
Содержание
- 1 Пример использования функции ЧАСТОТА в Excel
- 2 Пример определения вероятности используя функцию ЧАСТОТА в Excel
- 3 Как посчитать неповторяющиеся значения в Excel?
- 4 Функция ЧАСТОТА в Excel и особенности ее синтаксиса
- 4.1 Ссылки по теме
Функция ЧАСТОТА используется для определения количества вхождения определенных величин в заданный интервал и возвращает данные в виде массива значений. Используя функцию ЧАСТОТА, мы узнаем, как посчитать частоту в Excel.
Пример 1. Студенты одной из групп в университете сдали экзамен по физике. При оценке качества сдачи экзамена используется 100-бальная система. Для определения окончательной оценки по 5-бальной системе используют следующие критерии:
- От 0 до 50 баллов – экзамен не сдан.
- От 51 до 65 баллов – оценка 3.
- От 66 до 85 баллов – оценка 4.
- Свыше 86 баллов – оценка 5.
Для статистики необходимо определить, сколько студентов получили 5, 4, 3 баллов и количество тех, кому не удалось сдать экзамен.
Внесем данные в таблицу:
Для решения выделим области из 4 ячеек и введем следующую функцию:
Описание аргументов:
- B3:B20 – массив данных об оценках студентов;
- D3:D5 – массив критериев нахождения частоты вхождений в массиве данных об оценках.
Выделяем диапазон F3:F6 жмем сначала клавишу F2, а потом комбинацию клавиш Ctrl+Shift+Enter, чтобы функция ЧАСТОТА была выполнена в массиве. Подтверждением того что все сделано правильно будут служить фигурные скобки {} в строке формул по краям. Это значит, что формула выполняется в массиве. В результате получим:
То есть, 6 студентов не сдали экзамен, оценки 3, 4 и 5 получили 3, 4 и 5 студентов соответственно.
Пример определения вероятности используя функцию ЧАСТОТА в Excel
Пример 2. Известно то, что если существует только два возможных варианта развития событий, вероятности первого и второго равны 0,5 соответственно. Например, вероятности выпадения «орла» или «решки» у подброшенной монетки равны ½ и ½ (если пренебречь возможностью падения монетки на ребро). Аналогичное расчетное распределение вероятностей характерно для следующей функции СЛУЧМЕЖДУ(1;2), которая возвращает случайное число в интервале от 1 до 2. Было проведено 20 вычислений с использованием данной функции. Определить фактические вероятности появления чисел 1 и 2 соответственно на основании полученных результатов.
Заполним исходную таблицу случайными значениями от 1-го до 2-ух:
Для определения случайных значений в исходной таблице была использована специальная функция:
=СЛУЧМЕЖДУ(1;2)
Для определения количества сгенерированных 1 и 2 используем функцию:
=ЧАСТОТА(A2:A21;1)
Описание аргументов:
- A2:A21 – массив сгенерированных функцией =СЛУЧМЕЖДУ(1;2) значений;
- 1 – критерий поиска (функция ЧАСТОТА ищет значения от 0 до 1 включительно и значения >1).
В результате получим:
Вычислим вероятности, разделив количество событий каждого типа на общее их число:
Для подсчета количества событий используем функцию =СЧЁТ($A$2:$A$21). Или можно просто разделить на значение 20. Если заранее не известно количество событий и размер диапазона со случайными значениями, тогда можно использовать в аргументах функции СЧЁТ ссылку на целый столбец: =СЧЁТ(A:A). Таким образом будет автоматически подсчитывается количество чисел в столбце A.
Вероятности выпадения «1» и «2» — 0,45 и 0,55 соответственно. Не забудьте присвоить ячейкам E2:E3 процентный формат для отображения их значений в процентах: 45% и 55%.
Теперь воспользуемся более сложной формулой для вычисления максимальной частоты повторов:
Формулы в ячейках F2 и F3 отличаются только одним лишь числом после оператора сравнения «не равно»: 1 и 2.
Интересный факт! С помощью данной формулы можно легко проверить почему не работает стратегия удвоения ставок в рулетке казино. Данную стратегию управления ставками в азартных играх называют еще Мартингейл. Дело в том, что количество случайных повторов подряд может достигать 18-ти раз и более, то есть восемнадцать раз подряд красные или черные. Например, если ставку в 2 доллара 18 раз удваивать – это уже более пол миллиона долларов «просадки». Это уже провал по любым техникам планирования рисков. Так же следует учитывать, что кроме «черные» и «красные» иногда выпадает еще и «зеро», что окончательно уничтожает все шансы. Так же интересно, что сумма всех чисел в рулетке от 0 до 36 равна 666.
Как посчитать неповторяющиеся значения в Excel?
Пример 3. Определить количество уникальных вхождений в массив числовых данных, то есть не повторяющихся значений.
Исходная таблица:
Определим искомую величину с помощью формулы:
В данном случае функция ЧАСТОТА выполняет проверку наличия каждого из элементов массива данных в этом же массиве данных (оба аргумента совпадают). С помощью функции ЕСЛИ задано условие, которое имеет следующий смысл:
- Если искомый элемент содержится в диапазоне значений, вместо фактического количества вхождений будет возвращено 1;
- Если искомого элемента нет – будет возвращен 0 (нуль).
Полученное значение (количество единиц) суммируется.
В результате получим:
То есть, в указанном массиве содержится 8 уникальных значений.
Функция ЧАСТОТА в Excel и особенности ее синтаксиса
Данная функция имеет следующую синтаксическую запись:
=ЧАСТОТА(массив_данных;массив_интервалов)
Описание аргументов функции (оба являются обязательными для заполнения):
- массив_данных – данные в форме массива либо ссылка на диапазон значений, для которых необходимо определить частоты.
- массив_интервалов — данные в формате массива либо ссылка не множество значений, в которые группируются значения первого аргумента данной функции.
Примечания 1:
- Если в качестве аргумента массив_интервалов был передан пустой массив или ссылка на диапазон пустых значений, результатом выполнения функции ЧАСТОТА будет являться число элементов, входящих диапазон данных, которые были переданы в качестве первого аргумента.
- При использовании функции ЧАСТОТА в качестве обычной функции Excel будет возвращено единственное значение, соответствующее первому вхождению в массив_интервалов (то есть, первому критерию поиска частоты вхождения).
- Массив возвращаемых данной функцией элементов содержит на один элемент больше, чем количество элементов, содержащихся в массив_интервалов. Это происходит потому, что функция ЧАСТОТА вычисляет также количество вхождений величин, значения которых превышают верхнюю границу интервалов. Например, в наборе данных 2,7, 10, 13, 18, 4, 33, 26 необходимо найти количество вхождений величин из диапазонов от 1 до 10, от 11 до 20, от 21 до 30 и более 30. Массив интервалов должен содержать только их граничные значения, то есть 10, 20 и 30. Функция может быть записана в следующем виде: =ЧАСТОТА({2;7;10;13;18;4;33;26};{10;20;30}), а результатом ее выполнения будет столбец из четырех ячеек, которые содержат следующие значения: 4,2, 1, 1. Последнее значение соответствует количеству вхождений чисел > 30 в массив_данных. Такое число действительно является единственным – это 33.
- Если в состав массив_данных входят ячейки, содержащие пустые значения или текст, они будут пропущены функцией ЧАСТОТА в процессе вычислений.
Примечания 2:
- Функция может использоваться для выполнения статистического анализа, например, с целью определения наиболее востребованных для покупателей наименований продукции.
- Данная функция должна быть использована как формула массива, поскольку возвращаемые ей данные имеют форму массива. Для выполнения обычных формул после их ввода необходимо нажать кнопку Enter. В данном случае требуется использовать комбинацию клавиш Ctrl+Shift+Enter.
При анализе данных периодически возникает задача подсчитать количество значений, попадающих в заданные интервалы «от и до» (в статистике их называют «карманы»). Например, подсчитать количество звонков определенной длительности при разборе статистики по мобильной связи, чтобы понимать какой тариф для нас выгоднее:

Для решения подобной задачи можно воспользоваться функцией ЧАСТОТА (FREQUENCY). Ее синтаксис прост:
=ЧАСТОТА(Данные; Карманы)
где
- Карманы — диапазон с границами интервалов, попадание в которые нас интересует
- Данные — диапазон с исходными числовыми значениями, которые мы анализируем
Обратите внимание, что эта функция игнорирует пустые ячейки и ячейки с текстом, т.е. работает только с числами.
Для использования функции ЧАСТОТА нужно:
- заранее подготовить ячейки с интересующими нас интервалами-карманами (желтые F2:F5 в нашем примере)
- выделить пустой диапазон ячеек (G2:G6) по размеру на одну ячейку больший, чем диапазон карманов (F2:F5)
- ввести функцию ЧАСТОТА и нажать в конце сочетание Ctrl+Shift+Enter, т.е. ввести ее как формулу массива
Во всех предварительно выделенных ячейках посчитается количество попаданий в заданные интервалы. Само-собой, для реализации подобной задачи можно использовать и другие способы (функцию СЧЁТЕСЛИ, сводные таблицы и т.д.), но этот вариант весьма хорош.
Кроме того, с помощью функции ЧАСТОТА можно легко подсчитывать количество уникальных чисел в наборе с помощью простой формулы массива:

Ссылки по теме
- Как подсчитать количество уникальных элементов в списке
- Как сделать список без повторений
- Частотный анализ данных с помощью сводных таблиц и формул
Очень давно не писал блог. Расслабился совсем. Ну ничего, исправляюсь.
Продолжаю новую рубрику блога, посвященную анализу данных с помощью всем известного Microsoft Excel.
В современном мире к статистике проявляется большой интерес, поскольку это отличный инструмент для анализа и принятия решений, а также это отличное средство для поиска причин нарушений процесса и их устранения. Статистический анализ применим во многих сферах, где существуют большие массивы данных: естественно, в первую очередь я скажу, что металлургии, а также в экономике, биологии, политике, социологии и… много где еще. Статья эта будет, как несложно догадаться по ее названию, про использование некоторых средств статистического анализа, а именно — гистограммам.
Ну, поехали.
Статистический анализ в Excel можно осуществлять двумя способами:
• С помощью функций
• С помощью средств надстройки «Пакет анализа». Ее, как правило, еще необходимо установить.
Чтобы установить пакет анализа в Excel, выберите вкладку «Файл» (а в Excel 2007 это круглая цветная кнопка слева сверху), далее — «Параметры», затем выберите раздел «Надстройки». Нажмите «Перейти» и поставьте галочку напротив «Пакет анализа».
А теперь — к построению гистограмм распределения по частоте и их анализу.
Речь пойдет именно о частотных гистограммах, где каждый столбец соответствует частоте появления* значения в пределах границ интервалов. Например, мы хотим посмотреть, как у нас выглядит распределение значения предела текучести стали S355J2 в прокате толщиной 20 мм за несколько месяцев. В общем, хотим посмотреть, похоже ли наше распределение на нормальное (а оно должно быть таким).
*Примечание: для металловедческих целей типа оценки размера зерна или оценки объемной доли частиц этот вид гистограмм не пойдет, т.к. там высота столбика соответствует не частоте появления частиц определенного размера, а доле объема (а в плоскости шлифа — площади), которую эти частицы занимают.
График нормального распределения выглядит следующим образом:

График функции Гаусса
Мы знаем, что реально такой график может быть получен только при бесконечно большом количестве измерений. Реально же для конечного числа измерений строят гистограмму, которая внешне похожа на график нормального распределения и при увеличении количества измерений приближается к графику нормального распределения (распределения Гаусса).
Построение гистограмм с помощью программ типа Excel является очень быстрым способом проверки стабильности работы оборудования и добросовестности коллектива: если получим «кривую» гистограмму, значит, либо прибор не исправен или мы данные неверно собрали, либо кто-то где-то преднамеренно мухлюет или же просто неверно использует оборудование.
А теперь — построение гистограмм!
Способ 1-ый. Халявный.
- Идем во вкладку «Анализ данных» и выбираем «Гистограмма».
- Выбираем входной интервал.
- Здесь же предлагается задать интервал карманов, т.е. те диапазоны, в пределах которых будут лежать наши значения. Чем больше значений в интервале — тем выше столбик гистограммы. Если мы оставим поле «Интервалы карманов» пустым, то программа вычислит границы интервалов за нас.
- Если хотим сразу же вывести график,то ставим галочку напротив «Вывод графика».
- Нажимаем «ОК».
- Вот, вроде бы, и все: гистограмма готова. Теперь нужно сделать так, чтобы по вертикальной оси отображалась не абсолютная частота, а относительная.
- Под появившейся таблицей со столбцами «Карман» и «Частота» под столбцом «Частота» введем формулу «=СУММ» и сложим все абсолютные частоты.
- К появившейся таблице со столбцами «Карман» и «Частота» добавим еще один столбец и назовем его «Относительная частота».
- Во всех ячейках нового столбца введем формулу, которая будет рассчитывать относительную частоту: 100 умножить на абсолютную частоту (ячейка из столбца «частота») и разделить на сумму, которую мы вычислил в п. 7.
Способ 2-ой. Трудный, но интересный.
Будет полезен тому, кто по каким-либо причинам не смог установить Пакет анализа.
- Перво-наперво нужно задать интервалы тех самых карманов, которые мы не стали вычислять в способе, описанном выше.
- Интервал карманов вычисляют так: разность максимального значения и минимального значений массива, деленная на количество интервалов: (Xmax-Xmin)/n.
Для оценки оптимального для нашего массива данных количества интервалов можно воспользоваться формулой Стерджесса: n~1+3,322lgN, где N — количество всех значений величины. Например для N=100, n=7,6. Естественно, округляем до 8. - Для нахождения максимального и минимального значений воспользуемся соответствующими функциями: =МАКС(наш диапазон значений) и =МИН(наш диапазон значений).

- Найдем разность этих значений и разделим его на количество интервалов, которое нам захочется. Пусть будет 10. Так мы вычислили ширину нашего «кармана».
- Теперь в каждой ячейке шаг за шагом прибавляем полученное значение ширины кармана: сначала к минимальному значению нашего массива (п. 3), затем в следующей ячейке ниже — к полученной сумме и т.д. Так постепенно доходим до максимального значения. Вот мы и построили интервалы карманов в виде столбца значений. Интервалом считается следующий диапазон : (i-1; i] или iСкачать бесплатно видеокурc по Excel
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.


- Как составить частотный словарь в Excel?
- Простой анализ n-gram (анализ встречаемости)
- Анализ частотности слов, или как посчитать в тексте уникальные слова и вывести списком с их встречаемостью
- Анализ встречаемости биграмм (2-gram)
- Анализ n-gram с частотностью
- N-gram анализ по нескольким метрикам
- Заключение
Для поисковой рекламы и SEO анализ n-грамм – один из самых эффективных методов. Однако долгое время n-gram анализ оставался в силу сложности реализации алгоритма доступен только крупным агентствам с программистами в штате, или продвинутым специалистам со знанием программирования.
Чтобы популяризовать подход и сделать его доступным всем, у кого есть Windows и Excel, инструменты для анализа n-грамм были реализованы в !SEMTools для Excel. Ниже перечислены различные подходы анализа со схематичными примерами.
Во всех кейсах создается отдельный лист с результатами подсчета, исходные данные никак не изменяются.
Простой анализ n-gram (анализ встречаемости)
Данный подход самый простой — берётся N-грамма и для неё анализируется её встречаемость в тексте.
Анализ частотности слов, или как посчитать в тексте уникальные слова и вывести списком с их встречаемостью
Как посчитать, сколько раз встречается слово в Excel-таблице? Если мы ищем лишь одно слово, может помочь формула СЧЁТЕСЛИ. Формула ниже посчитает количество строк, в которых встречается последовательность символов «слова» вне зависимости от их регистра.
=СЧЁТЕСЛИ(A1:A100;"*слова*")
Символ звездочки определяет, что перед и после указанной последовательности символов могут быть любые другие или их отсутствие. В связи с этим могут быть учтены строки со словами «словарь», «словарный» и т.д. Чтобы найти слова по точному совпадению, нужно добавить символ пробела в начало и конец всех ячеек столбца, и воспользоваться подсчетом с учетом пробелов:
=СЧЁТЕСЛИ(A1:A100;"* слова *")
Но и это решение не убережет нас от ситуаций, когда слово повторяется в строке 2 и более раз, если мы хотим посчитать все повторения. Т.к. формула считает именно строки.
Поэтому был реализован макрос в !SEMTools, с легкостью выполняющий эту задачу.
Выделяем текст, выбираем слова, готово. Текст может быть как 5 строк, так и миллион строк – процедура займет секунды. Главное, чтобы уникальных слов в тексте было не больше 1048575 – иначе их не получится вывести на лист. Но такая ситуация — редкость.
Можно обратить внимание, что разные словоформы рассматриваются как отдельные слова, поэтому, если нужно проанализировать встречаемость без учета словоформ, текст нужно предварительно лемматизировать. Тогда вы составите не просто частотный словарь слов, а частотный словарь лемм.

Анализ встречаемости биграмм (2-gram)
Аналогично предыдущему, но берутся биграммы — последовательности из двух слов. Как посчитать в данном случае триграммы и т.д., кажется, уже понятно.

Анализ n-gram с частотностью
Когда текст состоит из фраз, и для каждой фразы известна определенная метрика (в поисковой рекламе это частотность), чтобы более достоверно измерить вес каждой словоформы или леммы, требуется производить анализ уже с учетом этой метрики.
В !SEMTools это вшито по умолчанию – просто нужно выделить два столбца вместе со столбцом используемой метрики. Аналогично можно составлять частотность биграмм, триграмм и т.д.

N-gram анализ по нескольким метрикам
Данный подход будет полезен PPC-специалистам для аналитики расчетных метрик, таких как CTR, CPC, CPA, CR, AOV, ROAS и тому подобные. Поскольку для их расчета используются несколько метрик, можно произвести n-gram анализ этих метрик и посчитать расчетные показатели в разрезе n-грамм.

Такая аналитика может дать много полезных инсайтов. Выявить высококонверсионные связки слов для последующего интенсивного биддинга на них, например. Или, наоборот, выявления низкоконверсионных связок для исключения их из рекламы, в то время как слова, из которых они составлены, в среднем по больнице не выделялись низкой конверсией.

Заключение
Примеры, приведенные выше, позволяют производить анализ не только поисковых запросов или ключевых слов, но и любого текста, который будет дан на вход, вне зависимости от его длины. Нужно только удалить лишние пробелы, перевести весь текст в нижний регистр и можно производить анализ.
Если у вас остались вопросы – подписывайтесь на канал автора и задавайте вопросы в чате: https://t.me/semtoolschat
Часто сталкиваетесь с этой или похожими задачами при работе в Excel?
Скачивайте !SEMTools и начинайте экономить рабочее время, выделяя его для более важных задач!
Содержание
- Как найти наиболее повторяющиеся значение в Excel
- Поиск наиболее повторяющегося значения в Excel
- Наиболее часто встречающееся слово в Excel
- Поиск и подсчет самых частых значений
- Поиск самых часто встречающихся чисел
- Частотный анализ по диапазонам функцией ЧАСТОТА
- Частотный анализ сводной таблицей с группировкой
- Поиск самого часто встречающегося текста
- Excel наиболее часто встречающееся текстовое значение
- Как найти наиболее распространенное значение (число или текстовую строку) из списка в Excel?
- Легко сортировать по частоте появления в Excel
Как найти наиболее повторяющиеся значение в Excel
Допустим у нас есть таблица регистра составленных заказов клиентов. Необходимо узнать с какого города поступило наибольшее количество заказов, а с какого – наименьшее. Для решения данной задачи будем использовать формулу с поисковыми и вычислительными функциями.
Поиск наиболее повторяющегося значения в Excel
Чтобы наглядно продемонстрировать работу формулы для примера воспользуемся такой схематической таблицей регистра заказов от клиентов:
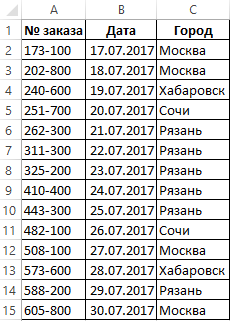
Теперь выполним простой анализ наиболее часто и редко повторяющихся значений таблицы в столбце «Город». Для этого:
- Сначала находим наиболее часто повторяющиеся названия городов. В ячейку E2 введите следующую формулу:
- Обязательно после ввода формулы нажмите комбинацию горячих клавиш CTRL+SHIFT+Enter, так как ее нужно выполнить в массиве.
- Для вычисления наиболее редко повторяющегося названия города вводим весьма похожую формулу:
Результат поиска названий самых популярных и самых редких городов клиентов в регистре заказов, отображен на рисунке:
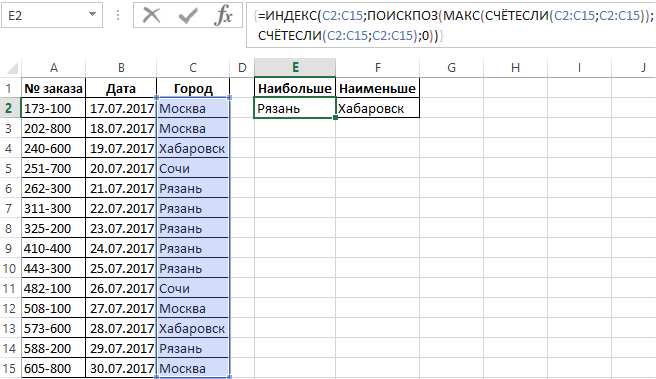
Если таблица содержит одинаковое количество двух самых часто повторяемых городов или два самых редко повторяющихся города в одном и том же столбце, тогда будет отображаться первый из них.
Принцип действия поиска популярных по повторению значений:
Если посмотреть на синтаксис формул то можно легко заметить, что они отличаются только одним из названием функций: =МАКС() и =МИН(). Все остальные аргументы формулы – идентичны. Функция =СЧЕТЕСЛИ() подсчитывает, сколько раз каждое название города повторяется в диапазоне ячеек C2:C16. Таким образом в памяти создается условный массив значений.
Функция МАКС или МИН выбирает из условного массива наибольшее или наименьшее значение. Функция =ПОИСКПОЗ() возвращает номер позиции на которой в столбце C название города соответственного наибольшему или наименьшему количеству повторений. Полученное значение будет передано в качестве аргумента для функции =ИНДЕКС(), которая возвращает конечный результат в ячейку.
Источник
Наиболее часто встречающееся слово в Excel
Из этого примера вы узнаете, как найти наиболее часто встречающееся слово в Excel.
Вы можете использовать функцию MODE (МОДА), чтобы найти наиболее часто встречающееся число. Но эта функция работает только с числами:
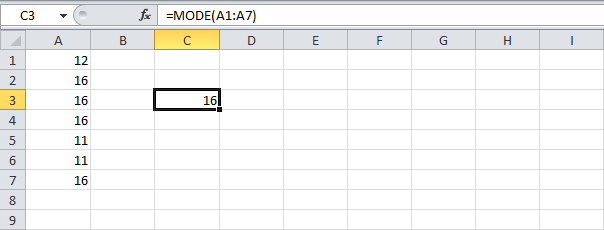
Вы можете использовать функцию COUNTIF (СЧЕТЕСЛИ), чтобы подсчитать количество вхождений каждого слова. Но нам ведь нужна одна единственная формула, которая возвратит наиболее часто встречающееся слово (в нашем примере – это слово «circle»).
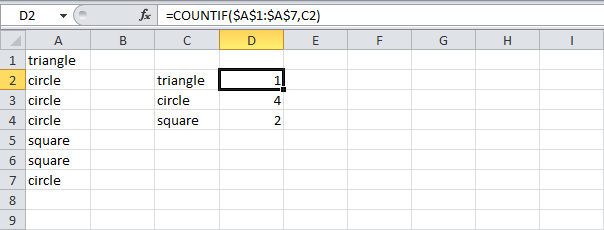
Чтобы найти наиболее часто встречающееся слово, следуйте инструкции ниже:
- Функция MATCH (ПОИСКПОЗ) возвращает позицию значения в заданном диапазоне.
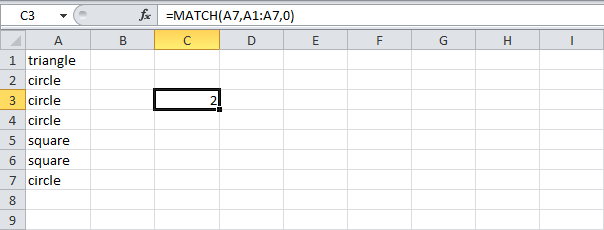
Пояснение: Cлово «circle» (А7) найдено в позиции 2 диапазона A1:A7. Ноль в третьем аргументе позволяет вернуть точное совпадение.
Чтобы найти положение наиболее часто встречающихся слов, добавим функцию MODE (МОДА) и заменим A7 на A1:A7.
Закончим нажатием Ctrl+Shift+Enter.
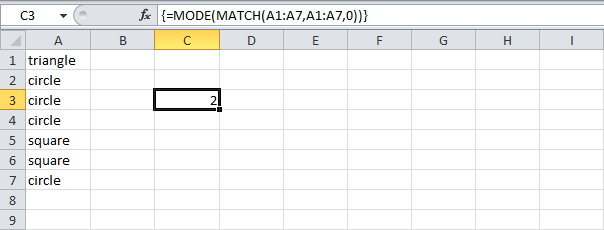
Примечание: Строка формул указывает, что это формула массива, заключая её в фигурные скобки <>. Их не нужно вводить самостоятельно. Они исчезнут, когда вы начнете редактировать формулу.
- Пояснение:
- Диапазон (массив констант), созданный с помощью функции MATCH (ПОИСКПОЗ), хранится в памяти Excel, а не в ячейках листа.
- Массив констант выглядит следующим образом: <1;2;2;2;5;5;2>. Цифры показывают, что слово «triangle» найдено в позиции 1, «circle» в позиции 2, «circle» в позиции 2 и т.д.
- Этот массив констант используется в качестве аргумента для функции MODE (МОДА), давая результат 2 (позиция наиболее часто встречающегося слова).
- Используйте этот результат и функцию INDEX (ИНДЕКС), чтобы вернуть второе слово из диапазона A1:A7, как наиболее часто встречающееся.
Источник
Поиск и подсчет самых частых значений
Необходимость поиска наибольших и наименьших значений в любом бизнесе очевидна: самые прибыльные товары или ценные клиенты, самые крупные поставки или партии и т.д.
Но наравне с этим, иногда приходится искать в данных не топовые, а самые часто встречающиеся значения, что хоть и звучит похоже, но, по факту, совсем не то же самое. Применительно к магазину, например, это может быть поиск не самых прибыльных, а самых часто покупаемых товаров или самое часто встречающееся количество позиций в заказе, минут в разговоре и т.п.
В такой ситуации задачу придется решать немного по-разному, в зависимости от того, с чем мы имеем дело — с числами или с текстом.
Поиск самых часто встречающихся чисел
Предположим, перед нами стоит задача проанализировать имеющиеся данные по продажам в магазине, с целью определить наиболее часто встречающееся количество купленных товаров. Для определения самого часто встречающегося числа в диапазоне можно использовать функцию МОДА (MODE) :
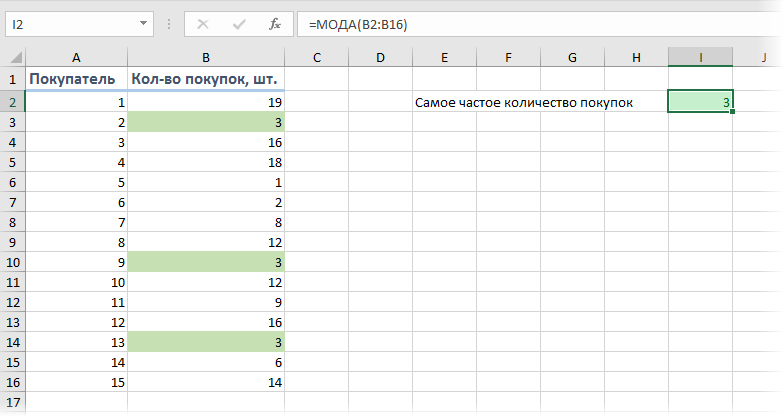
Т.е., согласно нашей статистике, чаще всего покупатели приобретают 3 шт. товара.
Если существует не одно, а сразу несколько значений, встречающихся одинаково максимальное количество раз (несколько мод), то для их выявления можно использовать функцию МОДА.НСК (MODE.MULT) . Ее нужно вводить как формулу массива, т.е. выделить сразу несколько пустых ячеек, чтобы хватило на все моды с запасом и ввести в строку формул =МОДА.НСК(B2:B16) и нажать сочетание клавиш Ctrl+Shift+Enter.
На выходе мы получим список всех мод из наших данных:
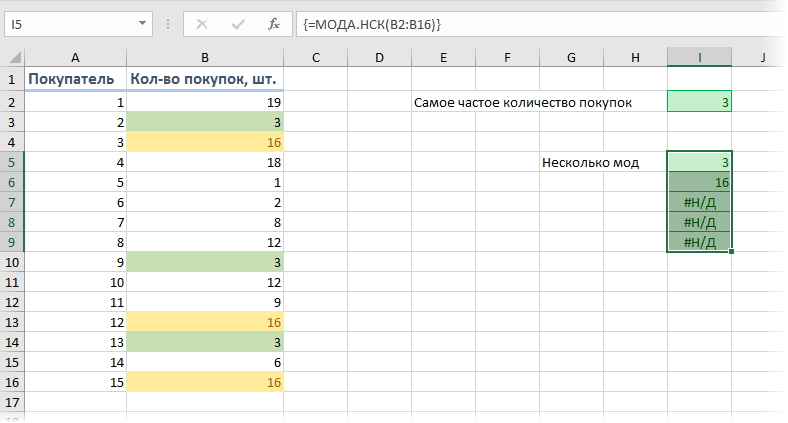
Т.е., судя по нашим данным, часто берут не только по 3, но и по 16 шт. товаров. Обратите внимание, что в наших данных только две моды (3 и 16), поэтому остальные ячейки, выделенные «про запас», будут с ошибкой #Н/Д.
Частотный анализ по диапазонам функцией ЧАСТОТА
Если же нужно проанализировать не целые, а дробные числа, то правильнее будет оценивать не количество одинаковых значений, а попадание их в заданные диапазоны. Например, нам необходимо понять какой вес чаще всего бывает у покупаемых товаров, чтобы правильно выбрать для магазина тележки и упаковочные пакеты подходящего размера. Другими словами, нам нужно определить сколько чисел попадает в интервал 1..5 кг, сколько в интервал 5..10 кг и т.д.
Для решения подобной задачи можно воспользоваться функцией ЧАСТОТА (FREQUENCY) . Для нее нужно заранее подготовить ячейки с интересующими нас интервалами (карманами) и затем выделить пустой диапазон ячеек (G2:G5) по размеру на одну ячейку больший, чем диапазон карманов (F2:F4) и ввести ее как формулу массива, нажав в конце сочетание Ctrl+Shift+Enter:
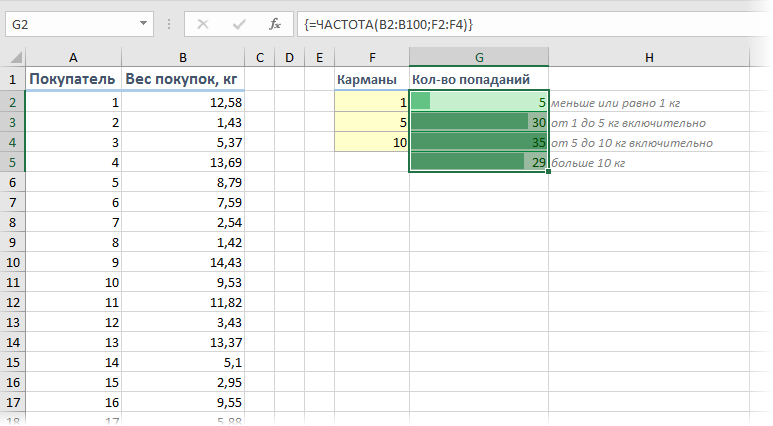
Частотный анализ сводной таблицей с группировкой
Альтернативный вариант решения задачи: создать сводную таблицу, где поместить вес покупок в область строк, а количество покупателей в область значений, а потом применить группировку — щелкнуть правой кнопкой мыши по значениям весов и выбрать команду Группировать (Group) . В появившемся окне можно задать пределы и шаг группировки:
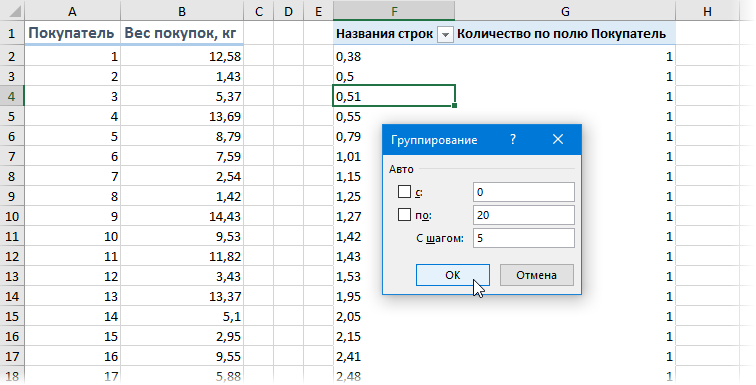
. и после нажатия на кнопку ОК получить таблицу с подсчетом количества попаданий покупателей в каждый диапазон группировки:
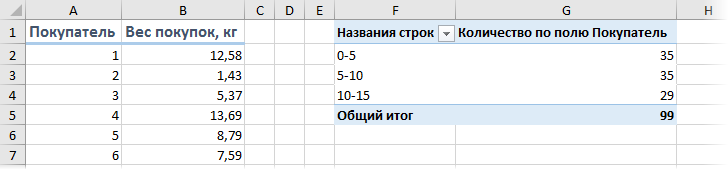
Минусы такого способа:
- шаг группировки может быть только постоянным, в отличие от функции ЧАСТОТА, где карманы можно задать абсолютно любые
- сводную таблицу нужно обновлять при изменении исходных данных (щелчком правой кнопки мыши — Обновить), а функция пересчитывается автоматически «на лету»
Поиск самого часто встречающегося текста
Если мы имеем дело не с числами, а с текстом, то подход к решению будет принципиально другой. Предположим, что у нас есть таблица из 100 строк с данными о проданных в магазине товарах, и нам нужно определить, какие товары покупались наиболее часто?
Самым простым и очевидным решением будет добавить рядом столбец с функцией СЧЁТЕСЛИ (COUNTIF) , чтобы подсчитать количество вхождений каждого товара в столбце А:
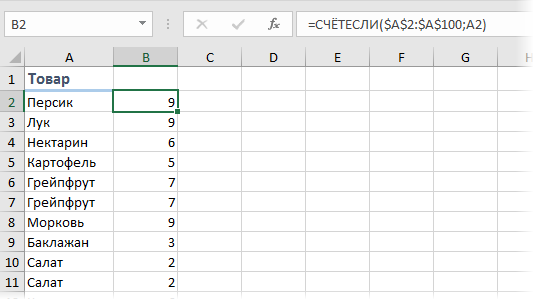
Затем, само-собой, отсортировать получившийся столбец по убыванию и посмотреть на первые строчки.
Или же добавить к исходному списку столбец с единичками и построить по получившейся таблице сводную, подсчитав суммарное количество единичек для каждого товара:
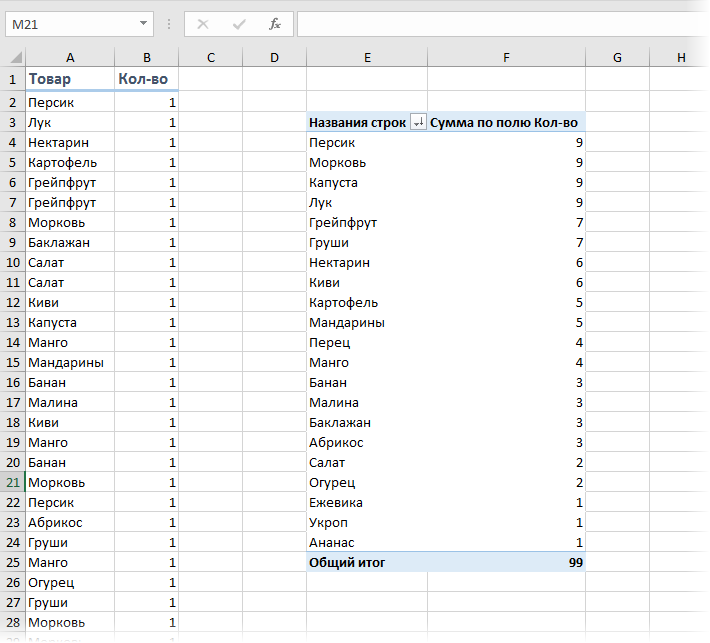
Если исходных данных не очень много и принципиально не хочется пользоваться сводными таблицами, то можно использовать формулу массива:
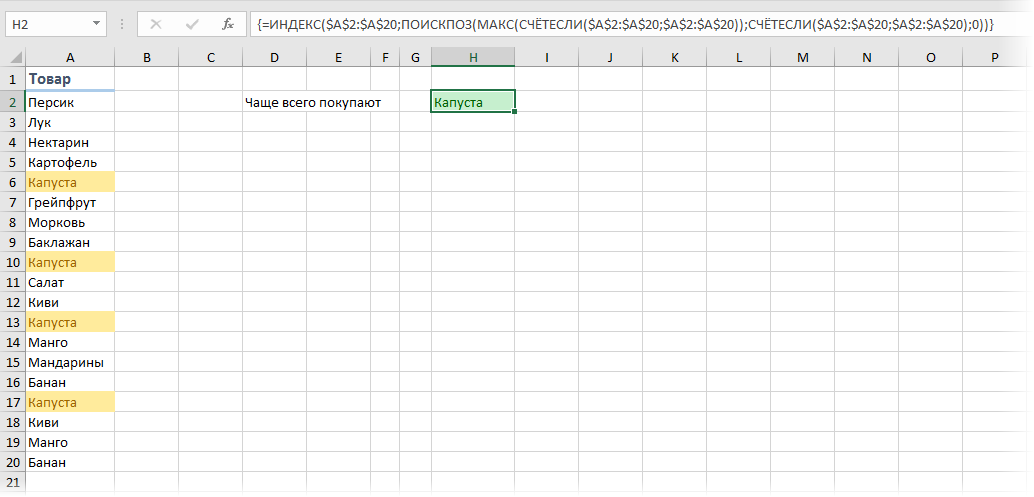
Давайте разберем ее по кусочкам:
- СЧЁТЕСЛИ(A2:A20;A2:A20) – формула массива, которая ищет по очереди количество вхождений каждого товара в диапазоне A2:A100 и выдаст на выходе массив с количеством повторений, т.е., фактически, заменяет собой дополнительный столбец
- МАКС – находит в массиве вхождений самое большое число, т.е. товар, который покупали чаще всего
- ПОИСКПОЗ – вычисляет порядковый номер строки в таблице, где МАКС нашла самое большое число
- ИНДЕКС – выдает из таблицы содержимое ячейки с номером, который нашла ПОИСКПОЗ
Источник
Excel наиболее часто встречающееся текстовое значение
Как найти наиболее распространенное значение (число или текстовую строку) из списка в Excel?
Предположим, у вас есть список имен, которые содержат несколько дубликатов, и теперь вы хотите извлечь наиболее часто встречающееся значение. Прямой способ — подсчитывать данные по одному из списка, чтобы получить результат, но если в столбце тысячи имен, этот способ будет хлопотным и трудоемким. Следующее руководство познакомит вас с некоторыми приемами, которые помогут быстро и удобно решить эту задачу.
Как правило, мы можем применить РЕЖИМ функции (= РЕЖИМ (A1: A16)), чтобы найти наиболее распространенное число из диапазона. Но эта функция РЕЖИМ не работает с текстовыми строками. Чтобы извлечь наиболее часто встречающееся значение, вы можете применить следующую формулу массива. Пожалуйста, сделайте так:
В пустой ячейке, помимо данных, введите формулу ниже и нажмите Shift + Ctrl + Enter ключи вместе.
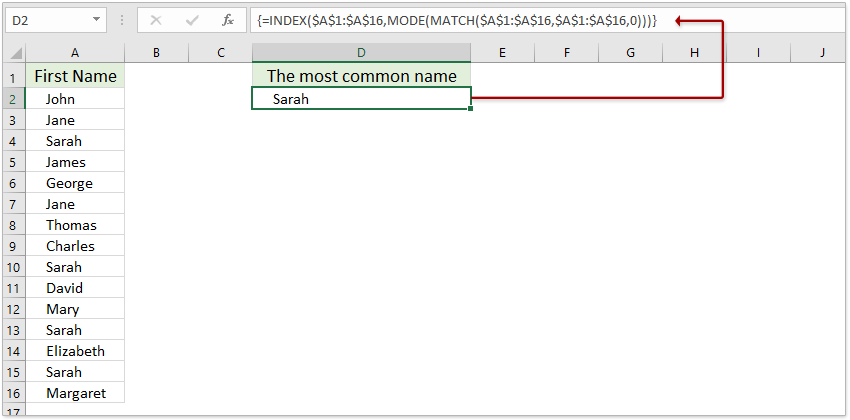
Заметки:
1. A1: A16 — это диапазон данных, значение которого вы хотите получать чаще всего. Вы можете изменить его по своему усмотрению.
2. Эта формула массива не может работать, если в списке есть пустые ячейки.
 |
Формула слишком сложна для запоминания? Сохраните формулу как запись Auto Text для повторного использования одним щелчком мыши в будущем! Подробнее . Бесплатная пробная версия |
Легко сортировать по частоте появления в Excel
Kutools для Excel Расширенная сортировка Утилита поддерживает быструю сортировку данных в Excel по длине текста, фамилии, абсолютному значению, частоте и т. д.

Kutools for Excel — Включает более 300 удобных инструментов для Excel. Полнофункциональная бесплатная пробная версия 30 -день, кредитная карта не требуется! Get It Now
С помощью следующего кода VBA вы можете не только найти наиболее часто встречающееся значение, но и подсчитать количество раз для наиболее распространенного слова.
1. Удерживайте ALT + F11 ключи, и он открывает Окно Microsoft Visual Basic для приложений.
2. Нажмите Вставить > Модулии вставьте следующий код в Окно модуля.
Код VBA: найти наиболее распространенное значение из списка
3, Затем нажмите F5 нажмите клавишу для запуска этого кода, и появится диалоговое окно с напоминанием о выборе диапазона, который вы хотите использовать. Смотрите скриншот: 
4, Затем нажмите OK, вы получите окно подсказки, в котором отображается следующая информация: 
Если у вас установлен Kutools for Excel, вы можете легко применить его Найдите наибольшее значение запятой формула, чтобы быстро получить наиболее частое значение из списка или столбца в Excel.
Kutools for Excel — Включает более 300 удобных инструментов для Excel. Полнофункциональная бесплатная пробная версия 30 -день, кредитная карта не требуется! Бесплатная пробная версия сейчас!
Kutools for Excel — Combines more than 300 Advanced Functions and Tools for Microsoft Excel
1. Выберите пустую ячейку, в которую вы поместите найденное значение, и нажмите Кутулс > Формула Помощник> Формула Помощник.
2. В диалоговом окне Помощник по формулам выберите Поиск из Тип формулы раскрывающийся список, щелкните, чтобы выбрать Найдите наиболее распространенное значение в Выберите формулу список, укажите список / столбец в Диапазон и нажмите Ok кнопка. Смотрите скриншот: 
И тогда вы увидите, что наиболее частое / частое значение было найдено и помещено в выбранную ячейку. Смотрите скриншот: 
Kutools for Excel — Включает более 300 удобных инструментов для Excel. Полнофункциональная бесплатная пробная версия 30 -день, кредитная карта не требуется! Get It Now
Источник
17 авг. 2022 г.
читать 2 мин
Вы можете использовать функцию СЧЁТЕСЛИ(диапазон, критерии) , чтобы подсчитать, как часто конкретный текст встречается в столбце Excel.
В следующих примерах показано, как использовать эту функцию на практике.
Пример 1: Подсчет частоты одного конкретного текста
Предположим, у нас есть следующий столбец в Excel, в котором показаны названия различных команд НБА:
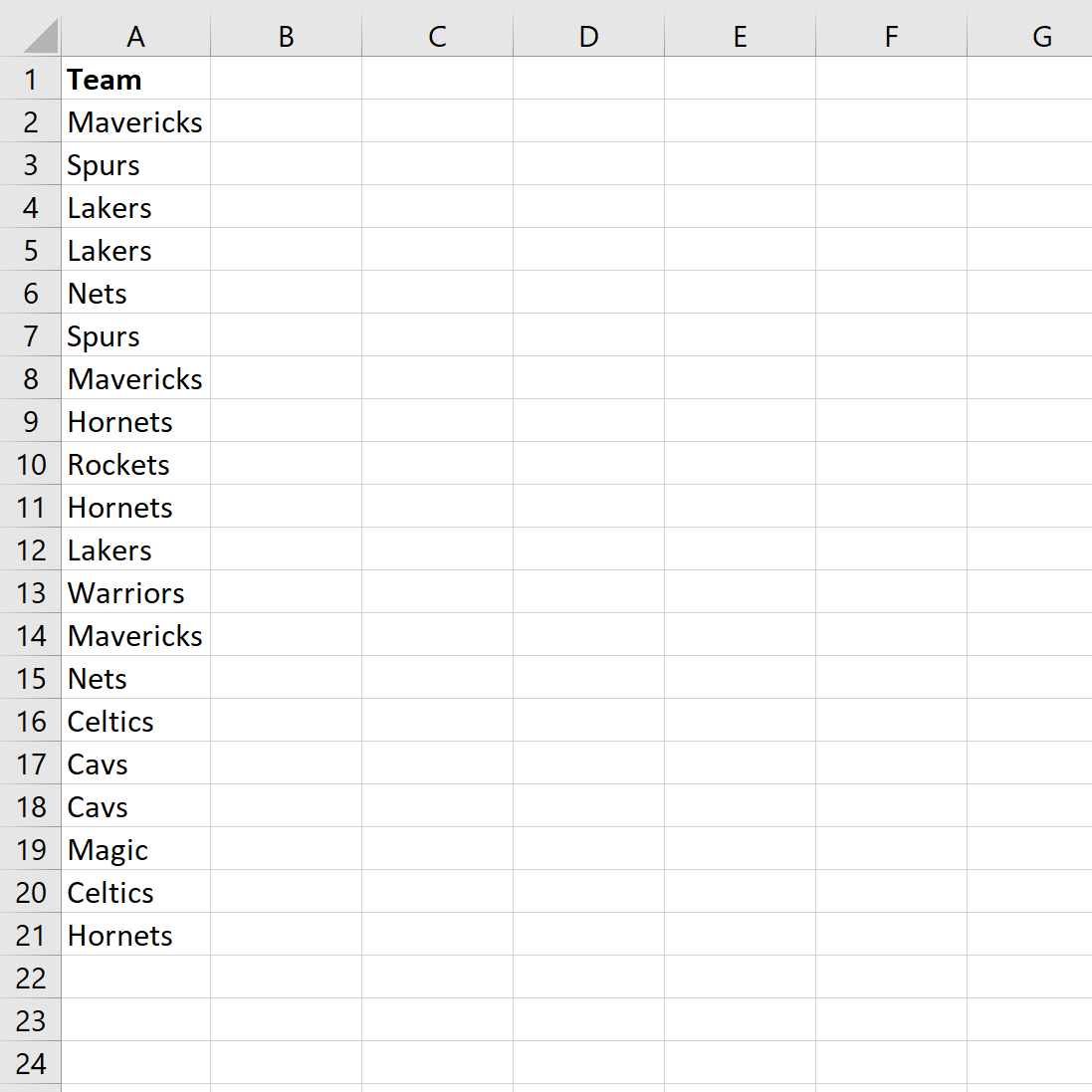
Если мы хотим подсчитать, как часто название команды «Шершни» появляется в столбце, мы можем использовать следующую формулу:
=COUNTIF( A2:A21 , "Hornets")
На следующем снимке экрана показано, как использовать эту формулу на практике:
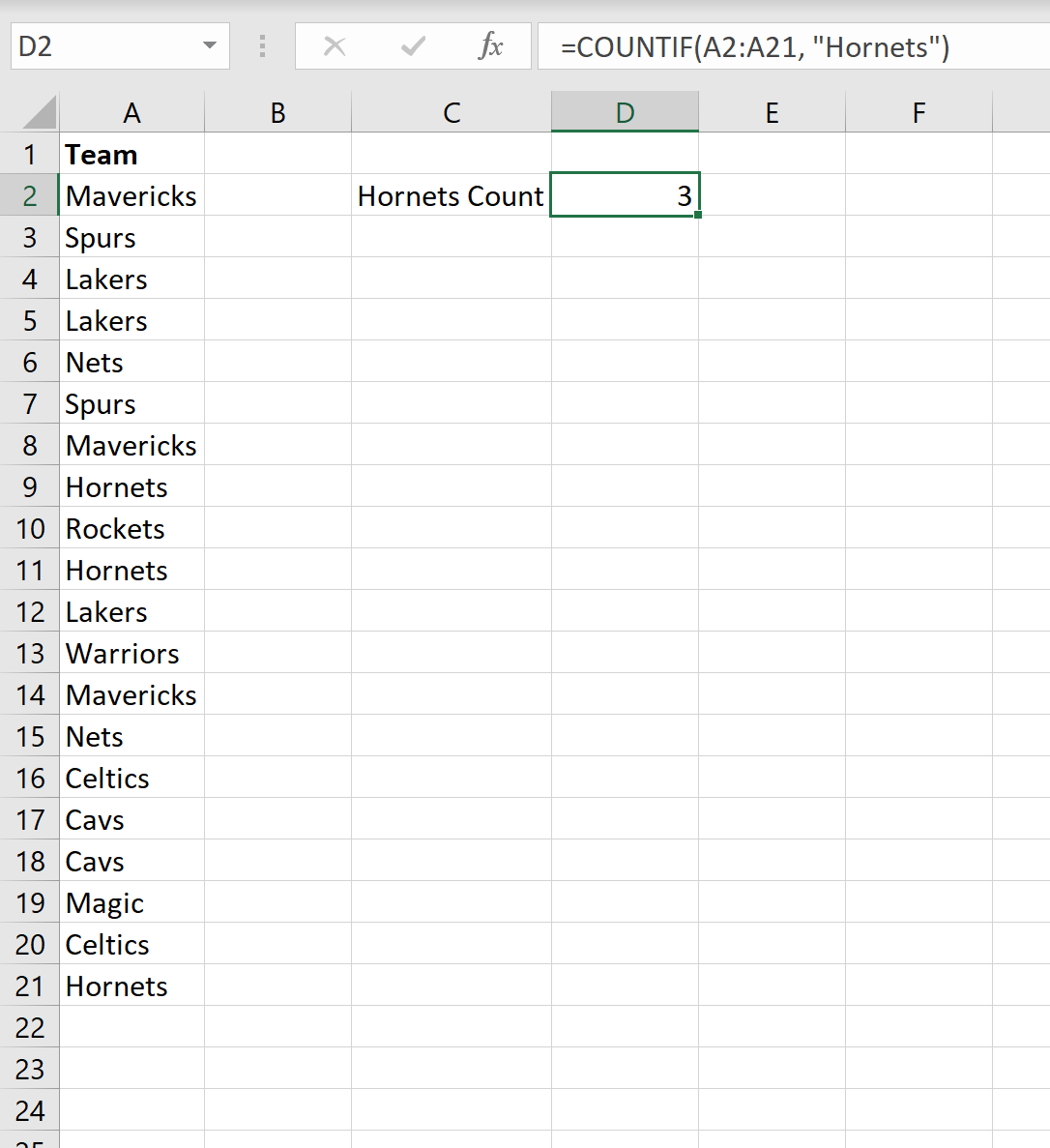
Мы видим, что «Шершни» появляются 3 раза.
Пример 2: Подсчет частоты нескольких текстов
Если мы хотим подсчитать частоту появления нескольких разных текстов, мы можем использовать функцию UNIQUE() , чтобы получить массив каждого уникального текста, который появляется в столбце:
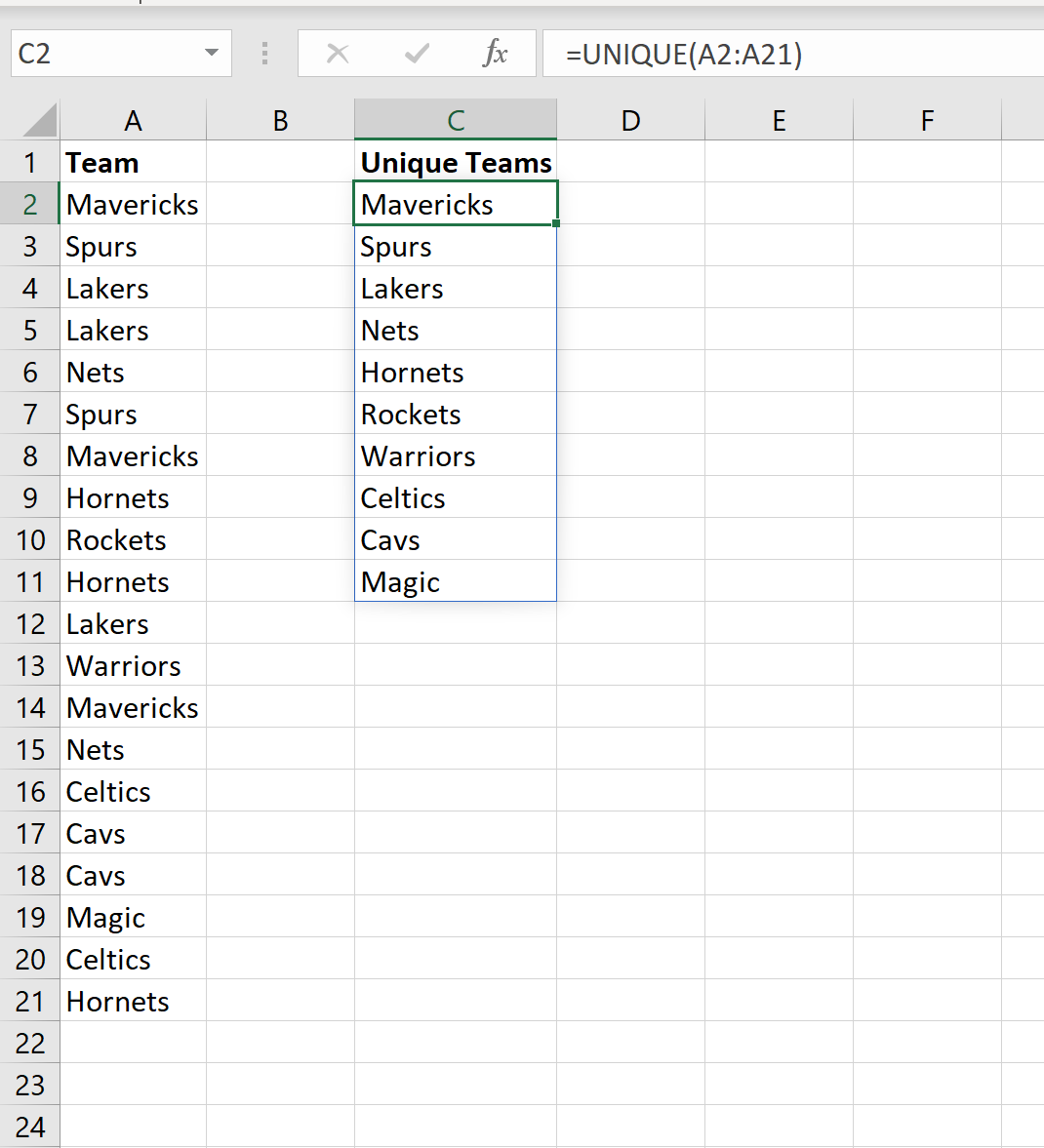
Затем мы можем использовать функцию COUNTIF() , чтобы подсчитать, как часто встречается название каждой команды:
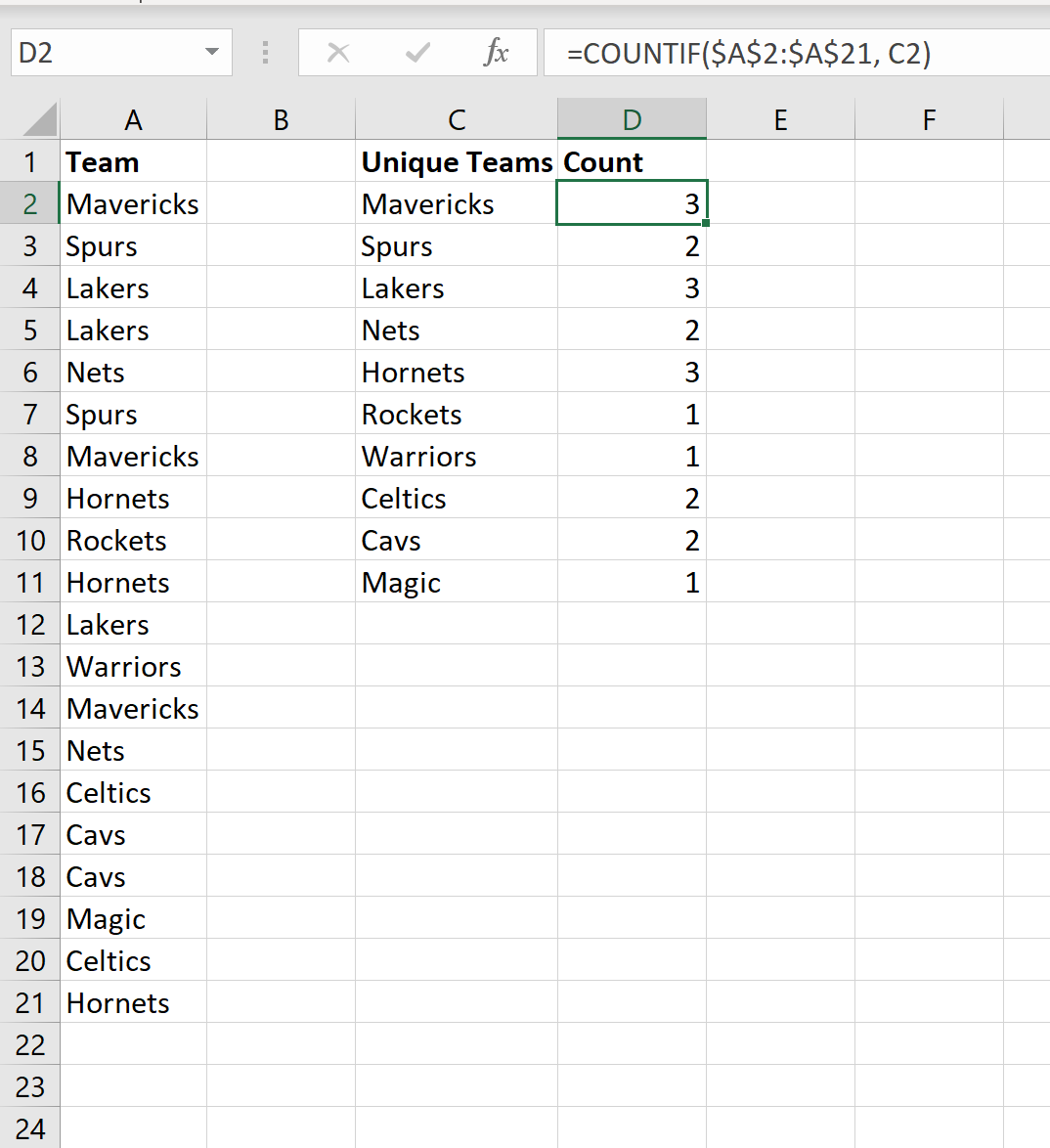
Мы видим, что:
- Название команды «Маверикс» встречается 3 раза.
- Название команды «Шпоры» встречается 2 раза.
- Название команды «Лейкерс» встречается 3 раза.
И так далее.
Дополнительные ресурсы
Следующие учебные пособия предлагают дополнительную информацию о том, как подсчитывать частоты в Excel:
Как создать частотное распределение в Excel
Как рассчитать относительную частоту в Excel
Как рассчитать кумулятивную частоту в Excel
Написано
![]()
Замечательно! Вы успешно подписались.
Добро пожаловать обратно! Вы успешно вошли
Вы успешно подписались на кодкамп.
Срок действия вашей ссылки истек.
Ура! Проверьте свою электронную почту на наличие волшебной ссылки для входа.
Успех! Ваша платежная информация обновлена.
Ваша платежная информация не была обновлена.
При анализе данных периодически возникает задача подсчитать количество значений, попадающих в заданные интервалы «от и до» (в статистике их называют «карманы»). Например, подсчитать количество звонков определенной длительности при разборе статистики по мобильной связи, чтобы понимать какой тариф для нас выгоднее:
")
Для решения подобной задачи можно воспользоваться функцией ЧАСТОТА (FREQUENCY). Ее синтаксис прост:
=ЧАСТОТА(Данные; Карманы)
где
- Карманы — диапазон с границами интервалов, попадание в которые нас интересует
- Данные — диапазон с исходными числовыми значениями, которые мы анализируем
Обратите внимание, что эта функция игнорирует пустые ячейки и ячейки с текстом, т.е. работает только с числами.
Для использования функции ЧАСТОТА нужно:
- заранее подготовить ячейки с интересующими нас интервалами-карманами (желтые F2:F5 в нашем примере)
- выделить пустой диапазон ячеек (G2:G6) по размеру на одну ячейку больший, чем диапазон карманов (F2:F5)
- ввести функцию ЧАСТОТА и нажать в конце сочетание Ctrl+Shift+Enter, т.е. ввести ее как формулу массива
Во всех предварительно выделенных ячейках посчитается количество попаданий в заданные интервалы. Само-собой, для реализации подобной задачи можно использовать и другие способы (функцию СЧЁТЕСЛИ, сводные таблицы и т.д.), но этот вариант весьма хорош.
Кроме того, с помощью функции ЧАСТОТА можно легко подсчитывать количество уникальных чисел в наборе с помощью простой формулы массива:

Ссылки по теме
- Как подсчитать количество уникальных элементов в списке
- Как сделать список без повторений
- Частотный анализ данных с помощью сводных таблиц и формул