
В своей работе мы часто анализируем большой объем данных. Давайте рассмотрим, как можно автоматизировать процесс анализа документов на примере библиотеки docx (способной обрабатывать документы в формате. docx).
А также расскажем другие возможности, которые предлагает Python: как отделить текст с нужным стилем форматирования? Как извлечь все изображения из документа?
Для установки библиотеки в командной строке необходимо ввести:
> pip install python-docx
После успешной установки библиотеки, её нужно импортировать в Python. Обратите внимание, что несмотря на то, что для установки использовалось название python-docx, при импорте следует называть библиотеку docx:
import docx
Как правило, мы обращаемся к автоматизации, когда нам нужно извлечь нужную информацию не из одного, а сразу из многих документов. Чтобы иметь возможность обработать все документы, для начала нужно собрать список таких документов. Здесь сможет помочь библиотека os, с помощью которой можно рекурсивно обойти директории, в которых хранятся документы. Предположим, что все они находятся внутри директории, где расположен скрипт:
import os
paths = []
folder = os.getcwd()
for root, dirs, files in os.walk(folder):
for file in files:
if file.endswith(‘docx’) and not file.startswith(‘~’):
paths.append(os.path.join(root, file))
Мы прошли по всем директориям и занесли в список paths все файлы с расширением. docx. Файлы, начинавшиеся с тильды, игнорировались (эти временные файлы возникают лишь тогда, когда в Windows открыт какой-либо из документов). Теперь, когда у нас уже есть список всех документов, можно начинать с ними работать:
for path in paths:
doc = docx.Document(path)
В блоке выше на каждом шаге цикла в переменную doc записывается экземпляр, представляющий собой весь документ. Мы можем посмотреть основные свойства такого документа:
properties = doc.core_properties
print(‘Автор документа:’, properties.author)
print(‘Автор последней правки:’, properties.last_modified_by)
print(‘Дата создания документа:’, properties.created)
print(‘Дата последней правки:’, properties.modified)
print(‘Дата последней печати:’, properties.last_printed)
print(‘Количество сохранений:’, properties.revision)
Из основных свойств можно получить автора документа, основные даты, количество сохранений документа и пр. Обратите внимание, что даты и время будут указаны в часовом поясе UTC+0.
Теперь поговорим о том, как можно проанализировать содержимое документа. Файлы с расширением docx обладают развитой внутренней структурой, которая в библиотеке docx представлена следующими объектами:
Объект Document, представляющий собой весь документ
- Список объектов Paragraph – абзацы документа
* Список объектов Run – фрагменты текста с различными стилями форматирования (курсив, цвет шрифта и т.п.)
- Список объектов Table – таблицы документа
* Список объектов Row – строки таблицы
* Список объектов Cell – ячейки в строке
* Список объектов Column – столбцы таблицы
* Список объектов Cell – ячейки в столбце
- Список объектов InlineShape – иллюстрации документа
Работа с текстом документа
Для начала давайте разберёмся, как работать с текстом документа. В библиотеке docx это возможно через обращение к абзацам документа. Можно получить как сам текст абзаца, так и его характеристики: тип выравнивания, величину отступов и интервалов, положение на странице.
Очень часто стоит задача получить весь текст из документа для дальнейшей обработки. Чтобы это сделать, достаточно лишь перебрать все абзацы документа:
text = []
for paragraph in doc.paragraphs:
text.append(paragraph.text)
print(‘n’.join(text))
Как мы видим, для получения текста абзаца нужно просто обратиться к объекту paragraph.text. Но что же делать, если нужно извлечь только абзацы с определёнными характеристиками и далее работать именно с ними? Рассмотрим основные характеристики абзацев, которые можно проанализировать.
В первую очередь, можно получить стиль выравнивания абзацев в документе:
for paragraph in doc.paragraphs:
print(‘Выравнивание абзаца:’, paragraph.alignment)
Значения alignment будут соответствовать одному из основных стилей выравнивания: LEFT (0), center (1), RIGHT (2) или justify (3). Однако если пользователь не установил стиль выравнивания, значение параметра alignment будет None.
Кроме того, можно получить и значения отступов у абзацев документа:
for paragraph in doc.paragraphs:
formatting = paragraph.paragraph_format
print(‘Отступ перед абзацем:’, formatting.space_before)
print(‘Отступ после абзаца:’, formatting.space_after)
print(‘Отступ слева:’, formatting.left_indent)
print(‘Отступ справа:’, formatting.right_indent)
print(‘Отступ первой строки абзаца:’, formatting.first_line_indent)
Как и в предыдущем примере, если отступы не были установлены, значения параметров будут None. В остальных случаях они будут представлены в виде целого числа в формате EMU (английские метрические единицы). Этот формат позволяет конвертировать число как в метрическую, так и в английскую систему мер. Привести полученные числа в привычный формат довольно просто, достаточно просто добавить нужные единицы исчисления после параметра (например, formatting.space_before.cm или formatting.space_before.pt). Главное помнить, что такое преобразование нельзя применять к значениям None.
Наконец, можно посмотреть на положение абзаца на странице. В меню Абзац… на вкладке Положение на странице находятся четыре параметра, значения которых также можно посмотреть при помощи библиотеки docx:
for paragraph in doc.paragraphs:
formatting = paragraph.paragraph_format
print(‘Не отрывать от следующего абзаца:’, formatting.keep_with_next)
print(‘Не разрывать абзац:’, formatting.keep_together)
print(‘Абзац с новой страницы:’, formatting.page_break_before)
print(‘Запрет висячих строк:’, formatting.widow_control)
Параметры будут иметь значение None для случаев, когда пользователь не устанавливал на них галочки, и True, если устанавливал.
Мы рассмотрели основные способы, которыми можно проанализировать абзац в документе. Но бывают ситуации, когда мы точно знаем, что информация, которую нужно извлечь, написана курсивом или выделена определённым цветом. Как быть в таком случае?
Можно получить список фрагментов с различными стилями форматирования (список объектов Run). Попробуем, к примеру, извлечь все фрагменты, написанные курсивом:
for paragraph in doc.paragraphs:
for run in paragraph.runs:
if run.italic:
print(run.text)
Очень просто, не так ли? Посмотрим, какие ещё стили форматирования можно извлечь:
for paragraph in doc.paragraphs:
for run in paragraph.runs:
print(‘Полужирный текст:’, run.bold)
print(‘Подчёркнутый текст:’, run.underline)
print(‘Зачёркнутый текст:’, run.strike)
print(‘Название шрифта:’, run.font.name)
print(‘Цвет текста, RGB:’, run.font.color.rgb)
print(‘Цвет заливки текста:’, run.font.highlight_color)
Если пользователь не менял стиль форматирования (отсутствует подчёркивание, используется стандартный шрифт и т.п.), параметры будут иметь значение None. Но если стиль определённого параметра изменялся, то:
- параметры italic, bold, underline, strike будут иметь значение True;
- параметр font.name – наименование шрифта;
- параметр font.color.rgb – код цвета текста в RGB;
- параметр font.highlight_color – наименование цвета заливки текста.
Делая цикл по фрагментам стоит иметь ввиду, что фрагменты с одинаковым форматированием могут быть разбиты на несколько, если в них встречаются символы разных типов (буквенные символы и цифры, кириллица и латиница).
Абзацы и их фрагменты могут быть оформлены в определённом стиле, соответствующем стилям Word (например, Normal, Heading 1, Intense Quote). Чем это может быть полезно? К примеру, обращение к стилям абзаца может пригодиться при выделении нумерованных или маркированных списков. Каждый элемент таких списков считается отдельным абзацев, однако каждому из них приписан особый стиль – List Paragraph. С помощью кода ниже можно извлечь только элементы списков:
for paragraph in doc.paragraphs:
if paragraph.style.name == ‘List Paragraph’:
print(paragraph.text)
Чтобы закрепить полученные знания, давайте разберём менее тривиальный случай. Предположим, что у нас есть множество документов с похожей структурой, из которых нужно извлечь названия продуктов. Проанализировав документы, мы установили, что продукты встречаются только в абзацах, начинающихся с новой страницы и выровненных по ширине. Притом сами названия написаны с использованием полужирного начертания, шрифт Arial Narrow. Посмотрим, как можно проанализировать документы:
for path in paths:
doc = docx.Document(path)
product_names = []
for paragraph in doc.paragraphs:
formatting = paragraph.paragraph_format
if formatting.page_break_before and paragraph.alignment == 3:
product_name, is_sequential = », False
for run in paragraph.runs:
if run.bold and run.font.name == ‘Arial Narrow’:
is_sequential = True
product_name += run.text
elif is_sequential == True:
product_names.append(product_name)
product_name, is_sequential = », False
В блоке кода выше последовательно обрабатываются все файлы из списка paths, преобразовываемые в ходе обработки в объект Document. В каждом документе происходит перебор абзацев и выполняются проверки: абзац должен начинаться с новой страницы и быть выровненным по ширине. Если проверки прошли успешно, внутри абзаца происходит уже перебор фрагментов с различными типами форматированием и проверки на начертание и шрифт.
Обратим внимание на переменную is_sequential, которая помогает определить, идут ли фрагменты, прошедшие проверку, друг за другом. Фрагменты с символами разных типов (буквы и числа, кириллица и латиница) разбиваются на несколько, но поскольку в названии продукта одновременно могут встретиться символы всех типов, все последовательно идущие фрагменты соединяются в один. Он и заносится в результирующий список product_names.
Работа с таблицами
Мы рассмотрели способы, которыми можно обрабатывать текст в документах, а теперь давайте перейдём к обработке таблиц. Любую таблицу можно перебирать как по строкам, так и по столбцам. Посмотрим, как можно построчно получить текст каждой ячейки в таблице:
for table in doc.tables:
for row in table.rows:
for cell in row.cells:
print(cell.text)
Если же во второй строке заменить rows на columns, то можно будет аналогичным образом прочитать таблицу по столбцам. Текст в ячейках таблицы тоже состоит из абзацев. Если мы захотим проанализировать абзацы или фрагменты внутри ячейки, то можно будет воспользоваться всеми методами объектов Paragraph и Run.
Часто может понадобиться проанализировать только таблицы, содержащие определённые заголовки. Попробуем, например, выделить из документа только таблицы, у которых в строке заголовка присутствуют названия Продукт и Стоимость. Для таких таблиц построчно распечатаем все значения из ячеек:
for table in doc.tables:
for index, row in enumerate(table.rows):
if index == 0:
row_text = list(cell.text for cell in row.cells)
if ‘Продукт’ not in row_text or ‘Стоимость’ not in row_text:
break
for cell in row.cells:
print(cell.text)
Также нам может понадобиться определить, какие из ячеек в таблице являются объединёнными. Стандартной функции для этого нет, однако мы можем воспользоваться тем, что нам доступно положение ячейки от каждого из краев таблицы:
for table in doc.tables:
unique, merged = set(), set()
for row in table.rows:
for cell in row.cells:
tc = cell._tc
cell_loc = (tc.top, tc.bottom, tc.left, tc.right)
if cell_loc in unique:
merged.add(cell_loc)
else:
unique.add(cell_loc)
print(merged)
Воспользовавшись этим кодом, можно получить все координаты объединённых ячеек для каждой из таблиц документа. Кроме того, разница координат tc.top и tc.bottom показывает, сколько строк в объединённой ячейке, а разница tc.left и tc.right – сколько столбцов.
Наконец, рассмотрим возможность выделения из таблиц ячеек, в которых фон окрашен в определённый цвет. Для этого понадобится с помощью регулярных выражений посмотреть на xml-код ячейки:
import re
pattern = re.compile(‘w:fill=»(S*)»‘)
for table in doc.tables:
for row in table.rows:
for cell in row.cells:
match = pattern.search(cell._tc.xml)
if match:
if match.group(1) == ‘FFFF00’:
print(cell.text)
В этом блоке кода мы выделили только те ячейки, фон которых был окрашен в жёлтый цвет ( #FFFF00 в формате RGB).
Работа с иллюстрациями
В библиотеке docx также реализована возможность работы с иллюстрациями документа. Стандартными способами можно посмотреть только на размеры изображений:
for shape in doc.inline_shapes:
print(shape.width, shape.height)
Однако при помощи сторонней библиотеки docx2txt и анализа xml-кода абзацев становится возможным не только выгрузить все иллюстрации документов, но и определить, в каком именно абзаце они встречались:
import os
import docx
import docx2txt
for path in paths:
splitted = os.path.split(path)
folders = [os.path.splitext(splitted[1])[0]]
while splitted[0]:
splitted = os.path.split(splitted[0])
folders.insert(0, splitted[1])
images_path = os.path.join(‘images’, *folders)
os.makedirs(images_path, exist_ok=True)
doc = docx.Document(path)
docx2txt.process(path, images_path)
rels = {}
for rel in doc.part.rels.values():
if isinstance(rel._target, docx.parts.image.ImagePart):
rels[rel.rId] = os.path.basename(rel._target.partname)
for paragraph in doc.paragraphs:
if ‘Graphic’ in paragraph._p.xml:
for rId in rels:
if rId in paragraph._p.xml:
print(os.path.join(images_path, rels[rId]))
print(paragraph.text)
В этом блоке мы выводим путь к изображению, которое сохранено на диске, и текст параграфа, в котором встретилось изображение. Все изображения находятся внутри директории images, а именно — в поддиректориях, соответствующих расположению исходного файла Word.
Microsoft.Office.Interop.Word
Как известно, Microsoft Word является COM-объектом, т.е. спроектирован таким образом, что позволяет другим программам подключаться к себе и управлять им. Программно можно проделать практически все операции, которые мы делаем вручную в Word: создать новый документ, внести в него правки, сохранить его и т.п. Но для ее работы требуется лицензия MS Office на каждом клиентском компьютере. Кроме того, MS Office загружается в фоновом режиме, вследствие чего занимает определенное количество оперативной памяти и загружает большое количество файлов и DLL. Приложения MS Office были разработаны как приложения для пользовательского интерфейса, и поэтому Microsoft.Office.Interop.Word работает очень медленно. Microsoft не рекомендует использовать Office Automation (или любой Office Interop) на сервере.
DocumentFormat.OpenXml
Open XML SDK предоставляет инструменты для работы с документами Office Word, Excel и PowerPoint. Он поддерживает такие сценарии, как заполнение содержимого в файлах Word из источника данных XML, разделение (измельчение) файла Word или PowerPoint на несколько файлов и объединение нескольких файлов Word, поиск и замена контента с использованием регулярных выражений. Но при присвоении некоторого стиля, в свойствах предоставляется только идентификатор предоставленого стиля, а сам стиль описывается отдельно в файле style.xml. В результате необходимости регулярного сопоставления ID стиля с контейнером style.xml для получения характеристик стилей абзацев, возрастает сложность программного использования библиотеки. link
Spire.Doc
Spire.Doc для .NET — это полностью независимая библиотека классов .NET Word, специально созданная для разработчиков, которая позволяет быстро генерировать, открывать, писать, редактировать и сохранять документы Word не требует установки в систему каждого пользователя MS Office, то есть возможность полностью независимой от него работы; объемная документация с примерами и пояснениями. Работать с библиотекой достатосно удобно. Однако полная версия Spire.Doc не является бесплатной, а бесплатная версия, FreeSpire.Doc, имеет определенные ограничения (например обработка не более 500 абзацев и 25 таблиц). link
Вопрос тот же, что и в заголовке, но исключая работу через сервер офиса в Interop (на слабых компах с новым офисом это работает просто ужасно).
В целом по функционалу полностью устраивает OpenXml SDK, но очень уж он громоздкий и почти нет «готовых» функций, всё надо писать в «лоб» (что в целом можно, но ведь наверняка кто-то всё это уже сделал).
Есть ли что-то бесплатное и более удобное чем OpenXml (пусть даже основанный на нем).
Тот же https://github.com/JanKallman/EPPlus из ссылки выше — платный. Из рекомендаций СтакОверфлоу тоже подключил какую-то библиотеку (уже забыл название), всё очень удобно — только создает дополнительный лист с надписью «это триал блабла, перейдите по ссылке, получите бесплатный код на год…». В общем не очень интересный вариант.
Можно и дальше перебирать варианты, но может кто подскажет с высоты опыта, что сейчас наиболее удобное?
Корпорация Майкрософт предлагает широкий выбор бесплатных и премиум-шаблонов Office для ежедневного использования. Создайте оригинальную открытку, предложите идею на миллион долларов или запланируйте следующий отпуск с помощью шаблонов Microsoft Office. Найдите идеальное решение для своей задачи или ситуации среди шаблонов PowerPoint, Excel и Word.
Среди бесплатных шаблонов для Word вы найдете множество отформатированных документов. Проводите мероприятие? Пригласите гостей с помощью шаблона приглашения или рекламной листовки. Выразите людям свою признательность, распечатав благодарственные открытки. А когда придет время заняться карьерой, воспользуйтесь настраиваемым профессионально оформленным шаблоном резюме или сопроводительного письма, чтобы получить работу мечты.
Широкий спектр шаблонов PowerPoint поможет справиться с любыми задачами дизайна и представления данных благодаря множеству тем, диаграмм и макетов. Используйте шаблон для своего следующего учебного проекта или добавьте на слайды диаграмму с данными инфографики для наглядности, чтобы сделать презентацию безупречной.
Шаблоны Excel упрощают управление данными и отслеживание информации. Управляйте своими бизнес-расходами с помощью шаблонов Excel для бюджетов, отслеживайте активы с помощью шаблона запасов и контролируйте участников группы с помощью шаблона диаграммы Ганта. Чтобы управлять личным временем, опубликуйте расписание домашних дел или организуйте следующую поездку с помощью шаблона планировщика отпусков.
Ознакомьтесь с обширной коллекцией шаблонов, предназначенных для любого события или случая. Воплощайте свои проекты и идеи в жизнь с помощью шаблона бизнес-плана или расскажите о себе с помощью предварительно отформатированного шаблона визитной карточки. Поздравьте близкого человека с днем рождения с помощью персонализированного шаблона поздравительной открытки или отслеживайте задачи с использованием распечатываемого шаблона календаря.
Вам не потребуется опыт по оформлению. Изучайте, настраивайте и создавайте с использованием шаблонов Майкрософт.
Многие пользователи во время работы с документами Word интересует вопрос о том, как сделать список литературы в Ворде. Подобный список литературы необходим в Ворде, если в тексте документа используются различные заимствования из других источников.
Список литературы Word — это перечень всех источников, например, книг, журналов, газетных статей, сайтов в интернете и т. д., процитированных в документе. Список использованной литературы Word, обычно, располагается в конце документа.
Содержание:
- Как сделать список литературы в Ворде автоматически
- Добавление сведений об источнике в списке литературы
- Цифровой список литературы Ворд (квадратные скобки)
- Как сделать список литературы по алфавиту в Ворде
- Как удалить список литературы в Word
- Выводы статьи
Если не показывать ссылки на источники, то автора данного документа могут обвинить в плагиате, потому что он не указал откуда он взял использованную информацию. Подобные сведения зачастую ссылаются на авторитетные источники, поэтому они придают дополнительный «вес» этому документу.
Существует два вида ссылок на источники информации: авторского и цифрового типов. Как оформить список литературы в Ворде зависит от предъявляемых требований, исходящих от вышестоящего органа, редакции журнала, руководства учебного заведения и т. п.
Ссылки в Ворде на список литературы состоят из ссылки в тексте документа на источник, находящийся в списке литературы. Благодаря этому, читатель сможет быстро узнать, на что именно ссылались в данном фрагменте текста.
В этой статье мы рассмотрим, как сделать список литературы в Word несколькими способами. Эти инструкции можно применять в следующих версиях приложения: Word для Microsoft 365, Word 2019, Word 2016, Word 2013, Word 2010, Word 2007. В интерфейсе программы Microsoft Word разных версий могут быть несущественные различия.
Как сделать список литературы в Ворде автоматически
Сначала мы попробуем создать автоматический список литературы в Ворде. В тексте документа будут проставлены ссылки на источники, которые будут добавлены в список литературы.
Выполните следующие действия в окне текстового редактора Word:
- Поместите курсор мыши в том месте фрагмента документа, где вам необходимо создать ссылку на источник информации.
- Откройте вкладку «Ссылки», перейдите в группу «Ссылки и списки литературы».
- В разделе «Стиль» нужно выбрать стиль ссылки.
Для общественно-политических и литературных источников, обычно, используются стили «MLA» и «APA». В технической литературе более распространены ссылки с цифрами, например, «ISO 690 — цифровая ссылка».
Если вам нужен список литературы в Ворде по ГОСТу, выберите соответствующий стиль. В Word список литературы по ГОСТ можно применять по двум вариантам: «ГОСТ — сортировка по имена» или «ГОСТ — сортировка по названиям».

- Сначала нажмите на кнопку «Вставить ссылку», а потом в выпадающем меню на пункт «Добавить новый источник…».

- Заполните необходимые поля в окне «Создать источник» введя все необходимые сведения.
Вам нужно выбрать тип источника (книга, журнал, реферат, отчет, веб-сайт и т. д.), а затем заполнить рекомендованные поля. Чтобы открыть дополнительные поля для конкретного типа источника, поставьте флажок в пункте «Показать все поля списка литературы».
После фамилии автора нужно поставить запятую перед его инициалами. Если у данной книги несколько авторов, активируйте пункт «Корпоративный автор», чтобы добавить сведения о всех авторах.
- Нажмите на кнопку «ОК».

- Подобным образом добавьте новую ссылку на источник в редактируемом тексте.
- В тексте документа появится ссылки на список литературы Word.

Если ранее созданную ссылку снова нужно ввести в текст, нажмите на кнопку «Вставить ссылку», а затем выберите ее из списка доступных.
- После добавления в данный текст всех источников, установите курсор мыши, как правило, в конце текста документа там, где должен располагаться список использованной литературы.
- Нажмите на значок «Список литературы», чтобы выбрать подходящий формат с помощью встроенных примеров: «Список литературы», Ссылки» или «Цитируемые труды».

- В документе появится список литературы по алфавиту в Ворде.

Добавление сведений об источнике в списке литературы
Если сведений о литературном источнике недостаточно, можно использовать функцию «Заполнитель». Заполнители ссылок не отображаются в списке литературы.
Пройдите последовательные шаги:
- Нажмите на значок «Вставить ссылку», выберите команду «Добавить заполнитель…».
- В окне «Имя-заполнитель» придумайте имя для конкретного заполнителя.
- Нажмите на «Управление источниками».
- В окне «Диспетчер источников», в поле «Текущий список» напротив имени заполнителя появится вопросительный знак.
Заполнители в текущем списке располагаются по именам тегов в алфавитном порядке с номерами в названии.
- Выделите заполнитель, нажмите на кнопку «Изменить…».
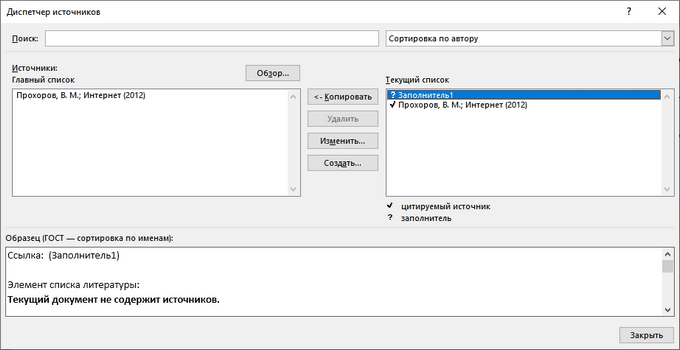
- В окне «Изменить источник» заполните необходимые сведения.
Цифровой список литературы Ворд (квадратные скобки)
При создании списка литературы часто используются ссылки в квадратных скобках с порядковыми числами. В квадратные скобки добавляется номер ссылки на источник, находящийся в списке использованной литературы.
Создание списка литературы в Word проходит следующим образом:
- Самостоятельно создайте список литературы.
- Выделите источники в списке.

- Откройте вкладку «Главная», перейдите к группе «Абзац».
- Нажмите на стрелку значка «Нумерация», выберите формат нумерации. используемый по умолчанию (арабская цифра с точкой).
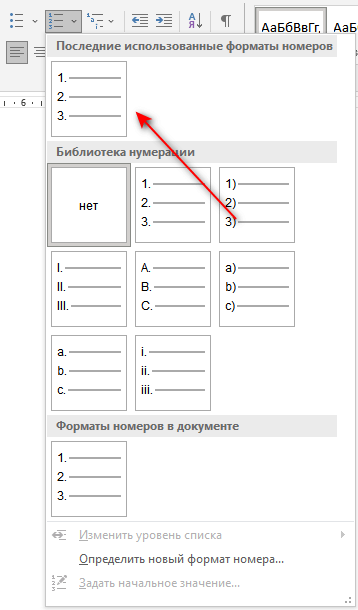
Ранее выделенный список литературы автоматически пронумеруется.
- Установите курсор в нужном месте фрагмента текста.
- Если вам необходима ссылка только на источник, то ничего не вставляйте в квадратные скобки — []. Если нужно добавить номер страницы, вставьте эти сведения в таком виде — [, с. 107].
- Перейдите во вкладку «Вставка».
- В разделе «Ссылки» нажмите на команду «Перекрестная ссылка».

- В окне «Перекрестные ссылки» выберите тип ссылки — «Нумерованный список» (или «Абзац»), а в поле «Вставить ссылку на:» — «Номер абзаца».
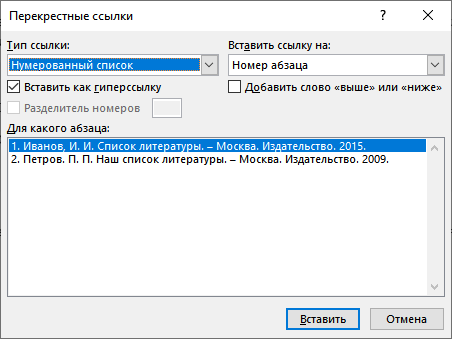
Проделайте подобную операцию со следующей ссылкой, находящейся в тексте документа Word.
Если вы после сохранения начали снова редактировать файл: вставлять новые или удалять старые ссылки, то нумерация в списке литературы может перестать совпадать. Решить эту проблему можно следующим образом:
- Выделите текст документа с помощью клавиш «Ctrl» + «A».
- Щелкните правой кнопкой мыши внутри документа.
- В открывшемся контекстном меню нажмите на «Обновить поле».
Список литературы будет заново автоматически пронумерован.
Как сделать список литературы по алфавиту в Ворде
В некоторых случаях, пользователям нужен список литературы в алфавитном порядке.
Сделать это можно следующим способом:
- Выделите список литературы.
- Если он уже пронумерован, нажмите на стрелку у кнопки «Нумерация».
- В выпадающем меню в библиотеке нумерации щелкните по формату «Нет».

- Войдите во вкладку «Главная».
- В группе «Абзац» нажмите на значок «Сортировка» (А-Я).
- В окне «Сортировка текста» нажмите на кнопку «ОК».
При настройках по умолчанию сортировка текста идет по возрастанию.

- Нажмите на кнопку «Нумерация», а потом выберите тип нумерации.
Как удалить список литературы в Word
В приложении MS Word не предусмотрен функционал для удаления ненужных ссылок на источники информации с помощью программных методов.
Если вы нажмете на значок «Управление источниками» в группе «Ссылки и списки литературы», то в окне «Диспетчер источников» при попытке удалить из списка ненужный источник, вы увидите, что кнопка «Удалить» не активна, поэтому у вас не получится воспользоваться этим функционалом.
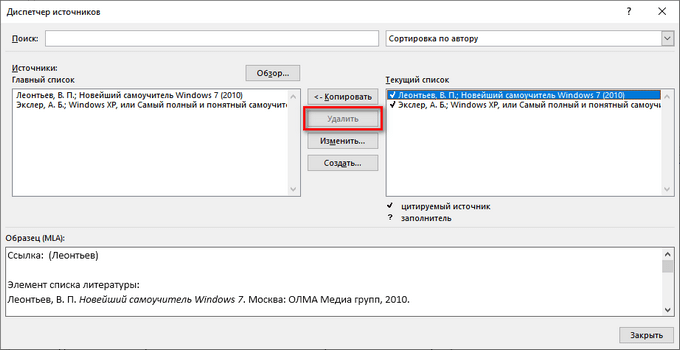
Ссылки на источники и сам список литературы вам придется удалить вручную.
Выполните следующее:
- Щелкните по полю со списком литературы.
- Нажмите на стрелку около значка «Списки литературы».

- В открывшемся меню нажмите на пункт «Преобразовать список литературы в текст».

- Выделите содержимое блока списка литературы.

- Нажмите на клавишу «Delete» (Del).
- Затем вручную удалите ссылки на источники в тексте документа — поочередно выделяя ссылки, а затем нажимая на клавишу «Del».
Если ссылок много, воспользуйтесь следующим способом:
- Выделите текст документа Word.
- Нажмите на клавиши «Ctrl» + «Shift» + «F9».
- В результате выполнения этой операции, будут удалены все ссылки из данного документа.
Список литературы вам нужно будет удалить вручную.
Выводы статьи
При написании статей, рефератов, дипломных работ или других типов документов, часто ссылаются на другие источники информации. Ссылки на использованные источники помещают в список литературы (цитируемые труды), находящийся в конце документа. Пользователь может создать с помощью нескольких способов список используемой литературы в текстовом редакторе Word.
Похожие публикации:
- Как сделать колонки в Word: полное руководство
- Как сжать документ Word — 13 способов
- Озвучивание текста в Ворде — «Прочесть вслух» или «Проговорить»
- Как сравнить два документа Word — 4 способа
- Как поставить ударение над буквой в Ворде — 3 способа
“
Продолжаем работу над приложением и сегодня изучим способы его взаимодействия с Word. Разберем основные методы программной работы с документами такого типа и попробуем применить их на практике.
Для успешного освоения материала рекомендуем вам изучить следующие понятия:
DB (Database), БД. Организованная структура, предназначенная для хранения, изменения и обработки взаимосвязанной информации, преимущественно больших объемов
Windows Presentation Foundation. Аналог WinForms, система для построения клиентских приложений Windows с визуально привлекательными возможностями взаимодействия с пользователем, графическая (презентационная) подсистема в составе .NET Framework (начиная с версии 3.0), использующая язык XAML
Демонстрация работы с документами Word в WPF
На данном занятии будет реализована возможность экспорта данных из приложения для визуализации расходов пользователей в документ Word. Расходы каждого пользователя будут экспортироваться на отдельную страницу, названием которой будет ФИО пользователя. Расходы будут просуммированы по категориям и представлены в виде таблицы. Под таблицей будет размещена информация о максимальном и минимальном платежах данного пользователя. Основные шаги построения приложения:
- Подготовительный этап
- Реализация экспорта в документ Word
- Завершение оформления документа Word
1. Подключаем библиотеку для работы с Word


Важно
Для экспорта данных в Word используется библиотека InteropWord (Object Library), расположенная во вкладке COM
2. Добавляем кнопку экспорта

Важно
Экспорт данных в Word будет осуществляться с помощью кнопки «Экспорт в Word»
3. Подключаем пространство имен для работы с Word

Важно
Требуемое пространство имен подключается с помощью директивы using
Реализация экспорта в документ Word
1. Получаем список пользователей и категорий

Важно
Список пользователей и категорий выгружается из базы данных
2. Создаем новый документ Word

Важно
После создания экземпляра Word в приложение добавляется новый документ, с которым далее происходит работа
3. Создаем параграф для хранения названий страниц

Важно
Основной структурной единицей текста является параграф, представленный объектом Paragraph. Все абзацы объединяются в коллекцию Paragraphs, причем новые параграфы добавляются с помощью метода Add. Доступ к тексту предоставляет объект Range, являющийся свойством Paragraph, а текстовое содержание абзаца доступно через Range.Text. В данном случае для хранения ФИО каждого пользователя создается новый параграф
4. Добавляем названия страниц

Важно
В качестве названия выбирается имя пользователя, к которому применяется стиль «Title», после чего добавляется новый параграф для таблицы с платежами
5. Добавляем и форматируем таблицу для хранения информации о платежах

Важно
После создания параграфа для таблицы и получения его Range, добавляется таблица с указанием числа строк (по количеству категорий + 1) и столбцов. Последние две строчки касаются указания границ (внутренних и внешних) и выравнивания ячеек (по центру и по вертикали)
6. Добавляем названия колонок и их форматирование

Важно
Таблица состоит из трех колонок с названиями «Иконка», «Категория» и «Сумма расходов». Названия колонок выделяются жирным шрифтом и выравниваются по центру
7. Заполняем первую колонку таблицы

Важно
Положение ячейки заносится в переменную cellRange. Метод AddPicture() класса InlineShape позволяет добавить изображение в ячейку. Иконки категорий размещаются в новой папке Assets, основные шаги создания которой изображены на скриншоте
8. Форматируем первую колонку таблицы

Важно
Для первой колонки устанавливаются длина, ширина, а также горизонтальное выравнивание по центру
9. Заполняем вторую и третью колонки

Важно
Сумма платежей приводится к нужному формату с указанием единиц измерения (руб.) непосредственно в коде
Завершение оформления документа Word
1. Добавляем максимальную величину платежа

Важно
Для поиска максимального платежа сначала платежи сортируются по стоимости. В случае, если такой платеж найден, добавляется новый параграф. Получается диапазон и выводится текст с информацией о наименовании платежа, его стоимости и дате совершения. В заключение устанавливается стиль и цвет текста (красный)
2. Добавляем минимальную величину платежа

Важно
Аналогично среди всех платежей данного пользователя определяется наименьший платеж и отображается шрифтом зеленого цвета
3. Делаем заключительные шаги

Важно
По завершении работы с данными пользователя добавляется разрыв страницы. Далее, разрешается отображение таблицы по завершении экспорта. Наконец, документ сохраняется в формате .docx и .pdf

“
Вы познакомились с основными программными методами работы с документами Word в WPF. Теперь давайте перейдем от теории к практике!
Для закрепления полученных знаний пройдите тест
Выберите неверное утверждение относительно работы с документами Word:
Paragraph содержит все абзацы документа
Range предоставляет доступ к тексту абзаца
Обращение к ячейке начинается с указания номера строки
Range.Text и Paragraphs являются:
К сожалению, вы ответили неправильно
Прочитайте лекцию и посмотрите видео еще раз
Но можно лучше. Прочитайте лекцию и посмотрите видео еще раз
Вы отлично справились. Теперь можете ознакомиться с другими компетенциями
Время на прочтение
8 мин
Количество просмотров 15K
Для языка Java (как, впрочем, и для любого другого языка программирования) всё еще не придумали более простого и действенного способа генерации документов docx, чем библиотека Apache POI. В конце нулевых появился сей высокоуровнеый API, позволящий говорить с формируемым документом не на языке разметки XML, а с помощью удобных полей и выводов.
Судя по моим Google-запросам на протяжении более чем года сообщество пользователей этой библиотеки продержалось года этак до 2012, в то время как новые версии библиотеки всё еще появляются на главной странице проекта. Не на все вопросы, касающиеся формирования самого примитивного документа, есть ответы в документации или stackoverflow, не говоря уже о текстах на русском языке. Постараемся компенсировать этот недостаток данных для тех, кому это может понадобиться.
Основные классы API
XWPFDocument — целостное представление Word документа. В нём не только содержится xml-код, интерпретируемый редакторами (Word, LibreOffice), но также содержатся и методы для определения метаданных отображения — набора стилей, сносок и т.п. В этой статье поговорим о первом, так как работа с метаданными не так явно задокументирована, к тому же многие редакторы успешно справляются с отображением документа и без подсказок.
Итак, предположим, у вас на руках есть (ненужный) файл docx. Преобразуем его в файл zip (осторожно, обратное преобразование путем переименования zip -> docx может сделать файл недоступным для вашего редактора(!)), в получившемся архиве откроем папку word, а в ней — файл document.xml. Перед нами xml-представление word-файла, которое также можно было бы получить через Apache POI, с меньшими трудностями.
File file = new File("C:/username/document.docx");
FileInputStream fis = new FileInputStream(file.getAbsolutePath());
XWPFDocument document = new XWPFDocument(fis); // Вот и объект описанного нами класса
String documentLine = document.getDocument().toString();
Для того, чтобы поближе познакомиться с содержимым документа, придется вооружиться еще двумя классами API: XWPFParagraph и XWPFTable.
XWPFParagraph — как следует из названия, представляет собой параграф документа. Расположен он может быть как внутри XWPFDocument,
document.getParagraphs();
XWPFParagraph lastParagraph = document.createParagraph();так и внутри таблицы (если точнее — внутри ячейки таблицы, вложенной в ряд таблицы, вложенного непосредственно в таблицу).
document.createTable().createRow().createCell().addParagraph();Параграф предоставляет изрядный набор информации для вёрстки и размещения текста. Официальная документация на этот счёт достаточно красноречива: отступы слева и справа, сверху и снизу, в том числе и между строками, добавление гиперссылок и границ для параграфа.
XWPFTable — класс, олицетворяющий таблицу. Также как и в XWPFParagraph, XWPFTable можно добавлять к самому документу и к ячейке таблицы (создавая, тем самым, таблицу внутри таблицы). Семантика в таком случае чуточку усложняется.
XWPFTable table = document.createTable(); //Здесь всё просто, создаем таблицу в документе и работаем с ней.
XWPFCell cell = table.createRow().createCell();//Добавим к таблице ряд, к ряду - ячейку, и используем её.
XWPFTable innerTable = new XWPFTable(cell.getCTTc().addNewTbl(), cell, 2, 2); // Воспользуемся конструктором для добавления таблицы - возьмем cell и её внутренние свойства, а так же зададим число рядов и колонок вложенной таблицы
cell.insertTable(cell.getTables().size(), innerTable);
XWPFRun — набор данных о выводе текста внутри параграфа. Находится может только внутри параграфа, создается через вызов метода параграфа-родителя:
paragraph.createRun();
Из нескольких «ранов», как я предпочитаю их называть, и состоит целый параграф текста в Word. Каждый «ран» имеет свою настройку шрифта, его цвета и размера, а также стилизации. Через добавление различных «ранов», подчиняющихся разметке параграфа, можно выводить тексты с совершенно разной стилизацией.
Как становится видно из обзора классов, перенос, скажем, css-стиля в документ будет связан с дополнительной сложностью: часть свойств необходимо будет применить к параграфу docx, часть — к объекту класса XWPFRun.
Итак, библиотека легла в External Libraries/jar лежит под рукой, пора творить.
Создадим документ, добавим таблицу 2х2 и параграф.
XWPFDocument document = new XWPFDocument();
XWPFTable table = document.createTable(2, 2);
XWPFParagraph paragraph = document.createParagraph();
fillTable(table);
fillParagraph(paragraph);
Заполним параграф, добавив ран для вывода текста. После перевода строки стилизация параграфа будет потеряна, и в Word новый параграф будет выведен без красной строки.
void fillParagraph(XWPFParagraph paragraph) {
paragraph.setIndent(20);
XWPFRun run = paragraph.createRun();
run.setFontSize(12);
run.setFontFamily("Times New Roman");
run.setText("My text");
run.addBreak();
run.setText("New line");
}
Теперь займёмся заполнением таблицы. Мы можем обращаться не только к уже созданным элементам, но и вызвать у сформированной таблицы метод для добавления рядов или колонок.
void fillTable(XWPFTable table) {
XWPFRow firstRow = table.getRows().get(0);
XWPFRow secondRow = table.getRows().get(1);
XWPFRow thirdRow = table.createRow();
fillRow(firstRow);
}
Опускаемся глубже, на уровень ряда таблицы. Именно в таком порядке предстаёт разбор таблицы в Apache POI — сначала ряды, потом клетки. Напрямую из таблицы можно получить лишь количество колонок в таблице:
table.getColBandSize();
Итак, ряд.
void fillRow(XWPFRow row) {
List<XWPFTableCell> cellsList = row.getCells();
cellsList.forEach(cell -> fillParagraph(cell.createParagraph()));
}
Оказавшись в ячейке двигаться глубже уже некуда, поэтому можно снова вызвать наш дуболомный метод по заполнению параграфа, предварительно создав его в таблице.
Итак, можно легко уловить суть структуры документа в Word: вкладывай одно в другое и предоставляй доступ (в том числе и к созданию новых экземпляров). К сожалению, далеко не всегда есть возможность получить последний элемент во вложенной коллекции. Чаще всего приходится пользоваться такими вот ухищрениями:
XWPFRun lastRunOfParagraph = paragraph.getRuns(paragraph.getRuns().size() - 1);
Хорошо, с содержимым таблицы разобрались. Что если нам нужно явно уточнить ширину таблицы, а не оставлять её для волной интерпретации редактора?
Для некоторых на первый взгляд числовых значений, например, ширины таблицы, в Apache POI существуют целые классы.
CTTblWidth widthRepr = table.getCTTbl().getTblPr().addNewTblW();
widthRepr.setType(STTblWidth.DXA);
widthRepr.setW(BigInteger.valueOf(4000));
С помощью типа укажем, какая именно ширина нам нужна: auto, pct или dxa. В первом случае таблицы займёт всю предоставленную ей ширину, во втором — процент от всей ширины, указанный позже методом setW. В нашем же случае вмешиватеся специальная единица измерения — dxa, равная 1/20 точки.
Классы, подобные CTTblWidth, используются повсеместно: для определения ширины страницы (PgSize), ширины ячейки и др.
Единцы измерения в Apache POI
В хорошем документе всё выверенно и расчерчено идеально, вплоть до самого пикселя. Возможно, в теории можно сделать всё средствами Apache POI и без углубления в тему единиц измерения, но лучше уделить им внимание сразу, чтобы избежать недопониманий в духе «почему это схлопнулось» и «когда переместил картинку в word на один сантиметр».
О поддержке сантиметров и остальной метрической системы тут остается только мечтать. Это резонно (каждый шрифт уникален, у каждого редактора своя специфика), но дико неудобно. Придется прибегнуть ко множеству конвертаций, если вы хотите задавать отступы (ведь именно в сантиметрах мы привыкли видеть их в word) в сантиметрах. Итак, указав тип измерения dxa для некоторой ширины, как описно в параграфе выше, мы получаем в распоряжение некоторое точное значение, но абсолютно не представляем как им воспользоваться. Для перевода в сантиметры на stackoverflow есть формула. Для всего остального существует класс Units. В нем определены как методы для перевода единиц измерения, так и сами соотношения между значениями.
Запись готового документа
Для записи в конечный файл есть удобный метод XWPFDocument — write. На вход принимается поток, в который пойдёт запись.
document.write(new FileOutputStream(new File("/path/to/file.docx")));
Если готовый документ нужно куда-то передать можно подать в качестве аргумента не File-, а ByteArrayOutputStream.
Информация об элементе отображения в формате xml
Имея документ, отображающийся корректно в определенном редакторе, полезно было бы узнать как именно представлен необходимый параграф или другой элемент. Для этого определенны специальные методы, возвращающие объекты классов пакета org.openxmlformats.schemas.wordprocessingml.x2006.main. Из названия (wordprocessingml) видно, что данный набор классов используется только для работы с документами word. Например, для xlsx документов есть пакет spreadsheetml, некоторые классы которого очень и очень похожи на классы wordprocessingml, поэтому конвертация между форматами достаточно затруднена.
paragraph.getCTP();
table.getCTTbl();
Так, пустой параграф будет иметь скромное представление
<xml-fragment/>Пустая таблица покажет больше интересного.
<xml-fragment xmlns:main="http://schemas.openxmlformats.org/wordprocessingml/2006/main">
<main:tblPr>
<main:tblW main:w="0" main:type="auto"/>
<main:tblBorders>
<main:top main:val="single"/>
<main:left main:val="single"/>
<main:bottom main:val="single"/>
<main:right main:val="single"/>
<main:insideH main:val="single"/>
<main:insideV main:val="single"/>
</main:tblBorders>
</main:tblPr>
<main:tr>
<main:tc>
<main:p/>
</main:tc>
<main:tc>
<main:p/>
</main:tc>
</main:tr>
<main:tr>
<main:tc>
<main:p/>
</main:tc>
<main:tc>
<main:p/>
</main:tc>
</main:tr>
<main:tr>
<main:tc>
<main:p/>
</main:tc>
<main:tc>
<main:p/>
</main:tc>
</main:tr>
</xml-fragment>
Что здесь интересного? Свойства tblPr — всевозможные свойства таблицы. Внутри уже описанная ширина таблицы (установлена 0, но свойство «auto» все равно выведет таблицу в приемлимой, автоматической ширине). Также tblBorders — набор информации о границах таблицы. Далее идёт явно выраженное представление внутренностей таблицы. tr — ряд таблицы, внутри вложенны tc. Внутри tc оказался бы набор вложенный параграфов, если бы мы добавили хотя бы один.
Попробуем пополнить параграф информацией и посмотреть что из этого получится.
XWPFParagraph xwpfParagraph = document.getParagraphs().get(0);
xwpfParagraph.setFirstLineIndent(10);
XWPFRun run = xwpfParagraph.createRun();
run.setFontFamily("Times New Roman");
run.setText("New text");Получаем:
<xml-fragment xmlns:main="http://schemas.openxmlformats.org/wordprocessingml/2006/main">
<main:pPr>
<main:ind main:firstLine="10"/>
</main:pPr>
<main:r>
<main:rPr>
<main:rFonts main:ascii="Times New Roman" main:hAnsi="Times New Roman" main:cs="Times New Roman" main:eastAsia="Times New Roman"/>
</main:rPr>
<main:t>New text</main:t>
</main:r>
</xml-fragment>Здесь ситуация ровно такая же: объект с мета-информацией (в него добавлена информация об отступе красной строки, который мы вложили в коде), а так же само содержимое: там размещается список «ранов». В первый и единственный мы добавили текст и информацию о шрифте. Эта информация также разделилась внутри «рана» — информация о шрифте попала в rPr, сам текст — в элемент t.
Вместо вывода
Apache POI предоставляет удобный, и, что не менее важно, бесплатный API для работы с документами. В нем непросто добиться единого отображения во всех редакторах (Office Online и LibreOffice обязательно будут выглядеть иначе), есть множество неудобств с единицами измерения, а так же непонятно где и какие свойства в элементах должны находиться. Тем не менее, работа с этими свойствами подчинена логике, а возможность подглядеть в xml не нарушая эту логику делает разработку гораздо более удобной.