
Преобразование отсканированных документов и изображений в редактируемые форматы Word, Pdf, Excel и Txt (простой текст)
Доступно страниц: 10 (Вы уже использовали 0 страниц)
Если вам нужно распознать больше страниц, пожалуйста, зарегистрируйтесь
Загрузите файлы для распознавания или перетащите их на эту страницу
Поддерживаемые форматы файлов:
pdf, jpg, bmp, gif, jp2, jpeg, pbm, pcx, pgm, png, ppm, tga, tiff, wbmp
- Китайский OCR
- Немецкий OCR
- Нидерландский OCR
- Английский OCR
- Французский OCR
- Итальянский OCR
Как распознать текст с изображения?
Шаг 1
Загрузите изображения или PDF-файлы
Выберите файлы с компьютера, Google Диска, Dropbox, по ссылке или перетащив их на страницу
Шаг 2
Язык и формат
Выберите все языки, используемые в документе. Кроме того, выберите .doc или любой другой формат, который вам нужен в результате (поддерживается больше 10 текстовых форматов)
Шаг 3
Конвертируйте и скачивайте
Нажмите «Распознать», и вы можете сразу загрузить распознанный текстовый файл
![]()
Загрузить PDF
![]()
Загрузить PDF
Из этой статьи вы узнаете, как на компьютере преобразовать отсканированный документ в документ Word. Это можно сделать с помощью программы Word, если отсканированный документ сохранен в формате PDF, или с помощью бесплатного конвертера, если отсканированный документ сохранен как изображение. Если у вас есть учетная запись Microsoft и смартфон, используйте бесплатное приложение Office Lens, чтобы отсканировать документ и сохранить его в виде документа Word в облачном хранилище OneDrive.
-

1
Убедитесь, что отсканированный документ сохранен в формате PDF. Microsoft Word может преобразовать такой документ без дополнительного программного обеспечения.[1]
- Если отсканированный документ сохранен как изображение (например, в формате JPG или PNG), воспользуйтесь сервисом New OCR.
-
2
Откройте PDF-документ в Word. Этот процесс зависит от операционной системы:
- в Windows щелкните правой кнопкой мыши по PDF-файлу, выберите «Открыть с помощью», а затем в меню нажмите «Word»;
- в Mac OS X щелкните по PDF-файлу, а потом нажмите «Файл» > «Открыть с помощью» > «Word».
-
3
Нажмите OK, когда появится запрос. Word приступит к преобразованию PDF-документа в формат DOC.
- Этот процесс может занять несколько минут, если в PDF-документе большой текст или много изображений.
-
4
Активируйте редактирование файла (если потребуется). Если в верхней части окна Word отобразилась желтая полоса с предупреждением, нажмите «Включить редактирование» на желтой полосе, чтобы разблокировать документ для редактирования.
- Обычно это относится только к скачанным файлам (например, если вы скачали отсканированный документ в формате PDF из облачного хранилища).
-
5
Отредактируйте документ. Преобразованный документ не будет абсолютной копией исходного — скорее всего, вам придется добавить отсутствующие слова, удалить лишние пробелы и исправить опечатки.
-
6
Сохраните документ. Чтобы сохранить отредактированный документ в формате DOC, выполните следующие действия:
- в Windows нажмите Ctrl+S, введите имя файла, выберите папку для сохранения и нажмите «Сохранить»;
- в Mac OS X нажмите ⌘ Command+S, введите имя файла, выберите папку для сохранения (в меню «Где») и нажмите «Сохранить».
Реклама






-
1
Откройте сайт сервиса New OCR. Перейдите на страницу http://www.newocr.com/ в веб-браузере компьютера.
-
2
Нажмите Обзор. Это серая кнопка в верхней части страницы. Откроется окно Проводника (Windows) или Finder (Mac).
-
3
Выберите отсканированный файл. В окне Проводника или Finder перейдите к отсканированному документу, который сохранен как изображение, и щелкните по нему.
-
4
Нажмите Открыть. Эта кнопка находится в нижнем правом углу окна. Файл загрузится на веб-сайт.
-
5
Щелкните по Upload + OCR (Загрузить и распознать). Вы найдете эту кнопку в нижней части страницы. Текст, который есть на изображении, будет распознан и отобразится на странице.
-
6
Прокрутите вниз и нажмите Download (Скачать). Эта ссылка находится в нижней левой части страницы над полем с текстом. Раскроется меню.
-
7
Щелкните по Microsoft Word (DOC). Эта опция находится в меню «Скачать». Документ Word скачается на компьютер.
-
8
Откройте скачанный документ в программе Word. Для этого дважды щелкните по нему. Теперь изображение является документом Microsoft Word.
- Возможно, вам придется нажать «Включить редактирование» в верхней части страницы, так как по умолчанию документ может быть заблокирован для редактирования.
-
9
Отредактируйте документ. Преобразованный документ не будет абсолютной копией исходного — скорее всего, вам придется добавить отсутствующие слова, удалить лишние пробелы и исправить опечатки.
Реклама









-
1
Запустите приложение Office Lens. Нажмите на красно-белый значок с камерой и буквой «L».
- Если у вас нет этого приложения, скачайте его на Play Маркете для Android-устройства или в App Store для iPhone.
-
2
Разрешите Office Lens получить доступ к телефону. Если вы впервые запускаете Office Lens, нажмите «Разрешить» или «OK», чтобы приложение получило доступ к файлам телефона.
-
3
Коснитесь Документ. Это вкладка внизу экрана.
-
4
Направьте камеру телефона на документе. Сделайте так, чтобы весь документ, который вы хотите отсканировать, отобразился на экране.
- Убедитесь, что документ хорошо освещен, чтобы запечатлеть как можно больше деталей.
-
5
Нажмите кнопку съемки. Это красный круг в нижней части экрана. Будет сделано фото документа.
-
6
Нажмите
. Этот значок находится в правом нижнем углу экрана.
- Чтобы отсканировать больше страниц, нажмите на символ «+» в нижней части экрана.
-
7
Коснитесь Word. Вы найдете эту опцию в разделе «Сохранить» на странице «Экспортировать в».
- На Android-устройстве коснитесь квадратного значка у «Word», а затем нажмите «Сохранить» в нижней части экрана.
-
8
Войдите в свою учетную запись Microsoft. Если вы еще не авторизовались, введите адрес электронной почты и пароль. Теперь документ Word загрузится в вашу учетную запись OneDrive.
- Это должна быть учетная запись, которую вы используете для входа в Microsoft Word.
-
9
Откройте Word на компьютере. Нажмите на синий значок с белой буквой «W».
-
10
Щелкните по Открыть другие документы. Эта опция находится в левой части раздела «Последние».
- На компьютере Mac просто щелкните по значку папки у «Открыть» в левой части окна.
-
11
Нажмите Персональный OneDrive. Эта опция находится в верхней части окна. Откроется папка OneDrive.
- Если вы не видите опцию «OneDrive», нажмите «+» > «Добавить место» > «OneDrive» и войдите в свою учетную запись Microsoft.
-
12
Перейдите в папку Office Lens. Откройте папку «Документы», а затем щелкните по папке «Office Lens». Они находятся на правой панели окна.
-
13
Дважды щелкните по документу Word, который был создан с помощью приложения «Office Lens».
Реклама














Советы
- Приложение Office Lens лучше работает с текстом на бумаге, чем с текстом на экране.
Реклама
Предупреждения
- Результат распознавания текста сервисом New OCR зависит от качества текста на изображении. Чтобы получить оптимальный результат, отсканируйте документ в PDF-файл, а затем преобразуйте его с помощью программы Word (как описано в первом разделе).
Реклама
Об этой статье
Эту страницу просматривали 341 433 раза.
Была ли эта статья полезной?
Платформа: Windows, iOS, Android, веб
Лицензия: пробная, от 5388 в год
Распознает: JPG, TIF, BMP, PNG, PDF, сигнал со сканера, снимки камеры
Сохраняет: DOC, DOCX, XLS, XLSX, ODT, TXT, RTF, PDF, PDF/A, PPTX, EPUB, FB2
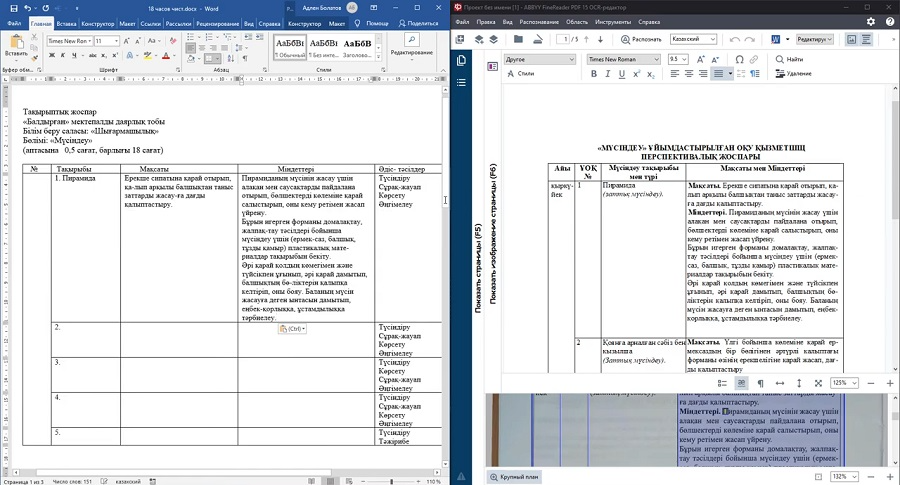
Abbyy FineReader известен своим точным модулем OCR, который позволяет быстро распознать текст с картинки. Приложение можно использовать как оцифровщик бумаг, так как он включает в себя инструмент для прямого перехвата фотографий со сканера. Их можно сразу сохранить в любой из доступных форматов, в том числе текстовые документы, HTML-файлы или PDF. Бесплатная версия накладывает ограничение на количество страниц: не более 10.
Особенности:
- большое количество доступных языков;
- оптимизация размера фотографий с минимальными потерями качества;
- автоматическая проверка орфографии и грамматики;
- работа с многостраничными документами;
- редактирование распознанного текста.
Плюсы:
- высокая точность результата даже при невысоком качестве фото.
- способно отличать разные языки в документе;
- доступна для установки на все версии Windows с любой разрядностью.
Минусы:
- обновления приобретаются отдельно;
- требуется регистрация аккаунта на официальном сайте;
- сбивается оригинальное форматирование и стиль документа.
Платформа: Windows, Linux, mac OS
Лицензия: бесплатная
Распознает: JPG, TIFF, BMP, PNG, снимки со сканера
Сохраняет: DOCX
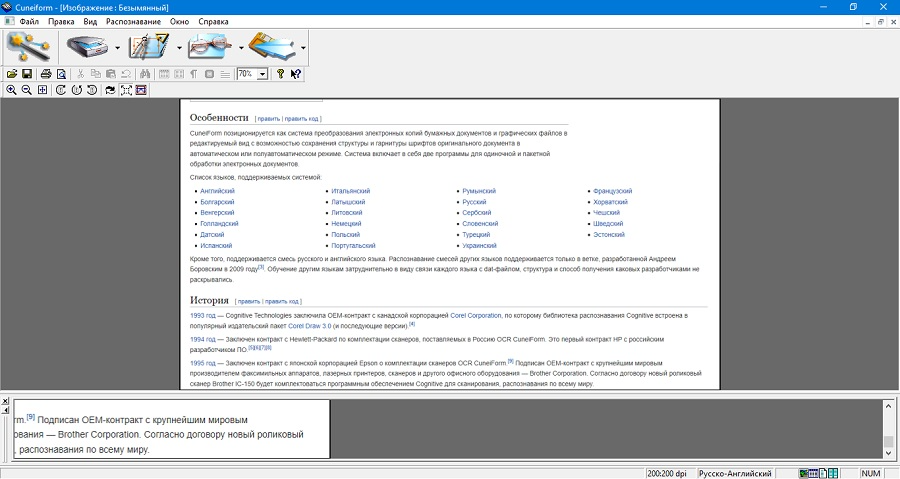
Программа для распознавания текста по фото OCR CUneiForm направлена только на одно действие – перехват со сканера изображений и преобразования содержащейся на них текстовой информации. Также допускается открытие графических файлов с персонального компьютера. После этого работу можно продолжить в любом текстовом редакторе. Разрешается работать в одиночном или пакетном режиме.
Особенности:
- может использоваться вместо стандартного софта для сканирования;
- преобразование графических файлов в редактируемый документ Ворд;
- анализ документа на наличие форм, таблиц, изображений;
- поиск по созданному текстовому файлу;
- распознавание на отдельных выбранных областях.
Плюсы:
- сохраняет оригинальную структуру документа и его форматирование;
- можно запускать в автоматическом режиме или настроить параметры;
- специальный режим для матричного принтера.
Минусы:
- допускается разрешение не выше 600;
- показал не очень хорошие результаты с фото плохого качества.
Платформа: Android, iOS
Лицензия: бесплатная
Распознает: фотографии с камеры
Сохраняет: PDF, PPT, DOCX
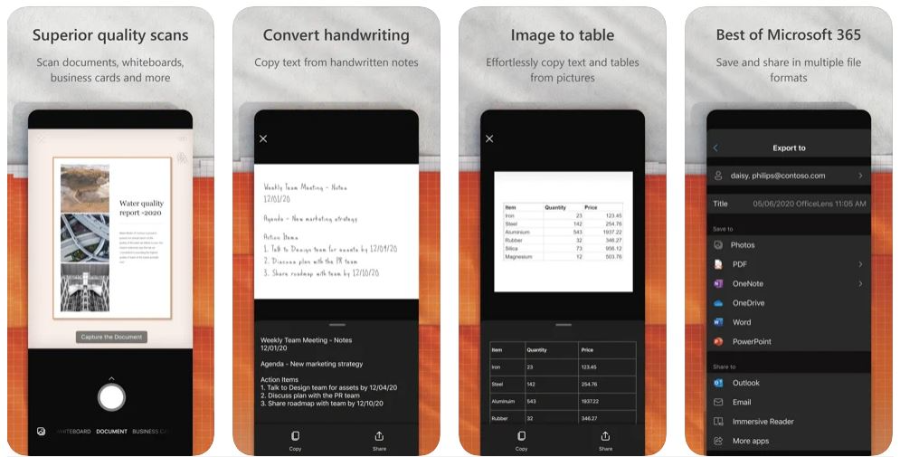
Ранее Office Lens (также известный как Microsoft Lens) был доступен для ПК, но теперь корпорация прекратила поддержку десктопной версии. Приложение превращает ваш телефон в продвинутый сканер, автоматически анализируя окружение и делая снимок документа. Возможна работа в том числе со снимками с неправильным отображением (положенные боком, перевернутые, лежащие на неровной поверхности и т.д.).
Особенности:
- корректировка результата после создания снимка;
- извлечение печатного и рукописного текста на русском и английском языке;
- распознавание таблиц и контактов;
- создание многостраничного документа из фотографий.
Плюсы:
- полностью бесплатный;
- есть разные пресеты и настройки для документов (лист, фото, доска, визитка);
- отправка файлов в облачные хранилища.
Минусы:
- для подключения модуля OCR требуется регистрация аккаунта;
- некорректные результаты при извлечении русских букв.
Платформа: Android, iOS
Лицензия: условно-бесплатная; от 349 рублей
Распознает: фотографии с камеры
Сохраняет: PDF
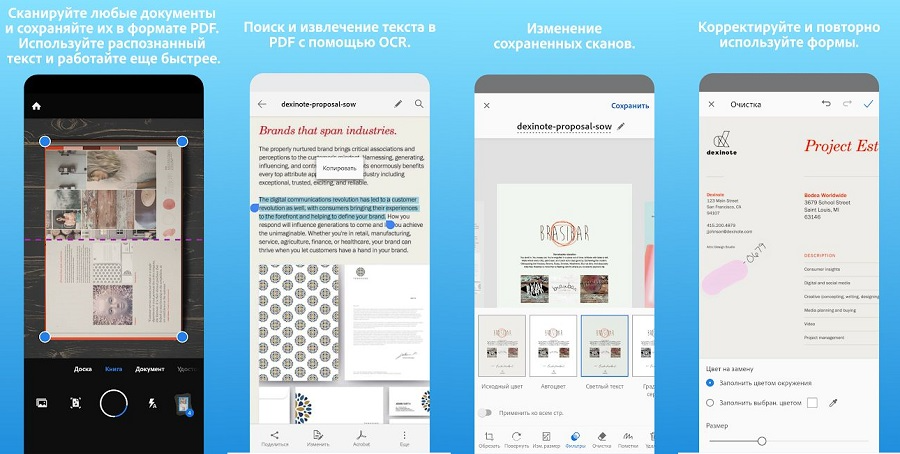
Как и продукт от Microsoft, Adobe Scan также сканирует текстовые данные через мобильную фотокамеру. Результат сохраняется как PDF-документ, оптимизированный для редактирования в программном обеспечении Acrobat. Все результаты сохраняются автоматически в облако Adobe Document Cloud.
Особенности:
- подходит для разного типа информации: книга, доска, удостоверение, визитка;
- автоматическое сканирование окружения на предмет документов;
- редактирование созданных фотографий;
- расшифровка и использование встроенных форм.
Плюсы:
- не требует оплаты;
- на файлы можно накладывать защиту;
- корректно работает с русскими буквами.
Минусы:
- нет автоматического сохранения;
- для использования приложения обязательно требуется регистрация.
Платформа: веб
Лицензия: условно-бесплатная
Распознает: JPG, GIF, TIFF, BMP, PNG, PCX, PDF
Сохраняет: TXT, DOC, DOCX, XLSX, PDF
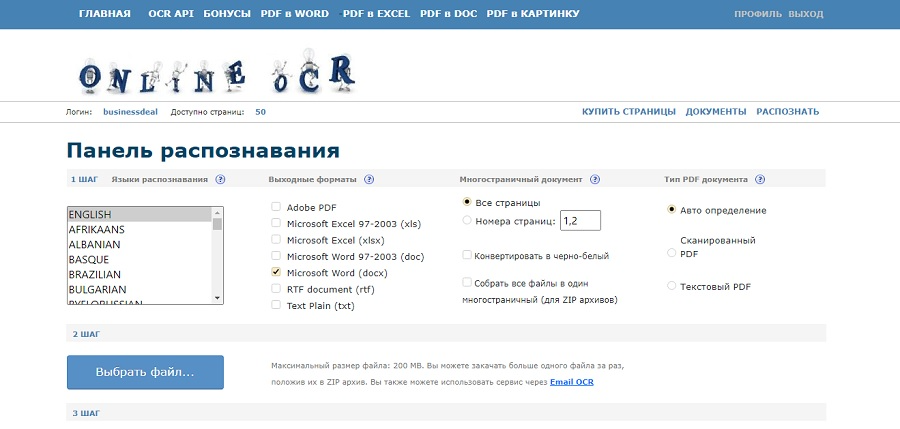
На этом сервисе пользователи могут провести распознавание текста бесплатно и сохранить результат в редактируемые текстовые файлы без установки софта. Поддерживается работа со сканами, популярными форматами графики, сканами и PDF. Без регистрации и оплаты доступно распознование только 15 страниц в час. После авторизации данный лимит повышается до 50, а также увеличивается допустимый размер (200 МБ).
Особенности:
- обработка текста в зависимости от особенностей оригинального языка;
- редактирование результата в режиме прямого времени;
- объединение обрабатываемых файлов в единый проект;
- анализ отдельных страниц документа.
Плюсы:
- удобное русскоязычное управление;
- автоматический определитель типа документа;
- ведется история загружаемых файлов.
Минусы:
- загруженные снимки нельзя отредактировать;
- не всегда корректный результат.
Платформа: веб
Лицензия: бесплатная
Распознает: JPEG, PNG, PDF
Сохраняет: PDF, TXT, DOCX, ODF
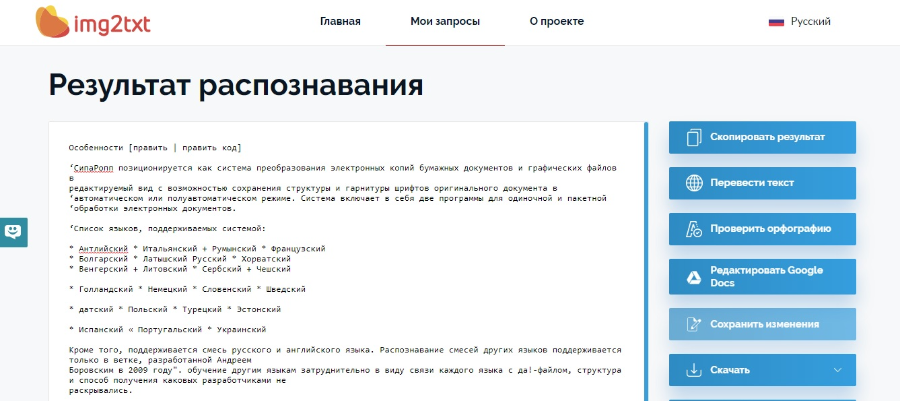
Бесплатный инструмент работает с популярными форматами графики и нередактируемыми документами ПДФ. Сервис ведет журнал ваших действий, поэтому при внезапном прерывании сети можно вернуться к работе без вторичной загрузки. Разработчики постоянно улучшают свой продукт и добавляют новые возможности, на данный момент в ней есть переводящая утилита, также анонсирована опция импорта файла по ссылке.
Особенности:
- изменение преобразованного текста прямо на сайте;
- перевод иностранных документов;
- проверка орфографии;
- копирование результата в буфер обмена.
Плюсы:
- работает полностью на бесплатной основе;
- быстрая скорость загрузки и обработки.
Минусы:
- документ не должен содержать картинок, таблиц и колонок;
- некорректно работает с файлами, в которых используется несколько языков.
Платформа: Windows, macOS
Лицензия: бесплатная
Распознает: JPEG, TIFF, PNG, BMP
Сохраняет: JPEG, TIFF, PNG, BMP
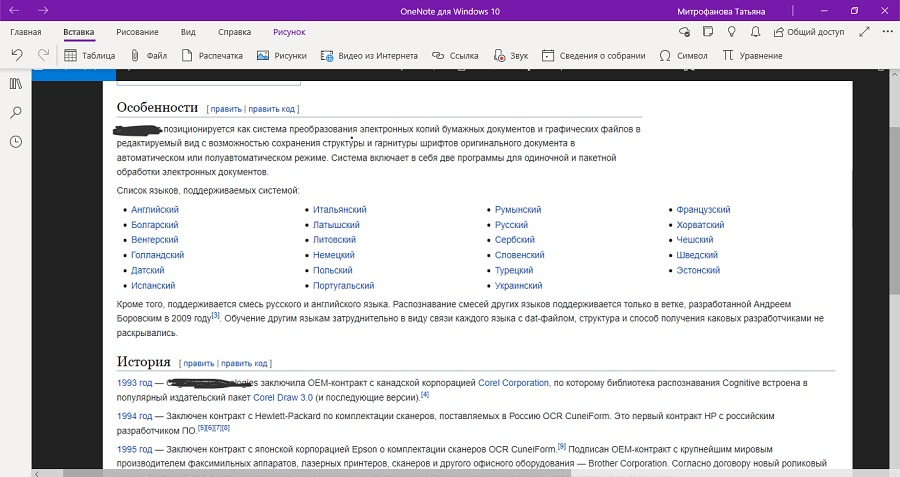
Записная книжка от разработчика Microsoft работает как отдельная программа, также ее можно приобрести в пакете с офисным ПО MS Office. Хотя софт также распространяется как мобильное приложение, распознавание текста с картинки поддерживается только в десктопном варианте на компьютере. Хотя изменять информацию на картинках нельзя, данные можно скопировать и вставить в текстовой редактор.
Особенности:
- загрузка фотографий с жесткого диска или подключенной фотокамеры;
- скрытие выбранных областей фотографии;
- можно добавлять пометки и конвертировать их в редактируемый текст;
- прослушивание открытого текста.
Плюсы:
- автоматические бэкап в облако предотвратит потерю важных данных;
- есть опция переводчика текста и проверка орфографии в документе.
Минусы:
- требуется вход с учетной записью Microsoft;
- текст на фотографиях нельзя исправлять.
Платформа: Windows, macOS
Лицензия: пробная; от $129
Распознает: JPEG, TIFF, PNG, BMP, PDF
Сохраняет: PDF, TXT, PPTX, DOCX, XLSX
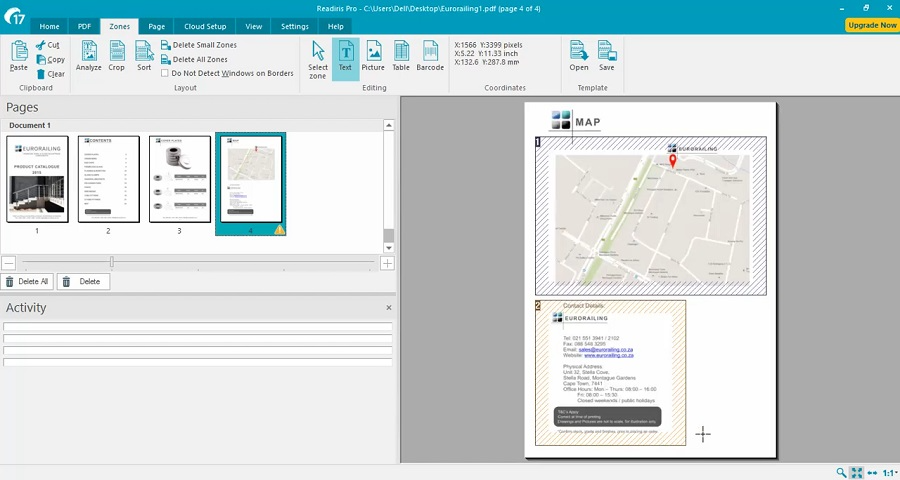
Readiris – один из немногих PDF-редакторов, умеющий различать печатный текст и даже ручной почерк и преобразовать его в стандартный текстовой массив. Программу можно использовать как сканер текста с фото, так как она работает со всеми популярными моделями сканирующих устройство. Софт корректно распознает кириллические символы и показывает высокую точность результатов. Пробная версия доступна в полном функционале в течение 10 дней.
Особенности:
- позволяет перехватывать и оптимизировать картинки со сканера;
- работает с более чем 170 языками и проверяет ошибки;
- сохраняет оригинальное форматирование документа;
- распознает таблицы, штрих-коды, формулы, нестандартные символы.
Плюсы:
- имеется пакетный режим;
- присутствуют инструменты редактирования.
Минусы:
- неудобная рабочая панель;
- высокая стоимость полной версии.
Платформа: Windows
Лицензия: бесплатная
Распознает: JPEG, TIFF, PNG, BMP, PSD
Сохраняет: DOC, TXT
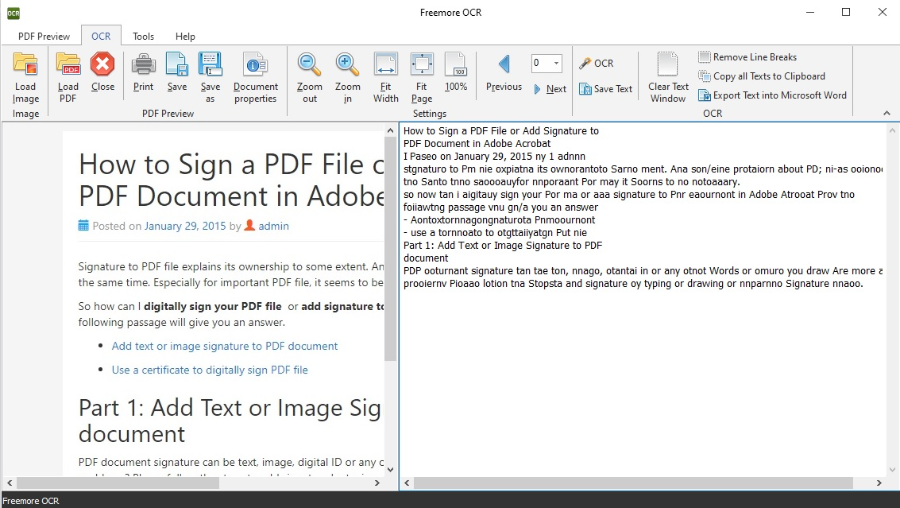
Freemore OCR – простая в управлении программа, считывающая текст с изображений или из нередактируемых ПДФ. Работа проводится в двухоконном режиме, что особенно удобно при проверке точности результатов. Стоит отметить, что при загрузке файл помечается как подозрительный, при установке некоторые антивирусы требуется на время отключить.
Особенности:
- корректно распознает текст, расположенный вокруг графических элементов;
- позволяет встраивать цифровую подпись;
- имеются возможности ручного редактирования результата;
- экспорт как новый файл или копирование всего текста в буфер обмена.
Плюсы:
- работает с защищенными паролем файлами;
- очень простое в управлении меню.
Минусы:
- не распознает кириллицу;
- при установке подгружает рекламный софт.
Платформа: Windows
Лицензия: условно-бесплатная; 499 руб
Распознает: PDF, BMP, JPG, TIFF, JP2, PNG
Сохраняет: DOCX, RTF, TXT, PDF
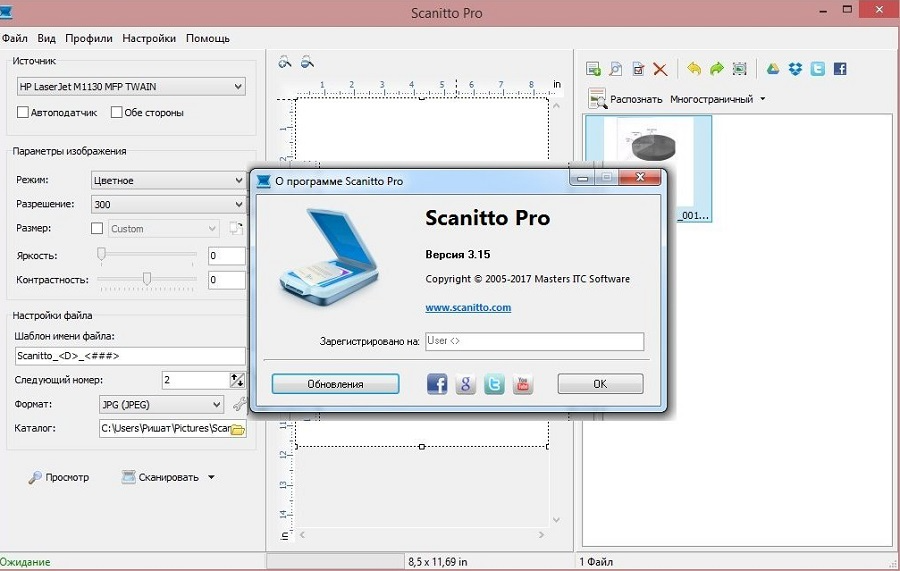
Если нужен сканер с распознаванием текста, выбирайте это простое средство для преобразования ксерокопий в документ. Софт работает с подключенным устройством, подменяя встроенную по умолчанию программу сканирования. Отличается удобными функциями выборочного анализа, разрешая отмечать фрагменты, которые нужно распознать.
Особенности:
- просматривайте результат перед выводом на экспорт;
- объединение изображений в многостраничные документы;
- поворот скана и очистка для шума для более точного анализа;
- оптическое распознавание более 7 языков (включая русский).
Плюсы:
- удобный пользовательский интерфейс с минимумом настроек;
- минимальные требования к системе и процессору компьютера.
Минусы:
- нельзя загружать фото с жесткого диска;
- сбивает структуру и удаляет оригинальное форматирование текста.
В заключение
Надеемся, что наш обзор помог вам понять, какая программа для сканирования и распознавания текста подойдет для вашей задачи. Все рассмотренные приложения в целом достойно справились с анализом сложных фото и показали высокую скорость работы. А если вам требуется обработка сохраненного ПДФ-файла, советуем скачать бесплатно PDF Commander. Он поможет создать из распознанного текста полноценный документ и разнообразить его дополнительными элементами.
Дополнительные настройки
Метод OCR
Исходный язык файла
Чтобы получить оптимальный результат, выберите все языки, которые есть в файле.
Улучшить OCR
Применить фильтр:
Конвертер DOCX
Преобразование из PDF в DOCX или из результатов сканирования в DOCX. PDF — очень удобный формат, но его сложно редактировать. Упростите извлечение цитат, редактирование текста или его повторное использование!
Поддерживаемые языки:
Afrikaans, Amharic, Arabic, Azerbaijani, Azerbaijani — Cyrillic, Belarusian, Bengali, Tibetan, Bosnian, Breton, Bulgarian, Catalan; Valencian, Cebuano, Czech, Chinese — Simplified, Chinese — Simplified Vertical, Chinese — Traditional, Chinese — Traditional Vertical, Cherokee; Tsalagi, Corsican, Welsh, Danish, German, Divehi, Dzongkha, Greek, English, English, Middle (1100-1500), Esperanto, Estonian, Basque, Faroese, Persian, Filipino (old — Tagalog), Finnish, French, German — Fraktur, French, Middle (1400-1600), Western Frisian, Scottish Gaelic, Irish, Galician, Greek, Ancient (to 1453), Gujarati, Haitian; Haitian Creole, Hebrew, Hindi, Croatian, Hungarian, Armenian, Inuktitut, Indonesian, Icelandic, Italian, Italian — Old, Javanese, Japanese, Japanese Vertical, Kannada, Georgian, Georgian — Old, Kazakh, Central Khmer, Kyrgyz, Kurmanji (Kurdish — Latin Script), Korean, Korean Vertical, Lao, Latin, Latvian, Lithuanian, Luxembourgish, Malayalam, Marathi, Macedonian, Maltese, Mongolian, Maori, Malay, Burmese, Nepali, Flemish, Norwegian, Occitan (post 1500), Oriya, Punjabi, Polish, Portuguese, Pashto, Quechua, Romanian; Moldovan, Russian, Sanskrit, Sinhala; Sinhalese, Slovak, Slovenian, Sindhi, Spanish; Castilian, Spanish; Castilian — Old, Albanian, Serbian, Serbian — Latin, Sundanese, Swahili, Swedish, Syriac, Tamil, Tatar, Telugu, Tajik, Thai, Tigrinya, Tonga, Turkish, Uyghur, Ukrainian, Urdu, Uzbek, Uzbek — Cyrillic, Vietnamese, Yiddish, Yoruba