
In this article, we are going to see how to get string length in Bash scripting.
Here are a few ways from which we can get the length of the string in BASH:
- Using the # operator
- Using while loop
- Using expr command
- Using awk command
- Using wc command
Using these mentioned tools and commands, we will be able to get the length of a string variable in the BASH script.
Method 1: Using the # operator
#!usr/bin/env bash
str="this is a string"
n=${#str}
echo "Length of the string is : $n "
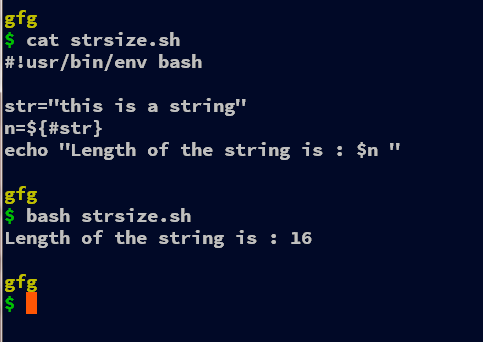
We can use the # operator to get the length of the string in BASH, we need to enclose the variable name enclosed in “{ }” and inside of that, we use the # to get the length of the string variable. Thus, using the “#” operator in BASH, we can get the length of the string variable.
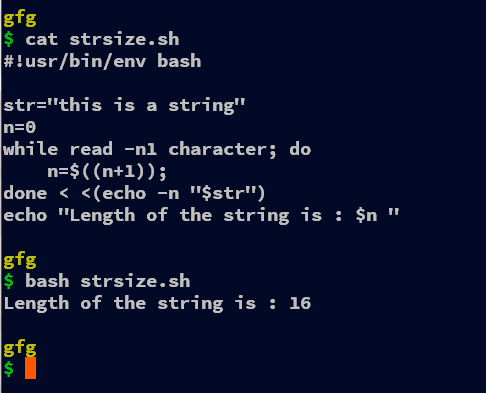
Method 2: Using while loop
In this example. we can use the while loop along with the read command to obtain the length of the string. Firstly we initialize the string to whatever you like, it can be a user input, positional parameter, etc. It’s quite easy to work with the variable, so therefore we create a variable for the string and also initialize the length “n” to 0. Then we start the while loop by reading characters by character using the argument -n1 i.e read just the single character from the entire string.
For every character in the variable “str” i.e. after every iteration, we increment the length “n” by one. In the while loop, we are reading from the string “str” with echo command along with -n argument which restricts to escape of the newline character. Thus at the end of the loop, we have the length of the string in the variable n which can be accessed as per requirements.
#!usr/bin/env bash
str="this is a string"
n=0
while read -n1 character; do
n=$((n+1));
done < <(echo -n "$str")
echo "Length of the string is : $n "
Method 3: Using expr command
#!usr/bin/env bash str="Test String@#$" n=`expr "$str" : '.*'` echo "Length of the string is : $n "
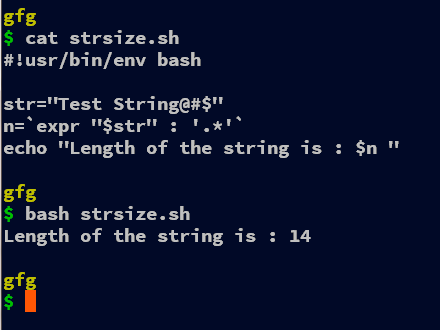
In this example, we are using the expr command to find the length of the string in BASH. The expr command takes the first argument as the string variable and then the comparison operator “:” that counts the number of common characters in the string and the next string provided after the “:” operator. For calculating the length of the string, we parse the previous string. For that “.*” is the regex that gets 0 or more characters of the previously provided token. Even parsing the string instead of “.*” will work
n=`expr "$str" : "$str"`
Here we have used the backticks(“` `“) but even using the $( ) there is no such advantage of using the former over the latter. Both serve the same purpose but the $( ) nests very effective than the backticks.
#!usr/bin/env bash str="Test String@#$" n=`expr length "$str"` echo "Length of the string is : $n "
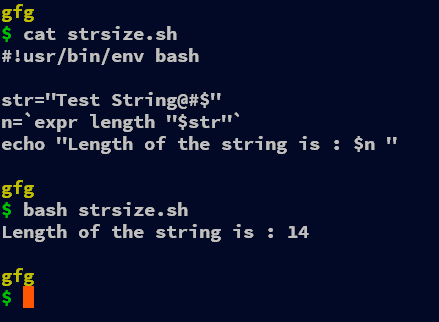
We can even use the built-in function in expr command “length” that gets the length of the string as a parameter just after the function. The length command as the name suggests gives us the length of the provided string or any variable.
Remember for every code snippet following this one, you can use the $( ) instead of backticks(` `).
n=$(expr length "$str")
Method 4: Using awk command
#!usr/bin/env bash
str="this is a string"
n=`echo $str | awk '{print length}'`
echo "Length of the string is : $n "
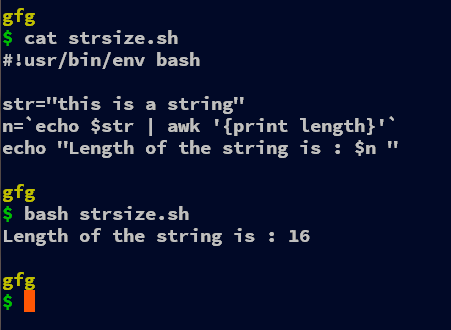
We can even use the awk command to get the length of the string. We use the function length which is built-in awk along with print that prints the value and thus stores the length of the string after piping (“|“) with the echo command.
In the expression, echo $str | awk ‘{print length}’ we echo the string variable “str” and then redirect (pipe) the output of it to the awk command. In the awk command, we print the output of the length function, which takes the str variable and stores it in the variable “n“.
Method 5: Using wc command
#!usr/bin/env bash str="this is a string" n=`echo -n "$str"|wc -c` echo "Length of the string is : $n "
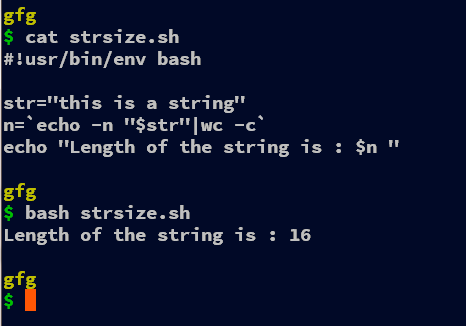
In this demonstration, we have used the wc command to get the length of the string. Inside of this command, “echo -n “$str” | wc -c” the echo command is given an argument -n which doesn’t escape the new line character. Next, the output of the echo command is redirected (piped) to the wc command which again is given the argument -c which counts the number of bytes in the provided variable, we can even use -m which also precisely counts the number of characters.
echo -n "$str" | wc -m
I would like to divide a line by word and then give for each the length and the position in the line.
for word in $line
do
start=`awk -v a="$Logline" -v b="$word" 'BEGIN{print index(a,b)}'`
count=`echo $word|wc -m`
echo $word : $start : $count
done
So let’s suppose:
line = ‘This is a test to test’
I would Obtain :
This : 0 : 4
is : 5 : 2
a : 8 : 1
test : 10 : 4
to : 15 : 2
test : 18 : 4
With this solution, the problem appears when two words are identical. Someone has an idea of how to do this?
asked Mar 21, 2014 at 22:57
![]()
museczmusecz
7777 silver badges17 bronze badges
4
May be you are trying to do this:
$ cat file
Hi my name is jaypal
i am a software software test engineer
scripting in awk awk awk is my hobby
$ awk '{for(i=1;i<=NF;i++)printf "Line=%d Length=%d Word=%sn",NR,length($i),$i}' file
Line=1 Length=2 Word=Hi
Line=1 Length=2 Word=my
Line=1 Length=4 Word=name
Line=1 Length=2 Word=is
Line=1 Length=6 Word=jaypal
Line=2 Length=1 Word=i
Line=2 Length=2 Word=am
Line=2 Length=1 Word=a
Line=2 Length=8 Word=software
Line=2 Length=8 Word=software
Line=2 Length=4 Word=test
Line=2 Length=8 Word=engineer
Line=3 Length=9 Word=scripting
Line=3 Length=2 Word=in
Line=3 Length=3 Word=awk
Line=3 Length=3 Word=awk
Line=3 Length=3 Word=awk
Line=3 Length=2 Word=is
Line=3 Length=2 Word=my
Line=3 Length=5 Word=hobby
answered Mar 22, 2014 at 1:58
![]()
jaypal singhjaypal singh
73.7k23 gold badges102 silver badges147 bronze badges
1
$ cat file
This is a test to test
$
$ cat tst.awk
BEGIN{ OFS=" : " }
{
start = 0
while ( match($0,/[^ ]+/) ) {
start = start + RSTART - 1
print substr($0,RSTART,RLENGTH), start, RLENGTH
$0 = substr($0,RSTART+RLENGTH)
start = start + RLENGTH
}
}
$
$ awk -f tst.awk file
This : 0 : 4
is : 5 : 2
a : 8 : 1
test : 10 : 4
to : 15 : 2
test : 18 : 4
answered Mar 22, 2014 at 13:56
![]()
Ed MortonEd Morton
184k17 gold badges76 silver badges183 bronze badges
0
If you have only one space between words, you could do:
$>echo "this test is a test" | sed 's/ / n/g'| awk 'BEGIN{i=0}{print $1, ":", i, length($1);i+=length($0)}'
this : 0 4
test : 5 4
is : 10 2
a : 13 1
test : 15 4
answered Mar 21, 2014 at 23:22
![]()
fredtantinifredtantini
15.7k8 gold badges49 silver badges55 bronze badges
7
pos=0
for word in $line
do
length=`expr length "$word"`
echo "$word : $pos : $length"
pos=`expr $pos + 1`
done
answered Mar 21, 2014 at 23:19
![]()
nettuxnettux
5,2302 gold badges23 silver badges33 bronze badges
I have 100 million rows in my file.
Each row has only one column.
e.g.
aaaaa
bb
cc
ddddddd
ee
I would like to list the character count
Like this
2 character words - 3
5 character words - 1
7 character words - 1
etc.
Is there any easy way to do this in terminal?
![]()
asked Oct 8, 2017 at 15:38
![]()
1
$ awk '{ print length }' file | sort -n | uniq -c | awk '{ printf("%d character words: %dn", $2, $1) }'
2 character words: 3
5 character words: 1
7 character words: 1
The first awk filter will just print the length of each line in the file called file. I’m assuming that this file contains one word per line.
The sort -n (sort the lines from the output of awk numerically in ascending order) and uniq -c (count the number of times each line occurs consecutively) will then create the following output from that for the given data:
3 2
1 5
1 7
This is then parsed by the second awk script which interprets each line as «X number of lines having Y characters» and produces the wanted output.
The alternative solution is to do it all in awk and keeping counts of lengths in an array. It’s a tradeoff between efficiency, readability/ease of understanding (and therefore maintainability) which solution is the «best».
Alternative solution:
$ awk '{ len[length]++ } END { for (i in len) printf("%d character words: %dn", i, len[i]) }' file
2 character words: 3
5 character words: 1
7 character words: 1
answered Oct 8, 2017 at 15:43
![]()
Kusalananda♦Kusalananda
312k35 gold badges614 silver badges909 bronze badges
3
Another way to do it all with awk alone
$ awk '{words[length()]++} END{for(k in words)print k " character words - " words[k]}' ip.txt
2 character words - 3
5 character words - 1
7 character words - 1
words[length()]++use length of input line as key to save countEND{for(k in words)print k " character words - " words[k]}after all lines are processed, print contents of array in desired format
Performance comparison, numbers selected are best of two runs
$ wc words.txt
71813 71813 655873 words.txt
$ perl -0777 -ne 'print $_ x 1000' words.txt > long_file.txt
$ du -h --apparent-size long_file.txt
626M long_file.txt
$ time awk '{words[length()]++} END{for(k in words)print k " character words - " words[k]}' long_file.txt > t1
real 0m20.632s
user 0m20.464s
sys 0m0.108s
$ time perl -lne '$h{length($_)}++ }{ for $n (sort keys %h) {print "$n character words - $h{$n}"}' long_file.txt > t2
real 0m19.749s
user 0m19.640s
sys 0m0.108s
$ time awk '{ print length }' long_file.txt | sort -n | uniq -c | awk '{ printf("%d character words - %dn", $2, $1) }' > t3
real 1m23.294s
user 1m24.952s
sys 0m1.980s
$ diff -s <(sort t1) <(sort t2)
Files /dev/fd/63 and /dev/fd/62 are identical
$ diff -s <(sort t1) <(sort t3)
Files /dev/fd/63 and /dev/fd/62 are identical
If file has only ASCII characters,
$ time LC_ALL=C awk '{words[length()]++} END{for(k in words)print k " character words - " words[k]}' long_file.txt > t1
real 0m15.651s
user 0m15.496s
sys 0m0.120s
Not sure why time for perl didn’t change much, probably encoding has to be set some other way
answered Oct 8, 2017 at 15:59
![]()
SundeepSundeep
11.4k2 gold badges25 silver badges55 bronze badges
9
Here’s a perl equivalent (with — optional — sort):
$ perl -lne '
$h{length($_)}++ }{ for $n (sort keys %h) {print "$n character words - $h{$n}"}
' file
2 character words - 3
5 character words - 1
7 character words - 1
answered Oct 8, 2017 at 16:50
![]()
steeldriversteeldriver
76.5k11 gold badges104 silver badges145 bronze badges
4
An alternative one call to GNU awk, using printf:
$ awk 'BEGIN { PROCINFO["sorted_in"] = "@ind_str_asc"}
{c[length($0)]++}
END{
for(i in c){printf("%s character words - %sn",i,c[i])}
}' infile
2 character words - 3
5 character words - 1
7 character words - 1
The core algorithm just collects character counts in an array.
The end part prints the collected counts formatted with printf.
Fast, simple, one single call to awk.
To be precise: some more memory is used to keep the array.
But no sort is called (numeric arrays indexes are set to be always traversed sorted upward with PROCINFO), and only one external program: awk, instead of several.
![]()
Jeff Schaller♦
65.6k34 gold badges106 silver badges242 bronze badges
answered Oct 8, 2017 at 17:55
3
Example
Returns the number of characters of the given String
Considerations
-
If a number is given instead a String, the result will be the length of the String representing the given number. I.e. If we execute
length(12345)the result will be the same aslength("12345"), that is 5 -
If no value is given, the result will be the length of the actual row being processed, that is
length($0)
- It can be used inside a pattern or inside code-blocks.
Examples
Here are a few examples demonstrating how length()works
$ cat file
AAAAA
BBBB
CCCC
DDDD
EEEE
Inside a pattern
Filter all lines with a length bigger than 4 characters
$ awk ' length($0) > 4 ' file
AAAAA
Inside a code block
Will print the size of the current line
$ awk '{ print length($0) }' file
5
4
4
4
4
With no data given
Will print the size of the current line
$ awk '{ print length }' file
5
4
4
4
4
Will print the size of the current line
$ awk '{ print length() }' file
5
4
4
4
4
Number given instead of String
Will print the size of the String representing the number
$ awk '{ print length(12345) }' file
5
5
5
5
5
Fixed String given
Will print the size of the String
$ awk '{ print length("12345") }' file
5
5
5
5
5
AWK has the following built-in String functions −
asort(arr [, d [, how] ])
This function sorts the contents of arr using GAWK’s normal rules for comparing values, and replaces the indexes of the sorted values arr with sequential integers starting with 1.
Example
[jerry]$ awk 'BEGIN {
arr[0] = "Three"
arr[1] = "One"
arr[2] = "Two"
print "Array elements before sorting:"
for (i in arr) {
print arr[i]
}
asort(arr)
print "Array elements after sorting:"
for (i in arr) {
print arr[i]
}
}'
On executing this code, you get the following result −
Output
Array elements before sorting: Three One Two Array elements after sorting: One Three Two
asorti(arr [, d [, how] ])
The behavior of this function is the same as that of asort(), except that the array indexes are used for sorting.
Example
[jerry]$ awk 'BEGIN {
arr["Two"] = 1
arr["One"] = 2
arr["Three"] = 3
asorti(arr)
print "Array indices after sorting:"
for (i in arr) {
print arr[i]
}
}'
On executing this code, you get the following result −
Output
Array indices after sorting: One Three Two
gsub(regex, sub, string)
gsub stands for global substitution. It replaces every occurrence of regex with the given string (sub). The third parameter is optional. If it is omitted, then $0 is used.
Example
[jerry]$ awk 'BEGIN {
str = "Hello, World"
print "String before replacement = " str
gsub("World", "Jerry", str)
print "String after replacement = " str
}'
On executing this code, you get the following result −
Output
String before replacement = Hello, World String after replacement = Hello, Jerry
index(str, sub)
It checks whether sub is a substring of str or not. On success, it returns the position where sub starts; otherwise it returns 0. The first character of str is at position 1.
Example
[jerry]$ awk 'BEGIN {
str = "One Two Three"
subs = "Two"
ret = index(str, subs)
printf "Substring "%s" found at %d location.n", subs, ret
}'
On executing this code, you get the following result −
Output
Substring "Two" found at 5 location.
length(str)
It returns the length of a string.
Example
[jerry]$ awk 'BEGIN {
str = "Hello, World !!!"
print "Length = ", length(str)
}'
On executing this code, you get the following result −
Length = 16
match(str, regex)
It returns the index of the first longest match of regex in string str. It returns 0 if no match found.
Example
[jerry]$ awk 'BEGIN {
str = "One Two Three"
subs = "Two"
ret = match(str, subs)
printf "Substring "%s" found at %d location.n", subs, ret
}'
On executing this code, you get the following result −
Output
Substring "Two" found at 5 location
split(str, arr, regex)
This function splits the string str into fields by regular expression regex and the fields are loaded into the array arr. If regex is omitted, then FS is used.
Example
[jerry]$ awk 'BEGIN {
str = "One,Two,Three,Four"
split(str, arr, ",")
print "Array contains following values"
for (i in arr) {
print arr[i]
}
}'
On executing this code, you get the following result −
Output
Array contains following values One Two Three Four
printf(format, expr-list)
This function returns a string constructed from expr-list according to format.
Example
[jerry]$ awk 'BEGIN {
param = 1024.0
result = sqrt(param)
printf "sqrt(%f) = %fn", param, result
}'
On executing this code, you get the following result −
Output
sqrt(1024.000000) = 32.000000
strtonum(str)
This function examines str and return its numeric value. If str begins with a leading 0, it is treated as an octal number. If str begins with a leading 0x or 0X, it is taken as a hexadecimal number. Otherwise, assume it is a decimal number.
Example
[jerry]$ awk 'BEGIN {
print "Decimal num = " strtonum("123")
print "Octal num = " strtonum("0123")
print "Hexadecimal num = " strtonum("0x123")
}'
On executing this code, you get the following result −
Output
Decimal num = 123 Octal num = 83 Hexadecimal num = 291
sub(regex, sub, string)
This function performs a single substitution. It replaces the first occurrence of the regex pattern with the given string (sub). The third parameter is optional. If it is omitted, $0 is used.
Example
[jerry]$ awk 'BEGIN {
str = "Hello, World"
print "String before replacement = " str
sub("World", "Jerry", str)
print "String after replacement = " str
}'
On executing this code, you get the following result −
Output
String before replacement = Hello, World String after replacement = Hello, Jerry
substr(str, start, l)
This function returns the substring of string str, starting at index start of length l. If length is omitted, the suffix of str starting at index start is returned.
Example
[jerry]$ awk 'BEGIN {
str = "Hello, World !!!"
subs = substr(str, 1, 5)
print "Substring = " subs
}'
On executing this code, you get the following result −
Output
Substring = Hello
tolower(str)
This function returns a copy of string str with all upper-case characters converted to lower-case.
Example
[jerry]$ awk 'BEGIN {
str = "HELLO, WORLD !!!"
print "Lowercase string = " tolower(str)
}'
On executing this code, you get the following result −
Output
Lowercase string = hello, world !!!
toupper(str)
This function returns a copy of string str with all lower-case characters converted to upper case.
Example
[jerry]$ awk 'BEGIN {
str = "hello, world !!!"
print "Uppercase string = " toupper(str)
}'
On executing this code, you get the following result −
Output
Uppercase string = HELLO, WORLD !!!
awk_built_in_functions.htm