
Время на прочтение
5 мин
Количество просмотров 63K
Excel — это чрезвычайно распространённый инструмент для анализа данных. С ним легко научиться работать, есть он практически на каждом компьютере, а тот, кто его освоил, может с его помощью решать довольно сложные задачи. Python часто считают инструментом, возможности которого практически безграничны, но который освоить сложнее, чем Excel. Автор материала, перевод которого мы сегодня публикуем, хочет рассказать о решении с помощью Python трёх задач, которые обычно решают в Excel. Эта статья представляет собой нечто вроде введения в Python для тех, кто хорошо знает Excel.

Загрузка данных
Начнём с импорта Python-библиотеки pandas и с загрузки в датафреймы данных, которые хранятся на листах sales и states книги Excel. Такие же имена мы дадим и соответствующим датафреймам.
import pandas as pd
sales = pd.read_excel('https://github.com/datagy/mediumdata/raw/master/pythonexcel.xlsx', sheet_name = 'sales')
states = pd.read_excel('https://github.com/datagy/mediumdata/raw/master/pythonexcel.xlsx', sheet_name = 'states')
Теперь воспользуемся методом .head() датафрейма sales для того чтобы вывести элементы, находящиеся в начале датафрейма:
print(sales.head())
Сравним то, что будет выведено, с тем, что можно видеть в Excel.
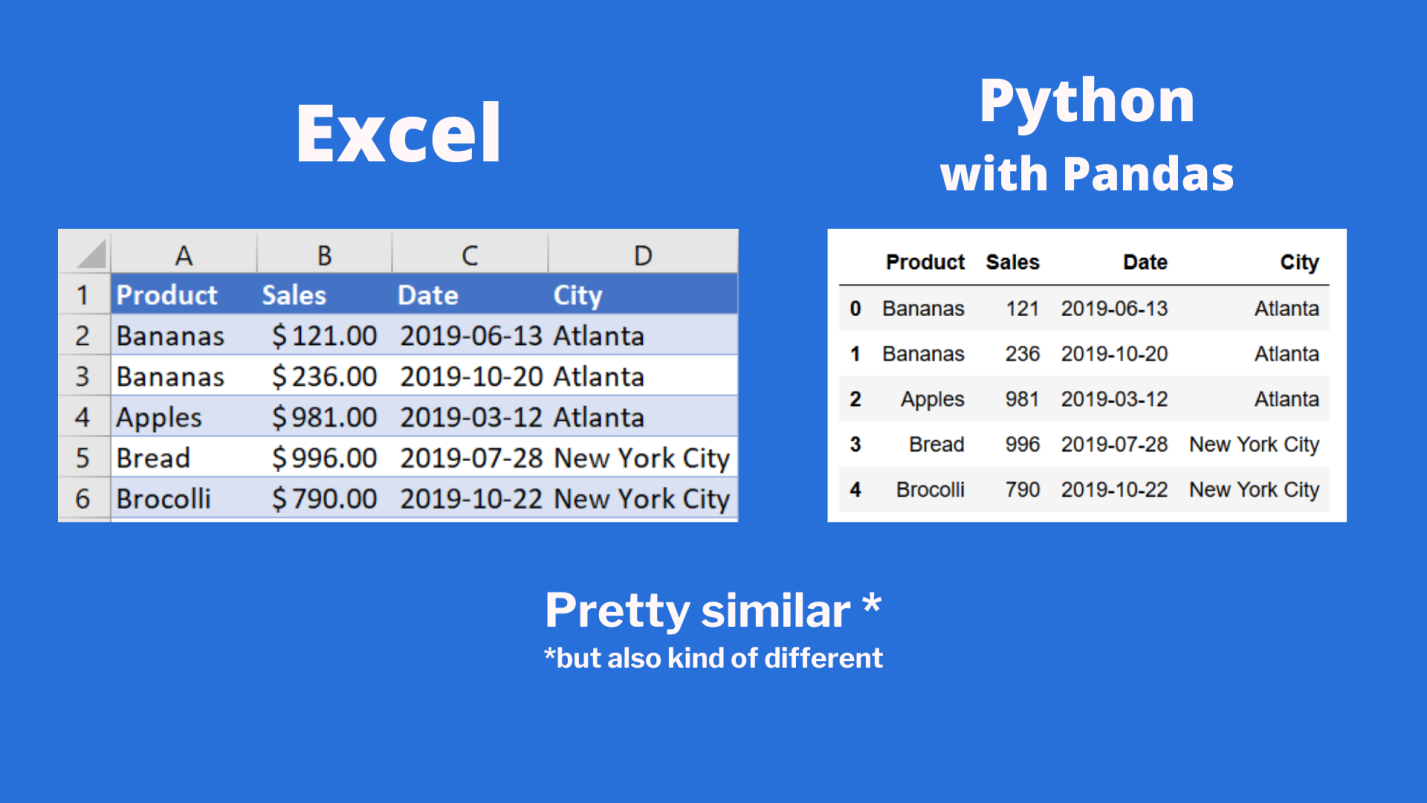
Сравнение внешнего вида данных, выводимых в Excel, с внешним видом данных, выводимых из датафрейма pandas
Тут можно видеть, что результаты визуализации данных из датафрейма очень похожи на то, что можно видеть в Excel. Но тут имеются и некоторые очень важные различия:
- Нумерация строк в Excel начинается с 1, а в pandas номер (индекс) первой строки равняется 0.
- В Excel столбцы имеют буквенные обозначения, начинающиеся с буквы
A, а в pandas названия столбцов соответствуют именам соответствующих переменных.
Продолжим исследование возможностей pandas, позволяющих решать задачи, которые обычно решают в Excel.
Реализация возможностей Excel-функции IF в Python
В Excel существует очень удобная функция IF, которая позволяет, например, записать что-либо в ячейку, основываясь на проверке того, что находится в другой ячейке. Предположим, нужно создать в Excel новый столбец, ячейки которого будут сообщать нам о том, превышают ли 500 значения, записанные в соответствующие ячейки столбца B. В Excel такому столбцу (в нашем случае это столбец E) можно назначить заголовок MoreThan500, записав соответствующий текст в ячейку E1. После этого, в ячейке E2, можно ввести следующее:
=IF([@Sales]>500, "Yes", "No")
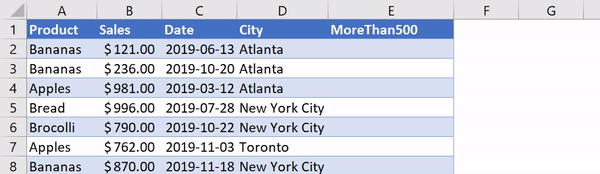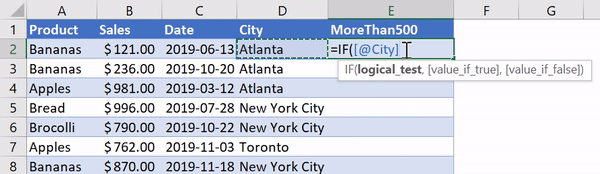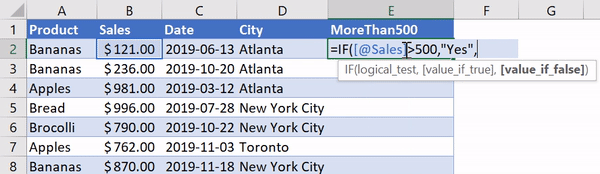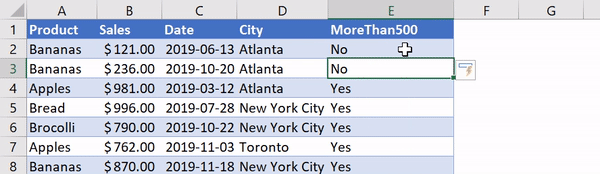
Использование функции IF в Excel
Для того чтобы сделать то же самое с использованием pandas, можно воспользоваться списковым включением (list comprehension):
sales['MoreThan500'] = ['Yes' if x > 500 else 'No' for x in sales['Sales']]

Списковые включения в Python: если текущее значение больше 500 — в список попадает Yes, в противном случае — No
Списковые включения — это отличное средство для решения подобных задач, позволяющее упростить код за счёт уменьшения потребности в сложных конструкциях вида if/else. Ту же задачу можно решить и с помощью if/else, но предложенный подход экономит время и делает код немного чище. Подробности о списковых включениях можно найти здесь.
Реализация возможностей Excel-функции VLOOKUP в Python
В нашем наборе данных, на одном из листов Excel, есть названия городов, а на другом — названия штатов и провинций. Как узнать о том, где именно находится каждый город? Для этого подходит Excel-функция VLOOKUP, с помощью которой можно связать данные двух таблиц. Эта функция работает по принципу левого соединения, когда сохраняется каждая запись из набора данных, находящегося в левой части выражения. Применяя функцию VLOOKUP, мы предлагаем системе выполнить поиск определённого значения в заданном столбце указанного листа, а затем — вернуть значение, которое находится на заданное число столбцов правее найденного значения. Вот как это выглядит:
=VLOOKUP([@City],states,2,false)
Зададим на листе sales заголовок столбца F как State и воспользуемся функцией VLOOKUP для того чтобы заполнить ячейки этого столбца названиями штатов и провинций, в которых расположены города.

Использование функции VLOOKUP в Excel
В Python сделать то же самое можно, воспользовавшись методом merge из pandas. Он принимает два датафрейма и объединяет их. Для решения этой задачи нам понадобится следующий код:
sales = pd.merge(sales, states, how='left', on='City')
Разберём его:
- Первый аргумент метода
merge— это исходный датафрейм. - Второй аргумент — это датафрейм, в котором мы ищем значения.
- Аргумент
howуказывает на то, как именно мы хотим соединить данные. - Аргумент
onуказывает на переменную, по которой нужно выполнить соединение (тут ещё можно использовать аргументыleft_onиright_on, нужные в том случае, если интересующие нас данные в разных датафреймах названы по-разному).
Сводные таблицы
Сводные таблицы (Pivot Tables) — это одна из самых мощных возможностей Excel. Такие таблицы позволяют очень быстро извлекать ценные сведения из больших наборов данных. Создадим в Excel сводную таблицу, выводящую сведения о суммарных продажах по каждому городу.
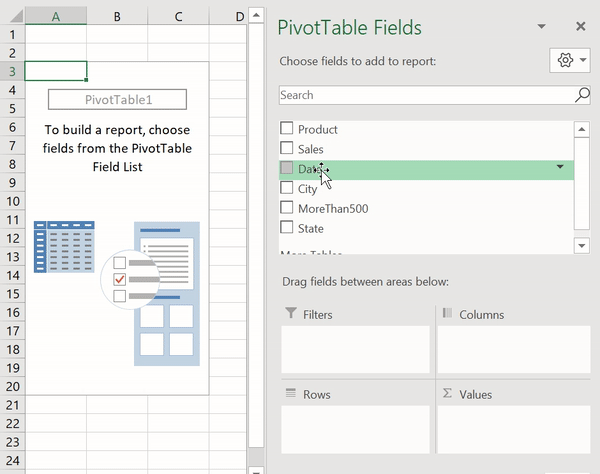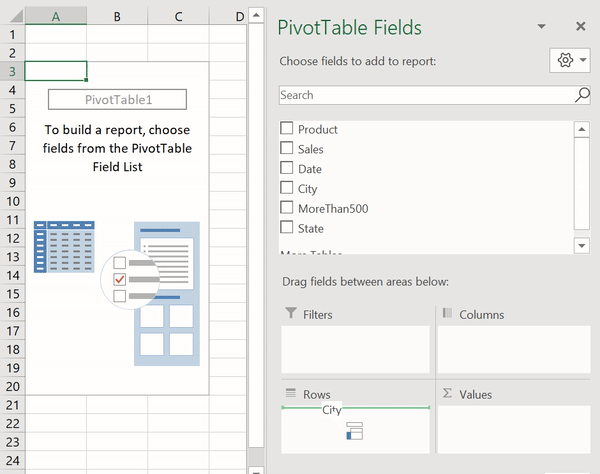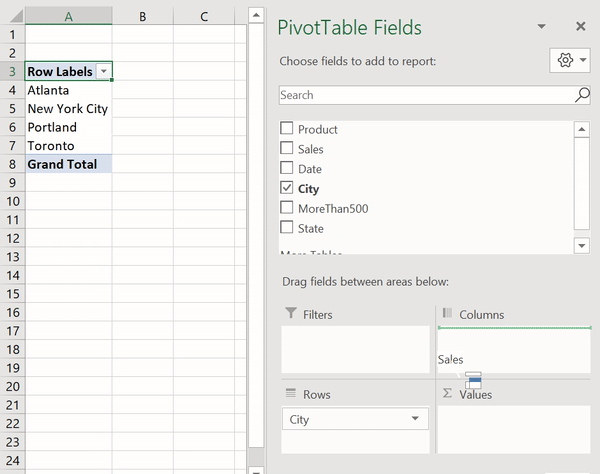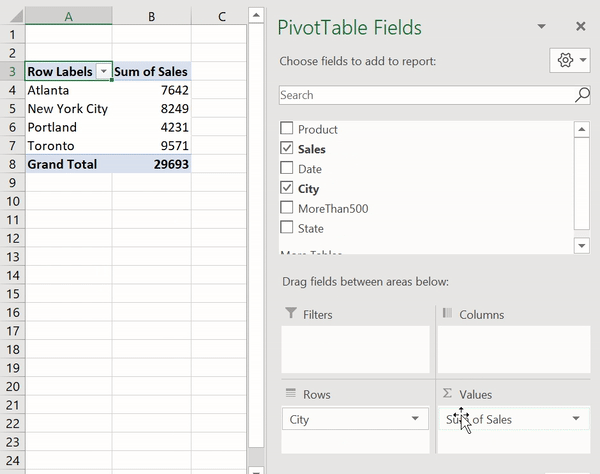
Создание сводной таблицы в Excel
Как видите, для создания подобной таблицы достаточно перетащить поле City в раздел Rows, а поле Sales — в раздел Values. После этого Excel автоматически выведет суммарные продажи для каждого города.
Для того чтобы создать такую же сводную таблицу в pandas, нужно будет написать следующий код:
sales.pivot_table(index = 'City', values = 'Sales', aggfunc = 'sum')
Разберём его:
- Здесь мы используем метод
sales.pivot_table, сообщая pandas о том, что мы хотим создать сводную таблицу, основанную на датафреймеsales. - Аргумент
indexуказывает на столбец, по которому мы хотим агрегировать данные. - Аргумент
valuesуказывает на то, какие значения мы собираемся агрегировать. - Аргумент
aggfuncзадаёт функцию, которую мы хотим использовать при обработке значений (тут ещё можно воспользоваться функциямиmean,max,minи так далее).
Итоги
Из этого материала вы узнали о том, как импортировать Excel-данные в pandas, о том, как реализовать средствами Python и pandas возможности Excel-функций IF и VLOOKUP, а также о том, как воспроизвести средствами pandas функционал сводных таблиц Excel. Возможно, сейчас вы задаётесь вопросом о том, зачем вам пользоваться pandas, если то же самое можно сделать и в Excel. На этот вопрос нет однозначного ответа. Python позволяет создавать код, который поддаётся тонкой настройке и глубокому исследованию. Такой код можно использовать многократно. Средствами Python можно описывать очень сложные схемы анализа данных. А возможностей Excel, вероятно, достаточно лишь для менее масштабных исследований данных. Если вы до этого момента пользовались только Excel — рекомендую испытать Python и pandas, и узнать о том, что у вас из этого получится.
А какие инструменты вы используете для анализа данных?
Напоминаем, что у нас продолжается конкурс прогнозов, в котором можно выиграть новенький iPhone. Еще есть время ворваться в него, и сделать максимально точный прогноз по злободневным величинам.

Перевод
Ссылка на автора

Проведя почти десять лет с моей первой любовью к Excel, пришло время двигаться дальше и искать лучшую половину того, кто в своих повседневных делах со мной, гораздо лучше и быстрее, и кто может дать мне преимущество в сложные технологические времена, когда новые технологии очень быстро угнетаются чем-то новым. Идея состоит в том, чтобы воспроизвести почти все функциональные возможности Excel в Python, будь то простой фильтр или сложная задача создания массива данных из строк и обработки их для получения фантастических результатов.
Используемый здесь подход состоит в том, чтобы начать с простых задач и перейти к сложным вычислительным задачам. Я призываю вас повторить шаги самостоятельно для лучшего понимания.
Источником вдохновения для создания чего-то подобного послужило отсутствие бесплатного учебного пособия, которое буквально дает все. Я внимательно читаю и слежу за документацией по Python, и вы найдете много вдохновения на этом сайте.
Ссылка на репозиторий GitHub
https://github.com/ank0409/Ditching-Excel-for-Python
Импорт файлов Excel в DataFrame Pandas
Первым шагом является импорт файлов Excel в DataFrame, чтобы мы могли выполнять с ним все наши задачи. Я буду демонстрироватьread_excelметод панд, который поддерживаетXLSа такжеXLSXРасширения файлов.
read_csvтак же, как использованиеread_excelМы не будем углубляться, но я поделюсь примером.
Хотяread_excelМетод включает в себя миллион аргументов, но я ознакомлю вас с наиболее распространенными аргументами, которые очень пригодятся в повседневных операциях.
Хотя метод read_excel содержит миллион аргументов, я ознакомлю вас с наиболее распространенными из них, которые очень пригодятся в повседневных операциях.
Я буду использовать образец набора данных Iris, который свободно доступен в Интернете для образовательных целей.
Пожалуйста, перейдите по ссылке ниже, чтобы загрузить набор данных и сохранить его в той же папке, где вы сохраняете свой файл Python
https://archive.ics.uci.edu/ml/datasets/iris
Первый шаг — импортировать необходимые библиотеки в Python.

Мы можем импортировать данные электронной таблицы в Python, используя следующий код:
pandas.read_excel (io, sheet_name = 0, header = 0, names = None, index_col = None, parse_cols = None, usecols = None, squeeze = False, dtype = None, engine = None, конвертеры = None, true_values = None, false_values = нет, skiprows = нет, nrows = нет, na_values = нет, keep_default_na = True, многословно = False, parse_dates = False, date_parser = нет, тысячи = нет, комментарий = нет, skip_footer = 0, skipfooter = 0, convert_float = 0 True, mangle_dupe_cols = True, ** kwds)
Поскольку имеется множество доступных аргументов, давайте рассмотрим наиболее часто используемые аргументы.
Важные опции read_excel для Pandas

Если мы используем путь для нашего локального файла по умолчанию, он разделен знаком «», однако python принимает «/», поэтому сделайте так, чтобы изменить косую черту или просто добавить файл в ту же папку, где находится ваш файл python. Если вам требуется подробное объяснение выше, обратитесь к статье ниже среднего. https://medium.com/@ageitgey/python-3-quick-tip-the-easy-way-to-deal-with-file-paths-on-windows-mac-and-linux-11a072b58d5f
Мы можем использовать Python для сканирования файлов в каталоге и выбрать те, которые нам нужны.

Импортировать определенный лист
По умолчанию первый лист в файле импортируется в фрейм данных как есть.
Используя аргумент sheet_name, мы можем явно указать лист, который мы хотим импортировать. Значение по умолчанию 0, то есть первый лист в файле.
Мы можем либо упомянуть имя листа (ов), либо передать целочисленное значение для ссылки на индекс листа

Использование столбца из листа в качестве индекса
Если явно не указано иное, в DataFrame добавляется столбец индекса, который по умолчанию начинается с 0.
Используя аргумент index_col, мы можем манипулировать столбцом индекса в нашем фрейме данных, если мы установим значение 0 из none, он будет использовать первый столбец в качестве нашего индекса.

Пропустить строки и столбцы
Параметры read_excel по умолчанию предполагают, что первая строка представляет собой список имен столбцов, который автоматически включается как метки столбцов в DataFrame.
Используя такие аргументы, как skiprows и header, мы можем манипулировать поведением импортированного DataFrame.

Импортировать определенные столбцы
Используя аргумент usecols, мы можем указать, нужно ли импортировать определенный столбец в наш DataFrame.

Это не конец доступных функций, но это начало, и вы можете поиграть с ними в соответствии с вашими требованиями
Давайте посмотрим на данные с 10 000 футов
Поскольку теперь у нас есть наш DataFrame, давайте посмотрим на данные с разных точек зрения, просто чтобы освоить их /
У панд есть множество доступных функций, которые мы можем использовать. Мы используем некоторые из них, чтобы получить представление о нашем наборе данных.
«Голова» к «Хвосту»:
Для просмотра первого или последнего5строки
По умолчанию пять, однако аргумент позволяет нам использовать конкретное число

Просмотр данных конкретного столбца

Получение имени всех столбцов

Информационный метод
Предоставляет сводку DataFrame

Форма Метод
Возвращает размеры DataFrame

Посмотрите на типы данных в DataFrame

Срезы и кубики, т.е. фильтры Excel
Описательные отчеты — это все о подмножествах данных и агрегациях. В тот момент, когда мы должны немного понять наши данные, мы начинаем использовать фильтры для просмотра небольших наборов данных или просмотра определенного столбца, возможно, для лучшего понимания.
Python предлагает множество различных методов для нарезки и нарезки кубиков данных, поэтому мы поэкспериментируем с несколькими из них, чтобы понять, как это работает
Просмотр определенного столбца
Существует три основных метода выбора столбцов:
- Используйте точечную запись: например, data.column_name
- Используйте квадратные скобки и название столбца: например, данные [ «column_name»]
- Используйте числовую индексацию и селектор iloc data.loc [:, ‘column_number’]

Просмотр нескольких столбцов

Просмотр данных конкретной строки
Используемый здесь метод — это нарезка с использованием функции loc, где мы можем указать начальную и конечную строки, разделенные двоеточием.
Помнить,Индекс начинается с 0, а не 1

Срезать строки и столбцы вместе

Фильтровать данные в столбце

Фильтровать несколько значений

Фильтрация нескольких значений с использованием списка

Фильтровать значения НЕ в списке или не равно в Excel

Фильтрация с использованием нескольких условий в нескольких столбцах
На входе всегда должен быть список
Мы можем использовать этот метод для репликации расширенной функции фильтра в Excel

Фильтр с использованием числовых условий

Скопируйте пользовательский фильтр в Excel

Объедините два фильтра, чтобы получить результат

Содержит функцию в Excel

Получите уникальные значения из DataFrame

Если мы хотим просмотреть весь DataFrame с уникальными значениями, мы можем использовать метод drop_duplicates

Сортировать значения
Сортировать данные по определенному столбцу, по умолчанию сортировка по возрастанию

Статистическая сводка данных
DataFrame Опишите метод
Генерировать описательную статистику, которая суммирует центральную тенденцию, дисперсию и форму распределения набора данных, исключая значения NaN

Сводная статистика символьных столбцов

Агрегация данных
Подсчет уникальных значений определенного столбца
Итоговый результат — серия. Вы можете сослаться на него как сводную таблицу с одним столбцом

Подсчет клеток
Подсчет не-NA клеток для каждого столбца или строки

сумма
Суммирование данных для получения снимка по строкам или столбцам

Копирует метод добавления итогового столбца для каждой строки.

Добавить итоговый столбец в существующий набор данных

Сумма конкретных столбцов, используйте методы loc и передайте имена столбцов

Или мы можем использовать метод ниже

Не нравится новый столбец, удалите его методом drop

Добавление общей суммы под каждым столбцом

Многое было сделано выше, подход, который мы используем:
- Sum_Total: сделать сумму столбцов
- T_Sum: преобразовать выходные данные серии в DataFrame и транспонировать
- Переиндексировать, чтобы добавить отсутствующие столбцы
- Row_Total: добавить T_Sum к существующему DataFrame
Сумма на основе критериев, т. Е. Sumif в Excel

SUMIFS

СРЕСЛИ

Максимум

Min

Groupby, то есть промежуточные итоги в Excel

Сводные таблицы в фреймах данных, т. Е. Сводные таблицы в Excel
Кому не нравится сводная таблица в Excel, это один из лучших способов анализа ваших данных, быстрый обзор информации, помощь в нарезке и нарезке данных с помощью супер удобного интерфейса, помощь в построении графиков на основе данных добавить расчетные столбцы и т. д.
Нет, у нас не будет интерфейса для работы, нам придется явно писать код, чтобы получить вывод. Нет, он не будет генерировать диаграммы для вас, но я не думаю, что мы сможем завершить учебник, не изучив таблицы Pivot. ,

Простая сводная таблица, показывающая нам сумму значений SepalWidth в значениях, SepalLength в столбце строк и имени в метках столбцов
Давайте посмотрим, сможем ли мы немного усложнить это.

Пробелы теперь заменяются на 0 с помощью аргумента fill_value

У нас могут быть индивидуальные вычисления значений с использованием словарного метода, а также может быть несколько вычислений значений

Если мы используем аргумент поля, мы можем добавить общую строку
ВПР
Какая волшебная формула vlookup в Excel, я думаю, это первое, что каждый хочет изучить, прежде чем научиться даже добавлять. Выглядит увлекательно, когда кто-то применяет vlookup, выглядит как волшебство, когда мы получаем вывод. Облегчает жизнь Я могу с большой уверенностью сказать, что это основа каждого действия по сбору данных, выполняемого в электронной таблице.
к несчастьюу нас нет функции vlookup в Пандах!
Поскольку у нас нет функции «Vlookup» в Pandas, Merge используется как альтернатива, аналогичная SQL. Всего доступно четыре варианта слияния:
- «Слева» — используйте общий столбец в левом фрейме данных и сопоставьте правый фрейм данных. Заполните любой N / A как NaN
- «Вправо» — используйте общий столбец из правого фрейма данных и сопоставьте его с левым фреймом данных. Заполните любой N / A как NaN
- «Внутренний» — отображать данные только в тех случаях, когда два общих столбца перекрываются. Метод по умолчанию.
- «External» — возвращает все записи, когда в левом или правом кадре данных есть совпадение.

Вышесказанное может быть не лучшим примером для поддержки концепции, однако работа такая же.
Как говорится, «идеального учебника не существует», как и моего 
Узнайте, как читать и импортировать файлы Excel в Python, как записывать данные в эти таблицы и какие библиотеки лучше всего подходят для этого.
Известный вам инструмент для организации, анализа и хранения ваших данных в таблицах — Excel — применяется и в data science. В какой-то момент вам придется иметь дело с этими таблицами, но работать именно с ними вы будете не всегда. Вот почему разработчики Python реализовали способы чтения, записи и управления не только этими файлами, но и многими другими типами файлов.
Из этого учебника узнаете, как можете работать с Excel и Python. Внутри найдете обзор библиотек, которые вы можете использовать для загрузки и записи этих таблиц в файлы с помощью Python. Вы узнаете, как работать с такими библиотеками, как pandas, openpyxl, xlrd, xlutils и pyexcel.
Данные как ваша отправная точка
Когда вы начинаете проект по data science, вам придется работать с данными, которые вы собрали по всему интернету, и с наборами данных, которые вы загрузили из других мест — Kaggle, Quandl и тд
Но чаще всего вы также найдете данные в Google или в репозиториях, которые используются другими пользователями. Эти данные могут быть в файле Excel или сохранены в файл с расширением .csv … Возможности могут иногда казаться бесконечными, но когда у вас есть данные, в первую очередь вы должны убедиться, что они качественные.
В случае с электронной таблицей вы можете не только проверить, могут ли эти данные ответить на вопрос исследования, который вы имеете в виду, но также и можете ли вы доверять данным, которые хранятся в электронной таблице.
Проверяем качество таблицы
- Представляет ли электронная таблица статические данные?
- Смешивает ли она данные, расчеты и отчетность?
- Являются ли данные в вашей электронной таблице полными и последовательными?
- Имеет ли ваша таблица систематизированную структуру рабочего листа?
- Проверяли ли вы действительные формулы в электронной таблице?
Этот список вопросов поможет убедиться, что ваша таблица не грешит против лучших практик, принятых в отрасли. Конечно, этот список не исчерпывающий, но позволит провести базовую проверку таблицы.
Лучшие практики для данных электронных таблиц
Прежде чем приступить к чтению вашей электронной таблицы на Python, вы также должны подумать о том, чтобы настроить свой файл в соответствии с некоторыми основными принципами, такими как:
- Первая строка таблицы обычно зарезервирована для заголовка, а первый столбец используется для идентификации единицы выборки;
- Избегайте имен, значений или полей с пробелами. В противном случае каждое слово будет интерпретироваться как отдельная переменная, что приведет к ошибкам, связанным с количеством элементов на строку в вашем наборе данных. По возможности, используйте:
- подчеркивания,
- тире,
- горбатый регистр, где первая буква каждого слова пишется с большой буквы
- объединяющие слова
- Короткие имена предпочтительнее длинных имен;
- старайтесь не использовать имена, которые содержат символы ?, $,%, ^, &, *, (,), -, #,? ,,, <,>, /, |, , [,], {, и };
- Удалите все комментарии, которые вы сделали в вашем файле, чтобы избежать добавления в ваш файл лишних столбцов или NA;
- Убедитесь, что все пропущенные значения в вашем наборе данных обозначены как NA.
Затем, после того, как вы внесли необходимые изменения или тщательно изучили свои данные, убедитесь, что вы сохранили внесенные изменения. Сделав это, вы можете вернуться к данным позже, чтобы отредактировать их, добавить дополнительные данные или изменить их, сохранив формулы, которые вы, возможно, использовали для расчета данных и т.д.
Если вы работаете с Microsoft Excel, вы можете сохранить файл в разных форматах: помимо расширения по умолчанию .xls или .xlsx, вы можете перейти на вкладку «Файл», нажать «Сохранить как» и выбрать одно из расширений, которые указаны в качестве параметров «Сохранить как тип». Наиболее часто используемые расширения для сохранения наборов данных в data science — это .csv и .txt (в виде текстового файла с разделителями табуляции). В зависимости от выбранного варианта сохранения поля вашего набора данных разделяются вкладками или запятыми, которые образуют символы-разделители полей вашего набора данных.
Теперь, когда вы проверили и сохранили ваши данные, вы можете начать с подготовки вашего рабочего окружения.
Готовим рабочее окружение
Как убедиться, что вы все делаете хорошо? Проверить рабочее окружение!
Когда вы работаете в терминале, вы можете сначала перейти в каталог, в котором находится ваш файл, а затем запустить Python. Убедитесь, что файл лежит именно в том каталоге, к которому вы обратились.
Возможно, вы уже начали сеанс Python и у вас нет подсказок о каталоге, в котором вы работаете. Тогда можно выполнить следующие команды:
# Import `os`
import os
# Retrieve current working directory (`cwd`)
cwd = os.getcwd()
cwd
# Change directory
os.chdir("/path/to/your/folder")
# List all files and directories in current directory
os.listdir('.')Круто, да?
Вы увидите, что эти команды очень важны не только для загрузки ваших данных, но и для дальнейшего анализа. А пока давайте продолжим: вы прошли все проверки, вы сохранили свои данные и подготовили рабочее окружение.
Можете ли вы начать с чтения данных в Python?
Установите библиотеки для чтения и записи файлов Excel
Даже если вы еще не знаете, какие библиотеки вам понадобятся для импорта ваших данных, вы должны убедиться, что у вас есть все, что нужно для установки этих библиотек, когда придет время.
Подготовка к дополнительной рабочей области: pip
Вот почему вам нужно установить pip и setuptools. Если у вас установлен Python2 ⩾ 2.7.9 или Python3 ⩾ 3.4, то можно не беспокоиться — просто убедитесь, что вы обновились до последней версии.
Для этого выполните следующую команду в своем терминале:
# Для Linux/OS X
pip install -U pip setuptools
# Для Windows
python -m pip install -U pip setuptoolsЕсли вы еще не установили pip, запустите скрипт python get-pip.py, который вы можете найти здесь. Следуйте инструкциям по установке.
Установка Anaconda
Другой вариант для работы в data science — установить дистрибутив Anaconda Python. Сделав это, вы получите простой и быстрый способ начать заниматься data science, потому что вам не нужно беспокоиться об установке отдельных библиотек, необходимых для работы.
Это особенно удобно, если вы новичок, но даже для более опытных разработчиков это способ быстро протестировать некоторые вещи без необходимости устанавливать каждую библиотеку отдельно.
Anaconda включает в себя 100 самых популярных библиотек Python, R и Scala для науки о данных и несколько сред разработки с открытым исходным кодом, таких как Jupyter и Spyder.
Установить Anaconda можно здесь. Следуйте инструкциям по установке, и вы готовы начать!
Загрузить файлы Excel в виде фреймов Pandas
Все, среда настроена, вы готовы начать импорт ваших файлов.
Один из способов, который вы часто используете для импорта ваших файлов для обработки данных, — с помощью библиотеки Pandas. Она основана на NumPy и предоставляет простые в использовании структуры данных и инструменты анализа данных Python.
Эта мощная и гибкая библиотека очень часто используется дата-инженерами для передачи своих данных в структуры данных, очень выразительных для их анализа.
Если у вас уже есть Pandas, доступные через Anaconda, вы можете просто загрузить свои файлы в Pandas DataFrames с помощью pd.Excelfile():
# импорт библиотеки pandas
import pandas as pd
# Загружаем ваш файл в переменную `file` / вместо 'example' укажите название свого файла из текущей директории
file = 'example.xlsx'
# Загружаем spreadsheet в объект pandas
xl = pd.ExcelFile(file)
# Печатаем название листов в данном файле
print(xl.sheet_names)
# Загрузить лист в DataFrame по его имени: df1
df1 = xl.parse('Sheet1')Если вы не установили Anaconda, просто выполните pip install pandas, чтобы установить библиотеку Pandas в вашей среде, а затем выполните команды, которые включены в фрагмент кода выше.
Проще простого, да?
Для чтения в файлах .csv у вас есть аналогичная функция для загрузки данных в DataFrame: read_csv(). Вот пример того, как вы можете использовать эту функцию:
# Импорт библиотеки pandas
import pandas as pd
# Загрузить csv файл
df = pd.read_csv("example.csv") Разделитель, который будет учитывать эта функция, по умолчанию является запятой, но вы можете указать альтернативный разделитель, если хотите. Перейдите к документации, чтобы узнать, какие другие аргументы вы можете указать для успешного импорта!
Обратите внимание, что есть также функции read_table() и read_fwf() для чтения файлов и таблиц с фиксированной шириной в формате DataFrames с общим разделителем. Для первой функции разделителем по умолчанию является вкладка, но вы можете снова переопределить это, а также указать альтернативный символ-разделитель. Более того, есть и другие функции, которые вы можете использовать для получения данных в DataFrames: вы можете найти их здесь.
Как записать Pandas DataFrames в файлы Excel
Допустим, что после анализа данных вы хотите записать данные обратно в новый файл. Есть также способ записать ваши Pandas DataFrames обратно в файлы с помощью функции to_excel().
Но, прежде чем использовать эту функцию, убедитесь, что у вас установлен XlsxWriter, если вы хотите записать свои данные в несколько листов в файле .xlsx:
# Установим `XlsxWriter`
pip install XlsxWriter
# Указать writer библиотеки
writer = pd.ExcelWriter('example.xlsx', engine='xlsxwriter')
# Записать ваш DataFrame в файл
yourData.to_excel(writer, 'Sheet1')
# Сохраним результат
writer.save()Обратите внимание, что в приведенном выше фрагменте кода вы используете объект ExcelWriter для вывода DataFrame.
Иными словами, вы передаете переменную Writer в функцию to_excel() и также указываете имя листа. Таким образом, вы добавляете лист с данными в существующую рабочую книгу: вы можете использовать ExcelWriter для сохранения нескольких (немного) разных DataFrames в одной рабочей книге.
Все это означает, что если вы просто хотите сохранить один DataFrame в файл, вы также можете обойтись без установки пакета XlsxWriter. Затем вы просто не указываете аргумент движка, который вы передаете в функцию pd.ExcelWriter(). Остальные шаги остаются прежними.
Аналогично функциям, которые вы использовали для чтения в файлах .csv, у вас также есть функция to_csv() для записи результатов обратно в файл, разделенный запятыми. Он снова работает так же, как когда вы использовали его для чтения в файле:
# Запишите DataFrame в csv
df.to_csv("example.csv")Если вы хотите иметь файл, разделенный табуляцией, вы также можете передать t аргументу sep. Обратите внимание, что есть другие функции, которые вы можете использовать для вывода ваших файлов. Вы можете найти их все здесь.
Пакеты для разбора файлов Excel и обратной записи с помощью Python
Помимо библиотеки Pandas, который вы будете использовать очень часто для загрузки своих данных, вы также можете использовать другие библиотеки для получения ваших данных в Python. Наш обзор основан на этой странице со списком доступных библиотек, которые вы можете использовать для работы с файлами Excel в Python.
Далее вы увидите, как использовать эти библиотеки с помощью некоторых реальных, но упрощенных примеров.
Использование виртуальных сред
Общий совет для установки — делать это в Python virtualenv без системных пакетов. Вы можете использовать virtualenv для создания изолированных сред Python: он создает папку, содержащую все необходимые исполняемые файлы для использования пакетов, которые потребуются проекту Python.
Чтобы начать работать с virtualenv, вам сначала нужно установить его. Затем перейдите в каталог, в который вы хотите поместить свой проект. Создайте virtualenv в этой папке и загрузите в определенную версию Python, если вам это нужно. Затем вы активируете виртуальную среду. После этого вы можете начать загрузку в другие библиотеки, начать работать с ними и т. д.
Совет: не забудьте деактивировать среду, когда закончите!
# Install virtualenv
$ pip install virtualenv
# Go to the folder of your project
$ cd my_folder
# Create a virtual environment `venv`
$ virtualenv venv
# Indicate the Python interpreter to use for `venv`
$ virtualenv -p /usr/bin/python2.7 venv
# Activate `venv`
$ source venv/bin/activate
# Deactivate `venv`
$ deactivateОбратите внимание, что виртуальная среда может показаться немного проблемной на первый взгляд, когда вы только начинаете работать с данными с Python. И, особенно если у вас есть только один проект, вы можете не понять, зачем вам вообще нужна виртуальная среда.
С ней будет гораздо легче, когда у вас одновременно запущено несколько проектов, и вы не хотите, чтобы они использовали одну и ту же установку Python. Или когда ваши проекты имеют противоречащие друг другу требования, виртуальная среда пригодится!
Теперь вы можете, наконец, начать установку и импорт библиотек, о которых вы читали, и загрузить их в таблицу.
Как читать и записывать файлы Excel с openpyxl
Этот пакет обычно рекомендуется, если вы хотите читать и записывать файлы .xlsx, xlsm, xltx и xltm.
Установите openpyxl с помощью pip: вы видели, как это сделать в предыдущем разделе.
Общий совет для установки этой библиотеки — делать это в виртуальной среде Python без системных библиотек. Вы можете использовать виртуальную среду для создания изолированных сред Python: она создает папку, которая содержит все необходимые исполняемые файлы для использования библиотек, которые потребуются проекту Python.
Перейдите в каталог, в котором находится ваш проект, и повторно активируйте виртуальную среду venv. Затем продолжите установку openpyxl с pip, чтобы убедиться, что вы можете читать и записывать файлы с ним:
# Активируйте virtualenv
$ source activate venv
# Установим `openpyxl` в `venv`
$ pip install openpyxlТеперь, когда вы установили openpyxl, вы можете загружать данные. Но что это за данные?
Доспутим Excel с данными, которые вы пытаетесь загрузить в Python, содержит следующие листы:
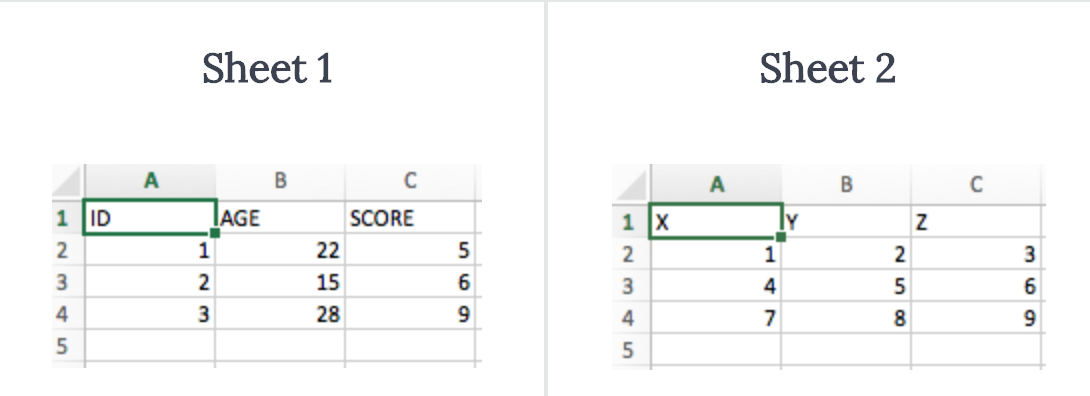
Функция load_workbook() принимает имя файла в качестве аргумента и возвращает объект рабочей книги, который представляет файл. Вы можете проверить это, запустив type (wb). Убедитесь, что вы находитесь в том каталоге, где находится ваша таблица, иначе вы получите error при импорте.
# Import `load_workbook` module from `openpyxl`
from openpyxl import load_workbook
# Load in the workbook
wb = load_workbook('./test.xlsx')
# Get sheet names
print(wb.get_sheet_names())Помните, что вы можете изменить рабочий каталог с помощью os.chdir().
Вы видите, что фрагмент кода выше возвращает имена листов книги, загруженной в Python.Можете использовать эту информацию, чтобы также получить отдельные листы рабочей книги.
Вы также можете проверить, какой лист в настоящее время активен с wb.active. Как видно из кода ниже, вы можете использовать его для загрузки другого листа из вашей книги:
# Get a sheet by name
sheet = wb.get_sheet_by_name('Sheet3')
# Print the sheet title
sheet.title
# Get currently active sheet
anotherSheet = wb.active
# Check `anotherSheet`
anotherSheetНа первый взгляд, с этими объектами рабочего листа вы не сможете многое сделать.. Однако вы можете извлечь значения из определенных ячеек на листе вашей книги, используя квадратные скобки [], в которые вы передаете точную ячейку, из которой вы хотите получить значение.
Обратите внимание, что это похоже на выбор, получение и индексирование массивов NumPy и Pandas DataFrames, но это не все, что вам нужно сделать, чтобы получить значение. Вам нужно добавить атрибут value:
# Retrieve the value of a certain cell
sheet['A1'].value
# Select element 'B2' of your sheet
c = sheet['B2']
# Retrieve the row number of your element
c.row
# Retrieve the column letter of your element
c.column
# Retrieve the coordinates of the cell
c.coordinateКак вы можете видеть, помимо значения, есть и другие атрибуты, которые вы можете использовать для проверки вашей ячейки, а именно: row, column и coordinate.
Атрибут row вернет 2;
Добавление атрибута column к c даст вам ‘B’
coordinate вернет ‘B2’.
Вы также можете получить значения ячеек с помощью функции cell(). Передайте row и column, добавьте к этим аргументам значения, соответствующие значениям ячейки, которую вы хотите получить, и, конечно же, не забудьте добавить атрибут value:
# Retrieve cell value
sheet.cell(row=1, column=2).value
# Print out values in column 2
for i in range(1, 4):
print(i, sheet.cell(row=i, column=2).value)Обратите внимание, что если вы не укажете атрибут value, вы получите <Cell Sheet3.B1>, который ничего не говорит о значении, которое содержится в этой конкретной ячейке.
Вы видите, что вы используете цикл for с помощью функции range(), чтобы помочь вам распечатать значения строк, имеющих значения в столбце 2. Если эти конкретные ячейки пусты, вы просто вернете None. Если вы хотите узнать больше о циклах for, пройдите наш курс Intermediate Python для Data Science.
Есть специальные функции, которые вы можете вызывать для получения некоторых других значений, например, get_column_letter() и column_index_from_string.
Две функции указывают примерно то, что вы можете получить, используя их, но лучше сделать их четче: хотя вы можете извлечь букву столбца с предшествующего, вы можете сделать обратное или получить адрес столбца, когда вы задаёте букву последнему. Вы можете увидеть, как это работает ниже:
# Импорт необходимых модулей из `openpyxl.utils`
from openpyxl.utils import get_column_letter, column_index_from_string
# Вывод 'A'
get_column_letter(1)
# Return '1'
column_index_from_string('A')Вы уже получили значения для строк, которые имеют значения в определенном столбце, но что вам нужно сделать, если вы хотите распечатать строки вашего файла, не сосредотачиваясь только на одном столбце? Использовать другой цикл, конечно!
Например, вы говорите, что хотите сфокусироваться на области между «А1» и «С3», где первая указывает на левый верхний угол, а вторая — на правый нижний угол области, на которой вы хотите сфокусироваться. ,
Эта область будет так называемым cellObj, который вы видите в первой строке кода ниже. Затем вы говорите, что для каждой ячейки, которая находится в этой области, вы печатаете координату и значение, которое содержится в этой ячейке. После конца каждой строки вы печатаете сообщение, которое указывает, что строка этой области cellObj напечатана.
# Напечатать строчку за строчкой
for cellObj in sheet['A1':'C3']:
for cell in cellObj:
print(cells.coordinate, cells.value)
print('--- END ---')Еще раз обратите внимание, что выбор области очень похож на выбор, получение и индексирование списка и элементов массива NumPy, где вы также используете [] и : для указания области, значения которой вы хотите получить. Кроме того, вышеприведенный цикл также хорошо использует атрибуты ячейки!
Чтобы сделать вышеприведенное объяснение и код наглядным, вы можете проверить результат, который вы получите после завершения цикла:
('A1', u'M')
('B1', u'N')
('C1', u'O')
--- END ---
('A2', 10L)
('B2', 11L)
('C2', 12L)
--- END ---
('A3', 14L)
('B3', 15L)
('C3', 16L)
--- END ---Наконец, есть некоторые атрибуты, которые вы можете использовать для проверки результата вашего импорта, а именно max_row и max_column. Эти атрибуты, конечно, и так — общие способы проверки правильности загрузки данных, но они все равно полезны.
# Вывести максимальное количество строк
sheet.max_row
# Вывести максимальное количество колонок
sheet.max_columnНаверное, вы думаете, что такой способ работы с этими файлами сложноват, особенно если вы еще хотите манипулировать данными.
Должно быть что-то попроще, верно? Так и есть!
openpyxl поддерживает Pandas DataFrames! Вы можете использовать функцию DataFrame() из библиотеки Pandas, чтобы поместить значения листа в DataFrame:
# Import `pandas`
import pandas as pd
# конвертировать Лист в DataFrame
df = pd.DataFrame(sheet.values)Если вы хотите указать заголовки и индексы, вам нужно добавить немного больше кода:
# Put the sheet values in `data`
data = sheet.values
# Indicate the columns in the sheet values
cols = next(data)[1:]
# Convert your data to a list
data = list(data)
# Read in the data at index 0 for the indices
idx = [r[0] for r in data]
# Slice the data at index 1
data = (islice(r, 1, None) for r in data)
# Make your DataFrame
df = pd.DataFrame(data, index=idx, columns=cols)Затем вы можете начать манипулировать данными со всеми функциями, которые предлагает библиотека Pandas. Но помните, что вы находитесь в виртуальной среде, поэтому, если библиотека еще не представлена, вам нужно будет установить ее снова через pip.
Чтобы записать ваши Pandas DataFrames обратно в файл Excel, вы можете легко использовать функцию dataframe_to_rows() из модуля utils:
# Import `dataframe_to_rows`
from openpyxl.utils.dataframe import dataframe_to_rows
# Initialize a workbook
wb = Workbook()
# Get the worksheet in the active workbook
ws = wb.active
# Append the rows of the DataFrame to your worksheet
for r in dataframe_to_rows(df, index=True, header=True):
ws.append(r)Но это точно не все! Библиотека openpyxl предлагает вам высокую гибкость при записи ваших данных обратно в файлы Excel, изменении стилей ячеек или использовании режима write-only. Эту библиотеку обязательно нужно знать, когда вы часто работаете с электронными таблицами ,
Совет: читайте больше о том, как вы можете изменить стили ячеек, перейти в режим write-only или как библиотека работает с NumPy здесь.
Теперь давайте также рассмотрим некоторые другие библиотеки, которые вы можете использовать для получения данных вашей электронной таблицы в Python.
Прежде чем закрыть этот раздел, не забудьте отключить виртуальную среду, когда закончите!
Чтение и форматирование Excel-файлов: xlrd
Эта библиотека идеально подходит для чтения и форматирования данных из Excel с расширением xls или xlsx.
# Import `xlrd`
import xlrd
# Open a workbook
workbook = xlrd.open_workbook('example.xls')
# Loads only current sheets to memory
workbook = xlrd.open_workbook('example.xls', on_demand = True)Когда вам не нужны данные из всей Excel-книги, вы можете использовать функции sheet_by_name() или sheet_by_index() для получения листов, которые вы хотите получить в своём анализе
# Load a specific sheet by name
worksheet = workbook.sheet_by_name('Sheet1')
# Load a specific sheet by index
worksheet = workbook.sheet_by_index(0)
# Retrieve the value from cell at indices (0,0)
sheet.cell(0, 0).valueТакже можно получить значение в определённых ячейках с вашего листа.
Перейдите к xlwt и xlutils, чтобы узнать больше о том, как они относятся к библиотеке xlrd.
Запись данных в Excel-файлы с xlwt
Если вы хотите создать таблицу со своими данными, вы можете использовать не только библиотеку XlsWriter, но и xlwt. xlwt идеально подходит для записи данных и форматирования информации в файлах с расширением .xls
Когда вы вручную создаёте файл:
# Import `xlwt`
import xlwt
# Initialize a workbook
book = xlwt.Workbook(encoding="utf-8")
# Add a sheet to the workbook
sheet1 = book.add_sheet("Python Sheet 1")
# Write to the sheet of the workbook
sheet1.write(0, 0, "This is the First Cell of the First Sheet")
# Save the workbook
book.save("spreadsheet.xls")Если вы хотите записать данные в файл, но не хотите делать все самостоятельно, вы всегда можете прибегнуть к циклу for, чтобы автоматизировать весь процесс. Составьте сценарий, в котором вы создаёте книгу и в которую добавляете лист. Укажите список со столбцами и один со значениями, которые будут заполнены на листе.
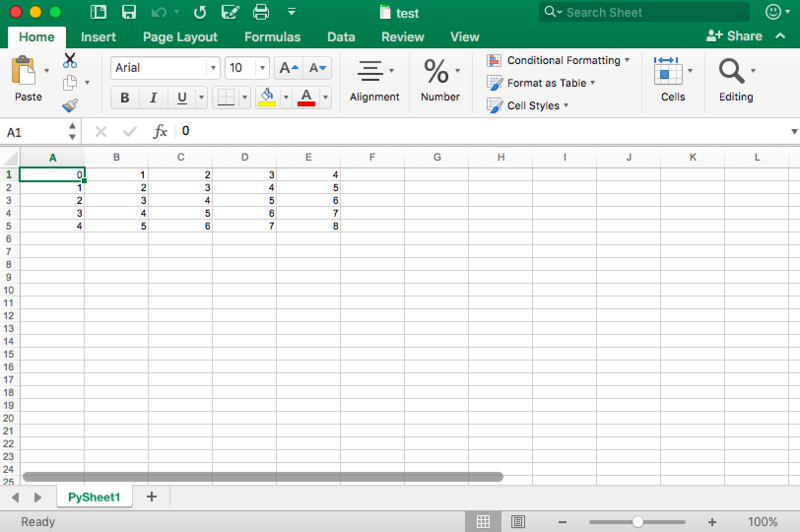
Далее у вас есть цикл for, который гарантирует, что все значения попадают в файл: вы говорите, что для каждого элемента в диапазоне от 0 до 4 (5 не включительно) вы собираетесь что-то делать. Вы будете заполнять значения построчно. Для этого вы указываете элемент строки, который появляется в каждом цикле. Далее у вас есть еще один цикл for, который будет проходить по столбцам вашего листа. Вы говорите, что для каждой строки на листе, вы будете смотреть на столбцы, которые идут с ним, и вы будете заполнять значение для каждого столбца в строке. Заполнив все столбцы строки значениями, вы перейдете к следующей строке, пока не останется строк.
# Initialize a workbook
book = xlwt.Workbook()
# Add a sheet to the workbook
sheet1 = book.add_sheet("Sheet1")
# The data
cols = ["A", "B", "C", "D", "E"]
txt = [0,1,2,3,4]
# Loop over the rows and columns and fill in the values
for num in range(5):
row = sheet1.row(num)
for index, col in enumerate(cols):
value = txt[index] + num
row.write(index, value)
# Save the result
book.save("test.xls")На скриншоте ниже представлен результат выполнения этого кода:
Теперь, когда вы увидели, как xlrd и xlwt работают друг с другом, пришло время взглянуть на библиотеку, которая тесно связана с этими двумя: xlutils.
Сборник утилит: xlutils
Эта библиотека — сборник утилит, для которого требуются и xlrd и xlwt, и которая может копировать, изменять и фильтровать существующие данные. О том, как пользоваться этими командами рассказано в разделе по openpyxl.
Вернитесь в раздел openpyxl, чтобы получить больше информации о том, как использовать этот пакет для получения данных в Python.
Использование pyexcel для чтения .xls или .xlsx файлов
Еще одна библиотека, которую можно использовать для чтения данных электронных таблиц в Python — это pyexcel; Python Wrapper, который предоставляет один API для чтения, записи и работы с данными в файлах .csv, .ods, .xls, .xlsx и .xlsm. Конечно, для этого урока вы просто сосредоточитесь на файлах .xls и .xls.
Чтобы получить ваши данные в массиве, вы можете использовать функцию get_array(), которая содержится в пакете pyexcel:
# Import `pyexcel`
import pyexcel
# Get an array from the data
my_array = pyexcel.get_array(file_name="test.xls")Вы также можете получить свои данные в упорядоченном словаре списков. Вы можете использовать функцию get_dict():
# Import `OrderedDict` module
from pyexcel._compact import OrderedDict
# Get your data in an ordered dictionary of lists
my_dict = pyexcel.get_dict(file_name="test.xls", name_columns_by_row=0)
# Get your data in a dictionary of 2D arrays
book_dict = pyexcel.get_book_dict(file_name="test.xls")Здесь видно, что если вы хотите получить словарь двумерных массивов или получить все листы рабочей книги в одном словаре, вы можете прибегнуть к get_book_dict().
Помните, что эти две структуры данных, которые были упомянуты выше, массивы и словари вашей таблицы, позволяют вам создавать DataFrames ваших данных с помощью pd.DataFrame(). Это облегчит обработку данных.
Кроме того, вы можете просто получить записи из таблицы с помощью pyexcel благодаря функции get_records(). Просто передайте аргумент file_name в функцию, и вы получите список словарей:
# Retrieve the records of the file
records = pyexcel.get_records(file_name="test.xls")Чтобы узнать, как управлять списками Python, ознакомьтесь с примерами из документации о списках Python.
Запись в файл с pyexcel
С помощью этой библиотеки можно не только загружать данные в массивы, вы также можете экспортировать свои массивы обратно в таблицу. Используйте функцию save_as() и передайте массив и имя файла назначения в аргумент dest_file_name:
# Get the data
data = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
# Save the array to a file
pyexcel.save_as(array=data, dest_file_name="array_data.xls")Обратите внимание, что если вы хотите указать разделитель, вы можете добавить аргумент dest_delimiter и передать символ, который вы хотите использовать в качестве разделителя между «».
Однако если у вас есть словарь, вам нужно использовать функцию save_book_as(). Передайте двумерный словарь в bookdict и укажите имя файла:
# The data
2d_array_dictionary = {'Sheet 1': [
['ID', 'AGE', 'SCORE']
[1, 22, 5],
[2, 15, 6],
[3, 28, 9]
],
'Sheet 2': [
['X', 'Y', 'Z'],
[1, 2, 3],
[4, 5, 6]
[7, 8, 9]
],
'Sheet 3': [
['M', 'N', 'O', 'P'],
[10, 11, 12, 13],
[14, 15, 16, 17]
[18, 19, 20, 21]
]}
# Save the data to a file
pyexcel.save_book_as(bookdict=2d_array_dictionary, dest_file_name="2d_array_data.xls")При использовании кода, напечатанного в приведенном выше примере, важно помнить, что порядок ваших данных в словаре не будет сохранен. Если вы не хотите этого, вам нужно сделать небольшой обход. Вы можете прочитать все об этом здесь.
Чтение и запись .csv файлов
Если вы все еще ищете библиотеки, которые позволяют загружать и записывать данные в файлы .csv, кроме Pandas, лучше всего использовать пакет csv:
# import `csv`
import csv
# Read in csv file
for row in csv.reader(open('data.csv'), delimiter=','):
print(row)
# Write csv file
data = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
outfile = open('data.csv', 'w')
writer = csv.writer(outfile, delimiter=';', quotechar='"')
writer.writerows(data)
outfile.close()Обратите внимание, что в пакете NumPy есть функция genfromtxt(), которая позволяет загружать данные, содержащиеся в файлах .csv, в массивы, которые затем можно поместить в DataFrames.
Финальная проверка данных
Когда у вас есть данные, не забудьте последний шаг: проверить, правильно ли загружены данные. Если вы поместили свои данные в DataFrame, вы можете легко и быстро проверить, был ли импорт успешным, выполнив следующие команды:
# Check the first entries of the DataFrame
df1.head()
# Check the last entries of the DataFrame
df1.tail()Если у вас есть данные в массиве, вы можете проверить их, используя следующие атрибуты массива: shape, ndim, dtype и т.д .:
# Inspect the shape
data.shape
# Inspect the number of dimensions
data.ndim
# Inspect the data type
data.dtype
Что дальше?
Поздравляем! Вы успешно прошли наш урок и научились читать файлы Excel на Python.
Если вы хотите продолжить работу над этой темой, попробуйте воспользоваться PyXll, который позволяет писать функции в Python и вызывать их в Excel.
Многие потенциальные пользователи pandas имеют некоторое представление о программах для работы с электронными таблицами, такими как Excel. На этой странице приведены примеры того, как выполняются различные операции с электронными таблицами с помощью pandas. На этой странице используется терминология Excel и ссылки на документацию Excel, но многое похожим образом делается в Google Таблицах, LibreOffice Calc, Apple Numbers и в другом программном обеспечении для работы с электронными таблицами, совместимом с Excel.
Если вы новичок в pandas, вы можете сначала прочитать 10 Minutes to pandas, чтобы ознакомиться с библиотекой.
Как обычно, импортируем pandas и NumPy следующим образом:
In [1]: import pandas as pd In [2]: import numpy as np
Структуры данных¶
Перевод общей терминологии¶
|
pandas |
Excel |
|---|---|
|
DataFrame |
лист |
|
Series |
столбец |
|
Index |
заголовки строк |
|
строка |
строка |
|
NaN |
пустая ячейка |
DataFrame¶
DataFrame в pandas аналогичен листу в Excel. В то время как книга Excel может содержать несколько листов, DataFrame в pandas существуют независимо друг от друга.
Series¶
Series — это структура данных, представляющая один столбец DataFrame. Работа с Series аналогична работе со столбцом электронной таблицы.
Index¶
У каждого DataFrame и Series есть Index, который является меткой для строк данных. В pandas, если индекс не указан, по умолчанию используется RangeIndex (первая строка = 0, вторая строка = 1 и так далее), аналогично заголовкам или номерам строк в электронных таблицах.
В pandas индекс можно установить на одно или несколько уникальных значений, что похоже на наличие столбца, который используется в качестве идентификатора строки на листе. В отличие от большинства электронных таблиц, эти значения Index могут фактически использоваться для ссылки на строки. (Обратите внимание, это можно сделать в Excel со структурированными ссылками.) Например, в электронных таблицах вы бы ссылались на первую строку как A1:Z1, а в pandas бы использовали populations.loc['Chicago'].
Значения индекса постоянны, поэтому, если вы измените порядок строк в DataFrame, метка для конкретной строки не изменится.
См. документацию по индексированию, чтобы узнать больше о том, как эффективно использовать Index.
Копии и операции на месте¶
Большинство операций pandas возвращают копии Series и DataFrame. Чтобы зафиксировать изменения, вам нужно либо назначить новую переменную:
sorted_df = df.sort_values("col1")
Либо перезаписать исходный объект:
df = df.sort_values("col1")
Примечание
Вы можете столкнуться с аргументом inplace=True, доступным для некоторых методов:
df.sort_values("col1", inplace=True)
Мы не рекомендуем его использовать.
Ввод и вывод данных¶
Построение DataFrame из значений¶
В электронной таблице значения можно вводить непосредственно в ячейки.
DataFrame в pandas можно создать разными способами, но для небольшого количества значений часто бывает удобно указать его как словарь Python, где ключи — это имена столбцов, а значения — это данные.
In [3]: df = pd.DataFrame({"x": [1, 3, 5], "y": [2, 4, 6]}) In [4]: df Out[4]: x y 0 1 2 1 3 4 2 5 6
Чтение данных из внешних источников¶
И Excel, и pandas могут импортировать данные из разных источников в разных форматах.
CSV¶
Давайте загрузим из тестов pandas и отобразим набор данных tips в формате CSV. В Excel вам нужно загрузить, а затем открыть файл CSV. В pandas вы передаете URL-адрес или локальный путь файла CSV в read_csv():
In [5]: url = ( ...: "https://raw.github.com/pandas-dev" ...: "/pandas/main/pandas/tests/io/data/csv/tips.csv" ...: ) ...: In [6]: tips = pd.read_csv(url) In [7]: tips Out[7]: total_bill tip sex smoker day time size 0 16.99 1.01 Female No Sun Dinner 2 1 10.34 1.66 Male No Sun Dinner 3 2 21.01 3.50 Male No Sun Dinner 3 3 23.68 3.31 Male No Sun Dinner 2 4 24.59 3.61 Female No Sun Dinner 4 .. ... ... ... ... ... ... ... 239 29.03 5.92 Male No Sat Dinner 3 240 27.18 2.00 Female Yes Sat Dinner 2 241 22.67 2.00 Male Yes Sat Dinner 2 242 17.82 1.75 Male No Sat Dinner 2 243 18.78 3.00 Female No Thur Dinner 2 [244 rows x 7 columns]
Подобно Мастеру импорта текста Excel, read_csv в pandas принимает ряд параметров, которые позволяют указать, как нужно проанализировать данные. Например, если бы данные были разделены табуляцией и не имели имен столбцов, команда pandas была бы такой:
tips = pd.read_csv("tips.csv", sep="t", header=None) # alternatively, read_table is an alias to read_csv with tab delimiter tips = pd.read_table("tips.csv", header=None)
Файлы Excel¶
Excel открывает файлы различных форматов Excel двойным щелчком мыши или через меню Открыть. В pandas используются специальные методы для чтения и записи файлов Excel.
Давайте сначала создадим новый файл Excel на основе данных tips из приведенного выше примера:
tips.to_excel("./tips.xlsx")
Если вы хотите впоследствии получить доступ к данным в файле tips.xlsx, вы можете прочитать его так:
tips_df = pd.read_excel("./tips.xlsx", index_col=0)
Вы только что прочитали файл Excel с помощью pandas!
Ограничение вывода¶
Программы для работы с электронными таблицами отображают данные, которые помещаются на экране, а затем позволяют прокручивать их, так что на самом деле нет необходимости ограничивать вывод. В pandas приходится подумать о том, как отображаются DataFrame.
По умолчанию pandas обрезает вывод больших DataFrame, чтобы показать первую и последнюю строки. Это можно переопределить, изменив параметры pandas или используя DataFrame.head() или DataFrame.tail().
In [8]: tips.head(5) Out[8]: total_bill tip sex smoker day time size 0 16.99 1.01 Female No Sun Dinner 2 1 10.34 1.66 Male No Sun Dinner 3 2 21.01 3.50 Male No Sun Dinner 3 3 23.68 3.31 Male No Sun Dinner 2 4 24.59 3.61 Female No Sun Dinner 4
Экспорт данных¶
По умолчанию программное обеспечение для работы с электронными таблицами сохраняет файлы в соответствующем формате (.xlsx, .ods и т. д.). Однако вы можете сохранить файл в другом формате.
pandas может создавать файлы Excel, CSV и файлы других форматов.
Операции с данными¶
Операции над столбцами¶
В электронных таблицах формулы часто создаются в отдельных ячейках. а затем перетаскиваются в другие ячейки, чтобы применить аналогичные операции ко всем ячейкам в столбце. В pandas вы можете напрямую выполнять операции над целыми столбцами.
pandas обеспечивает векторизованные операции, указывая отдельные Series в DataFrame. Таким же образом можно назначить новые столбцы. Метод DataFrame.drop() удаляет столбец из DataFrame.
In [9]: tips["total_bill"] = tips["total_bill"] - 2 In [10]: tips["new_bill"] = tips["total_bill"] / 2 In [11]: tips Out[11]: total_bill tip sex smoker day time size new_bill 0 14.99 1.01 Female No Sun Dinner 2 7.495 1 8.34 1.66 Male No Sun Dinner 3 4.170 2 19.01 3.50 Male No Sun Dinner 3 9.505 3 21.68 3.31 Male No Sun Dinner 2 10.840 4 22.59 3.61 Female No Sun Dinner 4 11.295 .. ... ... ... ... ... ... ... ... 239 27.03 5.92 Male No Sat Dinner 3 13.515 240 25.18 2.00 Female Yes Sat Dinner 2 12.590 241 20.67 2.00 Male Yes Sat Dinner 2 10.335 242 15.82 1.75 Male No Sat Dinner 2 7.910 243 16.78 3.00 Female No Thur Dinner 2 8.390 [244 rows x 8 columns] In [12]: tips = tips.drop("new_bill", axis=1)
Обратите внимание, что нам не пришлось выполнять вычитание по ячейкам — pandas сделал это за нас. См. как создать новые столбцы, производные от существующих столбцов.
Фильтрация¶
В Excel фильтрация осуществляется через графическое меню.
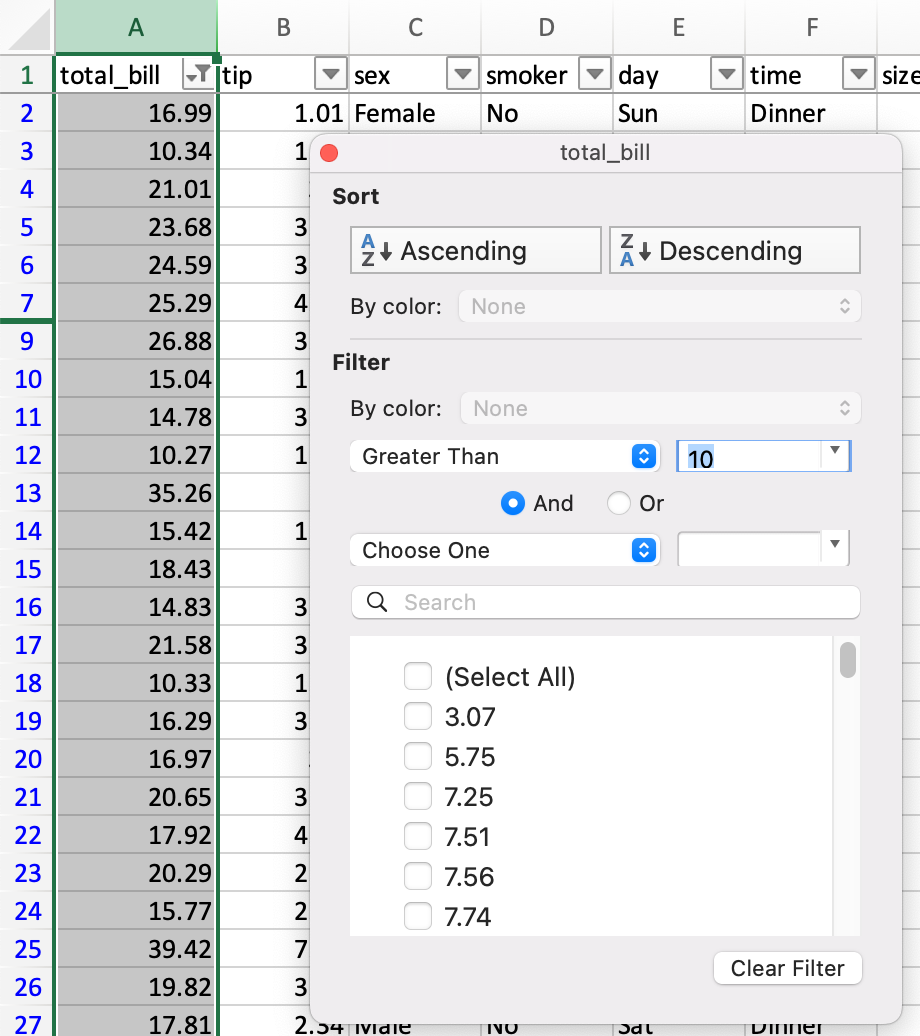
DataFrame можно фильтровать несколькими способами; наиболее интуитивным из них является использование логического индексирования.
In [13]: tips[tips["total_bill"] > 10] Out[13]: total_bill tip sex smoker day time size 0 14.99 1.01 Female No Sun Dinner 2 2 19.01 3.50 Male No Sun Dinner 3 3 21.68 3.31 Male No Sun Dinner 2 4 22.59 3.61 Female No Sun Dinner 4 5 23.29 4.71 Male No Sun Dinner 4 .. ... ... ... ... ... ... ... 239 27.03 5.92 Male No Sat Dinner 3 240 25.18 2.00 Female Yes Sat Dinner 2 241 20.67 2.00 Male Yes Sat Dinner 2 242 15.82 1.75 Male No Sat Dinner 2 243 16.78 3.00 Female No Thur Dinner 2 [204 rows x 7 columns]
Вышеприведенный оператор просто передает Series объектов True и False в DataFrame, возвращая все строки с True.
In [14]: is_dinner = tips["time"] == "Dinner" In [15]: is_dinner Out[15]: 0 True 1 True 2 True 3 True 4 True ... 239 True 240 True 241 True 242 True 243 True Name: time, Length: 244, dtype: bool In [16]: is_dinner.value_counts() Out[16]: True 176 False 68 Name: time, dtype: int64 In [17]: tips[is_dinner] Out[17]: total_bill tip sex smoker day time size 0 14.99 1.01 Female No Sun Dinner 2 1 8.34 1.66 Male No Sun Dinner 3 2 19.01 3.50 Male No Sun Dinner 3 3 21.68 3.31 Male No Sun Dinner 2 4 22.59 3.61 Female No Sun Dinner 4 .. ... ... ... ... ... ... ... 239 27.03 5.92 Male No Sat Dinner 3 240 25.18 2.00 Female Yes Sat Dinner 2 241 20.67 2.00 Male Yes Sat Dinner 2 242 15.82 1.75 Male No Sat Dinner 2 243 16.78 3.00 Female No Thur Dinner 2 [176 rows x 7 columns]
Логика if/then¶
Допустим, мы хотим создать столбец bucket со значениями low и high, в зависимости от того, меньше или больше 10 долларов значение в total_bill.
В электронных таблицах логическое сравнение можно выполнить с помощью условных формул. Мы бы использовали формулу =IF(A2 < 10, "low", "high"), перетащив ее во все ячейки в новом столбце bucket.
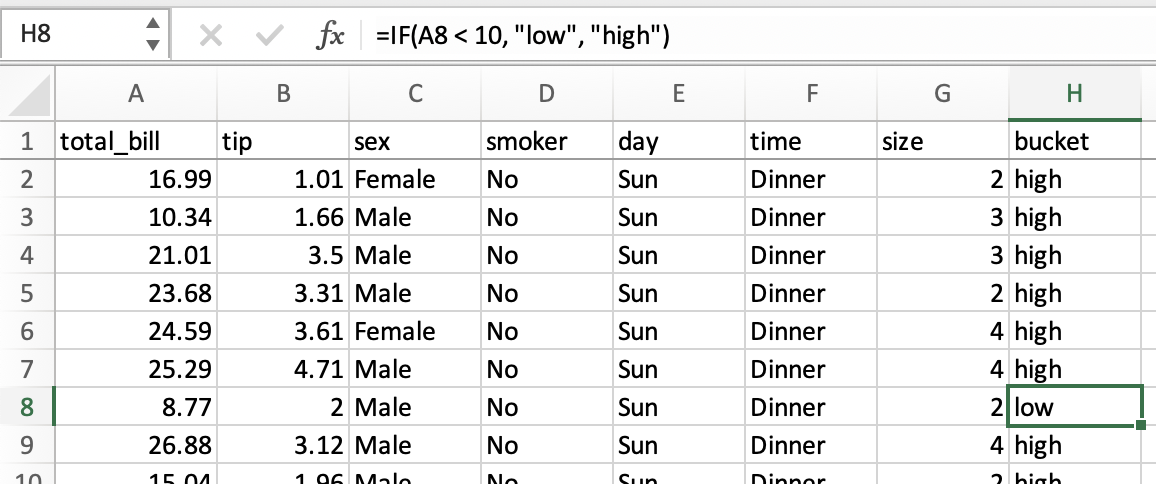
Ту же операцию в pandas можно выполнить с использованием метода where из numpy.
In [18]: tips["bucket"] = np.where(tips["total_bill"] < 10, "low", "high") In [19]: tips Out[19]: total_bill tip sex smoker day time size bucket 0 14.99 1.01 Female No Sun Dinner 2 high 1 8.34 1.66 Male No Sun Dinner 3 low 2 19.01 3.50 Male No Sun Dinner 3 high 3 21.68 3.31 Male No Sun Dinner 2 high 4 22.59 3.61 Female No Sun Dinner 4 high .. ... ... ... ... ... ... ... ... 239 27.03 5.92 Male No Sat Dinner 3 high 240 25.18 2.00 Female Yes Sat Dinner 2 high 241 20.67 2.00 Male Yes Sat Dinner 2 high 242 15.82 1.75 Male No Sat Dinner 2 high 243 16.78 3.00 Female No Thur Dinner 2 high [244 rows x 8 columns]
Функциональность даты¶
В этом разделе будут упоминаться «даты», но метки времени обрабатываются аналогичным образом.
Функционал даты можно разделить на две части: синтаксический анализ и вывод. В электронных таблицах значения даты обычно анализируются автоматически, хотя существует функция DATEVALUE. В pandas вам нужно явно преобразовать обычный текст в объекты даты и времени, либо при чтении из CSV, либо в DataFrame.
После анализа электронные таблицы отображают даты в формате по умолчанию, хотя формат можно изменить. В pandas при вычислениях над датами их обычно хранят как объекты datetime. Вывод частей дат (например, года) осуществляется в электронных таблицах с помощью функций даты, а в pandas с помощью свойств datetime.
Учитывая date1 и date2 в столбцах A и B электронной таблицы, у вас могут быть следующие формулы:
|
столбец |
формула |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
Эквивалентные операции pandas показаны ниже.
In [20]: tips["date1"] = pd.Timestamp("2013-01-15") In [21]: tips["date2"] = pd.Timestamp("2015-02-15") In [22]: tips["date1_year"] = tips["date1"].dt.year In [23]: tips["date2_month"] = tips["date2"].dt.month In [24]: tips["date1_next"] = tips["date1"] + pd.offsets.MonthBegin() In [25]: tips["months_between"] = tips["date2"].dt.to_period("M") - tips[ ....: "date1" ....: ].dt.to_period("M") ....: In [26]: tips[ ....: ["date1", "date2", "date1_year", "date2_month", "date1_next", "months_between"] ....: ] ....: Out[26]: date1 date2 date1_year date2_month date1_next months_between 0 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds> 1 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds> 2 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds> 3 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds> 4 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds> .. ... ... ... ... ... ... 239 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds> 240 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds> 241 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds> 242 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds> 243 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds> [244 rows x 6 columns]
См. более подробную информацию в разделе Time series / date functionality.
Выбор столбцов¶
В электронных таблицах вы можете выбрать нужные столбцы:
-
Скрытие столбцов
-
Удаление столбцов
-
Ссылка на диапазон с одного листа на другой
Поскольку столбцы электронной таблицы обычно именуются в строке заголовка, переименование столбца — это просто изменение текста в заголовочной ячейке.
Аналогичные операции в pandas продемонстрированы ниже.
Сохранить определенные столбцы¶
In [27]: tips[["sex", "total_bill", "tip"]] Out[27]: sex total_bill tip 0 Female 14.99 1.01 1 Male 8.34 1.66 2 Male 19.01 3.50 3 Male 21.68 3.31 4 Female 22.59 3.61 .. ... ... ... 239 Male 27.03 5.92 240 Female 25.18 2.00 241 Male 20.67 2.00 242 Male 15.82 1.75 243 Female 16.78 3.00 [244 rows x 3 columns]
Удалить столбец¶
In [28]: tips.drop("sex", axis=1) Out[28]: total_bill tip smoker day time size 0 14.99 1.01 No Sun Dinner 2 1 8.34 1.66 No Sun Dinner 3 2 19.01 3.50 No Sun Dinner 3 3 21.68 3.31 No Sun Dinner 2 4 22.59 3.61 No Sun Dinner 4 .. ... ... ... ... ... ... 239 27.03 5.92 No Sat Dinner 3 240 25.18 2.00 Yes Sat Dinner 2 241 20.67 2.00 Yes Sat Dinner 2 242 15.82 1.75 No Sat Dinner 2 243 16.78 3.00 No Thur Dinner 2 [244 rows x 6 columns]
Переименовать столбец¶
In [29]: tips.rename(columns={"total_bill": "total_bill_2"}) Out[29]: total_bill_2 tip sex smoker day time size 0 14.99 1.01 Female No Sun Dinner 2 1 8.34 1.66 Male No Sun Dinner 3 2 19.01 3.50 Male No Sun Dinner 3 3 21.68 3.31 Male No Sun Dinner 2 4 22.59 3.61 Female No Sun Dinner 4 .. ... ... ... ... ... ... ... 239 27.03 5.92 Male No Sat Dinner 3 240 25.18 2.00 Female Yes Sat Dinner 2 241 20.67 2.00 Male Yes Sat Dinner 2 242 15.82 1.75 Male No Sat Dinner 2 243 16.78 3.00 Female No Thur Dinner 2 [244 rows x 7 columns]
Сортировка по значениям¶
Сортировка в электронных таблицах осуществляется с помощью диалогового окна сортировки.
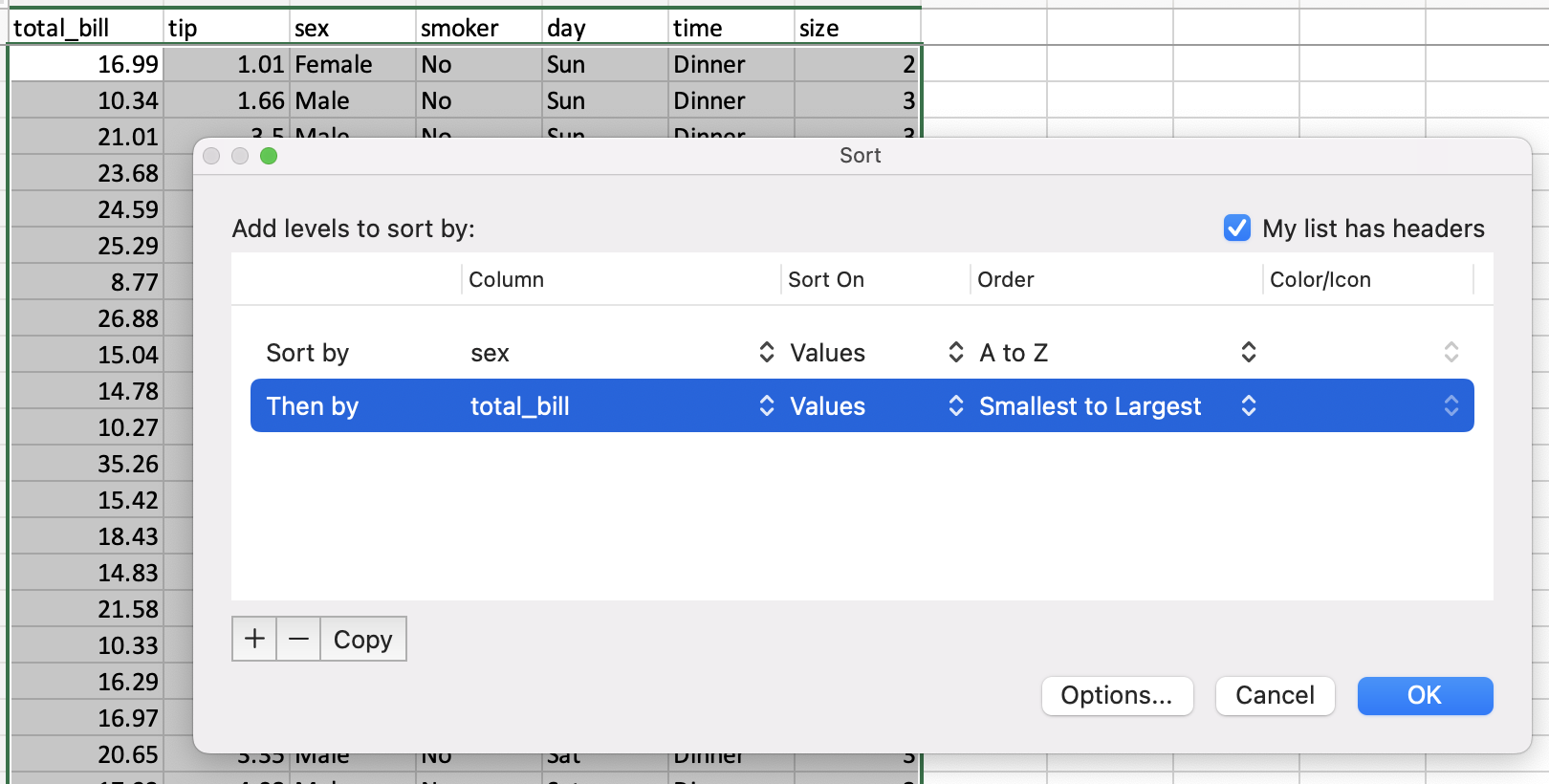
У pandas есть метод DataFrame.sort_values(), который принимает список столбцов для сортировки.
In [30]: tips = tips.sort_values(["sex", "total_bill"]) In [31]: tips Out[31]: total_bill tip sex smoker day time size 67 1.07 1.00 Female Yes Sat Dinner 1 92 3.75 1.00 Female Yes Fri Dinner 2 111 5.25 1.00 Female No Sat Dinner 1 145 6.35 1.50 Female No Thur Lunch 2 135 6.51 1.25 Female No Thur Lunch 2 .. ... ... ... ... ... ... ... 182 43.35 3.50 Male Yes Sun Dinner 3 156 46.17 5.00 Male No Sun Dinner 6 59 46.27 6.73 Male No Sat Dinner 4 212 46.33 9.00 Male No Sat Dinner 4 170 48.81 10.00 Male Yes Sat Dinner 3 [244 rows x 7 columns]
Обработка строк¶
Нахождение длины строки¶
В электронных таблицах количество символов в тексте можно узнать с помощью функции LEN. Ее можно использовать вместе с функцией TRIM, если нужно удалить лишние пробелы.
Вы можете узнать длину строки символов с помощью Series.str.len(). В Python 3 все строки являются строками Unicode. len включает конечные пробелы. Используйте len и rstrip, чтобы исключить пробелы в конце.
In [32]: tips["time"].str.len() Out[32]: 67 6 92 6 111 6 145 5 135 5 .. 182 6 156 6 59 6 212 6 170 6 Name: time, Length: 244, dtype: int64 In [33]: tips["time"].str.rstrip().str.len() Out[33]: 67 6 92 6 111 6 145 5 135 5 .. 182 6 156 6 59 6 212 6 170 6 Name: time, Length: 244, dtype: int64
Обратите внимание, что в этом случае множественные пробелы внутри строки останутся, так что функции эквивалентны не на 100%.
Поиск позиции подстроки¶
Функция электронной таблицы FIND возвращает позицию подстроки с первым символ 1.
В pandas вы можете найти положение символа в столбце строк с помощью метода Series.str.find(). find ищет первую позицию подстроки. Если подстрока найдена, метод возвращает ее позицию. Если не найдена, возвращается -1. Имейте в виду, что индексы Python отсчитываются от нуля.
In [34]: tips["sex"].str.find("ale") Out[34]: 67 3 92 3 111 3 145 3 135 3 .. 182 1 156 1 59 1 212 1 170 1 Name: sex, Length: 244, dtype: int64
Изменение регистра¶
В электронных таблицах есть функции UPPER, LOWER и PROPER для преобразование текста в верхний, нижний и заглавный регистр соответственно.
Эквивалентные методы pandas: Series.str.upper(), Series.str.lower() и Series.str.title().
In [40]: firstlast = pd.DataFrame({"string": ["John Smith", "Jane Cook"]}) In [41]: firstlast["upper"] = firstlast["string"].str.upper() In [42]: firstlast["lower"] = firstlast["string"].str.lower() In [43]: firstlast["title"] = firstlast["string"].str.title() In [44]: firstlast Out[44]: string upper lower title 0 John Smith JOHN SMITH john smith John Smith 1 Jane Cook JANE COOK jane cook Jane Cook
Объединение¶
В примерах объединения будут использоваться следующие таблицы:
In [45]: df1 = pd.DataFrame({"key": ["A", "B", "C", "D"], "value": np.random.randn(4)}) In [46]: df1 Out[46]: key value 0 A 0.469112 1 B -0.282863 2 C -1.509059 3 D -1.135632 In [47]: df2 = pd.DataFrame({"key": ["B", "D", "D", "E"], "value": np.random.randn(4)}) In [48]: df2 Out[48]: key value 0 B 1.212112 1 D -0.173215 2 D 0.119209 3 E -1.044236
В Excel объединение таблиц можно выполнить с помощью функции VLOOKUP.
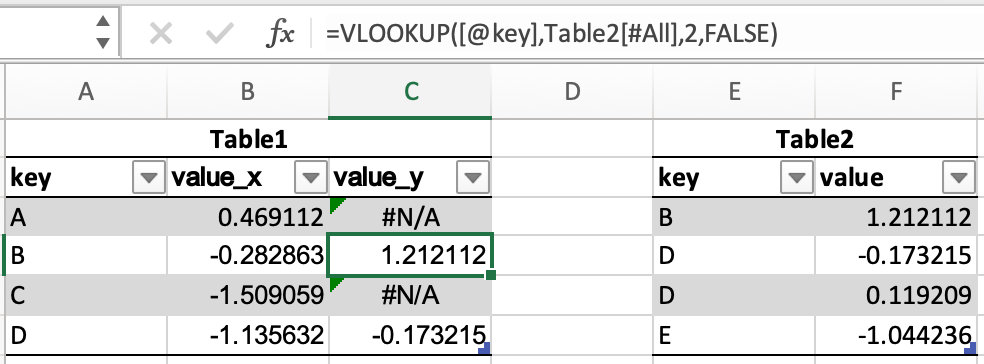
В pandas есть метод DataFrame.merge, который обеспечивает аналогичную функциональность. Данные не нужно сортировать заранее, а различные типы объединений выполняются с помощью ключевого слова how.
In [49]: inner_join = df1.merge(df2, on=["key"], how="inner") In [50]: inner_join Out[50]: key value_x value_y 0 B -0.282863 1.212112 1 D -1.135632 -0.173215 2 D -1.135632 0.119209 In [51]: left_join = df1.merge(df2, on=["key"], how="left") In [52]: left_join Out[52]: key value_x value_y 0 A 0.469112 NaN 1 B -0.282863 1.212112 2 C -1.509059 NaN 3 D -1.135632 -0.173215 4 D -1.135632 0.119209 In [53]: right_join = df1.merge(df2, on=["key"], how="right") In [54]: right_join Out[54]: key value_x value_y 0 B -0.282863 1.212112 1 D -1.135632 -0.173215 2 D -1.135632 0.119209 3 E NaN -1.044236 In [55]: outer_join = df1.merge(df2, on=["key"], how="outer") In [56]: outer_join Out[56]: key value_x value_y 0 A 0.469112 NaN 1 B -0.282863 1.212112 2 C -1.509059 NaN 3 D -1.135632 -0.173215 4 D -1.135632 0.119209 5 E NaN -1.044236
merge имеет ряд преимуществ перед VLOOKUP:
-
Искомое значение не обязательно должно быть в первом столбце таблицы поиска.
-
Если совпадают несколько строк, своя строка будет для каждого совпадения, а не только для первого.
-
Включаются все столбцы из таблицы поиска, а не только указанный столбец.
-
Поддерживаются более сложные операции объединения.
Другие соображения¶
Заполнение ячеек¶
Создайте ряд чисел по заданному шаблону в определенном наборе ячеек. В электронной таблице это можно сделать с помощью Shift + перетаскивания после ввода первого числа, или же путем ввода первых двух или трех значений с последующим перетаскиванием.
В pandas этого можно добиться, создав Series и назначив его нужным ячейкам.
In [57]: df = pd.DataFrame({"AAA": [1] * 8, "BBB": list(range(0, 8))}) In [58]: df Out[58]: AAA BBB 0 1 0 1 1 1 2 1 2 3 1 3 4 1 4 5 1 5 6 1 6 7 1 7 In [59]: series = list(range(1, 5)) In [60]: series Out[60]: [1, 2, 3, 4] In [61]: df.loc[2:5, "AAA"] = series In [62]: df Out[62]: AAA BBB 0 1 0 1 1 1 2 1 2 3 2 3 4 3 4 5 4 5 6 1 6 7 1 7
Удаление дубликатов¶
Excel имеет встроенную функцию удаления повторяющихся значений. Аналогичный функционал поддерживается в pandas с drop_duplicates().
In [63]: df = pd.DataFrame( ....: { ....: "class": ["A", "A", "A", "B", "C", "D"], ....: "student_count": [42, 35, 42, 50, 47, 45], ....: "all_pass": ["Yes", "Yes", "Yes", "No", "No", "Yes"], ....: } ....: ) ....: In [64]: df.drop_duplicates() Out[64]: class student_count all_pass 0 A 42 Yes 1 A 35 Yes 3 B 50 No 4 C 47 No 5 D 45 Yes In [65]: df.drop_duplicates(["class", "student_count"]) Out[65]: class student_count all_pass 0 A 42 Yes 1 A 35 Yes 3 B 50 No 4 C 47 No 5 D 45 Yes
Сводные таблицы¶
Сводные таблицы из электронных таблиц могут быть реплицированы в pandas, см. изменение формы и сводные таблицы. Снова используя набор данных tips, давайте найдем среднее вознаграждение в зависимости от масштаба вечеринки и пола официанта.
В Excel мы используем следующую конфигурацию для сводной таблицы:
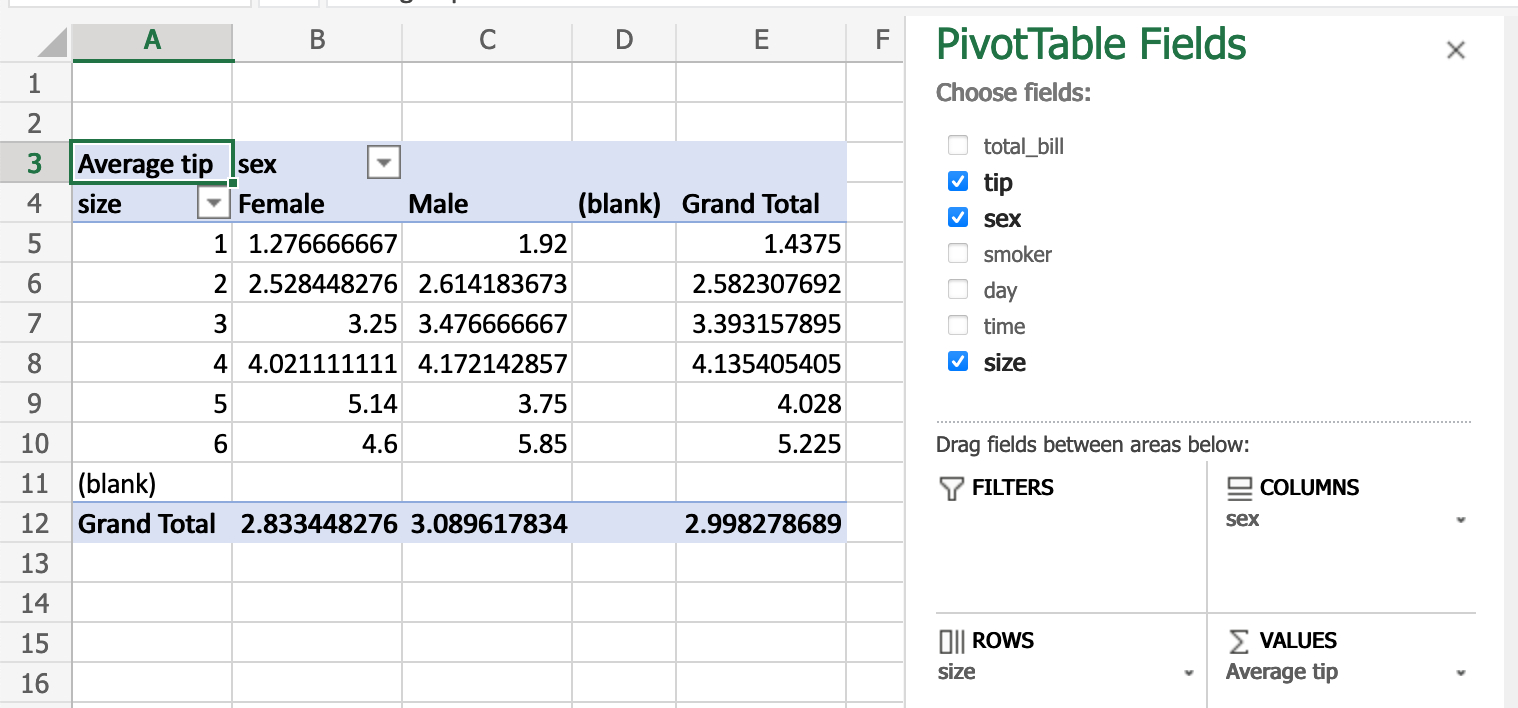
Эквивалент в pandas:
In [66]: pd.pivot_table( ....: tips, values="tip", index=["size"], columns=["sex"], aggfunc=np.average ....: ) ....: Out[66]: sex Female Male size 1 1.276667 1.920000 2 2.528448 2.614184 3 3.250000 3.476667 4 4.021111 4.172143 5 5.140000 3.750000 6 4.600000 5.850000
Добавление строки¶
Предполагая, что мы используем RangeIndex (с номером 0, 1 и т. д.), мы можем использовать concat(), чтобы добавить строку в конец DataFrame.
In [67]: df Out[67]: class student_count all_pass 0 A 42 Yes 1 A 35 Yes 2 A 42 Yes 3 B 50 No 4 C 47 No 5 D 45 Yes In [68]: new_row = pd.DataFrame([["E", 51, True]], ....: columns=["class", "student_count", "all_pass"]) ....: In [69]: pd.concat([df, new_row]) Out[69]: class student_count all_pass 0 A 42 Yes 1 A 35 Yes 2 A 42 Yes 3 B 50 No 4 C 47 No 5 D 45 Yes 0 E 51 True
Поиск и замена¶
Диалоговое окно поиска Excel показывает вам подходящие ячейки, одну за другой. В pandas эта операция обычно выполняется для всего столбца или DataFrame с помощью условных выражений.
In [70]: tips Out[70]: total_bill tip sex smoker day time size 67 1.07 1.00 Female Yes Sat Dinner 1 92 3.75 1.00 Female Yes Fri Dinner 2 111 5.25 1.00 Female No Sat Dinner 1 145 6.35 1.50 Female No Thur Lunch 2 135 6.51 1.25 Female No Thur Lunch 2 .. ... ... ... ... ... ... ... 182 43.35 3.50 Male Yes Sun Dinner 3 156 46.17 5.00 Male No Sun Dinner 6 59 46.27 6.73 Male No Sat Dinner 4 212 46.33 9.00 Male No Sat Dinner 4 170 48.81 10.00 Male Yes Sat Dinner 3 [244 rows x 7 columns] In [71]: tips == "Sun" Out[71]: total_bill tip sex smoker day time size 67 False False False False False False False 92 False False False False False False False 111 False False False False False False False 145 False False False False False False False 135 False False False False False False False .. ... ... ... ... ... ... ... 182 False False False False True False False 156 False False False False True False False 59 False False False False False False False 212 False False False False False False False 170 False False False False False False False [244 rows x 7 columns] In [72]: tips["day"].str.contains("S") Out[72]: 67 True 92 False 111 True 145 False 135 False ... 182 True 156 True 59 True 212 True 170 True Name: day, Length: 244, dtype: bool
Метод replace() в pandas сопоставим с Replace All в Excel.
In [73]: tips.replace("Thu", "Thursday") Out[73]: total_bill tip sex smoker day time size 67 1.07 1.00 Female Yes Sat Dinner 1 92 3.75 1.00 Female Yes Fri Dinner 2 111 5.25 1.00 Female No Sat Dinner 1 145 6.35 1.50 Female No Thur Lunch 2 135 6.51 1.25 Female No Thur Lunch 2 .. ... ... ... ... ... ... ... 182 43.35 3.50 Male Yes Sun Dinner 3 156 46.17 5.00 Male No Sun Dinner 6 59 46.27 6.73 Male No Sat Dinner 4 212 46.33 9.00 Male No Sat Dinner 4 170 48.81 10.00 Male Yes Sat Dinner 3 [244 rows x 7 columns]
Python is a popular tool for all kind of automation needs and therefore a great candidate for your reporting tasks.
There is a wealth of techniques and libraries available and we’re going to introduce five popular options here. After reading this blog post, you should be able to pick the right library for your next reporting project according to your needs and skill set.
Table of Contents
- Overview
- Pandas
- xlwings
- Plotly Dash
- Datapane
- ReportLab
- Conclusion
Overview
Before we begin, here is a high level comparison of the libraries presented in this post:
| Library | Technology | Summary |
|---|---|---|
| Pandas + HTML | HTML | You can generate beautiful reports in the form of static web pages if you know your way around HTML + CSS. The HTML report can also be turned into a PDF for printing. |
| Pandas + Excel | Excel | This is a great option if the report has to be in Excel. It can be run on a server where Excel is not installed, i.e. it’s an ideal candidate for a “download to Excel” button in a web app. The Excel file can be exported to PDF. |
| xlwings | Excel | xlwings allows the use of an Excel template so the formatting can be done by users without coding skills. It requires, however, an installation of Excel so it’s a good option when the report can be generated on a desktop, e.g. for ad-hoc reports. The Excel file can be exported to PDF. |
| Plotly Dash | HTML | Dash allows you to easily spin up a great looking web dashboard that is interactive without having to write any JavaScript code. If formatted properly, it can be used as a source for PDFs, too. Like Pandas + HTML, it requires good HTML + CSS skills to make it look the way you want. |
| Datapane | HTML | Datapane allows you to create HTML reports with interactive elements. It also offers a hosted solution so end users can change the input parameters that are used to create these reports. |
| ReportLab | ReportLab creates direct PDF files without going through HTML or Excel first. It’s very fast and powerful but comes with a steep learning curve. Used by Wikipedia for their PDF export. |
Pandas
I am probably not exaggerating when I claim that almost all reporting in Python starts with Pandas. It’s incredibly easy to create Pandas DataFrames with data from databases, Excel and csv files or json responses from a web API. Once you have the raw data in a DataFrame, it only requires a few lines of code to clean the data and slice & dice it into a digestible form for reporting. Accordingly, Pandas will be used in all sections of this blog post, but we’ll start by leveraging the built-in capabilities that Pandas offers for reports in Excel and HTML format.
Pandas + Excel
Required libraries: pandas, xlsxwriter
If you want to do something slightly more sophisticated than just dumping a DataFrame into an Excel spreadsheet, I found that Pandas and XlsxWriter is the easiest combination, but others may prefer OpenPyXL. In that case you should be able to easily adopt this snippet by replacing engine='xlsxwriter' with engine='openpyxl' and changing the book/sheet syntax so it works with OpenPyXL:
import pandas as pd
import numpy as np
# Sample DataFrame
df = pd.DataFrame(np.random.randn(5, 4), columns=['one', 'two', 'three', 'four'],
index=['a', 'b', 'c', 'd', 'e'])
# Dump Pandas DataFrame to Excel sheet
writer = pd.ExcelWriter('myreport.xlsx', engine='xlsxwriter')
df.to_excel(writer, sheet_name='Sheet1', startrow=2)
# Get book and sheet objects for futher manipulation below
book = writer.book
sheet = writer.sheets['Sheet1']
# Title
bold = book.add_format({'bold': True, 'size': 24})
sheet.write('A1', 'My Report', bold)
# Color negative values in the DataFrame in red
format1 = book.add_format({'font_color': '#E93423'})
sheet.conditional_format('B4:E8', {'type': 'cell', 'criteria': '<=', 'value': 0, 'format': format1})
# Chart
chart = book.add_chart({'type': 'column'})
chart.add_series({'values': '=Sheet1!B4:B8', 'name': '=Sheet1!B3', 'categories': '=Sheet1!$A$4:$A$8'})
chart.add_series({'values': '=Sheet1!C4:C8', 'name': '=Sheet1!C3'})
chart.add_series({'values': '=Sheet1!D4:D8', 'name': '=Sheet1!D3'})
chart.add_series({'values': '=Sheet1!E4:E8', 'name': '=Sheet1!E3'})
sheet.insert_chart('A10', chart)
writer.save()
Running this will produce the following report:
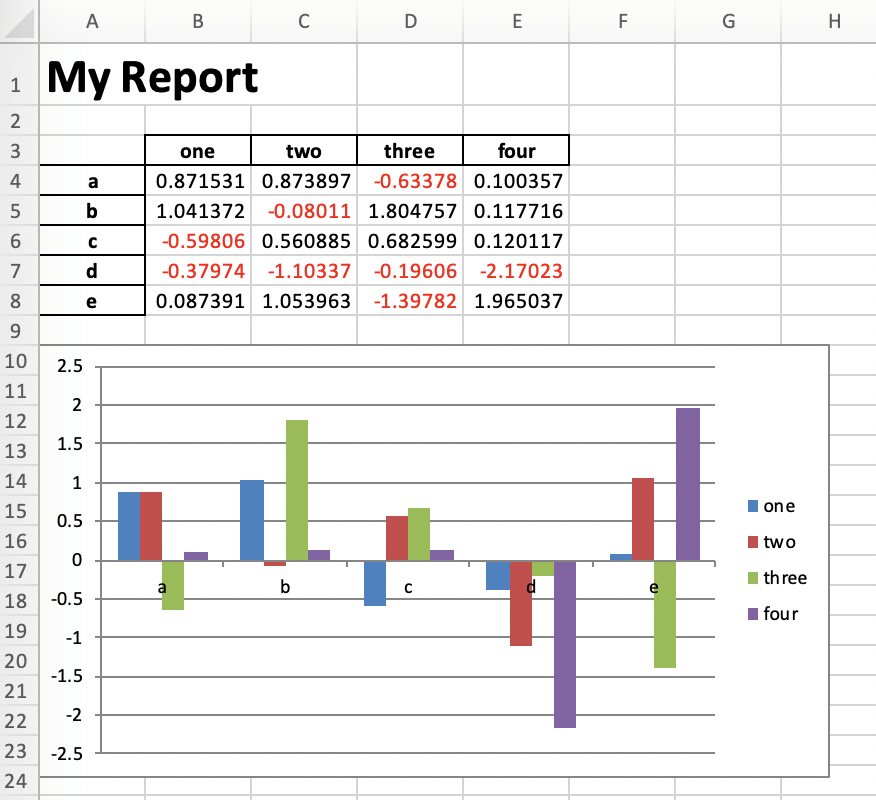
Of course, we could now go back to the script and add more code to style it a bit nicer, but I leave this as an exercise to the reader…
Pandas + HTML
Required libraries: pandas, jinja2
Creating an HTML report with pandas works similar to what’ve just done with Excel: If you want a tiny bit more than just dumping a DataFrame as a raw HTML table, then you’re best off by combining Pandas with a templating engine like Jinja:
First, let’s create a file called template.html:
<html>
<head>
<style>
* {
font-family: sans-serif;
}
body {
padding: 20px;
}
table {
border-collapse: collapse;
text-align: right;
}
table tr {
border-bottom: 1px solid
}
table th, table td {
padding: 10px 20px;
}
</style>
</head>
<body>
<h1>My Report</h1>
{{ my_table }}
<img src='plot.svg' width="600">
</body>
</html>
Then, in the same directory, let’s run the following Python script that will create our HTML report:
import pandas as pd
import numpy as np
import jinja2
# Sample DataFrame
df = pd.DataFrame(np.random.randn(5, 4), columns=['one', 'two', 'three', 'four'],
index=['a', 'b', 'c', 'd', 'e'])
# See: https://pandas.pydata.org/pandas-docs/stable/user_guide/style.html#Building-styles
def color_negative_red(val):
color = 'red' if val < 0 else 'black'
return f'color: {color}'
styler = df.style.applymap(color_negative_red)
# Template handling
env = jinja2.Environment(loader=jinja2.FileSystemLoader(searchpath=''))
template = env.get_template('template.html')
html = template.render(my_table=styler.render())
# Plot
ax = df.plot.bar()
fig = ax.get_figure()
fig.savefig('plot.svg')
# Write the HTML file
with open('report.html', 'w') as f:
f.write(html)
The result is a nice looking HTML report that could also be printed as a PDF by using something like WeasyPrint:
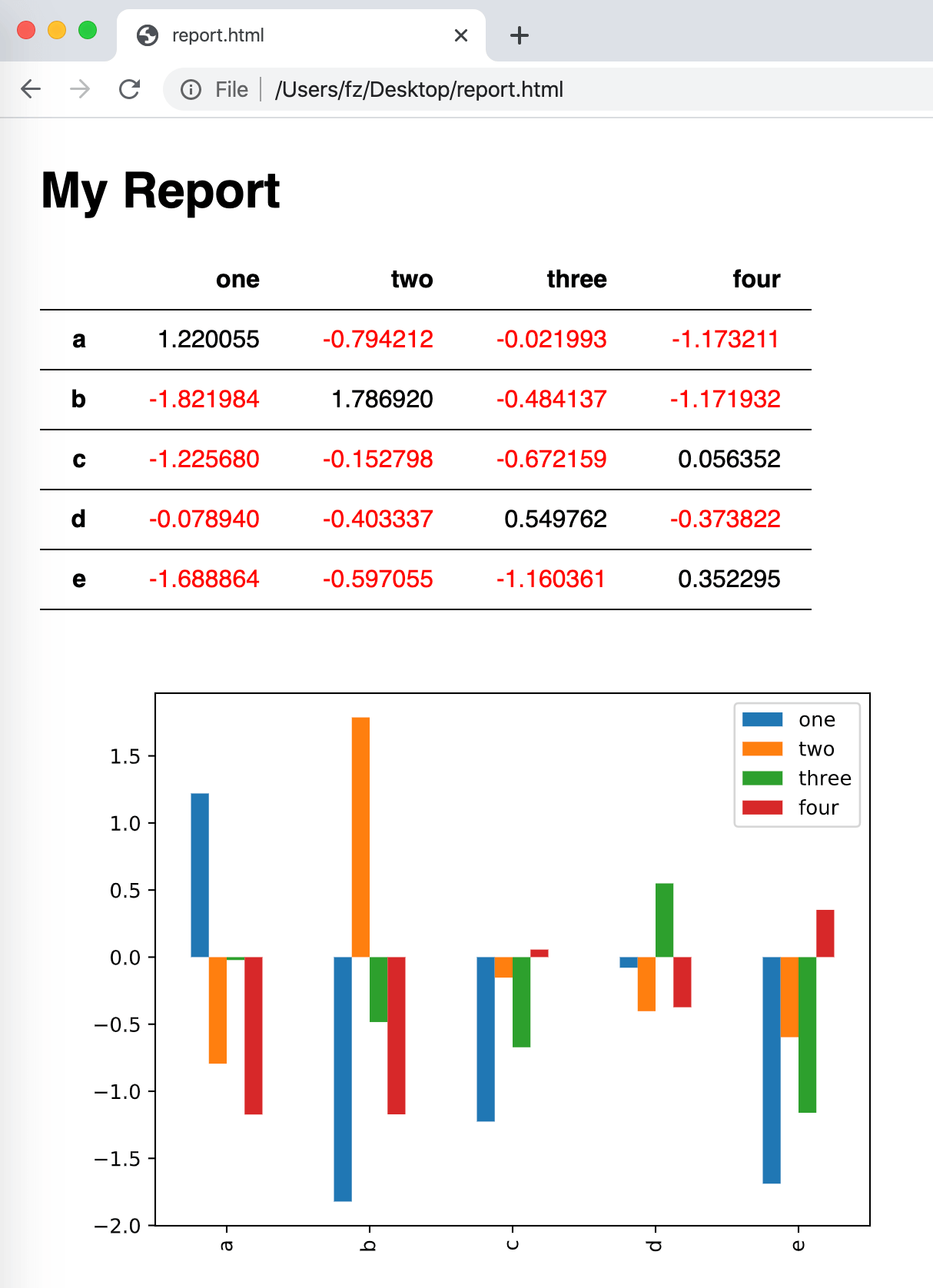
Note that for such an easy example, you wouldn’t necessarily need to use a Jinja template. But when things start to become more complex, it’ll definitely come in very handy.
xlwings
xlwings allows you to program and automate Excel with Python instead of VBA. The difference to XlsxWriter or OpenPyXL (used above in the Pandas section) is the following: XlsxWriter and OpenPyXL write Excel files directly on disk. They work wherever Python works and don’t require an installation of Microsoft Excel.
xlwings, on the other hand, can write, read and edit Excel files via the Excel application, i.e. a local installation of Microsoft Excel is required. xlwings also allows you to create macros and user-defined functions in Python rather than in VBA, but for reporting purposes, we won’t really need that.
While XlsxWriter/OpenPyXL are the best choice if you need to produce reports in a scalable way on your Linux web server, xlwings does have the advantage that it can edit pre-formatted Excel files without losing or destroying anything. OpenPyXL on the other hand (the only writer library with xlsx editing capabilities) will drop some formatting and sometimes leads to Excel raising errors during further manual editing.
xlwings (Open Source)
Replicating the sample we had under Pandas is easy enough with the open-source version of xlwings:
import xlwings as xw
import pandas as pd
import numpy as np
# Open a template file
wb = xw.Book('mytemplate.xlsx')
# Sample DataFrame
df = pd.DataFrame(np.random.randn(5, 4), columns=['one', 'two', 'three', 'four'],
index=['a', 'b', 'c', 'd', 'e'])
# Assign data to cells
wb.sheets[0]['A1'].value = 'My Report'
wb.sheets[0]['A3'].value = df
# Save under a new file name
wb.save('myreport.xlsx')
Running this will produce the following report:
So where does all the formatting come from? The formatting is done directly in the Excel template before running the script. This means that instead of having to program tens of lines of code to format a single cell with the proper font, colors and borders, I can just make a few clicks in Excel. xlwings then merely opens the template file and inserts the values.
This allows us to create a good looking report in your corporate design very fast. The best part is that the Python developer doesn’t necessarily have to do the formatting but can leave it to the business user who owns the report.
Note that you could instruct xlwings to run the report in a separate and hidden instance of Excel so it doesn’t interfere with your other work.
xlwings PRO
The Pandas + Excel as well as the xlwings (open source) sample both have a few issues:
- If, for example, you insert a few rows below the title, you will have to adjust the cell references accordingly in the Python code. Using named ranges could help but they have other limitations (like the one mentioned at the end of this list).
- The number of rows in the table might be dynamic. This leads to two issues: (a) data rows might not be formatted consistently and (b) content below the table might get overwritten if the table is too long.
- Placing the same value in a lot of different cells (e.g. a date in the source note of every table or chart) will cause duplicated code or unnecessary loops.
To fix these issues, xlwings PRO comes with a dedicated reports package:
- Separation of code and design: Users without coding skills can change the template on their own without having to touch the Python code.
- Template variables: Python variables (between double curly braces) can be directly used in cells , e.g.
{{ title }}. They act as placeholders that will be replaced by the values of the variables. - Frames for dynamic tables: Frames are vertical containers that dynamically align and style tables that have a variable number of rows. To see how Frames work, have a look at the documentation.
You can get a free trial for xlwings PRO here. When using the xlwings PRO reports package, your code simplifies to the following:
import pandas as pd
import numpy as np
from xlwings.pro.reports import create_report # part of xlwings PRO
# Sample DataFrame
df = pd.DataFrame(np.random.randn(5, 4), columns=['one', 'two', 'three', 'four'],
index=['a', 'b', 'c', 'd', 'e'])
# Create the report by passing in all variables as kwargs
wb = create_report('mytemplate.xlsx',
'myreport.xlsx',
title='My Report',
df=df)
All that’s left is to create a template with the placeholders for title and df:

Running the script will produce the same report that we generated with the open source version of xlwings above. The beauty of this approach is that there are no hard coded cell references anymore in your Python code. This means that the person who is responsible for the layout can move the placeholders around and change the fonts and colors without having to bug the Python developer anymore.
Plotly Dash
Required libraries: pandas, dash
Plotly is best known for their beautiful and open-source JavaScript charting library which builds the core of Chart Studio, a platform for collaboratively designing charts (no coding required).
To create a report though, we’re using their latest product Plotly Dash, an open-source framework that allows the creation of interactive web dashboards with Python only (no need to write JavaScript code). Plotly Dash is also available as Enterprise plan.
How it works is best explained by looking at some code, adopted with minimal changes from the official getting started guide:
import pandas as pd
import dash
import dash_core_components as dcc
import dash_html_components as html
from dash.dependencies import Input, Output
# Sample DataFrame
df = pd.read_csv('https://raw.githubusercontent.com/plotly/datasets/master/gapminderDataFiveYear.csv')
# Dash app - The CSS code is pulled in from an external file
app = dash.Dash(__name__, external_stylesheets=['https://codepen.io/chriddyp/pen/bWLwgP.css'])
# This defines the HTML layout
app.layout = html.Div([
html.H1('My Report'),
dcc.Graph(id='graph-with-slider'),
dcc.Slider(
id='year-slider',
min=df['year'].min(),
max=df['year'].max(),
value=df['year'].min(),
marks={str(year): str(year) for year in df['year'].unique()},
step=None
)
])
# This code runs every time the slider below the chart is changed
@app.callback(Output('graph-with-slider', 'figure'), [Input('year-slider', 'value')])
def update_figure(selected_year):
filtered_df = df[df.year == selected_year]
traces = []
for i in filtered_df.continent.unique():
df_by_continent = filtered_df[filtered_df['continent'] == i]
traces.append(dict(
x=df_by_continent['gdpPercap'],
y=df_by_continent['lifeExp'],
text=df_by_continent['country'],
mode='markers',
opacity=0.7,
marker={'size': 15, 'line': {'width': 0.5, 'color': 'white'}},
name=i
))
return {
'data': traces,
'layout': dict(
xaxis={'type': 'log', 'title': 'GDP Per Capita', 'range': [2.3, 4.8]},
yaxis={'title': 'Life Expectancy', 'range': [20, 90]},
margin={'l': 40, 'b': 40, 't': 10, 'r': 10},
legend={'x': 0, 'y': 1},
hovermode='closest',
transition={'duration': 500},
)
}
if __name__ == '__main__':
app.run_server(debug=True)
Running this script and navigating to http://localhost:8050 in your browser will give you this dashboard:
The charts look great by default and it’s very easy to make your dashboard interactive by writing simple callback functions in Python: You can choose the year by clicking on the slider below the chart. In the background, every change to our year-slider will trigger the update_figure callback function and hence update the chart.
By arranging your documents properly, you could create an interactive web dashboard that can also act as the source for your PDF factsheet, see for example their financial factsheet demo together with it’s source code.
Alternatives to Plotly Dash
If you are looking for an alternative to Plotly Dash, make sure to check out Panel. Panel was originally developed with the support of Anaconda Inc., and is now maintained by Anaconda developers and community contributors. Unlike Plotly Dash, Panel is very inclusive and supports a wide range of plotting libraries including: Bokeh, Altair, Matplotlib and others (including also Plotly).
Datapane
Required libraries: datapane
Datapane is a framework for reporting which allows you to generate interactive reports from pandas DataFrames, Python visualisations (such as Bokeh and Altair), and Markdown. Unlike solutions such as Dash, Datapane allows you to generate standalone reports which don’t require a running Python server—but it doesn’t require any HTML coding either.
Using Datapane, you can either generate one-off reports, or deploy your Jupyter Notebook or Python script so others can generate reports dynamically by entering parameters through an automatically generated web app.
Datapane (open-source library)
Datapane’s open-source library allows you to create reports from components, such as a Table component, a Plot component, etc. These components are compatible with Python objects such as pandas DataFrames, and many visualisation libraries, such as Altair:
import datapane as dp
import pandas as pd
import altair as alt
df = pd.read_csv('https://query1.finance.yahoo.com/v7/finance/download/GOOG?period2=1585222905&interval=1mo&events=history')
chart = alt.Chart(df).encode(
x='Date:T',
y='Open'
).mark_line().interactive()
r = dp.Report(dp.Table(df), dp.Plot(chart))
r.save(path='report.html')
This code renders a standalone HTML document with an interactive, searchable table and plot component.
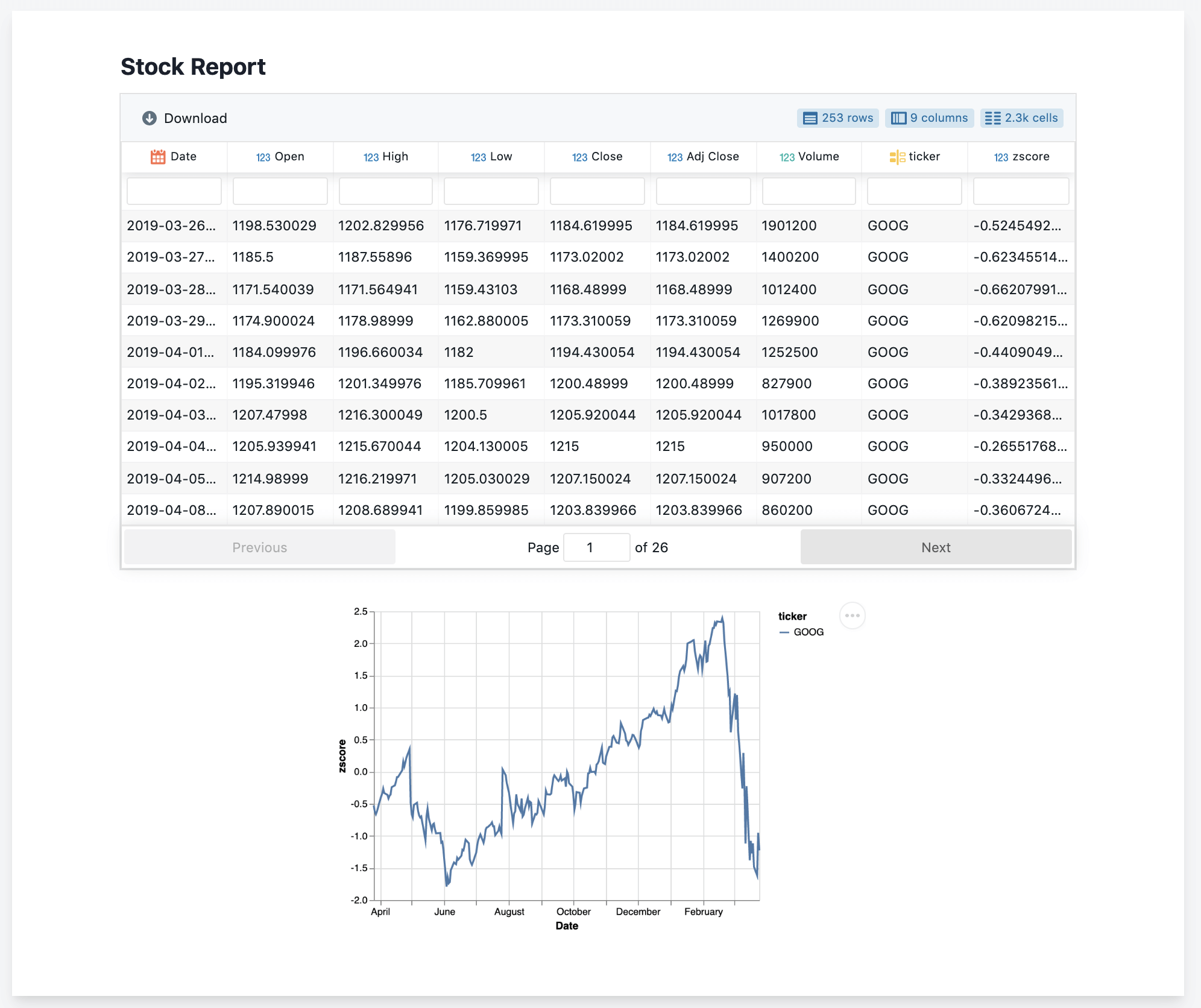
If you want to publish your report, you can login to Datapane (via $ datapane login) and use the publish method, which will give you a URL such as this which you can share or embed.
r.publish(name='my_report')
Hosted Reporting Apps
Datapane can also be used to deploy Jupyter Notebooks and Python scripts so that other people who are not familiar with Python can generate custom reports. By adding a YAML file to your folder, you can specify input parameters as well as dependencies (through pip, Docker, or local folders). Datapane also has support for managing secret variables, such as database passwords, and for storing and persisting files. Here is a sample script (stocks.py) and YAML file (stocks.yaml):
# stocks.py
import datapane as dp
import altair as alt
import yfinance as yf
dp.Params.load_defaults('./stocks.yaml')
tickers = dp.Params.get('tickers')
plot_type = dp.Params.get('plot_type')
period = dp.Params.get('period')
data = yf.download(tickers=' '.join(tickers), period=period, groupby='ticker').Close
df = data.reset_index().melt('Date', var_name='symbol', value_name='price')
base_chart = alt.Chart(df).encode(x='Date:T', y='price:Q', color='symbol').interactive()
chart = base_chart.mark_line() if plot_type == 'line' else base_chart.mark_bar()
dp.Report(dp.Plot(chart), dp.Table(df)).publish(name=f'stock_report', headline=f'Report on {" ".join(tickers)}')
# stocks.yaml
name: stock_analysis
script: stocks.py
# Script parameters
parameters:
- name: tickers
description: A list of tickers to plot
type: list
default: ['GOOG', 'MSFT', 'IBM']
- name: period
description: Time period to plot
type: enum
choices: ['1d','5d','1mo','3mo','6mo','1y','2y','5y','10y','ytd','max']
default: '1mo'
- name: plot_type
type: enum
default: line
choices: ['bar', 'line']
## Python packages required for the script
requirements:
- yfinance
Publishing this into a reporting app is easy as running $ datapane script deploy. For a full example see this example GitHub repository or read the docs.
ReportLab
Required libraries: pandas, reportlab
ReportLab writes PDF files directly. Most prominently, Wikipedia uses ReportLab to generate their PDF exports. One of the key strength of ReportLab is that it builds PDF reports “at incredible speeds”, to cite their homepage. Let’s have a look at some sample code for both the open-source and the commercial version!
ReportLab OpenSource
In its most basic functionality, ReportLab uses a canvas where you can place objects using a coordinate system:
from reportlab.pdfgen import canvas
c = canvas.Canvas("hello.pdf")
c.drawString(50, 800, "Hello World")
c.showPage()
c.save()
ReportLab also offers an advanced mode called PLATYPUS (Page Layout and Typography Using Scripts), which is able to define dynamic layouts based on templates at the document and page level. Within pages, Frames would then arrange Flowables (e.g. text and pictures) dynamically according to their height. Here is a very basic example of how you put PLATYPUS at work:
import pandas as pd
import numpy as np
from reportlab.pdfgen.canvas import Canvas
from reportlab.lib import colors
from reportlab.lib.styles import getSampleStyleSheet
from reportlab.lib.units import inch
from reportlab.platypus import Paragraph, Frame, Table, Spacer, TableStyle
# Sample DataFrame
df = pd.DataFrame(np.random.randn(5, 4), columns=['one', 'two', 'three', 'four'],
index=['a', 'b', 'c', 'd', 'e'])
# Style Table
df = df.reset_index()
df = df.rename(columns={"index": ""})
data = [df.columns.to_list()] + df.values.tolist()
table = Table(data)
table.setStyle(TableStyle([
('INNERGRID', (0, 0), (-1, -1), 0.25, colors.black),
('BOX', (0, 0), (-1, -1), 0.25, colors.black)
]))
# Components that will be passed into a Frame
story = [Paragraph("My Report", getSampleStyleSheet()['Heading1']),
Spacer(1, 20),
table]
# Use a Frame to dynamically align the compents and write the PDF file
c = Canvas('report.pdf')
f = Frame(inch, inch, 6 * inch, 9 * inch)
f.addFromList(story, c)
c.save()
Running this script will produce the following PDF:
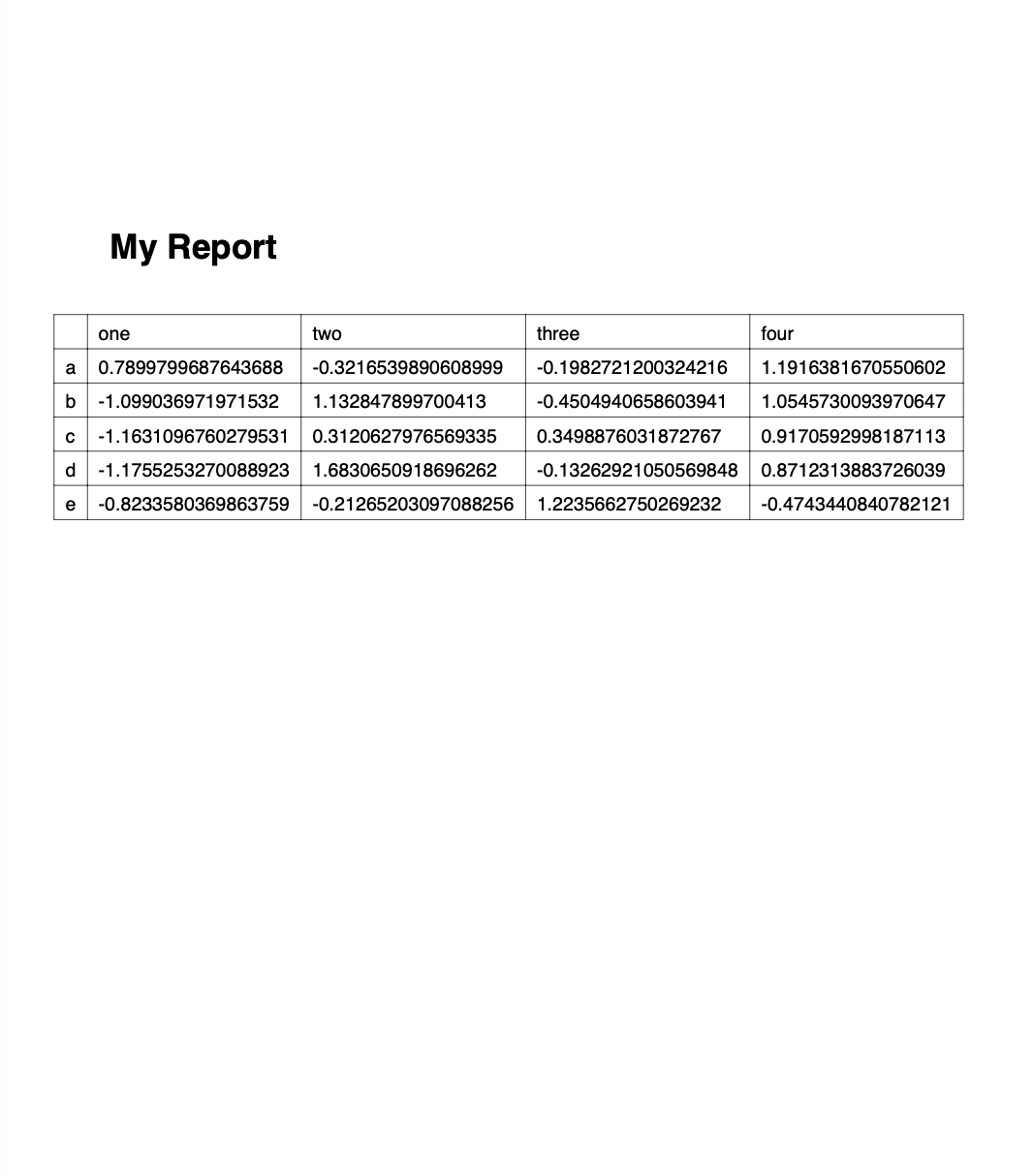
ReportLab PLUS
In comparison to the open-source version of ReportLab, the most prominent features of Reportlab PLUS are
- a templating language
- the ability to include vector graphics
The templating language is called RML (Report Markup Language), an XML dialect. Here is a sample of how it looks like, taken directly from the official documentation:
<!DOCTYPE document SYSTEM "rml.dtd">
<document filename="example.pdf">
<template>
<pageTemplate id="main">
<frame id="first" x1="72" y1="72" width="451" height="698" />
</pageTemplate>
</template>
<stylesheet>
</stylesheet>
<story>
<para>
This is the "story". This is the part of the RML document where
your text is placed.
</para>
<para>
It should be enclosed in "para" and "/para" tags to turn it into
paragraphs.
</para>
</story>
</document>
The idea here is that you can have any program produce such an RML document, not just Python, which can then be transformed into a PDF document by ReportLab PLUS.
Conclusion
Python offers various libraries to create professional reports and factsheets. If you are a good at HTML + CSS have a look at Plotly Dash or Panel or write your HTML documents directly with the help of the to_html method in Pandas.
If you need your report as Excel file (or if you hate CSS), Pandas + XlsxWriter/OpenPyXL or xlwings might be the right choice — you can still export your Excel document as PDF file. xlwings is the better choice if you want to split the design and code work. XlsxWriter/OpenPyxl is the better choice if it needs to be scalable and run on a server.
If you need to generate PDF files at high speed, check out ReportLab. It has a steep learning curve and requires to write quite some code but once the code has been written, it works at high speed.