
- A byte is a memory unit for storage
- A memory chip is full of such bytes.
Memory units are addressable. That is the only way we can use memory.
In reality, memory is only byte addressable. It means:
- A binary address always points to
a singlebyte only. - A word is just
a group ofbytes –2,4,8depending upon the data bussize ofthe CPU.
To understand the memory operation fully, you must be familiar with the various registers of the CPU and the memory ports of the RAM. I assume you know their meaning:
- MAR(memory address register)
- MDR(memory data register)
- PC(program counter register)
- MBR(memory buffer register)
RAM has two kinds of memory ports:
32-bitsfor data/addresses8-bitfor OPCODE.
Suppose CPU wants to read a word (say 4 bytes) from the address xyz onwards. CPU would put the address on the MAR, sends a memory read signal to the memory controller chip. On receiving the address and read signal, memory controller would connect the data bus to 32-bit port and 4 bytes starting from the address xyz would flow out of the port to the MDR.
If the CPU wants to fetch the next instruction, it would put the address onto the PC register and sends a fetch signal to the memory controller. On receiving the address and fetch signal, memory controller would connect the data bus to 8-bit port and a single byte long opcode located at the address received would flow out of the RAM into the CPU‘s MDR.
So that is what it means when we say a certain register is memory addressable or byte addressable. Now what will happen when you put, say decimal 2 in binary on the MAR with an intention to read the word 2, not (byte no 2)?
Word no 2 means bytes 4, 5, 6, 7 for 32-bit machine. In real physical memory is byte addressable only. So there is a trick to handle word addressing.
When MAR is placed on the address bus, its 32-bits do not map onto the 32 address lines(0-31 respectively). Instead, MAR bit 0 is wired to address bus line 2, MAR bit 1 is wired to address bus line 3 and so on. The upper 2 bits of MAR are discarded since they are only needed for word addresses above 2^32 none of which are legal for our 32 bit machine.
Using this mapping, when MAR is 1, address 4 is put on the bus, when MAR is 2, address 8 is put on the bus and so forth.
It is a bit difficult in the beginning to understand. I learnt it from Andrew Tanenbaums‘s structured computer organisation.
Improve Article
Save Article
Like Article
Improve Article
Save Article
Like Article
Memory is a storage component in the Computer used to store application programs. The Memory Chip is divided into equal parts called as “CELLS”. Each Cell is uniquely identified by a binary number called as “ADDRESS”. For example, the Memory Chip configuration is represented as ’64 K x 8′ as shown in the figure below.

The following information can be obtained from the memory chip representation shown above:
1. Data Space in the Chip = 64K X 8
2. Data Space in the Cell = 8 bits
3. Address Space in the Chip = log_{2} (64 K) =16 bits
Now we can clearly state the difference between Byte Addressable Memory & Word Addressable Memory.
| S. No. | Byte Addressable Memory | Word Addressable Memory |
|---|---|---|
| 1. | When the data space in the cell = 8 bits then the corresponding address space is called as Byte Address. | When the data space in the cell = word length of CPU then the corresponding address space is called as Word Address. |
| 2. | Based on this data storage i.e. Bytewise storage, the memory chip configuration is named as Byte Addressable Memory. | Based on this data storage i.e. Wordwise storage, the memory chip configuration is named as Word Addressable Memory. |
| 3. | For eg. : 64K X 8 chip has 16 bit Address and cell size = 8 bits (1 Byte) which means that in this chip, data is stored byte by byte. | For eg. : For a 16-bit CPU, 64K X 16 chip has 16 bit Address & cell size = 16 bits (Word Length of CPU) which means that in this chip, data is stored word by word. |
| 4. | It is suitable for the processes that require data comprising single byte at a time. A single address is issued for accessing a single byte in byte addressable memory. | In case of word addressable memory, the necessary condition involves computing the address of word that contains required byte, fetch that word and then extraction of needed byte from the two byte word takes place. So, it is indirectly accessible. Hence, modern machines are byte addressable. |
NOTE :
i) The most important point to be noted is that in case of either of Byte Address or Word Address, the address size can be any number of bits (depends on the number of cells in the chip) but the cell size differs in each case.
ii)The default memory configuration in the Computer design is Byte Addressable .
Like Article
Save Article
Memory locations and addresses determine how the computer’s memory is organized so that the user can efficiently store or retrieve information from the computer. The computer’s memory is made of a silicon chip which has millions of storage cell, where each storage cell is capable to store a bit of information which value is either 0 or 1.
But the fact is, computer memory holds instructions and data. And a single bit is very small to hold this information so bits are rarely used individually. As a solution to this, the bits are grouped in fixed sizes of n bits. The memory of the computer is organized in such a way that the group of these n bits can be stored and retrieved easily by the computer in a single operation.
The group of n bit is termed as word where n is termed as the word length. The word length of the computer has evolved from 8, 16, 24, 32 to 64 bits. General-purpose computers nowadays have 32 to 64 bits. The group of 8 bit is called a byte.
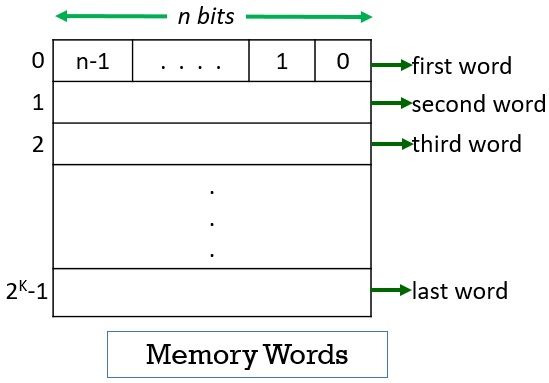
Now, whenever you want to store any instruction or data may it be of a byte or a word you have to access a memory location. To access the memory location either you must know the memory location by its unique name or it is required to provide a unique address to each memory location.
The memory locations are addressed from 0 to 2K-1 i.e. a memory has 2K addressable locations. And thus the address space of the computer has 2K addresses. Let us try some suitable values for K.
210 = 1024 = 1K (Kilobyte)
220 = 1,048,576 = 1M (Megabyte)
230 = 1073741824 = 1G (Gigabyte)
240 = 1.0995116e+12 = 1T (Terabyte)
Byte Addressability
Till now we have gone through three information storing quantities bit, byte and word. We have seen above that 8 bits together form a byte and this is the fix for every memory. But the word length varies from memory to memory and it ranges from 16 to 64 bit.
Well, it is impossible to allot a unique address to each bit in memory. As a solution, most modern computers assign successive addresses to successive byte locations in memory. This assignment of addresses to individual byte locations is termed byte addressability and memory is referred to as byte-addressable memory.
If we assign an address to individual byte locations in the memory like 0, 1, 2, 3…. .Now if the word length of the machine is 16 bit then the successive words are located at addresses 0, 2, 4, 6… where each word would have 2 bytes of information. Similarly, if we have a machine with a word length of 32 bit then the successive words are located at the addresses 0, 4, 8, 12… where each word would have 4 bytes of information and it could store or retrieve 4 bytes of instruction or data in a single and basic operation.
Big-Endian and Little-Endian Assignments in Byte Addresses
The big-endian and little-endian are two methods of assigning byte addresses across the words in the memory. In the big-endian assignment, the lower byte addresses are used for the leftmost bytes of the word. Observe the word 0 in the image below, the leftmost bytes of the word have lower byte addresses.
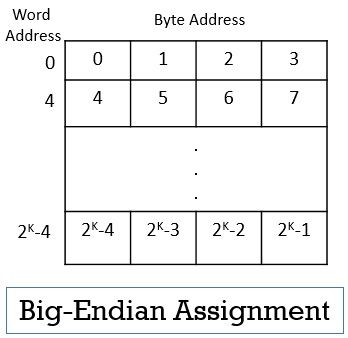
In the little-endian assignment, the lower byte addresses are used for the rightmost bytes of the word. Observe the word 0 in the image below the rightmost bytes of word 0 has lower byte addresses.
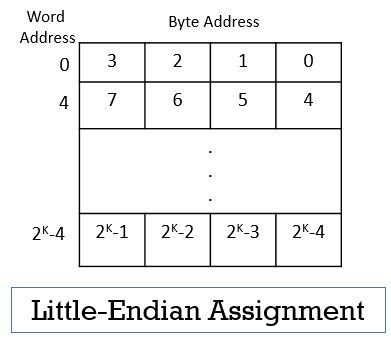
The leftmost bytes of the word are termed as most significant bytes and the rightmost bytes of the words are termed as least significant bytes.
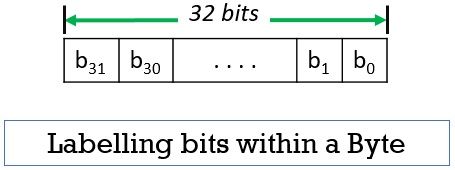
Thus the big-endian and little-endian specify the ordering of bytes inside a word. Similarly, the bits must be labelled inside the byte or a word and the most common way of labelling bits in a byte or word is as shown in the figure below i.e. labelling the bits as b7, b6,…….,b1, b0 from left to write as we do in little-endian assignment.
Word Alignment
In a machine with word length 32-bit, the word boundaries occur at the bytes addresses 0, 4, 8… It is said that the word has aligned addresses if they begin with the byte address that is multiple of the number of bytes present in that word. For example, the word address 4 has four bytes in it with byte address 4, 5 and 6. The word address 4 starts with the byte address 4 which is multiple of the number of bytes in word 4.
In case if the word address begins with the arbitrary byte address the word is said to have unaligned addresses. But conventionally the words have aligned addresses as this lets the access of memory operand more efficiently.
So, this is all about the memory locations and how they are addressed to store and retrieve the instructions or data more efficiently. With memory addresses, it becomes easy to identify a specific memory location.
In computer architecture, word addressing means that addresses of memory on a computer uniquely identify words of memory. It is usually used in contrast with byte addressing, where addresses uniquely identify bytes. Almost all modern computer architectures use byte addressing, and word addressing is largely only of historical interest. A computer that uses word addressing is sometimes called a word machine.

Tables showing the same data organized under byte and word addressing
Basics[edit]
Consider a computer which provides 524,288 (219) bits of memory. If that memory is arranged in a byte-addressable flat address space using 8-bit bytes, then there are 65,536 (216) valid addresses, from 0 to 65,535, each denoting an independent 8 bits of memory. If instead it is arranged in a word-addressable flat address space using 32-bit words, then there are 16,384 (214) valid addresses, from 0 to 16,383, each denoting an independent 32 bits.
More generally, the minimum addressable unit (MAU) is a property of a specific memory abstraction. Different abstractions within a computer may use different MAUs, even when they are representing the same underlying memory. For example, a computer might use 32-bit addresses with byte addressing in its instruction set, but the CPU’s cache coherence system might work with memory only at a granularity of 64-byte cache lines, allowing any particular cache line to be identified with only a 26-bit address and decreasing the overhead of the cache.
The address translation done by virtual memory often affects the structure and width of the address space, but it does not change the MAU.
Trade-offs of different minimum addressable units[edit]
The size of the minimum addressable unit of memory can have complex trade-offs. Using a larger MAU allows the same amount of memory to be covered with a smaller address, which can substantially decrease the memory requirements of a program. However, using a smaller MAU makes it easier to work efficiently with small items of data.
Suppose a program wishes to store one of the 12 traditional signs of Western astrology. A single sign can be stored in 4 bits. If a sign is stored in its own MAU, then 4 bits will be wasted with byte addressing (50% efficiency), while 28 bits will be wasted with 32-bit word addressing (12.5% efficiency). If a sign is «packed» into a MAU with other data, then it may be relatively more expensive to read and write. For example, to write a new sign into a MAU that other data has been packed into, the computer must read the current value of the MAU, overwrite just the appropriate bits, and then store the new value back. This will be especially expensive if it is necessary for the program to allow other threads to concurrently modify the other data in the MAU.
A more common example is a string of text. Common string formats such as UTF-8 and ASCII store strings as a sequence of 8-bit code points. With byte addressing, each code point can be placed in its own independently-addressable MAU with no overhead. With 32-bit word addressing, placing each code point in a separate MAU would increase the memory usage by 300%, which is not viable for programs that work with large amounts of text. Packing adjacent code points into a single word avoids this cost. However, many algorithms for working with text prefer to be able to independently address code points; to do this with packed code points, the algorithm must use a «wide» address which also stores the offset of the character within the word. If this wide address needs to be stored elsewhere within the program’s memory, it may require more memory than an ordinary address.
To evaluate these effects on a complete program, consider a web browser displaying a large and complex page. Some of the browser’s memory will be used to store simple data such as images and text; the browser will likely choose to store this data as efficiently as possible, and it will occupy about the same amount of memory regardless of the size of the MAU. Other memory will represent the browser’s model of various objects on the page, and these objects will include many references: to each other, to the image and text data, and so on. The amount of memory needed to store these object will depend greatly on the address width of the computer.
Suppose that, if all the addresses in the program were 32-bit, this web page would occupy about 10 Gigabytes of memory.
- If the web browser is running on a computer with 32-bit addresses and byte-addressable memory, the address space will cover 4 Gigabytes of memory, which is insufficient. The browser will either be unable to display this page, or it will need to be able to opportunistically move some of the data to slower storage, which will substantially hurt its performance.
- If the web browser is running on a computer with 64-bit addresses and byte-addressable memory, it will require substantially more memory in order to store the larger addresses. The exact overhead will depend on how much of the 10 Gigabytes is simple data and how much is object-like and dense with references, but a figure of 40% is not implausible, for a total of 14 Gigabytes required. This is, of course, well within the capabilities of a 64-bit address space. However, the browser will generally exhibit worse locality and make worse use of the computer’s memory caches within the computer, assuming equal resources with the alternatives.
- If the web browser is running on a computer with 32-bit addresses and 32-bit-word-addressable memory, it will likely require extra memory because of suboptimal packing and the need for a few wide addresses. This impact is likely to be relatively small, as the browser will use packing and non-wide addresses for most important purposes, and the browser will fit comfortably within the maximum addressable range of 16 Gigabytes. However, there may be a significant runtime overhead due to the widespread use of packed data for images and text. More importantly, 16 Gigabytes is a relatively low limit, and if the web page grows significantly, this computer will exhaust its address space and begin to have some of the same difficulties as the byte-addressed computer.
- If the web browser is running on a computer with 64-bit addresses and 32-bit-word-addressable memory, it will suffer from both of the above runtime overheads: it require substantially more memory to accommodate the larger 64-bit addresses, hurting locality, while also incurring the runtime overhead of working with extensive packing of text and image data. Word addressing means that the program can theoretically address up to 64 Exabytes of memory instead of only 16 Exabytes, but since the program is nowhere near needing this much memory (and in practice no real computer is capable of providing it), this provides no benefit.
Thus, word addressing allows a computer to address substantially more memory without increasing its address width and incurring the corresponding large increase in memory usage. However, this is valuable only within a relatively narrow range of working set sizes, and it can introduce substantial runtime overheads depending on the application. Programs which do relatively little work with byte-oriented data like images, text, files, and network traffic may be able to benefit most.
Sub-word accesses and wide addresses[edit]
A program running on a computer that uses word addressing can still work with smaller units of memory by emulating an access to the smaller unit. For a load, this requires loading the enclosing word and then extracting the desired bits. For a store, this requires loading the enclosing word, shifting the new value into place, overwriting the desired bits, and then storing the enclosing word.
Suppose that four consecutive code points from a UTF-8 string need to be packed into a 32-bit word. The first code point might occupy bits 0–7, the second 8-15, the third 16–23, and the fourth 24–31. (If the memory were byte-addressable, this would be a little endian byte order.)
In order to clearly elucidate the code necessary for sub-word accesses without tying the example too closely to any particular word-addressed architecture, the following examples use MIPS assembly. In reality, MIPS is a byte-addressed architecture with direct support for loading and storing 8-bit and 16-bit values, but the example will pretend that it only provides 32-bit loads and stores and that offsets within a 32-bit word must be stored separately from an address. MIPS has been chosen because it is a simple assembly language with no specialized facilities that would make these operations more convenient.
Suppose that a program wishes to read the third code point into register r1 from the word at an address in register r2. In the absence of any other support from the instruction set, the program must load the full word, right-shift by 16 to drop the first two code points, and then mask off the fourth code point:
ldw $r1, 0($r2) # Load the full word srl $r1, $r1, 16 # Shift right by 16 andi $r1, $r1, 0xFF # Mask off other code points
If the offset is not known statically, but instead a bit-offset is stored in the register r3, a slightly more complex approach is required:
ldw $r1, 0($r2) # Load the full word srlv $r1, $r1, $r3 # Shift right by the bit offset andi $r1, $r1, 0xFF # Mask off other code points
Suppose instead that the program wishes to assign the code point in register r1 to the third code point in the word at the address in r2. In the absence of any other support from the instruction set, the program must load the full word, mask off the old value of that code point, shift the new value into place, merge the values, and store the full word back:
sll $r1, $r1, 16 # Shift the new value left by 16 lhi $r5, 0x00FF # Construct a constant mask to select the third byte nor $r5, $r5, $zero # Flip the mask so that it clears the third byte ldw $r4, 0($r2) # Load the full word and $r4, $r5, $r4 # Clear the third byte from the word or $r4, $r4, $r1 # Merge the new value into the word stw $r4, 0($r2) # Store the result as the full word
Again, if the offset is instead stored in r3, a more complex approach is required:
sllv $r1, $r1, $r3 # Shift the new value left by the bit offset llo $r5, 0x00FF # Construct a constant mask to select a byte sllv $r5, $r5, $r3 # Shift the mask left by the bit offset nor $r5, $r5, $zero # Flip the mask so that it clears the selected byte ldw $r4, 0($r2) # Load the full word and $r4, $r5, $r4 # Clear the selected byte from the word or $r4, $r4, $r1 # Merge the new value into the word stw $r4, 0($r2) # Store the result as the full word
This code sequence assumes that another thread cannot modify other bytes in the word concurrently. If concurrent modification is possible, then one of the modifications might be lost. To solve this problem, the last few instructions must be turned into an atomic compare-exchange loop so that a concurrent modification will simply cause it to repeat the operation with the new value. No memory barriers are required in this case.
A pair of a word address and an offset within the word is called a wide address (also known as a fat address or fat pointer). (This should not be confused with other uses of wide addresses for storing other kinds of supplemental data, such as the bounds of an array.) The stored offset may be either a bit offset or a byte offset. The code sequences above benefit from the offset being denominated in bits because they use it as a shift count; an architecture with direct support for selecting bytes might prefer to just store a byte offset.
In these code sequences, the additional offset would have to be stored alongside the base address, effectively doubling the overall storage requirements of an address. This is not always true on word machines, primarily because addresses themselves are often not packed with other data to make accesses more efficient. For example, the Cray X1 uses 64-bit words, but addresses are only 32 bits; when an address is stored in memory, it is stored in its own word, and so the byte offset can be placed in the upper 32 bits of the word. The inefficiency of using wide addresses on that system is just all the extra logic to manipulate this offset and extract and insert bytes within words; it has no memory-use impact.
[edit]
The minimum addressable unit of a computer isn’t necessarily the same as the minimum memory access size of the computer’s instruction set. For example, a computer might use byte addressing without providing any instructions to directly read or write a single byte. Programs would be expected to emulate those operations in software with bit-manipulations, just like the example code sequences above do. This is relatively common in 64-bit computer architectures designed as successors to 32-bit supercomputers or minicomputers, such the DEC Alpha and the Cray X1.
The C standard states that a pointer is expected to have the usual representation of an address. C also allows a pointer to be formed to any object except a bit-field; this includes each individual element of an array of bytes. C compilers for computers that use word addressing often use different representations for pointers to different types depending on their size. A pointer to a type that’s large enough to fill a word will be a simple address, while a pointer such as char* or void* will be a wide pointer: a pair of the address of a word and the offset of a byte within that word. Converting between pointer types is therefore not necessarily a trivial operation and can lose information if done incorrectly.
Because the size of a C struct is not always known when deciding the representation of a pointer to that struct, it is not possible to reliably apply the rule above. Compilers may need to align the start of a struct so that it can use a more efficient pointer representation.
Examples[edit]
- The ERA 1103 uses word addressing with 36-bit words. Only addresses 0-1023 refer to random-access memory; others are either unmapped or refer to drum memory.
- The PDP-10 uses word addressing with 36-bit words and 18-bit addresses.
- Most Cray supercomputers from the 1980s and 1990s use word addressing with 64-bit words. The Cray-1 and Cray X-MP use 24-bit addresses, while most others use 32-bit addresses.
- The Cray X1 uses byte addressing with 64-bit addresses. It does not directly support memory accesses smaller than 64 bits, and such accesses must be emulated in software. The C compiler for the X1 was the first Cray compiler to support emulating 16-bit accesses.[1]
- The DEC Alpha uses byte addressing with 64-bit addresses. Early Alpha processors do not provide any direct support for 8-bit and 16-bit memory accesses, and programs are required to e.g. load a byte by loading the containing 64-bit word and then separately extracting the byte. Because the Alpha uses byte addressing, this offset is still represented in the least significant bits of the address (rather than separately as a wide address), and the Alpha conveniently provides load and store unaligned instructions (
ldq_uandstq_u) which ignore those bits and simply load and store the containing aligned word.[2] The later byte-word extensions to the architecture (BWX) added 8-bit and 16-bit loads and stores, starting with the Alpha 21164a.[3] Again, this extension was possible without serious software incompatibilities because the Alpha had always used byte addressing.
See also[edit]
- Byte addressing
References[edit]
- ^ Terry Greyzck, Cray Inc. Cray X1 Compiler Challenges (And How We Solved Them)
- ^ «The Alpha AXP, part 8: Memory access, storing bytes and words and unaligned data». 16 August 2017.
- ^ «Alpha: The History in Facts and Comments — Alpha 21164 (EV5, EV56) and 21164PC (PCA56, PCA57)».
Memory plays a vital role in any computer system and it is very important to understand how it works and how it stores the data. In general, we know that computer memory stores the data after converting into bits or bytes (which is nothing but collection of bits). In this article, we are going to explain how this storage take place and how to address those storage blocks.
Data, or in simple language, every word that we provide to a computer system is being stored in a memory, whether in temporary cache or permanent memory. But before storing it to memory, there is conversion of word into bits. Now the collection of these bits is going to be stored in the memory. The memory of a computer system is divided into chunks or we can say «sections» which basically hold the converted bits.
What is Word Addressable Memory?
Let us take an example. Suppose your computer memory configuration is 4096 * 32 bit which means that it has 4096 locations or sections and each of these sections can hold a word of size 32 bits. And let us suppose the address of the first section among 4096 sections is ‘i’, then the address of its subsequent section would be ‘i+1’ and of next is ‘i+3’, and so on. This type of addressing in which we treat each section of memory which is that storage of 32 bits or 4 bytes is known as Word Addressable Memory.
What is Byte Addressable Memory?
Continuing with the same example, we have a total of 4096 sections and each section stores a word of length 32 bits or simply 4 bytes. We can access each of these sections by adding one consecutive number to its current location, i.e., ‘i’, then next location is ‘i+1’, then ‘i+2’, and so on.
If the memory section which is storing the words is further treated as subsections of 4, i.e., as each section which is storing a word of 4 byte is divided in 4 subsection and each subsection is storing 1 byte.
Let us suppose that each subsection has an address, now each subsection has address like ‘j’ next would be ‘j+1’ then ‘j+3’ and so on. If we take the address of one section as ‘j’, then the address of the next section would be ‘j+4’, then for the next would be ‘j+8’, and so on.
This type of addressing in which the number of subsections, i.e., number of bytes stored in a section is added to get the address of the next section is known as Byte Addressable Memory.
If we take ‘i’ address in Word Addressable memory and ‘j’ in Byte Addressable memory address, then ‘i’ = ‘j’ ; ‘i=1’ = ‘j+4’ ; ‘i=3’ = ‘j+8’, and so on.
Difference between Byte Addressable Memory and Word Addressable Memory
The following are the important differences between byte addressable memory and word addressable memory −
|
S.No. |
Byte Addressable Memory |
Word Addressable Memory |
|---|---|---|
|
1. |
Byte addressable memory is one in which the data space in a cell is equal to 8 bits or 1 byte. |
Word addressable memory is one in which the data space in a cell is equal to the word length of the CPU. |
|
2. |
It is called byte addressable memory because it uses bytewise storage configuration. |
It is called word addressable memory because it uses wordwise storage configuration. |
|
3. |
Byte addressable memory is best suited for the processes that need a single byte data at a time. |
Word addressable memory is suitable for processes that requires data comprising single word at a time. |
|
4. |
The byte addressable memory issues a single address for accessing a single byte. |
The word accessible memory issues the address of word that contains required byte. |
|
5. |
Byte addressable memory is a default memory configuration in computer design. |
Word addressable memory is not a default configuration. |
|
6. |
A memory chip with 64K × 8 has 16 bit address and cell size equal to 8 bits, i.e. 1 byte. |
For a 16-bit processor, a memory chip with 64K × 16 has 16 bit address and cell size equal to 16 bits, i.e. word length of processor. |
|
7. |
Byte addressable memory chip stores data byte by byte. |
Word addressable memory chip stores data word by word. |
Conclusion
Both Byte addressable memory and Word addressable memory have address size that can be of any number of bits depending upon the number of cells in memory chip. But, the cell size is different in each case.
The most significant difference that you should note here is that byte addressable memory uses bytewise data storage, whereas word addressable memory uses wordwise data storage.