
Функции динамических массивов: СОРТ, ФИЛЬТР и УНИК
Эта статья является логическим продолжением предыдущего материала про новые динамические массивы (ДМ), появившиеся в Excel в Office 365. Если вы ещё с не ознакомились (кому лень читать — там есть видео), то очень советую сделать это сейчас, чтобы понимать о чём, собственно, идёт речь и как заполучить все эти радости в вашем Excel.
Обновление Office 365, которое подарило Microsoft Excel новый вычислительный движок с поддержкой динамических массивов, также добавило к нашему арсеналу 7 новых функций, заточенных специально для работы с массивами. В этой статье я хотел бы рассказать про три самых важных функции: СОРТ, ФИЛЬТР и УНИК. Остальные играют скорее вспомогательную роль — про них чуть позже.
Для простоты я буду во всех примерах я буду показывать работу этих функций на обычных таблицах, но можно иметь ввиду, что с «умными» таблицами (созданными через Главная — Форматировать как таблицу или сочетанием клавиш Ctrl+T) эти функции тоже отлично работают.
Итак, поехали…
Функция СОРТ (SORT)
Синтаксис:
=СОРТ(массив; [индекс_сортировки]; [порядок_сортировки]; [по_столбцу])
В самом простом варианте требует в качестве аргумента только массив (диапазон) и выдает его уже в отсортированном виде:
 - простой случай")
По умолчанию сортировка выполняется по возрастанию. Если нужен обратный порядок, то за это отвечает третий аргумент (1 — по возрастанию, -1 — по убыванию):

Если на входе указать диапазон из несколько колонок в данных, то сортировка происходит по первому столбцу. Если нужно сортировать не по первому, то в качестве второго аргумента можно указать номер столбца для сортировки:

Если хочется сортировать по нескольким столбцам сразу, то придётся задать массив номеров столбцов во втором аргументе в фигурных скобках. Одновременно аналогичным образом можно задать третьим аргументом и направление сортировки для каждого столбца.
Например, если мы хотим отсортировать наш список по городам по возрастанию и затем по суммам по убыванию, то это будет выглядеть так:

Последний аргумент используется, если нужно сортировать не строки, а столбцы, т.е. упорядочивать данные по горизонтали, что встречается существенно реже.
Вот так — просто и изящно. Особенно, если вспомнить какую монстрообразную формулу массива требовалось ввести раньше для сортировки всего лишь одного (!) столбца:

Бррр… 
Функция ФИЛЬТР (FILTER)
Синтаксис:
=ФИЛЬТР(массив; включить; [если_пусто])
Назначение этой функции — принять в качестве аргумента массив исходных ячеек и отфильтровать его по заданному условию(ям). Какие строки включить в результаты, а какие убрать — определяется вторым аргументом. Он должен представлять из себя массив логических значений ЛОЖЬ (FALSE) и ИСТИНА (TRUE), задающих статус для каждой строки:

Логическую ИСТИНУ и ЛОЖЬ можно, для компактности, заменить на 1 (или любое другое число) и 0 (или пустую ячейку):

А самое интересное, что логические значения могут быть результатом какого-либо выражения, например:

Если чуть подумать, то простор для фантазии тут открывается широкий. Вот вам для затравки несколько вариантов условий, с которыми замечательно будет работать эта функция:
- =ФИЛЬТР(B2:D25; D2:D25>=10000) — отбираем все заказы, где стоимость больше или равна 10 000
- =ФИЛЬТР(B2:D25; ЛЕВСИМВ(B2:B25) = «Б») — фильтрация всех строк, где название товара начинается с «Б» (блуза, брюки, бриджи и т.д.)
- =ФИЛЬТР(B2:D25; (B2:B25 = «Брюки») * (C2:C25 = «Анна»)) — отбор всех сделок Анны, где она продавала брюки
- =ФИЛЬТР(B2:D25; (C2:C25 = «Анна») + (C2:C25 = «Иван»)) — все сделки Анны и Ивана
- =ФИЛЬТР(B2:D25; ЕСЛИОШИБКА(ПОИСК(«Самара»;A2:A25);0)) — фильтрация всех сделок, где в названии города содержится слово Самара (г. Самара, Самара г., город Самара, Самара-городок и т.д.)
Если функция ФИЛЬТР не находит ни одного значения, удовлетворяющего условию, то она выдаёт ошибку #ВЫЧИСЛ! Чтобы вывести вместо неё что-то более осмысленное, можно использовать третий аргумент:

Функция УНИК (UNIQUE)
Синтаксис:
=УНИК(массив; [по_столбцам]; [один_раз])
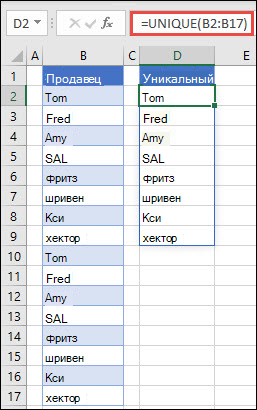
В самом простом варианте эта функция извлекает из входного массива все имеющиеся там значения, удаляет повторы и выдаёт то, что осталось:

Если в качестве исходного массива выделено несколько столбцов, то проверка на уникальность идёт по всем, т.е. по связке значений из всех ячеек каждой строки:

Очень интересно работает третий аргумент — он заставляет функцию извлечь из исходного массива только те данные, которые встречаются там всего один раз, т.е. не имеют клонов:

Комбинирование функций
Само-собой, никто не запрещает нам «женить» все упомянутые функций между собой — здесь-то и начинается настоящая магия, мощь и синергия.
Разберём, для примера, классическую задачу: предположим, что нам нужно сформировать справочник по городам для выпадающего списка на основе выгрузки из какой-нибудь базы данных. В исходной выгрузке города повторяются в случайном порядке, есть пустые ячейки и дубли. А необходимый нам справочник, содержащий эталонный набор городов, должен быть:
- без повторов
- без пустых ячеек
- отсортирован по возрастанию от А до Я
Делается всё вышеперечисленное одной (!) формулой:

В английской версии эта функция выглядит как:
=SORT(UNIQUE(FILTER(B2:B100000;NOT(ISEMPTY(B2:B100000)))))
Здесь:
- ФИЛЬТР — отбирает только те ячейки, где есть данные (не пусто)
- УНИК — убирает повторы в отобранном функцией ФИЛЬТР списке
- СОРТ — сортирует получившийся справочник по алфавиту
После этого останется только указать получившийся динамический массив как источник для выпадающего списка на вкладке Данные — Проверка данных (Data — Validation), не забыв добавить после адреса первой ячейки массива знак решётки:

Причем, несмотря на приличный размер исходного диапазона (100 тыс. строк!) никакого торможения при пересчёте такой формулы нет абсолютно — новый вычислительный движок Excel справляется «на ура». При этом классические формулы массива на подобных задачах начинали ощутимо подтупливать на таблицах уже с 3-5 тыс. строк, а на 100 тыс. просто загнали бы ваш Excel в кому.
Оглядываясь назад и вспоминая все свои выполненные проекты по автоматизации за последние Х лет, с грустью понимаю сколько дней и даже, наверное, недель можно было бы сэкономить, если бы динамические массивы и такие функции существовали тогда. Даааа….
Ну, лучше поздно, чем никогда, верно? По крайней мере, нашим детям точно будет проще 
Ссылки по теме
- Что такое динамические массивы в новом Excel и как они работают
- Как отсортировать список формулой
- Как создать выпдающий список в ячейке листа Excel
Skip to content
В статье описаны наиболее эффективные способы поиска, фильтрации и выделения уникальных значений в Excel.
Ранее мы рассмотрели различные способы подсчета уникальных значений в Excel. Но иногда вам может понадобиться только просмотреть уникальные или различные значения в столбце, не пересчитывая их. Но, прежде чем двигаться дальше, давайте убедимся, что мы понимаем, о чем будем говорить. Итак,
- Уникальные значения – это элементы, которые появляются в наборе данных только один раз.
- Различные – это элементы, которые появляются хотя бы один раз, то есть неповторяющиеся и первые вхождения повторяющихся значений.
А теперь давайте исследуем наиболее эффективные методы работы с уникальными и различными значениями в таблицах Excel.
- Как найти уникальные значения формулами.
- Фильтр для уникальных данных.
- Выделение цветом и условное форматирование.
- Быстрый и простой способ — Duplicate Remover.
Как найти уникальные значения при помощи формул.
Самый простой способ сделать это – использовать функции ЕСЛИ и СЧЁТЕСЛИ. В зависимости от типа данных, которые вы хотите найти, может быть несколько вариантов формулы, как показано в следующих примерах.
Как найти уникальные значения в столбце.
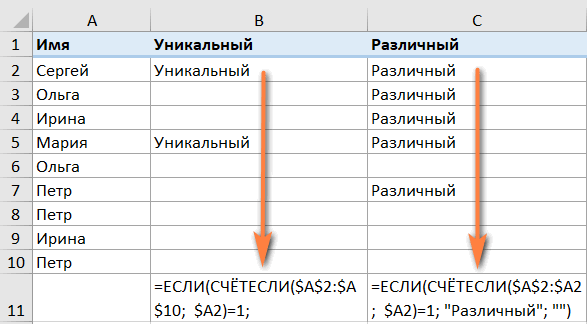
Чтобы найти различные или уникальные значения в списке, используйте одну из следующих формул, где A2 — первая, а A10 — последняя ячейка с данными.
Чтобы найти уникальные значения в Excel:
=ЕСЛИ(СЧЁТЕСЛИ($A$2:$A$10; $A2)=1; «Уникальный»; «»)
Чтобы определить различные значения:
=ЕСЛИ(СЧЁТЕСЛИ($A$2:$A2; $A2)=1; «Различный»; «»)
Во второй формуле есть только одно небольшое отличие во второй ссылке на ячейку, что, однако, имеет большое значение:
Совет. Если вы хотите найти уникальные значения между двумя столбцами , т.е. найти значения, которые присутствуют в одном столбце, но отсутствуют в другом, используйте формулу, описанную в статье Как сравнить 2 столбца на предмет различий.
Уникальные строки в таблице.
Аналогичным образом вы можете найти уникальные строки в таблице Excel на основе изучения записей не в одном, а в двух или более столбцах. В этом случае вам необходимо использовать СЧЁТЕСЛИМН вместо СЧЁТЕСЛИ для оценки значений (до 127 пар диапазон/критерий можно обработать в одной формуле).
Формула для получения уникальных строк:
=ЕСЛИ(СЧЁТЕСЛИМН($A$2:$A$10; $A2; $B$2:$B$10; $B2)=1; «Уникальная»; «»)
Формула для поиска различных строк:
=ЕСЛИ(СЧЁТЕСЛИМН($A$2:$A2; $A2; $B$2:$B2; $B2)=1; «Различная»; «»)

В нашем случае уникальная комбинация Имя+Фамилия встречается 2 раза. А всего в списке 6 человек, из которых трое дублируются.
Как найти уникальные записи с учетом регистра?
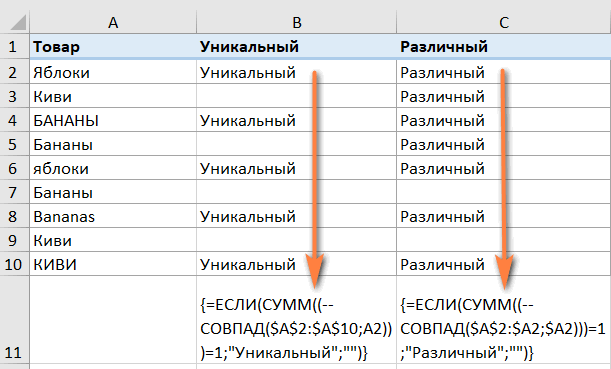
Если вы работаете с набором данных, где важен регистр букв, вам понадобится немного более сложная формула массива.
Поиск уникальных значений с учетом регистра :
{=ЕСЛИ(СУММ((—СОВПАД($A$2:$A$10;A2)))=1;»Уникальный»;»»)}
Поиск различных значений с учетом регистра :
{=ЕСЛИ(СУММ((—СОВПАД($A$2:$A2;$A2)))=1;»Различный»;»»)}
Поскольку обе они являются формулами массива, обязательно нажмите Ctrl + Shift + Enter, чтобы правильно их записать.
Когда уникальные или различные значения найдены, вы можете легко отфильтровать, выбрать или скопировать их, как будет описано ниже.
Фильтр для уникальных значений.
Чтобы просмотреть только уникальные или различные значения в списке, отфильтруйте их, выполнив следующие действия.
- Примените одну из приведенных выше формул для определения уникальных или различных ячеек или строк.
- Выберите диапазон и нажмите кнопку «Фильтр» на вкладке «Данные».
- Щелкните стрелку фильтрации в заголовке столбца, содержащего формулу, и выберите то, что хотите просмотреть:

Как выбрать уникальные из фильтра.
Если у вас относительно небольшой список уникальных, вы можете просто выбрать их обычным способом с помощью мыши при нажатой клавише Ctrl. Если отфильтрованный список содержит сотни или тысячи строк, то для экономии времени вы можете использовать один из следующих способов.
Чтобы быстро выбрать весь получившийся список, включая заголовки столбцов, отфильтруйте уникальные значения, щелкните любую ячейку в получившемся списке, а затем нажмите Ctrl + A.
Чтобы выбрать уникальные значения без заголовков столбцов, отфильтруйте их, выберите первую ячейку с данными и нажмите Ctrl + Shift + End, чтобы расширить выделение до последней ячейки.
Примечание. В некоторых редких случаях, в основном в очень больших книгах, рекомендованные выше комбинации клавиш могут выбирать как видимые, так и невидимые ячейки. Чтобы исправить это, нажмите сначала либо Ctrl + A или же Ctrl + Shift + End, а затем нажмите Alt +; для выбора только видимых ячеек, игнорируя скрытые строки.
Если вам сложно запомнить такое количество комбинаций, используйте этот визуальный способ: выделите весь список, затем перейдите на вкладку «Главная» > «Найти и выделить» > «Выделить группу ячеек» и выберите «Только видимые ячейки».
Как скопировать уникальные значения в другое место?
Чтобы скопировать список на новое место, сделайте следующее:
- Выберите отфильтрованные значения с помощью мыши или вышеупомянутых комбинаций клавиш.
- Нажмите
Ctrl + Cдля копирования выбранных значений. - Выберите верхнюю левую ячейку в целевом диапазоне (она может находиться на том же или другом листе) и нажмите Ctrl + V , чтобы вставить данные.
Выделение цветом уникальных значений в столбце.
Всякий раз, когда вам нужно выделить что-либо в Excel на основе определенного условия, перейдите прямо к функции условного форматирования. Более подробная информация и примеры приведены ниже.
Самый быстрый и простой способ выделить уникальные значения в Excel — применить встроенное правило условного форматирования:
- Выберите столбец данных, в котором вы хотите выделить уникальные.
- На вкладке Главная в группе Стили щелкните Условное форматирование > Правила выделения ячеек > Повторяющиеся значения …

- В диалоговом окне « Повторяющиеся значения » выберите «Уникальный» в левом поле и выберите желаемое форматирование в правом поле, затем нажмите « ОК» .

Совет. Если вас не устраивает какой-либо из предопределенных форматов, щелкните «Пользовательский формат …» (последний элемент в раскрывающемся списке) и установите цвет заливки и / или шрифта по своему вкусу.
Как видите, выделение уникальных значений в Excel — самая простая задача, которую можно себе представить. Однако встроенное правило Excel работает только для элементов, которые появляются в списке только один раз. Если вам нужно выделить различные значения — уникальные и первые вхождения дубликатов — то придется создать собственное правило на основе формулы.
Вам также потребуется создать настраиваемое правило для выделения уникальных строк на основе значений в одном или нескольких столбцах.
Как создать правило для условного форматирования уникальных значений?
Чтобы выделить уникальные или различные значения в столбце, выберите диапазон ячеек без заголовка столбца (вы же не хотите, чтобы заголовок выделялся, не так ли?) Затем создайте правило условного форматирования с помощью формулы.
Чтобы создать правило условного форматирования на основе формулы, выполните следующие действия:
- Перейдите на вкладку «Главная » и щелкните « Условное форматирование» > « Новое правило» > «Использовать формулу», чтобы с ее помощью определить, какие ячейки нужно форматировать .
- Введите формулу в поле «Форматировать значения …».
- Нажмите кнопку «Формат …» и выберите нужный цвет заливки и/или цвет шрифта.
- Наконец, нажмите кнопку ОК , чтобы применить правило.

Более подробные инструкции см. в статье: Как создать правила условного форматирования Excel на основе другого значения ячейки .
А теперь поговорим о том, какие формулы использовать и в каких случаях.
Выделяем цветом отдельные уникальные значения.
Чтобы выделить значения, которые появляются в списке только один раз, используйте следующую формулу:
=СЧЁТЕСЛИ($A$2:$A$10;$A2)=1
Где A2 — первая, а A10 — последняя ячейка диапазона.
Чтобы выделить все различные значения в столбце, то есть встречающиеся хотя бы однажды, используйте это выражение:
= СЧЁТЕСЛИ($A$2:$A2;$A2)=1
Где A2 — самая верхняя ячейка диапазона.
Как выделить строку с уникальным значением в одном столбце.
Чтобы выделить целые строки на основе уникальных значений в определенном столбце, используйте формулы, которые мы использовали в предыдущем примере, но применяйте правило ко всей таблице, а не к одному столбцу.
На следующем скриншоте показано, как выглядит правило, выделяющее строки на основе уникальных значений в столбце A:

Как видите, формула
=СЧЁТЕСЛИ($A$2:$A$10;$A2)=1
та же самая, что и раньше, но строка в диапазоне выделена вся.
А можно использовать и такое выражение:
=СУММ(Ч($A2&$B2=$A$2:$A$10&$B$2:$B$10))<2
Результат будет таким же.
Как выделить уникальные строки?
Если вы хотите выделить строки на основе значений в двух или более столбцах, используйте функцию СЧЁТЕСЛИМН, которая позволяет указать несколько критериев в одной формуле.
Чтобы выделить уникальные строки:
=СЧЁТЕСЛИМН($A$2:$A$10;$A2; $B$2:$B$10;$B2)=1
Чтобы выделить различные строки:
=СЧЁТЕСЛИМН($A$2:$A2;$A2; $B$2:$B2;$B2)=1

Быстрый и простой способ найти и выделить уникальные значения
Как вы только что видели, Microsoft Excel предоставляет довольно много полезных функций, которые могут помочь вам идентифицировать и выделять уникальные значения на ваших листах.
Однако все эти решения сложно назвать интуитивно понятными и простыми в использовании, поскольку они требуют запоминания нескольких различных формул. Конечно, для профессионалов Excel в этом нет ничего страшного
Для тех пользователей Excel, которые хотят сэкономить свое время и силы, позвольте мне показать быстрый и простой способ поиска уникальных значений в Excel.
В этом последнем разделе нашего сегодняшнего руководства мы собираемся использовать надстройку Duplicate Remover для Excel. Пожалуйста, пусть вас не смущает название инструмента. Помимо повторяющихся записей, он может отлично обрабатывать уникальные и различные записи.
Давайте посмотрим.
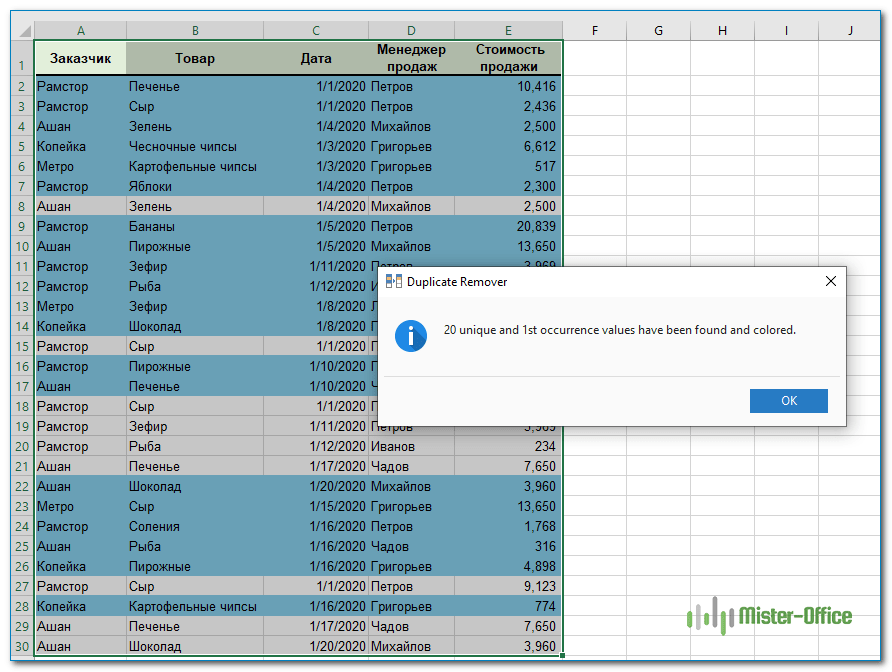
- Выберите любую ячейку в таблице, в которой вы хотите найти уникальные значения, и нажмите кнопку DuplicateRemover на вкладке AblebitsData в группе Dedupe.

Мастер запустится, и вся таблица будет выбрана автоматически. Итак, просто нажмите « Далее», чтобы перейти к следующему шагу.

- В зависимости от вашей цели выберите один из следующих вариантов и нажмите Далее :
- Уникальные
- Уникальные + 1е вхождения (различные)

- Выберите один или несколько столбцов, в которых вы хотите проверить значения.
В этом примере мы хотим найти уникальные сочетания Заказчик + Товар на основе значений в двух столбцах. Их и выбираем при помощи галочки. - Выберите один или несколько столбцов, в которых вы хотите проверить значения.

Если у вашей таблицы есть заголовки, обязательно установите флажок Mytable has headers. И если в вашей таблице могут встретиться пустые ячейки, то убедитесь, что установлен флажок Skipempty cells. Оба параметра находятся в верхней части диалогового окна и обычно выбираются по умолчанию.
Если вдруг в наших записях случайно появились лишние пробелы, то, думаю, стоит их игнорировать. Поэтому отмечаем также Ignore extra spaces.
Также наш поиск буден нечувствителен к регистру, то есть не будем при сравнении данных различать прописные и строчные буквы. Поэтому не активируем опцию Case-sensitive match.
- Выберите одно из следующих действий, которые нужно выполнить с найденными значениями:
- Выделить цветом.
- Выбрать и выделить.
- Отметить в колонке статуса.
- Копировать в другое место.

Если вы выберете опцию Select values, то все найденные значения окажутся выделенными, как будто вы кликали на них мышкой при нажатой клавише Ctrl. Пока они выделены, вы можете изменить их цвет фона и шрифта, границы и т.д. К сожалению, скопировать либо переместить их никуда не получится, так как такую операцию не поддерживает Excel.
В нашем случае чтобы найти уникальные значения, вполне достаточно будет просто выделить их цветом. Поэтому выберем Highlight with color.
Нажмите кнопку «Готово» и получите результат:
Вот как вы можете находить, выбирать и выделять уникальные значения в Excel с помощью надстройки Duplicate Remover. Это действительно просто, не правда ли?
Я рекомендую вам загрузить полнофункциональную ознакомительную версию Ultimate Suite и попробовать в работе Duplicate Remover и множество других инструментов, которые помогут сэкономить вам кучу времени при работе в Excel.
Хитрости »
1 Май 2011 532061 просмотров
Как получить список уникальных(не повторяющихся) значений?
Представим себе большой список различных наименований, ФИО, табельных номеров и т.п. А необходимо из этого списка оставить список все тех же наименований, но чтобы они не повторялись — т.е. удалить из этого списка все дублирующие записи. Как это иначе называют: создать список уникальных элементов, список неповторяющихся, без дубликатов. Для этого существует несколько способов: встроенными средствами Excel, встроенными формулами и, наконец, при помощи кода Visual Basic for Application(VBA) и сводных таблиц. В этой статье рассмотрим каждый из вариантов.
- При помощи встроенных возможностей Excel 2007 и выше
- При помощи Расширенного фильтра
- При помощи формул
- При помощи кодов Visual Basic for Application(VBA) — макросы, включая универсальный код выборки из произвольного диапазона
- При помощи сводных таблиц
В Excel 2007 и 2010 это сделать проще простого — есть специальная команда, которая так и называется — Удалить дубликаты (Remove Duplicates). Расположена она на вкладке Данные (Data) подраздел Работа с данными (Data tools)

Как использовать данную команду. Выделяете столбец(или несколько) с теми данными, в которых надо удалить дублирующие записи. Идете на вкладку Данные (Data) —Удалить дубликаты (Remove Duplicates).
Если выделить один столбец, но рядом с ним будут еще столбцы с данными(или хотя бы один столбец), то Excel предложит выбрать: расширить диапазон выборки этим столбцом или оставить выделение как есть и удалить данные только в выделенном диапазоне. Важно помнить, что если не расширить диапазон, то данные будут изменены лишь в одном столбце, а данные в прилегающем столбце останутся без малейших изменений.
Появится окно с параметрами удаления дубликатов

Ставите галочки напротив тех столбцов, дубликаты в которых надо удалить и жмете Ок. Если в выделенном диапазоне так же расположены заголовки данных, то лучше поставить флаг Мои данные содержат заголовки, чтобы случайно не удалить данные в таблице(если они вдруг полностью совпадают со значением в заголовке).
Способ 1: Расширенный фильтр
В случае с Excel 2003 все посложнее. Там нет такого инструмента, как Удалить дубликаты. Но зато есть такой замечательный инструмент, как Расширенный фильтр. В 2003 этот инструмент можно найти в Данные —Фильтр —Расширенный фильтр. Прелесть этого метода в том, с его помощью можно не портить исходные данные, а создать список в другом диапазоне.
В 2007-2010 Excel, он тоже есть, но немного запрятан. Расположен на вкладке Данные (Data), группа Сортировка и фильтр (Sort & Filter) — Дополнительно (Advanced)
Как его использовать: запускаем указанный инструмент — появляется диалоговое окно:

- Обработка: Выбираем Скопировать результат в другое место (Copy to another location).
- Исходный диапазон (List range): Выбираем диапазон с данными(в нашем случае это А1:А51).
- Диапазон критериев (Criteria range): в данном случае оставляем пустым.
- Поместить результат в диапазон (Copy to): указываем первую ячейку для вывода данных — любую пустую(на картинке — E2).
- Ставим галочку Только уникальные записи (Unique records only).
- Жмем Ок.
Примечание: если вы хотите поместить результат на другой лист, то просто так указать другой лист не получится. Вы сможете указать ячейку на другом листе, но…Увы и ах…Excel выдаст сообщение, что не может скопировать данные на другие листы. Но и это можно обойти, причем довольно просто. Надо всего лишь запустить Расширенный фильтр с того листа, на который хотим поместить результат. А в качестве исходных данных выбираем данные с любого листа — это дозволено.
Так же можно не выносить результат в другие ячейки, а отфильтровать данные на месте. Данные от этого никак не пострадают — это будет обычная фильтрация данных.
Для этого надо просто в пункте Обработка выбрать Фильтровать список на месте (Filter the list, in-place).
Способ 2: Формулы
Этот способ сложнее в понимании для неопытных пользователей, но зато он создает список уникальных значений, не изменяя при этом исходные данные. Ну и он более динамичен: если изменить данные в исходной таблице, то изменится и результат. Иногда это бывает полезно. Попытаюсь объяснить на пальцах что и к чему: допустим, список с данными у Вас расположен в столбце
А
(
А1:А51
, где
А1
— заголовок). Выводить список мы будем в столбец
С
, начиная с ячейки
С2
. Формула в
C2
будет следующая:
{=ИНДЕКС($A$2:$A$51;НАИМЕНЬШИЙ(ЕСЛИ(СЧЁТЕСЛИ($C$1:C1;$A$2:$A$51)=0;СТРОКА($A$1:$A$50));1))}
{=INDEX($A$2:$A$51;SMALL(IF(COUNTIF($C$1:C1;$A$2:$A$51)=0;ROW($A$1:$A$50));1))}
Детальный разбор работы данной формулы приведен в статье: Как просмотреть этапы вычисления формул
Надо отметить, что эта формула является формулой массива. Об этом могут сказать фигурные скобки, в которые заключена данная формула. А вводится такая формула в ячейку сочетанием клавиш —
Ctrl
+
Shift
+
Enter
(при этом сами скобки вводить не надо — они появятся сами после ввода формулы тремя клавишами
Ctrl
+
Shift
+
Enter
). После того, как мы ввели эту формулу в
C2
мы её должны скопировать и вставить в несколько строк так, чтобы точно отобразить все уникальные элементы. Как только формула в нижних ячейках вернет
#ЧИСЛО!(#NUM!)
— это значит все элементы отображены и ниже протягивать формулу нет смысла. Чтобы ошибку избежать и сделать формулу более универсальной(не протягивая каждый раз до появления ошибки) можно использовать нехитрую проверку:
для Excel 2007 и выше:
{=ЕСЛИОШИБКА(ИНДЕКС($A$2:$A$51;НАИМЕНЬШИЙ(ЕСЛИ(СЧЁТЕСЛИ($C$1:C1;$A$2:$A$51)=0;СТРОКА($A$1:$A$50));1));»»)}
{=IFERROR(INDEX($A$2:$A$51;SMALL(IF(COUNTIF($C$1:C1;$A$2:$A$51)=0;ROW($A$1:$A$50));1));»»)}
для Excel 2003:
{=ЕСЛИ(ЕОШ(НАИМЕНЬШИЙ(ЕСЛИ(СЧЁТЕСЛИ($C$1:C1;$A$2:$A$51)=0;СТРОКА($A$1:$A$50));1));»»;ИНДЕКС($A$2:$A$51;НАИМЕНЬШИЙ(ЕСЛИ(СЧЁТЕСЛИ($C$1:C1;$A$2:$A$51)=0;СТРОКА($A$1:$A$50));1)))}
{=IF(ISERR(SMALL(IF(COUNTIF($C$1:C1;$A$2:$A$51)=0;ROW($A$1:$A$50));1));»»;INDEX($A$2:$A$51;SMALL(IF(COUNTIF($C$1:C1;$A$2:$A$51)=0;ROW($A$1:$A$50));1)))}
Тогда вместо ошибки
#ЧИСЛО!(#NUM!)
у вас будут пустые ячейки(не совсем пустые, конечно — с формулами :-)).
Чуть подробнее про отличия и нюансы формул ЕСЛИОШИБКА и ЕСЛИ(ЕОШ можно прочесть в этой статье: Как в ячейке с формулой вместо ошибки показать 0
Для пользователей Excel 2021 выше, а так же пользователей Excel 365(с активной подпиской) — использовать формулы для извлечения уникальных элементов проще простого. В этих версиях появилась функция
УНИК(UNIQUE)
, которая как раз получает список уникальных значений на основании переданного диапазона:
=УНИК($A$2:$A$51)
=UNIQUE($A$2:$A$51)
Что самое важное в данном случае — это функция динамического массива и вводить её надо только в одну ячейку C2, а результат она поместит сама в нужное количество ячеек.
Способ 3: код VBA
Данный подход потребует разрешения макросов и базовых знаний о работе с ними. Если не уверены в своих знаниях для начала рекомендую прочитать эти статьи:
- Что такое макрос и где его искать? к статье приложен видеоурок
- Что такое модуль? Какие бывают модули? потребуется, чтобы понять куда вставлять приведенные ниже коды
Оба приведенных ниже кода следует помещать в стандартный модуль. Макросы должны быть разрешены.
Исходные данные оставим в том же порядке — список с данными расположен в столбце «А«(А1:А51, где А1 — заголовок). Только выводить список мы будем не в столбец С, а в столбец Е, начиная с ячейки Е2:
Sub Extract_Unique() Dim vItem, avArr, li As Long ReDim avArr(1 To Rows.Count, 1 To 1) With New Collection On Error Resume Next For Each vItem In Range("A2", Cells(Rows.Count, 1).End(xlUp)).Value 'Cells(Rows.Count, 1).End(xlUp) – определяет последнюю заполненную ячейку в столбце А .Add vItem, CStr(vItem) If Err = 0 Then li = li + 1: avArr(li, 1) = vItem Else: Err.Clear End If Next End With If li Then [E2].Resize(li).Value = avArr End Sub
С помощью данного кода можно извлечь уникальные не только из одного столбца, но и из любого диапазона столбцов и строк. Если вместо строки
Range(«A2», Cells(Rows.Count, 1).End(xlUp)).Value
указать Selection.Value, то результатом работы кода будет список уникальных элементов из выделенного на активном листе диапазона. Только тогда неплохо бы и ячейку вывода значений изменить — вместо [E2] поставить ту, в которой данных нет.
Так же можно указать конкретный диапазон:
Или другой столбец:
Range("C2", Cells(Rows.Count, 3).End(xlUp)).Value
здесь отдельно стоит обратить внимание то, что в данном случае помимо изменения А2 на С2 изменилась и цифра 1 на 3. Это указание на номер столбца, в котором необходимо определить последнюю заполненную ячейку, чтобы код не просматривал лишние ячейки. Подробнее про это можно прочитать в статье: Как определить последнюю ячейку на листе через VBA?
Универсальный код выбора уникальных значений
Код ниже можно применять для любых диапазонов. Достаточно запустить его, указать диапазон со значениями для отбора только неповторяющихся(допускается выделение более одного столбца) и ячейку для вывода результата. Указанные ячейки будут просмотрены, из них будут отобраны только уникальные значения(пустые ячейки при этом пропускаются) и результирующий список будет записан, начиная с указанной ячейки.
Sub Extract_Unique() Dim x, avArr, li As Long Dim avVals Dim rVals As Range, rResultCell As Range On Error Resume Next 'запрашиваем адрес ячеек для выбора уникальных значений Set rVals = Application.InputBox("Укажите диапазон ячеек для выборки уникальных значений", "Запрос данных", "A2:A51", Type:=8) If rVals Is Nothing Then 'если нажата кнопка Отмена Exit Sub End If 'если указана только одна ячейка - нет смысла выбирать If rVals.Count = 1 Then MsgBox "Для отбора уникальных значений требуется указать более одной ячейки", vbInformation, "www.excel-vba.ru" Exit Sub End If 'отсекаем пустые строки и столбцы вне рабочего диапазона Set rVals = Intersect(rVals, rVals.Parent.UsedRange) 'если указаны только пустые ячейки вне рабочего диапазона If rVals Is Nothing Then MsgBox "Недостаточно данных для выбора значений", vbInformation, "www.excel-vba.ru" Exit Sub End If avVals = rVals.Value 'запрашиваем ячейку для вывода результата Set rResultCell = Application.InputBox("Укажите ячейку для вставки отобранных уникальных значений", "Запрос данных", "E2", Type:=8) If rResultCell Is Nothing Then 'если нажата кнопка Отмена Exit Sub End If 'определяем максимально возможную размерность массива для результата ReDim avArr(1 To Rows.Count, 1 To 1) 'при помощи объекта Коллекции(Collection) 'отбираем только уникальные записи, 'т.к. Коллекции не могут содержать повторяющиеся значения With New Collection On Error Resume Next For Each x In avVals If Len(CStr(x)) Then 'пропускаем пустые ячейки .Add x, CStr(x) 'если добавляемый элемент уже есть в Коллекции - возникнет ошибка 'если же ошибки нет - такое значение еще не внесено, 'добавляем в результирующий массив If Err = 0 Then li = li + 1 avArr(li, 1) = x Else 'обязательно очищаем объект Ошибки Err.Clear End If End If Next End With 'записываем результат на лист, начиная с указанной ячейки If li Then rResultCell.Cells(1, 1).Resize(li).Value = avArr End Sub
Способ 4: Сводные таблицы
Несколько нестандартный способ извлечения уникальных значений.
- Выделяем один или несколько столбцов в таблице, переходим на вкладку Вставка(Insert) -группа Таблица(Table) —Сводная таблица(PivotTable)
- В диалоговом окне Создание сводной таблицы(Create PivotTable) проверяем правильность выделения диапазона данных (или установить новый источник данных)
- указываем место размещения Сводной таблицы:
- На новый лист (New Worksheet)
- На существующий лист (Existing Worksheet)
- подтверждаем создание нажатием кнопки OK
Т.к. сводные таблицы при обработке данных, которые помещаются в область строк или столбцов, отбирают из них только уникальные значения для последующего анализа, то от нас ровным счетом ничего не требуется, кроме как создать сводную таблицу и поместить в область строк или столбцов данные нужного столбца.
На примере приложенного к статье файла я:
- выделил диапазон A1:B51 на листе Извлечение по критерию
- вызвал меню вставки сводной таблицы: вкладка Вставка(Insert) -группа Таблица(Table) —Сводная таблица(PivotTable)
выбрал вставить на новый лист(New Worksheet) - назвал этот лист Уникальные сводной таблицей
- поле Данные поместил в область строк
- поле ФИО в область фильтра. Почему? Чтобы удобно было выбирать одно или несколько ФИО и в сводной отображался бы список уникальных месяцев только для выбранных фамилий


В чем неудобство работы со сводными в данном случае: при изменении в исходных данных сводную таблицу придется обновлять вручную: Выделить любую ячейку сводной таблицы -Правая кнопка мыши —Обновить(Refresh) или вкладка Данные(Data) —Обновить все(Refresh all) —Обновить(Refresh). А если исходные данные пополняются динамически и того хуже — надо будет заново указывать диапазон исходных данных. И еще один минус — данные внутри сводной таблицы нельзя менять. Поэтому если с полученным списком необходимо будет работать в дальнейшем, то после создания нужного списка при помощи сводной его надо скопировать и вставить на нужный лист.
Чтобы лучше понимать все действия и научиться обращаться со сводными таблицами настоятельно рекомендую ознакомиться со статьей Общие сведения о сводных таблицах — к ней приложен видеоурок, в котором я наглядно демонстрирую простоту и удобство работы с основными возможностями сводных таблиц.
В приложенном примере помимо описанных приемов, записана чуть более сложная вариация извлечения уникальных элементов формулой и кодом, а именно: извлечение уникальных элементов по критерию. О чем речь: если в одном столбце фамилии, а во втором(В) некие данные(в файле это месяцы) и требуется извлечь уникальные значения столбца В только для выбранной фамилии. Примеры подобных извлечений уникальных расположены на листе Извлечение по критерию.
Скачать пример:
 Tips_All_ExtractUnique.xls (108,0 KiB, 18 431 скачиваний)
Tips_All_ExtractUnique.xls (108,0 KiB, 18 431 скачиваний)
Также см.:
Работа с дубликатами
Как подсчитать количество повторений
Общие сведения о сводных таблицах
Статья помогла? Поделись ссылкой с друзьями!
![]() Видеоуроки
Видеоуроки
Поиск по меткам
Access
apple watch
Multex
Power Query и Power BI
VBA управление кодами
Бесплатные надстройки
Дата и время
Записки
ИП
Надстройки
Печать
Политика Конфиденциальности
Почта
Программы
Работа с приложениями
Разработка приложений
Росстат
Тренинги и вебинары
Финансовые
Форматирование
Функции Excel
акции MulTEx
ссылки
статистика
Подсчет уникальных значений в Excel
В этом руководстве вы узнаете, как подсчитывать уникальные значения в Excel с помощью формул и как это делать в сводной таблице. Мы также рассмотрим несколько примеров подсчета уникальных текстовых и числовых значений, в том числе с учетом регистра.
При работе с большим набором данных в Excel вам часто может потребоваться знать, сколько повторяющихся записей находится в таблице и сколько уникальных записей.
Если вы регулярно посещаете этот блог, вы уже знаете формулу Excel для подсчета дубликатов. Сегодня мы собираемся изучить различные способы подсчета уникальных значений в Excel. Но для ясности давайте сначала определим термины.
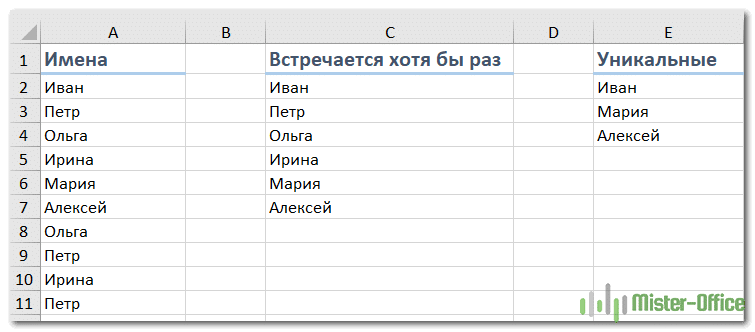
- Уникальные значения — это те, которые появляются в списке только один раз.
- Различные — это все, что есть в списке без учета повторений, т.е уникальные плюс первое появление повторяющихся.
Следующий рисунок иллюстрирует эту разницу:
Теперь давайте посмотрим, как их вычислить с помощью формул и функций сводной таблицы.
Ниже вы найдете несколько примеров для подсчета уникальных данных разных типов.
Считаем уникальные значения в столбце.
Предположим, у вас есть столбец имен на листе Excel, и вам нужно подсчитать, сколько их не дубликатов. Самое простое решение — использовать функцию СУММ в сочетании с ЕСЛИ и СЧЁТЕСЛИ :
= СУММ (ЕСЛИ (СЧЁТЕСЛИ (диапазон; диапазон) = 1,1,0))
Примечание. Это формула массива, поэтому обязательно нажмите Ctrl + Shift + Enter, чтобы ввести ее правильно. Как только это будет сделано, Excel автоматически заключит все выражение в {фигурные скобки}, как показано на снимке экрана ниже. Фигурные скобки ни в коем случае нельзя вводить вручную, не получится.
В этом примере мы подсчитываем уникальные имена в диапазоне A2: A10, поэтому наше выражение выглядит так:
{= СУММ (ЕСЛИ (СЧЁТЕСЛИ (A2: A10; A2: A10) = 1, 1, 0))}
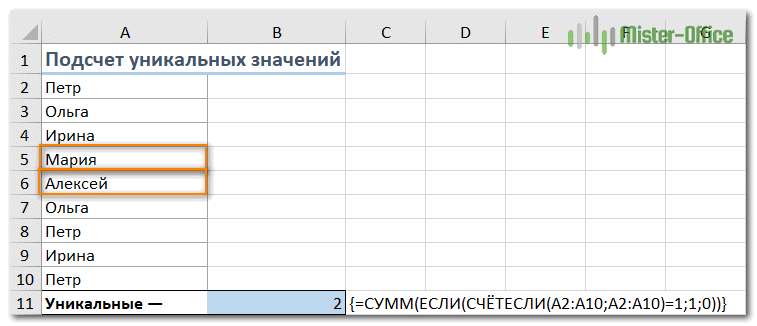
Этот метод подходит как для текстовых, так и для цифровых данных. Обратной стороной является то, что, будучи уникальным, он будет пересчитывать любой контент, включая ошибки.
Позже в этом руководстве мы обсудим несколько других подходов для подсчета уникальных значений разных типов. И поскольку в основном это вариации этой базовой формулы, имеет смысл присмотреться к ней поближе. Если вы понимаете, как это работает, вы можете настроить его для своих данных. Если кого-то не интересуют технические детали, можете сразу перейти к следующему примеру.
Как работает формула подсчета уникальных значений?
Как видите, здесь используются 3 разные функции: СУММ, ЕСЛИ и СЧЁТЕСЛИ. Посмотрим, что делает каждый из них:
- Функция СЧЁТЕСЛИ подсчитывает, сколько раз каждое отдельное значение появляется в анализируемом диапазоне.
В этом примере СЧЁТЕСЛИ (A2: A10; A2: A10) возвращает матрицу {3: 2: 2: 1: 1: 2: 3: 2: 3}.
- Функция ЕСЛИ оценивает каждый элемент в этом массиве, сохраняет все единицы (то есть уникальные) и заменяет все остальные цифры нулями.
Затем функция ЕСЛИ (СЧЁТЕСЛИ (A2: A10; A2: A10) = 1; 1; 0) преобразуется в ЕСЛИ ({3: 2: 2: 1: 1: 2: 3: 2: 3}) = 1,1, 0).
А затем он превращается в массив чисел {0: 0: 0: 1: 1: 0: 0: 0: 0}. Здесь 1 означает уникальное значение, а 0 означает, что оно встречается более 1 раза.
- Наконец, функция СУММ складывает числа в этот последний массив и возвращает общее количество уникальных значений. Что нам нужно.
Совет. Чтобы увидеть, как определенная часть выражения дает результаты, выберите эту часть в строке формул и нажмите функциональную клавишу F9.
Подсчет уникальных текстовых значений.
Если ваш список содержит как числа, так и текст, и вы хотите подсчитывать только уникальные текстовые строки, добавьте функцию ETEXT () к приведенной выше формуле массива:
{= СУММ (ЕСЛИ (ETEXT (A2: A10) * СЧЁТЕСЛИ (A2: A10; A2: A10) = 1; 1; 0))}
Функция ETEXT возвращает TRUE, если исследуемая ячейка является текстовой, и FALSE в противном случае. Поскольку звездочка (*) в формулах массива работает как оператор И, функция ЕСЛИ возвращает 1 только в том случае, если она считается как текстовой, так и уникальной, в противном случае мы получаем 0. И после того, как функция СУММ сложит все числа, вы получите количество уникальные текстовые значения в указанном диапазоне.
Не забудьте нажать Ctrl + Shift + Enter, чтобы правильно ввести формулу массива, и вы получите следующий результат:

Как вы можете видеть на скриншоте выше, мы получили общее количество уникальных текстовых значений, исключая пустые ячейки, числа, логические выражения и ошибки ИСТИНА и ЛОЖЬ.
Как сосчитать уникальные числовые значения.
Чтобы подсчитать уникальные числа в списке данных, используйте формулу массива, как мы только что сделали для подсчета текстовых данных. Разница в том, что вы используете ISNUMBER вместо ETEXT:
{= СУММ (ЕСЛИ (ЕЧИСЛО (A2: A10) * СЧЁТЕСЛИ (A2: A10; A2: A10) = 1; 1; 0))}
Вы можете увидеть пример и результат на скриншоте чуть выше.
Примечание. Поскольку Microsoft Excel хранит дату и время в виде чисел, они также участвуют в вычислениях.
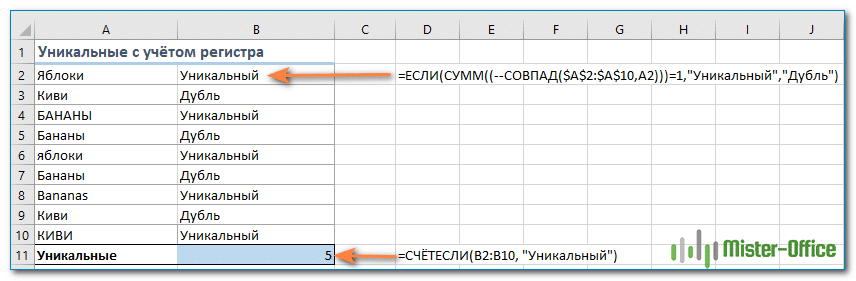
Уникальные значения с учетом регистра.
Если разница между прописными и строчными буквами критична для вас, самый простой способ подсчета — создать вспомогательный столбец со следующей формулой массива для определения повторяющихся и уникальных элементов:
{= ЕСЛИ (СУММ ((- ТОЧНЫЙ ($ A $ 2: $ A $ 10, A2))) = 1; «Уникальный»; «Двойной»)}
А затем используйте простую функцию СЧЁТЕСЛИ для подсчета уникальных значений:
= СЧЁТЕСЛИ (B2: B10; «Уникальный»)
Теперь посмотрим, как можно подсчитать количество значений, которые появляются хотя бы один раз, то есть так называемых разных значений.
Подсчет различных значений.
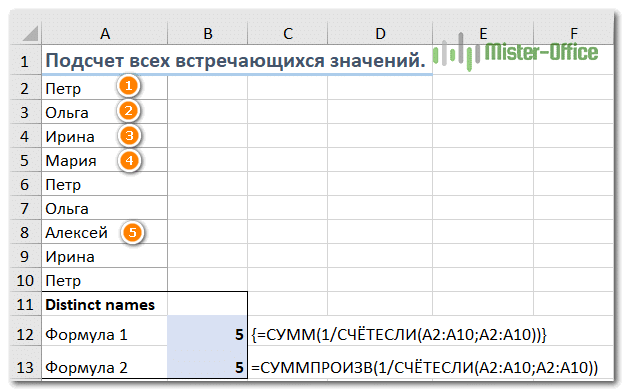
Используйте следующее общее выражение:
{= СУММ (1 / СЧЁТЕСЛИ (диапазон; диапазон))}
Помните, что это формула массива, поэтому вам следует нажать Ctrl + Shift + Enter вместо обычного Enter.
В качестве альтернативы вы можете использовать функцию СУММПРОИЗВ и написать формулу обычным способом:
= СУММПРОИЗВ (1 / СЧЁТЕСЛИ (интервал; интервал))
Например, чтобы подсчитать различные значения в диапазоне A2: A10, вы можете использовать выражение:
{= СУММ (1 / СЧЁТЕСЛИ (A2: A10; A2: A10))}
или
= СУММПРОИЗВ (1 / СЧЁТЕСЛИ (A2: A10; A2: A10))
Этот метод подходит не только для подсчета в столбце, но и для диапазона данных. Например, у нас есть два столбца для имен. Итак, давайте сделаем это:
{= СУММПРОИЗВ (1 / СЧЁТЕСЛИ (A2: B10; A2: B10))}
Этот способ подходит для текста, чисел, дат.
Единственное ограничение — диапазон должен быть непрерывным и не содержать пустых ячеек или ошибок.
Если у вас есть пустые ячейки в диапазоне данных, вы можете изменить:
{= СУММПРОИЗВ (1 / СЧЁТЕСЛИ (A2: A10; A2: A10&»»))}
Тогда пустая ячейка будет включена в расчет и будет засчитана.
Как это работает?
Как вы уже знаете, мы используем функцию СЧЁТЕСЛИ, чтобы узнать, сколько раз каждый отдельный элемент встречается в указанном диапазоне. В приведенном выше примере результатом функции СЧЁТЕСЛИ является числовой массив: {3: 2: 2: 1: 3: 2: 1: 2: 3}.
Затем выполняется серия операций деления, в которых одна делится на каждую цифру этой матрицы. Это преобразует все неуникальные значения в дробные числа, соответствующие количеству повторений. Например, если число или текст появляется в списке 2 раза, в массиве создаются 2 элемента, равных 0,5 (1/2 = 0,5). А если он встречается 3 раза, то в массиве создаются 3 элемента из 0,333333.
В нашем примере результатом вычисления выражения 1 / COUNTIF (A2: A10; A2: A10) является массив {0,3333333333333333: 0,5: 0,5: 1: 0,333333333333333: 0,5: 1: 0,5: 0,333333333333333}.
Все еще не совсем ясно? Это потому, что мы еще не применили функцию СУММ / СУММПРОИЗВ. Когда одна из этих функций добавляет числа в массив, сумма всех дробных чисел для любого отдельного элемента всегда дает 1, независимо от того, сколько раз оно встречается. И поскольку все уникальные элементы отображаются в массиве как единицы (1/1 = 1), конечный результат — это сумма всех значений, которые встречаются.
Как и в случае с подсчетом уникальных значений в Excel, вы можете использовать универсальные параметры формулы для обработки чисел, текста или чувствительности к регистру.
Помните, что все следующие выражения являются формулами массива и требуют нажатия Ctrl + Shift + Enter.
Подсчет различных значений без учета пустых ячеек
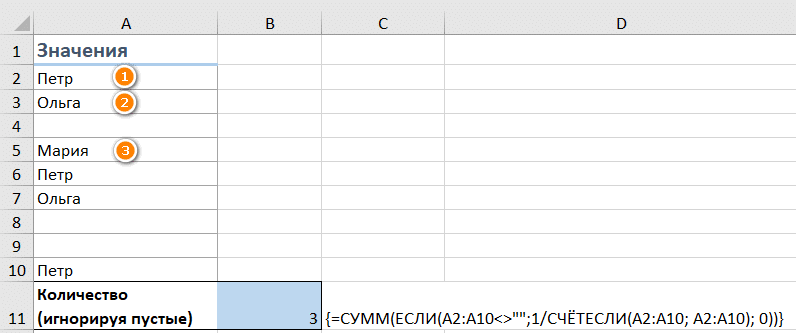
Если столбец, который вы хотите подсчитать, может содержать пустые ячейки, вам следует добавить функцию ЕСЛИ к уже знакомой формуле массива. Он проверит ячейки на наличие пробелов (в этом случае базовая формула Excel, описанная выше, вернет ошибку # DIV / 0):
= СУММ (ЕСЛИ (диапазон «»; 1 / СЧЁТЕСЛИ (диапазон; диапазон); 0))
Вот как, например, можно подсчитать количество отдельных значений, игнорируя пустые ячейки:
Мы используем:
{= СУММ (ЕСЛИ (A2: A10 «»; 1 / СЧЁТЕСЛИ (A2: A10; A2: A10), 0))}
Как видите, наш список состоит из трех имен.
Подсчет различных чисел.
Чтобы подсчитать несколько числовых значений (числа, даты и время), используйте функцию ЕЧИСЛО:
= СУММ (ЕСЛИ (ЕЧИСЛО (диапазон); 1 / СЧЁТЕСЛИ (диапазон; диапазон); «»))
Посчитаем, сколько разных чисел находится в диапазоне A2: A10:
{= СУММ (ЕСЛИ (ЕЧИСЛО (A2: A10), 1 / СЧЁТЕСЛИ (A2: A10, A2: A10);»»))}
Вы можете увидеть результат ниже.

Это довольно простое и элегантное решение, но оно намного медленнее, чем выражения, использующие функцию ЧАСТОТА для подсчета уникальных значений. Если у вас большие наборы данных, мы рекомендуем перейти на частотную формулу.
А вот еще один способ считать числа:
= СУММ (- (ЧАСТОТА (диапазон; диапазон)> 0))
Применяется к следующему примеру:
= СУММ (- (ЧАСТОТА (A2: A10; A2: A10)> 0))
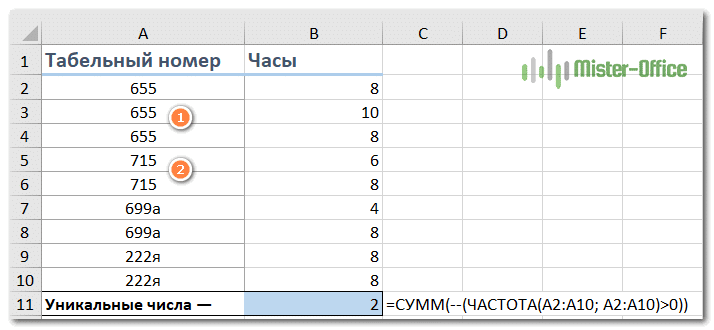
Как видите, записи, содержащие буквы, здесь игнорируются.
Посмотрим, как это работает пошагово.
Функция ЧАСТОТА возвращает массив цифр, которые соответствуют диапазонам, указанным доступными числами. В этом случае мы сравниваем один и тот же набор чисел для массива данных и для массива диапазонов.
В результате FREQUENCY () возвращает массив, который является счетчиком для каждого числового значения в массиве данных.
Это работает, потому что FREQUENCY () возвращает ноль для всех чисел, которые ранее появлялись в списке. Ноль также возвращается для текстовых данных. Таким образом, получившийся массив выглядит так:
{3: 0: 0: 2: 0: 0}
Как видите, обрабатываются только числа. Ячейки A7: A10 игнорируются, поскольку в них есть текст. А функция ЧАСТОТА () работает только с числами.
Теперь давайте проверим каждое из этих чисел на наличие условия «больше нуля».
У нас есть:
{ИСТИНА: ЛОЖЬ: ЛОЖЬ: ИСТИНА: ЛОЖЬ: ЛОЖЬ}
Теперь установите TRUE и FALSE соответственно на 1 и 0. Мы делаем это с двойным отрицанием. Проще говоря, это двойной минус, который не меняет величину числа, но позволяет по возможности получать действительные числа:
{1: 0: 0: 1: 0: 0}
А теперь функция СУММ складывает все, и мы получаем результат: 2.
Примечание. Вы можете легко использовать СУММПРОИЗВ вместо функции СУММ.
Различные текстовые значения.
Чтобы подсчитать отдельные текстовые записи в столбце, мы будем использовать тот же подход, что и для исключения пустых ячеек.
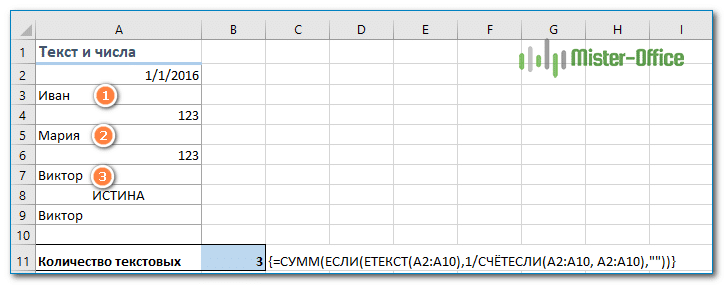
Как нетрудно догадаться, мы просто добавим функцию ETEXT и проверку состояния:
= СУММ (ЕСЛИ (ETEXT (диапазон); 1 / СЧЁТЕСЛИ (диапазон; диапазон); «»))
Рассчитываем количество отдельных символьных значений следующим образом:
{= СУММ (ЕСЛИ (ETEXT (A2: A10), 1 / СЧЁТЕСЛИ (A2: A10, A2: A10);»»))}
Не забывайте, что это формула массива.
Если в вашей таблице нет пустых ячеек и ошибок, вы можете применить формулу, которая использует несколько функций: ЧАСТОТА, ПОИСК, СТРОКА и СУММПРОИЗВ.
В целом это выглядит так:
= СУММПРОИЗВ (- (ЧАСТОТА (ПОИСК (диапазон; диапазон; 0); СТРОКА (диапазон) — СТРОКА (диапазон_первый_ячейка) +1)> 0))
Предположим, у вас есть список имен сотрудников с указанием часов, в течение которых они работали над проектом, и вы хотите знать, сколько людей было задействовано. Глядя на данные, можно увидеть, что названия повторяются. И вы хотите посчитать всех, кто хоть раз попадал в этот список.
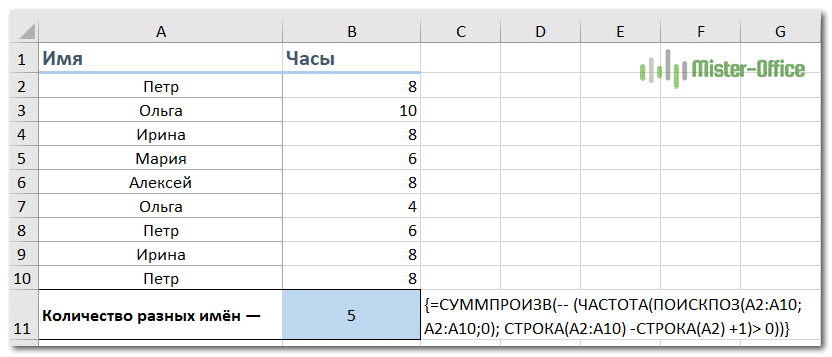
Применяем формулу массива:
{= СУММПРОИЗВ (- (ЧАСТОТА (ПОИСК (A2: A10; A2: A10,0); СТРОКА (A2: A10) -ЛИНИЯ (A2) +1)> 0))}
это сложнее, чем использование функции ЧАСТОТА () для подсчета разных чисел. Это потому, что FREQUENCY () не работает с текстом. Следовательно, MATCH преобразует имена в номера элементов, которые FREQUENCY () может обрабатывать().
Если какая-либо из ячеек в диапазоне пуста, вам нужно использовать более сложную формулу массива, которая включает функцию ЕСЛИ:
{= SUM (IF (FREQUENCY (IF (data «»; SEARCH (data; data; 0))); STRING (data) -LINE (data_first_cell) +1); 1))}
Примечание. Поскольку логический элемент управления в операторе IF содержит массив, наше выражение немедленно становится формулой массива, которая требует ввода с помощью Ctrl + Shift + Enter. Поэтому SUMPRODUCT был заменен на SUM.
В нашем примере это выглядит так:
{= СУММ (ЕСЛИ (ЧАСТОТА (ЕСЛИ (A2: A10 «», ПОИСК (A2: A10; A2: A10,0)), СТРОКА (A2: A10) -ЛИНИЯ (A2) +1), 1))}
Теперь этот расчет может быть «нарушен» только наличием ячеек с ошибками в исследуемом диапазоне.
Различные текстовые значения с условием.
Предположим, мы хотим пересчитать, сколько товаров заказал конкретный клиент.
В решении этой проблемы вам может помочь этот вариант:
{= СУММПРОИЗВ ((($ A $ 2: $ A $ 18 = E2)) / COUNTIF ($ A $ 2: $ A $ 18; $ A $ 2: $ A $ 18 & «»; $ B $ 2: $ B $ 18; $ B $ 2: $ B $ 18&»»))}
Введите его в пустую ячейку, куда вы хотите вставить результат, например F2. Затем нажмите одновременно Shift + Ctrl + Enter, чтобы получить правильный результат.
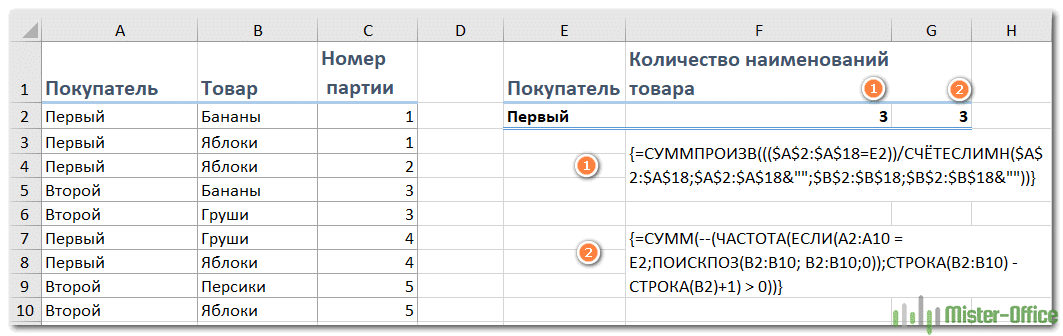
Поясним: здесь A2: A18 — это список покупателей с учетом того, какая область расчетов ограничена, B2: B18 — это список товаров, в которых вы хотите посчитать уникальные значения, E2 содержит критерий, на основании которого расчет ограничен только конкретным клиентом.
Второй способ.
Для уникальных значений в диапазоне с критериями можно использовать формулу массива, основанную на функции ЧАСТОТА.
{= СУММ (- (FREQUENCY (IF (критерий; MATCH (диапазон; диапазон; 0)); STRING (диапазон) -STRING (диапазон_первый_ячейка) +1)> 0))}
Применительно к нашему примеру:
{= СУММ (- (ЧАСТОТА (ЕСЛИ (LA2: A10 = E2; ПОИСК (B2: B10; B2: B10,0)); СТРОКА (B2: B10) — СТРОКА (B2) +1)> 0))}
На основе ограничений IF () функция ПОИСКПОЗ определяет порядковый номер только для строк, которые соответствуют критериям.
Если какая-либо из ячеек в диапазоне критериев пуста, вам необходимо изменить расчет, добавив дополнительный SE для обработки пустых ячеек. В противном случае они будут переданы функции ПОИСКПОЗ, которая в ответ сгенерирует сообщение об ошибке.
Вот что произошло после корректировки:
{= СУММ (- (ЧАСТОТА (ЕСЛИ (B2: B10 «»; ЕСЛИ (A2: A10 = E2; ПОИСК (B2: B10; B2: B10,0))); СТРОКА (B2: B10) -СТРОКА (B2) +1)> 0))}
То есть мы выполняем все действия и вычисления, если мы встретили непустую ячейку в столбце B: IF (B2: B10 «»….
Если у вас есть два критерия, вы можете расширить логику формулы, добавив еще один вложенный SE.
Мы объясняем. Определяем, сколько единиц товара было в первой партии покупателя.
Отметим критерии в G2 и G3.
В целом это выглядит так:
{= СУММ (- (ЧАСТОТА (ЕСЛИ (критерий1, ЕСЛИ (критерий2, ПОИСКПОЗ (диапазон, диапазон, 0)))), СТРОКА (диапазон) — СТРОКА (диапазон_первый_элемент) +1)> 0))}
Подставляем сюда реальные данные и получаем результат:
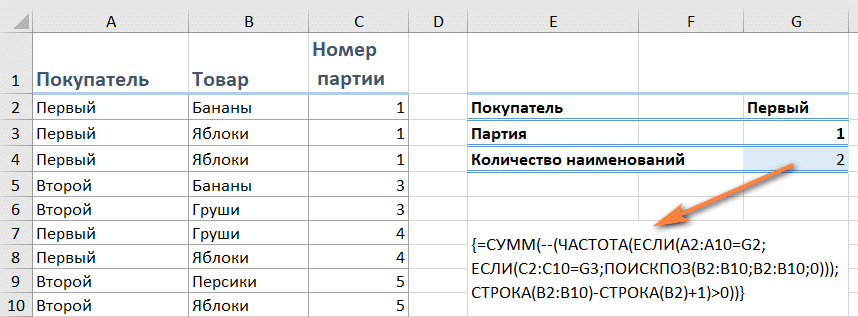
{= СУММ (- (ЧАСТОТА (ЕСЛИ (LA2: A10 = G2; ЕСЛИ (C2: C10 = G3; ПОИСК (B2: B10; B2: B10,0))); СТРОКА (B2: B10) -СТРОКА (B2) +1)> 0))}
У первого лота 2 товарных наименования, хотя есть 3 локации.
Различные числа с условием.
Если вам нужно пересчитать уникальные числа (с учетом первого вхождения) в диапазоне, с учетом некоторых ограничений, вы можете использовать формулу, основанную на СУММ и ЧАСТОТА, и одновременно применять критерии.
{= СУММ (- (ЧАСТОТА (ЕСЛИ (критерий, диапазон), диапазон)> 0))}
Предположим, у нас есть список сотрудников и количество отработанных часов в день. Необходимо посчитать, сколько человек проработали хотя бы один раз менее 8 часов, то есть неполную смену.
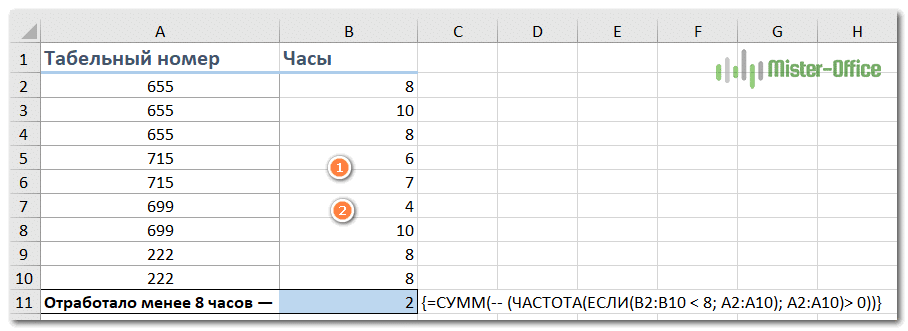
Вот наша матричная формула:
{= СУММ (- (ЧАСТОТА (ЕСЛИ (B2: B10 0))}
Как видите, таких случаев 3, но они связаны с двумя сотрудниками.
Различные значения с учетом регистра.
Подобно подсчету уникальных значений, самый простой способ подсчета различных значений с учетом регистра — это добавить вспомогательный столбец формулы массива, который идентифицирует нужные элементы, включая повторяющиеся первые вхождения.
Подход в основном такой же, как тот, который мы использовали для подсчета уникальных значений с учетом регистра, с одним небольшим изменением:
{= ЕСЛИ (СУММ ((- ТОЧНЫЙ ($ A $ 2: $ A2, $ A2))) = 1; «Уникальный»;»»)}
Как вы помните, все формулы массива в Excel требуют нажатия Ctrl + Shift + Enter.
Заметив это выражение, вы можете подсчитать «различные» значения, используя обычную функцию СЧЁТЕСЛИ, например:
= СЧЁТЕСЛИ (B2: B10; «Уникальный»)
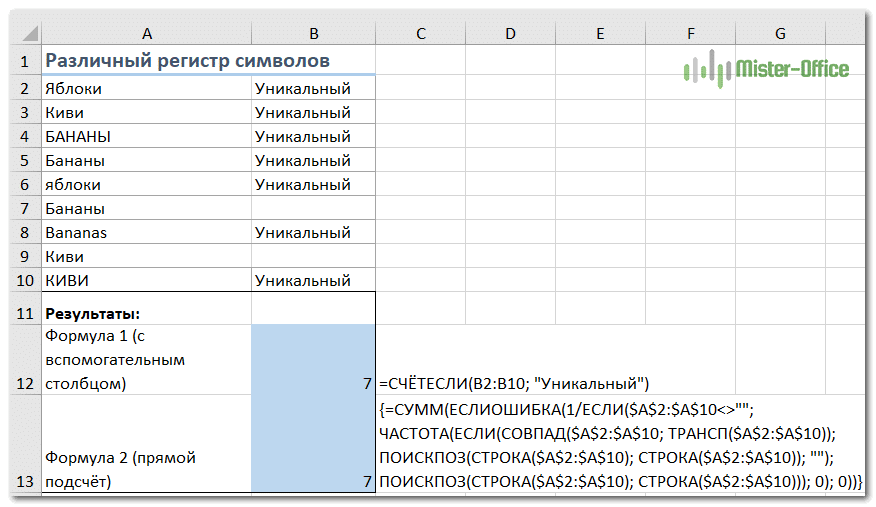
Если вы не можете добавить вспомогательный столбец на свой рабочий лист, вы можете использовать следующую более сложную формулу массива для подсчета различных значений с учетом регистра без создания дополнительного столбца:
{= СУММ (ЕСЛИОШИБКА (1 / IF ($ A $ 2: $ A $ 10 «»; FREQUENCY (IF (MATCH ($ A $ 2: $ A $ 10; TRANSPOSE ($ A $ 2: $ A $ 10)); ПОИСК (СТРОКА ($ A $ 2: $ A $ 10); СТРОКА ($ A $ 2: $ A $ 10)); «»); ПОИСК (СТРОКА ($ A $ 2: $ A $ 10)); LINE ($ A $ 2: $ A $ 10))); 0); 0))}
Как видите, обе формулы дают одинаковые результаты.
Подсчет уникальных строк в таблице.
Подсчет уникальных / различных строк в Excel аналогичен пересчету уникальных и различных значений. Единственное отличие состоит в том, что вы используете функцию СЧЁТЕСЛИ вместо СЧЁТЕСЛИ, которая позволяет вам указывать сразу несколько столбцов для проверки их уникальности.
Например, чтобы подсчитать уникальные строки на основе столбцов A (Имя) и B (Фамилия), используйте один из следующих вариантов:
Для уникальных строк:
{= СУММ (ЕСЛИ (СЧЁТЕСЛИМН (A3: A11; A3: A11; B3: B11; B3: B11) = 1; 1; 0))}
Для разных строк:
{= СУММ (1 / СЧЁТЕСЛИ (A3: A11; A3: A11; B3: B11; B3: B11))}
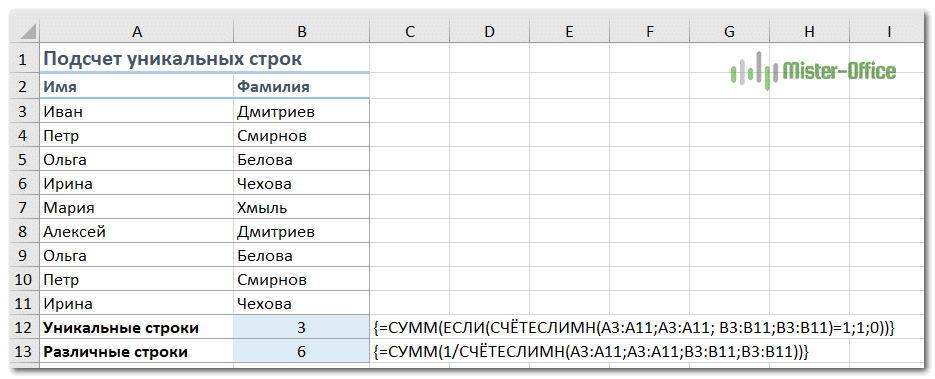
Конечно, вы не ограничены двумя столбцами. Функция СЧЁТЕСЛИ может обрабатывать до 127 пар диапазон / критерий.
Как можно использовать сводную таблицу.
Вот общая задача, которую все пользователи Excel должны время от времени выполнять. У вас есть список данных (например, названия продуктов), и вам нужно узнать количество уникальных позиций в этом списке. Как это сделать? Проще, чем вы думаете 🙂
Версии Excel до 2013 года имеют специальную функцию, которая позволяет автоматически пересчитывать различные значения в сводной таблице. На следующем рисунке показано, как выглядит этот счетчик:
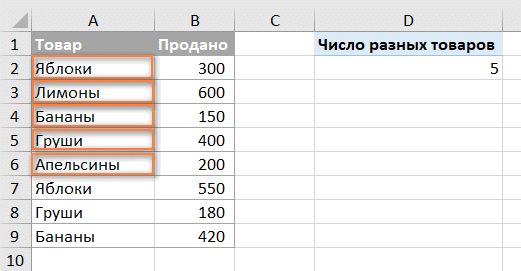
Чтобы создать сводную таблицу с подсчетом для определенного столбца, выполните следующие действия.
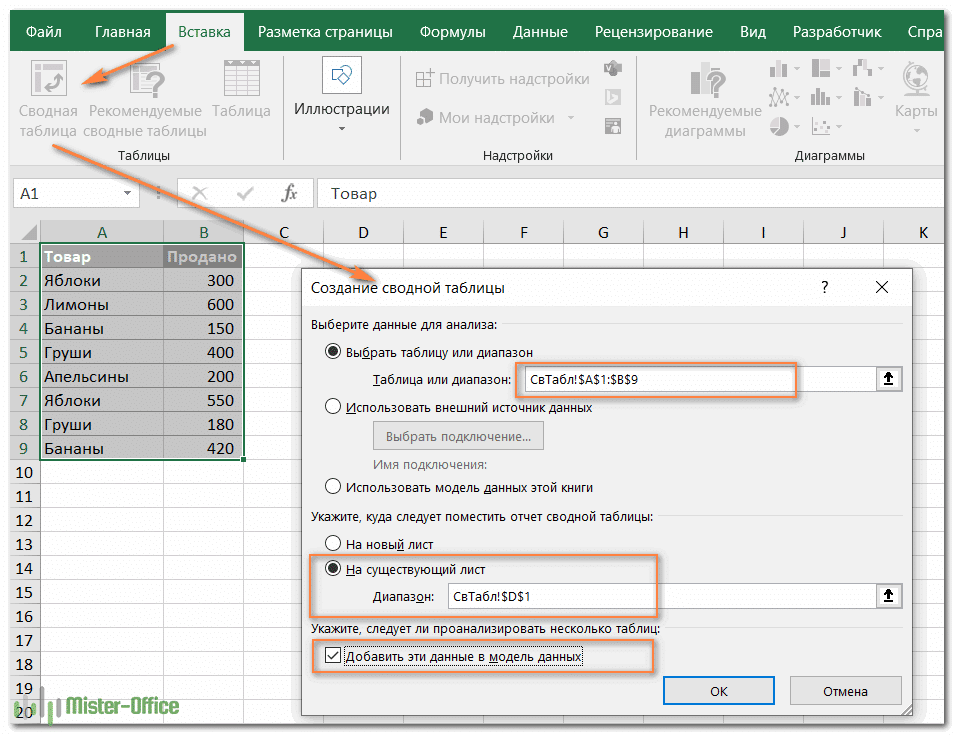
- Выберите данные для включения в сводную таблицу, перейдите на вкладку «Вставка» и нажмите кнопку «Сводная таблица» .
- В диалоговом окне «Создание сводной таблицы» выберите, следует ли разместить сводную таблицу на новом или существующем листе, и обязательно установите флажок «Добавить эти данные в модель данных» .
- Когда откроется сводная таблица, расположите области строк, столбцов и значений по своему усмотрению. Если у вас нет большого опыта работы со сводными таблицами Excel, вам могут быть полезны следующие подробные рекомендации: Создайте сводную таблицу в Excel.
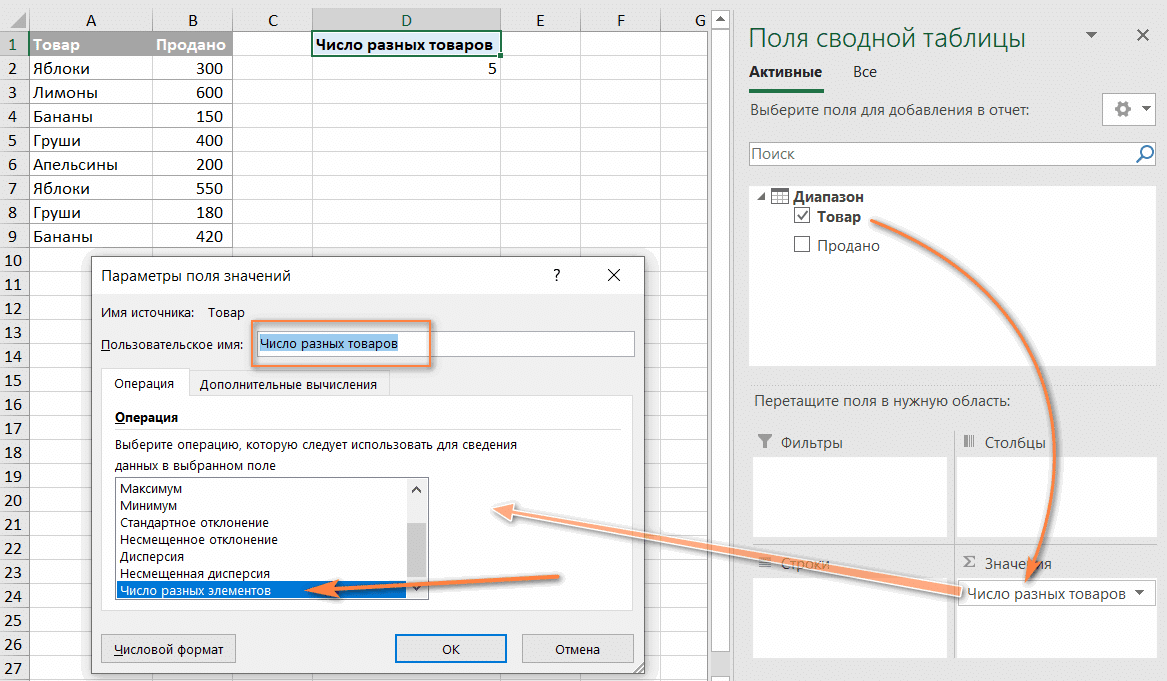
- Переместите поле, уникальное количество которого вы хотите вычислить (поле «Элемент» в этом примере), в область «Значения», щелкните его и выберите «Параметры значения поля…» из раскрывающегося меню.
- В открывшемся диалоговом окне прокрутите вниз до пункта «Количество разных элементов», который является последним элементом в списке, выберите его и нажмите «ОК .
Вы также можете присвоить своему глюкометру индивидуальное имя, если хотите.
Готовый! Во вновь созданной сводной таблице будет отображаться количество различных элементов, как показано на самом первом снимке экрана в этом разделе.
Комментарий. После обновления исходных данных обязательно обновите также сводную таблицу. Для этого нажмите кнопку «Обновить» на вкладке «Анализ» в группе «Данные».
Вот как подсчитать различные и уникальные значения в столбце и в таблице Excel.
Спасибо за чтение и надеюсь увидеть вас снова.
Hi everyone, I am struggling to get this but how can I make a formula similar to «unique» function on version excel 2019 and below?
I have this formula in o365 and used the unique function (since it is only available to o365) and couldn’t figure out how to do it on desktop version.
Basically, it is a cascading dropdown that is dependent on each other. Thanks in advance
Dropdown 1
=SORT(UNIQUE(JobCategory))Dropdown 2
=IFERROR(SORT(UNIQUE(FILTER(JobType,(EntityType=Pricing!B14)*(JobCategory=Pricing!A14)))),"")Dropdown 3
=IFERROR(SORT(UNIQUE(FILTER(InvoiceDescription,(JobType=Pricing!C14)*(EntityType=Pricing!B14)*(JobCategory=Pricing!A14)))),"")Dropdown 4
=IFERROR(FILTER(MinFee,(InvoiceDescription=Pricing!D14)*(JobType=Pricing!C14)*(EntityType=Pricing!B14)*(JobCategory=Pricing!A14)),"")
Excel для Microsoft 365 Excel для Microsoft 365 для Mac Excel для Интернета Excel 2021 Excel 2021 для Mac Excel для iPad Excel для iPhone Excel для планшетов с Android Excel для телефонов с Android Еще…Меньше
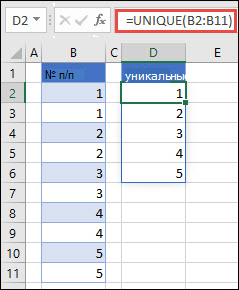
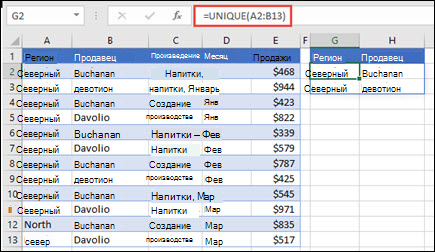
Функция УНИК возвращает список уникальных значений в списке или диапазоне.
Возвращение уникальных значений из списка значений
Возвращение уникальных имен из списка имен
=УНИК(массив,[by_col],[exactly_once])
Функция УНИК имеет следующие аргументы:
|
Аргумент |
Описание |
|---|---|
|
массив Обязательный |
Диапазон или массив, из которого возвращаются уникальные строки или столбцы |
|
[by_col] Необязательный |
Аргумент by_col является логическим значением, указывающим, как проводить сравнение. Значение ИСТИНА сравнивает столбцы друг с другом и возвращает уникальные столбцы Значение ЛОЖЬ (или отсутствующее значение) сравнивает строки друг с другом и возвращает уникальные строки |
|
[exactly_once] Необязательно |
Аргумент exactly_once является логическим значением, которое возвращает строки или столбцы, встречающиеся в диапазоне или массиве только один раз. Это концепция базы данных УНИК. Значение ИСТИНА возвращает из диапазона или массива все отдельные строки или столбцы, которые встречаются только один раз Значение ЛОЖЬ (или отсутствующее значение) возвращает из диапазона или массива все отдельные строки или столбцы |
Примечания:
-
Массив может рассматриваться как строка или столбец со значениями либо комбинация строк и столбцов со значениями. В примерах выше массивы для наших формул УНИК являются диапазонами D2:D11 и D2:D17 соответственно.
-
Функция УНИК возвращает массив, который будет рассеиваться, если это будет конечным результатом формулы. Это означает, что Excel будет динамически создавать соответствующий по размеру диапазон массива при нажатии клавиши ВВОД. Если ваши вспомогательные данные хранятся в таблице Excel, тогда массив будет автоматически изменять размер при добавлении и удалении данных из диапазона массива, если вы используете Структурированные ссылки. Дополнительные сведения см. в статье Поведение рассеянного массива.
-
Приложение Excel ограничило поддержку динамических массивов в операциях между книгами, и этот сценарий поддерживается, только если открыты обе книги. Если закрыть исходную книгу, все связанные формулы динамического массива вернут ошибку #ССЫЛКА! после обновления.
Примеры
Пример 1
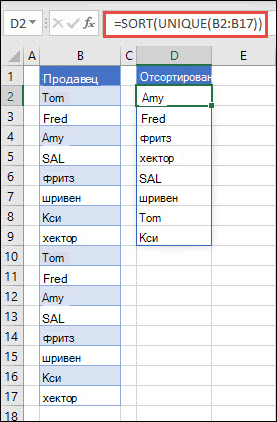
В этом примере СОРТ и УНИК используются совместно для возврата уникального списка имен в порядке возрастания.
Пример 2
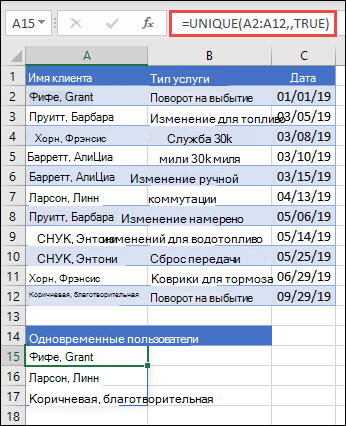
В этом примере аргумент exactly_once имеет значение ИСТИНА, и функция возвращает только тех клиентов, которые обслуживались один раз. Это может быть полезно, если вы хотите найти людей, которые не получали дополнительное обслуживание, и связаться с ними.
Пример 3
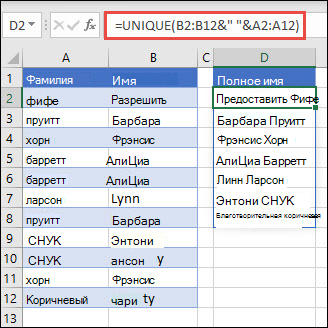
В этом примере используется амперсанд (&) для сцепления фамилии и имени в полное имя. Обратите внимание, что формула ссылается на весь диапазон имен в массивах A2:A12 и B2:B12. Это позволяет Excel вернуть массив всех имен.
Советы:
-
Если указать диапазон имен в формате таблицы Excel, формула автоматически обновляется при добавлении или удалении имен.
-
Чтобы отсортировать список имен, можно добавить функцию СОРТ: =СОРТ(УНИК(B2:B12&» «&A2:A12))
Пример 4
В этом примере сравниваются два столбца и возвращаются только уникальные значения в них.
Дополнительные сведения
Вы всегда можете задать вопрос специалисту Excel Tech Community или попросить помощи в сообществе Answers community.
См. также
Функция ФИЛЬТР
Функция СЛУЧМАССИВ
Функция ПОСЛЕДОВ
Функция СОРТ
Функция СОРТПО
Ошибки #SPILL! в Excel
Динамические массивы и поведение массива с переносом
Оператор неявного пересечения: @
Нужна дополнительная помощь?
Background
Have you heard of a function called UNIQUE()? As its name suggests, the Excel UNIQUE function extracts a dynamic array of unique values from a range or array. A big applause to Microsoft!
When you search online for a function to get unique values, the top results urge you to give the UNIQUE function a shot.
However, very likely you will find the UNIQUE function missing. This is because currently UNIQUE function is only available to Excel 365 users. For Excel users of earlier version, you won’t find UNIQUE function available in Excel. Unless you switch to Excel 365 version, you won’t be able to activate UNIQUE function.
If you wish to get unique value without using any formula, I suggest you take a look at this How to get unique values in Excel? (6 ways).
Do you have the following questions?
- Excel Unique function alternative
- How to get unique values without unique version?
- How to get unique values in Excel?
- Get unique values Excel formula
What can Excel users of other version do if they want to get unique values from a list?
In this article, I will show you how to extract unique values from Excel list without using Unique function. You can either use a standard formula or an array formula. You will find perfect substitute for Unique function in Excel.
Sample Workbook
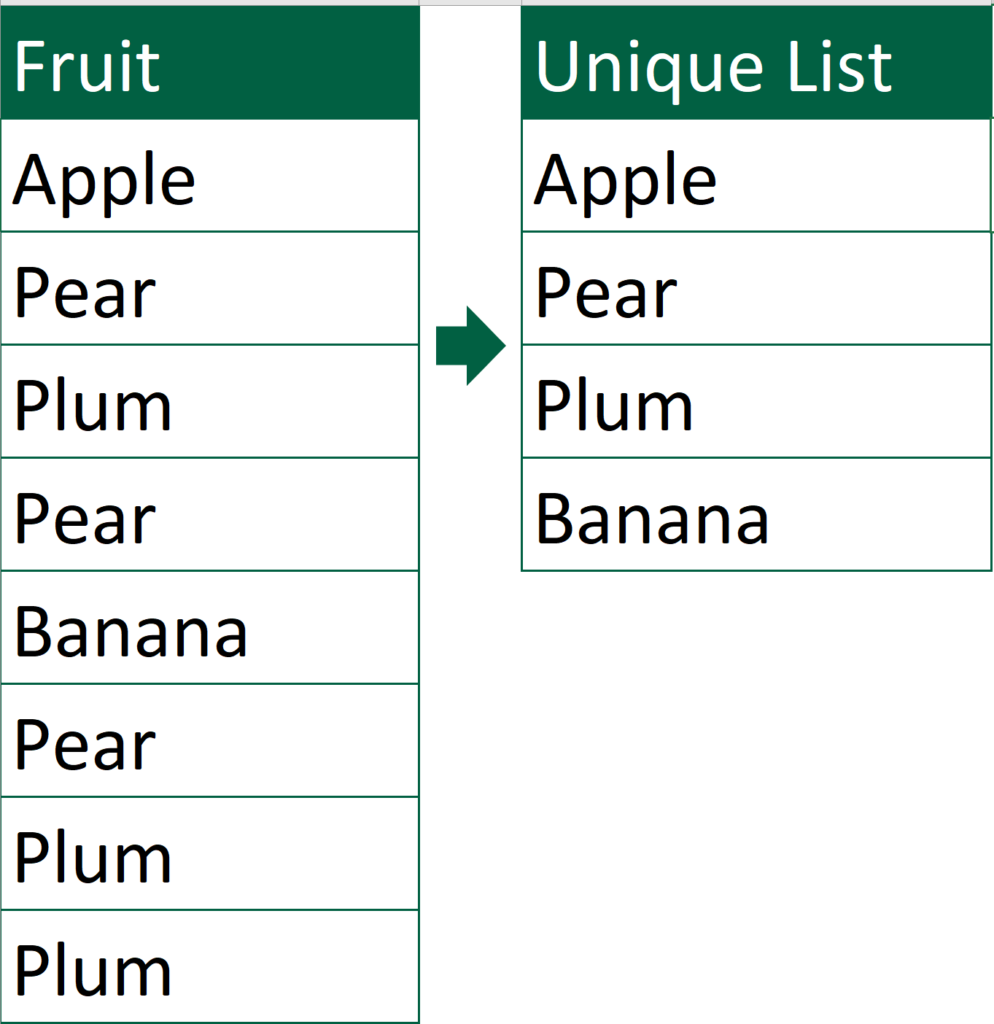
What we would like to achieve
To extract unique list of values from the “Fruit” list
Download the workbook to practice it by yourself!
Press the download button!

Get Unique Values Without Unique function With Standard Formula
First, I will show you how to extract unique values from excel column using formula without array.
I understand that array formula can be a bit difficult for Excel beginners.
Here is the formula without array.
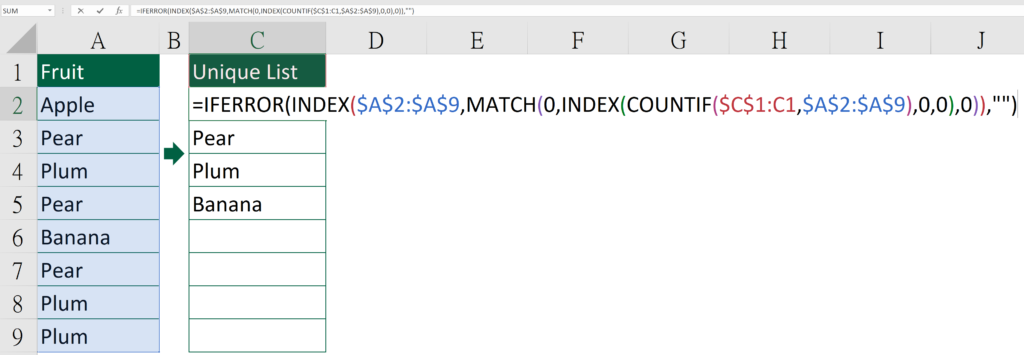
Formula of Cell C2
=IFERROR(INDEX($A$2:$A$9,MATCH(0,INDEX(COUNTIF($C$1:C1,$A$2:$A$9),0,0),0)),"")
Dollar Excel syntax
=IFERROR(INDEX(Original list, MATCH(0,INDEX(COUNTIF(Top cell of unique list column to itself, Original list),0,0),0)),"")
Things to be aware of
- Those highlighted in red means that you may need to change the reference
- Make sure the list start at row 2
- Make sure you don’t change any reference type
- Make sure the top cell of the unique list column doesn’t equal to other cell in the unique list
Get Unique Values Without Unique function With Array Formula
Formula of Cell C2
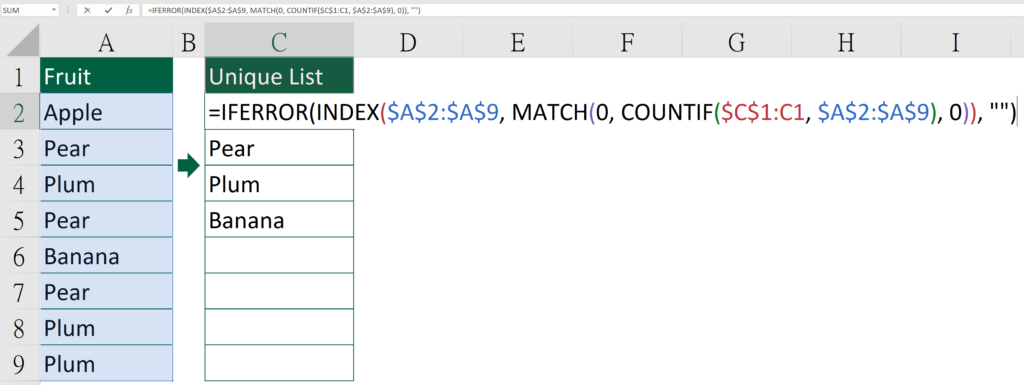
=IFERROR(INDEX($A$2:$A$9, MATCH(0, COUNTIF($C$1:C1, $A$2:$A$9), 0)), "")
Dollar Excel syntax
=IFERROR(INDEX(Original list, MATCH(0,COUNTIF(Top cell of unique list column to itself, Original list again),0),1),This is just an error handler to turn error value into zero)
Things to be aware of
- Those highlighted in red means that you may need to change the reference
- Make sure the list has a top cell
- Press Ctrl Shift Enter when finish editing the formula
- Make sure you don’t change any reference type
- Make sure the top cell of the unique list column doesn’t equal to other cell in the unique list
Explanation
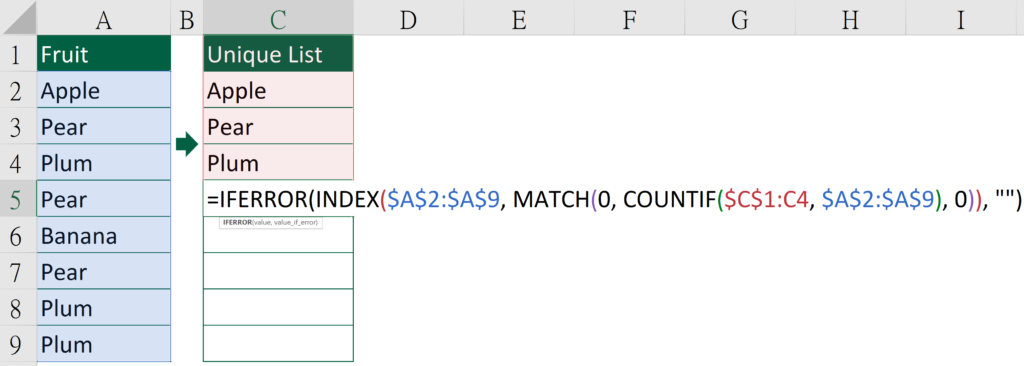
Formula of Cell C5
=IFERROR(INDEX($A$2:$A$9, MATCH(0, COUNTIF($C$1:C4, $A$2:$A$9), 0)), "")
Let’s dig deep into the array formula of extracting unique values.
To help you better understand the formula, I will explain each part of the formula according to the handling order.
This time we choose Cell C5 as the investigation object since you will be able to understand more with cell C5.
Part 1
COUNTIF($C$1:C1,$A$2:$A$9)
$C$1:C4 refers to “Unique List”, “Apple”, “Pear”, “Plum”

$A$2:$A$9 refers to “Apple”, “Pear”, “Plum”, “Pear”, “Banana”, “Pear”, “Plum”, “Plum”

COUNTIF function count cells that match certain criteria.
Here it counts the number of times $A$2:$A$9 appear in $C$1:C4.
Only “Banana” isn’t in the range $C$1:C4. It’s in Cell C5 instead.

The result is {1, 1, 1, 1, 0, 1, 1, 1}.
Part 2
MATCH(0, COUNTIF($C$1:C4, $A$2:$A$9), 0)
After replacing COUNTIF($C$1:C4, $A$2:$A$9), we get this instead.
MATCH(0, {1, 1, 1, 1, 0, 1, 1, 1}, 0)
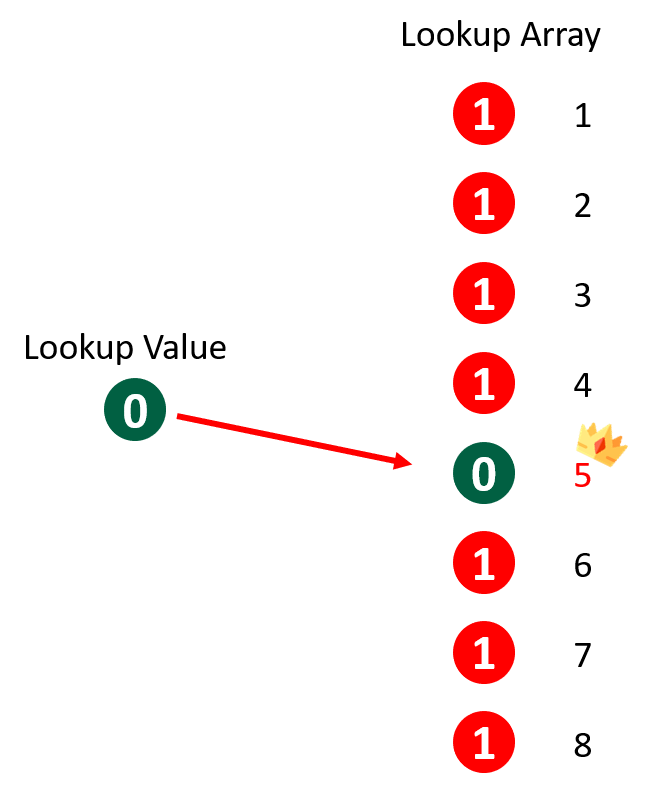
MATCH function returns the position of the matched value within an array.
Here the position of “0” in the lookup array is “5” so it will return a “5”.
Part 3
INDEX($A$2:$A$9, MATCH(0, COUNTIF($C$1:C4, $A$2:$A$9), 0))
After replacing above results, we get this instead.
INDEX($A$2:$A$9, 5)
INDEX function returns the nth item in an array.
Here we would like to return the 5th item in the $A$2:$A$9.

The result is “Banana”.
Part 4
IFERROR(INDEX($A$2:$A$9, MATCH(0, COUNTIF($C$1:C4, $A$2:$A$9), 0)), "")
After replacing above results, we get this instead.
IFERROR("Banana", "")
IFERROR returns a specified value if it detects an error.
Here we set the specified value as blank.
Without the error-handling function, the result would appear as below.
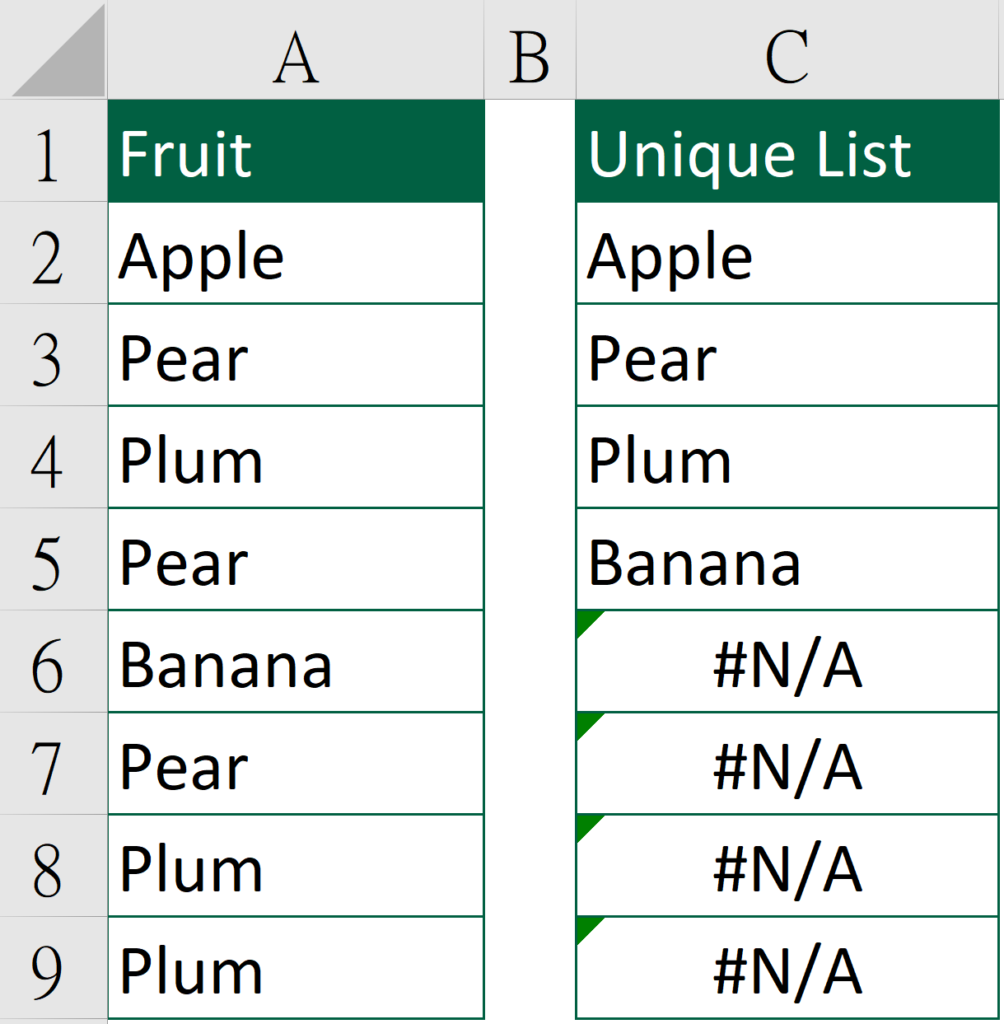
Since we don’t have any error in the formula, it will return the original value, which is “Banana”.
If unique function is not available in Excel, I highly recommend you to try these two formula.
Do you find this article helpful? Subscribe to our newsletter to get exclusive Excel tips!