
Распределяем список по наборам
Постановка задачи
Имеем список объектов (например, товаров) с пометкой, к какому набору (корзине) каждый из них относится. Необходимо разложить объекты по своим наборам, сформировав таблицу как на рисунке справа:

Похожие задачи встречаются на практике весьма часто — в случаях, когда приходится распределять те или иные ресурсы:
- сотрудников по командам
- водителей по маршрутам
- клиентов по менеджерам
- товары по корзинам и т.д.
В прошлом я уже делал статью и видео о похожей задаче, где мы разбирали как переложить одномерный столбец с данными в двумерную таблицу, но там ситуация была проще, т.к. каждый набор (строка) имел одинаковый размер (число столбцов). Здесь же количество элементов в наборах заранее не известно и не равно друг другу, так что подход придётся изменить.
Чтобы у вас был выбор, давайте разберем несколько способов решения этой задачи.
Способ 1. Вручную через сводную таблицу
Этот способ не предполагает автоматического обновления, поэтому годится только в тех случаях, когда нужно просто, быстро и разово решить такую задачу. Делаем следующее:
1. Ставим активную ячейку в любое место исходной таблицы и строим по ней сводную через Вставка — Сводная таблица (Insert — Pivot Table).
2. В панели полей сводной закидываем поле Корзина в область строк, поле Товары — в область столбцов и в область значений. На выходе должны получить сводную, где на пересечении корзины и товара будет число, если товар входит в заданную корзину:

3. Выделяем центральную область данных в сводной, не включая итоги (диапазон E3:S8 в примере выше), копируем и вставляем специальной вставкой как значения в любое место листа.
4. В скопированном диапазоне выделим снова только центральный блок с числами без подписей и затем заставим Excel выделить только ячейки с числами, нажав клавишу F5 — кнопка Выделить — Константы (F5 — Go to Special — Constants):

5. Аккуратно, чтобы не сбить получившееся выделение, вводим в первую выделенную ячейку (она будет белой) ссылку на соответствующий ей товар (в нашем случае это будет ссылка на Брокколи), жмём на клавишу F4, чтобы оставить знак доллара только перед цифрой (т.е. закрепить строку) и сочетание клавиш Ctrl+Enter (чтобы ввести аналогичные формулы сразу во все выделенные ячейки):

6. Заменяем формулы на значения во всей таблице специальной вставкой.
7. Используя уже знакомый по п.4 трюк с клавишей F5 — Выделить на этот раз выделяем пустые ячейки и удаляем их со сдвигом влево:

Задача решена.
Способ 2. Обновляемый запрос через Power Query
Этот способ чуть сложнее, но позволит не повторять весь процесс в будущем при изменении исходных данных — достаточно будет просто обновить наш запрос. Будем использовать для решения надстройку Power Query, которую для Excel 2010-2013 можно бесплатно скачать с сайта Microsoft. Начиная с версии Excel 2016, Power Query уже встроена в Microsoft Excel по умолчанию.
Чтобы решить нашу задачу, делаем следующее:
1. Превращаем исходную таблицу в динамическую «умную», чтобы не думать впоследствии о изменении её размеров. Можно использовать команду Главная — Форматировать как таблицу (Home — Format as Table) или сочетание клавиш Ctrl+T.
2. Загружаем полученную «умную» таблицу в Power Query через команду Данные — Из таблицы / диапазона (Data — From Table/Range).
3. Если хотим, чтобы в каждой корзине товары шли по алфавиту — сортируем таблицу сначала по корзинам, а потом по товарам, используя кнопки фильтра в шапке таблицы.
4. Группируем таблицу по корзинам, выбрав на вкладке Преобразование команду Группировать по (Transform — Group by) и задав в качестве операции Все строки (All rows):

Наша исходная таблица «схлопнется» до корзин, содержимое которых будет лежать во вложенных таблицах в последнем столбце:

5. Выбираем команду Добавление столбца — Настраиваемый столбец (Add Column — Custom column), чтобы добавить к каждой вложенной таблице столбец индекса с порядковым номером строки с помощью М-функции Table.AddIndexColumn:

6. Удаляем все столбцы, кроме последнего, а его содержимое разворачиваем иконкой с двойными стрелками в шапке таблицы. Получим, по сути, первоначальную таблицу, но с добавленной нумерацией товаров внутри каждой корзины:

7. Добавляем в последнем столбце к нумерации слово «Товар » с помощью команды Преобразование — Формат — Добавить префикс (Transform — Format — Add Prefix).
8. Последний штрих: выполняем свёртку по последнему столбцу с нумерацией с помощью команды Преобразование — Столбец сведения (Transform — Pivot Column):

Задача решена! Осталось выгрузить полученные результаты обратно в Excel через Главная — Закрыть и загрузить — Закрыть и загрузить в… (Home — Close & Load — Close & Load to…)

При изменении данных в исходной таблице необходимо будет обновить наш запрос, щёлкнув по результирующей таблице правой кнопкой мыши и выбрав команду Обновить (Refresh) или кнопку Обновить всё на вкладке Данные (Data — Refresh All).
Способ 3. Функции динамических массивов
Этот способ подойдет только тем, у кого установлены последние обновления Office 365, которые добавили к функционалу Excel поддержку динамических массивов и новые функции для работы с ними: СОРТ, УНИК, ФИЛЬТР, ПОСЛЕД и СЛУЧМАССИВ. Если у вас Office 365, но этих функций пока нет — значит соответствующие обновления до вас ещё не добрались (их рассылают волнами и не по всем пользователям сразу), так что нужно немного подождать.
Этот способ хорош, в первую очередь, тем, что при любых изменениях в исходных данных — результаты обновляются «на лету» автоматически. Да и сам процесс не сильно сложен — потребуется всего три формулы.
Поехали:
1. Превращаем исходную таблицу в динамическую «умную», чтобы не думать впоследствии о изменении её размеров. Можно использовать команду Главная — Форматировать как таблицу (Home — Format as Table) или сочетание клавиш Ctrl+T.
2. Формируем отсортированный список уникальных названий корзин из столбца [Корзина] нашей умной таблицы Таблица4 — с помощью функций СОРТ (SORT) и УНИК (UNIQUE), соответственно:

3. Выводим все товары из каждой корзины с помощью функции ФИЛЬТР (FILTER):

По умолчанию, функция ФИЛЬТР выводит результаты в столбец. Чтобы развернуть их по горизонтали — в строку — используем дополнительно функцию транспонирования ТРАНСП (TRANSPOSE).
4. Добавляем шапку для красоты:

Здесь логика такая:
- Функция СЧЁТЕСЛИ (COUNTIF) вычисляет массив с размерами каждой корзины — это, в нашем случае, будет {4,2,7,1,2}
- Затем функция МАКС (MAX) определяет в нём самое большое число (7)
- Новая функция динамических массивов ПОСЛЕД (SEQUENCE) генерирует числовую последовательность от 1 до 7, к которой затем приклеивается слово «Товар » в начало.
Ссылки по теме
- Динамические массивы — тихая революция в Excel
- Трансформация столбца в таблицу (формулами и через Power Query)
- Превращение строк в столбцы и обратно
Блеск и нищета сводных таблиц
Несколько слов о сессионных наборах
Новые возможности построения сводных отчетов
Маленькая ложка дегтя
Заключение
Предыдущая статья цикла была посвящена новым возможностям работы с многомерными пространствами, которые появились в последних версиях программы Microsoft Excel. В ней обсуждался новый инструмент по созданию пользовательских фильтров под названием Срезы данных. В настоящей публикации данная тема будет продолжена — речь пойдет о способах формирования наборов и вычисляемых элементов средствами клиентского приложения.
Несколько слов о сессионных наборах
Как известно, структура любого аналитического отчета и сводной таблицы Microsoft Excel в частности определяется тремя наборами элементов:
- набор, размещаемый на оси X отчета;
- набор, размещаемый на оси Y отчета;
- набор, определяющий измерение среза Slicer Dimension, также называемый Осью фильтров.
В службах Microsoft Analysis Services есть специальная операция, позволяющая значительно упростить создание сложных наборов и при этом повысить общую производительность запросов. Речь идет об именованных наборах (Named Set). Именованные множества, так же как и вычисляемые элементы, могут быть определены в различных областях действия (Scopes).
Для большинства пользователей привычными являются только два режима создания наборов:
добавление в сценарий MDX — такой вариант делает набор видимым для всех запросов, адресованных к кубу;
определение набора как части конкретного MDX-выражения посредством инструкции WITH — в этом случае набор доступен только в контексте заданного выражения.
Однако существует еще один вариант, находящийся в тени первых двух, — определение набора в рамках сессии. На аналитический сервер можно послать директиву следующего вида (выражение 1):
Выражение 1
CREATE SESSION SET [Выручка].[БГД] AS
{
[Компания].[Бета],
[Компания].[Гамма],
[Компания].[Дельта]
}
Выражение 1 предписывает создать в кубе [Выручка] новое множество [БГД], состоящее из трех элементов измерения [Компания]. После выполнения данной инструкции во всех последующих запросах можно ссылаться на множество [БГД] без его дополнительного объявления в операторе Select. Сессионные наборы никак не влияют на структуру исходного аналитического куба и, что особенно важно, не видны другим пользователям системы. Строго говоря, они недоступны даже самому пользователю при обращении к серверу в рамках другой сессии. Но, за исключением ограничений в области видимости, сессионные наборы ничем не отличаются от наборов, которые были добавлены в базовый сценарий MDX.
Перечисленные обстоятельства делают наборы, определенные в рамках сессии, подходящим инструментом для реализации модных в последнее время идей «персонального BI». Действительно, при их использовании можно совершенно не заботиться о том, что они будут кому-то мешать или влиять на общую производительность приложения. Сводные таблицы в рамках двухуровневой архитектуры взаимодействуют с аналитическим сервером через OLE DB-провайдер, на который возложены все обязанности по организации сеансов связи. Потенциально с активными подключениями можно связать пользовательские наборы, однако действующая в Microsoft Excel 2007 объектная модель не позволяла этого делать. В Microsoft Excel 2010 указанный недостаток был наконец исправлен. Более того, управлять сессионными наборами теперь можно непосредственно через графический интерфейс электронной таблицы.
Новые возможности построения сводных отчетов
Все операции с наборами выполняются в специальной форме Диспетчер наборов, которая вызывается командой Управление наборами из раздела Поля, элементы и наборы контекстной ленты Параметры при работе со сводными таблицами.
Добавление нового набора в отчет производится путем нажатия кнопки Создать. При этом пользователю предоставляется возможность выбрать желаемый способ его определения: на основании готовых строк или столбцов уже существующего макета сводного отчета либо посредством MDX-выражения.
Первый подход очень выручает в двух ситуациях: когда требуется быстро определить некоторое фиксированное подмножество элементов одного измерения, а также при создании асимметричных многомерных наборов. Операция по объединению элементов единственного измерения в набор предельно ясна, поэтому мы не будем на ней останавливаться. А вот действия по созданию асимметричных наборов, напротив, заслуживают обсуждения.
Жизненные реалии требуют проводить анализ данных по большему количеству аналитик. Для сводных таблиц это означает необходимость размещать на одной оси отчета элементы сразу из нескольких измерений. Про такие наборы из отчета говорят, что они состоят из кортежей элементов. С формированием наборов такого рода связано множество сложностей технического плана. Исходное решение, предложенное компанией Microsoft, было предельно простым. В «классическом» дизайнере сводных таблиц (до версии 2007 включительно) разрешен единственный способ создания многомерных наборов — посредством операции прямого произведения множеств. Прямое или декартово произведение множеств представляет собой всевозможные упорядоченные пары элементов из двух исходных множеств и всегда является симметричным. Иными словами, если в кубе есть измерение Год с элементами {[2009], [2010]}, а также измерение Сервис, содержащее элементы {[Абонентская плата], [Интернетдоступ]}, то на их базе можно составить единственный набор (набор 1).
Набор 1
{
([2009], [Абонентская плата])
([2009], [Интернетдоступ])
([2010], [Абонентская плата])
([2010], [Интернетдоступ])
}
Проблема заключалась в том, что раньше из набора 1 невозможно было удалить конкретный кортеж, например ([2009], [Интернетдоступ]). В арсенале доступных методов Microsoft Excel 2007 была единственная операция — выставление фильтра, то есть исключение какого-то элемента из базового одномерного набора. Понятно, что такая операция влечет за собой удаление из итогового набора всех кортежей, связанных с данным элементом. Так, если из набора элементов измерения Сервис удалить элемент [Интернетдоступ], то набор 1 потеряет не только кортеж ([2009], [Интернетдоступ]), что, собственно, и было нашей целью, но также кортеж ([2010], [Интернетдоступ]), наличие которого требовалось в выходном наборе.
В Microsoft Excel 2010 из имеющегося симметричного набора можно выделить его произвольное подмножество. Сначала в раздел строк отчета поместим измерения Год и Сервис. Затем в диспетчере наборов выберем опцию Создать набор по строкам… В открывшейся форме будет показан набор — прямое произведение исходных измерений (рис. 1).
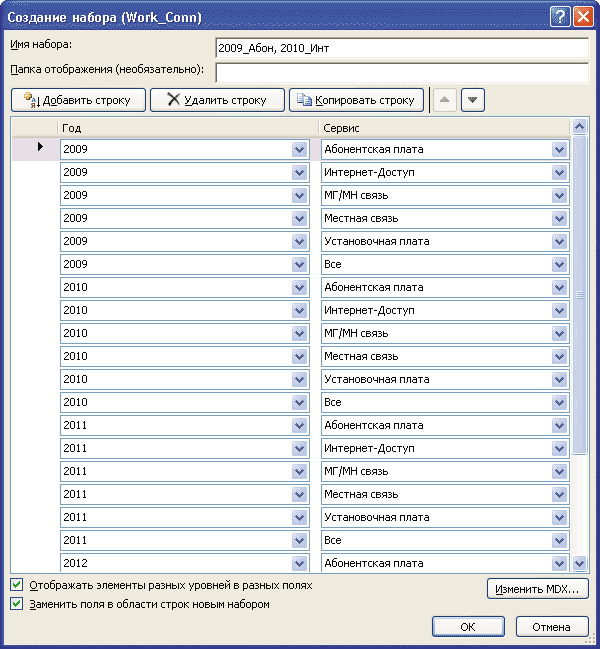
Рис. 1. Симметричный набор кортежей
Множество кортежей, представленных на рис. 1, всегда соответствует текущему состоянию набора из раздела строк отчета сводной таблицы. Соответственно при желании кардинальность базового набора можно уменьшить, например сохранив в нем кортежи, относящиеся к 2009 и 2010 годам. Для этого в конструкторе сводных отчетов при помощи фильтров оставим в измерении Год только нужные временные периоды.
После создания симметричного набора можно переходить ко второму этапу — составлению на его базе требуемого асимметричного множества. В распоряжении пользователя есть три операции: удаление либо копирование существующих кортежей, а также добавление новых. Назначение операций вытекает из их названий. От себя добавим, что в наборе можно иметь неограниченное количество дубликатов кортежей. Кроме того, следует учитывать, что фильтрация наборов в макете отчета никак не влияет на добавление новых элементов набора. Даже если вы принудительно ограничили периоды в исходном наборе 2010 и 2011 годами, впоследствии вы всё равно сможете добавить кортеж с любым годом.
После определения состава входящих в набор элементов ему присваивается уникальное имя. Если набор был создан на базе единственного измерения, то в окне метаданных конструктора сводных таблиц он сразу помещается в папку соответствующей группы измерений. В тех случаях, когда для составления набора использовалось нескольких измерений, он помещается в отдельный каталог Наборы. Для упрощения навигации и поиска нужных наборов создаваемые множества можно рассортировать по дополнительным папкам. Для этого в поле Папка отображения формы необходимо ввести название каталога, куда требуется поместить новый набор.
Наконец, последний элемент формы, заслуживающий пояснительных комментариев, — это кнопка Изменить MDX… Ее нажатие приводит к переводу формы в режим редактирования MDX-выражения, описывающего текущее определение набора. Данную кнопку следует нажимать с осторожностью, так как вернуться обратно в «классический» режим формы уже не получится.
Разобравшись с принципом создания наборов на базе имеющихся строк или столбцов сводной таблицы, перейдем к рассмотрению основного режима построения наборов — посредством MDX-выражений. Для примера создадим простой набор «Услуги_Телефонии» на базе одного измерения Сервис (рис. 2).
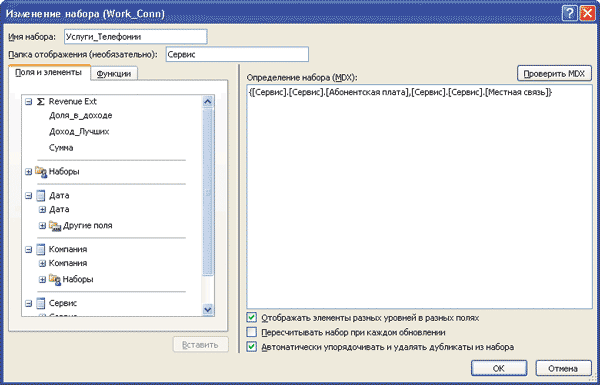
Рис. 2. Создание набора на базе элементов одного измерения
Как видно из рис. 2, мастер построения наборов практически идентичен генератору MDX-запросов из среды Microsoft SQL Server Management Studio. Вдвойне приятно, что в нем поддерживаются многие операции, привычные по работе с Management Studio. В частности, в мастере возможно добавление элементов в набор путем перетаскивания объектов методом drag-and-drop из репозитария метаданных, а также вставка функций с уже готовым шаблоном заполнения аргументов. Заметим, что пользователю доступны не только объекты, хранящиеся на стороне сервера, но также наборы, созданные ранее в среде Microsoft Excel.
Для глобальных и сессионных наборов можно задать два правила их дальнейшего поведения. Первый режим: состав элементов набора определяется однократно в момент его создания. Примером такого набора является множество «Услуги_Телефонии», представленное на рис. 2. Очевидно, что множество, состоящее из двух явным образом перечисленных элементов, не будет меняться с течением времени. Но такое условие соблюдается не всегда. Например, при добавлении фактических значений в новый период куба может измениться набор tail(nonempty([Дата].[Месяц].members),3). Представленное выше выражение определяет «хвосты» — последние значения из набора непустых периодов. И эти «хвосты» будут постепенно смещаться в сторону старших дат по мере заполнения куба. Таким образом, со временем будет меняться и сам набор. Справедливым будет возражение, что изменение аналитического пространства является нечастой операцией, оттого вероятность, что она придется на одну сессию, невелика. Соответственно можно не переживать по этому поводу, так как в следующей сессии все наборы будут созданы заново. Это действительно так. Но, кроме приведенного выше случая, существует еще ряд других распространенных ситуаций, в которых состав набора может измениться. Причем часть из них имеет непосредственное отношение к Microsoft Excel и, что самое печальное, приводит к серьезным ошибкам при генерации сводных отчетов.
Поясним смысл сказанного на примере. Для этого определим следующий сессионный набор:
Выражение 2
СREATE SESSION SET [Выручка].[Лучшие_по_году] AS
TopCount( [Компания].[Компания].levels(1).members, 5, ([Measures].[Сумма]))
Выражение 2 очень простое — оно определяет пять лучших по объему продаж компаний. Зададимся вопросом: за какой период были выделены данные компании? Ведь пятерка лидеров может меняться от месяца к месяцу, от года к году и т.д. Набор [Лучшие_по_году] был определен в текущем глобальном контексте. Для каждого измерения выбирался элемент Default Member, который для измерения типа Time равен значению [All]. Соответственно пять компаний из набора [Лучшие_по_году] были определены по результатам продаж за все периоды. Принципиально важным здесь является следующий момент: после того как компании определены, их состав жестко фиксируется и в дальнейшем уже не меняется. Такие наборы первого типа называются Статическими — STATIC. Попробуем разобраться, к чему приводит их применение на практике.
После объявления набора [Лучшие_по_году] последовательно выполним два запроса: выражение 3 и выражение 4.
Выражение 3
select [Лучшие_по_году] on 0
from [Выручка]
Выражение 4
select [Лучшие_по_году] on 0
from (select {[Дата].[Год].&[2009]} on 0 from [Выручка])
Результаты их исполнения представлены на рис. 3 и 4 соответственно.
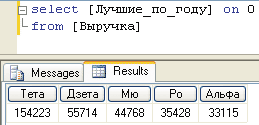
Рис. 3. Статический набор в глобальном контексте
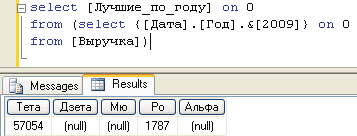
Рис. 4. Статический набор в контексте конкретного года
Отчет, представленный на рис. 3, выглядит абсолютно логично. В нем приводится суммарная выручка лучших компаний за весь период наблюдений. Но что касается данных, представленных на рис. 4, то нельзя однозначно утверждать, что они соответствуют ожиданиям пользователя. В представленном отчете показаны лучшие компании за весь период, но выручка приводится за 2009 год. Хорошо, если именно такой отчет был истинной целью его составителя. Сводная таблица Microsoft Excel, соответствующая выражению 4, содержит всего две строки (рис. 5).
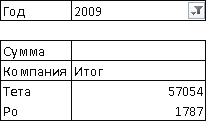
Рис. 5. Выручка лучших за весь
период компаний в 2009 году
Однако обычно пользователей интересует иное: «требуется выбрать пять лучших компаний по объему продаж именно 2009 года». Практически это означает необходимость заново пересчитать набор [Лучшие_по_году] — на этот раз в контексте выражения 4. А для этого придется отказаться от требования его неизменности во времени.
В службах Microsoft Analysis Services имеется возможность создать набор, который будет пересчитываться для каждого запроса, из которого он вызван. Такие наборы называют Динамическими — DYNAMIC. Соответственно пользователь должен сам выбрать, какой из двух режимов больше отвечает его потребностям и решаемым задачам. Тип набора в MDX-выражении указывается директивой STATIC или DYNAMIC. Так, выражение 2 можно переписать следующим образом (выражение 5).
Выражение 5
СREATE SESSION DYNAMIC SET [Выручка].[Лучшие_по_году] AS
TopCount( [Компания].[Компания].levels(1).members, 5, ([Measures].[Сумма]))
В результате чего при запуске выражения 4 будет возвращаться другой результирующий набор. В нем показываются лучшие компании 2009 года (рис. 6).
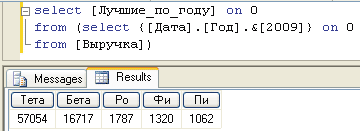
Рис. 6. Динамический набор
в контексте конкретного года
При создании сессионных наборов в среде Microsoft Excel пользователь избавлен от необходимости написания скриптовых команд. Выбор требуемого типа набора выполняется посредством выставления специального флага Пересчитывать набор при каждом обновлении в Диспетчере наборов (см. рис. 2). Поставленный флажок означает, что создаваемый набор должен быть динамическим. Следует отметить, что динамические наборы в среде Microsoft Excel налагают на разработчика определенные ограничения. Если в MDX-выражении, определяющем набор, в качестве аргументов присутствуют динамические наборы, то такой набор должен быть объявлен как динамический.
Маленькая ложка дегтя
Надеюсь, читатели убедились в несомненной полезности нового инструментария от Microsoft. К сожалению, за гибкость, легкость и простоту использования приходится расплачиваться потерей части функциональности.
Вопервых, в наборах, заданных в сессии, запрещено использование операторов, которые исполняются в контексте оператора Select. Для пояснения смысла последней фразы рассмотрим следующий код:
Выражение 6
with set [Лучшие_по_году] as TopCount([Компания].[Компания].[Компания].members,5,([Measures].[Сумма],Axis(0).Item(0)))
select [Дата].[Год].&[2010] on 0,
[Лучшие_по_году] on 1
from [Выручка]
В выражении 6 определяется набор [Лучшие_по_году], состоящий из первых пяти лучших по объему выручки компаний за период, значение которого является первым элементом набора, отложенного по оси Х. Оси добавляются в отчет в порядке их нумерации: сначала ось Х (номер 0), затем ось Y (номер 1). Поэтому к моменту создания набора для оси Y набор для оси X будет уже сформирован. Это, в свою очередь, означает, что к элементам данного набора можно обратиться программно — такая операция выполняется при помощи оператора Axis(0). В частности, инструкция Axis(0).Item(0) выбирает первый элемент из получившегося набора, который затем добавляется в кортеж. Результат исполнения выражения 6 показан на рис. 7.
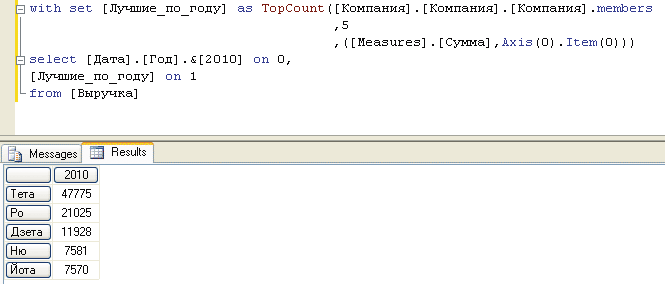
Рис. 7. Создание набора в контексте оператора Select
Но оператор Axis(0) имеет смысл только внутри запроса: пока не определена ось Х, не может быть создан и набор [Лучшие_по_году]. Набор [Лучшие_по_году] определяется посредством инструкции With, которая является неотъемлемой частью оператора Select. Поэтому о функциях, подобных Axis, говорят, что они выполняются в контексте оператора Select.
Вовторых, сессионные наборы, создаваемые внутри сводных таблиц Microsoft Excel, не переопределяют глобальный контекст. Вкратце напомним читателям, о чем идет речь. Как уже отмечалось, именованные множества могут быть созданы в трех режимах: глобальном контексте, контексте сессии либо контексте конкретного MDX-запроса. В случае одноименных наборов каждый последующий контекст переопределяет предыдущий.
Например, в сценарий MDX на уровне куба можно добавить именованный набор [Лучшие_по_году] следующего вида:
Выражение 7
CREATE SET CURRENTCUBE.[Лучшие_по_году] AS
TopCount( [Компания].[Компания].levels(1).members, 5, ([Measures].[Сумма], [Дата].[Год].&[2009]))
Как видно из записи выражения 3, исходный набор [Лучшие_по_году] выбирает пять лучших компаний по объемам дохода, полученного в 2009 году. Затем на уровне сессии допускается создать новый экземпляр набора [Лучшие_по_году]:
Выражение 8
CREATE SESSION SET [Выручка].[Лучшие_по_году] AS
TopCount( [Компания].[Компания].levels(1).members, 5, ([Measures].[Сумма], [Дата].[Год].[2010]))
Теперь при обращении к множеству [Лучшие_по_году] из последующих запросов, сделанных в рамках сессии, вместо лучших компаний 2009 года будут выводиться компании — лидеры 2010 года.
Но и это не предел. В конкретном запросе посредством директивы With можно определить еще одну версию набора [Лучшие_по_году].
Выражение 9
with set [Лучшие_по_году] as
TopCount( [Компания].[Компания].levels(1).members, 5, ([Measures].[Сумма], [Дата].[Год].[2011]))
select [Лучшие_по_году] on 0
from [Выручка]
Несмотря на то что в глобальном контексте множество [Лучшие_по_году] определяется по доходам компаний 2009 года, после чего в рамках сессии переопределяется заново на основании доходов 2010 года, в запросе из выражения 5 оно будет рассчитываться на основании своего последнего определения — по выручке 2011 года.
Операция переопределения наборов хороша тем, что носит «каскадный» характер. Иными словами, она синхронно меняет не только сам набор, но и все множества, созданные на его основе. Более того, в аналитическом сервере возможна интересная манипуляция. В базовый сценарий MDX исходный набор добавляется повторно под новым псевдонимом:
Выражение 10
CREATE SET CURRENTCUBE.[Лучшие_по_году_расш] AS
{[Лучшие_по_году]}
Затем в сценарии определяются новые вычисляемые элементы, использующие в качестве входных аргументов набор [Лучшие_по_году_расш]. При такой организации логики вычислений изменение текущего контекста конкретного набора приведет к изменению глобального контекста всех связанных с ним объектов — как наборов, так и вычисляемых элементов.
Что делать, если стандартных возможностей недостаточно
Во второй части статьи постараемся кратко ответить на вопрос, как следует поступать в тех ситуациях, когда стандартных возможностей сводных таблиц оказывается недостаточно? Рассмотрим типичную задачу по анализу деятельности компаний. Предположим, что нас интересуют только те организации, которые показали прирост выручки в определенный период. В этом случае наша задача сводится к формированию набора компаний, отвечающих некоторому изначально заданному условию.
Границы временного интервала могут быть как неизменными во времени, так и динамически вычисляемыми в контексте текущего ракурса. В первом варианте мы составляем статический набор — одна из возможных форм его записи представлена выражением 11.
Выражение 11
filter([Компания].[Компания].[Компания].members, ([Measures].[Сумма],[Дата].[Год].&[2011])>([Measures].[Сумма], [Дата].[Год].&[2010]))
Во втором — динамический набор (выражение 12).
Выражение 12
filter( [Компания].[Компания].[Компания].members, ([Measures].[Сумма]) > ([Measures].[Сумма], [Дата].[Год].PrevMember)).
Первый из представленных вариантов фиксирует единственный интервал (2010 г.; 2011 г.), второй позволяет получить все возможные временные диапазоны (2009 г.; 2010 г.), (2010 г.; 2011 г.), (2011 г.; 2012 г.), но только фиксированной длины — 1 год. Нас же интересует универсальное решение, при котором пользователь сможет указать любую начальную и конечную дату (отстоящие друг от друга на произвольное число календарных периодов) и сформировать для них соответствующий набор из клиентов компании. При помощи аналитических выражений такого результата достичь невозможно.
Единственный выход из сложившейся ситуации — исправить саму текстовую строку, содержащую MDX-выражение. Такую операцию всегда можно выполнить вручную при помощи формы управления наборами. Но если ее требуется повторять регулярно, то рутинные действия проще автоматизировать путем написания программного кода на языке VBA.
Работа со сводными таблицами изначально была основана на использовании двух специальных объектов от компании Panorama Software (создателя сводных таблиц) PivotCache и PivotTable. Первый из них представляет собой набор записей, полученных из определенного OLAP-источника, и связан с рабочей книгой в целом. Второй объект— PivotTable — определяет внешнее представление отчета конкретной сводной таблицы и связан с отдельным листом книги. В последних версиях Microsoft Excel (2007 и 2010) вместо объекта PivotCashe можно применять альтернативный вариант — коллекцию Connections. В нашем примере мы будем использовать именно ее.
Активные подключения, связанные с книгой, доступны для просмотра в форме Подключения, которая активируется одноименной командой на ленте Данные (рис. 8).
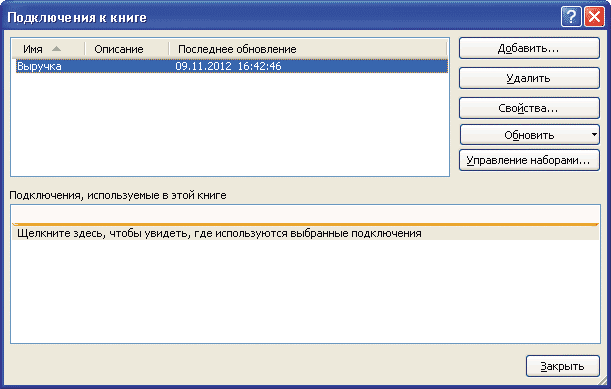
Рис. 8. Диспетчер активных подключений к книге
Как видно из рис. 8, в нашем примере с книгой ассоциировано единственное подключение Выручка, посредством которого в книге Microsoft Excel показываются данные по доходам отдельных компаний.
Кнопка Управление наборами позволяет добавлять в действующее подключение новые именованные наборы либо редактировать уже имеющиеся. Создадим новый набор «Растущие_Компании» на базе следующего MDX-выражения (выражение 13).
Выражение 13
Filter([Компания].[Компания].[Компания],[Дата].[Дата].[Год].&[2009]<[Дата].[Дата].[Год].&[2011])
После выполнения указанной операции набор «Растущие_Компании» можно использовать во всех сводных отчетах, созданных на основе подключения Выручка. Сформируем теперь новый сводный отчет, в котором на оси Y разместим недавно созданный набор (рис. 9).
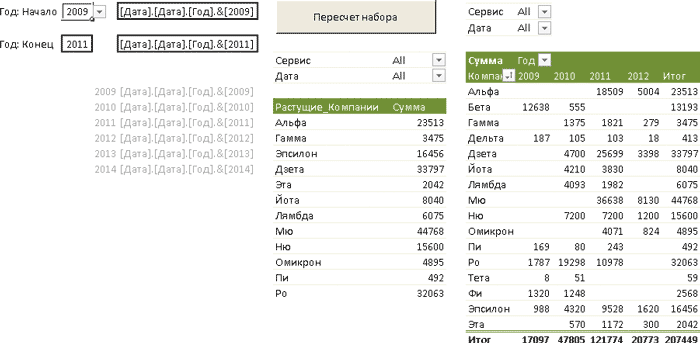
Рис. 9. Создание универсального отчета
Напомним, что нам требуется выбрать начальный и конечный периоды, а затем динамически вычислить удовлетворяющее заданному условию множество компаний. Выполним несколько подготовительных операций. На листе с отчетом определим две именованные ячейки Год_Начало и Год_Конец, куда при помощи оператора ВПР() будем подставлять выражение элемента из измерения [Дата] для выбранного пользователем года.
Кроме того, добавим на лист новый управляющий элемент типа «кнопка», который свяжем с процедурой Пересчет_Набора, представленной в листинге 1.
Листинг 1
Sub Пересчет_Набора()
Dim Formula_MDX As String
Formula_MDX = “Filter([Компания].[Компания].[Компания],” + Range(“Год_Начало”).Value + “<” + Range(“Год_Конец”).Value + “)”
With ActiveWorkbook.Connections(«Выручка»).OLEDBConnection
.CalculatedMembers(«[Растущие_Компании]»).Delete
.CalculatedMembers.Add Name:=»[Растущие_Компании]», _
Formula:=Formula_MDX, _
Type:=xlCalculatedSet
End With
ActiveSheet.PivotTables(«Раб_Отчет»).RefreshTable
End Sub
Процедура Пересчет_Набора состоит из трех этапов. Сначала в строковой переменной с именем Formula_MDX составляется новое MDX-выражение, куда подставляются текущие значения из ячеек Год_Начало и Год_Конец.
На втором шаге из подключения Выручка удаляется набор «Растущие_Компании». Затем в коллекцию CalculatedMembers данного подключения добавляется одноименный набор, но с MDX-выражением, заданным ранее определенной строкой Formula_MDX. Кроме того, в момент создания определяется тип нового вычисляемого элемента — xlCalculatedSet.
Заметим, что созданный с помощью процедуры набор получил название набора, который ранее уже был добавлен в сводный отчет. Поэтому нам не требуется изменять его положение в отчете, а для отображения нового множества в сводной таблице ее достаточно просто обновить. Соответствующая команда еActiveSheet.PivotTables(“Раб_Отчет»).RefreshTable завершает нашу процедуру.
Подход, основанный на программном обращении к свойствам объектов, обладает дополнительным преимуществом — с его помощью в отчеты сводных таблиц можно добавлять не только новые сессионные наборы, но и собственные вычисляемые элементы.
Предположим, что нам требуется рассчитать величину прироста дохода текущего периода по сравнению с предыдущим. Данный показатель (назовем его «Прирост») легко вычисляется по формуле:
Выражение 14
([Measures].[Сумма])-([Measures].[Сумма],[Дата].[Дата].PrevMember)
Чтобы на базе выражения 14 сделать новую вычисляемую меру, достаточно немного модифицировать код из листинга 1 (см. листинг 2):
Листинг 2
Sub New_Measure_Member()
With ActiveWorkbook.Connections(«Выручка»).OLEDBConnection
.CalculatedMembers.Add Name:=»[Прирост]», _
Formula:=»([Measures].[Сумма])-([Measures].[Сумма],[Дата].[Дата].PrevMember)», _
Type:=xlCalculatedMember
End With
End Sub
В представленном фрагменте кода, так же как и в программе из листинга 1, производится добавление нового элемента в коллекцию CalculatedMembers объекта Connection. Главное отличие состоит в типе (Type) создаваемого элемента: в первом случае это был xlCalculatedSet (Вычисляемый набор), а во втором — xlCalculatedMember (Вычисляемый элемент). После исполнения процедуры New_Measure_Member() в имеющемся подключении «Выручка» будет создана новая вычисляемая мера «Прирост». Она будет доступна для составления отчетов во всех сводных таблицах, организованных на базе данного подключения.
Похожим образом новые элементы добавляются на оси измерений. Однако в данном случае немного сложнее становится синтаксис объявления имени элемента. Он должен учитывать тот факт, что любое измерение всегда является множеством с заданным на нем отношением порядка. Иными словами, при создании элемента важно указать его место расположения.
Рассмотрим для примера иерархию Дата из группы измерений Дата, представленную четырьмя уровнями: All, Год, Квартал и Месяц. При желании вычисляемый элемент можно расположить на любом из них (рис. 10).
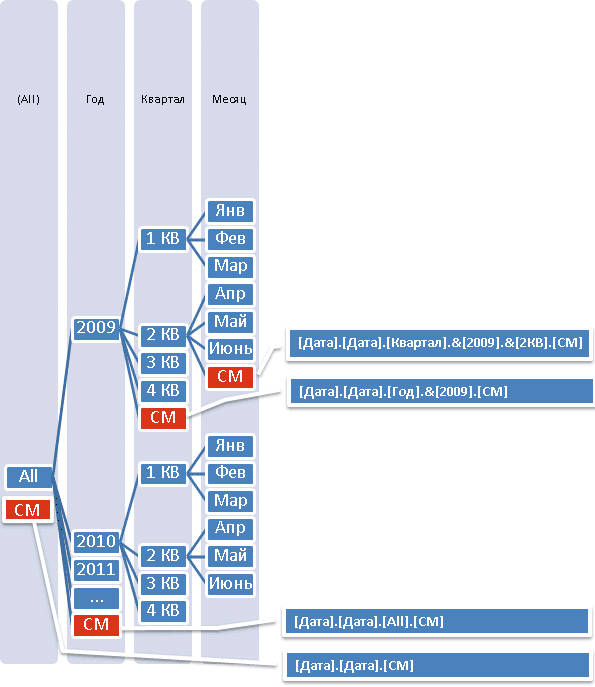
Рис. 10. Размещение вычисляемого элемента СМ на различных уровнях иерархии Дата
Выбор конкретного места в иерархии производится путем указания родительского элемента. Так, если требуется, чтобы вычисляемый элемент СМ присутствовал на уровне Год, его нужно определить следующим образом: [Дата].[Дата].[(All)].[All].[СМ]. Данная запись означает, что элемент СМ должен быть потомком элемента ALL, размещенного на уровне ALL. Принимая во внимание тот факт, что уровень ALL представлен единственным одноименным элементом, исходную запись можно сократить, сделав более компактной, — [Дата].[Дата].[All].[СМ].
Предположим теперь, что нам требуется разместить СМ на следующем уровне — Квартал. Все элементы с данного уровня объединены в группы по отношению к тому или иному году. Если мы хотим, чтобы новый вычисляемый элемент был помещен после кварталов, относящихся к 2009 году, но перед кварталами 2010 года, то должны указать 2009 год в качестве родительского для вычисляемого элемента: [Дата].[Дата].[Год].&[2009].[СМ]. Аналогичным образом следует поступить при размещении элемента на уровне Месяц. Например, чтобы вычисляемый элемент шел после месяцев II квартала 2009 года, его следует определить следующим образом: [Дата].[Дата].[Квартал].&[2009].&[2КВ].[СМ].
Важно понимать, что указание полного пути к элементуродителю в имени вычисляемого элемента определяет лишь его физическое размещение в иерархии, но сам он при этом не включается в структуру агрегации. Например, элемент [Дата].[Дата].[Год].&[2009].[СМ] хоть и входит в группу кварталов 2009 года, но не является его потомком. Однако для любого вычисляемого элемента определено отношение родства по восходящей линии — его предок на каждом вышестоящем уровне иерархии.
Рис. 11 иллюстрирует данную идею. В MDX-выражении задан вычисляемый элемент СМ, который размещается на уровне Месяц. Затем при помощи оператора Ascendants() успешно формируется набор из элементов-предков элемента СМ. Обратная операция — попытка показать СМ в наборе из потомков элемента верхнего уровня — будет безуспешной.
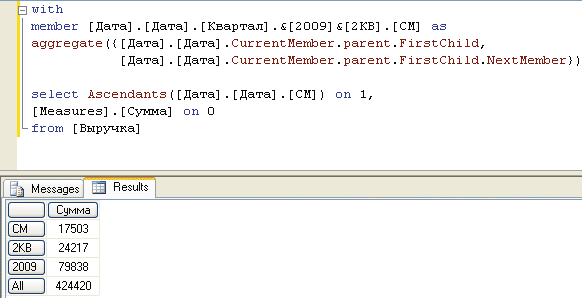
Рис. 11. Вычисляемый элемент имеет предков на вышестоящих уровнях…
Подобный дуализм в поведении вычисляемых элементов хоть и требует некоторого времени на привыкание, на самом деле весьма практичен. С одной стороны, он исключает необоснованное увеличение агрегационных сумм (вычисляемый элемент не является чьим-либо потомком), а с другой — позволяет использовать функции навигации в многомерном пространстве при составлении MDX-выражений (у вычисляемого элемента есть предки на каждом вышестоящем уровне).
Примером применения данного свойства в работе служит программа, представленная в листинге 3, которая создает в иерархии Дата три вычисляемых элемента с именем СМ. Все элементы определяются одним и тем же MDX-выражением, суммирующим показатели двух первых потомков от прямого предка вычисляемого элемента. Поскольку вычисляемые элементы размещены на разных уровнях иерархии Дата, это приводит к изменению контекста исполнения MDX-выражения, а в конечном счете — к различным значениям показателя СМ в сводном отчете (рис. 12).
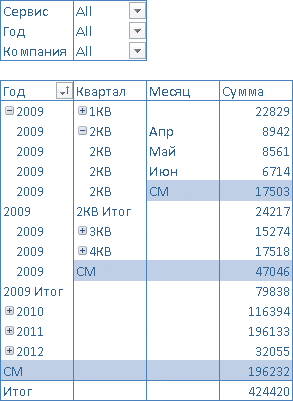
Рис. 12. Добавление вычисляемых элементов
в отчет сводной таблицы
Листинг 3
Public Sub New_Dim_Member()
Dim Formula_MDX As String
Formula_MDX = «aggregate({[Дата].[Дата].CurrentMember.Parent.FirstChild,[Дата].[Дата].CurrentMember.Parent.FirstChild.NextMember})»
With ActiveWorkbook.Connections(«Выручка»).OLEDBConnection
.CalculatedMembers.Add Name:=»[Дата].[Дата].[All].[CM]», _
Formula:=Formula_MDX, _
Type:=xlCalculatedMember
.CalculatedMembers.Add Name:=»[Дата].[Дата].[2009].[CM]», _
Formula:=Formula_MDX, _
Type:=xlCalculatedMember
.CalculatedMembers.Add Name:=»[Дата].[Дата].[2009].[2КВ].[CM]», _
Formula:=Formula_MDX, _
Type:=xlCalculatedMember
End With
End Sub
Заключение
В статье были рассмотрены различные способы создания наборов и вычисляемых элементов, доступные в последних версиях программы Microsoft Excel. Описанная функциональность позволяет значительно повысить гибкость разработки прикладных отчетов и реализовать в среде Microsoft Excel модель персонального BI.
КомпьютерПресс 08’2013
При работе с интерактивной аналитической OLAP сводной таблицей в Excel можно создавать именованные наборы, гибкие функции, которые можно использовать для:
-
Группирование общих наборов элементов, которые можно использовать повторно, даже если эти наборы не присутствуют в данных.
-
Объедините элементы из разных иерархий способами, которые были недоступны в более ранних версиях Excel, которые часто называют асимметричными отчетами.
-
Создайте именованный набор с помощью пользовательских многомерных выражений (MDX), языка запросов для баз данных OLAP, который предоставляет синтаксис вычислений, аналогичный формулам листа.
Если вы не знакомы с языком запросов многомерных выражений (MDX), можно создать именованный набор на основе элементов в строках или столбцах сводной таблицы. Дополнительные сведения о языке запросов многомерных выражений см. в статье «Запрос многомерных данных».
Если вы знакомы с языком запросов многомерных выражений, можно использовать многомерные выражения для создания или изменения именованного набора.
В этой статье
-
Создание именованного набора на основе элементов строк или столбцов
-
Создание именованного набора с помощью многомерных выражений
-
Изменение или удаление именованного набора
Создание именованного набора на основе элементов строк или столбцов
-
Щелкните сводную таблицу OLAP, для которой нужно создать именованный набор.
Откроется окно «Инструменты сводной таблицы» с добавлением вкладок «Параметры » и «Конструктор «.
-
На вкладке «Параметры» в группе «Вычисления» щелкните «Поля», «Элементы», «Наборы &«, а затем выберите команду «Создать набор на основе элементов строк» или «Создать набор на основе элементов столбцов».

Отобразится диалоговое окно «Новый набор». При необходимости можно изменить размер этого диалогового окна, перетащив маркер изменения размера в правом нижнем углу диалогового окна.
-
В поле «Задать имя » введите имя, которое вы хотите использовать для набора.
-
Чтобы указать строки, которые необходимо включить в именованный набор, выполните одно или несколько из следующих действий:
-
Чтобы удалить строку из списка элементов, щелкните область слева от нужной строки и нажмите кнопку «Удалить строку».
-
Чтобы добавить новую строку в список элементов, щелкните область слева от строки, под которой нужно добавить новую строку, а затем нажмите кнопку «Добавить строку».
-
Чтобы создать копию элемента, щелкните область слева от строки, которую нужно скопировать, а затем нажмите кнопку «Копировать строку».
-
Чтобы переместить элемент в другое место, щелкните область слева от строки, которую вы хотите переместить, а затем с помощью стрелок вверх и вниз переместите его в соответствующее расположение.
-
-
По умолчанию элементы из разных уровней будут отображаться в отдельных полях иерархии, а именованный набор заменяет текущие поля в области строк или столбцов.
-
Чтобы отобразить эти элементы в том же поле, что и другие элементы, снимите флажок «Отображаемые элементы с разных уровней » в отдельных полях .
-
Чтобы текущие поля отображались в области строк или столбцов, снимите флажок «Заменить поля в области строк» новым набором или замените поля в области столбцов новым флажком. Набор не будет отображаться в сводной таблице при нажатии кнопки «ОК», но будет доступен в списке полей сводной таблицы.
-
-
Нажмите кнопку « ОК», чтобы создать именованный набор.
Примечания:
-
Чтобы отменить все действия после закрытия диалогового окна, нажмите кнопку «Отменить» на панели быстрого доступа.
-
К именованным наборам нельзя применить фильтрацию любого типа.
-

К началу страницы
Создание именованного набора с помощью многомерных выражений
Важно: При использовании многомерных выражений для создания именованного набора или изменения определения многомерных выражений существующего именованного набора любые дополнительные изменения можно выполнить только с помощью многомерных выражений.
-
Щелкните сводную таблицу OLAP, для которой нужно создать пользовательский именованный набор.
-
На вкладке «Параметры» в группе «Вычисления» щелкните «Поля», «Элементы», «& Наборы«, а затем выберите пункт «Управление наборами».
Отобразится диалоговое окно «Диспетчер наборов». При необходимости можно изменить размер этого диалогового окна, перетащив маркер изменения размера в правом нижнем углу диалогового окна.
-
Нажмите кнопку «Создать», а затем нажмите кнопку «Создать набор» с помощью многомерных выражений.
-
В поле «Задать имя » введите имя, которое вы хотите использовать для набора.
-
Чтобы задать определение многомерных выражений для именованного набора, выполните одно из следующих действий:
-
В поле «Задать определение » введите или вставьте скопированное определение многомерных выражений.
-
На вкладке «Поля и элементы » выберите запись списка полей, которую нужно включить, и нажмите кнопку «Вставить».
Вы также можете перетащить запись списка полей в поле определения «Задать» или дважды щелкнуть запись списка полей.
Доступные записи списка полей
Запись списка полей
Примеры многомерных выражений, созданных с помощью куба Adventure Works
измерение
[Продукт]
Иерархия атрибутов (включает все элементы)
[Продукт]. [Категория]
Уровень иерархии атрибутов (не включает все члены)
[Продукт]. [Категория]. [Категория]
Элемент из иерархии атрибутов
[Продукт]. [Категория].&[4]
Иерархия пользователей
[Продукт]. [Категории продуктов]
Уровень иерархии пользователей
[Продукт]. [Категории продуктов]. [Категория]
Элемент из пользовательской иерархии
[Продукт]. [Категории продуктов]. [Категория].&[4]
Измерения
[Меры]. [Интернет-объем продаж]
Вычисляемая мера
[Меры]. [Отношение интернета к родительскому продукту]
Именованный набор
[Основная группа продуктов]
Значение ключевого показателя эффективности
KPIValue («Коэффициент валовой прибыли продукта)
Цель ключевого показателя эффективности
KPIGoal(«Product Gross Profit Margin»),
Состояние ключевого показателя эффективности
KPIStatus («Валовая прибыль продукта»)
Тренд ключевого показателя эффективности
KPITrend(«Валовая прибыль продукта»)
Свойство member из пользовательской иерархии
[Продукт]. [Категории продуктов]. Properties(«Class»)
Свойство member из иерархии атрибутов
[Продукт]. [Продукт]. Properties(«Class»)
-
На вкладке « Функции» выберите одну или несколько функций из доступных функций многомерных выражений, которые вы хотите использовать, и нажмите кнопку «Вставить». Функции многомерных выражений поддерживаются службами Analysis Services. они не включают функции VBA.
Аргументы функции помещаются внутри символов шеврона (<< >>). Вы можете заменить аргументы заполнителей, щелкнув их, а затем введя допустимые имена, которые вы хотите использовать.
Примеры функций многомерных выражений
ADDCALCULATEDMEMBERS( «Set» )
AGGREGATE( «Set»[, «Numeric Expression»] )
«Level»ALLMEMBERS
«Hierarchy» (Иерархия).ALLMEMBERS
ANCESTOR( «Member» «Level» )
ANCESTOR( «Member», «Distance» )
ANCESTORS( «Member», «Distance» )
ANCESTORS( «Member», «Level» )
ASCENDANTS( «Member» )
AVG( «Set»[, «Числовое выражение»] )
AXIS( «Числовое выражение» )
BOTTOMNCOUNT( «Set», «Count»[, «Numeric Expression»] )
BOTTOMPERCENT( «Set», «Percentage», «Numeric Expression» )
BOTTOMSUM ( «Set», «Value», «Numeric Expression» ) …
-
-
Чтобы протестировать новое определение многомерных выражений, щелкните «Тест многомерных выражений».
-
По умолчанию элементы из разных уровней будут отображаться в отдельных полях в иерархии, поля упорядочивания и повторяющиеся записи автоматически удаляются (так как в набор добавлены HIERARCHIZE и DISTINCT), а именованный набор заменяет текущие поля в строке или области столбца.
-
Чтобы отобразить эти элементы в том же поле, что и другие элементы, снимите флажок «Отображаемые элементы с разных уровней » в отдельных полях .
-
Чтобы изменить иерархию по умолчанию и сохранить повторяющиеся записи, снимите автоматический порядок и удалите дубликаты из установленного флажка.
-
Чтобы текущие поля отображались в области строк или столбцов, снимите флажок «Заменить поля в области строк» новым набором или замените поля в области столбцов новым флажком. Набор не будет отображаться в сводной таблице при нажатии кнопки «ОК», но будет доступен в списке полей сводной таблицы.
-
-
Если вы подключены к кубу SQL Server Analysis Services 2008, по умолчанию создается динамический именованный набор. Этот именованный набор автоматически пересчитывается при каждом обновлении.
-
Чтобы предотвратить пересчет именованного набора при каждом обновлении, снимите флажок «Пересчет» с каждым флажком обновления.
-
-
Нажмите кнопку « ОК», чтобы создать именованный набор.
Примечания:
-
Чтобы отменить все действия после закрытия диалогового окна, нажмите кнопку «Отменить» на панели быстрого доступа.
-
К именованным наборам нельзя применить фильтрацию любого типа.
-
К началу страницы
Изменение или удаление именованного набора
-
Щелкните сводную таблицу OLAP, содержащую именованный набор, который требуется изменить или удалить.
-
На вкладке «Параметры» в группе «Вычисления» щелкните «Поля», «Элементы», «& Наборы«, а затем выберите пункт «Управление наборами».
Отобразится диалоговое окно «Диспетчер наборов». При необходимости можно изменить размер этого диалогового окна, перетащив маркер изменения размера в правом нижнем углу диалогового окна.
-
Выберите набор, который требуется изменить или удалить.
-
Выполните одно из указанных ниже действий.
-
Чтобы изменить выбранный именованный набор, нажмите кнопку «Изменить» и внесите необходимые изменения.
-
Чтобы удалить выбранный именованный набор, нажмите кнопку «Удалить», а затем нажмите кнопку «Да «, чтобы подтвердить.
-
К началу страницы
Структурирование данных — необходимое условие для работы с электронными таблицами, если человек хочет эффективно обрабатывать большие объемы информации. Один из способов сделать это — использовать группировку. Он позволяет не только организовать большой объем информации, но и скрыть те элементы, которые в данный момент не нужны. В результате человек может полностью сосредоточиться только на значимых фрагментах, не отвлекаясь на то, что в данный момент не так важно. Какие шаги необходимо предпринять, чтобы сгруппировать информацию в Excel?
Как настроить группировку
Подготовка — очень важный подготовительный этап. Без него невозможно осчастливить человека конечным результатом. Чтобы правильно настроить группировку, точно следуйте этим инструкциям:
- Разверните вкладку «Данные» в документе, в котором вы хотите сгруппировать информацию.
- Открываем раздел «Структура», в котором мы расширяем набор инструментов.
- Появится окно, в котором нужно настроить параметры группировки. Предустановленные параметры следующие: результаты столбца регистрируются непосредственно справа от столбцов, а результаты строк регистрируются ниже. Людям часто не нравится эта идея, потому что они думают, что размещение имени сверху экономит много времени. Для этого снимите флажок, расположенный непосредственно рядом с соответствующим параметром. Как правило, все пользователи могут настраивать группировку в соответствии со своими потребностями. Но вы также можете автоматизировать формирование стиля, активировав соответствующий пункт.
- Подтверждаем свои действия после внесения необходимых изменений в параметры нажатием кнопки ОК.
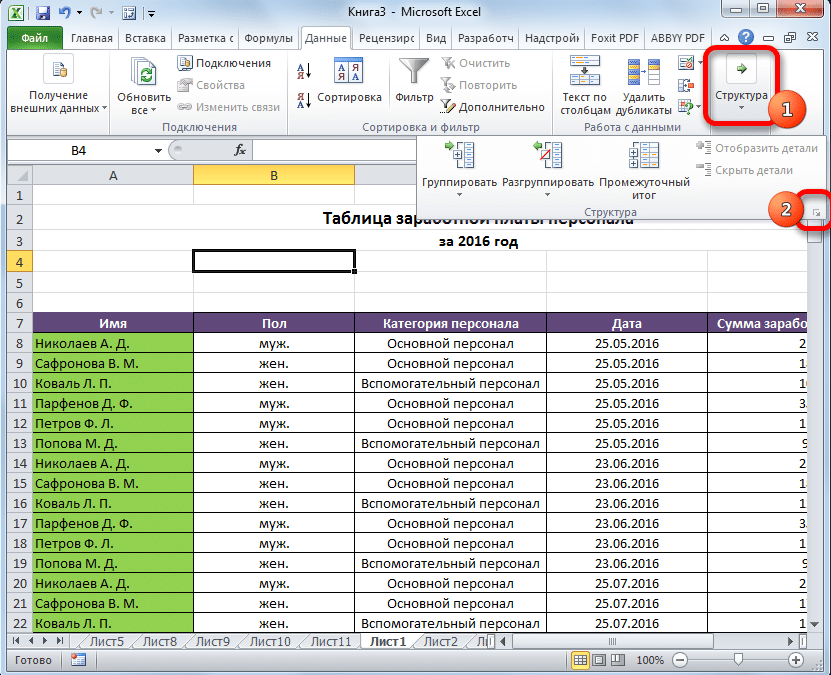
На этом подготовительный этап можно считать завершенным.
Группируем информацию по строкам.
Во-первых, нам нужно добавить дополнительную строку выше или ниже группы столбцов. Все зависит от того, где мы хотим разместить имя и булавки. Затем перейдите в новую ячейку, где мы даем группе имя. Желательно выбрать имя, наиболее подходящее к контексту.
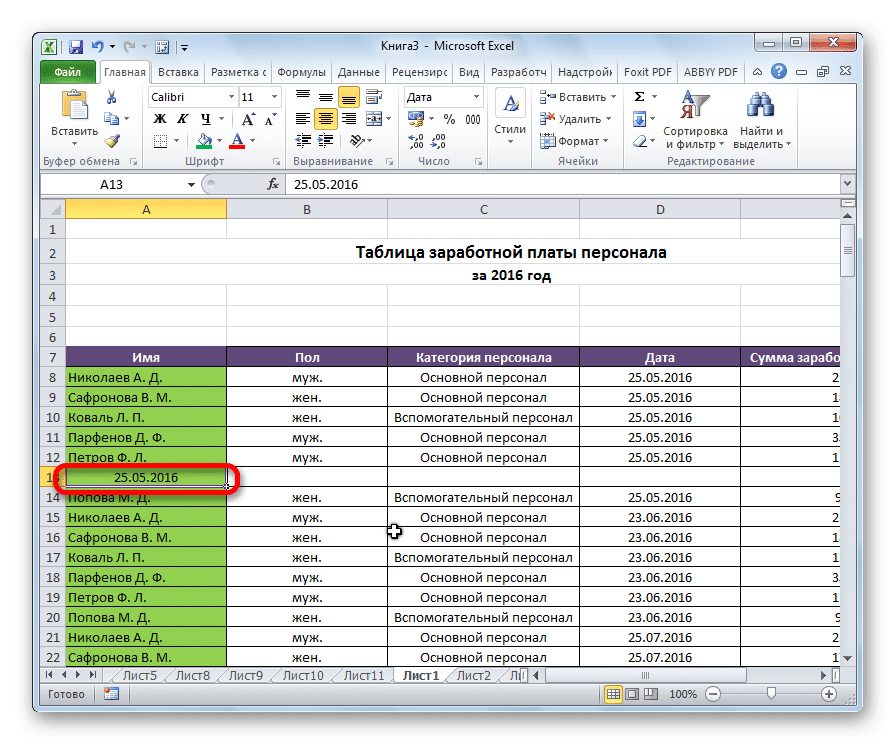
Затем выберите строки для объединения и откройте вкладку «Данные». Однако результирующая строка не входит в диапазон для группировки.
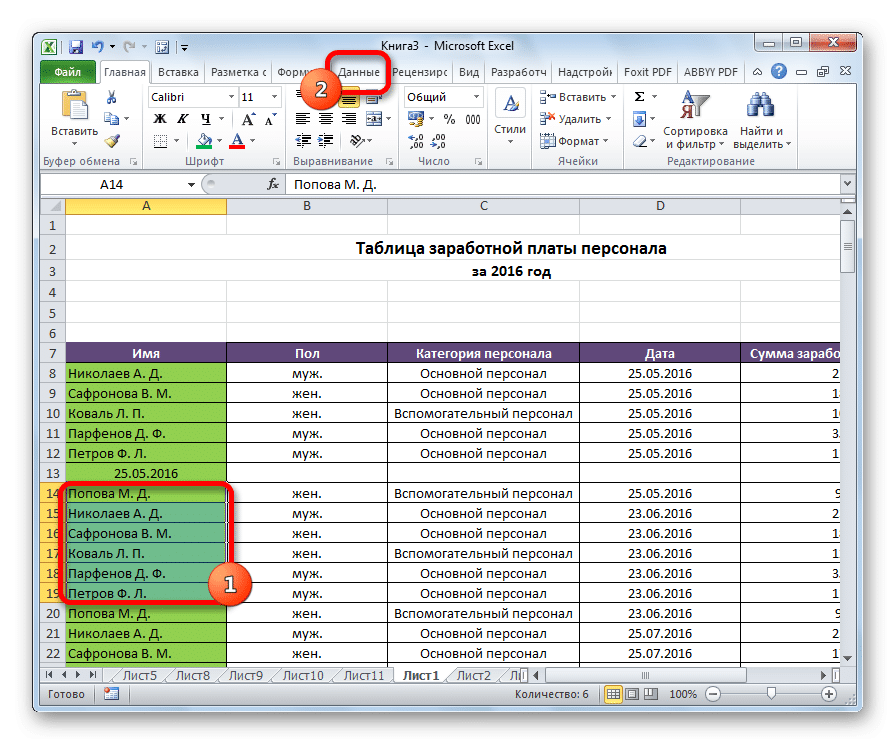
Теперь перейдите в раздел «Структура». Для этого нажмите соответствующую кнопку, расположенную в правой части ленты. Щелкните кнопку «Группа». Появится специальное меню, в котором мы нажимаем эту кнопку.
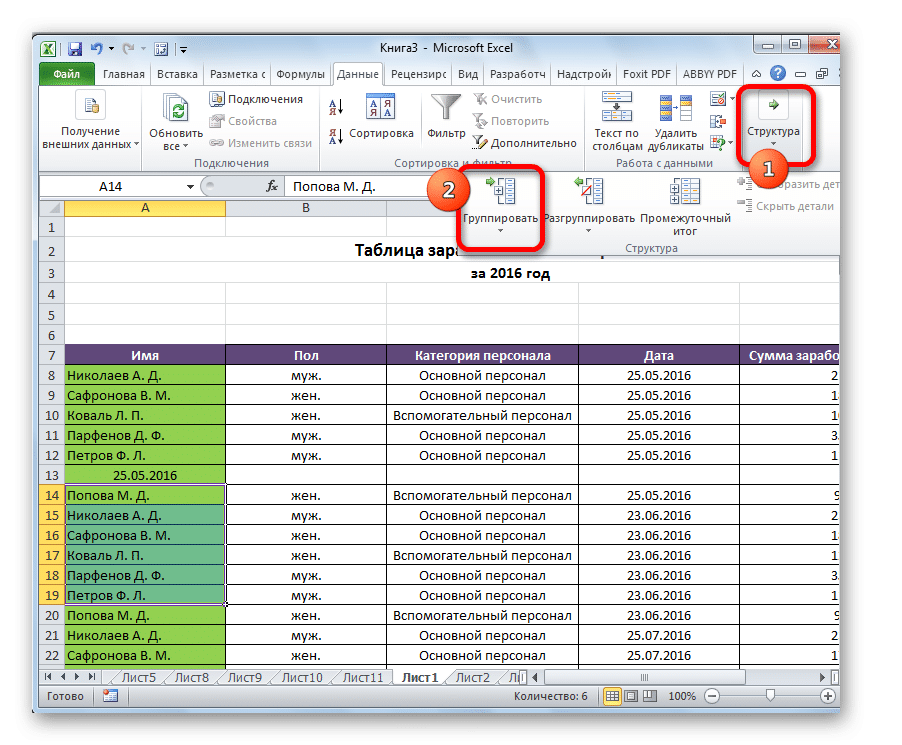
Затем программа предложит метод группировки по строкам или столбцам. Вы должны выбрать тот, который лучше всего подходит для конкретной ситуации. То есть в нашем случае построчно. Подтверждаем свои действия нажатием кнопки «ОК». Впоследствии процесс создания группы можно считать завершенным. Вы можете свернуть его со знаком минус.
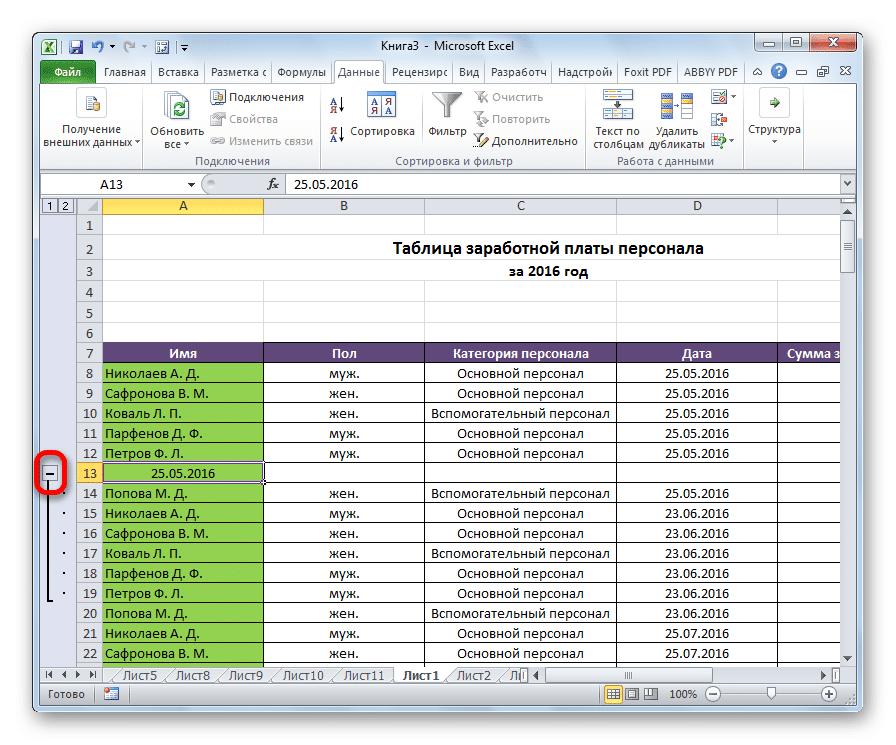
После того, как группа скроется, знак минус будет заменен знаком плюс. При нажатии на нее группа развернется.
Группировка по столбцам в Excel
Группировка по столбцам выполняется так же, как группировка по строкам, только тип группировки должен быть выбран по-другому в соответствующем диалоговом окне. Но в любом случае давайте по порядку.
- Решаем, какие данные нам нужно сгруппировать. Далее мы вставляем новый столбец, в который будет записан заголовок группы.
- Затем выберите ячейки для группировки. Как и в предыдущем примере, не выбирайте заголовок.
- Заходим в «Данные» и там находим пункт «Структура». После нажатия на эту кнопку откроется меню, в котором мы выбираем «Группировать».
- В появившемся диалоговом окне выберите пункт «Столбцы». Подтверждаем свои действия.
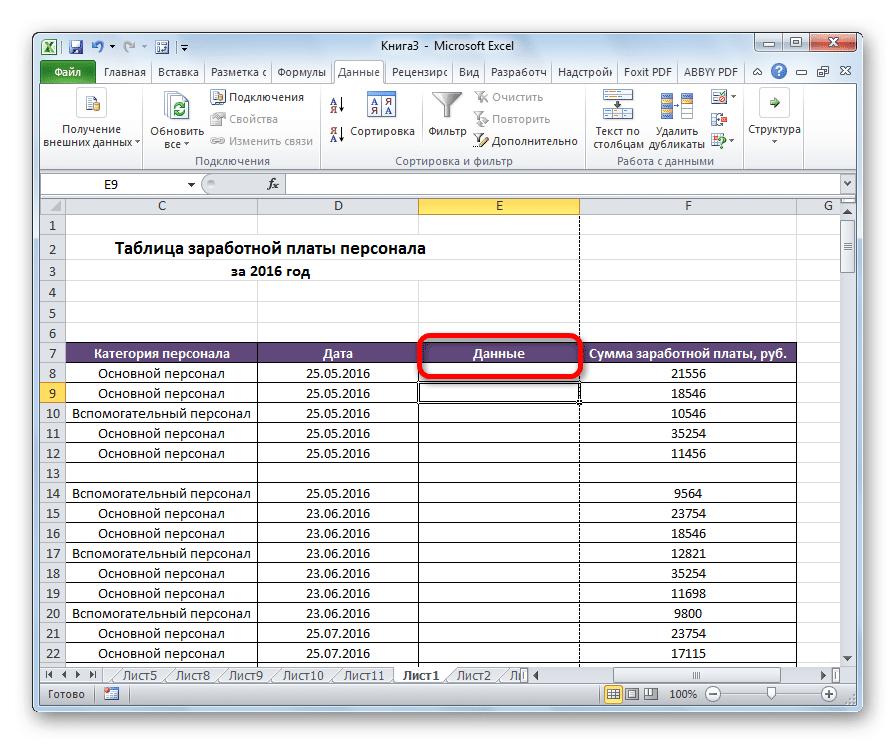
На этом группировка данных завершена. Так же, как и в предыдущем случае, вы можете свернуть и развернуть элементы группы с помощью клавиш «минус» или «плюс» соответственно.
Создание вложенных групп
Группировка не заканчивается на приведенных выше пунктах меню. Пользователь может создавать вложенные группы, которые позволяют получать более четко структурированную информацию. Логика действия в целом такая же. Только все шаги, описанные выше, необходимо выполнить в родительской группе. Последовательность действий следующая:
- Если родительская группа свернута, ее необходимо развернуть.
- Ячейки, которые должны быть отнесены к подгруппе, должны быть выделены.
- Далее откройте вкладку «Данные», перейдите в раздел «Структура» и нажмите «Группировать» там».
- Затем выбираем способ группировки — по строкам или по столбцам, после чего подтверждаем свои действия.
Далее у нас будет дополнительная вложенная группа. Сколько подгрупп может создать пользователь? Количество не ограничено. Мы видим, что числа появляются над знаками минус. Они позволяют быстро переключаться между уровнями вложенности.
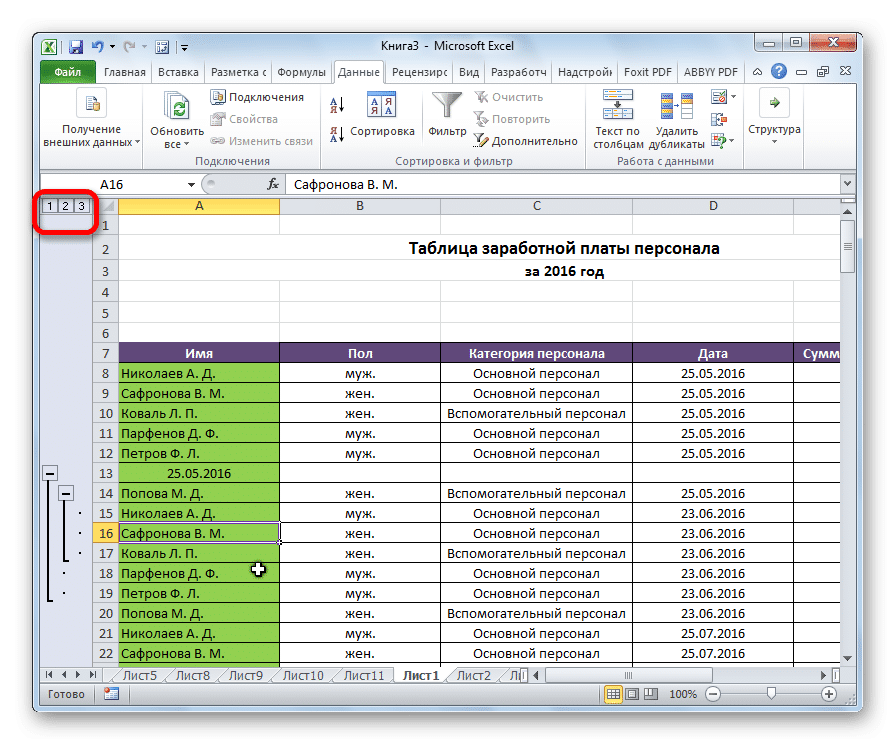
Если группировка выполняется по строкам, а не по столбцам и не по строкам, эти числа будут слева от листа (или знаки минус / плюс).
Разгруппирование в Эксель
Предположим, нам больше не нужна группа. Что делать в такой ситуации? Можно ли его удалить? Да, конечно. Это называется разделением. Сначала выберите все элементы группы, которые нужно растворить. Затем перейдите на вкладку «Данные» и найдите там раздел «Структура». После нажатия на соответствующую кнопку и в этом меню появится кнопка «Разгруппировать». Нажмите здесь.
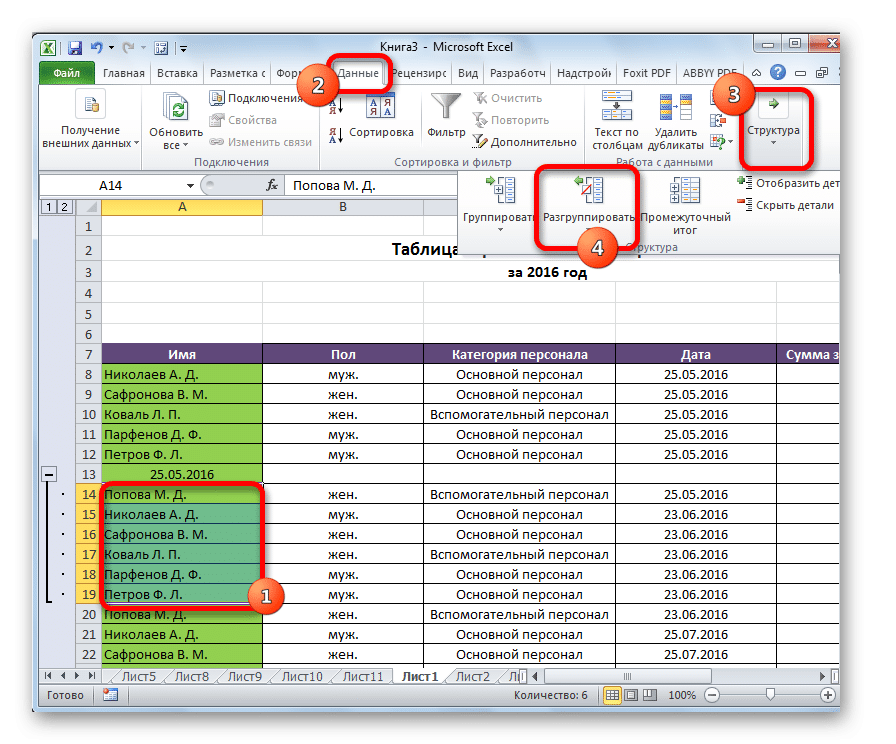
После этого появится диалоговое окно, в котором будет набор настроек, аналогичный тому, что было, когда мы хотели сгруппировать ячейки. Только на этот раз Excel спросит, что именно нам нужно разделить: столбцы или строки. Выберите то, что вам нужно, и нажмите кнопку «ОК». Впоследствии лист будет выглядеть так же, как и до создания соответствующей группы.
Многоуровневая группировка — пошаговая инструкция
Теперь давайте немного разберем полученную выше информацию и дадим готовую пошаговую инструкцию, как произвести многоуровневую группировку данных:
- Сначала выполним установку, соответствующую первому разделу этой статьи.
- Далее давайте создадим заголовок группы. Для этого мы создаем дополнительную строку или столбец, в зависимости от того, какие данные мы хотим сгруппировать.
- Мы присваиваем название группе в этом столбце или строке.
- Выберите ячейки, которые нужно объединить в группу.
- Переходим во вкладку «Данные» и там находим группу инструментов «Структура».
- Затем мы нажимаем кнопку «Группировать», выбираем тип группировки, необходимый в конкретной ситуации, и нажимаем кнопку ОК.
- Далее мы решаем, как вызвать вторую группу и создать дополнительную строку с этими данными.
- Выделите ячейки подгруппы, которые хотите выделить. Заголовок, как и в предыдущем примере, в группу не входит.
- Повторите шаги 5 и 6 для второго уровня группы.
- Повторите шаги 7–9 для каждого следующего уровня в группе.
Как видите, эта инструкция довольно проста для понимания и укладывается в 10 пунктов. Как только вы интуитивно это почувствуете, сразу не возникнет проблем с выполнением всех этих действий на практике. Теперь давайте взглянем на некоторые важные аспекты группировки данных.
Автоматическая структуризация в Excel
Весь приведенный выше метод является примером группировки данных электронной таблицы вручную. Но есть способ автоматизировать разделение информации на группы. Правда, выделение для группировки программа сама создаст. Но во многих ситуациях Excel правильно структурирует информацию.
Самым большим преимуществом автоматического структурирования данных в Excel является экономия времени. Хотя всегда нужно быть готовым к тому, что некоторые изменения придется вносить самостоятельно. К сожалению, роботы еще не научились читать мысли.
Когда лучше всего использовать автоматическую группировку? Лучше всего это работает, когда пользователь работает с формулами. В этом случае ошибок обычно не возникает.
Что нужно сделать, чтобы данные автоматически группировались? Вам необходимо открыть раздел «Группа» и выбрать там пункт «Создать структуру». Все остальное Excel сделает за вас.
Отмена автоматической группировки происходит немного иначе. Вам нужно выбрать пункт «Разгруппировать», но нажать на меню «Очистить структуру». После этого стол вернется к своей первоначальной форме.
Как сортировать данные таблицы
Сортировка данных может быть особенно полезна при сортировке информации в электронной таблице. Это можно сделать по целому ряду критериев. Опишем наиболее важные моменты, на которые следует обратить внимание.
Цветовое деление
Один из способов сортировки данных — раскрасить информацию, принадлежащую группе, особым цветом. Для этого откройте вкладку «Данные» и найдите раздел «Сортировка и фильтр». Дальнейшие действия зависят от используемой версии офисного пакета. Нужная нам функция может называться «Пользовательская» или «Сортировка». После нажатия на соответствующий пункт должно появиться всплывающее окно.
Затем перейдите в раздел «Колонка». Там находим группу «Сортировать по», поэтому выбираем нужный столбец в нашей ситуации. Далее мы устанавливаем критерий сортировки данных. Например, это может быть цвет ячеек. Если мы собираемся его использовать, мы должны сначала раскрасить соответствующие ячейки соответствующим цветом.
Чтобы определить цвет, в разделе «Порядок» нажмите на изображение стрелки. Рядом с ним будет элемент, с помощью которого можно определить, куда будут отправляться данные, в которые программа, отсортированная в автоматическом режиме, будет отправлять. Если вам нужно, чтобы они были размещены вверху, вам нужно нажать на соответствующую кнопку. Если вы хотите, чтобы смещение производилось в направлении линии, вам необходимо выбрать пункт «Влево».
Те же шаги можно выполнить с другими критериями, создав другой уровень. Для этого вам нужно найти в диалоговом окне пункт «Добавить слой». Далее мы сохраняем документ, после чего вы можете снова объединить данные, нажав кнопку «Применить повторно».
Объединение значений
Excel предлагает возможность группировать значения на основе значения, содержащегося в определенной ячейке. Это необходимо, например, когда вам нужно найти поля, содержащие определенные имена или разные типы данных (например, коды). Как это сделать? Первые два шага соответствуют предыдущему разделу, но вместо цветового критерия вам нужно настроить значение, по которому будет выполняться группировка.
В группе «Порядок» нас интересует пункт «Пользовательский список», нажав на который пользователь может создать свой список условий для сортировки или использовать предопределенные в Excel. Таким образом, вы можете комбинировать данные по любым критериям, включая дату, дни недели и т.д.
Как упростить большую таблицу Эксель
Excel позволяет выполнять в Excel одновременно разные типы группировок на основе разных критериев. Для этого следуйте этим инструкциям:
- Каждый диапазон должен иметь заголовок в начале и не содержать пустых ячеек. Заголовки должны включать один и тот же тип данных.
- Желательно заранее упорядочить данные в алфавитном порядке.
- Воспользуемся командой «Промежуточные итоги», которая находится в том же разделе — «Группа».
Далее группируем столбцы так же, как описано выше. В результате должна получиться многоуровневая таблица.