
17 авг. 2022 г.
читать 2 мин
Вы можете использовать функцию СЧЁТЕСЛИ(диапазон, критерии) , чтобы подсчитать, как часто конкретный текст встречается в столбце Excel.
В следующих примерах показано, как использовать эту функцию на практике.
Пример 1: Подсчет частоты одного конкретного текста
Предположим, у нас есть следующий столбец в Excel, в котором показаны названия различных команд НБА:
Если мы хотим подсчитать, как часто название команды «Шершни» появляется в столбце, мы можем использовать следующую формулу:
=COUNTIF( A2:A21 , "Hornets")
На следующем снимке экрана показано, как использовать эту формулу на практике:
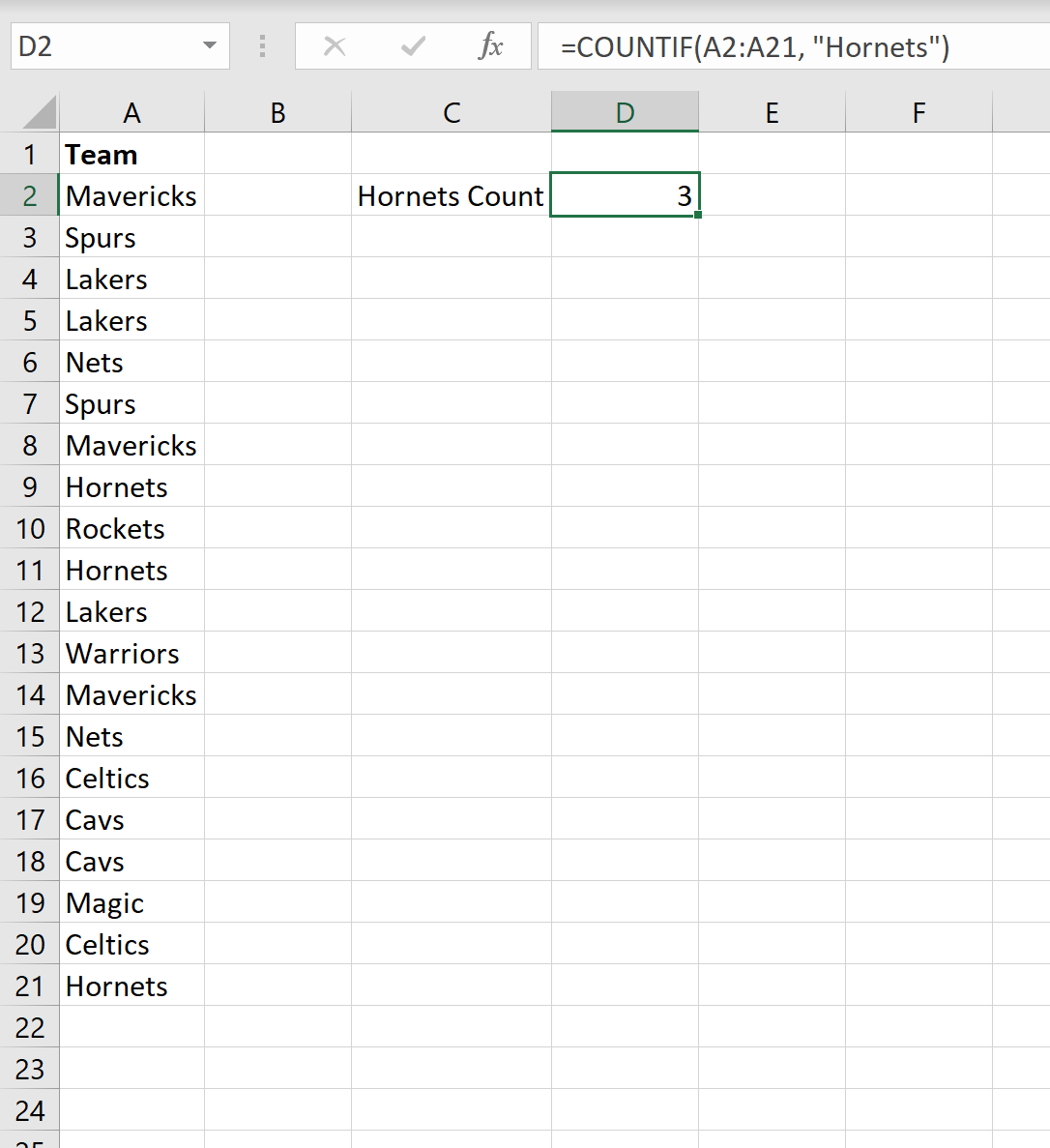
Мы видим, что «Шершни» появляются 3 раза.
Пример 2: Подсчет частоты нескольких текстов
Если мы хотим подсчитать частоту появления нескольких разных текстов, мы можем использовать функцию UNIQUE() , чтобы получить массив каждого уникального текста, который появляется в столбце:
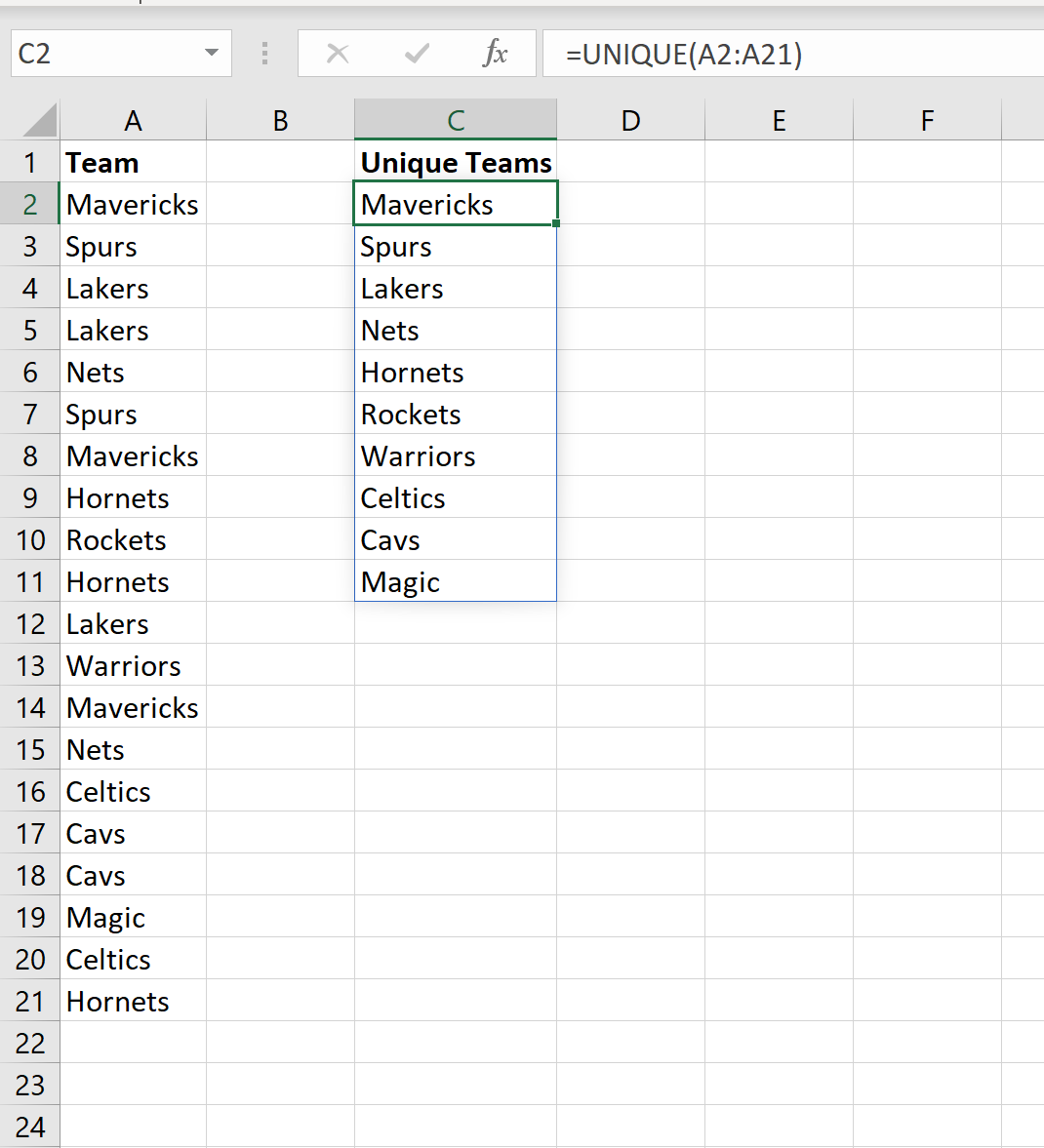
Затем мы можем использовать функцию COUNTIF() , чтобы подсчитать, как часто встречается название каждой команды:
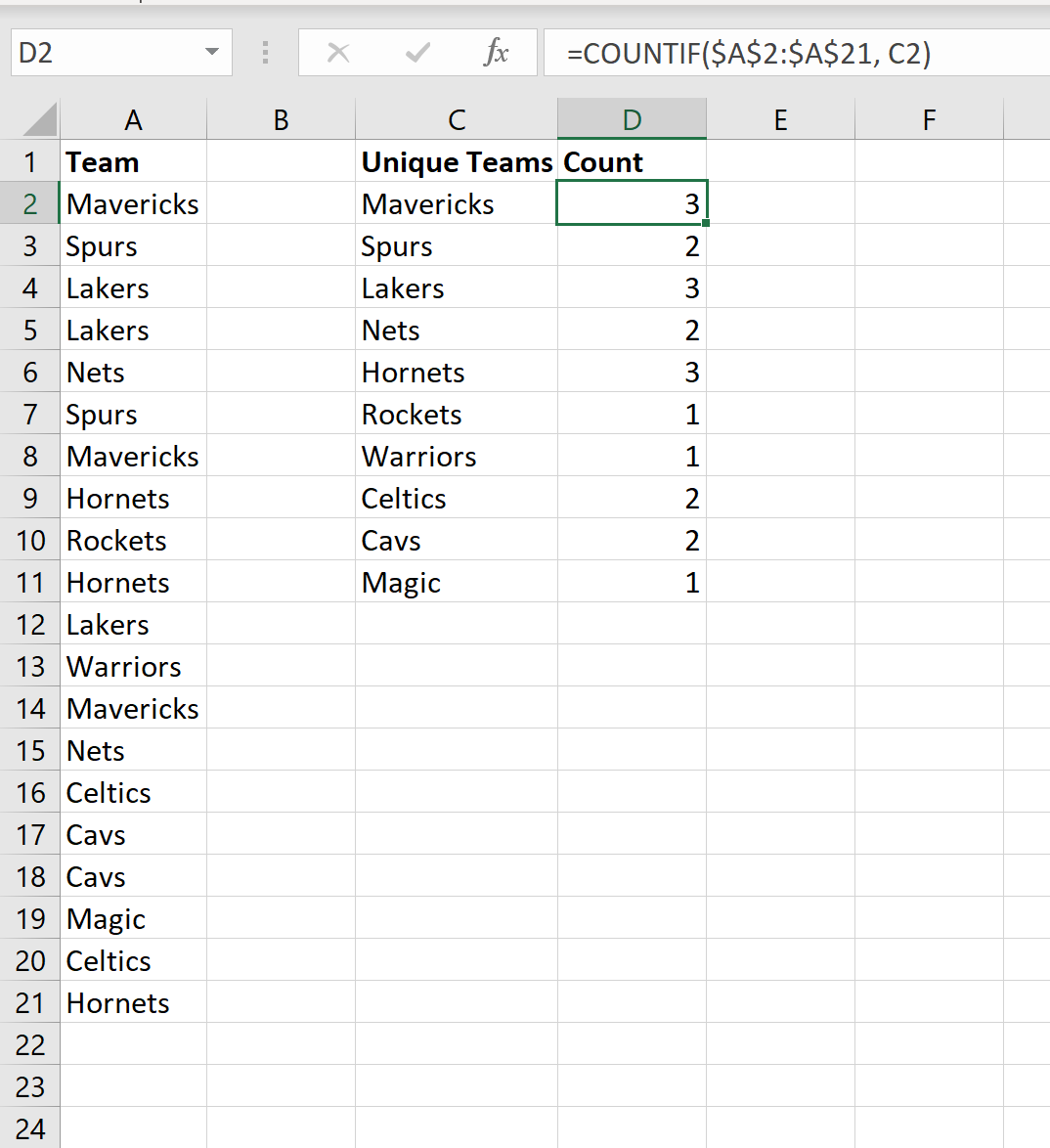
Мы видим, что:
- Название команды «Маверикс» встречается 3 раза.
- Название команды «Шпоры» встречается 2 раза.
- Название команды «Лейкерс» встречается 3 раза.
И так далее.
Дополнительные ресурсы
Следующие учебные пособия предлагают дополнительную информацию о том, как подсчитывать частоты в Excel:
Как создать частотное распределение в Excel
Как рассчитать относительную частоту в Excel
Как рассчитать кумулятивную частоту в Excel
Написано
![]()
Замечательно! Вы успешно подписались.
Добро пожаловать обратно! Вы успешно вошли
Вы успешно подписались на кодкамп.
Срок действия вашей ссылки истек.
Ура! Проверьте свою электронную почту на наличие волшебной ссылки для входа.
Успех! Ваша платежная информация обновлена.
Ваша платежная информация не была обновлена.
- Как составить частотный словарь в Excel?
- Простой анализ n-gram (анализ встречаемости)
- Анализ частотности слов, или как посчитать в тексте уникальные слова и вывести списком с их встречаемостью
- Анализ встречаемости биграмм (2-gram)
- Анализ n-gram с частотностью
- N-gram анализ по нескольким метрикам
- Заключение
Для поисковой рекламы и SEO анализ n-грамм – один из самых эффективных методов. Однако долгое время n-gram анализ оставался в силу сложности реализации алгоритма доступен только крупным агентствам с программистами в штате, или продвинутым специалистам со знанием программирования.
Чтобы популяризовать подход и сделать его доступным всем, у кого есть Windows и Excel, инструменты для анализа n-грамм были реализованы в !SEMTools для Excel. Ниже перечислены различные подходы анализа со схематичными примерами.
Во всех кейсах создается отдельный лист с результатами подсчета, исходные данные никак не изменяются.
Простой анализ n-gram (анализ встречаемости)
Данный подход самый простой — берётся N-грамма и для неё анализируется её встречаемость в тексте.
Анализ частотности слов, или как посчитать в тексте уникальные слова и вывести списком с их встречаемостью
Как посчитать, сколько раз встречается слово в Excel-таблице? Если мы ищем лишь одно слово, может помочь формула СЧЁТЕСЛИ. Формула ниже посчитает количество строк, в которых встречается последовательность символов «слова» вне зависимости от их регистра.
=СЧЁТЕСЛИ(A1:A100;"*слова*")
Символ звездочки определяет, что перед и после указанной последовательности символов могут быть любые другие или их отсутствие. В связи с этим могут быть учтены строки со словами «словарь», «словарный» и т.д. Чтобы найти слова по точному совпадению, нужно добавить символ пробела в начало и конец всех ячеек столбца, и воспользоваться подсчетом с учетом пробелов:
=СЧЁТЕСЛИ(A1:A100;"* слова *")
Но и это решение не убережет нас от ситуаций, когда слово повторяется в строке 2 и более раз, если мы хотим посчитать все повторения. Т.к. формула считает именно строки.
Поэтому был реализован макрос в !SEMTools, с легкостью выполняющий эту задачу.
Выделяем текст, выбираем слова, готово. Текст может быть как 5 строк, так и миллион строк – процедура займет секунды. Главное, чтобы уникальных слов в тексте было не больше 1048575 – иначе их не получится вывести на лист. Но такая ситуация — редкость.
Можно обратить внимание, что разные словоформы рассматриваются как отдельные слова, поэтому, если нужно проанализировать встречаемость без учета словоформ, текст нужно предварительно лемматизировать. Тогда вы составите не просто частотный словарь слов, а частотный словарь лемм.

Анализ встречаемости биграмм (2-gram)
Аналогично предыдущему, но берутся биграммы — последовательности из двух слов. Как посчитать в данном случае триграммы и т.д., кажется, уже понятно.

Анализ n-gram с частотностью
Когда текст состоит из фраз, и для каждой фразы известна определенная метрика (в поисковой рекламе это частотность), чтобы более достоверно измерить вес каждой словоформы или леммы, требуется производить анализ уже с учетом этой метрики.
В !SEMTools это вшито по умолчанию – просто нужно выделить два столбца вместе со столбцом используемой метрики. Аналогично можно составлять частотность биграмм, триграмм и т.д.

N-gram анализ по нескольким метрикам
Данный подход будет полезен PPC-специалистам для аналитики расчетных метрик, таких как CTR, CPC, CPA, CR, AOV, ROAS и тому подобные. Поскольку для их расчета используются несколько метрик, можно произвести n-gram анализ этих метрик и посчитать расчетные показатели в разрезе n-грамм.

Такая аналитика может дать много полезных инсайтов. Выявить высококонверсионные связки слов для последующего интенсивного биддинга на них, например. Или, наоборот, выявления низкоконверсионных связок для исключения их из рекламы, в то время как слова, из которых они составлены, в среднем по больнице не выделялись низкой конверсией.

Заключение
Примеры, приведенные выше, позволяют производить анализ не только поисковых запросов или ключевых слов, но и любого текста, который будет дан на вход, вне зависимости от его длины. Нужно только удалить лишние пробелы, перевести весь текст в нижний регистр и можно производить анализ.
Если у вас остались вопросы – подписывайтесь на канал автора и задавайте вопросы в чате: https://t.me/semtoolschat
Часто сталкиваетесь с этой или похожими задачами при работе в Excel?
Скачивайте !SEMTools и начинайте экономить рабочее время, выделяя его для более важных задач!
Эта статья о том, как распределить по группам
20–30 тысяч
ключевых слов. Поможет сэкономить время маркетологам, которые регулярно создают
рекламные
кампании.
Вручную группировать запросы не всегда эффективно: перебрать 200–300 запросов можно
за час,
на 20–30 тысяч уйдет неделя. Автоматическим сервисам группировку я не доверю,
так как она определяет
структуру и управляемость кампании.
Поэтому придумал свой метод, который ускоряет кластеризацию и даёт осознанный
результат.
Облегчает жизнь при работе с СЯ от 2–3 тысяч ключевых слов. Пробовал
работать с 45 000 —
Excel начинал умирать. Список из 200–300 запросов быстрее перебрать руками.
Далее расскажу про свой метод кластеризации в теории, а затем — как реализую
его в Excel. Дам ссылку на готовый Excel-кластеризатор. Но чтобы им пользоваться,
нужно хорошо понимать метод.
Метод
Кластеризация — распределение запросов по кластерам. Кластер — это группа
запросов,
схожих по смыслу и набору слов. Чтобы выделить такие запросы и объединить
их в кластер, нужен признак.
Используем для этого нормализованную форму запроса — уберём окончания и выстроим
слова в порядке важности:

Пример готовых кластеров
Удаление окончаний позволит охватить все возможные словоформы для конкретного слова,
а сортировка «по важности» —
игнорировать порядок слов.
Слово без окончания — это признак, который объединяет разные словоформы:

Объединение словоформ
Чтобы убирать окончания я использую mystem. Это лемматизатор
от Яндекса. Он обрабатывает список слов и возвращает нормализованные значения — леммы.
Если система не уверена, какая лемма правильная, то покажет 2–3 варианта.
Например,
для слова «банку» mystem вернёт две леммы: «банк» и «банка».
При проверке результатов мы выберем нужную.
Сортировка «по важности» позволит игнорировать порядок слов. При сортировке
нормализованных значений фраз по алфавиту мы получим готовые кластеры — группы
запросов, схожих по смыслу и набору слов.
Важность слова — вычисляемый параметр для конкретного списка ключевых слов. Он не определяет
важность слова в общей картине мира.
Важность слова рассчитывается из частотности и количества упоминаний слов в списке.
Рассмотрим на примере.
Берём список запросов с частотностью
- Купить бумеранг — 1000
- Бумеранги цена — 700
- Бумеранги в москве — 750
- Купить классический бумеранг — 450
- Цены на бумеранги в москве — 350
- Купить классический бумеранг в москве — 100
В списке запросов встречаются слова: купить, бумеранг, классический, москва, цена, в, на. Вес
слова равен сумме долей частотностей помноженных на количество упоминаний слова.
Считаем доли частотностей
- Купить бумеранг — 1000 = 1000/2 = 500
- Бумеранги цена — 700 = 700/2 = 350
- Бумеранги в москве — 750 = 750/3 = 250
- Купить классический бумеранг — 450 = 450/3 = 150
- Цены на бумеранги в москве — 350 = 350/5 = 70
- Купить классический бумеранг в москве — 100 = 100/5 = 20
Считаем вес слов
- Купить — (500+150+20)*3 = 2010
- Бумеранг — (500+350+250+150+70+20)*6 = 8040
- Классический — (150+20)*2 = 340
- Москва — (250+70)*2 = 640
- Цена — (350+70)*2 = 840
- В — 20
- На — 70
Сортируем по важности
- 8040 — бумеранг
- 2010 — купить
- 840 — цена
- 640 — москва
- 340 — классический
- 70 — на
- 20 — в
Располагаем запросы по важности
- Купить бумеранг — бумеранг | купить
- Бумеранги цена — бумеранг | цена
- Бумеранги в москве — бумеранг | москва
- Купить классический бумеранг — бумеранг | купить | классический
- Цены на бумеранги в москве — бумеранг | цена | москва | на | в
- Купить классический бумеранг в москве — бумеранг | купить | москва | классический
| в
Упорядочиваем и чистим
- Бумеранг | купить: купить бумеранг — 1000
- Бумеранг | купить | классический: купить классический бумеранг — 450
- Бумеранг | купить | москва | классический: купить классический бумеранг в москве — 100
- Бумеранг | москва: бумеранги в москве — 750
- Бумеранг | цена: бумеранги цена — 700
- Бумеранг | цена | москва: цены на бумеранги в москве — 350
В итоге получили первые группы объявлений, с которыми можно работать дальше: укрупнять,
объединять, кросс-минусовать. Для этого используем Excel.
Реализация в Excel
Выполняем последовательность действий в таблице
(XLS, 537 КБ) с формулами. Кластеризация 1000 запросов займет 30 минут.
Собираем СЯ → собираем частотность → разбиваем запросы по словам и вычисляем
доли весов → формируем таблицу-справочник с весами слов → выделяем леммы для слов
→ вычисляем
«вес» леммы → формируем таблицу-справочник с леммами → делаем первичную кластеризацию
→ укрупняем
полученные группы.
Лист «Кластеризация», таблица «Main»
Чтобы избежать правки формул называйте все листы и таблицы аналогично таблице-примеру
-
Вычисляем доли весов:
- Доли весов = Частотность / Кол-во слов.
- Кол-во слов =LEN ([@Ключ])-LEN (SUBSTITUTE ([@Ключ],» «,»»))+1.

Расчёт
кол-ва слов
и доли веса слова
-
Разбиваем слова по фразам функцией «Text to columns»:
Результаты работы функции «Text to columns»


Лист «Слова — Леммы», таблица «Word»
- Копируем столбцы W1—W7 на новый лист.
- Преобразуем таблицу из формата
[W1] [W2] [W3] [W4] [W5] [W6] [W7] [Доли весов] в формат:
[W1] → [Доли весов]
[W2] → [Доли весов]
[W3] → [Доли весов]
[W4] → [Доли весов]
[W5] → [Доли весов]
[W6] → [Доли весов]
[W7] → [Доли весов]:
Формирование справочника со словами
- Удаляем пустые ячейки и считаем кол-во упоминаний каждого слова.

Лист «Слова — Леммы», таблица «Word»
- Копируем полученный на прошлом шаге список слов «как есть».
- Обрабатываем через mystem
→ получаем леммы для каждого слова. - Считаем кол-во упоминаний каждой леммы.
Справочник слов

Лист «Леммы», таблица «Lemmas»
- Копируем полученный список лемм на новый лист и удаляем дубли.
- Из справочника со словами подтягиваем VLOOKUP-ом кол-во упоминаний каждой леммы.
- Считаем кол-во символов в лемме.
- Вычисляем «вес» леммы:
Вес Леммы= [Сумма долей весов слов, входящих в Лемму] * [Кол-во упоминаний Леммы].
Формула:
=(SUMIF (Words[Lemma],[@Лемма], Words[Доли весов]))*[@[Кол-во упоминаний]]. - Сортируем леммы по столбцу «вес» — от большего к меньшему.
- Проставляем «Статус» для лемм — минимальный для старшей леммы (лучше начать с 1 000),
дальше +1 к следующему статусу:
Справочник лемм

Лист «Кластеризация», таблица «Main»
Для каждого слова в столбцах W1—W7 подтягиваем VLOOKP-ом значения «Статус» → записываем
их столбцы
L1 – L7
:

«Статусы» слов
Итак, что мы сделали. Разбили запросы по словам. Для каждого слова выделили лемму — можем
объединить запросы по общим словам. Для каждой леммы посчитали вес. Остаётся выстроить
слова в запросе
в порядке важности. Тогда при сортировке по алфавиту запросы сами объединятся в группы
объявлений.
Выстраиваем слова в порядке важности функцией SMALL. В диапазоне статусов L1 – L7 ищем
самый маленький статус — это самое важное слово во фразе. Затем, ищем второй
самый маленький
статус — это второе по важности слово во фразе. И так еще пять раз — проверяем
оставшиеся столбцы L3 – L7.
Получаем последовательность статусов. Например, 37 → 100 → 200 → 700. Для каждого
статуса подтягиваем VLOOKP-ом соответствующую Лемму из справочника Лемм. Соединяем Леммы
CONCATENATE-ом и получаем нормализованное значение фразы. Я использую его как название
группы объявлений.
Сортируем по алфавиту:

Результаты работы Кластеризатора
Полная рабочая формула в файле-примере.
Игнорируя окончания и порядок слов, мы объединили запросы с одинаковым набором слов.
Количество групп стремится к количеству слов — это 100 % точность инструмента. Можно
использовать, если вы предпочитаете работать с запросами в точном
соответствии.
Чтобы укрупнить группы, нужно уменьшить точность — снизить количество лемм, которые составляют
«нормализованную форму».
Что можно удалить:
- одинокие буквы, цифры, предлоги, доменные зоны. Леммы длиной 1–3 символа;
- редкие леммы — кол-во упоминаний меньше среднего по списку;
- леммы с малым весом — недостаточно «важные»;
- в редких случаях — топонимы.
Важно: лемму не удаляем, только её «Статус» — этого достаточно, чтобы лемма
не попала
в «нормализованную форму»:

Процесс укрупнения групп объявлений
В основной таблице ничего править не надо — результат обновится
самостоятельно.
До какой степени укрупнять: я стремлюсь к среднему показателю 2–3 запроса в одной
группе объявлений и слежу за максимальным количеством фраз (помним про ограничения
систем
контекстной рекламы).

Дашборд для укрупнения в справочнике Лемм
Резюме
Полученный список групп удобно кросс-минусовать и двигать между кампаниями. Название группы
поможет писать объявления — вы сами определяете важные слова в названии группы.
Ещё раз алгоритм: собираем СЯ → собираем частотность → разбиваем запросы по словам
и вычисляем доли весов → формируем таблицу-справочник с весами слов → выделяем
леммы
для слов → вычисляем «вес» леммы → формируем таблицу-справочник с леммами → делаем
первичную кластеризацию → укрупняем полученные группы.
Отзывы джедаев о кластеризаторе
Илья Ерошкин, старший джедай:
«Я помогал Роме с созданием инструмента на ранних этапах. Всем рекомендую попробовать кластеризатор для ядра от 2000 ключевых слов → сэкономит время.
Инструмент можно улучшить и превратить в автоматический сервис. Также можно дорабатывать формулы определения веса лемм. Но и в текущем виде он поможет специалистам по контексту, которые работают с большой семантикой.»
Егор Холов, старший джедай:
«С помощью кластеризатора сильно удобнее и быстрее сгруппировать фразы и потом писать объявления для них. Из недостатков — первый раз кажется, что это сложновато. Но когда попробуешь, то всё довольно понятно. Но эту штуку лучше автоматизировать.»
Михаил Стерликов, старший джедай:
«Методику пробовал, но не использую в работе, потому что нечасто собираю контекст в больших объемах.
Хорошо подойдет для работы с большой семантикой, особенно в свете последних нововведений яндекса по низкочастотным запросам. Группировки помогут сэкономить много времени при подготовке ключевых фраз.
Методика на первый взгляд кажется сложной и громоздкой, но если разобраться, то процесс становится понятным и удобным.»
«Кластеризация от Ромы просто находка! Методом пользуюсь каждый раз когда работаю с семантикой — собираю или корректирую кампании.
Больше всего мне нравятся три вещи:
- я регулирую какие фразы попадут в группу. Если вес фразы небольшой, то объединяю с похожими. Не придерживаюсь принципа «один ключ — одна группа», иначе управлять кампанией сложно;
- понимаю механику и вижу какие фразы должны быть в заголовке. Конечно, важно делать полное вхождение ключевого слова. Часто оно не вмещается полностью и я строю заголовок из фраз с бо́льшим весом;
- это Excel, который всем знаком. Не нужно устанавливать дополнительные программы и платить за сервис. Если разобраться в формулах, то уже немного прокачаешься.
Из минусов: все формулы я копирую из готового шаблона и переключаться между окнами одной программы неудобно. Я бы хотела иметь формулы под рукой, а может сделать в будущем какой-нибудь шаблон, чтобы сократить количество копирований. Ещё хотелось бы сократить время группировки, но пока не нашла способ.
В целом, способ мне нравится тем, что механика простая и понятная, её легко внедрить и потом управлять кампаниями.»
Что дальше
Если у вас СЯ от 2–3 тысяч ключевых слов, используйте этот алгоритм.
Прогоните
алгоритм 2–3 раза, чтобы «впитать».
Если у вас список из 200–300 запросов, переберите
руками — так быстрее.
Если хотите готовое решение — попросите программистов написать скрипт.
Я постоянно дорабатываю кластеризатор. В следующих итерациях хочу проработать
кросс-минусовку
групп, добавить справочники минус-слов и максимально автоматизировать кластеризатор на Power
Query. Следите за обновлениями!
Будут вопросы — пишите: igoshinrmn@it-agency.ru или Facebook.
14 февраля 2017
Записал и отредактировал Виталий Семыкин
Подпишитесь, чтобы не пропустить свежие статьи
Новые статьи из Академии и открытые вакансии каждые две недели:
Функция ЧАСТОТА используется для определения количества вхождения определенных величин в заданный интервал и возвращает данные в виде массива значений. Используя функцию ЧАСТОТА, мы узнаем, как посчитать частоту в Excel.
Пример использования функции ЧАСТОТА в Excel
Пример 1. Студенты одной из групп в университете сдали экзамен по физике. При оценке качества сдачи экзамена используется 100-бальная система. Для определения окончательной оценки по 5-бальной системе используют следующие критерии:
- От 0 до 50 баллов – экзамен не сдан.
- От 51 до 65 баллов – оценка 3.
- От 66 до 85 баллов – оценка 4.
- Свыше 86 баллов – оценка 5.
Для статистики необходимо определить, сколько студентов получили 5, 4, 3 баллов и количество тех, кому не удалось сдать экзамен.
Внесем данные в таблицу:
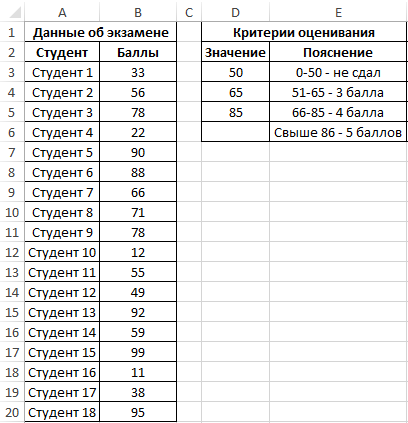
Для решения выделим области из 4 ячеек и введем следующую функцию:
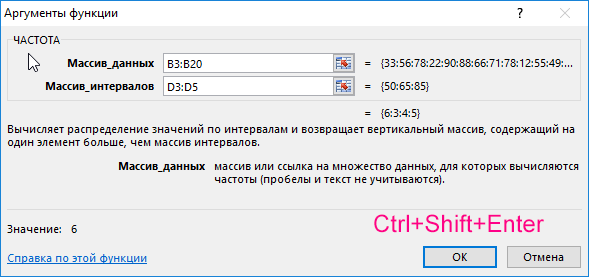
Описание аргументов:
- B3:B20 – массив данных об оценках студентов;
- D3:D5 – массив критериев нахождения частоты вхождений в массиве данных об оценках.
Выделяем диапазон F3:F6 жмем сначала клавишу F2, а потом комбинацию клавиш Ctrl+Shift+Enter, чтобы функция ЧАСТОТА была выполнена в массиве. Подтверждением того что все сделано правильно будут служить фигурные скобки {} в строке формул по краям. Это значит, что формула выполняется в массиве. В результате получим:
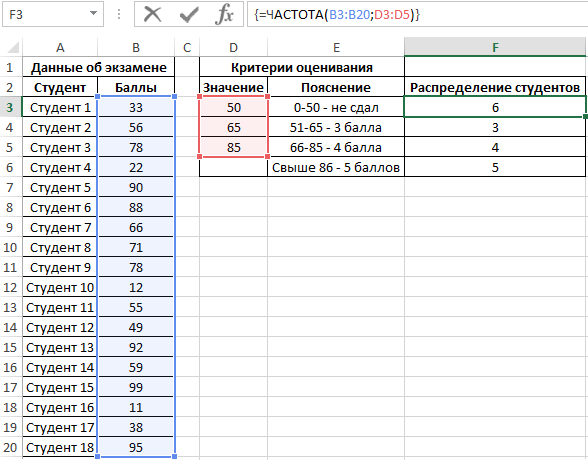
То есть, 6 студентов не сдали экзамен, оценки 3, 4 и 5 получили 3, 4 и 5 студентов соответственно.
Пример определения вероятности используя функцию ЧАСТОТА в Excel
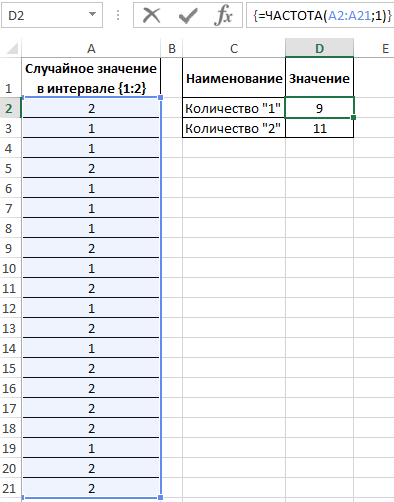
Пример 2. Известно то, что если существует только два возможных варианта развития событий, вероятности первого и второго равны 0,5 соответственно. Например, вероятности выпадения «орла» или «решки» у подброшенной монетки равны ½ и ½ (если пренебречь возможностью падения монетки на ребро). Аналогичное расчетное распределение вероятностей характерно для следующей функции СЛУЧМЕЖДУ(1;2), которая возвращает случайное число в интервале от 1 до 2. Было проведено 20 вычислений с использованием данной функции. Определить фактические вероятности появления чисел 1 и 2 соответственно на основании полученных результатов.
Заполним исходную таблицу случайными значениями от 1-го до 2-ух:
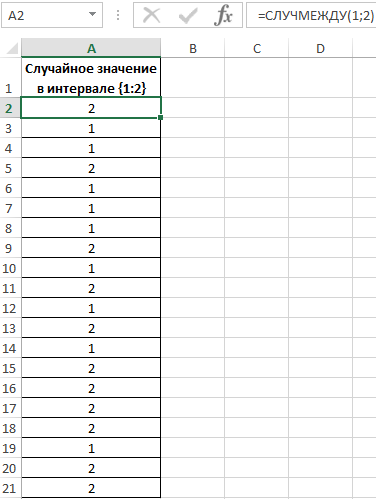
Для определения случайных значений в исходной таблице была использована специальная функция:
=СЛУЧМЕЖДУ(1;2)
Для определения количества сгенерированных 1 и 2 используем функцию:
=ЧАСТОТА(A2:A21;1)
Описание аргументов:
- A2:A21 – массив сгенерированных функцией =СЛУЧМЕЖДУ(1;2) значений;
- 1 – критерий поиска (функция ЧАСТОТА ищет значения от 0 до 1 включительно и значения >1).
В результате получим:
Вычислим вероятности, разделив количество событий каждого типа на общее их число:
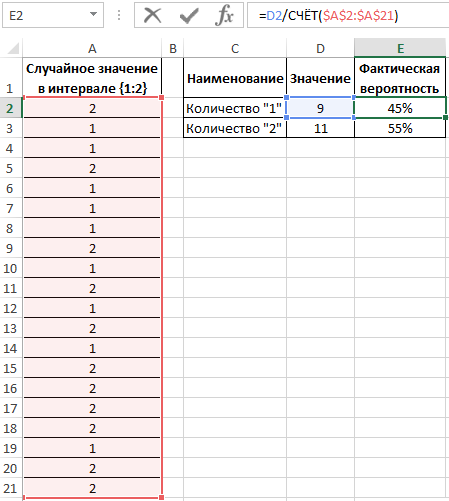
Для подсчета количества событий используем функцию =СЧЁТ($A$2:$A$21). Или можно просто разделить на значение 20. Если заранее не известно количество событий и размер диапазона со случайными значениями, тогда можно использовать в аргументах функции СЧЁТ ссылку на целый столбец: =СЧЁТ(A:A). Таким образом будет автоматически подсчитывается количество чисел в столбце A.
Вероятности выпадения «1» и «2» — 0,45 и 0,55 соответственно. Не забудьте присвоить ячейкам E2:E3 процентный формат для отображения их значений в процентах: 45% и 55%.
Теперь воспользуемся более сложной формулой для вычисления максимальной частоты повторов:
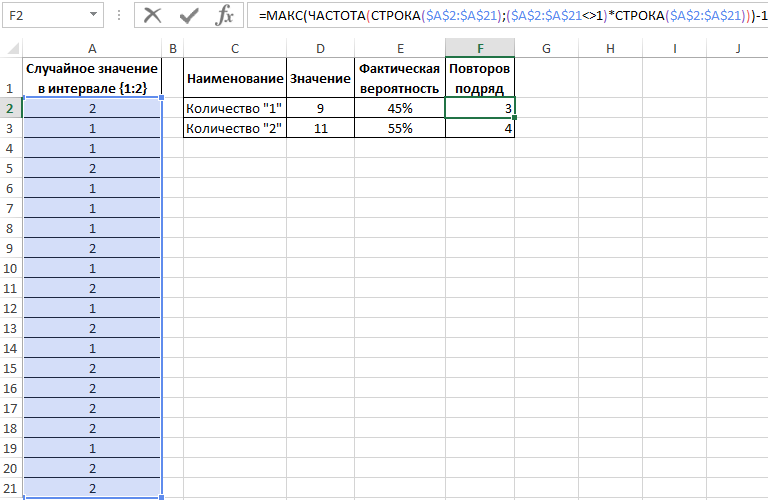
Формулы в ячейках F2 и F3 отличаются только одним лишь числом после оператора сравнения «не равно»: <>1 и <>2.
Интересный факт! С помощью данной формулы можно легко проверить почему не работает стратегия удвоения ставок в рулетке казино. Данную стратегию управления ставками в азартных играх называют еще Мартингейл. Дело в том, что количество случайных повторов подряд может достигать 18-ти раз и более, то есть восемнадцать раз подряд красные или черные. Например, если ставку в 2 доллара 18 раз удваивать – это уже более пол миллиона долларов «просадки». Это уже провал по любым техникам планирования рисков. Так же следует учитывать, что кроме «черные» и «красные» иногда выпадает еще и «зеро», что окончательно уничтожает все шансы. Так же интересно, что сумма всех чисел в рулетке от 0 до 36 равна 666.
Как посчитать неповторяющиеся значения в Excel?
Пример 3. Определить количество уникальных вхождений в массив числовых данных, то есть не повторяющихся значений.
Исходная таблица:
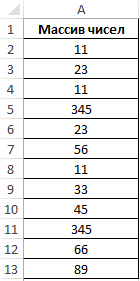
Определим искомую величину с помощью формулы:
В данном случае функция ЧАСТОТА выполняет проверку наличия каждого из элементов массива данных в этом же массиве данных (оба аргумента совпадают). С помощью функции ЕСЛИ задано условие, которое имеет следующий смысл:
- Если искомый элемент содержится в диапазоне значений, вместо фактического количества вхождений будет возвращено 1;
- Если искомого элемента нет – будет возвращен 0 (нуль).
Полученное значение (количество единиц) суммируется.
В результате получим:
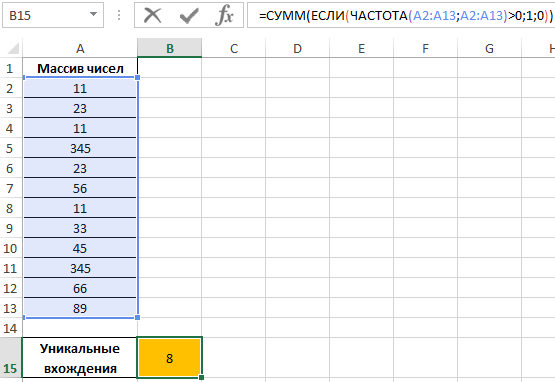
То есть, в указанном массиве содержится 8 уникальных значений.
Скачать пример функции ЧАСТОТА в Excel
Функция ЧАСТОТА в Excel и особенности ее синтаксиса
Данная функция имеет следующую синтаксическую запись:
Описание аргументов функции (оба являются обязательными для заполнения):
- массив_данных – данные в форме массива либо ссылка на диапазон значений, для которых необходимо определить частоты.
- массив_интервалов — данные в формате массива либо ссылка не множество значений, в которые группируются значения первого аргумента данной функции.
Примечания 1:
- Если в качестве аргумента массив_интервалов был передан пустой массив или ссылка на диапазон пустых значений, результатом выполнения функции ЧАСТОТА будет являться число элементов, входящих диапазон данных, которые были переданы в качестве первого аргумента.
- При использовании функции ЧАСТОТА в качестве обычной функции Excel будет возвращено единственное значение, соответствующее первому вхождению в массив_интервалов (то есть, первому критерию поиска частоты вхождения).
- Массив возвращаемых данной функцией элементов содержит на один элемент больше, чем количество элементов, содержащихся в массив_интервалов. Это происходит потому, что функция ЧАСТОТА вычисляет также количество вхождений величин, значения которых превышают верхнюю границу интервалов. Например, в наборе данных 2,7, 10, 13, 18, 4, 33, 26 необходимо найти количество вхождений величин из диапазонов от 1 до 10, от 11 до 20, от 21 до 30 и более 30. Массив интервалов должен содержать только их граничные значения, то есть 10, 20 и 30. Функция может быть записана в следующем виде: =ЧАСТОТА({2;7;10;13;18;4;33;26};{10;20;30}), а результатом ее выполнения будет столбец из четырех ячеек, которые содержат следующие значения: 4,2, 1, 1. Последнее значение соответствует количеству вхождений чисел > 30 в массив_данных. Такое число действительно является единственным – это 33.
- Если в состав массив_данных входят ячейки, содержащие пустые значения или текст, они будут пропущены функцией ЧАСТОТА в процессе вычислений.
Примечания 2:
- Функция может использоваться для выполнения статистического анализа, например, с целью определения наиболее востребованных для покупателей наименований продукции.
- Данная функция должна быть использована как формула массива, поскольку возвращаемые ей данные имеют форму массива. Для выполнения обычных формул после их ввода необходимо нажать кнопку Enter. В данном случае требуется использовать комбинацию клавиш Ctrl+Shift+Enter.
=ЧАСТОТА(массив_данных;массив_интервалов)
Как определить частоту символа / текста / строки в диапазоне Excel?
Если есть какие-то данные в диапазоне Excel, вы хотите определить частоту числа, текста или строки, кроме ручного подсчета их одного за другим, как вы можете решить эту проблему? В этом руководстве я представлю несколько различных методов, которые помогут вам быстро и легко определить частоту строки в Excel.
Определите частоту символа / текста / строки с помощью формулы
Определите частоту появления символа с помощью функции COUNCHAR![]()
Определите частоту появления слова с помощью функции подсчета раз, когда слово появляется![]()
Определите частоту символа / текста / строки с помощью формулы
Вот несколько формул, работающих в разных ситуациях.
Частота счета числа в диапазоне
Примечание: Эта формула может работать правильно, если каждая ячейка содержит только один символ в диапазоне.
Выберите ячейку и введите эту формулу = СУММ (ЕСЛИ (D1: D7 = E1,1,0)) (D1: D7 — это диапазон, в котором вы работаете, E1 содержит символ, который вы хотите подсчитать), нажмите Shift + Ctrl + Enter ключ. Смотрите скриншот:
Считать частоту появления буквенного символа в диапазоне
Внимание: Эта формула может работать правильно, если каждая ячейка содержит только один символ в диапазоне.
Вы также можете использовать эту формулу = СУММ (ЕСЛИ (D1: D7 = «k»; 1,0)) чтобы подсчитать частоту появления определенного алфавитного символа (D1: D7 — диапазон, k — символ, который вы хотите подсчитать), нажмите Shift + Ctrl + Enter ключи. Смотрите скриншот:
Считать частоту строки в диапазоне
Предположим, вы хотите подсчитать время строки, содержащей kte, выберите пустую ячейку и введите эту формулу = СЧЁТЕСЛИ (C13: C18; «* kte *»), (C13: C18 — это диапазон, в котором вы работаете, kte — это строка, которую вы хотите подсчитать), нажмите Enter ключ. Смотрите скриншот:
Определите частоту появления символа с помощью функции COUNCHAR
Если вы хотите подсчитать время нахождения символа в одной ячейке, вы можете применить Kutools for ExcelАвтора СЧЕТЧИК функцию.
После установки Kutools for Excel, пожалуйста, сделайте следующее:(Бесплатная загрузка Kutools for Excel Сейчас!)
1. Выберите пустую ячейку для вывода результата, щелкните Кутулс > Kutools Функции > Статистические и математические > СЧЕТЧИК. Смотрите скриншот:
2. в Функции Аргументы диалоговом окне выберите ячейку, которую вы хотите использовать в Внутри_текст поле и введите символ в двойных кавычках в Найти_текст поле, и вы можете увидеть результат, показанный ниже. Смотрите скриншот:
3. Нажмите OK, затем при необходимости перетащите маркер заполнения по ячейкам, чтобы подсчитать символ в каждой ячейке.
Определите частоту появления слова с помощью функции подсчета раз, когда слово появляется
Если вы хотите подсчитать, сколько раз слово появляется в одной ячейке или диапазоне, Считайте, сколько раз появляется слово особенность Kutools for Excel могу оказать вам услугу.
После установки Kutools for Excel, пожалуйста, сделайте следующее:(Бесплатная загрузка Kutools for Excel Сейчас!)
1. Выберите ячейку и щелкните Кутулс > Помощник по формулам > Статистический > Подсчитайте количество слова. Смотрите скриншот:
2. Затем в Формула Помощник диалоговом окне выберите ячейку или диапазон ячеек, которые вы хотите использовать в Текст поле введите слово, в которое вы хотите посчитать Word коробка. Смотрите скриншот:
3. Нажмите Ok.
Относительные статьи
- Как посчитать частоту появления текста / числа / символа в столбце Excel?
Лучшие инструменты для работы в офисе
Kutools for Excel Решит большинство ваших проблем и повысит вашу производительность на 80%
- Снова использовать: Быстро вставить сложные формулы, диаграммы и все, что вы использовали раньше; Зашифровать ячейки с паролем; Создать список рассылки и отправлять электронные письма …
- Бар Супер Формулы (легко редактировать несколько строк текста и формул); Макет для чтения (легко читать и редактировать большое количество ячеек); Вставить в отфильтрованный диапазон…
- Объединить ячейки / строки / столбцы без потери данных; Разделить содержимое ячеек; Объединить повторяющиеся строки / столбцы… Предотвращение дублирования ячеек; Сравнить диапазоны…
- Выберите Дубликат или Уникальный Ряды; Выбрать пустые строки (все ячейки пустые); Супер находка и нечеткая находка во многих рабочих тетрадях; Случайный выбор …
- Точная копия Несколько ячеек без изменения ссылки на формулу; Автоматическое создание ссылок на несколько листов; Вставить пули, Флажки и многое другое …
- Извлечь текст, Добавить текст, Удалить по позиции, Удалить пробел; Создание и печать промежуточных итогов по страницам; Преобразование содержимого ячеек в комментарии…
- Суперфильтр (сохранять и применять схемы фильтров к другим листам); Расширенная сортировка по месяцам / неделям / дням, периодичности и др .; Специальный фильтр жирным, курсивом …
- Комбинируйте книги и рабочие листы; Объединить таблицы на основе ключевых столбцов; Разделить данные на несколько листов; Пакетное преобразование xls, xlsx и PDF…
- Более 300 мощных функций. Поддерживает Office/Excel 2007-2021 и 365. Поддерживает все языки. Простое развертывание на вашем предприятии или в организации. Полнофункциональная 30-дневная бесплатная пробная версия. 60-дневная гарантия возврата денег.
")
Вкладка Office: интерфейс с вкладками в Office и упрощение работы
- Включение редактирования и чтения с вкладками в Word, Excel, PowerPoint, Издатель, доступ, Visio и проект.
- Открывайте и создавайте несколько документов на новых вкладках одного окна, а не в новых окнах.
- Повышает вашу продуктивность на 50% и сокращает количество щелчков мышью на сотни каждый день!
")