
Microsoft постоянно добавляет в Excel новые возможности в части анализа и визуализации данных. Работу с информацией в Excel можно представить в виде относительно независимых трех слоев:
- «правильно» организованные исходные данные
- математика (логика) обработки данных
- представление данных

Рис. 1. Анализ данных в Excel: а) исходные данные, б) мера в Power Pivot, в) дашборд; чтобы увеличить изображение кликните на нем правой кнопкой мыши и выберите Открыть картинку в новой вкладке
Скачать заметку в формате Word или pdf, примеры в формате Excel
Функции кубов и сводные таблицы
Наиболее простым и в тоже время очень мощным средством представления данных являются сводные таблицы. Они могут быть построены на основе данных, содержащихся: а) на листе Excel, б) кубе OLAP или в) модели данных Power Pivot. В последних двух случаях, помимо сводной таблицы, можно использовать аналитические функции (функции кубов) для формирования отчета на листе Excel. Сводные таблицы проще. Функции кубов сложнее, но предоставляют больше гибкости, особенно в оформлении отчетов, поэтому они широко применяются в дашбордах.
Дальнейшее изложение относится к формулам кубов и сводным таблицам на основе модели Power Pivot и в нескольких случаях на основе кубов OLAP.
Простой способ получить функции кубов
Когда (если) вы начинали изучать код VBA, то узнали, что проще всего получить код, используя запись макроса. Далее код можно редактировать, добавить циклы, проверки и др. Аналогично проще всего получить набор функций кубов, преобразовав сводную таблицу (рис. 2). Встаньте на любую ячейку сводной таблицы, перейдите на вкладку Анализ, кликните на кнопке Средства OLAP, и нажмите Преобразовать в формулы.

Рис. 2. Преобразование сводной таблицы в набор функций куба
Числа сохранятся, причем это будут не значения, а формулы, которые извлекают данные из модели данных Power Pivot (рис. 3). Получившуюся таблицу вы может отформатировать. В том числе, можно удалять и вставлять строки и столбцы внутрь таблицы. Срез остался, и он влияет на данные в таблице. При обновлении исходных данных числа в таблице также обновятся.

Рис. 3. Таблица на основе формул кубов
Функция КУБЗНАЧЕНИЕ()
Это, пожалуй, основная функция кубов. Она эквивалентна области Значения сводной таблицы. КУБЗНАЧЕНИЕ извлекает данные из куба или модели Power Pivot, и отражает их вне сводной таблицы. Это означает, что вы не ограничены пределами сводной таблицы и можете создавать отчеты с бесчисленными возможностями.
Написание формулы «с нуля»
Вам не обязательно преобразовывать готовую сводную таблицу. Вы можете написать любую формулу куба «с нуля». Например, в ячейку С10 введена следующая формула (рис. 4):
|
=КУБЗНАЧЕНИЕ(«ThisWorkbookDataModel»; «[Measures].[Total Sales]»; «[Products].[Category].[All].[Bikes]» ) |
 в ячейке С10 возвращает общие продажи велосипедов, как и в сводной таблице")
Рис. 4. Функция КУБЗНАЧЕНИЕ() в ячейке С10 возвращает продажи велосипедов за все годы, как и в сводной таблице
Маленькая хитрость. Чтобы удобнее было читать формулы кубов, желательно, чтобы в каждой строке помещался только один аргумент. Можно уменьшить окно Excel. Для этого кликните на значке Свернуть в окно, находящемся в правом верхнем углу экрана. А затем отрегулируйте размер окна по горизонтали. Альтернативный вариант – принудительно переносить текст формулы на новую строку. Для этого в строке формул поставьте курсор в том месте, где хотите сделать перенос и нажмите Alt+Enter.

Рис. 5. Свернуть окно
Синтаксис функции КУБЗНАЧЕНИЕ()
Справка Excel абсолютно точна и абсолютно бесполезна для начинающих:
КУБЗНАЧЕНИЕ(подключение; [выражение_элемента1]; [выражение_элемента2]; …)
Подключение – обязательный аргумент; текстовая строка, представляющая имя подключения к кубу.
Выражение_элемента – необязательный аргумент; текстовая строка, представляющая многомерное выражение, которое возвращает элемент или кортеж в кубе. Кроме того, «выражение_элемента» может быть множеством, определенным с помощью функции КУБМНОЖ. Используйте «выражение_элемента» в качестве среза, чтобы определить часть куба, для которой необходимо возвратить агрегированное значение. Если в аргументе «выражение_элемента» не указана мера, будет использоваться мера, заданная по умолчанию для этого куба.
Прежде, чем перейти к объяснению синтаксиса функции КУБЗНАЧЕНИЕ, пару слов о кубах, моделях данных, и загадочном кортеже.
Некоторые сведения о кубах OLAP и моделях данных Power Pivot
Кубы данных OLAP (Online Analytical Processing — оперативный анализ данных) были разработаны специально для аналитической обработки и быстрого извлечения из них данных. Представьте трехмерное пространство, где по осям отложены периоды времени, города и товары (рис. 5а). В узлах такой координатной сетки расположены значения различных мер: объем продаж, прибыль, затраты, количество проданных единиц и др. Теперь вообразите, что измерений десятки, или даже сотни… и мер тоже очень много. Это и будет многомерный куб OLAP. Создание, настройка и поддержание в актуальном состоянии кубов OLAP – дело ИТ-специалистов.

Рис. 5а. Трехмерный куб OLAP
Аналитические формулы Excel (формулы кубов) извлекают названия осей (например, Время), названия элементов на этих осях (август, сентябрь), значения мер на пересечении координат. Именно такая структура и позволяет сводным таблицам на основе кубов и формулам кубов быть столь гибкими, и подстраиваться под нужды пользователей. Сводные таблицы на основе листов Excel не используют меры, поэтому они не столь гибки в целях анализа данных.
Power Pivot – относительно новая фишка Microsoft. Это встроенная в Excel и отчасти независимая среда с привычным интерфейсом. Power Pivot значительно превосходит по своим возможностям стандартные сводные таблицы. Вместе с тем, разработка кубов в Power Pivot относительно проста, а самое главное – не требует участия ИТ-специалиста. Microsoft реализует свой лозунг: «Бизнес-аналитику – в массы!». Хотя модели Power Pivot не являются кубами на 100%, о них также можно говорить, как о кубах (подробнее см. вводный курс Марк Мур. Power Pivot и более объемное издание Роб Колли. Формулы DAX для Power Pivot).
Основные компоненты куба – это измерения, иерархии, уровни, элементы (или члены; по-английски members) и меры (measures). Измерение – основная характеристика анализируемых данных. Например, категория товаров, период времени, география продаж. Измерение – это то, что мы можем поместить на одну из осей сводной таблицы. Каждое измерение помимо уникальных значений включает элемент [ALL], выполняющий агрегацию всех элементов этого измерения.
Измерения построены на основе иерархии. Например, категория товаров может разбиваться на подкатегории, далее – на модели, и наконец – на названия товаров (рис. 5б) Иерархия позволяет создавать сводные данные и анализировать их на различных уровнях структуры. В нашем примере иерархия Категория включает 4 Уровня.

Рис. 5б. Иерархия категорий товаров
Элементы (отдельные члены) присутствуют на всех уровнях. Например, на уровне Category есть четыре элемента: Accessories, Bikes, Clothing, Components. Другие уровни имеют свои элементы.
Меры – это вычисляемые значения, например, объем продаж. Меры в кубах хранятся в собственном измерении, называемом [Measures] (см. ниже рис. 9). Меры не имеют иерархий. Каждая мера рассчитывает и хранит значение для всех измерений и всех элементов, и нарезается в зависимости от того, какие элементы измерений мы поместим на оси. Еще говорят, какие зададим координаты, или какой зададим контекст фильтра. Например, на рис. 5а в каждом маленьком кубике рассчитывается одна и та же мера – Прибыль. А возвращаемое мерой значение зависит от координат. Справа на рисунке 5а показано, что Прибыль (в трех координатах) по Москве в октябре на яблоках = 63 000 р. Меру можно трактовать, и как одно из измерений. Например, на рис. 5а вместо оси Товары, разместить ось Меры с элементами Объем продаж, Прибыль, Проданные единицы. Тогда каждая ячейка и будет каким-то значением, например, Москва, сентябрь, объем продаж.
Кортеж – несколько элементов разных измерений, задающие координаты по осям куба, в которых мы рассчитываем меру. Например, на рис. 5а Кортеж = Москва, октябрь, яблоки. Также допустимый кортеж – Пермь, яблоки. Еще один – яблоки, август. Не вошедшие в кортеж измерения присутствуют в нем неявно, и представлены членом по умолчанию [All]. Таким образом, ячейка многомерного пространства всегда определяется полным набором координат, даже если некоторые из них в кортеже опущены. Нельзя включить два элемента одного измерения в кортеж, не позволит синтаксис. Например, недопустимый кортеж Москва и Пермь, яблоки. Чтобы реализовать такое многомерное выражение потребуется набор двух кортежей: Москва и яблоки + Пермь и яблоки.
Набор элементов – несколько элементов одного измерения. Например, яблоки и груши. Набор кортежей – несколько кортежей, каждый из которых состоит из одинаковых измерений в одной и той же последовательности. Например, набор из двух кортежей: Москва, яблоки и Пермь, бананы.
Автозавершение в помощь
Вернемся к синтаксису функции КУБЗНАЧЕНИЕ. Воспользуемся автозавершением. Начните ввод формулы в ячейке:
=КУБЗНАЧЕНИЕ("
Excel предложит все доступные в книге Excel подключения:

Рис. 6. Подключение к модели данных Power Pivot всегда называется ThisWorkbookDataModel

Рис. 7. Подключения к кубам
Продолжим ввод формулы (в нашем случае для модели данных):
=КУБЗНАЧЕНИЕ("ThisWorkbookDataModel";"
Автозавершение предложит все доступные таблицы и меры модели данных:

Рис. 8. Доступные элементы первого уровня – имена таблиц и набор мер (выделен)
Выберите значок Measures. Поставьте точку:
=КУБЗНАЧЕНИЕ("ThisWorkbookDataModel";"[Measures].
Автозавершение предложит все доступные меры:

Рис. 9. Доступные элементы второго уровня в наборе мер
Выберите меру [Total Sales]. Добавьте кавычки, закрывающую скобку, нажмите Enter.
=КУБЗНАЧЕНИЕ("ThisWorkbookDataModel";"[Measures].[Total Sales]")

Рис. 10. Формула КУБЗНАЧЕНИЕ в ячейке Excel
Аналогичным образом можете добавить третий аргумент в формулу:
|
=КУБЗНАЧЕНИЕ(«ThisWorkbookDataModel»; «[Measures].[Total Sales]»; «[Products].[Category].[All].[Bikes]» ) |
В итоге формула возвращает продажи по категории Велосипеды (рис. 11). Автозавершение фактически ведет нас по иерархии модели данных:
- название самой модели
- название таблицы (или набор мер – Measures)
- название иерархии/столбца (или имя меры)
- общий итог по столбцу – [All]
- название элемента столбца
Чтобы правильно сослаться на элемент измерения, необходимо описать полный путь к нему по иерархии, начиная с самого верхнего уровня, например: [Products].[Category].[All].[Bikes]. Однако если имя члена уникально в пределах какой-то иерархии, то эту иерархию можно опустить. Если имя уникально в кубе, то можно опустить все промежуточные уровни (рис. 11). В тоже время лучшая практика заключается в том, чтобы оставить на месте все уровни. Это делает формулу более информативной.

Рис. 11. Общие продажи велосипедов; необязательные уровни
Если вы хотите, чтобы формула куба фильтровалась срезом, продолжите набор формулы: введите точку с запятой и продолжайте вводить сре… Выпадет список автозавершения для всех срезов в книге. Выберите один из них, и теперь эта ячейка будет фильтроваться в соответствии с текущими установками этого среза (в качестве аргументов функции КУБЗНАЧЕНИЕ вы можете последовательно добавить несколько срезов).

Рис. 12. Автозавершение предлагает все имеющиеся в модели срезы
В примерах выше выпадающий список появлялся после ввода двух символов:
" открывающие кавычки – в начале каждого аргумента; предлагаются доступные подключения, измерения/таблицы, набор мер;
. точка – после закрывающей прямоугольной скобки; предлагает элементы следующего уровня иерархии.
На самом деле, автозавершение срабатывает и после нескольких других символов. Мы рассмотрим их позже.
Режим автозавершения работает не только при наборе формул. В него можно перейти и для редактирования готовой формулы. Для этого встаньте на ячейку с формулой. Нажмите F2. Вы перейдете в режим редактирования формул (1 на рис. 12а). В левом нижнем углу окна Excel появится надпись Правка (2). Переместите курсор в интересующее вас место формулы (3). Или вместо шагов 1–3 сразу установите курсор в строке формул (4). Нажмите комбинацию клавиш Alt + стрелка вниз. Выпадающий динамический список отразит доступные опции. Обратите внимание, что в другой позиции курсора список иной (5).

Рис. 12а. Работа автозавершения при редактировании формул
Составные строки в качестве аргументов
Аргументы функции КУБЗНАЧЕНИЕ – текстовые строки (кроме срезов). Т.е., аргумент должен быть взят в кавычки, или содержать ссылку на ячейку, возвращающую текстовую строку. Текстовую строку также можно набрать из кусочков, соединенных оператором конкатенации &. Например,
![]()
Рис. 13. Аргумент, набранный из нескольких текстовых строк, сцепленных вместе
Кавычки (1 и 2) выделяют первый фрагмент текстовой строки. Знаки конкатенации (3 и 5) – операторы Excel, каждый из них соединяет предыдущий и последующий текстовые фрагменты. Ссылка на ячейку $Е$11 возвращает текст Bikes. Последний фрагмент текстовой строки ] взят в кавычки (6 и 7), поскольку это текст. Результат сцепки фрагментов – "[Products].[Category].[Bikes]".
Изучая формулы в Интернете я заметил, что многие авторы отделяют имена столбцов от конкретного значения знаком &. Например:
"[Products].[Category].[All].&[Bikes]"
Здесь этот знак необязателен. Я предполагаю, что наличие & является признаком хорошего стиля (или традиции), упрощающего чтение формулы. Причем & здесь не оператор конкатенации, а просто текстовый символ (поскольку находится между открывающими и закрывающими кавычками). Этот знак обрабатывается уже внутри модели Power Pivot, и не мешает распознать, к какому элементу обращается формула. Знак конкатенации в других частях аргумента возвращает ошибку:
"[Products].&[Category].[All].[Bikes]"
"[Products].[Category].&[All].[Bikes]"
Знак & также возвращает ошибку (в любом месте текстовой строки) при обращении к кубу OLAP. Т.е., Power Pivot «проглатывает» & в «правильном» месте, а куб OLAP – нет.
Возможно, использование знака & восходит к функции ПОЛУЧИТЬ.ДАННЫЕ.СВОДНОЙ.ТАБЛИЦЫ (см. ниже), где он является обязательным, и отделяет последний фрагмент внутри каждого из аргументов: элемент1, элемент2, …
Еще одна версия, & – элемент языка MDX (подробнее см. ниже), в котором к члену иерархии можно обратиться несколькими способами. Например:
[Calendar].[CY 2004].[H1 CY 2004].[Q1 CY 2004]
[Calendar].[Calendar Quarter].&[2004].&[1]
В первом варианте обращение к члену иерархии происходит через указание полного пути и полных имен членов на этом пути. Во втором варианте к члену иерархии обращаются по ключу в форме &[ЧастьИмени]. При использовании пути по ключу всегда используется символ & перед ключевыми частями имени члена.
Обязательные и необязательные аргументы
В справке MS по синтаксису функции КУБЗНАЧЕНИЕ указано, что обязательный аргумент один – Подключение. Формально это правильно, но… Если никаких аргументов более нет, а для куба не указана мера по умолчанию, то функция КУБЗНАЧЕНИЕ вернет пустоту (рис. 14). В модели данных Power Pivot меру по умолчанию, похоже, задать нельзя (для куба OLAP такая возможность есть). Так что, в общем случае нужно как минимум два аргумента – Подключение и Мера, чтобы было, что подсчитать и возвратить. Все остальные аргументы задают координаты куба (кортеж), для которых будет рассчитана мера.

Рис. 14. Одного аргумента в функции КУБЗНАЧЕНИЕ, как правило, мало
Это не является обязательным, но хороший стиль будет заключаться в том, чтобы сразу после Подключения указывать Меру, и лишь затем иные аргументы. И, естественно, не допускается указание более одной меры. Итак, более понятно синтаксис функции КУБЗНАЧЕНИЕ можно записать так:
КУБЗНАЧЕНИЕ(подключение; мера[; элемент1] [; элемент2] …)
Подключение – обязательный аргумент – текстовая строка, имя подключения к кубу.
Мера – обязательный аргумент – текстовая строка, имя меры.
Элемент1, Элемент2, … – необязательные аргументы; каждый из них – имя среза или текстовая строка, описывающая элемент измерения или кортеж в кубе. Мера будет рассчитана на совокупности всех элементов и кортежей, перечисленных в аргументах.
Два метода записи формул
Формулы на основе КУБЗНАЧЕНИЕ могут быть длинными и трудными для понимания и записи. Используют два основных метода:
- ссылки на ячейки
- полный путь к элементу куба
Преобразование сводной таблицы в формулы использует первый метод (см. строку формул на рис. 3). Например,
=КУБЗНАЧЕНИЕ("ThisWorkbookDataModel";$B3;C$2;Срез_Category)
Обратите внимание на смешанный тип ссылок: $B3 и C$2. Такой подход позволяет протягивать формулу по строкам и столбцам таблицы отчета. В ячейках же B3 и C2 содержатся формулы КУБЭЛЕМЕНТ(), ссылающиеся на элементы модели данных, соответствующие заголовкам строк и столбцов таблицы:
 в заголовках строк и столбцов таблицы")
Рис. 15. Формулы КУБЭЛЕМЕНТ() в заголовках строк и столбцов таблицы
Обратите внимание, что в таблице заголовки в ячейках В3 и С2 не могут быть представлены текстовыми строками, например, «2001» и «Total Sales». Если так, то КУБЭЛЕМЕНТ не поймет, что это элементы модели данных. Чтобы КУБЭЛЕМЕНТ справился c таким написанием, используйте второй метод записи формул, указывая полный путь к элементу куба/модели данных. При этом, часть пути может быть описана в виде ссылок на ячейки (в стиле, как на рис. 13). Формула в ячейке С3 примет вид:
|
=КУБЗНАЧЕНИЕ(«ThisWorkbookDataModel»; «[Calendar].[CalendarYear].[All].[«&$B3&«]»; «[Measures].[«&C$2&«]»; Срез_Category ) |
, когда в заголовках строк и столбцов текст")
Рис. 16. Формула КУБЭЛЕМЕНТ(), когда в заголовках строк и столбцов текст
Плюсы и минусы двух методов. В методе ссылок формула короче. Метод легко использовать, если на листе уже есть элементы таблицы, на основе формул КУБЭЛЕМЕНТ. Однако метод не позволяет, глядя на формулу КУБЗНАЧЕНИЕ, понять, какие измерения и элементы задают координаты для вычисления меры. Для прояснения ситуации нужно перейти в ячейки, на которые ссылается формула. Метод полного пути не требует перехода в другие ячейки для аудита формулы. Правда, формулы становятся длинными, что затрудняет чтение и запись.
Если вы создаете дашборд с большим количеством мест для пользовательского ввода (срезы, выпадающие списки и т.д.) тогда метод ссылок может оказаться лучше. Метод полного пути будет лучше для статичных отчетов, которые незначительно меняются с течением времени.
Преобразование ПОЛУЧИТЬ.ДАННЫЕ.СВОДНОЙ.ТАБЛИЦЫ в КУБЗНАЧЕНИЕ
Это еще один быстрый способ получить выражение аргументов функции КУБЗНАЧЕНИЕ. Когда вы начинаете вводить формулу " = ", а затем кликаете на ячейку в сводной таблице, автоматически появляется функция ПОЛУЧИТЬ.ДАННЫЕ.СВОДНОЙ.ТАБЛИЦЫ (при соответствующих настройках Excel). Если источником сводной таблицы является модель данных Power Pivot, формула ПОЛУЧИТЬ.ДАННЫЕ.СВОДНОЙ.ТАБЛИЦЫ будет содержать элементы модели данных.
Синтаксис функций ПОЛУЧИТЬ.ДАННЫЕ.СВОДНОЙ.ТАБЛИЦЫ и КУБЗНАЧЕНИЕ немного отличается, поэтому надо удалить кое-что лишнее (удаляемое выделено).
ПОЛУЧИТЬ.ДАННЫЕ.СВОДНОЙ.ТАБЛИЦЫ(поле_данных; сводная_таблица; [поле1; элемент1]; [поле2; элемент2]; …)
КУБЗНАЧЕНИЕ(подключение;[выражение_элемента1];[выражение_элемента2];…)
Вот пошаговое руководство по преобразованию:
Шаг 1. Введите " = " в ячейке, затем щелкните ячейку в сводной таблице. Будет создана формула ПОЛУЧИТЬ.ДАННЫЕ.СВОДНОЙ.ТАБЛИЦЫ.

Рис. 17. Наберите в ячейке Е10 " = ", кликните на ячейку С5
Шаг 2. Скопируйте весь текст между открывающей и закрывающей скобками в буфер.
Шаг 3. В другой ячейке введите =КУБЗНАЧЕНИЕ(«… Автозавершение предложит модель данных. Выберите.
Шаг 4. Вставьте текст из буфера.
Шаг 5. Отредактируйте текст. Функция…
|
=ПОЛУЧИТЬ.ДАННЫЕ.СВОДНОЙ.ТАБЛИЦЫ( «[Measures].[Total Sales]»; $B$2; «[Products].[Category]»;«[Products].[Category].&[Bikes]»; «[Calendar].[CalendarYear]»;«[Calendar].[CalendarYear].&[2002]» ) |
…превращается в…
|
=КУБЗНАЧЕНИЕ(«ThisWorkbookDataModel»; «[Measures].[Total Sales]»; «[Products].[Category].&[Bikes]»; «[Calendar].[CalendarYear].&[2002]» ) |
Шаг 6. Нажмите Enter.
Окно аргументов функции КУБЗНАЧЕНИЕ
Провести аудит функции КУБЗНАЧЕНИЕ можно и в окне Аргументы функции. Находясь в ячейке с формулой КУБЗНАЧЕНИЕ, кликните значок fx в строке формул. Откроется окно (рис. 18). Иногда аргументы такие длинные, что они целиком не помещаются в поле. К сожалению, Microsoft не предусмотрел возможность изменять размер этого окна.

Рис. 18. Окно Аргументы функции
По одному элементу за раз
Функции КУБЗНАЧЕНИЕ может обрабатывать по одному элементу группы за раз. Если вам нужно получить данные по двум элементам группы (например, продажи красных и серебристых велосипедов), формула типа…
|
=КУБЗНАЧЕНИЕ(«ThisWorkbookDataModel»; «[Measures].[Total Sales]»; «[Products].[Color].[All].[Red]|[Silver]» ) |
…или что-то подобное работать не будет (здесь оператор | соответствует логическому ИЛИ). Но можно просто сложить две функции:

Рис. 19. Продажи красных И серебристых велосипедов
На самом деле всё не так плохо, и мы вернемся к этому вопросу ниже.
Функция КУБЭЛЕМЕНТ()
Возвращает элемент (координату по одному измерению) или кортеж (набор координат по разным измерениям) из куба. Синтаксис:
КУБЭЛЕМЕНТ(подключение; выражение_элемента [; подпись])
Подключение – обязательный аргумент; текстовая строка, имя подключения к кубу.
Выражение_элемента – обязательный аргумент; текстовая строка, описывающая элемент в кубе или кортеж.
Подпись – необязательный аргумент; текстовая строка, которая отображается в ячейке вместо элемента измерения из куба.
С первыми двумя вы уже знакомы, а смысл третьего аргумента поясним на примере:

Рис. 20. Аргумент Подпись
При этом, любая мера в формуле КУБЗНАЧЕНИЕ вернет одинаковое значение при ссылке на ячейки А2 и В2. Это связано с тем, что КУБЗНАЧЕНИЕ, обращаясь к функции КУБЭЛЕМЕНТ, запрашивает второй аргумент, и не интересуется третьим.
КУБЭЛЕМЕНТ позволяет в аргументе Выражение_элемента указать кортеж. Последний берется в фигурные скобки:

Рис. 21. Аргумент Выражение_элемента в виде кортежа
Я не нашел объяснение такому синтаксису, и он отличается от стандартного для кортежей, который будет описан ниже.
Если аргумент Подпись отсутствует, в ячейке отражается последний элемент кортежа. На рис. 21 это было бы Bikes.
Если вам кажется, что составление таких формул отнимает много времени, попробуйте метод ссылок на ячейки. Функция КУБЭЛЕМЕНТ() допускает ссылку на диапазон ячеек:

Рис. 22. Аргумент Выражение_элемента в виде ссылки на диапазон ячеек
В качестве аргументов функций КУБ() можно использовать другие функции, возвращающие «правильный» тип данных (часто это текстовые строки). Например, формула…
|
=КУБЗНАЧЕНИЕ(«ThisWorkbookDataModel»; «[Measures].[Total Sales]»; КУБЭЛЕМЕНТ(«ThisWorkbookDataModel»; {«[Products].[Color].[All].[Red]»; «[Products].[Category].[All].[Bikes]»} ) ) |
…вернет продажи красных велосипедов.
Функции КУБЗНАЧЕНИЕ и КУБЭЛЕМЕНТ имеют ряд ограничений. Во-первых, любая иерархия может присутствовать на осях отчета только один раз. Поэтому если элемент куба в функции КУБЭЛЕМЕНТ() определяется с помощью кортежа, то присутствующие в нем измерения уже не могут применяться в КУБЗНАЧЕНИЕ(). Например, на рис. 22, если в ячейке В6 набрать формулу…
|
=КУБЗНАЧЕНИЕ(«ThisWorkbookDataModel»; «[Measures].[Total Sales]»; A5; «[Calendar].[CalendarYear].[All].[2003]» ) |
…она вернет ошибку #ЗНАЧ! Это связано с тем, что измерение [Calendar].[CalendarYear] в последнем аргументе уже присутствует неявно в А5.
Во-вторых, функции КУБЗНАЧЕНИЕ и КУБЭЛЕМЕНТ являются статическими. Т.е., при обновлении исходных данных эти функции не подхватят вновь появившиеся элементы (новую модель, или новые даты; в отличие от сводной таблицы, которая отразит новые элементы).
Семейство функций КУБ()
КУБЗНАЧЕНИЕ и КУБЭЛЕМЕНТ являются основными и, если так можно выразиться, естественными функциями кубов. Именно они появляются на листе Excel после преобразования сводной таблицы в формулы. По большому счету, их достаточно, чтобы извлечь значения мер и координаты измерений из куба. Остальные функции КУБ() являются вспомогательными, упрощают работу с наборами, ячейками листа, позволяют обновлять отчет при добавлении новых элементов и т.п. Вот полный перечень функций кубов:
")
Рис. 23. Список аналитических функций Excel (функций кубов)
Функция КУБМНОЖ()
Возвращает набор элементов или набор кортежей для их последующего использования в других функциях КУБ(). На вход КУБМНОЖ подаются аргументы в виде ссылок на ячейки Excel, или текстовых строк. На выходе – массив. Синтаксис:
КУБМНОЖ(подключение;выражение_множества;[подпись];[порядок_сортировки];[сорт_по])
Выражение_множества – обязательный аргумент; текстовая строка, задающая условия, какие наборы элементов (кортежей) извлечь из куба. Если Выражение_множества содержит более 255 символов, что является предельной длиной для аргументов функции, КУБМНОЖ возвращает ошибку #ЗНАЧ!. Для использования текстовых строк длиной свыше 255 символов введите строку в ячейку, а затем используйте ссылку на ячейку в качестве аргумента.
Подпись – необязательный аргумент; текстовая строка, отображаемая в ячейке вместо подписи из куба. Поскольку функция возвращает массив, в ячейке ничего не отражается. Присвойте аргументу Подпись значение, чтобы не «потерять» ячейку с функцией КУБМНОЖ.
Порядок_сортировки – необязательный аргумент; тип сортировки; цифры от нуля до шести (в английской версии Excel могут использоваться также смысловые константы); значение по умолчанию 0; при сортировке кортежей выполняется сортировка по последнему элементу кортежа. Значения 1 и 2 требуют наличия аргумента Сорт_по. Если его нет, то функция вернет ошибку. Остальные значения не требуют аргумента Сорт_по, а если он присутствует, то игнорируется.

Рис. 24. Порядок сортировки элементов/кортежей, возвращаемых функцией КУБМНОЖ
Сорт_по – необязательный аргумент; текстовая строка – мера, по которой нужно выполнить сортировку.
Синтаксис функций КУБ() это синтаксис MDX
На мой взгляд, самое загадочное в всей этой истории – это синтаксис формул куба, который довольно сильно отличается от стиля, принятого в Excel. Это связано с тем, что формулы куба унаследовали язык запросов к многомерным данным MDX (MultiDimensional eXpressions), который давно используют разработчики OLAP-кубов.
Чтобы правильно сослаться на элемент измерения, необходимо описать полный путь к нему по иерархии измерения, начиная с самого верхнего уровня, например:
[Products].[Category].[All].[Clothing]
У каждого измерения существует член по умолчанию, который используется в случае, если описание измерения в явном виде в запросе отсутствует. В роли элемента по умолчанию выступает элемент [All], который добавляется автоматически при создании измерения и содержит совокупные результаты по всем элементам измерения.
Я уже писал о двух символах, поддерживающих режим автозавершения: кавычки и точка (см. пояснения после рис. 12). Добавим еще три символа в эту коллекцию. Вспомните, что кортеж – совокупность элементов разных измерений, определяющая координаты точки в многомерном пространстве, для которой вычисляется мера. Например,
Элемент1а = [Products].[Color].[All].[Red]
Элемент1б = [Products].[Category].[All].[Bikes]
Кортеж1 = ([Products].[Color].[All].[Red],[Products].[Category].[All].[Bikes])
Обратите внимание! Элементы кортежа разделены запятой, а не точкой с запятой. Попробуйте в режиме автозавершения набрать формулу…
=КУБМНОЖ("ThisWorkbookDataModel";"([Products].[Color].[All].[Red]
…если вы продолжите точкой с запятой, автозавершение будет безмолвствовать (рис. 24а). Если же вы поставите запятую, автозавершение предложит варианты:

Рис. 24а. Запятая, разделяющая элементы кортежа; точка с запятой не работает
Набор – совокупность элементов или кортежей одинаковой структуры. Если кортеж выделяется круглыми скобками, то набор – фигурными. Вот как выглядит формула, использующая в качестве Выражения_множества набор из двух элементов:
|
=КУБМНОЖ(«ThisWorkbookDataModel»; «{[Products].[Color].[All].[Red], [Products].[Color].[All].[Silver]}»; «Набор из двух элементов» ) |
Обратите внимание! Если в кортеже объединяются элементы разных измерений, то в наборе элементы принадлежат одному измерению.
Еще сложнее формула, использующая в качестве Выражения_множества набор из двух кортежей:

Рис. 24б. Аргумент Выражения_множества в виде набора кортежей
Формула также может быть набрана из частей. Например так:

Рис. 24в. Аргумент Выражения_множества набран из фрагментов текста и ссылок на ячейки
Может быть запись второго аргумента – "{"&E15&","&E16&"}" – будет понятнее, если вместо конкатенации использовать функцию СЦЕПИТЬ:

Рис. 24г. Аргумент Выражения_множества на основе функции СЦЕПИТЬ
Ранее я описал особый синтаксис, который поддерживается функцией КУБЭЛЕМЕНТ (см. рис. 21). КУМНОЖ такой синтаксис не поддерживает…

Рис. 24д. Альтернативный (слева) и стандартный (справа) синтаксис кортежа в аргументе функции КУБЭЛЕМЕНТ
Порядок перечисления измерений и мер в кортеже не имеет существенного значения. Но лучше начать с меры. Синтаксис функций кубов поддерживает выражения на языке MDX. Ниже в примерах я покажу несколько таких трюков. Множество можно не заключать в фигурные скобки, если оно является результатом функции MDX, например:
|
=КУБМНОЖ(«ThisWorkbookDataModel»; «[Products].[Color].children»; «Результат функции MDX» ) |
Здесь множество [Products].[Color].children возвращает названия всех цветов.
Нельзя располагать одно и то же измерение по разным осям отчета, поскольку такая операция лишена смысла.
Вот полный список символов вызывающих автозавершение:
" открывающие кавычки – в начале каждого аргумента; показывают доступные подключения, измерения/таблицы, набор мер;
. точка – после закрывающей прямоугольной скобки; показывает следующие элементы иерархии;
( открывающая круглая скобка – после: а) открывающих кавычек, б) открывающей фигурной скобки, в) запятой – в текстовой строке с многомерными выражениями; говорит о начале кортежа;
, запятая – после закрывающей прямоугольной скобки в текстовой строке с многомерными выражениями; отделяет вторую часть кортежа;
{ открывающая фигурная скобка – после открывающих кавычек в текстовой строке с многомерными выражениями; обозначает начало набора элементов или кортежей;
: двоеточие – после закрывающей прямоугольной скобки в текстовой строке с многомерными выражениями; отделяет начальное значение от конечного, как в обычной ссылке Excel А2:А9.
КУБМНОЖ возвращает массив элементов на основе данных на листе Excel
С помощью КУБМНОЖ можно обойти ограничение функции КУБЗНАЧЕНИЕ (см. рис. 19), которая в качестве аргумента Элемент1 могла «кушать» по одному элементу за раз. Например, мы хотим подсчитать продажи красных велосипедов с 1 по 6 июля 2001 г.
Для начала посмотрим в каком формате эти даты хранятся в кубе. Для этого начните набирать…
=КУБМНОЖ("ThisWorkbookDataModel";"[Calendar].[Date].[All].
…автозавершение предложит варианты:

Рис. 25. Автозавершение покажет формат дат в кубе
Формат даты – "М/Д/ГГГГ". Теперь разместим на листе Excel столбец с интересующими нас датами (в любом удобно для нас формате, см. 1 на рис. 26). Поскольку КУБМНОЖ в качестве аргумента Выражение_множества требует текстовую строку, мы формируем таковую на основе конкатенации текстовых фрагментов и функции ТЕКСТ (2):
|
{=КУБМНОЖ(«ThisWorkbookDataModel»; «[Calendar].[Date].[All].[«&ТЕКСТ(A1:A6;«М/Д/ГГГГ»)&«]»; «множ» )} |
Вводим формулу в ячейку, как формулу массива. В ячейке хранится массив дат, а отображается текст, введенный нами в аргумент Подпись – множ (2). Любопытно, что диапазон А1:А6 должен быть или в одну строку или в один столбец. Прямоугольный диапазон возвращает ошибку.

Рис. 26. КУБМНОЖ позволяет сформировать массив элементов, передаваемых на ось для вычисления меры в функции КУБЗНАЧЕНИЕ
Формула с КУБЗНАЧЕНИЕ (3)…
|
=КУБЗНАЧЕНИЕ(«ThisWorkbookDataModel»; «[Measures].[Total Sales]»; B1; «[Products].[Color].[All].[Red]»; «[Products].[Category].[All].[Bikes]» ) |
…возвращает меру [Total Sales] для красных велосипедов, проданных в период, сформированный в ячейке В1.
И наконец, с помощью сводной таблицы (4) проверяем полученное значение.
Более того, функция КУБМНОЖ() дает возможность ввести первую и последнюю ячейки диапазона, разделив их двоеточием:
|
=КУБМНОЖ(«ThisWorkbookDataModel»; «{[Calendar].[Date].[All].[«&ТЕКСТ(A1;«М/Д/ГГГГ»)&«]: [Calendar].[Date].[All].[«&ТЕКСТ(A6;«М/Д/ГГГГ»)&«]}»; «множ» ) |
Формула вернет тот же массив дат с 1 по 6 июля 2001 г.
Функция КУБПОРЭЛЕМЕНТ()
Возвращает n-й элемент множества. Используется для возвращения одного или нескольких элементов в множестве, например, лучшего продавца или 10 лучших студентов. Синтаксис:
КУБПОРЭЛЕМЕНТ(подключение;выражение_множества;ранг;[подпись])
Выражение_множества – обязательный аргумент; текстовая строка, представляющая выражение множества, например, "[Products].[Category].[All].children". Здесь используется выражение MDX children, означающее все уникальные имена таблицы [Products], столбца [Category]. Выражение_множества также может быть функцией КУБМНОЖ или ссылкой на ячейку, содержащую функцию КУБМНОЖ. Например, КУБМНОЖ может возвращать массив категорий продуктов, отсортированных, по убыванию по объему продаж.
Ранг – обязательный аргумент; целое число. Если Ранг имеет значение 1, возвращается наибольшее значение, если Ранг имеет значение 2, возвращается второе по величине значение, и т.д. Чтобы возвратить 5 наибольших значений, вызовите функцию КУБПОРЭЛЕМЕНТ пять раз, указывая каждый раз новое значение Ранг: от 1 до 5. Если аргумент Выражение_множества представлен строкой типа "[Products].[Category].[All].children", то массив упорядочен в алфавитном порядке.
Подпись – необязательный аргумент; текстовая строка, которая отображается в ячейке вместо подписи из куба.
Функция используется, например, для извлечения элементов какого-то измерения:
|
=КУБПОРЭЛЕМЕНТ(«ThisWorkbookDataModel»; «[Products].[Color].[All].children»; СТРОКА() ) |

Рис. 27. Доступные цвета товаров
Ранг задан функцией СТРОКА(). Цвета выводятся в алфавитном порядке. Оказалось, что цветов 10, так что, начиная с 11-й строки формула возвращает ошибку #Н/Д.
Совместно использование КУБПОРЭЛЕМЕНТ и КУБМНОЖ
Роль функции КУБМНОЖ наилучшим образом раскрывается в связке с КУБПОРЭЛЕМЕНТ. Первая формирует массив на основе данных листа Excel или напрямую из куба, а вторая извлекает элементы массива в ранжированном порядке.
|
=КУБПОРЭЛЕМЕНТ(«ThisWorkbookDataModel»; КУБМНОЖ(«ThisWorkbookDataModel»; «[Products].[ModelName].children»; ; 2; «[Measures].[Total Sales]»); СТРОКА(А1) ) |
Функция КУБМНОЖ говорит кубу: «Верни все уникальные имена моделей из столбца [ModelName] таблицы [Products], и расположи их в массиве в порядке убывания по продажам [Total Sales]».

Рис. 28. Ранжированные продажи различных моделей
Проверяем вычисления с помощью обычной сводной таблицы:

Рис. 29. Проверочная сводная таблица
Ранжирование на основе кортежа
Задача усложняется, если нужно вывести ранжированный список, отфильтрованный не только по объему продаж, но и относящийся, например, к определенной категории продуктов или периоду времени. Повторим фрагмент приведенной выше формулы:
|
=КУБМНОЖ(«ThisWorkbookDataModel»; «[Products].[ModelName].children»; ; 2; «[Measures].[Total Sales]» ) |
Идея в том, чтобы массив "[Products].[ModelName].children", получаемый из куба, оставить без изменений, а дополнительные условия фильтрации отразить в последнем пятом аргументе. Вместо ссылки на меру "[Measures].[Total Sales]", можно сослаться на кортеж, возвращаемый функцией КУБЭЛЕМЕНТ:
|
КУБМНОЖ(«ThisWorkbookDataModel»; «[Products].[ModelName].children»; ; 2; КУБЭЛЕМЕНТ(«ThisWorkbookDataModel»; «([Measures].[Total Sales],[Products].[Category].[All].[Accessories])») ) |
Здесь функция КУБЭЛЕМЕНТ говорит функции КУБМНОЖ: «Ранжируй массив по продажам аксессуаров». Итоговая формула в ячейке В4:
|
=КУБПОРЭЛЕМЕНТ(«ThisWorkbookDataModel»; КУБМНОЖ(«ThisWorkbookDataModel»; «[Products].[ModelName].children»; ; 2; КУБЭЛЕМЕНТ(«ThisWorkbookDataModel»; «([Measures].[Total Sales],[Products]. [Category].[All].[Accessories])»)); СТРОКА(A1) ) |
Эту формулу можно протянуть вдоль столбца до ячейки В13:

Рис. 30. ТОП-10 моделей аксессуаров по объему продаж
Ранжирование с использованием срезов
Формулам ранжирования, описанным в предыдущих разделах можно добавить гибкости, если использовать срезы. Excel допускает использование срезов и без сводных таблиц. Для создание таких срезов можно: 1) создать сводную таблицу; создать к ней срезы, а затем удалить сводную таблицу; 2) создать срез, пройдя по меню Вставка –> Фильтр –> Срез. Каждому срезу соответствует именованный диапазон, начинающийся со слова Срез_ (рис. 31). Хотя срез отражается в Диспетчере имен, соответствующего ему диапазона ячеек в книге Excel нет. К срезу можно обратиться по имени только внутри функций КУБ(). Обращение к срезу возвращает массив элементов (подробнее см. Блеск и нищета сводных таблиц, часть 13).

Рис. 31. Срезы в диспетчере имен
Если вспомнить справку Excel для функции КУБЗНАЧЕНИЕ(), то в ней говорится, что можно использовать имя среза в качестве аргумента Выражение_элемента (см. рис. 12). Поскольку функция КУБЗНАЧЕНИЕ допускает использование нескольких аргументов Выражение_элемента, КУБЗНАЧЕНИЕ поддерживает прямое обращение к нескольким срезам.
В то же время, КУБЭЛЕМЕН() не поддерживает прямого обращения к срезу (хотя аргумент носит такое же имя, как и в функции КУБЗНАЧЕНИЕ – Выражение_элемента). Возможно, это связано с тем, что срез возвращает массив (даже, если выделен один элемент), а аргумент функции КУБЭЛЕМЕН ожидает уникальный элемент.
Создадим отчет, отбирающий ТОП-10 продаваемых моделей в выбранной стране, за один месяц. Добавим так же сравнение с продажами этих же моделей за предыдущий месяц:

Рис. 32. Ранжирование по продажам на основе срезов
Шаг 1. Поместим значения срезов в ячейки G18:G20. Для этого воспользуемся формулами типа
=КУБПОРЭЛЕМЕНТ("ThisWorkbookDataModel";Срез_Country;1)
Аргумент Срез_Country возвращает массив элементов среза, а функция КУБПОРЭЛЕМЕНТ возвращает первый в списке. Поскольку на срезе выбран один элемент, он и возвращается.
Шаг 2. В ячейках К4:К13 извлечем список моделей ранжированный по объему продаж в США за март 2004 года. Этот трюк вы видели ранее. Новый здесь фрагмент, отвечающий за фильтры:
КУБЭЛЕМЕНТ("ThisWorkbookDataModel";($G$17:$G$20)))
Он собирает набор из ячеек G17:G20, добавляя к значениям трех срезов меру [Total Sales]. Набор взят в круглые скобки. Если заменить ссылки на ячейки значениями, хранящимися в этих ячейках, функция КУБЭЛЕМЕНТ не позволит ввести формулу в ячейку К4 появится сообщение, что это не формула. Диапазон G17:G20 может иметь любую прямоугольную форму.
Шаг 3. В ячейке L3 располагаем название месяца из среза.
Шаг 4. В ячейке М3 располагаем название предыдущего месяца. И здесь еще один трюк с привлечением функции MDX lag(1), которая возвращает предыдущий к March элемент из столбца [MonthName]:
=КУБЭЛЕМЕНТ("ThisWorkbookDataModel";"[Calendar].[MonthName].[All].["&L3&"].lag(1)")
Шаг 5. В ячейке L4 прописываем формулу…
|
=КУБЗНАЧЕНИЕ(«ThisWorkbookDataModel»; «[Measures].[Total Sales]»; «[Products].[ModelName].[All].[«&$K4&«]»; Срез_Country; Срез_CalendarYear; «[Calendar].[MonthName].[All].[«&L$3&«]» ) |
… и протягиваем ее на диапазон L4:M13.
Если пользователь выбирает более одной позиции в любом из срезов, предложенное решение не гарантирует истинный ТОП-10. Причина в том, что несколько элементов одного измерения не могут участвовать в создании кортежа и поэтому ранжирование будет основано на первом выбранном элементе. При том что сводная таблица справится с этой задачей:
 дают сбой при выборе более одного элемента в срезе")
Рис. 33. Формулы КУБ() дают сбой при выборе более одного элемента в срезе
Если вы хотите проявить строгость в представлении данных, то можете устроить проверку того, что во всех срезах выбран один элемент. Например, разместите в ячейке В22 такую формулу:
|
=ЕСЛИ(КУБЧИСЛОЭЛМНОЖ(Срез_CalendarYear)* КУБЧИСЛОЭЛМНОЖ(Срез_Country)* КУБЧИСЛОЭЛМНОЖ(Срез_MonthName)>1; «Отчет отражает корректные данные только если выбран один элемент в каждом срезе»; «» ) |
Если хотя бы в одном срезе выбрано более одного элемента, произведение трех функций КУБЧИСЛОЭЛМНОЖ() будет более единицы, и в ячейке отобразится введенный текст. Если во всех срезах выбран один элемент, ячейка В22 останется пустой.
Функция КУБЧИСЛОЭЛМНОЖ()
Пожалуй, это самая простая и очевидная функция кубов. Возвращает число элементов в множестве. Синтаксис:
КУБЧИСЛОЭЛМНОЖ(множество)
Не требует указывать Подключение. Это означает, что аргумент Множество не может быть текстовой строкой (хотя справка MS утверждает именно это, пусть и с уточнениями). Аргумент Множество может быть именем среза, функцией КУБМНОЖ или ссылкой на ячейку, содержащую функцию КУБМНОЖ. На рис. 34 левая формула возвращает 9 – число элементов, выделенных на срезе; правая формула возвращает 10 – общее число элементов в множестве [Products].[Color].
")
Рис. 34. Функция КУБЧИСЛОЭЛМНОЖ()
Если КУБМНОЖ возвращает элементы, КУБЧИСЛОЭЛМНОЖ подсчитает число элементов. Если КУБМНОЖ возвращает кортежи, КУБЧИСЛОЭЛМНОЖ подсчитает число кортежей. Если в массиве, возвращаемом функцией КУБМНОЖ два одинаковых элемента (кортежа), КУБЧИСЛОЭЛМНОЖ посчитает их два раза. Также обратите внимание, что функция КУБЧИСЛОЭЛМНОЖ() подсчитывает только непустые кортежи (элементы):

Рис. 35. Кортежи, мера по которым равна нулю, не подсчитываются
Некоторые выражения MDX, используемые в формулах кубов
Язык MDX включает в себя огромное количество функций и выражений, позволяющих обрабатывать многомерные данные. Язык требует отдельного изучения, а задача раздела познакомить с несколькими выражениями, которые работают в формулах кубов, и могут быть полезны начинающим пользователям. (Можно использовать, как заглавные, так и строчные буквы.)
.children – возвращает упорядоченный по алфавиту набор, содержащий дочерние элементы указанного элемента верхнего уровня; если у элемента нет потомков, функция возвращает пустой набор.
.members – похоже на .children, но возвращает также элемент [All] на первом месте и все элементы более глубоких уровней, если таковые имеются. Например, если создать в модели данных иерархию с именем Territory с двумя подуровнями Continent и Country, то [Territory].children вернет 3 элемента, а [Territory].Members – 10:

Рис. 36. Выражения .members и .children; слева фрагмент модели данных Power Pivot
Ссылку на соседние члены измерения без указания имени члена обеспечивают выражения .PrevMember и .NextMember. Чтобы обратиться к элементу, отстоящему на два назад, можно повторить выражение два раза .PrevMember.PrevMember, но удобнее применить более общее выражение Lag(2). Отрицательное число в скобках меняет направление отсчета членов измерения.
Чтобы определить первый или последний элемент того же уровня можно использовать .FirstSibling и .LastSibling. Для дочерних элементов подойдет .FirstChild и .LastChild. Чтобы получить родителя воспользуйтесь .Parent. Это выражение можно применить, если нужно найти долю продаж элемента в классе, например:

Рис. 37. Выражение .Parent позволяет находить вклад элемента в общие продажи, прибыль, …
Для того чтобы определить «дедушку» (родителя родителя), можно использовать выражение: .Parent.Parent. Для этого в кубе должна быть определена соответствующая иерархия.
Функция КУБЭЛЕМЕНТКИП()
Возвращает свойство ключевого показателя эффективности, КПЭ, и отображает его имя в ячейке. (В аббревиатуре русского названия функции используется другое наименование – ключевой индикатор производительности, КИП. В английском варианте CubeKPImember). Синтаксис:
КУБЭЛЕМЕНТКИП(подключение;имя_КПЭ;свойство_КПЭ;[подпись])
Имя_КПЭ – обязательный аргумент; текстовая строка, представляющая имя ключевого показателя эффективности в кубе (как создать КПЭ см. раздел KPI заметки Марк Мур. Power Pivot).
Свойство_КПЭ – обязательный аргумент; указывает, какое именно свойство KPI следует вернуть функции КУБЭЛЕМЕНТКИП (рис. 38). В модели данных из примера доступны только первые три свойства.

Рис. 38. Возможные свойства ключевого показателя эффективности
Подпись – необязательный аргумент; альтернативная текстовая строка. Имя по умолчанию формируется так: Имя_КПЭ + Свойство_КПЭ (имя свойства Значение КИП опускается):

Рис. 39. Имена, возвращаемые для меры [Profit Pct]
Чтобы использовать КПЭ в вычислениях, нужно разместить функцию КУБЭЛЕМЕНТКИП в аргументе «выражение_элемента» функции КУБЗНАЧЕНИЕ (рис. 40). Данные отчета на основе функций КУБ() проверены с помощью сводной таблицы. В правой части рис. 40 выделены поля KPI. И сводная таблица (ячейки F12:F15), и отчет (F4:F7) возвращают числа от 0 до 1. При этом сводная таблица выводит значки благодаря внутренним механизмам, а для замены чисел на «светофор» в отчете применяется условное форматирование.

Рис. 40. Отчет о продажах с использованием функции КУБЭЛЕМЕНТКИП
Функция КУБСВОЙСТВОЭЛЕМЕНТА()
Возвращает значение свойства элемента куба. Используется для отображения свойства на осях отчета или для расчетов, если свойство числовое (например, сезонный коэффициент). Синтаксис:
КУБСВОЙСТВОЭЛЕМЕНТА(подключение; выражение_элемента; свойство)
Новым здесь является только третий элемент – имя свойства измерения. Если в процессе набора формулы автозавершение безмолвствует, значит свойство для данного измерения не определено. К сожалению, это единственная функция кубов, которая работает только с кубами OLAP (но не с моделями данных Power Pivot). Чтобы в кубе OLAP проверить, обладает ли измерение свойством, поместите измерение в сводную таблицу в область строк (или столбцов). Встаньте на одну из ячеек в этой области, и пройдите по меню Работа со сводными таблицами –> Анализ –> Средства OLAP –> Поля свойств (рис. 41).

Рис. 41. Проверка наличия свойств у измерения
Если у измерения есть свойства появится окно Выбор полей свойств для размерности (рис. 42). Если свойств у измерения нет появится сообщение об их отсутствии.

Рис. 42. Окно Выбор полей свойств для размерности
Если перенести свойства из левого окна в правое, они будут отражаться в сводной таблице. Но нас сейчас интересует лишь подтверждение того, что у измерения [Клиент] есть свойства. Теперь можно написать формулу:

Рис. 43. Автозавершение «увидело» свойства измерения
Функция КУБСВОЙСТВОЭЛЕМЕНТА может быть полезной для отображения на осях отчета неких измерений, связанных с базовым. Например, номера квартала по дате, e-mail по ID клиента, университета по имени игрока и т.п. С числовыми свойствами (в нашем примере это ИНН) можно выполнять все математические операции. Подробнее о свойствах измерений куба OLAP см. Павел Сухарев Блеск и нищета сводных таблиц, часть 5.
Как обойти ограничение Power Pivot и получить свойство элемента измерения
Хотя КУБСВОЙСТВОЭЛЕМЕНТА не поддерживает модели Power Pivot, можно эмулировать работу функции в этой среде. Попробуем на основе уникального ID клиента получить иные сведения о нем, хранящиеся в модели Power Pivot в таблице [Customers]. Для этого воспользуемся MDX функцией EXISTS. Она возвращает набор кортежей первого аргумента, которые встречаются во втором аргументе. Синтаксис:
Exists(Выражение1, Выражение2 [, Мера])
Выражение1 и Выражение2 – обязательные аргументы; многомерные выражения, возвращающее набор элементов (кортежей). Мера – необязательный аргумент; если он указан, то возвращаются только такие элементы (кортежи), для которых мера определена. Например, следующее выражение вернет клиентов, проживающих в Калифорнии и совершивших сделки в Интернете:
|
EXISTS( [Customer].members, [Customer].[State—Province].&[CA], [Internet Sales] ) |
Первый аргумент определит набор, который мы хотим вернуть, второй и третий – условия, которые мы проверяем. Поскольку в нашей задаче не важно, были ли продажи, мы можем опустить третий аргумент. Итак:

Рис. 44. Формула, эмулирующая работу КУБСВОЙСТВОЭЛЕМЕНТА в среде Power Pivot
Источники
Jon Acampora Tips & Tricks for Writing CUBEVALUE Formulas
Excel-файл с примерами я построил на основе модели из книги Роб Колли. Формулы DAX для Power Pivot (глава 15).
Обсуждение, можно ли задать в Power Pivot меру по умолчанию.
Павел Сухарев. Блеск и нищета сводных таблиц. Цикл статей в журнале Компьютер Пресс.
Статьи по формулам кубов на сайте powerpivotpro.com
Обсуждение, можно ли в функции КУБЗНАЧЕНИЕ использовать диапазоны дат.
Полина Трофимова, Алексей Шуленин. Введение в MDX. Цикл статей в журнале Компьютер Пресс.
Cube Functions in Microsoft Excel 2010
A CUBEMEMBERPROPERTY Equivalent With PowerPivot
Актуальность ссылок проверена 29 июня 2019 г.

Смотрите видео к статье:
Лирическое вступление
OLAP – это англ. online analytical processing, аналитическая технология обработки данных в реальном времени. Простым языком – хранилище с многомерными данными (Куб), еще проще – просто база данных, из которой можно получить данные в Excel и проанализировать с помощью инструмента Excel – Сводные таблицы.
Сводные таблицы – это пользовательский интерфейс для отображения многомерных данных. Иными словами — специальный вид таблиц, с помощью которых можно сделать практически любой отчет.
Чтобы было понятно, давайте сравним «Обычную таблицу» со «Сводной таблицей»
Обычная таблица:

Сводная таблица:

Основное отличие Сводных таблиц – это наличие окна «Список полей сводной таблицы», из которого можно выбирать нужные поля и получать любую таблицу автоматически!
Как пользоваться
Откройте файл Excel, который подключен к OLAP-кубу, например «BIWEB»:

Теперь, что это означает и как этим пользоваться?

Перетащите нужные поля, чтобы получить, например, такую таблицу:

«Плюсики» позволяют детализировать отчет. В этом примере «Бренд» детализируется до «Сокращенных названий», а «Квартал» до «Месяца», т.е. так:

OlAP — это технология, которая используется для у упорядочества крупных бизнес-баз данных и поддержки бизнес-аналитики. Базы данных OLAP разделены на один или несколько кубов, и каждый из них организован и разработан администратором куба так, чтобы получать и анализировать данные так, чтобы было проще создавать и использовать нужные отчеты сводная диаграмма и сводная диаграмма.
В этой статье
-
Что такое бизнес-аналитика?
-
Что такое OLAP?
-
Функции OLAP в Excel
-
Компоненты программного обеспечения, необходимые для доступа к источникам данных OLAP
-
Различия функций между исходными данными OLAP и данными, которые не являются источником OLAP
Что такое бизнес-аналитика?
Бизнес-аналитику часто требуется получить общую картину бизнеса, увидеть более широкие тенденции на основе совокупных данных и увидеть, что эти тенденции разбиты на любое количество переменных. Бизнес-аналитика — это процесс извлечения данных из базы данных OLAP, а затем их анализа для получения информации, которую можно использовать для принятия обоснованных бизнес-решений и принятия мер. Например, olAP и бизнес-аналитика помогают отвечать на следующие вопросы о бизнес-данных:
-
Как сопоставлять совокупные продажи всех продуктов за 2007 г. с совокупными продажами за 2006 г.?
-
Чем наша прибыльность по сравнению с тем же периодом времени за последние пять лет?
-
Сколько средств потратили клиенты в прошлом году за 35 лет и как изменилось это поведение с течением времени?
-
Сколько продуктов было продано в двух отдельных странах или регионах в этом месяце, а не в том же месяце прошлого года?
-
Что такое разбивка прибыли (как в процентах от прибыли, так и по итоговой) по категориям продуктов для каждой возрастной группы клиентов?
-
Поиск лучших и нижних продавцов, распространителей, поставщиков, клиентов, партнеров или клиентов.
К началу страницы
Что такое OLAP?
Базы данных OLAP упрощают запросы бизнес-аналитики. OLAP — это технология базы данных, оптимизированная для запросов и отчетов, а не для обработки транзакций. Источником данных для OLAP являются базы данных OLTP, которые обычно хранятся в хранилищах данных. Данные OLAP получаются на основе этих исторических данных и объединяются в структуры, которые позволяют сложный анализ. Данные OLAP также уорганизованы в иерархию и хранятся в кубах, а не в таблицах. Это сложная технология, использующая многомерные структуры для быстрого доступа к данным для анализа. Эта организация упрощает отображение высокоуровневых сводных отчетов, таких как итоги продаж по всей стране или региону, а также сведений о сайтах, где продажи являются особенно сильными или слабыми. сводная диаграмма
Базы данных OLAP ускоряют ирисовку данных. Так как сервер OLAP, а не Microsoft Office Excel вычисляет сводимые значения, при создании или изменении отчета на Excel меньше данных. Этот подход позволяет работать с намного большими объемами исходных данных, чем можно было бы, если бы они были у вас в традиционной базе данных, в которой Excel извлекает все отдельные записи и вычисляет сводимые значения.
Базы данных OLAP содержат два основных типа данных: показатели, которые являются числовые данные, количество и средние значения, которые используются для принятия обоснованных деловых решений, и измерения ( категории, которые вы используете для организации этих мер. Базы данных OLAP помогают упорядочесть данные по уровням детализации, используя те же категории, что и для анализа данных.
В следующих разделах подробно описаны все компоненты.
Куба Структура данных, которая собирает меры по уровням и иерархиям каждого измерения, которые вы хотите проанализировать. Кубы объединяют несколько измерений, таких как время, география и строки товаров, с обобщенными данными, такими как данные о продажах или складских запасах. Кубы не являются «кубами» в строгом математическом смысле, так как они не обязательно имеют одинаковые стороны. Однако они являются вехой в сложных концепциях.
Измерения Набор значений в кубе, основанных на столбце в таблице фактов куба и обычно числовом значении. Меры — это центральные значения в кубе, которые предварительно продвинуются, агрегируются и анализируются. Распространенные примеры: продажи, прибыль, доходы и затраты.
Член Элемент в иерархии, представляющий одно или несколько вхождений данных. Участник может быть уникальным или неуникционным. Например, 2007 и 2008 представляют уникальные участники на уровне года измерения времени, в то время как Январь — неинъюникционные участники на уровне месяца, так как измерение времени может иметь более одного января, если оно содержит данные за более чем один год.
Вычисляемая член Член измерения, значение которого вычисляется во время запуска с помощью выражения. Значения вычисляемого члена могут быть получены из значений других участников. Например, вычисляемого члена (Прибыль) можно определить путем вычитания значения участника (Затраты) из значения участника (Продажи).
измерение Набор из одной или более иерархий уровней в кубе, который пользователь понимает и использует в качестве основы для анализа данных. Например, географическое измерение может включать уровни «Страна/регион», «Область/край» и «Город». Или измерение времени может включать иерархию с уровнями года, квартала, месяца и дня. В отчете или отчете сводная диаграмма отчете каждая иерархия становится набором полей, которые можно развернуть и свернуть для более низкого или более высокого уровня.
Иерархия Логическая структура дерева, которая упорядочьт часть измерения, чтобы каждый член был одним родительским и нулевым или более членами ребенка. Ребенок — это участник следующего нижнего уровня иерархии, непосредственно связанный с текущим. Например, в иерархии «Время», содержащей уровни Квартал, Месяц и День, «Январь» является потомком Кв1. Родитель — это член на следующем более высоком уровне иерархии, непосредственно связанный с текущим. Родительское значение обычно является консолидацией значений всех ее детей. Например, в иерархии времени, которая содержит уровни Квартал, Месяц и День, Кв1 является родительским из января.
Уровень В иерархии данные можно организовать по нижнему и более высокому уровням детализации, например по годам, кварталам, месяцам и дням в иерархии времени.
К началу страницы
Функции OLAP в Excel
Сбор данных OLAP Вы можете подключаться к источникам данных OLAP так же, как к другим внешним источникам данных. Вы можете работать с базами данных, созданными в Microsoft SQL Server olAP Services версии 7.0, Microsoft SQL Server Analysis Services версии 2000 и Microsoft SQL Server Analysis Services версии 2005 , серверных продуктов Microsoft OLAP. Excel также можно работать со сторонними продуктами OLAP, совместимыми с OLE-DB для OLAP.
Данные OLAP можно отобразить только в отчете или отчете сводная диаграмма или на функции, преобразованной из отчета, но не как отчет диапазон внешних данных. Вы можете сохранять отчеты и отчеты сводная диаграмма OLAP в шаблонах отчетов, а также создавать ODC-файлы Office (ODC) для подключения к базам данных OLAP для запросов OLAP. Когда вы открываете ODC-файл, Excel отображает пустой отчет, который можно разложить.
Создание файлов куба для автономного использования Вы можете создать файл автономного куба (.cub) с подмножество данных из базы данных сервера OLAP. Автономные файлы кубов можно использовать для работы с данными OLAP, если вы не подключены к сети. Куб позволяет работать с большими объемами данных в отчете или отчете сводная диаграмма, чем в противном случае, и ускоряет искомые данные. Файлы кубов можно создавать только при использовании поставщик OLAP, например Microsoft SQL Analysis Services Server версии 2005, которая поддерживает эту функцию.
Действия сервера Действие сервера — это необязательная, но полезная функция, которую администратор куба OLAP может определить на сервере, который использует элемент куба или меру в качестве параметра в запросе для получения сведений в кубе или запуска другого приложения, например браузера. Excel поддерживает url-адрес, отчет, набор строк, детализацию и развернуть до подробных серверов, но не поддерживает проприетарные данные, statement и Dataset.
Ключевые показатели эффективности Ключевой показатель эффективности — это специальный вычисляемая мера, определяемая на сервере, которая позволяет отслеживать «ключевые показатели производительности», включая состояние (соответствует ли текущее значение определенному числу?) и тенденция (какое значение будет со временем?). Если они отображаются, сервер может отправлять связанные значки, похожие на новые значки Excel, которые указывают выше или ниже уровней состояния (например, значок «Остановить свет»), а также указывает ли значение вверх или вниз (например, на стрелку с направлением).
Форматирование сервера Администраторы кубов могут создавать меры и элементы с форматированием цветов, форматированием шрифтов и правилами условного форматирования, которые могут быть назначены корпоративным стандартным бизнес-правилом. Например, серверным форматом прибыли может быть числовом формате валюты, цветом ячейки зеленого цвета, если значение больше или равно 30 000, и красным, если значение меньше 30 000, и полужирным шрифтом, если значение меньше 30 000, и обычным, если значение больше или равно 30 000. Дополнительные сведения см. в этой ссылке.
Язык интерфейса Office Администратор куба может определять перевод данных и ошибок на сервере для пользователей, которым нужно видеть сведения из стебли на другом языке. Эта функция определяется как свойство подключения к файлу, и региональные параметры компьютера пользователя должны соответствовать языку интерфейса.
К началу страницы
Компоненты программного обеспечения, необходимые для доступа к источникам данных OLAP
Поставщик OLAP Чтобы настроить источники данных OLAP для Excel, требуется один из следующих поставщиков OLAP:
-
Поставщик Microsoft OLAP Excel включает программное обеспечение драйвер источника данных и клиентского программного обеспечения, необходимые для доступа к базам данных, созданным с помощью служб MICROSOFT SQL SERVER OLAP версии 7.0, Microsoft SQL Server OLAP Services версии 2000 (8.0) и Microsoft SQL Server Analysis Services версии 2005 (9.0).
-
Сторонние поставщики OLAP Для других продуктов OLAP необходимо установить дополнительные драйверы и клиентское программное обеспечение. Чтобы использовать Excel для работы с данными OLAP, сторонний продукт должен соответствовать стандарту OLE-DB для OLAP и Microsoft Office совместимости. Для получения сведений об установке и использовании сторонних поставщиков OLAP обратитесь к системного администратора или поставщику продукта OLAP.
Серверные базы данных и файлы кубов Клиент Excel OLAP поддерживает подключения к двум типам баз данных OLAP. Если база данных на olAP-сервере доступна в сети, вы можете извлечь исходные данные непосредственно из нее. Если у вас есть автономный файл куба данных OLAP или файл определение кубов, вы можете подключиться к этому файлу и извлечь из него исходные данные.
Источники данных Источник данных обеспечивает доступ ко всем данным в базе данных OLAP или автономном файле куба. После создания источника данных OLAP вы можете создавать на его основе отчеты и возвращать данные OLAP в Excel в виде отчета или отчета сводная диаграмма таблицы, а также в функции, преобразованной из отчета.
Microsoft Query Запрос можно использовать для извлечения данных из внешней базы данных, например Microsoft SQL Microsoft Access. Использовать запрос для извлечения данных из связанной с файлом куба с помощью запроса не требуется. Дополнительные сведения см. в том, как использовать Microsoft Query для извлечения внешних данных.
К началу страницы
Различия функций между исходными данными OLAP и данными, которые не являются источником OLAP
Если вы работаете с отчетами и отчетами сводная диаграмма, полученными как исходные данные OLAP, так и другими типами исходных данных, вы заметите некоторые отличия функций.
Ирисовка данных Сервер OLAP возвращает новые данные Excel каждый раз при изменении макета отчета. При обработке внешних исходных данных можно запрашивать все исходные данные одновременно или настроить параметры запроса только в том случае, если отображаются разные элементы полей фильтра отчета. Кроме того, есть несколько других способов обновления отчета.
В отчетах, основанных на исходных данных OLAP, параметры поля фильтра отчета недоступны, фоновый запрос недоступен, а оптимизировать параметр памяти недоступен.
Примечание: Оптимизация памяти также недоступна для источников данных OLEDB и отчетов с отчетами в отчетах, основанных на диапазоне ячеев.
Типы полей Исходные данные OLAP, измерение поля можно использовать только в качестве строк (рядов), столбцов (категорий) или полей страниц. Поля мер можно использовать только как поля значений. Для других типов исходных данных все поля можно использовать в любой части отчета.
Доступ к подробным данным Для исходных данных OLAP сервер определяет доступные уровни детализации и вычисляет итоги, поэтому подробные записи, которые составляют сводные значения, могут быть недоступны. Однако сервер может предоставлять поля свойств, которые можно отобразить. У других типов исходных данных нет полей свойств, но вы можете отобразить их значения и элементы, а также элементы без данных.
В полях фильтра отчета OLAP может не быть элемента Все, а команда Показать страницы фильтра отчета недоступна.
Порядок начальной сортировки Для исходных данных OLAP элементы сначала отображаются в том порядке, в котором они возвращаются сервером OLAP. После этого вы можете сортировать или переусортировать элементы вручную. Для других типов исходных данных элементы в новом отчете сначала отображаются в порядке возрастания по имени элемента.
Расчеты Серверы OLAP предоставляют сводные значения непосредственно для отчета, поэтому функции сведения для полей значений изменить нельзя. Для других типов исходных данных можно изменить функцию сведения для поля значений и использовать несколько функций сведения для одного поля значений. В отчетах с исходными данными OLAP нельзя создавать вычисляемые поля или вычисляемые объекты.
Промежуточные итоги В отчетах с исходными данными OLAP нельзя изменить функцию суммарных итогов. С помощью других типов исходных данных можно изменять функции суммарных итогов и показывать или скрывать итоги для всех полей строк и столбцов.
Для исходных данных OLAP при расчете итогов и общие итоги можно включать или исключать скрытые элементы. Для других типов исходных данных в подытогов можно включить скрытые элементы поля фильтра отчета, но скрытые элементы в других полях по умолчанию исключаются.
К началу страницы
1. Получаем разрешение на доступ к OLAP-кубу SQL Server Analysis Services (SSAS)
2. На вашем компьютере должен быть установлен MS Excel 2016 / 2013 / 2010 (можно и MS Excel 2007, но в нем работать не удобно, и совсем бедная функциональность MS Excel 2003)
3. Открываем MS Excel, запускаем мастер настройки соединения с аналитической службой:

3.1 Указываем имя или IP-адрес действующего сервера OLAP (иногда требуется указать номер открытого порта, например, 192.25.25.102:80); используется доменная аутентификация:

3.2 Выбираем многомерную базу данных и аналитический куб (в случае наличия прав доступа к кубу):

3.3 Настройки соединения с аналитической службой будут сохранены в odc-файле на Вашем компьютере:

3.4 Выбираем вид отчета (сводная таблица/график) и указываем место для его размещения:

Если в книге Excel уже создано подключение, то им можно воспользоваться повторно: главное меню «Данные» -> «Существующие подключения» -> выбираем подключение в этой книге -> вставляем сводную таблицу в указанную ячейку.
4. Успешно подключились к кубу, можно приступать к интерактивному анализу данных:

Приступая к интерактивному анализу данных необходимо определить, какие из полей будут участвовать в формировании строк, столбцов и фильтров (страниц) сводной таблицы. В общем случае сводная таблица является трехмерной, и можно считать, что третье измерение расположено перпендикулярно экрану, а мы наблюдаем сечения, параллельные плоскости экрана и определяемые тем, какая «страница» выбрана для отображения. Фильтрацию можно осуществить путем перетаскивания мышью соответствующих атрибутов измерений в область фильтров отчета. Фильтрация ограничивает пространство куба, уменьшая нагрузку на сервер OLAP, поэтому предпочтительнее в первую очередь установить необходимые фильтры. Затем следует размещать атрибуты измерений в областях строк, столбцов и показатели в область данных сводной таблицы.
Каждый раз, когда изменяется сводная таблица, на сервер OLAP автоматически отправляется MDX-инструкция, по исполнении которой возвращаются данные. Чем больше и сложнее объем обрабатываемых данных, рассчитываемых показателей, тем дольше время исполнения запроса. Отменить исполнение запроса можно нажатием клавиши Escape. Последние выполненные операции можно отменить (Ctrl+Z) или вернуть (Ctrl+Y).
Как правило, для наиболее часто используемых сочетаний атрибутов измерений в кубе хранятся заранее рассчитанные агрегированные данные, поэтому время отклика таких запросов несколько секунд. Однако все возможное комбинации агрегаций просчитать невозможно, так как для этого может потребоваться очень много времени и места для хранения. Для исполнения массивных запросов к данным на уровне детализации могут потребоваться значительные вычислительные ресурсы сервера, поэтому время их исполнения может быть продолжительным. После чтения данных с дисковых накопителей сервер помещает их в кэш оперативной памяти, что позволяет последующим таким запросам выполняться мгновенно, поскольку данные будут извлекаться уже из кэша.
Если Вы считаете, что ваш запрос будет часто использоваться и время его исполнения неудовлетворительно, Вы можете обратиться в службу сопровождения аналитических разработок для оптимизации выполнения запроса.
После размещения иерархии в области строк / столбцов возможно скрыть отдельные уровни:

У ключевых атрибутов (реже — для атрибутов выше по иерархии) измерений могут быть свойства — описательные характеристики, которые могут отображаться как во всплывающих подсказках, так и в виде полей:

Если требуется отобразить сразу несколько свойств полей, то можно воспользоваться соответствующим диалоговым списком:

Определяемые пользователем наборы
В Excel 2010 появилась возможность интерактивного создания собственных (определяемых пользователем) наборов из элементов измерения:

В отличие от наборов создаваемых и хранящихся централизованно на стороне куба, пользовательские наборы сохраняются локально в книге Excel и могут использоваться в дальнейшем:

Продвинутые пользователи могут создавать наборы, используя MDX конструкции:

Настройка свойств сводной таблицы
Посредством пункта «Параметры сводной таблицы…» контекстного меню (щелчок правой кнопкой мыши в рамках сводной таблицы) предоставляется возможность настройки сводной таблицы, например:
— вкладка «Вывод», параметр «Классический макет сводной таблицы» — сводная таблица становится интерактивной, можно перетаскивать поля (Drag&Drop);
— вкладка «Вывод», параметр «Показывать элементы без данных в строках» — в сводной таблице будут отображаться пустые строки, не содержащие ни одного значения показателя по соответствующим элементам измерений;
— вкладка «Разметка и формат», параметр «Сохранять форматирование ячеек при обновлении» — в сводной таблице можно переопределить и сохранить формат ячеек при обновлении данных;

Создание сводных диаграмм
Для имеющейся сводной OLAP-таблицы можно создать сводную диаграмму – круговую, линейчатую, гистограмму, график, точечную и другие виды диаграмм:

При этом сводная диаграмма будет синхронизирована со сводной таблицей – при изменении состава показателей, фильтров, измерений в сводной таблице также обновляется сводная таблица.
Создание информационных панелей
Выделим исходную сводную таблицу, скопируем ее в буфер обмена (Ctrl+C) и вставим её копию (Ctrl+V), в которой изменим состав показателей:

Для одновременного управления несколькими сводными таблицами вставим срез (новый функционал, доступный, начиная с версии MS Excel 2010). Подключим наш Slicer к сводным таблицам – щелчок правой кнопкой мыши в рамках среза, выбор в контекстном меню пункта «Подключения к сводной таблице…». Следует отметить, что может быть несколько панелей срезов, которые могут обслуживать одновременно сводные таблицы на разных листах, что позволяет создавать скоординированные информационные панели (Dashboard).
 в сводную таблицу OLAP")
Панели срезов можно настраивать: необходимо выделить панель, затем см. пункты «Размер и свойства…», «Настройки среза», «Назначить макрос» в контекстном меню, активируемого по правому щелку мыши или пункт «Параметры» главного меню. Так, возможно установить кличество столбцов для элементов (кнопок) среза, размеры кнопок среза и панели, определить для среза цветовую гамму и стиль оформления из имеющегося набора (или создать свой стиль), определить собственный заголовок панели, назначить программный макрос, посредством которого можно расширить функционал панели.

Исполнение MDX запроса из Excel
- Прежде всего, необходимо выполнить операцию DRILLTHROUGH на каком-нибудь показателе, т.е. спуститься к детализированным данным (детализированные данные отображаются на отдельном листе), и открыть список подключений;
- Открыть свойства подключения, перейти на вкладку «Определение»;
- Выбрать тип команды по умолчанию, а в поле текста команды разместить заранее подготовленный MDX запрос;
- При нажатии кнопки после проверки правильности синтаксиса запроса и наличия соответствующих прав доступа запрос исполнится на сервере, а результат будет представлен в текущем листе в виде обычной плоской таблицы.
Посмотреть текст MDX-запроса, генерируемого Excel, можно с помощью установки бесплатного дополнения OLAP PivotTable Extensions, которое предоставляет также и другие дополнительные функциональные возможности.

Перевод на другие языки
Аналитический куб поддерживает локализацию на русский и английский языки (при необходимости возможна локализация на другие языки). Переводы распространяются на наименования измерений, иерархий, атрибутов, папок, мер, а также элементы отдельных иерархий в случае наличия для них переводов на стороне учетных систем/ хранилища данных. Чтобы сменить язык, необходимо открыть свойства подключения и в строке подключения добавить следующую опцию:
Extended Properties=»Locale=1033″
где 1033 — локализация на английский язык
1049 — локализация на русский язык

Дополнительные расширения Excel для Microsoft OLAP
Возможности работы с OLAP-кубами Microsoft возрастут, если использовать дополнительные расширения, например, OLAP PivotTable Extensions, благодаря которому можно пользоваться быстрым поиском по измерению:

![]()
dvbi.ru
2011-01-11 16:57:00Z
Последнее изменение: 2021-12-12 22:27:25Z
Возрастная аудитория: 14-70
Комментариев: 0
Практическое
занятие
1:
Построение OLAP
кубов в программе MS
Excel
OLAP
— это не отдельно взятый программный
продукт, не язык программирования и
даже не конкретная технология. Если
постараться охватить OLAP во всех его
проявлениях, то это совокупность
концепций, принципов и требований,
лежащих в основе программных продуктов,
облегчающих аналитикам доступ к данным.
Выясним, зачем
аналитикам надо как-то специально
облегчать
доступ к данным.
Дело
в том, что аналитики — это особые
потребители корпоративной информации.
Задача
аналитика — находить закономерности в
больших массивах данных.
Поэтому аналитик не будет обращать
внимания на отдельно взятый факт, что
в четверг четвертого числа контрагенту
Чернову была продана партия черных
чернил — ему нужна информация о
сотнях и тысячах
подобных событий. Одиночные факты в
базе данных могут заинтересовать, к
примеру, бухгалтера или начальника
отдела продаж, в компетенции которого
находится сделка. Аналитику одной записи
мало — ему, к примеру, могут понадобиться
все сделки данного филиала или
представительства за месяц, год. Заодно
аналитик отбрасывает
ненужные ему подробности вроде ИНН
покупателя, его точного адреса и номера
телефона, индекса контракта и тому
подобного. В то же время данные, которые
требуются аналитику для работы,
обязательно содержат числовые значения
— это обусловлено самой сущностью его
деятельности.
Итак,
аналитику нужно много данных, эти данные
являются выборочными, а также носят
характер «набор
атрибутов — число«.
Последнее означает, что аналитик работает
с таблицами следующего типа:

Здесь
«Страна«,
«Товар«,
«Год»
являются атрибутами или измерениями,
а «Объем
продаж»
— тем самым числовым значением или мерой.
Задачей
аналитика, повторимся, является выявление
стойких взаимосвязей между атрибутами
и числовыми параметрами.
Посмотрев на таблицу, можно заметить,
что ее легко можно перевести в три
измерения: по одной из осей отложим
страны, по другой — товары, по третьей —
годы. А значениями в этом трехмерном
массиве у нас будут соответствующие
объемы продаж.
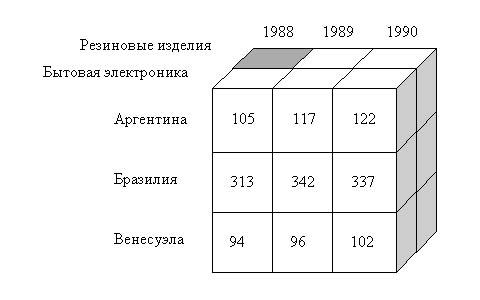
Трехмерное
представление таблицы. Серым сегментом
показано, что для Аргентины в 1988 году
данных нет
Вот
именно такой трехмерный массив в терминах
OLAP и называется кубом. На самом деле, с
точки зрения строгой математики кубом
такой массив будет далеко не всегда: у
настоящего куба количество элементов
во всех измерениях должно быть одинаковым,
а у кубов OLAP такого ограничения нет. Тем
не менее, несмотря на эти детали, термин
«кубы OLAP» ввиду своей краткости и
образности стал общепринятым. Куб OLAP
совсем не обязательно должен быть
трехмерным. Он может быть и двух-, и
многомерным — в зависимости от решаемой
задачи. Особо матерым аналитикам может
понадобиться порядка 20 измерений — и
серьезные OLAP-продукты именно на такое
количество и рассчитаны. Более простые
настольные приложения поддерживают
где-то 6 измерений.
Измерения
OLAP-кубов состоят из так называемых меток
или членов (members). Например, измерение
«Страна» состоит из меток «Аргентина»,
«Бразилия», «Венесуэла» и так
далее.
Должны
быть заполнены далеко не все элементы
куба: если нет информации о продажах
резиновых изделий в Аргентине в 1988 году,
значение в соответствующей ячейке
просто не будет определено. Совершенно
необязательно также, чтобы приложение
OLAP хранило данные непременно в многомерной
структуре — главное, чтобы для пользователя
эти данные выглядели именно так. Кстати
именно специальным способам компактного
хранения многомерных данных, «вакуум»
(незаполненные элементы) в кубах не
приводят к бесполезной трате памяти.
Однако
куб сам по себе для анализа не пригоден.
Если еще можно адекватно представить
или изобразить трехмерный куб, то с
шести — или девятнадцатимерным дело
обстоит значительно хуже. Поэтому перед
употреблением
из многомерного куба извлекают обычные
двумерные
таблицы.
Эта операция называется «разрезанием»
куба. Термин этот, опять же, образный.
Аналитик как бы берет и «разрезает»
измерения куба по интересующим его
меткам. Этим способом аналитик получает
двумерный срез куба и с ним работает.
Примерно так же лесорубы считают годовые
кольца на спиле.
Соответственно,
«неразрезанными», как правило,
остаются только два измерения — по числу
измерений таблицы. Бывает, «неразрезанным»
остается только измерение — если куб
содержит несколько видов числовых
значений, они могут откладываться по
одному из измерений таблицы.
Если
еще внимательнее всмотреться в таблицу,
которую мы изобразили первой, можно
заметить, что находящиеся в ней данные,
скорее всего, не являются первичными,
а получены в результате суммирования
по более мелким элементам. Например,
год делится на кварталы, кварталы на
месяцы, месяцы на недели, недели на дни.
Страна состоит из регионов, а регионы
— из населенных пунктов. Наконец в самих
городах можно выделить районы и конкретные
торговые точки. Товары можно объединять
в товарные группы и так далее. В терминах
OLAP такие многоуровневые объединения
совершенно логично называется иерархиями.
Средства OLAP дают возможность в любой
момент перейти на нужный уровень
иерархии. Причем, как правило, для одних
и тех же элементов поддерживается
несколько видов иерархий: например
день-неделя-месяц или день-декада-квартал.
Исходные данные берутся из нижних
уровней иерархий, а затем суммируются
для получения значений более высоких
уровней. Для того, чтобы ускорить процесс
перехода, просуммированные значения
для разных уровней хранятся в кубе.
Таким образом, то, что со стороны
пользователя выглядит одним кубом,
грубо говоря, состоит из множества более
примитивных кубов.
Пример
иерархии
В
этом заключается один из существенных
моментов, которые привели к появлению
OLAP — производительности и эффективности.
Представим себе, что происходит, когда
аналитику необходимо получить информацию,
а средства OLAP на предприятии отсутствуют.
Аналитик самостоятельно (что маловероятно)
или с помощью программиста делает
соответствующий SQL-запрос и получает
интересующие данные в виде отчета или
экспортирует их в электронную таблицу.
Проблем при этом возникает великое
множество. Во-первых, аналитик вынужден
заниматься не своей работой
(SQL-программированием) либо ждать, когда
за него задачу выполнят программисты
— все это отрицательно сказывается на
производительности труда, повышаются
штурмовщина, инфарктно-инсультный
уровень и так далее. Во-вторых,
один-единственный отчет или таблица,
как правило, не спасает гигантов мысли
и отцов русского анализа — и всю процедуру
придется повторять снова и снова.
В-третьих, как мы уже выяснили, аналитики
по мелочам не спрашивают — им нужно все
и сразу. Это означает (хотя техника и
идет вперед семимильными шагами), что
сервер корпоративной реляционной СУБД,
к которому обращается аналитик, может
задуматься глубоко и надолго, заблокировав
остальные транзакции.
Концепция
OLAP появилась именно для разрешения
подобных проблем. Кубы OLAP представляют
собой, по сути, мета-отчеты. Разрезая
мета-отчеты (кубы, то есть) по измерениям,
аналитик получает, фактически, интересующие
его «обычные» двумерные отчеты
(это не обязательно отчеты в обычном
понимании этого термина — речь идет о
структурах данных с такими же функциями).
Преимущества кубов очевидны — данные
необходимо запросить из реляционной
СУБД всего один раз — при построении
куба. Поскольку аналитики, как правило,
не работают с информацией, которая
дополняется и меняется «на лету»,
сформированный куб является актуальным
в течение достаточно продолжительного
времени. Благодаря этому, не только
исключаются перебои в работе сервера
реляционной СУБД (нет запросов с тысячами
и миллионами строк ответов), но и резко
повышается скорость доступа к данным
для самого аналитика. Кроме того, как
уже отмечалось, производительность
повышается и за счет подсчета промежуточных
сумм иерархий и других агрегированных
значений в момент построения куба. То
есть, если изначально наши данные
содержали информацию о дневной выручке
по конкретному товару в отдельно взятом
магазине, то при формировании куба
OLAP-приложение считает итоговые суммы
для разных уровней иерархий (недель и
месяцев, городов и стран).
Конечно,
за повышение таким способом
производительности надо платить. Иногда
говорят, что структура данных просто
«взрывается» — куб OLAP может занимать
в десятки и даже сотни раз больше места,
чем исходные данные.
Ответить
на вопросы:
-
Что
такое куб
OLAP? -
Что
такое метки
конкретного измерения? Привести примеры. -
Могут
ли меры
в кубе OLAP,
содержать нечисловые значения.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Набор инструментов ОLAP (Online Analytical Processing— оперативный анализ данных) позволяет эффективно извлекать и анализировать многомерные данные. В отличие от других типов баз данных, базы данных ОLAP разработаны специально для аналитической обработки и быстрого извлечения из них всевозможных наборов данных.
На самом деле существует несколько ключевых различий между стандартными реляционными базами данных, например Access или SQL Server, и базами данных OLAP. В реляционных базах данных информация представляется в виде записей, которые добавляются, удаляются и обновляются последовательно. В базах данных OLAP хранится только моментальный снимок данных. В базе данных OLAP информация заархивирована в виде единого блока данных и предназначается только для вывода по запросу. Хотя в базу данных OLAP и можно добавлять новую информацию, существующие данные редко редактируются и тем более удаляются.
Реляционные базы данных и базы данных OLAP при первом знакомстве различаются структурно. Реляционные базы данных обычно состоят из набора таблиц, которые связаны между собой. В отдельных случаях реляционная база данных содержит так много таблиц, что очень сложно определить, как же они все-таки связаны.
В базах данных OLAP взаимосвязь между отдельными типами данных определяется заранее и сохраняется в структуре, известной под названием кубов OLAP. В кубах данных хранятся полные сведения об иерархической структуре и связях базы данных, которые значительно упрошают навигацию по ней. К тому же создавать отчеты намного проще, если заранее известно, где располагаются извлекаемые данные и какие еще данные с ними связаны.
Основная же разница между реляционными базами данных и базами данных OLAP заключается в способе хранения информации. Данные в кубе OLAP редко представляются в общем виде. Кубы данных OLAP обычно содержат информацию, представленную в заранее разработанном формате. Таким образом, операции группировки, фильтрации, сортировки и объединения данных в кубах выполняются перед заполнением их информацией. Это делает извлечение и вывод запрашиваемых данных максимально упрощенной процедурой. В отличие от реляционных баз данных, нет необходимости в упорядочении информации должным образом перед выводом конечным пользователям.
Базы данных OLAP обычно настраиваются и поддерживаются администраторами IT-отдела. Если в вашей организации нет структуры, которая отвечает за управление базами данных OLAP, то можете обратиться к администратору реляционной базы данных с просьбой реализовать в корпоративной сети хотя бы отдельные OLAP-решения.

Кубы данных — не самая простая тема в дата-инжиниринге. Это тот самый случай, когда на пять запросов об определении приходятся пять разных вариантов ответа. Эта неоднозначность породила неудачную универсальную метафору, с помощью которой описываются кубы данных, — схему трехмерного куба. При этом в объяснениях нет примеров, рассказывающих, как в дата-пайплайне реализуется эта концепция.
Команда VK Cloud перевела статью, в которой заполняются пробелы и развенчиваются мифы, окружающие тему кубов данных.
Что такое куб данных
В общих чертах куб данных — это дизайн-паттерн, в котором показатели, например продажи, агрегируются по разным разрезам: региону, магазину или продукту.
Дизайн-паттерн реализован в основном в двух контекстах:
- Как предварительно агрегированная таблица в реляционной базе данных.
- Как объект данных в специализированной OLAP-системе.
В обоих контекстах кубы данных должны помогать бизнес-аналитикам предварительно упаковывать и агрегировать важные для стейкхолдеров показатели. Если вкратце, с 1980 по 2010 год специалисты прибегали к предварительной упаковке и агрегированию. Это помогало избежать оперативных агрегатных запросов, из-за которых резко снижалась доступная на тот момент пропускная способность обработки.
Сегодня эти проблемы стоят не так остро. Но к этой теме мы вернёмся позже.
Кубы данных в реляционных БД
Рассмотрим пример — таблицу с данными по продажам по региону, магазину и продукту:

Чтобы создать куб данных из взятого для примера дата-сета, нужно агрегировать сумму цен по каждой комбинации разрезов. В PostgreSQL и MS SQL имеется подблок GROUP BY под названием CUBE, который сделает эту работу за вас.
Вот как выглядит запрос CUBE с этими данными:
SELECT SUM(price) as total_sales,
region,
store,
product
FROM sales
GROUP BY CUBE(region, store, product);Поскольку у взятого для примера дата-сета есть три разреза: регион, магазин, продукт, — вышеуказанный запрос выдаст восемь сгруппированных множеств и 29 строк данных (исходя из количества уникальных значений по разрезам).
Чтобы рассчитать общее количество сгруппированных множеств, созданных кубом данных, воспользуйтесь формулой: 2^number_of_dimensions.
Сгруппированные множества для этого примера:
(region, store, product),
(region, store),
(region, product),
(store, product),
(region),
(store),
(product),
()В этом кубе данных нет ничего чрезмерно сложного: мы просто обобщили данные по каждому сочетанию разрезов. В прошлом дата-инженер создавал похожую таблицу и передавал её аналитику в виде общего представления по продажам.
Кубы данных в OLAP-системах
Как мы показали выше, куб данных можно реализовать в таблице стандартной БД, но их чаще используют в приложении Online Analytical Processing (OLAP).
Кубы — важная характеристика ядра традиционных OLAP-систем. Пожалуй, не будет преувеличением сказать, что OLAP и кубы данных — это в каком-то смысле синонимы.
Краткий исторический экскурс
Сейчас давайте ненадолго вернёмся в прошлое и разберёмся, что такое OLAP-системы и почему их вообще создали.
Сегодня, как и в 1970-х, бизнес-аналитика служит одной и той же цели: стейкхолдеры направляют запросы к данным и обобщают результаты по разным разрезам. К сожалению, десятилетия назад для выполнения этих запросов мог подойти только интерфейс используемых в компании рабочих баз данных SQL — тех самых, которые поддерживали цифровые бизнес-транзакции.
По современным меркам, компьютеры той эпохи работали очень медленно. Выполнять анализ непосредственно в рабочей базе данных было долго и дорого в плане затрат вычислительных ресурсов. Что ещё хуже, это мешало выполнять повседневные операции, для которых базы данных, собственно, и предназначались.
Приход OLAP-систем
В качестве решения этой проблемы разработчики ПО придумали отдельные хранилища, в которые загружали рабочие данные для анализа. Эти специализированные OLAP-системы хранили в предварительно агрегированном виде многомерную информацию, которую инженеры и аналитики называли OLAP-кубами.
Постепенно эти OLAP-системы доросли до полноценных приложений. В них аналитики или стейкхолдеры могли изучать OLAP-кубы, используя специальный синтаксис запросов или графический пользовательский интерфейс. Это позволяло выполнять нескольких функций, характерных для сводных таблиц:
- Roll up: объединить показатели в категории разрезов уровнем выше (город => область).
- Drill Down: разбить обобщённые категории на категории уровнем ниже (область => город).
- Slice and Dice: выбрать сегмент данных из одного или нескольких разрезов.
- Pivot: поменять оси табличного представления.
В этом контексте OLAP-куб — это агрегат многомерных данных, а OLAP-система — интерфейс сводных таблиц, предназначенный для исследования куба с помощью языка запросов или GUI. Современные версии OLAP-систем — это IMB Cognos, Oracle Olap и Oracle Essbase.
Если искать в интернете, что такое OLAP-куб, Google будет раз за разом выводить описания в виде трёхмерного изображения куба, который состоит из кубиков поменьше. Суть таких схем — наглядно представить, как вышеописанные функции работают в OLAP-системе и как выглядят сегменты агрегированных данных, созданных пересекающимися разрезами.
Но поскольку этому визуальному представлению не хватает контекста, оно скорее запутывает, чем проясняет дело. Зато теперь, когда мы разобрались с основами, эта схема может нам пригодиться.

OLAP drill up&down en.png со страницы Wikipedia
Вчера и сегодня
С тех пор как разработчики разворачивали кубы данных и OLAP-системы в качестве решения для бизнес-аналитики, технологический ландшафт кардинально изменился. Эффективность обработки данных экспоненциально выросла, а благодаря облачным платформам вроде AWS, GCP и VK Cloud, ещё и существенно подешевела. Кроме того, колоночные хранилища упростили доступ к большому объёму данных при стандартных нагрузках.
Благодаря этим переменам необходимость в кубах и OLAP-системах заметно снизилась.
Сегодня аналитики могут безо всяких проблем на лету агрегировать данные по разным разрезам с помощью платформ типа BigQuery и Snowflake. Да и использование GUI для сведения воедино больших объёмов данных уже не вызывает трудностей. Такие инструменты, как DOMO и PowerBI, позволяют аналитикам с лёгкостью фрагментировать и анализировать данные вдоль и поперёк.
Заключение
Вернёмся к исходному вопросу — так что же такое OLAP-куб? Если очень коротко, это многомерная сводная таблица в OLAP-системе. Если не брать в расчёт особенности технической реализации, она похожа на сводную таблицу Excel.
Команда VK Cloud развивает собственные Big Data-решения. Будем признательны, если вы их протестируете и дадите обратную связь. Для тестирования пользователям при регистрации начисляем 3000 бонусных рублей.
Сводные таблицы Excel
В стандартной сводной таблице исходные данные хранятся на локальном жестком диске. Таким образом, вы всегда можете управлять ими и переорганизовывать их, даже не имея доступа к сети. Но это ни в коей мере не касается сводных таблиц OLAP. В сводных таблицах OLAP кеш никогда не хранится на локальном жестком диске. Поэтому сразу же после отключения от локальной сети ваша сводная таблица утратит работоспособность. Вы не сможете переместить в ней ни одного поля.
Если вам все же необходимо анализировать OLAP-данные после отключения от сети, создайте автономный куб данных. Автономный куб данных — это отдельный файл, который представляет собой кеш сводной таблицы и хранит OLAP-данные, просматриваемые после отключения от локальной сети. OLAP-данные, скопированные в сводную таблицу, можно распечатать, на сайте http://everest.ua подробно об этом рассказано.
Чтобы создать автономный куб данных, сначала создайте сводную таблицу OLAP. Поместите курсор в пределах сводной таблицы и щелкните на кнопке Средства OLAP (OLAP Tools) контекстной вкладки Параметры (Tools), входящей в группу контекстных вкладок Работа со сводными таблицами (PivotTable Tools). Выберите команду Автономный режим OLAP (Offline OLAP) (рис. 9.8).

Рис. 9.8. Создание автономного куба данных
На экране появится диалоговое окно настроек автономного куба данных OLAP. Щелкните в нем на кнопке Создать автономный файл данных (Create Offline Data File). Вы запустили мастер создания файла куба данных. Щелкните на кнопке Далее (Next), чтобы продолжить процедуру.
Cначала необходимо указать размерности и уровни, которые будут включаться в куб данных. В диалоговом окне необходимо выбрать данные, которые будут импортироваться из базы данных OLAP. Идея состоит в том, чтобы указать только те размерности, которые понадобятся после отключения компьютера от локальной сети. Чем больше размерностей укажете, тем больший размер будет иметь автономный куб данных.
Щелкните на кнопке Далее для перехода к следующему диалоговому окну мастера. В нем вы получаете возможность указать члены или элементы данных, которые не будут включаться в куб. В частности, вам не потребуется мера Internet Sales-Extended Amount, поэтому флажок для нее будет сброшен в списке. Сброшенный флажок указывает на то, что указанный элемент не будет импортироваться и занимать лишнее место на локальном жестком диске.
На последнем этапе укажите расположение и имя куба данных. В нашем случае файл куба будет назван MyOfflineCube.cub и будет располагаться в папке Work.
Файлы кубов данных имеют расширение .cub
Спустя некоторое время Excel сохранит автономный куб данных в указанной папке. Чтобы протестировать его, дважды щелкните на файле, что приведет к автоматической генерации рабочей книги Excel, которая содержит сводную таблицу, связанную с выбранным кубом данных. После создания вы можете распространить автономный куб данных среди всех заинтересованных пользователей, которые работают в режиме отключенной локальной сети.
После подключения к локальной сети можно открыть автономный файл куба данных и обновить его, а также соответствующую таблицу данных. Главный принцип гласит, что автономный куб данных применяется только для работы при отключенной локальной сети, но он в обязательном порядке обновляется после восстановления соединения. Попытка обновления автономного куба данных после разрыва соединения приведет к сбою.
Работа с файлами автономного куба
автономный файл куба (. cub) хранит данные в форме куба OLAP (Online Analytical Processing). Эти данные могут представлять часть базы данных OLAP на сервере OLAP или могут создаваться независимо от базы данных OLAP. Используйте автономный файл куба, чтобы продолжить работу с отчетами сводной таблицы и сводной диаграммы, если сервер недоступен или когда вы отключены от сети.
Примечание по безопасности: Будьте внимательны при использовании или распространении файла автономного куба, содержащего конфиденциальные или личные данные. Вместо файла куба рекомендуется сохранить данные в книге, чтобы можно было управлять доступом к данным с помощью функции управления правами. Дополнительные сведения можно найти в разделе Управление правами на доступ к данным в Office.
При работе с отчетом сводной таблицы или сводной диаграммы, основанными на исходных данных сервера OLAP, вы можете с помощью мастера автономного куба скопировать исходные данные в отдельный файл автономного куба на компьютере. Для создания этих автономных файлов необходимо, чтобы поставщик данных OLAP поддерживал такую возможность, например MSOLAP из служб Microsoft SQL Server Analysis Services, установленных на компьютере.
Примечание: Создание и использование файлов автономных кубов из служб Microsoft SQL Server Analysis Services регулируется термином и лицензированием установки Microsoft SQL Server. Ознакомьтесь с соответствующими сведениями о лицензировании версии SQL Server.
Работа с мастером автономного куба
Для создания файла автономного куба вы можете выбрать подмножество данных в базе данных OLAP с помощью мастера автономного куба, а затем сохранить это подмножество. В отчете не нужно включать все поля, включенные в файл, а также выбирать из них любые из них и поля данных, доступные в базе данных OLAP. Чтобы сохранить файл как минимум, вы можете включить только те данные, которые должны отображаться в отчете. Вы можете опустить все измерения и для большинства типов измерений вы также можете исключить сведения о более низком уровне и элементы верхнего уровня, которые не нужно отображать. Для всех элементов, которые вы включаете, поля свойств, доступные в базе данных для этих элементов, также сохраняются в автономном файле.
Перевод данных в автономный режим и их обратное подключение
Для этого сначала нужно создать отчет сводной таблицы или сводной диаграммы, основанный на базе данных сервера, а затем создать файл автономного куба из отчета. После этого вы можете переключить отчет между базой данных сервера и автономным файлом в любое время. Например, если вы используете портативный компьютер для работы в домашних и видеопоездках, а затем снова подключите компьютер к сети.
Ниже описаны основные шаги, которые следует выполнить для автономной работы с данными, а затем снова перевести данные в Интернет.
Создайте или откройте сводную таблицу или отчет сводной диаграммы, основанную на данных OLAP, к которым вы хотите получить доступ в автономном режиме.
Создание автономный файл куба на компьютере. В разделе Создание файла автономного куба из базы данных OLAP-сервера (ниже в этой статье).
Отключение от сети и работа с файлом автономного куба.
Подключитесь к сети и повторно подключите файл куба автономно. Ознакомьтесь с разделом Повторное подключение файла автономного куба к базе данных OLAP-сервера (ниже, в этой статье).
Обновление файла автономного куба с новыми данными и повторное создание автономного файла куба. Ознакомьтесь с разделом обновление и повторное создание файла автономного куба (ниже в этой статье).
БЛОГ
Только качественные посты
Что такое Сводные таблицы Excel и OLAP кубы
Смотрите видео к статье:
OLAP – это англ. online analytical processing, аналитическая технология обработки данных в реальном времени. Простым языком – хранилище с многомерными данными (Куб), еще проще – просто база данных, из которой можно получить данные в Excel и проанализировать с помощью инструмента Excel – Сводные таблицы.
Сводные таблицы – это пользовательский интерфейс для отображения многомерных данных. Иными словами — специальный вид таблиц, с помощью которых можно сделать практически любой отчет.
Чтобы было понятно, давайте сравним «Обычную таблицу» со «Сводной таблицей»
Обычная таблица:

Сводная таблица:

Основное отличие Сводных таблиц – это наличие окна «Список полей сводной таблицы», из которого можно выбирать нужные поля и получать любую таблицу автоматически!
Как пользоваться
Откройте файл Excel, который подключен к OLAP-кубу, например «BIWEB»:

Теперь, что это означает и как этим пользоваться?

Перетащите нужные поля, чтобы получить, например, такую таблицу:

«Плюсики» позволяют детализировать отчет. В этом примере «Бренд» детализируется до «Сокращенных названий», а «Квартал» до «Месяца», т.е. так:
Аналитические функции в Excel (функции кубов)
Microsoft постоянно добавляет в Excel новые возможности в части анализа и визуализации данных. Работу с информацией в Excel можно представить в виде относительно независимых трех слоев:
- «правильно» организованные исходные данные
- математика (логика) обработки данных
- представление данных
Рис. 1. Анализ данных в Excel: а) исходные данные, б) мера в Power Pivot, в) дашборд; чтобы увеличить изображение кликните на нем правой кнопкой мыши и выберите Открыть картинку в новой вкладке
Скачать заметку в формате Word или pdf, примеры в формате Excel
Функции кубов и сводные таблицы
Наиболее простым и в тоже время очень мощным средством представления данных являются сводные таблицы. Они могут быть построены на основе данных, содержащихся: а) на листе Excel, б) кубе OLAP или в) модели данных Power Pivot. В последних двух случаях, помимо сводной таблицы, можно использовать аналитические функции (функции кубов) для формирования отчета на листе Excel. Сводные таблицы проще. Функции кубов сложнее, но предоставляют больше гибкости, особенно в оформлении отчетов, поэтому они широко применяются в дашбордах.
Дальнейшее изложение относится к формулам кубов и сводным таблицам на основе модели Power Pivot и в нескольких случаях на основе кубов OLAP.
Простой способ получить функции кубов
Когда (если) вы начинали изучать код VBA, то узнали, что проще всего получить код, используя запись макроса. Далее код можно редактировать, добавить циклы, проверки и др. Аналогично проще всего получить набор функций кубов, преобразовав сводную таблицу (рис. 2). Встаньте на любую ячейку сводной таблицы, перейдите на вкладку Анализ, кликните на кнопке Средства OLAP, и нажмите Преобразовать в формулы.
Рис. 2. Преобразование сводной таблицы в набор функций куба
Числа сохранятся, причем это будут не значения, а формулы, которые извлекают данные из модели данных Power Pivot (рис. 3). Получившуюся таблицу вы может отформатировать. В том числе, можно удалять и вставлять строки и столбцы внутрь таблицы. Срез остался, и он влияет на данные в таблице. При обновлении исходных данных числа в таблице также обновятся.
Рис. 3. Таблица на основе формул кубов
Функция КУБЗНАЧЕНИЕ()
Это, пожалуй, основная функция кубов. Она эквивалента области Значения сводной таблицы. КУБЗНАЧЕНИЕ извлекает данные из куба или модели Power Pivot, и отражает их вне сводной таблицы. Это означает, что вы не ограничены пределами сводной таблицы и можете создавать отчеты с бесчисленными возможностями.
Написание формулы «с нуля»
Вам не обязательно преобразовывать готовую сводную таблицу. Вы можете написать любую формулу куба «с нуля». Например, в ячейку С10 введена следующая формула (рис. 4):
Рис. 4. Функция КУБЗНАЧЕНИЕ() в ячейке С10 возвращает продажи велосипедов за все годы, как и в сводной таблице
Маленькая хитрость. Чтобы удобнее было читать формулы кубов, желательно, чтобы в каждой строке помещался только один аргумент. Можно уменьшить окно Excel. Для этого кликните на значке Свернуть в окно, находящемся в правом верхнем углу экрана. А затем отрегулируйте размер окна по горизонтали. Альтернативный вариант – принудительно переносить текст формулы на новую строку. Для этого в строке формул поставьте курсор в том месте, где хотите сделать перенос и нажмите Alt+Enter.
Рис. 5. Свернуть окно
Синтаксис функции КУБЗНАЧЕНИЕ()
Справка Excel абсолютно точна и абсолютно бесполезна для начинающих:
КУБЗНАЧЕНИЕ(подключение; [выражение_элемента1]; [выражение_элемента2]; …)
Подключение – обязательный аргумент; текстовая строка, представляющая имя подключения к кубу.
Выражение_элемента – необязательный аргумент; текстовая строка, представляющая многомерное выражение, которое возвращает элемент или кортеж в кубе. Кроме того, «выражение_элемента» может быть множеством, определенным с помощью функции КУБМНОЖ. Используйте «выражение_элемента» в качестве среза, чтобы определить часть куба, для которой необходимо возвратить агрегированное значение. Если в аргументе «выражение_элемента» не указана мера, будет использоваться мера, заданная по умолчанию для этого куба.
Прежде, чем перейти к объяснению синтаксиса функции КУБЗНАЧЕНИЕ, пару слов о кубах, моделях данных, и загадочном кортеже.
Некоторые сведения о кубах OLAP и моделях данных Power Pivot
Кубы данных OLAP (Online Analytical Processing — оперативный анализ данных) были разработаны специально для аналитической обработки и быстрого извлечения из них данных. Представьте трехмерное пространство, где по осям отложены периоды времени, города и товары (рис. 5а). В узлах такой координатной сетки расположены значения различных мер: объем продаж, прибыль, затраты, количество проданных единиц и др. Теперь вообразите, что измерений десятки, или даже сотни… и мер тоже очень много. Это и будет многомерный куб OLAP. Создание, настройка и поддержание в актуальном состоянии кубов OLAP – дело ИТ-специалистов.
Рис. 5а. Трехмерный куб OLAP
Аналитические формулы Excel (формулы кубов) извлекают названия осей (например, Время), названия элементов на этих осях (август, сентябрь), значения мер на пересечении координат. Именно такая структура и позволяет сводным таблицам на основе кубов и формулам кубов быть столь гибкими, и подстраиваться под нужды пользователей. Сводные таблицы на основе листов Excel не используют меры, поэтому они не столь гибки в целях анализа данных.
Power Pivot – относительно новая фишка Microsoft. Это встроенная в Excel и отчасти независимая среда с привычным интерфейсом. Power Pivot значительно превосходит по своим возможностям стандартные сводные таблицы. Вместе с тем, разработка кубов в Power Pivot относительно проста, а самое главное – не требует участия ИТ-специалиста. Microsoft реализует свой лозунг: «Бизнес-аналитику – в массы!». Хотя модели Power Pivot не являются кубами на 100%, о них также можно говорить, как о кубах (подробнее см. вводный курс Марк Мур. Power Pivot и более объемное издание Роб Колли. Формулы DAX для Power Pivot).
Основные компоненты куба – это измерения, иерархии, уровни, элементы (или члены; по-английски members) и меры (measures). Измерение – основная характеристика анализируемых данных. Например, категория товаров, период времени, география продаж. Измерение – это то, что мы можем поместить на одну из осей сводной таблицы. Каждое измерение помимо уникальных значений включает элемент [ALL], выполняющий агрегацию всех элементов этого измерения.
Измерения построены на основе иерархии. Например, категория товаров может разбиваться на подкатегории, далее – на модели, и наконец – на названия товаров (рис. 5б) Иерархия позволяет создавать сводные данные и анализировать их на различных уровнях структуры. В нашем примере иерархия Категория включает 4 Уровня.
Рис. 5б. Иерархия категорий товаров
Элементы (отдельные члены) присутствуют на всех уровнях. Например, на уровне Category есть четыре элемента: Accessories, Bikes, Clothing, Components. Другие уровни имеют свои элементы.
Меры – это вычисляемые значения, например, объем продаж. Меры в кубах хранятся в собственном измерении, называемом [Measures] (см. ниже рис. 9). Меры не имеют иерархий. Каждая мера рассчитывает и хранит значение для всех измерений и всех элементов, и нарезается в зависимости от того, какие элементы измерений мы поместим на оси. Еще говорят, какие зададим координаты, или какой зададим контекст фильтра. Например, на рис. 5а в каждом маленьком кубике рассчитывается одна и та же мера – Прибыль. А возвращаемое мерой значение зависит от координат. Справа на рисунке 5а показано, что Прибыль (в трех координатах) по Москве в октябре на яблоках = 63 000 р. Меру можно трактовать, и как одно из измерений. Например, на рис. 5а вместо оси Товары, разместить ось Меры с элементами Объем продаж, Прибыль, Проданные единицы. Тогда каждая ячейка и будет каким-то значением, например, Москва, сентябрь, объем продаж.
Кортеж – несколько элементов разных измерений, задающие координаты по осям куба, в которых мы рассчитываем меру. Например, на рис. 5а Кортеж = Москва, октябрь, яблоки. Также допустимый кортеж – Пермь, яблоки. Еще один – яблоки, август. Не вошедшие в кортеж измерения присутствуют в нем неявно, и представлены членом по умолчанию [All]. Таким образом, ячейка многомерного пространства всегда определяется полным набором координат, даже если некоторые из них в кортеже опущены. Нельзя включить два элемента одного измерения в кортеж, не позволит синтаксис. Например, недопустимый кортеж Москва и Пермь, яблоки. Чтобы реализовать такое многомерное выражение потребуется набор двух кортежей: Москва и яблоки + Пермь и яблоки.
Набор элементов – несколько элементов одного измерения. Например, яблоки и груши. Набор кортежей – несколько кортежей, каждый из которых состоит из одинаковых измерений в одной и той же последовательности. Например, набор из двух кортежей: Москва, яблоки и Пермь, бананы.
Автозавершение в помощь
Вернемся к синтаксису функции КУБЗНАЧЕНИЕ. Воспользуемся автозавершением. Начните ввод формулы в ячейке:
Excel предложит все доступные в книге Excel подключения:
Рис. 6. Подключение к модели данных Power Pivot всегда называется ThisWorkbookDataModel
Рис. 7. Подключения к кубам
Продолжим ввод формулы (в нашем случае для модели данных):
Автозавершение предложит все доступные таблицы и меры модели данных:
Рис. 8. Доступные элементы первого уровня – имена таблиц и набор мер (выделен)
Выберите значок Measures. Поставьте точку:
=КУБЗНАЧЕНИЕ( » ThisWorkbookDataModel » ; » [Measures].
Автозавершение предложит все доступные меры:
Рис. 9. Доступные элементы второго уровня в наборе мер
Выберите меру [Total Sales]. Добавьте кавычки, закрывающую скобку, нажмите Enter.
=КУБЗНАЧЕНИЕ( » ThisWorkbookDataModel » ; » [Measures].[Total Sales] » )
Рис. 10. Формула КУБЗНАЧЕНИЕ в ячейке Excel
Аналогичным образом можете добавить третий аргумент в формулу:
VBA в Excel Объект Excel.PivotTable и работа со сводными таблицами и кубами OLAP в Excel
10.8 Работа со сводными таблицами (объект PivotTable)
Объект Excel.PivotTable, программная работа со сводными таблицами и кубами OLAP в Excel средствами VBA, объект PivotCache, создание макета сводной таблицы
В процессе работы большинства предприятий накапливаются так называемые необработанные данные (raw data) о деятельности. Например, для торгового предприятия могут накапливаться данные о продажах товаров — по каждой покупке отдельно, для предприятий сотовой связи — статистика нагрузки на базовые станции и т.п. Очень часто менеджменту предприятия необходима аналитическая информация, которая генерируется на основе необработанной — например, посчитать вклад каждого вида товара в доходы предприятия или качество обслуживания в зоне данной станции. Из необработанной информации такие сведения извлечь очень тяжело: нужно выполнять очень сложные SQL-запросы, которые выполняются долго и часто мешают текущей работе. Поэтому все чаще в настоящее время необработанные данные сводятся вначале в хранилище архивных данных — Data Warehouse, а затем — в кубы OLAP, которые очень удобны для интерактивного анализа. Проще всего представить себе кубы OLAP как многомерные таблицы, в которых вместо стандартных двух измерений (столбцы и строки, как в обычных таблицах), измерений может быть очень много. Обычно для описания измерений в кубе используется термин «в разрезе». Например, отделу маркетинга может быть нужна информация во временном разрезе, в региональном разрезе, в разрезе типов продукта, в разрезе каналов продаж и т.п. При помощи кубов (в отличие от стандартных SQL-запросов) очень просто получать ответы на вопросы типа «сколько товаров такого-то типа было продано в четвертом квартале прошлого года в Северо-Западном регионе через региональных дистрибьюторов.
Конечно же, в обычных базах данных такие кубы не создать. Для работы с кубами OLAP требуются специализированные программные продукты. Вместе с SQL Server поставляется база данных OLAP от Microsoft, которая называется Analysis Services. Есть OLAP-решения от Oracle, IBM, Sybase и т.п.
Для работы с такими кубами в Excel встроен специальный клиент. По-русски он называется Сводная таблица (на графическом экране он доступен через меню Данные -> Сводная таблица), а по-английски — Pivot Table. Соответственно, объект, который представляет этот клиент, называется PivotTable. Необходимо отметить, что он умеет работать не только с кубами OLAP, но и с обычными данными в таблицах Excel или баз данных, но многие возможности при этом теряются.
Сводная таблица и объект PivotTable — это программные продукты фирмы Panorama Software, которые были приобретены Microsoft и интегрированы в Excel. Поэтому работа с объектом PivotTable несколько отличается от работы с другими объектами Excel. Догадаться, что нужно сделать, часто бывает непросто. Поэтому рекомендуется для получения подсказок активно использовать макрорекордер. В то же время при работе со сводными таблицами пользователям часто приходится выполнять одни и те же повторяющиеся операции, поэтому автоматизация во многих ситуациях необходима.
Как выглядит программная работа со сводной таблицей?
Первое, что нам потребуется сделать — создать объект PivotCache, который будет представлять набор записей, полученных с источника OLAP. Очень условно этот объект PivotCache можно сравнить с QueryTable. Для каждого объекта PivotTable можно использовать только один объект PivotCache. Создание объекта PivotCache производится при помощи метода Add() коллекции PivotCaches:
Dim PC1 As PivotCache
Set PC1 = ActiveWorkbook.PivotCaches.Add(xlExternal)
PivotCaches — стандартная коллекция, и из методов, которые заслуживают подробного рассмотрения, в ней можно назвать только метод Add(). Этот метод принимает два параметра:
- SourceType — обязательный, определяет тип источника данных для сводной таблицы. Можно указать создание PivotTable на основе диапазона в Excel, данных из базы данных, во внешнем источнике данных, другой PivotTable и т.п. На практике обычно OLAP есть смысл использовать только тогда, когда данных много — соответственно нужно специализированное внешнее хранилище (например, Microsoft Analysis Services). В этой ситуации выбирается значение xlExternal.
- SourceData — обязательный во всех случаях, кроме тех, когда значение первого параметра — xlExternal. Собственно говоря, определяет тот диапазон данных, на основе которого и будет создаваться PivotTable. Обычно принимает объект Range.
Следующая задача — настроить параметры объекта PivotCache. Как уже говорилось, этот объект очень напоминает QueryTable, и набор свойств и методов у него очень похожий. Некоторые наиболее важные свойства и методы:
- ADOConnection — возможность возвратить объект ADO Connection, который автоматически создается для подключения к внешнему источнику данных. Используется для дополнительной настройки свойств подключения.
- Connection — работает точно так же, как и одноименное свойство объекта QueryTable. Может принимать строку подключения, готовый объект Recordset, текстовый файл, Web-запрос. файл Microsoft Query. Чаще всего при работе с OLAP прописывается строка подключения напрямую (поскольку получать объект Recordset, например для изменения данных, большого смысла нет — источники данных OLAP практически всегда доступны только на чтение). Например, настройка этого свойства для подключения к базе данных Foodmart (учебная база данных Analysis Services) на сервере LONDON может выглядеть так:
PC1.Connection = «OLEDB;Provider=MSOLAP.2;Data Source=LONDON1;Initial Catalog = FoodMart 2000»
- свойства CommandType и CommandText точно так же описывают тип команды, которая передается на сервер баз данных, и текст самой команды. Например, чтобы обратиться на куб Sales и получить его целиком в кэш на клиенте, можно использовать код вида
- свойство LocalConnection позволяет подключиться к локальному кубу (файлу *.cub), созданному средствами Excel. Конечно, такие файлы для работы с «производственными» объемами данных использовать очень не рекомендуется — только для целей создания макетов и т.п.
- свойство MemoryUsed возвращает количество оперативной памяти, используемой PivotCache. Если PivotTable на основе этого PivotCache еще не создана и не открыта, возвращает 0. Можно использовать для проверок, если ваше приложение будет работать на слабых клиентах.
- свойство OLAP возвращает True, если PivotCache подключен к серверу OLAP.
- OptimizeCache — возможность оптимизировать структуру кэша. Изначальная загрузка данных будет производиться дольше, но потом скорость работы может возрасти. Для источников OLE DB не работает.
Остальные свойства объекта PivotCache совпадают с аналогичными свойствами объекта QueryTable, и поэтому здесь рассматриваться не будут.
Главный метод объекта PivotCache — это метод CreatePivotTable(). При помощи этого метода и производится следующий этап — создание сводной таблицы (объекта PivotTable). Этот метод принимает четыре параметра:
- TableDestination — единственный обязательный параметр. Принимает объект Range, в верхний левый угол которого будет помещена сводная таблица.
- TableName — имя сводной таблицы. Если не указано, то автоматически сгенерируется имя вида «СводнаяТаблица1».
- ReadData — если установить в True, то все содержимое куба будет автоматически помещено в кэш. С этим параметром нужно быть очень осторожным, поскольку неправильное его применение может резко увеличить нагрузку на клиента.
- DefaultVersion — это свойство обычно не указывается. Позволяет определить версию создаваемой сводной таблицы. По умолчанию используется наиболее свежая версия.
Создание сводной таблицы в первой ячейке первого листа книги может выглядеть так:
PC1.CreatePivotTable Range («A1»)
Сводная таблица у нас создана, однако сразу же после создания она пуста. В ней предусмотрено четыре области, в которые можно размещать поля из источника (на графическом экране все это можно настроить либо при помощи окна Список полей сводной таблицы — оно открывается автоматически, либо при помощи кнопки Макет на последнем экране мастера создания сводных таблиц):
- область столбцов — в нее помещаются те измерения («разрез», в котором будут анализироваться данные), членов которых меньше;
- область строк — те измерения, членов которых больше;
- область страницы — те измерения, по которым нужно только проводить фильтрацию (например, показать данные только по такому-то региону или только за такой-то год);
- область данных — собственно говоря, центральная часть таблицы. Те числовые данные (например, сумма продаж), которые мы и анализируем.
Полагаться на пользователя в том, что он правильно разместит элементы во всех четырех областях, трудно. Кроме того, это может занять определенное время. Поэтому часто требуется расположить данные в сводной таблице программным образом. Эта операция производится при помощи объекта CubeField. Главное свойство этого объекта — Orientation, оно определяет, где будет находиться то или иное поле. Например, помещаем измерение Customers в область столбцов:
PT1.CubeFields («[Customers]»).Orientation = xlColumnField
Затем — измерение Time в область строк:
PT1.CubeFields («[Time]»).Orientation = xlRowField
Затем — измерение Product в область страницы:
PT1.CubeFields («[Product]»).Orientation = xlPageField
И наконец, показатель (числовые данные для анализа) Unit Sales:
PT1.CubeFields(«[Measures].[Unit Sales]»).Orientation = xlDataField
Теперь сводная таблица создана и с ней вполне можно работать. Однако часто необходимо выполнить еще одну операцию — раскрыть нужный уровень иерархии измерения. Например, если нас интересует поквартальный анализ, то нужно раскрыть уровень Quarter измерения Time (по умолчанию показывается только самый верхний уровень). Конечно, пользователь может сделать это самостоятельно, но не всегда можно рассчитывать, что он догадается, куда щелкнуть мышью. Программным образом раскрыть, например, иерархию измерения Time на уровень кварталов для 1997 года можно при помощи объектов PivotField и PivotItem:

In an earlier post I wrote about the advantages of using the Data Model in Power Pivot. Not only does it save you time by not having to juggle with lookup formulas. It also comes with significant file size savings. That all sounds great. Yet for many users, the only way to work with data in the Data Model, is by using a Pivot Table. A Pivot Table unfortunately does not always offer the flexibility spreadsheet developers need. This could prevent Excel Pro’s from using the Data Model. Well, CUBE functions solve that problem!
Table of contents
- What are Cube Functions?
- How to use Cube Functions
- Data Setup
- Create a PivotTable using the Data Model
- Convert To Formulas
- The functions CUBEMEMBER and CUBEVALUE
- CUBEMEMBER
- CUBEVALUE
- Conclusion
What are Cube Functions?
Data residing in Power Pivot’s Data Model, is not directly visible in the worksheet. That means that there are no cells available on the worksheet for traditional Excel formulas to reference. And so traditional Excel formulas can’t retrieve the Data from the Data Model. Yet Cube Functions in Excel are formulas that allow users to retrieve data from certain kinds of sources. Cube functions can interact with the Data Model in Power Pivot.
Now you may say: “Hey I’ve invested all my time in learning DAX to do calculations on the Data Model. How is it that Cube functions retrieve data from the Data Model in the Excel Worksheet?“
There’s no need to worry. In fact, there’s a beautiful collaboration between DAX (measures) and Cube functinos. The DAX language is a necessary component to perform calculations on your dataset. The definition of a measure resides in a so called Measure and is saved as part of the Data Model.
Cube functions on the other hand reference members and get values from the data cube. A measure defined in DAX, is one of the possible members that cube functions can reference. You could say that Cube formulas are the portal between the Data Model and the Excel Worksheet. It is through this portal that the Excel user gains access to the Data Model data. Cube functions will never replace the DAX formula language. They instead depend on the measures defined in DAX. Since I don’t want to bore you by too much theory, let’s finally get our hands dirty.
How to use Cube Functions
The easiest way to get started with Cube functions is by using a Pivot Table that uses the Data Model as its Data Source.
Data Setup
Imagine you have the following dataset.

You can find a Product Sales table that’s connected to a Gender table and a Calendar table. The tables are part of Excel’s Data Model. The tables within the Data Model are connected as illustrated below.

The table Product Sales contains a measure with the DAX formula:
Total Sales = SUM( ‘Product Sales'[Sales])
Create a PivotTable using the Data Model
Knowing the data setup, you can now make a pivot showing the Total Sales per Day Name of the week.
- Click the tab Insert -> Pivot Table
- Use this Workbook’s Data Model -> OK
- Add Day Name to the rows, and the measure Total Sales as Value

Notice that the above Pivot makes use of the Data Model. The used tables (shown in bold font) are preceded by a Table Icon with a yellow database icon in the lower right corner. This yellow symbol indicates the table is part of PowerPivot’s Data Model.
Convert To Formulas
The Pivot Table shows the Total Sales categorized by Day Name. Up to now there’s nothing special about this setup. But from here we can transform the displayed values to Cube formulas. So how do you get from a Pivot Table to Cube formulas?

- Make sure your cursor is within the Pivot Table
- Click on the the contextual tab called Analyze. (Note: this tab only appears when you cursor is within the Pivot Table)
- Click OLAP Tools -> select Convert to Formulas
The displayed values in the Pivot Table transform from a Pivot Table to a Cube Formulas. And the output is the same.

To follow along you can use this example file:
Take a moment to examine the formulas. The coloured cells on the right contain similar formulas as the coloured cells on the left. The newly created cube functions are CUBEMEMBER() and CUBEVALUE().
- The orange marked cell is a CUBEMEMBER formula that contains a cell reference to the DAX Measure called Total Sales.
- The green marked cells are CUBEMEMBER formulas that contain references to a single member of the data model. In this case the column Day Name from the Calendar table filtered on Friday.
- The blue marked cell is a CUBEMEMBER formula that also references the column Day Name in the Calendar table. Yet it references all the values, instead of filtering a single day.
- The numbers are CUBEVALUE formulas that in this example reference two CUBEMEMBER formulas. Notice that the CUBEVALUE formula is the same for each value. It always references the Total Sales Measure, and the cube member to the left of it, referencing the day of the week. Without adjustments, the CUBEVALUE formula can easily be copied down.
The functions CUBEMEMBER and CUBEVALUE
The functions CUBEMEMBER and CUBEVALUE play a central role in retrieving data from the Data Model. Other Cube functions exist, yet to get started these two are the most important ones to master. So what’s the purpose of these Cube functions and how do they work?
CUBEMEMBER
The CUBEMEMBER function returns a member of the cube. It determines what part of the data cube your CUBEVALUE formula returns. The formula verifies whether the specified member exists in the data model/cube and if it does it will return this member. If the value does not exist, the formula will return #N/A.
The syntax of a CUBEMEMBER formula consists of 3 arguments:
CUBEMEMBER( connection, member_expression, caption)
- The first argument is the connection. This refers to the name of your Data Model. Excel automatically creates it, and generally for me this is “ThisWorkbookDataModel”.
- The Member_Expression comes second. This argument either slices the data cube through certain members, or indicates a DAX Measure.
- The third argument Caption is optional. If you want your CUBEMEMBER argument to show up with a user friendly name, this is where to fill this in. This argument is very flexible and can contain static text, cell references or formulas.
Some common Cube members are:
– Column References (e.g. Day Name or Year in a Calendar Table)
– Column References filtered on a single value (e.g. the value Friday in column Day Name in the Calendar Table)
– Measures (e.g. Total Sales in the Product Sales table).
Examples:

CUBEVALUE
The CUBEVALUE function combines the CUBEMEMBER functions it references. Then it returns an aggregated value. You can see it as an instruction on how to retrieve data from the Data Model. Its value depends on two elements. First of all it depends on CUBEMEMBER functions that slice the Data Model down to specified members. It’s like filtering down your data set. And second it depends on the DAX Measure that indicates what calculation it should perform. At the intersection of the referenced CUBEMEMBERS, the CUBEVALUE formula performs the DAX Measure. All the Cube Members functoin as a filter with an AND condition.
The CUBEVALUE formula syntax is:
CUBEVALUE(connection, member_expression1, member_expression2, …)
1. The Connection refers to the Data Model Name.
2. Member Expressions are references to CUBEMEMBER functions. Member expressions that come after the first one are optional. You can optionally add more of these as you require.
Conclusion
By themselves, the CUBEVALUE and CUBEMEMBER functions are not very useful. A single CUBEMEMBER formula can show you a Cube member. And a single CUBEVALUE formula won’t return any value. It is their synergy when working together that is invaluable. By leveraging the Data Model, knowing a little DAX and having Cube Formulas as a tool, you can make incredibly powerful Excel reports.