
Время на прочтение
10 мин
Количество просмотров 331K

Десктопные/облачные, платные/бесплатные, для SEO, для совместных покупок, для наполнения сайтов, для сбора цен… В обилии парсеров можно утонуть.
Мы разложили все по полочкам и собрали самые толковые инструменты парсинга — чтобы вы могли быстро и просто собрать открытую информацию с любого сайта.
Зачем нужны парсеры
Парсер — это программа, сервис или скрипт, который собирает данные с указанных веб-ресурсов, анализирует их и выдает в нужном формате.
С помощью парсеров можно делать много полезных задач:
- Цены. Актуальная задача для интернет-магазинов. Например, с помощью парсинга вы можете регулярно отслеживать цены конкурентов по тем товарам, которые продаются у вас. Или актуализировать цены на своем сайте в соответствии с ценами поставщика (если у него есть свой сайт).
- Товарные позиции: названия, артикулы, описания, характеристики и фото. Например, если у вашего поставщика есть сайт с каталогом, но нет выгрузки для вашего магазина, вы можете спарсить все нужные позиции, а не добавлять их вручную. Это экономит время.
- Метаданные: SEO-специалисты могут парсить содержимое тегов title, description и другие метаданные.
- Анализ сайта. Так можно быстро находить страницы с ошибкой 404, редиректы, неработающие ссылки и т. д.
Для справки. Есть еще серый парсинг. Сюда относится скачивание контента конкурентов или сайтов целиком. Или сбор контактных данных с агрегаторов и сервисов по типу Яндекс.Карт или 2Гис (для спам-рассылок и звонков). Но мы будем говорить только о белом парсинге, из-за которого у вас не будет проблем.
Где взять парсер под свои задачи
Есть несколько вариантов:
- Оптимальный — если в штате есть программист (а еще лучше — несколько программистов). Поставьте задачу, опишите требования и получите готовый инструмент, заточенный конкретно под ваши задачи. Инструмент можно будет донастраивать и улучшать при необходимости.
- Воспользоваться готовыми облачными парсерами (есть как бесплатные, так и платные сервисы).
- Десктопные парсеры — как правило, программы с мощным функционалом и возможностью гибкой настройки. Но почти все — платные.
- Заказать разработку парсера «под себя» у компаний, специализирующихся на разработке (этот вариант явно не для желающих сэкономить).
Первый вариант подойдет далеко не всем, а последний вариант может оказаться слишком дорогим.
Что касается готовых решений, их достаточно много, и если вы раньше не сталкивались с парсингом, может быть сложно выбрать. Чтобы упростить выбор, мы сделали подборку самых популярных и удобных парсеров.
Законно ли парсить данные?
В законодательстве РФ нет запрета на сбор открытой информации в интернете. Право свободно искать и распространять информацию любым законным способом закреплено в четвертом пункте 29 статьи Конституции.
Допустим, вам нужно спарсить цены с сайта конкурента. Эта информация есть в открытом доступе, вы можете сами зайти на сайт, посмотреть и вручную записать цену каждого товара. А с помощью парсинга вы делаете фактически то же самое, только автоматизированно.
Но если вы хотите собрать персональные данные пользователей и использовать их для email-рассылок или таргетированной рекламы, это уже будет незаконно (эти данные защищены законом о персональных данных).
Десктопные и облачные парсеры
Облачные парсеры
Основное преимущество облачных парсеров — не нужно ничего скачивать и устанавливать на компьютер. Вся работа производится «в облаке», а вы только скачиваете результаты работы алгоритмов. У таких парсеров может быть веб-интерфейс и/или API (полезно, если вы хотите автоматизировать парсинг данных и делать его регулярно).
Например, вот англоязычные облачные парсеры:
- Import.io,
- Mozenda (доступна также десктопная версия парсера),
- Octoparce,
- ParseHub.
Из русскоязычных облачных парсеров можно привести такие:
- Xmldatafeed,
- Диггернаут,
- Catalogloader.
Любой из сервисов, приведенных выше, можно протестировать в бесплатной версии. Правда, этого достаточно только для того, чтобы оценить базовые возможности и познакомиться с функционалом. В бесплатной версии есть ограничения: либо по объему парсинга данных, либо по времени пользования сервисом.
Десктопные парсеры
Большинство десктопных парсеров разработаны под Windows — на macOS их необходимо запускать с виртуальных машин. Также некоторые парсеры имеют портативные версии — можно запускать с флешки или внешнего накопителя.
Популярные десктопные парсеры:
- ParserOK,
- Datacol,
- Screaming Frog, ComparseR, Netpeak Spider — об этих инструментах чуть позже поговорим подробнее.
Виды парсеров по технологии
Браузерные расширения
Для парсинга данных есть много браузерных расширений, которые собирают нужные данные из исходного кода страниц и позволяют сохранять в удобном формате (например, в XML или XLSX).
Парсеры-расширения — хороший вариант, если вам нужно собирать небольшие объемы данных (с одной или парочки страниц). Вот популярные парсеры для Google Chrome:
- Parsers;
- Scraper;
- Data Scraper;
- Kimono.
Надстройки для Excel
Программное обеспечение в виде надстройки для Microsoft Excel. Например, ParserOK. В подобных парсерах используются макросы — результаты парсинга сразу выгружаются в XLS или CSV.
Google Таблицы
С помощью двух несложных формул и Google Таблицы можно собирать любые данные с сайтов бесплатно.
Эти формулы: IMPORTXML и IMPORTHTML.
IMPORTXML
Функция использует язык запросов XPath и позволяет парсить данные с XML-фидов, HTML-страниц и других источников.
Вот так выглядит функция:
IMPORTXML("https://site.com/catalog"; "//a/@href")Функция принимает два значения:
- ссылку на страницу или фид, из которого нужно получить данные;
- второе значение — XPath-запрос (специальный запрос, который указывает, какой именно элемент с данными нужно спарсить).
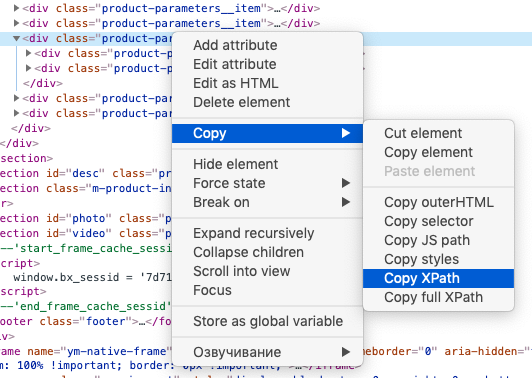
Хорошая новость в том, что вам не обязательно изучать синтаксис XPath-запросов. Чтобы получить XPath-запрос для элемента с данными, нужно открыть инструменты разработчика в браузере, кликнуть правой кнопкой мыши по нужному элементу и выбрать: Копировать → Копировать XPath.
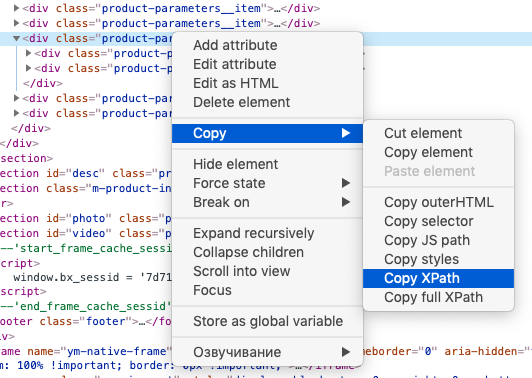
С помощью IMPORTXML можно собирать практически любые данные с html-страниц: заголовки, описания, мета-теги, цены и т.д.
IMPORTHTML
У этой функции меньше возможностей — с ее помощью можно собрать данные из таблиц или списков на странице. Вот пример функции IMPORTHTML:
IMPORTHTML("https://https://site.com/catalog/sweets"; "table"; 4)Она принимает три значения:
- Ссылку на страницу, с которой необходимо собрать данные.
- Параметр элемента, который содержит нужные данные. Если хотите собрать информацию из таблицы, укажите «table». Для парсинга списков — параметр «list».
- Число — порядковый номер элемента в коде страницы.
Об использовании 16 функций Google Таблиц для целей SEO читайте в нашей статье. Здесь все очень подробно расписано, с примерами по каждой функции.
Виды парсеров по сферам применения
Для организаторов СП (совместных покупок)
Есть специализированные парсеры для организаторов совместных покупок (СП). Их устанавливают на свои сайты производители товаров (например, одежды). И любой желающий может прямо на сайте воспользоваться парсером и выгрузить весь ассортимент.
Чем удобны эти парсеры:
- интуитивно понятный интерфейс;
- возможность выгружать отдельные товары, разделы или весь каталог;
- можно выгружать данные в удобном формате. Например, в Облачном парсере доступно большое количество форматов выгрузки, кроме стандартных XLSX и CSV: адаптированный прайс для Tiu.ru, выгрузка для Яндекс.Маркета и т. д.
Популярные парсеры для СП:
- SPparser.ru,
- Облачный парсер,
- Турбо.Парсер,
- PARSER.PLUS,
- Q-Parser.
Парсеры цен конкурентов
Инструменты для интернет-магазинов, которые хотят регулярно отслеживать цены конкурентов на аналогичные товары. С помощью таких парсеров вы можете указать ссылки на ресурсы конкурентов, сопоставлять их цены с вашими и корректировать при необходимости.
Вот три таких инструмента:
- Marketparser,
- Xmldatafeed,
- ALL RIVAL.
Парсеры для быстрого наполнения сайтов
Такие сервисы собирают названия товаров, описания, цены, изображения и другие данные с сайтов-доноров. Затем выгружают их в файл или сразу загружают на ваш сайт. Это существенно ускоряет работу по наполнению сайта и экономят массу времени, которое вы потратили бы на ручное наполнение.
В подобных парсерах можно автоматически добавлять свою наценку (например, если вы парсите данные с сайта поставщика с оптовыми ценами). Также можно настраивать автоматический сбор или обновление данных по расписания.
Примеры таких парсеров:
- Catalogloader,
- Xmldatafeed,
- Диггернаут.
Парсеры для SEO-специалистов
Отдельная категория парсеров — узко- или многофункциональные программы, созданные специально под решение задач SEO-специалистов. Такие парсеры предназначены для упрощения комплексного анализа оптимизации сайта. С их помощью можно:
- анализировать содержимое robots.txt и sitemap.xml;
- проверять наличие title и description на страницах сайта, анализировать их длину, собирать заголовки всех уровней (h1-h6);
- проверять коды ответа страниц;
- собирать и визуализировать структуру сайта;
- проверять наличие описаний изображений (атрибут alt);
- анализировать внутреннюю перелинковку и внешние ссылки;
- находить неработающие ссылки;
- и многое другое.
Пройдемся по нескольким популярным парсерам и рассмотрим их основные возможности и функционал.
Парсер метатегов и заголовков PromoPult
Стоимость: первые 500 запросов — бесплатно. Стоимость последующих запросов зависит от количества: до 1000 — 0,04 руб./запрос; от 10000 — 0,01 руб.
Возможности
С помощью парсера метатегов и заголовков можно собирать заголовки h1-h6, а также содержимое тегов title, description и keywords со своего или чужих сайтов.
Инструмент пригодится при оптимизации своего сайта. С его помощью можно обнаружить:
- страницы с пустыми метатегами;
- неинформативные заголовки или заголовки с ошибками;
- дубли метатегов и т.д.
Также парсер полезен при анализе SEO конкурентов. Вы можете проанализировать, под какие ключевые слова конкуренты оптимизируют страницы своих сайтов, что прописывают в title и description, как формируют заголовки.
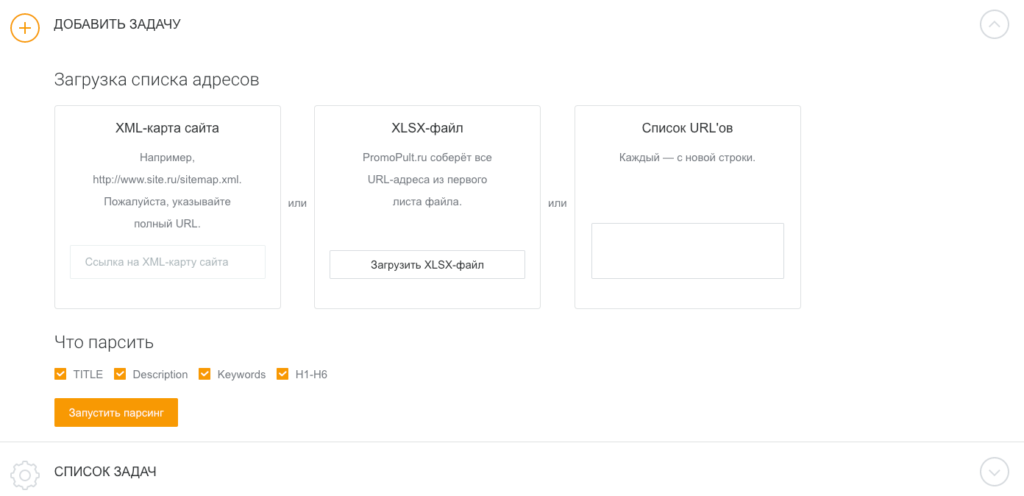
Сервис работает «в облаке». Для начала работы необходимо добавить список URL и указать, какие данные нужно спарсить. URL можно добавить вручную, загрузить XLSX-таблицу со списком адресов страниц, или вставить ссылку на карту сайта (sitemap.xml).
Работа с инструментом подробно описана в статье «Как в один клик собрать мета-теги и заголовки с любого сайта?».
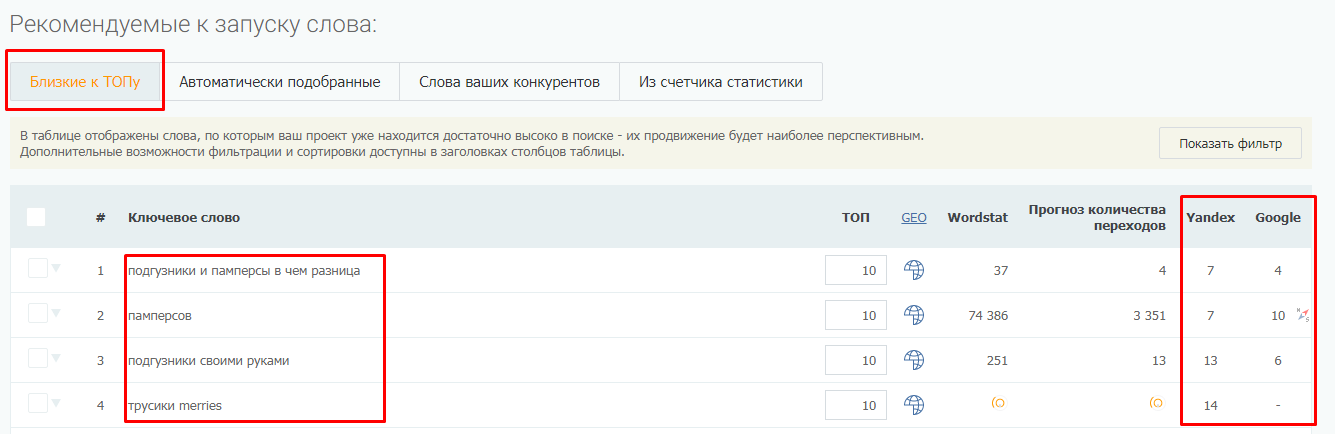
Парсер метатегов и заголовков — не единственный инструмент системы PromoPult для парсинга. В SEO-модуле системы можно бесплатно спарсить ключевые слова, по которым добавленный в систему сайт занимает ТОП-50 в Яндексе/Google.
Здесь же на вкладке “Слова ваших конкурентов” вы можете выгрузить ключевые слова конкурентов (до 10 URL за один раз).
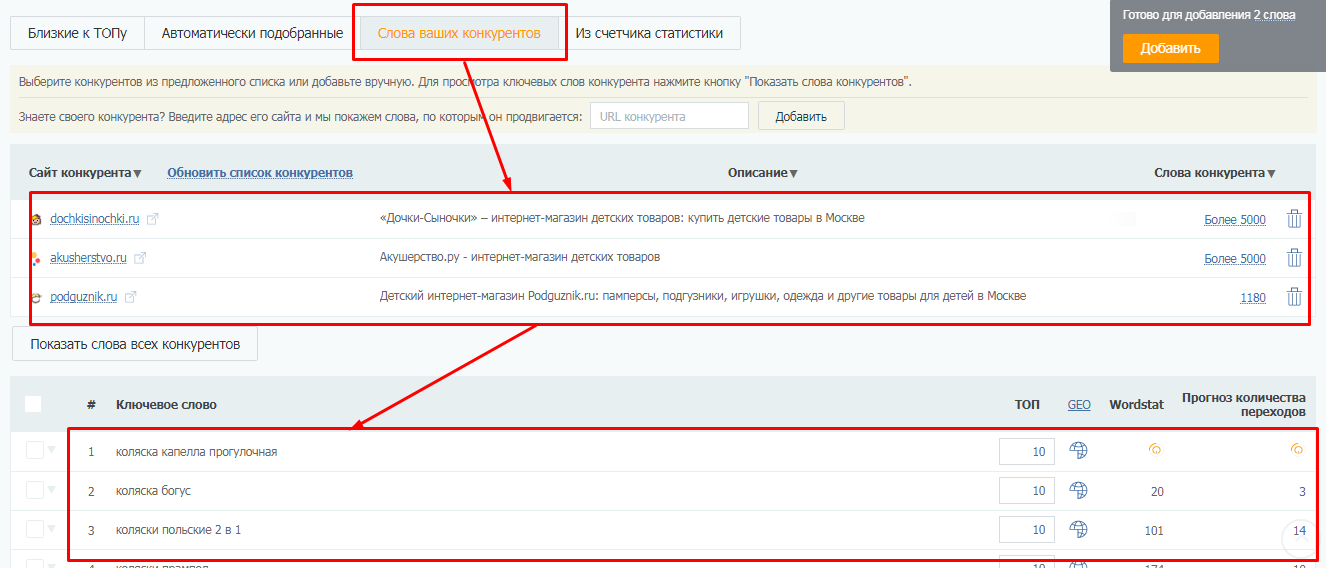
Подробно о работе с парсингом ключей в SEO-модуле PromoPult читайте здесь.
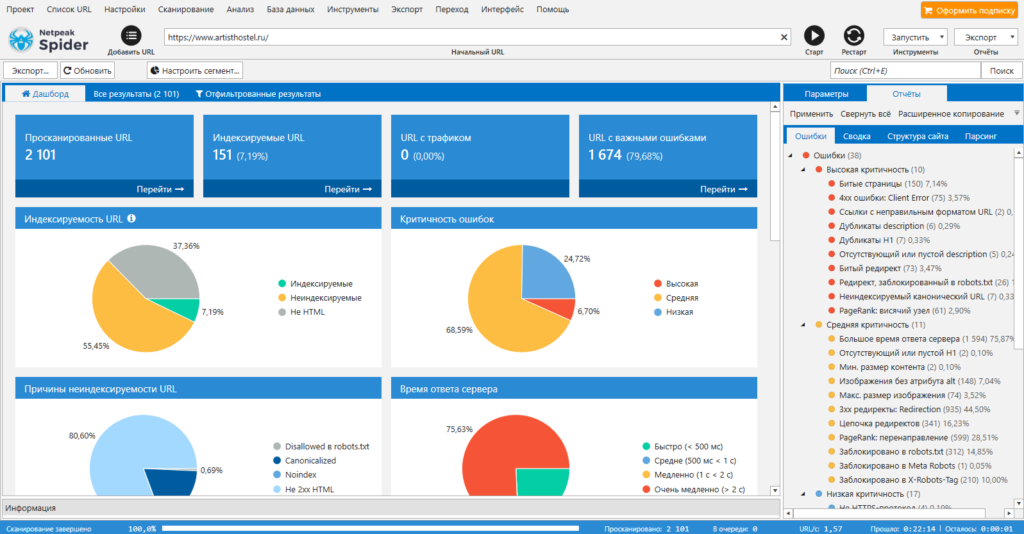
Netpeak Spider
Стоимость: от 19$ в месяц, есть 14-дневный пробный период.
Парсер для комплексного анализа сайтов. С Netpeak Spider можно:
- провести технический аудит сайта (обнаружить битые ссылки, проверить коды ответа страниц, найти дубли и т.д.). Парсер позволяет находить более 80 ключевых ошибок внутренней оптимизации;
- проанализировать основные SEO-параметры (файл robots.txt, проанализировать структуру сайта, проверить редиректы);
- парсить данные с сайтов с помощью регулярных выражений, XPath-запросов и других методов;
- также Netpeak Spider может импортировать данные из Google Аналитики, Яндекс.Метрики и Google Search Console.
Screaming Frog SEO Spider
Стоимость: лицензия на год — 149 фунтов, есть бесплатная версия.
Многофункциональный инструмент для SEO-специалистов, подходит для решения практически любых SEO-задач:
- поиск битых ссылок, ошибок и редиректов;
- анализ мета-тегов страниц;
- поиск дублей страниц;
- генерация файлов sitemap.xml;
- визуализация структуры сайта;
- и многое другое.
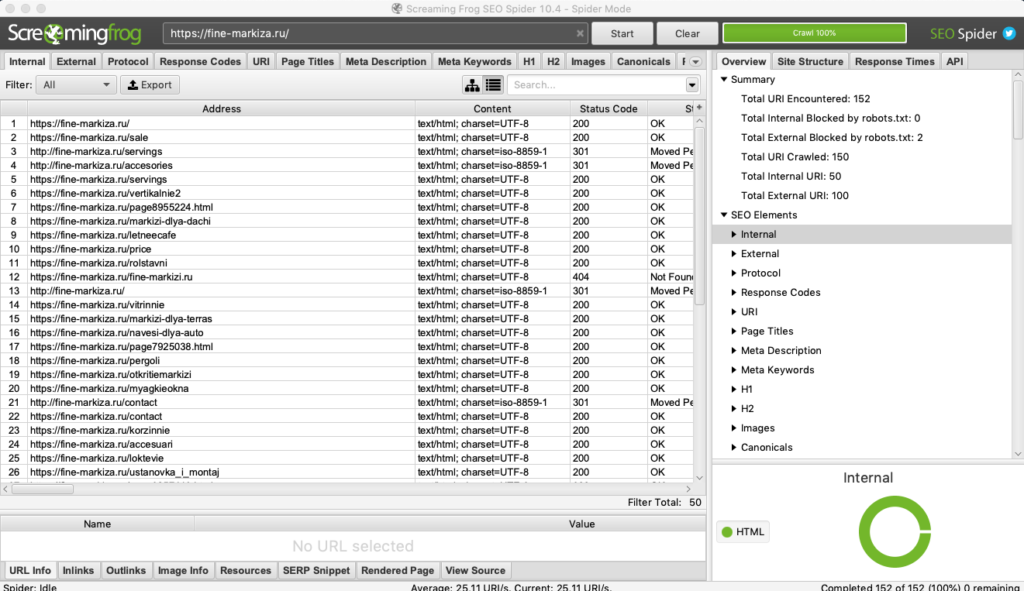
В бесплатной версии доступен ограниченный функционал, а также есть лимиты на количество URL для парсинга (можно парсить всего 500 url). В платной версии таких лимитов нет, а также доступно больше возможностей. Например, можно парсить содержимое любых элементов страниц (цены, описания и т.д.).
Подробно том, как пользоваться Screaming Frog, мы писали в статье «Парсинг любого сайта «для чайников»: ни строчки программного кода».
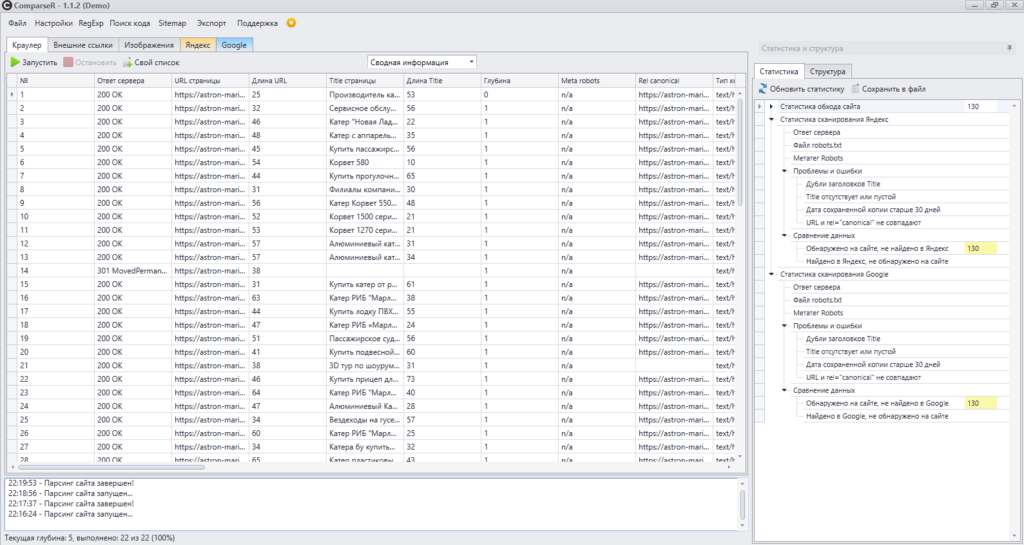
ComparseR
Стоимость: 2000 рублей за 1 лицензию. Есть демо-версия с ограничениями.
Еще один десктопный парсер. С его помощью можно:
- проанализировать технические ошибки на сайте (ошибки 404, дубли title, внутренние редиректы, закрытые от индексации страницы и т.д.);
- узнать, какие страницы видит поисковой робот при сканировании сайта;
- основная фишка ComparseR — парсинг выдачи Яндекса и Google, позволяет выяснить, какие страницы находятся в индексе, а какие в него не попали.
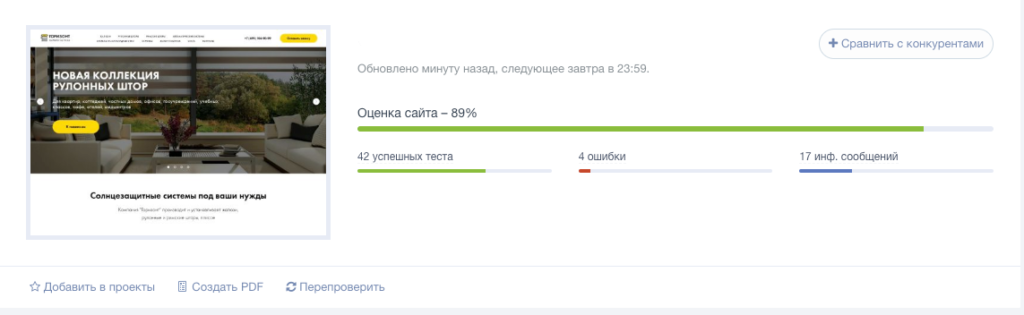
Анализ сайта от PR-CY
Стоимость: платный сервис, минимальный тариф — 990 рублей в месяц. Есть 7-дневная пробная версия с полным доступом к функционалу.
Онлайн-сервис для SEO-анализа сайтов. Сервис анализирует сайт по подробному списку параметров (70+ пунктов) и формирует отчет, в котором указаны:
- обнаруженные ошибки;
- варианты исправления ошибок;
- SEO-чеклист и советы по улучшению оптимизации сайта.
Анализ сайта от SE Ranking
Стоимость: платный облачный сервис. Доступно две модели оплаты: ежемесячная подписка или оплата за проверку.
Стоимость минимального тарифа — 7$ в месяц (при оплате годовой подписки).
Возможности:
- сканирование всех страниц сайта;
- анализ технических ошибок (настройки редиректов, корректность тегов canonical и hreflang, проверка дублей и т.д.);
- поиск страниц без мета-тегов title и description, определение страниц со слишком длинными тегами;
- проверка скорости загрузки страниц;
- анализ изображений (поиск неработающих картинок, проверка наличия заполненных атрибутов alt, поиск «тяжелых» изображений, которые замедляют загрузку страниц);
- анализ внутренних ссылок.
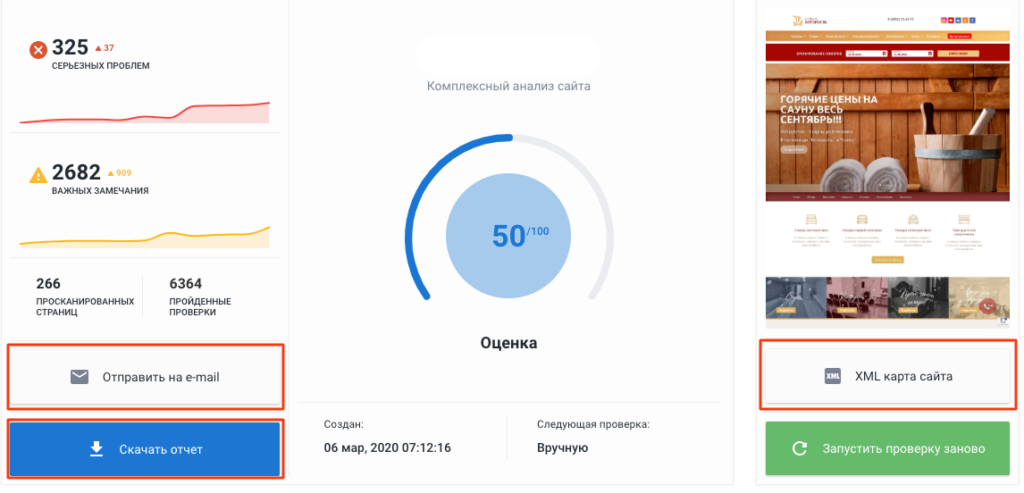
Xenu’s Link Sleuth
Стоимость: бесплатно.
Десктопный парсер для Windows. Используется для парсинга все url, которые есть на сайте:
- ссылки на внешние ресурсы;
- внутренние ссылки (перелинковка);
- ссылки на изображения, скрипты и другие внутренние ресурсы.
Часто применяется для поиска неработающих ссылок на сайте.
A-Parser
Стоимость: платная программа с пожизненной лицензией. Минимальный тарифный план — 119$, максимальный — 279$. Есть демо-версия.
Многофункциональный SEO-комбайн, объединяющий 70+ разных парсеров, заточенных под различные задачи:
- парсинг ключевых слов;
- парсинг данных с Яндекс и Google карт;
- мониторинг позиций сайтов в поисковых системах;
- парсинг контента (текст, изображения, видео) и т.д.
Кроме набора готовых инструментов, можно создать собственный парсер с помощью регулярных выражений, языка запросов XPath или Javascript. Есть доступ по API.

Чек-лист по выбору парсера
Краткий чек-лист, который поможет выбрать наиболее подходящий инструмент или сервис.
- Четко определите, для каких задач вам нужен парсер: анализ SEO конкурентов или мониторинг цен, сбор данных для наполнения каталога, съем позиций и т.д.
- Определите, какой объем данных и в каком виде нужно получать.
- Определите, как часто вам нужно собирать данные: единоразово или с определенной периодичностью (раз в день/неделю/месяц).
- Выберите несколько инструментов, которые подходят для решения ваших задач. Попробуйте демо-версии. Узнайте, предоставляется ли техническая поддержка (желательно даже протестировать ее — задать парочку вопросов и посмотреть, как быстро вы получите ответ и насколько он будет исчерпывающим).
- Выберите наиболее подходящий сервис по соотношению цена/качество.
Для крупных проектов, где требуется парсить большие объемы данных и производить сложную обработку, более выгодной может оказаться разработка собственного парсера под конкретные задачи.
Для большинства же проектов достаточно будет стандартных решений (возможно, вам может быть достаточно бесплатной версии любого из парсеров или пробного периода).

Надстройка Parser для Excel — простое и удобное решение для парсинга любых сайтов (интернет-магазинов, соцсетей, площадок объявлений) с выводом данных в таблицу Excel (формата XLS* или CSV), а также скачивания файлов.
Особенность программы — очень гибкая настройка постобработки полученных данных (множество текстовых функций, всевозможные фильтры, перекодировки, работа с переменными, разбиение значения на массив и обработка каждого элемента в отдельности, вывод характеристик в отдельные столбцы, автоматический поиск цены товара на странице, поддержка форматов JSON и XML).
В парсере сайтов поддерживается авторизация на сайтах, выбор региона, GET и POST запросы, приём и отправка Cookies и заголовков запроса, получение исходных данных для парсинга с листа Excel, многопоточность (до 200 потоков), распознавание капчи через сервис RuCaptcha.com, работа через браузер (IE), кеширование, рекурсивный поиск страниц на сайте, сохранение загруженных изображений товара под заданными именами в одну или несколько папок, и многое другое.
Поиск нужных данных на страницах сайта выполняется в парсере путем поиска тегов и/или атрибутов тегов (по любому свойству и его значению). Специализированные функции для работы с HTML позволяют разными способами преобразовывать HTML-таблицы в текст (или пары вида название-значение), автоматически находить ссылки пейджера, чистить HTML от лишних данных.
За счёт тесной интеграции с Excel, надстройка Parser может считывать любые данные из файлов Excel, создавать отдельные листы и файлы, динамически формировать столбцы для вывода, а также использовать всю мощь встроенных в Excel возможностей.
Поддерживается также сбор данных из текстовых файлов (формата Word, XML, TXT) из заданной пользователем папки, а также преобразование файлов Excel из одного формата таблицы в другой (обработка и разбиение данных на отдельные столбцы)
В программе «Парсер сайтов» можно настроить обработку нескольких сайтов. Перед запуском парсинга (кнопкой на панели инструментов Excel) можно выбрать ранее настроенный сайт из выпадающего списка.
Пример использования парсера для мониторинга цен конкурентов
Дополнительные видеоинструкции, а также подробное описание функционала, можно найти в разделе Справка по программе
В программе можно настроить несколько парсеров (обработчиков сайтов).
Любой из парсеров настраивается и работает независимо от других.
Примеры настроенных парсеров (можно скачать, запустить, посмотреть настройки)
Видеоинструкция (2 минуты), как запустить готовый (уже настроенный) парсер
Настройка программы, — дело не самое простое (для этого, надо хоть немного разбираться в HTML)
Если вам нужен готовый парсер, но вы не хотите разбираться с настройкой,
— закажите настройку парсера разработчику программы. Стоимость настройки под конкретный сайт — от 2000 рублей.
(настройка под заказ выполняется только при условии приобретения лицензии на надстройку «Парсер» (3300 руб)
Инструкция (с видео) по заказу настройки парсера
По всем вопросам, готов проконсультировать вас в Скайпе.
Программа не привязана к конкретному файлу Excel.
Вы в настройках задаёте столбец с исходными данными (ссылками или артикулами),
настраиваете формирование ссылок и подстановку данных с сайта в нужные столбцы,
нажимаете кнопку, — и ваша таблица заполняется данными с сайта.
Программа «Парсер сайтов» может быть полезна для формирования каталога товаров интернет-магазинов,
поиска и загрузки фотографий товара по артикулам (если для получения ссылки на фото, необходимо анализировать страницу товара),
загрузки актуальных данных (цен и наличия) с сайтов поставщиков, и т.д. и т.п.
Справка по программе «Парсер сайтов»
Можно попробовать разобраться с работой программы на примерах настроенных парсеров
Парсить сайты в Excel достаточно просто если использовать облачную версию софта Google Таблицы (Sheets/Doc), которые без труда позволяют использовать мощности поисковика для отправки запросов на нужные сайты.
- Подготовка;
- IMPORTXML;
- IMPORTHTML;
- Обратная конвертация.
Видеоинструкция
Подготовка к парсингу сайтов в Excel (Google Таблице)
Для того, чтобы начать парсить сайты потребуется в первую очередь перейти в Google Sheets, что можно сделать открыв страницу:
https://www.google.com/intl/ru_ru/sheets/about/
Потребуется войти в Google Аккаунт, после чего нажать на «Создать» (+).
Теперь можно переходить к парсингу, который можно выполнить через 2 основные функции:
- IMPORTXML. Позволяет получить практически любые данные с сайта, включая цены, наименования, картинки и многое другое;
- IMPORTHTML. Позволяет получить данные из таблиц и списков.
Однако, все эти методы работают на основе ссылок на страницы, если таблицы с URL-адресами нет, то можно ускорить этот сбор через карту сайта (Sitemap). Для этого добавляем к домену сайта конструкцию «/robots.txt». Например, «seopulses.ru/robots.txt».
Здесь открываем URL с картой сайта:
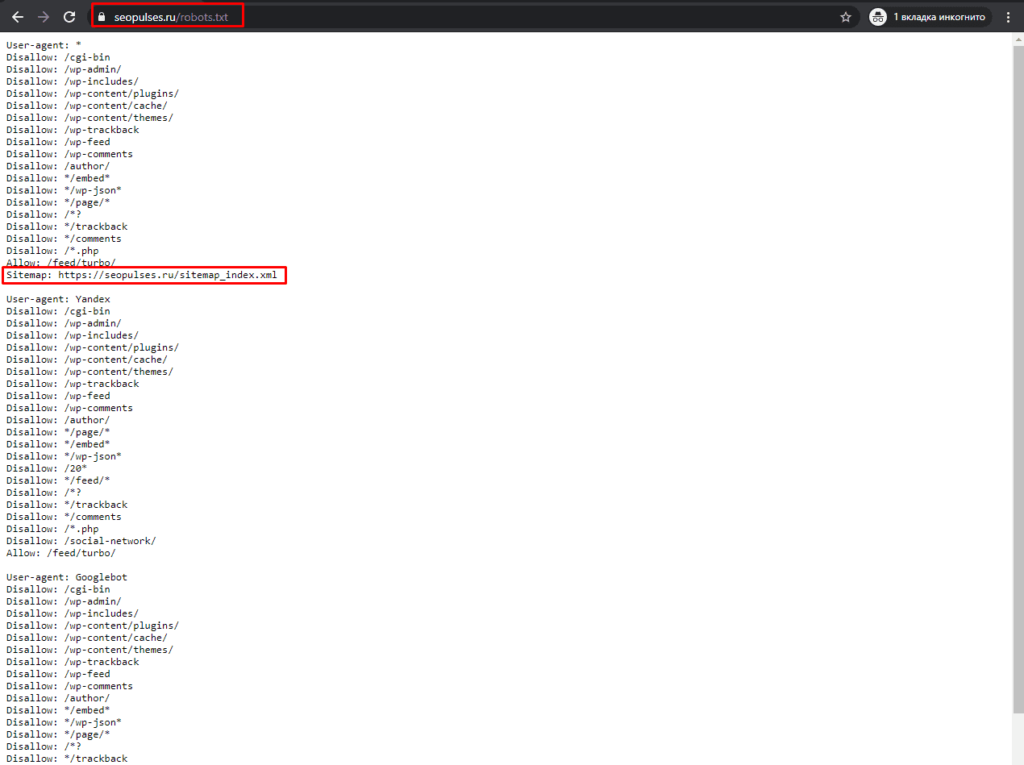
Нас интересует список постов, поэтому открываем первую ссылку.
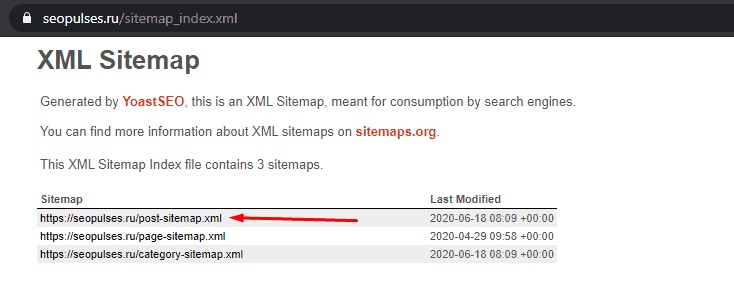
Получаем полный список из URL-адресов, который можно сохранить, кликнув правой кнопкой мыши и нажав на «Сохранить как» (в Google Chrome).
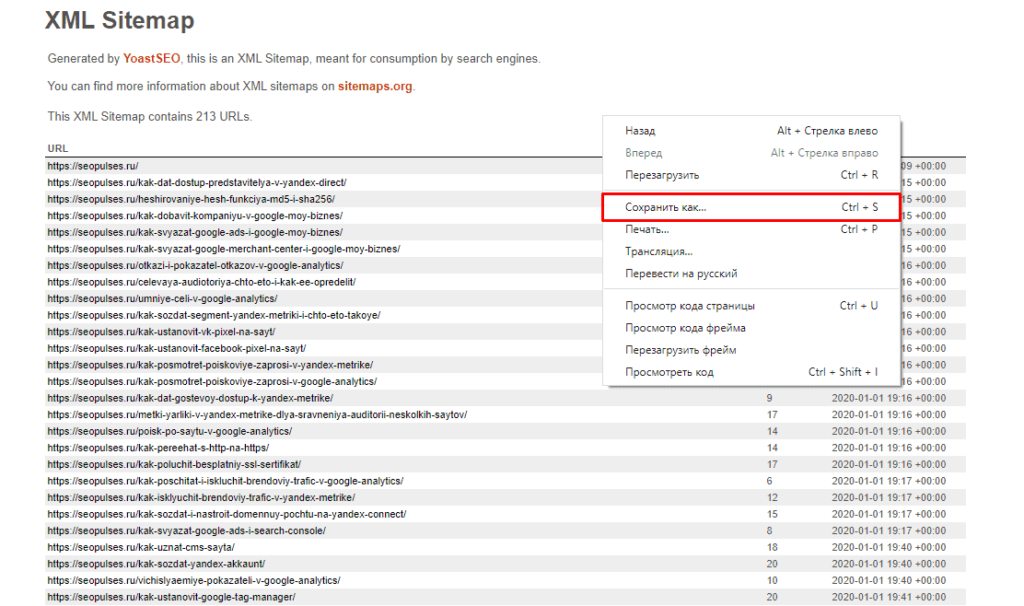
Теперь на компьютере сохранен файл XML, который можно открыть через текстовые редакторы, например, Sublime Text или NotePad++.
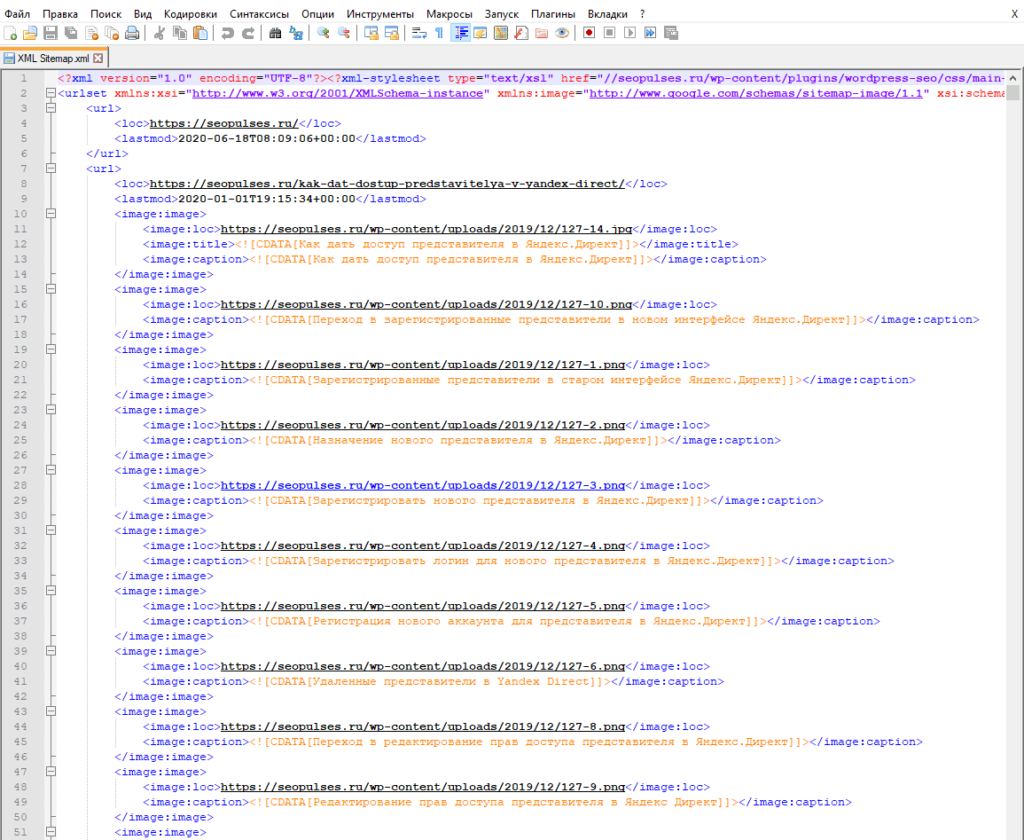
Чтобы обработать информацию корректно следует ознакомиться с инструкцией открытия XML-файлов в Excel (или создания), после чего данные будут поданы в формате таблицы.
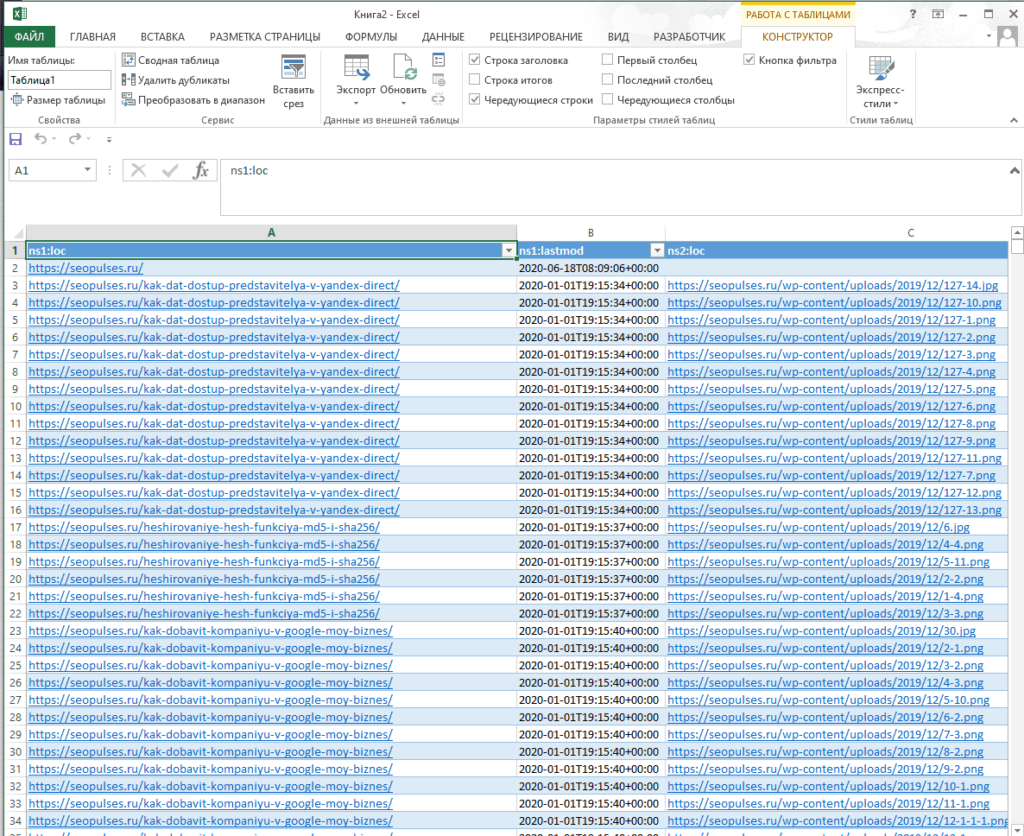
Все готово, можно переходить к методам парсинга.
IPMORTXML для парсинга сайтов в Excel
Синтаксис IMPORTXML в Google Таблице
Для того, чтобы использовать данную функцию потребуется в таблице написать формулу:
=IMPORTXML(Ссылка;Запрос)
Где:
- Ссылка — URL-адрес страницы;
- Запрос – в формате XPath.
С примером можно ознакомиться в:
https://docs.google.com/spreadsheets/d/1xmzdcBPap6lA5Gtwm1hjQfDHf3kCQdbxY3HM11IqDqY/edit#gid=0
Примеры использования IMPORTXML в Google Doc
Парсинг названий
Для работы с парсингом через данную функцию потребуется знание XPATH и составление пути в этом формате. Сделать это можно открыв консоль разработчика. Для примера будет использоваться сайт крупного интернет-магазина и в первую очередь необходимо в Google Chrome открыть окно разработчика кликнув правой кнопкой мыли и в выпавшем меню выбрать «Посмотреть код» (сочетание клавиш CTRL+Shift+I).
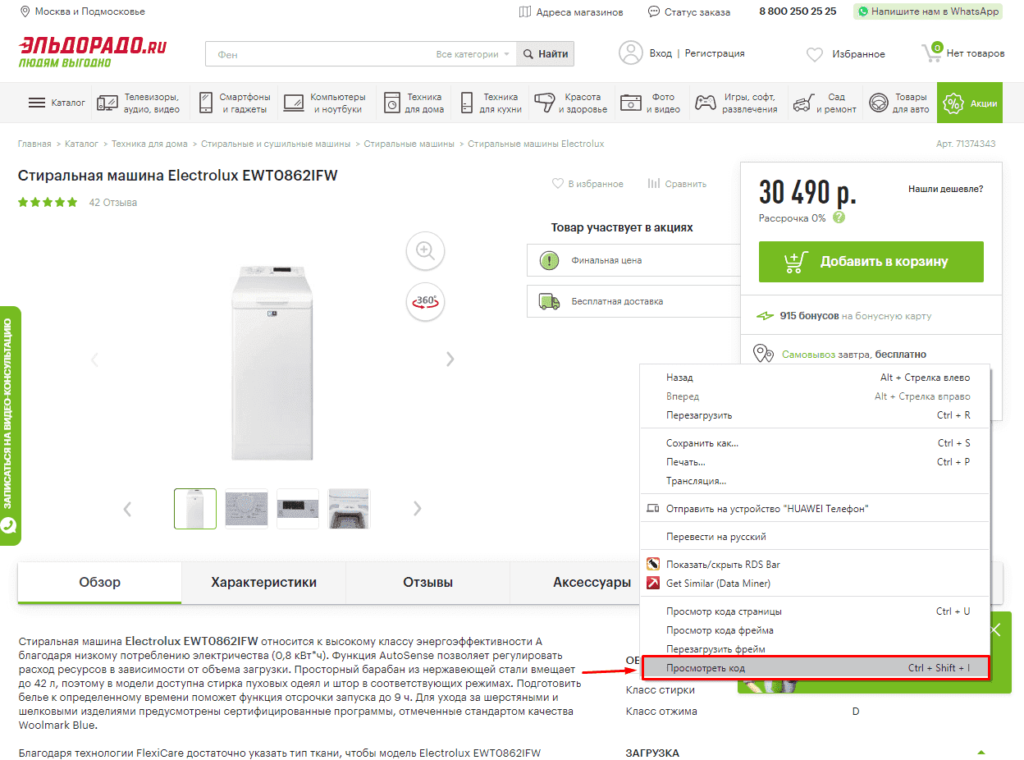
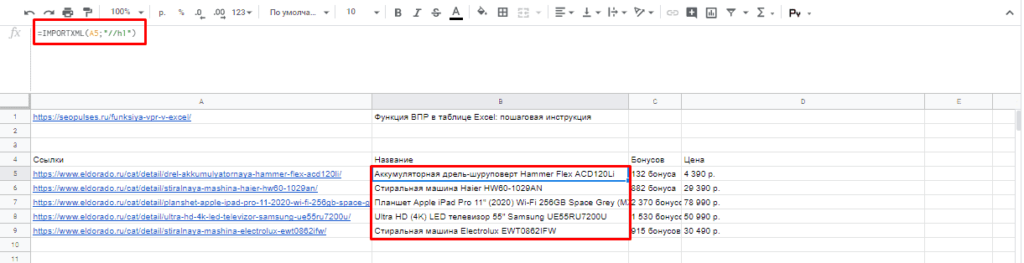
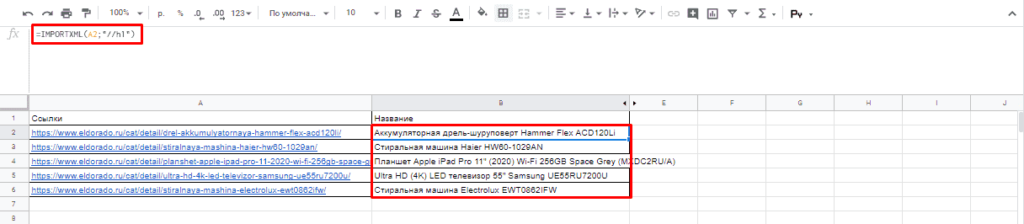
После этого пытаемся получить название товара, которое содержится в H1, единственным на странице, поэтому запрос должен быть:
//h1
И как следствие формула:
=IMPORTXML(A2;»//h1″)
Важно! Запрос XPath пишется в кавычках «запрос».
Парсинг различных элементов
Если мы хотим получить баллы, то нам потребуется обратиться к элементу div с классом product-standart-bonus поэтому получаем:
//div[@class=’product-standart-bonus’]
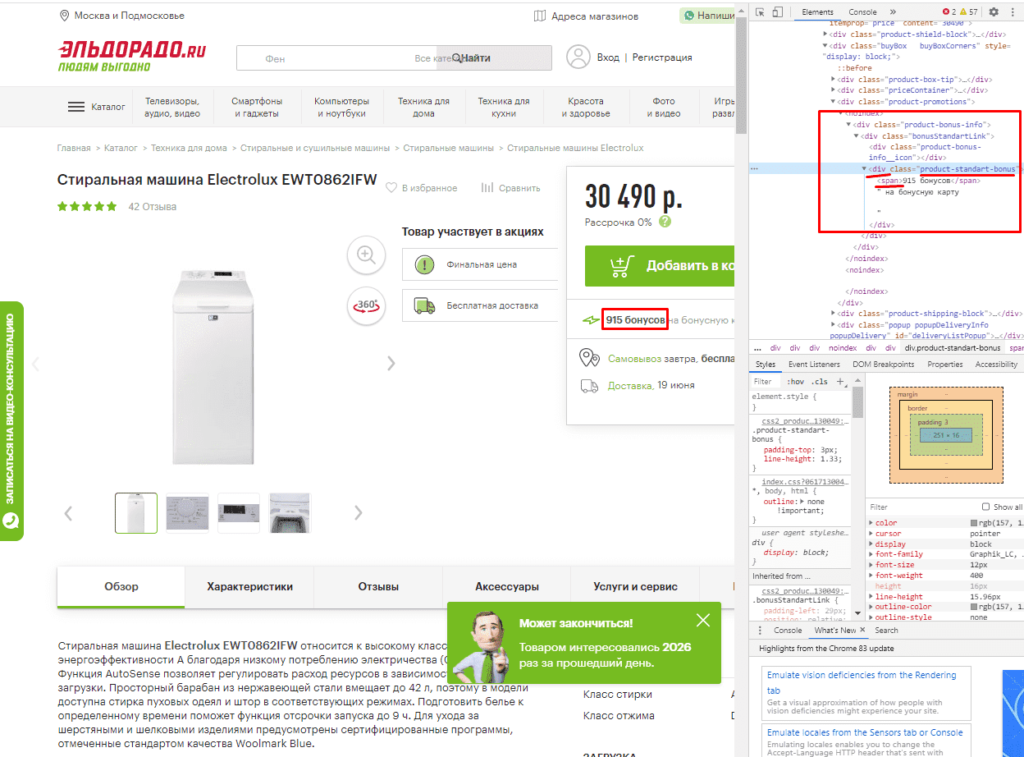
В этом случае первый тег div обозначает то, откуда берутся данные, когда в скобках [] уточняется его уникальность.
Для уточнения потребуется указать тип в виде @class, который может быть и @id, а после пишется = и в одинарных кавычках ‘значение’ пишется запрос.
Однако, нужное нам значение находиться глубже в теге span, поэтому добавляем /span и вводим:
//div[@class=’product-standart-bonus’]/span
В документе:

Парсинг цен без знаний XPath
Если нет знаний XPath и необходимо быстро получить информацию, то требуется выбрав нужный элемент в консоли разработчика кликнуть правой клавишей мыши и в меню выбрать «Copy»-«XPath». Например, при поиске запроса цены получаем:
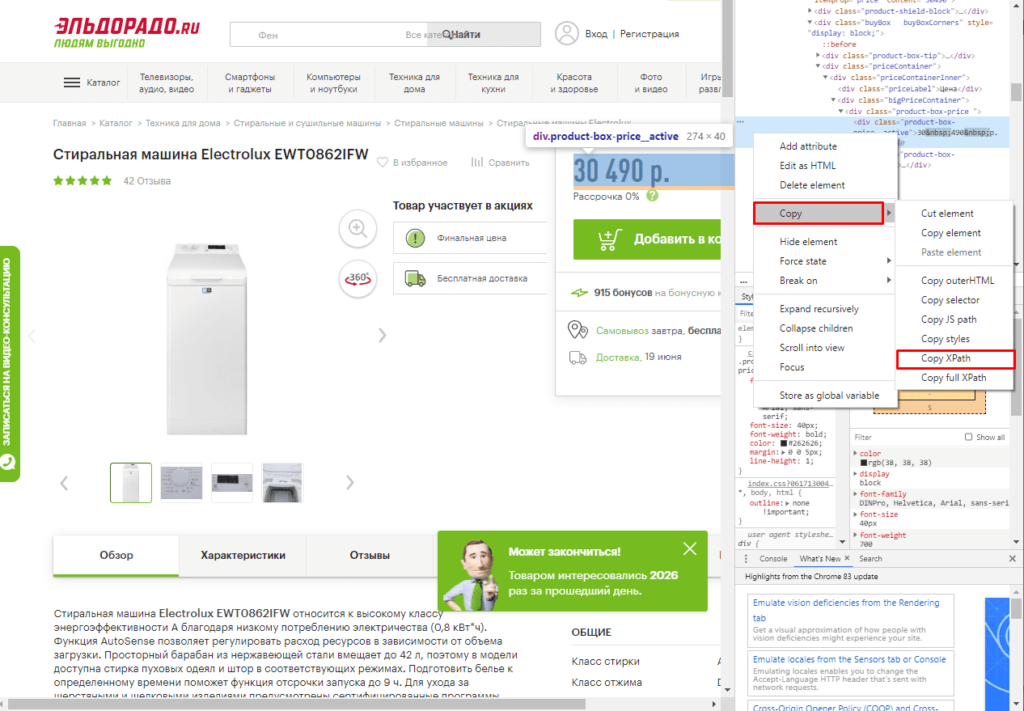
//*[@id=»showcase»]/div/div[3]/div[2]/div[2]/div[1]/div[2]/div/div[1]
Важно! Следует изменить » на одинарные кавычки ‘.
Далее используем ее вместе с IMPORTXML.
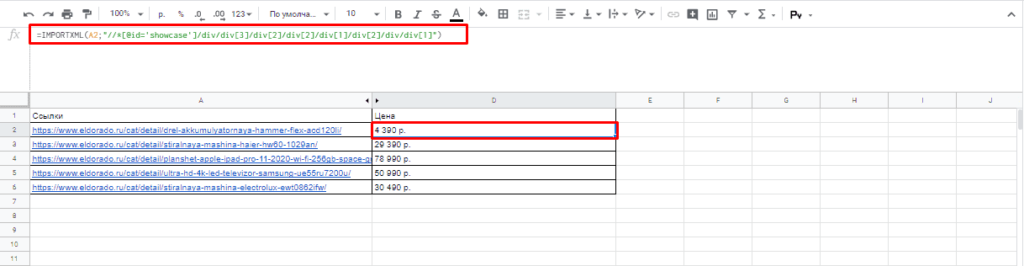
Все готово цены получены.
Простые формулы с IMPORTXML в Google Sheets
Чтобы получить title страницы необходимо использовать запрос:
=IMPORTXML(A3;»//title»)
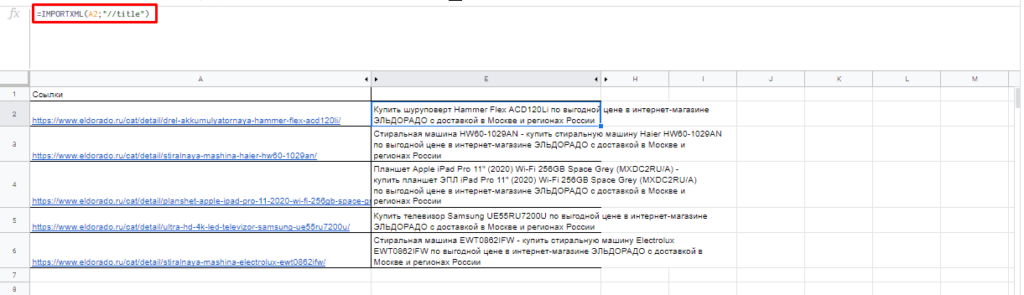
Для вывода description стоит использовать:
=IMPORTXML(A3;»//description»)
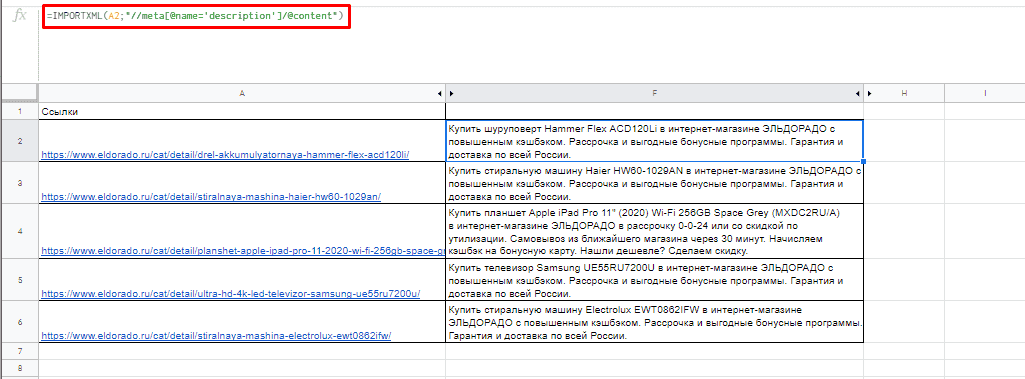
Первый заголовок (или любой другой):
=IMPORTXML(A3;»//h1″)

IMPORTHTML для создания парсера веи-ресурсов в Эксель
Синтаксис IMPORTXML в Google Таблице
Для того, чтобы использовать данную функцию потребуется в таблице написать формулу:
=IMPORTXML(Ссылка;Запрос;Индекс)
Где:
- Ссылка — URL-адрес страницы;
- Запрос – может быть в формате «table» или «list», выгружающий таблицу и список, соответственно.
- Индекс – порядковый номер элемента.
С примерами можно ознакомиться в файле:
https://docs.google.com/spreadsheets/d/1GpcGZd7CW4ugGECFHVMqzTXrbxHhdmP-VvIYtavSp4s/edit#gid=0
Пример использования IMPORTHTML в Google Doc
Парсинг таблиц
В примерах будет использоваться данная статья, перейдя на которую можно открыть консоль разработчика (в Google Chrome это можно сделать кликнув правой клавишей мыши и выбрав пункт «Посмотреть код» или же нажав на сочетание клавиш «CTRL+Shift+I»).
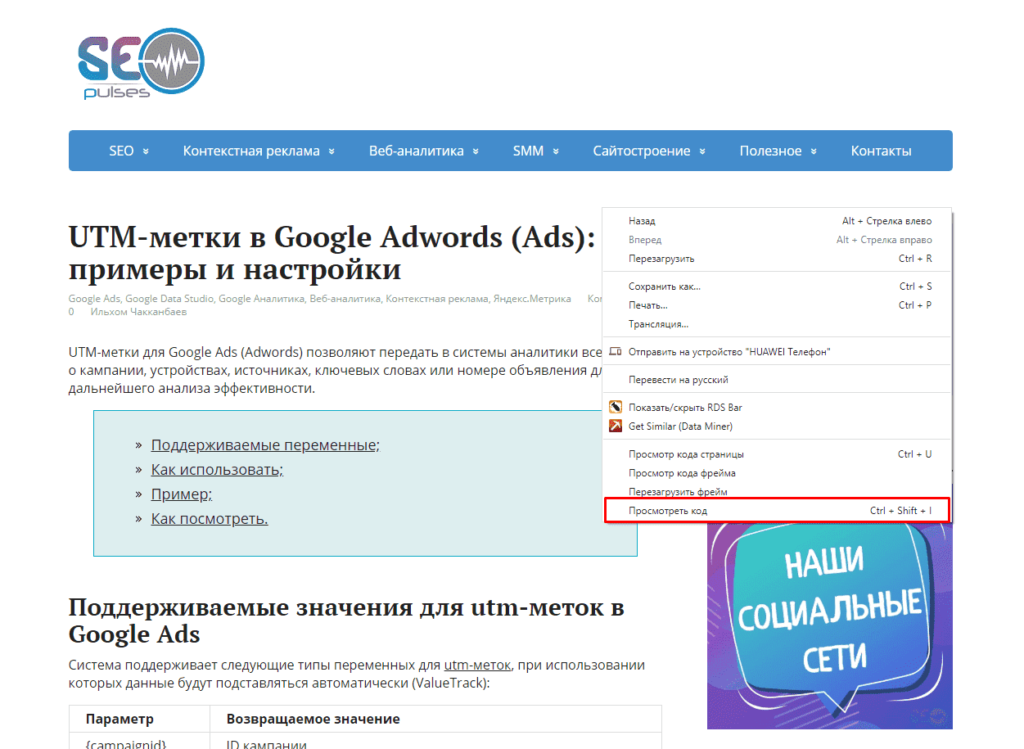
Теперь просматриваем код таблицы, которая заключена в теге <table>.
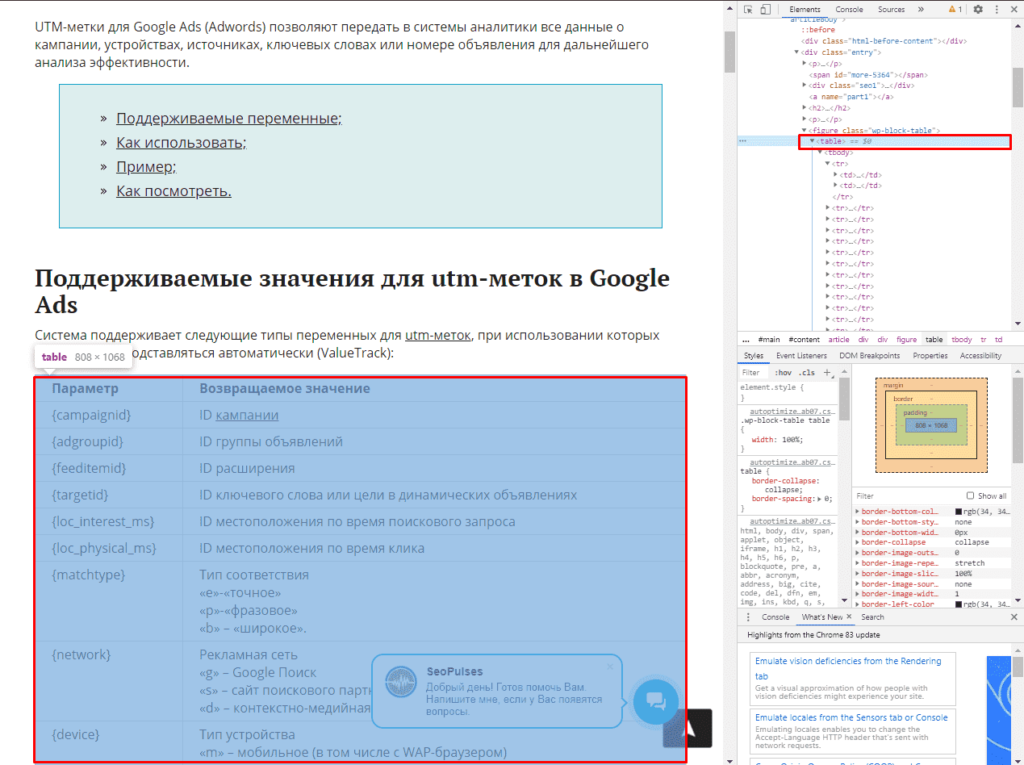
Данный элемент можно будет выгрузить при помощи конструкции:
=IMPORTHTML(A2;»table»;1)
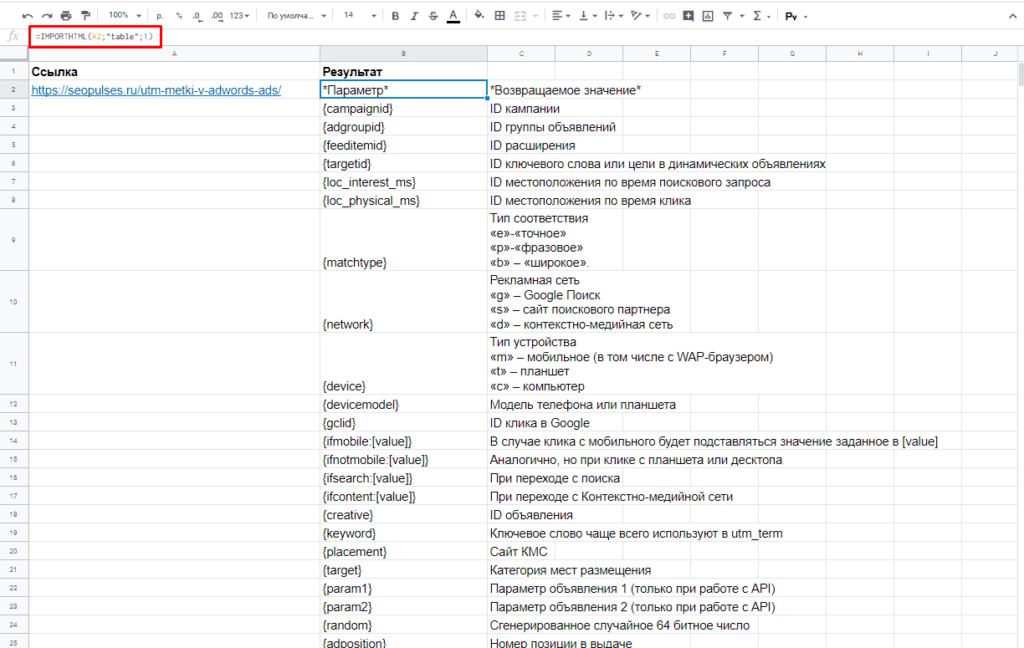
- Где A2 ячейка со ссылкой;
- table позволяет получить данные с таблицы;
- 1 – номер таблицы.
Важно! Сам запрос table или list записывается в кавычках «запрос».
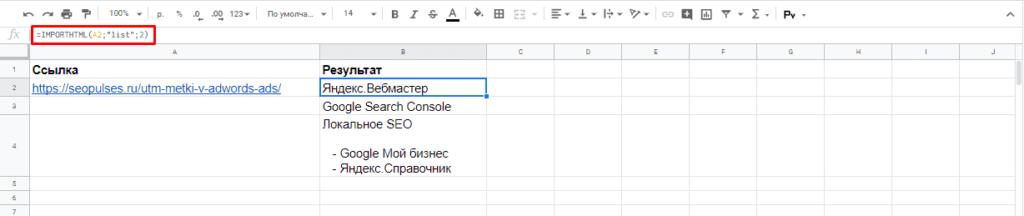
Парсинг списков
Получить список, заключенный в тегах <ul>…</ul> при помощи конструкции.
=IMPORTHTML(A2;»list»;1)
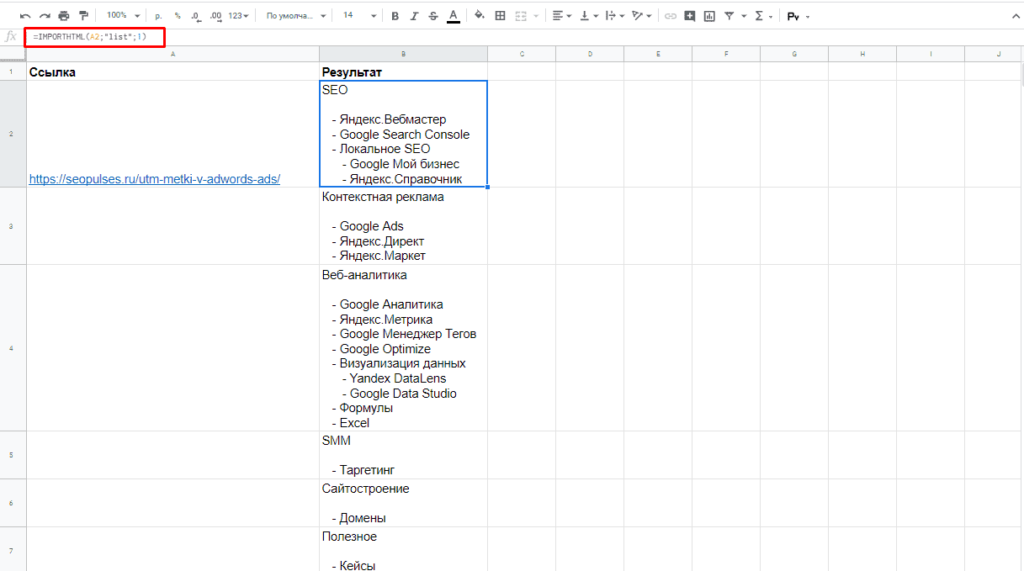
В данном случае речь идет о меню, которое также представлено в виде списка.
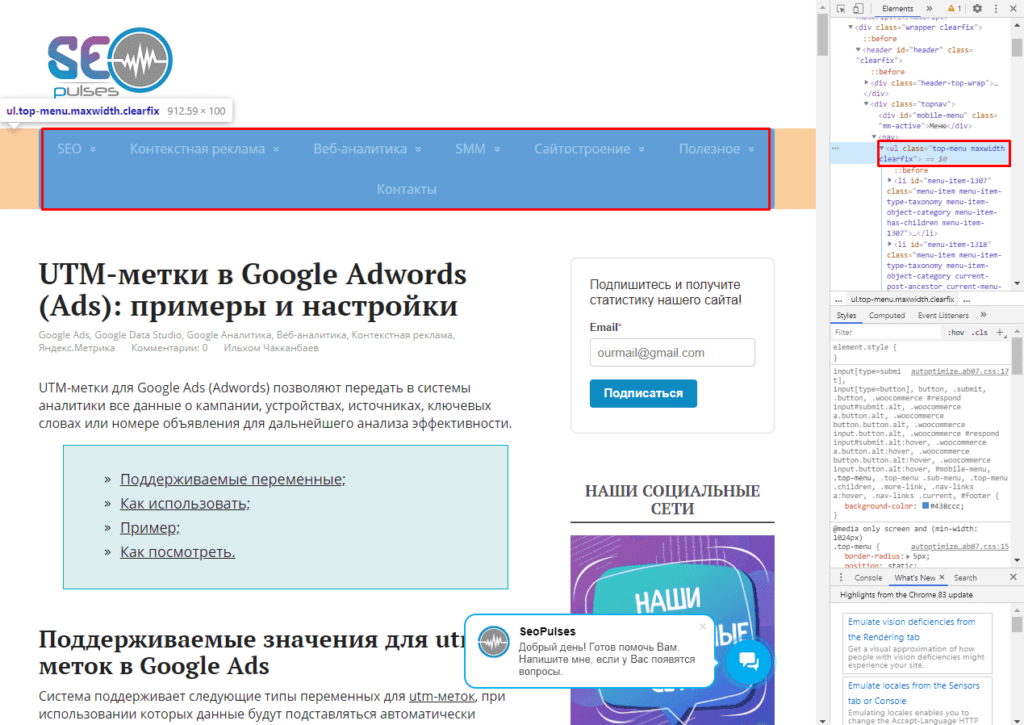
Если использовать индекс третей таблицы, то будут получены данные с третей таблицы в меню:
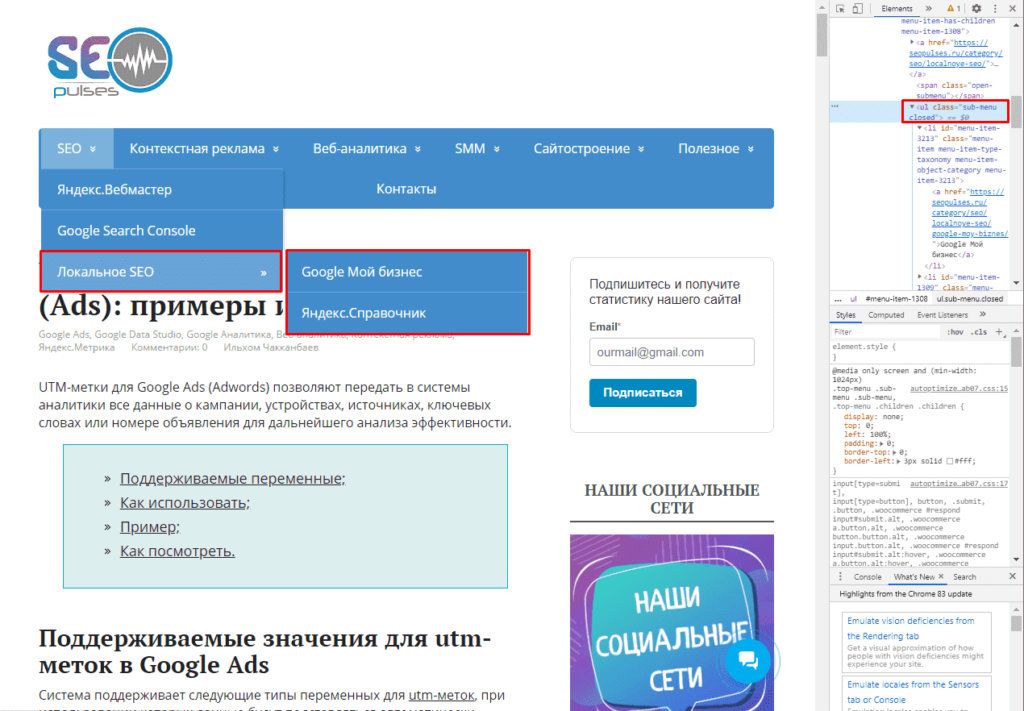
Формула:
=IMPORTHTML(A2;»list»;2)
Все готово, данные получены.
Обратная конвертация
Чтобы превратить Google таблицу в MS Excel потребуется кликнуть на вкладку «Файл»-«Скачать»-«Microsoft Excel».
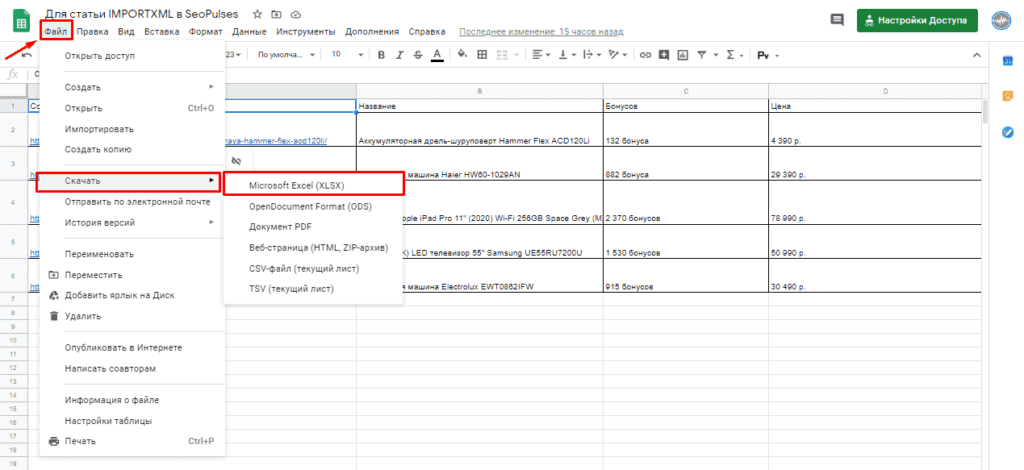
Все готово, пример можно скачать ниже.
Пример:
https://docs.google.com/spreadsheets/d/1xmzdcBPap6lA5Gtwm1hjQfDHf3kCQdbxY3HM11IqDqY/edit
Парсинг (web scraping) — это автоматизированный сбор открытой информации в интернете по заданным условиям. Парсить можно данные с сайтов, поисковой выдачи, форумов и социальных сетей, порталов и агрегаторов. В этой статье разбираемся с парсерами сайтов.
Часто требуется получить и проанализировать большой массив технической и коммерческой информации, размещенной на своих проектах или сайтах конкурентов. Для сбора таких данных незаменимы парсеры — программы или сервисы, которые «вытаскивают» нужную информацию и представляют ее в структурированном виде.
Парсинг — это законно?
Сбор открытой информации в интернете не запрещен законодательством РФ. Более того, в п.4 статьи 29 Конституции закреплено «право свободно искать, получать, передавать, производить и распространять информацию любым законным способом». Парсинг данных часто сравнивают с фотографированием ценников в магазинах: если информация есть в открытом доступе, не защищена авторским правом или другими ограничениями, значит, ее можно копировать и распространять.
Применительно к данным в интернете это значит, что законным является сбор сведений, для получения которых не требуется авторизация. А вот персональные данные пользователей защищены отдельным законом и парсить их с целью таргетирования рекламы или email-рассылок нельзя.
Кому и зачем нужны парсеры сайтов
Классификация парсеров
Парсеры сайтов по способу доступа к интерфейсу
Облачные парсеры
Программы-парсеры
Парсеры сайтов в зависимости от используемой технологии
Парсеры на основе Python и PHP
Парсеры-расширения для браузеров
Парсеры сайтов на основе Excel
Парсинг при помощи Google Таблиц
Парсеры сайтов в зависимости от решаемых задач
Парсеры для организаторов совместных покупок (СП)
Сервисы мониторинга конкурентов
Сбор данных и автонаполнение контентом
Многофункциональные парсеры
SEO-парсеры
Screaming Frog SEO Spider
Netpeak Spider
ComparseR
SiteAnalyzer от Majento
Анализ сайта от SE Ranking
A-Parser
Анализ сайта от PR-CY
Xenu’s Link Sleuth
Парсер метатегов и заголовков PromoPult
Как выбрать парсер
Кому и зачем нужны парсеры сайтов
Парсеры экономят время на сбор большого объема данных и группировку их в нужный вид. Такими сервисами пользуются интернет-маркетологи, вебмастера, SEO-специалисты, сотрудники отделов продаж.
Парсеры могут выполнять следующие задачи:
- Сбор цен и ассортимента. Это полезно для интернет-магазинов. При помощи парсера можно мониторить цены конкурентов и наполнять каталог на своем ресурсе в автоматическом режиме.
- Парсинг метаданных сайта (title, description, заголовков H1) пригодится SEO-специалистам.
- Анализ технической оптимизации ресурса (битые ссылки, ошибки 404, неработающие редиректы и др.) потребуется сеошникам и вебмастерам.
- Программы для скачивания сайтов целиком или парсеры контента (текстов, картинок, ссылок) находятся в «серой» зоне. С их помощью недобросовестные вебмастера клонируют сайты для последующей продажи с них ссылок. Сюда же отнесем парсинг данных с агрегаторов и картографических сервисов: Авито, Яндекс.Карт, 2gis и других. Собранные базы используются для спамных обзвонов и рассылок.
Кому и для каких целей требуются парсеры, разобрались. Если вам нужен этот инструмент, есть несколько способов его заполучить.
- При наличии программистов в штате проще всего поставить им задачу сделать парсер под нужные цели. Так вы получите гибкие настройки и оперативную техподдержку. Самые популярные языки для создания парсеров — PHP и Python.
- Воспользоваться бесплатным или платным облачным сервисом.
- Установить подходящую по функционалу программу.
- Обратиться в компанию, которая разработает инструмент под ваши нужды (ожидаемо самый дорогой вариант).
С первым и последним вариантом все понятно. Но выбор из готовых решений может занять немало времени. Мы упростили эту задачу и сделали обзор инструментов.
Классификация парсеров
Парсеры можно классифицировать по различным признакам.
- По способу доступа к интерфейсу: облачные решения и программы, которые требуют установки на компьютер.
- По технологии: парсеры на основе языков программирования (Python, PHP), расширения для браузеров, надстройки в Excel, формулы в Google таблицах.
- По назначению: мониторинг конкурентов, сбор данных в определенной нише рынка, парсинг товаров и цен для наполнения каталога интернет-магазина, парсеры данных соцсетей (сообществ и пользователей), проверка оптимизации своего ресурса.
Разберем парсеры по разным признакам, подробнее остановимся на парсерах по назначению.
Парсеры сайтов по способу доступа к интерфейсу
Облачные парсеры
Облачные сервисы не требуют установки на ПК. Все данные хранятся на серверах разработчиков, вы скачиваете только результат парсинга. Доступ к программному обеспечению осуществляется через веб-интерфейс или по API.
Примеры облачных парсеров с англоязычным интерфейсом:
- http://import.io/,
- Mozenda (есть также ПО для установки на компьютер),
- Octoparce,
- ParseHub.
Примеры облачных парсеров с русскоязычным интерфейсом:
- Xmldatafeed,
- Диггернаут,
- Catalogloader.
У всех сервисов есть бесплатная версия, которая ограничена или периодом использования, или количеством страниц для сканирования.
Программы-парсеры
ПO для парсинга устанавливается на компьютер. В подавляющем большинстве случаев такие парсеры совместимы с ОС Windows. Обладателям mac OS можно запускать их с виртуальных машин. Некоторые программы могут работать со съемных носителей.
Примеры парсеров-программ:
- ParserOK,
- Datacol,
- SEO-парсеры — Screaming Frog, ComparseR, Netpeak Spider и другие.
Парсеры сайтов в зависимости от используемой технологии
Парсеры на основе Python и PHP
Такие парсеры создают программисты. Без специальных знаний сделать парсер самостоятельно не получится. На сегодня самый популярный язык для создания таких программ Python. Разработчикам, которые им владеют, могут быть полезны:
- библиотека Beautiful Soup;
- фреймворки с открытым исходным кодом Scrapy, Grab и другие.
Заказывать разработку парсера с нуля стоит только для нестандартных задач. Для большинства целей можно подобрать готовые решения.
Парсеры-расширения для браузеров
Парсить данные с сайтов могут бесплатные расширения для браузеров. Они извлекают данные из html-кода страниц при помощи языка запросов Xpath и выгружают их в удобные для дальнейшей работы форматы — XLSX, CSV, XML, JSON, Google Таблицы и другие. Так можно собрать цены, описания товаров, новости, отзывы и другие типы данных.
Примеры расширений для Chrome: Parsers, Scraper, Data Scraper, kimono.
Парсеры сайтов на основе Excel
В таких программах парсинг с последующей выгрузкой данных в форматы XLS* и CSV реализован при помощи макросов — специальных команд для автоматизации действий в MS Excel. Пример такой программы — ParserOK. Бесплатная пробная версия ограничена периодом в 10 дней.
Парсинг при помощи Google Таблиц
В Google Таблицах парсить данные можно при помощи двух функций — importxml и importhtml.
- Функция IMPORTXML импортирует данные из источников формата XML, HTML, CSV, TSV, RSS, ATOM XML в ячейки таблицы при помощи запросов Xpath. Синтаксис функции:
IMPORTXML("https://site.com/catalog"; "//a/@href")
IMPORTXML(A2; B2)
Расшифруем: в первой строке содержится заключенный в кавычки url (обязательно с указанием протокола) и запрос Xpath.
Знание языка запросов Xpath для использования функции не обязательно, можно воспользоваться опцией браузера «копировать Xpath»:
Вторая строка указывает ячейки, куда будут импортированы данные.
IMPORTXML можно использовать для сбора метатегов и заголовков, количества внешних ссылок со страницы, количества товаров на странице категории и других данных.
- У IMPORTHTML более узкий функционал — она импортирует данные из таблиц и списков, размещенных на странице сайта. Синтаксис функции:
IMPORTHTML("https://https://site.com/catalog/sweets"; "table"; 4)
IMPORTHTML(A2; B2; C2)
Расшифруем: в первой строке, как и в предыдущем случае, содержится заключенный в кавычки URL (обязательно с указанием протокола), затем параметр “table”, если хотите получить данные из таблицы, или “list”, если из списка. Числовое значение (индекс) означает порядковый номер таблицы или списка в html-коде страницы.
Парсеры сайтов в зависимости от решаемых задач
Чтобы не ошибиться с выбором ПО или облачного сервиса для парсинга, нужно понимать спектр задач, которые они решают. Мы разделили парсеры по сферам применения.
Парсеры для организаторов совместных покупок (СП)
Отдельная категория парсеров предназначена для тех, кто занимается организацией совместных покупок в соцсетях ВКонтакте и Одноклассники. Владельцы групп СП закупают партии товара мелким оптом по цене дешевле, чем в розницу. Для этого нужно постоянно мониторить ассортимент и цены на сайтах поставщиков. Чтобы сократить трудозатраты, можно использовать специализированные парсеры.
У таких парсеров простой, интуитивно понятный интерфейс панели управления, в котором можно указать необходимые настройки — страницы для парсинга, расписание, группы в соцсетях для выгрузки и другие.
Примеры сервисов:
- SPparser.ru,
- Турбо.Парсер,
- PARSER.PLUS,
- Q-Parser,
- Облачный парсер.
Что умеют парсеры для СП:
- парсить товары из интернет-магазинов и групп в соцсетях;
- выгружать товары с фото и ценами в альбомы соцсетей — Одноклассники и ВКонтакте;
- выгружать данные в формате CSV и XLS(X);
- обновлять информацию в автоматическом режиме — подгружать новые товары и удалять те, которых нет в наличии.
Сервисы мониторинга конкурентов
Эта группа парсеров позволяет ценам в интернет-магазине оставаться на уровне рынка. Сервисы мониторят заданные ресурсы, сопоставляют товары и цены на них с вашим каталогом и предоставляет возможность скорректировать цену на более привлекательную. Такие парсеры мониторят сайты конкурентов, обновляемые прайсы в форматах XLS(X), CSV и других, маркетплейсы (Яндекс.Маркет, e-katalog и другие прайс-агрегаторы).
Примеры парсеров цен конкурентов:
- Marketparser,
- Xmldatafeed,
- ALL RIVAL.
Сбор данных и автонаполнение контентом
Такие парсеры облегчают работу контент-менеджерам интернет-магазинов тем, что заменяют ручной мониторинг сайтов поставщиков, сравнение и изменение ассортимента, описаний, цен. Парсер собирает данные с сайтов-доноров (названия и описания товаров, цены, изображения и др.), выгружает их в файл или сразу на сайт. В настройках есть возможность сделать наценку, объединить данные с нескольких сайтов, запускать сбор данных в автоматическом режиме по расписанию или вручную.
Примеры парсеров для наполнения интернет-магазинов:
- Catalogloader,
- Xmldatafeed,
- Диггернаут
Многофункциональные парсеры
Такие инструменты способны собирать данные под разные задачи — наполнение интернет-магазинов, мониторинг цен конкурентов, парсинг агрегаторов данных, сбор SEO-параметров и прочее. К этой группе относятся все браузерные расширения с функцией парсинга.
Другие примеры многофункциональных парсеров:
- Import.io, Mozenda — комплексы инструментов для извлечения и визуализации данных. Подходят для среднего и крупного бизнеса с большим объемом задач.
- Octoparce — инструмент для мониторинга цен и сбора данных с любого сайта. Данные выгружаются в форматы CSV или Excel. Есть доступ по API.
- ParseHub — облачный парсер для сбора цен, контактов, маркетинговых данных, скачивания файлов, мониторинга конкурентов. Работает со всеми типами сайтов, в том числе, агрегаторами и маркетплейсами. Данные доступны в форматах CSV, Excel, Google Sheets, предоставляется доступ по API.
- Datacol. Извлекает данные с сайтов, агрегаторов, соцсетей, Яндекс.Карт и других источников. Базовые функции можно расширить при помощи плагинов. Программа платная, но есть демо-версия для тестирования.
- ParserOK. С помощью программы можно парсить данные из интернет-магазинов, контактов, загружать файлы различных форматов в облачное хранилище.
SEO-парсеры
Парсеры используются SEO-специалистами для комплексного анализа сайта: внутренней, технической и внешней оптимизации. У одних может быть узкий функционал, другие представляют собой мощные SEO-комбайны из различных профессиональных инструментов.
Задачи, которые могут выполнять SEO-парсеры:
- указывать на корректность настройки главного зеркала;
- анализировать содержание robots.txt и sitemap.xml;
- указывать наличие, длину и содержание метатегов title и description, количество и содержание заголовков h1 — h6;
- определять коды ответа страниц;
- генерировать XML-карту сайта;
- определять уровень вложенности страниц и визуализировать структуру сайта;
- указывать наличие/отсутствие атрибутов alt у картинок;
- определять битые ссылки;
- определять наличие атрибута rel=»canonical»;
- предоставлять данные по внутренней перелинковке и внешней ссылочной массе;
- отображать сведения о технической оптимизации: скорости загрузки, валидности кода, оптимизации под мобильные устройства и др.
Кратко охарактеризуем функционал популярных SEO-парсеров:
- Screaming Frog SEO Spider
- Netpeak Spider
- ComparseR
- SiteAnalyzer от Majento
- SE Ranking
- A-Parser
- PR-CY
- Xenu’s Link Sleuth
Screaming Frog SEO Spider
Пожалуй, самый популярный SEO-анализатор от британских разработчиков. С его помощью можно быстро и наглядно выяснить:
- содержимое, код ответа, статус индексации каждой страницы;
- длину и содержимое title и description;
- наличие и содержимое заголовков h1 и h2;
- информацию об изображениях на сайте — формат, размер, статус индексации;
- информацию по настройке канонических ссылок и пагинации;
- другие важные данные.
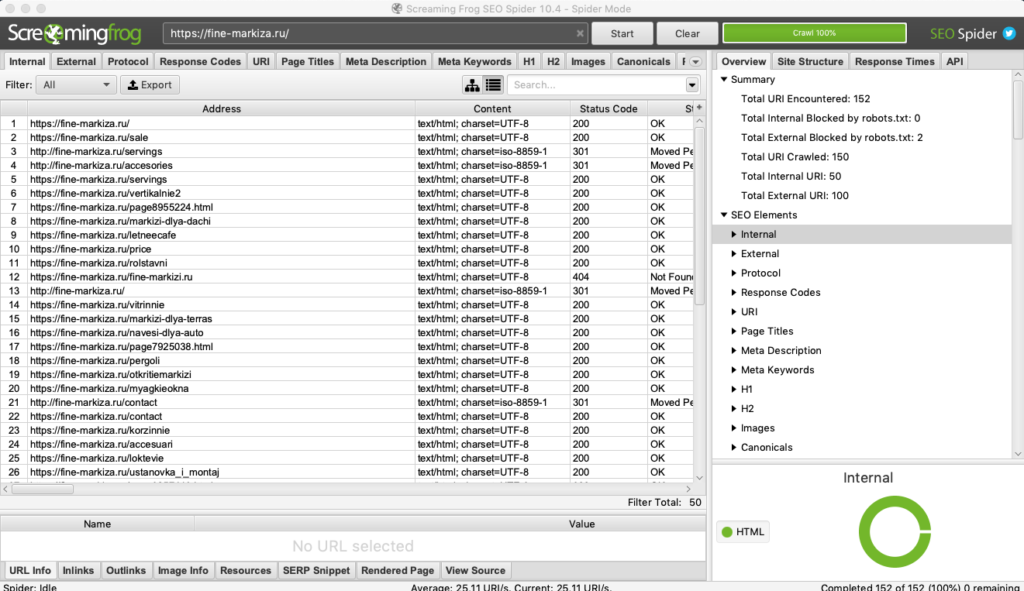 Интерфейс бесплатной версии Screaming Frog
Интерфейс бесплатной версии Screaming Frog
Бесплатная версия ограничена 500-ми url. В платной (лицензию можно купить на год) количество страниц для парсинга не ограничено, и она имеет гораздо больше возможностей. Среди них — парсинг цен, названий и описаний товаров с любого сайта. Как это сделать, мы подробно описали в гайде.
Netpeak Spider
Популярный инструмент для комплексного анализа сайта. Проверяет ресурс на ошибки внутренней оптимизации, анализирует важные для SEO параметры: битые ссылки, дубли страниц и метатегов, коды ответа, редиректы и другие. Можно импортировать данные из Google Search Console и систем веб-аналитики. Для агентств есть возможность сформировать брендированный отчет.
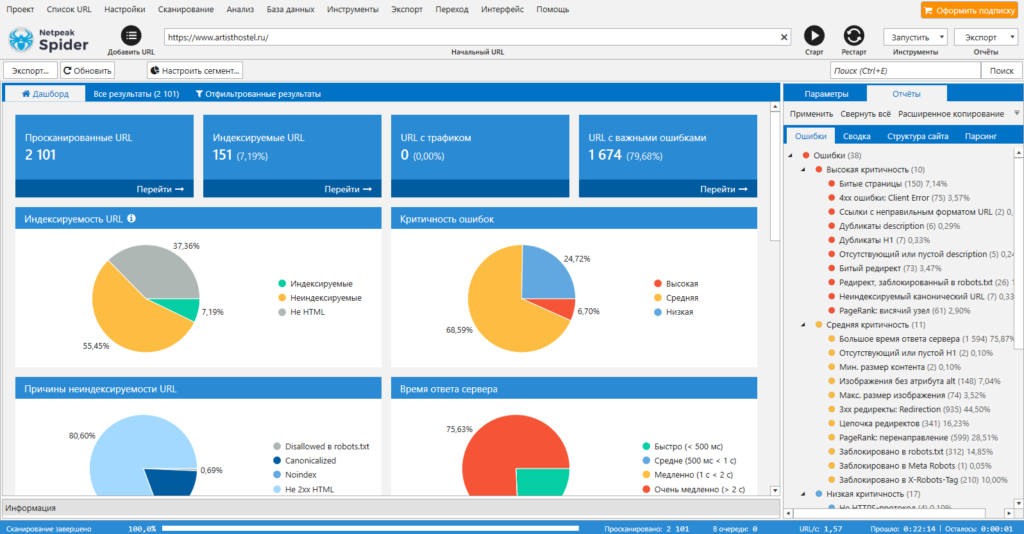 Интерфейс Netpeak Spider
Интерфейс Netpeak Spider
Инструмент платный, базовые функции доступны доступны во всех тарифах. Бесплатный пробный период — 14 дней.
ComparseR
Это программа, которая анализирует ресурс на предмет технических ошибок. Особенность парсера в том, что он также показывает все страницы сайта в индексе Яндекс и Google. Эта функция полезна, чтобы выяснить, какие url не попали в индекс, а какие находятся в поиске (и те ли это страницы, которые нужны оптимизатору).
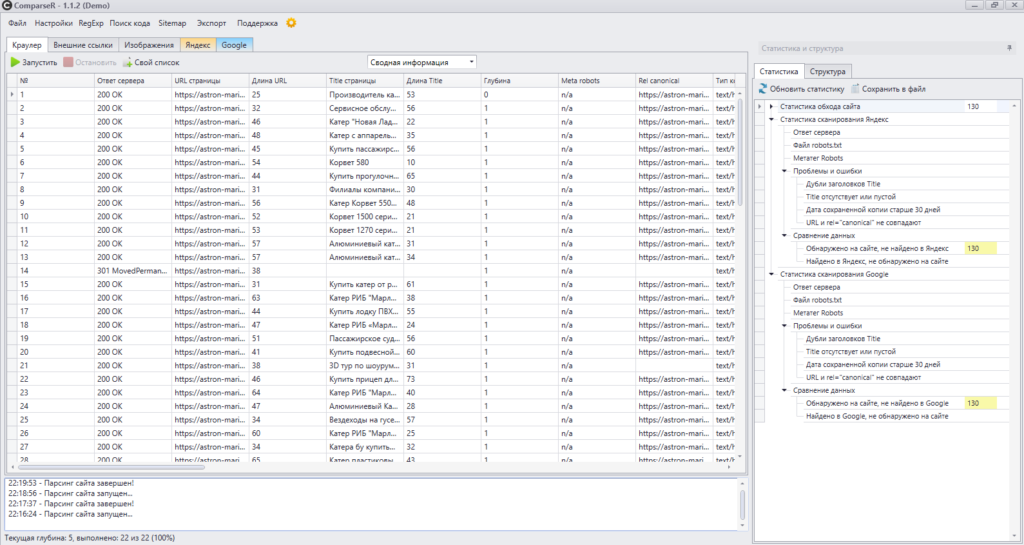 Интерфейс демо-версии ComparseR 1.1.2.
Интерфейс демо-версии ComparseR 1.1.2.
Программу можно купить и установить на один компьютер. Для того, чтобы ознакомиться с принципом работы, скачайте демо-версию.
SiteAnalyzer от Majento
Бесплатная программа для сканирования всех страниц, скриптов, документов и изображений сайта. Используется для проведения технического SEO-аудита. Требует установки на ПК (ОС Windows), но может работать и со съемного носителя. «Вытаскивает» следующие данные: коды ответа сервера, наличие и содержимое метатегов и заголовков, определение атрибута rel=»canonical», внешние и внутренние ссылки для каждой страницы, дубли страниц и другие.
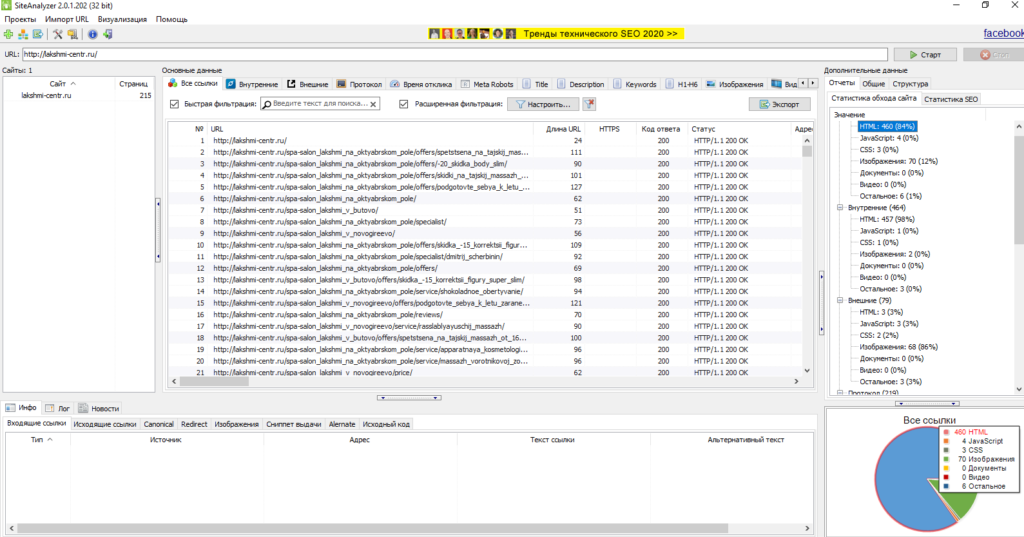 Интерфейс SiteAnalyzer 2.0.
Интерфейс SiteAnalyzer 2.0.
Отчет можно экспортировать в форматы CSV, XLS и PDF.
Анализ сайта от SE Ranking
Инструмент анализирует ключевые параметры оптимизации сайта: наличие robots.txt и sitemap.xml, настройка главного зеркала, дубли страниц, коды ответа, метатеги и заголовки, технические ошибки, скорость загрузки, внутренние ссылки. По итогам сканирования сайту выставляется оценка по 100-балльной шкале. Есть опция создания XML-карты сайта. Полезная возможность для агентств — формирование брендированного отчета, который можно скачать в удобном формате или отправить на email. Отчеты запускаются вручную или по расписанию.
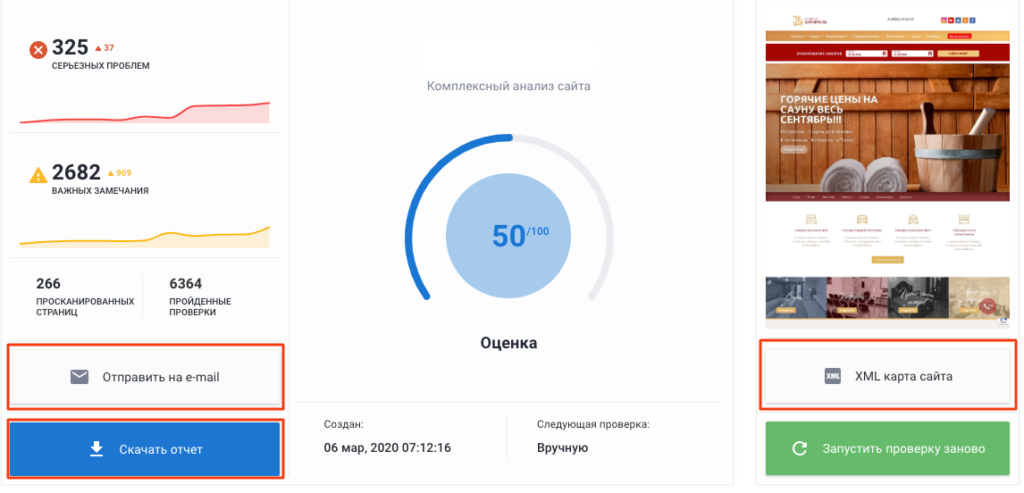 Дашборд со сводными данными анализа сайта от SE Ranking
Дашборд со сводными данными анализа сайта от SE Ranking
Возможны две модели оплаты — за проверки позиций и ежемесячная подписка. Бесплатный пробный период — 2 недели.
A-Parser
Этот сервис объединяет более 70 парсеров под разные цели: парсинг выдачи популярных поисковых систем, ключевых слов, приложений, социальных сетей, Яндекс и Google карт, крупнейших интернет-магазинов, контента и другие. Кроме использования готовых инструментов есть возможности для программирования собственных парсеров на основе регулярных выражений, XPath, JavaScript. Разработчики также предоставляют доступ по API.
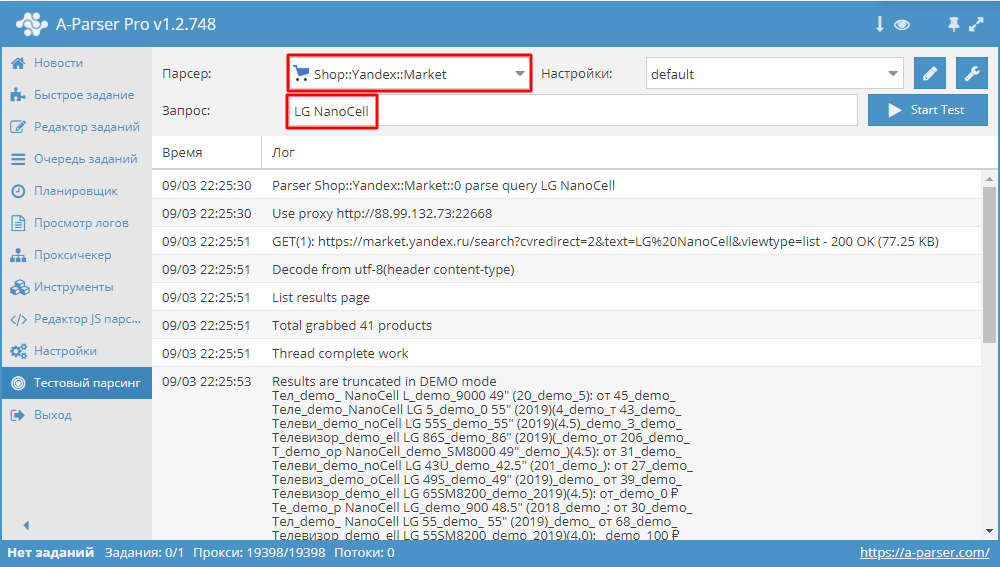 Интерфейс демо-версии A-Parser: парсинг результатов Яндекс.Маркета по названию модели телевизора.
Интерфейс демо-версии A-Parser: парсинг результатов Яндекс.Маркета по названию модели телевизора.
Тарифы зависят от количества опций и срока бесплатных обновлений. Возможности парсера можно оценить в демо-версии, которая будет доступна в течение шести часов после регистрации.
Анализ сайта от PR-CY
Онлайн-инструмент для анализа сайтов более чем по 70 пунктам. Указывает на ошибки оптимизации, предлагает варианты их решения, формирует SEO-чеклист и рекомендации по улучшению ресурса. По итогам сканирования сайту выставляется оценка в процентах.
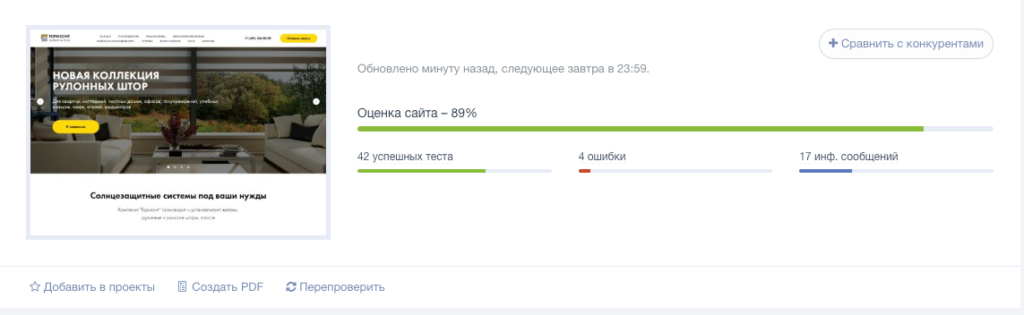 Сводные данные сканирования сайта в интерфейсе PR-CY
Сводные данные сканирования сайта в интерфейсе PR-CY
Бесплатно можно получить лишь общую информацию по количеству страниц в индексе, наличию/отсутствию вирусов и фильтров поисковых систем, ссылочному профилю и некоторые другие данные. Более детальный анализ платный. Тариф зависит от количества сайтов, страниц в них и проверок на аккаунте. Есть возможность для ежедневного мониторинга, сравнения с показателями конкурентов и выгрузки брендированных отчетов. Бесплатный пробный период — 7 дней.
Упомянем также о парсерах, которые решают узконаправленные задачи и могут быть полезны владельцам сайтов, вебмастерам и SEO-специалистам.
Xenu’s Link Sleuth
Бесплатная программа для парсинга всех url сайта: внешних и внутренних ссылок, ссылок на картинки и скрипты и т.д. Можно использовать для разных задач, в том числе, для поиска битых ссылок на сайте. Программу нужно скачать и установить на компьютер (ОС Windows).
По каждой ссылке будет показан ее статус, тип (например, text/plain или text/html), размер, анкор и ошибка.
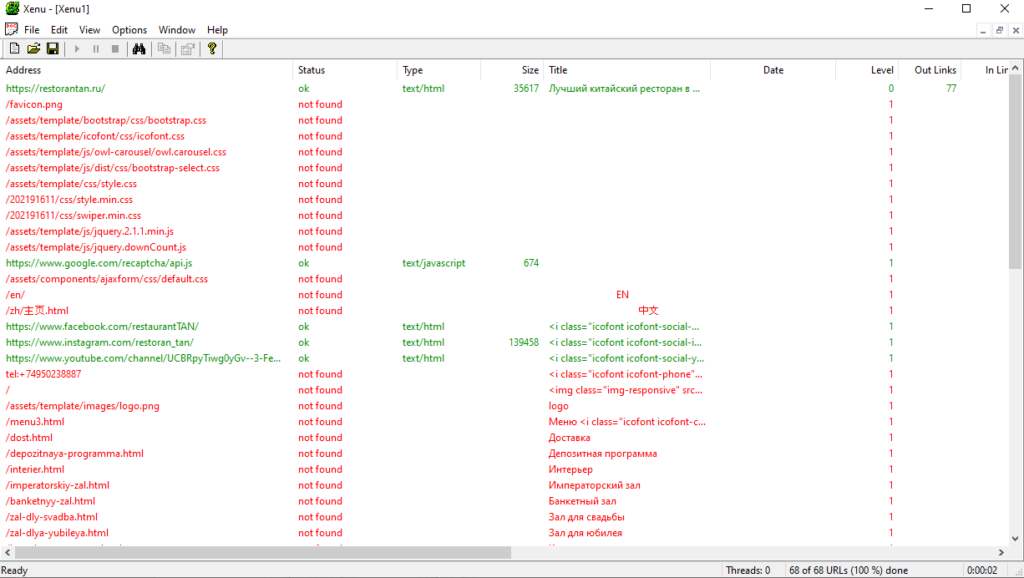 Интерфейс программы Xenu’s Link Sleuth
Интерфейс программы Xenu’s Link Sleuth
Парсер метатегов и заголовков PromoPult
Это инструмент, который парсит метатеги title, description, keywords и заголовки h1-h6. Можно воспользоваться им для анализа своего проекта или сайтов-конкурентов. В первом случае легко выявить незаполненные, неинформативные, слишком длинные или короткие метатеги, дубли метаданных, во втором — выяснить, какие ключевые запросы используют конкуренты, определить структуру и логику формирования метатегов.
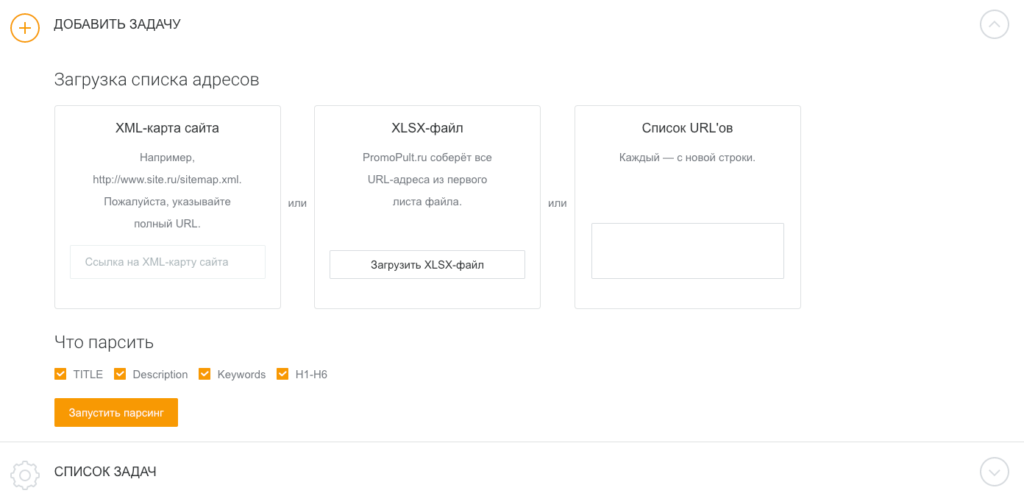
Добавить список url можно вручную, XLSX-файлом или ссылкой на XML-карту сайта. Отчеты выгружаются в форматах HTML и XLSX. Первые 500 запросов — бесплатно. Все нюансы работы с инструментом мы описали в гайде.
Как выбрать парсер
- Определитесь с целью парсинга: мониторинг конкурентов, наполнение каталога, проверка SEO-параметров, совмещение нескольких задач.
- Выясните, какие данные в каком объеме и в каком виде вам нужно получить на выходе.
- Подумайте о том, насколько регулярно вам нужно собирать и обрабатывать данные: разово, ежемесячно, ежедневно?
- Если у вас большой ресурс со сложным функционалом, имеет смысл заказать создание парсера с гибкими настройками под ваши цели. Для стандартных проектов на рынке достаточно готовых решений.
- Выберите несколько инструментов и изучите отзывы. Особое внимание обратите на качество технической поддержки.
- Соотнесите уровень подготовки (свой или ответственного за работу с данными лица) со сложностью инструмента.
- На основе перечисленных выше параметров выберите подходящий инструмент и тариф. Возможно, под ваши задачи хватит бесплатного функционала или пробного периода.
На первый взгляд Excel и парсинг понятия несовместимые. Как с помощью табличного редактора можно получать информацию из сети? И ведь многие недооценивают Excel, а это вполне посильная задача для него. При этом все делается стандартными методами без необходимости дополнительно что-то устанавливать/настраивать.
Разберем на конкретном примере по получению информации с сайта Минюста, а именно, нам необходим перечень действующих адвокатов Российской Федерации. Кнопки «выгрузить списочно всех адвокатов» — конечно же, нет. На официальном сайте http://lawyers.minjust.ru/ выводится по 20 адвокатов на 1 странице, всего 74 754 страниц, итого на выходе мы должны получить чуть меньше 150 тыс. адвокатов.
Для начала открываем VBA и создаем объект InternetExplorer, посредством которого будем получать данные.
Затем надо определить, как будем переходить между страницами на сайте – для этого просматриваем элемент перехода на следующую страницу. Ссылка между станицами отличается значением в конце и соответствует номеру страницы – 1.
Имея информацию о ссылке страницы — осуществляем их перебор, загружаем в InternetExplorer и забираем все данные со страницы.
В коде страницы представлена структура таблицы со всеми столбцами, которые нам необходимы: реестровый номер, ФИО адвоката, субъект РФ, номер удостоверения, текущий статус.
Для получения этой информации с помощью ключевых слов осуществляем поиск по тегам и забираем требуемые данные.
В итоге получаем список всех адвокатов в таблицу Excel для дальнейшей обработки.