
Функция
ЧАСТОТА(
)
, английская версия FREQUENCY()
,
вычисляет частоту попадания значений в заданные пользователем интервалы и возвращает соответствующий массив чисел.
Функцией
ЧАСТОТА()
можно воспользоваться, например, для подсчета количества результатов тестирования, попадающих в определенные интервалы (См.
Файл примера
)
Синтаксис функции
ЧАСТОТА
(
массив_данных
;
массив_интервалов
)
Массив_данных
— массив или ссылка на множество ЧИСЛОвых данных, для которых вычисляются частоты.
Массив_интервалов
— массив или ссылка на множество интервалов, в которые группируются значения аргумента «массив_данных».
Функция
ЧАСТОТА()
вводится как
формула массива
после выделения диапазона смежных ячеек, в которые требуется вернуть полученный массив распределения (частот). Т.е. после ввода формулы необходимо вместо нажатия клавиши
ENTER
нажать сочетание клавиш
CTRL+SHIFT+ENTER
.
Количество элементов в возвращаемом массиве на единицу больше числа элементов в массиве «
массив_интервалов
». Дополнительный элемент в возвращаемом массиве содержит количество значений, превышающих верхнюю границу интервала, содержащего наибольшие значения (см. пример ниже).
Пример
Пусть в диапазоне
А2:А101
имеется исходный массив чисел от 1 до 100.
Подсчитаем количество чисел, попадающих в интервалы 1-10; 11-20; …91-100.
Сформируем столбце
С
массив верхних границ диапазонов (интервалов). Для наглядности в столбце
D
сформируем текстовые значения соответствующие границам интервалов (1-10; 11-20; …91-100).
Для ввода формулы выделим диапазон
Е2:Е12
, состоящий из 11 ячеек (на 1 больше, чем число верхних границ интервалов). В
Строке формул
введем
=ЧАСТОТА($A$2:$A$101;$C$2:$C$11)
. После ввода формулы необходимо нажать сочетание клавиш
CTRL+SHIFT+ENTER
. Диапазон
Е2:Е12
заполнится значениями:
-
в
Е2
— будет содержаться количество значений из
А2:А101
, которые меньше или равны 10; -
в
Е3
— количество значений из
А2:А101
, которые меньше или равны 20, но больше 10; -
в
Е11
— количество значений из
А2:А101
, которые меньше или равны 100, но больше 90; -
в
Е12
— количество значений из
А2:А101
, которые больше 100 (таких нет, т.к. исходный массив содержит числа от 1 до 100).
Примечание
. Функцию
ЧАСТОТА()
можно заменить формулой =
СУММПРОИЗВ(($A$5:$A$104>C5)*($A$5:$A$104<=C6))
(См.
Файл примера
)
Excel for Microsoft 365 Excel for Microsoft 365 for Mac Excel for the web Excel 2021 Excel 2021 for Mac Excel 2019 Excel 2019 for Mac Excel 2016 Excel 2016 for Mac Excel 2013 Excel 2010 Excel 2007 Excel for Mac 2011 Excel Starter 2010 More…Less
The FREQUENCY function calculates how often values occur within a range of values, and then returns a vertical array of numbers. For example, use FREQUENCY to count the number of test scores that fall within ranges of scores. Because FREQUENCY returns an array, it must be entered as an array formula.
FREQUENCY(data_array, bins_array)
The FREQUENCY function syntax has the following arguments:
-
data_array Required. An array of or reference to a set of values for which you want to count frequencies. If data_array contains no values, FREQUENCY returns an array of zeros.
-
bins_array Required. An array of or reference to intervals into which you want to group the values in data_array. If bins_array contains no values, FREQUENCY returns the number of elements in data_array.
Note: If you have a current version of Microsoft 365, then you can simply enter the formula in the top-left-cell of the output range, then press ENTER to confirm the formula as a dynamic array formula. Otherwise, the formula must be entered as a legacy array formula by first selecting the output range, entering the formula in the top-left-cell of the output range, and then pressing CTRL+SHIFT+ENTER to confirm it. Excel inserts curly brackets at the beginning and end of the formula for you. For more information on array formulas, see Guidelines and examples of array formulas.
-
The number of elements in the returned array is one more than the number of elements in bins_array. The extra element in the returned array returns the count of any values above the highest interval. For example, when counting three ranges of values (intervals) that are entered into three cells, be sure to enter FREQUENCY into four cells for the results. The extra cell returns the number of values in data_array that are greater than the third interval value.
-
FREQUENCY ignores blank cells and text.
Example
Need more help?
You can always ask an expert in the Excel Tech Community or get support in the Answers community.
Need more help?
Возвращает обратное значение для F-распределения вероятности
Возвращает обратное значение для F-распределения вероятности
Возвращает F-распределение вероятности
Возвращает F-распределение вероятности
Возвращает результат F-теста
Возвращает обратное значение для F-распределения вероятности
Возвращает одностороннее значение вероятности z-теста
Возвращает обратную интегральную функцию указанного бета-распределения
Возвращает интегральную функцию бета-распределения
Возвращает наименьшее значение, для которого интегральное биномиальное распределение меньше заданного значения или равно ему
Возвращает отдельное значение вероятности биномиального распределения
Возвращает вероятность пробного результата с помощью биномиального распределения
Возвращает распределение Вейбулла
Возвращает вероятность того, что значение из диапазона находится внутри заданных пределов
Возвращает значение гамма-функции
Возвращает обратное значение интегрального гамма-распределения
Возвращает гамма-распределение
Возвращает натуральный логарифм гамма-функции, Г(x)
Возвращает натуральный логарифм гамма-функции, Г(x)
Возвращает значение на 0,5 меньше стандартного нормального распределения
Возвращает гипергеометрическое распределение
Оценивает дисперсию по выборке
Вычисляет дисперсию по генеральной совокупности
Оценивает дисперсию по выборке, включая числа, текст и логические значения
Вычисляет дисперсию для генеральной совокупности, включая числа, текст и логические значения
Возвращает доверительный интервал для среднего генеральной совокупности
Возвращает доверительный интервал для среднего генеральной совокупности, используя t-распределение Стьюдента
Возвращает сумму квадратов отклонений
Возвращает квартиль набора данных
Возвращает квартиль набора данных на основе значений процентили из диапазона от 0 до 1, исключая границы
Возвращает квадрат коэффициента корреляции Пирсона
Возвращает значение ковариации выборки, среднее попарных произведений отклонений для всех точек данных в двух наборах данных
Возвращает значение ковариации, среднее произведений парных отклонений
Возвращает коэффициент корреляции между двумя множествами данных
Возвращает параметры экспоненциального тренда
Возвращает параметры линейного тренда
Возвращает обратное значение интегрального логарифмического нормального распределения
Возвращает интегральное логарифмическое нормальное распределение
Возвращает наибольшее значение в списке аргументов
Возвращает наибольшее значение в списке аргументов, включая числа, текст и логические значения
Возвращает максимальное значение из заданных определенными условиями или критериями ячеек
Возвращает медиану заданных чисел
Возвращает наименьшее значение в списке аргументов
Возвращает наименьшее значение в списке аргументов, включая числа, текст и логические значения
Возвращает минимальное значение из ячеек, заданных определенными условиями или критериями
Возвращает вертикальный массив наиболее часто встречающихся или повторяющихся значений в массиве или диапазоне данных
Возвращает значение моды набора данных
Возвращает k-ое наибольшее значение в множестве данных
Возвращает k-ое наименьшее значение в множестве данных
Возвращает наклон линии линейной регрессии
Возвращает нормальное интегральное распределение
Возвращает обратное значение стандартного нормального интегрального распределения
Возвращает стандартное нормальное интегральное распределение
Возвращает нормализованное значение
Возвращает обратное значение нормального интегрального распределения
Возвращает отрицательное биномиальное распределение
Возвращает отрезок, отсекаемый на оси линией линейной регрессии
Возвращает количество перестановок для заданного числа объектов
Возвращает количество перестановок для заданного числа объектов (с повторами), которые можно выбрать из общего числа объектов
Возвращает коэффициент корреляции Пирсона
Возвращает значение линейного тренда
Возвращает будущее значение на основе существующих (ретроспективных) данных с использованием версии AAA алгоритма экспоненциального сглаживания (ETS)
Возвращает длину повторяющегося фрагмента, обнаруженного программой Excel в заданном временном ряду
Возвращает статистическое значение, являющееся результатом прогнозирования временного ряда
Возвращает доверительный интервал для прогнозной величины на указанную дату
Возвращает будущее значение на основе существующих значений
Возвращает k-ю процентиль для значений диапазона
Возвращает k-ю процентиль значений в диапазоне, где k может принимать значения от 0 до 1, исключая границы
Возвращает процентную норму значения в наборе данных
Возвращает ранг значения в наборе данных как процентную долю набора (от 0 до 1, исключая границы)
Возвращает распределение Пуассона
Возвращает ранг числа в списке чисел
Возвращает ранг числа в списке чисел
Возвращает значения в соответствии с экспоненциальным трендом
Возвращает среднее значение (среднее арифметическое) всех ячеек, которые удовлетворяют нескольким условиям
Возвращает асимметрию распределения
Возвращает асимметрию распределения на основе заполнения: характеристика степени асимметрии распределения относительно его среднего
Возвращает среднее гармоническое
Возвращает среднее геометрическое
Возвращает среднее арифметическое аргументов
Возвращает среднее арифметическое аргументов, включая числа, текст и логические значения
Возвращает среднее значение (среднее арифметическое) всех ячеек в диапазоне, которые удовлетворяют заданному условию
Возвращает среднее арифметическое абсолютных значений отклонений точек данных от среднего
Оценивает стандартное отклонение по выборке
Вычисляет стандартное отклонение по генеральной совокупности
Оценивает стандартное отклонение по выборке, включая числа, текст и логические значения
Вычисляет стандартное отклонение по генеральной совокупности, включая числа, текст и логические значения
Возвращает стандартную ошибку предсказанных значений y для каждого значения x в регрессии
Возвращает значение t для t-распределения Стьюдента как функцию вероятности и степеней свободы
Возвращает обратное t-распределение Стьюдента
Возвращает процентные точки (вероятность) для t-распределения Стьюдента
Возвращает t-распределение Стьюдента
Возвращает вероятность, соответствующую проверке по критерию Стьюдента
Возвращает процентные точки (вероятность) для t-распределения Стьюдента
Подсчитывает количество чисел в списке аргументов
Подсчитывает количество ячеек в диапазоне, удовлетворяющих заданному условию
Подсчитывает количество ячеек внутри диапазона, удовлетворяющих нескольким условиям
Подсчитывает количество пустых ячеек в диапазоне
Возвращает значения в соответствии с линейным трендом
Возвращает среднее внутренности множества данных
Возвращает значение функции плотности для стандартного нормального распределения
Возвращает преобразование Фишера
Возвращает обратное преобразование Фишера
Возвращает интегральную функцию плотности бета-вероятности
Возвращает обратное значение односторонней вероятности распределения хи-квадрат
Возвращает интегральную функцию плотности бета-вероятности
Возвращает одностороннюю вероятность распределения хи-квадрат
Возвращает тест на независимость
Возвращает распределение частот в виде вертикального массива
Возвращает экспоненциальное распределение
Возвращает эксцесс множества данных

- Блог
Математические и тригонометрические функции – Math & Trig
Математические функции (округление)
Математические функции (базовые математические операции)
Математические функции (остальное)
Тригонометрические функции
Логические функции – Logical
Функции даты и времени – Date & Time
Финансовые функции – Financial
Функции баз данных – Database
Инженерные функции – Engineering
Проверка свойств и значений и Информационные функции – Information
Ссылки и массивы – Lookup & Reference
Статистические функции – Statistical
Microsoft Excel — мощный инструмент для расчётов и работы с информацией. Убедитесь в этом сами. Мы поможем! 
Мы используем файлы Cookie для хранения данных. Продолжая использовать сайт, вы даёте согласие на работу с этими файлами.
Close

© 2019-2022 Effema LLC
Любые оперативные вопросы вы можете задать нам в Телеграм
Close
Подписка на рассылку мероприятия от компании Effema
Нажимая кнопку «Подписаться», Вы соглашаетесь на обработку персональных данных.
В соответствии с Федеральным законом РФ от 27 июля 2006 г. №152-ФЗ «О персональных данных».
Функция ЧАСТОТА() — Подсчет ЧИСЛОвых значений в MS EXCEL
Функция ЧАСТОТА( ) , английская версия FREQUENCY(), вычисляет частоту попадания значений в заданные пользователем интервалы и возвращает соответствующий массив чисел.
Функцией ЧАСТОТА() можно воспользоваться, например, для подсчета количества результатов тестирования, попадающих в определенные интервалы (См. Файл примера )
Синтаксис функции
ЧАСТОТА(массив_данных;массив_интервалов)
Массив_данных — массив или ссылка на множество ЧИСЛОвых данных, для которых вычисляются частоты.
Массив_интервалов — массив или ссылка на множество интервалов, в которые группируются значения аргумента «массив_данных».
Функция ЧАСТОТА() вводится как формула массива после выделения диапазона смежных ячеек, в которые требуется вернуть полученный массив распределения (частот). Т.е. после ввода формулы необходимо вместо нажатия клавиши ENTER нажать сочетание клавиш CTRL+SHIFT+ENTER.
Количество элементов в возвращаемом массиве на единицу больше числа элементов в массиве «массив_интервалов». Дополнительный элемент в возвращаемом массиве содержит количество значений, превышающих верхнюю границу интервала, содержащего наибольшие значения (см. пример ниже).
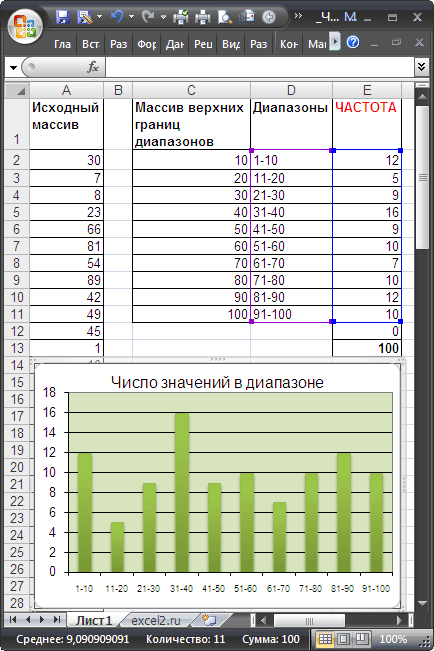
Пусть в диапазоне А2:А101 имеется исходный массив чисел от 1 до 100.
Подсчитаем количество чисел, попадающих в интервалы 1-10; 11-20; . 91-100.
Сформируем столбце С массив верхних границ диапазонов (интервалов). Для наглядности в столбце D сформируем текстовые значения соответствующие границам интервалов (1-10; 11-20; . 91-100).
Для ввода формулы выделим диапазон Е2:Е12, состоящий из 11 ячеек (на 1 больше, чем число верхних границ интервалов). В Строке формул введем =ЧАСТОТА($A$2:$A$101;$C$2:$C$11) . После ввода формулы необходимо нажать сочетание клавиш CTRL+SHIFT+ENTER. Диапазон Е2:Е12 заполнится значениями:
- в Е2 — будет содержаться количество значений из А2:А101, которые меньше или равны 10;
- в Е3 — количество значений из А2:А101, которые меньше или равны 20, но больше 10;
- в Е11 — количество значений из А2:А101, которые меньше или равны 100, но больше 90;
- в Е12 — количество значений из А2:А101, которые больше 100 (таких нет, т.к. исходный массив содержит числа от 1 до 100).
Примечание. Функцию ЧАСТОТА() можно заменить формулой = СУММПРОИЗВ(($A$5:$A$104>C5)*($A$5:$A$104 Похожие задачи
Глава 16. Функция массива ЧАСТОТА
Это глава из книги: Майкл Гирвин. Ctrl+Shift+Enter. Освоение формул массива в Excel.
Знакомство с функциями массива началось в главе 9. Мы узнали о функциях: ТРАНСП, МОДА.НСК и ТЕНДЕНЦИЯ. Настоящая заметка знакомит с четвертой функцией массива – ЧАСТОТА. Эта функция очень простая, но весьма мощная и универсальная. Она находит массу применений. Основная задача функции ЧАСТОТА – подсчитать, сколько чисел попадают в диапазон (рис. 16.1).

Рис. 16.1. Функция ЧАСТОТА подсчитывает, сколько результатов попали в тот или иной диапазон; диапазоны в D5:D10 не являются частью формулы; они показаны для иллюстрации
Скачать заметку в формате Word или pdf, примеры в формате Excel
Функция ЧАСТОТА в диапазоне Е5:Е10 введена с помощью Ctrl+Shift+Enter. Функция возвращает вертикальный массив, показывающий число вхождений результатов гонки в каждую категорию (диапазон). Например, в диапазон от 45 до 50 с попало 5 результатов. Функция содержит два аргумента: массив_данных и массив_интервалов (массив_карманов). Обратите внимание, что функция возвращает значений на одно больше чем массив_интервалов. Экстра-значение нужно на случай, если вы не предоставите «правильное» максимальное значение в массиве интервалов, и найдутся значения, выходящие за верхнюю границу максимального диапазона. Обратите внимание:
- Первый диапазон включает все значения, которые меньше или равны первой границе.
- Далее диапазоны формируются так, что нижняя граница не входит в диапазон, а верхняя – входит.
- Последний диапазон включает все значения, которые больше, чем последняя граница.
- Функция возвращает вертикальный массив. Если вам нужен горизонтальный массив, используйте функцию ТРАНСП (рис. 16.2).
- Если аргумент массив_карманов содержит N значений, диапазон введения функции ЧАСТОТА должен содержать N+1 ячеек.
- Функция ЧАСТОТА игнорирует пустые ячейки и текст.
- Если массив_интервалов содержит дубли, во все диапазоны-дубли, кроме первого, функция вернет 0.
- После того, как функция введена с помощью Ctrl+Shift+Enter, результирующий массив становится единым блоком и отдельные ячейки нельзя ни удалить, ни отредактировать. Но вы можете удалить все значения.
- Функция ЧАСТОТА может использоваться внутри больших формул массивов, возвращая вертикальный массив.

Рис. 16.2. Используйте функцию массива ТРАНСП, если нужно получить горизонтальный массив
Сравнение функций СЧЁТЕСЛИ, СЧЁТЕСЛИМН и ЧАСТОТА
Когда ваша цель – подсчет числа вхождений между нижней и верхней границами, вы должны рассмотреть, будут ли значения границ входить в диапазоны. Если у вас есть категории, подобные показанным на рис. 16.3, использовать функцию ЧАСТОТА гораздо проще, чем функции СЧЁТЕСЛИ или СЧЁТЕСЛИМН. Вы видите, что вам придется создать три разные формулы, если вы все же решите использовать СЧЁТЕСЛИ или СЧЁТЕСЛИМН вместо функции ЧАСТОТА. В данном примере ваш выбор однозначен – функция ЧАСТОТА.

Рис. 16.3. Функции СЧЁТЕСЛИ и СЧЁТЕСЛИМН сложнее, чем ЧАСТОТА; Чтобы увеличить изображение кликните на нем правой кнопкой мыши и выберите Открыть картинку в новой вкладке
Однако, если диапазоны включает нижнюю границу, но не верхнюю (рис. 16.4) функция ЧАСТОТА не подойдет. Кроме того, вы можете предусмотреть введение нижней и верхней границ для всех диапазонов, так что формулы примут одинаковый вид. В этом примере, вы отметаете функцию ЧАСТОТА, и скорее всего, предпочтете СЧЁТЕСЛИМН.

Рис. 16.4. СЧЁТЕСЛИ и СЧЁТЕСЛИМН более гибки по сравнению с функцией ЧАСТОТА при задании различных условий по вхождению границ в диапазоны
В следующей главе вы используете полученные знания о функции ЧАСТОТА для построения формул подсчета уникальных элементов в списке.
Частотный анализ по интервалам функцией ЧАСТОТА (FREQUENCY)
При анализе данных периодически возникает задача подсчитать количество значений, попадающих в заданные интервалы «от и до» (в статистике их называют «карманы»). Например, подсчитать количество звонков определенной длительности при разборе статистики по мобильной связи, чтобы понимать какой тариф для нас выгоднее:
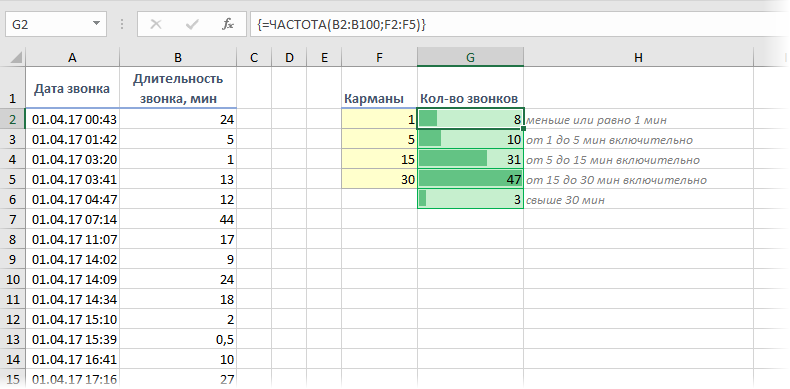
Для решения подобной задачи можно воспользоваться функцией ЧАСТОТА (FREQUENCY) . Ее синтаксис прост:
=ЧАСТОТА( Данные ; Карманы )
- Карманы — диапазон с границами интервалов, попадание в которые нас интересует
- Данные — диапазон с исходными числовыми значениями, которые мы анализируем
Обратите внимание, что эта функция игнорирует пустые ячейки и ячейки с текстом, т.е. работает только с числами.
Для использования функции ЧАСТОТА нужно:
- заранее подготовить ячейки с интересующими нас интервалами-карманами (желтые F2:F5 в нашем примере)
- выделить пустой диапазон ячеек (G2:G6) по размеру на одну ячейку больший, чем диапазон карманов (F2:F5)
- ввести функцию ЧАСТОТА и нажать в конце сочетание Ctrl+Shift+Enter, т.е. ввести ее как формулу массива
Во всех предварительно выделенных ячейках посчитается количество попаданий в заданные интервалы. Само-собой, для реализации подобной задачи можно использовать и другие способы (функцию СЧЁТЕСЛИ, сводные таблицы и т.д.), но этот вариант весьма хорош.
Кроме того, с помощью функции ЧАСТОТА можно легко подсчитывать количество уникальных чисел в наборе с помощью простой формулы массива:
Функция ЧАСТОТА
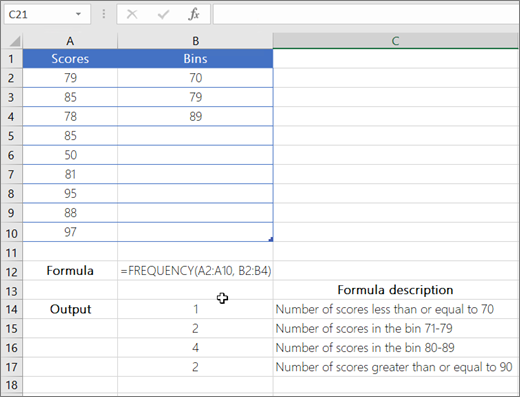
Функция частота Вычисляет частоту возникновения значений в диапазоне значений и возвращает вертикальный массив чисел. Функцией ЧАСТОТА можно воспользоваться, например, для подсчета количества результатов тестирования, попадающих в интервалы результатов. Поскольку данная функция возвращает массив, ее необходимо вводить как формулу массива.
Аргументы функции ЧАСТОТА описаны ниже.
дата_аррай Обязательный. Массив или ссылка на множество значений, для которых вычисляются частоты. Если аргумент «массив_данных» не содержит значений, функция ЧАСТОТА возвращает массив нулей.
бинс_аррай — обязательный аргумент. Массив или ссылка на множество интервалов, в которые группируются значения аргумента «массив_данных». Если аргумент «массив_интервалов» не содержит значений, функция ЧАСТОТА возвращает количество элементов в аргументе «массив_данных».
Примечание: Если у вас установлена текущая версия Office 365, можно просто ввести формулу в верхней левой ячейке диапазона вывода и нажать клавишу ВВОД, чтобы подтвердить использование формулы динамического массива. Иначе формулу необходимо вводить с использованием прежней версии массива, выбрав диапазон вывода, введя формулу в левой верхней ячейке диапазона и нажав клавиши CTRL+SHIFT+ВВОД для подтверждения. Excel автоматически вставляет фигурные скобки в начале и конце формулы. Дополнительные сведения о формулах массива см. в статье Использование формул массива: рекомендации и примеры.
Количество элементов в возвращаемом массиве на единицу больше числа элементов в массиве «массив_интервалов». Дополнительный элемент в возвращаемом массиве содержит количество значений, превышающих верхнюю границу интервала, содержащего наибольшие значения. Например, при подсчете трех диапазонов значений (интервалов), введенных в три ячейки, убедитесь в том, что функция ЧАСТОТА возвращает значения в четырех ячейках. Дополнительная ячейка возвращает число значений в аргументе «массив_данных», превышающих значение верхней границы третьего интервала.
Функция ЧАСТОТА пропускает пустые ячейки и текст.
Дополнительные сведения
Вы всегда можете задать вопрос специалисту Excel Tech Community, попросить помощи в сообществе Answers community, а также предложить новую функцию или улучшение на веб-сайте Excel User Voice.
Примечание: Эта страница переведена автоматически, поэтому ее текст может содержать неточности и грамматические ошибки. Для нас важно, чтобы эта статья была вам полезна. Была ли информация полезной? Для удобства также приводим ссылку на оригинал (на английском языке).
KT Богомолов / МУ / ЗАДАНИЕ_1_СТАТИСТИКА / Дополнительные материалы / Построение гистограмм в Excel_2014
![]()
Построение гистограмм в Microsoft Excel
Перед построением гистограммы выполняется группировка данных по близким признакам. При группировании по количественному признаку все множество значений признака делится на
Для определения оптимального количества интервалов может быть использована формула Стерджесса:
n = 1 + (3,322 × lgN )
где N — количество наблюдений. В этом случае величина интервала:
h = ( V max — V min )/ n
Поскольку количество групп не может быть дробным числом, то полученную по этой формуле величину округляют до целого большего числа.
Нижнюю границу первого интервала принимают равной минимальному значению x min . Верхняя граница первого интервала соответствует значению ( x min + h ). Для последующих групп
границы определяются аналогично, то есть последовательно прибавляется величина интервала h .
В Excel для построения гистограмм используются статистическая функция ЧАСТОТА в сочетании с мастером построения обычных диаграмм и процедура Гистограмма из пакета анализа .
Функция ЧАСТОТА (массив_данных, двоичный_массив) вычисляет частоты появления случайной величины в интервалах значений и выводит их как массив цифр, где
• Массив_данных — массив исходных данных, для которых вычисляются частоты;
• Массив_интервалов — это массив интервалов, по которым группируются значения выборки .
Перед вызовом функции ЧАСТОТА необходимо выделить столбец c числом ячеек, равным числу интервалов n , в который будут выведены результаты выполнения функции.
Вызвать Мастер функций (кнопка f x ):
и функцию ЧАСТОТА .

В поле Массив_данных ввести диапазон данных наблюдений А3:А102 (с листа ‘Расчетные данные’) . В поле Массив_интервалов ввести диапазон интервалов с того же листа ([‘Расчетные данные’!F16:F23] – в данном примере).
При завершении ввода данных нажать комбинацию клавиш Ctrl+Shift+Enter.
В предварительно выделенном столбце (C5:C12 – в данном примере) должен появиться массив
Столбец Накопленные частоты получается последовательным суммированием относительных частот (в процентном формате) в направлении от первого интервала к последнему.
В завершении с помощью Мастера диаграмм строится диаграмма абсолютных и накопленных частот с выбором типа диаграммы соотвественно гистограмма и график.
Для автоматизированного построения гистограммы средствами Excel необходимо обратиться к меню « Сервис Анализ данных» . (Excel 2003) или на вкладке Данные выбрать Анализ данных
(Excel 2007. 2010):
В появившемся списке выбрать инструмент Гистограмма и щелкнуть на кнопке ОК. Появится окно гистограммы, где задаются следующие параметры:

Входной интервал :– адреса ячеек, содержащие выборочные данные.
Интервал карманов : (необязательный параметр) – адреса ячеек, содержащие границы интервалов. Это поле предлагается оставить пустым, предоставив Excel самому вычислить границы интервалов (карманов – в терминах Excel).
Метки – флажок, включаемый, если первая строка во входных данных содержит заголовки. Если заголовки отсутствуют, то флажок следует выключить.
Выходной интервал: / Новый рабочий лист: / Новая рабочая книга.
Включенный переключатель Выходной интервал требует ввода адреса верхней ячейки, начиная с которой будут размещаться вычисленные относительные частоты j .
В положении переключателя Новый рабочий лист: открывается новый лист, в котором начиная с ячейки А1 размещаются частности j .
В положении переключателя Новая рабочая книга открывается новая книга, на первом листе которой начиная с ячейки А1 размещаются частности j .
Парето ( отсортированная гистограмма ) – устанавливается, чтобы представить j в порядке их убывания. Если параметр выключен, то j приводятся в порядке следования интервалов.
Интегральный процент – устанавливается в активное состояние для расчета выраженных в процентах накопленных относительных частот (аналог значений столбца Накопленные частоты ).
Вывод графика – устанавливается в активное состояние для автоматического создания встроенной диаграммы на листе, содержащем частоты.
Как правило, гистограммы изображаются в виде смежных прямоугольных областей. Поэтому столбики гистограммы следует расширить до соприкосновения друг с другом. Для этого необходимо щелкнуть мышью на диаграмме, далее на панель инструментов Диаграмма , раскрыть список инструментов и выбрать элемент Ряд ‘Частота’ , после чего щелкнуть на кнопке Формат ряда . В появившемся одноименном диалоговом окне необходимо активизировать закладку Параметры и в поле Ширина зазора установить значение 0 ((Excel 2003):

В Excel 2007. 2010 встать на любой столбик гистограммы и правой кнопкой мыши выбрать
Формат ряда данных:
Для построения теоретической кривой нормального распределения по эмпирическим данным необходимо найти теоретические частоты.
В Excel для вычисления значений нормального распределения используются функция НОРМРАСП, которая вычисляет значения вероятности нормальной функции распределения для указанного среднего и стандартного отклонения.
Функция имеет параметры:
НОРМРАСП (х; среднее; стандартное_откл; интегральная) , где:
х — значения выборки, для которых строится распределение; среднее — среднее арифметическое выборки; стандартное_откл — стандартное отклонение распределения;
интегральный — логическое значение, определяющее форму функции. Если интегральная имеет значение ИСТИНА(1), то функция НОРМРАСП возвращает интегральную функцию распределения; если это аргумент имеет значение ЛОЖЬ (0), то вычисляет значение функция плотности распределения.
Для получения абсолютных значений плотностей распределения (теоретических частот) достаточно найденные значения вероятности умножить на величину интервала h и количество наблюдений N = 100 по каждой строке.
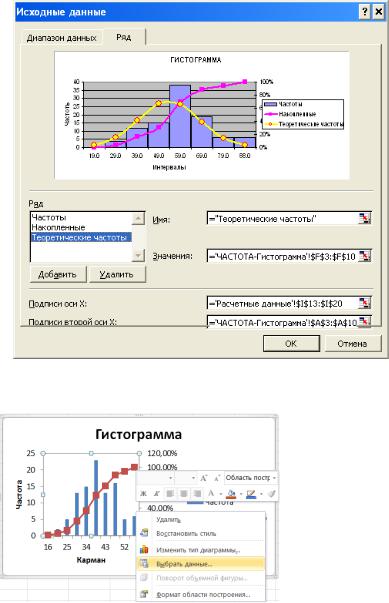
Для завершения выполнения задания необходимо внести полученные значения теоретических частот на рисунок с гистограммой, добавив ряд в закладке Исходные данные и выбрав тип диаграммы
– график ((Excel 2003):
В Excel 2007. 2010 находясь в обласи гистограммы по правой кнопке мыши выбрать Выбрать данные (или по одноименной кнопке на вкладке Конструктор ):
и в появившемся окне провести манипуляции с вводом нового ряда «Теоретические частоты»: