
I’m looking for a very very fast method to insert a timestamp into a Word document. I always know the shortcuts ShiftAltD and ShiftAltT, but doing so inserts a field, that is always automatically updated. And because I need a real timestamp, I consequently have to use CtrlF9 to get a fixed date-time string:
To sum up:
- ShiftAltD
- ShiftAltT
- Mark both fields
- CtrlF9
And that is not a shortcut, that’s expensive overhead! So I’m always faster when I write all by 10-fingers touch-typing.
I search for a real one-hand keyboard shortcut for inserting a fixed date-time.
![]()
m4573r
5,5411 gold badge24 silver badges37 bronze badges
asked Jan 5, 2014 at 11:13
![]()
Record a macro for these actions and assign it to a single keyboard shortcut. This is the exact usecase macros are made for.
answered Jan 7, 2014 at 13:22
![]()
AdamAdam
7,3032 gold badges25 silver badges41 bronze badges
1
You’ve probably found your solution by now but for those of you still looking, Word still has the old date time formats box. In the ribbon its on the Insert tab | Text group. It’s the icon that looks like a calendar with a clock in the lower right-hand corner. From the box, you can select your preferred format, make it the default and insert an icon on the QAT. That makes it a 2 click function or you can create a keyboard macro from the 2 click function for faster results.
answered Oct 13, 2015 at 18:46
![]()
 Please Note:
Please Note:
This article is written for users of the following Microsoft Word versions: 97, 2000, 2002, and 2003. If you are using a later version (Word 2007 or later), this tip may not work for you. For a version of this tip written specifically for later versions of Word, click here: Adding Automatic Time Stamps.
![]()
Written by Allen Wyatt (last updated December 26, 2020)
This tip applies to Word 97, 2000, 2002, and 2003
Kim wants to use bulleted lists to record notes during a classroom observation. Each note (each bulleted item in a list) needs to have a time stamp to indicate when it was observed and created. She wonders about the best way to automatically add the time stamp to each bulleted list item as it is created.
There are a couple ways you can approach a solution to this need, and each approach requires the use of a macro. The reason is because Word doesn’t include any shortcuts or tools that automatically add a time stamp to your document. You could, of course, just use the traditional tools to insert a date and time (such as pressing Alt+Shift+T), but you’ll find that unsatisfactory—the tools insert a field that is updated to the current date and time whenever fields are updated.
A simple solution is to create a macro that inserts the date and time:
Public Sub TimeStamp
Selection.InsertDateTime _
DateTimeFormat:="MM/dd/yyyy hh:mm:ss" & _
" - ", InsertAsField:=False
End Sub
You could assign the macro to a keyboard shortcut. That way, as you are typing you could press the shortcut and thereby insert a static date and time at any point in your document.
A more complete solution might be to create a macro that not only inserts the date and time, but also inserts a paragraph and formats it using your desired bullet style. Start by creating a paragraph style (I’ll call it «MyBullet») that reflects all the formatting you want in the paragraph—font, size, indent, bullet format, spacing, etc. Then, create a macro similar to the following:
Sub Observe()
Selection.TypeParagraph
Selection.Style = ActiveDocument.Styles("MyBullet")
Selection.Font.ColorIndex = wdRed
Selection.InsertDateTime _
DateTimeFormat:="MM/dd/yyyy hh:mm:ss" & _
" - ", InsertAsField:=False
Selection.Font.ColorIndex = wdAuto
End Sub
When you run the macro, it inserts a new paragraph at the insertion point, formats that paragraph using the MyBullet style, inserts the date and time in red, and then remain ready for you to type your observation.
Now, all this being said, you should understand that Word may not be the best application for the purpose described by Kim. A better approach might be to use OneNote, which allows the easy creation of notes (observations) and time stamping those notes. Information in OneNote could then, after your observation sessions, be copied to a Word document for creating your final report.
If you would like to know how to use the macros described on this page (or on any other page on the WordTips sites), I’ve prepared a special page that includes helpful information. Click here to open that special page in a new browser tab.
WordTips is your source for cost-effective Microsoft Word training.
(Microsoft Word is the most popular word processing software in the world.)
This tip (11459) applies to Microsoft Word 97, 2000, 2002, and 2003. You can find a version of this tip for the ribbon interface of Word (Word 2007 and later) here: Adding Automatic Time Stamps.
Author Bio
With more than 50 non-fiction books and numerous magazine articles to his credit, Allen Wyatt is an internationally recognized author. He is president of Sharon Parq Associates, a computer and publishing services company. Learn more about Allen…
MORE FROM ALLEN
Picking a Group of Cells
Excel makes it easy to select a group of contiguous cells. However, it also makes it easy to select non-contiguous groups …
Discover More
Inconsistent Output for Empty Columns in a CSV File
When you create a CSV file in Excel, the information stored in the file may not contain all the fields that you think it …
Discover More
Always Opening a Workbook that is Editable
When you send a workbook to a coworker, it can be bothersome if that person has problems using what you created. There is …
Discover More
It’s possible to use Google’s Speech recognition API to get a transcription for an audio file (WAV, MP3, etc.) by doing a request to http://www.google.com/speech-api/v2/recognize?...
Example: I have said «one two three for five» in a WAV file. Google API gives me this:
{
u'alternative':
[
{u'transcript': u'12345'},
{u'transcript': u'1 2 3 4 5'},
{u'transcript': u'one two three four five'}
],
u'final': True
}
Question: is it possible to get the time (in seconds) at which each word has been said?
With my example:
['one', 0.23, 0.80], ['two', 1.03, 1.45], ['three', 1.79, 2.35], etc.
i.e. the word «one» has been said between time 00:00:00.23 and 00:00:00.80,
the word «two» has been said between time 00:00:01.03 and 00:00:01.45 (in seconds).
PS: looking for an API supporting other languages than English, especially French.
whisper-timestamped
Multilingual Automatic Speech Recognition with word-level timestamps and confidence.
- Description
- Notes on other approaches
- Installation
- First installation
- Additional packages that might be needed
- Docker
- Light installation for CPU
- Upgrade to the latest version
- First installation
- Usage
- Python
- Command line
- Plotting word alignment
- Example output
- Options that may improve results
- Acknowlegment
- Citations
Description
Whisper is a set of multi-lingual robust speech recognition models, trained by OpenAI,
that achieve state-of-the-art in many languages.
Whisper models were trained to predict approximative timestamps on speech segments (most of the times with 1 sec accuracy),
but cannot originally predict word timestamps.
This repository proposes an implementation to predict word timestamps, and give more accurate estimation of speech segments, when transcribing with Whipser models.
Besides, a confidence score is assigned to each word and each segment (both computed as «exp(mean(log probas))» on the probabilities of subword tokens).
The approach is based on approach Dynamic Time Warping (DTW) applied to cross-attention weights,
as done by this notebook by Jong Wook Kim.
There are some additions to this notebook:
- The start/end estimation is more accurate.
- Confidence scores are assigned to each word.
- If possible (without beam search…), there no additional inference steps are required to predict word timestamps (word alignment is done on the fly, after each speech segment is decoded).
- There is a special care about memory usage:
whisper-timestampedis able to process long files, with little additional memory with respect to the regular use of Whisper model.
whisper-timestamped is an extension of openai-whisper python package
and is meant to compatible with any version of openai-whisper.
Notes on other approaches
An alternative relevant approach to recover word-level timestamps consists in using wav2vec models that predict characters,
as successfully implemented in whisperX.
But these approaches have several drawbacks, which does not have approaches based on cross-attention weights such as whisper_timestamped.
These drawbacks are:
- The need to find one wav2vec model per language to support, which badly scales to the multi-lingual capabilities of Whisper.
- The need to handle (at least) one additional neural network (wav2vec model), which consumes memory.
- The need to normalize characters in whisper transcription to match the character set of wav2vec model.
This involves awkward language-dependent conversions, like converting numbers to words («2» -> «two»), symbols to words («%» -> «percent», «€» -> «euro(s)»)… - The lack of robustness around speech disfluencies (fillers, hesitations, repeated words…) that are usually removed by Whisper.
An alternative approach, that does not require an additional model, is to look at the probabilities of timestamp tokens
estimated by the Whisper model after each (sub)word token is predicted.
It was implemented for instance in whisper.cpp and stable-ts.
But this approach lacks of robustness, because Whisper models do not have been trained to output meaningful timestamps after each word.
Whisper models tend to predict timestamps only after a certain number of words have been predicted (typically at the end of a sentence),
and the probability distribution of timestamps outside this condition may be inaccurate.
In practice, these methods can produce results that are totally out-of-sync on some periods of time (we observed that especially when there is jingle music).
Also the timestamp precision of Whisper models tend to be rounded to 1 second (as in many video subtitles), which is too inaccurate for words, and reaching a better accuracy is tricky.
Installation
First installation
Requirements:
python3(version higher or equal to 3.7, at least 3.9 is recommended)ffmpeg(see instructions for installation on the whisper repository
You can install whisper-timestamped either by using pip:
pip3 install git+https://github.com/linto-ai/whisper-timestamped
or by cloning this repository and running installation:
git clone https://github.com/linto-ai/whisper-timestamped
cd whisper-timestamped/
python3 setup.py install
Additional packages that might be needed
If you want to plot alignement between audio timestamps and words (as in this section), you also need matplotlib
If you want to use VAD option (Voice Activity Detection before running Whisper model), you also need torchaudio
Docker
A docker image of about 9GB can be built using:
git clone https://github.com/linto-ai/whisper-timestamped cd whisper-timestamped/ docker build -t whisper_timestamped:latest .
Light installation for CPU
If you don’t have GPU (or don’t want to use it), then you don’t need to install CUDA dependencies.
You should then just install a light version of torch before installing whisper-timestamped, for instance as follows:
pip3 install
torch==1.13.1+cpu
torchaudio==0.13.1+cpu
-f https://download.pytorch.org/whl/torch_stable.html
A specific docker image of about 3.5GB can also be built using:
git clone https://github.com/linto-ai/whisper-timestamped cd whisper-timestamped/ docker build -t whisper_timestamped_cpu:latest -f Dockerfile.cpu .
Upgrade to the latest version
When using pip, the library can be updated to the latest version using
pip3 install --upgrade --no-deps --force-reinstall git+https://github.com/linto-ai/whisper-timestamped
A specific version of openai-whisper can be used by running, for example:
pip3 install openai-whisper==20230124
Usage
Python
In python, you can use the function whisper_timestamped.transcribe() that is similar to the fonction whisper.transcribe()
import whisper_timestamped help(whisper_timestamped.transcribe)
The main difference with whisper.transcribe() is that
the output will include a key "words" for all segments, with the word start and end position. Note that word will include punctuation. See example below.
Besides, default decoding options are different, in order to favour efficient decoding (greedy decoding instead of beam search, and no temperature sampling fallback).
To have same default as in whisper, use beam_size=5, best_of=5, temperature=(0.0, 0.2, 0.4, 0.6, 0.8, 1.0).
There are also additional options related to word alignement.
In general, by importing whisper_timestamped instead of whisper in your python script, it should do the job, if you use transcribe(model, ...) instead of model.transcribe(...):
import whisper_timestamped as whisper
audio = whisper.load_audio("AUDIO.wav")
model = whisper.load_model("tiny", device="cpu")
result = whisper.transcribe(model, audio, language="fr")
import json
print(json.dumps(result, indent = 2, ensure_ascii = False))
Note that you can use a finetuned Whisper model from HuggingFace or a local folder, by using the load_model method of whisper_timestamped.
For instance, if you want to use https://huggingface.co/NbAiLab/whisper-large-v2-nob you simply can do:
import whisper_timestamped as whisper
model = whisper.load_model("NbAiLab/whisper-large-v2-nob", device="cpu")
# ...
Command line
You can also use whisper_timestamped on the command line, similarly to whisper. See help with:
whisper_timestamped --help
The main differences with whisper CLI are:
- Output files:
- The output JSON contains word timestamps and confidence scores. See example below.
- There is an additional CSV output format
- For SRT, VTT, TSV formats, there will be additional files saved with word timestamps
- Some default options are different:
- By default, no output folder is set: Use
--output_dir .for Whisper default - By default, there is no verbose: Use
--verbose Truefor Whisper default - By default, beam search decoding and temperature sampling fallback are disabled, to favour an efficient decoding.
To set the same as Whisper default, you can use--accurate(which is an alias for--beam_size 5 --temperature_increment_on_fallback 0.2 --best_of 5).
- By default, no output folder is set: Use
- There are some additional specific options:
--compute_confidenceto enable/disable the computation of confidence scores for each word.--punctuations_with_wordsto decide whether punctuation marks should be included or not with preceding words.
An example command line to process several files with the tiny model and output results in the current folder as whisper would do by default:
whisper_timestamped audio1.flac audio2.mp3 audio3.wav --model tiny --output_dir .
Note that you can use a finetuned Whisper model from HuggingFace or a local folder.
For instance, if you want to use https://huggingface.co/NbAiLab/whisper-large-v2-nob you simply can do:
whisper_timestamped --model NbAiLab/whisper-large-v2-nob <...>
Plot of word alignment
Note that you can use option plot_word_alignment of python function whisper_timestamped.transcribe(), or option --plot of whisper_timestamped CLI in order to see the word alignment for each segment.

- The upper plot represents the transformation of cross-attention weights that is used for the alignement with Dynamic Time Warping.
The abscissa represents the time and the ordinate represents the predicted tokens; with special timestamp tokens at first and at last, and then (sub)words and punctuations in the middle. - The lower plot is a MFCC representation of the input signal (features used by Whisper, based on Mel-frequency cepstrum).
- The vertical dotted red lines show where the word boundaries are found (with punctuation marks «glued» with the previous word).
Example output
Here is an example output of whisper_timestamped.transcribe(), that can be seen by using CLI
whisper_timestamped AUDIO_FILE.wav --model tiny --language fr
{
"text": " Bonjour! Est-ce que vous allez bien?",
"segments": [
{
"id": 0,
"seek": 0,
"start": 0.5,
"end": 1.2,
"text": " Bonjour!",
"tokens": [ 25431, 2298 ],
"temperature": 0.0,
"avg_logprob": -0.6674491882324218,
"compression_ratio": 0.8181818181818182,
"no_speech_prob": 0.10241222381591797,
"confidence": 0.51,
"words": [
{
"text": "Bonjour!",
"start": 0.5,
"end": 1.2,
"confidence": 0.51
}
]
},
{
"id": 1,
"seek": 200,
"start": 2.02,
"end": 4.48,
"text": " Est-ce que vous allez bien?",
"tokens": [ 50364, 4410, 12, 384, 631, 2630, 18146, 3610, 2506, 50464 ],
"temperature": 0.0,
"avg_logprob": -0.43492694334550336,
"compression_ratio": 0.7714285714285715,
"no_speech_prob": 0.06502953916788101,
"confidence": 0.595,
"words": [
{
"text": "Est-ce",
"start": 2.02,
"end": 3.78,
"confidence": 0.441
},
{
"text": "que",
"start": 3.78,
"end": 3.84,
"confidence": 0.948
},
{
"text": "vous",
"start": 3.84,
"end": 4.0,
"confidence": 0.935
},
{
"text": "allez",
"start": 4.0,
"end": 4.14,
"confidence": 0.347
},
{
"text": "bien?",
"start": 4.14,
"end": 4.48,
"confidence": 0.998
}
]
}
],
"language": "fr"
}
Options that may improve results
Here are some options not abled by default that might improve results.
Accurate Whisper transcription
As mentioned before, some decoding options are disabled by default for offering a better efficiency.
But the quality of the transcription can be impacted.
To run with the options that have the best chance to provide a good transcription, use the following options.
- In python:
results = whisper_timestamped.transcribe(model, audio, beam_size=5, best_of=5, temperature=(0.0, 0.2, 0.4, 0.6, 0.8, 1.0), ...)
- In the command line:
whisper_timestamped --accurate ...
Running Voice Activity Detection (VAD) before sending to Whisper
Whisper models can «hallucinate» text when a segment without speech is given.
This can be avoided by running VAD and gluing speech segments together before transcribing with the Whisper model.
This is possible in whisper-timestamped.
- In python:
results = whisper_timestamped.transcribe(model, audio, vad=True, ...)
- In the command line:
whisper_timestamped --vad True ...
Detecting disfluencies
Whisper models tend to remove speech disfluencies (filler words, hesitations, repetitions, …).
Without precautions, the disfluencies that are not transcribed will have an influence on the timestamp of the word that follows: the timestamp of the beginning of the word will actually be the timestamp of the beginning of the disfluencies.
whisper-timestamped can implement some heuristics to avoid that.
- In python:
results = whisper_timestamped.transcribe(model, audio, detect_disfluencies=True, ...)
- In the command line:
whisper_timestamped --detect_disfluencies True ...
Important: Note that when using this options, possible disfluencies will appear in the transcription as a special «[*]» word.
Acknowlegment
- whisper: Whisper speech recognition (License MIT).
- dtw-python: Dynamic Time Warping (License GPL v3).
Citations
If you use this in your research, just cite the repo,
@misc{lintoai2023whispertimestamped, title={whisper-timestamped}, author={Louradour, J{'e}r{^o}me}, journal={GitHub repository}, year={2023}, publisher={GitHub}, howpublished = {url{https://github.com/linto-ai/whisper-timestamped}} }
as well as OpenAI Whisper paper,
@article{radford2022robust, title={Robust speech recognition via large-scale weak supervision}, author={Radford, Alec and Kim, Jong Wook and Xu, Tao and Brockman, Greg and McLeavey, Christine and Sutskever, Ilya}, journal={arXiv preprint arXiv:2212.04356}, year={2022} }
and this paper for Dynamic-Time-Warping
@article{JSSv031i07, title={Computing and Visualizing Dynamic Time Warping Alignments in R: The dtw Package}, author={Giorgino, Toni}, journal={Journal of Statistical Software}, year={2009}, volume={31}, number={7}, doi={10.18637/jss.v031.i07} }
When you’re writing content such as technical content, news articles, etc., you may sometimes want to insert the current date or timestamp in a program or editor you’re using. In Notepad, you can add the timestamp by pressing the F5 key.
Microsoft Office Word, OneNote allows the Alt + Shift + D and Alt + Shift + T hotkey combinations to insert the current date and current time respectively.
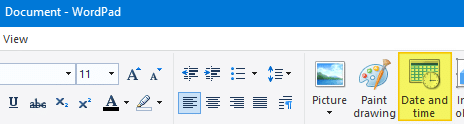
Similarly, WordPad has the Date and time toolbar button that lets you insert the date or timestamp in your preferred format from the list of 13 choices.
But, if you’re using a program which doesn’t have a built-in feature to insert current date and time, you may need a third-party macro or automation tool for that purpose. With automation tools, you also have the advantage of using a single hotkey combination to insert the date or timestamp in any program.
AutoHotkey is a free, open-source scripting language for Windows that allows users to easily create small to complex scripts for all kinds of tasks such as form fillers, auto-clicking, macros, etc.
- Download AutoHotkey and install it.
- Right-click on the desktop, click New and select AutoHotkey Script.
- Rename the script file
New AutoHotkey Script.ahktoinsert_date.ahk - Right-click the file and choose Edit Script
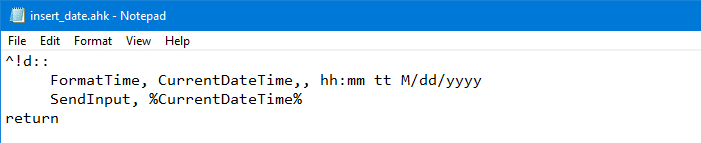
- Remove all lines in the script and replace it with the following code:
^!d:: FormatTime, CurrentDateTime,, hh:mm tt M/dd/yyyy SendInput, %CurrentDateTime% return
- Save the file
insert_date.ahkand close the editor. - Double-click to run the script. It will show up in the notification area.
- Now, switch to the program where you want to insert the date or timestamp.
- Press Ctrl + Alt + D to insert the timestamp at the current cursor position.
Script Customization
You can change the keyboard hotkey in the (1st line of the) script if you need. Here are the modifiers.
!{Alt}+{Shift}^{Ctrl}#{Winkey}
For example, for Ctrl + Alt + Shift + D, you’d use ^!+d.
For the full list of keys you can send or intercept, see AutoHotkey SendInput documentation
Without using hotkeys
If you want to insert the timestamp by typing a specific word — e.g., td, then edit the .ahk script and replace its contents with the following:
::td::
FormatTime, CurrentDateTime,, hh:mm tt M/dd/yyyy
SendInput, %CurrentDateTime%
return
Now, type td (and followed by a space) in any program. The words td will be replaced by the current date/timestamp. See this animation:
Similarly, you can customize the Date or timestamp format.
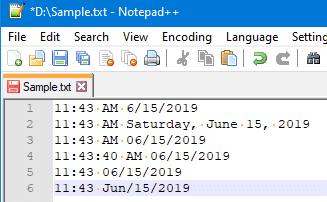
| Date format | Result |
| hh:mm tt M/dd/yyyy | 11:26 AM 6/15/2019 |
| hh:mm tt MM/dd/yyyy | 11:26 AM 06/15/2019 |
| hh:mm:ss tt MM/dd/yyyy | 11:26:22 AM 06/15/2019 |
| HH:mm MM/dd/yyyy | 11:26 06/15/2019 |
| HH:mm MMM/dd/yyyy | 11:26 Jun/15/2019 |
| (no formatting) | 11:26 AM Saturday, June 15, 2019 |
See FormatTime Syntax AutoHotkey documentation for more information.
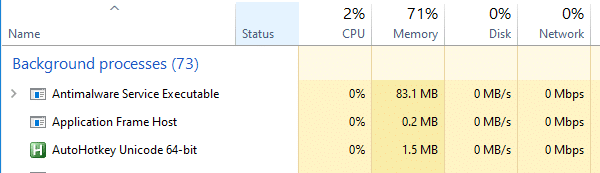
The above AutoHotkey script uses merely 1.5 MB of memory.
And you can even compile the .ahk script to a .exe file so that you don’t need to have the AutoHotkey program installed. This is especially helpful if you manage a lot of computers as part of your home or work network.
One small request: If you liked this post, please share this?
One «tiny» share from you would seriously help a lot with the growth of this blog.
Some great suggestions:
- Pin it!
- Share it to your favorite blog + Facebook, Reddit
- Tweet it!
So thank you so much for your support. It won’t take more than 10 seconds of your time. The share buttons are right below. 