
I’m using https://regexr.com/ to test a regular expression. I’m trying to validate a name input on a form, so:
- Only letter characters
- No non-letter characters except backspace and space
In my validation function, I can have:
if (/d/.test(charStr)) {
return false;
}
/d/ will match numbers. So far, so good.
Changing it to:
if (/d|W/.test(charStr)) {
return false;
}
..will match numbers d or | non-word characters W, which is good, except that it’s also matching whitespace characters like space and backspace.
So, I’m trying to somehow use W, but with the exception of whitespace characters.
I tried:
if (/d|W[^s]/.test(charStr)) {
return false;
}
So, match numbers d, or non-word characters W excepting whitespace characters [^s], but my syntax appears to be wrong here.
What am I doing wrong? Thanks.
The backslash character has several uses. Firstly, if it is
followed by a non-alphanumeric character, it takes away any
special meaning that character may have. This use of
backslash as an escape character applies both inside and
outside character classes.
For example, if you want to match a «*» character, you write
«*» in the pattern. This applies whether or not the
following character would otherwise be interpreted as a
meta-character, so it is always safe to precede a non-alphanumeric
with «» to specify that it stands for itself. In
particular, if you want to match a backslash, you write «\».
Note:
Single and double quoted PHP strings have special
meaning of backslash. Thus if has to be matched with a regular
expression \, then «\\» or ‘\\’ must be used in PHP code.
If a pattern is compiled with the
PCRE_EXTENDED option,
whitespace in the pattern (other than in a character class) and
characters between a «#» outside a character class and the next newline
character are ignored. An escaping backslash can be used to include a
whitespace or «#» character as part of the pattern.
A second use of backslash provides a way of encoding
non-printing characters in patterns in a visible manner. There
is no restriction on the appearance of non-printing characters,
apart from the binary zero that terminates a pattern,
but when a pattern is being prepared by text editing, it is
usually easier to use one of the following escape sequences
than the binary character it represents:
- a
-
alarm, that is, the BEL character (hex 07)
- cx
-
«control-x», where x is any character
- e
-
escape (hex 1B)
- f
-
formfeed (hex 0C)
- n
-
newline (hex 0A)
- p{xx}
-
a character with the xx property, see
unicode properties
for more info
- P{xx}
-
a character without the xx property, see
unicode properties
for more info
- r
-
carriage return (hex 0D)
- R
-
line break: matches n, r and rn
- t
-
tab (hex 09)
- xhh
-
character with hex code hh
- ddd
-
character with octal code ddd, or backreference
The precise effect of «cx» is as follows:
if «x» is a lower case letter, it is converted
to upper case. Then bit 6 of the character (hex 40) is inverted.
Thus «cz» becomes hex 1A, but
«c{» becomes hex 3B, while «c;»
becomes hex 7B.
After «x«, up to two hexadecimal digits are
read (letters can be in upper or lower case).
In UTF-8 mode, «x{...}» is
allowed, where the contents of the braces is a string of hexadecimal
digits. It is interpreted as a UTF-8 character whose code number is the
given hexadecimal number. The original hexadecimal escape sequence,
xhh, matches a two-byte UTF-8 character if the value
is greater than 127.
After «» up to two further octal digits are read.
In both cases, if there are fewer than two digits, just those that
are present are used. Thus the sequence «x7»
specifies two binary zeros followed by a BEL character. Make sure you
supply two digits after the initial zero if the character
that follows is itself an octal digit.
The handling of a backslash followed by a digit other than 0
is complicated. Outside a character class, PCRE reads it
and any following digits as a decimal number. If the number
is less than 10, or if there have been at least that many
previous capturing left parentheses in the expression, the
entire sequence is taken as a back reference. A description
of how this works is given later, following the discussion
of parenthesized subpatterns.
Inside a character class, or if the decimal number is
greater than 9 and there have not been that many capturing
subpatterns, PCRE re-reads up to three octal digits following
the backslash, and generates a single byte from the
least significant 8 bits of the value. Any subsequent digits
stand for themselves. For example:
- 40
- is another way of writing a space
- 40
-
is the same, provided there are fewer than 40
previous capturing subpatterns
- 7
- is always a back reference
- 11
-
might be a back reference, or another way of
writing a tab
- 11
- is always a tab
- 113
- is a tab followed by the character «3»
- 113
-
is the character with octal code 113 (since there
can be no more than 99 back references)
- 377
- is a byte consisting entirely of 1 bits
- 81
-
is either a back reference, or a binary zero
followed by the two characters «8» and «1»
Note that octal values of 100 or greater must not be
introduced by a leading zero, because no more than three octal
digits are ever read.
All the sequences that define a single byte value can be
used both inside and outside character classes. In addition,
inside a character class, the sequence «b»
is interpreted as the backspace character (hex 08). Outside a character
class it has a different meaning (see below).
The third use of backslash is for specifying generic
character types:
- d
- any decimal digit
- D
- any character that is not a decimal digit
- h
- any horizontal whitespace character
- H
- any character that is not a horizontal whitespace character
- s
- any whitespace character
- S
- any character that is not a whitespace character
- v
- any vertical whitespace character
- V
- any character that is not a vertical whitespace character
- w
- any «word» character
- W
- any «non-word» character
Each pair of escape sequences partitions the complete set of
characters into two disjoint sets. Any given character
matches one, and only one, of each pair.
The «whitespace» characters are HT (9), LF (10), FF (12), CR (13),
and space (32). However, if locale-specific matching is happening,
characters with code points in the range 128-255 may also be considered
as whitespace characters, for instance, NBSP (A0).
A «word» character is any letter or digit or the underscore
character, that is, any character which can be part of a
Perl «word«. The definition of letters and digits is
controlled by PCRE’s character tables, and may vary if locale-specific
matching is taking place. For example, in the «fr» (French) locale, some
character codes greater than 128 are used for accented letters,
and these are matched by w.
These character type sequences can appear both inside and
outside character classes. They each match one character of
the appropriate type. If the current matching point is at
the end of the subject string, all of them fail, since there
is no character to match.
The fourth use of backslash is for certain simple
assertions. An assertion specifies a condition that has to be met
at a particular point in a match, without consuming any
characters from the subject string. The use of subpatterns
for more complicated assertions is described below. The
backslashed assertions are
- b
- word boundary
- B
- not a word boundary
- A
- start of subject (independent of multiline mode)
- Z
-
end of subject or newline at end (independent of
multiline mode)
- z
- end of subject (independent of multiline mode)
- G
- first matching position in subject
These assertions may not appear in character classes (but
note that «b» has a different meaning, namely the backspace
character, inside a character class).
A word boundary is a position in the subject string where
the current character and the previous character do not both
match w or W (i.e. one matches
w and the other matches
W), or the start or end of the string if the first
or last character matches w, respectively.
The A, Z, and
z assertions differ from the traditional
circumflex and dollar (described in anchors ) in that they only
ever match at the very start and end of the subject string,
whatever options are set. They are not affected by the
PCRE_MULTILINE or
PCRE_DOLLAR_ENDONLY
options. The difference between Z and
z is that Z matches before a
newline that is the last character of the string as well as at the end of
the string, whereas z matches only at the end.
The G assertion is true only when the current
matching position is at the start point of the match, as specified by
the offset argument of
preg_match(). It differs from A
when the value of offset is non-zero.
Q and E can be used to ignore
regexp metacharacters in the pattern. For example:
w+Q.$.E$ will match one or more word characters,
followed by literals .$. and anchored at the end of
the string. Note that this does not change the behavior of
delimiters; for instance the pattern #Q#E#$
is not valid, because the second # marks the end
of the pattern, and the E# is interpreted as invalid
modifiers.
K can be used to reset the match start.
For example, the pattern fooKbar matches
«foobar», but reports that it has matched «bar». The use of
K does not interfere with the setting of captured
substrings. For example, when the pattern (foo)Kbar
matches «foobar», the first substring is still set to «foo».
mike at eastghost dot com ¶
11 years ago
"line break" is ill-defined:
-- Windows uses CR+LF (rn)
-- Linux LF (n)
-- OSX CR (r)
Little-known special character:
R in preg_* matches all three.
preg_match( '/^R$/', "matchnany\nrlinernendingr" ); // match any line endings
Wirek ¶
5 years ago
Significantly updated version (with new $pat4 utilising R properly, its results and comments):
Note that there are (sometimes difficult to grasp at first glance) nuances of meaning and application of escape sequences like r, R and v - none of them is perfect in all situations, but they are quite useful nevertheless. Some official PCRE control options and their changes come in handy too - unfortunately neither (*ANYCRLF), (*ANY) nor (*CRLF) is documented here on php.net at the moment (although they seem to be available for over 10 years and 5 months now), but they are described on Wikipedia ("Newline/linebreak options" at https://en.wikipedia.org/wiki/Perl_Compatible_Regular_Expressions) and official PCRE library site ("Newline convention" at http://www.pcre.org/original/doc/html/pcresyntax.html#SEC17) pretty well. The functionality of R appears somehow disappointing (with default configuration of compile time option) according to php.net as well as official description ("Newline sequences" at https://www.pcre.org/original/doc/html/pcrepattern.html#newlineseq) when used improperly.
A hint for those of you who are trying to fight off (or work around at least) the problem of matching a pattern correctly at the end ($) of any line in multiple lines mode (/m).
<?php
// Various OS-es have various end line (a.k.a line break) chars:
// - Windows uses CR+LF (rn);
// - Linux LF (n);
// - OSX CR (r).
// And that's why single dollar meta assertion ($) sometimes fails with multiline modifier (/m) mode - possible bug in PHP 5.3.8 or just a "feature"(?).
$str="ABC ABCnn123 123rndef defrnop noprn890 890nQRS QRSrr~-_ ~-_";
// C 3 p 0 _
$pat1='/w$/mi'; // This works excellent in JavaScript (Firefox 7.0.1+)
$pat2='/wr?$/mi'; // Slightly better
$pat3='/wR?$/mi'; // Somehow disappointing according to php.net and pcre.org when used improperly
$pat4='/w(?=R)/i'; // Much better with allowed lookahead assertion (just to detect without capture) without multiline (/m) mode; note that with alternative for end of string ((?=R|$)) it would grab all 7 elements as expected
$pat5='/wv?$/mi';
$pat6='/(*ANYCRLF)w$/mi'; // Excellent but undocumented on php.net at the moment (described on pcre.org and en.wikipedia.org)
$n=preg_match_all($pat1, $str, $m1);
$o=preg_match_all($pat2, $str, $m2);
$p=preg_match_all($pat3, $str, $m3);
$r=preg_match_all($pat4, $str, $m4);
$s=preg_match_all($pat5, $str, $m5);
$t=preg_match_all($pat6, $str, $m6);
echo $str."n1 !!! $pat1 ($n): ".print_r($m1[0], true)
."n2 !!! $pat2 ($o): ".print_r($m2[0], true)
."n3 !!! $pat3 ($p): ".print_r($m3[0], true)
."n4 !!! $pat4 ($r): ".print_r($m4[0], true)
."n5 !!! $pat5 ($s): ".print_r($m5[0], true)
."n6 !!! $pat6 ($t): ".print_r($m6[0], true);
// Note the difference among the three very helpful escape sequences in $pat2 (r), $pat3 and $pat4 (R), $pat5 (v) and altered newline option in $pat6 ((*ANYCRLF)) - for some applications at least.
/* The code above results in the following output:
ABC ABC
123 123
def def
nop nop
890 890
QRS QRS
~-_ ~-_
1 !!! /w$/mi (3): Array
(
[0] => C
[1] => 0
[2] => _
)
2 !!! /wr?$/mi (5): Array
(
[0] => C
[1] => 3
[2] => p
[3] => 0
[4] => _
)
3 !!! /wR?$/mi (5): Array
(
[0] => C
[1] => 3
[2] => p
[3] => 0
[4] => _
)
4 !!! /w(?=R)/i (6): Array
(
[0] => C
[1] => 3
[2] => f
[3] => p
[4] => 0
[5] => S
)
5 !!! /wv?$/mi (5): Array
(
[0] => C
[1] => 3
[2] => p
[3] => 0
[4] => _
)
6 !!! /(*ANYCRLF)w$/mi (7): Array
(
[0] => C
[1] => 3
[2] => f
[3] => p
[4] => 0
[5] => S
[6] => _
)
*/
?>
Unfortunately, I haven't got any access to a server with the latest PHP version - my local PHP is 5.3.8 and my public host's PHP is version 5.2.17.
Anonymous ¶
3 years ago
A non breaking space is not considered as a space and cannot be caught by s.
it can be found with :
- [xc2xa0] in utf-8
- x{00a0} in unicode
grigor at the domain gatchev.info ¶
11 years ago
As v matches both single char line ends (CR, LF) and double char (CR+LF, LF+CR), it is not a fixed length atom (eg. is not allowed in lookbehind assertions).
tharabar at gmail dot com ¶
3 years ago
Required to use 07 instead of a
Wirek ¶
5 years ago
Note that there are (sometimes difficult to grasp at first glance) nuances of meaning and application of escape sequences like r, R and v - none of them is perfect in all situations, but they are quite useful nevertheless. Some official PCRE control options and their changes come in handy too - unfortunately neither (*ANYCRLF), (*ANY) nor (*CRLF) is documented here on php.net at the moment (although they seem to be available for over 10 years and 5 months now), but they are described on Wikipedia ("Newline/linebreak options" at https://en.wikipedia.org/wiki/Perl_Compatible_Regular_Expressions) and official PCRE library site ("Newline convention" at http://www.pcre.org/original/doc/html/pcresyntax.html#SEC17) pretty well. The functionality of R appears somehow disappointing (with default configuration of compile time option) according to php.net as well as official description ("Newline sequences" at https://www.pcre.org/original/doc/html/pcrepattern.html#newlineseq).
A hint for those of you who are trying to fight off (or work around at least) the problem of matching a pattern correctly at the end ($) of any line in multiple lines mode (/m).
<?php
// Various OS-es have various end line (a.k.a line break) chars:
// - Windows uses CR+LF (rn);
// - Linux LF (n);
// - OSX CR (r).
// And that's why single dollar meta assertion ($) sometimes fails with multiline modifier (/m) mode - possible bug in PHP 5.3.8 or just a "feature"(?).
$str="ABC ABCnn123 123rndef defrnop noprn890 890nQRS QRSrr~-_ ~-_";
// C 3 p 0 _
$pat1='/w$/mi'; // This works excellent in JavaScript (Firefox 7.0.1+)
$pat2='/wr?$/mi';
$pat3='/wR?$/mi'; // Somehow disappointing according to php.net and pcre.org
$pat4='/wv?$/mi';
$pat5='/(*ANYCRLF)w$/mi'; // Excellent but undocumented on php.net at the moment
$n=preg_match_all($pat1, $str, $m1);
$o=preg_match_all($pat2, $str, $m2);
$p=preg_match_all($pat3, $str, $m3);
$r=preg_match_all($pat4, $str, $m4);
$s=preg_match_all($pat5, $str, $m5);
echo $str."n1 !!! $pat1 ($n): ".print_r($m1[0], true)
."n2 !!! $pat2 ($o): ".print_r($m2[0], true)
."n3 !!! $pat3 ($p): ".print_r($m3[0], true)
."n4 !!! $pat4 ($r): ".print_r($m4[0], true)
."n5 !!! $pat5 ($s): ".print_r($m5[0], true);
// Note the difference among the three very helpful escape sequences in $pat2 (r), $pat3 (R), $pat4 (v) and altered newline option in $pat5 ((*ANYCRLF)) - for some applications at least.
/* The code above results in the following output:
ABC ABC
123 123
def def
nop nop
890 890
QRS QRS
~-_ ~-_
1 !!! /w$/mi (3): Array
(
[0] => C
[1] => 0
[2] => _
)
2 !!! /wr?$/mi (5): Array
(
[0] => C
[1] => 3
[2] => p
[3] => 0
[4] => _
)
3 !!! /wR?$/mi (5): Array
(
[0] => C
[1] => 3
[2] => p
[3] => 0
[4] => _
)
4 !!! /wv?$/mi (5): Array
(
[0] => C
[1] => 3
[2] => p
[3] => 0
[4] => _
)
5 !!! /(*ANYCRLF)w$/mi (7): Array
(
[0] => C
[1] => 3
[2] => f
[3] => p
[4] => 0
[5] => S
[6] => _
)
*/
?>
Unfortunately, I haven't got any access to a server with the latest PHP version - my local PHP is 5.3.8 and my public host's PHP is version 5.2.17.
info at maisuma dot jp ¶
8 years ago
You can use Unicode character escape sequences (tested on PHP 5.3.3 & PCRE 7.8).
<?php
//This source is supposed to be written in UTF-8.
$a='€';
var_dump(preg_match('/\x{20ac}/u',$a)); //Match!
bluemoehre at gmx dot de ¶
9 years ago
Using R in character classes is NOT possible:
var_dump( preg_match('#R+#',"n") ); -> int(1)
var_dump( preg_match('#[R]+#',"n") ); -> int(0)
error17191 at gmail dot com ¶
7 years ago
Some escape sequence like the tab character t won't work inside single quotes 't', But they work inside double quotes.
Other escape sequences like the backspace character won't work unless you use its ascii codepoint and chr() function i.e. chr(8)
vea dot git at gmail dot com ¶
5 years ago
b BS
$str=""
$str =str_replace("b", "", $str);
//echo
$str =str_replace(chr(8), "", $str);
//echo
$str =str_replace("\b", "", $str);
//echo
collons at ya dot com ¶
9 years ago
The pattern "/\A/" may be replaced by "/\A/" in order to match a "A" string. Any other escaped "" looks to work fine so you can use "/\S/", for instance, to match a "S" string.
Improve Article
Save Article
Like Article
Improve Article
Save Article
Like Article
Regex stands for Regular Expression, which is used to define a pattern for a string. It is used to find the text or to edit the text. Java Regex classes are present in java.util.regex package, which needs to be imported before using any of the methods of regex classes.
java.util.regex package consists of 3 classes:
- Pattern
- Matcher
- PatternSyntaxException
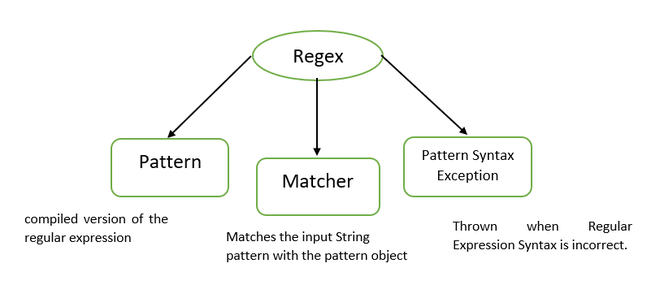
Classes in regex package
Metacharacters
Metacharacters are like short-codes for common matching patterns.
|
Regular Expression |
Description |
|---|---|
|
d |
Any digits, short-code for [0-9] |
|
D |
Any non-digits, short-code for [^0-9] |
|
s |
Any white space character, short-code for [tnx0Bfr] |
|
S |
Any non-whitespace character |
|
w |
Any word character, short-code for [a-zA-Z_0-9] |
|
W |
Any non-word character |
|
b |
Represents a word boundary |
|
B |
Represents a non-word boundary |
Usage of Metacharacters
- Precede the metacharacter with backslash ().
Explanation of Metacharacters
1. Digit & Non Digit related Metacharacters: (d, D)
Java
import java.io.*;
import java.util.regex.*;
class GFG {
public static void main(String[] args)
{
System.out.println(Pattern.matches("\d", "2"));
System.out.println(Pattern.matches("\d", "a"));
System.out.println(Pattern.matches("\D", "a"));
System.out.println(Pattern.matches("\D", "2"));
}
}
Output
true false true false
Explanation
- d metacharacter represents a digit from 0 to 9. So when we compare “d” within the range, it then returns true. Else return false.
- D metacharacter represents a non-digit that accepts anything except numbers. So when we compare “D” with any number, it returns false. Else True.
2. Whitespace and Non-Whitespace Metacharacters: (s, S)
Java
import java.io.*;
import java.util.regex.*;
class GFG {
public static void main(String[] args)
{
System.out.println(Pattern.matches("\s", " "));
System.out.println(Pattern.matches("\s", "2"));
System.out.println(Pattern.matches("\S", "2"));
System.out.println(Pattern.matches("\S", " "));
}
}
Output
true false true false
Explanation
- s represents whitespace characters like space, tab space, newline, etc. So when we compare “s” with whitespace characters, it returns true. Else false.
- S represents a Non-whitespace character that accepts everything except whitespace, So when we compare “S” with whitespace characters, it returns false. Else true
3. Word & Non Word Metacharacters: (w, W)
Java
import java.io.*;
import java.util.regex.*;
class GFG {
public static void main(String[] args)
{
System.out.println(Pattern.matches("\w", "a"));
System.out.println(Pattern.matches("\w", "2"));
System.out.println(Pattern.matches("\w", "$"));
System.out.println(Pattern.matches("\W", "2"));
System.out.println(Pattern.matches("\W", " "));
System.out.println(Pattern.matches("\W", "$"));
}
}
Output
true true false false true true
Explanation
- w represents word character which accepts alphabets (Capital & small) and digits [0-9]. So when we compare “w” with an alphabet or number returns true. Else false.
- W represents a non-word character that accepts anything except alphabets and digits. So when we compare “W” with an alphabet or number returns false. Else true.
4. Word & Non-Word Boundary Metacharacters: (b, B)
Java
import java.io.*;
import java.util.regex.*;
class GFG {
public static void main(String[] args)
{
System.out.println(
Pattern.matches("\bGFG\b", "GFG"));
System.out.println(
Pattern.matches("\b@GFG\b", "@GFG"));
System.out.println(Pattern.matches(
"\B@GFG@\B", "@GFG@"));
System.out.println(
Pattern.matches("\BGFG\B", "GFG"));
}
}
Output
true false true false
Explanation:
- b indicates a string must have boundary elements of word characters, i.e., either digits or alphabets. So here, the GFG string has boundaries G, G, which are word characters so returns true. For the @GFG string, the boundary elements are @, G where @ is not word character, so return false.
- B indicates a string must have boundary elements of Non-word characters, i.e., it may have anything except digits or alphabets. So here @GFG@ string has boundaries @,@ which are Non-word characters so returns true. For the GFG string, the boundary elements are G, G, which are word characters, returning false.
Example:
Java
import java.io.*;
import java.util.regex.*;
class GFG {
public static void main(String[] args)
{
System.out.println(Pattern.matches(
"\d\D\s\S\w\W", "1G FG!"));
System.out.println(Pattern.matches(
"\d\D\s\S\w\W", "Geeks!"));
}
}
Like Article
Save Article
Regex Reference
The regular expression (regex) syntax and semantics implemented in BareGrep are common to PHP, Perl and Java.
Characters and Escapes
Logical Operators
Character Classes
Quantifiers
Assertions
There is also an example.
Characters and Escapes
|
. |
Any character«.» matches any character. For example: ... would match any three character sequence. To specify a literal «.», escape it with «». For example: www.baremetalsoft.com would match «www.baremetalsoft.com». |
|
x |
The literal character xAll characters which do not have a special meaning in a regex match themselves. For example: fred would match the string «fred». |
|
a |
Alert character (bell)BEL — ASCII code 07. |
|
cx |
Control-x characterFor example: cM would be equivalent to key sequence Control-M or character ASCII code 0D hexidecimal. |
|
d |
A digitA digit from 0 to 9. This is eqivalent to the regex: [0-9] |
|
D |
Any non-digitAny character which is not a digit. This is eqivalent to the regex: [^0-9] |
|
e |
Escape characterESC — ASCII code 27 (1B hexidecimal). |
|
f |
Form feed characterFF — ASCII code 12 (0C hexidecimal). |
|
r |
Carriage return character
CR — ASCII code 13 (0D hexidecimal). Carriage return characters are automatically stripped
Note: to match the start-of-line use the «^» assertion. To match the end-of-line |
|
s |
Any whitespace characterThe whitespace characters include space, tab, new-line, carriage-return and form-feed. This is eqivalent to the regex: [ trnf] |
|
S |
Any non-whitespace characterThis is eqivalent to the regex: [^ trnf] |
|
t |
Tab characterA horizontal tab character. HT — ASCII code 09. |
|
nnn |
The character with octal value nnn |
|
w |
Any word character
Any word character (in the set «A» to «Z», «a» This is equivalent to the regex: [0-9_A-Za-z] |
|
W |
Any non-word characterAny non-word character. A character in the set: [^0-9_A-Za-z] |
|
xhh |
The character with hexidecimal value hh |
Logical Operators
|
XY |
CatenationRegex X then Y regex. For example: abc would match the string «abc». |
|
X|Y |
AlternationX or Y For example: ERROR|FATAL would match «ERROR» or «FATAL». |
|
(?:X) |
GroupGrouping and operator precedence over-ride. For example: (?:A|B)(?:C|D) would match «AC», «BC», «AD» or «BD». Whereas: A|BC|D would match «A», «BC», or «D». |
|
(X) |
Capturing group
Grouping and capturing of the regex X. Capturing groups also imply operator precedence over-ride. For example: (A|B)(C|D) would match «AC», «BC», «AD» or «BD». Whereas: A|BC|D would match «A», «BC», or «D».
Note: Using capturing involves a significant performance overhead (the search runs slower), |
Character Classes
|
[abc] |
Character setA single a, b or c character. For example: [0123456789ABCDEFabcdef]
would match any hexidecimal digit character |
|
[^abc] |
Inverse character setAny character other than a, b or c. For example: [^0123456789ABCDEFabcdef] would match any character which is not an hexidecimal digit character. |
|
[a-b] |
Character set rangeA character in the range a to b. For example: [0-9_A-Za-z]
would match any word character (in the set «A» to «Z», «a» |
Quantifiers
|
X* |
Set closureThe regex X zero or more times. For example: .* would match anything (or nothing, because it may match zero times). For example: As*=s*B would match «A=B», «A = B» or even «A= B» (ignoring whitespace around the «=»). |
|
X+ |
Kleene closureThe regex X one or more times. For example: d+ would match a sequence of digits that is at least one character in length. |
|
X? |
Zero or oneThe regex X zero or one times. For example: d? would match zero or one digits only. |
|
X{n} |
Exactly n timesThe regex X exactly n times. For example: d{4}
would match exactly 4 digits. |
|
X{n,} |
At least n timesThe regex X at least n times. For example: d{4,}
would match 4 or more digits. |
|
X{n,m} |
Between n and m timesThe regex X at least n times, but no more than m times. For example: d{4,6}
would match 4, 5 or 6 or more digits. |
Assertions
|
^ |
Start-of-lineThe start of a line. For example: ^Status would match «Status» only at the start of a line. |
|
$ |
End-of-lineThe end of a line. For example: Status$ would match «Status» only at the end of a line. |
Example
Question
Given the following lines:
#Fields: date time c-ip cs-username s-computername s-ip cs-method cs-uri-stem cs-uri-query sc-status sc-bytes cs-bytes time-taken s-port cs(User-Agent)
2005-01-04 00:31:32 10.67.65.57 — VENUS 10.7.40.91 GET /xpedio/ — 302 288 241 0 80 Mozilla/4.0+(compatible;+MSIE+6.0;+Windows+NT+5.1;+.NET+CLR+1.0.3705;+.NET+CLR+1.1.4322)
2005-01-04 00:31:32 10.67.65.57 — VENUS 10.7.40.91 GET /xpedio/login.html — 200 1337 242 125 80 Mozilla/4.0+(compatible;+MSIE+6.0;+Windows+NT+5.1;+.NET+CLR+1.0.3705;+.NET+CLR+1.1.4322)
2005-01-04 00:31:32 10.67.65.57 — VENUS 10.7.40.91 GET /xpedio/images/FAHC/sm_idoclogo2.gif — 200 1898 310 16 80 Mozilla/4.0+(compatible;+MSIE+6.0;+Windows+NT+5.1;+.NET+CLR+1.0.3705;+.NET+CLR+1.1.4322)
2005-01-04 00:31:32 10.67.65.57 — VENUS 10.7.40.91 GET /intradoc-cgi/idc_cgi_isapi.dll IdcService=LOGIN&Action=GetTemplatePage&Page=HOME_PAGE&Auth=Intranet 200 15431 546 141 80 Mozilla/4.0+(compatible;+MSIE+6.0;+Windows+NT+5.1;+.NET+CLR+1.0.3705;+.NET+CLR+1.1.4322)
2005-01-04 00:31:32 10.67.65.57 FAHCKioskUser VENUS 10.7.40.91 GET /intradoc-cgi/idc_cgi_isapi.dll IdcService=LOGIN&Action=GetTemplatePage&Page=HOME_PAGE&Auth=Intranet 200 23943 768 390 80 Mozilla/4.0+(compatible;+MSIE+6.0;+Windows+NT+5.1;+.NET+CLR+1.0.3705;+.NET+CLR+1.1.4322)
2005-01-04 00:31:33 10.67.65.57 FAHCKioskUser VENUS 10.7.40.91 GET /xpedio/images/xpedio/enthome2.gif — 200 650 494 32 80 Mozilla/4.0+(compatible;+MSIE+6.0;+Windows+NT+5.1;+.NET+CLR+1.0.3705;+.NET+CLR+1.1.4322)
2005-01-04 00:31:33 10.67.65.57 — VENUS 10.7.40.91 GET /xpedio/images/xpedio/enthome.gif — 200 662 493 62 80 Mozilla/4.0+(compatible;+MSIE+6.0;+Windows+NT+5.1;+.NET+CLR+1.0.3705;+.NET+CLR+1.1.4322)
2005-01-04 00:31:33 10.67.65.57 FAHCKioskUser VENUS 10.7.40.91 GET /xpedio/images/xpedio/home.gif — 200 523 490 62 80 Mozilla/4.0+(compatible;+MSIE+6.0;+Windows+NT+5.1;+.NET+CLR+1.0.3705;+.NET+CLR+1.1.4322)
2005-01-04 00:31:33 10.67.65.57 — VENUS 10.7.40.91 GET /xpedio/images/xpedio/home2.gif — 200 525 491 16 80 Mozilla/4.0+(compatible;+MSIE+6.0;+Windows+NT+5.1;+.NET+CLR+1.0.3705;+.NET+CLR+1.1.4322)
2005-01-04 00:31:33 10.67.65.57 FAHCKioskUser VENUS 10.7.40.91 GET /xpedio/images/xpedio/library2.gif — 200 698 494 47 80 Mozilla/4.0+(compatible;+MSIE+6.0;+Windows+NT+5.1;+.NET+CLR+1.0.3705;+.NET+CLR+1.1.4322)
2005-01-04 00:31:33 10.67.65.57 — VENUS 10.7.40.91 GET /xpedio/images/xpedio/library.gif — 200 701 493 31 80 Mozilla/4.0+(compatible;+MSIE+6.0;+Windows+NT+5.1;+.NET+CLR+1.0.3705;+.NET+CLR+1.1.4322)
2005-01-04 00:31:33 10.67.65.57 FAHCKioskUser VENUS 10.7.40.91 GET /xpedio/images/xpedio/search2.pdf — 200 570 493 31 80 Mozilla/4.0+(compatible;+MSIE+6.0;+Windows+NT+5.1;+.NET+CLR+1.0.3705;+.NET+CLR+1.1.4322)
2005-01-04 00:31:33 10.67.65.57 — VENUS 10.7.40.91 GET /xpedio/images/xpedio/help2.gif — 200 553 491 31 80 Mozilla/4.0+(compatible;+MSIE+6.0;+Windows+NT+5.1;+.NET+CLR+1.0.3705;+.NET+CLR+1.1.4322)
2005-01-04 00:31:33 10.67.65.57 FAHCKioskUser VENUS 10.7.40.91 GET /xpedio/images/xpedio/search.gif — 200 574 492 16 80 Mozilla/4.0+(compatible;+MSIE+6.0;+Windows+NT+5.1;+.NET+CLR+1.0.3705;+.NET+CLR+1.1.4322)
I need to generate a report with the FAHCusername and the .pdf file
they accessed. I can do either one individually, but not sure how to do both.
Here’s the regex that works for the username:
(FAHC\S+)
and the regex that works for the .pdf file:
(S+.pdf)
but how do I format the «find» field for both?
Answer
In this case, as every line has the same format, I would first try to
construct a regex which matches the entire line.
So I’d start with something like:
S+ S+ S+ S+ S+ S+ S+ S+ S+ S+ S+ S+ S+ S+ S+
Then I’d pick out the columns I’m interested in:
S+ S+ S+ (S+) S+ S+ S+ (S+) S+ S+ S+ S+ S+ S+ S+
You can then refine the sub-regex for the two columns you’re
interested in:
S+ S+ S+ FAHC\(S+) S+ S+ S+ (S+.pdf) S+ S+ S+ S+ S+ S+ S+
There are various other ways this could also be done, but this is the
first way that sprung to mind.
Another way would be:
FAHC\(S+).* (S+.pdf)
This uses «.*» in the middle which means «match anything».
Oracle Regular Expression
Catalog
- 1. Matching Characters
- 2. Duplicate Characters
- 3. Positioning Characters
-
4. Grouping Characters
- 4.1() Capture Group
- 4.2 (?:) Non-capture group
- 4.3 (?) Capture group naming
- 4.4 (?=) Positive declaration
- 4.5 (?!) Negative declaration
- 4.6 (?
- 4.7 (?
- 4.8 (?>) Non-backtracking group
-
5. Decision Characters
- 5.1 Regular Expression Decision Characters
- 5.2 sets of decision characters
- 6. Replacement Characters
- 7. Escape Sequences
- 8. Option Marks
-
9. Brief introduction to regular expression of oracle
- 9.1 REGEXP_REPLACE(source_string,pattern,replace_string,position,occurtence,match_parameter) function (new 10g function)
- 9.2 REGEXP_SUBSTR(source_String, pattern[, position[, occurrence[, match_Parameter]]) function (10g new function)
- 9.3 REGEXP_LIKE(source_string, pattern[, match_parameter]) function (10g new function)
- 9.4 REGEXP_INSTR(source_string, pattern[, start_position[, occurrence[, return_option[, match_parameter]]) function (10g new function)
- 9.5 Special Characters:
- 9.6 num capture reference
- 9.7 Escape Character
- 9.8 Operational priority of various operators
-
10. Examples of test data
- 10.1 Test Data
-
10.2 Test Samples
- 10.2.1 REGEXP_LIKE
- 10.2.2 REGEXP_INSTR
- 10.2.3 REGEXP_SUBSTR
- 10.2.4 REGEXP_REPLACE
-
11. Official Instructions (original English Instructions)
- 11.1 Match Options Character Class Description
- 11.2 Posix Characters Character Class Description
- 11.3 Quantifier Characters Character Class Description
- 11.4 Alternative Matching And Grouping Characters Character Class Description
-
Twelve English Example Demo
- 12.1 REGEXP_COUNT
- 12.2 REGEXP_INSTR
- 12.3 REGEXP_LIKE
- 12.4 REGEXP_REPLACE
- 12.5 REGEXP_SUBSTR
It is a text pattern composed of ordinary characters (such as characters a to z) and special characters (called metacharacters).This pattern describes one or more strings to be matched when finding the body of a text.A regular expression acts as a template to match a character pattern to the string it searches for.
This article details the various characters that can be used in regular expressions to match text.It can be a quick reference when you need to interpret an existing regular expression.
1. Matching Characters
| Character class | Matched Characters | Give an example |
|---|---|---|
| d | Any number from 0-9 | dd matches 72, but does not match aa or 7a |
| D | Any non-numeric character | DDD D matches abc but does not match 123 |
| w | Any word character, including A-Z,a-z,0-9 and underscores | wwwwww matches Ab-2, but does not match $%* or Ab_@ |
| W | Any non-word character | W matches, but does not match a |
| s | Any blank character, including tabs, line breaks, carriage returns, page breaks, and vertical tabs | Matches all traditional white space characters in HTML,XML, and other standard definitions |
| S | Any non-whitespace character | Any character other than white space, such as A%&g3; etc. |
| . | Any character | Match any character except line breaks unless MultiLine precedent is set |
| […] | Any character in parentheses | [a B c] will match a single character, a,b or C. |
| [a-z] | Will match any character from a to z | |
| [^…] | Any character not in parentheses | [^a B c] will match a single character other than a,b, c, either a,b or a,b, C |
| [a-z] | Will match any character that does not belong to a-z, but will match all uppercase letters |
2. Duplicate Characters
| Repeat Character | Meaning | Give an example |
|---|---|---|
| {n} | Match previous characters n times | x{2} matches x x, but does not match X or x x x |
| {n,} | Match preceding characters at least n times | x{2} matches two or more x, such as x x x, x x x.. |
| {n,m} | Match the preceding characters at least N times and at most m times.If n is 0, this parameter is optional | x{2,4} matches x x, x x x, x x x x, but does not match x x x x x |
| ? | Matching the preceding character 0 or 1 times is essentially optional | X? Matches X or zero x |
| + | Match previous characters 0 or more times | X + matches X or x x or any number of x greater than 0 |
| * | Match previous characters 0 or more times | X* matches 0,1 or more x |
3. Positioning Characters
| Positioning Characters | Description |
|---|---|
| ^ | The subsequent pattern must be at the beginning of the string, or at the beginning of the line if it is a multiline string.For multiline text (a string containing a carriage return), you need to set a multiline flag |
| $ | The previous pattern must be at the end of the string, or at the end of the line if it is a multiline string |
| A | The previous pattern must be at the beginning of the string, ignoring the multiline flag |
| z | The previous pattern must be at the end of the string, ignoring the multiline flag |
| Z | The preceding pattern must be at the end of the string or before a line break |
| b | Match a word boundary, that is, a point between a word character and a non-word character.To remember that a word character is a character in [a-zA-Z0-9].The beginning of a word |
| B | Matches a non-word character boundary position, not the beginning of a word |
Note: Positioning characters can be applied to characters or combinations and placed at the left or right end of a string
4. Grouping Characters
Examples of grouping characters and definitions
4.1() Capture Group
() This character combines the characters matched by the pattern within parentheses and is a capture group, that is, the character matched by the pattern is the final ExplicitCapture option set — the character is not part of the match by default
Give an example:
The input string is: ABC1DEF2XY
Regular expressions that match three characters from A to Z and one number: ([A-Z]{3}d)
Two matches will occur: Match 1=ABC1;Match 2=DEF2
Each match corresponds to one group: the first group of Match1 = ABC; the first group of Match2 = DEF
With a reverse reference, you can access the group by its number in the regular expression, as well as by its C#and class Group,GroupCollection.If the ExplicitCapture option is set, you cannot use what the group captures.
4.2 (?:) Non-capture group
(?:) This character combines characters matched by patterns within parentheses and is a non-capture group, meaning that the characters of a pattern will not be captured as a group, but it forms part of the final match.It’s basically the same group type as above, but you need to set the option ExplicitCapture
Example:
The input string is: 1A BB SA1 C
A regular expression that matches a number or a letter from A to Z followed by any word character is (?:d|[A-Z]w)
It will produce three matches: the first match = 1A; the second match = BB; and the third match = SA, but no group is captured
4.3 (?) Capture group naming
(?) This option combines the characters matched by the pattern within brackets and names the group with the value specified in the angle brackets.In regular expressions, you can use names instead of numbers to reverse references.Even if the ExplicitCapture option is not set, it is also a capture group.This means that a reverse reference can be accessed using matching characters within a group or through a Group class
Example:
The input string is: Characters in Sienfeld included Jerry Seinfeld,Elaine Benes,Cosno Kramer and George Costanza are able to match their names and capture the names in a group llastName with the regular expression: b[A-Z][a-z]+(?[A-Z][a-z]+)b
It produces four matches: First Match=Jerry Seinfeld; Second Match=Elaine Benes; Third Match=Cosmo Kramer; Fourth Match=George Costanza
Each match corresponds to a lastName group:
First match: lastName group=Seinfeld
Second match: lastName group=Benes
Third match: lastName group=Kramer
4th Match: lastName group=Costanza
Groups will be captured regardless of whether the option ExplictCapture is set or not
4.4 (?=) Positive declaration
(?=) Positive declaration. The right side of the declaration must be the pattern specified in parentheses.This pattern does not form part of the final match
Example:
The input string for the regular expression S+(?=.NET) to match is: The languages were Java,C#.NET,VB.NET,C,Jscript.NET,Pascal
The following matches will occur:
C#
VB
JScript
4.5 (?!) Negative declaration
(?!) Negative declaration.It states that the pattern cannot be immediately to the right of the declaration.This pattern does not form part of the final match
Example:
d{3}(?![A-Z]) The input string to match is 123A 456 789111C
The following matches will occur:
456
789
4.6 (?<=) Reverse positive declaration
(?<=) Reverse positive declaration.The left side of the declaration must be the specified pattern within parentheses.This pattern does not form part of the final match
Example:
The input string to be matched for the regular expression (?<=News) ([A-Z][a-z]+) is: The following states,New Mexico,West Virginia,Washington, New England
It will produce the following matches:
Mexico
England
4.7 (?<=) Reverse negative declaration
(?<!) Reverse positive declaration.The left side of a declaration must not be the specified pattern within parentheses.This pattern does not form part of the final match
Example:
The input string for the regular expression (?<!1)d{2}([A-Z]) to match is as follows:123A456F789C111A
It will match as follows:
56F
89C
4.8 (?>) Non-backtracking group
(?>) Non-backtracking group.Prevent Regex engine backtracking and one match
Example:
Suppose you want to match all words that end with «ing».The input string is as follows:He was very trusing
The regular expression is:. *ing
It will make a match — the word trusting.’. ‘matches any character, and of course’ing’.So the Regex engine backtraces one bit and stops at the second «t» and matches the specified pattern «ing».However, if backtracking is disabled: (?>. *)
It will make 0 matches.’. ‘matches all characters, including’ing’ — does not match and therefore fails to match
5. Decision Characters
5.1 Regular Expression Decision Characters
(?(regex)yes_regex|no_regex) If the expression regex matches, an attempt is made to match the expression yes.Otherwise, the expression no is matched.The regular expression no is a first argument.Note that the pattern width for making the decision is 0. This means that the expression yes or no will start matching from the same location as the regex expression
Example:
The input string for the regular expression (?(d)dA|(A-Z)B) to match is: 1A CB3A5C 3B
It matches:
1A
CB
3A
5.2 sets of decision characters
(?(group name or number)yes_regex|no_regex) If the regular expressions in the group match, then try to match the yes regular expression.Otherwise, an attempt is made to match the regular expression No.No is a prior parameter
Example:
Regular expression (d7)?-(?(1)dd[A-Z]|[A-Z][A-Z] The input string to match is:
77-77A 69-AA 57-B
It achieves the following matches:
77-77A
-AA
Note: The characters listed in the table above force the processor to perform an if-else decision
6. Replacement Characters
- Value of group number specified by $group with group
- The value of the last substring of the ${name} matched by a (?) group
-
[Represents a character$
] - $^ represents all text before the input string matches
- $’represents all text after the input string matches
- $+ represents the last captured group
- $_Represents the entire input string
Note: The above are commonly used replacement characters, incomplete
7. Escape Sequences
- Match character»
- Match character’..
- *Match character’*’
- +Match character’+’
- ? Matches the character’?’
- | Match character’|’
- (Matches the character'(‘
- ) Match character’)’
- {Match character'{‘
- } Match character’}’
- ^ Match character’^’
- $Matching character’$’
- n Matches line breaks
- r Matches carriage return
- t Matches tabs
- v Matches Vertical Tabs
- f Matches face breaks
- nnn matches an 8-digit number with the ASCII character specified by nnn.For example103;matches C in upper case
- xnn matches a 16-digit number, the ASCII character specified by nn.For example, x43 matches uppercase C
- unnnn matches Unicode characters specified by a 4-bit 16-digit number (represented by nnnnnn)
- cV matches a control character, such ascV matches Ctrl-V
8. Option Marks
- I IgnoreCase
- M Multiline
- N ExplicitCapture
- S SingleLine
- X IgnorePatternWhitespace
Note: The letter meaning of the option itself is shown in the following table:
Flag name:
- IgnoreCase makes pattern matching case insensitive.The default option is to match case sensitive
- RightToLeft searches the input string from right to left.The default is to read from left to right in accordance with English, etc., but not Arabic or Hebrew
- None does not set flags.This is the default option
- Multiline specifies that ^ and $can match the beginning and end of a line, as well as the beginning and end of a string.This means that each line separated by a newline character can be matched.However, the character’. ‘still does not match the line break
- SingleLine specifies that the special character’. ‘matches any character, including line breaks.By default, the special character’. ‘does not match a line break.Usually used with the MultiLine option
- ECMAScript. ECMA(European Coputer Manufacturer’s Association) has defined how regular expressions should be implemented and implemented in the ECMAScript specification, which is a standard-based JavaScript.This option can only be used with the IgnoreCase and MultiLine flags.ECMAScript will cause exceptions when used with any other flags
- IgnorePatternWhitespace This option removes all non-escaped white space characters from the regular expression pattern used.It allows an expression to span multiple lines of text, but it must ensure that all blanks in the pattern are escaped.If this option is set, you can also use the’#’character to comment on the following regular expression
- Complied compiles regular expressions into code that is closer to machine code.It’s so fast, but no modifications are allowed
9. Brief introduction to regular expression of oracle
At present, regular expressions have been widely used in many software, including *nix (Linux, Unix, etc.), operating systems such as HP, development environments such as PHP, C#, Java, etc.
Oracle 10g regular expressions improve SQL flexibility.Effectively solves data validity, duplicate word identification, irrelevant white space detection, or decomposition of multiple regular components
String issues such as.
Oracle 10g supports four new functions for regular expressions: REGEXP_LIKE, REGEXP_INSTR, REGEXP_SUBSTR, and REGEXP_REPLACE.
They use POSIX regular expressions instead of the old percent sign (%) and wildcard ()Character.
9.1 REGEXP_REPLACE(source_string,pattern,replace_string,position,occurtence,match_parameter) function (new 10g function)
Description: String replacement function.Equivalent to the enhanced replace function.Source_string specifies the source character expression; pattern specifies the regular expression; replace_string specifies the string to replace; position specifies the starting search location; occurtence specifies the nth string to replace; match_The parameter specifies the text string for the default match operation.
Where replace_String, position, occurtence, match_The parameter is optional.
9.2 REGEXP_SUBSTR(source_String, pattern[, position[, occurrence[, match_Parameter]]) function (10g new function)
Description: Returns a substring of the matching pattern.Equivalent to enhanced substr Function. Source_string Specify the source character expression; pattern Specify the rule expression; position Specify the starting search location; occurtence Specify the number of substitutions that occur n Strings; match_parameter A text string specifying the default match operation. among position,occurtence,match_parameter Parameters are optional
match_option values are as follows:
- ‘c’indicates case sensitivity when matching (default value);
- ‘i’means that matching is case insensitive;
- ‘n’allows operators that match any character;
- ‘m’treats x as a string containing multiple lines.
9.3 REGEXP_LIKE(source_string, pattern[, match_parameter]) function (10g new function)
Description: Returns a string that satisfies the matching pattern.Equivalent to enhanced like Function. Source_string Specify the source character expression; pattern Specify the rule expression; match_parameter A text string specifying the default match operation. among position,occurtence,match_parameter Parameters are optional
9.4 REGEXP_INSTR(source_string, pattern[, start_position[, occurrence[, return_option[, match_parameter]]) function (10g new function)
Description: This function finds a pattern and returns the first location of the pattern.You can freely specify the start_you want to start your searchPosition.The occurrence parameter defaults to 1 unless you specify that you want to find a pattern that appears next.Return_The default value of option is 0, which returns the starting position of the pattern; a value of 1 returns the starting position of the next character that meets the matching criteria
9.5 Special Characters:
- ‘^’matches the starting position of the input string and is used in square bracket expressions, where it indicates that the character set is not accepted.
- ‘$’matches the end of the input string.If the Multiline property of the RegExp object is set, $also matches’n’or’r’.
- ‘. ‘matches any single character except line break n.
- ‘?’matches the previous subexpression zero or once.
- ‘*’matches the previous subexpression zero or more times.
- ‘+’matches the previous subexpression one or more times.
- ‘()’marks the start and end of a subexpression.
- ‘[]’marks a bracket expression.
- ‘{m,n}’is an exact range of occurrences, m= < occurrences <=n,'{m}’ means occurrences of m, and'{m,}’means occurrences of at least M.
- ‘|’ indicates a choice between two items.The example’^([a-z]+ |[0-9]+)$’represents a string of all lowercase letters or numbers combined.
9.6 num capture reference
Num matches num, where num is a positive integer.References to matches obtained.
A useful feature of regular expressions is that they can be saved for later use, called Backreferencing. Allows complex substitution capabilities
For example, adjust a pattern to a new location or indicate the position of the replaced character or word. The matched subexpression is stored in a temporary buffer.
Buffers are numbered from left to right and are accessed through numeric symbols.The following example lists changing the name aa bb cc to cc, bb, aa.
Sentence:
Select REGEXP_REPLACE(‘aa bb cc’,'(.) (.) (.*)’, ‘3, 2, 1’) FROM dual;
Result:
cc, bb, aa
9.7 Escape Character
Character Cluster:
- [[: alpha:]] Any letter.
- [[: digit:]] Any number.
- [[: alnum:]] Any letter and number.
- [[: space:]] Any white character.
- [[: upper:]] Any capital letter.
- [[: lower:]] Any lowercase letter.
- [[: punct:]] Any punctuation.
- [[: xdigit:]] Any hexadecimal number equivalent to [0-9a-fA-F].
9.8 Operational priority of various operators
Priority decreases from left to right and from top to bottom
(), (?_, (?=), [] parentheses and square brackets
*, +,?, {n}, {n,}, {n,m} qualifiers
^, $, anymetacharacter location and order
|’or’operation
10. Examples of test data
10.1 Test Data
create table test(mc varchar2(60));
insert into test values('112233445566778899');
insert into test values('22113344 5566778899');
insert into test values('33112244 5566778899');
insert into test values('44112233 5566 778899');
insert into test values('5511 2233 4466778899');
insert into test values('661122334455778899');
insert into test values('771122334455668899');
insert into test values('881122334455667799');
insert into test values('991122334455667788');
insert into test values('aabbccddee');
insert into test values('bbaaaccddee');
insert into test values('ccabbddee');
insert into test values('ddaabbccee');
insert into test values('eeaabbccdd');
insert into test values('ab123');
insert into test values('123xy');
insert into test values('007ab');
insert into test values('abcxy');
insert into test values('The final test is is is how to find duplicate words.');
commit;
10.2 Test Samples
10.2.1 REGEXP_LIKE
select * from test where regexp_like(mc,'^a{1,3}');
select * from test where regexp_like(mc,'a{1,3}');
select * from test where regexp_like(mc,'^a.*e$');
select * from test where regexp_like(mc,'^[[:lower:]] |[[:digit:]]');
select * from test where regexp_like(mc,'^[[:lower:]]');
Select mc FROM test Where REGEXP_LIKE(mc,'[^[:digit:]]');
Select mc FROM test Where REGEXP_LIKE(mc,'^[^[:digit:]]');
10.2.2 REGEXP_INSTR
Select REGEXP_INSTR(mc,'[[:digit:]]$') from test;
Select REGEXP_INSTR(mc,'[[:digit:]]+$') from test;
Select REGEXP_INSTR('The price is $400.','$[[:digit:]]+') FROM DUAL;
Select REGEXP_INSTR('onetwothree','[^[[:lower:]]]') FROM DUAL;
Select REGEXP_INSTR(',,,,,','[^,]*') FROM DUAL;
Select REGEXP_INSTR(',,,,,','[^,]') FROM DUAL;
10.2.3 REGEXP_SUBSTR
SELECT REGEXP_SUBSTR(mc,'[a-z]+') FROM test;
SELECT REGEXP_SUBSTR(mc,'[0-9]+') FROM test;
SELECT REGEXP_SUBSTR('aababcde','^a.*b') FROM DUAL;
10.2.4 REGEXP_REPLACE
Select REGEXP_REPLACE('Joe Smith','( ){2,}', ',') AS RX_REPLACE FROM dual;
Select REGEXP_REPLACE('aa bb cc','(.*) (.*) (.*)', '3, 2, 1') FROM dual;
SQL> select * from test;
ID MC
-------------------- ------------------------------------------------------------
A AAAAA
a aaaaa
B BBBBB
b bbbbb
SQL> select * from test where regexp_like(id,'b','i'); --Case insensitive
ID MC
-------------------- ------------------------------------------------------------
B BBBBB
b bbbbb
General Information
Anchoring Characters Character Class Description
^ Anchor the expression to the start of a line
$ Anchor the expression to the end of a line
11. Official Instructions (original English Instructions)
Equivalence Classes Character Class Description
= = Oracle supports the equivalence classes through the POSIX ‘[==]’ syntax. A base letter and all of its accented versions
constitute an equivalence class. For example, the equivalence class ‘[=a=]’ matches ?nd ?The equivalence classes are valid only
inside the bracketed expression
11.1 Match Options Character Class Description
- c Case sensitive matching
- i Case insensitive matching
- m Treat source string as multi-line activating Anchor chars
- n Allow the period (.) to match any newline character
11.2 Posix Characters Character Class Description
- [:alnum:] Alphanumeric characters
- [:alpha:] Alphabetic characters
- [:blank:] Blank Space Characters
- [:cntrl:] Control characters (nonprinting)
- [:digit:] Numeric digits
- [:graph:] Any [:punct:], [:upper:], [:lower:], and [:digit:] chars
- [:lower:] Lowercase alphabetic characters
- [:print:] Printable characters
- [:punct:] Punctuation characters
- [:space:] Space characters (nonprinting), such as carriage return, newline, vertical tab, and form feed
- [:upper:] Uppercase alphabetic characters
- [:xdigit:] Hexidecimal characters
11.3 Quantifier Characters Character Class Description
-
- Match 0 or more times
- ? Match 0 or 1 time
-
- Match 1 or more times
- {m} Match exactly m times
- {m,} Match at least m times
- {m, n} Match at least m times but no more than n times
- n Cause the previous expression to be repeated n times
11.4 Alternative Matching And Grouping Characters Character Class Description
| Separates alternates, often used with grouping operator ()
( ) Groups subexpression into a unit for alternations, for quantifiers, or for backreferencing (see «Backreferences» section)
[char] Indicates a character list; most metacharacters inside a character list are understood as literals, with the exception of
character classes, and the ^ and — metacharacters
Twelve English Example Demo
Table CREATE TABLE test (
testcol VARCHAR2(50));
INSERT INTO test VALUES ('abcde');
INSERT INTO test VALUES ('12345');
INSERT INTO test VALUES ('1a4A5');
INSERT INTO test VALUES ('12a45');
INSERT INTO test VALUES ('12aBC');
INSERT INTO test VALUES ('12abc');
INSERT INTO test VALUES ('12ab5');
INSERT INTO test VALUES ('12aa5');
INSERT INTO test VALUES ('12AB5');
INSERT INTO test VALUES ('ABCDE');
INSERT INTO test VALUES ('123-5');
INSERT INTO test VALUES ('12.45');
INSERT INTO test VALUES ('1a4b5');
INSERT INTO test VALUES ('1 3 5');
INSERT INTO test VALUES ('1 45');
INSERT INTO test VALUES ('1 5');
INSERT INTO test VALUES ('a b c d');
INSERT INTO test VALUES ('a b c d e');
INSERT INTO test VALUES ('a e');
INSERT INTO test VALUES ('Steven');
INSERT INTO test VALUES ('Stephen');
INSERT INTO test VALUES ('111.222.3333');
INSERT INTO test VALUES ('222.333.4444');
INSERT INTO test VALUES ('333.444.5555');
INSERT INTO test VALUES ('abcdefabcdefabcxyz');
COMMIT;
12.1 REGEXP_COUNT
Syntax REGEXP_COUNT(<source_string>, [[, <start_position>], [<match_parameter>]])
— match parameter:
- ‘c’ = case sensitive
- ‘i’ = case insensitive search
- ‘m’ = treats the source string as multiple lines
- ‘n’ = allows the period (.) wild character to match newline
- ‘x’ = ignore whitespace characters
Count’s occurrences based on a regular expression SELECT REGEXP_COUNT(testcol, ‘2a’, 1, ‘i’) RESULT
FROM test;
SELECT REGEXP_COUNT(testcol, 'e', 1, 'i') RESULT FROM test;
12.2 REGEXP_INSTR
Syntax REGEXP_INSTR(<source_string>, [[, <start_position>][, ][, <return_option>][, <match_parameter>][, <sub_expression>]])
- Find words beginning with ‘s’ or ‘r’ or ‘p’ followed by any 4 alphabetic characters: case insensitive
SELECT REGEXP_INSTR('500 Oracle Pkwy, Redwood Shores, CA', '[o][[:alpha:]]{3}', 1, 1, 0, 'i') RESULT FROM dual;
SELECT REGEXP_INSTR('500 Oracle Pkwy, Redwood Shores, CA', '[o][[:alpha:]]{3}', 1, 1, 1, 'i') RESULT
FROM dual;
SELECT REGEXP_INSTR('500 Oracle Pkwy, Redwood Shores, CA', '[o][[:alpha:]]{3}', 1, 2, 0, 'i') RESULT
FROM dual;
SELECT REGEXP_INSTR('500 Oracle Pkwy, Redwood Shores, CA', '[o][[:alpha:]]{3}', 1, 2, 1, 'i') RESULT
FROM dual;
- Find the position of try, trying, tried or tries
SELECT REGEXP_INSTR('We are trying to make the subject easier.', 'tr(y(ing)?|(ied)|(ies))') RESULTNUM
FROM dual;
- Using Sub-Expression option
SELECT testcol, REGEXP_INSTR(testcol, 'ab', 1, 1, 0, 'i', 0) FROM test; SELECT testcol, REGEXP_INSTR(testcol, 'ab', 1, 1, 0, 'i', 1) FROM test; SELECT testcol, REGEXP_INSTR(testcol, 'a(b)', 1, 1, 0, 'i', 1) FROM test;
12.3 REGEXP_LIKE
Syntax REGEXP_LIKE(<source_string>, , <match_parameter>)
- AlphaNumeric Characters
SELECT * FROM test
WHERE REGEXP_LIKE(testcol, '[[:alnum:]]');
SELECT *
FROM test
WHERE REGEXP_LIKE(testcol, '[[:alnum:]]{3}');
SELECT *
FROM test
WHERE REGEXP_LIKE(testcol, '[[:alnum:]]{5}');
- Alphabetic Characters
SELECT *
FROM test
WHERE REGEXP_LIKE(testcol, '[[:alpha:]]');
SELECT *
FROM test
WHERE REGEXP_LIKE(testcol, '[[:alpha:]]{3}');
SELECT *
FROM test
WHERE REGEXP_LIKE(testcol, '[[:alpha:]]{5}');
- Control Characters
INSERT INTO test VALUES ('zyx' || CHR(13) || 'wvu');
COMMIT;
SELECT *
FROM test
WHERE REGEXP_LIKE(testcol, '[[:cntrl:]]{1}');
Digits
SELECT *
FROM test
WHERE REGEXP_LIKE(testcol, '[[:digit:]]');
SELECT *
FROM test
WHERE REGEXP_LIKE(testcol, '[[:digit:]]{3}');
SELECT *
FROM test
WHERE REGEXP_LIKE(testcol, '[[:digit:]]{5}');
- Lower Case
SELECT *
FROM test
WHERE REGEXP_LIKE(testcol, '[[:lower:]]');
SELECT *
FROM test
WHERE REGEXP_LIKE(testcol, '[[:lower:]]{2}');
SELECT *
FROM test
WHERE REGEXP_LIKE(testcol, '[[:lower:]]{3}');
SELECT *
FROM test
WHERE REGEXP_LIKE(testcol, '[[:lower:]]{5}');
- Printable Characters
SELECT *
FROM test
WHERE REGEXP_LIKE(testcol, '[[:print:]]{5}');
SELECT *
FROM test
WHERE REGEXP_LIKE(testcol, '[[:print:]]{6}');
SELECT *
FROM test
WHERE REGEXP_LIKE(testcol, '[[:print:]]{7}');
- Punctuation
TRUNCATE TABLE test;
SELECT * FROM test WHERE REGEXP_LIKE(testcol, '[[:punct:]]'); - Spaces
SELECT *
FROM test
WHERE REGEXP_LIKE(testcol, ‘[[:space:]]’);
SELECT *
FROM test
WHERE REGEXP_LIKE(testcol, ‘[[:space:]]{2}’);
SELECT *
FROM test
WHERE REGEXP_LIKE(testcol, ‘[[:space:]]{3}’);
SELECT *
FROM test
WHERE REGEXP_LIKE(testcol, ‘[[:space:]]{5}’);
- Upper Case
```sql
SELECT *
FROM test
WHERE REGEXP_LIKE(testcol, '[[:upper:]]');
SELECT *
FROM test
WHERE REGEXP_LIKE(testcol, '[[:upper:]]{2}');
SELECT *
FROM test
WHERE REGEXP_LIKE(testcol, '[[:upper:]]{3}');
Values Starting with 'a%b' SELECT testcol
FROM test
WHERE REGEXP_LIKE(testcol, '^ab*');
- ‘a’ is the third value
SELECT testcol FROM test WHERE REGEXP_LIKE(testcol, '^..a.');
- Contains two consecutive occurances of the letter ‘a’ or ‘z’
SELECT testcol FROM test WHERE REGEXP_LIKE(testcol, '([az])1', 'i');
- Begins with ‘Ste’ ends with ‘en’ and contains either ‘v’ or ‘ph’ in the center
SELECT testcol FROM test WHERE REGEXP_LIKE(testcol, '^Ste(v|ph)en$');
- Use a regular expression in a check constraint
CREATE TABLE mytest (c1 VARCHAR2(20), CHECK (REGEXP_LIKE(c1, '^[[:alpha:]]+$')));
- Identify SSN
CREATE TABLE ssn_test (
ssn_col VARCHAR2(20));
INSERT INTO ssn_test VALUES ('111-22-3333');
INSERT INTO ssn_test VALUES ('111=22-3333');
INSERT INTO ssn_test VALUES ('111-A2-3333');
INSERT INTO ssn_test VALUES ('111-22-33339');
INSERT INTO ssn_test VALUES ('111-2-23333');
INSERT INTO ssn_test VALUES ('987-65-4321');
COMMIT;
SELECT ssn_col
from ssn_test
WHERE REGEXP_LIKE(ssn_col,'^[0-9]{3}-[0-9]{2}-[0-9]{4}$');
12.4 REGEXP_REPLACE
Syntax REGEXP_REPLACE(<source_string>, ,
<replace_string>, , , <match_parameter>)
- Looks for the pattern xxx.xxx.xxxx and reformats pattern to (xxx) xxx-xxxx
col testcol format a15
col result format a15
SELECT testcol, REGEXP_REPLACE(testcol,
'([[:digit:]]{3}).([[:digit:]]{3}).([[:digit:]]{4})',
'(1) 2-3') RESULT
FROM test
WHERE LENGTH(testcol) = 12;
- Put a space after every character
SELECT testcol, REGEXP_REPLACE(testcol, '(.)', '1 ') RESULT
FROM test
WHERE testcol like 'S%';
Replace multiple spaces with a single space SELECT REGEXP_REPLACE('500 Oracle Parkway, Redwood Shores, CA', '( ){2,}', ' ') RESULT
FROM dual;
- Insert a space between a lower case character followed by an upper case character
SELECT REGEXP_REPLACE('George McGovern', '([[:lower:]])([[:upper:]])', '1 2') CITY
FROM dual;
Replace the period with a string (note use of '') SELECT REGEXP_REPLACE('We are trying to make the subject easier.','.',' for you.') REGEXT_SAMPLE
FROM dual;
Demo CREATE TABLE t(
testcol VARCHAR2(10));
INSERT INTO t VALUES ('1');
INSERT INTO t VALUES ('2 ');
INSERT INTO t VALUES ('3 new ');
- col newval format a10
SELECT LENGTH(testcol) len, testcol origval, REGEXP_REPLACE(testcol, 'W+$', ' ') newval, LENGTH(REGEXP_REPLACE(testcol, 'W+$', ' ')) newlen FROM t;
12.5 REGEXP_SUBSTR
Syntax REGEXP_SUBSTR(source_string, pattern[, position [, occurrence[, match_parameter]]])
- Searches for a comma followed by one or more occurrences of non-comma characters followed by a comma
SELECT REGEXP_SUBSTR('500 Oracle Parkway, Redwood Shores, CA', ',[^,]+,') RESULT
FROM dual;
- Look for http:// followed by a substring of one or more alphanumeric characters and optionally, a period (.)
col result format a50
SELECT REGEXP_SUBSTR('Go to http://www.oracle.com/products and click on database',
'http://([[:alnum:]]+.?){3,4}/?') RESULT
FROM dual;
- Extracts try, trying, tried or tries
SELECT REGEXP_SUBSTR('We are trying to make the subject easier.','tr(y(ing)?|(ied)|(ies))')
FROM dual;
``
- Extract the 3rd field treating ':' as a delimiter
```sql
SELECT REGEXP_SUBSTR('system/pwd@orabase:1521:sidval',
'[^:]+', 1, 3) RESULT
FROM dual;
- Extract from string with vertical bar delimiter
CREATE TABLE regexp (
testcol VARCHAR2(50));
INSERT INTO regexp
(testcol)
VALUES
('One|Two|Three|Four|Five');
SELECT * FROM regexp;
SELECT REGEXP_SUBSTR(testcol,'[^|]+', 1, 3)
FROM regexp;
- Equivalence classes
SELECT REGEXP_SUBSTR('iSelfSchooling NOT ISelfSchooling', '[[=i=]]SelfSchooling') RESULT
FROM dual;
- Parsing Demo set serveroutput on
DECLARE x VARCHAR2(2); y VARCHAR2(2); c VARCHAR2(40) := '1:3,4:6,8:10,3:4,7:6,11:12'; BEGIN x := REGEXP_SUBSTR(c,'[^:]+', 1, 1); y := REGEXP_SUBSTR(c,'[^,]+', 3, 1); dbms_output.put_line(x ||' '|| y); END; /
Posted by yyj011
at Sep 08, 2020 — 2:22 AM
Tag:
Oracle