
Парсер поддерживает следующие типы файлов Word:
- .doc, .docx, .docm, и т.п. — «обычные» документы Word
- .rtf, .odt и другие форматы, поддерживаемые Word
Для сбора данных из файлов Word используется стандартный алгоритм парсера файлов, со следующими особенностями:
- Для чтения файла используется действие «Загрузить содержимое из файла MS Word», с параметром «Тип результата» text или HTML:
Действие Параметр Значение Загрузить содержимое из файла MS Word Путь к файлу Запускать новый экземпляр MS Word нет Открыть в режиме «только чтение» да Тип результата text / HTML Принудительно закрывать файлы Word не требуется (данные из файла считываются, и файл сразу закрывается)
- Тип результата «text» подойдет для простых документов, где есть к чему привязаться для извлечения значений.
Например, если данные в документе имеют вид Дата: 25.04.2021, то парсер для получения даты может взять текст между словом Дата: и переводом строки {NL}
Учитывать стили абзацев в данном случае ни к чему (потому разметка HTML не нужна для парсинга)
- Для документов сложной структуры, или с большим объёмом данных, имеет смысл использовать тип результата HTML, и производить разбор данных из файла с учётом стилей (размер шрифта и т.п.).
Кроме того, в этом случае есть возможность считывать данные из различных объектов Word, таких как например надписи и колонтитулы.
- Есть возможность выгружать фотографии из документа, при помощи действия «Выгрузить картинки из файла Word»
Примеры настройки парсера файлов Word можно найти в каталоге парсеров файлов:
- парсер пропусков
- парсер дипломов
- парсер базы контактов
Разобрать файл Word и извлечь данные с помощью любого современного браузера
Loading…
Обработка Пожалуйста, подождите…
Копировать ссылку
![]()
![]()
Обработка Пожалуйста, подождите…
Файл отправлен на
![]()
Ваше мнение важно для нас, пожалуйста, оцените это приложение.
★
★
★
★
★
Спасибо за оценку нашего приложения!
Word parser
Word Parser – это бесплатный инструмент, который позволяет извлекать текст и таблицы из Word файлов, управлять содержимым документов без установки дополнительного программного обеспечения, из любого браузера и с любого устройства. Извлекайте текст из XLS, XLSX, PPT, PPTX, PDF, DOC, DOCX, RTF, HTML, EPUB и многих других форматов файлов и документов.
![]()
Скоро будет
Как Разобрать Word
- Щелкните внутри области перетаскивания или перетащите файл.
- Дождитесь завершения загрузки и обработки.
- После завершения загрузки и обработки файла вы увидите страницу результатов.
- На странице результатов нажмите кнопку «Синтаксический анализ», чтобы начать анализ вашего файла.
- Вы также можете поделиться своим файлом с помощью ссылки для копирования или электронной почты.
![]()
часто задаваемые вопросы
Q: Как разобрать файл Word?
A: Во-первых, вам нужно загрузить файл: перетащите файл или щелкните внутри области загрузки, чтобы выбрать файл, чтобы начать его обработку. После завершения обработки нажмите кнопку «Разобрать», чтобы начать анализ вашего документа.
Q: Нужно ли мне устанавливать дополнительное программное обеспечение, чтобы иметь возможность анализировать файл Word?
A: Нет, приложение для анализа документов Conholdate — это полностью облачная служба, которая не требует установки дополнительного программного обеспечения.
Q: Могу ли я анализировать файлы в ОС Linux, Mac или Android?
A: Конечно, Conholdate Parser — это полностью облачный сервис, который не требует установки какого-либо программного обеспечения и может использоваться в любой операционной системе с веб-браузером.
Q: Безопасно ли анализировать файлы Word с помощью бесплатного Conholdate.App?
A: Да, это абсолютно безопасно. Ваши файлы хранятся на нашем защищенном сервере и защищены от любого несанкционированного доступа. Через 24 часа все файлы удаляются безвозвратно.
Q: Можно ли разобрать текст из документа Word?
A: Да, выберите инструмент текстового поля на верхней панели инструментов синтаксического анализатора Word, выберите нужную область на странице документа Word и нажмите кнопку синтаксического анализа.
Q: Могу ли я разобрать таблицу из документа Word?
A: Да, выберите инструмент таблицы на верхней панели инструментов синтаксического анализатора Word, выберите таблицу на странице документа Word и нажмите кнопку синтаксического анализа.
Q: Как получить Word результатов синтаксического анализа?
A: Вы можете загрузить результаты в виде файла CSV, нажав кнопку загрузки, расположенную в верхней части диалогового окна анализатора Word. Также вы можете сохранить шаблон синтаксического анализа для дальнейшего использования, для этого просто щелкните значок загрузки, расположенный в верхней правой части панели инструментов синтаксического анализатора.
Еще приложений
Еще parser приложений
Выбрать язык
В процессе анализа информации часто возникает потребность в обработке данных из документов в форматах MS Word или Excel. Как считывать информации из таких файлов с использованием языка C #.
Из практического опыта сотрудника, который всегда успешно решает поставленные задачи.
Для работы с файлами Word и Excel я решил выбрать библиотеки Microsoft.Office.Interop.Word и Microsoft.Office.Interop.Excel, предоставляющие программные интерфейсы для взаимодействия с объектами MS Word и Excel.
Преимущества использования этих библиотек:
- созданы корпорацией Microsoft, следовательно, взаимодействие с объектами программ пакета MS Office реализовано наиболее оптимально,
- нужный пакет Visual Studio Tool for Office поставляется вместе с Visual Studio (достаточно отметить его при установке VS).
Также следует заметить, что у такого похода есть и недостаток: для того, чтобы написанная программа работала на ПК пользователя необходимо, чтобы на нём были установлены программы MS Office и MS Excel. Поэтому такой подход плохо подходит для серверных решений. Также такая программа не будет являться кроссплатформенной.
Добавление библиотек в проект Visual Studio
Библиотеки поставляются вместе с пакетом Visual Studio Tool for Office (платформа .NET Framework).
Для использования библиотеки нужно:
- добавить ссылку на неё: в обозревателе решений необходимо кликнуть правой кнопкой мыши по пункту Ссылки (Рис. 1) и найти нужную библиотеку по ключевым словам (после добавления ссылка появится в списке),
- указать используемое пространство имён в файле программы (в примере ему назначен алиас Word): (Рис. 2):
Можно прочитать основные форматы: .doc,. docx,. rtf.
Ниже приведён листинг с примером считывания текста из документа MS Word:
object FileName = @»C:test.doc»;
object rOnly = true;
object SaveChanges = false;
object MissingObj = System.Reflection.Missing.Value;
Word.Application app = new Word.Application();
Word.Document doc = null;
Word.Range range = null;
try
{
doc = app.Documents.Open(ref FileName, ref MissingObj, ref rOnly, ref MissingObj,
ref MissingObj, ref MissingObj, ref MissingObj, ref MissingObj,
ref MissingObj, ref MissingObj, ref MissingObj, ref MissingObj,
ref MissingObj, ref MissingObj, ref MissingObj, ref MissingObj);
object StartPosition = 0;
object EndPositiojn = doc.Characters.Count;
range = doc.Range(ref StartPosition, ref EndPositiojn);
// Получение основного текста со страниц (без учёта сносок и колонтитулов)
string MainText = (range == null || range.Text == null) ? null : range.Text;
if (MainText != null)
{
/* Обработка основного текста документа*/
}
// Получение текста из нижних и верхних колонтитулов
foreach (Word.Section section in doc.Sections)
{
// Нижние колонтитулы
foreach (Word.HeaderFooter footer in section.Footers)
{
string FooterText = (footer.Range == null || footer.Range.Text == null) ? null : footer.Range.Text;
if (FooterText != null)
{
/* Обработка текста */
}
}
// Верхние колонтитулы
foreach (Word.HeaderFooter header in section.Headers)
{
string HeaderText = (header.Range == null || header.Range.Text == null) ? null : header.Range.Text;
if (HeaderText != null)
{
/* Обработка текста */
}
}
}
// Получение текста сносок
if (doc.Footnotes.Count != 0)
{
foreach (Word.Footnote footnote in doc.Footnotes)
{
string FooteNoteText = (footnote.Range == null || footnote.Range.Text == null) ? null : footnote.Range.Text;
if (FooteNoteText != null)
{
/* Обработка текста */
}
}
}
} catch (Exception ex)
{
/* Обработка исключений */
}
finally
{
/* Очистка неуправляемых ресурсов */
if(doc != null)
{
doc.Close(ref SaveChanges);
}
if(range != null)
{
Marshal.ReleaseComObject(range);
range = null;
}
if(app != null)
{
app.Quit();
Marshal.ReleaseComObject(app);
app = null;
}
}
Примечания:
- в коде приводится пример считывания основного текста документа, текста верхних и нижних колонтитулов, а также текста сносок,
- в коде производится очистка неуправляемых ресурсов с использованием класса Marshal
Пример парсинга файла MS Excel
Можно прочитать основные форматы: .xls,. xlsx.
Ниже приведён листинг с примером считывания текста из документа MS Excel (по ячейкам):
string FileName = @»C:UsersbeeDownloadstest.xlsx»;
object rOnly = true;
object SaveChanges = false;
object MissingObj = System.Reflection.Missing.Value;
Excel.Application app = new Excel.Application();
Excel.Workbooks workbooks = null;
Excel.Workbook workbook = null;
Excel.Sheets sheets = null;
try
{
workbooks = app.Workbooks;
workbook = workbooks.Open(FileName, MissingObj, rOnly, MissingObj, MissingObj,
MissingObj, MissingObj, MissingObj, MissingObj, MissingObj,
MissingObj, MissingObj, MissingObj, MissingObj, MissingObj);
// Получение всех страниц докуента
sheets = workbook.Sheets;
foreach(Excel.Worksheet worksheet in sheets)
{
// Получаем диапазон используемых на странице ячеек
Excel.Range UsedRange = worksheet.UsedRange;
// Получаем строки в используемом диапазоне
Excel.Range urRows = UsedRange.Rows;
// Получаем столбцы в используемом диапазоне
Excel.Range urColums = UsedRange.Columns;
// Количества строк и столбцов
int RowsCount = urRows.Count;
int ColumnsCount = urColums.Count;
for(int i = 1; i <= RowsCount; i++)
{
for(int j = 1; j <= ColumnsCount; j++)
{
Excel.Range CellRange = UsedRange.Cells[i, j];
// Получение текста ячейки
string CellText = (CellRange == null || CellRange.Value2 == null) ? null :
(CellRange as Excel.Range).Value2.ToString();
if(CellText != null)
{
/* Обработка текста */
}
}
}
// Очистка неуправляемых ресурсов на каждой итерации
if (urRows != null) Marshal.ReleaseComObject(urRows);
if (urColums != null) Marshal.ReleaseComObject(urColums);
if (UsedRange != null) Marshal.ReleaseComObject(UsedRange);
if (worksheet != null) Marshal.ReleaseComObject(worksheet);
}
} catch (Exception ex)
{
/* Обработка исключений */
}
finally
{
/* Очистка оставшихся неуправляемых ресурсов */
if (sheets != null) Marshal.ReleaseComObject(sheets);
if (workbook != null)
{
workbook.Close(SaveChanges);
Marshal.ReleaseComObject(workbook);
workbook = null;
}
if (workbooks != null)
{
workbooks.Close();
Marshal.ReleaseComObject(workbooks);
workbooks = null;
}
if (app != null)
{
app.Quit();
Marshal.ReleaseComObject(app);
app = null;
}
}
Примечания:
- при обработке текста каждой ячейки приходится заранее знать количество задействованных строк и столбцов на текущем листе документа,
- такой перебор не совсем оптимален (временная сложность алгоритма O(n2)): при желании его можно ускорить (например, разбив обработку на несколько потоков): в данной статье приводится лишь пример получения текста из каждой ячейки,
- при таком переборе ячеек необходимо на каждой итерации освобождать неуправляемые ресурсы, чтобы избежать утечек памяти (аналогично предыдущему примеру, используется класс Marshal).
Приведенные примеры хорошо подходят для реализации приложения по обработке документов Word и Excel на платформе .NET Framework.
С помощью указанных библиотек можно не только читать текст из документов, но и создавать новые файлы форматов MS Word и Excel.
Время на прочтение
10 мин
Количество просмотров 20K
Хочу представить вашему вниманию способ извлечения данных с документа word в виде картинок. Возможно, представленные идеи будут для кого-то примитивными и очевидными. Но мне пришлось провести пару бессонных ночей, прежде чем дойти до нормального решения. Итак, начинаю.
Было начало 2015-го. Зима. Я радовался хорошей погоде и восхищенно думал, что универ я наконец закончу (вру, сейчас поступаю в магистратуру). Свой диплом я недавно закончил, поэтому радовался еще сильнее. Однако вскоре, по натуре человеческой, состояние безмятежности плавно стало сменяться скукой. И тут, как будто специально, тишину сменил телефонный звонок.
«Алло, привет, как поживаешь?» — прозвучал голос знакомой.
Интуиция тут же определила, что скорее всего разговор будет на тему «тыжпрограммиста». Так оно и было. С унылым видом сначала я слушал про тяжкие времена знакомой и про все остальное, однако ее конечная просьба заставила меня заинтересоваться.
«Ты не мог мне помочь с дипломом? В общем, необходимо сделать сайт-тренажер по математике» — сказала она.
Это было интересно. Меня как раз увлекает разработка сложных фронтендов. Просьбу я тут же одобрил.
На реализацию тренажера ушло суммарно не более 2-х дней. Сайт-тренажер позволяет проходить тесты по высшей математике и просматривать теорию. Тесты можно проходить в двух режимах: в режиме тренировки с подсвечиванием ответов и в режиме тестирования с выводом результата в конце. Реализация была сделана на ReactJS и Bootstrap и сам процесс был достаточно приятным. Но это было только начало. Необходимо было как заполнить данными базу вопросов тестов, которые отнюдь не были в виде готовых упорядоченных данных.
Постановка задачи
Пока я удовлетворенно смотрел на результат работы, знакомая позвонила повторно. Она уведомила меня, что прислала мне небольшой архивчик с вопросами в *.doc файлах на почту. «Если что, я могу помочь перекинуть вопросы и ответы в БД» — добавила она.
Это немного подпортило мое настроение, ведь я не думал, что придется еще заполнять самостоятельно базу тестовых вопросов.
Ладно. Пошел я открывать свой GMail и тут:
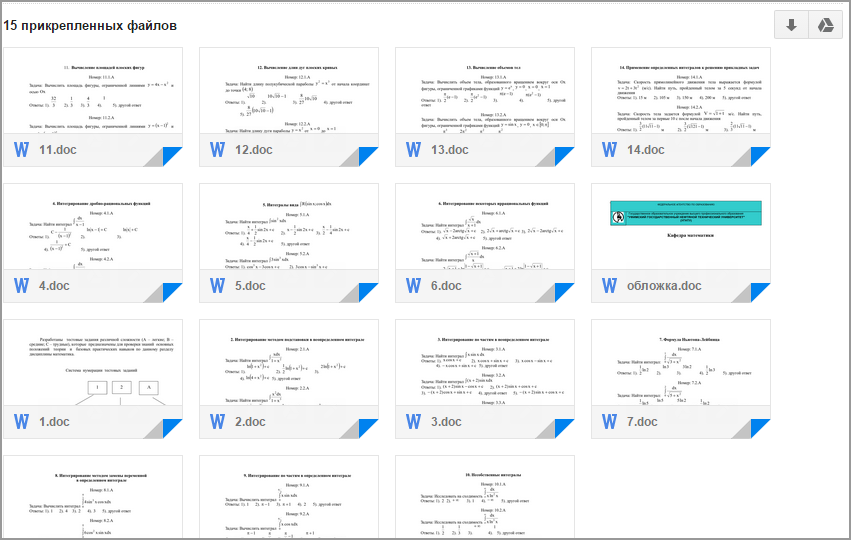
И в каждом файле ~50 тестовых заданий в виде:

Мда уж, вручную забивать все это в БД вряд ли получится. К слову, каждое тестовое задание в БД хранилось в виде одной картинки-вопроса, пяти картинок-ответов, уровня сложности (A, B, C) и номера верного ответа (1-5). Расстроенный, я решил пока что отложить этот вопрос на долгий ящик, благо времени было достаточно. Но через несколько дней на почту упало еще одно сообщение от знакомой, а потом еще… В итоге, набралось 4 раздела по высшей математике, каждый из разделов состоял из 14-23 подразделов, каждый подраздел содержал примерно 30-100 тестовых заданий. И тут я окончательно убедился, что вручную все это вбить в базу данных точно не получится.
Кстати про БД. Это MySQL с тремя таблицами: разделов, подразделов и тестовых вопросов. Картинки вопроса задания и пяти ответов хранятся непосредственно в БД, в столбце BLOB. Мне кажется так удобней, поскольку этих картинок очень много, к тому же весят они мало. И будут все они храниться в одном месте, вместе с другими данными.
Итак, что было необходимо? В наилучшем варианте нужно было из папки со всеми word файлами тестовых заданий получить готовые соответствующие записи в БД, что практически и было получено в конечном результате. Нас же интересует главное: непосредственно само извлечение картинок.
Входные данные: файл word с тестовыми заданиями.
Выходные данные (например): папка с изображениями PNG, где задание имеет имя вида 1.png, а ответы имеют имена 1.1.png, 1.2.png, 1.3.png, 1.4.png, 1.5.png, плюс к этому файл answers.txt, внутри которого i-я строка содержит число от 1 до 5, соответствующую правильному ответу i-го задания.
Реализация
Я люблю Qt Creator. А с чего мне его любить? Скорее всего потому, что в универе нас натаскивают именно по нему, я сам не знаю. А еще во время пользования им я испытываю какой-то тихий восторг. Ну в общем вы поняли, на чем я стал писать программу-парсер.
Вначале я гадал, как же вообще взаимодействовать с этим вордом, чтобы как то уж выдергивать оттуда данные. На ум приходили всякие ужасные мысли наподобие конвертации word файла в HTML с последующей обработкой. Но гугление сразу же направило меня на адекватный путь, дав информацию о языке VBA. Я тут же был поражен обилием готовых функций, узнал, что такое параграфы, позиции и т.п., одновременно офигевая от сложности устройства дерева документа word.
Однако я был разочарован, поскольку так и не понял, как же превратить кусок текста в картинку. Сначала было хотел использовать что-либо наподобие text2png, предварительно выдернув нужный кусок текста. Но как же с формулами и картинками? Встроенной функции в VBA не было. В один момент у меня ненарком промелькнуло мыслишко, что вроде бы как я раньше вставлял в документ word ячейки из excel в виде картинок. Так и было! Называлось это «специальной вставкой» и позволяло вставлять любой участок документа в виде картинки. Допустим мы занесли в буфер обмена некий кусок документа, который необходимо сохранить в виде картинки. Но как эту картинку сохранить на диск? Гугление также помогло найти решение. Участок кода ниже сохраняет содержимое буфера обмена на диск в виде универсального векторного файла EMF.
#include <windows.h>
void clipboardDataToEmfFile(QString fileName){
OpenClipboard(0);
GetEnhMetaFileBits((HENHMETAFILE)GetClipboardData(14),0,0);
HENHMETAFILE returnValue = CopyEnhMetaFileA((HENHMETAFILE)GetClipboardData(14),
QDir::toNativeSeparators(fileName).toStdString().c_str());
EmptyClipboard();
CloseClipboard();
DeleteEnhMetaFile(returnValue);
}
Отлично. Однако что это за зверь такой, этот EMF? Необходимо было его превратить в PNG. Начал я искать конвертеры изображений. Перебрав кучу, так и не нашел адекватного. И тут опять (кто-нибудь верит в интуицию?) в голове начал вспоминаться какой-то навороченный просмотрщик изображений, который я ставил в школьные годы из диска с «Золотым софтом» забавы ради. Но вроде это был не конвертер. Однако необходимо было убедиться. В голове крутилось какое-то то ли «Ifran», то ли «Irfan», в общем программа была найдена. Бесплатная, с функцией пакетной обработки изображений, поддерживает командную строку! И самое главное, поддерживает EMF. Это было то, что надо. Исполняемый файл IrfanView с нужными DLL и ini-файлом параметров лежит в одной папке со скомпилированной программой (надеюсь это не нарушает лицензию) и используется через функцию вот так.
void convertEmfsToPng(QString inFolder, QString outFolder){
QProcess proc;
QString exeStr = """ + QDir::toNativeSeparators(QDir::currentPath()+"/i_view32.exe") + """;
QString inFilesStr = """ + QDir::toNativeSeparators(inFolder + "*.emf") + """;
QString outFilesStr = """ + QDir::toNativeSeparators(outFolder + "*.png") + """;
QString iniFolderStr = """ + QDir::toNativeSeparators(QDir::currentPath()) + """;
proc.start(exeStr + " " + inFilesStr + " /advancedbatch /ini=" + iniFolderStr + " /convert=" + outFilesStr);
proc.waitForFinished(30*60*1000);
}
Теперь осталось копировать в буфер нужные куски из документа word. Для этого необходимо придумать алгоритм разбиения исходного текста на отдельные блоки с заданием, с ответами, с номером верного ответа и уровня сложности.
Первой попыткой реализации было следующее. Берем исходный документ, заменяем в нем текст вида ([1-5])) на n$1), т.е. перед началом каждого ответа добавляем перевод строки. На VBA строки замены пишутся по-другому, я уже не помню. Теперь в параметрах документа ставим ширину страницы максимальной, а шрифт для всего документа уменьшаем. В результате получается, что в документе каждое задание будет занимать ровно 8 строк, причем:
- строка 8*i — это текст с номером верного ответа и уровнем сложности
- строка 8*i+1 — это задание
- строка 8*i+2 — это вариант ответа №1
- …
- строка 8*i+6 — это вариант ответа №5
- строка 8*i+7 — пустая
Повторно, как выглядят задания
Теперь после этой обработки ничего не остается, кроме как пройтись по массиву коллекции строк документа, заведя счетчик i, и в зависимости от i % 8 сохранять картинки задания/ответов или извлекать номер верного ответа с уровнем сложности.
Но это не подошло. Виноваты длинные задания, которые будучи написаны в одну строку, выглядят ужасно, мелко и не всегда вмещаются. К тому же иногда замена текста «1)» затрагивает другие места кроме номеров ответов. Опечаленный результатом, я вновь начал думать, что можно будет сделать в данном случае. И тут я вспомнил про конечные автоматы. Вспомнил про состояние, вспомнил про посимвольный ввод. Вспомнил синтаксический анализатор. Возможно это другим было очевидным решением, но я как человек далекий от сложных алгоритмов был безумно рад своей идее.
Теперь настал черед писать и пробовать код парсера на основе конечного автомата. Состояний у нас 7:
- считывание пространства между заданиями, начинается с пустой строки
- считывание строки с номером задания, в котором номер верного ответа и уровень сложности, начинается с «Номер»
- считывание текста задания, начинается с «Задача»
- считывание текста ответа №1, начинается с «Ответы: 1).»
- считывание текста ответа №2, начинается с «2).»
- …
- считывание текста ответа №5, начинается с «5).»
Реализуем, используя условия начала следующего состояния. После тестирования первой версии парсера все прошло великолепно. Картинки получались как в самом word документе, красивенько, крупно. Но тут… время от времени появлялись косяки, например в одной картинке захватывался лишний кусок до следующего блока задания. Значит парсер некорректно распознавал. В чем же дело? Все оказалось просто — задания в word документе набирались вручную и поэтому имел место человеческий фактор, например:
- вместо «Задача» писалось «Задание»
- вместо «Ответы» писалось «Ответ»
- вместо «1).» писалось «1 ).» или «1)» или вообще «1) .»
Это был кошмар. Благо основные ошибки были в написании номеров заданий, их худо-бедно учитывал парсер. Остальные ошибки после извлечения картинок обнаруживались беглым просмотром наиболее больших и маленьких по размеру картинок с последующим исправлением и повторным извлечением.
Итоговым куском парсера является код ниже. Он ужасен, просьба не судить строго. Для хранения VBA-объектов используется QAxObject.
Разъяснения имен переменных, состояния автомата, используемых дополнительных функций
- status — состояние автомата:
- -3 — между заданиями
- -2 — внутри номера задания
- -1 — внутри задания
- 0 — после слова Ответы
- 1 — внутри ответа 1
- 2 — внутри ответа 2
- 3 — внутри ответа 3
- 4 — внутри ответа 4
- 5 — внутри ответа 5
- startind — позиция начала текущего блока (задание, ответ, строка с номером верного ответа и уровнем сложности)
- n — порядковый номер задания
- nstr — строка порядкового номера задания с ведущими нулями до трехзначного
- str — строка текущего блока до текущей позиции
- lineStart, lineEnd — номера позиций начала и конца текущего абзаца
- lines — объект коллекции абзацев документа
- tline — объект текущего абзаца
- line — объект Range текущего абзаца
- ipar — номер текущего абзаца
- tmpObj — объект Range текущего символа
- currChar — текущий символ
- outdir — строка пути выходной папки картинок
- функция getAnswerLine(QString) — возвращает строку из двух чисел: уровень сложности (1-3) и номер верного ответа (1-5), например 24 — это задание с уровнем сложности B и правильным ответом под номером 4
- функция rangeToEmfFile(QString fname, int start, int end, QAxObject *activeDoc) — сохраняет кусок документа между позициями start и end документа activeDoc как EMF-файл с именем fname
Ужасный, длинный код
QAxObject *activeDoc = wordApp->querySubObject("ActiveDocument");
int status = -3;
int startind = 0;
int n=0;
QString nstr;
QString str = "";
int lineStart, lineEnd;
QAxObject *lines = activeDoc->querySubObject("Paragraphs");
if (onlyAsnwers)
for (int ipar = 1; ipar <= lines->property("Count").toInt(); ipar++){
QAxObject *tline = lines->querySubObject("Item(QVariant)", ipar);
QAxObject *line = tline->querySubObject("Range");
QString str = line->property("Text").toString();
line->clear(); delete line;
tline->clear(); delete tline;
int ind = str.indexOf("Номер:");
if (ind != -1){
str = str.mid(ind+6);
answersTxt << getAnswerLine(str);
}
}
else
for (int ipar = 1; ipar <= lines->property("Count").toInt(); ipar++){
QAxObject *tline = lines->querySubObject("Item(QVariant)", ipar);
QAxObject *line = tline->querySubObject("Range");
lineStart = line->property("Start").toInt();
lineEnd = line->property("End").toInt();
line->clear(); delete line;
tline->clear(); delete tline;
str = "";
for (int j=lineStart; j<lineEnd; j++){
QAxObject *tmpObj = activeDoc->querySubObject("Range(QVariant,QVariant)", j, j+1);
QString currChar = tmpObj->property("Text").toString();
tmpObj->clear(); delete tmpObj;
str += currChar;
switch (status){
case -3:
if (j>=4 && str.right(5) == "Номер"){
status = -2;
startind = j+1;
}
break;
case -2:
if (str.right(6) == "Задача"){
n++; nstr = QString::number(n); while (nstr.length() < 3) nstr = "0" + nstr;
status = -1;
QAxObject *tmpObj = activeDoc->querySubObject("Range(QVariant,QVariant)", startind, j-6);
QString tmp = tmpObj->property("Text").toString();
tmpObj->clear(); delete tmpObj;
answersTxt << getAnswerLine(tmp);
startind = j+2;
} else if (str.right(7) == "Задание"){
n++; nstr = QString::number(n); while (nstr.length() < 3) nstr = "0" + nstr;
status = -1;
QAxObject *tmpObj = activeDoc->querySubObject("Range(QVariant,QVariant)", startind, j-7);
QString tmp = tmpObj->property("Text").toString();
tmpObj->clear(); delete tmpObj;
answersTxt << getAnswerLine(tmp);
startind = j+2;
}
break;
case -1:
if (str.right(7) == "Ответы:"){
status = 0;
rangeToEmfFile(outdir+nstr+".emf", startind, j-7, activeDoc);
startind = j+1;
} else if (str.right(6) == "Ответ:"){
status = 0;
rangeToEmfFile(outdir+nstr+".emf", startind, j-6, activeDoc);
startind = j+1;
}
break;
case 0:
if (str.right(2) == "1)" || str.right(3) == "1 )"){
status = 1;
startind = j+2;
}
break;
case 1:
if (str.right(2) == "2)"){
rangeToEmfFile(outdir+nstr+".1.emf", startind, j-2, activeDoc);
status = 2;
startind = j+2;
} else if (str.right(3) == "2 )"){
rangeToEmfFile(outdir+nstr+".1.emf", startind, j-3, activeDoc);
status = 2;
startind = j+2;
}
break;
case 2:
if (str.right(2) == "3)"){
rangeToEmfFile(outdir+nstr+".2.emf", startind, j-2, activeDoc);
status = 3;
startind = j+2;
} else if (str.right(3) == "3 )"){
rangeToEmfFile(outdir+nstr+".2.emf", startind, j-3, activeDoc);
status = 3;
startind = j+2;
}
break;
case 3:
if (str.right(2) == "4)"){
rangeToEmfFile(outdir+nstr+".3.emf", startind, j-2, activeDoc);
status = 4;
startind = j+2;
} else if (str.right(3) == "4 )"){
rangeToEmfFile(outdir+nstr+".3.emf", startind, j-3, activeDoc);
status = 4;
startind = j+2;
}
break;
case 4:
if (str.right(2) == "5)"){
rangeToEmfFile(outdir+nstr+".4.emf", startind, j-2, activeDoc);
status = 5;
startind = j+2;
} else if (str.right(3) == "5 )"){
rangeToEmfFile(outdir+nstr+".4.emf", startind, j-3, activeDoc);
status = 5;
startind = j+2;
}
break;
case 5:
if (j>=4 && str.right(5) == "Номер"){
rangeToEmfFile(outdir+nstr+".5.emf", startind, j-5, activeDoc);
status = -2;
str = "Номер";
} else if (lineEnd-lineStart < 2){
rangeToEmfFile(outdir+nstr+".5.emf", startind, j, activeDoc);
status = -3;
}
break;
}
}
if (status == 5)
rangeToEmfFile(outdir+nstr+".5.emf", startind, lineEnd, activeDoc);
}
lines->clear(); delete lines;
activeDoc->clear(); delete activeDoc;
Логика работы приведенного кода немного отличается от описанной выше. Она использует еще разбиение на абзацы. Но это не сильно меняет главную идею.
Вот таким вот образом получилось «победить» этот Word!
Заключение
В итоге были извлечены все задания в количестве ~4 тыс. Нужная оболочка парсера была написана. Программа закачки заданий на удаленную БД и администрирования ею также была написана. Гонорар был получен, ее диплом защищен на отлично, мой также защищен на отлично.
Спасибо за внимание, надеюсь этот пост поможет кому нибудь в аналогичной проблеме. А может кто знает лучшую реализацию?
Update:
Word парсер это бесплатное простое онлайн приложение которое позволяет извлекать картинки и текст из Word документа. Когда это приложение будет вам полезно? Например вам прислали фотоальбом в виде Word документа, и вам необходимо извлечь все фотографии в оригинальном формате. В решении этой задачи вам поможет приложение Word парсер, просто откройте страницу приложения, выберите исходный документ и нажмите кнопку извлечь. Ваш документ будет отправлен на сервер, через мгновение вы получите архив в котором будет все извлеченные данные из вашего документа.
Парсер картинок и текста из Word документа работает онлайн через любой популярный браузер, на любой платформе Windows, MacOs, Linux или Android. Ваши документы хранятся у нас в надежном хранилище на протяжении 24 часов, а потом автоматически удаляются. Для немедленного удаления ваших документов просто нажмите кнопку удалить в окне скачивания результата.
Быстрый и легкий парсинг
Загрузите свой документ и нажмите кнопку «PARSE». Вы получите текстовый файл или zip-файл с текстом и изображениями сразу после выполнения парсинга.
Парсинг где угодно
Работает со всех платформ, включая Windows, Mac, Android и iOS. Все файлы обрабатываются на наших серверах. Вам не требуется установка плагинов или программного обеспечения.
Качественный парсинг
. Все файлы обрабатываются с использованием Aspose APIs, которое используются многими компаниями из списка Fortune 100 в 114 странах мира.
|
0 / 0 / 0 Регистрация: 25.01.2018 Сообщений: 19 |
|
|
1 |
|
|
26.01.2018, 01:21. Показов 9442. Ответов 29
Уважаемые форумчане! Вот посоветовали задать вопрос в этой теме. Суть решаемой мной задачи: есть файл Word, который содержит данные (текстовые, числовые, даты). Необходимо их упорядочить и результат записать в файл Excel. Т.е. используя данные из файла Word надо создать таблицу в Excel. Помогите а? п.с. — сам не являюсь программистом, но вроде как уже написал (ну … подправил чужой код) в VB net код для создания таблицы в Excel с нужным количеством столбцов и сохранения ее в виде файла .xls. Теперь вот парсер пробую …..сотворить.
0 |

|
99 / 94 / 23 Регистрация: 30.08.2015 Сообщений: 457 |
|
|
26.01.2018, 10:17 |
2 |
|
Данные word можно связать с excel и далее средствами excel управлять ими… Кликните здесь для просмотра всего текста
0 |

|
0 / 0 / 0 Регистрация: 25.01.2018 Сообщений: 19 |
|
|
26.01.2018, 11:02 [ТС] |
3 |
|
Спасибо за ответ! Я наверное не до конца изложил все нюансы. Конечно, Вы правы, если записей (ну в смысле переменных хотя-бы десяток), то можно и руками «прописать» связи как на приведенном примере. Но когда в файле Word содержится примерно 1200 переменных (это порядка 600 листов тестовой информации с шрифтом 12), к каждой из них надо «привязывать» по 10 значений…. и эти значения изменяются примерно раз в две недели. Тут уж точно требуется автоматизация.
0 |
|
1588 / 661 / 225 Регистрация: 09.06.2011 Сообщений: 1,334 |
|
|
26.01.2018, 12:13 |
4 |
|
ну … подправил чужой код На данный момент вижу только постановку задачи — где ваши попытки?
1 |

|
0 / 0 / 0 Регистрация: 25.01.2018 Сообщений: 19 |
|
|
26.01.2018, 17:48 [ТС] |
5 |
|
Кодю….. ! Ну вообще-то примеры кода и правда присутствуют на форуме. Но… совместимость с VB 2010 Express мягко говоря хромает… Рою кучу самоучителей.. и т.п. … Плюс народ подсказывает всякие вещи — ну например я не знал, что обработка данных в .txt осуществляется быстрее чем в формате .doc. Следовательно в моем коде должна быть подпрограмма перевода файла .doc в .txt. п.с. — но был-бы признателен если вдруг найдется «Дед мороз», который чирканет хотя бы ссылочку на существующий парсер (ищем текст в Ворде и записываем в ячейку Экселя).
0 |

|
4278 / 3417 / 827 Регистрация: 02.02.2013 Сообщений: 3,308 Записей в блоге: 2 |
|
|
26.01.2018, 19:46 |
6 |
|
Конечно, странно использовать Word для сохранения данных, когда в данном случае за глаза хватит txt. Привожу пример, как можно выполнить описываемую вами операцию, к сожалению, у меня старый Office (2003) и все расписано для doc и xls. Хотя при переходе к новым версиям справедливость представляемых операций в целом сохраняется. Правда нужно сразу сказать, что данное решение не быстрое, а для версий Office2007 и старше учитывая формат файлов можно предложить более оптимальное решение. Можно вообще отказаться от использования Word и Excel, а заменить их на доступные библиотеки на базе OpenOfficeXML.
0 |
|
0 / 0 / 0 Регистрация: 25.01.2018 Сообщений: 19 |
|
|
27.01.2018, 00:13 [ТС] |
7 |
|
Ovva, огромное спасибо за Вашу помощь! п.с. — немного надо «подкрутить» чем и занимаюсь сейчас….. Для сведения (вдруг Вам тоже будет интересно) приложи некий скрин ….. (пытаюсь сам разобраться ибо интересно…). Миниатюры
0 |
|
4278 / 3417 / 827 Регистрация: 02.02.2013 Сообщений: 3,308 Записей в блоге: 2 |
|
|
27.01.2018, 12:03 |
8 |
|
KorSar72, судя по картинке, вы не подключили требуемые библиотеки, а именно
0 |
|
0 / 0 / 0 Регистрация: 25.01.2018 Сообщений: 19 |
|
|
27.01.2018, 17:26 [ТС] |
9 |
|
Ну приплыли… Но… Бро Гугл помог в очередной раз! )))) Вот, вдруг у кого тоже проблемки с отсуствием указанных библиотек: https://www.microsoft.com/en-u… px?id=3508 The redistributable contains the PIAs for the following products: Supported Operating System Добавлено через 37 минут
0 |


|
Razvedka2020 40 / 35 / 9 Регистрация: 01.01.2014 Сообщений: 201 |
||||||||
|
27.01.2018, 17:51 |
10 |
|||||||
|
Эти библиотеки устанавливаются с пакетом MS Office и на вкладке COM называются Microsoft Exel xx.0 Object Library и Microsoft Word xx.0 Object Library соответственно, где хх.0 зависит от установленного у тебя офиса. Например для 2003 офиса это будет 10.0 (если не ошибаюсь), а для 2010 14.0
вместо:
0 |
|
0 / 0 / 0 Регистрация: 25.01.2018 Сообщений: 19 |
|
|
27.01.2018, 17:57 [ТС] |
11 |
|
Значит-ли это, что в коде вместо: надо написать: Imports WRD = Microsoft.Word 12.0 Object Library я правильно предполагаю?
0 |
|
Razvedka2020 40 / 35 / 9 Регистрация: 01.01.2014 Сообщений: 201 |
||||
|
27.01.2018, 18:05 |
12 |
|||
|
Это значит что в обозревателе решений тебе нужно добавить ссылки на эти библиотеки или вообще отказаться от
и использовать позднее связывание
0 |
|
4278 / 3417 / 827 Регистрация: 02.02.2013 Сообщений: 3,308 Записей в блоге: 2 |
|
|
27.01.2018, 19:37 |
13 |
|
KorSar72, если у вас установлены программы Excel и Word, то у вас эти библиотеки должны быть в наличии и ссылки на них м.б. установлены как я уже писал (именно на вкладке NET)
См. меню VS: Project/Add Reference…/NET Если установлено несколько версий этих программ, то в доступе будет и несколько версий этих библиотек. Для Office2003 будет v.11.
0 |
|
0 / 0 / 0 Регистрация: 25.01.2018 Сообщений: 19 |
|
|
27.01.2018, 22:55 [ТС] |
14 |
|
У меня установлены только Word 2007 и Excel 2007. Других версий указанных программ нет. При этом в Microsoft Visual Basic 2010 Express (на чем я и пытаюсь написать код) нет библиотек Microsoft.Office.Interop.Word и Microsoft.Office.Interop.Excel (ни в NET, ни в COM. Установить их с официального сайта (как я писал ранее) не получается). При этом в COM имеются Microsoft.Word 12.0 Object Library и Microsoft.Excel 12.0 Object Library.
0 |
|
0 / 0 / 0 Регистрация: 25.01.2018 Сообщений: 19 |
|
|
28.01.2018, 01:24 [ТС] |
15 |
|
Ну я чего-то не понимаю, что твориться с моим Microsoft Visual Basic 2010 Express! Есть код, который нормально работает, но …. только один раз. Если закрыть проект и потом снова его открыть исчезает как форма, так и кнопка в панели управления «пуск» (ну запуск проекта). Imports Excel = Microsoft.Office.Interop.Excel и код работает без ошибок (это не смотря на то, что я писал выше про отсутствие указанных библиотек). Закрываю указанный проект, перезапускаю (или не перезапускаю) Microsoft Visual Basic 2010 Express, создаю новый код (или открываю любой другой проект) где содержится аналогичная строка — Imports Excel = Microsoft.Office.Interop.Excel — сразу получаю в списке ошибок сообщение — «Не найден адресуемый компонент Microsoft.Office.Interop.Excel». Что такое? Криво стоит Microsoft Visual Basic 2010 Express????? (прикладываю указанный рабочий код).
0 |

|
Razvedka2020 40 / 35 / 9 Регистрация: 01.01.2014 Сообщений: 201 |
||||||||||||||||||||||||
|
28.01.2018, 10:00 |
16 |
|||||||||||||||||||||||
|
Попробую объяснить настолько просто, насколько смогу (да простят меня Гуру форума за мою безграмотность).
Для удобства использования библиотеки и сокращения писанины ты можешь объявить пространство имен (зависит от твоих потребностей и целей):
И теперь обращаться к объектам библиотеки в сокращенной записи (в зависимости от того как объявил):
Так же ты можешь объявить свое собственное пространство имен, как это сделал Ovva:
И также обращаться к объектам библиотеки в сокращенной записи, минуя Microsoft.Office.Interop.Word:
Метод раннего связывания хороший и удобный, но накладывает ограничения, например если добавишь библиотеку из Word 2013, то программа не будет работать где установлен Word 2003-2010.
Метод геморный, но зато универсальный. Главное чтобы на целевом компе стоял Word и неважно какой версии (конечно если ты не будишь использовать специфический методы из поздних версий), программа сама подхватывает имеющуюся библиотеку и работает с ней.
0 |
|
0 / 0 / 0 Регистрация: 25.01.2018 Сообщений: 19 |
|
|
28.01.2018, 16:25 [ТС] |
17 |
|
Спасибо всем!
0 |
|
4278 / 3417 / 827 Регистрация: 02.02.2013 Сообщений: 3,308 Записей в блоге: 2 |
|
|
29.01.2018, 13:15 |
18 |
|
РешениеKorSar72, предлагаю вариант решения без использования Word и Excel в явном виде (они вообще могут отсутствовать на компьютере). Требуется добавить ссылку на библиотеку (NET) DocumentFormat.OpenXml. Справедливо для структуры данных примера Prim_IsxData1.doc. Миниатюры
0 |
 Сообщение было отмечено KorSar72 как решение
Сообщение было отмечено KorSar72 как решение
|
0 / 0 / 0 Регистрация: 25.01.2018 Сообщений: 19 |
|
|
29.01.2018, 23:22 [ТС] |
19 |
|
Требуется добавить ссылку на библиотеку (NET) DocumentFormat.OpenXml. Многоуважаемый Ovva! В очередной раз не могу найти у себя в VB 2010 Express в (NET) — >> DocumentFormat.OpenXml. п.с. — я уже себя чувствую даже не нубом….((((. Че ж все такое «кривое» у меня стоит на ноуте….. Добавлено через 1 час 11 минут Кое-что все равно надо поправить… ошибки и предупреждения! Работаю. Добавлено через 32 минуты — Imports DocumentFormat.OpenXml.Packaging Предупреждение 1-2-3 Пространство имен или тип, указанные в операторе Imports «DocumentFormat.OpenXml.Packaging» Вот тут — https://msdn.microsoft.com/ru-… aging.aspx — написано: У меня стоит Office 2007 .. думаю в этом и кроется проблема. Надо офис ставить хотя-бы 2010. Добавлено через 10 минут DocumentFormat.OpenXml.Packaging Namespace — Office 2007 Other Versions — No comment! даже скачать неоткуда теперь ;(
0 |
|
4278 / 3417 / 827 Регистрация: 02.02.2013 Сообщений: 3,308 Записей в блоге: 2 |
|
|
30.01.2018, 00:20 |
20 |
|
Не понимаю что там у вас происходит. Попробуйте установить библиотеку из прилагаемого архива. Как это нужно сделать:
И продолжаете отладку программы.
0 |
|
IT_Exp Эксперт 87844 / 49110 / 22898 Регистрация: 17.06.2006 Сообщений: 92,604 |
30.01.2018, 00:20 |
|
20 |
Время прочтения: 6 мин.
В
процессе аудита часто возникает потребность в обработке данных из документов в
форматах MS Word или Excel. В своей статье я хочу поделиться опытом считывания
информации из таких файлов с использованием языка C#.
Для
работы с файлами Word и Excel
я решил выбрать библиотеки Microsoft.Office.Interop.Word и Microsoft.Office.Interop.Excel, предоставляющие программные интерфейсы для
взаимодействия с объектами MS
Word и
Excel.
Преимущества
использования этих библиотек:
- созданы корпорацией Microsoft, следовательно, взаимодействие с объектами программ пакета MS Office реализовано наиболее оптимально,
- нужный пакет Visual Studio Tool for Office поставляется вместе с Visual Studio (достаточно отметить его при установке VS).
Также
следует заметить, что у такого похода есть и недостаток: для того, чтобы
написанная программа работала на ПК пользователя необходимо, чтобы на нём были
установлены программы MS
Office и
MS Excel. Поэтому такой
подход плохо подходит для серверных решений. Также такая программа не будет
являться кроссплатформенной.
Добавление библиотек в проект Visual Studio
Библиотеки
поставляются вместе с пакетом Visual
Studio
Tool
for
Office (платформа .NET Framework).
Для
использования библиотеки нужно:
- добавить ссылку на неё: в обозревателе решений необходимо кликнуть правой кнопкой мыши по пункту Ссылки (Рис. 1) и найти нужную библиотеку по ключевым словам (после добавления ссылка появится в списке),

- указать используемое пространство имён в файле программы (в примере ему назначен алиас Word): (Рис. 2):

Пример парсинга файла MS Word
Можно прочитать основные
форматы: .doc, .docx, .rtf.
Ниже
приведён листинг с примером считывания текста из документа MS Word:
object FileName = @"C:test.doc";
object rOnly = true;
object SaveChanges = false;
object MissingObj = System.Reflection.Missing.Value;
Word.Application app = new Word.Application();
Word.Document doc = null;
Word.Range range = null;
try
{
doc = app.Documents.Open(ref FileName, ref MissingObj, ref rOnly, ref MissingObj,
ref MissingObj, ref MissingObj, ref MissingObj, ref MissingObj,
ref MissingObj, ref MissingObj, ref MissingObj, ref MissingObj,
ref MissingObj, ref MissingObj, ref MissingObj, ref MissingObj);
object StartPosition = 0;
object EndPositiojn = doc.Characters.Count;
range = doc.Range(ref StartPosition, ref EndPositiojn);
// Получение основного текста со страниц (без учёта сносок и колонтитулов)
string MainText = (range == null || range.Text == null) ? null : range.Text;
if (MainText != null)
{
/* Обработка основного текста документа*/
}
// Получение текста из нижних и верхних колонтитулов
foreach (Word.Section section in doc.Sections)
{
// Нижние колонтитулы
foreach (Word.HeaderFooter footer in section.Footers)
{
string FooterText = (footer.Range == null || footer.Range.Text == null) ? null : footer.Range.Text;
if (FooterText != null)
{
/* Обработка текста */
}
}
// Верхние колонтитулы
foreach (Word.HeaderFooter header in section.Headers)
{
string HeaderText = (header.Range == null || header.Range.Text == null) ? null : header.Range.Text;
if (HeaderText != null)
{
/* Обработка текста */
}
}
}
// Получение текста сносок
if (doc.Footnotes.Count != 0)
{
foreach (Word.Footnote footnote in doc.Footnotes)
{
string FooteNoteText = (footnote.Range == null || footnote.Range.Text == null) ? null : footnote.Range.Text;
if (FooteNoteText != null)
{
/* Обработка текста */
}
}
}
} catch (Exception ex)
{
/* Обработка исключений */
}
finally
{
/* Очистка неуправляемых ресурсов */
if(doc != null)
{
doc.Close(ref SaveChanges);
}
if(range != null)
{
Marshal.ReleaseComObject(range);
range = null;
}
if(app != null)
{
app.Quit();
Marshal.ReleaseComObject(app);
app = null;
}
}Примечания:
- в коде приводится пример считывания основного текста документа, текста верхних и нижних колонтитулов, а также текста сносок,
- в коде производится очистка неуправляемых ресурсов с использованием класса Marshal (подробнее можно почитать по ссылке )
Пример парсинга файла MS Excel
Можно прочитать основные
форматы: .xls, .xlsx.
Ниже
приведён листинг с примером считывания текста из документа MS Excel (по
ячейкам):
string FileName = @"C:UsersbeeDownloadstest.xlsx";
object rOnly = true;
object SaveChanges = false;
object MissingObj = System.Reflection.Missing.Value;
Excel.Application app = new Excel.Application();
Excel.Workbooks workbooks = null;
Excel.Workbook workbook = null;
Excel.Sheets sheets = null;
try
{
workbooks = app.Workbooks;
workbook = workbooks.Open(FileName, MissingObj, rOnly, MissingObj, MissingObj,
MissingObj, MissingObj, MissingObj, MissingObj, MissingObj,
MissingObj, MissingObj, MissingObj, MissingObj, MissingObj);
// Получение всех страниц докуента
sheets = workbook.Sheets;
foreach(Excel.Worksheet worksheet in sheets)
{
// Получаем диапазон используемых на странице ячеек
Excel.Range UsedRange = worksheet.UsedRange;
// Получаем строки в используемом диапазоне
Excel.Range urRows = UsedRange.Rows;
// Получаем столбцы в используемом диапазоне
Excel.Range urColums = UsedRange.Columns;
// Количества строк и столбцов
int RowsCount = urRows.Count;
int ColumnsCount = urColums.Count;
for(int i = 1; i <= RowsCount; i++)
{
for(int j = 1; j <= ColumnsCount; j++)
{
Excel.Range CellRange = UsedRange.Cells[i, j];
// Получение текста ячейки
string CellText = (CellRange == null || CellRange.Value2 == null) ? null :
(CellRange as Excel.Range).Value2.ToString();
if(CellText != null)
{
/* Обработка текста */
}
}
}
// Очистка неуправляемых ресурсов на каждой итерации
if (urRows != null) Marshal.ReleaseComObject(urRows);
if (urColums != null) Marshal.ReleaseComObject(urColums);
if (UsedRange != null) Marshal.ReleaseComObject(UsedRange);
if (worksheet != null) Marshal.ReleaseComObject(worksheet);
}
} catch (Exception ex)
{
/* Обработка исключений */
}
finally
{
/* Очистка оставшихся неуправляемых ресурсов */
if (sheets != null) Marshal.ReleaseComObject(sheets);
if (workbook != null)
{
workbook.Close(SaveChanges);
Marshal.ReleaseComObject(workbook);
workbook = null;
}
if (workbooks != null)
{
workbooks.Close();
Marshal.ReleaseComObject(workbooks);
workbooks = null;
}
if (app != null)
{
app.Quit();
Marshal.ReleaseComObject(app);
app = null;
}
}Примечания:
- при обработке текста каждой ячейки
приходится заранее знать количество задействованных строк и столбцов на текущем
листе документа, - такой перебор не совсем оптимален
(временная сложность алгоритма O(n2)):
при желании его можно ускорить (например, разбив обработку на несколько
потоков): в данной статье приводится лишь пример получения текста из каждой
ячейки, - при таком переборе ячеек необходимо
на каждой итерации освобождать неуправляемые ресурсы, чтобы избежать утечек
памяти (аналогично предыдущему примеру, используется класс Marshal).
Приведенные
примеры хорошо подходят для реализации приложения по обработке документов Word и
Excel
на платформе .NET Framework.
С
помощью указанных библиотек можно не только читать текст из документов, но и
создавать новые файлы форматов MS Word и
Excel.
В 2017 году пакет Microsoft Office был популярной целью для атак хакеров. Вместе с большим числом найденных уязвимостей и опубликованных proof-of-concept эксплойтов у авторов вредоносного ПО появилась необходимость в предотвращении детекта новых модификаций эксплойтов антивирусными средствами. Также стало ясно, что использования легитимных особенностей RTF-парсера более недостаточно для эффективного избегания анализа и обнаружения. Вместе с увеличением атак посредством MS Office, когда файл формата RTF используется как контейнер для эксплойта, мы нашли большое количество сэмплов, которые «эксплуатировали» RTF-парсер в Microsoft Word, чтобы «сломать» все другие имплементации RTF-парсера, включая те, которые используются в антивирусном программном обеспечении.
Для того, чтобы достичь точного парсинга, как в MS Office, нам было необходимо провести реверс-инжиниринг. Работа была начата с MS Office 2010 т.к. когда дело касается парсинга, лучше начать с более старой имплементации, а затем сравнили находки с тем, что удалось обнаружить в более новых версиях.
RTF-парсер представляет собой машину состояний (state machine) с 37 состояниями, 22 из которых уникальны:

Мы рассмотрим самые главные состояния и те, которые относятся к парсингу objdata – контрольного слова (control word), обозначающего назначение (destination) которое содержит данные «обьекта». Эти состояния:
enum
{
PARSER_BEGIN = 0,
PARSER_CHECK_CONTROL_WORD = 2,
PARSER_PARSE_CONTROL_WORD = 3,
PARSER_PARSE_CONTROL_WORD_NUM_PARAMETER = 4,
PARSER_PARSE_HEX_DATA = 5,
PARSER_PARSE_HEX_NUM_MSB = 7,
PARSER_PARSE_HEX_NUM_LSB = 8,
PARSER_PROCESS_CMD = 0xE,
PARSER_END_GROUP = 0x10,
// …
};
Microsoft Office поставляется без отладочных символов, поэтому я не смог восстановить оригинальные имена. Но верю, что выбрал наиболее подходящие по их функциональности.
Первое состояние, которое выполняется на открытом RTF-файле — PARSER_BEGIN. В большинстве случаев оно также выставляется после обработки очередного контрольного слова. Главная цель состояния – определить следующее состояние, исходя из встреченных символов, установленного назначения, и других значений, содержащихся в ‘this’ структуре и установленных обработчиками контрольных слов. По умолчанию следующее установленное состояние это PARSER_CHECK_CONTROL_WORD.
case PARSER_BEGIN:
// … — checks that we dont need
while (data.pos != data.end)
{
byte = *(uint8_t*)data.pos;
data.pos++;
if (this->bin_size > 0)
{
goto unexpected_char;
}
// …
if (byte == 9)
{
// …
continue;
}
if (byte == 0xA || byte == 0xD)
{
// …
break;
}
if (byte == ‘’)
{
uint8_t byte1 = *(uint8_t*)data.pos;
if (byte1 == »’)
{
if (this->destination == listname ||
this->destination == fonttbl ||
this->destination == revtbl ||
this->destination == falt ||
this->destination == leveltext ||
this->destination == levelnumbers ||
this->destination == liststylename ||
this->destination == protusertbl ||
this->destination == lsdlockedexcept)
goto unexpected_char;
state = PARSER_CHECK_CONTROL_WORD;
// …
break;
}
if (byte1 == ‘u’)
{
// …
break;
}
state = PARSER_CHECK_CONTROL_WORD;
// …
break;
}
if (byte == ‘{‘)
{
create_new_group();
// …
break;
}
if (byte == ‘}’)
{
state = PARSER_END_GROUP;
break;
}
unexpected_char:
// it will set next state depending on destination / or go to unexpected_cmd to do more checks and magic
// …
if (this->destination == pict ||
this->destination == objdata ||
this->destination == objalias ||
this->destination == objsect ||
this->destination == datafield ||
this->destination == fontemb ||
this->destination == svb ||
this->destination == macro ||
this->destination == tci ||
this->destination == datastore ||
this->destination == mmconnectstrdata ||
this->destination == mmodsoudldata ||
this->destination == macrosig)
{
state = PARSER_PARSE_HEX_DATA;
data.pos—;
break;
}
// …
break;
}
break;
PARSER_CHECK_CONTROL_WORD проверит, является ли следующий символ началом контрольного слова или же это контрольный символ (control symbol), после чего установит следующее состояние соответственно результату проверки.
case PARSER_CHECK_CONTROL_WORD:
byte = *(uint8_t*)data.pos;
if ((byte >= ‘a’ && byte <= ‘z’) || (byte == ‘ ‘) || (byte >= ‘A’ && byte <= ‘Z’))
{
state = PARSER_PARSE_CONTROL_WORD;
this->cmd_len = 0;
}
else
{
data.pos++;
this->temp[0] = 1;
this->temp[1] = byte;
this->temp[2] = 0;
state = PARSER_PROCESS_CMD;
this->cmd_len = 1;
break;
}
Состояния PARSER_PARSE_CONTROL_WORD и PARSER_PARSE_CONTROL_WORD_NUM_PARAMETER сохранят Null-терминированное контрольное слово, состоящее из латинских символов, и Null-терминированный числовой параметр (если он имеется) во временный буфер фиксированного размера.
case PARSER_PARSE_CONTROL_WORD:
pos = this->temp + 1;
parsed = this->temp + 1;
while (data.pos != data.end)
{
byte = *(uint8_t*)data.pos;
// length of null-terminated strings cmd + num should be <= 0xFF
if ((byte == ‘-‘) || (byte >= ‘0’ && byte <= ‘9’))
{
//if parsed == temp_end
// goto raise_exception
*parsed = 0;
parsed++;
pos = parsed;
if (parsed >= temp_end)
{
parsed = temp_end — 1;
*parsed = 0;
state = PARSER_PROCESS_CMD;
this->cmd_len = pos — (this->temp + 1);
break;
}
data.pos++;
this->cmd_len = pos — (this->temp + 1);
*parsed = byte;
parsed++;
pos = parsed;
state = PARSER_PARSE_CONTROL_WORD_NUM_PARAMETER;
break;
}
if (byte == ‘ ‘)
{
data.pos++;
if (parsed >= temp_end)
{
parsed = temp_end — 1;
}
*parsed = 0;
state = PARSER_PROCESS_CMD;
this->cmd_len = pos — (this->temp + 1);
break;
}
if ((byte >= ‘a’ && byte <= ‘z’) || (byte >= ‘A’ && byte <= ‘Z’))
{
if (parsed — this->temp >= 0xFF)
{
if (parsed >= temp_end)
{
parsed = temp_end — 1;
}
*parsed = 0;
state = PARSER_PROCESS_CMD;
this->cmd_len = pos — (this->temp + 1);
break;
}
//if parsed == temp_end
// goto raise_exception
*parsed = byte;
parsed++;
pos = parsed;
data.pos++;
}
else
{
if (parsed >= temp_end)
{
parsed = temp_end — 1;
}
*parsed = 0;
state = PARSER_PROCESS_CMD;
this->cmd_len = pos — (this->temp + 1);
break;
}
}
break;
case PARSER_PARSE_CONTROL_WORD_NUM_PARAMETER:
while (data.pos != data.end)
{
byte = *(uint8_t*)data.pos;
// length of null-terminated strings cmd + num should be <= 0xFF
if (byte == ‘ ‘)
{
data.pos++;
if (parsed >= temp_end)
{
parsed = temp_end — 1;
}
*parsed = 0;
state = PARSER_PROCESS_CMD;
break;
}
if (byte >= ‘0’ && byte <= ‘9’)
{
if (parsed — this->temp >= 0xFF)
{
if (parsed >= temp_end)
{
parsed = temp_end — 1;
}
*parsed = 0;
state = PARSER_PROCESS_CMD;
break;
}
//if parsed == temp_end
// goto raise_exception
*parsed = byte;
*parsed++;
data.pos++;
}
else
{
if (parsed >= temp_end)
{
parsed = temp_end — 1;
}
*parsed = 0;
state = PARSER_PROCESS_CMD;
break;
}
}
break;
case PARSER_PROCESS_CMD:
case PARSER_SKIP_DATA:
case PARSER_END_GROUP:
case PARSER_SKIP_DATA_CHECK_B:
case PARSER_SKIP_DATA_CHECK_I:
case PARSER_SKIP_DATA_CHECK_N:
case PARSER_SKIP_DATA_GET_BIN_VAL:
case PARSER_SKIP_DATA_INNER_DATA:
this->state = state;
cmd_parser(&data);
state = this->state;
break;
Этот буфер обрабатывается в состоянии PARSER_PROCESS_CMD, которое вызывает другую функцию ответственную за обработку контрольных слов и контрольных символов. Эта функция учитывает текущее состояние и устанавливает следующее.
В коде есть несколько состояний, ответственных за парсинг шестнадцатеричных данных. Для нас наиболее интересно PARSER_PARSE_HEX_DATA – как можно увидеть, это состояние устанавливается в PARSER_BEGIN, если установлено назначение objdata.
case PARSER_PARSE_HEX_DATA:
parsed_data = this->temp;
if (this->bin_size <= 0)
{
while (data.pos != data.end)
{
byte = *(uint8_t*)data.pos;
if (byte == ‘{‘ || byte == ‘}’ || byte == ‘’)
{
state = PARSER_BEGIN;
if (parsed_data != this->temp)
{
push_data(parsed_data — this->temp);
parsed_data = this->temp;
}
break;
}
if (this->flag & 0x4000)
{
data.pos++;
continue;
}
if (byte >= ‘0’ && byte <= ‘9’)
{
val = byte — 0x30;
}
else if (byte >= ‘a’ && byte <= ‘f’)
{
val = byte — 0x57;
}
else if (byte >= ‘A’ && byte <= ‘F’)
{
val = byte — 0x37;
}
else if (byte == 9 || byte == 0xA || byte == 0xD || byte == 0x20)
{
data.pos++;
continue;
}
else
{
// show message that there are not enough memory
this->flag |= 0x4000;
data.pos++;
continue;
}
if (this->flag & 0x8000)
{
this->hex_data_byte = val << 4;
this->flag &= 0x7FFF;
}
else
{
if (parsed_data == temp_end)
{
push_data(sizeof(this->temp));
parsed_data = this->temp;
}
this->hex_data_byte |= val;
*parsed_data = this->hex_data_byte;
parsed_data++;
this->flag |= 0x8000;
}
data.pos++;
}
}
else
{
if (this->flag & 0x4000)
{
uint32_t size;
if (this->bin_size <= data.end — data.pos)
{
size = this->bin_size;
}
else
{
size = data.end — data.pos;
}
this->bin_size -= size;
data.pos += size;
}
else
{
while (this->bin_size > 0)
{
if (parsed_data == temp_end)
{
push_data(sizeof(this->temp));
parsed_data = this->temp;
}
byte = *(uint8_t*)data.pos;
*parsed_data = byte;
parsed_data++;
data.pos++;
this->bin_size—;
}
}
}
if (parsed_data != this->temp)
{
push_data(parsed_data — this->temp);
parsed_data = this->temp;
}
break;
Это состояние распарсит шестнадцатеричные и бинарные данные, если они были объявлены.
Состояния PARSER_PARSE_HEX_NUM_MSB и PARSER_PARSE_HEX_NUM_LSB используются в паре для парисинга шестнадцатеричных значений (данные контрольного слова panose и контрольного символа ‘).
case PARSER_PARSE_HEX_NUM_MSB:
this->flag |= 0x8000;
this->hex_num_byte = 0;
state = PARSER_PARSE_HEX_NUM_LSB;
case PARSER_PARSE_HEX_NUM_LSB:
// …
byte = *(uint8_t*)data.pos;
data.pos++;
val = 0;
if (byte — ‘0’ <= 9)
{
val = byte — 0x30;
}
else if (byte — ‘a’ <= 5)
{
val = byte — 0x57;
}
else if (byte — ‘A’ <= 5)
{
val = byte — 0x37;
}
this->hex_num_byte |= val << ((this->flag >> 0xF) << 2);
this->flag = ((~this->flag ^ this->flag) & 0x7FFF) ^ ~this->flag;
if (this->flag & 0x8000)
{
// …
state = PARSER_BEGIN;
}
else
{
break;
}
break;
Сброс состояния
Внимательно изучив код состояний PARSER_PARSE_HEX_NUM_MSB, PARSER_PARSE_HEX_NUM_LSB и PARSER_PARSE_HEX_DATA, легко заметить баг. Несмотря на то, что они используют разные переменные для декодированных шестнадцатеричных значений, состояния используют одинаковый бит для определения какой ниббл (полубайт) декодируется сейчас – верхний (MSB) или нижний (LSB). И PARSER_PARSE_HEX_NUM_MSB всегда сбрасывает этот бит на MSB.
Тем самым можно заставить байты исчезнуть из финального результата декодирования, если в контексте PARSER_PARSE_HEX_DATA вынудить смену состояния на PARSER_PARSE_HEX_NUM_MSB.
Для этого достаточно вставить ‘XX в данные, которые идут после контрольного слова objdata. В этом случае, когда данные будут обрабатываться в PARSER_PARSE_HEX_DATA, парсер встретит и вернется в PARSER_BEGIN, а в конце концов попадет в состояние PARSER_PROCESS_CMD. Логика для контрольного символа ‘ устроена так, что назначение не будет изменено, но будет выставлено состояние PARSER_PARSE_HEX_NUM_MSB. После PARSER_PARSE_HEX_NUM_MSB и PARSER_PARSE_HEX_NUM_LSB управление снова перейдет в PARSER_BEGIN и PARSER_PARSE_HEX_DATA, т.к. назначение все еще равно objdata. После этого снова будет декодироваться верхний ниббл.
Также примечательно, что PARSER_PARSE_HEX_NUM_LSB не проверяет валидность значений, т.е. после ‘ могут идти два абсолютно любых байта.
Это можно наблюдать в следующем примере:
 «f’cc»будут удалены
«f’cc»будут удалены
Когда исполнение в первый раз передается состоянию PARSER_PARSE_HEX_DATA, после того, как контрольное слово objdata обработано, MSB бит уже установлен. Давайте рассмотрим, как это происходит и как следующий пример будет обработан парсером:

Проведя некоторое время над функцией ответственной за обработку контрольных слов и контрольных символов, я нашел список всех контрольных слов и их структуры.

С этой информацией мы можем найти и взглянуть на конструктор objdata:

Как можно заметить, конструктор устанавливает бит MSB, выделяет новый буфер и заменяет указатель на старый. Таким образом, данные, декодированные между двумя контрольными словами objdata, не используются.
 «d0cf11e0a1b11ae1» будут удалены
«d0cf11e0a1b11ae1» будут удалены
Пункт назначения
Мы знаем, что если вставить ‘ и objdata, то это изменит выходные данные. Но что по поводу других контрольных слов и символов? Ведь их в парсере больше 1500!
По большей части ничего.
Т.к. часть контрольных слов обозначают назначение, они не могут применяться – результатом будет изменение objdata на назначение контрольного слова, а для декодирования данных нам нужно назначение objdata.
Часть других контрольных слов не имеют эффекта на назначение objdata.
Единственный способ задать другое назначение таким образом, чтобы можно было вернуть назначение objdata без потери декодированных данных, это воспользоваться особыми символами – открывающая фигурная скобка ({) и закрывающая фигурная скобка (}). Эти символы обозначают начало и конец группы.
После того, как парсер встретит конец группы в PARSER_BEGIN, назначение, которое было установлено перед началом группы, будет восстановлено.
Таким образом, если после objdata вставить {aftncn FF}, то FF не попадут в данные objdata, т.к. FF теперь относятся к назначению aftncn и будут обработаны согласно его логике.
В противном случае, если вставить {aftnnalc FF}, то FF попадут в objdata т.к. назначение все еще равно objdata.
Также стоит отметить, что {objdata FF} все-еще нельзя использовать т.к. буфер не будет восстановлен.
Точный список назначений был составлен благодаря простому фаззеру.
Фиксированный буфер
Другая техника обфускации, которая приходит в голову при взгляде на код RTF-парсера, не относится к этому «MSB» багу, но также может использоваться для удаления шестнадцатеричных данных. Техника относится к размеру временного буфера и к тому, как контрольные слова и числовые параметры парсятся в состояниях PARSER_PARSE_CONTROL_WORD и PARSER_PARSE_CONTROL_WORD_NUM_PARAMETER.
Пример злоупотребления представлен на следующей картинке:

В этом примере размер данных, которые будут удалены как часть числового параметра, считается по формуле: 0xFF (размер временного буфера) — 0xB (размер контрольного слова «oldlinewrap») — 2 (null-терминаторы) = 0xF2.
Ненужные данные
Описанные ранее техники относятся к основам парсинга формата RTF, но дополнительная путаница скрывается в обработке особых контрольных слов.
Согласно спецификации, если контрольный символ * находился перед неизвестным контрольным словом или контрольным символом, то считается, что это неизвестное назначение и все данные перед скобкой (}), которая закрывает эту группу, должны быть выкинуты. В MS Office содержатся контрольные слова, которые не упоминаются в спецификации, и вызывает опасение то, что список контрольных слов будет изменен в будущем, оказывая влияние на парсинг документа в различных версиях MS Office. Когда функция, ответственная за обработку контрольных слов и контрольных символов, встретит такой случай или одно из особых контрольных слов (такие как comment, generator, nonshppict и др.), состояние будет установлено на PARSER_SKIP_DATA, а число встреченных открывающих скобок ({) на 1.
enum
{
// …
PARSER_SKIP_DATA = 0xF,
// …
PARSER_SKIP_DATA_CHECK_B = 0x13,
PARSER_SKIP_DATA_CHECK_I = 0x14,
PARSER_SKIP_DATA_CHECK_N = 0x15,
PARSER_SKIP_DATA_GET_BIN_VAL = 0x16,
PARSER_SKIP_DATA_INNER_DATA = 0x17,
// …
};
Немного магии
Во время анализа состояний из группы PARSER_SKIP_DATA открылись факты, которые идут не только в разрез со спецификацией, но и в разрез с основным кодом парсера.
В поисках контрольного слова bin эти состояния будут пропускать байты, изменяя количество встреченных открывающих и закрывающих скобок, пока их количество не будет равно 0. Западня кроется в том, как обрабатывается числовой параметр в PARSER_SKIP_DATA_GET_BIN_VAL.
Во-первых, максимально допустимая длина числового параметра увеличена до 0xFF байт, длина контрольного слова не учитывается.
Во-вторых, числовой параметр теперь вовсе не числовой! Парсер позволяет передать не только числа, но и латинские буквы. Потом этот параметр передается в кастомную функцию strtol, тем самым позволяя задать длину данных, которые должны быть пропущены, без учета открывающих и закрывающих скобок как шестнадцатеричное число.
Благодаря этим примитивам возможны новые способы обфускации, которые еще не встречались in the wild.
Заключение
Реверс-инжиниринг показал себя как наиболее эффективный способ создания парсера, и в случае с RTF, скорее всего, не удалось бы добиться желаемого результата иначе.
Точный парсинг больше зависит от малых деталей в имплементации и алгоритмических багах, чем от спецификации, которая может быть не точной либо утверждать вещи, противоположные правде.
Продукты «Лаборатории Касперского» распознают все виды RTF-обфускаций и выполняют наиболее корректную обработку документов формата RTF, обеспечивая максимальную защиту для наших пользователей.