
- Авторы
- Файлы работы
- Сертификаты
Коваль О.В. 1, Аверьянова С.Ю. 2
1Филиал Южного федерального универстета в г.Новошахтинске
2Филиал Южного федерального университета в г.Новошахтинске Ростовской области
Комментарии
Текст работы размещён без изображений и формул.
Полная версия работы доступна во вкладке «Файлы работы» в формате PDF
овладеть навыками расчета числовых характеристик выборки с помощью Надстройки Пакет Анализа ЭТ MS Excel.
Краткая теория
В ЭТ MS Excel имеется набор мощных инструментов для работы с выборками и углубленного статистического анализа данных, называемый Пакет анализа, который может быть использован для решения задач статистической обработки выборочных данных.
Надстройка Пакет анализа вызывается командой главного меню Данные → Анализ данных. В появившемся окне Анализ данных выбираем пункт Описательная статистика.
Далее откроется окно Описательная статистика, в котором необходимо сделать нужные установки.
Входной диапазон. Ссылка на диапазон, содержащий анализируемые данные. Ссылка должна состоять не менее чем из двух смежных диапазонов данных, данные в которых расположены по строкам или столбцам.
Группирование. Установите переключатель в положение «По столбцам» или «По строкам» в зависимости от расположения данных во входном диапазоне.
Метки в первой строке/Метки в первом столбце. Если первая строка исходного диапазона содержит названия столбцов, установите переключатель в положение Метки в первой строке. Если названия строк находятся в первом столбце входного диапазона, установите переключатель в положение Метки в первом столбце. Если входной диапазон не содержит меток, то необходимые заголовки в выходном диапазоне будут созданы автоматически.
Уровень надежности. Установите флажок, если в выходную таблицу необходимо вывести границу доверительного интервала для среднего. В поле введите требуемое значение в процентах. Например, значение 95% вычисляет уровень надежности среднего с уровнем значимости 0,05.
К-ый наибольший. Установите флажок, если в выходную таблицу необходимо включить строку для k-го наибольшего значения для каждого диапазона данных. В соответствующем окне введите число k. Если k равно 1, эта строка будет содержать максимальное значение выборки.
К-ый наименьший. Установите флажок, если в выходную таблицу необходимо включить строку для k-го наименьшего значения для каждого диапазона данных. В соответствующем окне введите число k. Если k равно 1, эта строка будет содержать минимальное значение выборки.
Выходной диапазон. Введите ссылку на левую верхнюю ячейку выходного диапазона. Этот инструмент анализа выводит два столбца сведений для каждого набора данных. Левый столбец содержит метки статистических данных; правый столбец содержит статистические данные. Состоящий их двух столбцов диапазон статистических данных будет выведен для каждого столбца или для каждой строки входного диапазона в зависимости от положения переключателя Группирование.
Если хотим вывести результаты расчета на новый лист, то установите переключатель, чтобы открыть новый лист в книге и вставить результаты анализа, начиная с ячейки A1. Если в этом есть необходимость, введите имя нового листа в поле, расположенном напротив соответствующего положения переключателя.
Если хотим вывести результаты расчета в новой книге, то установите переключатель, чтобы открыть новую книгу и вставить результаты анализа в ячейку A1 на первом листе в этой книге.
Итоговая статистика. Установите флажок, если в выходном диапазоне необходимо получить по одному полю для каждого из следующих видов статистических данных, представленных в таблице 2.
Таблица 2.
|
Значение |
Примечания |
|
Среднее |
Выборочное среднее х=1n∙i=1nxi. Функция СРЗНАЧ. |
|
Стандартная ошибка |
Оценка среднеквадратичного отклонения выборочного среднего. Вычисляется по формуле 1n∙(n-1)∙i=1n(xi-x)2 |
|
Медиана |
Число, которое является серединой множества чисел, то есть половина чисел имеют значения большие, чем медиана, а половина чисел имеют значения меньшие, чем медиана. Функция МЕДИАНА. |
|
Мода |
Наиболее часто встречающееся значение в выборке. Если нет одинаковых значений, то возвращается значение ошибки #Н/Д. Функция МОДА.ОДН. |
|
Стандартное отклонение |
Оценка среднеквадратичного отклонения генеральной совокупности S=1n-1∙i=1n(xi-x)2. Функция СТАНДОТКЛОН.В. |
|
Дисперсия выборки |
Оценка дисперсии генеральной совокупности . Функция ДИСП.В. |
|
Эксцесс |
Выборочный эксцесс. Функция ЭКСЦЕСС. |
|
Асимметрич-ность |
Коэффициент асимметрии. Функция СКОС. |
|
Интервал |
Размах варьирования R = xmax ‒ xmin . |
|
Минимум |
Минимальное значение в выборке. Функция МИН. |
|
Максимум |
Максимальное значение в выборке. Функция МАКС. |
|
Сумма |
Сумма всех значений в выборке. Функция СУММ. |
|
Счет |
Объем выборки. Функция СЧЕТ. |
|
Наибольший |
k-тое наибольшее значение выборки. Если k=1, то выводится максимальное значение. Функция НАИБОЛЬШИЙ. |
|
Наименьший |
k-тое наименьшее значение выборки. Если k=1, то выводится минимальное значение. Функция НАИМЕНЬШИЙ |
|
Уровень надежности |
Параметр показывает возможность отклонения среднего по выборке, от среднего для генеральной совокупности, при заданном уровне надежности. |
Замечание. Следует обратить внимание на то, что расчет параметров в режиме Описательная статистика имеет ряд важных особенностей:
1. В качестве значений параметров: Стандартное отклонение, Дисперсия выборки, Эксцесс, Асимметричность – Excel генерирует оценки соответствующих параметров для генеральной совокупности, а не для выборки.
2. Для применения Описательной статистики предварительное ранжирование исходных данных не требуется: при вычислении показателей ранжирование выполняется автоматически.
3. Появление в ячейке Мода индикатора ошибки #Н/Д указывает на то, что в анализируемых данных нет одинаковых значений признака. В этом случае в качестве моды Мо выбирается то значение признака, которое соответствует максимальной ординате теоретической кривой распределения.
4. Индикатор ошибки #ДЕЛ/0! В ячейке Эксцесс и/или Асимметричность означает, что в результативной таблице стандартное отклонение является нулевым или же заданный входной диапазон данных содержит менее четырех элементов данных
5. Стандартная ошибка ‒ это разность между ожидаемыми и наблюдаемыми значениями исследуемого признака.
Стандартная ошибка или ошибка среднегонаходится из выражения
m=Sn .
Стандартная ошибка – это параметр, характеризующий степень возможного отклонения среднего значения, полученного на исследуемой ограниченной выборке, от истинного среднего значения, полученного на всей совокупности элементов. С помощью стандартной ошибки задается так называемый доверительный интервал. 95%-ый доверительный интервал, равный х ± 2т , обозначает диапазон, в который с вероятностью р = 0,95 (при достаточно большом числе наблюдений п>30) попадает среднее значение генеральной совокупности.
Пример выполнения
Постановка задачи. Приведены объемы дневной выручки (в тыс. руб.) 24 продавцов колбасных изделий, работающих в разных районах города (см. табл.1).
Таблица 1.
|
20,2 |
19,3 |
19,9 |
23,1 |
18,8 |
17,4 |
|
19,9 |
18,3 |
16,4 |
17,3 |
18,3 |
15,8 |
|
20,5 |
20,6 |
19,4 |
18,7 |
16,3 |
18,4 |
|
21,6 |
21,2 |
19,3 |
19,1 |
19,3 |
18,8 |
Требуется: выполнить описательную статистику выборки с помощью Надстройки Пакет Анализа ЭТ MS Excel.
Решение задачи в среде ЭТ MSExcel. Для решения задачи в среде ЭТ MS Excel необходимо выполнить следующие действия:
1. Идентифицируйте свою работу, переименовав Лист1 в Титульный лист и записав номер лабораторной работы, ее название, кто выполнил и проверил.
2. Переименуйте Лист 2 в Исходные данные и наберите столбец исходных данных.
3. Вычислите величины хmax, хmin, R, n, N, Nокругл., Δ и Δокругл. , используя встроенные функции Excel МАКС, МИН, СЧЕТ, КОРЕНЬ и ОКРУГЛ.
4. Сформируйте столбец интервалов группировки. Наберите команду Данные → Анализ данных → Гистограмма и в появившемся диалоговом окне выполните нужные установки. Отформатируйте полученную таблицу и построенную гистограмму выборки.
5. Наберите команду Данные → Анализ данных → Описательная статистика и в появившемся диалоговом окне выполните нужные установки.
6. Щелчок по кнопке «ОК» приводит к появлению результирующей таблицы статистических характеристик выборки.
7. Повторно вычислим найденные характеристики с помощью встроенных функций MS Excel или формул. Сравним полученные результаты.
8. Сделайте выводы и сохраните работу в вашем каталоге.
Исходные данные для самостоятельного решения
Задание. Имеется выборка объема n = 27 (табл. 2).
Требуется: выполнить описательную статистику выборки с помощью Надстройки Пакет Анализа ЭТ MS Excel.
Таблица 2.
|
№ варианта |
Выборка |
||||||||
|
1 |
22,5 |
20,2 |
19,3 |
19,9 |
23,1 |
18,8 |
17,4 |
21,6 |
19,1 |
|
21,6 |
19,9 |
18,3 |
16,4 |
17,3 |
18,3 |
15,8 |
21,2 |
19,3 |
|
|
17,8 |
20,5 |
20,6 |
19,4 |
18,7 |
16,3 |
18,4 |
19,3 |
18,8 |
|
|
2 |
18,8 |
20,2 |
19,3 |
19,9 |
23,2 |
22,5 |
17,4 |
21,8 |
19,2 |
|
19,4 |
18,7 |
16,3 |
18,4 |
19,3 |
18,8 |
19,4 |
18,7 |
16,3 |
|
|
20,5 |
20,6 |
19,4 |
18,7 |
16,3 |
18,4 |
19,3 |
18,8 |
17,8 |
|
|
2 |
20,2 |
19,3 |
19,9 |
23,1 |
18,8 |
17,4 |
21,6 |
19,1 |
22,4 |
|
18,7 |
20,2 |
19,3 |
19,9 |
23,2 |
22,5 |
17,4 |
21,8 |
19,2 |
|
|
18,1 |
19,8 |
18,2 |
16,4 |
17,2 |
21,8 |
15,8 |
21,2 |
19,2 |
|
|
3 |
19,4 |
18,7 |
16,3 |
18,4 |
19,3 |
18,8 |
19,4 |
18,7 |
16,3 |
|
18,5 |
20,6 |
19,4 |
20,7 |
16,3 |
18,4 |
19,3 |
18,8 |
17,8 |
|
|
20,1 |
19,3 |
19,9 |
23,1 |
18,8 |
17,4 |
21,6 |
19,1 |
22,4 |
|
|
4 |
19,7 |
20,2 |
19,3 |
18,9 |
23,2 |
22,5 |
17,4 |
21,8 |
19,2 |
|
18,3 |
19,8 |
18,2 |
16,4 |
17,2 |
21,8 |
15,8 |
21,2 |
19,2 |
|
|
19,7 |
18,7 |
16,3 |
18,4 |
19,3 |
18,8 |
19,4 |
18,7 |
16,3 |
|
|
5 |
19,4 |
20,7 |
16,3 |
18,4 |
19,3 |
18,8 |
17,8 |
18,7 |
20,2 |
|
19,9 |
23,1 |
18,8 |
17,4 |
21,6 |
19,1 |
22,4 |
18,1 |
19,8 |
|
|
19,3 |
18,9 |
23,2 |
22,5 |
17,4 |
21,8 |
19,2 |
19,4 |
18,7 |
|
|
6 |
18,7 |
16,3 |
18,4 |
19,3 |
18,8 |
19,4 |
18,7 |
18,5 |
20,6 |
|
20,6 |
19,4 |
20,7 |
16,3 |
18,4 |
19,3 |
18,8 |
18,4 |
19,3 |
|
|
19,3 |
19,9 |
23,1 |
18,8 |
17,4 |
21,6 |
19,1 |
18,4 |
19,3 |
|
|
7 |
16,3 |
18,4 |
19,3 |
18,8 |
19,4 |
18,7 |
18,5 |
20,6 |
18,7 |
|
19,4 |
20,7 |
16,3 |
18,4 |
19,3 |
18,8 |
18,4 |
19,3 |
20,6 |
|
|
19,9 |
23,1 |
18,8 |
17,4 |
21,6 |
19,1 |
18,4 |
19,3 |
19,3 |
|
|
8 |
19,3 |
19,9 |
23,1 |
18,8 |
17,4 |
21,6 |
19,1 |
22,5 |
20,2 |
|
18,3 |
16,4 |
17,3 |
18,3 |
15,8 |
21,2 |
19,3 |
21,6 |
19,9 |
|
|
20,6 |
19,4 |
18,7 |
16,3 |
18,4 |
19,3 |
18,8 |
17,8 |
20,5 |
|
|
9 |
19,4 |
20,7 |
16,3 |
18,4 |
19,3 |
18,8 |
17,8 |
18,7 |
20,2 |
|
19,9 |
23,1 |
18,8 |
17,4 |
21,6 |
19,1 |
22,4 |
18,1 |
19,8 |
|
|
19,3 |
18,9 |
23,2 |
22,5 |
17,4 |
21,8 |
19,2 |
19,4 |
18,7 |
|
|
10 |
18,7 |
16,3 |
18,4 |
19,3 |
18,8 |
19,4 |
18,7 |
18,5 |
20,6 |
|
20,6 |
19,4 |
20,7 |
16,3 |
18,4 |
19,3 |
18,8 |
18,4 |
19,3 |
|
|
16,4 |
20,4 |
20,8 |
19,4 |
18,7 |
17,8 |
18,4 |
19,4 |
18,8 |
Просмотров работы: 3443
Код для цитирования:
Рассмотрим инструмент Описательная статистика, входящий в надстройку Пакет Анализа. Рассчитаем показатели выборки: среднее, медиана, мода, дисперсия, стандартное отклонение и др.
Задача
описательной статистики
(descriptive statistics) заключается в том, чтобы с использованием математических инструментов свести сотни значений
выборки
к нескольким итоговым показателям, которые дают представление о
выборке
.В качестве таких статистических показателей используются:
среднее
,
медиана
,
мода
,
дисперсия, стандартное отклонение
и др.
Опишем набор числовых данных с помощью определенных показателей. Для чего нужны эти показатели? Эти показатели позволят сделать определенные
статистические выводы о распределении
, из которого была взята
выборка
. Например, если у нас есть
выборка
значений толщины трубы, которая изготавливается на определенном оборудовании, то на основании анализа этой
выборки
мы сможем сделать, с некой определенной вероятностью, заключение о состоянии процесса изготовления.
Содержание статьи:
- Надстройка Пакет анализа;
-
Среднее выборки
;
-
Медиана выборки
;
-
Мода выборки
;
-
Мода и среднее значение
;
-
Дисперсия выборки
;
-
Стандартное отклонение выборки
;
-
Стандартная ошибка
;
-
Ассиметричность
;
-
Эксцесс выборки
;
-
Уровень надежности
.
Надстройка Пакет анализа
Для вычисления статистических показателей одномерных
выборок
, используем
надстройку Пакет анализа
. Затем, все показатели рассчитанные надстройкой, вычислим с помощью встроенных функций MS EXCEL.
СОВЕТ
: Подробнее о других инструментах надстройки
Пакет анализа
и ее подключении – читайте в статье
Надстройка Пакет анализа MS EXCEL
.
Выборку
разместим на
листе
Пример
в файле примера
в диапазоне
А6:А55
(50 значений).
Примечание
: Для удобства написания формул для диапазона
А6:А55
создан
Именованный диапазон
Выборка.
В диалоговом окне
Анализ данных
выберите инструмент
Описательная статистика
.

После нажатия кнопки
ОК
будет выведено другое диалоговое окно,
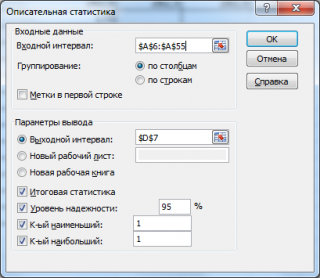
в котором нужно указать:
входной интервал
(Input Range) – это диапазон ячеек, в котором содержится массив данных. Если в указанный диапазон входит текстовый заголовок набора данных, то нужно поставить галочку в поле
Метки в первой строке (
Labels
in
first
row
).
В этом случае заголовок будет выведен в
Выходном интервале.
Пустые ячейки будут проигнорированы, поэтому нулевые значения необходимо обязательно указывать в ячейках, а не оставлять их пустыми;
выходной интервал
(Output Range). Здесь укажите адрес верхней левой ячейки диапазона, в который будут выведены статистические показатели;
Итоговая статистика (
Summary
Statistics
)
. Поставьте галочку напротив этого поля – будут выведены основные показатели выборки:
среднее, медиана, мода, стандартное отклонение
и др.;-
Также можно поставить галочки напротив полей
Уровень надежности (
Confidence
Level
for
Mean
)
,
К-й наименьший
(Kth Largest) и
К-й наибольший
(Kth Smallest).
В результате будут выведены следующие статистические показатели:
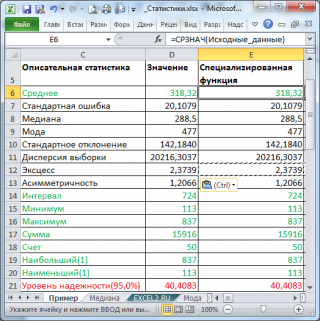
Все показатели выведены в виде значений, а не формул. Если массив данных изменился, то необходимо перезапустить расчет.
Если во
входном интервале
указать ссылку на несколько столбцов данных, то будет рассчитано соответствующее количество наборов показателей. Такой подход позволяет сравнить несколько наборов данных. При сравнении нескольких наборов данных используйте заголовки (включите их во
Входной интервал
и установите галочку в поле
Метки в первой строке
). Если наборы данных разной длины, то это не проблема — пустые ячейки будут проигнорированы.
Зеленым цветом на картинке выше и в
файле примера
выделены показатели, которые не требуют особого пояснения. Для большинства из них имеется специализированная функция:
Интервал
(Range) — разница между максимальным и минимальным значениями;
Минимум
(Minimum) – минимальное значение в диапазоне ячеек, указанном во
Входном интервале
(см.статью про функцию
МИН()
);
Максимум
(Maximum)– максимальное значение (см.статью про функцию
МАКС()
);
Сумма
(Sum) – сумма всех значений (см.статью про функцию
СУММ()
);
Счет
(Count) – количество значений во
Входном интервале
(пустые ячейки игнорируются, см.статью про функцию
СЧЁТ()
);
Наибольший
(Kth Largest) – выводится К-й наибольший. Например, 1-й наибольший – это максимальное значение (см.статью про функцию
НАИБОЛЬШИЙ()
);
Наименьший
(Kth Smallest) – выводится К-й наименьший. Например, 1-й наименьший – это минимальное значение (см.статью про функцию
НАИМЕНЬШИЙ()
).
Ниже даны подробные описания остальных показателей.
Среднее выборки
Среднее
(mean, average) или
выборочное среднее
или
среднее выборки
(sample average) представляет собой
арифметическое среднее
всех значений массива. В MS EXCEL для вычисления среднего выборки используется функция
СРЗНАЧ()
.
Выборочное среднее
является «хорошей» (несмещенной и эффективной) оценкой
математического ожидания
случайной величины (подробнее см. статью
Среднее и Математическое ожидание в MS EXCEL
).
Медиана выборки
Медиана
(Median) – это число, которое является серединой множества чисел (в данном случае выборки): половина чисел множества больше, чем
медиана
, а половина чисел меньше, чем
медиана
. Для определения
медианы
необходимо сначала
отсортировать множество чисел
. Например,
медианой
для чисел 2, 3, 3,
4
, 5, 7, 10 будет 4.
Если множество содержит четное количество чисел, то вычисляется
среднее
для двух чисел, находящихся в середине множества. Например,
медианой
для чисел 2, 3,
3
,
5
, 7, 10 будет 4, т.к. (3+5)/2.
Если имеется длинный хвост распределения, то
Медиана
лучше, чем
среднее значение
, отражает «типичное» или «центральное» значение. Например, рассмотрим несправедливое распределение зарплат в компании, в которой руководство получает существенно больше, чем основная масса сотрудников.
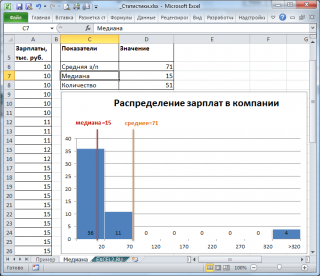
Очевидно, что средняя зарплата (71 тыс. руб.) не отражает тот факт, что 86% сотрудников получает не более 30 тыс. руб. (т.е. 86% сотрудников получает зарплату в более, чем в 2 раза меньше средней!). В то же время медиана (15 тыс. руб.) показывает, что
как минимум
у 50% сотрудников зарплата меньше или равна 15 тыс. руб.
Для определения
медианы
в MS EXCEL существует одноименная функция
МЕДИАНА()
, английский вариант — MEDIAN().
Медиану
также можно вычислить с помощью формул
=КВАРТИЛЬ.ВКЛ(Выборка;2) =ПРОЦЕНТИЛЬ.ВКЛ(Выборка;0,5).
Подробнее о
медиане
см. специальную статью
Медиана в MS EXCEL
.
СОВЕТ
: Подробнее про
квартили
см. статью, про
перцентили (процентили)
см. статью.
Мода выборки
Мода
(Mode) – это наиболее часто встречающееся (повторяющееся) значение в
выборке
. Например, в массиве (1; 1;
2
;
2
;
2
; 3; 4; 5) число 2 встречается чаще всего – 3 раза. Значит, число 2 – это
мода
. Для вычисления
моды
используется функция
МОДА()
, английский вариант MODE().
Примечание
: Если в массиве нет повторяющихся значений, то функция вернет значение ошибки #Н/Д. Это свойство использовано в статье
Есть ли повторы в списке?
Начиная с
MS EXCEL 2010
вместо функции
МОДА()
рекомендуется использовать функцию
МОДА.ОДН()
, которая является ее полным аналогом. Кроме того, в MS EXCEL 2010 появилась новая функция
МОДА.НСК()
, которая возвращает несколько наиболее часто повторяющихся значений (если количество их повторов совпадает). НСК – это сокращение от слова НеСКолько.
Например, в массиве (1; 1;
2
;
2
;
2
; 3;
4
;
4
;
4
; 5) числа 2 и 4 встречаются наиболее часто – по 3 раза. Значит, оба числа являются
модами
. Функции
МОДА.ОДН()
и
МОДА()
вернут значение 2, т.к. 2 встречается первым, среди наиболее повторяющихся значений (см.
файл примера
, лист
Мода
).
Чтобы исправить эту несправедливость и была введена функция
МОДА.НСК()
, которая выводит все
моды
. Для этого ее нужно ввести как
формулу массива
.
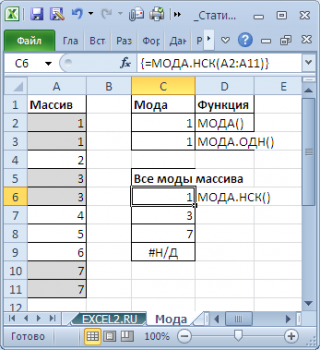
Как видно из картинки выше, функция
МОДА.НСК()
вернула все три
моды
из массива чисел в диапазоне
A2:A11
: 1; 3 и 7. Для этого, выделите диапазон
C6:C9
, в
Строку формул
введите формулу
=МОДА.НСК(A2:A11)
и нажмите
CTRL+SHIFT+ENTER
. Диапазон
C
6:
C
9
охватывает 4 ячейки, т.е. количество выделяемых ячеек должно быть больше или равно количеству
мод
. Если ячеек больше чем м
о
д, то избыточные ячейки будут заполнены значениями ошибки #Н/Д. Если
мода
только одна, то все выделенные ячейки будут заполнены значением этой
моды
.
Теперь вспомним, что мы определили
моду
для выборки, т.е. для конечного множества значений, взятых из
генеральной совокупности
. Для
непрерывных случайных величин
вполне может оказаться, что выборка состоит из массива на подобие этого (0,935; 1,211; 2,430; 3,668; 3,874; …), в котором может не оказаться повторов и функция
МОДА()
вернет ошибку.
Даже в нашем массиве с
модой
, которая была определена с помощью
надстройки Пакет анализа
, творится, что-то не то. Действительно,
модой
нашего массива значений является число 477, т.к. оно встречается 2 раза, остальные значения не повторяются. Но, если мы посмотрим на
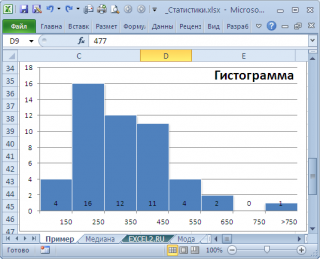
гистограмму распределения
, построенную для нашего массива, то увидим, что 477 не принадлежит интервалу наиболее часто встречающихся значений (от 150 до 250).
Проблема в том, что мы определили
моду
как наиболее часто встречающееся значение, а не как наиболее вероятное. Поэтому,
моду
в учебниках статистики часто определяют не для выборки (массива), а для функции распределения. Например, для
логнормального распределения
мода
(наиболее вероятное значение непрерывной случайной величины х), вычисляется как
exp
(
m
—
s
2
)
, где m и s параметры этого распределения.
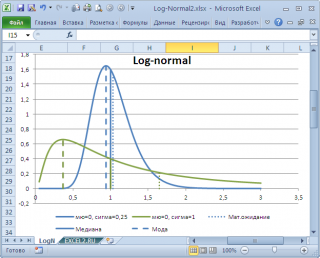
Понятно, что для нашего массива число 477, хотя и является наиболее часто повторяющимся значением, но все же является плохой оценкой для
моды
распределения, из которого взята
выборка
(наиболее вероятного значения или для которого плотность вероятности распределения максимальна).
Для того, чтобы получить оценку
моды
распределения, из
генеральной совокупности
которого взята
выборка
, можно, например, построить
гистограмму
. Оценкой для
моды
может служить интервал наиболее часто встречающихся значений (самого высокого столбца). Как было сказано выше, в нашем случае это интервал от 150 до 250.
Вывод
: Значение
моды
для
выборки
, рассчитанное с помощью функции
МОДА()
, может ввести в заблуждение, особенно для небольших выборок. Эта функция эффективна, когда случайная величина может принимать лишь несколько дискретных значений, а размер
выборки
существенно превышает количество этих значений.
Например, в рассмотренном примере о распределении заработных плат (см. раздел статьи выше, о Медиане),
модой
является число 15 (17 значений из 51, т.е. 33%). В этом случае функция
МОДА()
дает хорошую оценку «наиболее вероятного» значения зарплаты.
Примечание
: Строго говоря, в примере с зарплатой мы имеем дело скорее с
генеральной совокупностью
, чем с
выборкой
. Т.к. других зарплат в компании просто нет.
О вычислении
моды
для распределения
непрерывной случайной величины
читайте статью
Мода в MS EXCEL
.
Мода и среднее значение
Не смотря на то, что
мода
– это наиболее вероятное значение случайной величины (вероятность выбрать это значение из
Генеральной совокупности
максимальна), не следует ожидать, что
среднее значение
обязательно будет близко к
моде
.
Примечание
:
Мода
и
среднее
симметричных распределений совпадает (имеется ввиду симметричность
плотности распределения
).
Представим, что мы бросаем некий «неправильный» кубик, у которого на гранях имеются значения (1; 2; 3; 4; 6; 6), т.е. значения 5 нет, а есть вторая 6.
Модой
является 6, а среднее значение – 3,6666.
Другой пример. Для
Логнормального распределения
LnN(0;1)
мода
равна =EXP(m-s2)= EXP(0-1*1)=0,368, а
среднее значение
1,649.
Дисперсия выборки
Дисперсия выборки
или
выборочная дисперсия (
sample
variance
) характеризует разброс значений в массиве, отклонение от
среднего
.
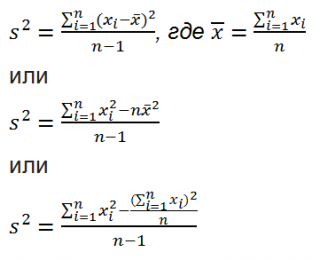
Из формулы №1 видно, что
дисперсия выборки
это сумма квадратов отклонений каждого значения в массиве
от среднего
, деленная на размер выборки минус 1.
В MS EXCEL 2007 и более ранних версиях для вычисления
дисперсии выборки
используется функция
ДИСП()
. С версии MS EXCEL 2010 рекомендуется использовать ее аналог — функцию
ДИСП.В()
.
Дисперсию
можно также вычислить непосредственно по нижеуказанным формулам (см.
файл примера
):
=КВАДРОТКЛ(Выборка)/(СЧЁТ(Выборка)-1) =(СУММКВ(Выборка)-СЧЁТ(Выборка)*СРЗНАЧ(Выборка)^2)/ (СЧЁТ(Выборка)-1)
– обычная формула
=СУММ((Выборка -СРЗНАЧ(Выборка))^2)/ (СЧЁТ(Выборка)-1)
–
формула массива
Дисперсия выборки
равна 0, только в том случае, если все значения равны между собой и, соответственно, равны
среднему значению
.
Чем больше величина
дисперсии
, тем больше разброс значений в массиве относительно
среднего
.
Размерность
дисперсии
соответствует квадрату единицы измерения исходных значений. Например, если значения в выборке представляют собой измерения веса детали (в кг), то размерность
дисперсии
будет кг
2
. Это бывает сложно интерпретировать, поэтому для характеристики разброса значений чаще используют величину равную квадратному корню из
дисперсии – стандартное отклонение
.
Подробнее о
дисперсии
см. статью
Дисперсия и стандартное отклонение в MS EXCEL
.
Стандартное отклонение выборки
Стандартное отклонение выборки
(Standard Deviation), как и
дисперсия
, — это мера того, насколько широко разбросаны значения в выборке
относительно их среднего
.
По определению,
стандартное отклонение
равно квадратному корню из
дисперсии
:
![]()
Стандартное отклонение
не учитывает величину значений в
выборке
, а только степень рассеивания значений вокруг их
среднего
. Чтобы проиллюстрировать это приведем пример.
Вычислим стандартное отклонение для 2-х
выборок
: (1; 5; 9) и (1001; 1005; 1009). В обоих случаях, s=4. Очевидно, что отношение величины стандартного отклонения к значениям массива у
выборок
существенно отличается.
В MS EXCEL 2007 и более ранних версиях для вычисления
Стандартного отклонения выборки
используется функция
СТАНДОТКЛОН()
. С версии MS EXCEL 2010 рекомендуется использовать ее аналог
СТАНДОТКЛОН.В()
.
Стандартное отклонение
можно также вычислить непосредственно по нижеуказанным формулам (см.
файл примера
):
=КОРЕНЬ(КВАДРОТКЛ(Выборка)/(СЧЁТ(Выборка)-1)) =КОРЕНЬ((СУММКВ(Выборка)-СЧЁТ(Выборка)*СРЗНАЧ(Выборка)^2)/(СЧЁТ(Выборка)-1))
Подробнее о
стандартном отклонении
см. статью
Дисперсия и стандартное отклонение в MS EXCEL
.
Стандартная ошибка
В
Пакете анализа
под термином
стандартная ошибка
имеется ввиду
Стандартная ошибка среднего
(Standard Error of the Mean, SEM).
Стандартная ошибка среднего
— это оценка
стандартного отклонения
распределения
выборочного среднего
.
Примечание
: Чтобы разобраться с понятием
Стандартная ошибка среднего
необходимо прочитать о
выборочном распределении
(см. статью
Статистики, их выборочные распределения и точечные оценки параметров распределений в MS EXCEL
) и статью про
Центральную предельную теорему
.
Стандартное отклонение распределения выборочного среднего
вычисляется по формуле σ/√n, где n — объём
выборки, σ — стандартное отклонение исходного
распределения, из которого взята
выборка
. Т.к. обычно
стандартное отклонение
исходного распределения неизвестно, то в расчетах вместо
σ
используют ее оценку
s
—
стандартное отклонение выборки
. А соответствующая величина s/√n имеет специальное название —
Стандартная ошибка среднего.
Именно эта величина вычисляется в
Пакете анализа.
В MS EXCEL
стандартную ошибку среднего
можно также вычислить по формуле
=СТАНДОТКЛОН.В(Выборка)/ КОРЕНЬ(СЧЁТ(Выборка))
Асимметричность
Асимметричность
или
коэффициент асимметрии
(skewness) характеризует степень несимметричности распределения (
плотности распределения
) относительно его
среднего
.
Положительное значение
коэффициента асимметрии
указывает, что размер правого «хвоста» распределения больше, чем левого (относительно среднего). Отрицательная асимметрия, наоборот, указывает на то, что левый хвост распределения больше правого.
Коэффициент асимметрии
идеально симметричного распределения или выборки равно 0.

Примечание
:
Асимметрия выборки
может отличаться расчетного значения асимметрии теоретического распределения. Например,
Нормальное распределение
является симметричным распределением (
плотность его распределения
симметрична относительно
среднего
) и, поэтому имеет асимметрию равную 0. Понятно, что при этом значения в
выборке
из соответствующей
генеральной совокупности
не обязательно должны располагаться совершенно симметрично относительно
среднего
. Поэтому,
асимметрия выборки
, являющейся оценкой
асимметрии распределения
, может отличаться от 0.
Функция
СКОС()
, английский вариант SKEW(), возвращает коэффициент
асимметрии выборки
, являющейся оценкой
асимметрии
соответствующего распределения, и определяется следующим образом:
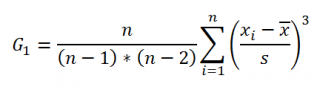
где n – размер
выборки
, s –
стандартное отклонение выборки
.
В
файле примера на листе СКОС
приведен расчет коэффициента
асимметрии
на примере случайной выборки из
распределения Вейбулла
, которое имеет значительную положительную
асимметрию
при параметрах распределения W(1,5; 1).
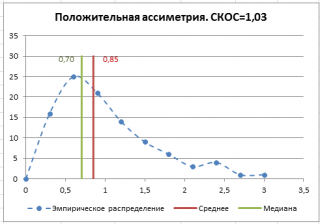
Эксцесс выборки
Эксцесс
показывает относительный вес «хвостов» распределения относительно его центральной части.
Для того чтобы определить, что относится к хвостам распределения, а что к его центральной части, можно использовать границы μ +/-
σ
.
Примечание
: Не смотря на старания профессиональных статистиков, в литературе еще попадается определение
Эксцесса
как меры «остроконечности» (peakedness) или сглаженности распределения. Но, на самом деле, значение
Эксцесса
ничего не говорит о форме пика распределения.
Согласно определения,
Эксцесс
равен четвертому
стандартизированному моменту:
![]()
Для
нормального распределения
четвертый момент равен 3*σ
4
, следовательно,
Эксцесс
равен 3. Многие компьютерные программы используют для расчетов не сам
Эксцесс
, а так называемый Kurtosis excess, который меньше на 3. Т.е. для
нормального распределения
Kurtosis excess равен 0. Необходимо быть внимательным, т.к. часто не очевидно, какая формула лежит в основе расчетов.
Примечание
: Еще большую путаницу вносит перевод этих терминов на русский язык. Термин Kurtosis происходит от греческого слова «изогнутый», «имеющий арку». Так сложилось, что на русский язык оба термина Kurtosis и Kurtosis excess переводятся как
Эксцесс
(от англ. excess — «излишек»). Например, функция MS EXCEL
ЭКСЦЕСС()
на самом деле вычисляет Kurtosis excess.
Функция
ЭКСЦЕСС()
, английский вариант KURT(), вычисляет на основе значений выборки несмещенную оценку
эксцесса распределения
случайной величины и определяется следующим образом:
![]()
Как видно из формулы MS EXCEL использует именно Kurtosis excess, т.е. для выборки из
нормального распределения
формула вернет близкое к 0 значение.
Если задано менее четырех точек данных, то функция
ЭКСЦЕСС()
возвращает значение ошибки #ДЕЛ/0!
Вернемся к
распределениям случайной величины
.
Эксцесс
(Kurtosis excess) для
нормального распределения
всегда равен 0, т.е. не зависит от параметров распределения μ и σ. Для большинства других распределений
Эксцесс
зависит от параметров распределения: см., например,
распределение Вейбулла
или
распределение Пуассона
, для котрого
Эксцесс
= 1/λ.
Уровень надежности
Уровень
надежности
— означает вероятность того, что
доверительный интервал
содержит истинное значение оцениваемого параметра распределения.
Вместо термина
Уровень
надежности
часто используется термин
Уровень доверия
. Про
Уровень надежности
(Confidence Level for Mean) читайте статью
Уровень значимости и уровень надежности в MS EXCEL
.
Задав значение
Уровня
надежности
в окне
надстройки Пакет анализа
, MS EXCEL вычислит половину ширины
доверительного интервала для оценки среднего (дисперсия неизвестна)
.
Тот же результат можно получить по формуле (см.
файл примера
):
=ДОВЕРИТ.СТЬЮДЕНТ(1-0,95;s;n)
s —
стандартное отклонение выборки
, n – объем
выборки
.
Подробнее см. статью про
построение доверительного интервала для оценки среднего (дисперсия неизвестна)
.
Процедура «Описательные статистики » пакета «Анализ данных.

В процедуре автоматически вычисляются следующие числовые характеристики выборки:
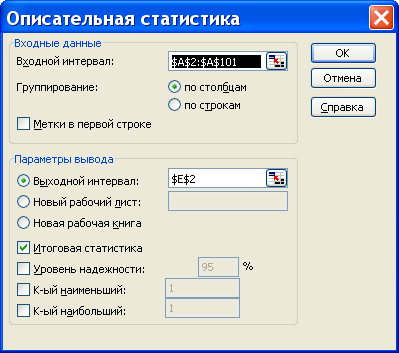
Для того чтобы выполнить вычисления, вводим в поле «Водной интервал» адреса ячеек, в которых записаны выборочные значения;
помечаем «Выходной интервал» и вводим в поле адрес первой ячейки, начиная с которой в листе Excel будет отображён резгультат; помечаем «Итоговая статистика»:
Результаты вычислений процедуры представлены в виде таблицы:
|
Столбец1 |
|
|
Среднее |
120.10 |
|
Стандартная ошибка |
0.22 |
|
Медиана |
120.12 |
|
Мода |
118.69 |
|
Стандартное отклонение |
2.15 |
|
Дисперсия выборки |
4.63 |
|
Эксцесс |
0.21 |
|
Асимметричность |
-0.16 |
|
Интервал |
11.21 |
|
Минимум |
114.46 |
|
Максимум |
125.67 |
|
Сумма |
12010.34 |
|
Счет |
100 |
Здесь: «Асимметричность» – коэффициент асимметрии, «Интервал» – размах варьирования, «Счёт» – объём выборки.
Функция «Квартиль» для вычисления квартилей и межквартильного размаха
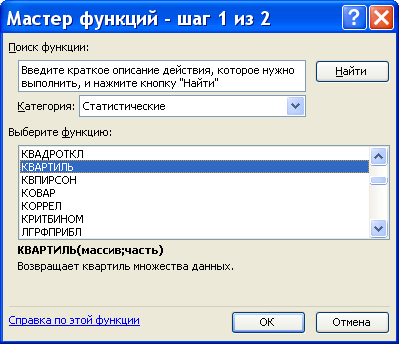
КВАРТИЛЬ(массив;часть)
Функция вычисляет (в зависимости от значения параметра «Часть»), выборочные значения верхней квартили («Часть» = 3) или нижней квартили («Часть» = 13), медиану («Часть» = 2) , наибольшее («Часть» = 4) или наименьшее («Часть» = 03) значения для выборки, определённой как «массив»..
3.1. Описательные статистики
Любая
функция вариант называется статистикой.
Для сжатого описания выборки используют
статистики, аналогичные числовым
характеристикам распределений случайных
величин.
Модой
выборки
![]() называют
называют
значение варианта с максимальной
частотой. Если выборка представлена
интервальным вариационным рядом с
равными интервалами, то значение моды
принимают равным середине интервала с
максимальной частотой. При различной
ширине интервалов![]() эту величину принимают равной середине
эту величину принимают равной середине
интервала с максимальной плотностью
вариант![]() .
.
Медианой
выборки МЕ(Х) называют
такое значение признака, для которого
доля вариант с меньшей его величиной
равна половине.
Квартилями
выборки (нижним
![]() и верхним
и верхним![]() )называют
)называют
такие значения признака, для которых
доля вариант с меньшей его величиной
составляет одну четверть для
![]() и три четверти
и три четверти
для
![]() ..
..
Средним
(арифметическим) значением выборки
называют
величину
![]()
 .
.
При
обработке интервальных вариационных
рядов за
![]() принимают середину
принимают середину![]() ого
ого
интервала.
Выборочным
моментом
![]() ого
ого
порядка
называют величину
 .
.
Выборочным
центральным моментом – величину
 .
.
Выборочной
дисперсией
–величину
 .
.
Выборочной
асиметрией – величину
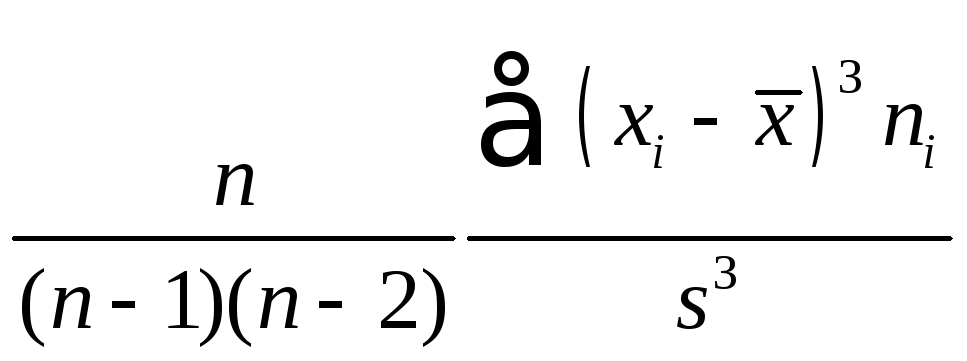 .
.
Выборочным
эксцессом – величину
 .
.
Последние
две величины служат для сравнения
выборочного распределения с нормальным.
3.2. Обработка выборки в среде Excel.
 При
При
большом объёме выборки её анализ требует
большого объёма вычислений, поэтому
естественно проводить его за компьютером.
Имеется большое число программных
средств, как специально предназначенных
для статистического анализа, так и
содержащихся в у ниверсальных
ниверсальных
программах в качестве подпрограмм и
опций. Достаточно возможностей для
этого предоставляет, в частности,
доступная всем программаExcel.
Команды для
проведения статистического анализа
можно найти в меню «Сервис![]() Анализ
Анализ
данных» и в меню «Функции![]() Статистические»
Статистические»
и «Функции![]() Работа
Работа
с базами данных».
Т аблица
аблица
1.
Рассмотрим
работу в этой среде на следующем примере.
В лабораторном практикуме группа из 25
студентов определяла концентрацию
некоторого вещества в выданном им
растворе. Каждый из них сделал по 4
параллельных определения. Их результаты,
округлённые до 0,5 г/л я занёс в таблицу
Excel
(табл.1).У
меня образовался массив, содержащий 4
столбца B,C,D
и E,
и 25 строк с №2 до №26. Далее я хочу найти
минимальное число из этого массива –
нижнюю границу выборки. Я щёлкаю по
пустой ячейке, в которой хочу найти
ответ, затем навожу курсор на «![]() »,
»,
и нажимаю левую клавишу мыши. Открывается
окно выбора функций – «Мастер функций».
В разделе «Категории» я открываю
«статистические» и нахожу тамМИН.
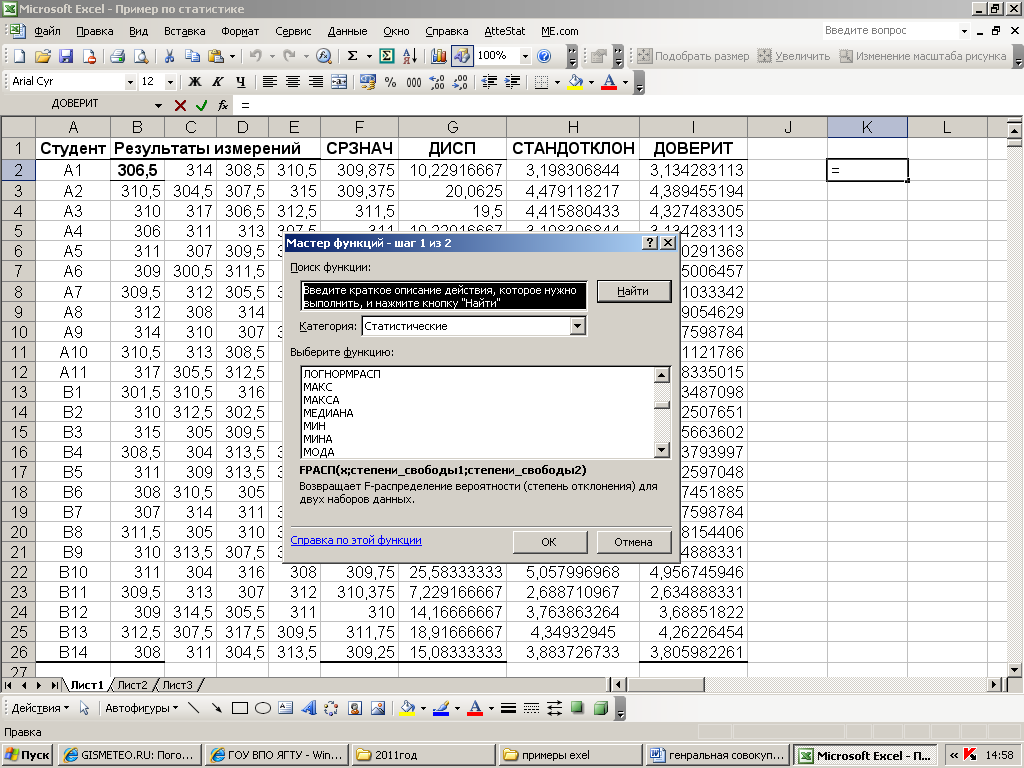

После
щелчка мышью по этому названию и “OK”
открывается диалоговое окно «Аргументы
функции» с пометкой МИН.
В окошко,
помеченное «Число 1», можно ввести сами
числа, что, конечно, неудобно. Вместо
этого я щёлкаю мышью по крайней левой
верхней клетке массива, затем нажимаю
“Shift”
и одновременно щёлкаю по крайней правой
нижней клетке. При этом в вышеуказанном
окошке появляются границы массива в
виде “$B$2:$E$26.
Ответ «300,5» появляется сразу, а при
щелчке «OK»
— в заготовленной клетке. Точно так же
я могу применить эту функцию к любой
прямоугольной части этого массива,
вызвав саму функцию МИН
(теперь её
позывной можно найти в категории
«Последние») и отметив, как описано
выше, щелчками мыши, клетки в начале и
конце выбранной части массива. Впрочем,
выделять массив можно и движением мыши,
если сначала навести курсор на начало
массива, нажать левую клавишу мыши, и,
не снимая нажатия, провести курсор до
конечной точки массива.
Конечно,
такое подробное описание вызовет улыбку
у продвинутого пользователя, но, возможно,
среди читателей есть и такие, которые
впервые в жизни откроют документ Excel.
Для
краткого описания действий при
использовании других функций будем
использовать следующие обозначения:
ЩАа
– щелчок по клетке начала диапазона,
ЪЩЯя
— щелчок по клетке конца диапазона с
одновременным нажатием Shift,
ЩСс
– щелчок по свободной ячейке, в которой
будет указан результат.
![]() ,
,
серв., дигр., адат, стат. – щелчки по
значкам
![]() ,
,
«сервис», «диаграмма», «анализ данных»,
«статистические» соответственно.
Напомним, что если какая-либо функция
используется повторно, то быстрее найти
её не через «статистические», а через
«последние».
Итак,
считаем, что в таблицу Excel
внесены
данные выборки в виде строки, столбца,
или двумерного массива. Цели и действия
представлены в таблице 2.
Таблица
2.
|
Что |
Действия |
|
Объём |
ЩСс, |
|
Нижнюю |
ЩСс, |
|
Верхнюю |
ЩСс, |
|
Среднее |
ЩСс, |
|
Моду |
ЩСс, |
|
Медиану |
ЩСс, |
|
Нижний |
ЩСс, |
|
Верхний |
ЩСс, |
|
Выборочную |
ЩСс, |
|
|
ЩСс, |
|
Доверительный |
ЩСс, |
|
Асимметрию |
ЩСс, |
|
Эксцесс |
ЩСс, |
В
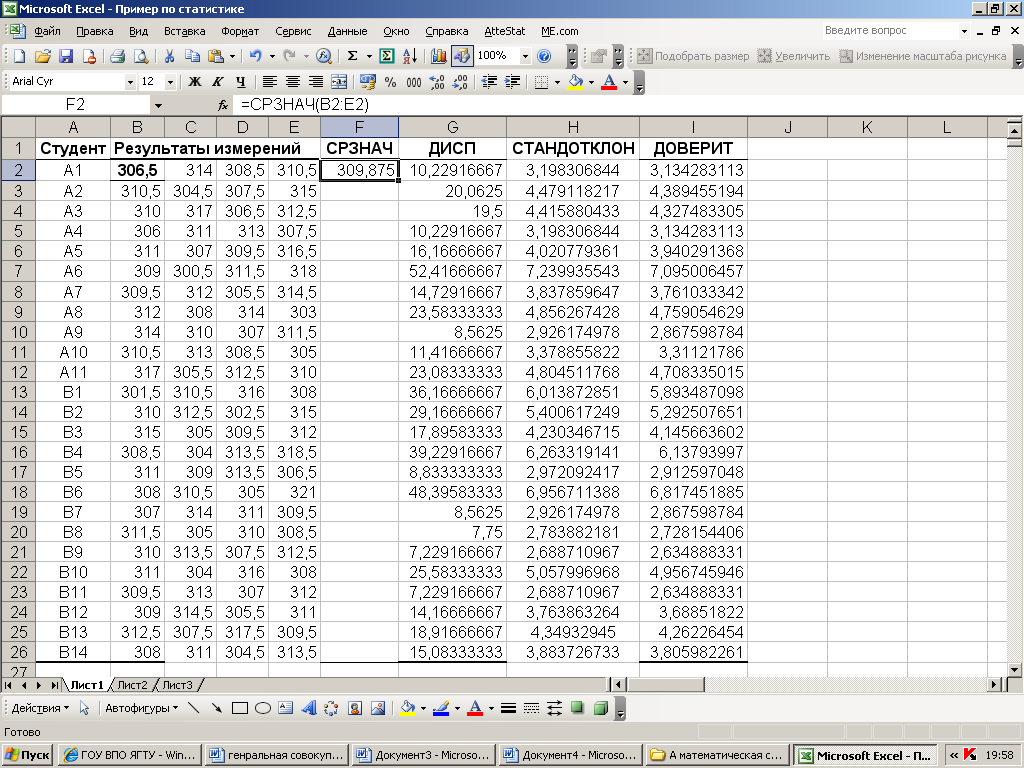
таблице 1 в столбцах F—I
вы видите результаты выполнения
соответствующих функций для каждой из
25 строк массива. При этом нет необходимости
вводить формулу функции в каждую строку
отдельно – достаточно ввести её в первую
строку, а в окошко аргументов ввести
координаты начала и конца этой строки:

После
нажатия «![]() »
»
в ячейке, в которую введена данная
формула, появляется соответствующий
результат:
Если
теперь навести курсор на чёрный квадратик
в нижнем правом углу этой ячейки, и при
нажатой левой клавише мыши провести
его вдоль столбца до последней строки
массива данных, то после отпускания
клавиши весь столбец заполнится
результатами, полученными для всех
остальных строк по той же формуле.
Для
группировки данных и получения
интервального ряда можно использовать
функцию ЧАСТОТА.
Для её
применения
сначала
формируем столбец интервалов. Для нашего
примера, в котором объём выборки
![]() ,
,![]() ,
,
удобно выборку разбить на 7 равных
интервалов шириной 3 . При этом в ячейки
для массива интервалов вводим только
значения верхних границ интервалов.
Так, в ячейку![]() я внёс число 303 для интервала
я внёс число 303 для интервала![]() ,
,
в![]() — число 306 для интервала
— число 306 для интервала![]() ,
,
…, в![]() — 321 для интервала
— 321 для интервала![]() .
.
Затем я выделяю свободную ячейку![]() ,
,
и щёлкаю по![]() .
.
Появляется мастер функций, в котором я
нахожуЧАСТОТА
и раскрываю
шаблон для ввода аргументов. После
ввода вышеописанным способом границ
массива данных щёлкаем по окну массив
интервалов и
выделяем для ввода ячейки
![]() .
.
Обратите внимание, что выделена одна
дополнительная ячейка, как этого требует
синтаксис функции.
 После
После
нажатия
![]() в ячейке
в ячейке![]() появляется число вариант со значением
появляется число вариант со значением![]() ,
,![]() .
.
Для вывода остальных значений![]() надо выделить ячейки
надо выделить ячейки![]() ,
,
после чего нажать клавишу![]() ,
,
а затем![]() .
.
В результате в столбце![]() и появятся все компоненты вектора
и появятся все компоненты вектора
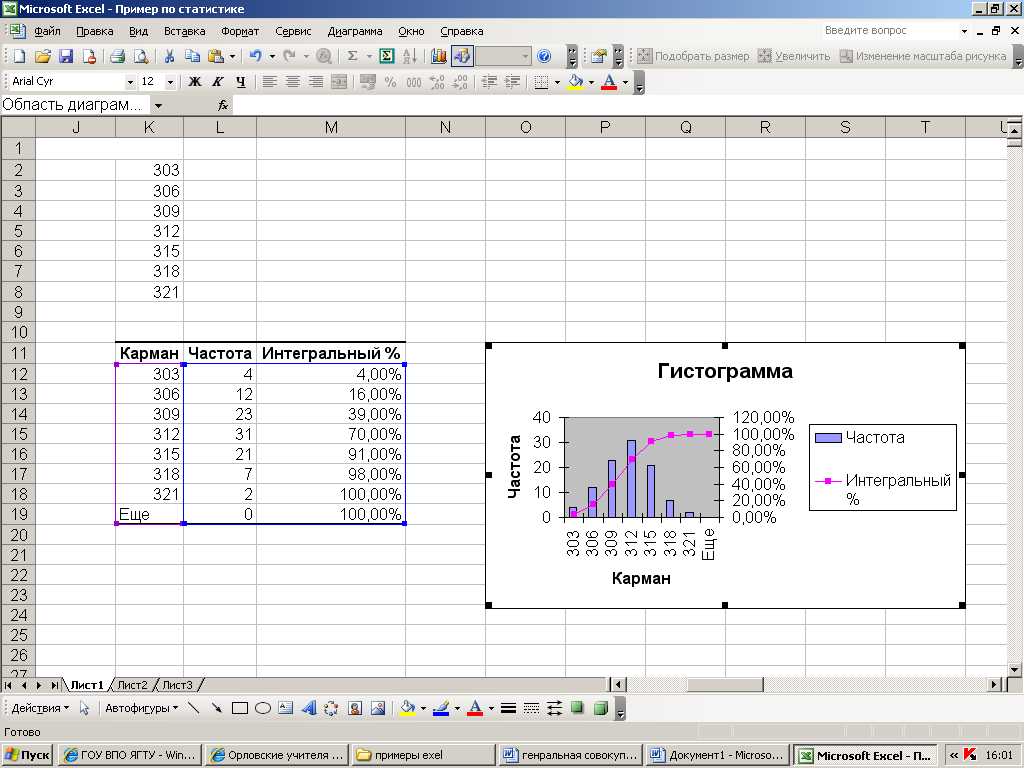
частот.
|
ЧАСТОТА |
|
|
303 |
4 |
|
306 |
12 |
|
309 |
23 |
|
312 |
31 |
|
315 |
21 |
|
318 |
7 |
|
321 |
2 |
Рассмотрим
теперь, какие возможности для первичной
обработки выборки имеются в меню
«сервис
![]() анализ данных». Раскроем диалоговое
анализ данных». Раскроем диалоговое
окно«описательная
статистика».
Первая
строка «Входной
интервал»
нам уже знакома: данные в неё можно
внести действиями ЩАа, ЪЩЯя, или
движениями мыши с нажатой правой кнопкой,
или непосредственно введя в окошко
номера левой верхней и правой нижней
ячеек массива, разделённые двоеточием
Аа:Яя. Далее предлагается выбрать
группировку – «По
строкам»
или «По
столбцам».
Дело в том, что эта «описательная
статистика»
может обрабатывать одновременно большое
количество выборок, каждая из которых
может быть введена либо в виде строки,
либо в виде столбца. Поэтому, если мы
выделим массив, содержащий 25 строк и 4
столбца, то программа не
будет рассматривать его как одну выборку,
содержащую 100 вариант. Если мы пометим
окошко «По
столбцам», то
программа будет обрабатывать массив
как 4 выборки по 25 вариант в каждой.
Соответственно, при флажке «По
строкам» мы
получим обработку 25 выборок по 4 варианта.
Далее следует окошко
«Метки в первой строке/столбце». Если
его не помечать, то результаты обработки
каждой из выборок будут помечены
надписями «Строка (Столбец) 1», «Строка
(Столбец) 2», «Строка (Столбец)3»… .Если
же мы хотим , чтобы результаты были
обозначены иначе, (например, фамилиями
студентов), то мы при вводе указаний
массива данных в строку Входной
диапазон должны
захватить и стоящий перед ним столбец
(строку) меток (фамилий или номеров
опытов в данном примере). На этом ввод
данных завершается.
Куда
выводить результаты:
|
Строка1 |
|
|
Среднее |
309,875 |
|
Стандартная |
1,599153422 |
|
Медиана |
309,5 |
|
Мода |
#Н/Д |
|
Стандартное |
3,198306844 |
|
Дисперсия |
10,22916667 |
|
Эксцесс |
-0,02453947 |
|
Асимметричность |
0,598903954 |
|
Интервал |
7,5 |
|
Минимум |
306,5 |
|
Максимум |
314 |
|
Сумма |
1239,5 |
|
Счет |
4 |
Параметры
вывода. Обычно при открытии
диалогового окна активизировано окошко
Новый рабочий лист.
Это означает, что результаты будут
выведены на новом листе, номер которого
при желании можно задать, так же как и
номер новой книги в окошке Новая
рабочая книга. Если же
надо поместить результаты на исходном
листе, то надо активизировать окошко
Выходной интервал,
после чего щёлкнуть по свободной ячейке,
которая будет левой верхней ячейкой
выходного массива.
Что
выводить.
При
установке флажка
«Итоговая статистика» для
каждой выборки будет выведена таблица
такого вида:
В
этой таблице под стандартным отклонением
понимается величина выборочного
стандарта
![]() ,
,
под стандартной ошибкой – выборочный
стандарт среднего![]() ,
,
интервал – разность между максимальным
и минимальным значениями выборки, сумма
– сумма всех значений выборки, счёт –
объём выборки. Остальные термины
пояснения не требуют.
Если
активизировать окошко «Уровень
надёжности»,
то выводится строка со значением
полуширины симметричного доверительного
интервала, соответствующим указанной
в этом окошке доверительной вероятности
и равным произведению
![]() на соответствующий квантиль распределения
на соответствующий квантиль распределения
Стьюдента:
|
Уровень |
5,089219898 |
Активизация
окошек К-ый
наименьший и
К-ый наибольший позволяет
выводить к-ое в порядке возрастания и
(или) к-ое в порядке убывания значения
в выборке, соответствующие указанным
номерам. Значениям к=1 соответствуют
минимальное и максимальное значения
вариант.

Обратимся
теперь к графическому изображению
данных. Для этого в меню Анализ
данных есть
функция Гистограмма,
в диалоговом окне которой в окошко
Входной
интервал вводим
одним из описанных ранее способов номера
ячеек начала и конца массива данных.
Затем в окошко Интервал
карманов вводим
таким же образом номера массива, в
котором указаны верхние границы
интервалов, на которые мы решили разбить
выборку (см. выше описание функции
Частота).
Флажок Метки
надо устанавливать только в том случае,
если в массив данных включён и столбец
меток. Как и в вышеописанных функциях
ставим флажок Новый
лист или
Новая книга (с
указанием номера или без), или Выходной
интервал. В
последнем случае в активизированное
окошко вводим номер левой верхней ячейки
диапазона вывода результата. Игнорируя
надпись Парето,
помечаем
Интегральный процент и
Вывод графика.
![]() выводит нам
выводит нам
во-первых,
таблицу, два первых столбца, как и после
исполнения функции Частота
представляют
интервальный вариационный ряд, а третий
столбец – аналог интегральной функции
распределения, показывает долю вариант
в выборки, имеющих значение меньшее или
равное указанного в первом столбце.
Кроме этого, появляется и графическое
изображение – гистограмма и график
интегрального процента. Можно редактировать
это изображение, но здесь мы не будем
рассматривать все многочисленные
возможности этого.

Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Содержание
- Выполнение выборки
- Способ 1: применение расширенного автофильтра
- Способ 2: применение формулы массива
- Способ 3: выборка по нескольким условиям с помощью формулы
- Способ 4: случайная выборка
- Вопросы и ответы

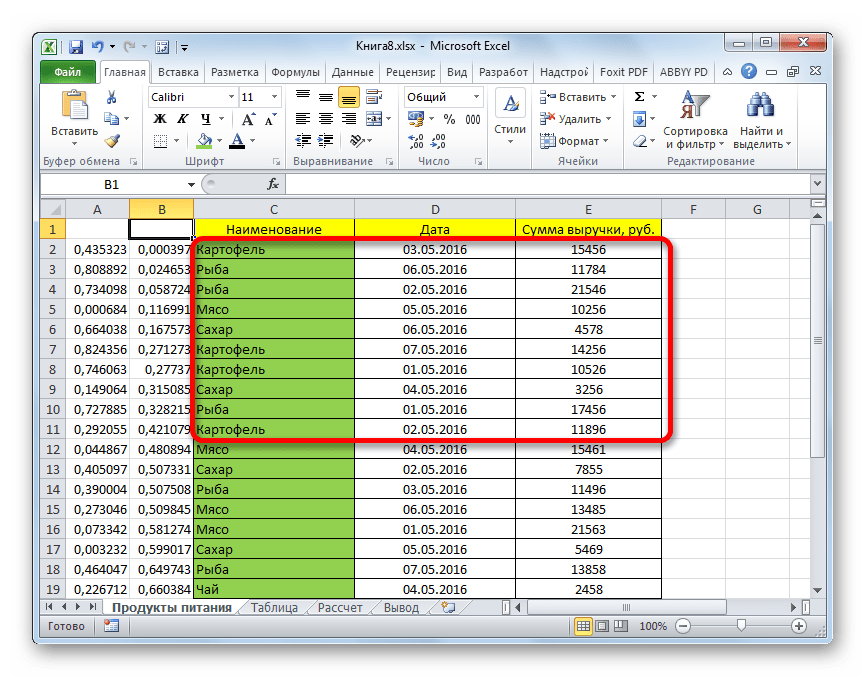
При работе с таблицами Excel довольно часто приходится проводить отбор в них по определенному критерию или по нескольким условиям. В программе сделать это можно различными способами при помощи ряда инструментов. Давайте выясним, как произвести выборку в Экселе, используя разнообразные варианты.
Выполнение выборки
Выборка данных состоит в процедуре отбора из общего массива тех результатов, которые удовлетворяют заданным условиям, с последующим выводом их на листе отдельным списком или в исходном диапазоне.
Способ 1: применение расширенного автофильтра
Наиболее простым способом произвести отбор является применение расширенного автофильтра. Рассмотрим, как это сделать на конкретном примере.
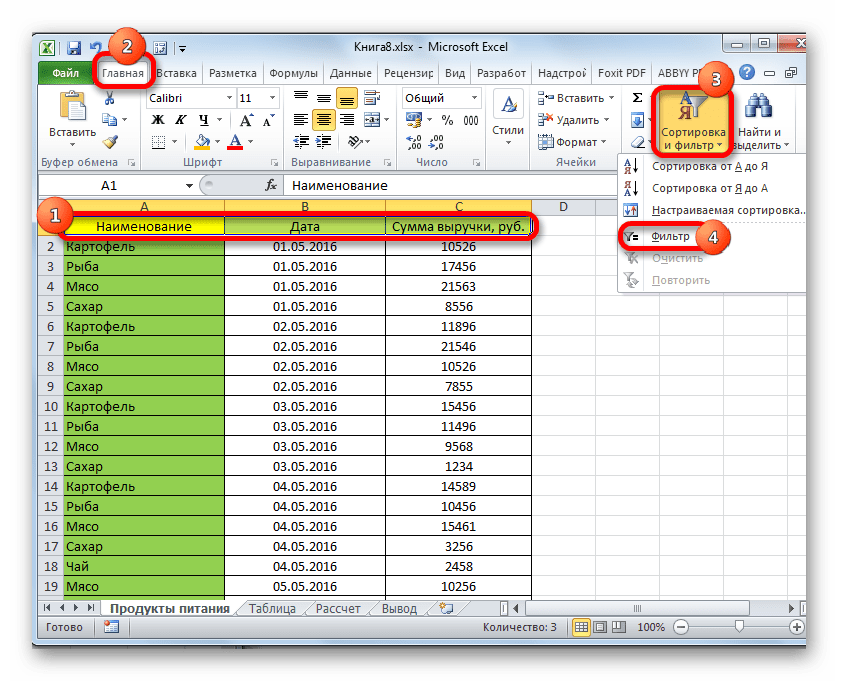
- Выделяем область на листе, среди данных которой нужно произвести выборку. Во вкладке «Главная» щелкаем по кнопке «Сортировка и фильтр». Она размещается в блоке настроек «Редактирование». В открывшемся после этого списка выполняем щелчок по кнопке «Фильтр».

Есть возможность поступить и по-другому. Для этого после выделения области на листе перемещаемся во вкладку «Данные». Щелкаем по кнопке «Фильтр», которая размещена на ленте в группе «Сортировка и фильтр».
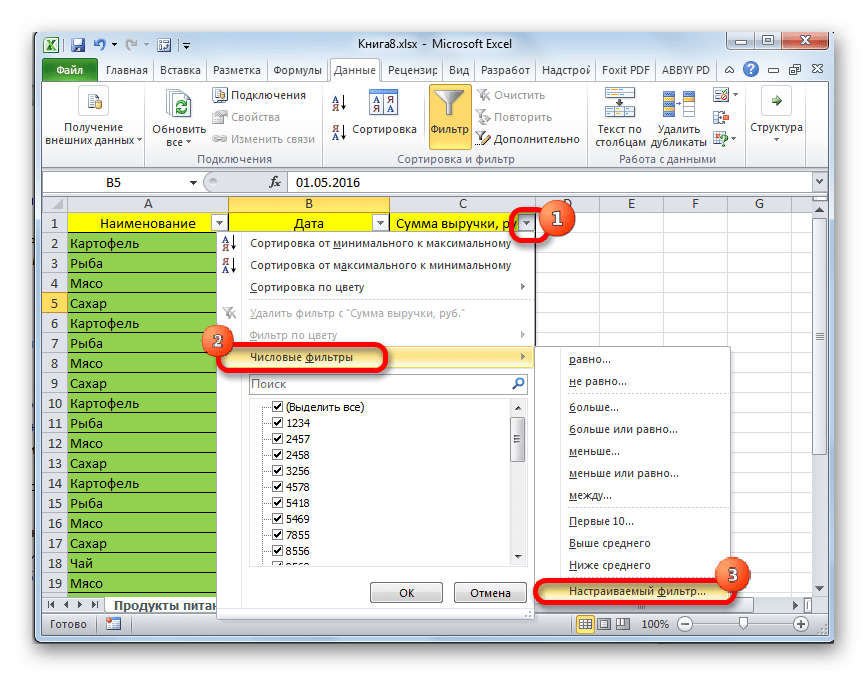
- После этого действия в шапке таблицы появляются пиктограммы для запуска фильтрования в виде перевернутых острием вниз небольших треугольников на правом краю ячеек. Кликаем по данному значку в заглавии того столбца, по которому желаем произвести выборку. В запустившемся меню переходим по пункту «Текстовые фильтры». Далее выбираем позицию «Настраиваемый фильтр…».
- Активируется окно пользовательской фильтрации. В нем можно задать ограничение, по которому будет производиться отбор. В выпадающем списке для столбца содержащего ячейки числового формата, который мы используем для примера, можно выбрать одно из пяти видов условий:
- равно;
- не равно;
- больше;
- больше или равно;
- меньше.
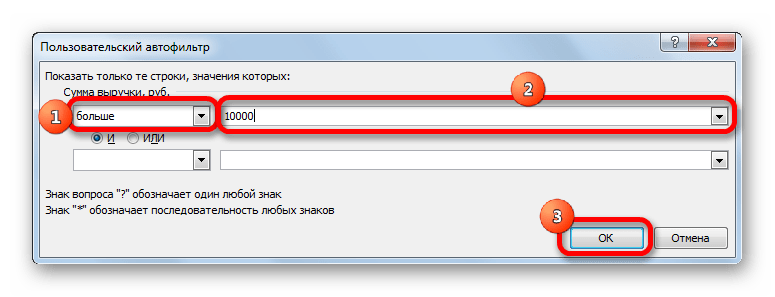
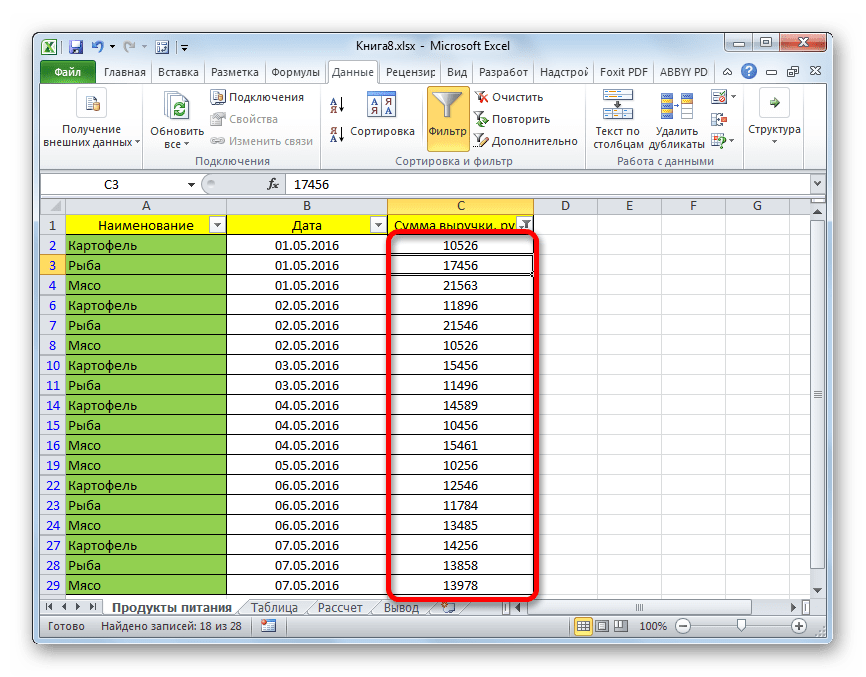
Давайте в качестве примера зададим условие так, чтобы отобрать только значения, по которым сумма выручки превышает 10000 рублей. Устанавливаем переключатель в позицию «Больше». В правое поле вписываем значение «10000». Чтобы произвести выполнение действия, щелкаем по кнопке «OK».
- Как видим, после фильтрации остались только строчки, в которых сумма выручки превышает 10000 рублей.
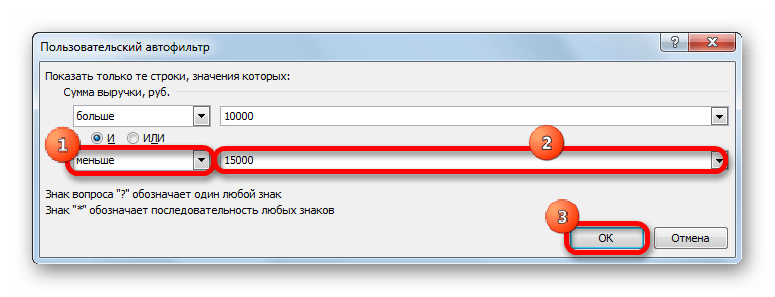
- Но в этом же столбце мы можем добавить и второе условие. Для этого опять возвращаемся в окно пользовательской фильтрации. Как видим, в его нижней части есть ещё один переключатель условия и соответствующее ему поле для ввода. Давайте установим теперь верхнюю границу отбора в 15000 рублей. Для этого выставляем переключатель в позицию «Меньше», а в поле справа вписываем значение «15000».
Кроме того, существует ещё переключатель условий. У него два положения «И» и «ИЛИ». По умолчанию он установлен в первом положении. Это означает, что в выборке останутся только строчки, которые удовлетворяют обоим ограничениям. Если он будет выставлен в положение «ИЛИ», то тогда останутся значения, которые подходят под любое из двух условий. В нашем случае нужно выставить переключатель в положение «И», то есть, оставить данную настройку по умолчанию. После того, как все значения введены, щелкаем по кнопке «OK».
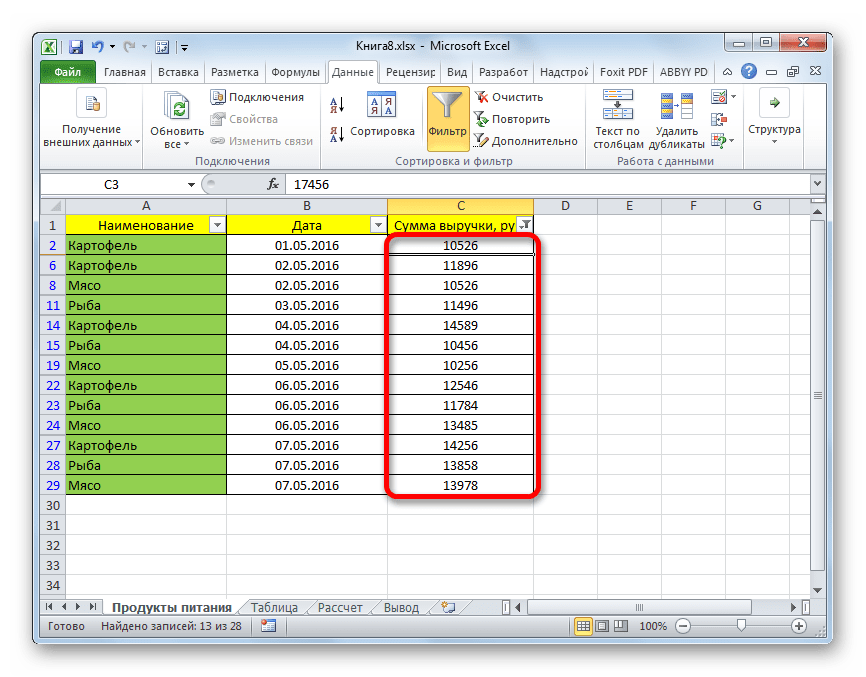
- Теперь в таблице остались только строчки, в которых сумма выручки не меньше 10000 рублей, но не превышает 15000 рублей.
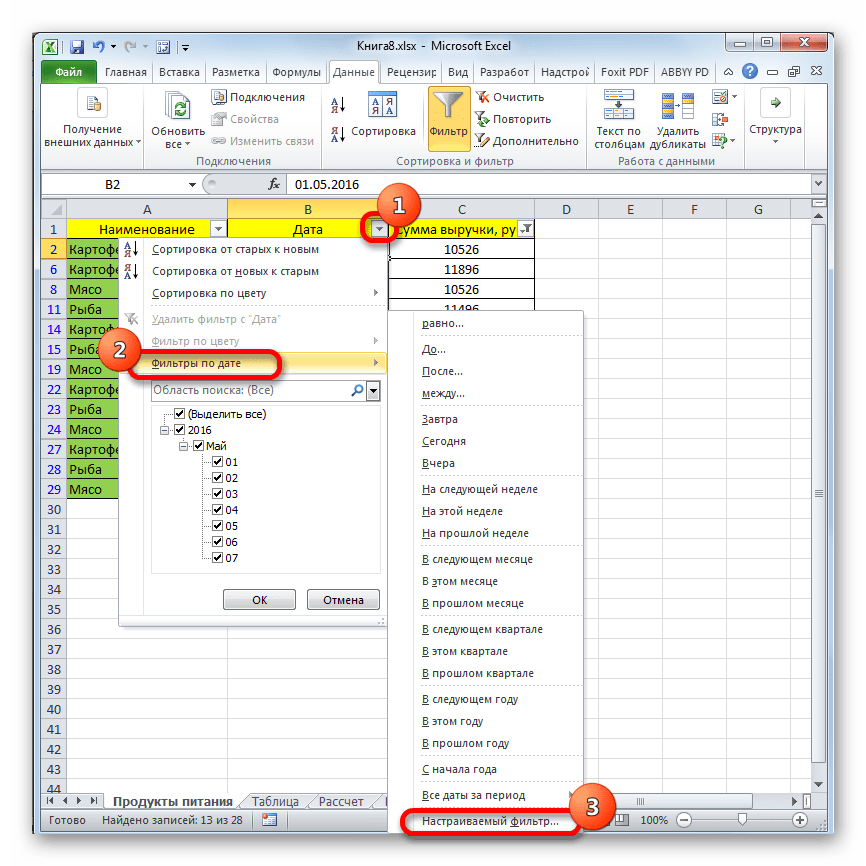
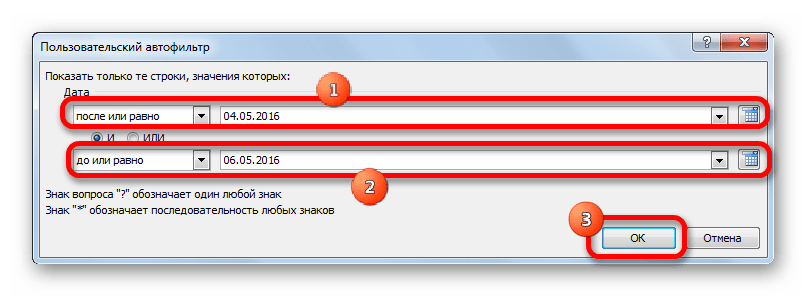
- Аналогично можно настраивать фильтры и в других столбцах. При этом имеется возможность сохранять также фильтрацию и по предыдущим условиям, которые были заданы в колонках. Итак, посмотрим, как производится отбор с помощью фильтра для ячеек в формате даты. Кликаем по значку фильтрации в соответствующем столбце. Последовательно кликаем по пунктам списка «Фильтр по дате» и «Настраиваемый фильтр».
- Снова запускается окно пользовательского автофильтра. Выполним отбор результатов в таблице с 4 по 6 мая 2016 года включительно. В переключателе выбора условий, как видим, ещё больше вариантов, чем для числового формата. Выбираем позицию «После или равно». В поле справа устанавливаем значение «04.05.2016». В нижнем блоке устанавливаем переключатель в позицию «До или равно». В правом поле вписываем значение «06.05.2016». Переключатель совместимости условий оставляем в положении по умолчанию – «И». Для того, чтобы применить фильтрацию в действии, жмем на кнопку «OK».
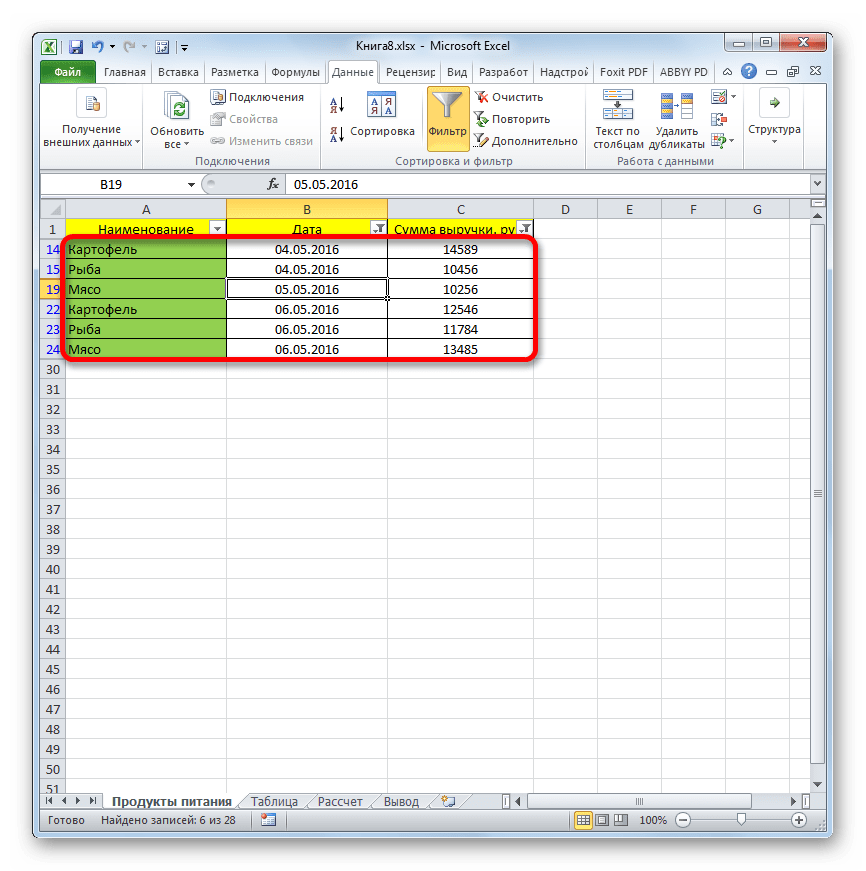
- Как видим, наш список ещё больше сократился. Теперь в нем оставлены только строчки, в которых сумма выручки варьируется от 10000 до 15000 рублей за период с 04.05 по 06.05.2016 включительно.
- Мы можем сбросить фильтрацию в одном из столбцов. Сделаем это для значений выручки. Кликаем по значку автофильтра в соответствующем столбце. В выпадающем списке щелкаем по пункту «Удалить фильтр».
- Как видим, после этих действий, выборка по сумме выручки будет отключена, а останется только отбор по датам (с 04.05.2016 по 06.05.2016).
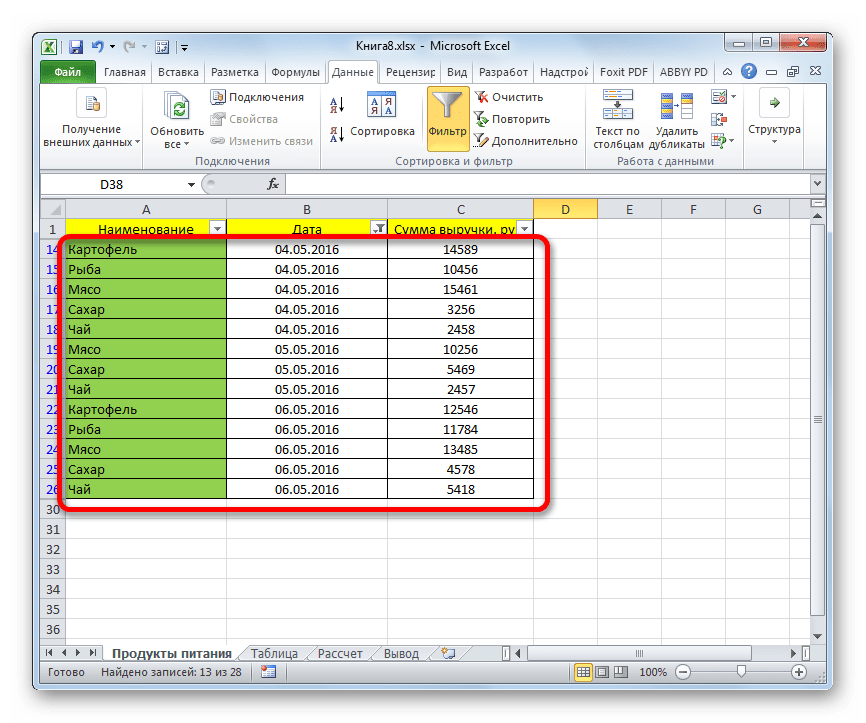
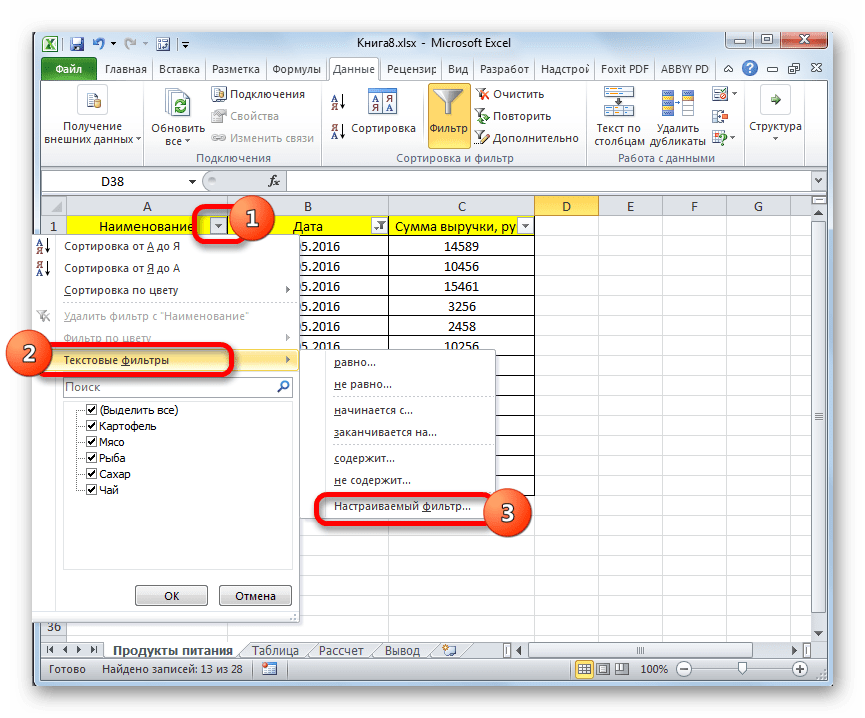
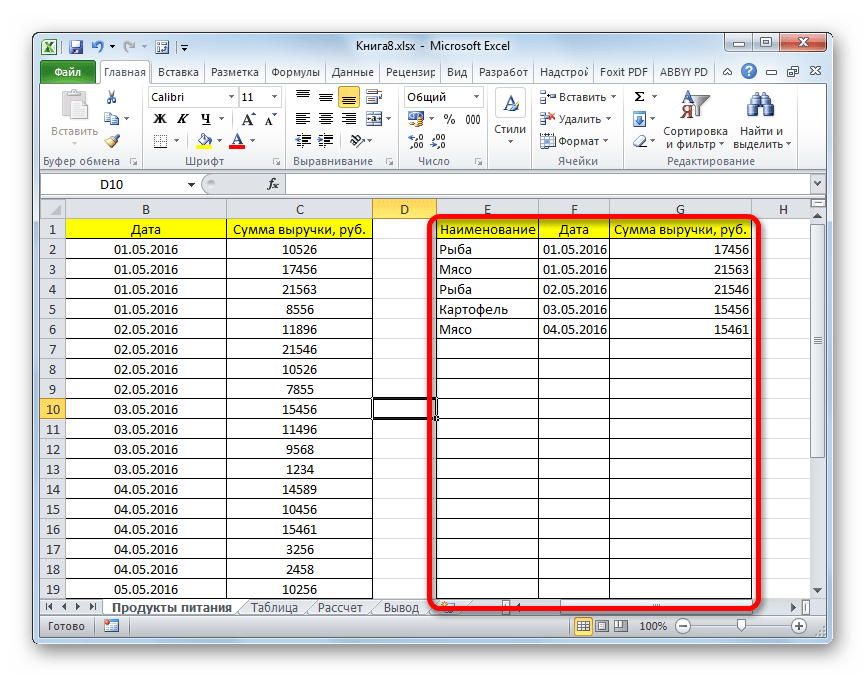
- В данной таблице имеется ещё одна колонка – «Наименование». В ней содержатся данные в текстовом формате. Посмотрим, как сформировать выборку с помощью фильтрации по этим значениям.
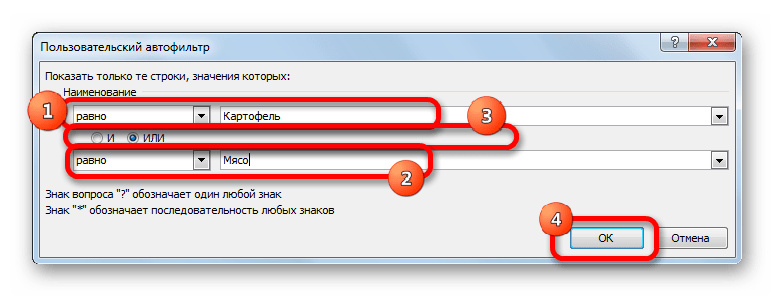
Кликаем по значку фильтра в наименовании столбца. Последовательно переходим по наименованиям списка «Текстовые фильтры» и «Настраиваемый фильтр…».
- Опять открывается окно пользовательского автофильтра. Давайте сделаем выборку по наименованиям «Картофель» и «Мясо». В первом блоке переключатель условий устанавливаем в позицию «Равно». В поле справа от него вписываем слово «Картофель». Переключатель нижнего блока так же ставим в позицию «Равно». В поле напротив него делаем запись – «Мясо». И вот далее мы выполняем то, чего ранее не делали: устанавливаем переключатель совместимости условий в позицию «ИЛИ». Теперь строчка, содержащая любое из указанных условий, будет выводиться на экран. Щелкаем по кнопке «OK».
- Как видим, в новой выборке существуют ограничения по дате (с 04.05.2016 по 06.05.2016) и по наименованию (картофель и мясо). По сумме выручки ограничений нет.
- Полностью удалить фильтр можно теми же способами, которые использовались для его установки. Причем неважно, какой именно способ применялся. Для сброса фильтрации, находясь во вкладке «Данные» щелкаем по кнопке «Фильтр», которая размещена в группе «Сортировка и фильтр».

Второй вариант предполагает переход во вкладку «Главная». Там выполняем щелчок на ленте по кнопке «Сортировка и фильтр» в блоке «Редактирование». В активировавшемся списке нажимаем на кнопку «Фильтр».
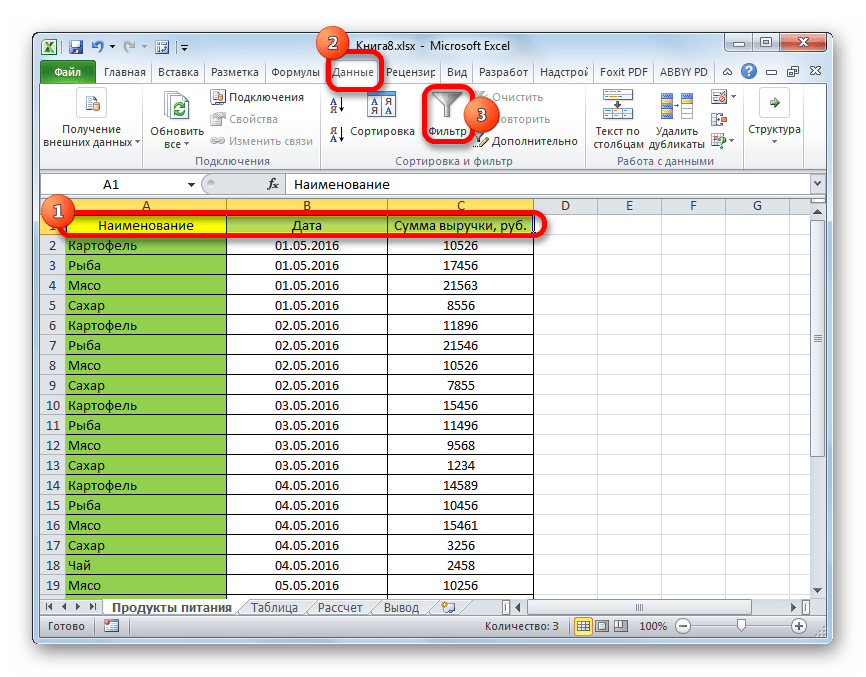




При использовании любого из двух вышеуказанных методов фильтрация будет удалена, а результаты выборки – очищены. То есть, в таблице будет показан весь массив данных, которыми она располагает.
Урок: Функция автофильтр в Excel
Способ 2: применение формулы массива
Сделать отбор можно также применив сложную формулу массива. В отличие от предыдущего варианта, данный метод предусматривает вывод результата в отдельную таблицу.
- На том же листе создаем пустую таблицу с такими же наименованиями столбцов в шапке, что и у исходника.
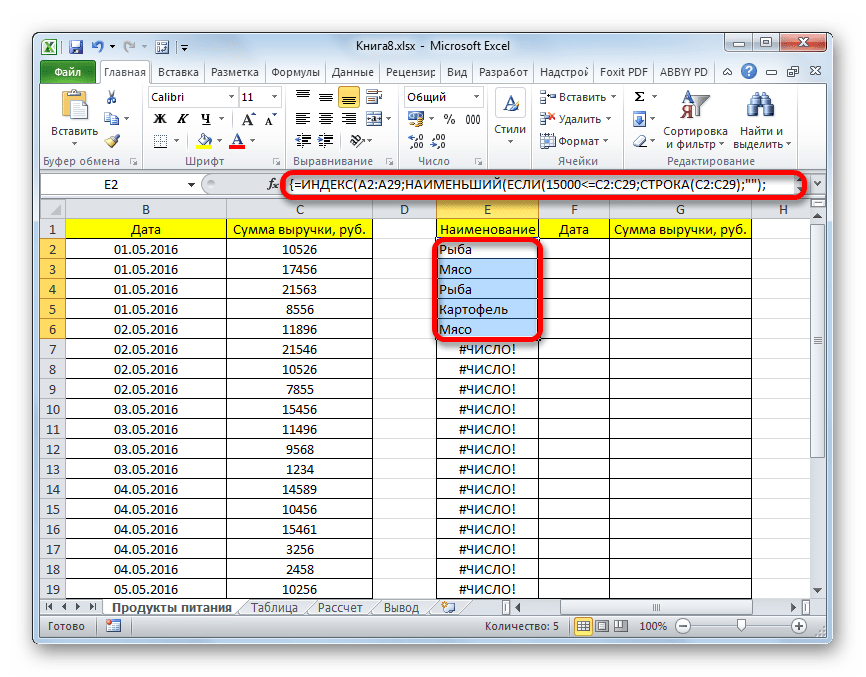
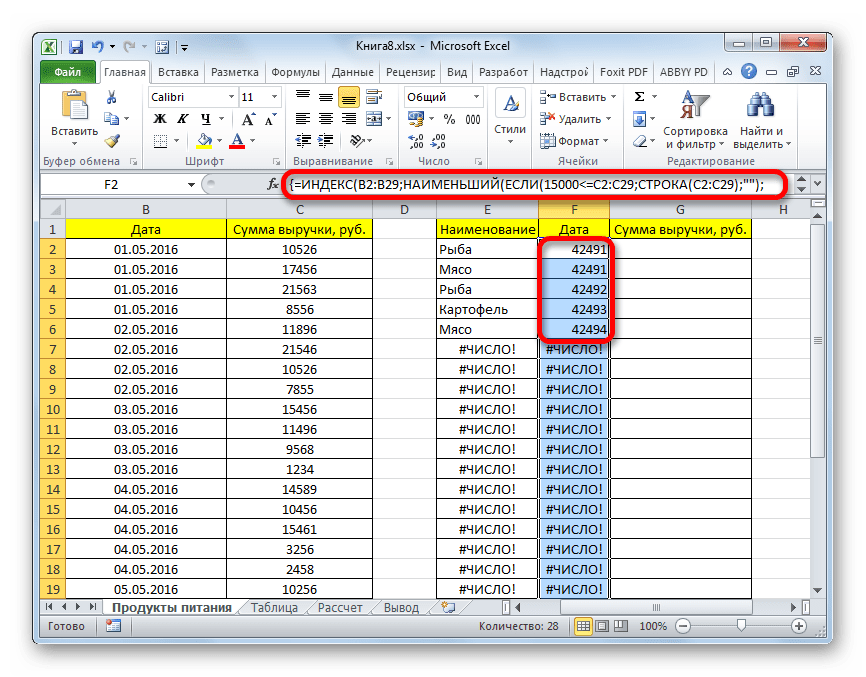
- Выделяем все пустые ячейки первой колонки новой таблицы. Устанавливаем курсор в строку формул. Как раз сюда будет заноситься формула, производящая выборку по указанным критериям. Отберем строчки, сумма выручки в которых превышает 15000 рублей. В нашем конкретном примере, вводимая формула будет выглядеть следующим образом:
=ИНДЕКС(A2:A29;НАИМЕНЬШИЙ(ЕСЛИ(15000<=C2:C29;СТРОКА(C2:C29);"");СТРОКА()-СТРОКА($C$1))-СТРОКА($C$1))Естественно, в каждом конкретном случае адрес ячеек и диапазонов будет свой. На данном примере можно сопоставить формулу с координатами на иллюстрации и приспособить её для своих нужд.
- Так как это формула массива, то для того, чтобы применить её в действии, нужно нажимать не кнопку Enter, а сочетание клавиш Ctrl+Shift+Enter. Делаем это.
- Выделив второй столбец с датами и установив курсор в строку формул, вводим следующее выражение:
=ИНДЕКС(B2:B29;НАИМЕНЬШИЙ(ЕСЛИ(15000<=C2:C29;СТРОКА(C2:C29);"");СТРОКА()-СТРОКА($C$1))-СТРОКА($C$1))Жмем сочетание клавиш Ctrl+Shift+Enter.
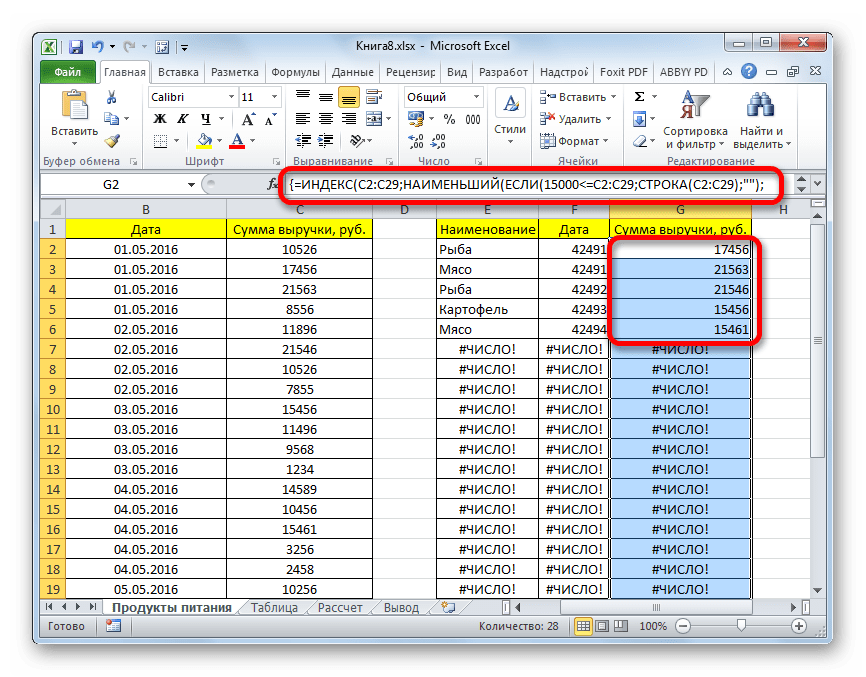
- Аналогичным образом в столбец с выручкой вписываем формулу следующего содержания:
=ИНДЕКС(C2:C29;НАИМЕНЬШИЙ(ЕСЛИ(15000<=C2:C29;СТРОКА(C2:C29);"");СТРОКА()-СТРОКА($C$1))-СТРОКА($C$1))Опять набираем сочетание клавиш Ctrl+Shift+Enter.
Во всех трех случаях меняется только первое значение координат, а в остальном формулы полностью идентичны.
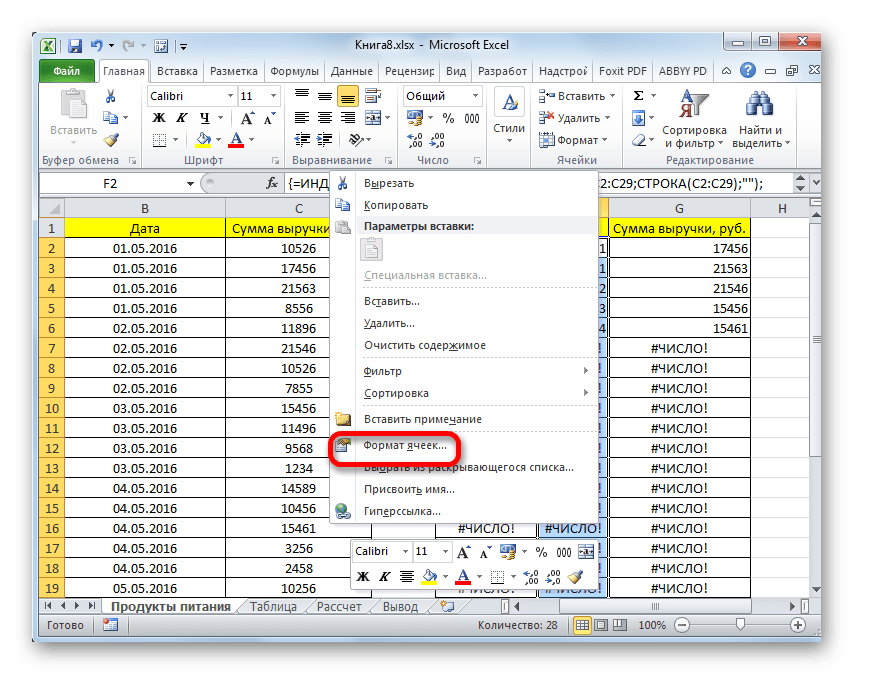
- Как видим, таблица заполнена данными, но внешний вид её не совсем привлекателен, к тому же, значения даты заполнены в ней некорректно. Нужно исправить эти недостатки. Некорректность даты связана с тем, что формат ячеек соответствующего столбца общий, а нам нужно установить формат даты. Выделяем весь столбец, включая ячейки с ошибками, и кликаем по выделению правой кнопкой мыши. В появившемся списке переходим по пункту «Формат ячейки…».
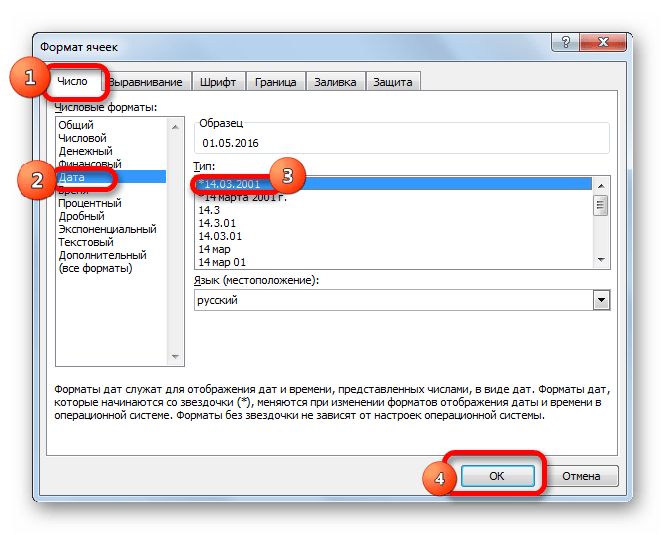
- В открывшемся окне форматирования открываем вкладку «Число». В блоке «Числовые форматы» выделяем значение «Дата». В правой части окна можно выбрать желаемый тип отображения даты. После того, как настройки выставлены, жмем на кнопку «OK».
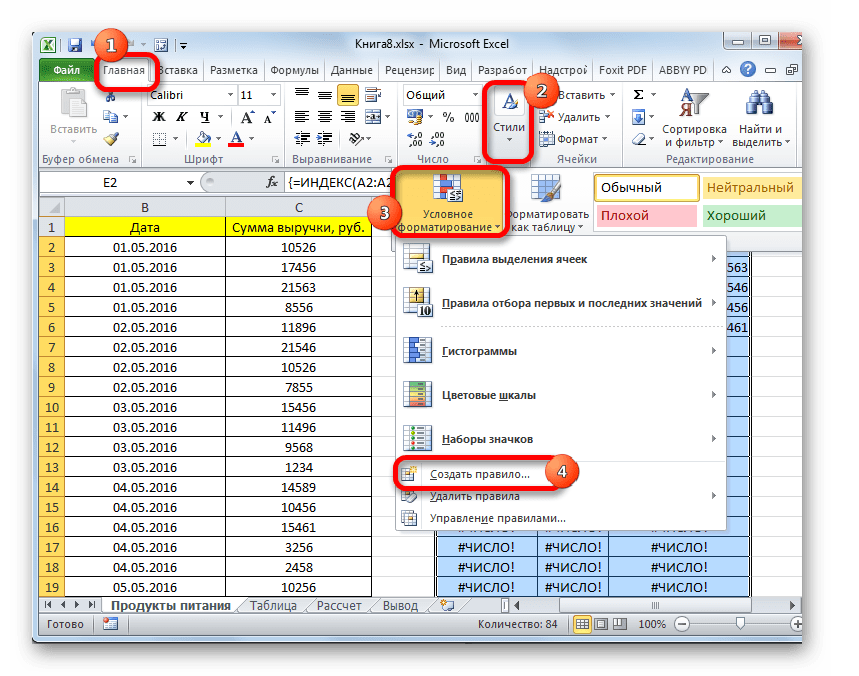
- Теперь дата отображается корректно. Но, как видим, вся нижняя часть таблицы заполнена ячейками, которые содержат ошибочное значение «#ЧИСЛО!». По сути, это те ячейки, данных из выборки для которых не хватило. Более привлекательно было бы, если бы они отображались вообще пустыми. Для этих целей воспользуемся условным форматированием. Выделяем все ячейки таблицы, кроме шапки. Находясь во вкладке «Главная» кликаем по кнопке «Условное форматирование», которая находится в блоке инструментов «Стили». В появившемся списке выбираем пункт «Создать правило…».
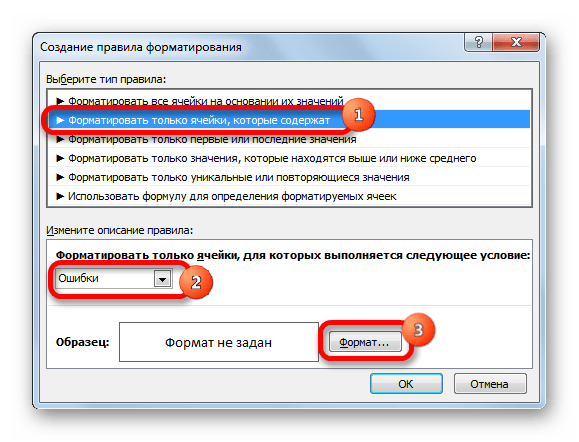
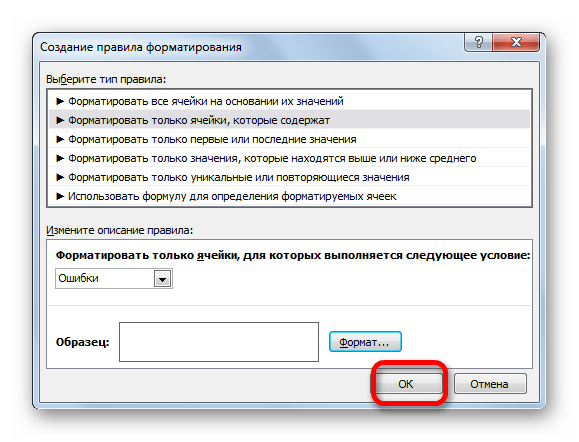
- В открывшемся окне выбираем тип правила «Форматировать только ячейки, которые содержат». В первом поле под надписью «Форматировать только ячейки, для которых выполняется следующее условие» выбираем позицию «Ошибки». Далее жмем по кнопке «Формат…».
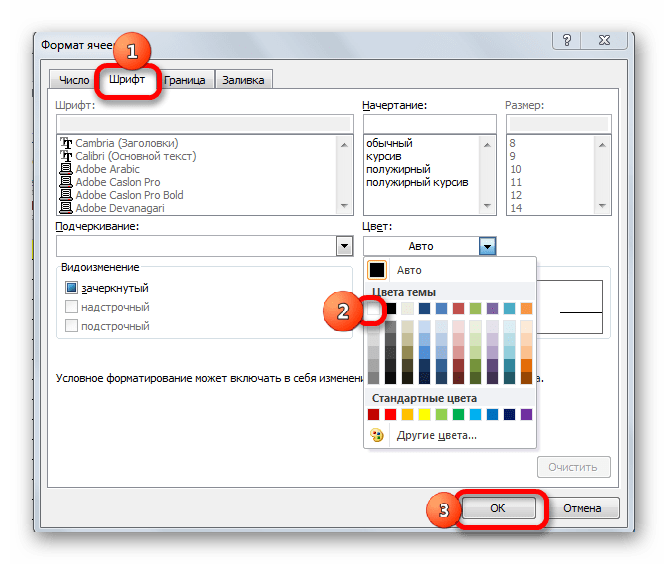
- В запустившемся окне форматирования переходим во вкладку «Шрифт» и в соответствующем поле выбираем белый цвет. После этих действий щелкаем по кнопке «OK».
- На кнопку с точно таким же названием жмем после возвращения в окно создания условий.


Теперь у нас имеется готовая выборка по указанному ограничению в отдельной надлежащим образом оформленной таблице.
Урок: Условное форматирование в Excel
Способ 3: выборка по нескольким условиям с помощью формулы
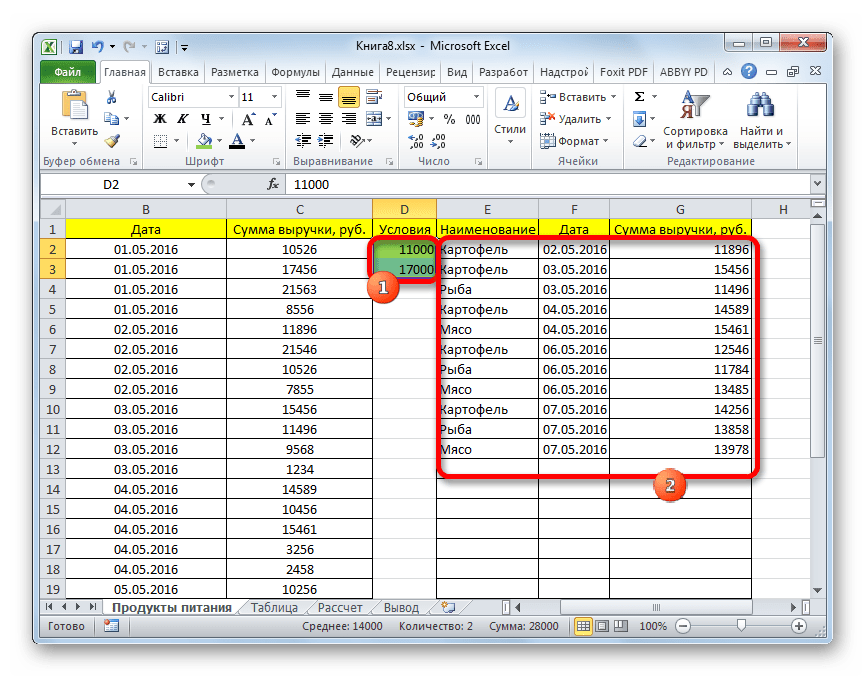
Так же, как и при использовании фильтра, с помощью формулы можно осуществлять выборку по нескольким условиям. Для примера возьмем всю ту же исходную таблицу, а также пустую таблицу, где будут выводиться результаты, с уже выполненным числовым и условным форматированием. Установим первым ограничением нижнюю границу отбора по выручке в 15000 рублей, а вторым условием верхнюю границу в 20000 рублей.
- Вписываем в отдельном столбце граничные условия для выборки.
- Как и в предыдущем способе, поочередно выделяем пустые столбцы новой таблицы и вписываем в них соответствующие три формулы. В первый столбец вносим следующее выражение:
=ИНДЕКС(A2:A29;НАИМЕНЬШИЙ(ЕСЛИ(($D$2=C2:C29);СТРОКА(C2:C29);"");СТРОКА(C2:C29)-СТРОКА($C$1))-СТРОКА($C$1))В последующие колонки вписываем точно такие же формулы, только изменив координаты сразу после наименования оператора ИНДЕКС на соответствующие нужным нам столбцам, по аналогии с предыдущим способом.
Каждый раз после ввода не забываем набирать сочетание клавиш Ctrl+Shift+Enter.
- Преимущество данного способа перед предыдущим заключается в том, что если мы захотим поменять границы выборки, то совсем не нужно будет менять саму формулу массива, что само по себе довольно проблематично. Достаточно в колонке условий на листе поменять граничные числа на те, которые нужны пользователю. Результаты отбора тут же автоматически изменятся.


Способ 4: случайная выборка
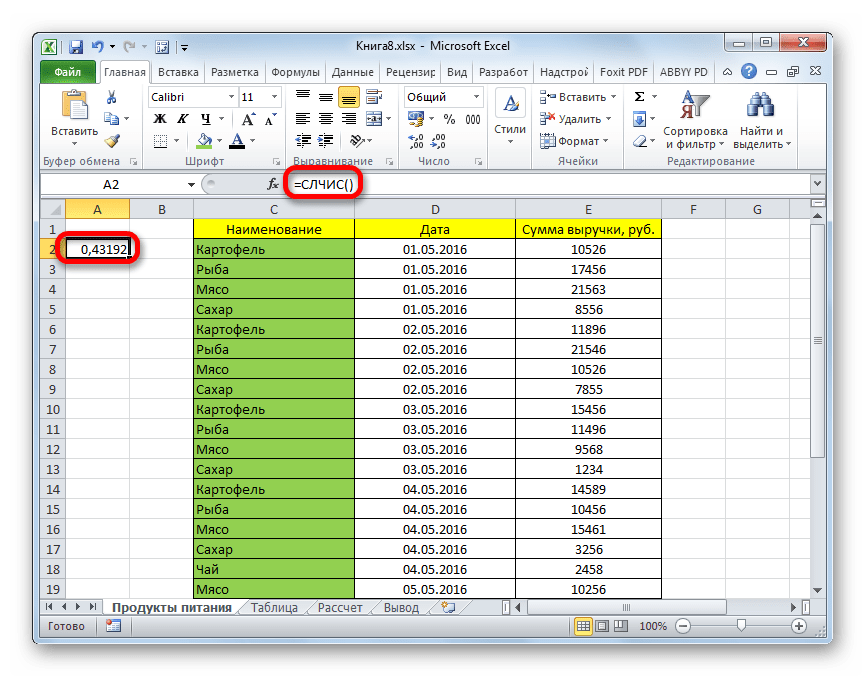
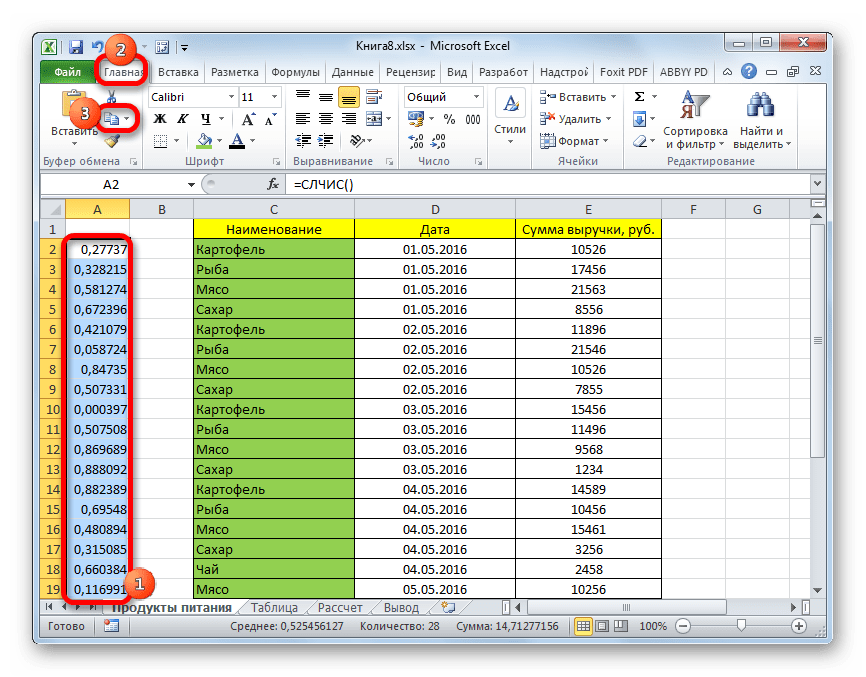
В Экселе с помощью специальной формулы СЛЧИС можно также применять случайный отбор. Его требуется производить в некоторых случаях при работе с большим объемом данных, когда нужно представить общую картину без комплексного анализа всех данных массива.
- Слева от таблицы пропускаем один столбец. В ячейке следующего столбца, которая находится напротив первой ячейки с данными таблицы, вписываем формулу:
=СЛЧИС()Эта функция выводит на экран случайное число. Для того, чтобы её активировать, жмем на кнопку ENTER.
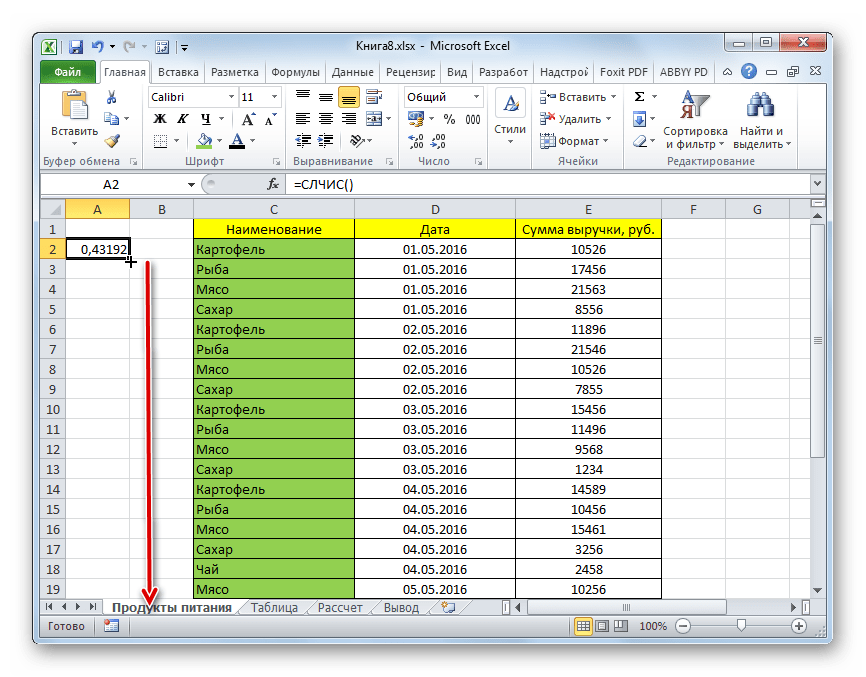
- Для того, чтобы сделать целый столбец случайных чисел, устанавливаем курсор в нижний правый угол ячейки, которая уже содержит формулу. Появляется маркер заполнения. Протягиваем его вниз с зажатой левой кнопкой мыши параллельно таблице с данными до её конца.
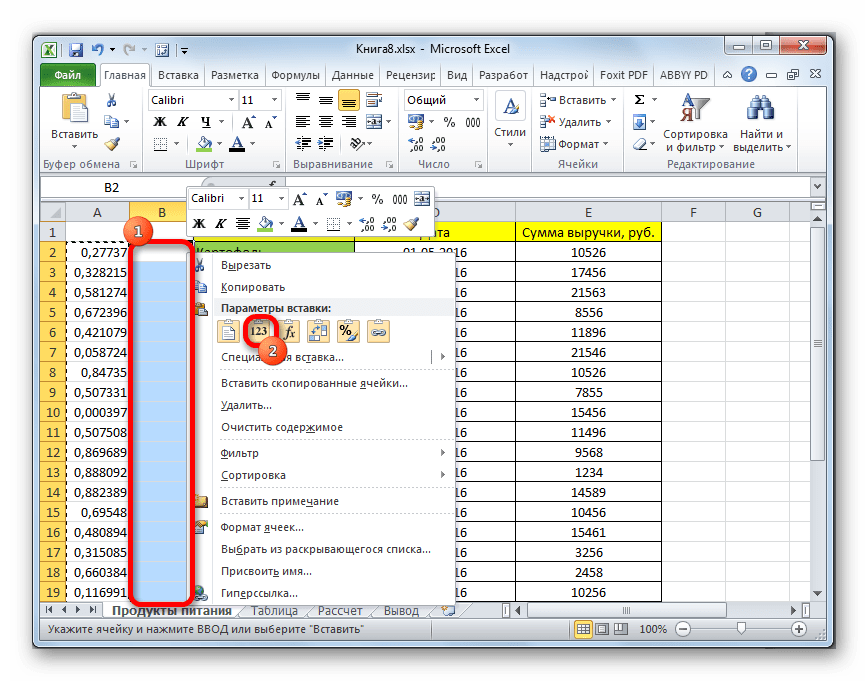
- Теперь у нас имеется диапазон ячеек, заполненный случайными числами. Но, он содержит в себе формулу СЛЧИС. Нам же нужно работать с чистыми значениями. Для этого следует выполнить копирование в пустой столбец справа. Выделяем диапазон ячеек со случайными числами. Расположившись во вкладке «Главная», щелкаем по иконке «Копировать» на ленте.
- Выделяем пустой столбец и кликаем правой кнопкой мыши, вызывая контекстное меню. В группе инструментов «Параметры вставки» выбираем пункт «Значения», изображенный в виде пиктограммы с цифрами.
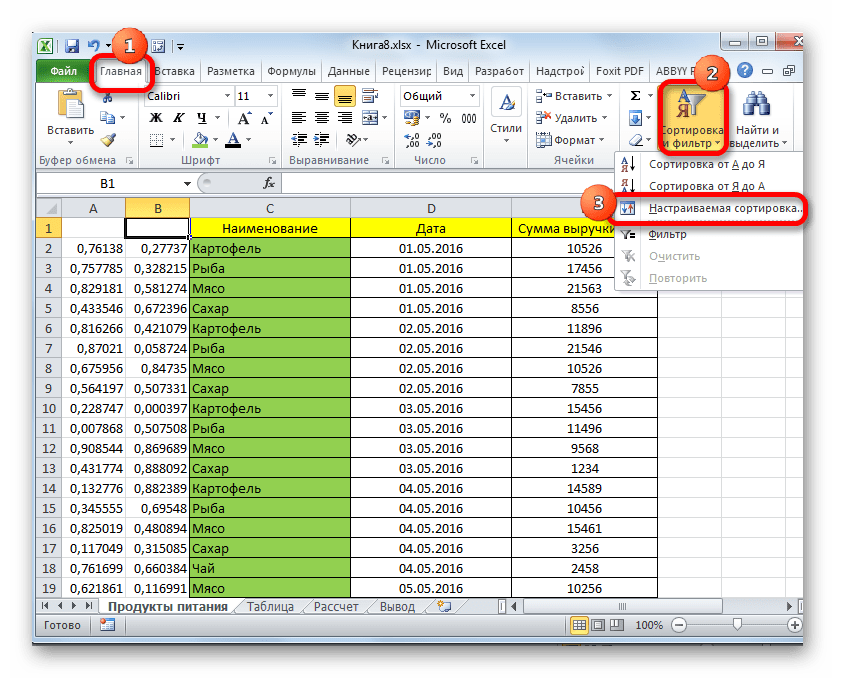
- После этого, находясь во вкладке «Главная», кликаем по уже знакомому нам значку «Сортировка и фильтр». В выпадающем списке останавливаем выбор на пункте «Настраиваемая сортировка».
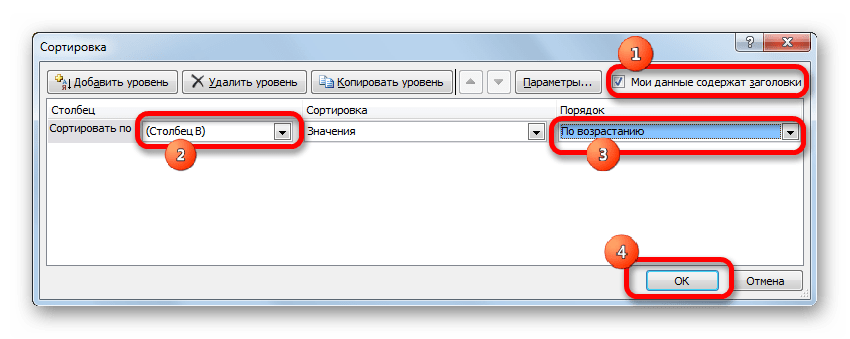
- Активируется окно настройки сортировки. Обязательно устанавливаем галочку напротив параметра «Мои данные содержат заголовки», если шапка имеется, а галочки нет. В поле «Сортировать по» указываем наименование того столбца, в котором содержатся скопированные значения случайных чисел. В поле «Сортировка» оставляем настройки по умолчанию. В поле «Порядок» можно выбрать параметр как «По возрастанию», так и «По убыванию». Для случайной выборки это значения не имеет. После того, как настройки произведены, жмем на кнопку «OK».
- После этого все значения таблицы выстраиваются в порядке возрастания или убывания случайных чисел. Можно взять любое количество первых строчек из таблицы (5, 10, 12, 15 и т.п.) и их можно будет считать результатом случайной выборки.
Урок: Сортировка и фильтрация данных в Excel
Как видим, выборку в таблице Excel можно произвести, как с помощью автофильтра, так и применив специальные формулы. В первом случае результат будет выводиться в исходную таблицу, а во втором – в отдельную область. Имеется возможность производить отбор, как по одному условию, так и по нескольким. Кроме того, можно осуществлять случайную выборку, использовав функцию СЛЧИС.
Еще статьи по данной теме:
Помогла ли Вам статья?
Цель:
- Совершенствование умений и навыков нахождения статистических
характеристик случайной величины, работа с расчетами в Excel; - применение информационно коммутативных технологий для анализа данных;
работа с различными информационными носителями.
Ход урока
- Сегодня на уроке мы научимся рассчитывать статистические характеристики
для больших по объему выборок, используя возможности современных
компьютерных технологий. - Для начала вспомним:
– что называется случайной величиной? (Случайной величиной называют
переменную величину, которая в зависимости от исхода испытания принимает одно
значение из множества возможных значений.)
– Какие виды случайных величин мы знаем? (Дискретные, непрерывные.)
– Приведите примеры непрерывных случайных величин (рост дерева), дискретных
случайных величин (количество учеников в классе).
– Какие статистические характеристики случайных величин мы знаем (мода,
медиана, среднее выборочное значение, размах ряда).
– Какие приемы используются для наглядного представления статистических
характеристик случайной величины (полигон частот, круговые и столбчатые
диаграммы, гистограммы).
- Рассмотрим, применение инструментов Excel для решения статистических
задач на конкретном примере.
Пример. Проведена проверка в 100 компаниях. Даны значения количества
работающих в компании (чел.):
| 23 25 24 25 30 24 30 26 28 26 32 33 31 31 25 33 25 29 30 28 23 30 29 24 33 30 30 28 26 25 26 29 27 29 26 28 27 26 29 28 29 30 27 30 28 32 28 26 30 26 31 27 30 27 33 28 26 30 31 29 27 30 30 29 27 26 28 31 29 28 33 27 30 33 26 31 34 28 32 22 29 30 27 29 34 29 32 29 29 30 29 29 36 29 29 34 23 28 24 28 |
рассчитать числовые характеристики:
|
Ход работы.
1. Занести данные в EXCEL, каждое число в отдельную ячейку.
| 23 | 25 | 24 | 25 | 30 | 24 | 30 | 26 | 28 | 26 |
| 32 | 33 | 31 | 31 | 25 | 33 | 25 | 29 | 30 | 28 |
| 23 | 30 | 29 | 24 | 33 | 30 | 30 | 28 | 26 | 25 |
| 26 | 29 | 27 | 29 | 26 | 28 | 27 | 26 | 29 | 28 |
| 29 | 30 | 27 | 30 | 28 | 32 | 28 | 26 | 30 | 26 |
| 31 | 27 | 30 | 27 | 33 | 28 | 26 | 30 | 31 | 29 |
| 27 | 30 | 30 | 29 | 27 | 26 | 28 | 31 | 29 | 28 |
| 33 | 27 | 30 | 33 | 26 | 31 | 34 | 28 | 32 | 22 |
| 29 | 30 | 27 | 29 | 34 | 29 | 32 | 29 | 29 | 30 |
| 29 | 29 | 36 | 29 | 29 | 34 | 23 | 28 | 24 | 28 |
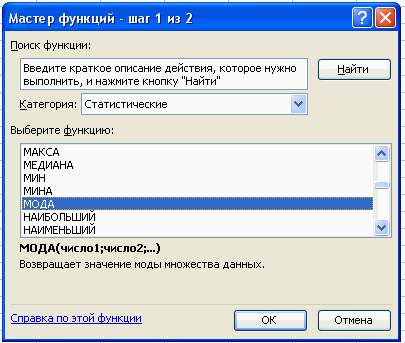
2. Для расчета числовых характеристик используем опцию Вставка – Функция. И в
появившемся окне в строке категория выберем — статистические, в списке: МОДА
В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:
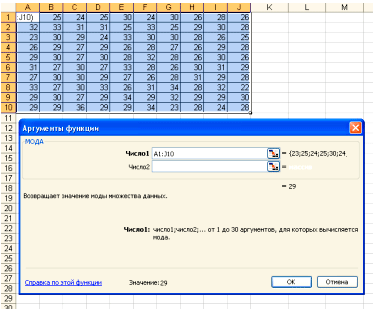
Нажимаем клавишу ОК. Получили Мо = 29 (чел) – Фирм у которых в
штате 29 человек больше всего.
Используя тот же путь вычисляем медиану.
Вставка – Функция – Статистические – Медиана.
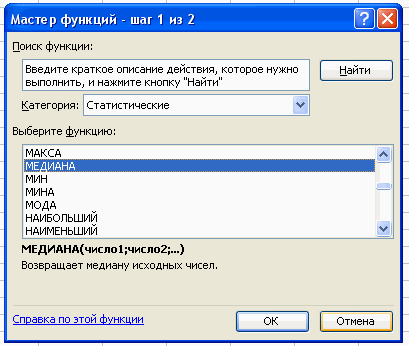
В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:
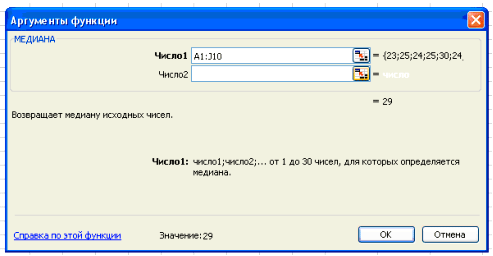
Нажимаем клавишу ОК. Получили Ме = 29 (чел) – среднее значение
сотрудников в фирме.
Размах ряда чисел – разница между наименьшим и наибольшим возможным значением
случайной величины. Для вычисления размаха ряда нужно найти наибольшее и
наименьшее значения нашей выборки и вычислить их разность.
Вставка – Функция – Статистические – МАКС.
В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:
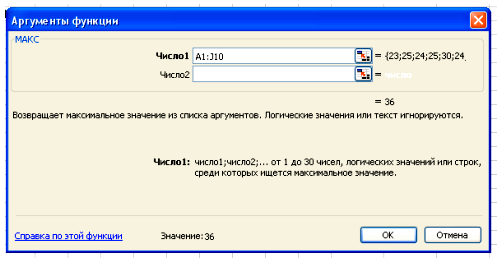
Нажимаем клавишу ОК. Получили наибольшее значение = 36.
Вставка – Функция – Статистические – МИН.
В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:
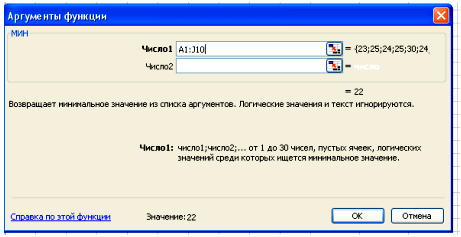
Нажимаем клавишу ОК. Получили наименьшее значение = 22.
36 – 22 = 14 (чел) – разница между фирмой с наибольшим штатом сотрудников и
фирмой с наименьшим штатом сотрудников.
Для построения диаграммы и полигона частот необходимо задать закон
распределения, т.е. составить таблицу значений случайной величины и
соответствующих им частот. Мы ухе знаем, что наименьшее число сотрудников в
фирме = 22, а наибольшее = 36. Составим таблицу, в которой значения xi
случайной величины меняются от 22 до 36 включительно шагом 1.
| xi | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 |
| ni |
Чтобы сосчитать частоту каждого значения воспользуемся
Вставка – Функция – Статистические – СЧЕТЕСЛИ.
В окне Диапазон ставим курсор и выделяем нашу выборку, а в окне Критерий
ставим число 22
Нажимаем клавишу ОК, получаем значение 1, т.е. число 22 в нашей выборке
встречается 1 раз и его частота =1. Аналогичным образом заполняем всю таблицу.
| xi | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 |
| ni | 1 | 3 | 4 | 5 | 11 | 9 | 13 | 18 | 16 | 6 | 4 | 6 | 3 | 0 | 1 |
Для проверки вычисляем объем выборки, сумму частот (Вставка – Функция –
Математические — СУММА). Должно получиться 100 (количество всех фирм).
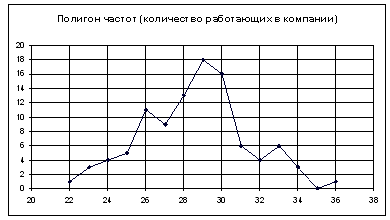
Чтобы построить полигон частот выделяем таблицу – Вставка – Диаграмма –
Стандартные – Точечная (точечная диаграмма на которой значения соединены
отрезками)
Нажимаем клавишу Далее, в Мастере диаграмм указываем название диаграммы
(Полигон частот), удаляем легенду, редактируем шкалу и характеристики диаграммы
для наибольшей наглядности.
Получаем:
Для построения столбчатой и круговой диаграмм используем тот же путь (выбирая
нужный нам тип диаграммы).
Диаграмма – Стандартные – Круговая.
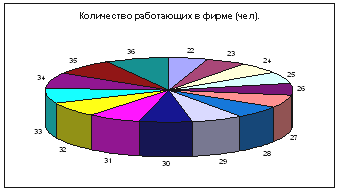
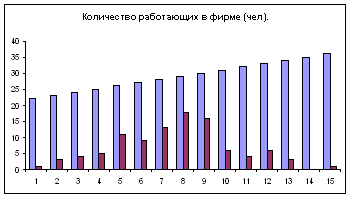
Диаграмма – Стандартные – Гистограмма.
4. Сегодня на уроке мы научились применять компьютерные технологии для
анализа и обработки статистической информации.
Числовые характеристики выборки
Английский статистик Р.Фишер писал: «Статистика может быть охарактеризована как наука о сокращении и анализе материала, полученного в наблюдениях». Предыдущая глава была посвящена «борьбе» с обилием статистической информации. Мы научились представлять ее более наглядно и более компактно: в виде таблиц, графиков, диаграмм.
Теперь мы пойдем еще дальше и попробуем охарактеризовать всю совокупность числовых данных, полученных в выборке, одним-двумя числами, которые будут своеобразной квинтэссенцией всей выборки.
5.1. Характеристики среднего
Среднее значение.
Пример 1. Средний балл по географии
Вычисление среднего в MS Excel.
Пример 2. Средняя цена монитора
Свойства среднего. «Средняя температура по больнице»
Мода. Всегда ли существует мода? Мода для нечисловых данных
Вычисление моды в MS Excel.
Пример 3. Самый «модный» счет
Медиана
Вычисление медианы в MS Excel.
Пример 4. Самый «средний» ноутбук
Устойчивость медианы
Какая характеристика лучше?
Пример 5. «Средний» гвоздь
Пример 6. «Среднее» время ДТП
Пример 7. «Средний» результат
НЕОБХОДИМЫЕ СВЕДЕНИЯ |
|||||||
| Характеристики среднего (или средние характеристики) описывают положение всего статистического ряда на числовой прямой. | |||||||
| Среднее значение | Наиболее известной и употребительной такой характеристикой является среднее арифметическое всех членов данного ряда, т.е.
(для обозначения среднего используется черточка над буквой В статистике эту величину называют еще средним значением или выборочным средним. В большинстве реальных исследований именно среднее арифметическое несет наиболее важную (но, разумеется, не всю!) информацию об изучаемом явлении. Достаточно вспомнить выражения «средний балл», «средняя зарплата», «средний доход», хорошо знакомые и понятные большинству людей, далеких от математики. |
||||||
| Пример 1.
Средний балл по географии |
Ученик получил в течение первой учебной четверти следующие отметки по географии: 5, 2, 4, 5, 5, 4, 4, 5, 5, 5. Найдем его средний балл, т.е. среднее арифметическое всех членов ряда:
Именно эта величина, скорее всего, будет главным ориентиром для учителя при выставлении четвертной оценки. Заметьте, что среднее значение ряда вполне может не совпадать ни с одним из его элементов. В нашем примере средний балл получился 4,4, хотя все оценки выражались целыми числами. |
||||||
|
Вычисление среднего в MS Excel |
В MS Excel среднее значение можно вычислить как непосредственно по определению (найти сумму всех членов ряда и поделить на их количество), так и с помощью специальной функции СРЗНАЧ(), для которой достаточно задать диапазон ячеек, в которых записан числовой ряд. На ³ показаны оба этих способа. | ||||||
|
Пример 2. Средняя цена монитора |
На ³ записан прайс-лист с ценами на различные модели мониторов. Для каждой категории мониторов (категории берутся по размерам) вычисляется средняя цена. Для вычислений используется статистическая функция СРЗНАЧ(). | ||||||
| Свойства среднего | Среднее арифметическое числового ряда Из определения среднего арифметического вытекает и еще целый ряд замечательных свойств, многие из которых вы откроете самостоятельно, выполняя задания практикума. |
||||||
| «Средняя температура по больнице» | Понятно, что среднее значение дает далеко неполное представление о поведении изучаемой величины. Например, на планете Меркурий средняя температура +15°. Исходя из этого статистического показателя, можно подумать, что на Меркурии умеренный климат, удобный для жизни людей. Однако на самом деле это не так. Температура на Меркурии колеблется от -150° до +350°.
Вообще, неполнота информации, заключенной в средних величинах, – излюбленная тема для всевозможных статистических шуток и анекдотов. Наиболее любимый из них: «средняя температура по больнице – 36,6°». |
||||||
| Мода | Вернемся к примеру 1 с оценками по географии: 5, 2, 4, 5, 5, 4, 4, 5, 5, 5. Среднее значение этого ряда получилось 4,4. Следуя этому результату, итоговую оценку, скорее всего, придется поставить 4. Но справедливо ли это? Ведь из 10-ти полученных учеником оценок целых шесть – пятерки. И это весомый аргумент в пользу итоговой пятерки: ведь именно такую оценку ученик получал в течение четверти чаще всего. В статистике она называется модой.
Итак, модой числового ряда называют число, которое встречается в этом ряду наиболее часто. Можно сказать, что оно в этом ряду самое «модное». Для нашего примера мода равна 5. |
||||||
| Всегда ли существует мода? | В отличие от среднего арифметического, которое можно вычислить для любого числового ряда, моды у ряда может вообще не быть. Пусть, например, тот же ученик получил следующие оценки: 3, 2, 4, 5, 5, 4, 4, 4, 5, 5. Здесь нет числа, встречающегося чаще других. Оценки 4 и 5 встречаются в этом ряду одинаково часто. Значит, у этого ряда нет моды. Иногда используют в этой связи другую терминологию: ряд, имеющий единственную моду, называют унимодальным, а ряд, у которого моды нет (или, если угодно, мод несколько) – полимодальным. | ||||||
| Мода для нечисловых данных | Особенностью моды является то, что ее, в отличие от среднего арифметического, можно использовать не только в числовых рядах. Если, например, опросить большую группу учеников, какой школьный предмет им нравится больше всего, то модой этого ряда ответов окажется тот предмет, который будут называть чаще остальных. Это одна из причин, по которой мода широко используется при изучении спроса и проведении других социологических исследований. Например, при решении вопросов, в пачки какого веса фасовать масло, какие открывать авиарейсы и т. п. предварительно изучается спрос и выявляется мода — наиболее часто встречающийся заказ. И даже выборы президента, с точки зрения статистики, не более, чем определение моды … | ||||||
|
Вычисление моды в MS Excel |
Для небольших по объему выборок моду можно вычислить «методом пристального взгляда» — правда, перед этим данные лучше ранжировать. Для больших выборок удобно использовать специальную функцию MS Excel, которая так и называется МОДА(). При ее вызове достаточно указать диапазон ячеек, в которых записаны данные выборки. На ³ показано, как это делается. | ||||||
|
Пример 3. Самый «модный» счет |
На ³ представлены результаты матчей чемпионата России по футболу 2006 года. По результатам этой выборки построен ряд, показывающий количество мячей, забитых в каждом матче, и найдена его мода.
? А что делать, если нас интересует самый модный счет, который был зафиксирован? В этом случае пользоваться количеством забитых голов уже нельзя – одному и тому количеству голов может соответствовать разный счет. |
||||||
| Медиана | Еще одной важной средней характеристикой числового ряда является его медиана – число, которое делит его на две равных половины. Более точно, медианой числового ряда называют число этого ряда (или полусумму двух его чисел), которое будет находиться ровно посередине ряда после его ранжирования (т.е. упорядочения).
Чтобы найти медиану числового ряда, сначала его нужно ранжировать и получить вариационный ряд. В нашем примере 1 с оценками по географии он выглядит так: 2, 4, 4, 4, 5, 5, 5, 5, 5, 5. Если вариационный ряд содержит нечетное количество чисел, то нужно взять число, которое находится ровно посередине. Если же ряд содержит четное количество чисел (как в нашем примере), то нужно взять два средних числа и найти их полусумму: |
||||||
|
Вычисление медианы в MS Excel |
Вычисление медианы в MS Excel можно провести по описанному выше алгоритму: сначала упорядочить ряд, а потом взять его среднее число (или полусумму двух средних). Но есть и специальная функция МЕДИАНА(), которая позволяет найти медиану автоматически по указанному диапазону ячеек. На ³ приведен пример такого вычисления. | ||||||
|
Пример 4. Самый «средний» ноутбук |
Очень часто, покупая какую-либо техническую новинку, мы стараемся выбрать не очень дорогую (жалко денег!), но и не очень дешевую (плохое качество!) модель – «что-то среднее».
На ³ записан прайс-лист на ноутбуки. С помощью медианы найдена эта средняя цена и соответствующие ей модели компьютеров. |
||||||
|
Устойчивость медианы |
Достоинством медианы является ее бόльшая по сравнению со средним арифметическим устойчивость к ошибкам. Представим себе, что при записи числового ряда
15,5; 13,4; 12,4; 16,2; 14,6; 12,8; 13,5; 14,3; 16,4; 15,9 произошла досадная оплошность: в одном из чисел мы пропустили десятичную запятую и вместо 16,2 написали 162. Тогда среднее арифметическое возрастет с 14,5 до 29,08 (в два раза), а медиана как была 14,45, так и останется! ? Убедитесь в этом с помощью таблицы, приведенной на ³. |
||||||
| Какая характеристика лучше? | Итак, мы ввели в рассмотрение три числовые характеристики для описания поведения числового ряда в среднем: среднее арифметическое; мода; медиана. Какая из них лучше характеризует поведение ряда? Ответить на этот вопрос однозначно нельзя: в каждом конкретном примере это может быть любая из них. | ||||||
|
Пример 5. «Средний» гвоздь |
Гвозди в магазине продают на вес. Чтобы оценить, сколько гвоздей содержится в одном килограмме, покупатель решил найти вес одного гвоздя. Для повышения точности измерений он взвесил на лабораторных весах несколько разных гвоздей и получил следующий ряд чисел (вес гвоздей в граммах):
4,47; 4,44; 4,64; 4,32; 4,45; 4,32; 4,54; 4,58 Какую из характеристик – среднее арифметическое, моду или медиану этого ряда ему следует взять в качестве оценки для веса одного гвоздя? Найдем все три характеристики:
Самой подходящей по смыслу задачи является среднее арифметическое. Несильно отличается от него и медиана, которая тоже вполне пригодна для оценки среднего веса. А вот мода здесь вряд ли подойдет, поскольку все значения полученного ряда разные и совпадение двух чисел 4,32 вряд ли отражает какую-то существенную закономерность в изготовлении гвоздей. Таким образом, при формальном существовании всех трех характеристик, разумно использовать можно только две из них. Какую именно – все равно, поскольку они в данном случае очень близки друг к другу. |
||||||
|
Пример 6. «Среднее» время ДТП |
А вот пример, в котором наоборот, мода содержит больше полезной информации. На ³ записан ранжированный ряд, представляющий данные о времени дорожно-транспортных происшествий на улицах Москвы в течение одних суток (в виде час : мин):
0:15, 0:55, 1:20, … , 21:30, 21:45, 22:10, 22:35 Как и для любого ряда в данном случае мы можем найти среднее арифметическое — оно равно 13:33. Однако вряд ли имеет какой-то смысл утверждение типа «аварии на улицах Москвы происходят в среднем в 13 часов 33 минуты». В то же время, если сгруппировать данные этого ряда в интервалы, можно найти такой временной интервал, когда происходит наибольшее количество ДТП (такую характеристику называют модальным интервалом). Получив такую характеристику, соответствующим службам имеет смысл серьезно проанализировать, почему именно в этот временной интервал происходит наибольшее количество происшествий, и попытаться устранить их причины. |
||||||
|
Пример 7. «Средний» результат |
На школьной спартакиаде проводится несколько квалификационных забегов на 100 метров, из которых в финал выходит ровно половина от числа всех участников. На ³ представлены результаты всех спортсменов:
15,5; 16,8; 21,8; 18,4; 16,2; 32,3; 19,9; 15,5; 14,7; 19,8; 20,5; 15,4. Какое время позволяет пройти в финал? Здесь для ответа на вопрос нужно вычислить медиану: 17,6. Спортсменов, которые имеют результат выше найденного, будет как раз половина от числа всех участников. А вот результат выше среднего арифметического, которое равно здесь 18,9, еще не позволяет рассчитывать на выход в финал: в списке есть спортсмен с результатом 18,4, который не попадает в финал. Мода этого ряда равна 15,5 и дает слишком завышенную оценку для «среднего результата». |
||||||
ТЕСТЫ |
|||||||
| Вопрос №1 | Укажите соответствие:
|
||||||
| Вопрос №2 | Какую среднюю характеристику можно использовать в нечисловых рядах?
|
||||||
| Вопрос №3 | Какая средняя характеристика наиболее устойчива к случайным ошибкам при записи данных?
|
||||||
| Вопрос №4 | На стадионе «Локомотив» была зафиксирована следующая посещаемость первых четырех футбольных матчей: 24000, 18000, 22000, 24000.
а) Какова была средняя посещаемость этих матчей? б) Сколько зрителей должно посетить следующий матч, чтобы средняя посещаемость выросла?
|
||||||
| Вопрос №5 | Найдите медиану следующих рядов данных:
а) 8, 4, 9, 5, 2; б) |
||||||
| Вопрос №6 | Дан ряд из четырех чисел: 18, 25, 24, 25. Определите, какая из средних характеристик находится в каждом из следующих пунктов:
а) 18+25+24+25=92; 92 : 4 = 23; ? = 23 р. б) 18, 24, 25, 25; (24+25) : 2 = 24,5; ? = 24,5 р. в) 18, 25, 24, 25; ? = 25 р. |
||||||
ПРАКТИКУМ |
|||||||
|
Задание №1 |
На ³ таблица с данными многолетних наблюдений за максимальным уровнем весеннего подъема воды в реке Оке в районе г.Калуги. Найдите все средние характеристики этого числового ряда. | ||||||
|
Задание №2 |
На ³ данные обо всех голах чемпионата Росси по футболу 2003 года. В одном из столбцов таблицы имеются сведения о том, на какой минуте матча был забит каждый гол. Найдите среднее, моду и медиану этого ряда данных. Как вы думаете, какие из этих характеристик могут оказаться полезными для футбольных тренеров? | ||||||
|
Задание №3 |
На одной из станций московского метрополитена были замерены интервалы времени между поездами и получены результаты, представленные на ³ (в формате мин : сек). Найдите среднее значение интервала времени между поездами метро. Ответ получите в виде мин : сек. | ||||||
|
Задание №4 |
На ³ записаны три таблицы с расписанием движения поездов с трех железнодорожных вокзалов Москвы. Найдите среднюю продолжительность одного рейса для каждого из вокзалов. Сравните полученные результаты и попробуйте их объяснить. | ||||||
|
Задание №5 |
На ³ представлены результаты всех матчей чемпионата России по футболу 2006 года. Найдите самый «модный» счет.
Указание 1. С помощью MS Excel превратите счет каждого матча в двузначное число, например: 3:1 в 31. Указание 2. Чтобы 3:1 и 1:3 превращалось в одно число берите в качестве первой цифры максимальную. |
||||||
|
Задание №6 |
На ³ имеются данные о результатах трех мировых чемпионатов: по хоккею с шайбой, хоккею с мячом и футболу. Найдите среднее значение, моду и медиану для числа голов, забитых в одном матче, на каждом из этих чемпионатов. Сравните полученные величины между собой. | ||||||
|
Задание №7 |
Проведите в ВЛ «Классическая вероятность» 5000 испытаний с двумя кубиками и найдите в каждом из них сумму очков и максимальное из чисел, выпавших на кубиках. У вас получится четыре ряда: первый кубик, второй кубик, сумма и максимум. Для каждого из этих рядов вычислите среднее, моду и медиану.
Сравните свои результаты с тем, что получилось у одноклассников, при помощи . |
||||||
|
Задание №8 |
На ³ записана таблица простых чисел от 1 до 10 000. Найдите среднюю длину интервала между соседними простыми числами. | ||||||
|
Задание №9 |
На ³ содержатся сведения о продажах автомобилей различных марок в одном из автосалонов г. Владимира. Найдите все средние характеристики для числа автомобилей, проданных за один день. Оцените, сколько автомобилей этот автосалон продаст за год? | ||||||
|
Задание №10 |
На ³ записаны результаты финала Всероссийской олимпиады школьников по информатике 2007 года. Найдите среднее количество баллов по каждому классу и сравните эти средние между собой. | ||||||
|
Задание №11 |
На ³ представлены данные экологического контроля за состоянием воздуха над различными районами Москвы – содержание оксида углерода в долях предельно допустимой концентрации. На основании этих данных ответьте на следующие вопросы:
|
||||||
|
Задание №12 |
На ³ записана итоговая таблица с результатами чемпионата России по футболу 2006 года. Понятно, что установить по ней количество голов, которое забивалось в каждой игре, невозможно. Какую из трех средних характеристик — среднее значение, моду или медиану — для этой величины можно вычислить по данной таблице? Вычислите ее. | ||||||
|
Задание №13 |
С помощью найдите средний рост и вес своих одноклассников.
Сравните полученные результаты с идеальным весом и ростом, приведенным в таблице. |
||||||
|
Задание №14 |
С помощью проведите опрос: сколько времени каждый из вас тратит на приготовление домашних заданий и просмотр телевизора. Найдите средние характеристики каждого из этих рядов. Какие выводы можно сделать по полученным результатам? | ||||||
|
Задание №15 |
С помощью ВЛ «Анализ случайной выборки» постройте пять числовых рядов, у которых:
|
||||||
|
Задание №16 |
С помощью ВЛ «Анализ случайной выборки» найдите для числового ряда
1, 2, 3, 4, все возможные значения
|
||||||
|
Задание №17 |
На ³ представлены экономические показатели различных регионов России за несколько последних лет. В первой строке таблицы приведена средняя зарплата по всей России в целом, далее – по каждому из регионов. Найдите среднее арифметическое зарплат по регионам. Как вы думаете, почему оно не совпадает со средней зарплатой по России? | ||||||
ИССЛЕДОВАНИЯ |
|||||||
| СВОЙСТВА СРЕДНИХ | Каждое число исходного числового ряда увеличили на 10. Что произойдет с его средним арифметическим? модой? медианой? А если каждое число увеличили на Все числа исходного числового ряда увеличили в два раза. Что произойдет с его средним арифметическим? модой? медианой? А если каждое число увеличили в |
Здравствуйте на этой странице я собрала теорию и практику с примерами решения задач по предмету эконометрика в программе Microsoft Excel с решением по каждой теме, чтобы вы смогли освежить знания!
Если что-то непонятно — вы всегда можете написать мне в WhatsApp и я вам помогу!
Эконометрика
Становление эконометрики как научной дисциплины представляет значительный интерес с точки зрения как определения объектов исследования, так и формирования набора методов. Сам термин «эконометрика» сформировался из двух частей: «эконо-» – от «экономика» и «-метрика» – от «измерение». Поэтому статистический анализ экономических данных называется эконометрикой, что буквально означает «наука об экономических измерениях».
Эконометрика – это наука, связанная с эмпирическим выводом экономических законов.
Статистические ряды данных
Методы систематизации, обработки и использования статистических данных, выявление закономерностей являются основой эконометрических исследований. Пусть требуется исследовать какой-нибудь признак, свойственный большой группе однородных объектов. Напомним основные понятия и характеристики статистических данных.
Возможно эта страница вам будет полезна:
Генеральной совокупностью (генеральной выборкой) называется совокупность значений признака всех объектов данного типа, а их число  объемом совокупности. При этом предполагается, что число большое, такое, что исследование физически невозможно. Тогда из всей совокупности выбирают ограниченное число объектов и подвергают их изучению.
объемом совокупности. При этом предполагается, что число большое, такое, что исследование физически невозможно. Тогда из всей совокупности выбирают ограниченное число объектов и подвергают их изучению.
Выборочной совокупностью (выборкой) называется совокупность случайно отобранных объектов, а её объем обозначается 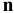 .
.
Статистические исследования позволяют распространить выводы, сделанные на основе случайной выборки, на всю генеральную совокупность исследуемых случайных величин. Это является основой выборочного метода.
Графическое представление статистических данных
Пусть из генеральной совокупности извлекается выборка объема , причем значение признака 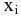 наблюдается
наблюдается 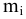 раз, где сумма равна объему выборки .
раз, где сумма равна объему выборки .
Статистическим распределением выборки называется перечень наблюдаемых значений и соответствующих им частот или относительных частот (частостей)
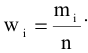
Упорядоченный в порядке возрастания или убывания ряд значений признака с соответствующими ему частотами называют вариационным рядом.
В целях наглядности строятся различные графики статистического распределения.
Полигоном частот (относительных частот) называется ломаная линия, которая соединяет точки с координатами 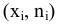 или
или 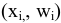 .
.
Для построения гистограммы частот (относительных частот) необходимо найти границы интервалов признаков. Если данные наблюдений представляют в виде рядов с равными интервалами, то их величина находится по формуле Стэрд-жесса:
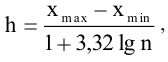
где — объем выборки;
 — наибольшее и наименьшее значения вариантов выборки. Гистограмма представляет собой столбчатую диаграмму.
— наибольшее и наименьшее значения вариантов выборки. Гистограмма представляет собой столбчатую диаграмму.
По оси абсцисс откладываются границы интервалов так, чтобы они покрыли все значения вариационного ряда, а по оси ординат откладываются абсолютная плотность распределения 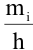 или относительную плотность
или относительную плотность 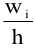 .
.
Аналогом функции распределения 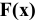 для вариационного ряда является функция накопленных частот, её обозначают
для вариационного ряда является функция накопленных частот, её обозначают 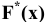 а график строят по следующему правилу:
а график строят по следующему правилу:
по оси абсцисс откладывают значения признака, а по оси ординат — накопленные частоты или частости. Такую кривую иногда называют кумулятой: по данным интервального ряда на оси абсцисс откладывают точки, являющиеся верхними границами интервалов, а на оси ординат накопленные частоты (частости) соответствующих интервалов. Часто добавляют ещё одну точку, абсцисса которой соответствует левой границе первого интервала, а ордината равна нулю.
Числовые характеристики статистических распределений
Для описания статистических распределений обычно используют три вида характеристик:
- средние, или характеристики центральной тенденции;
- характеристики изменения вариант (рассеяния);
- характеристики, отражающие дополнительные особенности распределений, в частности их форму.
Все эти характеристики вычисляются по результатам наблюдений и построенных вариационных рядов.
Основным видом средних характеристик является средняя арифметическая (среднее выборочное значение), определяемая по формуле:
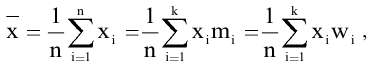
где — значение признака в вариационном ряде (дискретном или интервальном); — соответствующая ему частота;
Довольно часто в статистическом анализе применяют структурные или порядковые средние:
1) медиана 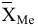 — значение признака, разделяющее вариационный ряд на две численно равные группы, такие, что элементы первой группы строго меньше медианы, второй строго больше её значения. Можно определить графически с помощью кумуляты, так как
— значение признака, разделяющее вариационный ряд на две численно равные группы, такие, что элементы первой группы строго меньше медианы, второй строго больше её значения. Можно определить графически с помощью кумуляты, так как 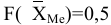 ;
;
2) мода 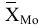 — значение признака, которому соответствует большая частота.
— значение признака, которому соответствует большая частота.
Величины моды и медианы определяются по интерполяционным формулам, непосредственно из их определения, которые можно найти в дополнительной литературе.
Средние характеристики должны быть дополнены изменением вариации признака (рассеянием). Для этого рассчитываются квадраты отклонений вариант от среднего арифметического значения. Средний квадрат отклонений по данной выборке называется дисперсией и вычисляется по формуле:
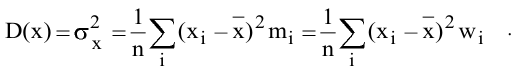
На базе дисперсии вводятся две характеристики:
1) среднее квадратическое отклонение 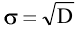 ;
;
2) коэффициент вариации, равный процентному отношению среднего квадратического отклонения к значению средней арифметической исследуемой случайной величины, помогает решить вопрос об однородности выборки:
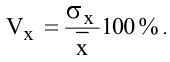
Величина о является чаще всего применяемой характеристикой рассеяния. Для характеристики формы распределения вводятся моменты к-того порядка, впервые предложенные Чебышсвым П. Л.:
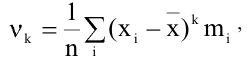
которые называются центральными моментами к-того порядка. Чем больше моментов для данного признака вычислено, тем точнее можно описать свойства распределения. Однако с ростом К растет влияние случайных погрешностей, поэтому на практике используются моменты до четвертого порядка.
Центральный момент третьего порядка называется асимметрией  распределения, а четвертого — эксцесс
распределения, а четвертого — эксцесс  .
.
Инструмент анализа описательная статистика и гистограмма в Excel
Наиболее полный анализ статистических данных позволяет выполнить пакет Анализ данных из меню Сервис. Если команда Анализ данных отсутствует в меню Сервис, выберите Надстройки и в появившемся списке отметьте Analysis ToolPak (Пакет анализа). В случае отсутствия этого пункта в Надстройках, вам придется установить его вручную с помощью Microsoft Excel Setup (меню Сервис > Надстройки > подключите Пакет Анализа).
При выполнении этой лабораторной работы будут использоваться инструменты Описательная статистика и Гистограмма из Анализа данных. Надо сказать, что в Excel есть набор встроенных статистических функций, которыми можно пользоваться, если нет необходимости во всех характеристиках исследуемых данных. Для вызова нужной функции необходимо выполнить действия: из меню Вставка и выбрать команду Функция и перейти к категории Статистические.
Возможно эта страница вам будет полезна:
Пример с решением №1.1.
При обследовании 50 семей получены данные о количестве детей, которые имеют БИНОМРАСЩ) с числом испытаний равным 10 и вероятностью успеха 0,3 (сгенерировать с помощью пакета Анализа данных). Определите средний размер семьи. Охарактеризуйте колеблемость размера семьи с помощью показателя вариации. Постройте гистограмму и функцию распределения.
Данные для решения примера задают изначально в виде таблиц и их надо поместить на лист Excel; или можно воспользоваться инструментом Анализа данных Генерация случайных чисел.
Генерация случайных чисел позволяет быстро получить нужное количество значений одной или нескольких вариант, имеющих одно из распределений: Равномерное, Нормальное, Бернулли, Биномиальное, Пуассона и другие. Надо помнить, что каждое распределение имеет свои параметры, которые задаются пользователем. Достоверность полученных выводов в этом случае мала.
- В меню Сервис выберите Анализ данных, а затем выделите инструмент анализа Генерация случайных чисел (найти его можно с помощью линейки прокрутки). Выделите в диалоговом окне нужный инструмент и нажмите ОК (рис. 1.1).
- Заполните поля диалогового окна так же как на рис. 1.2 и нажмите ОК. Результатом является набор из пятидесяти чисел, которые располагаются в столбце В рис 1.3.
- Примените инструмент Описательная статистика для поиска числовых характеристик выборочных данных, расположенных в диапазоне В2:В51. Для этого выберите инструмент анализа Описательная статистика в диалоговом окне Анализ данных рис. 1.1. В одноименном диалоговом окне надо указать: входной интервал (В2:В51), ячейку левого верхнего угла для вывода итогов D1, обязательно включите опцию Итоговая Статистика. Результат применения инструмента Описательная статистика показан на рис. 1.3. в диапазоне D1:Е18.
Значения в диапазоне Е2: Е18 не обновляются в случае изменения исходных данных В2:В51.
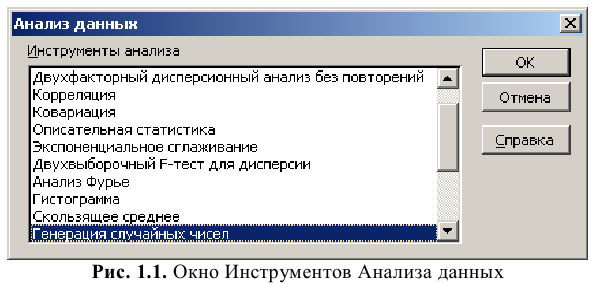
В столбце 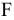 рис. 1.3. приводятся встроенные функции Excel, которые позволяют получить те же результаты, что и при использовании инструмента Описательная статистика. Функции листа следует использовать, если необходим автоматический перерасчет значений числовых характеристик выборки или нет необходимости во всех значениях Описательной статистики.
рис. 1.3. приводятся встроенные функции Excel, которые позволяют получить те же результаты, что и при использовании инструмента Описательная статистика. Функции листа следует использовать, если необходим автоматический перерасчет значений числовых характеристик выборки или нет необходимости во всех значениях Описательной статистики.
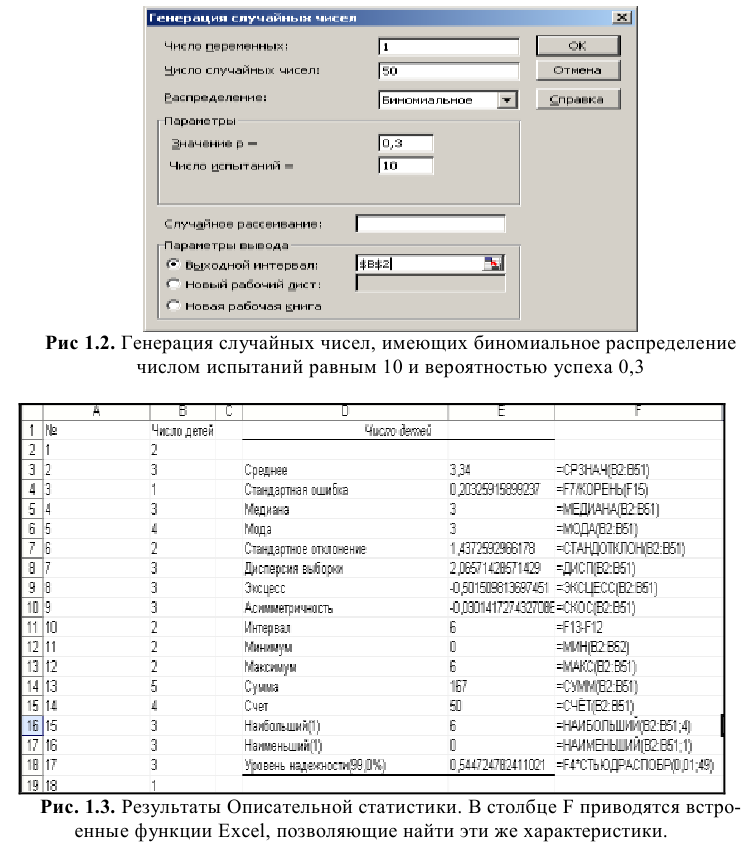
Построение гистограммы и функции распределения можно выполнить, выбрав инструмент, Гистограмма (рис. 1.1). Перед использованием этого инструмента надо решить вопрос об интервале разбиения ( — Excel называет это значение карманом, а список всех границ интервалов — интервал карманов). Вы можете найти его сами по формуле Стэрджесса или разрешить Excel разбить на равные интервалы (тогда заполнять поле Интервал карманов не надо). Включите опцию вывод графика.
— Excel называет это значение карманом, а список всех границ интервалов — интервал карманов). Вы можете найти его сами по формуле Стэрджесса или разрешить Excel разбить на равные интервалы (тогда заполнять поле Интервал карманов не надо). Включите опцию вывод графика.
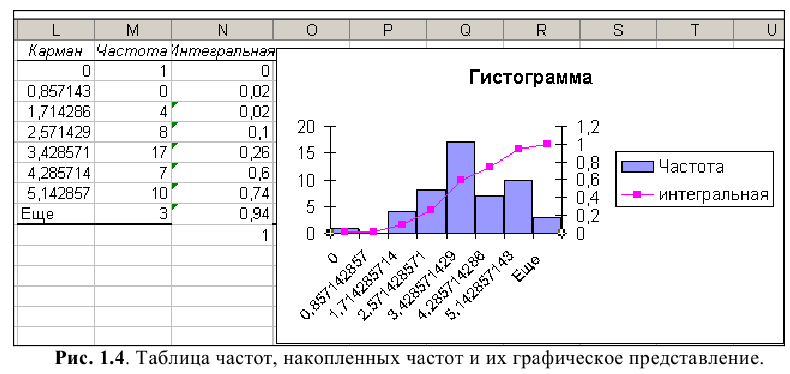
Описание результатов.
Описательная статистика содержит три результата средней характеристики исследования числа детей в пятидесяти семьях: Среднее (3,34), Моду (3) и Медиану (3). Найдем значение коэффициента вариации по формуле (1.4):
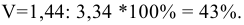
Так как 43% > 35%, можно сделать вывод, что изучаемая совокупность семей является неоднородной, чем и объясняется высокая колеблемость количества детей в семьях. В виду неоднородности семей, попавших в выборку, можно в качестве среднего использовать моду или медиану
Стандартное отклонение (1,44) — наиболее широко используемая характеристика изменения данных — измеряется в тех же единицах, что и исходные данные.
Стандартная ошибка является характеристикой достоверности среднего выборочного значения и используется в статистических исследованиях (0,20).
Эксцесс и Асснметрнн позволяют сделать вывод о незначительных отклонениях гистограммы частостей от нормально распределенной случайной величины, характеризующей количество детей в семьях с средним равным 3,34 и средним квад-ратическим отклонением 1,44.
Напомним, что эталоном этих величин являются нормальное распределение (рис. 1.5), для которого Ассиметрия равна нулю, а центральный момент четвертого порядка (1.5) равен трем.
Ассиметрия имеет отрицательное значение. Это означает, что гистограмма не симметрична по отношению к среднему значению выборки и имеет скос вправо, то есть количество семей имеющих менее трех детей больше, чем семей количество детей в которых больше трех.
Эксцесс тоже имеет отрицательное значение. То есть значение гистограммы в точке 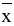 ниже аналогичного нормального распределения.
ниже аналогичного нормального распределения.
Математическая статистика статистические оценки
Имеется случайная величина  , закон распределения которой известен и зависит от параметров
, закон распределения которой известен и зависит от параметров  . Требуется на основании наблюдаемых данных оценить значения этих параметров.
. Требуется на основании наблюдаемых данных оценить значения этих параметров.
Числовые характеристики генеральной совокупности, как правило, неизвестны. Их называют параметрами генеральной совокупности (среднее, дисперсия, среднее квадратическое отклонение, доля признака генеральной совокупности объема  ).
).
Из генеральной совокупности извлекается выборка объёма  . По данным выборки рассчитывают числовые характеристики, которые называют статистиками (выборочное среднее, выборочная дисперсия и выборочное среднее квадратическое отклонение). Статистики, полученные по различным выборкам, могут отличаться друг от друга, поэтому они являются только оценками неизвестных параметров генеральной совокупности и обозначают
. По данным выборки рассчитывают числовые характеристики, которые называют статистиками (выборочное среднее, выборочная дисперсия и выборочное среднее квадратическое отклонение). Статистики, полученные по различным выборкам, могут отличаться друг от друга, поэтому они являются только оценками неизвестных параметров генеральной совокупности и обозначают 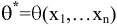 .
.
Обозначим через 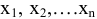 выбранные значения наблюдаемой случайной величины (СВ) . Пусть на основе данных выборки получена статистика , которая является оценкой параметра
выбранные значения наблюдаемой случайной величины (СВ) . Пусть на основе данных выборки получена статистика , которая является оценкой параметра 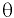 . Наблюдаемые значения
. Наблюдаемые значения 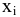 случайные величины, каждая из которых распределена по тому же закону, что и случайная величина . Поэтому
случайные величины, каждая из которых распределена по тому же закону, что и случайная величина . Поэтому 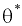 тоже является величиной случайной, закон распределения которой зависит от распределения СВ и объема выборки . Для того, чтобы имела практическую ценность, она должна обладать свойствами несмещенности, состоятельности и эффективности.
тоже является величиной случайной, закон распределения которой зависит от распределения СВ и объема выборки . Для того, чтобы имела практическую ценность, она должна обладать свойствами несмещенности, состоятельности и эффективности.
Несмещенной называют оценку, для которой выполняется условие:
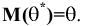
Состоятельной называется оценка, удовлетворяющая условию:
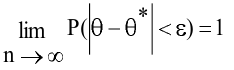
Для выполнения условия 2.2 достаточно, чтобы:
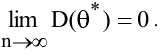
Эффективной считается оценка, которая при заданном объеме выборки имеет наименьшую возможную дисперсию.
Выборочная средняя является несмещенной и состоятельной оценкой генеральной средней и вычисляется по формуле (1.1).
Выборочная дисперсия найденная по формуле (1.2) является смещенной оценкой для дисперсии генеральной совокупности.
Вводится понятие исправленной выборочной дисперсии, которая является несмещенной оценкой генеральной дисперсии и вычисляется по формуле:
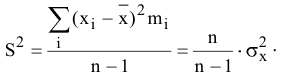
Исправленное выборочное средне квадратическое отклонение будет равно:
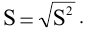
Теоретическое обоснование использования этих выборочных оценок для определения характеристик генеральной совокупности дают закон больших чисел и предельные теоремы.
Основные виды распределения и функции excel, позволяющие проводить статистическое оценивание
Чтобы построить модели статистических закономерностей возникает необходимость использовать известные виды распределения. Каждое распределение характеризует некоторую случайную величину — результат определенного вида испытаний. С функциями, задающими эти распределения, а также их параметрами можно познакомиться в любом учебнике по теории вероятностей. Выбранное распределение может рассматриваться только как теоретическое (генеральное), а результат опыта — как статистическое (выборочное) распределение. Последнее, в силу ограниченности числа наблюдений, будет лишь приближенно характеризовать теоретическое распределение.
По виду гистограммы и полученным числовым характеристикам выборки делается предположение о теоретическом виде распределения исследуемого признака. Если это удается, то можно найти оценки числовых характеристик и сделать выводы о параметрах генеральной совокупности. Если закон распределения не возможно установить, то подбирается кривая, наилучшим образом сглаживающая данные статистического ряда. Распределения делятся на дискретные и непрерывные.
Дискретные распределения описываются конечные набором чисел и соответствующими им частотами. Например, оценки, которые может получить студент на экзамене, описываются множеством (2, 3, 4, 5). Поэтому случайная величина -получить определенную оценку на экзамене будет иметь дискретное распределение
Непрерывные распределения описывают случайные величины с непрерывной областью значений. Для непрерывных распределений вероятность сопоставляется не с отдельным значением, а интервалом чисел. Непрерывные распределения в теории вероятностей задаются функцией плотности распределения 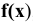 , которую называют плотность вероятности или функцией распределения
, которую называют плотность вероятности или функцией распределения 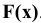 .
.
Площадь фигуры, ограниченной и прямыми  , осью
, осью  определяет вероятность попадания случайной величины в интервал
определяет вероятность попадания случайной величины в интервал 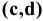 , которую обозначим
, которую обозначим 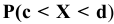 . Так как вероятность в точке для непрерывного распределения равна нулю, то имеет место равенство:
. Так как вероятность в точке для непрерывного распределения равна нулю, то имеет место равенство:
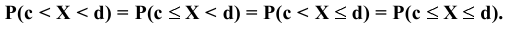
Нормальное распределение
Чаще других в статистических исследованиях применяется нормальное распределение. Теоретическим основанием к его применению служит центральная предельная теорема Ляпунова. Оно имеет два параметра: среднее (а) и стандартное отклонение  . В дальнейшем будем использовать сокращенную запись для обозначения этого распределения
. В дальнейшем будем использовать сокращенную запись для обозначения этого распределения 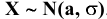 .
.
Синтаксис функции:
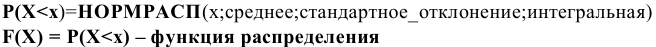
Значение функции распределения случайной величины , распределенной по нормальному закону распределения, получится, если аргумент интегральная равен ИСТИНА (1). Если аргумент интегральная имеет значение ЛОЖЬ (0), то получите значение плотности вероятности нормального распределения 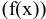 .
.
Графики плотности распределения и функции распределения случайной величины 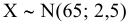 построенные в Excel изображены на рис. 2.1.
построенные в Excel изображены на рис. 2.1.
Вероятность попадания случайной величины в интервал (с, d) определяется по формуле:
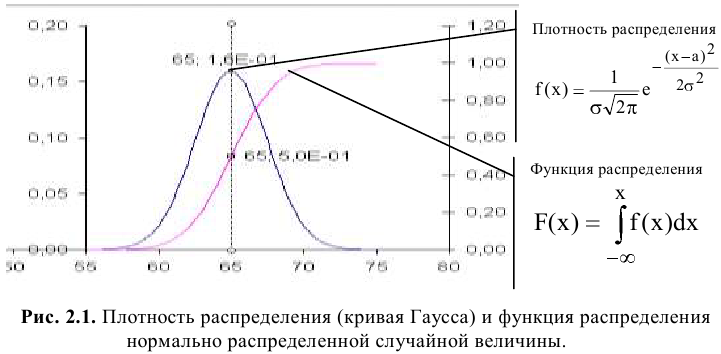
Если случайная величина нормально распределена и имеет среднее арифметическое равное нулю и среднее квадратическое отклонение равное единицы, то её называют стандартизованной а для вычисления вероятности попадания в интервал таких случайных величин в Excel существует функция:
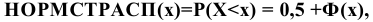
которая возвращает интегральное стандартное распределение.
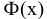 называют интегральной функцией Лапласа. Для ее вычисления созданы специальные таблицы.
называют интегральной функцией Лапласа. Для ее вычисления созданы специальные таблицы.
При статистических исследованиях оценок довольно часто приходится решать обратную задачу: находить значение варианты 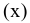 по заданной вероятности. Для этого в Excel имеются обратные функции, позволяющие её решить: НОРМОБР (вероятность;
по заданной вероятности. Для этого в Excel имеются обратные функции, позволяющие её решить: НОРМОБР (вероятность;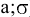 ) и НОРМСТОБР (вероятность).
) и НОРМСТОБР (вероятность).
Распределения, связанные с нормальным распределением
Несмотря на широкое распространение нормального распределения, в некоторых случаях при построении статистических моделей возникает необходимость в использовании других распределений. Приведем примеры некоторых функций в Excel.
Логнормальное распределение
Свидетельством близости распределения к логнормальному является значительная ассиметрия, обусловленная ограничением 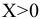 . Например, может использоваться для описания распределения доходов банковских вкладов, месячной заработной платы, посевных площадей и т.д.
. Например, может использоваться для описания распределения доходов банковских вкладов, месячной заработной платы, посевных площадей и т.д.
Функция ЛОГНОРМРАСП(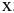 ; среднее; стандартное откл) используется для анализа данных, которые были логарифмически преобразованы. Возвращает интегральное логарифмическое нормальное распределение для , где
; среднее; стандартное откл) используется для анализа данных, которые были логарифмически преобразованы. Возвращает интегральное логарифмическое нормальное распределение для , где 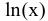 является нормально распределенным с параметрами среднее и стандартное откл.
является нормально распределенным с параметрами среднее и стандартное откл.
Хи-квадрат распределение
Чаще всего это распределение используется для определения критического значения статистики с заданным уровнем значимости 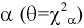 , для которого выполняется равенство
, для которого выполняется равенство 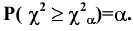
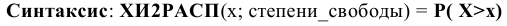
— значение, для которого требуется вычислить распределение, степени свободы — число слагаемых минус число линейных связей между элементами совокупности.
Если задано значение вероятности, то функция ХИ20БР позволяет найти значение , для которого справедливо равенство
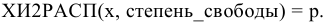
В функции ХИ20БР для поиска применяется метод итераций. Если поиск не закончится после 100 итераций, функция возвращает сообщение об ошибке #Н/Д.
Распределение стьюдента t
Это распределение имеет важное значение для статистических выводов. Функция СТЬЮДРАСП возвращает вероятностную меру «хвостов» распределения. Её синтаксис:
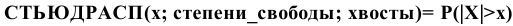
— численное значение, для которого требуется вычислить распределение; степени свободы — целое, указывающее число степеней свободы; хвосты — число возвращаемых хвостов распределения.
Если «хвосты» = 1, то функция СТЬЮДРАСП возвращает одностороннее распределение (вероятность правого хвоста).
Если «хвосты» = 2, то функция СТЬЮДРАСП возвращает двухстороннее распределение.
При этом значение не должно быть отрицательным.
Так как функция симметричная относительно нуля, то справедливо следующие равенства:
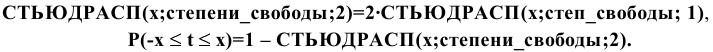
Функция СТЬЮДРАСПОБР(вероятность; степени свободы) является обратной для распределения Стьюдента и соответствует положительному значению для которого задана вероятность суммы двух «хвостов».
РАСПРЕДЕЛЕНИЕ ФИШЕРА Эту функцию можно использовать, чтобы определить, имеют ли два множества данных различные степени разброса результатов. Например, можно проанализировать результаты тестирования старшеклассников и определить, различается ли разброс результатов для мальчиков и девочек.
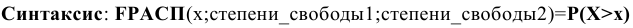
— значение, для которого вычисляется функция; степени свободы1— число степеней свободы числителя; степенисвободы2—число степеней свободы знаменателя.
Обратное значение для  -распределения вероятностей возвращает функция
-распределения вероятностей возвращает функция
Распределения дискретной случайной величины в excel биномиальное распределение
Распределение используется для моделирования случайной величины с конечным числом испытанной. В каждом испытании случайная величина может принимать только два значения: успех или неуспех (0 или 1). Вероятность успеха постоянна и не зависит от результатов других испытаний. Биномиальное распределение описывает общее число успехов при указанном числе испытаний. Данное распределение требует указать два параметра: число испытаний 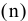 и вероятность успеха
и вероятность успеха 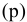 .
.
Пример с решением №2.1.
Группа из 20 студентов сдает экзамен. Вероятность сдать экзамен по данным прошлых лет равна 0,3. Отобрано 5 человек составьте закон распределения случайной величины  — числа студентов, сдавших экзамен.
— числа студентов, сдавших экзамен.
В ячейку В7 помещена функция БИНОМРАСЩА7; SBS1; $В$2; 0) (рис 2.3.). Скопируйте формулу для остальных ячеек столбца В, как показано на рис. 2.2. Чтобы получить данные столбца С надо в качестве аргумента интегральная поставить единицу.
С помощью функции БИНОМРАСП можно получить только вероятности равные числу успеха к (интегральная равна нулю) или не большие к (интегральная равна единицы). Для вычисления других вероятностей надо воспользуйтесь значениями столбцов  и
и  . Значения в столбцах
. Значения в столбцах  находятся по формулам:
находятся по формулам:
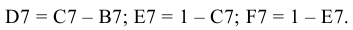
Для построение диаграммы биномиального распределения выделите ячейки В7:В12 и нажмите кнопку мастер диаграмм на стандартной панели инструментов. Отформатируйте её как показано на рис. 2.2.
В качестве обратной функции к БИНОМРАСП в Exccl рассматривается функция КРИТБИНОМ. Её синтаксис:
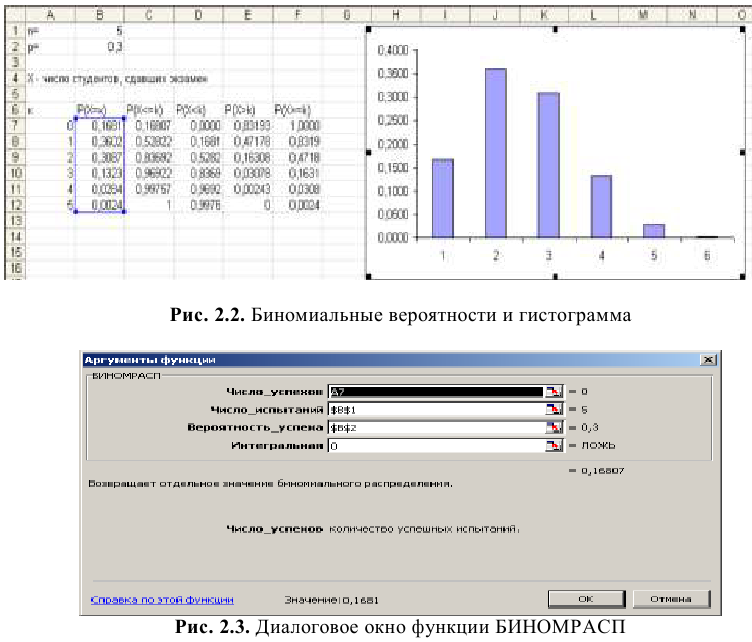
Гипергеометрическое распределение
Распределение возвращает вероятность заданного количества успехов в выборке, если заданы: размер выборки 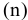 , количество успехов в генеральной совокупности
, количество успехов в генеральной совокупности 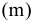 и размер генеральной совокупности
и размер генеральной совокупности 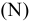 . Функция ГИПЕРГЕОМЕТ используется для задач с конечным числом элементов генеральной совокупностью, где каждое наблюдение — это успех или неудача, а каждое подмножество заданного размера () выбирается с вероятностью равной
. Функция ГИПЕРГЕОМЕТ используется для задач с конечным числом элементов генеральной совокупностью, где каждое наблюдение — это успех или неудача, а каждое подмножество заданного размера () выбирается с вероятностью равной
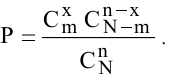
Синтаксис:
ГИПЕРГЕОМЕТ (числоуспеховввыборке; размер выборки; числоуспеховвсовокупности; размерсовокумности)
Распределение Пуассона
Обычное применение распределения Пуассона состоит в предсказании количества событий, происходящих за определенное время, например: количество машин, появляющихся за 1 минуту на станции техобслуживания.
Синтаксис: ПУАССОН(; среднее; интегральная)
— количество событий.
среднее — ожидаемое численное значение.
интегральная — логическое значение, определяющее форму возвращаемого распределения вероятностей.
Если аргумент «интегральная» имеет значение ИСТИНА, то функция ПУАССОН возвращает интегральное распределение Пуассона, то есть вероятность того, что число случайных событий будет от 0 до включительно.
Если этот аргумент имеет значение ЛОЖЬ, то вычисляется значение функции плотности распределения Пуассона, то есть вероятность того, что событий появится равно раз.
Интервальные оценки
Величина оценки 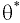 , найденная по выборке, является лишь приближенным значением неизвестного параметра
, найденная по выборке, является лишь приближенным значением неизвестного параметра 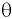 . Вопрос о точности оценки в математической статистике устанавливается с помощью соотношения:
. Вопрос о точности оценки в математической статистике устанавливается с помощью соотношения:
где  — доверительная вероятность или надежность интервальной оценки (принимает значения 90%, 91%,…99%, 99,9%);
— доверительная вероятность или надежность интервальной оценки (принимает значения 90%, 91%,…99%, 99,9%);
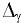 — предельная ошибка (точность) оценки. Для случайной величины, имеющей нормальное распределенние
— предельная ошибка (точность) оценки. Для случайной величины, имеющей нормальное распределенние
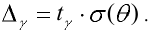
Значение 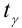 вычисляется с помощью функции Лапласа, если
вычисляется с помощью функции Лапласа, если  задано в условии по формуле
задано в условии по формуле  .
.
Если стандартное отклонение находится по выборке, то рассматривают два случая:
1) 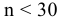 используется функция Стьюдента:
используется функция Стьюдента:
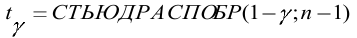
2)  используется функция Лапласа
используется функция Лапласа
Если раскрыть модуль в уравнении (2.7), то получим неравенство:
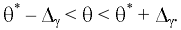
Числа 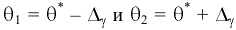 называют доверительными границами, а интервал
называют доверительными границами, а интервал  — доверительным интервалом или интервальной оценкой параметра .
— доверительным интервалом или интервальной оценкой параметра .
Границы доверительного интервала симметричны относительно точечной оценки . Поэтому точность оценки  . иногда называют половиной длины доверительного интервала.
. иногда называют половиной длины доверительного интервала.
Так как величина случайная, то границы доверительного интервала могут меняться, кроме того, они будут меняться с изменением доверительной вероятности, поэтому соотношение (2.7) следует читать так: «со статистической надежностью -100% доверительный интервал содержит параметр генеральной совокупности ».
Рассмотрим на примерах, как строятся доверительные интервалы для математического ожидания, дисперсии и среднего квадратического отклонения нормально распределенного количественного признака  .
.
Доверительный интервал для математического ожидания с известной дисперсией
При построении доверительного интервала используется функция НОРМОБР для 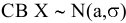 . Границы доверительного интервала можно определить из уравнений:
. Границы доверительного интервала можно определить из уравнений:
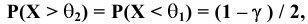
где 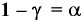 называют уровнем значимости.
называют уровнем значимости.
Пример с решением №2.2.
Спонсоры телевизионных программ хотят знать, сколько времени дети проводят за экраном телевизора. После опроса 100 человек оказалось, что среднее число часов в неделю соответствует 27,5 часов, а средне квадратическое отклонение равно 8,0 часов. Найдите 95% доверительный интервал для оценки среднего количества часов в неделю, которое дети проводят за просмотром телепередач
На основании исследований с 95% вероятностью можно утверждать, что за просмотром телевизора дети проводят от 25,93 до 28,65 часов. Формулы для вычисления приведены на рис 2.4.

Доверительный интервал для математического ожидания с неизвестной дисперсией
Как правило, дисперсия оцениваемого параметра является величиной неизвестной. Тогда находят исправленную выборочную дисперсию, а доверительный интервал строится с помощью  -распределения (Стьюдента).
-распределения (Стьюдента).
Функция СТЬЮДРАСПОБРО возвращает значение , для которого:
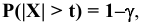
где — это случайная величина, соответствующая распределению Стьюдента и
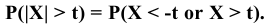
Пример с решением №2.3.
Владелец таксопарка хочет спрогнозировать свои расходы на следующий год. Основной статьей расходов является покупка топлива. Так как бензин стоит дорого, владелец стал использовать газ. Были выбраны восемь такси, и оказалось, что число миль на галлон соответственно равно 28,1, 33,6, 41,1, 37,5, 27,6,36,8, 39,0 и 29,4. Оцените с доверительной вероятностью 95% средний пробег на один галлон газа для всех такси в парке, предполагая, что он распределен нормально.
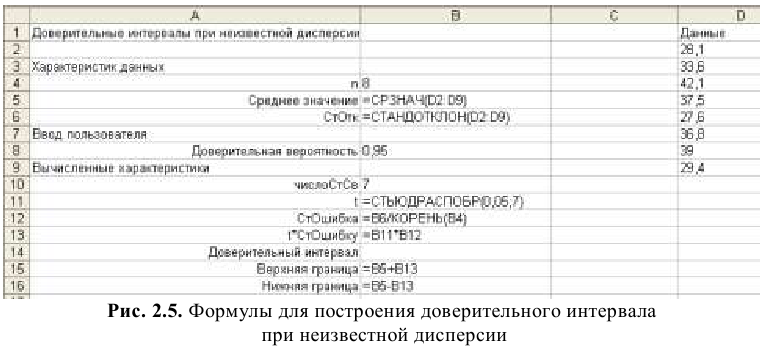
После исследования оказалось, что средний пробег на один галлон для всех такси в парке находится между 29,71 и 38,81 миль на галлон. Формулы для вычисления приведены на рис.2.5.
Доверительный интервал для дисперсии и среднего квадратического отклонения
Рассмотрим нормально распределенную случайную величину, дисперсия 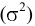 которой неизвестна. По результатам наблюдений:
которой неизвестна. По результатам наблюдений: 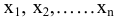 можно определить среднее значение
можно определить среднее значение 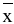 (1.1) и исправленную выборочную дисперсию
(1.1) и исправленную выборочную дисперсию 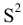 (2.4).
(2.4).
Теперь с доверительной вероятностью определим половину длины доверительного интервала для которого выполняется условие:
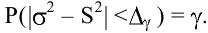
Доверительный интервал для дисперсии запишется в виде неравенства:
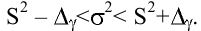
Выборочня исправленная дисперсия несмещенная оценка генеральной дисперсии равна:
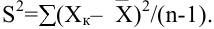
Так как — результаты независимых наблюдений нормально распределенной СВ, значит сумма квадратов
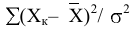
имеет  распределение с
распределение с 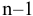 степенью свободы. Выразив
степенью свободы. Выразив 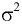 через
через 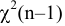 и , получим:
и , получим:
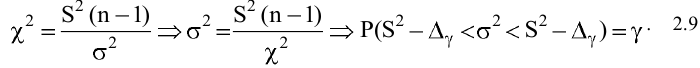
Тогда уравнение 2.9 примет вид:
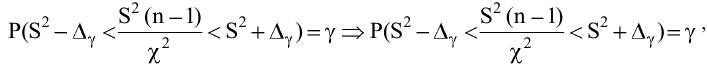
из которого доверительный интервал для :
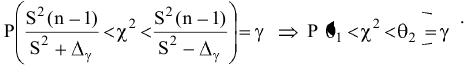
С помощью функции ХИ20БР можно найти верхнюю и нижнюю границы  и
и  для :
для :
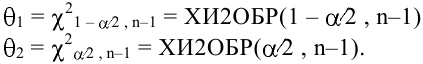
Подставив найденные значения в уравнения:
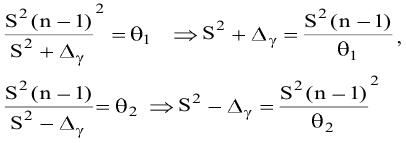
получим верхнюю и нижнюю границы доверительного интервала для дисперсии:
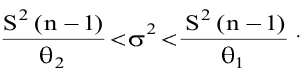
Доверительный интервал для среднего выборочного значения а получится, если извлечь корень из каждой части предыдущего неравенства.
Доверительный интервал для доли признака генеральной совокупности
Проводится серия из  испытаний, в каждом из которых наблюдается событие
испытаний, в каждом из которых наблюдается событие 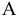 (событие может произойти или нет). Пусть событие произошло
(событие может произойти или нет). Пусть событие произошло 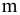 раз, тогда
раз, тогда 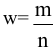 называют частотой появления события или выборочной долей признака.
называют частотой появления события или выборочной долей признака.
Если 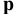 вероятность с которой событие может произойти (называют генеральной долей распределения количественного признака) в каждом из испытаний, то частота является точечной несмещенной оценкой вероятности .
вероятность с которой событие может произойти (называют генеральной долей распределения количественного признака) в каждом из испытаний, то частота является точечной несмещенной оценкой вероятности .
Зададим доверительную вероятность 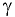 и найдем такие числа
и найдем такие числа 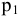 и
и 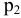 для которых выполняется соотношение
для которых выполняется соотношение
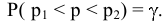
Интервал 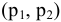 является доверительным интервалом для , отвечающий надежности .
является доверительным интервалом для , отвечающий надежности .
При большом числе испытаний Бернулли 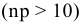 выборочная доля является нормально распределенной случайной величиной
выборочная доля является нормально распределенной случайной величиной
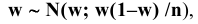
где 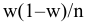 является дисперсией выборочной доли признака,
является дисперсией выборочной доли признака,
a 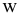 её математическим ожиданием.
её математическим ожиданием.
Тогда доверительный интервал генеральной доли признака можно найти, используя функцию Лапласа:
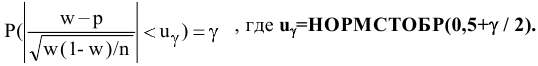
Откуда
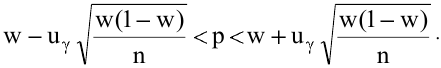
Рассматривают два случая: большое количество проведенных испытаний и малое. В случае малого объема выборки найти и можно с помощью специальных таблиц распределения Бернулли.
Проверка статистических гипотез о числовых значениях параметров нормального распределения
Данные выборочных обследований часто являются основой для принятия одного из нескольких решений. При этом любое суждение о генеральной совокупности будет сопровождаться случайной погрешностью и поэтому может рассматриваться лишь как предположительное.
Под статистической гипотезой понимается всякое высказывание о виде неизвестного распределения, или параметрах генеральной совокупности известных распределений, или о равенстве параметров двух распределений, или о независимости выборок, которое можно проверить статистически, то есть опираясь на результаты случайных наблюдений.
Наиболее часто формулируются и проверяются гипотезы о числовых значениях параметров генеральной совокупности, подчиняющихся одному из известных законов распределения: нормальному, Стьюдента, Фишера и др.
Основные понятия статистической гипотезы
Подлежащая проверке гипотеза называется основной (нулевой) обозначают её  . Содержание гипотезы записывается после двоеточия
. Содержание гипотезы записывается после двоеточия 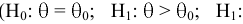
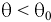
Каждой основной гипотезе противопоставляется альтернативная (конкурирующая) гипотеза 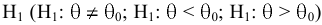 . Как правило, основной гипотезе можно противопоставить несколько альтернативных гипотез. Если выборочные данные противоречат гипотезе , то гипотеза отклоняется, в противном случае принимается.
. Как правило, основной гипотезе можно противопоставить несколько альтернативных гипотез. Если выборочные данные противоречат гипотезе , то гипотеза отклоняется, в противном случае принимается.
Статистическая проверка гипотез, основанная на результатах выборки, связана с риском, принять ложное решение. Если по выборочным данным основная гипотеза отвергнута, в то время как для генеральной совокупности она справедлива, то говорят об ошибке первого рода. Вероятность допустить такую ошибку принято называть уровнем значимости и обозначать а (10%, 9%,… 1%).
Рассматривается и ошибка второго рода, когда основная гипотеза принимается, в действительности же верной оказывается альтернативная гипотеза. В таком случае говорят об ошибке второго рода, а вероятность допустить эту ошибку обозначают 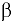 , величину 1- называют мощностью критерия.
, величину 1- называют мощностью критерия.
Поскольку ошибки первого и второго рода исключить невозможно, то в каждом конкретном случае пытаются минимизировать потери от этих ошибок. Увеличение объема выборки является одним из таких путей.
Критерии проверки. Критическая область
Вывод о соответствии выборочных данных с проверяемой гипотезой делается на основе некоторого критерия. Критерий проверки гипотезы реализуют с помощью некоторой статистики 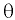 (статистической характеристики определяемой по выборочным данным). Эту величину принято обозначать:
(статистической характеристики определяемой по выборочным данным). Эту величину принято обозначать:  — если она нормально распределена с
— если она нормально распределена с 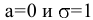 ,
, 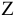 — если она нормально распределена с
— если она нормально распределена с 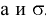 ,
,  — если она распределена по закону Стьюдента,
— если она распределена по закону Стьюдента, 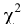 — если она распределена по закону ,
— если она распределена по закону ,  — если она имеет распределение Фишера.
— если она имеет распределение Фишера.
После выбора критерия множество всех его возможных значений разбивают на два непересекающихся подмножества. Одно содержит значения критерия, при которых нулевая гипотеза отклоняется, это множество значений называют критической областью. Другое, называют областью принятия гипотезы — содержит совокупность значений, при которых нулевая гипотеза принимается.
Вычисленное по выборке значение критерия () может принадлежать одному из этих множеств и в зависимости от этого нулевая гипотеза принимается, если принадлежит области принятия гипотезы и отвергается в противном случае. Точки, разделяющие эти две области, называют критическими и обозначают 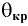 . Различают три вида критических областей: левосторонняя
. Различают три вида критических областей: левосторонняя 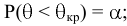 правосторонняя
правосторонняя 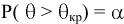 и двухсторонняя
и двухсторонняя 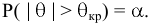
Если 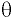 попадает в критическую область, то надо говорят, что основная гипотеза отвергается в пользу альтернативной при заданном уровне значимости.
попадает в критическую область, то надо говорят, что основная гипотеза отвергается в пользу альтернативной при заданном уровне значимости.
Общая схема проверки гипотезы
Проверка гипотезы с помощью уровня значимости.
- Формулируется нулевая гипотеза и альтернативная ей.
- Выбирается уровень значимости.
- Определяется критическая область и область принятия гипотезы.
- Выбирают критерий, и находят его расчетное значение по выборочным данным.
- Вычисляют критические точки.
- Принимается решение.
Другим способом проверки гипотезы является вывод р-значения (значения вероятности). В этом случае не указывается уровень значимости и не принимается решения об отбрасывании нулевой гипотезы. Вместо этого проверяем насколько правдоподобно, что полученная оценка соответствует значению генеральной совокупности. При левостороннем или правостороннем критерии рассчитываются вероятности попадания статистики 0 в критическую область. Если применяется двухсторонний критерий, то оценивается разность между выборочным средним и предполагаемым средним совокупности по модулю. Если р-значснис мало, то выборочное среднее значительно отличается от среднего совокупности.
Проверка гипотезы о математическом ожидании нормально распределенной (m0) случайной величины при известной дисперсии
Пусть генеральная совокупность имеет нормальное распределение, причем её математическое ожидание равно 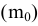 , а дисперсия равна
, а дисперсия равна 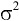 . По выборочным данным найдено
. По выборочным данным найдено 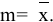 . Есть основания утверждать, что
. Есть основания утверждать, что 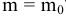 ?
?
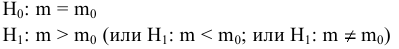
На рис. 2.6. приведены возможные варианты проверки нулевой гипотезы. Результаты проверки включают в себя решение о принятии нулевой или альтернативной гипотез, основанные на уровне значимости альфа и р-значении.
Пример с решением №2.4.
Клиенты банка в среднем снимают со своего счета 100$ при среднем квадратическом отклонении 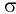 = 50$. Если выплаты отдельным клиентам независимы, то, сколько денег должно быть зарезервировано в банке на выплаты клиентам, чтобы их хватило на 100 человек с вероятностью 0,95? Каков при этом будет остаток денег, гарантированный с той же надежностью, если для выплат зарезервировано 16000$?
= 50$. Если выплаты отдельным клиентам независимы, то, сколько денег должно быть зарезервировано в банке на выплаты клиентам, чтобы их хватило на 100 человек с вероятностью 0,95? Каков при этом будет остаток денег, гарантированный с той же надежностью, если для выплат зарезервировано 16000$?
На каждого клиента банк резервирует сумму в 160$. По выборочным данным эта сумма составляет 100$.
Проверим гипотезу, может ли банк снизить свои резервы, то есть основная гипотеза может быть записана
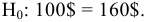
В качестве альтернативной гипотезы рассмотрим ситуацию: «банк сможет обеспечить клиентов, если расчетная сумма выплат для каждого клиента будет снижена до 100$», тогда
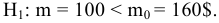

Принимается гипотеза  (рис2.7)., что означает: банк может снизить сумму резервов до 10000$. Используя р-значения можно сделать вывод, если альтернативная гипотеза верна (в среднем клиент берет 100S и меньше), то с вероятностью 100%, случайная величина
(рис2.7)., что означает: банк может снизить сумму резервов до 10000$. Используя р-значения можно сделать вывод, если альтернативная гипотеза верна (в среднем клиент берет 100S и меньше), то с вероятностью 100%, случайная величина  ( 100$, 50$).
( 100$, 50$).
С надежностью 95% можно гарантировать, что у банка имеется остаток более 6000$.
Проверка гипотезы о математическом ожидании при неизвестной дисперсии
Пусть генеральная совокупность имеет нормальное распределение, причем её дисперсия неизвестна. Данная ситуация более реалистична, чем предыдущая. Пусть есть основания утверждать, что .
По результатам выборки найдем  и
и 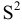 .Сформулируем основную гипотезу:
.Сформулируем основную гипотезу:
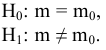
где 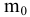 — нормативное значение. Введем статистику:
— нормативное значение. Введем статистику:
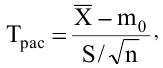
которая имеет распределение Стьюдента с 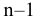 степенью свободы. Зададим уровень значимости альфа и найдем критическую область. На рис. 2.8 приведены формулы левостороннего, правостороннего или двухстороннего критериев проверки среднего выборки с использованием распределения Стьюдента.
степенью свободы. Зададим уровень значимости альфа и найдем критическую область. На рис. 2.8 приведены формулы левостороннего, правостороннего или двухстороннего критериев проверки среднего выборки с использованием распределения Стьюдента.
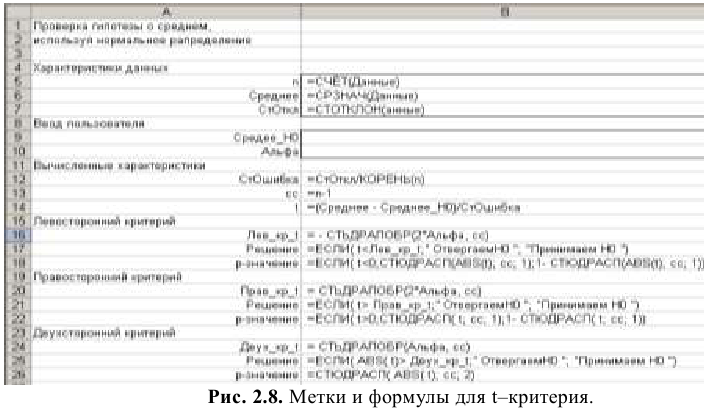
Пример с решением №2.5.
Производитель выпускает стальные стержни. Для улучшения качества планируется внедрить новую технологию, которая получить стержни по средней прочности лучшие на излом. Текущий стандарт прочности на излом составлял 500 фунтов.
Характеристики прочности стержней, произведенных по новой технологии, представлены в D3:D14 рис. 2.9. сформулируем гипотезу об увеличении прочности стержней.
Если
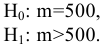
Возьмем выборочное среднее 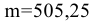 и проверим правосторонний критерий. Результаты приведены на рис. 2.9.
и проверим правосторонний критерий. Результаты приведены на рис. 2.9.
Новая технология позволит улучшить среднюю прочность стержней. Так как  , то можно с уверенностью сказать, что новая технология дает статистически существенные изменения показателя прочности на излом.
, то можно с уверенностью сказать, что новая технология дает статистически существенные изменения показателя прочности на излом.

Построим сравнительные графики новой технологии и стандарта (рис2.10).
Большинство наблюдений превышает стандартную прочность излома стержней. Такая ситуация практически невозможна, если случайная величина имеет нормальное распределение со средним значением 500 фунтов следовательно по данным выборки можно предположить, что новая технология дает увеличение прочности.
Проверка гипотезы относительно доли признака
Рассматривается два основных типа задач:
1) сравнение выборочной доли признака 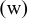 с генеральной долей
с генеральной долей 
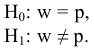
Для проверки этой гипотезы используют статистику :
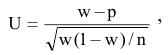
которая имеет нормальное распределение 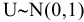 .
.
Критическое значение этой статистики можно найти по заданному уровню значимости  с помощью функции НОРМСТОБР см. рис.2.6.
с помощью функции НОРМСТОБР см. рис.2.6.
2) для сравнения долей признака двух выборок 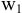 и
и 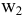 выдвигается гипотеза: что две выборки из одной совокупности с долей признака
выдвигается гипотеза: что две выборки из одной совокупности с долей признака 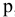 , а полученное расхождение есть результат случайностей, сопровождаемых отбором.
, а полученное расхождение есть результат случайностей, сопровождаемых отбором.
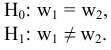
Для больших выборок вводится статистика 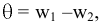 имеющая
имеющая
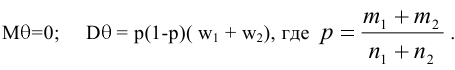
Используют функцию НОРМРАСПОБР для поиска критического значения по уровню значимости альфа, и сравнивают с расчетным значением
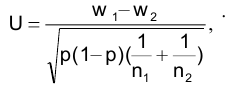
Малые выборки (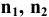 — малые числа) не могут быть исследованы с помощью нормального распределения.
— малые числа) не могут быть исследованы с помощью нормального распределения.
Оценка среднего по двум выборкам
При анализе экономических показателей довольно часто приходится сравнивать две генеральные совокупности. Например, можно сравнить два варианта инвестирования по размерам средних дивидендов, качество знаний студентов двух университетов — по среднему баллу на комплексном тестовом экзамене. Если дисперсии известны, то можно использовать Двухвыборочный z-тест для средних. Кроме этого существуют три варианта Двухвыборочный t-тестов. Эти три средства допускают следующие условия: равные дисперсии генерального распределения, дисперсии выборок не равны, а также представление двух выборок до и после наблюдения по одному и тому же субъекту.
Для запуска этих инструментов анализа данных надо выполнить действия меню Сервис/Анализ данных выберите из списка нужный вам пункт.
Для выполнения таких проверок инструментами анализа Excel требуется наличие двух выборок, оценка полагаемой разницы между средними значениями выборок и альфа — уровень значимости. Все перечисленные критерии предполагают, что рассматриваемые совокупности нормально распределены, и выборки получены случайно.
Случай равных дисперсий
Рассмотрим данный критерий на примере.
Пример с решением №4.1.
На заводе проводится эксперимент по оценке новой технологии сборки устройств. Рабочие делятся на две группы; одна обучается новой технологии, другая — стандартной. В конце обучения измеряется время (в минутах), необходимое рабочему для сборки устройства. Результаты приведены в диапазоне A L:В10 рис 4.1. Можно ли сделать вывод, исходя из данных выборок, что время сборки по новой технологии меньше, чем по стандартной.
На листе Exccl постройте графики для выборок Стандартная и Новая. Разброс (дисперсии равны) данных практически одинаковый, этот вывод можно сделать, изучив амплитуды колебания графиков (рис. 4.1). Маркеры графика Новая расположены ниже, поэтому можно предположить, что среднее время сбора устройств по новой технологии меньше.
Выдвигаем гипотезу: «Среднее время сборки по новой технологии не изменилось», . эту гипотезу можно записать в виде:
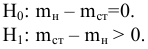
 альтернативная гипотеза, утверждающая «Новая технология сокращает время сборки». Необходимо проверить левосторонний критерий для основной гипотезы.
альтернативная гипотеза, утверждающая «Новая технология сокращает время сборки». Необходимо проверить левосторонний критерий для основной гипотезы.
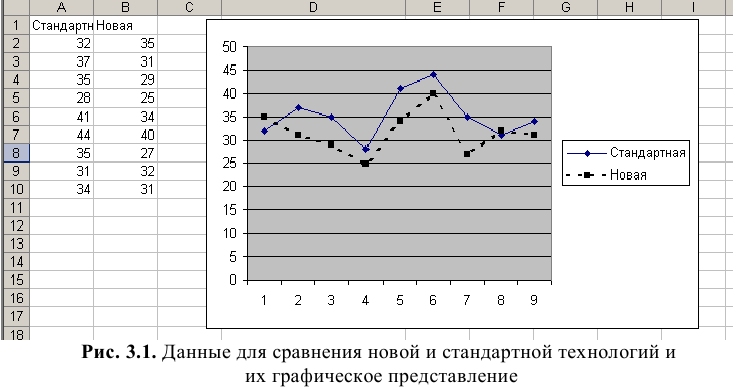
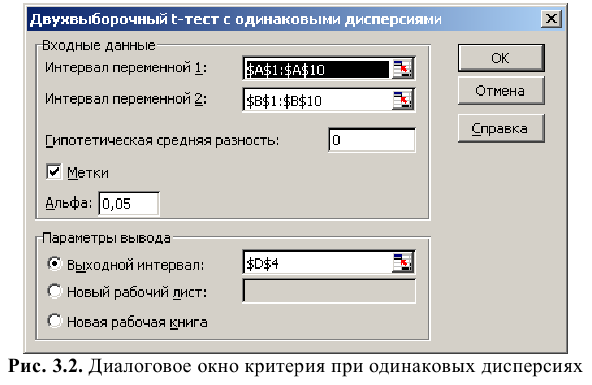
В диалоговом окне Анализ данных и выберите Двухвыборочный t-тест с одинаковыми дисперсиями. Заполните поля, как показано на рис.3.2. и нажмите кнопку ОК. результат появится на листе Excel в диапазоне D4: F16, как на рис 3.3.

Описание полученных результатов сравнения средних двух выборок (рис.3.3).
Объединенная дисперсия — это взвешенное среднее выборочных дисперсий, со степенями свободы каждой дисперсии в качестве весов (8). Она является оценкой общей дисперсии двух выборок и используется для определения стандартной ошибки разности средних.
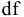 — число степеней свободы критерия (18-2).
— число степеней свободы критерия (18-2).
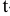 -статистика вычисляется как отношение разности средних к стандартной ошибке.
-статистика вычисляется как отношение разности средних к стандартной ошибке.
 одностороннее является односторонним -значением, если
одностороннее является односторонним -значением, если  если
если  то
то  . Двухстороннее -значение равно удвоенному одностороннему -значению.
. Двухстороннее -значение равно удвоенному одностороннему -значению.
Найденное расчетное значение -статистика= 1,649 и -критическое равное 1,746 сравниваем с учетом, что рассматривалась правосторонняя критическая область, делаем вывод: «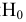 принимается». С 5% уровнем значимости мы не можем отвергнуть предположение о равенстве средних значений выборки.
принимается». С 5% уровнем значимости мы не можем отвергнуть предположение о равенстве средних значений выборки.
Если бы рассматривалась левосторонняя гипотеза, то:
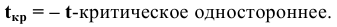
Можно построить доверительный интервал для разности средних значений выборок (результат в диапазоне Н3:18 рис. 3.4).
Среднее разности находится как разность ЕЗ — F3,
— статистика для разности равна критическому двухстороннему (Е14), стандартная ошибка найдена делением (13 -Е8)/ ЕЮ.
Половина длины равна произведению на стандартную ошибку.
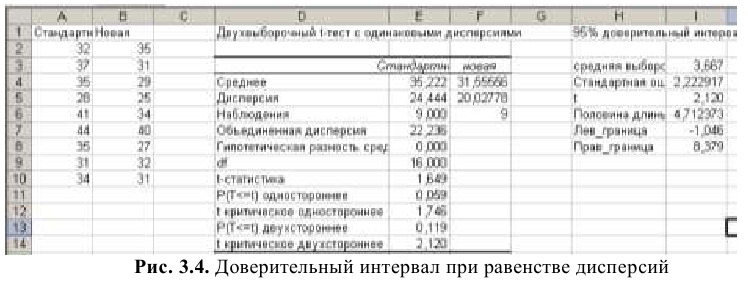
Доверительный интервал для разности средних значений равен (-1,046; 8,379) с вероятностью 95%.
Случай разных дисперсий
В данном случае не предполагается равенство дисперсий выборок, но сохраняется требование их нормальности и независимости.
Для принятия решения в таких случаях надо использовать Двухвыборочный t-тест с различными дисперсиями.
Пример с решением №3.2.
Для производства нового продукта предлагается две схемы размещения рабочих. Шесть случайно отобранных рабочих собирают изделие по схеме А, а другие восемь — по схеме В. Время сборки записывается соответственно в столбец А и В рис 3.5. Можно ли сделать вывод с 5% уровнем значимости, что время сборки различаются в схемах, при условии, что они нормальные.
Построим диаграммы данных выборок и сравним среднее время сборки и разброс.
Сравнивая графики для схем  и
и  можно сделать вывод, что разброс данных в схеме больше, однако среднее время сборки меньше.
можно сделать вывод, что разброс данных в схеме больше, однако среднее время сборки меньше.
Выдвинем гипотезу: «Размещение рабочих не влияет на время сборки изделий:
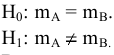
В качестве альтернативной гипотезы выдвинем предположение: «время сборки изделий по схеме и не равны».
Для проверки этой гипотезы следует применить двухсторонний критерий. Инструкции по использованию -теста те же, что и в примере 4.1. Результаты применения критерия приведены на рис.3.6.
Сравнивая расчетное значение -статистики и -критическое двухстороннее можно сделать вывод, что принимается гипотеза , то есть размещение рабочих не влияет на время сборки изделий.
Используя -значение 0,180 (18%) можно сделать вывод, что с вероятностью 18% можно получить выборку со средним отличающимся на 1,6 мин в любом направлении. Доверительный интервал для разности средних составил (-4,138; 0,938).
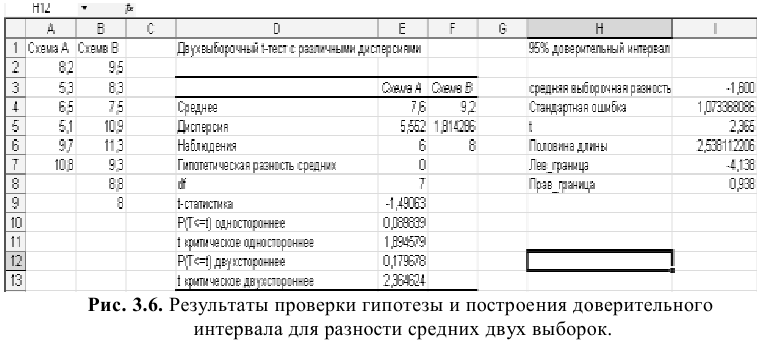
Парный выборочный критерий
Критерий используется в случае, когда одна и та же группа наблюдается дважды. Обычно это происходит при измерении характеристик до и после эксперимента. Например, студенты могут тестироваться дважды до и после курса по некоторой дисциплине. Можно использовать критерий и для других естественных пар наблюдений.
Пример с решением №3.3.
Исследователь хочет определить, имеется ли разница в успешности автомобильных сделок при их проведении продавцами женского и мужского пола. Для этого были выбраны восемь продавщиц и определена комиссия, заработанная каждой в прошедшем году. Так как опытность влияет на размер комиссии, то исследователь записала и стаж работы для каждой из восьми женщин. Данные приведены в столбцах и рис. 3.7. Для проверки предположения были взяты продавцы с тем же стажем работы, что и женщины; значения комиссий мужчин приведены в столбце С рис.4.7. Можем ли мы с уровнем значимости 5% утверждать, что женщины имеют существенно другие показатели, по сравнению с продавцами мужчинами?
Нулевая гипотеза состоит в том, что разность средних совокупностей равна нулю. Однако по результатам выборок получено среднее значение разности и она равна 2,25 тыс. рублей. Тогда в качестве альтернативной гипотезы рассмотрим утверждение, что продавцы различных полов имеют различные показатели. Для проверки гипотез применим Двухвыборочных парный t-тест для средних. После его запуска в диапазоне F1 :Н 14 будут помещены результаты применения этого критерия. Они практически ничем не отличаются от предыдущих результатов (пример 4.1, пример 4.2), только в ячейке G7 содержится коэффициент корреляции.
Принимая решение, для данного теста мы вынуждены принять гипотезу о равенстве средних значений комиссии у продавцов мужчин и женщин. Об этом говорят значения и  : -2,365<1,895<2,365.
: -2,365<1,895<2,365.
В случае проверки с гипотезы с помощью -значения (=14%) можно с вероятностью 14% получить выборку с разностью меньшей чем -2,25 тыс. рублей или большей, чем 2,25 тыс. рублей.
В диапазоне J1:K7 представлены вычисления 95% доверительного интервала для разности средних выборок.
Анализ дисперсий
 -распределение может быть использовано для проверки нулевой гипотезы о равенстве дисперсий двух выборок. Критерий предполагает, что выборки из генеральной совокупности независимы и нормально распределены.
-распределение может быть использовано для проверки нулевой гипотезы о равенстве дисперсий двух выборок. Критерий предполагает, что выборки из генеральной совокупности независимы и нормально распределены.
Двухсторонний критерий применяется в случае, если альтернативная гипотеза состоит в том, что дисперсии выборок различны. Для этого составляется отношение дисперсий, которое сравнивается с единицей.
Если альтернативная гипотеза проверяет утверждение о том, что дисперсия одной выборки строго больше дисперсии другой выборки, применяется односторонний критерий.
Напомним, что заданный уровень значимости альфа для двухстороннего критерия делится пополам.
В примере 3.2. проверялась гипотеза о равенстве средних значений выборок, представляющих две схемы размещения рабочих мест. При этом предполагалось, что дисперсии этих выборок не равны. Воспользуемся данными этого примера и проверим гипотезу о равенстве дисперсий. Применим двухсторонний тест для 10% уровня значимости (5% на каждый хвост распределения) для проверки нулевой гипотезы о равенстве дисперсий. В качестве альтернативной гипотезы рассматривается утверждение, что дисперсии не равны. На рис. 4.1. приведены данные -теста. Значение -статистики записано в ячейке Е8 и равно 3,060. в ячейке Е9 приведены данные р-значения, которое является правосторонней вероятностью получить значение большее или равное -статистики. Критическое значение для правосторонней области находится в ячейке ЕЮ и равно 3,972. такое же значение будет иметь правая граница двухсторонней области с уровнем значимости 10%. На рис. 4.1. в столбце I найдено критическое значение для левой границы. Так как =3,060 меньше  =3,972, мы не можем отвергнуть нулевую гипотезу равенства дисперсий.
=3,972, мы не можем отвергнуть нулевую гипотезу равенства дисперсий.
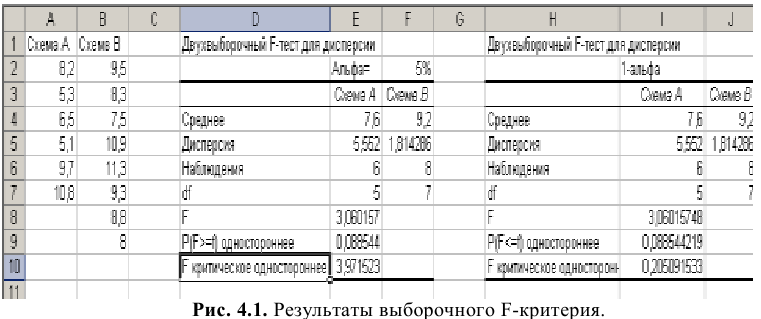
Можно не использовать двухвыборочный -тест для проверки гипотезы о равенстве дисперсий, а воспользоваться функцией FPACTIOBP, которая имеет синтаксис РРАСПОБР(всроятность;степенисвоб1; степенисвоб2), т.е.
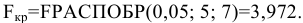
Значение статистики тоже легко находится с использованием встроенных функций Excel.
Критерий хи-квадрат (критерий согласия)
Этот критерий используют для проверки гипотезы о виде распределения выборки. Её проверка состоит в том, чтобы на основе сравнения фактических и теоретических частот сделать вывод о соответствии фактического распределения аредполагаемому. В критерии используется статистика:
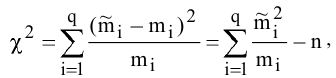
где 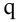 — число групп, на которое разбито распределение;
— число групп, на которое разбито распределение;
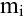 — теоретическая частота, рассчитанная по предполагаемому распределению;
— теоретическая частота, рассчитанная по предполагаемому распределению;
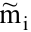 — наблюдаемая (фактическая) частота признака в
— наблюдаемая (фактическая) частота признака в  -той группе.
-той группе.
Статистика 6.1 подчиняется ХИ-квадрат распределению с 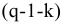 степенями свободы, где
степенями свободы, где  — число параметров генерального распределения, вычисляемых по выборочным данным. В таблице 6.1. указывается значение для основных видов распределения.
— число параметров генерального распределения, вычисляемых по выборочным данным. В таблице 6.1. указывается значение для основных видов распределения.
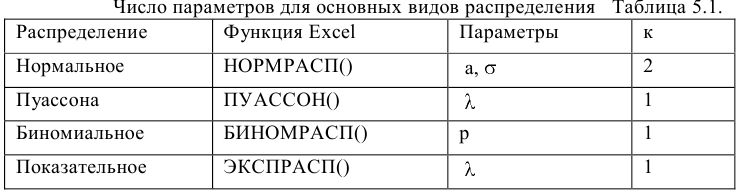
В некоторых случаях сравнение может проводиться с заранее данным распределением, или с распределением у которого часть параметров указана (а не рассчитывается по выборочным данным). В этом случае число к (параметров генерального распределения) уменьшается.
Для применения критерия ХИ-квадрат требуется выполнение условий:
- экспериментальные данные должны быть независимыми;
- объем выборки должен быть достаточно большим (не менее 50);
- частота в каждой группе должна быть не менее 5. Если это условие не выполняется, то проводят объединение малочисленных интервалов, при этом частоты объединенных интервалов суммируются.
При полном совпадении теоретического и фактического распределений 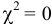 , в противном случае
, в противном случае 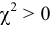 . Проверка гипотезы о равенстве распределений
. Проверка гипотезы о равенстве распределений 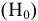 осуществляется с помощью
осуществляется с помощью
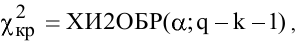
которое находится по заданному уровню значимости. Гипотеза 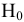 принимается, если
принимается, если  , в противном случае отвергается
, в противном случае отвергается
Основанием для выдвижения гипотезы о виде распределения генеральной совокупности могут служить:
- формальные свойства числовых характеристик выборочных данных:
a. равенство нулю ассиметрии и эксцесса является признаком нормального распределения;
b. дисперсия и среднее значение выборки равны является признаком распределения Пуассона и т.д;
- графический анализ выборочных данных: полигон, гистограмма, функция накопленных частот их сравнение с теоретическими функциями известных распределений.
Если статистический ряд не является интервальным, то его данные подвергаются группировке и представляются в виде q интервалов равной длины. Далее находят количество вариант, попавших в каждый частичный интервал. Если значения статистического ряда являются равноотстоящими вариантами с заданными частотами, то данные можно и не группировать.
Проверка гипотезы о нормальном распределении генеральной совокупности
В предыдущих примерах мы пользовались тем, что значения выборки распределены по нормальному закону распределения. Рассмотрим применение критерия согласия, проверяющего справедливость гипотезы о наличии нормального распределения в совокупности на примере.
Пример с решением №5.1.
Чтобы установить гарантийный срок на товар, производитель хочет проверить является ли срок службы выпускаемого товара нормально распределенным. Случайным образом отобранные 200 единиц товара при проверке распределились следующим образом по количеству отработанных часов:

Запишем нулевую и альтернативную гипотезы:
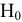 : Совокупность сроков службы нормально распределена.
: Совокупность сроков службы нормально распределена.
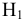 : Совокупность сроков службы имеет другое распределение.
: Совокупность сроков службы имеет другое распределение.
Проверку будем проводить с помощью встроенных функций Excel. Для этого внесем данные, как показано на рис. 5.1 в ячейки А7:В11.
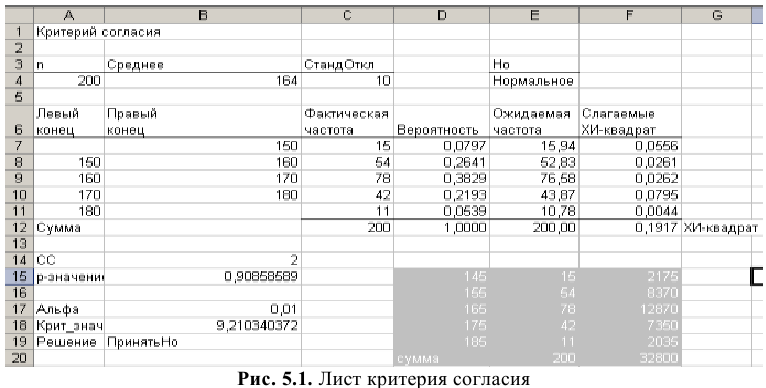
ШАГ 1. Найдите среднее значение и дисперсию интервального ряда по формулам 1.1 и 1.2. Для этого в ячейки D15:D19 занесите середины интервалов. Середина первого интервала определяется по формуле:
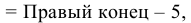
где пять половина длины следующего интервала. Аналогично вычисляется середина последнего интервала, только учитывается половина длины предшествующего интервала. В диапазон Е15:Е19 скопируйте фактические частоты. В ячейку Е20 запишите формулу: =СУММ(Е15:Е19).
В ячейку F15 поместите произведениех^ =D15*E15 и скопируйте в остальные ячейки диапазона F15:F 19. Теперь можете воспользоваться формулой 1.1 для определения среднего, значение которого поместите в ячейку В4.
Дисперсию найдите самостоятельно, для этого лучше воспользоваться формулой:
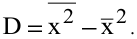
Сначала выполните следующие действия в ячейках G 15:G19 найдите 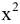 , а в Н15:Н 19 —
, а в Н15:Н 19 — 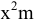 . Результаты оформите как показано в таблице 6.2: В ячейке С4 (рис.6.1) находится среднее квадратическое отклонение, которое определяется по формуле 1.3
. Результаты оформите как показано в таблице 6.2: В ячейке С4 (рис.6.1) находится среднее квадратическое отклонение, которое определяется по формуле 1.3

ШАГ 2. В столбце «Вероятность» (рис.5.1) находится вероятность попадания случайной величины в соответствующий интервал. Для вычисления этих значений использовалась функция НОРМРАСП. Для первого интервала левым концом является минус бесконечность, поэтому в ячейку С8 запишите формулу:
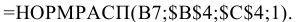
Для последнего интервала находим
поэтому вычисление проводится по формуле:
Для вычисления вероятности попадания в интервал 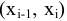 воспользуйтесь формулой 2.6:
воспользуйтесь формулой 2.6:
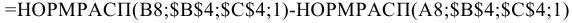
ШАГ 3. Диапазон «Ожидаемая частота» вычисляется как произведение соответствующих значений столбца «Вероятность» на объем выборки (200). ШАГ 4. Столбец представляет собой слагаемые формулы 6.1, вычисляемые по формуле:
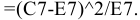
В примере рассматривается пять интервалов, а количество параметров предполагаемого распределения два (среднее и стандартное отклонение) рассчитывается по выборке, поэтому число степеней свободы (СС) равно двум (5-2-1=2). В ячейки А14:В19 введите формулы согласно рис. 5.2.

В ячейке В19 делается вывод, что распределение часов работы, выпускаемого товара нормальное, это же подтверждает и р-значение.
Проверка гипотезы о распределении генеральной совокупности но закону Пуассона
Параметром этого распределения является 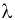 -среднее значение. Поэтому по выборочным данным надо найти
-среднее значение. Поэтому по выборочным данным надо найти 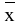 и взять его в качестве оценки параметра . Напомним, что дискретная случайная величина, имеющая распределение Пуассона, может принимать неотрицательные целые значения. Рассмотрим использование критерия Хи-квадрат для проверки гипотезы о распределении случайной величины по закону Пуассона на примере.
и взять его в качестве оценки параметра . Напомним, что дискретная случайная величина, имеющая распределение Пуассона, может принимать неотрицательные целые значения. Рассмотрим использование критерия Хи-квадрат для проверки гипотезы о распределении случайной величины по закону Пуассона на примере.
Пример с решением №5.2.
Проведено наблюдение за числом вызовов такси в праздничные дни. Для этого анализировалось 100 случайно выбранных одно минутных интервалов времени. Число вызовов такси в минуту распределилось следующим образом:

Проверить, используя критерий Хи-квадрат, гипотезу о том, что число вызовов согласуется с законом Пуассона с уровнем значимости 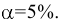 .
.

ШАГ 1. Внесите данные на лист Excel и найдите теоретические частоты (диапазон D2:D7), как показано на рис 5.3.
ШАГ2. Найдите слагаемые формулы 5.1. Для этого скопируйте значения фактических и теоретических частот, как показано на рис. 5.4, в ячейку С12 запишите формулу:
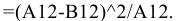
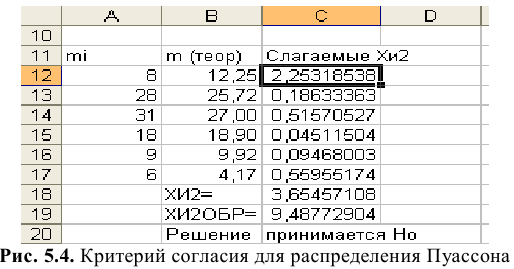
Можно сделать вывод о том, что число вызовов такси в праздничные дни имеет распределение Пуассона.
Проверка гипотезы о распределении генеральной совокупности но равномерному закону
Пусть случайная величина 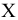 распределена равномерно на отрезке
распределена равномерно на отрезке 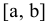 выборочные данные сгруппируйте по частичным интервалам одинаковой длины и найдите соответствующие частоты. Для каждого интервала вычислите вероятность попадания
выборочные данные сгруппируйте по частичным интервалам одинаковой длины и найдите соответствующие частоты. Для каждого интервала вычислите вероятность попадания 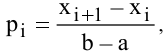 , а затем теоретические частоты по формуле пр,.
, а затем теоретические частоты по формуле пр,.
Пример с решением №6.3.
На рис.6.5 приведена частота появление на остановке автобусов определенного маршрута, имеющих интервал движения, пять минут  . Проверьте гипотезу о равномерном законе распределения.
. Проверьте гипотезу о равномерном законе распределения.
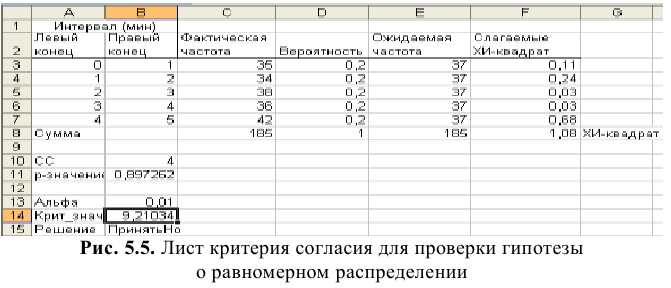
При проверке гипотезы, так же как и в случае нормального распределения найдено критическое значение (рис. 5.2) и р-значение, которое характеризует вероятность выполнения гипотезы : можно утверждать, что она выполняется для 90% выборочных данных. В ячейке В15 сделан вывод о том, что гипотеза о равномерном распределении движения автобусов принимается.
Проверка гипотезы о распределении генеральной совокупности но показательному закону
Как и в предыдущих проверках, выборочные данные сгруппируйте и запишите в виде последовательности частичных интервалов и соответствующих им частот. Найдите выборочное среднее значение . Параметр показательного распределения (таблица 6.1) замените оценкой:
Вероятности попадания случайной величины в интервалы определите с помощью функции ЭКСПРАСП.
Выполните расчеты как показано на рис. 5.6. Столбцы Е, F заполните как в примере 5.1. В столбце вероятность:
В ячейку D4 запишите =ЭКСПРАСП(В4;$Р$19;1);
В ячейку D5 поместите =ЭКСПРАСП(В5;$Р$ 19; 1 )-ЭКСГ1РАСП(A5;$F$ 19; 1), скопируйте её в остальные ячейки столбца D.
Сравнивая критическое и расчетное значение статистики ХИ-квадрат при 5% уровне значимости, можно сделать вывод, что нет оснований отвергать гипотезу можно считать данные выборки (рис 5.6) распределены по показательному (экспоненциальному) закону распределения.
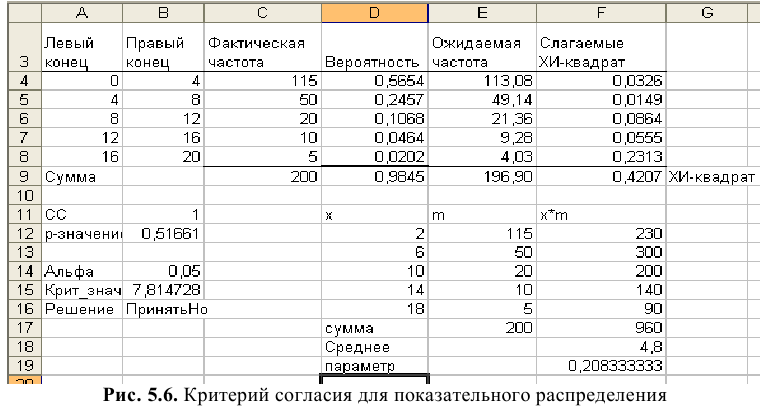
Проверка гипотезы о распределении генеральной совокупности но биномиальному закону распределения
Пример с решением №5.4.
В библиотеке отобрано 200 партий по пять книг для обучения студентов в семестре. Каждому студенту было предложено заполнить опросный лист числа повреждений в книге. В итоге был получен вариационный ряд:

При уровне значимости 5% проверьте гипотезу о биномиальном распределении числа повреждений в книгах.
Биномиальное распределение имеет один неизвестный параметр —  , который надо оценить
, который надо оценить 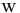 по выборочным данным. Проведем все расчеты в Excel (рис. 5.7).
по выборочным данным. Проведем все расчеты в Excel (рис. 5.7).
Выделенные ячейки следует объединить в одну группу, тогда количество рассматриваемых интервалов равно четырем.
Относительная частота находится по формуле
Прежде чем перейти к столбцу вероятность найдите оценку  параметра , используя формулы рис. 5.8.
параметра , используя формулы рис. 5.8.

Столбец вероятность заполните с помощью формул :
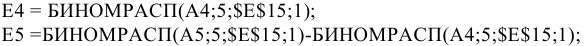
Остальные ячейки заполняем, копируя полученную формулу.
Вывод: можно считать число повреждений в книге подчиняется биномиальному закону распределения.
Использование статистики ХИ-квадрат для изучения зависимостей двух переменных
Одним из приложений критерия 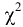 является его использование при анализе таблиц сопряженности двух переменных для установления факта наличия и уровня значимости их взаимосвязи. Для этого выдвигается нулевая гипотеза: связи между рассматриваемыми переменными нет, в противном случае связь между переменными существует с уровнем значимости альфа.
является его использование при анализе таблиц сопряженности двух переменных для установления факта наличия и уровня значимости их взаимосвязи. Для этого выдвигается нулевая гипотеза: связи между рассматриваемыми переменными нет, в противном случае связь между переменными существует с уровнем значимости альфа.
Пример с решением №5.5.
Компания продает четыре сорта колы в Москве. Чтобы определить, будет ли успешным тот же способ распространения в Ростове и Краснодаре, фирма анализирует связь между предпочтениями и городом потребителя. Аналитик распределяет покупателей на четыре класса по предпочтениям сортов колы: обычная, без кофеина и сахара, только без кофеина, только без сахара. Опрашивают 250 случайно выбранных потребителей колы из трех городов и записывают их предпочтения. В результате получается таблица частот.

Так как аналитик определяет связь между городом и предпочтением определенного вида колы, то нулевая и альтернативная гипотезы следующие: : Классификации статистически независимы.
Классификации зависимы.
На лист Excel поместим данные о распространении сортов кофе в диапазон В5:Е7 (рис 6.8). Расчет ожидаемых частот проводится в предположении, что нулевая гипотеза выполняется, то есть переменные независимые, а значит вероятность их произведения равна произведению вероятностей каждой их них. Поэтому таблица ожидаемых частот строится по формуле:
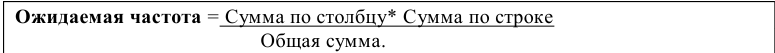
Ожидаемые частоты поместите в диапазон В12:Е 14. Для их вычисления, воспользуйтесь смешанной и абсолютной ссылками на ячейки сумма по строке, сумма по столбцу, общая сумма. Результаты вычисления приведены на рис. 6.9.
Для сравнения ожидаемых и фактических частот воспользуемся ХИ2ТЕСТОМ (рис. 5.8). В ячейку В17 внесите формулу:
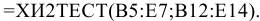
Получите р-значение равное 0,00000013, которое определяет вероятность выполнения нулевой гипотезы. Можно сделать вывод, что нулевая гипотеза отвергается, то есть люди из разных городов предпочитают различные сорта колы.
Проверим эту же гипотезу с помощью статистики ХИ-квадрат. Слагаемые формулы 6.1 найдем с помощью Фактических и Ожидаемых частот. Для этого в ячейку В21 введите формулу:
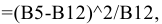
и скопируйте её для всего диапазона B21:F23 (рис.5.9).
- Сумму слагаемых ХИ-квадрат поместите в ячейку В25 (рис.5.9).
- В ячейке В27 задайте уровень значимости (альфа равно 0,01).
- Число степеней свободы (СС) найдите по формуле:
- Критическое значение (В29) найдем с помощью
- В ячейку ВЗО помести функцию:
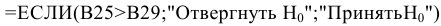
Так как ХИ-квадрат больше критического значения, то принимается гипотеза .

Критерии Колмогорова-Смирнова
Этот критерий является альтернативой критерию ХИ-квадрат. Его применение не требует вычисления ожидаемых частот и может использоваться для малых выборок. Данные должны представлять случайную выборку и обязательно должна быть сформулирована гипотеза о распределении генеральной совокупности. Нулевая гипотеза утверждает, что генеральная совокупность имеет выбранное распределение с определенным уровнем значимости.
Применение критерия Колмогорова-Смирнова основано на оценке разности функции накопленных частот 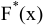 и функции распределения
и функции распределения 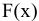 , найденной в предположении, что нулевая гипотеза верна. Статистика критерия вычисляется по формуле:
, найденной в предположении, что нулевая гипотеза верна. Статистика критерия вычисляется по формуле:
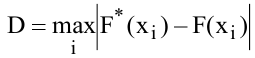
где 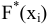 — функция накопленных частот для
— функция накопленных частот для 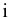 -того значения или интервала;
-того значения или интервала; 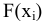 — функция распределения в точке
— функция распределения в точке 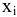 .
.
Если D больше критического значения, взятого из таблицы соответствующего критерия для объема выборки п и уровня значимости 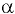 , то нулевая гипотеза отклоняется. В противном случае нулевая гипотеза принимается. Для большого объема выборки используется предельное распределение критерия.
, то нулевая гипотеза отклоняется. В противном случае нулевая гипотеза принимается. Для большого объема выборки используется предельное распределение критерия.
Если необходимо проверить нулевую гипотезу о принадлежности двух выборок (объема 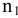 и
и 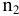 ) одной и той же генеральной совокупности, то строится статистика:
) одной и той же генеральной совокупности, то строится статистика:
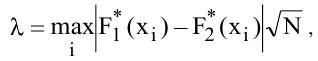
где 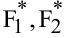 — функции накопленных частот, построенные по первой и второй выборкам соответственно;
— функции накопленных частот, построенные по первой и второй выборкам соответственно;
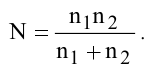
Статистика сравнивается с критическим значением 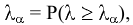 значения которой находятся по таблице критических точек распределения Колмогорова:
значения которой находятся по таблице критических точек распределения Колмогорова:

Пример с решением №6.1.
Получена случайная выборка о среднем дневном заработке, руб/день, для пяти работников: 288, 231, 249, 146, 291. можно ли считать на 10% уровне значимости, что выборка проведена из нормально распределенной генеральной совокупности со средним значением
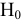 : выборка взята из нормально распределенной генеральной совокупности с
: выборка взята из нормально распределенной генеральной совокупности с 
 нет оснований утверждать, что выборка взята из нормально распределенной генеральной совокупности с
нет оснований утверждать, что выборка взята из нормально распределенной генеральной совокупности с 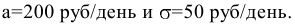 . Вычисления проведем в Excel, как показано на рис.6.1.
. Вычисления проведем в Excel, как показано на рис.6.1.
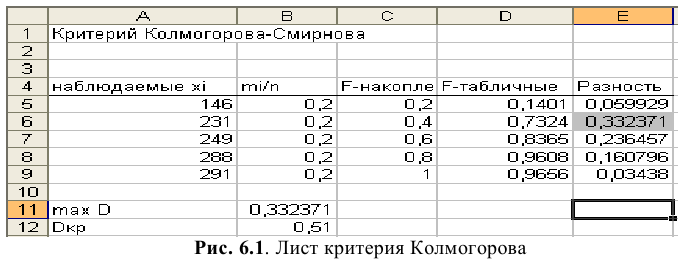
ШАГ 1. Заполните диапазон А5:А9 выборочными данными и отсортируйте их по возрастанию.
ШАГ 2. Найдите относительные частоты для перечисленных вариант и поместите их в столбец В.
ШАГ 3. Для определения значений функции накопленных частот в ячейку С5 внесите формулу: = В5, в ячейку С6 запишите: =С5+В6 и скопируйте её для ячеек диапазона С7:С9.
ШАГ 3. Для заполнения столбца D, внесите в ячейку D5 формулу:
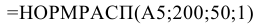
и скопируйте её на остальные ячейки диапазона D6: D9.
ШАГ 4. В ячейку Е5 внесите формулу: =ABS(C5-D5) и скопируйте для остальных ячеек диапазона Е5:Е9
ШАГ 5. Найдите максимальное значение статистики D и сравните с критическим, взятым из таблицы при уровне значимости 10% и числе степеней свободы равном пяти. Сравнивая эти можно сделать вывод, что выборка взята из нормально распределенной генеральной совокупности с
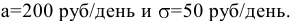
Линейная регрессия и корреляция
Регрессия и корреляция широко используется при анализе связей между явлениями. Прежде всего, в экономике — исследование зависимости объемов производства от целого ряда факторов: размера основных фондов, обеспеченности предприятия квалифицированным персоналом и других; зависимости спроса или потребления населения от уровня дохода, цен на товары и т.д. Экономические показатели являются многомерными случайными величинами.
В большинстве случаев между переменными, характеризующими экономические величины, существуют зависимости, отличающиеся от функциональных. Она возникает, когда один из факторов зависит не только от другого, но и от ряда случайных условий, оказывающих влияние на один или оба фактора. В этом случае ее называют стохастической (корреляционной) и говорят, что переменные коррелируют. Виды стохастических связей между факторами могут быть линейными и нелинейными, положительными или отрицательными. Возможна такая ситуация, когда между факторами невозможно установить какую-либо зависимость.
Однако при изучении влияния одного явления на другое удобно работать именно с функциями, связывающими эти явления. Задачи построения функциональной зависимости между факторами, анализа полученных результатов и прогнозирования решаются с помощью регрессионного анализа.
В пособии приводятся решения задач содержащих небольшое количество данных, для того чтобы пользователь мог быстро ввести значения в таблицу Excel. Каждое решение содержит подробную инструкцию. Сначала рассмотрите пример и проверьте результаты. Затем примените пошаговые инструкции к собственному множеству данных.
Корреляционная зависимость
Для изучения зависимости между двумя числовыми переменными (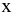 и
и 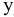 ) сначала строят графики рассеяния. В Excel данный вид графиков называется точечной диаграммой. Используя графическое представление, можно сделать вывод о корреляционной зависимости или независимости рассматриваемых данных. Если в массиве данных присутствуют «выбросы», то их следует исключить из рассмотрения, если это возможно сделать, или усреднить, используя соседние элементы.
) сначала строят графики рассеяния. В Excel данный вид графиков называется точечной диаграммой. Используя графическое представление, можно сделать вывод о корреляционной зависимости или независимости рассматриваемых данных. Если в массиве данных присутствуют «выбросы», то их следует исключить из рассмотрения, если это возможно сделать, или усреднить, используя соседние элементы.
Теперь можно выдвинуть предположение о существовании линейной или нелинейной зависимости между переменными. Для этого найдите коэффициент корреляции и проверьте его значимость.
Тесноту линейной зависимости изучаемых явлений оценивает линейный коэффициент парной корреляции 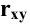 :
:
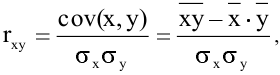
где 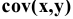 обозначают смешенный момент второго порядка (1.5), который называется ковариацией.
обозначают смешенный момент второго порядка (1.5), который называется ковариацией.
Ковариация является мерой взаимосвязи случайных величин и может служить для определения направления их изменения:
если  , то случайные величины изменяются в одном направлении;
, то случайные величины изменяются в одном направлении;
если  , то случайные величины изменяются в разных направлениях.
, то случайные величины изменяются в разных направлениях.
Очевидными свойствами ковариации являются:
Коэффициент корреляции (1.1) является величиной безразмерной. Случайные величины  и
и 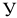 называют некоррелированными, если
называют некоррелированными, если 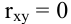 (отсутствует линейная зависимость между и ), в противном случаем можно говорить о линейной зависимости между величинами и , а величины называю коррелированными. Свойства коэффициента корреляции:
(отсутствует линейная зависимость между и ), в противном случаем можно говорить о линейной зависимости между величинами и , а величины называю коррелированными. Свойства коэффициента корреляции:
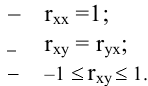
В пакете Анализ данных есть инструменты Ковариации и Корреляция, позволяющие сделать вывод о линейной зависимости случайных величин.
Пример с решением №7.1.
Для анализа зависимости объема потребления (у.е.) хозяйств от располагаемого ежемесячного дохода (у.е.) отобрана выборка  , представленная таблицей.
, представленная таблицей.

Постройте график рассеяния и сделайте вывод о виде функциональной зависимости между объемом потребления и ежемесячным доходом в семье.
Инструкции по выполнению задания
- Расположите данные в столбцах таблицы так, чтобы значения х были слева, а у справа (рис. 1.1).
- Выделите диапазон ячеек.
- Щелкните мышью по кнопке Мастер диаграмм и выберите тип Точечная. Для форматирования диаграммы удобно использовать контекстное меню, которое вызывается щелчком правой кнопки мыши на форматируемом объекте.
- Дайте название диаграмме Корреляционное поле.
- Расположите диаграмму на листе, содержащем данные, как показано на рис.
Применим встроенную функцию КОРРЕЛ(диапазон ; диапазон) для установления линейной зависимости между переменными (рис. 1.1). Найденный коэффициент корреляции 0,99 свидетельствует о сильной линейной зависимости между объёмом потребления и уровнем доходов в семье.
Проверим значимость коэффициента корреляции. Для этого сформулируем основную и альтернативную гипотезы:
 : , коэффициент незначимый;
: , коэффициент незначимый;
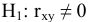 , коэффициент значимый.
, коэффициент значимый.
Для проверки гипотезы воспользуемся  -критерием и уровнем значимости 5%,
-критерием и уровнем значимости 5%,
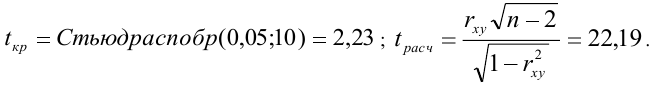
Сравнивая эти значения, сделаем вывод о том, что основная гипотеза отклоняется в пользу альтернативной, т.е. коэффициент корреляции значим. По расположению точек на рис. 1.1 можно предположить, что между и существует линейная зависимость:
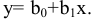
Корреляционный анализ данных
При выполнении многомерного анализа данных изучают корреляцию между каждой парой переменных. Эти результаты представляют в виде корреляционной матрицы. Инструмент анализа Корреляция позволяет определить парные корреляции для многих переменных. После его запуска получится нижняя треугольная часть матрицы, на диагонали которой будут стоять единицы 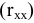 . Верхняя часть матрицы является зеркальным отражением нижней ее части, поскольку
. Верхняя часть матрицы является зеркальным отражением нижней ее части, поскольку 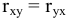 .
.
Если надо изучить зависимость между переменными при условии управления одной или несколькими переменными, то находят коэффициенты частной корреляции. Частные коэффициенты корреляции могут оказаться полезными при определении ложных связей.
Например, изучается зависимость 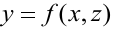 . Коэффициенты парной корреляции между
. Коэффициенты парной корреляции между  и
и  высокие, однако зависимость будет считаться ложной, если линейно зависит от
высокие, однако зависимость будет считаться ложной, если линейно зависит от  . Если исключить влияние переменной , то корреляционная зависимость между и может исчезнуть,
. Если исключить влияние переменной , то корреляционная зависимость между и может исчезнуть,
Надо найти частные коэффициенты корреляции, т.е. элиминировать один из факторов (устранить его влияние). В случае трех факторов корреляцию между и при элиминированном факторе можно найти по формуле:
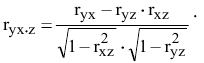
Подобным образом находят и остальные коэффициенты частной корреляции.
Пример с решением №7.2.
Формируется три портфеля из десяти акций. Первый состоит из 10 акций вида  , второй содержит по 5 акций и
, второй содержит по 5 акций и  ; а третий включает 5 акций вида , 3 вида и 2 вида
; а третий включает 5 акций вида , 3 вида и 2 вида  . Данные о прибыли по каждому виду акций за десять месяцев представлены на рис 1.3.
. Данные о прибыли по каждому виду акций за десять месяцев представлены на рис 1.3.
Имеется ли зависимость между акциями , и ? Отличаются ли данные портфели по доходности и риску?
Инструкции по выполнению задания
- Введите данные в ячейки A1: C11, как показано на рис. 1.2.
- В меню сервис выберите Анализ данных / инструмент Корреляция. Заполните поля диалогового окна, как показано на рис. 1.3. и нажмите ОК.
- Аналогично найдите матрицу парных ковариаций.
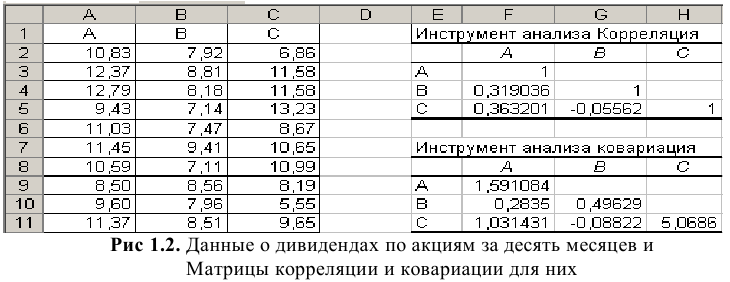
Описание результатов
Коэффициенты корреляции не очень высокие:
Акции плохо коррелируют между собой, то есть между дивидендами по акциям существует слабая линейная зависимость.
Так как коэффициент ковариации для дивидендов по акциям и отрицательный, то прибыль по ним будет изменяться в разных направлениях (при увеличении дивидендов по акциям дивиденды по акциям будут уменьшаться). Правда, эти изменения не очень велики, около 10%.
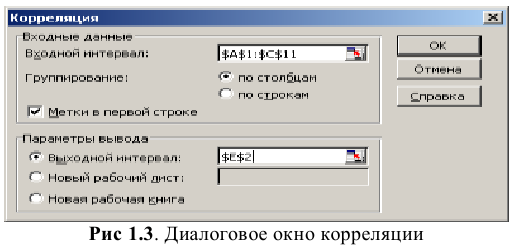
Если рынок ценных бумаг устойчивый, то желательно исключить акции вида из портфеля, так как 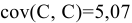 наибольшая, а значит риск в их вложение высокий.
наибольшая, а значит риск в их вложение высокий.
Акции и коррелируют слабо 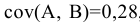 , поэтому есть основания считать, что вложение капитала в равных долях в эти акции будет наименее рискованным. Для более правильного вывода надо вычислить дисперсии для каждого портфеля и сравнить их.
, поэтому есть основания считать, что вложение капитала в равных долях в эти акции будет наименее рискованным. Для более правильного вывода надо вычислить дисперсии для каждого портфеля и сравнить их.
Дисперсии для первого портфеля :
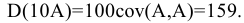
Для второго:
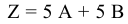
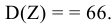
Третий портфель имеет дисперсию:
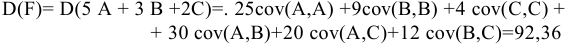
Вывод: наименьший риск получается при покупке акций и в равных долях.
Чтобы принять окончательное решение надо построить множество Парето, характеризующее зависимость доходности портфеля от его риска, т.е. математического ожидания и дисперсии:
Построение тренда для двух рядов данных
Задача построения функциональной зависимости может быть выполнена с помощью команды Добавить линию тренда. В этом случае необходимо визуально исследовать зависимость между х и у и выбрать график элементарной функции, который даст лучшее приближение к экспериментальным данным. Форматирование графиков выполняется с помощью меню Диаграмма. Напомним, что форматируемый объект должен быть выделен.
Существуют и другие способы форматирования: контекстное меню — вызывается для объекта с помощью правой клавиши мыши.
Прежде всего, надо исследовать корреляционное поле и сделать вывод о характере зависимости между переменными. Затем выполните действия (тренд построен для данных примера 1.1):
- На диаграмме (рис. 1.1) выделите маркеры, щелкнув по любой из точек данных.
- В меню диаграмма выберите Добавить линию тренда (можно воспользоваться контекстным меню).
- Перейдите на вкладку Тип диалогового окна Линия тренда, как показано на рис. 1.5 и выделите пиктограмму Линейный.
- Откройте вкладку Параметры (рис. 1.6) включите опции Показывать уравнение на диаграмме и Поместить на диаграмму величину достоверности аппроксимации
 .
.
 .
.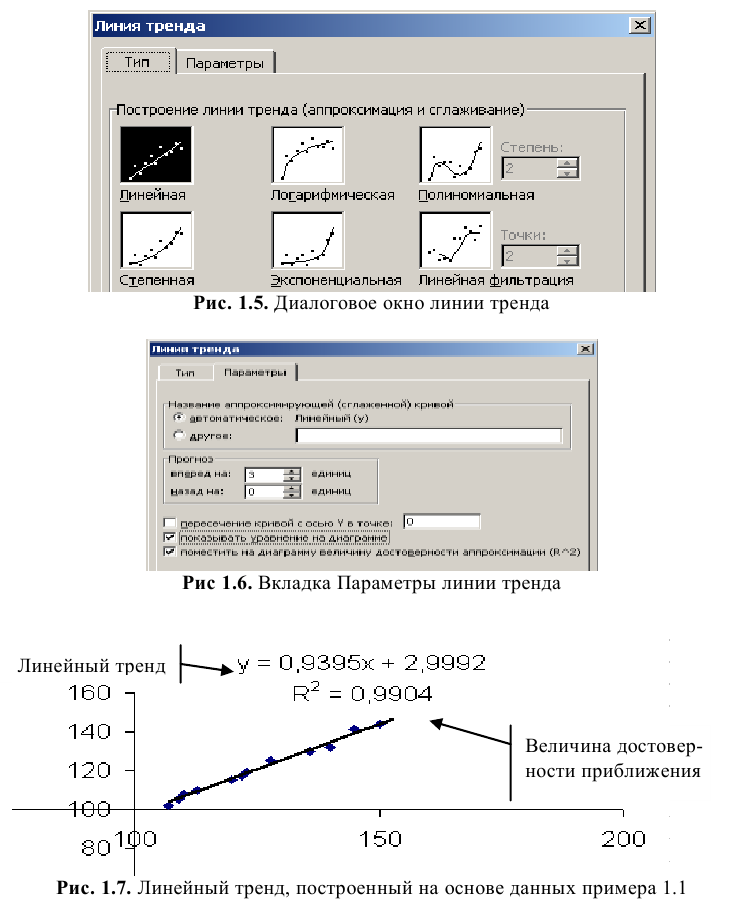
На вкладке параметры имеются и другие типы функциональных зависимостей. Предлагается самостоятельно построить остальные виды тренда и записать их уравнения. Не забывайте включать опции из пункт 4, приведенной выше инструкции.
Инструмент анализа регрессия
Дает возможность провести более полный анализ, полученного уравнения линейного тренда с использованием методов математической статистики.
Коэффициенты уравнения линейной регрессии находятся по выборочным данным и являются величинами случайными, поэтому надо провести анализ их значимости (значимости). Надо определить значимость всего уравнения регрессии и самое главное построить прогноз по построенному уравнению, а затем провести его оценку значимости.
При построении линейного тренда предполагается, что линейная модель наилучшим образом характеризует зависимость между и :
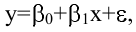
где 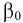 и
и 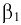 параметры модели;
параметры модели; 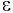 — случайная величина (возмущение), характеризующая влияние неучтенных факторов.
— случайная величина (возмущение), характеризующая влияние неучтенных факторов.
Уравнение прямой (1.2), коэффициенты которого находят по выборочным данным, называют уравнением регрессии и обозначают 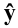 :
:
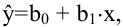
Коэффициенты регрессии 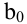 и
и 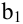 находят по методу наименьших квадратов. Они являются только оценками параметров модели (соответственно и ). Для получения наилучших оценок необходимо, чтобы выполнялся ряд предпосылок относительно случайного отклонения
находят по методу наименьших квадратов. Они являются только оценками параметров модели (соответственно и ). Для получения наилучших оценок необходимо, чтобы выполнялся ряд предпосылок относительно случайного отклонения
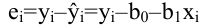
индекс 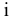 означает значение факторов в одноименном испытании. Это условия Гаусса-Маркова (Приложение 1), а так же предположения:
означает значение факторов в одноименном испытании. Это условия Гаусса-Маркова (Приложение 1), а так же предположения:
• случайные отклонения имеют нормальный закон распределения;
• отсутствуют ошибки спецификации;
• число наблюдений достаточно большое: как минимум в шесть раз превышает число объясняющих факторов и другие.
Оценку называют коэффициентом регрессии. Ее значение показывает среднее изменение результата у с изменением фактора х на одну единицу.
Можно установить зависимость между коэффициентом регрессии и коэффициентом корреляции:
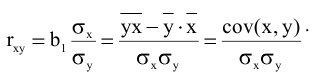
В качестве меры рассеивания фактического значения у относительно теоретического значения (находится по уравнению регрессии) используется стандартная ошибка уравнения регрессии, которая определяется по формуле:
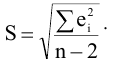
Оценка качества полученного уравнения регрессии содержит следующие пункты:
- Оценка значимости коэффициентов регрессии;
- Построение доверительных интервалов для каждого коэффициента;
- Оценка значимости всего уравнения регрессии;
- Построение прогнозного значения и доверительного интервала к ним. Для определения статистической значимости коэффициентов регрессии и корреляции необходимо рассчитать -статистики Стьюдента лучше всего это сделать с помощью встроенной функции СТЬДРАСПОБР [1].
Оценка значимости коэффициентов регрессии и корреляции
Устанавливает надежность полученных результатов. Случайные ошибки коэффициента корреляции и оценок параметров линейной модели вычисляются по формулам:
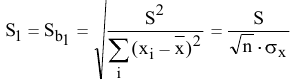
стандартное отклонение коэффициента .
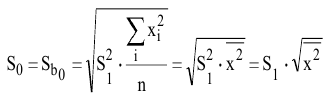
стандартное отклонение коэффициента .
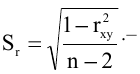
стандартное отклонение коэффициента корреляции.
Любое стандартное отклонение иногда называют стандартной ошибкой соответствующего коэффициента.
Рассматривается основная гипотеза о равенстве параметров регрессии нулю.
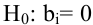 — коэффициент незначим;
— коэффициент незначим; 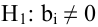 — коэффициент значимый По выборке находят
— коэффициент значимый По выборке находят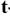 -статистики
-статистики 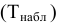 :
:
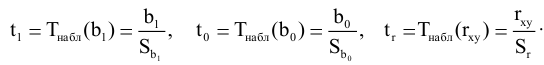
Критическое значение 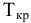 для
для  -статистик находят с помощью распределения Стьюдента. Для этого надо знать объем выборки и задать уровень значимости
-статистик находят с помощью распределения Стьюдента. Для этого надо знать объем выборки и задать уровень значимости  . Например, для
. Например, для
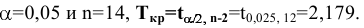
Выдвинутая гипотеза:
Часто при проверке качества коэффициентов используют «грубое правило»:
• если 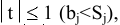 то коэффициент статистически незначим;
то коэффициент статистически незначим;
• если 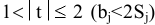 , то коэффициент относительно слабо значим, рекомендуется воспользоваться таблицей критических точек распределения Стьюдента;
, то коэффициент относительно слабо значим, рекомендуется воспользоваться таблицей критических точек распределения Стьюдента;
• если 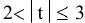 , то коэффициент значим (это утверждение считается гарантированным при
, то коэффициент значим (это утверждение считается гарантированным при 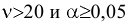 );
);
• если 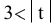 , то коэффициент считается сильно значимым (вероятность ошибки при достаточном числе наблюдений не превосходит 0,001).
, то коэффициент считается сильно значимым (вероятность ошибки при достаточном числе наблюдений не превосходит 0,001).
Каждая оценка дополняется доверительным интервалом. Для этого определяют предельную ошибку [1] для каждого коэффициента:
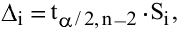
откуда границы доверительных интервалов находятся по формуле:
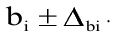
Коэффициент детерминации для парной регрессии совпадает с квадратом коэффициента корреляции  и характеризует долю дисперсии результативного признака
и характеризует долю дисперсии результативного признака  , объясняемую регрессией в общей дисперсии результативного при-знака. Соответственно величина
, объясняемую регрессией в общей дисперсии результативного при-знака. Соответственно величина 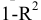 характеризует долю дисперсии у, вызванную влиянием неучтенных факторов в общей дисперсии признака .
характеризует долю дисперсии у, вызванную влиянием неучтенных факторов в общей дисперсии признака .
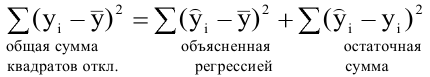
Разделив обе части уравнения на общую сумму квадратов отклонений, получим:
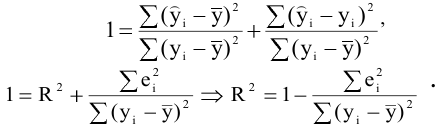
Таким образом, коэффициент детерминации 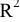 является мерой, позволяющей определить, в какой степени найденная прямая регрессии дает лучший результат для объяснения поведения зависимой переменной , чем горизонтальная прямая
является мерой, позволяющей определить, в какой степени найденная прямая регрессии дает лучший результат для объяснения поведения зависимой переменной , чем горизонтальная прямая  . Очевидно, что
. Очевидно, что  . Откуда следует, что чем ближе он к единице, тем больше уравнение регрессии объясняет поведение фактических значений . Поэтому хотелось бы стремятся построить регрессию с наибольшим значением .
. Откуда следует, что чем ближе он к единице, тем больше уравнение регрессии объясняет поведение фактических значений . Поэтому хотелось бы стремятся построить регрессию с наибольшим значением .
Корень квадратный из коэффициента детерминации называется индексом корреляции и обозначают 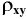 .
.
Для проверки общего качества уравнения регрессии выдвигается предположение, что коэффициенты 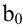 и
и 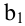 одновременно равны нулю, тогда уравнение считают незначимым, в противном случае значимым. Данная гипотеза проверяется на основе дисперсионного анализа, при этом сравниваются объясненная и остаточная дисперсии:
одновременно равны нулю, тогда уравнение считают незначимым, в противном случае значимым. Данная гипотеза проверяется на основе дисперсионного анализа, при этом сравниваются объясненная и остаточная дисперсии:
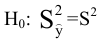 — уравнение незначимо,
— уравнение незначимо,
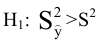 — уравнение значимо. Строится
— уравнение значимо. Строится  -статистика:
-статистика:
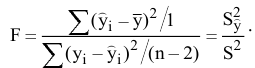
При выполнении условий МНК статистика имеет распределение Фишера с числом степеней свободы  . При уровне значимости
. При уровне значимости  находят критичекую точку
находят критичекую точку 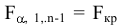 с помощью функции FHOBP и сравнивают его с наблюдаемым значением . Так как рассматриваемая гипотеза правосторонняя [1], то:
с помощью функции FHOBP и сравнивают его с наблюдаемым значением . Так как рассматриваемая гипотеза правосторонняя [1], то:
■ если 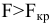 то гипотеза
то гипотеза  отклоняется в пользу
отклоняется в пользу  что означает объясненная дисперсия существенно больше остаточной, следовательно, уравнение регрессии достаточно качественно отражает динамику изменения зависимой переменной от объясняющей.
что означает объясненная дисперсия существенно больше остаточной, следовательно, уравнение регрессии достаточно качественно отражает динамику изменения зависимой переменной от объясняющей.
■ если 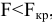 , то гипотеза принимается, т.е. объясненная дисперсия соизмерима с остаточной дисперсией, вызванной случайными факторами. Это позволяет считать влияние объясняющих переменных модели несущественным, а следовательно, общее качество уравнения регрессии невысоким.
, то гипотеза принимается, т.е. объясненная дисперсия соизмерима с остаточной дисперсией, вызванной случайными факторами. Это позволяет считать влияние объясняющих переменных модели несущественным, а следовательно, общее качество уравнения регрессии невысоким.
В случае линейной регрессии проверка нулевой гипотезы для -статистики равносильна проверке нулевой гипотезы для  -статистики для коэффициента корреляции:
-статистики для коэффициента корреляции:
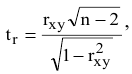
Можно доказать равенство:
Самостоятельную значимость коэффициент 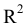 приобретает в случае множественной регрессии.
приобретает в случае множественной регрессии.
Поиск прогнозного значения и его оценка
Прогнозное значение 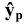 определяется, если в уравнение регрессии подставить значение
определяется, если в уравнение регрессии подставить значение 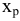 :
:
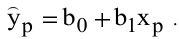
Границы доверительного интервала для параметра 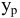 будут равны:
будут равны:
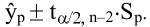
Чтобы найти стандартную ошибку 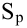 прогнозного значения можно использовать два подхода: либо рассматривать параметр как отдельное значение переменной ; или разброс найти как условное среднее значение при известном значении .
прогнозного значения можно использовать два подхода: либо рассматривать параметр как отдельное значение переменной ; или разброс найти как условное среднее значение при известном значении .
Доверительный интервал для отдельного значения учитывает источники рассеяния: для коэффициентов регрессии (1.5, 1.6) и всего уравнения регрессии (1.4). В этом случае стандартная ошибка прогноза вычисляется по формуле:
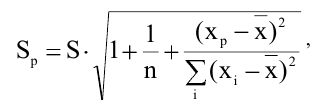
Доверительный интервал для условного среднего не учитывает дисперсию для всего уравнения регрессии (1.4), поэтому формула для вычисления ошибки прогноза имеет вид:
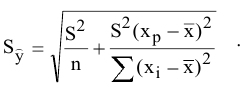
Пример с решением №7.3.
Воспользуемся данными примера 1.1 для выполнения следующих заданий:
- по данным выборок постройте линейную модель ;
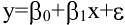 ;
;a. оценить параметры уравнения регрессии  ;
;
b. оценить статистическую значимость коэффициентов регрессии;
c. оценить силу линейной зависимости между  и
и 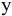 ;
;
d. спрогнозируйте потребление при доходе  .
.
- постройте модель, не содержащую свободный член .
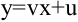 .
.a. найдите коэффициент регрессии  ,
,
b. оценить статистическую значимость коэффициента ;
c. оценить силу общее качество уравнения регрессии;
- значимо или нет различаются коэффициенты на?
- какую модель вы выбираете?
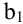 на?
на?Инструкции для выполнения примера с помощью инструмента Регрессия пакета анализ.
Для задания 1.
- Наберите исходные данные на лист Excel, как и раньше по столбцам (рис 1.1).
- Найдите инструмент Регрессия в пакете Анализ данных и нажмите ОК. появится диалоговое окно (рис. 1.8)
- Входной интервал : введите ссылки на значения переменной , включая метки диапазона.
- Входной интервал : введите ссылки на значения переменной , включая метки диапазона.
- Включите опцию Метки.
- Включите опцию Уровень надежности и введите в поле значение 98.
- Установите параметр вывода результатов, имя ячейки.
- Включите опцию вывод остатков для получения теоретических значений .
- Нажмите ОК.
- Появятся итоговые результаты (рис 1.9).
- Выделите диапазон Вывод остатков и перенесите его, как показано на рис. 1.9.
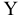 : введите ссылки на значения переменной
: введите ссылки на значения переменной 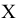 : введите ссылки на значения переменной
: введите ссылки на значения переменной Все оценки по умолчанию проводятся в excel с уровнем значимости 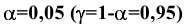
Описание результатов поданным примера 1.1
Рисунок 1.9. состоит из четырех блоков: Регрессионная статистика, Дисперсионный анализ, данных для коэффициентов регрессии и их оценок, вывод остатков. Опишем более подробно полученные результаты.
Регрессионная статистика содержит строки, характеризующие построенное уравнение регрессии:
Для парной регрессии Множественный 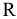 равен коэффициенту корреляции
равен коэффициенту корреляции 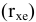 . По его значению 0,9952 можно сказать, что между и существует сильная линейная зависимость.
. По его значению 0,9952 можно сказать, что между и существует сильная линейная зависимость.
Строка -квадрат равна коэффициенту корреляции в квадрате. Нормированный -квадрат рассчитывается с учетом степеней свободы числителя  и знаменателя
и знаменателя  по формуле 1.11. Более подробно свойства этого коэффициента будут рассмотрены в разделе множественная линейная регрессия. Стандартная ошибка
по формуле 1.11. Более подробно свойства этого коэффициента будут рассмотрены в разделе множественная линейная регрессия. Стандартная ошибка  регрессии вычисляется по формуле 1.4. Последняя строка содержит количество выборочных данных
регрессии вычисляется по формуле 1.4. Последняя строка содержит количество выборочных данных  .
.
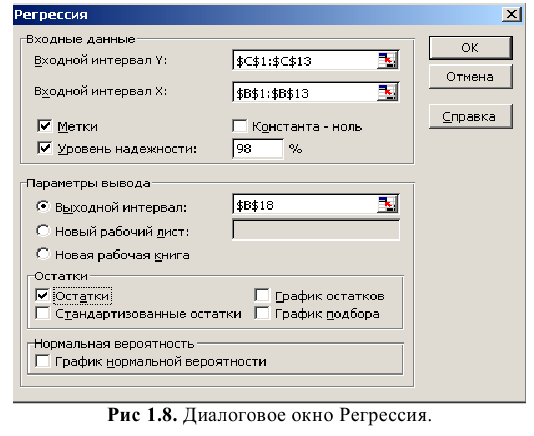

Дисперсионный анализ
Он позволяет исследовать общую дисперсию у (строка ИТОГО), дисперсию для теоретических данных (строка Регрессия) и остаточную дисперсию (строка Остаток).
Второй столбец  содержит число степеней свободы для каждой из сумм формулы 1.11*.
содержит число степеней свободы для каждой из сумм формулы 1.11*.
В третьем столбе 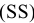 находятся суммы квадратов (1.11*).
находятся суммы квадратов (1.11*).
Четвертый столбец 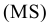 содержит средние значения
содержит средние значения 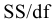 для регрессии и остатков.
для регрессии и остатков.
В пятом столбце вычисляется по выборочным данным значение статистика 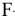 (1.12). Последний столбец, содержит -значение равное
(1.12). Последний столбец, содержит -значение равное
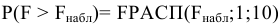
с уровнем значимости 0,05. С его помощью можно оценить значимость всего уравнения регрессии. Это значение можно считать вероятностью выполнения гипотезы  . В нашем случае она практически равна нулю, следовательно, построенное уравнение дает хорошее приближение к исходным данным.
. В нашем случае она практически равна нулю, следовательно, построенное уравнение дает хорошее приближение к исходным данным.
Построение уравнения регрессии и оценка значимости ее коэффициентов
Этот блок состоит из трех строк:
названия столбцов — первая строка
 — пересечение — содержит все характеристики для коэффициента
— пересечение — содержит все характеристики для коэффициента  ; третья строка
; третья строка 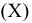 содержит все характеристики для коэффициента
содержит все характеристики для коэффициента  . В столбце коэффициенты находятся их значения
. В столбце коэффициенты находятся их значения
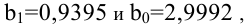
используя их можно записать уравнение линейной регрессии:
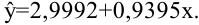
Столбец Стандартная ошибка содержит значения
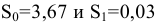
В столбце 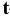 -статистики находятся значения, вычисленные по выборочным данным:
-статистики находятся значения, вычисленные по выборочным данным:
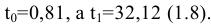
По «грубому правилу» можно сделать вывод, что сильно значимый коэффициент, а незначим.
Подтвердить эти выводы можно с помощью данных столбца 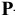 -значение. В этом столбе вычисляются вероятности
-значение. В этом столбе вычисляются вероятности
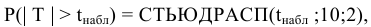
которое можно считать вероятностью выполнения гипотезы  . Эта вероятность для равна нулю, что подтверждает вывод, сделанный по грубому правилу. Для коэффициента с надежностью 43% случаев можно говорить о его незначимости.
. Эта вероятность для равна нулю, что подтверждает вывод, сделанный по грубому правилу. Для коэффициента с надежностью 43% случаев можно говорить о его незначимости.
Доверительные интервалы строятся для коэффициентов по умолчанию с доверительной вероятностью 95%. Границы интервалов находятся в столбцах Нижнее 95%, Верхнее 95%:
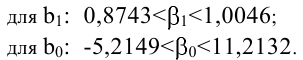
Так как нами была включена опция уровень надежности 98%, то получены доверительные интервалы и для этого значения 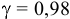 :
:

Описания, приведенные выше, практически позволили ответить на все вопросы задания 1, кроме построения прогнозного значения и доверительного интервала для него. Выполнить это задание можно с помощью блока вывод остатков и функции ТЕНДЕЦИЯ() или непосредственно по формулам (1.14-1.18).
Прогнозируемое потребление при доходе 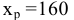 составит для данной модели:
составит для данной модели:
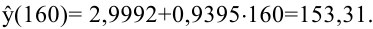
Границы доверительного интервала условного среднего значения 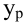 (1.17):
(1.17):
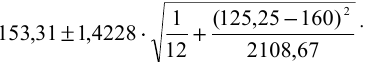
Таким образом, среднее потребление при доходе 160 у.е. с надежностью 95% будет находиться в интервале (152,8993; 15464624).
Для определения границ интервала, в котором сосредоточено не менее 95% возможных объемов потребления при неограниченно большом числе наблюдений и уровне дохода =160, воспользуемся формулой (1.16):
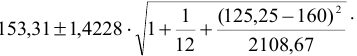
Получим границы интервала для прогнозного значения (151,4791; 155,61409). Нетрудно заметить, что он включает в себя интервал для среднего потребления.
Коэффициент может трактоваться как предельная склонность к потреблению. Фактически он показывает, на какую величину изменится объем потребления, если предполагаемый доход возрастет на единицу.
Свободный член уравнения регрессии определяет прогнозируемое значение при величине располагаемого дохода , равной нулю (т.е. автономное потребление). В нашем примере =2,9992 говорит о том, что при нулевом располагаемом доходе расходы на потребление составят 2,99992 у.е. Это можно объяснить для отдельных хозяйств (каждое может тратить накопленные или одолженные деньги), но для совокупности хозяйств коэффициент теряет смысл.
Следует помнить, что полученное уравнение регрессии отражает лишь общую тенденцию в поведении рассматриваемых переменных. Индивидуальные значения могут отклоняться от модельных.
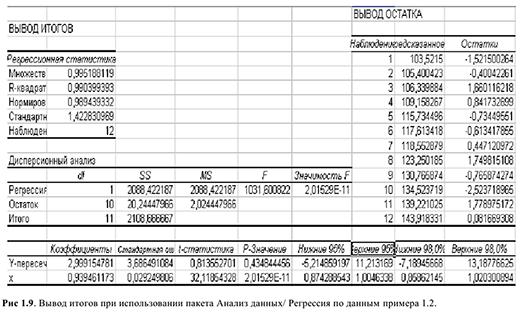
Задание2.
Рассмотрим модельное уравнение, не содержащее свободного члена:
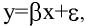
тогда соответствующее ему уравнение регрессии:
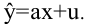
Проведем исследование этого уравнения, так же как и в задании 1. Запустим инструмент Регрессия. Для заполнения полей диалогового окна (рис. 1.8) повторите действия 3 — 6 из задания 1; обязательно включите опцию Константа ноль и измените параметры выходного интервала так, чтобы вывод итогов задания 1 и задания 2 не пересекались.
Вывод итогов в этом случае представлен на рис 1.12. Строка, соответствующая свободному члену уравнения, содержит запись #Н/Д, так как он отсутствует в уравнении.
Проведите описание результатов самостоятельно для полученного уравнения регрессии 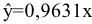 также как в задании 1.
также как в задании 1.
Обратите внимание, что столбцы Верхнее 95% и Нижнее 95% повторяются, так как опция уровень надежности отключена.
Задание 3.
Проверим значимо или нет, различаются коэффициенты и  . Для этого сформулируем гипотезу о равенстве математических ожиданий:
. Для этого сформулируем гипотезу о равенстве математических ожиданий:
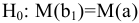 — коэффициенты совпадают, значимого различия нет;
— коэффициенты совпадают, значимого различия нет; 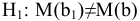 — коэффициенты различаются значимо.
— коэффициенты различаются значимо.
Для проверки гипотезы построим статистику
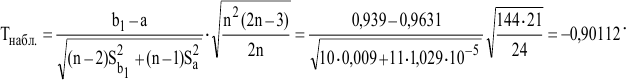
Сравним наблюдаемое значение с критическим при уровне значимости 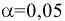 и числом степеней свободы
и числом степеней свободы 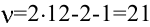 .
.
Найдем критическое значение с помощью встроенной функции Стьюдента 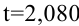 . Поскольку
. Поскольку 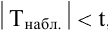 , то нет оснований для отклонения нулевой гипотезы. Это дает основания утверждать, что различия в коэффициентах незначимо.
, то нет оснований для отклонения нулевой гипотезы. Это дает основания утверждать, что различия в коэффициентах незначимо.
Задание 4.
Необходимо сравнить коэффициенты детерминации двух уравнений, значения которых возьмите из отчетов Вывод Итогов (рис. 1.9, рис. 1.10):
для первого уравнения
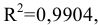
для второго уравнения
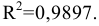
Так как для первого уравнения это значение больше, чем для второго, то можно предположить, что первое уравнение
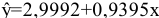
описывает поведение зависимой переменной лучше, чем второе
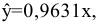
так как её коэффициент детерминации больше. Сравнение двух уравнений регрессии с помощью -статистики будет рассмотрено в разделе множественная линейная регрессия.
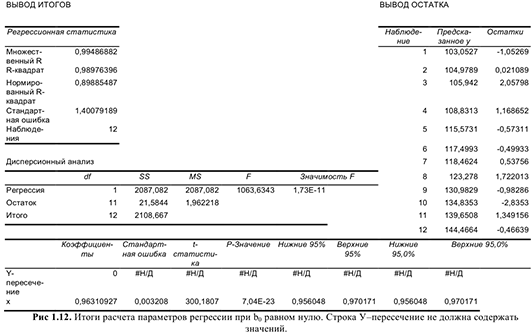
Множественная линейная регрессия
Как правило, на изучаемый фактор  оказывает влияние не один, а несколько факторов
оказывает влияние не один, а несколько факторов  . Например, спрос зависит не только от цены товара, но и от доходов потребителей, а также от цены на замещающие его товары и других факторов.
. Например, спрос зависит не только от цены товара, но и от доходов потребителей, а также от цены на замещающие его товары и других факторов.
Пусть зависимая переменная в 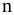 наблюдениях определяется m объясняющими факторами
наблюдениях определяется m объясняющими факторами 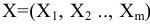 , а функциональная зависимость между ними имеет вид линейной модели:
, а функциональная зависимость между ними имеет вид линейной модели:
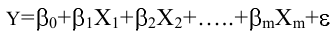
или для индивидуальных наблюдений 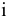 ,где
,где 
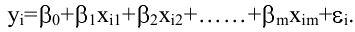
Уравнение регрессии для индивидуальных наблюдений:
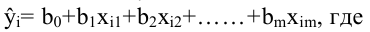
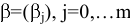 — вектор неизвестных параметров,
— вектор неизвестных параметров,
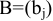 — вектор оценочных параметров,
— вектор оценочных параметров,
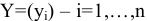 вектор значений зависимой переменной,
вектор значений зависимой переменной,
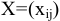 — матрица значений независимых переменных, где
— матрица значений независимых переменных, где 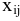 — значение переменной
— значение переменной
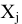 в -том наблюдении,
в -том наблюдении, 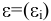 — случайные возмущения,
— случайные возмущения,
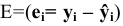 случайный вектор отклонений теоретических значений
случайный вектор отклонений теоретических значений 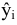 от фактических
от фактических 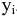 .
.
Тогда уравнение (1.18) можно записать в матричном виде:
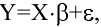
а так же уравнение (1.20):
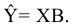
Чтобы найти коэффициенты линейной регрессии (1.20), надо решить уравнение (1.22) относительно матрицы В. Для этого умножают обе части матричного уравнения (1.22) на транспонированную матрицу 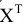 и из полученного уравнения:
и из полученного уравнения:
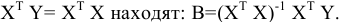
Полученное решение справедливо для уравнений регрессии с произвольным количеством объясняющих факторов 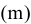 , где
, где 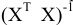 обратная матрица к матрице
обратная матрица к матрице 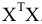 .
.
Решение (1.23) уравнения регрессии (1.22) можно найти:
- с использованием методов матричной алгебры;
- с помощью встроенных функций Excel для работы с массивами: МОБР(), ТРАНСП(), МУМНОЖ();
- применить инструмент анализа Регрессия.
Первый способ изучается в курсе Математика и для его реализации необходимо записать все матрицы, характеризующие уравнение 1.23.
Для реализации второго способа коэффициенты этих матриц надо занести на лист Excel, а затем применить правила работы с массивами данных. Необходимо помнить, что матрицы для этих методов имеют вид:
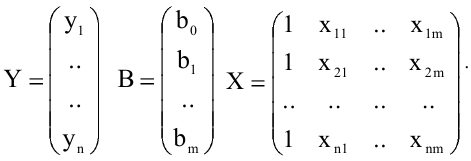
Матрица 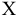 в первом столбце содержит единицы, которые являются коэффициентом при неизвестном
в первом столбце содержит единицы, которые являются коэффициентом при неизвестном 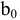 линейной регрессии 1.20.
линейной регрессии 1.20.
Наиболее простым является последний способ поиска коэффициентов регрессии 1.20. Рассмотрим его применение на примере.
Пример с решением №7.4.
Анализируется объем сбережений 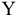 населения за 10 лет. Предполагается, что его размер
населения за 10 лет. Предполагается, что его размер 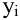 в текущем году зависит от величины
в текущем году зависит от величины 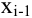 располагаемого дохода в предыдущем году и от величины
располагаемого дохода в предыдущем году и от величины 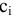 реальной процентной ставки
реальной процентной ставки 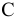 в рассматриваемом году. Статистические данные приведены в таблице:
в рассматриваемом году. Статистические данные приведены в таблице:

Задание:
1) найдите коэффициенты линейной регрессии 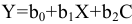
2) оцените статистическую значимость найденных коэффициентов регрессии 
3) оцените силу влияния факторов на объем сбережений населения;
4) постройте 95% -е доверительные интервалы для найденных коэффициентов;
5) вычислите коэффициент детерминации  и оценить его статистическую значимость при
и оценить его статистическую значимость при 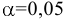 ;
;
6) рассчитайте коэффициенты частной корреляции;
7) определите, какой процент разброса зависимой переменной объясняется данной регрессией;
 найдите скорректированным коэффициент детерминации
найдите скорректированным коэффициент детерминации  и сравните его с коэффициент детерминации .
и сравните его с коэффициент детерминации .
9) оцените предельную склонность граждан к сбережению. Существенно ли отличается она от 0,5?
10) определите, увеличивается или уменьшается объем сбережений с ростом процентной ставки; будет ли ответ статистически обоснованным;
11) спрогнозируйте средний объем сбережений в 2011 году, если предполагаемый доход составит 270 тыс. руб., а процентная ставка будет равна 5,5%.
12) выводы по качеству построенной модели;
Все расчеты выполним с помощью ППП Excel.
Инструкции для выполнения
- Наберите исходные данные на лист Excel, как и раньше по столбцам (рис 1.13).
- Найдите инструмент Регрессия в пакете Анализ данных и нажмите , появится диалоговое окно (рис. 1.8)
- Входной интервал : введите ссылки на значения переменной в столбце , включая метки диапазона.
- Входной интервал : введите ссылки на значения переменной в столбцах и , включая метки диапазона.
- Включите опцию Метки.
- Включите опцию Уровень надежности и введите в поле значение 99.
- Установите параметр вывода результатов, имя ячейки.
- Включите опцию вывод остатков для получения теоретических значений .
- Нажмите .
- Появятся итоговые результаты (рис 1.14).
 , появится диалоговое окно (рис. 1.8)
, появится диалоговое окно (рис. 1.8) : введите ссылки на значения переменной в столбце
: введите ссылки на значения переменной в столбце  , включая метки диапазона.
, включая метки диапазона. : введите ссылки на значения переменной в столбцах
: введите ссылки на значения переменной в столбцах  .
.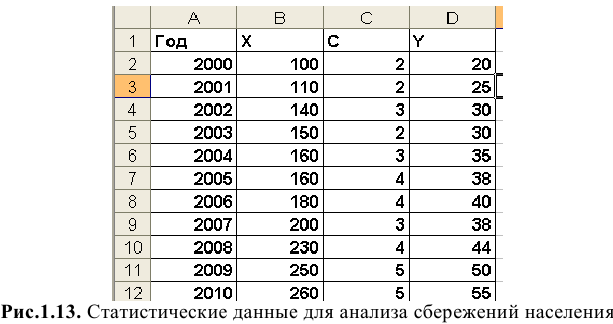
Описание результатов уравнение линейной регрессии
Используя столбец Коэффициенты, запишем уравнение регрессии:
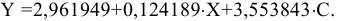
При изменении доходов в предшествующем году на одну тысячу рублей сбережения увеличатся на 120 рублей, если экономическая ситуация будет стабильной. При увеличении процентной ставки на 1% сбережения могут увеличиться на 350 рублей.
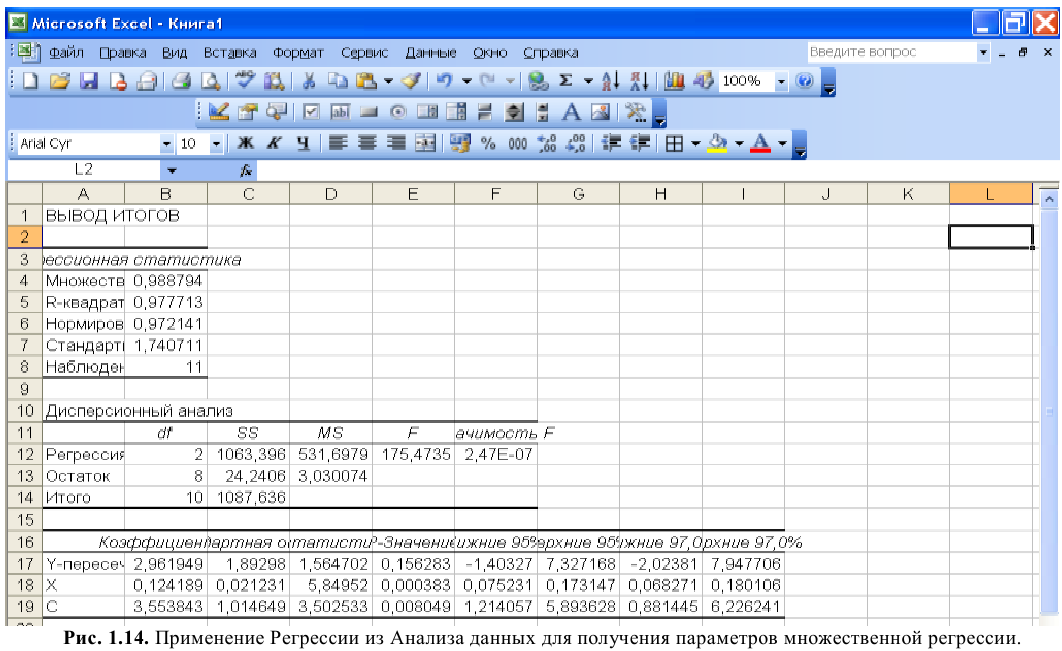
Значимость коэффициентов регрессии
Значение  — статистик находятся в столбце с одноименным названием:
— статистик находятся в столбце с одноименным названием:
Используя «грубое правило», можно сделать вывод, что коэффициенты 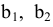 значимы, так как они превышают значение три. Коэффициент
значимы, так как они превышают значение три. Коэффициент  относительно слабо значим. Убедится в этих выводах можно используя СТЬЮДРАСПОБР(), с помощью которой найдите критические точки и постройте двухстороннюю критическую область. Для различных уровней значимости:
относительно слабо значим. Убедится в этих выводах можно используя СТЬЮДРАСПОБР(), с помощью которой найдите критические точки и постройте двухстороннюю критическую область. Для различных уровней значимости:
Этот же вывод получите, если исследуете показания столбца  -значение. Коэффициент существенного влияния на переменную
-значение. Коэффициент существенного влияния на переменную 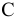 не оказывает, т.е. может быть исключен из модели. Однако, учитывая, что в экономике, свободный член отражает экзогенную среду, лучше его оставить в уравнении регрессии, так как наличие свободного члена в линейном уравнении может только уточнить вид зависимости.
не оказывает, т.е. может быть исключен из модели. Однако, учитывая, что в экономике, свободный член отражает экзогенную среду, лучше его оставить в уравнении регрессии, так как наличие свободного члена в линейном уравнении может только уточнить вид зависимости.
Значение -статистики для коэффициента -пересечение обычно не используется.
Сравнение коэффициентов регрессии
Простое сопоставление коэффициентов регрессии по модулю не может оценить силу влияния факторов на признак у: такое сопоставление лишено смысла. Однако их можно нормировать (стандартизировать), используя формулу:
где 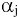 — коэффициент регрессии после нормирования,
— коэффициент регрессии после нормирования,  — стандартная ошибка переменной
— стандартная ошибка переменной 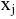 ;
; 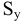 — стандартная ошибка переменной
— стандартная ошибка переменной  .
.
Нормированные коэффициенты можно сравнивать и делать вывод о влиянии факторов на переменную . Факторы с наименьшим по модулю значением оказывают на наименьшее влияние.
Уравнение регрессии в стандартизованном масштабе имеет вид:
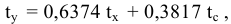
это означает, что влияние процентной ставки 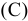 на объем вкладов
на объем вкладов 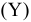 меньше, чем влияние уровня доходов за предшествующий период
меньше, чем влияние уровня доходов за предшествующий период 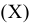 .
.
Доверительные интервалы для коэффициентов
Находятся в столбцах нижнее/верхнее 95%:
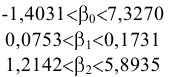
Можно построить доверительные интервалы с уровнем надежности 97% (Рис. 1.14).
Коэффициент детерминации
Коэффициент детерминации находится по формуле (1.11):
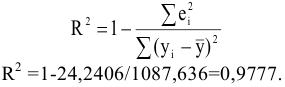
Он характеризует долю разброса значений зависимой переменной 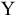 , объясненной уравнением регрессии. В нашем примере, 98% разброса переменной объясняется построенным уравнением регрессии.
, объясненной уравнением регрессии. В нашем примере, 98% разброса переменной объясняется построенным уравнением регрессии.
Скорректированный коэффициент детерминации
В случае множественной регрессии коэффициент детерминации является неубывающей функцией числа объясняющих переменных, т.е. добавление новой переменной увеличивает значение 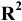 . Поэтому при расчете коэффициента детерминации для получения несмещенных оценок в числителе и знаменателе формулы 1.11 делается поправка на число степеней свободы. Найденное значение называется скорректированным коэффициентом детерминации:
. Поэтому при расчете коэффициента детерминации для получения несмещенных оценок в числителе и знаменателе формулы 1.11 делается поправка на число степеней свободы. Найденное значение называется скорректированным коэффициентом детерминации:
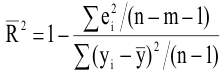
■ 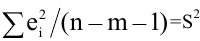 — является несмещенной оценкой остаточной дисперсии, т.е. дисперсией случайных отклонений точек наблюдений от линии регрессии. Ее число степеней свободы равно
— является несмещенной оценкой остаточной дисперсии, т.е. дисперсией случайных отклонений точек наблюдений от линии регрессии. Ее число степеней свободы равно 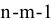 , где
, где 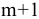 степень свободы связана с необходимостью решения системы линейного уравнения;
степень свободы связана с необходимостью решения системы линейного уравнения;
■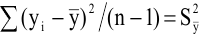 — является несмещенной оценкой общей дисперсии, т.е. дисперсией отклонения
— является несмещенной оценкой общей дисперсии, т.е. дисперсией отклонения 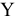 от
от 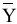 , где одна степень теряется при вычислении .
, где одна степень теряется при вычислении .
Заметим, что несмещенная оценка объясненной дисперсии 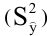 , т.е. дисперсии отклонения точек
, т.е. дисперсии отклонения точек 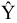 от
от 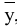 , имеет
, имеет 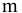 степеней свободы.
степеней свободы.
Все суммы можно найти в столбце 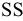 дисперсионного анализа, их средние значения в столбце
дисперсионного анализа, их средние значения в столбце 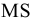 , а число степеней свободы в столбце
, а число степеней свободы в столбце 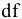 этого же блока.
этого же блока.
Для нашего примера 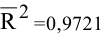 находится в блоке регрессионная статистика в строке нормированный.
находится в блоке регрессионная статистика в строке нормированный.
Можно получить формулу, устанавливающую связь между скорректированным коэффициентом детерминации и коэффициентом детерминации:
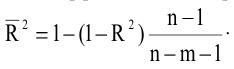
Очевидно, что:
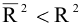 для
для 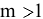 ,
, 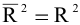 только при
только при 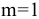 .
.
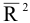 может принимать отрицательные значения (например, если
может принимать отрицательные значения (например, если 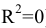 )
)
Коэффициент корректируется с ростом числа объясняющих переменных. Доказано, что скорректированный коэффициент корреляции увеличивается при добавлении новой переменной тогда и только тогда, когда  — статистика этой переменной по модулю больше единицы. Поэтому добавление в модель новых переменных осуществляется до тех пор, пока он растет.
— статистика этой переменной по модулю больше единицы. Поэтому добавление в модель новых переменных осуществляется до тех пор, пока он растет.
В пакете Анализ данных приводятся значения  и
и  . Значимость коэффициента детерминации и скорректированного коэффициента при исследовании уравнения регрессии большая, однако, не абсолютная. При неправильной спецификации модели можно получить очень высокие значения этих коэффициентов, поэтому и рассматриваются как один из ряда показателей, которые нужно проанализировать, чтобы уточнить строящуюся модель.
. Значимость коэффициента детерминации и скорректированного коэффициента при исследовании уравнения регрессии большая, однако, не абсолютная. При неправильной спецификации модели можно получить очень высокие значения этих коэффициентов, поэтому и рассматриваются как один из ряда показателей, которые нужно проанализировать, чтобы уточнить строящуюся модель.
Индекс множественной корреляции
Теснота линейной взаимосвязи в линейной регрессии выполняется с помощью индекса корреляции:
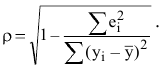
Если  — неслучайная величина, то
— неслучайная величина, то  характеризует качество подбора уравнения регрессии. Если же — случайная переменная, то индекс корреляции является мерой тесноты линейной взаимосвязи между
характеризует качество подбора уравнения регрессии. Если же — случайная переменная, то индекс корреляции является мерой тесноты линейной взаимосвязи между  и набором факторов .
и набором факторов .
Для нашего примера 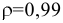 находим в строке Множественный рис 1.18.
находим в строке Множественный рис 1.18.
Коэффициенты частной корреляции
Используются для выделения определяющего фактора и второстепенных. Необходимо определить частные зависимости между 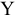 и
и 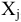 , при условии, что воздействие остальных факторов исключено (элиминировано). В случае трех переменных
, при условии, что воздействие остальных факторов исключено (элиминировано). В случае трех переменных 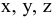 можно получить коэффициенты парной корреляции
можно получить коэффициенты парной корреляции 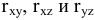 по формулам:
по формулам:
Воспользуйтесь инструкциями примера 1.2. и найдите коэффициенты парной корреляции для вычисления коэффициентов частной корреляции.
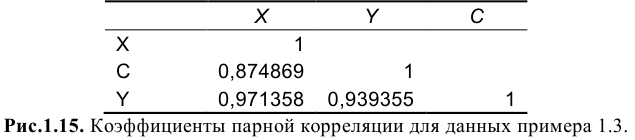
Анализируя, полученные данные можно сказать, что факторы и дублируют друг друга 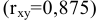 . Сравнивая их влияние на фактор
. Сравнивая их влияние на фактор  можно сделать вывод об исключении переменной из уравнения регрессии, так как
можно сделать вывод об исключении переменной из уравнения регрессии, так как 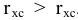 . Постройте уравнение регрессии, не содержащее фактор
. Постройте уравнение регрессии, не содержащее фактор 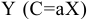 . Сравните коэффициенты детерминации двух уравнений и сделайте вывод: следует исключать фактор или оставить его при построении уравнения регрессии.
. Сравните коэффициенты детерминации двух уравнений и сделайте вывод: следует исключать фактор или оставить его при построении уравнения регрессии.
Доверительный интервал прогноза
Если уравнение регрессии имеет вид:
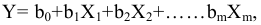
то прогнозное значение вычисляется так же как в случае парной регрессии. Необходимо подставить заданные значения прогноза
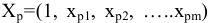
в уравнение регрессии.
Найдем средний объем сбережений в 2011 году, если предполагаемый доход в 2010 году составит 270 тыс. рублей, а процентная ставка вырастет до 5,5%. Подставив эти значения в уравнение регрессии, получим средний объем сбережений в 2011 году: 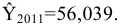
Точечная оценка объема сбережений в 2011 году может быть дополнена интервальной оценкой, полученной по формуле 1.15:
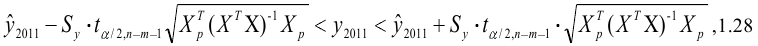
где
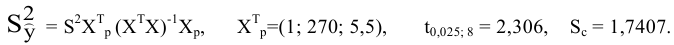
Используя встроенные функции Excel, найдем матричное произведение:
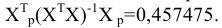
Подставив все значения в 1.28, найдем интервальные оценки среднего сбережения населения в 2011 году:
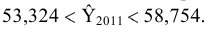
Склонность населения к сбережению в данной модели отражается через коэффициент 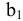 , определяющий на какую величину вырастет объем сбережений
, определяющий на какую величину вырастет объем сбережений 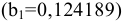 при росте располагаемого дохода на одну единицу.
при росте располагаемого дохода на одну единицу.
Для анализа, существенно или нет коэффициент 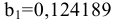 отличается от 0,5, проверим гипотезу:
отличается от 0,5, проверим гипотезу:
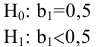
Построим 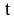 статистику, которая имеет распределение Стьюдента. Зададим уровень значимости
статистику, которая имеет распределение Стьюдента. Зададим уровень значимости 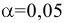 , число степеней свободы
, число степеней свободы 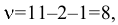 тогда:
тогда:
Так как
то  должна быть отклонена. Действительно 50% склонность населения к сбережениям явно завышена по сравнению с модельным значением в 12,4%.
должна быть отклонена. Действительно 50% склонность населения к сбережениям явно завышена по сравнению с модельным значением в 12,4%.
Рост процентной ставки увеличивает объем сбережений
Эта зависимость характеризуется коэффициентом 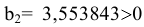 . Так как коэффициент статистически значим, то ответ будет статистически обоснованным.
. Так как коэффициент статистически значим, то ответ будет статистически обоснованным.
Анализ качества уравнения регрессии
Первое построенное по выборке уравнение редко является удовлетворительным по тем или иным характеристикам. Поэтому следующей задачей эконометрического анализа является проверка качества уравнения регрессии. Эта проверка проводится по следующим этапам:
■ проверка статистической значимости коэффициентов регрессии;
■ проверка общего качества уравнения регрессии;
■ проверка свойств данных: проверка выполнимости МНК.
По всем показателям нашего примера 1.3 модель может быть признана удовлетворительной:
■ высокие -статистики;
■ коэффициент детерминации близок к единице;
Это означает, что модель может быть использована для целей анализа и прогнозирования. Мы не проверили выполнимость МНК и значимость коэффициента детерминации.
Анализ значимости
Проверяется гипотеза об одновременном равенстве нулю всех объясняющих переменных — уравнение считается незначимым:
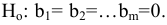
Если данная гипотеза не отклоняется, то делается вывод, что совокупное влияние всех m объясняющих переменных на зависимую переменную можно считать статистически незначимым, а общее качество уравнения регрессии невысоким.
Проверка данной гипотезы проводится на основе дисперсионного анализа, при этом сравниваются объясненная и остаточная дисперсии.
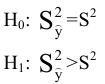
Для проверки гипотезы строится 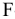 -статистика:
-статистика:
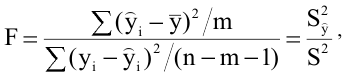
которая при выполнении МНК имеет распределение Фишера с числом степеней свободы
Критическое значение находится с помощью:
при уровне значимости  .
.
■ Если 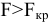 то гипотеза отклоняется в пользу
то гипотеза отклоняется в пользу 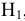 что означает объясненная дисперсия существенно больше остаточной, следовательно, уравнение регрессии достаточно качественно отражает динамику изменения зависимой переменной от объясняющей.
что означает объясненная дисперсия существенно больше остаточной, следовательно, уравнение регрессии достаточно качественно отражает динамику изменения зависимой переменной от объясняющей.
■ Если 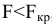 , то гипотеза принимается, т.е. объясненная дисперсия соизмерима с остаточной дисперсией, вызванной случайными факторами. Это позволяет считать влияние объясняющих переменных модели несущественным, а следовательно, общее качество уравнения регрессии невысоким.
, то гипотеза принимается, т.е. объясненная дисперсия соизмерима с остаточной дисперсией, вызванной случайными факторами. Это позволяет считать влияние объясняющих переменных модели несущественным, а следовательно, общее качество уравнения регрессии невысоким.
На практике вместо указанной гипотезы проверяется, связанная с ней гипотеза о статистической значимости коэффициента детерминации  .
.
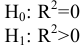
Очевидно, что если  , а линия регрессии
, а линия регрессии  является наилучшей по МНК, т.е. величина
является наилучшей по МНК, т.е. величина 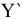 линейно не зависит от
линейно не зависит от 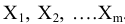 . Анализ статистики
. Анализ статистики  позволяет сделать вывод о том, что для принятия гипотезы об одновременном равенстве нулю всех коэффициентов линейной регрессии коэффициент детерминации
позволяет сделать вывод о том, что для принятия гипотезы об одновременном равенстве нулю всех коэффициентов линейной регрессии коэффициент детерминации  не должен существенно отличаться от нуля. Его критическое значение уменьшается при росте числа наблюдений и может стать сколь угодно малым.
не должен существенно отличаться от нуля. Его критическое значение уменьшается при росте числа наблюдений и может стать сколь угодно малым.
Для проверки этой гипотезы числитель и знаменатель формулы 1.29 поделим на общую сумму квадратов отклонений 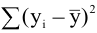 и получим:
и получим:
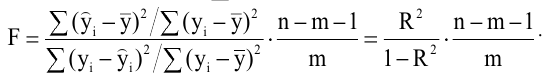
Вернемся к результатам нашего примера 1.3. (рис. 1.14).Найдем по таблице распределения Фишера критическую точку для уровня значимости 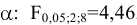 . Сравнивая критическое и наблюдаемое значения
. Сравнивая критическое и наблюдаемое значения 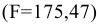 , можно сделать вывод, что коэффициент детерминации статистически значим. Это означает, что совокупное влияние переменных
, можно сделать вывод, что коэффициент детерминации статистически значим. Это означает, что совокупное влияние переменных  и
и 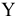 на переменную
на переменную 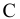 существенно. Этот же вывод можно сделать по столбцу значимость , который характеризует вероятность выполнения гипотезы .
существенно. Этот же вывод можно сделать по столбцу значимость , который характеризует вероятность выполнения гипотезы .
Проверка качества двух коэффициентов детерминации
Статистику можно использовать и для обоснования случая исключения или добавления в уравнение регрессии 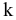 объясняющих переменных. Добавлять (исключать) переменные надо по одному.
объясняющих переменных. Добавлять (исключать) переменные надо по одному.
Использовать лучше 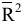 так как всегда растет при добавлении новой объясняющей переменной. Зависимая переменная должна быть представлена в том же виде, что и уже существующие в исследуемом уравнении регрессии. Число наблюдений для обеих моделей должно быть одинаковым.
так как всегда растет при добавлении новой объясняющей переменной. Зависимая переменная должна быть представлена в том же виде, что и уже существующие в исследуемом уравнении регрессии. Число наблюдений для обеих моделей должно быть одинаковым.
Пусть первоначально построенное по п наблюдениям уравнение регрессии имело вид:
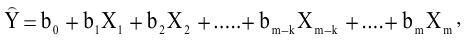
и скорректированный коэффициент детерминации равен 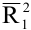 .
.
Исключим из уравнения переменных, оказывающих наименьшее влияние на По 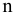 наблюдениям построим новое уравнение регрессии:
наблюдениям построим новое уравнение регрессии:
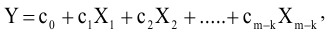
скорректированный коэффициент детерминации, для которого равен 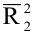 .
.
Необходимо определить существенно ли ухудшилось качество описания зависимой переменной . Для этого выдвинем гипотезы:
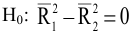 — ничего не изменилось
— ничего не изменилось
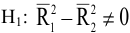 — уравнение ухудшилось, если разность больше нуля. По выборочным данным найдите статистику:
— уравнение ухудшилось, если разность больше нуля. По выборочным данным найдите статистику:
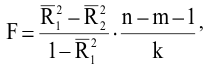
которая имеет распределения Фишера с числом степеней свободы
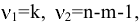
где
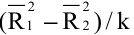 — потеря качества уравнения в результате того, что переменных было отброшено. В результате появляется дополнительных степеней свободы;
— потеря качества уравнения в результате того, что переменных было отброшено. В результате появляется дополнительных степеней свободы; 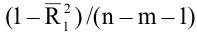 — остаточная дисперсия первоначального уравнения.
— остаточная дисперсия первоначального уравнения.
Сравним критическое значение  и с наблюдаемым при уровне значимости
и с наблюдаемым при уровне значимости 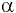 :
:
■ Если 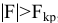 , то гипотеза
, то гипотеза  отклоняется в пользу
отклоняется в пользу  , что означает, одновременное исключение объясняющих переменных существенно повлияет на качество первоначального уравнения.
, что означает, одновременное исключение объясняющих переменных существенно повлияет на качество первоначального уравнения.
■ Если 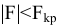 , то гипотеза принимается, т.е. разность
, то гипотеза принимается, т.е. разность 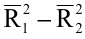 ; незначительная. Это позволяет считать, что исключение объясняющих переменных модели допустимым, так как общее качество уравнения регрессии изменится несущественно.
; незначительная. Это позволяет считать, что исключение объясняющих переменных модели допустимым, так как общее качество уравнения регрессии изменится несущественно.
Аналогично проверяется гипотеза о добавлении к объясняющих переменных в уравнение регрессии. В этом случае составляется статистика:
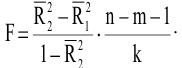
Исключим фактор из уравнения регрессии примера 1.3. построим зависимость между и . с помощью инструмента Регрессия получим уравнение:
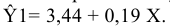
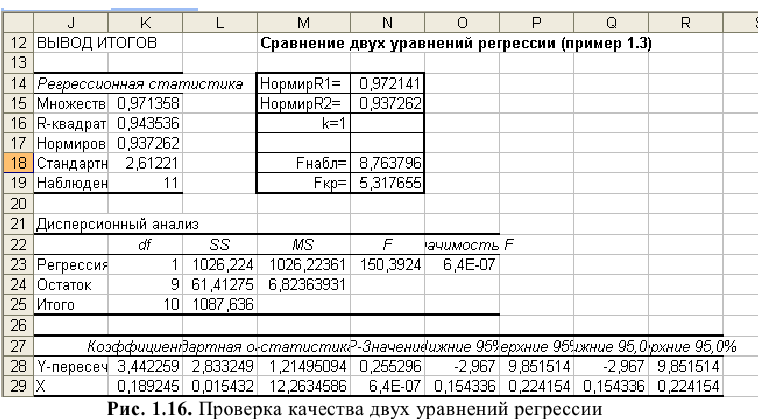
Коэффициенты и все остальные характеристики для этого уравнения регрессии можно посмотреть на рис 1.16. Сравним новое уравнений с уравнением полученным ранее.
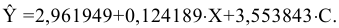
В ячейке N18 находится значение -статистики вычисленное по формуле 1.31. Критическое значение (ячейка N19) находится с помощью встроенной функции Excel при уровне значимости 0,05:
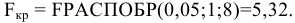
Сравнивая эти два значения делаем вывод, что гипотеза отклоняется в пользу гипотезы то есть новое уравнение ухудшило качество приближения к выборочным данным.
Проверка качества двух коэффициентов детерминации
Необходимо сравнить два уравнения регрессии для отдельных групп наблюдений, т.е. будет одним и тем же уравнение регрессии для этих выборок. Для проверки этой гипотезы используется тест Чоу.
Пусть имеются две выборки объемом 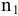 и
и 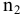 . Для каждой из этих выборок получено уравнение регрессии:
. Для каждой из этих выборок получено уравнение регрессии:
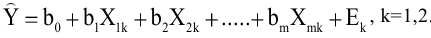
Суммы квадратов отклонений  от линий регрессии обозначим
от линий регрессии обозначим  для первого и
для первого и  для второго уравнения регрессии.
для второго уравнения регрессии.
Выдвинем гипотезу о равенстве соответствующих коэффициентов регрессии
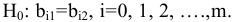
Объединим обе выборки в одну. Для выборки объема  найдем еще одно уравнение регрессии, сумму квадратов отклонений которой обозначим
найдем еще одно уравнение регрессии, сумму квадратов отклонений которой обозначим  . Тогда для проверки гипотезы
. Тогда для проверки гипотезы 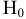 строится статистика:
строится статистика:
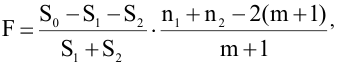
которая имеет распределение Фишера с числом степеней свободы 
Если 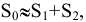 , то значение
, то значение  -статистики приближается к нулю, а это значит, что уравнения регрессии обеих выборок практически одинаковые. А дальше сравним наблюдаемое и критическое значения и делаете вывод принимается или отклоняется гипотеза .
-статистики приближается к нулю, а это значит, что уравнения регрессии обеих выборок практически одинаковые. А дальше сравним наблюдаемое и критическое значения и делаете вывод принимается или отклоняется гипотеза .
Данные исследования отвечают на вопрос, можно ли за рассматриваемый период времени построить единое уравнение регрессии или же нужно разбить его на части и для каждого временного интервала построить свое уравнение регрессии.
Проверка выполнимости мнк. Автокорреляция остатков. Статистика дарбина-уотсона
Все предыдущие рассуждения основаны на том, что выполняются предпосылки МНК: мы предполагали, что случайные отклонения являются независимыми случайными величинами со средней, равной нулю. При работе с фактическими данными, такое допущение не всегда выполняется. Например, если вид функции выбран неудачно, то отклонения от регрессии вряд ли будут независимыми. В этом случае замечается концентрация положительных или отрицательных отклонений от регрессии и можно сомневаться в их случайном характере.
Если последовательные значения 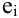 коррелируют (зависят) между собой, то говорят, что имеет место автокорреляция остатков.
коррелируют (зависят) между собой, то говорят, что имеет место автокорреляция остатков.
МНК в случае автокорреляции дает несмещенные и состоятельные оценки, однако полученные в этом случае доверительные интервалы имеют мало смысла в силу своей ненадежности. Значительная автокорреляция говорит о том, что спецификация модели неправильная. Проверка остатков на автокорреляцию должна выполняться обязательно. Наиболее простым приемом обнаружения автокорреляции является метод Дарбина-Уотсона ( ). Идея, которого состоит в том, что проверяются на коррелированность не любые, а только соседние величины . Соседними обычно считаются соседние по возрастанию объясняющей переменной
). Идея, которого состоит в том, что проверяются на коррелированность не любые, а только соседние величины . Соседними обычно считаются соседние по возрастанию объясняющей переменной  ( в случае перекрестной выборки) или по времени (в случае временных рядов) значения .
( в случае перекрестной выборки) или по времени (в случае временных рядов) значения .
Статистика рассчитывается по формуле:
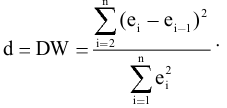
При условии что  и
и  большое число можно предположить
большое число можно предположить
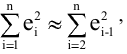
тогда после преобразования получим:
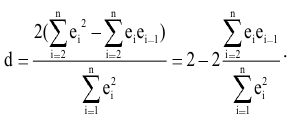
Очевидно, что  так как коэффициент корреляции
так как коэффициент корреляции
■  , если
, если  — автокорреляция отсутствует;
— автокорреляция отсутствует;
■  -полная положительная автокорреляция;
-полная положительная автокорреляция;
■  -полная отрицательная автокорреляция.
-полная отрицательная автокорреляция.
Возникает вопрос, какие значения 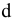 можно считать близкими к 2? Для обнаружения границ наблюдений статистики существуют специальные таблицы. Для заданных
можно считать близкими к 2? Для обнаружения границ наблюдений статистики существуют специальные таблицы. Для заданных 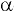 — уровня значимости; — числа наблюдений и
— уровня значимости; — числа наблюдений и 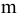 -числа объясняющих переменных указывается два числа:
-числа объясняющих переменных указывается два числа: 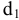 — нижняя граница и
— нижняя граница и 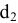 — верхняя граница. Не обращаясь к таблице критических точек DW можно воспользоваться правилом, если l,5<<2,5, автокорреляция отсутствует. Изобразим на рисунке числовой отрезок , используемый для проверки гипотезы об отсутствии автокорреляции.
— верхняя граница. Не обращаясь к таблице критических точек DW можно воспользоваться правилом, если l,5<<2,5, автокорреляция отсутствует. Изобразим на рисунке числовой отрезок , используемый для проверки гипотезы об отсутствии автокорреляции.
Статистику для примера 1.3 находим по формуле (1.35):
Для вычисления этой статистики запустите инструмент Регрессия, включив опции Остатки и График остатков, как показано на рис. 1.18. В результате получите значение случайных отклонений е, и их графики, которые Excel строит для каждой независимой переменной, как показано на рис. 1.20 и 1.21. Чтобы найти , можно использовать функции СУММКВРАЗН и СУММКВ.
Если зависимость между  и
и  линейная, то график остатков должен иметь случайный вид. На рис. 1.21 видим систематический рисунок, поэтому скорее всего между и
линейная, то график остатков должен иметь случайный вид. На рис. 1.21 видим систематический рисунок, поэтому скорее всего между и  существует нелинейная зависимость, а значит надо изменить модель, включая в нее нелинейную зависимость.
существует нелинейная зависимость, а значит надо изменить модель, включая в нее нелинейную зависимость.
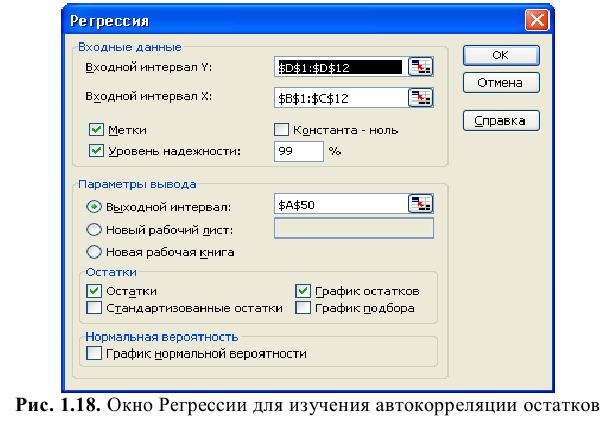
Для проверки статистической значимости надо воспользоваться таблицей критических точек Дарбина-Уотсона, например, при уровне значимости 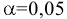 и числе наблюдений
и числе наблюдений
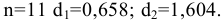
Можно считать, что автокорреляция отсутствует, так как найденная статистика попадает в критический интервал: 1,604<<2,396, что является подтверждением высокого качества модели.
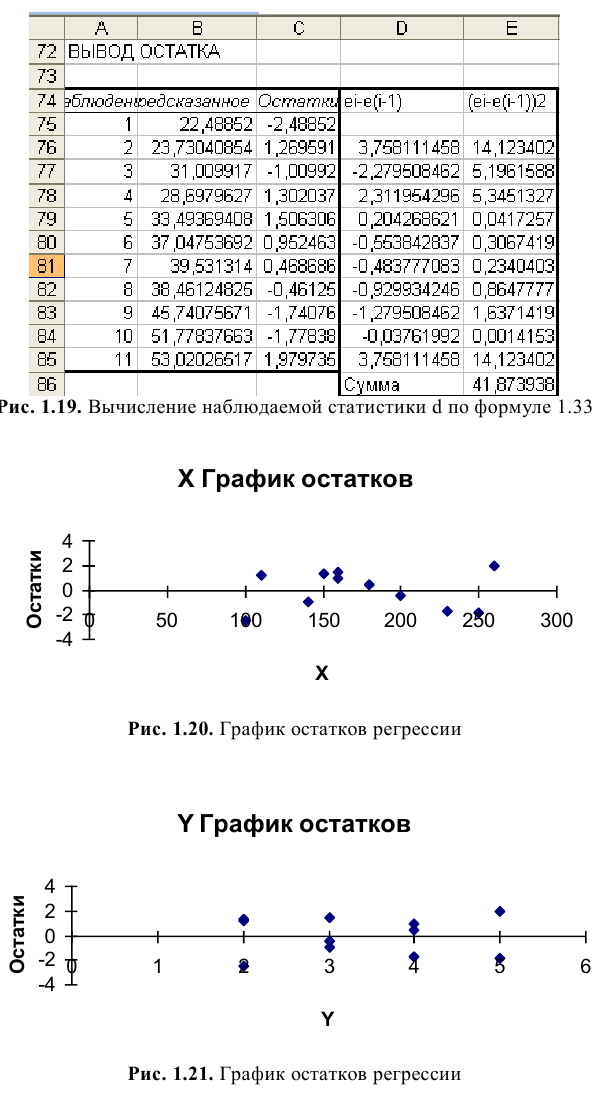
Мультиколлинеарность
Увеличение числа переменных в уравнении множественной регрессии повышает точность описания взаимосвязи, однако при этом должно выполняться условие, что 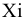 — объясняющие переменные, линейно независимые величины.
— объясняющие переменные, линейно независимые величины.
Под мулыиколлинеарностью понимают взаимосвязь объясняющих переменных регрессии. Если между переменными 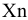 и
и  существует функциональная зависимость
существует функциональная зависимость 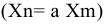 , то говорят о строгой мультиколлинеарности. Чаще всего между переменными существует довольно сильная корреляционная зависимость — в этом случае мультиколлинеарность называют нестрогой.
, то говорят о строгой мультиколлинеарности. Чаще всего между переменными существует довольно сильная корреляционная зависимость — в этом случае мультиколлинеарность называют нестрогой.
При строгой мультиколлинеарности решение матричного уравнения 1.22 становится невозможным, так как матрица 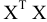 вырожденная — её определитель равен нулю.
вырожденная — её определитель равен нулю.
Если же мультиколлинеарность нестрогая, то решение матричного уравнения формально можно найти, однако все оценки мало надежны.
Чтобы обнаружить мультиколлинеарность надо найти определитель матрицы . Вместо этого проверяется определитель матрицы межфакторной корреляции, которую получают с помощью инструмента КОРРЕЛ.
Устранение мультиколлинеарности заключается в исключении одной из двух, находящихся во взаимосвязи переменных, либо путем пересмотра структуры уравнения регрессии. Для оценки влияния факторов на результирующий фактор в случае используются показатели частной корреляции (1.26). Если число переменных больше трех, то для их определения удобно пользоваться формулой:
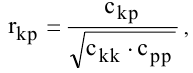
где 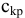 коэффициенты матрицы обратной к матрице парных коэффициентов корреляции.
коэффициенты матрицы обратной к матрице парных коэффициентов корреляции.
Гомоскедастичность (постоянство дисперсии случайных отклонений)
Для применения МНК требуется, чтобы дисперсия остатков была величиной постоянной. Невыполнимость этого условия называется гетероскедастичностью и влечёт смещенность дисперсий оценок, так как стандартная ошибка регрессии (1.4) становится смещенной.
Обнаружение гетероскедастичности является сложной задачей потому что необходимо знать распределение 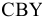 , соответствующее выбранному значению переменной
, соответствующее выбранному значению переменной 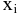 . В тесте Голфелда-Квандта предполагается, что стандартное отклонение пропорционально значению переменной
. В тесте Голфелда-Квандта предполагается, что стандартное отклонение пропорционально значению переменной 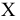 и
и 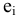 нормально распределены, автокорреляция остатков отсутствует. Проверка на гомоскедастичность по этому тесту содержит следующие шаги:
нормально распределены, автокорреляция остатков отсутствует. Проверка на гомоскедастичность по этому тесту содержит следующие шаги:
- Все наблюдений упорядочивают по величине.
- Упорядоченная выборка разбивается на три подвыборки размерностью , и соответственно.
- Центральные наблюдения исключаются из дальнейшего рассмотрения.
- Строят регрессии для первой и последней групп и находят остаточные суммы квадратов и соответственно. Если условие гомоскедастичности выполняется, то , в противном случае .
- Построенная -статистика, имеет распределение Фишера с степенями свободы, где число объясняющих переменных в уравнении регрессии.
- Чем больше превышает значение , тем более нарушена предпосылка о равенстве остаточных дисперсий.
- НЕЛИНЕЙНАЯ РЕГРЕССИЯ
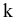 ,
, 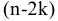 и
и 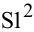 и
и 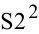 соответственно. Если условие гомоскедастичности выполняется, то
соответственно. Если условие гомоскедастичности выполняется, то 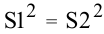 , в противном случае
, в противном случае 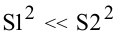 .
.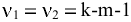 степенями свободы, где
степенями свободы, где 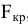 , тем более нарушена предпосылка о равенстве остаточных дисперсий.
, тем более нарушена предпосылка о равенстве остаточных дисперсий.Если между экономическими явлениями существуют нелинейные соотношения, то они выражаются с помощью соответствующих функций:
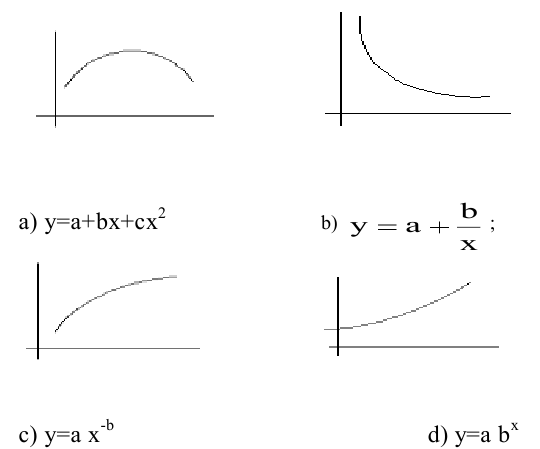
a) квадратичная функция (полином любой степени);
b) равносторонняя гипербола;
c) степенная;
d) показательная и др.
Кроме указанных функций для описания связи двух переменных можно использовать и другие типы кривых:
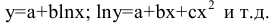
Различают два класса нелинейных уравнений:
1) регрессии, нелинейные относительно включенных объясняющих переменных,
но линейные по оцениваемым параметрам;
2) регрессии, нелинейные по оцениваемым параметрам.
К первому классу — нелинейные по переменным — относятся кривые а и b (рис 2.1). Нелинейными по параметрам (второй класс) являются зависимости c и d на рис. 2.1.
Линейные по параметру
Такие модели легко приводятся к линейному виду — линеаризуются. Для линейных но параметру моделей вводят новую переменную (таблица 2.1) и переходят к построению линейной регрессии по преобразованным данным. Применяя инструмент Регрессия, к преобразованным данным можно найти все оценки параметров преобразованных моделей и оценить их качество.
Качество исходной модели можно оценить, используя индекс корреляции (1.26). Оценка статистической значимости индекса корреляции проводится с помощью 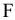 — статистики, так же как и коэффициента детерминации (1.29). Довольно часто в экономических исследованиях для оценки качества построенного уравнения используют среднюю ошибку аппроксимации, которая вычисляется по формуле:
— статистики, так же как и коэффициента детерминации (1.29). Довольно часто в экономических исследованиях для оценки качества построенного уравнения используют среднюю ошибку аппроксимации, которая вычисляется по формуле:
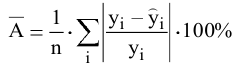
и оценивает по модулю величину отклонений расчетных значений от фактических. Допустимый предел значений средней ошибки аппроксимации не более 8-10%.
Приведем примеры использования нелинейных моделей, перечисленных в таблице 2.1.
Полиномиальная модель (1) может отражать зависимость между объемом выпуска 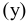 и издержками производства
и издержками производства 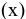 ; или расходами на рекламу и прибылью и т.д. В экономике наиболее часто используют многочлен второй степени реже третьей степени. Ограничения в применении многочленов более высоких степеней связано с требованием однородности исследуемой совокупности: чем выше степень многочлена, тем больше изгибов имеет кривая и соответственно меньше однородность по результативному признаку. Надо помнить, что графики многочленов имеют промежутки монотонности и точки экстремумов, поэтому параметры применения этих моделей не всегда могут быть логически истолкованы. Поэтому, если такая зависимость четко не определена графически (параболическая), то её лучше заменить другой нелинейной функцией.
; или расходами на рекламу и прибылью и т.д. В экономике наиболее часто используют многочлен второй степени реже третьей степени. Ограничения в применении многочленов более высоких степеней связано с требованием однородности исследуемой совокупности: чем выше степень многочлена, тем больше изгибов имеет кривая и соответственно меньше однородность по результативному признаку. Надо помнить, что графики многочленов имеют промежутки монотонности и точки экстремумов, поэтому параметры применения этих моделей не всегда могут быть логически истолкованы. Поэтому, если такая зависимость четко не определена графически (параболическая), то её лучше заменить другой нелинейной функцией.
Гиперболическая модель (2) — классическим примером этой модели является кривая Филлипса  , характеризующая соотношение между уровнем безработицы и процентом прироста заработной платы . При
, характеризующая соотношение между уровнем безработицы и процентом прироста заработной платы . При  кривая характеризуется нижней асимптотой
кривая характеризуется нижней асимптотой 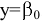 . Соответственно можно определить уровень безработицы, при котором заработная плата стабильна и темп её прироста равен нулю. При
. Соответственно можно определить уровень безработицы, при котором заработная плата стабильна и темп её прироста равен нулю. При 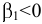 гиперболическая функция будет медленно расти для и имеет горизонтальную асимптоту . Такие кривые называют кривыми Энгеля, который сформулировал закономерность: с ростом доходов доля доходов, расходуемых на продовольствие уменьшается.
гиперболическая функция будет медленно расти для и имеет горизонтальную асимптоту . Такие кривые называют кривыми Энгеля, который сформулировал закономерность: с ростом доходов доля доходов, расходуемых на продовольствие уменьшается.

Полулогарифмические модели (3) используются, когда необходимо определить темп роста или прироста экономических показателей. Например, при анализе банковского вклада по процентной ставке, при исследовании зависимости прироста объема выпуска продукции от процентного увеличения затрат на расходы, бюджетного дефицита от темпа роста ВВП, темп роста инфляции от объема денежной массы и т.д.
Нелинейные по параметру
Уравнения нелинейные по параметру можно разделить на:
- внутренне линейные — можно привести к линейному виду путем преобразований;
- внутренне нелинейные, которые не могут быть сведены к линейной модели.
Степенная модель:
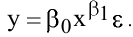
Если прологарифмировать обе части уравнения 2.2, получится модель, легко приводящаяся к линейному виду:
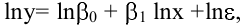
Надо сделать замену:
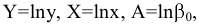
получим линейную модель (1.1).
Коэффициент модели 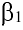 определяет эластичность переменной
определяет эластичность переменной 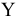 по переменной
по переменной 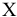 , то есть процентное изменение при изменении на 1%. Степенная модель имеет постоянную эластичность, это легко увидеть, если продифференцировать обе части уравнения (2.3):
, то есть процентное изменение при изменении на 1%. Степенная модель имеет постоянную эластичность, это легко увидеть, если продифференцировать обе части уравнения (2.3):
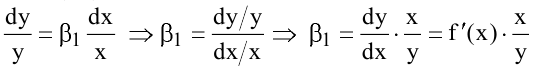
Так как константа, то модель 2.3 называют моделью постоянной эластичности.
В случае парной регрессии использование обоснование использования степенной модели достаточно просто. Надо построить корреляционное поле для точек  , если их расположение соответствует прямой линии, то произведенная замена хорошая и можно использовать степенную модель.
, если их расположение соответствует прямой линии, то произведенная замена хорошая и можно использовать степенную модель.
Данная модель легко обобщается на большее число переменных. Наиболее известная — производственная функция Кобба-Дугласа:  , где — объем выпуска; — затраты капитала;
, где — объем выпуска; — затраты капитала;  — затраты труда.
— затраты труда.
Лог-линейные модели широко используются в банковском и финансовом анализе:
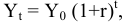
где 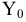 — первоначальный банковский вклад,
— первоначальный банковский вклад, 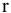 — процентная ставка,
— процентная ставка,  — размер вклада на момент
— размер вклада на момент 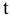 .
.
Прологарифмируем обе части этой модели
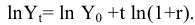
Введя замену
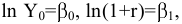
получим полулогарифмическую модель:
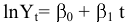
Коэффициент в уравнении 2.6 имеет смысл темпа прироста переменной по переменной , то есть характеризует относительное изменение к абсолютному изменению . Продифференцируем 2.6 по , получим:
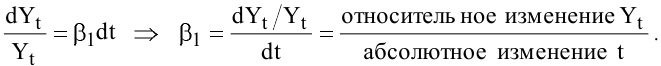
Умножив на 100%, получим темп прироста . Надо сказать, что коэффициент
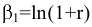
определяет мгновенный темп прироста, а
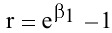
характеризует темп прироста сложного процента.
Показательные модели используются, когда анализируется изменение переменной с постоянным темпом прироста во времени :
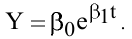
Если провести логарифмирование, то получится уравнение аналогичное 2.5 В общем виде показательная модель имеет вид:
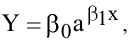
но в силу равенства
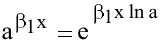
сводится к уравнению 2.8.
Коэффициент эластичности
Рассматривая степенную модель, мы ввели понятие эластичности функции: предел отношения относительных приращений независимой переменной и зависимой называется эластичностью функции
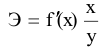
показывает на сколько процентов изменится в среднем результат, если фактор х изменится на 1%.
Для других форм связи Э зависит от значения фактора 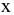 и не является величиной постоянной, поэтому рассчитывается средний коэффициент эластичности, который показывает, на сколько процентов в среднем по совокупности изменится результат
и не является величиной постоянной, поэтому рассчитывается средний коэффициент эластичности, который показывает, на сколько процентов в среднем по совокупности изменится результат  от своей средней величины, если фактор изменится на 1% от своего среднего значения. Формула для расчета:
от своей средней величины, если фактор изменится на 1% от своего среднего значения. Формула для расчета:
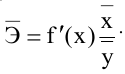
Несмотря на широкое использование в экономике коэффициентов эластичности, возможны случаи, когда они не имеют экономического смысла. Составьте таблицу коэффициентов эластичности для всех рассмотренных нелинейных моделей самостоятельно.
2.4. ПОСТРОЕНИЕ НЕЛИНЕЙНЫХ РЕГРЕССИЙ
Можно воспользоваться командой Добавить линию тренда, так же как в случае линейного тренда (раздел 1.3): необходимо построить корреляционное поле  и выбрать одну из зависимостей на вкладке параметры: полиномиальный, логарифмический, показательный и экспоненциальный. Такой способ удобен для случая двух переменных.
и выбрать одну из зависимостей на вкладке параметры: полиномиальный, логарифмический, показательный и экспоненциальный. Такой способ удобен для случая двух переменных.
Использовать инструмент Регрессия можно только для преобразованных данных. Этот способ дает много не нужной информации.
Пример 3.1. По семи территориям Южного федерального округа за 2001 год известны значения двух признаков:
Задание
- Постройте уравнения регрессии для модели:
a) линейной;
b) степенной;
c) экспоненциальной;
d) логарифмической; гиперболы.
- Оцените каждую модель через среднюю ошибку аппроксимации и -критерий Фишера.
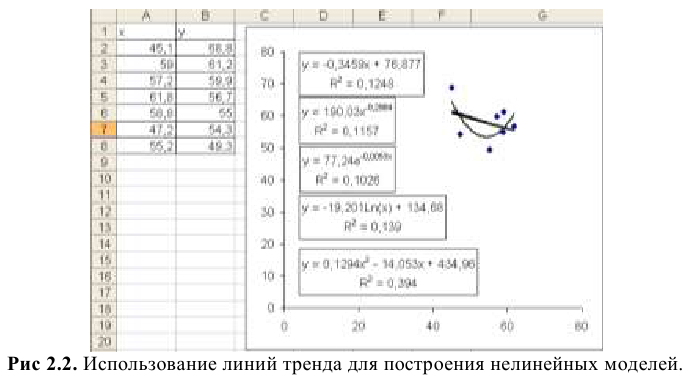
Проще всего построить поле корреляции, а затем добавить линии тренда (см. параграф 1.З.). Для полученных уравнений надо найти коэффициент аппроксимации и проверить  -критерий.
-критерий.
1а. Уравнение линейной регрессии:

Вариация результата на 12% объясняется вариацией фактора  — статистику найдем по формуле 1.13
— статистику найдем по формуле 1.13
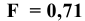
Так как
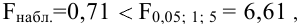
то параметры линейного уравнения и показатель тесноты связи между и статистически незначимы и гипотеза о линейности уравнения регрессии отклоняется. Самостоятельно вычислите величину средней ошибки аппроксимации:
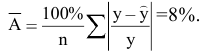
l.b. Степенная модель
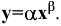
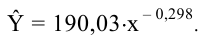
Подставляя в уравнение регрессии фактические значения , получим 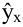 . По этим значениям, используя формулу для индекса корреляции (1.26), получим
. По этим значениям, используя формулу для индекса корреляции (1.26), получим
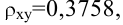
и среднюю ошибку аппроксимации:
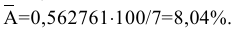
Характеристики степенной модели указывают, что она не намного лучше линейной функции описывает связь между и .
1с. Аналогично l.b. для показательной модели
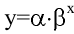
сначала нужно выполнить линеаризацию
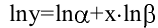
и после замены переменных
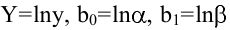
рассмотрим линейное уравнение:
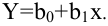
Используя столбцы для и из предыдущей таблицы, получим коэффициенты:
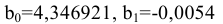
и уравнение
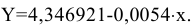
После потенциирования запишем уравнение в обычной форме:
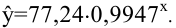
Все эти расчеты можно не делать, если воспользоваться для вычисления параметров  и
и 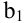 модели
модели 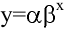 встроенной статистической функцией ЛГРФПРИБЛ. Выполните самостоятельно и сравните результаты. Убедитесь, что значения вычисленные по формулам и полученные с помощью функции ЛГРФПРИБЛ() совпадают (рис.2.4)
встроенной статистической функцией ЛГРФПРИБЛ. Выполните самостоятельно и сравните результаты. Убедитесь, что значения вычисленные по формулам и полученные с помощью функции ЛГРФПРИБЛ() совпадают (рис.2.4)
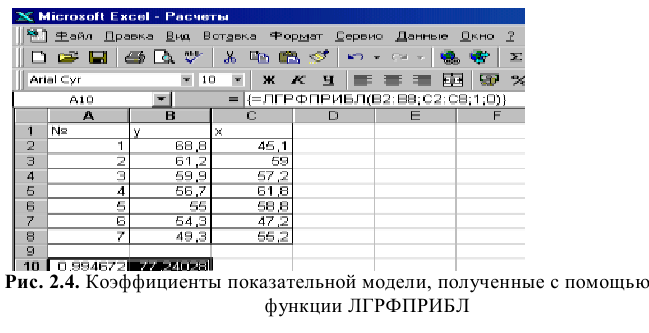
Тесноту связи оценим с помощью индекса корреляции
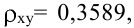
который вычисляется по формуле (1.26). Связь между и небольшая. Коэффициент аппроксимации, вычисленный по формуле (3.3) 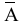 =8% говорит о повышенной ошибке приближения, но в допустимых пределах. Сравнивая, показатели степенной и показательной функций можно сделать вывод, что степенная функция чуть лучше описывает связь между и чем показательная.
=8% говорит о повышенной ошибке приближения, но в допустимых пределах. Сравнивая, показатели степенной и показательной функций можно сделать вывод, что степенная функция чуть лучше описывает связь между и чем показательная.
l.d. Аналогичные расчеты надо провести и для равносторонней гиперболы 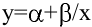 , которая линеаризуется заменой
, которая линеаризуется заменой 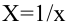 .
.
Для этого уравнения в таблицу исходных значений надо добавить столбец , а все остальные вычисления проведите, используя один из описанных выше способов:
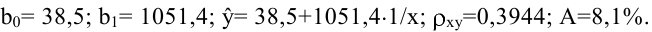
Получена наибольшая оценка тесноты связи по сравнению с линейной, степенной и показательной регрессиями, а остается в пределах допустимого значения, это означает, что для описания зависимости расходов на покупку продовольственных товаров в общих расходах ( в %) от среднедневной заработной платы одного работающего ( в руб.) необходимо из предложенных моделей выбрать гиперболическую.
- Введем гипотезу : уравнение регрессии статистически незначимо и рассмотрим статистику (1.30):
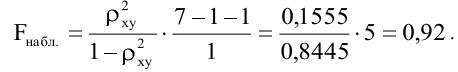
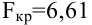 при уровне значимости
при уровне значимости  смотри в пункте l.a.
смотри в пункте l.a.
Гипотеза  о статистической незначимости параметров уравнения принимается. Результат можно объяснить небольшим числом наблюдений и сравнительно невысокой теснотой гиперболической зависимости между и .
о статистической незначимости параметров уравнения принимается. Результат можно объяснить небольшим числом наблюдений и сравнительно невысокой теснотой гиперболической зависимости между и .
Возможно эти страницы вам будут полезны:
- Курсовая работа по эконометрике
- Заказать работу по эконометрике
- Лабораторная работа по эконометрике
- Помощь по эконометрике
- Системы эконометрических уравнений

17 авг. 2022 г.
читать 3 мин
Выборочное распределение — это вероятностное распределение определенной статистики , основанное на множестве случайных выборок из одной совокупности .
В этом руководстве объясняется, как выполнить следующие действия с выборочными распределениями в Excel:
- Сгенерируйте выборочное распределение.
- Визуализируйте распределение выборки.
- Рассчитайте среднее значение и стандартное отклонение выборочного распределения.
- Рассчитайте вероятности относительно выборочного распределения.
Создание выборочного распределения в Excel
Предположим, мы хотим сгенерировать выборочное распределение, состоящее из 1000 выборок, в каждой из которых размер выборки равен 20 и происходит от нормального распределения со средним значением 5,3 и стандартным отклонением 9 .
Мы можем легко сделать это, введя следующую формулу в ячейку A2 нашего рабочего листа:
= NORM.INV ( RAND (), 5.3, 9)
Затем мы можем навести указатель мыши на правый нижний угол ячейки, пока не появится крошечный + , и перетащить формулу на 20 ячеек вправо и на 1000 ячеек вниз:
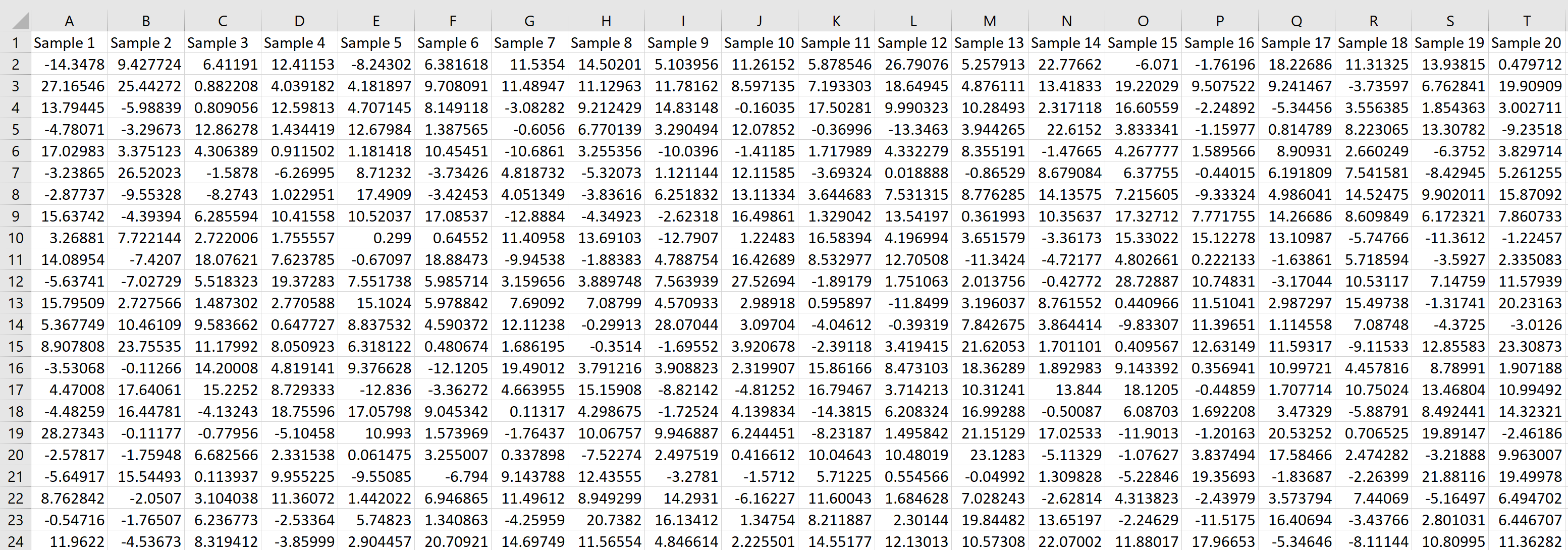
Каждая строка представляет выборку размера 20, в которой каждое значение получено из нормального распределения со средним значением 5,3 и стандартным отклонением 9.
Найдите среднее значение и стандартное отклонение
Чтобы найти среднее значение и стандартное отклонение этого выборочного распределения средних значений выборки, мы можем сначала найти среднее значение каждой выборки, введя следующую формулу в ячейку U2 нашего рабочего листа:
= AVERAGE (A2:T2)
Затем мы можем навести указатель мыши на правый нижний угол ячейки, пока не появится крошечный + , и дважды щелкнуть, чтобы скопировать эту формулу в каждую другую ячейку в столбце U:

Мы видим, что первая выборка имела среднее значение 7,563684, вторая выборка имела среднее значение 10,97299 и так далее.
Затем мы можем использовать следующие формулы для расчета среднего значения и стандартного отклонения среднего значения выборки:

Теоретически среднее значение выборочного распределения должно быть 5,3. Мы видим, что фактическое среднее значение выборки в этом примере равно 5,367869 , что близко к 5,3.
И теоретически стандартное отклонение выборочного распределения должно быть равно s/√n, что будет равно 9/√20 = 2,012. Мы видим, что фактическое стандартное отклонение выборочного распределения составляет 2,075396 , что близко к 2,012.
Визуализируйте распределение выборки
Мы также можем создать простую гистограмму для визуализации выборочного распределения выборочных средних.
Для этого просто выделите все средние значения выборки в столбце U, щелкните вкладку « Вставка », затем выберите параметр « Гистограмма » в разделе « Диаграммы ».
В результате получается следующая гистограмма:
Мы видим, что распределение выборки имеет форму колокола с пиком около значения 5.
Однако из хвостов распределения мы можем видеть, что некоторые выборки имели средние значения больше 10, а некоторые — меньше 0.
Рассчитать вероятности
Мы также можем рассчитать вероятность получения определенного значения среднего значения выборки на основе среднего значения совокупности, стандартного отклонения совокупности и размера выборки.
Например, мы можем использовать следующую формулу, чтобы найти вероятность того, что среднее значение выборки меньше или равно 6, учитывая, что среднее значение генеральной совокупности равно 5,3, стандартное отклонение генеральной совокупности равно 9 и размер выборки равен:
= COUNTIF (U2:U1001, " <=6 ")/ COUNT (U2:U1001)
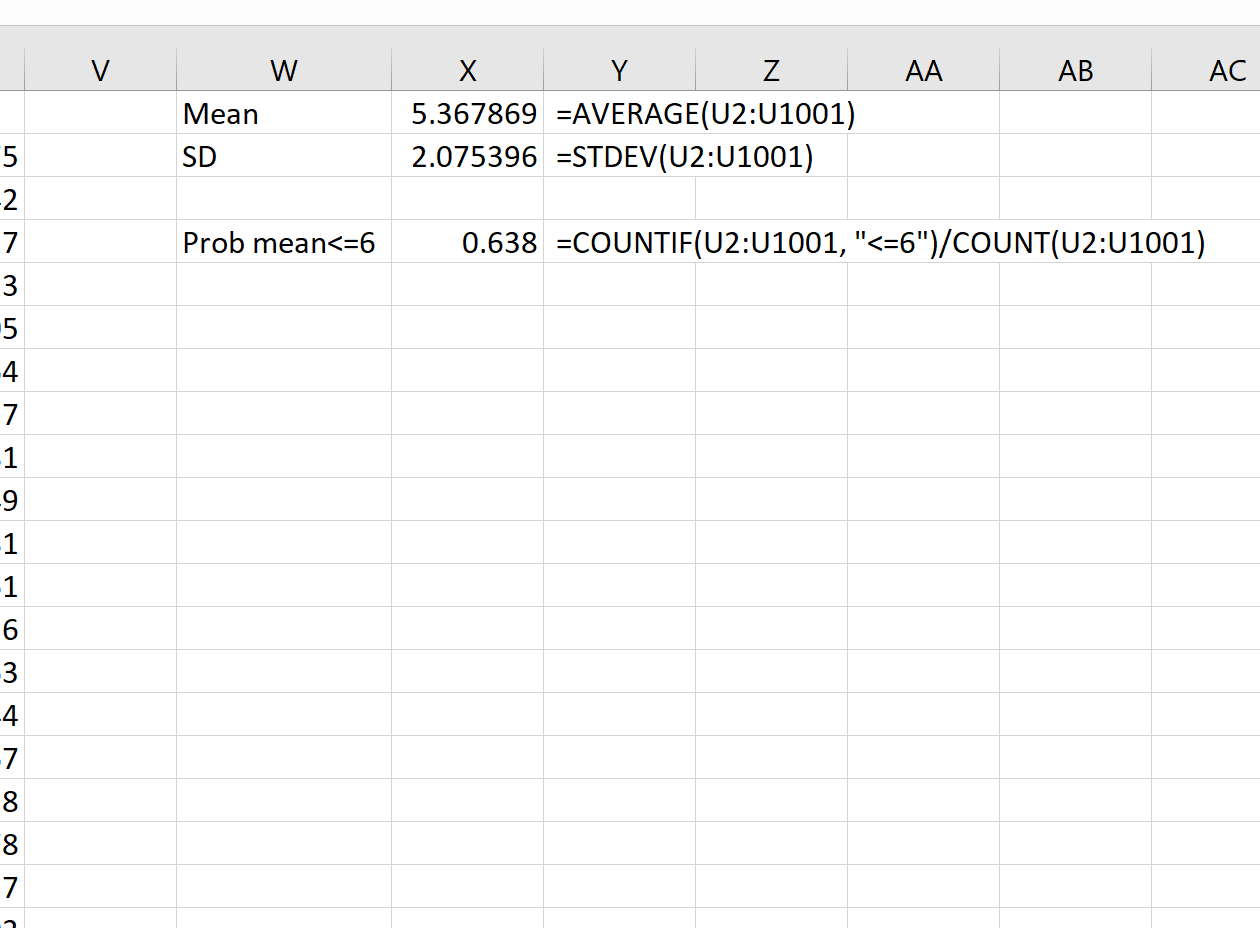
Мы видим, что вероятность того, что среднее значение выборки меньше или равно 6, составляет 0,638.
Это очень близко к вероятности, рассчитанной Калькулятором распределения выборки :

Дополнительные ресурсы
Введение в выборочные распределения
Калькулятор распределения выборки
Введение в центральную предельную теорему