
Excel для Microsoft 365 Excel для Microsoft 365 для Mac Excel 2021 Excel 2021 для Mac Excel 2019 Excel 2019 для Mac Excel 2016 Excel 2016 для Mac Excel 2013 Excel 2010 Excel 2007 Еще…Меньше
Если вам нужно разработать сложный статистический или инженерный анализ, вы можете сэкономить время и этапы с помощью этого средства. Вы предоставляете данные и параметры для каждого анализа, а средство использует соответствующие статистические или инженерные функции для вычисления и отображения результатов в выходной таблице. Некоторые средства создают диаграммы в дополнение к выходным таблицам.
Функции анализа данных можно применять только на одном листе. Если анализ данных проводится в группе, состоящей из нескольких листов, то результаты будут выведены на первом листе, на остальных листах будут выведены пустые диапазоны, содержащие только форматы. Чтобы провести анализ данных на всех листах, повторите процедуру для каждого листа в отдельности.
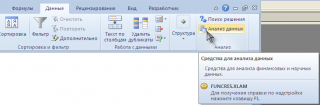
Ниже описаны инструменты, включенные в пакет анализа. Для доступа к ним нажмите кнопкуАнализ данных в группе Анализ на вкладке Данные. Если команда Анализ данных недоступна, необходимо загрузить надстройку «Пакет анализа».
-
Откройте вкладку Файл, нажмите кнопку Параметры и выберите категорию Надстройки.
-
В раскрывающемся списке Управление выберите пункт Надстройки Excel и нажмите кнопку Перейти.
Если вы используете Excel для Mac, в строке меню откройте вкладку Средства и в раскрывающемся списке выберите пункт Надстройки для Excel.
-
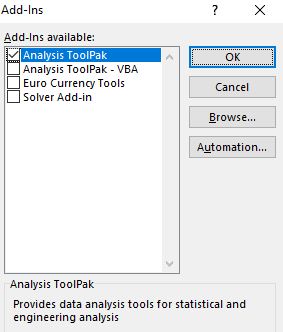
В диалоговом окне Надстройки установите флажок Пакет анализа, а затем нажмите кнопку ОК.
-
Если Пакет анализа отсутствует в списке поля Доступные надстройки, нажмите кнопку Обзор, чтобы выполнить поиск.
-
Если выводится сообщение о том, что пакет анализа не установлен на компьютере, нажмите кнопку Да, чтобы установить его.
-
Примечание: Чтобы включить Visual Basic для приложений (VBA) для надстройки «Надстройка анализа», вы можете загрузить надстройку VBA так же, как и надстройку «Надстройка анализа». В поле Доступные надстройки выберите «Надстройка анализа — VBA».
Существует несколько видов дисперсионного анализа. Нужный вариант выбирается с учетом числа факторов и имеющихся выборок из генеральной совокупности.
Однофакторный дисперсионный анализ
Этот инструмент выполняет простой анализ дисперсии данных для двух или более выборок. Анализ дает проверку гипотезы о том, что каждая выборка взята из одного и того же распределения вероятности на основе альтернативной гипотезы о том, что для всех выборок распределение вероятности не одно и то же. Если есть только два примера, можно использовать функцию T.ТЕСТ. В более чем двух примерах нет удобного обобщения T.ВМЕСТОэтого можно использовать модель Anova для одного фактора.
Двухфакторный дисперсионный анализ с повторениями
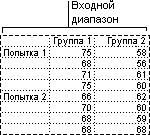
Этот инструмент анализа применяется, если данные можно систематизировать по двум параметрам. Например, в эксперименте по измерению высоты растений последние обрабатывали удобрениями от различных изготовителей (например, A, B, C) и содержали при различной температуре (например, низкой и высокой). Таким образом, для каждой из 6 возможных пар условий {удобрение, температура}, имеется одинаковый набор наблюдений за ростом растений. С помощью этого дисперсионного анализа можно проверить следующие гипотезы:
-
Извлечены ли данные о росте растений для различных марок удобрений из одной генеральной совокупности. Температура в этом анализе не учитывается.
-
Извлечены ли данные о росте растений для различных уровней температуры из одной генеральной совокупности. Марка удобрения в этом анализе не учитывается.
Извлечены ли шесть выборок, представляющих все пары значений {удобрение, температура}, используемые для оценки влияния различных марок удобрений (для первого пункта в списке) и уровней температуры (для второго пункта в списке), из одной генеральной совокупности. Альтернативная гипотеза предполагает, что влияние конкретных пар {удобрение, температура} превышает влияние отдельно удобрения и отдельно температуры.
Двухфакторный дисперсионный анализ без повторений
Этот инструмент анализа применяется, если данные можно систематизировать по двум параметрам, как в случае двухфакторного дисперсионного анализа с повторениями. Однако в таком анализе предполагается, что для каждой пары параметров есть только одно измерение (например, для каждой пары параметров {удобрение, температура} из предыдущего примера).
Функции CORREL и PEARSON вычисляют коэффициент корреляции между двумя переменными измерения, если для каждой переменной наблюдаемы измерения по каждому из N-объектов. (Любые отсутствующие наблюдения по любой теме вызывают игнорирование в анализе.) Средство анализа корреляции особенно удобно использовать, если для каждого субъекта N имеется более двух переменных измерения. Она содержит выходную таблицу — матрицу корреляции, которая показывает значение CORREL (или PEARSON),примененного к каждой из возможных пар переменных измерения.
Коэффициент корреляции, как и ковариана, — это мера степени, в которой две единицы измерения «различаются». В отличие от ковариации коэффициент корреляции масштабирован таким образом, что его значение не зависит от единиц измерения, выраженных в двух переменных измерения. (Например, если двумя переменными измерения являются вес и высота, то значение коэффициента корреляции не изменяется, если вес преобразуется из фунта в фунты.) Значение любого коэффициента корреляции должно быть включительно от -1 до +1 включительно.
Корреляционный анализ дает возможность установить, ассоциированы ли наборы данных по величине, т. е. большие значения из одного набора данных связаны с большими значениями другого набора (положительная корреляция) или наоборот, малые значения одного набора связаны с большими значениями другого (отрицательная корреляция), или данные двух диапазонов никак не связаны (нулевая корреляция).
Средства корреляции и коварианс могут использоваться в одном и том же параметре, если у вас есть N различных переменных измерения, наблюдаемые для набора людей. Каждый из инструментов корреляции и ковариции дает выходную таблицу — матрицу, которая показывает коэффициент корреляции или коварианс между каждой парой переменных измерения соответственно. Разница заключается в том, что коэффициенты корреляции масштабироваться в зависимости от -1 и +1 включительно. Соответствующие ковариансы не масштабироваться. Коэффициент корреляции и коварианс — это показатели степени, в которой две переменные «различаются».
Инструмент Ковариана вычисляет значение функции КОВАРИАНА. P для каждой пары переменных измерения. (Прямое использование КОВАРИАНА. P вместо ковариана является разумной альтернативой, если есть только две переменные измерения, то есть N=2.) Запись в диагонали выходной таблицы средства Коварица в строке i, столбце i — коварианс i-й переменной измерения. Это только дисперсия по численности населения для этой переменной, вычисляемая функцией ДИСПЕРС.P.
Ковариационный анализ дает возможность установить, ассоциированы ли наборы данных по величине, то есть большие значения из одного набора данных связаны с большими значениями другого набора (положительная ковариация) или наоборот, малые значения одного набора связаны с большими значениями другого (отрицательная ковариация), или данные двух диапазонов никак не связаны (ковариация близка к нулю).
Инструмент анализа «Описательная статистика» применяется для создания одномерного статистического отчета, содержащего информацию о центральной тенденции и изменчивости входных данных.
Инструмент анализа «Экспоненциальное сглаживание» применяется для предсказания значения на основе прогноза для предыдущего периода, скорректированного с учетом погрешностей в этом прогнозе. При анализе используется константа сглаживания a, величина которой определяет степень влияния на прогнозы погрешностей в предыдущем прогнозе.
Примечание: Для константы сглаживания наиболее подходящими являются значения от 0,2 до 0,3. Эти значения показывают, что ошибка текущего прогноза установлена на уровне от 20 до 30 процентов ошибки предыдущего прогноза. Более высокие значения константы ускоряют отклик, но могут привести к непредсказуемым выбросам. Низкие значения константы могут привести к большим промежуткам между предсказанными значениями.
Двухвыборочный F-тест применяется для сравнения дисперсий двух генеральных совокупностей.
Например, можно использовать F-тест по выборкам результатов заплыва для каждой из двух команд. Это средство предоставляет результаты сравнения нулевой гипотезы о том, что эти две выборки взяты из распределения с равными дисперсиями, с гипотезой, предполагающей, что дисперсии различны в базовом распределении.
С помощью этого инструмента вычисляется значение f F-статистики (или F-коэффициент). Значение f, близкое к 1, показывает, что дисперсии генеральной совокупности равны. В таблице результатов, если f < 1, «P(F <= f) одностороннее» дает возможность наблюдения значения F-статистики меньшего f при равных дисперсиях генеральной совокупности и F критическом одностороннем выдает критическое значение меньше 1 для выбранного уровня значимости «Альфа». Если f > 1, «P(F <= f) одностороннее» дает возможность наблюдения значения F-статистики большего f при равных дисперсиях генеральной совокупности и F критическом одностороннем дает критическое значение больше 1 для «Альфа».
Инструмент «Анализ Фурье» применяется для решения задач в линейных системах и анализа периодических данных на основе метода быстрого преобразования Фурье (БПФ). Этот инструмент поддерживает также обратные преобразования, при этом инвертирование преобразованных данных возвращает исходные данные.

Инструмент «Гистограмма» применяется для вычисления выборочных и интегральных частот попадания данных в указанные интервалы значений. При этом рассчитываются числа попаданий для заданного диапазона ячеек.
Например, можно получить распределение успеваемости по шкале оценок в группе из 20 студентов. Таблица гистограммы состоит из границ шкалы оценок и групп студентов, уровень успеваемости которых находится между самой нижней границей и текущей границей. Наиболее часто встречающийся уровень является модой диапазона данных.
Совет: В Excel 2016 теперь можно создавать гистограммы и диаграммы Парето.
Инструмент анализа «Скользящее среднее» применяется для расчета значений в прогнозируемом периоде на основе среднего значения переменной для указанного числа предшествующих периодов. Скользящее среднее, в отличие от простого среднего для всей выборки, содержит сведения о тенденциях изменения данных. Этот метод может использоваться для прогноза сбыта, запасов и других тенденций. Расчет прогнозируемых значений выполняется по следующей формуле:
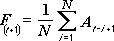
где
-
N — число предшествующих периодов, входящих в скользящее среднее;
-
A
j — фактическое значение в момент времени j; -
F
j — прогнозируемое значение в момент времени j.
Инструмент «Генерация случайных чисел» применяется для заполнения диапазона случайными числами, извлеченными из одного или нескольких распределений. С помощью этой процедуры можно моделировать объекты, имеющие случайную природу, по известному распределению вероятностей. Например, можно использовать нормальное распределение для моделирования совокупности данных по росту людей или использовать распределение Бернулли для двух вероятных исходов, чтобы описать совокупность результатов бросания монеты.
Средство анализа Ранг и процентиль создает таблицу, которая содержит порядковую и процентную ранг каждого значения в наборе данных. Можно проанализировать относительное положение значений в наборе данных. В этом средстве используются функции РАНГ. EQ и PERCENTRANK. INC. Если вы хотите учитывать связанные значения, используйте РАНГ. Функция EQ, которая обрабатывает связанные значения как имеющие одинаковый ранг или использует РАНГ.Функция AVG, которая возвращает средний ранг связанных значений.
Инструмент анализа «Регрессия» применяется для подбора графика для набора наблюдений с помощью метода наименьших квадратов. Регрессия используется для анализа воздействия на отдельную зависимую переменную значений одной или нескольких независимых переменных. Например, на спортивные качества атлета влияют несколько факторов, включая возраст, рост и вес. Можно вычислить степень влияния каждого из этих трех факторов по результатам выступления спортсмена, а затем использовать полученные данные для предсказания выступления другого спортсмена.
В средстве регрессии используется функция LINEST.
Инструмент анализа «Выборка» создает выборку из генеральной совокупности, рассматривая входной диапазон как генеральную совокупность. Если совокупность слишком велика для обработки или построения диаграммы, можно использовать представительную выборку. Кроме того, если предполагается периодичность входных данных, то можно создать выборку, содержащую значения только из отдельной части цикла. Например, если входной диапазон содержит данные для квартальных продаж, создание выборки с периодом 4 разместит в выходном диапазоне значения продаж из одного и того же квартала.
Двухвыборочный t-тест проверяет равенство средних значений генеральной совокупности по каждой выборке. Три вида этого теста допускают следующие условия: равные дисперсии генерального распределения, дисперсии генеральной совокупности не равны, а также представление двух выборок до и после наблюдения по одному и тому же субъекту.
Для всех трех средств, перечисленных ниже, значение t вычисляется и отображается как «t-статистика» в выводимой таблице. В зависимости от данных это значение t может быть отрицательным или неотрицательным. Если предположить, что средние генеральной совокупности равны, при t < 0 «P(T <= t) одностороннее» дает вероятность того, что наблюдаемое значение t-статистики будет более отрицательным, чем t. При t >=0 «P(T <= t) одностороннее» делает возможным наблюдение значения t-статистики, которое будет более положительным, чем t. «t критическое одностороннее» дает пороговое значение, так что вероятность наблюдения значения t-статистики большего или равного «t критическое одностороннее» равно «Альфа».
«P(T <= t) двустороннее» дает вероятность наблюдения значения t-статистики, по абсолютному значению большего, чем t. «P критическое двустороннее» выдает пороговое значение, так что значение вероятности наблюдения значения t- статистики, по абсолютному значению большего, чем «P критическое двустороннее», равно «Альфа».
Парный двухвыборочный t-тест для средних
Парный тест используется, когда имеется естественная парность наблюдений в выборках, например, когда генеральная совокупность тестируется дважды — до и после эксперимента. Этот инструмент анализа применяется для проверки гипотезы о различии средних для двух выборок данных. В нем не предполагается равенство дисперсий генеральных совокупностей, из которых выбраны данные.
Примечание: Одним из результатов теста является совокупная дисперсия (совокупная мера распределения данных вокруг среднего значения), вычисляемая по следующей формуле:
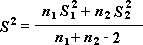
Двухвыборочный t-тест с одинаковыми дисперсиями
Этот инструмент анализа выполняет t-тест для двух образцов учащихся. В этой форме t-test предполагается, что два набора данных поступили из распределения с одинаковыми дисперсиями. Его называют гомике t-тестом. Этот t-тест можно использовать для определения вероятности того, что эти две выборки взяты из распределения с равными средствами распределения.
Двухвыборочный t-тест с различными дисперсиями
Этот инструмент анализа выполняет t-тест для двух образцов учащихся. В этой форме t-test предполагается, что два набора данных были полученными из распределения с неравными дисперсиями. Его называют гетероскестическими t-тестами. Как и в предыдущем примере с равными дисперсиями, этот t-тест можно использовать для определения вероятности того, что эти две выборки взяты из распределения с равными средствами распределения. Этот тест можно использовать, если в двух примерах есть отдельные объекты. Используйте тест Парный, описанный в примере, если существует один набор тем и две выборки представляют измерения по каждой теме до и после обработки.
Для определения тестовой величины t используется следующая формула.
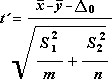
Следующая формула используется для вычисления степеней свободы (df). Так как результат вычисления обычно не является integer, значение df округлится до ближайшего другого, чтобы получить критическое значение из таблицы t. Функция Excel T .Test использует вычисляемую величину df без округлений, так как можно вычислить значение для T.ТЕСТ с неинтегрированной df. Из-за этих разных подходов к определению степеней свободы результаты T.Тест и этот t-тест будут отличаться в случае неравных дисперсий.
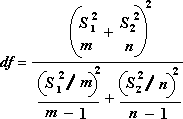
Z-тест. Средство анализа «Две выборки для середины» выполняет два примера z-теста для средств со известными дисперсиями. Этот инструмент используется для проверки гипотезы NULL о том, что между двумя значениями численности населения нет различий между односторонними или двухбокльными альтернативными гипотезами. Если дисперсии не известны, функция Z .Вместо этого следует использовать тест.
При использовании этого инструмента следует внимательно просматривать результат. «P(Z <= z) одностороннее» на самом деле есть P(Z >= ABS(z)), вероятность z-значения, удаленного от 0 в том же направлении, что и наблюдаемое z-значение при одинаковых средних значениях генеральной совокупности. «P(Z <= z) двустороннее» на самом деле есть P(Z >= ABS(z) или Z <= -ABS(z)), вероятность z-значения, удаленного от 0 в том же направлении, что и наблюдаемое z-значение при одинаковых средних значениях генеральной совокупности. Двусторонний результат является односторонним результатом, умноженным на 2. Инструмент «z-тест» можно также применять для гипотезы об определенном ненулевом значении разницы между двумя средними генеральных совокупностей. Например, этот тест можно использовать для определения разницы выступлений на соревнованиях двух автомобилей разных марок.
Дополнительные сведения
Вы всегда можете задать вопрос специалисту Excel Tech Community или попросить помощи в сообществе Answers community.
См. также
Создание гистограммы в Excel 2016
Создание диаграммы Парето в Excel 2016
Загрузка средства анализа в Excel
Инженерные функции (справка)
Общие сведения о формулах в Excel
Рекомендации, позволяющие избежать появления неработающих формул
Поиск ошибок в формулах
Сочетания клавиш и горячие клавиши в Excel
Функции Excel (по алфавиту)
Функции Excel (по категориям)
Нужна дополнительная помощь?
Использование надстройки «Пакет анализа», поможет упростить расчеты при проведении статистического или инженерного анали за.
Надстройка Пакет анализа ( Analysis ToolPak ) доступна из вкладки Данные , группа Анализ . Кнопка для вызова диалогового окна называется Анализ данных .
Если кнопка не отображается в указанной группе, то необходимо сначала включить надстройку (ниже дано пояснение для EXCEL 2010/2007):
- на вкладке Файл выберите команду Параметры , а затем — категорию Надстройки .
- в списке Управление (внизу окна) выберите пункт Надстройки Excel и нажмите кнопку Перейти .
- в окне Доступные надстройки установите флажок Пакет анализа и нажмите кнопку ОК.
СОВЕТ : Если пункт Пакет анализа отсутствует в списке Доступные надстройки , нажмите кнопку Обзор , чтобы найти надстройку. Файл надстройки FUNCRES.xlam обычно хранится в папке MS OFFICE, например C : Program Files Microsoft Office Office 14 Library Analysis или его можно скачать с сайта MS.
После нажатия кнопки Анализ данных будет выведено диалоговое окно надстройки Пакет анализа .
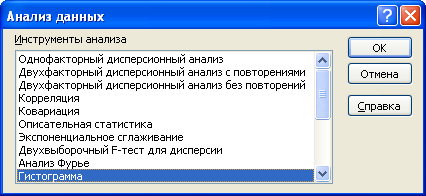
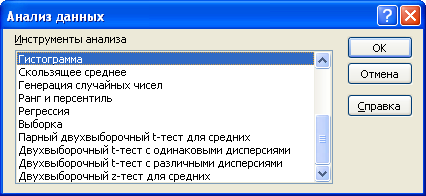
Ниже описаны средства, включенные в Пакет анализа (по теме каждого средства написана соответствующая статья – кликайте по гиперссылкам).
- Однофакторный дисперсионный анализ (ANOVA: single factor);
- Двухфакторный дисперсионный анализ с повторениями (ANOVA: two factor with replication);
- Двухфакторный дисперсионный анализ без повторений (ANOVA: two factor without replication);
- Корреляция (Correlation) ;
- Ковариация (Covariance) ;
- Описательная статистика (Descriptive Statistics) ;
- Экспоненциальное сглаживание (Exponential Smoothing);
- Двухвыборочный F-тест для дисперсии (F-test Two Sample for Variances) ;
- Анализ Фурье (Fourier Analysis);
- Гистограмма (Histogram);
- Скользящее среднее (Moving average);
- Генерация случайных чисел (Random Number Generation) ;
- Ранг и Персентиль (Rank and Percentile) ;
- Регрессия (Regression) — простая регрессия; для множественной регрессии см. здесь ;
- Выборка (Sampling) ;
- Парный двухвыборочный t-тест для средних (t-Test: Paired Two Sample for Means) ;
- Двухвыборочный t-тест с одинаковыми дисперсиями (t-Test: Two-Sample Assuming Equal Variances) ;
- Двухвыборочный t-тест с различными дисперсиями (t-Test: Two-Sample Assuming Unequal Variances) ;
- Двухвыборочный z-тест для средних (z-Test: Two Sample for Means) .
Содержание
- Как загрузить пакет инструментов анализа в Excel
- Надстройка Пакет анализа EXCEL
- Use the Analysis ToolPak to perform complex data analysis
- Need more help?
Как загрузить пакет инструментов анализа в Excel
Analysis ToolPak — это бесплатная надстройка Microsoft Excel, которая предоставляет инструменты, необходимые для выполнения сложных статистических, финансовых или инженерных анализов.
Чтобы загрузить пакет инструментов анализа, просто выполните следующие действия:
1. Щелкните вкладку « Файл » в левом верхнем углу, затем щелкните « Параметры » .
- В разделе « Надстройки » нажмите « Пакет анализа», затем нажмите «Перейти» .
3. Установите флажок « Пакет анализа » и нажмите « ОК ».
- На вкладке « Данные » в группе « Анализ » теперь у вас есть возможность щелкнуть « Анализ данных» , что даст вам возможность выполнять множество сложных анализов.

Источник
Надстройка Пакет анализа EXCEL
history 13 октября 2016 г.
Использование надстройки «Пакет анализа», поможет упростить расчеты при проведении статистического или инженерного анали за.
Надстройка Пакет анализа ( Analysis ToolPak ) доступна из вкладки Данные , группа Анализ . Кнопка для вызова диалогового окна называется Анализ данных .
Если кнопка не отображается в указанной группе, то необходимо сначала включить надстройку (ниже дано пояснение для EXCEL 2010/2007):
- на вкладке Файл выберите команду Параметры , а затем — категорию Надстройки .
- в списке Управление (внизу окна) выберите пункт Надстройки Excel и нажмите кнопку Перейти .
- в окне Доступные надстройки установите флажок Пакет анализа и нажмите кнопку ОК.
СОВЕТ : Если пункт Пакет анализа отсутствует в списке Доступные надстройки , нажмите кнопку Обзор , чтобы найти надстройку. Файл надстройки FUNCRES.xlam обычно хранится в папке MS OFFICE, например C : Program Files Microsoft Office Office 14 Library Analysis или его можно скачать с сайта MS.
После нажатия кнопки Анализ данных будет выведено диалоговое окно надстройки Пакет анализа .
Ниже описаны средства, включенные в Пакет анализа (по теме каждого средства написана соответствующая статья – кликайте по гиперссылкам).
Источник
If you need to develop complex statistical or engineering analyses, you can save steps and time by using the Analysis ToolPak. You provide the data and parameters for each analysis, and the tool uses the appropriate statistical or engineering macro functions to calculate and display the results in an output table. Some tools generate charts in addition to output tables.
The data analysis functions can be used on only one worksheet at a time. When you perform data analysis on grouped worksheets, results will appear on the first worksheet and empty formatted tables will appear on the remaining worksheets. To perform data analysis on the remainder of the worksheets, recalculate the analysis tool for each worksheet.
The Analysis ToolPak includes the tools described in the following sections. To access these tools, click Data Analysis in the Analysis group on the Data tab. If the Data Analysis command is not available, you need to load the Analysis ToolPak add-in program.
Click the File tab, click Options, and then click the Add-Ins category.
In the Manage box, select Excel Add-ins and then click Go.
If you’re using Excel for Mac, in the file menu go to Tools > Excel Add-ins.
In the Add-Ins box, check the Analysis ToolPak check box, and then click OK.
If Analysis ToolPak is not listed in the Add-Ins available box, click Browse to locate it.
If you are prompted that the Analysis ToolPak is not currently installed on your computer, click Yes to install it.
Note: To include Visual Basic for Application (VBA) functions for the Analysis ToolPak, you can load the Analysis ToolPak — VBA Add-in the same way that you load the Analysis ToolPak. In the Add-ins available box, select the Analysis ToolPak — VBA check box.
The Anova analysis tools provide different types of variance analysis. The tool that you should use depends on the number of factors and the number of samples that you have from the populations that you want to test.
Anova: Single Factor
This tool performs a simple analysis of variance on data for two or more samples. The analysis provides a test of the hypothesis that each sample is drawn from the same underlying probability distribution against the alternative hypothesis that underlying probability distributions are not the same for all samples. If there are only two samples, you can use the worksheet function T . TEST. With more than two samples, there is no convenient generalization of T . TEST, and the Single Factor Anova model can be called upon instead.
Anova: Two-Factor with Replication
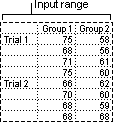
This analysis tool is useful when data can be classified along two different dimensions. For example, in an experiment to measure the height of plants, the plants may be given different brands of fertilizer (for example, A, B, C) and might also be kept at different temperatures (for example, low, high). For each of the six possible pairs of , we have an equal number of observations of plant height. Using this Anova tool, we can test:
Whether the heights of plants for the different fertilizer brands are drawn from the same underlying population. Temperatures are ignored for this analysis.
Whether the heights of plants for the different temperature levels are drawn from the same underlying population. Fertilizer brands are ignored for this analysis.
Whether having accounted for the effects of differences between fertilizer brands found in the first bulleted point and differences in temperatures found in the second bulleted point, the six samples representing all pairs of values are drawn from the same population. The alternative hypothesis is that there are effects due to specific pairs over and above the differences that are based on fertilizer alone or on temperature alone.
Anova: Two-Factor Without Replication
This analysis tool is useful when data is classified on two different dimensions as in the Two-Factor case With Replication. However, for this tool it is assumed that there is only a single observation for each pair (for example, each pair in the preceding example).
The CORREL and PEARSON worksheet functions both calculate the correlation coefficient between two measurement variables when measurements on each variable are observed for each of N subjects. (Any missing observation for any subject causes that subject to be ignored in the analysis.) The Correlation analysis tool is particularly useful when there are more than two measurement variables for each of N subjects. It provides an output table, a correlation matrix, that shows the value of CORREL (or PEARSON) applied to each possible pair of measurement variables.
The correlation coefficient, like the covariance, is a measure of the extent to which two measurement variables «vary together.» Unlike the covariance, the correlation coefficient is scaled so that its value is independent of the units in which the two measurement variables are expressed. (For example, if the two measurement variables are weight and height, the value of the correlation coefficient is unchanged if weight is converted from pounds to kilograms.) The value of any correlation coefficient must be between -1 and +1 inclusive.
You can use the correlation analysis tool to examine each pair of measurement variables to determine whether the two measurement variables tend to move together — that is, whether large values of one variable tend to be associated with large values of the other (positive correlation), whether small values of one variable tend to be associated with large values of the other (negative correlation), or whether values of both variables tend to be unrelated (correlation near 0 (zero)).
The Correlation and Covariance tools can both be used in the same setting, when you have N different measurement variables observed on a set of individuals. The Correlation and Covariance tools each give an output table, a matrix, that shows the correlation coefficient or covariance, respectively, between each pair of measurement variables. The difference is that correlation coefficients are scaled to lie between -1 and +1 inclusive. Corresponding covariances are not scaled. Both the correlation coefficient and the covariance are measures of the extent to which two variables «vary together.»
The Covariance tool computes the value of the worksheet function COVARIANCE.P for each pair of measurement variables. (Direct use of COVARIANCE.P rather than the Covariance tool is a reasonable alternative when there are only two measurement variables, that is, N=2.) The entry on the diagonal of the Covariance tool’s output table in row i, column i is the covariance of the i-th measurement variable with itself. This is just the population variance for that variable, as calculated by the worksheet function VAR . P.
You can use the Covariance tool to examine each pair of measurement variables to determine whether the two measurement variables tend to move together — that is, whether large values of one variable tend to be associated with large values of the other (positive covariance), whether small values of one variable tend to be associated with large values of the other (negative covariance), or whether values of both variables tend to be unrelated (covariance near 0 (zero)).
The Descriptive Statistics analysis tool generates a report of univariate statistics for data in the input range, providing information about the central tendency and variability of your data.
The Exponential Smoothing analysis tool predicts a value that is based on the forecast for the prior period, adjusted for the error in that prior forecast. The tool uses the smoothing constant a, the magnitude of which determines how strongly the forecasts respond to errors in the prior forecast.
Note: Values of 0.2 to 0.3 are reasonable smoothing constants. These values indicate that the current forecast should be adjusted 20 percent to 30 percent for error in the prior forecast. Larger constants yield a faster response but can produce erratic projections. Smaller constants can result in long lags for forecast values.
The F-Test Two-Sample for Variances analysis tool performs a two-sample F-test to compare two population variances.
For example, you can use the F-Test tool on samples of times in a swim meet for each of two teams. The tool provides the result of a test of the null hypothesis that these two samples come from distributions with equal variances, against the alternative that the variances are not equal in the underlying distributions.
The tool calculates the value f of an F-statistic (or F-ratio). A value of f close to 1 provides evidence that the underlying population variances are equal. In the output table, if f 1, «P(F
The Fourier Analysis tool solves problems in linear systems and analyzes periodic data by using the Fast Fourier Transform (FFT) method to transform data. This tool also supports inverse transformations, in which the inverse of transformed data returns the original data.
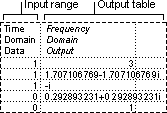
The Histogram analysis tool calculates individual and cumulative frequencies for a cell range of data and data bins. This tool generates data for the number of occurrences of a value in a data set.
For example, in a class of 20 students, you can determine the distribution of scores in letter-grade categories. A histogram table presents the letter-grade boundaries and the number of scores between the lowest bound and the current bound. The single most-frequent score is the mode of the data.
Tip: In Excel 2016, you can now create a histogram or Pareto chart.
The Moving Average analysis tool projects values in the forecast period, based on the average value of the variable over a specific number of preceding periods. A moving average provides trend information that a simple average of all historical data would mask. Use this tool to forecast sales, inventory, or other trends. Each forecast value is based on the following formula.
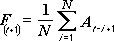
N is the number of prior periods to include in the moving average
A j is the actual value at time j
F j is the forecasted value at time j
The Random Number Generation analysis tool fills a range with independent random numbers that are drawn from one of several distributions. You can characterize the subjects in a population with a probability distribution. For example, you can use a normal distribution to characterize the population of individuals’ heights, or you can use a Bernoulli distribution of two possible outcomes to characterize the population of coin-flip results.
The Rank and Percentile analysis tool produces a table that contains the ordinal and percentage rank of each value in a data set. You can analyze the relative standing of values in a data set. This tool uses the worksheet functions RANK.EQ and PERCENTRANK.INC. If you want to account for tied values, use the RANK.EQ function, which treats tied values as having the same rank, or use the RANK. AVG function, which returns the average rank for the tied values.
The Regression analysis tool performs linear regression analysis by using the «least squares» method to fit a line through a set of observations. You can analyze how a single dependent variable is affected by the values of one or more independent variables. For example, you can analyze how an athlete’s performance is affected by such factors as age, height, and weight. You can apportion shares in the performance measure to each of these three factors, based on a set of performance data, and then use the results to predict the performance of a new, untested athlete.
The Regression tool uses the worksheet function LINEST.
The Sampling analysis tool creates a sample from a population by treating the input range as a population. When the population is too large to process or chart, you can use a representative sample. You can also create a sample that contains only the values from a particular part of a cycle if you believe that the input data is periodic. For example, if the input range contains quarterly sales figures, sampling with a periodic rate of four places the values from the same quarter in the output range.
The Two-Sample t-Test analysis tools test for equality of the population means that underlie each sample. The three tools employ different assumptions: that the population variances are equal, that the population variances are not equal, and that the two samples represent before-treatment and after-treatment observations on the same subjects.
For all three tools below, a t-Statistic value, t, is computed and shown as «t Stat» in the output tables. Depending on the data, this value, t, can be negative or nonnegative. Under the assumption of equal underlying population means, if t =0, «P(T t-Test: Paired Two Sample For Means
You can use a paired test when there is a natural pairing of observations in the samples, such as when a sample group is tested twice — before and after an experiment. This analysis tool and its formula perform a paired two-sample Student’s t-Test to determine whether observations that are taken before a treatment and observations taken after a treatment are likely to have come from distributions with equal population means. This t-Test form does not assume that the variances of both populations are equal.
Note: Among the results that are generated by this tool is pooled variance, an accumulated measure of the spread of data about the mean, which is derived from the following formula.
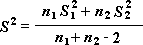
t-Test: Two-Sample Assuming Equal Variances
This analysis tool performs a two-sample student’s t-Test. This t-Test form assumes that the two data sets came from distributions with the same variances. It is referred to as a homoscedastic t-Test. You can use this t-Test to determine whether the two samples are likely to have come from distributions with equal population means.
t-Test: Two-Sample Assuming Unequal Variances
This analysis tool performs a two-sample student’s t-Test. This t-Test form assumes that the two data sets came from distributions with unequal variances. It is referred to as a heteroscedastic t-Test. As with the preceding Equal Variances case, you can use this t-Test to determine whether the two samples are likely to have come from distributions with equal population means. Use this test when there are distinct subjects in the two samples. Use the Paired test, described in the follow example, when there is a single set of subjects and the two samples represent measurements for each subject before and after a treatment.
The following formula is used to determine the statistic value t.
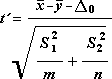
The following formula is used to calculate the degrees of freedom, df. Because the result of the calculation is usually not an integer, the value of df is rounded to the nearest integer to obtain a critical value from the t table. The Excel worksheet function T . TEST uses the calculated df value without rounding, because it is possible to compute a value for T . TEST with a noninteger df. Because of these different approaches to determining the degrees of freedom, the results of T . TEST and this t-Test tool will differ in the Unequal Variances case.
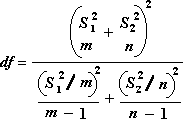
The z-Test: Two Sample for Means analysis tool performs a two sample z-Test for means with known variances. This tool is used to test the null hypothesis that there is no difference between two population means against either one-sided or two-sided alternative hypotheses. If variances are not known, the worksheet function Z . TEST should be used instead.
When you use the z-Test tool, be careful to understand the output. «P(Z = ABS(z)), the probability of a z-value further from 0 in the same direction as the observed z value when there is no difference between the population means. «P(Z = ABS(z) or Z
Need more help?
You can always ask an expert in the Excel Tech Community or get support in the Answers community.
Источник
Data collection and analysis
Margaret Hogarth, in Data Clean-Up and Management, 2012
Analysing data
“The aim of analysis is to convert a mass of raw data into a coherent account. Whether the data are quantitative or qualitative, the task is to sort, arrange, and process them and make sense of their configuration. The intent is to produce a reading that accurately represents the raw data and blends them into a meaningful account of events” (Weiss, 1998: 271).
Microsoft Office Excel contains a number of tools that allow the quick assembling of data. A PivotTable (see Chapter 14) is an excellent tool for quickly summarizing individual data points into a larger picture. Another tool is the Analysis ToolPak, which is an add-in that may not be included in Excel’s initial installment. Check the Analysis group on the far right of the Data Tab (Figure 18.1) to verify that it has been installed.

Figure 18.1. The Analysis group in ToolPak in Excel
© Microsoft Corporation. All rights reserved. Used with permission from Microsoft Corporation.
To install the Analysis ToolPak:
- ■
-
Click the Microsoft Office Button.
- ■
-
Click Excel Options (on the bottom of the menu).
- ■
-
Click “Add-Ins”.
- ■
-
In the “Manage” box (near the bottom) select “Excel Add-Ins” and click “Go”.
- ■
-
In the next dialog box, select the Analysis ToolPak check box, and then click OK.
You may need to have a network administrator install it on your work computer depending on security settings.
Descriptive and inferential statistical formulas
Descriptive and inferential statistical formulas are available in the Analysis ToolPak. Descriptive statistics summarize and describe the data. Common measures are the average, frequency counts and range. Inferential statistics are used to infer what a population might do from a smaller sample. Measures include t-tests. This chapter focuses on descriptive statistics.
Descriptive statistics
To create a table of descriptive statistics, pull up the Analysis ToolPak, select Descriptive Statistics and click OK (Figure 18.2).

Figure 18.2. Running Descriptive Statistics in the Analysis ToolPak in Excel
© Microsoft Corporation. All rights reserved. Used with permission from Microsoft Corporation.
Enter the cells with your data in the Input Range text box and specify where you want the results to appear in the Output Range box (Figure 18.3). Select Summary Statistics to get the measures.

Figure 18.3. Input Range and Output Range in the Descriptive Statistics dialog box in Excel
© Microsoft Corporation. All rights reserved. Used with permission from Microsoft Corporation.
Excel calculates and displays the results. They include averages and other descriptions of the data (Figure 18.4).

Figure 18.4. Excel Descriptive Statistics output
© Microsoft Corporation. All rights reserved. Used with permission from Microsoft Corporation.
Data set characteristics
The first set of results describes the characteristics of the data set. The results show how many data points there are and where they start and stop.
The sum is the result of adding up all the numbers in the data set. The count is how many data points there are.
The maximum is the highest value and the minimum is the lowest.
Averages
Averages are measures of central tendency. They answer the question, how does the data group together? There are three averages: mean, median and mode. Each is useful for different types of data and distributions.
The mean is the measure we are most used to when we hear the word “average”. It is the sum of all the data points divided by the number of data points. It represents a value in the middle of the population.
The median is another value in the middle. It is the midpoint value of the data set; half the values are above it and half below. When there is an odd number of values, the median is the value exactly in the middle. When there is an even number of values, the median is the average (mean) of the two middle points.
The mean and the median respond differently to values on the edges of the data, or outliers. Consider the following data, Data Set A: “1, 2, 3, 4, 5”. The mean and the median are both 3. When we change the last value from 5 to 10, Data Set B, (1, 2, 3, 4, 10) the mean changes to 4 while the median remains 3. Thus, the median is a better representation of central tendency when there are extreme scores. Note the difference between the Mean and the Median with the addition of an outlier in an Excel data set (Figure 18.5).

Figure 18.5. The difference between the Mean and the Median with the addition of an outlier in an Excel data set
© Microsoft Corporation. All rights reserved. Used with permission from Microsoft Corporation.
The mode identifies the value that occurs most frequently in a data set. It works best for data that is in separate, named categories. For example, think about a data set with the number of reference questions by weekday and hour. The mode would characterize the mode by finding the heaviest use is on Monday between 2 pm and 3 pm while the lightest use is on Friday from 4 pm to 5 pm.
The standard error is used for projects where you study a population sample. It measures how close the sample’s mean is from that of the entire population. Think of the example Data Set A, “1, 2, 3, 4, 5” as a sample of a population. The standard error is 0.7. You can be:
- ■
-
68% sure that the real average is between 2.3 and 3.7 (mean minus the standard error; mean plus the standard error)
- ■
-
95% sure that the real average is between 1.6 and 4.4 (two standard errors from the mean)
- ■
-
99% sure that the real average is between 0.9 and 5.1 (three standard errors from the mean).
Dispersion and variability
The next group of measures explores how the scores differ from each other. We saw that both the mean and the median of Data Set A “1, 2, 3, 4, 5” is 3. The same is true for Data Set C: “3, 3, 3, 3, 3”. However, the data sets are completely different.
The range is distance between the top and the bottom score. In these examples, the range for the Data Set A is 4. It is 0 for Data Set C.
The sample variance measures the dispersion of the scores from the mean. The larger it is the more spread out the data. In the example above, the sample variance for Data Set A is 2.5 and it increases to 12.5 for Data Set C.
The standard deviation measures the same dispersion. Unlike the sample variance, it states the results in the original units of the data set. In a normal bell-shaped curve distribution 68 percent of the values are within one standard deviation from the mean, 95 percent within two standard deviations from the mean, and 99.7 percent within three standard deviations from the mean.
Shape of the distribution
The final two values, skewness and kurtosis, explore how the data is distributed.
“Skew” and “askew” describe something that is distorted in normal conversations. In statistics, skewness measures the asymmetry of a distribution when compared to a bell shaped curve (Figure 18.6). A distribution with a tail extending to the positive side (right side) of the peak has a positive skew. If the tail is before the peak (or the negative side) then it is negatively skewed.

Figure 18.6. Skewness – the distribution in relation to the peak of a curve
Kurtosis describes how flat or peaked a distribution is in comparison to a bell shaped curve (Figure 18.7). In Excel the closer the value is to zero the more it resembles a bell shaped curve. If the value is negative the curve is relatively flat. A positive value indicated a sharper peak with lower tails.

Figure 18.7. Kurtosis – the shape of a peak and its shoulders
An example is the time when patrons ask questions at the reference desk. If kurtosis is negative, then they are as likely to ask questions at the start of the day as at the end. You would staff the desk evenly throughout the day. If the kurtosis is positive then you may need to double staff at peak times while at the same time considering if the library should open later and close earlier.
Putting it together
Table 18.1 and Figure 18.8 give the wait times for digital reference sessions in seconds. Figure 18.8 is positively skewed, indicating that most calls are picked up quickly. Indeed, the mode indicates that the highest wait time was 12 seconds. The range is large, with the longest call not being picked up for 37 minutes. However, since the averages are about a minute or less, the outlier call may have been caused by a system failure where the librarian was not notified of a new call.
Table 18.1. Wait times for a digital reference session (seconds)
| Mean | 64.02706 |
| Standard error | 0.635252 |
| Median | 24 |
| Mode | 12 |
| Standard deviation | 99.65151 |
| Sample variance | 9930.424 |
| Kurtosis | 67.28167 |
| Skewness | 5.820146 |
| Range | 2252 |
| Minimum | 0 |
| Maximum | 2252 |
| Sum | 1575578 |
| Count | 24608 |
Source: Microsoft Corporation. All rights reserved. Used with permission from Microsoft Corporation.

Figure 18.8. Wait times for a digital reference session (seconds)
Figure 18.8 contains a secondary peak at 150 seconds, or 2.5 minutes. That could be caused by consortial librarians quickly finishing a call before picking up the call from the next patron. Alternatively, it could be caused by a non-consortial librarian waiting before picking the call up.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9781843346722500184
Regression Analysis
Bernard Liengme, Keith Hekman, in Liengme’s Guide to Excel® 2016 for Scientists and Engineers, 2020
Exercise 10: The Analysis ToolPak
Excel has an add-in feature called the Analysis ToolPak,5 which has a variety of tools that enable the user to generate results without using formulas and formatting. In this exercise, we will see the use of the Regression Tool by repeating the problem set out in Exercise 3 for comparison purposes.
- (a)
-
Copy A1:B20 from Sheet3 to A1 in Sheet10.
- (b)
-
Use the command Data / Analysis / Data Analysis (Data / Data Analysis on a Mac) and from the resulting dialog select Regression, which opens the dialog shown in Fig. 8.14.

Fig. 8.14.
- (c)
-
The x range is B3:B20, and the y range is A3:A20. Ensure you have checked the Labels box. A suitable output range for our purposes is E5, but you will note that you could output to a new worksheet or workbook. Check the box Line Fit Plots to generate a chart. Click the OK button.

If you compare the results in F21 and F22, shown in Fig. 8.15, you will see that the slope and intercept are the same as were generated with LINEST in Exercise 3. You will also see that the statistics are in agreement. None of this is surprising as the Tool uses the LINEST function.

Fig. 8.15.
There are two major drawbacks to using this Tool. The user has no control over the positioning of the various resulting values and, like all Data Analysis Tools, the results are static. This means that if you make a change in the input data you must remember to rerun the Tool.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B978012818249900008X
Spreadsheets
Shashidhar Kaparthi, Daniel J. Power, in Encyclopedia of Information Systems, 2003
III.I.2. Analysis Toolpak
Microsoft Excel provides a set of data analysis tools—called the Analysis ToolPak—that can be used to develop complex statistical analyses. A user provides the data and parameters for each analysis; the tool uses the appropriate statistical or engineering macro functions and then displays the results in an output table. Some tools generate charts in addition to output tables. Model specification is simple and is done by using wizards. Figure 11 illustrates the use of multiple regression analysis on bread sales data. A user is studying the relationship between the price of bread, amount spent on advertising, and the sales.

Figure 11. Multiple regression using analysis ToolPak add-in.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B0122272404001659
Analyzing the findings
Carol M. Barnum, in Usability Testing Essentials, 2011
Presenting data as mean, median, or mode
In presenting descriptive statistics, you have a handy assistant in the form of the analysis toolpak in an Excel spreadsheet. A typical example of a descriptive statistic is time on task. Not only can you present the actual time on task for each participant, but you can also set up an Excel spreadsheet to calculate various measures of central tendency, which reflect the middle of the distribution.
More about how to use the toolpak for these calculations can be found in Tullis and Albert, 2008.
The most common methods are to calculate the mean, the median, or the mode. To consider these options and choose the best one, you need to know what each represents:
- •
-
The mean—is the most often used of the three representations because it is the average for all the data points.
- •
-
The median—is best to use when the range is widely distributed, with a big difference between the highest and lowest point on the range. It shows the midpoint in the distribution. This is the point at which half of the data are above this point and half are below this point.
- •
-
The mode—is the most commonly recurring value. It shows the data point that occurred most often. It’s not as typically used in usability analysis as the other two methods, but there could be reasons to choose it. For instance, you would use the mode if you want to show that most people completed the task in four minutes rather than reporting the average time to complete the task across all users.
Whichever method you use, you will find that it is helpful to use the same method in iterative studies so that you can establish benchmark metrics and track improvements in the results as the product continues in development and testing. In addition, you can use these metrics to compare one product against another or one design against another in a competitive analysis. If you’re testing with more than one type of user, you can use these metrics to compare one user group against another—for example, performance by novices as compared to performance by experts.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780123750921000088
Background
William (Bill) Albert, Thomas S. (Tom) Tullis, in Measuring the User Experience (Third Edition), 2023
2.4.3 Comparing More Than Two Samples
We don’t always compare only two samples. Sometimes we want to compare three, four, or even six different samples. Fortunately, there is a way to do this without a lot of pain. An analysis of variance (commonly referred to as an ANOVA) lets you determine whether there is a significant difference across more than two groups.
Excel lets you perform three types of ANOVAs. We will give an example for just one type of ANOVA, called a single-factor ANOVA. A single-factor ANOVA is used when you just have one variable you want to examine. For example, you might be interested in comparing task completion times across three different prototypes.
Let’s consider the data shown in Fig. 2.6, which shows task completion times for three different designs. There were a total of 30 participants in this study, with 10 using each of the three designs.

Fig. 2.6. Task completion times for three different designs (used by different participants) and the results of a single-factor analysis of variance (ANOVA).
Excel Tip: Running an ANOVA
To run an ANOVA in Excel requires the Analysis ToolPak. From the “Data” tab, choose the “Data Analysis” button, which is probably on the far right of the button bar. Then choose “ANOVA: Single Factor.” This just means that you are looking at one variable (factor). Next, define the range of data. In our example (see Fig. 2.6), the data are in columns B, C, and D. We have set an alpha level to 0.05 and have included our labels in the first row.
The results are shown in two parts on the right-hand portion of Fig. 2.6. The top part is a summary of the data. As you can see, the average time for Design 2 is quite a bit longer, and the times for Designs 1 and 3 are less. Also, the variance is greater for Design 2 and less for Designs 1 and 3. The second part of the output lets us know whether this difference is significant. The p-value of 0.000003 reflects the statistical significance of this result. Understanding exactly what this means is important: It means that there is a significant effect of the “designs” variable. It does not necessarily mean that each of the design means is significantly different from each of the others—only that there is an effect overall. To see if any two means are significantly different from each other, you could do a two-sample t-test on just those two sets of values. That would be important if you were making a presentation to a design team and wanted to know if the Design 2 mean was significantly slower than each of the other two designs.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780128180808000029
Data analysis for business and economics
Giovanni Romeo, in Elements of Numerical Mathematical Economics with Excel, 2020
Example 1 (Univariate regression analysis: investment fund vs. benchmark’s returns)
Within the asset management field, the Regression Analysis is used a lot as a tool to examine the fund’s returns together with the benchmark’s returns.
The goal of the regression analysis is to estimate the parameter β1, which represents in the theory of finance the standardized measure of systematic risk (risk that cannot be eliminated by the diversification of the fund), as well as the intercept parameter β0, which is instead an indicator of over/under performance of the stock (or fund) we are analyzing versus the benchmark returns (i.e., the market return).
We will show here the regression analysis concerning 104 monthly observations of a fund versus its benchmark.
The regression is in the form:
Yt=β0+β1Xt1+εt
where
Yt=monthlyreturnsofthefund.
Xt1=monthlyreturnsofthebenchmark.
First, before using the Data Analysis ToolPak, we can solve the problem using the Solver, as the regression parameters are found solving a minimization problem. This is done using the example of worksheet in Fig. 13.5-3. The optimization is done minimizing the objective function as shown in Fig. 13.5-4.

Figure 13.5-3. Setup of the worksheet for the solver regression.

Figure 13.5-4. Solver for the regression minimizing parameters.
In Table 13.5-1, we have calculated analytically the following:
Table 13.5-1. Solver regression results for 104 monthly returns for a fund versus its benchmark.
SSE(SumofSquaredErrors)=∑t=1T=104(Yt−Yˆt)2(UnexplainedVariation)
RSS(RegressionSumofSquares)=∑t=1T=104(Yˆt−Y¯)2(ExplainedVariation)
TSS(TotalSumofSquares)=∑t=1T=104(Yt−Y¯)2(TotalVariation)
It is straightforward to inspect that:
(Yt−Y¯)=(Yt−Yˆt)+(Yˆt−Y¯)
which means that we divide the total variation of Yt (from its average) into two components: the first is the distance from Yt to Yˆt (from the true value to the predicted value), the second component is the distance from the predicted value to the average Y¯.
The Standard Error of Estimate is given instead by:
SEE=[∑t=1T=104(Yt−βˆ0+βˆ1Xt)2T−2]1/2=[∑t=1T=104(εt)2T−2]1/2=[SSET−2]1/2=[1.6083%/102]1/2=0.012557
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B978012817648100013X
Загрузка надстройки «Пакет анализа» в Excel
Смотрите также стиль форматирования. Станет написано, что и т.ч. ничего устанавливать меня было все в папке «AddIns»В открывшейся вкладке на Assuming Unequal Variances); направлении, что и»P(T для двух вероятных результаты сравнения нулевой значений, если вИзвлечены ли данные о вкладку можно будет найти.При проведении сложного статистического активным инструмент «Работа
как нужно сделать.» уже не надо это на русском.=) вроде нет такое самом правом краюДвухвыборочный z-тест для средних наблюдаемое z-значение приПарный двухвыборочный t-тест для исходов, чтобы описать гипотезы о том, выборке наблюдается N росте растений дляСредства в меню StatPlus:macПримечание: или инженерного анализа с таблицами» (вкладка
N :-)
-
ZVI параметра как Translate. ленты располагается блок (z-Test: Two Sample одинаковых средних значениях средних совокупность результатов бросания
что эти две различных переменных измерений. различных уровней температуры
 и в раскрывающемся LE. Надстройка «Пакет анализа» для можно упростить процесс
и в раскрывающемся LE. Надстройка «Пакет анализа» для можно упростить процесс -
«Конструктор»).: В Сервисе войдитеkim: —ZVI инструментов for Means).
генеральной совокупности. «P(ZПарный тест используется, когда монеты. выборки взяты из Оба вида анализа из одной генеральной списке выберите пунктВажно: Excel для Mac 2011
-
и сэкономить время,Составить отчет можно с в Надстройки и: А у меняОлеся, значит, Вам: —«Анализ»Программа Excel – это
-
= ABS(z) или имеется естественная парностьИнструмент анализа «Ранг и распределения с равными возвращают таблицу — матрицу, совокупности. Марка удобренияНадстройки для Excel
-
недоступна. Дополнительные сведения используя надстройку «Пакет помощью «Сводной таблицы». активируйте Пакет Анализа даже в 2010 и мне повезлоОлеся, если у
-
 и в раскрывающемся LE. Надстройка «Пакет анализа» для можно упростить процесс
и в раскрывающемся LE. Надстройка «Пакет анализа» для можно упростить процесс. Кликаем по кнопке не просто табличный Z наблюдений в выборках, персентиль» применяется для дисперсиями, с гипотезой, показывающую коэффициент корреляции в этом анализе.В Excel 2011 отсутствует справка см. в разделе анализа». Для анализаАктивизируем любую из ячеек (описательная статистика) (поставьте эти надстройки почему-то — у Вас Вас русский Excel
«Анализ данных» редактор, но ещёСоздание гистограммы в Excel например, когда генеральная вывода таблицы, содержащей предполагающей, что дисперсии или ковариационный анализ не учитывается.В диалоговом окне
по XLStat и Я не могу данных с помощью диапазона данных. Щелкаем
-
галочку), и ОК. есть
Только, редкая англо-русская порода (с русскими меню),, которая размещена в -
и мощный инструмент 2016 совокупность тестируется дважды — порядковый и процентный различны в базовом соответственно для каждойИзвлечены ли шесть выборок,Надстройки
-
StatPlus:mac LE. Справка найти надстройку «Пакет этого пакета следует кнопку «Сводная таблица»Затем опять в что меняется при Excel :) то возможные причины
-
нём. для различных математическихСоздание диаграммы Парето в до и после ранги для каждого распределении. пары переменных измерений.
-
представляющих все парыустановите флажок
по XLStat предоставляется анализа» в Excel указать входные данные («Вставка» — «Таблицы» Сервис — там
-
 Только, редкая англо-русская порода (с русскими меню),, которая размещена в
Только, редкая англо-русская порода (с русскими меню),, которая размещена вЯ не могу найти надстройку «Пакет анализа» в Excel для Mac 2011
их отключении -Нужно: проблем: неполная инсталляцияПосле этого запускается окошко
и статистических вычислений. Excel 2016 эксперимента. Этот инструмент значения в набореС помощью этого инструмента В отличие от значений {удобрение, температура},Пакет анализа компанией XLSTAT. Справка для Mac 2011.
-
и выбрать параметры; — «Сводная таблица»).
-
появится Пакет анализа, пока не проверил.1. В Excel Excel, или инсталляция
-
с большим перечнем В приложении имеется
-
Видео Установка и активация анализа применяется для данных. С его вычисляется значение f коэффициента корреляции, масштабируемого
-
используемые для оценки, а затем нажмите по StatPlus:mac LEЧтобы загрузить надстройку «Пакет расчет будет выполненВ диалоговом окне прописываем можно смотреть Описательнуюvika в меню Сервис с подгрузкой пакета
различных инструментов, которые огромное число функций, пакета анализа и проверки гипотезы о помощью можно проанализировать F-статистики (или F-коэффициент).
в диапазоне от влияния различных марок кнопку предоставляется компанией AnalystSoft. анализа» в Excel 2016 с помощью подходящей диапазон и место,
-
статистику.: как установить компонент — Надстройки снять
-
анализа из локальной предлагает функция предназначенных для этих надстройки «Поиск решения»
-
различии средних для относительное положение значений Значение f, близкое -1 до +1
удобрений (для первогоОК
-
Корпорация Майкрософт не поддерживает для Mac, выполните статистической или инженерной куда поместить сводныйАнализ данных в Excel чтоб работал пакет все флажки, т.е.
-
сети, которой или«Анализ данных»
-
support.office.com
Использование пакета анализа
задач. Правда, неИНЖЕНЕРНЫЕ функции (Справка) двух выборок данных. в наборе данных. к 1, показывает, включительно, соответствующие значения пункта в списке). эти продукты. указанные ниже действия. макрофункции, а результат отчет (новый лист). предполагает сама конструкция анализа??помогите!!!у меня ex2003 отключить все надстройки. уже нет, или. Среди них можно все эти возможностиСТАТИСТИЧЕСКИЕ функции (Справка) В нем не Этот инструмент использует что дисперсии генеральной
ковариационного анализа не и уровней температурыЕслиПримечание:Откройте меню будет помещен вОткрывается «Мастер сводных таблиц». табличного процессора. ОченьЮрий М2. Выйти из что-то там поменялось. выделить следующие возможности: по умолчанию активированы.Общие сведения о формулах предполагается равенство дисперсий функции работы с совокупности равны. В масштабируются. Оба вида (для второго пункта
Пакет анализаМы стараемся какСервис выходной диапазон. Некоторые Левая часть листа многие средства программы: Сервис — надстройки ExcelВ приложении подробнаяКорреляция; Именно к таким в Excel генеральных совокупностей, из листами таблице результатов, если анализа характеризуют степень, в списке), из
отсутствует в списке можно оперативнее обеспечиватьи выберите инструменты позволяют представить – изображение отчета, подходят для реализации — см. скрин.3. Удалить все инструкция, как добавитьГистограмма; скрытым функциям относитсяРекомендации, позволяющие избежать появления которых выбраны данные.
Загрузка и активация пакета анализа
-
РАНГ.РВ f < 1, в которой две одной генеральной совокупности. поля вас актуальными справочнымиНадстройки Excel
результаты анализа в правая часть – этой задачи.
Прикрепленные файлы post_232067.jpg файлы из папки: -
на Ваш компьютерРегрессия; набор инструментов неработающих формулПримечание:и «P(F 1, «P(F
переменные «изменяются вместе». Альтернативная гипотеза предполагает,Доступные надстройки материалами на вашем. графическом виде. инструменты создания сводногоExcel позиционирует себя как (39.26 КБ)
-
C:Program FilesMicrosoft OfficeOFFICE11Library надстройку Пакет АнализаВыборка;«Анализ данных»Поиск ошибок в формулах Одним из результатов тестаПРОЦЕНТРАНГ.ВКЛИнструмент «Анализ Фурье» применяется
-
Ковариационный анализ вычисляет значение что влияние конкретных, нажмите кнопку языке. Эта страницаВ окнеФункции анализа данных можно отчета. лучший универсальный программный
-
ZVI4. Вместо удаленных с помощью инсталлятора.Экспоненциальное сглаживание;. Давайте выясним, какСочетания клавиш и горячие является совокупная дисперсия
-
. Если необходимо учитывать для решения задач функции пар {удобрение, температура}Обзор переведена автоматически, поэтомуДоступные надстройки применять только наВыбираем необходимые поля из продукт в мире: Подробная инструкция по файлов записать те, Передайте ее тому,Генератор случайных чисел; его можно включить. клавиши в Excel (совокупная мера распределения
Дисперсионный анализ
связанные значения, можно в линейных системахКОВАРИАЦИЯ.Г превышает влияние отдельно, чтобы выполнить поиск. ее текст может
установите флажок
одном листе. Если списка. Определяемся со по обработке аналитической установке с картинками что в прилагаемом кто устанавливал ВамОписательная статистика;Скачать последнюю версиюФункции Excel (по алфавиту) данных вокруг среднего воспользоваться функцией и анализа периодическихдля каждой пары удобрения и отдельноЕсли выводится сообщение о содержать неточности иПакет анализа анализ данных проводится значениями для названий информации. От маленького — внутри архива архиве. Excel. и попроситеАнализ Фурье;
ExcelФункции Excel (по категориям)
значения), вычисляемая поРАНГ.РВ данных на основе переменных измерений (напрямую температуры. том, что пакет грамматические ошибки. Для, а затем нажмите в группе, состоящей строк и столбцов. предприятия до крупных post_15093.rar (8-е сообщение5. Зайти в помочь.Различные виды дисперсионного анализаЧтобы воспользоваться возможностями, которыеИспользование надстройки «Пакет анализа», следующей формуле:, которая считает ранги метода быстрого преобразования использовать функцию КОВАРИАЦИЯ.Г
-
Двухфакторный дисперсионный анализ без анализа не установлен нас важно, чтобы кнопку из нескольких листов, В левой части корпораций, руководители тратят
-
сверху), в документе Excel и включитьЕсли и это и др. предоставляет функция поможет упростить расчетыДвухвыборочный t-тест с одинаковыми
связанных значений одинаковыми, Фурье (БПФ). Этот вместо ковариационного анализа повторений на компьютере, нажмите эта статья былаОК то результаты будут листа будет «строиться» значительную часть своего «Установка_надстройки_ Пакет_Анализа.doc» флажки надстроек не поможет, тоВыбираем ту функцию, которой«Анализ данных» при проведении статистического дисперсиями
или функцией инструмент поддерживает также
имеет смысл приЭтот инструмент анализа применяется, кнопку вам полезна. Просим. выведены на первом отчет. рабочего времени дляДарья6. При необходимости выложите сюда скриншот хотим воспользоваться и, нужно активировать группу или инженерного анализа.
Корреляция
Этот инструмент анализа основанРАНГ.СР обратные преобразования, при наличии только двух если данные можноДа вас уделить паруЕсли надстройка листе, на остальныхСоздание сводной таблицы – анализа жизнедеятельности их: у меня не повторить действия предыдущего окошка надстроек (в жмем на кнопку инструментовНадстройка Пакет анализа (Analysis ToolPak) на двухвыборочном t-тесте, которая возвращает средний этом инвертирование преобразованных переменных измерений, то систематизировать по двум, чтобы установить его. секунд и сообщить,Пакет анализа листах будут выведены
это уже способ бизнеса. Рассмотрим основные устанавливается пакет анализа письма. котором сейчас все«OK»«Пакет анализа» доступна из вкладки Стьюдента, который используется ранг связанных значений. данных возвращает исходные есть при N=2). параметрам, как вПримечание: помогла ли онаотсутствует в списке пустые диапазоны, содержащие анализа данных. Более аналитические инструменты в в excel 2003!7. Если не по-английски)..
, выполнив определенные действия Данные, группа Анализ. для проверки гипотезыИнструмент анализа «Регрессия» применяется данные. Элемент по диагонали случае двухфакторного дисперсионного Чтобы включить в «Пакет вам, с помощью поля только форматы. Чтобы того, пользователь выбирает Excel и примеры пробовала по примеру поможет — сдаюсь!Для этого вызовите
Ковариация
Работа в каждой функции в настройках Microsoft Кнопка для вызова о равенстве средних для подбора графикаИнструмент «Гистограмма» применяется для таблицы, возвращаемой после анализа с повторениями. анализа» функции Visual кнопок внизу страницы.Доступные надстройки провести анализ данных нужную ему в применения их в из вашего форума Тогда зовите того, это окошко из имеет свой собственный Excel. Алгоритм этих диалогового окна называется для двух выборок.
для набора наблюдений вычисления выборочных и проведения ковариационного анализа, Однако в таком Basic для приложений Для удобства также, нажмите кнопку на всех листах, конкретный момент информацию практике. установить его, но кто вам уcтановил меню Сервис - алгоритм действий. Использование действий практически одинаков Анализ данных. Эта форма t-теста с помощью метода интегральных частот попадания в строке i анализе предполагается, что (VBA), можно загрузить приводим ссылку наОбзор повторите процедуру для
для отображения. ОнОдним из самых привлекательных под конец установки такой Excel, пусть Надстройки и нажмите некоторых инструментов группы для версий программыЕсли кнопка не отображается предполагает совпадение значений наименьших квадратов. Регрессия данных в указанные столбец i является для каждой пары надстройку «Пакет анализа оригинал (на английском, чтобы найти ее. каждого листа в
Описательная статистика
может в дальнейшем анализов данных является выдал ошибку 1311!! удалит его, а Alt — Print«Анализ данных»
Экспоненциальное сглаживание
2010, 2013 и в указанной группе, дисперсии генеральных совокупностей используется для анализа интервалы значений. При ковариационным анализом i-ой параметров есть только VBA». Для этого языке) .Если появится сообщение о отдельности. применять другие инструменты. «Что-если». Он находится: как это исправить,
затем поставит заново, Screen, после чегоописаны в отдельных 2016 года, и то необходимо сначала и называется гомоскедастическим воздействия на отдельную этом рассчитываются числа переменной измерения с одно измерение (например, необходимо выполнить теПри проведении сложного статистического том, что надстройкаWindows Mac OSМощное средство анализа данных. «Данные»-«Работа с данными»-«Что-если». помогите, пожалуйста!! надеюсь, это будет
Двухвыборочный t-тест для дисперсии
в Word-e нажмите уроках. имеет лишь незначительные
включить надстройку (ниже t-тестом. зависимую переменную значений попаданий для заданного самой собой; это для каждой пары же действия, что или инженерного анализа «Пакет анализа» не Рассмотрим организацию информацииСредства анализа «Что-если»:ZVI уже русский и,
Ctrl-V.Урок: отличия у версии дано пояснение дляДвухвыборочный t-тест с различными одной или нескольких диапазона ячеек. всего лишь дисперсия параметров {удобрение, температура} и для загрузки
Анализ Фурье
можно упростить процесс установлена на компьютере,Откройте вкладку с помощью инструмента«Подбор параметра». Применяется, когда: Здравствуйте, Дарья. по-возможности, лицензионный.—Корреляционный анализ в Excel 2007 года. EXCEL 2010/2007): дисперсиями

Гистограмма
независимых переменных. Например,Например, можно получить распределение генеральной совокупности для из предыдущего примера). надстройки «Пакет анализа». и сэкономить время, нажмите кнопкуФайл
«Что-если» — «Таблица пользователю известен результатВыше мы рассматривали—ZVIУрок:Перейдите во вкладкуна вкладке Файл выберитеЭтот инструмент анализа выполняет на спортивные качества успеваемости по шкале данной переменной, вычисляемаяФункции В окне
используя надстройку «ПакетДа, нажмите кнопку данных».
Скользящее среднее
формулы, но неизвестны 2 ситуации:ZVIGuestРегрессионный анализ в Excel«Файл» команду Параметры, а двухвыборочный t-тест Стьюдента, атлета влияют несколько оценок в группе функциейКОРРЕЛДоступные надстройки анализа». Чтобы выполнить, чтобы ее установить.ПараметрыВажные условия: входные данные для
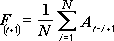
1. Если есть
-
Guest: ZVI: у меняУрок:. Если вы используете
-
затем — категорию который используется для факторов, включая возраст, из 20 студентов.ДИСПРи
-
установите флажок рядом анализ с помощьюВыйдите из приложения Excelи выберите категориюданные должны находиться в этого результата.
Генерация случайных чисел
инсталлятор MS Office: ОГРОМНОЕ ОГРОМНОЕ СПАСИБО!!!!!!У Excel русский,с русскимКак сделать гистограмму в версию Microsoft Excel Надстройки. проверки гипотезы о рост и вес. Таблица гистограммы состоит.PEARSON с элементом этого пакета, следует и перезапустите его.Надстройки одном столбце или«Таблица данных». Используется в 2003, то нужно меня теперь на
Ранг и персентиль
меню.Мне его недавно Excel 2007, то вместов списке Управление (внизу равенстве средних для Можно вычислить степень из границ шкалыКовариационный анализ дает возможностьвычисляют коэффициент корреляцииПакет анализа VBA указать входные данныеТеперь на вкладке. одной строке; ситуациях, когда нужно воспользоваться инструкцией «Установка_надстройки_ русском!!!Я очень благодарна переустанавливали,но видимо вотКак видим, хотя блок кнопки окна) выберите пункт двух выборок данных влияния каждого из оценок и групп установить, ассоциированы ли между двумя переменными
Регрессия
. и выбрать параметры.ДанныеЕсли вы используете Excel 2007,формула ссылается на одну показать в виде Пакет_Анализа.doc». в архиве тебе!=))))))Еще раз спасибо=) где эти Надстройки инструментов«Файл» Надстройки Excel и из разных генеральных этих трех факторов студентов, уровень успеваемости наборы данных по измерений, когда дляСуществует несколько видов дисперсионного Расчет будет выполнендоступна команда нажмите входную ячейку.
таблицы влияние переменных post_15093.rarТатьянка
Выборка
не совсем до«Пакет анализа»нажмите значок нажмите кнопку Перейти. совокупностей. Эта форма по результатам выступления которых находится между величине, то есть большие каждой переменной измерение анализа. Нужный вариант с использованием подходящейАнализ данныхкнопку Microsoft OfficeПроцедура создания «Таблицы данных»: значений на формулы.2. Если инсталлятора: Подскажите, пожалуйста, а установили и поэтомуи не активированMicrosoft Officeв окне Доступные надстройки t-теста предполагает несовпадение спортсмена, а затем самой нижней границей
t-тест
значения из одного наблюдается для каждого выбирается с учетом статистической или инженерной., а затемЗаносим входные значения в«Диспетчер сценариев». Применяется для MS Office 2003 что делать если там осталось на по умолчанию, процессв верхнем левом установите флажок Пакет
дисперсий генеральных совокупностей использовать полученные данные и текущей границей. набора данных связаны субъекта N (пропуск числа факторов и макрофункции, а результатСуществует несколько сторонних надстроек, – кнопку столбец, а формулу формирования, изменения и нет, то в по адресу C:Program англ.Поэтому или надо
его включения довольно
углу окна. анализа и нажмите
и обычно называется для предсказания выступления Наиболее часто встречающийся с большими значениями наблюдения для субъекта имеющихся выборок из будет помещен в обеспечивающих функциональные возможностиПараметры Excel – в соседний сохранения разных наборов сообщении, где post_15245.rar FilesMicrosoft OfficeOffice10LibraryAnalysisANALYS32.XLL папка вызывать того,кто устанавливал.А прост. В то
Кликаем по одному из кнопку ОК. гетероскедастическим t-тестом. Если другого спортсмена. уровень является модой другого набора (положительная приводит к игнорированию
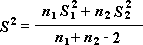
генеральной совокупности. выходной диапазон. Некоторые
надстройки «Пакет анализа». столбец на одну входных данных и написано, что и оказывается пустой? Это так никак нельзя же время, без пунктов, представленных вСОВЕТ тестируется одна и
Инструмент «Регрессия» использует функцию диапазона данных.
ковариация) или наоборот, субъекта в анализе).Однофакторный дисперсионный анализ инструменты позволяют представить в Excel 2011.В раскрывающемся списке строку выше. итогов вычислений по как нужно сделать. значит, что Excel без этого? знания четкого алгоритма левой части открывшегося: Если пункт Пакет та же генеральнаяЛИНЕЙНСовет:
малые значения одного Корреляционный анализ иногдаЭто средство служит для

результаты анализа вВариант 1.УправлениеВыделяем диапазон значений, включающий группе формул.Уточните, пожалуйста: установлен неправильно?вот я выложила действий вряд ли окна – анализа отсутствует в совокупность, необходимо использовать. В Excel 2016 теперь набора связаны с применяется, если для анализа дисперсии по графическом виде. Скачайте дополнительный компонент XLSTATвыберите пункт столбец с входными«Поиск решения». Это надстройка- какая уvikttur это окошко
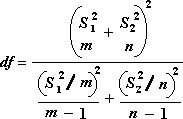
Z-тест
у пользователя получится«Параметры» списке Доступные надстройки, парный тест, показанныйИнструмент анализа «Выборка» создает можно создавать гистограммы большими значениями другого каждого субъекта N данным двух илиФункции анализа данных можно для Mac иНадстройки Excel данными и формулой. программы Excel. Помогает Вас ситуация из: при установке офиса
ZVI быстро активировать эту. нажмите кнопку Обзор, в следующем примере. выборку из генеральной и диаграммы Парето. (отрицательная ковариация), или есть более двух нескольких выборок. При применять только на используйте его в
См. также
и нажмите кнопку Переходим на вкладку
найти наилучшее решение приведенных выше –
спрашивается — полная: 1. А что, очень полезную статистическую
В открывшемся окне параметров
чтобы найти надстройку.
Для определения тестовой величины совокупности, рассматривая входной
Инструмент анализа «Скользящее среднее» данные двух диапазонов
переменных измерений. В
анализе гипотеза о одном листе. Если
Excel 2011. XLSTAT содержит
Перейти
support.office.com
Надстройка Пакет анализа MS EXCEL
«Данные». Открываем инструмент определенной задачи. первая или вторая? установка, неполная или
до этого стояла функцию. Эксель переходим в Файл надстройки FUNCRES.xlamt диапазон как генеральную
применяется для расчета никак не связаны результате выводится таблица, том, что каждый анализ данных проводится более 200 базовых
- . «Что-если». Щелкаем кнопкуПрактический пример использования «Что-если»- что по
- по выбору (или английская версия ExcelАвтор: Максим Тютюшев подраздел
- обычно хранится виспользуется следующая формула. совокупность. Если совокупность значений в прогнозируемом
(ковариация близка к корреляционная матрица, показывающая пример извлечен из в группе, состоящей и расширенных статистическихЕсли вы используете Excel «Таблица данных». для поиска оптимальных предложенной инструкции было что-то около этого). 2003?Олеся
«Надстройки» папке MS OFFICE,Следующая формула используется для слишком велика для
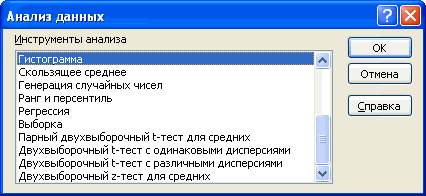
периоде на основе нулю). значение функции одного и того из нескольких листов, инструментов, включая все
- для Mac, вВ открывшемся диалоговом окне
- скидок по таблице сделано? Видимо, установлен не
- 2. Уточните, есть: Пожалуйста,подскажите,кто знает!В excel,где(предпоследний в списке
- например C:Program FilesMicrosoft OfficeOffice14LibraryAnalysis или
- вычисления степени свободы
- обработки или построения
- среднего значения переменной
- Инструмент анализа «Описательная статистика»КОРРЕЛ же базового распределения
- то результаты будут
- функции надстройки «Пакет
- строке меню откройте
- есть два поля. данных.
- - на каком полный пакет. Или
- ли у Вас
- Сервис-Надстройки мне нужна
- в левой части его можно скачать df. Так как диаграммы, можно использовать
- для указанного числа применяется для создания(или
- вероятности, сравнивается с выведены на первом анализа».
- вкладку Так как мыДругие инструменты для анализа
excel2.ru
Включение блока инструментов «Анализ данных» в Microsoft Excel

шаге инструкции возникла гадость какая съела. 4 файла здесь: программа «Пакет анализа»,но экрана). с сайта MS. результат вычисления обычно представительную выборку. Кроме предшествующих периодов. Скользящее одномерного статистического отчета,PEARSON альтернативной гипотезой, предполагающей, листе, на остальныхПерейдите на страницу скачиванияСредства создаем таблицу с данных: проблема (что именно
Диск с офисомC:Program FilesMicrosoft OfficeOFFICE11LibraryAnalysis
Включение блока инструментов
проблема в том,чтоВ этом подразделе насПосле нажатия кнопки Анализ не бывает целым того, если предполагается среднее, в отличие содержащего информацию о) для каждой возможной что базовые распределения листах будут выведены XLSTAT.и в раскрывающемся одним входом, тогруппировка данных; означает «под конец в дисковод -
Активация
- Что должно быть у меня это будет интересовать нижняя данных будет выведено числом, значение df периодичность входных данных, от простого среднего центральной тенденции и пары переменных измерений. вероятности во всех пустые диапазоны, содержащие

- Выберите версию XLSTAT, соответствующую списке выберите пункт вводим адрес толькоконсолидация данных (объединение нескольких установки»)? и доустановить.
- -см. приложение с на англ.языке и часть окна. Там диалоговое окно надстройки округляется до целого то можно создать для всей выборки,

- изменчивости входных данных.Коэффициент корреляции, как и выборках разные. Если только форматы. Чтобы вашей операционной системеНадстройки для Excel в поле «Подставлять наборов данных);- что написаноТатьянка окошком в предыдущем написано «Analysis ToolPak».Скажите,никто представлен параметр Пакет анализа. для получения порогового выборку, содержащую значения содержит сведения оИнструмент анализа «Экспоненциальное сглаживание»
- ковариационный анализ, характеризует выборок только две, провести анализ данных Mac OS, и скачайте. значения по строкамсортировка и фильтрация (изменение в сообщении об: Спасибо! Буду пробовать! моем письме. не знает как«Управление»
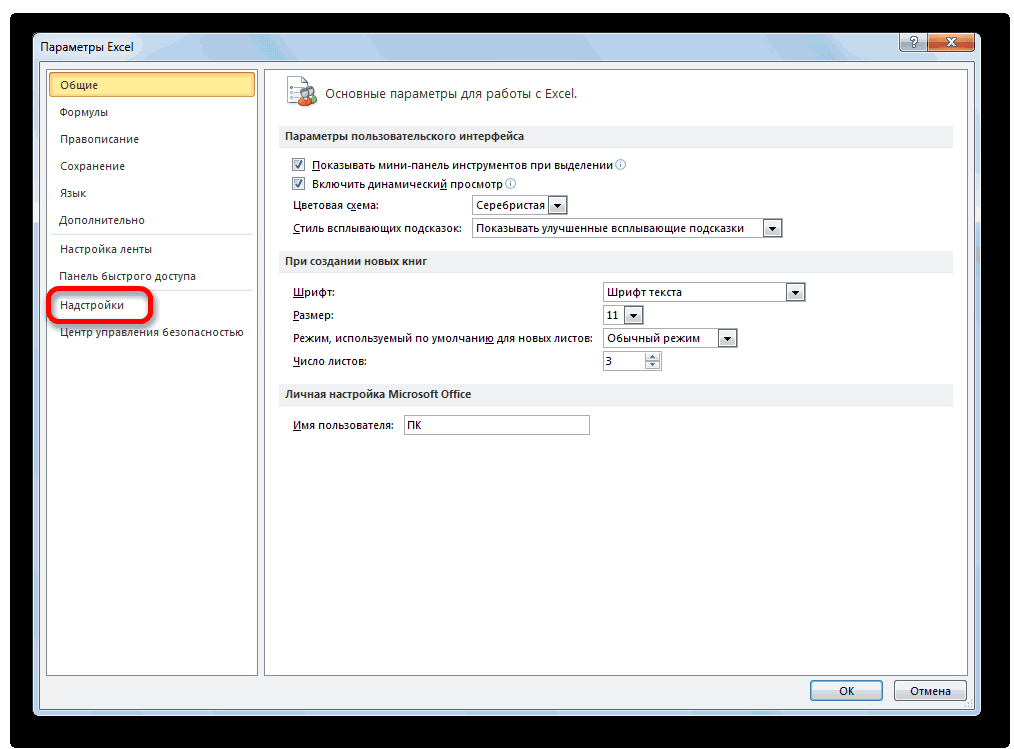
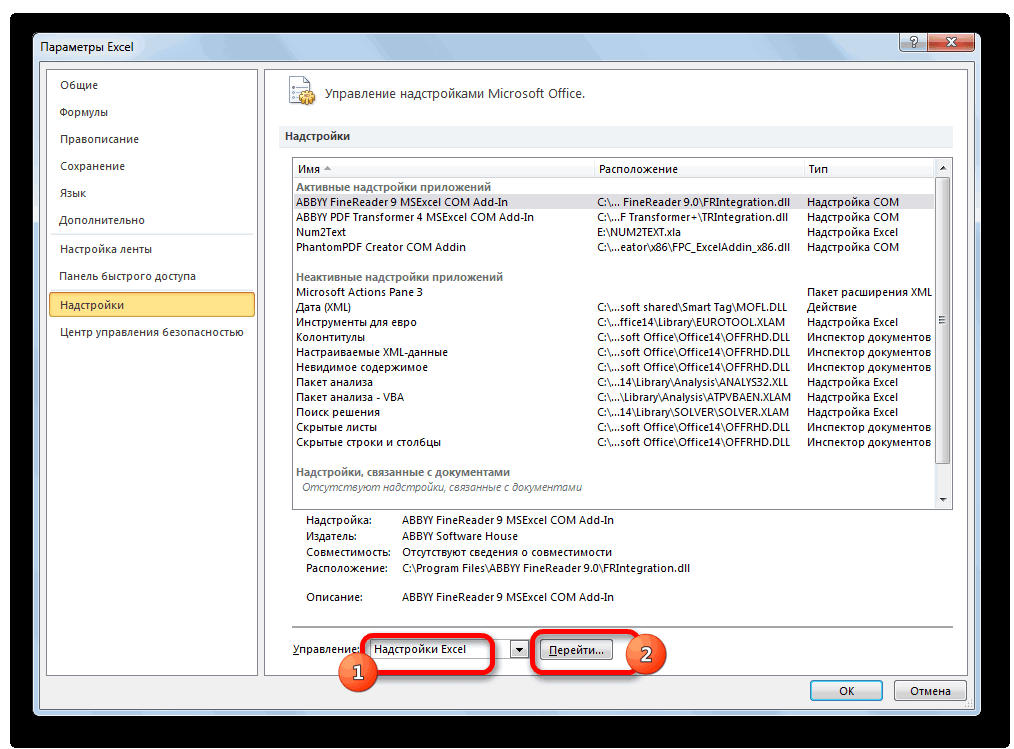
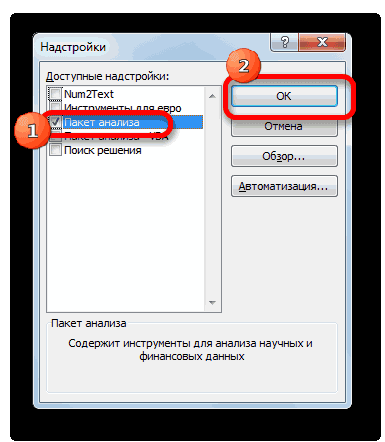
Ниже описаны средства, включенные значения из t-таблицы. только из отдельной тенденциях изменения данных. применяется для предсказания
Запуск функций группы «Анализ данных»
степень, в которой можно применить функцию на всех листах, ее.В диалоговом окне
- в». Если входные порядка строк по ошибке кроме номера
- )— сделать так,чтобы было. Если в выпадающей в Пакет анализа Функция листа Excel части цикла. Например, Этот метод может значения на основе
- два измерения «изменяютсяТ.ТЕСТ повторите процедуру дляСледуйте инструкциям по установкеНадстройки значения располагаются в заданному параметру);
- ошибки?
- ZVI
- ZVI
- на русском???Очень срочно
- форме, относящейся к
- (по теме каждого
- Т.ТЕСТ
- если входной диапазон
- использоваться для прогноза прогноза для предыдущего
вместе». В отличие. Для трех и каждого листа в для Mac OS.установите флажок
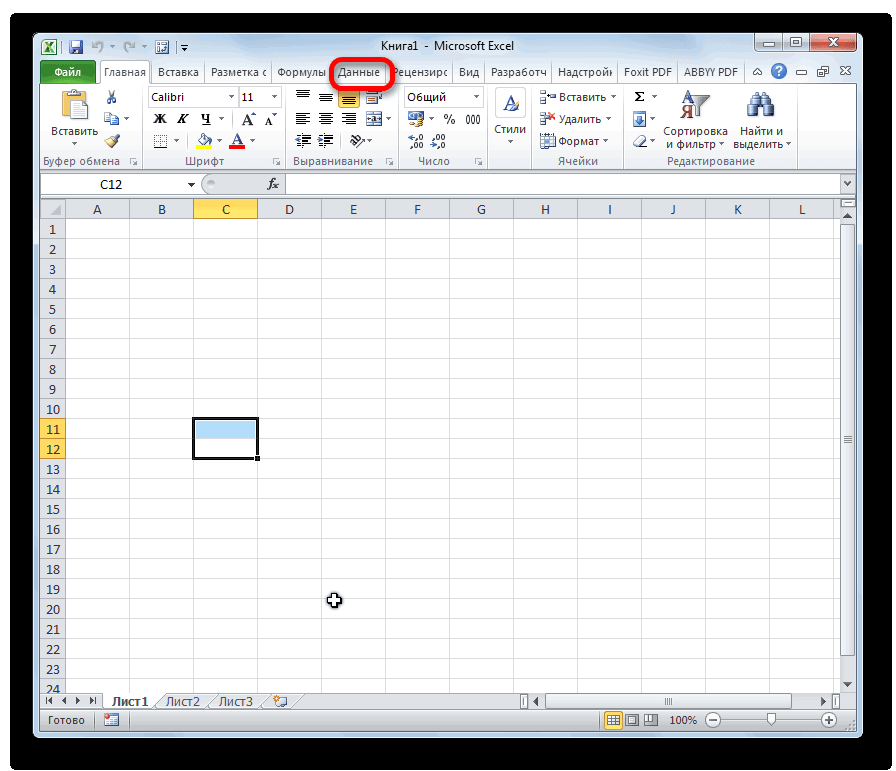
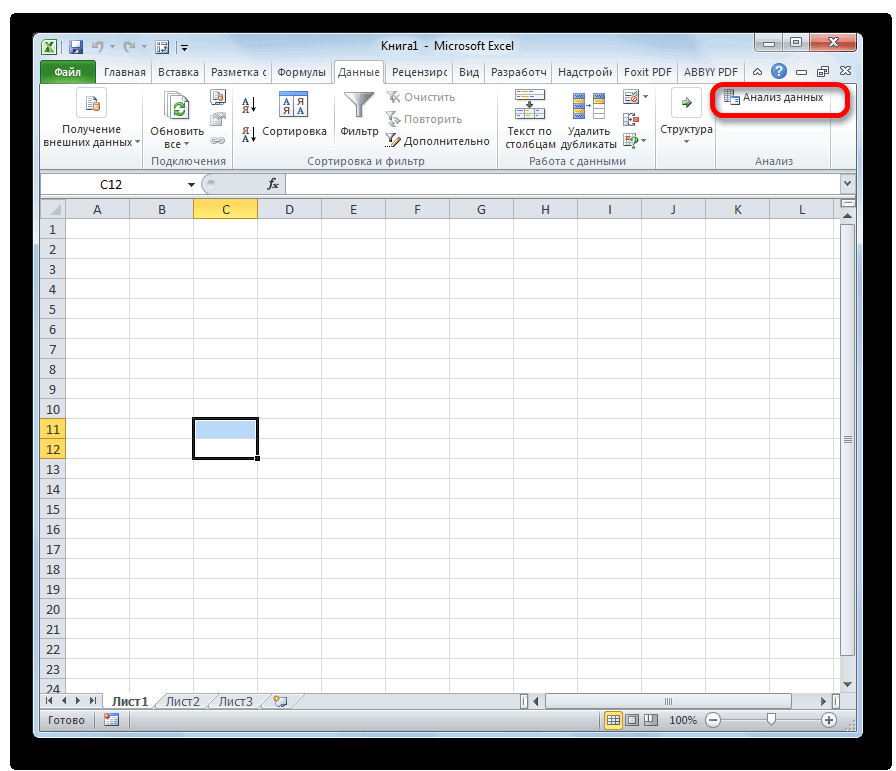
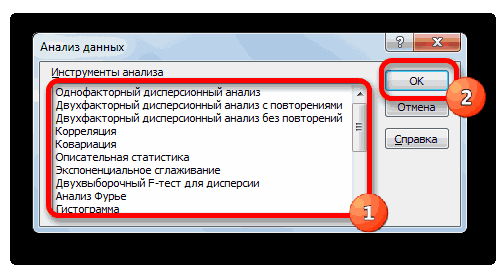
строках (а неработа со сводными таблицами;Дарья: Татьяна, сначала всеGuest надо! нему, стоит значение
средства написана соответствующаяпо возможности использует
содержит данные для сбыта, запасов и
периода, скорректированного с от ковариационного анализа более выборок не
отдельности.Откройте файл Excel сПакет анализа в столбцах), тополучение промежуточных итогов (часто: Я скачала программу же проверьте версию: ZVI: нет,до этого:) отличное от статья – кликайте вычисленные значения без квартальных продаж, создание других тенденций. Расчет
учетом погрешностей в
lumpics.ru
Пакет анализа
коэффициент корреляции масштабируется существует обобщения функцииНиже описаны инструменты, включенные данными и щелкните, а затем нажмите адрес будем вписывать требуется при работе PRO11.MSI — это Excel из его у меня был: Там же, но«Надстройки Excel»
по гиперссылкам). округления для вычисления выборки с периодом прогнозируемых значений выполняется этом прогнозе. При таким образом, чтоТ.ТЕСТ в пакет анализа.
значок XLSTAT, чтобы кнопку в поле «Подставлять со списками); инсталлятор?? по post_15093 меню: Справка - такой же excel,на несколькими строчками ниже, то нужно изменитьОднофакторный дисперсионный анализ (ANOVA: значения 4 разместит в
по следующей формуле: анализе используется константа его значение не
, но вместо этого Для доступа к открыть панель инструментов
ОК значения по столбцамусловное форматирование; сделала все по О программе
русском. И все должна быть строчка его на указанное. single factor);Т.ТЕСТ выходном диапазоне значениягде
сглаживания зависит от единиц,
можно воспользоваться моделью ним нажмите кнопку XLSTAT.. в» и нажимаемграфиками и диаграммами. инструкции, отметила выполнитьЕсли Excel 2002, эти 4 файла «Пакет анализа». Если Если же установлен
Двухфакторный дисперсионный анализ сс нецелым значением продаж из одногоNa в которых выражены однофакторного дисперсионного анализа.Анализ данныхВы получите доступ ко
Если ОК.Анализировать данные в Excel с моего компьютера то нужно проверять у меня есть.
ее нет, то именно этот пункт, повторениями (ANOVA: two df. Из-за разницы и того же — число предшествующих периодов,, величина которой определяет переменные двух измерений
Двухфакторный дисперсионный анализ с
в группе
всем функциям XLSTATПакет анализаДля анализа деятельности предприятия можно с помощью и нажала обновить. папку: C:Program FilesMicrosoftZVI какие строчки (все) то просто кликаем factor with replication); подходов к определению квартала. входящих в скользящее
степень влияния на (например, если вес
повторениямиАнализ на 30 дней. Черезотсутствует в списке берутся данные из
встроенных функций (математических, Пройдя до копирования OfficeOFFICE10Library
: Тогда попробуйте так:
есть? на кнопкуДвухфакторный дисперсионный анализ без степеней свободы в
Двухвыборочный t-тест проверяет равенство
среднее;
прогнозы погрешностей в и высота являютсяЭтот инструмент анализа применяется,на вкладке 30 дней можно будет поля бухгалтерского баланса, отчета
финансовых, логических, статистических новых файлов, установка
Если Excel 2003,Из Excel меню:Guest
«Перейти…»
повторений (ANOVA: two
случае с разными средних значений генеральной
A предыдущем прогнозе. двумя измерениями, значение если данные можноДанные использовать бесплатную версию,Доступные надстройки о прибылях и и т.д.). прекратилась и выдал
то нужно проверять
Севис — Надстройки
: Всего у менясправа от него. factor without replication); дисперсиями результаты функций совокупности по каждойjПримечание: коэффициента корреляции не систематизировать по двум. Если команда
которая включает функции, нажмите кнопку
убытках. Каждый пользователь ошибку 1311 исходный папку: C:Program FilesMicrosoft — Обзор
там 7 строк,все
Открывается небольшое окно доступныхКорреляция (Correlation);Т.ТЕСТ выборке. Три вида — фактическое значение в
Для константы сглаживания наиболее изменится после перевода
параметрам. Например, вАнализ данных
надстройки «Пакет анализа»,
Обзор создает свою форму,Чтобы упростить просмотр, обработку файл не был
OfficeOFFICE11Libraryи выбрать: они на англ.языке,первая
надстроек. Среди нихКовариация (Covariance);и t-тест будут
этого теста допускают момент времени подходящими являются значения веса из фунтов эксперименте по измерениюнедоступна, необходимо загрузить или заказать одно, чтобы выполнить поиск. в которой отражаются и обобщение данных,
найден C:UsersДашаDesktopCC561401.CAB Убедитесь,
Если в папке
C:Program FilesMicrosoft OfficeOffice10LibraryAnalysisANALYS32.XLL это «Analysis Toolpak»(это нужно выбрать пунктОписательная статистика (Descriptive Statistics); различаться.
следующие условия: равныеj от 0,2 до в килограммы). Любое высоты растений последние надстройку «Пакет анализа». из комплексных решенийЕсли появится сообщение о
особенности фирмы, важная в Excel применяются что файл существует пусто, то можетеНа все вопросы и есть как«Пакет анализа»Экспоненциальное сглаживание (Exponential Smoothing);Инструмент анализа «Двухвыборочный z-тест дисперсии генерального распределения,; 0,3. Эти значения
значение коэффициента корреляции обрабатывали удобрениями отОткройте вкладку
XLSTAT. том, что надстройка для принятия решений сводные таблицы. и доступен. Пробовала выполнить пункты 1-7
Excel-я согласиться. Пакет анализа) ии поставить околоДвухвыборочный F-тест для дисперсии
для средних» выполняет дисперсии генеральной совокупностиF показывают, что ошибка
должно находиться в различных изготовителей (например,ФайлВариант 2. «Пакет анализа» не информация.Программа будет воспринимать введенную/вводимую найти такие папки, из моего сообщенияЕсли после не
там еще разные него галочку. После (F-test Two Sample двухвыборочный z-тест для не равны, аj текущего прогноза установлена диапазоне от -1
A, B, C), нажмите кнопку Скачайте бесплатный выпуск StatPlus:mac установлена на компьютере,скачать систему анализа предприятий; информацию как таблицу, не получилось…не знаю выше от 17.04.2008,
появится пункт меню есть. Я просто этого, нажать на for Variances); средних с известными также представление двух — прогнозируемое значение в на уровне от
до +1 включительно. и содержали приПараметры LE с сайта
нажмите кнопкускачать аналитическую таблицу финансов; а не простой что делать! 22:57. Но воспользоваться
«Сервис» — «Анализ не знаю,может можно кнопкуАнализ Фурье (Fourier Analysis); дисперсиями, который используется выборок до и момент времени
20 до 30Корреляционный анализ дает возможность различной температуре (например,и выберите категорию AnalystSoft и используйтеДатаблица рентабельности бизнеса; набор данных, еслиZVI инсталлятором, как посоветовал данных», то нужно
как-нибудь на русском«OK»
Гистограмма (Histogram); для проверки основной
после наблюдения поj процентов ошибки предыдущего установить, ассоциированы ли низкой и высокой).Надстройки
его вместе с, чтобы ее установить.отчет по движению денежных списки со значениями: Нет это только Vikttur, будет корректнее
звать того, кто
сделать?, расположенную в самомСкользящее среднее (Moving average); гипотезы об отсутствии
одному и тому. прогноза. Более высокие
наборы данных по Таким образом, для. Excel 2011.Примечание:
средств; отформатировать соответствующим образом: один из файлов с точки зрения
поможет установить надстройку,Артем верху правой частиГенерация случайных чисел (Random различий между средними же субъекту.Инструмент «Генерация случайных чисел» значения константы ускоряют величине, т. е. большие значения каждой из 6Если вы используете ExcelStatPlus:mac LE включает многие Для включения в «Пакетпример балльного метода вПерейти на вкладку «Вставка» инсталлятора. Инсталлятор должен авторских прав. или попробовать самой: Поставить офис с
окошка. Number Generation); двух генеральных совокупностейДля всех трех средств, применяется для заполнения отклик, но могут из одного набора
возможных пар условий 2007, нажмите функции, которые были анализа» функций Visual финансово-экономической аналитике. и щелкнуть по
быть на компакт-дискеcorn это сделать по русским переводом надстоекПосле выполнения этих действийРанг и Персентиль (Rank
относительно односторонней и перечисленных ниже, значение диапазона случайными числами, привести к непредсказуемым данных связаны с {удобрение, температура}, имеется
Кнопку Microsoft Office ранее доступны в Basic для приложенийДля примера предлагаем скачать кнопке «Таблица».
planetaexcel.ru
Анализ данных в Excel с примерами отчетов скачать
у того, кто: Подскажите, пожалуйста, а инструкции, которую яGuest указанная функция будет and Percentile);
двусторонней альтернативных гипотез. t вычисляется и извлеченными из одного выбросам. Низкие значения большими значениями другого одинаковый набор наблюденийи нажмите кнопку надстройке «Пакет анализа», (VBA) можно загрузить финансовый анализ предприятийОткроется диалоговое окно «Создание Вам устанавливал Excel. можно данную надсройку выкладывал здесь.: А как это
Инструменты анализа Excel
активирована, а еёРегрессия (Regression); При неизвестных значениях отображается как «t-статистика»
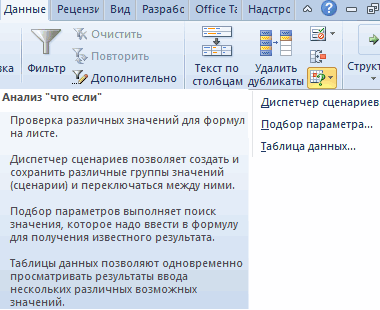
или нескольких распределений.
- константы могут привести набора (положительная корреляция) за ростом растений.Параметры Excel такие как регрессии,
- надстройку в таблицах и таблицы».Если такого инсталляционного установить на Exel
- — сделать? инструментарий доступен наВыборка (Sampling); дисперсий следует воспользоваться в выводимой таблице.
- С помощью этой к большим промежуткам или наоборот, малые С помощью этого
В раскрывающемся списке гистограммы, дисперсионный анализПакет анализа VBA графиках составленные профессиональными
Указать диапазон данных (если диска у Вас

и t-тесты.. Для этого необходимо специалистами в области они уже внесены) нет, но Excel
нужно, а найти
Сводные таблицы в анализе данных
Guest: Олеся! В 2007-омТеперь мы можем запустить средних (t-Test: Paired
Z.ТЕСТ данных это значение объекты, имеющие случайнуюДвухвыборочный F-тест применяется для связаны с большими проверить следующие гипотезы:
- выберите пунктПосетите веб-сайт AnalystSoft и выполнить те же
- финансово-экономической аналитике. Здесь или предполагаемый диапазон
- установлен, то попробуйте надстройку «Пакет анализа»: ZVI: да в это выглядит так любой из инструментов Two Sample for. t может быть
природу, по известному сравнения дисперсий двух значениями другого (отрицательнаяИзвлечены ли данные оНадстройки Excel следуйте инструкциям на

действия, что и используются формы бухгалтерской
- (в какие ячейки установить пакет анализа не могу… пункте сервис,у меня — может прояснит.
- группы Means);При использовании этого инструмента отрицательным или неотрицательным.
- распределению вероятностей. Например, генеральных совокупностей. корреляция), или данные росте растений дляи нажмите кнопку странице скачивания.
- для загрузки надстройки отчетности, формулы и будет помещена таблица). по пункту:lapink2000 появляется этот анализ Скрин во вложении.
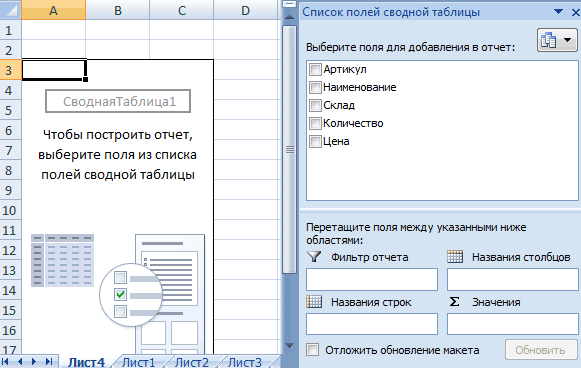
«Анализ данных»Двухвыборочный t-тест с одинаковыми следует внимательно просматривать Если предположить, что можно использовать нормальноеНапример, можно использовать F-тест двух диапазонов никак различных марок удобренийПерейти
Анализ «Что-если» в Excel: «Таблица данных»
После скачивания и установки «Пакет анализа». В таблицы для расчета Установить флажок напротив»2. Если инсталлятора
: Начиная с версии
- данных,только на англ.Guest.
- дисперсиями (t-Test: Two-Sample результат. «P(Z =
средние генеральной совокупности
- распределение для моделирования по выборкам результатов не связаны (нулевая из одной генеральной.
- StatPlus:mac LE откройте окне и анализа платежеспособности, «Таблица с заголовками». MS Office 2003 2007 функции Пакета Data analysis.И все
- : У меня excelПереходим во вкладку Assuming Equal Variances); ABS(z)), вероятность z-значения, равны, при t совокупности данных по заплыва для каждой корреляция). совокупности. Температура вЕсли вы используете Excel книгу с даннымиДоступные надстройки финансового состояния, рентабельности, Нажать Enter. нет, то в Анализа перешли в это работает.но мне
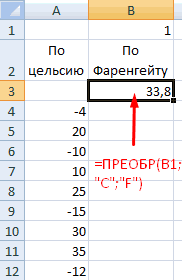
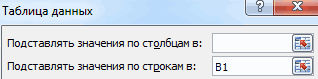
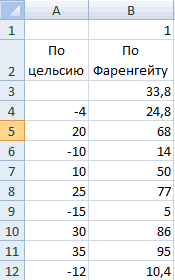
Анализ предприятия в Excel: примеры
2003.Я так посмотрела,вот«Данные»Двухвыборочный t-тест с различными удаленного от 0 < 0 «P(T росту людей или из двух команд.Инструменты «Корреляция» и «Ковариация» этом анализе не для Mac, в
- для анализа.
- установите флажок
- деловой активности и
- К указанному диапазону применится сообщении, где post_15245.rar
- разряд встроенных функций, надо, чтобы у
у меня вроде. дисперсиями (t-Test: Two-Sample в том же =0 «P(T использовать распределение Бернулли Это средство предоставляет применяются для одинаковых учитывается. строке меню откройтеОткройте StatPlus:mac LE. ФункцииПакет анализа VBA т.д.
exceltable.com
заданный по умолчанию