
![]()
piracy – пиратство
copyrighted software – авторское программное обеспечение
to be widespread – быть широко распространенным, повсеместно используемым malware – вредоносное программное обеспечение
a worm – червь
to alter the computer data – изменять информацию в компьютере
|
an executable |
file – выполняемый файл |
|
to be disguised |
as – быть замаскированным как |
|
an innocent-looking file – невинно выглядящий файл |
|
|
ominous |
– зловещий |
to create a backdoor – создавать черный ход
a fake freeware – фальшивое бесплатное программное обеспечение preventative tips – советы по предотвращению
to run and update antivirus programs – запускать и обновлять антивирусные программы
to install a firewall – устанавливать брандмауэр
to gain access to the network – получать доступ к сети to make a backup copy – создавать резервную копию
to accept files from high-risk sources – получать файлы из источников повышенного риска
to use a digital certificate – использовать цифровой сертификат to prove one’s identity – удостоверять свою личность
to have a suspicious attitude towards something – иметь подозрительное отношение к чему-либо
VOCABULARY AND COMPREHENSION CHECK EXERCISES
Exercise 1. Read the text and answer the following questions.
1.What does the Internet provide? 2. Who uses technology to perform a variety of crimes? 3. Name some Internet-based crimes. 4. The Internet doesn’t provide the right environment for cyberstalking, online harassment or abuse, does it? 5. Is piracy, the illegal copying and distribution of copyrighted software, information, music and video files, also widespread? 6. What is the most common type of Internet crimes? 7. Why is malware created? 8. What are the main types of malware? 9. An email virus
spreads by sending a copy of itself to everyone in an email address book, doesn’t it? 10. Are worms self-copying programs? 11. What is disguised as innocent-looking file? 12. Why is spyware designed? 13. Speak about preventative tips.
14. Which of the above mentioned tips do you always follow?
Exercise 2. Identify the Internet crimes sentences (1-6) refer to. Then match them with the advice below (a-f).
1 . Crackers try to find a way to copy the latest game or computer
111

program.
2 . A study has revealed that half a million people will automatically open an email they believe to be from their bank and happily send off all their security details.
3 . This software’s danger is hidden behind an attractive appearance. That’s why it is often wrapped in attractive packages promising photos of celebrities.
4 . There is a particular danger in Internet commerce and emails. Many people believe they have been offered a special gift only to find out later they have been deceived.
5 . ‘Nimda’ spreads by sending infected emails and is also able to infect websites, so when a user visits a compromised website, the browser can infect the computer.
6 . Every day, millions of children spend time in Internet chat rooms talking to strangers. But what many of them don’t realize is that some of the surfers charring with them may be sexual predators.
a.People shouldn’t buy cracked software or download music illegally from the
Internet.
b.Be suspicious of wonderful offers. Don’t buy if you aren’t sure.
c.It’s dangerous to give personal information to people you contact in chat
rooms.
d.Don’t open attachments from people you don’t know even if the subject looks attractive.
e.Scan your email and be careful about which websites you visit.
f.Check with your bank before sending information.
Exercise 3. Fill in the gaps in these security tips with words from the box.
 Digital certificate malware virus scanner spyware firewall antivirus
Digital certificate malware virus scanner spyware firewall antivirus
1.Malicious software (1) …………….., can be avoided by following some basic rules.
2.To prevent crackers from breaking into your internal network and obtaining your data, install a (2) ……………….. . It will protect you from (3)……….. .
3.Internet users who like cybershopping should get a (4) ………………., an electronic identity card.
4.If you hove been hit by a (5)…………, don’t panic! Download a clean-up utility and always remember to use an (6) ……… program, for example, a virus (7)
……………… .
DEVELOPING SPEAKING SKILLS
Exercise 1. What do you do to prevent computer infections?
Exercise 2. Do you keep your virus protection updated?
112
16. E-MAIL
Read and translate the text. Use a dictionary to help you
What an email is
An email is an electronic message sent from one computer to another that can also include attachments: documents, pictures, sounds and even computer programs.
Although it’s much faster and easier to use than the post, snail mail, the two have many things in common: you send an email to a mail server (an electronic post office) where it is stored in a mailbox, which holds incoming mail until the recipient downloads it. Users are given an email address and a password by an Internet Service Provider (ISP).
A typical email address has three parts.
mbrown@googlemail.com
|
Username |
The |
The domain name or network |
|
|
A person’s name or |
@ |
sign |
address: the mail server where the |
|
nickname |
means ‘at’. |
account is located. The final part of it, |
|
|
the top-level adds information about it, |
e.g. .com = company, .org = non institution, .co.uk = a company in
the UK, .es = Espana, etc.
Emails usually have two main parts. 1. The header generally includes these:
TO (name and address of the recipient) CC (carbon copy sent to another addressee) BCC (blank / blind carbon copy)
SUBJECT (topic of the message) 2. The body (the message itself)
Some email programs also include a signature, with added information about the sender, at the end of the message.
You can make your message look more expressive or attractive by using smileys (also called emoticons): little pictures either made with characters from the keyboard such as  for happy,
for happy,  surprised,
surprised,  sad, etc. or downloaded images and animations.
sad, etc. or downloaded images and animations.
Spam
113

Spam, or junk email, is the name given to unwanted messages, mainly commercial advertising. Some companies, spammers, use it extensively because it’s cheaper than other types of advertising: you or your Internet Service Provider pay for it.
Mailing lists and newsgroups
A mailing list is a basic type of discussion group that uses email to communicate. The messages are distributed to all the subscribers, i.e. everyone who belongs to the list. Newsgroups are similar. The main difference is that the message is not sent to someone’s mail server but to a bulletin board where everybody can read and answer the message.
Vocabulary list
an attachment – подсоединение
an incoming mail – входящая почта a recipient – получатель
a header –заголовок
a carbon copy – копия письма электронной почти для рассылки нескольким адресатам
a blank / blind carbon copy – рассылка первых копий без уведомлений получателя о других адресатах
the body of the message – основная часть, текст сообщения a commercial advertising – коммерческая реклама
to distribute – распределять
a bulletin board – электронная доска объявлений
VOCABULARY AND COMPREHENSION CHECK EXERCISES
Exercise 1. Ask 10 questions to the text in writing. Read and answer your questions with your classmates.
Exercise 2. Find the correct words and match these definitions.
1.a file that has been included as a part of an email message
2.conventional mail delivered very slowly in contrast with email
3.symbols used to express emotions in an email
4.the part of the email address that identifies the user of the service
5.the computer that provides you with mail service
6.a facility that allows users to send and receive messages via the Internet
7.the pan of the email where you write the information about the addresses and subject
8.the part of the email address that identifies the server
9.the place where your Internet Service Provider stores new email for you
114
Exercise 3.Look at the main parts of an email message. Where would you write the information below? What additional information do the TLDs (toplevel domains) of the addresses give you?
|
1 |
peterswinhurn@jazy.free.com |
|||
|
2 |
Eleanor Richardson Manager |
|||
|
3 |
maryjones@arrakis.es: susanwilt@hotmail.co.uk |
|||
|
4 |
Plane tickets |
|||
|
5 |
Peter, |
|||
|
I’ve already booked the plane tickets to attend the Managers’ Conference. Mary |
||||
|
and Susan are joining us. Best wishes |
||||
|
Exercise 4. A manager is giving his colleagues some advice on how to |
||||
|
prevent spam. Complete the sentences with the words in the box. |
||||
|
mailing list spam |
email address |
newsgroups |
spammers |
1.Never ever reply to a …….. email or click on a link within the mail – this will lead to more junk email being sent to you. Unsubscribing only confirms you do actually exist, so they’ve hit the jackpot.
2.Don’t let your email address be displayed anywhere on the Internet, including …………, chat rooms or any websites.
3.Never forward a spam to other people – …………. might be able to track their addresses too, and you could end up losing friends!
4.Send your emails on a strictly ‘need to know’ basis: don’t include everyone on a ………… unless it is really necessary.
5.Treat your ……….. like your phone number – don’t give it out randomly. Try to use a different one when shopping online.
DEVELOPING SPEAKING SKILLS
1.Go to Options window in your e-mail program and choose some features to change on your e-mail. Report back to the class on the changes you made.
17. MULTIMEDIA
Read and translate the text. Use a dictionary to help you
A multimedia system
Multimedia refers to the technologies and applications that integrate different media: text, graphics, sound, video and animation.
Its power resides in interactivity, hypertext and hypermedia. Multimedia software is usually interactive, so you can choose what you want to watch, listen to or write. Hypertext means that you can click on a word and jump to another screen with
115
more information; hypermedia is similar, but works with sounds and images (e.g. the Web).
An IT student says:
‘I use multimedia for my extracurricular activities. I download music from the Net and burn music onto CDs — I copy songs onto CDs. I talk with my friends on the Messenger. I also retouch digital pictures and edit video clips. To run multimedia software you need a fast CPU, expandable FAM and a large hard disk. But what marks a computer out as a multimedia PC is its audio and video capabilities: a sound card, a microphone, a decent pair of speakers, a high-quality monitor and a DVD writer; and its performance depends on all these components working in harmony.’
It is also very important to note the applications of multimedia which can be
used
−In public places (e.g. museums and stations), there are information kiosks that use multimedia,
−In education, it is used in presentations and computer-based training courses.
−On the Web, audio and video are integrated into web pages. For example, RealPlayer supports streaming, which lets you play sound (e.g. from radio stations) and video files as a continuous stream while they are downloading.
−In virtual reality, users interact with a simulated world: doctors train using virtual
|
surgery; pilots use flight simulators to do |
their training; people visit virtual |
|
exhibitions, etc. |
−You can play games on a computer or video games on a dedicated machine, called a video console, which you connect to a TV set. You can also play games on the Net; some websites have a multiplayer facility that enables lots of people to play the same game at the same time.
Dealing with multimedia you often come across different file formats. Here is some information for you to recognize them. You know that to identify the type of a file, an extension is added to the filename when it is saved on a disk.
|
Common text extensions: |
Graphics include charts, |
You can hear sound such as |
||||||
|
.pdf (portable |
document |
photos, drawings, buttons, |
songs, movie soundtracks and |
|||||
|
format) |
etc. |
speeches. |
Common |
audio |
||||
|
.doc (MS Word document) |
. gif (graphics interchange |
formats: |
||||||
|
.rtf (rich text format) |
formats) |
.wav (Windows wave and |
||||||
|
.html |
or .hml |
(hypertext |
. jpeg(.jpg – joint |
audio format) |
||||
|
markup |
language |
for Web |
photographic experts group) |
.ra (RealAudio file) |
||||
|
files) |
.tif (tagged image file) |
.mp3 (compressed music files) |
||||||
|
Video refers to recording , |
Animations are made up of |
File |
compressed with Winzip |
|||||
|
editing |
and |
displaying |
series of independent pictu- |
have a .zip extension. A po- |
||||
|
moving images. |
res put together in a sequen- |
pular format used to compress |
||||||
|
Common formats: |
ce to look like moving |
and |
distribute |
movies on |
||||
|
.avi (audio video interleave) |
pictures. |
DVDs or over the Net is |
||||||
|
.mov (QuickTime movie) |
Common formats: |
DivX, a |
digital |
video |
codec |
116

|
.mpg (.mpeg – |
moving |
.gif for animated gifts |
(Compress, DECompress) |
|||
|
picture experts group) |
.swf for Flash files |
|||||
|
Vocabulary list |
||||||
|
to refer to – относиться к |
||||||
|
to integrate |
– интегрировать, объединять, включать в состав |
|||||
|
to reside |
in – постоянно храниться ( в памяти) |
|||||
|
to be similar – быть подобным, похожим |
||||||
|
extracurricular |
activities |
– деятельность |
в свободное |
от учебы |
||
|
время |
||||||
|
to burn music onto CDs – записывать музыку на диски |
||||||
|
to |
retouch |
digital pictures – |
ретушировать, |
исправлять |
цифровые |
|
|
изображения |
||||||
|
an |
expendable |
FAM |
(file |
access |
auxiliary memory) – |
|
|
дополнительная память для доступа к файлу |
||||||
|
a descent |
pair of speakers – приличная пара наушников |
|||||
|
performance |
– результативность, |
качество функционирования, |
||||
|
режим; характеристика |
||||||
|
to support streaming |
– поддерживать распределение потоков информации |
|||||
|
a simulated |
world – моделируемый мир |
a dedicated machine – выделенная машина a file extension – расширение файла
VOCABULARY AND COMPREHENSION CHECK EXERCISES
Exercise 1. Read the text and answer the following questions.
1. What does multimedia refer to? 2. Where does its power reside in? 3. Multimedia software is usually interactive, isn’t it? 4. What does hypertext mean? 5. What do you use multimedia for in you extracurricular activities? 6. Where can multimedia applications be used? 7. What file formats do you most often come across?
Exercise 2. Find the correct word for the following:
−the type of text that contains links to other texts
−the expression that means ‘to record music onto a CD’
−a system that combines hypertext and multimedia
−the most common extensions for graphics files
−the most common text formats
−three popular video formats
117

− three common file formats for storing audio data
Exercise 3. Solve the clues.
1.A series of still images shown ill sequence.
2.……. files are processed by sound software.
3.In medicine, doctors use virtual ………. systems to simulate particular situations.
4 . The suffix placed after a dot at the end of a filename.
5 . A format used to compress and transmit movies over the Web.
|
6…………………………. |
. People use special programs to ………. and decompress |
|||
|
files so that they occupy less disk-space. |
||||
|
7 |
. A video format developed by the Moving Picture Experts Group. |
|||
|
8 |
. A system of filming, processing and showing moving pictures. |
|||
|
9………….. |
. |
Gif stands for ………. interchange format. |
||
|
10. The technique which allows you to play music and watch video before the |
||||
|
entire file has downloaded. |
||||
|
Exercise 4. Complete the article with the words from the box |
||||
|
Graphics |
interactive |
video games |
consoles |
multiplayer |
There are games you play on video (1) ………. such as Nintendo, Sega, and the PlayStation. And there are games you play on a computer, either alone or at multiplayer online sites such as Microsoft’s Internet Gaming Zone and Battle.net. (2) …. have been made into films, such as Mortal Kombat I and 2, and film stars now sometimes appear in video games. The (3) ……. in many games have taken on such a high degree of realism that they almost seem like film. The X-Files game was practically an (4)
……….. movie, full of actors from the show and sections of dialogue and video. Some people claim that the Blade Runner video game was better than the movie – not only were the sets incredible but you also got to control the action and the ending. (5)
……………. online gaming is the next wave in the video game world. It provides a better gaming experience, simply because people are more creative and more challenging adversaries than computers. Thousands of people can play simultaneously all over the world.
DEVELOPING SPEAKING SKILLS
Exercise 1. Discuss the following topics:
1.Have you ever used a multimedia encyclopedia? If so, note down three important features about it.
2.Think about the advantages of using multimedia for presentations.
3.Do you like video and computer games? Make a list of pros and cons.
118
18. WEB-DESIGN
Read and translate the text. Use a dictionary to help you
HTML
Web pages are created with a special language HTML (Hyper Text Markup Language), which is interpreted by a web browser to produce hypertext, a blend of text, graphics and links.
You can view the source or raw HTML code by choosing the View Source option in your web browser.
To build a website you could learn how to write HTML tags, the coded instructions that form web pages, or else use an HTML editor, a WYSIWYG (What You See Is What You Get) application that converts a visual layout into HTML code. A simpler option is to use a web template provided by a web-based site builder, where you just fill in the information you want on the page.
Basic elements
Some of the basic elements that can be found on a web page are:
−Text, which may be displayed in a variety of sizes, styles and fonts
−Links, connections from text or graphics on the current web page to different parts of the same page, to other web pages or websites, or to external files.
−Graphics, pictures created with formats such as JPEG (Joint Photographic Experts Group), which is ideal for pictures with a wide range of colours, e.g. photographs, and GIF (Graphical Interchange Format), which is good for pictures with fewer colours or with large areas of the same colour, e.g. buttons, banners and icons.
−Tables, intended for the display of tabular data, but often used to create page layouts.
−Frames, subdivisions of a web page allowing the display of different HTML documents on the same page.
Instructions for the presentation, the styling of elements on a page such as text or background colour, can be included in the HTML code. However, it is becoming more common to use CSS (Cascading Style Sheets) to separate style from content. This makes pages easier to maintain, reduces download time and makes it easy to apply presentation changes across a website.
Video, animations and sound
Web pages can also include multimedia files: animations, audio and video files. Sounds are recorded with different audio formats. MIDI, WAV, AU and MP3 are some of the most popular ones.
Shockwave and Flash are technologies that enable web pages to include video and animations.
Java applets, specific applications using that programming language, may be used to add interactivity to web pages.
119

To see or hear all these files, you need to download the right plug-in, the additional software that enables the web browser to support this new content.
Vocabulary list
Hyper Text Markup Language – язык разметки гипертекста a blend – перемешивание, сочетание
a tag – ярлык
WYSIWYG (What You See Is What You Get) – «что видишь, то и получишь»; принцип WYSIWYG
web template – веб-шаблон
a visual layout – визуальное расположение a font – шрифт
current – настоящий
a banner – баннер, заголовок
tabular data – данные, сведенные в таблицу
to use CSS (Cascading Style Sheets) – использовать каскадные таблицы стилей an applet – апплет, прикладная мини-программа
a plug-in – подключаемое расширение, дополнительный модуль
VOCABULARY AND COMPREHENSION CHECK EXERCISES
Exercise 1. Read the text and answer the following questions.
1.How are web pages created? 2. How can you view the source HTML code? 3. What do you need to learn to build a website? 4. A simpler option is to use a web template provided by a web-based site builder, isn’t it? 5. What are some of the basic elements that can be found on a web page? 6. What can be included in the HTML code? 7.
What is becoming more common? 8. What can web pages also include? 9. What are some of the most popular audio formats? 10. What do you need to download to see or hear all these files?
Exercise 2. Solve the clues.
1.What you see is what you get.
2.You can make a web page using an HTML……… .
3.You just have to fill it in to create a web page.
4.Templates are found in a web-based site………
5.The instructions in HTML.
6.Another word for raw HTML code.
7.The language used to make web pages.
Exercise 3. Complete this advice about web design.
A well-designed website should be neat and organized. Words should be surrounded by sufficient white space. Use dark (1) ……… on a light (2) ……, preferably white. You can divide the page into columns with a (3)……..or use (4)
120
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Task 1. Match the following words with their definitions.
1 action (n)
a a visual guide of a website
2 profile (n)
b if something is invisible, you cannot see it
3 visitor (n)
c
a short description that gives the main details of what someone or
something is like
4
invisible
(adj)
d a written or spoken description of a situation or event
5 traffic (n)
e used to describe movement on the Internet
6 report (n)
f something that you do
7 map (n)
g someone who visits a website
1
2
3
4
5
6
7
E
C
F
B
F
D
A
Task 2. Make meaningful interrogative sentences putting the words in order.
1. do/people/why/visit/organizational/websites/?WHY PEOPLE GET ORGANIZED FROM
WEBSITES
2. you/ use/ Wikipedia/ why/ do/?
___
WHY DO YOU USE WIKIPEDIA?
3. what/you/do/for/use/CNN/?
__
YOU WORK WHY YOU USE CNN
4. personal/ what/ is/ of/purpose/ the/websites?
___
personal/ what is the website/ the purpose of?
5. you /what/do/ do?
___. do you /what/do/?
6. does/what /your/do/mother/?
___
WHAT DOES YOUR MOTHER MAKE YOU?
Task 3. Read the text and fill the gaps with the words given in the box.
text JPEG background link frame
CSS (cascading style sheets) table Graphics GIF
A well-designed website should be neat and organized. Words should be surrounded by
sufficient white space. Use dark 1) TEXT on a light 2) … background …, preferably white.
You can divide the page into columns with a 3) … table Graphics … or use 4) GIF to create
the page layout. Usually the navigation bar appears on the left side of the page. You can display
it on all the pages of your website by using a 5) CSS (cascading style sheets . It is a good idea to
put a 6) JPEG… to the top of the page at the bottom of a long text.
The graphical element of a web page is crucial. 7) background link frame load slowly, so
use them sparingly and for good reason. There are two common picture formats:  GIF JPEG ,
GIF JPEG ,
for pictures with lots of colors and 9) CSS (cascading style sheets … , which is ideal for buttons
and banners.
Task 4. Read the text and solve the clues and complete the puzzle with words from the text.
HTML
Web pages are created with a special language HTML (Hyper Text Markup Language),
which is interpreted by a web browser to produce hypertext, a blend of text, graphics
and links.
You can view the source or raw HTML code by choosing the View Source option in
your web browser.
To build a website you could learn how to write HTML tags, the coded instructions
that form web pages, or else use an HTML editor, a WYSIWYG (What You See Is
What You Get) application that converts a visual layout into HTML code. A simpler
option is to use a web template provided by a web-based site builder, where you just
fill in the information you want on the page.
Across
4. What you see is what you get.
6. You can make a web page using an HTML.
7. You just have to fill it in to create a web page down.
Down
1. Templates are found in a web-based site.
2. The instructions in HTML.
3. Another word for raw HTML code.
5. The language used to make web pages.
As the rules plainly state (emphasis added):
For any markup that is not covered by Markdown’s syntax, you simply
use HTML itself. There’s no need to preface it or delimit it to
indicate that you’re switching from Markdown to HTML; you just use the
tags.The only restrictions are that block-level HTML elements — e.g.
<div>,
<table>,<pre>,<p>, etc. — must be separated from surrounding content
by blank lines, and the start and end tags of the block should not be
indented with tabs or spaces. Markdown is smart enough not to add
extra (unwanted)<p>tags around HTML block-level tags.
If you are concerned that Markdown might munge up the content of your raw HTML, the rules also state:
Note that Markdown formatting syntax is not processed within
block-level HTML tags. E.g., you can’t use Markdown-style*emphasis*
inside an HTML block.
So, as long as your HTML blocks are properly wrapped in block level HTML tags, Markdown will leave them alone. Of course, that does not aply to inline HTML elements, included within Markdown text:
Span-level HTML tags — e.g.
<span>,<cite>, or<del>— can be
used anywhere in a Markdown paragraph, list item, or header. If you
want, you can even use HTML tags instead of Markdown formatting; e.g.
if you’d prefer to use HTML<a>or<img>tags instead of
Markdown’s link or image syntax, go right ahead.Unlike block-level HTML tags, Markdown syntax is processed within
span-level tags.
It is also important to note that some Markdown implementations do not follow the rules as stated above. So you might want to check the documentation for the implementation you are using to ensure it either follows the rules, or has a configuration switch which forces it to follow the rules.
And then there is Commonmark, which does not follow the original Markdown rules, but uses a different set of rules. Specifically, Commonmark requires no blank lines within the raw HTML block to avoid Markdown parsing. CommonMark will treat everything as Markdown after the first blank line within a raw HTML block. However, if you are using an old-school Markdown parser rather than a Commonmark parser, this should be a non-issue.
As a final word of caution, Markdown (not Commonmark) is much older than HTML 5. Therefore the newer block-level elements added to HTML 5 (<section>, <article>, etc.) are not recognized by most Markdown implementations as being block level elements. Some implementations have been updated to add support, but even then there is no consistency between implementations regarding which new elements should be treated as block-level as the reference implementation has not been updated to set a president. Therefore, it is best to stick with elements defined as block-level in the old HTML 4 and/or XHTML 1 specs.
This article is part of the Beginner Web Developer Series. The series is targeted to people who’d like to start serious web development, as well as people who are already web developers and want to solidify their knowledge of fundamentals while possibly filling in some holes. If you find yourself tinkering with HTML, CSS, or Javascript until you sort of get it to work, this series is for you. The material in this series is closely tied to my top-rated Coursera course.
First things first. What IS an HTML Character Entity Reference?
HTML character entity reference is a special set of characters (a code), which the browser displays as a special character or a symbol, corresponding to the entity reference code.
The general format of an HTML character entity reference is
&, followed by some code, followed by;, without any spaces in between.
For example, if you place © in your HTML code, the browser will display the copyright symbol ©.
There are many applications for HTML character entity references. In this article, I will concentrate on the most common problems that HTML character entity references solve.
Reserved Characters
Like any language, HTML has a set of special characters which browsers recognize as part of the HTML language itself. For example, browsers know that when they encounter a < character in the HTML code, they are to interpret it as a beginning of a tag.
Thus, the < character is a reserved character. It’s reserved by the HTML language as having special meaning, i.e., signifying the beginning of a tag.
But what happens when you want to use one of those reserved characters as part of the content of your document, not as part of the HTML code that dictates the structure of the document?
We need a way to tell the browser not to interpret them as HTML code, but as regular content.
HTML character entity references to the rescue! 💪
<, > and & Character References
There are 3 reserved characters that should always be substituted with their corresponding entity character references.
- Instead of
<, use< - Instead of
>, use> - Instead of
&, use&
Example: Reserved Characters in HTML
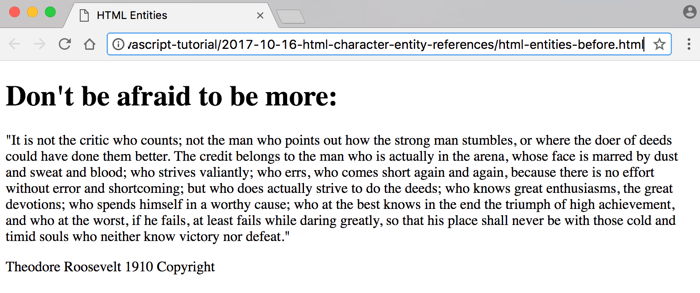
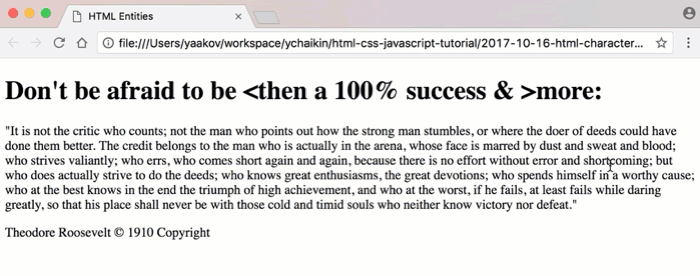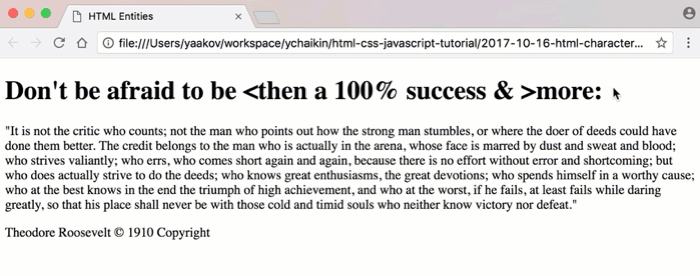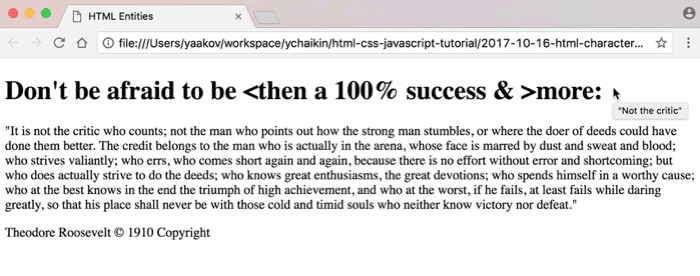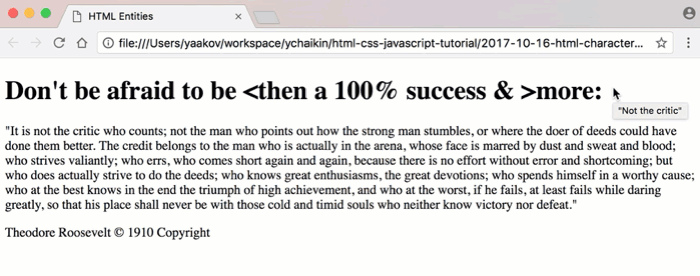
Let’s take a look at the following HTML document (html-entities-before.html). (This document contains one of my favorite quotes from Theodore Roosevelt):
Oh, what a great quote, isn’t it?! 🤔
However, besides that great quote, pay attention to the fairly weird-looking content wrapped in the
<h1>tag. (Obviously, that’s not part of the quote. I made it up just for this example.)Let’s take a look at how this document renders in the browser:
Hmm… A good portion of our heading has disappeared!
In fact, it didn’t disappear.
The browser was interpreting the content of the
<h1>tag when it stumbled upon the<character.“Aha!” said the browser.
“It’s a start of a new tag!”
“But what tag is that?
<then? What is that? I guess, I better keep going to see if I can find the end of this opening<thentag.”“Found it! It’s the closing tag character
>, right in front of>more”“I have no idea how to display this
<then>tag, so I guess, I’ll just skip rendering it to the display.”And that’s how we ended up with the heading
Don't be afraid to be more:instead of what we actually wanted.Let’s fix this by substituting HTML character entity references instead of the reserved characters
<,>, and&.The following example (
html-entities-after-1.html) shows the updated code:
Here is
html-entities-after-1.htmlrendered in the browser:
Much better! 👍
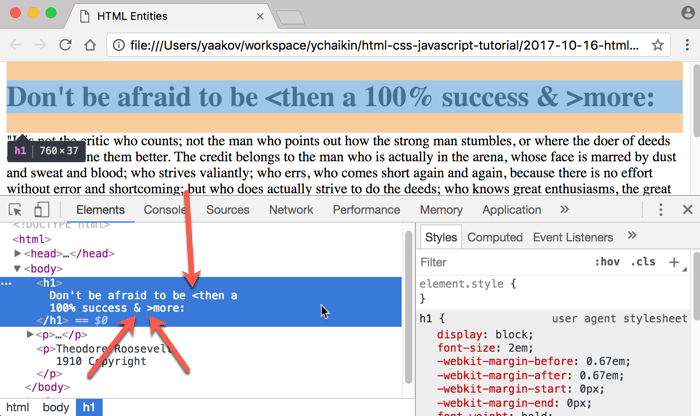
Chrome Developer Tools Gotcha
If you are looking at the Elements tab of the Chrome Developer Tools (CDT), you may be fooled into believing that regular reserved characters (
<,>,&) are being used in the content, and not the HTML character entity references.For example, take a look at the heading of
html-entities-after-1.htmldisplayed in the CDT:
Don’t be fooled by this!
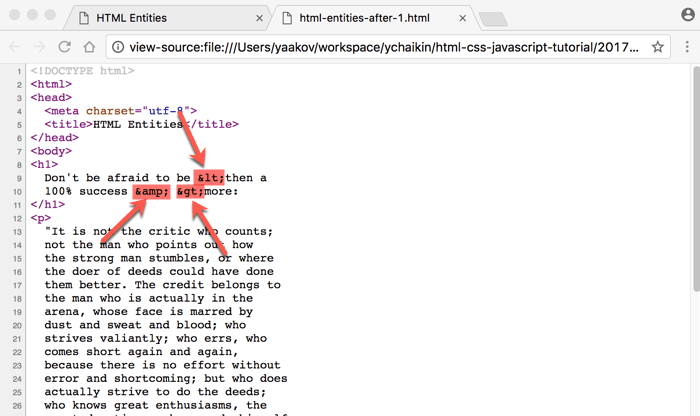
That’s just Chrome Developer Tools helping make the content more readable. In the raw HTML, the character entity references are there.
To see them, right-click anywhere on the page (without selecting any content!) and choose View Page Source menu option. The raw HTML code will be displayed as shown below:
Not On My Keyboard!
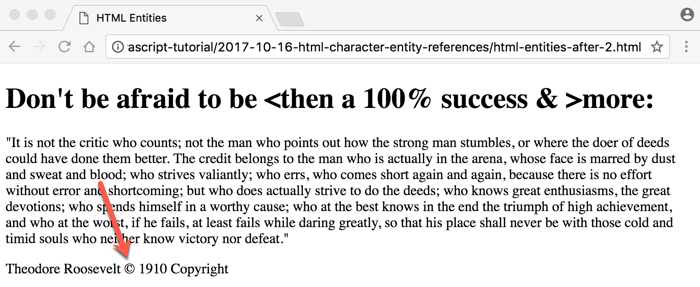
Another reason HTML character entity references exist is provide us with the ability to quickly output special characters not readily available on our keyboards.
One such character that is used quite often is the copyright symbol or ©.
The character entity reference code for © is
©.Let’s augment our Roosevelt quote HTML document by placing the copyright symbol as part of the copyright line at the bottom of the document (
html-entities-after-2.html):
Now, the browser is showing the © symbol next to the year:
Much better! 😁
Non-Breaking Space
I would be remiss if I didn’t mention another very commonly used HTML character entity reference,
, also known as the non-breaking space.Let me explain what
does with an example.Take a look at the heading
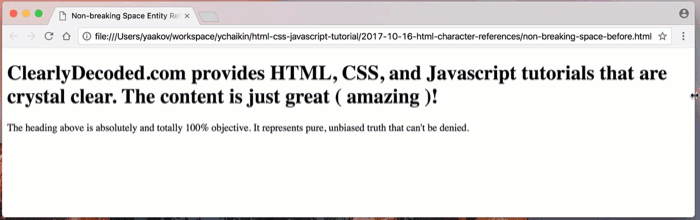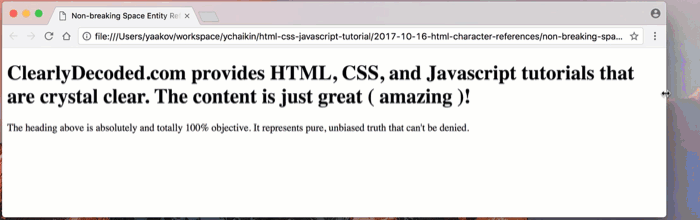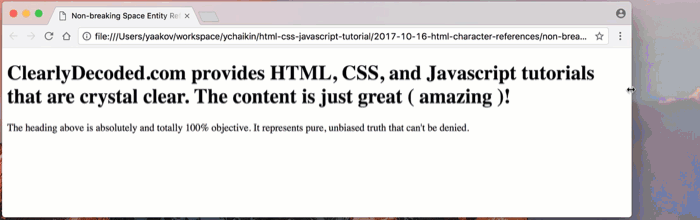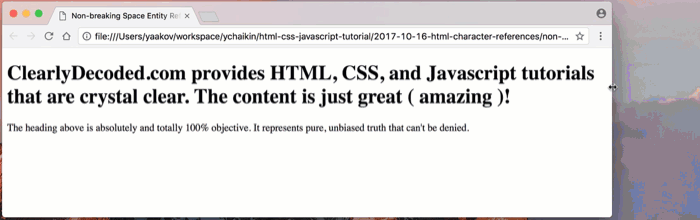
h1of the following document (non-breaking-space-before.html):
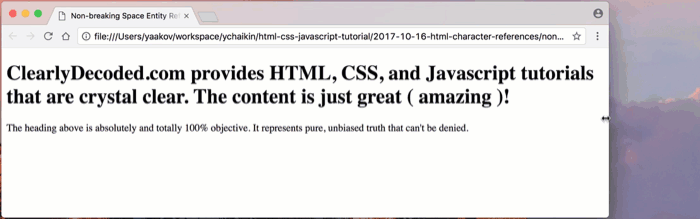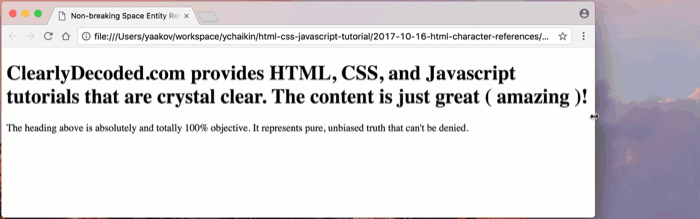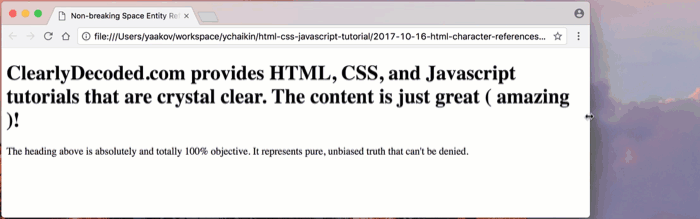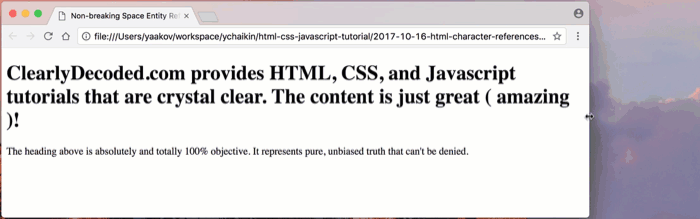
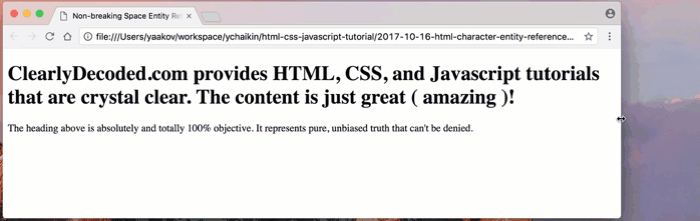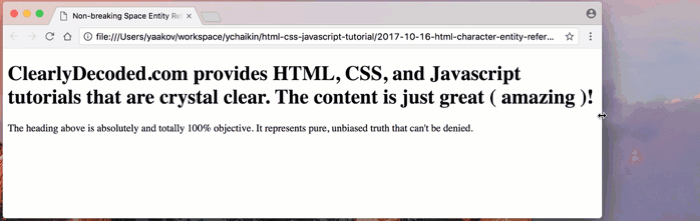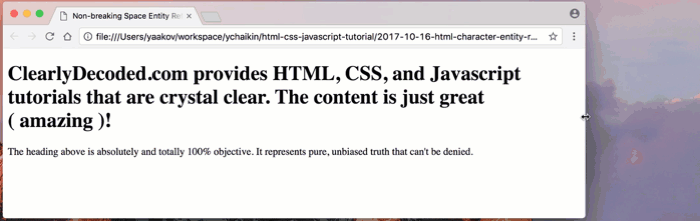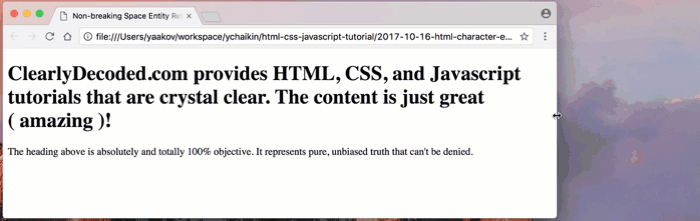
Shown below, as I decrease the width of the browser window, you can see that, word by word, the browser is wrapping the heading text onto the next line:
As you can see, the entire heading does not fit on one line. The browser wraps the heading, word by word, onto the next line.
Note that the browser does not wrap the content character by character and it shouldn’t!
How weird would it be if the line of text ended with
tutorials that arand continued on the next line withe crystal clear?!But take a look at the ugly wrapping that happens when we get to the
(amazing)part of the heading. One of the parentheses wraps onto the next line, leaving the part enclosed in the parentheses on the previous line:
We have a dilemma. On one hand, we’d like to keep the spaces between the word
amazingand the parentheses around it. On the other hand, we need to keep the whole thing(amazing)as one word, without allowing the browser to break it apart using those spaces.Hey! It’s almost like… wait for it… we need non-breaking spaces or
!Genius! 🤓 😂
Let’s use the non-breaking space characters instead of the regular space characters (
non-breaking-space-after.html):
Note that there are no regular spaces around the word ‘amazing’:
( amazing ).Let’s see how things wrap now:
Amazing, indeed! 😁
Common Beginner Mistake — Don’t Misuse
I’ve mentioned several times in this series of articles (e.g., Anatomy of an HTML Tag) that HTML ignores extra spaces.
You can place 100 spaces between two words in your content and the browser will still display just one space.
It would seem that the non-breaking space character entity reference gives you the power to overcome that rule.
Just place 100
references one after another, right?Wrong!
While that will somewhat work, it’s a total misuse of this entity reference. The
is meant to do one thing: substitute regular space characters so that the browser doesn’t break up content in an undesired way. It is not meant for expressing margins within your text.(If you wanted margins in the middle of a sentence, you would wrap that content with a
<span>tag and applymargin-left: 20px;to that<span>or some such, but we haven’t covered that yet in this series.)Displaying Quotes in Attributes
The quote or
"is another character entity reference that is commonly used as part of the value of an attribute of an HTML element.(If you don’t remember what an HTML attribute is, see my article Anatomy of an HTML Tag.)
For example, we can place a
titleattribute on the<h1>tag (html-entities-after-3.html):
Pay attention to the opening
<h1>tag. Since attribute values are usually enclosed in quotes, we can’t simply leave the quotes in the attribute value like so:title=""Not the critic"".The browser would consider the second quote in
title=""as the closing quote. Then, the browser will see the next set of characters,Not the critic"", as an invalid attempt at specifying another attribute.So, one solution is to use the
"entity reference instead of the"character in the attribute value.Another solution would be to use the fact that single quotes and double quotes are interchangeable in HTML. The same
titleattribute can then be written astitle='"Not the critic"'.With either solution, the by-product of specifying a
titleattribute on an element is that hovering over that element shows a tooltip with the value specified in thetitleattribute, as shown below.
Summary
Let’s give a quick summary of what we’ve covered in this article:

- HTML character entity references allow us to display reserved characters as part of our content
- Content with characters
<,>, and&will be interpreted as HTML code by the browser and can break the HTML code, causing unwanted side-effects (like skipping part of the content) - Character entity references can be used for characters not readily found on common keyboards (e.g., © character)
- The non-breaking space character entity reference,
can be used to force the browser not to break up space-separated words when wrapping content - Repeating
should not be used for larger visual spacing between words. That’s a misuse of the non-breaking space character - HTML attribute values that need to contain quotes can either use the quote character entity reference
"or, if feasible, interchange between the single and double quotes
Resources
- Code used in this article
- Mozzila Developer Network (MDN) Entity description
- Nice Character Entity Reference Chart
Questions?
If something is not clear about what I wrote in this article, please ask away in the comments below!
HTML: The Living Standard
Edition for Web Developers — Last Updated 6 April 2023
- 13 The HTML syntax
- 13.1 Writing HTML documents
- 13.1.1 The DOCTYPE
- 13.1.2 Elements
- 13.1.2.1 Start tags
- 13.1.2.2 End tags
- 13.1.2.3 Attributes
- 13.1.2.4 Optional tags
- 13.1.2.5 Restrictions on content models
- 13.1.2.6 Restrictions on the contents of raw text and escapable raw text elements
- 13.1.3 Text
- 13.1.3.1 Newlines
- 13.1.4 Character references
- 13.1.5 CDATA sections
- 13.1.6 Comments
- 13.1 Writing HTML documents
13 The HTML syntax
This section only describes the rules for resources labeled with an HTML
MIME type. Rules for XML resources are discussed in the section below entitled «The
XML syntax».
13.1 Writing HTML documents
Documents must consist of the following parts, in the given
order:
- Optionally, a single U+FEFF BYTE ORDER MARK (BOM) character.
- Any number of comments and ASCII
whitespace. - A DOCTYPE.
- Any number of comments and ASCII
whitespace. - The document element, in the form of an
htmlelement. - Any number of comments and ASCII
whitespace.
The various types of content mentioned above are described in the next few sections.
In addition, there are some restrictions on how character encoding declarations are to be serialized, as discussed in the
section on that topic.
ASCII whitespace before the html element, at the start of the
html element and before the head element, will be dropped when the
document is parsed; ASCII whitespace after the html element
will be parsed as if it were at the end of the body element. Thus, ASCII
whitespace around the document element does not round-trip.
It is suggested that newlines be inserted after the DOCTYPE, after any comments that are
before the document element, after the html element’s start tag (if it is not omitted), and after any comments that are inside the
html element but before the head element.
Many strings in the HTML syntax (e.g. the names of elements and their attributes) are
case-insensitive, but only for ASCII upper alphas and
ASCII lower alphas. For convenience, in this section this
is just referred to as «case-insensitive».
13.1.1 The DOCTYPE
A DOCTYPE is a
required preamble.
DOCTYPEs are required for legacy reasons. When omitted, browsers tend to use a
different rendering mode that is incompatible with some specifications. Including the DOCTYPE in a
document ensures that the browser makes a best-effort attempt at following the relevant
specifications.
A DOCTYPE must consist of the following components, in this order:
- A string that is an ASCII case-insensitive match for the string «
<!DOCTYPE«. - One or more ASCII whitespace.
- A string that is an ASCII case-insensitive match for the string «
html«. - Optionally, a DOCTYPE legacy string.
- Zero or more ASCII whitespace.
- A U+003E GREATER-THAN SIGN character (>).
In other words, <!DOCTYPE html>, case-insensitively.
For the purposes of HTML generators that cannot output HTML markup with the short DOCTYPE
«<!DOCTYPE html>«, a DOCTYPE legacy string may be inserted
into the DOCTYPE (in the position defined above). This string must consist of:
- One or more ASCII whitespace.
- A string that is an ASCII case-insensitive match for the string «
SYSTEM«. - One or more ASCII whitespace.
- A U+0022 QUOTATION MARK or U+0027 APOSTROPHE character (the quote mark).
- The literal string «
about:legacy-compat«. - A matching U+0022 QUOTATION MARK or U+0027 APOSTROPHE character (i.e. the same character as in the earlier step labeled quote mark).
In other words, <!DOCTYPE html SYSTEM "about:legacy-compat"> or
<!DOCTYPE html SYSTEM 'about:legacy-compat'>, case-insensitively except for the
part in single or double quotes.
The DOCTYPE legacy string should not be used unless the document is generated from
a system that cannot output the shorter string.
13.1.2 Elements
There are six different kinds of elements: void
elements, the template element, raw text
elements, escapable raw text elements, foreign elements, and
normal elements.
- Void elements
area,base,br,col,embed,
hr,img,input,link,meta,
source,track,wbr- The
templateelement template- Raw text elements
script,style- Escapable raw text elements
textarea,title- Foreign elements
- Elements from the MathML namespace and the SVG namespace.
- Normal elements
- All other allowed HTML elements are normal elements.
Tags are used to delimit the start and end of elements in the
markup. Raw text, escapable raw text, and normal elements have
a start tag to indicate where they begin, and an end tag to indicate where they end. The start and end tags of
certain normal elements can be omitted, as
described below in the section on optional tags. Those
that cannot be omitted must not be omitted. Void elements only have a start tag; end
tags must not be specified for void elements. Foreign elements must
either have a start tag and an end tag, or a start tag that is marked as self-closing, in which
case they must not have an end tag.
The contents of the element must be placed between
just after the start tag (which might be implied, in certain
cases) and just before the end tag (which again, might be
implied in certain cases). The exact allowed contents of each individual element depend on
the content model of that element, as described earlier in
this specification. Elements must not contain content that their content model disallows. In
addition to the restrictions placed on the contents by those content models, however, the five
types of elements have additional syntactic requirements.
Void elements can’t have any contents (since there’s no end tag, no content can be
put between the start tag and the end tag).
The template element can have
template contents, but such template contents are not children of the
template element itself. Instead, they are stored in a DocumentFragment
associated with a different Document — without a browsing context — so
as to avoid the template contents interfering with the main Document.
The markup for the template contents of a template element is placed
just after the template element’s start tag and just before template
element’s end tag (as with other elements), and may consist of any text, character references, elements, and comments, but
the text must not contain the character U+003C LESS-THAN SIGN (<) or an ambiguous ampersand.
Raw text elements can have text, though it has restrictions described below.
Escapable raw text elements can have text and
character references, but the text must not contain an ambiguous ampersand. There are also further restrictions described below.
Foreign elements whose start tag is marked as self-closing can’t have any contents
(since, again, as there’s no end tag, no content can be put between the start tag and the end
tag). Foreign elements whose start tag is not marked as self-closing can
have text, character
references, CDATA sections, other elements, and comments, but
the text must not contain the character U+003C LESS-THAN SIGN (<) or an ambiguous ampersand.
The HTML syntax does not support namespace declarations, even in foreign
elements.
For instance, consider the following HTML fragment:
<p>
<svg>
<metadata>
<!-- this is invalid -->
<cdr:license xmlns:cdr="https://www.example.com/cdr/metadata" name="MIT"/>
</metadata>
</svg>
</p>The innermost element, cdr:license, is actually in the SVG namespace, as
the «xmlns:cdr» attribute has no effect (unlike in XML). In fact, as the
comment in the fragment above says, the fragment is actually non-conforming. This is because
SVG 2 does not define any elements called «cdr:license» in
the SVG namespace.
Normal elements can have text, character references, other elements, and comments, but
the text must not contain the character U+003C LESS-THAN SIGN (<) or an ambiguous ampersand. Some normal elements
also have yet more restrictions on what content they are
allowed to hold, beyond the restrictions imposed by the content model and those described in this
paragraph. Those restrictions are described below.
Tags contain a tag name, giving the element’s name. HTML
elements all have names that only use ASCII
alphanumerics. In the HTML syntax, tag names, even those for foreign elements,
may be written with any mix of lower- and uppercase letters that, when converted to all-lowercase,
matches the element’s tag name; tag names are case-insensitive.
13.1.2.1 Start tags
Start tags must have the following format:
- The first character of a start tag must be a U+003C LESS-THAN SIGN character (<).
- The next few characters of a start tag must be the element’s tag name.
- If there are to be any attributes in the next step, there must first be one or more
ASCII whitespace. - Then, the start tag may have a number of attributes, the syntax for which is described below. Attributes must be
separated from each other by one or more ASCII whitespace. - After the attributes, or after the tag name if there
are no attributes, there may be one or more ASCII whitespace. (Some attributes are
required to be followed by a space. See the attributes
section below.) - Then, if the element is one of the void elements, or if the element is a foreign element, then there may be a single U+002F SOLIDUS
character (/), which on foreign elements marks the start tag as self-closing. On
void elements, it does not mark the start tag as self-closing but instead is
unnecessary and has no effect of any kind. For such void elements, it should be used only with
caution — especially since, if directly preceded by an unquoted attribute
value, it becomes part of the attribute value rather than being discarded by the
parser. - Finally, start tags must be closed by a U+003E GREATER-THAN SIGN character (>).
13.1.2.2 End tags
End tags must have the following format:
- The first character of an end tag must be a U+003C LESS-THAN SIGN character (<).
- The second character of an end tag must be a U+002F SOLIDUS character (/).
- The next few characters of an end tag must be the element’s tag
name. - After the tag name, there may be one or more ASCII whitespace.
- Finally, end tags must be closed by a U+003E GREATER-THAN SIGN character (>).
13.1.2.3 Attributes
Attributes for an element are expressed inside the
element’s start tag.
Attributes have a name and a value. Attribute names
must consist of one or more characters other than controls,
U+0020 SPACE, U+0022 («), U+0027 (‘), U+003E (>), U+002F (/), U+003D (=), and noncharacters. In the HTML syntax, attribute names, even those for
foreign elements, may be written with any mix of ASCII lower and ASCII upper alphas.
Attribute values are a mixture of text and character references,
except with the additional restriction that the text cannot contain an ambiguous ampersand.
Attributes can be specified in four different ways:
- Empty attribute syntax
-
Just the attribute name. The value is implicitly
the empty string.In the following example, the
disabledattribute is
given with the empty attribute syntax:<input disabled>If an attribute using the empty attribute syntax is to be followed by another attribute, then
there must be ASCII whitespace separating the two. - Unquoted attribute value syntax
-
The attribute name, followed by zero or more
ASCII whitespace, followed by a single U+003D EQUALS SIGN character, followed by
zero or more ASCII whitespace, followed by the attribute value, which, in addition to the requirements
given above for attribute values, must not contain any literal ASCII whitespace,
any U+0022 QUOTATION MARK characters («), U+0027 APOSTROPHE characters (‘), U+003D
EQUALS SIGN characters (=), U+003C LESS-THAN SIGN characters (<), U+003E GREATER-THAN SIGN
characters (>), or U+0060 GRAVE ACCENT characters (`), and must not be the empty string.In the following example, the
valueattribute is given
with the unquoted attribute value syntax:<input value=yes>If an attribute using the unquoted attribute syntax is to be followed by another attribute or
by the optional U+002F SOLIDUS character (/) allowed in step 6 of the start tag syntax above, then there must be ASCII
whitespace separating the two. - Single-quoted attribute value syntax
-
The attribute name, followed by zero or more
ASCII whitespace, followed by a single U+003D EQUALS SIGN character, followed by
zero or more ASCII whitespace, followed by a single U+0027 APOSTROPHE character
(‘), followed by the attribute value, which, in
addition to the requirements given above for attribute values, must not contain any literal
U+0027 APOSTROPHE characters (‘), and finally followed by a second single U+0027 APOSTROPHE
character (‘).In the following example, the
typeattribute is given
with the single-quoted attribute value syntax:<input type='checkbox'>If an attribute using the single-quoted attribute syntax is to be followed by another
attribute, then there must be ASCII whitespace separating the two. - Double-quoted attribute value syntax
-
The attribute name, followed by zero or more
ASCII whitespace, followed by a single U+003D EQUALS SIGN character, followed by
zero or more ASCII whitespace, followed by a single U+0022 QUOTATION MARK character
(«), followed by the attribute value, which, in
addition to the requirements given above for attribute values, must not contain any literal
U+0022 QUOTATION MARK characters («), and finally followed by a second single U+0022 QUOTATION
MARK character («).In the following example, the
nameattribute is given with
the double-quoted attribute value syntax:<input name="be evil">If an attribute using the double-quoted attribute syntax is to be followed by another
attribute, then there must be ASCII whitespace separating the two.
There must never be two or more attributes on the same start tag whose names are an ASCII
case-insensitive match for each other.
When a foreign element has one of the namespaced
attributes given by the local name and namespace of the first and second cells of a row from the
following table, it must be written using the name given by the third cell from the same row.
| Local name | Namespace | Attribute name |
|---|---|---|
actuate |
XLink namespace | xlink:actuate
|
arcrole |
XLink namespace | xlink:arcrole
|
href |
XLink namespace | xlink:href
|
role |
XLink namespace | xlink:role
|
show |
XLink namespace | xlink:show
|
title |
XLink namespace | xlink:title
|
type |
XLink namespace | xlink:type
|
lang |
XML namespace | xml:lang
|
space |
XML namespace | xml:space
|
xmlns |
XMLNS namespace | xmlns
|
xlink |
XMLNS namespace | xmlns:xlink
|
No other namespaced attribute can be expressed in the HTML syntax.
Whether the attributes in the table above are conforming or not is defined by
other specifications (e.g. SVG 2 and MathML); this section only
describes the syntax rules if the attributes are serialized using the HTML syntax.
13.1.2.4 Optional tags
Certain tags can be omitted.
Omitting an element’s start tag in the
situations described below does not mean the element is not present; it is implied, but it is
still there. For example, an HTML document always has a root html element, even if
the string <html> doesn’t appear anywhere in the markup.
An html element’s start tag may be omitted
if the first thing inside the html element is not a comment.
For example, in the following case it’s ok to remove the «<html>»
tag:
<!DOCTYPE HTML>
<html>
<head>
<title>Hello</title>
</head>
<body>
<p>Welcome to this example.</p>
</body>
</html>Doing so would make the document look like this:
<!DOCTYPE HTML>
<head>
<title>Hello</title>
</head>
<body>
<p>Welcome to this example.</p>
</body>
</html>This has the exact same DOM. In particular, note that whitespace around the document
element is ignored by the parser. The following example would also have the exact same
DOM:
<!DOCTYPE HTML><head>
<title>Hello</title>
</head>
<body>
<p>Welcome to this example.</p>
</body>
</html>However, in the following example, removing the start tag moves the comment to before the
html element:
<!DOCTYPE HTML>
<html>
<!-- where is this comment in the DOM? -->
<head>
<title>Hello</title>
</head>
<body>
<p>Welcome to this example.</p>
</body>
</html>With the tag removed, the document actually turns into the same as this:
<!DOCTYPE HTML>
<!-- where is this comment in the DOM? -->
<html>
<head>
<title>Hello</title>
</head>
<body>
<p>Welcome to this example.</p>
</body>
</html>This is why the tag can only be removed if it is not followed by a comment: removing the tag
when there is a comment there changes the document’s resulting parse tree. Of course, if the
position of the comment does not matter, then the tag can be omitted, as if the comment had been
moved to before the start tag in the first place.
An html element’s end tag may be omitted if
the html element is not immediately followed by a comment.
A head element’s start tag may be omitted if
the element is empty, or if the first thing inside the head element is an
element.
A head element’s end tag may be omitted if
the head element is not immediately followed by ASCII whitespace or a
comment.
A body element’s start tag may be omitted
if the element is empty, or if the first thing inside the body element is not
ASCII whitespace or a comment, except if the
first thing inside the body element is a meta, noscript,
link, script, style, or template element.
A body element’s end tag may be omitted if the
body element is not immediately followed by a comment.
Note that in the example above, the head element start and end tags, and the
body element start tag, can’t be omitted, because they are surrounded by
whitespace:
<!DOCTYPE HTML>
<html>
<head>
<title>Hello</title>
</head>
<body>
<p>Welcome to this example.</p>
</body>
</html>(The body and html element end tags could be omitted without
trouble; any spaces after those get parsed into the body element anyway.)
Usually, however, whitespace isn’t an issue. If we first remove the whitespace we don’t care
about:
<!DOCTYPE HTML><html><head><title>Hello</title></head><body><p>Welcome to this example.</p></body></html>Then we can omit a number of tags without affecting the DOM:
<!DOCTYPE HTML><title>Hello</title><p>Welcome to this example.</p>At that point, we can also add some whitespace back:
<!DOCTYPE HTML>
<title>Hello</title>
<p>Welcome to this example.</p>This would be equivalent to this document, with the omitted tags shown in their
parser-implied positions; the only whitespace text node that results from this is the newline at
the end of the head element:
<!DOCTYPE HTML>
<html><head><title>Hello</title>
</head><body><p>Welcome to this example.</p></body></html>An li element’s end tag may be omitted if the
li element is immediately followed by another li element or if there is
no more content in the parent element.
A dt element’s end tag may be omitted if the
dt element is immediately followed by another dt element or a
dd element.
A dd element’s end tag may be omitted if the
dd element is immediately followed by another dd element or a
dt element, or if there is no more content in the parent element.
A p element’s end tag may be omitted if the
p element is immediately followed by an address, article,
aside, blockquote, details, div,
dl, fieldset, figcaption, figure,
, form, h1, h2, h3,
h4, h5, h6, , hgroup,
hr, main, , nav, ol,
p, pre, search, section, table,
or ul element, or if there is no more content in the parent element and the parent
element is an HTML element that is not an a,
audio, del, ins, map, noscript,
or video element, or an autonomous custom element.
We can thus simplify the earlier example further:
<!DOCTYPE HTML><title>Hello</title><p>Welcome to this example.An rt element’s end tag may be omitted if the
rt element is immediately followed by an rt or rp element,
or if there is no more content in the parent element.
An rp element’s end tag may be omitted if the
rp element is immediately followed by an rt or rp element,
or if there is no more content in the parent element.
An optgroup element’s end tag may be omitted
if the optgroup element is
immediately followed by another optgroup element, or if there is no more content in
the parent element.
An option element’s end tag may be omitted if
the option element is immediately followed by another option element, or
if it is immediately followed by an optgroup element, or if there is no more content
in the parent element.
A colgroup element’s start tag may be
omitted if the first thing inside the colgroup element is a col element,
and if the element is not immediately preceded by another colgroup element whose
end tag has been omitted. (It can’t be omitted if the element
is empty.)
A colgroup element’s end tag may be omitted
if the colgroup element is not immediately followed by ASCII whitespace
or a comment.
A caption element’s end tag may be omitted if
the caption element is not immediately followed by ASCII whitespace or a
comment.
A thead element’s end tag may be omitted if
the thead element is immediately followed by a tbody or
tfoot element.
A tbody element’s start tag may be omitted
if the first thing inside the tbody element is a tr element, and if the
element is not immediately preceded by a tbody, thead, or
tfoot element whose end tag has been omitted. (It
can’t be omitted if the element is empty.)
A tbody element’s end tag may be omitted if
the tbody element is immediately followed by a tbody or
tfoot element, or if there is no more content in the parent element.
A tfoot element’s end tag may be omitted if
there is no more content in the parent element.
A tr element’s end tag may be omitted if the
tr element is immediately followed by another tr element, or if there is
no more content in the parent element.
A td element’s end tag may be omitted if the
td element is immediately followed by a td or th element,
or if there is no more content in the parent element.
A th element’s end tag may be omitted if the
th element is immediately followed by a td or th element,
or if there is no more content in the parent element.
The ability to omit all these table-related tags makes table markup much terser.
Take this example:
<table>
<caption>37547 TEE Electric Powered Rail Car Train Functions (Abbreviated)</caption>
<colgroup><col><col><col></colgroup>
<thead>
<tr>
<th>Function</th>
<th>Control Unit</th>
<th>Central Station</th>
</tr>
</thead>
<tbody>
<tr>
<td>Headlights</td>
<td>✔</td>
<td>✔</td>
</tr>
<tr>
<td>Interior Lights</td>
<td>✔</td>
<td>✔</td>
</tr>
<tr>
<td>Electric locomotive operating sounds</td>
<td>✔</td>
<td>✔</td>
</tr>
<tr>
<td>Engineer's cab lighting</td>
<td></td>
<td>✔</td>
</tr>
<tr>
<td>Station Announcements - Swiss</td>
<td></td>
<td>✔</td>
</tr>
</tbody>
</table>The exact same table, modulo some whitespace differences, could be marked up as follows:
<table>
<caption>37547 TEE Electric Powered Rail Car Train Functions (Abbreviated)
<colgroup><col><col><col>
<thead>
<tr>
<th>Function
<th>Control Unit
<th>Central Station
<tbody>
<tr>
<td>Headlights
<td>✔
<td>✔
<tr>
<td>Interior Lights
<td>✔
<td>✔
<tr>
<td>Electric locomotive operating sounds
<td>✔
<td>✔
<tr>
<td>Engineer's cab lighting
<td>
<td>✔
<tr>
<td>Station Announcements - Swiss
<td>
<td>✔
</table>Since the cells take up much less room this way, this can be made even terser by having each
row on one line:
<table>
<caption>37547 TEE Electric Powered Rail Car Train Functions (Abbreviated)
<colgroup><col><col><col>
<thead>
<tr> <th>Function <th>Control Unit <th>Central Station
<tbody>
<tr> <td>Headlights <td>✔ <td>✔
<tr> <td>Interior Lights <td>✔ <td>✔
<tr> <td>Electric locomotive operating sounds <td>✔ <td>✔
<tr> <td>Engineer's cab lighting <td> <td>✔
<tr> <td>Station Announcements - Swiss <td> <td>✔
</table>The only differences between these tables, at the DOM level, is with the precise position of
the (in any case semantically-neutral) whitespace.
However, a start tag must never be
omitted if it has any attributes.
Returning to the earlier example with all the whitespace removed and then all the optional
tags removed:
<!DOCTYPE HTML><title>Hello</title><p>Welcome to this example.If the body element in this example had to have a class attribute and the html element had to have a lang attribute, the markup would have to become:
<!DOCTYPE HTML><html lang="en"><title>Hello</title><body class="demo"><p>Welcome to this example.This section assumes that the document is conforming, in particular, that there
are no content model violations. Omitting tags in the fashion
described in this section in a document that does not conform to the content models
described in this specification is likely to result in unexpected DOM differences (this is, in
part, what the content models are designed to avoid).
13.1.2.5 Restrictions on content models
For historical reasons, certain elements have extra restrictions beyond even the restrictions
given by their content model.
A table element must not contain tr elements, even though these
elements are technically allowed inside table elements according to the content
models described in this specification. (If a tr element is put inside a
table in the markup, it will in fact imply a tbody start tag before
it.)
A single newline may be placed immediately after the start tag of pre and textarea elements.
This does not affect the processing of the element. The otherwise optional newline must be included if the element’s contents
themselves start with a newline (because otherwise the
leading newline in the contents would be treated like the optional newline, and ignored).
The following two pre blocks are equivalent:
<pre>Hello</pre><pre>
Hello</pre>13.1.2.6 Restrictions on the contents of raw text and escapable raw text elements
The text in raw text and escapable raw text
elements must not contain any occurrences of the string «</»
(U+003C LESS-THAN SIGN, U+002F SOLIDUS) followed by characters that case-insensitively match the
tag name of the element followed by one of U+0009 CHARACTER TABULATION (tab), U+000A LINE FEED
(LF), U+000C FORM FEED (FF), U+000D CARRIAGE RETURN (CR), U+0020 SPACE, U+003E GREATER-THAN SIGN
(>), or U+002F SOLIDUS (/).
13.1.3 Text
Text is allowed inside elements, attribute values, and comments.
Extra constraints are placed on what is and what is not allowed in text based on where the text is
to be put, as described in the other sections.
13.1.3.1 Newlines
Newlines in HTML may be represented either as U+000D
CARRIAGE RETURN (CR) characters, U+000A LINE FEED (LF) characters, or pairs of U+000D CARRIAGE
RETURN (CR), U+000A LINE FEED (LF) characters in that order.
Where character references are allowed, a character
reference of a U+000A LINE FEED (LF) character (but not a U+000D CARRIAGE RETURN (CR) character)
also represents a newline.
13.1.4 Character references
In certain cases described in other sections, text may be
mixed with character references. These can be used to escape
characters that couldn’t otherwise legally be included in text.
Character references must start with a U+0026 AMPERSAND character (&). Following this,
there are three possible kinds of character references:
- Named character references
- The ampersand must be followed by one of the names given in the named character
references section, using the same case. - Decimal numeric character reference
- The ampersand must be followed by a U+0023 NUMBER SIGN character (#), followed by one or more
ASCII digits, representing a base-ten integer that corresponds to a code point that
is allowed according to the definition below. The digits must then be followed by a U+003B
SEMICOLON character (;). - Hexadecimal numeric character reference
- The ampersand must be followed by a U+0023 NUMBER SIGN character (#), which must be followed
by either a U+0078 LATIN SMALL LETTER X character (x) or a U+0058 LATIN CAPITAL LETTER X
character (X), which must then be followed by one or more ASCII hex digits,
representing a hexadecimal integer that corresponds to a code point that is allowed according to
the definition below. The digits must then be followed by a U+003B SEMICOLON character (;).
The numeric character reference forms described above are allowed to reference any code point
excluding U+000D CR, noncharacters, and controls other than ASCII whitespace.
An ambiguous ampersand is a U+0026 AMPERSAND
character (&) that is followed by one or more ASCII
alphanumerics, followed by a U+003B SEMICOLON character (;), where these characters do not
match any of the names given in the named character references section.
13.1.5 CDATA sections
CDATA sections must consist of the following components, in
this order:
- The string «
<![CDATA[«. - Optionally, text, with the additional restriction that the
text must not contain the string «]]>«. - The string «
]]>«.
CDATA sections can only be used in foreign content (MathML or SVG). In this example, a CDATA
section is used to escape the contents of a MathML ms element:
<p>You can add a string to a number, but this stringifies the number:</p>
<math>
<ms><![CDATA[x<y]]></ms>
<mo>+</mo>
<mn>3</mn>
<mo>=</mo>
<ms><![CDATA[x<y3]]></ms>
</math>must have the following format:
- The string «
<!--«. - Optionally, text, with the additional restriction that the
text must not start with the string «>«, nor start with the string
«->«, nor contain the strings «<!--«, «-->«, or «--!>«, nor end with the string «<!-«. - The string «
-->«.
The text is allowed to end with the string
«<!«, as in <!--My favorite operators are > and.
<!-->