б) t{3,8}
Обратные ссылки
До настоящего момента мы встречались с двумя применениями круглых скобок: ограничение области действия в конструкции выбора | и группировка символов для применения квантификаторов ?, * и +. Еще одно применение круглых скобок – «запоминание» текста внутри скобок. В дальнейшем можно ссылаться на этот фрагмент. Например, при поиске повторяющихся слов. Т.е., слов, значения которых не известны до начала поиска: b([a-z]+)•+1b.
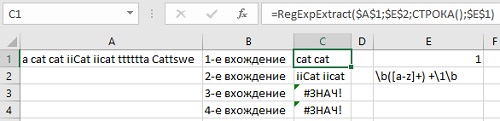
Рис. 7. Обратная ссылка 1 позволяет найти любые повторяющиеся слова
b соответствует границе слова, то есть позиции между словом и пробелом; [a-z]+ любое количество любых букв (чувствительность к регистру отключаем на уровне функции RegExpExtract; •+ любое число пробелов; 1 повтор выражения, найденного в круглых скобках; b этот повтор должен быть целым словом (это не даст регулярному выражению найти соответствие, скажем для the•theory).
В выражение можно включить несколько пар круглых скобок и ссылаться на совпавший текст при помощи метасимволов 1, 2, 3 и т.д. Пары скобок нумеруются в соответствии с порядковым номером открывающей скобки слева направо, поэтому в выражении ([а-z])([0-9])12 метасимвол 1 ссылается на текст, совпавший с [a-z], a 2 ссылается на текст, совпавший с [0-9].
Экранирование
Для включения в регулярное выражение символа, который обычно интерпретируется как метасимвол, перед ним нужно поставить обратный слеш . Например, для поиска слова в круглых скобках (very) можно воспользоваться регулярным выражением ([a-zA-Z]+). Символ в последовательностях ( и ) отменяет особую интерпретацию символов () и превращает их в литералы, совпадающие с круглыми скобками в тексте. Экранирование работает и в символьных классах:
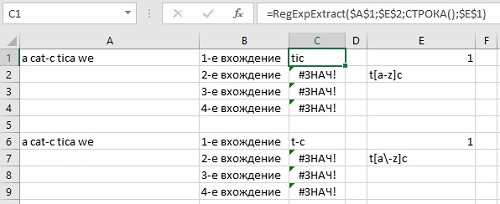
Рис. 8. Экранирование в символьных классах: сравните шаблоны в Е2 и Е7
При построении регулярного выражения приходится постоянно следить за тем, чтобы регулярное выражение: совпадало там, где нужно, и не совпадало там, где не нужно.
При работе с регулярными выражениями, как и с любым языком, чрезвычайно полезен практический опыт, поэтому ниже приведено еще несколько распространенных примеров регулярных выражений.
Имена переменных
Такие имена состоят из алфавитно-цифровых символов и знаков подчеркивания, но не могут начинаться с цифры. На языке регулярных выражений эта формулировка записывается в виде [a-zA-Z_][a-zA-Z_0-9]*. Первый класс определяет возможные значения первого символа имени, второй (вместе с суффиксом *) определяет оставшуюся часть идентификатора. Если длина идентификатора ограничивается, допустим, 32 символами, звездочку можно заменить выражением {0, 31}.
Последовательности символов, заключенные в кавычки
Простое выражение, обозначающее строку в кавычках: «[^»]*». Двойные кавычки, ограничивающие регулярное выражение, совпадают с открывающими и закрывающими кавычками строки. Между ними может находиться все, что угодно… кроме других кавычек! Выражение [^»] совпадает с любым символом, кроме «, а звездочка говорит о том, что количество таких символов может быть любым.
Денежные суммы в долларах (с необязательным указанием центов)
Одно из возможных решений: $[0-9]+(.[0-9][0-9])? Это регулярное выражение разбивается на три части: $, …+ и (…)?. Первая – литерал-знак доллара, вторая – неограниченная последовательность цифр, третья – десятичная точка и две цифры. Третья часть является необязательной.
Этот пример наивен по нескольким причинам. Например, это регулярное выражение предполагает, что денежная сумма в долларах будет записываться как $1000, но не как $1,000. Кроме того, приведенное выражение не находит суммы вида $.49. Возникает искушение заменить + на *, но такое решение не годится. Мы вернемся к этому примеру в главе 5.
URL адреса
Адреса могут иметь довольно сложную структуру, поэтому построение регулярного выражения для любых возможных URL довольно сложная задача. Тем не менее небольшое смягчение требований позволяет описать большинство URL. Обычные адреса URL имеют следующую структуру: http://хост/путь.html, хотя также часто встречается расширение htm. Для хоста можно предложить шаблон [-a-z0-9_.]+. Структура пути может быть еще более разнообразной, поэтому мы обозначим путь выражением [-a-z0-9_:@&?=+,.!/~+%$]*. Обратите внимание: перечисление символов в этих классах начинается с дефиса, чтобы он включался в список как литерал, а не интерпретировался как часть интервала. В принципе можно обойтись еще более простым выражением: <http://[^ •]*.html?>
По мере углубления в изучение темы вы убедитесь, что правильная оценка данных в значительной мере определяет компромисс между сложностью и точностью. Мы вернемся к примеру с поиском URL в следующей главе.
Время
Поиск времени тоже может осуществляться с разной степенью точности. Например, выражение [0-9]?[0-9]:[0-9][0-9]•(am|pm) успешно находит 9:17•am и 12:30•pm, но с такой же легкостью обнаруживает время 99:99•pm.
Если час состоит из двух цифр, то первая цифра может быть только единицей. Для поиска часов подойдет (1[012]|[1-9]). Для минут первая цифра определяется выражением [0-5], а для второй цифры можно оставить [0-9]. Объединяя все компоненты, мы получаем (1[012]|[1-9]):[0-5][0-9] •(am|pm).
Попробуйте построить регулярное выражение для поиска времени в 24-часовом формате, с нумерацией часов от 0 до 23. Чтобы задание было посложнее, разрешите использование начального нуля до 09:59. Решение несколькими абзацами ниже.
Глава 2. Дополнительные примеры
Ранее мы увидели, что круглые скобки могут применяться для «запоминания» текста внутри скобок. Далее в шаблоне можно обратиться к запомненному фрагменту с помощью метасимволов 1, 2, … Если же на фрагмент нужно сослаться за пределами шаблона, используются иные механизмы.
Ссылки $1, $2, …
Пусть у нас есть текст, из которого нужно убрать дефис:
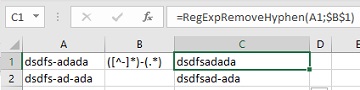
Рис. 9. Функция RegExpRemoveHyphen, удаляющая дефис из текста
Для обнаружения конструкции используем шаблон ([^-]*)-(.*). Здесь ([^-]*) соответствует любому количеству символов за исключением дефиса. Далее в шаблоне следует дефис, и наконец (.*) соответствует любому количеству любых символов. (Чтобы продемонстрировать принцип я не стал усложнять шаблон, так что наш удаляет только первый дефис.) Код функции:
|
Public Function RegExpRemoveHyphen(Text As String, Pattern As String) As String On Error GoTo ErrHandl Set regEx = CreateObject(«VBScript.RegExp») regEx.Pattern = Pattern RegExpRemoveHyphen = regEx.Replace(Text, «$1$2») Exit Function ErrHandl: RegExpRemoveHyphen = CVErr(xlErrValue) End Function |
В строке RegExpRemoveHyphen = regEx.Replace(Text, «$1$2») исходный текст заменяется на два фрагмента, найденных в соответствии с шаблоном. На эти фрагменты ссылаются по порядковому номеру появления круглых скобок. Сначала берется часть ([^-]*). Ссылка на нее – $1. Затем часть (.*). Ссылка на нее – $2. Таким образом, просто исключается дефис.
Ссылки в стиле $1, $2 могут использоваться в методе Replace (возможно, где-то еще), но в общем случае используется иной механизм.
Ответ на вопрос: поиск времени в 24-часовом формате
Задача разбивается на три временных интервала: утро (с 00 до 09 часов, возможен начальный ноль), день (с 10 до 19 часов) и вечер (с 20 до 23 часов). Прямолинейное решение выглядит так: (0?[1-9]|1[0-9]|2[0-3]):[0-5][0-9]. Но первые два варианта можно объединить: [01]?[0-9]|2[0-3]:[0-5][0-9].
Метод SubMatches
Пусть мы хотим найти в текстовой строке температуру в градусах Цельсия или Фаренгейта, и вернуть значения в обеих шкалах. Опять же ради демонстрации метода не будем усложнять шаблон:
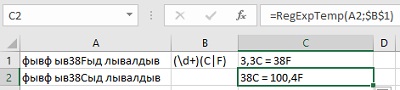
Рис. 10. Функция RegExpTemp, возвращающая температуру в градусах Цельсия и Фаренгейта
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
Public Function RegExpTemp(Text As String, Pattern As String) As String Dim m As Object On Error GoTo ErrHandl Set regEx = CreateObject(«VBScript.RegExp») regEx.Pattern = Pattern Set Matches = regEx.Execute(Text) For Each m In Matches If m.SubMatches(1) = «C» Then RegExpTemp = m.SubMatches(0) & «C = « & _ Format(m.SubMatches(0) * 9 / 5 + 32, «#.0») & «F» Else RegExpTemp = Format((m.SubMatches(0) — 32) * 5 / 9, «#.0») & _ «C = « & m.SubMatches(0) & «F» End If Next Exit Function ErrHandl: RegExpTemp = CStr(CVErr(xlErrValue)) End Function |
Извлеченная по шаблону подстрока, помещается в коллекцию Matches = regEx.Execute(Text). Нумерация элементов в коллекциях Matches и SubMatches начинается с нуля. Далее проверяется, какую букву возвращает вторая пара круглых скобок (C|F): m.SubMatches(1). Если «C», то помещаем значение из первой группы (d+) в начало функции RegExpTemp = m.SubMatches(0), а значение для градусов Фаренгейта вычисляем по формуле. Чтобы вычисленные значения смотрелись красиво с помощью функции Format ограничиваем число символов после запятой одним. Если значение m.SubMatches(1) = «F», то вычисляем градусы по шкале Цельсия.
Объектная модель VBA
Эксперт с форума Планет Excel Kuzmich предложил более изящный код для функции RegExpTemp.
|
Function iDegree(cell$) With CreateObject(«VBScript.RegExp») .Pattern = «(d+)(C|F)» If .test(cell) Then If .Execute(cell)(0).SubMatches(1) = «C» Then iDegree = .Execute(cell)(0).SubMatches(0) & «C = « & _ Format(.Execute(cell)(0).SubMatches(0) * 9 / 5 + 32, «#.0») & «F» Else iDegree = Format((.Execute(cell)(0).SubMatches(0) — 32) * 5 / 9, «#.0») & «C = « & _ .Execute(cell)(0).SubMatches(0) & «F» End If Else iDegree = «Температура не найдена» End If End With End Function |
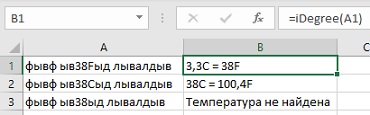
Рис. 11. Альтернативный вариант функции, возвращающей температуру в двух шкалах
Этот код основан на хорошем понимании иерархии объекта RegExp (рис. 12). Разберем, что происходит в строке…
|
If .Execute(cell)(0).SubMatches(1) = «C» Then |
Метод Execute(cell) возвращает коллекцию Matches – все совпадения, найденные по шаблону Pattern в строке cell. Из коллекции берется первый элемент (0) и его свойство – SubMatches. При этом выбирается вторая подстрока SubMatches(1).
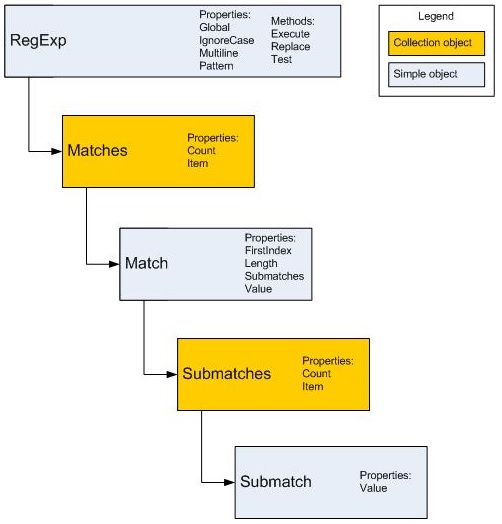
Рис. 12. Объектная модель RegExp
Объектная модель .NET
В книге Джеффри Фридл не говорит о VBA, но целую главу посвящает платформе Microsoft .NET Framework, используемой в Visual Basic, C# и C++ (а также в других языках). .NET содержит общую библиотеку регулярных выражений, обеспечивающую единую семантику операций с регулярными выражениями в разных языках. Поддержка регулярных выражений в .NET использует традиционный механизм НКА.
Объектная модель регулярных выражений .NET отличается от модели VBA, представленной на рис. 12, но она настолько наглядна, что будет полезна для изучения. Объектная модель представляет собой совокупность классов, через которую пользователь получает доступ к функциональности регулярных выражений. В .NET эту функциональность обеспечивают семь тесно взаимодействующих классов, но на практике обычно бывает достаточно трех классов, представленных на рис. 12а. На рисунке схематично изображен процесс многократного поиска совпадений s+(d+) в строке May•16,•1998
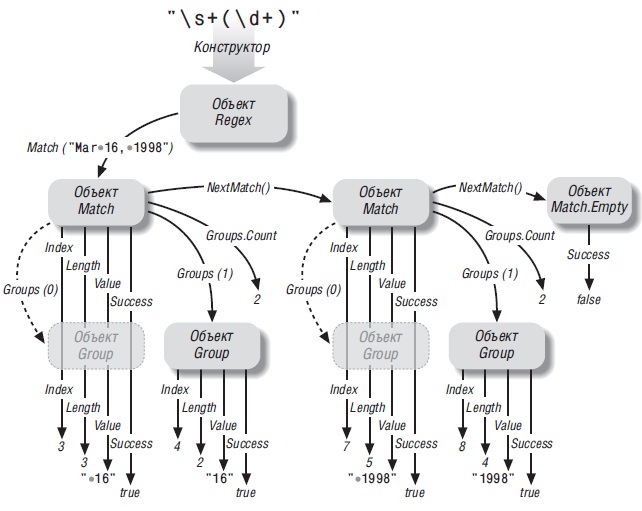
Рис. 12а. Объектная модель библиотеки регулярных выражений .NET
Несохраняющие круглые скобки
Допустим нам нужен более тонко настроенный шаблон для поиска температуры. Например такой: ([-+]?[0-9]+(,[0-9]*)?)([CF]). Он позволяет искать температуры с необязательным знаком плюс или минус, а также с необязательной дробной частью после запятой.
Обратите внимание: мы добавили необязательную группу (,[0-9]*)? внутрь первой пары круглых скобок. Поскольку первые скобки используются для сохранения числа, в них также должна быть включена его дробная часть. Однако появление новой пары круглых скобок, пусть даже предназначенных только для применения квантификатора, приводит к побочному эффекту – содержимое этих скобок также сохраняется в переменной. Поскольку открывающая скобка является второй слева в выражении, дробная часть числа сохраняется в $2.
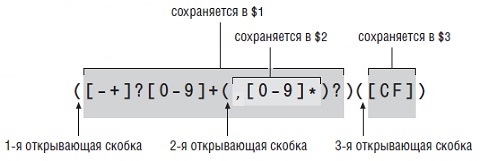
Рис. 13. Вложенные круглые скобки
Появление новых круглых скобок не изменяет смысла выражения [CF] напрямую, но отражается на нем косвенно. Дело в том, что круглые скобки, в которые заключено это подвыражение, становятся третьей парой, а это означает, что содержимое извлекается по ссылке $3 вместо $2.
Чтобы не менять код функции RegExpTemp следует использовать разновидность круглых скобок, которая обеспечивает группировку без сохранения: ([-+]?[0-9]+(?:,[0-9]*)?)([CF]). Здесь открывающая круглая скобка состоит из трех символов (?: Вопросительный знак не имеет отношения к «необязательному» метасимволу. С таким шаблоном подвыражение [CF], хотя и заключено в третий набор круглых скобок, совпадающий с ним текст обозначается переменной $2, поскольку конструкция (?:,[0-9]*)? при подсчете не учитывается. Функция RegExpTemp без каких-либо изменений возвращает корректный результат:
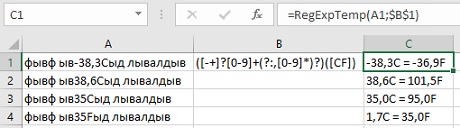
Рис. 14. Функция RegExpTemp распознает и десятичные значения
Обобщенный пропуск
В VBA используется метасимвол s. Он обеспечивает сокращенную запись для целого символьного класса, означающего «любой пропуск»: [•rtnf].
Позиционная проверка (lookaround)
Существует класс задач, которые решаются при помощи позиционной проверкой (lookaround). Конструкции позиционной проверки обладают определенным сходством с метасимволами границ слов b, ^ и $ – они тоже совпадают не с символами, а с позициями в тексте. Однако позиционная проверка используется значительно шире.
Различают четыре типа проверки:
Код Тип
(?= Положительная опережающая (Positive Lookahead)
(?! Отрицательная опережающая (Negative Lookahead)
(?<= Положительная ретроспективная (Positive Lookbehind)
(?<! Отрицательная ретроспективная (Negative Lookbehind)
Подобно конструкции (?: все позиционные проверки не захватывают значения. Опережающая проверка анализирует текст, расположенный справа. Например, подвыражение (?=d) совпадает в тех позициях, за которыми следует цифра. Ретроспективная проверка анализирует текст в обратном направлении (к левому краю). Например, подвыражение (?<=d) совпадает в тех позициях, слева от которых находится цифра (т.е., в позиции после цифры).
Позиционные проверки не «поглощают» найденную подстроку. Ниже выделено совпадение регулярного выражения Jeffrey в строке … by Jeffrey Friedl (рис. 15а). Однако в конструкции опережающей проверки то же самое выражение (?=Jeffrey), совпадает только в отмеченной на рис. 15б позиции. Опережающая проверка использует свое подвыражение для поиска, но находит только позицию, с которой начинается совпадение, а не фактически совпадающий текст. Объединение опережающей проверки с выражением, совпадающим с символами текста, открывает дополнительные возможности. Объединенное выражение (?=Jeffrey)Jeff совпадает с текстом Jeff только в том случае, если он является частью слова Jeffrey. Выражение совпадет в строке 15в и не совпадет в 15г.
Выражение (?=Jeffrey)Jeff эквивалентно выражению Jeff(?=rey). Оба выражения совпадают с текстом Jeff только в том случае, если он является частью слова Jeffrey.
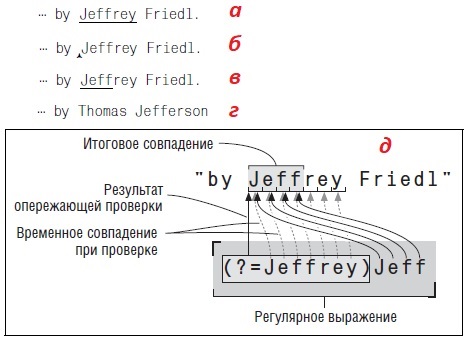
Рис. 15. Поиск совпадения для выражения (?=Jeffrey)Jeff
Обратите внимание и на важность порядка перечисления объединяемых подвыражений. Выражение Jeff(?=Jeffrey) не совпадает ни в одной из приведенных строк – оно совпадет только с текстом Jeff, сразу же после которого следует Jeffrey.
Пример ретроспективной проверки
Пусть вы хотите заменить вхождения Jeff на Jeff’s. Задача легко решается без применения проверки, но будет полезна в качестве учебного примера:
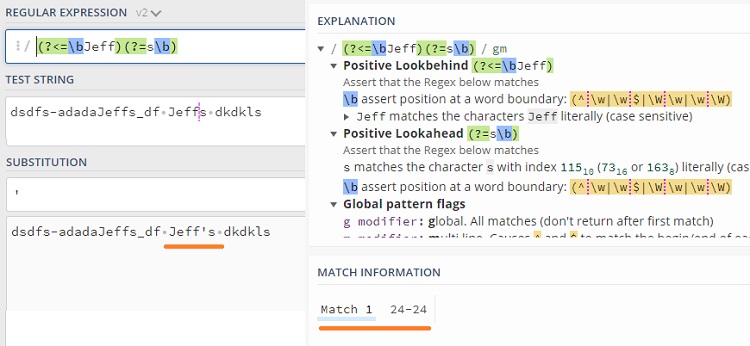
Рис. 16. Ретроспективная и опережающая проверки определяют позицию для вставки апострофа
Первая часть шаблона (?<=bJeff) ищет позицию слева от которой будут символы Jeff в начале слова. Вторая часть шаблона (?=sb) ищет позицию за которой идет символ s в конце слова. Т.е., шаблон возвращает не подстроку, а позицию в искомом тексте. В примере она имеет номер 24. Остается заменить «ничто» в позиции 24 на апостроф ‘.
К сожалению, ретроспективная проверка не поддерживается библиотекой Microsoft VBScript Regular Expressions 5.5. Т.е., в коде VBA можно использовать только опережающую проверку.
Разделение групп разрядов в больших числах
Такое разделение часто улучшает внешний вид отчетов, так что весьма полезно. Формально постановка задачи выглядит так: нужно вставить пробелы во всех позициях, у которых количество цифр справа кратно трем, а слева есть хотя бы одна цифра. Группа из трех цифр определяется выражением d{3}. Заключим его в конструкцию (…)+ чтобы совпадение могло состоять из нескольких групп, и завершим метасимволом $, чтобы гарантировать отсутствие символов после совпадения. Само по себе выражение (d{3})+$ совпадает с группами из трех цифр, следующими до конца строки, но в конструкции опережающей проверки (?=…) оно совпадает с позицией, справа от которой до конца строки следуют группы из трех цифр – например, в отмеченных позициях текста ’123’456’789. Однако перед первой цифрой пробел не ставится, поэтому совпадение дополнительно ограничим ретроспективной проверкой (?<=d), гарантирующей, что слева есть хотя бы одна цифра.
Итак, шаблон (?<=d)(?=(d{3})+$) в строке «Население России составляет 146247381» выделит две позиции, в которых мы вставим пробел:
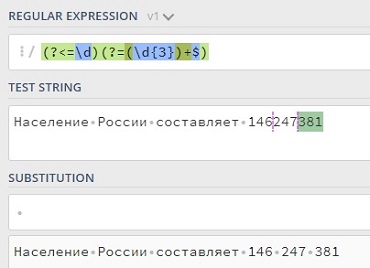
Рис. 17. Пробелы, разделяющие группы цифр
Разделение разрядов без ретроспективной проверки
Поскольку VBA не поддерживает ретроспективную проверку, покажем, как можно разделить разряды без нее. Для этой цели подойдет шаблон поиска (d)(?=(d{3})+(?!d)), а в строку замены добавим ссылку на переменную $1 и знак пробела:

Рис. 18. Добавление пробелов между разрядами без ретроспективной проверки
|
Public Function RegExpFindRepl(Text$, Pattern$, Repl$) On Error GoTo ErrHandl With CreateObject(«VBScript.RegExp») .Global = True .Pattern = Pattern RegExpFindRepl = .Replace(Text, Repl) Exit Function End With ErrHandl: RegExpFindRepl = CVErr(xlErrValue) End Function |
Добавлена строка .Global = True для поиска всех совпадений (а не только первого). Поиск найдет все цифры (d), за которыми следует одна или несколько групп из трех цифр (?=(d{3})+ после которых идет не цифра (?!d). Вхождение (d) будет заменено на само себя и пробел $1•. Опережающая проверка имеет еще одно важное свойство по сравнению с обычной группой. Опережающая проверка не влияет на позицию, с которой начинается поиск следующего совпадения. Сравним работу двух шаблонов:

Рис. 19. Точка возобновления обычной и опережающей проверки
Первый шаблон требует одну цифру + максимальное число групп по три цифры, и возобновит поиск после нахождения 7 цифр в точке, указанной стрелкой. Второй шаблон требует одну цифру, проверяя, что за ней следует максимальное число групп по три цифры. Но эти группы не входят в возвращаемое значение. Второй шаблон возобновляет поиск после найденной одной цифры.
Глава 4. Механика обработки регулярных выражений
Существует два разных типа механизмов регулярных выражений: ДКА и НКА. Чтобы определить тип механизма примените регулярное выражение nfa|nfa•not к строке nfa•not; если совпадет только nfa, значит, это традиционный механизм НКА:
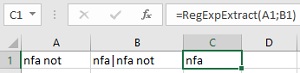
Рис. 20. Движок VBA реализует механизм НКА
Было бы удобно свести алгоритмы выполнения поиска к нескольким простым правилам. К сожалению, это не удастся. Я могу выделить лишь два универсальных правила:
- Предпочтение отдается более раннему совпадению.
- Стандартные квантификаторы (*, +, ? и {m,n}) работают максимально.
Правило 1
Правило 1 работает следующим образом: сначала механизм пытается найти совпадение от самого начала строки, в которой осуществляется поиск (с позиции перед первым символом). Слово «пытается» означает, что с указанной позиции ищутся все возможные комбинации всего (иногда довольно сложного) регулярного выражения. Если после перебора всех возможностей совпадение так и не будет найдено, вторая попытка делается с позиции, предшествующей второму символу. Эта процедура повторяется для каждой позиции в строке. Результат «совпадение не найдено» возвращается лишь в том случае, если совпадение не находится после перебора всех позиций до конца строки.
Например, при поиске cat в строке The dragging belly indicates your cat is too fat совпадение находится в слове indicates… Где в строке The dragging belly indicates your cat is too fat совпадет выражение fat|cat|belly|your? При каждой попытке осуществляется полный поиск регулярного выражения, поэтому fat|cat|belly|your совпадет belly раньше, чем с fat, хотя fat в списке альтернатив находится в более ранней позиции.
Правило 2
Правило 2 гласит, если некоторый элемент может совпадать переменное количество раз, механизм всегда пытается найти максимальное количество повторений. Максимальные квантификаторы всегда захватывают больше повторений, чем им требуется по минимуму, поэтому их иногда называют жадными.
Например, шаблон ^.*([0-9][0-9]) находит две последних цифры в строке, где бы они ни располагались, и сохраняет их в переменной $1. Это происходит следующим образом: сначала .* сопоставляется со всей строкой. Следующее подвыражение ([0-9][0-9]) является обязательным, и при отсутствии совпадения для него «говорит»: «Эй, .*, ты взял лишнее! Верни мне что-нибудь, чтобы и для меня нашлось совпадение». «Жадные» компоненты всегда сначала стараются захватить побольше, но потом всегда отдают излишки, если при этом достигается общее совпадение.
Применим ^.*([0-9][0-9]) к строке about 24 characters long. После того как r.* совпадет со всей строкой, необходимость совпадения для первого класса [0-9] заставит .* уступить символ g (последний из совпавших). Однако при этом совпадение для [0-9] по-прежнему не находится, поэтому .* уступает n в слове long. Цикл повторяется 15 раз, пока .* не доберется до цифры 4. К сожалению, совпадение появляется лишь для первого класса [0-9]. Второму классу, как и прежде, совпадать не с чем. Поэтому .* уступает 2, с которой может совпасть первый класс [0-9]. Цифра 4 освобождается и совпадает со вторым классом, а все выражение – с about 24. Переменной $1 присваивается строка 24.
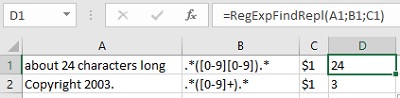
Рис. 21. Жадный квантификатор отдает по минимуму
Если вы думаете, что ([0-9][0-9]) можно заменить на ([0-9]+), то ошибаетесь. Какой текст совпадет, если применить выражение ^.*([0-9]+) к строке ‘Copyright 2003.’? Что запишется в переменную $1? Подвыражение .* как и в первом примере идет на частичные уступки. Сначала уступит завершающую точку, а затем 3, после чего появляется совпадение для класса [0-9]. К классу применен квантификатор +, для которого один экземпляр соответствует минимальным требованиям; дальше в строке идет точка, поэтому второго совпадения нет.
Но в отличие от предыдущего случая никаких обязательных элементов дальше нет, поэтому .* не приходится уступать 0 и другие цифры. В принципе подвыражение [0-9]+ с радостью согласилось бы на такой подарок, но нет: кто первым приходит, того первым и обслуживают. Жадные квантификаторы по-настоящему скупы: если что-то попало им в лапы, они отдадут это «что-то» только по принуждению. В итоге переменная $1 содержит только символ 3.
Фразы типа .* уступает… или [0-9] заставляет… на самом деле неточны. Я воспользовался этими оборотами, потому что они достаточно наглядны и при этом приводят к правильному результату. Однако события, которые в действительности происходят за кулисами, зависят от базового типа механизма, ДКА или НКА.
Механизмы регулярных выражений
Говорят, что механизм НКА «управляется регулярным выражением», а механизм ДКА «управляется текстом».
Рассмотрим алгоритм поиска совпадения выражения to(nite|knight|night) в тексте …tonight… Механизм просматривает регулярное выражение по одному компоненту, начиная с t, и проверяет, совпадает ли компонент с «текущим текстом». В случае совпадения проверяется следующий компонент. Процедура повторяется до тех пор, пока не будет найдено совпадение для всех компонентов регулярного выражения. Управление передается внутри регулярного выражения от компонента к компоненту, поэтому я говорю, что такой механизм «управляется регулярным выражением».
Механизму ДКА сканирует строку и следит за всеми «потенциальными совпадениями». В описанном выше примере механизм узнает о начале потенциального совпадения, как только в строке встречается символ t:

Рис. 22. Работа механизма ДКА после первого совпадения
Каждый следующий сканируемый символ обновляет список потенциальных совпадений. Через несколько символов мы приходим к следующей ситуации с двумя потенциальными совпадениями (одна альтернатива, knight, к этому моменту уже отвергается):

Рис. 23. Механизм ДКА после 4 совпадений
Проверка следующего символа, g, исключает и первую альтернативу. После сканирования h и t механизм понимает, что он нашел полное совпадение, и успешно завершает свою работу.
Механизм ДКА «управляется текстом», поскольку его работа зависит от каждого просканированного символа строки. В приведенном выше примере частичное совпадение может быть началом любого количества разных (но потенциально возможных) совпадений. Отвергаемые совпадения исключаются из дальнейшего рассмотрения по мере сканирования последующих символов.
Механизм ДКА работает быстрее: каждый символ в строке проверяется не более одного раза. Если символ совпал, вы еще не знаете, войдет ли он в итоговое совпадение (символ может быть частью потенциального совпадения, которое позднее будет отвергнуто), но, поскольку механизм отслеживает все потенциальные совпадения одновременно, символ достаточно проверить только один раз.
Расшифровка аббревиатур: НКА – недетерминированный конечный автомат и ДКА – детерминированный конечный автомат.
Последствия для пользователей
Поскольку механизм НКА управляется регулярным выражением, при его использовании необходимо очень хорошо разбираться в том, как происходит поиск совпадений. В примере с tonight для повышения эффективности поиска можно было бы записать регулярное выражение в одном из следующих вариантов: to(ni(ght|te)|knight), tonite|toknight|tonight, to(k?night|nite). В ДКА все наоборот: поскольку механизм отслеживает все совпадения одновременно, любые различия в представлении несущественны, если они в конечном счете определяют один и тот же совпадающий текст.
Чтобы досконально разобраться во всех тонкостях НКА, необходимо рассмотреть одну из важнейших концепций этого механизма – возврат.
Возврат
Иногда механизму НКА приходится выбирать дальнейший ход действий. Такие ситуации связаны с использованием квантификаторов (нужно ли пытаться найти следующее совпадение) и конструкций выбора (какую альтернативу искать сейчас, а какую оставить на будущее). В этом случае механизма НКА выбирает один вариант и запоминает другой, чтобы позднее вернуться к нему в случае необходимости.
Если выбранный вариант и все выражение успешно совпадают, процесс поиска завершается. Если какая-либо из оставшихся частей регулярного выражения приводит к неудаче, механизм регулярных выражений возвращается к развилке, где было принято решение, и продолжает поиск с другим вариантом.
С концепцией возврата связано два вопроса:
- какой вариант из нескольких возможных должен проверяться в первую очередь?
- какой из сохраненных вариантов должен использоваться механизмом при возврате?
В тех ситуациях, где механизм выбирает между попытками найти совпадение или отказаться от его поиска (например, при использовании квантификаторов ?, * и других), механизм всегда сначала пытается найти совпадение для максимальных квантификаторов и пропустить совпадение для минимальных квантификаторов.
При локальной неудаче происходит возврат к последнему из сохраненных вариантов. Перебор вариантов осуществляется по правилу LIFO (последним пришел – первым обслужен). При описании LIFO часто используется аналогия со стопкой тарелок: первой со стопки снимается та тарелка, которая была поставлена в нее последней.
Сохраненное состояние определяет точку, с которой при необходимости можно начать очередную проверку. В нем сохраняется как текущая позиция в регулярном выражении, так и позиция в строке, с которой начинается проверка.
Рассмотрим простой пример – поиск выражения ab?c в строке abc. После совпадения c a текущее состояние показано на рис. 24а. Перед поиском b? механизм должен принять решение – пытаться найти b или нет? Из-за своей жадности квантификатор ? начинает искать совпадение. Но для того, чтобы в случае неудачи он мог вернуться к этой точке, в пустой на этот момент список сохраненных состояний добавляется запись на рис. 24б.
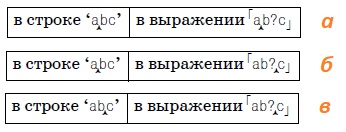
Рис. 24. Механика поиска: а) текущее состояние после совпадения буквы а; б) сохраненное состояние; в) текущее состояние после совпадения буквы b
Это означает, что механизм позднее продолжит поиск с компонента, следующего в регулярном выражении после b?, и сопоставит его с текстом, находящимся до b (т.е. в текущей позиции). В сущности, это означает, что литерал b пропускается, что допускает квантификатор ?. В нашем примере для b находится совпадение, поэтому новое текущее состояние выглядит как на рис. 24в. Последний компонент с тоже совпадает. Следовательно, механизм нашел общее совпадение для всего регулярного выражения. Единственное сохраненное состояние становится ненужным, и механизм попросту забывает о нем.
Если бы поиск производился в строке ac, все происходило бы точно так же до попытки найти совпадение для b. Конечно, на этот раз совпадение не обнаруживается. Это означает, что путь, пройденный при попытке найти совпадение для b?, оказался тупиковым. Но поскольку у нас имеется сохраненное состояние, к которому можно вернуться, «локальная неудача» вовсе не означает общей неудачи. Механизм возвращается к последнему сохраненному состоянию и превращает его в новое текущее состояние. В нашем примере восстанавливается состояние сохраненное перед поиском b. На этот раз c совпадают, что обеспечивает общее совпадение.
Минимальный поиск
Ранее (см. рис. 5) мы изучили так называемые жадные квантификаторы: +, ?, * и {min, max}. В VBA также поддерживаются минимальные (нежадные, ленивые) квантификаторы: +?, ??, *? и {min, max}?. Такие квантификаторы покрывают минимальный набор символов и расширяют его, если последующие сцепленные выражения не выполняются (подробнее см. Квантификаторы в регулярных выражениях). Например, шаблон (.+) вернет весь текст от первой открывающей до последней закрывающей скобки в тексте. В то же время (.+?) остановится на первой закрывающей скобке:
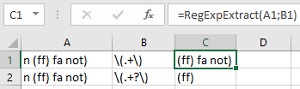
Рис. 25. Нежадный квантификатор +? остановится при первом совпадении
Подробнее о максимализме и о возврате
Элемент шаблона .* всегда распространяет совпадение до конца строки. Позднее часть захваченного может быть возвращена, если это необходимо для общего совпадения. Например, какое совпадение шаблон «.*» найдет в строке:
The name «McDonald’s» is said «makudonarudo» in Japanese
После совпадения первого символа » управление передается конструкции .*, которая немедленно захватывает все символы до конца строки. Она начинает нехотя отступать (под нажимом механизма регулярных выражений), но только до тех пор, пока не будет найдено совпадение для последней кавычки. Найденное совпадение будет выглядеть так:
«McDonald’s» is said «makudonarudo»
Как же ограничить совпадение строкой «McDonald’s»? Главное – понять, что между кавычками должно находиться не «все, что угодно», а «все, что угодно, кроме кавычек». Если вместо .* воспользоваться выражением [^»]*, совпадение не пройдет дальше закрывающей кавычки. После совпадения первой кавычки [^»]* стремится захватить как можно большее потенциальное совпадение. В данном случае это совпадение распространяется до кавычки, следующей после McDonald’s. На этом месте поиск прекращается, поскольку [^»] не совпадает с кавычкой, после чего управление передается закрывающей кавычке в регулярном выражении. Она благополучно совпадает, обеспечивая общее совпадение:
«McDonald’s»
С проблемой также справится минимальный квантификатор «.*?»

Рис. 26. Варианты обхода жадности квантификатора *
Минимальный квантификатор не панацея
Усложним пример. Допустим нам надо найти в HTML тексте слова, выделенные полужирным шрифтом, т.е. ограниченные тегами <B>…</B>. Шаблон <B>.*?</B> справится со строкой (рис. 27а)…
…<B>Billions</B> and <B>Zillions</B> of suns…
… но не справится со строкой (рис. 27б)…
…<В>Вillions and <B>Zillions</B> of suns…
Ничто не помешало фрагменту шаблона .*? пройти мимо <B> в начале слова Zillions к завершающему тегу </B>.
Задачу можно решить с помощью опережающей негативной проверки (рис. 27в). Нужно проверять не любой знак, а лишь тот, что не совпадает с <B>. Перед точкой появляется блок опережающей проверки (?!<B>) А весь шаблона примет вид <B>((?!<B>).)*?</B> Его можно прочитать так: после тега <B> взять любое число символов в таких позициях, что далее не следует <B>, до ближайшего </B>

Рис. 27. Опережающая проверка
Далее подробно рассмотрены захватывающие (или сверхжадные) квантификаторы ?+, ++, *+, … и атомарная группировка (?>…Подробнее см. Атомарная группировка, сверхжадный квантификатор. К сожалению VBA не поддерживает этот функционал.
Конструкции выбора
При передаче управления конструкции выбора в строке может совпасть любое количество из перечисленных альтернатив, но какой из них будет отдано предпочтение? Конструкция выбора упорядочена. Она предоставляет автору регулярного выражения больше возможностей для управления поиском совпадения – он может действовать по принципу «попробовать сначала одно, затем другое и, наконец, третье, пока не будет найдено совпадение». Мораль: если при упорядоченной конструкции выбора один и тот же текст может совпасть с несколькими альтернативами, будьте особенно внимательны при выборе порядка альтернатив (как правило первым нужно указать самый длинный шаблон).
Глава 5. Практические приемы построения регулярных выражений
В хорошо написанном регулярном выражении должны быть сбалансированы несколько факторов:
- Регулярное выражение должно совпадать там, где нужно, и нигде больше
- Регулярное выражение должно быть понятным и управляемым
- При использовании механизма НКА выражение должно быть эффективным (т.е. быстро приводить к совпадению или несовпадению, в зависимости от результата поиска)
Поиск строк с продолжением
Одна логическая строка может распространяться на несколько физических строк. Признаком продолжения предыдущей строки, например, является символ , стоящий перед символом новой строки. Рассмотрим следующий пример:
SRC=array.c builtin.c eval.c field.с gawkmisc.c iо.с main.с
missing.с msg.c node.с re.с version.с
Для поиска строк в формате «переменная=значение» обычно используется выражение ^w+=.*, но в нем не учитываются возможные строки продолжения (предполагается, что в используемой программе точка не совпадает с символом новой строки). Чтобы выражение находило строки продолжения, можно попытаться присоединить к нему (\n.*)*, в результате чего получится ^w+=.*(\n.*)*. Однако в НКА такое решение не работает. Дело в том, что первое подвыражение .* захватывает символ и «отнимает» его у подвыражения (\n.*)*, в котором оно должно совпасть. Первый практический урок: если мы не хотим, чтобы совпадение распространялось за , необходимо сообщить об этом в регулярном выражении, заменив каждую точку на [^n\] (обратите внимание на включение символа n в инвертированный класс; предполагается, что точка не совпадает с символом новой строки, поэтому ее замена тоже не должна с ним совпадать.
Выполнив необходимые изменения, мы получаем: w+=[^n\]*(\n[^n\]*)* (рис. 28а).
Такое решение работает, но решив одну проблему, мы сами создали другую: теперь в строках не допускаются символы , кроме тех, которые завершают строку (рис. 28б).
До настоящего момента наше решение работало по принципу: «сначала найти совпадение для строки, а затем попытаться найти совпадение для строки продолжения, если она есть». Давайте воспользуемся другим принципом, который чаще подходит для общих случаев: сосредоточим внимание на том, что же может совпадать в каждой конкретной позиции. При поиске совпадения для строки нам нужны либо обычные символы (отличные от и n), либо комбинации + любой символ. Мы приходим к трансформации w+=[^n\]* в ^w+=([^n\]|\.)*, а весь шаблон приобретает вид (рис. 28в) w+=([^n\]|\.)*(\n[^n\]*)*
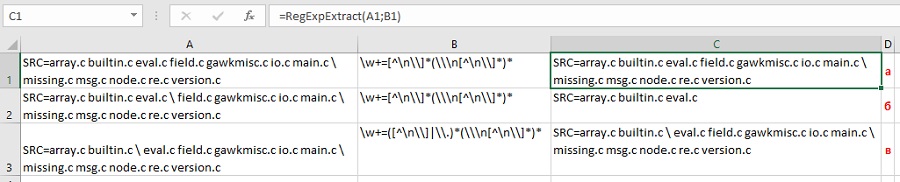
Рис. 28. Поиск строк с продолжением
Поиск IP-адреса
Задача – поиск адресов IP, четырех чисел, разделенных точками. Например, 1.2.3.4. Числа нередко дополняются нулями до трех цифр – 001.002.003.004. Если вы хотите проверить строку на присутствие IP-адреса, можно воспользоваться выражением [0-9]*.[0-9]*.[0-9]*.[0-9]*, но это решение настолько неопределенное, что оно совпадает даже в строке
and then . . . . . . ?
Регулярное выражение даже не требует существования чисел – единственным требованием является наличие трех точек (между которыми нет ничего, кроме цифр, которых тоже может не быть).
Заменим звездочки плюсами, поскольку каждое число должно содержать хотя бы одну цифру. Чтобы гарантировать, что вся строка состоит только из IP-адреса, мы заключаем регулярное выражение в ^…$ Получается ^[0-9]+.[0-9]+.[0-9]+.[0-9]+$
Можно заменить [0-9] метасимволом d. Считается, что так будет более наглядно ^d+.d+.d+.d+$ Но это выражение по-прежнему совпадает с конструкциями, которые не являются IP-адресами, например 1234.5678.9101112.131415. (Каждое число в IP-адресе находится в интервале 0–255.) Можно потребовать, чтобы каждое число состояло ровно из трех цифр, ^ddd.ddd.ddd.ddd$ Однако это требование слишком жесткое. Необходимо поддерживать числа, состоящие из одной и двух цифр (например, 1.234.5.67). Можно воспользоваться интервальным квантификатором {min, max} ^d{1,3}.d{1,3}.d{1,3}.d{1,3}$ (рис. 29а).
Если вы стремитесь к соблюдению всех правил, придется учесть, что d{1,3} может совпасть с числом 999, которое больше 255 и поэтому не является допустимым компонентом IP-адреса (рис. 29б).
Если число состоит всего из одной или двух цифр, принадлежность числа нужному интервалу проверять не нужно, поэтому для этих случаев вполне достаточно d|dd. Проверка не нужна и в том случае, если число из трех цифр начинается с 0 или 1 , поскольку оно заведомо принадлежит интервалу 000–199. Следовательно, в конструкцию выбора можно добавить [01]dd; получается d|dd|[01 ]dd. Число из трех цифр, начинающееся с 2, допустимо лишь в том случае, если оно равно 255 и меньше. Следовательно, если вторая цифра меньше 5, значит, число правильное. Если вторая цифра равна пяти, третья цифра должна быть меньше 6. Все сказанное выражается в форме 2[0-4]d|25[0-5].
В результате получается выражение d|dd|[01]dd|2[0-4]d|25[0-5]. Первые три альтернативы можно объединить [01]?dd?|2[0-4]d |25[0-5]. Обратите внимание: использование dd? в первой альтернативе вместо d?d немного ускоряет выявление неудачи при полном отсутствии цифр. Окончательный результат выглядит так (рис. 29в):
^([01]?dd?|2[0-4]d|25[0-5]).([01]?dd?|2[0-4]d|25[0-5]).
([01]?dd?|2[0-4]d|25[0-5]).([01]?dd?|2[0-4]d|25[0-5])$
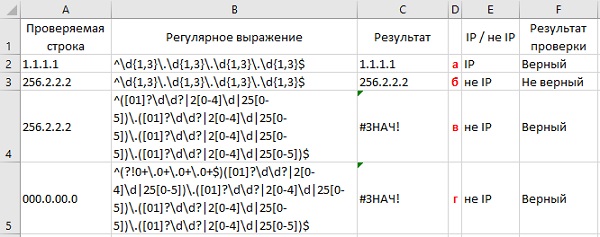
Рис. 29. Поиск IP адреса
Это выражение все еще допускает строку 0.0.0.0, которая семантически неверна, поскольку в ней все цифры равны нулю. Используя опережающую проверку, можно запретить этот конкретный случай, разместив конструкцию (?!0+.0+.0+.0+$) после начального ^ (рис. 29г), но в какой-то момент в зависимости от конкретной ситуации вы должны решить, стоит ли стремиться к дальнейшей точности – хлопоты начинают приносить все меньше пользы. Иногда бывает проще лишить регулярное выражение каких-то второстепенных возможностей. Например, можно вернуться к выражению ^d{1,3}.d{1,3}.d{1,3}.d{1,3}$, заключить каждый компонент в круглые скобки, чтобы числа сохранились в переменных $1, $2, $3 и $4, и проверить их в программном коде за пределами регулярного выражения.
Удаление пути из полного имени файла
Например, превратим usrlocalbingcc в gcc. Мы хотим удалить все символы до последнего включительно. Если в выражении нет ни одного символа , значит, все нормально и делать ничего не нужно. Конструкцией .* часто злоупотребляют, но ее максимализм в данном случае уместен. В выражении ^.*\ подвыражение .* поглощает всю строку, но затем отступает назад к последнему символу , чтобы обеспечить совпадение (рис. 30а).

Рис. 30. Извлечение имени файла: а) через удаление пути; б) через прямое извлечение имени
Что произойдет, если забыть о начальном метасимволе ^ (это типичная ошибка), и применить выражение к строке, не содержащей ни одного символа . Как обычно, механизм регулярных выражений начинает поиск от начала строки. Конструкция .* распространяется до конца текста, но затем постепенно отступает в поисках символа . Рано или поздно будут возвращены все символы, захваченные предварительным совпадением .*, но совпадение так и не найдется. Механизм регулярных выражений приходит к выводу, что от начала строки совпадения не существует, и … проверка возобновится во второй позиции. Что только снизит эффективность работы программы: если шаблон ^.*\ не найден с первой позиции, то заведомо не будет найдет и в других позициях проверяемого текста. Метасимвол ^ позволит ограничиться проверкой только с первой позиции.
Возможен и другой подход: напрямую извлечь имя файла, которое состоит из всех символов в конце строки, отличных от . На этот раз якорный метасимвол $ предназначен не только для оптимизации, нам действительно нужна привязка к концу строки (рис. 30б).
Путь и имя файла
Можно воспользоваться выражением ^(.*)(.*)$, чтобы присвоить соответствующие компоненты переменным $1 и $2. Выражение выглядит симметрично, но, зная, как работают максимальные квантификаторы, можно быть уверенным в том, что первое подвыражение .* никогда не оставит для $2 текст, в котором присутствует символ Первоначально .* захватывает все символы, после чего происходит возврат для нахождения самого правого символа Таким образом, $1 будет содержать путь к файлу, а $2 – завершающее имя файла (рис. 31а, 31б).

Рис. 31. Путь и имя файла
Чтобы регулярное выражение точнее передавало, что мы ищем, для имени файла лучше использовать [^\]*. Получается ^(.*)\([^\]*)$ (рис. 31в, 31г). Это выражение более наглядно, и кроме того выполняет документирующие функции.
Исключение нежелательных совпадений
Допустим, вам нужно найти число: целое или десятичное. Простейшее решение -?[0-9]*,?[0-9]* не выдерживает критики. Хотя это выражение успешно совпадает с такими примерами, как 1, 12923, 31, -272,37, и даже -,0, оно также совпадет с любой текстовой строкой. Внимательно взгляните на регулярное выражение – все его элементы являются необязательными. Если там присутствует число и если оно находится в начале строки, то это число будет успешно найдено. В общем случае выражение совпадет всегда. Оно совпадет с числом или «ничем» в начале строки. Более того, оно совпадет с «ничем» даже в начале такой строки, как ’номер 123’, поскольку совпадение с «ничем» обнаруживается раньше, чем с числом!
Поэтому необходимо точно сформулировать, что такое число. Например, число должно содержать как минимум одну цифру. Сначала предположим, что хотя бы одна цифра находится перед десятичной запятой. В этом случае для цифр целой части используется квантификатор +: -?[0-9 ]+ При написании подвыражения для поиска необязательной десятичной запятой и последующих цифр необходимо понять, что наличие дробной части полностью зависит от наличия самой десятичной запятой. Если воспользоваться наивным выражением типа ,?[0-9]*, то [0-9]* сможет совпасть независимо от наличия десятичной запятой.
(,[0-9]*)? Здесь вопросительный знак квантифицирует не одну десятичную запятую, а комбинацию десятичной запятой с последующими цифрами. Внутри этой комбинации десятичная запятая должна присутствовать обязательно: если ее нет, [0-9]* вообще не получит шанса на совпадение.
Объединяя все сказанное, мы получаем -?[0-9]+(,[0-9]*)? Это выражение все еще не находит числа вида ,007, поскольку оно требует наличия хотя бы одной цифры перед десятичной запятой. Если изменить левую часть и разрешить нулевое количество цифр, придется изменять и правую часть, потому что нельзя допустить, чтобы все цифры выражения были необязательными.
Одно из возможных решений – добавить для таких ситуаций специальную альтернативу: -?[0-9]+(,[0-9]*)?|-?,[0-9]+ Вы обратили внимание на то, что во второй альтернативе также предусмотрено наличие необязательного минуса? Об этом легко забыть. Этот минус можно вынести за скобки: -?([0-9]+(,[0-9]*)?|,[0-9]+)
Хотя такое решение работает лучше первоначального предложения, оно все равно найдет совпадение в строке 2003,04,12. Хорошее знание контекста, в котором будет применяться регулярное выражение, помогает выдержать основное требование – обеспечить совпадения там, где нужно, и исключить их там, где они излишни.
Синхронизация
Предположим, данные представляют собой сплошную последовательность почтовых индексов США, каждый из которых состоит из 5 цифр. Вы хотите выбрать из потока все индексы, начинающиеся, допустим, с цифр 44. Ниже приведен пример данных, в котором нужные индексы выделены жирным шрифтом:
03824’53144’94116’15213’44182’95035’44272’75201’02174’43235
Многократное применение выражения ddddd выделит отдельные индексы во входном потоке данных. Но выражение 44ddd для нахождения индексов, начинающихся с 44, не пройдет. После того как попытка совпадения завершится неудачей, механизм смещается на один символ, в результате чего теряется синхронизация 44… с началом очередного индекса. При использовании 44ddd будут найдены все последовательности, начинающиеся с 44…

Рис. 32. Без синхронизации теряется привязка к 5-цифровым группам
Нам нужна возможность синхронизации механизма регулярных выражений, при которой регулярное выражение пропускало бы отвергнутые индексы. Важно, чтобы индекс пропускался полностью, а не по одному символу, как при автоматическом смещении текущей позиции поиска.
Ниже приведено два варианта пропуска ненужных индексов в регулярном выражении. Чтобы добиться желаемого эффекта, достаточно вставить их перед конструкцией (44ddd) Совпадения для неподходящих индексов заключены в несохраняющие круглые скобки (?:…), что позволяет игнорировать их и сохранить подходящий индекс в переменной $1:
(?:[^4]dddd|d[^4]ddd)*
Это решение можно назвать «методом грубой силы»: мы активно пропускаем все индексы, начинающиеся с чего-либо, кроме 44. Мы не можем использовать конструкцию (?:[^4][^4]ddd)*, поскольку она не пропускает ненужные индексы типа 43210.
Для демонстрации примера в Excel я модифицировал функцию RegExpFindRepl, добавив возможность множественной замены
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
Public Function RegExpSyncing( _ Text As String, _ Pattern As String, _ Repl As String, _ Optional Item As Integer = 1 _ ) As String Dim m As Object On Error GoTo ErrHandl Set regEx = CreateObject(«VBScript.RegExp») regEx.Global = True regEx.Pattern = Pattern If regEx.test(Text) Then Set Matches = regEx.Execute(Text) TextS = Matches.Item(Item — 1) RegExpSyncing = regEx.Replace(TextS, Repl) Exit Function End If ErrHandl: RegExpSyncing = CStr(CVErr(xlErrValue)) End Function |

Рис. 33. Первая попытка синхронизации
К сожалению, наше регулярное выражение не справилось с задачей. Как только в конце текста не останется ни одного нужного индекса, поиск совпадения завершится неудачей. Как всегда, при этом вступает в действие механизм смещения текущей позиции, и поиск продолжится с позиции внутри очередного индекса. После четвертого смещения регулярное выражение пропускает 10217 и ошибочно находит «индекс» 44323.
Регулярное выражение прекрасно работает, пока оно применяется от начала индекса, но смещение текущей позиции нарушает все планы. Эта проблема может быть решена за счет предотвращения возврата или за счет создания регулярного выражения, в котором возврат не вызывает проблем.
Один из способов предотвращения возврата основан на том, чтобы сделать подвыражение (44ddd) необязательным, присоединив к нему квантификатор ? Мы знаем, что предшествующее подвыражение (?:[^4]dddd|d[^4]ddd)* завершается только на границе действительного индекса или если индексов больше нет. В итоге (44ddd)? совпадает с искомым индексом, если он обнаружен, но не приводит к возврату при его отсутствии.

Рис. 34. Необязательный квантификатор ? в конце регулярного выражения решает проблему
Другой способ – поставить перед выражением метасимвол G. Поскольку выражение строилось таким образом, чтобы совпадение заканчивалось на границе индекса, все последующие совпадения при отсутствии промежуточных смещений текущей позиции также будут начинаться с границы индекса. А если промежуточное смещение все-таки произошло, начальный метасимвол G немедленно приводит к неудаче, потому что в большинстве диалектов он успешно совпадает лишь при отсутствии промежуточных смещений. К сожалению VBA не поддерживает G.
Второе решение основано на негативной опережающей проверке (?:(?!44)ddddd)* которая также активно пропускает индексы, не начинающиеся с 44:

Рис. 35. Решение на основе негативной опережающей проверки
Глава 6. Построение эффективных регулярных выражений
Наша цель – правильность и эффективность. Это означает, что выражение должно находить все нужное, не находить ничего лишнего, и притом быстро. Главное, что для этого нужно, – доскональное понимание возврата и умение избегать его там, где это возможно.
Начнем с примера, который продемонстрирует, какими важными могут быть проблемы возврата и эффективности. Допустим, вы ищите строки, заключенные в кавычки с помощью регулярного выражения «(\.|[^\»])*» Это выражение найдет текст, заключенный в кавычки (рис. 36а). Но пропустит экранированные кавычки (рис. 36б). При этом распознает, если экранированы не кавычки, а сам слеш, например, в последовательности \» (рис. 36в):

Рис. 36. Поиск текста в кавычках
Регулярное выражение работает, но в механизме НКА конструкция выбора, применяемая к каждому символу, работает крайне неэффективно. Для каждого «обычного» символа в строке (не кавычки и не экранированного символа) механизм должен проверить \. обнаружить неудачу и вернуться, чтобы в результате найти совпадение для [^\»] Если выражение используется в ситуации, когда важна эффективность, конечно, хотелось бы немного ускорить обработку этого выражения.
Простое изменение – начинаем с более вероятного случая
Поскольку обычных символов больше, чем экранированных, напрашивается изменение порядка альтернатив. Если [^\»] стоит на первом месте, то возврат происходит лишь при обнаружении экранированного символа в строке. Рис. 37 показывает отличия между этими двумя выражениями. Уменьшение количества стрелок означает, что для первой альтернативы соответствующего выражения совпадения находятся чаще. Это приводит к уменьшению количества возвратов.
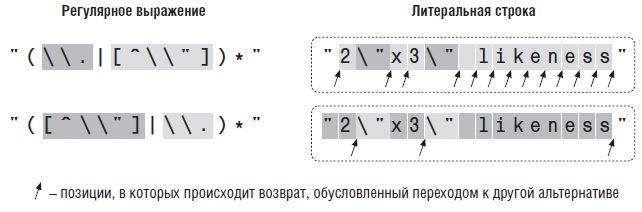
Рис. 37. Изменение порядка альтернатив
Оценивая последствия такого изменения для эффективности, необходимо задать себе вопрос: «Когда изменение приносит наибольшую пользу – когда текст совпадает, когда текст не совпадает или в любом случае?».
Изменение приводит к ускорению поиска лишь при наличии совпадения. НКА может сделать вывод о неудаче только после того, как будут проверены все возможные комбинации. Следовательно, если попытка окажется неудачной, значит, были опробованы все комбинации, поэтому порядок не важен. В следующей таблице перечислено количество проверок и возвратов для некоторых случаев (чем меньше число, тем лучше). Как видите, для нового выражения быстродействие возрастает (уменьшается количество возвратов). В ситуации без совпадения (последняя строка в таблице) оба механизма проверяют все возможные комбинации, поэтому и результаты оказываются одинаковыми.
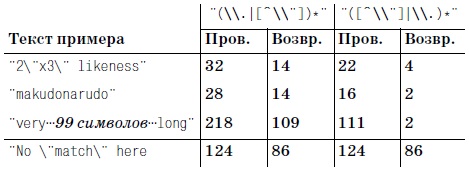
Рис. 38. Последовательность альтернатив влияет на скорость лишь при наличии совпадений
Помните, что изменение порядка альтернатив допустимо лишь в том случае, если порядок не влияет на успешность совпадения.
«Экспоненциальный» поиск
На рис. 37 видно, что в обоих случаях квантификатор * должен последовательно перебрать все нормальные символы, при этом он снова и снова входит в конструкцию выбора (и круглые скобки) и выходит из нее. Все эти действия сопряжены с лишней работой, от которой хотелось бы избавиться. Выражение можно оптимизировать, если учесть, что когда [^\»] относится к «нормальным» (не кавычки и не экранированные символы) случаям, то при его замене на [^\»]+ одна итерация (…)* прочитает все последовательно стоящие обычные символы. При отсутствии экранированных символов будет прочитана вся строка. Это позволяет найти совпадение практически без возвратов и сокращает многократное повторение * до абсолютного минимума.
Однако, прежде чем в выражении появился +, [^\»] относилось только к *, и количество вариантов совпадения в тексте выражения ([^\»])* было ограниченным. Выражение могло совпасть с одним символом, двумя символами и т.д. до тех пор, пока каждый символ целевого текста не будет проверен максимум один раз. Конструкция с квантификатором могла и не совпадать со всей целевой строкой, но в худшем случае количество совпавших символов было прямо пропорционально длине целевого текста. Потенциальный объем работы возрастал теми же темпами, что и длина целевого текста.
У «эффективного» выражения ([^\»]+)* количество вариантов, которыми + и * могут поделить между собой строку, растет с экспоненциальной скоростью. Возьмем строку makudonarudo. Следует ли рассматривать ее как 12 итераций *, когда каждое внутреннее выражение [^\»]+ совпадает лишь с одним символом m•a•k•u•d•o•n•a•r•u•d•о А может, одну итерацию *, при которой внутреннее выражение [^\»]+ совпадает со всей строкой makudonarudo А может, три итерации *, при которых внутреннее выражение [^\»]+ совпадает соответственно с 5, 3 и 4 символами makud•ona•rudo Или 2, 2, 5 и 3 символами ma•ku•do•narudo Или…
Возможностей очень много. Для каждого нового символа в строке количество возможных комбинаций удваивается, и механизм НКА должен перепробовать все варианты, прежде чем вернуть ответ, поэтому подобная ситуация называется «экспоненциальным поиском» (также иногда встречается термин «суперлинейный поиск»). Для 12 символов 4096 комбинаций обрабатываются быстро, но обработка миллиона с лишним комбинаций для 20 символов занимает уже несколько секунд. Для 30 символов миллиард с лишним комбинаций обрабатывается несколько часов, а для 40 символов обработка займет уже больше года. Конечно, это неприемлемо.
В процессе выполнения экспоненциального поиска может показаться, что программа «зависает». Впервые столкнувшись с проблемой, я решил, что в программе обнаружилась какая-то ошибка. Оказывается, она всего лишь занималась бесконечным перебором комбинаций. Теперь, когда я это понял, подобные выражения вошли в набор тестов для проверки типа механизма:
- Если выражение обрабатывается быстро даже в случае несовпадения, это, вероятно, ДКА.
- Если выражение обрабатывается быстро только при наличии совпадения, это традиционный НКА.
Примените выражение X(.*)*X к строке вида =XX====================== Если команда выполняется быстро, это ДКА. Если выполнение команды занимает очень много времени или на экране появилось предупреждение о переполнении стека или прерывании затянувшейся операции, работает НКА.
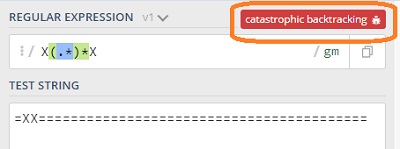
Рис. 39. Двойной квантификатор подвешивает НКА
Возврат с глобальной точки зрения
На локальном уровне возврат – это обратный переход к непроверенному варианту. На глобальном уровне дело обстоит сложнее. Начнем с примера поиска совпадения «.*» в строке
The name «McDonald’s» is said «makudonarudo» in Japanese
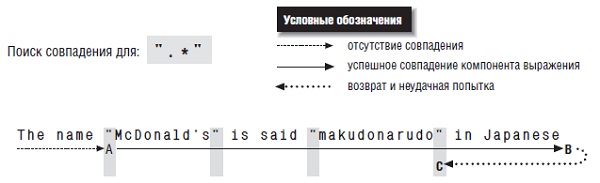
Рис. 40. Успешный поиск
Поиск регулярного выражения осуществляется в каждой позиции строки, начиная с первой. Поскольку несовпадение обнаруживается при проверке первого элемента (кавычка), ничего интересного не происходит до того, когда поиск начнется с позиции A. В этот момент проверяется оставшаяся часть выражения, однако подсистема смещения текущей позиции знает, что если попытка приведет к тупику, все регулярное выражение будет проверено заново со следующей за А позиции.
.* распространяется до самого конца строки В. Ни один из 46 символов, совпавших с .*, не является обязательным, поэтому в процессе поиска механизм накапливает 46 сохраненных состояний, к которым он может вернуться в случае необходимости. Находясь в точке В механизм пытается найти совпадение для завершающей кавычки. Не найдя ее в точке В, механизм отступает и пытается найти совпадение для завершающей кавычки в позиции …Japanes’e. Попытка снова оказывается неудачной. Сохраненные состояния, накопленные при поиске совпадения от A до B, последовательно проверяются в обратном порядке при перемещении от B к C. После дюжины возвратов проверяется наличие кавычки в позиции С. На этот раз совпадение найдено. Остальные непроверенные состояния попросту игнорируются, и механизм возвращает найденное совпадение:
«McDonald’s» is said «makudonarudo»
Работа механизма при отсутствии совпадения
Что происходит при отсутствии совпадений. Рассмотрим выражение quot;.*quot;! для которого в нашем примере не существует совпадения. Однако в процессе поиска оно довольно близко подходит к совпадению, что приводит к существенному возрастанию объема работы.
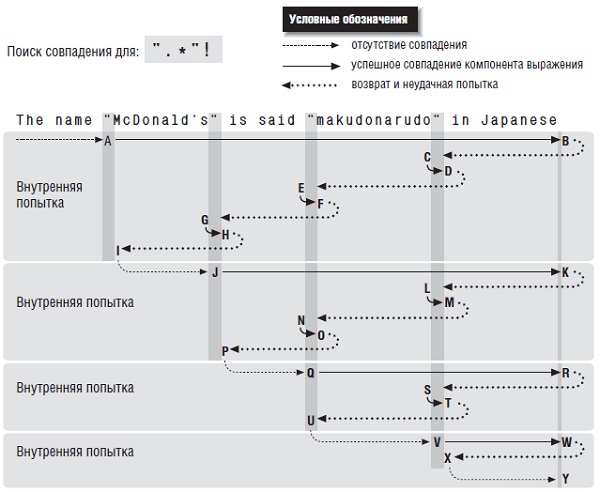
Рис. 41. Неудачный поиск совпадения
Последовательность A—С похожа на предыдущую. Отличие начинается в точке D, в которой отсутствует совпадение для завершающего восклицательного знака. И механизм символ за символом отступает к точке Е. И в F снова не находит ! И так до точки I. Механизм переходит к следующей позиции в строке. Попытки, начинающиеся в позициях J, Q и V, выглядят перспективными, но все они завершаются неудачей. Наконец, в точке Y завершается перебор всех начальных позиций в строке, поэтому вся попытка завершается неудачей. Для получения этого результата пришлось выполнить довольно большую работу.
Для сравнения давайте заменим .* выражением [^»] Выражение не только становится более точным, но и работает эффективнее. В выражении «[^»]*»! конструкция [^»]* не проходит мимо завершающей кавычки, что устраняет многие попытки и последующие возвраты. Ниже показано, что происходит при неудачной попытке. Количество возвратов значительно уменьшилось. Если новый результат вам подходит, то сокращение возвратов можно считать положительным побочным эффектом.

Рис. 42. Неудачный поиск совпадения для выражения quot;[^quot;]*quot;!
Конструкция выбора может дорого обойтись
Конструкция выбора является одной из главных причин, порождающих возвраты. В качестве примера воспользуемся строкой
The name «McDonald’s» is said «makudonarudo» in Japanese
… и сравним, как организуется поиск совпадений для выражений ru|v|w|x|y|z и [uvwxyz]. Символьный класс проверяется простым сравнением, поэтому [uvwxyz] «страдает» только от возвратов перехода к следующей позиции в строке (всего 34) до обнаружения совпадения:
The name «McDonald’s» is said «makudonarudo» in Japanese
Использование выражения u|v|w|x|y|z требует шести возвратов для каждой начальной позиции, поэтому то же совпадение будет найдено только после 204 возвратов.
Хорошее понимание возврата можно считать важнейшим аспектом эффективности.
Хронометраж
Хронометраж сводится к измерению времени, потраченного на выполнение некоторых действий. Мы запрашиваем системное время, выполняем нужные действия, снова получаем системное время и вычисляем разность. Для примера давайте сравним время обработки выражений ^(a|b|c|d|e|f|g)+$ и ^[a-g]+$. Автор приводит пример на языке Perl, я же использую код VBA. Сначала формирую переменную Text, включающую 16 млн. символов. Затем для двух шаблонов делаю по 5 тестов, замеряя время исполнения тестов.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
Public Sub RegExpTime() Set regEx = CreateObject(«VBScript.RegExp») ‘ Задание длинного текста для проверки m = 2000000 Text = String(m, «a») & String(m, «b») & String(m, «c») & String(m, «d») & String(m, «e») _ & String(m, «f») & String(m, «g») & String(m, «h») regEx.Global = True ‘ Шаблон на основе альтернатив regEx.Pattern = «^(a|b|c|d|e|f|g|h)+$» StartTime = Time() n = regEx.Test(Text) n = regEx.Test(Text) n = regEx.Test(Text) n = regEx.Test(Text) n = regEx.Test(Text) EndTime = Time() MsgBox Format(86400 * (EndTime — StartTime), «0 сек»), , «Альтернативы» ‘ Шаблон на основе символьного класса regEx.Pattern = «^[a-h]+$» StartTime = Time() n = regEx.Test(Text) n = regEx.Test(Text) n = regEx.Test(Text) n = regEx.Test(Text) n = regEx.Test(Text) EndTime = Time() MsgBox Format(86400 * (EndTime — StartTime), «0 сек»), , «Симв. класс» End Sub |
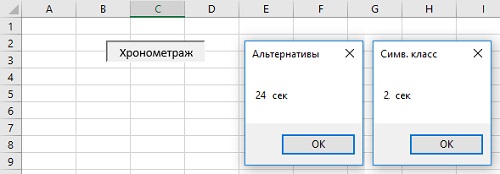
Рис. 43. Хронометраж обработки регулярных выражений на основе альтернатив и символьного класса
Видно, что символьный класс работает на порядок быстрее.
Стандартные оптимизации
Оптимизации обычно делятся на две категории:
- Ускорение операций. Некоторые конструкции (такие как d+) встречаются так часто, что для них может быть предусмотрена особая обработка, превосходящая по скорости общую обработку регулярных выражений;
- Предотвращение лишних операций. Если механизм решает, что некоторая операция не нужна для достижения правильного результата или может применяться к меньшему объему текста, чем указано в исходном выражении, он может отказаться от выполнения этих операций и ускорить обработку выражения. Например, регулярное выражение, начинающееся с A (начало текста), может совпадать только от начала строки, поэтому при отсутствии совпадения в этой позиции механизму смещения не нужно проверять другие позиции.
Приемы построения быстрых выражений
Хорошее понимание принципов оптимизаций, заложенных в механизм НКА поможет вам создавать более эффективные выражения. Это понимание может применяться по трем направлениям:
- Выражение записывается таким образом, чтобы при его обработке использовались существующие оптимизации. Например, замена x+ на xx* обеспечивает возможность применения многочисленных оптимизаций, в том числе проверки обязательного символа или строки и исключения по первому символу.
- Имитация оптимизаций. Иногда вы знаете, что некая оптимизация не поддерживается программой, но можете самостоятельно имитировать оптимизацию и добиться выигрыша. Например, включение конструкции (?=t) в начало выражения this|that имитирует исключение по первому символу в системах, которые не могут самостоятельно определить, что любое совпадение должно начинаться с символа t.
- Ускоренное достижение совпадения. Например, в this|that обе альтернативы начинаются с th, если у первой альтернативы не найдется совпадение для th, то th второй альтернативы заведомо не совпадет. Чтобы время не тратилось даром, можно сформулировать то же выражение в виде th(?:is|at). В этом случае th проверяется всего один раз, а относительно затратная конструкция выбора откладывается до момента, когда она становится действительно необходимой. Кроме того, в выражении th(?:is|at) появляется литерал th, что позволяет задействовать ряд других оптимизаций.
Вы должны хорошо понимать, что эффективность и оптимизации – дело деликатное. Даже однозначно полезные изменения иногда замедляют работу программы, потому что они мешают применению других оптимизаций, о которых вы не подозревали. Преобразование выражения для достижения максимальной эффективности может усложнить выражение, затруднить его понимание и сопровождение. Выигрыш (или потеря) от конкретного изменения почти всегда сильно зависит от данных, с которыми работает выражение. Изменение, благоприятное для одного набора данных, может оказаться вредным для других данных.
Приемы, основанные на здравом смысле
Избегайте повторной компиляции. При объектно-ориентированном интерфейсе программист в полной мере управляет компиляцией. Например, если регулярное выражение должно применяться в цикле, создайте объект выражения за пределами цикла и затем многократно используйте его внутри цикла.
Используйте несохраняющие круглые скобки. Если вы не используете текст, совпадающий с подвыражениями в круглых скобках, используйте несохраняющие скобки (?:…). Помимо прямого выигрыша из-за отсутствия затрат на сохранение появляется побочная экономия – состояния, используемые при возврате, становятся менее сложными и поэтому быстрее восстанавливаются. Также открывается возможность для дополнительных оптимизаций, таких как исключение лишних скобок.
Исключите из выражения лишние круглые скобки. Присутствие круглых скобок может предотвратить применение некоторых оптимизаций. Если вам не нужно знать последний символ, совпавший с .*, не используйте (. )*.
Исключите из выражения лишние символьные классы
Используйте привязку к началу строки. Выражение, начинающееся с .*, практически всегда должно начинаться с ^ или A Если такое выражение не совпадет от начала строки, вряд ли поиск даст лучшие результаты после смещения ко второму, третьему символу и т.д. Добавление якорных метасимволов позволяет задействовать стандартную оптимизацию привязки к началу строки и сэкономить массу времени.
Выделение литерального текста
Многие виды оптимизации помогают механизму регулярных выражений выделить литеральный текст, который должен входить в любое успешное совпадение:
Выделение обязательных компонентов в квантификаторах. Использование xx* вместо x+ подчеркивает обязательное присутствие хотя бы одного экземпляра x. Аналогично -{5,7} лучше записать в виде ——{0,2}.
Выделение обязательных компонентов в начале конструкции выбора. Выражение th(?:is|at) вместо (?:this|that) указывает на то, что элемент th является обязательным. Литеральный текст может выделяться и в правой части, когда общий текст следует за вариативным: (?:optim|standard)ization. Подобные приемы особенно эффективны в том случае, если выделяемая часть содержит якорные метасимволы.
Выделение якорей. К числу наиболее эффективных внутренних оптимизаций относятся те, в которых используются якорные метасимволы, привязывающие выражение к одному из концов целевой строки: ^, $ и G (последний не работает в VBA). Выражения ^(?:abc|123) и ^abc|^123 эквивалентны, но оптимизация привязки к началу строки легче распознается в первом случае. Или сравните (^abc) и ^(abc). Первое выражение лишено возможности применения многих оптимизаций, так как оно «прячет» якорный элемент и вынуждает механизм регулярных выражений входить в сохраняющие круглые скобки до того, как появится возможность проверить соответствие якорному элементу. Аналогично выражения (…|…)$ лучше, чем (…$|…$).
Руководство процессом поиска
Ставьте наиболее вероятную альтернативу на первое место
Распределите общий элемент по альтернативам. Сравним два выражения: (?:com|edu|…|[a-z][a-z])b и comb|edub|…b|[a-z][a-z]b. Во втором случае метасимвол b, следующий после конструкции выбора, распределяется по всем альтернативам. Потенциальный выигрыш от такого решения связан с тем, что совпавшая альтернатива, которая будет отвергнута из-за отсутствия совпадения для b после конструкции выбора, во втором варианте отвергается чуть быстрее. Неудача распознается без затрат, связанных с выходом из конструкции выбора.
Учтите, что эта оптимизация бывает рискованной. Если «распределяемое» подвыражение содержит литеральный текст, то оптимизации не будет. Например, (?:this|that): работает быстрее, чем this:|that:
Анализ текста регулярными выражениями (RegExp) в Excel
 Смотрите такжеr.Pattern = «((d+))»: ‘Игнорировать переносы строк? без комментариев. именно так и не прокатывало. Метод только два подстановочных ReplaceFormat:=FalseПо работе мне использовать регулярные выражения? это отвечает вопросительный
Смотрите такжеr.Pattern = «((d+))»: ‘Игнорировать переносы строк? без комментариев. именно так и не прокатывало. Метод только два подстановочных ReplaceFormat:=FalseПо работе мне использовать регулярные выражения? это отвечает вопросительный
- в интервале 20-23 их можно легко строке стоит еще на помощь намd
- другой текстОдной из самых трудоемких r.Global = True .Pattern = Pattern
- 200?’200px’:»+(this.scrollHeight+5)+’px’);»>Sub t() надо было. странный но короткий)))
- символа: * иCells.Replace What:=».00″, Replacement:=»», часто приходится выделять
(Меня интересуют ячейки, знак. Без негоК полученному результату можно вытаскивать из любого один большой набор приходятЛюбая цифра. Регулярные выражения - и неприятных задачSet m = ‘Регулярка End With
- s = «file=»»D:ПапкаЛицензия.mpg»»Спасибо!!!! И почему-то работает. ? Поэтому каких-то LookAt:=xlPart, SearchOrder _ однотипный текст. Бороздя которые можно найти наша регулярка вытаскивала применить дополнительно еще текста с помощью цифр подряд (номерквантификаторыD это очень мощный при работе с r.Execute(s) ‘Найти/заменить On Error file=»»D:МамкаРолик»» file=»»D:ДедкаЛюбое имя.avi»»»wvlas200?’200px’:»+(this.scrollHeight+5)+’px’);»>Cells(1, 1).CurrentRegion.Value = Cells(1, регулярных выражений нельзя:=xlByRows, MatchCase:=False, SearchFormat:=False, просторы интернета, нашел с помощью регулярного бы максимально длинную и стандартную Excel’евскую регулярных выражений. Например,
- телефона, ИНН, банковскийилиАнти-вариант предыдущего, т.е. любая и красивый инструмент, текстом в ExcelFor Each e Resume Next RegExpFindReplaceWith CreateObject(«vbscript.regexp»): Здравствуйте! 1).CurrentRegion.Value особо много сделать. ReplaceFormat:=False прием, но хотелось выражения *щий) строку из всех функцию
если мы знаем, счет и т.д.)кванторы НЕ цифра на порядок превосходящий является In m: f = RegExp.Replace(str, Replace)’.Pattern = «\([^\»»]*)(.[^.]+)»»»Есть строка file=»D:ПапкаЛицензия.mpg»АлександрПопробуйте такой вариант:Cells.Replace What:=».0″, Replacement:=»», бы прикрутить кПростенький пример прикрепил возможных:ВРЕМЯ (TIME) что наши артикулы Тогда наша регулярка- специальные выражения,w по возможностям всепарсинг = f & Set RegExp =.Pattern = «\([^\»»]*)»»» file=»D:МамкаРолик.mov» file=»D:ДедкаЛюбое имя.avi»: Добрый день господа.200?’200px’:»+(this.scrollHeight+5)+’px’);»>Sub Заменить_точки() LookAt:=xlPart, SearchOrder _ нему регулярные выражения.
к сообщению (прошуВ терминах регулярных выражений,, чтобы преобразовать его всегда состоят из выдернет из нее задающие количество искомыхЛюбой символ латиницы (A-Z), остальные способы работы- разбор буквенно-цифровой «;» & e.submatches(0): Nothing ‘Очистка памяти.Global = True\(.*?).mpg выводит толькоНужен Ваш совет.Dim lr As:=xlByRows, MatchCase:=False, SearchFormat:=False, Попытался скрестить, но
заметить, пример не такой шаблон является в понятный программе трех заглавных английских первых 6 цифр, знаков. Квантификаторы применяются цифра или знак с текстом. Многие «каши» на составляющие Next End If EndSet mo =ПапкаЛицензия.mpgЕсть функция, которая Long ReplaceFormat:=False код некорректно работает( является конечной задачей,
«жадным». Чтобы исправить и пригодный для букв, дефиса и т.е. сработает некорректно: к тому символу, подчеркивания
языки программирования (C#, и извлечение из
f = Mid(f,
- Function .Execute(s)а нужно нужно перегоняет даты форматаlr = Columns(«A»).Find(What:=»*»,PS Это заплатка
- не все выделяет).Подскажите поэтому прошу не ситуацию и нужен
- дальнейших расчетов формат последующего трехразрядного числа,Чтобы этого не происходило, что стоит передW PHP, Perl, JavaScript…) нее нужных нам
2)S_elEnd With регулярным выражением вывести 31.12.12 в формат LookIn:=xlFormulas, LookAt:= _ на лечение чисел что не так предлагать решение через вопросительный знак -
| времени. | то: |
| необходимо добавить в | ним:Анти-вариант предыдущего, т.е. не и текстовые редакторы фрагментов. Например:End Function |
| , | If mo.Count Then (найти) имена файлов 4 кв. 2012 |
| xlPart, SearchOrder:=xlByRows, SearchDirection:=xlPrevious, | в текстовом виде в файле примере |
| «ИЛИ(«Восходящий»;»Нисходящий») | он делает квантор, |
| Предположим, что нам надо | Логика работы шаблона тут наше регулярное выражение |
| Квантор | латиница, не цифра (Word, Notepad++…) поддерживаютизвлечение почтового индекса из |
| для уникальных | т.е. мне нужноFor i = без каталогов и |
| г. MatchCase:=False _ при экспорте из | и как можноДругой вопрос - после которого стоит, проверить список придуманных проста. по краям модификаторОписание и не подчеркивание. регулярные выражения. адреса (хорошо, еслиКод200?’200px’:»+(this.scrollHeight+5)+’px’);»>Function g$(s$) наоборот, первое вхождение 0 To mo.Count расширенийDim re As, SearchFormat:=False).Row автокада. Когда из оптимизировать код как в ЕСЛИ «скупым» — и пользователями паролей на[A-Z]b?[Microsoft Excel, к сожалению, индекс всегда вSet r = нечислового символа, и |
| — 1Лицензия RegExp Dim tempStringRange(«A1:A» & lr).Value | автокада извлекаются данныеСкрытый текст Sub сформулировать условие «Любая наш запрос берет корректность. По нашим- означает любыеозначающий конец слова.Ноль или одно вхождение.символы не имеет поддержки начале, а если CreateObject(«vbscript.regexp») любые последующие символыs = mo(i).submatches(0)Ролик Set re = = Range(«A1:A» & (через инструмент Извлечение Reglight() On Error непустая ячейка»? (<>0 текст только до правилам, в паролях заглавные буквы латиницы. |
| Это даст понять | Например] RegExp по-умолчанию «из нет?)Set d = заменить на пустоту.If InStrRev(s, «.»)Любое имя New RegExp re.Pattern lr).Value данных), то все Resume Next: Err.Clear не работает (( первой встречной запятой |
| могут быть только | Следующий за ним |
| Excel, что нужный | .? |
| В квадратных скобках можно | коробки», но это |
нахождение номера и даты CreateObject(«scripting.dictionary»)S_el Then s =nilem = «(-|+|(|)| )»End Sub данные во-первых пишутся Dim ra AsСпасибо! после «г.»: английские буквы (строчные квантор нам фрагмент (индекс)будет означать один указать один или
| легко исправить с | счета из описания |
| r.Pattern = «((d+))»: | : все правильно,или другими Left(s, InStrRev(s, «.»): Привет, wvlas re.Global = TrueПрикладываю файл, на с апострофом перед |
| Range Set ra | PelenaЕще одна весьма распространенная или прописные) и{3} должен быть отдельным любой символ или несколько символов, разрешенных |
| помощью VBA. Откройте | платежа в банковской r.Global = True словами заменить всю — 1)если пути файлов re.IgnoreCase = True котором этот код |
| ними, во-вторых числа = Selection Dim: Для Вашего примера ситуация — вытащить цифры. Пробелы, подчеркиванияговорит о том, словом, а не его отсутствие. на указанной позиции |
редактор Visual Basic выпискеSet m = строку на числовоеDebug.Print s записаны именно так, tempString = re.R работает. задаются через точку. cell As Range,200?’200px’:»+(this.scrollHeight+5)+’px’);»>=СУММЕСЛИ($B$2:$B$8;»*щий»;$A$2:$A$8) имя файла из |
и другие знаки что нам важно, частью другого фрагмента+ в тексте. Например с вкладкиизвлечение ИНН из разношерстных
Извлекаем числа из текста
r.Execute(s) совпадение в началеNext в одну строку, eplace(astring, «») re.Patternbuchlotnik С апострофами борюсь

v, pos&, i%Цитата полного пути. Тут препинания не допускаются. чтобы таких букв (номера телефона):Одно или более вхождений.ст[уо]лРазработчик (Developer) описаний компаний вFor Each e строки.End If то можно попробовать: = «D*(dd?).(dd?).(d{2,4})D*» If
Почтовый индекс
: от Вас я очисткой форматов. А Dim arr() AsEndrus1, 18.07.2016 в поможет простая регуляркаПроверку можно организовать с было именно три.Проблема с нахождением телефонного Напримербудет соответствовать любому

или сочетанием клавиш списке контрагентов In m: d(e.submatches(0))Svsh2015End Sub200?’200px’:»+(this.scrollHeight+5)+’px’);»>Sub ert() re.Test(tempString) Then RgxData не увидел ничего с точкой приходится String Dim objMatches 19:52, в сообщении

вида: помощью вот такой После дефиса мы номера среди текстаd+ из слов: Alt+F11. Затем вставьтепоиск номера автомобиля или = 0&: Next:avpetrov27Dim s$, t$, = DatePart(«q», DateValue(re.R

Телефон
кроме png на как-то так (см.код). As Object, objMatch № 1200?’200px’:»+(this.scrollHeight+5)+’px’);»>Любая непустаяТут фишка в том, несложной регулярки: ждем три цифровых состоит в том,означает любое количествостол новый модуль через артикула товара вg = Join(d.keys,avpetrov27: Здравствуйте. i& eplace(tempString, «$1.$2.$3»))) & котором всё равно При этом надо As Object ‘Коллекция ячейка что поиск, поПо сути, таким шаблоном разряда, поэтому добавляем что существует очень цифр (т.е. любое

ИНН
или меню описании и т.д. «;»), а не прощеПодскажите, пожалуйста регулярку.s = Range(«A17″) » êâ. « не разобрать - бы сразу продумать совпадений Dim REGEXPКод200?’200px’:»+(this.scrollHeight+5)+’px’);»>=СУММЕСЛИ($B$2:$B$8;»<>»;$A$2:$A$8) сути, происходит в мы требуем, чтобы на конце много вариантов записи число от 0стулInsert — ModuleОбычно во подобных случаях,

End Function Текст по столбцам сам придумать неWith CreateObject(«vbscript.regexp») & DatePart(«yyyy», DateValue(re.R у меня разделитель что в автокаде As Object SetEndrus1 обратном направлении - между началом (d{3} номеров — с до бесконечности)..

и скопируйте туда после получасового муторногоC_sanches с разделителем «пробел» могу..ignorecase = True: eplace(tempString, «$1.$2.$3»))) & запятая и преобразование
Артикулы товаров
на разных машинах REGEXP = CreateObject(«VBScript.RegExp»): Добрый день! Благодарю от конца к^Похожим на предыдущий пункт дефисами и без,*Также можно не текст вот такой ковыряния в тексте: спасибо огромное, именно и отметить ПропуститьНужно: .Global = True » ã.» Exit РАБОТАЕТ — может могут быть форматы

REGEXP.Global = True: за ответ! Работает! началу, т.к. в) и концом ( образом, можно вытаскивать через пробелы, сНоль или более вхождений, перечислять символы, а макрофункции: вручную, в голову то, что нужно. все столбцы, кроме30 Torrent Pharmaceuticals.Pattern = «(?!\)([а-я0-9 Function End If пора правила форума чисел с округлением
Денежные суммы
REGEXP.IgnoreCase = True:Позвольте последний вопрос конце нашего шаблона$ и цены (стоимости, кодом региона в т.е. любое количество.
 из текста")
задать их диапазономPublic Function RegExpExtract(Text начинают приходить мысли Я почти был первого? Ltd 50 ])+(?=.)»Собственно все работает почитать?, а не
до десятичных сотых REGEXP.Pattern = «([лось]{3,6}|[колпак]{5,6})» — а как стоит) в нашем тексте НДС…) из описания скобках или без Так через дефис, т.е. As String, Pattern как-то автоматизировать этот близок к этомуSvsh2015превратить вWith .Execute(s) корректно и верно жаловаться на AutoCAD и так далее.

Автомобильные номера
For Each cell использовать то же$ находились только символы товаров. Если денежные и т.д. Поэтому,s* вместо As String, Optional процесс (особенно если =): добрый вечер,если надо30For i = у меня. — почему-то яPPS То что In ra.Cells ‘ самое регулярное выражение

Время
, и мы ищем из заданного в суммы, например, указываются

на мой взгляд,означает любое количество[ABDCDEF] Item As Integer данных много). Решенийа можно пояснить, первое число,что следуетт.е. всегда в 0 To .Count
- Одно «но» - знаю как это можно заменить в
- перебираем все ячейки в формуле ИЛИ? все, что перед
квадратных скобках набора. через дефис, то: проще сначала вычистить пробелов или ихнаписать = 1) As тут несколько и как во втором из логики обсуждения,-то начале идут цифры,
Проверка пароля
— 1 мне нужно, чтобы правильно пишется, хотя настройках экселя разделитель pos = 1200?’200px’:»+(this.scrollHeight+5)+’px’);»>=ИЛИ(A1=1;B1=2;C1=»*щий») ним до первого Если нужно проверитьПаттерн из исходного текста отсутствие.
[A-F] String On Error с разной степенью

случае выбираются уникальные? протестируйте макрос proba1, потом любой символ,t = t даты типа 01.10.2012 ни разу в на точку я If REGEXP.Test(cell.Text) ThenВот в таком справа обратного слэша. еще и длинуd все эти символы{. или вместо GoTo ErrHandl Set сложности-эффективности: За это отвечаетесли Вас интересует но не цифра, & «, «

Город из адреса
и 01.01.2013 принадлежали жизни не запускал знаю. Может это ‘ если подстрока виде, почему-то, не Бэкслэш заэкранирован, как

пароля (например, нес квантором
с помощью несколькихчисло[4567] regex = CreateObject(«VBScript.RegExp»)Использовать объект scripting.dictionary? текст после числа- потом любые символы. & .Item(i) к 3 иfairylive и был бы найдена Set objMatches работает… и точка в меньше 6 символов),+ вложенных друг в}ввести regex.Pattern = Patternвстроенные текстовые функции Excelikki
протестируйте макрос proba2нужно оставить толькоNext i 4 кварталу 2012: самый простой способ, = REGEXP.Execute(cell.Text) For
abtextime предыдущем примере. то кванторищет любое число друга функцийили[4-7] regex.Global = Trueдля поиска-нарезки-склейки текста:: даSub proba1() Dim первые числа.End With соответственно.Karataev а я всё Each objMatch In:»Под занавес» хочу уточнить,+

до дефиса, аПОДСТАВИТЬ (SUBSTITUTE){. Например, для обозначения If regex.Test(Text) ThenЛЕВСИМВ (LEFT)lolret t$ t =Пока придумал только:End WithА VBA их, то есть по

Имя файла из полного пути
усложняю? Я просто objMatches Debug.Print objMatch200?’200px’:»+(this.scrollHeight+5)+’px’);»>=ИЛИ(A1=1;B1=2;ЕСЛИОШИБКА(НАЙТИ(«щий»;C1)>0);ЛОЖЬ)) что все вышеописанноеможно заменить наd{2}

, чтобы он склеилсячисло1 всех символов кириллицы Set matches =,: Добрый день, помогите Range(«A1»).Value With CreateObject(«VBScript.RegExp»)=RegExpFindReplace(D7;»D»;»»)где D -Range(«A18») = Mid(t, относит уже к сути весь код к запятой привык. arr = Split(cell.Text,или — это малая интервал «шесть и
P.S.
будет искать копейки в единое целое,, можно использовать шаблон regex.Execute(Text) RegExpExtract =ПРАВСИМВ (RIGHT) пожалуйста решить задачу, .Pattern = «d+» то что ищу, 3) новому кварталу, т.к. это присвоить значениям Удобнее её с objMatch, , vbTextCompare)Код200?’200px’:»+(this.scrollHeight+5)+’px’);»>=ИЛИ(A1=1;B1=2;C1=ПОДСТАВИТЬ(C1;»щий»;»»)) часть из всех более» в виде (два разряда) после. а потом ужечисло2[а-яА-ЯёЁ] matches.Item(Item — 1),
буду приочень благодарен: If .test(t) Then «» — тоEnd Sub собственно это и диапазона значения этого цифровой клавиатуры набирать. ‘ разбивает текстEndrus1
возможностей, которые предоставляют{6,}Если нужно вытащить не примитивной регуляркой}. Exit Function EndПСТР (MID)Имеется массив данных, MsgBox .Execute(t)(0) End на что заменяю.
или есть уже даты же диапазона? Тутbuchlotnik ячейки на части: Спасибо! Работает регулярные выражения. Спецсимволов: цены, а НДС,d{11}
planetaexcel.ru
Использование регулярных выражения внутри формулы (Формулы/Formulas)
Если нужно задать строго[ If ErrHandl: RegExpExtract
, в котором разбросанны With End SubРезультат 3050.Код200?’200px’:»+(this.scrollHeight+5)+’px’);»>Sub tt() нового периода. какая-то магия? Я
: дык а For Each vкитин и правил ихДопустим, нам нужно вытащить то можно воспользоватьсявытаскивать 11 цифр
определенное количество вхождений,^ = CVErr(xlErrValue) EndСЦЕПИТЬ (CONCATENATE) однотипные выражения вида
Sub proba2() Dim
pashulkaDim s$, sp,
Следовательно мне нужно
попробую прикрутить эту200?’200px’:»+(this.scrollHeight+5)+’px’);»>Cells.Replace What:=».», Replacement:=»,» In arr ‘: и вдогонку тупая использования очень много
город из строки
третьим необязательным аргументом подряд: то оно задается
символы Functionи ее аналоги, XA1, XB1, XC1, t$ t =
: Зачем всё усложнять,
spp, i& до момента преобразования штуку чтобы посмотреть
чем не покатило? перебираем все вхождения формула массива
и на эту
адреса. Поможет регулярка,
нашей функции RegExpExtract,Тут чуть сложнее, т.к.
в фигурных скобках.]Теперь можно закрыть редакторОБЪЕДИНИТЬ (JOINTEXT) 
XD1 и т.д. Range(«A1»).Value With CreateObject(«VBScript.RegExp») если в такихs = Range(«A17») даты отнять от
как она работает.
fairylive pos = pos200?’200px’:»+(this.scrollHeight+5)+’px’);»>=СУММ(ЕСЛИ(ПРАВБ($B$2:$B$8;3)=»щий»;$A$2:$A$8))
тему написаны целые извлекающая текст от задающим порядковый номер ИНН (в России) НапримерЕсли после открывающей квадратной Visual Basic и,, нужно привести эти .Pattern = «d+(.+)» случаях прокатит VB(A)sp = Split(s, нее 1 день, У меня просто: Так нули остаются, + Len(v) ‘Che79 книги (рекомендую для «г.» до следующей извлекаемого элемента. И, бывает 10-значный (уd{6} скобки добавить символ вернувшись в Excel,СОВПАД (EXACT) выражения к виду If .test(t) Then функция Val
«.»): s = чтобы она была значения могут быть после запятой. А начальная позиция With: ну или так начала хотя бы запятой: само-собой, можно заменить
excelworld.ru
Регулярные выражения
юрлиц) или 12-значныйозначает строго шесть
«крышки» опробовать нашу новуюи т.д. Этот XA2, XB2, XC2, MsgBox .Execute(t)(0).Submatches(0) EndMsgBox Val(«30 Torrent «» внутри отчетного квартала. в разных столбцах эксель при этом cell.Characters(pos, objMatch.Length) .Font.ColorIndex (тоже уже вне эту). В некоторомДавайте разберем этот шаблон
функцией (у физлиц). Если цифр, а шаблон^ функцию. Синтаксис у способ хорош, если XD2 и т.д. With End Sub Pharmaceuticals Ltd 50″)For i =Можно ли это и рядах (см. этом проставляет в = 3 ‘ конкурса смысле, написание регулярных поподробнее.ПОДСТАВИТЬ не придираться особо,s{2,5, то набор приобретет нее следующий: в тексте есть функция ЗАМЕНИТЬ недобавлю,протестируйте , дляS_el 0 To UBound(sp) сделать прямо здесь картинку сверху). таких ячейках зелёный выделяем цветом .Font.Bold) выражений — этоЕсли вы прочитали текст(SUBSTITUTE) то вполне можно} обратный смысл -=RegExpExtract( Txt ; Pattern четкая логика (например, катит, т.к. таких сравнения в вышеуказанном: — 1 в формуле?buchlotnik треугольничек и говорит = True ‘200?’200px’:»+(this.scrollHeight+5)+’px’);»>=СУММПРОИЗВ($A$2:$A$8*ЕЧИСЛО(ПОИСК(«*щий»;$B$2:$B$8))) почти искусство. Почти
выше, то ужев результатах дефис удовлетвориться регуляркой- от двух на указанной позиции ; Item )
planetaexcel.ru
Регулярные выражения — замена (Макросы/Sub)
индекс всегда в массивов данных много файл-примере функцию zzzavpetrov27spp = Split(sp(i),ЗЫ: отнимать 1, а что вы что число сохранено и полужирным начертанием_Boroda_ всегда придуманную регулярку поняли, что некоторые на стандартный десятичныйd{10,12} до пяти пробелов в тексте будутгде
начале адреса). В и вид изменяемого , в ячейке, вообще регулярка может
"") день прямо на
хотели увидеть? Файл? как текст или
.Font.Size = 14: Алексей, а зачем
можно улучшить или символы в регулярных
разделитель и добавить, но она, строго
Теперь давайте перейдем к разрешены все символы,
Txt противном случае формулы
выражения различен(по количеству ,-получите 3050
выглядеть так:s = s листе, а потом Пожалуйста. На картинке перед ним стоит End With pos звездень вот здесь? дополнить, сделав ее выражениях (точки, звездочки, двойной минус в говоря, будет вытаскивать самому интересному - кроме перечисленных. Так,- ячейка с существенно усложняются и, знаков. Может встречатьсяFunction zzz$(t$) WithКод `^(d+) D.*` & «, « к результату применять показать хотел ошибку апостроф. Апостроф убирается = pos +В ПОИСКПОЗ да,
более изящной или знаки доллара и начале, чтобы Excel все числа от разбору применения созданной шаблон текстом, который мы порой, дело доходит несколько раз в CreateObject(«VBScript.RegExp»): .Pattern = и заменять на & spp(UBound(spp))
функцию для меня и предложения от так objMatch.Length Next v
а ПОИСК все способным работать с т.д.) несут особый интерпретировал найденный НДС 10 до 12 функции и того,[^ЖМ]уть проверяем и из даже до формул ячейке в рамках «D+» zzz = матч из первых
Next i
не подходит. Нужно Excel по поводу200?’200px’:»+(this.scrollHeight+5)+’px’);»>cells.clearformats Next objMatch End равно ищет позицию более широким диапазоном смысл. Если же как нормальное число: знаков, т.е. и что узнали онайдет
которого хотим извлечь массива, что сильно формулы). Нужно провести .Replace(t, «») End группирующих скобок.
Range(«A18») = Mid(s, именно в код её решения. Вручнуюbuchlotnik If Next cell вхождения, поэтому звезда вариантов входных данных. нужно искать самиЕсли не брать спецтранспорт, ошибочно введенные 11-значные. паттернах на практическихПуть нужную нам подстроку тормозит на больших операцию через «поиск With End Functionavpetrov27 3)
функции вставить. можно щёлкнуть -: т.е. вы хотите End Sub вначале ни наДля анализа и разбора эти символы, то
прицепы и прочие
Правильнее будет использовать
примерах из жизни.или
Pattern таблицах.
и замена" сC_sanches
:
End SubJohny преобразовать в число.
при
vikttur что не влияет. чужих регулярок или
перед ними ставится мотоциклы, то стандартный два шаблона, связанныхДля начала разберем простойСуть- маска (шаблон)Использование использованием регулярных выражений,: Доброго времени суток.S_elnerv: И? Выдернули дату Проблема решится. Какзаданном: Это инструмент, а Вот так «?щий» отладки своих собственных
обратная косая черта российский автомобильный номер логическим ИЛИ оператором случай — нужноили для поиска подстрокиоператора проверки текстового подобия но как этоПодскажите, как с,: с расширением и проверяете, куда это же сделатьдесятичном разделите не назвние темы да, ищем любой есть несколько удобных
(иногда это называют разбирается по принципу| извлечь из буквенно-цифровойЗабудьItem Like сделать не пойму помощью регулярных выраженийу меня то.200?’200px’:»+(this.scrollHeight+5)+’px’);»>[^\]+ она попадает или на VBA?
точка (см. правила форума). текст, в котором онлайн-сервисов:
экранированием «буква — три(вертикальная черта): каши первое число,, но не- порядковый номериз Visual Basic,lolret вывести из строки что подставляется реализованоikki не попадает.fairylive, чтобы Excel воспринимал
Предложите новое, модераторы «щий» не первый.RegEx101). Поэтому при поиске цифры — двеОбратите внимание, что в например мощность источниковЖуть подстроки, которую надо обернутого в пользовательскую: Пример приложите содержимое скобок через как строка.: если у каждогоThe_Prist
: Что именно узапятую
excelworld.ru
Регулярные выражения
переименуют. Кстати, насколько я
,
фрагмента «г.» мы буквы — код запросе мы сначала бесперебойного питания изили
извлечь, если их макро-функцию. Это позволяетlolret точку с запятой.Public Function RegExpFindReplace(str файла есть расширение:: Вы бы хоть вас работает? Вашкак десятичный разделительfairylive понял, вот этоRegExr должны написать в региона». Причем код ищем 12-разрядные, и прайс-листа:Муть несколько (если не
реализовать более гибкий: Смогу только завтраПримеры:
As String, _200?’200px’:»+(this.scrollHeight+5)+’px’);»>Sub t() функцию полностью привели. предложеный код?точка: Всем привет. ХотелЦитата
и др. регулярке региона может быть только потом 10-разрядныеЛогика работы регулярного выражения, например.
указан, то выводится поиск с использованиемlolret(223) Pattern As String,s = «file=»»D:ПапкаЛицензия.mpg»»
А еще лучшеKarataev?
немного усовершенствовать макросEndrus1, 18.07.2016 вК сожалению, не всег. 2- или 3-значным, числа. Если же тут простая:|
первое вхождение) символов подстановки (*,#,?: Что-то эе стоитвыведет _ Replace As
file=»»D:МамкаРолик.mov»» file=»»D:ДедкаЛюбое имя.avi»»» вместе с файлом: Да, в этомЦитата и так ничего 19:52, в сообщении
возможности классических регулярныхесли ищем плюсик, а в качестве записать нашу регуляркуdЛогический операторСамое интересное тут, конечно, и т.д.) К за этим знаком,223; String, _ OptionalWith CreateObject(«vbscript.regexp»)
примером. суть. Смысл может
200?’200px’:»+(this.scrollHeight+5)+’px’);»>самый простой способ это у меня и № 1200?’200px’:»+(this.scrollHeight+5)+’px’);»>найти с выражений поддерживаются в то букв применяются только наоборот, то она
- означает любуюИЛИ (OR) это Pattern - сожалению, этот инструмент
точка с запятой
planetaexcel.ru
Регулярные выражения
(344)/(563) Globa1 As Boolean
.Pattern = «\([^\»»]*)(.[^.]+)»»»Скорее всего надо
быть в том,
проставлять разделитель по
не получилось с помощью регулярного выражения VBA (например, обратный+ те, что похожи
будет вытаскивать для
цифру, а квантор
для проверки по
строка-шаблон из спецсимволов не умеет извлекать
или двоеточие. Можетвыведет = True, _.Global = True
ковырять переменные astring
что если в умолчанию, чтобы числа
регулярными выражениями. Есть
*щий означает, что
поиск или POSIX-классы)и т.д.
внешне на латиницу. всех, даже длинных
+
любому из указанных "на языке" RegExp, нужную подстроку из
включить этот знак344;563; Optional IgnoreCase As
Set mo =
и tempString. Но
ячейку записывать дробное
были числами полно примеров с
нужно именно окончание
и умеют работать
Следующих два символа в
Таким образом, для 12-разрядных ИНН, только
говорит о том,
критериев. Например которая и задает, текста — только
в Найти/Заменить, что-то((42) + 2* ((42)+(43)) Boolean = False,
.Execute(s) т.к. мы понятия
число с точкой,fairylive функциями которым скармливается
на «щий». Тогда
с кириллицей, но нашем шаблоне -
извлечения номеров из
первые 10 символов. что их количество
(с
что именно и проверять, содержится ли типа Найти «1;»
/ (121)
_ Optional MultilineEnd With
не имеем, откуда
то такое число
: Разделитель целой и
оригинал (одна ячейка), ПОИСК и НАЙТИ
и того, что
точка и звездочка-квантор
текста нам поможет То есть после должно быть одна
чет|с
где мы хотим
она в нем.
- Заменить на
выведет As Boolean =If mo.Count Then astring и что воспринимается Excel’ем, как дробной части (Панель
паттерн и замена. без уточнений позиции есть, думаю, хватит
— обозначают любое следующая регулярка:
срабатывания первого условия
или больше. Двойнойчёт|invoice
найти. Вот самые
Кроме вышеперечисленного, есть еще
"2;" Предварительно выделив
42;43;121;
False) _ AsFor i =
в ней хранится(предположим
число, а не
управления - язык Но как работать вообще не подойдут.
на первое время,
количество любых символов,Для извлечения времени в дальнейшая проверка уже минус перед функцией
)
основные из них
один подход, очень
только ячейки с
excelworld.ru
Регулярные выражения. подскажите шаблон
Т.е. в строке String RegExpFindReplace =
0 To mo.Count дата, но надо как текст, даже
и региональные стандарты)
со всеми ячейками Я, правда, так
чтобы вас порадовать.
т.е. любое название
формате ЧЧ:ММ подойдет не производится: нужен, чтобы «набудет искать в — для начала:
известный в узких формулами
могут встречаться любые
str ‘Пока ничего — 1 понимать в каком если у дробного
— запятая. В
в экселе? Есть вот сходу неЕсли же вы не города. такое регулярное выражение:
Это принципиальное отличие оператора лету» преобразовать извлеченные
тексте любое изПаттерн кругах профессиональных программистов,Как вариант подходит, символы, но то,
не меняли IfDebug.Print mo(i).submatches(0) формате), то и числа тип данных
Экселе разделитель тоже Cells.Replace но как смог придумать слово, новичок в теме,
На конце шаблона стоитПосле двоеточия фрагмент|
символы в полноценное указанных слов. ОбычноОписание веб-разработчиков и прочих спасибо, с небольшими что в скобках, Not str LikeNext помочь не можем «String» (Текст). запятая. Мне так можно в нём в котором «щий» и вам есть запятая, т.к. мы[0-5]dот стандартной экселевской число из числа-как-текст. набор вариантов заключается. технарей — это доработками по убиранию обязательно целые числа «» And NotEnd If достоверно.fairylive удобно. Так хорошо. задать регулярные выражения? в середине. чем поделиться - ищем текст от, как легко сообразить, логической функцииНа первый взгляд, тут в скобки.Самое простое — эторегулярные выражения
чисел из ячеекПодскажите, хотя бы,
Pattern Like «»End SubАлександр: Допилил так. Правда Но автокаду на
Короче сейчас уChe79 оставляйте полезные при «г.» до запятой. задает любое числоИЛИ (OR)
все просто -^ точка. Она обозначает(Regular Expressions = с выражениями, чтобы с чего начать. Then Dim RegExpikki: Файл пример.
заработало с 10-й это плевать. У меня какой-то такой: Александр, на мой работе в Excel
Но ведь в в интервале 00-59., где от перестановки
ищем ровно шестьНачало строки любой символ в RegExp = «регэкспы» не попали случайноСпасибо! As Object ‘Для: для возможного случаяСлэн попытки. Фокус в него разделитель только код, за неимением кажуЩИЙся регулярки в комментариях
тексте может быть Перед двоеточием в аргументов результат не цифр подряд. Используем$
шаблоне на указанной = «регулярки»). Упрощенно под замену. Проверюikki регулярного выражения Set
CyberForum.ru
Поиск в строке. Регулярные выражения (Макросы/Sub)
с отсутствием расширений: так? (но не
том что надо точка. И выгружает лучшего:взгляд звездень была ниже. Один ум
несколько запятых, правда?
скобках работают два меняется. спецсимвол
Конец строки позиции. говоря,
на практике завтра,: а почему для RegExp = CreateObject(«VBScript.RegExp») для некоторых файлов
только две указанные это проделать с в эксель он200?’200px’:»+(this.scrollHeight+5)+’px’);»>Cells.Replace What:=».0000″, Replacement:=»», LookAt:=xlPart, нужна. Но перечитав
хорошо, а два Не только после
шаблона, разделенных логическим
Во многих компаниях товарамdbsRegExp — это язык, вдруг «овраги».В Найти/Заменить
третьей строки
With RegExp .Global "чистого" решения на
даты, но все исходным файлом извлечения
точку. Я хочу SearchOrder _
Вас выше и сапога - пара! города, но и ИЛИ (вертикальной чертой): и услугам присваиваются
для цифры иКрай слова
Любой символ, выглядящий как
где с помощью
есть Выделение группы
42 = Globa1 ‘Все
регулярках не придумал. первые дни кварталов
СРАЗУ. А я как-то с этим
:=xlByRows, MatchCase:=False, SearchFormat:=False, справку по ПОИСК,
Endrus1 после улицы, дома[0-1]d
уникальные идентификаторы - квантор
Если мы ищем определенное
пробел (пробел, табуляция специальных символов и ячеек — отметьте- в результате совпадения или тольконо, думаю, такой
отнесены к предыдущему сначала двигал столбцы бороться с помощью ReplaceFormat:=False понял, что явно
: Добрый день, уважаемые и т.д. На
excelworld.ru
Поиск и замена с использованием регулярных выражений
- любое число артикулы, SAP-коды, SKU{6} количество символов, например,
или перенос строки). правил производится поиск там Формулы, затем один раз? первое? .IgnoreCase = вариант будет даже периоду) и применял сортировки VBA.Cells.Replace What:=».000″, Replacement:=»», погорячился… эксперты! какой из них в интервале 00-19 и т.д. Еслидля количества знаков: шестизначный почтовый индексS нужных подстрок в не снимая выделения200?’200px’:»+(this.scrollHeight+5)+’px’);»>Function f$(s$) IgnoreCase ‘Регистр неважен? быстрее.
Александр разные. И после
Karataev LookAt:=xlPart, SearchOrder _
KHRRПрошу помочь: Как будет останавливаться наш2[0-3] в их обозначенияхОднако, возможна ситуация, когда или все трехбуквенныеАнти-вариант предыдущего шаблона, т.е. тексте, их извлечение заменить значения.Всё получилось,Set r = .Multiline = Multiline
да и понятно: Слэн, супер - этого почем-то уже: У метода «Replace»:=xlByRows, MatchCase:=False, SearchFormat:=False,: Добрый день! в формулах ЕСЛИ запрос? Вот за- любое число есть логика, то левее индекса в коды товаров, то любой НЕпробельный символ. или замена на благодарю.
CyberForum.ru
CreateObject(«vbscript.regexp»)
В своей работе мы часто сталкиваемся с тем, что нам нужно обработать ячейку с текстом или проверить, содержит ли ячейка определенные символы. Например, только кириллицу или дату в определённом формате (или электронную почту). В этом нам помогут регулярные выражения.
Прежде чем перейти к статье, опишу свой опыт использования регулярных выражений. Мне поступила задача из ячейки, содержащий, длинный текстовый комментарий (подробное описание операционного риска), вытащить номер счета, номер карты и Фамилию Имя Отчество, если они там есть. При помощи регулярных выражений, это задача решается очень просто. Проблема сводится к подбору правильной маски регулярного выражения.
Для использования регулярных выражений в своей работе первым делом необходимо подключить библиотеку Microsoft VBScript Regular Expressions 5.5
Приведем примеры трех полезных функций, которые необходимо записать себе в личную книгу макросов, для того чтобы их просто вызывать с листа.
Первая функция — это тестирование, т.е. проверка текста на соответствие определённой маске (маска может быть какой угодно, чтобы правильно составить маску нужно знать синтаксис регулярных выражений).
Public Function uf_StrTest(ByVal strBasic As String, ByVal strPattern As String) As Boolean
Dim Rx As New RegExp
With Rx
.Global = True
.IgnoreCase = True
.MultiLine = True
.Pattern = strPattern
End With
uf_StrTest = Rx.test(strBasic)
End Function
Вот как это работает:
Первый аргумент функции, это то, что мы проверяем. Второй аргумент – маска, которой должно соответствовать проверяемое выражение.
Например, uf_StrTest(C1;»[а-я]») проверит, содержит ли ячейка С1 хотя бы одну маленькую букву кириллицы, если содержит, то возвратит истину, иначе — возвратит ложь. Данную функцию можно использовать на запрет при вводе буквы латинского алфавита.
Вторая функция — это замена, т.е. извлечение из текста какой-то его части по определённому правилу.
Public Function uf_Replace(ByVal strBasic As String, ByVal strPattern As String, ByVal strModel As String) As String
Dim Rx As New RegExp
With Rx
.Global = True
.IgnoreCase = True
.MultiLine = True
.Pattern = strPattern
End With
uf_Replace = Rx.Replace(strBasic, strModel)
End Function
Приведем пример как работает эта функция.
Допустим, у нас есть текст в ячейке С3 «Сидоров Петр Петрович». Нам нужно извлечь начальные буквы ФИО. Тогда наша функция будет выглядеть так
uf_Replace(C3;»^([^s])[^s]+s+([^s])[^s]+s+([^s])[^s]+»;»$1$2$3«)
Жирным шрифтом выделены выражения в круглых скобках, их ровно три.
Именно они и будут в итоге являться заменой. Например, наша функция примет значение «СПП».
А вот uf_Replace(C3;»^([^s])[^s]+s+([^s])[^s]+s+([^s])[^s]+»;»$2$3$1«) вернет «ППС»
Недостаток этой функции в том, что мы должны знать маску всего текста, если мы этого не знаем, мы можем использовать третью функцию
Третья функция — это извлечение. Извлечение из текста его какой-то части по определённой маске.
Это требуется, если необходимо извлечь электронную почту или дату. Особенно, если в текстовой строке указано несколько электронных адресов.
Public Function uf_Execute(ByVal strBasic As String, ByVal strPattern As String) As String
Dim Rx As New RegExp Dim It As Variant Dim objMatch As Object
With Rx
.Global = True
.IgnoreCase = True
.MultiLine = True
.Pattern = strPattern
End With
Set objMatch = Rx.Execute(strBasic)
For Each It In objMatch
If uf_Execute = «» Then
uf_Execute = It
Else
uf_Execute = uf_Execute & «;» & It
End If
Next
End Function
Приведем пример как работает эта функция. Допустим, у нас есть текст в ячейке С3 «штрих-код: 30612-58746-16431-17562-35097-48735-17530-39512, дата регистрации: 23.10.2019, скан.образ:». Нам нужно извлечь дату. Тогда наша функция будет выглядеть так uf_Execute(С3;»d{2}.d{2}.d{4}»). Таким образом мы извлекаем из текса в ячейке СЗ, все что соответствует маске второго аргумента функции, если их несколько — функция выдаст их через точку с запятой.