
17 авг. 2022 г.
читать 3 мин
Двухфакторный дисперсионный анализ («дисперсионный анализ») используется для определения того, существует ли статистически значимое различие между средними значениями трех или более независимых групп, разделенных на два фактора.
В этом руководстве объясняется, как выполнить двусторонний дисперсионный анализ в Excel.
Пример. Двухфакторный дисперсионный анализ в Excel
Ботаник хочет знать, влияет ли на рост растений воздействие солнечного света и частота полива. Она сажает 40 семян и дает им расти в течение двух месяцев при различных условиях солнечного света и частоты полива. Через два месяца она записывает высоту каждого растения. Результаты показаны ниже:
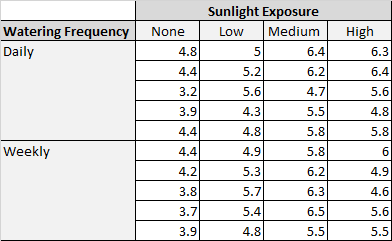
В таблице выше мы видим, что в каждой комбинации условий выращивалось по пять растений. Например, было пять растений, выращенных с ежедневным поливом и без солнечного света, и их высота через два месяца составила 4,8 дюйма, 4,4 дюйма, 3,2 дюйма, 3,9 дюйма и 4,4 дюйма:
Мы можем использовать следующие шаги для выполнения двустороннего анализа этих данных:
Шаг 1: Выберите пакет инструментов анализа данных.
На вкладке « Данные » нажмите « Анализ данных» :

Если вы не видите этот вариант, вам нужно сначала загрузить бесплатный пакет инструментов для анализа данных .
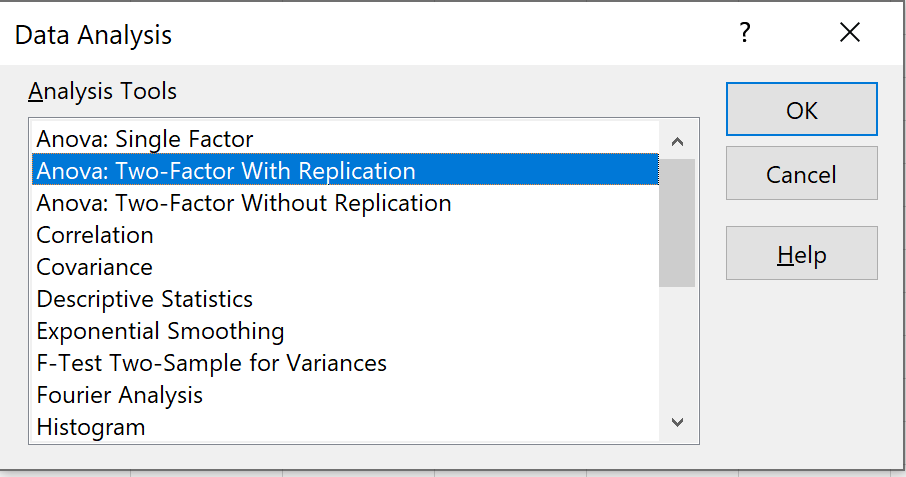
2. Выберите Anova: двухфакторный с репликацией
Выберите вариант с надписью Anova: Two-Factor With Replication , затем нажмите OK .
В этом контексте «повторение» означает наличие нескольких наблюдений в каждой группе. Например, было несколько растений, которые выращивались без воздействия солнечного света и ежедневного полива. Если бы вместо этого мы выращивали только одно растение в каждой комбинации условий, мы бы использовали «без повторения», но размер нашей выборки был бы намного меньше.
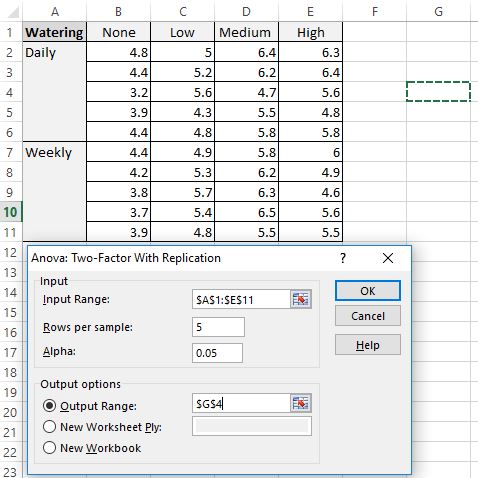
3. Введите необходимые значения.
Далее заполните следующие значения:
- Диапазон ввода: выберите диапазон ячеек, в котором находятся наши данные, включая заголовки.
- Рядов на образец: введите «5», поскольку в каждом образце 5 растений.
- Альфа: выберите уровень значимости для использования. Мы выберем 0,05.
- Выходной диапазон: выберите ячейку, в которой должны появиться выходные данные двухфакторного дисперсионного анализа. Мы выберем ячейку $G$4.
Шаг 4: Интерпретируйте вывод.
Как только мы нажмем OK , появятся результаты двухфакторного дисперсионного анализа:
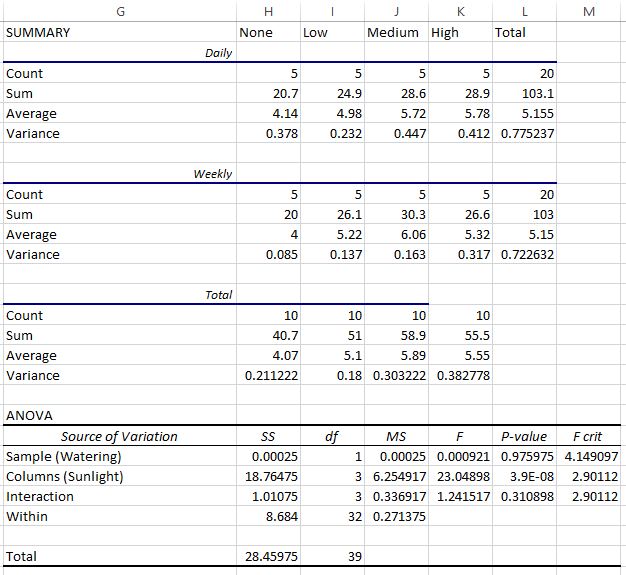
Первые три таблицы показывают сводную статистику для каждой группы. Например:
- Средняя высота растений, которые ежедневно поливали, но не освещали солнечным светом, составляла 4,14 дюйма.
- Средняя высота растений, которые поливали еженедельно и получали мало солнечного света, составляла 5,22 дюйма.
- Средняя высота всех ежедневно поливаемых растений составляла 5,115 дюйма.
- Средняя высота всех растений, которые поливали еженедельно, составляла 5,15 дюйма.
- Средняя высота всех растений, получавших много солнечного света, составляла 5,55 дюйма.
И так далее.
В последней таблице показан результат двухфакторного дисперсионного анализа. Мы можем наблюдать следующее:
- Значение p для взаимодействия между частотой полива и воздействием солнечного света составило 0,310898.Это не является статистически значимым при уровне альфа 0,05.
- Значение p для частоты полива составило 0,975975.Это не является статистически значимым при уровне альфа 0,05.
- Значение p для воздействия солнечного света составило 3,9E-8 (0,000000039).Это статистически значимо при уровне альфа 0,05.
Эти результаты показывают, что воздействие солнечного света является единственным фактором, статистически значимо влияющим на высоту растений. А поскольку эффекта взаимодействия нет, эффект воздействия солнечного света одинаков для каждого уровня частоты полива. То есть, поливают ли растение ежедневно или еженедельно, это не влияет на то, как воздействие солнечного света влияет на растение.
Чтобы проанализировать изменчивость признака под воздействием контролируемых переменных, применяется дисперсионный метод.
Для изучения связи между значениями – факторный метод. Рассмотрим подробнее аналитические инструменты: факторный, дисперсионный и двухфакторный дисперсионный метод оценки изменчивости.
Дисперсионный анализ в Excel
Условно цель дисперсионного метода можно сформулировать так: вычленить из общей вариативности параметра 3 частные вариативности:
- 1 – определенную действием каждого из изучаемых значений;
- 2 – продиктованную взаимосвязью между исследуемыми значениями;
- 3 – случайную, продиктованную всеми неучтенными обстоятельствами.
В программе Microsoft Excel дисперсионный анализ можно выполнить с помощью инструмента «Анализ данных» (вкладка «Данные» — «Анализ»). Это надстройка табличного процессора. Если надстройка недоступна, нужно открыть «Параметры Excel» и включить настройку для анализа.
Работа начинается с оформления таблицы. Правила:
- В каждом столбце должны быть значения одного исследуемого фактора.
- Столбцы расположить по возрастанию/убыванию величины исследуемого параметра.
Рассмотрим дисперсионный анализ в Excel на примере.
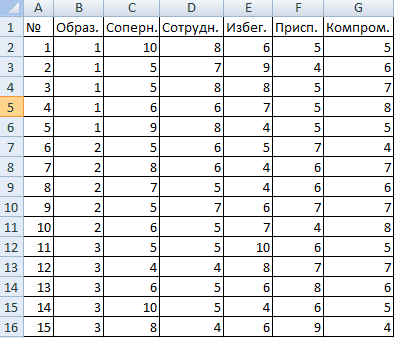
Психолог фирмы проанализировал с помощью специальной методики стратегии поведения сотрудников в конфликтной ситуации. Предполагается, что на поведение влияет уровень образования (1 – среднее, 2 – среднее специальное, 3 – высшее).
Внесем данные в таблицу Excel:
- Открываем диалоговое окно нашего аналитического инструмента. В раскрывшемся списке выбираем «Однофакторный дисперсионный анализ» и нажимаем ОК.
- В поле «Входной интервал» ввести ссылку на диапазон ячеек, содержащихся во всех столбцах таблицы.
- «Группирование» назначить по столбцам.
- «Параметры вывода» — новый рабочий лист. Если нужно указать выходной диапазон на имеющемся листе, то переключатель ставим в положение «Выходной интервал» и ссылаемся на левую верхнюю ячейку диапазона для выводимых данных. Размеры определятся автоматически.
- Результаты анализа выводятся на отдельный лист (в нашем примере).
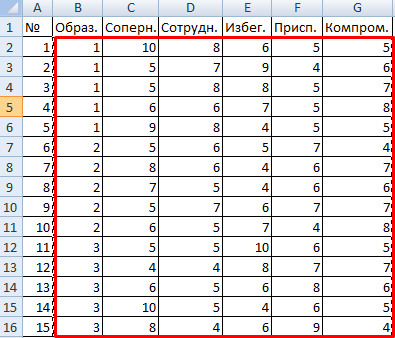
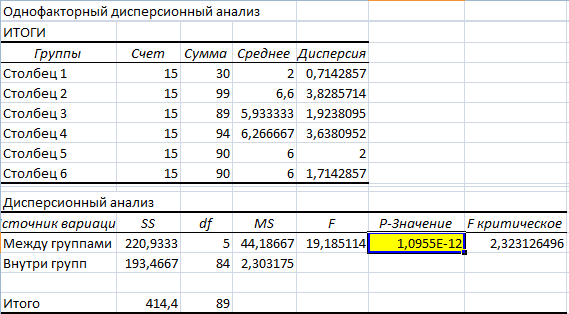
Значимый параметр залит желтым цветом. Так как Р-Значение между группами больше 1, критерий Фишера нельзя считать значимым. Следовательно, поведение в конфликтной ситуации не зависит от уровня образования.
Факторный анализ в Excel: пример
Факторным называют многомерный анализ взаимосвязей между значениями переменных. С помощью данного метода можно решить важнейшие задачи:
- всесторонне описать измеряемый объект (причем емко, компактно);
- выявить скрытые переменные значения, определяющие наличие линейных статистических корреляций;
- классифицировать переменные (определить взаимосвязи между ними);
- сократить число необходимых переменных.
Рассмотрим на примере проведение факторного анализа. Допустим, нам известны продажи каких-либо товаров за последние 4 месяца. Необходимо проанализировать, какие наименования пользуются спросом, а какие нет.
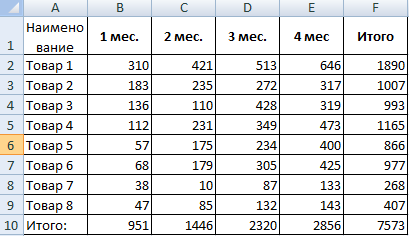
- Посмотрим, за счет, каких наименований произошел основной рост по итогам второго месяца. Если продажи какого-то товара выросли, положительная дельта – в столбец «Рост». Отрицательная – «Снижение». Формула в Excel для «роста»: =ЕСЛИ((C2-B2)>0;C2-B2;0), где С2-В2 – разница между 2 и 1 месяцем. Формула для «снижения»: =ЕСЛИ(J3=0;B2-C2;0), где J3 – ссылка на ячейку слева («Рост»). Во втором столбце – сумма предыдущего значения и предыдущего роста за вычетом текущего снижения.
- Рассчитаем процент роста по каждому наименованию товара. Формула: =ЕСЛИ(J3/$I$11=0;-K3/$I$11;J3/$I$11). Где J3/$I$11 – отношение «роста» к итогу за 2 месяц, ;-K3/$I$11 – отношение «снижения» к итогу за 2 месяц.
- Выделяем область данных для построения диаграммы. Переходим на вкладку «Вставка» — «Гистограмма».
- Поработаем с подписями и цветами. Уберем накопительный итог через «Формат ряда данных» — «Заливка» («Нет заливки»). С помощью данного инструментария меняем цвет для «снижения» и «роста».
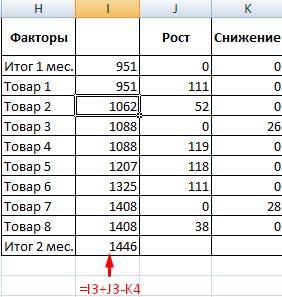
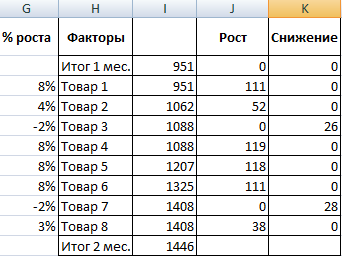
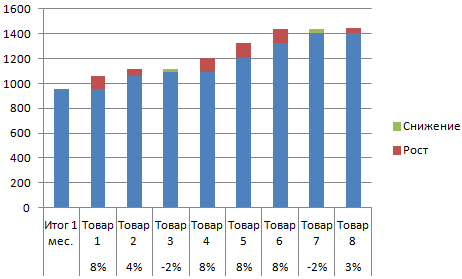
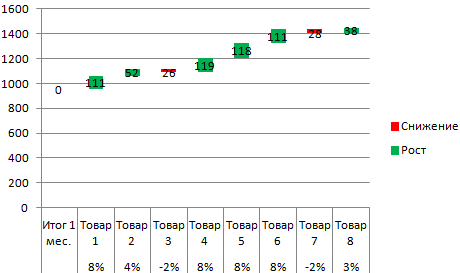
Теперь наглядно видно, продажи какого товара дают основной рост.
Двухфакторный дисперсионный анализ в Excel
Показывает, как влияет два фактора на изменение значения случайной величины. Рассмотрим двухфакторный дисперсионный анализ в Excel на примере.
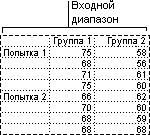
Задача. Группе мужчин и женщин предъявляли звук разной громкости: 1 – 10 дБ, 2 – 30 дБ, 3 – 50 дБ. Время ответа фиксировали в миллисекундах. Необходимо определить, влияет ли пол на реакцию; влияет ли громкость на реакцию.
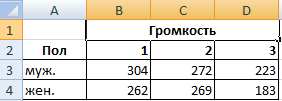
- Переходим на вкладку «Данные» — «Анализ данных» Выбираем из списка «Двухфакторный дисперсионный анализ без повторений».
- Заполняем поля. В диапазон должны войти только числовые значения.
- Результат анализа выводится на новый лист (как было задано).
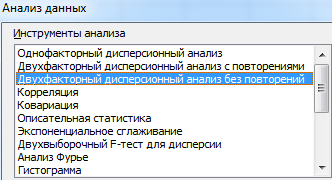
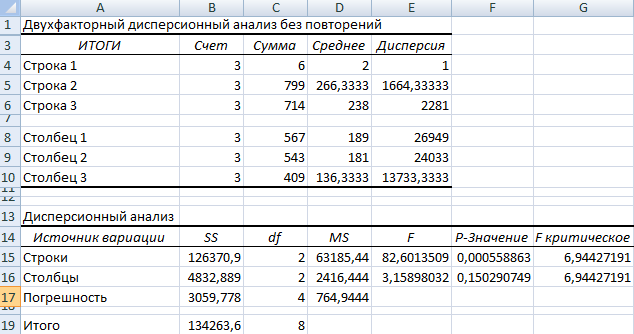
Та как F-статистики (столбец «F») для фактора «Пол» больше критического уровня F-распределения (столбец «F-критическое»), данный фактор имеет влияние на анализируемый параметр (время реакции на звук).
Скачать пример факторного и дисперсионного анализа
скачать факторный анализ отклонений
скачать пример 2
Для фактора «Громкость»: 3,16 < 6,94. Следовательно, данный фактор не влияет на время ответа.
Для примера также прилагаем факторный анализ отклонений в маржинальном доходе.

В
программе MS
Excel для
статистического анализа данных имеется
надстройка «Пакет
анализа«,
которая позволяет проводить дисперсионный
анализ следующих видов:
-
однофакторный
дисперсионный анализ, -
двухфакторный
дисперсионный анализ без повторений, -
двухфакторный
дисперсионный анализ с повторениями.
-
Однофакторный дисперсионный анализ.
Условием применения
такого анализа является повторность
данных.
Например:
Необходимо оценить влияние условий и
характера труда (в данном случае профиля
цеха) на заболеваемость рабочих острым
и хроническим гастритом. Повторность
данных – обеспечена наблюдением за
работниками предприятий, схожими по
профилю. Исходные данные представлены
в таблице ():
Согласно
таблице исследуемый фактор имеет 3
уровня: доменный, мартеновский и прокатный
цеха. В каждой группе имеется только по
4 наблюдения – 1,2,3,4 заводы, которые
рассматриваются как повторности
наблюдений.
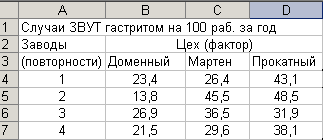
Рисунок 100.
Исходные данные однофакторного комплекса
Для
решения задачи в MS
Excel:
1.Сформируйте
таблицу с исходными данными ().
2.Выберите
<Пакет
анализа>
из меню <Сервис>.
3.В
соответствии с условиями задачи выберите
в появившемся диалоговом окне метод
«Однофакторный
дисперсионный анализ»
и нажмите кнопку [OK].
4.В
окне «Однофакторный
дисперсионный анализ»
установите для входных данных следующие
параметры:
-
входной
интервал ($B$4:$D$7), -
метки
(выбранный нами входной диапазон не
содержит метки, то есть названий строк
и столбцов), -
альфа
(уровень значимости =0,05).
5.Для
параметров вывода установите переключатель
в положение
«Выходной интервал»
и укажите клетку с координатой (Е1).
6.После
завершения настройки параметров нажмите
кнопку [OK].
Диалоговое
окно с заполненными исходными параметрами
должно выглядеть следующим образом
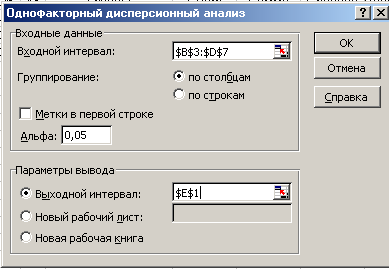
Рисунок
101. Окно исходных параметров однофакторного
дисперсионного комплекса
Результаты
дисперсионного анализа будут состоять
из двух таблиц. В первой таблице для
каждого столбца исходной таблицы, в
которых располагаются анализируемые
группы, приведены числовые параметры:
количество чисел (счет), суммы по столбцам,
средние дисперсии по столбцам.
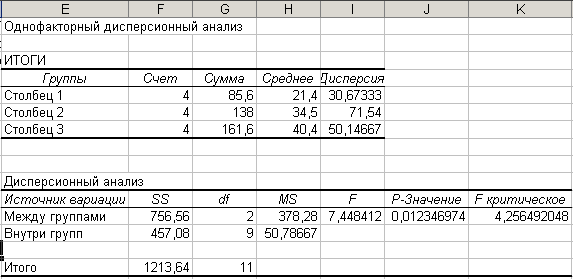
Рисунок
102. Результаты анализа однофакторного
комплекса
Во
второй части результатов MS
Excel использует
следующие обозначения:
-
SS
— сумма квадратов, -
df
— степени свободы, -
MS
— средний квадрат (дисперсия), -
F
— F-статистика Фишера (фактическое
значение), -
p-значение
– общая значимость результатов
дисперсионного анализа данных,
расположенных по столбцам; -
F-критическое
— критическое значение F-статистики
(Фишера) при заданном ранее p=0,05.
Таким
образом, сумма квадратов, обусловленная
влиянием исследуемого фактора
(межгрупповая сумма), равна 756,56 Остаточная
сумма квадратов (внутригрупповая) равна
457,08. Соответствующие дисперсии
межгрупповая (для исследуемого фактора)
— 378,28. , остаточная, внутригрупповая —
55,79.
Основной
вывод
из полученных результатов заключается
в следующем:
Есть
основания отвергать нулевую гипотезу
об отсутствии влияния рассмотренного
фактора (условия и характер работы в
разных цехах) на заболеваемость рабочих
гастритом: т.к. выполняется неравенство
FFкр.,
при котором величина значимости Р
= 0,012. Для отрицания нулевой гипотезы
она должна быть не более 0,05.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
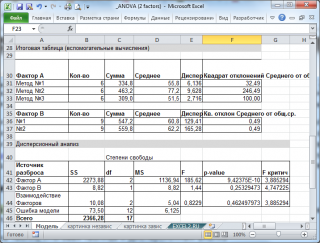
Пусть имеется случайная переменная
Y
, значения которой мы можем измерять. Исследователь предполагает, что эта переменная зависит от 2-х факторов, значения которых мы можем контролировать, т.е. задавать с требуемой точностью. Покажем как методом дисперсионного анализа проверить гипотезу о наличии или отсутствии влияния указанных факторов на зависимую переменную
Y
.
Disclaimer
: Эта статья – о применении MS EXCEL для целей
Дисперсионного анализа, поэтому
данную статью не стоит рассматривать, как пересказ главы из учебника по статистике. Статья не обладает ни полнотой, ни строгостью изложения положений статистической науки. Теоретические отступления приведены лишь из соображения логики изложения. Использование данной статьи для изучения теории
Дисперсионного анализа
– плохая идея. Хорошая идея — найти в этой статье формулы MS EXCEL для проведения
Дисперсионного анализа.
Напомним, что
дисперсионный анализ
(ANOVA, ANalysis Of VAriance) позволяет
проверить гипотезу
о равенстве
средних значений
выборок (взяты ли выборки из одного распределения или из разных распределений). Данная задача возникает, например, когда необходимо исследовать зависимость некой
количественной
величины Y от одной или нескольких переменных (факторов), которые мы можем контролировать (устанавливать их значения). Действительно, если фактор оказывает влияние на зависимую переменную Y, то при разных уровнях фактора мы должны
в среднем
получать различные значения Y, т.е. мы должны получить «заметно отличающиеся»
средние значения выборок
. В статье будет показано, что значит
средние выборок
«заметно отличаются».
В этой статье рассмотрим метод дисперсионного анализа в случае двух факторов (Фактор А и Фактор В) (Two Factor ANOVA with Replication).
СОВЕТ
: Перед прочтением этой статьи рекомендуется освежить в памяти
Однофакторный дисперсионный анализ
.
Обозначения
Отдельные, заданные значения каждого фактора называются уровнями (
levels
) или испытаниями (
treatments
).
Уровни фактора А будем обозначать буквой j (j изменяется от 1 до
a
). Уровни фактора В будем обозначать буквой i (i изменяется от 1 до
b
). Каждой паре уровней факторов соответствует одна выборка, которая состоит из
m
измерений, каждое измерение будем обозначать буквой k (k от 1 до m). Таким образом, измеренные значения Y при уровне j фактора А и при уровне i фактора В будем обозначать y ijk . Всего выборок
a*b
.
Предполагается, что
дисперсии
всех выборок σ 2 неизвестны, но равны между собой.
Рассмотрим
двухфакторный дисперсионный анализ
при решении задачи.
Задача
В компании, изготавливающей изделия путем механообработки, необходимо исследовать влияние на качество изделия двух факторов: Метода обработки поверхности детали, и Исходного материала детали (используется сталь с различным легированием).
Метод обработки представляет собой
фактор А
, который может принимать 3 значения (Метод 1, Метод 2, Метод 3), а Исходный материал
представляет собой
фактор В
, который может принимать 2 значения (№ 1, № 2). Качество изделий будем определять по количеству дефектных изделий в партии (это будет зависимой переменной Y).
Всего различных комбинаций 2-х факторов 6=3*2=a*b. Для каждой комбинации факторов было проведено по 3 измерения (т.е. m=3). Исходные данные приведены в файле примера .

Другими словами мы имеем 6 выборок по 3 значения в каждой. Средние этих выборок для каждой комбинации факторов ij можно вычислить по формуле:
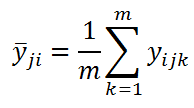
Также для дальнейших вычислений нам потребуется вычислить еще несколько средних значений. Во-первых, вычислим среднее всех измерений, относящихся к каждому уровню i Фактора А:
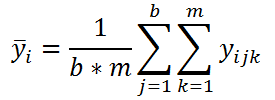
Во-вторых, вычислим среднее всех измерений, относящихся к каждому уровню j Фактора В:
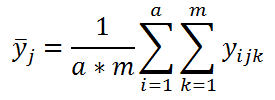
Взаимодействие факторов
Теперь, используя эти 6 средних значений, построим диаграмму, которая
состоит из 2-х рядов
.
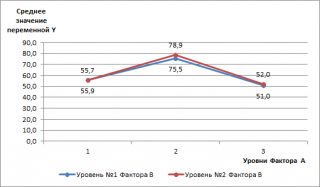
По оси Х (абсцисс) отложены уровни
Фактора А
, по оси ординат отложены средние значения переменной Y (среднее количество дефектов для заданных уровней факторов). Средние значения сгруппированы по 2-м уровням Фактора В (Синяя и красная линии. Каждая линия представляет собой отдельный ряд диаграммы).
Как видно из диаграммы – синяя и красная линии практически параллельны друг другу. Это означает, что взаимодействие между факторами практически отсутствует (они не влияют друг на друга). Действительно, выбор метода обработки никак не может влиять на выбор конкретного исходного материала.
Вот еще одна диаграмма, демонстрирующая независимость 2-х факторов.
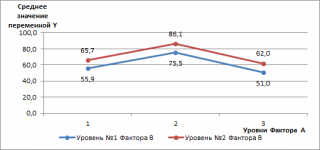
Обратная ситуация показана на диаграмме ниже, когда оба фактора взаимодействуют.
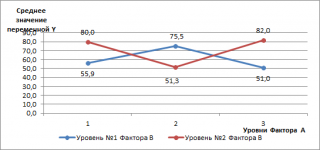
Из этой диаграммы видно, что при
уровне №1 фактора В
(синяя линия) количество дефектов сначала возрастает, затем снижается (когда мы переходим от метода №1 к №2, затем к №3). Мы наблюдаем диаметрально противоположную ситуацию при
уровне №2 фактора В
(красная линия): количество дефектов сначала снижается, а затем возрастает. В этом случае говорят о наличии взаимодействия факторов.
В случае взаимодействия факторов А и В, эффект от их взаимодействия может быть рассмотрен как некий
третий фактор АВ
. Чтобы пояснить это рассмотрим задачу анализа влияния на урожайность свеклы 2-х факторов:
Вид семян
и
Тип почвы
. Очевидно, что факторы
Вид семян
и
Тип почвы
не являются независимыми: можно утверждать, что для всех с/х культур на разных почвах разные типы семян дадут разную всхожесть. Различные комбинации
Вид семян
—
Тип почвы
могут сильно влиять на урожайность и поэтому взаимодействие факторов может вносить определенный вклад в разброс исходных данных.
Взаимодействие факторов было рассмотрено столь подробно, так как отсутствие или наличие взаимодействия принципиально влияет на ход
дисперсионного анализа
. При отсутствии взаимодействия влияние каждого фактора на переменную Y может быть рассмотрено по отдельности. При наличии взаимодействия анализировать влияние каждого фактора по отдельности нельзя. Альтернативным вариантом анализа в этом случае является
однофакторный дисперсионный анализ,
целью которого может быть поиск оптимального сочетания 2-х факторов.
Возвращаемся к диаграммам взаимодействия. Очевидно, что делать заключение о наличии или отсутствии взаимодействия факторов невозможно лишь по взаимному расположению линий на диаграмме. Для формулирования утверждения о взаимодействии требуется составить математическое выражение. Это выражение должно вычисляться на основании исходных данных, а результат должен сравниваться с неким критическим значением. Займемся этим в следующем разделе.
Определяем причины изменчивости исходных данных
По аналогии с однофакторным
дисперсионным анализом
общую изменчивость (разброс) значений Y относительно
общего среднего
(SST = Sum of Squares Total, общая сумма квадратов) определим как сумму нескольких компонентов, в данном случае 4-х:
SST=SSA+SSB+ SS взаим +SSE
- SSA – изменчивость, которую можно объяснить выбором метода обработки (фактор А)
- SSВ — изменчивость обусловленная выбором материала детали (фактор В)
- SS взаим — изменчивость обусловленная взаимодействием 2-х факторов
- SSE — ошибка модели (Error Sum of Squares).
SST и все 4 компонента вычисляются на основании имеющихся исходных данных:
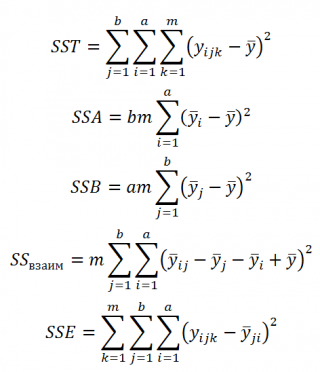
Примечание
: Вычисления SST и всех 4-х компонентов выполнены в файле примера .
Также в
дисперсионном анализе
используется понятие
среднего квадрата отклонений
(Mean Square) или сокращенно MS. Соответственно для SST имеем MST=SST/(N-1), где N= a*b*m является общим количеством измерений (18). Для других SS степени свободы приведены в таблице ниже.
Таким образом, MS имеет смысл средней изменчивости на 1 наблюдение (с некоторой поправкой). Эта поправка отражает тот факт, что MS должна вычисляться не делением SS на соответствующее количество наблюдений, а делением на число
степеней свободы
(degrees of freedom, DF). Например, чтобы вычислить MST, мы из N (общего количества наблюдений) должны вычесть 1, т.к. в выражении SST присутствует одно (1) среднее значение (аналогично тому, как мы делали при
вычислении дисперсии
).

В случае
двухфакторного дисперсионного анализа
формируется 3
нулевых гипотезы
.
- Гипотеза Н 0 взаим об отсутствии взаимодействия Фактора А и Фактора В. Альтернативная гипотеза Н 1взаим формулируется о наличии взаимодействия.
- гипотеза Н 01 заключается в том, что уровень фактора А (метод обработки поверхности) не влияет на измеренные значения Y (количество дефектов), т.е. средние значения выборок, относящиеся к различным уровням Фактора А не отличаются статистически значимо (их различие может быть объяснено лишь случайностью выборок).
- гипотеза Н 0 2 заключается в том, что уровень фактора В (Исходный материал) не влияет на измеренные значения Y (количество дефектов), т.е. средние значения выборок, относящиеся к различным уровням Фактора В не отличаются статистически значимо.
Сначала тестируют гипотезу об отсутствии взаимодействия между факторами. Мы можем отклонить Н 0 взаим в пользу Н 1взаим при заданном
уровне значимости
α (альфа), если вычисленное значение тестовой статистики F= MS взаим /MSE больше F критич альфа – значения случайной величины F имеющей
распределение Фишера
с (b-1)*(a-1) и a*b*(m-1) степенями свободы.
Если взаимодействие между факторами отсутствует, то можно начинать тестировать гипотезы Н 01 и Н 0 2 . При наличии взаимодействия анализировать влияние каждого фактора по отдельности нельзя. Альтернативным вариантом анализа в этом случае является
однофакторный дисперсионный анализ
, целью которого может быть поиск оптимального сочетания 2-х факторов.
Чтобы проверить гипотезы необходимо вычислить значения тестовых статистик и сравнить их с соответствующими критическими значениями F крит ич , вычисленными для заданного уровня значимости
альфа
. Если вычисленное значение F 01 = MSА/MSE больше F 1крит ич , то нулевую гипотезу Н 0 1 об отсутствии влияния уровней Фактора А отклоняют. Аналогичные умозаключения справедливы и для Фактора В.
Проверить гипотезу Н 01 можно и через вычисление
p
-значения,
которое представляет собой вероятность того, что случайная величина F 1 = MSА/MSE примет значение более F 01 . Далее
p
-значение
сравнивают с уровнем значимости. Если
p
-значение
менее уровня значимости, то нулевую гипотезу отклоняют. Действительно, если вычисленное значение F 01 получить маловероятно, то это ставит под сомнение справедливость того, что случайная величина F 1 = MSА/MSE имеет
распределение Фишера
с
a
-1
и
a
*
b
*(
m
-1)
степенями свободы, а следовательно и саму нулевую гипотезу. В этом случае мы можем считать, что справедлива альтернативная гипотеза: уровни фактора А влияют на зависимую переменную Y.
Вычисления в MS EXCEL
В файле примера приведено решение вышеуказанной задачи: вычислены средние значения выборок, суммы квадратов (SS), степеней свобод, средние квадратов отклонений (MS).
Для вычислений критических значений в MS EXCEL имеется специальная функция = F.ОБР.ПХ()
Формула для вычисления F 1критич = F.ОБР.ПХ(a-1; a*b*(m-1);альфа)
В MS EXCEL первое
p
-значение
(вероятность того, что случайная величина F 1 = MSА/MSE примет значение более F 01 ) можно вычислить по формуле:
= F.РАСП.ПХ((MSА/MSE; a-1; a*b*(m-1))
Второе
p
-значение
(вероятность того, что случайная величина F 2 = MSВ/MSE примет значение более F 0 2 ) вычисляется по аналогичным формулам.
В нашей задаче
p
-значения
получились 0,000 и 0,253, что значительно меньше обычно принимаемого в качестве
уровня значимости
0,05. Таким образом, обе нулевых гипотезы отклоняются.
Excel для Microsoft 365 Excel для Microsoft 365 для Mac Excel 2021 Excel 2021 для Mac Excel 2019 Excel 2019 для Mac Excel 2016 Excel 2016 для Mac Excel 2013 Excel 2010 Excel 2007 Еще…Меньше
Если вам нужно разработать сложный статистический или инженерный анализ, вы можете сэкономить время и этапы с помощью этого средства. Вы предоставляете данные и параметры для каждого анализа, а средство использует соответствующие статистические или инженерные функции для вычисления и отображения результатов в выходной таблице. Некоторые средства создают диаграммы в дополнение к выходным таблицам.
Функции анализа данных можно применять только на одном листе. Если анализ данных проводится в группе, состоящей из нескольких листов, то результаты будут выведены на первом листе, на остальных листах будут выведены пустые диапазоны, содержащие только форматы. Чтобы провести анализ данных на всех листах, повторите процедуру для каждого листа в отдельности.
Ниже описаны инструменты, включенные в пакет анализа. Для доступа к ним нажмите кнопкуАнализ данных в группе Анализ на вкладке Данные. Если команда Анализ данных недоступна, необходимо загрузить надстройку «Пакет анализа».
-
Откройте вкладку Файл, нажмите кнопку Параметры и выберите категорию Надстройки.
-
В раскрывающемся списке Управление выберите пункт Надстройки Excel и нажмите кнопку Перейти.
Если вы используете Excel для Mac, в строке меню откройте вкладку Средства и в раскрывающемся списке выберите пункт Надстройки для Excel.
-
В диалоговом окне Надстройки установите флажок Пакет анализа, а затем нажмите кнопку ОК.
-
Если Пакет анализа отсутствует в списке поля Доступные надстройки, нажмите кнопку Обзор, чтобы выполнить поиск.
-
Если выводится сообщение о том, что пакет анализа не установлен на компьютере, нажмите кнопку Да, чтобы установить его.
-
Примечание: Чтобы включить Visual Basic для приложений (VBA) для надстройки «Надстройка анализа», вы можете загрузить надстройку VBA так же, как и надстройку «Надстройка анализа». В поле Доступные надстройки выберите «Надстройка анализа — VBA».
Существует несколько видов дисперсионного анализа. Нужный вариант выбирается с учетом числа факторов и имеющихся выборок из генеральной совокупности.
Однофакторный дисперсионный анализ
Этот инструмент выполняет простой анализ дисперсии данных для двух или более выборок. Анализ дает проверку гипотезы о том, что каждая выборка взята из одного и того же распределения вероятности на основе альтернативной гипотезы о том, что для всех выборок распределение вероятности не одно и то же. Если есть только два примера, можно использовать функцию T.ТЕСТ. В более чем двух примерах нет удобного обобщения T.ВМЕСТОэтого можно использовать модель Anova для одного фактора.
Двухфакторный дисперсионный анализ с повторениями
Этот инструмент анализа применяется, если данные можно систематизировать по двум параметрам. Например, в эксперименте по измерению высоты растений последние обрабатывали удобрениями от различных изготовителей (например, A, B, C) и содержали при различной температуре (например, низкой и высокой). Таким образом, для каждой из 6 возможных пар условий {удобрение, температура}, имеется одинаковый набор наблюдений за ростом растений. С помощью этого дисперсионного анализа можно проверить следующие гипотезы:
-
Извлечены ли данные о росте растений для различных марок удобрений из одной генеральной совокупности. Температура в этом анализе не учитывается.
-
Извлечены ли данные о росте растений для различных уровней температуры из одной генеральной совокупности. Марка удобрения в этом анализе не учитывается.
Извлечены ли шесть выборок, представляющих все пары значений {удобрение, температура}, используемые для оценки влияния различных марок удобрений (для первого пункта в списке) и уровней температуры (для второго пункта в списке), из одной генеральной совокупности. Альтернативная гипотеза предполагает, что влияние конкретных пар {удобрение, температура} превышает влияние отдельно удобрения и отдельно температуры.
Двухфакторный дисперсионный анализ без повторений
Этот инструмент анализа применяется, если данные можно систематизировать по двум параметрам, как в случае двухфакторного дисперсионного анализа с повторениями. Однако в таком анализе предполагается, что для каждой пары параметров есть только одно измерение (например, для каждой пары параметров {удобрение, температура} из предыдущего примера).
Функции CORREL и PEARSON вычисляют коэффициент корреляции между двумя переменными измерения, если для каждой переменной наблюдаемы измерения по каждому из N-объектов. (Любые отсутствующие наблюдения по любой теме вызывают игнорирование в анализе.) Средство анализа корреляции особенно удобно использовать, если для каждого субъекта N имеется более двух переменных измерения. Она содержит выходную таблицу — матрицу корреляции, которая показывает значение CORREL (или PEARSON),примененного к каждой из возможных пар переменных измерения.
Коэффициент корреляции, как и ковариана, — это мера степени, в которой две единицы измерения «различаются». В отличие от ковариации коэффициент корреляции масштабирован таким образом, что его значение не зависит от единиц измерения, выраженных в двух переменных измерения. (Например, если двумя переменными измерения являются вес и высота, то значение коэффициента корреляции не изменяется, если вес преобразуется из фунта в фунты.) Значение любого коэффициента корреляции должно быть включительно от -1 до +1 включительно.
Корреляционный анализ дает возможность установить, ассоциированы ли наборы данных по величине, т. е. большие значения из одного набора данных связаны с большими значениями другого набора (положительная корреляция) или наоборот, малые значения одного набора связаны с большими значениями другого (отрицательная корреляция), или данные двух диапазонов никак не связаны (нулевая корреляция).
Средства корреляции и коварианс могут использоваться в одном и том же параметре, если у вас есть N различных переменных измерения, наблюдаемые для набора людей. Каждый из инструментов корреляции и ковариции дает выходную таблицу — матрицу, которая показывает коэффициент корреляции или коварианс между каждой парой переменных измерения соответственно. Разница заключается в том, что коэффициенты корреляции масштабироваться в зависимости от -1 и +1 включительно. Соответствующие ковариансы не масштабироваться. Коэффициент корреляции и коварианс — это показатели степени, в которой две переменные «различаются».
Инструмент Ковариана вычисляет значение функции КОВАРИАНА. P для каждой пары переменных измерения. (Прямое использование КОВАРИАНА. P вместо ковариана является разумной альтернативой, если есть только две переменные измерения, то есть N=2.) Запись в диагонали выходной таблицы средства Коварица в строке i, столбце i — коварианс i-й переменной измерения. Это только дисперсия по численности населения для этой переменной, вычисляемая функцией ДИСПЕРС.P.
Ковариационный анализ дает возможность установить, ассоциированы ли наборы данных по величине, то есть большие значения из одного набора данных связаны с большими значениями другого набора (положительная ковариация) или наоборот, малые значения одного набора связаны с большими значениями другого (отрицательная ковариация), или данные двух диапазонов никак не связаны (ковариация близка к нулю).
Инструмент анализа «Описательная статистика» применяется для создания одномерного статистического отчета, содержащего информацию о центральной тенденции и изменчивости входных данных.
Инструмент анализа «Экспоненциальное сглаживание» применяется для предсказания значения на основе прогноза для предыдущего периода, скорректированного с учетом погрешностей в этом прогнозе. При анализе используется константа сглаживания a, величина которой определяет степень влияния на прогнозы погрешностей в предыдущем прогнозе.
Примечание: Для константы сглаживания наиболее подходящими являются значения от 0,2 до 0,3. Эти значения показывают, что ошибка текущего прогноза установлена на уровне от 20 до 30 процентов ошибки предыдущего прогноза. Более высокие значения константы ускоряют отклик, но могут привести к непредсказуемым выбросам. Низкие значения константы могут привести к большим промежуткам между предсказанными значениями.
Двухвыборочный F-тест применяется для сравнения дисперсий двух генеральных совокупностей.
Например, можно использовать F-тест по выборкам результатов заплыва для каждой из двух команд. Это средство предоставляет результаты сравнения нулевой гипотезы о том, что эти две выборки взяты из распределения с равными дисперсиями, с гипотезой, предполагающей, что дисперсии различны в базовом распределении.
С помощью этого инструмента вычисляется значение f F-статистики (или F-коэффициент). Значение f, близкое к 1, показывает, что дисперсии генеральной совокупности равны. В таблице результатов, если f < 1, «P(F <= f) одностороннее» дает возможность наблюдения значения F-статистики меньшего f при равных дисперсиях генеральной совокупности и F критическом одностороннем выдает критическое значение меньше 1 для выбранного уровня значимости «Альфа». Если f > 1, «P(F <= f) одностороннее» дает возможность наблюдения значения F-статистики большего f при равных дисперсиях генеральной совокупности и F критическом одностороннем дает критическое значение больше 1 для «Альфа».
Инструмент «Анализ Фурье» применяется для решения задач в линейных системах и анализа периодических данных на основе метода быстрого преобразования Фурье (БПФ). Этот инструмент поддерживает также обратные преобразования, при этом инвертирование преобразованных данных возвращает исходные данные.

Инструмент «Гистограмма» применяется для вычисления выборочных и интегральных частот попадания данных в указанные интервалы значений. При этом рассчитываются числа попаданий для заданного диапазона ячеек.
Например, можно получить распределение успеваемости по шкале оценок в группе из 20 студентов. Таблица гистограммы состоит из границ шкалы оценок и групп студентов, уровень успеваемости которых находится между самой нижней границей и текущей границей. Наиболее часто встречающийся уровень является модой диапазона данных.
Совет: В Excel 2016 теперь можно создавать гистограммы и диаграммы Парето.
Инструмент анализа «Скользящее среднее» применяется для расчета значений в прогнозируемом периоде на основе среднего значения переменной для указанного числа предшествующих периодов. Скользящее среднее, в отличие от простого среднего для всей выборки, содержит сведения о тенденциях изменения данных. Этот метод может использоваться для прогноза сбыта, запасов и других тенденций. Расчет прогнозируемых значений выполняется по следующей формуле:
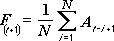
где
-
N — число предшествующих периодов, входящих в скользящее среднее;
-
A
j — фактическое значение в момент времени j; -
F
j — прогнозируемое значение в момент времени j.
Инструмент «Генерация случайных чисел» применяется для заполнения диапазона случайными числами, извлеченными из одного или нескольких распределений. С помощью этой процедуры можно моделировать объекты, имеющие случайную природу, по известному распределению вероятностей. Например, можно использовать нормальное распределение для моделирования совокупности данных по росту людей или использовать распределение Бернулли для двух вероятных исходов, чтобы описать совокупность результатов бросания монеты.
Средство анализа Ранг и процентиль создает таблицу, которая содержит порядковую и процентную ранг каждого значения в наборе данных. Можно проанализировать относительное положение значений в наборе данных. В этом средстве используются функции РАНГ. EQ и PERCENTRANK. INC. Если вы хотите учитывать связанные значения, используйте РАНГ. Функция EQ, которая обрабатывает связанные значения как имеющие одинаковый ранг или использует РАНГ.Функция AVG, которая возвращает средний ранг связанных значений.
Инструмент анализа «Регрессия» применяется для подбора графика для набора наблюдений с помощью метода наименьших квадратов. Регрессия используется для анализа воздействия на отдельную зависимую переменную значений одной или нескольких независимых переменных. Например, на спортивные качества атлета влияют несколько факторов, включая возраст, рост и вес. Можно вычислить степень влияния каждого из этих трех факторов по результатам выступления спортсмена, а затем использовать полученные данные для предсказания выступления другого спортсмена.
В средстве регрессии используется функция LINEST.
Инструмент анализа «Выборка» создает выборку из генеральной совокупности, рассматривая входной диапазон как генеральную совокупность. Если совокупность слишком велика для обработки или построения диаграммы, можно использовать представительную выборку. Кроме того, если предполагается периодичность входных данных, то можно создать выборку, содержащую значения только из отдельной части цикла. Например, если входной диапазон содержит данные для квартальных продаж, создание выборки с периодом 4 разместит в выходном диапазоне значения продаж из одного и того же квартала.
Двухвыборочный t-тест проверяет равенство средних значений генеральной совокупности по каждой выборке. Три вида этого теста допускают следующие условия: равные дисперсии генерального распределения, дисперсии генеральной совокупности не равны, а также представление двух выборок до и после наблюдения по одному и тому же субъекту.
Для всех трех средств, перечисленных ниже, значение t вычисляется и отображается как «t-статистика» в выводимой таблице. В зависимости от данных это значение t может быть отрицательным или неотрицательным. Если предположить, что средние генеральной совокупности равны, при t < 0 «P(T <= t) одностороннее» дает вероятность того, что наблюдаемое значение t-статистики будет более отрицательным, чем t. При t >=0 «P(T <= t) одностороннее» делает возможным наблюдение значения t-статистики, которое будет более положительным, чем t. «t критическое одностороннее» дает пороговое значение, так что вероятность наблюдения значения t-статистики большего или равного «t критическое одностороннее» равно «Альфа».
«P(T <= t) двустороннее» дает вероятность наблюдения значения t-статистики, по абсолютному значению большего, чем t. «P критическое двустороннее» выдает пороговое значение, так что значение вероятности наблюдения значения t- статистики, по абсолютному значению большего, чем «P критическое двустороннее», равно «Альфа».
Парный двухвыборочный t-тест для средних
Парный тест используется, когда имеется естественная парность наблюдений в выборках, например, когда генеральная совокупность тестируется дважды — до и после эксперимента. Этот инструмент анализа применяется для проверки гипотезы о различии средних для двух выборок данных. В нем не предполагается равенство дисперсий генеральных совокупностей, из которых выбраны данные.
Примечание: Одним из результатов теста является совокупная дисперсия (совокупная мера распределения данных вокруг среднего значения), вычисляемая по следующей формуле:
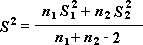
Двухвыборочный t-тест с одинаковыми дисперсиями
Этот инструмент анализа выполняет t-тест для двух образцов учащихся. В этой форме t-test предполагается, что два набора данных поступили из распределения с одинаковыми дисперсиями. Его называют гомике t-тестом. Этот t-тест можно использовать для определения вероятности того, что эти две выборки взяты из распределения с равными средствами распределения.
Двухвыборочный t-тест с различными дисперсиями
Этот инструмент анализа выполняет t-тест для двух образцов учащихся. В этой форме t-test предполагается, что два набора данных были полученными из распределения с неравными дисперсиями. Его называют гетероскестическими t-тестами. Как и в предыдущем примере с равными дисперсиями, этот t-тест можно использовать для определения вероятности того, что эти две выборки взяты из распределения с равными средствами распределения. Этот тест можно использовать, если в двух примерах есть отдельные объекты. Используйте тест Парный, описанный в примере, если существует один набор тем и две выборки представляют измерения по каждой теме до и после обработки.
Для определения тестовой величины t используется следующая формула.
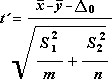
Следующая формула используется для вычисления степеней свободы (df). Так как результат вычисления обычно не является integer, значение df округлится до ближайшего другого, чтобы получить критическое значение из таблицы t. Функция Excel T .Test использует вычисляемую величину df без округлений, так как можно вычислить значение для T.ТЕСТ с неинтегрированной df. Из-за этих разных подходов к определению степеней свободы результаты T.Тест и этот t-тест будут отличаться в случае неравных дисперсий.
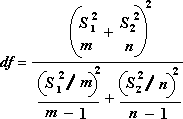
Z-тест. Средство анализа «Две выборки для середины» выполняет два примера z-теста для средств со известными дисперсиями. Этот инструмент используется для проверки гипотезы NULL о том, что между двумя значениями численности населения нет различий между односторонними или двухбокльными альтернативными гипотезами. Если дисперсии не известны, функция Z .Вместо этого следует использовать тест.
При использовании этого инструмента следует внимательно просматривать результат. «P(Z <= z) одностороннее» на самом деле есть P(Z >= ABS(z)), вероятность z-значения, удаленного от 0 в том же направлении, что и наблюдаемое z-значение при одинаковых средних значениях генеральной совокупности. «P(Z <= z) двустороннее» на самом деле есть P(Z >= ABS(z) или Z <= -ABS(z)), вероятность z-значения, удаленного от 0 в том же направлении, что и наблюдаемое z-значение при одинаковых средних значениях генеральной совокупности. Двусторонний результат является односторонним результатом, умноженным на 2. Инструмент «z-тест» можно также применять для гипотезы об определенном ненулевом значении разницы между двумя средними генеральных совокупностей. Например, этот тест можно использовать для определения разницы выступлений на соревнованиях двух автомобилей разных марок.
Дополнительные сведения
Вы всегда можете задать вопрос специалисту Excel Tech Community или попросить помощи в сообществе Answers community.
См. также
Создание гистограммы в Excel 2016
Создание диаграммы Парето в Excel 2016
Загрузка средства анализа в Excel
Инженерные функции (справка)
Общие сведения о формулах в Excel
Рекомендации, позволяющие избежать появления неработающих формул
Поиск ошибок в формулах
Сочетания клавиш и горячие клавиши в Excel
Функции Excel (по алфавиту)
Функции Excel (по категориям)
Нужна дополнительная помощь?
 If you thought there were a lot of functions and features already packed in to Excel, you may be surprised that there are even more available. Both Microsoft and third party developers publish additional tools, called add-ins, that are typically used for specialized number crunching in various fields.
If you thought there were a lot of functions and features already packed in to Excel, you may be surprised that there are even more available. Both Microsoft and third party developers publish additional tools, called add-ins, that are typically used for specialized number crunching in various fields.
If you are working on statistical analysis and, more specifically, undertaking a variation analysis, there is a tool available through add-ins that should help make the process much easier. Regardless of how complex the research you are working with, the ANOVA tool is simple and user friendly. Here we will briefly take a look at the tool and walk through the steps involved in using it.
If you are interested in learning more about Excel’s advanced analytical capabilities, you might be interested in an online advanced Excel course.
Understanding ANOVA in Excel
The ANOVA function in Excel is the analytical tool used for variance analysis. A form of hypothesis testing, it will determine whether two or more factors have the same mean. Currently, it has three different variations depending on the test you want to perform: Single factor, two-factor with replication and two factor without replication.
Single-factor: This offers a test on data of two or more samples. With it, you can test the hypothesis that each of the samples is drawn from the same underlying probability distribution against the hypothesis that the underlying probability distribution is not the same.
If you are working with only two samples, note that Excel gives you an alternative called T-Test, which is built in to its regular set of functions. If you would like to understand how this and other standard functions operate in Excel, you can take an online course in advanced Excel.
two-factor with replication: when you have two factors on which the variance depends and you are collecting multiple data points for a specified condition, you will want to use this option.
two-factor without replication: When variance depends on two factors and you are collecting a single dat point for a specified condition, you will use this test.
This tutorial assumes that you are familiar with these statistical concepts and will focus on explaining how to use Excel to help you run the tests. If, however, you need to brush up on concepts in statistics, you can take an online introduction to statistics that should serve as a refresher.
Enable the Analysis Toolpak
The ANOVA function is part of an add-in for Excel, so if you haven’t already, you will need to enable the Excel Analysis Toolpak before you can use it. In addition to ANOVA, this add-in for Excel will give you access to a number of helpful tools for running statistical analysis in your workbooks. If you would like to dive in and understand the power of Excel for working with statistics, you can take a course on Excel’s statistical functions.
Here are instructions for enabling the toolpak in Excel 2010. Depending on the version you are using, the method may vary slightly. So if this does not work for you, you should be able to search for another method or find it on Office.com
1. Go to the file menu
2. Select Options
3. From the options menu, select add-ins from the left column
4. At the bottom of the menu, you will see a label that says “Manage:” followed by a drop-down box. Make sure Excel add-ins is selected from that drop-down and click Go.

5. Another menu will appear, showing you the available add-ins. Check the box next to Analysis Toolpak, and click OK
If the Analysis toolpak is not listed, click browse to locate it. If the program tells you it isn’t installed, click Yes to install it.
You should now have the Analysis Toolpak enabled. To verify, click on the data tab from the main ribbon. You should see a data analysis option on the right. If you click on that Anova should be among the first options available.
Running ANOVA
Now that you have the Analysis toolpak enabled, you have what you need to complete the test.
Running the ANOVA function
To start with the Anova function, open the workbook containing the data you want to run the test on. Then, follow these steps:
1. click in a cell on your spreadsheet where your output will begin. The results, of course, will cover a range of cells.
2. Click on the Data tab from the main ribbon and select data analysis, which should be in the analysis menu on the right.
3. Select the appropriate Anova test from the options in the Data Analysis menu.
4. The function’s menu will pop up. Start by putting in the range containing the data to be analyzed. If you click the button to the right of the text box (containing a red arrow) you can select your cell range by clicking and dragging.

5. Select the number of rows each sample contains.
6. Specify the alpha (the default 0.05 represents a 95% confidence interval.
7. Specify the output range. Again, you can click the button to the right of the text box to click and drag. All you really need to consider here is where the first cell of the results will be located. You do not need to indicate the exact number of rows and columns for the result. Note that the output will be contained in a range of 7 columns by 30 rows.
You now have your result. All that’s left is interpreting it! If you are a little bit fuzzy on what the numbers mean, don’t worry, you have resources available to help out. In fact you can take an online course that includes a walkthrough of ANOVA and its results.
Hopefully, your test has run smoothly and produced a useable outcome.
Однофакторный дисперсионный анализ изучает влияния одного фактора на анализируемый признак.
В таблицы приведены статистические данные по количеству изготовленных деталей на заводе каждым мастером в течение каждой недели.
Необходимо выяснить зависимость количества изготовленных деталей от производительности мастера. Уровень значимости равен α=0.05.
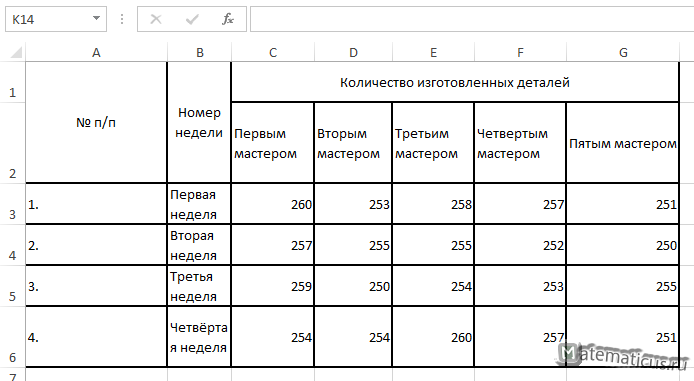
| № п/п | Номер недели | Количество изготовленных деталей | ||||
| Первым мастером | Вторым мастером | Третьим мастером | Четвертым мастером | Пятым мастером | ||
| 1. | Первая неделя | 260 | 253 | 258 | 257 | 251 |
| 2. | Вторая неделя | 257 | 255 | 255 | 252 | 250 |
| 3. | Третья неделя | 259 | 250 | 254 | 253 | 255 |
| 4. | Четвёртая неделя | 254 | 254 | 260 | 257 | 251 |
Решение
Переходим на вкладку Данные -> Анализ данных. Выбираем однофакторный дисперсионный анализ и жмём Ок.
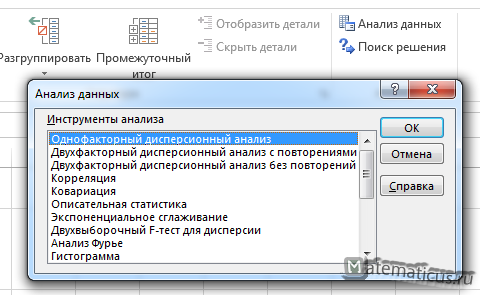
Появляется окно, здесь во входном интервале выбираем диапазон данный в нашей таблицы в нашем случае это диапазон ячеек $C$3:$G$6, альфа ставим 0,05 (обычно в Excel данная величина стоит по умолчанию) и в выходном интервале указываем произвольную ячейку на листе Excel, где желаете, чтобы отобразился результат, далее Ок.
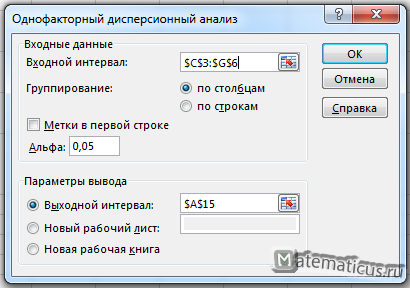
В результате получим решение в виде таблицы.
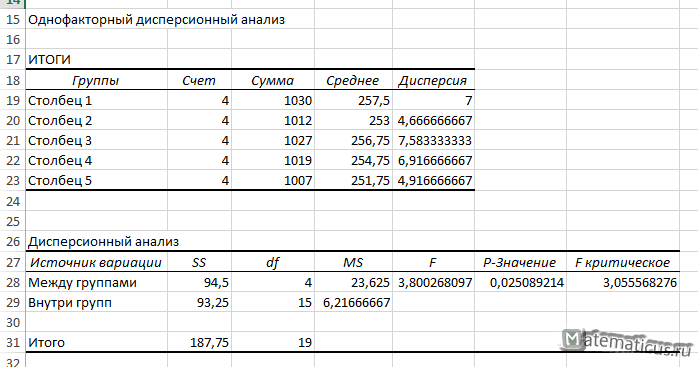
| Однофакторный дисперсионный анализ | ||||||
| ИТОГИ | ||||||
| Группы | Счет | Сумма | Среднее | Дисперсия | ||
| Столбец 1 | 4 | 1030 | 257,5 | 7 | ||
| Столбец 2 | 4 | 1012 | 253 | 4,666666667 | ||
| Столбец 3 | 4 | 1027 | 256,75 | 7,583333333 | ||
| Столбец 4 | 4 | 1019 | 254,75 | 6,916666667 | ||
| Столбец 5 | 4 | 1007 | 251,75 | 4,916666667 | ||
| Дисперсионный анализ | ||||||
| Источник вариации | SS | df | MS | F | P-Значение | F критическое |
| Между группами | 94,5 | 4 | 23,625 | 3,800268097 | 0,025089214 | 3,055568276 |
| Внутри групп | 93,25 | 15 | 6,21666667 | |||
| Итого | 187,75 | 19 |
Из таблицы значения F-критерия равно Fнабл=3.8, а Fкрит=3, правосторонний интервал (3; +∞) Fнабл>Fкрит, отсюда следует, что Fнабл лежит в этом интервале, следовательно, нулевую гипотезу H0 о равенстве групповых матожиданий — отвергаем, следовательно фактор — количества изготовленных деталей зависит от признака — производительности мастера.
Найдём выборочный коэффициент детерминации:
${R^2} = frac{{frac{{94,5}}{{20}}}}{{frac{{187,75}}{{20}}}} approx 0,5$
Этот показатель говорит о том, что около половины еженедельного количества изготовленных деталей мастерами связано с номером недели.
![]() 7286
7286