
В статье подробно показано, что такое нормальный закон распределения случайной величины и как им пользоваться при решении практически задач.
Нормальное распределение в статистике
История закона насчитывает 300 лет. Первым открывателем стал Абрахам де Муавр, который придумал аппроксимацию биномиального распределения еще 1733 году. Через много лет Карл Фридрих Гаусс (1809 г.) и Пьер-Симон Лаплас (1812 г.) вывели математические функции.
Лаплас также обнаружил замечательную закономерность и сформулировал центральную предельную теорему (ЦПТ), согласно которой сумма большого количества малых и независимых величин имеет нормальное распределение.
Нормальный закон не является фиксированным уравнением зависимости одной переменной от другой. Фиксируется только характер этой зависимости. Конкретная форма распределения задается специальными параметрами. Например, у = аx + b – это уравнение прямой. Однако где конкретно она проходит и под каким наклоном, определяется параметрами а и b. Также и с нормальным распределением. Ясно, что это функция, которая описывает тенденцию высокой концентрации значений около центра, но ее точная форма задается специальными параметрами.
Кривая нормального распределения Гаусса имеет следующий вид.

График нормального распределения напоминает колокол, поэтому можно встретить название колоколообразная кривая. У графика имеется «горб» в середине и резкое снижение плотности по краям. В этом заключается суть нормального распределения. Вероятность того, что случайная величина окажется около центра гораздо выше, чем то, что она сильно отклонится от середины.

На рисунке выше изображены два участка под кривой Гаусса: синий и зеленый. Основания, т.е. интервалы, у обоих участков равны. Но заметно отличаются высоты. Синий участок удален от центра, и имеет существенно меньшую высоту, чем зеленый, который находится в самом центре распределения. Следовательно, отличаются и площади, то бишь вероятности попадания в обозначенные интервалы.
Формула нормального распределения (плотности) следующая.
![]()
Формула состоит из двух математических констант:
π – число пи 3,142;
е – основание натурального логарифма 2,718;
двух изменяемых параметров, которые задают форму конкретной кривой:
m – математическое ожидание (в различных источниках могут использоваться другие обозначения, например, µ или a);
σ2 – дисперсия;
ну и сама переменная x, для которой высчитывается плотность вероятности.
Конкретная форма нормального распределения зависит от 2-х параметров: математического ожидания (m) и дисперсии (σ2). Кратко обозначается N(m, σ2) или N(m, σ). Параметр m (матожидание) определяет центр распределения, которому соответствует максимальная высота графика. Дисперсия σ2 характеризует размах вариации, то есть «размазанность» данных.
Параметр математического ожидания смещает центр распределения вправо или влево, не влияя на саму форму кривой плотности.

А вот дисперсия определяет остроконечность кривой. Когда данные имеют малый разброс, то вся их масса концентрируется у центра. Если же у данных большой разброс, то они «размазываются» по широкому диапазону.

Плотность распределения не имеет прямого практического применения. Для расчета вероятностей нужно проинтегрировать функцию плотности.
Вероятность того, что случайная величина окажется меньше некоторого значения x, определяется функцией нормального распределения:
![]()
Используя математические свойства любого непрерывного распределения, несложно рассчитать и любые другие вероятности, так как
P(a ≤ X < b) = Ф(b) – Ф(a)
Стандартное нормальное распределение
Нормальное распределение зависит от параметров средней и дисперсии, из-за чего плохо видны его свойства. Хорошо бы иметь некоторый эталон распределения, не зависящий от масштаба данных. И он существует. Называется стандартным нормальным распределением. На самом деле это обычное нормальное нормальное распределение, только с параметрами математического ожидания 0, а дисперсией – 1, кратко записывается N(0, 1).
Любое нормальное распределение легко превращается в стандартное путем нормирования:
![]()
где z – новая переменная, которая используется вместо x;
m – математическое ожидание;
σ – стандартное отклонение.
Для выборочных данных берутся оценки:
![]()
Среднее арифметическое и дисперсия новой переменной z теперь также равны 0 и 1 соответственно. В этом легко убедиться с помощью элементарных алгебраических преобразований.
В литературе встречается название z-оценка. Это оно самое – нормированные данные. Z-оценку можно напрямую сравнивать с теоретическими вероятностями, т.к. ее масштаб совпадает с эталоном.
Посмотрим теперь, как выглядит плотность стандартного нормального распределения (для z-оценок). Напомню, что функция Гаусса имеет вид:
![]()
Подставим вместо (x-m)/σ букву z, а вместо σ – единицу, получим функцию плотности стандартного нормального распределения:
![]()
График плотности:

Центр, как и ожидалось, находится в точке 0. В этой же точке функция Гаусса достигает своего максимума, что соответствует принятию случайной величиной своего среднего значения (т.е. x-m=0). Плотность в этой точке равна 0,3989, что можно посчитать даже в уме, т.к. e0=1 и остается рассчитать только соотношение 1 на корень из 2 пи.
Таким образом, по графику хорошо видно, что значения, имеющие маленькие отклонения от средней, выпадают чаще других, а те, которые сильно отдалены от центра, встречаются значительно реже. Шкала оси абсцисс измеряется в стандартных отклонениях, что позволяет отвязаться от единиц измерения и получить универсальную структуру нормального распределения. Кривая Гаусса для нормированных данных отлично демонстрирует и другие свойства нормального распределения. Например, что оно является симметричным относительно оси ординат. В пределах ±1σ от средней арифметической сконцентрирована большая часть всех значений (прикидываем пока на глазок). В пределах ±2σ находятся большинство данных. В пределах ±3σ находятся почти все данные. Последнее свойство широко известно под названием правило трех сигм для нормального распределения.
Функция стандартного нормального распределения позволяет рассчитывать вероятности.
![]()
Понятное дело, вручную никто не считает. Все подсчитано и размещено в специальных таблицах, которые есть в конце любого учебника по статистике.
Таблица нормального распределения
Таблицы нормального распределения встречаются двух типов:
— таблица плотности;
— таблица функции (интеграла от плотности).
Таблица плотности используется редко. Тем не менее, посмотрим, как она выглядит. Допустим, нужно получить плотность для z = 1, т.е. плотность значения, отстоящего от матожидания на 1 сигму. Ниже показан кусок таблицы.

В зависимости от организации данных ищем нужное значение по названию столбца и строки. В нашем примере берем строку 1,0 и столбец 0, т.к. сотых долей нет. Искомое значение равно 0,2420 (0 перед 2420 опущен).
Функция Гаусса симметрична относительно оси ординат. Поэтому φ(z)= φ(-z), т.е. плотность для 1 тождественна плотности для -1, что отчетливо видно на рисунке.

Чтобы не тратить зря бумагу, таблицы печатают только для положительных значений.
На практике чаще используют значения функции стандартного нормального распределения, то есть вероятности для различных z.
В таких таблицах также содержатся только положительные значения. Поэтому для понимания и нахождения любых нужных вероятностей следует знать свойства стандартного нормального распределения.
Функция Ф(z) симметрична относительно своего значения 0,5 (а не оси ординат, как плотность). Отсюда справедливо равенство:
![]()
Это факт показан на картинке:

Значения функции Ф(-z) и Ф(z) делят график на 3 части. Причем верхняя и нижняя части равны (обозначены галочками). Для того, чтобы дополнить вероятность Ф(z) до 1, достаточно добавить недостающую величину Ф(-z). Получится равенство, указанное чуть выше.
Если нужно отыскать вероятность попадания в интервал (0; z), то есть вероятность отклонения от нуля в положительную сторону до некоторого количества стандартных отклонений, достаточно от значения функции стандартного нормального распределения отнять 0,5:
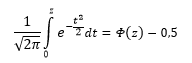
Для наглядности можно взглянуть на рисунок.

На кривой Гаусса, эта же ситуация выглядит как площадь от центра вправо до z.

Довольно часто аналитика интересует вероятность отклонения в обе стороны от нуля. А так как функция симметрична относительно центра, предыдущую формулу нужно умножить на 2:

Рисунок ниже.

Под кривой Гаусса это центральная часть, ограниченная выбранным значением –z слева и z справа.

Указанные свойства следует принять во внимание, т.к. табличные значения редко соответствуют интересующему интервалу.
Для облегчения задачи в учебниках обычно публикуют таблицы для функции вида:

Если нужна вероятность отклонения в обе стороны от нуля, то, как мы только что убедились, табличное значение для данной функции просто умножается на 2.
Теперь посмотрим на конкретные примеры. Ниже показана таблица стандартного нормального распределения. Найдем табличные значения для трех z: 1,64, 1,96 и 3.

Как понять смысл этих чисел? Начнем с z=1,64, для которого табличное значение составляет 0,4495. Проще всего пояснить смысл на рисунке.

То есть вероятность того, что стандартизованная нормально распределенная случайная величина попадет в интервал от 0 до 1,64, равна 0,4495. При решении задач обычно нужно рассчитать вероятность отклонения в обе стороны, поэтому умножим величину 0,4495 на 2 и получим примерно 0,9. Занимаемая площадь под кривой Гаусса показана ниже.

Таким образом, 90% всех нормально распределенных значений попадает в интервал ±1,64σ от средней арифметической. Я не случайно выбрал значение z=1,64, т.к. окрестность вокруг средней арифметической, занимающая 90% всей площади, иногда используется для проверки статистических гипотез и расчета доверительных интервалов. Если проверяемое значение не попадает в обозначенную область, то его наступление маловероятно (всего 10%).
Для проверки гипотез, однако, чаще используется интервал, накрывающий 95% всех значений. Половина вероятности от 0,95 – это 0,4750 (см. второе выделенное в таблице значение).

Для этой вероятности z=1,96. Т.е. в пределах почти ±2σ от средней находится 95% значений. Только 5% выпадают за эти пределы.

Еще одно интересное и часто используемое табличное значение соответствует z=3, оно равно по нашей таблице 0,4986. Умножим на 2 и получим 0,997. Значит, в рамках ±3σ от средней арифметической заключены почти все значения.

Так выглядит правило 3 сигм для нормального распределения на диаграмме.
С помощью статистических таблиц можно получить любую вероятность. Однако этот метод очень медленный, неудобный и сильно устарел. Сегодня все делается на компьютере. Далее переходим к практике расчетов в Excel.
В Excel есть несколько функций для подсчета вероятностей или обратных значений нормального распределения.

Функция НОРМ.СТ.РАСП
Функция НОРМ.СТ.РАСП предназначена для расчета плотности ϕ(z) или вероятности Φ(z) по нормированным данным (z).
=НОРМ.СТ.РАСП(z;интегральная)
z – значение стандартизованной переменной
интегральная – если 0, то рассчитывается плотность ϕ(z), если 1 – значение функции Ф(z), т.е. вероятность P(Z<z).
Рассчитаем плотность и значение функции для различных z: -3, -2, -1, 0, 1, 2, 3 (их укажем в ячейке А2).
Для расчета плотности потребуется формула =НОРМ.СТ.РАСП(A2;0). На диаграмме ниже – это красная точка.
Для расчета значения функции =НОРМ.СТ.РАСП(A2;1). На диаграмме – закрашенная площадь под нормальной кривой.

В реальности чаще приходится рассчитывать вероятность того, что случайная величина не выйдет за некоторые пределы от средней (в среднеквадратичных отклонениях, соответствующих переменной z), т.е. P(|Z|<z).

Определим, чему равна вероятность попадания случайной величины в пределы ±1z, ±2z и ±3z от нуля. Потребуется формула 2Ф(z)-1, в Excel =2*НОРМ.СТ.РАСП(A2;1)-1.

На диаграмме отлично видны основные основные свойства нормального распределения, включая правило трех сигм. Функция НОРМ.СТ.РАСП – это автоматическая таблица значений функции нормального распределения в Excel.
Может стоять и обратная задача: по имеющейся вероятности P(Z<z) найти стандартизованную величину z ,то есть квантиль стандартного нормального распределения.
Функция НОРМ.СТ.ОБР
НОРМ.СТ.ОБР рассчитывает обратное значение функции стандартного нормального распределения. Синтаксис состоит из одного параметра:
=НОРМ.СТ.ОБР(вероятность)
вероятность – это вероятность.
Данная формула используется так же часто, как и предыдущая, ведь по тем же таблицам искать приходится не только вероятности, но и квантили.

Например, при расчете доверительных интервалов задается доверительная вероятность, по которой нужно рассчитать величину z.

Учитывая то, что доверительный интервал состоит из верхней и нижней границы и то, что нормальное распределение симметрично относительно нуля, достаточно получить верхнюю границу (положительное отклонение). Нижняя граница берется с отрицательным знаком. Обозначим доверительную вероятность как γ (гамма), тогда верхняя граница доверительного интервала рассчитывается по следующей формуле.
![]()
Рассчитаем в Excel значения z (что соответствует отклонению от средней в сигмах) для нескольких вероятностей, включая те, которые наизусть знает любой статистик: 90%, 95% и 99%. В ячейке B2 укажем формулу: =НОРМ.СТ.ОБР((1+A2)/2). Меняя значение переменной (вероятности в ячейке А2) получим различные границы интервалов.

Доверительный интервал для 95% равен 1,96, то есть почти 2 среднеквадратичных отклонения. Отсюда легко даже в уме оценить возможный разброс нормальной случайной величины. В общем, доверительным вероятностям 90%, 95% и 99% соответствуют доверительные интервалы ±1,64, ±1,96 и ±2,58 σ.
В целом функции НОРМ.СТ.РАСП и НОРМ.СТ.ОБР позволяют произвести любой расчет, связанный с нормальным распределением. Но, чтобы облегчить и уменьшить количество действий, в Excel есть несколько других функций. Например, для расчета доверительных интервалов средней можно использовать ДОВЕРИТ.НОРМ. Для проверки статистической гипотезы о средней арифметической есть формула Z.ТЕСТ.
Рассмотрим еще пару полезных формул с примерами.
Функция НОРМ.РАСП
Функция НОРМ.РАСП отличается от НОРМ.СТ.РАСП лишь тем, что ее используют для обработки данных любого масштаба, а не только нормированных. Параметры нормального распределения указываются в синтаксисе.
=НОРМ.РАСП(x;среднее;стандартное_откл;интегральная)
x – значение (или ссылка на ячейку), для которого рассчитывается плотность или значение функции нормального распределения
среднее – математическое ожидание, используемое в качестве первого параметра модели нормального распределения
стандартное_откл – среднеквадратичное отклонение – второй параметр модели
интегральная – если 0, то рассчитывается плотность, если 1 – то значение функции, т.е. P(X<x).
Например, плотность для значения 15, которое извлекли из нормальной выборки с матожиданием 10, стандартным отклонением 3, рассчитывается так:

Если последний параметр поставить 1, то получим вероятность того, что нормальная случайная величина окажется меньше 15 при заданных параметрах распределения. Таким образом, вероятности можно рассчитывать напрямую по исходным данным.
Функция НОРМ.ОБР
Это квантиль нормального распределения, т.е. значение обратной функции. Синтаксис следующий.
=НОРМ.ОБР(вероятность;среднее;стандартное_откл)
вероятность – вероятность
среднее – матожидание
стандартное_откл – среднеквадратичное отклонение
Назначение то же, что и у НОРМ.СТ.ОБР, только функция работает с данными любого масштаба.
Пример показан в ролике в конце статьи.
Моделирование нормального распределения
Для некоторых задач требуется генерация нормальных случайных чисел. Готовой функции для этого нет. Однако В Excel есть две функции, которые возвращают случайные числа: СЛУЧМЕЖДУ и СЛЧИС. Первая выдает случайные равномерно распределенные целые числа в указанных пределах. Вторая функция генерирует равномерно распределенные случайные числа между 0 и 1. Чтобы сделать искусственную выборку с любым заданным распределением, нужна функция СЛЧИС.
Допустим, для проведения эксперимента необходимо получить выборку из нормально распределенной генеральной совокупности с матожиданием 10 и стандартным отклонением 3. Для одного случайного значения напишем формулу в Excel.
=НОРМ.ОБР(СЛЧИС();10;3)
Протянем ее на необходимое количество ячеек и нормальная выборка готова.
Для моделирования стандартизованных данных следует воспользоваться НОРМ.СТ.ОБР.
Процесс преобразования равномерных чисел в нормальные можно показать на следующей диаграмме. От равномерных вероятностей, которые генерируются формулой СЛЧИС, проведены горизонтальные линии до графика функции нормального распределения. Затем от точек пересечения вероятностей с графиком опущены проекции на горизонтальную ось.

На выходе получаются значения с характерной концентрацией около центра. Вот так обратный прогон через функцию нормального распределения превращает равномерные числа в нормальные. Excel позволяет за несколько секунд воспроизвести любое количество выборок любого размера.
Как обычно, прилагаю ролик, где все вышеописанное показывается в действии.
Скачать файл с примером.
Поделиться в социальных сетях:
Рассмотрим Нормальное распределение. С помощью функции
MS EXCEL
НОРМ.РАСП()
построим графики функции распределения и плотности вероятности. Сгенерируем массив случайных чисел, распределенных по нормальному закону, произведем оценку параметров распределения, среднего значения и стандартного отклонения
.
Нормальное распределение
(также называется распределением Гаусса) является самым важным как в теории, так в приложениях системы контроля качества. Важность значения
Нормального распределения
(англ.
Normal
distribution
)
во многих областях науки вытекает из
Центральной предельной теоремы
теории вероятностей.
Определение
: Случайная величина
x
распределена по
нормальному закону
, если она имеет
плотность распределения
:
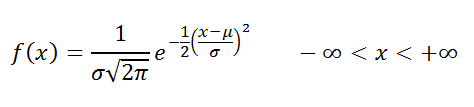
СОВЕТ
: Подробнее о
Функции распределения
и
Плотности вероятности
см. статью
Функция распределения и плотность вероятности в MS EXCEL
.
Нормальное распределение
зависит от двух параметров: μ
(мю)
— является
математическим ожиданием (средним значением случайной величины)
, и σ (
сигма)
— является
стандартным отклонением
(среднеквадратичным отклонением). Параметр μ определяет положение центра
плотности вероятности
нормального распределения
, а σ — разброс относительно центра (среднего).
Примечание
: О влиянии параметров μ и σ на форму распределения изложено в статье про
Гауссову кривую
, а в
файле примера на листе Влияние параметров
можно с помощью
элементов управления Счетчик
понаблюдать за изменением формы кривой.
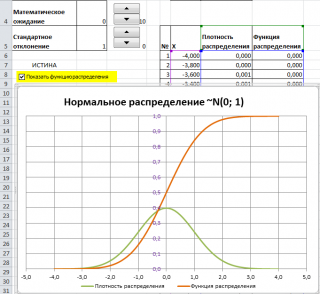
Нормальное распределение в MS EXCEL
В MS EXCEL, начиная с версии 2010, для
Нормального распределения
имеется функция
НОРМ.РАСП()
, английское название — NORM.DIST(), которая позволяет вычислить
плотность вероятности
(см. формулу выше) и
интегральную функцию распределения
(вероятность, что случайная величина X, распределенная по
нормальному закону
, примет значение меньше или равное x). Вычисления в последнем случае производятся по следующей формуле:
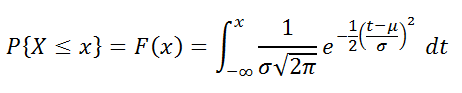
Вышеуказанное распределение имеет обозначение
N
(μ; σ).
Так же часто используют обозначение через
дисперсию
N
(μ; σ
2
).
Примечание
: До MS EXCEL 2010 в EXCEL была только функция
НОРМРАСП()
, которая также позволяет вычислить функцию распределения и плотность вероятности.
НОРМРАСП()
оставлена в MS EXCEL 2010 для совместимости.
Стандартное нормальное распределение
Стандартным нормальным распределением
называется
нормальное распределение
с
математическим ожиданием
μ=0 и
дисперсией
σ=1. Вышеуказанное распределение имеет обозначение
N
(0;1).
Примечание
: В литературе для случайной величины, распределенной по
стандартному
нормальному закону,
закреплено специальное обозначение z.
Любое
нормальное распределение
можно преобразовать в стандартное через замену переменной
z
=(
x
-μ)/σ
. Этот процесс преобразования называется
стандартизацией
.
Примечание
: В MS EXCEL имеется функция
НОРМАЛИЗАЦИЯ()
, которая выполняет вышеуказанное преобразование. Хотя в MS EXCEL это преобразование называется почему-то
нормализацией
. Формулы
=(x-μ)/σ
и
=НОРМАЛИЗАЦИЯ(х;μ;σ)
вернут одинаковый результат.
В MS EXCEL 2010 для
стандартного нормального распределения
имеется специальная функция
НОРМ.СТ.РАСП()
и ее устаревший вариант
НОРМСТРАСП()
, выполняющий аналогичные вычисления.
Продемонстрируем, как в MS EXCEL осуществляется процесс стандартизации
нормального распределения
N
(1,5; 2).
Для этого вычислим вероятность, что случайная величина, распределенная по
нормальному закону
N(1,5; 2)
, меньше или равна 2,5. Формула выглядит так:
=НОРМ.РАСП(2,5; 1,5; 2; ИСТИНА)
=0,691462. Сделав замену переменной
z
=(2,5-1,5)/2=0,5
, запишем формулу для вычисления
Стандартного нормального распределения:
=НОРМ.СТ.РАСП(0,5; ИСТИНА)
=0,691462.
Естественно, обе формулы дают одинаковые результаты (см.
файл примера лист Пример
).
Обратите внимание, что
стандартизация
относится только к
интегральной функции распределения
(аргумент
интегральная
равен ИСТИНА), а не к
плотности вероятности
.
Примечание
: В литературе для функции, вычисляющей вероятности случайной величины, распределенной по
стандартному
нормальному закону,
закреплено специальное обозначение Ф(z). В MS EXCEL эта функция вычисляется по формуле
=НОРМ.СТ.РАСП(z;ИСТИНА)
. Вычисления производятся по формуле
![]()
В силу четности функции
плотности стандартного нормального
распределения f(x), а именно f(x)=f(-х), функция
стандартного нормального распределения
обладает свойством Ф(-x)=1-Ф(x).
Обратные функции
Функция
НОРМ.СТ.РАСП(x;ИСТИНА)
вычисляет вероятность P, что случайная величина Х примет значение меньше или равное х. Но часто требуется провести обратное вычисление: зная вероятность P, требуется вычислить значение х. Вычисленное значение х называется
квантилем
стандартного
нормального распределения
.
В MS EXCEL для вычисления
квантилей
используют функцию
НОРМ.СТ.ОБР()
и
НОРМ.ОБР()
.
Графики функций
В
файле примера
приведены
графики плотности распределения
вероятности и
интегральной функции распределения
.
Как известно, около 68% значений, выбранных из совокупности, имеющей
нормальное распределение
, находятся в пределах 1 стандартного отклонения (σ) от μ(среднего или математического ожидания); около 95% — в пределах 2-х σ, а в пределах 3-х σ находятся уже 99% значений. Убедиться в этом для
стандартного нормального распределения
можно записав формулу:
=
НОРМ.СТ.РАСП(1;ИСТИНА)-НОРМ.СТ.РАСП(-1;ИСТИНА)
которая вернет значение 68,2689% — именно такой процент значений находятся в пределах +/-1 стандартного отклонения от
среднего
(см.
лист График в файле примера
).
В силу четности функции
плотности стандартного нормального
распределения:
f
(
x
)=
f
(-х)
, функция
стандартного нормального распределения
обладает свойством F(-x)=1-F(x). Поэтому, вышеуказанную формулу можно упростить:
=
2*НОРМ.СТ.РАСП(1;ИСТИНА)-1
Для произвольной
функции нормального распределения
N(μ; σ) аналогичные вычисления нужно производить по формуле:
=2* НОРМ.РАСП(μ+1*σ;μ;σ;ИСТИНА)-1
Вышеуказанные расчеты вероятности требуются для
построения доверительных интервалов
.
Примечание
: Для построения
функции распределения
и
плотности вероятности
можно использовать диаграмму типа
График
или
Точечная
(со сглаженными линиями и без точек). Подробнее о построении
диаграмм
читайте статью
Основные типы диаграмм
.
Примечание
: Для удобства написания формул в
файле примера
созданы
Имена
для параметров распределения: μ и σ.
Генерация случайных чисел
С помощью надстройки
Пакет анализа
можно сгенерировать случайные числа, распределенные по
нормальному закону
.
СОВЕТ
: О надстройке
Пакет анализа
можно прочитать в статье
Надстройка Пакет анализа MS EXCEL
.
Сгенерируем 3 массива по 100 чисел с различными μ и σ. Для этого в окне
Генерация
случайных чисел
установим следующие значения для каждой пары параметров:
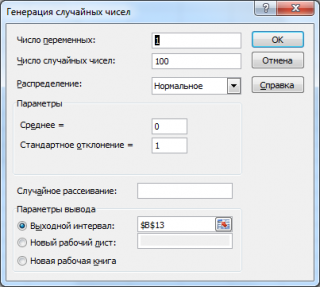
Примечание
: Если установить опцию
Случайное рассеивание
(
Random Seed
), то можно выбрать определенный случайный набор сгенерированных чисел. Например, установив эту опцию равной 25, можно сгенерировать на разных компьютерах одни и те же наборы случайных чисел (если, конечно, другие параметры распределения совпадают). Значение опции может принимать целые значения от 1 до 32 767. Название опции
Случайное рассеивание
может запутать. Лучше было бы ее перевести как
Номер набора со случайными числами
.
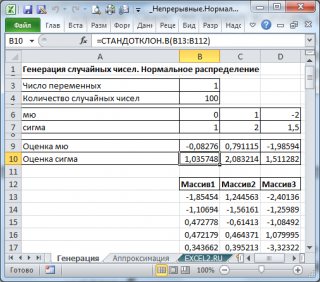
В итоге будем иметь 3 столбца чисел, на основании которых можно, оценить параметры распределения, из которого была произведена выборка: μ и σ
.
Оценку для μ можно сделать с использованием функции
СРЗНАЧ()
, а для σ – с использованием функции
СТАНДОТКЛОН.В()
, см.
файл примера лист Генерация
.
Примечание
: Для генерирования массива чисел, распределенных по
нормальному закону
, можно использовать формулу
=НОРМ.ОБР(СЛЧИС();μ;σ)
. Функция
СЛЧИС()
генерирует
непрерывное равномерное распределение
от 0 до 1, что как раз соответствует диапазону изменения вероятности (см.
файл примера лист Генерация
).
Задачи
Задача1
. Компания изготавливает нейлоновые нити со средней прочностью 41 МПа и стандартным отклонением 2 МПа. Потребитель хочет приобрести нити с прочностью не менее 36 МПа. Рассчитайте вероятность, что партии нити, изготовленные компанией для потребителя, будут соответствовать требованиям или превышать их.
Решение1
: =
1-НОРМ.РАСП(36;41;2;ИСТИНА)
Задача2
. Предприятие изготавливает трубы, средний внешний диаметр которых равен 20,20 мм, а стандартное отклонение равно 0,25мм. Согласно техническим условиям, трубы признаются годными, если диаметр находится в пределах 20,00+/- 0,40 мм. Какая доля изготовленных труб соответствует ТУ?
Решение2
: =
НОРМ.РАСП(20,00+0,40;20,20;0,25;ИСТИНА)- НОРМ.РАСП(20,00-0,40;20,20;0,25)
На рисунке ниже, выделена область значений диаметров, которая удовлетворяет требованиям спецификации.
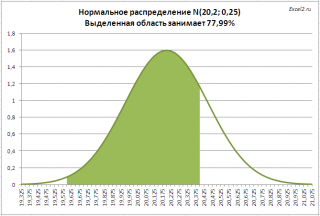
Решение приведено в
файле примера лист Задачи
.
Задача3
. Предприятие изготавливает трубы, средний внешний диаметр которых равен 20,20 мм, а стандартное отклонение равно 0,25мм. Внешний диаметр не должен превышать определенное значение (предполагается, что нижняя граница не важна). Какую верхнюю границу в технических условиях необходимо установить, чтобы ей соответствовало 97,5% всех изготавливаемых изделий?
Решение3
: =
НОРМ.ОБР(0,975; 20,20; 0,25)
=20,6899 или =
НОРМ.СТ.ОБР(0,975)*0,25+20,2
(произведена «дестандартизация», см. выше)
Задача 4
. Нахождение параметров
нормального распределения
по значениям 2-х
квантилей
(или
процентилей
). Предположим, известно, что случайная величина имеет нормальное распределение, но не известны его параметры, а только 2-я
процентиля
(например, 0,5-
процентиль
, т.е. медиана и 0,95-я
процентиль
). Т.к. известна
медиана
, то мы знаем
среднее
, т.е. μ. Чтобы найти
стандартное отклонение
нужно использовать
Поиск решения
. Решение приведено в
файле примера лист Задачи
.
Примечание
: До MS EXCEL 2010 в EXCEL были функции
НОРМОБР()
и
НОРМСТОБР()
, которые эквивалентны
НОРМ.ОБР()
и
НОРМ.СТ.ОБР()
.
НОРМОБР()
и
НОРМСТОБР()
оставлены в MS EXCEL 2010 и выше только для совместимости.
Линейные комбинации нормально распределенных случайных величин
Известно, что линейная комбинация нормально распределённых случайных величин
x
(
i
)
с параметрами μ
(
i
)
и σ
(
i
)
также распределена нормально. Например, если случайная величина Y=x(1)+x(2), то Y будет иметь распределение с параметрами μ
(1)+ μ(2)
и
КОРЕНЬ(σ(1)^2+ σ(2)^2).
Убедимся в этом с помощью MS EXCEL.
С помощью надстройки
Пакет анализа
сгенерируем 2 массива по 100 чисел с различными μ и σ.
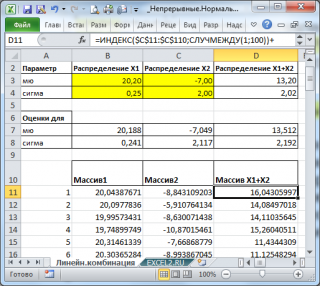
Теперь сформируем массив, каждый элемент которого является суммой 2-х значений, взятых из каждого массива.
С помощью функций
СРЗНАЧ()
и
СТАНДОТКЛОН.В()
вычислим
среднее
и
дисперсию
получившейся
выборки
и сравним их с расчетными.
Кроме того, построим
График проверки распределения на нормальность
(
Normal
Probability
Plot
), чтобы убедиться, что наш массив соответствует выборке из
нормального распределения
.
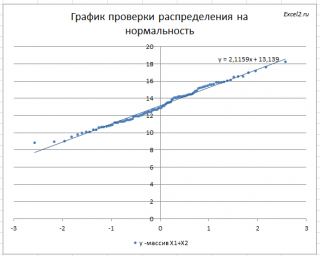
Прямая линия, аппроксимирующая полученный график, имеет уравнение y=ax+b. Наклон кривой (параметр а) может служить оценкой
стандартного отклонения
, а пересечение с осью y (параметр b) –
среднего
значения.
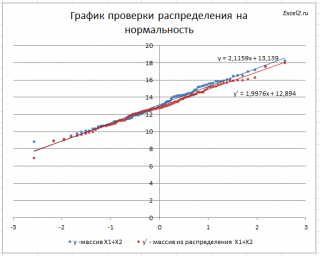
Для сравнения сгенерируем массив напрямую из распределения
N
(μ(1)+ μ(2); КОРЕНЬ(σ(1)^2+ σ(2)^2)
).
Как видно на рисунке ниже, обе аппроксимирующие кривые достаточно близки.
В качестве примера можно провести следующую задачу.
Задача
. Завод изготавливает болты и гайки, которые упаковываются в ящики парами. Пусть известно, что вес каждого из изделий является нормальной случайной величиной. Для болтов средний вес составляет 50г, стандартное отклонение 1,5г, а для гаек 20г и 1,2г. В ящик фасуется 100 пар болтов и гаек. Вычислить какой процент ящиков будет тяжелее 7,2 кг.
Решение
. Сначала переформулируем вопрос задачи: Вычислить какой процент пар болт-гайка будет тяжелее 7,2кг/100=72г. Учитывая, что вес пары представляет собой случайную величину = Вес(болта) + Вес(гайки) со средним весом (50+20)г, и
стандартным отклонением
=КОРЕНЬ(СУММКВ(1,5;1,2))
, запишем решение =
1-НОРМ.РАСП(72; 50+20; КОРЕНЬ(СУММКВ(1,5;1,2));ИСТИНА)
Ответ
: 15% (см.
файл примера лист Линейн.комбинация
)
Аппроксимация Биномиального распределения Нормальным распределением
Если параметры
Биномиального распределения
B(n;p) находятся в пределах 0,1<=p<=0,9 и n*p>10, то
Биномиальное распределение
можно аппроксимировать
Нормальным распределением
.
При значениях
λ
>15
,
Распределение Пуассона
хорошо аппроксимируется
Нормальным распределением
с параметрами: μ
=λ
, σ
2
=
λ
.
Подробнее о связи этих распределений, можно прочитать в статье
Взаимосвязь некоторых распределений друг с другом в MS EXCEL
. Там же приведены примеры аппроксимации, и пояснены условия, когда она возможна и с какой точностью.
СОВЕТ
: О других распределениях MS EXCEL можно прочитать в статье
Распределения случайной величины в MS EXCEL
.
Содержание
- Выполнение аппроксимации
- Способ 1: линейное сглаживание
- Способ 2: экспоненциальная аппроксимация
- Способ 3: логарифмическое сглаживание
- Способ 4: полиномиальное сглаживание
- Способ 5: степенное сглаживание
- Вопросы и ответы

Среди различных методов прогнозирования нельзя не выделить аппроксимацию. С её помощью можно производить приблизительные подсчеты и вычислять планируемые показатели, путем замены исходных объектов на более простые. В Экселе тоже существует возможность использования данного метода для прогнозирования и анализа. Давайте рассмотрим, как этот метод можно применить в указанной программе встроенными инструментами.
Выполнение аппроксимации
Наименование данного метода происходит от латинского слова proxima – «ближайшая» Именно приближение путем упрощения и сглаживания известных показателей, выстраивание их в тенденцию и является его основой. Но данный метод можно использовать не только для прогнозирования, но и для исследования уже имеющихся результатов. Ведь аппроксимация является, по сути, упрощением исходных данных, а упрощенный вариант исследовать легче.
Главный инструмент, с помощью которого проводится сглаживания в Excel – это построение линии тренда. Суть состоит в том, что на основе уже имеющихся показателей достраивается график функции на будущие периоды. Основное предназначение линии тренда, как не трудно догадаться, это составление прогнозов или выявление общей тенденции.
Но она может быть построена с применением одного из пяти видов аппроксимации:
- Линейной;
- Экспоненциальной;
- Логарифмической;
- Полиномиальной;
- Степенной.
Рассмотрим каждый из вариантов более подробно в отдельности.
Урок: Как построить линию тренда в Excel
Способ 1: линейное сглаживание
Прежде всего, давайте рассмотрим самый простой вариант аппроксимации, а именно с помощью линейной функции. На нем мы остановимся подробнее всего, так как изложим общие моменты характерные и для других способов, а именно построение графика и некоторые другие нюансы, на которых при рассмотрении последующих вариантов уже останавливаться не будем.
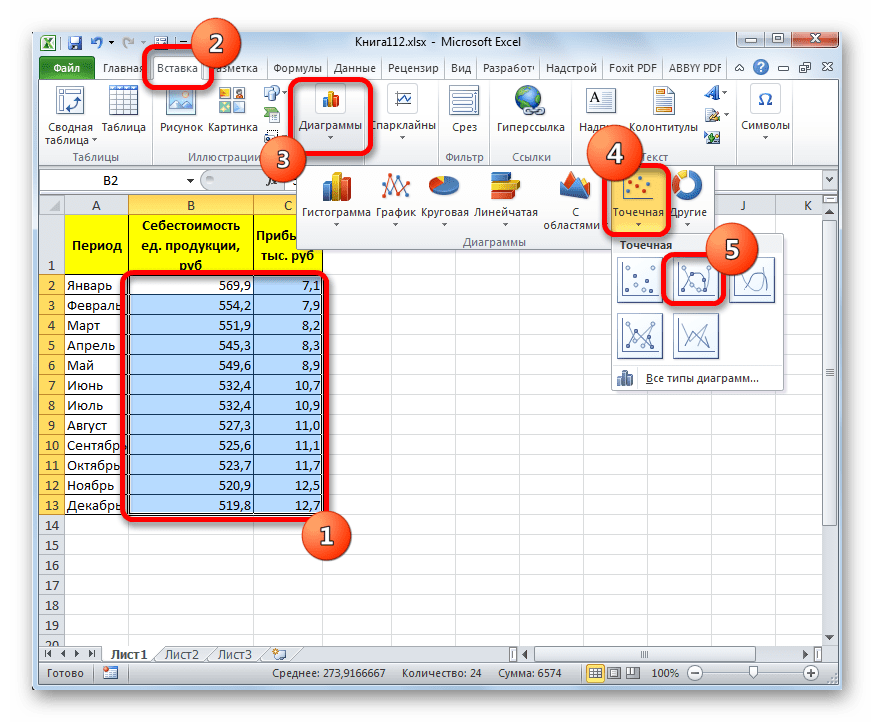
Прежде всего, построим график, на основании которого будем проводить процедуру сглаживания. Для построения графика возьмем таблицу, в которой помесячно указана себестоимость единицы продукции, производимой предприятием, и соответствующая прибыль в данном периоде. Графическая функция, которую мы построим, будет отображать зависимость увеличения прибыли от уменьшения себестоимости продукции.
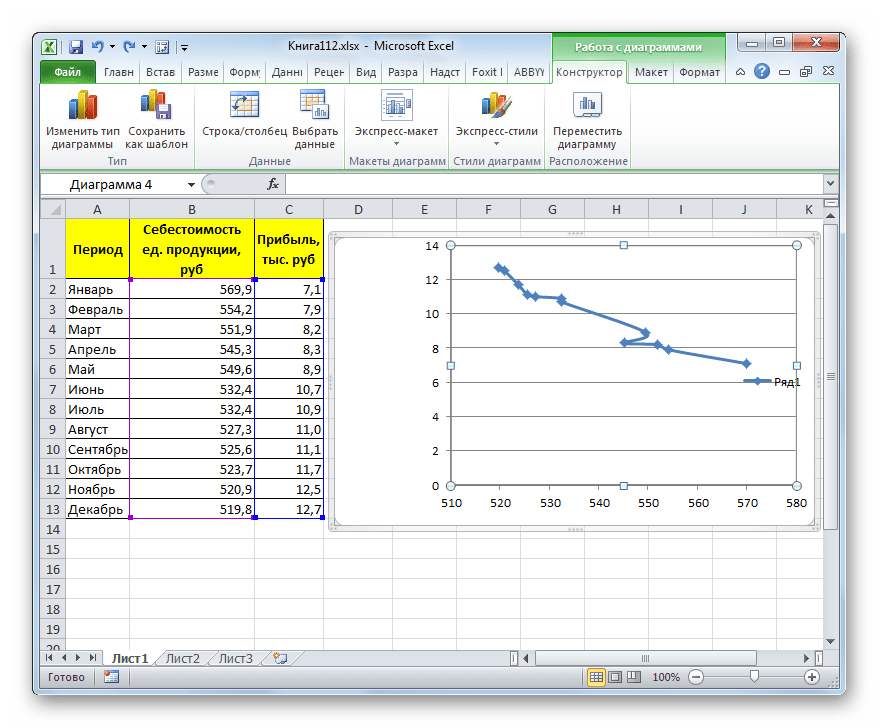
- Для построения графика, прежде всего, выделяем столбцы «Себестоимость единицы продукции» и «Прибыль». После этого перемещаемся во вкладку «Вставка». Далее на ленте в блоке инструментов «Диаграммы» щелкаем по кнопке «Точечная». В открывшемся списке выбираем наименование «Точечная с гладкими кривыми и маркерами». Именно данный вид диаграмм наиболее подходит для работы с линией тренда, а значит, и для применения метода аппроксимации в Excel.
- График построен.
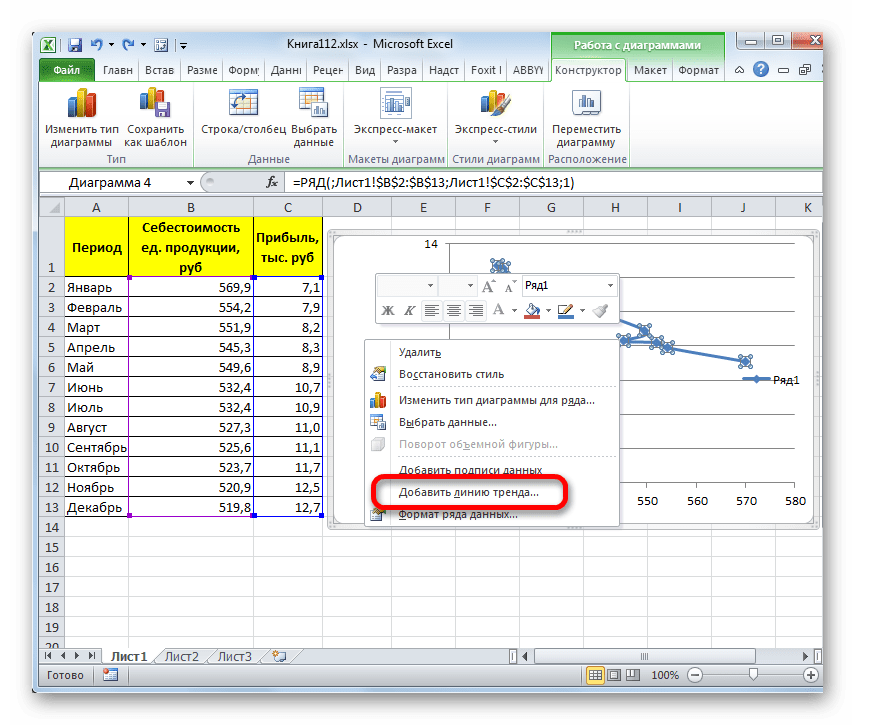
- Для добавления линии тренда выделяем его кликом правой кнопки мыши. Появляется контекстное меню. Выбираем в нем пункт «Добавить линию тренда…».

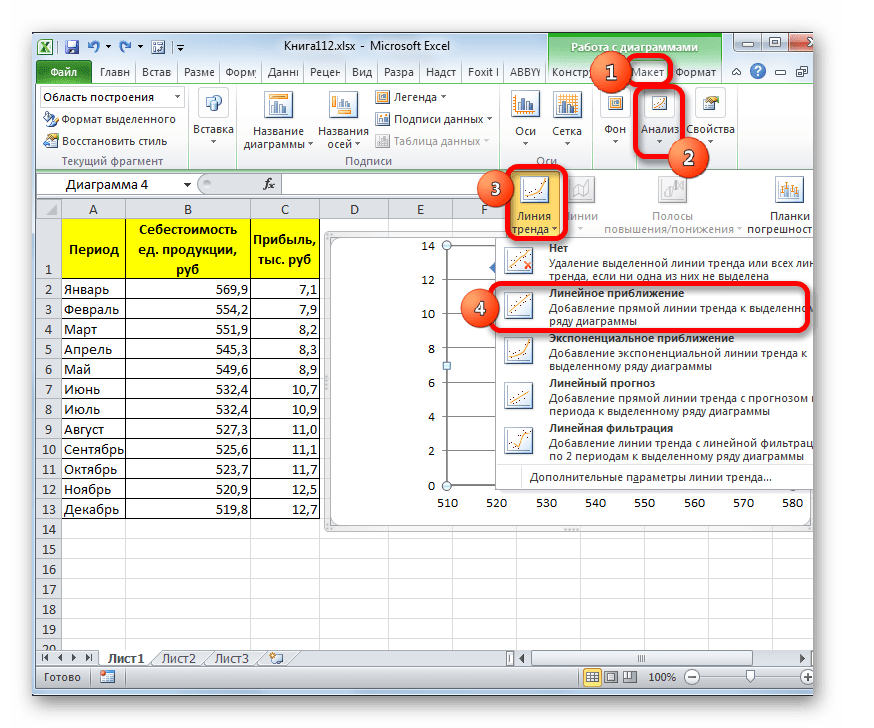
Существует ещё один вариант её добавления. В дополнительной группе вкладок на ленте «Работа с диаграммами» перемещаемся во вкладку «Макет». Далее в блоке инструментов «Анализ» щелкаем по кнопке «Линия тренда». Открывается список. Так как нам нужно применить линейную аппроксимацию, то из представленных позиций выбираем «Линейное приближение».
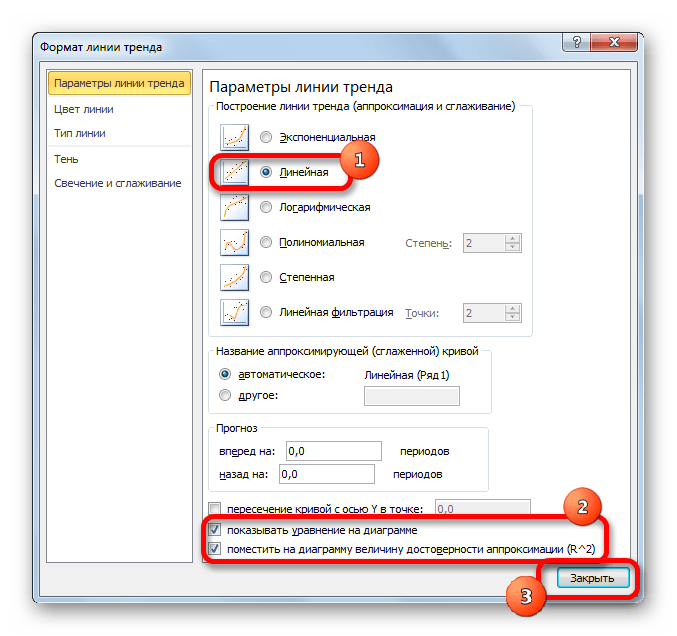
- Если же вы выбрали все-таки первый вариант действий с добавлением через контекстное меню, то откроется окно формата.
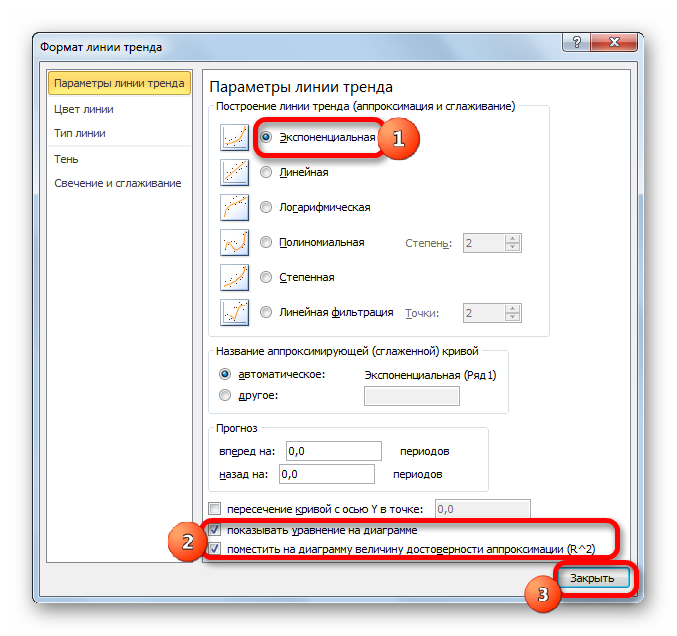
В блоке параметров «Построение линии тренда (аппроксимация и сглаживание)» устанавливаем переключатель в позицию «Линейная».
При желании можно установить галочку около позиции «Показывать уравнение на диаграмме». После этого на диаграмме будет отображаться уравнение сглаживающей функции.Также в нашем случае для сравнения различных вариантов аппроксимации важно установить галочку около пункта «Поместить на диаграмму величину достоверной аппроксимации (R^2)». Данный показатель может варьироваться от 0 до 1. Чем он выше, тем аппроксимация качественнее (достовернее). Считается, что при величине данного показателя 0,85 и выше сглаживание можно считать достоверным, а если показатель ниже, то – нет.

После того, как провели все вышеуказанные настройки. Жмем на кнопку «Закрыть», размещенную в нижней части окна.
- Как видим, на графике линия тренда построена. При линейной аппроксимации она обозначается черной прямой полосой. Указанный вид сглаживания можно применять в наиболее простых случаях, когда данные изменяются довольно быстро и зависимость значения функции от аргумента очевидна.

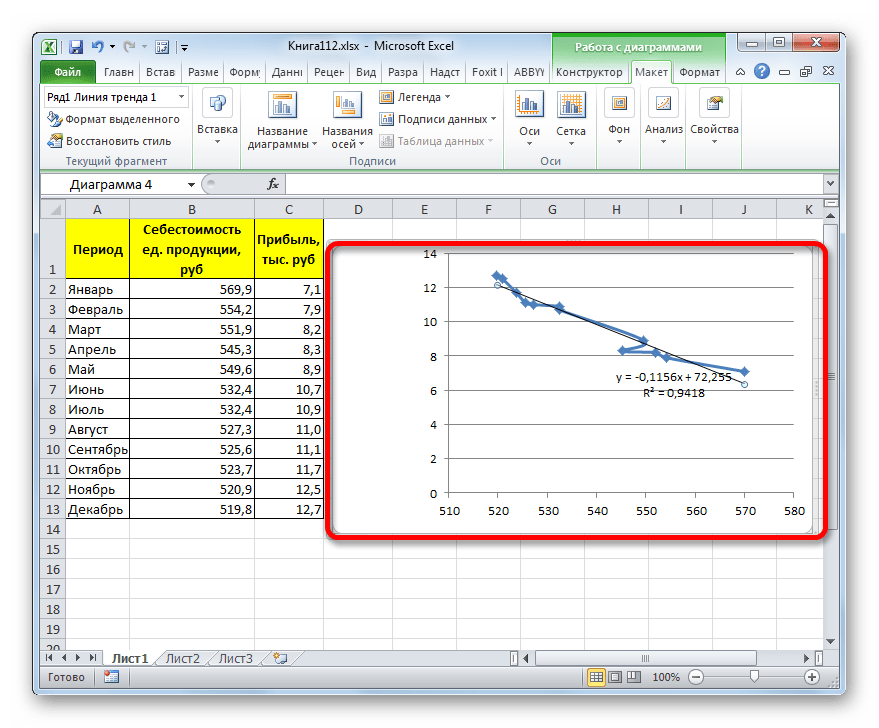
Сглаживание, которое используется в данном случае, описывается следующей формулой:
y=ax+b
В конкретно нашем случае формула принимает такой вид:
y=-0,1156x+72,255
Величина достоверности аппроксимации у нас равна 0,9418, что является довольно приемлемым итогом, характеризующим сглаживание, как достоверное.
Способ 2: экспоненциальная аппроксимация
Теперь давайте рассмотрим экспоненциальный тип аппроксимации в Эксель.
- Для того, чтобы изменить тип линии тренда, выделяем её кликом правой кнопки мыши и в раскрывшемся меню выбираем пункт «Формат линии тренда…».
- После этого запускается уже знакомое нам окно формата. В блоке выбора типа аппроксимации устанавливаем переключатель в положение «Экспоненциальная». Остальные настройки оставим такими же, как и в первом случае. Щелкаем по кнопке «Закрыть».
- После этого линия тренда будет построена на графике. Как видим, при использовании данного метода она имеет несколько изогнутую форму. При этом уровень достоверности равен 0,9592, что выше, чем при использовании линейной аппроксимации. Экспоненциальный метод лучше всего использовать в том случае, когда сначала значения быстро изменяются, а потом принимают сбалансированную форму.
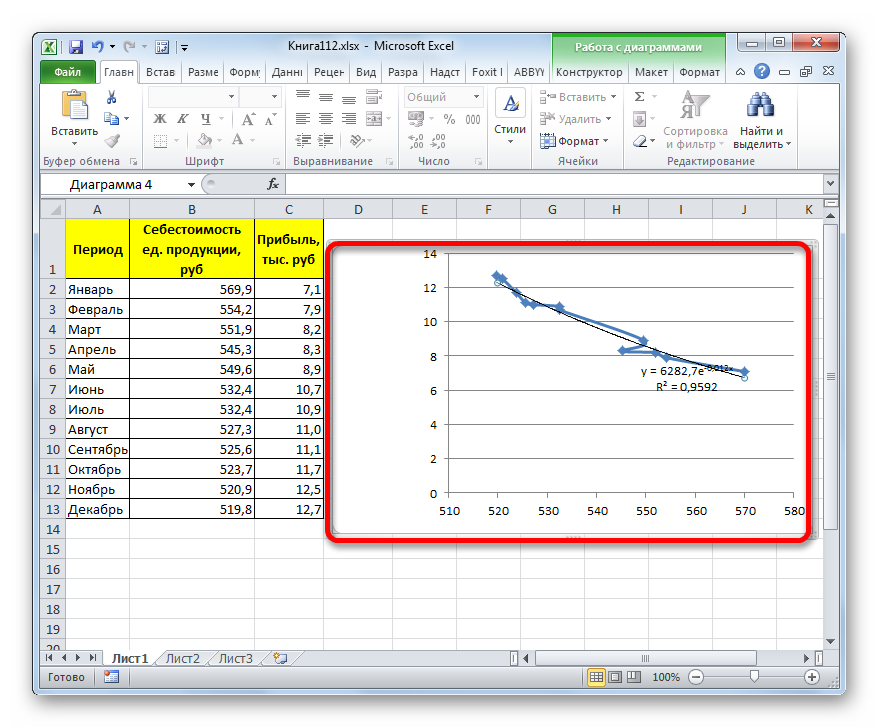
Общий вид функции сглаживания при этом такой:
y=be^x
где e – это основание натурального логарифма.
В конкретно нашем случае формула приняла следующую форму:
y=6282,7*e^(-0,012*x)
Способ 3: логарифмическое сглаживание
Теперь настала очередь рассмотреть метод логарифмической аппроксимации.
- Тем же способом, что и в предыдущий раз через контекстное меню запускаем окно формата линии тренда. Устанавливаем переключатель в позицию «Логарифмическая» и жмем на кнопку «Закрыть».
- Происходит процедура построения линии тренда с логарифмической аппроксимацией. Как и в предыдущем случае, такой вариант лучше использовать тогда, когда изначально данные быстро изменяются, а потом принимают сбалансированный вид. Как видим, уровень достоверности равен 0,946. Это выше, чем при использовании линейного метода, но ниже, чем качество линии тренда при экспоненциальном сглаживании.
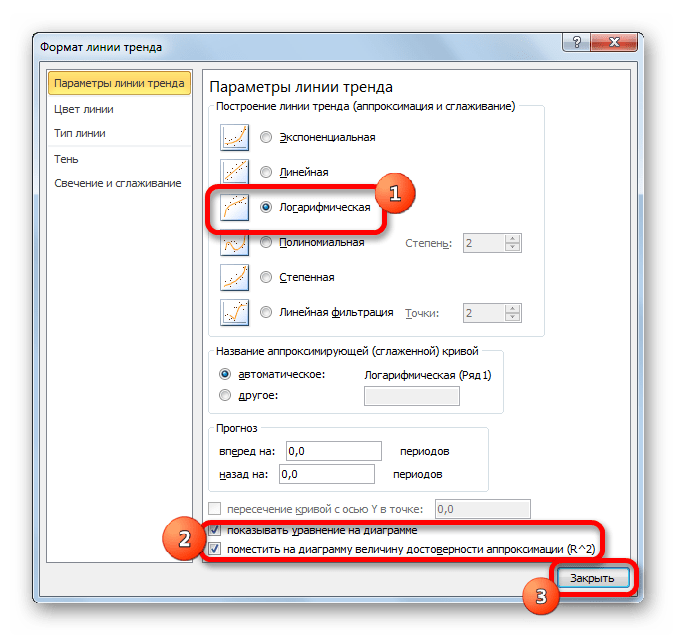
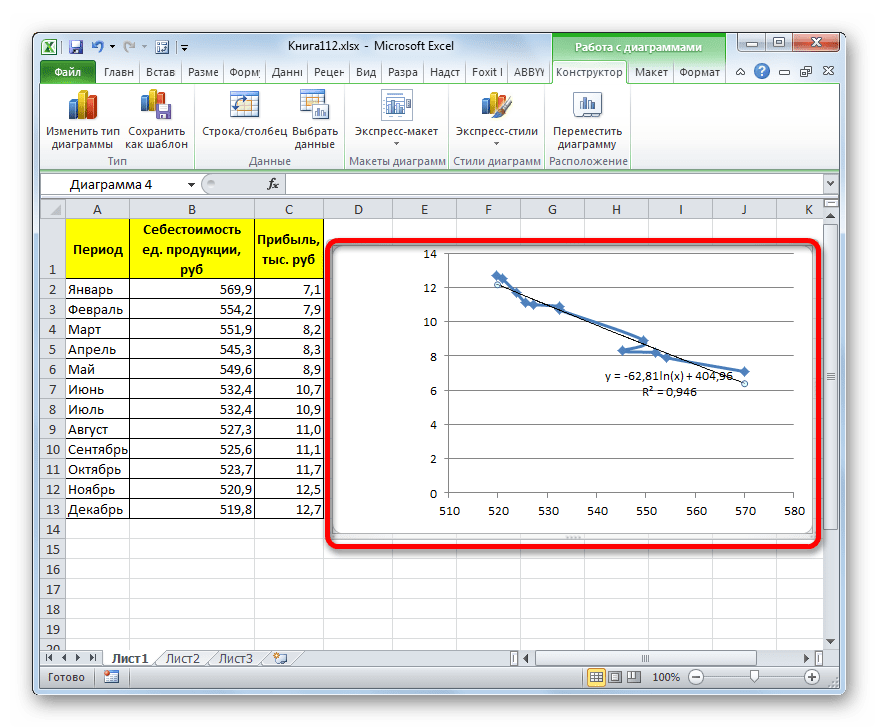
В общем виде формула сглаживания выглядит так:
y=a*ln(x)+b
где ln – это величина натурального логарифма. Отсюда и наименование метода.
В нашем случае формула принимает следующий вид:
y=-62,81ln(x)+404,96
Способ 4: полиномиальное сглаживание
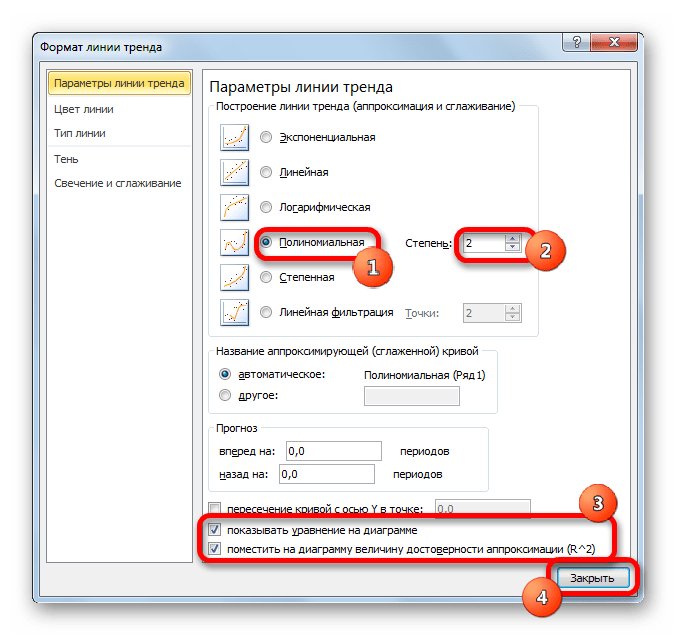
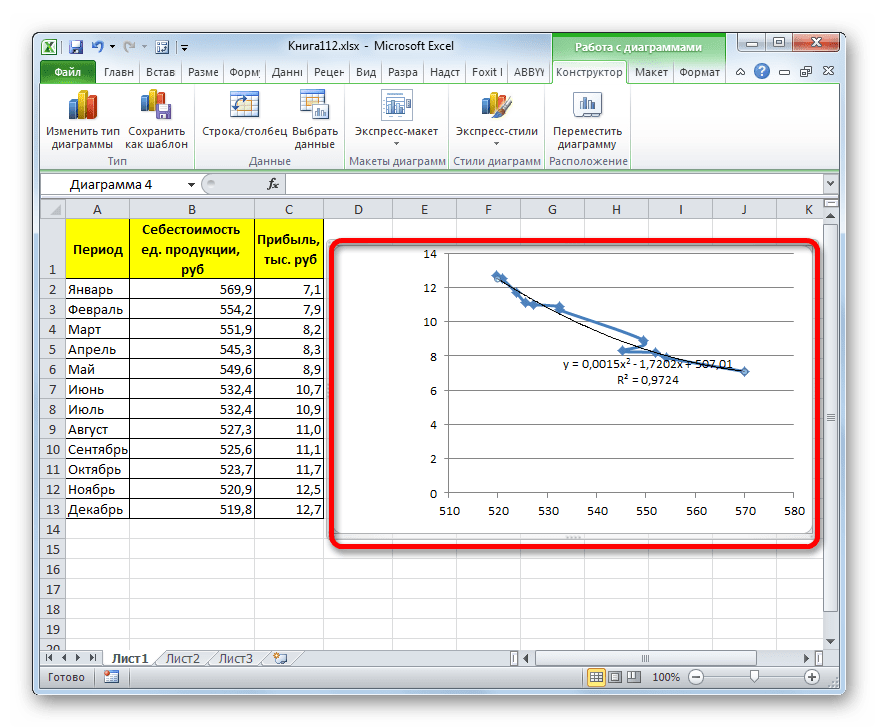
Настал черед рассмотреть метод полиномиального сглаживания.
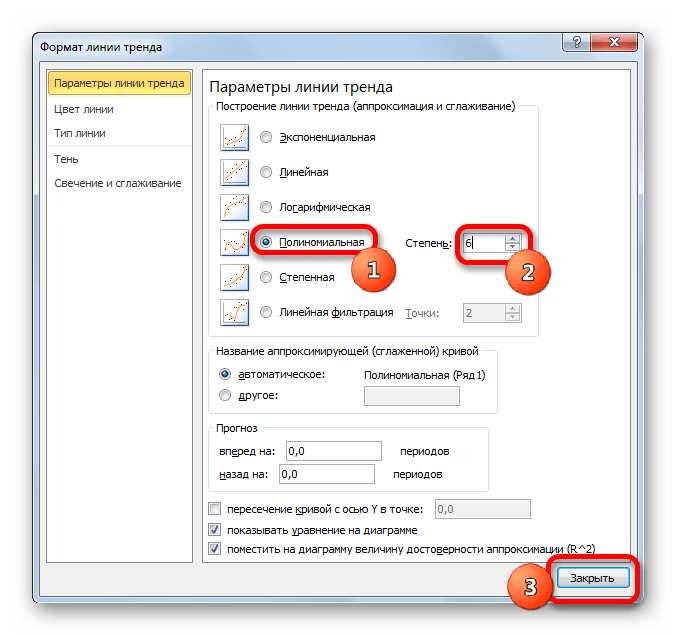
- Переходим в окно формата линии тренда, как уже делали не раз. В блоке «Построение линии тренда» устанавливаем переключатель в позицию «Полиномиальная». Справа от данного пункта расположено поле «Степень». При выборе значения «Полиномиальная» оно становится активным. Здесь можно указать любое степенное значение от 2 (установлено по умолчанию) до 6. Данный показатель определяет число максимумов и минимумов функции. При установке полинома второй степени описывается только один максимум, а при установке полинома шестой степени может быть описано до пяти максимумов. Для начала оставим настройки по умолчанию, то есть, укажем вторую степень. Остальные настройки оставляем такими же, какими мы выставляли их в предыдущих способах. Жмем на кнопку «Закрыть».
- Линия тренда с использованием данного метода построена. Как видим, она ещё более изогнута, чем при использовании экспоненциальной аппроксимации. Уровень достоверности выше, чем при любом из использованных ранее способов, и составляет 0,9724.

Данный метод наиболее успешно можно применять в том случае, если данные носят постоянно изменчивый характер. Функция, описывающая данный вид сглаживания, выглядит таким образом:
y=a1+a1*x+a2*x^2+…+an*x^nВ нашем случае формула приняла такой вид:
y=0,0015*x^2-1,7202*x+507,01 - Теперь давайте изменим степень полиномов, чтобы увидеть, будет ли отличаться результат. Возвращаемся в окно формата. Тип аппроксимации оставляем полиномиальным, но напротив него в окне степени устанавливаем максимально возможное значение – 6.
- Как видим, после этого наша линия тренда приняла форму ярко выраженной кривой, у которой число максимумов равно шести. Уровень достоверности повысился ещё больше, составив 0,9844.
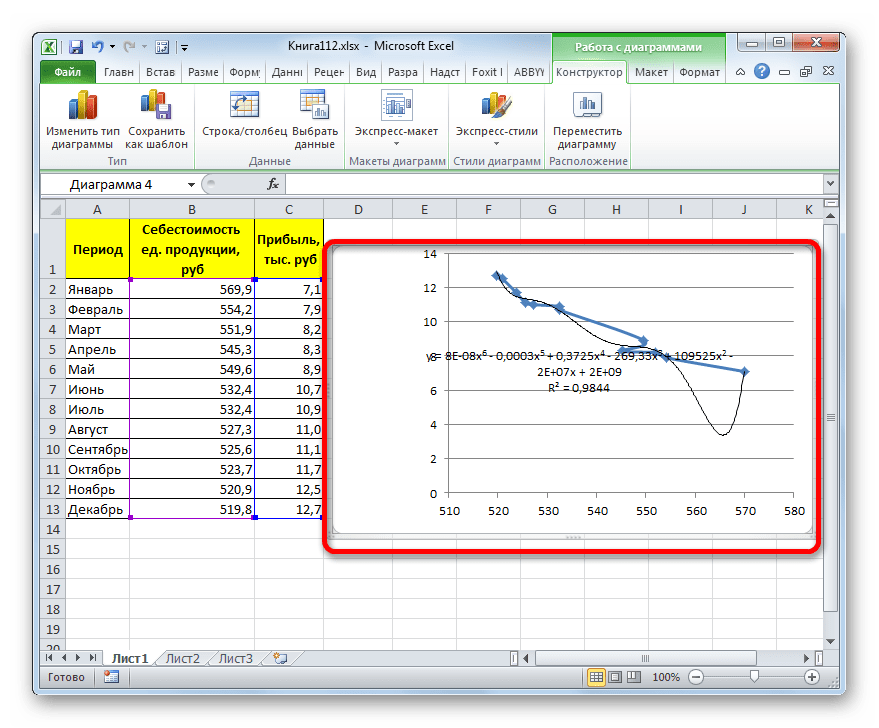
Формула, которая описывает данный тип сглаживания, приняла следующий вид:
y=8E-08x^6-0,0003x^5+0,3725x^4-269,33x^3+109525x^2-2E+07x+2E+09
Способ 5: степенное сглаживание
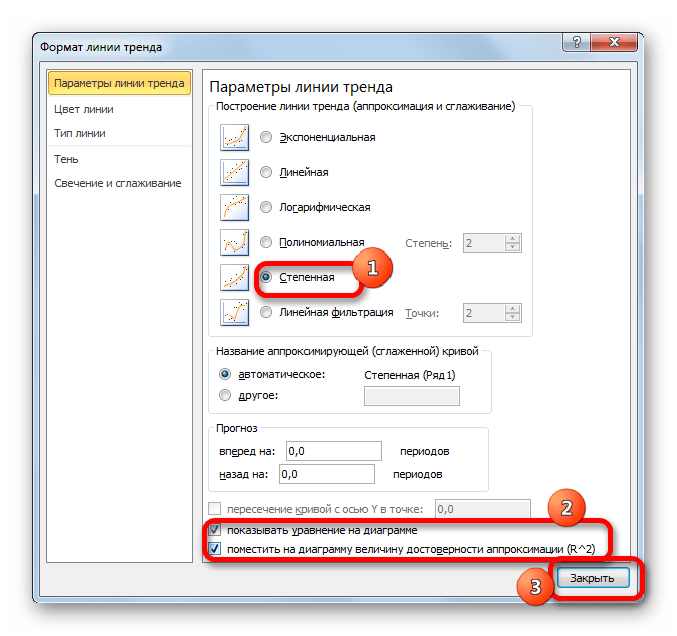
В завершении рассмотрим метод степенной аппроксимации в Excel.
- Перемещаемся в окно «Формат линии тренда». Устанавливаем переключатель вида сглаживания в позицию «Степенная». Показ уравнения и уровня достоверности, как всегда, оставляем включенными. Жмем на кнопку «Закрыть».
- Программа формирует линию тренда. Как видим, в нашем случае она представляет собой линию с небольшим изгибом. Уровень достоверности равен 0,9618, что является довольно высоким показателем. Из всех вышеописанных способов уровень достоверности был выше только при использовании полиномиального метода.
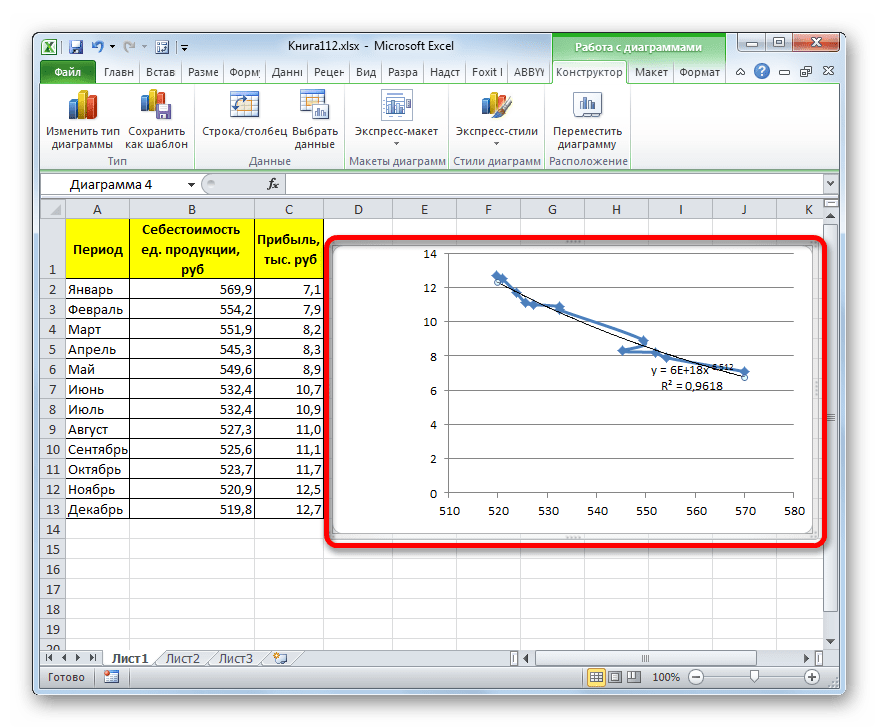
Данный способ эффективно используется в случаях интенсивного изменения данных функции. Важно учесть, что этот вариант применим только при условии, что функция и аргумент не принимают отрицательных или нулевых значений.
Общая формула, описывающая данный метод имеет такой вид:
y=bx^n
В конкретно нашем случае она выглядит так:
y = 6E+18x^(-6,512)
Как видим, при использовании конкретных данных, которые мы применяли для примера, наибольший уровень достоверности показал метод полиномиальной аппроксимации с полиномом в шестой степени (0,9844), наименьший уровень достоверности у линейного метода (0,9418). Но это совсем не значит, что такая же тенденция будет при использовании других примеров. Нет, уровень эффективности у приведенных выше методов может значительно отличаться, в зависимости от конкретного вида функции, для которой будет строиться линия тренда. Поэтому, если для этой функции выбранный метод наиболее эффективен, то это совсем не означает, что он также будет оптимальным и в другой ситуации.
Если вы пока не можете сразу определить, основываясь на вышеприведенных рекомендациях, какой вид аппроксимации подойдет конкретно в вашем случае, то есть смысл попробовать все методы. После построения линии тренда и просмотра её уровня достоверности можно будет выбрать оптимальный вариант.
Нормальное распределение. Построение графика в Excel. Концепция шести сигм
Наверное, не все знают, что в Excel есть встроенная функция для построения нормального распределения. Графики нормального распределения часто используются для демонстрации идей статистической обработки данных.
Функция НОРМРАСП имеет следующий синтаксис:
НОРМРАСП (Х; среднее; стандартное_откл; интегральная)
Х — аргумент функции; фактически НОРМРАСП можно трактовать как y=f(x); при этом функция возвращает вероятность реализации события Х
Среднее (µ) — среднее арифметическое распределения; чем дальше Х от среднего, тем ниже вероятность реализации такого события
Стандартное_откл (σ) — стандартное отклонение распределения; мера кучности; чем меньше σ, тем выше вероятность у тех Х, которые расположены ближе к среднему
Интегральная — логическое значение, определяющее форму функции. Если «интегральная» имеет значение ИСТИНА, функция НОРМРАСП возвращает интегральную функцию распределения, тот есть суммарную вероятность всех событий для аргументов от -∞ до Х; если «интегральная» имеет значение ЛОЖЬ, возвращается вероятность реализации события Х, точнее говоря, вероятность событий находящихся в некотором диапазоне вокруг Х
Например, для µ=0 имеем:
Скачать заметку в формате Word, пример в формате Excel
Здесь по оси абсцисс единица измерения – σ, или (что то же самое), можно сказать, что график построен для σ = 1. То есть, «-2» на графике означает -2σ. По оси ординат шкала убрана умышленно, так как она лишена смысла. Точнее говоря, высота кривой зависит от плотности точек на оси абсцисс, по которым мы строим график. Например, если на интервал от 0 до 1σ приходится 10 точек, то высота в максимуме составит 4%, а если 20 точек – 2%. Здесь проценты означают вероятность попадания случайной величины в узкий диапазон окрестности точки на оси абсцисс. Зато имеет смысл площадь под кривой на определенном интервале. И эта площадь не зависит от плотности точек. Так, например, площадь под кривой на интервале от 0 до 1σ составляет 34,13%. Это значение можно интерпретировать следующим образом: с вероятностью 68,26% случайная величина Х попадет в диапазон µ ± σ.
Теперь, наверное, вам будет лучше понятен смысл выражения «качество шести сигм». Оно означает, что производство налажено таким образом, что случайная величина Х (например, диаметр вала) находясь в диапазон µ ± 6σ, всё еще удовлетворяет техническим условиям (допускам). Это достигается за счет значительного уменьшения сигмы, то есть случайная величина Х очень близка к нормативному значению µ. На графике ниже представлено три ситуации, когда границы допуска остаются неизменными, а благодаря повышению качества (уменьшению вариабельности, сужению сигма) доля брака сокращается:
На первом рисунке только 1,5σ попадают в границы допуска, то есть только 86,6% деталей являются годными. На втором рисунке уже 3σ попадают в границы допуска, то есть 99,75% являются годными. Но всё еще 25 деталей из каждых 10 000 произведенных являются браком. На третьем рисунке целых 6σ попадают в границы допуска, то есть в брак попадут только две детали на миллиард изготовленных!
Вообще-то говоря, измерение качества в терминах сигм использует не совсем нормальное распределение. Вот что пишет на эту тему Википедия:
Опыт показывает, что показатели процессов имеют тенденцию изменяться с течением времени. В результате со временем в промежуток между границами поля допуска будет входить меньше, чем было установлено первоначально. Опытным путём было установлено, что изменение параметров во времени можно учесть с помощью смещения в 1,5 сигма. Другими словами, с течением времени длина промежутка между границами поля допуска под кривой нормального распределения уменьшается до 4,5 сигма вследствие того, что среднее процесса с течением времени смещается и/или среднеквадратическое отклонение увеличивается.
Широко распространённое представление о «процессе шесть сигма» заключается в том, что такой процесс позволяет получить уровень качества 3,4 дефектных единиц на миллион готовых изделий при условии, что длина под кривой слева или справа от среднего будет соответствовать 4,5 сигма (без учёта левого или правого конца кривой за границей поля допуска). Таким образом, уровень качества 3,4 дефектных единиц на миллион готовых изделий соответствует длине промежутка 4,5 сигма, получаемых разницей между 6 сигма и сдвигом в 1,5 сигма, которое было введено, чтобы учесть изменение показателей с течением времени. Такая поправка создана для того, чтобы предупредить неправильною оценку уровня дефектности, встречающееся в реальных условиях.
С моей точки зрения, не вполне внятное объяснение. Тем не менее, во всем мире принята следующая таблица соответствия числа дефектов и уровня качества в сигмах:
Блог о программе Microsoft Excel: приемы, хитрости, секреты, трюки
Как построить график с нормальным распределением в Excel
Так как я часто имею дело с большим количеством данных, у меня время от времени возникает необходимость генерировать массивы значений для проверки моделей в Excel. К примеру, если я хочу увидеть распределение веса продукта с определенным стандартным отклонением, потребуются некоторые усилия, чтобы привести результат работы формулы СЛУЧМЕЖДУ() в нормальный вид. Дело в том, что формула СЛУЧМЕЖДУ() выдает числа с единым распределением, т.е. любое число с одинаковой долей вероятности может оказаться как у нижней, так и у верхней границы запрашиваемого диапазона. Такое положение дел не соответствует действительности, так как вероятность возникновения продукта уменьшается по мере отклонения от целевого значения. Т.е. если я произвожу продукт весом 100 грамм, вероятность, что я произведу 97-ми или 103-граммовый продукт меньше, чем 100 грамм. Вес большей части произведенной продукции будет сосредоточен рядом с целевым значением. Такое распределение называется нормальным. Если построить график, где по оси Y отложить вес продукта, а по оси X – количество произведенного продукта, график будет иметь колоколообразный вид, где наивысшая точка будет соответствовать целевому значению.
Таким образом, чтобы привести массив, выданный формулой СЛУЧМЕЖДУ(), в нормальный вид, мне приходилось ручками исправлять пограничные значения на близкие к целевым. Такое положение дел меня, естественно, не устраивало, поэтому, покопавшись в интернете, открыл интересный способ создания массива данных с нормальным распределением. В сегодняшней статье описан способ генерации массива и построения графика с нормальным распределением.
Характеристики нормального распределения
Непрерывная случайная переменная, которая подчиняется нормальному распределению вероятностей, обладает некоторыми особыми свойствами. Предположим, что вся производимая продукция подчиняется нормальному распределению со средним значением 100 грамм и стандартным отклонением 3 грамма. Распределение вероятностей для такой случайной переменной представлено на рисунке.
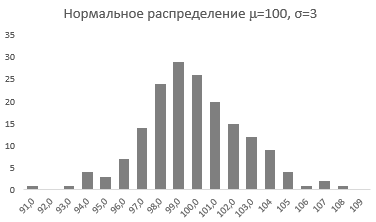
Из этого рисунка мы можем сделать следующие наблюдения относительно нормального распределения — оно имеет форму колокола и симметрично относительно среднего значения.
Стандартное отклонение имеет немаловажную роль в форме изгиба. Если посмотреть на предыдущий рисунок, то можно заметить, что практически все измерения веса продукта попадают в интервал от 95 до 105 граммов. Давайте рассмотрим следующий рисунок, на котором представлено нормальное распределение с той же средней – 100 грамм, но со стандартным отклонением всего 1,5 грамма
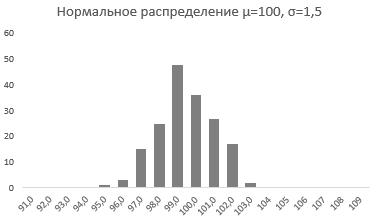
Здесь вы видите, что измерения значительно плотней прилегают к среднему значению. Почти все производимые продукты попадают в интервал от 97 до 102 грамм.
Небольшое значение стандартного отклонения выражается в более «тощей и высокой кривой, плотно прижимающейся к среднему значению. Чем больше стандартное, тем «толще», ниже и растянутее получается кривая.
Создание массива с нормальным распределением
Итак, чтобы сгенерировать массив данных с нормальным распределением, нам понадобится функция НОРМ.ОБР() – это обратная функция от НОРМ.РАСП(), которая возвращает нормально распределенную переменную для заданной вероятности для определенного среднего значения и стандартного отклонения. Синтаксис формулы выглядит следующим образом:
=НОРМ.ОБР(вероятность; среднее_значение; стандартное_отклонение)
Другими словами, я прошу Excel посчитать, какая переменная будет находится в вероятностном промежутке от 0 до 1. И так как вероятность возникновения продукта с весом в 100 грамм максимальная и будет уменьшаться по мере отдаления от этого значения, то формула будет выдавать значения близких к 100 чаще, чем остальных.
Давайте попробуем разобрать на примере. Выстроим график распределения вероятностей от 0 до 1 с шагом 0,01 для среднего значения равным 100 и стандартным отклонением 1,5.
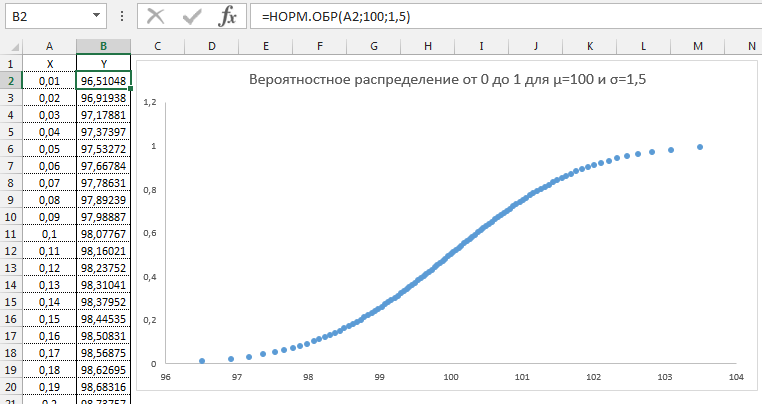
Как видим из графика точки максимально сконцентрированы у переменной 100 и вероятности 0,5.
Этот фокус мы используем для генерирования случайного массива данных с нормальным распределением. Формула будет выглядеть следующим образом:
=НОРМ.ОБР(СЛЧИС(); среднее_значение; стандартное_отклонение)
Создадим массив данных для нашего примера со средним значением 100 грамм и стандартным отклонением 1,5 грамма и протянем нашу формулу вниз.
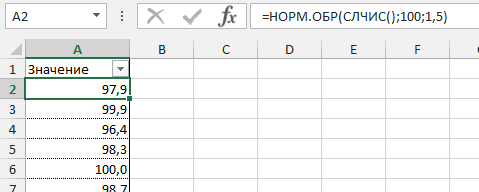
Теперь, когда массив данных готов, мы можем выстроить график с нормальным распределением.
Построение графика нормального распределения
Прежде всего необходимо разбить наш массив на периоды. Для этого определяем минимальное и максимальное значение, размер каждого периода или шаг, с которым будет увеличиваться период.
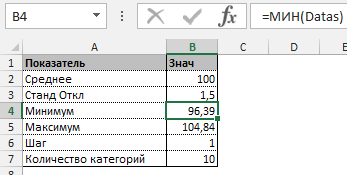
Далее строим таблицу с категориями. Нижняя граница (B11) равняется округленному вниз ближайшему кратному числу. Остальные категории увеличиваются на значение шага. Формула в ячейке B12 и последующих будет выглядеть:
В столбце X будет производится подсчет количества переменных в заданном промежутке. Для этого воспользуемся формулой ЧАСТОТА(), которая имеет два аргумента: массив данных и массив интервалов. Выглядеть формула будет следующим образом =ЧАСТОТА(Data!A1:A175;B11:B20). Также стоит отметить, что в таком варианте данная функция будет работать как формула массива, поэтому по окончании ввода необходимо нажать сочетание клавиш Ctrl+Shift+Enter.
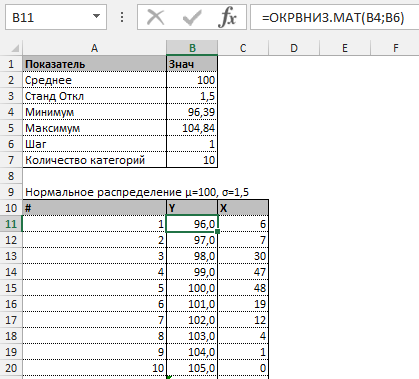
Таким образом у нас получилась таблица с данными, с помощью которой мы сможем построить диаграмму с нормальным распределением. Воспользуемся диаграммой вида Гистограмма с группировкой, где по оси значений будет отложено количество переменных в данном промежутке, а по оси категорий – периоды.
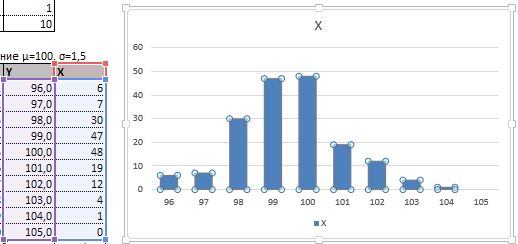
Осталось отформатировать диаграмму и наш график с нормальным распределением готов.
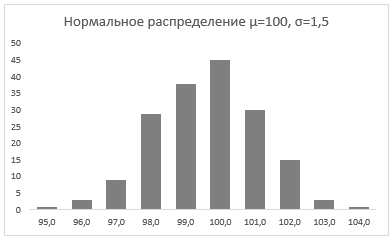
Итак, мы познакомились с вами с нормальным распределением, узнали, что Excel позволяет генерировать массив данных с помощью формулы НОРМ.ОБР() для определенного среднего значения и стандартного отклонения и научились приводить данный массив в графический вид.
Вам также могут быть интересны следующие статьи
12 комментариев
Ренат, добрый день.
Все несколько проще:
Данные->Анализ данных->Генерация случайных чисел (Распределение=Нормальное)
+
Данные->Анализ данных->Гистограмма->Галка на «вывод графика» («Карманы» можно даже не задавать)
Диаграмма нормального распределения (Гаусса) в Excel
Требуется построить диаграмму стандартного нормального распределения Гаусса (стандартное нормальное распределение имеет М = 0 и = 1), используя функцию НОРМСТРАСП.
1. В ячейку A3 введем символ х, а в ячейку ВЗ — символ функции плотности вероятности f(x).
2. Вычислим нижнюю М — За границу диапазона значений х, для чего установим курсор в ячейку С2 и введем формулу =0-3*1, а также верхнюю границу — в ячейку Е2 введем формулу =0+3*1.
3. Скопируем формулу из ячейки С2 в ячейку А4, полученное в ячейке А4 значение нижней границы будет началом последовательности арифметической прогрессии.
4. Создадим последовательность значений х в требуемом диапазоне, для чего установим курсор в ячейку А4 и выполним команду меню Правка/Заполнить/Прогрессия.
5. В открывшемся окне диалога Прогрессия установим переключатели арифметическая, по столбцам, в поле Шаг введем значение 0,5, а в поле Предельное значение — число, равное верхней границе диапазона.
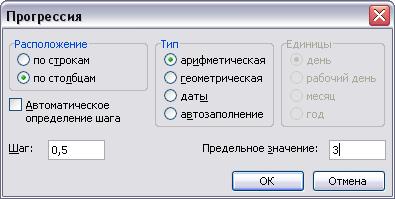
Функция НОРМРАСПР в EXCEL
6. Щелкнем на кнопке ОК. В диапазоне А4:А16 будет сформирована последовательность значений х.
7. Установим курсор в ячейку В4 и выполним команду меню Вставка/Функция. В открывшемся окне Мастер функций выберем категорию Статистические, а в списке функций — НОРМРАСП.
8. Установим значения параметров функции НОРМРАСП: для параметра х установим ссылку на ячейку А4, для параметра Среднее — введем число 0, для параметра Стандартное_откл — число 1, для параметра Интегральное — число 0 (весовая).
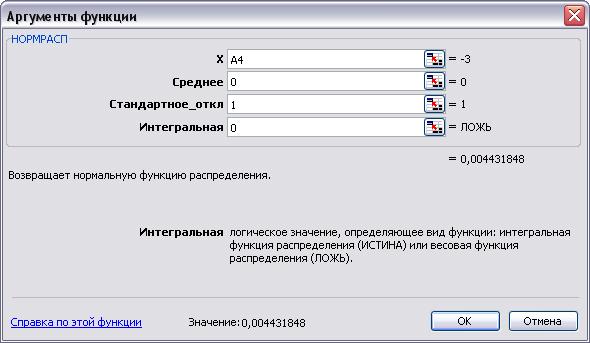
Диаграмма нормального интегрального распределения в EXCEL
9. Используя маркер буксировки, скопируем полученную формулу в диапазон ячеек В5:В16.
10. Выделим диапазон полученных табличных значений функции f(х) (ВЗ:В16) и выполним команду меню Вставка/Диаграмма. В окне Мастер диаграмм во вкладке Стандартные выберем График, а в поле Вид — вид графика, щелкнем на кнопке Далее.
11. В окне Мастер диаграмм (шаг 2) выберем закладку Ряд. В поле Подписи оси х укажем ссылку на диапазон, содержащий значения х (А4:А16). Щелкнем на кнопке Далее.
В окне Мастер диаграмм (шаг 3) введем подписи: Название диаграммы, Ось х, Ось у. Щелкнем на кнопке Готово. На рабочий лист будет выведена диаграмма плотности вероятности .
Нормальное распределение (Гаусса) в Excel
В статье подробно показано, что такое нормальный закон распределения случайной величины и как им пользоваться при решении практически задач.
Нормальное распределение в статистике
История закона насчитывает 300 лет. Первым открывателем стал Абрахам де Муавр, который придумал аппроксимацию биномиального распределения еще 1733 году. Через много лет Карл Фридрих Гаусс (1809 г.) и Пьер-Симон Лаплас (1812 г.) вывели математические функции.
Лаплас также обнаружил замечательную закономерность и сформулировал центральную предельную теорему (ЦПТ), согласно которой сумма большого количества малых и независимых величин имеет нормальное распределение.
Нормальный закон не является фиксированным уравнением зависимости одной переменной от другой. Фиксируется только характер этой зависимости. Конкретная форма распределения задается специальными параметрами. Например, у = аx + b – это уравнение прямой. Однако где конкретно она проходит и под каким наклоном, определяется параметрами а и b. Также и с нормальным распределением. Ясно, что это функция, которая описывает тенденцию высокой концентрации значений около центра, но ее точная форма задается специальными параметрами.
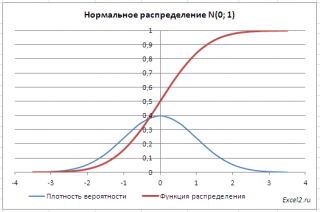
Кривая нормального распределения Гаусса имеет следующий вид.

График нормального распределения напоминает колокол, поэтому можно встретить название колоколообразная кривая. У графика имеется «горб» в середине и резкое снижение плотности по краям. В этом заключается суть нормального распределения. Вероятность того, что случайная величина окажется около центра гораздо выше, чем то, что она сильно отклонится от середины.
На рисунке выше изображены два участка под кривой Гаусса: синий и зеленый. Основания, т.е. интервалы, у обоих участков равны. Но заметно отличаются высоты. Синий участок удален от центра, и имеет существенно меньшую высоту, чем зеленый, который находится в самом центре распределения. Следовательно, отличаются и площади, то бишь вероятности попадания в обозначенные интервалы.
Формула нормального распределения (плотности) следующая.
Формула состоит из двух математических констант:
π – число пи 3,142;
е – основание натурального логарифма 2,718;
двух изменяемых параметров, которые задают форму конкретной кривой:
m – математическое ожидание (в различных источниках могут использоваться другие обозначения, например, µ или a);
ну и сама переменная x, для которой высчитывается плотность вероятности.
Конкретная форма нормального распределения зависит от 2-х параметров: математического ожидания (m) и дисперсии (σ 2 ). Кратко обозначается N(m, σ 2 ) или N(m, σ). Параметр m (матожидание) определяет центр распределения, которому соответствует максимальная высота графика. Дисперсия σ 2 характеризует размах вариации, то есть «размазанность» данных.
Параметр математического ожидания смещает центр распределения вправо или влево, не влияя на саму форму кривой плотности.
А вот дисперсия определяет остроконечность кривой. Когда данные имеют малый разброс, то вся их масса концентрируется у центра. Если же у данных большой разброс, то они «размазываются» по широкому диапазону.
Плотность распределения не имеет прямого практического применения. Для расчета вероятностей нужно проинтегрировать функцию плотности.
Вероятность того, что случайная величина окажется меньше некоторого значения x, определяется функцией нормального распределения:
Используя математические свойства любого непрерывного распределения, несложно рассчитать и любые другие вероятности, так как
P(a ≤ X 0 =1 и остается рассчитать только соотношение 1 на корень из 2 пи.
Таким образом, по графику хорошо видно, что значения, имеющие маленькие отклонения от средней, выпадают чаще других, а те, которые сильно отдалены от центра, встречаются значительно реже. Шкала оси абсцисс измеряется в стандартных отклонениях, что позволяет отвязаться от единиц измерения и получить универсальную структуру нормального распределения. Кривая Гаусса для нормированных данных отлично демонстрирует и другие свойства нормального распределения. Например, что оно является симметричным относительно оси ординат. В пределах ±1σ от средней арифметической сконцентрирована большая часть всех значений (прикидываем пока на глазок). В пределах ±2σ находятся большинство данных. В пределах ±3σ находятся почти все данные. Последнее свойство широко известно под названием правило трех сигм для нормального распределения.
Функция стандартного нормального распределения позволяет рассчитывать вероятности.
Понятное дело, вручную никто не считает. Все подсчитано и размещено в специальных таблицах, которые есть в конце любого учебника по статистике.
Таблица нормального распределения
Таблицы нормального распределения встречаются двух типов:
— таблица плотности;
— таблица функции (интеграла от плотности).
Таблица плотности используется редко. Тем не менее, посмотрим, как она выглядит. Допустим, нужно получить плотность для z = 1, т.е. плотность значения, отстоящего от матожидания на 1 сигму. Ниже показан кусок таблицы.
В зависимости от организации данных ищем нужное значение по названию столбца и строки. В нашем примере берем строку 1,0 и столбец , т.к. сотых долей нет. Искомое значение равно 0,2420 (0 перед 2420 опущен).
Функция Гаусса симметрична относительно оси ординат. Поэтому φ(z)= φ(-z), т.е. плотность для 1 тождественна плотности для -1, что отчетливо видно на рисунке.
Чтобы не тратить зря бумагу, таблицы печатают только для положительных значений.
На практике чаще используют значения функции стандартного нормального распределения, то есть вероятности для различных z.
В таких таблицах также содержатся только положительные значения. Поэтому для понимания и нахождения любых нужных вероятностей следует знать свойства стандартного нормального распределения.
Функция Ф(z) симметрична относительно своего значения 0,5 (а не оси ординат, как плотность). Отсюда справедливо равенство:
Это факт показан на картинке:
Значения функции Ф(-z) и Ф(z) делят график на 3 части. Причем верхняя и нижняя части равны (обозначены галочками). Для того, чтобы дополнить вероятность Ф(z) до 1, достаточно добавить недостающую величину Ф(-z). Получится равенство, указанное чуть выше.
Если нужно отыскать вероятность попадания в интервал (0; z), то есть вероятность отклонения от нуля в положительную сторону до некоторого количества стандартных отклонений, достаточно от значения функции стандартного нормального распределения отнять 0,5:
Для наглядности можно взглянуть на рисунок.
На кривой Гаусса, эта же ситуация выглядит как площадь от центра вправо до z.
Довольно часто аналитика интересует вероятность отклонения в обе стороны от нуля. А так как функция симметрична относительно центра, предыдущую формулу нужно умножить на 2:
Под кривой Гаусса это центральная часть, ограниченная выбранным значением –z слева и z справа.
Указанные свойства следует принять во внимание, т.к. табличные значения редко соответствуют интересующему интервалу.
Для облегчения задачи в учебниках обычно публикуют таблицы для функции вида:
Если нужна вероятность отклонения в обе стороны от нуля, то, как мы только что убедились, табличное значение для данной функции просто умножается на 2.
Теперь посмотрим на конкретные примеры. Ниже показана таблица стандартного нормального распределения. Найдем табличные значения для трех z: 1,64, 1,96 и 3.
Как понять смысл этих чисел? Начнем с z=1,64, для которого табличное значение составляет 0,4495. Проще всего пояснить смысл на рисунке.
То есть вероятность того, что стандартизованная нормально распределенная случайная величина попадет в интервал от до 1,64, равна 0,4495. При решении задач обычно нужно рассчитать вероятность отклонения в обе стороны, поэтому умножим величину 0,4495 на 2 и получим примерно 0,9. Занимаемая площадь под кривой Гаусса показана ниже.
Таким образом, 90% всех нормально распределенных значений попадает в интервал ±1,64σ от средней арифметической. Я не случайно выбрал значение z=1,64, т.к. окрестность вокруг средней арифметической, занимающая 90% всей площади, иногда используется для проверки статистических гипотез и расчета доверительных интервалов. Если проверяемое значение не попадает в обозначенную область, то его наступление маловероятно (всего 10%).
Для проверки гипотез, однако, чаще используется интервал, накрывающий 95% всех значений. Половина вероятности от 0,95 – это 0,4750 (см. второе выделенное в таблице значение).
Для этой вероятности z=1,96. Т.е. в пределах почти ±2σ от средней находится 95% значений. Только 5% выпадают за эти пределы.
Еще одно интересное и часто используемое табличное значение соответствует z=3, оно равно по нашей таблице 0,4986. Умножим на 2 и получим 0,997. Значит, в рамках ±3σ от средней арифметической заключены почти все значения.
Так выглядит правило 3 сигм для нормального распределения на диаграмме.
С помощью статистических таблиц можно получить любую вероятность. Однако этот метод очень медленный, неудобный и сильно устарел. Сегодня все делается на компьютере. Далее переходим к практике расчетов в Excel.
Нормальное распределение в Excel
В Excel есть несколько функций для подсчета вероятностей или обратных значений нормального распределения.
Функция НОРМ.СТ.РАСП
Функция НОРМ.СТ.РАСП предназначена для расчета плотности ϕ( z ) или вероятности Φ(z) по нормированным данным (z).
z – значение стандартизованной переменной
интегральная – если 0, то рассчитывается плотность ϕ( z ) , если 1 – значение функции Ф(z), т.е. вероятность P(Z
Примеры решений распределения с помощью функции ГАУСС в Excel
Функция ГАУСС, подлежащая применению в версиях Excel начиная от 2013 года или новее. Она позволяет вычислить такую вероятность, с которой элемент стандартной нормальной совокупности будет находиться в интервале между средними и стандартными отклонениями от среднего.
Примеры использования функции ГАУСС в Excel
Синтаксис рассматриваемой функции не представляет из себя ничего сложного, ведь функции ГАУСС присущ всего один обязательный аргумент – Z – возвращающий число.
Важно отметить, что существует определенная связь между функцией ГАУСС и такой статистической функцией, как стандартное нормальное распределение, иначе говоря – НОРМ.СТ.РАСП.
Итак, всегда функция НОРМ.СТ.РАСП (0; Истина) делает возврат 0,5, тогда как ГАУСС (z) имеет в результате значение меньше на 0,5, чем результат функции НОРМ.СТ.РАСП. На рисунке, расположенном ниже, приведен пример использования данных статистических функций для возвращения числа 1,5.

Для наглядности продемонстрируем зависимость между значениями функций графическим способом. Для этого – сформируем таблицу с выборкой чисел, например на интервале от -5 до 5 с шагом 0,5, а затем по имеющимся данным построим график:
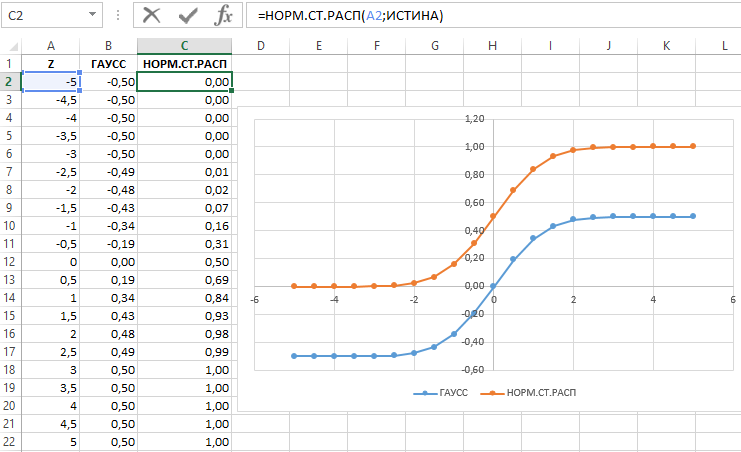
На графике четко прослеживается пропорциональная корреляция результатов вычислений функций ГАУСС и НОРМ.СТ.РАСП.
Решение системы вероятности методом ГАУССА в Excel
Задача представляет собой вычисление вероятности возможных значений при бросании двух костей.
Пример с игрой в кости является наиболее наглядным, так как мы имеем ограниченный набор данных, которые соответствуют вероятностям. Так, вероятность имеет значение от нуля до единицы, к которому стремится наблюдаемая частота при бесконечно большой выборке или повторении эксперимента.
Существует 36 возможных комбинаций. При этом, вероятность того, что при бросании двух костей выпадет 2 очка равна 1/36, а 7 очков – 1/6. Отобразим перечень возможных значений бросания двух игральных костей в таблице, приведя при этом все вероятности к общему знаменателю.
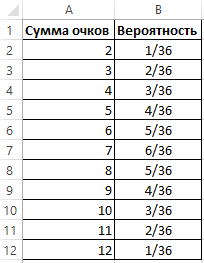
Однако, такой ряд данных не дает возможности для выявления полного распределения, поэтому следует отобразить данные об отдельных вероятностях в рассчитанную по функции распределения. Так необходимо, все вероятности просуммировать последовательно (1+2+3+4+5+6+5+4+3+2+1).
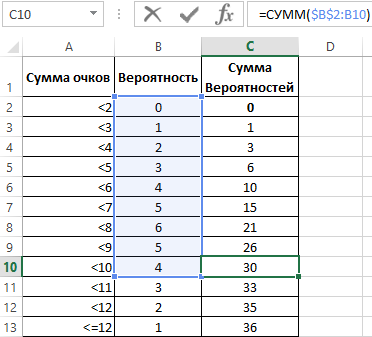
Теперь определяем коэффициент вероятности разделив по отдельности последовательную сумму вероятностей на максимально возможное количество комбинаций 36.
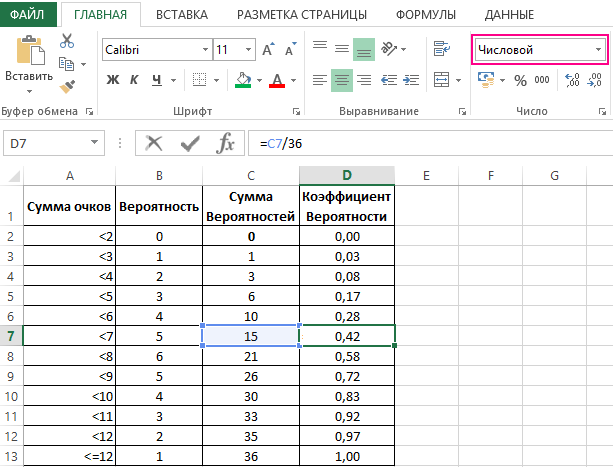
В первом случае нами были рассмотрены отдельные вероятности, во втором – сумма вероятностей от первого возможного значения до заданного.
Необходимо преобразовать диапазон ячеек D2:D13 в числовой формат данных, иначе при обращении на них функции ГАУСС будет иметь место ошибка.
В созданный рядом с первоначальной таблицей столбец E введем формулу, которая в качестве аргумента делает обращение к ячейке D2.
Далее, протянем формулу вниз по столбцу, и получим ряд вероятностей с использованием функции ГАУСС.
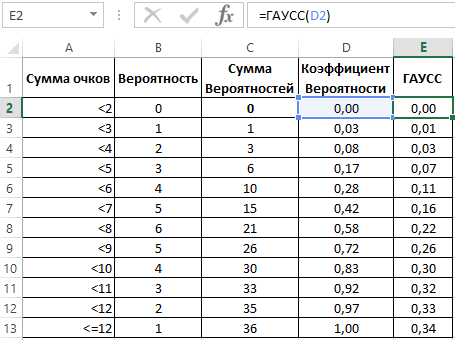
Для более наглядной визуализации, построим график вероятности:
Решение вероятности методом распределения кривой Гаусса в Excel
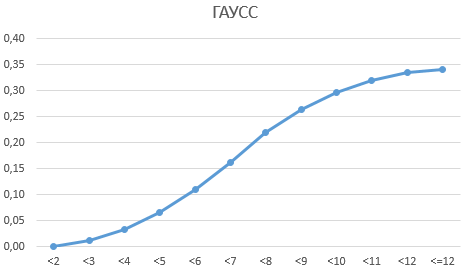
Теперь в качестве примера нормального распределения с помощью функции ГАУСС решим задачу о вероятностном соотношении результатов стрельбы по мишени.
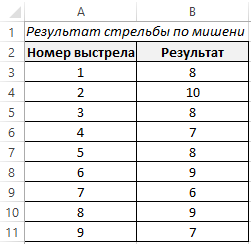
Для этого построим базовую таблицу, которая отражает результаты стрельбы по мишени в девяти подходах.
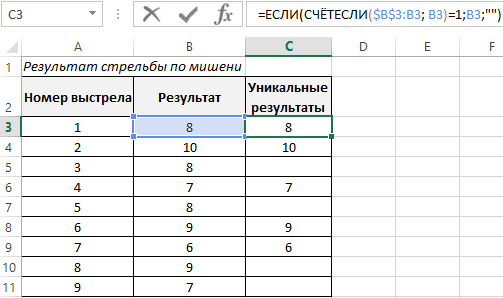
Затем, выберем только уникальные результаты, для этого используем хитрую формулу:
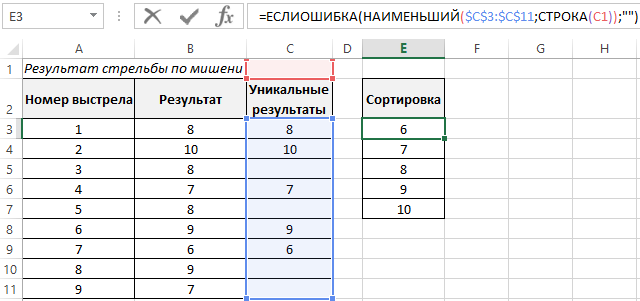
Делаем сортировку формулой для результатов по возрастанию и выводим в отдельную табличку:
После чего определим частоту встречающихся только для уникальных результатов:
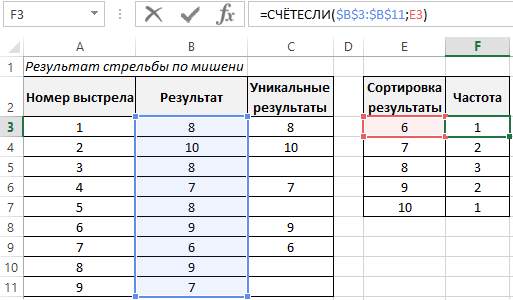
Далее применим функцию ГАУСС к значениям ячеек с частотой встречаемости. Отразим результаты вычислений на графике:
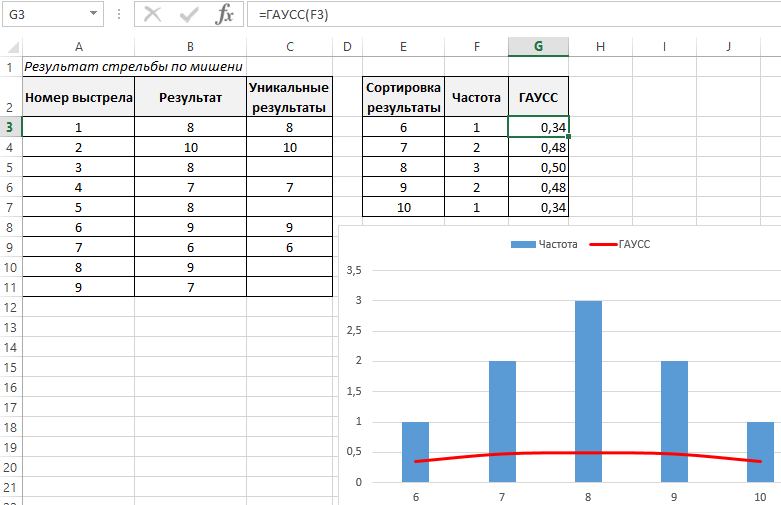
На графике красной линией определено нормальное распределение кривой Гаусса.
17 авг. 2022 г.
читать 3 мин
«Колокольная кривая» — это прозвище, данное форме нормального распределения , которая имеет отчетливую форму «колокола»:
В этом руководстве объясняется, как построить кривую нормального распределения в Excel для заданного среднего значения и стандартного отклонения, и даже предоставляется бесплатный загружаемый шаблон, который можно использовать для создания собственной кривой нормального распределения в Excel.
Пример: кривая нормального распределения в Excel
Используйте следующие шаги, чтобы сделать кривую колокола в Excel.
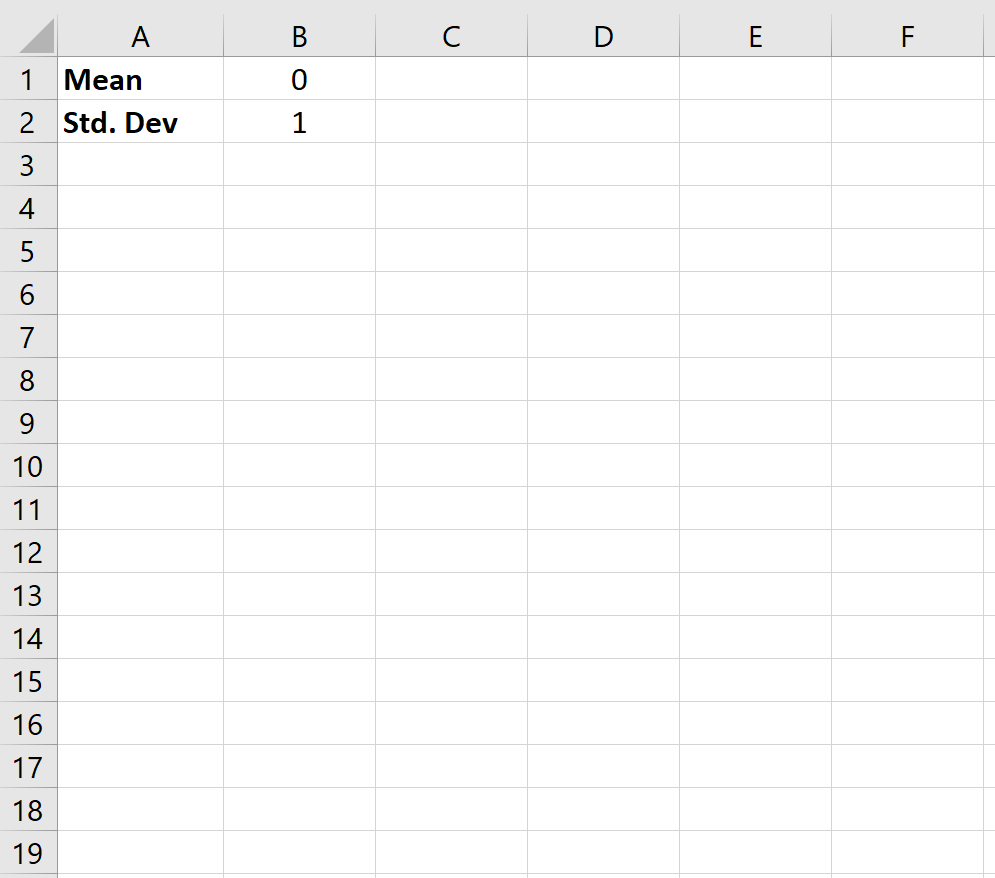
Шаг 1: Создайте ячейки для среднего значения и стандартного отклонения.
Шаг 2: Создайте ячейки для процентилей от -4 до 4 с шагом 0,1.
…
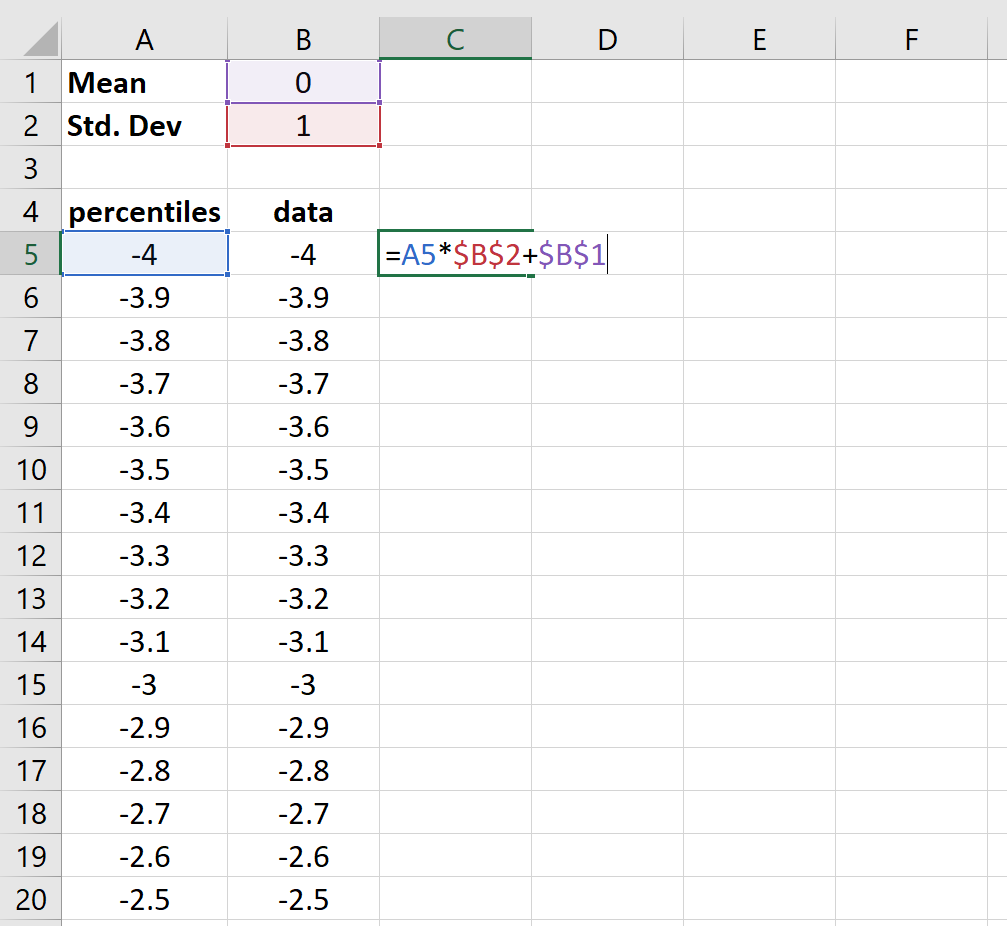
Шаг 3: Создайте столбец значений данных, которые будут использоваться на графике.
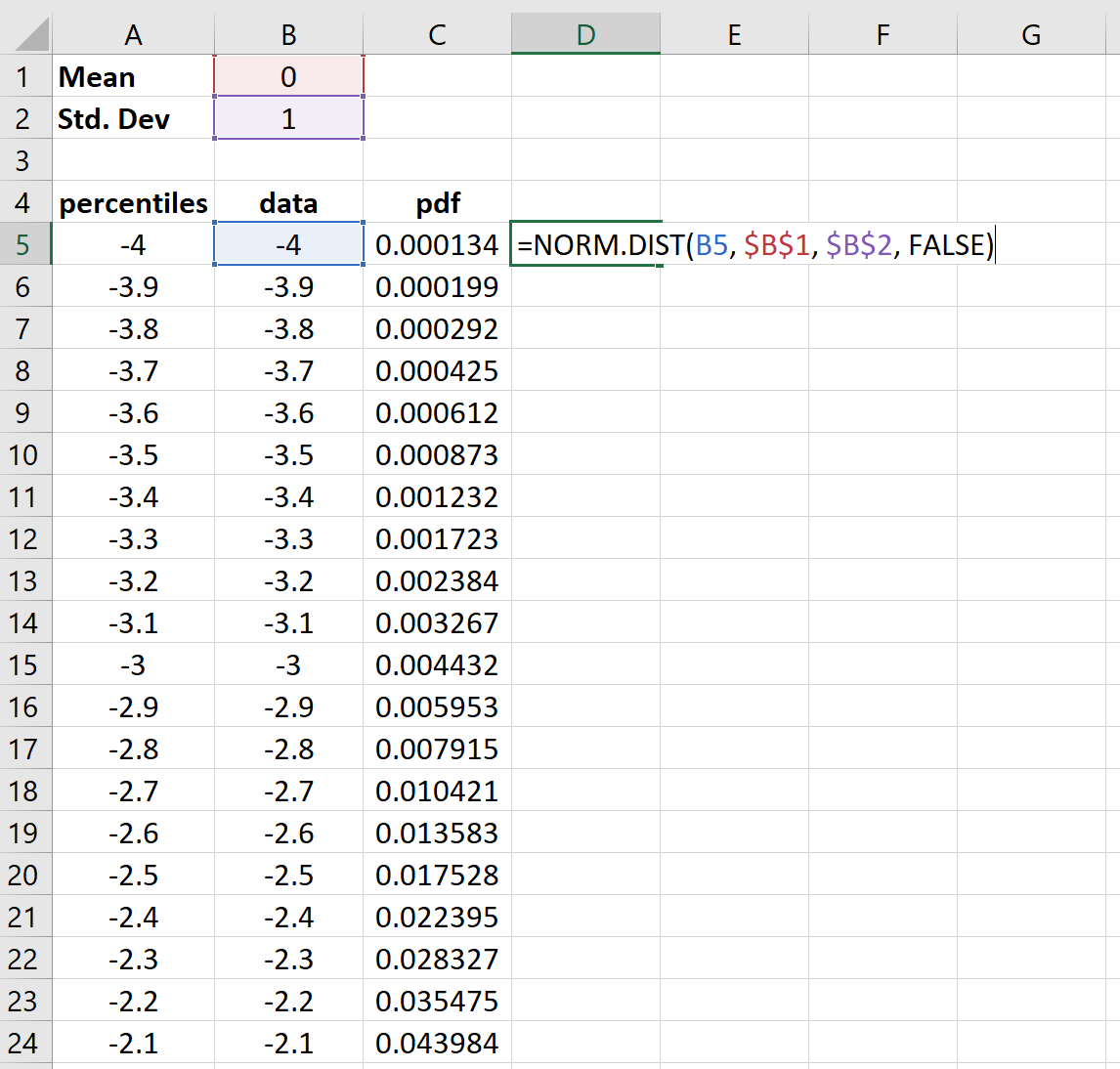
Шаг 4: Найдите значения для нормального распределения PDF.
Шаг 5: Создайте метки графика по оси X только для целочисленных процентилей.
Шаг 6: Сделайте кривую колокола.
Сначала выделите все значения в столбце pdf :
Затем в группе « Диаграммы » на вкладке « Вставка » щелкните первый параметр графика в категории « Вставить линию или диаграмму с областями»:
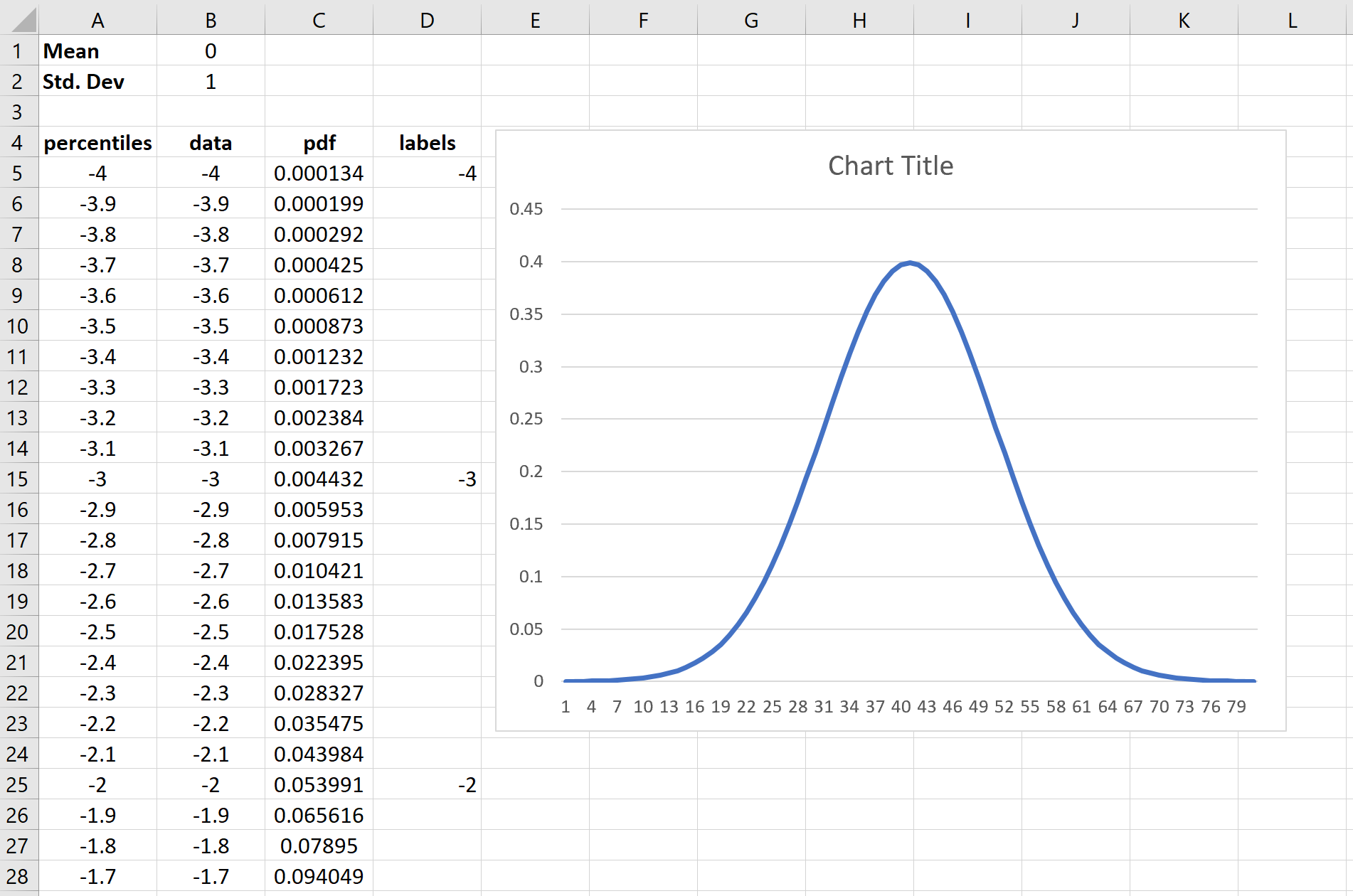
Автоматически появится кривая нормального распределения:
Шаг 7: Измените метки оси X.
Щелкните правой кнопкой мыши в любом месте диаграммы и выберите Выбрать данные.Появится новое окно. Нажмите кнопку « Редактировать » в разделе «Метки горизонтальной оси»:
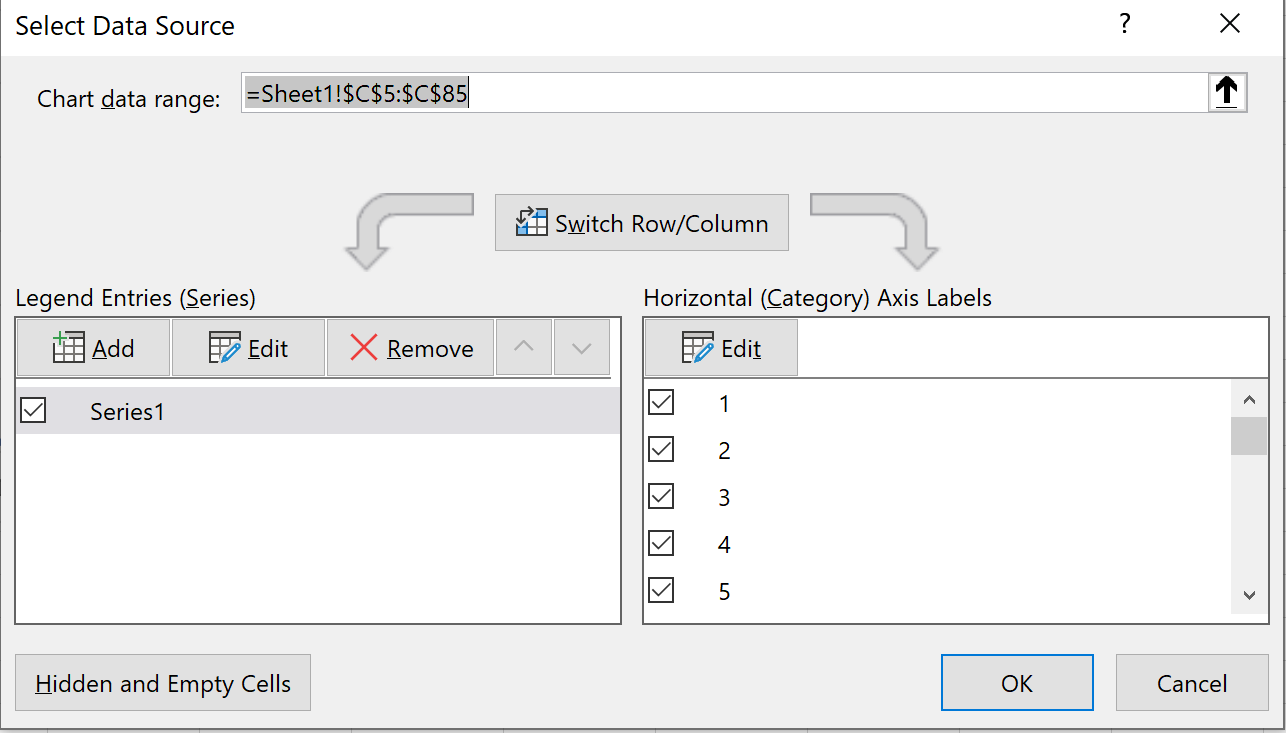
Выберите диапазон ячеек, в которых расположены метки оси X. В нашем случае это диапазон ячеек D5:D85.Затем нажмите ОК .
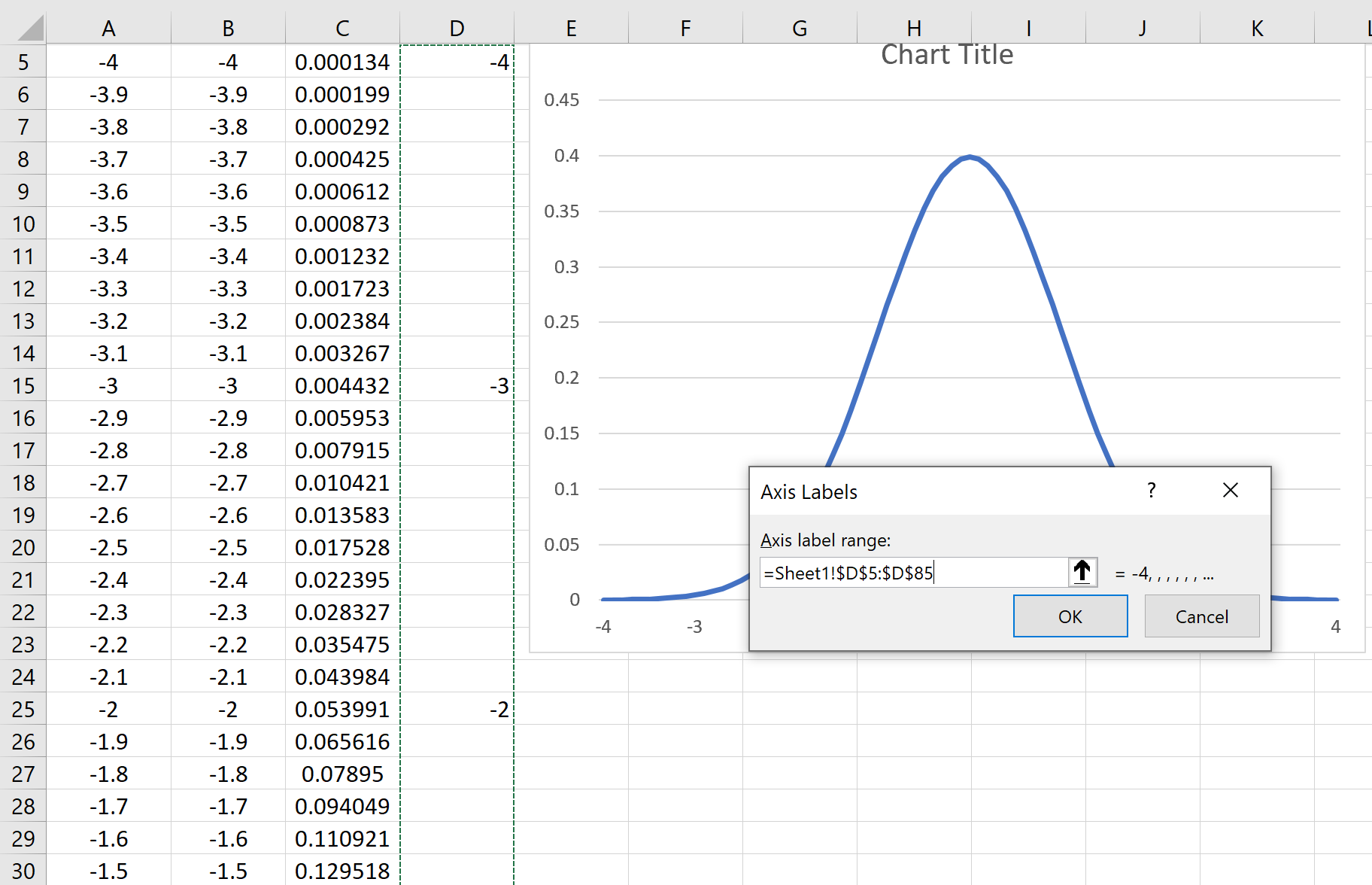
Метки оси X будут обновляться автоматически:
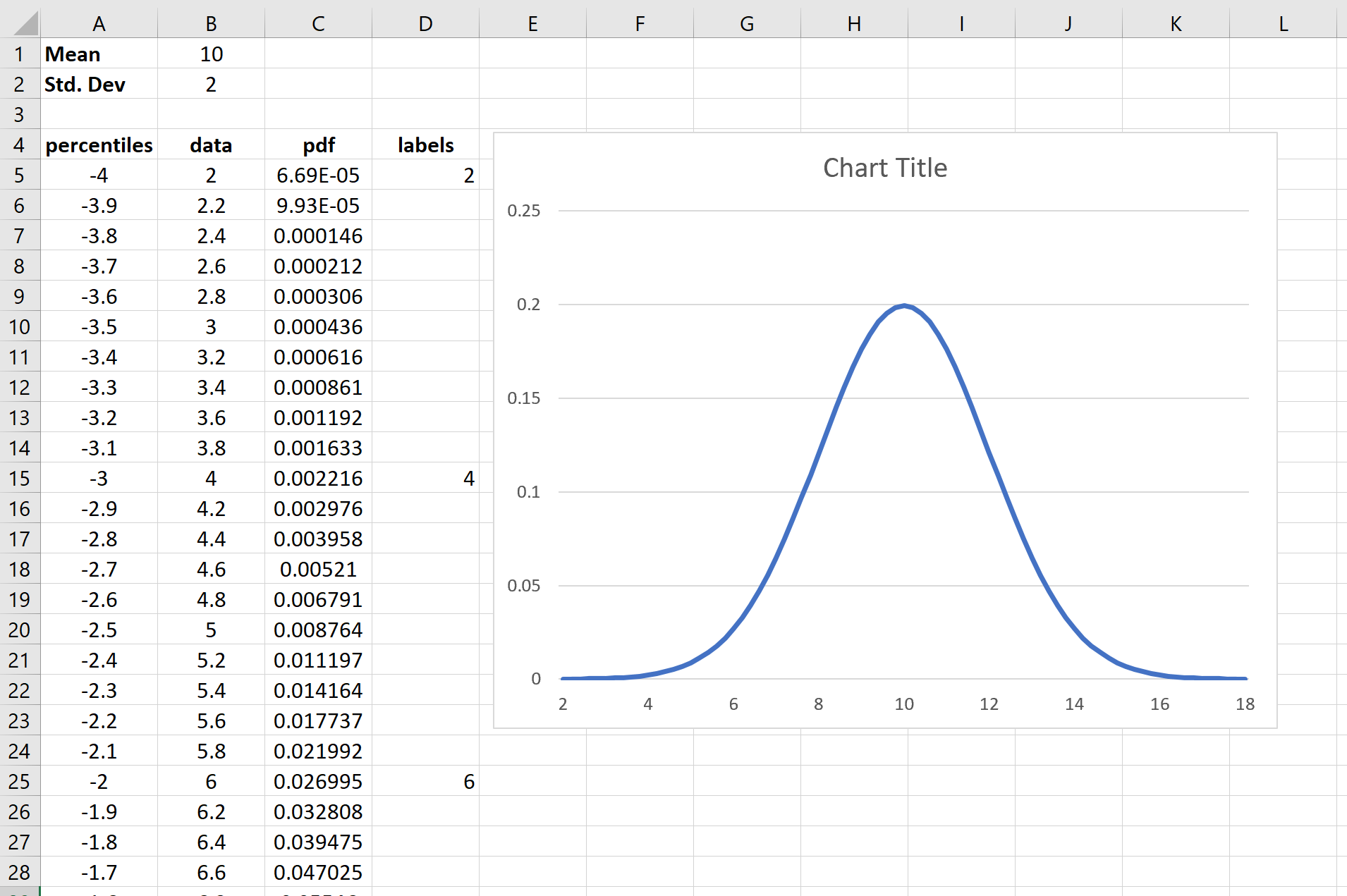
Вы заметите, что если вы измените среднее значение и стандартное отклонение, кривая нормального распределения обновится автоматически. Например, вот во что превращается кривая нормального распределения, если мы используем среднее значение = 10 и стандартное отклонение = 2:
Вы можете изменить заголовок диаграммы, добавить метки осей и изменить цвет, если хотите сделать диаграмму более эстетичной.
Бесплатный шаблон
Не стесняйтесь загружать этот бесплатный шаблон , который использовался для создания точной колоколообразной кривой в этом уроке.
Дополнительные ресурсы
Введение в нормальное распределение
Обычный калькулятор CDF
Как построить нормальное распределение в R